
Adapter/LoRA
#Efficiency/SpeedUp#NLP#Finetuning (SFT)#Reasoning
Issue Date: 2025-03-19 The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, arXiv25 Comment斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成 ... #MachineTranslation#Analysis#NLP#LanguageModel#Finetuning (SFT)
Issue Date: 2025-01-02 How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes, Inacio Vieira+, arXiv24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQLoRAでLlama 8B InstructをMTのデータでSFTした場合のサンプル数に対する性能の変化を検証している。ただし、検証 ... #Pocket#NLP#LanguageModel#Finetuning (SFT)
Issue Date: 2025-01-02 LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qfull finetuningとLoRAの性質の違いを理解するのに有用 ...
Issue Date: 2025-03-19 The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, arXiv25 Comment斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成 ... #MachineTranslation#Analysis#NLP#LanguageModel#Finetuning (SFT)
Issue Date: 2025-01-02 How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes, Inacio Vieira+, arXiv24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQLoRAでLlama 8B InstructをMTのデータでSFTした場合のサンプル数に対する性能の変化を検証している。ただし、検証 ... #Pocket#NLP#LanguageModel#Finetuning (SFT)
Issue Date: 2025-01-02 LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qfull finetuningとLoRAの性質の違いを理解するのに有用 ...
#ComputerVision#MachineLearning#Pocket#Finetuning (SFT)#InstructionTuning#Catastrophic Forgetting
Issue Date: 2024-11-12 Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv24 Comment ... #Analysis#MachineLearning#Pocket#NLP#LanguageModel
Issue Date: 2024-11-09 LoRA vs Full Fine-tuning: An Illusion of Equivalence, Reece Shuttleworth+, arXiv24 Comment元ポスト: https://x.com/aratako_lm/status/1854838012909166973?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q#1423 や #1475 、双方の知見も交えて、LoRAの挙動を考察する必要がある気がする。それぞれ異なるデータセットやモデ ... #NLP#Finetuning (SFT)#InstructionTuning
Issue Date: 2024-10-30 Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING24 CommentLow-Rank Adaptation (LoRA) is a widespread parameter-efficient fine-tuning algorithm for large-scale language models. It has been commonly accepted tL ... #Efficiency/SpeedUp#Pocket#NLP#LanguageModel
Issue Date: 2024-03-05 LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, arXiv24 Summary本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 CommentLoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法 ... #RecommenderSystems#LanguageModel#Contents-based#Finetuning (SFT)#Zero/FewShotLearning#RecSys
Issue Date: 2025-03-30 TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys23 Comment下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初 ... #Efficiency/SpeedUp#Pocket#Quantization
Issue Date: 2024-09-24 LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models, Yixiao Li+, N_A, arXiv23 #Efficiency/SpeedUp#MachineLearning#Finetuning (SFT)
Issue Date: 2024-01-17 VeRA: Vector-based Random Matrix Adaptation, Dawid J. Kopiczko+, N_A, arXiv23 Summary本研究では、大規模な言語モデルのfine-tuningにおいて、訓練可能なパラメータの数を削減するための新しい手法であるベクトルベースのランダム行列適応(VeRA)を提案する。VeRAは、共有される低ランク行列と小さなスケーリングベクトルを使用することで、同じ性能を維持しながらパラメータ数を削減する。GLUEやE2Eのベンチマーク、画像分類タスクでの効果を示し、言語モデルのインストラクションチューニングにも応用できることを示す。 #Pocket
Issue Date: 2023-11-23 MultiLoRA: Democratizing LoRA for Better Multi-Task Learning, Yiming Wang+, N_A, arXiv23 SummaryLoRAは、LLMsを効率的に適応させる手法であり、ChatGPTのようなモデルを複数のタスクに適用することが求められている。しかし、LoRAは複雑なマルチタスクシナリオでの適応性能に制限がある。そこで、本研究ではMultiLoRAという手法を提案し、LoRAの制約を緩和する。MultiLoRAは、LoRAモジュールをスケーリングし、パラメータの依存性を減らすことで、バランスの取れたユニタリ部分空間を得る。実験結果では、わずかな追加パラメータでMultiLoRAが優れたパフォーマンスを示し、上位特異ベクトルへの依存性が低下していることが確認された。 #Pocket
Issue Date: 2023-11-23 ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs, Viraj Shah+, N_A, arXiv23 Summary概要:概念駆動型のパーソナライズのための生成モデルの微調整手法であるZipLoRAを提案。ZipLoRAは、独立してトレーニングされたスタイルと主題のLoRAを統合し、任意の主題とスタイルの組み合わせで生成することができる。実験結果は、ZipLoRAが主題とスタイルの忠実度を改善しながら魅力的な結果を生成できることを示している。 #Efficiency/SpeedUp#MachineLearning#Pocket#NLP#Dataset#QuestionAnswering#Finetuning (SFT)#LongSequence
Issue Date: 2023-09-30 LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv23 Summary本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment# 概要 context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になって ...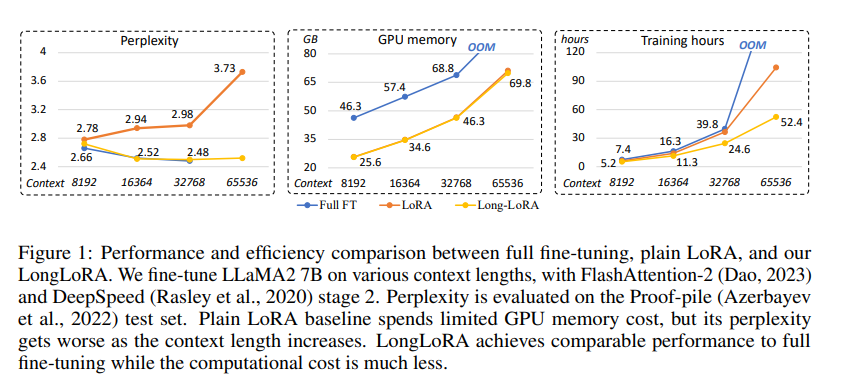 #MachineLearning#NLP#LanguageModel
#MachineLearning#NLP#LanguageModel
Issue Date: 2023-08-08 LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition, Chengsong Huang+, N_A, arXiv23 Summary本研究では、大規模言語モデル(LLMs)を新しいタスクに適応させるための低ランク適応(LoRA)を検討し、LoraHubというフレームワークを提案します。LoraHubを使用すると、少数の例から複数のLoRAモジュールを組み合わせて柔軟に適応性のあるパフォーマンスを実現できます。また、追加のモデルパラメータや勾配は必要ありません。実験結果から、LoraHubが少数の例でのインコンテキスト学習のパフォーマンスを効果的に模倣できることが示されています。さらに、LoRAコミュニティの育成と共有リソースの提供にも貢献しています。 Comment学習されたLoRAのパラメータをモジュールとして捉え、新たなタスクのinputが与えられた時に、LoRA Hub上の適切なモジュールをLLMに組み合わせることで、ICL無しで汎化を実現するというアイデア。few shotのexampleを人間が設計する必要なく、同等の性能を達成。複数のLoRAモジュ ... #Efficiency/SpeedUp#MachineLearning#Pocket#Quantization
#Efficiency/SpeedUp#MachineLearning#Pocket#Quantization
Issue Date: 2023-07-22 QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, arXiv23 Summary私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment実装: https://github.com/artidoro/qloraPEFTにもある参考: https://twitter.com/hillbig/status/1662946722690236417?s=46&t=TDHYK31QiXKxggPzhZbcAQ ... #NaturalLanguageGeneration#Controllable#NLP
Issue Date: 2023-07-15 Focused Prefix Tuning for Controllable Text Generation, ACL23 Summary本研究では、注釈のない属性によって制御可能なテキスト生成データセットのパフォーマンスが低下する問題に対して、「focused prefix tuning(FPT)」という手法を提案しています。FPTは望ましい属性に焦点を当てることで、制御精度とテキストの流暢さを向上させることができます。また、FPTは複数属性制御タスクにおいても、既存のモデルを再トレーニングすることなく新しい属性を制御する柔軟性を持ちながら、制御精度を保つことができます。 #Pocket
Issue Date: 2023-06-16 One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning, Arnav Chavan+, N_A, arXiv23 Summary本研究では、汎用的なファインチューニングタスクのための高度な手法であるGeneralized LoRA (GLoRA)を提案し、事前学習済みモデルの重みを最適化し、中間アクティベーションを調整することで、多様なタスクとデータセットに対してより柔軟性と能力を提供する。GLoRAは、各レイヤーの個別のアダプタを学習するスケーラブルでモジュラーなレイヤーごとの構造探索を採用することで、効率的なパラメータの適応を促進する。包括的な実験により、GLoRAは、自然言語、専門分野、構造化ベンチマークにおいて、従来のすべての手法を上回り、様々なデータセットでより少ないパラメータと計算で優れた精度を達成することが示された。 #Analysis#Pocket#NLP
Issue Date: 2024-10-01 Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, Armen Aghajanyan+, N_A, ACL21 CommentACL ver:https://aclanthology.org/2021.acl-long.568.pdf下記の元ポストを拝読の上論文を斜め読み。モデルサイズが大きいほど、特定の性能(論文中では2種類のデータセットでの90%のsentence prediction性能)をfinetuningで達成 ... #DocumentSummarization#NeuralNetwork#NaturalLanguageGeneration#NLP#LanguageModel#ACL
Issue Date: 2021-09-09 Prefix-Tuning: Optimizing Continuous Prompts for Generation, Lisa+ (Percy Liang), Stanford University, ACL21 Comment言語モデルをfine-tuningする際,エンコード時に「接頭辞」を潜在表現として与え,「接頭辞」部分のみをfine-tuningすることで(他パラメータは固定),より少量のパラメータでfine-tuningを実現する方法を提案.接頭辞を潜在表現で与えるこの方法は,GPT-3のpromptingに着 ... #Article#Article
Issue Date: 2023-11-20 Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation) #Article#Efficiency/SpeedUp#NLP#LanguageModel#Finetuning (SFT)#Catastrophic Forgetting
Issue Date: 2023-10-29 大規模言語モデルのFine-tuningによるドメイン知識獲得の検討 Comment以下記事中で興味深かった部分を引用> まとめると、LoRAは、[3]で言われている、事前学習モデルは大量のパラメータ数にもかかわらず低い固有次元を持ち、Fine-tuningに有効な低次元のパラメータ化も存在する、という主張にインスパイアされ、ΔWにおける重みの更新の固有次元も低いという仮説のもと ... #Article#Efficiency/SpeedUp#NLP#LanguageModel#Quantization
Issue Date: 2023-07-22 LLaMA2を3行で訓練 CommentLLaMA2を3行で、1つのA100GPU、QLoRAで、自前のデータセットで訓練する方法 ... #Article#NeuralNetwork#Efficiency/SpeedUp#NLP#LanguageModel#Library
Issue Date: 2023-04-25 LoRA論文解説, Hayato Tsukagoshi, 2023.04 Commentベースとなる事前学習モデルの一部の線形層の隣に、低ランク行列A,Bを導入し、A,Bのパラメータのみをfinetuningの対象とすることで、チューニングするパラメータ数を激減させた上で同等の予測性能を達成し、推論速度も変わらないようにするfinetuning手法の解説LoRAを使うと、でかすぎるモデ ... #Article#NeuralNetwork#NLP#LanguageModel
Issue Date: 2022-08-19 The Power of Scale for Parameter-Efficient Prompt Tuning, Lester+, Google Research, EMNLP‘21 Comment日本語解説: https://qiita.com/kts_plea/items/79ffbef685d362a7b6ceT5のような大規模言語モデルに対してfinetuningをかける際に、大規模言語モデルのパラメータは凍結し、promptをembeddingするパラメータを独立して学習する手法 ...
Issue Date: 2024-11-12 Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv24 Comment ... #Analysis#MachineLearning#Pocket#NLP#LanguageModel
Issue Date: 2024-11-09 LoRA vs Full Fine-tuning: An Illusion of Equivalence, Reece Shuttleworth+, arXiv24 Comment元ポスト: https://x.com/aratako_lm/status/1854838012909166973?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q#1423 や #1475 、双方の知見も交えて、LoRAの挙動を考察する必要がある気がする。それぞれ異なるデータセットやモデ ... #NLP#Finetuning (SFT)#InstructionTuning
Issue Date: 2024-10-30 Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING24 CommentLow-Rank Adaptation (LoRA) is a widespread parameter-efficient fine-tuning algorithm for large-scale language models. It has been commonly accepted tL ... #Efficiency/SpeedUp#Pocket#NLP#LanguageModel
Issue Date: 2024-03-05 LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, arXiv24 Summary本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 CommentLoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法 ... #RecommenderSystems#LanguageModel#Contents-based#Finetuning (SFT)#Zero/FewShotLearning#RecSys
Issue Date: 2025-03-30 TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys23 Comment下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初 ... #Efficiency/SpeedUp#Pocket#Quantization
Issue Date: 2024-09-24 LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models, Yixiao Li+, N_A, arXiv23 #Efficiency/SpeedUp#MachineLearning#Finetuning (SFT)
Issue Date: 2024-01-17 VeRA: Vector-based Random Matrix Adaptation, Dawid J. Kopiczko+, N_A, arXiv23 Summary本研究では、大規模な言語モデルのfine-tuningにおいて、訓練可能なパラメータの数を削減するための新しい手法であるベクトルベースのランダム行列適応(VeRA)を提案する。VeRAは、共有される低ランク行列と小さなスケーリングベクトルを使用することで、同じ性能を維持しながらパラメータ数を削減する。GLUEやE2Eのベンチマーク、画像分類タスクでの効果を示し、言語モデルのインストラクションチューニングにも応用できることを示す。 #Pocket
Issue Date: 2023-11-23 MultiLoRA: Democratizing LoRA for Better Multi-Task Learning, Yiming Wang+, N_A, arXiv23 SummaryLoRAは、LLMsを効率的に適応させる手法であり、ChatGPTのようなモデルを複数のタスクに適用することが求められている。しかし、LoRAは複雑なマルチタスクシナリオでの適応性能に制限がある。そこで、本研究ではMultiLoRAという手法を提案し、LoRAの制約を緩和する。MultiLoRAは、LoRAモジュールをスケーリングし、パラメータの依存性を減らすことで、バランスの取れたユニタリ部分空間を得る。実験結果では、わずかな追加パラメータでMultiLoRAが優れたパフォーマンスを示し、上位特異ベクトルへの依存性が低下していることが確認された。 #Pocket
Issue Date: 2023-11-23 ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs, Viraj Shah+, N_A, arXiv23 Summary概要:概念駆動型のパーソナライズのための生成モデルの微調整手法であるZipLoRAを提案。ZipLoRAは、独立してトレーニングされたスタイルと主題のLoRAを統合し、任意の主題とスタイルの組み合わせで生成することができる。実験結果は、ZipLoRAが主題とスタイルの忠実度を改善しながら魅力的な結果を生成できることを示している。 #Efficiency/SpeedUp#MachineLearning#Pocket#NLP#Dataset#QuestionAnswering#Finetuning (SFT)#LongSequence
Issue Date: 2023-09-30 LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv23 Summary本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment# 概要 context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になって ...
Issue Date: 2023-08-08 LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition, Chengsong Huang+, N_A, arXiv23 Summary本研究では、大規模言語モデル(LLMs)を新しいタスクに適応させるための低ランク適応(LoRA)を検討し、LoraHubというフレームワークを提案します。LoraHubを使用すると、少数の例から複数のLoRAモジュールを組み合わせて柔軟に適応性のあるパフォーマンスを実現できます。また、追加のモデルパラメータや勾配は必要ありません。実験結果から、LoraHubが少数の例でのインコンテキスト学習のパフォーマンスを効果的に模倣できることが示されています。さらに、LoRAコミュニティの育成と共有リソースの提供にも貢献しています。 Comment学習されたLoRAのパラメータをモジュールとして捉え、新たなタスクのinputが与えられた時に、LoRA Hub上の適切なモジュールをLLMに組み合わせることで、ICL無しで汎化を実現するというアイデア。few shotのexampleを人間が設計する必要なく、同等の性能を達成。複数のLoRAモジュ ...
Issue Date: 2023-07-22 QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, arXiv23 Summary私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment実装: https://github.com/artidoro/qloraPEFTにもある参考: https://twitter.com/hillbig/status/1662946722690236417?s=46&t=TDHYK31QiXKxggPzhZbcAQ ... #NaturalLanguageGeneration#Controllable#NLP
Issue Date: 2023-07-15 Focused Prefix Tuning for Controllable Text Generation, ACL23 Summary本研究では、注釈のない属性によって制御可能なテキスト生成データセットのパフォーマンスが低下する問題に対して、「focused prefix tuning(FPT)」という手法を提案しています。FPTは望ましい属性に焦点を当てることで、制御精度とテキストの流暢さを向上させることができます。また、FPTは複数属性制御タスクにおいても、既存のモデルを再トレーニングすることなく新しい属性を制御する柔軟性を持ちながら、制御精度を保つことができます。 #Pocket
Issue Date: 2023-06-16 One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning, Arnav Chavan+, N_A, arXiv23 Summary本研究では、汎用的なファインチューニングタスクのための高度な手法であるGeneralized LoRA (GLoRA)を提案し、事前学習済みモデルの重みを最適化し、中間アクティベーションを調整することで、多様なタスクとデータセットに対してより柔軟性と能力を提供する。GLoRAは、各レイヤーの個別のアダプタを学習するスケーラブルでモジュラーなレイヤーごとの構造探索を採用することで、効率的なパラメータの適応を促進する。包括的な実験により、GLoRAは、自然言語、専門分野、構造化ベンチマークにおいて、従来のすべての手法を上回り、様々なデータセットでより少ないパラメータと計算で優れた精度を達成することが示された。 #Analysis#Pocket#NLP
Issue Date: 2024-10-01 Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, Armen Aghajanyan+, N_A, ACL21 CommentACL ver:https://aclanthology.org/2021.acl-long.568.pdf下記の元ポストを拝読の上論文を斜め読み。モデルサイズが大きいほど、特定の性能(論文中では2種類のデータセットでの90%のsentence prediction性能)をfinetuningで達成 ... #DocumentSummarization#NeuralNetwork#NaturalLanguageGeneration#NLP#LanguageModel#ACL
Issue Date: 2021-09-09 Prefix-Tuning: Optimizing Continuous Prompts for Generation, Lisa+ (Percy Liang), Stanford University, ACL21 Comment言語モデルをfine-tuningする際,エンコード時に「接頭辞」を潜在表現として与え,「接頭辞」部分のみをfine-tuningすることで(他パラメータは固定),より少量のパラメータでfine-tuningを実現する方法を提案.接頭辞を潜在表現で与えるこの方法は,GPT-3のpromptingに着 ... #Article#Article
Issue Date: 2023-11-20 Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation) #Article#Efficiency/SpeedUp#NLP#LanguageModel#Finetuning (SFT)#Catastrophic Forgetting
Issue Date: 2023-10-29 大規模言語モデルのFine-tuningによるドメイン知識獲得の検討 Comment以下記事中で興味深かった部分を引用> まとめると、LoRAは、[3]で言われている、事前学習モデルは大量のパラメータ数にもかかわらず低い固有次元を持ち、Fine-tuningに有効な低次元のパラメータ化も存在する、という主張にインスパイアされ、ΔWにおける重みの更新の固有次元も低いという仮説のもと ... #Article#Efficiency/SpeedUp#NLP#LanguageModel#Quantization
Issue Date: 2023-07-22 LLaMA2を3行で訓練 CommentLLaMA2を3行で、1つのA100GPU、QLoRAで、自前のデータセットで訓練する方法 ... #Article#NeuralNetwork#Efficiency/SpeedUp#NLP#LanguageModel#Library
Issue Date: 2023-04-25 LoRA論文解説, Hayato Tsukagoshi, 2023.04 Commentベースとなる事前学習モデルの一部の線形層の隣に、低ランク行列A,Bを導入し、A,Bのパラメータのみをfinetuningの対象とすることで、チューニングするパラメータ数を激減させた上で同等の予測性能を達成し、推論速度も変わらないようにするfinetuning手法の解説LoRAを使うと、でかすぎるモデ ... #Article#NeuralNetwork#NLP#LanguageModel
Issue Date: 2022-08-19 The Power of Scale for Parameter-Efficient Prompt Tuning, Lester+, Google Research, EMNLP‘21 Comment日本語解説: https://qiita.com/kts_plea/items/79ffbef685d362a7b6ceT5のような大規模言語モデルに対してfinetuningをかける際に、大規模言語モデルのパラメータは凍結し、promptをembeddingするパラメータを独立して学習する手法 ...