
CIKM
RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms, Zhao+, CIKM'21
Paper/Blog Link My Issue
#RecommenderSystems #Tools #Library #Reference Collection Issue Date: 2022-03-29 GPT Summary- RecBoleは、推薦アルゴリズムのオープンソース実装を標準化するための統一的で効率的なライブラリであり、73のモデルを28のベンチマークデータセット上で実装。PyTorchに基づき、一般的なデータ構造や評価プロトコル、自動パラメータ調整機能を提供し、推薦システムの実装と評価を促進する。プロジェクトはhttps://recbole.io/で公開。 Comment
参考リンク:
-
https://www.google.co.jp/amp/s/techblog.zozo.com/entry/deep-learning-recommendation-improvement%3famp=1
-
https://techlife.cookpad.com/entry/2021/11/04/090000
-
https://qiita.com/fufufukakaka/items/77878c1e23338345d4fa
[Paper Note] Neural Review Summarization Leveraging User and Product Information, Liu+, CIKM'19
Paper/Blog Link My Issue
#DocumentSummarization #NLP #review Issue Date: 2023-05-06
[Paper Note] BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, Fei Sun+, arXiv'19, 2019.04
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #LanguageModel #SequentialRecommendation #One-Line Notes #Initial Impression Notes Issue Date: 2021-05-25 GPT Summary- ユーザーの動的嗜好をモデル化するために、BERT4RecというTransformerに基づく双方向エンコーダを導入。従来の順序型モデルの限界を克服し、Clozeタスクを用いて左側と右側の文脈を共同で条件付けしてアイテムを予測。さまざまなベンチマークデータセットにおいて、提案モデルが最先端の逐次モデルを一貫して上回る結果を示す。 Comment
BERTをrecsysのsequential recommendationタスクに転用してSoTA。
しっかり読んで無いけどモデル構造はほぼBERTと一緒。
異なる点は、Training時にNext Sentence Predictionは行わずClozeのみ行なっているという点。Clozeとは、実質Masked Language Modelであり、sequenceの一部を[mask]に置き換え、置き換えられたアイテムを左右のコンテキストから予測するタスク。異なる点としては、sequential recommendationタスクでは、次のアイテムを予測したいので、マスクするアイテムの中に、sequenceの最後のアイテムをマスクして予測する事例も混ぜた点。
もう一個異なる点として、BERT4Recはend-to-endなモデルで、BERTはpretraining modelだ、みたいなこと言ってるけど、まあ確かに形式的にはそういう違いはあるけど、なんかその違いを主張するのは違和感を覚える…。
sequential recommendationで使うuser behaviorデータでNext item predictionで学習したいことが、MLMと単に一致していただけ、なのでは…。
BERT4Recのモデル構造。next item predictionしたいsessionの末尾に [mask] をconcatし、[MASK]部分のアイテムを予測する構造っぽい?
オリジナルはtensorflow実装
pytorchの実装はこちら:
https://github.com/jaywonchung/BERT4Rec-VAE-Pytorch/tree/master/models
[Paper Note] Derivative Delay Embedding: Online Modeling of Streaming Time Series, Zhifei Zhang+, CIKM'16, 2016.09
Paper/Blog Link My Issue
#TimeSeriesDataProcessing #MachineLearning #One-Line Notes Issue Date: 2017-12-31 GPT Summary- DDE-MGMという新しいオンラインモデリング手法を提案。従来の固定長や整列データの仮定を排除し、導関数遅延埋め込みを用いてストリーミング時系列データを効率的に処理。非パラメトリックマルコフ地理モデルでパターンをモデル化し、優れた分類精度を実現。実験結果は最先端手法と比較して効果的であることを示す。 Comment
スライド: https://www.slideshare.net/akihikowatanabe3110/brief-survey-of-datatotext-systems
(管理人が作成した過去のスライドより)
[Paper Note] Deep Match between Geology Reports and Well Logs Using Spatial Information, Tong+, CIKM'16
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Others #NLP #DataToTextGeneration Issue Date: 2017-12-31
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, Huang+, CIKM'13
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #InformationRetrieval #Contents-based Issue Date: 2021-06-01 Comment
[Paper Note] How Does Clickthrough Data Reflect Retrieval Quality?, Radlijnski+, CIKM'08
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #Interleaved Issue Date: 2018-01-01
[Paper Note] Comments-Oriented Blog Summarization by Sentence Extraction, CIKM'07, [Hu+, 2007], 2007.11
My Issue
#DocumentSummarization #GraphBased #Comments #NLP #Extractive Issue Date: 2017-12-28 Comment
[Paper Note] Learning query-biased web page summarization, Wang et al., CIKM’07, 2007.11
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Snippets #QueryBiased #KeyPoint Notes Issue Date: 2017-12-28 Comment
・従来のquery-biasedな要約におけるclassificationアプローチは,training内のdocumentの情報が未知のdocumentのsentenceのclassificationに役立つというものだった.これは,たとえば似たような情報を多く含むscientific articleだったら有用だが,様々な情報を含むweb pageにはあまり適切ではない(これはtraining set内のdocumentの情報とtarget pageの情報を比較するみたいなアプローチに相当する).この研究では,target page内の’sentenceの中で’はスニペットに含めるべき文かどうかという比較ができるという仮定のもと,learning to rankを用いてスニペットを生成する.
・query biased summarizationではrelevanceとfidelityの両者が担保された要約が良いとされている.
relevanceとはクエリと要約の適合性,fidelityとは,要約とtarget documentとの対応の良さである.
・素性は,relevanceに関してはクエリとの関連度,fidelityに関しては,target page内のsentenceに関しては文の位置や,文の書式(太字)などの情報を使う.contextの文ではそういった情報が使えないので,タイトルやanchor textのフレーズを用いてfidelityを担保する(詳しくかいてない).あとはterm occurence,titleとextracted title(先行研究によると,TRECデータの33.5%のタイトルが偽物だったというものがあるのでextracted titleも用いる),anchor textの情報を使う.あまり深く読んでいない.
・全ての素性を組み合わせたほうがintrinsicなevaluationにおいて高い評価値.また,contextとcontent両方組み合わせたほうが良い結果がでた.
[Paper Note] Document Update Summarization Using Incremental Hierarchical Clustering, Wang+, CIKM’10
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #KeyPoint Notes Issue Date: 2017-12-28 Comment
・既存のMDSではdocumentをbatch処理するのが前提.typicalなクラスタリングベースの手法やグラフベースの手法はsentence-graphを構築して要約を行う.しかし,情報がsequentialに届き,realtimeで要約を行いたいときにこのような手法を使うと,毎回すでに処理したことがあるテキストを処理することになり,time consumingだし,無駄な処理が多い.特に災害時などでは致命的.このような問題に対処するために,ドキュメントがarriveしたときに,ただちにupdate summaryが生成できる手法を提案する.
・既存のヒューリスティックなfeature(tf-isfやキーワード数など)を用いたスコアリングは,existing sentencesとnewly coming sentencesが独立しているため,real world scenarioにおいて実用的でないし,hardly perform wellである.
・なので,incremental hierarchical clusteringの手法でsentence clusterをre-organizeすることで,効果的に要約のupdateを行う.このとき,sentence同士のhierarchical relationshipはreal timeにre-constructされる.
・TACのupdate summarizationとは定義が微妙に違うらしい.主に2点.TACではnewly coming documentsだけを対象にしているが,この研究 ではすべてのドキュメントを対象にする.さらに,TACでは一度だけupdate summarizationする(document set Bのみ)が,この研究ではdocumentsがsequenceでarriveするのを前提にする.なので,TACに対しても提案手法は適用可能.
・Sequence Update Summarizationの先駆け的な研究かもしれない.SUSがのshared taskになったのは2013だし.
・incremental hierarchical clusteringにはCOBWEB algorithm (かなりpopularらしい)を使う.COBWEBアルゴリズムは,新たなelementが現れたとき,Category Utilityと呼ばれるcriterionを最大化するように,4種類の操作のうち1つの操作を実行する(insert(クラスタにsentenceを挿入), create(新たなクラスタつくる), merge(2クラスタを1つに),split(existingクラスタを複数のクラスタに)).ただ,もとのCOBWEBで使われているnormal attribute distributionはtext dataにふさわしくないので,Katz distributionをword occurrence distributionとして使う(Sahooらが提案している.).元論文読まないと詳細は不明.
・要約の生成は,実施したoperationごとに異なる.
- Insertの場合: クラスタを代表するsentenceをクエリとのsimilarity, クラスタ内のsentenceとのintra similarityを計算して決めて出力する.
- createの場合: 新たに生成したクラスタcluster_kを代表する文を,追加したsentence s_newとする.
- mergeの場合: cluster_aとcluster_bをmergeして新たなcluster_cを作った場合,cluster_cを代表する文を決める.cluster_cを代表する文は,cluster_aとcluster_bを代表する文とクエリとのsimilarityをはかり,similarityが大きいものとする.
- splitの場合: cluster_aをsplitしてn個の新たなクラスタができたとき,各新たなn個のクラスタにおいて代表する文を,original subtreeの根とする.
・TAC08のデータとHurricane Wilma Releasesのデータ(disaster systemからtop 10 queryを取得,5人のアノテータに正解を作ってもらう)を使って評価.(要約の長さを揃えているのかが気になる。長さが揃っていないからROUGEのF値で比較している?)
・一応ROUGEのF値も高いし,速度もbaselineと比べて早い.かなりはやい.genericなMDSとTAC participantsと比較.TAC Bestと同等.GenericMDSより良い.document setAの情報を使ってredundancy removalをしていないのにTAC Bestを少しだけoutperform.おもしろい.
・かつ,TAC bestはsentence combinationを繰り返す手法らしく,large-scale online dataには適していないと言及.
[Paper Note] Incremental Update Summarization: Adaptive Sentence Selection based on Prevalence and Novelty, McCreadie et al., CIKM’14
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #KeyPoint Notes Issue Date: 2017-12-28 Comment
・timelyなeventに対してupdate summarizationを適用する場合を考える.たとえば6日間続いたeventがあったときにその情報をユーザが追う為に何度もupdate summarizationシステムを用いる状況を考える.6日間のうち新しい情報が何も出てこない期間はirrelevantでredundantな内容を含む要約が出てきてしまう.これをなんとかする手法が必要だというのがmotivation.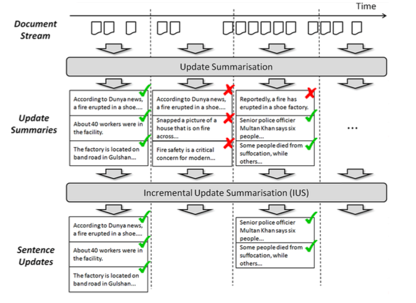
・どのような手法かというと,news streamsからnovel updatesをtimely mannerで自動抽出し,一方で,抽出するupdatesはirrelevant, uninformative or redundant contentを最小化するようなもの手法
・手法は既存のUpdate Summarization手法(lambdaMART, learning to rank baseの手法)で10文を出力し,何文目までを残すか(rank-cut off problem)を解くことで,いらないsentenceをはぶいている.
・rank cut offをする際はlinear regressionとModel Treesを使っているが,linear regressionのような単純な手法だと精度があがらず,Model Treesを使ったほうがいい結果が出た.
・素性は主にprevalence (sentenceが要約したいトピックに沿っているか否か),novelty(sentenceが新しい情報を含んでいるか),quality(sentenceがそもそも重要かどうか)の3種類の素性を使っている.気持ちとしては,prevalenceとnoveltyの両方が高いsentenceだけを残したいイメージ.つまり,トピックに沿っていて,なおかつ新しい情報を含んでいるsentence
・loss functionには,F値のような働きをするものを採用(とってきたrelevant updateのprecisionとrecallをはかっているイメージ).具体的には,Expected Latency GainとLatency Comprehensivenessと呼ばれるTREC2013のquality measureに使われている指標を使っている.
・ablation testの結果を見ると,qualityに関する素性が最もきいている.次にnovelty,次点でprevalence
・提案手法はevent発生から時間が経過すると精度が落ちていく場合がある.
・classicalなupdate summarizationの手法と比較しているが,Classyがかなり強い,Model treesを使わない提案手法や,他のbaselineを大きくoutperform. ただ,classyはmodel treesを使ったAdaptive IUSには勝てていない.
・TREC 2013には,Sequantial Update Summarizationタスクなるものがあるらしい.ユーザのクエリQと10個のlong-runnning event(典型的には10日間続くもの,各イベントごとに800〜900万記事),正解のnuggetsとそのtimestampが与えられたときにupdate summarizationを行うタスクらしい.
[Paper Note] Update Summarization using Semi-Supervised Learning Based on Hellinger Distance, Wang et al., CIKM’15, 2015.10
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #KeyPoint Notes Issue Date: 2017-12-28 Comment
・Hellinger Distanceを用いてSentence Graphを構築.ラベル伝搬により要約に含める文を決定する手法
・update summarizationの研究ではsimilarityをはかるときにcosine similarityを用いることが多い.
・cosine similarityはユークリッド距離から直接的に導くことができる.
・Vector Space Modelはnonnegativeなmatrixを扱うので,確率的なアプローチで取り扱いたいが,ユークリッド距離は確率を扱うときにあまり良いmetricではない.そこでsqrt-cos similarityを提案する.sqrt-cosは,Hellinger Distanceから求めることができ,Hellinger Distanceは対称的で三角不等式を満たすなど,IRにおいて良いdistance measureの性質を持っている.(Hellinger Distanceを活用するために結果的に類似度の尺度としてsqrt-cosが出てきたとみなせる)
・またHellinger DistanceはKL Divergenceのsymmetric middle pointとみなすことができ,文書ベクトル生成においてはtf_idfとbinary weightingのちょうど中間のような重み付けを与えているとみなせる.
・要約を生成する際は,まずはset Aの文書群に対してMMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
を適用する(redundancyの項がmaxではなくて平均になっている).similarityはsqrt-cosを用いる.
・sqrt-cosと,set Aの要約結果を用いると,sentence graphを構築できる.sentence graphはset Aとset Bの各sentenceをノードとするグラフで,エッジの重みはsqrt-cosとなっている.このsentence graph上でset Aの要約結果のラベルをset B側のノードに伝搬させることで,要約に含めるべき文を選択する.
・ラベル伝搬にはGreen’s functionを用いる.set Bにlabel “1”がふられるものは,given topicとset Aのcontentsにrelevantなsentenceとなる.
・TAC2011のデータで評価した結果,standardなMMRを大幅にoutperform, co-ranking, Centroidベースの手法などよりも良い結果.