
Controllable
[Paper Note] DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents, Zhaorun Chen+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #Security #Initial Impression Notes #Environment #Author Thread-Post #RedTeaming Issue Date: 2026-05-12 GPT Summary- AIエージェントは複雑なワークフローを自動化する一方で、重要なセキュリティリスクを引き起こす。エージェントが操作されることで、APIキー漏えいや未承認の取引などが発生する可能性があり、そのセキュリティ評価は動的な環境下で困難である。これに対抗するため、DecodingTrust-Agent Platform(DTap)を導入し、14の現実世界ドメインを再現したインタラクティブなレッドチーミングプラットフォームを提供。また、初の自律的レッドチーミングエージェントDTap-Redを提案し、さまざまな攻撃戦略を自律的に探索する。これにより、DTap-Benchという大規模なレッドチーミングデータセットをキュレーションし、安全な次世代エージェント開発のための重要な洞察を提供する。 Comment
元ポスト:
Opus-4.6が本ベンチマーク上は最もセキュリティリスクに対して安全で、良性なタスクに対する性能を発揮するモデルに見える。
論文は279ページもある🤯
[Paper Note] MultiShotMaster: A Controllable Multi-Shot Video Generation Framework, Qinghe Wang+, CVPR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #CVPR #VideoGeneration/Understandings #3D (Video) Issue Date: 2026-02-24 GPT Summary- MultiShotMasterは、マルチショット動画生成のための高度に制御可能なフレームワークを提案する。これにより、ショット遷移の位相シフトを適用し、柔軟なショット配置を実現。参照トークンとグラウンディング信号を用いた設計により、時空間的参照を強化し、データ不足を克服するための自動データ注釈パイプラインを確立。結果として、テキスト駆動の一貫性とカスタム対象を持つマルチショット動画生成を支援し、高性能と卓越した制御性を示した。 Comment
pj page: https://qinghew.github.io/MultiShotMaster/
元ポスト:
[Paper Note] VerseCrafter: Dynamic Realistic Video World Model with 4D Geometric Control, Sixiao Zheng+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #OpenWeight #WorldModels #3D (Video) #Geometric Issue Date: 2026-01-14 GPT Summary- VerseCrafterは、カメラとオブジェクトの動きを一貫して制御する4Dビデオワールドモデルを提案。静的な背景と3Dガウス軌跡を使用して、オブジェクトの確率的な3D占有を表現し、高忠実度なビデオ生成を可能にする。自動データエンジンにより、大規模な4Dアノテーションデータセットを野生のビデオから抽出し、モデルのトレーニングを支援。 Comment
pj page: https://sixiaozheng.github.io/VerseCrafter_page/
元ポスト:
[Paper Note] Light-X: Generative 4D Video Rendering with Camera and Illumination Control, Tianqi Liu+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #SyntheticData #DiffusionModel #ICLR #VideoGeneration/Understandings #3D (Video) #One-Line Notes #Relighting #Author Thread-Post Issue Date: 2025-12-06 GPT Summary- Light-Xは、単眼動画から視点と照明を制御可能にする動画生成フレームワークで、幾何学と照明信号を分離する設計を採用。これにより高品質な照明を実現し、ペアのマルチビューおよびマルチ照明動画の不足に対処するために逆マッピングを用いた合成手法を導入。実験結果では、Light-Xがカメラと照明の共同制御において従来手法を上回る性能を示した。 Comment
pj page: https://lightx-ai.github.io/
元ポスト:
著者ポスト:
openreview: https://openreview.net/forum?id=VBew6vESGL
単眼で撮影された動画の視点と照明を同時に制御しながら動画を生成するフレームワークな模様。
背景画像をあたえた
単眼で撮影された動画の視点と照明を同時に制御しながら動画を生成するフレームワークな模様。
背景画像を与えた上での動画のRelighting, Text Promptに基づくRelighting, ユーザがtrajectoryを指定した上でのRelightingなどができるようである。
[Paper Note] GameFactory: Creating New Games with Generative Interactive Videos, Jiwen Yu+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #Transformer #DiffusionModel #Architecture #PostTraining #VideoGeneration/Understandings #ICCV #Game #One-Line Notes #Reading Reflections Issue Date: 2026-04-02 GPT Summary- GameFactoryは、アクション制御とシーン一般化を両立させたゲームビデオ生成のフレームワーク。GF-Minecraftというデータセットを用いてキーボードとマウス入力を正確に制御し、自己回帰生成を可能にする。さらに、オープンドメイン生成事前知識を活用し、固定スタイルを超えた多様なゲームの創出を支援。ドメインアダプターによる学習戦略によって、アクション制御が特定ゲームスタイルに縛られず、シーン一般化が実現。実験により、GameFactoryが効果的にオープンドメインのゲームビデオを生成できることが確認された。 Comment
github: https://github.com/KlingAIResearch/GameFactory
小規模なマイクラデータでaction control moduleと呼ばれるモジュールを学習することで、動画生成モデルに対して、マウス、キーボード入力によるコントロール能力を転移し、ゲーム映像を生成できる、という話に見える。
4.2節に書かれているように、transformerのブロックにaction control moduleと呼ばれる、キーボードとマウスの入力をwindowでグルーピングしてエンコードするようなブロックを挿入し、エンコードされたvideo側の潜在表現に対して条件付けを行い生成を可能にしているようである(Figure 3, 4)。学習する際はFigure 6に示されているように、まずはopen domainのデータで事前学習、その後LoRAでgame video dataのドメイン情報を入れ、他モジュールはfreezeした上で、action control moduleのみを学習する。
transformerアーキテクチャにドメイン依存のブロックを後でplugし性能向上させるアプローチはおもしろいと感じる。
[Paper Note] TimeBill: Time-Budgeted Inference for Large Language Models, Qi Fan+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #Architecture #Decoding #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-12-31 GPT Summary- LLMsの推論効率と応答性能を向上させるために、時間予算に基づくフレームワーク「TimeBill」を提案。細粒度の応答長予測器と実行時間推定器を用いてエンドツーエンドの実行時間を予測し、KVキャッシュの排出比率を適応的に調整。実験により、タスク完了率の向上と応答性能の維持を実証。 Comment
元ポスト:
興味深いアイデア
レスポンスの長さをbucket単位で予測し、実際のハードウェア上での過去のデータなどに基づいてruntimeを予測。予測したruntimeのworstcaseよりも遅延しないようにKV Cacheを削減することで限られた時間的な予算の中でresponceを返すような手法な模様。
[Paper Note] Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control, Zekai Gu+, SIGGRAPH'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #SIGGRAPH #VideoGeneration/Understandings Issue Date: 2025-12-21 GPT Summary- 新しいアプローチ「Diffusion as Shader(DaS)」を提案し、3D制御信号を活用して動画生成の多様な制御を実現。従来の2D制御信号に対し、3Dトラッキング動画を用いることで、時間的一貫性が向上し、幅広い動画制御タスクに強力な性能を発揮。 Comment
pj page: https://igl-hkust.github.io/das/
[Paper Note] Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising, Assaf Singer+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #VideoGeneration/Understandings Issue Date: 2025-11-14 GPT Summary- Time-to-Move(TTM)は、画像から動画への拡散モデルを用いたトレーニング不要の動画生成フレームワークで、動きと外観を制御する。ユーザーが得た粗いアニメーションを動きの手がかりとして利用し、二重時計デノイジングにより外観を保持しつつ動きの整合性を強化。TTMは追加のトレーニングなしでリアリズムと動きの制御において既存手法と同等以上の性能を示し、ピクセルレベルの条件付けを通じて外観制御の精度を向上させた。 Comment
元ポスト:
[Paper Note] OminiControl: Minimal and Universal Control for Diffusion Transformer, Zhenxiong Tan+, ICCV'25 Highlight, 2024.11
Paper/Blog Link My Issue
#ComputerVision #Transformer #DiffusionModel #VariationalAutoEncoder #Selected Papers/Blogs #ICCV #KeyPoint Notes Issue Date: 2025-10-22 GPT Summary- OminiControlは、Diffusion Transformer(DiT)アーキテクチャにおける画像条件付けの新しいアプローチで、パラメータオーバーヘッドを最小限に抑えつつ、柔軟なトークン相互作用と動的な位置エンコーディングを実現。広範な実験により、複数の条件付けタスクで専門的手法を上回る性能を示し、合成された画像ペアのデータセット「Subjects200K」を導入。効率的で多様な画像生成システムの可能性を示唆。 Comment
元ポスト:
DiTのアーキテクチャは(MMA以外は)変更せずに、Condition Image C_IをVAEでエンコードしたnoisy inputをDiTのinputにconcatし順伝播させることで、DiTをunified conditioningモデル(=C_Iの特徴量を他のinputと同じlatent spaceで学習させ統合的に扱う)として学習する[^1]。
[^1]: 既存研究は別のエンコーダからエンコードしたfeatureが加算されていて(式3)、エンコーダ部分に別途パラメータが必要だっただけでなく、加算は空間的な対応関係が存在しない場合はうまく対処できず(featureの次元が空間的な情報に対応しているため)、conditional tokenとimageの交互作用を妨げていた。
また、positional encodingのindexをconditional tokenとnoisy image tokensと共有すると、空間的な対応関係が存在するタスク(edge guided generation等)はうまくいったが、被写体を指定する生成(subject driven generation)のような対応関係が存在しないタスク(non-aligned task)の場合はうまくいかなかった。しかし、non-aligned taskの場合は、indexにオフセットを加えシフトさせる(式4)ことで、conditional text/image token間で空間的にoverlapしないようにすることで性能が大幅に改善した。
既存研究では、C_Iの強さをコントロールするために、ハイパーパラメータとして定数を導入し、エンコードされたfeatureを加算する際の強さを調整していたが(3.2.3節)、本手法ではconcatをするためこのような方法は使えない。そのため、Multi-Modal Attention(MMA)にハイパーパラメータによって強さを調整可能なbias matrixを導入し、C_IとXのattentionの交互作用の強さを調整することで対応した(式5,6)。
[Paper Note] Ctrl-VI: Controllable Video Synthesis via Variational Inference, Haoyi Duan+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #ComputerUse #VideoGeneration/Understandings #3D (Video) Issue Date: 2025-10-19 GPT Summary- ビデオ生成モデルの制約を克服するために、Ctrl-VIという新しいビデオ合成手法を提案。指定要素に対して高い制御性を持ち、非指定要素には多様性を維持。変分推論を用いて複数のビデオ生成バックボーンで合成分布を近似し、KLダイバージェンスの最小化を段階的に行う。実験により、制御性、多様性、3Dの一貫性が向上したことを示す。 Comment
元ポスト:
[Paper Note] Towards Reliable Benchmarking: A Contamination Free, Controllable Evaluation Framework for Multi-step LLM Function Calling, Seiji Maekawa+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #LongSequence #Contamination-free Issue Date: 2025-10-04 GPT Summary- TaLMsの評価のために、汚染のないフレームワークFuncBenchGenを提案。ツール使用をDAG上のトラバーサルとして捉え、モデルは正しい関数呼び出しシーケンスを構成。7つのLLMを異なる難易度のタスクで評価した結果、GPT-5が特に優れた性能を示し、依存の深さが増すと性能が低下。古い引数値の伝播が問題であることが判明し、再表現戦略を導入したところ、成功率が62.5%から81.3%に向上した。 Comment
元ポスト:
[Paper Note] Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs, Ziyue Li+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Search #LanguageModel #Test-Time Scaling #Decoding #KeyPoint Notes Issue Date: 2025-08-30 GPT Summary- 事前学習済みのLLMの層をモジュールとして操作し、各サンプルに最適なアーキテクチャを構築する手法を提案。モンテカルロ木探索を用いて、数学および常識推論のベンチマークで最適な層の連鎖(CoLa)を特定。CoLaは柔軟で動的なアーキテクチャを提供し、推論効率を改善する可能性を示唆。75%以上の正しい予測に対して短いCoLaを見つけ、60%以上の不正確な予測を正すことができることが明らかに。固定アーキテクチャの限界を克服する道を開く。 Comment
解説:
事前学習済み言語モデルのforward pathにおける各layerをbuilding blocksとみなして、入力に応じてスキップ、あるいは再帰的な利用をMCTSによって選択することで、test time時のモデルの深さや、モデルの凡化性能をタスクに対して適用させるような手法を提案している模様。モデルのパラメータの更新は不要。k, r ∈ {1,2,3,4} の範囲で、"k個のlayerをskip"、あるいはk個のlayerのブロックをr回再帰する、とすることで探索範囲を限定的にしtest時の過剰な計算を抑止している。また、MCTSにおけるsimulationの回数は200回。length penaltyを大きくすることでcompactなforward pathになるように調整、10%の確率でまだ探索していない子ノードをランダムに選択することで探索を促すようにしている。オリジナルと比較して実行時間がどの程度増えてしまうのか?に興味があったが、モデルの深さという観点で推論効率は考察されているように見えたが、実行時間という観点ではざっと見た感じ記載がないように見えた。
以下の広範なQA、幅広い難易度を持つ数学に関するデータで評価(Appendix Bに各データセットごとに500 sampleを利用と記載がある)をしたところ、大幅に性能が向上している模様。ただし、8B程度のサイズのモデルでしか実験はされていない。
- [Paper Note] Think you have Solved Question Answering? Try ARC, the AI2 Reasoning
Challenge, Peter Clark+, arXiv'18
- [Paper Note] DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving, Yuxuan Tong+, NeurIPS'24
関連:
- [Paper Note] Looped Transformers are Better at Learning Learning Algorithms, Liu Yang+, ICLR'24
- [Paper Note] Looped Transformers for Length Generalization, Ying Fan+, ICLR'25
- [Paper Note] Universal Transformers, Mostafa Dehghani+, ICLR'19
- [Paper Note] Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation, Sangmin Bae+, NeurIPS'25
[Paper Note] OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation, Jianwen Jiang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #DiffusionModel Issue Date: 2025-08-29 GPT Summary- 「OmniHuman-1.5」は、物理的妥当性と意味的一貫性を兼ね備えたキャラクターアニメーションを生成するフレームワークである。マルチモーダル大規模言語モデルを活用し、音声、画像、テキストの共同意味を解釈することで、感情や意図に基づいた動作を生成。新しいマルチモーダルDiTアーキテクチャにより、異なるモダリティ間の対立を軽減し、リップシンク精度や動作の自然さで優れたパフォーマンスを達成。複雑なシナリオへの拡張性も示している。 Comment
pj page: https://omnihuman-lab.github.io/v1_5/
元ポスト:
promptによって状況や感情などの表現のコントロールが可能らしい
解説:
[Paper Note] AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders, Zhengxuan Wu+, ICLR'25 Spotlight
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #Prompting #Evaluation #ICLR #read-later #ActivationSteering/ITI #Selected Papers/Blogs #InstructionFollowingCapability #Steering Issue Date: 2025-08-02 GPT Summary- 言語モデルの出力制御は安全性と信頼性に重要であり、プロンプトやファインチューニングが一般的に用いられるが、さまざまな表現ベースの技術も提案されている。これらの手法を比較するためのベンチマークAxBenchを導入し、Gemma-2-2Bおよび9Bに関する実験を行った。結果、プロンプトが最も効果的で、次いでファインチューニングが続いた。概念検出では表現ベースの手法が優れており、SAEは競争力がなかった。新たに提案した弱教師あり表現手法ReFT-r1は、競争力を持ちながら解釈可能性を提供する。AxBenchとともに、ReFT-r1およびDiffMeanのための特徴辞書を公開した。 Comment
openreview: https://openreview.net/forum?id=K2CckZjNy0
[Paper Note] CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning, Kuniaki Saito+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NaturalLanguageGeneration #NLP #LanguageModel #VisionLanguageModel Issue Date: 2025-07-25 GPT Summary- CaptionSmithsは、画像キャプショニングモデルがキャプションの特性(長さ、記述性、単語の独自性)を柔軟に制御できる新しいアプローチを提案。人間の注釈なしで特性を定量化し、短いキャプションと長いキャプションの間で補間することで条件付けを実現。実証結果では、出力キャプションの特性をスムーズに変化させ、語彙的整合性を向上させることが示され、誤差を506%削減。コードはGitHubで公開。 Comment
元ポスト:
従来はDiscreteに表現されていたcaptioningにおける特性をCondition Caluculatorを導入することでcontinuousなrepresentationによって表現し、Caluculatorに人間によるinput, あるいは表現したいConditionを持つexampleをinputすることで、生成時に反映させるような手法を提案している模様。Conditionで利用するpropertyについては、提案手法ではLength, Descriptive, Uniqueness of Vocabulariesの3つを利用している(が、他のpropertyでも本手法は適用可能と思われる)。このとき、あるpropertyの値を変えることで他のpropertyが変化してしまうと制御ができなくなるため、property間のdecorrelationを実施している。これは、あるproperty Aから別のproperty Bの値を予測し、オリジナルのpropertyの値からsubtractする、といった処理を順次propertyごとに実施することで実現される。Appendixに詳細が記述されている。
[Paper Note] Controllable Generation with Text-to-Image Diffusion Models: A Survey, Pu Cao+, arXiv'24
Paper/Blog Link My Issue
#Survey #ComputerVision #NLP #DiffusionModel #TextToImageGeneration Issue Date: 2025-08-07 GPT Summary- 拡散モデルはテキスト誘導生成において大きな進展を遂げたが、テキストのみでは多様な要求に応えられない。本調査では、T2I拡散モデルの制御可能な生成に関する文献をレビューし、理論的基盤と実践的進展をカバー。デノイジング拡散確率モデルの基本を紹介し、制御メカニズムを分析。生成条件の異なるカテゴリに整理した文献リストを提供。
[Paper Note] Precise Length Control in Large Language Models, Bradley Butcher+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #LanguageModel #PositionalEncoding #Length #Initial Impression Notes Issue Date: 2025-01-03 GPT Summary- デコーダー専用LLMを応答長を正確に制御するために適応。補助的な位置エンコーディングを用いて、設定された応答長までカウントダウン。ファインチューニングにより整合的な応答が可能となり、平均トークン誤差は3トークン未満に。Max New Tokens++ を導入し、柔軟な長さ制御を実現。実験結果は応答品質を損なわずに正確な長さ制御が可能であることを示す。 Comment
元ポスト:
- [Paper Note] Controlling Output Length in Neural Encoder-Decoders, Yuta Kikuchi+, EMNLP'16
などのEncoder-Decoderモデルで行われていたoutput lengthの制御をDecoder-onlyモデルでもやりました、という話に見える。
[Paper Note] Controllable Text Generation for Large Language Models: A Survey, Xun Liang+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Survey #NaturalLanguageGeneration #NLP Issue Date: 2024-08-25 GPT Summary- 大規模言語モデル(LLMs)のテキスト生成品質を向上させるため、制御可能なテキスト生成(CTG)技術が進化している。これにより、安全性や感情、テーマの一貫性を考慮しつつ、ユーザーの多様なニーズに応える生成が求められる。本論文はCTGの最新の進展をレビューし、コンテンツ制御と属性制御の2つのタスクに分類。また、モデル再訓練やファインチューニング、強化学習等の手法の特性を分析し、生成制御のための細かな洞察を提供する。さらに、CTGの評価方法や現状の課題にも言及し、実世界の応用に重点を置く必要があると提案している。
[Paper Note] Following Length Constraints in Instructions, Weizhe Yuan+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #InstructionTuning #EMNLP #Length #InstructionFollowingCapability #One-Line Notes Issue Date: 2024-07-30 GPT Summary- 指示追従モデルは整合性を高めることでユーザーの要求に応える。しかし、評価において長さのバイアスが影響し、モデルは長い応答を出す傾向がある。本研究では、望ましい応答長を制御する指示を用いてモデルを訓練し、長さ指示付き評価で従来のモデルを超える性能を示す。 Comment
SoTA LLMがOutput長の制約に従わないことを示し、それを改善する学習手法LIFT-DPOを提案
元ツイート:
[Paper Note] Generating Summaries with Controllable Readability Levels, Leonardo F. R. Ribeiro+, EMNLP'23, 2023.10
Paper/Blog Link My Issue
#DocumentSummarization #NLP #LanguageModel #ReinforcementLearning #EMNLP #PostTraining #Readability Issue Date: 2026-01-19 GPT Summary- 可読性とは、読者がテキストを理解する容易さを指し、複雑さや主題、読者の背景知識が影響を与える。可読性レベルに基づく要約生成は、様々なオーディエンスに知識を提供するために重要だが、現行の生成アプローチは制御に欠け、特化したテキストが作成されていない。本研究では、特定の可読性レベルで要約を生成する技術を提案し、三つのアプローチを開発した:(1) 指示ベースの可読性制御、(2) 強化学習による可読性ギャップの最小化、(3) 先読み方式による次ステップの可読性予測。これにより、ニュース要約における可読性制御が大幅に向上し、人間の評価によっても強固な基準が確立された。 Comment
openreview: https://openreview.net/forum?id=IFNbElsnCi
[Paper Note] Adding Conditional Control to Text-to-Image Diffusion Models, Lvmin Zhang+, arXiv'23
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #TextToImageGeneration Issue Date: 2025-08-07 GPT Summary- ControlNetは、テキストから画像への拡散モデルに空間的な条件制御を追加するためのニューラルネットワークアーキテクチャであり、事前学習済みのエンコーディング層を再利用して多様な条件制御を学習します。ゼロ畳み込みを用いてパラメータを徐々に増加させ、有害なノイズの影響を軽減します。Stable Diffusionを用いて様々な条件制御をテストし、小規模および大規模データセットに対して堅牢性を示しました。ControlNetは画像拡散モデルの制御における広範な応用の可能性を示唆しています。 Comment
ControlNet論文
[Paper Note] An Extensible Plug-and-Play Method for Multi-Aspect Controllable Text Generation, Xuancheng Huang+, ACL'23, 2022.12
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #ACL Issue Date: 2023-07-18 GPT Summary- 多側面制御テキスト生成では、プレフィックスチューニングによって効率的な制御が可能だが、複数のプレフィックス間の干渉が制約を劣化させる。本研究では、干渉の理論的下限を示し、層の数が増えると干渉が増加することを実証。学習可能なゲートを用いて干渉を抑制し、トレーニング時に見えない側面の組み合わせへの拡張を容易にする方法を提案。カテゴリカルと自由形式の制約を両方扱う統一的アプローチを実施し、テキスト生成および機械翻訳において精度、品質、拡張性でベースラインを上回る結果を得た。
[Paper Note] An Invariant Learning Characterization of Controlled Text Generation, Carolina Zheng+, ACL'23, 2023.05
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #ACL Issue Date: 2023-07-18 GPT Summary- ユーザープロンプトに基づくコントロールされた生成では、生成されたテキストの分布が訓練された予測器の分布と異なる場合に性能が低下することを示す。本論文では、この問題を不変学習として定式化し、効果的な予測器は複数のテキスト環境において不変であるべきと論じる。実験を通じて、分布シフトの影響と不変性方法の可能性を評価した。
[Paper Note] Controllable Text Generation via Probability Density Estimation in the Latent Space, Yuxuan Gu+, ACL'23, 2022.12
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #ACL Issue Date: 2023-07-15 GPT Summary- 潜在空間の確率密度推定を基にした新しい制御フレームワークを提案。ノーマライズフローを利用し、先行空間での柔軟な制御を実現。実験により、属性の関連性とテキストの質で強力なベースラインを上回り、柔軟な制御戦略の効果を示した。
[Paper Note] On Improving Summarization Factual Consistency from Natural Language Feedback, Yixin Liu+, ACL'23, 2022.12
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #NLP #Dataset #Factuality #ACL Issue Date: 2023-07-15 GPT Summary- ユーザーの期待に応えるために、言語生成モデルの出力品質を向上させることを目指す本研究では、「DeFacto」という高品質データセットを用いて、要約の事実的一貫性を強化するための自然言語フィードバックの活用を検討。また、人間のフィードバックに基づく要約編集や事実誤りの訂正を行うことで、生成タスクの改善を図る。微調整されたモデルは事実的一貫性を向上できる一方で、大規模言語モデルはゼロショット学習において課題が残ることが示された。
[Paper Note] Tailor: A Prompt-Based Approach to Attribute-Based Controlled Text Generation, Kexin Yang+, ACL'23, 2022.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #PEFT(Adaptor/LoRA) #ACL #KeyPoint Notes #SoftPrompt Issue Date: 2023-07-15 GPT Summary- 属性に基づくCTGでは、プロンプトを使用して望ましい属性を満たす文を生成。新手法Tailorは、各属性を連続ベクトルとして表し、固定PLMの生成を誘導。実験によりマルチ属性生成が実現できるが、流暢さの低下が課題。マルチ属性プロンプトマスクと再インデックス位置ID列でこのギャップを埋め、学習可能なプロンプトコネクタにより属性間の連結も可能に。11の生成タスクで強力な性能を示し、GPT-2の最小限のパラメータで有効性を確認。 Comment
Soft Promptを用いてattributeを連続値ベクトルで表現しconcatすることで生成をコントロールする。このとき、複数attuributeを指定可能である。
工夫点としては、attention maskにおいて
soft prompt同士がattendしないようにし、交互作用はMAP Connectorと呼ばれる交互作用そのものを学習するコネクタに移譲する点、(複数のsoft promptをconcatすることによる)Soft Promptのpositionのsensitivityを低減するために、末尾のsoft prompt以外はreindexしている点のようである。
[Paper Note] Focused Prefix Tuning for Controllable Text Generation, Congda Ma+, ACL'23 Short, 2023.06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #PEFT(Adaptor/LoRA) #ACL #Short Issue Date: 2023-07-15 GPT Summary- 制御可能なテキスト生成での無関係な学習信号を軽減するため、フォーカスプレフィックスチューニング(FPT)を提案。FPTは単一属性制御で優れた精度と流暢さを実現し、マルチ属性制御でも最先端の精度を達成。新属性の制御に既存モデルの再訓練なしで対応。 Comment
Prefix Tuning:
- [Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
[Paper Note] Explicit Syntactic Guidance for Neural Text Generation, Yafu Li+, ACL'23, 2023.06
Paper/Blog Link My Issue
#BeamSearch #NaturalLanguageGeneration #NLP #LanguageModel #Transformer #ACL #Decoder Issue Date: 2023-07-13 GPT Summary- 本研究では、構文に基づいた生成スキーマを提案し、構成素解析木に従ってシーケンスを生成する新しいテキスト生成モデルを開発。デコーディングプロセスは、構文コンテキスト内での埋め込みテキストの予測と、構成素のマッピングによる構文構造の構築に分かれ、構造的ビームサーチ手法を用いて階層的な構文構造を探索。実験結果は、提案手法がパラフレーズ生成と機械翻訳において自己回帰型ベースラインを上回り、解釈可能性や制御可能性、多様性においても優れていることを示した。
[Paper Note] Sketching the Future (STF): Applying Conditional Control Techniques to Text-to-Video Models, Rohan Dhesikan+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NLP #VideoGeneration/Understandings #TextToVideoGeneration Issue Date: 2023-05-12 GPT Summary- ゼロショットのテキストからビデオ生成にControlNetを組み合わせた新しいアプローチを提案。複数のスケッチ風フレームを入力とし、それに一致するビデオを生成。フレーム補間とControlNetによる制御で高品質で一貫性のあるビデオを実現。デモ動画やリソースも提供し、さらなる研究を促進。
[Paper Note] Controlled Text Generation with Natural Language Instructions, Wangchunshu Zhou+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #Prompting #SyntheticData #In-ContextLearning #ICML #PostTraining #One-Line Notes Issue Date: 2023-04-30 GPT Summary- 自然言語の指示に従い、多様なタスクを解決可能な大規模言語モデルの制御を改善するために、「InstructCTG」というフレームワークを提案。自然テキストの制約を抽出し、これを自然言語の指示に変換することで弱教師あり訓練データを形成。異なるタイプの制約に柔軟に対応し、生成の質や速度への影響を最小限に抑えつつ、再訓練なしで新しい制約に適応できる能力を持つ。 Comment
制約に関する指示とデモンスとレーションに関するデータを合成して追加のinstruction tuningを実施することで、promptで指示された制約を満たすような(controllableな)テキストの生成能力を高める手法
[Paper Note] Tractable Control for Autoregressive Language Generation, Honghua Zhang+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #LanguageModel #ICML #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 自己回帰型大規模言語モデルは複雑な制約を満たすテキスト生成に課題がある。これに対処するため、語彙的制約を扱う確率モデル(TPMs)を用いたGeLaToフレームワークを提案。蒸留された隠れマルコフモデルを利用し、自己回帰生成の効率的な指導を可能にし、制約付きテキスト生成において最先端の性能を達成。研究は大規模言語モデルの制御に新たな道を開き、TPMsのさらなる発展を促進する。 Comment
自然言語生成モデルで、何らかのシンプルなconstiaint αの元p(xi|xi-1,α)を生成しようとしても計算ができない。このため、言語モデルをfinetuningするか、promptで制御するか、などがおこなわれる。しかしこの方法は近似的な解法であり、αがたとえシンプルであっても(何らかの語尾を付与するなど)、必ずしも満たした生成が行われるとは限らない。これは単に言語モデルがautoregressiveな方法で次のトークンの分布を予測しているだけであることに起因している。そこで、この問題を解決するために、tractable probabilistic model(TPM)を導入し、解決した。
評価の結果、CommonGenにおいて、SoTAを達成した。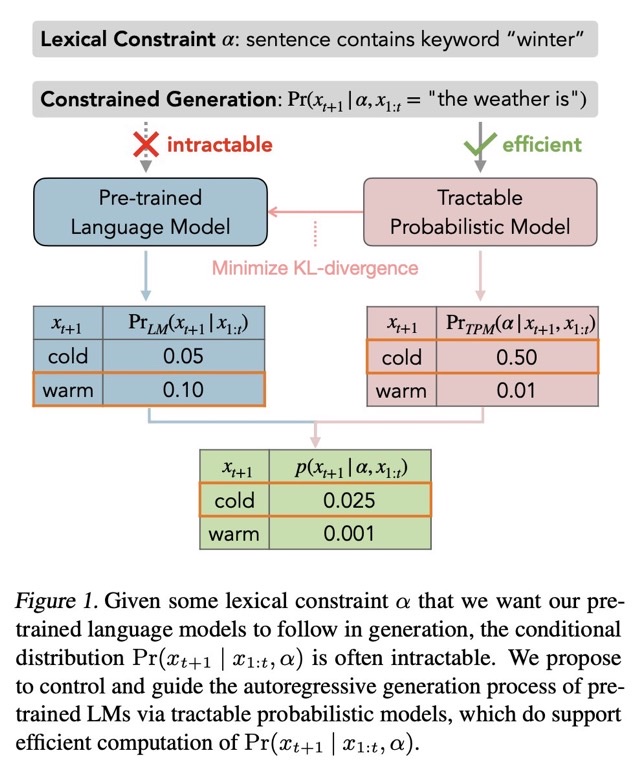
尚、TPMについては要勉強である
[Paper Note] Controlled Language Generation for Language Learning Items, Kevin Stowe+, EMNLP'22 Industry Track, 2022.11
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Education #EMNLP #Encoder-Decoder #IndustryTrack Issue Date: 2026-01-16 GPT Summary- 自然言語生成を活用し、英語学習アプリ向けに迅速に教材を生成。深層事前学習モデルを用いて、熟達度に応じた多様な文や文法テストの引数構造を制御する新手法を開発。人間評価では高い文法スコアを得て、上級モデルは基準を超える長さと複雑さを実現。多様で特注のコンテンツを提供し、強力なパフォーマンスを示す。
[Paper Note] CTRL: A Conditional Transformer Language Model for Controllable Generation, Nitish Shirish Keskar+, arXiv'19, 2019.09
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #LanguageModel #Transformer #Selected Papers/Blogs #Decoder Issue Date: 2026-01-16 GPT Summary- CTRLは、スタイルや内容、タスク特有の振る舞いを制御するコードに基づいて訓練された条件付きトランスフォーマー言語モデルで、1.63億パラメータを持つ。このモデルは、無監督学習の利点を生かしつつ、テキスト生成に対する明示的な制御を提供。CTRLは与えられたシーケンスに基づいて最も可能性のあるトレーニングデータを予測でき、データ分析の新たなアプローチを提示する。また、複数の事前訓練済みバージョンが公開されている。 Comment
Control Code(いわゆるタグ)によって条件付けることで生成されるテキストのスタイルや内容等をcontrollableにする研究の先駆け
[Paper Note] Toward Controlled Generation of Text, Zhiting Hu+, ICML'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #ConceptToTextGeneration #GenerativeAdversarialNetwork #ICML #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 属性に基づいて制御された自然言語文を生成するために、変分オートエンコーダと属性識別器を組み合わせた新しい生成モデルを提案。微分可能な近似を用いて解釈可能な表現を学習し、望ましい属性を持つ文を生成。定量的評価で生成の正確性を確認。 Comment
Text Generationを行う際は、現在は基本的に学習された言語モデルの尤度に従ってテキストを生成するのみで、outputされるテキストをcontrolすることができないので、できるようにしましたという論文。 VAEによるテキスト生成にGANを組み合わせたようなモデル。 decodingする元となるfeatureのある次元が、たとえばpolarityなどに対応しており、その次元の数値をいじるだけで生成されるテキストをcontrolできる。
テキストを生成する際に、生成されるテキストをコントロールするための研究。 テキストを生成する際には、基本的にはVariational Auto Encoder(VAE)を用いる。
VAEは、入力をエンコードするEncoderと、エンコードされた潜在変数zからテキストを生成するGeneratorの2つの機構によって構成されている。
この研究では、生成されるテキストをコントロールするために、VAEの潜在変数zに、生成するテキストのattributeを表す変数cを新たに導入。
たとえば、一例として、変数cをsentimentに対応させた場合、変数cの値を変更すると、生成されるテキストのsentimentが変化するような生成が実現可能。
次に、このような生成を実現できるようなパラメータを学習したいが、学習を行う際のポイントは、以下の二つ。
cで指定されたattributeが反映されたテキストを生成するように学習
潜在変数zとattributeに関する変数cの独立性を保つように学習 (cには制御したいattributeに関する情報のみが格納され、その他の情報は潜在変数zに格納されるように学習する)
1を実現するために、新たにdiscriminatorと呼ばれる識別器を用意し、VAEが生成したテキストのattributeをdiscriminatorで分類し、その結果をVAEのGeneratorにフィードバックすることで、attributeが反映されたテキストを生成できるようにパラメータの学習を行う。 (これにはラベル付きデータが必要だが、少量でも学習できることに加えて、sentence levelのデータだけではなくword levelのデータでも学習できる。)
また、2を実現するために、VAEが生成したテキストから、生成する元となった潜在変数zが再現できるようにEncoderのパラメータを学習。
実験では、sentimentとtenseをコントロールする実験が行われており、attributeを表す変数cを変更することで、以下のようなテキストが生成されており興味深い。
[sentimentを制御した例]
this movie was awful and boring. (negative)
this movie was funny and touching. (positive)
[tenseを制御した例]
this was one of the outstanding thrillers of the last decade
this is one of the outstanding thrillers of the all time
this will be one of the great thrillers of the all time
VAEは通常のAutoEncoderと比較して、奥が深くて勉強してみておもしろかった。 Reparametrization Trickなどは知らなかった。
管理人による解説資料:
[Controllable Text Generation.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1595121/Controllable.Text.Generation.pdf)
slideshare: https://www.slideshare.net/akihikowatanabe3110/towards-controlled-generation-of-text
[Paper Note] Controlling Output Length in Neural Encoder-Decoders, Yuta Kikuchi+, EMNLP'16
Paper/Blog Link My Issue
#NeuralNetwork #NLP #EMNLP #Length #Selected Papers/Blogs #Encoder-Decoder #One-Line Notes Issue Date: 2025-01-03 GPT Summary- ニューラルエンコーダ-デコーダモデルの出力長を制御する方法を提案。特にテキスト要約において、デコーディングと学習に基づく2つのアプローチを用い、学習ベースの方法が要約の質を保ちながら長さを調整できることを示した。 Comment
Encoder-Decoderモデルにおいてoutput lengthを制御する手法を提案した最初の研究
Reasoning models struggle to control their chains of thought, and that’s good, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Chain-of-Thought #Evaluation #Blog #Reasoning #read-later #Author Thread-Post Issue Date: 2026-03-06 Comment
元ポスト:
著者ポスト:
Waypoint-1: Real-time Interactive Video Diffusion from Overworld, Overworld, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Transformer #MultiModal #DiffusionModel #OpenWeight #WorldModels #interactive #3D (Video) #One-Line Notes #RectifiedFlow #Realtime Issue Date: 2026-01-22 Comment
blog:
https://over.world/blog/the-path-to-real-time-worlds-and-why-it-matters
pj page:
https://over.world/
元ポスト:
リアルタイムにzero latencyでマウス(カメラも自由に動かせる)、キーボード、テキストでinteraction可能なworld model
[Paper Note] ArgU: A Controllable Factual Argument Generator, Sougata Saha+, ACL23, 2023.05
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #NLP #Argument #ACL Issue Date: 2023-07-18 GPT Summary- 効果的な論証の自動生成は難しいが、Waltonの論証スキームに基づく制御コードを用いたArgUを提案。69,428の論証からなる注釈付きコーパスを公開し、多様な論証を生成可能であることを実験で示した。