
Encoder-Decoder
[Paper Note] End-to-End Context Compression at Scale, Ang Li+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #LanguageModel #ContextEngineering #One-Line Notes #Compression Issue Date: 2026-06-11 GPT Summary- 長文脈言語モデルの推論ではKVキャッシュの増大がメモリのボトルネックとなるが、従来の圧縮手法はモデルの品質を犠牲にするか、リソースを大量に消費する。そこで、本研究ではエンコーダ-デコーダ圧縮を再検討し、最適な設計と訓練手法を模索。特に、0.6Bエンコーダ・4Bデコーダモデル群を事前学習し、圧縮比1:4、1:8、1:16で性能を向上させるLatent Context Language Models(LCLMs)を提案。LCLMsは効率的な長期エージェントのバックボーンとして機能し、圧縮された文脈から適応的に情報を展開できることを示した。 Comment
元ポスト:
input tokenを圧縮し潜在表現にエンコードするencoderを導入し、decoderへ入力するcontextを圧縮する
[Paper Note] Efficiently Reconstructing Dynamic Scenes One D4RT at a Time, Chuhan Zhang+, CVPR'26 Best Paper, 2025.12
Paper/Blog Link My Issue
#ComputerVision #CVPR #read-later #4D Reconstruction Issue Date: 2026-06-08 GPT Summary- 動画から動的シーンの幾何と運動を理解・再構成するための新しい前方伝播モデルD4RTを提案。単一の動画から深度や時空間対応を一括推定可能で、新しいクエリ機構により計算負担と複雑さを軽減。これにより、3D位置の探索が効率化され、4D再構成タスクで従来を超える性能を実現した。 Comment
元ポスト:
pj page: https://d4rt-paper.github.io/
解説:
[Paper Note] What Matters in Practical Learned Image Compression, Kedar Tatwawadi+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #2D (Image) #ConvolutionalModels #Compression Issue Date: 2026-06-01 GPT Summary- 実用的な学習済み画像コーデックを目指し、知覚品質と実行時のバランスを追求。新技術を含む主要なモデリング選択を検討し、性能を最大化。評価結果に基づき、既存コーデックに比べてビットレートを2.3〜3倍削減、同時に高速なエンコードとデコードを実現。 Comment
pj page: https://apple.github.io/ml-pico/
解説:
[Paper Note] Generative Recursive Reasoning, Junyeob Baek+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #NLP #LanguageModel #Architecture #Test-Time Scaling #read-later #Selected Papers/Blogs #LatentReasoning #RecursiveModels #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- 将来のニューラル推論システムにおける拡張計算の実装として、Generative Recursive reasoning Models (GRAM)を提案。GRAMは、再帰的潜在推論を確率的な複数の潜在軌道に変換し、条件付き推論や無条件生成を可能にする。これにより、従来の決定論的モデルよりも改善された性能を示し、構造化推論や制約充足タスクにおいて有効性を発揮。 Comment
pj page: https://ahn-ml.github.io/gram-website/
元ポスト:
先行研究:
- [Paper Note] Looped Transformers are Better at Learning Learning Algorithms, Liu Yang+, ICLR'24
- [Paper Note] Hierarchical Reasoning Model, Guan Wang+, arXiv'25
- [Paper Note] Less is More: Recursive Reasoning with Tiny Networks, Alexia Jolicoeur-Martineau, arXiv'25, 2025.10
全然まだ理解できていないが、depth(iterative refinement)のみではなく、width(multiple parallel trajectories)方向にinference-time scaling可能なrecursiveなアーキテクチャの提案で、
LoopedTransformerのようなモデルはdeterministicな推論プロセスなため単一の軌跡に収束する(同じ入力に対して同じ出力をする)が、本研究では再帰的な推論プロセスにおいて、deterministicなhidden stateの推論に加えて、確率的でlearnableなguidance ε_t(ε_tの分散の大きさによって探索の度合いを変化させられる)をサンプリングして加えることで、多様なlatent trajectoryを生成可能にするで、自然なparallel inference-time scalingを可能にする
という感じだろうか。
[Paper Note] Image Generation with a Sphere Encoder, Kaiyu Yue+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Transformer #Encoder #2D (Image) #KeyPoint Notes #ImageSynthesis Issue Date: 2026-02-17 GPT Summary- Sphere Encoderは、1回のフォワードパスで画像を生成できる効率的な生成フレームワークです。球面潜在空間への均一な写像を行うエンコーダと、ランダムな潜在ベクトルを画像空間に変換するデコーダを学習し、画像再構成損失のみで訓練を行います。このアプローチにより、複数のデータセットにおいて最先端の拡散モデルに匹敵する性能を示しながら、推論コストを大幅に削減しています。 Comment
元ポスト:
画像を球面状(i.e., 3次元の)の潜在表現にエンコードするエンコーダと、エンコーダに摂動を加えた球面上の点からデコーダを通じて元画像を再構成するデコーダを学習することで、潜在表現から画像のピクセルを直接生成する枠組み。球面上の潜在表現から1回のforward pathで画像を構成するよっに学習するため高速に生成ができる。また、生成した画像をさらにエンコードしデコードすることで、追加のデノイジングstepを実施することができ、画像をより洗練させることができる。4ステップ程度でDiffusion Modelには及ばないものの(ImageNet 256*256でgFID 1.38--2.77)、gFID 4.02--4.76程度のスコア(GAN以上、ADM-Gと呼ばれるDiffusionモデルと同等程度)の画像を生成可能(Table3)という感じに見える。
loss functionはピクセル単位の再構成loss、ピクセルの一貫性に関するloss (i.e., 2つの摂動を加えた潜在表現vが類似した画像を生成するか)をL1_perception lossによって学習する(i.e., ピクセル同士の誤差をスムージングしながら直接測るlossと、既存の学習済み画像エンコーダの潜在表現上でのFeature MapのL1/2距離の組み合わせ)と、
潜在空間の一貫性に関するloss(i.e., 元の潜在表現と、潜在表現をデコード→エンコードした後得られる潜在表現のコサイン類似度)が用いられる式(7,8,9,10)。
[Paper Note] JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation, Kai Liu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #VideoGeneration/Understandings #3D (Video) #Omni #One-Line Notes #audio #AudioVisualGeneration Issue Date: 2026-01-03 GPT Summary- JavisGPTは、音声と映像の理解・生成のための初の統合型マルチモーダル大規模言語モデルであり、SyncFusionモジュールを用いて音声と映像の融合を実現。三段階のトレーニングパイプラインを設計し、高品質な指示データセットJavisInst-Omniを構築。広範な実験により、JavisGPTは既存のモデルを上回る性能を示し、特に複雑な同期設定で優れた結果を出した。 Comment
pj page: https://javisverse.github.io/JavisGPT-page/
元ポスト:
音声と映像を同時に生成可能なadapterタイプのMLLM
[Paper Note] Generation is Required for Data-Efficient Perception, Jack Brady+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Analysis #RepresentationLearning #Generalization #Encoder Issue Date: 2025-12-24 GPT Summary- 生成的アプローチが人間レベルの視覚認知に必要かを検討。生成的手法は帰納的バイアスを容易に強制でき、構成的一般化を実現可能。一方、非生成的手法は一般化に苦労し、大規模な事前学習が必要。生成的手法はデコーダの逆転を通じて構成的一般化を改善し、追加データなしで効果を発揮。 Comment
元ポスト:
[Paper Note] T5Gemma 2: Seeing, Reading, and Understanding Longer, Biao Zhang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #MultiModal #SmallModel #MultiLingual #OpenWeight #KeyPoint Notes Issue Date: 2025-12-19 GPT Summary- T5Gemma 2は、軽量なオープンエンコーダーデコーダーモデルで、多言語・多モーダル・長文コンテキスト能力を備えています。T5Gemmaの適応レシピに基づき、デコーダー専用モデルをエンコーダーデコーダーモデルに拡張し、効率向上のために埋め込みの共有とマージドアテンションを導入しました。実験により、長文コンテキストモデリングにおける強みが確認され、事前学習性能はGemma 3と同等以上、事後学習性能は大幅に向上しました。今後、事前学習済みモデルをコミュニティに公開予定です。 Comment
初めてのマルチモーダル、long-context、かつ140言語に対応したencoder-decoderモデルとのこと。
事前学習済みのdecoder-only model (今回はGemma2)によってencoder/decoderをそれぞれ初期化し、UL2 (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
) によって事前学習する。encoder / decoder側双方のword embeddingは共有し、encoder側のattentionはcausal attentionからbidirectional attentionに変更する。また、decoder側はself-attention/cross-attentionをマージする。
- UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
merged attentionとは、式(1) -- (5)で表されるものであり、Qはdecoderのinput X を用いて、KVの計算する際には、単にdecoder側のinput X とencoder側の隠れ状態 H をconcatしてから、KVを算出する(K, Vのmatrixの次元がHの分大きくなる)というものである。また、マスクトークンの正方行列ではなくなりencoder次元分大きくなり、decoder/encoder部分の両方のvisibilityを制御する。(論文中の当該部分に明記されていないが、普通に考えると)encoder部分は常にvisibleな状態となる。self-/cross attentionは似たような機能を有する(=過去の情報から関連する情報を収集する)ことが先行研究で知られており、単一のモジュールで処理できるという気持ちのようである。H, Xがそれぞれconcatされるので、encoder側の情報とdecoderのこれまでのoutput tokenの情報の両方を同時に考慮することができる。
元ポスト:
HF: https://huggingface.co/collections/google/t5gemma-2
ポイント解説:
[Paper Note] Latent Diffusion Model without Variational Autoencoder, Minglei Shi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #Selected Papers/Blogs #Backbone #KeyPoint Notes #ImageSynthesis Issue Date: 2025-12-17 GPT Summary- VAEを用いない新しい潜在拡散モデルSVGを提案。SVGは自己教師あり表現を活用し、明確な意味的識別性を持つ特徴空間を構築。これにより、拡散トレーニングが加速し、生成品質が向上。実験結果はSVGの高品質な視覚表現能力を示す。 Comment
openreview: https://openreview.net/forum?id=kdpeJNbFyf
これまでの拡散モデルベースのImage GeneiationモデルにおけるVAEを、事前学習済み(self supervised learning)のvision encoder(本稿ではDINOv3)に置き換えfreezeし、それとは別途Residual Encoderと呼ばれるViTベースのEncoderを学習する。前者は画像の意味情報を捉える能力をそのまま保持し、Residual Encoder側でReconstructionをする上でのPerceptualな情報等の(vision encoderでは失われてしまう)より精緻な特徴を捉える。双方のEncoder出力はchannel次元でconcatされ、SVG Featureを形成する。SVG Decoderは、SVG FeatureをPixelスペースに戻す役割を果たす。このアーキテクチャはシンプルで軽量だが、DINOv3による強力な意味的な識別力を保ちつつ、精緻な特徴を捉える能力を補完できる。Figure 5を見ると、実際にDINOv3のみと比較して、Residual Encoderによって、細かい部分がより正確なReconstructionが実現できていることが定性的にわかる。学習時はReconstruction lossを使うが、Residual Encoderに過剰に依存するだけめなく、outputの数値的な値域が異なり、DINOv3の意味情報を損なう恐れが足るため、Residual Encoderの出力の分布をDINOv3とalignするように学習する。
VAE Encoderによるlatent vectorは低次元だが、提案手法はより高次元なベクトルを扱うため、Diffusionモデルの学習が難しいと考えられるが、SVG Featureの特徴量はうまく分散しており、安定してFlow Matchingで学習ができるとのこと。
実際、実験結果を見ると安定して、しかもサンプル効率がベースラインと比較して大幅に高く収束していることが見受けられる。
[Paper Note] Constructing Efficient Fact-Storing MLPs for Transformers, Owen Dugan+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #LanguageModel #Transformer #Factuality #read-later Issue Date: 2025-11-30 GPT Summary- LLMの事実知識の格納能力に基づき、新たに改善されたMLP構築フレームワークを提案。主な改善点は、1)全入力出力ペアに機能し、2)情報理論的制約に一致するパラメータ効率を実現し、3)Transformers内での使いやすさを確保。これにより、事実のスケーリングやエンコーダ・デコーダメカニズムの特定、使いやすさとのトレードオフを明らかにし、モジュラー事実編集の概念実証も行った。 Comment
元ポスト:
[Paper Note] RF-DETR: Neural Architecture Search for Real-Time Detection Transformers, Isaac Robinson+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Transformer #NeuralArchitectureSearch #ObjectDetection #Realtime Issue Date: 2025-11-14 GPT Summary- RF-DETRは、オープンボキャブラリ検出器の一般化問題を解決するために導入された軽量の専門検出トランスフォーマーであり、重み共有ニューラルアーキテクチャサーチ(NAS)を用いて精度とレイテンシのトレードオフを評価します。RF-DETRは、COCOおよびRoboflow100-VLで従来の手法を大幅に上回り、特にRF-DETR(2x-large)はCOCOで60 APを超えた初のリアルタイム検出器です。 Comment
元ポスト:
[Paper Note] Searching Latent Program Spaces, Matthew V Macfarlane+, NeurIPS'25, 2024.11
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Search #Coding #NeurIPS Issue Date: 2025-09-21 GPT Summary- 新しいスキルを効率的に習得し、一般化するためのLatent Program Network(LPN)を提案。LPNは、入力を出力にマッピングする潜在空間を学習し、テスト時に勾配を用いて探索。シンボリックアプローチの適応性とニューラル手法のスケーラビリティを兼ね備え、事前定義されたDSLを不要にする。ARC-AGIベンチマークでの実験により、LPNは分布外タスクでの性能を2倍に向上させることが示された。 Comment
元ポスト:
[Paper Note] 4DNeX: Feed-Forward 4D Generative Modeling Made Easy, Zhaoxi Chen+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Dataset #Transformer #DiffusionModel #PEFT(Adaptor/LoRA) #3D (Video) Issue Date: 2025-09-16 GPT Summary- 4DNeXは、単一の画像から動的3Dシーンを生成する初のフィードフォワードフレームワークであり、事前学習されたビデオ拡散モデルをファインチューニングすることで効率的な4D生成を実現。大規模データセット4DNeX-10Mを構築し、RGBとXYZシーケンスを統一的にモデル化。実験により、4DNeXは既存手法を上回る効率性と一般化能力を示し、動的シーンの生成的4Dワールドモデルの基盤を提供。 Comment
pj page: https://4dnex.github.io
元ポスト:
[Paper Note] LiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation, Keisuke Kamahori+, EMNLP'25
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #NLP #AutomaticSpeechRecognition(ASR) #EMNLP Issue Date: 2025-08-22 GPT Summary- LiteASRは、現代の自動音声認識モデルのエンコーダを低ランク圧縮する手法で、推論コストを大幅に削減しつつ転写精度を維持します。主成分分析を用いて低ランク行列の乗算を近似し、自己注意機構を最適化することで、Whisper large-v3のエンコーダサイズを50%以上圧縮し、Whisper mediumと同等のサイズでより良い転写精度を実現しました。 Comment
元ポスト:
現代のASRモデルはencoderが計算効率の上でボトルネックとなっていたが、Forward Passにおける activatrion Y を PCA (式2, 3)に基づいて2つの低ランク行列の積(とバイアス項の加算; 式5)によって近似し計算効率を大幅に向上させた、という話な模様。weightを低ランクに写像するV_kとバイアス項のY_M(データセット全体に対するactivation Yの平均)はcalibrfationデータによって事前に計算可能とのこと。また、PCAのrank kがattention headの次元数より小さい場合、self-attentionの計算もより(QWKへ写像するWを低ランク行列で近似することで)効率的な手法を採用でき、そちらについても提案されている模様。(ざっくりしか読めていないので誤りがあるかもしれない。)
[Paper Note] AR-GRPO: Training Autoregressive Image Generation Models via Reinforcement Learning, Shihao Yuan+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Transformer #ReinforcementLearning #TextToImageGeneration #GRPO #On-Policy Issue Date: 2025-08-12 GPT Summary- AR-GRPOは、自己回帰画像生成モデルにオンライン強化学習を統合した新しいアプローチで、生成画像の品質を向上させるためにGRPOアルゴリズムを適用。クラス条件およびテキスト条件の画像生成タスクで実験を行い、標準のARモデルと比較して品質と人間の好みを大幅に改善した。結果は、AR画像生成における強化学習の有効性を示し、高品質な画像合成の新たな可能性を開く。 Comment
元ポスト:
[Paper Note] Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, CVPR'24, 2023.12
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #Transformer #InstructionTuning #MultiModal #SpeechProcessing #CVPR #Selected Papers/Blogs #Robotics #UMM #EmbodiedAI #KeyPoint Notes #Surface-level Notes Issue Date: 2023-12-29 GPT Summary- 初の自己回帰型マルチモーダルモデル「Unified-IO 2」を提案し、画像、テキスト、音声、アクションを統一した意味空間で処理。トレーニングの安定化のためにアーキテクチャを改善し、120のデータセットで微調整を行い、GRITベンチマークで最先端のパフォーマンスを達成。35以上のベンチマークにおいて強力な結果を示し、すべてのモデルを公開。 Comment
画像、テキスト、音声、アクションを理解できる初めてのautoregressive model。AllenAI
モデルのアーキテクチャ図
マルチモーダルに拡張したことで、訓練が非常に不安定になったため、アーキテクチャ上でいくつかの工夫を加えている:
- 2D Rotary Embedding
- Positional EncodingとしてRoPEを採用
- 画像のような2次元データのモダリティの場合はRoPEを2次元に拡張する。具体的には、位置(i, j)のトークンについては、Q, Kのembeddingを半分に分割して、それぞれに対して独立にi, jのRoPE Embeddingを適用することでi, j双方の情報を組み込む。
- QK Normalization
- image, audioのモダリティを組み込むことでMHAのlogitsが非常に大きくなりatteetion weightが0/1の極端な値をとるようになり訓練の不安定さにつながった。このため、dot product attentionを適用する前にLayerNormを組み込んだ。
- Scaled Cosine Attention
- Image Historyモダリティにおいて固定長のEmbeddingを得るためにPerceiver Resamplerを扱ったているが、こちらも上記と同様にAttentionのlogitsが極端に大きくなったため、cosine類似度をベースとしたScaled Cosine Attention [Paper Note] Swin Transformer V2: Scaling Up Capacity and Resolution, Ze Liu+, arXiv'21
を利用することで、大幅に訓練の安定性が改善された。
- その他
- attention logitsにはfp32を適用
- 事前学習されたViTとASTを同時に更新すると不安定につながったため、事前学習の段階ではfreezeし、instruction tuningの最後にfinetuningを実施
目的関数としては、Mixture of Denoisers (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
)に着想を得て、Multimodal Mixture of Denoisersを提案。MoDでは、
- \[R\]: 通常のspan corruption (1--5 token程度のspanをmaskする)
- \[S\]: causal language modeling (inputを2つのサブシーケンスに分割し、前方から後方を予測する。前方部分はBi-directionalでも可)
- \[X\]: extreme span corruption (12>=token程度のspanをmaskする)
の3種類が提案されており、モダリティごとにこれらを使い分ける:
- text modality: UL2 (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
)を踏襲
- image, audioがtargetの場合: 2つの類似したパラダイムを定義し利用
- \[R\]: patchをランダムにx%マスクしre-constructする
- \[S\]: inputのtargetとは異なるモダリティのみの情報から、targetモダリティを生成する
訓練時には prefixとしてmodality token \[Text\], \[Image\], \[Audio\] とparadigm token \[R\], \[S\], \[X\] をタスクを指示するトークンとして利用している。
また、image, audioのマスク部分のdenoisingをautoregressive modelで実施する際には普通にやるとdecoder側でリークが発生する(a)。これを防ぐには、Encoder側でマスクされているトークンを、Decoder側でteacher-forcingする際にの全てマスクする方法(b)があるが、この場合、生成タスクとdenoisingタスクが相互に干渉してしまいうまく学習できなくなってしまう(生成タスクでは通常Decoderのinputとして[mask]が入力され次トークンを生成する、といったことは起きえないが、愚直に(b)をやるとそうなってしまう)。ので、(c)に示したように、マスクされているトークンをinputとして生成しなければならない時だけ、マスクを解除してdecoder側にinputする、という方法 (Dynamic Masking) でこの問題に対処している。
[Paper Note] Recommender Systems with Generative Retrieval, Shashank Rajput+, NeurIPS'23
Paper/Blog Link My Issue
#RecommenderSystems #Transformer #VariationalAutoEncoder #NeurIPS #read-later #Selected Papers/Blogs #ColdStart #SemanticID Issue Date: 2025-07-28 GPT Summary- 新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを用いて次のアイテムを予測するTransformerベースのモデルを訓練。これにより、従来のレコメンダーシステムを大幅に上回る性能を達成し、過去の対話履歴がないアイテムに対しても改善された検索性能を示す。 Comment
openreview: https://openreview.net/forum?id=BJ0fQUU32w
Semantic IDを提案した研究
アイテムを意味的な情報を保持したdiscrete tokenのタプル(=Semantic ID)で表現し、encoder-decoderでNext ItemのSemantic IDを生成するタスクに落としこむことで推薦する。SemanticIDの作成方法は後で読んで理解したい。
UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #MultiModal #ICLR #Encoder #KeyPoint Notes Issue Date: 2024-09-26 GPT Summary- 本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 Comment
OpenReview: https://openreview.net/forum?id=6ruVLB727MC
encoder-decoder/decoder-onlyなど特定のアーキテクチャに依存しないアーキテクチャagnosticな事前学習手法であるMoDを提案。
MoDでは3種類のDenoiser [R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを活用する。学習時には与えらえたタスクに対して適切なモードをスイッチできるようにparadigm token ([R], [S], [X])を与え挙動を変化させられるようにしており[^1]、finetuning時においては事前にタスクごとに定義をして与えるなどのことも可能。
[^1]: 事前学習中に具体的にどのようにモードをスイッチするのかはよくわからなかった。ランダムに変更するのだろうか。
[Paper Note] CodeT5+: Open Code Large Language Models for Code Understanding and Generation, Yue Wang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #CodeGeneration #One-Line Notes Issue Date: 2023-05-20 GPT Summary- コードLLMsは特定のアーキテクチャに依存しがちで、事前学習タスクの制約により性能が低下することがある。本研究では、この問題を解決するために「CodeT5+」を提案。CodeT5+は柔軟な部品モジュールの組み合わせを可能にし、 diverseな事前学習目的でタスク要求に応じる。更に、既存のLLMを初期化に利用し効率的にスケールアップ。20以上のコードベンチマークで評価し、指示調整済みのCodeT5+がHumanEvalタスクで新たな最先端性能を達成した。 Comment
様々なコードの理解と生成タスクをサポート
異なる訓練手法によって計算効率改善
20種類のコードベンチマークで、様々な設定「ゼロショット、finetuning, instruction tuning等)を実施した結果、コード補完、math programming, text to code retrievalにおいてSoTA達成
[Paper Note] Vcc: Scaling Transformers to 128K Tokens or More by Prioritizing Important Tokens, Zhanpeng Zeng+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Transformer #LongSequence #NeurIPS #Encoder #needs-revision Issue Date: 2023-05-09 GPT Summary- 超長いシーケンスに対するトランスフォーマーの効率を向上させる新しい手法を提案。VIPトークンに基づく圧縮方式を用い、シーケンスを選択的に圧縮することで、効率化を実現。競争力のある性能を提供し、最大128Kトークンにスケール可能。
[Paper Note] Controlled Language Generation for Language Learning Items, Kevin Stowe+, EMNLP'22 Industry Track, 2022.11
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #Controllable #NLP #Education #EMNLP #IndustryTrack Issue Date: 2026-01-16 GPT Summary- 自然言語生成を活用し、英語学習アプリ向けに迅速に教材を生成。深層事前学習モデルを用いて、熟達度に応じた多様な文や文法テストの引数構造を制御する新手法を開発。人間評価では高い文法スコアを得て、上級モデルは基準を超える長さと複雑さを実現。多様で特注のコンテンツを提供し、強力なパフォーマンスを示す。
[Paper Note] Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, Mitchell Wortsman+, ICML'22, 2022.03
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NLP #ICML #Selected Papers/Blogs #OOD #Finetuning #Generalization #Encoder #KeyPoint Notes #Souping Issue Date: 2025-11-28 GPT Summary- ファインチューニングされたモデルの重みを平均化する「モデルスープ」手法を提案し、精度と堅牢性を向上させることを示す。従来のアンサンブル手法とは異なり、追加のコストなしで複数のモデルを平均化でき、ImageNetで90.94%のトップ1精度を達成。さらに、画像分類や自然言語処理タスクにも適用可能で、分布外性能やゼロショット性能を改善することが確認された。 Comment
transformerベースの事前学習済みモデル(encoder-only, encoder-decoderモデル)のファインチューニングの話で、共通のベースモデルかつ共通のパラメータの初期化を持つ、様々なハイパーパラメータで学習したモデルの重みを平均化することでよりロバストで高性能なモデルを作ります、という話。似たような手法にアンサンブルがあるが、アンサンブルでは利用するモデルに対して全ての推論結果を得なければならないため、計算コストが増大する。一方、モデルスープは単一モデルと同じ計算量で済む(=計算量は増大しない)。
スープを作る際は、Validation dataのAccが高い順に異なるFinetuning済みモデルをソートし、逐次的に重みの平均をとりValidation dataのAccが上がる場合に、当該モデルをsoupのingridientsとして加える。要は、開発データで性能が高い順にモデルをソートし、逐次的にモデルを取り出していき、現在のスープに対して重みを平均化した時に開発データの性能が上がるなら平均化したモデルを採用し、上がらないなら無視する、といった処理を繰り返す。これをgreedy soupと呼ぶ。他にもuniform soup, learned soupといった手法も提案され比較されているが、画像系のモデル(CLIP, ViTなど)やNLP(T5, BERT)等で実験されており、greedy soupの性能とロバストさ(OOD;分布シフトに対する予測性能)が良さそうである。
[Paper Note] High-Resolution Image Synthesis with Latent Diffusion Models, Robin Rombach+, CVPR'22, 2021.12
Paper/Blog Link My Issue
#ComputerVision #TextToImageGeneration #VariationalAutoEncoder #CVPR #Selected Papers/Blogs #ImageSynthesis #U-Net Issue Date: 2025-10-10 GPT Summary- 拡散モデル(DMs)は、逐次的なデノイジングオートエンコーダを用いて画像生成プロセスを効率化し、最先端の合成結果を達成。従来のピクセル空間での訓練に比べ、強力な事前訓練されたオートエンコーダの潜在空間での訓練により、計算リソースを削減しつつ視覚的忠実度を向上。クロスアテンション層を導入することで、テキストやバウンディングボックスに基づく柔軟な生成が可能となり、画像インペインティングや無条件画像生成などで競争力のある性能を発揮。 Comment
ここからtext等による条件付けをした上での生成が可能になった(らしい)
日本語解説:
https://qiita.com/UMAboogie/items/afa67842e0461f147d9b
前提知識:
- [Paper Note] Denoising Diffusion Probabilistic Models, Jonathan Ho+, NeurIPS'20, 2020.06
[Paper Note] On Layer Normalizations and Residual Connections in Transformers, Sho Takase+, arXiv'22
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #Normalization Issue Date: 2025-07-04 GPT Summary- 本研究では、Transformerアーキテクチャのレイヤー正規化の位置に関するPost-LNとPre-LNの違いを調査。Post-LNは浅い層で優れた性能を示す一方、深い層では不安定なトレーニングを引き起こす消失勾配問題があることを発見。これを踏まえ、Post-LNの修正により安定したトレーニングを実現する方法を提案し、実験でPre-LNを上回る結果を示した。 Comment
Pre-LNの安定性を持ちながらもPost-LNのような高い性能を発揮する良いとこ取りのB2TConnectionを提案
NLP2022: https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/A2-5.pdf
[Paper Note] UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models, Tianbao Xie+, EMNLP'22, 2022.01
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #MultitaskLearning #PEFT(Adaptor/LoRA) #EMNLP #Grounding Issue Date: 2022-12-05 GPT Summary- UnifiedSKGフレームワークを提案し、21の構造化知識のグラウンディング(SKG)タスクをテキスト対テキスト形式に統合。これにより、体系的なSKG研究を促進し、異なるサイズのT5で最先端の性能を達成。マルチタスクチューニングが性能向上に寄与し、SKGのゼロショットおよび少数ショット学習における課題を示した。UnifiedSKGは他のタスクへの拡張も可能で、オープンソースとして公開されている。
[Paper Note] Improved Denoising Diffusion Probabilistic Models, Alex Nichol+, ICML'21, 2021.02
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #DiffusionModel #ICML #Selected Papers/Blogs #ScoreMatching #U-Net Issue Date: 2025-10-10 GPT Summary- DDPMは高品質なサンプル生成が可能な生成モデルであり、簡単な修正により競争力のある対数尤度を達成できることを示す。逆拡散プロセスの分散を学習することで、サンプリング回数を大幅に削減しつつサンプル品質を維持。DDPMとGANのターゲット分布のカバー能力を比較し、モデルの容量とトレーニング計算量に対してスケーラブルであることを明らかにした。コードは公開されている。 Comment
関連:
- [Paper Note] Denoising Diffusion Probabilistic Models, Jonathan Ho+, NeurIPS'20, 2020.06
[Paper Note] Diffusion Models Beat GANs on Image Synthesis, Prafulla Dhariwal+, NeurIPS'21 Spotlight, 2021.05
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #DiffusionModel #TextToImageGeneration #NeurIPS #Selected Papers/Blogs #ScoreMatching #U-Net Issue Date: 2025-10-10 GPT Summary- 拡散モデルが最先端の生成モデルを上回る画像サンプル品質を達成。無条件画像合成ではアーキテクチャの改善、条件付き画像合成では分類器のガイダンスを用いて品質向上。ImageNetでのFIDスコアは、128×128で2.97、256×256で4.59、512×512で7.72を達成し、BigGAN-deepに匹敵。分類器のガイダンスはアップサンプリング拡散モデルと組み合わせることでさらに改善され、256×256で3.94、512×512で3.85を記録。コードは公開中。 Comment
openreview: https://openreview.net/forum?id=AAWuCvzaVt
日本語解説: https://qiita.com/UMAboogie/items/160c1159811743c49d99
バックボーンとして使われているU-Netはこちら:
- [Paper Note] U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger+, MICCAI'15, 2015.05
[Paper Note] Denoising Diffusion Probabilistic Models, Jonathan Ho+, NeurIPS'20, 2020.06
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #EfficiencyImprovement #DiffusionModel #NeurIPS #Selected Papers/Blogs #ScoreMatching #ImageSynthesis #U-Net Issue Date: 2025-10-10 GPT Summary- 拡散確率モデルを用いた高品質な画像合成を提案。新しい重み付き変分境界でのトレーニングにより、優れた結果を得る。無条件CIFAR10で9.46のInceptionスコア、256x256のLSUNでProgressiveGANに匹敵する品質を達成。実装はGitHubで公開。 Comment
日本語解説: https://qiita.com/ground0state/items/565de257807b12dba52a
[Paper Note] On Layer Normalization in the Transformer Architecture, Ruibin Xiong+, arXiv'20
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #Normalization Issue Date: 2025-07-05 GPT Summary- 本論文では、Transformerの学習率のウォームアップ段階の重要性を理論的に研究し、レイヤー正規化の位置が訓練の安定性に与える影響を示す。特に、Post-LN Transformerでは大きな勾配が不安定さを引き起こすため、ウォームアップが有効である一方、Pre-LN Transformerでは勾配が良好に振る舞うため、ウォームアップを省略できることを示す。実験により、ウォームアップなしのPre-LN Transformerがベースラインと同等の結果を達成し、訓練時間とハイパーパラメータの調整が削減できることを確認した。 Comment
OpenReview: https://openreview.net/forum?id=B1x8anVFPr
Encoder-DecoderのTransformerにおいて、Post-LNの場合は、Warmupを無くすと最終的な性能が悪化し、またWarmUpステップの値によって(500 vs. 4000で実験)も最終的な性能が変化する。これには学習時にハイパーパラメータをしっかり探索しなければならず、WarmUPを大きくすると学習効率が落ちるというデメリットがある。
Post-LNの場合は、Pre-LNと比較して勾配が大きく、Warmupのスケジュールをしっかり設計しないと大きな勾配に対して大きな学習率が適用され学習が不安定になる。これは学習率を非常に小さくし、固定値を使うことで解決できるが、収束が非常に遅くなるというデメリットがある。
一方、Pre-LNはWarmup無しでも、高い性能が達成でき、上記のようなチューニングの手間や学習効率の観点から利点がある、みたいな話の模様。
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Patrick Lewis+, N_A, NeurIPS'20
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #NeurIPS #Selected Papers/Blogs #ContextEngineering Issue Date: 2023-12-01 GPT Summary- 大規模な事前学習言語モデルを使用した検索強化生成(RAG)の微調整手法を提案しました。RAGモデルは、パラメトリックメモリと非パラメトリックメモリを組み合わせた言語生成モデルであり、幅広い知識集約的な自然言語処理タスクで最先端の性能を発揮しました。特に、QAタスクでは他のモデルを上回り、言語生成タスクでは具体的で多様な言語を生成することができました。 Comment
RAGを提案した研究
Retrieverとして利用されているDense Passage Retrieval (DPR)はこちら:
- [Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04
[Paper Note] Leveraging Pre-trained Checkpoints for Sequence Generation Tasks, Sascha Rothe+, TACL'20, 2019.07
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #MachineTranslation #NLP #Transformer #pretrained-LM #TACL #Encoder #KeyPoint Notes Issue Date: 2022-12-01 GPT Summary- 事前学習された大規模なニューラルモデルがシーケンス生成においても有効であることを示し、BERT、GPT-2、RoBERTaと互換性のあるTransformerベースのモデルを開発。これにより、機械翻訳やテキスト要約などのタスクで新たな最先端の成果を達成。 Comment
# 概要
BERT-to-BERT論文。これまでpre-trainedなチェックポイントを利用する研究は主にNLUで行われてきており、Seq2Seqでは行われてきていなかったので、やりました、という話。
publicly availableなBERTのcheckpointを利用し、BERTをencoder, decoder両方に採用することでSeq2Seqを実現。実現する上で、
1. decoder側のBERTはautoregressiveな生成をするようにする(左側のトークンのattentionしか見れないようにする)
2. encoder-decoder attentionを新たに導入する
の2点を工夫している。
# 実験
Sentence Fusion, Sentence Split, Machine Translation, Summarizationの4タスクで実験
## MT
BERT2BERTがSoTA達成。Edunov+の手法は、data _augmentationを利用した手法であり、純粋なWMT14データを使った中ではSoTAだと主張。特にEncoder側でBERTを使うと、Randomにinitializeした場合と比べて性能が顕著に上昇しており、その重要性を主張。
Sentence Fusion, Sentence Splitでは、encoderとdecoderのパラメータをshareするのが良かったが、MTでは有効ではなかった。これはMTではmodelのcapacityが非常に重要である点、encoderとdecoderで異なる文法を扱うためであると考えられる。
## Summarization
BERTSHARE, ROBERTASHAREの結果が良かった。
Learning to Generate Move-by-Move Commentary for Chess Games from Large-Scale Social Forum Data, Jhamtani+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Dataset #DataToTextGeneration #TabularData #ACL Issue Date: 2025-08-06 Comment
データセットの日本語解説(過去の自分の資料): https://speakerdeck.com/akihikowatanabe/data-to-text-datasetmatome-summary-of-data-to-text-datasets?slide=66
[Paper Note] Personalized Review Generation by Expanding Phrases and Attending on Aspect-Aware Representations, Ni+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ReviewGeneration #Personalization #ACL #RecurrentModels Issue Date: 2018-07-25 GPT Summary- ユーザーのレビュー作成を支援するシステムを、短いフレーズから個別化されたレビューを生成するエンコーダー-デコーダーのフレームワークで構築。アスペクトエンコーダーを使用し、アスペクトに基づいたユーザーおよびアイテムの表現を学習。アテンションフュージョン層を導入し、生成プロセスを制御。実験により、一貫性と多様性を兼ね備えたレビュー生成が可能で、学習したアスペクト重視の表現がユーザーの好みに合ったテキスト生成を支援することを示した。
[Paper Note] Personalizing Dialogue Agents: I have a dog, do you have pets too?, Saizheng Zhang+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DialogueGeneration #ACL #RecurrentModels Issue Date: 2018-02-08 GPT Summary- プロフィール情報を基にchit-chatを魅力的にするタスクを提案。モデルはプロフィールに基づく条件付けと相手の情報を考慮し、次の発話を予測することで対話を改善。対話者のプロフィール情報を予測するために、個人的な話題で引き込むように訓練された。
[Paper Note] Generating Sentences by Editing Prototypes, Kelvin Guu+, TACL'18, 2017.09
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #TACL #Editing Issue Date: 2017-12-31 GPT Summary- 新しい生成モデルを提案し、トレーニングコーパスからプロトタイプ文をサンプリングして編集することで新しい文を生成。従来のモデルと異なり、困惑度を改善し、高品質な出力を実現。さらに、文の類似性や文レベルの類推を捉える編集ベクトルを生成。
[Paper Note] Learning to Generate Market Comments from Stock Prices, Murakami+, ACL'17
Paper/Blog Link My Issue
#NLP #DataToTextGeneration #NumericReasoning #Financial #ACL #numeric Issue Date: 2025-11-27 GPT Summary- 株価から市場コメントを生成する新しいエンコーダ-デコーダモデルを提案。モデルは短期・長期の株価変化をエンコードし、適切な算術演算を選択して数値を生成。実験により、最良モデルが人間の生成したテキストに近い流暢さと情報量を持つことが確認された。
[Paper Note] Google's Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation, Melvin Johnson+, TACL'17, 2016.11
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP #TransferLearning #MultiLingual #Zero/FewShotLearning #TACL #LowResource Issue Date: 2025-11-19 GPT Summary- 単一のNMTモデルを用いて多言語翻訳を実現するシンプルな手法を提案。入力文の先頭に人工トークンを追加することでターゲット言語を指定し、モデルのアーキテクチャは変更せずに共有語彙を使用。これにより、パラメータを増やさずに翻訳品質を向上させ、WMT'14およびWMT'15ベンチマークで最先端の結果を達成。訓練中に見たことのない言語ペア間での暗黙のブリッジングを学習し、転移学習とゼロショット翻訳の可能性を示す。 Comment
[Paper Note] Learning to Paraphrase for Question Answering, Li Dong+, EMNLP'17
Paper/Blog Link My Issue
#NeuralNetwork #NLP #QuestionAnswering #EMNLP #One-Line Notes #RecurrentModels Issue Date: 2018-06-29 GPT Summary- QAシステムにおけるパラフレーズの重要性に着目し、質問と回答のペアを用いたエンドツーエンドの学習フレームワークを提案。ニューラルスコアリングモデルを通じて、正しい回答を得る可能性の高い表現に重みを付ける。実験結果は、提案手法が性能を向上させ、シンプルなQAモデルでも競争力のある結果を達成することを示す。 Comment
question-answeringタスクにおいて、paraphrasingを活用して精度向上させる研究
似たような意味の質問が、異なる表現で出現することがあるので、
questionの様々なparaphrasingを用意して活用したいという気持ち。
たとえば、
- Is the campus far from Shibuya?
- Is the campus near the city center?
のような例があげられる。
手法としては、paraphrasing modelとqa modelを用意し、あるquestionが与えられたときに、paraphrasing modelでparaphraseのスコアを算出、その後、各paraphrasingの候補に対してqa modelで解答を予測し、両者のスコアの積のsummationによって最終的なanswerを決定
QAはデータセットのサイズが小さいので、paraphrasingのような手法が有効に働いているのかもしれない
[Paper Note] Adapting Sequence Models for Sentence Correction, Allen Schmaltz+, EMNLP'17, 2017.07
Paper/Blog Link My Issue
#NeuralNetwork #NLP #EMNLP #SentenceCorrection Issue Date: 2018-01-01 GPT Summary- 文字ベースのシーケンス・ツー・シーケンスモデルが、単語ベースやサブワードモデルよりも文修正タスクで効果的であることが示された。出力を差分としてモデル化することで、標準的なアプローチよりも性能が向上し、最強のモデルはフレーズベースの機械翻訳モデルを6 M2ポイント改善した。また、CoNLL-2014データ環境において、差分モデル化により、シンプルなモデルで少ないデータでも同等以上のM2スコアを達成できることが確認された。
[Paper Note] Multi-Task Video Captioning with Video and Entailment Generation, Ramakanth Pasunuru+, ACL'17, 2017.04
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NaturalLanguageGeneration #NLP #MultitaskLearning #ACL #3D (Video) #One-Line Notes #VideoCaptioning Issue Date: 2017-12-31 GPT Summary- ビデオキャプショニングの改善のため、教師なしビデオ予測タスクと論理的言語含意生成タスクを共有し、リッチなビデオエンコーダ表現を学習。パラメータを共有するマルチタスク学習モデルを提案し、標準データセットで大幅な改善を達成。 Comment
multitask learningで動画(かなり短め)のキャプション生成を行なった話
[Paper Note] Unsupervised Pretraining for Sequence to Sequence Learning, Prajit Ramachandran+, EMNLP'17, 2016.11
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #Unsupervised #NLP #EMNLP #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 本研究では、seq2seqモデルの精度向上のために、事前学習済みの言語モデルの重みでエンコーダとデコーダを初期化し、ラベル付きデータでファインチューニングする教師なし学習手法を提案。機械翻訳や抽象的要約のベンチマークで性能が大幅に向上し、特にWMT英語→ドイツ語タスクで最先端の結果を達成。BLEUスコアで1.3の改善を記録し、抽象的要約においても教師あり学習のベースラインを有意に上回った。 Comment
seq2seqにおいてweightのpretrainingを行う手法を提案
seq2seqでは訓練データが小さいとoverfittingしやすいという弱点があるので、大規模なデータでunsupervisedにpretrainingし、その後目的のデータでfinetuneすることで精度を向上させましょう、というお話。
WMTの翻訳タスクにおいて、1.3ポイント BLEUスコアが改善、abstractive summarizationでも実験したが、精度は向上せず。しかしながら要約ではpretrainingによってrepetitionが減少したと主張。
encoder, decoderそれぞれを切り離して考えると、それぞれ言語モデルとみなすことができるため(encoderにはoutput-layerを追加)、それぞれの言語モデルを独立に大規模なラベルなしデータでpretrainingする。
fine-tuneする際は、targetデータだけでなく、pretrainingする際のデータも同時に学習を続ける(LM Objective)
LM Objectiveは、target側のobjective functionにpretraining側のobjective functionの項を重み付きで追加したもの。
Abltion studyによると、MTにおいてはsoftmax-layerをpretrainingすることが重要。softmax-layerのpretrainingをablationするとBLEUスコアが1.6ポイント減少。
LM objectiveをなくすと、pretrainingの効果がほとんどなくなる(BLEUスコア-2.0ポイント)。
sumarizationにおいては、embeddingのpretrainingが大幅なROUGEスコアの改善を見せた。また、MTと異なり、encoder側のpretrainingがスコア向上に寄与。
LM Objectiveは結構使えそうな印象
[Paper Note] Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu+, arXiv'16, 2016.09
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP #Subword #Tokenizer #RecurrentModels Issue Date: 2025-11-19 GPT Summary- GNMTは、計算コストの高いNMTの問題に対処するために、8層のLSTMネットワークを用い、注意機構と残差接続を採用。希少な単語の処理を改善するために、一般的なサブワードユニットに分割し、翻訳精度を向上。ビームサーチ技術により、出力文のカバレッジを高め、WMT'14のベンチマークで最先端の結果を達成し、翻訳エラーを60%削減。 Comment
GNMT論文。wordpieceを提案
[Paper Note] Controlling Output Length in Neural Encoder-Decoders, Yuta Kikuchi+, EMNLP'16
Paper/Blog Link My Issue
#NeuralNetwork #Controllable #NLP #EMNLP #Length #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-01-03 GPT Summary- ニューラルエンコーダ-デコーダモデルの出力長を制御する方法を提案。特にテキスト要約において、デコーディングと学習に基づく2つのアプローチを用い、学習ベースの方法が要約の質を保ちながら長さを調整できることを示した。 Comment
Encoder-Decoderモデルにおいてoutput lengthを制御する手法を提案した最初の研究
[Paper Note] Neural Headline Generation with Minimum Risk Training, Ayana+, arXiv'16, 2016.04
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #NLP #RecurrentModels Issue Date: 2018-10-06 GPT Summary- 最小リスク訓練を用いることで、自動ヘッドライン生成におけるモデルの性能を改善。従来の手法のパラメータ最適化の制約を克服し、英語と中国語のヘッドライン生成において最先端の成果を上回ることを示した。
[Paper Note] Neural Text Generation from Structured Data with Application to the Biography Domain, Remi Lebret+, EMNLP'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Dataset #ConceptToTextGeneration #EMNLP #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 大規模なWikipediaの伝記データセットを用いて、テキスト生成のためのニューラルモデルを提案。モデルは条件付きニューラル言語モデルに基づき、固定語彙とサンプル固有の単語を組み合わせるコピーアクションを採用。提案モデルは古典的なKneser-Neyモデルを約15 BLEUポイント上回る性能を示した。 Comment
Wikipediaの人物に関するinfo boxから、その人物のbiographyの冒頭を生成するタスク。
Neural Language Modelに、新たにTableのEmbeddingを入れられるようにtable embeddingを提案し、table conditioned language modelを提案している。
inputはテーブル(図中のinput textっていうのは、少し用語がconfusingだが、言語モデルへのinputとして、過去に生成した単語の系列を入れるというのを示しているだけ)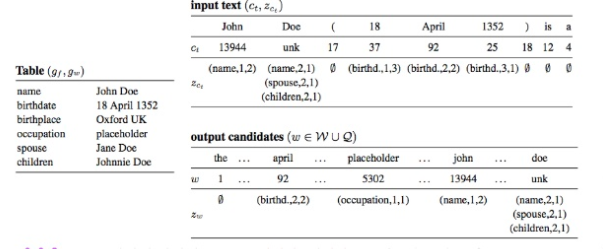
モデル全体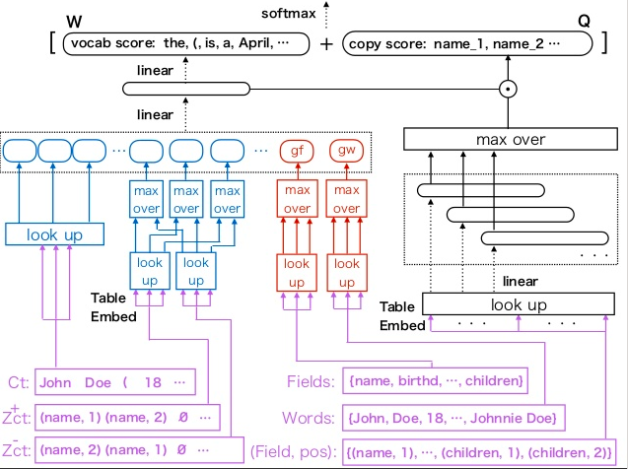
Wikipediaから生成した、Biographyに関するデータセットも公開している。
template basedなKNSmoothingを使ったベースラインよりも高いBLEUスコアを獲得。さらに、テーブルのGlobalな情報を入れる手法が、性能向上に寄与(たとえばチーム名・リーグ・ポジションなどをそれぞれ独立に見ても、バスケットボールプレイヤーなのか、ホッケープレイヤーなのかはわからないけど、テーブル全体を見ればわかるよねという気持ち)。
[Paper Note] U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger+, MICCAI'15, 2015.05
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Selected Papers/Blogs #Backbone #U-Net Issue Date: 2025-09-22 GPT Summary- データ拡張を活用した新しいネットワークアーキテクチャを提案し、少ない注釈付きサンプルからエンドツーエンドでトレーニング可能であることを示す。電子顕微鏡スタックの神経構造セグメンテーションで従来手法を上回り、透過光顕微鏡画像でも優れた結果を達成。512x512画像のセグメンテーションは1秒未満で完了。実装とトレーニング済みネットワークは公開されている。
[Paper Note] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever+, NIPS'14
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #NeurIPS #Selected Papers/Blogs Issue Date: 2025-09-19 GPT Summary- DNNはシーケンス学習において優れた性能を示すが、シーケンス間のマッピングには限界がある。本研究では、LSTMを用いたエンドツーエンドのシーケンス学習アプローチを提案し、英語からフランス語への翻訳タスクで34.8のBLEUスコアを達成。LSTMは長文にも対応し、SMTシステムの出力を再ランク付けすることでBLEUスコアを36.5に向上させた。また、単語の順序を逆にすることで性能が向上し、短期的依存関係の最適化が容易になった。 Comment
いまさらながらSeq2Seqを提案した研究を追加
NDLOCR-Liteの公開について, NDL Lab, 2026.02
Paper/Blog Link My Issue
#Article #NeuralNetwork #ComputerVision #NLP #Blog #Repository #Japanese #Selected Papers/Blogs #OCR #One-Line Notes Issue Date: 2026-02-28 Comment
元ポスト:
江戸期以前の和古書、清代以前の漢籍といった古典籍資料のデジタル化画像からテキストデータを作成するOCRとのこと。以前はGPUで動作していたが、CPUで動作するようにした軽量版とのこと。すごい。
論文解説:VoiceStar, Aratako, Zenn, 2025.12
Paper/Blog Link My Issue
#Article #SpeechProcessing #Blog #PositionalEncoding #TTS Issue Date: 2025-12-22 Comment
vector quantization:
- [Paper Note] Autoregressive Image Generation using Residual Quantization, Doyup Lee+, CVPR'22, 2022.03
- [Paper Note] Taming Transformers for High-Resolution Image Synthesis, Patrick Esser+, CVPR'21, 2020.12
DeepSeek-OCR: Contexts Optical Compression, DeepSeek, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiLingual #read-later #Selected Papers/Blogs #DocParser #OCR #Reference Collection #Compression Issue Date: 2025-10-20 Comment
元ポスト:
英語と中国語では使えそうだが、日本語では使えるのだろうか?p.17 Figure11を見ると100言語に対して学習したと書かれているように見える。
所見:
所見:
OCRベンチマーク:
- [Paper Note] OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations, Linke Ouyang+, CVPR'25, 2024.12
(DeepSeek-OCRの主題はOCRの性能向上というわけではないようだが)
所見:
所見+ポイント解説:
所見:
textxをimageとしてエンコードする話は以下の2023年のICLRの研究でもやられているよというポスト:
- [Paper Note] Language Modelling with Pixels, Phillip Rust+, ICLR'23, 2022.07
関連:
- [Paper Note] Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text
Inputs in Multimodal LLMs, Yanhong Li+, arXiv'25, 2025.10
- [Paper Note] PixelWorld: Towards Perceiving Everything as Pixels, Zhiheng Lyu+, arXiv'25, 2025.01
関連:
literature:
上記ポストでは本研究はこれらliteratureを完全に無視し “an initial investigation into the feasibility of compressing long contexts via optical 2D mapping.” と主張しているので、先行研究を認識し引用すべきだと述べられているようだ。
karpathy氏のポスト:
Wan-S2V: Audio-Driven Cinematic Video Generation, Alibaba, 2025.08
Paper/Blog Link My Issue
#Article #ComputerVision #Transformer #OpenWeight #VideoGeneration/Understandings Issue Date: 2025-08-27 Comment
元ポスト:
関連:
- Wan2.2, Alibaba Wan, 2025.07
image+Audio-to-video generation
Audioモダリティ: wav2vec+AudioEncoder
Visionモダリティ: 3D VAE Encoder
Textモダリティ: T5 Encoder
モダリティ統合: DiT Block(おそらくT5 Encoderの出力を用いてprompt情報を条件付け)とAudio Block?
3D VAE Decoderでデコードというアーキテクチャ?詳細が書かれておらずよくわからない。
[Paper Note] What to talk about and how? Selective Generation using LSTMs with Coarse-to-Fine Alignment, Hongyuan Mei+, NAACL-HLT’16, 2015.09
Paper/Blog Link My Issue
#Article #NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #NAACL #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- エンドツーエンドのドメイン非依存型ニューラルエンコーダー-アライナー-デコーダーモデルを提案。LSTMを用いてデータベースイベントをエンコードし、アライナーで重要なレコードを特定、デコーダーで自由形式の説明を生成。WeatherGovデータセットで最良の結果を達成し、k近傍ビームフィルターでさらに改善。RoboCupデータセットでも競争力のある結果を得た。 Comment
content-selectionとsurface realizationをencoder-decoder alignerを用いて同時に解いたという話。
普通のAttention basedなモデルにRefinerとPre-Selectorと呼ばれる機構を追加。通常のattentionにはattentionをかける際のaccuracyに問題があるが、data2textではきちんと参照すべきレコードを参照し生成するのが大事なので、RefinerとPre-Selectorでそれを改善する。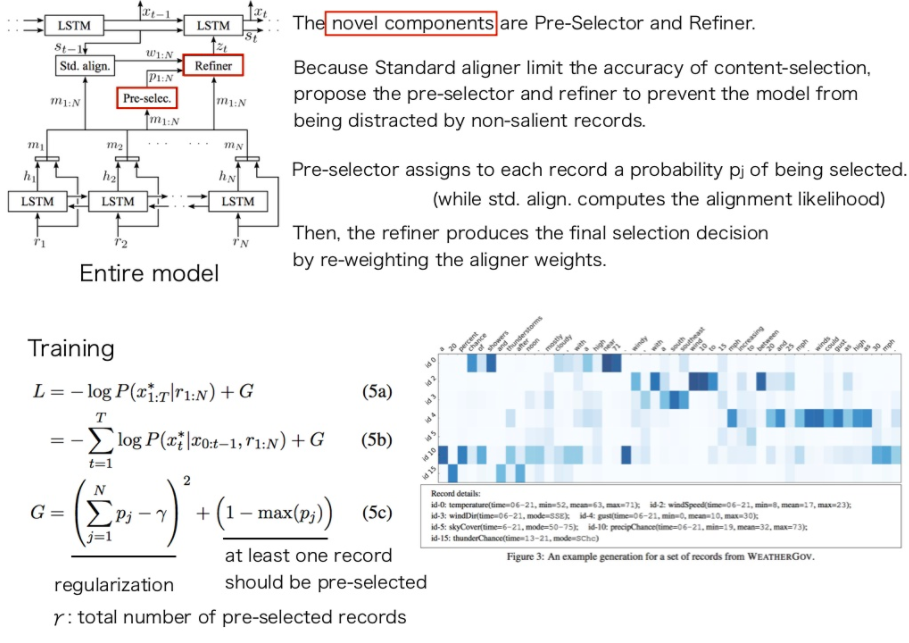
Pre-selectorは、それぞれのレコードが選択される確率を推定する(通常のattentionはalignmentの尤度を計算するのみ)。
Refinerはaligner(attention)のweightをreweightingすることで、最終的にどのレコードを選択するか決定する。
加えて、ロス関数のRegularizationのかけかたを変え、最低一つのレコードがpreselectorに選ばれるようにバイアスをかけている。
ほぼ初期のNeural Network basedなData2Text研究