
Personalization
[Paper Note] Self-Evolving LLM Memory Extraction Across Heterogeneous Tasks, Yuqing Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #memory #KeyPoint Notes #Clustering-based #Reading Reflections #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- 異質な記憶を保持するためのLLMベースのアシスタントの必要性に対して、\textbf{BEHEMOTH}というベンチマークを導入。18のデータセットを再利用し、タスクごとの有用性を評価する。実証分析により、均質なプロンプトが効果的でないことが確認され、\textbf{CluE}を提案。これは訓練例をクラスタに分け、各クラスタを独立に分析することで、抽出プロンプトを効果的に更新し、BEHEMOTHで実験した結果、従来の方法よりも一般化能力が向上したことを示した。 Comment
元ポスト:
現在のAI Agentのメモリは同種のタスクに対して構築され評価されるが、実際の環境、特によりpersonalizationが進んだ状況下では、さまざまな異質なユーザの会話を単一のエージェントが扱い、ユーザのリクエストに応じて適切にメモリからcontextを抽出できなければならず、このような能力を測定するベンチマークは存在しない。
このため、ベンチマークを構築し既存のメモリ手法(promptingベースの手法)を評価したところ、LLMがメモリをmanageする際に、単一のmemory抽出のプロンプトや、自己進化ベースのpromptingではうまくいかないことがわかった。
提案手法 (CluE) では、各サンプルごとに背後にあるシナリオ(どのような情報が欲しいのか, 抽出時にどのような点がchallengingなのか等)をsummarizerにより解釈し、シナリオ単位でクラスタリング。個々のクラスタを分析することで、クラスタごとにどのような場合に成功/失敗するのか等を分析しクラスタ単位のrecommendationを得る。最終的に、クラスタ間のrecommendationを統合して構造化された一つの抽出promptに仕立てる。このとき、競合がある場合は適切なメモリグループにスコープを絞り解決する、といった手法のようである。
既存手法と比較してCluEによって抽出性能が向上
問題設定が実践的でおもしろい
[Paper Note] Your Language Model Secretly Contains Personality Subnetworks, Ruimeng Ye+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ICLR #Personality #Author Thread-Post Issue Date: 2026-04-19 GPT Summary- LLMsは、異なるペルソナを自然に適応させる能力を持ち、その知識は既存のパラメータに埋め込まれていることを示す。小規模な比較データセットを用いて、特定のペルソナに関連する活性化の特徴を特定し、ペルソナサブネットワークを分離するマスキング戦略を開発。二値的な対立性を持つペルソナ間の統計的発散を生み出す対照的剪定戦略も提案し、完全な訓練を必要としない。得られたサブネットワークは、外部知識を必要とする手法よりもペルソナ整合性を大幅に向上させ、LLMsのパーソナライズに新たな視点を提供する。 Comment
元ポスト:
[Paper Note] Personalized RewardBench: Evaluating Reward Models with Human Aligned Personalization, Qiyao Ma+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation Issue Date: 2026-04-17 GPT Summary- 報酬モデル(RMs)の個別化評価が未解決の課題である中、Personalized RewardBench(PRB)という新しいベンチマークを導入。これにより個々のユーザーの嗜好を厳密にモデル化する能力を評価。人間の評価では、両応答が一般的な品質を維持しつつ、嗜好の識別が個別に調整され、既存の報酬モデルは個別化に苦戦していることが明らかに。PRBは下流タスクにおいて既存の性能と比べて高い相関を示し、報酬モデルの評価における信頼性のある指標として確立された。 Comment
元ポスト:
[Paper Note] HippoCamp: Benchmarking Contextual Agents on Personal Computers, Zhe Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Search #Dataset #AIAgents #Evaluation #MultiModal #VisionLanguageModel #One-Line Notes #Environment Issue Date: 2026-04-04 GPT Summary- HippoCampは、エージェントのマルチモーダルファイル管理能力を評価する新しいベンチマーク。ユーザー中心の環境でエージェントを評価し、個々のユーザープロファイルをモデル化し、膨大な個人ファイルを検索。42.4 GBに及ぶ2,000件以上の実世界ファイルから581のQAペアを構築し、エージェントの検索や推論能力を評価。最先端のマルチモーダル大規模言語モデルは、ユーザープロファイリング精度が48.3%に留まり、個人ファイルシステムにおける検索や推論に苦戦。HippoCampは、現行エージェントの制約を浮き彫りにし、次世代AIアシスタント開発の基盤を提供。 Comment
pj page: https://hippocamp-ai.github.io/
元ポスト:
「私の水曜日の予定はなんですか?」といったような、user-centricなタスクにおける、ユーザ個人のcontextを含むファイル検索やプロファイリング、reasoningを必要とする、よりuser-centricな情報を扱う必要があるベンチマークのようである。ユーザのプロファイルやpersonal情報が格納されたEnvironmentが提供されている。
environment: https://hippocamp-ai.github.io/hippocamp/
[Paper Note] Learning Personalized Agents from Human Feedback, Kaiqu Liang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #memory #One-Line Notes Issue Date: 2026-02-23 GPT Summary- PAHFは、個ユーザーの嗜好をリアルタイムで学習し続けるためのフレームワークで、三段階のループを実装。具体的には、事前アクションの明確化、嗜好に基づく行動根拠の提供、嗜好変化時のメモリ更新を行う。新たなベンチマークを用いて、エージェントがゼロから嗜好を学び変化に適応する能力を評価し、明示的メモリと二つのフィードバックチャネルの統合が学習速度やパーソナライゼーション誤差の改善に寄与することを実証。 Comment
元ポスト:
ユーザ専用のmemoryを用意しmemory上にユーザのpreferenceを蓄積し更新することによってpersonalizationを実施する。memoryへの更新はcontextやテキストによるフィードバックに基づいて実施される。
[Paper Note] Learning to summarize user information for personalized reinforcement learning from human feedback, Hyunji Nam+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#DocumentSummarization #NLP #LanguageModel #Alignment #ReinforcementLearning #In-ContextLearning #ICLR #read-later Issue Date: 2026-02-08 GPT Summary- 新しいLLMアシスタントでの応答のパーソナライズを目指し、「要約を用いた好み学習(PLUS)」フレームワークを提案。これにより、各ユーザーの特徴や過去の対話に基づいた要約を生成し、個々の好みに沿った報酬モデルを条件付ける。PLUSは、ユーザー要約モデルと報酬モデルを同時に訓練し、精度向上を実現。新しいユーザーやトピックに対する堅牢性や、独自モデルによる強化されたパーソナライズ能力を示し、ユーザーの解釈可能な表現を提供することで透明性を高める。 Comment
pj page: https://sites.google.com/stanford.edu/plus/home
元ポスト:
[Paper Note] TOM-SWE: User Mental Modeling For Software Engineering Agents, Xuhui Zhou+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #AIAgents #TheoryOfMind Issue Date: 2025-11-01 GPT Summary- ToM-SWEは、ユーザーのメンタル状態をモデル化する心の理論エージェントとソフトウェアエンジニアリングエージェントを組み合わせた二重エージェントアーキテクチャで、指示の不明確さを克服し、ユーザーの目標や好みを推測します。これにより、タスク成功率とユーザー満足度が向上し、特に状態を持つSWEベンチマークで59.7%の成功率を達成しました。プロの開発者の86%がToM-SWEを有用と感じ、ユーザーモデリングの重要性が示されました。 Comment
元ポスト:
[Paper Note] Memory-Efficient Backpropagation for Fine-Tuning LLMs on Resource-Constrained Mobile Devices, Congzheng Song+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #SmallModel #PostTraining Issue Date: 2025-10-30 GPT Summary- モバイルデバイス向けに、メモリ効率の良いバックプロパゲーション実装(MeBP)を提案。これにより、メモリ使用量と計算時間のトレードオフを改善し、ゼロ次最適化よりも速く収束し、優れたパフォーマンスを実現。iPhone 15 Pro Maxでの検証により、0.5Bから4Bのパラメータを持つLLMが1GB未満のメモリでファインチューニング可能であることを示した。実装例は公開済み。 Comment
元ポスト:
iPhone上で4BモデルまでFinetuningができるようになった模様。
[Paper Note] Personalized Reasoning: Just-In-Time Personalization and Why LLMs Fail At It, Shuyue Stella Li+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #UserModeling #Dataset #LanguageModel #UserBased #Evaluation #Conversation #read-later #One-Line Notes Issue Date: 2025-10-03 GPT Summary- 現在のLLMは、タスク解決とユーザーの好みの整合性を別々に扱っており、特にジャストインタイムのシナリオでは効果的ではない。ユーザーの好みを引き出し、応答を適応させる「パーソナライズド推論」が必要である。新たに提案された評価手法「PREFDISCO」は、ユーザーのコンテキストに応じた異なる推論チェーンを生成し、パーソナライズの重要性を示す。評価結果から、単純なパーソナライズが一般的な応答よりも劣ることが明らかになり、専用の開発が必要であることが示唆された。PREFDISCOは、教育や医療などの分野でのパーソナライズの重要性を強調する基盤を提供する。 Comment
元ポスト:
ざーっとしか読めていないのが、ユーザから与えられたタスクとマルチターンの会話の履歴に基づいて、LLM側が質問を投げかけて、Personalizationに必要なattributeを取得する。つまり、ユーザプロファイルは (attribute, value, weight)のタプルによって構成され、この情報に基づいて生成がユーザプロファイルにalignするように生成する、といった話に見える。膨大なとりうるattributeの中から、ユーザのタスクとcontextに合わせてどのattributeに関する情報を取得するかが鍵となると思われる。また、セッション中でユーザプロファイルを更新し、保持はしない前提な話に見えるので、Personalizationのカテゴリとしては一時的個人化に相当すると思われる。
Personalizationの研究は評価が非常に難しいので、どのような評価をしているかは注意して読んだ方が良いと思われる。
[Paper Note] Benchmarking and Improving LLM Robustness for Personalized Generation, Chimaobi Okite+, EMNLP'25 Findings, 2025.09
Paper/Blog Link My Issue
#EMNLP #Findings Issue Date: 2025-09-28 GPT Summary- LLMsの応答の個別化において、事実性も重要であると主張し、堅牢性を評価するフレームワークPERGとデータセットPERGDataを導入。14のモデルを評価した結果、LLMsは堅牢な個別化に苦労しており、特に大規模モデルでも正確性が低下することが判明。クエリの性質やユーザーの好みによって堅牢性が影響を受けることを示し、二段階のアプローチPref-Alignerを提案し、平均25%の堅牢性向上を実現。研究は評価手法のギャップを明らかにし、信頼性の高いLLMの展開を支援するツールを提供。 Comment
元ポスト:
[Paper Note] 360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation, Hamed Firooz+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #FoundationModel Issue Date: 2025-01-29 GPT Summary- ランキングおよび推奨システムを改善するために、大規模基盤モデルを用いてテキストインターフェースを導入。これにより、複数の予測タスクを同時に扱えるほか、新しい領域への一般化も可能に。360Brew V1.0は150Bパラメータの単一デコーダーモデルで、LinkedInのデータを使用し、30以上の予測タスクにおいて従来の専用モデルと同等以上の性能を示す。 Comment
元ポスト:
[Paper Note] Preference Discerning with LLM-Enhanced Generative Retrieval, Fabian Paischer+, TMLR'25, 2024.12
Paper/Blog Link My Issue
#RecommenderSystems #Dataset #LanguageModel #SessionBased #Evaluation #TMLR Issue Date: 2024-12-31 GPT Summary- 逐次推薦システムのパーソナライズを向上させるために、「好みの識別」という新しいパラダイムを提案。大規模言語モデルを用いてユーザーの好みを生成し、包括的な評価ベンチマークを導入。新手法Menderは、既存手法を改善し、最先端の性能を達成。Menderは未観察の人間の好みにも効果的に対応し、よりパーソナライズされた推薦を実現する。コードとベンチマークはオープンソース化予定。 Comment
openreview: https://openreview.net/forum?id=74mrOdhvvT
[Paper Note] On the Way to LLM Personalization: Learning to Remember User Conversations, Lucie Charlotte Magister+, L2M2'24,
Paper/Blog Link My Issue
#LanguageModel Issue Date: 2024-11-21 GPT Summary- LLMのパーソナライズを過去の会話の知識を注入することで実現するため、PLUMというデータ拡張パイプラインを提案。会話の時間的連続性とパラメータ効率を考慮し、ファインチューニングを行う。初めての試みでありながら、RAGなどのベースラインと競争力を持ち、81.5%の精度を達成。
Personalization of Large Language Models: A Survey, Zhehao Zhang+, arXiv'24
Paper/Blog Link My Issue
#Survey #LanguageModel Issue Date: 2024-11-10 GPT Summary- 大規模言語モデル(LLMs)のパーソナライズに関する研究のギャップを埋めるため、パーソナライズされたLLMsの分類法を提案。パーソナライズの概念を統合し、新たな側面や要件を定義。粒度、技術、データセット、評価方法に基づく体系的な分類を行い、文献を統一。未解決の課題を強調し、研究者と実務者への明確なガイドを提供することを目指す。
Leveraging User-Generated Reviews for Recommender Systems with Dynamic Headers, Shanu Vashishtha+, N_A, PAIS'24
Paper/Blog Link My Issue
#RecommenderSystems #PersonalizedGeneration #One-Line Notes Issue Date: 2024-09-14 GPT Summary- Eコマースプラットフォームの推薦カルーセルのヘッダー生成をカスタマイズする新手法「Dynamic Text Snippets(DTS)」を提案。ユーザーのレビューから特定の属性を抽出し、グラフニューラルネットワークを用いて複数のヘッダーテキストを生成。これにより、コンテキストに配慮した推薦システムの可能性を示す。 Comment
e-commerceでDynamicにitemsetに対するスニペット(見出し)を生成する研究。Attributeに基づいてスニペットを生成する。
斜め読みだが、Anchor ItemがGivenであり、kNNされたアイテム集合から抽出されたに基づいて生成するので、Anchor Itemをユーザが与えるのであれば一時的個人化によるpersonalizationとみなせる。Anchor Itemをユーザの履歴からシステムが複数件選び集約して推薦するみたいなパラダイムになれば、永続的個人化とも言えそう。が、後者の場合共通のAttributeが見出せるか不明。
User-LLM: Efficient LLM Contextualization with User Embeddings, Lin Ning+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Initial Impression Notes Issue Date: 2024-02-24 GPT Summary- LLMsを活用したUser-LLMフレームワークが提案された。ユーザーエンベッディングを使用してLLMsをコンテキストに位置付けし、ユーザーコンテキストに動的に適応することが可能になる。包括的な実験により、著しい性能向上が示され、Perceiverレイヤーの組み込みにより計算効率が向上している。 Comment
next item prediction, favorite genre or category predictimnreview generationなどで評価している
[Paper Note] General then Personal: Decoupling and Pre-training for Personalized Headline Generation, Song+, TACL'23, 2023.12
Paper/Blog Link My Issue
#NLP #PersonalizedGeneration #PersonalizedHeadlineGeneration #TACL Issue Date: 2025-11-27 GPT Summary- ユーザーの閲覧履歴に基づくパーソナライズされたヘッドライン生成のために、General Then Personal (GTP)フレームワークを提案。タスクを生成とカスタマイズにデカップリングし、情報自己ブースティングとマスクユーザーモデリングを導入。PENSデータセットでの実験により、GTPが最先端手法を上回ることを示し、デカップリングと事前学習の重要性を強調。人間評価によって効果を検証。
[Paper Note] Personalized Soups: Personalized Large Language Model Alignment via Post-hoc Parameter Merging, Joel Jang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #ReinforcementLearning #Souping #Initial Impression Notes Issue Date: 2023-10-24 GPT Summary- 人間のフィードバックを用いた強化学習(RLHF)は、LLMsを一般的な好みに合わせるが、個別の視点には最適でない。本研究では、個別のフィードバックを考慮した強化学習(RLPHF)を提案し、複数の好みに対応するために多目的強化学習(MORL)としてモデル化。好みを複数の次元に分解することで、個別のアライメントを達成できることを示し、これらの次元が独立して訓練され、効果的に結合可能であることを実証。コードは公開されている。 Comment
どこまでのことが実現できるのかが気になる。
[Paper Note] Generating User-Engaging News Headlines, Cai+, ACL'23
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #PersonalizedGeneration #PersonalizedHeadlineGeneration #ACL #Surface-level Notes Issue Date: 2023-07-22 GPT Summary- ニュース記事の見出しを個別化するために、ユーザープロファイリングを組み込んだ新しいフレームワークを提案。ユーザーの閲覧履歴に基づいて個別のシグネチャフレーズを割り当て、それを使用して見出しを個別化する。幅広い評価により、提案したフレームワークが多様な読者のニーズに応える個別の見出しを生成する効果を示した。 Comment
# モチベーション
推薦システムのヘッドラインは未だに全員に同じものが表示されており、ユーザが自身の興味とのつながりを正しく判定できるとは限らず、推薦システムの有用性を妨げるので、ユーザごとに異なるヘッドラインを生成する手法を提案した。ただし、クリックベイトは避けるようなヘッドラインを生成しなければならない。
# 手法
1. Signature Phrase Identification
2. User Signature Selection
3. Signature-Oriented Headline Generation
## Signature Phrase Identification
テキスト生成タスクに帰着させる。ニュース記事、あるいはヘッドラインをinputされたときに、セミコロン区切りのSignature Phraseを生成するモデルを用いる。今回は[KPTimes daasetでpretrainingされたBART](
https://huggingface.co/ankur310794/bart-base-keyphrase-generation-kpTimes)を用いた。KPTimesは、279kのニュース記事と、signature
phraseのペアが存在するデータであり、本タスクに最適とのこと。
## User Signature Selection
ターゲットドキュメントdのSignature Phrases Z_dが与えられたとき、ユーザのreading History H_uに基づいて、top-kのuser signature phrasesを選択する。H_uはユーザが読んだニュースのヘッドラインの集合で表現される。あるSignature Phrase z_i ∈ Z_dが与えられたとき、(1)H_uをconcatしたテキストをベクトル化したものと、z_iのベクトルの内積でスコアを計算、あるいは(2) 個別のヘッドラインt_jを別々にエンコーディングし、内積の値が最大のものをスコアとする手法の2種類のエンコーディング方法を用いて、in-batch contrastive learningを用いてモデルを訓練する。つまり、正しいSignature Phraseとは距離が近く、誤ったSignature Phraseとは距離が遠くなるように学習をする。
実際はユーザにとっての正解Signature Phraseは分からないが、今回は人工的に作成したユーザを用いるため、正解が分かる設定となっている。
## Signature-Oriented Headline Generation
ニュース記事d, user signature phrasesZ_d^uが与えられたとき、ヘッドラインを生成するモデルを訓練する。この時も、ユーザにとって正解のヘッドラインは分からないため、既存ニュースのヘッドラインが正解として用いられる。既存ニュースのヘッドラインが正解として用いられていても、そのヘッドラインがそのユーザにとっての正解となるように人工的にユーザが作成されているため、モデルの訓練ができる。モデルはBARTを用いた。
# Dataset
Newsroom, Gigawordコーパスを用いる。これらのコーパスに対して、それぞれ2種類のコーパスを作成する。
1つは、Synthesized User Datasetで、これはUse Signature Selection modelの訓練と評価に用いる。もう一つはheadline generationデータセットで、こちらはheadline generationモデルの訓練に利用する。
## Synthesized User Creation
実データがないので、実ユーザのreading historiesを模倣するように人工ユーザを作成する。具体的には、
1. すべてのニュース記事のSignature Phrasesを同定する
2. それぞれのSignature Phraseと、それを含むニュース記事をマッピングする
3. ランダムにphraseのサブセットをサンプリングし、そのサブセットをある人工ユーザが興味を持つエリアとする。
4. サブセット中のinterest phraseを含むニュース記事をランダムにサンプリングし、ユーザのreading historyとする
train, dev, testセット、それぞれに対して上記操作を実施しユーザを作成するが、train, devはContrastive Learningを実現するために、user signature phrases (interest phrases)は1つのみとした(Softmaxがそうなっていないと訓練できないので)。一方、testセットは1~5の範囲でuser signature phrasesを選択した。これにより、サンプリングされる記事が多様化され、ユーザのreadinig historyが多様化することになる。基本的には、ユーザが興味のあるトピックが少ない方が、よりタスクとしては簡単になることが期待される。また、ヘッドラインを生成するときは、ユーザのsignature phraseを含む記事をランダムに選び、ヘッドラインを背衛星することとした。これは、relevantな記事でないとヘッドラインがそもそも生成できないからである。
## Headline Generation
ニュース記事の全てのsignature phraseを抽出し、それがgivenな時に、元のニュース記事のヘッドラインが生成できるようなBARTを訓練した。ニュース記事のtokenは512でtruncateした。平均して、10個のsignature phraseがニュース記事ごとに選択されており、ヘッドライン生成の多様さがうかがえる。user signature phraseそのものを用いて訓練はしていないが、そもそもこのようにGenericなデータで訓練しても、何らかのphraseがgivenな時に、それにバイアスがかかったヘッドラインを生成することができるので、user signature phrase selectionによって得られたphraseを用いてヘッドラインを生成することができる。
# 評価
自動評価と人手評価をしている。
## 自動評価
人手評価はコストがかかり、特に開発フェーズにおいては自動評価ができることが非常に重要となる。本研究では自動評価し方法を提案している。Headline-User DPR + SBERT, REC Scoreは、User Adaptation Metricsであり、Headline-Article DPR + SBERT, FactCCはArticle Loyalty Metricsである。
### Relevance Metrics
PretrainedなDense Passage Retrieval (DPR)モデルと、SentenceBERTを用いて、headline-user間、headline-article間の類似度を測定する。前者はヘッドラインがどれだけユーザに適応しているが、後者はヘッドラインが元記事に対してどれだけ忠実か(クリックベイトを防ぐために)に用いられる。前者は、ヘッドラインとuser signaturesに対して類似度を計算し、後者はヘッドラインと記事全文に対して類似度を計算する。user signatures, 記事全文をどのようにエンコードしたかは記述されていない。
### Recommendation Score
ヘッドラインと、ユーザのreadinig historyが与えられたときに、ニュースを推薦するモデルを用いて、スコアを算出する。モデルとしては、MIND datsetを用いて学習したモデルを用いた。
### Factual Consistency
pretrainedなFactCCモデルを用いて、ヘッドラインとニュース記事間のfactual consisency score を算出する。
### Surface Overlap
オリジナルのヘッドラインと、生成されたヘッドラインのROUGE-L F1と、Extractive Coverage (ヘッドラインに含まれる単語のうち、ソースに含まれる単語の割合)を用いる。
### 評価結果
提案手法のうち、User Signature Selection modelをfinetuningしたものが最も性能が高かった。エンコード方法は、(2)のヒストリのタイトルとフレーズの最大スコアをとる方法が最も性能が高い。提案手法はUser Adaptationをしつつも、Article Loyaltyを保っている。このため、クリックベイトの防止につながる。また、Vanilla Humanは元記事のヘッドラインであり、Extracitve Coverageが低いため、より抽象的で、かつ元記事に対する忠実性が低いことがうかがえる。
## 人手評価
16人のevaluatorで評価。2260件のニュース記事を収集(113 topic)し、記事のヘッドラインと、対応するトピックを見せて、20個の興味に合致するヘッドラインを選択してもらった。これをユーザのinterest phraseとreading _historyとして扱う。そして、ユーザのinterest phraseを含むニュース記事のうち、12個をランダムに選択し、ヘッドラインを生成した。生成したヘッドラインに対して、
1. Vanilla Human
2. Vanilla System
3. SP random (ランダムにsignature phraseを選ぶ手法)
4. SP individual-N
5. SP individual-F (User Signature Phraseを選択するモデルをfinetuningしたもの)
の5種類を評価するよう依頼した。このとき、3つの観点から評価をした。
1, User adaptation
2. Headline appropriateness
3. Text Quality
結果は以下。
SP-individualがUser Adaptationで最も高い性能を獲得した。また、Vanilla Systemが最も高いHeadline appropriatenessを獲得した。しかしながら、後ほど分析した結果、Vanilla Systemでは、記事のメインポイントを押さえられていないような例があることが分かった(んーこれは正直他の手法でも同じだと思うから、ディフェンスとしては苦しいのでは)。
また、Vanilla Humanが最も高いスコアを獲得しなかった。これは、オーバーにレトリックを用いていたり、一般的な人にはわからないようなタイトルになっているものがあるからであると考えられる。
# Ablation Study
Signature Phrase selectionの性能を測定したところ以下の通りになり、finetuningした場合の性能が良かった。
Headline Generationの性能に影響を与える要素としては、
1. ユーザが興味のあるトピック数
2. User signature phrasesの数
がある。
ユーザのInterest Phrasesが増えていけばいくほど、User Adaptationスコアは減少するが、Article Loyaltyは維持されたままである。このため、興味があるトピックが多ければ多いほど生成が難しいことがわかる。また、複数のuser signature phraseを用いると、factual errorを起こすことが分かった(Billgates, Zuckerbergの例を参照)。これは、モデルが本来はirrelevantなフレーズを用いてcoherentなヘッドラインを生成しようとしてしまうためである。
※interest phrases => gold user signatures という理解でよさそう。
※signature phrasesを複数用いるとfactual errorを起こすため、今回はk=1で実験していると思われる
GPT3にもヘッドラインを生成させてみたが、提案手法の方が性能が良かった(自動評価で)。
なぜPENS dataset [Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
を利用しないで研究したのか?
[Paper Note] FABRIC: Personalizing Diffusion Models with Iterative Feedback, Dimitri von Rütte+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #One-Line Notes Issue Date: 2023-07-22 GPT Summary- 生成モデルへの人間のフィードバック統合が重要な機会を提供する中、本研究では拡散モデルを用いたテキストから画像への生成に反復的フィードバックを組み込む手法、FABRICを提案。トレーニング不要で、多様な拡散モデルに適用可能。自己注意層を利用し、フィードバックで条件付けされた生成プロセスを評価。反復的フィードバックによる生成結果の改善を示し、パーソナライズされたコンテンツ作成への応用の可能性を探る。 Comment
upvote downvoteをフィードバックし、iterativeなmannerでDiffusionモデルの生成結果を改善できる手法。多くのDiffusion based Modelに対して適用可能
デモ:
https://huggingface.co/spaces/dvruette/fabric
Explainable Recommendation with Personalized Review Retrieval and Aspect Learning, ACL'23
Paper/Blog Link My Issue
#RecommenderSystems #Explanation #review #ACL Issue Date: 2023-07-18 GPT Summary- 説明可能な推薦において、テキスト生成の精度向上とユーザーの好みの捉え方の改善を目指し、ERRAモデルを提案。ERRAは追加情報の検索とアスペクト学習を組み合わせることで、より正確で情報量の多い説明を生成することができる。さらに、ユーザーの関心の高いアスペクトを選択することで、関連性の高い詳細なユーザー表現をモデル化し、説明をより説得力のあるものにする。実験結果は、ERRAモデルが最先端のベースラインを上回ることを示している。
MPCHAT: Towards Multimodal Persona-Grounded Conversation, ACL'23
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #MultiModal #Conversation #ACL Issue Date: 2023-07-15 GPT Summary- 本研究では、テキストと画像の両方を使用してパーソナを拡張し、マルチモーダルな対話エージェントを構築するためのデータセットであるMPCHATを提案します。さらに、マルチモーダルパーソナを組み込むことで、応答予測、パーソナのグラウンディング予測、話者の識別といったタスクのパフォーマンスを統計的に有意に改善できることを示します。この研究は、マルチモーダルな対話理解においてマルチモーダルパーソナの重要性を強調し、MPCHATが高品質なリソースとして役立つことを示しています。
Adaptive and Personalized Exercise Generation for Online Language Learning, ACL'23
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Education #AdaptiveLearning #KnowledgeTracing #QuestionGeneration #ACL Issue Date: 2023-07-14 GPT Summary- 本研究では、オンライン言語学習のための適応的な演習生成の新しいタスクを研究しました。学習履歴から学生の知識状態を推定し、その状態に基づいて個別化された演習文を生成するモデルを提案しました。実データを用いた実験結果から、学生の状態に応じた演習を生成できることを示しました。さらに、教育アプリケーションでの利用方法についても議論し、学習の効率化を促進できる可能性を示しました。 Comment
Knowledge Tracingで推定された習熟度に基づいて、エクササイズを自動生成する研究。KTとNLGが組み合わさっており、非常におもしろい。
Photoswap: Personalized Subject Swapping in Images, Jing Gu+, N_A, arXiv'23
Paper/Blog Link My Issue
#ComputerVision Issue Date: 2023-06-16 GPT Summary- 本研究では、Photoswapという新しいアプローチを提案し、既存の画像において個人的な対象物の交換を可能にすることを目的としています。Photoswapは、参照画像から対象物の視覚的な概念を学習し、トレーニングフリーでターゲット画像に交換することができます。実験により、Photoswapが効果的で制御可能であり、ベースライン手法を大幅に上回る人間の評価を得ていることが示されました。Photoswapは、エンターテインメントからプロの編集まで幅広い応用可能性を持っています。
[Paper Note] ViCo: Plug-and-play Visual Condition for Personalized Text-to-image Generation, Shaozhe Hao+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#ComputerVision #NLP #DiffusionModel #TextToImageGeneration Issue Date: 2023-06-16 GPT Summary- ViCoは、個別化されたテキストから画像を生成する軽量な拡散モデルで、従来のモデルのファインチューニングを不要とし、柔軟でスケーラブルな展開を実現します。ViCoは、画像アテンションモジュールを通じて視覚セマンティクスを統合し、約6%のパラメータ学習で最先端モデルと同等の性能を達成。個別化テキストからの画像生成における有効性を示し、今後の展望が期待されます。
Towards Personalized Review Summarization by Modeling Historical Reviews from Customer and Product Separately, Xin Cheng+, N_A, arXiv'23
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #review Issue Date: 2023-05-05 GPT Summary- レビュー要約は、Eコマースのウェブサイトにおいて製品レビューの主要なアイデアを要約することを目的としたタスクである。本研究では、評価情報を含む2種類の過去のレビューをグラフ推論モジュールと対比損失を用いて別々にモデル化するHHRRSを提案する。レビューの感情分類と要約を共同で行うマルチタスクフレームワークを採用し、4つのベンチマークデータセットでの徹底的な実験により、HHRRSが両方のタスクで優れた性能を発揮することが示された。
[Paper Note] Personalisation within bounds: A risk taxonomy and policy framework for the alignment of large language models with personalised feedback, Hannah Rose Kirk+, arXiv'23, 2023.03
Paper/Blog Link My Issue
#NLP #LanguageModel #needs-revision Issue Date: 2023-04-26 GPT Summary- LLMの個別化には、人間の嗜好と整合させる必要があり、アラインメント技術がその課題を緩和するが、全ての嗜好を表現するのは難しい。ユーザーの多様な価値観に基づくマイクロレベルの個別化は有望だが、規範的課題が存在する。本文では、整合の定義、主観的嗜好の押し付け、文書化不足の問題を概観し、個別化されたLLMの利点とリスクを整理。最後に、安全なLLMの挙動を維持するための三層政策フレームワークを提案。 Comment
# abst
LLMをPersonalizationすることに関して、どのような方法でPersonalizationすべきかを検討した研究。以下の問題点を指摘。
1. アラインメント(RLHFのように何らかの方向性にalignするように補正する技術のこと?)が何を意味するのか明確ではない
2. 技術提供者が本質的に主観的な好みや価値観の定義を規定する傾向があること
3. クラウドワーカーがの専制によって、我々が実際に何にアラインメントしているのかに関する文書が不足していること
そして、PersonalizedなLLMの利点やリスクの分類を提示する。
# 導入
LLMがさまざまな製品に統合されたことで、人間の嗜好に合致し、危険かつ不正確な情報を出力を生成しないことを確保する必要がある。RLHFやred-teamingはこれに役立つが、このような集合的な(多くの人に一つのアラインメントの結果を提示すること)finetuningプロセスが人間の好みや価値観の幅広い範囲を十分に表現できるとは考えにくい。異なる人々はさまざまな意見や価値観を持っており、マイクロレベルのfinetuningプロせせ雨を通じてLLMをPersonalizationすることで、各ユーザとより良いアラインメントが可能になる可能性がある。これを社会的に受け入れられるようにするためにいくつか課題があるので、それについて論じた。
[Paper Note] Personalized News Headline Generation System with Fine-grained User Modeling, Jiaohong Yao, MSN'22
Paper/Blog Link My Issue
#NLP #PersonalizedGeneration #PersonalizedHeadlineGeneration Issue Date: 2023-08-11
Personalized Headline Generation with Enhanced User Interest Perception, Zhang+, ICANN'22
Paper/Blog Link My Issue
#NLP #PersonalizedGeneration #PersonalizedHeadlineGeneration Issue Date: 2023-08-11
[Paper Note] Personalized Chit-Chat Generation for Recommendation Using External Chat Corpora, Chen+, KDD'22
Paper/Blog Link My Issue
#RecommenderSystems #NLP #PersonalizedGeneration #SIGKDD Issue Date: 2023-08-11
[Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Dataset #LanguageModel #PersonalizedGeneration #PersonalizedHeadlineGeneration #ACL #Surface-level Notes Issue Date: 2023-05-31 GPT Summary- この論文では、ユーザーの興味とニュース本文に基づいて、ユーザー固有のタイトルを生成するパーソナライズされたニュース見出し生成の問題を解決するためのフレームワークを提案します。また、この問題のための大規模なデータセットであるPENSを公開し、ベンチマークスコアを示します。データセットはhttps://msnews.github.io/pens.htmlで入手可能です。 Comment
# 概要
ニュース記事に対するPersonalizedなHeadlineの正解データを生成。103名のvolunteerの最低でも50件のクリックログと、200件に対する正解タイトルを生成した。正解タイトルを生成する際は、各ドキュメントごとに4名異なるユーザが正解タイトルを生成するようにした。これらを、Microsoft Newsの大規模ユーザ行動ログデータと、ニュース記事本文、タイトル、impressionログと組み合わせてPENSデータを構成した。
# データセット生成手順
103名のenglish-native [speakerの学生に対して、1000件のニュースヘッドラインの中から最低50件興味のあるヘッドラインを選択してもらう。続いて、200件のニュース記事に対して、正解ヘッドラインを生成したもらうことでデータを生成した。正解ヘッドラインを生成する際は、同一のニュースに対して4人がヘッドラインを生成するように調整した。生成されたヘッドラインは専門家によってqualityをチェックされ、factual informationにエラーがあるものや、極端に長い・短いものなどは除外された。
# データセット統計量
# 手法概要
Transformer Encoder + Pointer GeneratorによってPersonalizedなヘッドラインを生成する。
Transformer Encoderでは、ニュースの本文情報をエンコードし、attention distributionを生成する。Decoder側では、User Embeddingを組み合わせて、テキストをPointer Generatorの枠組みでデコーディングしていき、ヘッドラインを生成する。
User Embeddingをどのようにinjectするかで、3種類の方法を提案しており、1つ目は、Decoderの初期状態に設定する方法、2つ目は、ニュース本文のattention distributionの計算に利用する方法、3つ目はデコーディング時に、ソースからvocabをコピーするか、生成するかを選択する際に利用する方法。1つ目は一番シンプルな方法、2つ目は、ユーザによって記事で着目する部分が違うからattention distributionも変えましょう、そしてこれを変えたらcontext vectorも変わるからデコーディング時の挙動も変わるよねというモチベーション、3つ目は、選択するvocabを嗜好に合わせて変えましょう、という方向性だと思われる。最終的に、2つ目の方法が最も性能が良いことが示された。
# 訓練手法
まずニュース記事推薦システムを訓練し、user embeddingを取得できるようにする。続いて、genericなheadline generationモデルを訓練する。最後に両者を組み合わせて、Reinforcement LearningでPersonalized Headeline Generationモデルを訓練する。Rewardとして、
1. Personalization: ヘッドラインとuser embeddingのdot productで報酬とする
2. Fluency: two-layer LSTMを訓練し、生成されたヘッドラインのprobabilityを推定することで報酬とする
3. Factual Consistency: 生成されたヘッドラインと本文の各文とのROUGEを測りtop-3 scoreの平均を報酬とする
とした。
1,2,3の平均を最終的なRewardとする。
# 実験結果
Genericな手法と比較して、全てPersonalizedな手法が良かった。また、手法としては②のattention distributionに対してuser informationを注入する方法が良かった。News Recommendationの性能が高いほど、生成されるヘッドラインの性能も良かった。
# Case Study
ある記事に対するヘッドラインの一覧。Pointer-Genでは、重要な情報が抜け落ちてしまっているが、提案手法では抜け落ちていない。これはRLの報酬のfluencyによるものだと考えられる。また、異なるユーザには異なるヘッドラインが生成されていることが分かる。
[Paper Note] ニュース記事に対する談話構造と興味度のアノテーション ~ニュース対話システムのパーソナライズに向けて~, 高津+, NLP'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Dataset Issue Date: 2023-04-30 Comment
ニュース記事に対して談話構造および,ユーザのプロフィールと記事の話題・文に対するユーザの興味度を付与したデータセット。
プロフィールとして以下を収集:
- 性別
- 年齢,
- 住んでいる地域
- 職種
- 業種
- ニュースを見る頻度,
- ニュースをよくチェックする時間帯
- 映像・音声・文字のうちニュースへの接触方法として多いものはどれか
- ニュースを知る手段
- ニュースを読む際使用している新聞やウェブサイト・アプリ
- 有料でニュースを読んでいるか
- 普段積極的に読む・見る・聞くニュースのジャンル
- ニュースのジャンルに対する興味の程度,趣味.
Refocusing on Relevance: Personalization in NLG, Shiran Dudy+, Department of Computer Science University of Colorado, EMNLP'21
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #EMNLP #One-Line Notes Issue Date: 2023-04-26 Comment
従来のNLGはソーステキストに焦点を当て、ターゲットを生成することに注力してきた。が、ユーザの意図やcontextがソーステキストだけに基づいて復元できない場合、このアプローチでは不十分であることを指摘。
この研究ではNLGシステムが追加のcontextを利用することに大きな重点をおくべきであり、IR等で活用されているrelevancyをユーザ指向のテキスト生成タスクを設計するための重要な指標として考えることを提案している。
Returning the N to NLP: Towards Contextually Personalized Classification Models, Lucie Flek, Mainz University of Applied Sciences Germany, ACL'20
Paper/Blog Link My Issue
#Survey #NLP #ACL #One-Line Notes Issue Date: 2023-04-26 Comment
NLPのけるPersonalized Classificationモデルのliteratureを振り返る論文
Towards Personalized Review Summarization via User-Aware Sequence Network, Li+, AAAI'19
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #AAAI #Surface-level Notes Issue Date: 2023-05-08 Comment
同じレビューに対しても、異なるユーザは異なるSumamryを生成するよね、というところがモチベーションとなり、Personalized Review Summarizationを提案。初めてPersonalizationの問題について提案した研究。
user embeddingによってユーザ情報を埋め込む方法と、user vocabulary memoryによって、ユーザが好むvocabularyを積極的にsummaryに利用できるようなモジュールの2種類をモデルに導入している
Trip advisorのレビューデータを収集。レビューのtitleをreference summaryとみなしてデータセット生成。ただタイトルを利用するだけだと、無意味なタイトルが多く含まれているでフィルタリングしている。
Trip Advisorはクローリングを禁止していた気がするので、割とアウトなのでは。
あと、各レビューをランダムにsplitしてtrain/dev/testを作成したと言っているが、本当にそれでいいの?user-stratifiedなsplitをした方が良いと思う。
PGN [Paper Note] Get To The Point: Summarization with Pointer-Generator Networks, Abigail See+, arXiv'17, 2017.04
やlead-1と比較した結果、ROUGEの観点で高い性能を達成
また人手評価として、ユーザのgold summaryに含まれるaspectと、generated summaryに含まれるaspectがどれだけ一致しているか、1000件のreviewとtest setからサンプリングして2人の学生にアノテーションしてもらった。結果的に提案手法が最もよかったが、アノテーションプロセスの具体性が薄すぎる。2人の学生のアノテーションのカッパ係数すら書かれていない。
case studyとしてあるユーザのレビュと生成例をのせている。userBの過去のレビューを見たら、room, locationに言及しているものが大半であり、このアスペクトをきちんと含められているよね、ということを主張している。
[Paper Note] Automatic Generation of Personalized Comment Based on User Profile, Wenhuan Zeng+, ACL'19 SRW
Paper/Blog Link My Issue
#NLP #CommentGeneration #ACL #Workshop Issue Date: 2019-09-11 GPT Summary- ソーシャルメディアの多様なコメント生成の難しさを考慮し、ユーザーのプロフィールに基づくパーソナライズされたコメント生成タスク(AGPC)を提案。パーソナライズドコメント生成ネットワーク(PCGN)を用いて、ユーザーの特徴をモデル化し、外部ユーザー表現を考慮することで自然で人間らしいコメントを生成することに成功した。
[Paper Note] Personalized Review Generation by Expanding Phrases and Attending on Aspect-Aware Representations, Ni+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ReviewGeneration #ACL #Encoder-Decoder #RecurrentModels Issue Date: 2018-07-25 GPT Summary- ユーザーのレビュー作成を支援するシステムを、短いフレーズから個別化されたレビューを生成するエンコーダー-デコーダーのフレームワークで構築。アスペクトエンコーダーを使用し、アスペクトに基づいたユーザーおよびアイテムの表現を学習。アテンションフュージョン層を導入し、生成プロセスを制御。実験により、一貫性と多様性を兼ね備えたレビュー生成が可能で、学習したアスペクト重視の表現がユーザーの好みに合ったテキスト生成を支援することを示した。
[Paper Note] Joint Optimization of User-desired Content in Multi-document Summaries by Learning from User Feedback, P.V.S+, ACL'17, 2017.08
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #IntegerLinearProgramming (ILP) #ACL #interactive #In-Depth Notes Issue Date: 2017-12-28 GPT Summary- ユーザーフィードバックを活用した抽出的マルチドキュメント要約システムを提案。インタラクティブにフィードバックを取得し、ILPフレームワークを用いて要約の質を向上。最小限の反復で高品質な要約を生成し、シミュレーション実験で効果を分析。 Comment
# 一言で言うと
ユーザとインタラクションしながら重要なコンセプトを決め、そのコンセプトが含まれるようにILPな手法で要約を生成するPDS手法。Interactive Personalized Summarizationと似ている(似ているが引用していない、引用した方がよいのでは)。
# 手法
要約モデルは既存のMDS手法を採用。Concept-based ILP Summarization
フィードバックをユーザからもらう際は、要約を生成し、それをユーザに提示。提示した要約から重要なコンセプトをユーザに選択してもらう形式(ユーザが重要と判断したコンセプトには定数重みが与えられる)。
ユーザに対して、τ回フィードバックをもらうまでは、フィードバックをもらっていないコンセプトの重要度が高くなるようにし、フィードバックをもらったコンセプトの重要度が低くなるように目的関数を調整する。これにより、まだフィードバックを受けていないコンセプトが多く含まれる要約が生成されるため、これをユーザに提示することでユーザのフィードバックを得る。τ回を超えたら、ユーザのフィードバックから決まったweightが最大となるように目的関数を修正する。
ユーザからコンセプトのフィードバックを受ける際は、効率的にフィードバックを受けられると良い(最小のインタラクションで)。そこで、Active Learningを導入する。コンセプトの重要度の不確実性をSVMで判定し、不確実性が高いコンセプトを優先的に含むように目的関数を修正する手法(AL)、SVMで重要度が高いと推定されたコンセプトを優先的に要約に含むように目的関数を修正する手法(AL+)を提案している。
# 評価
oracle-based approachというものを使っている。要は、要約をシステムが提示しリファレンスと被っているコンセプトはユーザから重要だとフィードバックがあったコンセプトだとみなすというもの。
評価結果を見ると、ベースラインのMDSと比べてupper bound近くまでROUGEスコアが上がっている。フィードバックをもらうためのイテレーションは最大で10回に絞っている模様(これ以上ユーザとインタラクションするのは非現実的)。
実際にユーザがシステムを使用する場合のコンテキストに沿った評価になっていないと思う。
この評価で示せているのは、ReferenceSummary中に含まれる単語にバイアスをかけて要約を生成していくと、ReferenceSummaryと同様な要約が最終的に作れます、ということと、このときPool-basedなActiveLearningを使うと、より少ないインタラクションでこれが実現できますということ。
これを示すのは別に良いと思うのだが、feedbackをReferenceSummaryから与えるのは少し現実から離れすぎている気が。たとえばユーザが新しいことを学ぶときは、ある時は一つのことを深堀し、そこからさらに浅いところに戻って別のところを深堀するみたいなプロセスをする気がするが、この深堀フェーズなどはReferenceSummaryからのフィードバックからでは再現できないのでは。
# 所感
評価が甘いと感じる。十分なサイズのサンプルを得るのは厳しいからorable-based approachとりましたと書いてあるが、なんらかの人手評価もあったほうが良いと思う。
ユーザに数百単語ものフィードバックをもらうというのはあまり現時的ではない気が。
oracle-based approachでユーザのフィードバックをシミュレーションしているが、oracleの要約は、人がそのドキュメントクラスタの内容を完璧に理解した上で要約しているものなので、これを評価に使うのも実際のコンテキストと違うと思う。実際にユーザがシステムを使うときは、ドキュメントクラスタの内容なんてなんも知らないわけで、そのユーザからもらえるフィードバックをoracle-based approachでシミュレーションするのは無理がある。仮に、ドキュメントクラスタの内容を完璧に理解しているユーザのフィードバックをシミュレーションするというのなら、わかる。が、そういうユーザのために要約作って提示したいわけではないはず。
[Paper Note] Personalized Mathematical Word Problem Generation, Polozov+, IJCAI'15
Paper/Blog Link My Issue
#NLP #Education #PersonalizedGeneration #QuestionGeneration #IJCAI Issue Date: 2019-10-11
[Paper Note] Extended Recommendation Framework: Generating the Text of a User Review as a Personalized Summary Poussevin+, CBRecsys'15, 2015.09
Paper/Blog Link My Issue
#NLP #ReviewGeneration #One-Line Notes Issue Date: 2017-12-28 Comment
review generationの結果をrating predictionに伝搬することで性能よくしました、という話だと思う
[Paper Note] Generating Personalized Snippets for Web Page Recommender Systems, Akihiko+, WI-IAT'14
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #RecommenderSystems #NLP #Snippets #Explanation #PersonalizedGeneration #WI Issue Date: 2025-11-27 Comment
ジャーナル(日本語): https://www.jstage.jst.go.jp/article/tjsai/31/5/31_C-G41/_article/-char/en
Context-enhanced personalized social summarization, Po+, COLING'12, 18
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #One-Line Notes Issue Date: 2023-05-05 Comment
ざっくり言うと、ソーシャルタギングシステムにおいて、ユーザ uと類似したユーザのタグ付け情報と、原文書d _と同じトピックに属する文書をそれぞれ考慮することによって、ユーザのinterestに関する情報(と原文書のinformativenessに関する情報)を拡張し、これらの情報を活用して、全てのクラスタリングしたドキュメントの中で重要文をランキングした上で、対象文書に対するsentenceのみを冗長性がないように抽出することで、Personalized_ Summarizationしましょう、という話
[Paper Note] Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #EMNLP #Selected Papers/Blogs #interactive #KeyPoint Notes Issue Date: 2017-12-28 Comment
ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。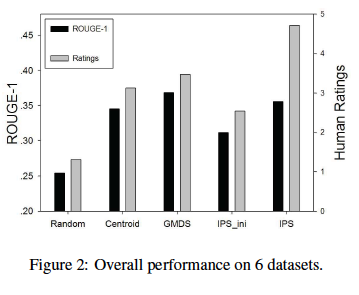
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
[Paper Note] Personalized Multi-Document Summarization using N-Gram Topic Model Fusion, Hennig+, SPIM'10, 2010.05
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #One-Line Notes Issue Date: 2017-12-28 Comment
・unigramの共起だけでなく,bigramの共起も考慮したPLSIモデルを提案し,jointで学習.与えられたクエリやnarrativeなどとsentenceの類似度(latent spaceで計算)を計算し重要文を決定。
・user-modelを使ったPersonalizationはしていない.
[Paper Note] Collaborative Summarization: When Collaborative Filtering Meets Document Summarization, Qu+, PACLIC'09, 2009.12
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #RecommenderSystems #CollaborativeFiltering #GraphBased #PACLIC #KeyPoint Notes Issue Date: 2017-12-28 Comment
Collaborative Filteringと要約を組み合わせる手法を提案した最初の論文と思われる。
ソーシャルブックマークのデータから作成される、ユーザ・アイテム・タグのTripartite Graphと、ドキュメントのsentenceで構築されるGraphをのノード間にedgeを張り、co-rankingする手法を提案している。
評価
100個のEnglish wikipedia記事をDLし、文書要約のセットとした。
その上で、5000件のwikipedia記事に対する1084ユーザのタギングデータをdelicious.comから収集し、合計で8396の異なりタグを得た。
10人のdeliciousのアクティブユーザの協力を得て、100記事に対するtop5のsentenceを抽出してもらった。ROUGE1で評価。
[Paper Note] Incremental Personalised Summarisation with Novelty Detection, Campana+, FQAS'09, 2009.10
Paper/Blog Link My Issue
#Single #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Search #KeyPoint Notes Issue Date: 2017-12-28 Comment
https://link.springer.com/content/pdf/10.1007/978-3-642-04957-6_55.pdf
[Paper Note] Personalized PageRank based Multi-document summarization, Liu+, WSCS'08, 2008.07
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #KeyPoint Notes Issue Date: 2017-12-28 Comment
・クエリがあるのが前提
・基本的にPersonalized PageRankの事前分布を求めて,PageRankアルゴリズムを適用する
・文のsalienceを求めるモデルと(パラグラフ,パラグラフ内のポジション,statementなのかdialogなのか,文の長さ),クエリとの関連性をはかるrelevance model(クエリとクエリのnarrativeに含まれる固有表現が文内にどれだけ含まれているか)を用いて,Personalized PageRankの事前分布を決定する
・評価した結果,DUC2007のtop1とtop2のシステムの間のROUGEスコアを獲得
[Paper Note] Personalized Multi-document Summarization in Information Retrieval, Yang+, Machine Learning and Cybernetics'08, 2008.07
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #InformationRetrieval #NLP #QueryBiased #KeyPoint Notes Issue Date: 2017-12-28 Comment
・検索結果に含まれるページのmulti-document summarizationを行う.クエリとsentenceの単語のoverlap, sentenceの重要度を
Affinity-Graphから求め,両者を結合しスコアリング.MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
likeな手法で冗長性を排除し要約を生成する.
・4人のユーザに,実際にシステムを使ってもらい,5-scaleで要約の良さを評価(ベースラインなし).relevance, importance,
usefulness, complement of summaryの視点からそれぞれを5-scaleでrating.それぞれのユーザは,各トピックごとのドキュメントに
全て目を通してもらい,その後に要約を読ませる.
[Paper Note] Aspect-Based Personalized Text Summarization, Berkovsky+(Tim先生のグループ), AH'2008, 2008.07
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #Analysis #NLP #KeyPoint Notes Issue Date: 2017-12-28 Comment

Aspect-basedなPDSに関して調査した研究。
たとえば、Wikipediaのクジラに関するページでは、biological taxonomy, physical dimensions, popular cultureのように、様々なアスペクトからテキストが記述されている。ユーザモデルは各アスペクトに対する嗜好の度合いで表され、それに従い生成される要約に含まれる各種アスペクトに関する情報の量が変化する。
UserStudyの結果、アスペクトベースなユーザモデルとよりfitした、擬似的なユーザモデルから生成された要約の方が、ユーザの要約に対するratingが上昇していくことを示した。
また、要約の圧縮率に応じて、ユーザのratingが変化し、originalの長さ>長めの要約>短い要約の順にratingが有意に高かった。要約が長すぎても、あるいは短すぎてもあまり良い評価は得られない(しかしながら、長すぎる要約は実はそこまで嫌いではないことをratingは示唆している)。
Genericな要約とPersonalizedな要約のfaitufulnessをスコアリングしてもらった結果、Genericな要約の方が若干高いスコアに。しかしながら有意差はない。実際、平均して83%のsentenceはGenericとPersonalizedでoverlapしている。faitufulnessの観点から、GenericとPersonalizedな要約の間に有意差はないことを示した。
museum等で応用することを検討
[Paper Note] Generating Personalized Summaries Using Publicly Available Web Documents, Kumar+, WI-IAT'08, 2008.12
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #WI #One-Line Notes Issue Date: 2017-12-28 Comment
評価
5人の研究者による人手評価。
25種類の異なるトピックが選択され、各トピックには5-10の記事が紐づいている。
generic,personalizedな要約を提示しrelevanceを判定してもらった。具体的には、informativenessを5段階評価。
データ非公開、ニュース記事を使ったとしか記述されておらず再現不可
[Paper Note] Learning User Profiles from Tagging Data and Leveraging them for Personal(ized) Information Access, Michlmayr+, WWW'07, 2007.05
Paper/Blog Link My Issue
#UserModeling #WWW #One-Line Notes Issue Date: 2017-12-28 Comment
social bookmarkのタグを使ってどのようにユーザモデルを作成する手法が提案されている。タグの時系列も扱っているみたいなので、参考になりそう。
[Paper Note] Personalizing Search via Automated Analysis of Interests and Activities, Teevan+, SIGIR'05, 2005.08
Paper/Blog Link My Issue
#InformationRetrieval #SIGIR #One-Line Notes Issue Date: 2017-12-28 Comment
・userに関するデータがrichなほうが、Personalizationは改善する。
・queries, visited web pages, emails, calendar items, stored desktop
documents、全てのsetを用いた場合が最も良かった
(次点としてqueriesのみを用いたモデルが良かった)
[Paper Note] WebInEssence: A Personalized Web-Based Multi-Document Summarization and Recommendation System, Radev+, NAACL'01, 2001.06
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Search #NAACL #KeyPoint Notes Issue Date: 2017-12-28 Comment
・ドキュメントはオフラインでクラスタリングされており,各クラスタごとにmulti-document summarizationを行うことで,
ユーザが最も興味のあるクラスタを同定することに役立てる.あるいは検索結果のページのドキュメントの要約を行う.
要約した結果には,extractした文の元URLなどが付与されている.
・Personalizationをかけるためには,ユーザがドキュメントを選択し,タイトル・ボディなどに定数の重みをかけて,その情報を要約に使う.
・特に評価していない.システムのoutputを示しただけ.
Project Deal, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #AIAgents #read-later #One-Line Notes #Sales Issue Date: 2026-04-26 Comment
元ポスト:
AI同士が商取引をしたら何が起きるかという社内実験のようである。69人の社員に何を売りたいか/買いたいををインタビューし、カスタム指示が与えられた上でAI Agentに取引をさせたところ、きちんと商取引が行われ、186件、$4000のやりとりがあったとのこと。そして賢いモデルが大幅に有利に取引を終えて、実際の参加者はこの事実に気づかなかったとのこと。また、カスタム指示(e.g., 強行姿勢, 礼儀正しいなど)はあまり良い成果を上げる上では重要ではなかった、
といった話が元ポストに書かれている。
nanomem: An Extremely Simple, Inference-Time Memory Module, The Open Anonymity Project, 2026.04
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #AIAgents #SoftwareEngineering #Selected Papers/Blogs #Privacy #memory #One-Line Notes Issue Date: 2026-04-19 Comment
github: https://github.com/OpenAnonymity/nanomem
元ポスト:
マークダウン形式でメモリを管理するシンプルな実装で、シンプルながらもさまざまな利点を持つとのこと:
- マークダウンで管理されているためメモリ情報をディレクトリ分けするだけで簡単に分離できる
- ただのテキストファイルなので可用性が高く、ユーザ自身が保持できる
- テキストファイルなのでなので、解釈ができ、ユーザ自身が編集できる
- 前方互換性があり、モデルが賢くなっても同じ方法でメモリを読み込め、モデルの性能が上がるとメモリ自身の性能(スピード、品質)も向上する
- モジュール化が可能で、取り込み、検索、圧縮などを個別に最適化できる
Act I:
- Unlinkable Inference as a User Privacy Architecture, The Open Anonymity Project, 2026.02
HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing, Tencent HY Team, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #PEFT(Adaptor/LoRA) #2D (Image) #memory #Editing #One-Line Notes #ImageSynthesis #Adaptive Issue Date: 2026-03-06 Comment
元ポスト:
source imageとpromptから、frozenされたモデルに対するadapter weightを(finetuningなしで)動的に生成し、インスタンス固有のパラメータを用いることでinstance specificな演算を実現する
関連:
- [Paper Note] Doc-to-LoRA: Learning to Instantly Internalize Contexts, Rujikorn Charakorn+, arXiv'26, 2026.02
- [Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25, 2025.06
supermemory, supermemoryai, 2025.10
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #API #SoftwareEngineering #memory Issue Date: 2025-10-13
Pepper: A Real‑Time, Event‑Driven Architecture for Proactive Agentic Systems, Agentica Team, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #AIAgents #Blog #Architecture #interactive Issue Date: 2025-10-03 Comment
元ポスト:
受動的なエージェントではなく、ユーザに対して能動的に働きかけてくるイベントドリブンなAI Agentのアーキテクチャ提案と、そのためのライブラリな模様。
Personalized news filtering and summarization on the web, Xindong+, 2011 IEEE 23rd International Conference on Tools with Artificial Intelligence, 29
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #NLP #One-Line Notes Issue Date: 2023-05-05 Comment
summarizationではなく、keyword extractionの話だった
Personalized summarization of customer reviews based on user’s browsing history, Zehra+, International Journal on Computer Science and Information Systems 8.2, 12
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #NLP #review Issue Date: 2023-05-05
Towards personalized summaries in spanish based on learning styles theory, Uriel+, Res. Comput. Sci. 148.5, 1
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #NLP #Education Issue Date: 2023-05-05
Personalized Text Content Summarizer for Mobile Learning: An Automatic Text Summarization System with Relevance Based Language Model, Guangbing+, IEEE Fourth International Conference on Technology for Education, 2012, 22
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #NLP #Education Issue Date: 2023-05-05
Personalized text summarization based on important terms identification, Robert+, 23rd International Workshop on Database and Expert Systems Applications, 2012, 43
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #NLP #One-Line Notes Issue Date: 2023-05-05 Comment
(あまりしっかりよめていない)
学習者のrevision(復習?)のための教材の要約手法の提案。personalizationするために、さまざまなRaterを定義し、Raterからの単語wに対する評価を集約し、最終的にuser-specificなsentence-term matrixを構築。 SVDを適用することで要約を作成する。personalizedな重み付けに活用されているものとしては、あるコンセプトiに対する学習者の習熟度に基づく重み付けや、学習者の教材に対するannnotationに関する情報などが、単語の重み付けに活用されている。
When does web-based personalization really work? The distinction between actual personalization and perceived personalization, Li Cong, Computers in human behavior, 2016
Paper/Blog Link My Issue
#Article #HumanComputerInteraction #One-Line Notes Issue Date: 2023-04-28 Comment
personalizedされたメッセージに対するユーザーの認識は、メッセージの以前のpersonalize processに必ずしも依存するのではなく、受信したコンテンツが受信者の期待にどの程度一致しているかに依存することを明らかにした研究
Understanding the impact of web personalization on user information processing and decision outcomes, Tam+, MIS quarterly, 2006
Paper/Blog Link My Issue
#Article #HumanComputerInteraction #KeyPoint Notes Issue Date: 2023-04-28 Comment
コンテンツのrelevancy, 自己言及的なコミュニケーション(名前を呼ぶ等)が、オンラインにおけるユーザの注意や認知プロセス、および意思決定に影響を与えることを示している。特に、これらが、パーソナライズされたコンテンツを受け入れ、意思決定を支援することにつながることを示している(らしい)。
かなり有名な研究らしい。
名前を呼んだメッセージングと、relevantなコンテンツを提供することの両方で、エンドユーザはpersonalizedされたと認知し、後から思い出すのはrelevantなコンテンツの内容だけだったという実験結果が出ており、メッセージングで注意を引くことも大事だし、ちゃんとrelevantなコンテンツも提供しないといけないよね、という示唆が得られているのだと思われる。
Measuring the impact of online personalisation: Past, present and future
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #InformationRetrieval #KeyPoint Notes #needs-revision Issue Date: 2023-04-28 Comment
Personalizationに関するML, RecSys, HCI, Personalized IRといったさまざまな分野の評価方法に関するSurvey
ML + RecSys系では、オフライン評価が主流であり、よりaccuracyの高い推薦が高いUXを実現するという前提に基づいて評価されてきた。一方HCIの分野ではaccuracyに特化しすぎるとUXの観点で不十分であることが指摘されており、たとえば既知のアイテムを推薦してしまったり、似たようなアイテムばかりが選択されユーザにとって有用ではなくなる、といったことが指摘されている。このため、ML, RecSys系の評価ではdiversity, novelty, serendipity, popularity, freshness等の新たなmetricが評価されるように変化してきた。また、accuracyの工場がUXの向上に必ずしもつながらないことが多くの研究で示されている。
一方、HCIやInformation Systems, Personalized IRはuser centricな実験が主流であり、personalizationは
- 情報アクセスに対するコストの最小化
- UXの改善
- コンピュータデバイスをより効率的に利用できるようにする
という3点を実現するための手段として捉えられている。HCIの分野では、personalizationの認知的な側面についても研究されてきた。
たとえば、ユーザは自己言及的なメッセージやrelevantなコンテンツが提示される場合、両方の状況においてpersonalizationされたと認知し、後から思い出せるのはrelevantなコンテンツに関することだという研究成果が出ている。このことから、自己言及的なメッセージングでユーザをstimulusすることも大事だが、relevantなコンテンツをきちんと提示することが重要であることが示されている。また、personalizationされたとユーザが認知するのは、必ずしもpersonalizationのプロセスに依存するのではなく、結局のところユーザが期待したメッセージを受け取ったか否かに帰結することも示されている。
user-centricな評価とオフライン評価の間にも不一致が見つかっている。たとえば
- オフラインで高い精度を持つアルゴリズムはニッチな推薦を隠している
- i.e. popularityが高くrelevantな推薦した方がシステムの精度としては高く出るため
- オフライン vs. オンラインの比較で、ユーザがアルゴリズムの精度に対して異なる順位付けをする
といったことが知られている。
そのほかにも、企業ではofflineテスト -> betaテスターによるexploratoryなテスト -> A/Bテストといった流れになることが多く、Cognitive Scienceの分野の評価方法等にも触れている。
Preface to Special Issue on User Modeling for Web Information Retrieval, Brusilovsky+, User Modeling and User-Adapted Interaction , 2004
Paper/Blog Link My Issue
#Article #InformationRetrieval #One-Line Notes Issue Date: 2023-04-28 Comment
Personalized Information Retrievalの先駆け的研究
[Paper Note] Adaptive Web Search Based on User Profile Constructed without Any Effort from Users, Sugiyama+, NAIST, WWW’04
と同時期
User Profiles for Personalized Information Access, Gauch+, The adaptive Web: methods and strategies of Web personalization, 2007
Paper/Blog Link My Issue
#Article #Survey #InformationRetrieval #One-Line Notes Issue Date: 2023-04-28 Comment
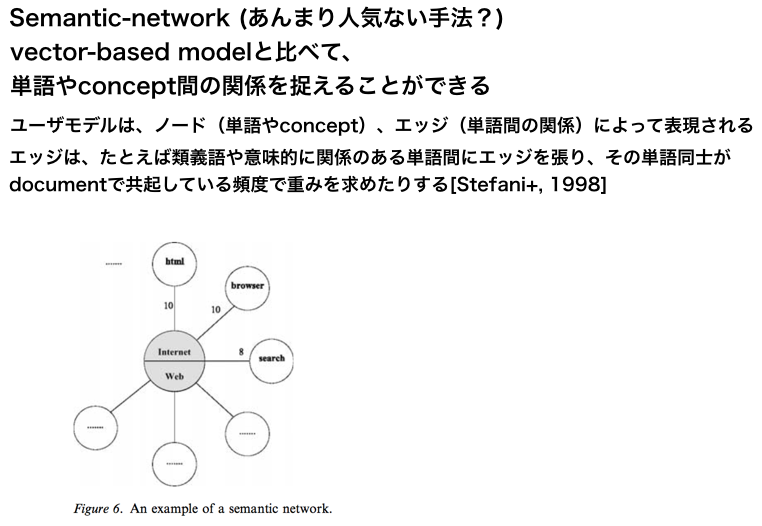
IR分野におけるuser profileの構築方法についてまとめられたsurvey
- 加重キーワード
- セマンティックネットワーク
- 加重コンセプト
について記述されている。また、プロファイルの構築方法についても詳述されている。
[Paper Note] Adaptive Web Search Based on User Profile Constructed without Any Effort from Users, Sugiyama+, NAIST, WWW’04
Paper/Blog Link My Issue
#Article #CollaborativeFiltering #InformationRetrieval #RelevanceFeedback #Search #WebSearch #KeyPoint Notes Issue Date: 2023-04-28 Comment
検索結果のpersonalizationを初めてuser profileを用いて実現した研究
user profileはlong/short term preferenceによって構成される。
- long term: さまざまなソースから取得される
- short term: 当日のセッションの中だけから収集される
① browsing historyの活用
- browsing historyのTFから求め Profile = P_{longterm} + P_{shortterm}とする
② Collaborative Filtering (CF) の活用
- user-item matrixではなく、user-term matrixを利用
- userの未知のterm-weightをCFで予測する
- => missing valueのterm weightが予測できるのでprofileが充実する
実験結果
- 検証結果(googleの検索結果よりも提案手法の方が性能が良い)
- 検索結果のprecision向上にlong/short term preferenceの両方が寄与
- longterm preferenceの貢献の方が大きいが、short termも必要(interpolation weight 0.6 vs. 0.4)
- short termにおいては、その日の全てのbrowsing historyより、現在のセッションのterm weightをより考慮すべき(interpolation weight 0.2 vs. 0.8)
[Paper Note] SCENE: A Scalable Two-Stage Personalized News Recommendation System, Li et al., SIGIR’11
Paper/Blog Link My Issue
#Article #RecommenderSystems #Document #NewsRecommendation #SIGIR #One-Line Notes Issue Date: 2017-12-28 Comment
・ニュース推薦には3つのチャレンジがある。
1. スケーラビリティ より高速なreal-time processing
2. あるニュース記事を読むと、続いて読む記事に影響を与える
3. popularityとrecencyが時間経過に従い変化するので、これらをどう扱うか
これらに対処する手法を提案
[Paper Note] Segmentation Based, Personalized Web Page Summarization Model, [Journal of advances in information technology, vol. 3, no.3, 2012], 2012.08
Paper/Blog Link My Issue
#Article #Single #PersonalizedDocumentSummarization #DocumentSummarization #NLP #KeyPoint Notes Issue Date: 2017-12-28 Comment
・Single-document
・ページ内をセグメントに分割し,どのセグメントを要約に含めるか選択する問題
・要約に含めるセグメントは4つのfactor(segment weight, luan’s significance factor, profile keywords, compression ratio)から決まる.基本的には,ページ内の高頻度語(stop-wordは除く)と,profile keywordsを多く含むようなセグメントが要約に含まれるように選択される.図の場合はAlt要素,リンクはアンカテキストなどから単語を取得しセグメントの重要度に反映する.
[Paper Note] Automatic Text Summarization based on the Global Document Annotation, Nagao+, COLING-ACL;98, 1998.08
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #ACL #COLING #KeyPoint Notes Issue Date: 2017-12-28 Comment
Personalized summarizationの評価はしていない。提案のみ。以下の3種類の手法を提案
- keyword-based customization
- 関心のあるキーワードをユーザが入力し、コーパスやwordnet等の共起関係から関連語を取得し要約に利用する
- 文書の要素をinteractiveに選択することによる手法
- 文書中の関心のある要素(e.g. 単語、段落等)
- browsing historyベースの手法
- ユーザのbrowsing historyのドキュメントから、yahooディレクトリ等からカテゴリ情報を取得し、また、トピック情報も取得し(要約技術を活用するとのこと)特徴量ベクトルを作成
- ユーザがアクセスするたびに特徴ベクトルが更新されることを想定している?
[Paper Note] A Study for Documents Summarization based on Personal Annotation, Zhang+, HLT-NAACL-DUC’03, 2003.05
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #NAACL #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 Comment
(過去に管理人が作成したスライドでの論文メモのスクショ)


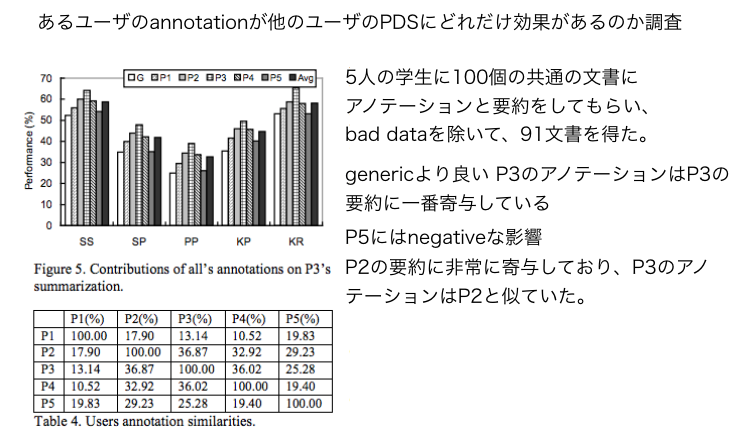
重要論文だと思われる。
[Paper Note] Personalised Information retrieval: survey and classification, Rami+, User Modeling and User-Adapted Interaction, 2012.05
Paper/Blog Link My Issue
#Article #Survey #InformationRetrieval #KeyPoint Notes Issue Date: 2017-12-28 Comment
(以下は管理人が当時作成したスライドでのメモのスクショ)

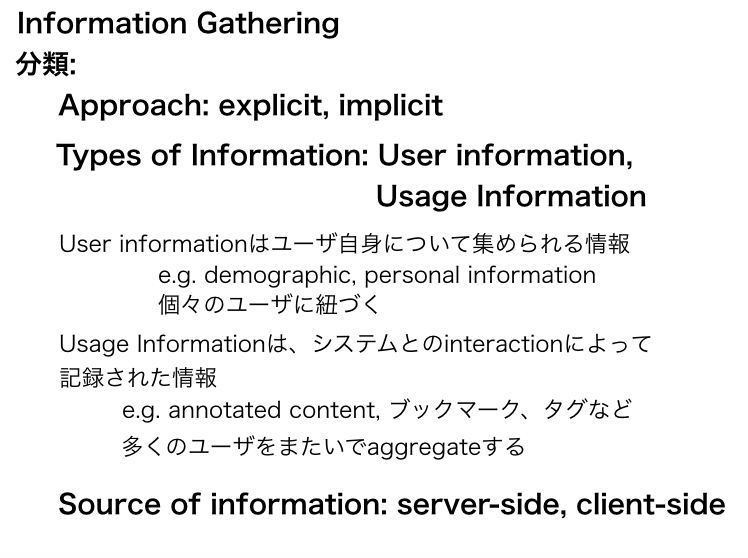
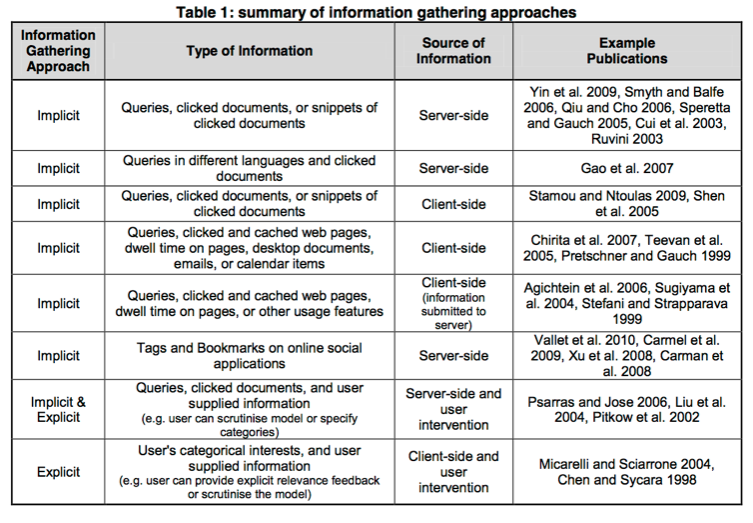


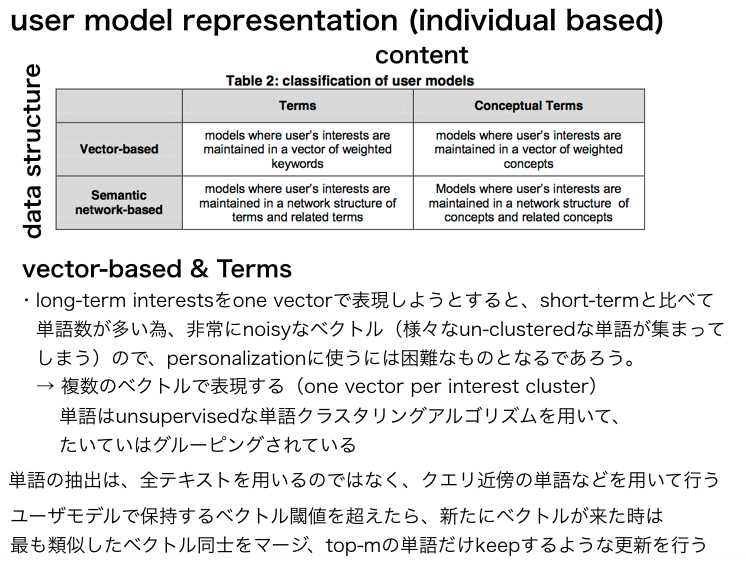




完全に途中で力尽きている感
[Paper Note] User-model based personalized summarization, Diaz+, Information Processing and Management 2007.11
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #RecommenderSystems #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-28 Comment
PDSの先駆けとなった重要論文。必ずreferすべき。