
post-pretraining
#Pocket#NLP#LanguageModel
Issue Date: 2024-01-24 LLaMA Pro: Progressive LLaMA with Block Expansion, Chengyue Wu+, N_A, arXiv24 Summary本研究では、大規模言語モデル(LLMs)の新しい事前学習後の手法を提案し、モデルの知識を効果的かつ効率的に向上させることを目指しました。具体的には、Transformerブロックの拡張を使用し、新しいコーパスのみを使用してモデルを調整しました。実験の結果、提案手法はさまざまなベンチマークで優れたパフォーマンスを発揮し、知的エージェントとして多様なタスクに対応できることが示されました。この研究は、自然言語とプログラミング言語を統合し、高度な言語エージェントの開発に貢献するものです。 Comment追加の知識を導入したいときに使えるかも?事前学習したLLaMA Blockに対して、追加のLLaMA Blockをstackし、もともとのLLaMA Blockのパラメータをfreezeした上でドメインに特化したコーパスで事後学習することで、追加の知識を挿入する。LLaMA Blockを挿入するとき ...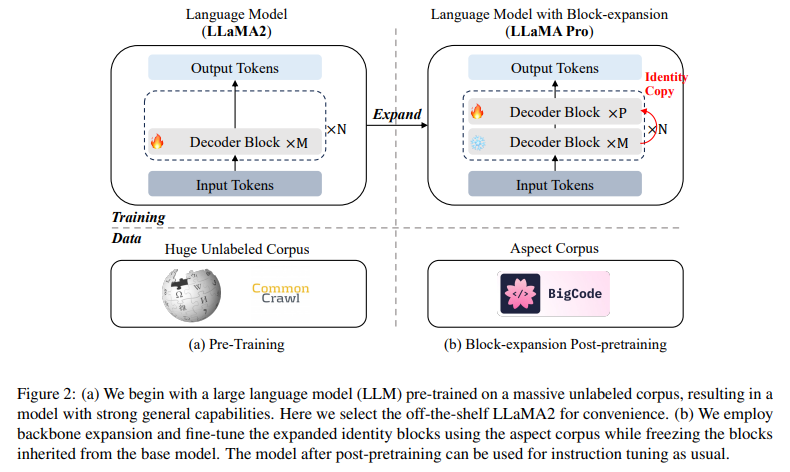
Issue Date: 2024-01-24 LLaMA Pro: Progressive LLaMA with Block Expansion, Chengyue Wu+, N_A, arXiv24 Summary本研究では、大規模言語モデル(LLMs)の新しい事前学習後の手法を提案し、モデルの知識を効果的かつ効率的に向上させることを目指しました。具体的には、Transformerブロックの拡張を使用し、新しいコーパスのみを使用してモデルを調整しました。実験の結果、提案手法はさまざまなベンチマークで優れたパフォーマンスを発揮し、知的エージェントとして多様なタスクに対応できることが示されました。この研究は、自然言語とプログラミング言語を統合し、高度な言語エージェントの開発に貢献するものです。 Comment追加の知識を導入したいときに使えるかも?事前学習したLLaMA Blockに対して、追加のLLaMA Blockをstackし、もともとのLLaMA Blockのパラメータをfreezeした上でドメインに特化したコーパスで事後学習することで、追加の知識を挿入する。LLaMA Blockを挿入するとき ...