
COLING
[Paper Note] Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs, Yu Xia+, COLING'25
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Chain-of-Thought Issue Date: 2025-05-29 GPT Summary- Chain-of-Thought(CoT)を基にしたChain-of-X(CoX)手法の調査を行い、LLMsの課題に対処するための多様なアプローチを分類。ノードの分類とアプリケーションタスクに基づく分析を通じて、既存の手法の意義と今後の可能性を議論。研究者にとって有用なリソースを提供することを目指す。
Towards Adaptive Mechanism Activation in Language Agent, Ziyang Huang+, COLING'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #AIAgents #PostTraining #One-Line Notes #needs-revision Issue Date: 2024-12-10 GPT Summary- 自己探索によるメカニズム活性化学習(ALAMA)を提案し、固定されたメカニズムに依存せずに適応的なタスク解決を目指す。調和のとれたエージェントフレームワーク(UniAct)を構築し、タスク特性に応じてメカニズムを自動活性化。実験結果は、動的で文脈に敏感なメカニズム活性化の有効性を示す。 Comment
元ポスト:
手法としては、SFTとKTOを活用しpost trainingするようである
- [Paper Note] KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, ICML'24, 2024.02
[Paper Note] VLR-Bench: Multilingual Benchmark Dataset for Vision-Language Retrieval Augmented Generation, Hyeonseok Lim+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#ComputerVision #InformationRetrieval #NLP #Dataset #RAG(RetrievalAugmentedGeneration) #MultiLingual #VisionLanguageModel #One-Line Notes Issue Date: 2024-12-16 GPT Summary- 視覚言語モデル(VLM)を評価するための新しいベンチマークVLR-Benchを提案。これは5つの入力パッセージを用いて、特定のクエリに対する有用な情報の判断能力をテストする。32,000の自動生成された指示からなるデータセットVLR-IFを構築し、VLMのRAG能力を強化。Llama3ベースのモデルで性能を検証し、両データセットはオンラインで公開。 Comment
Multilingual VLMを用いたRAGのベンチマークデータセット
[Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #PEFT(Adaptor/LoRA) #PostTraining #read-later #One-Line Notes #LREC Issue Date: 2024-10-30 GPT Summary- LoRAは大規模言語モデルのファインチューニング手法で、特にマルチタスク設定での性能向上に挑戦する。本研究では、LoRAのパフォーマンスを多様なタスクとリソースで検証し、適切なランク設定により高リソース環境でもフルファインチューニングに匹敵する結果を得られることを示した。学習能力の制約がLoRAの一般化能力を高めることが明らかになり、LoRAの適用可能性を広げる方向性を示唆している。 Comment
LoRAのランク数をめちゃめちゃ大きくすると(1024以上)、full-parameterをチューニングするよりも、Unseenタスクに対する汎化性能が向上しますよ、という話っぽい
## LoRA Finetuning details
- W_{q,k,v,o}にLoRAを適用
- dropout rateは0.05
- LoRA rankを最小4, 最大4096の範囲で変化
- LoRAのαをなんとrankの2倍にしている
- original paperでは16が推奨されている
- learning_rate: 5e-5
- linear sheculeで learning_rate を減衰させる
- optimizerはAdamW
- batch_size: 128
[Paper Note] RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners, Chi Hu+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #NLP #LanguageModel #Prompting #Reasoning #Reranking #Initial Impression Notes #LREC Issue Date: 2024-04-07 GPT Summary- LLMの論理的エラーを解決するために、自己ランク付けを可能にする新手法RankPromptを提案。これは、多様な応答を比較し、LLMの文脈的生成能力を活用する。実験ではChatGPTやGPT-4の性能が最大13%向上し、AlpacaEvalデータセットでは人間の判断との74%の一致率を示した。また、応答の順序や一貫性の変動にも強い耐性を持つことが確認された。RankPromptは高品質なフィードバックを引き出す有効な手法である。 Comment
LLMでランキングをするためのプロンプト手法。独立したプロンプトでスコアリングしスコアリング結果からランキングするのではなく、LLMに対して比較するためのルーブリックやshotを入れ、全てのサンプルを含め、1回のPromptingでランキングを生成するような手法に見える。大量の候補をランキングするのは困難だと思われるが、リランキング手法としては利用できる可能性がある。また、実験などでランキングを実施するサンプル数に対してどれだけ頑健なのかなどは示されているだろうか?
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic, Xufeng Zhao+, N_A, COLING'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-10-09 GPT Summary- 大規模言語モデルの進歩は驚異的だが、多段階の推論には改善の余地がある。大規模言語モデルは知識を持っているが、推論には一貫性がなく、幻覚を示すことがある。そこで、Logical Chain-of-Thought(LogiCoT)というフレームワークを提案し、論理による推論パラダイムの効果を示した。
Point precisely: Towards ensuring the precision of data in generated texts using delayed copy mechanism., Li+, Peking University, COLING'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #Surface-level Notes Issue Date: 2021-10-25 Comment
# 概要
DataToTextタスクにおいて、生成テキストのデータの精度を高める手法を提案。two stageアルゴリズムを提案。①encoder-decoerモデルでslotを含むテンプレートテキストを生成。②Copy Mechanismでslotのデータを埋める、といった手法。
①と②はそれぞれ独立に学習される。
two stageにするモチベーションは、
・これまでのモデルでは、単語の生成確率とコピー確率を混合した分布を考えていたが、どのように両者の確率をmergeするのが良いかはクリアではない。
→ 生成とコピーを分離して不確実性を減らした
・コピーを独立して考えることで、より効果的なpair-wise ranking loss functionを利用することができる
・テンプレート生成モデルは、テンプレートの生成に集中でき、slot fillingモデルはスロットを埋めるタスクに集中できる。これらはtrainingとtuningをより簡便にする。
# モデル概要
モデルの全体像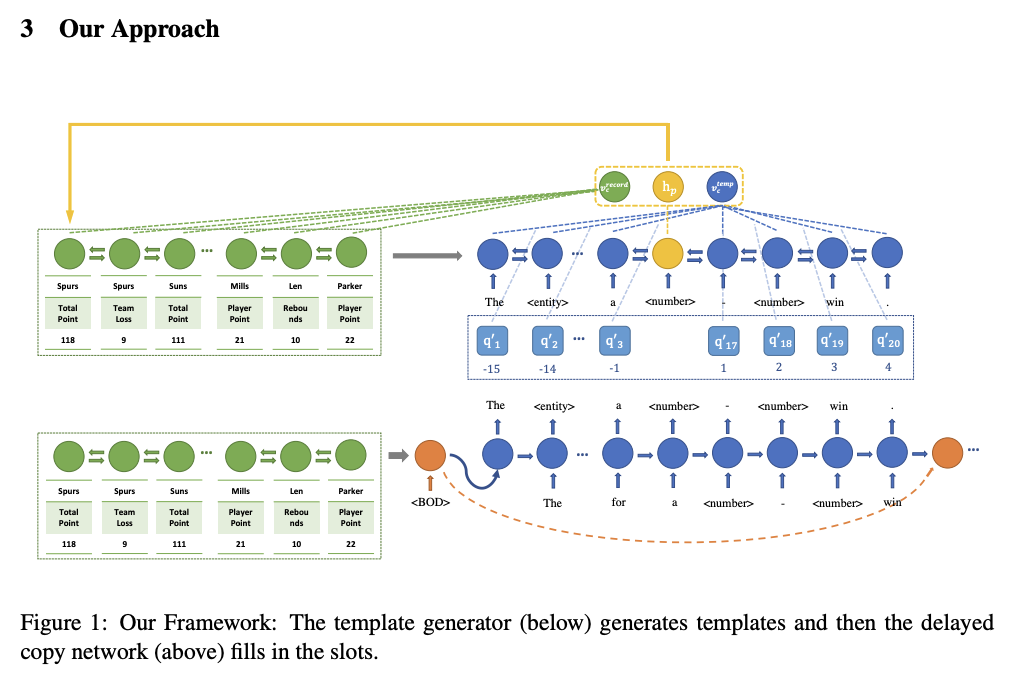
オリジナルテキストとテンプレートの例。テンプレートテキストの生成を学習するencoder-decoder(①)はTarget Templateを生成できるように学習する。テンプレートではエンティティが"
# 実験結果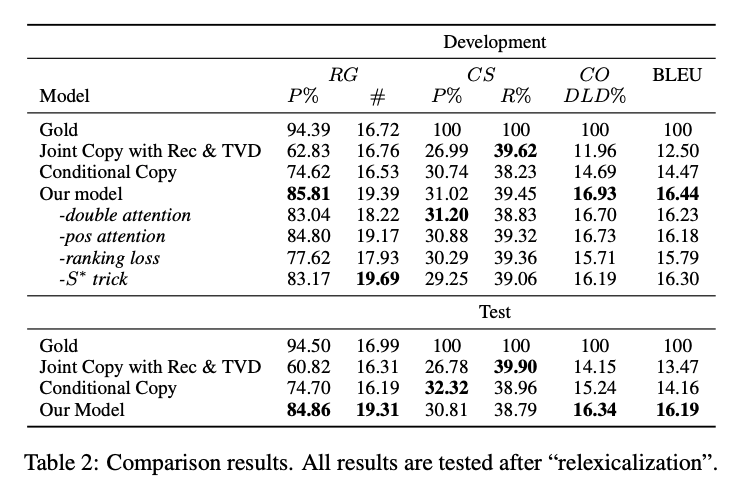
Relation Generation (RG)がCCと比べて10%程度増加しているので、data fidelityが改善されている。
また、BLEUスコアも約2ポイント改善。これはentityやnumberが適切に埋められるようになっただけでなく、テンプレートがより適切に生成されているためであると考えられる。
## 参考:
• Relation Generation (RG):出力文から(entity, value)の関係を抽出し,抽出された関係の数と,それらの関係が入力データに対して正しいかどうかを評価する (Precision).ただし entity はチーム名や選手名などの動作の主体,value は得点数やアシスト数などの記録である.
• Content Selection (CS):出力文とリファレンスから (entity, value) の関係を抽出し,出力文から抽出された関係のリファレンスから抽出された関係に対する Precision,Recall で評価する.
• Content Ordering (CO):出力文とリファレンスから (entity, value) の関係を抽出し,それらの間の正規化 DamerauLevenshtein 距離 [7] で評価する.
(from [Paper Note] 過去情報の内容選択を取り入れた スポーツダイジェストの自動生成, 加藤+, NLP'21
)
[Paper Note] Learning to Generate Coherent Sumamry with Discriminative Hidden Semi-Markov Model, Nishikawa+, COLING'14
Paper/Blog Link My Issue
#Single #DocumentSummarization #Document #Supervised #NLP #Abstractive #Extractive #KeyPoint Notes Issue Date: 2018-01-01 Comment
Hidden-semi-markovモデルを用いた単一文書要約手法を提案。
通常のHMMでは一つの隠れ状態に一つのunit(要約の文脈だと文?)が対応するが、hidden-semi-markov(HSMM)モデルでは複数のunitを対応づけることが可能。
隠れ状態に対応するunitを文だと考えると、ある文の複数の亜種を考慮できるようになるため、ナップサック制約を満たしつつ最適な文の亜種を選択するといったことが可能となる。
とかまあ色々難しいことが前半の節に書いてある気がするが、3.3節を見るのがわかりやすいかもしれない。
定式化を見ると、基本的なナップサック問題による要約の定式化に、Coherenceを表すtermと文の変種を考慮するような変数が導入されているだけである。
文のweightや、coherenceのweightは構造学習で学習し、Passive Aggressiveを用いて、loss functionとしてはROUGEを用いている(要はROUGEが高くなるように、outputの要約全体を考慮しながら、weightを学習するということ)。
文の変種としては、各文を文圧縮したものを用意している。
また、動的計画法によるデコーディングのアルゴリズムも提案されている。
構造学習を行う際には大量の教師データが必要となるが、13,000記事分のニュース記事と対応する人手での要約のデータを用いて学習と評価を行なっており、当時これほど大規模なデータで実験した研究はなかった。
ROUGEでの評価の結果、文の変種(文圧縮)を考慮するモデルがベースラインを上回る結果を示したが、LEADとは統計的には有意差なし。しかしながら、人手で生成した要約との完全一致率が提案手法の方が高い。
また、ROUGEの評価だけでなく、linguistic quality(grammaticality, structure/coherenceなど)を人手で評価した結果、ベースラインを有意にoutperform。LEADはgrammaticalityでかなり悪い評価になっていて、これは要約を生成すると部分文が入ってしまうため。
訓練事例数を変化させてROUGEスコアに関するlearning curveを描いた結果、訓練事例の増加に対してROUGEスコアも単調増加しており、まだサチる気配を見せていないので、事例数増加させたらまだ性能よくなりそうという主張もしている。
評価に使用した記事が報道記事だったとするならば、quality的にはLeadに勝ってそうな雰囲気を感じるので、結構すごい気はする(単一文書要約で報道記事においてLEADは最強感あったし)。
ただ、要約の評価においてinformativenessを評価していないので、ROUGEスコア的にはLeadとcomparableでも、実際に生成される要約の情報量として果たしてLEADに勝っているのか興味がある。
[Paper Note] Generative alignment and semantic parsing for learning from ambiguous supervision, Kim+, COLING'10
Paper/Blog Link My Issue
#NaturalLanguageGeneration #SingleFramework #NLP #ConceptToTextGeneration Issue Date: 2017-12-31
[Paper Note] A Formal Model for Information Selection in Multi-Sentence Text Extraction, Filatova+, COLING'04
Paper/Blog Link My Issue
#Multi #DocumentSummarization #Document #NLP #Extractive #One-Line Notes Issue Date: 2018-01-17 Comment
初めて文書要約を最大被覆問題として定式化した研究。
[Paper Note] HMM-based word alignment in statistical translation, Vogel+, COLING'96
Paper/Blog Link My Issue
#MachineTranslation #NLP #WordAlignment Issue Date: 2018-01-15
[Paper Note] A Scalable MMR Approach to Sentence Scoring for Multi-Document Update Summarization, Boudin et al., COLING’08, 2008.08
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #KeyPoint Notes Issue Date: 2017-12-28 Comment
・MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
をupdate summarization用に拡張.History(ユーザが過去に読んだsentence)の数が多ければ多いほどnon-redundantな要約を出す (Queryに対するRelevanceよりもnon-redundantを重視する)
・Historyの大きさによって,redundancyの項の重みを変化させる.
・MMRのredundancyの項を1-max Sim2(s, s_history)にすることでnoveltyに変更.ORよりANDの方が直感的なので二項の積にする.
・MMRのQueryとのRelevanceをはかる項のSimilarityは,cossimとJaro-Winkler距離のinterpolationで決定. Jaro-Winkler距離とは,文字列の一致をはかる距離で,値が大きいほど近い文字列となる.文字ごとの一致だけでなく,ある文字を入れ替えたときにマッチ可能かどうかも見る.一致をはかるときはウィンドウを決めてはかるらしい.スペルミスなどの検出に有用.クエリ内の単語とselected sentences内の文字列のJaro-Winkler距離を計算.各クエリごとにこれらを求めクエリごとの最大値の平均をとる.
・冗長性をはかるSim2では,normalized longest common substringを使う.
[Paper Note] Update Summarization Based on Co-Ranking with Constraints, Wiaojun Wan, COLING’12, 2012.12
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #KeyPoint Notes Issue Date: 2017-12-28 Comment
・PageRankの枠組みを拡張してold datasetとnew dataset内のsentenceをco-ranking
・co-rankingするときは,update scoreとconsistency scoreというものを求め相互作用させる.
・update scoreが高いsentenceは同じdataset内では正の関係,異なるdataset内では負の関係を持つ.
・consistency scoreが高いsentenceは同じdataset内では正の関係,異なるdataset内では正の関係を持つ.
・負の関係はdissimilarity matrixを用いて表現する.
・あとはupdate scoreとconsistency scoreを相互作用させながらPageRankでスコアを求める.デコーディングはupdate scoreをgreedyに.
・update scoreとconsistency scoreの和は定数と定義,この論文では定数をsentenceのinformative scoreとしている.これがタイトルにある制約.informative scoreはAffinity GraphにPageRankを適用して求める.
・制約が入ることで,consistency scoreが低いとupdate scoreは高くなるような効果が生まれる.逆もしかり.
[Paper Note] Automatic Text Summarization based on the Global Document Annotation, Nagao+, COLING-ACL;98, 1998.08
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #ACL #KeyPoint Notes Issue Date: 2017-12-28 Comment
Personalized summarizationの評価はしていない。提案のみ。以下の3種類の手法を提案
- keyword-based customization
- 関心のあるキーワードをユーザが入力し、コーパスやwordnet等の共起関係から関連語を取得し要約に利用する
- 文書の要素をinteractiveに選択することによる手法
- 文書中の関心のある要素(e.g. 単語、段落等)
- browsing historyベースの手法
- ユーザのbrowsing historyのドキュメントから、yahooディレクトリ等からカテゴリ情報を取得し、また、トピック情報も取得し(要約技術を活用するとのこと)特徴量ベクトルを作成
- ユーザがアクセスするたびに特徴ベクトルが更新されることを想定している?