
CVPR
[Paper Note] EgoLife: Towards Egocentric Life Assistant, Jingkang Yang+, CVPR'26, 2025.03
Paper/Blog Link My Issue
#Author Thread-Post Issue Date: 2026-06-11 GPT Summary- エゴライフプロジェクトは、AI搭載ウェアラブル眼鏡を用いて生産性を向上させる自己中心的ライフアシスタントの開発を目指す。6名の参加者が1週間の共同生活を通じて、AI眼鏡で日常活動を記録し、「EgoLife Dataset」を生成。これに基づいて、長大な文脈を前提とした「EgoLifeQA」を提案し、自己中心データに対する視覚-音声モデルやアイデンティティ認識、長大な文脈質問応答に挑戦。EgoButlerシステムを導入し、EgoGPTとEgoRAGを統合することで、性能を向上させた。データセットやモデルの公開により、自己中心的AIアシスタントの研究を進める。 Comment
元ポスト:
[Paper Note] Efficiently Reconstructing Dynamic Scenes One D4RT at a Time, Chuhan Zhang+, CVPR'26 Best Paper, 2025.12
Paper/Blog Link My Issue
#ComputerVision #read-later #Encoder-Decoder #4D Reconstruction Issue Date: 2026-06-08 GPT Summary- 動画から動的シーンの幾何と運動を理解・再構成するための新しい前方伝播モデルD4RTを提案。単一の動画から深度や時空間対応を一括推定可能で、新しいクエリ機構により計算負担と複雑さを軽減。これにより、3D位置の探索が効率化され、4D再構成タスクで従来を超える性能を実現した。 Comment
元ポスト:
pj page: https://d4rt-paper.github.io/
解説:
[Paper Note] MRT: Masked Region Transformer for Layered Image Generation and Editing at Scale, Zhicong Tang+, CVPR'26, 2026.05
Paper/Blog Link My Issue
#ComputerVision #Transformer #DiffusionModel #2D (Image) #Editing #ImageSynthesis #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-28 GPT Summary- 多層透明画像の生成と編集に特化した200億パラメータのマスク領域拡散モデル「MRT」を提案。テキストおよび画像からのレイヤー生成を統合し、柔軟なレイヤー単位の操作を実現。オーバーフロー対応のキャンバスレイヤーによって、透明な背景合成をサポートし、リアルタイムの生成を可能に。実験により、従来の技術を大きく上回る性能を示し、特に編集品質や推論速度で優位を獲得。 Comment
元ポスト:
pj page: https://mrt-cvpr.github.io/
画像生成ではなく、layer生成にフォーカスした研究で、text-to-layer generation, image-to-layer decomposition, layer-to-layer addition, layer-to-layer restylizationなどが可能なようである。
[Paper Note] VGGT-$Ω$, Jianyuan Wang+, CVPR'26, 2026.05
Paper/Blog Link My Issue
#ComputerVision #Transformer #Architecture #read-later #Selected Papers/Blogs #3D Reconstruction #3D (Scene) #Backbone #Scalability Issue Date: 2026-05-27 GPT Summary- VGGT-Ωは、フィードフォワード再構成モデルの新たなアプローチを提案し、静的および動的シーンの再構成精度と効率を向上させます。アーキテクチャの改良により、GPUメモリ使用量を約30%に抑えつつ、15倍の監視付きデータを活用。レジスタを用いたコンパクトな情報表現により、フレーム間の情報交換を効率化しました。VGGT-Ωは複数のベンチマークで優れた結果を示し、Sintelでは従来ベストを77%上回る精度を達成。学習済みのレジスタは視覚・言語モデルの向上に貢献し、再構成が空間理解の強力なタスクとして機能する可能性を示しています。 Comment
pj page: https://vggt-omega.github.io/
元ポスト:
関連:
- [Paper Note] VGGT: Visual Geometry Grounded Transformer, Jianyuan Wang+, CVPR'25
[Paper Note] MultiBanana: A Challenging Benchmark for Multi-Reference Text-to-Image Generation, Yuta Oshima+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation #TextToImageGeneration #LLM-as-a-Judge #2D (Image) #ImageSynthesis Issue Date: 2026-05-26 GPT Summary- マルチ参照生成モデルは複数の参照画像から新たな文脈で被写体を描画するが、既存のデータセットは単一もしくは少数の参照に偏っているため性能評価に限界がある。本研究では、マルチ参照設定に特化したMultiBananaを提案し、参照数やドメイン不一致、スケール不一致、まれな概念、多言語テキストに関する問題を網羅してモデルの限界を評価する。分析により性能と改善点を明らかにし、公正な比較のための標準化された基盤を提供する。 Comment
元ポスト:
[Paper Note] MARCO: Navigating the Unseen Space of Semantic Correspondence, Claudia Cuttano+, CVPR'26, 2026.04
Paper/Blog Link My Issue
#read-later Issue Date: 2026-04-25 GPT Summary- DINOv2と拡散バックボーンを組み合わせた新しいデュアルエンコーダーアーキテクチャMARCOを提案。粗さから細かさへ進む精度向上と疎な監視を強化する自己蒸留フレームワークにより、限られたキーポイントから意味的に整合した対応を実現。SPair-71k、AP-10K、PF-PASCALで新たな最先端性能を達成し、未見のキーポイントへの一般化も向上。効率も高く、拡散ベースの手法より3倍小さく、10倍速い。 Comment
pj page: https://visinf.github.io/MARCO/
元ポスト:
[Paper Note] TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment, Bingyi Cao+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#read-later #Author Thread-Post Issue Date: 2026-04-16 GPT Summary- 視覚-言語モデルの密なパッチ-テキスト整合性を向上させる新手法を提案。パッチレベルの蒸留が有効で、蒸留済みモデルが教師モデルを上回る整合性を示す。iBOT++を導入し、未マスクのトークンが損失に寄与。学習効率向上のためのキャプションサンプリング戦略を追加。TIPSv2として新しい画像-テキストエンコーダを開発し、広範な下流アプリケーションにおいて強力な性能を実現。 Comment
元ポスト:
[Paper Note] A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens, Tommie Kerssies+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #read-later #Selected Papers/Blogs #WorldModels #One-Line Notes #Author Thread-Post Issue Date: 2026-04-11 GPT Summary- ビデオ世界モデリングにおいて、多様な未来状態を効率的に予測するために、DeltaTokというトークナイザーを導入。これによりVFM特徴の差を連続的な「デルタ」トークンにエンコードし、DeltaWorldという生成的世界モデルを提案。これにより、ビデオを一次元の時系列に圧縮、512×512フレームでトークン数を1,024倍削減。多仮説訓練を通じて多様な未来を平行に生成し、単一のフォワードパスで多様な予測を得られる。実験結果においてDeltaWorldは、従来のモデルよりもパラメータ数が35倍、FLOPsは2000倍少ないにもかかわらず、現実に近い未来を予測することを示した。 Comment
過去と現在のフレームを入力し差分の潜在表現を出力するDeltaEncoderを学習し、潜在表現に基づいてnext token predictionをする(複数の推論結果を出力させ、最も学習データに近いものを用いて学習する。複数の候補を出力するため推論時は多様な候補を得られる)。
これにより、予測に必要なトークン数が大幅に削減され(Dino-basedなモデルと比較して1024--2048倍)、パラメータ数が削減されFLOPSも低下(generative modelsと比較して、35倍パラメータ数が小さく、2000倍計算に要するFLOPSが低下)。
といった話が著者ポストで説明されている。
[Paper Note] ARM-Thinker: Reinforcing Multimodal Generative Reward Models with Agentic Tool Use and Visual Reasoning, Shengyuan Ding+, CVPR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #MultiModal #PostTraining #VisionLanguageModel #RewardModel #GenerativeVerifier #ToolUse Issue Date: 2026-03-25 GPT Summary- ARM-Thinkerは、視覚と言語の報酬モデルを向上させるためのエージェント型システムであり、外部ツールを自律的に活用して結果を検証可能にする。これにより、幻覚や視覚的グラウンディングの弱さを克服し、複数ページの証拠を比較して推論を支持する能力を持つ。多段階強化学習によって訓練され、ツール呼び出しの意思決定と判断精度を最適化。新たに導入したARMBench-VLで評価した結果、報酬モデリングで平均+16.2%、ツール使用タスクで+9.6%の改善を達成。エージェント的なアプローチが精度と解釈性の向上に寄与することを示している。 Comment
元ポスト:
元ポスト:
[Paper Note] AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model, Sofian Chaybouti+, CVPR'26, 2025.12
Paper/Blog Link My Issue
Issue Date: 2026-03-07 GPT Summary- マルチティーチャー蒸留を用いて視覚基盤モデルの訓練を探求し、効率的な学習ダイナミクスを明らかに。複数の教師知識をMixture-of-Experts学生モデルに蒸留するAMoEを提案し、非対称関係知識蒸留ロスが知識移転を促進。解像度に対応したトークン処理により安定した表現学習を実現し、階層的クラスタリングによるサンプリング法が効率を向上。これらを活かして200M画像のOpenLVD200Mコーパスを生成し、モデルとデータを公開。 Comment
元ポスト:
[Paper Note] VidEoMT: Your ViT is Secretly Also a Video Segmentation Model, Narges Norouzi+, CVPR'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Transformer #ImageSegmentation #read-later #Selected Papers/Blogs #Encoder #2D (Image) #3D (Video) #Initial Impression Notes Issue Date: 2026-02-28 GPT Summary- VidEoMTは、専用の追跡モジュールなしで動画セグメンテーションを実現するエンコーダーのみのモデルである。軽量なクエリ伝搬機構を導入し、前フレームの情報を活用することで、フレーム間の連携を図る。時系列に依存しない学習済みクエリと融合により、利益を生み出しつつ追加の複雑さを回避し、最大160 FPSで競争力のある精度を達成した。 Comment
元ポスト:
他タスクでも色々使えそうなアーキテクチャに見える
[Paper Note] Text-Printed Image: Bridging the Image-Text Modality Gap for Text-centric Training of Large Vision-Language Models, Shojiro Yamabe+, CVPR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #DataAugmentation #SyntheticData #VisionLanguageModel #text Issue Date: 2026-02-28 GPT Summary- テキスト中心訓練を用いて、画像収集のコストを削減する新たなアプローチとしてText-Printed Image(TPI)を提案。TPIはテキストを白いキャンバスに直接レンダリングすることで合成画像を生成し、VQAタスクでのモダリティギャップを軽減。系統的な実験により、TPIは合成画像生成モデルよりも効果的な性能を示し、LVLMsの自動データ生成の可能性を強調。 Comment
元ポスト:
[Paper Note] CaptionQA: Is Your Caption as Useful as the Image Itself?, Shijia Yang+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #One-Line Notes #Initial Impression Notes #ImageToTextGeneration Issue Date: 2026-02-26 GPT Summary- 画像キャプションはマルチモーダルシステムにおける視覚コンテンツの代理表現として機能するが、キャプションが実際のタスクで画像の代わりになり得るかを評価する必要がある。そこで、新たにユーティリティベースのベンチマークCaptionQAを提案し、キャプションの質を下流タスクへの支援度で測定する。CaptionQAは四つのドメインにわたり、33,027件の詳細な多肢選択問題を提供し、キャプションが視覚情報を必要とする質問に対応する力を検証する。LLMによる評価により、キャプションの有用性が画像よりも最大32%低下することが確認され、CaptionQAはオープンソースとして公開される。 Comment
元ポスト:
興味深い研究。MLLMの性能をCaption生成を通じて評価している。
良いCaptionであればdownstream taskに活用した際により良い性能が得られるという仮定の元[^1]、MLLMの性能をAnswer=LLM(Question, Caption)で判断する。AnswerはMultiple Choice Questionであり、Cannot Answerなども含まれる。よりQAに対して適切に回答できるCaptionを生成できたMLLMが優れているというutility-basedな評価となっている。
MLLMに対してCaptionを生成する際は、Questionに関する情報は与えずに、画像の情報のみでCaptionを生成する(ように見える)。セクション9に記述されている通り、4種類のバリエーションのpromptを用いる(long, short, simple, taxonomy hinted)。
skim readingしかできていないのだが、脚注1に記述した通り、モデルによって実画像がgivenな状態とCaptionのみで評価した場合でgapの出方に差がある点と、そもそも到達しているスコアの絶対値の対比が出せる点が個人的に興味深い。これにより特定のMLLMが、画像とテキスト、どちらの情報を"理解"するのに優れているのか、あるいは理解した情報に基づいて"生成"するのに優れているのかも間接的に評価できるのではないかと感じる。たとえばGPT-5は他モデルと比べて双方の能力秀でているが、Gemini-2.5-Proは画像を考慮することは得意だが、画像からテキストを生成する能力は少し劣ることがGPT-5とのgapの差から伺える。GLM4.1-VやLLaVAなどは画像理解は得意だが、画像から重要な情報を生成する能力は大きく低いことがわかる。
同じdownstreamタスクを通じてgapを測定でき、かつ単にベンチマークのスコアという以上の一段深い情報が得られる点がこれまでと異なりおもしろいと感じる。
[^1]:実際、セクション5を見ると実際の画像を与えた場合とCaptionのみの場合で評価した場合でgapがあることが示されており、Captionが画像中のdownstream taskに対してrelevantな情報を完全に保持していないことが示唆される。また、モデルに応じてgapが異なっており、モデルによってCaption生成能力が大きく異なることが示唆される。
この評価のパラダイムは一段抽象化をすると、特定のモダリティの情報に対する理解力と、異なるモダリティに変換して生成する能力をdownstreamタスクを通じて観測することになり、Captionの場合は画像-テキスト間だが、他にも動画-テキスト、音声-テキスト、あるいはそれらの逆など、Omniモーダルなモデルの評価やUMMの評価に使えそうな話だな、と思うなどした。
[Paper Note] MultiShotMaster: A Controllable Multi-Shot Video Generation Framework, Qinghe Wang+, CVPR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Controllable #VideoGeneration/Understandings #3D (Video) Issue Date: 2026-02-24 GPT Summary- MultiShotMasterは、マルチショット動画生成のための高度に制御可能なフレームワークを提案する。これにより、ショット遷移の位相シフトを適用し、柔軟なショット配置を実現。参照トークンとグラウンディング信号を用いた設計により、時空間的参照を強化し、データ不足を克服するための自動データ注釈パイプラインを確立。結果として、テキスト駆動の一貫性とカスタム対象を持つマルチショット動画生成を支援し、高性能と卓越した制御性を示した。 Comment
pj page: https://qinghew.github.io/MultiShotMaster/
元ポスト:
[Paper Note] Multi-Crit: Benchmarking Multimodal Judges on Pluralistic Criteria-Following, Tianyi Xiong+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #VisionLanguageModel #2D (Image) Issue Date: 2026-02-24 GPT Summary- Multi-Critは、大規模マルチモーダルモデル(LMMs)の評価能力を測定するためのベンチマークであり、複数基準への適合性や判断信頼性を評価する。厳格なデータキュレーションを通じて収集された応答ペアは、オープンエンド生成と検証可能な推論タスクを含む。分析の結果、商用およびオープンソースモデルは多様な基準への適合に課題があり、ファインチューニングが視覚的根拠づけを高めるが、多元的基準判断に至らないことがわかった。Multi-Critは、信頼できるマルチモーダルAI評価の基盤を構築する。 Comment
元ポスト:
[Paper Note] Generative Scenario Rollouts for End-to-End Autonomous Driving, Rajeev Yasarla+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #Planning #Reasoning #Robotics #VisionLanguageActionModel Issue Date: 2026-02-23 GPT Summary- VLAモデルを用いた自動運転システムのためのGeRoフレームワークを提案。エゴ車両の動態を潜在トークンにエンコードし、言語条件付きの自己回帰生成を通じて交通シーンを共同生成。整合性損失を利用して予測を安定化し、長期的推論を支援。Bench2Driveで運転スコアを+15.7ポイント、成功率を+26.2ポイント改善。生成的かつ言語条件付けられた推論の有望性を示す。 Comment
元ポスト:
[Paper Note] PhyCritic: Multimodal Critic Models for Physical AI, Tianyi Xiong+, arXiv'26, 2026.02
Paper/Blog Link My Issue
Issue Date: 2026-02-13 GPT Summary- PhyCriticは、物理AIタスク向けに最適化されたマルチモーダル批評モデルであり、物理的な知覚と因果推論を強化するウォームアップ段階と自己参照批評の微調整段階を持つ。これにより、応答評価の安定性と正確性が向上し、オープンソースのベースラインに対してパフォーマンスが向上。物理的タスクにおける知覚と推論を改善するポリシーモデルとしても活用される。 Comment
pj page: https://research.nvidia.com/labs/lpr/phycritic/
元ポスト:
[Paper Note] WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World, Ao Liang+, CVPR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation #read-later #Selected Papers/Blogs #WorldModels #3D (Video) #One-Line Notes #Author Thread-Post Issue Date: 2026-01-30 GPT Summary- 生成的世界モデルはリアルな4D環境を合成しますが、物理的または行動的に失敗することが多いです。この課題に対処するため、WorldLensを導入し、生成された世界の評価を行う全範囲ベンチマークを提供します。これには生成、再構成、行動追従など五つの側面が含まれ、視覚的現実性や物理的妥当性を評価します。既存モデルには広範囲に優れたものがなく、WorldLens-26Kという大規模な人間注釈付きデータセットを構築し、評価モデルWorldLens-Agentを開発しました。これにより、世界の忠実性を測定する統一されたエコシステムを形成し、リアルな見た目と行動の両面で評価基準を標準化します。 Comment
pj page: https://worldbench.github.io/worldlens
元ポスト:
github: https://github.com/worldbench/WorldLens
(自動運転に関する)World Model(には限られないかもしれないが)を多角的な軸から評価できるベンチマーク。3D object detection/Tracking, Novel-view Discrepancy/Quality, Occupacy Prediction, Subject Fidelity/Consistency/Coherence, Temporal Concistencyなど、20以上のdimensionから評価可能なようである。
著者ポスト:
[Paper Note] FocusUI: Efficient UI Grounding via Position-Preserving Visual Token Selection, Mingyu Ouyang+, CVPR'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #VisionLanguageModel #Grounding #GUI Issue Date: 2026-01-13 GPT Summary- 視覚言語モデル(VLM)を用いたUIグラウンディングタスクに関する研究で、FocusUIという効率的なフレームワークを提案。冗長トークンを排除し、指示に関連する視覚トークンを選択しつつ、位置的連続性を保持する新戦略を採用。これにより、4つのベンチマークで優れた性能を発揮し、特にScreenSpot-Proでは3.7%の性能向上を達成。視覚トークン保持率が30%でも高い推論速度と低メモリ使用を実現。 Comment
元ポスト:
[Paper Note] NitroGen: An Open Foundation Model for Generalist Gaming Agents, Loïc Magne+, CVPR'26 Best Paper Honorable Mention, 2026.01
Paper/Blog Link My Issue
#ComputerVision #Dataset #read-later #Selected Papers/Blogs #Game #UMM #3D (Video) #VisionActionModel Issue Date: 2025-12-21 GPT Summary- NitroGenは、1,000以上のゲームを対象に40,000時間のプレイ動画で訓練された汎用ゲーミングエージェント向けのビジョン-アクション基盤モデルです。プレイヤーの操作を自動抽出したビデオ-アクションデータセット、クロスゲーム一般化を測るマルチゲームベンチマーク、ビヘイビア・クローン学習によるモデルを含みます。3Dアクションゲーム、2Dプラットフォーマー及び手続き的生成世界において高い能力を示し、未見のゲームでも最大52%のタスク成功率向上を実現。データセットやモデルの重みを公開し、汎用的な体現エージェントの研究を促進します。 Comment
元ポスト:
HF:
https://huggingface.co/nvidia/NitroGen
pj page:
https://nitrogen.minedojo.org/
1000以上のゲームの40000時間を超えるゲームプレイから学習されたVideo to Action Model
CVPR Best Paper Honorable Mention:
[Paper Note] PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image, Ziang Cao+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #RepresentationLearning #SyntheticData #VisionLanguageModel #3D (Scene) #Robotics #EmbodiedAI #One-Line Notes #Geometric #Physics #Simulation #3D Object Generation Issue Date: 2025-11-20 GPT Summary- PhysX-Anythingは、単一の野外画像から高品質なシミュレーション準備済みの3D資産を生成する新しいフレームワークで、ジオメトリ、関節、物理的属性を明示的に持つ。VLMベースのモデルと新しい3D表現を提案し、トークン数を193倍削減。新データセットPhysX-Mobilityにより物理3Dデータの多様性を拡張し、2,000以上の実世界オブジェクトを含む。実験により、生成性能と一般化能力が確認され、ロボティックポリシー学習に直接利用可能であることが示された。 Comment
元ポスト:
ポイント解説:
CVPRにアクセプト:
pj page: https://physx-anything.github.io/
simulation-readyな3Dオブジェクトを生成するVLMベースのモデルとのこと
[Paper Note] ViT$^3$: Unlocking Test-Time Training in Vision, Dongchen Han+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Initial Impression Notes #Test Time Training (TTT) Issue Date: 2026-06-21 GPT Summary- テスト時学習(TTT)を用い、視覚シーケンスモデルを線形計算量で最適化。内部設計の原則を確立し、Vision Test-Time Training (ViT)^3モデルを提案。これにより、画像分類や物体検出などのタスクで従来モデルと同等またはそれ以上の性能を達成。今後の研究の基盤となることを期待。 Comment
元ポスト:
Vision分野でのTTT
[Paper Note] HoneyBee: Data Recipes for Vision-Language Reasoners, Hritik Bansal+, arXiv'25, 2025.10
Paper/Blog Link My Issue
Issue Date: 2026-02-21 GPT Summary- VLMの推論タスクにおける性能向上のため、データキュレーション手法を調査。文脈ソースの影響や画像・質問・CoTのスケーリングを分析し、戦略の効果を明らかに。新たに導入したHoneyBeeデータセットで、VLMは最先端モデルを上回り、デコードコストを73%削減する手法も提案。VL推論データセットの改善戦略を提示。 Comment
元ポスト:
[Paper Note] Text-Printed Image: Bridging the Image-Text Modality Gap for Text-centric Training of Large Vision-Language Models, Shojiro Yamabe+, arXiv'25, 2025.12
Paper/Blog Link My Issue
Issue Date: 2026-02-21 GPT Summary- テキストのみを用いたVQAタスクに向けた「テキスト中心の学習」を提案。画像収集が難しい中、テキストから直接合成画像を生成する「Text-Printed Image(TPI)」を導入し、低コストで効果的なデータ拡張を実現。系統的な実験により、TPIが従来の合成画像よりも優れた学習効果を示し、LVLMsの自動データ生成への新たな道を示した。 Comment
元ポスト:
[Paper Note] ShowUI-$π$: Flow-based Generative Models as GUI Dexterous Hands, Siyuan Hu+, CVPR'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #AIAgents #SyntheticData #ComputerUse #read-later #Selected Papers/Blogs #VisionLanguageModel #GUI #Dragging #Author Thread-Post Issue Date: 2026-01-16 GPT Summary- ShowUI-$\pi$は、GUIエージェントにおける連続的な操作を可能にするフローベースの生成モデルです。これにより、離散的なクリックと連続的なドラッグを統合し、滑らかで安定したトラジェクトリーを実現します。2万のドラッグトラジェクトリーを用いたScreenDragプロトコルによる評価で、既存のGUIエージェントと比較して優れた性能を発揮しました。この研究は、人間のような器用な自動化の実現を促進します。 Comment
pj page: https://showlab.github.io/showui-pi/
元ポスト:
大規模なドラッグに関するデータセットを収集しており、エージェントのGUIの操作の今後の進展に大きく寄与しインパクトが大きいと考えられるため、重要論文に見える。
著者ポイント解説:
[Paper Note] SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos, Yuzheng Liu+, CVPR'25 Highlight, 2024.12
Paper/Blog Link My Issue
#ComputerVision #3D Reconstruction Issue Date: 2025-11-20 GPT Summary- SLAM3Rは、RGBビデオを用いたリアルタイムの高品質な密な3D再構築システムで、フィードフォワードニューラルネットワークを活用してローカル3D再構築とグローバル座標登録を統合。スライディングウィンドウメカニズムでビデオを重なり合ったクリップに変換し、RGB画像から直接3Dポイントマップを回帰。実験により、最先端の再構築精度と20 FPS以上のリアルタイム性能を達成。コードは公開されている。 Comment
元ポスト:
[Paper Note] OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations, Linke Ouyang+, CVPR'25, 2024.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #Selected Papers/Blogs #DocParser #OCR #One-Line Notes Issue Date: 2025-10-21 GPT Summary- 文書内容抽出のための新しいベンチマーク「OmniDocBench」を提案。これは、9つの文書ソースにわたる高品質な注釈を特徴とし、エンドツーエンド評価やタスク特化型分析をサポート。異なる文書タイプにおける手法の強みと弱みを明らかにし、文書解析の公平で詳細な評価基準を設定。データセットとコードは公開されている。 Comment
OCR系のモデルの評価で標準的に用いられるベンチマーク
[Paper Note] VGGT: Visual Geometry Grounded Transformer, Jianyuan Wang+, CVPR'25
Paper/Blog Link My Issue
#ComputerVision #Transformer #read-later #Selected Papers/Blogs #3D Reconstruction #Backbone #Reference Collection Issue Date: 2025-06-22 GPT Summary- VGGTは、シーンの主要な3D属性を複数のビューから直接推測するフィードフォワードニューラルネットワークであり、3Dコンピュータビジョンの分野において新たな進展を示します。このアプローチは効率的で、1秒未満で画像を再構築し、複数の3Dタスクで最先端の結果を達成します。また、VGGTを特徴バックボーンとして使用することで、下流タスクの性能が大幅に向上することが示されています。コードは公開されています。 Comment
元ポスト:
様々な研究のBackboneとして活用されている。
[Paper Note] Generative Omnimatte: Learning to Decompose Video into Layers, Yao-Chih Lee+, CVPR'25
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #One-Line Notes #Author Thread-Post Issue Date: 2025-06-06 GPT Summary- オムニマット手法は、ビデオを意味的に有意義な層に分解することを目指すが、既存手法は静的背景や正確なポーズを前提としており、これが破られると性能が低下する。新たに提案する生成的層状ビデオ分解フレームワークは、静止シーンや深度情報を必要とせず、動的領域の補完を行う。核心的なアイデアは、ビデオ拡散モデルを訓練し、シーン効果を特定・除去することであり、これにより高品質な分解と編集結果を実現する。 Comment
元ポスト:
ざっくりしか読めていないが、Inputとして動画とmask(白:残す, 黒:消す, グレー: 不確定なオブジェクトやエフェクトが含まれるエリア≒背景?)を受け取り、Casperと呼ばれるモデルでオブジェクトを消し消した部分をinpaintingすることで、layerっぽいものを作成するっぽい?Casperは
project pageがサンプルもありとてもわかりやすい: https://gen-omnimatte.github.io
[Paper Note] AM-RADIO: Agglomerative Vision Foundation Model -- Reduce All Domains Into One, Mike Ranzinger+, CVPR'25
Paper/Blog Link My Issue
#ComputerVision #Transformer #FoundationModel #OpenWeight #One-Line Notes #Author Thread-Post Issue Date: 2025-04-11 GPT Summary- 視覚基盤モデル(VFM)をマルチティーチャー蒸留を通じて統合するアプローチAM-RADIOを提案。これにより、ゼロショットの視覚-言語理解やピクセルレベルの理解を向上させ、個々のモデルの性能を超える。新しいアーキテクチャE-RADIOは、ティーチャーモデルよりも少なくとも7倍速い。包括的なベンチマークで様々な下流タスクを評価。 Comment
元ポスト:
vision系のfoundation modelはそれぞれ異なる目的関数で訓練されてきており(CLIPは対照学習 Learning Transferable Visual Models From Natural Language Supervision, Radford+, OpenAI, ICML'21
, DINOv2は自己教師あり学習 [Paper Note] DINOv2: Learning Robust Visual Features without Supervision, Maxime Oquab+, TMLR'24
, SAMはsegmentation [Paper Note] Segment Anything, Alexander Kirillov+, arXiv'23, 2023.04
)それぞれ別の能力を持ってたが、それらを一個のモデルに蒸留しました、という話らしい
lossの文脈でいうと、SigLIPも広義の対照学習の一種である。
- [Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23
[Paper Note] Transformers without Normalization, Jiachen Zhu+, CVPR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #Transformer #Architecture #Normalization #One-Line Notes #Author Thread-Post Issue Date: 2025-03-14 GPT Summary- 本研究では、正規化層なしのトランスフォーマーがDynamic Tanh(DyT)を用いることで、同等またはそれ以上のパフォーマンスを達成できることを示します。DyTは、レイヤー正規化の代替として機能し、ハイパーパラメータの調整なしで効果を発揮します。多様な設定での実験により、正規化層の必要性に対する新たな洞察を提供します。 Comment
なん…だと…。LayerNormalizationを下記アルゴリズムのようなtanhを用いた超絶シンプルなレイヤー(parameterized thnh [Lecun氏ポスト](
同等以上の性能を維持しながらモデル全体のinference, trainingの時間を8%程度削減。
[Paper Note] V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs, Penghao Wu+, CVPR'24, 2023.12
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #read-later #Selected Papers/Blogs #VisionLanguageModel #ThinkingWithImages Issue Date: 2026-02-20 GPT Summary- 視覚的タスク遂行には、選択的な視覚処理が重要であるが、現在のMLLMにはこの機能が欠如している。そこで、LLMの知識を活用する視覚検索機構V*を導入。MLLMとの統合により、推論と文脈理解が向上し、特定の視覚要素を正確に狙えるようになる。この統合はSEALという新しいメタアーキテクチャを生み出し、高解像度画像の処理能力を評価するためのV*Benchも作成。視覚検索機能の重要性を際立たせた研究である。
[Paper Note] SpatialTracker: Tracking Any 2D Pixels in 3D Space, Yuxi Xiao+, CVPR'24, 2024.04
Paper/Blog Link My Issue
#ComputerVision #2D (Image) #3D (Scene) #3D (Video) #DepthEstimation #MotionEstimation Issue Date: 2025-12-21 GPT Summary- 本研究では、動画における密な長距離ピクセル運動の回復の難しさを解決するため、3D空間における点の軌跡を推定する手法SpatialTrackerを提案。単眼深度推定器を用いて2Dピクセルを3Dに変換し、トランスフォーマーで3D軌跡を推定。剛体制約を活用しつつ、ピクセルをクラスタリングする剛性埋め込みを同時に学習。評価の結果、特に平面外回転のシナリオで最先端の追跡性能を達成した。
[Paper Note] Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data, Lihe Yang+, CVPR'24, 2024.01
Paper/Blog Link My Issue
#ComputerVision #DataAugmentation #FoundationModel #2D (Image) #DepthEstimation Issue Date: 2025-11-18 GPT Summary- Depth Anythingは、堅牢な単眼深度推定のための基盤モデルを提案し、6200万の未ラベルデータを自動的に注釈付けしてデータセットを拡大。データ拡張と補助的な監視を用いてモデルの一般化能力を向上させ、ゼロショット評価で優れた結果を示した。NYUv2およびKITTIでファインチューニングし、最先端の性能を達成。モデルは公開されている。 Comment
[Paper Note] Shadows Don't Lie and Lines Can't Bend Generative Models don't know Projective Geometry...for now, Ayush Sarkar+, CVPR'24, 2023.11
Paper/Blog Link My Issue
#ComputerVision #Analysis #DiffusionModel #TextToImageGeneration #ImageSynthesis #GeometryUnderstanding Issue Date: 2025-10-24 GPT Summary- 生成モデルはリアルな画像を生成するが、幾何学的特徴において実際の画像と異なることを示す。事前に選別された生成画像を用いて、幾何学的特性に基づく分類器が生成画像を高精度で識別できることを確認。3つの分類器を使用し、画像の透視場、線、物体と影の関係を分析。これにより、生成画像の検出精度が向上し、現在の生成器は実際の画像の幾何学的特性を再現できないと結論付ける。 Comment
[Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #Pretraining #MultiModal #FoundationModel #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-08-23 GPT Summary- 大規模視覚-言語基盤モデル(InternVL)は、60億パラメータで設計され、LLMと整合させるためにウェブ規模の画像-テキストデータを使用。視覚認知タスクやゼロショット分類、検索など32のベンチマークで最先端の性能を達成し、マルチモーダル対話システムの構築に寄与。ViT-22Bの代替として強力な視覚能力を持つ。コードとモデルは公開されている。 Comment
既存のResNetのようなSupervised pretrainingに基づくモデル、CLIPのようなcontrastive pretrainingに基づくモデルに対して、text encoder部分をLLMに置き換えて、contrastive learningとgenerativeタスクによる学習を組み合わせたパラダイムを提案。
InternVLのアーキテクチャは下記で、3 stageの学習で構成される。最初にimage text pairをcontrastive learningし学習し、続いてモデルのパラメータはfreezeしimage text retrievalタスク等でモダリティ間の変換を担う最終的にQlLlama(multilingual性能を高めたllama)をvision-languageモダリティを繋ぐミドルウェアのように捉え、Vicunaをテキストデコーダとして接続してgenerative cossで学習する、みたいなアーキテクチャの模様(斜め読みなので少し違う可能性あり
現在のVLMの主流であるvision encoderとLLMをadapterで接続する方式はここからかなりシンプルになっていることが伺える。
[Paper Note] MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI, Xiang Yue+, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #Reasoning Issue Date: 2025-08-09 GPT Summary- MMMUは、大学レベルの専門知識と意図的な推論を必要とするマルチモーダルモデルの評価のための新しいベンチマークで、11,500のマルチモーダル質問を含む。6つの主要分野をカバーし、30種類の画像タイプを使用。既存のベンチマークと異なり、専門家が直面するタスクに類似した課題を提供。GPT-4VとGeminiの評価では、56%と59%の精度にとどまり、改善の余地があることを示す。MMMUは次世代のマルチモーダル基盤モデルの構築に寄与することが期待されている。 Comment
MMMUのリリースから20ヶ月経過したが、いまだに人間のエキスパートのアンサンブルには及ばないとのこと
MMMUのサンプルはこちら。各分野ごとに専門家レベルの知識と推論が求められるとのこと。
[Paper Note] Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic, Sachin Goyal+, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #Analysis #NLP #Dataset #Scaling Laws #VisionLanguageModel #DataFiltering Issue Date: 2025-07-20 GPT Summary- 視覚と言語のモデル(VLMs)のトレーニングにおいて、高品質なデータのフィルタリングが重要であるが、計算リソースとは無関係に行われることが多い。本研究では、データの品質と量のトレードオフ(QQT)に対処するため、ウェブデータの非均質性を考慮したニューラルスケーリング法則を提案。これにより、データの有用性の違いや繰り返し使用による劣化を評価し、複数のデータプールの組み合わせによるモデルのパフォーマンスを推定可能にする。最適なデータプールのキュレーションを通じて、計算リソースに応じた最高のパフォーマンスを達成できることを示した。 Comment
元ポスト:
高品質なデータにフィルタリングすることで多くの研究がモデルがより高い性能を達成できることを示しているが、高品質なデータには限りがあることと、繰り返し学習をすることですぐにその効用が低下する(Quality-Quantity tradeoff!)という特性がある。このような状況において、たとえば計算の予算がデータ6パケット分の時に、めちゃめちゃフィルタリングを頑張っg高品質なデータプールEのみを使って6 epoch学習するのが良いのか、少し品質は落ちるデータDも混ぜてE+Dを3 epoch学習するのが良いのか、ときにどちらが良いのか?という話のようである。
[Paper Note] Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, CVPR'24, 2023.12
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #Transformer #InstructionTuning #MultiModal #SpeechProcessing #Selected Papers/Blogs #Encoder-Decoder #Robotics #UMM #EmbodiedAI #KeyPoint Notes #Surface-level Notes Issue Date: 2023-12-29 GPT Summary- 初の自己回帰型マルチモーダルモデル「Unified-IO 2」を提案し、画像、テキスト、音声、アクションを統一した意味空間で処理。トレーニングの安定化のためにアーキテクチャを改善し、120のデータセットで微調整を行い、GRITベンチマークで最先端のパフォーマンスを達成。35以上のベンチマークにおいて強力な結果を示し、すべてのモデルを公開。 Comment
画像、テキスト、音声、アクションを理解できる初めてのautoregressive model。AllenAI
モデルのアーキテクチャ図
マルチモーダルに拡張したことで、訓練が非常に不安定になったため、アーキテクチャ上でいくつかの工夫を加えている:
- 2D Rotary Embedding
- Positional EncodingとしてRoPEを採用
- 画像のような2次元データのモダリティの場合はRoPEを2次元に拡張する。具体的には、位置(i, j)のトークンについては、Q, Kのembeddingを半分に分割して、それぞれに対して独立にi, jのRoPE Embeddingを適用することでi, j双方の情報を組み込む。
- QK Normalization
- image, audioのモダリティを組み込むことでMHAのlogitsが非常に大きくなりatteetion weightが0/1の極端な値をとるようになり訓練の不安定さにつながった。このため、dot product attentionを適用する前にLayerNormを組み込んだ。
- Scaled Cosine Attention
- Image Historyモダリティにおいて固定長のEmbeddingを得るためにPerceiver Resamplerを扱ったているが、こちらも上記と同様にAttentionのlogitsが極端に大きくなったため、cosine類似度をベースとしたScaled Cosine Attention [Paper Note] Swin Transformer V2: Scaling Up Capacity and Resolution, Ze Liu+, arXiv'21
を利用することで、大幅に訓練の安定性が改善された。
- その他
- attention logitsにはfp32を適用
- 事前学習されたViTとASTを同時に更新すると不安定につながったため、事前学習の段階ではfreezeし、instruction tuningの最後にfinetuningを実施
目的関数としては、Mixture of Denoisers (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
)に着想を得て、Multimodal Mixture of Denoisersを提案。MoDでは、
- \[R\]: 通常のspan corruption (1--5 token程度のspanをmaskする)
- \[S\]: causal language modeling (inputを2つのサブシーケンスに分割し、前方から後方を予測する。前方部分はBi-directionalでも可)
- \[X\]: extreme span corruption (12>=token程度のspanをmaskする)
の3種類が提案されており、モダリティごとにこれらを使い分ける:
- text modality: UL2 (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
)を踏襲
- image, audioがtargetの場合: 2つの類似したパラダイムを定義し利用
- \[R\]: patchをランダムにx%マスクしre-constructする
- \[S\]: inputのtargetとは異なるモダリティのみの情報から、targetモダリティを生成する
訓練時には prefixとしてmodality token \[Text\], \[Image\], \[Audio\] とparadigm token \[R\], \[S\], \[X\] をタスクを指示するトークンとして利用している。
また、image, audioのマスク部分のdenoisingをautoregressive modelで実施する際には普通にやるとdecoder側でリークが発生する(a)。これを防ぐには、Encoder側でマスクされているトークンを、Decoder側でteacher-forcingする際にの全てマスクする方法(b)があるが、この場合、生成タスクとdenoisingタスクが相互に干渉してしまいうまく学習できなくなってしまう(生成タスクでは通常Decoderのinputとして[mask]が入力され次トークンを生成する、といったことは起きえないが、愚直に(b)をやるとそうなってしまう)。ので、(c)に示したように、マスクされているトークンをinputとして生成しなければならない時だけ、マスクを解除してdecoder側にinputする、という方法 (Dynamic Masking) でこの問題に対処している。
VILA: On Pre-training for Visual Language Models, Ji Lin+, N_A, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pretraining #NLP #LanguageModel #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2023-12-14 GPT Summary- 最近の大規模言語モデルの成功により、ビジュアル言語モデル(VLM)が進歩している。本研究では、VLMの事前学習のためのデザインオプションを検討し、以下の結果を示した:(1) LLMを凍結することでゼロショットのパフォーマンスが達成できるが、文脈に基づいた学習能力が不足している。(2) 交互に行われる事前学習データは有益であり、画像とテキストのペアだけでは最適ではない。(3) テキストのみの指示データを画像とテキストのデータに再ブレンドすることで、VLMのタスクの精度を向上させることができる。VILAというビジュアル言語モデルファミリーを構築し、最先端モデルを凌駕し、優れたパフォーマンスを発揮することを示した。マルチモーダルの事前学習は、VILAの特性を向上させる。 Comment
関連:
- Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N/A, CVPR'24
Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N_A, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #QuestionAnswering #OpenWeight #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes Issue Date: 2023-10-09 GPT Summary- LLaVAは、ビジョンと言語のクロスモーダルコネクタであり、データ効率が高く強力な性能を持つことが示されています。CLIP-ViT-L-336pxを使用し、学術タスク指向のVQAデータを追加することで、11のベンチマークで最先端のベースラインを確立しました。13Bのチェックポイントはわずか120万の公開データを使用し、1日で完全なトレーニングを終えます。コードとモデルは公開されます。 Comment
画像分析が可能なオープンソースLLMとのこと。
# Overview
画像生成をできるわけではなく、inputとして画像を扱えるのみ。
pj page: https://llava-vl.github.io
[Paper Note] CLIPPO: Image-and-Language Understanding from Pixels Only, Michael Tschannen+, CVPR'23, 2022.12
Paper/Blog Link My Issue
#ComputerVision #MultiModal #ContrastiveLearning #Encoder #OCR #Pixel-based Issue Date: 2026-07-08 GPT Summary- CLIPPOは、統一されたピクセルベースのエンコーダを用いて、対照損失のみで訓練されたマルチモーダルモデル。テキストと画像の両方を処理し、CLIPスタイルの性能を保ちながら、パラメータ数を半減。言語モデルなしで自然言語理解タスクや視覚質問応答でも優れた成果を示し、多言語検索にも対応可能。
[Paper Note] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture, Mahmoud Assran+, CVPR'23, 2023.01
Paper/Blog Link My Issue
#ComputerVision #Pretraining #RepresentationLearning #Transformer #Self-SupervisedLearning #read-later #Selected Papers/Blogs #WorldModels #One-Line Notes #LatentRepresentation Issue Date: 2025-07-24 GPT Summary- 本論文では、手作りのデータ拡張に依存せずに意味的な画像表現を学習するI-JEPAという自己教師あり学習アプローチを提案。I-JEPAは、単一のコンテキストブロックから異なるターゲットブロックの表現を予測する。重要な設計選択として、意味的に大きなターゲットブロックと情報量の多いコンテキストブロックのサンプリングが挙げられる。実験により、I-JEPAはVision Transformersと組み合わせることでスケーラブルであり、ImageNet上で強力な下流性能を達成した。 Comment
Joint-Embedding Predictive Architecture (JEPA)を提案した研究。ピクセルやトークンのreconstruction lossではなく、潜在表現を再構成するようなself-supervised learningによってより意味的な特徴を学習するように誘導するもの(と思われるがこれが本質的な理解として正しいかは自信がない)。
[Paper Note] Masked Autoencoders Are Scalable Vision Learners, Kaiming He+, CVPR'22, 2021.11
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Transformer #Self-SupervisedLearning #Selected Papers/Blogs #Encoder #Backbone #One-Line Notes #AutoEncoder #2D Reconstruction Issue Date: 2026-04-29 GPT Summary- MAEは、入力画像のランダムなパッチをマスクし、欠損部分を再構成するシンプルな自己教師付き学習モデルである。非対称のエンコーダ-デコーダ構造を用い、エンコーダは可視パッチのみを処理。75%をマスクすることで、非自明な自己教師付きタスクを生み出し、高速かつ効果的なモデル訓練を実現。一般化性能に優れ、ViT-HugeモデルがImageNet-1Kデータで最高精度(87.8%)を達成し、転移性能も監督付き事前学習を上回る。 Comment
元ポスト:
AutoEncoderを通じてMaskされたパッチを再構築できるように学習する(25%のパッチから予測する)ことで、(decoderを排除した場合に)downstream taskで良い性能を発揮するViTエンコーダを学習する。デコーダのパラメータ数は意図的に小さくし、Encoder側で特徴がきちんと学習されるように誘導する。
[Paper Note] Autoregressive Image Generation using Residual Quantization, Doyup Lee+, CVPR'22, 2022.03
Paper/Blog Link My Issue
#ComputerVision #VectorQuantization Issue Date: 2025-12-23 GPT Summary- 高解像度画像生成のために、二段階フレームワークを提案。RQ-VAEが画像特徴を離散コードとして表現し、RQ-Transformerが次のコードを予測。これにより、計算コストを削減しつつ高品質な画像を生成。従来のARモデルを上回る性能とサンプリング速度の向上を実現。
[Paper Note] High-Resolution Image Synthesis with Latent Diffusion Models, Robin Rombach+, CVPR'22, 2021.12
Paper/Blog Link My Issue
#ComputerVision #TextToImageGeneration #VariationalAutoEncoder #Selected Papers/Blogs #Encoder-Decoder #ImageSynthesis #U-Net Issue Date: 2025-10-10 GPT Summary- 拡散モデル(DMs)は、逐次的なデノイジングオートエンコーダを用いて画像生成プロセスを効率化し、最先端の合成結果を達成。従来のピクセル空間での訓練に比べ、強力な事前訓練されたオートエンコーダの潜在空間での訓練により、計算リソースを削減しつつ視覚的忠実度を向上。クロスアテンション層を導入することで、テキストやバウンディングボックスに基づく柔軟な生成が可能となり、画像インペインティングや無条件画像生成などで競争力のある性能を発揮。 Comment
ここからtext等による条件付けをした上での生成が可能になった(らしい)
日本語解説:
https://qiita.com/UMAboogie/items/afa67842e0461f147d9b
前提知識:
- [Paper Note] Denoising Diffusion Probabilistic Models, Jonathan Ho+, NeurIPS'20, 2020.06
[Paper Note] Taming Transformers for High-Resolution Image Synthesis, Patrick Esser+, CVPR'21, 2020.12
Paper/Blog Link My Issue
Issue Date: 2025-12-23 GPT Summary- トランスフォーマーとCNNの特性を組み合わせ、高解像度画像のモデル化と合成を行う手法を提案。CNNで文脈に富んだ語彙を学習し、トランスフォーマーで効率的に構成をモデル化。条件付き合成タスクに適用可能で、クラス条件付きImageNetで最先端の成果を達成。
[Paper Note] A Multi-view Stereo Benchmark with High-Resolution Images and Multi-camera Videos, Schöps+, CVPR'17
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation Issue Date: 2025-11-20 GPT Summary- 新しいマルチビュー立体視データセットを提案し、高精度のレーザースキャナーと低解像度のステレオビデオを用いて多様なシーンを記録。幾何学に基づく手法で画像とレーザースキャンを整合。従来のデータセットとは異なり、自然および人工環境をカバーし、高解像度のデータを提供。データセットは手持ちのモバイルデバイスの使用ケースにも対応し、オンライン評価サーバーで利用可能。
[Paper Note] ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes, Angela Dai+, CVPR'17, 2017.02
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation Issue Date: 2025-11-20 GPT Summary- 限られたRGB-Dシーン理解のために、1513シーンの2.5Mビューを含むScanNetデータセットを導入。自動表面再構築とクラウドソースによるセマンティックアノテーションを用いたキャプチャシステムを設計し、3Dオブジェクト分類やセマンティックボクセルラベリングで最先端のパフォーマンスを達成。データセットは無料で提供。
[Paper Note] Attend to You: Personalized Image Captioning with Context Sequence Memory Networks, Park+, CVPR'17
Paper/Blog Link My Issue
#ComputerVision #NLP #CommentGeneration #One-Line Notes Issue Date: 2019-09-27 Comment
画像が与えられたときに、その画像に対するHashtag predictionと、personalizedなpost generationを行うタスクを提案。
InstagramのPostの簡易化などに応用できる。
Postを生成するためには、自身の言葉で、画像についての説明や、contextといったことを説明しなければならず、image captioningをする際にPersonalization Issueが生じることを指摘。
official implementation: https://github.com/cesc-park/attend2u
[Paper Note] Deep Residual Learning for Image Recognition, Kaiming He+, CVPR'16, 2015.12
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Selected Papers/Blogs #Backbone #KeyPoint Notes #ResidualStream #Reading Reflections Issue Date: 2021-11-04 GPT Summary- 残差学習フレームワークを提案し、深いニューラルネットワークのトレーニングを容易にする。参照層の入力に基づいて残差関数を学習することで、最適化が容易になり、精度が向上。152層の残差ネットはImageNetで低い複雑性を保ちながら高い性能を示し、ILSVRC 2015で1位を獲得。COCOデータセットでも28%の改善を達成。 Comment
ResNet論文
ResNetでは、レイヤーの計算する関数を、残差F(x)と恒等関数xの和として定義する。これにより、レイヤーが入力との差分だけを学習すれば良くなり、モデルを深くしても最適化がしやすくなる効果ぎある。数レイヤーごとにResidual Connectionを導入し、恒等関数によるショートカットができるようにしている。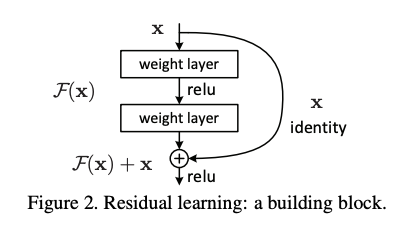
ResNetが提案される以前、モデルを深くすれば表現力が上がるはずなのに、実際には精度が下がってしまうことから、理論上レイヤーが恒等関数となるように初期化すれば、深いモデルでも浅いモデルと同等の表現が獲得できる、と言う考え方を発展させた。
(ステートオブAIガイドに基づく)
同じパラメータ数でより層を深くできる(Plainな構造と比べると層が1つ増える)Bottleneckアーキテクチャも提案している。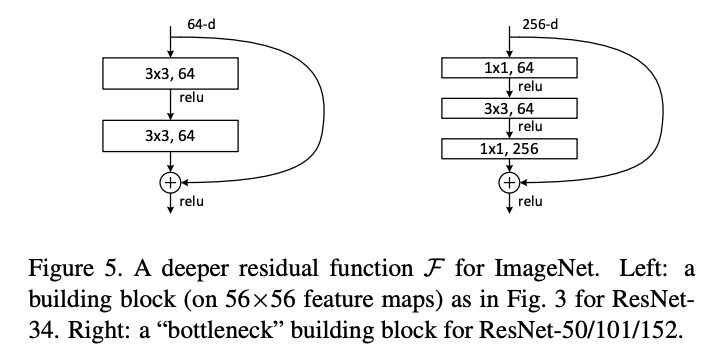
今や当たり前のように使われているResidual Connectionは、層の深いネットワークを学習するために必須の技術なのだと再認識。
[Paper Note] Generating Visual Explanations, Lisa Anne Hendricks+, CVPR'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Visual Words #One-Line Notes Issue Date: 2017-12-28 GPT Summary- 分類決定の説明は重要であり、既存の深層視覚認識アプローチは不透明である。新たに提案するモデルは、可視オブジェクトの識別特性に基づき、クラスラベルを予測し、その理由を説明する。サンプリングと強化学習に基づく新しい損失関数を用いて、グローバルな文の特性を実現する。実験結果は、提案モデルが一貫性のある識別的な説明を生成できることを示している。 Comment
画像そのものだけでなく、モデルへのInputにVisual Wordsを明示的に加えることで、captioningの精度が上がりましたという論文
[Paper Note] What value do explicit high level concepts have in vision to language problems?, Qi Wu+, CVPR'16
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Visual Words Issue Date: 2017-12-28 GPT Summary- CNN-RNNアプローチに高次の概念を組み込むことで、画像キャプショニングと視覚的質問応答の性能を向上。外部の意味情報を導入することでさらなる改善を実現し、V2L問題における高次の意味情報の重要性を分析。
[Paper Note] Scene Coordinate Regression Forests for Camera Relocalization in RGB-D Images, Shotton+, CVPR'13
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation #CameraPoseEstimation Issue Date: 2025-11-20
[Paper Note] Scene Coordinate Regression Forests for Camera Relocalization in RGB-D Images,Shotton+, CVPR'13
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation Issue Date: 2025-11-20
[Paper Note] LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding, Wang+, 2026.05
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #read-later #Selected Papers/Blogs #ObjectLocalization #VisionLanguageModel #2D (Image) #UMM #3D (Video) #text #ObjectDetection #GUI #Author Thread-Post Issue Date: 2026-05-30 Comment
元ポスト:
【学会聴講報告】CVPR2025からみるVision最先端トレンド, Yuki Ono (Sony Corporation), 2025.07
Paper/Blog Link My Issue
#Article #Survey #Video Issue Date: 2025-07-28 Comment
関連:
- CVPR 2025 速報, Kataoka+, 2025.06
元ポスト:
CVPR 2025 速報, Kataoka+, 2025.06
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #Slide Issue Date: 2025-06-26 Comment
元ポスト:
すごいまとめだ…