
EDM
[Paper Note] Using Neural Network-Based Knowledge Tracing for a Learning System with Unreliable Skill Tags, Karumbaiah+, (w_ Ryan Baker), EDM'22
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #KnowledgeTracing #In-Depth Notes Issue Date: 2022-08-26 Comment
超重要論文。しっかり読むべき
# 一言で言うと
KTを利用することを最初から念頭に置いていなかったシステムでは、問題に対して事後的にスキルをマッピングする作業が生じてしまい、これは非常に困難なことが多い。論文中で使用したアメリカの商用の数学のblended learningのシステムのデータでは、途中で企業が買収された経緯もあり、古いコンテンツと新しいコンテンツの間でスキルタグのマッピングの間で、矛盾や一貫性がないものができあがってしまった(複数の異なるチームがコンテンツの提供やスキルのタグ付けを行なった結果)。このような例はレアケースかもしれないが、問題とスキルタグが異なるチームによって開発されるということは珍しいことではないし、現代のオンライン学習システムの多くは、さまざまな教科書のデータを統合し、長年にわたってコンテンツ作成チームのメンバーを変更し、複数の州の基準や内部コンテンツスキーマに従ってコンテンツにタグをづけをしているので、少なからずこういった問題(i.e. 一貫性がなく、矛盾をかかえたitem-skill mapping)を抱えている。
こうした中で、NNを用いたモデルを用いることで、unreliableなKCモデルを用いるくらいならば、KCモデルを用いない方が正答率予測が高い精度で実施できることを示した。これは少なくとも、生徒の問題に対する将来のパフォーマンスを予測する問題に関して言えば、既存のアプリケーションにおいて、KCモデルを構築するステップを回避できる可能性を示唆している。
# モチベーション
Cognitive Tutorのようなシステムは、もともとKTを利用するために設計されているシステムだったが、多くのreal-worldの学習システムはアダプティブラーニングやKTを念頭に置いて作られたものではない。そういったシステムでアダプティブな機能を追加するといった事例が増えてきている。こういったシステムが、もともとKTを実施することを念頭するために作られたシステムとの違いとして、問題とスキルのマッピング方法にある。
最初から KT を使用するように設計されたシステムは、最初にどのスキルを含めるかを選択し、次にそれらのスキルに合わせたアイテムを開発する。 一方、KTを使用するために改良をする場合、最初にアイテムが作成され、次にアイテムにスキルのラベルが付けられる。
既存のアイテムにスキルのラベルを付けるのは、スキルの新しいアイテムを作成するよりもはるかに困難である。 多くの場合、アイテムは複数の著者によって時間をかけて開発されたものであるか、異なる教科書などの異なる元のソースからのものである。この異種のコンテンツ (場合によっては数万のアイテム) を一連のスキルにマッピングすることは、非常に困難な作業になる可能性がある。
多くの場合、アイテムは政府のカリキュラム基準の観点からタグ付けされているが、これらの基準は一般的に、KTモデルで使用されるスキルよりも非常に粗いものとなっている。
したがって、最初からKTを利用することを念頭に置かれていないシステムでKTを利用することには課題がある。
この論文では、NNベースなKTモデルが、この課題の部分的な解決策になることを示す。
このために、商用の数学のblended learningシステムでのケーススタディを実施した。
中学生が 2 年間システムを使用して収集したデータを使用して、KT モデルの性能を次の3 つのシナリオで比較し:
- 1) システムが提供する (おそらくunreliableな)スキルタグを利用した場合
- 2) 州の基準に基づくタグを利用した場合
- 3) コンテンツとスキルタグのマッピングを一切入力しない場合
DKVMNでの実験の結果、1)が最も悪い性能を示し、3)が最も良い問題の正誤予測の性能を示した。
これは、もともとKT モデルで動作するように設計されていなかった現実世界の学習システムでKCモデリングを回避する可能性を示唆している。特に、目的が将来のアイテムに対する学習者の成績を予測することだけである場合はこれに該当する。
# 実験結果
スキルの情報を用いず、ExerciseIDをそのままinputする方法が、最も高いAUCを獲得している。
# つまり
- きちんと一貫性があり矛盾のないItem-KCマッピングを用いないとモデルがきちんと学習できない
- 特に元々KTを適用することを念頭に置いていないシステムでは困難な作業となる可能性が高い
# KTの歴史
- 30年ほど研究されている(1995年のCorbett and AndersonらのBKTあたりから)
- 最初はBKTが広く採用された
- その後、最近ではlogistic regressionに基づくモデルが提案されるようになってきたが、実際のシステムで利用されることはまだ稀
- Elo や Temporal IRT などのIRTに関連するアルゴリズムも、最近文献でより広く見られるようになり、いくつかの学習システムで大規模に使用されている
- Elo およびTemporal IRT は KCモデルなしで使用できるが、通常、いくつかのスキルごとに個別の Elo モデルが利用される。
- NNベースなモデルは過去5年で活発に研究され、将来のパフォーマンスを予測する性能は飛躍的に向上した
- ただし、予測不可能な動作(reconstruction problemや習熟度のfluctuation)や、mastery learningや生徒にスキルをレポーティングするためにこのタイプのモデルを用いるという課題のために、実際のシステムで運用するよりも、論文を執筆する方が一般的になった。
- これに関するNNモデルの問題の1 つは、特定の問題の正答率を予測するが、それを人間が解釈できるスキルの習熟度にマッピングしないことにある。
Behavioral Testing of Deep Neural Network Knowledge Tracing Models, Kim+, Riiid, EDM'21
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #KnowledgeTracing Issue Date: 2022-08-31
pyBKT: An Accessible Python Library of Bayesian Knowledge Tracing Models, Bardrinath+, EDM'20
Paper/Blog Link My Issue
#Tools #Library #AdaptiveLearning #EducationalDataMining #KnowledgeTracing #KeyPoint Notes #needs-revision Issue Date: 2022-07-27 Comment
pythonによるBKTの実装。scikit-learnベースドなinterfaceを持っているので使いやすそう。
# モチベーション
BKTの研究は古くから行われており、研究コミュニティで人気が高まっているにもかかわらず、アクセス可能で使いやすいモデルの実装と、さまざまな文献で提案されている多くの変種は、理解しにくいものとなっている。そこで、モダンなpythonベースドな実装としてpyBKTを実装し、研究コミュニティがBKT研究にアクセスしやすいようにした。ライブラリのインターフェースと基礎となるデータ表現は、過去の BKTの変種を再現するのに十分な表現力があり、新しいモデルの提案を可能にする。 また、既存モデルとstate-of-the-artの比較評価も容易にできるように設計されている。
# BKTとは
BKTの説明は Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX, Pardos+, MIT, EDM'13
あたりを参照のこと。
BKTはHidden Markov Model (HMM) であり、ある時刻tにおける観測変数(問題に対する正誤)と隠れ変数(学習者のknowledge stateを表す)によって構成される。パラメータは prior(生徒が事前にスキルを知っている確率), learn (transition probability; 生徒がスキルを学習することでスキルに習熟する確率), slip, guess (emission probability; スキルに習熟しているのに問題に正解する確率, スキルに習熟していないのに問題に正解する確率)の4種類のパラメータをEMアルゴリズムで学習する。
ここで、P(L_t)が時刻tで学習者がスキルtに習熟している確率を表す。BKTでは、P(L_t)を観測された正解/不正解のデータに基づいてP(L_t)をアップデートし、下記式で事後確率を計算する
また、時刻t+1の事前確率は下記式で計算される。
一般的なBKTモデルではforgettingは生じないようになっている。
Corbett and Andersonが提案している初期のBKTだけでなく、さまざまなBKTの変種も実装している。
# サポートしているモデル
- KT-IDEM (Item Difficulty Effect): BKTとは異なり、個々のquestionごとにguess/slipパラメータを学習するモデル KT-IDEM: Introducing Item Difficulty to the Knowledge Tracing Model, Pardos+ (w/ Neil T. Heffernan), UMAP'11
- KT-PPS: 個々の生徒ごとにprior knowledgeのパラメータを持つ学習するモデル Modeling individualization in a bayesian networks implementation of knowledge tracing, Pardos+ (w/ Neil T. Heffernan), UMAP'00
- BKT+Forget: 通常のBKTでは一度masterしたスキルがunmasteredに遷移することはないが、それが生じるようなモデル。直近の試行がより重視されるようになる。 How Deep is Knowledge Tracing?, Mozer+, EDM'16
- Item Order Effect: TBD
- Item Learning Effect: TBD
[Paper Note] Deep-IRT: Make Deep Learning Based Knowledge Tracing Explainable Using Item Response Theory, Chun-Kit Yeung, EDM'19
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #AdaptiveLearning #EducationalDataMining #KnowledgeTracing #In-Depth Notes Issue Date: 2022-07-22 Comment
# 一言で言うと
DKVMN [Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
のサマリベクトルf_tと、KC embedding k_tを、それぞれ独立にFully connected layerにかけてスカラー値に変換し、生徒のスキルごとの能力パラメータθと、スキルの困難度パラメータβを求められるようにして、解釈性を向上させた研究。最終的にθとβをitem response function (シグモイド関数)に適用することで、KC j を正しく回答できる確率を推定する。
# モデル
基本的なモデルはDKVMNで、DKVMNのサマリベクトルf_tに対してstudent ability networkを適用し、KC embedding k_tに対してdifficulty networkを適用するだけ。
生徒の能力パラメータθとスキルの困難度パラメータβを求め、最終的に下記item response functionを適用することで、入力されたスキルに対する反応予測を実施する:
# 気持ち
古典的なKnowledge Tracing手法は、学習者の能力パラメータや項目の困難度パラメータといった人間が容易に解釈できるパラメータを用いて反応予測を行えるが、精度が低い。一方、DeepなKnowledge Tracingは性能は高いが学習されるパラメータの解釈性が低い。そこで、IRTと最近提案されたDKVMNを組み合わせることで、高性能な反応予測も実現しつつ、直接的にpsychological interpretationが可能なパラメータを学習するモデルを提案した。
DKVMNがinferenceに利用する情報は、意味のある情報に拡張することができることを主張。
1つめは、各latent conceptのknowledge stateは、生徒の能力パラメータを計算することに利用できる。具体的には、DKVMNによって求められるベクトルf_tは、read vector r (該当スキルに対する生徒のmastery level を表すベクトル)とKCのembedding k_t から求められる。これは、生徒のスキルに対するknowledge staeteとスキルそのもののembeddedされた情報の両者を含んでいるので、f_tをNNで追加で処理することで、生徒のスキルq_tに対する能力を推定することができるのではないかと主張。
同様に、q_tの困難度パラメータもKC embedding vector k_tをNNに渡すことで求めることができると主張。
生徒の能力を求めるネットワークを、student ability network, スキルの困難度パラメータを求めるネットワークをdifficulty networkと呼ぶ。
# 性能
実験の結果、DKT, DKVMN, Deep-IRTはそれぞれ似たようなAUCとなり、反応予測の性能はcomparable
# Discussion
## 学習された困難度パラメータについて
複数のソース(1. データセットのpublisherが設定している3段階の難易度, 2. item analysisによって求めた難易度(生徒が問題に取り組んだとき不正解となった割合), 3. IRTによって推定した困難度パラメータ, 4. PFAによって推定した困難度パラメータ)とDeep-IRTが学習したKC Difficulty levelの間で相関係数を測ることで、Deep-IRTが学習した困難度パラメータが妥当か検討している。ソース2, 3については、困難度推定に使うデータがtest environmentではなく学習サービスによるものなので、生徒のquestionに対するfirst attemptから困難度パラメータを予測した。一方、PFAの場合はtest environmentによる推定ではなく、knowledge tracingの設定で困難度パラメータを推定した(i.e. 利用するデータをfirst attemptに限定しない)。
相関係数をは測った結果が上図で、正直見方があまりわからない。著者らの主張としては、Deep-IRTは他の困難度ソースの大部分と強い相関があった(ソース1を除く)、と主張しているが、相関係数の値だけ見ると明らかにPFAの方が全てのソースに対して高い相関係数を持っている。また、困難度を推定するモデルの設定(test environment vs. learning environment)や複雑度が近ければ近いほど、相関係数が高かった(ソース2, 3間は相関係数は0.96、一方ソース2とDeep-IRTは相関係数0.56)。また、Deep-IRTはソース1の困難度パラメータとの相関係数が0.08であり非常に低い(他のソースは0.3~0.4程度の相関係数が出ている)。この結果を見ると、Deep-IRTによって推定された困難度パラメータは古典的な手法とは少し違った傾向を持っているのではないかと推察される。
=> DeepIRTによって推定された困難度パラメータは、古典的な手法と比較してめっちゃ近いというわけでもなく、人手で付与された難易度と全く相関がない(そもそも人手で付与された難易度が良いものかどうかも怪しい)。結局DeepIRTによる困難度パラメータがどれだけ適切かは評価されていないので、古典的な手法とは少し似ているけど、なんか傾向が違う困難度パラメータが出ていそうです〜くらいのことしかわからない。
## 学習された生徒の能力パラメータについて
reconstruction問題がDKTと同様に生じている。たとえば、“equation solving more than two steps” (red) に不正解したにもかかわらず、対応する生徒の能力が向上してしまっている。また、スキル間のpre-requisite関係も捉えられない。具体的には、“equation solving two or fewer steps” (blue) に正解したにもかかわらず、“equation solving more than two steps” (red) の能力は減少してしまっている。
# 所感
生徒の能力パラメータは、そもそもDKTVMモデルでも入力されたスキルタグに対する反応予測結果が、まさに生徒の該当スキルタグに対する能力パラメータだったのでは?と思う。困難度パラメータについては推定できることで使い道がありそうだが、DeepIRTによって推定された困難度パラメータがどれだけ良いものかはこの論文では検証されていないので、なんともいえない。
# 関連研究
- Item Response Theory (IRT): 受験者の能力パラメータはテストを受けている間は不変であるという前提をおいており(i.e. testing environmentを前提としている)、Knowledgte Tracingタスクのような、学習者の能力が動的に変化する(i.e. learning environment)状況ではIRTをKnowledge Tracingに直接利用できない(と主張しているが、 [Paper Notes] Back to the basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation, Ekanadham+, EDM'16
あたりではIRTで項目の反応予測に利用してDKTをoutperformしている)
- Bayesian Knowledge Tracing (BKT): 「全ての生徒と、同じスキルを必要とする問題がモデル上で等価に扱われる」という非現実的な仮定が置かれている。言い換えれば、生徒ごとの、あるいは問題ごとのパラメータが存在しないということ。
- Latent Factor Analysis (LFA): IRTと類似しているが、スキルレベルのパラメータを利用してKnowledge Tracingタスクに取り組んだ。生徒の能力パラメータθと、問題に紐づいたスキルごとの難易度パラメータβと学習率γ(γ x 正答数で該当スキルに対する学習度合いを求める)を持つ。これにより「学習」に対してもモデルを適用できるようにしている。
- Performance Factor Analysis (PFA): 生徒の能力値よりも、生徒の過去のパフォーマンスがKTタスクにより強い影響があると考え、LFAを拡張し、スキルごとに正解時と不正解時のlearning rateを導入し、過去の該当スキルの正解/不正解数によって生徒の能力値を求めるように変更。これにより、スキルごとに生徒の能力パラメータが存在するようなモデルとみなすことができる。
=> LFAとPFAでは、複数スキルに対する「学習」タスクを扱うことができる。一方で、スキルタグについては手動でラベル付をする必要があり、またスキル間の依存関係については扱うことができない。また、LFAでは問題に対する正答率が問題に対するattempt数に対して単調増加するため、生徒のknowledge stateがlearnedからunlearnedに遷移することがないという問題がある。PFAでは失敗したattemptの数を導入することでこの仮定を緩和しているが、生徒が大量の正答を該当スキルに対して実施した後では問題に対する正答率を現象させることは依然として困難。
- Deep Knowledge Tracing (DKT): DeepLearningの導入によって、これまで性能を向上させるために人手で設計されたfeature(e.g. recency effect, contextualized trial sequence, inter-skill relationship, student’s ability variation)などを必要とせず、BKTやPFAをoutperformした。しかし、RNNによって捉えられた情報は全て同じベクトル空間(hidden layer)に存在するため、時間の経過とともに一貫性した予測を提供することが困難であり、結果的に生徒が得意な、あるいは不得意なKCをピンポイントに特定できないという問題がある(ある時刻tでは特定のスキルのマスタリーがめっちゃ高かったが、別の問題に回答しているうちにマスタリーがめっちゃ下がるみたいな現象が起きるから?)。
- Dynamic Key Value Memory Network (DKVMN): DKTでは全てのコンセプトに対するknowledge stateを一つのhidden stateに集約することから、生徒が特定のコンセプトをどれだけマスターしたのかをトレースしたり、ピンポイントにどのコンセプトが得意, あるいは不得意なのかを特定することが困難であった(←でもこれはただの感想だと思う)。DKTのこのような問題点を改善するために提案された。DKVMNではDKTと比較して、DKTを予測性能でoutperformするだけでなく(しかしこれは後の追試によって性能に大差がないことがわかっている)、overfittingしづらく、Knowledge Component (=スキルタグ)の背後に潜むコンセプトを正確に見つけられることを示した。しかし、KCの学習プロセスを、KCのベクトルや、コンセプトごとにメモリを用意しメモリ上でknowledge stateを用いて表現することで的確にモデル化したが、依然としてベクトル表現の解釈性には乏しい。したがって、IRTやBKT, PFAのような、パラメータが直接的にpsychological interpretationが可能なモデルと、パラメータやrepresentationの解釈が難しいDKTやDKVMNなどのモデルの間では、learning science communityの間で対立が存在した。
=> なので、IRTとDKVMNを組み合わせることで、DKVMNをよりexplainableにすることで、この対立を緩和します。という流れ
著者による実装: https://github.com/ckyeungac/DeepIRT
A Self-Attentive model for Knowledge Tracing, Pandy+ (with George Carypis), EDM'19
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #StudentPerformancePrediction #Selected Papers/Blogs #In-Depth Notes Issue Date: 2021-10-28 Comment
Knowledge Tracingタスクに初めてself-attention layerを導入した研究
interaction (e_{t}, r_{t}) および current exercise (e_{t+1}) が与えられた時に、current_exerciseの正誤を予測したい。
* e_{t}: 時刻tのexercise
* r_{t}: 時刻tでの正誤
interactionからKey, Valueを生成し、current exerciseからQueryを生成し、multi-head attentionを適用する。その後、得られたcontext vectorをFFNにかけて、正誤を予測する。

DKTや、DKVMNを全てのデータセットでoutperform
Context-Aware Attentive Knowledge Tracing, Ghosh+, University of Massachusetts Amherst, KDD'20
においてはSAKTがDKT, DKVMN等に勝てていないのに対し(ASSSITments Data + Statics Data)
An Empirical Comparison of Deep Learning Models for Knowledge Tracing on Large-Scale Dataset, Pandey+, AAAI workshop on AI in Education'21
Do we need to go Deep? Knowledge Tracing with Big Data, Varun+, University of Maryland Baltimore County, AAAI'21 Workshop on AI Education
においてはSAKTはDKT, DKVMNに勝っている(EdNet Data)
When is Deep Learning the Best Approach to Knowledge Tracing?, Theophile+ (Ken Koedinger), CMU+, JEDM'20
においてもSAKTがDKTに勝てないことが報告されている(ASSISTments Data + Statics Data + Bridge to Algebra, Squirrel dataなど)。ただし、Interaction数が大きいデータセット(Squirrel data)ではDKTの性能に肉薄している。
Large ScaleなデータだとSAKTが強いが、Large Scaleなデータでなければあまり強くないということだと思われる。
Large Scaleの基準は、なかなか難しいが、1億Interaction程度あれば(EdNetデータ)SAKTの方が優位に強くなりそう。
数十万、数百万Interaction程度のデータであれば、DKTとSAKTはおそらくcomparableだと思われる。
(追記)
しかし Learning Process-consistent Knowledge Tracing, Shen+, SIGKDD'21
においてはSAKTはEdNetデータセット(Large Scale)においてDKT, DKT+, DKVMNとcomparableなので、
正直何を信じたら良いか分からない。
Modeling Hint-Taking Behavior and Knowledge State of Students with Multi-Task Learning, Chaudry+, Indian Institute of Technology, EDM'18
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #StudentPerformancePrediction #One-Line Notes Issue Date: 2021-11-12 Comment
DKVMN ([Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
)をhint-takingタスクとmulti-task learningした研究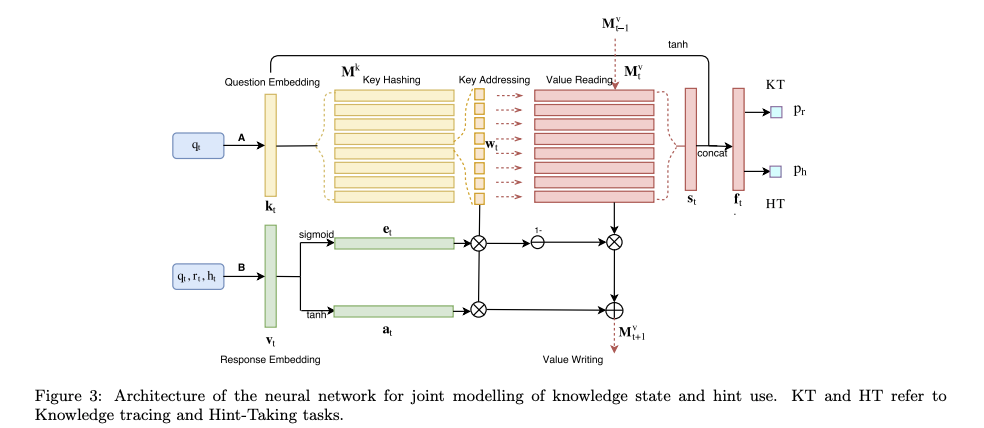
DKVMNと比較して、微小ながら性能向上
Learning to Represent Student Knowledge on Programming Exercises Using Deep Learning, Wang+, Stanford University, EDM'17
Paper/Blog Link My Issue
#EducationalDataMining #KnowledgeTracing #One-Line Notes Issue Date: 2021-07-04 Comment
DKT [Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15
のPiech氏も共著に入っている。
プログラミングの課題を行なっている時(要複数回のソースコードサブミット)、
1. 次のexerciseが最終的に正解で終われるか否か
2. 現在のexerciseを最終的に正解で終われるか否か
を予測するタスクを実施
[Paper Notes] Back to the basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation, Ekanadham+, EDM'16
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KeyPoint Notes #Reading Reflections Issue Date: 2021-05-29 Comment
Knewton社の研究。IRTとIRTを拡張したモデルでStudent Performance Predictionを行い、3種類のデータセットでDKT [Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15
と比較。比較の結果、IRT、およびIRTを拡張したモデルがDKTと同等、もしくはそれ以上の性能を出すことを示した。IRTはDKTと比べて、trainingが容易であり、パラメータチューニングも少なく済むし、DKTを数万のアイテムでtrainingするとメモリと計算時間が非常に大きくなるので、性能とパフォーマンス両方の面で実用上はIRTベースドな手法のほうが良いよね、という主張。
AUCを測る際に、具体的に何に大してAUCを測っているのかがわからない。モデルで何を予測しているかが明示的に書かれていないため(普通に考えたら、生徒のquizに対する回答の正誤を予測しているはず。IRTではquizのIDをinputして予測できるがDKTでは基本的にknowledge componentに対するproficiencyという形で予測される(table 1が各モデルがどのidに対して予測を行なったかの対応を示しているのだと思われる))。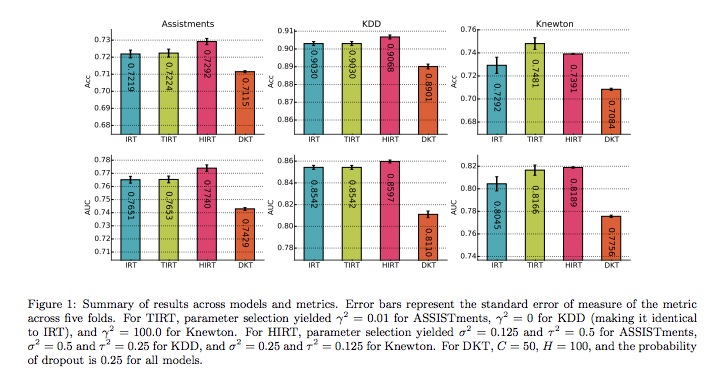
knewton社は自社のアダプティブエンジンでIRTベースの手法を利用しており、DKTに対するIRTベースな手法の性能の比較に興味があったのだと思われる。
なお、論文の著者であるKnewton社のKevin H. Wilson氏はすでにknewton社を退職されている。
https://kevinhayeswilson.com/
Going Deeper with Deep Knowledge Tracing, Beck+, EDM'16
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #KeyPoint Notes #Reading Reflections Issue Date: 2021-05-28 Comment
BKT, PFA, DKTのinputの違いが記載されており非常にわかりやすい

BKT, PFA, DKTを様々なデータセットで性能を比較している。また、ASSISTmentsデータに問題点があったことを指摘し(e.g. duplicate records問題など)、ASSSTmentsデータの問題点を取り除いたデータでも比較実験をしている。結論としては、ASSISTmentsデータの問題点を取り除いたデータで比較すると、DKTがめっちゃ強いというわけではなく、PFAと性能大して変わらなかった、ということ。
KDD cupのデータではDKTが優位だが、これはPFAをKDD Cupデータに適用する際に、難易度を適切に求められない場面があったから、とのこと(問題+ステップ名のペアで難易度を測らざるを得ないが、そもそも1人の生徒しかそういったペアに回答していない場合があり、難易度が1.0 / 0.0 等の極端な値になってしまう。これらがoverfittingの原因になったりするので、そういった問題-ステップペアの難易度をスキルの難易度で置き換えたりしている)。
ちなみにこの手のDKTこれまでのモデルと性能大して変わんないよ?系の主張は、当時だったらそうかもしれないが、2020年のRiiiDの結果みると、オリジナルなDKTがシンプルな構造すぎただけであって、SAKT+RNNみたいな構造だったら多分普通にoutperformする、と個人的には思っている。
ASSISTmentsデータにはduplicate records問題以外にも、複数種類のスキルタグが付与された問題があったときに、1つのスキルタグごとに1レコードが列挙されるようなデータになっている点が、BKTと比較してDKTが有利だった点として指摘している。スキルA, Bが付与されている問題が2問あった時に、それらにそれぞれ正解・不正解した場合のASSISTments09-10データの構造は下図のようになる。DKTを使ってこのようなsequenceを学習した場合、スキルタグBの正誤予測には、一つ前のtime-stempのスキルタグAの正誤予測がそのまま利用できる、といった関係性を学習してしまう可能性が高い。BKTはスキルタグごとにモデルを構築するので、これではBKTと比較してDKTの方が不当に有利だよね、ということも指摘している。
複数タグが存在する場合の対処方法として、シンプルに複数タグを連結して新しいタグとする、ということを提案している。
How Deep is Knowledge Tracing?, Mozer+, EDM'16
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #KeyPoint Notes Issue Date: 2021-05-28 Comment
DKTでは考慮できているが、BKTでは考慮できていない4種類のregularityを指摘し、それらを考慮ようにBKT(forgetting, interactions among skills, incorporasting latent student abilities)を拡張したところ、DKTと同等のパフォーマンスを発揮したことを示した研究。
- Recency Effects, Contextualized Trial Sequence, Inter-skill similarity, Individual variation in ability
DKTの成功は、deep learningによって得られた新たなrepresentationに基づくものではなく、上記input/outputの統計的なregularityを捉えることができる柔軟性と一般性によるものだと分析している(DKTは、汎用のリカレントニューラルネットワークモデルであり、学習と忘却のモデル化、スキルの発見、学生の能力の推論に特化した構成要素はないにもかかわらず、それらを捉えることができた。この柔軟性により、DKTは、ドメイン知識・事前分析がほとんどなくても、様々なデータセットでロバストに動作する)。が、DKTはこのようなドメイン知識等がなく良い性能を達成できている代償として、解釈生を犠牲にしている。BKTのようなshallowなモデルでも上記4種類の規則性を導入することでより解釈性があり、説明性があるモデルを獲得できる、と述べている。教育に応用する上で、解釈性・説明性は非常に重要な要素であり、同等の性能が達成できるなら、BKT拡張したほうがいいじゃん?っていう主張だと思われる。
DKTのAUC計算は、trialごとに該当スキルのpredictionを行い、全てのスキルに関してAUCを計算しているのに対し、
BKTは、個々のスキルごとにAUCを計算し、最終的にそれらを平均することでAUCを算出している点を指摘している(中身の実装を読んで)。
BKTのAUC計算方法の方が、DKTよりもAUCが低くなることを述べ、どちらかに統一した方が良いことを述べている。
Khan AcademyデータをDKTの共著者に使わせてもらえないかきいてみたところ、使わせてもらえなかったとも書いてある。
BKT+Forgetsは、ある特定のスキルの間に何回のtrialがあったかを数えておき、そのfrialの機会ごとにForgetが生じる機会が生じると考えるような定式化になっている。
たとえば、A_1 - A_2 - B_1 - A_3 - B_2 - B_3 - A_4 という問題の系列があったとする(A, Bはスキル名で、添字はスキルのinstance)。そうすると、A_1とA_2間でforgettingが生じる確率はF、A_2とA_3の間でforgettingが生じる確率は1-(1-F)^2、A_3とA_4の間でforgettingが生じる確率は1-(1-F)^3となる。
※ スキルAを連続してtrialした場合はFでforgettingするが、
スキルAをtrialしない場合は 1 - (スキルAを覚えている確率) = Aを忘れている確率 ということだろうか。
BKT+Forgetsは pyBKT: An Accessible Python Library of Bayesian Knowledge Tracing Models, Bardrinath+, EDM'20
に実装されている。
General Features in Knowledge Tracing: Applications to Multiple Subskills, Temporal Item Response Theory, and Expert Knowledge, Brusilovsky+, EDM'14
Paper/Blog Link My Issue
#AdaptiveLearning #StudentPerformancePrediction #KnowledgeTracing #One-Line Notes Issue Date: 2021-10-29 Comment
BKTでは1種類のスキルしか扱えなかった問題を改善(skillだけでなく、sub-skillも扱えるように)
様々なFeatureを組み合わせることが可能
実装:
https://github.com/ml-smores/fast
ただし、GPL-2.0ライセンス
Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX, Pardos+, MIT, EDM'13
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #KnowledgeTracing #needs-revision Issue Date: 2022-07-27 Comment
# Motivation
MOOCsではITSとはことなり、on-demandなチュートリアルヘルプを提供しておらず、その代わりに、知識は自己探求され様々なタイプのリソースの冗長性によって提供され、システムを介して学生は様々な経路やリソースを選択する。このようなデータは、さまざまな条件下で学生の行動の有効性を調査する機会を提供するが、この調査を計測するためのモデルがない。
そこで、既存の学習者モデリングテクニックであるBKTを、どのようにしてMOOCsのコースに適用できるかを示した。
これには3つのチャレンジがある:
1. questionに対応するKCの、対象分野の専門家によるマッピングが不足していること
2.
3.
# データ概要
生徒のgradeは12の宿題と、12のvirtual labs (それぞれ15%の重みで無制限に回答できる)、そして中間テストと最終テスト(それぞれ30%と40%の重みで、3回の回答が許される)によって決まる。レクチャー中の問題は正誤がつくが、gradeにはカウントされないが即座にフィードバックが与えられる。104個のレクチャに289個のスコアリング可能な要素があり(すなわち、problemのsub-partをカウントした)、他にも37種類の宿題のproblemには197個、5つの中間テストproblemに26個、10個の最終テストproblemに47個のスコアリング可能なsub-partが存在する。
weeklyの宿題は複数のproblemで構成されており、それぞれがsingle web pageで表示される。典型的には図といくつかの回答フォームがある(これをsub-partsと呼ぶ)。subpartの回答チェックは、生徒がcheckボタンを押すと開始され、正誤がつく。subpartは任意の順番で回答できるが、いくつかのproblemのsubpartは、以前のsubpartの回答結果を必要とするものも存在する。もし生徒が全てのsubpartsを最初のチェックの前に回答したら、どの順番でsubpartに回答したかは分からない。しかしながら、多くの生徒は回答する度にチェックボタンを押すことを選択している。ほとんどのITSとは異なり、宿題は、最初の回答ではなく、ユーザーが入力した最後の回答に基づいて採点された。
# データセット
154,000人の登録者がいたが、108,000人が実際にコースに入学し、10,000人がコースを最終的に終えた。その中で、7158人が少なくとも60%のweighted averatgeを獲得したという証明書を受け取った。
データセットは2,000人のcertificateを獲得したランダムに選択された生徒によって構成される。さらに、homework, lecture sequence, exam problemの中から、ランダムに10個のproblem(およびそのsubparts)を選択した。
データはJSONのログファイルとして生成され、ログファイルはユーザ単位でJSONレコードとして分割された。そして人間が解釈可能なMOOCsのコンポーネントとのインタラクションのtime seriesにparseされている。
最後的には、problemごとにイベントログを作成した。このログは、そのproblemに関連する学生のイベントごとに1行で構成されている。これは、イベントで消費した時間、subpartの正誤、生徒が回答を入力したあるいは変更した場合、回答のattemptの回数、回答の間にアクセスしたリソースなどが含まれている。
# BKT
KTはmastery learningを実現したいというモチベーションからきていて、mastery learningではスbエテの生徒は自分のペースでスキルを学習していき、前提知識をマスターするまでは、より複雑なmaterialへはチャレンジできないように構成されている。これを実現するためにN問連続で正解するなどのシンプルなmastery基準などが存在しており、ASSISTments Platformのskill builder problem setで利用されている。Cognitive Tutorでは、取得可能な知識は、宣言型であろうと手続き型であろうと、通常は対象分野の専門家によって定義されるKnowledge Component(KC)と呼ばれるきめ細かいatomic piecesによって定義されます。tutorのanswer stepにはこれらのKCのタグが付けられており、生徒の過去の回答履歴は、KCの習熟度を示しています。この文脈では、KCが生徒によって高い確率で知られている(通常は> = 0.95)ときに習熟したと推測されます。
standardなBKTモデルでは、四つのパラメータが定義される:
- prior knowledge p(L_0)
- probability of learning p(T)
- probability of guessing p(G)
- probability of slipping p(S)
これらのパラメータによって、生徒の時刻nでの知識の習熟確率p(L_n)が推論される。また、これらのパラメータは生徒の回答の正誤の予測にも利用できる:
KCは、平均して習得するのに必要な難易度と練習の量が異なるため、これらのパラメーターの値はKCに依存し、以前の学生のログデータなどのトレーニングデータによってfittingすることができる。
パラメータのfittingはEMアルゴリズムかgrid searchによって、観測されたcorrectnessに対する予測された確率の残差平方和によるloss functionを最大化するようなパラメータが探索される。
ただし、どちらのフィッティング手順も、他の手順よりも一貫して優れていることは証明されていません。 グリッド検索は、基本的なBKTモデルのフィッティングは高速ですが、パラメーターの数が増えると指数関数的に増加します。これは、パラメーター化が高いBKTの拡張に関する懸念事項です。どちらのフィッティング手法も、目的は観測されたデータ(生徒の特定のKCの問題に対する正誤の系列)に最もマッチするパラメータを見つけることです。
KTの利用は2つのステージに分かれており、一つは4つのパラメータを学習するステージ、そしてもう一つは生徒の知識を彼らのレスポンスから予測することです。
inferenceのステージでは、時刻nの知識の習熟度は、観測データが与えられたときに以下の指揮で計算できる。観測データが正解だった場合は
であり、不正解の場合は
となる。
右辺のp(L_n)は、時刻nでの知識の習熟度に関する事前確率であり、p(L_n | Evidence_n)はその時点でのobservationを考慮し計算される事後確率です。両方の式はベイズの定理の適用であり、観察されたresponseの説明が学生がKCを知っているということである可能性を計算します。生徒にはフィードバックが提供されるため、KCを学習する機会があります。学生が機会からKCを学習する確率は、下記指揮によって導かれる:
これらの数式がmasxteryを決定するのに利用される。この知識モデルは、学習現象を研究するためのプラットフォームとして機能するように拡張されています。BKTアプローチを採用することで、MOOCで実現することを目指しているのは、この発見能力です。
# Model Adaptation Challenge
## KCモデルの不足
"learning"には広い意味があるが、masteryの文脈では特定のスキル, あるいはKCの獲得を意味する。このようなスキルとquestionのマッピングは、Q-matrixと一般的に呼ばれるが、多くの場合は対象分野の専門家によって提供される。
これらのスキルは、psychometrics literatureの中でcognitive operationsと呼ばれ、スキルの識別プロセスは、ITSおよびエキスパートシステムの文脈では一般にcognitive task analysisと呼ばれます。
KCマッピングの評価手法である学習曲線分析は、優れたスキルマッピングの証拠は、スキルに関連するquestionに回答する機会を通じて、エラー率が単調に減少することであると主張しています。同様に、fluencyは、特定のスキルに対して正解するにつれて増加する(解決する時間が減少する)と期待されている。
たとえば、MOOCまたはGeometryなどの教科内のquestionを一次元で表示すると、カリキュラムに新しいトピック資料が導入されると、すぐにエラー率と応答時間が急増するため、パフォーマンスとfluencyのプロットにノイズが発生します。
対象分野の専門家が定義したKCまたは学習目標は、将来のMOOCsでは計画されていますが、それらは一般的ではなく、本論文で使用される6.002xコースデータには存在しません。したがって、我々のゴールはコースの構成要素を利用して、KCとquestionのマッピングを実現することである。課題のproblemとsubpartの構造を利用して、problemそのものをKCとみなし、subpartをKCに紐づくquestionとみなします。この選択の理論的根拠は、コースの教授はしばしば、それぞれのproblemにおいて、特定のconceptを利用することを念頭に置いていることが多いことです。subpartのパフォーマンスは、生徒がこのconceptを理解しているかの証拠となります。このタイプのマッピングの利点は、ドメインに依存せず、任意のMOOCのベースラインKCモデルとして利用できることです。欠点は、特定のKCへの回答が特定の週の課題の問題内でのみ発生するため、1週をまたいだ学習の長期評価ができないことです。Corbett&Conrad [14]がコースの問題構造に対する質問の同様の表面的なマッピングを評価し、これがより体系的で窒息する学習曲線を達成することを実際に犠牲にしていることを発見したため、モデルの適合性の低下は別の欠点です(←ちょっとよくわからない)。だが、このマッピングは、problem内での現象を研究することを可能にする合理的な出発点であると信じており(これは「問題分析」と呼ばれます)、ここで説明した方法とモデルは、教科の専門家によって導かれた、あるいはデータから推論された、またはその両者のハイブリッドによる別のKCモデルにも適用できると信じています。
[Paper Note] Factorization Models for Forecasting Student Performance, Thai-Nghe+, EDM'11
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #StudentPerformancePrediction #One-Line Notes Issue Date: 2018-12-22 Comment
student performanceは、推薦システムの問題において、下記の2種類にcastできる:
1. rating prediction task, すなわち、ユーザ・アイテム・ratingを、生徒・タスク・パフォーマンスとみなす
2. sequentialなエフェクトを考慮して、forecasting problemに落とす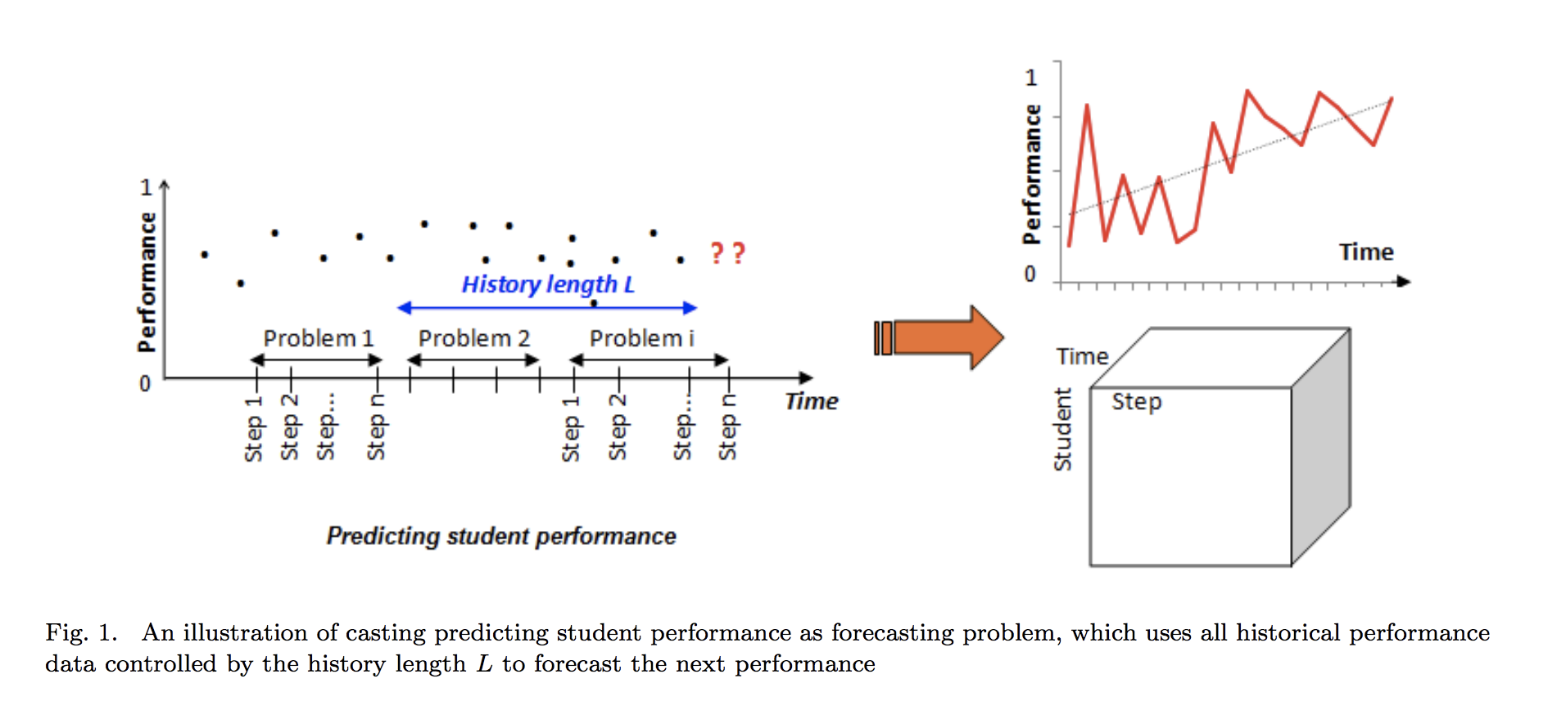
TensorFactorizationで、欠損値を予測
cold-start problem(new-user, new item)への対処としては、global averageをそれぞれ用いることで対処(more sophisticatedなやり方が提案されているとも述べている)
使用している手法としては、この辺?
https://pdfs.semanticscholar.org/8e6b/5991f9c1885006aa204d80cc2c23682d8d31.pdf