
EducationalDataMining
[Paper Note] Learning to Make MISTAKEs: Modeling Incorrect Student Thinking And Key Errors, Alexis Ross+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #SyntheticData #Reasoning #Label-free Issue Date: 2025-10-16 GPT Summary- 新手法MISTAKEを提案し、不正確な推論パターンをモデル化。サイクル整合性を利用して高品質な推論エラーを合成し、教育タスクでの学生シミュレーションや誤解分類において高精度を達成。専門家の選択肢との整合性も向上。 Comment
元ポスト:
Engaging an LLM to Explain Worked Examples for Java Programming: Prompt Engineering and a Feasibility Study, Hassany+, EDM'24 Workshop, 2024.07
Paper/Blog Link My Issue
#LanguageModel #Workshop Issue Date: 2025-01-06 Comment
元ポスト:
LearnLM: Improving Gemini for Learning, LearnLM Team+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Education Issue Date: 2024-12-31 GPT Summary- 生成AIシステムは従来の情報提示に偏っているため、教育的行動を注入する「教育的指示の遵守」を提案。これにより、モデルの振る舞いを柔軟に指定でき、教育データを追加することでGeminiモデルの学習を向上。LearnLMモデルは、さまざまな学習シナリオで専門家から高く評価され、GPT-4oやClaude 3.5に対しても優れた性能を示した。
Covering Uncommon Ground: Gap-Focused Question Generation for Answer Assessment, ACL'23
Paper/Blog Link My Issue
#NLP #Education #QuestionGeneration #ACL Issue Date: 2023-07-15 GPT Summary- 本研究では、教育的な対話における情報のギャップに焦点を当て、自動的に質問を生成する問題に取り組んでいます。良い質問の要素を明確にし、それを満たすモデルを提案します。また、人間のアノテーターによる評価を行い、生成された質問の競争力を示します。
Knowledge Tracing: A Survey, ABDELRAHMAN+, Australian National University, ACM Computing Surveys'23
Paper/Blog Link My Issue
#Survey #AdaptiveLearning #KnowledgeTracing Issue Date: 2022-08-02
[Paper Note] Using Neural Network-Based Knowledge Tracing for a Learning System with Unreliable Skill Tags, Karumbaiah+, (w_ Ryan Baker), EDM'22
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #KnowledgeTracing #EDM #In-Depth Notes Issue Date: 2022-08-26 Comment
超重要論文。しっかり読むべき
# 一言で言うと
KTを利用することを最初から念頭に置いていなかったシステムでは、問題に対して事後的にスキルをマッピングする作業が生じてしまい、これは非常に困難なことが多い。論文中で使用したアメリカの商用の数学のblended learningのシステムのデータでは、途中で企業が買収された経緯もあり、古いコンテンツと新しいコンテンツの間でスキルタグのマッピングの間で、矛盾や一貫性がないものができあがってしまった(複数の異なるチームがコンテンツの提供やスキルのタグ付けを行なった結果)。このような例はレアケースかもしれないが、問題とスキルタグが異なるチームによって開発されるということは珍しいことではないし、現代のオンライン学習システムの多くは、さまざまな教科書のデータを統合し、長年にわたってコンテンツ作成チームのメンバーを変更し、複数の州の基準や内部コンテンツスキーマに従ってコンテンツにタグをづけをしているので、少なからずこういった問題(i.e. 一貫性がなく、矛盾をかかえたitem-skill mapping)を抱えている。
こうした中で、NNを用いたモデルを用いることで、unreliableなKCモデルを用いるくらいならば、KCモデルを用いない方が正答率予測が高い精度で実施できることを示した。これは少なくとも、生徒の問題に対する将来のパフォーマンスを予測する問題に関して言えば、既存のアプリケーションにおいて、KCモデルを構築するステップを回避できる可能性を示唆している。
# モチベーション
Cognitive Tutorのようなシステムは、もともとKTを利用するために設計されているシステムだったが、多くのreal-worldの学習システムはアダプティブラーニングやKTを念頭に置いて作られたものではない。そういったシステムでアダプティブな機能を追加するといった事例が増えてきている。こういったシステムが、もともとKTを実施することを念頭するために作られたシステムとの違いとして、問題とスキルのマッピング方法にある。
最初から KT を使用するように設計されたシステムは、最初にどのスキルを含めるかを選択し、次にそれらのスキルに合わせたアイテムを開発する。 一方、KTを使用するために改良をする場合、最初にアイテムが作成され、次にアイテムにスキルのラベルが付けられる。
既存のアイテムにスキルのラベルを付けるのは、スキルの新しいアイテムを作成するよりもはるかに困難である。 多くの場合、アイテムは複数の著者によって時間をかけて開発されたものであるか、異なる教科書などの異なる元のソースからのものである。この異種のコンテンツ (場合によっては数万のアイテム) を一連のスキルにマッピングすることは、非常に困難な作業になる可能性がある。
多くの場合、アイテムは政府のカリキュラム基準の観点からタグ付けされているが、これらの基準は一般的に、KTモデルで使用されるスキルよりも非常に粗いものとなっている。
したがって、最初からKTを利用することを念頭に置かれていないシステムでKTを利用することには課題がある。
この論文では、NNベースなKTモデルが、この課題の部分的な解決策になることを示す。
このために、商用の数学のblended learningシステムでのケーススタディを実施した。
中学生が 2 年間システムを使用して収集したデータを使用して、KT モデルの性能を次の3 つのシナリオで比較し:
- 1) システムが提供する (おそらくunreliableな)スキルタグを利用した場合
- 2) 州の基準に基づくタグを利用した場合
- 3) コンテンツとスキルタグのマッピングを一切入力しない場合
DKVMNでの実験の結果、1)が最も悪い性能を示し、3)が最も良い問題の正誤予測の性能を示した。
これは、もともとKT モデルで動作するように設計されていなかった現実世界の学習システムでKCモデリングを回避する可能性を示唆している。特に、目的が将来のアイテムに対する学習者の成績を予測することだけである場合はこれに該当する。
# 実験結果
スキルの情報を用いず、ExerciseIDをそのままinputする方法が、最も高いAUCを獲得している。
# つまり
- きちんと一貫性があり矛盾のないItem-KCマッピングを用いないとモデルがきちんと学習できない
- 特に元々KTを適用することを念頭に置いていないシステムでは困難な作業となる可能性が高い
# KTの歴史
- 30年ほど研究されている(1995年のCorbett and AndersonらのBKTあたりから)
- 最初はBKTが広く採用された
- その後、最近ではlogistic regressionに基づくモデルが提案されるようになってきたが、実際のシステムで利用されることはまだ稀
- Elo や Temporal IRT などのIRTに関連するアルゴリズムも、最近文献でより広く見られるようになり、いくつかの学習システムで大規模に使用されている
- Elo およびTemporal IRT は KCモデルなしで使用できるが、通常、いくつかのスキルごとに個別の Elo モデルが利用される。
- NNベースなモデルは過去5年で活発に研究され、将来のパフォーマンスを予測する性能は飛躍的に向上した
- ただし、予測不可能な動作(reconstruction problemや習熟度のfluctuation)や、mastery learningや生徒にスキルをレポーティングするためにこのタイプのモデルを用いるという課題のために、実際のシステムで運用するよりも、論文を執筆する方が一般的になった。
- これに関するNNモデルの問題の1 つは、特定の問題の正答率を予測するが、それを人間が解釈できるスキルの習熟度にマッピングしないことにある。
GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering, Yoonseok Yang+, NAACL'22
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #EfficiencyImprovement #CollaborativeFiltering #KnowledgeTracing #Contents-based #NAACL Issue Date: 2022-08-01 GPT Summary- コンテンツベースの協調フィルタリング(CCF)において、PLMを用いたエンドツーエンドのトレーニングはリソースを消費するため、GRAM(勾配蓄積手法)を提案。Single-step GRAMはアイテムエンコーディングの勾配を集約し、Multi-step GRAMは勾配更新の遅延を増加させてメモリを削減。これにより、Knowledge TracingとNews Recommendationのタスクでトレーニング効率を最大146倍改善。
Empirical Evaluation of Deep Learning Models for Knowledge Tracing: Of Hyperparameters and Metrics on Performance and Replicability, Sami+, Aalto University, JEDM'22
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #Surface-level Notes Issue Date: 2022-04-28 Comment
DKTの説明が秀逸で、元論文では書かれていない分かりづらいところまできちんと説明してくれている。
(inputは(スキルタグ, 正誤)のtupleで、outputはスキルタグ次元数のベクトルyで、各次元が対応するスキルのmasteryを表しており、モデルのtrainingはnext attemptに対応するスキルのprobabilityのみをyから抽出しBinary Cross Entropyを計算する点、など)
入力や出力の仕方によって性能がどの程度変化しているかを検証しているのがおもしろい。
- Input: one-hot encoding (one hot vectorをinputする) vs. embedding layer (embeddingをinputする)
- Output: output per skill (スキルタグの次元数を持つベクトルyをoutputする) vs. skills-to-scalar output (skill summary layer + Scalar; 次のattemptに対する正答率のみをscalarでoutputする)
下図ではDKTの例が書かれているが、DKVMNやSAKTでもこれらの違いは適用可能。
output per skillで出力をすれば、Knowledge TrackingはDKTと同様どのようなモデルでも可能なのではないか。
◆Inputについて
基本的には大きな差はないが、one-hot encodingを利用した場合、DKVMN-PaperとSAKTがembeddingと比較して3.3~4.6%程度AUCが悪くなることがあった。
最高の性能を模索したい時はembedding layerを利用し、one-hot encodingはハイパーパラメータの選択をミスった場合でもロバストな結果(あまり性能が悪化しなかった)だったので、より安全な選択肢と言える。
◆Outputについて
全体として、DKT(およびDKTの亜種)については、output per skillの方が良かった。
DKVMNはこれとは逆で、skills-to-scalar outputの方が性能が良かった。
SAKTではoutput per skillの方がworst scoreがskills-to-scalar outputよりも高いため、よりrobustだと判断できる。
結論:
1. Deep Learning basedなモデルはnon-deep learning basedなモデルやシンプルなベースラインよりも一般的に予測性能が良い
2. LSTMを用いたDKT(LSTM-DKT), LSTM-DKTに次のexerciseのスキルタグ情報をconcatして予測をするDKT(LSTM-DKT-S), DKVMNの性能がDeep Learning Basedな手法では性能が良かった。が、Deep Learningベースドなモデルの間での性能の差は僅かだった(SAKTとも比較している)。
3. one-hot encoding vs. embedding layer, output per skill vs. skills-to-scalar output については、最大で4.6%ほどAUCの変化があり(SAKTにone-hot encodingを入力した場合embeddingを利用しない場合よりも4.6%ほど性能が低下している)、パフォーマンスに大きな違いをもたらした
論文中のDKVMN, DKVMN-Paperの違いは、著者が実装を公開しているMXNetの実装だと論文(Paper)に書かれているアーキテクチャと実装が違うのでDKVMNとして記述している。DKVMN-Paperは論文通りに実装したものを指している。
この研究では、KTする際に全てのDeep Learning basedなモデル(DKT, DKVMN, SAKT)において、入力の系列をx_tを(s_t, c_t)で表現し検証している。s_tはスキルタグで、c_tは正解したか否か。
outputも output-per-skill の場合は、スキルタグ次元のベクトルとなっている。
Behavioral Testing of Deep Neural Network Knowledge Tracing Models, Kim+, Riiid, EDM'21
Paper/Blog Link My Issue
#NeuralNetwork #KnowledgeTracing #EDM Issue Date: 2022-08-31
Option Tracing: Beyond Correctness Analysis in Knowledge Tracing, Ghosh+, AIED'21
Paper/Blog Link My Issue
#AdaptiveLearning #OptionTracing #AIED #One-Line Notes Issue Date: 2022-08-18 Comment
これまでのKTは問題の正誤(correctness)に対してfittingしていたが、この研究ではmultiple choice questionでどの選択肢を選択するかを予測するタスクを提案している。
Learning Process-consistent Knowledge Tracing, Shen+, SIGKDD'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #SIGKDD #In-Depth Notes Issue Date: 2022-05-02 Comment
DKTでは問題を間違えた際に、対応するconceptのproficiencyを下げてしまうけど、実際は間違えても何らかのlearning gainは得ているはずだから、おかしくね?というところに端を発した研究。
student performance predictionの性能よりも、Knowledge Tracingのクオリティーにもっと焦点を当てようよという主張をした論文。
Forgettingもモデル化しているところが特徴。
現在は引用数2だけど、この課題感は非常に重要で、重要論文だと思う。
# モチベ
下図はDKTによる習熟度の変化を表しており赤枠で囲まれている部分は、問題に不正解した際に習熟度が下がることを示している。しかし実際な問題に間違っていたとしても何らかのLearning Gainを得ているはずであり、この挙動はcognitive theoryに反している。実際に先行研究では、エラーは学習において自然な要素であり、学習者はエラーから学び、好ましいエラーによって学習を促進できることを指摘している。
これまでのknowledge tracing研究が、student performance predictionの性能ばかりにフォーカスされているのに対し、本研究では、Knowledge Tracingの解釈性とstudent performance predictionのaccuracyの両方にフォーカスしている。
# Problem Definition
本研究では、1学習の基本要素(learning cell)は exercise-answertime-correctness の3つ組によって表現され、learning cell同士は、interval timeによって隔たれていると考える。answertimeを導入することで、学習者のlearning processを表現する能力を高め、interval timeはLearning Gainを算出する際に役立てる(一般的にinterval timeが短い方がより多くのknowledgeを吸収する傾向にあるなど、interval timeはlearning gainの多様性を捉えるのに役立つ)。
つまり、学習の系列は x = {(e1, at1, a1),it1, (e2, at2, a2),it2, ...,(et, att, at ),itt } と表せる。
KTタスクは、t+1時点での生徒のknowledge stateと、生徒のパフォーマンスを予測する問題として表せる。
# モデル
学習者のLearning Processをきちんとモデル化することに念頭をおいている。具体的には、①学習者は学習を通じて常に何らかのLearning Gain(ある2点間でのパフォーマンスの差; 本研究では前回の学習と今回の学習の両方のlearning cell + interval time + 前ステップでのknowledge stateからLGを推定)を得ており、②忘却曲線にならい学習者は時間がたつと学習した内容を忘却していき(anwertimeとinterval timeが関係する)、③現在のknowledge stateから正誤予測が実施される。
モデルの全体像が下図であり、①がLearning Module, ②がForgetting Module, ③がPredicting Moduleに相当している。
## Embedding
本研究ではTime EmbeddingとLearning Embedding, Knowledge Embeddingの三種類のEmbeddingを扱う。
### Time Embedding
answer timeとinterval timeをembeddingで表現する。両者はスケールが異なるため、answer timeは秒で、interval timeは分でdiscretizeしone-hot-encodingし、Embeddingとして表現する。ここで、interval timeが1ヶ月を超えた場合は1ヶ月として表現する。
### Learning Embedding
learning cellをembeddingで表現する。exercise, answertime, correctnessそれぞれをembeddingで表現し、それらをconcatしMLPにかけることでlearning embeddingを獲得する。ここで、correctnessのembeddingは、正解の場合は全ての要素が1のベクトル, 不正解の場合は全ての要素が0のベクトルとする。
### Knowledge Embedding
学習プロセスにおけるknowledge stateの保存とアップデートを担うEmbedding。
Knowledge Embedding h は、(M x dk)次元で表され、Mはknowledge conceptの数である。すなわち、hの各行が対応するknowledge conceptのmasteryに対応している。learning interactionにおいて、それぞれのknowledge conceptに対するlearning gainや、忘却効果をknowledge embeddingを更新することによって反映させる。
また、knowledge embeddingを更新する際にはQ-matrixを利用する。Q-matrixは、exerciseとknowledge conceptの対応関係を表した行列のことである。Qjmが1の場合、exercise ej が knowledge concept km と関係していることを表し、そうでない場合は0でQ-matrixは表現される。もし値が0の場合、exercise ej のパフォーマンスは、knowledge concept km のmasteryに一切影響がないことを表している。が、人手て定義されたQ-matrixはエラーが含まれることは避けられないし、主観的なバイアスが存在するため、本研究ではこれらの影響(Q-matrix上の対応関係の見落としや欠落)を緩和するためにenhanced Q-matrix q (J x M次元)を定義する。具体的には、通常のQ-matrixで値が0となる部分を、小さな正の値γとしてセットする。
今回はこのようなシンプルなenhanced Q-matrixを利用するが、どのようなQ-matrixの定義が良いかはfuture workとする。
## Learning Module
learning gainを測るためのモジュール。2つの連続したlearning interactionのパフォーマンスの差によってgainを測定する(learning embeddingを使う)。ただこれだけではlearning gainの多様性を捉えることができないため(たとえば同じ連続したlearning embeddingを持って生徒がいたとしてもlearning gainが一緒とは限らない)、interval timeとprevious knowledge stateを活用する。
interval timeはlearning processの鍵となる要素の一つであり、これはlearning gainの差異を反映してる。一般tネキには、interval timeが短い方が生徒はより多くの知識を獲得する傾向にある。
さらに、previous knowledge stateもlearning gainに関係しており、たとえばmasteryが低い生徒は改善の可能性が非常に高い。
previous knowledge stateを利用する際は、現在のexerciseと関連するknowledge conceptにフォーカスするために、knowledge embeddingをknowledge concept vector q_etとの内積をとり、関連するknowledge conceptのknowledge stateを得る:
(q_etの詳細が書かれていないので分からないが、おそらくenhanced Q-matrixのexercise e_tに対応する行ベクトルだと思われる。e_tと関連するknowledge conceptと対応する要素が1で、その他が正の定数γのベクトル)
そしてlearning gain lg_t (dk次元ベクトル)は2つの連続したlearning embedding, と現在の問題と関連するknowledge stateとinterval time embeddingをconcatしMLPにかけることで算出する。
さらに、全てのlearning gainが生徒のknowledgeの成長に寄与するとは限らないので、生徒の吸収能力を考慮するために learning gate Γ^l_t (dk次元ベクトル)を定義する(learning gainと構成要素は同じ):
そして先ほど求めたlearning gateとlearning gainの内積をとり、さらにknowledge concept vector q_etとの内積をとることで、ある時刻tのexercise e_tにと関連するknowledge conceptのlearning gain ~LG_tを得る:
ここで、(lg_t+1)/2しているのは、tanhの値域が(-1, 1)なためであり、これにより値域を(0, 1)に補正している。従ってLG_tは常に正の値となる。これは、本研究の前提である、生徒はそれぞれのlearning interactionから知識を着実に獲得しているという前提を反映している。
## Forgetting Module
~LG_tは生徒のknowledge stateを向上させる働きをするが、反対の忘却現象は、時間が経つにつれてどれだけの知識が忘れられるかに影響します。forgetting curve theoryによると、記憶されている学習教材の量は時間経過に従い指数的に減衰していく。しかしながら、knowledge stateとinterval timeの複雑な関係性を捉えるためには、manual-designedな指数減衰関数では十分ではない。
そこで、forgetting effectをモデル化するために、forgetting gate Γ^f_tを導入する。これは、knowledge embeddingから3つの要素をMLPにかけることで失われる情報の度合いを学習するしたものであり、その3つの要素とは (1) 生徒のprevious knowledge state h_t-1, (2)生徒の現在のlearning gain LG_t, (3) interval time it_tである。
これらを用いてforgetting gate (dk次元) は以下のように計算される:
forgetting gateをh_t-1と積をとることで、忘却の影響を考慮することができる。そして、生徒がt番目のlearning interactionを完了した後のknowledge state h_tは次の式で更新される:
## Predicting Module
これでlearning gainとforgetting effectの両方を考慮した生徒のknowledge state h_tが算出できたので、これをe_t+1のexerciseのperformance予測に活用する。e_t+1を生徒が解く時は、対応するknowledge conceptを適用することで回答をするので、knowledge stateのうち、e_t+1と関連するknowledge state ~h_tを利用する(knowledge concept vector q_et+1との内積で求める)。式で表すと下記になる:
~h_tにexercise e_t+1のembeddingをconcatしてMLPにかけている。
# Objective Function
正則化項つきのcross-entropy log lossを利用する。
# 実験結果
## knowledge tracingの結果
先述のDKTの例とは異なり、問題の回答に誤っていたとしてもproficiencyが向上するようになっている。ただ、e_7が不正解となっている際に、proficiencyが減少していることもわかる。これは、モデルがproficiencyの推定をまだしっかりできていない状態だったため、モデル側がproficiencyを補正したためだ、と論文中では述べられているが、こういった現象がどれだけ起きるのだろうか。こういう例があると、図中の赤枠はたまたま不正解の時にproficiencyが向上しただけ、というふうにも見えてしまう(逆に言うとDKTでも不正解の時にproficiencyが向上することはあるよねっていう)。
また、忘却効果により時間経過に伴い、proficiencyが減少していることもわかる。ただ、この現象もDKTの最初の例でもたとえば①の例はproficiencyが時間経過に伴い減少していっていたし、もともとDKTでもそうなってたけど?と思ってしまう。
ただ、②についてはDKTの例ではproficiencyが時間経過に伴い減少して行っていなかったため、LPKTではきちんとforgetting effectがモデリングできていそうでもある。また、図中右では、最初のinteractionと各knowledge conceptの習熟度の最大値、最後のinteraction時の習熟度がレーダーチャートとして書かれており、学習が進むにつれてどこかで習熟度は最大値となり、忘却効果によって習熟度は下がっているが、学習の最初よりは習熟度が高く弱実に学習が進んでいますよ、というのを図示している。interactionをもっと長く続けた際に(あるknowledge conceptを放置し続けた際に)、忘却効果によってどの程度習熟度がshrinkするのかが少し気になる(習熟度が大きくなった状態が時間発展しても維持されるということが、このモデルでは存在しないのでは?)。
=> Knowledge Tracingの結果については、cherry pickingされているだけであって、全体として見たらどれだけ良くなっているかが正直分からないんじゃないか、という感想。
## student performance predictoin
全てのベースラインに勝っている。特に系列長の長いASSISTchallでAKTに対して大きく勝っており、系列長の長いデータに対してもrobustであることがわかる。
## Ablation Study
learning module, forgetting module, time embeddingをablationした場合に性能がどう変化するかを観察した。forgetting moduleをablationした場合に、性能が大きく低下しているので、forgetting moduleの重要性がわかる。おもしろいのは、time embeddingを除いてもあまり性能は変化していないので、実際はstudent performance predictionするだけならtime embeddingはあまり必要ないのかもしれない。が、論文中では「time embedding (answer timeとinterval time)を除外するのはlearning processを正確にモデル化する上でharmfulだ」と言及しているに留まっており、具体的にどうharmfulなのかは全くデータが提示されていない。time embeddingを除外したことでknowledge tracingの結果がどう変化するのかは気になるところではある、が、実はあまり効いていないんじゃない?という気もする。
## Exercises Clustering
最後に、学習したexerciseのembeddingをt-SNEで可視化しクラスタリングしている。クラスタリングした結果、共通のknowledge conceptを持つexercise同士はある程度同じクラスタに属する例がいくつか見受けられるような結果となっている。
# 所感
answer timeとinterval timeのデータがなくても高い性能で予測ができそうなのでアリ。ただ、そういった場合にknowledge tracingの結果がどうなるかが不安要素ではある。もちろんanswer timeとinterval timeが存在するのがベストではあるが。
また、DKT+で指摘されているような、inputがreconstructionされない問題や、proficiencyが乱高下するといった現象が、このモデルにおいてどの程度起きるのかが気になる。
DKTのようなシンプルなモデルではないので、少しは解消されていたりするのだろうか。実用上あのような現象が生じるとかなり困ると思う。
KCのproficiencyの可視化方法について論文中に記述されていないが、下記リポジトリのIssue 29で質問されている。
knowledge matrix hは各KCのproficiencyに関する情報をベクトルで保持しており、ベクトルをsummationし、シグモイド関数をかけることで0.0~1.0に写像しているとのこと。
BEKT: Deep Knowledge Tracing with Bidirectional Encoder Representations from Transformers, Tian+ (緒方先生), Kyoto University, ICCE'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #One-Line Notes #ICCE Issue Date: 2022-04-28 Comment
KTにBERTを利用した研究
Empirical Evaluation of Deep Learning Models for Knowledge Tracing: Of Hyperparameters and Metrics on Performance and Replicability, Sami+, Aalto University, JEDM'22
などでDeepLearningBasedなモデル間であまり差がないことが示されているので、本研究が実際どれだけ強いのかは気になるところ。
Do we need to go Deep? Knowledge Tracing with Big Data, Varun+, University of Maryland Baltimore County, AAAI'21 Workshop on AI Education
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #AAAI #Workshop #One-Line Notes Issue Date: 2022-04-28 GPT Summary- インタラクティブ教育システム(IES)を用いて学生の知識を追跡し、パフォーマンスモデルを開発する研究が進展。深層学習モデルが従来のモデルを上回るかは未検証であり、EdNetデータセットを用いてその精度を比較。結果、ロジスティック回帰モデルが深層モデルを上回ることが確認され、LIMEを用いて予測に対する特徴の影響を解釈する研究を行った。 Comment
データ量が小さいとSAKTはDKTはcomparableだが、データ量が大きくなるとSAKTがDKTを上回る。
An Empirical Comparison of Deep Learning Models for Knowledge Tracing on Large-Scale Dataset, Pandey+, AAAI workshop on AI in Education'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #One-Line Notes Issue Date: 2022-04-28 Comment
EdNetデータにおいて、DKT, DKVMN, SAKT, RKTの性能を比較した論文
RKTがも最もパフォーマンスが良く、SAKTもDKT, DKVMNに勝っている
A Survey of Knowledge Tracing, Liu+, IEEE Transactions on Learning Technologies, arXiv'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #One-Line Notes Issue Date: 2022-04-27 Comment
古典的なBKT, PFAだけでなくDKT, DKVMN, EKT, AKTなどDeepなモデルについてもまとまっている。

SAINT+: Integrating Temporal Features for EdNet Correctness Prediction, Shin+, RiiiD AI Research, LAK'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #StudentPerformancePrediction #Transformer #LAK #Selected Papers/Blogs #One-Line Notes Issue Date: 2021-10-28 Comment
Student Performance PredictionにTransformerを初めて利用した研究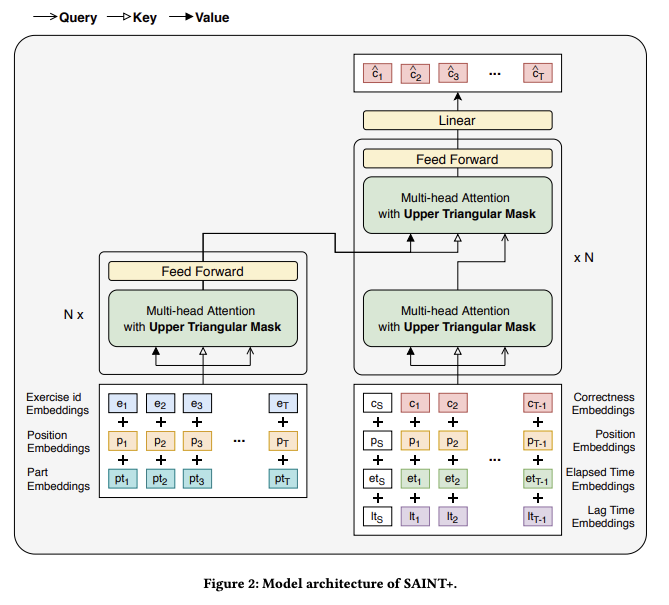
Reinforcement Learning for the Adaptive Scheduling of Educational Activities, Bassen+, Stanford University, CHI'20
Paper/Blog Link My Issue
#Education #AdaptiveLearning Issue Date: 2022-12-27
Extending Deep Knowledge Tracing: Inferring Interpretable Knowledge and Predicting Post-System Performance, Richard+ (w_ Ryan Baker), ICCE'20
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #Surface-level Notes #Reading Reflections #ICCE Issue Date: 2022-08-29 Comment
# 概要
ざっくりとしか読めていないが
- DeepLearningBasedなKT手法は、latentな学習者の知識を推定しているわけではなく、「正誤」を予測しているだけであることを指摘
- → 一方BKTはきちんとlatent knowledgeがモデリングされている
- → 昔はknowledge inferenceした結果を、post-testで測定したスキルのmasteryとしっかり比較する文化があったが、近年のDeepLearningベースな研究では全く実施されていないことも指摘
- → learning systemの中でどのようなパフォーマンスが発揮されるかではなく、learning systemの外でどれだけスキルが発揮できるか、というところにBKTなどの時代は強い焦点が置かれていたのだと思われる
- DeepLearningBasedなKT手法でもknowledgeのinferenceが行える手法を提案し、BKTやPFAによるknowledge estimateよりもposttestのスコアと高い相関を示すことを実験した
- → 手法: それぞれの問題のfirst attemptに対する正誤データの「全て」をtraining dataとし、DKT, DKVMN, BKT, PFAを学習。
-(おそらく)学習したモデルを用いてある生徒AのスキルBのknowledgeをinferenceしたい場合、生徒Aが回答したスキルBと紐づいた問題に対する平均正答率を推定した習熟度とした
- 生徒Aはtraining dataに含まれている生徒
- すなわち、生徒Aにとって未知の問題の正答率を予測しているわけではなく、モデルがパラメータを推定するために利用した既知の問題-回答ペアデータに対して、モデルがパラメータをfittingした後にinferenceできる正答率の平均値を習熟度としている
# 結果
- 4種類のスキルに対するpost-testのスコアと相関係数をモデルごとに比較した結果、DKT, DKVMNなどは、BKTよりも高い相関を示し、PFAとはcomparableな結果となった
# 所感
- この手法のリアルタイムな運用は難しいと思った(knowledgeをinferするために毎回モデルをtrainingしなおさなければならない)
- BKTが推定するスキルのmasteryはこのcase studyだけ見ると全くあてにならない・・・
- ユーザが回答した問題と紐づいたスキルのknowledgeしか推定できないところもlimitationの一つだと思う
- この手法がtraining dataに含まれていない「未知の問題」に対する正答率予測を平均することで、knowledgeをinferenceできるという話だったのであれば、非常に興味深いと思った。
- 実際どうなんだろうか?
pyBKT: An Accessible Python Library of Bayesian Knowledge Tracing Models, Bardrinath+, EDM'20
Paper/Blog Link My Issue
#Tools #Library #AdaptiveLearning #KnowledgeTracing #EDM #KeyPoint Notes #needs-revision Issue Date: 2022-07-27 Comment
pythonによるBKTの実装。scikit-learnベースドなinterfaceを持っているので使いやすそう。
# モチベーション
BKTの研究は古くから行われており、研究コミュニティで人気が高まっているにもかかわらず、アクセス可能で使いやすいモデルの実装と、さまざまな文献で提案されている多くの変種は、理解しにくいものとなっている。そこで、モダンなpythonベースドな実装としてpyBKTを実装し、研究コミュニティがBKT研究にアクセスしやすいようにした。ライブラリのインターフェースと基礎となるデータ表現は、過去の BKTの変種を再現するのに十分な表現力があり、新しいモデルの提案を可能にする。 また、既存モデルとstate-of-the-artの比較評価も容易にできるように設計されている。
# BKTとは
BKTの説明は Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX, Pardos+, MIT, EDM'13
あたりを参照のこと。
BKTはHidden Markov Model (HMM) であり、ある時刻tにおける観測変数(問題に対する正誤)と隠れ変数(学習者のknowledge stateを表す)によって構成される。パラメータは prior(生徒が事前にスキルを知っている確率), learn (transition probability; 生徒がスキルを学習することでスキルに習熟する確率), slip, guess (emission probability; スキルに習熟しているのに問題に正解する確率, スキルに習熟していないのに問題に正解する確率)の4種類のパラメータをEMアルゴリズムで学習する。
ここで、P(L_t)が時刻tで学習者がスキルtに習熟している確率を表す。BKTでは、P(L_t)を観測された正解/不正解のデータに基づいてP(L_t)をアップデートし、下記式で事後確率を計算する
また、時刻t+1の事前確率は下記式で計算される。
一般的なBKTモデルではforgettingは生じないようになっている。
Corbett and Andersonが提案している初期のBKTだけでなく、さまざまなBKTの変種も実装している。
# サポートしているモデル
- KT-IDEM (Item Difficulty Effect): BKTとは異なり、個々のquestionごとにguess/slipパラメータを学習するモデル KT-IDEM: Introducing Item Difficulty to the Knowledge Tracing Model, Pardos+ (w/ Neil T. Heffernan), UMAP'11
- KT-PPS: 個々の生徒ごとにprior knowledgeのパラメータを持つ学習するモデル Modeling individualization in a bayesian networks implementation of knowledge tracing, Pardos+ (w/ Neil T. Heffernan), UMAP'00
- BKT+Forget: 通常のBKTでは一度masterしたスキルがunmasteredに遷移することはないが、それが生じるようなモデル。直近の試行がより重視されるようになる。 How Deep is Knowledge Tracing?, Mozer+, EDM'16
- Item Order Effect: TBD
- Item Learning Effect: TBD
When is Deep Learning the Best Approach to Knowledge Tracing?, Theophile+ (Ken Koedinger), CMU+, JEDM'20
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #KeyPoint Notes Issue Date: 2022-04-28 Comment
下記モデルの性能をAUCとRMSEの観点から9つのデータセットで比較した研究
- DLKT
- DKT
- SAKT
- FFN
- Regression Models
- IRT
- PFA
- DAS3H
- Logistinc Regression
- variation of BKT
- BKT+ (add individualization, forgetting, discovery of knowledge components)
DKT、およびLogistic Regressionが最も良い性能を示し、DKTは5種類のデータセットで、Logistic Regressionは4種類のデータセットでbestな結果を示した。
SAKTは A Self-Attentive model for Knowledge Tracing, Pandy+ (with George Carypis), EDM'19
で示されている結果とは異なり、全てのデータセットにおいてDKTの性能を下回った。
また、データセットのサイズがモデルのパフォーマンスに影響していることを示しており、
小さなデータセットの場合はLogistic Regressionのパフォーマンスがよく、
大きなデータセットの場合はDKTの性能が良かった。
(アイテムごとの学習者数の中央値、およびKCごとの学習者数の中央値が小さければ小さいほど、Logistic Regressionモデルが強く、DLKTモデルはoverfitしてしまった; たとえば、アイテムごとの学習者数の中央値が1, 4, 10とかのデータではLRが強い; アイテムごとの学習者数の中央値が仮に大きかったとしても、KCごとの学習者数の中央値が少ないデータ(200程度; Spanish)では、Logistic Regressionが強い)。
加えて、DKTはLogistic Regressionと比較して、より早くピークパフォーマンスに到達することがわかった。
ちなみに、一つのアイテムに複数のKCが紐づいている場合は、それらを組み合わせ新たなKCを作成することで、DKTとSAKTに適用したと書いてある(この辺がずっと分かりづらかった)。
データセットの統計量はこちら:
データセットごとに、連続して同じトピックの問題(i.e. 連続した問題IDの問題を順番に解いている)を解いている割合(i.e. どれだけ順番に問題を解いていっているか)を算出した結果が下図。
同じトピックの問題を連続して解いている場合(i.e. 順番に問題を解いていっている場合)に、DKTの性能が良い。
またパフォーマンスに影響を与える要因として、学習者ごとのインタラクション数が挙げられる。ほとんどのデータセットでは、power-lawに従い中央値が数百程度だが、bridge06やspanishのように、power-lawになっておらず中央値が数千といったデータが存在する。こういったデータではDKTはlong-termの情報を捉えきれず、高い性能を発揮しない。
実験に利用した実装はこちら:
https://github.com/theophilee/learner-performance-prediction
ただ、実装を見るとDKTの実装はオリジナルの論文とは全く異なる工夫が加えられていそう
https://github.com/theophilee/learner-performance-prediction/blob/master/model_dkt2.py
これをDKTって言っていいの・・・?
オリジナルのDKTの実装はDKT1として実装されていそうだけど、その性能は報告されていないと思われる・・・。
DKT1の実装じゃないと、KCのマスタリーは取得できないんでは。
追記:と思ったら、DKTのAblation Studyで報告されている Input/Output をKC, Itemsで変化させた場合のAUCの性能の変化の表において、best performingだった場合のAUCスコアが9つのデータセットに対するDKTの予測性能に記載されている・・・。
じゃあDKT2はどこで使われているの・・・。
DKTは、inputとしてquestion_idを使うかKCのidを使うか選択できる。また、outputもquestion_idに対するprobabilityをoutputするか、KCに対するprobabilityをoutputするか選択できる。
これらの組み合わせによって、予測性能がどの程度変化するかを検証した結果が下記。
KCをinputし、question_idをoutputとする方法が最も性能が良かった。
明記されていないが、おそらくこの検証にはDKT1の実装を利用していると思われる。input / outputをquestionかKCかを選べるようになっていたので。
実際にIssueでも、assistments09のAUC0.75を再現したかったら、dkt1をinput/output共にKCに指定して実行しろと著者が回答している。
ちなみに論文中の9つのデータセットに対するAUCの比較では、各々のモデルはKCに対して正答率を予測しているのではなく、個々の問題単位で正答率を予測していると思われる(実装を見た感じ)。
Context-Aware Attentive Knowledge Tracing, Ghosh+, University of Massachusetts Amherst, KDD'20
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #SIGKDD #Reading Reflections Issue Date: 2022-04-27 Comment
この論文の実験ではSAKTがDKVMNやDKTに勝てていない
Assessment Modeling: Fundamental Pre-training Tasks for Interactive Educational Systems, Choi+, RiiiD Research, arXiv'20
Paper/Blog Link My Issue
#AdaptiveLearning #LearningAnalytics #Assessment #Surface-level Notes #needs-revision Issue Date: 2022-04-18 Comment
# 概要
テストのスコアや、gradeなどはシステムの外側で取得されるものであり、取得するためにはコストがかかるし、十分なラベル量が得られない(label-scarce problem)。そこで、pre-training/fine-tuningの手法を用いて、label-scarce probleを緩和する手法を提案。
# Knowledge Tracingタスクの定義
手法を提案する前に、Knowledge Tracingタスクを定義した。Knowledge Tracingタスクを、マスクしたt番目のinteractionのk番目のfeatureを予測するタスクと定義した。
このような定義にすると、たとえば、予測するfeatureとしては、回答の正誤にかかわらず以下のようなものも挙げられる。

# Assessmentを予測するタスク
また、このようなKTの定義に則り、assessmentを予測するタスクを下記のように定義した。ここで、Assesmentとはinteractionの中で教育的な評価と関連するinteractionのことである。
assesmentの例としては下図のAssessment Modelingに示したようなfeatureが挙げられる。
# label-scarceなeducational featureの例
また、label-scarceなeducational featureとして、以下を例として挙げている。この論文では、assessment予測をpre-trainingタスクとして定義し、これらlabel-scarceなeducational featureを予測することを目標としている。
- Non Interactive Educational Feature
- exam_score: A student’s score on a standardized exam.
- grade: A student’s final grade in a course.
- certification: Professional certifications obtained by completion of educational programs or examinations.
- Sporadic Assessments(たまにしか発生しない偶発的なassessmentのこと)
- course_dropout: Whether a student drops out of the entire class.
- review_correctness: Whether a student responds correctly to a previously solved exercise.
# モデル
これらassessmentsのlabel-scarce problemに対処するために、pre-training/fine-tuningのパラダイムを活用する。
モデルはBERTを利用した。inputのうち、M%をランダムにマスクし、マスクしたassesment featureをlinear layerで予測するタスクを、pre-trainingフェーズで実施する。
inputとしては全てのfeatureを使うのは計算量的に現実的ではないのでknowledge-tracingタスクでよく利用される下記を用いる:
- exercise_id: We assign a latent vector unique to each exercise id.
- exercise_category: Each exercise has its own category tag that represents the type of the exercise. We assign a latent vector to each tag.
- position: The relative position 𝑡 of the interaction 𝐼𝑡 in the input sequence. We use the sinusoidal positional encoding that is used in [24].
- correctness: The value is 1 if a student response is correct and 0 otherwise. We assign a latent vector corresponding to each possible value 0 and 1.
- elapsed_time: The time taken for a student to respond is recorded in seconds. We cap any time exceeding 300 seconds to 300 seconds and normalize it by dividing by 300 to have a value between 0 and 1. The elapsed time embedding vector is calculated by multiplying the normalized time by a single latent embedding vector.
- inactive_time: The time interval between adjacent interactions is recorded in seconds. We set maximum inactive time as 86400 seconds (24 hours) and any time more than that is capped off to 86400 seconds. Also, the inactive time is normalized to have a value between 0 and 1 by dividing the value by 86400. Similar to the elapsed time embedding vector, we calculate the inactive time embedding vector by multiplying the time by a single latent embedding vector
ここで、interaction I_tのrepresentationは、e_t + c_t + et_t + it_t で表される。ここで、e_tはexercise_id, exercise_category, position embeddingを合計したもの、c_t, et_t, it_t は、それぞれcorrectness, elapsed_time, inactive_timeのembeddingである。
たとえば、assesment予測として、correctnessと、elapsed_timeを予測対象とした場合、inputのcorrectnessとelapsed_timeに関わるembeddingをmask embeddingに置き換える。すなわち、input representationは、e_t + c_t + et_t + it_t から、c_t + et_t がmaskに置き換えられ、e_t + it_t + mask となる。
Loss functionは、pre-training taskごとに定義する。
# 評価
試験のスコア予測(non-interactive educational feature)と、review correctness予測タスク(a sporadic assessment)に適用し評価した。
## Dataset
EdNetデータセットを利用。pre-trainingのためのデータセットを作成するために、chronological orderでInteractionのデータを作成した。このとき、downstreamタスクで利用するユーザは全てpre-trainingデータセットから除外した。最終的に、414,375 user, 93,121,528 interactionsのデータとなった。
## Exam Score Prediction
2594件のSantaユーザのTOEICスコアを使用(報酬を用意してユーザに報告してもらった)。これだけの量のデータを集める音に6ヶ月を要した。
## review correctness prediction
生徒の学習ログを見て、最低2回解いている問題を見つけ、1回目と2回目に問題を解いている間のinteraction sequenceをinputとし、2回目に同じ問題を解いた時の正誤をラベルとして抽出した。
最終的に4540個のラベル付されたsequenceを得た。
## モデルのセットアップ
モデルは100 interactionsをinputとした。Mは0.6とした(60%をマスクした)。
また、fine-tuningする際には、label-scarce probleに対処するためにdata-augmentationを行った。具体的には、input sequenceのうち50%の確率で各エントリを選択しsubsequenceを作成することで、学習データに利用した。
# 実験結果
## pre-trainingタスクがdown-streamタスクに与える影響
correctness + timelinessの予測を行った場合に、最も性能がよかった。
## 性能
既存のcontents-basedな手法と比べて、Assessment Modelが高い性能を発揮した。
Deep Attentive Study Session Dropout Prediction in Mobile Learning Environment, Riiid AI Research, Lee+, CSEDU'20
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #DropoutPrediction #Surface-level Notes Issue Date: 2022-04-14 Comment
従来のdropout研究では、学校のドロップアウトやコースのドロップアウト、MOOCsなどでのドロップアウトが扱われてきたが、モバイル学習環境を考慮した研究はあまり行われてこなかった。モバイル学習環境では着信やソーシャルアプリなど、多くの外敵要因が存在するため、学習セッションのドロップアウトが頻繁に発生する。
学習セッションを、隣接するアクティビティと1時間のインターバルが空いていないアクティビティのsequenceと定義
Transformerを利用したモデルを提案。
利用したFeatureは以下の通り
AUCでの評価の結果、LSTM,GRUを用いたモデルをoutperform
また、Transformerに入力するinput sequenceのsizeで予測性能がどれだけ変化するかを確認したところ、sequence sizeが5の場合に予測性能が最大となった。
これは、session dropoutの予測には、生徒の最新のinteractionの情報と相関があることを示している。だが、sequence sizeが2のときに予測性能は低かったため、ある程度のcontext情報が必要なことも示唆している。
また、inputに利用するfeatureとしては、問題を解く際のelapsed_timeと、session内でのposition、またdropoutしたか否かのラベルが予測性能の向上に大きく寄与した。
Q. AUCの評価はどうやって評価しているのか。dropoutしたラベルの部分のみを評価しているのか否かがわからない。
Q. dropoutラベルをinputのfeatureに利用するのは実用上問題があるのでは?次の1問を解いたときにdropoutするか否かしか予測できなくなってしまうのでは。まあでもそれはelapsed_timeとかも一緒か。
[Paper Note] Deep-IRT: Make Deep Learning Based Knowledge Tracing Explainable Using Item Response Theory, Chun-Kit Yeung, EDM'19
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #AdaptiveLearning #KnowledgeTracing #EDM #In-Depth Notes Issue Date: 2022-07-22 Comment
# 一言で言うと
DKVMN [Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
のサマリベクトルf_tと、KC embedding k_tを、それぞれ独立にFully connected layerにかけてスカラー値に変換し、生徒のスキルごとの能力パラメータθと、スキルの困難度パラメータβを求められるようにして、解釈性を向上させた研究。最終的にθとβをitem response function (シグモイド関数)に適用することで、KC j を正しく回答できる確率を推定する。
# モデル
基本的なモデルはDKVMNで、DKVMNのサマリベクトルf_tに対してstudent ability networkを適用し、KC embedding k_tに対してdifficulty networkを適用するだけ。
生徒の能力パラメータθとスキルの困難度パラメータβを求め、最終的に下記item response functionを適用することで、入力されたスキルに対する反応予測を実施する:
# 気持ち
古典的なKnowledge Tracing手法は、学習者の能力パラメータや項目の困難度パラメータといった人間が容易に解釈できるパラメータを用いて反応予測を行えるが、精度が低い。一方、DeepなKnowledge Tracingは性能は高いが学習されるパラメータの解釈性が低い。そこで、IRTと最近提案されたDKVMNを組み合わせることで、高性能な反応予測も実現しつつ、直接的にpsychological interpretationが可能なパラメータを学習するモデルを提案した。
DKVMNがinferenceに利用する情報は、意味のある情報に拡張することができることを主張。
1つめは、各latent conceptのknowledge stateは、生徒の能力パラメータを計算することに利用できる。具体的には、DKVMNによって求められるベクトルf_tは、read vector r (該当スキルに対する生徒のmastery level を表すベクトル)とKCのembedding k_t から求められる。これは、生徒のスキルに対するknowledge staeteとスキルそのもののembeddedされた情報の両者を含んでいるので、f_tをNNで追加で処理することで、生徒のスキルq_tに対する能力を推定することができるのではないかと主張。
同様に、q_tの困難度パラメータもKC embedding vector k_tをNNに渡すことで求めることができると主張。
生徒の能力を求めるネットワークを、student ability network, スキルの困難度パラメータを求めるネットワークをdifficulty networkと呼ぶ。
# 性能
実験の結果、DKT, DKVMN, Deep-IRTはそれぞれ似たようなAUCとなり、反応予測の性能はcomparable
# Discussion
## 学習された困難度パラメータについて
複数のソース(1. データセットのpublisherが設定している3段階の難易度, 2. item analysisによって求めた難易度(生徒が問題に取り組んだとき不正解となった割合), 3. IRTによって推定した困難度パラメータ, 4. PFAによって推定した困難度パラメータ)とDeep-IRTが学習したKC Difficulty levelの間で相関係数を測ることで、Deep-IRTが学習した困難度パラメータが妥当か検討している。ソース2, 3については、困難度推定に使うデータがtest environmentではなく学習サービスによるものなので、生徒のquestionに対するfirst attemptから困難度パラメータを予測した。一方、PFAの場合はtest environmentによる推定ではなく、knowledge tracingの設定で困難度パラメータを推定した(i.e. 利用するデータをfirst attemptに限定しない)。
相関係数をは測った結果が上図で、正直見方があまりわからない。著者らの主張としては、Deep-IRTは他の困難度ソースの大部分と強い相関があった(ソース1を除く)、と主張しているが、相関係数の値だけ見ると明らかにPFAの方が全てのソースに対して高い相関係数を持っている。また、困難度を推定するモデルの設定(test environment vs. learning environment)や複雑度が近ければ近いほど、相関係数が高かった(ソース2, 3間は相関係数は0.96、一方ソース2とDeep-IRTは相関係数0.56)。また、Deep-IRTはソース1の困難度パラメータとの相関係数が0.08であり非常に低い(他のソースは0.3~0.4程度の相関係数が出ている)。この結果を見ると、Deep-IRTによって推定された困難度パラメータは古典的な手法とは少し違った傾向を持っているのではないかと推察される。
=> DeepIRTによって推定された困難度パラメータは、古典的な手法と比較してめっちゃ近いというわけでもなく、人手で付与された難易度と全く相関がない(そもそも人手で付与された難易度が良いものかどうかも怪しい)。結局DeepIRTによる困難度パラメータがどれだけ適切かは評価されていないので、古典的な手法とは少し似ているけど、なんか傾向が違う困難度パラメータが出ていそうです〜くらいのことしかわからない。
## 学習された生徒の能力パラメータについて
reconstruction問題がDKTと同様に生じている。たとえば、“equation solving more than two steps” (red) に不正解したにもかかわらず、対応する生徒の能力が向上してしまっている。また、スキル間のpre-requisite関係も捉えられない。具体的には、“equation solving two or fewer steps” (blue) に正解したにもかかわらず、“equation solving more than two steps” (red) の能力は減少してしまっている。
# 所感
生徒の能力パラメータは、そもそもDKTVMモデルでも入力されたスキルタグに対する反応予測結果が、まさに生徒の該当スキルタグに対する能力パラメータだったのでは?と思う。困難度パラメータについては推定できることで使い道がありそうだが、DeepIRTによって推定された困難度パラメータがどれだけ良いものかはこの論文では検証されていないので、なんともいえない。
# 関連研究
- Item Response Theory (IRT): 受験者の能力パラメータはテストを受けている間は不変であるという前提をおいており(i.e. testing environmentを前提としている)、Knowledgte Tracingタスクのような、学習者の能力が動的に変化する(i.e. learning environment)状況ではIRTをKnowledge Tracingに直接利用できない(と主張しているが、 [Paper Notes] Back to the basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation, Ekanadham+, EDM'16
あたりではIRTで項目の反応予測に利用してDKTをoutperformしている)
- Bayesian Knowledge Tracing (BKT): 「全ての生徒と、同じスキルを必要とする問題がモデル上で等価に扱われる」という非現実的な仮定が置かれている。言い換えれば、生徒ごとの、あるいは問題ごとのパラメータが存在しないということ。
- Latent Factor Analysis (LFA): IRTと類似しているが、スキルレベルのパラメータを利用してKnowledge Tracingタスクに取り組んだ。生徒の能力パラメータθと、問題に紐づいたスキルごとの難易度パラメータβと学習率γ(γ x 正答数で該当スキルに対する学習度合いを求める)を持つ。これにより「学習」に対してもモデルを適用できるようにしている。
- Performance Factor Analysis (PFA): 生徒の能力値よりも、生徒の過去のパフォーマンスがKTタスクにより強い影響があると考え、LFAを拡張し、スキルごとに正解時と不正解時のlearning rateを導入し、過去の該当スキルの正解/不正解数によって生徒の能力値を求めるように変更。これにより、スキルごとに生徒の能力パラメータが存在するようなモデルとみなすことができる。
=> LFAとPFAでは、複数スキルに対する「学習」タスクを扱うことができる。一方で、スキルタグについては手動でラベル付をする必要があり、またスキル間の依存関係については扱うことができない。また、LFAでは問題に対する正答率が問題に対するattempt数に対して単調増加するため、生徒のknowledge stateがlearnedからunlearnedに遷移することがないという問題がある。PFAでは失敗したattemptの数を導入することでこの仮定を緩和しているが、生徒が大量の正答を該当スキルに対して実施した後では問題に対する正答率を現象させることは依然として困難。
- Deep Knowledge Tracing (DKT): DeepLearningの導入によって、これまで性能を向上させるために人手で設計されたfeature(e.g. recency effect, contextualized trial sequence, inter-skill relationship, student’s ability variation)などを必要とせず、BKTやPFAをoutperformした。しかし、RNNによって捉えられた情報は全て同じベクトル空間(hidden layer)に存在するため、時間の経過とともに一貫性した予測を提供することが困難であり、結果的に生徒が得意な、あるいは不得意なKCをピンポイントに特定できないという問題がある(ある時刻tでは特定のスキルのマスタリーがめっちゃ高かったが、別の問題に回答しているうちにマスタリーがめっちゃ下がるみたいな現象が起きるから?)。
- Dynamic Key Value Memory Network (DKVMN): DKTでは全てのコンセプトに対するknowledge stateを一つのhidden stateに集約することから、生徒が特定のコンセプトをどれだけマスターしたのかをトレースしたり、ピンポイントにどのコンセプトが得意, あるいは不得意なのかを特定することが困難であった(←でもこれはただの感想だと思う)。DKTのこのような問題点を改善するために提案された。DKVMNではDKTと比較して、DKTを予測性能でoutperformするだけでなく(しかしこれは後の追試によって性能に大差がないことがわかっている)、overfittingしづらく、Knowledge Component (=スキルタグ)の背後に潜むコンセプトを正確に見つけられることを示した。しかし、KCの学習プロセスを、KCのベクトルや、コンセプトごとにメモリを用意しメモリ上でknowledge stateを用いて表現することで的確にモデル化したが、依然としてベクトル表現の解釈性には乏しい。したがって、IRTやBKT, PFAのような、パラメータが直接的にpsychological interpretationが可能なモデルと、パラメータやrepresentationの解釈が難しいDKTやDKVMNなどのモデルの間では、learning science communityの間で対立が存在した。
=> なので、IRTとDKVMNを組み合わせることで、DKVMNをよりexplainableにすることで、この対立を緩和します。という流れ
著者による実装: https://github.com/ckyeungac/DeepIRT
Knowledge Tracing with Sequential Key-Value Memory Networks, Ghodai+, Research School of Computer Science, Australian National University, SIGIR'19
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #SIGIR Issue Date: 2022-04-28
A Self-Attentive model for Knowledge Tracing, Pandy+ (with George Carypis), EDM'19
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #StudentPerformancePrediction #EDM #Selected Papers/Blogs #In-Depth Notes Issue Date: 2021-10-28 Comment
Knowledge Tracingタスクに初めてself-attention layerを導入した研究
interaction (e_{t}, r_{t}) および current exercise (e_{t+1}) が与えられた時に、current_exerciseの正誤を予測したい。
* e_{t}: 時刻tのexercise
* r_{t}: 時刻tでの正誤
interactionからKey, Valueを生成し、current exerciseからQueryを生成し、multi-head attentionを適用する。その後、得られたcontext vectorをFFNにかけて、正誤を予測する。

DKTや、DKVMNを全てのデータセットでoutperform
Context-Aware Attentive Knowledge Tracing, Ghosh+, University of Massachusetts Amherst, KDD'20
においてはSAKTがDKT, DKVMN等に勝てていないのに対し(ASSSITments Data + Statics Data)
An Empirical Comparison of Deep Learning Models for Knowledge Tracing on Large-Scale Dataset, Pandey+, AAAI workshop on AI in Education'21
Do we need to go Deep? Knowledge Tracing with Big Data, Varun+, University of Maryland Baltimore County, AAAI'21 Workshop on AI Education
においてはSAKTはDKT, DKVMNに勝っている(EdNet Data)
When is Deep Learning the Best Approach to Knowledge Tracing?, Theophile+ (Ken Koedinger), CMU+, JEDM'20
においてもSAKTがDKTに勝てないことが報告されている(ASSISTments Data + Statics Data + Bridge to Algebra, Squirrel dataなど)。ただし、Interaction数が大きいデータセット(Squirrel data)ではDKTの性能に肉薄している。
Large ScaleなデータだとSAKTが強いが、Large Scaleなデータでなければあまり強くないということだと思われる。
Large Scaleの基準は、なかなか難しいが、1億Interaction程度あれば(EdNetデータ)SAKTの方が優位に強くなりそう。
数十万、数百万Interaction程度のデータであれば、DKTとSAKTはおそらくcomparableだと思われる。
(追記)
しかし Learning Process-consistent Knowledge Tracing, Shen+, SIGKDD'21
においてはSAKTはEdNetデータセット(Large Scale)においてDKT, DKT+, DKVMNとcomparableなので、
正直何を信じたら良いか分からない。
GRAPH-BASED KNOWLEDGE TRACING: MODELING STUDENT PROFICIENCY USING GRAPH NEURAL NETWORK, Nakagawa+, Tokyo University, WI'19
Paper/Blog Link My Issue
#NeuralNetwork #GraphConvolutionalNetwork #Education #KnowledgeTracing #WI #One-Line Notes Issue Date: 2021-07-08 Comment
graph neural networkでKnoelwdge Tracingした論文。各conceptのproficiencyの可視化までしっかりやってそう。
[Paper Note] EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction, Qi Liu+, IEEE TKDE'19, 2019.06
Paper/Blog Link My Issue
#NeuralNetwork #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #Selected Papers/Blogs #In-Depth Notes Issue Date: 2021-05-28 GPT Summary- 学生のパフォーマンス予測のために、演習記録と教材情報を統合するEERNNフレームワークを提案。双方向LSTMを用いて演習内容をエンコードし、マルコフ特性とアテンションメカニズムを持つ2つの実装を提供。さらに、知識概念を追跡するEKTに拡張し、演習が知識習得に与える影響を定量化。実験により、予測精度と解釈可能性の向上が確認された。 Comment
DKT等のDeepなモデルでは、これまで問題テキストの情報等は利用されてこなかったが、learning logのみならず、問題テキストの情報等もKTする際に活用した研究。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
をより洗練させjournal化させたものだと思われる。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
ではKTというより、問題の正誤を予測するモデルとなっており、個々のconceptに対するproficiencyを推定するというKTの考え方はあまり導入されていなかった。
EKTの方では、個々のknowledge componentのproficiency scoreを算出する方法も提案されている。
モデル自体は、基本的にはattention-basedなRNNモデル。

Exercise EmbeddingはBidireictional-RNNを利用して、問題文をエンコードすることによって求める。
EKTによるmastery levelを可視化したもの。T=0とT=30では各conceptに対するmastery levelが大きく異なっている。基本的に、たくさん正解したconceptはmastery levelが向上し、不正解しまくったconceptはどんどんmastery levelがshrinkしていく。
予測性能。問題のContentを考慮することで、正誤予測のAUCは圧倒的に高くなる。DKTよりも10ポイント程度EKTAの方がAUCが高いように見える。
各モデルの特徴や、knowledge tracingが行えるか否か、といった性質を整理した表。わかりやすい。しかしDKTのknowledge tracking?が×になっているのは誤りでは?
各knowledge conceptの時刻tにおけるmastery levelの求め方。
EKTでは、生徒の各knowledge conceptの状態を保持した行列H_t^i(0 <= i <= # of concepts)を保持している。correctness probabilityを最終的に求める際には、H_t^iの各knowledge conceptに対する重みβ_iで重みづけた上でsummationをとり、各知識の状態を統合したベクトルsを作成し、sとexercise embedding xをconcatした上でスコアを予測する。
このスコアの予測部分を変更し、β_iをmastery levelを測定したいconceptのone-hot encodingに置き換え、さらにexercise embeddingをmaskしたベクトル=masked exercise embedding = zero vectorをconcatした上で、スコアを予測するようにする。
こうすることで、exerciseの影響を除き、かつone-hot encodingで指定したknowledgeのmasteryのみが考慮されたスコアを抽出できるため、そのスコアをmastery levelとする。
単にStudent Performance Predictionして終わり!ってんじゃなく、knowledge tracing的な側面をきちんと考慮している点で、この研究めっちゃ好き。
スキルタグごとにLSTMのhidden_stateを保持しないといけないので、メモリの消費量がえぐいことになりそう。小規模なスキルタグのデータセットじゃないと動かないのでは?
実際、実験では37種類のスキルタグが存在するデータセットしか扱っていない。
Modeling Hint-Taking Behavior and Knowledge State of Students with Multi-Task Learning, Chaudry+, Indian Institute of Technology, EDM'18
Paper/Blog Link My Issue
#NeuralNetwork #StudentPerformancePrediction #EDM #One-Line Notes Issue Date: 2021-11-12 Comment
DKVMN ([Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
)をhint-takingタスクとmulti-task learningした研究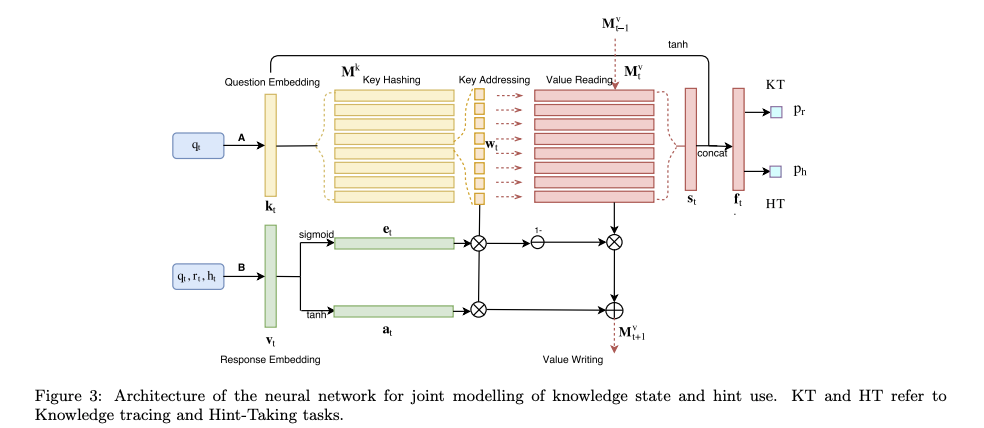
DKVMNと比較して、微小ながら性能向上
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
Paper/Blog Link My Issue
#NeuralNetwork #LearningAnalytics #StudentPerformancePrediction #AAAI #KeyPoint Notes Issue Date: 2021-05-28 Comment
従来のStudent Performance PredictionタスクではKnowledge Componentと問題に対する過去の正誤を入力として予測を行っていて、問題テキストを通じて得られる問題そのものの難しさは明示的に考慮できていなかった。
なので、knowledge componentではなく、問題テキストそのものを使ってStudent Performance Predictionしてみたら性能よくなりました、という話。
問題テキストを利用してNeural-basedなアプローチでStudent Performance Predictionした最初の論文だと思う。
本論文ではKnowledge Tracing的なknowledge componentに対するproficiencyを求めることは考慮されていないが、ジャーナル版 [Paper Note] EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction, Qi Liu+, IEEE TKDE'19, 2019.06
では、そのような点も考慮されたモデルの拡張が行われていてさらに洗練されている。
Learning to Represent Student Knowledge on Programming Exercises Using Deep Learning, Wang+, Stanford University, EDM'17
Paper/Blog Link My Issue
#KnowledgeTracing #EDM #One-Line Notes Issue Date: 2021-07-04 Comment
DKT [Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15
のPiech氏も共著に入っている。
プログラミングの課題を行なっている時(要複数回のソースコードサブミット)、
1. 次のexerciseが最終的に正解で終われるか否か
2. 現在のexerciseを最終的に正解で終われるか否か
を予測するタスクを実施
Deep Model for Dropout Prediction in MOOCs, Wang+, ICCSE'17
Paper/Blog Link My Issue
#NeuralNetwork #LearningAnalytics #Surface-level Notes Issue Date: 2021-06-10 Comment
MOOCsにおける一つの大きな問題点としてDropout率が高いことがあげられ、これを防止するために様々なモデルが提案されてきた。これまで提案されてきたモデルでは人手によるfeature-engineeringが必要であることが問題である。なぜなら、feature-engineeringはdomain expertでないとできないし、time-consumingだから。加えて、あるデータにおいて有効だったfeatureが別のデータセットにおいて有効とは限らないことも多い。
そこで、neural networkを用いて人手でのfeature engineeringなしで、dropout predictionする手法を提案する。
評価した結果、feature-engineeringを行う既存手法とcomparableな性能を得た。
Recorded periodのactivity logが与えられたときに、Prediction Periodにおいてdropoutするか否かをbinary classificationする問題として定式化
Prediction periodに生徒のactivity logがあった場合、生徒はdropoutしていないとみなす。acitivity logが存在しない場合、生徒はdropoutしたとみなす。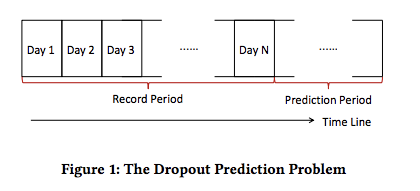
提案モデルはCNNとRNNの組み合わせ。個々のtime-unitごとのactivityをvectorに変換しInput Matrixを作成。その後、個々のtime-stepごとにCNNを適用しfeature mapを取得。取得したtime-stepごとのfeature mapをRNNに食わせて、最後にdropoutするか否かbinary classificationを行う。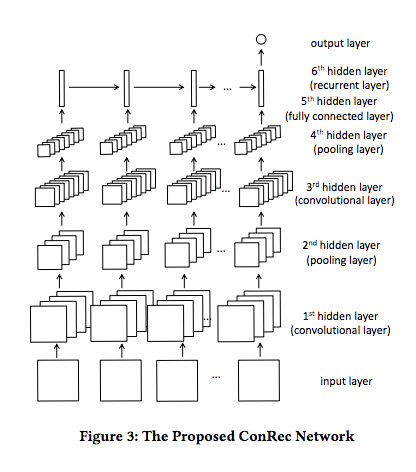
## 評価
KDDCup 2015のデータを利用。データセットはユーザの各コースへのenrollmentを表すデータと、各enrollmentIDごとのactivity _logの二種類のデータから構成される。実験では、record periodを30日とし、その後のprediction periodを10日とした(過去1ヶ月のデータを利用し、10日以内にdropoutするか否かを予測するタスク)。
time-unit(time-sliceを構築する単位)は1時間とし、該当するtime-unitに存在するactivity records中のレコードは足し合わされ、該当time-unitのvectorとして表現。time-slice(時刻tとしてinputする単位)を1日とし、24個のtime-unit vectorのmatrixとして、時刻tのinputは表現される。実際はrecord periodが30日なので、このtime-slice のmatrixが30個(T=30)入力されることとなる。activity recordsのうち、source, event, course_IDの3種類のレコードをtime-unitのベクトルとして表現するために利用される。具体的には、source, event, course_IDをそれぞれone-hot vectorに変換し、それらのベクトルのtime-unit内に存在する全てのベクトルに対して足し合わせることで、time-unit vectorを表現している(正直これがあまり良いとは思わない)。
評価の結果、予測結果は他の既存手法とcomparableな性能を達成した。
→ 正直one-hot encodingを足し合わせるだけの入力方法(embeddingを学習しないで、実質各eventが発生した回数をFeatureとして考慮しているだけなのでは?)だと、既存手法のfeature-engineeringとやっていることは対して変わらない気はするので、comparableな結果というのもうなずける。
なぜembeddingを学習しないのか。
[Paper Note] Improving Sensor-Free Affect Detection Using Deep Learning, Botelho+, AIED'17
Paper/Blog Link My Issue
#NeuralNetwork #LearningAnalytics #AffectDetection #AIED #Surface-level Notes Issue Date: 2021-06-08 Comment
DKTが実はBKTと対して性能変わらない、みたいな話がreference付きで書かれている。Ryan Baker氏とNeil Heffernan氏の論文
Affect Detectionは、physical/psychological sensorを利用する研究が行われてきており、それらは様々な制約により(e.g. 経済的な問題や、政治の問題)実際のアプリケーションとしてdeployするには難しさがあった。これを克服するために、sensor-freeなモデルが研究されてきたが、予測性能はあまり高くなくreal-timeなinterventionを行うのに十分な性能となっていなかった。
一方で、近年DeepLearningが様々な分野で成功を収めてきており、教育分野での活用が限定的であるという状況がある。そこで、deepなsensor-freeモデルを提案。その結果、従来モデルをoutperformした。
データセットはASSISTmentsデータを利用し、フィールドワーカーが20秒おきに、class roomでASSISTmentsを利用する生徒を観察し、生徒のAffective Stateをラベル付けした(ラウンドロビン方式)。ラベルは下記の通り:
- bored
- frustrated
- confused
- engaged concentration
- other/impossible
ビデオコーディングなどとは違って、ラウンドロビン方式では特定の生徒の間でラベルの欠落が生まれるが(常に特定の生徒を監視しているわけにはいかず、class-room全体を巡回しなければいけないから?)、全てのラベルにはタイムスタンプが付与されているので、欠落はわかるようになっている。
合計で6つの学校における、646人の生徒に対する、7663のobservationが得られた。
また、各特定の感情ラベルが付与されている際には実際に生徒はASSISTmentsを利用しており、先行研究では51種類のaction-level featureが利用されており(生徒とシステムのinteractionを捉える; e.g. reponse behavior, timeworking, hintやscaffoldingの利用の有無など)、今回もそういったfeatureも予測に利用する。
各observationのinterval(=clip)には複数のアクションが含まれており、それらを集約することで、最終的に204種類のfeatureをobservation intervalごとに作成し利用(feature engineeringしてるっぽい)。
RNN, LSTM, GRUの3種類のNNを用いて、204次元のfeature vectorをinputとし、各clipの4種類の感情ラベル(bored, frustrated, confused, engaged concentration)をsoftmaxで予測する。
前回のclipが5分未満のclipについては、連続したclipとしてモデルに入力し、5分を超過したものについては新たな別のsequenceとして扱った模様。

従来手法を大幅にoutperform。しっかり読んでいないが、resampoingは、ラベルの偏りを調整したか否かだと思われる。
[Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
Paper/Blog Link My Issue
#NeuralNetwork #StudentPerformancePrediction #KnowledgeTracing #WWW #In-Depth Notes Issue Date: 2021-05-28 GPT Summary- 動的キー・バリューメモリネットワーク(DKVMN)を提案し、学生の知識状態を追跡する新しい手法を開発。従来の手法の限界を克服し、基礎概念間の関係を活用して習得レベルを直接出力。実験により、DKVMNはKTデータセットで最先端モデルを上回る性能を示し、演習の基礎概念を自動発見する能力も持つ。 Comment
DeepなKnowledge Tracingの代表的なモデルの一つ。KT研究において、DKTと並んでbaseline等で比較されることが多い。
DKVMNと呼ばれることが多く、Knowledge Trackingができることが特徴。
モデルは下図の左側と右側に分かれる。左側はエクササイズqtに対する生徒のパフォーマンスptを求めるネットワークであり、右側はエクササイズqtに対する正誤情報rtが与えられた時に、メモリのvalueを更新するネットワークである。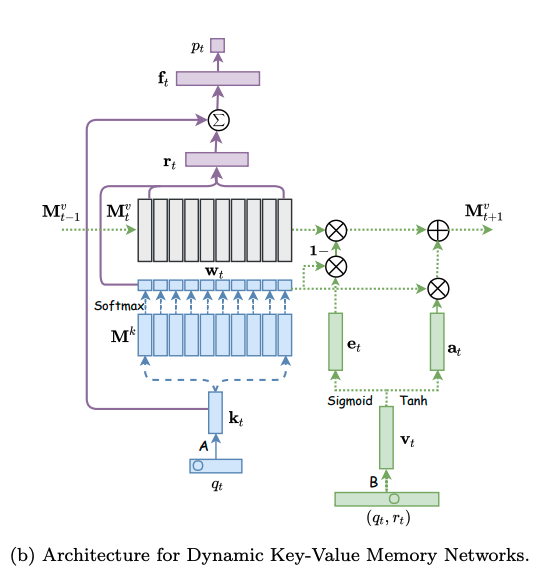
メモリとは生徒のknowledge stateを保持している行列であり、keyとvalueのペアによって形成される。keyとvalueは両者共にdv次元のベクトルで表現される。keyはコンセプトを表し、valueがそれぞれのコンセプトに対する生徒のknowledge stateを表している。ここで、コンセプトとスキルタグは異なる概念であり、スキルタグを生成される元となった概念のことをコンセプトと呼んでいる。コンセプトは基本的には専門家がタグ付しない限り、観測できない変数だと思われる。すなわち、コンセプトとはsynthetic-5データでいうところのc_t(5種類のコンセプト)に該当し、個々のコンセプトによって生成された50種類のexerciseがエクササイズタグに相当する。ASSISTments15データでいうところの、100種類のスキルタグがエクササイズタグで、それぞれのスキルタグのコンセプトはデータに明示されていない。
# ptの求め方
ptを求める際には、エクササイズqt(qtのサイズはエクササイズタグ次元Q; エクササイズタグが何を指すかは分かりづらく、基本的にはスキルタグのことだが、synthetic-5のように50種類のquestion_idをそのまま利用することも可)のembedding kt(dk次元)を求め、ktをメモリのkey M^k(N x dk次元)とのmatmulをとることによって、各コンセプトとのcorrelation weight w を求める。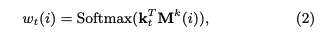
correlation weight wは、メモリのvalue(knowledge state)からknowledge stateのread contentベクトルrを生成する際に用いられる。read contentベクトルは、エクササイズqtに関する生徒のmastery levelのサマリとみなすことができる。
read contentベクトルrは、各キーのcorrelation weight w(scalar)とメモリのvalueベクトル(dv次元)との積をメモリサイズ(コンセプト数)Nでsummationすることによって求められる。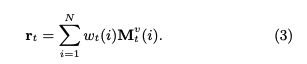
read contentベクトルを求めたのち、生徒のqtに対するmastery levelと取り組む問題qtの難易度を集約したサマリベクトルftをfully connected layerによって求める。求める際には、rとkt(qtのembedding)をconcatし、fully connected layerにかける。
最終的にサマリベクトルftを異なるfully connected layerにかけることによって、エクササイズqtに対するレスポンスを予測する。
# メモリの更新方法
エクササイズqtとそれに対する正誤rtが与えられたとき(qt, rt)、この情報のembedding vtを求める。求める際は、2Q x dv次元のembedding matrixをlookupする。このvtは、生徒がエクササイズに回答したことによってどれだけのknowledge growthを得たかを表している。
その後LSTMのforget gateに着想を得て、メモリのvalueをupdateする際に、最初にeraseベクトルを求めてvalueのうち忘却した情報を削除し、その後add vectorを利用してknowledge growthをvalueに反映させる。
eraseベクトルは、knowledge growth vtと(dv x dv)次元のtransformation matrix Eを利用して変換することによって求める。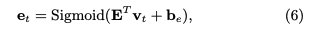
そして、メモリのvalueはこのeraseベクトルを用いて次の式で更新される。基本的には求めたeraseベクトルの分だけ全てのコンセプトのvalueがshrinkするように計算されているが、各コンセプトごとにshrinkさせる度合いをcorrelation weight wによって制御することによってvalueに対して忘却の概念を取り入れている。correlation weightとeraseベクトルのelementのうち、両方とも1となるelementに対応するvalueのelementが、0にリセットされるような挙動となる。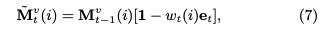
その後、knowledge growth vt から、新たなtransformation matrix D(dv x dv)を用いて、adding vector aが計算される。
最終的に、メモリの各valueは、adding vectorに対してcorrelation weightの重み分だけ各elementの値が更新される。
このような erase-followed-by-addな構造により、生徒の忘却と学習のlearning processを再現している。
# 予測性能
DKVMNが全てのデータセットにおいて性能が良かった。が、これは後のさまざまな研究の追試によりDKTとDKVMNの性能はcomparableであることが検証されているため、あまりこの結果は信用できない。
# learning curve
DKTとDKVMNの両者についてlearning curveを描いた結果が下記。DKTはtrainingとvalidationのlossの差が非常に大きくoverfittingしていることがわかるが、DKVMNはそのような挙動はなく、overfittingしにくいことを言及している。
# Concept Discovery
Figure4がsynthetic-5に対するConcept Discovery, Figure5がASSISTments15に対するConcept Discoveryの結果。synthetic-5は5種類のコンセプトによって50種類のエクササイズが生成されているが、メモリサイズNを5にすることによって完璧な各エクササイズのクラスタリングが実施できた(驚くべきことに、N=50でも5つのクラスタにきっちり分けることができた)。ASSISTments15データについても、類似したコンセプトのスキルタグが同じクラスタに属し、近い距離にマッピングされているため、コンセプトを見つけられたと主張している。
# Knowledge State Depiction
Synthetic-5に対する、各コンセプトのmasteryを可視化した結果が下図。
ここで注意すべきは、DKVMNが可視化するのは、メモリサイズNで指定した個々のkeyに該当するコンセプトのmasteryを可視化する方法を説明している点である。個々のスキルタグ(エクササイズタグ)に対するmasteryを可視化するわけではない点に注意。個々のスキルタグに対するmasteryは、DKTと同様にptがそれに該当するものと思われる。
個々のコンセプトのmasteryを可視化する手順は下記の通り。
まず、read content vector rを求める際に、masteryを可視化したいコンセプトのCorrelation weightのみを1とし、他のコンセプトのCorrelation weightを0とすることでrを算出する。
その後、次の式によって、エクササイズの難易度情報をマスクすること(weight matrixのうち、エクササイズembeddingが乗算される部分のみ0にマスクする)によってサマリベクトルftを求め、ftからfully connected layerを通じてptを求めることで、そのptを該当するコンセプトのmastery levelとみなす。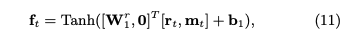
# 所感
スキルタグの背後にある隠れたコンセプトを見つけ、その隠れたコンセプトに対する習熟度を測るという点においてはDKTよりもDKVMNの方が優れていそう。
だが、スキルタグに対する習熟度を測るという点については、DKT, DKVMNのAUCにほとんど差がないことを鑑みるにDKVMNをわざわざ使う意味がどれだけあるのかな、という気がした。
特に Empirical Evaluation of Deep Learning Models for Knowledge Tracing: Of Hyperparameters and Metrics on Performance and Replicability, Sami+, Aalto University, JEDM'22
で報告されているように、DKVMNでリアルタイムに全てのスキルタグに対する習熟度をトラッキングするためには、DKVMNのoutputをoutput-per-skillにする必要があるが、DKVMNにおいてoutput-per-skillベクトルをoutputに採用すると予測性能が低下することがわかっている。このため、わざわざスキルタグに対する習熟度を求める際にDKVMNを使う必要もないのでは、という気がしている。
そうすると、現状スキルタグに対する習熟度をいい感じに求める手法は、DKT, DKT+ or EKTということになるのだろうか・・・。
追記:DKVMNのDKTと比較して良い点は、メモリネットワーク上にknowledge stateが保存されていて、inputはある一回の問題に対するtrialの正誤のみという点。DKTなどでは入力する系列の長さの上限が決まってしまうが、原理上はDKVMNは扱える系列の長さに制限がないことになる。この性質は非常に有用。
Applications of the Elo Rating System in Adaptive Educational Systems, Pelanek, Computers & Educations'16
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #One-Line Notes Issue Date: 2022-09-05 Comment
Elo rating systemの教育応用に関して詳細に記述されている
Estimating student proficiency: Deep learning is not the panacea, Wilson+, Knewton+, NIPS'16 workshop
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #LearningAnalytics #KnowledgeTracing #NeurIPS #One-Line Notes Issue Date: 2022-04-27 Comment
DKTの性能をBKTやPFA等の手法と比較した研究
How Deep is Knowledge Tracing?, Mozer+, EDM'16
を引用し、DKTとBKTのAUCの計算方法の違いについて言及している
[Paper Notes] Back to the basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation, Ekanadham+, EDM'16
Paper/Blog Link My Issue
#NeuralNetwork #LearningAnalytics #StudentPerformancePrediction #EDM #KeyPoint Notes #Reading Reflections Issue Date: 2021-05-29 Comment
Knewton社の研究。IRTとIRTを拡張したモデルでStudent Performance Predictionを行い、3種類のデータセットでDKT [Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15
と比較。比較の結果、IRT、およびIRTを拡張したモデルがDKTと同等、もしくはそれ以上の性能を出すことを示した。IRTはDKTと比べて、trainingが容易であり、パラメータチューニングも少なく済むし、DKTを数万のアイテムでtrainingするとメモリと計算時間が非常に大きくなるので、性能とパフォーマンス両方の面で実用上はIRTベースドな手法のほうが良いよね、という主張。
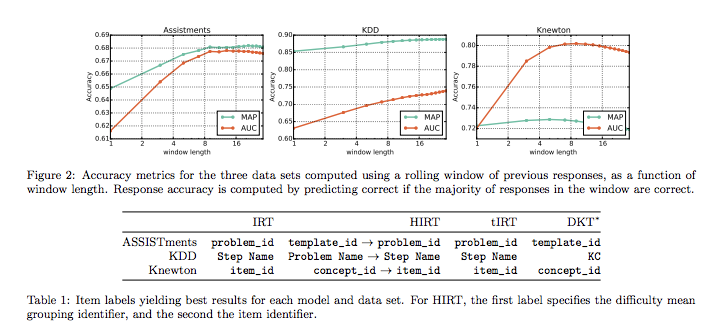
AUCを測る際に、具体的に何に大してAUCを測っているのかがわからない。モデルで何を予測しているかが明示的に書かれていないため(普通に考えたら、生徒のquizに対する回答の正誤を予測しているはず。IRTではquizのIDをinputして予測できるがDKTでは基本的にknowledge componentに対するproficiencyという形で予測される(table 1が各モデルがどのidに対して予測を行なったかの対応を示しているのだと思われる))。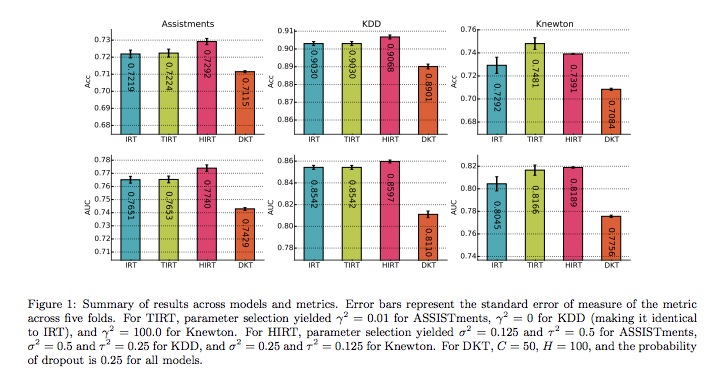
knewton社は自社のアダプティブエンジンでIRTベースの手法を利用しており、DKTに対するIRTベースな手法の性能の比較に興味があったのだと思われる。
なお、論文の著者であるKnewton社のKevin H. Wilson氏はすでにknewton社を退職されている。
https://kevinhayeswilson.com/
Going Deeper with Deep Knowledge Tracing, Beck+, EDM'16
Paper/Blog Link My Issue
#NeuralNetwork #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #EDM #KeyPoint Notes #Reading Reflections Issue Date: 2021-05-28 Comment
BKT, PFA, DKTのinputの違いが記載されており非常にわかりやすい

BKT, PFA, DKTを様々なデータセットで性能を比較している。また、ASSISTmentsデータに問題点があったことを指摘し(e.g. duplicate records問題など)、ASSSTmentsデータの問題点を取り除いたデータでも比較実験をしている。結論としては、ASSISTmentsデータの問題点を取り除いたデータで比較すると、DKTがめっちゃ強いというわけではなく、PFAと性能大して変わらなかった、ということ。
KDD cupのデータではDKTが優位だが、これはPFAをKDD Cupデータに適用する際に、難易度を適切に求められない場面があったから、とのこと(問題+ステップ名のペアで難易度を測らざるを得ないが、そもそも1人の生徒しかそういったペアに回答していない場合があり、難易度が1.0 / 0.0 等の極端な値になってしまう。これらがoverfittingの原因になったりするので、そういった問題-ステップペアの難易度をスキルの難易度で置き換えたりしている)。
ちなみにこの手のDKTこれまでのモデルと性能大して変わんないよ?系の主張は、当時だったらそうかもしれないが、2020年のRiiiDの結果みると、オリジナルなDKTがシンプルな構造すぎただけであって、SAKT+RNNみたいな構造だったら多分普通にoutperformする、と個人的には思っている。
ASSISTmentsデータにはduplicate records問題以外にも、複数種類のスキルタグが付与された問題があったときに、1つのスキルタグごとに1レコードが列挙されるようなデータになっている点が、BKTと比較してDKTが有利だった点として指摘している。スキルA, Bが付与されている問題が2問あった時に、それらにそれぞれ正解・不正解した場合のASSISTments09-10データの構造は下図のようになる。DKTを使ってこのようなsequenceを学習した場合、スキルタグBの正誤予測には、一つ前のtime-stempのスキルタグAの正誤予測がそのまま利用できる、といった関係性を学習してしまう可能性が高い。BKTはスキルタグごとにモデルを構築するので、これではBKTと比較してDKTの方が不当に有利だよね、ということも指摘している。
複数タグが存在する場合の対処方法として、シンプルに複数タグを連結して新しいタグとする、ということを提案している。
How Deep is Knowledge Tracing?, Mozer+, EDM'16
Paper/Blog Link My Issue
#NeuralNetwork #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #EDM #KeyPoint Notes Issue Date: 2021-05-28 Comment
DKTでは考慮できているが、BKTでは考慮できていない4種類のregularityを指摘し、それらを考慮ようにBKT(forgetting, interactions among skills, incorporasting latent student abilities)を拡張したところ、DKTと同等のパフォーマンスを発揮したことを示した研究。
- Recency Effects, Contextualized Trial Sequence, Inter-skill similarity, Individual variation in ability
DKTの成功は、deep learningによって得られた新たなrepresentationに基づくものではなく、上記input/outputの統計的なregularityを捉えることができる柔軟性と一般性によるものだと分析している(DKTは、汎用のリカレントニューラルネットワークモデルであり、学習と忘却のモデル化、スキルの発見、学生の能力の推論に特化した構成要素はないにもかかわらず、それらを捉えることができた。この柔軟性により、DKTは、ドメイン知識・事前分析がほとんどなくても、様々なデータセットでロバストに動作する)。が、DKTはこのようなドメイン知識等がなく良い性能を達成できている代償として、解釈生を犠牲にしている。BKTのようなshallowなモデルでも上記4種類の規則性を導入することでより解釈性があり、説明性があるモデルを獲得できる、と述べている。教育に応用する上で、解釈性・説明性は非常に重要な要素であり、同等の性能が達成できるなら、BKT拡張したほうがいいじゃん?っていう主張だと思われる。
DKTのAUC計算は、trialごとに該当スキルのpredictionを行い、全てのスキルに関してAUCを計算しているのに対し、
BKTは、個々のスキルごとにAUCを計算し、最終的にそれらを平均することでAUCを算出している点を指摘している(中身の実装を読んで)。
BKTのAUC計算方法の方が、DKTよりもAUCが低くなることを述べ、どちらかに統一した方が良いことを述べている。
Khan AcademyデータをDKTの共著者に使わせてもらえないかきいてみたところ、使わせてもらえなかったとも書いてある。
BKT+Forgetsは、ある特定のスキルの間に何回のtrialがあったかを数えておき、そのfrialの機会ごとにForgetが生じる機会が生じると考えるような定式化になっている。
たとえば、A_1 - A_2 - B_1 - A_3 - B_2 - B_3 - A_4 という問題の系列があったとする(A, Bはスキル名で、添字はスキルのinstance)。そうすると、A_1とA_2間でforgettingが生じる確率はF、A_2とA_3の間でforgettingが生じる確率は1-(1-F)^2、A_3とA_4の間でforgettingが生じる確率は1-(1-F)^3となる。
※ スキルAを連続してtrialした場合はFでforgettingするが、
スキルAをtrialしない場合は 1 - (スキルAを覚えている確率) = Aを忘れている確率 ということだろうか。
BKT+Forgetsは pyBKT: An Accessible Python Library of Bayesian Knowledge Tracing Models, Bardrinath+, EDM'20
に実装されている。
Autonomously Generating Hints by Inferring Problem Solving Policies, Piech+, Stanford University, L@S'15
Paper/Blog Link My Issue
#LearningAnalytics #L@S Issue Date: 2021-07-05
Predicting MOOC Dropout over Weeks Using Machine Learning Methods, EMNLP'14 Workshop, Marius Kloft
Paper/Blog Link My Issue
#AdaptiveLearning #LearningAnalytics #DropoutPrediction #EMNLP #KeyPoint Notes Issue Date: 2021-10-29 Comment
EMNLP'14のWorkshop論文。引用数が120件とかなり多め。
MOOCsのclickstreamデータから、numericalなfeatureを作成。SVMに食わせて学習し、Dropout Predictionを行なっている。
psychologyのMOOCコースからデータ収集。12週に渡って講義が行われる。統計量は以下:
初週のユーザ数:11,607
最後の週まで残ったユーザ数:3,861
参加した全体のユーザ数:20,828
DropOut率:81.4%
コース自体は19週間受講可能なので、その間のデータがある。
dropoutか否かのラベルは、翌週にターゲットユーザのIDと紐づいたアクティビティがあるかどうかで判断。ユーザuの各週Wiに対して、i=1, ..., 19の +1 / -1 ラベルが付与される。
+1 がDropout, -1がNo Dropout。
特徴量:

最初の1 -- 9週の間は、あまりDropoutが予測できないが、それ以後はhistory featureが効いて予測ができるようになる。
Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX, Pardos+, MIT, EDM'13
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #EDM #needs-revision Issue Date: 2022-07-27 Comment
# Motivation
MOOCsではITSとはことなり、on-demandなチュートリアルヘルプを提供しておらず、その代わりに、知識は自己探求され様々なタイプのリソースの冗長性によって提供され、システムを介して学生は様々な経路やリソースを選択する。このようなデータは、さまざまな条件下で学生の行動の有効性を調査する機会を提供するが、この調査を計測するためのモデルがない。
そこで、既存の学習者モデリングテクニックであるBKTを、どのようにしてMOOCsのコースに適用できるかを示した。
これには3つのチャレンジがある:
1. questionに対応するKCの、対象分野の専門家によるマッピングが不足していること
2.
3.
# データ概要
生徒のgradeは12の宿題と、12のvirtual labs (それぞれ15%の重みで無制限に回答できる)、そして中間テストと最終テスト(それぞれ30%と40%の重みで、3回の回答が許される)によって決まる。レクチャー中の問題は正誤がつくが、gradeにはカウントされないが即座にフィードバックが与えられる。104個のレクチャに289個のスコアリング可能な要素があり(すなわち、problemのsub-partをカウントした)、他にも37種類の宿題のproblemには197個、5つの中間テストproblemに26個、10個の最終テストproblemに47個のスコアリング可能なsub-partが存在する。
weeklyの宿題は複数のproblemで構成されており、それぞれがsingle web pageで表示される。典型的には図といくつかの回答フォームがある(これをsub-partsと呼ぶ)。subpartの回答チェックは、生徒がcheckボタンを押すと開始され、正誤がつく。subpartは任意の順番で回答できるが、いくつかのproblemのsubpartは、以前のsubpartの回答結果を必要とするものも存在する。もし生徒が全てのsubpartsを最初のチェックの前に回答したら、どの順番でsubpartに回答したかは分からない。しかしながら、多くの生徒は回答する度にチェックボタンを押すことを選択している。ほとんどのITSとは異なり、宿題は、最初の回答ではなく、ユーザーが入力した最後の回答に基づいて採点された。
# データセット
154,000人の登録者がいたが、108,000人が実際にコースに入学し、10,000人がコースを最終的に終えた。その中で、7158人が少なくとも60%のweighted averatgeを獲得したという証明書を受け取った。
データセットは2,000人のcertificateを獲得したランダムに選択された生徒によって構成される。さらに、homework, lecture sequence, exam problemの中から、ランダムに10個のproblem(およびそのsubparts)を選択した。
データはJSONのログファイルとして生成され、ログファイルはユーザ単位でJSONレコードとして分割された。そして人間が解釈可能なMOOCsのコンポーネントとのインタラクションのtime seriesにparseされている。
最後的には、problemごとにイベントログを作成した。このログは、そのproblemに関連する学生のイベントごとに1行で構成されている。これは、イベントで消費した時間、subpartの正誤、生徒が回答を入力したあるいは変更した場合、回答のattemptの回数、回答の間にアクセスしたリソースなどが含まれている。
# BKT
KTはmastery learningを実現したいというモチベーションからきていて、mastery learningではスbエテの生徒は自分のペースでスキルを学習していき、前提知識をマスターするまでは、より複雑なmaterialへはチャレンジできないように構成されている。これを実現するためにN問連続で正解するなどのシンプルなmastery基準などが存在しており、ASSISTments Platformのskill builder problem setで利用されている。Cognitive Tutorでは、取得可能な知識は、宣言型であろうと手続き型であろうと、通常は対象分野の専門家によって定義されるKnowledge Component(KC)と呼ばれるきめ細かいatomic piecesによって定義されます。tutorのanswer stepにはこれらのKCのタグが付けられており、生徒の過去の回答履歴は、KCの習熟度を示しています。この文脈では、KCが生徒によって高い確率で知られている(通常は> = 0.95)ときに習熟したと推測されます。
standardなBKTモデルでは、四つのパラメータが定義される:
- prior knowledge p(L_0)
- probability of learning p(T)
- probability of guessing p(G)
- probability of slipping p(S)
これらのパラメータによって、生徒の時刻nでの知識の習熟確率p(L_n)が推論される。また、これらのパラメータは生徒の回答の正誤の予測にも利用できる:
KCは、平均して習得するのに必要な難易度と練習の量が異なるため、これらのパラメーターの値はKCに依存し、以前の学生のログデータなどのトレーニングデータによってfittingすることができる。
パラメータのfittingはEMアルゴリズムかgrid searchによって、観測されたcorrectnessに対する予測された確率の残差平方和によるloss functionを最大化するようなパラメータが探索される。
ただし、どちらのフィッティング手順も、他の手順よりも一貫して優れていることは証明されていません。 グリッド検索は、基本的なBKTモデルのフィッティングは高速ですが、パラメーターの数が増えると指数関数的に増加します。これは、パラメーター化が高いBKTの拡張に関する懸念事項です。どちらのフィッティング手法も、目的は観測されたデータ(生徒の特定のKCの問題に対する正誤の系列)に最もマッチするパラメータを見つけることです。
KTの利用は2つのステージに分かれており、一つは4つのパラメータを学習するステージ、そしてもう一つは生徒の知識を彼らのレスポンスから予測することです。
inferenceのステージでは、時刻nの知識の習熟度は、観測データが与えられたときに以下の指揮で計算できる。観測データが正解だった場合は
であり、不正解の場合は
となる。
右辺のp(L_n)は、時刻nでの知識の習熟度に関する事前確率であり、p(L_n | Evidence_n)はその時点でのobservationを考慮し計算される事後確率です。両方の式はベイズの定理の適用であり、観察されたresponseの説明が学生がKCを知っているということである可能性を計算します。生徒にはフィードバックが提供されるため、KCを学習する機会があります。学生が機会からKCを学習する確率は、下記指揮によって導かれる:
これらの数式がmasxteryを決定するのに利用される。この知識モデルは、学習現象を研究するためのプラットフォームとして機能するように拡張されています。BKTアプローチを採用することで、MOOCで実現することを目指しているのは、この発見能力です。
# Model Adaptation Challenge
## KCモデルの不足
"learning"には広い意味があるが、masteryの文脈では特定のスキル, あるいはKCの獲得を意味する。このようなスキルとquestionのマッピングは、Q-matrixと一般的に呼ばれるが、多くの場合は対象分野の専門家によって提供される。
これらのスキルは、psychometrics literatureの中でcognitive operationsと呼ばれ、スキルの識別プロセスは、ITSおよびエキスパートシステムの文脈では一般にcognitive task analysisと呼ばれます。
KCマッピングの評価手法である学習曲線分析は、優れたスキルマッピングの証拠は、スキルに関連するquestionに回答する機会を通じて、エラー率が単調に減少することであると主張しています。同様に、fluencyは、特定のスキルに対して正解するにつれて増加する(解決する時間が減少する)と期待されている。
たとえば、MOOCまたはGeometryなどの教科内のquestionを一次元で表示すると、カリキュラムに新しいトピック資料が導入されると、すぐにエラー率と応答時間が急増するため、パフォーマンスとfluencyのプロットにノイズが発生します。
対象分野の専門家が定義したKCまたは学習目標は、将来のMOOCsでは計画されていますが、それらは一般的ではなく、本論文で使用される6.002xコースデータには存在しません。したがって、我々のゴールはコースの構成要素を利用して、KCとquestionのマッピングを実現することである。課題のproblemとsubpartの構造を利用して、problemそのものをKCとみなし、subpartをKCに紐づくquestionとみなします。この選択の理論的根拠は、コースの教授はしばしば、それぞれのproblemにおいて、特定のconceptを利用することを念頭に置いていることが多いことです。subpartのパフォーマンスは、生徒がこのconceptを理解しているかの証拠となります。このタイプのマッピングの利点は、ドメインに依存せず、任意のMOOCのベースラインKCモデルとして利用できることです。欠点は、特定のKCへの回答が特定の週の課題の問題内でのみ発生するため、1週をまたいだ学習の長期評価ができないことです。Corbett&Conrad [14]がコースの問題構造に対する質問の同様の表面的なマッピングを評価し、これがより体系的で窒息する学習曲線を達成することを実際に犠牲にしていることを発見したため、モデルの適合性の低下は別の欠点です(←ちょっとよくわからない)。だが、このマッピングは、problem内での現象を研究することを可能にする合理的な出発点であると信じており(これは「問題分析」と呼ばれます)、ここで説明した方法とモデルは、教科の専門家によって導かれた、あるいはデータから推論された、またはその両者のハイブリッドによる別のKCモデルにも適用できると信じています。
Multi-Relational Factorization Models for Predicting Student Performance, Nguyen+, KDD Cup'11
Paper/Blog Link My Issue
#CollaborativeFiltering #MatrixFactorization #StudentPerformancePrediction #One-Line Notes Issue Date: 2021-10-29 Comment
過去のCollaborative Filteringを利用したStudent Performance Prediction (Collaborative Filtering Applied to Educational Data Mining, Andreas+, KDD Cup'10
など)では、単一の関係性(student-skill, student-task等の関係)のみを利用していたが、この研究では複数の関係性(task-required skill-learnt skill)を利用してCFモデルの性能を向上させ、Bayesian Knowledge TracingやMatrix Factorizationに基づく手法をRMSEの観点でoutperformした。
[Paper Note] Factorization Models for Forecasting Student Performance, Thai-Nghe+, EDM'11
Paper/Blog Link My Issue
#AdaptiveLearning #StudentPerformancePrediction #EDM #One-Line Notes Issue Date: 2018-12-22 Comment
student performanceは、推薦システムの問題において、下記の2種類にcastできる:
1. rating prediction task, すなわち、ユーザ・アイテム・ratingを、生徒・タスク・パフォーマンスとみなす
2. sequentialなエフェクトを考慮して、forecasting problemに落とす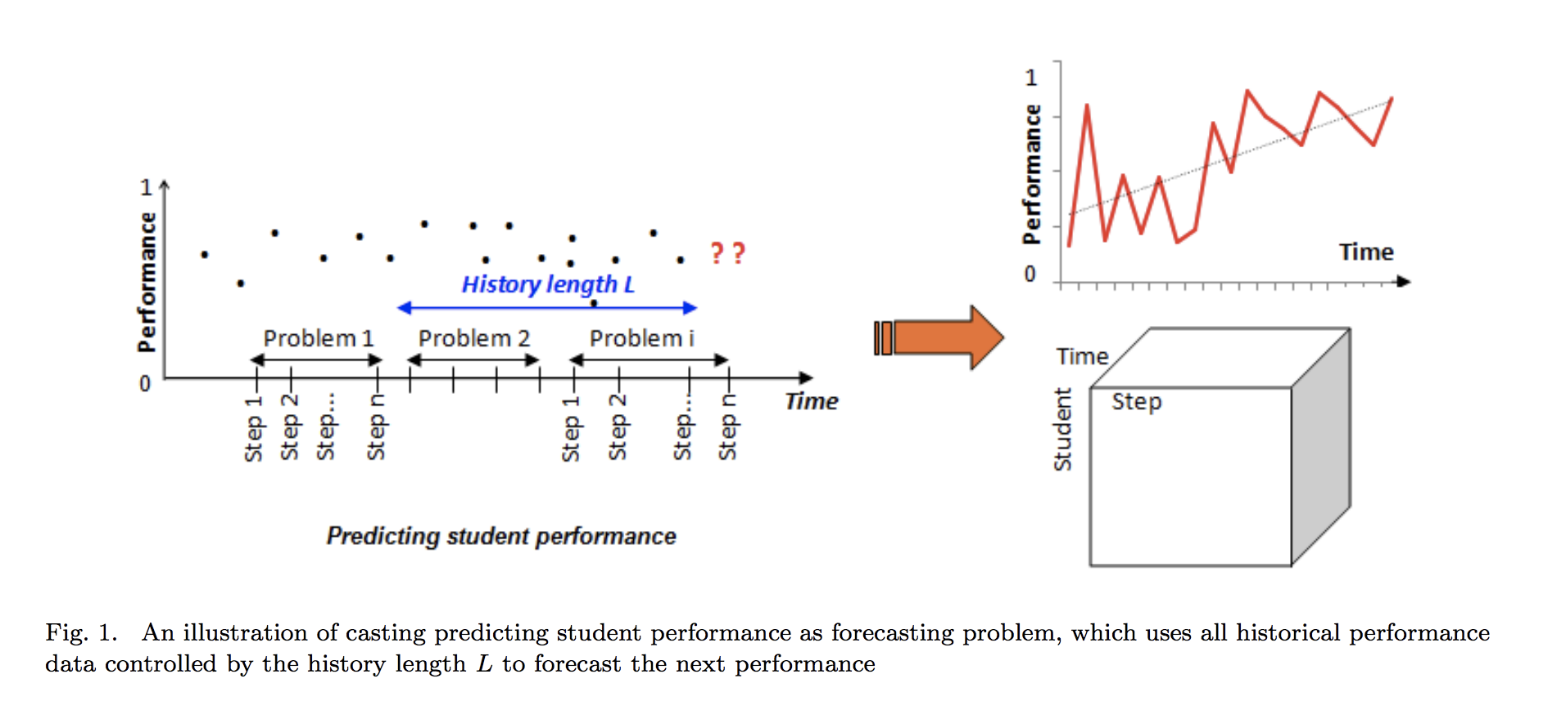
TensorFactorizationで、欠損値を予測
cold-start problem(new-user, new item)への対処としては、global averageをそれぞれ用いることで対処(more sophisticatedなやり方が提案されているとも述べている)
使用している手法としては、この辺?
https://pdfs.semanticscholar.org/8e6b/5991f9c1885006aa204d80cc2c23682d8d31.pdf
Collaborative Filtering Applied to Educational Data Mining, Andreas+, KDD Cup'10
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #MatrixFactorization #StudentPerformancePrediction #One-Line Notes Issue Date: 2021-10-29 Comment
KDD Cup'10のStudent Performance Predictionタスクにおいて3位をとった手法
メモリベースドな協調フィルタリングと、Matirx Factorizationモデルを利用してStudent Performance Predictionを実施。
最終的にこれらのモデルをニューラルネットでensembleしている。
局所的変分法による非補償型時系列IRT, 玉野+, NEC+, 人工知能学会研究会資料, 2020.03
Paper/Blog Link My Issue
#Article #AdaptiveLearning #LearningAnalytics #KnowledgeTracing Issue Date: 2025-02-14
Dynamic Key-Value Memory Networks With Rich Features for Knowledge Tracing, Sun+, IEEE TRANSACTIONS ON CYBERNETICS, 2022.08
Paper/Blog Link My Issue
#Article #KnowledgeTracing Issue Date: 2024-11-30 Comment
後で読みたい
Score Prediction dataset
Paper/Blog Link My Issue
#Article #Dataset #Education #AdaptiveLearning #ScorePrediction #KeyPoint Notes #Reference Collection Issue Date: 2022-08-23
独立な学習者・項目ネットワークをもつ Deep-IRT, 堤+, 電子情報通信学会論文誌, 2021
Paper/Blog Link My Issue
#Article #NeuralNetwork #AdaptiveLearning #KnowledgeTracing #In-Depth Notes Issue Date: 2022-07-25 Comment
# モチベーション
Deep-IRTで推定される能力値は項目の特性に依存しており、同一スキル内の全ての項目が等質であると仮定しているため、異なる困難度を持つ項目からの能力推定値を求められない。このため、能力パラメータや困難度パラメータの解釈性は、従来のIRTと比較して制約がある。一方、木下らが提案したItem Deep Response Theoryでは、項目特性に依存せずに学習者の能力値を推定でき、推定値の信頼性と反応予測精度が高いことが示されているが、能力の時系列変化を考慮していないため、学習家庭での能力変化を表現できない。これらを解決するための手法を提案。
# 手法
論文中の数式に次元数が一切書かれておらず、論文だけを読んで再現できる気がしない。
提案手法は、学習者の能力推定値が項目の特性に依存せず、複数のスキルに関する多次元の能力を表現できる(とあるが、が、どういう意味かよくわからない・・・)。
下図が提案手法の概要図。スキルタグ入力だけでなく、項目IDそのものも入力して活用するのが特徴。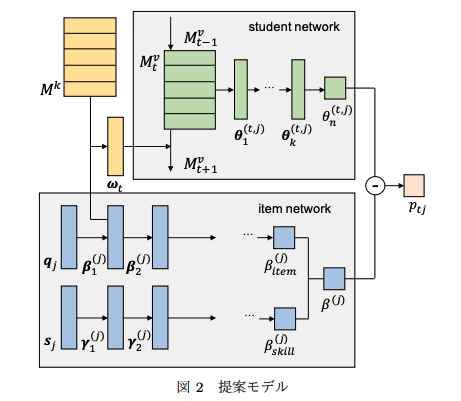
基本的に、生徒の能力値を推定するstudent networkと、スキル/項目の難易度を推定するitem networkに分かれている。ある時刻tでの生徒の能力値はメモリM上の全てのhidden conceptに対するvalueを足し合わせ、足し合わせて得られたベクトルに対してMLPをかけることによって計算している。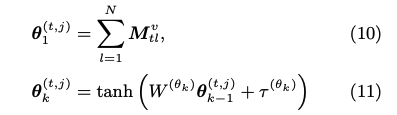
最終的にitem response functionを見ると、ここで得られる生徒の能力値はスカラー値でなければならないと思うのだが、MLPをかけて得られたベクトルからどのように生徒の能力値を算出するかがジャーナル上では書かれていない。EDM'21の方を見ると、inputとなったスキルタグのembeddingとメモリのkeyとの関連度から求めたアテンションベクトルω_tとの内積でスカラーに変換しているようなので、おそらくそのような操作をしていると思われる。
item networkも同様に、スキルタグのembedding q_j と 項目のembedding s_j を別々にMLPにかけて、最終的に1次元に写像することで、スキル/項目の難易度パラメータを推論していると思われる。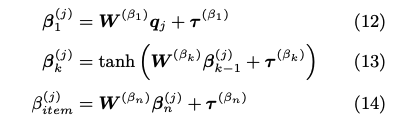
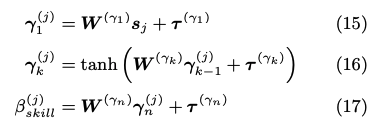
最終的に下記item response functionによって反応予測を行う。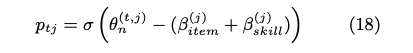
ただし、EDM'21の論文だと能力値パラメータθに3が乗じられているのに対し、こちらはそのような操作がされていない。どちらが正しいのか分からない。
また、メモリネットワークのmemory valueの更新は [Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
と同じ方法である。
# 予測性能評価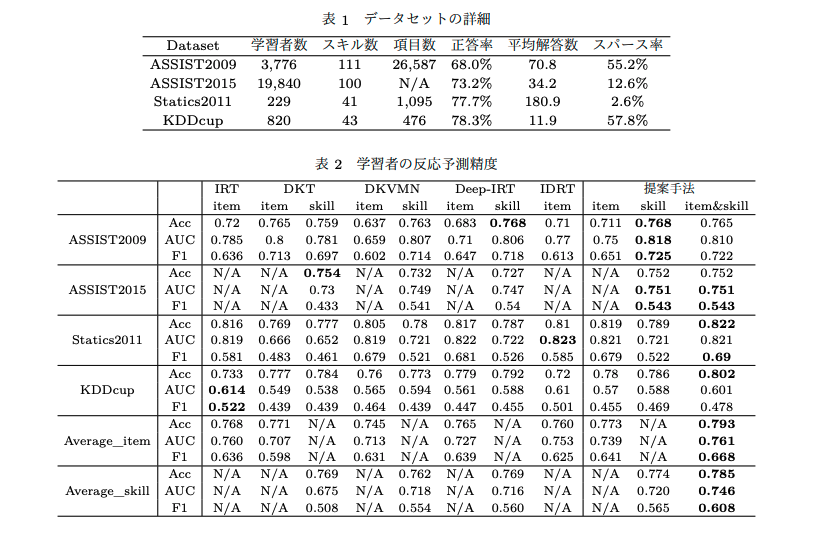
提案手法が全てのデータセットで平均すると最も良い予測性能を示している。IRTもKDDCupデータでは性能が良く、KDDCupデータは回答ログの正答率が非常に高くデータに偏りがあり、加えてデータのスパース率(10 人以下
の学習者が解答した項目の割合)も高いため(学習者の平均回答数が少ない)、DeepLearningベースドな手法は反応の偏りと少数データに脆弱である可能性を指摘している。
ちなみにEDM'21論文だと下記のような結果になっている: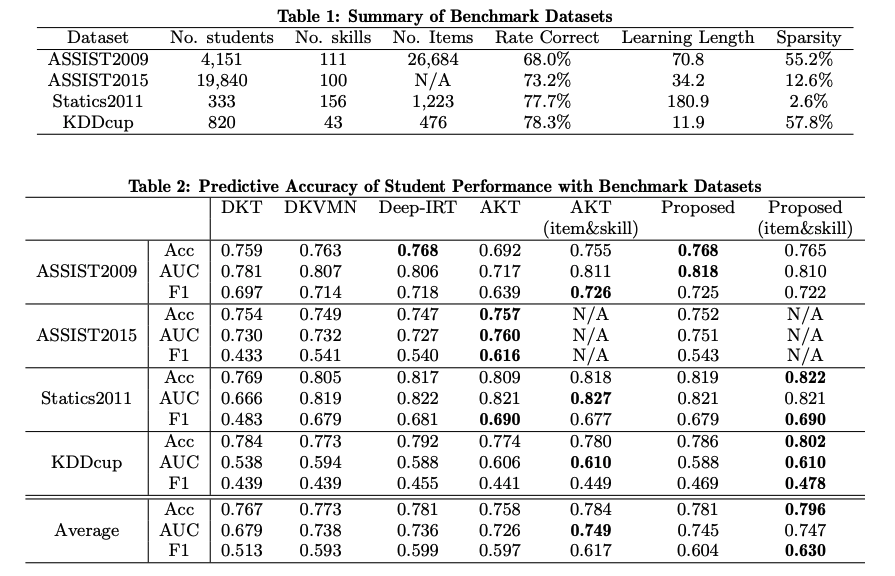
こちらの結果を見ると、AKTよりも高い性能を示していることがわかる。AKTに勝つのは結構すごそうなのだが Learning Process-consistent Knowledge Tracing, Shen+, SIGKDD'21
でのAKTの性能に比べ、DKT等の手法に対するAKTの性能の伸びが小さいのが非常に気になる。何を信じたら良いのか分からない・・・。
# 解釈性評価実験について
DeepIRTとのパラメータの能力パラメータ、困難度パラメータの解釈性の検証をしているようだが、所感に書いてある通りまずDeepIRTの能力値パラメータを正しく採用できているのかが怪しい。困難度パラメータについては、シミュレーションデータを用いて提案手法がDeepIRTと比べて真の困難度に対する相関が高いことを示しているが、詳細が書かれておらずよくわからない・・・。一応IRTと同等の解釈性能を持つと主張している。
# 所感
解釈性の評価実験において下記の記述があるが、
> しかし,彼ら によって公開された Deep-IRT のプログラムコードで は一次元の能力値推移しか出力できず,論文で示され た複数スキルに対応した結果を再現できない.このた め,本実験では,式 (7) で得られる θ (t,j) 3 を多次元で 出力した値を Deep-IRT における多次元のスキルの能 力値推移とする.
ここでどのような操作をしているのかがいまいち分からないが、時刻tのメモリM_tが与えられたとき、DeepIRTは入力ベクトルq_tに対応する一次元の能力値を返すモデルのはずで、q_tを測定したい能力のスキルタグに対するone-hot encodingにすれば能力値推移は再現できるのでは?「θ (t,j) 3を多次元で出力した値」というのは、1次元のスカラー値を出力するのではなく、多次元のベクトルとしてθ (t,j) 3を出力し、ベクトルの各要素をスキルに対する能力値とみなしているのだろうか。もしそういう操作をしているのだとしたらDeepIRTが出力する能力値パラメータとの比較になっていないと思う。
θ_n^(t, j)を学習者の能力値ベクトルとしてみなすと論文中に記述されているが、実際にどの次元がどのスキルの習熟度に対応しているかは人間が回答ログに対する習熟度の推移を観察して決定しなければならない。これは非常にダルい。
しかもθ_n^(t, j)の各次元の値は、スキルタグに対する習熟度ではなく、スキルタグの背後にあるhidden conceptの習熟度だと思う。論文では問題の正解/不正解に対して、習熟度が上下する様子から、能力値ベクトルの特定の次元の数値が特定のスキルの習熟度となっていることを解釈しているが、その解釈が正しい保証はないような・・・。
Addressing Two Problems in Deep Knowledge Tracing via Prediction-Consistent Regularization, Yeung+, 2018, L@S
Paper/Blog Link My Issue
#Article #NeuralNetwork #AdaptiveLearning #StudentPerformancePrediction #KnowledgeTracing #L@S #KeyPoint Notes Issue Date: 2021-10-29 Comment
Deep Knowledge Tracing (DKT)では、下記の問題がある:
- 該当スキルに正解/不正解 したのにmasteryが 下がる/上がる (Inputをreconstructしない)
- いきなり習熟度が伸びたり、下がったりする(時間軸に対してmastery levelがconsistentではない)
上記問題に対処するようなモデルDKT+を提案。
DKT+では、DKTのloss functionに対して3つのregularization termを追加することで上記問題に対処している。
DKT+はDKTの性能を落とすことなく、上記2問題を緩和できたとのこと。
実装: https://github.com/ckyeungac/deep-knowledge-tracing-plus

DKT+とDKTのheatmapを比較すると、問題点は確かに緩和されているかもしれないが、
依然としてinputはreconstructionされていないし、習熟度も乱高下しているように見える。
根本的な解決にはなっていないのでは。
Deep Knowledge Tracingの拡張による擬似知識タグの生成, 中川+, 人口知能学会論文誌, 33巻, 33号, C, 2018
Paper/Blog Link My Issue
#Article #NeuralNetwork #LearningAnalytics #KnowledgeTracing #KeyPoint Notes Issue Date: 2021-06-02 Comment
DKTモデルは、前提として各問題に対して知識タグ(knowledge component)が付与されていることが前提となっている。しかし世の中には、知識タグが振られているデータばかりではないし、そもそもプログラミング教育といった伝統的な教育ではない分野については、そもそも知識タグを構造的に付与すること自体が成熟していない分野も存在する。
そのような知識タグが存在しない、付与しづらい分野に対してもDKTが適用できるように、知識タグそのものを自動的に学習した上で、Knowledge Tracingするモデルを提案しました、という話。
Deep Knowledge Tracingの入力ベクトルの日本語例が書いてあり、わかりやすい。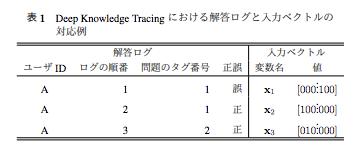
提案モデルの構造は下記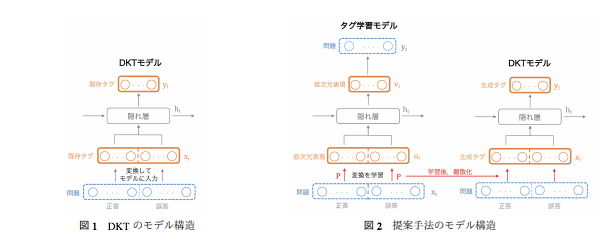
ASSISTments, KDD Cup Dataでの既存タグを利用した場合と、擬似生成タグを利用した場合の評価結果
既存タグを利用した場合とcomparable, もしくはoutperformしている。
既存タグと擬似生成タグタグの依存関係を可視化したネットワーク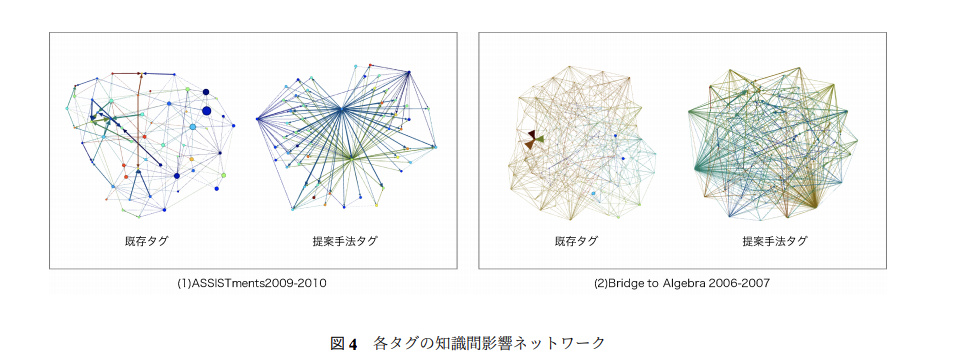
既存タグと擬似生成タグの内容的関係性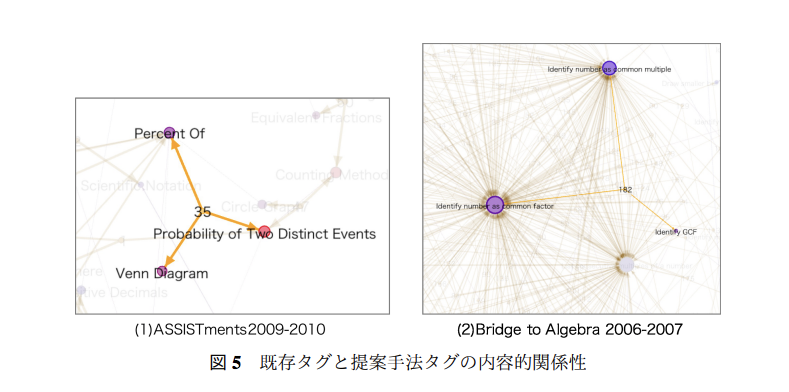
既存タグは人間が理解しやすい形で構成されているが、擬似生成タグは予測に最適化されているためそのような生成のされ方はされない。つまり、解釈性に問題がある。
Knowledge Tracingモデルは教育の観点から、生徒がどのconceptにどれだけ習熟しているか、といったことを教員側が把握し適切なinterventionを行なったり、あるいは生徒側が内省を行い自信をmotivatingしたりする側面があるため、どのようにして解釈性の高いタグを自動生成するか、はunsolved question。
[Paper Note] The Knowledge-Learning-Instruction Framework: Bridging the Science-Practice Chasm to Enhance Robust Student Learning, Pelanek, User Modeling and User-Adapted Interaction, 2017
Paper/Blog Link My Issue
#Article #Tutorial #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #KeyPoint Notes Issue Date: 2021-05-30 Comment
Learner Modelingに関するチュートリアル。Learner Modelingの典型的なコンテキストや、KCにどのような種類があるか(KLI Frameworkに基づいた場合)、learner modeling techniques (BKTやPFA等)のチュートリアルなどが記載されている(Figure 1,2,3,4, Table 1,2)。
knowledgeをmodelingする際に利用されるデータの典型的な構造
donain modelingの典型的なアプローチ
モデルのaspectと、model purposes, learning processesのrelevanceを図示したもの。色が濃いほうが重要度が高い
Learner ModelingのMetrics
cross validation方法の適用方法(同じ学習者内と、異なる学習者間での違い。学習者内での予測性能を見たいのか、学習者間での汎化性能を見たいのかで変わるはず)
BKT、PFAや、それらを用いるContext(どのモデルをどのように自分のcontextに合わせて選択するか)、KLI Frameworkに基づくKCの構成のされ方、モデル評価方法等を理解したい場合、読んだほうが良さそう?
ざっとしか見ていないけど、重要な情報がめちゃめちゃ書いてありそう。後でしっかり読む・・・。
[Paper Note] Knowledge Tracing: Modeling the Acquisition of Procedural Knowledge, Corbett+, User Modeling and User-Adapted Interaction, 1995
Paper/Blog Link My Issue
#Article #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #One-Line Notes Issue Date: 2021-05-30 Comment
Bayesian Knowledge Tracing (BKT)を提案した論文。Knowledge Tracingについて研究するなら必ず抑えておくべき。
以後、BKTを拡張した研究が数多く提案されている。
Student Performance Prediction _ Knowledge Tracing Dataset
Paper/Blog Link My Issue
#Article #Survey #Dataset #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing Issue Date: 2021-05-29
Behavior-Based Grade Prediction for MOOCs Via Time Series Neural Networks, Chiang+, IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 11, NO. 5, AUGUST 2017
Paper/Blog Link My Issue
#Article #NeuralNetwork #LearningAnalytics #StudentPerformancePrediction #KeyPoint Notes Issue Date: 2021-05-29 Comment
MOOCsでの生徒のgradeを予測するモデルを提案。MOOCsでは生徒のassessmentに対するreponseがsparseで、かつpersonalizedなモデルが必要なため成績予測はチャレンジングなタスク。
lecture-video-watching clickstreams を利用し、time-series neural network (tステップのデータをMLPに入力するもの?あまりしっかり読んでいない)を使って、prioer performanceとclickstreamでtrainingすることでこれらを克服する。
2種類のMOOCsデータセットで評価したところ、past performanceの平均を利用するbaselineに対しては60%程度、lasso regression baselineよりも15%程度outperformした。
全体像

一般的なMOOCsでのvideo-lestureのsequence図解
生徒のj回のquizに回答したあとのaverage Correct First Attempt (CFA)を生徒の成績と定義し、RMSEで評価をしている模様?

上図のように、クイズに回答する毎のaverage CFAの変遷(=y)と、クイズjが含まれる生徒のvideo tにおけるclickstream input features(=x)を利用し、次のクイズに回答した時のaverage CFAを予測している?
NFMB/NI [Paper Notes] Back to the basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation, Ekanadham+, EDM'16 データセットを利用している
Educational Data Mining and Learning Analytics, Baker+, 2014
Paper/Blog Link My Issue
#Article #Survey #AdaptiveLearning #LearningAnalytics #Selected Papers/Blogs Issue Date: 2018-12-22 Comment
Ryan BakerらによるEDM Survey