MatrixFactorization
[Paper Note] Neural Collaborative Filtering vs. Matrix Factorization Revisited, Steffen Rendle+, RecSys'20
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #RecSys #read-later #Selected Papers/Blogs #Reproducibility Issue Date: 2025-05-16 GPT Summary- 埋め込みベースのモデルにおける協調フィルタリングの研究では、MLPを用いた学習された類似度が提案されているが、適切なハイパーパラメータ選択によりシンプルなドット積が優れた性能を示すことが確認された。MLPは理論的には任意の関数を近似可能だが、実用的にはドット積の方が効率的でコストも低いため、MLPは慎重に使用すべきであり、ドット積がデフォルトの選択肢として推奨される。
[Paper Note] Neural Collaborative Filtering, Xiangnan He+, WWW'17, 2017.08
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #WWW #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-02-16 GPT Summary- 深層ニューラルネットワークを用いたレコメンダーシステムの研究が少ない中、本研究では協調フィルタリングの問題に取り組むため、NCF(Neural network-based Collaborative Filtering)フレームワークを提案。内積をニューラルアーキテクチャに置き換え、ユーザーとアイテムの相互作用を多層パーセプトロンでモデル化。実験により、提案手法が最先端技術に対して顕著な改善を示し、深層ニューラルネットワークの層を深くすることでレコメンデーション性能が向上することが確認された。 Comment
Collaborative FilteringをMLPで一般化したNeural Collaborative Filtering、およびMatrix Factorizationはuser, item-embeddingのelement-wise product + linear transofmration + activation で一般化できること(GMF; Generalized Matrix Factorization)を示し、両者を組み合わせたNeural Matrix Factorizationを提案している。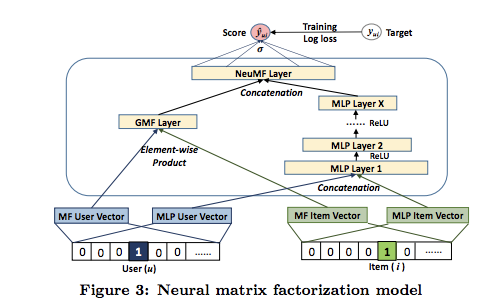
学習する際は、Implicit Dataの場合は負例をNegative Samplingし、LogLoss(Binary Cross-Entropy Loss)で学習する。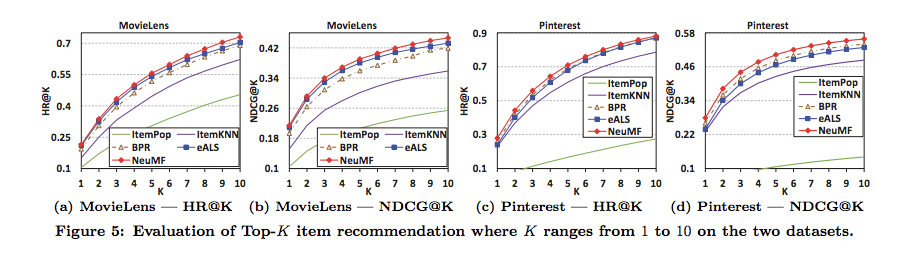
Neural Matrix Factorizationが、ItemKNNやBPRといったベースラインをoutperform
Negative Samplingでサンプリングする負例の数は、3~4程度で良さそう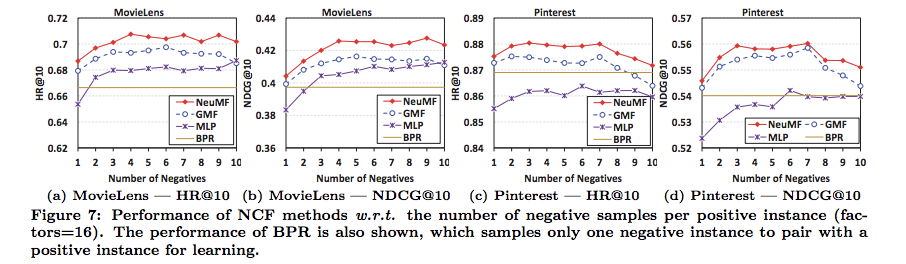
[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #SIGKDD #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2018-01-11 GPT Summary- 協調フィルタリング(CF)はレコメンダーシステムで広く用いられるが、評価がまばらな場合に性能が低下する。これに対処するため、補助情報を活用する協調トピック回帰(CTR)が提案されているが、補助情報がまばらな場合には効果が薄い。そこで、本研究では協調深層学習(CDL)という階層ベイズモデルを提案し、コンテンツ情報の深い表現学習とCFを共同で行う。実験により、CDLが最先端技術を大幅に上回る性能を示すことが確認された。 Comment
Rating Matrixからuserとitemのlatent vectorを学習する際に、Stacked Denoising Auto Encoder(SDAE)によるitemのembeddingを活用する話。
Collaborative FilteringとContents-based Filteringのハイブリッド手法。
Collaborative FilteringにおいてDeepなモデルを活用する初期の研究。
通常はuser vectorとitem vectorの内積の値が対応するratingを再現できるように目的関数が設計されるが、そこにitem vectorとSDAEによるitemのEmbeddingが近くなるような項(3項目)、SDAEのエラー(4項目)を追加する。
(3項目の意義について、解説ブログより)アイテム i に関する潜在表現 vi は学習データに登場するものについては推定できるけれど,未知のものについては推定できない.そこでSDAEの中間層の結果を「推定したvi」として「真の」 vi にできる限り近づける,というのがこの項の気持ち
cite-ulikeデータによる論文推薦、Netflixデータによる映画推薦で評価した結果、ベースライン(Collective Matrix Factorization [Paper Note] Relational learning via collective matrix factorization, Singh+, KDD'08
, SVDFeature [Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
, DeepMusic [Paper Note] Deep content-based music recommendation, Oord+, NIPS'13
, Collaborative Topic Regresison [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
)をoutperform。
(下記は管理人が過去に作成した論文メモスライドのスクショ)




[Paper Note] Deep content-based music recommendation, Oord+, NIPS'13
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NeurIPS #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-11 Comment
Contents-Basedな音楽推薦手法(cold-start problemに強い)。
Weighted Matrix Factorization (WMF) (Implicit Feedbackによるデータに特化したMatrix Factorization手法) [Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008.12
に、Convolutional Neural Networkによるmusic audioのlatent vectorの情報が組み込まれ、item vectorが学習されるような仕組みになっている。
CNNでmusic audioのrepresentationを生成する際には、audioのtime-frequencyの情報をinputとする。学習を高速化するために、window幅を3秒に設定しmusic clipをサンプルしinputする。music clip全体のrepresentationを求める際には、consecutive windowからpredictionしたrepresentationを平均したものを使用する。
[Paper Note] Multi-relational matrix factorization using bayesian personalized ranking for social network data, Krohn-Grimberghe+, WSDM'12, 2012.02
Paper/Blog Link My Issue
#Multi #RecommenderSystems #WSDM #ColdStart #One-Line Notes Issue Date: 2017-12-28 Comment
multi-relationalな場合でも適用できるmatrix factorizationを提案。特にcold start problemにフォーカス。social networkのデータなどに適用できる。
Multi-Relational Factorization Models for Predicting Student Performance, Nguyen+, KDD Cup'11
Paper/Blog Link My Issue
#CollaborativeFiltering #EducationalDataMining #StudentPerformancePrediction #One-Line Notes Issue Date: 2021-10-29 Comment
過去のCollaborative Filteringを利用したStudent Performance Prediction (Collaborative Filtering Applied to Educational Data Mining, Andreas+, KDD Cup'10
など)では、単一の関係性(student-skill, student-task等の関係)のみを利用していたが、この研究では複数の関係性(task-required skill-learnt skill)を利用してCFモデルの性能を向上させ、Bayesian Knowledge TracingやMatrix Factorizationに基づく手法をRMSEの観点でoutperformした。
[Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #SIGKDD #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-11 Comment
Probabilistic Matrix Factorization (PMF) [Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08
に、Latent Dirichllet Allocation (LDA) を組み込んだCollaborative Topic Regression (CTR)を提案 (Figure2)。
LDAによりitemのlatent vectorを求め、このitem vectorと、user vectorの内積を(平均値として持つ正規表現からのサンプリング)用いてratingを生成する(式6)。
CFとContents-basedな手法が双方向にinterationするような手法
Collaborative Filtering Applied to Educational Data Mining, Andreas+, KDD Cup'10
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #EducationalDataMining #StudentPerformancePrediction #One-Line Notes Issue Date: 2021-10-29 Comment
KDD Cup'10のStudent Performance Predictionタスクにおいて3位をとった手法
メモリベースドな協調フィルタリングと、Matirx Factorizationモデルを利用してStudent Performance Predictionを実施。
最終的にこれらのモデルをニューラルネットでensembleしている。
[Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08
Paper/Blog Link My Issue
#RecommenderSystems #NeurIPS #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-11 Comment
Matrix Factorizationを確率モデルとして表した論文。
解説:
http://yamaguchiyuto.hatenablog.com/entry/2017/07/13/080000
既存のMFは大規模なデータに対してスケールしなかったが、PMFではobservationの数に対して線形にスケールし、さらには、large, sparse, imbalancedなNetflix datasetで良い性能が出た(Netflixデータセットは、rating件数が少ないユーザとかも含んでいる。MovieLensとかは含まれていないのでより現実的なデータセット)。
また、Constrained PMF(同じようなsetの映画にrateしているユーザは似ているといった仮定に基づいたモデル[^1])を用いると、少ないratingしかないユーザに対しても良い性能が出た。
[^1]: ratingの少ないユーザの潜在ベクトルは平均から動きにくい、つまりなんの特徴もない平均的なユーザベクトルになってしまうので、同じ映画をratingした人は似た事前分布を持つように制約を導入したモデル
[Paper Note] Relational learning via collective matrix factorization, Singh+, KDD'08
Paper/Blog Link My Issue
#RecommenderSystems #SIGKDD #One-Line Notes Issue Date: 2018-01-11 Comment
従来のMatrix Factorization(MF)では、pair-wiseなrelation(たとえば映画とユーザと、映画に対するユーザのrating)からRating Matrixを生成し、その行列を分解していたが、multipleなrelation(たとえば、user-movie ratingの5-scale Matrixとmovie - genreの binary Matrixなど)を扱うことができなかったので、それを可能にした話。
これができると、たとえば ユーザの映画に対するratingを予測する際に、あるユーザが特定のジャンルの映画に対して高いratingを付けるような情報も考慮して予測ができたりする。
[Paper Note] Matrix Factorization Techniques for Recommender Systems, Koren+, Computer'07
Paper/Blog Link My Issue
#RecommenderSystems #Survey #CollaborativeFiltering #Selected Papers/Blogs #Reading Reflections Issue Date: 2018-01-01 Comment
Matrix Factorizationについてよくまとまっている
[Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #CollaborativeFiltering #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-11 Comment
Implicit Feedbackなデータに特化したMatrix Factorization (MF)、Weighted Matrix Factorization (WMF)を提案。
ユーザのExplicitなFeedback(ratingやlike, dislikeなど)がなくても、MFが適用可能。
目的関数は式(3)のようになっている。
通常のMFでは、ダイレクトにrating r_{ui}を予測したりするが、WMFでは r_{ui}をratingではなく、たとえばユーザuがアイテムiを消費した回数などに置き換え、binarizeした数値p_{ui}を目的関数に用いる。
このとき、itemを消費した回数が多いほど、そのユーザはそのitemを好んでいると仮定し、そのような事例については重みが高くなるようにconfidence c_{ui}を計算し、目的関数に導入している。
日本語での解説: https://cympfh.cc/paper/WRMF
Implicit Implicit でのAlternating Least Square (ALS)という手法が、この手法の実装に該当する。
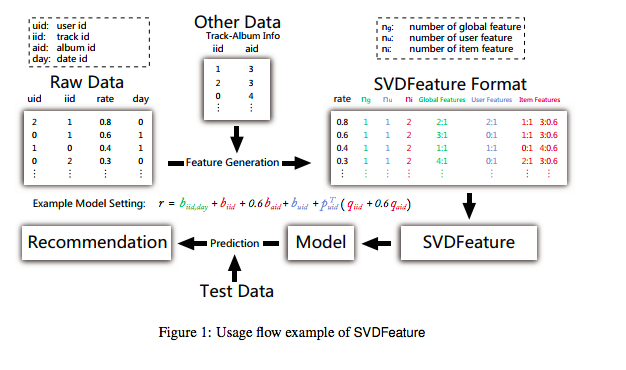
[Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tools #CollaborativeFiltering #One-Line Notes #JMLR Issue Date: 2018-01-11 Comment
tool: http://apex.sjtu.edu.cn/projects/33
Ratingの情報だけでなく、Auxiliaryな情報も使ってMatrix Factorizationができるツールを作成した。
これにより、Rating Matrixの情報だけでなく、自身で設計したfeatureをMFに組み込んでモデルを作ることができる。