
OpenWeightLLM
#ComputerVision#Pocket#Transformer#FoundationModel#CVPR
Issue Date: 2025-04-11 AM-RADIO: Agglomerative Vision Foundation Model -- Reduce All Domains Into One, Mike Ranzinger+, CVPR25 Comment元ポスト:https://x.com/pavlomolchanov/status/1910391609927360831?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qvision系のfoundation modelはそれぞれ異なる目的関数で訓練されてきており(CLIPは対照学習 #55 ... #ComputerVision#Pocket#NLP#LanguageModel#MulltiModal#SpeechProcessing#Video
Issue Date: 2025-03-31 Qwen2.5-Omni Technical Report, Jin Xu+, arXiv25 CommentQwen TeamによるマルチモーダルLLM。テキスト、画像、動画音声をinputとして受け取り、テキスト、音声をoutputする。。スマホにデプロイできるレベルのサイズで、GPT3.5Turbo程度の性能を実現したらしいLlama2と同じブロックを利用しているため、アーキテクチャはLlama2と共通。 ... #Pocket#NLP#LanguageModel#OpenSource
Issue Date: 2024-03-05 OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, N_A, arXiv24 SummaryLMsの商業的重要性が高まる中、最も強力なモデルは閉鎖されており、その詳細が非公開になっている。そのため、本技術レポートでは、本当にオープンな言語モデルであるOLMoの初回リリースと、言語モデリングの科学を構築し研究するためのフレームワークについて詳細に説明している。OLMoはモデルの重みだけでなく、トレーニングデータ、トレーニングおよび評価コードを含むフレームワーク全体を公開しており、オープンな研究コミュニティを強化し、新しいイノベーションを促進することを目指している。 CommentModel Weightsを公開するだけでなく、training/evaluation codeとそのデータも公開する真にOpenな言語モデル(truly Open Language Model)。AllenAI ... #Pocket#NLP#LanguageModel
Issue Date: 2024-01-09 Mixtral of Experts, Albert Q. Jiang+, N_A, arXiv24 SummaryMixtralは、Sparse Mixture of Experts(SMoE)言語モデルであり、各レイヤーが8つのフィードフォワードブロックで構成されています。Mixtralは、トークンごとに2つのエキスパートを選択し、それらの出力を組み合わせます。Mixtralは、Llama 2 70BとGPT-3.5を上回る性能を持ち、数学、コード生成、多言語のベンチマークで特に優れています。また、Mixtral 8x7B Instructという指示に従うモデルも提供されており、人間のベンチマークを凌駕しています。 CommentMixture of experts Layer: inputを受け取ったrouterが、8つのexpertsのうち2つを選択し順伝搬。2つのexpertsのoutputを加重平均することで最終的なoutputとする。 #Article#NLP#Library#Supervised-FineTuning (SFT)#Article#MoE(Mixture-of-Experts)#PostTraining
#Article#NLP#Library#Supervised-FineTuning (SFT)#Article#MoE(Mixture-of-Experts)#PostTraining
Issue Date: 2025-05-11 ms-swiftによるMegatron-LMベースのQwen3のファインチューニング, Aratako, 2025.05 Comment元ポスト:https://x.com/aratako_lm/status/1921401994532487174?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMegatron-SWIFTというAlibaba製のライブラリを利用しQwen3の継続事前学習とSFTを実施する方法を、ベストプ ... #Article#NLP#LanguageModel#Supervised-FineTuning (SFT)#ReinforcementLearning#Reasoning#SmallModel#GRPO
Issue Date: 2025-05-01 Phi-4-reasoning Technical Report, 2025.04 Comment元ポスト:https://x.com/dimitrispapail/status/1917731614899028190?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこちらの解説が非常によくまとまっている:https://x.com/_philschmid/status/1918216 ... #Article#NLP#LanguageModel#Alignment#Supervised-FineTuning (SFT)#ReinforcementLearning#InstructionTuning#Article#LongSequence#MultiLingual#MoE(Mixture-of-Experts)#PostTraining
Issue Date: 2025-04-29 Qwen3, Qwen Team, 2025.04 Comment119言語をサポートMoEモデル #1911 30B-A3B / 235B-A22N 128K context window Qwen2.5はMoEを採用していないので新たなアーキテクチャとなるDenseモデル(非MoEモデル)も公開BestPracticeに関するポスト:http ... #Article#ComputerVision#Pocket#NLP#LLMAgent#MulltiModal#Article#Reasoning#x-Use
Issue Date: 2025-04-18 Introducing UI-TARS-1.5, ByteDance, 2025.04 Commentpaper:https://arxiv.org/abs/2501.12326色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)関連#1794元 ... #Article#NLP#LanguageModel#Reasoning
Issue Date: 2025-04-12 Seed-Thinking-v1.5, ByteDance, 2025.04 CommentDeepSeek-R1を多くのベンチで上回る200B, 20B activated paramのreasoning model最近のテキストのOpenWeightLLMはAlibaba, DeepSeek, ByteDance, Nvidiaの4強という感じかな…?(そのうちOpenAIがオープンに ... #Article#NLP#LanguageModel#Alignment#Supervised-FineTuning (SFT)#ReinforcementLearning#InstructionTuning#Pruning#Reasoning
Issue Date: 2025-04-08 Llama-3_1-Nemotron-Ultra-253B-v1, Nvidia, 2025.04 CommentDeepSeek-R1をGPQA Diamond #1155, AIME2024/2025, Llama4 MaverickをBFCLv2(Tool Calling, #1875), IFEVal #1137 で上回り, そのほかはArenaHardを除きDeepSeekR1と同等 ... #Article#Survey#NLP#Dataset#LanguageModel#Evaluation#Repository#Japanese#OpenSource
Issue Date: 2024-12-02 日本語LLMまとめ, LLM-jp, 2024.12 CommentLLM-jpによる日本語LLM(Encoder-Decoder系, BERT系, Bi-Encoders, Cross-Encodersを含む)のまとめ。テキスト生成に使うモデル、入力テキスト処理に使うモデル、Embedding作成に特化したモデル、視覚言語モデル、音声言語モデル、日本語LLM評価 ... #Article#Pretraining#NLP#LanguageModel#Japanese
Issue Date: 2024-11-25 Sarashina2-8x70Bの公開, SB Intuitions, 2024.11 CommentMoE Layerの説明、Sparse Upcyclingの説明、MoEモデルを学習する際に、学習時の学習率の設定が大きすぎると初期に損失が増大し、小さすぎると損失の増大は防げるがlong runで学習した際の性能向上が小さかったこと、元のモデルのパラメータを毀損しないように、Upcyclingをし ... #Article#Survey#NLP#LanguageModel#Article#OpenSource
Issue Date: 2024-11-15 ローカルLLMのリリース年表, npaka, 随時更新, 2024.11 CommentローカルLLMを含むOpenLLMのリリース日が年表としてまとまっており、随時更新されている模様。すごい。 ... #Article#NLP#LanguageModel#Japanese
Issue Date: 2024-11-09 sarashina2-8x70B, SBIntuitions, 2024.11 Commentプレスリリース:https://www.sbintuitions.co.jp/news/press/20241108_01/商用利用不可な点には注意アーキテクチャは70Bモデルx8のMixture of Experts(MoE)モデルカードによると、inferenceにはBF16で、A100 80G ... #Article#NLP#MultiLingual
Issue Date: 2024-10-24 Aya Expanse, Cohere, 2024.10 CommentCohereによるマルチリンガルLLM, 8B, 32Bのモデルが存在する。8BモデルのArenaHardでの評価 ... #Article#NLP
Issue Date: 2024-10-17 Llama-3.1-Nemotron-70B-Instruct, Nvidia, 2024.10 Commentpaper:https://arxiv.org/abs/2410.01257MTBench, Arena HardでGPT4o-20240513,Claude-3.5-sonnet-20240620をoutperform。Response lengthの平均が長いこと模様なので、そもそも同じInputなのでfair comparisonですよ、という話に仮になるのだとしたら、そもそもどういう設定で比較実験 ... #Article#Analysis#LanguageModel#Slide#Japanese
Issue Date: 2024-09-03 LLMに日本語テキストを学習させる意義, Koshiro Saito+, 第261回自然言語処理研究発表会, 2024.08 Comment英日翻訳や日本特有の知識を問われるようなQAにおいて、日本語データによる学習の効果があることが示唆されている模様。たとえば、#1359 に示されている通り、Llama2における日本語データの割合は0.2%とかなので、英語圏のOpenLLMにおいて、日本語データの比率がどれだけ少ないかがわかる。 ... #Article#Tutorial#NLP#LanguageModel#Slide
Issue Date: 2024-08-26 論文紹介 _ The Llama 3 Herd of Models, 2024.08 CommentLlama3の事前学習や事後学習のノウハウが詰まっており(安全性なども含む)、LLM学習に必要な要素が図解されており、非常に分かりやすい。 たとえば下記図(スライド中より引用)などは、LLMの学習過程を説明する際にわかりやすそう  is the latest in Microsoft's family of Small Language Models ... #Article#NLP#Quantization
Issue Date: 2024-08-20 4-bit Llama 3.1, NeuralMagic, 2024.08 #Article#EfficiencyImprovement#Library#Article#LLMServing
Issue Date: 2024-08-05 DeepSpeed, vLLM, CTranslate2 で rinna 3.6b の生成速度を比較する, 2024.06 Comment[vllm](https://github.com/vllm-project/vllm)を使うのが一番お手軽で、inference速度が速そう。PagedAttentionと呼ばれるキャッシュを利用して高速化しているっぽい。 (図はブログ中より引用)  。モデルは商用利用可能なA ... #Article#NLP#LanguageModel
Issue Date: 2024-07-03 Llama 3 Swallow #Article#NLP#LanguageModel
Issue Date: 2024-04-18 LLaMA3, Apr, 2024 Commentライセンスによると、LLaMA3を利用したモデルはどんな場合でもLlama3をprefixとして付与しないといけないらしい元ツイート:https://x.com/gneubig/status/1781083579273089442?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLaMA ...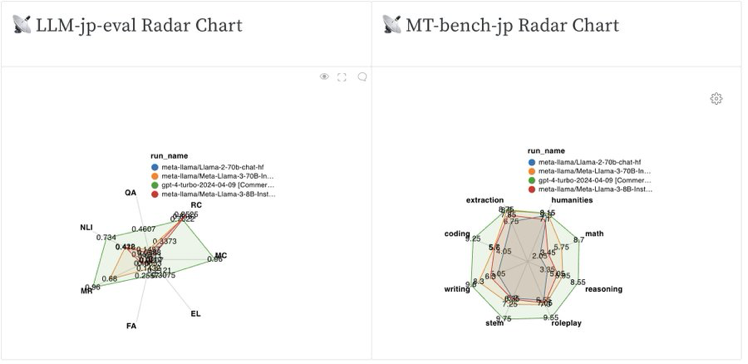 #Article#NLP#LanguageModel
#Article#NLP#LanguageModel
Issue Date: 2024-04-10 Mixtral-8x22B-v0.1, 2024 CommentApache-2.0ライセンス, 日本語非対応 ... #Article#NLP#LanguageModel#ProprietaryLLM
Issue Date: 2024-04-10 Command R+, Cohere, 2024 CommentChatbot arenaでGPT-4-0314と同等の Elo Rate を獲得し(20240410時点)、日本語を含む10ヶ国語をサポート。コンテキストウィンドウサイズ128k。商用利用はAPIから、研究目的であればHuggingFaceから利用可能。 ...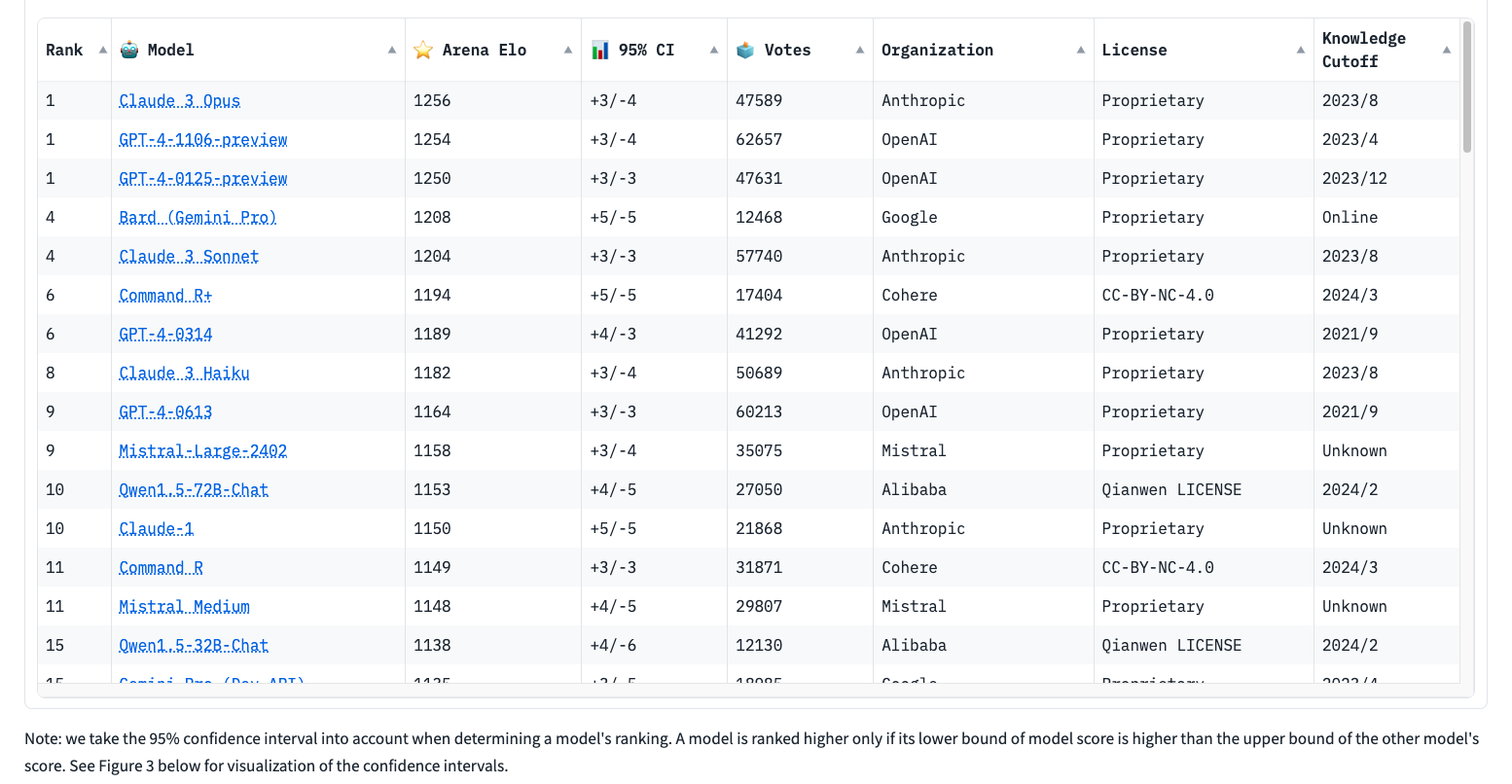 #Article#NLP#LanguageModel
#Article#NLP#LanguageModel
Issue Date: 2024-04-08 Gemma: Open Models Based on Gemini Research and Technology, 2024 CommentアーキテクチャはTransformer Decoderを利用。モデルのサイズは2Bと7B。 オリジナルのTransformer Decoderアーキテクチャから、下記改善を実施している: Multi Query Attention #1272 を利用 RoPE Embedding #1Mistral ...
Issue Date: 2024-04-23 Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, Marah Abdin+, N_A, arXiv24 Summaryphi-3-miniは38億パラメータの言語モデルであり、3.3兆トークンで訓練されています。Mixtral 8x7BやGPT-3.5などの大規模モデルに匹敵する総合的なパフォーマンスを持ちながら、スマートフォンにデプロイ可能なサイズです。このモデルは、厳密にフィルタリングされたWebデータと合成データで構成されており、堅牢性、安全性、およびチャット形式に適合しています。また、phi-3-smallとphi-3-mediumというより大規模なモデルも紹介されています。 Comment#1039 の次の次(Phi2.0についてはメモってなかった)。スマホにデプロイできるレベルのサイズで、GPT3.5Turbo程度の性能を実現したらしいLlama2と同じブロックを利用しているため、アーキテクチャはLlama2と共通。 ... #Pocket#NLP#LanguageModel#OpenSource
Issue Date: 2024-03-05 OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, N_A, arXiv24 SummaryLMsの商業的重要性が高まる中、最も強力なモデルは閉鎖されており、その詳細が非公開になっている。そのため、本技術レポートでは、本当にオープンな言語モデルであるOLMoの初回リリースと、言語モデリングの科学を構築し研究するためのフレームワークについて詳細に説明している。OLMoはモデルの重みだけでなく、トレーニングデータ、トレーニングおよび評価コードを含むフレームワーク全体を公開しており、オープンな研究コミュニティを強化し、新しいイノベーションを促進することを目指している。 CommentModel Weightsを公開するだけでなく、training/evaluation codeとそのデータも公開する真にOpenな言語モデル(truly Open Language Model)。AllenAI ... #Pocket#NLP#LanguageModel
Issue Date: 2024-01-09 Mixtral of Experts, Albert Q. Jiang+, N_A, arXiv24 SummaryMixtralは、Sparse Mixture of Experts(SMoE)言語モデルであり、各レイヤーが8つのフィードフォワードブロックで構成されています。Mixtralは、トークンごとに2つのエキスパートを選択し、それらの出力を組み合わせます。Mixtralは、Llama 2 70BとGPT-3.5を上回る性能を持ち、数学、コード生成、多言語のベンチマークで特に優れています。また、Mixtral 8x7B Instructという指示に従うモデルも提供されており、人間のベンチマークを凌駕しています。 CommentMixture of experts Layer: inputを受け取ったrouterが、8つのexpertsのうち2つを選択し順伝搬。2つのexpertsのoutputを加重平均することで最終的なoutputとする。#ReinforcementLearning#Reasoning#SmallModel#GRPO
Issue Date: 2025-05-01 Phi-4-reasoning Technical Report, 2025.04 Comment元ポスト:https://x.com/dimitrispapail/status/1917731614899028190?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこちらの解説が非常によくまとまっている:https://x.com/_philschmid/status/1918216 ... #Article#NLP#LanguageModel#Alignment#Supervised-FineTuning (SFT)#ReinforcementLearning#InstructionTuning#Article#LongSequence#MultiLingual#MoE(Mixture-of-Experts)#PostTraining
Issue Date: 2025-04-29 Qwen3, Qwen Team, 2025.04 Comment119言語をサポートMoEモデル #1911 30B-A3B / 235B-A22N 128K context window Qwen2.5はMoEを採用していないので新たなアーキテクチャとなるDenseモデル(非MoEモデル)も公開BestPracticeに関するポスト:http ... #Article#ComputerVision#Pocket#NLP#LLMAgent#MulltiModal#Article#Reasoning#x-Use
Issue Date: 2025-04-18 Introducing UI-TARS-1.5, ByteDance, 2025.04 Commentpaper:https://arxiv.org/abs/2501.12326色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)関連#1794元 ... #Article#NLP#LanguageModel#Reasoning
Issue Date: 2025-04-12 Seed-Thinking-v1.5, ByteDance, 2025.04 CommentDeepSeek-R1を多くのベンチで上回る200B, 20B activated paramのreasoning model最近のテキストのOpenWeightLLMはAlibaba, DeepSeek, ByteDance, Nvidiaの4強という感じかな…?(そのうちOpenAIがオープンに ... #Article#NLP#LanguageModel#Alignment#Supervised-FineTuning (SFT)#ReinforcementLearning#InstructionTuning#Pruning#Reasoning
Issue Date: 2025-04-08 Llama-3_1-Nemotron-Ultra-253B-v1, Nvidia, 2025.04 CommentDeepSeek-R1をGPQA Diamond #1155, AIME2024/2025, Llama4 MaverickをBFCLv2(Tool Calling, #1875), IFEVal #1137 で上回り, そのほかはArenaHardを除きDeepSeekR1と同等 ... #Article#Survey#NLP#Dataset#LanguageModel#Evaluation#Repository#Japanese#OpenSource
Issue Date: 2024-12-02 日本語LLMまとめ, LLM-jp, 2024.12 CommentLLM-jpによる日本語LLM(Encoder-Decoder系, BERT系, Bi-Encoders, Cross-Encodersを含む)のまとめ。テキスト生成に使うモデル、入力テキスト処理に使うモデル、Embedding作成に特化したモデル、視覚言語モデル、音声言語モデル、日本語LLM評価 ... #Article#Pretraining#NLP#LanguageModel#Japanese
Issue Date: 2024-11-25 Sarashina2-8x70Bの公開, SB Intuitions, 2024.11 CommentMoE Layerの説明、Sparse Upcyclingの説明、MoEモデルを学習する際に、学習時の学習率の設定が大きすぎると初期に損失が増大し、小さすぎると損失の増大は防げるがlong runで学習した際の性能向上が小さかったこと、元のモデルのパラメータを毀損しないように、Upcyclingをし ... #Article#Survey#NLP#LanguageModel#Article#OpenSource
Issue Date: 2024-11-15 ローカルLLMのリリース年表, npaka, 随時更新, 2024.11 CommentローカルLLMを含むOpenLLMのリリース日が年表としてまとまっており、随時更新されている模様。すごい。 ... #Article#NLP#LanguageModel#Japanese
Issue Date: 2024-11-09 sarashina2-8x70B, SBIntuitions, 2024.11 Commentプレスリリース:https://www.sbintuitions.co.jp/news/press/20241108_01/商用利用不可な点には注意アーキテクチャは70Bモデルx8のMixture of Experts(MoE)モデルカードによると、inferenceにはBF16で、A100 80G ... #Article#NLP#MultiLingual
Issue Date: 2024-10-24 Aya Expanse, Cohere, 2024.10 CommentCohereによるマルチリンガルLLM, 8B, 32Bのモデルが存在する。8BモデルのArenaHardでの評価 ... #Article#NLP
Issue Date: 2024-10-17 Llama-3.1-Nemotron-70B-Instruct, Nvidia, 2024.10 Commentpaper:https://arxiv.org/abs/2410.01257MTBench, Arena HardでGPT4o-20240513,Claude-3.5-sonnet-20240620をoutperform。Response lengthの平均が長いこと模様なので、そもそも同じInputなのでfair comparisonですよ、という話に仮になるのだとしたら、そもそもどういう設定で比較実験 ... #Article#Analysis#LanguageModel#Slide#Japanese
Issue Date: 2024-09-03 LLMに日本語テキストを学習させる意義, Koshiro Saito+, 第261回自然言語処理研究発表会, 2024.08 Comment英日翻訳や日本特有の知識を問われるようなQAにおいて、日本語データによる学習の効果があることが示唆されている模様。たとえば、#1359 に示されている通り、Llama2における日本語データの割合は0.2%とかなので、英語圏のOpenLLMにおいて、日本語データの比率がどれだけ少ないかがわかる。 ... #Article#Tutorial#NLP#LanguageModel#Slide
Issue Date: 2024-08-26 論文紹介 _ The Llama 3 Herd of Models, 2024.08 CommentLlama3の事前学習や事後学習のノウハウが詰まっており(安全性なども含む)、LLM学習に必要な要素が図解されており、非常に分かりやすい。 たとえば下記図(スライド中より引用)などは、LLMの学習過程を説明する際にわかりやすそう  is the latest in Microsoft's family of Small Language Models ... #Article#NLP#Quantization
Issue Date: 2024-08-20 4-bit Llama 3.1, NeuralMagic, 2024.08 #Article#EfficiencyImprovement#Library#Article#LLMServing
Issue Date: 2024-08-05 DeepSpeed, vLLM, CTranslate2 で rinna 3.6b の生成速度を比較する, 2024.06 Comment[vllm](https://github.com/vllm-project/vllm)を使うのが一番お手軽で、inference速度が速そう。PagedAttentionと呼ばれるキャッシュを利用して高速化しているっぽい。 (図はブログ中より引用)  。モデルは商用利用可能なA ... #Article#NLP#LanguageModel
Issue Date: 2024-07-03 Llama 3 Swallow #Article#NLP#LanguageModel
Issue Date: 2024-04-18 LLaMA3, Apr, 2024 Commentライセンスによると、LLaMA3を利用したモデルはどんな場合でもLlama3をprefixとして付与しないといけないらしい元ツイート:https://x.com/gneubig/status/1781083579273089442?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLaMA ...
Issue Date: 2024-04-10 Mixtral-8x22B-v0.1, 2024 CommentApache-2.0ライセンス, 日本語非対応 ... #Article#NLP#LanguageModel#ProprietaryLLM
Issue Date: 2024-04-10 Command R+, Cohere, 2024 CommentChatbot arenaでGPT-4-0314と同等の Elo Rate を獲得し(20240410時点)、日本語を含む10ヶ国語をサポート。コンテキストウィンドウサイズ128k。商用利用はAPIから、研究目的であればHuggingFaceから利用可能。 ...
Issue Date: 2024-04-08 Gemma: Open Models Based on Gemini Research and Technology, 2024 CommentアーキテクチャはTransformer Decoderを利用。モデルのサイズは2Bと7B。 オリジナルのTransformer Decoderアーキテクチャから、下記改善を実施している: Multi Query Attention #1272 を利用 RoPE Embedding #1Mistral ...