
Prompting
[Paper Note] Steered LLM Activations are Non-Surjective, Aayush Mishra+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Safety #Selected Papers/Blogs #reading #One-Line Notes #Steering #Interpretability #Reading Reflections #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- アクティベーション・ステアリングは、モデルの活性化を調整し、その挙動に変化を与える手法であり、解釈可能性や安全性研究で広く利用されている。しかし、任意のテキストプロンプトによってこの挙動が実現可能かは不明である。本研究では、この問題を全射的な観点から考察し、すべてのステアされた活性化が前像を持つかを調査する。実証的結果から、活性化ステアリングは任意のプロンプトによって同じ内部挙動を再現できないことを示し、ホワイトボックス的なステアリングとブラックボックス的なプロンプティングの違いを明確にする評価プロトコルを提案する。 Comment
元ポスト:
steeringされたactivationを自然に生み出すプロンプトは存在しない。言い換えると、steeringによって得られる挙動はpromptでは再現できない。これにより以下が示唆される:
- prompt levelのbehaviorとactivation/weightに介入することによるbehaviorの変化は、根源的に異なる現象なので分けて考えなければならない
- white-boxなstteering手法によってjailbreakができたとしても、black-boxな手法(e.g., promptingによる脆弱性など)による脆弱性があることの証拠にはならない
Steeringされたactivationは下記のようなAutoencoderを学習することでverbalizeできるのだろうか?hidden_stateのreconstruction lossを通じてverbalizeするためできそうではある。元々のactivationがpromptによって到達不可能な点にいたときに、promptによって到達不能なだけであって内部のネットワークが状態を解釈できないというわけではないので(ここがめちゃめちゃなら何も学習できないということになるがそうではなさそうなので)普通にできそうではある:
- Natural Language Autoencoders: Turning Claude’s thoughts into text, Anthropic, 2026.05
[Paper Note] String Seed of Thought: Prompting LLMs for Distribution-Faithful and Diverse Generation, Kou Misaki+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Bias #ICLR #Test-Time Scaling #Diversity #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-21 GPT Summary- String Seed of Thought(SSoT)という新しいプロンプティング手法を提案し、Probabilistic Instruction Following(PIF)のパフォーマンスを改善します。PIFは選択肢を確率に基づいて選ぶタスクですが、LLMはしばしば非決定論的な挙動が要求される場面で偏りを生じることがあります。SSoTは、まずLLMにランダムな文字列を生成させ、これを操作することで多様性を維持しつつ制約を遵守した答えを導く手法です。実験により、SSoTがPIFの改善に寄与し、応答の多様性を高めることを示しました。 Comment
openreview: https://openreview.net/forum?id=luXtbX1lVK
元ポスト:
LLMが内包するバイアスを抑制し、出力の多様性を高めるPrompting手法っぽい。興味深い。
ランダムな文字列を生成させてから、その文字列を操作させて出力を得るようなアプローチとのこと。
著者ポスト:
-
-
[Paper Note] WildDet3D: Scaling Promptable 3D Detection in the Wild, Weikai Huang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Dataset #Transformer #Architecture #read-later #Selected Papers/Blogs #3D (Scene) #ObjectDetection #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-17 GPT Summary- 単一画像から3D物体を検出するために、WildDet3Dという統一的幾何認識アーキテクチャを提案。テキスト・点・ボックスのプロンプトを受け入れ、深度信号を組み込む。新しいオープン3DデータセットWildDet3D-Dataを生成し、13,500カテゴリの100万枚以上の画像を提供。複数のベンチマークで最先端の性能を達成し、特に深度手掛かりの活用により、平均+20.7 APの向上を実現。 Comment
pj page: https://allenai.github.io/WildDet3D/
元ポスト:
最大級の3D detection data+アーキテクチャの提案
training codeなどがリリース:
https://github.com/allenai/WildDet3D
[Paper Note] Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity, Jiayi Zhang+, ICML'26 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ICML #Diversity #Selected Papers/Blogs Issue Date: 2025-12-13 GPT Summary- ポストトレーニングアライメントによるモード崩壊の原因を、好みデータにおける典型性バイアスに特定。これを基に「Verbalized Sampling(VS)」というプロンプティング戦略を提案し、モデルに応答の確率分布を言語化させる。実験により、VSが創造的執筆や対話シミュレーションなどで多様性を1.6〜2.1倍向上させることを示し、特に能力の高いモデルがより恩恵を受ける傾向が確認された。研究はモード崩壊に対する新たな視点を提供し、生成的多様性を解放する実用的な解決策を提示。 Comment
元ポスト:
preference dataに内在するtypicality bias(=人間が特定の応答を好む傾向)が、post trainingのalignmentフェーズにおいて増長されてモデルがモード崩壊を起こす(=特定の人間が典型的に好む応答のみを答えるようにalignされることで、出力の多様性が損なわれる)ことを明らかにし、「複数の出力と出力ごとの確率を出力させる」ようなpromptingによって、モデルが学習している確率分布そのものをverbalizeさせることで出力の多様性を引き出す、という話に見える。
pj page:
https://www.verbalized-sampling.com
コピペ可能なmagic promptが記載されている。test-time scalingと相性が良さそうである。
[Paper Note] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, Lakshya A Agrawal+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #AutomaticPromptEngineering #ICLR #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-07-29 GPT Summary- GEPA(Genetic-Pareto)は、LLMsのプロンプト最適化手法であり、自然言語を用いて試行錯誤から高レベルのルールを学習する。これにより、数回のロールアウトで品質向上が可能となり、GRPOを平均10%、最大20%上回る結果を示した。GEPAは、主要なプロンプト最適化手法MIPROv2をも超える性能を発揮し、コード最適化にも有望な結果を示している。 Comment
元ポスト:
openreview:
https://openreview.net/forum?id=RQm2KQTM5r
alpharxiv:
https://www.alphaxiv.org/overview/2507.19457v1
自動的なプロンプトエンジニアリングでGRPOを上回れるのであれば、downstreamタスクにLLMを適用したい場合に、手元にデータがあるのであれば、強めのGPUマシンがなくても非常に汎用性が高い手法となるので重要研究に見える。
[Paper Note] SAM 2: Segment Anything in Images and Videos, Nikhila Ravi+, ICLR'25, 2024.08
Paper/Blog Link My Issue
#ComputerVision #Transformer #ImageSegmentation #FoundationModel #2D (Image) #3D (Video) Issue Date: 2025-11-09 GPT Summary- Segment Anything Model 2(SAM 2)は、プロンプト可能な視覚セグメンテーションのための基盤モデルで、ユーザーのインタラクションを通じてデータを改善するデータエンジンを構築し、最大の動画セグメンテーションデータセットを収集。シンプルなトランスフォーマーアーキテクチャを用い、リアルタイム動画処理に対応。SAM 2は、動画セグメンテーションで従来の手法より3倍少ないインタラクションで高精度を達成し、画像セグメンテーションでも従来モデルより精度が高く、6倍速い。データ、モデル、コード、デモを公開し、関連タスクの重要なマイルストーンを目指す。 Comment
openreview: https://openreview.net/forum?id=Ha6RTeWMd0
SAMはこちら:
- [Paper Note] Segment Anything, Alexander Kirillov+, arXiv'23, 2023.04
[Paper Note] Training-Free Group Relative Policy Optimization, Yuzheng Cai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #AutomaticPromptEngineering #One-Line Notes Issue Date: 2025-10-29 GPT Summary- 最近のLLMエージェントは一般的な能力を示すが、専門的なドメインでのパフォーマンスは外部ツールとの統合に課題がある。従来の強化学習手法はコストがかかるが、我々は経験的知識を用いて出力分布を改善できると主張する。これを実現するために、Training-Free GRPOを提案し、パラメータ更新なしでLLMの性能を向上させる。実験により、Training-Free GRPOが少数のトレーニングサンプルでファインチューニングされた小型LLMを上回ることを示した。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=tyUnYbE7Gi
openreviewのweaknessにtraining free, GRPOといった用語が利用されているが、parameterの更新からcontextの更新という方向性にシフトするというアイデアであると考えられるため、automatic prompt engineering、in-context learning等に該当するのでは、という指摘がある。
また、実験結果のベースモデルが揃っていないので、公平な比較になっておらず、追加の検証が必要という指摘もある。
[Paper Note] Multimodal Prompt Optimization: Why Not Leverage Multiple Modalities for MLLMs, Yumin Choi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #AutomaticPromptEngineering Issue Date: 2025-10-14 GPT Summary- マルチモーダルプロンプト最適化(MPO)を提案し、テキストと非テキストのプロンプトを共同最適化する新たなアプローチを示す。MPOは、ベイズに基づく選択戦略を用いて候補プロンプトを選定し、画像や動画など多様なモダリティにおいてテキスト専用手法を上回る性能を発揮。これにより、MLLMsの潜在能力を最大限に引き出す重要なステップを確立。 Comment
元ポスト:
[Paper Note] MK2 at PBIG Competition: A Prompt Generation Solution, Xu+, IJCAI WS AgentScen'25, 2025.08
Paper/Blog Link My Issue
#NLP #AIAgents #Planning #Reasoning #IJCAI #Workshop #IdeaGeneration Issue Date: 2025-08-30 Comment
元ポスト:
Patentからmarket-readyなプロダクトのコンセプトを生成し評価するタスク(PBIG)に取り組んでいる。
Reasoningモデルはコストとレスポンスの遅さから利用せず(iterationを重ねることを重視)、LLMのアシストを受けながらpromptを何度もhuman in the loopでiterationしながら品質を高めていくアプローチをとり、リーダーボードで1st placeを獲得した模様。
[Paper Note] Prompt Orchestration Markup Language, Yuge Zhang+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #read-later Issue Date: 2025-08-22 GPT Summary- POML(プロンプトオーケストレーションマークアップ言語)を導入し、LLMsのプロンプトにおける構造、データ統合、フォーマット感受性の課題に対処。コンポーネントベースのマークアップやCSSスタイリングシステムを採用し、動的プロンプトのテンプレート機能や開発者ツールキットを提供。POMLの有効性を2つのケーススタディで検証し、実際の開発シナリオでの効果を評価。 Comment
pj page: https://microsoft.github.io/poml/latest/
元ポスト:
これは非常に興味深い
[Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Outstanding Paper
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ACL #read-later #reading #MajorityVoting Issue Date: 2025-08-03 GPT Summary- 本研究では、LLMのテスト時の計算スケーリングにおけるプロンプト戦略の効果を調査。6つのLLMと8つのプロンプト戦略を用いた実験により、複雑なプロンプト戦略が単純なChain-of-Thoughtに劣ることを示し、理論的な証明を提供。さらに、スケーリング性能を予測し最適なプロンプト戦略を特定する手法を提案し、リソース集約的な推論プロセスの必要性を排除。複雑なプロンプトの再評価と単純なプロンプト戦略の潜在能力を引き出すことで、テスト時のスケーリング性能向上に寄与することを目指す。 Comment
non-thinkingモデルにおいて、Majority Voting (i.e. Self Consistency)によるtest-time scalingを実施する場合のさまざまなprompting戦略のうち、budgetとサンプリング数が小さい場合はCoT以外の適切なprompting戦略はモデルごとに異なるが、budgetやサンプリング数が増えてくるとシンプルなCoT(実験ではzeroshot CoTを利用)が最適なprompting戦略として支配的になる、という話な模様。
さらに、なぜそうなるかの理論的な分析と最適な与えられた予算から最適なprompting戦略を予測する手法も提案している模様。
が、評価データの難易度などによってこの辺は変わると思われ、特にFigure39に示されているような、**サンプリング数が増えると簡単な問題の正解率が上がり、逆に難しい問題の正解率が下がるといった傾向があり、CoTが簡単な問題にサンプリング数を増やすと安定して正解できるから支配的になる**、という話だと思われるので、常にCoTが良いと勘違いしない方が良さそうだと思われる。たとえば、**解こうとしているタスクが難問ばかりであればCoTでスケーリングするのが良いとは限らない、といった点には注意が必要**だと思うので、しっかり全文読んだ方が良い。時間がある時に読みたい(なかなかまとまった時間取れない)
最適なprompting戦略を予測する手法では、
- 問題の難易度に応じて適応的にスケールを変化させ(なんとO(1)で予測ができる)
- 動的に最適なprompting戦略を選択
することで、Majority@10のAcc.を8Bスケールのモデルで10--50%程度向上させることができる模様。いやこれほんとしっかり読まねば。
[Paper Note] AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders, Zhengxuan Wu+, ICLR'25 Spotlight
Paper/Blog Link My Issue
#Controllable #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #Evaluation #ICLR #read-later #ActivationSteering/ITI #Selected Papers/Blogs #InstructionFollowingCapability #Steering Issue Date: 2025-08-02 GPT Summary- 言語モデルの出力制御は安全性と信頼性に重要であり、プロンプトやファインチューニングが一般的に用いられるが、さまざまな表現ベースの技術も提案されている。これらの手法を比較するためのベンチマークAxBenchを導入し、Gemma-2-2Bおよび9Bに関する実験を行った。結果、プロンプトが最も効果的で、次いでファインチューニングが続いた。概念検出では表現ベースの手法が優れており、SAEは競争力がなかった。新たに提案した弱教師あり表現手法ReFT-r1は、競争力を持ちながら解釈可能性を提供する。AxBenchとともに、ReFT-r1およびDiffMeanのための特徴辞書を公開した。 Comment
openreview: https://openreview.net/forum?id=K2CckZjNy0
[Paper Note] Do We Need a Detailed Rubric for Automated Essay Scoring using Large Language Models?, Lui Yoshida, AIED'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AES(AutomatedEssayScoring) #AIED Issue Date: 2025-07-29 GPT Summary- 本研究では、LLMを用いた自動エッセイ採点におけるルーブリックの詳細さが採点精度に与える影響を調査。TOEFL11データセットを用いて、完全なルーブリック、簡略化されたルーブリック、ルーブリックなしの3条件を比較。結果、3つのモデルは簡略化されたルーブリックでも精度を維持し、トークン使用量を削減。一方、1つのモデルは詳細なルーブリックで性能が低下。簡略化されたルーブリックが多くのLLMにとって効率的な代替手段であることが示唆されるが、モデルごとの評価も重要。
[Paper Note] EduThink4AI: Translating Educational Critical Thinking into Multi-Agent LLM Systems, Xinmeng Hou+, arXiv'25
Paper/Blog Link My Issue
#Multi #NLP #AIAgents Issue Date: 2025-07-29 GPT Summary- EDU-Promptingは、教育的批判的思考理論とLLMエージェント設計を結びつけ、批判的でバイアスを意識した説明を生成する新しいマルチエージェントフレームワーク。これにより、AI生成の教育的応答の真実性と論理的妥当性が向上し、既存の教育アプリケーションに統合可能。 Comment
元ポスト:
Critiqueを活用したマルチエージェントのようである(具体的なCritiqueの生成方法については読めていない。その辺が重要そう
[Paper Note] Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation, Genki Kusano+, RecSys'25
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #Evaluation #RecSys #Reproducibility #KeyPoint Notes Issue Date: 2025-07-21 GPT Summary- LLMを用いた単一ユーザー設定の推薦タスクにおいて、プロンプトエンジニアリングが重要であることを示す。23種類のプロンプトタイプを比較した結果、コスト効率の良いLLMでは指示の言い換え、背景知識の考慮、推論プロセスの明確化が効果的であり、高性能なLLMではシンプルなプロンプトが優れることが分かった。精度とコストのバランスに基づくプロンプトとLLMの選択に関する提案を行う。 Comment
元ポスト:
RecSysにおける網羅的なpromptingの実験。非常に興味深い
実験で利用されたPrompting手法と相対的な改善幅
RePhrase,StepBack,Explain,Summalize-User,Recency-Focusedが、様々なモデル、データセット、ユーザの特性(Light, Heavy)において安定した性能を示しており(少なくともベースラインからの性能の劣化がない)、model agnosticに安定した性能を発揮できるpromptingが存在することが明らかになった。一方、Phi-4, nova-liteについてはBaselineから有意に性能が改善したPromptingはなかった。これはモデルは他のモデルよりもそもそもの予測性能が低く、複雑なinstructionを理解する能力が不足しているため、Promptデザインが与える影響が小さいことが示唆される。
特定のモデルでのみ良い性能を発揮するPromptingも存在した。たとえばRe-Reading, Echoは、Llama3.3-70Bでは性能が改善したが、gpt-4.1-mini, gpt-4o-miniでは性能が悪化した。ReActはgpt-4.1-miniとLlamd3.3-70Bで最高性能を達成したが、gpt-4o-miniでは最も性能が悪かった。
NLPにおいて一般的に利用されるprompting、RolePlay, Mock, Plan-Solve, DeepBreath, Emotion, Step-by-Stepなどは、推薦のAcc.を改善しなかった。このことより、ユーザの嗜好を捉えることが重要なランキングタスクにおいては、これらプロンプトが有効でないことが示唆される。
続いて、LLMやデータセットに関わらず高い性能を発揮するpromptingをlinear mixed-effects model(ランダム効果として、ユーザ、LLM、メトリックを導入し、これらを制御する項を線形回帰に導入。promptingを固定効果としAccに対する寄与をfittingし、多様な状況で高い性能を発揮するPromptを明らかにする)によって分析した結果、ReAct, Rephrase, Step-Backが有意に全てのデータセット、LLMにおいて高い性能を示すことが明らかになった。
[Paper Note] REST: Stress Testing Large Reasoning Models by Asking Multiple Problems at Once, Zhuoshi Pan+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reasoning #Batch Issue Date: 2025-07-16 GPT Summary- RESTという新しい評価フレームワークを提案し、LRMsを同時に複数の問題にさらすことで、実世界の推論能力を評価。従来のベンチマークの限界を克服し、文脈優先配分や問題間干渉耐性を測定。DeepSeek-R1などの最先端モデルでもストレステスト下で性能低下が見られ、RESTはモデル間の性能差を明らかにする。特に「考えすぎの罠」が性能低下の要因であり、「long2short」技術で訓練されたモデルが優れた結果を示すことが確認された。RESTはコスト効率が高く、実世界の要求に適した評価手法である。 Comment
元ポスト:
[Paper Note] Perspective Transition of Large Language Models for Solving Subjective Tasks, Xiaolong Wang+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #ACL #Findings #One-Line Notes #Initial Impression Notes Issue Date: 2025-01-25 GPT Summary- 視点遷移を通じた推論(RPT)手法により、LLMsが主観的タスクにおいて視点を動的に選択できるようにします。本手法は専門家や第三者の視点を活用し、文脈をより適切に解釈することで、ニュアンスのある回答を提供します。広範な実験により、従来の固定視点手法を大きく上回る成果を示しました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=cFGPlRony5
"Subjective Task"とは例えば「メタファーの認識」や「ダークユーモアの検知」などがあり、これらは定量化しづらい認知的なコンテキストや、ニュアンスや感情などが強く関連しており、現状のLLMではチャレンジングだと主張している。
Subjective Taskでは、Reasoningモデルのように自動的にCoTのpathwayを決めるのは困難で、手動でpathwayを記述するのはチャレンジングで一貫性を欠くとした上で、複数の視点を組み合わせたPrompting(direct perspective, role-perspective, third-person perspectivfe)を実施し、最もConfidenceの高いanswerを採用することでこの課題に対処すると主張している。
イントロしか読めていないが、自動的にCoTのpathwayを決めるのも手動で決めるのも難しいという風にイントロで記述されているが、手法自体が最終的に3つの視点から回答を生成させるという枠組みに則っている(つまりSubjective Taskを解くための形式化できているので、自動的な手法でもできてしまうのではないか?と感じた)ので、イントロで記述されている主張の”難しさ”が薄れてしまっているかも・・・?と感じた。論文が解こうとしている課題の”難しさ”をサポートする材料がもっとあった方がよりmotivationが分かりやすくなるかもしれない、という感想を持った。
[Paper Note] Logic-of-Thought: Injecting Logic into Contexts for Full Reasoning in Large Language Models, Tongxuan Liu+, NAACL'25, 2024.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #NAACL #Initial Impression Notes Issue Date: 2024-09-29 GPT Summary- LLMの論理推論能力は依然として課題が残る。Chain-of-Thoughtなどの手法は改善をもたらすが、信頼性に問題がある。そこで、命題論理を利用したLogic-of-Thought(LoT)プロンプトを提案し、論理情報を強化することで推論能力を向上させる。実験では、LoTが多数の論理推論タスクで既存手法の性能を大幅に向上させることを示し、特にReClorおよびRuleTakerデータセットでの改善が顕著であった。 Comment
※ このメモは当初の原稿に対するものであり、NAACLの原稿では修正されている。
SNSで話題になっているようだがGPT-3.5-TurboとGPT-4でしか比較していない上に、いつの時点のモデルかも記述されていないので、unreliableに見える
ReClorデータセットで性能が向上しているのは個人的に興味深い。
[Paper Note] Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting, Melanie Sclar+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Evaluation #OpenWeight #ICLR #Selected Papers/Blogs Issue Date: 2026-01-21 GPT Summary- LLMの性能特性化が重要であり、プロンプト設計がモデル挙動に強く影響することを示す。特に、プロンプトフォーマットに対するLLMの感度に注目し、微妙な変更で最大76ポイントの性能差が見られる。感度はモデルサイズや少数ショットの数に依存せず、プロンプトの多様なフォーマットにわたる性能範囲の報告が必要。モデル間のフォーマットパフォーマンスが弱く相関することから、固定されたプロンプトフォーマットでの比較の妥当性が疑問視される。迅速なフォーマット評価のための「FormatSpread」アルゴリズムを提案し、摂動の影響や内部表現も探る。 Comment
openreview: https://openreview.net/forum?id=RIu5lyNXjT
[Paper Note] Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models, Mosh Levy+, ACL'24, 2024.02
Paper/Blog Link My Issue
#Analysis #NLP #ACL #Length Issue Date: 2025-10-02 GPT Summary- 本研究では、入力長の拡張が大規模言語モデル(LLMs)の性能に与える影響を評価する新しいQA推論フレームワークを提案。異なる長さやタイプのパディングを用いて、LLMsの推論性能が短い入力長で著しく低下することを示した。さらに、次の単語予測がLLMsの性能と負の相関を持つことを明らかにし、LLMsの限界に対処するための戦略を示唆する失敗モードを特定した。
[Paper Note] Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing, Xinyu Hu+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #AutomaticPromptEngineering #ICLR Issue Date: 2025-09-24 GPT Summary- Evokeという自動プロンプト洗練フレームワークを提案。レビュアーと著者のLLMがフィードバックループを形成し、プロンプトを洗練。難しいサンプルを選択することで、LLMの深い理解を促進。実験では、Evokeが論理的誤謬検出タスクで80以上のスコアを達成し、他の手法を大幅に上回る結果を示した。 Comment
openreview: https://openreview.net/forum?id=OXv0zQ1umU
pj page:
https://sites.google.com/view/evoke-llms/home
github:
https://github.com/microsoft/Evoke
githubにリポジトリはあるが、プロンプトテンプレートが書かれたtsvファイルが配置されているだけで、実験を再現するための全体のパイプラインは存在しないように見える。
[Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Zero/Few/ManyShotPrompting #In-ContextLearning #NeurIPS Issue Date: 2025-09-01 GPT Summary- 大規模言語モデル(LLMs)は、少数ショットから多くのショットのインコンテキスト学習(ICL)において顕著な性能向上を示す。新たな設定として、モデル生成の思考過程を用いる強化されたICLと、ドメイン特有の質問のみを用いる無監督ICLを提案。これらは特に複雑な推論タスクに効果的であり、多くのショット学習は事前学習のバイアスを覆し、ファインチューニングと同等の性能を発揮することが示された。また、推論コストは線形に増加し、最前線のLLMsは多くのショットのICLから恩恵を受けることが確認された。 Comment
many-shotを提案
[Paper Note] As Generative Models Improve, People Adapt Their Prompts, Eaman Jahani+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #Analysis Issue Date: 2025-08-25 GPT Summary- オンライン実験で1893人の参加者を対象に、DALL-E 2とDALL-E 3のプロンプトの重要性の変化を調査。DALL-E 3を使用した参加者は、DALL-E 2よりも高いパフォーマンスを示し、これは技術的能力の向上とプロンプトの質の変化によるもの。特に、DALL-E 3の参加者はより長く、意味的に類似したプロンプトを作成。プロンプト修正機能を持つDALL-E 3はさらに高いパフォーマンスを示したが、その利点は減少。結果として、モデルの進化に伴い、プロンプトも適応されることが示唆される。 Comment
元ポスト:
[Paper Note] Visual Prompting in Multimodal Large Language Models: A Survey, Junda Wu+, arXiv'24
Paper/Blog Link My Issue
#Survey #ComputerVision #NLP #VisionLanguageModel Issue Date: 2025-08-07 GPT Summary- 本論文は、マルチモーダル大規模言語モデル(MLLMs)における視覚的プロンプト手法の包括的な調査を行い、視覚的プロンプトの生成や構成的推論、プロンプト学習に焦点を当てています。既存の視覚プロンプトを分類し、自動プロンプト注釈の生成手法を議論。視覚エンコーダとバックボーンLLMの整合性を向上させる手法や、モデル訓練と文脈内学習による視覚的プロンプトの理解向上についても述べています。最後に、MLLMsにおける視覚的プロンプト手法の未来に関するビジョンを提示します。
[Paper Note] The Impact of Example Selection in Few-Shot Prompting on Automated Essay Scoring Using GPT Models, Lui Yoshida, AIED'24
Paper/Blog Link My Issue
#NLP #LanguageModel #AES(AutomatedEssayScoring) #AIED Issue Date: 2025-07-29 GPT Summary- 本研究では、GPTモデルを用いた少数ショットプロンプティングにおける例の選択が自動エッセイ採点(AES)のパフォーマンスに与える影響を調査。119のプロンプトを用いて、GPT-3.5とGPT-4のモデル間でのスコア一致を二次重み付きカッパ(QWK)で測定。結果、例の選択がモデルによって異なる影響を及ぼし、特にGPT-3.5はバイアスの影響を受けやすいことが判明。慎重な例の選択により、GPT-3.5が一部のGPT-4モデルを上回る可能性があるが、GPT-4は最も高い安定性とパフォーマンスを示す。これにより、AESにおける例の選択の重要性とモデルごとのパフォーマンス評価の必要性が強調される。
[Paper Note] PromptWizard: Task-Aware Prompt Optimization Framework, Eshaan Agarwal+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #AutomaticPromptEngineering #One-Line Notes Issue Date: 2025-02-10 GPT Summary- 大規模言語モデル(LLMs)の効果的な活用に向けて、完全自動化されたプロンプト最適化フレームワーク「PromptWizard」を提案。自己進化・自己適応機能に基づき、プロンプトと文脈内例を反復的に洗練し、優れた品質のプロンプトを生成。45のタスクで高性能を示し、限られたデータや小規模モデルでも適用可能。コスト分析により効率性と優位性が確認される。 Comment
Github:
https://github.com/microsoft/PromptWizard?tab=readme-ov-file
元ポスト:
初期に提案された
- Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
と比較すると大分性能が上がってきているように見える。
reasoning modelではfewshot promptingをすると性能が落ちるという知見があるので、reasoningモデル向けのAPE手法もそのうち出現するのだろう(既にありそう)。
OpenReview:
https://openreview.net/forum?id=VZC9aJoI6a
ICLR'25にrejectされている
[Paper Note] Does Prompt Formatting Have Any Impact on LLM Performance?, Jia He+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reading Reflections Issue Date: 2024-11-27 GPT Summary- プロンプト最適化はLLMの性能に重要であり、異なるプロンプトテンプレートがモデルの性能に与える影響を調査。実験では、GPT-3.5-turboがプロンプトテンプレートによってコード翻訳タスクで最大40%変動する一方、GPT-4はより堅牢であることが示された。これにより、固定プロンプトテンプレートの再考が必要であることが強調された。 Comment
(以下、個人の感想です)
本文のみ斜め読みして、Appendixは眺めただけなので的外れなことを言っていたらすみません。
まず、実務上下記知見は有用だと思いました:
- プロンプトのフォーマットによって性能に大きな差がある
- より大きいモデルの方がプロンプトフォーマットに対してロバスト
ただし、フォーマットによって性能差があるというのは経験的にある程度LLMを触っている人なら分かることだと思うので、驚きは少なかった。
個人的に気になる点は、学習データもモデルのアーキテクチャもパラメータ数も分からないGPT3.5, GPT4のみで実験をして「パラメータサイズが大きい方がロバスト」と結論づけている点と、もう少し深掘りして考察したらもっとおもしろいのにな、と感じる点です。
実務上は有益な知見だとして、では研究として見たときに「なぜそうなるのか?」というところを追求して欲しいなぁ、という感想を持ちました。
たとえば、「パラメータサイズが大きいモデルの方がフォーマットにロバスト」と論文中に書かれているように見えますが、
それは本当にパラメータサイズによるものなのか?学習データに含まれる各フォーマットの割合とか(これは事実はOpenAIの中の人しか分からないので、学習データの情報がある程度オープンになっているOpenLLMでも検証するとか)、評価するタスクとフォーマットの相性とか、色々と考察できる要素があるのではないかと思いました。
その上で、大部分のLLMで普遍的な知見を見出した方が研究としてより面白くなるのではないか、と感じました。
参考: Data2Textにおける数値データのinput formatによる性能差を分析し考察している研究
- [Paper Note] Prompting for Numerical Sequences: A Case Study on Market Comment Generation, Masayuki Kawarada+, arXiv'24, 2024.04
[Paper Note] The Prompt Report: A Systematic Survey of Prompt Engineering Techniques, Sander Schulhoff+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #One-Line Notes Issue Date: 2024-09-02 GPT Summary- 生成型人工知能(GenAI)のプロンプト設計とエンジニアリングについての包括的な総説を提供。プロンプト技術のタクソノミーと適用分析を通じて、体系的理解を確立し、ベストプラクティスを包括的に紹介。33語の語彙表と58のLLMプロンプト技法、さらにChatGPT向けの設計ガイドラインを含む。 Comment
Promptingに関するサーベイ
初期の手法からかなり網羅的に記述されているように見える。
また、誤用されていたり、色々な意味合いで使われてしまっている用語を、きちんと定義している。
たとえば、Few shot LearningとFew shot Promptingの違い、そもそもPromptingの定義、Examplarなど。
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications, Pranab Sahoo+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel Issue Date: 2024-07-30 GPT Summary- プロンプトエンジニアリングは、LLMsやVLMsの能力を拡張するための重要な技術であり、モデルのパラメータを変更せずにタスク固有の指示であるプロンプトを活用してモデルの効果を向上させる。本研究は、プロンプトエンジニアリングの最近の進展について構造化された概要を提供し、各手法の強みと制限について掘り下げることで、この分野をよりよく理解し、将来の研究を促進することを目的としている。 Comment
[Paper Note] RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners, Chi Hu+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #NLP #LanguageModel #Reasoning #COLING #Reranking #Initial Impression Notes #LREC Issue Date: 2024-04-07 GPT Summary- LLMの論理的エラーを解決するために、自己ランク付けを可能にする新手法RankPromptを提案。これは、多様な応答を比較し、LLMの文脈的生成能力を活用する。実験ではChatGPTやGPT-4の性能が最大13%向上し、AlpacaEvalデータセットでは人間の判断との74%の一致率を示した。また、応答の順序や一貫性の変動にも強い耐性を持つことが確認された。RankPromptは高品質なフィードバックを引き出す有効な手法である。 Comment
LLMでランキングをするためのプロンプト手法。独立したプロンプトでスコアリングしスコアリング結果からランキングするのではなく、LLMに対して比較するためのルーブリックやshotを入れ、全てのサンプルを含め、1回のPromptingでランキングを生成するような手法に見える。大量の候補をランキングするのは困難だと思われるが、リランキング手法としては利用できる可能性がある。また、実験などでランキングを実施するサンプル数に対してどれだけ頑健なのかなどは示されているだろうか?
[Paper Note] Prompting for Numerical Sequences: A Case Study on Market Comment Generation, Masayuki Kawarada+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #DataToTextGeneration #NumericReasoning #KeyPoint Notes Issue Date: 2024-04-04 GPT Summary- 大規模言語モデル(LLMs)を用いて時系列の数値データからテキスト生成を行う研究が進展中。特に、株価の数値列を市場コメントに変換する実験では、プログラミング言語に似たフォーマットのプロンプトが効果的であり、自然言語や長文フォーマットは効果が薄いことが明らかに。これにより、数値シーケンスからのテキスト生成におけるプロンプト作成の新たな洞察を得られる。 Comment
Data-to-Text系のタスクでは、しばしば数値列がInputとなり、そこからテキストを生成するが、この際にどのようなフォーマットで数値列をPromptingするのが良いかを調査した研究。Pythonリストなどのプログラミング言語に似たプロンプトが高い性能を示し、自然言語やhtml, latextなどのプロンプトは効果が低かったとのこと
Chain-of-Thought Reasoning Without Prompting, Xuezhi Wang+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #One-Line Notes Issue Date: 2024-03-05 GPT Summary- LLMsの推論能力を向上させるための新しいアプローチに焦点を当てた研究が行われている。この研究では、LLMsがプロンプトなしで効果的に推論できるかどうかを検証し、CoT推論パスをデコーディングプロセスを変更することで引き出す方法を提案している。提案手法は、従来の貪欲なデコーディングではなく、代替トークンを調査することでCoTパスを見つけることができることを示しており、様々な推論ベンチマークで有効性を示している。 Comment
以前にCoTを内部的に自動的に実施されるように事前学習段階で学習する、といった話があったと思うが、この研究はデコーディング方法を変更することで、promptingで明示的にinstructionを実施せずとも、CoTを実現するもの、ということだと思われる。
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models, Wenhao Yu+, N_A, EMNLP'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #RAG(RetrievalAugmentedGeneration) #EMNLP #KeyPoint Notes Issue Date: 2023-11-17 GPT Summary- 検索補完言語モデル(RALM)は、外部の知識源を活用して大規模言語モデルの性能を向上させるが、信頼性の問題や知識の不足による誤った回答がある。そこで、Chain-of-Noting(CoN)という新しいアプローチを導入し、RALMの頑健性を向上させることを目指す。CoNは、順次の読み取りノートを生成し、関連性を評価して最終的な回答を形成する。ChatGPTを使用してCoNをトレーニングし、実験結果はCoNを装備したRALMが標準的なRALMを大幅に上回ることを示している。特に、ノイズの多いドキュメントにおいてEMスコアで平均+7.9の改善を達成し、知識範囲外のリアルタイムの質問に対する拒否率で+10.5の改善を達成している。 Comment
モデルに検索されたドキュメント対するqueryのrelevance/accuracyの観点からnote-takingをさせることで、RAGの正確性や透明性を向上させる。たとえば、
- surface-levelの情報に依存せずにモデルに理解を促す
- 相反する情報が存在してもrelevantな情報を適切に考慮する,
- 回答プロセスの透明性・解釈性を向上させる
- 検索された文書に対する過剰な依存をなくす(文書が古い, あるいはノイジーな場合に有用)
などが利点として挙げられている。
下記が付録中のCoNで実際に利用されているプロンプト。
非常にシンプルな手法だが、結果としてはノイズが多い場合、CoNによるゲインが大きいことがわかる。
Prompt Engineering a Prompt Engineer, Qinyuan Ye+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#NLP #LanguageModel #AutomaticPromptEngineering #ACL #Findings Issue Date: 2023-11-13 GPT Summary- プロンプトエンジニアリングは、LLMsのパフォーマンスを最適化するための重要なタスクであり、本研究ではメタプロンプトを構築して自動的なプロンプトエンジニアリングを行います。改善されたパフォーマンスにつながる推論テンプレートやコンテキストの明示などの要素を導入し、一般的な最適化概念をメタプロンプトに組み込みます。提案手法であるPE2は、さまざまなデータセットやタスクで強力なパフォーマンスを発揮し、以前の自動プロンプトエンジニアリング手法を上回ります。さらに、PE2は意味のあるプロンプト編集を行い、カウンターファクトの推論能力を示します。
[Paper Note] Re-Reading Improves Reasoning in Large Language Models, Xiaohan Xu+, EMNLP'24, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #EMNLP #KeyPoint Notes #Reading Reflections Issue Date: 2023-10-30 GPT Summary- Re2は、質問を再読することでLLMの推論能力を高める簡潔かつ効果的なプロンプティング手法です。これは、入力を二度処理することにより理解を深め、CoTなどの思考誘発型手法とも互換性があります。Re2は単方向デコーダーのLLMに対しても双方向エンコーディングを促進し、広範な推論ベンチマークでその有効性を示しました。結果として、Re2は単純な再読戦略を通じてLLMの推論性能を一貫して向上させることが示され、異なるモデルや手法と効果的に統合可能です。 Comment
問題文を2,3回promptで繰り返すだけで、数学のベンチマークとCommonsenseのベンチマークの性能が向上したという非常に簡単なPrompting。self-consistencyなどの他のPromptingとの併用も可能。
なぜ性能が向上するかというと、
1. LLMはAuporegressiveなモデルであり、bidirectionalなモデルではない。このため、forwardパスのみでは読解力に限界がある。(たとえば人間はしばしばテキストを読み返したりする)。そこで、一度目の読解で概要を理解し、二度目の読解でsalience partを読み込むといったような挙動を実現することで、より問題文に対するComprehensionが向上する。
2. LLMはしばしばpromptの重要な箇所の読解を欠落させてしまう。たとえば、[Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
では、promptのmiddle partを軽視する傾向があることが示されている。このような現象も軽減できると考えられる。
問題文の繰り返しは、3回までは性能が向上する。
このpromptingは複雑な問題であればあるほど効果があると推察される。
本手法はReasoningモデル登場依然のものであり、おそらくReasoningモデルではReasoning tokenの生成を通じて動的にcontextにattentionを貼る(つまり必要な箇所は自然にre-readingされる)ため、re-readingと同等以上の効果を得ていることが推察される。
このため、直感的にはこの手法はnon-thinkingモデルに対しては依然として有効な場合はあるかもしれないが、Reasoningモデルにおいては非推奨だと個人的には考える。
[Paper Note] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #ICML #One-Line Notes Issue Date: 2023-10-12 GPT Summary- Step-Back Promptingは、大規模言語モデル(LLMs)を使用して推論の手順をガイドするシンプルなプロンプティング技術です。この技術により、LLMsは具体的な詳細から高レベルの概念や基本原則を抽象化し、正しい推論経路をたどる能力を向上させることができます。実験により、Step-Back PromptingはSTEM、Knowledge QA、Multi-Hop Reasoningなどのタスクにおいて大幅な性能向上が観察されました。具体的には、MMLU Physics and Chemistryで7%、11%、TimeQAで27%、MuSiQueで7%の性能向上が確認されました。 Comment
また新しいのが出た。ユーザのクエリに対して直接応答しようとするのではなく、より高次で抽象的・原則的な問いを生成しそこから事実情報を得て、その事実情報にgroundingされた推論によって答えを導く。
openreview: https://openreview.net/forum?id=3bq3jsvcQ1
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic, Xufeng Zhao+, N_A, COLING'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #COLING Issue Date: 2023-10-09 GPT Summary- 大規模言語モデルの進歩は驚異的だが、多段階の推論には改善の余地がある。大規模言語モデルは知識を持っているが、推論には一貫性がなく、幻覚を示すことがある。そこで、Logical Chain-of-Thought(LogiCoT)というフレームワークを提案し、論理による推論パラダイムの効果を示した。
Graph Neural Prompting with Large Language Models, Yijun Tian+, N_A, AAAI'24
Paper/Blog Link My Issue
#GraphBased #NLP #LanguageModel #KnowledgeGraph #AAAI #One-Line Notes #SoftPrompt Issue Date: 2023-10-09 GPT Summary- 本研究では、大規模言語モデル(LLMs)を知識グラフと組み合わせるための新しい手法であるGraph Neural Prompting(GNP)を提案しています。GNPは、標準的なグラフニューラルネットワークエンコーダやクロスモダリティプーリングモジュールなどの要素から構成されており、異なるLLMのサイズや設定において、常識的な推論タスクやバイオメディカル推論タスクで優れた性能を示すことが実験によって示されました。 Comment
元ツイート:
事前学習されたLLMがKGから有益な知識を学習することを支援する手法を提案。
しっかり論文を読んでいないが、freezeしたLLMがあった時に、KGから求めたGraph Neural Promptを元のテキストと組み合わせて、新たなLLMへの入力を生成し利用する手法な模様。
Graph Neural Promptingでは、Multiple choice QAが入力された時に、その問題文や選択肢に含まれるエンティティから、KGのサブグラフを抽出し、そこから関連性のある事実や構造情報をエンコードし、Graph Neural Promptを獲得する。そのために、GNNに基づいたアーキテクチャに、いくつかの工夫を施してエンコードをする模様。
つまりKGの情報を保持したSoft Prompting手法というイメージだろうか。
[Paper Note] Chain-of-Verification Reduces Hallucination in Large Language Models, Shehzaad Dhuliawala+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #Chain-of-Thought #Hallucination #ACL #Selected Papers/Blogs #Verification Issue Date: 2023-09-30 GPT Summary- 私たちは、言語モデルが根拠のない情報を生成する問題に取り組んでいます。Chain-of-Verification(CoVe)メソッドを開発し、モデルが回答を作成し、検証し、最終的な回答を生成するプロセスを経ることで、幻想を減少させることができることを実験で示しました。 Comment
# 概要
ユーザの質問から、Verificationのための質問をplanningし、質問に対して独立に回答を得たうえでオリジナルの質問に対するaggreementを確認し、最終的に生成を実施するPrompting手法
# 評価
## dataset
- 全体を通じてclosed-bookの設定で評価
- Wikidata
- Wikipedia APIから自動生成した「“Who are some [Profession]s who were born in [City]?”」に対するQA pairs
- Goldはknowledge baseから取得
- 全56 test questions
- Gold Entityが大体600程度ありLLMは一部しか回答しないので、precisionで評価
- Wiki category list
- QUEST datasetを利用 [Paper Note] QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, arXiv'23, 2023.05
- 回答にlogical operationが不要なものに限定して頭に"Name some"をつけて質問を生成
- "Name some Mexican animated horror films" or "Name some Endemic orchids of Vietnam"
- 8個の回答を持つ55 test questionsを作成
- MultiSpanQA
- Reading Comprehensionに関するBenchmark dataset
- 複数の独立した回答(回答は連続しないスパンから回答が抽出される)から構成される質問で構成
- 特に、今回はclosed-book setting で実施
- すなわち、与えられた質問のみから回答しなければならず、知っている知識が問われる問題
- 418のtest questsionsで、各回答に含まれる複数アイテムのspanが3 token未満となるようにした
- QA例:
- Q: Who invented the first printing press and in what year?
- A: Johannes Gutenberg, 1450.
# 評価結果
提案手法には、verificationの各ステップでLLMに独立したpromptingをするかなどでjoint, 2-step, Factored, Factor+Revisedの4種類のバリエーションがあることに留意。
- joint: 全てのステップを一つのpromptで実施
- 2-stepは2つのpromptに分けて実施
- Factoredは各ステップを全て異なるpromptingで実施
- Factor+Revisedは異なるpromptで追加のQAに対するcross-checkをかける手法
結果を見ると、CoVEでhallucinationが軽減(というより、モデルが持つ知識に基づいて正確に回答できるサンプルの割合が増えるので実質的にhallucinationが低減したとみなせる)され、特にjointよりも2-step, factoredの方が高い性能を示すことがわかる。
Graph of Thoughts: Solving Elaborate Problems with Large Language Models, Maciej Besta+, N_A, AAAI'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #AAAI Issue Date: 2023-08-22 GPT Summary- 私たちは、Graph of Thoughts(GoT)というフレームワークを紹介しました。これは、大規模言語モデル(LLMs)のプロンプティング能力を進化させるもので、任意のグラフとしてモデル化できることが特徴です。GoTは、思考の組み合わせやネットワーク全体の本質の抽出、思考の強化などを可能にします。さまざまなタスクで最先端の手法に比べて利点を提供し、LLMの推論を人間の思考に近づけることができます。 Comment
Chain of Thought [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
=> Self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
=> Thought Decomposition Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding, Yuxi Xie+, N/A, arXiv'23
=> Tree of Thoughts [Paper Note] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, arXiv'23, 2023.05
Tree of Thought Large Language Model Guided Tree-of-Thought, Jieyi Long, N/A, arXiv'23
=> Graph of Thought
[Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Chain-of-Thought #AutomaticPromptEngineering #NAACL #Findings #Surface-level Notes Issue Date: 2023-04-25 GPT Summary- Iter-CoTは、LLMsの推論チェーンのエラーを修正し、正確で包括的な推論を実現するための反復的ブートストラッピングアプローチを提案。適度な難易度の質問を選択することで、一般化能力を向上させ、10のデータセットで競争力のある性能を達成。 Comment
Zero shot CoTからスタートし、正しく問題に回答できるようにreasoningを改善するようにpromptをreviseし続けるループを回す。最終的にループした結果を要約し、それらをプールする。テストセットに対しては、プールの中からNshotをサンプルしinferenceを行う。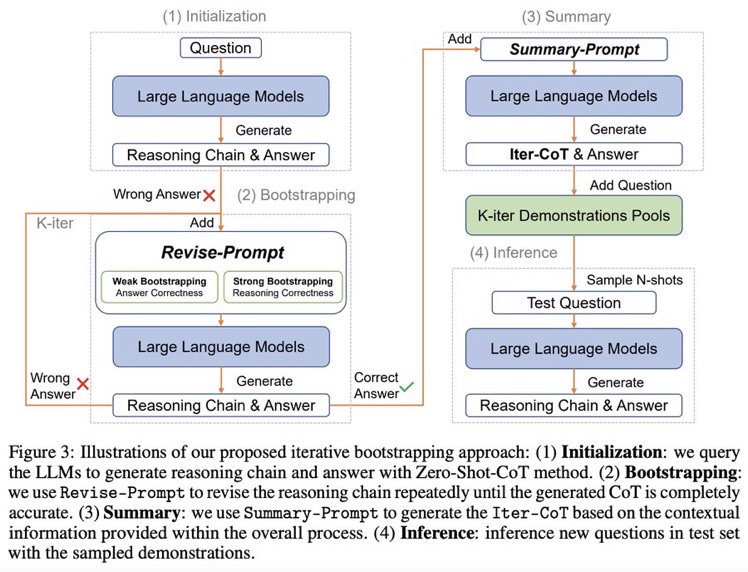
できそうだなーと思っていたけど、早くもやられてしまった
実装: https://github.com/GasolSun36/Iter-CoT
# モチベーション: 既存のCoT Promptingの問題点
## Inappropriate Examplars can Reduce Performance
まず、既存のCoT prompting手法は、sampling examplarがシンプル、あるいは極めて複雑な(hop-based criterionにおいて; タスクを解くために何ステップ必要かという情報; しばしば人手で付与されている?)サンプルをサンプリングしてしまう問題がある。シンプルすぎるサンプルを選択すると、既にLLMは適切にシンプルな回答には答えられるにもかかわらず、demonstrationが冗長で限定的になってしまう。加えて、極端に複雑なexampleをサンプリングすると、複雑なquestionに対しては性能が向上するが、シンプルな問題に対する正答率が下がってしまう。
続いて、demonstration中で誤ったreasoning chainを利用してしまうと、inference時にパフォーマンスが低下する問題がある。下図に示した通り、誤ったdemonstrationが増加するにつれて、最終的な予測性能が低下する傾向にある。
これら2つの課題は、現在のメインストリームな手法(questionを選択し、reasoning chainを生成する手法)に一般的に存在する。
- [Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
- [Paper Note] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, KaShun Shum+, EMNLP'23, 2023.02
のように推論時に適切なdemonstrationを選択するような取り組みは行われてきているが、test questionに対して推論するために、適切なexamplarsを選択するような方法は計算コストを増大させてしまう。
これら研究は誤ったrationaleを含むサンプルの利用を最小限に抑えて、その悪影響を防ぐことを目指している。
一方で、この研究では、誤ったrationaleを含むサンプルを活用して性能を向上させる。これは、たとえば学生が難解だが回答可能な問題に取り組むことによって、問題解決スキルを向上させる方法に類似している(すなわち、間違えた部分から学ぶ)。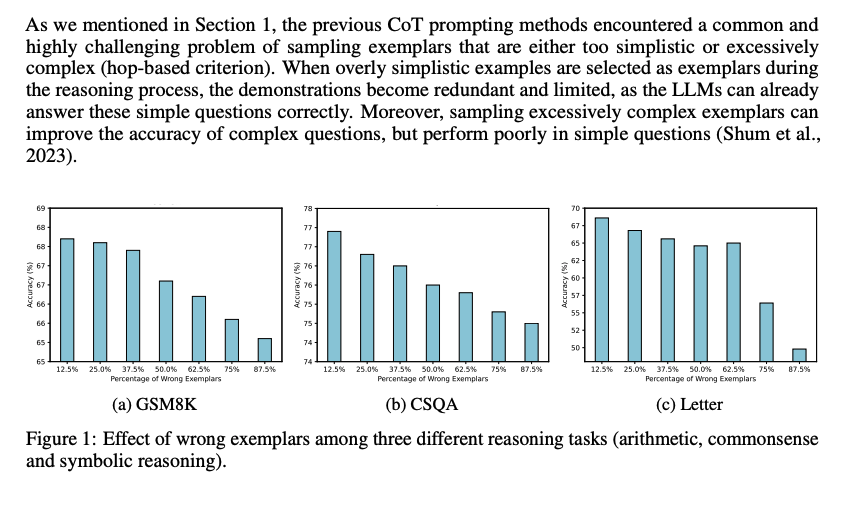
## Large Language Models can self-Correct with Bootstrapping
Zero-Shot CoTでreasoning chainを生成し、誤ったreasoning chainを生成したpromptを**LLMに推敲させ(self-correction)**正しい出力が得られるようにする。こういったプロセスを繰り返し、correct sampleを増やすことでどんどん性能が改善していった。これに基づいて、IterCoTを提案。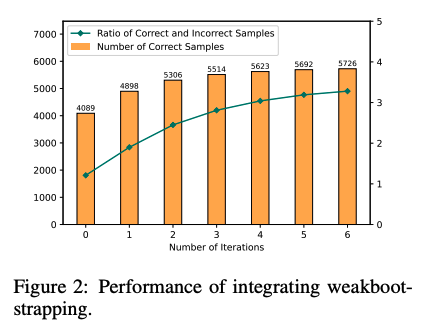
# IterCoT: Iterative Bootstrapping in Chain-of-Thought Prompting
IterCoTはweak bootstrappingとstrong bootstrappingによって構成される。
## Weak bootstrapping
- Initialization
- Training setに対してZero-shot CoTを実施し、reasoning chainとanswerを得
- Bootstrapping
- 回答が誤っていた各サンプルに対して、Revise-Promptを適用しLLMに誤りを指摘し、新しい回答を生成させる。
- 回答が正確になるまでこれを繰り返す。
- Summarization
- 正しい回答が得られたら、Summary-Promptを利用して、これまでの誤ったrationaleと、正解のrationaleを利用し、最終的なreasoning chain (Iter-CoT)を生成する。
- 全体のcontextual informationが加わることで、LLMにとって正確でわかりやすいreasoning chainを獲得する。
- Inference
- questionとIter-Cotを組み合わせ、demonstration poolに加える
- inference時はランダムにdemonstraction poolからサンプリングし、In context learningに利用し推論を行う
## Strong Bootstrapping
コンセプトはweak bootstrappingと一緒だが、Revise-Promptでより人間による介入を行う。具体的には、reasoning chainのどこが誤っているかを明示的に指摘し、LLMにreasoning chainをreviseさせる。
これは従来のLLMからの推論を必要としないannotationプロセスとは異なっている。何が違うかというと、人間によるannnotationをLLMの推論と統合することで、文脈情報としてreasoning chainを修正することができるようになる点で異なっている。
# 実験
Manual-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Random-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Auto-CoT
- [Paper Note] Active Prompting with Chain-of-Thought for Large Language Models, Shizhe Diao+, ACL'24, 2023.02
と比較。
Iter-CoTが11個のデータセット全てでoutperformした。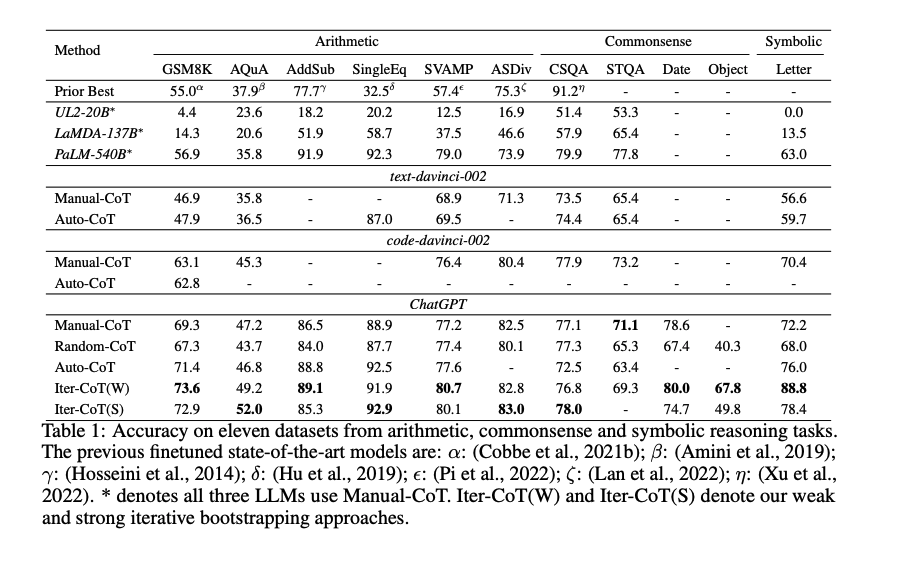
weak bootstrapingのiterationは4回くらいで頭打ちになった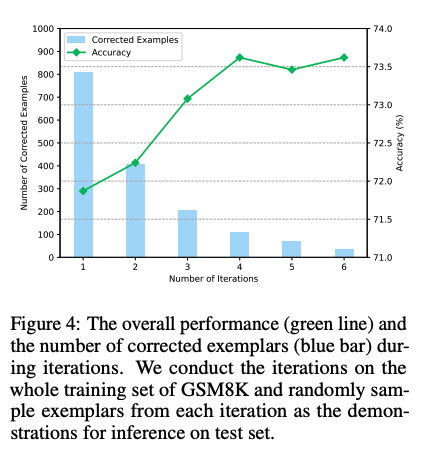
また、手動でreasoning chainを修正した結果と、contextにannotation情報を残し、最後にsummarizeする方法を比較した結果、後者の方が性能が高かった。このため、contextの情報を利用しsummarizeすることが効果的であることがわかる。
[Paper Note] Learning to Compress Prompts with Gist Tokens, Jesse Mu+, NeurIPS'23, 2023.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #NeurIPS #Compression Issue Date: 2026-02-02 GPT Summary- プロンプトはLMのマルチタスク機能における効率性に課題をもたらすため、私たちは「ギスティング」を提案。これはプロンプトを小さなトークンセットに圧縮し、再利用することで計算効率を向上させる方法で、トレーニングコストは標準的な指示ファインチューニングと同等。実験により、最大26倍のプロンプト圧縮と最大40%のFLOPs削減を達成し、出力品質を保持しつつ効率化を実現。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=2DtxPCL3T5
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks, Wenhu Chen+, TMLR'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #TMLR #KeyPoint Notes Issue Date: 2025-01-05 GPT Summary- 段階的な推論を用いた数値推論タスクにおいて、Chain-of-thoughts prompting(CoT)の進展があり、推論をプログラムとして表現する「Program of Thoughts」(PoT)を提案。PoTは外部コンピュータで計算を行い、5つの数学問題データセットと3つの金融QAデータセットで評価した結果、少数ショットおよびゼロショット設定でCoTに対して約12%の性能向上を示した。自己一貫性デコーディングとの組み合わせにより、数学問題データセットで最先端の性能を達成。データとコードはGitHubで公開。 Comment
1. LLMsは算術演算を実施する際にエラーを起こしやすく、特に大きな数に対する演算を実施する際に顕著
2. LLMsは複雑な数式(e.g. 多項式, 微分方程式)を解くことができない
3. LLMsはiterationを表現するのが非常に非効率
の3点を解決するために、外部のインタプリタに演算処理を委譲するPoTを提案。PoTでは、言語モデルにreasoning stepsをpython programで出力させ、演算部分をPython Interpreterに実施させる。
テキスト、テーブル、対話などの多様なinputをサポートする5つのMath Word Problem (MWP), 3つのFinancial Datasetで評価した結果、zero-shot, few-shotの両方の設定において、PoTはCoTをoutpeformし、また、Self-Consistencyと組み合わせた場合も、PoTはCoTをoutperformした。
Visual In-Context Prompting, Feng Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#ComputerVision #ImageSegmentation #In-ContextLearning Issue Date: 2023-11-23 GPT Summary- 本研究では、ビジョン領域における汎用的なビジュアルインコンテキストプロンプティングフレームワークを提案します。エンコーダーデコーダーアーキテクチャを使用し、さまざまなプロンプトをサポートするプロンプトエンコーダーを開発しました。さらに、任意の数の参照画像セグメントをコンテキストとして受け取るように拡張しました。実験結果から、提案手法が非凡な参照および一般的なセグメンテーション能力を引き出し、競争力のあるパフォーマンスを示すことがわかりました。 Comment
Image Segmentationには、ユーザが与えたプロンプトと共通のコンセプトを持つすべてのオブジェクトをセグメンテーションするタスクと、ユーザの入力の特定のオブジェクトのみをセグメンテーションするタスクがある。従来は個別のタスクごとに、特定の入力方法(Visual Prompt, Image Prompt)を前提とした手法や、個々のタスクを実施できるがIn-Context Promptしかサポートしていない手法しかなかったが、この研究では、Visual Prompt, Image Prompt, In-Context Promptをそれぞれサポートし両タスクを実施できるという位置付けの模様。また、提案手法ではストローク、点、ボックスといったユーザの画像に対する描画に基づくPromptingをサポートし、Promptingにおける参照セグメント数も任意の数指定できるとのこと。
[Paper Note] System 2 Attention (is something you might need too), Jason Weston+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#NLP #LanguageModel #ContextEngineering Issue Date: 2023-11-21 GPT Summary- S2Aを用いて、LLMsが注意を向けるべき部分を選択することで、無関係な情報を除外し最終応答を導出。QA、数学の文章題、長文生成において標準アテンションを上回り、事実性と客観性を高め、迎合性を低減。 Comment
おそらく重要論文
How is System 2 Attention different from prompt engineering specialized in factual double checks?
I'm very sorry for the extremely delayed response. It's been two years, so you may no longer have a chance to see this, but I'd still like to share my thoughts.
I believe that System 2 Attention is fundamentally different in concept from prompt engineering techniques such as factual double-checking. Unlike ad-hoc prompt engineering or approaches that enrich the context by adding new facts through prompting, System 2 Attention aims to improve the model’s reasoning ability itself by mitigating the influence of irrelevant tokens. It does so by selectively generating a new context composed only of relevant tokens, in a way that resembles human System 2 thinking—that is, more objective and deliberate reasoning.
From today’s perspective, two years later, I would say that this concept is more closely aligned with what we now refer to as Context Engineering. Thank you.
Contrastive Chain-of-Thought Prompting, Yew Ken Chia+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-11-19 GPT Summary- 言語モデルの推論を改善するために、対照的なchain of thoughtアプローチを提案する。このアプローチでは、有効な推論デモンストレーションと無効な推論デモンストレーションの両方を提供し、モデルが推論を進める際にミスを減らすようにガイドする。また、自動的な方法を導入して対照的なデモンストレーションを構築し、汎化性能を向上させる。実験結果から、対照的なchain of thoughtが一般的な改善手法として機能することが示された。
[Paper Note] Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster, Hongxuan Zhang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Chain-of-Thought #Initial Impression Notes Issue Date: 2023-11-15 GPT Summary- FastCoTは、追加トレーニングやLLM改変なしに並列デコードを実現するモデル非依存のフレームワークです。可変長コンテキストウィンドウを使用し、並列かつ自己回帰的なデコードを行うことで、GPUリソースを最適化します。これにより、因果型トランスフォーマーの従来手法よりも迅速な応答が可能になります。実験結果では、FastCoTが推論時間を約20%短縮しつつ、性能低下も最小限であることが示されています。 Comment
論文中の図を見たが、全くわからなかった・・・。ちゃんと読まないとわからなそうである。
[Paper Note] Eliminating Reasoning via Inferring with Planning: A New Framework to Guide LLMs' Non-linear Thinking, Yongqi Tong+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Chain-of-Thought #Initial Impression Notes Issue Date: 2023-10-24 GPT Summary- 非線形思考を模倣するために、Inferential Exclusion Prompting (IEP) を提案。IEPは計画後にNLIを活用し、解に対する推論を振り返ることで複雑な思考過程を再現。実証研究により、IEPがCoTを一貫して上回ることを確認。IEPとCoTを統合することでLLMsの性能向上も観察。新たに導入したMental-Ability Reasoning Benchmark (MARB)は9,115問からなり、LLMsの論理能力を評価するための有望な方法とされ、近日中に公開予定。 Comment
論文自体は読めていないのだが、CoTが線形的だという主張がよくわからない。
CoTはAutoregressiveな言語モデルに対して、コンテキストを自己生成したテキストで利用者の意図した方向性にバイアスをかけて補完させ、
利用者が意図した通りのアウトプットを最終的に得るためのテクニック、だと思っていて、
線形的だろうが非線形的だろうがどっちにしろCoTなのでは。
[Paper Note] Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models, Anni Zou+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Initial Impression Notes Issue Date: 2023-10-13 GPT Summary- GeM-CoTは、未知の入力問に対する一般化可能なCoTプロンプティング手法を提案。問の型を分類し、データプールから自動デモを生成することで、性能と一般化のギャップを解消。これにより、10の公開推論タスクと23のBBHタスクで優れたパフォーマンスを実現。 Comment
色々出てきたがなんかもう色々組み合わせれば最強なんじゃね?って気がしてきた。
openreview: https://openreview.net/forum?id=79tJB1eTmb
[Paper Note] Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #AutomaticPromptEngineering #ICML #Reading Reflections Issue Date: 2023-10-09 GPT Summary- Promptbreederは、LLMの推論能力を向上させる自己改善メカニズムであり、特定のドメインに対してプロンプトを進化・適応させる。タスクプロンプトの集団を突然変異させ、訓練データで評価することで、LLMが生成・改善する変異プロンプトによって統治される。これにより、Chain-of-ThoughtやPlan-and-Solve Promptingを上回り、ヘイトスピーチ分類のような複雑なタスクにも対応可能なプロンプトを進化させる。 Comment
詳細な解説記事: https://aiboom.net/archives/56319
APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…?
[Paper Note] Large Language Models as Analogical Reasoners, Michihiro Yasunaga+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #In-ContextLearning #ICLR #KeyPoint Notes #Reading Reflections Issue Date: 2023-10-07 GPT Summary- アナロジー的プロンプティングを用いて、言語モデルに問題解決前に関連する例示を生成させる新手法を提案。ラベリング不要で汎用性が高く、適応性もある。実験では、GSM8K、MATH、Codeforces、BIG-Benchの推論タスクで0ショットおよび少数ショットCoTを上回る性能を示した。 Comment
以下、著者ツイートのざっくり翻訳:
人間は新しい問題に取り組む時、過去に解いた類義の問題を振り返り、その経験を活用する。これをLLM上で実践できないか?というのがアイデア。
Analogical Promptingでは、問題を解く前に、適切なexamplarを自動生成(problemとsolution)させ、コンテキストとして利用する。
これにより、examplarは自己生成されるため、既存のCoTで必要なexamplarのラベリングや検索が不要となることと、解こうとしている問題に合わせてexamplarを調整し、推論に対してガイダンスを提供することが可能となる。
実験の結果、数学、コード生成、BIG-Benchでzero-shot CoT、few-shot CoTを上回った。
LLMが知っており、かつ得意な問題に対してならうまく働きそう。一方で、LLMが苦手な問題などは人手作成したexamplarでfew-shotした方が(ある程度)うまくいきそうな予感がする。うまくいきそうと言っても、そもそもLLMが苦手な問題なのでfew-shotした程度では焼石に水だとは思うが。
openreview: https://openreview.net/forum?id=AgDICX1h50
Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #AutomaticPromptEngineering #ICLR Issue Date: 2023-09-05 GPT Summary- 大規模言語モデル(LLMs)は、自然言語の指示に基づいて一般的な用途のコンピュータとして優れた能力を持っています。しかし、モデルのパフォーマンスは、使用されるプロンプトの品質に大きく依存します。この研究では、自動プロンプトエンジニア(APE)を提案し、LLMによって生成された指示候補のプールから最適な指示を選択するために最適化します。実験結果は、APEが従来のLLMベースラインを上回り、19/24のタスクで人間の生成した指示と同等または優れたパフォーマンスを示しています。APEエンジニアリングされたプロンプトは、モデルの性能を向上させるだけでなく、フューショット学習のパフォーマンスも向上させることができます。詳細は、https://sites.google.com/view/automatic-prompt-engineerをご覧ください。 Comment
プロジェクトサイト: https://sites.google.com/view/automatic-prompt-engineer
openreview: https://openreview.net/forum?id=92gvk82DE-
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models, Bilgehan Sel+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-09-04 GPT Summary- 大規模言語モデル(LLMs)の推論能力を向上させるために、新しい戦略「Algorithm of Thoughts」を提案している。この戦略では、LLMsをアルゴリズム的な推論経路に導き、わずか1つまたは数個のクエリでアイデアの探索を拡大する。この手法は、以前の単一クエリ手法を上回り、マルチクエリ戦略と同等の性能を発揮する。また、LLMを指導するアルゴリズムを使用することで、アルゴリズム自体を上回るパフォーマンスが得られる可能性があり、LLMが最適化された検索に自己の直感を織り込む能力を持っていることを示唆している。
Large Language Model Guided Tree-of-Thought, Jieyi Long, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-08-22 GPT Summary- この論文では、Tree-of-Thought(ToT)フレームワークを紹介し、自己回帰型の大規模言語モデル(LLM)の問題解決能力を向上させる新しいアプローチを提案しています。ToTは、人間の思考方法に触発された技術であり、複雑な推論タスクを解決するためにツリー状の思考プロセスを使用します。提案手法は、LLMにプロンプターエージェント、チェッカーモジュール、メモリモジュール、およびToTコントローラーなどの追加モジュールを組み込むことで実現されます。実験結果は、ToTフレームワークがSudokuパズルの解決成功率を大幅に向上させることを示しています。
Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding, Yuxi Xie+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel Issue Date: 2023-08-22 GPT Summary- 私たちは、大規模言語モデル(LLMs)を使用して、推論の品質と多様性を向上させるための効果的なプロンプティングアプローチを提案しました。自己評価によるガイド付き確率的ビームサーチを使用して、GSM8K、AQuA、およびStrategyQAのベンチマークで高い精度を達成しました。また、論理の失敗を特定し、一貫性と堅牢性を向上させることもできました。詳細なコードはGitHubで公開されています。
[Paper Note] Metacognitive Prompting Improves Understanding in Large Language Models, Yuqing Wang+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #NAACL Issue Date: 2023-08-12 GPT Summary- メタ認知的プロンプティング(MP)を導入し、LLMsの論理推論を向上させる新しい戦略を提示。MPにより、広範な知識を引き出す自己評価プロセスを実施。主要なLLMs(Llama2、PaLM2、GPT-3.5、GPT-4)を用いた実験で、GPT-4が全タスクで優れた性能を示し、他モデルもMPによって著しい進歩を達成。また、MPは既存のプロンプティング手法を一貫して上回り、LLMsの理解能力向上の可能性を示唆している。 Comment
CoTより一貫して性能が高いので次のデファクトになる可能性あり
[Paper Note] Do Multilingual Language Models Think Better in English?, Julen Etxaniz+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel Issue Date: 2023-08-07 GPT Summary- self-translateは、多言語モデルの少数ショット翻訳能力を活用し、外部翻訳システムを不要にする新しいアプローチを提案。5つのタスクにおける実験結果は、直接推論において一貫して優位性を示し、非英語プロンプト時に多言語ポテンシャルの非活用を確認できる。 Comment
参考:
[Paper Note] LLM-Rec: Personalized Recommendation via Prompting Large Language Models, Hanjia Lyu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #NAACL #Findings #One-Line Notes Issue Date: 2023-08-02 GPT Summary- テキストベースのレコメンデーションは汎用性が高いが、元のアイテム説明だけではユーザー嗜好との整合性が不足することがある。大規模言語モデル(LLMs)の進歩を活かし、4つのテキスト強化プロンプト戦略を取り入れたアプローチ、LLM-Recを提案。実験により、LLM拡張テキストの使用が推奨品質を向上させることが確かめられ、基本的なMLPモデルでも高い成果を上げることが示された。成功の要因はプロンプト戦略であり、多様な技術がLLMsの推奨効果を高める重要性を示している。 Comment
LLMのpromptingの方法を変更しcontent descriptionだけでなく、様々なコンテキストの追加(e.g. このdescriptionを推薦するならどういう人におすすめ?、アイテム間の共通項を見つける)、内容の拡張等を行いコンテントを拡張して活用するという話っぽい。
[Paper Note] Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #LanguageModel #EMNLP #Selected Papers/Blogs #Batch #KeyPoint Notes #IndustryTrack Issue Date: 2023-07-24 GPT Summary- 大規模言語モデル(LLM)を使ったバッチプロンプティングにより、サンプルをバッチ単位で推論し、トークンコストと推論時間を削減。few-shot in-context learningで、コストはバッチ内サンプル数に反比例して低下。100のデータセットでの検証では、最大5倍のコスト削減を実現し、性能は向上または維持。GPT-3.5やGPT-4でも効果を確認し、タスクの複雑さが性能に影響を与えることを示唆。バッチプロンプティングは他の推論手法にも適用可能。 Comment
10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。
Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、contextが長ければ長いほど、バッチサイズを大きくした際のパフォーマンスの低下が著しい。
Reasoning with Language Model Prompting: A Survey, ACL'23
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Reasoning #ACL Issue Date: 2023-07-18 GPT Summary- 本論文では、推論に関する最新の研究について包括的な調査を行い、初心者を支援するためのリソースを提供します。また、推論能力の要因や将来の研究方向についても議論します。リソースは定期的に更新されています。
[Paper Note] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting, Zhen Qin+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PairWise #NLP #LanguageModel #NAACL #Surface-level Notes #needs-revision Issue Date: 2023-07-11 GPT Summary- LLMを用いた文書ランキングは有望だが、既存手法を上回るのは難しい。本稿では、既存のpointwiseおよびlistwise手法がLLMに理解されにくいことを指摘し、新たにPairwise Ranking Prompting(PRP)を提案。中規模のオープンソースLLMで、TREC-DLで商用GPT-4を上回る成果を取得し、BEIRタスクでも教師ありベースラインやChatGPTを超えることを示した。PRPの変種によって効率性を向上させ、競争力を持つ結果も達成。 Comment
open source LLMにおいてスタンダードなランキングタスクのベンチマークでSoTAを達成できるようなprompting技術を提案
従来のランキングのためのpromptingはpoint-wiseとlist wiseしかなかったが、前者は複数のスコアを比較するためにスコアのcalibrationが必要だったり、OpenAIなどのAPIはlog probabilityを提供しないため、ランキングのためのソートができないという欠点があった。後者はinputのorderingに非常にsensitiveであるが、listのすべての組み合わせについてorderingを試すのはexpensiveなので厳しいというものであった。このため(古典的なlearning to rankでもおなじみや)pairwiseでサンプルを比較するランキング手法PRPを提案している。
PRPはペアワイズなのでorderを入れ替えて評価をするのは容易である。また、generation modeとscoring mode(outputしたラベルのlog probabilityを利用する; OpenLLMを使うのでlog probabilityを計算できる)の2種類を採用できる。ソートの方法についても、すべてのペアの勝敗からから単一のスコアを計算する方法(AllPair), HeapSortを利用する方法、LLMからのoutputを得る度にon the flyでリストの順番を正しくするSliding Windowの3種類を提案して比較している。
下表はscoring modeでの性能の比較で、GPT4に当時は性能が及んでいなかった20BのOpenLLMで近しい性能を達成している。
また、PRPがinputのorderに対してロバストなことも示されている。
[Paper Note] A Survey of Large Language Models, Wayne Xin Zhao+, arXiv'23, 2023.03
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #One-Line Notes Issue Date: 2023-07-11 GPT Summary- 言語は複雑な表現体系であり、その理解・生成のためのAIアルゴリズム開発は難題である。近年、事前学習済み言語モデル(PLMs)がTransformerモデルを用いた大規模コーパスの学習により高い能力を示しており、特に大規模言語モデル(LLM)が注目されている。モデルスケーリングが性能向上をもたらし、一定のパラメータ規模を超えると新たな能力が現れることが確認されている。LLMsはAIコミュニティ全体に重要な影響を与えており、本調査ではその背景、主要な発見、技術を概説し、特に事前学習、適応調整、活用、容量評価に焦点を当てる。また、リソース整理や未解決課題についても論じる。 Comment
現状で最も詳細なLLMのサーベイ
600個のリファレンス、LLMのコレクション、promptingのtips、githubリポジトリなどがまとめられている
[Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #In-ContextLearning #TACL #Selected Papers/Blogs #ContextEngineering #KeyPoint Notes #needs-revision Issue Date: 2023-07-11 GPT Summary- 言語モデルは長い文脈を扱う能力を持つが、実際に関連情報を効果的に利用できているかは未解明。複数文書に基づく質問応答とキー・バリュー検索を通じて、関連情報の位置による性能変動を分析した結果、関連情報が文脈の先頭や末尾にあるときに高性能を示し、中央にある場合に顕著に性能が低下することが明らかになった。この考察は、言語モデルの文脈使用に関する理解を深め、長い文脈への評価プロトコルの方向性を示唆している。 Comment
元ツイート
非常に重要な知見がまとめられている
1. モデルはコンテキストのはじめと最後の情報をうまく活用でき、真ん中の情報をうまく活用できない
2. 長いコンテキストのモデルを使っても、コンテキストをより短いコンテキストのモデルよりもうまく考慮できるわけではない
3. モデルのパフォーマンスは、コンテキストが長くなればなるほど悪化する
SNLP'24での解説スライド:
https://speakerdeck.com/kichi/snlp2024
[Paper Note] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-05-20 GPT Summary- 言語モデルは一般的な問題解決に広がっているが、推論は依然としてトークンレベルの左から右への決定に制限されている。これを克服するために、新しい「Tree of Thoughts(ToT)」フレームワークを導入。ToTは、思考の連鎖を一般化し、中間ステップを探索できるようにし、複数の推論経路を自己評価することで意図的な意思決定を可能にする。実験では、ToTがGame of 24やCreative Writingなどの新規タスクで言語モデルの問題解決能力を顕著に向上させることが示された。例えば、Game of 24では新手法が74%の成功率を達成した。 Comment
Self Concistencyの次
Non trivialなプランニングと検索が必要な新たな3つのタスクについて、CoT w/ GPT4の成功率が4%だったところを、ToTでは74%を達成
論文中の表ではCoTのSuccessRateが40%と書いてあるような?
[Paper Note] Controlled Text Generation with Natural Language Instructions, Wangchunshu Zhou+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #SyntheticData #In-ContextLearning #ICML #PostTraining #One-Line Notes Issue Date: 2023-04-30 GPT Summary- 自然言語の指示に従い、多様なタスクを解決可能な大規模言語モデルの制御を改善するために、「InstructCTG」というフレームワークを提案。自然テキストの制約を抽出し、これを自然言語の指示に変換することで弱教師あり訓練データを形成。異なるタイプの制約に柔軟に対応し、生成の質や速度への影響を最小限に抑えつつ、再訓練なしで新しい制約に適応できる能力を持つ。 Comment
制約に関する指示とデモンスとレーションに関するデータを合成して追加のinstruction tuningを実施することで、promptで指示された制約を満たすような(controllableな)テキストの生成能力を高める手法
[Paper Note] Boosting Theory-of-Mind Performance in Large Language Models via Prompting, Shima Rahimi Moghaddam+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #TheoryOfMind #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- LLMのToM性能を評価し、文脈内学習が理解を向上させる効果を検討。2ショットの連鎖思考と段階的思考指示を用いたプロンプトで、RLHF訓練モデルはToM精度を80%以上に。特にGPT-4は文脈内学習で100%に達し、適切なプロンプト付けがLLMの推論を強化することを示した。 Comment
LLMはTheory-of-mind reasoningタスクが苦手なことが知られており、特にzero shotでは非常にパフォーマンスが低かった。ToMタスクとは、エージェントの信念、ゴール、メンタルstate、エージェントが何を知っているか等をトラッキングすることが求められるタスクのこと。このようなタスクはLLMが我々の日常生活を理解する上で重要。
↑のToM Questionのシナリオと問題
Scenario: "The morning of the high school dance Sarah placed her high heel shoes under her dress and then went shopping. That afternoon, her sister borrowed the shoes and later put them under Sarah's bed."
Question: When Sarah gets ready, does she assume her shoes are under her dress?
しかし、Zero shot CoTのようなstep by step thinking, CoTを適切に行うことで、OpenAIの直近3つのモデルのAccuracyが80%を超えた。特に、GPT4は100%のAccuracyを達成。人間は87%だった。
この結果は、少なくとのこの論文でテストしたドメインではLLMのsocial reasoningのパフォーマンスをどのようにブーストするかを示しており、LLMのbehaviorは複雑でsensitiveであることを示唆している。
[Paper Note] Exploring the Curious Case of Code Prompts, Li Zhang+, NLRSE'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Reasoning #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- コード風のプロンプトによる構造化推論の性能向上が示されたが、その効果は限られたタスクに留まる。本研究では、davinci系のモデルに対して、QAや感情分析など幅広いタスクでコードとテキストプロンプトを比較し、全体としてコードプロンプトがテキストプロンプトを上回ることはなかった。タスクによってはコードプロンプトが有利な場合もあったが、全てのタスクに当てはまるわけではなく、テキスト指示によるファインチューニングがコードプロンプトの性能向上に寄与することを示した。 Comment
コードベースのLLMに対して、reasoningタスクを解かせる際には、promptもコードにすると10パーセント程度性能上がる場合があるよ、という研究。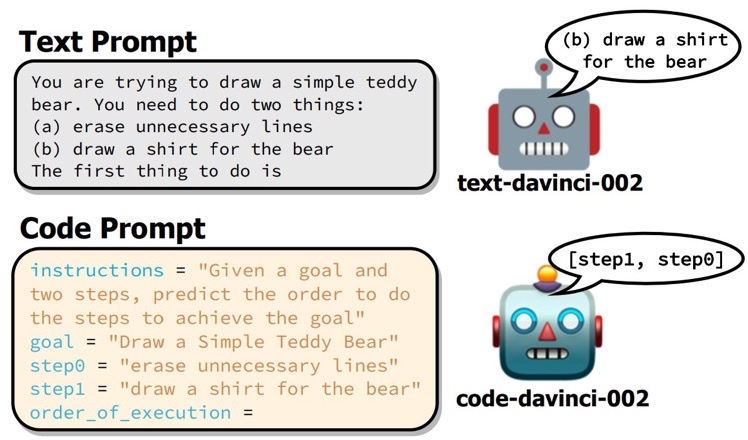
ただし、平均的にはテキストプロンプトの方が良く、一部タスクで性能が改善する、という温度感な模様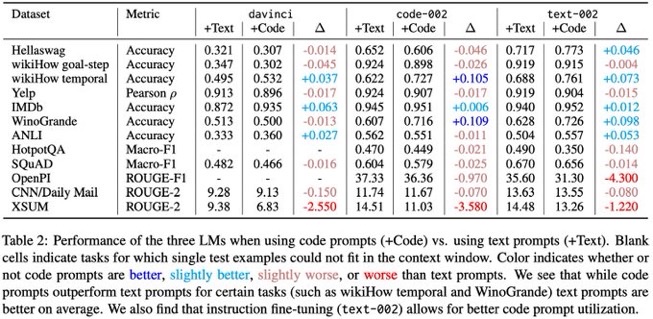
コードベースのモデルをtextでinstruction tuningしている場合でも、効果があるタスクがある。
[Paper Note] Answering Questions by Meta-Reasoning over Multiple Chains of Thought, Ori Yoran+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #Chain-of-Thought #EMNLP #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 複数の推論チェーンを考慮したMulti-Chain Reasoning(MCR)を提案。これにより、異なるチェーン間の情報を統合し、回答生成時に関連性の高い事実を選択することで、より質の高い説明を提供。7つのマルチホップQAデータセットで優れた性能を示し、人間による検証も可能な高品質な説明を実現。 Comment
self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
のようなvoting basedなアルゴリズムは、複数のCoTのintermediate stepを捨ててしまい、結果だけを採用するが、この研究は複数のCoTの中からquestionに回答するために適切なfactual informationを抽出するMeta Reasonerを導入し、複数のCoTの情報を適切に混在させて適切な回答を得られるようにした。
7個のMulti Hop QAデータでstrong baselineをoutperformし、人間が回答をverificationするための高品質な説明を生成できることを示した。
openreview: https://openreview.net/forum?id=ebSOK1nV2r
[Paper Note] Large Language Models are Zero-Shot Reasoners, Takeshi Kojima+, arXiv'22, 2022.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Zero/Few/ManyShotPrompting #Chain-of-Thought #NeurIPS #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)は自然言語処理において少数ショット学習の能力が高く、CoT promptingにより複雑な多段階推論を効果的に引き出す。特に「Let's think step by step」の追加で、ゼロショット推論能力が向上し、様々な論理推論タスクで手作りの例を使わずに性能を大幅に向上させた。例えば、InstructGPTモデルでのMultiArithの精度が17.7%から78.7%へ、GSM8Kが10.4%から40.7%と劇的な改善が見られた。この研究はLLMsの潜在的なゼロショット能力を示し、ファインチューニングや少数ショットの前にその知識を探求する重要性が強調されている。 Comment
Zero-Shot CoT (Let's think step-by-step.)論文

Zero-Shot-CoTは2つのステップで構成される:
- STEP1: Reasoning Extraction
- 元のquestionをxとし、zero-shot-CoTのtrigger sentenceをtとした時に、テンプレート "Q: [X]. A. [T]" を用いてprompt x'を作成
- このprompt x'によって得られる生成テキストzはreasoningのrationaleとなっている。
- STEP2: Answer Extraction
- STEP1で得られたx'とzを用いて、テンプレート "[X'] [Z] [A]" を用いてpromptを作成し、quiestionに対する回答を得る
- このとき、Aは回答を抽出するためのtrigger sentenceである。
- Aはタスクに応じて変更するのが効果的であり、たとえば、multi-choice QAでは "Therefore, among A through E, the answer is" といったトリガーを用いたり、数学の問題では "Therefore, the answer (arabic numerals) is" といったトリガーを用いる。
# 実験結果
表中の性能指標の左側はタスクごとにAnswer Triggerをカスタマイズしたもので、右側はシンプルに"The answer is"をAnswer Triggerとした場合。Zero-shot vs. Zero-shot-CoTでは、Zero-Shot-CoTが多くのb現地マークにおいて高い性能を示している。ただし、commonsense reasoningではperformance gainを得られなかった。これは [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
で報告されている通り、commonsense reasoningタスクでは、Few-Shot CoTでもLambda135Bで性能が向上せず、Palm540Bで性能が向上したように、モデルのparameter数が足りていない可能性がある(本実験では17種類のモデルを用いているが、特に注釈がなければtext-davinci-002を利用した結果)。
## 他ベースラインとの比較
他のベースラインとarithmetic reasoning benchmarkで性能比較した結果。Few-Shot-CoTには勝てていないが、standard Few-shot Promptingtを大幅に上回っている。
## zero-shot reasoningにおけるモデルサイズの影響
さまざまな言語モデルに対して、zero-shotとzero-shot-CoTを実施した場合の性能比較。[Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
と同様にモデルサイズが小さいとZero-shot-CoTによるgainは得られないが、モデルサイズが大きくなると一気にgainが大きくなる。
## Zero-shot CoTにおけるpromptの選択による影響
input promptに対するロバスト性を確認した。instructiveカテゴリ(すなわち、CoTを促すトリガーであれば)性能が改善している。特に、どのようなsentenceのトリガーにするかで性能が大きくかわっている。今回の実験では、"Let's think step by step"が最も高い性能を占め最多。
## Few-shot CoTのprompt選択における影響
CommonsenseQAのexampleを用いて、AQUA-RAT, MultiArithをFew-shot CoTで解いた場合の性能。どちらのケースもドメインは異なるが、前者は回答のフォーマットは共通である。異なるドメインでも、answer format(multiple choice)の場合、ドメインが異なるにもかかわらず、zero-shotと比較して性能が大幅に向上した。一方、answer formatが異なる場合はperformance gainが小さい。このことから、LLMはtask自体よりも、exampleにおけるrepeated formatを活用していることを示唆している。また、CommonSennseをExamplarとして用いたFew-Shot-CoTでは、どちらのデータセットでもZero-Shot-CoTよりも性能が劣化している。つまり、Few-Shot-CoTでは、タスク特有のサンプルエンジニアリングが必要であることがわかる(一方、Zero-shot CoTではそのようなエンジニアリングは必要ない)。
[Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Paper/Blog Link My Issue
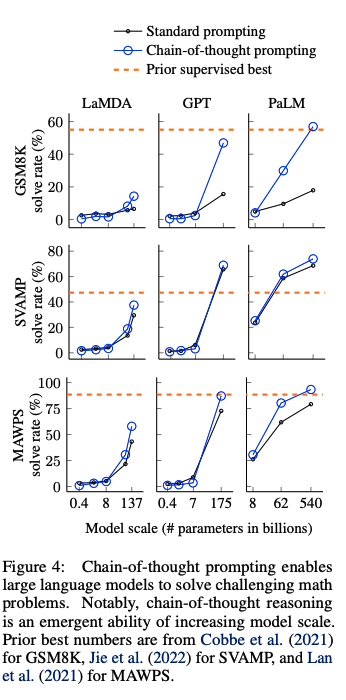
#NLP #LanguageModel #Zero/Few/ManyShotPrompting #Chain-of-Thought #NeurIPS #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-04-27 GPT Summary- 思考の連鎖によって、大規模言語モデルの推論能力が向上することを探求。チェーン・オブ・ソート思考のプロンプトを用いる事例を示し、3つのモデルでの実験を通じて算術や常識、象徴的推論において性能向上を確認。特に、5400億パラメータのモデルに8つのデモをプロンプトとして与えただけで、数学問題のGSM8Kベンチマークで最先端の精度を達成した。 Comment
Chain-of-Thoughtを提案した論文。CoTをする上でパラメータ数が100B未満のモデルではあまり効果が発揮されないということは念頭に置いた方が良さそう。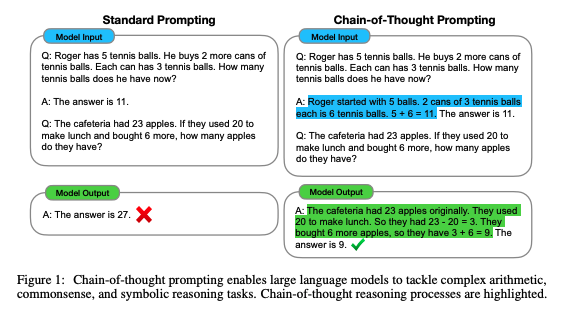
先行研究では、reasoningが必要なタスクの性能が低い問題をintermediate stepを明示的に作成し、pre-trainedモデルをfinetuningすることで解決していた。しかしこの方法では、finetuning用の高品質なrationaleが記述された大規模データを準備するのに多大なコストがかかるという問題があった。
このため、few-shot promptingによってこの問題を解決することが考えられるが、reasoning能力が必要なタスクでは性能が悪いという問題あがった。そこで、両者の強みを組み合わせた手法として、chain-of-thought promptingは提案された。
# CoTによる実験結果
以下のベンチマークを利用
- math word problem: GSM8K, SVAMP, ASDiv, AQuA, MAWPS
- commonsense reasoning: CSQA, StrategyQA, Big-bench Effort (Date, Sports), SayCan
- Symbolic Reasoning: Last Letter concatenation, Coin Flip
- Last Letter concatnation: 名前の単語のlast wordをconcatするタスク("Amy Brown" -> "yn")
- Coin Flip: コインをひっくり返す、 あるいはひっくり返さない動作の記述の後に、コインが表向きであるかどうかをモデルに回答するよう求めるタスク
## math word problem benchmark
- モデルのサイズが大きくなるにつれ性能が大きく向上(emergent ability)することがあることがわかる
- 言い換えるとCoTは<100Bのモデルではパフォーマンスに対してインパクトを与えない
- モデルサイズが小さいと、誤ったCoTを生成してしまうため
- 複雑な問題になればなるほど、CoTによる恩恵が大きい
- ベースラインの性能が最も低かったGSM8Kでは、パフォーマンスの2倍向上しており、1 stepのreasoningで解決できるSingleOpやMAWPSでは、性能の向上幅が小さい
- Task specificなモデルをfinetuningした以前のSoTAと比較してcomparable, あるいはoutperformしている
- 
## Ablation Study
CoTではなく、他のタイプのpromptingでも同じような効果が得られるのではないか?という疑問に回答するために、3つのpromptingを実施し、CoTと性能比較した:
- Equation Only: 回答するまえに数式を記載するようなprompt
- promptの中に数式が書かれているから性能改善されているのでは?という疑問に対する検証
- => GSM8Kによる結果を見ると、equation onlyでは性能が低かった。これは、これは数式だけでreasoning stepsを表現できないことに起因している
- Variable compute only: dotのsequence (...) のみのprompt
- CoTは難しい問題に対してより多くの計算(intermediate token)をすることができているからでは?という疑問に対する検証
- variable computationとCoTの影響を分離するために、dotのsequence (...) のみでpromptingする方法を検証
- => 結果はbaselineと性能変わらず。このことから、variableの計算自体が性能向上に寄与しているわけではないことがわかる。
- Chain of Thought after answer: 回答の後にCoTを出力するようなprompting
- 単にpretrainingの際のrelevantな知識にアクセスしやすくなっているだけなのでは?という疑問を検証
- => baselineと性能は変わらず、単に知識を活性化させるだけでは性能が向上しないことがわかる。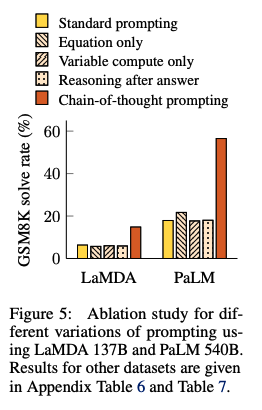
## CoTのロバスト性
人間のAnnotatorにCoTを作成させ、それらを利用したCoTpromptingとexamplarベースな手法によって性能がどれだけ変わるかを検証。standard promptingを全ての場合で上回る性能を獲得した。このことから、linguisticなstyleにCoTは影響を受けていないことがわかる。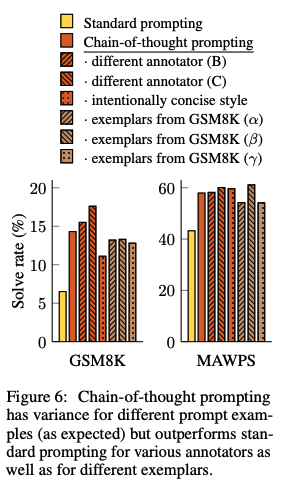
# commonsense reasoning
全てのデータセットにおいて、CoTがstandard promptingをoutperformした。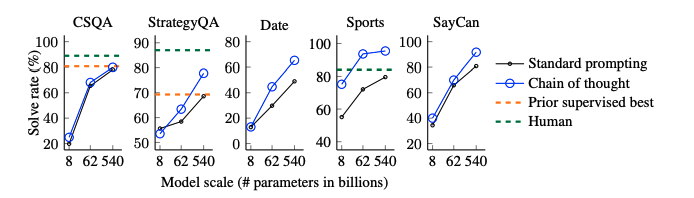
# Symbolic Reasoning
in-domain test setとout-of-domain test setの2種類を用意した。前者は必要なreasoning stepがfew-shot examplarと同一のもの、後者は必要なreasoning stepがfew-shot examplarよりも多いものである。
CoTがStandard proimptingを上回っている。特に、standard promptingではOOV test setではモデルをスケールさせても性能が向上しなかったのに対し、CoTではより大きなgainを得ている。このことから、CoTにはreasoning stepのlengthに対しても汎化能力があることがわかる。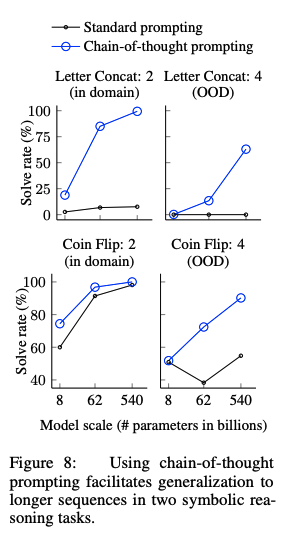
A Field Guide to Fable: Finding Your Unknowns, Claude, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #reading Issue Date: 2026-07-25 Comment
元ポスト:
プロンプトの再現性をAI に自動チューニングさせる方法 ~ 暗黙知を排除する, mizchi, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #SoftwareEngineering Issue Date: 2026-04-20 Comment
元ポスト:
How we optimized Dash's relevance judge with DSPy, Dropbox, 2026.03
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #AutomaticPromptEngineering #LLM-as-a-Judge #read-later #Initial Impression Notes Issue Date: 2026-04-07 Comment
元ポスト:
APEを使ってモデルを変更した際のプロンプト適応を効率化した話な模様。
Building Safer AI Browsers with BrowseSafe, Perplenity Team, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Evaluation #Blog #OpenWeight #Safety #Safeguard Issue Date: 2025-12-03 Comment
元ポスト:
prompt injectionをリアルタイムに検知するモデルとそのベンチマークとのこと
dataset:
https://huggingface.co/datasets/perplexity-ai/browsesafe-bench
model:
https://huggingface.co/perplexity-ai/browsesafe
[Paper Notes] Structured Prompting Enables More Robust, Holistic Evaluation of Language Models, Aali+, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-11-30 GPT Summary- 高品質な言語モデル(LM)の評価には、HELMのようなフレームワークが重要だが、固定プロンプトに依存するため過小評価のリスクがある。DSPyのような宣言的プロンプトフレームワークは、タスクごとに最適化されたプロンプトを提供するが、体系的な評価が不足している。本研究では、再現可能なDSPy+HELMフレームワークを提案し、構造化プロンプトを用いてLMのパフォーマンスをより正確に評価する。4つのプロンプト手法を用いて7つのベンチマークで評価した結果、HELMがLMのパフォーマンスを平均4%過小評価し、パフォーマンスの変動が大きくなることが示された。この研究は、LMの挙動を特徴付ける初の大規模ベンチマーク研究であり、オープンソースの統合とプロンプト最適化パイプラインを提供する。 Comment
AI Agentsの評価でもハーネスによって性能が変わるし、一般的なLLMでの評価もpromptingで性能変わるだろうなぁ、とは思っていたが、やはりそうだった模様。重要論文
しかしそもそもLLMの評価は変数が多すぎて、網羅的な評価は難しく、活用する際にベンチマークスコアは参考程度にした方が良いとは思う。自前データがあるなら自前で手元で評価すべし、という気はするが、評価するLLMの候補を選定する際には有用だと思われる(小並感)
関連:
- [Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
元ポスト:
プロンプトインジェクション2.0 : 進化する防御機構とその回避手法, yuasa, 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Slide #Attack Issue Date: 2025-07-23
LLM Prompt Tuning Playbook, 2024.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP Issue Date: 2024-11-13 Comment
- Prompt-Engineering-Guide, DAIR.AI も参照のこと
Prompt-Engineering-Guide, DAIR.AI
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Repository #One-Line Notes Issue Date: 2024-10-20 Comment
LLMのsettingから、few-shot, self-consistencyなどのprompting技術、さまざまなタスクの実例などが網羅的にまとまっている
A few prompt engineering tips that Ilya Sutskever picked up at OpenAI, Ilya Sutskever, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Post Issue Date: 2024-09-08
multimodal-maestro
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Library #MultiModal #AutomaticPromptEngineering Issue Date: 2023-12-01 Comment
Large Multimodal Model (LMM)において、雑なpromptを与えるても自動的に良い感じoutputを生成してくれるっぽい?
以下の例はリポジトリからの引用であるが、この例では、"Find dog." という雑なpromptから、画像中央に位置する犬に[9]というラベルを与えました、というresponseを得られている。pipelineとしては、Visual Promptに対してまずSAMを用いてイメージのsegmentationを行い、各セグメントにラベルを振る。このラベルが振られた画像と、"Find dog." という雑なpromptを与えるだけで良い感じに処理をしてくれるようだ。
LLMのプロンプト技術まとめ, fuyu_quant (Toma Tanaka), Qiita, 2023.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Reading Reflections Issue Date: 2023-10-29 Comment
ざっと見たが現時点で主要なものはほぼ含まれているのでは、という印象
実際のプロンプト例が載っているので、理解しやすいかもしれない。
日本語LLMベンチマークと自動プロンプトエンジニアリング, PFN Blog, 2023.10
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #AutomaticPromptEngineering #One-Line Notes Issue Date: 2023-10-13 Comment
面白かった。特に、promptingによってrinnaとcyberのLLMの順位が逆転しているのが興味深かった。GAを使ったプロンプトチューニングは最近論文も出ていたが、日本語LLMで試されているのは面白かった。
Measuring Faithfulness in Chain-of-Thought Reasoning, Anthropic, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Chain-of-Thought #Faithfulness #needs-revision Issue Date: 2023-07-23
Prompt Engineering vs. Blind Prompting, 2023
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Blog #One-Line Notes #needs-revision Issue Date: 2023-05-12 Comment
experimentalな手法でprompt engineeringする際のoverview