SpokenLanguageProcessing
Issue Date: 2025-07-02 [Paper Note] AudioBERTScore: Objective Evaluation of Environmental Sound Synthesis Based on Similarity of Audio embedding Sequences, Minoru Kishi+, arXiv'25 GPT Summary- 新しい客観的評価指標AudioBERTScoreを提案し、合成音声の性能向上を目指す。従来の客観的指標は主観的評価との相関が弱いため、AudioBERTScoreは合成音声と参照音声の埋め込みの類似性を計算し、主観的評価との相関が高いことを実験で示した。 Comment
元ポスト:
text-to-audioの自動評価が可能な模様
#Survey #Pocket #Evaluation #FoundationModel #Speech
Issue Date: 2024-04-21 A Large-Scale Evaluation of Speech Foundation Models, Shu-wen Yang+, N_A, arXiv'24 GPT Summary- 基盤モデルパラダイムは、共有基盤モデルを使用して最先端のパフォーマンスを達成し、下流特有のモデリングやデータ注釈を最小限に抑えることを目指す。このアプローチは、自然言語処理(NLP)の分野で成功しているが、音声処理分野では類似したセットアップが不足している。本研究では、音声処理ユニバーサルパフォーマンスベンチマーク(SUPERB)を設立し、音声に対する基盤モデルパラダイムの効果を調査する。凍結された基盤モデルに続いて、タスク専用の軽量な予測ヘッドを使用して、SUPERB内の音声処理タスクに取り組むための統一されたマルチタスキングフレームワークを提案する。結果は、基盤モデルパラダイムが音声に有望であり、提案されたマルチタスキングフレームワークが効果的であることを示し、最も優れた基盤モデルがほとんどのSUPERBタスクで競争力のある汎化性能を持つことを示している。 Comment
Speech関連のFoundation Modelの評価結果が載っているらしい。
図は下記ツイートより引用
参考:
#ComputerVision #Pocket #NLP #LanguageModel #MultiModal #SpeechProcessing
Issue Date: 2023-07-22 Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, N_A, arXiv'23 GPT Summary- 本研究では、マルチモーダル学習のためのMeta-Transformerというフレームワークを提案しています。このフレームワークは、異なるモダリティの情報を処理し関連付けるための統一されたネットワークを構築することを目指しています。Meta-Transformerは、対応のないデータを使用して12のモダリティ間で統一された学習を行うことができ、テキスト、画像、ポイントクラウド、音声、ビデオなどの基本的なパーセプションから、X線、赤外線、高分光、IMUなどの実用的なアプリケーション、グラフ、表形式、時系列などのデータマイニングまで、幅広いタスクを処理することができます。Meta-Transformerは、トランスフォーマーを用いた統一されたマルチモーダルインテリジェンスの開発に向けた有望な未来を示しています。 Comment
12種類のモダリティに対して学習できるTransformerを提案
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
音声とテキストのOpenSourceマルチモーダルモデル。inputは音声のみ?に見えるが、出力はテキストと音声の両方を実施できる。GPT-4oレベルのspeech capabilityを目指すとaboutに記載されている。興味深い。
installの説明に `Whisper-large-v3` をインストールする旨が記載されているので、Whisper-large-v3で認識した内容に特化したSpeech Encoder/Adapterが学習されていると考えられる。https://github.com/user-attachments/assets/cea090e7-a42a-476d-85f6-50199d9ae180"
/>
- MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N/A, ACL'24 Findings
マルチモーダルなLLMの基本的な概念については上記参照のこと。
#Article #Repository Issue Date: 2024-10-04 textlesslib, FAIR, 2022.02 Comment
>テキストへの依存を脱し、生の音声録音のみを入力として表現力豊かな音声を生成する初の言語モデルである GSLM
元ポスト:
#Article #NLP #Library #SpokenLanguageGeneration Issue Date: 2023-05-04 Bark Comment
テキストプロンプトで音声生成ができるモデル。MIT License
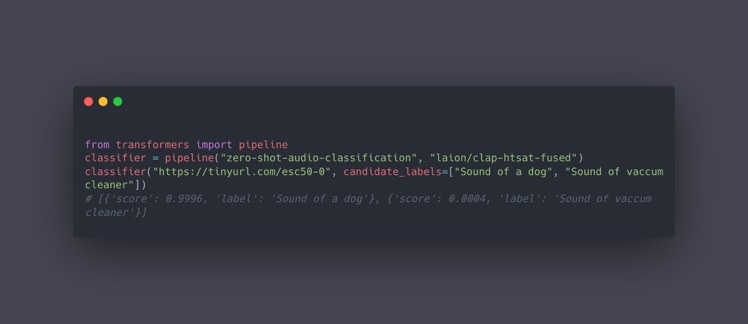
#Article #Embeddings #NLP #Library #RepresentationLearning Issue Date: 2023-04-25 CLAP Comment
テキストとオーディオの大量のペアを事前学習することで、テキストとオーディオ間を同じ空間に写像し、類似度を測れるようにしたモデル
たとえばゼロショットでaudio分類ができる