
TabularData
[Paper Note] Mixture-of-Minds: Multi-Agent Reinforcement Learning for Table Understanding, Yuhang Zhou+, ACL'26, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #ReinforcementLearning #AIAgents #SelfImprovement #ACL #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2026-04-07 GPT Summary- 表の理解と推論を高めるため、マルチエージェントフレームワークMixture-of-Mindsを提案。計画、コーディング、回答の役割に分割し、各エージェントが特定の側面を担う。自己改善トレーニングにモンテカルロ木探索を用いて強化学習を最適化。実験結果ではTableBenchで62.13%の改善を達成し、構造化されたアプローチの有効性を示す。 Comment
元ポスト:
複雑なタスクを特化型のエージェントに分解し、個々のエージェントを学習するためのpseudo-gold trajectoryを合成しエージェントをFinetuning。その後、FinetuningしたエージェントをGRPOによってend-to-endで学習する、という話に見える。pseudo-gold trajectoryは、個々の特化型のエージェントに対して複数の解候補を出力させ、解候補を次のエージェントに入力し解候補を生成...という手順をsequentialに適用していき、最終的に正しい応答を導き出せたtrajectoryを後ろ向きにたどることによって、pseudo-gold trajectoryを得る。FinetuningとRLがどのような順番で実施されるか、あるいは繰り返されるのか、といった部分についてはしっかり読み解けていない。
表データで実験をしているが、それは一つの応用例であり、汎用的に利用可能な手法と考えられる。
[Paper Note] TabArena: A Living Benchmark for Machine Learning on Tabular Data, Nick Erickson+, NeurIPS'25 Spotlight, 2025.06
Paper/Blog Link My Issue
#MachineLearning #NLP #Dataset #Evaluation #Selected Papers/Blogs #Live #One-Line Notes Issue Date: 2025-11-14 GPT Summary- TabArenaは、表形式データのための初の生きたベンチマークシステムであり、継続的に更新されることを目的としています。手動でキュレーションされたデータセットとモデルを用いて、公開リーダーボードを初期化しました。結果は、モデルのベンチマークにおける検証方法やハイパーパラメータ設定の影響を示し、勾配ブースティング木が依然として強力である一方、深層学習手法もアンサンブルを用いることで追いついてきていることを観察しました。また、基盤モデルは小規模データセットで優れた性能を発揮し、モデル間のアンサンブルが表形式機械学習の進展に寄与することを示しました。TabArenaは、再現可能なコードとメンテナンスプロトコルを提供し、https://tabarena.ai で利用可能です。 Comment
pj page:
https://github.com/autogluon/tabarena
leaderboard:
https://huggingface.co/spaces/TabArena/leaderboard
liveデータに基づくベンチマークで、手動で収集された51のtabularデータセットが活用されているとのこと。またあるモデルに対して数百にも登るハイパーパラメータ設定での実験をしアンサンブルをすることで単一モデルが到達しうるピーク性能を見ることに主眼を置いている、またいな感じらしい。そしてやはり勾配ブースティング木が強い。tunedは単体モデルの最も性能が良い設定での性能で、ensembleは複数の設定での同一モデルのアンサンブルによる結果だと思われる。
> TabArena currently consists of:
> 51 manually curated tabular datasets representing real-world tabular data tasks.
> 9 to 30 evaluated splits per dataset.
> 16 tabular machine learning methods, including 3 tabular foundation models.
> 25,000,000 trained models across the benchmark, with all validation and test predictions cached to enable tuning and post-hoc ensembling analysis.
> A live TabArena leaderboard showcasing the results.
openreview: https://openreview.net/forum?id=jZqCqpCLdU
[Paper Note] TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models, Léo Grinsztajn+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #FoundationModel Issue Date: 2025-11-14 GPT Summary- 次世代の表形式基盤モデルTabPFN-2.5は、最大50,000のデータポイントと2,000の特徴量を持つデータセット向けに設計され、TabPFNv2と比較してデータセルが20倍増加。業界標準のTabArenaで主要な手法となり、以前のモデルを上回る精度を達成。小規模から中規模のデータセットに対して100%の勝率を持ち、大規模データセットでも高い勝率を誇る。商用ユース向けに新しい蒸留エンジンを導入し、低レイテンシーでの展開を実現。これにより、TabPFNエコシステムに基づくアプリケーションのパフォーマンスが向上する。 Comment
TabArenaの2025.11時点でのSoTA
- [Paper Note] TabArena: A Living Benchmark for Machine Learning on Tabular Data, Nick Erickson+, NeurIPS'25 Spotlight, 2025.06
元ポスト:
[Paper Note] Scaling Generalist Data-Analytic Agents, Shuofei Qiao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #ScientificDiscovery #numeric #MajorityVoting Issue Date: 2025-10-09 GPT Summary- DataMindは、オープンソースのデータ分析エージェントを構築するためのスケーラブルなデータ合成とエージェントトレーニングの手法を提案。主な課題であるデータリソース、トレーニング戦略、マルチターンロールアウトの不安定性に対処し、合成クエリの多様性を高めるタスク分類や、動的なトレーニング目標を採用。DataMind-12Kという高品質なデータセットを作成し、DataMind-14Bはデータ分析ベンチマークで71.16%のスコアを達成し、最先端のプロプライエタリモデルを上回った。DataMind-7Bも68.10%でオープンソースモデル中最高のパフォーマンスを示した。今後、これらのモデルをコミュニティに公開予定。 Comment
元ポスト:
7B程度のSLMで70B級のモデルと同等以上の性能に到達しているように見える。論文中のp.2にコンパクトに内容がまとまっている。
Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey, Xi Fang+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #DataToTextGeneration #One-Line Notes Issue Date: 2024-03-05 GPT Summary- 最近の大規模言語モデリングの進展により、様々なタスクにおける応用が容易になっているが、包括的なレビューが不足している。この研究は、最近の進歩をまとめ、データセット、メトリクス、方法論を調査し、将来の研究方向に洞察を提供することを目的としている。また、関連するコードとデータセットの参照も提供される。 Comment
Tabular DataにおけるLLM関連のタスクや技術等のサーベイ
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding, Zilong Wang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #DataToTextGeneration #Chain-of-Thought #ICLR #KeyPoint Notes Issue Date: 2024-01-24 GPT Summary- LLMsを使用したChain-of-Tableフレームワークは、テーブルデータを推論チェーン内で活用し、テーブルベースの推論タスクにおいて高い性能を発揮することが示された。このフレームワークは、テーブルの連続的な進化を表現し、中間結果の構造化情報を利用してより正確な予測を可能にする。さまざまなベンチマークで最先端のパフォーマンスを達成している。 Comment
Table, Question, Operation Historyから次のoperationとそのargsを生成し、テーブルを順次更新し、これをモデルが更新の必要が無いと判断するまで繰り返す。最終的に更新されたTableを用いてQuestionに回答する手法。Questionに回答するために、複雑なテーブルに対する操作が必要なタスクに対して有効だと思われる。
Table and Image Generation for Investigating Knowledge of Entities in Pre-trained Vision and Language Models, ACL'23
Paper/Blog Link My Issue
#ComputerVision #NaturalLanguageGeneration #NLP #LanguageModel #TextToImageGeneration #ACL Issue Date: 2023-07-15 GPT Summary- 本研究では、Vision&Language(V&L)モデルにおけるエンティティの知識の保持方法を検証するために、テーブルと画像の生成タスクを提案します。このタスクでは、エンティティと関連する画像の知識を含むテーブルを生成する第一の部分と、キャプションとエンティティの関連知識を含むテーブルから画像を生成する第二の部分があります。提案されたタスクを実行するために、Wikipediaの約20万のinfoboxからWikiTIGデータセットを作成しました。最先端のV&LモデルOFAを使用して、提案されたタスクのパフォーマンスを評価しました。実験結果は、OFAが一部のエンティティ知識を忘れることを示しています。
[Paper Note] StructGPT: A General Framework for Large Language Model to Reason over Structured Data, Jinhao Jiang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #Reasoning #One-Line Notes Issue Date: 2023-05-21 GPT Summary- 本研究では、構造化データに基づく質問応答タスクを解決するためにIterative Reading-then-Reasoning(IRR)アプローチ、StructGPTを開発。特化した関数を用いることで、関連証拠を収集し推論を行うプロセスを構築。さらに、外部インターフェースを利用したinvoking-linearization-generation手順を提案し、反復的に解答に近づく。実験結果は、ChatGPTの性能を大幅に向上させ、教師ありチューニングと同等の成果を示す。 Comment
構造化データに対するLLMのゼロショットのreasoning能力を改善。構造化データに対するQAタスクで手法が有効なことを示した。
[Paper Note] Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning, Yunhu Ye+, SIGIR'23, 2023.01
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #SIGIR #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- LLMを活用して、表ベースの推論における巨大な証拠を小さなサブ証拠に分解し、複雑な質問をシンプルなサブ質問に分解。各ステップで論理と数値計算を分離することで、思考の連鎖における幻覚を防止。提案手法は、TabFactで人間を超える性能を達成。 Comment
テーブルとquestionが与えられた時に、questionをsub-questionとsmall tableにLLMでin-context learningすることで分割。subquestionの解を得るためのsqlを作成しスポットを埋め、hallucinationを防ぐ。最終的にLLM Reasonerが解答を導出する。TabFact Reasoningで初めて人間を超えた性能を発揮。
[Paper Note] Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes, Simran Arora+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #One-Line Notes #Data Issue Date: 2023-04-27 GPT Summary- LLMを用いた半構造化文書の自動処理システムEVAPORATEを提案。文書からの値を直接抽出する方法と、抽出コードを合成する方法の二つを評価。コード合成はコストが低いが精度が劣るため、EVAPORATE-CODE+を導入し、品質を向上。弱教師あり学習を用いた抽出のアンサンブルにより、文書処理の効率を大幅に改善。処理トークン数を平均110倍に削減し、最先端システムを超える成果を達成。 Comment
LLMを使うことで、半構造化文章から自動的にqueryableなテーブルを作成することを試みた研究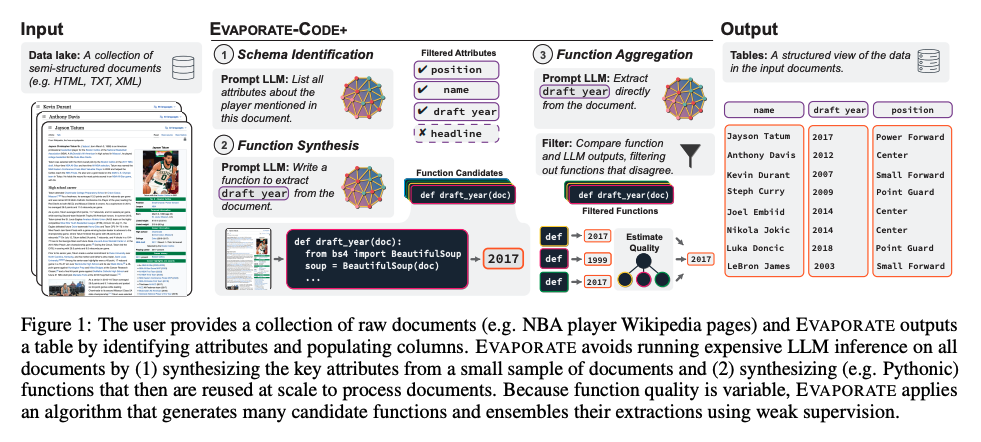
[Paper Note] Why do tree-based models still outperform deep learning on tabular data?, Léo Grinsztajn+, NeurIPS'22, 2022.07
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Transformer #InductiveBias #NeurIPS #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 深層学習はテキストと画像で進展を見せているが、表形式データでの優位性は不明。標準と新規の深層学習法を木ベースのモデルと比較し、45のデータセットでベンチマークを実施。結果は、中規模データにおいて木ベースモデルが依然として優れた性能を示すことを示す。木ベースモデルとニューラルネットワークのバイアスの違いを実証的に調査し、表形式データ特化のNN開発に向けた課題を提示。標準的ベンチマーク用の生データを提供し、各学習器のハイパーパラメータ探索に20,000時間の計算資源を投入した。 Comment
tree basedなモデルがテーブルデータに対してニューラルモデルよりも優れた性能を発揮することを確認し、なぜこのようなことが起きるかいくつかの理由を説明した論文。
NNよりもtree basedなモデルがうまくいく理由として、モデルの帰納的バイアスがテーブルデータに適していることを調査している。考察としては
1. NNはスムーズなターゲットを学習する能力が高いが、表形式のような不規則なデータを学習するのに適していない
- Random Forestでは、x軸においてirregularなパターンも学習できているが、NNはできていない。
2. uninformativeなfeaatureがMLP-likeなNNに悪影響を与える
- Tabular dataは一般にuninformativeな情報を多く含んでおり、実際MLPにuninformativeなfeatureを組み込んだ場合tree-basedな手法とのgapが増加した
3. データはrotationに対して不変ではないため、学習手順もそうあるべき(この辺がよくわからなかった)
- ResNetはRotationを加えても性能が変わらなかった(rotation invariantな構造を持っている)
openreview: https://openreview.net/forum?id=Fp7__phQszn
[Paper Note] Revisiting Pretraining Objectives for Tabular Deep Learning, Ivan Rubachev+, arXiv'22, 2022.07
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #MachineLearning #One-Line Notes Issue Date: 2022-12-01 GPT Summary- 深層学習モデルは、GBDTと競争できるものの、事前学習手法の有効性や選択基準は明確でない。本研究では、表形式データに対する深層学習モデルの事前学習のベストプラクティスを特定し、ターゲットラベルを活用することが性能向上に寄与することを示した。適切な事前学習により、深層学習モデルはGBDTをしばしば上回る。 Comment
Tabular Dataを利用した場合にKaggleなどでDeepなモデルがGBDT等に勝てないことが知られているが、GBDT等とcomparable になる性能になるようなpre-trainingを提案したよ、的な内容っぽい
ICLR 2023 OpenReview: https://openreview.net/forum?id=kjPLodRa0n
Learning to Generate Move-by-Move Commentary for Chess Games from Large-Scale Social Forum Data, Jhamtani+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Dataset #DataToTextGeneration #ACL #Encoder-Decoder Issue Date: 2025-08-06 Comment
データセットの日本語解説(過去の自分の資料): https://speakerdeck.com/akihikowatanabe/data-to-text-datasetmatome-summary-of-data-to-text-datasets?slide=66
NVIDIA-Nemotron-Parse-v1.1, NVIDIA, 2025.11
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #OpenWeight #read-later #DocParser #VisionLanguageModel #OCR Issue Date: 2025-11-20 Comment
元ポスト:
olmocr2と比較して性能はどうだろうか、特に日本語
- olmOCR 2: Unit test rewards for document OCR, Ai2, 2025.10
FindWiki, Guilherme Penedo, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #LanguageModel #Mathematics #MultiLingual #DataFiltering #One-Line Notes Issue Date: 2025-10-22 Comment
元ポスト:
2023年時点で公開されたWikipediaデータをさらに洗練させたデータセット。文字のレンダリング、数式、latex、テーブルの保持(従来は捨てられてしまうことが多いとのこと)、記事に関係のないコンテンツのフィルタリング、infoboxを本文から分離してメタデータとして保持するなどの、地道な前処理をして洗練化させたとのこと。
Table Transformer Demo
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Transformer Issue Date: 2023-12-01 Comment
PDF中のテーブルとその構造(行列セル)をdetectするモデル
Exampleは以下のような感じ(日本語だとどれくらいできるのかな...)