
Update
DUC 2007, Update Summarization Dataset, 2006.10
My Issue
#Article #DocumentSummarization #NLP #Dataset #One-Line Notes Issue Date: 2017-12-28 Comment
DUC 2007: https://duc.nist.gov/duc2007/tasks.html
[Paper Note] Update Summary Update, Copeck et al., TAC’08
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #One-Line Notes Issue Date: 2017-12-28 Comment
被引用数は少ないが、良い論文からreferされているイメージ
[Paper Note] DualSum: a Topic-Model based approach for update summarization, Delort et al., EACL’12
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #EACL #KeyPoint Notes Issue Date: 2017-12-28 Comment
・大半のupdate summarizationの手法はdocument set Aがgivenのとき,document set Bのupdate summarizationをつくる際には,redundancy removalの問題として扱っている.
・この手法は,1つのsentenceの中にredundantな情報とnovelな情報が混在しているときに,そのsentenceをredundantなsentenceだと判別してしまう問題点がある.加えて,novel informationを含んでいると判別はするけれども,明示的にnovel informationがなんなのかということをモデル化していない.
・Bayesian Modelを使うことによって,他の手法では抜け落ちている確率的な取り扱いが可能にし, unsupervisedでできるようにする.
[Paper Note] Document Update Summarization Using Incremental Hierarchical Clustering, Wang+, CIKM’10
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #CIKM #KeyPoint Notes Issue Date: 2017-12-28 Comment
・既存のMDSではdocumentをbatch処理するのが前提.typicalなクラスタリングベースの手法やグラフベースの手法はsentence-graphを構築して要約を行う.しかし,情報がsequentialに届き,realtimeで要約を行いたいときにこのような手法を使うと,毎回すでに処理したことがあるテキストを処理することになり,time consumingだし,無駄な処理が多い.特に災害時などでは致命的.このような問題に対処するために,ドキュメントがarriveしたときに,ただちにupdate summaryが生成できる手法を提案する.
・既存のヒューリスティックなfeature(tf-isfやキーワード数など)を用いたスコアリングは,existing sentencesとnewly coming sentencesが独立しているため,real world scenarioにおいて実用的でないし,hardly perform wellである.
・なので,incremental hierarchical clusteringの手法でsentence clusterをre-organizeすることで,効果的に要約のupdateを行う.このとき,sentence同士のhierarchical relationshipはreal timeにre-constructされる.
・TACのupdate summarizationとは定義が微妙に違うらしい.主に2点.TACではnewly coming documentsだけを対象にしているが,この研究 ではすべてのドキュメントを対象にする.さらに,TACでは一度だけupdate summarizationする(document set Bのみ)が,この研究ではdocumentsがsequenceでarriveするのを前提にする.なので,TACに対しても提案手法は適用可能.
・Sequence Update Summarizationの先駆け的な研究かもしれない.SUSがのshared taskになったのは2013だし.
・incremental hierarchical clusteringにはCOBWEB algorithm (かなりpopularらしい)を使う.COBWEBアルゴリズムは,新たなelementが現れたとき,Category Utilityと呼ばれるcriterionを最大化するように,4種類の操作のうち1つの操作を実行する(insert(クラスタにsentenceを挿入), create(新たなクラスタつくる), merge(2クラスタを1つに),split(existingクラスタを複数のクラスタに)).ただ,もとのCOBWEBで使われているnormal attribute distributionはtext dataにふさわしくないので,Katz distributionをword occurrence distributionとして使う(Sahooらが提案している.).元論文読まないと詳細は不明.
・要約の生成は,実施したoperationごとに異なる.
- Insertの場合: クラスタを代表するsentenceをクエリとのsimilarity, クラスタ内のsentenceとのintra similarityを計算して決めて出力する.
- createの場合: 新たに生成したクラスタcluster_kを代表する文を,追加したsentence s_newとする.
- mergeの場合: cluster_aとcluster_bをmergeして新たなcluster_cを作った場合,cluster_cを代表する文を決める.cluster_cを代表する文は,cluster_aとcluster_bを代表する文とクエリとのsimilarityをはかり,similarityが大きいものとする.
- splitの場合: cluster_aをsplitしてn個の新たなクラスタができたとき,各新たなn個のクラスタにおいて代表する文を,original subtreeの根とする.
・TAC08のデータとHurricane Wilma Releasesのデータ(disaster systemからtop 10 queryを取得,5人のアノテータに正解を作ってもらう)を使って評価.(要約の長さを揃えているのかが気になる。長さが揃っていないからROUGEのF値で比較している?)
・一応ROUGEのF値も高いし,速度もbaselineと比べて早い.かなりはやい.genericなMDSとTAC participantsと比較.TAC Bestと同等.GenericMDSより良い.document setAの情報を使ってredundancy removalをしていないのにTAC Bestを少しだけoutperform.おもしろい.
・かつ,TAC bestはsentence combinationを繰り返す手法らしく,large-scale online dataには適していないと言及.
[Paper Note] Incremental Update Summarization: Adaptive Sentence Selection based on Prevalence and Novelty, McCreadie et al., CIKM’14
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #CIKM #KeyPoint Notes Issue Date: 2017-12-28 Comment
・timelyなeventに対してupdate summarizationを適用する場合を考える.たとえば6日間続いたeventがあったときにその情報をユーザが追う為に何度もupdate summarizationシステムを用いる状況を考える.6日間のうち新しい情報が何も出てこない期間はirrelevantでredundantな内容を含む要約が出てきてしまう.これをなんとかする手法が必要だというのがmotivation.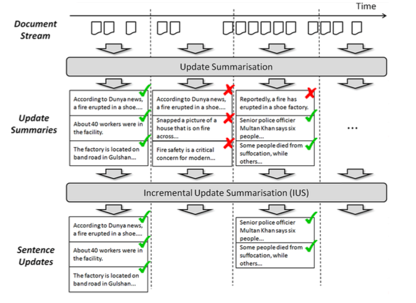
・どのような手法かというと,news streamsからnovel updatesをtimely mannerで自動抽出し,一方で,抽出するupdatesはirrelevant, uninformative or redundant contentを最小化するようなもの手法
・手法は既存のUpdate Summarization手法(lambdaMART, learning to rank baseの手法)で10文を出力し,何文目までを残すか(rank-cut off problem)を解くことで,いらないsentenceをはぶいている.
・rank cut offをする際はlinear regressionとModel Treesを使っているが,linear regressionのような単純な手法だと精度があがらず,Model Treesを使ったほうがいい結果が出た.
・素性は主にprevalence (sentenceが要約したいトピックに沿っているか否か),novelty(sentenceが新しい情報を含んでいるか),quality(sentenceがそもそも重要かどうか)の3種類の素性を使っている.気持ちとしては,prevalenceとnoveltyの両方が高いsentenceだけを残したいイメージ.つまり,トピックに沿っていて,なおかつ新しい情報を含んでいるsentence
・loss functionには,F値のような働きをするものを採用(とってきたrelevant updateのprecisionとrecallをはかっているイメージ).具体的には,Expected Latency GainとLatency Comprehensivenessと呼ばれるTREC2013のquality measureに使われている指標を使っている.
・ablation testの結果を見ると,qualityに関する素性が最もきいている.次にnovelty,次点でprevalence
・提案手法はevent発生から時間が経過すると精度が落ちていく場合がある.
・classicalなupdate summarizationの手法と比較しているが,Classyがかなり強い,Model treesを使わない提案手法や,他のbaselineを大きくoutperform. ただ,classyはmodel treesを使ったAdaptive IUSには勝てていない.
・TREC 2013には,Sequantial Update Summarizationタスクなるものがあるらしい.ユーザのクエリQと10個のlong-runnning event(典型的には10日間続くもの,各イベントごとに800〜900万記事),正解のnuggetsとそのtimestampが与えられたときにupdate summarizationを行うタスクらしい.
[Paper Note] Update Summarization using Semi-Supervised Learning Based on Hellinger Distance, Wang et al., CIKM’15, 2015.10
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #CIKM #KeyPoint Notes Issue Date: 2017-12-28 Comment
・Hellinger Distanceを用いてSentence Graphを構築.ラベル伝搬により要約に含める文を決定する手法
・update summarizationの研究ではsimilarityをはかるときにcosine similarityを用いることが多い.
・cosine similarityはユークリッド距離から直接的に導くことができる.
・Vector Space Modelはnonnegativeなmatrixを扱うので,確率的なアプローチで取り扱いたいが,ユークリッド距離は確率を扱うときにあまり良いmetricではない.そこでsqrt-cos similarityを提案する.sqrt-cosは,Hellinger Distanceから求めることができ,Hellinger Distanceは対称的で三角不等式を満たすなど,IRにおいて良いdistance measureの性質を持っている.(Hellinger Distanceを活用するために結果的に類似度の尺度としてsqrt-cosが出てきたとみなせる)
・またHellinger DistanceはKL Divergenceのsymmetric middle pointとみなすことができ,文書ベクトル生成においてはtf_idfとbinary weightingのちょうど中間のような重み付けを与えているとみなせる.
・要約を生成する際は,まずはset Aの文書群に対してMMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
を適用する(redundancyの項がmaxではなくて平均になっている).similarityはsqrt-cosを用いる.
・sqrt-cosと,set Aの要約結果を用いると,sentence graphを構築できる.sentence graphはset Aとset Bの各sentenceをノードとするグラフで,エッジの重みはsqrt-cosとなっている.このsentence graph上でset Aの要約結果のラベルをset B側のノードに伝搬させることで,要約に含めるべき文を選択する.
・ラベル伝搬にはGreen’s functionを用いる.set Bにlabel “1”がふられるものは,given topicとset Aのcontentsにrelevantなsentenceとなる.
・TAC2011のデータで評価した結果,standardなMMRを大幅にoutperform, co-ranking, Centroidベースの手法などよりも良い結果.
[Paper Note] TimedTextRank: Adding the Temporal Dimension to Multi-Document Summarization, Xiaojun Wan, SIGIR’07, 2007.07
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #SIGIR #KeyPoint Notes Issue Date: 2017-12-28 Comment
・evolving topicsを要約するときは,基本的に新しい情報が重要だが,TextRankはそれが考慮できないので拡張したという話.
・dynamic document setのnew informationをより重視するTimedTextRankを提案
・TextRankのvoteの部分に重み付けをする.old sentenceからのvoteよりも,new documentsに含まれるsentenceからのvoteをより重要視
・評価のときは,news pageをクローリングし,incremental single-pass clustering algorithmでホットなトピックを抽出しユーザにみせて評価(ただしこれはPreliminary Evaluation).
[Paper Note] The LIA Update Summarization Systems at TAC-2008, Boudin et al. TAC’08, 2008.11
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #KeyPoint Notes Issue Date: 2017-12-28 Comment
・Scalable MMR [Paper Note] A Scalable MMR Approach to Sentence Scoring for Multi-Document Update Summarization, Boudin et al., COLING’08, 2008.08
とVariable length intersection gap n-term modelを組み合わせる.
・Variable length intersection gap n-term modelは,あるトピックのterm sequenceは他の異なる語と一緒にでてくる?という直感にもとづく.要は,drugs.*treat.*mental.*illnessなどのパターンをとってきて活用する.このようなパターンをn-gram, n-stem, n-lemmaごとにつくり3種類のモデルを構築.この3種類のモデルに加え,coverage rate (topic vocabularyがセグメント内で一度でもみつかる割合)とsegmentのpositionの逆数を組みあわせて,sentenceのスコアを計算(先頭に近いほうが重要).
・coherenceを担保するために,sentenceを抽出した後,以下のpost-processingを行う.
Acronym rewriting(初めてでてくるNATOなどの頭字語はfull nameにする)
Date and number rewriting(US standard formsにする)
Temporal references rewriting (next yearなどの曖昧なreferenceを1993などの具体的なものにする)
Discursive form rewriting (いきなりButがでてくるときとかは削るなど)
カッコやカギカッコは除き,句読点をcleanedする
・TAC 2008におけるROUGE-2の順位は72チーム中32位
[Paper Note] A Scalable MMR Approach to Sentence Scoring for Multi-Document Update Summarization, Boudin et al., COLING’08, 2008.08
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #COLING #KeyPoint Notes Issue Date: 2017-12-28 Comment
・MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
をupdate summarization用に拡張.History(ユーザが過去に読んだsentence)の数が多ければ多いほどnon-redundantな要約を出す (Queryに対するRelevanceよりもnon-redundantを重視する)
・Historyの大きさによって,redundancyの項の重みを変化させる.
・MMRのredundancyの項を1-max Sim2(s, s_history)にすることでnoveltyに変更.ORよりANDの方が直感的なので二項の積にする.
・MMRのQueryとのRelevanceをはかる項のSimilarityは,cossimとJaro-Winkler距離のinterpolationで決定. Jaro-Winkler距離とは,文字列の一致をはかる距離で,値が大きいほど近い文字列となる.文字ごとの一致だけでなく,ある文字を入れ替えたときにマッチ可能かどうかも見る.一致をはかるときはウィンドウを決めてはかるらしい.スペルミスなどの検出に有用.クエリ内の単語とselected sentences内の文字列のJaro-Winkler距離を計算.各クエリごとにこれらを求めクエリごとの最大値の平均をとる.
・冗長性をはかるSim2では,normalized longest common substringを使う.
[Paper Note] Improving Update Summarization via Supervised ILP and Sentence Reranking, Li et al. NAACL’15, 2015.05
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #IntegerLinearProgramming (ILP) #NAACL #KeyPoint Notes Issue Date: 2017-12-28 Comment
・update summarizationをILPで定式化.基本的なMDSのILPのterm weightingにsalienceの要素に加えてnoveltyの要素を加える.term weightingにはbigramを用いる.bigram使うとよくなることがupdate summarizationだと知られている.weightingは平均化パーセプトロンで学習
・ILPでcandidate sentencesを求めたあと,それらをSVRを用いてRerankingする.SVRのloss functionはROUGE-2を使う.
・Rerankingで使うfeatureはterm weightingした時のsentenceレベルのfeatureを使う.
・RerankingをするとROUGE-2スコアが改善する.2010, 2011のTAC Bestと同等,あるいはそれを上回る結果.novelty featureを入れると改善.
・noveltyのfeatureは,以下の通り.
Bigram Level
-bigramのold datasetにおけるDF
-bigram novelty value (new datasetのbigramのDFをold datasetのDFとDFの最大値の和で割ったもの)
-bigram uniqueness value (old dataset内で出たbigramは0, すでなければ,new dataset内のDFをDFの最大値で割ったもの)
Sentence Level
-old datasetのsummaryとのsentence similarity interpolated n-gram novelty (n-gramのnovelty valueをinterpolateしたもの)
-interpolated n-gram uniqueness (n-gramのuniqueness valueをinterpolateしたもの)
・TAC 2011の評価の値をみると,Wanらの手法よりかなり高いROUGE-2スコアを得ている.
[Paper Note] Update Summarization Based on Co-Ranking with Constraints, Wiaojun Wan, COLING’12, 2012.12
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #COLING #KeyPoint Notes Issue Date: 2017-12-28 Comment
・PageRankの枠組みを拡張してold datasetとnew dataset内のsentenceをco-ranking
・co-rankingするときは,update scoreとconsistency scoreというものを求め相互作用させる.
・update scoreが高いsentenceは同じdataset内では正の関係,異なるdataset内では負の関係を持つ.
・consistency scoreが高いsentenceは同じdataset内では正の関係,異なるdataset内では正の関係を持つ.
・負の関係はdissimilarity matrixを用いて表現する.
・あとはupdate scoreとconsistency scoreを相互作用させながらPageRankでスコアを求める.デコーディングはupdate scoreをgreedyに.
・update scoreとconsistency scoreの和は定数と定義,この論文では定数をsentenceのinformative scoreとしている.これがタイトルにある制約.informative scoreはAffinity GraphにPageRankを適用して求める.
・制約が入ることで,consistency scoreが低いとupdate scoreは高くなるような効果が生まれる.逆もしかり.