
WWW
[Paper Note] Pre-train and Fine-tune: Recommenders as Large Models, Zhenhao Jiang+, WWW'25, 2025.01
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel Issue Date: 2025-01-28 GPT Summary- ユーザーの興味は時期や地域によって変動するが、既存の推奨システムはこれに対応しきれない。マルチドメイン学習が解決策として考えられるが、産業用システムはデータ量やコストの面で複雑である。そこで推奨システムを大規模な事前学習モデルと捉え、ファインチューニングの手法を提案。情報認識型適応カーネル(IAK)を用いて知識圧縮と知識マッチングの二段階のプロセスを定義し、高い解釈性を持つ手法を設計。広範な実験により効果を確認し、オンラインプラットフォームでの展開によるビジネスへの貢献も報告。ファインチューニングに関連する問題点と対策も提示。 Comment
元ポスト:
[Paper Note] Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks, Brian J Chan+, WWW'25 Short Paper
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #One-Line Notes #KV Cache #Short Issue Date: 2025-01-26 GPT Summary- キャッシュ拡張生成(CAG)は、RAGの課題を克服するために提案された手法で、LLMの拡張コンテキストに事前に関連リソースをロードし、検索なしでクエリに応答する。CAGは検索の遅延を排除し、エラーを最小限に抑えつつ、コンテキストの関連性を維持。性能評価では、CAGが従来のRAGを上回るか補完することが示され、特に制約のある知識ベースにおいて効率的な代替手段となることが示唆されている。 Comment
元ポスト:
外部知識として利用したいドキュメントがそこまで大きく無いなら、事前にLLMで全てのKey Valueを計算しておきKV Cacheとして利用可能にしておけば、生成時に検索をすることもなく、contextとして利用して生成できるじゃん、という研究
[Paper Note] ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation, Jianghao Lin+, WWW'24
Paper/Blog Link My Issue
#RecommenderSystems #NLP #UserModeling #LanguageModel #CTRPrediction #RAG(RetrievalAugmentedGeneration) #LongSequence #KeyPoint Notes Issue Date: 2025-03-27 GPT Summary- 本論文では、ゼロショットおよび少ショットの推薦タスクにおいて、大規模言語モデル(LLMs)を強化する新しいフレームワーク「ReLLa」を提案。LLMsが長いユーザー行動シーケンスから情報を抽出できない問題に対処し、セマンティックユーザー行動検索(SUBR)を用いてデータ品質を向上させる。少ショット設定では、検索強化指示チューニング(ReiT)を設計し、混合トレーニングデータセットを使用。実験により、少ショットReLLaが従来のCTRモデルを上回る性能を示した。 Comment
LLMでCTR予測する際の性能を向上した研究。
そもそもLLMでCTR予測をする際は、ユーザのデモグラ情報とアクティビティログなどのユーザプロファイルと、ターゲットアイテムの情報でpromptingし、yes/noを出力させる。yes/noトークンのスコアに対して2次元のソフトマックスを適用して[0, 1]のスコアを得ることで、CTR予測をする(式1, 2)。
この研究ではコンテキストにユーザのログを入れても性能がスケールしない問題に対処するために (Figure 1)
直近のアクティビティログではなく、ターゲットアイテムと意味的に類似したアイテムに関するログをコンテキストに入れ(SUBR)、zero shotのinferenceに活用する (Figure 3)。
few-shot recommendation(少量のクリックスルーログを用いてLLMをSFTすることでCTR予測する手法)においては、上述の意味的に類似したアイテムをdata augmentationに利用し(i.e, promptに埋め込むアクティビティログの量を増やして)学習する (Figure 5)。
zeroshotにおいて、SUBRで性能改善。fewshot recommendationにといて、10%未満のデータで既存の全データを用いる手法を上回る。また、下のグラフを見るとpromptに利用するアクティビティログの量が増えるほど性能が向上するようになった。
ただし、latencyは100倍以上なのでユースケースが限定される。
[Paper Note] Beyond Utility: Evaluating LLM as Recommender, Chumeng Jiang+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #Evaluation Issue Date: 2024-11-05 GPT Summary- LLMを推奨システムとして利用する研究が増加しているが、有用性を超える評価は未開拓である。本研究では、履歴長さの感度や候補位置のバイアス、生成過程、幻覚といった4つの新評価次元を提案し、多次元評価フレームワークを構築。7つのLLMベースの推奨モデルを評価し、従来モデルとの比較を実施。結果、LLMsは短い履歴でのランキングやリランキング設定で優れた性能を発揮するも、候補位置のバイアスや幻覚の問題が顕著であることを確認。評価フレームワークはLLMの推奨システム研究の進展に寄与することを目指す。 Comment
実装: https://github.com/JiangDeccc/EvaLLMasRecommender
openreview: https://openreview.net/forum?id=YiIdHqqoCd
Deep Interest Highlight Network for Click-Through Rate Prediction in Trigger-Induced Recommendation, Qijie Shen+, WWW'22
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CTRPrediction #One-Line Notes Issue Date: 2024-11-19 GPT Summary- トリガー誘発推薦(TIR)を提案し、ユーザーの瞬時の興味を引き出す新しい推薦手法を紹介。従来のモデルがTIRシナリオで効果的でない問題を解決するため、Deep Interest Highlight Network(DIHN)を開発。DIHNは、ユーザー意図ネットワーク(UIN)、融合埋め込みモジュール(FEM)、ハイブリッド興味抽出モジュール(HIEM)の3つのコンポーネントから成り、実際のeコマースプラットフォームでの評価で優れた性能を示した。 Comment
- [Paper Note] Collaborative Contrastive Network for Click-Through Rate Prediction, Chen Gao+, arXiv'24
の実験で利用されているベースライン
[Paper Note] Review Response Generation in E-Commerce Platforms with External Product Information, Zhao+, WWW'19
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration Issue Date: 2019-08-17
[Paper Note] Multimodal Review Generation for Recommender Systems, Truong+, WWW'19
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #One-Line Notes Issue Date: 2019-05-31 Comment
Personalized Review Generationと、Rating Predictionを同時学習した研究(同時学習自体はすでに先行研究がある)。
また、先行研究のinputは、たいていはuser, itemであるが、multi-modalなinputとしてレビューのphotoを活用したという話。
まだあまりしっかり読んでいないが、モデルのstructureはシンプルで、rating predictionを行うDNN、テキスト生成を行うLSTM(fusion gateと呼ばれる新たなゲートを追加)、画像の畳み込むCNNのハイブリッドのように見える。
[Paper Note] DKN: Deep Knowledge-Aware Network for News Recommendation, Hongwei Wang+, arXiv'18, 2018.01
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Contents-based #NewsRecommendation #Surface-level Notes Issue Date: 2021-06-01 GPT Summary- オンラインニュース推薦システムの課題を解決するために、知識グラフを活用した深層知識認識ネットワーク(DKN)を提案。DKNは、ニュースの意味と知識を融合する多チャネルの知識認識畳み込みニューラルネットワーク(KCNN)を用い、ユーザーの履歴を動的に集約する注意モジュールを搭載。実験により、DKNが最先端の推薦モデルを大幅に上回る性能を示し、知識の有効性も確認。 Comment
# Overview
Contents-basedな手法でCTRを予測しNews推薦。newsのタイトルに含まれるentityをknowledge graphと紐づけて、情報をよりリッチにして活用する。
CNNでword-embeddingのみならず、entity embedding, contextual entity embedding(entityと関連するentity)をエンコードし、knowledge-awareなnewsのrepresentationを取得し予測する。
※ contextual entityは、entityのknowledge graph上でのneighborhoodに存在するentityのこと(neighborhoodの情報を活用することでdistinguishableでよりリッチな情報を活用できる)
CNNのinputを\[\[word_ embedding\], \[entity embedding\], \[contextual entity embedding\]\](画像のRGB)のように、multi-channelで構成し3次元のフィルタでconvolutionすることで、word, entity, contextual entityを表現する空間は別に保ちながら(同じ空間で表現するのは適切ではない)、wordとentityのalignmentがとれた状態でのrepresentationを獲得する。
# Experiments
BingNewsのサーバログデータを利用して評価。
データは (timestamp, userid, news url, news title, click count (0=no click, 1=click))のレコードによって構成されている。
2016年11月16日〜2017年6月11日の間のデータからランダムサンプリングしtrainingデータセットとした。
また、2017年6月12日〜2017年8月11日までのデータをtestデータセットとした。
word/entity embeddingの次元は100, フィルタのサイズは1,2,3,4とした。loss functionはlog lossを利用し、Adamで学習した。

DeepFM超えを達成。
entity embedding, contextual entity embeddingをablationすると、AUCは2ポイントほど現象するが、それでもDeepFMよりは高い性能を示している。
また、attentionを抜くとAUCは1ポイントほど減少する。
1ユーザのtraining/testセットのサンプル
Sentiment analysis with deeply learned distributed representations of variable length texts, Hong+, Technical Report. Technical report, Stanford University, 2015
によって経験的にRNN, Recursive Neural Network等と比較して、sentenceのrepresentationを獲得する際にCNNが優れていることが示されているため、CNNでrepresentationを獲得することにした模様(footprint 7より)
Factorization Machinesベースドな手法(LibFM, DeepFM)を利用する際は、TF-IDF featureと、averaged entity embeddingによって構成し、それをuser newsとcandidate news同士でconcatしてFeatureとして入力した模様
content情報を一切利用せず、ユーザのimplicit feedbackデータ(news click)のみを利用するDMF(Deep Matrix Factorization)の性能がかなり悪いのもおもしろい。やはりuser-item-implicit feedbackデータのみだけでなく、コンテンツの情報を利用した方が強い。
(おそらく)著者によるtensor-flowでの実装: https://github.com/hwwang55/DKN
[Paper Note] Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising, Junwei Pan+, arXiv'18, 2018.06
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #One-Line Notes Issue Date: 2020-08-29 GPT Summary- クリック率(CTR)予測はオンライン広告での重要なタスクであり、マルチフィールドのカテゴリカルデータが使用される。フィールド認識型因子分解機(FFMs)は異なるフィールド間の特徴相互作用を効果的にモデル化するが、パラメータ数が膨大で実用的ではない。提案するField-weighted Factorization Machines(FwFMs)は、メモリ効率よく相互作用をモデル化し、わずか4%のパラメータで競争力のある性能を発揮。実験では、FwFMsがFFMsよりも0.92%および0.47%のAUC改善を達成した。 Comment
CTR予測でbest-performingなモデルと言われているField Aware Factorization Machines(FFM)では、パラメータ数がフィールド数×特徴数のorderになってしまうため非常に多くなってしまうが、これをよりメモリを効果的に利用できる手法を提案。FFMとは性能がcomparableであるが、パラメータ数をFFMの4%に抑えることができた。
[Paper Note] Netizen-Style Commenting on Fashion Photos: Dataset and Diversity Measures, Wen Hua Lin+, WWW'18
Paper/Blog Link My Issue
#NeuralNetwork #NLP #CommentGeneration Issue Date: 2019-08-24 GPT Summary- 深層ニューラルネットワークを用いた画像キャプショニングは進展しているが、生成される文は浅く、ユーザーのスタイルや意図を反映していない。これに対処するため、ネットユーザースタイルコメント(NSC)を提案し、ファッション写真に対して特徴的なコメントを自動生成する。新たに構築した「NetiLook」データセットを用い、コメントの多様性を評価する指標を提案し、トピックモデルとニューラルネットワークを組み合わせることで、画像キャプショニングの精度と多様性を向上させることを実証した。
[Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #StudentPerformancePrediction #KnowledgeTracing #In-Depth Notes Issue Date: 2021-05-28 GPT Summary- 動的キー・バリューメモリネットワーク(DKVMN)を提案し、学生の知識状態を追跡する新しい手法を開発。従来の手法の限界を克服し、基礎概念間の関係を活用して習得レベルを直接出力。実験により、DKVMNはKTデータセットで最先端モデルを上回る性能を示し、演習の基礎概念を自動発見する能力も持つ。 Comment
DeepなKnowledge Tracingの代表的なモデルの一つ。KT研究において、DKTと並んでbaseline等で比較されることが多い。
DKVMNと呼ばれることが多く、Knowledge Trackingができることが特徴。
モデルは下図の左側と右側に分かれる。左側はエクササイズqtに対する生徒のパフォーマンスptを求めるネットワークであり、右側はエクササイズqtに対する正誤情報rtが与えられた時に、メモリのvalueを更新するネットワークである。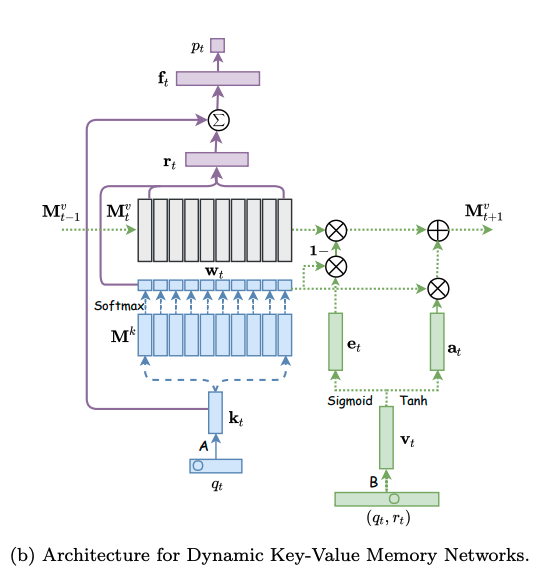
メモリとは生徒のknowledge stateを保持している行列であり、keyとvalueのペアによって形成される。keyとvalueは両者共にdv次元のベクトルで表現される。keyはコンセプトを表し、valueがそれぞれのコンセプトに対する生徒のknowledge stateを表している。ここで、コンセプトとスキルタグは異なる概念であり、スキルタグを生成される元となった概念のことをコンセプトと呼んでいる。コンセプトは基本的には専門家がタグ付しない限り、観測できない変数だと思われる。すなわち、コンセプトとはsynthetic-5データでいうところのc_t(5種類のコンセプト)に該当し、個々のコンセプトによって生成された50種類のexerciseがエクササイズタグに相当する。ASSISTments15データでいうところの、100種類のスキルタグがエクササイズタグで、それぞれのスキルタグのコンセプトはデータに明示されていない。
# ptの求め方
ptを求める際には、エクササイズqt(qtのサイズはエクササイズタグ次元Q; エクササイズタグが何を指すかは分かりづらく、基本的にはスキルタグのことだが、synthetic-5のように50種類のquestion_idをそのまま利用することも可)のembedding kt(dk次元)を求め、ktをメモリのkey M^k(N x dk次元)とのmatmulをとることによって、各コンセプトとのcorrelation weight w を求める。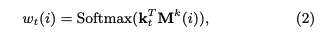
correlation weight wは、メモリのvalue(knowledge state)からknowledge stateのread contentベクトルrを生成する際に用いられる。read contentベクトルは、エクササイズqtに関する生徒のmastery levelのサマリとみなすことができる。
read contentベクトルrは、各キーのcorrelation weight w(scalar)とメモリのvalueベクトル(dv次元)との積をメモリサイズ(コンセプト数)Nでsummationすることによって求められる。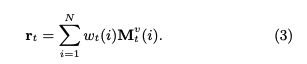
read contentベクトルを求めたのち、生徒のqtに対するmastery levelと取り組む問題qtの難易度を集約したサマリベクトルftをfully connected layerによって求める。求める際には、rとkt(qtのembedding)をconcatし、fully connected layerにかける。
最終的にサマリベクトルftを異なるfully connected layerにかけることによって、エクササイズqtに対するレスポンスを予測する。
# メモリの更新方法
エクササイズqtとそれに対する正誤rtが与えられたとき(qt, rt)、この情報のembedding vtを求める。求める際は、2Q x dv次元のembedding matrixをlookupする。このvtは、生徒がエクササイズに回答したことによってどれだけのknowledge growthを得たかを表している。
その後LSTMのforget gateに着想を得て、メモリのvalueをupdateする際に、最初にeraseベクトルを求めてvalueのうち忘却した情報を削除し、その後add vectorを利用してknowledge growthをvalueに反映させる。
eraseベクトルは、knowledge growth vtと(dv x dv)次元のtransformation matrix Eを利用して変換することによって求める。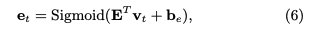
そして、メモリのvalueはこのeraseベクトルを用いて次の式で更新される。基本的には求めたeraseベクトルの分だけ全てのコンセプトのvalueがshrinkするように計算されているが、各コンセプトごとにshrinkさせる度合いをcorrelation weight wによって制御することによってvalueに対して忘却の概念を取り入れている。correlation weightとeraseベクトルのelementのうち、両方とも1となるelementに対応するvalueのelementが、0にリセットされるような挙動となる。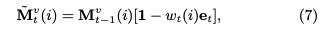
その後、knowledge growth vt から、新たなtransformation matrix D(dv x dv)を用いて、adding vector aが計算される。
最終的に、メモリの各valueは、adding vectorに対してcorrelation weightの重み分だけ各elementの値が更新される。
このような erase-followed-by-addな構造により、生徒の忘却と学習のlearning processを再現している。
# 予測性能
DKVMNが全てのデータセットにおいて性能が良かった。が、これは後のさまざまな研究の追試によりDKTとDKVMNの性能はcomparableであることが検証されているため、あまりこの結果は信用できない。
# learning curve
DKTとDKVMNの両者についてlearning curveを描いた結果が下記。DKTはtrainingとvalidationのlossの差が非常に大きくoverfittingしていることがわかるが、DKVMNはそのような挙動はなく、overfittingしにくいことを言及している。
# Concept Discovery
Figure4がsynthetic-5に対するConcept Discovery, Figure5がASSISTments15に対するConcept Discoveryの結果。synthetic-5は5種類のコンセプトによって50種類のエクササイズが生成されているが、メモリサイズNを5にすることによって完璧な各エクササイズのクラスタリングが実施できた(驚くべきことに、N=50でも5つのクラスタにきっちり分けることができた)。ASSISTments15データについても、類似したコンセプトのスキルタグが同じクラスタに属し、近い距離にマッピングされているため、コンセプトを見つけられたと主張している。
# Knowledge State Depiction
Synthetic-5に対する、各コンセプトのmasteryを可視化した結果が下図。
ここで注意すべきは、DKVMNが可視化するのは、メモリサイズNで指定した個々のkeyに該当するコンセプトのmasteryを可視化する方法を説明している点である。個々のスキルタグ(エクササイズタグ)に対するmasteryを可視化するわけではない点に注意。個々のスキルタグに対するmasteryは、DKTと同様にptがそれに該当するものと思われる。
個々のコンセプトのmasteryを可視化する手順は下記の通り。
まず、read content vector rを求める際に、masteryを可視化したいコンセプトのCorrelation weightのみを1とし、他のコンセプトのCorrelation weightを0とすることでrを算出する。
その後、次の式によって、エクササイズの難易度情報をマスクすること(weight matrixのうち、エクササイズembeddingが乗算される部分のみ0にマスクする)によってサマリベクトルftを求め、ftからfully connected layerを通じてptを求めることで、そのptを該当するコンセプトのmastery levelとみなす。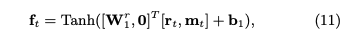
# 所感
スキルタグの背後にある隠れたコンセプトを見つけ、その隠れたコンセプトに対する習熟度を測るという点においてはDKTよりもDKVMNの方が優れていそう。
だが、スキルタグに対する習熟度を測るという点については、DKT, DKVMNのAUCにほとんど差がないことを鑑みるにDKVMNをわざわざ使う意味がどれだけあるのかな、という気がした。
特に Empirical Evaluation of Deep Learning Models for Knowledge Tracing: Of Hyperparameters and Metrics on Performance and Replicability, Sami+, Aalto University, JEDM'22
で報告されているように、DKVMNでリアルタイムに全てのスキルタグに対する習熟度をトラッキングするためには、DKVMNのoutputをoutput-per-skillにする必要があるが、DKVMNにおいてoutput-per-skillベクトルをoutputに採用すると予測性能が低下することがわかっている。このため、わざわざスキルタグに対する習熟度を求める際にDKVMNを使う必要もないのでは、という気がしている。
そうすると、現状スキルタグに対する習熟度をいい感じに求める手法は、DKT, DKT+ or EKTということになるのだろうか・・・。
追記:DKVMNのDKTと比較して良い点は、メモリネットワーク上にknowledge stateが保存されていて、inputはある一回の問題に対するtrialの正誤のみという点。DKTなどでは入力する系列の長さの上限が決まってしまうが、原理上はDKVMNは扱える系列の長さに制限がないことになる。この性質は非常に有用。
[Paper Note] Neural Collaborative Filtering, Xiangnan He+, WWW'17, 2017.08
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #MatrixFactorization #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-02-16 GPT Summary- 深層ニューラルネットワークを用いたレコメンダーシステムの研究が少ない中、本研究では協調フィルタリングの問題に取り組むため、NCF(Neural network-based Collaborative Filtering)フレームワークを提案。内積をニューラルアーキテクチャに置き換え、ユーザーとアイテムの相互作用を多層パーセプトロンでモデル化。実験により、提案手法が最先端技術に対して顕著な改善を示し、深層ニューラルネットワークの層を深くすることでレコメンデーション性能が向上することが確認された。 Comment
Collaborative FilteringをMLPで一般化したNeural Collaborative Filtering、およびMatrix Factorizationはuser, item-embeddingのelement-wise product + linear transofmration + activation で一般化できること(GMF; Generalized Matrix Factorization)を示し、両者を組み合わせたNeural Matrix Factorizationを提案している。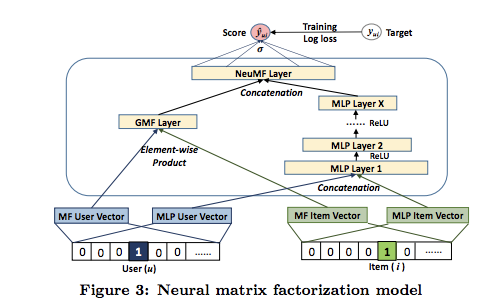
学習する際は、Implicit Dataの場合は負例をNegative Samplingし、LogLoss(Binary Cross-Entropy Loss)で学習する。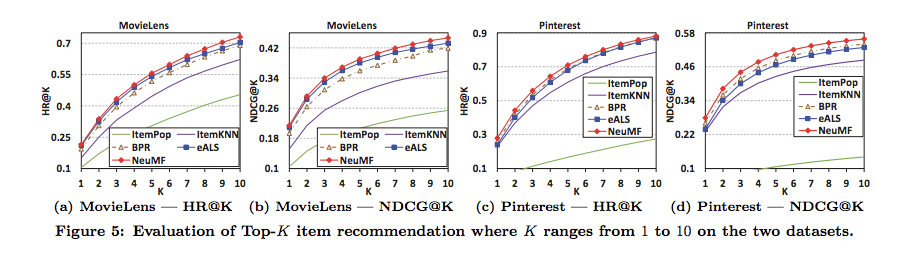
Neural Matrix Factorizationが、ItemKNNやBPRといったベースラインをoutperform
Negative Samplingでサンプリングする負例の数は、3~4程度で良さそう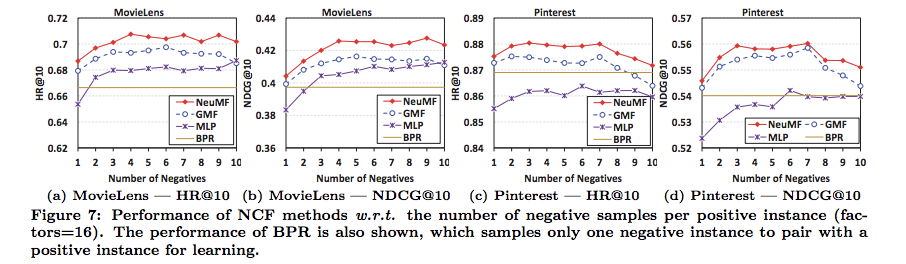
[Paper Note] Care to Comment? Recommendations for Commenting on News Stories, Shmueli+, WWW'12
Paper/Blog Link My Issue
#RecommenderSystems #Comments #One-Line Notes Issue Date: 2018-01-15 Comment
過去のユーザのコメントに対するratingに基づいて、ユーザが(コメントを通じて)議論に参加したいようなNews Storyを推薦する研究。
[Paper Note] Learning User Profiles from Tagging Data and Leveraging them for Personal(ized) Information Access, Michlmayr+, WWW'07, 2007.05
Paper/Blog Link My Issue
#UserModeling #Personalization #One-Line Notes Issue Date: 2017-12-28 Comment
social bookmarkのタグを使ってどのようにユーザモデルを作成する手法が提案されている。タグの時系列も扱っているみたいなので、参考になりそう。
[Paper Note] Leave a Reply: An Analysis of Weblog Comments, Mishne+, WWW'06
Paper/Blog Link My Issue
#Analysis #Comments #InformationRetrieval #KeyPoint Notes Issue Date: 2018-01-15 Comment
従来のWeblog研究では、コメントの情報が無視されていたが、コメントも重要な情報を含んでいると考えられる。
この研究では、以下のことが言及されている。
* (収集したデータの)ブログにコメントが付与されている割合やコメントの長さ、ポストに対するコメントの平均などの統計量
* ブログ検索におけるコメント活用の有効性(一部のクエリでRecallの向上に寄与、Precisionは変化なし)。記事単体を用いるのとは異なる観点からのランキングが作れる。
* コメント数とPV数、incoming link数の関係性など
* コメント数とランキングの関係性など
* コメントにおける議論の同定など
相当流し読みなので、読み違えているところや、重要な箇所の読み落とし等あるかもしれない。
[Paper Note] Item-based collaborative filtering recommendation algorithms, Sarwar+(with Konstan), WWW'01, 2021.04
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #ItemBased #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
アイテムベースな協調フィルタリングを提案した論文(GroupLens)
[Paper Note] Modeling Anchor Text and Classifying Queries to Enhance Web Document Retrieval, WWW’08, [Fujii, 2008], 2008.04
Paper/Blog Link My Issue
#Article #InformationRetrieval #KeyPoint Notes Issue Date: 2017-12-28