
AES(AutomatedEssayScoring)
[Paper Note] Do We Need a Detailed Rubric for Automated Essay Scoring using Large Language Models?, Lui Yoshida, AIED'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AIED Issue Date: 2025-07-29 GPT Summary- 本研究では、LLMを用いた自動エッセイ採点におけるルーブリックの詳細さが採点精度に与える影響を調査。TOEFL11データセットを用いて、完全なルーブリック、簡略化されたルーブリック、ルーブリックなしの3条件を比較。結果、3つのモデルは簡略化されたルーブリックでも精度を維持し、トークン使用量を削減。一方、1つのモデルは詳細なルーブリックで性能が低下。簡略化されたルーブリックが多くのLLMにとって効率的な代替手段であることが示唆されるが、モデルごとの評価も重要。
[Paper Note] The Impact of Example Selection in Few-Shot Prompting on Automated Essay Scoring Using GPT Models, Lui Yoshida, AIED'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AIED Issue Date: 2025-07-29 GPT Summary- 本研究では、GPTモデルを用いた少数ショットプロンプティングにおける例の選択が自動エッセイ採点(AES)のパフォーマンスに与える影響を調査。119のプロンプトを用いて、GPT-3.5とGPT-4のモデル間でのスコア一致を二次重み付きカッパ(QWK)で測定。結果、例の選択がモデルによって異なる影響を及ぼし、特にGPT-3.5はバイアスの影響を受けやすいことが判明。慎重な例の選択により、GPT-3.5が一部のGPT-4モデルを上回る可能性があるが、GPT-4は最も高い安定性とパフォーマンスを示す。これにより、AESにおける例の選択の重要性とモデルごとのパフォーマンス評価の必要性が強調される。
Japanese-English Sentence Translation Exercises Dataset for Automatic Grading, Miura+, EACL'24, 2024.03
Paper/Blog Link My Issue
#NLP #Dataset #Japanese #One-Line Notes Issue Date: 2024-11-28 GPT Summary- 第二言語学習の文翻訳演習の自動評価タスクを提案し、評価基準に基づいて学生の回答を採点する。日本語と英語の間で3,498の学生の回答を含むデータセットを作成。ファインチューニングされたBERTモデルは約90%のF1スコアで正しい回答を分類するが、誤った回答は80%未満。少数ショット学習を用いたGPT-3.5はBERTより劣る結果を示し、提案タスクが大規模言語モデルにとっても難しいことを示す。 Comment
STEsの図解。分かりやすい。いわゆる日本人が慣れ親しんでいる和文英訳、英文和訳演習も、このタスクの一種だということなのだろう。2-shotのGPT4とFinetuningしたBERTが同等程度の性能に見えて、GPT3.5では5shotしても勝てていない模様。興味深い。
Improving Domain Generalization for Prompt-Aware Essay Scoring via Disentangled Representation Learning, ACL'23
Paper/Blog Link My Issue
#General #NLP #RepresentationLearning #ACL Issue Date: 2023-07-18 GPT Summary- 自動エッセイスコアリング(AES)は、エッセイを評価するためのモデルですが、既存のモデルは特定のプロンプトにしか適用できず、新しいプロンプトに対してはうまく汎化できません。この研究では、プロンプトに依存しない特徴とプロンプト固有の特徴を抽出するためのニューラルAESモデルを提案し、表現の汎化を改善するための分離表現学習フレームワークを提案しています。ASAPとTOEFL11のデータセットでの実験結果は、提案手法の有効性を示しています。
[Paper Note] AI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays, Steffen Herbold+, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Education #ChatGPT #One-Line Notes Issue Date: 2023-04-28 GPT Summary- ChatGPTが生成したエッセイは、人間が書いたものよりも質が高いと評価されることが大規模な研究で示された。生成されたエッセイは独自の言語的特徴を持ち、教育者はこの技術を活用する新たな教育コンセプトを開発する必要がある。 Comment
ChatGPTは人間が書いたエッセイよりも高品質なエッセイが書けることを示した。
また、AIモデルの文体は、人間が書いたエッセイとは異なる言語的特徴を示している。たとえば、談話や認識マーカーが少ないが、名詞化が多く、語彙の多様性が高いという特徴がある、とのこと。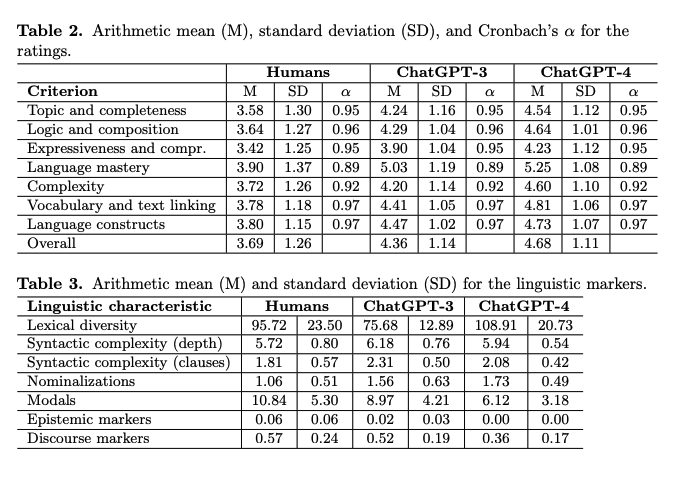
Cross-prompt Pre-finetuning of Language Models for Short Answer Scoring, Funayama+, 2024.09
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #Surface-level Notes Issue Date: 2024-11-28 Comment
SASでは回答データが限られているので、限られたデータからより効果的に学習をするために、事前に他のデータでモデルをpre-finetuningしておき、対象データが来たらpre-finetuningされたモデルをさらにfinetuningするアプローチを提案。ここで、prompt中にkeyphraseを含めることが有用であると考え、実験的に有効性を示している。
BERTでfinetuningをした場合は、key-phraseを含めた方が性能が高く、特にfinetuningのサンプル数が小さい場合にその差が顕著であった。
次に、LLM(swallow-8B, 70B)をpre-finetuningし、pre-finetuningを実施しない場合と比較することで、pre-finetuningがLLMのzero-shot、およびICL能力にどの程度影響を与えるかを検証した。検証の結果、pre-finetuningなしでは、そもそも10-shotにしてもQWKが非常に低かったのに対し、pre-finetuningによってzero-shotの能力が大幅に性能が向上した。一方、few-shotについては3-shotで性能が頭打ちになっているようにみえる。ここで、Table1のLLMでは、ターゲットとする問題のpromptでは一切finetuningされていないことに注意する(Unseenな問題)。
続いて、LLMをfinetuningした場合も検証。提案手法が高い性能を示し、200サンプル程度ある場合にHuman Scoreを上回っている(しかもBERTは200サンプルでサチったが、LLMはまだサチっていないように見える)。また、サンプル数がより小さい場合に、提案手法がより高いgainを得ていることがわかる。
また、個々の問題ごとにLLMをfinetuningするのは現実的に困難なので、個々の問題ごとにfinetuningした場合と、全ての問題をまとめてfinetuningした場合の性能差を比較したところ、まとめて学習しても性能は低下しない、どころか21問中18問で性能が向上した(LLMのマルチタスク学習の能力のおかげ)。
[Perplexity(hallucinationに注意)]( https://www.perplexity.ai/search/tian-fu-sitalun-wen-wodu-mi-ne-3_TrRyxTQJ.2Bm2fJLqvTQ#0)
国語記述問題自動採点システムの開発と評価, Yutaka Ishii+, 日本教育工学会, 2024.05
Paper/Blog Link My Issue
#Article #NLP #Japanese Issue Date: 2024-11-28
Exploring the Potential of Using an AI Language Model for Automated Essay Scoring, Mizumoto+, Research Methods in Applied Linguistics‘23
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Education #Author Thread-Post Issue Date: 2023-04-01 Comment
著者によるポスト:
著者によるブログ:
https://mizumot.com/lablog/archives/1805