
AIF(AI Feedback)
#Article#Pocket#NLP#LanguageModel#Alignment#InstructionTuning#LLM-as-a-Judge#ICML
Issue Date: 2024-01-22 Self-Rewarding Language Models, Weizhe Yuan+, N_A, ICML24 Summary将来のモデルのトレーニングには超人的なフィードバックが必要であり、自己報酬を提供するSelf-Rewarding Language Modelsを研究している。LLM-as-a-Judgeプロンプトを使用して、言語モデル自体が自己報酬を提供し、高品質な報酬を得る能力を向上させることを示した。Llama 2 70Bを3回のイテレーションで微調整することで、既存のシステムを上回るモデルが得られることを示した。この研究は、改善可能なモデルの可能性を示している。 Comment人間の介入無しで(人間がアノテーションしたpreference data無しで)LLMのAlignmentを改善していく手法。LLM-as-a-Judge Promptingを用いて、LLM自身にpolicy modelとreward modelの役割の両方をさせる。unlabeledなprompt ...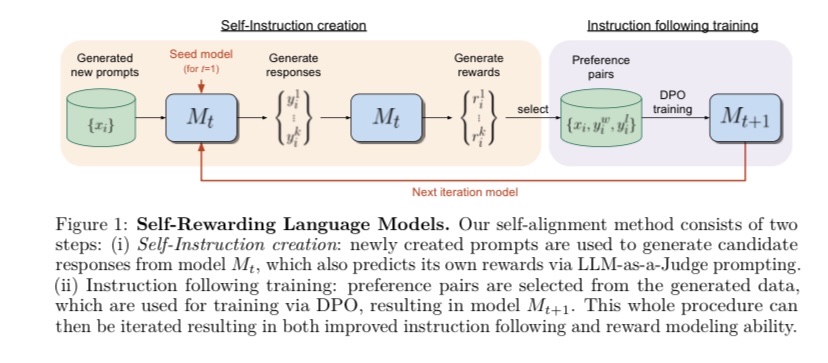
Issue Date: 2024-01-22 Self-Rewarding Language Models, Weizhe Yuan+, N_A, ICML24 Summary将来のモデルのトレーニングには超人的なフィードバックが必要であり、自己報酬を提供するSelf-Rewarding Language Modelsを研究している。LLM-as-a-Judgeプロンプトを使用して、言語モデル自体が自己報酬を提供し、高品質な報酬を得る能力を向上させることを示した。Llama 2 70Bを3回のイテレーションで微調整することで、既存のシステムを上回るモデルが得られることを示した。この研究は、改善可能なモデルの可能性を示している。 Comment人間の介入無しで(人間がアノテーションしたpreference data無しで)LLMのAlignmentを改善していく手法。LLM-as-a-Judge Promptingを用いて、LLM自身にpolicy modelとreward modelの役割の両方をさせる。unlabeledなprompt ...