
Admin’sPick
#Pretraining
#Pocket
#NLP
#LanguageModel
#Alignment
#Supervised-FineTuning (SFT)
#OpenWeight
#Architecture
#PostTraining
#DataMixture
Issue Date: 2025-08-25 [Paper Note] Motif 2.6B Technical Report, Junghwan Lim+, arXiv'25 SummaryMotif-2.6Bは、26億パラメータを持つ基盤LLMで、長文理解の向上や幻覚の減少を目指し、差分注意やポリノルム活性化関数を採用。広範な実験により、同サイズの最先端モデルを上回る性能を示し、効率的でスケーラブルな基盤LLMの発展に寄与する。 Comment元ポスト:https://x.com/scaling01/status/1959604841577357430?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHF:https://huggingface.co/Motif-Technologies/Motif-2.6B・アーキテクチャ
・1466
・2538
・学習手法
・1979
・8B token学習するごとに直近6つのcheckpointのelement-wiseの平均をとりモデルマージ。当該モデルに対して学習を継続、ということを繰り返す。これにより、学習のノイズを低減し、突然パラメータがシフトすることを防ぐ
・1060
・Adaptive Base Frequency (RoPEのbase frequencyを10000から500000にすることでlong contextのattention scoreが小さくなりすぎることを防ぐ)
・2540
・事前学習データ
・1943
・2539
・2109
を利用したモデル。同程度のサイズのモデルとの比較ではかなりのgainを得ているように見える。興味深い。
DatasetのMixtureの比率などについても記述されている。
 #Pocket
#NLP
#LanguageModel
#Decoding
#read-later
#Pocket
#NLP
#LanguageModel
#Decoding
#read-later
Issue Date: 2025-08-24 [Paper Note] Deep Think with Confidence, Yichao Fu+, arXiv'25 Summary「Deep Think with Confidence(DeepConf)」は、LLMの推論タスクにおける精度と計算コストの課題を解決する手法で、モデル内部の信頼性信号を活用して低品質な推論を動的にフィルタリングします。追加の訓練や調整を必要とせず、既存のフレームワークに統合可能です。評価の結果、特に難易度の高いAIME 2025ベンチマークで99.9%の精度を達成し、生成トークンを最大84.7%削減しました。 Commentpj page:https://jiaweizzhao.github.io/deepconf
vLLMでの実装:https://jiaweizzhao.github.io/deepconf/static/htmls/code_example.html元ポスト:https://x.com/jiawzhao/status/1958982524333678877?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtooluse、追加の訓練なしで、どのようなタスクにも適用でき、85%生成トークン量を減らした上で、OpenModelで初めてAIME2025において99% Acc.を達成した手法とのこと。vLLMを用いて50 line程度で実装できるらしい。reasoning traceのconfidence(i.e., 対数尤度)をgroup sizeを決めてwindow単位で決定し、それらをデコーディングのプロセスで活用することで、品質の低いreasoning traceに基づく結果を排除しつつ、majority votingに活用する方法。直感的にもうまくいきそう。オフラインとオンラインの推論によって活用方法が提案されている。あとでしっかり読んで書く。Confidenceの定義の仕方はグループごとのbottom 10%、tailなどさまざまな定義方法と、それらに基づいたconfidenceによるvotingの重み付けが複数考えられ、オフライン、オンラインによって使い分ける模様。
vLLMにPRも出ている模様? #Pocket #NLP #LanguageModel #LLMAgent #x-Use #read-later
Issue Date: 2025-08-15 [Paper Note] OpenCUA: Open Foundations for Computer-Use Agents, Xinyuan Wang+, arXiv'25 SummaryOpenCUAは、CUAデータと基盤モデルをスケールさせるためのオープンソースフレームワークであり、アノテーションインフラ、AgentNetデータセット、反射的なChain-of-Thought推論を持つスケーラブルなパイプラインを提供。OpenCUA-32Bは、CUAベンチマークで34.8%の成功率を達成し、最先端の性能を示す。研究コミュニティのために、アノテーションツールやデータセットを公開。 Comment元ポスト:https://x.com/gm8xx8/status/1956157162830418062?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/xywang626/status/1956400403911962757?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCUAにおいてProprietaryモデルに近い性能を達成した初めての研究な模様。重要
Issue Date: 2025-08-25 [Paper Note] Motif 2.6B Technical Report, Junghwan Lim+, arXiv'25 SummaryMotif-2.6Bは、26億パラメータを持つ基盤LLMで、長文理解の向上や幻覚の減少を目指し、差分注意やポリノルム活性化関数を採用。広範な実験により、同サイズの最先端モデルを上回る性能を示し、効率的でスケーラブルな基盤LLMの発展に寄与する。 Comment元ポスト:https://x.com/scaling01/status/1959604841577357430?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHF:https://huggingface.co/Motif-Technologies/Motif-2.6B・アーキテクチャ
・1466
・2538
・学習手法
・1979
・8B token学習するごとに直近6つのcheckpointのelement-wiseの平均をとりモデルマージ。当該モデルに対して学習を継続、ということを繰り返す。これにより、学習のノイズを低減し、突然パラメータがシフトすることを防ぐ
・1060
・Adaptive Base Frequency (RoPEのbase frequencyを10000から500000にすることでlong contextのattention scoreが小さくなりすぎることを防ぐ)
・2540
・事前学習データ
・1943
・2539
・2109
を利用したモデル。同程度のサイズのモデルとの比較ではかなりのgainを得ているように見える。興味深い。
DatasetのMixtureの比率などについても記述されている。
Issue Date: 2025-08-24 [Paper Note] Deep Think with Confidence, Yichao Fu+, arXiv'25 Summary「Deep Think with Confidence(DeepConf)」は、LLMの推論タスクにおける精度と計算コストの課題を解決する手法で、モデル内部の信頼性信号を活用して低品質な推論を動的にフィルタリングします。追加の訓練や調整を必要とせず、既存のフレームワークに統合可能です。評価の結果、特に難易度の高いAIME 2025ベンチマークで99.9%の精度を達成し、生成トークンを最大84.7%削減しました。 Commentpj page:https://jiaweizzhao.github.io/deepconf
vLLMでの実装:https://jiaweizzhao.github.io/deepconf/static/htmls/code_example.html元ポスト:https://x.com/jiawzhao/status/1958982524333678877?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtooluse、追加の訓練なしで、どのようなタスクにも適用でき、85%生成トークン量を減らした上で、OpenModelで初めてAIME2025において99% Acc.を達成した手法とのこと。vLLMを用いて50 line程度で実装できるらしい。reasoning traceのconfidence(i.e., 対数尤度)をgroup sizeを決めてwindow単位で決定し、それらをデコーディングのプロセスで活用することで、品質の低いreasoning traceに基づく結果を排除しつつ、majority votingに活用する方法。直感的にもうまくいきそう。オフラインとオンラインの推論によって活用方法が提案されている。あとでしっかり読んで書く。Confidenceの定義の仕方はグループごとのbottom 10%、tailなどさまざまな定義方法と、それらに基づいたconfidenceによるvotingの重み付けが複数考えられ、オフライン、オンラインによって使い分ける模様。
vLLMにPRも出ている模様? #Pocket #NLP #LanguageModel #LLMAgent #x-Use #read-later
Issue Date: 2025-08-15 [Paper Note] OpenCUA: Open Foundations for Computer-Use Agents, Xinyuan Wang+, arXiv'25 SummaryOpenCUAは、CUAデータと基盤モデルをスケールさせるためのオープンソースフレームワークであり、アノテーションインフラ、AgentNetデータセット、反射的なChain-of-Thought推論を持つスケーラブルなパイプラインを提供。OpenCUA-32Bは、CUAベンチマークで34.8%の成功率を達成し、最先端の性能を示す。研究コミュニティのために、アノテーションツールやデータセットを公開。 Comment元ポスト:https://x.com/gm8xx8/status/1956157162830418062?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/xywang626/status/1956400403911962757?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCUAにおいてProprietaryモデルに近い性能を達成した初めての研究な模様。重要
#Pocket
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#read-later
Issue Date: 2025-08-09
[Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, arXiv'25
Summary大規模言語モデル(LLM)の教師ありファインチューニング(SFT)の一般化能力を向上させるため、動的ファインチューニング(DFT)を提案。DFTはトークンの確率に基づいて目的関数を再スケーリングし、勾配更新を安定化させる。これにより、SFTを大幅に上回る性能を示し、オフライン強化学習でも競争力のある結果を得た。理論的洞察と実践的解決策を結びつけ、SFTの性能を向上させる。コードは公開されている。
Comment元ポスト:https://x.com/theturingpost/status/1953960036126142645?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは大変興味深い。数学以外のドメインでの評価にも期待したい。3節冒頭から3.2節にかけて、SFTとon policy RLのgradientを定式化し、SFT側の数式を整理することで、SFT(のgradient)は以下のようなon policy RLの一つのケースとみなせることを導出している。そしてSFTの汎化性能が低いのは 1/pi_theta によるimportance weightingであると主張し、実験的にそれを証明している。つまり、ポリシーがexpertのgold responseに対して低い尤度を示してしまった場合に、weightか過剰に大きくなり、Rewardの分散が過度に大きくなってしまうことがRLの観点を通してみると問題であり、これを是正することが必要。さらに、分散が大きい報酬の状態で、報酬がsparse(i.e., expertのtrajectoryのexact matchしていないと報酬がzero)であることが、さらに事態を悪化させている。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
・1746
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。日本語解説:https://x.com/hillbig/status/1960108668336390593?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
一歩先の視点が考察されており、とても勉強になる。 #EfficiencyImprovement #Pocket #NLP #LanguageModel #Optimizer #read-later #ModelMerge #Stability Issue Date: 2025-08-02 [Paper Note] WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training, Changxin Tian+, arXiv'25 Summary学習率スケジューリングの新たなアプローチとして、Warmup-Stable and Merge(WSM)を提案。WSMは、学習率の減衰とモデルマージの関係を確立し、さまざまな減衰戦略を統一的に扱う。実験により、マージ期間がモデル性能において重要であることを示し、従来のWSDアプローチを上回る性能向上を達成。特に、MATHで+3.5%、HumanEvalで+2.9%、MMLU-Proで+5.5%の改善を記録。 Comment元ポスト:https://x.com/stochasticchasm/status/1951427541803106714?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWeight Decayを無くせるらしいエッセンスの解説:https://x.com/wenhaocha1/status/1951790366900019376?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
チェックポイントさえ保存しておいて事後的に活用することだで、細かなハイパラ調整のための試行錯誤する手間と膨大な計算コストがなくなるのであれば相当素晴らしいのでは…? #Pocket #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #GRPO #read-later #Non-VerifiableRewards #RewardModel Issue Date: 2025-07-22 [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25 Summary強化学習を用いてLLMsの推論能力を向上させるため、報酬モデリング(RM)のスケーラビリティを探求。ポイントワイズ生成報酬モデリング(GRM)を採用し、自己原則批評調整(SPCT)を提案してパフォーマンスを向上。並列サンプリングとメタRMを導入し、スケーリング性能を改善。実験により、SPCTがGRMの質とスケーラビリティを向上させ、既存の手法を上回る結果を示した。DeepSeek-GRMは一部のタスクで課題があるが、今後の取り組みで解決可能と考えられている。モデルはオープンソースとして提供予定。 Comment・inputに対する柔軟性と、
・同じresponseに対して多様なRewardを算出でき (= inference time scalingを活用できる)、
・Verifiableな分野に特化していないGeneralなRewardモデルである
Inference-Time Scaling for Generalist Reward Modeling (GRM) を提案

 #MachineLearning
#Pocket
#NLP
#LanguageModel
#Optimizer
#read-later
Issue Date: 2025-07-14
[Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
SummaryMuonオプティマイザーを大規模モデルにスケールアップするために、ウェイトデケイとパラメータごとの更新スケール調整を導入。これにより、Muonは大規模トレーニングで即座に機能し、計算効率がAdamWの約2倍に向上。新たに提案するMoonlightモデルは、少ないトレーニングFLOPで優れたパフォーマンスを達成し、オープンソースの分散Muon実装や事前トレーニング済みモデルも公開。
Comment解説ポスト:https://x.com/hillbig/status/1944902706747072678?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこちらでも紹介されている:
#MachineLearning
#Pocket
#NLP
#LanguageModel
#Optimizer
#read-later
Issue Date: 2025-07-14
[Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
SummaryMuonオプティマイザーを大規模モデルにスケールアップするために、ウェイトデケイとパラメータごとの更新スケール調整を導入。これにより、Muonは大規模トレーニングで即座に機能し、計算効率がAdamWの約2倍に向上。新たに提案するMoonlightモデルは、少ないトレーニングFLOPで優れたパフォーマンスを達成し、オープンソースの分散Muon実装や事前トレーニング済みモデルも公開。
Comment解説ポスト:https://x.com/hillbig/status/1944902706747072678?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこちらでも紹介されている:
・2208 #Pocket #NLP #LanguageModel #Transformer #Architecture #Normalization Issue Date: 2025-07-03 [Paper Note] The Curse of Depth in Large Language Models, Wenfang Sun+, arXiv'25 Summary本論文では、「深さの呪い」という現象を紹介し、LLMの深い層が期待通りに機能しない理由を分析します。Pre-LNの使用が出力の分散を増加させ、深い層の貢献を低下させることを特定。これを解決するために層正規化スケーリング(LNS)を提案し、出力分散の爆発を抑制します。実験により、LNSがLLMの事前トレーニング性能を向上させることを示し、教師ありファインチューニングにも効果があることを確認しました。 Comment元ポスト:https://x.com/shiwei_liu66/status/1940377801032446428?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1795
ではそもそもLayerNormalizationを無くしていた(正確にいうとparametrize tanhに置換)が、どちらが優れているのだろうか?

 ・1332
・1332
では知識ニューロンの存在が示唆されており、これはTransformerの層の深い位置に存在し、かつ異なる知識間で知識ニューロンはシェアされない傾向にあった(ただしこれはPost-LNのBERTの話で本研究はPre-LNの話だが。Post-LNの勾配消失問題を緩和し学習を安定化させる研究も2141 のように存在する)。これはこの研究が明らかにしたこととどういう関係性があるだろうか。
また、LayerNormalizationのScalingによって深いTransformerブロックの導関数が単位行列となる(学習に寄与しなくなる)ことが改善された場合、知識ニューロンはどのように変化するだろうか?
(下記Geminiの応答を見た上での感想)なんとなーくだけれども、おそらく知識ニューロンの局所化が解消されるのかなーという気がする。
となると次の疑問としては、MoEアーキテクチャにはどのような影響があるだろうか?
そもそも知識ニューロンが局所化しているからMoEアーキテクチャのルータによって関連するExpertsのみをactivateすれば(というより結果的にそうなるように学習される)性能を劣化させずに計算効率を上げられていた、と仮定する。そうすると、知識ニューロンが局所化せずに多くのニューロンでシェアされるようになると、2110 のように、サブネットワーク間の情報を互いにやりとりできます、みたいな仕組みがより効いてきそうな気がする。
参考までに、Gemini2.5-Proに考察させてみた結果をメモとして残しておく(あくまで参考程度に...)
```
ご質問ありがとうございます。非常に興味深い着眼点ですね。「Knowledge Neurons in Pretrained Transformers」と「The Curse of Depth in Large Language Models」は、一見すると全く異なるテーマを扱っているように見えますが、「Transformerの深い層における振る舞い」という共通点で結びつけて考察すると、非常に示唆に富んだ関係性が見えてきます。
以下に、両方の論文の概要を解説し、その関係性について考察します。
1. Knowledge Neurons in Pretrained Transformers の概要
この研究は、事前学習済みTransformerモデル(特にBERTなど)の内部で、特定の事実知識がどのように格納されているかを調査したものです。
発見: モデルの中間層、特に全結合層(Feed-Forward Network, FFN)に、特定の知識(例:「ダンテ・アリギエーリはイタリアで生まれた」)に強く反応する「知識ニューロン」が存在することを発見しました。
特徴: これらの知識ニューロンは、モデルの深い層(後方の層)に、より多く存在する傾向がありました。
意味: これまでブラックボックスとされてきた大規模言語モデルの内部で、知識がどのように表現・局在化しているかについて、具体的な手がかりを与えた画期的な研究です。
2. The Curse of Depth in Large Language Models の概要
この研究は、LLMをより深く(層を多く)することの難しさに焦点を当て、その原因と解決策を提案したものです。
問題(深さの呪い): Transformerの標準的なアーキテクチャ(Pre-LN)では、層が深くなるにつれて、LayerNormalization(LN)への入力の分散が指数関数的に増大してしまいます。
結果:
出力が大きくなりすぎて学習が不安定になります。
さらに深刻なのは、深い層ではモデルの出力に関する導関数(勾配計算に必要)がほぼ単位行列になってしまうことです。これは、その層が入力に対してほとんど変換を行わなくなり、学習に寄与しなくなることを意味します。
解決策: この問題を解決するため、各層のLayerNormalizationをその深さ(レイヤー番号 l)に応じてスケーリングするというシンプルな手法を提案しました。これにより、深い層でも勾配が適切に伝播し、学習が安定・改善することが示されました。
考察:2つの研究の関係性
これら2つの研究は、「学習の安定性」と「知識の格納方法」という異なる側面から、Transformerの深い層を分析していますが、両者には以下のような深い関係性があると考えられます。
学習の不安定性が「知識ニューロン」形成の背景にある可能性
「The Curse of Depth」で指摘されているように、標準的なTransformerの深い層は、本質的に学習が不安定で、勾配情報が失われやすい環境にあります。
この劣悪な学習環境こそが、「知識ニューロン」という形で知識が局所的に格納される原因の一つになっている可能性があります。つまり、
学習の非効率性: 深い層のほとんどのニューロンは、勾配消失問題のために効率的に学習を進めることができません。
専門化の発生: そのような不安定な環境下で、たまたま特定の知識パターンをうまく捉えることができた一部のニューロンが、その知識を一身に背負う形で強く活性化するよう特化(専門化)していったのではないか、と考えられます。これは、ネットワーク全体で協調して学習するのが難しい状況で、一部のユニットだけが突出して学習を担う、という現象と解釈できます。
学習の安定化が、より効率的な知識獲得につながる
では、「The Curse of Depth」で提案された手法(LNのスケーリング)によって深い層の学習が安定化すると、知識の格納方法はどのように変わるでしょうか。
これは非常に興味深い問いであり、2つの可能性が考えられます。
可能性A: より強固な知識ニューロンの形成:
学習が安定することで、各知識ニューロンはより明確に、そして効率的に特定の知識をエンコードできるようになるかもしれません。ノイズの多い環境で偶然生まれた専門家ではなく、安定した環境で育成された真の専門家へと変化するイメージです。
可能性B: 知識の分散化:
ネットワークの全ニューロンが効率的に学習に寄与できるようになるため、一つの知識を少数のニューロンに集中させる必要がなくなり、より多くのニューロンに分散して知識が格納されるようになる可能性も考えられます。
現在のところ、学習の安定化は、知識ニューロンがより効率的に形成・機能するための基盤を提供すると考えるのが最も妥当でしょう。「深さの呪い」という問題を解決することは、モデルが知識をどのように獲得し、整理するかという、より根源的なメカニズム(知識ニューロンの振る舞い)にも直接的な影響を与えるはずです。
まとめ
「Knowledge Neurons」は深い層に存在する知識の「状態」を明らかにし、「The Curse of Depth」は深い層で発生する学習の「問題」とその解決策を提示しました。
これらを統合すると、「深い層における学習の不安定性という問題が、知識ニューロンという局所的な知識表現を生み出す一因となっており、この問題を解決することで、より効率的で安定した知識の獲得・格納が可能になるかもしれない」という関係性が見えてきます。
両者は、LLMの能力と限界を異なる角度から照らし出しており、組み合わせることでモデルの内部動作の解明をさらに一歩前進させる、非常に重要な研究だと言えます。
``` #ComputerVision #Pretraining #Pocket #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #MulltiModal #RLHF #Reasoning #LongSequence #mid-training #RewardHacking #PostTraining #CurriculumLearning #RLVR #VisionLanguageModel Issue Date: 2025-07-03 [Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25 Summary視覚言語モデルGLM-4.1V-Thinkingを発表し、推論中心のトレーニングフレームワークを開発。強力な視覚基盤モデルを構築し、カリキュラムサンプリングを用いた強化学習で多様なタスクの能力を向上。28のベンチマークで最先端のパフォーマンスを達成し、特に難しいタスクで競争力のある結果を示す。モデルはオープンソースとして公開。 Comment元ポスト:https://x.com/sinclairwang1/status/1940331927724232712?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQwen2.5-VLよりも性能が良いVLM
 アーキテクチャはこちら。が、pretraining(データのフィルタリング, マルチモーダル→long context継続事前学習)->SFT(cold startへの対処, reasoning能力の獲得)->RL(RLVRとRLHFの併用によるパフォーマンス向上とAlignment, RewardHackingへの対処,curriculum sampling)など、全体の学習パイプラインの細かいテクニックの積み重ねで高い性能が獲得されていると考えられる。
アーキテクチャはこちら。が、pretraining(データのフィルタリング, マルチモーダル→long context継続事前学習)->SFT(cold startへの対処, reasoning能力の獲得)->RL(RLVRとRLHFの併用によるパフォーマンス向上とAlignment, RewardHackingへの対処,curriculum sampling)など、全体の学習パイプラインの細かいテクニックの積み重ねで高い性能が獲得されていると考えられる。
 #EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#Dataset
#LanguageModel
#MultiLingual
Issue Date: 2025-06-28
[Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, arXiv'25
Summary多言語LLMsの性能向上のために、FineWebに基づく新しい事前学習データセットキュレーションパイプラインを提案。9つの言語に対して設計選択肢を検証し、非英語コーパスが従来のデータセットよりも高性能なモデルを生成できることを示す。データセットの再バランス手法も導入し、1000以上の言語にスケールアップした20テラバイトの多言語データセットFineWeb2を公開。
Comment元ポスト:https://x.com/gui_penedo/status/1938631842720022572?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qv1
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#Dataset
#LanguageModel
#MultiLingual
Issue Date: 2025-06-28
[Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, arXiv'25
Summary多言語LLMsの性能向上のために、FineWebに基づく新しい事前学習データセットキュレーションパイプラインを提案。9つの言語に対して設計選択肢を検証し、非英語コーパスが従来のデータセットよりも高性能なモデルを生成できることを示す。データセットの再バランス手法も導入し、1000以上の言語にスケールアップした20テラバイトの多言語データセットFineWeb2を公開。
Comment元ポスト:https://x.com/gui_penedo/status/1938631842720022572?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qv1
・1942abstを見る限りFinewebを多言語に拡張した模様 #Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #mid-training #PostTraining #read-later Issue Date: 2025-06-27 [Paper Note] OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling, Zengzhi Wang+, arXiv'25 Summary異なるベース言語モデル(LlamaやQwen)の強化学習(RL)における挙動を調査し、中間トレーニング戦略がRLのダイナミクスに与える影響を明らかに。高品質の数学コーパスがモデルのパフォーマンスを向上させ、長い連鎖的思考(CoT)がRL結果を改善する一方で、冗長性や不安定性を引き起こす可能性があることを示す。二段階の中間トレーニング戦略「Stable-then-Decay」を導入し、OctoThinkerモデルファミリーを開発。オープンソースのモデルと数学推論コーパスを公開し、RL時代の基盤モデルの研究を支援することを目指す。 Comment元ポスト:https://x.com/sinclairwang1/status/1938244843857449431?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qmid-trainingの観点から、post trainingにおけるRLがスケーリングする条件をsystematicallyに調査している模様論文中にはmid-training[^1]の定義が記述されている:

[^1]: mid-trainingについてはコミュニティの間で厳密な定義はまだ無くバズワードっぽく使われている、という印象を筆者は抱いており、本稿は文献中でmid-trainingを定義する初めての試みという所感 #Pocket #NLP #LanguageModel #ReinforcementLearning #Reasoning #PostTraining #read-later Issue Date: 2025-06-22 [Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, arXiv'25 SummaryGuruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。 Comment元ポスト:https://x.com/chengzhoujun/status/1936113985507803365?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpost-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。Qwenシリーズで実験。以下ポストのまとめ。
・mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
・一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
・簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
・各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
・必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
・たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
・一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
・異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
・(これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
・非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
・RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
・モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
・モデルサイズが大きいとより多様なreasoningパスがunlockされている
・pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた #Pocket #NLP #LanguageModel #Evaluation #ICLR #Contamination Issue Date: 2025-05-23 LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25 Summaryテストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Commentテストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究 #EfficiencyImprovement #Pretraining #Pocket #NLP #Dataset #LanguageModel #ACL Issue Date: 2025-05-10 Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25 SummaryFineWeb-EduとDCLMは、モデルベースのフィルタリングによりデータの90%を削除し、トレーニングに適さなくなった。著者は、アンサンブル分類器や合成データの言い換えを用いて、精度とデータ量のトレードオフを改善する手法を提案。1Tトークンで8Bパラメータモデルをトレーニングし、DCLMに対してMMLUを5.6ポイント向上させた。新しい6.3Tトークンデータセットは、DCLMと同等の性能を持ちながら、4倍のユニークなトークンを含み、長トークンホライズンでのトレーニングを可能にする。15Tトークンのためにトレーニングされた8Bモデルは、Llama 3.1の8Bモデルを上回る性能を示した。データセットは公開されている。 #Metrics #NLP #LanguageModel #GenerativeAI #Evaluation Issue Date: 2025-03-31 Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25 Summary新しい指標「50%-タスク完了時間ホライズン」を提案し、AIモデルの能力を人間の観点から定量化。Claude 3.7 Sonnetは約50分の時間ホライズンを持ち、AIの能力は2019年以降約7か月ごとに倍増。信頼性や論理的推論の向上が要因とされ、5年以内にAIが多くのソフトウェアタスクを自動化できる可能性を示唆。 Comment元ポスト:https://x.com/hillbig/status/1902854727089656016?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q確かに線形に見える。てかGPT-2と比べるとAIさん進化しすぎである…。
 利用したデータセットは
利用したデータセットは
・HCAST: 46のタスクファミリーに基づく97種類のタスクが定義されており、たとえばサイバーセキュリティ、機械学習、ソフトウェアエンジニアリング、一般的な推論タスク(wikipediaから事実情報を探すタスクなど)などがある
・数分で終わるタスク: 上述のwikipedia
・数時間で終わるタスク: Pytorchのちょっとしたバグ修正など
・数文でタスクが記述され、コード、データ、ドキュメント、あるいはwebから入手可能な情報を参照可能
・タスクの難易度としては当該ドメインに数年間携わった専門家が解ける問題
・RE-Bench Suite
・7つのopen endedな専門家が8時間程度を要するMLに関するタスク
・e.g., GPT-2をQA用にFinetuningする, Finetuningスクリプトが与えられた時に挙動を変化させずにランタイムを可能な限り短縮する、など
・[RE-Bench Technical Report](https://metr.org/AI_R_D_Evaluation_Report.pdf)のTable2等を参照のこと
・SWAA Suite: 66種類の1つのアクションによって1分以内で終わるソフトウェアエンジニアリングで典型的なタスク
・1分以内で終わるタスクが上記データになかったので著者らが作成
であり、画像系やマルチモーダルなタスクは含まれていない。

タスクと人間がタスクに要する時間の対応に関するサンプルは下記
 タスク-エージェントペアごとに8回実行した場合の平均の成功率。確かにこのグラフからはN年後には人間で言うとこのくらいの能力の人がこのくらい時間を要するタスクが、このくらいできるようになってます、といったざっくり感覚値はなかなか想像できない。
タスク-エージェントペアごとに8回実行した場合の平均の成功率。確かにこのグラフからはN年後には人間で言うとこのくらいの能力の人がこのくらい時間を要するタスクが、このくらいできるようになってます、といったざっくり感覚値はなかなか想像できない。
 成功率とタスクに人間が要する時間に関するグラフ。ロジスティック関数でfittingしており、赤い破線が50% horizon。Claude 3.5 Sonnet (old)からClaude 3.7 Sonnetで50% horizonは18分から59分まで増えている。実際に数字で見るとイメージが湧きやすくおもしろい。
成功率とタスクに人間が要する時間に関するグラフ。ロジスティック関数でfittingしており、赤い破線が50% horizon。Claude 3.5 Sonnet (old)からClaude 3.7 Sonnetで50% horizonは18分から59分まで増えている。実際に数字で見るとイメージが湧きやすくおもしろい。
 こちらで最新モデルも随時更新される:
こちらで最新モデルも随時更新される:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/ #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Reasoning #LongSequence #RewardHacking #PostTraining Issue Date: 2025-02-07 Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, arXiv'25 Summary本研究では、大規模言語モデル(LLMs)における長い思考の連鎖(CoTs)推論のメカニズムを調査し、重要な要因を特定。主な発見は、(1) 教師ありファインチューニング(SFT)は必須ではないが効率を向上させる、(2) 推論能力は計算の増加に伴い現れるが、報酬の形状がCoTの長さに影響、(3) 検証可能な報酬信号のスケーリングが重要で、特に分布外タスクに効果的、(4) エラー修正能力は基本モデルに存在するが、RLを通じて効果的に奨励するには多くの計算が必要。これらの洞察は、LLMsの長いCoT推論を強化するためのトレーニング戦略の最適化に役立つ。 Comment元ポスト:https://x.com/xiangyue96/status/1887332772198371514?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q元ポストのスレッド中に論文の11個の知見が述べられている。どれも非常に興味深い。DeepSeek-R1のテクニカルペーパーと同様、
・Long CoTとShort CoTを比較すると前者の方が到達可能な性能のupper bonudが高いことや、
・SFTを実施してからRLをすると性能が向上することや、
・RLの際にCoTのLengthに関する報酬を入れることでCoTの長さを抑えつつ性能向上できること、
・数学だけでなくQAペアなどのノイジーだが検証可能なデータをVerifiableな報酬として加えると一般的なreasoningタスクで数学よりもさらに性能が向上すること、
・より長いcontext window sizeを活用可能なモデルの訓練にはより多くの学習データが必要なこと、
・long CoTはRLによって学習データに類似したデータが含まれているためベースモデルの段階でその能力が獲得されていることが示唆されること、
・aha momentはすでにベースモデル時点で獲得されておりVerifiableな報酬によるRLによって強化されたわけではなさそう、
など、興味深い知見が盛りだくさん。非常に興味深い研究。あとで読む。 #ComputerVision #Analysis #MachineLearning #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #ICML #PostTraining #read-later Issue Date: 2025-01-30 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25 SummarySFTとRLの一般化能力の違いを研究し、GeneralPointsとV-IRLを用いて評価。RLはルールベースのテキストと視覚変種に対して優れた一般化を示す一方、SFTは訓練データを記憶し分布外シナリオに苦労。RLは視覚認識能力を向上させるが、SFTはRL訓練に不可欠であり、出力形式を安定させることで性能向上を促進。これらの結果は、複雑なマルチモーダルタスクにおけるRLの一般化能力を示す。 Comment元ポスト:https://x.com/hillbig/status/1884731381517082668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qopenreview:https://openreview.net/forum?id=dYur3yabMj&referrer=%5Bthe%20profile%20of%20Yi%20Ma%5D(%2Fprofile%3Fid%3D~Yi_Ma4) #ComputerVision #Pretraining #Pocket #MulltiModal #FoundationModel #CVPR #VisionLanguageModel Issue Date: 2025-08-23 [Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24 Summary大規模視覚-言語基盤モデル(InternVL)は、60億パラメータで設計され、LLMと整合させるためにウェブ規模の画像-テキストデータを使用。視覚認知タスクやゼロショット分類、検索など32のベンチマークで最先端の性能を達成し、マルチモーダル対話システムの構築に寄与。ViT-22Bの代替として強力な視覚能力を持つ。コードとモデルは公開されている。 Comment既存のResNetのようなSupervised pretrainingに基づくモデル、CLIPのようなcontrastive pretrainingに基づくモデルに対して、text encoder部分をLLMに置き換えて、contrastive learningとgenerativeタスクによる学習を組み合わせたパラダイムを提案。

InternVLのアーキテクチャは下記で、3 stageの学習で構成される。最初にimage text pairをcontrastive learningし学習し、続いてモデルのパラメータはfreezeしimage text retrievalタスク等でモダリティ間の変換を担う最終的にQlLlama(multilingual性能を高めたllama)をvision-languageモダリティを繋ぐミドルウェアのように捉え、Vicunaをテキストデコーダとして接続してgenerative cossで学習する、みたいなアーキテクチャの模様(斜め読みなので少し違う可能性あり
 現在のVLMの主流であるvision encoderとLLMをadapterで接続する方式はここからかなりシンプルになっていることが伺える。
#Pocket
#NLP
#LanguageModel
#LongSequence
#ICLR
Issue Date: 2025-08-02
[Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
SummaryYaRN(Yet another RoPE extensioN method)は、トランスフォーマーベースの言語モデルにおける位置情報のエンコードを効率的に行い、コンテキストウィンドウを従来の方法よりも10倍少ないトークンと2.5倍少ない訓練ステップで拡張する手法を提案。LLaMAモデルが長いコンテキストを効果的に利用できることを示し、128kのコンテキスト長まで再現可能なファインチューニングを実現。
Commentopenreview:https://openreview.net/forum?id=wHBfxhZu1u現在主流なコンテキストウィンドウ拡張手法らしい日本語解説:https://zenn.dev/bilzard/scraps/de7ecd3c380b6e
#Pocket
#NLP
#Dataset
#LanguageModel
#ReinforcementLearning
#Reasoning
#ICLR
#PRM
Issue Date: 2025-06-26
[Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24
Summary大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。
CommentOpenReview:https://openreview.net/forum?id=v8L0pN6EOiPRM800K:https://github.com/openai/prm800k/tree/main
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#Dataset
#LanguageModel
Issue Date: 2025-05-10
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale, Guilherme Penedo+, arXiv'24
Summary本研究では、15兆トークンからなるFineWebデータセットを紹介し、LLMの性能向上に寄与することを示します。FineWebは高品質な事前学習データセットのキュレーション方法を文書化し、重複排除やフィルタリング戦略を詳細に調査しています。また、FineWebから派生した1.3兆トークンのFineWeb-Eduを用いたLLMは、MMLUやARCなどのベンチマークで優れた性能を発揮します。データセット、コードベース、モデルは公開されています。
Comment日本語解説:https://zenn.dev/deepkawamura/articles/da9aeca6d6d9f9
#Analysis
#NLP
#LanguageModel
#SyntheticData
#read-later
Issue Date: 2025-05-06
Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers, Zeyuan Allen-Zhu+, ICML'24 Tutorial
Comment元ポスト:https://x.com/hillbig/status/1919878625488449849?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCanon層の発見著者による解説:https://x.com/zeyuanallenzhu/status/1918684257058197922?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#Pocket
#NLP
#LanguageModel
#SyntheticData
#ICML
Issue Date: 2025-05-03
Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
Summary大規模言語モデル(LLMs)の知識抽出能力は、訓練データの多様性と強く相関しており、十分な強化がなければ知識は記憶されても抽出可能ではないことが示された。具体的には、エンティティ名の隠れ埋め込みに知識がエンコードされているか、他のトークン埋め込みに分散しているかを調査。LLMのプレトレーニングに関する重要な推奨事項として、補助モデルを用いたデータ再構成と指示微調整データの早期取り入れが提案された。
Comment解説:
現在のVLMの主流であるvision encoderとLLMをadapterで接続する方式はここからかなりシンプルになっていることが伺える。
#Pocket
#NLP
#LanguageModel
#LongSequence
#ICLR
Issue Date: 2025-08-02
[Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
SummaryYaRN(Yet another RoPE extensioN method)は、トランスフォーマーベースの言語モデルにおける位置情報のエンコードを効率的に行い、コンテキストウィンドウを従来の方法よりも10倍少ないトークンと2.5倍少ない訓練ステップで拡張する手法を提案。LLaMAモデルが長いコンテキストを効果的に利用できることを示し、128kのコンテキスト長まで再現可能なファインチューニングを実現。
Commentopenreview:https://openreview.net/forum?id=wHBfxhZu1u現在主流なコンテキストウィンドウ拡張手法らしい日本語解説:https://zenn.dev/bilzard/scraps/de7ecd3c380b6e
#Pocket
#NLP
#Dataset
#LanguageModel
#ReinforcementLearning
#Reasoning
#ICLR
#PRM
Issue Date: 2025-06-26
[Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24
Summary大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。
CommentOpenReview:https://openreview.net/forum?id=v8L0pN6EOiPRM800K:https://github.com/openai/prm800k/tree/main
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#Dataset
#LanguageModel
Issue Date: 2025-05-10
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale, Guilherme Penedo+, arXiv'24
Summary本研究では、15兆トークンからなるFineWebデータセットを紹介し、LLMの性能向上に寄与することを示します。FineWebは高品質な事前学習データセットのキュレーション方法を文書化し、重複排除やフィルタリング戦略を詳細に調査しています。また、FineWebから派生した1.3兆トークンのFineWeb-Eduを用いたLLMは、MMLUやARCなどのベンチマークで優れた性能を発揮します。データセット、コードベース、モデルは公開されています。
Comment日本語解説:https://zenn.dev/deepkawamura/articles/da9aeca6d6d9f9
#Analysis
#NLP
#LanguageModel
#SyntheticData
#read-later
Issue Date: 2025-05-06
Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers, Zeyuan Allen-Zhu+, ICML'24 Tutorial
Comment元ポスト:https://x.com/hillbig/status/1919878625488449849?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCanon層の発見著者による解説:https://x.com/zeyuanallenzhu/status/1918684257058197922?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#Pocket
#NLP
#LanguageModel
#SyntheticData
#ICML
Issue Date: 2025-05-03
Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
Summary大規模言語モデル(LLMs)の知識抽出能力は、訓練データの多様性と強く相関しており、十分な強化がなければ知識は記憶されても抽出可能ではないことが示された。具体的には、エンティティ名の隠れ埋め込みに知識がエンコードされているか、他のトークン埋め込みに分散しているかを調査。LLMのプレトレーニングに関する重要な推奨事項として、補助モデルを用いたデータ再構成と指示微調整データの早期取り入れが提案された。
Comment解説:
・1834 #Pocket #NLP #LanguageModel #Evaluation #Decoding Issue Date: 2025-04-14 Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, arXiv'24 Summary本研究では、5つの決定論的LLMにおける非決定性を8つのタスクで調査し、最大15%の精度変動と70%のパフォーマンスギャップを観察。全てのタスクで一貫した精度を提供できないことが明らかになり、非決定性が計算リソースの効率的使用に寄与している可能性が示唆された。出力の合意率を示す新たなメトリクスTARr@NとTARa@Nを導入し、研究結果を定量化。コードとデータは公開されている。 Comment・論文中で利用されているベンチマーク:
・785
・901 同じモデルに対して、seedを固定し、temperatureを0に設定し、同じ計算機環境に対して、同じinputを入力したら理論上はLLMの出力はdeterministicになるはずだが、deterministicにならず、ベンチマーク上の性能とそもそものraw response自体も試行ごとに大きく変化する、という話。
ただし、これはプロプライエタリLLMや、何らかのinferenceの高速化を実施したInferenceEngine(本研究ではTogetherと呼ばれる実装を使っていそう。vLLM/SGLangだとどうなるのかが気になる)を用いてinferenceを実施した場合での実験結果であり、後述の通り計算の高速化のためのさまざまな実装無しで、deterministicな設定でOpenLLMでinferenceすると出力はdeterministicになる、という点には注意。
GPTやLlama、Mixtralに対して上記ベンチマークを用いてzero-shot/few-shotの設定で実験している。Reasoningモデルは実験に含まれていない。

LLMのraw_response/multiple choiceのparse結果(i.e., 問題に対する解答部分を抽出した結果)の一致(TARr@N, TARa@N; Nはinferenceの試行回数)も理論上は100%になるはずなのに、ならないことが報告されている。

correlation analysisによって、応答の長さ と TAR{r, a}が強い負の相関を示しており、応答が長くなればなるほど不安定さは増すことが分析されている。このため、ontput tokenの最大値を制限することで出力の安定性が増すことを考察している。また、few-shotにおいて高いAcc.の場合は出力がdeterministicになるわけではないが、性能が安定する傾向とのこと。また、OpenAIプラットフォーム上でGPTのfinetuningを実施し実験したが、安定性に寄与はしたが、こちらもdeterministicになるわけではないとのこと。
deterministicにならない原因として、まずmulti gpu環境について検討しているが、multi-gpu環境ではある程度のランダム性が生じることがNvidiaの研究によって報告されているが、これはseedを固定すれば決定論的にできるため問題にならないとのこと。
続いて、inferenceを高速化するための実装上の工夫(e.g., Chunk Prefilling, Prefix Caching, Continuous Batching)などの実装がdeterministicなハイパーパラメータでもdeterministicにならない原因であると考察しており、実際にlocalマシン上でこれらinferenceを高速化するための最適化を何も実施しない状態でLlama-8Bでinferenceを実施したところ、outputはdeterministicになったとのこと。論文中に記載がなかったため、どのようなInferenceEngineを利用したか公開されているgithubを見ると下記が利用されていた:
・Together: https://github.com/togethercomputer/together-python?tab=readme-ov-file
Togetherが内部的にどのような処理をしているかまでは追えていないのだが、異なるInferenceEngineを利用した場合に、どの程度outputの不安定さに差が出るのか(あるいは出ないのか)は気になる。たとえば、transformers/vLLM/SGLangを利用した場合などである。
論文中でも報告されている通り、昔管理人がtransformersを用いて、deterministicな設定でzephyrを用いてinferenceをしたときは、出力はdeterministicになっていたと記憶している(スループットは絶望的だったが...)。あと個人的には現実的な速度でオフラインでinference engineを利用した時にdeterministicにはせめてなって欲しいなあという気はするので、何が原因なのかを実装レベルで突き詰めてくれるととても嬉しい(KV Cacheが怪しい気がするけど)。
たとえば最近SLMだったらKVCacheしてVRAM食うより計算し直した方が効率良いよ、みたいな研究があったような。そういうことをしたらlocal llmでdeterministicにならないのだろうか。 #NLP #LanguageModel #Alignment #DPO #PostTraining #read-later Issue Date: 2024-09-25 Direct Preference Optimization: Your Language Model is Secretly a Reward Model, Rafael Rafailov+, N_A, NeurIPS'24 Summary大規模無監督言語モデル(LM)の制御性を向上させるために、報酬モデルの新しいパラメータ化を導入し、単純な分類損失でRLHF問題を解決する「直接的な好み最適化(DPO)」アルゴリズムを提案。DPOは安定性と性能を持ち、ファインチューニング中のサンプリングやハイパーパラメータ調整を不要にし、既存の方法と同等以上の性能を示す。特に、生成物の感情制御においてPPOベースのRLHFを上回り、応答の質を改善しつつ実装が簡素化される。 CommentDPOを提案した研究

解説ポスト:
https://x.com/theturingpost/status/1940194999993585925?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pocket #Transformer #DiffusionModel #read-later #Backbone Issue Date: 2025-08-27 [Paper Note] Scalable Diffusion Models with Transformers, William Peebles+, ICCV'23 Summary新しいトランスフォーマーに基づく拡散モデル(Diffusion Transformers, DiTs)を提案し、U-Netをトランスフォーマーに置き換えた。DiTsは高いGflopsを持ち、低いFIDを維持しながら良好なスケーラビリティを示す。最大のDiT-XL/2モデルは、ImageNetのベンチマークで従来の拡散モデルを上回り、最先端のFID 2.27を達成した。 Comment日本語解説:https://qiita.com/sasgawy/items/8546c784bc94d94ef0b2よく見るDiT
・2526
も同様の呼称だが全く異なる話なので注意 #RecommenderSystems #Pocket #Transformer #VariationalAutoEncoder #NeurIPS #read-later #ColdStart #Encoder-Decoder #SemanticID Issue Date: 2025-07-28 [Paper Note] Recommender Systems with Generative Retrieval, Shashank Rajput+, NeurIPS'23 Summary新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを用いて次のアイテムを予測するTransformerベースのモデルを訓練。これにより、従来のレコメンダーシステムを大幅に上回る性能を達成し、過去の対話履歴がないアイテムに対しても改善された検索性能を示す。 Commentopenreview:https://openreview.net/forum?id=BJ0fQUU32wSemantic IDを提案した研究アイテムを意味的な情報を保持したdiscrete tokenのタプル(=Semantic ID)で表現し、encoder-decoderでNext ItemのSemantic IDを生成するタスクに落としこむことで推薦する。SemanticIDの作成方法は後で読んで理解したい。


 #ComputerVision
#Pretraining
#Pocket
#LanguageModel
#MulltiModal
#ICCV
Issue Date: 2025-06-29
[Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23
Summaryシンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。
CommentSigLIP論文
#MachineLearning
#Pocket
#NLP
#LanguageModel
#Hallucination
#NeurIPS
#read-later
#ActivationSteering/ITI
#Probing
#Trustfulness
Issue Date: 2025-05-09
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23
SummaryInference-Time Intervention (ITI)を提案し、LLMsの真実性を向上させる技術を紹介。ITIは推論中にモデルの活性化を調整し、LLaMAモデルの性能をTruthfulQAベンチマークで大幅に改善。Alpacaモデルでは真実性が32.5%から65.1%に向上。真実性と有用性のトレードオフを特定し、介入の強度を調整する方法を示す。ITIは低コストでデータ効率が高く、数百の例で真実の方向性を特定可能。LLMsが虚偽を生成しつつも真実の内部表現を持つ可能性を示唆。
CommentInference Time Interventionを提案した研究。Attention Headに対して線形プロービング[^1]を実施し、真実性に関連するであろうHeadをtopKで特定できるようにし、headの出力に対し真実性を高める方向性のベクトルvを推論時に加算することで(=intervention)、モデルの真実性を高める。vは線形プロービングによって学習された重みを使う手法と、正答と誤答の活性化の平均ベクトルを計算しその差分をvとする方法の二種類がある。後者の方が性能が良い。topKを求める際には、線形プロービングをしたモデルのvalidation setでの性能から決める。Kとαはハイパーパラメータである。
#ComputerVision
#Pretraining
#Pocket
#LanguageModel
#MulltiModal
#ICCV
Issue Date: 2025-06-29
[Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23
Summaryシンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。
CommentSigLIP論文
#MachineLearning
#Pocket
#NLP
#LanguageModel
#Hallucination
#NeurIPS
#read-later
#ActivationSteering/ITI
#Probing
#Trustfulness
Issue Date: 2025-05-09
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23
SummaryInference-Time Intervention (ITI)を提案し、LLMsの真実性を向上させる技術を紹介。ITIは推論中にモデルの活性化を調整し、LLaMAモデルの性能をTruthfulQAベンチマークで大幅に改善。Alpacaモデルでは真実性が32.5%から65.1%に向上。真実性と有用性のトレードオフを特定し、介入の強度を調整する方法を示す。ITIは低コストでデータ効率が高く、数百の例で真実の方向性を特定可能。LLMsが虚偽を生成しつつも真実の内部表現を持つ可能性を示唆。
CommentInference Time Interventionを提案した研究。Attention Headに対して線形プロービング[^1]を実施し、真実性に関連するであろうHeadをtopKで特定できるようにし、headの出力に対し真実性を高める方向性のベクトルvを推論時に加算することで(=intervention)、モデルの真実性を高める。vは線形プロービングによって学習された重みを使う手法と、正答と誤答の活性化の平均ベクトルを計算しその差分をvとする方法の二種類がある。後者の方が性能が良い。topKを求める際には、線形プロービングをしたモデルのvalidation setでの性能から決める。Kとαはハイパーパラメータである。
[^1]: headのrepresentationを入力として受け取り、線形モデルを学習し、線形モデルの2値分類性能を見ることでheadがどの程度、プロービングの学習に使ったデータに関する情報を保持しているかを測定する手法
日本語解説スライド:https://www.docswell.com/s/DeepLearning2023/Z38P8D-2024-06-20-131813p1これは相当汎用的に使えそうな話だから役に立ちそう #EfficiencyImprovement #NLP #LanguageModel #Transformer #LongSequence #PositionalEncoding #NeurIPS Issue Date: 2025-04-06 The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad+, NeurIPS'23 Summary長さ一般化はTransformerベースの言語モデルにおける重要な課題であり、位置エンコーディング(PE)がその性能に影響を与える。5つの異なるPE手法(APE、T5の相対PE、ALiBi、Rotary、NoPE)を比較した結果、ALiBiやRotaryなどの一般的な手法は長さ一般化に適しておらず、NoPEが他の手法を上回ることが明らかになった。NoPEは追加の計算を必要とせず、絶対PEと相対PEの両方を表現可能である。さらに、スクラッチパッドの形式がモデルの性能に影響を与えることも示された。この研究は、明示的な位置埋め込みが長いシーケンスへの一般化に必須でないことを示唆している。 Comment・1863
において、Llama4 Scoutが10Mコンテキストウィンドウを実現できる理由の一つとのこと。
元ポスト:https://x.com/drjimfan/status/1908615861650547081?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Llama4のブログポストにもその旨記述されている:
>A key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings. Additionally, we employ inference time temperature scaling of attention to enhance length generalization.
[The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation](https://ai.meta.com/blog/llama-4-multimodal-intelligence/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4)斜め読みだが、length generalizationを評価する上でdownstream taskに焦点を当て、3つの代表的なカテゴリに相当するタスクで評価したところ、この観点においてはT5のrelative positinal encodingとNoPE(位置エンコードディング無し)のパフォーマンスが良く、


NoPEは絶対位置エンコーディングと相対位置エンコーディングを理論上実現可能であり[^1]

実際に学習された異なる2つのモデルに対して同じトークンをそれぞれinputし、同じ深さのLayerの全てのattention distributionの組み合わせからJensen Shannon Divergenceで距離を算出し、最も小さいものを2モデル間の当該layerの距離として可視化すると下記のようになり、NoPEとT5のrelative positional encodingが最も類似していることから、NoPEが学習を通じて(実用上は)相対位置エンコーディングのようなものを学習することが分かった。

[^1]:深さ1のLayerのHidden State H^1から絶対位置の復元が可能であり(つまり、当該レイヤーのHが絶対位置に関する情報を保持している)、この前提のもと、後続のLayerがこの情報を上書きしないと仮定した場合に、相対位置エンコーディングを実現できる。また、CoT/Scratchpadはlong sequenceに対する汎化性能を向上させることがsmall scaleではあるが先行研究で示されており、Positional Encodingを変化させた時にCoT/Scratchpadの性能にどのような影響を与えるかを調査。
具体的には、CoT/Scratchpadのフォーマットがどのようなものが有効かも明らかではないので、5種類のコンポーネントの組み合わせでフォーマットを構成し、mathematical reasoningタスクで以下のような設定で訓練し
・さまざまなコンポーネントの組み合わせで異なるフォーマットを作成し、
・全ての位置エンコーディングあり/なしモデルを訓練
これらを比較した。この結果、CoT/Scratchpadはフォーマットに関係なく、特定のタスクでのみ有効(有効かどうかはタスク依存)であることが分かった。このことから、CoT/Scratcpad(つまり、モデルのinputとoutputの仕方)単体で、long contextに対する汎化性能を向上させることができないので、Positional Encoding(≒モデルのアーキテクチャ)によるlong contextに対する汎化性能の向上が非常に重要であることが浮き彫りになった。

また、CoT/Scratchpadが有効だったAdditionに対して各Positional Embeddingモデルを学習し、生成されたトークンのattentionがどの位置のトークンを指しているかを相対距離で可視化したところ(0が当該トークン、つまり現在のScratchpadに着目しており、1が遠いトークン、つまりinputに着目していることを表すように正規化)、NoPEとRelative Positional Encodingがshort/long rangeにそれぞれフォーカスするようなbinomialな分布なのに対し、他のPositional Encodingではよりuniformな分布であることが分かった。このタスクにおいてはNoPEとRelative POの性能が高かったため、binomialな分布の方がより最適であろうことが示唆された。

#Analysis #Pocket #NLP #LanguageModel #ReversalCurse Issue Date: 2023-10-09 [Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23 Summary自己回帰型大規模言語モデル(LLMs)は、「AはBである」という文から「BはAである」と逆の関係を自動的に一般化できない「逆転の呪い」を示す。例えば、モデルが「ワレンティナ・テレシコワは宇宙に行った最初の女性である」と訓練されても、「宇宙に行った最初の女性は誰か?」に正しく答えられない。実験では、架空の文を用いてGPT-3とLlama-1をファインチューニングし、逆転の呪いの存在を確認。ChatGPT(GPT-3.5およびGPT-4)でも、実在の有名人に関する質問で正答率に大きな差が見られた。 CommentA is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
著者ツイート: https://x.com/owainevans_uk/status/1705285631520407821?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
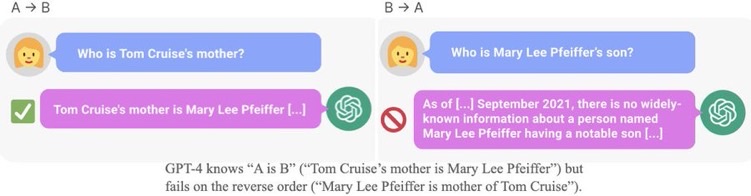
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。

また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。

このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。関連:
・1923 #EfficiencyImprovement #MachineLearning #Pocket #Quantization #PEFT(Adaptor/LoRA) #NeurIPS Issue Date: 2023-07-22 QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, NeurIPS'23 Summary私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment実装: https://github.com/artidoro/qlora
PEFTにもある参考: https://twitter.com/hillbig/status/1662946722690236417?s=46&t=TDHYK31QiXKxggPzhZbcAQOpenReview:https://openreview.net/forum?id=OUIFPHEgJU&referrer=%5Bthe%20profile%20of%20Ari%20Holtzman%5D(%2Fprofile%3Fid%3D~Ari_Holtzman1) #Pocket #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2023-07-03 Holistic Evaluation of Language Models, Percy Liang+, TMLR'23 Summary言語モデルの透明性を向上させるために、Holistic Evaluation of Language Models(HELM)を提案する。HELMでは、潜在的なシナリオとメトリックを分類し、広範なサブセットを選択して評価する。さらに、複数のメトリックを使用し、主要なシナリオごとに評価を行う。30の主要な言語モデルを42のシナリオで評価し、HELM以前に比べて評価のカバレッジを改善した。HELMはコミュニティのためのベンチマークとして利用され、新しいシナリオ、メトリック、モデルが継続的に更新される。 CommentOpenReview:https://openreview.net/forum?id=iO4LZibEqWHELMを提案した研究
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/ #NLP #LanguageModel #LLMAgent Issue Date: 2023-04-13 REACT : SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS, Yao+, Princeton University and Google brain, ICLR'23 Comment概要
人間は推論と行動をシナジーさせることで、さまざまな意思決定を行える。近年では言語モデルにより言語による推論を意思決定に組み合わせる可能性が示されてきた。たとえば、タスクをこなすための推論トレースをLLMが導けることが示されてきた(Chain-of-Thought)が、CoTは外部リソースにアクセスできないため知識がアップデートできず、事後的に推論を行うためhallucinationやエラーの伝搬が生じる。一方で、事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われているが、これらの研究では、高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
そこで、REACTを提案。REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みであり、推論トレースとアクションを交互に生成するため、動的に推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
・要はいままではGeneralなタスク解決モデルにおいては、推論とアクションの生成は独立にしかやられてこなかったけど、推論とアクションを交互作用させることについて研究したよ
・そしたら性能がとってもあがったよ
・reasoningを人間が編集すれば、エージェントのコントロールもできるよ という感じ
イントロ
人間は推論と行動の緊密なシナジーによって、不確実な状況に遭遇しても適切な意思決定が行える。たとえば、任意の2つの特定のアクションの間で、進行状況をトレースするために言語で推論したり(すべて切り終わったからお湯を沸かす必要がある)、例外を処理したり、状況に応じて計画を調整したりする(塩がないから代わりに醤油と胡椒を使おう)。また、推論をサポートし、疑問(いまどんな料理を作ることができるだろうか?)を解消するために、行動(料理本を開いてレシピを読んで、冷蔵庫を開いて材料を確確認したり)をすることもある。
近年の研究では言語での推論を、インタラクティブな意思決定を組み合わせる可能性についてのヒントが得られてきた。一つは、適切にPromptingされたLLMが推論トレースを実行できることを示している。推論トレースとは、解決策に到達するための一連のステップを経て推論をするためのプロセスのことである。しかしながらChain-of-thoughytは、このアプローチでは、モデルが外界対してgroundingできず、内部表現のみに基づい思考を生成するため限界がある。これによりモデルが事後対応的に推論したり、外部情報に基づいて知識を更新したりできないため、推論プロセス中にhallucinationやエラーの伝搬などの問題が発生する可能性が生じる。
一方、近年の研究では事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われている。これらの研究では、通常マルチモーダルな観測結果をテキストに変換し、言語モデルを使用してドメイン固有のアクション、またはプランを生成し、コントローラーを利用してそれらを選択または実行する。ただし、これらのアプローチは高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。
推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
LLMにおける推論と行動を組み合わせて、言語推論と意思決定タスクを解決するREACTと呼ばれる手法を提案。REACTでは、推論と行動の相乗効果を高めることが可能。推論トレースによりアクションプランを誘発、追跡、更新するのに役立ち、アクションでは外部ソースと連携して追加情報を収集できる。
REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みである。REACTのpromptはLLMにverbalな推論トレースとタスクを実行するためのアクションを交互に生成する。これにより、モデルは動的な推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
手法
変数を以下のように定義する:
・O_t: Observertion on time t
・a_t: Action on time t
・c_t: context, i.e. (o_1, a_1, o_2, a_2, ..., a_t-1, o_t)
・policy pi\(a\_t | c\_t): Action Spaceからアクションを選択するポリシー
・A: Action Space
・O: Observation Space
普通はc_tが与えられたときに、ポリシーに従いAからa_tを選択しアクションを行い、アクションの結果o_tを得て、c_t+1を構成する、といったことを繰り返していく。
このとき、REACTはAをA ∪ Lに拡張しする。ここで、LはLanguage spaceである。LにはAction a_hatが含まれ、a_hatは環境に対して作用をしない。単純にthought, あるいは reasoning traceを実施し、現在のcontext c_tをアップデートするために有用な情報を構成することを目的とする。Lはunlimitedなので、事前学習された言語モデルを用いる。今回はPaLM-540B(c.f. GPT3は175Bパラメータ)が利用され、few-shotのin-context exampleを与えることで推論を行う。それぞれのin-context exampleは、action, thoughtsそしてobservationのtrajectoryを与える。
推論が重要なタスクでは、thoughts-action-observationステップから成るtask-solving trajectoryを生成する。一方、多数のアクションを伴う可能性がある意思決定タスクでは、thoughtsのみを行うことをtask-solving trajectory中の任意のタイミングで、自分で判断して行うことができる。
意思決定と推論能力がLLMによってもたらされているため、REACTは4つのuniqueな特徴を持つ:
・直感的で簡単なデザイン
・REACTのpromptは人間のアノテータがアクションのトップに思考を言語で記述するようなストレートなものであり、ad-hocなフォーマットの選択、思考のデザイン、事例の選定などが必要ない。
・一般的で柔軟性が高い
・柔軟な thought spaceと thought-actionのフォーマットにより、REACTはさまざまなタスクにも柔軟に対応できる
・高性能でロバスト
・REACTは1-6個の事例によって、新たなタスクに対する強力な汎化を示す。そして推論、アクションのみを行うベースラインよりも高い性能を示している。REACTはfinetuningの斧系も得ることができ、promptの選択に対してREACTの性能はrobustである。
・人間による調整と操作が可能
・REACTは、解釈可能な意思決定と推論のsequenceを前提としているため、人間は簡単に推論や事実の正しさを検証できる。加えて、thoughtsを編集することによって、m人間はエージェントの行動を制御、あるいは修正できる。
KNOWLEDGE INTENSIVE REASONING TASKS #Pocket #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICLR #PostTraining Issue Date: 2025-05-12 LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22 SummaryLoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。 CommentOpenrReview:https://openreview.net/forum?id=nZeVKeeFYf9LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。 #MachineLearning #Pocket #NLP #LanguageModel #NeurIPS #Scaling Laws Issue Date: 2025-03-23 Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22 Summaryトランスフォーマー言語モデルの訓練において、計算予算内で最適なモデルサイズとトークン数を調査。モデルサイズと訓練トークン数は同等にスケールする必要があり、倍増するごとにトークン数も倍増すべきと提案。Chinchillaモデルは、Gopherなどの大規模モデルに対して優れた性能を示し、ファインチューニングと推論の計算量を削減。MMLUベンチマークで67.5%の精度を達成し、Gopherに対して7%以上の改善を実現。 CommentOpenReview: https://openreview.net/forum?id=iBBcRUlOAPRchinchilla則 #EfficiencyImprovement #Pretraining #Pocket #NLP #Transformer #Architecture #MoE(Mixture-of-Experts) Issue Date: 2025-02-11 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22 SummarySwitch Transformerを提案し、Mixture of Experts (MoE)の複雑さや通信コスト、トレーニングの不安定性を改善。これにより、低精度フォーマットでの大規模スパースモデルのトレーニングが可能になり、最大7倍の事前トレーニング速度向上を実現。さらに、1兆パラメータのモデルを事前トレーニングし、T5-XXLモデルに対して4倍の速度向上を達成。 #Analysis #Pocket #NLP #Transformer #ACL #KnowledgeEditing #FactualKnowledge #Encoder Issue Date: 2024-07-11 Knowledge Neurons in Pretrained Transformers, Damai Dai+, N_A, ACL'22, 2022.05 Summary大規模な事前学習言語モデルにおいて、事実知識の格納方法についての研究を行いました。具体的には、BERTのfill-in-the-blank cloze taskを用いて、関連する事実を表現するニューロンを特定しました。また、知識ニューロンの活性化と対応する事実の表現との正の相関を見つけました。さらに、ファインチューニングを行わずに、知識ニューロンを活用して特定の事実知識を編集しようと試みました。この研究は、事前学習されたTransformers内での知識の格納に関する示唆に富んでおり、コードはhttps://github.com/Hunter-DDM/knowledge-neuronsで利用可能です。 Comment1108 日本語解説: https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022関連:
・2140上記資料によると、特定の知識を出力する際に活性化する知識ニューロンを特定する手法を提案。MLMを用いたclozeタスクによる実験で[MASK]部分に当該知識を出力する実験をした結果、知識ニューロンの重みをゼロとすると性能が著しく劣化し、値を2倍にすると性能が改善するといった傾向がみられた。 ケーススタディとして、知識の更新と、知識の削除が可能かを検証。どちらとも更新・削除がされる方向性[^1]へモデルが変化した。
また、知識ニューロンはTransformerの層の深いところに位置している傾向にあり、異なるrelationを持つような関係知識同士では共有されない傾向にある模様。
[^1]: 他の知識に影響を与えず、完璧に更新・削除できたわけではない。知識の更新・削除に伴いExtrinsicな評価によって性能向上、あるいはPerplexityが増大した、といった結果からそういった方向性へモデルが変化した、という話 #ComputerVision #Pocket #Transformer #ICLR #Backbone Issue Date: 2025-08-25 [Paper Note] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy+, ICLR'21 Summary純粋なトランスフォーマーを画像パッチのシーケンスに直接適用することで、CNNへの依存なしに画像分類タスクで優れた性能を発揮できることを示す。大量のデータで事前学習し、複数の画像認識ベンチマークで最先端のCNNと比較して優れた結果を達成し、計算リソースを大幅に削減。 Commentopenreview:https://openreview.net/forum?id=YicbFdNTTyViTを提案した研究 #Pocket #NLP #Dataset #LanguageModel #Evaluation #CodeGeneration Issue Date: 2025-08-15 [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21 Summary本論文では、汎用プログラミング言語におけるプログラム合成の限界を大規模言語モデルを用いて評価します。MBPPとMathQA-Pythonの2つのベンチマークで、モデルサイズに対する合成性能のスケールを調査。最も大きなモデルは、少数ショット学習でMBPPの59.6%の問題を解決可能で、ファインチューニングにより約10%の性能向上が見られました。MathQA-Pythonでは、ファインチューニングされたモデルが83.8%の精度を達成。人間のフィードバックを取り入れることでエラー率が半減し、エラー分析を通じてモデルの弱点を明らかにしました。最終的に、プログラム実行結果の予測能力を探るも、最良のモデルでも特定の入力に対する出力予測が困難であることが示されました。 Comment代表的なコード生成のベンチマーク。
MBPPデータセットは、promptで指示されたコードをモデルに生成させ、テストコード(assertion)を通過するか否かで評価する。974サンプル存在し、pythonの基礎を持つクラウドワーカーによって生成。クラウドワーカーにタスクdescriptionとタスクを実施する一つの関数(関数のみで実行可能でprintは不可)、3つのテストケースを記述するよう依頼。タスクdescriptionは追加なclarificationなしでコードが記述できるよう十分な情報を含むよう記述するように指示。ground truthの関数を生成する際に、webを閲覧することを許可した。

MathQA-Pythonは、MathQAに含まれるQAのうち解答が数値のもののみにフィルタリングしたデータセットで、合計で23914サンプル存在する。pythonコードで与えられた数学に関する問題を解くコードを書き、数値が一致するか否かで評価する、といった感じな模様。斜め読みなので少し読み違えているかもしれない。
 #Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
#CodeGeneration
Issue Date: 2025-08-15
[Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
SummaryCodexはGitHubのコードでファインチューニングされたGPT言語モデルで、Pythonコード生成能力を評価。新しい評価セットHumanEvalでは、Codexが28.8%の問題を解決し、GPT-3は0%、GPT-Jは11.4%だった。繰り返しサンプリングが難しいプロンプトに対しても効果的な戦略を用い、70.2%の問題を解決。モデルの限界として、長い操作の説明や変数へのバインドに苦労する点が明らかに。最後に、コード生成技術の影響について安全性や経済に関する議論を行う。
CommentHumanEvalデータセット。Killed by LLMによると、GPT4oによりすでに90%程度の性能が達成され飽和している。
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
#CodeGeneration
Issue Date: 2025-08-15
[Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
SummaryCodexはGitHubのコードでファインチューニングされたGPT言語モデルで、Pythonコード生成能力を評価。新しい評価セットHumanEvalでは、Codexが28.8%の問題を解決し、GPT-3は0%、GPT-Jは11.4%だった。繰り返しサンプリングが難しいプロンプトに対しても効果的な戦略を用い、70.2%の問題を解決。モデルの限界として、長い操作の説明や変数へのバインドに苦労する点が明らかに。最後に、コード生成技術の影響について安全性や経済に関する議論を行う。
CommentHumanEvalデータセット。Killed by LLMによると、GPT4oによりすでに90%程度の性能が達成され飽和している。
164個の人手で記述されたprogrammingの問題で、それぞれはfunction signature, docstring, body, unittestを持つ。unittestは問題当たり約7.7 test存在。handwrittenという点がミソで、コンタミネーションの懸念があるためgithubのような既存ソースからのコピーなどはしていない。pass@k[^1]で評価。
[^1]: k個のサンプルを生成させ、k個のサンプルのうち、サンプルがunittestを一つでも通過する確率。ただ、本研究ではよりバイアスをなくすために、kよりも大きいn個のサンプルを生成し、その中からランダムにk個を選択して確率を推定するようなアプローチを実施している。2.1節を参照のこと。
 #ComputerVision
#Pocket
#Transformer
#Attention
#Architecture
#ICCV
#Backbone
Issue Date: 2025-07-19
[Paper Note] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu+, ICCV'21
SummarySwin Transformerは、コンピュータビジョンの新しいバックボーンとして機能する階層的トランスフォーマーを提案。シフトウィンドウ方式により、効率的な自己注意計算を実現し、さまざまなスケールでのモデリングが可能。画像分類や物体検出、セマンティックセグメンテーションなどで従来の最先端を上回る性能を示し、トランスフォーマーのビジョンバックボーンとしての可能性を示唆。コードは公開されている。
Comment日本語解説:https://qiita.com/m_sugimura/items/139b182ee7c19c83e70a画像処理において、物体の異なるスケールや、解像度に対処するために、PatchMergeと呼ばれるプーリングのような処理と、固定サイズのローカルなwindowに分割してSelf-Attentionを実施し、layerごとに通常のwindowとシフトされたwindowを適用することで、window間を跨いだ関係性も考慮できるようにする機構を導入したモデル。
#ComputerVision
#Pocket
#Transformer
#Attention
#Architecture
#ICCV
#Backbone
Issue Date: 2025-07-19
[Paper Note] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu+, ICCV'21
SummarySwin Transformerは、コンピュータビジョンの新しいバックボーンとして機能する階層的トランスフォーマーを提案。シフトウィンドウ方式により、効率的な自己注意計算を実現し、さまざまなスケールでのモデリングが可能。画像分類や物体検出、セマンティックセグメンテーションなどで従来の最先端を上回る性能を示し、トランスフォーマーのビジョンバックボーンとしての可能性を示唆。コードは公開されている。
Comment日本語解説:https://qiita.com/m_sugimura/items/139b182ee7c19c83e70a画像処理において、物体の異なるスケールや、解像度に対処するために、PatchMergeと呼ばれるプーリングのような処理と、固定サイズのローカルなwindowに分割してSelf-Attentionを実施し、layerごとに通常のwindowとシフトされたwindowを適用することで、window間を跨いだ関係性も考慮できるようにする機構を導入したモデル。


 #Analysis
#Pocket
#NLP
#Transformer
#EMNLP
#FactualKnowledge
Issue Date: 2025-07-04
[Paper Note] Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, EMNLP'21
Summaryフィードフォワード層はトランスフォーマーモデルの大部分を占めるが、その役割は未探求。研究により、フィードフォワード層がキー・バリュー・メモリとして機能し、トレーニング例のテキストパターンと相関することを示す。実験で、下層は浅いパターン、上層は意味的なパターンを学習し、バリューが出力分布を誘導することが確認された。最終的に、フィードフォワード層の出力はメモリの合成であり、残差接続を通じて洗練される。
Comment日本語解説(p.5より): https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022?slide=5
#DocumentSummarization
#Metrics
#Tools
#NLP
#Dataset
#Evaluation
Issue Date: 2023-08-13
SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
Comment自動評価指標が人手評価の水準に達しないことが示されており、結局のところROUGEを上回る自動性能指標はほとんどなかった。human judgmentsとのKendall;'s Tauを見ると、chrFがCoherenceとRelevance, METEORがFluencyで上回ったのみだった。また、LEAD-3はやはりベースラインとしてかなり強く、LEAD-3を上回ったのはBARTとPEGASUSだった。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
#LM-based
Issue Date: 2023-08-13
BARTSCORE: Evaluating Generated Text as Text Generation, Yuan+ (w_ Neubig氏), NeurIPS'21
Summary本研究では、生成されたテキストの評価方法について検討しました。具体的には、事前学習モデルを使用してテキスト生成の問題をモデル化し、生成されたテキストを参照出力またはソーステキストに変換するために訓練されたモデルを使用しました。提案したメトリックであるBARTSCOREは、情報量、流暢さ、事実性などの異なる視点のテキスト評価に柔軟に適用できます。実験結果では、既存のトップスコアリングメトリックを上回る性能を示しました。BARTScoreの計算に使用するコードは公開されており、インタラクティブなリーダーボードも利用可能です。
CommentBARTScore概要
#Analysis
#Pocket
#NLP
#Transformer
#EMNLP
#FactualKnowledge
Issue Date: 2025-07-04
[Paper Note] Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, EMNLP'21
Summaryフィードフォワード層はトランスフォーマーモデルの大部分を占めるが、その役割は未探求。研究により、フィードフォワード層がキー・バリュー・メモリとして機能し、トレーニング例のテキストパターンと相関することを示す。実験で、下層は浅いパターン、上層は意味的なパターンを学習し、バリューが出力分布を誘導することが確認された。最終的に、フィードフォワード層の出力はメモリの合成であり、残差接続を通じて洗練される。
Comment日本語解説(p.5より): https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022?slide=5
#DocumentSummarization
#Metrics
#Tools
#NLP
#Dataset
#Evaluation
Issue Date: 2023-08-13
SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
Comment自動評価指標が人手評価の水準に達しないことが示されており、結局のところROUGEを上回る自動性能指標はほとんどなかった。human judgmentsとのKendall;'s Tauを見ると、chrFがCoherenceとRelevance, METEORがFluencyで上回ったのみだった。また、LEAD-3はやはりベースラインとしてかなり強く、LEAD-3を上回ったのはBARTとPEGASUSだった。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
#LM-based
Issue Date: 2023-08-13
BARTSCORE: Evaluating Generated Text as Text Generation, Yuan+ (w_ Neubig氏), NeurIPS'21
Summary本研究では、生成されたテキストの評価方法について検討しました。具体的には、事前学習モデルを使用してテキスト生成の問題をモデル化し、生成されたテキストを参照出力またはソーステキストに変換するために訓練されたモデルを使用しました。提案したメトリックであるBARTSCOREは、情報量、流暢さ、事実性などの異なる視点のテキスト評価に柔軟に適用できます。実験結果では、既存のトップスコアリングメトリックを上回る性能を示しました。BARTScoreの計算に使用するコードは公開されており、インタラクティブなリーダーボードも利用可能です。
CommentBARTScore概要
ソーステキストが与えられた時に、BARTによって生成テキストを生成する尤度を計算し、それをスコアとする手法。テキスト生成タスクをテキスト生成モデルでスコアリングすることで、pre-trainingされたパラメータをより有効に活用できる(e.g. BERTScoreやMoverScoreなどは、pre-trainingタスクがテキスト生成ではない)。BARTScoreの特徴は
1. parameter・and data-efficientである。pre-trainingに利用されたパラメータ以外の追加パラメータは必要なく、unsupervisedなmetricなので、human judgmentのデータなども必要ない。
2. 様々な観点から生成テキストを評価できる。conditional text generation problemにすることでinformativeness, coherence, factualityなどの様々な観点に対応可能。
3. BARTScoreは、(i) pre-training taskと類似したpromptを与えること、(ii) down stream generation taskでfinetuningすること、でより高い性能を獲得できる
BARTScoreを16種類のデータセットの、7つの観点で評価したところ、16/22において、top-scoring metricsよりも高い性能を示した。また、prompting starategyの有効性を示した。たとえば、シンプルに"such as"というフレーズを翻訳テキストに追加するだけで、German-English MTにおいて3%の性能向上が見られた。また、BARTScoreは、high-qualityなテキスト生成システムを扱う際に、よりロバストであることが分析の結果分かった。
前提
Problem Formulation
生成されたテキストのqualityを測ることを目的とする。本研究では、conditional text generation (e.g. 機械翻訳)にフォーカスする。すなわち、ゴールは、hypothesis h_bar を source text s_barがgivenな状態で生成することである。一般的には、人間が作成したreference r_barが評価の際は利用される。
Gold-standard Human Evaluation
評価のgold standardは人手評価であり、人手評価では多くの観点から評価が行われる。以下に代表的な観点を示す:
1. Informativeness: ソーステキストのキーアイデアをどれだけ捉えているか
2. Relevance: ソーステキストにあ地して、どれだけconsistentか
3. Fluency formatting problem, capitarlization errorや非文など、どの程度読むのが困難か
4. Coherence: 文間のつながりが、トピックに対してどれだけcoherentか
5. Factuality: ソーステキストに含意されるstatementのみを生成できているか
6. Semantic Coverage: 参照テキスト中のSemantic Content Unitを生成テキストがどれだけカバーできているか
7: Adequacy 入力文に対してアウトプットが同じ意味を出力できているかどうか、あるいは何らかのメッセージが失われる、追加される、歪曲していないかどうか
多くの性能指標は、これらの観点のうちのsubsetをカバーするようにデザインんされている。たとえば、BLEUは、翻訳におけるAdequacyとFluencyをとらえることを目的としている。一方、ROUGEは、semantic coverageを測るためのメトリックである。
BARTScoreは、これらのうち多くの観点を評価することができる。
Evaluation as Different Tasks
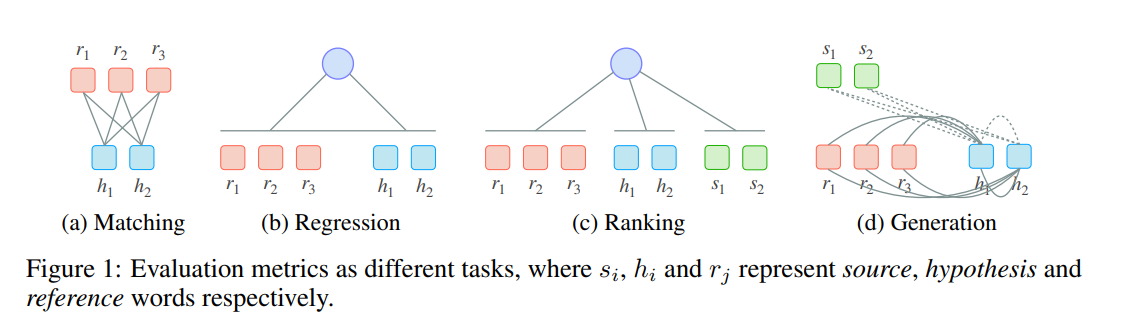
ニューラルモデルを異なる方法で自動評価に活用するのが最近のトレンドである。下図がその分類。この分類は、タスクにフォーカスした分類となっている。
1. Unsupervised Matching: ROUGE, BLEU, CHRF, BERTScore, MoverScoreのように、hypothesisとreference間での意味的な等価性を測ることが目的である。このために、token-levelのマッチングを用いる。これは、distributedな表現を用いる(BERTScore, MoverScore)場合もあれば、discreteな表現を用いる(ROUGE, BLEU, chrF)場合もある。また、意味的な等価性だけでなく、factual consistencyや、source-hypothesis間の関係性の評価に用いることもできると考えられるが先行研究ではやられていなかったので、本研究で可能なことを示す。
2. Supervised Regression: BLEURT, COMET, S^3, VRMのように、regression layer を用いてhuman judgmentをsupervisedに予測する方法である。最近のメトリックtおしては、BLEURT, COMETがあげられ、古典的なものとしては、S^3, VRMがあげられる。
4. Supervised Ranking: COMET, BEERのような、ランキング問題としてとらえる方法もある。これは優れたhypothesisを上位にランキングするようなスコア関数を学習する問題に帰着する。COMETやBEERが例としてあげられ、両者はMTタスクにフォーカスされている。COMETはhunan judgmentsをregressionすることを通じてランキングを作成し、BEERは、多くのシンプルな特徴量を組み合わせて、linear layerでチューニングされる。
5. Text Generation: PRISM, BARTScoreが例として挙げられる。BARTScoreでは、生成されたテキストの評価をpre-trained language modelによるテキスト生成タスクとしてとらえる。基本的なアイデアとしては、高品質のhypothesisは、ソース、あるいはreferenceから容易に生成可能であろう、というものである。これはPRISMを除いて、先行研究ではカバーされていない。BARTScoreは、PRISMとはいくつかの点で異なっている。(i) PRISMは評価をparaphrasing taskとしてとらえており、これが2つの意味が同じテキストを比較する前提となってしまっているため、手法を適用可能な範囲を狭めてしまっている。たとえば、文書要約におけるfactual consistencyの評価では、semantic spaceが異なる2つのテキストを比較する必要があるが、このような例には対応できない。(ii) PRISMはparallel dataから学習しなけえrばならないが、BARTScoreは、pre-trainedなopen-sourceのseq2seq modelを利用できる。(iii) BARTScoreでは、PRISMが検証していない、prompt-basedのlearningもサポートしている。
BARTScore
Sequence-to-Sequence Pre-trained Models
pre-trainingされたモデルは、様々な軸で異なっているが、その一つの軸としては訓練時の目的関数である。基本的には2つの大きな変種があり、1つは、language modeling objectives (e.g. MLM)、2つ目は、seq2seq objectivesである。特に、seq2seqで事前学習されたモデルは、エンコーダーとデコーダーによって構成されているため特に条件付き生成タスクに対して適しており、予測はAutoRegressiveに行われる。本研究ではBARTを用いる。付録には、preliminary experimentsとして、BART with T5, PEGASUSを用いた結果も添付する。
BARTScore
最も一般的なBARTScoreの定式化は下記である。

weighted log probabilityを利用する。このweightsは、異なるトークンに対して、異なる重みを与えることができる。たておば、IDFなどが利用可能であるが、本研究ではすべてのトークンを等価に扱う(uniform weightingだがstopwordを除外、IDFによる重みづけ、事前分布を導入するなど色々試したが、uniform weightingを上回るものがなかった)。
BARTScoreを用いて、様々な方向に用いて生成を行うことができ、異なる評価のシナリオに対応することができる。
・Faithfulness (s -> h):
・hypothesisがどれだけsource textに基づいて生成されているかを測ることができる。シナリオとしては、FactualityやRelevanceなどが考えられる。また、CoherenceやFluencyのように、target textのみの品質を測るためにも用いることができる。
・Precision (r -> h):
・hypothesisがどれだけgold-referenceに基づいてこう良くされているかを亜評価でき、precision-focusedなシナリオに適している
・Recall (h -> r):
・hypothesisから、gold referenceをどれだけ容易に再現できるかを測ることができる。そして、要約タスクのpyramid-basedな評価(i.e. semantic coverage等) に適している。pyramid-scoreはSemantic Content Unitsがどれだけカバーされているかによって評価される。
・F Score (r <-> h):
・双方向を考慮し、Precisioon / RecallからF値を算出する。この方法は、referenceと生成テキスト間でのsemantic overlap (informativenss, adequacy)などの評価に広く利用される。
BARTScore Variants
BARTScoreの2つの拡張を提案。(i) xとyをpromptingによって変更する。これにより、評価タスクをpre-training taskと近づける。(ii) パラメータΘを異なるfinetuning taskを考慮して変更する。すなわち、pre-trainingのドメインを、evaluation taskに近づける。
Prompt
Promptingはinput/outputに対して短いフレーズを追加し、pre-trained modelに対して特定のタスクを遂行させる方法である。BARTにも同様の洞察を簡単に組み込むことができる。この変種をBARTScore-PROMPTと呼ぶ。
prompt zが与えられたときに、それを (i) source textに追加し、新たなsource textを用いてBARTScoreを計算する。(ii) target textの先頭に追加し、new target textに対してBARTScoreを計算する。
Fine-tuning Task
classification-basedなタスクでfine-tuneされるのが一般的なBERT-based metricとは異なり、BARTScoreはgeneration taskでfine-tuneされるため、pre-training domainがevaluation taskと近い。本研究では、2つのdownstream taskを検証する。
1つめは、summarizationで、BARTをCNNDM datasetでfinetuningする。2つめは、paraphrasingで、summarizationタスクでfinetuningしたBARTをParaBank2 datasetでさらにfinetuningする。実験
baselines and datasets
Evaluation Metrics
supervised metrics: COMET, BLEURT
unsupervised: BLEU, ROUGE-1, ROUGE-2, ROUGE-L, chrF, PRISM, MoverScore, BERTScore
と比較
Measures for Meta Evaluation
Pearson Correlationでlinear correlationを測る。また、Spearman Correlationで2変数間の単調なcorrelationを測定する(線形である必要はない)。Kendall's Tauを用いて、2つの順序関係の関係性を測る。最後に、Accuracyでfactual textsとnon-factual textの間でどれだけ正しいランキングを得られるかを測る。
Datasets
Summarization, MT, DataToTextの3つのデータセットを利用。

Setup
Prompt Design
seedをparaphrasingすることで、 s->h方向には70個のpromptを、h<->rの両方向には、34のpromptを得て実験で用いた。

Settings
Summarizationとdata-to-textタスクでは、全てのpromptを用いてデコーダの頭に追加してスコアを計算しスコアを計算した。最終的にすべての生成されたスコアを平均することである事例に対するスコアを求めた(prompt unsembling)。MTについては、事例数が多くcomputational costが多くなってしまうため、WMT18を開発データとし、best prompt "Such as"を選択し、利用した。
BARTScoreを使う際は、gold standard human evaluationがrecall-basedなpyrmid methodの場合はBARTScore(h->r)を用い、humaan judgmentsがlinguistic quality (coherence fluency)そして、factual correctness、あるいは、sourceとtargetが同じモダリティ(e.g. language)の場合は、faitufulness-based BARTScore(s->h)を用いた。最後に、MTタスクとdata-to-textタスクでは、fair-comparisonのためにBARTScore F-score versionを用いた。
実験結果
MT
・BARTScoreはfinetuning tasksによって性能が向上し、5つのlanguage pairsにおいてその他のunsupervised methodsを統計的に優位にoutperformし、2つのlanguage pairでcomparableであった。
-Such asというpromptを追加するだけで、BARTScoreの性能が改善した。特筆すべきは、de-enにおいては、SoTAのsupervised MetricsであるBLEURTとCOMETを上回った。
・これは、有望な将来のmetric designとして「human judgment dataで訓練する代わりに、pre-trained language modelに蓄積された知識をより適切に活用できるpromptを探索する」という方向性を提案している。

Text Summarization
・vanilla BARTScoreはBERTScore, MoverScoreをInfo perspective以外でlarge marginでうくぁ回った。
・REALSum, SummEval dataseetでの改善は、finetuning taskによってさらに改善した。しかしながら、NeR18では改善しなかった。これは、データに含まれる7つのシステムが容易に区別できる程度のqualityであり、既にvanilla BARTScoreで高いレベルのcorrelationを達成しているからだと考えられる。
・prompt combination strategyはinformativenssに対する性能を一貫して改善している。しかし、fluency, factualityでは、一貫した改善は見られなかった。

Factuality datasetsに対する分析を行った。ゴールは、short generated summaryが、元のlong documentsに対してfaithfulか否かを判定するというものである。
・BARTScore+CNNは、Rank19データにおいてhuman baselineに近い性能を達成し、ほかのベースラインを上回った。top-performingなfactuality metricsであるFactCCやQAGSに対してもlarge marginで上回った。
・paraphraseをfine-tuning taskで利用すると、BARTScoreのパフォーマンスは低下した。これは妥当で、なぜなら二つのテキスト(summary and document)は、paraphrasedの関係性を保持していないからである。
・promptを導入しても、性能の改善は見受けられず、パフォーマンスは低下した。

Data-to-Text
・CNNDMでfine-tuningすることで、一貫してcorrelationが改善した。
・加えて、paraphraseデータセットでfinetuningすることで、さらに性能が改善した。
・prompt combination strategyは一貫してcorrelationを改善した。

Analysis
Fine-grained Analysis
・Top-k Systems: MTタスクにおいて、評価するシステムをtop-kにし、各メトリックごとにcorrelationの変化を見た。その結果、BARTScoreはすべてのunsupervised methodをすべてのkにおいて上回り、supervised metricのBLEURTも上回った。また、kが小さくなるほど、より性能はsmoothになっていき、性能の低下がなくなっていった。これはつまり、high-quality textを生成するシステムに対してロバストであることを示している。
・Reference Length: テストセットを4つのバケットにreference lengthに応じてブレイクダウンし、Kendall's Tauの平均のcorrelationを、異なるメトリック、バケットごとに言語をまたいで計算した。unsupervised metricsに対して、全てのlengthに対して、引き分けかあるいは上回った。また、ほかのmetricsと比較して、長さに対して安定感があることが分かった。

Prompt Analysis
(1) semantic overlap (informativeness, pyramid score, relevance), (2) linguistic quality (fluency, coherence), (3) factual correctness (factuality) に評価の観点を分類し、summarizationとdata-to-textをにおけるすべてのpromptを分析することで、promptの効果を分析した。それぞれのグループに対して、性能が改善したpromptの割合を計算した。その結果、semantic overlapはほぼ全てのpromptにて性能が改善し、factualityはいくつかのpromptでしか性能の改善が見られなかった。linguistic qualityに関しては、promptを追加することによる効果はどちらとも言えなかった。
Bias Analysis
BARTScoreが予測不可能な方法でバイアスを導入してしまうかどうかを分析した。バイアスとは、human annotatorが与えたスコアよりも、値が高すぎる、あるいは低すぎるような状況である。このようなバイアスが存在するかを検証するために、human annotatorとBARTScoreによるランクのサを分析した。これを見ると、BARTScoreは、extractive summarizationの品質を区別する能力がabstractive summarizationの品質を区別する能力よりも劣っていることが分かった。しかしながら、近年のトレンドはabstractiveなseq2seqを活用することなので、この弱点は軽減されている。
Implications and Future Directions
prompt-augmented metrics: semantic overlapではpromptingが有効に働いたが、linguistic qualityとfactualityでは有効ではなかった。より良いpromptを模索する研究が今後期待される。
Co-evolving evaluation metrics and systems: BARTScoreは、メトリックデザインとシステムデザインの間につながりがあるので、より性能の良いseq2seqシステムが出たら、それをメトリックにも活用することでよりreliableな自動性能指標となることが期待される。

#Sentence #Embeddings #Pocket #NLP #LanguageModel #RepresentationLearning #ContrastiveLearning #Catastrophic Forgetting Issue Date: 2023-07-27 SimCSE: Simple Contrastive Learning of Sentence Embeddings, Tianyu Gao+, N_A, EMNLP'21 Summaryこの論文では、SimCSEという対比学習フレームワークを提案しています。このフレームワークは、文の埋め込み技術を進化させることができます。教師なしアプローチでは、入力文をノイズとして扱い、自己を対比的に予測します。教師ありアプローチでは、自然言語推論データセットから注釈付きのペアを使用して対比学習を行います。SimCSEは、意味的テキスト類似性タスクで評価され、以前の手法と比較して改善を実現しました。対比学習は、事前学習された埋め込みの空間を均一に正則化し、教師信号が利用可能な場合には正のペアをよりよく整列させることが示されました。 Comment462 よりも性能良く、unsupervisedでも学習できる。STSタスクのベースラインにだいたい入ってる手法概要
Contrastive Learningを活用して、unsupervised/supervisedに学習を実施する。
Unsupervised SimCSEでは、あるsentenceをencoderに2回入力し、それぞれにdropoutを適用させることで、positive pairを作成する。dropoutによって共通のembeddingから異なる要素がマスクされた(noiseが混ざった状態とみなせる)類似したembeddingが作成され、ある種のdata augmentationによって正例を作成しているともいえる。負例はnegative samplingする。(非常にsimpleだが、next sentence predictionで学習するより性能が良くなる)
Supervised SimCSEでは、アノテーションされたsentence pairに基づいて、正例・負例を決定する。本研究では、NLIのデータセットにおいて、entailment関係にあるものは正例として扱う。contradictions(矛盾)関係にあるものは負例として扱う。
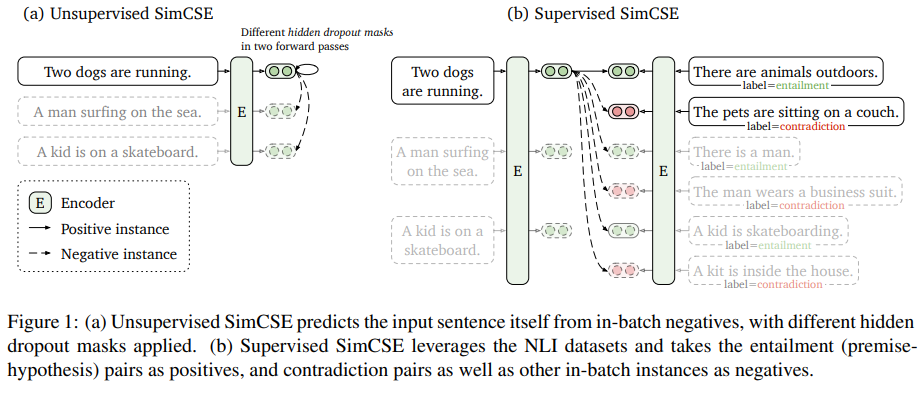
Siamese Networkで用いられるmeans-squared errrorとContrastiveObjectiveの違い
どちらもペアワイズで比較するという点では一緒だが、ContrastiveObjectiveは正例と近づいたとき、負例と遠ざかったときにlossが小さくなるような定式化がされている点が異なる。

(画像はこのブログから引用。ありがとうございます。https://techblog.cccmk.co.jp/entry/2022/08/30/163625)
Unsupervised SimCSEの実験
異なるdata augmentation手法と比較した結果、dropoutを適用する手法の方が性能が高かった。MLMや, deletion, 類義語への置き換え等よりも高い性能を獲得しているのは興味深い。また、Next Sentence Predictionと比較しても、高い性能を達成。Next Sentence Predictionは、word deletion等のほぼ類似したテキストから直接的に類似関係にあるペアから学習するというより、Sentenceの意味内容のつながりに基づいてモデルの言語理解能力を向上させ、そのうえで類似度を測るという間接的な手法だが、word deletionに負けている。一方、dropoutを適用するだけの(直接的に類似ペアから学習する)本手法はより高い性能を示している。
[image](https://github.com/AkihikoWatanabe/paper_notes/assets/12249301/0ea3549e-3363-4857-94e6-a1ef474aa191)
なぜうまくいくかを分析するために、異なる設定で実験し、alignment(正例との近さ)とuniformity(どれだけembeddingが一様に分布しているか)を、10 stepごとにplotした結果が以下。dropoutを適用しない場合と、常に同じ部分をマスクする方法(つまり、全く同じembeddingから学習する)設定を見ると、学習が進むにつれuniformityは改善するが、alignmentが悪くなっていっている。一方、SimCSEはalignmentを維持しつつ、uniformityもよくなっていっていることがわかる。


Supervised SimCSEの実験
アノテーションデータを用いてContrastiveLearningするにあたり、どういったデータを正例としてみなすと良いかを検証するために様々なデータセットで学習し性能を検証した。
・QQP4: Quora question pairs
・Flickr30k (Young et al., 2014): 同じ画像に対して、5つの異なる人間が記述したキャプションが存在
・ParaNMT (Wieting and Gimpel, 2018): back-translationによるparaphraseのデータセットa
・NLI datasets: SNLIとMNLI
実験の結果、NLI datasetsが最も高い性能を示した。この理由としては、NLIデータセットは、crowd sourcingタスクで人手で作成された高品質なデータセットであることと、lexical overlapが小さくなるようにsentenceのペアが作成されていることが起因している。実際、NLI datsetのlexical overlapは39%だったのに対し、ほかのデータセットでは60%であった。
また、condunctionsとなるペアを明示的に負例として与えることで、より性能が向上した(普通はnegative samplingする、というかバッチ内の正例以外のものを強制的に負例とする。こうすると、意味が同じでも負例になってしまう事例が出てくることになる)。より難しいNLIタスクを含むANLIデータセットを追加した場合は、性能が改善しなかった。この理由については考察されていない。性能向上しそうな気がするのに。

他手法との比較結果
SimCSEがよい。

Ablation Studies
異なるpooling方法で、どのようにsentence embeddingを作成するかで性能の違いを見た。originalのBERTの実装では、CLS token のembeddingの上にMLP layerがのっかっている。これの有無などと比較。
Unsupervised SimCSEでは、training時だけMLP layerをのっけて、test時はMLPを除いた方が良かった。一方、Supervised SimCSEでは、 MLP layerをのっけたまんまで良かったとのこと。

また、SimCSEで学習したsentence embeddingを別タスクにtransferして活用する際には、SimCSEのobjectiveにMLMを入れた方が、catastrophic forgettingを防げて性能が高かったとのこと。
 ablation studiesのhard negativesのところと、どのようにミニバッチを構成するか、それぞれのtransferしたタスクがどのようなものがしっかり読めていない。あとでよむ。
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
#ICLR
Issue Date: 2023-07-24
Measuring Massive Multitask Language Understanding, Dan Hendrycks+, N_A, ICLR'21
Summary私たちは、マルチタスクのテキストモデルの正確性を測定するための新しいテストを提案しています。このテストは57のタスクをカバーし、広範な世界知識と問題解決能力が必要です。現在のモデルはまだ専門家レベルの正確性に達しておらず、性能に偏りがあります。私たちのテストは、モデルの弱点を特定するために使用できます。
CommentOpenReview:https://openreview.net/forum?id=d7KBjmI3GmQMMLU論文
#Pocket
Issue Date: 2025-07-24
[Paper Note] Exploring Simple Siamese Representation Learning, Xinlei Chen+, arXiv'20
SummarySiameseネットワークを用いた教師なし視覚表現学習に関する研究で、ネガティブサンプルペア、大きなバッチ、モーメンタムエンコーダーを使用せずに意味のある表現を学習できることを示した。ストップグラディエント操作が崩壊解を防ぐ重要な役割を果たすことを確認し、SimSiamメソッドがImageNetおよび下流タスクで競争力のある結果を達成した。これにより、Siameseアーキテクチャの役割を再考するきっかけとなることを期待している。
Comment日本語解説:
ablation studiesのhard negativesのところと、どのようにミニバッチを構成するか、それぞれのtransferしたタスクがどのようなものがしっかり読めていない。あとでよむ。
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
#ICLR
Issue Date: 2023-07-24
Measuring Massive Multitask Language Understanding, Dan Hendrycks+, N_A, ICLR'21
Summary私たちは、マルチタスクのテキストモデルの正確性を測定するための新しいテストを提案しています。このテストは57のタスクをカバーし、広範な世界知識と問題解決能力が必要です。現在のモデルはまだ専門家レベルの正確性に達しておらず、性能に偏りがあります。私たちのテストは、モデルの弱点を特定するために使用できます。
CommentOpenReview:https://openreview.net/forum?id=d7KBjmI3GmQMMLU論文
#Pocket
Issue Date: 2025-07-24
[Paper Note] Exploring Simple Siamese Representation Learning, Xinlei Chen+, arXiv'20
SummarySiameseネットワークを用いた教師なし視覚表現学習に関する研究で、ネガティブサンプルペア、大きなバッチ、モーメンタムエンコーダーを使用せずに意味のある表現を学習できることを示した。ストップグラディエント操作が崩壊解を防ぐ重要な役割を果たすことを確認し、SimSiamメソッドがImageNetおよび下流タスクで競争力のある結果を達成した。これにより、Siameseアーキテクチャの役割を再考するきっかけとなることを期待している。
Comment日本語解説:
https://qiita.com/saliton/items/2f7b1bfb451df75a286f
https://qiita.com/koshian2/items/a31b85121c99af0eb050 #Pocket Issue Date: 2025-07-24 [Paper Note] Bootstrap your own latent: A new approach to self-supervised Learning, Jean-Bastien Grill+, arXiv'20 SummaryBYOL(Bootstrap Your Own Latent)は、自己教師あり画像表現学習の新しい手法で、オンラインネットワークとターゲットネットワークの2つのニューラルネットワークを用いて学習を行う。BYOLは、ネガティブペアに依存せずに最先端の性能を達成し、ResNet-50でImageNetにおいて74.3%の分類精度を達成、より大きなResNetでは79.6%に達する。転送学習や半教師ありベンチマークでも優れた性能を示し、実装と事前学習済みモデルはGitHubで公開されている。 Comment日本語解説:
https://sn-neural-compute.netlify.app/202006250/ #ComputerVision #Pocket #DataAugmentation #ContrastiveLearning #Self-SupervisedLearning #ICLR Issue Date: 2025-05-18 A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen+, ICML'20 Summary本論文では、視覚表現の対比学習のためのシンプルなフレームワークSimCLRを提案し、特別なアーキテクチャやメモリバンクなしで対比自己教師あり学習を簡素化します。データ拡張の重要性、学習可能な非線形変換の導入による表現の質向上、対比学習が大きなバッチサイズと多くのトレーニングステップから利益を得ることを示し、ImageNetで従来の手法を上回る結果を達成しました。SimCLRによる自己教師あり表現を用いた線形分類器は76.5%のトップ1精度を達成し、教師ありResNet-50に匹敵します。ラベルの1%でファインチューニングした場合、85.8%のトップ5精度を達成しました。 Comment日本語解説:https://techblog.cccmkhd.co.jp/entry/2022/08/30/163625 #DocumentSummarization #NeuralNetwork #NLP #ICML Issue Date: 2025-05-13 PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization, Jingqing Zhang+, ICML'20 Summary大規模なテキストコーパスに対して新しい自己教師ありの目的でトランスフォーマーを事前学習し、抽象的なテキスト要約に特化したモデルPEGASUSを提案。重要な文を削除またはマスクし、残りの文から要約を生成。12の下流要約タスクで最先端のROUGEスコアを達成し、限られたリソースでも優れたパフォーマンスを示す。人間評価でも複数のデータセットで人間のパフォーマンスに達したことを確認。 CommentPEGASUSもなかったので追加。BARTと共に文書要約のBackboneとして今でも研究で利用される模様。関連:
・984 #NeuralNetwork #Pretraining #Pocket #NLP #TransferLearning #PostTraining Issue Date: 2025-05-12 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Colin Raffel+, JMLR'20 Summary転移学習はNLPにおいて強力な技術であり、本論文ではテキストをテキストに変換する統一フレームワークを提案。事前学習の目的やアーキテクチャを比較し、最先端の結果を達成。データセットやモデル、コードを公開し、今後の研究を促進する。 CommentT5もメモっていなかったので今更ながら追加。全てのNLPタスクをテキスト系列からテキスト系列へ変換するタスクとみなし、Encoder-DecoderのTransformerを大規模コーパスを用いて事前学習をし、downstreamタスクにfinetuningを通じて転移する。 #Pocket #NLP #LanguageModel #ICLR #Decoding Issue Date: 2025-04-14 The Curious Case of Neural Text Degeneration, Ari Holtzman+, ICLR'20 Summary深層ニューラル言語モデルは高品質なテキスト生成において課題が残る。尤度の使用がモデルの性能に影響を与え、人間のテキストと機械のテキストの間に分布の違いがあることを示す。デコーディング戦略が生成テキストの質に大きな影響を与えることが明らかになり、ニュークリアスsamplingを提案。これにより、多様性を保ちながら信頼性の低い部分を排除し、人間のテキストに近い質を実現する。 Comment現在のLLMで主流なNucleus (top-p) Samplingを提案した研究 #MachineTranslation #Metrics #Pocket #NLP #Evaluation #EMNLP Issue Date: 2024-05-26 COMET: A Neural Framework for MT Evaluation, Ricardo Rei+, N_A, EMNLP'20 SummaryCOMETは、多言語機械翻訳評価モデルを訓練するためのニューラルフレームワークであり、人間の判断との新しい最先端の相関レベルを達成します。クロスリンガル事前学習言語モデリングの進展を活用し、高度に多言語対応かつ適応可能なMT評価モデルを実現します。WMT 2019 Metrics shared taskで新たな最先端のパフォーマンスを達成し、高性能システムに対する堅牢性を示しています。 CommentBetter/Worseなhypothesisを利用してpair-wiseにランキング関数を学習する


Inference時は単一のhypothesisしかinputされないので、sourceとreferenceに対してそれぞれhypothesisの距離をはかり、その調和平均でスコアリングする
ACL2024, EMNLP2024あたりのMT研究のmetricをざーっと見る限り、BLEU/COMETの双方で評価する研究が多そう #NeuralNetwork #NLP #LanguageModel #Transformer #ActivationFunction Issue Date: 2024-05-24 GLU Variants Improve Transformer, Noam Shazeer, N_A, arXiv'20 SummaryGLUのバリエーションをTransformerのフィードフォワード・サブレイヤーでテストし、通常の活性化関数よりもいくつかのバリエーションが品質向上をもたらすことを発見した。 Comment一般的なFFNでは、linear layerをかけた後に、何らかの活性化関数をかませる方法が主流である。
このような構造の一つとしてGLUがあるが、linear layerと活性化関数には改良の余地があり、様々なvariantが考えられるため、色々試しました、というはなし。


オリジナルのGLUと比較して、T5と同じ事前学習タスクを実施したところ、perplexityが改善

また、finetuningをした場合の性能も、多くの場合オリジナルのGLUよりも高い性能を示した。



#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-05-10 BERTScore: Evaluating Text Generation with BERT, Tianyi Zhang+, N_A, ICLR'20 SummaryBERTScoreは、文脈埋め込みを使用してトークンの類似度を計算するテキスト生成の自動評価メトリックであり、363の機械翻訳および画像キャプションシステムの出力を使用して評価されました。BERTScoreは、既存のメトリックよりも人間の判断との相関が高く、より強力なモデル選択性能を提供し、敵対的な言い換え検出タスクにおいてもより堅牢であることが示されました。 Comment概要
既存のテキスト生成の評価手法(BLEUやMETEOR)はsurface levelのマッチングしかしておらず、意味をとらえられた評価になっていなかったので、pretrained BERTのembeddingを用いてsimilarityを測るような指標を提案しましたよ、という話。
prior metrics
n-gram matching approaches
n-gramがreferenceとcandidateでどれだけ重複しているかでPrecisionとrecallを測定
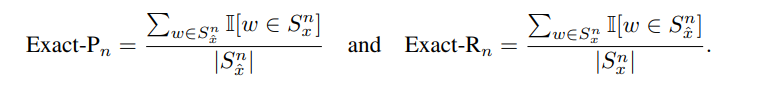
BLEU
MTで最も利用される。n-gramのPrecision(典型的にはn=1,2,3,4)と短すぎる候補訳にはペナルティを与える(brevity penalty)ことで実現される指標。SENT-BLEUといった亜種もある。BLEUと比較して、BERTScoreは、n-gramの長さの制約を受けず、潜在的には長さの制限がないdependencyをcontextualized embeddingsでとらえることができる。
METEOR
669 METEOR 1.5では、内容語と機能語に異なるweightを割り当て、マッチングタイプによってもweightを変更する。METEOR++2.0では、学習済みの外部のparaphrase resourceを活用する。METEORは外部のリソースを必要とするため、たった5つの言語でしかfull feature setではサポートされていない。11の言語では、恥部のfeatureがサポートされている。METEORと同様に、BERTScoreでも、マッチに緩和を入れていることに相当するが、BERTの事前学習済みのembeddingは104の言語で取得可能である。BERTScoreはまた、重要度によるweightingをサポートしている(コーパスの統計量で推定)。
Other Related Metrics
・NIST: BLEUとは異なるn-gramの重みづけと、brevity penaltyを利用する
・ΔBLEU: multi-reference BLEUを、人手でアノテーションされたnegative reference sentenceで変更する
・CHRF: 文字n-gramを比較する
・CHRF++: CHRFをword-bigram matchingに拡張したもの
・ROUGE: 文書要約で利用される指標。ROUGE-N, ROUGE^Lといった様々な変種がある。
・CIDEr: image captioningのmetricであり、n-gramのtf-idfで重みづけされたベクトルのcosine similrityを測定する
Edit-distance based Metrics
・Word Error Rate (WER): candidateからreferenceを再現するまでに必要なedit operationの数をカウントする手法
・Translation Edit Rate (TER): referenceの単語数によってcandidateからreferenceまでのedit distanceを正規化する手法
・ITER: 語幹のマッチと、より良い正規化に基づく手法
・PER: positionとは独立したError Rateを算出
・CDER: edit operationにおけるblock reorderingをモデル化
・CHARACTER / EED: character levelで評価
Embedding-based Metrics
・MEANT 2.0: lexical, structuralの類似度を測るために、word embeddingとshallow semantic parsesを利用
・YISI-1: MEANT 2.0と同様だが、semantic parseの利用がoptionalとなっている
これらはBERTScoreと同様の、similarityをシンプルに測るアプローチで、BERTScoreもこれにinspireされている。が、BERTScoreはContextualized Embeddingを利用する点が異なる。また、linguistic structureを生成するような外部ツールは利用しない。これにより、BERTScoreをシンプルで、新たなlanguageに対しても使いやすくしている。greedy matchingの代わりに、WMD, WMDo, SMSはearth mover's distanceに基づく最適なマッチングを利用することを提案している。greedy matchingとoptimal matchingのtradeoffについては研究されている。sentence-levelのsimilarityを計算する手法も提案されている。これらと比較して、BERTScoreのtoken-levelの計算は、重要度に応じて、tokenに対して異なる重みづけをすることができる。
Learned Metrics
様々なmetricが、human judgmentsとのcorrelationに最適化するために訓練されてきた。
・BEER: character-ngram, word bigramに基づいたregresison modelを利用
・BLEND: 29の既存のmetricを利用してregressionを実施
・RUSE: 3種類のpre-trained sentence embedding modelを利用する手法
これらすべての手法は、コストのかかるhuman judgmentsによるsupervisionが必要となる。そして、新たなドメインにおける汎化能力の低さのリスクがある。input textが人間が生成したものか否か予測するneural modelを訓練する手法もある。このアプローチは特定のデータに対して最適化されているため、新たなデータに対して汎化されないリスクを持っている。これらと比較して、BERTScoreは特定のevaluation taskに最適化されているモデルではない。
BERTScore
referenceとcandidateのトークン間のsimilarityの最大値をとり、それらを集約することで、Precision, Recallを定義し、PrecisionとRecallを利用してF値も計算する。Recallは、reference中のすべてのトークンに対して、candidate中のトークンとのcosine similarityの最大値を測る。一方、Precisionは、candidate中のすべてのトークンに対して、reference中のトークンとのcosine similarityの最大値を測る。ここで、類似度の式が単なる内積になっているが、これはpre-normalized vectorを利用する前提であり、正規化が必要ないからである。

また、IDFによるトークン単位でのweightingを実施する。IDFはテストセットの値を利用する。TFを使わない理由は、BERTScoreはsentence同士を比較する指標であるため、TFは基本的に1となりやすい傾向にあるためである。IDFを計算する際は出現数を+1することによるスムージングを実施。

さらに、これはBERTScoreのランキング能力には影響を与えないが、BERTScoreの値はコサイン類似度に基づいているため、[-1, 1]となるが、実際は学習したcontextual embeddingのgeometryに値域が依存するため、もっと小さなレンジでの値をとることになってしまう。そうすると、人間による解釈が難しくなる(たとえば、極端な話、スコアの0.1程度の変化がめちゃめちゃ大きな変化になってしまうなど)ため、rescalingを実施。rescalingする際は、monolingualコーパスから、ランダムにsentenceのペアを作成し(BETRScoreが非常に小さくなるケース)、これらのBERTScoreを平均することでbを算出し、bを利用してrescalingした。典型的には、rescaling後は典型的には[0, 1]の範囲でBERTScoreは値をとる(ただし数式を見てわかる通り[0, 1]となることが保証されているわけではない点に注意)。これはhuman judgmentsとのcorrelationとランキング性能に影響を与えない(スケールを変えているだけなので)。


実験
Contextual Embedding Models
12種類のモデルで検証。BERT, RoBERTa, XLNet, XLMなど。
Machine Translation
WMT18のmetric evaluation datasetを利用。149種類のMTシステムの14 languageに対する翻訳結果, gold referencesと2種類のhuman judgment scoreが付与されている。segment-level human judgmentsは、それぞれのreference-candiate pairに対して付与されており、system-level human judgmentsは、それぞれのシステムに対して、test set全体のデータに基づいて、単一のスコアが付与されている。pearson correlationの絶対値と、kendall rank correration τをmetricsの品質の評価に利用。そしてpeason correlationについてはWilliams test、kendall τについては、bootstrap re-samplingによって有意差を検定した。システムレベルのスコアをBERTScoreをすべてのreference-candidate pairに対するスコアをaveragingすることによって求めた。また、ハイブリッドシステムについても実験をした。具体的には、それぞれのreference sentenceについて、システムの中からランダムにcandidate sentenceをサンプリングした。これにより、system-level experimentをより多くのシステムで実現することができる。ハイブリッドシステムのシステムレ4ベルのhuman judgmentsは、WMT18のsegment-level human judgmentsを平均することによって作成した。BERTScoreを既存のメトリックと比較した。
通常の評価に加えて、モデル選択についても実験した。10kのハイブリッドシステムを利用し、10kのうち100をランダムに選択、そして自動性能指標でそれらをランキングした。このプロセスを100K回繰り返し、human rankingとmetricのランキングがどれだけagreementがあるかをHits@1で評価した(best systemの一致で評価)。モデル選択の指標として新たにtop metric-rated systemとhuman rankingの間でのMRR, 人手評価でtop-rated systemとなったシステムとのスコアの差を算出した。WMT17, 16のデータセットでも同様の評価を実施した。
Image Captioning
COCO 2015 captioning challengeにおける12種類のシステムのsubmissionデータを利用。COCO validationセットに対して、それぞれのシステムはimageに対するcaptionを生成し、それぞれのimageはおよそ5個のreferenceを持っている。先行研究にならい、Person Correlationを2種類のシステムレベルmetricで測定した。
・M1: 人間によるcaptionと同等、あるいはそれ以上と評価されたcaptionの割合
・M2: 人間によるcaptionと区別がつかないcaptionの割合
BERTScoreをmultiple referenceに対して計算し、最も高いスコアを採用した。比較対象のmetricはtask-agnostic metricを採用し、BLEU, METEOR, CIDEr, BEER, EED, CHRF++, CHARACTERと比較した。そして、2種類のtask-specific metricsとも比較した:SPICE, LEIC
実験結果
Machine Translation
system-levelのhuman judgmentsとのcorrelationの比較、hybrid systemとのcorrelationの比較、model selection performance
to-Englishの結果では、BERTScoreが最も一貫して性能が良かった。RUSEがcompetitiveな性能を示したが、RUSEはsupervised methodである。from-Englishの実験では、RUSEは追加のデータと訓練をしないと適用できない。



以下は、segment-levelのcorrelationを示したものである。BERTScoreが一貫して高い性能を示している。BLEUから大幅な性能アップを示しており、特定のexampleについての良さを検証するためには、BERTScoreが最適であることが分かる。BERTScoreは、RUSEをsignificantlyに上回っている。idfによる重要度のweightingによって、全体としては、small benefitがある場合があるが全体としてはあんまり効果がなかった。importance weightingは今後の課題であり、テキストやドメインに依存すると考えられる。FBERTが異なる設定でも良く機能することが分かる。異なるcontextual embedding model間での比較などは、appendixに示す。

Image Captioning
task-agnostic metricの間では、BETRScoreはlarge marginで勝っている。image captioningはchallengingな評価なので、n-gramマッチに基づくBLEU, ROUGEはまったく機能していない。また、idf weightingがこのタスクでは非常に高い性能を示した。これは人間がcontent wordsに対して、より高い重要度を置いていることがわかる。最後に、LEICはtrained metricであり、COCO dataに最適化されている。この手法は、ほかのすべてのmetricを上回った。

Speed
pre-trained modelを利用しているにもかかわらず、BERTScoreは比較的高速に動作する。192.5 candidate-reference pairs/secondくらい出る(GTX-1080Ti GPUで)。WMT18データでは、15.6秒で処理が終わり、SacreBLEUでは5.4秒である。計算コストそんなにないので、BERTScoreはstoppingのvalidationとかにも使える。Robustness analysis
BERTScoreのロバスト性をadversarial paraphrase classificationでテスト。Quora Question Pair corpus (QQP) を利用し、Word Scrambling dataset (PAWS) からParaphrase Adversariesを取得。どちらのデータも、各sentenceペアに対して、それらがparaphraseかどうかラベル付けされている。QQPの正例は、実際のduplicate questionからきており、負例は関連するが、異なる質問からきている。PAWSのsentence pairsは単語の入れ替えに基づいているものである。たとえば、"Flights from New York to Florida" は "Flights from Florida to New York" のように変換され、良いclassifierはこれらがparaphraseではないと認識できなければならない。PAWSはPAWS_QQPとPAWS_WIKIによって構成さえrており、PAWS_QQPをdevelpoment setとした。automatic metricsでは、paraphrase detection training dataは利用しないようにした。自動性能指標で高いスコアを獲得するものは、paraphraseであることを想定している。
下図はAUCのROC curveを表しており、PAWS_QQPにおいて、QQPで訓練されたclassifierはrandom guessよりも性能が低くなることが分かった。つまりこれらモデルはadversaial exampleをparaphraseだと予測してしまっていることになる。adversarial examplesがtrainingデータで与えられた場合は、supervisedなモデルも分類ができるようになる。が、QQPと比べると性能は落ちる。多くのmetricsでは、QQP ではまともなパフォーマンスを示すが、PAWS_QQP では大幅なパフォーマンスの低下を示し、ほぼrandomと同等のパフォーマンスとなる。これは、これらの指標がより困難なadversarial exampleを区別できないことを示唆している。一方、BERTSCORE のパフォーマンスはわずかに低下するだけであり、他の指標よりもロバスト性が高いことがわかる。

Discussion
・BERTScoreの単一の設定が、ほかのすべての指標を明確に上回るということはない
・ドメインや言語を考慮して、指標や設定を選択すべき
・一般的に、機械翻訳の評価にはFBERTを利用することを推奨
・英語のテキスト生成の評価には、24層のRoBERTa largeモデルを使用して、BERTScoreを計算したほうが良い
・非英語言語については、多言語のBERT_multiが良い選択肢だが、このモデルで計算されたBERTScoreは、low resource languageにおいて、パフォーマンスが安定しているとは言えない #NeuralNetwork #Pocket #NLP #LanguageModel #Zero/FewShotPrompting #In-ContextLearning #NeurIPS Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 SummaryGPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 CommentIn-Context Learningを提案した論文論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。

この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。 #NeuralNetwork #ComputerVision #EfficiencyImprovement #Pocket #ICML #Scaling Laws #Backbone Issue Date: 2025-05-12 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan+, ICML'19 Summary本論文では、ConvNetsのスケーリングを深さ、幅、解像度のバランスを考慮して体系的に研究し、新しいスケーリング手法を提案。これにより、MobileNetsやResNetのスケールアップを実証し、EfficientNetsという新しいモデルファミリーを設計。特にEfficientNet-B7は、ImageNetで84.3%のトップ1精度を達成し、従来のConvNetsよりも小型かつ高速である。CIFAR-100やFlowersなどのデータセットでも最先端の精度を記録。ソースコードは公開されている。 Comment元論文をメモってなかったので追加。
・346
も参照のこと。 #RecommenderSystems #Pocket #Transformer #SequentialRecommendation #ICDM Issue Date: 2025-07-04 [Paper Note] Self-Attentive Sequential Recommendation, Wang-Cheng Kang+, ICDM'18 Summary自己注意に基づく逐次モデル(SASRec)を提案し、マルコフ連鎖と再帰型ニューラルネットワークの利点を統合。SASRecは、少数のアクションから次のアイテムを予測し、スパースおよび密なデータセットで最先端のモデルを上回る性能を示す。モデルの効率性と注意重みの視覚化により、データセットの密度に応じた適応的な処理が可能であることが確認された。 #RecommenderSystems #NeuralNetwork #General #Embeddings #MachineLearning #RepresentationLearning #AAAI Issue Date: 2017-12-28 StarSpace: Embed All The Things, Wu+, AAAI'18 Comment分類やランキング、レコメンドなど、様々なタスクで汎用的に使用できるEmbeddingの学習手法を提案。
Embeddingを学習する対象をEntityと呼び、Entityはbag-of-featureで記述される。
Entityはbag-of-featureで記述できればなんでもよく、
これによりモデルの汎用性が増し、異なる種類のEntityでも同じ空間上でEmbeddingが学習される。
学習方法は非常にシンプルで、Entity同士のペアをとったときに、relevantなpairであれば類似度が高く、
irelevantなペアであれば類似度が低くなるようにEmbeddingを学習するだけ。
たとえば、Entityのペアとして、documentをbag-of-words, bag-of-ngrams, labelをsingle wordで記述しテキスト分類、
あるいは、user_idとユーザが過去に好んだアイテムをbag-of-wordsで記述しcontent-based recommendationを行うなど、 応用範囲は幅広い。
5種類のタスクで提案手法を評価し、既存手法と比較して、同等かそれ以上の性能を示すことが示されている。
手法の汎用性が高く学習も高速なので、色々な場面で役に立ちそう。
また、異なる種類のEntityであっても同じ空間上でEmbeddingが学習されるので、学習されたEmbeddingの応用先が広く有用。実際にSentimentAnalysisで使ってみたが(ポジネガ二値分類)、少なくともBoWのSVMよりは全然性能良かったし、学習も早いし、次元数めちゃめちゃ少なくて良かった。
StarSpaceで学習したembeddingをBoWなSVMに入れると性能が劇的に改善した。解説:
https://www.slideshare.net/akihikowatanabe3110/starspace-embed-all-the-things #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #MatrixFactorization #WWW Issue Date: 2018-02-16 Neural Collaborative Filtering, He+, WWW'17 CommentCollaborative FilteringをMLPで一般化したNeural Collaborative Filtering、およびMatrix Factorizationはuser, item-embeddingのelement-wise product + linear transofmration + activation で一般化できること(GMF; Generalized Matrix Factorization)を示し、両者を組み合わせたNeural Matrix Factorizationを提案している。
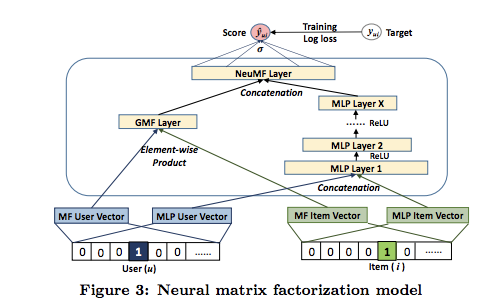
学習する際は、Implicit Dataの場合は負例をNegative Samplingし、LogLoss(Binary Cross-Entropy Loss)で学習する。
Neural Matrix Factorizationが、ItemKNNやBPRといったベースラインをoutperform
Negative Samplingでサンプリングする負例の数は、3~4程度で良さそう
#NeuralNetwork #MachineTranslation #NLP #Transformer #Attention #PositionalEncoding #NeurIPS Issue Date: 2018-01-19 Attention is all you need, Vaswani+, NIPS'17 CommentTransformer (self-attentionを利用) 論文
解説スライド:https://www.slideshare.net/DeepLearningJP2016/dlattention-is-all-you-need
解説記事:https://qiita.com/nishiba/items/1c99bc7ddcb2d62667c6
新しい翻訳モデル(Transformer)を提案。既存のモデルよりも並列化に対応しており、短時間の訓練で(既存モデルの1/4以下のコスト)高いBLEUスコアを達成した。
TransformerはRNNやCNNを使わず、attentionメカニズムに基づいている。
(解説より)分かりやすい:
https://qiita.com/halhorn/items/c91497522be27bde17ceTransformerの各コンポーネントでのoutputのshapeや、attention_maskの形状、実装について記述されており有用:
https://qiita.com/FuwaraMiyasaki/items/239f3528053889847825集合知 #NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #EMNLP Issue Date: 2018-01-01 Challenges in Data-to-Document Generation, Wiseman+ (with Rush), EMNLP'17 Comment・RotoWire(NBAのテーブルデータ + サマリ)データを収集し公開

・Rotowireデータの統計量
 【モデルの概要】
【モデルの概要】
・attention-based encoder-decoder model
・BaseModel
・レコードデータ r の各要素(r.e: チーム名等のENTITY r.t: POINTS等のデータタイプ, r.m: データのvalue)からembeddingをlookupし、1-layer MLPを適用し、レコードの各要素のrepresentation(source data records)を取得
・Luongらのattentionを利用したLSTM Decoderを用意し、source data recordsとt-1ステップ目での出力によって条件付けてテキストを生成していく
・negative log likelihoodがminimizeされるように学習する
・Copying
・コピーメカニズムを導入し、生成時の確率分布に生成テキストを入力からコピーされるか否かを含めた分布からテキストを生成。コピーの対象は、入力レコードのvalueがコピーされるようにする。
・コピーメカニズムには下記式で表現される Conditional Copy Modelを利用し、p\(zt|y1:t-1, s)はMLPで表現する。

・またpcopyは、生成している文中にあるレコードのエンティティとタイプが出現する場合に、対応するvalueをコピーし生成されるように、下記式で表現する

・ここで r(yt) =

#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #ACL Issue Date: 2017-12-31 Get To The Point: Summarization with Pointer-Generator Networks, See+, ACL'17 Comment解説スライド:https://www.slideshare.net/akihikowatanabe3110/get-to-the-point-summarization-with-pointergenerator-networks/1単語の生成と単語のコピーの両方を行えるハイブリッドなニューラル文書要約モデルを提案。
同じ単語の繰り返し現象(repetition)をなくすために、Coverage Mechanismも導入した。
136 などと比較するとシンプルなモデル。一般的に、PointerGeneratorと呼ばれる。
OpenNMTなどにも実装されている: https://opennmt.net/OpenNMT-py/_modules/onmt/modules/copy_generator.html(参考)Pointer Generator Networksで要約してみる:
https://qiita.com/knok/items/9a74430b279e522d5b93 #NeuralNetwork #Sentence #Embeddings #NLP #RepresentationLearning #ICLR Issue Date: 2017-12-28 A structured self-attentive sentence embedding, Li+ (Bengio group), ICLR'17 CommentOpenReview:https://openreview.net/forum?id=BJC_jUqxe #NeuralNetwork #Pocket #SpeechProcessing Issue Date: 2025-06-13 [Paper Note] WaveNet: A Generative Model for Raw Audio, Aaron van den Oord+, arXiv'16 Summary本論文では、音声波形を生成する深層ニューラルネットワークWaveNetを提案。自己回帰的なモデルでありながら、効率的に音声データを訓練可能。テキストから音声への変換で最先端の性能を示し、人間のリスナーに自然な音と評価される。話者の特性を忠実に捉え、アイデンティティに基づく切り替えが可能。音楽生成にも応用でき、リアルな音楽の断片を生成。また、音素認識のための有望な識別モデルとしての利用も示唆。 #RecommenderSystems #SessionBased #ICLR #SequentialRecommendation Issue Date: 2019-08-02 SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS, Hidasi+, ICLR'16 CommentRNNを利用したsequential recommendation (session-based recommendation)の先駆け的論文。日本語解説: https://qiita.com/tatamiya/items/46e278a808a51893deac #RecommenderSystems #NeuralNetwork #Pocket #RecSys Issue Date: 2018-12-27 Deep Neural Networks for YouTube Recommendations, Covington+, RecSys'16 #NeuralNetwork #MachineLearning #Pocket #GraphConvolutionalNetwork #NeurIPS Issue Date: 2018-03-30 Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering, Defferrard+, NIPS'16 CommentGCNを勉強する際は読むと良いらしい。
あわせてこのへんも:
Semi-Supervised Classification with Graph Convolutional Networks, Kipf+, ICLR'17
https://github.com/tkipf/gcn #NeuralNetwork #MachineLearning #Normalization Issue Date: 2018-02-19 Layer Normalization, Ba+, arXiv'16 Summaryバッチ正規化の代わりにレイヤー正規化を用いることで、リカレントニューラルネットワークのトレーニング時間を短縮。レイヤー内のニューロンの合計入力を正規化し、各ニューロンに独自の適応バイアスとゲインを適用。トレーニング時とテスト時で同じ計算を行い、隠れ状態のダイナミクスを安定させる。実証的に、トレーニング時間の大幅な短縮を確認。 Comment解説スライド:
https://www.slideshare.net/KeigoNishida/layer-normalizationnips
#NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #CoNLL Issue Date: 2018-02-14 Generating Sentences from a Continuous Space, Bowman+, CoNLL'16 CommentVAEを利用して文生成【Variational Autoencoder徹底解説】
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24 #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #WSDM Issue Date: 2018-01-02 Collaborative Denoising Auto-Encoders for Top-N Recommender Systems, Wu+, WSDM'16 CommentDenoising Auto-Encoders を用いたtop-N推薦手法、Collaborative Denoising Auto-Encoder (CDAE)を提案。
モデルベースなCollaborative Filtering手法に相当する。corruptedなinputを復元するようなDenoising Auto Encoderのみで推薦を行うような手法は、この研究が初めてだと主張。
学習する際は、userのitemsetのsubsetをモデルに与え(noiseがあることに相当)、全体のitem setを復元できるように、学習する(すなわちDenoising Auto-Encoder)。
推薦する際は、ユーザのその時点でのpreference setをinputし、new itemを推薦する。
221 もStacked Denoising Auto EncoderとCollaborative Topic Regression 226 を利用しているが、221 ではarticle recommendationというspecificな問題を解いているのに対して、提案手法はgeneralなtop-N推薦に利用できることを主張。 #Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #ACL Issue Date: 2017-12-31 Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL'16 Comment解説スライド:https://www.slideshare.net/akihikowatanabe3110/incorporating-copying-mechanism-in-sequene-to-sequence-learning単語のコピーと生成、両方を行えるネットワークを提案。
location based addressingなどによって、生成された単語がsourceに含まれていた場合などに、copy-mode, generate-modeを切り替えるような仕組みになっている。
65 と同じタイミングで発表 #NeuralNetwork #MachineTranslation #NLP #ACL Issue Date: 2017-12-28 Pointing the unknown words, Gulcehre+, ACL'16 Commentテキストを生成する際に、source textからのコピーを行える機構を導入することで未知語問題に対処した話CopyNetと同じタイミングで(というか同じconferenceで)発表 #NeuralNetwork #MachineTranslation #Pocket #NLP #Attention #ICLR Issue Date: 2025-05-12 Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15 Summaryニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している) #MachineLearning #Pocket #LanguageModel #Transformer #ICML #Normalization Issue Date: 2025-04-02 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe+, ICML'15 Summaryバッチ正規化を用いることで、深層ニューラルネットワークのトレーニングにおける内部共変量シフトの問題を解決し、高い学習率を可能にし、初期化の注意を軽減。これにより、同じ精度を14倍少ないトレーニングステップで達成し、ImageNet分類で最良の公表結果を4.9%改善。 Commentメモってなかったので今更ながら追加した共変量シフトやBatch Normalizationの説明は
・261
記載のスライドが分かりやすい。 #NeuralNetwork #MachineTranslation #NLP #EMNLP Issue Date: 2021-06-02 Effective Approaches to Attention-based Neural Machine Translation, Luong+, EMNLP'15 CommentLuong論文。attentionの話しはじめると、だいたいBahdanau+か、Luong+論文が引用される。
Global Attentionと、Local Attentionについて記述されている。Global Attentionがよく利用される。
Global Attention
Local Attention
やはり菊池さんの解説スライドが鉄板。
https://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention参考までに、LuongらのGlobal Attentionの計算の流れは下記となっている:
・h_t -> a_t -> c_t -> h^~_t
BahdanauらのAttentionは下記
・h_t-1 -> a_t -> c_t -> h_t
t-1のhidden stateを使うのか、input feeding後の現在のhidden stateをattention weightの計算に使うのかが異なっている。また、過去のalignmentの情報を考慮した上でデコーディングしていくために、input-feeding approachも提案
input-feeding appproachでは、t-1ステップ目のoutputの算出に使ったh^~_t(hidden_stateとcontext vectorをconcatし、tanhのactivationを噛ませた線形変換を行なったベクトル)を、時刻tのinput embeddingにconcatして、RNNに入力する。 #NLP #LanguageModel #ACL #IJCNLP Issue Date: 2018-03-30 Unsupervised prediction of acceptability judgements, Lau+, ACL-IJCNLP'15 Comment文のacceptability(容認度)論文。
文のacceptabilityとは、native speakerがある文を読んだときに、その文を正しい文として容認できる度合いのこと。
acceptabilityスコアが低いと、Readabilityが低いと判断できる。
言語モデルをトレーニングし、トレーニングした言語モデルに様々な正規化を施すことで、acceptabilityスコアを算出する。 #NeuralNetwork #MachineLearning #ICML Issue Date: 2018-02-19 An Empirical Exploration of Recurrent Network Architectures, Jozefowicz+, ICML'15 CommentGRUとLSTMの違いを理解するのに最適 #NeuralNetwork #NLP #ACL Issue Date: 2018-02-13 Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks, Tai+, ACL'15 CommentTree-LSTM論文 #DocumentSummarization #NeuralNetwork #Sentence #Supervised #NLP #Abstractive #EMNLP Issue Date: 2017-12-31 A Neural Attention Model for Sentence Summarization, Rush+, EMNLP'15 Comment解説スライド:https://www.slideshare.net/akihikowatanabe3110/a-neural-attention-model-for-sentence-summarization-65612331 #Single #DocumentSummarization #NeuralNetwork #Sentence #Document #NLP #Dataset #Abstractive #EMNLP Issue Date: 2017-12-28 LCSTS: A large scale chinese short text summarizatino dataset, Hu+, EMNLP'15 CommentLarge Chinese Short Text Summarization (LCSTS) datasetを作成
データセットを作成する際は、Weibo上の特定のorganizationの投稿の特徴を利用。
Weiboにニュースを投稿する際に、投稿の冒頭にニュースのvery short summaryがまず記載され、その後ニュース本文(短め)が記載される特徴があるので、この対をsource-reference対として収集した。
収集する際には、約100個のルールに基づくフィルタリングやclearning, 抽出等を行なっている。

データセットのpropertyとしては、下記のPartI, II, IIIに分かれている。
PartI: 2.4Mのshort text ・summary pair
PartII: PartIからランダムにサンプリングされた10kのpairに対して、5 scaleで要約のrelevanceをratingしたデータ。ただし、各pairにラベルづけをしたevaluatorは1名のみ。
PartIII: 2kのpairに対して(PartI, PartIIとは独立)、3名のevaluatorが5-scaleでrating。evaluatorのratingが一致した1kのpairを抽出したデータ。

RNN-GRUを用いたSummarizerも提案している。

CopyNetなどはLCSTSを使って評価している。他にも使ってる論文あったはず。ACL'17のPointer Generator Networkでした。 #DocumentSummarization #NeuralNetwork #Sentence #NLP #EMNLP Issue Date: 2017-12-28 Sentence Compression by Deletion with LSTMs, Fillipova+, EMNLP'15 Commentslide:https://www.slideshare.net/akihikowatanabe3110/sentence-compression-by-deletion-with-lstms #Multi #DocumentSummarization #NLP #Extractive #ACL Issue Date: 2017-12-28 Hierarchical Summarization: Scaling Up Multi-Document Summarization, Christensen+, ACL'14 Comment概要
だいぶ前に読んだ。好きな研究。
テキストのsentenceを階層的にクラスタリングすることで、抽象度が高い情報から、関連する具体度の高いsentenceにdrill downしていけるInteractiveな要約を提案している。
手法
通常のMDSでのデータセットの規模よりも、実際にMDSを使う際にはさらに大きな規模のデータを扱わなければならないことを指摘し(たとえばNew York Timesで特定のワードでイベントを検索すると数千、数万件の記事がヒットしたりする)そのために必要な事項を検討。
これを実現するために、階層的なクラスタリングベースのアプローチを提案。
提案手法では、テキストのsentenceを階層的にクラスタリングし、下位の層に行くほどより具体的な情報になるようにsentenceを表現。さらに、上位、下位のsentence間にはエッジが張られており、下位に紐付けられたsentence
は上位に紐付けられたsentenceの情報をより具体的に述べたものとなっている。
これを活用することで、drill down型のInteractiveな要約を実現。 #Multi #DocumentSummarization #NLP #Dataset #QueryBiased #Extractive #ACL Issue Date: 2017-12-28 Query-Chain Focused Summarization, Baumel+, ACL'14 Comment(管理人が作成した過去の紹介資料)
[Query-Chain Focused Summarization.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1590916/Query-Chain.Focused.Summarization.pdf)
上記スライドは私が当時作成した論文紹介スライドです。スライド中のスクショは説明のために論文中のものを引用しています。 #RecommenderSystems #NeuralNetwork #MatrixFactorization #NeurIPS Issue Date: 2018-01-11 Deep content-based music recommendation, Oord+, NIPS'13 CommentContents-Basedな音楽推薦手法(cold-start problemに強い)。
Weighted Matrix Factorization (WMF) (Implicit Feedbackによるデータに特化したMatrix Factorization手法) 225 に、Convolutional Neural Networkによるmusic audioのlatent vectorの情報が組み込まれ、item vectorが学習されるような仕組みになっている。

CNNでmusic audioのrepresentationを生成する際には、audioのtime-frequencyの情報をinputとする。学習を高速化するために、window幅を3秒に設定しmusic clipをサンプルしinputする。music clip全体のrepresentationを求める際には、consecutive windowからpredictionしたrepresentationを平均したものを使用する。 #NeuralNetwork #ComputerVision #NeurIPS #ImageClassification #Backbone Issue Date: 2025-05-13 ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky+, NIPS'12 CommentILSVRC 2012において圧倒的な性能示したことで現代のDeepLearningの火付け役となった研究AlexNet。メモってなかったので今更ながら追加した。AlexNet以前の画像認識技術については牛久先生がまとめてくださっている(当時の課題とそれに対する解決法、しかしまだ課題が…と次々と課題に直面し解決していく様子が描かれており非常に興味深かった)。現在でも残っている技術も紹介されている。:
https://speakerdeck.com/yushiku/pre_alexnet
> 過去の技術だからといって聞き流していると時代背景の変化によってなし得たイノベーションを逃すかも
これは肝に銘じたい。 #RecommenderSystems #CollaborativeFiltering #MatrixFactorization #SIGKDD Issue Date: 2018-01-11 Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11 CommentProbabilistic Matrix Factorization (PMF) 227 に、Latent Dirichllet Allocation (LDA) を組み込んだCollaborative Topic Regression (CTR)を提案。
LDAによりitemのlatent vectorを求め、このitem vectorと、user vectorの内積を(平均値として持つ正規表現からのサンプリング)用いてratingを生成する。



CFとContents-basedな手法が双方向にinterationするような手法解説ブログ:http://d.hatena.ne.jp/repose/20150531/1433004688 #RecommenderSystems #Survey Issue Date: 2018-01-01 Collaborative Filtering Recommender Systems, Ekstrand+ (with Joseph A. Konstan), Foundations and TrendsR in Human–Computer Interaction'11 #Multi #PersonalizedDocumentSummarization #InteractivePersonalizedSummarization #NLP #EMNLP Issue Date: 2017-12-28 Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07 Comment
ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
 #RecommenderSystems
#MachineLearning
#CollaborativeFiltering
#FactorizationMachines
#ICDM
Issue Date: 2018-12-22
Factorization Machines, Steffen Rendle, ICDM'10
Comment解説ブログ:http://echizen-tm.hatenablog.com/entry/2016/09/11/024828
#RecommenderSystems
#MachineLearning
#CollaborativeFiltering
#FactorizationMachines
#ICDM
Issue Date: 2018-12-22
Factorization Machines, Steffen Rendle, ICDM'10
Comment解説ブログ:http://echizen-tm.hatenablog.com/entry/2016/09/11/024828
DeepFMに関する動向:https://data.gunosy.io/entry/deep-factorization-machines-2018
非常に完結でわかりやすい説明
FMのFeature VectorのExample
各featureごとにlatent vectorが学習され、featureの組み合わせのweightが内積によって表現される

Matrix Factorizationの一般形のような形式 #RecommenderSystems #Survey Issue Date: 2018-01-01 Content-based Recommender Systems: State of the Art and Trends, Lops+, Recommender Systems Handbook'10 CommentRecSysの内容ベースフィルタリングシステムのユーザプロファイルについて知りたければこれ #ComputerVision #Dataset #ImageClassification #ObjectRecognition #ObjectLocalization Issue Date: 2025-05-13 ImageNet: A Large-Scale Hierarchical Image Database, Deng+, CVPR'09 #RecommenderSystems #LearningToRank #ImplicitFeedback #UAI Issue Date: 2017-12-28 BPR: Bayesian Personalized Ranking from Implicit Feedback, Rendle+, UAI'09, 2009.06 Comment重要論文
ユーザのアイテムに対するExplicit/Implicit Ratingを利用したlearning2rank。
AUCを最適化するようなイメージ。
負例はNegative Sampling。
計算量が軽く、拡張がしやすい。
Implicitデータを使ったTop-N Recsysを構築する際には検討しても良い。
また、MFのみならず、Item-Based KNNに活用することなども可能。
http://tech.vasily.jp/entry/2016/07/01/134825参考: https://techblog.zozo.com/entry/2016/07/01/134825pytorchでのBPR実装: https://github.com/guoyang9/BPR-pytorch #Pocket #NLP #MultitaskLearning #ICML Issue Date: 2018-02-05 A unified architecture for natural language processing: Deep neural networks with multitask learning, Collobert+, ICML'2008. CommentDeep Neural Netを用いてmultitask learningを行いNLPタスク(POS tagging, Semantic Role Labeling, Chunking etc.)を解いた論文。
被引用数2000を超える。
multitask learningの学習プロセスなどが引用されながら他論文で言及されていたりする。 #RecommenderSystems #MatrixFactorization #NeurIPS Issue Date: 2018-01-11 Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08 CommentMatrix Factorizationを確率モデルとして表した論文。
解説:http://yamaguchiyuto.hatenablog.com/entry/2017/07/13/080000
既存のMFは大規模なデータに対してスケールしなかったが、PMFではobservationの数に対して線形にスケールし、さらには、large, sparse, imbalancedなNetflix datasetで良い性能が出た(Netflixデータセットは、rating件数が少ないユーザとかも含んでいる。MovieLensとかは含まれていないのでより現実的なデータセット)。

また、Constrained PMF(同じようなsetの映画にrateしているユーザは似ているといった仮定に基づいたモデル ※1)を用いると、少ないratingしかないユーザに対しても良い性能が出た。
※1 ratingの少ないユーザの潜在ベクトルは平均から動きにくい、つまりなんの特徴もない平均的なユーザベクトルになってしまうので、同じ映画をratingした人は似た事前分布を持つように制約を導入したモデル
(解説ブログ、解説スライドより) #MachineTranslation #NLP #LanguageModel Issue Date: 2024-12-24 Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07 Summary本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。 CommentN-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
 元ポスト:https://x.com/odashi_t/status/1871024428739604777?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLarge Language Modelsという用語が利用されたのはこの研究が初めてなのかも…?
#Multi
#DocumentSummarization
#Document
#NLP
#IntegerLinearProgramming (ILP)
#Extractive
#ECIR
Issue Date: 2018-01-17
A study of global inference algorithms in multi-document summarization, Ryan McDonald, ECIR'07
Comment文書要約をナップサック問題として定式化し、厳密解(動的計画法、ILP Formulation)、近似解(Greedy)を求める手法を提案。
#InformationRetrieval
#LearningToRank
#ListWise
#ICML
Issue Date: 2018-01-01
Learning to Rank: From Pairwise Approach to Listwise Approach (ListNet), Cao+, ICML'2007
Comment解説スライド:http://www.nactem.ac.uk/tsujii/T-FaNT2/T-FaNT.files/Slides/liu.pdf
元ポスト:https://x.com/odashi_t/status/1871024428739604777?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLarge Language Modelsという用語が利用されたのはこの研究が初めてなのかも…?
#Multi
#DocumentSummarization
#Document
#NLP
#IntegerLinearProgramming (ILP)
#Extractive
#ECIR
Issue Date: 2018-01-17
A study of global inference algorithms in multi-document summarization, Ryan McDonald, ECIR'07
Comment文書要約をナップサック問題として定式化し、厳密解(動的計画法、ILP Formulation)、近似解(Greedy)を求める手法を提案。
#InformationRetrieval
#LearningToRank
#ListWise
#ICML
Issue Date: 2018-01-01
Learning to Rank: From Pairwise Approach to Listwise Approach (ListNet), Cao+, ICML'2007
Comment解説スライド:http://www.nactem.ac.uk/tsujii/T-FaNT2/T-FaNT.files/Slides/liu.pdf
解説ブログ:https://qiita.com/koreyou/items/a69750696fd0b9d88608従来行われてきたLearning to Rankはpairwiseな手法が主流であったが、pairwiseな手法は2つのインスタンス間の順序が正しく識別されるように学習されているだけであった。
pairwiseなアプローチには以下の問題点があった:
インスタンスのペアのclassification errorを最小化しているだけで、インスタンスのランキングのerrorを最小化しているわけではない。
インスタンスペアが i.i.d な分布から生成されるという制約は強すぎる制約
queryごとに生成されるインスタンスペアは大きく異なるので、インスタンスペアよりもクエリに対してバイアスのかかった学習のされ方がされてしまう
これらを解決するために、listwiseなアプローチを提案。
listwiseなアプローチを用いると、インスタンスのペアの順序を最適化するのではなく、ランキング全体を最適化できる。
listwiseなアプローチを用いるために、Permutation Probabilityに基づくloss functionを提案。loss functionは、2つのインスタンスのスコアのリストが与えられたとき、Permutation Probability Distributionを計算し、これらを用いてcross-entropy lossを計算するようなもの。
また、Permutation Probabilityを計算するのは計算量が多すぎるので、top-k probabilityを提案。
top-k probabilityはPermutation Probabilityの計算を行う際のインスタンスをtop-kに限定するもの。
論文中ではk=1を採用しており、k=1はsoftmaxと一致する。
パラメータを学習する際は、Gradient Descentを用いる。k=1の設定で計算するのが普通なようなので、普通にoutputがsoftmaxでlossがsoftmax cross-entropyなモデルとほぼ等価なのでは。 #RecommenderSystems #Survey #Explanation Issue Date: 2018-01-01 A Survey of Explanations in Recommender Systems, Tintarev+, ICDEW'07 #RecommenderSystems #Survey #CollaborativeFiltering #MatrixFactorization Issue Date: 2018-01-01 Matrix Factorization Techniques for Recommender Systems, Koren+, Computer'07 CommentMatrix Factorizationについてよくまとまっている #MachineLearning #DomainAdaptation #NLP #ACL Issue Date: 2017-12-31 Frustratingly easy domain adaptation, Daum'e, ACL'07 Comment
domain adaptationをする際に、Source側のFeatureとTarget側のFeatureを上式のように、Feature Vectorを拡張し独立にコピーし表現するだけで、お手軽にdomain adaptationができることを示した論文。
イメージ的には、SourceとTarget、両方に存在する特徴は、共通部分の重みが高くなり、Source, Targetドメイン固有の特徴は、それぞれ拡張した部分のFeatureに重みが入るような感じ。 #InformationRetrieval #LearningToRank #PairWise #ICML Issue Date: 2018-01-01 Learning to Rank using Gradient Descent (RankNet), Burges+, ICML'2005 Commentpair-wiseのlearning2rankで代表的なRankNet論文
解説ブログ:https://qiita.com/sz_dr/items/0e50120318527a928407
lossは2個のインスタンスのpair、A, Bが与えられたとき、AがBよりも高くランクされる場合は確率1, AがBよりも低くランクされる場合は確率0、そうでない場合は1/2に近くなるように、スコア関数を学習すれば良い。 #RecommenderSystems #Survey Issue Date: 2018-01-01 Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions, Adomavicius+, IEEE Transactions on Knowledge and Data Engineering'05 Comment有名なやつ #Single #DocumentSummarization #Document #GraphBased #NLP #Extractive #EMNLP Issue Date: 2018-01-01 TextRank: Bringing Order into Texts, Mihalcea+, EMNLP'04 CommentPageRankベースの手法で、キーワード抽出/文書要約 を行う手法。
キーワード抽出/文書要約 を行う際には、ノードをそれぞれ 単語/文 で表現する。
ノードで表現されている 単語/文 のsimilarityを測り、ノード間のedgeの重みとすることでAffinity Graphを構築。
あとは構築したAffinity Graphに対してPageRankを適用して、ノードの重要度を求める。
ノードの重要度に従いGreedyに 単語/文 を抽出すれば、キーワード抽出/文書要約 を行うことができる。単一文書要約のベースラインとして使える。gensimに実装がある。
個人的にも実装している:https://github.com/AkihikoWatanabe/textrank #RecommenderSystems #Survey Issue Date: 2018-01-01 Evaluating Collaborative Filtering Recommener Systems, Herlocker+, TOIS'04 CommentGroupLensのSurvey #InformationRetrieval #LearningToRank #PointWise #NeurIPS Issue Date: 2018-01-01 PRanking with Ranking, Crammer+, NIPS'01 CommentPoint-WiseなLearning2Rankの有名手法 #RecommenderSystems #CollaborativeFiltering #ItemBased #WWW Issue Date: 2018-01-01 Item-based collaborative filtering recommendation algorithms, Sarwar+(with Konstan), WWW'01 Commentアイテムベースな協調フィルタリングを提案した論文(GroupLens) #DocumentSummarization #Document #NLP #NAACL Issue Date: 2018-01-21 Cut and paste based text summarization, Jing+, NAACL'00 CommentAbstractiveなSummarizationの先駆け的研究。
AbstractiveなSummarizationを研究するなら、押さえておいたほうが良い。 #DocumentSummarization #InformationRetrieval #NLP #Search #SIGIR Issue Date: 2018-01-17 The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98 CommentMaximal Marginal Relevance (MMR) 論文。
検索エンジンや文書要約において、文書/文のランキングを生成する際に、既に選んだ文書と類似度が低く、かつqueryとrelevantな文書をgreedyに選択していく手法を提案。
ILPによる定式化が提案される以前のMulti Document Summarization (MDS) 研究において、冗長性の排除を行う際には典型的な手法。 #Article #Pretraining #NLP #LanguageModel #DiffusionModel Issue Date: 2025-08-09 Diffusion Language Models are Super Data Learners, Jinjie Ni and the team, 2025.08 CommentdLLMは学習データの繰り返しに強く、データ制約下においては十分な計算量を投入してepochを重ねると、性能向上がサチらずにARモデルを上回る。
 ・2268
・2268
・追記: 上記研究の著者による本ポストで取り上げられたissueに対するclarification
・https://x.com/mihirp98/status/1954240474891653369?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
でも同様の知見が得られている。
が、スレッド中で両者の違いが下記のように(x rollrng reviewなるものを用いて)ポストされており、興味がある場合は読むといいかも。(ところで、x rolling reviewとは、、?もしやLLMによる自動的な査読システム?)
 ・1829
・1829
において、ARモデルではrepetitionは4回までがコスパ良いという話と比べると、dLLMにとんでもない伸び代があるような話に見える。個人的にはアーキテクチャのさらなる進化は興味深いが、ユーザが不完全な質問をLLMに投げた時に、LLMがユーザの意図が「不明な部分のcontextを質問を返すことによって補う」という挙動があると嬉しい気がするのだが、そういった研究はないのだろうか。
ただ、事前学習時点でそういったデータが含まれて知識として吸収され、かつmid/post-trainingでそういった能力を引き出すと言う両軸で取り組まないと、最悪膨大な計算資源を投じたものの「わからない!どういうこと!?」と返し続けるLLMが完成し全く役に立たない、ということになりそうで怖い。
gpt5が出た時に、「3.9と3.11はどちらが大きいですか?」というクエリを投げた際にいまだに「3.11」と回答してくる、みたいなポストが印象的であり、これはLLMが悪いと言うより、ユーザ側が算数としての文脈できいているのか、ソフトウェアのバージョンの文脈できいているのか、を指定していないことが原因であり、上記の回答はソフトウェアのバージョニングという文脈では正答となる。LLMが省エネになって、ユーザのデータを蓄積しまくって、一人一人に対してあなただけのLLM〜みたいな時代がくれば少しは変わるのだろうが、それでもユーザがプロファイルとして蓄積した意図とは異なる意図で質問しなければならないという状況になると、上記のような意図の取り違えが生じるように思う。
なのでやはりりLLM側が情報が足りん〜と思ったら適切なturn数で、最大限の情報をユーザから引き出せるような逆質問を返すみたいな挙動、あるいは足りない情報があったときに、いくつかの候補を提示してユーザ側に提示させる(e.g., 算数の話?それともソフトウェアの話?みたいな)、といった挙動があると嬉しいなぁ、感。
んでそこの部分の性能は、もしやるな、promptingでもある程度は実現でき、それでも全然性能足りないよね?となった後に、事前学習、事後学習でより性能向上します、みたいな流れになるのかなぁ、と想像するなどした。
しかしこういう話をあまり見ないのはなぜだろう?私の観測範囲が狭すぎる or 私のアイデアがポンコツなのか、ベンチマーク競争になっていて、そこを向上させることに業界全体が注力してしまっているからなのか、はたまた裏ではやられているけど使い物にならないのか、全然わからん。 #Article #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #AttentionSinks #read-later Issue Date: 2025-08-05 gpt-oss-120b, OpenAI, 2025.08 Commentblog:https://openai.com/index/introducing-gpt-oss/
HF:
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.mdアーキテクチャで使われている技術まとめ:
・https://x.com/gneubig/status/1952799735900979219?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/yampeleg/status/1952875217367245195?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/adamzweiger/status/1952799642636148917?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/cwolferesearch/status/1956132685102887059?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・こちらにも詳細に論文がまとめられている上記ポスト中のアーキテクチャの論文メモリンク(管理人が追加したものも含む)
・Sliding Window Attention
・2388
・2359
・MoE
・1754
・RoPE w/ YaRN
・1310
・2338
・Attention Sinks
・1861
・Attention Sinksの定義とその気持ちについてはこのメモを参照のこと。
・1860
・Attention Sinksが実際にどのように効果的に作用しているか?についてはこちらのメモを参照。
・1862
・https://x.com/gu_xiangming/status/1952811057673642227?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・Attention Sinkの導入により、decodei-onlyモデルの深い層でのrepresentationのover mixingを改善し、汎化性能を高め、promptに対するsensitivityを抑えていると考えられる。
・GQA
・1271
・SwiGLU
・1311-
・(Attentionの計算に利用する) SoftmaxへのLearned bias の導入 (によるスケーリング)
・1863
・1866
・Softmaxはlong contextになると、attentionの分布が均一になり、重要な情報にattendする能力が下がるためスケーリングが必要で、そのために分母にlearnedなbiasを導入していると考えられる。Llamaや上記研究では分子に係数としてlearnableなパラメータを導入しているが、少し形式が違う。もしかしたら解釈が違うかもしれない。・group size 8でGQAを利用
・Context Windowは128k
・学習データの大部分は英語のテキストのみのデータセット
・STEM, Coding, general knowledgeにフォーカス
・https://openai.com/index/gpt-oss-model-card/
あとで追記する他Open Weight Modelとのベンチマークスコア比較:
・https://x.com/gneubig/status/1952795149584482665?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/artificialanlys/status/1952887733803991070?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/terryyuezhuo/status/1952829578130670053?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/artificialanlys/status/1952823565642023044?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・long context
・https://x.com/thienhn97/status/1953152808334852124?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・Multihop QA解説:
https://x.com/gm8xx8/status/1952915080229863761?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qlearned attention sinks, MXFP4の解説:
https://x.com/carrigmat/status/1952779877569978797?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QSink Valueの分析:
https://x.com/wenhaocha1/status/1952851897414762512?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qgpt-oss の使い方:
https://note.com/npaka/n/nf39f327c3bde?sub_rt=share_sb9fd064b2-338a-4f8d-953c-67e458658e39Qwen3との深さと広さの比較:
・2364Phi4と同じtokenizerを使っている?:
https://x.com/bgdidenko/status/1952829980389343387?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpost-training / pre-trainingの詳細はモデルカード中に言及なし:
・https://x.com/teortaxestex/status/1952806676492689652?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/okoge_kaz/status/1952787196253265955?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qattention headsのsoftmaxの分母にlearnableなパラメータが導入されている:
https://x.com/okoge_kaz/status/1952785895352041784?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・1866
で得られている知見と同様に、long contextになった場合にsoftmaxの値が平坦になる問題に対して、learnableなパラメータを導入してスケーリングすることで対処しているのだと考えられる。使ってみた所見:
・https://x.com/imai_eruel/status/1952825403263046073?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/wenhuchen/status/1953100554793828406?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/jasondeanlee/status/1953031988635451556?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qライセンスに関して:
> Apache 2.0 ライセンスおよび当社の gpt-oss 利用規約に基づくことで利用可能です。
引用元: https://openai.com/ja-JP/index/gpt-oss-model-card/
gpt-oss利用規約: https://github.com/openai/gpt-oss/blob/main/USAGE_POLICYcookbook全体:https://cookbook.openai.com/topic/gpt-ossgpt-oss-120bをpythonとvLLMで触りながら理解する:https://tech-blog.abeja.asia/entry/gpt-oss-vllm #Article #NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-07-29 GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07 Comment元ポスト:https://x.com/scaling01/status/1949825490488795275?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHF:https://huggingface.co/collections/zai-org/glm-45-687c621d34bda8c9e4bf503b詳細なまとめ:https://x.com/gm8xx8/status/1949879437547241752?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2128こちらでもMuon Optimizerが使われており、アーキテクチャ的にはGQAやMulti Token Prediction, QK Normalization, MoE, 広さよりも深さを重視の構造、みたいな感じな模様?
・2202 #Article #Tutorial #NLP #LanguageModel #LLMServing #SoftwareEngineering #read-later Issue Date: 2025-07-22 LLM Servingを支える技術, Kotoba Technologies, 2025.07 Commentこちらも参照のこと:
・2263 #Article #Tutorial #Metrics #NLP #LanguageModel #LLMServing #MoE(Mixture-of-Experts) #SoftwareEngineering #Parallelism #Inference #Batch Issue Date: 2025-07-21 LLM推論に関する技術メモ, iwashi.co, 2025.07 Comment```
メモリ (GB) = P × (Q ÷ 8) × (1 + オーバーヘッド)
・P:パラメータ数(単位は10億)
・Q:ビット精度(例:16、32)、8で割ることでビットをバイトに変換
・オーバーヘッド(%):推論中の追加メモリまたは一時的な使用量(例:KVキャッシュ、アクティベーションバッファ、オプティマイザの状態)
```
↑これ、忘れがちなのでメモ…関連(量子化関連研究):
・2264
・1570
・1043すごいメモだ…勉強になります #Article #NLP #LanguageModel #Evaluation #Slide #Japanese #SoftwareEngineering Issue Date: 2025-07-16 論文では語られないLLM開発において重要なこと Swallow Projectを通して, Kazuki Fujii, NLPコロキウム, 2025.07 Comment独自LLM開発の私の想像など遥かに超える非常に困難な側面が記述されており、これをできるのはあまりにもすごいという感想を抱いた(小並感だけど本当にすごいと思う。すごいとしか言いようがない) #Article #NLP #LanguageModel #Optimizer #OpenWeight #MoE(Mixture-of-Experts) #read-later #Stability Issue Date: 2025-07-12 Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07 Comment元ポスト:https://x.com/kimi_moonshot/status/1943687594560332025?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q1T-A32Bのモデル。さすがに高性能。

(追記) Reasoningモデルではないのにこの性能のようである。1T-A32Bのモデルを15.5Tトークン訓練するのに一度もtraining instabilityがなかったらしい
元ポスト:https://x.com/eliebakouch/status/1943689105721667885?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2188量子化したモデルが出た模様:
https://x.com/ivanfioravanti/status/1944069021709615119?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
仕事早すぎるDeepSeek V3/R1とのアーキテクチャの違い:
https://x.com/rasbt/status/1944056316424577525?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
MLAのヘッドの数が減り、エキスパートの数を増加させている解説ポスト:https://x.com/hillbig/status/1944902706747072678?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q利用されているOptimizer:
・22022つほどバグがあり修正された模様:
https://x.com/kimi_moonshot/status/1945050874067476962?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qchatbot arenaでOpenLLMの中でトップのスコア
元ポスト:https://x.com/lmarena_ai/status/1945866381880373490?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qテクニカルペーパーが公開:https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
元ポスト:https://x.com/iscienceluvr/status/1947384629314396302?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qテクニカルレポートまとめ:https://x.com/scaling01/status/1947400424622866793?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q以下のような技術が使われている模様
・1937
・MLA 1621
・MuonCip
・MuonOptimizer 2202
・QK-Clip
・参考(こちらはLayerNormを使っているが): 1202
・RLVR
・1719
・Self-Critique
・関連: 2274
・2017
・Temperature Decay
・最初はTemperatureを高めにした探索多めに、後半はTemperatureを低めにして効用多めになるようにスケジューリング
・Tool useのためのSynthetic Data
 Reward Hackingに対処するため、RLVRではなくpairwise comparisonに基づくself judging w/ critique を利用きており、これが非常に効果的な可能性があるのでは、という意見がある:
Reward Hackingに対処するため、RLVRではなくpairwise comparisonに基づくself judging w/ critique を利用きており、これが非常に効果的な可能性があるのでは、という意見がある:
https://x.com/grad62304977/status/1953408751521632401?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #LanguageModel #Zero/FewShotLearning Issue Date: 2025-06-15 [Paper Note] Language Models are Unsupervised Multitask Learners, Radford+, OpenAI, 2019 Comment今更ながら、GPT-2論文をメモってなかったので追加。
従来のモデルは特定のタスクを解くためにタスクごとに個別のモデルをFinetuningする必要があったが、大規模なWebTextデータ(Redditにおいて最低3つのupvoteを得たポストの外部リンクを収集)によって言語モデルを訓練し、モデルサイズをスケーリングさせることで、様々なタスクで高い性能を獲得でき、Zero-Shot task transfer, p\(output | input, task) , が実現できるよ、という話。
今ざっくり見返すと、Next Token Predictionという用語は論文中に出てきておらず、かつ "Language Modeling" という用語のみで具体的なlossは記述されておらず(当時はRNN言語モデルで広く学習方法が知られていたからだろうか?)、かつソースコードも学習のコードは提供されておらず、lossの定義も含まれていないように見える。
ソースコードのモデル定義:
https://github.com/openai/gpt-2/blob/master/src/model.pyL169 #Article #NLP #LanguageModel #InstructionTuning #PostTraining Issue Date: 2025-05-12 Stanford Alpaca: An Instruction-following LLaMA Model, Taori +, 2023.03 Comment今更ながらメモに追加。アカデミアにおけるOpenLLMに対するInstruction Tuningの先駆け的研究。 #Article #Analysis #NLP #LanguageModel #Blog Issue Date: 2025-03-25 言語モデルの物理学, 佐藤竜馬, 2025.03 Comment必読 #Article #NeuralNetwork #ComputerVision #CVPR #Backbone Issue Date: 2021-11-04 Deep Residual Learning for Image Recognition, He+, Microsoft Research, CVPR’16 CommentResNet論文
ResNetでは、レイヤーの計算する関数を、残差F(x)と恒等関数xの和として定義する。これにより、レイヤーが入力との差分だけを学習すれば良くなり、モデルを深くしても最適化がしやすくなる効果ぎある。数レイヤーごとにResidual Connectionを導入し、恒等関数によるショートカットができるようにしている。
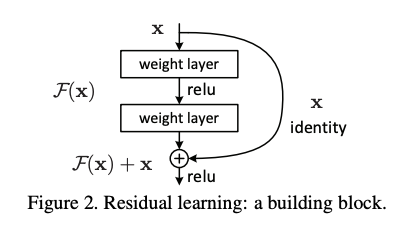
ResNetが提案される以前、モデルを深くすれば表現力が上がるはずなのに、実際には精度が下がってしまうことから、理論上レイヤーが恒等関数となるように初期化すれば、深いモデルでも浅いモデルと同等の表現が獲得できる、と言う考え方を発展させた。
(ステートオブAIガイドに基づく)同じパラメータ数でより層を深くできる(Plainな構造と比べると層が1つ増える)Bottleneckアーキテクチャも提案している。
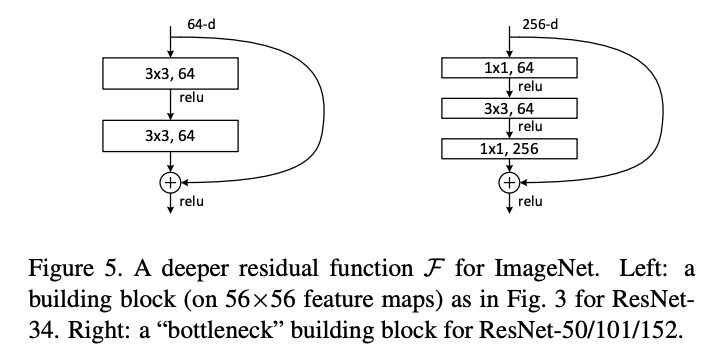
今や当たり前のように使われているResidual Connectionは、層の深いネットワークを学習するために必須の技術なのだと再認識。 #Article #NeuralNetwork #Survey #NLP #LanguageModel #Slide Issue Date: 2019-11-09 事前学習言語モデルの動向 _ Survey of Pretrained Language Models, Kyosuke Nishida, 2019 Comment[2019/06まで]
・ELMo(双方向2層LSTM言語モデル)
・GPT(left-to-rightの12層Transformer自己回帰言語モデル)
・BERT(24層のTransformer双方向言語モデル)
・MT-DNN(BERTの上にマルチタスク層を追加した研究)
・XLM(パラレル翻訳コーパスを用いてクロスリンガルに穴埋めを学習)
・TransformerXL(系列長いに制限のあった既存モデルにセグメントレベルの再帰を導入し長い系列を扱えるように)
・GPT-2(48層Transformerの自己回帰言語モデル)
・ERNIE 1.0(Baidu, エンティティとフレーズの外部知識を使ってマスクに利用)
・ERNIE(Tsinghua, 知識グラフの情報をfusionしたLM)
・Glover(ドメイン、日付、著者などを条件とした生成を可能としたGPT)
・MASS(Encoder-Decoder型の生成モデルのための事前学習)
・UniLM(Sequence-to-Sequenceを可能にした言語モデル)
・XLNet(自己回帰(単方向)モデルと双方向モデルの両方の利点を得ることを目指す)
[2019/07~]
・SpanBERT(i.i.dではなく範囲でマスクし、同時に範囲の境界も予測する)
・ERNIE 2.0(Baidu, マルチタスク事前学習; 単語レベル・構造レベル・意味レベル)
・RoBERTa(BERTと同じ構造で工夫を加えることで性能向上)
・より大きなバッチサイズを使う(256から8192)
・より多くのデータを使う(16GBから160GB)
・より長いステップ数の学習をする(BERT換算で16倍)
・次文予測(NSP)は不要
→ GLUEでBERT, XLNetをoutperform
・StructBERT (ALICE, NSPに代わる学習の目的関数を工夫)
・マスクした上で単語の順番をシャッフルし元に戻す
・ランダム・正順・逆順の3種類を分類
→ BERTと同サイズ、同データでBERT, RoBERTa超え
・DistilBERT(蒸留により、12層BERTを6層に小型化(40%減))
・BERTの出力を教師として、生徒が同じ出力を出すように学習
・幅(隠れ層)サイズを減らすと、層数を経あrスよりも悪化
→ 推論は60%高速化、精度は95%程度を保持
・Q8BERT(精度を落とさずにfine-tuning時にBERTを8bit整数に量子化)
・Embedding, FCは8bit化、softmax, LNorm, GELUは32bitをキープ
→ モデルサイズ1/4, 速度3.7倍
・CTRL(条件付き言語モデル)
・条件となる制御テキストを本文の前に与えて学習
・48層/1280次元Transformer(パラメータ数1.6B)
・MegatronLM(72層、隠れ状態サイズ3072、長さ1024; BERTの24倍サイズ)
・ALBERT(BERTの層のパラメータをすべて共有することで学習を高速化; 2020年あたりのデファクト)
・Largeを超えたモデルは学習が難しいため、表現は落ちるが学習しやすくした
・単語埋め込みを低次元にすることでパラメータ数削減
・次文予測を、文の順序入れ替え判定に変更
→ GLUE, RACE, SQuADでSoTAを更新
・T5(NLPタスクをすべてtext-to-textとして扱い、Enc-Dec Transformerを745GBコーパスで事前学習して転移する)
・モデルはEncoder-DecoderのTransformer
・学習タスクをエンコーダ・デコーダに合わせて変更
・エンコーダ側で範囲を欠落させて、デコーダ側で予測
→ GLUE, SuperGLUE, SQuAD1.1, CNN/DMでSoTA更新
・BART(Seq2Seqの事前学習として、トークンマスク・削除、範囲マスク、文の入れ替え、文書の回転の複数タスクで学習)
→ CNN/DMでT5超え、WMT'16 RO-ENで逆翻訳を超えてSoTAELMo, GPT, BERT, GPT-2, XLNet, RoBERTa, DistilBERT, ALBERT, T5あたりは良く見るような感各データセットでの各モデルの性能も後半に記載されており興味深い。
ちなみに、CNN/DailyMail Datasetでは、T5, BARTあたりがSoTA。
R2で比較すると
・Pointer-Generator + Coverage Vectorが17,28
・LEAD-3が17.62
・BARTが21.28
・T5が21.55
となっている #Article #RecommenderSystems #Library Issue Date: 2019-09-11 Implicit CommentImplicitデータに対するCollaborative Filtering手法がまとまっているライブラリ
Bayesian Personalized Ranking, Logistic Matrix Factorizationなどが実装。Implicitの使い方はこの記事がわかりやすい:
https://towardsdatascience.com/building-a-collaborative-filtering-recommender-system-with-clickstream-data-dffc86c8c65ALSの元論文の日本語解説
https://cympfh.cc/paper/WRMF #Article #RecommenderSystems #Dataset Issue Date: 2019-04-12 Recommender System Datasets, Julian McAuley CommentRecommender Systems研究に利用できる各種データセットを、Julian McAuley氏がまとめている。
氏が独自にクロールしたデータ等も含まれている。
非常に有用。 #Article #RecommenderSystems #Tutorial #Explanation Issue Date: 2019-01-23 Designing and Evaluating Explanations for Recommender Systems, Tintarev+, Recommender Systems Handbook, 2011 CommentRecommender Systems HandbookのChapter。162 のSurveyと同じ著者による執筆。
推薦のExplanationといえばこの人というイメージ。D論:http://navatintarev.com/papers/Nava%20Tintarev_PhD_Thesis_(2010).pdf #Article #AdaptiveLearning #StudentPerformancePrediction #NeurIPS Issue Date: 2018-12-22 Deep Knowledge Tracing, Piech+, NIPS, 2015 CommentKnowledge Tracingタスクとは:
特定のlearning taskにおいて、生徒によってとられたインタラクションの系列x0, ..., xtが与えられたとき、次のインタラクションxt+1を予測するタスク
典型的な表現としては、xt={qt, at}, where qt=knowledge component (KC) ID (あるいは問題ID)、at=正解したか否か
モデルが予測するときは、qtがgivenな時に、atを予測することになる

Contribution:
1. A novel way to encode student interactions as input to a recurrent neural network.
2. A 25% gain in AUC over the best previous result on a knowledge tracing benchmark.
3. Demonstration that our knowledge tracing model does not need expert annotations.
4. Discovery of exercise influence and generation of improved exercise curricula.
モデル:

Inputは、ExerciseがM個あったときに、M個のExerciseがcorrectか否かを表すベクトル(長さ2Mベクトルのone-hot)。separateなrepresentationにするとパフォーマンスが下がるらしい。
Output ytの長さは問題数Mと等しく、各要素は、生徒が対応する問題を正答する確率。
InputとしてExerciseを用いるか、ExerciseのKCを用いるかはアプリケーション次第っぽいが、典型的には各スキルの潜在的なmasteryを測ることがモチベーションなのでKCを使う。
(もし問題数が膨大にあるような設定の場合は、各問題-正/誤答tupleに対して、random vectorを正規分布からサンプリングして、one-hot high-dimensional vectorで表現する。)
hidden sizeは200, mini-batch sizeは100としている。
[Educational Applicationsへの応用]
生徒へ最適なパスの学習アイテムを選んで提示することができること
生徒のknowledge stateを予測し、その後特定のアイテムを生徒にassignすることができる。たとえば、生徒が50個のExerciseに回答した場合、生徒へ次に提示するアイテムを計算するだけでなく、その結果期待される生徒のknowledge stateも推測することができる
Exercises間の関係性を見出すことができる
y\( j | i )を考える。y\( j | i )は、はじめにexercise iを正答した後に、second time stepでjを正答する確率。これによって、pre-requisiteを明らかにすることができる。
[評価]
3種類のデータセットを用いる。
1. simulated Data
2000人のvirtual studentを作り、1〜5つのコンセプトから生成された、50問を、同じ順番で解かせた。このとき、IRTモデルを用いて、シミュレーションは実施した。このとき、hidden stateのラベルには何も使わないで、inputは問題のIDと正誤データだけを与えた。さらに、2000人のvirtual studentをテストデータとして作り、それぞれのコンセプト(コンセプト数を1〜5に変動させる)に対して、20回ランダムに生成したデータでaccuracyの平均とstandard errorを測った。
2. Khan Academy Data
1.4MのExerciseと、69の異なるExercise Typeがあり、47495人の生徒がExerciseを行なっている。
PersonalなInformationは含んでいない。
3. Assistsments bemchmark Dataset
2009-2011のskill builder public benchmark datasetを用いた。Assistmentsは、online tutorが、数学を教えて、教えるのと同時に生徒を評価するような枠組みである。
それぞれのデータセットに対して、AUCを計算。
ベースラインは、BKTと生徒がある問題を正答した場合の周辺確率?


simulated dataの場合、問題番号5がコンセプト1から生成され、問題番号22までの問題は別のコンセプトから生成されていたにもかかわらず、きちんと二つの問題の関係をとらえられていることがわかる。
Khan Datasetについても同様の解析をした。これは、この結果は専門家が見たら驚くべきものではないかもしれないが、モデルが一貫したものを学習したと言える。
[Discussion]
提案モデルの特徴として、下記の2つがある:
専門家のアノテーションを必要としない(concept patternを勝手に学習してくれる)
ベクトル化された生徒のinputであれば、なんでもoperateすることができる
drawbackとしては、大量のデータが必要だということ。small classroom environmentではなく、online education environmentに向いている。
今後の方向性としては、
・incorporate other feature as inputs (such as time taken)
・explore other educational impacts (hint generation, dropout prediction)
・validate hypotheses posed in education literature (such as spaced repetition, modeling how students forget)
・open-ended programmingとかへの応用とか(proramのvectorizationの方法とかが最近提案されているので)
などがある。knewtonのグループが、DKTを既存手法であるIRTの変種やBKTの変種などでoutperformすることができることを示す:
https://arxiv.org/pdf/1604.02336.pdf
vanillaなDKTはかなりナイーブなモデルであり、今後の伸びが結構期待できると思うので、単純にoutperformしても、今後の発展性を考えるとやはりDKTには注目せざるを得ない感DKT元論文では、BKTを大幅にoutperformしており、割と衝撃的な結果だったようだが、
後に論文中で利用されているAssistmentsデータセット中にdupilcate entryがあり、
それが原因で性能が不当に上がっていることが判明。
結局DKTの性能的には、BKTとどっこいみたいなことをRyan Baker氏がedXで言っていた気がする。Deep Knowledge TracingなどのKnowledge Tracingタスクにおいては、
基本的に問題ごとにKnowledge Component(あるいは知識タグ, その問題を解くのに必要なスキルセット)が付与されていることが前提となっている。
ただし、このような知識タグを付与するには専門家によるアノテーションが必要であり、
適用したいデータセットに対して必ずしも付与されているとは限らない。
このような場合は、DKTは単なる”問題”の正答率予測モデルとして機能させることしかできないが、
知識タグそのものもNeural Networkに学習させてしまおうという試みが行われている:
https://www.jstage.jst.go.jp/article/tjsai/33/3/33_C-H83/_article/-char/jaDKTに関する詳細な説明が書かれているブログポスト:
expectimaxアルゴリズムの説明や、最終的なoutput vector y_i の図解など、説明が省略されガチなところが詳細に書いてあって有用。(英語に翻訳して読むと良い)
https://hcnoh.github.io/2019-06-14-deep-knowledge-tracingこちらのリポジトリではexpectimaxアルゴリズムによってvirtualtutorを実装している模様。
詳細なレポートもアップロードされている。
https://github.com/alessandroscoppio/VirtualIntelligentTutorDKTのinputの次元数が 2 num_skills, outputの次元数がnum_skillsだと明記されているスライド。
元論文だとこの辺が言及されていなくてわかりづらい・・・
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_tutorial_Application.pdf
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_Tutorial.pdf
こちらのページが上記チュートリアルのページ
http://gdac.uqam.ca/Workshop@EDM20/ #Article #Survey #AdaptiveLearning #EducationalDataMining #LearningAnalytics Issue Date: 2018-12-22 Educational Data Mining and Learning Analytics, Baker+, 2014 CommentRyan BakerらによるEDM Survey #Article #RecommenderSystems #Classic #ContextAware Issue Date: 2018-12-22 Context-Aware Recommender Systems, Adomavicius+, Recommender Systems Handbook, 2011 CommentContext-aware Recsysのパイオニア的研究通常のuser/item paradigmを拡張して、いかにコンテキストの情報を考慮するかを研究。
コンテキスト情報は、
Explicit: ユーザのマニュアルインプットから取得
Implicit: 自動的に取得
inferred: ユーザとツールやリソースのインタラクションから推測(たとえば現在のユーザのタスクとか)
いくつかの異なるパラダイムが提案された:
1. recommendation via context-driven querying and search approach
コンテキストの情報を、特定のリポジトリのリソース(レストラン)に対して、クエリや検索に用いる。そして、best matchingなリソースを(たとえば、現在開いているもっとも近いレストランとか)をユーザに推薦。
2. Contextual preference elicitation and estimation approach
こっちは2012年くらいの主流。contextual user preferencesをモデル化し学習する。データレコードをしばしば、<user, item, context, rating>の形式で表現する。これによって、特定のアイテムが特定のコンテキストでどれだけ好まれたか、が評価できるようになる。
3. contextual prefiltering approach
contextualな情報を(学習したcontextualなpreferenceなどを)、tradittionalなrecommendation algorithmを適用する前にデータのフィルタリングに用いる。
4. contextual postfiltering approach
entire setから推薦を作り、あとでcontextの情報を使ってsetを整える。
5. Contextual modeling
contextualな情報を、そのままrecommendationの関数にぶちこんでしまい、アイテムのratingのexplicitなpredictorとして使う。
3, 4はtraditionalな推薦アルゴリズムが適用できる。
1,2,5はmulti-dimensionalな推薦アルゴリズムになる。heuristic-based, model-based approachesが述べられているらしい。 #Article #Classic #AdaptiveLearning #LearningStyle Issue Date: 2018-12-22 LEARNING AND TEACHING STYLES IN ENGINEERING EDUCATION, Felder, Engr. Education, 78(7), 674–681 (1988) CommentLearningStyleに関して研究している古典的な研究。
context-aware recsysの研究初期の頃は、だいたいはこのFelder-Silverman Theoryというのをベースに研究されていたらしい。 #Article #NeuralNetwork #Tutorial #NLP #Slide Issue Date: 2018-01-15 自然言語処理のためのDeep Learning, Yuta Kikuchi #Article #RecommenderSystems #CollaborativeFiltering #MatrixFactorization Issue Date: 2018-01-11 Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008 CommentImplicit Feedbackなデータに特化したMatrix Factorization (MF)、Weighted Matrix Factorization (WMF)を提案。
ユーザのExplicitなFeedback(ratingやlike, dislikeなど)がなくても、MFが適用可能。
目的関数は下のようになっている。
通常のMFでは、ダイレクトにrating r_{ui}を予測したりするが、WMFでは r_{ui}をratingではなく、たとえばユーザuがアイテムiを消費した回数などに置き換え、binarizeした数値p_{ui}を目的関数に用いる。
このとき、itemを消費した回数が多いほど、そのユーザはそのitemを好んでいると仮定し、そのような事例については重みが高くなるようにc_{ui}を計算し、目的関数に導入している。



日本語での解説: https://cympfh.cc/paper/WRMFImplicit 324 でのAlternating Least Square (ALS)という手法が、この手法の実装に該当する。 #Article #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #MatrixFactorization #SIGKDD Issue Date: 2018-01-11 Collaborative Deep Learning for Recommender Systems Wang+, KDD’15 CommentRating Matrixからuserとitemのlatent vectorを学習する際に、Stacked Denoising Auto Encoder(SDAE)によるitemのembeddingを活用する話。
Collaborative FilteringとContents-based Filteringのハイブリッド手法。
Collaborative FilteringにおいてDeepなモデルを活用する初期の研究。
通常はuser vectorとitem vectorの内積の値が対応するratingを再現できるように目的関数が設計されるが、そこにitem vectorとSDAEによるitemのEmbeddingが近くなるような項(3項目)、SDAEのエラー(4項目)を追加する。
(3項目の意義について、解説ブログより)アイテム i に関する潜在表現 vi は学習データに登場するものについては推定できるけれど,未知のものについては推定できない.そこでSDAEの中間層の結果を「推定したvi」として「真の」 vi にできる限り近づける,というのがこの項の気持ち
cite-ulikeデータによる論文推薦、Netflixデータによる映画推薦で評価した結果、ベースライン(Collective Matrix Factorization 222 , SVDFeature 223 , DeepMusic 224 , Collaborative Topic Regresison 226 )をoutperform。
(下記は管理人が過去に作成した論文メモスライドのスクショ)





解説ブログ:http://d.hatena.ne.jp/repose/20150531/1433004688 #Article #DocumentSummarization #NLP #Alignment #SIGIR Issue Date: 2018-01-11 The Decomposition of Human-Written Summary Sentences. Hongyan Jing et al. SIGIR’99. Comment参照要約 ・原文書対が与えられた時に、参照要約中の単語と原文書中の単語のアライメントをとるHMMベースな手法を提案。

outputはこんな感じ。 #Article #Multi #Single #DocumentSummarization #Document #Unsupervised #GraphBased #NLP #Extractive Issue Date: 2018-01-01 LexRank: Graph-based Lexical Centrality as Salience in Text Summarization, Erkan+, Journal of Artificial Intelligence Research, 2004 Comment代表的なグラフベースな(Multi) Document Summarization手法。
ほぼ 214 と同じ手法。
2種類の手法が提案されている:
[LexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを計算し閾値以上となったsentenceの間にのみedgeを張る(重みは確率的に正規化)。その後べき乗法でPageRank。
[ContinousLexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを用いてAffinity Graphを計算し、PageRankを適用(べき乗法)。
DUC2003, 2004(MDS)で評価。
Centroidベースドな手法をROUGE-1の観点でoutperform。
document clusterの17%をNoisyなデータにした場合も実験しており、Noisyなデータを追加した場合も性能劣化が少ないことも示している。 #Article #RecommenderSystems #Survey Issue Date: 2018-01-01 推薦システムのアルゴリズム, 神嶌, 2016 #Article #RecommenderSystems #CollaborativeFiltering #Novelty Issue Date: 2017-12-28 Discovery-oriented Collaborative Filtering for Improving User Satisfaction, Hijikata+, IUI’09 Comment・従来のCFはaccuracyをあげることを目的に研究されてきたが,ユーザがすでに知っているitemを推薦してしまう問題がある.おまけに(推薦リスト内のアイテムの観点からみた)diversityも低い.このような推薦はdiscoveryがなく,user satisfactionを損ねるので,ユーザがすでに何を知っているかの情報を使ってよりdiscoveryのある推薦をCFでやりましょうという話.
・特徴としてユーザのitemへのratingに加え,そのitemをユーザが知っていたかどうかexplicit feedbackしてもらう必要がある.
・手法は単純で,User-based,あるいはItem-based CFを用いてpreferenceとあるitemをユーザが知っていそうかどうかの確率を求め,それらを組み合わせる,あるいはrating-matrixにユーザがあるitemを知っていたか否かの数値を組み合わせて新たなmatrixを作り,そのmatrix上でCFするといったもの.
・offline評価の結果,通常のCF,topic diversification手法と比べてprecisionは低いものの,discovery ratioとprecision(novelty)は圧倒的に高い.
・ユーザがitemを知っていたかどうかというbinary ratingはユーザに負荷がかかるし,音楽推薦の場合previewがなければそもそも提供されていないからratingできないなど,必ずしも多く集められるデータではない.そこで,データセットのratingの情報を25%, 50%, 75%に削ってratingの数にbiasをかけた上で実験をしている.その結果,事前にratingをcombineし新たなmatrixを作る手法はratingが少ないとあまりうまくいかなかった.
・さらにonlineでuser satisfaction(3つの目的のもとsatisfactionをratingしてもらう 1. purchase 2. on-demand-listening 3. discovery)を評価した. 結果,purchaseとdiscoveryにおいては,ベースラインを上回った.ただし,これは推薦リスト中の満足したitemの数の問題で,推薦リスト全体がどうだった
かと問われた場合は,ベースラインと同等程度だった.重要論文 #Article #PersonalizedDocumentSummarization #NLP #NAACL Issue Date: 2017-12-28 A Study for Documents Summarization based on Personal Annotation, HLT-NAACL-DUC’03, [Zhang+, 2003], 2003.05 Comment(過去に管理人が作成したスライドでの論文メモのスクショ)



重要論文だと思われる。 #Article #PersonalizedDocumentSummarization #RecommenderSystems Issue Date: 2017-12-28 User-model based personalized summarization, Diaz+, Information Processing and Management 2007.11 CommentPDSの先駆けとなった重要論文。必ずreferすべき。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
・1746
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。日本語解説:https://x.com/hillbig/status/1960108668336390593?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
一歩先の視点が考察されており、とても勉強になる。 #EfficiencyImprovement #Pocket #NLP #LanguageModel #Optimizer #read-later #ModelMerge #Stability Issue Date: 2025-08-02 [Paper Note] WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training, Changxin Tian+, arXiv'25 Summary学習率スケジューリングの新たなアプローチとして、Warmup-Stable and Merge(WSM)を提案。WSMは、学習率の減衰とモデルマージの関係を確立し、さまざまな減衰戦略を統一的に扱う。実験により、マージ期間がモデル性能において重要であることを示し、従来のWSDアプローチを上回る性能向上を達成。特に、MATHで+3.5%、HumanEvalで+2.9%、MMLU-Proで+5.5%の改善を記録。 Comment元ポスト:https://x.com/stochasticchasm/status/1951427541803106714?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWeight Decayを無くせるらしいエッセンスの解説:https://x.com/wenhaocha1/status/1951790366900019376?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
チェックポイントさえ保存しておいて事後的に活用することだで、細かなハイパラ調整のための試行錯誤する手間と膨大な計算コストがなくなるのであれば相当素晴らしいのでは…? #Pocket #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #GRPO #read-later #Non-VerifiableRewards #RewardModel Issue Date: 2025-07-22 [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25 Summary強化学習を用いてLLMsの推論能力を向上させるため、報酬モデリング(RM)のスケーラビリティを探求。ポイントワイズ生成報酬モデリング(GRM)を採用し、自己原則批評調整(SPCT)を提案してパフォーマンスを向上。並列サンプリングとメタRMを導入し、スケーリング性能を改善。実験により、SPCTがGRMの質とスケーラビリティを向上させ、既存の手法を上回る結果を示した。DeepSeek-GRMは一部のタスクで課題があるが、今後の取り組みで解決可能と考えられている。モデルはオープンソースとして提供予定。 Comment・inputに対する柔軟性と、
・同じresponseに対して多様なRewardを算出でき (= inference time scalingを活用できる)、
・Verifiableな分野に特化していないGeneralなRewardモデルである
Inference-Time Scaling for Generalist Reward Modeling (GRM) を提案
・2208 #Pocket #NLP #LanguageModel #Transformer #Architecture #Normalization Issue Date: 2025-07-03 [Paper Note] The Curse of Depth in Large Language Models, Wenfang Sun+, arXiv'25 Summary本論文では、「深さの呪い」という現象を紹介し、LLMの深い層が期待通りに機能しない理由を分析します。Pre-LNの使用が出力の分散を増加させ、深い層の貢献を低下させることを特定。これを解決するために層正規化スケーリング(LNS)を提案し、出力分散の爆発を抑制します。実験により、LNSがLLMの事前トレーニング性能を向上させることを示し、教師ありファインチューニングにも効果があることを確認しました。 Comment元ポスト:https://x.com/shiwei_liu66/status/1940377801032446428?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1795
ではそもそもLayerNormalizationを無くしていた(正確にいうとparametrize tanhに置換)が、どちらが優れているのだろうか?
では知識ニューロンの存在が示唆されており、これはTransformerの層の深い位置に存在し、かつ異なる知識間で知識ニューロンはシェアされない傾向にあった(ただしこれはPost-LNのBERTの話で本研究はPre-LNの話だが。Post-LNの勾配消失問題を緩和し学習を安定化させる研究も2141 のように存在する)。これはこの研究が明らかにしたこととどういう関係性があるだろうか。
また、LayerNormalizationのScalingによって深いTransformerブロックの導関数が単位行列となる(学習に寄与しなくなる)ことが改善された場合、知識ニューロンはどのように変化するだろうか?
(下記Geminiの応答を見た上での感想)なんとなーくだけれども、おそらく知識ニューロンの局所化が解消されるのかなーという気がする。
となると次の疑問としては、MoEアーキテクチャにはどのような影響があるだろうか?
そもそも知識ニューロンが局所化しているからMoEアーキテクチャのルータによって関連するExpertsのみをactivateすれば(というより結果的にそうなるように学習される)性能を劣化させずに計算効率を上げられていた、と仮定する。そうすると、知識ニューロンが局所化せずに多くのニューロンでシェアされるようになると、2110 のように、サブネットワーク間の情報を互いにやりとりできます、みたいな仕組みがより効いてきそうな気がする。
参考までに、Gemini2.5-Proに考察させてみた結果をメモとして残しておく(あくまで参考程度に...)
```
ご質問ありがとうございます。非常に興味深い着眼点ですね。「Knowledge Neurons in Pretrained Transformers」と「The Curse of Depth in Large Language Models」は、一見すると全く異なるテーマを扱っているように見えますが、「Transformerの深い層における振る舞い」という共通点で結びつけて考察すると、非常に示唆に富んだ関係性が見えてきます。
以下に、両方の論文の概要を解説し、その関係性について考察します。
1. Knowledge Neurons in Pretrained Transformers の概要
この研究は、事前学習済みTransformerモデル(特にBERTなど)の内部で、特定の事実知識がどのように格納されているかを調査したものです。
発見: モデルの中間層、特に全結合層(Feed-Forward Network, FFN)に、特定の知識(例:「ダンテ・アリギエーリはイタリアで生まれた」)に強く反応する「知識ニューロン」が存在することを発見しました。
特徴: これらの知識ニューロンは、モデルの深い層(後方の層)に、より多く存在する傾向がありました。
意味: これまでブラックボックスとされてきた大規模言語モデルの内部で、知識がどのように表現・局在化しているかについて、具体的な手がかりを与えた画期的な研究です。
2. The Curse of Depth in Large Language Models の概要
この研究は、LLMをより深く(層を多く)することの難しさに焦点を当て、その原因と解決策を提案したものです。
問題(深さの呪い): Transformerの標準的なアーキテクチャ(Pre-LN)では、層が深くなるにつれて、LayerNormalization(LN)への入力の分散が指数関数的に増大してしまいます。
結果:
出力が大きくなりすぎて学習が不安定になります。
さらに深刻なのは、深い層ではモデルの出力に関する導関数(勾配計算に必要)がほぼ単位行列になってしまうことです。これは、その層が入力に対してほとんど変換を行わなくなり、学習に寄与しなくなることを意味します。
解決策: この問題を解決するため、各層のLayerNormalizationをその深さ(レイヤー番号 l)に応じてスケーリングするというシンプルな手法を提案しました。これにより、深い層でも勾配が適切に伝播し、学習が安定・改善することが示されました。
考察:2つの研究の関係性
これら2つの研究は、「学習の安定性」と「知識の格納方法」という異なる側面から、Transformerの深い層を分析していますが、両者には以下のような深い関係性があると考えられます。
学習の不安定性が「知識ニューロン」形成の背景にある可能性
「The Curse of Depth」で指摘されているように、標準的なTransformerの深い層は、本質的に学習が不安定で、勾配情報が失われやすい環境にあります。
この劣悪な学習環境こそが、「知識ニューロン」という形で知識が局所的に格納される原因の一つになっている可能性があります。つまり、
学習の非効率性: 深い層のほとんどのニューロンは、勾配消失問題のために効率的に学習を進めることができません。
専門化の発生: そのような不安定な環境下で、たまたま特定の知識パターンをうまく捉えることができた一部のニューロンが、その知識を一身に背負う形で強く活性化するよう特化(専門化)していったのではないか、と考えられます。これは、ネットワーク全体で協調して学習するのが難しい状況で、一部のユニットだけが突出して学習を担う、という現象と解釈できます。
学習の安定化が、より効率的な知識獲得につながる
では、「The Curse of Depth」で提案された手法(LNのスケーリング)によって深い層の学習が安定化すると、知識の格納方法はどのように変わるでしょうか。
これは非常に興味深い問いであり、2つの可能性が考えられます。
可能性A: より強固な知識ニューロンの形成:
学習が安定することで、各知識ニューロンはより明確に、そして効率的に特定の知識をエンコードできるようになるかもしれません。ノイズの多い環境で偶然生まれた専門家ではなく、安定した環境で育成された真の専門家へと変化するイメージです。
可能性B: 知識の分散化:
ネットワークの全ニューロンが効率的に学習に寄与できるようになるため、一つの知識を少数のニューロンに集中させる必要がなくなり、より多くのニューロンに分散して知識が格納されるようになる可能性も考えられます。
現在のところ、学習の安定化は、知識ニューロンがより効率的に形成・機能するための基盤を提供すると考えるのが最も妥当でしょう。「深さの呪い」という問題を解決することは、モデルが知識をどのように獲得し、整理するかという、より根源的なメカニズム(知識ニューロンの振る舞い)にも直接的な影響を与えるはずです。
まとめ
「Knowledge Neurons」は深い層に存在する知識の「状態」を明らかにし、「The Curse of Depth」は深い層で発生する学習の「問題」とその解決策を提示しました。
これらを統合すると、「深い層における学習の不安定性という問題が、知識ニューロンという局所的な知識表現を生み出す一因となっており、この問題を解決することで、より効率的で安定した知識の獲得・格納が可能になるかもしれない」という関係性が見えてきます。
両者は、LLMの能力と限界を異なる角度から照らし出しており、組み合わせることでモデルの内部動作の解明をさらに一歩前進させる、非常に重要な研究だと言えます。
``` #ComputerVision #Pretraining #Pocket #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #MulltiModal #RLHF #Reasoning #LongSequence #mid-training #RewardHacking #PostTraining #CurriculumLearning #RLVR #VisionLanguageModel Issue Date: 2025-07-03 [Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25 Summary視覚言語モデルGLM-4.1V-Thinkingを発表し、推論中心のトレーニングフレームワークを開発。強力な視覚基盤モデルを構築し、カリキュラムサンプリングを用いた強化学習で多様なタスクの能力を向上。28のベンチマークで最先端のパフォーマンスを達成し、特に難しいタスクで競争力のある結果を示す。モデルはオープンソースとして公開。 Comment元ポスト:https://x.com/sinclairwang1/status/1940331927724232712?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQwen2.5-VLよりも性能が良いVLM
・1942abstを見る限りFinewebを多言語に拡張した模様 #Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #mid-training #PostTraining #read-later Issue Date: 2025-06-27 [Paper Note] OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling, Zengzhi Wang+, arXiv'25 Summary異なるベース言語モデル(LlamaやQwen)の強化学習(RL)における挙動を調査し、中間トレーニング戦略がRLのダイナミクスに与える影響を明らかに。高品質の数学コーパスがモデルのパフォーマンスを向上させ、長い連鎖的思考(CoT)がRL結果を改善する一方で、冗長性や不安定性を引き起こす可能性があることを示す。二段階の中間トレーニング戦略「Stable-then-Decay」を導入し、OctoThinkerモデルファミリーを開発。オープンソースのモデルと数学推論コーパスを公開し、RL時代の基盤モデルの研究を支援することを目指す。 Comment元ポスト:https://x.com/sinclairwang1/status/1938244843857449431?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qmid-trainingの観点から、post trainingにおけるRLがスケーリングする条件をsystematicallyに調査している模様論文中にはmid-training[^1]の定義が記述されている:
[^1]: mid-trainingについてはコミュニティの間で厳密な定義はまだ無くバズワードっぽく使われている、という印象を筆者は抱いており、本稿は文献中でmid-trainingを定義する初めての試みという所感 #Pocket #NLP #LanguageModel #ReinforcementLearning #Reasoning #PostTraining #read-later Issue Date: 2025-06-22 [Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, arXiv'25 SummaryGuruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。 Comment元ポスト:https://x.com/chengzhoujun/status/1936113985507803365?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpost-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。Qwenシリーズで実験。以下ポストのまとめ。
・mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
・一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
・簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
・各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
・必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
・たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
・一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
・異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
・(これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
・非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
・RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
・モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
・モデルサイズが大きいとより多様なreasoningパスがunlockされている
・pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた #Pocket #NLP #LanguageModel #Evaluation #ICLR #Contamination Issue Date: 2025-05-23 LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25 Summaryテストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Commentテストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究 #EfficiencyImprovement #Pretraining #Pocket #NLP #Dataset #LanguageModel #ACL Issue Date: 2025-05-10 Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25 SummaryFineWeb-EduとDCLMは、モデルベースのフィルタリングによりデータの90%を削除し、トレーニングに適さなくなった。著者は、アンサンブル分類器や合成データの言い換えを用いて、精度とデータ量のトレードオフを改善する手法を提案。1Tトークンで8Bパラメータモデルをトレーニングし、DCLMに対してMMLUを5.6ポイント向上させた。新しい6.3Tトークンデータセットは、DCLMと同等の性能を持ちながら、4倍のユニークなトークンを含み、長トークンホライズンでのトレーニングを可能にする。15Tトークンのためにトレーニングされた8Bモデルは、Llama 3.1の8Bモデルを上回る性能を示した。データセットは公開されている。 #Metrics #NLP #LanguageModel #GenerativeAI #Evaluation Issue Date: 2025-03-31 Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25 Summary新しい指標「50%-タスク完了時間ホライズン」を提案し、AIモデルの能力を人間の観点から定量化。Claude 3.7 Sonnetは約50分の時間ホライズンを持ち、AIの能力は2019年以降約7か月ごとに倍増。信頼性や論理的推論の向上が要因とされ、5年以内にAIが多くのソフトウェアタスクを自動化できる可能性を示唆。 Comment元ポスト:https://x.com/hillbig/status/1902854727089656016?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q確かに線形に見える。てかGPT-2と比べるとAIさん進化しすぎである…。
・HCAST: 46のタスクファミリーに基づく97種類のタスクが定義されており、たとえばサイバーセキュリティ、機械学習、ソフトウェアエンジニアリング、一般的な推論タスク(wikipediaから事実情報を探すタスクなど)などがある
・数分で終わるタスク: 上述のwikipedia
・数時間で終わるタスク: Pytorchのちょっとしたバグ修正など
・数文でタスクが記述され、コード、データ、ドキュメント、あるいはwebから入手可能な情報を参照可能
・タスクの難易度としては当該ドメインに数年間携わった専門家が解ける問題
・RE-Bench Suite
・7つのopen endedな専門家が8時間程度を要するMLに関するタスク
・e.g., GPT-2をQA用にFinetuningする, Finetuningスクリプトが与えられた時に挙動を変化させずにランタイムを可能な限り短縮する、など
・[RE-Bench Technical Report](https://metr.org/AI_R_D_Evaluation_Report.pdf)のTable2等を参照のこと
・SWAA Suite: 66種類の1つのアクションによって1分以内で終わるソフトウェアエンジニアリングで典型的なタスク
・1分以内で終わるタスクが上記データになかったので著者らが作成
であり、画像系やマルチモーダルなタスクは含まれていない。
タスクと人間がタスクに要する時間の対応に関するサンプルは下記
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/ #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Reasoning #LongSequence #RewardHacking #PostTraining Issue Date: 2025-02-07 Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, arXiv'25 Summary本研究では、大規模言語モデル(LLMs)における長い思考の連鎖(CoTs)推論のメカニズムを調査し、重要な要因を特定。主な発見は、(1) 教師ありファインチューニング(SFT)は必須ではないが効率を向上させる、(2) 推論能力は計算の増加に伴い現れるが、報酬の形状がCoTの長さに影響、(3) 検証可能な報酬信号のスケーリングが重要で、特に分布外タスクに効果的、(4) エラー修正能力は基本モデルに存在するが、RLを通じて効果的に奨励するには多くの計算が必要。これらの洞察は、LLMsの長いCoT推論を強化するためのトレーニング戦略の最適化に役立つ。 Comment元ポスト:https://x.com/xiangyue96/status/1887332772198371514?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q元ポストのスレッド中に論文の11個の知見が述べられている。どれも非常に興味深い。DeepSeek-R1のテクニカルペーパーと同様、
・Long CoTとShort CoTを比較すると前者の方が到達可能な性能のupper bonudが高いことや、
・SFTを実施してからRLをすると性能が向上することや、
・RLの際にCoTのLengthに関する報酬を入れることでCoTの長さを抑えつつ性能向上できること、
・数学だけでなくQAペアなどのノイジーだが検証可能なデータをVerifiableな報酬として加えると一般的なreasoningタスクで数学よりもさらに性能が向上すること、
・より長いcontext window sizeを活用可能なモデルの訓練にはより多くの学習データが必要なこと、
・long CoTはRLによって学習データに類似したデータが含まれているためベースモデルの段階でその能力が獲得されていることが示唆されること、
・aha momentはすでにベースモデル時点で獲得されておりVerifiableな報酬によるRLによって強化されたわけではなさそう、
など、興味深い知見が盛りだくさん。非常に興味深い研究。あとで読む。 #ComputerVision #Analysis #MachineLearning #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #ICML #PostTraining #read-later Issue Date: 2025-01-30 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25 SummarySFTとRLの一般化能力の違いを研究し、GeneralPointsとV-IRLを用いて評価。RLはルールベースのテキストと視覚変種に対して優れた一般化を示す一方、SFTは訓練データを記憶し分布外シナリオに苦労。RLは視覚認識能力を向上させるが、SFTはRL訓練に不可欠であり、出力形式を安定させることで性能向上を促進。これらの結果は、複雑なマルチモーダルタスクにおけるRLの一般化能力を示す。 Comment元ポスト:https://x.com/hillbig/status/1884731381517082668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qopenreview:https://openreview.net/forum?id=dYur3yabMj&referrer=%5Bthe%20profile%20of%20Yi%20Ma%5D(%2Fprofile%3Fid%3D~Yi_Ma4) #ComputerVision #Pretraining #Pocket #MulltiModal #FoundationModel #CVPR #VisionLanguageModel Issue Date: 2025-08-23 [Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24 Summary大規模視覚-言語基盤モデル(InternVL)は、60億パラメータで設計され、LLMと整合させるためにウェブ規模の画像-テキストデータを使用。視覚認知タスクやゼロショット分類、検索など32のベンチマークで最先端の性能を達成し、マルチモーダル対話システムの構築に寄与。ViT-22Bの代替として強力な視覚能力を持つ。コードとモデルは公開されている。 Comment既存のResNetのようなSupervised pretrainingに基づくモデル、CLIPのようなcontrastive pretrainingに基づくモデルに対して、text encoder部分をLLMに置き換えて、contrastive learningとgenerativeタスクによる学習を組み合わせたパラダイムを提案。
InternVLのアーキテクチャは下記で、3 stageの学習で構成される。最初にimage text pairをcontrastive learningし学習し、続いてモデルのパラメータはfreezeしimage text retrievalタスク等でモダリティ間の変換を担う最終的にQlLlama(multilingual性能を高めたllama)をvision-languageモダリティを繋ぐミドルウェアのように捉え、Vicunaをテキストデコーダとして接続してgenerative cossで学習する、みたいなアーキテクチャの模様(斜め読みなので少し違う可能性あり
・1834 #Pocket #NLP #LanguageModel #Evaluation #Decoding Issue Date: 2025-04-14 Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, arXiv'24 Summary本研究では、5つの決定論的LLMにおける非決定性を8つのタスクで調査し、最大15%の精度変動と70%のパフォーマンスギャップを観察。全てのタスクで一貫した精度を提供できないことが明らかになり、非決定性が計算リソースの効率的使用に寄与している可能性が示唆された。出力の合意率を示す新たなメトリクスTARr@NとTARa@Nを導入し、研究結果を定量化。コードとデータは公開されている。 Comment・論文中で利用されているベンチマーク:
・785
・901 同じモデルに対して、seedを固定し、temperatureを0に設定し、同じ計算機環境に対して、同じinputを入力したら理論上はLLMの出力はdeterministicになるはずだが、deterministicにならず、ベンチマーク上の性能とそもそものraw response自体も試行ごとに大きく変化する、という話。
ただし、これはプロプライエタリLLMや、何らかのinferenceの高速化を実施したInferenceEngine(本研究ではTogetherと呼ばれる実装を使っていそう。vLLM/SGLangだとどうなるのかが気になる)を用いてinferenceを実施した場合での実験結果であり、後述の通り計算の高速化のためのさまざまな実装無しで、deterministicな設定でOpenLLMでinferenceすると出力はdeterministicになる、という点には注意。
GPTやLlama、Mixtralに対して上記ベンチマークを用いてzero-shot/few-shotの設定で実験している。Reasoningモデルは実験に含まれていない。
LLMのraw_response/multiple choiceのparse結果(i.e., 問題に対する解答部分を抽出した結果)の一致(TARr@N, TARa@N; Nはinferenceの試行回数)も理論上は100%になるはずなのに、ならないことが報告されている。
correlation analysisによって、応答の長さ と TAR{r, a}が強い負の相関を示しており、応答が長くなればなるほど不安定さは増すことが分析されている。このため、ontput tokenの最大値を制限することで出力の安定性が増すことを考察している。また、few-shotにおいて高いAcc.の場合は出力がdeterministicになるわけではないが、性能が安定する傾向とのこと。また、OpenAIプラットフォーム上でGPTのfinetuningを実施し実験したが、安定性に寄与はしたが、こちらもdeterministicになるわけではないとのこと。
deterministicにならない原因として、まずmulti gpu環境について検討しているが、multi-gpu環境ではある程度のランダム性が生じることがNvidiaの研究によって報告されているが、これはseedを固定すれば決定論的にできるため問題にならないとのこと。
続いて、inferenceを高速化するための実装上の工夫(e.g., Chunk Prefilling, Prefix Caching, Continuous Batching)などの実装がdeterministicなハイパーパラメータでもdeterministicにならない原因であると考察しており、実際にlocalマシン上でこれらinferenceを高速化するための最適化を何も実施しない状態でLlama-8Bでinferenceを実施したところ、outputはdeterministicになったとのこと。論文中に記載がなかったため、どのようなInferenceEngineを利用したか公開されているgithubを見ると下記が利用されていた:
・Together: https://github.com/togethercomputer/together-python?tab=readme-ov-file
Togetherが内部的にどのような処理をしているかまでは追えていないのだが、異なるInferenceEngineを利用した場合に、どの程度outputの不安定さに差が出るのか(あるいは出ないのか)は気になる。たとえば、transformers/vLLM/SGLangを利用した場合などである。
論文中でも報告されている通り、昔管理人がtransformersを用いて、deterministicな設定でzephyrを用いてinferenceをしたときは、出力はdeterministicになっていたと記憶している(スループットは絶望的だったが...)。あと個人的には現実的な速度でオフラインでinference engineを利用した時にdeterministicにはせめてなって欲しいなあという気はするので、何が原因なのかを実装レベルで突き詰めてくれるととても嬉しい(KV Cacheが怪しい気がするけど)。
たとえば最近SLMだったらKVCacheしてVRAM食うより計算し直した方が効率良いよ、みたいな研究があったような。そういうことをしたらlocal llmでdeterministicにならないのだろうか。 #NLP #LanguageModel #Alignment #DPO #PostTraining #read-later Issue Date: 2024-09-25 Direct Preference Optimization: Your Language Model is Secretly a Reward Model, Rafael Rafailov+, N_A, NeurIPS'24 Summary大規模無監督言語モデル(LM)の制御性を向上させるために、報酬モデルの新しいパラメータ化を導入し、単純な分類損失でRLHF問題を解決する「直接的な好み最適化(DPO)」アルゴリズムを提案。DPOは安定性と性能を持ち、ファインチューニング中のサンプリングやハイパーパラメータ調整を不要にし、既存の方法と同等以上の性能を示す。特に、生成物の感情制御においてPPOベースのRLHFを上回り、応答の質を改善しつつ実装が簡素化される。 CommentDPOを提案した研究
解説ポスト:
https://x.com/theturingpost/status/1940194999993585925?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pocket #Transformer #DiffusionModel #read-later #Backbone Issue Date: 2025-08-27 [Paper Note] Scalable Diffusion Models with Transformers, William Peebles+, ICCV'23 Summary新しいトランスフォーマーに基づく拡散モデル(Diffusion Transformers, DiTs)を提案し、U-Netをトランスフォーマーに置き換えた。DiTsは高いGflopsを持ち、低いFIDを維持しながら良好なスケーラビリティを示す。最大のDiT-XL/2モデルは、ImageNetのベンチマークで従来の拡散モデルを上回り、最先端のFID 2.27を達成した。 Comment日本語解説:https://qiita.com/sasgawy/items/8546c784bc94d94ef0b2よく見るDiT
・2526
も同様の呼称だが全く異なる話なので注意 #RecommenderSystems #Pocket #Transformer #VariationalAutoEncoder #NeurIPS #read-later #ColdStart #Encoder-Decoder #SemanticID Issue Date: 2025-07-28 [Paper Note] Recommender Systems with Generative Retrieval, Shashank Rajput+, NeurIPS'23 Summary新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを用いて次のアイテムを予測するTransformerベースのモデルを訓練。これにより、従来のレコメンダーシステムを大幅に上回る性能を達成し、過去の対話履歴がないアイテムに対しても改善された検索性能を示す。 Commentopenreview:https://openreview.net/forum?id=BJ0fQUU32wSemantic IDを提案した研究アイテムを意味的な情報を保持したdiscrete tokenのタプル(=Semantic ID)で表現し、encoder-decoderでNext ItemのSemantic IDを生成するタスクに落としこむことで推薦する。SemanticIDの作成方法は後で読んで理解したい。
[^1]: headのrepresentationを入力として受け取り、線形モデルを学習し、線形モデルの2値分類性能を見ることでheadがどの程度、プロービングの学習に使ったデータに関する情報を保持しているかを測定する手法
日本語解説スライド:https://www.docswell.com/s/DeepLearning2023/Z38P8D-2024-06-20-131813p1これは相当汎用的に使えそうな話だから役に立ちそう #EfficiencyImprovement #NLP #LanguageModel #Transformer #LongSequence #PositionalEncoding #NeurIPS Issue Date: 2025-04-06 The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad+, NeurIPS'23 Summary長さ一般化はTransformerベースの言語モデルにおける重要な課題であり、位置エンコーディング(PE)がその性能に影響を与える。5つの異なるPE手法(APE、T5の相対PE、ALiBi、Rotary、NoPE)を比較した結果、ALiBiやRotaryなどの一般的な手法は長さ一般化に適しておらず、NoPEが他の手法を上回ることが明らかになった。NoPEは追加の計算を必要とせず、絶対PEと相対PEの両方を表現可能である。さらに、スクラッチパッドの形式がモデルの性能に影響を与えることも示された。この研究は、明示的な位置埋め込みが長いシーケンスへの一般化に必須でないことを示唆している。 Comment・1863
において、Llama4 Scoutが10Mコンテキストウィンドウを実現できる理由の一つとのこと。
元ポスト:https://x.com/drjimfan/status/1908615861650547081?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Llama4のブログポストにもその旨記述されている:
>A key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings. Additionally, we employ inference time temperature scaling of attention to enhance length generalization.
[The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation](https://ai.meta.com/blog/llama-4-multimodal-intelligence/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4)斜め読みだが、length generalizationを評価する上でdownstream taskに焦点を当て、3つの代表的なカテゴリに相当するタスクで評価したところ、この観点においてはT5のrelative positinal encodingとNoPE(位置エンコードディング無し)のパフォーマンスが良く、
NoPEは絶対位置エンコーディングと相対位置エンコーディングを理論上実現可能であり[^1]
実際に学習された異なる2つのモデルに対して同じトークンをそれぞれinputし、同じ深さのLayerの全てのattention distributionの組み合わせからJensen Shannon Divergenceで距離を算出し、最も小さいものを2モデル間の当該layerの距離として可視化すると下記のようになり、NoPEとT5のrelative positional encodingが最も類似していることから、NoPEが学習を通じて(実用上は)相対位置エンコーディングのようなものを学習することが分かった。
[^1]:深さ1のLayerのHidden State H^1から絶対位置の復元が可能であり(つまり、当該レイヤーのHが絶対位置に関する情報を保持している)、この前提のもと、後続のLayerがこの情報を上書きしないと仮定した場合に、相対位置エンコーディングを実現できる。また、CoT/Scratchpadはlong sequenceに対する汎化性能を向上させることがsmall scaleではあるが先行研究で示されており、Positional Encodingを変化させた時にCoT/Scratchpadの性能にどのような影響を与えるかを調査。
具体的には、CoT/Scratchpadのフォーマットがどのようなものが有効かも明らかではないので、5種類のコンポーネントの組み合わせでフォーマットを構成し、mathematical reasoningタスクで以下のような設定で訓練し
・さまざまなコンポーネントの組み合わせで異なるフォーマットを作成し、
・全ての位置エンコーディングあり/なしモデルを訓練
これらを比較した。この結果、CoT/Scratchpadはフォーマットに関係なく、特定のタスクでのみ有効(有効かどうかはタスク依存)であることが分かった。このことから、CoT/Scratcpad(つまり、モデルのinputとoutputの仕方)単体で、long contextに対する汎化性能を向上させることができないので、Positional Encoding(≒モデルのアーキテクチャ)によるlong contextに対する汎化性能の向上が非常に重要であることが浮き彫りになった。
また、CoT/Scratchpadが有効だったAdditionに対して各Positional Embeddingモデルを学習し、生成されたトークンのattentionがどの位置のトークンを指しているかを相対距離で可視化したところ(0が当該トークン、つまり現在のScratchpadに着目しており、1が遠いトークン、つまりinputに着目していることを表すように正規化)、NoPEとRelative Positional Encodingがshort/long rangeにそれぞれフォーカスするようなbinomialな分布なのに対し、他のPositional Encodingではよりuniformな分布であることが分かった。このタスクにおいてはNoPEとRelative POの性能が高かったため、binomialな分布の方がより最適であろうことが示唆された。
#Analysis #Pocket #NLP #LanguageModel #ReversalCurse Issue Date: 2023-10-09 [Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23 Summary自己回帰型大規模言語モデル(LLMs)は、「AはBである」という文から「BはAである」と逆の関係を自動的に一般化できない「逆転の呪い」を示す。例えば、モデルが「ワレンティナ・テレシコワは宇宙に行った最初の女性である」と訓練されても、「宇宙に行った最初の女性は誰か?」に正しく答えられない。実験では、架空の文を用いてGPT-3とLlama-1をファインチューニングし、逆転の呪いの存在を確認。ChatGPT(GPT-3.5およびGPT-4)でも、実在の有名人に関する質問で正答率に大きな差が見られた。 CommentA is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
著者ツイート: https://x.com/owainevans_uk/status/1705285631520407821?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。
また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。
このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。関連:
・1923 #EfficiencyImprovement #MachineLearning #Pocket #Quantization #PEFT(Adaptor/LoRA) #NeurIPS Issue Date: 2023-07-22 QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, NeurIPS'23 Summary私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment実装: https://github.com/artidoro/qlora
PEFTにもある参考: https://twitter.com/hillbig/status/1662946722690236417?s=46&t=TDHYK31QiXKxggPzhZbcAQOpenReview:https://openreview.net/forum?id=OUIFPHEgJU&referrer=%5Bthe%20profile%20of%20Ari%20Holtzman%5D(%2Fprofile%3Fid%3D~Ari_Holtzman1) #Pocket #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2023-07-03 Holistic Evaluation of Language Models, Percy Liang+, TMLR'23 Summary言語モデルの透明性を向上させるために、Holistic Evaluation of Language Models(HELM)を提案する。HELMでは、潜在的なシナリオとメトリックを分類し、広範なサブセットを選択して評価する。さらに、複数のメトリックを使用し、主要なシナリオごとに評価を行う。30の主要な言語モデルを42のシナリオで評価し、HELM以前に比べて評価のカバレッジを改善した。HELMはコミュニティのためのベンチマークとして利用され、新しいシナリオ、メトリック、モデルが継続的に更新される。 CommentOpenReview:https://openreview.net/forum?id=iO4LZibEqWHELMを提案した研究
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/ #NLP #LanguageModel #LLMAgent Issue Date: 2023-04-13 REACT : SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS, Yao+, Princeton University and Google brain, ICLR'23 Comment概要
人間は推論と行動をシナジーさせることで、さまざまな意思決定を行える。近年では言語モデルにより言語による推論を意思決定に組み合わせる可能性が示されてきた。たとえば、タスクをこなすための推論トレースをLLMが導けることが示されてきた(Chain-of-Thought)が、CoTは外部リソースにアクセスできないため知識がアップデートできず、事後的に推論を行うためhallucinationやエラーの伝搬が生じる。一方で、事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われているが、これらの研究では、高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
そこで、REACTを提案。REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みであり、推論トレースとアクションを交互に生成するため、動的に推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
・要はいままではGeneralなタスク解決モデルにおいては、推論とアクションの生成は独立にしかやられてこなかったけど、推論とアクションを交互作用させることについて研究したよ
・そしたら性能がとってもあがったよ
・reasoningを人間が編集すれば、エージェントのコントロールもできるよ という感じ
イントロ
人間は推論と行動の緊密なシナジーによって、不確実な状況に遭遇しても適切な意思決定が行える。たとえば、任意の2つの特定のアクションの間で、進行状況をトレースするために言語で推論したり(すべて切り終わったからお湯を沸かす必要がある)、例外を処理したり、状況に応じて計画を調整したりする(塩がないから代わりに醤油と胡椒を使おう)。また、推論をサポートし、疑問(いまどんな料理を作ることができるだろうか?)を解消するために、行動(料理本を開いてレシピを読んで、冷蔵庫を開いて材料を確確認したり)をすることもある。
近年の研究では言語での推論を、インタラクティブな意思決定を組み合わせる可能性についてのヒントが得られてきた。一つは、適切にPromptingされたLLMが推論トレースを実行できることを示している。推論トレースとは、解決策に到達するための一連のステップを経て推論をするためのプロセスのことである。しかしながらChain-of-thoughytは、このアプローチでは、モデルが外界対してgroundingできず、内部表現のみに基づい思考を生成するため限界がある。これによりモデルが事後対応的に推論したり、外部情報に基づいて知識を更新したりできないため、推論プロセス中にhallucinationやエラーの伝搬などの問題が発生する可能性が生じる。
一方、近年の研究では事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われている。これらの研究では、通常マルチモーダルな観測結果をテキストに変換し、言語モデルを使用してドメイン固有のアクション、またはプランを生成し、コントローラーを利用してそれらを選択または実行する。ただし、これらのアプローチは高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。
推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
LLMにおける推論と行動を組み合わせて、言語推論と意思決定タスクを解決するREACTと呼ばれる手法を提案。REACTでは、推論と行動の相乗効果を高めることが可能。推論トレースによりアクションプランを誘発、追跡、更新するのに役立ち、アクションでは外部ソースと連携して追加情報を収集できる。
REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みである。REACTのpromptはLLMにverbalな推論トレースとタスクを実行するためのアクションを交互に生成する。これにより、モデルは動的な推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
手法
変数を以下のように定義する:
・O_t: Observertion on time t
・a_t: Action on time t
・c_t: context, i.e. (o_1, a_1, o_2, a_2, ..., a_t-1, o_t)
・policy pi\(a\_t | c\_t): Action Spaceからアクションを選択するポリシー
・A: Action Space
・O: Observation Space
普通はc_tが与えられたときに、ポリシーに従いAからa_tを選択しアクションを行い、アクションの結果o_tを得て、c_t+1を構成する、といったことを繰り返していく。
このとき、REACTはAをA ∪ Lに拡張しする。ここで、LはLanguage spaceである。LにはAction a_hatが含まれ、a_hatは環境に対して作用をしない。単純にthought, あるいは reasoning traceを実施し、現在のcontext c_tをアップデートするために有用な情報を構成することを目的とする。Lはunlimitedなので、事前学習された言語モデルを用いる。今回はPaLM-540B(c.f. GPT3は175Bパラメータ)が利用され、few-shotのin-context exampleを与えることで推論を行う。それぞれのin-context exampleは、action, thoughtsそしてobservationのtrajectoryを与える。
推論が重要なタスクでは、thoughts-action-observationステップから成るtask-solving trajectoryを生成する。一方、多数のアクションを伴う可能性がある意思決定タスクでは、thoughtsのみを行うことをtask-solving trajectory中の任意のタイミングで、自分で判断して行うことができる。
意思決定と推論能力がLLMによってもたらされているため、REACTは4つのuniqueな特徴を持つ:
・直感的で簡単なデザイン
・REACTのpromptは人間のアノテータがアクションのトップに思考を言語で記述するようなストレートなものであり、ad-hocなフォーマットの選択、思考のデザイン、事例の選定などが必要ない。
・一般的で柔軟性が高い
・柔軟な thought spaceと thought-actionのフォーマットにより、REACTはさまざまなタスクにも柔軟に対応できる
・高性能でロバスト
・REACTは1-6個の事例によって、新たなタスクに対する強力な汎化を示す。そして推論、アクションのみを行うベースラインよりも高い性能を示している。REACTはfinetuningの斧系も得ることができ、promptの選択に対してREACTの性能はrobustである。
・人間による調整と操作が可能
・REACTは、解釈可能な意思決定と推論のsequenceを前提としているため、人間は簡単に推論や事実の正しさを検証できる。加えて、thoughtsを編集することによって、m人間はエージェントの行動を制御、あるいは修正できる。
KNOWLEDGE INTENSIVE REASONING TASKS #Pocket #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICLR #PostTraining Issue Date: 2025-05-12 LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22 SummaryLoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。 CommentOpenrReview:https://openreview.net/forum?id=nZeVKeeFYf9LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。 #MachineLearning #Pocket #NLP #LanguageModel #NeurIPS #Scaling Laws Issue Date: 2025-03-23 Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22 Summaryトランスフォーマー言語モデルの訓練において、計算予算内で最適なモデルサイズとトークン数を調査。モデルサイズと訓練トークン数は同等にスケールする必要があり、倍増するごとにトークン数も倍増すべきと提案。Chinchillaモデルは、Gopherなどの大規模モデルに対して優れた性能を示し、ファインチューニングと推論の計算量を削減。MMLUベンチマークで67.5%の精度を達成し、Gopherに対して7%以上の改善を実現。 CommentOpenReview: https://openreview.net/forum?id=iBBcRUlOAPRchinchilla則 #EfficiencyImprovement #Pretraining #Pocket #NLP #Transformer #Architecture #MoE(Mixture-of-Experts) Issue Date: 2025-02-11 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22 SummarySwitch Transformerを提案し、Mixture of Experts (MoE)の複雑さや通信コスト、トレーニングの不安定性を改善。これにより、低精度フォーマットでの大規模スパースモデルのトレーニングが可能になり、最大7倍の事前トレーニング速度向上を実現。さらに、1兆パラメータのモデルを事前トレーニングし、T5-XXLモデルに対して4倍の速度向上を達成。 #Analysis #Pocket #NLP #Transformer #ACL #KnowledgeEditing #FactualKnowledge #Encoder Issue Date: 2024-07-11 Knowledge Neurons in Pretrained Transformers, Damai Dai+, N_A, ACL'22, 2022.05 Summary大規模な事前学習言語モデルにおいて、事実知識の格納方法についての研究を行いました。具体的には、BERTのfill-in-the-blank cloze taskを用いて、関連する事実を表現するニューロンを特定しました。また、知識ニューロンの活性化と対応する事実の表現との正の相関を見つけました。さらに、ファインチューニングを行わずに、知識ニューロンを活用して特定の事実知識を編集しようと試みました。この研究は、事前学習されたTransformers内での知識の格納に関する示唆に富んでおり、コードはhttps://github.com/Hunter-DDM/knowledge-neuronsで利用可能です。 Comment1108 日本語解説: https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022関連:
・2140上記資料によると、特定の知識を出力する際に活性化する知識ニューロンを特定する手法を提案。MLMを用いたclozeタスクによる実験で[MASK]部分に当該知識を出力する実験をした結果、知識ニューロンの重みをゼロとすると性能が著しく劣化し、値を2倍にすると性能が改善するといった傾向がみられた。 ケーススタディとして、知識の更新と、知識の削除が可能かを検証。どちらとも更新・削除がされる方向性[^1]へモデルが変化した。
また、知識ニューロンはTransformerの層の深いところに位置している傾向にあり、異なるrelationを持つような関係知識同士では共有されない傾向にある模様。
[^1]: 他の知識に影響を与えず、完璧に更新・削除できたわけではない。知識の更新・削除に伴いExtrinsicな評価によって性能向上、あるいはPerplexityが増大した、といった結果からそういった方向性へモデルが変化した、という話 #ComputerVision #Pocket #Transformer #ICLR #Backbone Issue Date: 2025-08-25 [Paper Note] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy+, ICLR'21 Summary純粋なトランスフォーマーを画像パッチのシーケンスに直接適用することで、CNNへの依存なしに画像分類タスクで優れた性能を発揮できることを示す。大量のデータで事前学習し、複数の画像認識ベンチマークで最先端のCNNと比較して優れた結果を達成し、計算リソースを大幅に削減。 Commentopenreview:https://openreview.net/forum?id=YicbFdNTTyViTを提案した研究 #Pocket #NLP #Dataset #LanguageModel #Evaluation #CodeGeneration Issue Date: 2025-08-15 [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21 Summary本論文では、汎用プログラミング言語におけるプログラム合成の限界を大規模言語モデルを用いて評価します。MBPPとMathQA-Pythonの2つのベンチマークで、モデルサイズに対する合成性能のスケールを調査。最も大きなモデルは、少数ショット学習でMBPPの59.6%の問題を解決可能で、ファインチューニングにより約10%の性能向上が見られました。MathQA-Pythonでは、ファインチューニングされたモデルが83.8%の精度を達成。人間のフィードバックを取り入れることでエラー率が半減し、エラー分析を通じてモデルの弱点を明らかにしました。最終的に、プログラム実行結果の予測能力を探るも、最良のモデルでも特定の入力に対する出力予測が困難であることが示されました。 Comment代表的なコード生成のベンチマーク。
MBPPデータセットは、promptで指示されたコードをモデルに生成させ、テストコード(assertion)を通過するか否かで評価する。974サンプル存在し、pythonの基礎を持つクラウドワーカーによって生成。クラウドワーカーにタスクdescriptionとタスクを実施する一つの関数(関数のみで実行可能でprintは不可)、3つのテストケースを記述するよう依頼。タスクdescriptionは追加なclarificationなしでコードが記述できるよう十分な情報を含むよう記述するように指示。ground truthの関数を生成する際に、webを閲覧することを許可した。
MathQA-Pythonは、MathQAに含まれるQAのうち解答が数値のもののみにフィルタリングしたデータセットで、合計で23914サンプル存在する。pythonコードで与えられた数学に関する問題を解くコードを書き、数値が一致するか否かで評価する、といった感じな模様。斜め読みなので少し読み違えているかもしれない。
164個の人手で記述されたprogrammingの問題で、それぞれはfunction signature, docstring, body, unittestを持つ。unittestは問題当たり約7.7 test存在。handwrittenという点がミソで、コンタミネーションの懸念があるためgithubのような既存ソースからのコピーなどはしていない。pass@k[^1]で評価。
[^1]: k個のサンプルを生成させ、k個のサンプルのうち、サンプルがunittestを一つでも通過する確率。ただ、本研究ではよりバイアスをなくすために、kよりも大きいn個のサンプルを生成し、その中からランダムにk個を選択して確率を推定するようなアプローチを実施している。2.1節を参照のこと。
ソーステキストが与えられた時に、BARTによって生成テキストを生成する尤度を計算し、それをスコアとする手法。テキスト生成タスクをテキスト生成モデルでスコアリングすることで、pre-trainingされたパラメータをより有効に活用できる(e.g. BERTScoreやMoverScoreなどは、pre-trainingタスクがテキスト生成ではない)。BARTScoreの特徴は
1. parameter・and data-efficientである。pre-trainingに利用されたパラメータ以外の追加パラメータは必要なく、unsupervisedなmetricなので、human judgmentのデータなども必要ない。
2. 様々な観点から生成テキストを評価できる。conditional text generation problemにすることでinformativeness, coherence, factualityなどの様々な観点に対応可能。
3. BARTScoreは、(i) pre-training taskと類似したpromptを与えること、(ii) down stream generation taskでfinetuningすること、でより高い性能を獲得できる
BARTScoreを16種類のデータセットの、7つの観点で評価したところ、16/22において、top-scoring metricsよりも高い性能を示した。また、prompting starategyの有効性を示した。たとえば、シンプルに"such as"というフレーズを翻訳テキストに追加するだけで、German-English MTにおいて3%の性能向上が見られた。また、BARTScoreは、high-qualityなテキスト生成システムを扱う際に、よりロバストであることが分析の結果分かった。
前提
Problem Formulation
生成されたテキストのqualityを測ることを目的とする。本研究では、conditional text generation (e.g. 機械翻訳)にフォーカスする。すなわち、ゴールは、hypothesis h_bar を source text s_barがgivenな状態で生成することである。一般的には、人間が作成したreference r_barが評価の際は利用される。
Gold-standard Human Evaluation
評価のgold standardは人手評価であり、人手評価では多くの観点から評価が行われる。以下に代表的な観点を示す:
1. Informativeness: ソーステキストのキーアイデアをどれだけ捉えているか
2. Relevance: ソーステキストにあ地して、どれだけconsistentか
3. Fluency formatting problem, capitarlization errorや非文など、どの程度読むのが困難か
4. Coherence: 文間のつながりが、トピックに対してどれだけcoherentか
5. Factuality: ソーステキストに含意されるstatementのみを生成できているか
6. Semantic Coverage: 参照テキスト中のSemantic Content Unitを生成テキストがどれだけカバーできているか
7: Adequacy 入力文に対してアウトプットが同じ意味を出力できているかどうか、あるいは何らかのメッセージが失われる、追加される、歪曲していないかどうか
多くの性能指標は、これらの観点のうちのsubsetをカバーするようにデザインんされている。たとえば、BLEUは、翻訳におけるAdequacyとFluencyをとらえることを目的としている。一方、ROUGEは、semantic coverageを測るためのメトリックである。
BARTScoreは、これらのうち多くの観点を評価することができる。
Evaluation as Different Tasks
ニューラルモデルを異なる方法で自動評価に活用するのが最近のトレンドである。下図がその分類。この分類は、タスクにフォーカスした分類となっている。
1. Unsupervised Matching: ROUGE, BLEU, CHRF, BERTScore, MoverScoreのように、hypothesisとreference間での意味的な等価性を測ることが目的である。このために、token-levelのマッチングを用いる。これは、distributedな表現を用いる(BERTScore, MoverScore)場合もあれば、discreteな表現を用いる(ROUGE, BLEU, chrF)場合もある。また、意味的な等価性だけでなく、factual consistencyや、source-hypothesis間の関係性の評価に用いることもできると考えられるが先行研究ではやられていなかったので、本研究で可能なことを示す。
2. Supervised Regression: BLEURT, COMET, S^3, VRMのように、regression layer を用いてhuman judgmentをsupervisedに予測する方法である。最近のメトリックtおしては、BLEURT, COMETがあげられ、古典的なものとしては、S^3, VRMがあげられる。
4. Supervised Ranking: COMET, BEERのような、ランキング問題としてとらえる方法もある。これは優れたhypothesisを上位にランキングするようなスコア関数を学習する問題に帰着する。COMETやBEERが例としてあげられ、両者はMTタスクにフォーカスされている。COMETはhunan judgmentsをregressionすることを通じてランキングを作成し、BEERは、多くのシンプルな特徴量を組み合わせて、linear layerでチューニングされる。
5. Text Generation: PRISM, BARTScoreが例として挙げられる。BARTScoreでは、生成されたテキストの評価をpre-trained language modelによるテキスト生成タスクとしてとらえる。基本的なアイデアとしては、高品質のhypothesisは、ソース、あるいはreferenceから容易に生成可能であろう、というものである。これはPRISMを除いて、先行研究ではカバーされていない。BARTScoreは、PRISMとはいくつかの点で異なっている。(i) PRISMは評価をparaphrasing taskとしてとらえており、これが2つの意味が同じテキストを比較する前提となってしまっているため、手法を適用可能な範囲を狭めてしまっている。たとえば、文書要約におけるfactual consistencyの評価では、semantic spaceが異なる2つのテキストを比較する必要があるが、このような例には対応できない。(ii) PRISMはparallel dataから学習しなけえrばならないが、BARTScoreは、pre-trainedなopen-sourceのseq2seq modelを利用できる。(iii) BARTScoreでは、PRISMが検証していない、prompt-basedのlearningもサポートしている。
BARTScore
Sequence-to-Sequence Pre-trained Models
pre-trainingされたモデルは、様々な軸で異なっているが、その一つの軸としては訓練時の目的関数である。基本的には2つの大きな変種があり、1つは、language modeling objectives (e.g. MLM)、2つ目は、seq2seq objectivesである。特に、seq2seqで事前学習されたモデルは、エンコーダーとデコーダーによって構成されているため特に条件付き生成タスクに対して適しており、予測はAutoRegressiveに行われる。本研究ではBARTを用いる。付録には、preliminary experimentsとして、BART with T5, PEGASUSを用いた結果も添付する。
BARTScore
最も一般的なBARTScoreの定式化は下記である。
weighted log probabilityを利用する。このweightsは、異なるトークンに対して、異なる重みを与えることができる。たておば、IDFなどが利用可能であるが、本研究ではすべてのトークンを等価に扱う(uniform weightingだがstopwordを除外、IDFによる重みづけ、事前分布を導入するなど色々試したが、uniform weightingを上回るものがなかった)。
BARTScoreを用いて、様々な方向に用いて生成を行うことができ、異なる評価のシナリオに対応することができる。
・Faithfulness (s -> h):
・hypothesisがどれだけsource textに基づいて生成されているかを測ることができる。シナリオとしては、FactualityやRelevanceなどが考えられる。また、CoherenceやFluencyのように、target textのみの品質を測るためにも用いることができる。
・Precision (r -> h):
・hypothesisがどれだけgold-referenceに基づいてこう良くされているかを亜評価でき、precision-focusedなシナリオに適している
・Recall (h -> r):
・hypothesisから、gold referenceをどれだけ容易に再現できるかを測ることができる。そして、要約タスクのpyramid-basedな評価(i.e. semantic coverage等) に適している。pyramid-scoreはSemantic Content Unitsがどれだけカバーされているかによって評価される。
・F Score (r <-> h):
・双方向を考慮し、Precisioon / RecallからF値を算出する。この方法は、referenceと生成テキスト間でのsemantic overlap (informativenss, adequacy)などの評価に広く利用される。
BARTScore Variants
BARTScoreの2つの拡張を提案。(i) xとyをpromptingによって変更する。これにより、評価タスクをpre-training taskと近づける。(ii) パラメータΘを異なるfinetuning taskを考慮して変更する。すなわち、pre-trainingのドメインを、evaluation taskに近づける。
Prompt
Promptingはinput/outputに対して短いフレーズを追加し、pre-trained modelに対して特定のタスクを遂行させる方法である。BARTにも同様の洞察を簡単に組み込むことができる。この変種をBARTScore-PROMPTと呼ぶ。
prompt zが与えられたときに、それを (i) source textに追加し、新たなsource textを用いてBARTScoreを計算する。(ii) target textの先頭に追加し、new target textに対してBARTScoreを計算する。
Fine-tuning Task
classification-basedなタスクでfine-tuneされるのが一般的なBERT-based metricとは異なり、BARTScoreはgeneration taskでfine-tuneされるため、pre-training domainがevaluation taskと近い。本研究では、2つのdownstream taskを検証する。
1つめは、summarizationで、BARTをCNNDM datasetでfinetuningする。2つめは、paraphrasingで、summarizationタスクでfinetuningしたBARTをParaBank2 datasetでさらにfinetuningする。実験
baselines and datasets
Evaluation Metrics
supervised metrics: COMET, BLEURT
unsupervised: BLEU, ROUGE-1, ROUGE-2, ROUGE-L, chrF, PRISM, MoverScore, BERTScore
と比較
Measures for Meta Evaluation
Pearson Correlationでlinear correlationを測る。また、Spearman Correlationで2変数間の単調なcorrelationを測定する(線形である必要はない)。Kendall's Tauを用いて、2つの順序関係の関係性を測る。最後に、Accuracyでfactual textsとnon-factual textの間でどれだけ正しいランキングを得られるかを測る。
Datasets
Summarization, MT, DataToTextの3つのデータセットを利用。
Setup
Prompt Design
seedをparaphrasingすることで、 s->h方向には70個のpromptを、h<->rの両方向には、34のpromptを得て実験で用いた。
Settings
Summarizationとdata-to-textタスクでは、全てのpromptを用いてデコーダの頭に追加してスコアを計算しスコアを計算した。最終的にすべての生成されたスコアを平均することである事例に対するスコアを求めた(prompt unsembling)。MTについては、事例数が多くcomputational costが多くなってしまうため、WMT18を開発データとし、best prompt "Such as"を選択し、利用した。
BARTScoreを使う際は、gold standard human evaluationがrecall-basedなpyrmid methodの場合はBARTScore(h->r)を用い、humaan judgmentsがlinguistic quality (coherence fluency)そして、factual correctness、あるいは、sourceとtargetが同じモダリティ(e.g. language)の場合は、faitufulness-based BARTScore(s->h)を用いた。最後に、MTタスクとdata-to-textタスクでは、fair-comparisonのためにBARTScore F-score versionを用いた。
実験結果
MT
・BARTScoreはfinetuning tasksによって性能が向上し、5つのlanguage pairsにおいてその他のunsupervised methodsを統計的に優位にoutperformし、2つのlanguage pairでcomparableであった。
-Such asというpromptを追加するだけで、BARTScoreの性能が改善した。特筆すべきは、de-enにおいては、SoTAのsupervised MetricsであるBLEURTとCOMETを上回った。
・これは、有望な将来のmetric designとして「human judgment dataで訓練する代わりに、pre-trained language modelに蓄積された知識をより適切に活用できるpromptを探索する」という方向性を提案している。
Text Summarization
・vanilla BARTScoreはBERTScore, MoverScoreをInfo perspective以外でlarge marginでうくぁ回った。
・REALSum, SummEval dataseetでの改善は、finetuning taskによってさらに改善した。しかしながら、NeR18では改善しなかった。これは、データに含まれる7つのシステムが容易に区別できる程度のqualityであり、既にvanilla BARTScoreで高いレベルのcorrelationを達成しているからだと考えられる。
・prompt combination strategyはinformativenssに対する性能を一貫して改善している。しかし、fluency, factualityでは、一貫した改善は見られなかった。
Factuality datasetsに対する分析を行った。ゴールは、short generated summaryが、元のlong documentsに対してfaithfulか否かを判定するというものである。
・BARTScore+CNNは、Rank19データにおいてhuman baselineに近い性能を達成し、ほかのベースラインを上回った。top-performingなfactuality metricsであるFactCCやQAGSに対してもlarge marginで上回った。
・paraphraseをfine-tuning taskで利用すると、BARTScoreのパフォーマンスは低下した。これは妥当で、なぜなら二つのテキスト(summary and document)は、paraphrasedの関係性を保持していないからである。
・promptを導入しても、性能の改善は見受けられず、パフォーマンスは低下した。
Data-to-Text
・CNNDMでfine-tuningすることで、一貫してcorrelationが改善した。
・加えて、paraphraseデータセットでfinetuningすることで、さらに性能が改善した。
・prompt combination strategyは一貫してcorrelationを改善した。
Analysis
Fine-grained Analysis
・Top-k Systems: MTタスクにおいて、評価するシステムをtop-kにし、各メトリックごとにcorrelationの変化を見た。その結果、BARTScoreはすべてのunsupervised methodをすべてのkにおいて上回り、supervised metricのBLEURTも上回った。また、kが小さくなるほど、より性能はsmoothになっていき、性能の低下がなくなっていった。これはつまり、high-quality textを生成するシステムに対してロバストであることを示している。
・Reference Length: テストセットを4つのバケットにreference lengthに応じてブレイクダウンし、Kendall's Tauの平均のcorrelationを、異なるメトリック、バケットごとに言語をまたいで計算した。unsupervised metricsに対して、全てのlengthに対して、引き分けかあるいは上回った。また、ほかのmetricsと比較して、長さに対して安定感があることが分かった。
Prompt Analysis
(1) semantic overlap (informativeness, pyramid score, relevance), (2) linguistic quality (fluency, coherence), (3) factual correctness (factuality) に評価の観点を分類し、summarizationとdata-to-textをにおけるすべてのpromptを分析することで、promptの効果を分析した。それぞれのグループに対して、性能が改善したpromptの割合を計算した。その結果、semantic overlapはほぼ全てのpromptにて性能が改善し、factualityはいくつかのpromptでしか性能の改善が見られなかった。linguistic qualityに関しては、promptを追加することによる効果はどちらとも言えなかった。
Bias Analysis
BARTScoreが予測不可能な方法でバイアスを導入してしまうかどうかを分析した。バイアスとは、human annotatorが与えたスコアよりも、値が高すぎる、あるいは低すぎるような状況である。このようなバイアスが存在するかを検証するために、human annotatorとBARTScoreによるランクのサを分析した。これを見ると、BARTScoreは、extractive summarizationの品質を区別する能力がabstractive summarizationの品質を区別する能力よりも劣っていることが分かった。しかしながら、近年のトレンドはabstractiveなseq2seqを活用することなので、この弱点は軽減されている。
Implications and Future Directions
prompt-augmented metrics: semantic overlapではpromptingが有効に働いたが、linguistic qualityとfactualityでは有効ではなかった。より良いpromptを模索する研究が今後期待される。
Co-evolving evaluation metrics and systems: BARTScoreは、メトリックデザインとシステムデザインの間につながりがあるので、より性能の良いseq2seqシステムが出たら、それをメトリックにも活用することでよりreliableな自動性能指標となることが期待される。
#Sentence #Embeddings #Pocket #NLP #LanguageModel #RepresentationLearning #ContrastiveLearning #Catastrophic Forgetting Issue Date: 2023-07-27 SimCSE: Simple Contrastive Learning of Sentence Embeddings, Tianyu Gao+, N_A, EMNLP'21 Summaryこの論文では、SimCSEという対比学習フレームワークを提案しています。このフレームワークは、文の埋め込み技術を進化させることができます。教師なしアプローチでは、入力文をノイズとして扱い、自己を対比的に予測します。教師ありアプローチでは、自然言語推論データセットから注釈付きのペアを使用して対比学習を行います。SimCSEは、意味的テキスト類似性タスクで評価され、以前の手法と比較して改善を実現しました。対比学習は、事前学習された埋め込みの空間を均一に正則化し、教師信号が利用可能な場合には正のペアをよりよく整列させることが示されました。 Comment462 よりも性能良く、unsupervisedでも学習できる。STSタスクのベースラインにだいたい入ってる手法概要
Contrastive Learningを活用して、unsupervised/supervisedに学習を実施する。
Unsupervised SimCSEでは、あるsentenceをencoderに2回入力し、それぞれにdropoutを適用させることで、positive pairを作成する。dropoutによって共通のembeddingから異なる要素がマスクされた(noiseが混ざった状態とみなせる)類似したembeddingが作成され、ある種のdata augmentationによって正例を作成しているともいえる。負例はnegative samplingする。(非常にsimpleだが、next sentence predictionで学習するより性能が良くなる)
Supervised SimCSEでは、アノテーションされたsentence pairに基づいて、正例・負例を決定する。本研究では、NLIのデータセットにおいて、entailment関係にあるものは正例として扱う。contradictions(矛盾)関係にあるものは負例として扱う。
Siamese Networkで用いられるmeans-squared errrorとContrastiveObjectiveの違い
どちらもペアワイズで比較するという点では一緒だが、ContrastiveObjectiveは正例と近づいたとき、負例と遠ざかったときにlossが小さくなるような定式化がされている点が異なる。
(画像はこのブログから引用。ありがとうございます。https://techblog.cccmk.co.jp/entry/2022/08/30/163625)
Unsupervised SimCSEの実験
異なるdata augmentation手法と比較した結果、dropoutを適用する手法の方が性能が高かった。MLMや, deletion, 類義語への置き換え等よりも高い性能を獲得しているのは興味深い。また、Next Sentence Predictionと比較しても、高い性能を達成。Next Sentence Predictionは、word deletion等のほぼ類似したテキストから直接的に類似関係にあるペアから学習するというより、Sentenceの意味内容のつながりに基づいてモデルの言語理解能力を向上させ、そのうえで類似度を測るという間接的な手法だが、word deletionに負けている。一方、dropoutを適用するだけの(直接的に類似ペアから学習する)本手法はより高い性能を示している。
[image](https://github.com/AkihikoWatanabe/paper_notes/assets/12249301/0ea3549e-3363-4857-94e6-a1ef474aa191)
なぜうまくいくかを分析するために、異なる設定で実験し、alignment(正例との近さ)とuniformity(どれだけembeddingが一様に分布しているか)を、10 stepごとにplotした結果が以下。dropoutを適用しない場合と、常に同じ部分をマスクする方法(つまり、全く同じembeddingから学習する)設定を見ると、学習が進むにつれuniformityは改善するが、alignmentが悪くなっていっている。一方、SimCSEはalignmentを維持しつつ、uniformityもよくなっていっていることがわかる。
Supervised SimCSEの実験
アノテーションデータを用いてContrastiveLearningするにあたり、どういったデータを正例としてみなすと良いかを検証するために様々なデータセットで学習し性能を検証した。
・QQP4: Quora question pairs
・Flickr30k (Young et al., 2014): 同じ画像に対して、5つの異なる人間が記述したキャプションが存在
・ParaNMT (Wieting and Gimpel, 2018): back-translationによるparaphraseのデータセットa
・NLI datasets: SNLIとMNLI
実験の結果、NLI datasetsが最も高い性能を示した。この理由としては、NLIデータセットは、crowd sourcingタスクで人手で作成された高品質なデータセットであることと、lexical overlapが小さくなるようにsentenceのペアが作成されていることが起因している。実際、NLI datsetのlexical overlapは39%だったのに対し、ほかのデータセットでは60%であった。
また、condunctionsとなるペアを明示的に負例として与えることで、より性能が向上した(普通はnegative samplingする、というかバッチ内の正例以外のものを強制的に負例とする。こうすると、意味が同じでも負例になってしまう事例が出てくることになる)。より難しいNLIタスクを含むANLIデータセットを追加した場合は、性能が改善しなかった。この理由については考察されていない。性能向上しそうな気がするのに。
他手法との比較結果
SimCSEがよい。
Ablation Studies
異なるpooling方法で、どのようにsentence embeddingを作成するかで性能の違いを見た。originalのBERTの実装では、CLS token のembeddingの上にMLP layerがのっかっている。これの有無などと比較。
Unsupervised SimCSEでは、training時だけMLP layerをのっけて、test時はMLPを除いた方が良かった。一方、Supervised SimCSEでは、 MLP layerをのっけたまんまで良かったとのこと。
また、SimCSEで学習したsentence embeddingを別タスクにtransferして活用する際には、SimCSEのobjectiveにMLMを入れた方が、catastrophic forgettingを防げて性能が高かったとのこと。
https://qiita.com/saliton/items/2f7b1bfb451df75a286f
https://qiita.com/koshian2/items/a31b85121c99af0eb050 #Pocket Issue Date: 2025-07-24 [Paper Note] Bootstrap your own latent: A new approach to self-supervised Learning, Jean-Bastien Grill+, arXiv'20 SummaryBYOL(Bootstrap Your Own Latent)は、自己教師あり画像表現学習の新しい手法で、オンラインネットワークとターゲットネットワークの2つのニューラルネットワークを用いて学習を行う。BYOLは、ネガティブペアに依存せずに最先端の性能を達成し、ResNet-50でImageNetにおいて74.3%の分類精度を達成、より大きなResNetでは79.6%に達する。転送学習や半教師ありベンチマークでも優れた性能を示し、実装と事前学習済みモデルはGitHubで公開されている。 Comment日本語解説:
https://sn-neural-compute.netlify.app/202006250/ #ComputerVision #Pocket #DataAugmentation #ContrastiveLearning #Self-SupervisedLearning #ICLR Issue Date: 2025-05-18 A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen+, ICML'20 Summary本論文では、視覚表現の対比学習のためのシンプルなフレームワークSimCLRを提案し、特別なアーキテクチャやメモリバンクなしで対比自己教師あり学習を簡素化します。データ拡張の重要性、学習可能な非線形変換の導入による表現の質向上、対比学習が大きなバッチサイズと多くのトレーニングステップから利益を得ることを示し、ImageNetで従来の手法を上回る結果を達成しました。SimCLRによる自己教師あり表現を用いた線形分類器は76.5%のトップ1精度を達成し、教師ありResNet-50に匹敵します。ラベルの1%でファインチューニングした場合、85.8%のトップ5精度を達成しました。 Comment日本語解説:https://techblog.cccmkhd.co.jp/entry/2022/08/30/163625 #DocumentSummarization #NeuralNetwork #NLP #ICML Issue Date: 2025-05-13 PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization, Jingqing Zhang+, ICML'20 Summary大規模なテキストコーパスに対して新しい自己教師ありの目的でトランスフォーマーを事前学習し、抽象的なテキスト要約に特化したモデルPEGASUSを提案。重要な文を削除またはマスクし、残りの文から要約を生成。12の下流要約タスクで最先端のROUGEスコアを達成し、限られたリソースでも優れたパフォーマンスを示す。人間評価でも複数のデータセットで人間のパフォーマンスに達したことを確認。 CommentPEGASUSもなかったので追加。BARTと共に文書要約のBackboneとして今でも研究で利用される模様。関連:
・984 #NeuralNetwork #Pretraining #Pocket #NLP #TransferLearning #PostTraining Issue Date: 2025-05-12 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Colin Raffel+, JMLR'20 Summary転移学習はNLPにおいて強力な技術であり、本論文ではテキストをテキストに変換する統一フレームワークを提案。事前学習の目的やアーキテクチャを比較し、最先端の結果を達成。データセットやモデル、コードを公開し、今後の研究を促進する。 CommentT5もメモっていなかったので今更ながら追加。全てのNLPタスクをテキスト系列からテキスト系列へ変換するタスクとみなし、Encoder-DecoderのTransformerを大規模コーパスを用いて事前学習をし、downstreamタスクにfinetuningを通じて転移する。 #Pocket #NLP #LanguageModel #ICLR #Decoding Issue Date: 2025-04-14 The Curious Case of Neural Text Degeneration, Ari Holtzman+, ICLR'20 Summary深層ニューラル言語モデルは高品質なテキスト生成において課題が残る。尤度の使用がモデルの性能に影響を与え、人間のテキストと機械のテキストの間に分布の違いがあることを示す。デコーディング戦略が生成テキストの質に大きな影響を与えることが明らかになり、ニュークリアスsamplingを提案。これにより、多様性を保ちながら信頼性の低い部分を排除し、人間のテキストに近い質を実現する。 Comment現在のLLMで主流なNucleus (top-p) Samplingを提案した研究 #MachineTranslation #Metrics #Pocket #NLP #Evaluation #EMNLP Issue Date: 2024-05-26 COMET: A Neural Framework for MT Evaluation, Ricardo Rei+, N_A, EMNLP'20 SummaryCOMETは、多言語機械翻訳評価モデルを訓練するためのニューラルフレームワークであり、人間の判断との新しい最先端の相関レベルを達成します。クロスリンガル事前学習言語モデリングの進展を活用し、高度に多言語対応かつ適応可能なMT評価モデルを実現します。WMT 2019 Metrics shared taskで新たな最先端のパフォーマンスを達成し、高性能システムに対する堅牢性を示しています。 CommentBetter/Worseなhypothesisを利用してpair-wiseにランキング関数を学習する


Inference時は単一のhypothesisしかinputされないので、sourceとreferenceに対してそれぞれhypothesisの距離をはかり、その調和平均でスコアリングする
ACL2024, EMNLP2024あたりのMT研究のmetricをざーっと見る限り、BLEU/COMETの双方で評価する研究が多そう #NeuralNetwork #NLP #LanguageModel #Transformer #ActivationFunction Issue Date: 2024-05-24 GLU Variants Improve Transformer, Noam Shazeer, N_A, arXiv'20 SummaryGLUのバリエーションをTransformerのフィードフォワード・サブレイヤーでテストし、通常の活性化関数よりもいくつかのバリエーションが品質向上をもたらすことを発見した。 Comment一般的なFFNでは、linear layerをかけた後に、何らかの活性化関数をかませる方法が主流である。
このような構造の一つとしてGLUがあるが、linear layerと活性化関数には改良の余地があり、様々なvariantが考えられるため、色々試しました、というはなし。
オリジナルのGLUと比較して、T5と同じ事前学習タスクを実施したところ、perplexityが改善
また、finetuningをした場合の性能も、多くの場合オリジナルのGLUよりも高い性能を示した。
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-05-10 BERTScore: Evaluating Text Generation with BERT, Tianyi Zhang+, N_A, ICLR'20 SummaryBERTScoreは、文脈埋め込みを使用してトークンの類似度を計算するテキスト生成の自動評価メトリックであり、363の機械翻訳および画像キャプションシステムの出力を使用して評価されました。BERTScoreは、既存のメトリックよりも人間の判断との相関が高く、より強力なモデル選択性能を提供し、敵対的な言い換え検出タスクにおいてもより堅牢であることが示されました。 Comment概要
既存のテキスト生成の評価手法(BLEUやMETEOR)はsurface levelのマッチングしかしておらず、意味をとらえられた評価になっていなかったので、pretrained BERTのembeddingを用いてsimilarityを測るような指標を提案しましたよ、という話。
prior metrics
n-gram matching approaches
n-gramがreferenceとcandidateでどれだけ重複しているかでPrecisionとrecallを測定
BLEU
MTで最も利用される。n-gramのPrecision(典型的にはn=1,2,3,4)と短すぎる候補訳にはペナルティを与える(brevity penalty)ことで実現される指標。SENT-BLEUといった亜種もある。BLEUと比較して、BERTScoreは、n-gramの長さの制約を受けず、潜在的には長さの制限がないdependencyをcontextualized embeddingsでとらえることができる。
METEOR
669 METEOR 1.5では、内容語と機能語に異なるweightを割り当て、マッチングタイプによってもweightを変更する。METEOR++2.0では、学習済みの外部のparaphrase resourceを活用する。METEORは外部のリソースを必要とするため、たった5つの言語でしかfull feature setではサポートされていない。11の言語では、恥部のfeatureがサポートされている。METEORと同様に、BERTScoreでも、マッチに緩和を入れていることに相当するが、BERTの事前学習済みのembeddingは104の言語で取得可能である。BERTScoreはまた、重要度によるweightingをサポートしている(コーパスの統計量で推定)。
Other Related Metrics
・NIST: BLEUとは異なるn-gramの重みづけと、brevity penaltyを利用する
・ΔBLEU: multi-reference BLEUを、人手でアノテーションされたnegative reference sentenceで変更する
・CHRF: 文字n-gramを比較する
・CHRF++: CHRFをword-bigram matchingに拡張したもの
・ROUGE: 文書要約で利用される指標。ROUGE-N, ROUGE^Lといった様々な変種がある。
・CIDEr: image captioningのmetricであり、n-gramのtf-idfで重みづけされたベクトルのcosine similrityを測定する
Edit-distance based Metrics
・Word Error Rate (WER): candidateからreferenceを再現するまでに必要なedit operationの数をカウントする手法
・Translation Edit Rate (TER): referenceの単語数によってcandidateからreferenceまでのedit distanceを正規化する手法
・ITER: 語幹のマッチと、より良い正規化に基づく手法
・PER: positionとは独立したError Rateを算出
・CDER: edit operationにおけるblock reorderingをモデル化
・CHARACTER / EED: character levelで評価
Embedding-based Metrics
・MEANT 2.0: lexical, structuralの類似度を測るために、word embeddingとshallow semantic parsesを利用
・YISI-1: MEANT 2.0と同様だが、semantic parseの利用がoptionalとなっている
これらはBERTScoreと同様の、similarityをシンプルに測るアプローチで、BERTScoreもこれにinspireされている。が、BERTScoreはContextualized Embeddingを利用する点が異なる。また、linguistic structureを生成するような外部ツールは利用しない。これにより、BERTScoreをシンプルで、新たなlanguageに対しても使いやすくしている。greedy matchingの代わりに、WMD, WMDo, SMSはearth mover's distanceに基づく最適なマッチングを利用することを提案している。greedy matchingとoptimal matchingのtradeoffについては研究されている。sentence-levelのsimilarityを計算する手法も提案されている。これらと比較して、BERTScoreのtoken-levelの計算は、重要度に応じて、tokenに対して異なる重みづけをすることができる。
Learned Metrics
様々なmetricが、human judgmentsとのcorrelationに最適化するために訓練されてきた。
・BEER: character-ngram, word bigramに基づいたregresison modelを利用
・BLEND: 29の既存のmetricを利用してregressionを実施
・RUSE: 3種類のpre-trained sentence embedding modelを利用する手法
これらすべての手法は、コストのかかるhuman judgmentsによるsupervisionが必要となる。そして、新たなドメインにおける汎化能力の低さのリスクがある。input textが人間が生成したものか否か予測するneural modelを訓練する手法もある。このアプローチは特定のデータに対して最適化されているため、新たなデータに対して汎化されないリスクを持っている。これらと比較して、BERTScoreは特定のevaluation taskに最適化されているモデルではない。
BERTScore
referenceとcandidateのトークン間のsimilarityの最大値をとり、それらを集約することで、Precision, Recallを定義し、PrecisionとRecallを利用してF値も計算する。Recallは、reference中のすべてのトークンに対して、candidate中のトークンとのcosine similarityの最大値を測る。一方、Precisionは、candidate中のすべてのトークンに対して、reference中のトークンとのcosine similarityの最大値を測る。ここで、類似度の式が単なる内積になっているが、これはpre-normalized vectorを利用する前提であり、正規化が必要ないからである。
また、IDFによるトークン単位でのweightingを実施する。IDFはテストセットの値を利用する。TFを使わない理由は、BERTScoreはsentence同士を比較する指標であるため、TFは基本的に1となりやすい傾向にあるためである。IDFを計算する際は出現数を+1することによるスムージングを実施。
さらに、これはBERTScoreのランキング能力には影響を与えないが、BERTScoreの値はコサイン類似度に基づいているため、[-1, 1]となるが、実際は学習したcontextual embeddingのgeometryに値域が依存するため、もっと小さなレンジでの値をとることになってしまう。そうすると、人間による解釈が難しくなる(たとえば、極端な話、スコアの0.1程度の変化がめちゃめちゃ大きな変化になってしまうなど)ため、rescalingを実施。rescalingする際は、monolingualコーパスから、ランダムにsentenceのペアを作成し(BETRScoreが非常に小さくなるケース)、これらのBERTScoreを平均することでbを算出し、bを利用してrescalingした。典型的には、rescaling後は典型的には[0, 1]の範囲でBERTScoreは値をとる(ただし数式を見てわかる通り[0, 1]となることが保証されているわけではない点に注意)。これはhuman judgmentsとのcorrelationとランキング性能に影響を与えない(スケールを変えているだけなので)。
実験
Contextual Embedding Models
12種類のモデルで検証。BERT, RoBERTa, XLNet, XLMなど。
Machine Translation
WMT18のmetric evaluation datasetを利用。149種類のMTシステムの14 languageに対する翻訳結果, gold referencesと2種類のhuman judgment scoreが付与されている。segment-level human judgmentsは、それぞれのreference-candiate pairに対して付与されており、system-level human judgmentsは、それぞれのシステムに対して、test set全体のデータに基づいて、単一のスコアが付与されている。pearson correlationの絶対値と、kendall rank correration τをmetricsの品質の評価に利用。そしてpeason correlationについてはWilliams test、kendall τについては、bootstrap re-samplingによって有意差を検定した。システムレベルのスコアをBERTScoreをすべてのreference-candidate pairに対するスコアをaveragingすることによって求めた。また、ハイブリッドシステムについても実験をした。具体的には、それぞれのreference sentenceについて、システムの中からランダムにcandidate sentenceをサンプリングした。これにより、system-level experimentをより多くのシステムで実現することができる。ハイブリッドシステムのシステムレ4ベルのhuman judgmentsは、WMT18のsegment-level human judgmentsを平均することによって作成した。BERTScoreを既存のメトリックと比較した。
通常の評価に加えて、モデル選択についても実験した。10kのハイブリッドシステムを利用し、10kのうち100をランダムに選択、そして自動性能指標でそれらをランキングした。このプロセスを100K回繰り返し、human rankingとmetricのランキングがどれだけagreementがあるかをHits@1で評価した(best systemの一致で評価)。モデル選択の指標として新たにtop metric-rated systemとhuman rankingの間でのMRR, 人手評価でtop-rated systemとなったシステムとのスコアの差を算出した。WMT17, 16のデータセットでも同様の評価を実施した。
Image Captioning
COCO 2015 captioning challengeにおける12種類のシステムのsubmissionデータを利用。COCO validationセットに対して、それぞれのシステムはimageに対するcaptionを生成し、それぞれのimageはおよそ5個のreferenceを持っている。先行研究にならい、Person Correlationを2種類のシステムレベルmetricで測定した。
・M1: 人間によるcaptionと同等、あるいはそれ以上と評価されたcaptionの割合
・M2: 人間によるcaptionと区別がつかないcaptionの割合
BERTScoreをmultiple referenceに対して計算し、最も高いスコアを採用した。比較対象のmetricはtask-agnostic metricを採用し、BLEU, METEOR, CIDEr, BEER, EED, CHRF++, CHARACTERと比較した。そして、2種類のtask-specific metricsとも比較した:SPICE, LEIC
実験結果
Machine Translation
system-levelのhuman judgmentsとのcorrelationの比較、hybrid systemとのcorrelationの比較、model selection performance
to-Englishの結果では、BERTScoreが最も一貫して性能が良かった。RUSEがcompetitiveな性能を示したが、RUSEはsupervised methodである。from-Englishの実験では、RUSEは追加のデータと訓練をしないと適用できない。
以下は、segment-levelのcorrelationを示したものである。BERTScoreが一貫して高い性能を示している。BLEUから大幅な性能アップを示しており、特定のexampleについての良さを検証するためには、BERTScoreが最適であることが分かる。BERTScoreは、RUSEをsignificantlyに上回っている。idfによる重要度のweightingによって、全体としては、small benefitがある場合があるが全体としてはあんまり効果がなかった。importance weightingは今後の課題であり、テキストやドメインに依存すると考えられる。FBERTが異なる設定でも良く機能することが分かる。異なるcontextual embedding model間での比較などは、appendixに示す。
Image Captioning
task-agnostic metricの間では、BETRScoreはlarge marginで勝っている。image captioningはchallengingな評価なので、n-gramマッチに基づくBLEU, ROUGEはまったく機能していない。また、idf weightingがこのタスクでは非常に高い性能を示した。これは人間がcontent wordsに対して、より高い重要度を置いていることがわかる。最後に、LEICはtrained metricであり、COCO dataに最適化されている。この手法は、ほかのすべてのmetricを上回った。
Speed
pre-trained modelを利用しているにもかかわらず、BERTScoreは比較的高速に動作する。192.5 candidate-reference pairs/secondくらい出る(GTX-1080Ti GPUで)。WMT18データでは、15.6秒で処理が終わり、SacreBLEUでは5.4秒である。計算コストそんなにないので、BERTScoreはstoppingのvalidationとかにも使える。Robustness analysis
BERTScoreのロバスト性をadversarial paraphrase classificationでテスト。Quora Question Pair corpus (QQP) を利用し、Word Scrambling dataset (PAWS) からParaphrase Adversariesを取得。どちらのデータも、各sentenceペアに対して、それらがparaphraseかどうかラベル付けされている。QQPの正例は、実際のduplicate questionからきており、負例は関連するが、異なる質問からきている。PAWSのsentence pairsは単語の入れ替えに基づいているものである。たとえば、"Flights from New York to Florida" は "Flights from Florida to New York" のように変換され、良いclassifierはこれらがparaphraseではないと認識できなければならない。PAWSはPAWS_QQPとPAWS_WIKIによって構成さえrており、PAWS_QQPをdevelpoment setとした。automatic metricsでは、paraphrase detection training dataは利用しないようにした。自動性能指標で高いスコアを獲得するものは、paraphraseであることを想定している。
下図はAUCのROC curveを表しており、PAWS_QQPにおいて、QQPで訓練されたclassifierはrandom guessよりも性能が低くなることが分かった。つまりこれらモデルはadversaial exampleをparaphraseだと予測してしまっていることになる。adversarial examplesがtrainingデータで与えられた場合は、supervisedなモデルも分類ができるようになる。が、QQPと比べると性能は落ちる。多くのmetricsでは、QQP ではまともなパフォーマンスを示すが、PAWS_QQP では大幅なパフォーマンスの低下を示し、ほぼrandomと同等のパフォーマンスとなる。これは、これらの指標がより困難なadversarial exampleを区別できないことを示唆している。一方、BERTSCORE のパフォーマンスはわずかに低下するだけであり、他の指標よりもロバスト性が高いことがわかる。
Discussion
・BERTScoreの単一の設定が、ほかのすべての指標を明確に上回るということはない
・ドメインや言語を考慮して、指標や設定を選択すべき
・一般的に、機械翻訳の評価にはFBERTを利用することを推奨
・英語のテキスト生成の評価には、24層のRoBERTa largeモデルを使用して、BERTScoreを計算したほうが良い
・非英語言語については、多言語のBERT_multiが良い選択肢だが、このモデルで計算されたBERTScoreは、low resource languageにおいて、パフォーマンスが安定しているとは言えない #NeuralNetwork #Pocket #NLP #LanguageModel #Zero/FewShotPrompting #In-ContextLearning #NeurIPS Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 SummaryGPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 CommentIn-Context Learningを提案した論文論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。
この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。 #NeuralNetwork #ComputerVision #EfficiencyImprovement #Pocket #ICML #Scaling Laws #Backbone Issue Date: 2025-05-12 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan+, ICML'19 Summary本論文では、ConvNetsのスケーリングを深さ、幅、解像度のバランスを考慮して体系的に研究し、新しいスケーリング手法を提案。これにより、MobileNetsやResNetのスケールアップを実証し、EfficientNetsという新しいモデルファミリーを設計。特にEfficientNet-B7は、ImageNetで84.3%のトップ1精度を達成し、従来のConvNetsよりも小型かつ高速である。CIFAR-100やFlowersなどのデータセットでも最先端の精度を記録。ソースコードは公開されている。 Comment元論文をメモってなかったので追加。
・346
も参照のこと。 #RecommenderSystems #Pocket #Transformer #SequentialRecommendation #ICDM Issue Date: 2025-07-04 [Paper Note] Self-Attentive Sequential Recommendation, Wang-Cheng Kang+, ICDM'18 Summary自己注意に基づく逐次モデル(SASRec)を提案し、マルコフ連鎖と再帰型ニューラルネットワークの利点を統合。SASRecは、少数のアクションから次のアイテムを予測し、スパースおよび密なデータセットで最先端のモデルを上回る性能を示す。モデルの効率性と注意重みの視覚化により、データセットの密度に応じた適応的な処理が可能であることが確認された。 #RecommenderSystems #NeuralNetwork #General #Embeddings #MachineLearning #RepresentationLearning #AAAI Issue Date: 2017-12-28 StarSpace: Embed All The Things, Wu+, AAAI'18 Comment分類やランキング、レコメンドなど、様々なタスクで汎用的に使用できるEmbeddingの学習手法を提案。
Embeddingを学習する対象をEntityと呼び、Entityはbag-of-featureで記述される。
Entityはbag-of-featureで記述できればなんでもよく、
これによりモデルの汎用性が増し、異なる種類のEntityでも同じ空間上でEmbeddingが学習される。
学習方法は非常にシンプルで、Entity同士のペアをとったときに、relevantなpairであれば類似度が高く、
irelevantなペアであれば類似度が低くなるようにEmbeddingを学習するだけ。
たとえば、Entityのペアとして、documentをbag-of-words, bag-of-ngrams, labelをsingle wordで記述しテキスト分類、
あるいは、user_idとユーザが過去に好んだアイテムをbag-of-wordsで記述しcontent-based recommendationを行うなど、 応用範囲は幅広い。
5種類のタスクで提案手法を評価し、既存手法と比較して、同等かそれ以上の性能を示すことが示されている。
手法の汎用性が高く学習も高速なので、色々な場面で役に立ちそう。
また、異なる種類のEntityであっても同じ空間上でEmbeddingが学習されるので、学習されたEmbeddingの応用先が広く有用。実際にSentimentAnalysisで使ってみたが(ポジネガ二値分類)、少なくともBoWのSVMよりは全然性能良かったし、学習も早いし、次元数めちゃめちゃ少なくて良かった。
StarSpaceで学習したembeddingをBoWなSVMに入れると性能が劇的に改善した。解説:
https://www.slideshare.net/akihikowatanabe3110/starspace-embed-all-the-things #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #MatrixFactorization #WWW Issue Date: 2018-02-16 Neural Collaborative Filtering, He+, WWW'17 CommentCollaborative FilteringをMLPで一般化したNeural Collaborative Filtering、およびMatrix Factorizationはuser, item-embeddingのelement-wise product + linear transofmration + activation で一般化できること(GMF; Generalized Matrix Factorization)を示し、両者を組み合わせたNeural Matrix Factorizationを提案している。
学習する際は、Implicit Dataの場合は負例をNegative Samplingし、LogLoss(Binary Cross-Entropy Loss)で学習する。
Neural Matrix Factorizationが、ItemKNNやBPRといったベースラインをoutperform
Negative Samplingでサンプリングする負例の数は、3~4程度で良さそう
#NeuralNetwork #MachineTranslation #NLP #Transformer #Attention #PositionalEncoding #NeurIPS Issue Date: 2018-01-19 Attention is all you need, Vaswani+, NIPS'17 CommentTransformer (self-attentionを利用) 論文
解説スライド:https://www.slideshare.net/DeepLearningJP2016/dlattention-is-all-you-need
解説記事:https://qiita.com/nishiba/items/1c99bc7ddcb2d62667c6
新しい翻訳モデル(Transformer)を提案。既存のモデルよりも並列化に対応しており、短時間の訓練で(既存モデルの1/4以下のコスト)高いBLEUスコアを達成した。
TransformerはRNNやCNNを使わず、attentionメカニズムに基づいている。
(解説より)分かりやすい:
https://qiita.com/halhorn/items/c91497522be27bde17ceTransformerの各コンポーネントでのoutputのshapeや、attention_maskの形状、実装について記述されており有用:
https://qiita.com/FuwaraMiyasaki/items/239f3528053889847825集合知 #NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #EMNLP Issue Date: 2018-01-01 Challenges in Data-to-Document Generation, Wiseman+ (with Rush), EMNLP'17 Comment・RotoWire(NBAのテーブルデータ + サマリ)データを収集し公開
・Rotowireデータの統計量
【モデルの概要】
・attention-based encoder-decoder model
・BaseModel
・レコードデータ r の各要素(r.e: チーム名等のENTITY r.t: POINTS等のデータタイプ, r.m: データのvalue)からembeddingをlookupし、1-layer MLPを適用し、レコードの各要素のrepresentation(source data records)を取得
・Luongらのattentionを利用したLSTM Decoderを用意し、source data recordsとt-1ステップ目での出力によって条件付けてテキストを生成していく
・negative log likelihoodがminimizeされるように学習する
・Copying
・コピーメカニズムを導入し、生成時の確率分布に生成テキストを入力からコピーされるか否かを含めた分布からテキストを生成。コピーの対象は、入力レコードのvalueがコピーされるようにする。
・コピーメカニズムには下記式で表現される Conditional Copy Modelを利用し、p\(zt|y1:t-1, s)はMLPで表現する。
・またpcopyは、生成している文中にあるレコードのエンティティとタイプが出現する場合に、対応するvalueをコピーし生成されるように、下記式で表現する
・ここで r(yt) =
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #ACL Issue Date: 2017-12-31 Get To The Point: Summarization with Pointer-Generator Networks, See+, ACL'17 Comment解説スライド:https://www.slideshare.net/akihikowatanabe3110/get-to-the-point-summarization-with-pointergenerator-networks/1単語の生成と単語のコピーの両方を行えるハイブリッドなニューラル文書要約モデルを提案。
同じ単語の繰り返し現象(repetition)をなくすために、Coverage Mechanismも導入した。
136 などと比較するとシンプルなモデル。一般的に、PointerGeneratorと呼ばれる。
OpenNMTなどにも実装されている: https://opennmt.net/OpenNMT-py/_modules/onmt/modules/copy_generator.html(参考)Pointer Generator Networksで要約してみる:
https://qiita.com/knok/items/9a74430b279e522d5b93 #NeuralNetwork #Sentence #Embeddings #NLP #RepresentationLearning #ICLR Issue Date: 2017-12-28 A structured self-attentive sentence embedding, Li+ (Bengio group), ICLR'17 CommentOpenReview:https://openreview.net/forum?id=BJC_jUqxe #NeuralNetwork #Pocket #SpeechProcessing Issue Date: 2025-06-13 [Paper Note] WaveNet: A Generative Model for Raw Audio, Aaron van den Oord+, arXiv'16 Summary本論文では、音声波形を生成する深層ニューラルネットワークWaveNetを提案。自己回帰的なモデルでありながら、効率的に音声データを訓練可能。テキストから音声への変換で最先端の性能を示し、人間のリスナーに自然な音と評価される。話者の特性を忠実に捉え、アイデンティティに基づく切り替えが可能。音楽生成にも応用でき、リアルな音楽の断片を生成。また、音素認識のための有望な識別モデルとしての利用も示唆。 #RecommenderSystems #SessionBased #ICLR #SequentialRecommendation Issue Date: 2019-08-02 SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS, Hidasi+, ICLR'16 CommentRNNを利用したsequential recommendation (session-based recommendation)の先駆け的論文。日本語解説: https://qiita.com/tatamiya/items/46e278a808a51893deac #RecommenderSystems #NeuralNetwork #Pocket #RecSys Issue Date: 2018-12-27 Deep Neural Networks for YouTube Recommendations, Covington+, RecSys'16 #NeuralNetwork #MachineLearning #Pocket #GraphConvolutionalNetwork #NeurIPS Issue Date: 2018-03-30 Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering, Defferrard+, NIPS'16 CommentGCNを勉強する際は読むと良いらしい。
あわせてこのへんも:
Semi-Supervised Classification with Graph Convolutional Networks, Kipf+, ICLR'17
https://github.com/tkipf/gcn #NeuralNetwork #MachineLearning #Normalization Issue Date: 2018-02-19 Layer Normalization, Ba+, arXiv'16 Summaryバッチ正規化の代わりにレイヤー正規化を用いることで、リカレントニューラルネットワークのトレーニング時間を短縮。レイヤー内のニューロンの合計入力を正規化し、各ニューロンに独自の適応バイアスとゲインを適用。トレーニング時とテスト時で同じ計算を行い、隠れ状態のダイナミクスを安定させる。実証的に、トレーニング時間の大幅な短縮を確認。 Comment解説スライド:
https://www.slideshare.net/KeigoNishida/layer-normalizationnips
#NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #CoNLL Issue Date: 2018-02-14 Generating Sentences from a Continuous Space, Bowman+, CoNLL'16 CommentVAEを利用して文生成【Variational Autoencoder徹底解説】
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24 #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #WSDM Issue Date: 2018-01-02 Collaborative Denoising Auto-Encoders for Top-N Recommender Systems, Wu+, WSDM'16 CommentDenoising Auto-Encoders を用いたtop-N推薦手法、Collaborative Denoising Auto-Encoder (CDAE)を提案。
モデルベースなCollaborative Filtering手法に相当する。corruptedなinputを復元するようなDenoising Auto Encoderのみで推薦を行うような手法は、この研究が初めてだと主張。
学習する際は、userのitemsetのsubsetをモデルに与え(noiseがあることに相当)、全体のitem setを復元できるように、学習する(すなわちDenoising Auto-Encoder)。
推薦する際は、ユーザのその時点でのpreference setをinputし、new itemを推薦する。
221 もStacked Denoising Auto EncoderとCollaborative Topic Regression 226 を利用しているが、221 ではarticle recommendationというspecificな問題を解いているのに対して、提案手法はgeneralなtop-N推薦に利用できることを主張。 #Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #ACL Issue Date: 2017-12-31 Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL'16 Comment解説スライド:https://www.slideshare.net/akihikowatanabe3110/incorporating-copying-mechanism-in-sequene-to-sequence-learning単語のコピーと生成、両方を行えるネットワークを提案。
location based addressingなどによって、生成された単語がsourceに含まれていた場合などに、copy-mode, generate-modeを切り替えるような仕組みになっている。
65 と同じタイミングで発表 #NeuralNetwork #MachineTranslation #NLP #ACL Issue Date: 2017-12-28 Pointing the unknown words, Gulcehre+, ACL'16 Commentテキストを生成する際に、source textからのコピーを行える機構を導入することで未知語問題に対処した話CopyNetと同じタイミングで(というか同じconferenceで)発表 #NeuralNetwork #MachineTranslation #Pocket #NLP #Attention #ICLR Issue Date: 2025-05-12 Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15 Summaryニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している) #MachineLearning #Pocket #LanguageModel #Transformer #ICML #Normalization Issue Date: 2025-04-02 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe+, ICML'15 Summaryバッチ正規化を用いることで、深層ニューラルネットワークのトレーニングにおける内部共変量シフトの問題を解決し、高い学習率を可能にし、初期化の注意を軽減。これにより、同じ精度を14倍少ないトレーニングステップで達成し、ImageNet分類で最良の公表結果を4.9%改善。 Commentメモってなかったので今更ながら追加した共変量シフトやBatch Normalizationの説明は
・261
記載のスライドが分かりやすい。 #NeuralNetwork #MachineTranslation #NLP #EMNLP Issue Date: 2021-06-02 Effective Approaches to Attention-based Neural Machine Translation, Luong+, EMNLP'15 CommentLuong論文。attentionの話しはじめると、だいたいBahdanau+か、Luong+論文が引用される。
Global Attentionと、Local Attentionについて記述されている。Global Attentionがよく利用される。
Global Attention
Local Attention
やはり菊池さんの解説スライドが鉄板。
https://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention参考までに、LuongらのGlobal Attentionの計算の流れは下記となっている:
・h_t -> a_t -> c_t -> h^~_t
BahdanauらのAttentionは下記
・h_t-1 -> a_t -> c_t -> h_t
t-1のhidden stateを使うのか、input feeding後の現在のhidden stateをattention weightの計算に使うのかが異なっている。また、過去のalignmentの情報を考慮した上でデコーディングしていくために、input-feeding approachも提案
input-feeding appproachでは、t-1ステップ目のoutputの算出に使ったh^~_t(hidden_stateとcontext vectorをconcatし、tanhのactivationを噛ませた線形変換を行なったベクトル)を、時刻tのinput embeddingにconcatして、RNNに入力する。 #NLP #LanguageModel #ACL #IJCNLP Issue Date: 2018-03-30 Unsupervised prediction of acceptability judgements, Lau+, ACL-IJCNLP'15 Comment文のacceptability(容認度)論文。
文のacceptabilityとは、native speakerがある文を読んだときに、その文を正しい文として容認できる度合いのこと。
acceptabilityスコアが低いと、Readabilityが低いと判断できる。
言語モデルをトレーニングし、トレーニングした言語モデルに様々な正規化を施すことで、acceptabilityスコアを算出する。 #NeuralNetwork #MachineLearning #ICML Issue Date: 2018-02-19 An Empirical Exploration of Recurrent Network Architectures, Jozefowicz+, ICML'15 CommentGRUとLSTMの違いを理解するのに最適 #NeuralNetwork #NLP #ACL Issue Date: 2018-02-13 Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks, Tai+, ACL'15 CommentTree-LSTM論文 #DocumentSummarization #NeuralNetwork #Sentence #Supervised #NLP #Abstractive #EMNLP Issue Date: 2017-12-31 A Neural Attention Model for Sentence Summarization, Rush+, EMNLP'15 Comment解説スライド:https://www.slideshare.net/akihikowatanabe3110/a-neural-attention-model-for-sentence-summarization-65612331 #Single #DocumentSummarization #NeuralNetwork #Sentence #Document #NLP #Dataset #Abstractive #EMNLP Issue Date: 2017-12-28 LCSTS: A large scale chinese short text summarizatino dataset, Hu+, EMNLP'15 CommentLarge Chinese Short Text Summarization (LCSTS) datasetを作成
データセットを作成する際は、Weibo上の特定のorganizationの投稿の特徴を利用。
Weiboにニュースを投稿する際に、投稿の冒頭にニュースのvery short summaryがまず記載され、その後ニュース本文(短め)が記載される特徴があるので、この対をsource-reference対として収集した。
収集する際には、約100個のルールに基づくフィルタリングやclearning, 抽出等を行なっている。
データセットのpropertyとしては、下記のPartI, II, IIIに分かれている。
PartI: 2.4Mのshort text ・summary pair
PartII: PartIからランダムにサンプリングされた10kのpairに対して、5 scaleで要約のrelevanceをratingしたデータ。ただし、各pairにラベルづけをしたevaluatorは1名のみ。
PartIII: 2kのpairに対して(PartI, PartIIとは独立)、3名のevaluatorが5-scaleでrating。evaluatorのratingが一致した1kのpairを抽出したデータ。
RNN-GRUを用いたSummarizerも提案している。
CopyNetなどはLCSTSを使って評価している。他にも使ってる論文あったはず。ACL'17のPointer Generator Networkでした。 #DocumentSummarization #NeuralNetwork #Sentence #NLP #EMNLP Issue Date: 2017-12-28 Sentence Compression by Deletion with LSTMs, Fillipova+, EMNLP'15 Commentslide:https://www.slideshare.net/akihikowatanabe3110/sentence-compression-by-deletion-with-lstms #Multi #DocumentSummarization #NLP #Extractive #ACL Issue Date: 2017-12-28 Hierarchical Summarization: Scaling Up Multi-Document Summarization, Christensen+, ACL'14 Comment概要
だいぶ前に読んだ。好きな研究。
テキストのsentenceを階層的にクラスタリングすることで、抽象度が高い情報から、関連する具体度の高いsentenceにdrill downしていけるInteractiveな要約を提案している。
手法
通常のMDSでのデータセットの規模よりも、実際にMDSを使う際にはさらに大きな規模のデータを扱わなければならないことを指摘し(たとえばNew York Timesで特定のワードでイベントを検索すると数千、数万件の記事がヒットしたりする)そのために必要な事項を検討。
これを実現するために、階層的なクラスタリングベースのアプローチを提案。
提案手法では、テキストのsentenceを階層的にクラスタリングし、下位の層に行くほどより具体的な情報になるようにsentenceを表現。さらに、上位、下位のsentence間にはエッジが張られており、下位に紐付けられたsentence
は上位に紐付けられたsentenceの情報をより具体的に述べたものとなっている。
これを活用することで、drill down型のInteractiveな要約を実現。 #Multi #DocumentSummarization #NLP #Dataset #QueryBiased #Extractive #ACL Issue Date: 2017-12-28 Query-Chain Focused Summarization, Baumel+, ACL'14 Comment(管理人が作成した過去の紹介資料)
[Query-Chain Focused Summarization.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1590916/Query-Chain.Focused.Summarization.pdf)
上記スライドは私が当時作成した論文紹介スライドです。スライド中のスクショは説明のために論文中のものを引用しています。 #RecommenderSystems #NeuralNetwork #MatrixFactorization #NeurIPS Issue Date: 2018-01-11 Deep content-based music recommendation, Oord+, NIPS'13 CommentContents-Basedな音楽推薦手法(cold-start problemに強い)。
Weighted Matrix Factorization (WMF) (Implicit Feedbackによるデータに特化したMatrix Factorization手法) 225 に、Convolutional Neural Networkによるmusic audioのlatent vectorの情報が組み込まれ、item vectorが学習されるような仕組みになっている。
CNNでmusic audioのrepresentationを生成する際には、audioのtime-frequencyの情報をinputとする。学習を高速化するために、window幅を3秒に設定しmusic clipをサンプルしinputする。music clip全体のrepresentationを求める際には、consecutive windowからpredictionしたrepresentationを平均したものを使用する。 #NeuralNetwork #ComputerVision #NeurIPS #ImageClassification #Backbone Issue Date: 2025-05-13 ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky+, NIPS'12 CommentILSVRC 2012において圧倒的な性能示したことで現代のDeepLearningの火付け役となった研究AlexNet。メモってなかったので今更ながら追加した。AlexNet以前の画像認識技術については牛久先生がまとめてくださっている(当時の課題とそれに対する解決法、しかしまだ課題が…と次々と課題に直面し解決していく様子が描かれており非常に興味深かった)。現在でも残っている技術も紹介されている。:
https://speakerdeck.com/yushiku/pre_alexnet
> 過去の技術だからといって聞き流していると時代背景の変化によってなし得たイノベーションを逃すかも
これは肝に銘じたい。 #RecommenderSystems #CollaborativeFiltering #MatrixFactorization #SIGKDD Issue Date: 2018-01-11 Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11 CommentProbabilistic Matrix Factorization (PMF) 227 に、Latent Dirichllet Allocation (LDA) を組み込んだCollaborative Topic Regression (CTR)を提案。
LDAによりitemのlatent vectorを求め、このitem vectorと、user vectorの内積を(平均値として持つ正規表現からのサンプリング)用いてratingを生成する。
CFとContents-basedな手法が双方向にinterationするような手法解説ブログ:http://d.hatena.ne.jp/repose/20150531/1433004688 #RecommenderSystems #Survey Issue Date: 2018-01-01 Collaborative Filtering Recommender Systems, Ekstrand+ (with Joseph A. Konstan), Foundations and TrendsR in Human–Computer Interaction'11 #Multi #PersonalizedDocumentSummarization #InteractivePersonalizedSummarization #NLP #EMNLP Issue Date: 2017-12-28 Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07 Comment
ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
#RecommenderSystems
#MachineLearning
#CollaborativeFiltering
#FactorizationMachines
#ICDM
Issue Date: 2018-12-22
Factorization Machines, Steffen Rendle, ICDM'10
Comment解説ブログ:http://echizen-tm.hatenablog.com/entry/2016/09/11/024828
DeepFMに関する動向:https://data.gunosy.io/entry/deep-factorization-machines-2018
非常に完結でわかりやすい説明
FMのFeature VectorのExample
各featureごとにlatent vectorが学習され、featureの組み合わせのweightが内積によって表現される
Matrix Factorizationの一般形のような形式 #RecommenderSystems #Survey Issue Date: 2018-01-01 Content-based Recommender Systems: State of the Art and Trends, Lops+, Recommender Systems Handbook'10 CommentRecSysの内容ベースフィルタリングシステムのユーザプロファイルについて知りたければこれ #ComputerVision #Dataset #ImageClassification #ObjectRecognition #ObjectLocalization Issue Date: 2025-05-13 ImageNet: A Large-Scale Hierarchical Image Database, Deng+, CVPR'09 #RecommenderSystems #LearningToRank #ImplicitFeedback #UAI Issue Date: 2017-12-28 BPR: Bayesian Personalized Ranking from Implicit Feedback, Rendle+, UAI'09, 2009.06 Comment重要論文
ユーザのアイテムに対するExplicit/Implicit Ratingを利用したlearning2rank。
AUCを最適化するようなイメージ。
負例はNegative Sampling。
計算量が軽く、拡張がしやすい。
Implicitデータを使ったTop-N Recsysを構築する際には検討しても良い。
また、MFのみならず、Item-Based KNNに活用することなども可能。
http://tech.vasily.jp/entry/2016/07/01/134825参考: https://techblog.zozo.com/entry/2016/07/01/134825pytorchでのBPR実装: https://github.com/guoyang9/BPR-pytorch #Pocket #NLP #MultitaskLearning #ICML Issue Date: 2018-02-05 A unified architecture for natural language processing: Deep neural networks with multitask learning, Collobert+, ICML'2008. CommentDeep Neural Netを用いてmultitask learningを行いNLPタスク(POS tagging, Semantic Role Labeling, Chunking etc.)を解いた論文。
被引用数2000を超える。
multitask learningの学習プロセスなどが引用されながら他論文で言及されていたりする。 #RecommenderSystems #MatrixFactorization #NeurIPS Issue Date: 2018-01-11 Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08 CommentMatrix Factorizationを確率モデルとして表した論文。
解説:http://yamaguchiyuto.hatenablog.com/entry/2017/07/13/080000
既存のMFは大規模なデータに対してスケールしなかったが、PMFではobservationの数に対して線形にスケールし、さらには、large, sparse, imbalancedなNetflix datasetで良い性能が出た(Netflixデータセットは、rating件数が少ないユーザとかも含んでいる。MovieLensとかは含まれていないのでより現実的なデータセット)。
また、Constrained PMF(同じようなsetの映画にrateしているユーザは似ているといった仮定に基づいたモデル ※1)を用いると、少ないratingしかないユーザに対しても良い性能が出た。
※1 ratingの少ないユーザの潜在ベクトルは平均から動きにくい、つまりなんの特徴もない平均的なユーザベクトルになってしまうので、同じ映画をratingした人は似た事前分布を持つように制約を導入したモデル
(解説ブログ、解説スライドより) #MachineTranslation #NLP #LanguageModel Issue Date: 2024-12-24 Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07 Summary本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。 CommentN-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
解説ブログ:https://qiita.com/koreyou/items/a69750696fd0b9d88608従来行われてきたLearning to Rankはpairwiseな手法が主流であったが、pairwiseな手法は2つのインスタンス間の順序が正しく識別されるように学習されているだけであった。
pairwiseなアプローチには以下の問題点があった:
インスタンスのペアのclassification errorを最小化しているだけで、インスタンスのランキングのerrorを最小化しているわけではない。
インスタンスペアが i.i.d な分布から生成されるという制約は強すぎる制約
queryごとに生成されるインスタンスペアは大きく異なるので、インスタンスペアよりもクエリに対してバイアスのかかった学習のされ方がされてしまう
これらを解決するために、listwiseなアプローチを提案。
listwiseなアプローチを用いると、インスタンスのペアの順序を最適化するのではなく、ランキング全体を最適化できる。
listwiseなアプローチを用いるために、Permutation Probabilityに基づくloss functionを提案。loss functionは、2つのインスタンスのスコアのリストが与えられたとき、Permutation Probability Distributionを計算し、これらを用いてcross-entropy lossを計算するようなもの。
また、Permutation Probabilityを計算するのは計算量が多すぎるので、top-k probabilityを提案。
top-k probabilityはPermutation Probabilityの計算を行う際のインスタンスをtop-kに限定するもの。
論文中ではk=1を採用しており、k=1はsoftmaxと一致する。
パラメータを学習する際は、Gradient Descentを用いる。k=1の設定で計算するのが普通なようなので、普通にoutputがsoftmaxでlossがsoftmax cross-entropyなモデルとほぼ等価なのでは。 #RecommenderSystems #Survey #Explanation Issue Date: 2018-01-01 A Survey of Explanations in Recommender Systems, Tintarev+, ICDEW'07 #RecommenderSystems #Survey #CollaborativeFiltering #MatrixFactorization Issue Date: 2018-01-01 Matrix Factorization Techniques for Recommender Systems, Koren+, Computer'07 CommentMatrix Factorizationについてよくまとまっている #MachineLearning #DomainAdaptation #NLP #ACL Issue Date: 2017-12-31 Frustratingly easy domain adaptation, Daum'e, ACL'07 Comment
domain adaptationをする際に、Source側のFeatureとTarget側のFeatureを上式のように、Feature Vectorを拡張し独立にコピーし表現するだけで、お手軽にdomain adaptationができることを示した論文。
イメージ的には、SourceとTarget、両方に存在する特徴は、共通部分の重みが高くなり、Source, Targetドメイン固有の特徴は、それぞれ拡張した部分のFeatureに重みが入るような感じ。 #InformationRetrieval #LearningToRank #PairWise #ICML Issue Date: 2018-01-01 Learning to Rank using Gradient Descent (RankNet), Burges+, ICML'2005 Commentpair-wiseのlearning2rankで代表的なRankNet論文
解説ブログ:https://qiita.com/sz_dr/items/0e50120318527a928407
lossは2個のインスタンスのpair、A, Bが与えられたとき、AがBよりも高くランクされる場合は確率1, AがBよりも低くランクされる場合は確率0、そうでない場合は1/2に近くなるように、スコア関数を学習すれば良い。 #RecommenderSystems #Survey Issue Date: 2018-01-01 Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions, Adomavicius+, IEEE Transactions on Knowledge and Data Engineering'05 Comment有名なやつ #Single #DocumentSummarization #Document #GraphBased #NLP #Extractive #EMNLP Issue Date: 2018-01-01 TextRank: Bringing Order into Texts, Mihalcea+, EMNLP'04 CommentPageRankベースの手法で、キーワード抽出/文書要約 を行う手法。
キーワード抽出/文書要約 を行う際には、ノードをそれぞれ 単語/文 で表現する。
ノードで表現されている 単語/文 のsimilarityを測り、ノード間のedgeの重みとすることでAffinity Graphを構築。
あとは構築したAffinity Graphに対してPageRankを適用して、ノードの重要度を求める。
ノードの重要度に従いGreedyに 単語/文 を抽出すれば、キーワード抽出/文書要約 を行うことができる。単一文書要約のベースラインとして使える。gensimに実装がある。
個人的にも実装している:https://github.com/AkihikoWatanabe/textrank #RecommenderSystems #Survey Issue Date: 2018-01-01 Evaluating Collaborative Filtering Recommener Systems, Herlocker+, TOIS'04 CommentGroupLensのSurvey #InformationRetrieval #LearningToRank #PointWise #NeurIPS Issue Date: 2018-01-01 PRanking with Ranking, Crammer+, NIPS'01 CommentPoint-WiseなLearning2Rankの有名手法 #RecommenderSystems #CollaborativeFiltering #ItemBased #WWW Issue Date: 2018-01-01 Item-based collaborative filtering recommendation algorithms, Sarwar+(with Konstan), WWW'01 Commentアイテムベースな協調フィルタリングを提案した論文(GroupLens) #DocumentSummarization #Document #NLP #NAACL Issue Date: 2018-01-21 Cut and paste based text summarization, Jing+, NAACL'00 CommentAbstractiveなSummarizationの先駆け的研究。
AbstractiveなSummarizationを研究するなら、押さえておいたほうが良い。 #DocumentSummarization #InformationRetrieval #NLP #Search #SIGIR Issue Date: 2018-01-17 The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98 CommentMaximal Marginal Relevance (MMR) 論文。
検索エンジンや文書要約において、文書/文のランキングを生成する際に、既に選んだ文書と類似度が低く、かつqueryとrelevantな文書をgreedyに選択していく手法を提案。
ILPによる定式化が提案される以前のMulti Document Summarization (MDS) 研究において、冗長性の排除を行う際には典型的な手法。 #Article #Pretraining #NLP #LanguageModel #DiffusionModel Issue Date: 2025-08-09 Diffusion Language Models are Super Data Learners, Jinjie Ni and the team, 2025.08 CommentdLLMは学習データの繰り返しに強く、データ制約下においては十分な計算量を投入してepochを重ねると、性能向上がサチらずにARモデルを上回る。
・追記: 上記研究の著者による本ポストで取り上げられたissueに対するclarification
・https://x.com/mihirp98/status/1954240474891653369?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
でも同様の知見が得られている。
が、スレッド中で両者の違いが下記のように(x rollrng reviewなるものを用いて)ポストされており、興味がある場合は読むといいかも。(ところで、x rolling reviewとは、、?もしやLLMによる自動的な査読システム?)
において、ARモデルではrepetitionは4回までがコスパ良いという話と比べると、dLLMにとんでもない伸び代があるような話に見える。個人的にはアーキテクチャのさらなる進化は興味深いが、ユーザが不完全な質問をLLMに投げた時に、LLMがユーザの意図が「不明な部分のcontextを質問を返すことによって補う」という挙動があると嬉しい気がするのだが、そういった研究はないのだろうか。
ただ、事前学習時点でそういったデータが含まれて知識として吸収され、かつmid/post-trainingでそういった能力を引き出すと言う両軸で取り組まないと、最悪膨大な計算資源を投じたものの「わからない!どういうこと!?」と返し続けるLLMが完成し全く役に立たない、ということになりそうで怖い。
gpt5が出た時に、「3.9と3.11はどちらが大きいですか?」というクエリを投げた際にいまだに「3.11」と回答してくる、みたいなポストが印象的であり、これはLLMが悪いと言うより、ユーザ側が算数としての文脈できいているのか、ソフトウェアのバージョンの文脈できいているのか、を指定していないことが原因であり、上記の回答はソフトウェアのバージョニングという文脈では正答となる。LLMが省エネになって、ユーザのデータを蓄積しまくって、一人一人に対してあなただけのLLM〜みたいな時代がくれば少しは変わるのだろうが、それでもユーザがプロファイルとして蓄積した意図とは異なる意図で質問しなければならないという状況になると、上記のような意図の取り違えが生じるように思う。
なのでやはりりLLM側が情報が足りん〜と思ったら適切なturn数で、最大限の情報をユーザから引き出せるような逆質問を返すみたいな挙動、あるいは足りない情報があったときに、いくつかの候補を提示してユーザ側に提示させる(e.g., 算数の話?それともソフトウェアの話?みたいな)、といった挙動があると嬉しいなぁ、感。
んでそこの部分の性能は、もしやるな、promptingでもある程度は実現でき、それでも全然性能足りないよね?となった後に、事前学習、事後学習でより性能向上します、みたいな流れになるのかなぁ、と想像するなどした。
しかしこういう話をあまり見ないのはなぜだろう?私の観測範囲が狭すぎる or 私のアイデアがポンコツなのか、ベンチマーク競争になっていて、そこを向上させることに業界全体が注力してしまっているからなのか、はたまた裏ではやられているけど使い物にならないのか、全然わからん。 #Article #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #AttentionSinks #read-later Issue Date: 2025-08-05 gpt-oss-120b, OpenAI, 2025.08 Commentblog:https://openai.com/index/introducing-gpt-oss/
HF:
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.mdアーキテクチャで使われている技術まとめ:
・https://x.com/gneubig/status/1952799735900979219?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/yampeleg/status/1952875217367245195?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/adamzweiger/status/1952799642636148917?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/cwolferesearch/status/1956132685102887059?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・こちらにも詳細に論文がまとめられている上記ポスト中のアーキテクチャの論文メモリンク(管理人が追加したものも含む)
・Sliding Window Attention
・2388
・2359
・MoE
・1754
・RoPE w/ YaRN
・1310
・2338
・Attention Sinks
・1861
・Attention Sinksの定義とその気持ちについてはこのメモを参照のこと。
・1860
・Attention Sinksが実際にどのように効果的に作用しているか?についてはこちらのメモを参照。
・1862
・https://x.com/gu_xiangming/status/1952811057673642227?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・Attention Sinkの導入により、decodei-onlyモデルの深い層でのrepresentationのover mixingを改善し、汎化性能を高め、promptに対するsensitivityを抑えていると考えられる。
・GQA
・1271
・SwiGLU
・1311-
・(Attentionの計算に利用する) SoftmaxへのLearned bias の導入 (によるスケーリング)
・1863
・1866
・Softmaxはlong contextになると、attentionの分布が均一になり、重要な情報にattendする能力が下がるためスケーリングが必要で、そのために分母にlearnedなbiasを導入していると考えられる。Llamaや上記研究では分子に係数としてlearnableなパラメータを導入しているが、少し形式が違う。もしかしたら解釈が違うかもしれない。・group size 8でGQAを利用
・Context Windowは128k
・学習データの大部分は英語のテキストのみのデータセット
・STEM, Coding, general knowledgeにフォーカス
・https://openai.com/index/gpt-oss-model-card/
あとで追記する他Open Weight Modelとのベンチマークスコア比較:
・https://x.com/gneubig/status/1952795149584482665?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/artificialanlys/status/1952887733803991070?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/terryyuezhuo/status/1952829578130670053?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/artificialanlys/status/1952823565642023044?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・long context
・https://x.com/thienhn97/status/1953152808334852124?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・Multihop QA解説:
https://x.com/gm8xx8/status/1952915080229863761?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qlearned attention sinks, MXFP4の解説:
https://x.com/carrigmat/status/1952779877569978797?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QSink Valueの分析:
https://x.com/wenhaocha1/status/1952851897414762512?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qgpt-oss の使い方:
https://note.com/npaka/n/nf39f327c3bde?sub_rt=share_sb9fd064b2-338a-4f8d-953c-67e458658e39Qwen3との深さと広さの比較:
・2364Phi4と同じtokenizerを使っている?:
https://x.com/bgdidenko/status/1952829980389343387?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpost-training / pre-trainingの詳細はモデルカード中に言及なし:
・https://x.com/teortaxestex/status/1952806676492689652?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/okoge_kaz/status/1952787196253265955?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qattention headsのsoftmaxの分母にlearnableなパラメータが導入されている:
https://x.com/okoge_kaz/status/1952785895352041784?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・1866
で得られている知見と同様に、long contextになった場合にsoftmaxの値が平坦になる問題に対して、learnableなパラメータを導入してスケーリングすることで対処しているのだと考えられる。使ってみた所見:
・https://x.com/imai_eruel/status/1952825403263046073?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/wenhuchen/status/1953100554793828406?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/jasondeanlee/status/1953031988635451556?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qライセンスに関して:
> Apache 2.0 ライセンスおよび当社の gpt-oss 利用規約に基づくことで利用可能です。
引用元: https://openai.com/ja-JP/index/gpt-oss-model-card/
gpt-oss利用規約: https://github.com/openai/gpt-oss/blob/main/USAGE_POLICYcookbook全体:https://cookbook.openai.com/topic/gpt-ossgpt-oss-120bをpythonとvLLMで触りながら理解する:https://tech-blog.abeja.asia/entry/gpt-oss-vllm #Article #NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-07-29 GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07 Comment元ポスト:https://x.com/scaling01/status/1949825490488795275?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHF:https://huggingface.co/collections/zai-org/glm-45-687c621d34bda8c9e4bf503b詳細なまとめ:https://x.com/gm8xx8/status/1949879437547241752?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2128こちらでもMuon Optimizerが使われており、アーキテクチャ的にはGQAやMulti Token Prediction, QK Normalization, MoE, 広さよりも深さを重視の構造、みたいな感じな模様?
・2202 #Article #Tutorial #NLP #LanguageModel #LLMServing #SoftwareEngineering #read-later Issue Date: 2025-07-22 LLM Servingを支える技術, Kotoba Technologies, 2025.07 Commentこちらも参照のこと:
・2263 #Article #Tutorial #Metrics #NLP #LanguageModel #LLMServing #MoE(Mixture-of-Experts) #SoftwareEngineering #Parallelism #Inference #Batch Issue Date: 2025-07-21 LLM推論に関する技術メモ, iwashi.co, 2025.07 Comment```
メモリ (GB) = P × (Q ÷ 8) × (1 + オーバーヘッド)
・P:パラメータ数(単位は10億)
・Q:ビット精度(例:16、32)、8で割ることでビットをバイトに変換
・オーバーヘッド(%):推論中の追加メモリまたは一時的な使用量(例:KVキャッシュ、アクティベーションバッファ、オプティマイザの状態)
```
↑これ、忘れがちなのでメモ…関連(量子化関連研究):
・2264
・1570
・1043すごいメモだ…勉強になります #Article #NLP #LanguageModel #Evaluation #Slide #Japanese #SoftwareEngineering Issue Date: 2025-07-16 論文では語られないLLM開発において重要なこと Swallow Projectを通して, Kazuki Fujii, NLPコロキウム, 2025.07 Comment独自LLM開発の私の想像など遥かに超える非常に困難な側面が記述されており、これをできるのはあまりにもすごいという感想を抱いた(小並感だけど本当にすごいと思う。すごいとしか言いようがない) #Article #NLP #LanguageModel #Optimizer #OpenWeight #MoE(Mixture-of-Experts) #read-later #Stability Issue Date: 2025-07-12 Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07 Comment元ポスト:https://x.com/kimi_moonshot/status/1943687594560332025?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q1T-A32Bのモデル。さすがに高性能。
(追記) Reasoningモデルではないのにこの性能のようである。1T-A32Bのモデルを15.5Tトークン訓練するのに一度もtraining instabilityがなかったらしい
元ポスト:https://x.com/eliebakouch/status/1943689105721667885?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2188量子化したモデルが出た模様:
https://x.com/ivanfioravanti/status/1944069021709615119?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
仕事早すぎるDeepSeek V3/R1とのアーキテクチャの違い:
https://x.com/rasbt/status/1944056316424577525?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
MLAのヘッドの数が減り、エキスパートの数を増加させている解説ポスト:https://x.com/hillbig/status/1944902706747072678?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q利用されているOptimizer:
・22022つほどバグがあり修正された模様:
https://x.com/kimi_moonshot/status/1945050874067476962?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qchatbot arenaでOpenLLMの中でトップのスコア
元ポスト:https://x.com/lmarena_ai/status/1945866381880373490?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qテクニカルペーパーが公開:https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
元ポスト:https://x.com/iscienceluvr/status/1947384629314396302?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qテクニカルレポートまとめ:https://x.com/scaling01/status/1947400424622866793?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q以下のような技術が使われている模様
・1937
・MLA 1621
・MuonCip
・MuonOptimizer 2202
・QK-Clip
・参考(こちらはLayerNormを使っているが): 1202
・RLVR
・1719
・Self-Critique
・関連: 2274
・2017
・Temperature Decay
・最初はTemperatureを高めにした探索多めに、後半はTemperatureを低めにして効用多めになるようにスケジューリング
・Tool useのためのSynthetic Data
https://x.com/grad62304977/status/1953408751521632401?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #LanguageModel #Zero/FewShotLearning Issue Date: 2025-06-15 [Paper Note] Language Models are Unsupervised Multitask Learners, Radford+, OpenAI, 2019 Comment今更ながら、GPT-2論文をメモってなかったので追加。
従来のモデルは特定のタスクを解くためにタスクごとに個別のモデルをFinetuningする必要があったが、大規模なWebTextデータ(Redditにおいて最低3つのupvoteを得たポストの外部リンクを収集)によって言語モデルを訓練し、モデルサイズをスケーリングさせることで、様々なタスクで高い性能を獲得でき、Zero-Shot task transfer, p\(output | input, task) , が実現できるよ、という話。
今ざっくり見返すと、Next Token Predictionという用語は論文中に出てきておらず、かつ "Language Modeling" という用語のみで具体的なlossは記述されておらず(当時はRNN言語モデルで広く学習方法が知られていたからだろうか?)、かつソースコードも学習のコードは提供されておらず、lossの定義も含まれていないように見える。
ソースコードのモデル定義:
https://github.com/openai/gpt-2/blob/master/src/model.pyL169 #Article #NLP #LanguageModel #InstructionTuning #PostTraining Issue Date: 2025-05-12 Stanford Alpaca: An Instruction-following LLaMA Model, Taori +, 2023.03 Comment今更ながらメモに追加。アカデミアにおけるOpenLLMに対するInstruction Tuningの先駆け的研究。 #Article #Analysis #NLP #LanguageModel #Blog Issue Date: 2025-03-25 言語モデルの物理学, 佐藤竜馬, 2025.03 Comment必読 #Article #NeuralNetwork #ComputerVision #CVPR #Backbone Issue Date: 2021-11-04 Deep Residual Learning for Image Recognition, He+, Microsoft Research, CVPR’16 CommentResNet論文
ResNetでは、レイヤーの計算する関数を、残差F(x)と恒等関数xの和として定義する。これにより、レイヤーが入力との差分だけを学習すれば良くなり、モデルを深くしても最適化がしやすくなる効果ぎある。数レイヤーごとにResidual Connectionを導入し、恒等関数によるショートカットができるようにしている。
ResNetが提案される以前、モデルを深くすれば表現力が上がるはずなのに、実際には精度が下がってしまうことから、理論上レイヤーが恒等関数となるように初期化すれば、深いモデルでも浅いモデルと同等の表現が獲得できる、と言う考え方を発展させた。
(ステートオブAIガイドに基づく)同じパラメータ数でより層を深くできる(Plainな構造と比べると層が1つ増える)Bottleneckアーキテクチャも提案している。
今や当たり前のように使われているResidual Connectionは、層の深いネットワークを学習するために必須の技術なのだと再認識。 #Article #NeuralNetwork #Survey #NLP #LanguageModel #Slide Issue Date: 2019-11-09 事前学習言語モデルの動向 _ Survey of Pretrained Language Models, Kyosuke Nishida, 2019 Comment[2019/06まで]
・ELMo(双方向2層LSTM言語モデル)
・GPT(left-to-rightの12層Transformer自己回帰言語モデル)
・BERT(24層のTransformer双方向言語モデル)
・MT-DNN(BERTの上にマルチタスク層を追加した研究)
・XLM(パラレル翻訳コーパスを用いてクロスリンガルに穴埋めを学習)
・TransformerXL(系列長いに制限のあった既存モデルにセグメントレベルの再帰を導入し長い系列を扱えるように)
・GPT-2(48層Transformerの自己回帰言語モデル)
・ERNIE 1.0(Baidu, エンティティとフレーズの外部知識を使ってマスクに利用)
・ERNIE(Tsinghua, 知識グラフの情報をfusionしたLM)
・Glover(ドメイン、日付、著者などを条件とした生成を可能としたGPT)
・MASS(Encoder-Decoder型の生成モデルのための事前学習)
・UniLM(Sequence-to-Sequenceを可能にした言語モデル)
・XLNet(自己回帰(単方向)モデルと双方向モデルの両方の利点を得ることを目指す)
[2019/07~]
・SpanBERT(i.i.dではなく範囲でマスクし、同時に範囲の境界も予測する)
・ERNIE 2.0(Baidu, マルチタスク事前学習; 単語レベル・構造レベル・意味レベル)
・RoBERTa(BERTと同じ構造で工夫を加えることで性能向上)
・より大きなバッチサイズを使う(256から8192)
・より多くのデータを使う(16GBから160GB)
・より長いステップ数の学習をする(BERT換算で16倍)
・次文予測(NSP)は不要
→ GLUEでBERT, XLNetをoutperform
・StructBERT (ALICE, NSPに代わる学習の目的関数を工夫)
・マスクした上で単語の順番をシャッフルし元に戻す
・ランダム・正順・逆順の3種類を分類
→ BERTと同サイズ、同データでBERT, RoBERTa超え
・DistilBERT(蒸留により、12層BERTを6層に小型化(40%減))
・BERTの出力を教師として、生徒が同じ出力を出すように学習
・幅(隠れ層)サイズを減らすと、層数を経あrスよりも悪化
→ 推論は60%高速化、精度は95%程度を保持
・Q8BERT(精度を落とさずにfine-tuning時にBERTを8bit整数に量子化)
・Embedding, FCは8bit化、softmax, LNorm, GELUは32bitをキープ
→ モデルサイズ1/4, 速度3.7倍
・CTRL(条件付き言語モデル)
・条件となる制御テキストを本文の前に与えて学習
・48層/1280次元Transformer(パラメータ数1.6B)
・MegatronLM(72層、隠れ状態サイズ3072、長さ1024; BERTの24倍サイズ)
・ALBERT(BERTの層のパラメータをすべて共有することで学習を高速化; 2020年あたりのデファクト)
・Largeを超えたモデルは学習が難しいため、表現は落ちるが学習しやすくした
・単語埋め込みを低次元にすることでパラメータ数削減
・次文予測を、文の順序入れ替え判定に変更
→ GLUE, RACE, SQuADでSoTAを更新
・T5(NLPタスクをすべてtext-to-textとして扱い、Enc-Dec Transformerを745GBコーパスで事前学習して転移する)
・モデルはEncoder-DecoderのTransformer
・学習タスクをエンコーダ・デコーダに合わせて変更
・エンコーダ側で範囲を欠落させて、デコーダ側で予測
→ GLUE, SuperGLUE, SQuAD1.1, CNN/DMでSoTA更新
・BART(Seq2Seqの事前学習として、トークンマスク・削除、範囲マスク、文の入れ替え、文書の回転の複数タスクで学習)
→ CNN/DMでT5超え、WMT'16 RO-ENで逆翻訳を超えてSoTAELMo, GPT, BERT, GPT-2, XLNet, RoBERTa, DistilBERT, ALBERT, T5あたりは良く見るような感各データセットでの各モデルの性能も後半に記載されており興味深い。
ちなみに、CNN/DailyMail Datasetでは、T5, BARTあたりがSoTA。
R2で比較すると
・Pointer-Generator + Coverage Vectorが17,28
・LEAD-3が17.62
・BARTが21.28
・T5が21.55
となっている #Article #RecommenderSystems #Library Issue Date: 2019-09-11 Implicit CommentImplicitデータに対するCollaborative Filtering手法がまとまっているライブラリ
Bayesian Personalized Ranking, Logistic Matrix Factorizationなどが実装。Implicitの使い方はこの記事がわかりやすい:
https://towardsdatascience.com/building-a-collaborative-filtering-recommender-system-with-clickstream-data-dffc86c8c65ALSの元論文の日本語解説
https://cympfh.cc/paper/WRMF #Article #RecommenderSystems #Dataset Issue Date: 2019-04-12 Recommender System Datasets, Julian McAuley CommentRecommender Systems研究に利用できる各種データセットを、Julian McAuley氏がまとめている。
氏が独自にクロールしたデータ等も含まれている。
非常に有用。 #Article #RecommenderSystems #Tutorial #Explanation Issue Date: 2019-01-23 Designing and Evaluating Explanations for Recommender Systems, Tintarev+, Recommender Systems Handbook, 2011 CommentRecommender Systems HandbookのChapter。162 のSurveyと同じ著者による執筆。
推薦のExplanationといえばこの人というイメージ。D論:http://navatintarev.com/papers/Nava%20Tintarev_PhD_Thesis_(2010).pdf #Article #AdaptiveLearning #StudentPerformancePrediction #NeurIPS Issue Date: 2018-12-22 Deep Knowledge Tracing, Piech+, NIPS, 2015 CommentKnowledge Tracingタスクとは:
特定のlearning taskにおいて、生徒によってとられたインタラクションの系列x0, ..., xtが与えられたとき、次のインタラクションxt+1を予測するタスク
典型的な表現としては、xt={qt, at}, where qt=knowledge component (KC) ID (あるいは問題ID)、at=正解したか否か
モデルが予測するときは、qtがgivenな時に、atを予測することになる
Contribution:
1. A novel way to encode student interactions as input to a recurrent neural network.
2. A 25% gain in AUC over the best previous result on a knowledge tracing benchmark.
3. Demonstration that our knowledge tracing model does not need expert annotations.
4. Discovery of exercise influence and generation of improved exercise curricula.
モデル:
Inputは、ExerciseがM個あったときに、M個のExerciseがcorrectか否かを表すベクトル(長さ2Mベクトルのone-hot)。separateなrepresentationにするとパフォーマンスが下がるらしい。
Output ytの長さは問題数Mと等しく、各要素は、生徒が対応する問題を正答する確率。
InputとしてExerciseを用いるか、ExerciseのKCを用いるかはアプリケーション次第っぽいが、典型的には各スキルの潜在的なmasteryを測ることがモチベーションなのでKCを使う。
(もし問題数が膨大にあるような設定の場合は、各問題-正/誤答tupleに対して、random vectorを正規分布からサンプリングして、one-hot high-dimensional vectorで表現する。)
hidden sizeは200, mini-batch sizeは100としている。
[Educational Applicationsへの応用]
生徒へ最適なパスの学習アイテムを選んで提示することができること
生徒のknowledge stateを予測し、その後特定のアイテムを生徒にassignすることができる。たとえば、生徒が50個のExerciseに回答した場合、生徒へ次に提示するアイテムを計算するだけでなく、その結果期待される生徒のknowledge stateも推測することができる
Exercises間の関係性を見出すことができる
y\( j | i )を考える。y\( j | i )は、はじめにexercise iを正答した後に、second time stepでjを正答する確率。これによって、pre-requisiteを明らかにすることができる。
[評価]
3種類のデータセットを用いる。
1. simulated Data
2000人のvirtual studentを作り、1〜5つのコンセプトから生成された、50問を、同じ順番で解かせた。このとき、IRTモデルを用いて、シミュレーションは実施した。このとき、hidden stateのラベルには何も使わないで、inputは問題のIDと正誤データだけを与えた。さらに、2000人のvirtual studentをテストデータとして作り、それぞれのコンセプト(コンセプト数を1〜5に変動させる)に対して、20回ランダムに生成したデータでaccuracyの平均とstandard errorを測った。
2. Khan Academy Data
1.4MのExerciseと、69の異なるExercise Typeがあり、47495人の生徒がExerciseを行なっている。
PersonalなInformationは含んでいない。
3. Assistsments bemchmark Dataset
2009-2011のskill builder public benchmark datasetを用いた。Assistmentsは、online tutorが、数学を教えて、教えるのと同時に生徒を評価するような枠組みである。
それぞれのデータセットに対して、AUCを計算。
ベースラインは、BKTと生徒がある問題を正答した場合の周辺確率?
simulated dataの場合、問題番号5がコンセプト1から生成され、問題番号22までの問題は別のコンセプトから生成されていたにもかかわらず、きちんと二つの問題の関係をとらえられていることがわかる。
Khan Datasetについても同様の解析をした。これは、この結果は専門家が見たら驚くべきものではないかもしれないが、モデルが一貫したものを学習したと言える。
[Discussion]
提案モデルの特徴として、下記の2つがある:
専門家のアノテーションを必要としない(concept patternを勝手に学習してくれる)
ベクトル化された生徒のinputであれば、なんでもoperateすることができる
drawbackとしては、大量のデータが必要だということ。small classroom environmentではなく、online education environmentに向いている。
今後の方向性としては、
・incorporate other feature as inputs (such as time taken)
・explore other educational impacts (hint generation, dropout prediction)
・validate hypotheses posed in education literature (such as spaced repetition, modeling how students forget)
・open-ended programmingとかへの応用とか(proramのvectorizationの方法とかが最近提案されているので)
などがある。knewtonのグループが、DKTを既存手法であるIRTの変種やBKTの変種などでoutperformすることができることを示す:
https://arxiv.org/pdf/1604.02336.pdf
vanillaなDKTはかなりナイーブなモデルであり、今後の伸びが結構期待できると思うので、単純にoutperformしても、今後の発展性を考えるとやはりDKTには注目せざるを得ない感DKT元論文では、BKTを大幅にoutperformしており、割と衝撃的な結果だったようだが、
後に論文中で利用されているAssistmentsデータセット中にdupilcate entryがあり、
それが原因で性能が不当に上がっていることが判明。
結局DKTの性能的には、BKTとどっこいみたいなことをRyan Baker氏がedXで言っていた気がする。Deep Knowledge TracingなどのKnowledge Tracingタスクにおいては、
基本的に問題ごとにKnowledge Component(あるいは知識タグ, その問題を解くのに必要なスキルセット)が付与されていることが前提となっている。
ただし、このような知識タグを付与するには専門家によるアノテーションが必要であり、
適用したいデータセットに対して必ずしも付与されているとは限らない。
このような場合は、DKTは単なる”問題”の正答率予測モデルとして機能させることしかできないが、
知識タグそのものもNeural Networkに学習させてしまおうという試みが行われている:
https://www.jstage.jst.go.jp/article/tjsai/33/3/33_C-H83/_article/-char/jaDKTに関する詳細な説明が書かれているブログポスト:
expectimaxアルゴリズムの説明や、最終的なoutput vector y_i の図解など、説明が省略されガチなところが詳細に書いてあって有用。(英語に翻訳して読むと良い)
https://hcnoh.github.io/2019-06-14-deep-knowledge-tracingこちらのリポジトリではexpectimaxアルゴリズムによってvirtualtutorを実装している模様。
詳細なレポートもアップロードされている。
https://github.com/alessandroscoppio/VirtualIntelligentTutorDKTのinputの次元数が 2 num_skills, outputの次元数がnum_skillsだと明記されているスライド。
元論文だとこの辺が言及されていなくてわかりづらい・・・
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_tutorial_Application.pdf
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_Tutorial.pdf
こちらのページが上記チュートリアルのページ
http://gdac.uqam.ca/Workshop@EDM20/ #Article #Survey #AdaptiveLearning #EducationalDataMining #LearningAnalytics Issue Date: 2018-12-22 Educational Data Mining and Learning Analytics, Baker+, 2014 CommentRyan BakerらによるEDM Survey #Article #RecommenderSystems #Classic #ContextAware Issue Date: 2018-12-22 Context-Aware Recommender Systems, Adomavicius+, Recommender Systems Handbook, 2011 CommentContext-aware Recsysのパイオニア的研究通常のuser/item paradigmを拡張して、いかにコンテキストの情報を考慮するかを研究。
コンテキスト情報は、
Explicit: ユーザのマニュアルインプットから取得
Implicit: 自動的に取得
inferred: ユーザとツールやリソースのインタラクションから推測(たとえば現在のユーザのタスクとか)
いくつかの異なるパラダイムが提案された:
1. recommendation via context-driven querying and search approach
コンテキストの情報を、特定のリポジトリのリソース(レストラン)に対して、クエリや検索に用いる。そして、best matchingなリソースを(たとえば、現在開いているもっとも近いレストランとか)をユーザに推薦。
2. Contextual preference elicitation and estimation approach
こっちは2012年くらいの主流。contextual user preferencesをモデル化し学習する。データレコードをしばしば、<user, item, context, rating>の形式で表現する。これによって、特定のアイテムが特定のコンテキストでどれだけ好まれたか、が評価できるようになる。
3. contextual prefiltering approach
contextualな情報を(学習したcontextualなpreferenceなどを)、tradittionalなrecommendation algorithmを適用する前にデータのフィルタリングに用いる。
4. contextual postfiltering approach
entire setから推薦を作り、あとでcontextの情報を使ってsetを整える。
5. Contextual modeling
contextualな情報を、そのままrecommendationの関数にぶちこんでしまい、アイテムのratingのexplicitなpredictorとして使う。
3, 4はtraditionalな推薦アルゴリズムが適用できる。
1,2,5はmulti-dimensionalな推薦アルゴリズムになる。heuristic-based, model-based approachesが述べられているらしい。 #Article #Classic #AdaptiveLearning #LearningStyle Issue Date: 2018-12-22 LEARNING AND TEACHING STYLES IN ENGINEERING EDUCATION, Felder, Engr. Education, 78(7), 674–681 (1988) CommentLearningStyleに関して研究している古典的な研究。
context-aware recsysの研究初期の頃は、だいたいはこのFelder-Silverman Theoryというのをベースに研究されていたらしい。 #Article #NeuralNetwork #Tutorial #NLP #Slide Issue Date: 2018-01-15 自然言語処理のためのDeep Learning, Yuta Kikuchi #Article #RecommenderSystems #CollaborativeFiltering #MatrixFactorization Issue Date: 2018-01-11 Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008 CommentImplicit Feedbackなデータに特化したMatrix Factorization (MF)、Weighted Matrix Factorization (WMF)を提案。
ユーザのExplicitなFeedback(ratingやlike, dislikeなど)がなくても、MFが適用可能。
目的関数は下のようになっている。
通常のMFでは、ダイレクトにrating r_{ui}を予測したりするが、WMFでは r_{ui}をratingではなく、たとえばユーザuがアイテムiを消費した回数などに置き換え、binarizeした数値p_{ui}を目的関数に用いる。
このとき、itemを消費した回数が多いほど、そのユーザはそのitemを好んでいると仮定し、そのような事例については重みが高くなるようにc_{ui}を計算し、目的関数に導入している。
日本語での解説: https://cympfh.cc/paper/WRMFImplicit 324 でのAlternating Least Square (ALS)という手法が、この手法の実装に該当する。 #Article #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #MatrixFactorization #SIGKDD Issue Date: 2018-01-11 Collaborative Deep Learning for Recommender Systems Wang+, KDD’15 CommentRating Matrixからuserとitemのlatent vectorを学習する際に、Stacked Denoising Auto Encoder(SDAE)によるitemのembeddingを活用する話。
Collaborative FilteringとContents-based Filteringのハイブリッド手法。
Collaborative FilteringにおいてDeepなモデルを活用する初期の研究。
通常はuser vectorとitem vectorの内積の値が対応するratingを再現できるように目的関数が設計されるが、そこにitem vectorとSDAEによるitemのEmbeddingが近くなるような項(3項目)、SDAEのエラー(4項目)を追加する。
(3項目の意義について、解説ブログより)アイテム i に関する潜在表現 vi は学習データに登場するものについては推定できるけれど,未知のものについては推定できない.そこでSDAEの中間層の結果を「推定したvi」として「真の」 vi にできる限り近づける,というのがこの項の気持ち
cite-ulikeデータによる論文推薦、Netflixデータによる映画推薦で評価した結果、ベースライン(Collective Matrix Factorization 222 , SVDFeature 223 , DeepMusic 224 , Collaborative Topic Regresison 226 )をoutperform。
(下記は管理人が過去に作成した論文メモスライドのスクショ)
解説ブログ:http://d.hatena.ne.jp/repose/20150531/1433004688 #Article #DocumentSummarization #NLP #Alignment #SIGIR Issue Date: 2018-01-11 The Decomposition of Human-Written Summary Sentences. Hongyan Jing et al. SIGIR’99. Comment参照要約 ・原文書対が与えられた時に、参照要約中の単語と原文書中の単語のアライメントをとるHMMベースな手法を提案。
outputはこんな感じ。 #Article #Multi #Single #DocumentSummarization #Document #Unsupervised #GraphBased #NLP #Extractive Issue Date: 2018-01-01 LexRank: Graph-based Lexical Centrality as Salience in Text Summarization, Erkan+, Journal of Artificial Intelligence Research, 2004 Comment代表的なグラフベースな(Multi) Document Summarization手法。
ほぼ 214 と同じ手法。
2種類の手法が提案されている:
[LexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを計算し閾値以上となったsentenceの間にのみedgeを張る(重みは確率的に正規化)。その後べき乗法でPageRank。
[ContinousLexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを用いてAffinity Graphを計算し、PageRankを適用(べき乗法)。
DUC2003, 2004(MDS)で評価。
Centroidベースドな手法をROUGE-1の観点でoutperform。
document clusterの17%をNoisyなデータにした場合も実験しており、Noisyなデータを追加した場合も性能劣化が少ないことも示している。 #Article #RecommenderSystems #Survey Issue Date: 2018-01-01 推薦システムのアルゴリズム, 神嶌, 2016 #Article #RecommenderSystems #CollaborativeFiltering #Novelty Issue Date: 2017-12-28 Discovery-oriented Collaborative Filtering for Improving User Satisfaction, Hijikata+, IUI’09 Comment・従来のCFはaccuracyをあげることを目的に研究されてきたが,ユーザがすでに知っているitemを推薦してしまう問題がある.おまけに(推薦リスト内のアイテムの観点からみた)diversityも低い.このような推薦はdiscoveryがなく,user satisfactionを損ねるので,ユーザがすでに何を知っているかの情報を使ってよりdiscoveryのある推薦をCFでやりましょうという話.
・特徴としてユーザのitemへのratingに加え,そのitemをユーザが知っていたかどうかexplicit feedbackしてもらう必要がある.
・手法は単純で,User-based,あるいはItem-based CFを用いてpreferenceとあるitemをユーザが知っていそうかどうかの確率を求め,それらを組み合わせる,あるいはrating-matrixにユーザがあるitemを知っていたか否かの数値を組み合わせて新たなmatrixを作り,そのmatrix上でCFするといったもの.
・offline評価の結果,通常のCF,topic diversification手法と比べてprecisionは低いものの,discovery ratioとprecision(novelty)は圧倒的に高い.
・ユーザがitemを知っていたかどうかというbinary ratingはユーザに負荷がかかるし,音楽推薦の場合previewがなければそもそも提供されていないからratingできないなど,必ずしも多く集められるデータではない.そこで,データセットのratingの情報を25%, 50%, 75%に削ってratingの数にbiasをかけた上で実験をしている.その結果,事前にratingをcombineし新たなmatrixを作る手法はratingが少ないとあまりうまくいかなかった.
・さらにonlineでuser satisfaction(3つの目的のもとsatisfactionをratingしてもらう 1. purchase 2. on-demand-listening 3. discovery)を評価した. 結果,purchaseとdiscoveryにおいては,ベースラインを上回った.ただし,これは推薦リスト中の満足したitemの数の問題で,推薦リスト全体がどうだった
かと問われた場合は,ベースラインと同等程度だった.重要論文 #Article #PersonalizedDocumentSummarization #NLP #NAACL Issue Date: 2017-12-28 A Study for Documents Summarization based on Personal Annotation, HLT-NAACL-DUC’03, [Zhang+, 2003], 2003.05 Comment(過去に管理人が作成したスライドでの論文メモのスクショ)
重要論文だと思われる。 #Article #PersonalizedDocumentSummarization #RecommenderSystems Issue Date: 2017-12-28 User-model based personalized summarization, Diaz+, Information Processing and Management 2007.11 CommentPDSの先駆けとなった重要論文。必ずreferすべき。