
ChatGPT
On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability, Kevin Wang+, N_A, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #Initial Impression Notes Issue Date: 2024-11-02 GPT Summary- 本研究では、OpenAIのo1モデルの計画能力を評価し、実現可能性、最適性、一般化の3つの側面に焦点を当てています。特に、制約の多いタスクや空間的に複雑な環境における強みとボトルネックを特定しました。o1-previewは、構造化された環境での制約遵守においてGPT-4を上回る一方で、冗長なアクションを伴う最適でない解を生成し、一般化に苦労しています。この研究は、LLMsの計画における限界を明らかにし、今後の改善の方向性を示しています。 Comment
o1のplanningの性能について知りたくなったら読む
[Paper Note] Can Large Language Models Be an Alternative to Human Evaluations?, Cheng-Han Chiang+, ACL'23, 2023.05
Paper/Blog Link My Issue
#Analysis #LanguageModel #Evaluation #LLM-as-a-Judge #Attack #ACL #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-07-22 GPT Summary- 人間評価の再現性が低いため、NLPモデル間の公正な比較が難しい。そこで、大規模言語モデル(LLM)を人間評価の代替手段として利用することを探求。本研究では、LLMに同一指示とサンプルを与え、評価を実施するLLM評価を提案。オープンエンドのストーリー生成や敵対的攻撃のタスクに対する評価結果は、人間専門家の評価と高い一致を示し、評価の安定性も確認。LLMを用いたテキスト評価の可能性やその限界、倫理的課題についても考察。 Comment
LLMがテキストの品質評価において、人間による評価者の代替となりうるか?という疑問を初めて実験的に示した研究で、インパクトが大きく重要論文と判断。ただし、実験のスコープは物語生成と敵対的生成(テキスト分類器を騙すような摂動を加える)の2タスクである点、には注意。
ChatGPT(おそらくGPT-3.5)が人間の評価者(3人のEnglish teacher)とopen-endで生成された物語にたいして、以下の4つの観点に関してratingの平均で見た時に同様の傾向のスコアを付与することを実験的に明らかにした:
- Grammaticality [^1]: テキストの文法の正しさ
- Cohesiveness: テキストの一貫性
- Likeability: テキストが読んでいて楽しいか
- Relevance: promptに対してどれだけ適切なテキストが生成されているか
ただし、T0やtext-curie-001 においてはこのような傾向は見受けられなかった。[^2]
また、ChatGPTによる説明とratingを人間の評価者に対してblindで提示したところ、人間が見ても妥当な判断だと認知された。
全体の傾向としてではなく、個別のratingがどの程度同じような傾向を示すか(i.e., 人間があるstoryを高くratingしたら、LLMも高くratingするか?)をケンドールの順位相関係数で分析(200サンプルに対して3人の英語教員のスコアの平均, text-davinciによる3回の独立したratingを実施した平均スコアを用いて計算)したところ、4つの観点のうち全てにおいて正の相関が見受けられた(Table2, p-valueは<0.05で統計的に有意)。が、Relevanceのみが強い相関を示し、他の指標については弱い相関にとどまっている。しかし、Table6に示されている通り、2人の英語の先生同士で個別のjudgeに感して同様にケンドールの順位相関係数を測定しても、人間-LLM間と同様の傾向が見受けられる。すなわち、Relevanceのみが強い相関で他は弱い相関。このことから、人間同士でも個別のサンプルに対する判断は一致しない(=主観的なタスク)ということは留意する必要がある。
敵対的生成に関する実験については、Synonym Substitution Attack (SSAs; 良性のサンプルを同義語で置換する手法で、全体的な意味は保たれるため一般的な人間は正しく認知してしまうが、実際には文法がおかしくなったり不自然になったり、意味が変わってしまうことが先行研究によって知られているようなものらしい)によって実験。Fluency / Meaning Preservingの2つの指標で英語教員とLLMによる評価を比較した結果、人間は正しくadversarialなサンプルと良性なサンプルを区別できており、ChatGPT(おそらくGPT-3.5)も区別ができている(Table4)。ただし、人間のスコアと比較するとChatGPTは高めのスコアを出す傾向がある点には注意ではあるものの、良性サンプル > 敵対的サンプル という序列の判断に関しては人間と同様の傾向を示していることが示唆された。
[^1]: ただし、LLMはpunctuationのミスを文法エラーと判断するが、一人の英語の先生は文法エラーとしてみなさないなどの現象も観察され、人間は独自の評価criteriaを保持していることも窺える
[^2]: (感想)ある程度能力の高いLLMかRLHFなどを用いて人間の好みに対してalignmentがとられていないとうまくいかないのかもしれない
本研究は非常に初期の研究であり、現在のfrontierモデル群(特にreasoningモデル)を用いた場合にはどの程度改善しているか?という点は気になる。
[Paper Note] How is ChatGPT's behavior changing over time?, Lingjiao Chen+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #Evaluation #Reading Reflections Issue Date: 2023-07-22 GPT Summary- GPT-3.5とGPT-4の2023年版を、数学、敏感な質問、意見調査、知識集約型質問、コード生成、医師免許試験、視覚推論のタスクで評価した結果、両者の性能が時間とともに大きく変化することが明らかになった。特に、GPT-4(3月版)が素数識別では84%の正答率を示したが、6月版では51%に低下。GPT-3.5は6月にこのタスクで向上し、GPT-4は敏感な質問への回答意欲が減少した。全体として、LLMの挙動は短期間で変化し得るため、継続的な監視が必要であることを示唆している。 Comment
GPT3.5, GPT4共にfreezeされてないのなら、研究で利用すると結果が再現されないので、研究で使うべきではない。
↑(2025.10追記)
当時の私はこのように感じたようだが、以下を確認した方が良いと思う:
- 実験設定として、エンドポイントのモデル名にはタイムスタンプが付与されているが、同じモデルシリーズの異なるタイムスタンプモデル間の比較なのか、それとも全く同じタイムスタンプのモデルでの比較なのか
- サンプリングパラメータの設定や推論の試行回数なとがreliableな比較ができうる設定になっているか。
あとは上記を確認したとしても、研究で使うべきではない、は言い過ぎで、実験の比較対象の一部として使う分には良いと思う(ただし、実験結果の主要な知見は再現可能な設定から得られるべきと考える。
(当時は随分脊髄反射的にコメントを書いていますね…)
[Paper Note] A Review of ChatGPT Applications in Education, Marketing, Software Engineering, and Healthcare: Benefits, Drawbacks, and Research Directions, Mohammad Fraiwan+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#Survey #Education Issue Date: 2023-05-04 GPT Summary- ChatGPTは深層学習を用いた人間のようなテキスト応答生成AIであり、2022年11月の登場以降、強力な能力と多様な応用、さらには悪用のリスクで注目を集めている。最近ではGoogle BardやMeta LLaMAなどの競合モデルも登場し、教育や医療、マーケティングなどの分野での変革が期待されている。本論文ではAI言語モデルの概略、応用、限界、今後の研究の方向性について考察する。
[Paper Note] AI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays, Steffen Herbold+, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Education #AES(AutomatedEssayScoring) #One-Line Notes Issue Date: 2023-04-28 GPT Summary- ChatGPTが生成したエッセイは、人間が書いたものよりも質が高いと評価されることが大規模な研究で示された。生成されたエッセイは独自の言語的特徴を持ち、教育者はこの技術を活用する新たな教育コンセプトを開発する必要がある。 Comment
ChatGPTは人間が書いたエッセイよりも高品質なエッセイが書けることを示した。
また、AIモデルの文体は、人間が書いたエッセイとは異なる言語的特徴を示している。たとえば、談話や認識マーカーが少ないが、名詞化が多く、語彙の多様性が高いという特徴がある、とのこと。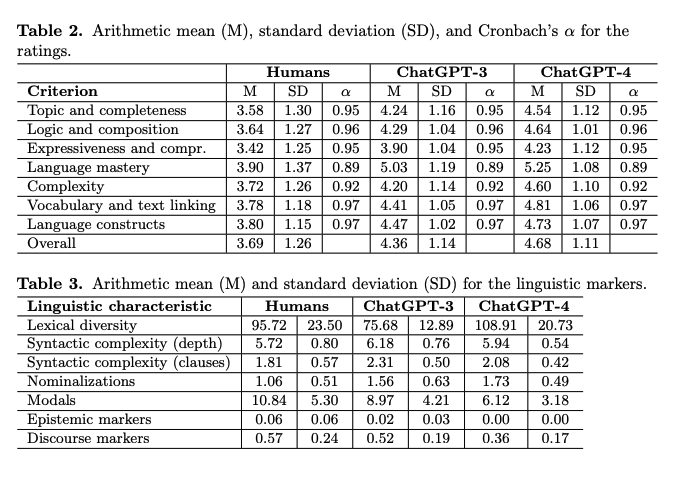
[Paper Note] Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness, Bo Li+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #Explanation #InformationExtraction #Evaluation #KeyPoint Notes #Reading Reflections Issue Date: 2023-04-25 GPT Summary- 本研究では、ChatGPTの能力を7つの情報抽出(IE)タスクを通じて評価し、パフォーマンス、説明可能性、キャリブレーション、信頼性を分析しました。標準IE設定ではパフォーマンスが低い一方、オープンIE設定では人間評価で優れた結果を示しました。ChatGPTは高品質な説明を提供するものの、予測に対して過信する傾向があり、キャリブレーションが低いことが明らかになりました。また、元のテキストに対して高い信頼性を示しました。研究のために手動で注釈付けした7つのIEタスクのテストセットと14のデータセットを公開しています。 Comment
情報抽出タスクにおいてChatGPTを評価した研究。スタンダードなIEの設定ではBERTベースのモデルに負けるが、OpenIEの場合は高い性能を示した。
また、ChatGPTは予測に対してクオリティが高く信頼に足る説明をしたが、一方で自信過剰な傾向がある。また、ChatGPTの予測はinput textに対して高いfaithfulnessを示しており、予測がinputから根ざしているものであることがわかる。(らしい)
あまりしっかり読めていないが、Entity Typing, NER, Relation Classification, Relation Extraction, Event Detection, Event Argument Extraction, Event Extractionで評価。standardIEでは、ChatGPTにタスクの説明と選択肢を与え、与えられた選択肢の中から正解を探す設定とした。一方OpenIEでは、選択肢を与えず、純粋にタスクの説明のみで予測を実施させた。OpenIEの結果を、3名のドメインエキスパートが出力が妥当か否か判定した結果、非常に高い性能を示すことがわかった。表を見ると、同じタスクでもstandardIEよりも高い性能を示している(そんなことある???)
つまり、選択肢を与えてどれが正解ですか?ときくより、選択肢与えないでCoTさせた方が性能高いってこと?比較可能な設定で実験できているのだろうか。promptは付録に載っているが、output exampleが載ってないのでなんともいえない。StandardIEの設定をしたときに、CoTさせてるかどうかが気になる。もししてないなら、そりゃ性能低いだろうね、という気がする。
Training language models to follow instructions with human feedback, Long Ouyang+, N_A, NeurIPS'22
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #RLHF #PPO (ProximalPolicyOptimization) #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-04-28 GPT Summary- 大規模な言語モデルは、ユーザーの意図に合わない出力を生成することがあります。本研究では、人間のフィードバックを使用してGPT-3を微調整し、InstructGPTと呼ばれるモデルを提案します。この手法により、13億パラメータのInstructGPTモデルの出力が175BのGPT-3の出力よりも好まれ、真実性の向上と有害な出力の削減が示されました。さらに、一般的なNLPデータセットにおける性能の低下は最小限でした。InstructGPTはまだ改善の余地がありますが、人間のフィードバックを使用した微調整が有望な方向であることを示しています。 Comment
ChatGPTの元となる、SFT→Reward Modelの訓練→RLHFの流れが提案された研究。DemonstrationデータだけでSFTするだけでは、人間の意図したとおりに動作しない問題があったため、人間の意図にAlignするように、Reward Modelを用いたRLHFでSFTの後に追加で学習を実施する。Reward Modelは、175Bモデルは学習が安定しなかった上に、PPOの計算コストが非常に大きいため、6BのGPT-3を様々なNLPタスクでSFTしたモデルをスタートにし、モデルのアウトプットに対して人間がランキング付けしたデータをペアワイズのloss functionで訓練した。最終的に、RMのスコアが最大化されるようにSFTしたGPT-3をRLHFで訓練するが、その際に、SFTから出力が離れすぎないようにする項と、NLPベンチマークでの性能が劣化しないようにpretrain時のタスクの性能もloss functionに加えている。
GPT-5.6: Frontier lntelligence that scales with your ambitlon, OpenAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-10 Comment
元ポスト:
GPT-5.6の変更点まとめ:
Model Guidance: https://developers.openai.com/api/docs/guides/latest-model?model=gpt-5.6
全体的に性能が高いだけでなく、コストパフォーマンスも良いという印象
コストパフォーマンス比:
Terra Ultra並の性能が必要なければ、Lunaのreasoning effortを上げるのがコスパ良いという話:
Previewing GPT‑5.6 Sol: a next-generation model, OpenAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes #Author Thread-Post Issue Date: 2026-06-27 Comment
元ポスト:
OpenAIによる新たなフロンティアモデルで、terminal benchでMythos 5, Fable 5超え。まずは少数のパートナーに提供し、その後数週間以内にGAを目指す、という感じらしい。
所見:
ベンチマーク:
- [Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
- [Paper Note] ExploitBench: A Capability Ladder Benchmark for LLM Cybersecurity Agents, Seunghyun Lee+, arXiv'26, 2026.05
- CyScenarioBench: Evaluating LLM Cyber Capabilities Through Scenario-Based Benchmarking, IRREGULAR, 2026.06
- [Paper Note] HealthBench Professional: Evaluating Large Language Models on Real Clinician Chats, Rebecca Soskin Hicks+, arXiv'26, 2026.04
- [Paper Note] CyberGym: Evaluating AI Agents' Real-World Cybersecurity Capabilities at Scale, Zhun Wang+, arXiv'25, 2025.06
サイバーセキュリティに関するベンチマークの報告が増えてきたなぁ
ワークスペースエージェントでチームを拡張, OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #GenerativeAI #Blog #Author Thread-Post #WorkspaceAgents Issue Date: 2026-04-25 Comment
元ポスト:
関連:
- OpenClaw — Personal AI Assistant, openclaw, 2026.03
- 🍫 Local Cocoa: Your Personal AI Assistant, Fully Local 💻, synvo-ai, 2026.01
- Cowork: Claude Code for the rest of your work, Anthropic, 2026.01
Introducing GPT‑5.5, OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Proprietary #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #Reference Collection #Reading Reflections #Author Thread-Post Issue Date: 2026-04-24 Comment
元ポスト:
- FrontierMath, Terminal-Bench, GDPValでOpus 4.7を上回りダントツのトップ
- Artificial Analysis IndexでもOpus 4.7超え
しかし、Terminal-Benchは"ターミナル操作を通じた多様、かつlong horizonなタスクを評価する(多くはソフトウェアエンジニアタスクであるコーディングもタスクには含まれるが)"のベンチマークであり、SWE Bench Proのような一般的なcoding能力を測るベンチマークのスコアが掲載されていない。HLEやVisual Reasoning系のベンチマークのスコアも報告されていないように見える。
恣意的にGPT-5.5が強いデータ、比較対象をピックアップしているのではないか、という印象を持った。
- [Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
- Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
Artificial Analysisによる評価:
所見:
サイバー分野でMythosと同等?
Introducing ChatGPT Images 2.0: A new era of image generation, OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #TextToImageGeneration #Proprietary #Selected Papers/Blogs #ImageSynthesis #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-22 Comment
元ポスト:
めとゃめちゃ良くなってそう
関連:
関連:
Artificial Analysisによる評価(SoTA):
GPT‑5.4 mini と nano が登場, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Proprietary #VisionLanguageModel Issue Date: 2026-03-18 Comment
元ポスト:
Artificial Analysisによるベンチマーク:
Introducing GPT‑5.4, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #Proprietary #VisionLanguageModel #Reference Collection #Reading Reflections Issue Date: 2026-03-06 Comment
元ポスト:
Artiflcial Analysisによる評価:
所見:
所見:
評判が良い。管理人も利用しているが、指示で曖昧な点をきちんと質問してくれる点が便利。かつ応答として、選択可能なオプションを提示し、自由記述もできる。実装の内容はClaude 4.6 Opusと比べるとコードがシンプルな印象を受けるが、これも指示次第な気はする。
曖昧な点があったら質問を投げかけるという挙動はopenhandsのPosition Paperとも整合する流れである。
- [Paper Note] Position: Humans are Missing from AI Coding Agent Research, Wang+, 2026.02
GPT‑5.3 Instant:よりスムーズで、日常会話にもっと役立つ, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Proprietary #VisionLanguageModel Issue Date: 2026-03-04 Comment
元ポスト:
なんだかなあ
Introducing Prism, OpenAI, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #GenerativeAI #MultiModal #AcademicWriting #DeepResearch #One-Line Notes Issue Date: 2026-01-29 Comment
デモを見るとdraftをベースに関連研究をdeepresearchしてワンクリックでbibtexにexport, ホワイトボードに描いた図をドラッグ&ドロップして論文に反映などしている。Overleafの競合。
元ポスト:
所見:
ChatGPT ヘルスケアが登場, OpenAI, 2026.01
Paper/Blog Link My Issue
#Article #GenerativeAI #Blog #Health Issue Date: 2026-01-09 Comment
元ポスト:
Reverse Engineering a Phase Change in GPT's Training Data... with the Seahorse Emoji 🌊🐴, PRATYUSH MAINI, 2025.12
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Reasoning #SelfCorrection #mid-training #One-Line Notes Issue Date: 2025-12-28 Comment
元ポスト:
Is there seahorse emoji?という質問に対するLLMのreasoning trajectoryと、self correctionの挙動が、OpenAIのどの時点のモデルで出現するか、しないかを線引くことで、mid-trainingにself correction形式のデータが追加されたのがいつ頃なのかを考察している。
ChatGPTの記憶システムはRAGを使っていなかった - 4層アーキテクチャの衝撃, UrayahaDays, 2025.12
Paper/Blog Link My Issue
#Article #Blog Issue Date: 2025-12-15 Comment
元ポスト:
GPT-5.2 が登場 専門的な業務や長時間稼働するエージェント向けの、最先端のフロンティアモデル。, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #GenerativeAI #Reasoning #Proprietary #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-12-12 Comment
元ポスト:
OpenAIがGPT-5.2をリリースし、再び様々なベンチマークにおいてGemini 3 Proをoutperform。
フロントエンド開発(デザイン)(アリーナ形式)ではOpus, Gemini 3 Proの勝利らしい:
https://www.designarena.ai
ポイント解説:
GDPval:
- [Paper Note] GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks, Tejal Patwardhan+, arXiv'25, 2025.10
- GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09
GDPvalのclearwinがGPT-5.2- Thinkingで49.8%なので、14年程度の専門家がこなす米国主要産業の一部のタスクは数値上は置き換え可能という風に見える。Proに至っては60.0%である。
が、GDPvalはたとえば以下のようなlimitationがあり、数値の解釈には注意が必要である:
- 完全なcontextが与えられる前提
- 暗黙知が多いタスクは対象外
- 自己完結型で他社とのコミュニケーションが必要とされないタスクを対象
- 1職種あたり30タスク程度の限定的な網羅性
- コンピュータを利用したタスクのみ
- ...
実際の現場で活用しようと思うと、完全なcontextを揃えられるか、揃わない場合に不完全なcontextでタスクを遂行できるか、そのための社内での運用フローの整備等、モデルを活用するための周辺のシステムや運用フローの設計が重要(かつ膨大)である点には(ベンチマークのスコアを見ると驚くべき進歩だが)留意する必要がある。
Vals AI IndexというGDPvalに類似したベンチマークでもSoTAとのこと:
関連:
非常に簡単な論理的な推論でも誤る例:
GPT-5.1: A smarter, more conversational ChatGPT, OpenAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Reasoning #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Routing #One-Line Notes #Reference Collection Issue Date: 2025-11-13 Comment
元ポスト:
instantモデルはよりあたたかい応答でより指示追従能力を高め、thinkingモデルは入力に応じてより適応的に思考トークン数を調整する。autoモデルは入力に応じてinstant, thinkingに適切にルーティングをする。
所見:
Artificial Analysisによるベンチマーキング:
GPT-5.1-Codex-maxの50% time horizon:
Introducing ChatGPT Atlas, OpenAI, 2025.10
Paper/Blog Link My Issue
#Article #GenerativeAI #Blog Issue Date: 2025-10-23 Comment
元ポスト:
ブラウザのサイドバーでchatgptにサイトに関して質問できたり、agenticな使い方もできる模様?
nanochat, karpathy, 2025.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Repository #mid-training #GRPO #read-later #Selected Papers/Blogs #Inference #MinimalCode #KV Cache Issue Date: 2025-10-22 Comment
元ポスト:
新たなスピードランが...!!
FP8で記録更新とのこと:
nano chatの過去の改善のポイントまとめ:
nanochatにおいてKarpathy氏がAIによる自動改善をするエージェントをセットアップしたところ、12時間で110の変更が加わり、ValLossを0.864215から0.85039まで改善しているとのこと。
現在の最高性能は2時間で0.71854なのでまだまだ及んでいないが、このまま回しておいたらどこまで改善するだろうか?
ポストに本人が返信をしているが、Karpathy氏の関心は、どのハーネスがnanochatに最も大きな改善をもたらすか、という点らしい。
OpenAI DevDay 2025 発表まとめ, ぬこぬこ, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #Blog Issue Date: 2025-10-08 Comment
元ポスト:
Why GPT-5 used less training compute than GPT-4.5 (but GPT-6 probably won’t), EPOCH AI, 2025.09
Paper/Blog Link My Issue
#Article #Analysis #Pretraining #NLP #LanguageModel #Blog #PostTraining Issue Date: 2025-09-29 Comment
元ポスト:
GPT-5 System Card, OpenAI, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiModal #Proprietary #VisionLanguageModel #KeyPoint Notes #Reference Collection Issue Date: 2025-08-07 Comment
日本語性能。MMLUを専門の翻訳家を各言語に翻訳。
ざーっとシステムカードを見たが、ベンチマーク上では、Safetyをめっちゃ強化し、hallucinationが低減され、コーディング能力が向上した、みたいな印象(小並感)
longContextの性能が非常に向上しているらしい
-
-
gpt-ossではAttentionSinkが使われていたが、GPT-5では使われているだろうか?もし使われているならlong contextの性能向上に寄与していると思われる。
50% time horizonもscaling lawsに則り進展:
-
- [Paper Note] Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
個別のベンチが数%向上、もしくはcomparableです、ではもはやどれくらい進展したのかわからない(が、個々の能力が交互作用して最終的な出力がされると考えるとシナジーによって全体の性能は大幅に底上げされる可能性がある)からこの指標を見るのが良いのかも知れない
METR's Autonomy Evaluation Resources
-
https://metr.github.io/autonomy-evals-guide/gpt-5-report/
-
HLEに対するツール利用でのスコアの比較に対する所見:
Document Understandingでの評価をしたところOutput tokenが大幅に増えている:
GPT5 Prompting Guide:
https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guide
GPT-5: Key characteristics, pricing and model card
-
https://simonwillison.net/2025/Aug/7/gpt-5/
-
システムカード中のSWE Bench Verifiedの評価結果は、全500サンプルのうちの477サンプルでしか実施されておらず、単純にスコアを比較することができないことに注意。実行されなかった23サンプルをFailedとみなすと(実行しなかったものを正しく成功できたとはみなせない)、スコアは減少する。同じ477サンプル間で評価されたモデル間であれば比較可能だが、500サンプルで評価された他のモデルとの比較はできない。
-
- SWE Bench リーダーボード: https://www.swebench.com
まとめ:
所見:
-
-
OpenHandsでの評価:
SWE Bench Verifiedの性能は71.8%。全部の500サンプルで評価した結果だと思うので公式の発表より低めではある。
AttentionSinkについて:
o3と比較してGPT5は約1/3の時間でポケモンレッド版で8個のバッジを獲得した模様:
より温かみのあるようなalignmentが実施された模様:
GPT5はlong contextになるとmarkdownよりめxmlの方が適していると公式ドキュメントに記載があるらしい:
Smallow LLM Leaderboard v2での性能:
GPT5の性能が際立って良く、続いてQwen3, gptossも性能が良い。
OpenAI o1 System Card, OpenAI, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #Proprietary #VisionLanguageModel Issue Date: 2024-12-10
OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化, AIDB, 2023.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #Initial Impression Notes Issue Date: 2023-09-30 Comment
おう…やべえな…
HuggingChat, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #One-Line Notes Issue Date: 2023-04-27 Comment
closedな世界で開発されるOpenAIのChatGPTに対して、Openなものが必要ということで、huggingfaceが出したchatシステム
公開はすでに終了している模様