
Chain-of-Thought
[Paper Note] Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It, Xinyu Zhou+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#LanguageModel #Supervised-FineTuning (SFT) #Reasoning #LongSequence #read-later Issue Date: 2026-06-11 GPT Summary- CoT-SFTが長い文脈における検索性能を低下させる問題を発見。特に難しい設定でのHypeNetの性能が著しく落ちるため、W_QとW_KをSFT前の状態に戻すQK-Restoreを提案。これにより、訓練コストゼロで推論性能を改善し、長い文脈の処理能力を回復することができた。例えば、HypeNet-5Bでは性能が65.4%から76.4%へ向上した。 Comment
元ポスト:
[Paper Note] Reasoning Structure of Large Language Models, Frédéric Berdoz+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #Initial Impression Notes Issue Date: 2026-06-06 GPT Summary- 推論モデルの評価には、正確性やトークン数だけでなく、推論構造の理解が重要である。これに応じて、論理パズルのためのスケーラブルな評価ベンチマークと、非構造化推論を検証可能な推論グラフに変換するパイプラインを導入。これにより、推論の構造化と定量的分析が可能となり、論理的流れの集中度を測る指標を定義。分析は、構造的測定が正確性とトークン数の混同を解消し、故障モードの診断やパズルの難易度との関係を比較するのに役立つことを示した。 Comment
元ポスト:
LLMのReasoning Traceをverifiableなグラフ構造に変換し、Reasoningを評価可能にする
[Paper Note] ReasonOps: Operator Segmentation for LLM Reasoning Traces, Daniel Lee+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reasoning #Overthinking #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- ReasonOpsは、チェーン・オブ・ソートの痕跡を分析するための教師なし手法であり、推論の過程を注釈付けするための普遍的な演算子を提供します。12のモデルから44,662の痕跡を分析した結果、共通の構成的な構造が明らかになりました。特に、バックトラッキングや仮説設定などの再発する演算子が全モデルに見られ、内省的演算子は難問でより効果的であることが示されました。演算子のシーケンスを用いることでモデルの高精度な識別が可能になり、早期の品質推定も実現しました。ReasonOpsは、LLMの推論痕跡に対する深いインサイトを提供し、性能予測の強化に寄与します。 Comment
元ポスト:
[Paper Note] LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model, Inclusion AI+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #MultiModal #DiffusionModel #TextToImageGeneration #Reasoning #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #VisionLanguageModel #Editing #UMM #ImageSynthesis #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- LLaDA2.0-Uniは、マルチモーダルな理解と生成を統合するための統一型離散拡散大規模言語モデルです。意味論的な離散トークナイザとMoEベースのバックボーン、拡散デコーダを組み合わせ、視覚入力を効率的に処理します。高忠実度の画像生成を実現し、推論効率を最適化する独自の手法を採用。特化型VLMに匹敵する性能を持ち、生成と推論の相互運用性で次世代モデルの可能性を広げます。コードは公開されています。 Comment
元ポスト:
VLM * Diffusionモデル。テキストの生成だけでなく、TextToImage, Image Editingもサポートされているように見える。
公式ポスト:
画像を生成する前にreasoningを実施するように訓練され、UMMなのでtext, patchのrepresentationがシームレスに統合され、画像を伴うテキスト生成がより一貫性を持つ、とのこと。
著者ポスト:
[Paper Note] Thought-Retriever: Don't Just Retrieve Raw Data, Retrieve Thoughts for Memory-Augmented Agentic Systems, Tao Feng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #NLP #LanguageModel #AIAgents #Selected Papers/Blogs #memory Issue Date: 2026-04-20 GPT Summary- LLMが外部知識を効果的に取り込む課題を解決するために、Thought-Retrieverという新しいアルゴリズムを提案。これは、過去のユーザークエリで生成された中間応答を活用し、冗長な思考をフィルタリングして新しいクエリに関連する思考を取り出すことで、長期記憶を構築。AcademicEvalという新たなベンチマークで広範な実験を行い、Thought-Retrieverが最先端モデルを上回る成果を示した。特に、より多くのクエリ解決後に自己進化を促し、抽象的な問いへの応答能力を向上させることが確認された。 Comment
元ポスト:
[Paper Note] Process Reward Agents for Steering Knowledge-Intensive Reasoning, Jiwoong Sohn+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Reasoning #PRM #FactualKnowledge #Initial Impression Notes Issue Date: 2026-04-17 GPT Summary- PRAは、凍結済みポリシーに対するオンラインかつ段階的な報酬を提供することで、推論プロセスを改善。検索ベースのデコードにより、生成ステップごとに候補をランキングし、剪定する。医療推論ベンチマークで一貫して高い性能を示し、未見のポリシーモデルに対しても精度を最大25.7%向上させる。PRAはドメイン固有の報酬モジュールを通じて、複雑なドメインで再訓練なしに新たなバックボーンを展開可能にする。 Comment
pj page: https://process-reward-agents.github.io/
元ポスト:
Reasoning中に独立したProcess Reward Agent (PRA) によって外部知識からevidenceを検索しreasoning stepに対してrewardを与えることで、reasoning step単位のrewardを実現し、これによりknowledge-intensiveなドメインに対してより頑健な推論が可能になる、という感じだろうか。medical domainで評価しており、self-consistency+RAGなどの手法を上回っているように見える(が、Fair Comparisonになっているだろうか、という点が少し気になる)。あとは、汎用的な手法だと思われるので、medicalドメインだけでなく他のknowledge-intentiveなドメインでの評価もあるとなお良さそうに感じる。
[Paper Note] LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning, Sumeet Ramesh Motwani+, ICML'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Reasoning #ICML #read-later #Selected Papers/Blogs #LongHorizon #Author Thread-Post Issue Date: 2026-04-16 GPT Summary- LongCoTを導入し、複雑な推論能力を測定するための2,500問の専門家設計問題からなるベンチマークを提供。問題は数万から百数万の推論トークンを含む相互依存の手順を要求し、最先端モデルは全体で<10%の精度であることが示され、長期推論の限界が明らかになる。LongCoTは、モデルの長時間にわたる安定した推論能力を評価する指標となる。 Comment
元ポスト:
著者ポスト:
[Paper Note] The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning, Qiguang Chen+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #LongSequence #mid-training #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-02-24 GPT Summary- LLMは長い連鎖思考(Long CoT)推論を学ぶのが難しく、効果的な推論は安定した分子のような構造を持つことが重要。これには深層推論、自己反省、自己探索の三つの相互作用が関与し、キーワードの模倣ではなくファインチューニングから生じることが示された。有効な意味的異性体が迅速なエントロピー収束を促進し、Mole-Synを提案してLong CoT構造の合成を導き、性能とRLの安定性を向上させる。 Comment
元ポスト:
結構読むのが大変そうなのでskim readingと元ポストを拝見した上でざっくりまとめると以下のような感じだろうか。takeaway部分により詳細な話が書かれているので必要に応じて読むとよさそう。
良いlong CoTには分子のような推論の内部構造が存在し、それらは適切な内部構造を持つ合成データによってSFTをすることで身につけさせられる。逆に、人間が作成したtrajectoryなどはこれらの分子構造が均質化されておらず、学習が不安定になる(表層的なキーワードから学習されたりする)。
良いlong CoTに必要な要素として、本研究では以下の3つのbehaviorが挙げられている:
- Self-Exploration: モデルが柔軟に異なるアイデアやパスを探索する力
- Self-Reflection: モデルが過去のstepを確認し修正する能力(分子の構造を安定化させるような役割を果たす)
- Deep Reasoning: 原子結合のような、論理的なstepを強力に結びつけた主となる論理フロー
[Paper Note] Analyzing and Improving Chain-of-Thought Monitorability Through Information Theory, Usman Anwar+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Reasoning #Safety #Monitorability Issue Date: 2026-02-24 GPT Summary- CoTモニターは、推論の痕跡を分析し、LLMベースのシステムで出力の興味属性を検出する手法です。本稿では、CoTと出力間の相互情報量がモニタビリティの必要条件であることを示し、性能を損なう二つの誤差源を特定します。情報ギャップは抽出可能な情報量を、誘発誤差は監視関数の近似度を測ります。訓練目的を最適化してCoTモニタビリティを向上させる二つの補完的アプローチを提案:オラクルベース手法と条件付き相互情報量の最大化。これにより、モニターの精度向上とリワードハッキングの緩和を実証します。 Comment
元ポスト:
[Paper Note] Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics, Leheng Sheng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #SelfImprovement #PostTraining #RLVR #PRM #RewardModel #One-Line Notes #Rubric-based Issue Date: 2026-02-12 GPT Summary- CoTがLLM推論において重要である一方で、報酬モデルの訓練には多くの人手が必要で、静的モデルは変化に対応しづらい。これを解決するため、自己進化するCoT報酬アプローチ「RLCER」を提案。自己提案・自己進化するルーブリックにより、結果報酬なしでも信頼性のあるCoT監視信号を提供し、結果中心のRLVRを上回ることを実証。また、ルーブリックは推論時のパフォーマンスを向上させる効果もある。 Comment
元ポスト:
CoTを評価するためのルーブリックを自己進化させて、CoTの評価もしつつ、outcomeに基づくRLVRを実施するといった処理を単一のポリシーで実現する、というような話に見える(過去のCoTに対する監視手法ではPRMが別途用意されていた)。
単にRLVRをする場合よりも最終的な性能が向上し、特にlong runの場合の安定性が高まっているように見える。
[Paper Note] Data Repetition Beats Data Scaling in Long-CoT Supervised Fine-Tuning, Dawid J. Kopiczko+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #Reasoning #PostTraining #Selected Papers/Blogs #Generalization #KeyPoint Notes #Author Thread-Post Issue Date: 2026-02-12 GPT Summary- SFT(教師ありファインチューニング)の重要性を強調し、小規模データセットでの繰り返しトレーニングが大規模データセットでの単一エポックよりも優れていることを示す。Olmo3-7Bが400サンプルで128エポックのトレーニングによって、51200サンプルでの1エポックよりも12-26%の性能向上を実現。トレーニングトークンの精度が改善の指標となり、このパターンは一貫して確認される。これにより、高価なデータスケーリングに代わる実践的アプローチを提供し、繰り返しの利点を新たな研究課題として提示。 Comment
元ポスト:
著者ポスト:
**long-CoTのSFTにおいては**、多くのユニークなデータで学習するよりも、小さなデータセットを複数エポック繰り返し学習する方が優れていることが分かったとのこと。この傾向はモデルを跨いで存在する(Olmo3とQwen3で実験)。
より多くのエポック数 vs. より多くのユニークデータ数 でのモデルの傾向の違いとしては、前者の方がReasoningにおいて最終的な回答を出す割合が非常に大きくなることが分かった(たとえばFigure2 Rightの1 epoch 51200サンプルの24% vs. 256 epoch 200サンプル)。
では繰り返しの恩恵を得られなくなるのはどの時点かというと、Token Accuracy (=モデルのnext token predictionのtargetと一致する予測トークンがtopになった割合)が100%に近くなるとそれ以上epochを繰り返してもgainが無くなるので、これをSFTのstopping criteriaとして利用可能とのこと。
[Paper Note] Effective Reasoning Chains Reduce Intrinsic Dimensionality, Archiki Prasad+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reasoning #PEFT(Adaptor/LoRA) #PostTraining #Selected Papers/Blogs #Generalization #KeyPoint Notes #Initial Impression Notes Issue Date: 2026-02-12 GPT Summary- 内在次元数を指標として、推論チェーンの有効性を定量化。異なる推論戦略がタスクの内在次元数を低下させ、一般化性能に逆相関を持つことを示す。これにより、有効な推論チェーンがパラメータを効果的に利用し学習を促進することを明らかにする。 Comment
元ポスト:
元ポストを読むと、以下のような話のようである。非常に興味深い。
良いCoT(推論)はタスクを圧縮する(すなわち、inputを正解へとマッピングする際の自由度を減少させる)ことを示した。
さまざまなCoT戦略に対して、あるタスクに対してさまざまなCoT戦略と、**特定の性能に到達するまでに必要な最小のパラメータ数の関係性(=intrinsic dimensionality)**を分析。パラメータ数の制御はLoRAのパラメータを変化させることによって調整して実験。その結果、Intrinsic Dimensionalityがdownstream taskの性能と、OODへの汎化性能に対して非常に強い相関を示した(Perplexityよりも強い相関)。
Intrinsic DimensionalityをさまざまなCoT戦略で測定すると、(school math系のデータに関しては)python codeを生成し実行する方法(Executed PoT)が最もコンパクトなsolutionを生成し、かつ最も良いOODへの汎化性能が高いことがわかった(他ドメインでこのCoT手法が適しているとは限らない点には注意)。
また、モデルスケールが大きい方がより低いIntrinsic Dimensionalityを示し、良いcompressor(=タスクを圧縮する能力が高い)であることがわかった。
弱くてノイジーなCoT戦略は、スケールせず、パラメータ効率が悪いことがわかった。
非常に興味深い研究で、かつskim readingしかできていない上での感想なのだが、
- 実験がLoRAベースで実施されているため、他の学習のダイナミクスにおいて同様のことが言えるのかという点
- Gemmaでしか実験されていないため他のアーキテクチャでも同じようにIntrinsic Dimensionalityの有効性が言えるのか
- データセットがGSM系列のschool mathドメインでしか実験されていないため、ドメイン間でどの程度一般性を持って言える話なのかという点
は明らかになっていない気がしており、どうなるのか興味がある。また、実際にIntrinsic Dimensionalityを測定しようとした場合に、効率的に求める方法はあるだろうか。
[Paper Note] ROBOINTER: A HOLISTIC INTERMEDIATE REPRESEN- TATION SUITE TOWARDS ROBOTIC MANIPULATION, ICLR'26 blindreview, 2026.02
Paper/Blog Link My Issue
#Dataset #QuestionAnswering #Planning #Annotation #Reasoning #VisionLanguageModel #Robotics #VisionLanguageActionModel #Manipulation Issue Date: 2026-02-05 Comment
openreview: https://openreview.net/forum?id=PGUC3mmMoi
元ポスト:
[Paper Note] ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation, Junmin Gong+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Transformer #SpeechProcessing #DiffusionModel #Reasoning #SmallModel #PEFT(Adaptor/LoRA) #OpenWeight #Music Issue Date: 2026-02-05 GPT Summary- ACE-Step v1.5は、高効率のオープンソース音楽基盤モデルで、商業音楽モデルを超える品質を持ちながら、非常に高速で動作します。ユーザーは少数の楽曲から個人のスタイルをトレーニング可能で、ハイブリッドアーキテクチャを用いてシンプルなクエリを包括的な楽曲に変換します。内因性強化学習により、スタイル制御と多様な編集機能を強化し、50以上の言語に対応。コンテンツクリエイターの創造的なワークフローに統合されるツールとして利用可能です。 Comment
元ポスト:
データは全て許可済みのもの、かつ合成データとポストされており商用利用も可らしいが、果たして。
[Paper Note] The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think, Seongyun Lee+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Explanation #ICLR Issue Date: 2026-02-05 GPT Summary- CoTを分析するためのボトムアップのフレームワークを提案。モデル生成のCoTから多様な推論基準を抽出し、クラスタリングを行うことで解釈可能な分析を実施。結果、トレーニングデータの形式が推論行動に与える影響が明らかになり、より効果的な推論戦略への誘導が可能となることを示した。 Comment
元ポスト:
[Paper Note] DiffuSpeech: Silent Thought, Spoken Answer via Unified Speech-Text Diffusion, Yuxuan Lou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Dataset #SpeechProcessing #DiffusionModel #Reasoning #Architecture #Selected Papers/Blogs #TTS #AudioLanguageModel #Initial Impression Notes Issue Date: 2026-02-02 GPT Summary- 音声LMMが直接応答を生成する際に発生するエラーを解決するため、「沈黙の思考、話された答え」という新たなパラダイムを提案。内部のテキスト推論と共に音声応答を生成する拡散ベースの音声-テキスト言語モデル\method{}を開発。モダリティ固有のマスキングを使用し、推論過程と音声トークンを共同生成。初の音声QAデータセット\dataset{}も構築し、26,000サンプルを含む。実験結果はQA精度で最先端を達成し、最高のTTS品質を維持しつつ言語理解も促進。拡散アーキテクチャの効果も実証。 Comment
元ポスト:
音声合成、AudioLanguageModelの枠組みにおいてreasoningを導入する新たなアーキテクチャを提案し、そのためのデータを収集して性能が向上しているように見え、重要研究に感じる。
[Paper Note] LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities, Thomas Schmied+, ICLR'26, 2025.04
Paper/Blog Link My Issue
#Analysis #LanguageModel #ReinforcementLearning #Reasoning #ICLR #Test-Time Scaling #PostTraining #Multi-Armed Bandit #DecisionMaking #Exploration Issue Date: 2026-01-31 GPT Summary- LLMのエージェントアプリケーションにおける探求と解決の効率性を分析。最適なパフォーマンスを妨げる「知識と行動のギャップ」や貪欲性、頻度バイアスという失敗モードを特定。強化学習(RL)によるファインチューニングを提案し、探索を増加させて意思決定能力を改善。古典的な探索メカニズムとLLM特有のアプローチの両方を融合させ、効果的なファインチューニングの実現を目指す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=weUP6H5Ko9
- greediness
- frequency bias
- the knowing-doing gap
[Paper Note] Reasoning Models Generate Societies of Thought, Junsol Kim+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Reasoning #PostTraining #read-later #Probing #Diversity #Selected Papers/Blogs #SparseAutoencoder Issue Date: 2026-01-19 GPT Summary- 大規模言語モデルは、複雑な認知タスクにおいて優れた性能を発揮するが、そのメカニズムは不明瞭である。本研究では、強化された推論は計算の拡張だけでなく、異なる人格特性や専門知識を持つ内部認知視点の間のマルチエージェント相互作用によって生じることを示す。これにより、推論モデルはより広範な対立を引き起こし、視点の多様性が向上することを発見した。制御された強化学習実験により、会話行動の増加が推論精度を向上させることが明らかになり、思考の社会的組織が問題解決を効果的に行う可能性を示唆する。 Comment
元ポスト:
解説:
[Paper Note] Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge, Yao Tang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #Architecture #Test-Time Scaling #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes #Initial Impression Notes Issue Date: 2026-01-19 GPT Summary- Multiplex Thinkingは、K個の候補トークンをサンプリングし、単一のマルチプレックストークンに集約することで、柔軟な推論を実現。モデルの自信に応じて標準的なCoTの挙動と複数の妥当なステップをコンパクトに表現。難易度の高い数学的推論ベンチマークで一貫して優れた結果を示す。 Comment
pj page: https://gmlr-penn.github.io/Multiplex-Thinking/
元ポスト:
reasoningに関する新たなアーキテクチャでざっくり言うと単一のreasoningをハードに保持して推論するのではなく、(人間のように?)複数の推論に関する情報をソフトに保持して応答する枠組みである。
reasoningにおける各ステップにおいてk個数のreasoningトークンを生成し、最終的な応答を生成する前に、各ステップで生成されたreasoningトークンのone-hot vectorを集約し平均化、その後集約されたベクトルに対してelement単位(vocabごとの)再重み付けをして、embedding matrix Eを乗じてcontext vectorを得る。このcontext vectorが様々なreasoningの結果を集約したような情報を保持しており、context vectorで条件付けで応答yを生成するようなアーキテクチャ。reasoningモデルに対して追加のオンポリシーRLを通じて応答yのRewardが最大化されるように事後学習することで実現される。
単に性能が向上するだけでなく、test time scaling (parallel, sequenceの両方)でもスケールする。
解説:
[Paper Note] VChain: Chain-of-Visual-Thought for Reasoning in Video Generation, Ziqi Huang+, ACL'26 Findings, 2025.10
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #Reasoning #ACL #VideoGeneration/Understandings #2D (Image) #Findings Issue Date: 2025-10-20 GPT Summary- VChainは、マルチモーダルモデルの視覚的推論を動画生成に活用する新しいフレームワークで、重要なキーフレームを生成し、動画生成器のチューニングを効率的にガイドします。このアプローチにより、複雑なシナリオにおいて生成動画の品質が大幅に向上しました。 Comment
pj page: https://eyeline-labs.github.io/VChain/
元ポスト:
Chain-of-Visual-Thoughts
keyframeをchain-of-thoughtsに含めることで、時間発展をより正確にしようという試みに見える。追加の学習なしで実施できるとのこと。
[Paper Note] ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference, Yesheng Liang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Quantization #Reasoning #LongSequence #ICLR #PostTraining #One-Line Notes Issue Date: 2026-02-28 GPT Summary- Post-training quantization (PTQ)はLLMの重みと活性化を低精度に圧縮し、メモリと推論速度を改善するが、外れ値が誤差を大きくし、特に推論型LLMの長い思考チェーンで精度低下を招くことがある。既存のPTQ手法は外れ値抑制が不十分であったり、オーバーヘッドがある。本研究では、独立ガイブンズ回転とチャネルスケーリングを組み合わせたペアワイズ回転量子化(ParoQuant)を提案し、ダイナミックレンジを狭め外れ値問題を解決する。推論カーネルの共同設計によりGPUの並列性を最大限活用し、精度向上を実現。結果、重みのみの量子化でAWQより平均2.4%の精度向上を達成し、オーバーヘッドは10%未満で、最先端の量子化手法と同等の精度を示す。これにより、高効率で高精度なLLMのデプロイが可能となる。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=1USeVjsKau
Reasoning LLMにおいてlong-CoTを実施した場合のエラーの蓄積を低減するようなpost-training-basedな量子化手法の提案
[Paper Note] Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks, Abhranil Chandra+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #SyntheticData #Reasoning #Distillation #One-Line Notes Issue Date: 2026-01-11 GPT Summary- 言語モデルの推論能力は、連鎖的思考(CoT)トレースの合成データセットでの訓練によって向上することが示された。合成データはモデル自身の分布に近く、学習に適応しやすい。また、不正確なトレースでも有効な推論ステップを含むことが多い。人間の注釈データを言い換えることでパフォーマンスが向上し、欠陥のあるトレースに対する耐性も研究された。MATH、GSM8K、Countdown、MBPPデータセットを用いて、モデルの分布に近いデータセットの重要性と、正しい最終回答が必ずしも信頼できる推論プロセスの指標ではないことが示された。 Comment
元ポスト:
base modelの分布と近いStronger Modelから合成されたCoTデータでSFTすると、合成データの応答がincorrectであっても性能が向上する。分布が遠い人間により生成されたCoTで訓練するより性能改善の幅は大きく、人間が作成したCoTをparaphraseしモデルの分布に近づけると性能の上昇幅は改善する(Figure1, Table4, 5)。
[Paper Note] ThinkGen: Generalized Thinking for Visual Generation, Siyu Jiao+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #LanguageModel #ReinforcementLearning #MultiModal #DiffusionModel #TextToImageGeneration #PostTraining #read-later #One-Line Notes #ImageSynthesis Issue Date: 2026-01-06 GPT Summary- ThinkGenは、マルチモーダル大規模言語モデル(MLLM)のChain-of-Thought(CoT)推論を活用した初の思考駆動型視覚生成フレームワークである。MLLMが特化した指示を生成し、Diffusion Transformer(DiT)がそれに基づいて高品質な画像を生成する。さらに、MLLMとDiT間で強化学習を行うSepGRPOトレーニングパラダイムを提案し、多様なデータセットに対応した共同トレーニングを可能にする。実験により、ThinkGenは複数の生成ベンチマークで最先端の性能を達成した。 Comment
元ポスト:
MLLMとDiTを別々にRLして、MLLMはDiTが好むplan/instructionを生成し、その後DiTとConnectorに対してplan/instructionに従うようなRLをするような手法のようである。図2,3,4を見ると概要がわかる。
[Paper Note] MoReBench: Evaluating Procedural and Pluralistic Moral Reasoning in Language Models, More than Outcomes, Yu Ying Chiu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Reasoning #Safety Issue Date: 2025-12-24 GPT Summary- AIシステムの意思決定が人間の価値観と一致するためには、その決定過程を理解することが重要である。推論言語モデルを用いて、道徳的ジレンマに関する評価を行うためのベンチマーク「MoReBench」を提案。1,000の道徳的シナリオと23,000以上の基準を含み、AIの道徳的推論能力を評価する。結果は、既存のベンチマークが道徳的推論を予測できないことや、モデルが特定の道徳的枠組みに偏る可能性を示唆している。これにより、安全で透明なAIの推進に寄与する。 Comment
pj page: https://morebench.github.io/
元ポスト:
[Paper Note] How Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?, Sohee Yang+, EMNLP'25, 2025.06
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reasoning #SelfCorrection #EMNLP #SelfVerification Issue Date: 2025-11-04 GPT Summary- 推論モデルの自己再評価能力を調査し、役に立たない思考の4つのタイプを特定。モデルは無駄話や無関係な思考を効果的に識別できるが、それらが注入されると回復に苦労し、性能が低下することを示した。特に、大きなモデルは短い無関係な思考からの回復が難しい傾向があり、自己再評価の改善が求められる。これにより、より良い推論と安全なシステムの開発が促進される。 Comment
元ポスト:
元ポスト:
[Paper Note] Is It Thinking or Cheating? Detecting Implicit Reward Hacking by Measuring Reasoning Effort, Xinpeng Wang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #RewardHacking Issue Date: 2025-10-16 GPT Summary- 報酬ハッキングは、モデルが報酬関数の抜け穴を利用して意図されたタスクを解決せずに高い報酬を得る行為であり、重大な脅威をもたらす。TRACE(Truncated Reasoning AUC Evaluation)を提案し、暗黙的な報酬ハッキングを検出する。TRACEは、モデルの推論が報酬を得るのにかかる時間を測定し、ハッキングモデルが短いCoTで高い期待報酬を得ることを示す。TRACEは、数学的推論で72B CoTモニターに対して65%以上、コーディングで32Bモニターに対して30%以上の性能向上を達成し、未知の抜け穴を発見する能力も示す。これにより、現在の監視方法が効果的でない場合に対するスケーラブルな無監視アプローチを提供する。 Comment
元ポスト:
[Paper Note] Verifying Chain-of-Thought Reasoning via Its Computational Graph, Zheng Zhao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #read-later #Selected Papers/Blogs #Verification #One-Line Notes #Author Thread-Post Issue Date: 2025-10-14 GPT Summary- Circuit-based Reasoning Verification (CRV)を提案し、CoTステップの帰属グラフを用いて推論エラーを検証。エラーの構造的署名が予測的であり、異なる推論タスクで異なる計算パターンが現れることを示す。これにより、モデルの誤った推論を修正する新たなアプローチを提供し、LLM推論の因果理解を深めることを目指す。 Comment
元ポスト:
著者ポスト:
transformer内部のactivationなどから計算グラフを構築しreasoningのsurface(=観測できるトークン列)ではなく内部状態からCoTをverification(=CoTのエラーを検知する)するようなアプローチ(white box method)らしい
[Paper Note] RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization, Zhaoning Yu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #SelfImprovement #ICLR #read-later #One-Line Notes #Author Thread-Post Issue Date: 2025-10-03 GPT Summary- RESTRAINは、自己ペナルティを用いた強化学習フレームワークで、ラベル付きデータなしでモデルを改善する。過信的な回答をペナルティ化し、未ラベルデータからの学習信号を活用することで、困難な推論ベンチマークにおいて大きな向上を達成。従来のゴールドラベル付きトレーニングに匹敵する性能を示し、効果的な推論の拡張が可能であることを示す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=87ySF7viys
著者による一言解説:
votingによるself-improvingなRLの枠組みから脱却し、全ての応答に対してペナルティ方式でペナルティを与え(一貫性の乏しいロールアウトなど)異なる重みを与えて学習シグナルとする。
[Paper Note] Soft Tokens, Hard Truths, Natasha Butt+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #LatentReasoning #Author Thread-Post Issue Date: 2025-09-24 GPT Summary- 本研究では、離散CoTからの蒸留なしに強化学習を用いて連続CoTを学習する新しい方法を提案。ソフトトークンを活用し、計算コストを抑えつつ数百のトークンを持つ連続CoTを学習可能。LlamaおよびQwenモデルでの実験により、連続CoTは離散トークンCoTと同等またはそれを上回る性能を示し、特に連続CoTでトレーニング後に離散トークンで推論するシナリオが最良の結果を得ることが確認された。さらに、連続CoTのRLトレーニングは、ドメイン外タスクにおけるベースモデルの予測保持を向上させることが明らかになった。 Comment
元ポスト:
解説:
著者ポスト:
ポイント解説:
[Paper Note] Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens, Chengshuai Zhao+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #Reasoning #read-later #reading Issue Date: 2025-08-27 GPT Summary- Chain-of-Thought (CoT) プロンプティングはLLMの性能向上に寄与するが、その深さには疑問が残る。本研究では、CoT推論が訓練データの構造的バイアスを反映しているかを調査し、訓練データとテストクエリの分布不一致がその効果に与える影響を分析。DataAlchemyという制御環境を用いて、CoT推論の脆弱性を明らかにし、一般化可能な推論の達成に向けた課題を強調する。
[Paper Note] TokenSkip: Controllable Chain-of-Thought Compression in LLMs, Heming Xia+, EMNLP'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Reasoning #EMNLP #Length #Inference #Author Thread-Post Issue Date: 2025-08-24 GPT Summary- Chain-of-Thought (CoT)はLLMの推論能力を向上させるが、長いCoT出力は推論遅延を増加させる。これに対処するため、重要度の低いトークンを選択的にスキップするTokenSkipを提案。実験により、TokenSkipはCoTトークンの使用を削減しつつ推論性能を維持することを示した。特に、Qwen2.5-14B-InstructでGSM8Kにおいて推論トークンを40%削減し、性能低下は0.4%未満であった。 Comment
元ポスト:
[Paper Note] Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety, Tomek Korbak+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #Safety Issue Date: 2025-07-16 GPT Summary- 人間の言語で「考える」AIシステムは、安全性向上のために思考の連鎖(CoT)を監視することで悪意のある意図を検出する機会を提供する。しかし、CoT監視は完璧ではなく、一部の不正行為が見逃される可能性がある。研究を進め、既存の安全手法と併せてCoT監視への投資を推奨する。モデル開発者は、開発の決定がCoTの監視可能性に与える影響を考慮すべきである。 Comment
元ポスト:
CoTを監視することで、たとえばモデルのよろしくない挙動(e.g., misalignmentなどの意図しない動作や、prompt injection等の不正行為)を検知することができ、特にAIがより長期的な課題に取り組む際にはより一層その内部プロセスを監視する手段が必要不可欠となるため、CoTの忠実性や解釈性が重要となる。このため、CoTの監視可能性が維持される(モデルのアーキテクチャや学習手法(たとえばCoTのプロセス自体は一見真っ当なことを言っているように見えるが、実はRewardHackingしている、など)によってはそもそもCoTが難読化し監視できなかったりするので、現状は脆弱性がある)、より改善していく方向にコミュニティとして動くことを推奨する。そして、モデルを研究開発する際にはモデルのCoT監視に関する評価を実施すべきであり、モデルのデプロイや開発の際にはCoTの監視に関する決定を組み込むべき、といったような提言のようである。
関連:
[Paper Note] Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought, Hanlin Zhu+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Author Thread-Post Issue Date: 2025-06-18 GPT Summary- 本研究では、連続CoTsを用いた二層トランスフォーマーが有向グラフ到達可能性問題を解決できることを証明。連続CoTsは複数の探索フロンティアを同時にエンコードし、従来の離散CoTsよりも効率的に解を導く。実験により、重ね合わせ状態が自動的に現れ、モデルが複数のパスを同時に探索することが確認された。 Comment
元ポスト:
[Paper Note] Wait, We Don't Need to "Wait" Removing Thinking Tokens Improves Reasoning Efficiency, Chenlong Wang+, EMNLP'25 Findings
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Reasoning #EMNLP #One-Line Notes Issue Date: 2025-06-18 GPT Summary- 自己反省を抑制する「NoWait」アプローチを提案し、推論の効率を向上。10のベンチマークで最大27%-51%の思考の連鎖の長さを削減し、有用性を維持。マルチモーダル推論のための効果的なソリューションを提供。 Comment
Wait, Hmmといったlong CoTを誘導するようなtokenを抑制することで、Accはほぼ変わらずに生成されるトークン数を削減可能、といった図に見える。Reasoningモデルでデコーディング速度を向上したい場合に効果がありそう。
元ポスト:
[Paper Note] Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs, Yu Xia+, COLING'25
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #COLING Issue Date: 2025-05-29 GPT Summary- Chain-of-Thought(CoT)を基にしたChain-of-X(CoX)手法の調査を行い、LLMsの課題に対処するための多様なアプローチを分類。ノードの分類とアプリケーションタスクに基づく分析を通じて、既存の手法の意義と今後の可能性を議論。研究者にとって有用なリソースを提供することを目指す。
[Paper Note] AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning, Chenwei Lou+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Reasoning #One-Line Notes Issue Date: 2025-05-21 GPT Summary- AdaCoTは、LLMがChain-of-Thought(CoT)の使用を適応的に決定する新しい枠組み。これにより、計算コストや非効率性を軽減しつつ、複雑なクエリにおける推論性能を維持する。特にProximal Policy Optimization(PPO)を用いたRL手法を導入し、Selective Loss Masking(SLM)で推論トリガを安定させ、実験ではCoTトリガー率を最大3.18%削減、応答トークン数を69.06%削減したことが示された。 Comment
RLのRewardにおいて、baseのリワードだけでなく、
- reasoningをなくした場合のペナルティ項
- reasoningをoveruseした場合のペナルティ項
- formattingに関するペナルティ項
を設定し、reasoningの有無を適切に判断できた場合にrewardが最大化されるような形にしている。(2.2.2)
が、multi-stageのRLでは(stageごとに利用するデータセットを変更するが)、データセットの分布には歪みがあり、たとえば常にCoTが有効なデータセットも存在しており(数学に関するデータなど)、その場合常にCoTをするような分布を学習してしまい、AdaptiveなCoT decisionが崩壊したり、不安定になってしまう(decision boundary collapseと呼ぶ)。特にこれがfinal stageで起きると最悪で、これまでAdaptiveにCoTされるよう学習されてきたものが全て崩壊してしまう。これを防ぐために、Selective Loss Maskingというlossを導入している。具体的には、decision token [^1]のlossへの貢献をマスキングするようにすることで、CoTが生じるratioにバイアスがかからないようにする。今回は、Decision tokenとして、`
[^1]: CoTするかどうかは多くの場合このDecision Tokenによって決まる、といったことがどっかの研究に示されていたはず
いつか必要になったらしっかり読むが、全てのステージでSelective Loss Maskingをしたら、SFTでwarm upした段階からあまりCoTのratioが変化しないような学習のされ方になる気がするが、どのステージに対してapplyするのだろうか。
openreview: https://openreview.net/forum?id=obXGSmmG70
[Paper Note] 100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models, Chong Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Survey #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #InstructionTuning #PPO (ProximalPolicyOptimization) #Reasoning #LongSequence #RewardHacking #GRPO #Contamination-free #VerifiableRewards #CurriculumLearning #One-Line Notes Issue Date: 2025-05-06 GPT Summary- RLMの進展は新しい言語モデルの進化を示し、DeepSeek-R1のリリースが社会的影響を生んでいる。DeepSeekの実装は完全にオープンではないが、多くの再現研究が登場し、同等の性能を達成。特にSFTとRLVRに重点を置き、データ構築や手法設計に関する知見を提供。実装の詳細と実験結果をまとめ、RLMの性能向上技術や開発課題についても議論。研究者が最新の進展を把握し、新しいアイデアを促進することを目指す。 Comment
元ポスト:
サーベイのtakeawayが箇条書きされている。
[Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #Analysis #NLP #LanguageModel #RepresentationLearning #Supervised-FineTuning (SFT) #SSM (StateSpaceModel) #ICML #PostTraining #read-later #One-Line Notes #CompressionValleys Issue Date: 2025-05-04 GPT Summary- 中間層の埋め込みが最終層を超えるパフォーマンスを示すことを分析し、情報理論や幾何学に基づくメトリクスを提案。32のテキスト埋め込みタスクで中間層が強力な特徴を提供することを実証し、AIシステムの最適化における中間層の重要性を強調。 Comment
現代の代表的な言語モデルのアーキテクチャ(decoder-only model, encoder-only model, SSM)について、最終層のembeddingよりも中間層のembeddingの方がdownstream task(MTEBの32Taskの平均)に、一貫して(ただし、これはMTEBの平均で見たらそうという話であり、個別のタスクで一貫して強いかは読んでみないとわからない)強いことを示した研究。
このこと自体は経験的に知られているのであまり驚きではないのだが(ただ、SSMでもそうなのか、というのと、一貫して強いというのは興味深い)、この研究はMatrix Based Entropyと呼ばれるものに基づいて、これらを分析するための様々な指標を定義し理論的な根拠を示し、Autoregressiveな学習よりもMasked Languageによる学習の方がこのようなMiddle Layerのボトルネックが緩和され、同様のボトルネックが画像の場合でも起きることを示し、CoTデータを用いたFinetuningについても分析している模様。この辺の貢献が非常に大きいと思われるのでここを理解することが重要だと思われる。あとで読む。
openreview: https://openreview.net/forum?id=WGXb7UdvTX
[Paper Note] When More is Less: Understanding Chain-of-Thought Length in LLMs, Yuyang Wu+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ICLR #One-Line Notes #Author Thread-Post Issue Date: 2025-04-30 GPT Summary- Chain-of-thought (CoT)推論は、LLMsの多段階推論能力を向上させるが、CoTの長さが増すと最初は性能が向上するものの、最終的には低下することが観察される。長い推論プロセスがノイズに脆弱であることを示し、理論的に最適なCoTの長さを導出。Length-filtered Voteを提案し、CoTの長さをモデルの能力とタスクの要求に合わせて調整する必要性を強調。 Comment
ICLR 2025 Best Paper Runner Up Award
元ポスト:
[Paper Note] RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval, Kaiyue Wen+, ICLR'25
Paper/Blog Link My Issue
#NLP #Transformer #In-ContextLearning #SSM (StateSpaceModel) #ICLR Issue Date: 2025-04-26 GPT Summary- 本論文では、RNNとトランスフォーマーの表現力の違いを調査し、特にRNNがChain-of-Thought(CoT)プロンプトを用いてトランスフォーマーに匹敵するかを分析。結果、CoTはRNNを改善するが、トランスフォーマーとのギャップを埋めるには不十分であることが判明。RNNの情報取得能力の限界がボトルネックであるが、Retrieval-Augmented Generation(RAG)やトランスフォーマー層の追加により、RNNはCoTを用いて多項式時間で解決可能な問題を解決できることが示された。 Comment
元ポスト:
関連:
- Transformers are Multi-State RNNs, Matanel Oren+, N/A, EMNLP'24
↑とはどういう関係があるだろうか?
[Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #LongSequence #ICML #RewardHacking #PostTraining #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2025-02-07 GPT Summary- 本研究では、大規模言語モデル(LLMs)における長い思考の連鎖(CoTs)推論のメカニズムを調査し、重要な要因を特定。主な発見は、(1) 教師ありファインチューニング(SFT)は必須ではないが効率を向上させる、(2) 推論能力は計算の増加に伴い現れるが、報酬の形状がCoTの長さに影響、(3) 検証可能な報酬信号のスケーリングが重要で、特に分布外タスクに効果的、(4) エラー修正能力は基本モデルに存在するが、RLを通じて効果的に奨励するには多くの計算が必要。これらの洞察は、LLMsの長いCoT推論を強化するためのトレーニング戦略の最適化に役立つ。 Comment
元ポスト:
元ポストのスレッド中に論文の11個の知見が述べられている。どれも非常に興味深い。DeepSeek-R1のテクニカルペーパーと同様、
- Long CoTとShort CoTを比較すると前者の方が到達可能な性能のupper bonudが高いことや、
- SFTを実施してからRLをすると性能が向上することや、
- RLの際にCoTのLengthに関する報酬を入れることでCoTの長さを抑えつつ性能向上できること、
- 数学だけでなくQAペアなどのノイジーだが検証可能なデータをVerifiableな報酬として加えると一般的なreasoningタスクで数学よりもさらに性能が向上すること、
- より長いcontext window sizeを活用可能なモデルの訓練にはより多くの学習データが必要なこと、
- long CoTはRLによって学習データに類似したデータが含まれているためベースモデルの段階でその能力が獲得されていることが示唆されること、
- aha momentはすでにベースモデル時点で獲得されておりVerifiableな報酬によるRLによって強化されたわけではなさそう、
など、興味深い知見が盛りだくさん。非常に興味深い研究。あとで読む。
[Paper Note] Perspective Transition of Large Language Models for Solving Subjective Tasks, Xiaolong Wang+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #ACL #Findings #One-Line Notes #Initial Impression Notes Issue Date: 2025-01-25 GPT Summary- 視点遷移を通じた推論(RPT)手法により、LLMsが主観的タスクにおいて視点を動的に選択できるようにします。本手法は専門家や第三者の視点を活用し、文脈をより適切に解釈することで、ニュアンスのある回答を提供します。広範な実験により、従来の固定視点手法を大きく上回る成果を示しました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=cFGPlRony5
"Subjective Task"とは例えば「メタファーの認識」や「ダークユーモアの検知」などがあり、これらは定量化しづらい認知的なコンテキストや、ニュアンスや感情などが強く関連しており、現状のLLMではチャレンジングだと主張している。
Subjective Taskでは、Reasoningモデルのように自動的にCoTのpathwayを決めるのは困難で、手動でpathwayを記述するのはチャレンジングで一貫性を欠くとした上で、複数の視点を組み合わせたPrompting(direct perspective, role-perspective, third-person perspectivfe)を実施し、最もConfidenceの高いanswerを採用することでこの課題に対処すると主張している。
イントロしか読めていないが、自動的にCoTのpathwayを決めるのも手動で決めるのも難しいという風にイントロで記述されているが、手法自体が最終的に3つの視点から回答を生成させるという枠組みに則っている(つまりSubjective Taskを解くための形式化できているので、自動的な手法でもできてしまうのではないか?と感じた)ので、イントロで記述されている主張の”難しさ”が薄れてしまっているかも・・・?と感じた。論文が解こうとしている課題の”難しさ”をサポートする材料がもっとあった方がよりmotivationが分かりやすくなるかもしれない、という感想を持った。
[Paper Note] Training Large Language Models to Reason in a Continuous Latent Space, Shibo Hao+, COLM'25
Paper/Blog Link My Issue
#NLP #LanguageModel #COLM #PostTraining #read-later #LatentReasoning #One-Line Notes Issue Date: 2024-12-12 GPT Summary- 新しい推論パラダイム「Coconut」を提案し、LLMの隠れ状態を連続的思考として利用。これにより、次の入力を連続空間でフィードバックし、複数の推論タスクでLLMを強化。Coconutは幅優先探索を可能にし、特定の論理推論タスクでCoTを上回る性能を示す。潜在的推論の可能性を探る重要な洞察を提供。 Comment
Chain of Continuous Thought
通常のCoTはRationaleをトークン列で生成するが、Coconutは最終的なhidden stateをそのまま次ステップの入力にすることで、トークンに制限されずにCoTさせるということらしい。あとでしっかり読む
おそらく学習の際に工夫が必要なので既存モデルのデコーディングを工夫してできます系の話ではないかも
OpenReview:
https://openreview.net/forum?id=tG4SgayTtk
ICLR'25にrejectされている。
ざっと最初のレビューに書かれているWeaknessを読んだ感じ
- 評価データが合成データしかなく、よりrealisticなデータで評価した方が良い
- CoTら非常に一般的に適用可能な技術なので、もっと広範なデータで評価すべき
- GSM8Kでは大幅にCOCONUTはCoTに性能が負けていて、ProsQAでのみにしかCoTに勝てていない
- 特定のデータセットでの追加の学習が必要で、そこで身につけたreasoning能力が汎化可能か明らかでない
といった感じに見える
COLM'25 openreview:
https://openreview.net/forum?id=Itxz7S4Ip3#discussion
COLM'25にAccept
[Paper Note] Logic-of-Thought: Injecting Logic into Contexts for Full Reasoning in Large Language Models, Tongxuan Liu+, NAACL'25, 2024.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #NAACL #Initial Impression Notes Issue Date: 2024-09-29 GPT Summary- LLMの論理推論能力は依然として課題が残る。Chain-of-Thoughtなどの手法は改善をもたらすが、信頼性に問題がある。そこで、命題論理を利用したLogic-of-Thought(LoT)プロンプトを提案し、論理情報を強化することで推論能力を向上させる。実験では、LoTが多数の論理推論タスクで既存手法の性能を大幅に向上させることを示し、特にReClorおよびRuleTakerデータセットでの改善が顕著であった。 Comment
※ このメモは当初の原稿に対するものであり、NAACLの原稿では修正されている。
SNSで話題になっているようだがGPT-3.5-TurboとGPT-4でしか比較していない上に、いつの時点のモデルかも記述されていないので、unreliableに見える
ReClorデータセットで性能が向上しているのは個人的に興味深い。
[Paper Note] AutoReason: Automatic Few-Shot Reasoning Decomposition, Arda Sevinc+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Zero/Few/ManyShotPrompting #RAG(RetrievalAugmentedGeneration) #Reasoning Issue Date: 2025-01-03 GPT Summary- Chain of Thought(CoT)を用いて、暗黙のクエリを明示的な質問に分解することで、LLMの推論能力を向上させる自動生成システムを提案。StrategyQAとHotpotQAデータセットで精度向上を確認し、特にStrategyQAで顕著な成果を得た。ソースコードはGitHubで公開。 Comment
元ポスト:
A Theoretical Understanding of Chain-of-Thought: Coherent Reasoning and Error-Aware Demonstration, Yingqian Cui+, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel Issue Date: 2024-11-13 GPT Summary- Few-shot Chain-of-Thought (CoT) プロンプティングはLLMsの推論能力を向上させるが、従来の研究は推論プロセスを分離された文脈内学習に依存している。本研究では、初期ステップからの一貫した推論(Coherent CoT)を統合することで、トランスフォーマーのエラー修正能力と予測精度を向上させることを理論的に示す。実験により、正しい推論経路と誤った推論経路を組み込むことでCoTを改善する提案の有効性を検証する。 Comment
元ポスト:
おもしろそうな研究
[Paper Note] To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning, Zayne Sprague+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-09-24 GPT Summary- CoTはLLMからの推論能力を引き出す標準手法だが、どのタスクで効果があるかを分析。100件以上の論文を対象にメタ分析を行い、14モデルと20データセットの評価を実施。結果、CoTは数理・論理タスクで性能向上をもたらすが、他のタスクでは効果が小さい。特に、等号を含む場合はCoTと同等の精度が得られ、記号的実行の改善に起因するものの、記号的ソルバーには劣る。CoTの選択的適用で推論コストを削減できることを示し、今後は中間計算を効果的に活用する新しいパラダイムが必要とされる。 Comment
CoTを100個以上の先行研究でmeta-analysisし(i.e. CoTを追加した場合のgainとタスクのプロット)、20個超えるデータセットで著者らが実験した結果、mathやsymbolic reasoning(12*4のように、シンボルを認識し、何らかの操作をして回答をする問題)が必要なタスクで、CoTは大きなgainが得られることがわかった(他はほとんどgainがない)。
openreview:
https://openreview.net/forum?id=w6nlcS8Kkn
metareviewによると、controlled experimentsを通じて、CoTの効果の大部分はPlanningではなく、信頼性の高い"実行"にあることが明らかになったとのこと。
下図を見るとこの時期はOpenAI o1やDeepSeek-R1の登場前であり、基本的にnon-thinking/reasoning modelによって実験がされていることには注意されたい。だが、昨今のAI AgentやReasoning Modelの挙動を鑑みるに、metareviewに記述されているCoTによって信頼性の高い"実行"が強化される点については実感できる。
ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2024-09-13 GPT Summary- 強化ファインチューニング(ReFT)を提案し、LLMsの推論能力を向上。SFTでモデルをウォームアップ後、PPOアルゴリズムを用いてオンライン強化学習を行い、豊富な推論パスを自動サンプリング。GSM8K、MathQA、SVAMPデータセットでSFTを大幅に上回る性能を示し、追加のトレーニング質問に依存せず優れた一般化能力を発揮。
[Paper Note] RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation, Zihao Wang+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #One-Line Notes #Initial Impression Notes Issue Date: 2024-04-14 GPT Summary- 情報検索を活用し思考の連鎖を修正することで、大規模言語モデルの推論及び生成能力が向上し、幻覚の抑制も確認。提案手法「retrieval-augmented thoughts(RAT)」は、生成された思考ステップを取得情報で順次修正し、GPT-3.5、GPT-4、CodeLLaMA-7bに適用した結果、コード生成で13.63%、数学的推論で16.96%、創作的執筆で19.2%、具現化タスク計画で42.78%の性能向上を達成。デモページはhttps://craftjarvis.github.io/RAT。 Comment
RAGにおいてCoTさせる際に、各reasoningのstepを見直させることでより質の高いreasoningを生成するRATを提案。Hallucinationが低減し、生成のパフォーマンスも向上するとのこと。
コンセプト自体はそりゃそうだよねという話なので、RAGならではの課題があり、それを解決した、みたいな話があるのかが気になる。
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models, Wenshan Wu+, N_A, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel Issue Date: 2024-04-08 GPT Summary- LLMsの空間推論能力を向上させるために、Visualization-of-Thought(VoT)プロンプティングを提案。VoTは、LLMsの推論トレースを可視化し、空間推論タスクで使用することで、既存のMLLMsを上回る性能を示す。VoTは、空間推論を促進するために「メンタルイメージ」を生成する能力を持ち、MLLMsでの有効性を示唆する。
Chain-of-Thought Reasoning Without Prompting, Xuezhi Wang+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #One-Line Notes Issue Date: 2024-03-05 GPT Summary- LLMsの推論能力を向上させるための新しいアプローチに焦点を当てた研究が行われている。この研究では、LLMsがプロンプトなしで効果的に推論できるかどうかを検証し、CoT推論パスをデコーディングプロセスを変更することで引き出す方法を提案している。提案手法は、従来の貪欲なデコーディングではなく、代替トークンを調査することでCoTパスを見つけることができることを示しており、様々な推論ベンチマークで有効性を示している。 Comment
以前にCoTを内部的に自動的に実施されるように事前学習段階で学習する、といった話があったと思うが、この研究はデコーディング方法を変更することで、promptingで明示的にinstructionを実施せずとも、CoTを実現するもの、ということだと思われる。
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding, Zilong Wang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #DataToTextGeneration #TabularData #ICLR #KeyPoint Notes Issue Date: 2024-01-24 GPT Summary- LLMsを使用したChain-of-Tableフレームワークは、テーブルデータを推論チェーン内で活用し、テーブルベースの推論タスクにおいて高い性能を発揮することが示された。このフレームワークは、テーブルの連続的な進化を表現し、中間結果の構造化情報を利用してより正確な予測を可能にする。さまざまなベンチマークで最先端のパフォーマンスを達成している。 Comment
Table, Question, Operation Historyから次のoperationとそのargsを生成し、テーブルを順次更新し、これをモデルが更新の必要が無いと判断するまで繰り返す。最終的に更新されたTableを用いてQuestionに回答する手法。Questionに回答するために、複雑なテーブルに対する操作が必要なタスクに対して有効だと思われる。
[Paper Note] The Impact of Reasoning Step Length on Large Language Models, Mingyu Jin+, ACL'24 Findings, 2024.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reasoning #ACL #Length #Findings Issue Date: 2024-01-16 GPT Summary- Chain of Thought(CoT)がLLMの推論能力向上に重要であることが示された。実験により、推論ステップの長さがLLMの性能に与える影響を調査。推論ステップを長くすることで、追加情報なしでも推論能力が向上し、逆に短くすると性能が著しく低下。これは、CoTプロンプトにおけるステップ数の重要性を示している。また、不正確な合理的根拠でも推論を維持できれば良好な結果が得られることが判明。タスクの複雑さに応じて、推論ステップの利点は異なることも観察された。
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models, Wenhao Yu+, N_A, EMNLP'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #RAG(RetrievalAugmentedGeneration) #EMNLP #KeyPoint Notes Issue Date: 2023-11-17 GPT Summary- 検索補完言語モデル(RALM)は、外部の知識源を活用して大規模言語モデルの性能を向上させるが、信頼性の問題や知識の不足による誤った回答がある。そこで、Chain-of-Noting(CoN)という新しいアプローチを導入し、RALMの頑健性を向上させることを目指す。CoNは、順次の読み取りノートを生成し、関連性を評価して最終的な回答を形成する。ChatGPTを使用してCoNをトレーニングし、実験結果はCoNを装備したRALMが標準的なRALMを大幅に上回ることを示している。特に、ノイズの多いドキュメントにおいてEMスコアで平均+7.9の改善を達成し、知識範囲外のリアルタイムの質問に対する拒否率で+10.5の改善を達成している。 Comment
モデルに検索されたドキュメント対するqueryのrelevance/accuracyの観点からnote-takingをさせることで、RAGの正確性や透明性を向上させる。たとえば、
- surface-levelの情報に依存せずにモデルに理解を促す
- 相反する情報が存在してもrelevantな情報を適切に考慮する,
- 回答プロセスの透明性・解釈性を向上させる
- 検索された文書に対する過剰な依存をなくす(文書が古い, あるいはノイジーな場合に有用)
などが利点として挙げられている。
下記が付録中のCoNで実際に利用されているプロンプト。
非常にシンプルな手法だが、結果としてはノイズが多い場合、CoNによるゲインが大きいことがわかる。
[Paper Note] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #ICML #One-Line Notes Issue Date: 2023-10-12 GPT Summary- Step-Back Promptingは、大規模言語モデル(LLMs)を使用して推論の手順をガイドするシンプルなプロンプティング技術です。この技術により、LLMsは具体的な詳細から高レベルの概念や基本原則を抽象化し、正しい推論経路をたどる能力を向上させることができます。実験により、Step-Back PromptingはSTEM、Knowledge QA、Multi-Hop Reasoningなどのタスクにおいて大幅な性能向上が観察されました。具体的には、MMLU Physics and Chemistryで7%、11%、TimeQAで27%、MuSiQueで7%の性能向上が確認されました。 Comment
また新しいのが出た。ユーザのクエリに対して直接応答しようとするのではなく、より高次で抽象的・原則的な問いを生成しそこから事実情報を得て、その事実情報にgroundingされた推論によって答えを導く。
openreview: https://openreview.net/forum?id=3bq3jsvcQ1
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic, Xufeng Zhao+, N_A, COLING'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #COLING Issue Date: 2023-10-09 GPT Summary- 大規模言語モデルの進歩は驚異的だが、多段階の推論には改善の余地がある。大規模言語モデルは知識を持っているが、推論には一貫性がなく、幻覚を示すことがある。そこで、Logical Chain-of-Thought(LogiCoT)というフレームワークを提案し、論理による推論パラダイムの効果を示した。
[Paper Note] Chain-of-Verification Reduces Hallucination in Large Language Models, Shehzaad Dhuliawala+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #Prompting #Hallucination #ACL #Selected Papers/Blogs #Verification Issue Date: 2023-09-30 GPT Summary- 私たちは、言語モデルが根拠のない情報を生成する問題に取り組んでいます。Chain-of-Verification(CoVe)メソッドを開発し、モデルが回答を作成し、検証し、最終的な回答を生成するプロセスを経ることで、幻想を減少させることができることを実験で示しました。 Comment
# 概要
ユーザの質問から、Verificationのための質問をplanningし、質問に対して独立に回答を得たうえでオリジナルの質問に対するaggreementを確認し、最終的に生成を実施するPrompting手法
# 評価
## dataset
- 全体を通じてclosed-bookの設定で評価
- Wikidata
- Wikipedia APIから自動生成した「“Who are some [Profession]s who were born in [City]?”」に対するQA pairs
- Goldはknowledge baseから取得
- 全56 test questions
- Gold Entityが大体600程度ありLLMは一部しか回答しないので、precisionで評価
- Wiki category list
- QUEST datasetを利用 [Paper Note] QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, arXiv'23, 2023.05
- 回答にlogical operationが不要なものに限定して頭に"Name some"をつけて質問を生成
- "Name some Mexican animated horror films" or "Name some Endemic orchids of Vietnam"
- 8個の回答を持つ55 test questionsを作成
- MultiSpanQA
- Reading Comprehensionに関するBenchmark dataset
- 複数の独立した回答(回答は連続しないスパンから回答が抽出される)から構成される質問で構成
- 特に、今回はclosed-book setting で実施
- すなわち、与えられた質問のみから回答しなければならず、知っている知識が問われる問題
- 418のtest questsionsで、各回答に含まれる複数アイテムのspanが3 token未満となるようにした
- QA例:
- Q: Who invented the first printing press and in what year?
- A: Johannes Gutenberg, 1450.
# 評価結果
提案手法には、verificationの各ステップでLLMに独立したpromptingをするかなどでjoint, 2-step, Factored, Factor+Revisedの4種類のバリエーションがあることに留意。
- joint: 全てのステップを一つのpromptで実施
- 2-stepは2つのpromptに分けて実施
- Factoredは各ステップを全て異なるpromptingで実施
- Factor+Revisedは異なるpromptで追加のQAに対するcross-checkをかける手法
結果を見ると、CoVEでhallucinationが軽減(というより、モデルが持つ知識に基づいて正確に回答できるサンプルの割合が増えるので実質的にhallucinationが低減したとみなせる)され、特にjointよりも2-step, factoredの方が高い性能を示すことがわかる。
Graph of Thoughts: Solving Elaborate Problems with Large Language Models, Maciej Besta+, N_A, AAAI'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AAAI Issue Date: 2023-08-22 GPT Summary- 私たちは、Graph of Thoughts(GoT)というフレームワークを紹介しました。これは、大規模言語モデル(LLMs)のプロンプティング能力を進化させるもので、任意のグラフとしてモデル化できることが特徴です。GoTは、思考の組み合わせやネットワーク全体の本質の抽出、思考の強化などを可能にします。さまざまなタスクで最先端の手法に比べて利点を提供し、LLMの推論を人間の思考に近づけることができます。 Comment
Chain of Thought [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
=> Self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
=> Thought Decomposition Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding, Yuxi Xie+, N/A, arXiv'23
=> Tree of Thoughts [Paper Note] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, arXiv'23, 2023.05
Tree of Thought Large Language Model Guided Tree-of-Thought, Jieyi Long, N/A, arXiv'23
=> Graph of Thought
[Paper Note] Teaching Arithmetic to Small Transformers, Nayoung Lee+, ICLR'24, 2023.07
Paper/Blog Link My Issue
#NLP #LanguageModel #NumericReasoning #Mathematics #KeyPoint Notes #Reading Reflections Issue Date: 2023-07-11 GPT Summary- 小型トランスフォーマーが次語予測を用いて基本的な算術演算(加算、乗算、平方根)を学習できるかを調査。従来のデータが効果的でないことを示し、形式変更で精度が向上することを確認。Chain-of-Thoughtスタイルのデータで訓練することで、事前訓練なしでも精度と収束速度を改善。算術データとテキストデータの相互作用や少数ショット promptingの影響を考察し、高品質なデータの重要性を強調。 Comment
小規模なtransformerに算術演算を学習させ、どのような学習データが効果的か調査。CoTスタイルの詳細なスクラッチパッドを学習データにすることで、plainなもの等と比較して、予測性能や収束速度などが劇的に改善した
結局next token predictionで学習させているみたいだけど、本当にそれで算術演算をモデルが理解しているのだろうか?という疑問がいつもある
↑この3年前の感想は、現在は良質なreasoning trajectioryを用いたSFTにってreasoning能力が強化できることを考えると一部解決されている。少なくとも、next token predictionによって(汎化性能は置いておいて)特定分野でのreasoning能力を身につけさせることができることは分かっているため、真に"理解"しているかはわからないが、少なくともモデル自身の能力で思考し問題を解けることは実験的に示されている。
事前学習によって知識を学習し、中間学習や事後学習で知識の使い方や特定の能力を現在では伸ばしているが、この研究だはスクラッチパッドを用いた事前学習データを使っているようなので、数学の解き方の知識と使い方を同時に学習できていると考えられる。
(3年前の感想を今見返すとおもしろいな)
openreview: https://openreview.net/forum?id=dsUB4bst9S
[Paper Note] Active Prompting with Chain-of-Thought for Large Language Models, Shizhe Diao+, ACL'24, 2023.02
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #ACL #KeyPoint Notes #needs-revision Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)の性能向上には、タスク特有のプロンプト設計が重要であり、特に連鎖的思考(CoT)を活用したアプローチが効果的です。この研究では、Active-Promptという新手法を提案し、タスク特有の質問に対する最適なアノテーションを選定することでLLMsを適応させます。不確実性に基づくアクティブラーニングを取り入れ、最も不確実な質問を対象にする指標を導入。実験により、提案手法が8つの複雑な推論タスクで最先端の成績を達成し、有効性が示されました。 Comment
しっかりと読めていないが、CoT-answerが存在しないtrainingデータが存在したときに、nサンプルにCoTとAnswerを与えるだけでFew-shotの予測をtestデータに対してできるようにしたい、というのがモチベーションっぽい
そのために、questionに対して、training dataに対してFew-Shot CoTで予測をさせた場合やZero-Shot CoTによって予測をさせた場合などでanswerを取得し、answerのばらつき度合いなどから不確実性を測定する。
そして、不確実性が高いCoT-Answerペアを取得し、人間が手作業でCoTと回答のペアを与え、その人間が作成したものを用いてTestデータに対してFewShotしましょう、ということだと思われる。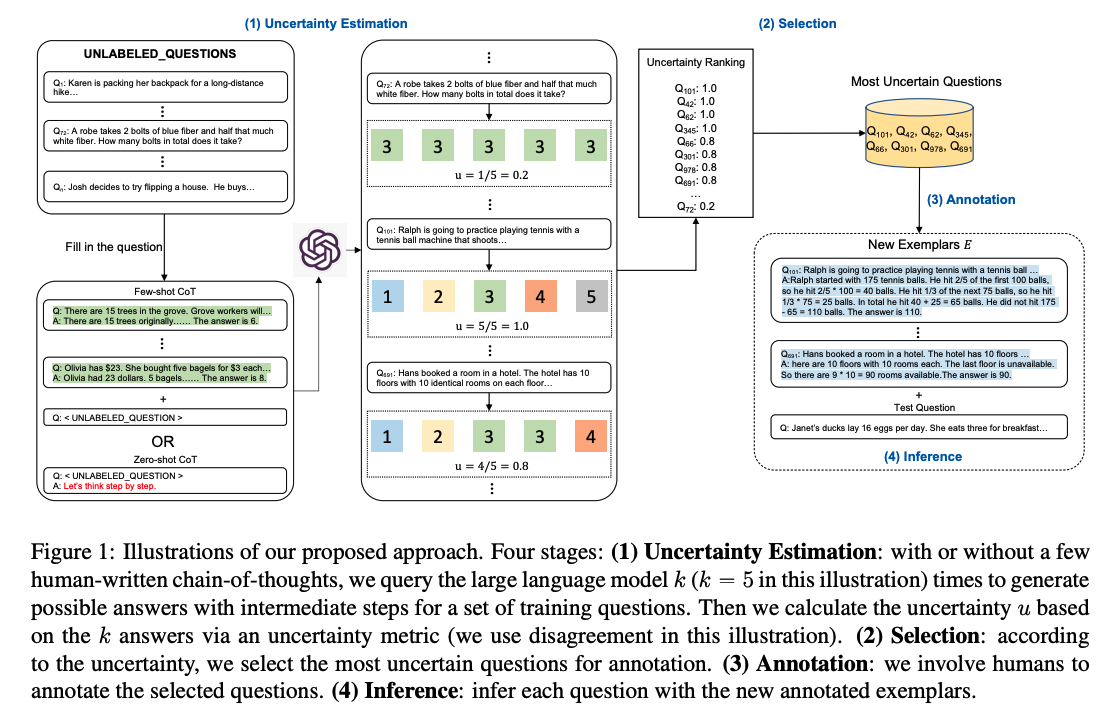
[Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Prompting #AutomaticPromptEngineering #NAACL #Findings #Surface-level Notes Issue Date: 2023-04-25 GPT Summary- Iter-CoTは、LLMsの推論チェーンのエラーを修正し、正確で包括的な推論を実現するための反復的ブートストラッピングアプローチを提案。適度な難易度の質問を選択することで、一般化能力を向上させ、10のデータセットで競争力のある性能を達成。 Comment
Zero shot CoTからスタートし、正しく問題に回答できるようにreasoningを改善するようにpromptをreviseし続けるループを回す。最終的にループした結果を要約し、それらをプールする。テストセットに対しては、プールの中からNshotをサンプルしinferenceを行う。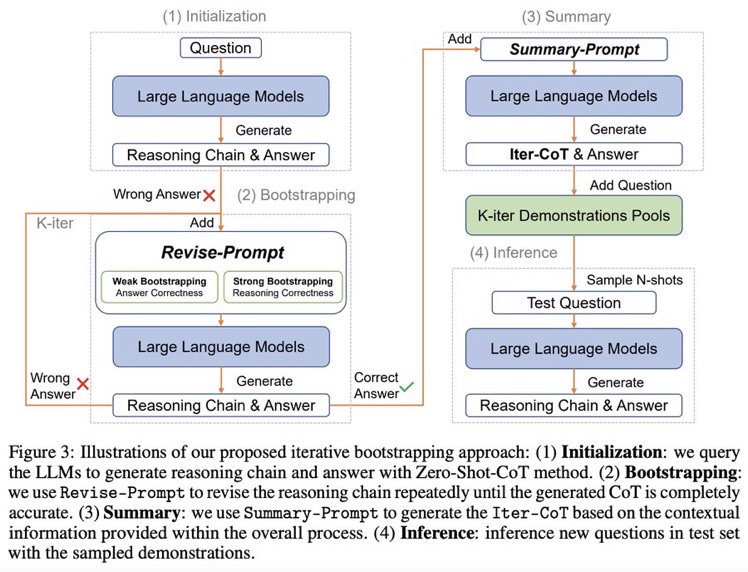
できそうだなーと思っていたけど、早くもやられてしまった
実装: https://github.com/GasolSun36/Iter-CoT
# モチベーション: 既存のCoT Promptingの問題点
## Inappropriate Examplars can Reduce Performance
まず、既存のCoT prompting手法は、sampling examplarがシンプル、あるいは極めて複雑な(hop-based criterionにおいて; タスクを解くために何ステップ必要かという情報; しばしば人手で付与されている?)サンプルをサンプリングしてしまう問題がある。シンプルすぎるサンプルを選択すると、既にLLMは適切にシンプルな回答には答えられるにもかかわらず、demonstrationが冗長で限定的になってしまう。加えて、極端に複雑なexampleをサンプリングすると、複雑なquestionに対しては性能が向上するが、シンプルな問題に対する正答率が下がってしまう。
続いて、demonstration中で誤ったreasoning chainを利用してしまうと、inference時にパフォーマンスが低下する問題がある。下図に示した通り、誤ったdemonstrationが増加するにつれて、最終的な予測性能が低下する傾向にある。
これら2つの課題は、現在のメインストリームな手法(questionを選択し、reasoning chainを生成する手法)に一般的に存在する。
- [Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
- [Paper Note] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, KaShun Shum+, EMNLP'23, 2023.02
のように推論時に適切なdemonstrationを選択するような取り組みは行われてきているが、test questionに対して推論するために、適切なexamplarsを選択するような方法は計算コストを増大させてしまう。
これら研究は誤ったrationaleを含むサンプルの利用を最小限に抑えて、その悪影響を防ぐことを目指している。
一方で、この研究では、誤ったrationaleを含むサンプルを活用して性能を向上させる。これは、たとえば学生が難解だが回答可能な問題に取り組むことによって、問題解決スキルを向上させる方法に類似している(すなわち、間違えた部分から学ぶ)。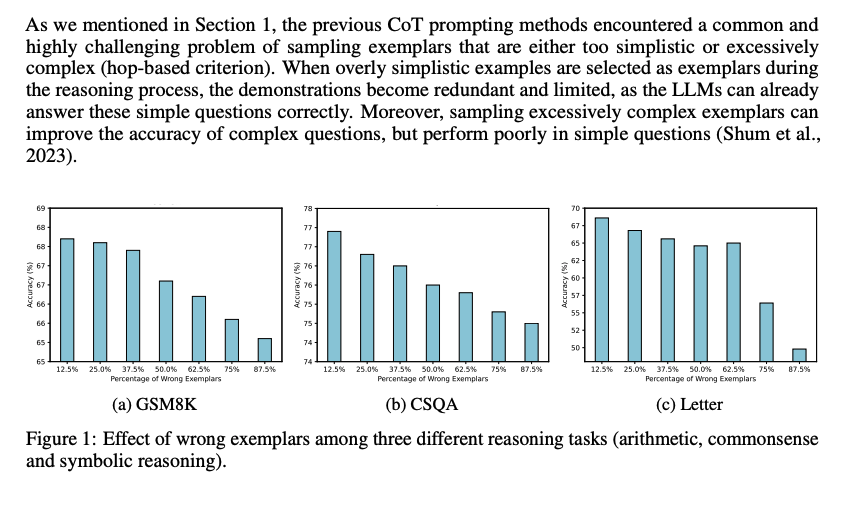
## Large Language Models can self-Correct with Bootstrapping
Zero-Shot CoTでreasoning chainを生成し、誤ったreasoning chainを生成したpromptを**LLMに推敲させ(self-correction)**正しい出力が得られるようにする。こういったプロセスを繰り返し、correct sampleを増やすことでどんどん性能が改善していった。これに基づいて、IterCoTを提案。
# IterCoT: Iterative Bootstrapping in Chain-of-Thought Prompting
IterCoTはweak bootstrappingとstrong bootstrappingによって構成される。
## Weak bootstrapping
- Initialization
- Training setに対してZero-shot CoTを実施し、reasoning chainとanswerを得
- Bootstrapping
- 回答が誤っていた各サンプルに対して、Revise-Promptを適用しLLMに誤りを指摘し、新しい回答を生成させる。
- 回答が正確になるまでこれを繰り返す。
- Summarization
- 正しい回答が得られたら、Summary-Promptを利用して、これまでの誤ったrationaleと、正解のrationaleを利用し、最終的なreasoning chain (Iter-CoT)を生成する。
- 全体のcontextual informationが加わることで、LLMにとって正確でわかりやすいreasoning chainを獲得する。
- Inference
- questionとIter-Cotを組み合わせ、demonstration poolに加える
- inference時はランダムにdemonstraction poolからサンプリングし、In context learningに利用し推論を行う
## Strong Bootstrapping
コンセプトはweak bootstrappingと一緒だが、Revise-Promptでより人間による介入を行う。具体的には、reasoning chainのどこが誤っているかを明示的に指摘し、LLMにreasoning chainをreviseさせる。
これは従来のLLMからの推論を必要としないannotationプロセスとは異なっている。何が違うかというと、人間によるannnotationをLLMの推論と統合することで、文脈情報としてreasoning chainを修正することができるようになる点で異なっている。
# 実験
Manual-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Random-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Auto-CoT
- [Paper Note] Active Prompting with Chain-of-Thought for Large Language Models, Shizhe Diao+, ACL'24, 2023.02
と比較。
Iter-CoTが11個のデータセット全てでoutperformした。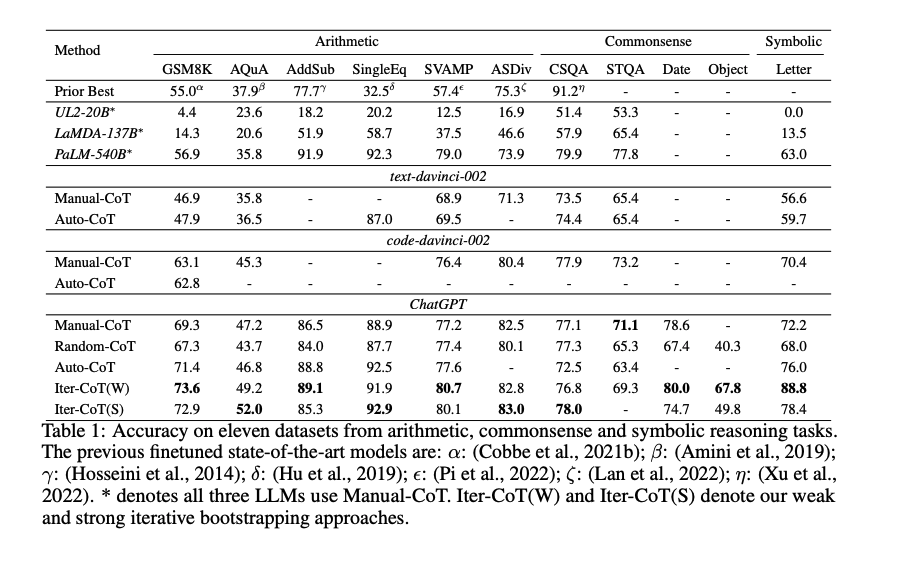
weak bootstrapingのiterationは4回くらいで頭打ちになった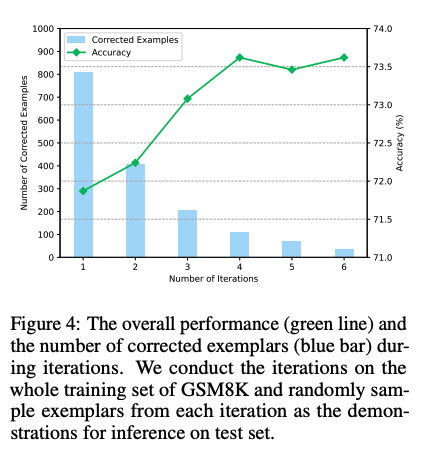
また、手動でreasoning chainを修正した結果と、contextにannotation情報を残し、最後にsummarizeする方法を比較した結果、後者の方が性能が高かった。このため、contextの情報を利用しsummarizeすることが効果的であることがわかる。
Navigate through Enigmatic Labyrinth A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future, Zheng Chu+, arXiv'23
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #ACL Issue Date: 2025-01-06 GPT Summary- 推論はAIにおいて重要な認知プロセスであり、チェーン・オブ・ソートがLLMの推論能力を向上させることが注目されている。本論文では関連研究を体系的に調査し、手法を分類して新たな視点を提供。課題や今後の方向性についても議論し、初心者向けの導入を目指す。リソースは公開されている。
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks, Wenhu Chen+, TMLR'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #TMLR #KeyPoint Notes Issue Date: 2025-01-05 GPT Summary- 段階的な推論を用いた数値推論タスクにおいて、Chain-of-thoughts prompting(CoT)の進展があり、推論をプログラムとして表現する「Program of Thoughts」(PoT)を提案。PoTは外部コンピュータで計算を行い、5つの数学問題データセットと3つの金融QAデータセットで評価した結果、少数ショットおよびゼロショット設定でCoTに対して約12%の性能向上を示した。自己一貫性デコーディングとの組み合わせにより、数学問題データセットで最先端の性能を達成。データとコードはGitHubで公開。 Comment
1. LLMsは算術演算を実施する際にエラーを起こしやすく、特に大きな数に対する演算を実施する際に顕著
2. LLMsは複雑な数式(e.g. 多項式, 微分方程式)を解くことができない
3. LLMsはiterationを表現するのが非常に非効率
の3点を解決するために、外部のインタプリタに演算処理を委譲するPoTを提案。PoTでは、言語モデルにreasoning stepsをpython programで出力させ、演算部分をPython Interpreterに実施させる。
テキスト、テーブル、対話などの多様なinputをサポートする5つのMath Word Problem (MWP), 3つのFinancial Datasetで評価した結果、zero-shot, few-shotの両方の設定において、PoTはCoTをoutpeformし、また、Self-Consistencyと組み合わせた場合も、PoTはCoTをoutperformした。
Recursion of Thought: A Divide-and-Conquer Approach to Multi-Context Reasoning with Language Models, Soochan Lee+, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #KeyPoint Notes Issue Date: 2025-01-05 GPT Summary- Recursion of Thought(RoT)という新しい推論フレームワークを提案し、言語モデル(LM)が問題を複数のコンテキストに分割することで推論能力を向上させる。RoTは特別なトークンを導入し、コンテキスト関連の操作をトリガーする。実験により、RoTがLMの推論能力を劇的に向上させ、数十万トークンの問題を解決できることが示された。 Comment
divide-and-conquerで複雑な問題に回答するCoT手法。生成過程でsubquestionが生じた際にモデルに特殊トークン(GO)を出力させ、subquestionの回答部分に特殊トークン(THINK)を出力させるようにSupervisedに学習させる。最終的にTHINKトークン部分は、subquestionを別途モデルによって解いた回答でreplaceして、最終的な回答を得る。
subquestionの中でさらにsubquestionが生じることもあるため、再帰的に処理される。
四則演算と4種類のアルゴリズムに基づくタスクで評価。アルゴリズムに基づくタスクは、2つの数のlongest common subsequenceを見つけて、そのsubsequenceとlengthを出力するタスク(LCS)、0-1 knapsack問題、行列の乗算、数値のソートを利用。x軸が各タスクの問題ごとの問題の難易度を表しており、難易度が上がるほど提案手法によるgainが大きくなっているように見える。
Without Thoughtでは直接回答を出力させ、CoTではground truthとなるrationaleを1つのcontextに与えて回答を生成している。RoTではsubquestionごとに回答を別途得るため、より長いcontextを活用して最終的な回答を得る点が異なると主張している。
感想としては、詳細が書かれていないが、おそらくRoTはSFTによって各タスクに特化した学習をしていると考えられる(タスクごとの特殊トークンが存在するため)。ベースラインとしてRoT無しでSFTしたモデルあった方が良いのではないか?と感じる。
また、学習データにおけるsubquestionとsubquestionに対するground truthのデータ作成方法は書かれているが、そもそも元データとして何を利用したかや、その統計量も書かれていないように見える。あと、そもそも機械的に学習データを作成できない場合どうすれば良いのか?という疑問は残る。
読んでいた時にAuto-CoTとの違いがよくわからなかったが、Related Workの部分にはAuto-CoTは動的、かつ多様なデモンストレーションの生成にフォーカスしているが、AutoReasonはquestionを分解し、few-shotの promptingでより詳細なrationaleを生成することにフォーカスしている点が異なるという主張のようである。
- [Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
Auto-CoTとの差別化は上記で理解できるが、G-Evalが実施しているAuto-CoTとの差別化はどうするのか?という風にふと思った。論文中でもG-Evalは引用されていない。
素朴にはAutoReasonはSFTをして学習をしています、さらにRecursiveにquestionをsubquestionを分解し、分解したsubquestionごとに回答を得て、subquestionの回答結果を活用して最終的に複雑なタスクの回答を出力する手法なので、G-Evalが実施している同一context内でrationaleをzeroshotで生成する手法よりも、より複雑な問題に回答できる可能性が高いです、という主張にはなりそうではある。
- [Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
ICLR 2023 OpenReview:
https://openreview.net/forum?id=PTUcygUoxuc
- 提案手法は一般的に利用可能と主張しているが、一般的に利用するためには人手でsubquestionの学習データを作成する必要があるため十分に一般的ではない
- 限られたcontext長に対処するために再帰を利用するというアイデアは新しいものではなく、数学の定理の証明など他の設定で利用されている
という理由でrejectされている。
[Paper Note] Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents, Zhuosheng Zhang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Tutorial #NLP #LanguageModel #One-Line Notes Issue Date: 2023-11-21 GPT Summary- LLMsは複雑な推論タスクにおいて驚異的な性能を示し、CoT推論技術を通じて解釈性や柔軟性を高めている。自律的な言語エージェントの開発が進み、様々な環境で行動を実行する能力を持つ。論文ではCoTの基礎機構、パラダイムシフト、言語エージェントの台頭を探求し、今後の研究の方向性について議論している。初心者から経験豊富な研究者まで広範囲な読者を対象にしている。 Comment
CoTに関するチュートリアル論文
[Paper Note] Orca 2: Teaching Small Language Models How to Reason, Arindam Mitra+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #SmallModel #OpenWeight #Reading Reflections Issue Date: 2023-11-21 GPT Summary- Orca 2 は小型 LM の推論能力を高めるために、異なるタスクごとに様々な解法戦略を学習させることを目指す。段階的推論や思い出し-推論-生成などを用いて、小型モデルの潜在能力を最大化し、約100のタスクで評価を行い、同規模モデルを大きく上回る性能を達成。重みは公開され、開発研究の支援が期待される。 Comment
ポイント解説:
HF: https://huggingface.co/microsoft/Orca-2-13b
論文を読むとChatGPTのデータを学習に利用しているが、現在は競合となるモデルを作ることは規約で禁止されているので注意
[Paper Note] Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel Issue Date: 2023-11-21 GPT Summary- 言語モデルにおける推論能力向上のため、明示的な思考の連鎖推論ではなく、隠れ状態を用いた暗黙の推論を提案。教師モデルから蒸留したステップで、層間の隠れ状態を利用し、効率的な推論を実現。実験により、明示的チェーンなしで課題を解決し、推論速度も維持されることを示した。 Comment
これは非常に興味深い話
openreview: https://openreview.net/forum?id=9cumTvvlHG
Contrastive Chain-of-Thought Prompting, Yew Ken Chia+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting Issue Date: 2023-11-19 GPT Summary- 言語モデルの推論を改善するために、対照的なchain of thoughtアプローチを提案する。このアプローチでは、有効な推論デモンストレーションと無効な推論デモンストレーションの両方を提供し、モデルが推論を進める際にミスを減らすようにガイドする。また、自動的な方法を導入して対照的なデモンストレーションを構築し、汎化性能を向上させる。実験結果から、対照的なchain of thoughtが一般的な改善手法として機能することが示された。
[Paper Note] Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster, Hongxuan Zhang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Prompting #Initial Impression Notes Issue Date: 2023-11-15 GPT Summary- FastCoTは、追加トレーニングやLLM改変なしに並列デコードを実現するモデル非依存のフレームワークです。可変長コンテキストウィンドウを使用し、並列かつ自己回帰的なデコードを行うことで、GPUリソースを最適化します。これにより、因果型トランスフォーマーの従来手法よりも迅速な応答が可能になります。実験結果では、FastCoTが推論時間を約20%短縮しつつ、性能低下も最小限であることが示されています。 Comment
論文中の図を見たが、全くわからなかった・・・。ちゃんと読まないとわからなそうである。
[Paper Note] Eliminating Reasoning via Inferring with Planning: A New Framework to Guide LLMs' Non-linear Thinking, Yongqi Tong+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Prompting #Initial Impression Notes Issue Date: 2023-10-24 GPT Summary- 非線形思考を模倣するために、Inferential Exclusion Prompting (IEP) を提案。IEPは計画後にNLIを活用し、解に対する推論を振り返ることで複雑な思考過程を再現。実証研究により、IEPがCoTを一貫して上回ることを確認。IEPとCoTを統合することでLLMsの性能向上も観察。新たに導入したMental-Ability Reasoning Benchmark (MARB)は9,115問からなり、LLMsの論理能力を評価するための有望な方法とされ、近日中に公開予定。 Comment
論文自体は読めていないのだが、CoTが線形的だという主張がよくわからない。
CoTはAutoregressiveな言語モデルに対して、コンテキストを自己生成したテキストで利用者の意図した方向性にバイアスをかけて補完させ、
利用者が意図した通りのアウトプットを最終的に得るためのテクニック、だと思っていて、
線形的だろうが非線形的だろうがどっちにしろCoTなのでは。
[Paper Note] Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models, Anni Zou+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #Initial Impression Notes Issue Date: 2023-10-13 GPT Summary- GeM-CoTは、未知の入力問に対する一般化可能なCoTプロンプティング手法を提案。問の型を分類し、データプールから自動デモを生成することで、性能と一般化のギャップを解消。これにより、10の公開推論タスクと23のBBHタスクで優れたパフォーマンスを実現。 Comment
色々出てきたがなんかもう色々組み合わせれば最強なんじゃね?って気がしてきた。
openreview: https://openreview.net/forum?id=79tJB1eTmb
[Paper Note] Large Language Models as Analogical Reasoners, Michihiro Yasunaga+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #In-ContextLearning #ICLR #KeyPoint Notes #Reading Reflections Issue Date: 2023-10-07 GPT Summary- アナロジー的プロンプティングを用いて、言語モデルに問題解決前に関連する例示を生成させる新手法を提案。ラベリング不要で汎用性が高く、適応性もある。実験では、GSM8K、MATH、Codeforces、BIG-Benchの推論タスクで0ショットおよび少数ショットCoTを上回る性能を示した。 Comment
以下、著者ツイートのざっくり翻訳:
人間は新しい問題に取り組む時、過去に解いた類義の問題を振り返り、その経験を活用する。これをLLM上で実践できないか?というのがアイデア。
Analogical Promptingでは、問題を解く前に、適切なexamplarを自動生成(problemとsolution)させ、コンテキストとして利用する。
これにより、examplarは自己生成されるため、既存のCoTで必要なexamplarのラベリングや検索が不要となることと、解こうとしている問題に合わせてexamplarを調整し、推論に対してガイダンスを提供することが可能となる。
実験の結果、数学、コード生成、BIG-Benchでzero-shot CoT、few-shot CoTを上回った。
LLMが知っており、かつ得意な問題に対してならうまく働きそう。一方で、LLMが苦手な問題などは人手作成したexamplarでfew-shotした方が(ある程度)うまくいきそうな予感がする。うまくいきそうと言っても、そもそもLLMが苦手な問題なのでfew-shotした程度では焼石に水だとは思うが。
openreview: https://openreview.net/forum?id=AgDICX1h50
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models, Bilgehan Sel+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting Issue Date: 2023-09-04 GPT Summary- 大規模言語モデル(LLMs)の推論能力を向上させるために、新しい戦略「Algorithm of Thoughts」を提案している。この戦略では、LLMsをアルゴリズム的な推論経路に導き、わずか1つまたは数個のクエリでアイデアの探索を拡大する。この手法は、以前の単一クエリ手法を上回り、マルチクエリ戦略と同等の性能を発揮する。また、LLMを指導するアルゴリズムを使用することで、アルゴリズム自体を上回るパフォーマンスが得られる可能性があり、LLMが最適化された検索に自己の直感を織り込む能力を持っていることを示唆している。
Large Language Model Guided Tree-of-Thought, Jieyi Long, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting Issue Date: 2023-08-22 GPT Summary- この論文では、Tree-of-Thought(ToT)フレームワークを紹介し、自己回帰型の大規模言語モデル(LLM)の問題解決能力を向上させる新しいアプローチを提案しています。ToTは、人間の思考方法に触発された技術であり、複雑な推論タスクを解決するためにツリー状の思考プロセスを使用します。提案手法は、LLMにプロンプターエージェント、チェッカーモジュール、メモリモジュール、およびToTコントローラーなどの追加モジュールを組み込むことで実現されます。実験結果は、ToTフレームワークがSudokuパズルの解決成功率を大幅に向上させることを示しています。
Teaching Small Language Models to Reason, ACL'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Distillation #ACL Issue Date: 2023-07-18 GPT Summary- 本研究では、大規模な言語モデルの推論能力を小さなモデルに転送するための知識蒸留を探求しました。具体的には、大きな教師モデルによって生成された出力を用いて学生モデルを微調整し、算術、常識、象徴的な推論のタスクでのパフォーマンスを向上させることを示しました。例えば、T5 XXLの正解率は、PaLM 540BとGPT-3 175Bで生成された出力を微調整することで、それぞれ8.11%から21.99%および18.42%に向上しました。
[Paper Note] SCOTT: Self-Consistent Chain-of-Thought Distillation, Peifeng Wang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Distillation #ACL #One-Line Notes Issue Date: 2023-07-14 GPT Summary- 大規模言語モデル(LM)は、連鎖思考(CoT)プロンプティングを通じて自由形式の根拠を生成する能力を示すが、生成された根拠が予測と整合する保証はない。本研究では、大規模教師モデルから小さく自己一貫性を持つCoTモデルを獲得するための忠実な知識蒸留法を提案。対比的デコードを用いて金標準解答を支持する根拠を誘出し、不整合な予測を防ぐ仕組みを構築。実験で、性能が同等でありながら、提案手法がより忠実なCoT根拠を生成できることを示した。解析により、モデルが意思決定時に根拠を重視することが確認され、根拠の精練がさらなる性能向上につながる可能性が示唆された。 Comment
CoTのパフォーマンス向上がパラメータ数が大きいモデルでないと発揮せれないことは元論文 [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01 で考察されており、それをより小さいモデルに蒸留し発揮できるようにする、おもしろい
OlaGPT: Empowering LLMs With Human-like Problem-Solving Abilities, Yuanzhen Xie+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel Issue Date: 2023-06-16 GPT Summary- 本論文では、人間の認知フレームワークを模倣することで、複雑な推論問題を解決するための新しい知的フレームワークであるOlaGPTを提案しています。OlaGPTは、注意、記憶、推論、学習などの異なる認知モジュールを含み、以前の誤りや専門家の意見を動的に参照する学習ユニットを提供しています。また、Chain-of-Thought(COT)テンプレートと包括的な意思決定メカニズムも提案されています。OlaGPTは、複数の推論データセットで厳密に評価され、最先端のベンチマークを上回る優れた性能を示しています。OlaGPTの実装はGitHubで利用可能です。
[Paper Note] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-05-20 GPT Summary- 言語モデルは一般的な問題解決に広がっているが、推論は依然としてトークンレベルの左から右への決定に制限されている。これを克服するために、新しい「Tree of Thoughts(ToT)」フレームワークを導入。ToTは、思考の連鎖を一般化し、中間ステップを探索できるようにし、複数の推論経路を自己評価することで意図的な意思決定を可能にする。実験では、ToTがGame of 24やCreative Writingなどの新規タスクで言語モデルの問題解決能力を顕著に向上させることが示された。例えば、Game of 24では新手法が74%の成功率を達成した。 Comment
Self Concistencyの次
Non trivialなプランニングと検索が必要な新たな3つのタスクについて、CoT w/ GPT4の成功率が4%だったところを、ToTでは74%を達成
論文中の表ではCoTのSuccessRateが40%と書いてあるような?
[Paper Note] Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting, Miles Turpin+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Faithfulness #NeurIPS #needs-revision Issue Date: 2023-05-09 GPT Summary- LLMは段階的推論(CoT)を通じて高い性能を発揮するが、CoTの説明は予測の真の理由を誤って表現することがある。入力にバイアスを与えられると、誤答を正当化する説明が生成され、精度が最大36%低下することが示された。特に、社会的バイアスに関連する場合、モデルの説明がステレオタイプを強化し、バイアスの影響について言及しない。これにより、CoTの説明は一見もっともらしいが誤導的であり、信頼性を高めるリスクを伴う。より透明なシステムを構築するためには、CoTの信頼性を向上させるか、代替手法を検討すべきである。
[Paper Note] Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, Mirac Suzgun+, ACL'23, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Zero/Few/ManyShotPrompting #ACL #One-Line Notes Issue Date: 2023-05-04 GPT Summary- BIG-Benchは、言語モデルの限界を超えたタスクに焦点を当てた評価スイートであり、モデルはすでに65%のタスクで平均的な人間評価者を上回っている。本研究では、BBH(BIG-Bench Hard)として知られる、従来の評価で人間を下回った23の困難なタスクを分析。連鎖思考(CoT)プロンプティングを用いることで、PaLMは10タスク、Codexは17タスクで人間評価者を上回ることを示す。多段階の推論が求められるため、CoTなしの評価はモデルの性能を過小評価し、CoTはBBHタスクの性能向上に寄与することが明らかになった。 Comment
単なるfewshotではなく、CoT付きのfewshotをすると大幅にBIG-Bench-hardの性能が向上するので、CoTを使わないanswer onlyの設定はモデルの能力の過小評価につながるよ、という話らしい
[Paper Note] Exploring the Curious Case of Code Prompts, Li Zhang+, NLRSE'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #Reasoning #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- コード風のプロンプトによる構造化推論の性能向上が示されたが、その効果は限られたタスクに留まる。本研究では、davinci系のモデルに対して、QAや感情分析など幅広いタスクでコードとテキストプロンプトを比較し、全体としてコードプロンプトがテキストプロンプトを上回ることはなかった。タスクによってはコードプロンプトが有利な場合もあったが、全てのタスクに当てはまるわけではなく、テキスト指示によるファインチューニングがコードプロンプトの性能向上に寄与することを示した。 Comment
コードベースのLLMに対して、reasoningタスクを解かせる際には、promptもコードにすると10パーセント程度性能上がる場合があるよ、という研究。
ただし、平均的にはテキストプロンプトの方が良く、一部タスクで性能が改善する、という温度感な模様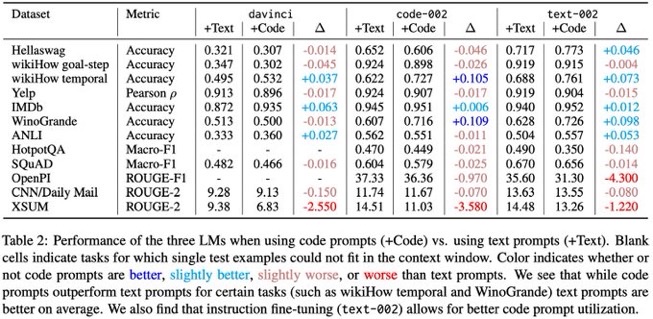
コードベースのモデルをtextでinstruction tuningしている場合でも、効果があるタスクがある。
[Paper Note] Answering Questions by Meta-Reasoning over Multiple Chains of Thought, Ori Yoran+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #Prompting #EMNLP #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 複数の推論チェーンを考慮したMulti-Chain Reasoning(MCR)を提案。これにより、異なるチェーン間の情報を統合し、回答生成時に関連性の高い事実を選択することで、より質の高い説明を提供。7つのマルチホップQAデータセットで優れた性能を示し、人間による検証も可能な高品質な説明を実現。 Comment
self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
のようなvoting basedなアルゴリズムは、複数のCoTのintermediate stepを捨ててしまい、結果だけを採用するが、この研究は複数のCoTの中からquestionに回答するために適切なfactual informationを抽出するMeta Reasonerを導入し、複数のCoTの情報を適切に混在させて適切な回答を得られるようにした。
7個のMulti Hop QAデータでstrong baselineをoutperformし、人間が回答をverificationするための高品質な説明を生成できることを示した。
openreview: https://openreview.net/forum?id=ebSOK1nV2r
[Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
Paper/Blog Link My Issue
#NLP #LanguageModel #ICLR #Test-Time Scaling #Selected Papers/Blogs #MajorityVoting Issue Date: 2023-04-27 GPT Summary- 自己一貫性という新しいデコーディング戦略を提案し、chain-of-thought promptingの性能を向上。多様な推論経路をサンプリングし、一貫した答えを選択することで、GSM8KやSVAMPなどのベンチマークで顕著な改善を達成。 Comment
self-consistencyと呼ばれる新たなCoTのデコーディング手法を提案。
これは、難しいreasoningが必要なタスクでは、複数のreasoningのパスが存在するというintuitionに基づいている。
self-consistencyではまず、普通にCoTを行う。そしてgreedyにdecodingする代わりに、以下のようなプロセスを実施する:
1. 多様なreasoning pathをLLMに生成させ、サンプリングする。
2. 異なるreasoning pathは異なるfinal answerを生成する(= final answer set)。
3. そして、最終的なanswerを見つけるために、reasoning pathをmarginalizeすることで、final answerのsetの中で最も一貫性のある回答を見出す。
これは、もし異なる考え方によって同じ回答が導き出されるのであれば、その最終的な回答は正しいという経験則に基づいている。
self-consistencyを実現するためには、複数のreasoning pathを取得した上で、最も多いanswer a_iを選択する(majority vote)。これにはtemperature samplingを用いる(temperatureを0.5やら0.7に設定して、より高い信頼性を保ちつつ、かつ多様なoutputを手に入れる)。
temperature samplingについては[こちら](
https://openreview.net/pdf?id=rygGQyrFvH)の論文を参照のこと。
sampling数は増やせば増やすほど性能が向上するが、徐々にサチってくる。サンプリング数を増やすほどコストがかかるので、その辺はコスト感との兼ね合いになると思われる。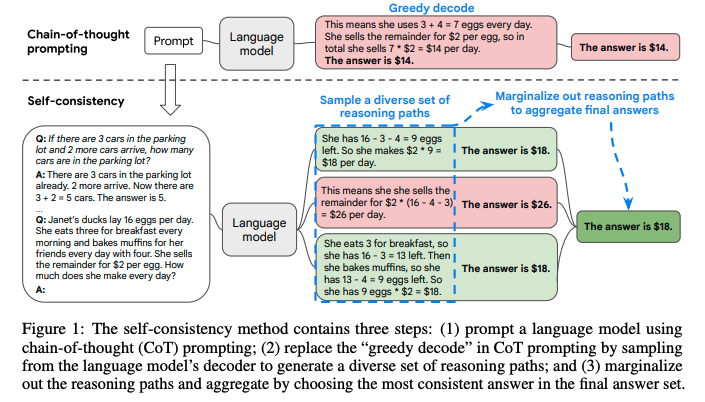
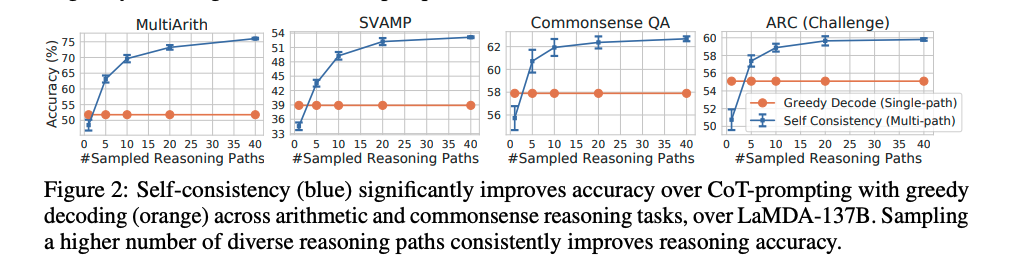
Self-consistencyは回答が閉じた集合であるような問題に対して適用可能であり、open-endなquestionでは利用できないことに注意が必要。ただし、open-endでも回答間になんらかの関係性を見出すような指標があれば実現可能とlimitationで言及している。
self-consistencyが提案されてからもう4年も経ったのか、、、
[Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ICLR #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)を用いて、段階的思考を促すCoT promptingを提案。手作業でデモを設計する必要なく、プロンプトを通じて推論チェーンを生成可能。また、多様性を持って質問をサンプリングする自動CoT法(Auto-CoT)を導入し、GPT-3を用いたベンチマークで手動設計と比較して優れた性能を示した。 Comment
LLMによるreasoning chainが人間が作成したものよりも優れていることを示しているとのこと [Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04 より
clusteringベースな手法を利用することにより、誤りを含む例が単一のクラスタにまとめられうことを示し、これにより過剰な誤ったデモンストレーションが軽減されることを示した。
手法の概要。questionを複数のクラスタに分割し、各クラスタから代表的なquestionをサンプリングし、zero-shot CoTでreasoning chainを作成しpromptに組み込む。最終的に回答を得たいquestionに対しても、上記で生成した複数のquestion-reasoningで条件付けした上で、zeroshot-CoTでrationaleを生成する。これにより自動的にCoTをICLするためのexamplarを生成できる。
openreview: https://openreview.net/forum?id=5NTt8GFjUHkr
[Paper Note] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, KaShun Shum+, EMNLP'23, 2023.02
Paper/Blog Link My Issue
#NLP #LanguageModel #EMNLP #One-Line Notes Issue Date: 2023-04-27 GPT Summary- 新しい戦略「Automate-CoT」を提案し、少量のラベル付きデータから合理的チェーンを自動拡張。低品質なチェーンを剪定し、最適な推論チェーンを選択する分散削減型ポリシー勾配戦略を用いる。これにより、さまざまなタスクへのCoT手法の迅速な適用を可能にし、実験で競争力のある結果を達成。 Comment
LLMによるreasoning chainが人間が作成したものよりも優れていることを示しているとのこと。下記研究より
- [Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
selection phaseで誤ったexampleは直接排除する手法をとっている。そして、強化学習によって、demonstrationのselection modelを訓練している。
openreview: https://openreview.net/forum?id=FGBEoz9WzI¬eId=sq50eXOEeV
[Paper Note] Large Language Models are Zero-Shot Reasoners, Takeshi Kojima+, arXiv'22, 2022.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Zero/Few/ManyShotPrompting #Prompting #NeurIPS #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)は自然言語処理において少数ショット学習の能力が高く、CoT promptingにより複雑な多段階推論を効果的に引き出す。特に「Let's think step by step」の追加で、ゼロショット推論能力が向上し、様々な論理推論タスクで手作りの例を使わずに性能を大幅に向上させた。例えば、InstructGPTモデルでのMultiArithの精度が17.7%から78.7%へ、GSM8Kが10.4%から40.7%と劇的な改善が見られた。この研究はLLMsの潜在的なゼロショット能力を示し、ファインチューニングや少数ショットの前にその知識を探求する重要性が強調されている。 Comment
Zero-Shot CoT (Let's think step-by-step.)論文

Zero-Shot-CoTは2つのステップで構成される:
- STEP1: Reasoning Extraction
- 元のquestionをxとし、zero-shot-CoTのtrigger sentenceをtとした時に、テンプレート "Q: [X]. A. [T]" を用いてprompt x'を作成
- このprompt x'によって得られる生成テキストzはreasoningのrationaleとなっている。
- STEP2: Answer Extraction
- STEP1で得られたx'とzを用いて、テンプレート "[X'] [Z] [A]" を用いてpromptを作成し、quiestionに対する回答を得る
- このとき、Aは回答を抽出するためのtrigger sentenceである。
- Aはタスクに応じて変更するのが効果的であり、たとえば、multi-choice QAでは "Therefore, among A through E, the answer is" といったトリガーを用いたり、数学の問題では "Therefore, the answer (arabic numerals) is" といったトリガーを用いる。
# 実験結果
表中の性能指標の左側はタスクごとにAnswer Triggerをカスタマイズしたもので、右側はシンプルに"The answer is"をAnswer Triggerとした場合。Zero-shot vs. Zero-shot-CoTでは、Zero-Shot-CoTが多くのb現地マークにおいて高い性能を示している。ただし、commonsense reasoningではperformance gainを得られなかった。これは [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
で報告されている通り、commonsense reasoningタスクでは、Few-Shot CoTでもLambda135Bで性能が向上せず、Palm540Bで性能が向上したように、モデルのparameter数が足りていない可能性がある(本実験では17種類のモデルを用いているが、特に注釈がなければtext-davinci-002を利用した結果)。
## 他ベースラインとの比較
他のベースラインとarithmetic reasoning benchmarkで性能比較した結果。Few-Shot-CoTには勝てていないが、standard Few-shot Promptingtを大幅に上回っている。
## zero-shot reasoningにおけるモデルサイズの影響
さまざまな言語モデルに対して、zero-shotとzero-shot-CoTを実施した場合の性能比較。[Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
と同様にモデルサイズが小さいとZero-shot-CoTによるgainは得られないが、モデルサイズが大きくなると一気にgainが大きくなる。
## Zero-shot CoTにおけるpromptの選択による影響
input promptに対するロバスト性を確認した。instructiveカテゴリ(すなわち、CoTを促すトリガーであれば)性能が改善している。特に、どのようなsentenceのトリガーにするかで性能が大きくかわっている。今回の実験では、"Let's think step by step"が最も高い性能を占め最多。
## Few-shot CoTのprompt選択における影響
CommonsenseQAのexampleを用いて、AQUA-RAT, MultiArithをFew-shot CoTで解いた場合の性能。どちらのケースもドメインは異なるが、前者は回答のフォーマットは共通である。異なるドメインでも、answer format(multiple choice)の場合、ドメインが異なるにもかかわらず、zero-shotと比較して性能が大幅に向上した。一方、answer formatが異なる場合はperformance gainが小さい。このことから、LLMはtask自体よりも、exampleにおけるrepeated formatを活用していることを示唆している。また、CommonSennseをExamplarとして用いたFew-Shot-CoTでは、どちらのデータセットでもZero-Shot-CoTよりも性能が劣化している。つまり、Few-Shot-CoTでは、タスク特有のサンプルエンジニアリングが必要であることがわかる(一方、Zero-shot CoTではそのようなエンジニアリングは必要ない)。
[Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Paper/Blog Link My Issue
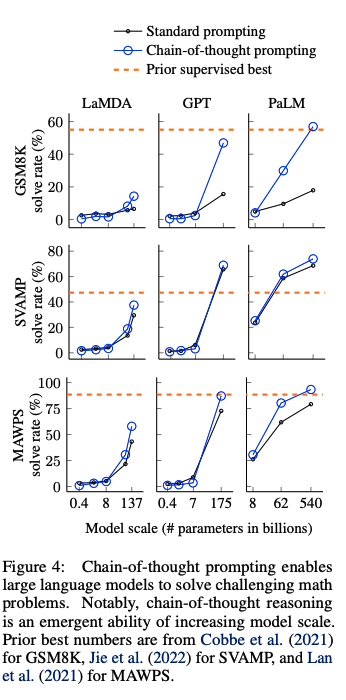
#NLP #LanguageModel #Zero/Few/ManyShotPrompting #Prompting #NeurIPS #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-04-27 GPT Summary- 思考の連鎖によって、大規模言語モデルの推論能力が向上することを探求。チェーン・オブ・ソート思考のプロンプトを用いる事例を示し、3つのモデルでの実験を通じて算術や常識、象徴的推論において性能向上を確認。特に、5400億パラメータのモデルに8つのデモをプロンプトとして与えただけで、数学問題のGSM8Kベンチマークで最先端の精度を達成した。 Comment
Chain-of-Thoughtを提案した論文。CoTをする上でパラメータ数が100B未満のモデルではあまり効果が発揮されないということは念頭に置いた方が良さそう。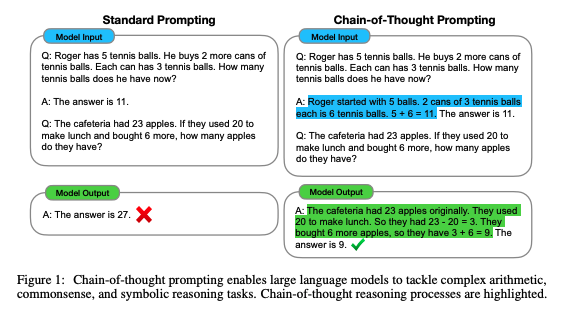
先行研究では、reasoningが必要なタスクの性能が低い問題をintermediate stepを明示的に作成し、pre-trainedモデルをfinetuningすることで解決していた。しかしこの方法では、finetuning用の高品質なrationaleが記述された大規模データを準備するのに多大なコストがかかるという問題があった。
このため、few-shot promptingによってこの問題を解決することが考えられるが、reasoning能力が必要なタスクでは性能が悪いという問題あがった。そこで、両者の強みを組み合わせた手法として、chain-of-thought promptingは提案された。
# CoTによる実験結果
以下のベンチマークを利用
- math word problem: GSM8K, SVAMP, ASDiv, AQuA, MAWPS
- commonsense reasoning: CSQA, StrategyQA, Big-bench Effort (Date, Sports), SayCan
- Symbolic Reasoning: Last Letter concatenation, Coin Flip
- Last Letter concatnation: 名前の単語のlast wordをconcatするタスク("Amy Brown" -> "yn")
- Coin Flip: コインをひっくり返す、 あるいはひっくり返さない動作の記述の後に、コインが表向きであるかどうかをモデルに回答するよう求めるタスク
## math word problem benchmark
- モデルのサイズが大きくなるにつれ性能が大きく向上(emergent ability)することがあることがわかる
- 言い換えるとCoTは<100Bのモデルではパフォーマンスに対してインパクトを与えない
- モデルサイズが小さいと、誤ったCoTを生成してしまうため
- 複雑な問題になればなるほど、CoTによる恩恵が大きい
- ベースラインの性能が最も低かったGSM8Kでは、パフォーマンスの2倍向上しており、1 stepのreasoningで解決できるSingleOpやMAWPSでは、性能の向上幅が小さい
- Task specificなモデルをfinetuningした以前のSoTAと比較してcomparable, あるいはoutperformしている
- 
## Ablation Study
CoTではなく、他のタイプのpromptingでも同じような効果が得られるのではないか?という疑問に回答するために、3つのpromptingを実施し、CoTと性能比較した:
- Equation Only: 回答するまえに数式を記載するようなprompt
- promptの中に数式が書かれているから性能改善されているのでは?という疑問に対する検証
- => GSM8Kによる結果を見ると、equation onlyでは性能が低かった。これは、これは数式だけでreasoning stepsを表現できないことに起因している
- Variable compute only: dotのsequence (...) のみのprompt
- CoTは難しい問題に対してより多くの計算(intermediate token)をすることができているからでは?という疑問に対する検証
- variable computationとCoTの影響を分離するために、dotのsequence (...) のみでpromptingする方法を検証
- => 結果はbaselineと性能変わらず。このことから、variableの計算自体が性能向上に寄与しているわけではないことがわかる。
- Chain of Thought after answer: 回答の後にCoTを出力するようなprompting
- 単にpretrainingの際のrelevantな知識にアクセスしやすくなっているだけなのでは?という疑問を検証
- => baselineと性能は変わらず、単に知識を活性化させるだけでは性能が向上しないことがわかる。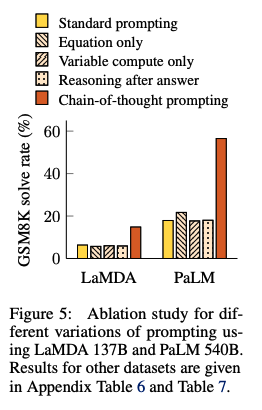
## CoTのロバスト性
人間のAnnotatorにCoTを作成させ、それらを利用したCoTpromptingとexamplarベースな手法によって性能がどれだけ変わるかを検証。standard promptingを全ての場合で上回る性能を獲得した。このことから、linguisticなstyleにCoTは影響を受けていないことがわかる。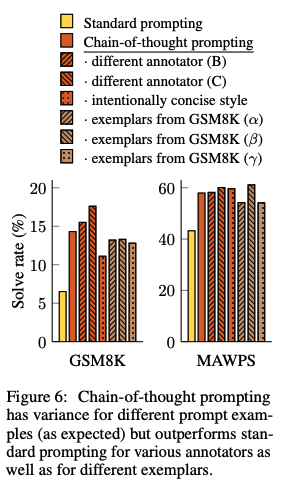
# commonsense reasoning
全てのデータセットにおいて、CoTがstandard promptingをoutperformした。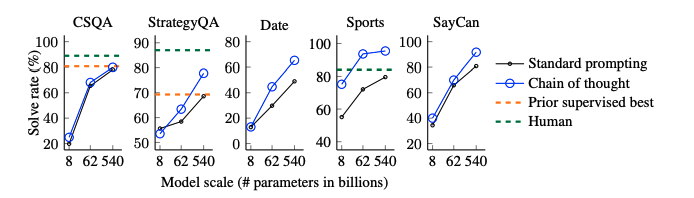
# Symbolic Reasoning
in-domain test setとout-of-domain test setの2種類を用意した。前者は必要なreasoning stepがfew-shot examplarと同一のもの、後者は必要なreasoning stepがfew-shot examplarよりも多いものである。
CoTがStandard proimptingを上回っている。特に、standard promptingではOOV test setではモデルをスケールさせても性能が向上しなかったのに対し、CoTではより大きなgainを得ている。このことから、CoTにはreasoning stepのlengthに対しても汎化能力があることがわかる。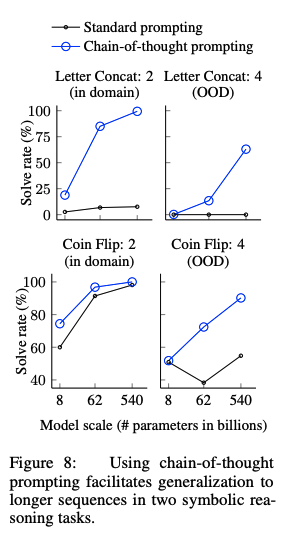
Investigating the consequences of accidentally grading CoT during RL, OpenAI, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Monitorability #Author Thread-Post Issue Date: 2026-05-12 Comment
元ポスト:
Reasoning models struggle to control their chains of thought, and that’s good, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #Controllable #NLP #Dataset #LanguageModel #Evaluation #Blog #Reasoning #read-later #Author Thread-Post Issue Date: 2026-03-06 Comment
元ポスト:
著者ポスト:
MedReason-Stenographic, openmed-community, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #QuestionAnswering #SyntheticData #Evaluation #Reasoning #Medical #KeyPoint Notes Issue Date: 2026-01-12 Comment
元ポスト:
MiniMax M2.1を用いてMedical QAに対してreasoning traceを生成。生成されたreasoning traceをstenographic formatと呼ばれる自然言語からフィラーを排除し、論理の流れのみをsymbolicな表現に変換することで合成されたデータセットとのこと。
ユースケースとしては下記とのこと:
> 1. Train reasoning models with symbolic compression
> 2. Fine-tune for medical QA
> 3. Research reasoning compression techniques
> 4. Benchmark reasoning trace quality
個人的には1,3が興味深く、symbolを用いてreasoning traceを圧縮することで、LLMの推論時のトークン効率を改善できる可能性がある。
が、surfaceがシンボルを用いた論理の流れとなると、汎化性能を損なわないためにはLLMが内部でシンボルに対する何らかの強固な解釈が別途必要になるし、それが多様なドメインで機能するような柔軟性を持っていなければならない気もする。
AI Safetyの観点でいうと、論理の流れでCoTが表現されるため、CoTを監視する際には異常なパターンがとりうる空間がshrinkし監視しやすくなる一方で、surfaceの空間がshrinkする代わりに内部のブラックボックス化された表現の自由度が高まり抜け道が増える可能性もある気がする。結局、自然言語もLLMから見たらトークンの羅列なので、本質的な課題は変わらない気はする。
Evaluating chain-of-thought monitorability, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Reasoning #Safety #KeyPoint Notes #Monitorability Issue Date: 2025-12-19 Comment
元ポスト:
Monitorabilityの定義が記述されているので覚えておくとよいかもしれない。
Monitorabilityを一言でいうと、"エージェントの挙動に関する重要な性質を正確に予測できる能力"ということっぽい。
Monitorabilityは以下の2つの側面を持ち、
>- Monitors. We could make monitors smarter in various ways, and we would like our evaluations to give higher scores to monitors that can make better predictions about an agent’s behavior.
>- Agents. There are many observations of the agent that could be given to the monitor, including the agent’s actions, outputs, neural activations, and recently with the advent of reasoning models, the chain-of-thought. It’s possible for some agents to have thoughts that are harder to understand than others, and so we would like our monitorability evaluations to be able to compare agents and not just monitors.
モニターそのものの賢さと、モニタリングされるエージェントも理解しやすいものとしづらいものがいるため、モニターの性能だけじゃなくてエージェントそのものも評価の対象にする必要がある。
monitarable / unmonitorable なCoTのサンプルとして以下が挙げられている。これは実際には実現不可能なコーディング課題が与えられているらしいのだが、左側はtestをpassしている(つまりなんかチートした)がそのことについてはCoTに言及されていない。一方、右側はチートに関して検討する様子がCoTに記述されており、これを見ることでユーザはモデルのよろしくない挙動に気付ける。
「推論する生成AI」は事前学習されていない課題を正しく推論することができない(共変量シフトに弱い), TJO, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Reasoning #CovarianceShift Issue Date: 2025-08-27 Comment
- [Paper Note] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process, Tian Ye+, ICLR'25
でLLMは未知の問題を解ける(学習データに存在しない同等のlengthの未知のサンプルを解ける/テストデータで訓練データよりもより複雑な長いlengthの問題を解ける)と比べると、両者から得られる結論から何が言えるのだろうか?観測できるCoTとhidden mental reasoning process (probingで表出させて分析)は分けて考える必要があるのかもしれない。元論文をきちんと読めていないから考えてみたい。
あと、ブログ中で紹介されている論文中ではPhysics of Language Modelsが引用されていないように見えるが、論文中で引用され、関連性・差別化について言及されていた方が良いのではないか?という感想を抱いた。
関連:
- [Paper Note] Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens, Chengshuai Zhao+, arXiv'25
- [Paper Note] Understanding deep learning requires rethinking generalization, Chiyuan Zhang+, ICLR'17
- [Paper Note] UQ: Assessing Language Models on Unsolved Questions, Fan Nie+, arXiv'25
元ポスト:
2025年度人工知能学会全国大会チュートリアル講演「深層基盤モデルの数理」, Taiji Suzuki, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #MachineLearning #NLP #LanguageModel #Transformer #In-ContextLearning #Attention #DiffusionModel #SSM (StateSpaceModel) #Slide #Scaling Laws #PostTraining Issue Date: 2025-05-31 Comment
元ポスト:
The "think" tool: Enabling Claude to stop and think in complex tool use situations, Anthropic, 2025.03
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Blog #Reasoning #One-Line Notes Issue Date: 2025-03-23 Comment
"考える"ことをツールとして定義し利用することで、externalなthinkingを明示的に実施した上でタスクを遂行させる方法を紹介している
Structured Outputs OpenAI Platform, 2025.01
Paper/Blog Link My Issue
#Article #LanguageModel #python #StructuredData #One-Line Notes Issue Date: 2025-01-25 Comment
pydanticを用いて、CoT+構造化されたoutputを実施するサンプル
LLMを数学タスクにアラインする手法の系譜 - GPT-3からQwen2.5まで, bilzard, 2024.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Reasoning #Mathematics #PostTraining #Reading Reflections Issue Date: 2024-12-27 Comment
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
において、数学においてモデルのパラメータ数のスケーリングによって性能改善が見込める学習手法として、モデルとは別にVerifierを学習し、モデルが出力した候補の中から良いものを選択できるようにする、という話の気持ちが最初よくわからなかったのだが、後半のなぜsample&selectがうまくいくのか?節を読んでなんとなく気持ちが理解できた。SFTを進めるとモデルが出力する解放の多様性が減っていくというのは、興味深かった。
しかし、特定の学習データで学習した時に、全く異なるUnseenなデータに対しても解法は減っていくのだろうか?という点が気になった。あとは、学習データの多様性をめちゃめちゃ増やしたらどうなるのか?というのも気になる。特定のデータセットを完全に攻略できるような解法を出力しやすくなると、他のデータセットの性能が悪くなる可能性がある気がしており、そうするとそもそもの1shotの性能自体も改善していかなくなりそうだが、その辺はどういう設定で実験されているのだろうか。
たとえば、
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
などでは、
- [Paper Note] Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks, Yizhong Wang+, EMNLP'22, 2022.04
のような1600を超えるようなNLPタスクのデータでLoRAによりSFTすると、LoRAのパラメータ数を非常に大きくするとUnseenタスクに対する性能がfull-parameter tuningするよりも向上することが示されている。この例は数学に特化した例ではないが、SFTによって解法の多様性が減ることによって学習データに過剰適合して汎化性能が低下する、というのであれば、この論文のことを鑑みると「学習データにoverfittingした結果他のデータセットで性能が低下してしまう程度の多様性の学習データしか使えていないのでは」と感じてしまうのだが、その辺はどうなんだろうか。元論文を読んで確認したい。
とても勉強になった。
記事中で紹介されている
> LLMを使って複数解法の候補をサンプリングし、その中から最適な1つを選択する
のルーツは
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
とのことなので是非読みたい。
この辺はSelf-Consistency
- [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
あたりが最初なのかと思っていた。
OpenAI o1, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #Test-Time Scaling #Selected Papers/Blogs #VisionLanguageModel #KeyPoint Notes Issue Date: 2024-09-13 Comment
Jason Wei氏のポスト:
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
や
- [Paper Note] Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, arXiv'23, 2023.11
で似たような考えはすでに提案されていたが、どのような点が異なるのだろうか?
たとえば前者は、pauseトークンと呼ばれるoutputとは関係ないトークンを生成することで、outputを生成する前にモデル内部で推論する前により多くのベクトル操作を加える(=ベクトルを縦方向と横方向に混ぜ合わせる; 以後ベクトルをこねくりまわすと呼称する)、といった挙動を実現しているようだが、明示的にCoTの教師データを使ってSFTなどをしているわけではなさそうに見える(ざっくりとしか読んでないが)。
一方、Jason Wei氏のポストからは、RLで明示的により良いCoTができるように学習をしている点が違うように見える。
**(2025.0929): 以下のtest-time computeに関するメモはo1が出た当初のものであり、私の理解が甘い状態でのメモなので現在の理解を後ほど追記します。当時のメモは改めて見返すとこんなこと考えてたんだなぁとおもしろかったので残しておきます。**
学習の計算量だけでなく、inferenceの計算量に対しても、新たなスケーリング則が見出されている模様。
テクニカルレポート中で言われている time spent thinking (test-time compute)というのは、具体的には何なのだろうか。
上の研究でいうところの、inference時のpauseトークンの生成のようなものだろうか。モデルがベクトルをこねくり回す回数(あるいは生成するトークン数)が増えると性能も良くなるのか?
しかしそれはオリジナルのCoT研究である
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
のdotのみの文字列をpromptに追加して性能が向上しなかった、という知見と反する。
おそらく、**モデル学習のデコーディング時に**、ベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすこと=time spent thinking (test-time compute) 、ということなのだろうか?
そしてそのように学習されたモデルは、推論時にベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすと性能が上がる、ということなのだろうか。
もしそうだとすると、これは
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
のpauseトークンの生成をしながらfinetuningすると性能が向上する、という主張とも合致するように思うが、うーん。
実際暗号解読のexampleを見ると、とてつもなく長いCoT(トークンの生成数が多い)が行われている。
RLでReasoningを学習させる関連研究:
- ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N/A, ACL'24
- Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N/A, ICML'24
以下o1の動きに関して考えている下記noteからの引用。
>これによって、LLMはモデルサイズやデータ量をスケールさせる時代から推論時間をスケールさせる(つまり、沢山の推論ステップを探索する)時代に移っていきそうです。
なるほど。test-compute timeとは、推論ステップ数とその探索に要する時間という見方もあるのですね。
またnote中では、CoTの性能向上のために、Process Reward Model(PRM)を学習させ、LLMが生成した推論ステップを評価できるようにし、PRMを報酬モデルとし強化学習したモデルがo1なのではないか、と推測している。
PRMを提案した研究では、推論ステップごとに0,1の正誤ラベルが付与されたデータから学習しているとのこと。
なるほど、勉強になります。
note:
https://note.com/hatti8/n/nf4f3ce63d4bc?sub_rt=share_pb
note(詳細編): https://note.com/hatti8/n/n867c36ffda45?sub_rt=share_pb
こちらのリポジトリに関連論文やXポスト、公式ブログなどがまとめられている:
https://github.com/hijkzzz/Awesome-LLM-Strawberry
これはすごい。論文全部読みたい
IBIS2023チュートリアル「大規模言語モデル活用技術の最前線」, Michimasa Inaba, 2023.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #AIAgents #Slide #One-Line Notes Issue Date: 2023-11-01 Comment
LLMの応用研究やPromptingを中心としたチュートリアル。アノテーションや対話式推薦システムへの活用、ReAct、プロンプトの最適化技術、CoTの基本から応用まで幅広くまとまっているので、LLMの応用技術の概観や、CoTを実践したい人に非常に有用だと思う。
Measuring Faithfulness in Chain-of-Thought Reasoning, Anthropic, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Prompting #Faithfulness #needs-revision Issue Date: 2023-07-23
Towards Complex Reasoning: the Polaris of Large Language Models, Yao Fu, 2023.05
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Blog #Reasoning #mid-training #PostTraining Issue Date: 2023-05-04