
CollaborativeFiltering
[Paper Note] RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning, Sichun Luo+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#RecommenderSystems #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Reasoning #Initial Impression Notes Issue Date: 2025-03-27 GPT Summary- RALLRec+は、LLMsを用いてレコメンダーシステムのretrievalとgenerationを強化する手法。retrieval段階では、アイテム説明を生成し、テキスト信号と協調信号を結合。生成段階では、推論LLMsを評価し、知識注入プロンプティングで汎用LLMsと統合。実験により、提案手法の有効性が確認された。 Comment
元ポスト:
Reasoning LLMをRecSysに応用する初めての研究(らしいことがRelated Workに書かれている)
arxivのadminより以下のコメントが追記されている
> arXiv admin note: substantial text overlap with arXiv:2502.06101
コメント中の研究は下記である
- [Paper Note] ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation, Jianghao Lin+, WWW'24
[Paper Note] Revisiting BPR: A Replicability Study of a Common Recommender System Baseline, Aleksandr Milogradskii+, RecSys'24
Paper/Blog Link My Issue
#RecommenderSystems #Analysis #Library #Evaluation #RecSys #Initial Impression Notes Issue Date: 2025-04-10 GPT Summary- BPRは協調フィルタリングのベンチマークだが、実装の微妙な点が見落とされ、他手法に劣るとされている。本研究ではBPRの特徴と実装の不一致を分析し、最大50%の性能低下を示す。適切なハイパーパラメータ調整により、BPRはトップn推薦タスクで最先端手法に近い性能を達成し、Million Song DatasetではMult-VAEを10%上回る結果を示した。 Comment
BPR、実装によってまるで性能が違う…
実装の違い
[Paper Note] Graph Collaborative Signals Denoising and Augmentation for Recommendation, Ziwei Fan+, SIGIR'23, 2023.04
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #GraphBased #SIGIR #KeyPoint Notes #Short Issue Date: 2023-04-26 GPT Summary- 新たなグラフ隣接行列を提案し、ユーザーとアイテムの相互作用を最適化。ユーザー間・アイテム間の相関を組み込み、相互作用のバランスを取ることで、従来の方法よりも顕著な推薦効果を実現。これにより、豊富な相互作用を持つユーザーと乏しいユーザー双方への推薦が改善された。 Comment
グラフ協調フィルタリングを改善する手法を提案している。既存のグラフ協調フィルタリングはユーザ-アイテム間の隣接行列に基づく二部グラフによって学習されるが、これにはいくつか課題がある:
- ノイズが多く、スパースで、バイアスを含み、long tailな性質(ほとんどのユーザがアイテムとほとんどinterctionしていない)を持つがこれらに対処できていない
- また、interactionの情報がリッチなアクティブユーザはinteractionに多くのノイズ情報を含むが、うまくモデル化されていない
- グラフ協調フィルタリングのmessage passinpによって、user間、item間の情報が事前に学習されるが、message passingの回数が増えるとノイズが多くなる
これらに対処するために、学習を2つのプロセスに分ける方法を提案している。具体的には、GCNを用いて、まず通常通り隣接行列に基づいてuser, itemノードのembeddingを事前学習する。続いて、隣接行列に対して下記2種類の拡張を行う。
- user-item interaction: 事前学習したembeddingを用いて、user-item間のTopKのneighborを見つけ、TopKのみにフィルタリングして隣接行列を再構築する(アクティブユーザーはノイズ除去、インアクティブユーザはインタラクション情報の拡張につながる)
- user-user / item-item interaction: 同じく事前学習したembeddingを用いて、それぞれのneighborsを見つけてuser-user, item-item interactionの要素が非ゼロとなるように拡張する(message passingによるノイズを低減しつつ、ユーザ間、アイテム間の情報を取り入れる)
元ポスト:
[Paper Note] Revisiting the Performance of iALS on Item Recommendation Benchmarks, Steffen Rendle+, RecSys'22
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #Evaluation #RecSys Issue Date: 2025-04-15 GPT Summary- iALSを再検討し、調整を行うことで、レコメンダーシステムにおいて競争力を持つことを示す。特に、4つのベンチマークで他の手法を上回る結果を得て、iALSのスケーラビリティと高品質な予測が再評価されることを期待。
GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering, Yoonseok Yang+, NAACL'22
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #EfficiencyImprovement #EducationalDataMining #KnowledgeTracing #Contents-based #NAACL Issue Date: 2022-08-01 GPT Summary- コンテンツベースの協調フィルタリング(CCF)において、PLMを用いたエンドツーエンドのトレーニングはリソースを消費するため、GRAM(勾配蓄積手法)を提案。Single-step GRAMはアイテムエンコーディングの勾配を集約し、Multi-step GRAMは勾配更新の遅延を増加させてメモリを削減。これにより、Knowledge TracingとNews Recommendationのタスクでトレーニング効率を最大146倍改善。
[Paper Note] Neural Collaborative Filtering vs. Matrix Factorization Revisited, Steffen Rendle+, RecSys'20
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #MatrixFactorization #RecSys #read-later #Selected Papers/Blogs #Reproducibility Issue Date: 2025-05-16 GPT Summary- 埋め込みベースのモデルにおける協調フィルタリングの研究では、MLPを用いた学習された類似度が提案されているが、適切なハイパーパラメータ選択によりシンプルなドット積が優れた性能を示すことが確認された。MLPは理論的には任意の関数を近似可能だが、実用的にはドット積の方が効率的でコストも低いため、MLPは慎重に使用すべきであり、ドット積がデフォルトの選択肢として推奨される。
[Paper Note] Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, Maurizio Ferrari Dacrema+, RecSys'19, 2019.07
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #Evaluation #RecSys #Selected Papers/Blogs #Reproducibility #KeyPoint Notes #Reading Reflections Issue Date: 2022-04-11 GPT Summary- 深層学習技術はレコメンダーシステムの研究で広く用いられているが、再現性やベースライン選択に問題がある。18のトップnレコメンデーションアルゴリズムを分析した結果、再現できたのは7つのみで、6つは単純なヒューリスティック手法に劣っていた。残りの1つはベースラインを上回ったが、非ニューラル手法には及ばなかった。本研究は機械学習の実践における問題を指摘し、改善を呼びかけている。 Comment
RecSys'19のベストペーパー
日本語解説:
https://qiita.com/smochi/items/98dbd9429c15898c5dc7
TopN推薦におけるDNNを用いた研究を追試した研究で、トップ会議の手法のうち18本の追試を試みたところ、追試のための現実的な努力や著者に連絡をするといったことを実施した上で再現できたものは7本であり、そのうち6/7が適切なハイパーパラメータ調整を行なったkNNベースのシンプルな手法に勝てなかった(かつ残りの一つも線形モデルに対して負ける場合もあった)、という話で、業界における評価における再現性の問題(ハイパーパラメータ調整の記載がない等)や、適切な実験設定の欠如(ベースラインのハイパーパラメータチューニングをせずに先行研究の記述内容をそのまま踏襲等、テストデータを用いたエポック数の調整、ランダムサンプリングのはずなのに明らかに提案手法に有利となるような偏ったサンプリングを実施...)、ベースラインの適切な選定(多くの研究がNeural Collaboraive Filteringをベースラインにしているが果たしてそれが適切か)などについて警鐘を鳴らす内容になっている。
過去の先行研究([Paper Note] Sequence-Aware Recommender Systems, Massimo Quadrana+, ACM Computing Surveys (CSUR), Volume 51, Issue 4, 2018.02
)でも、研究者の間でデータセットの分割に関して、標準化されていない旨が記述されている。また、管理人が研究を追う中でも、共通のフレームワークで評価がされているとは言い難い印象を持っている(**このコメントは論文を読んだ当時を思い起こし2026年に追記しているが、この頃から業界はどのようにシフトしただろうか?最近は追えていない**)。
たとえば評価をする際には、データセットの選択だけでなく、データセットの中でどの規模感のデータセットを使うのか(MovieLens一つとっても様々なバリエーションがある)、leave-one-outをするのか、時系列性を考慮した履歴の分割をするのか、negative samplingをする際の件数やサンプリング方法、なんらかのstratifiedなk-fold cross validationをするのか否か、coldstartなデータを排除するのか否か、排除する際の足切りの基準、ハイパーパラメータ。最適化する際のメトリックと最適化をするパラメータ、平均を取る際の実験の試行回数、性能を測るメトリック(Precision, Recall, NDCG, MAP, MRR, AUC, HITS@N...)など様々な変数が存在し、これらの設定が異なると性能は確かに大きく変化すると思われる。実際に推薦モデルの検証をする際には適切な検証となるよう細心の注意を払いたい。
私個人としては本研究を知った以後、オフラインでの実験のみでなくらA/Bテストが実施されている研究に対する信頼性をより高めるようになった。
おそらくこれを受けてRecboleのようなフレームワークが登場したと思うが、現在は更新がされていないという認識である。いまはどのように再現性に関する取り組みがされているだろうか?
- Autonomously Generating Hints by Inferring Problem Solving Policies, Piech+, Stanford University, L@S'15
[Paper Note] Deep Learning Recommendation Model for Personalization and Recommendation Systems, Maxim Naumov+, arXiv'19, 2019.05
Paper/Blog Link My Issue
#RecommenderSystems #FactorizationMachines #One-Line Notes Issue Date: 2021-07-02 GPT Summary- 深層学習に基づく推薦モデル(DLRM)を開発し、PyTorchとCaffe2で実装。埋め込みテーブルのモデル並列性を活用し、メモリ制約を軽減しつつ計算をスケールアウト。DLRMの性能を既存モデルと比較し、Big Basin AIプラットフォームでの有用性を示す。 Comment
Facebookが開発したopen sourceのDeepな推薦モデル(MIT Licence)。
モデル自体はシンプルで、continuousなfeatureをMLPで線形変換、categoricalなfeatureはembeddingをlook upし、それぞれfeatureのrepresentationを獲得。
その上で、それらをFactorization Machines layer(second-order)にぶちこむ。すなわち、Feature間の2次の交互作用をembedding間のdot productで獲得し、これを1次項のrepresentationとconcatしMLPにぶちこむ。最後にシグモイド噛ませてCTRの予測値とする。
実装: https://github.com/facebookresearch/dlrm
Parallelism以後のセクションはあとで読む
[Paper Note] DKN: Deep Knowledge-Aware Network for News Recommendation, Hongwei Wang+, arXiv'18, 2018.01
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #Contents-based #NewsRecommendation #WWW #Surface-level Notes Issue Date: 2021-06-01 GPT Summary- オンラインニュース推薦システムの課題を解決するために、知識グラフを活用した深層知識認識ネットワーク(DKN)を提案。DKNは、ニュースの意味と知識を融合する多チャネルの知識認識畳み込みニューラルネットワーク(KCNN)を用い、ユーザーの履歴を動的に集約する注意モジュールを搭載。実験により、DKNが最先端の推薦モデルを大幅に上回る性能を示し、知識の有効性も確認。 Comment
# Overview
Contents-basedな手法でCTRを予測しNews推薦。newsのタイトルに含まれるentityをknowledge graphと紐づけて、情報をよりリッチにして活用する。
CNNでword-embeddingのみならず、entity embedding, contextual entity embedding(entityと関連するentity)をエンコードし、knowledge-awareなnewsのrepresentationを取得し予測する。
※ contextual entityは、entityのknowledge graph上でのneighborhoodに存在するentityのこと(neighborhoodの情報を活用することでdistinguishableでよりリッチな情報を活用できる)
CNNのinputを\[\[word_ embedding\], \[entity embedding\], \[contextual entity embedding\]\](画像のRGB)のように、multi-channelで構成し3次元のフィルタでconvolutionすることで、word, entity, contextual entityを表現する空間は別に保ちながら(同じ空間で表現するのは適切ではない)、wordとentityのalignmentがとれた状態でのrepresentationを獲得する。
# Experiments
BingNewsのサーバログデータを利用して評価。
データは (timestamp, userid, news url, news title, click count (0=no click, 1=click))のレコードによって構成されている。
2016年11月16日〜2017年6月11日の間のデータからランダムサンプリングしtrainingデータセットとした。
また、2017年6月12日〜2017年8月11日までのデータをtestデータセットとした。
word/entity embeddingの次元は100, フィルタのサイズは1,2,3,4とした。loss functionはlog lossを利用し、Adamで学習した。

DeepFM超えを達成。
entity embedding, contextual entity embeddingをablationすると、AUCは2ポイントほど現象するが、それでもDeepFMよりは高い性能を示している。
また、attentionを抜くとAUCは1ポイントほど減少する。
1ユーザのtraining/testセットのサンプル
Sentiment analysis with deeply learned distributed representations of variable length texts, Hong+, Technical Report. Technical report, Stanford University, 2015
によって経験的にRNN, Recursive Neural Network等と比較して、sentenceのrepresentationを獲得する際にCNNが優れていることが示されているため、CNNでrepresentationを獲得することにした模様(footprint 7より)
Factorization Machinesベースドな手法(LibFM, DeepFM)を利用する際は、TF-IDF featureと、averaged entity embeddingによって構成し、それをuser newsとcandidate news同士でconcatしてFeatureとして入力した模様
content情報を一切利用せず、ユーザのimplicit feedbackデータ(news click)のみを利用するDMF(Deep Matrix Factorization)の性能がかなり悪いのもおもしろい。やはりuser-item-implicit feedbackデータのみだけでなく、コンテンツの情報を利用した方が強い。
(おそらく)著者によるtensor-flowでの実装: https://github.com/hwwang55/DKN
[Paper Note] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Jianxun Lian+, arXiv'18, 2018.03
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #FactorizationMachines #CTRPrediction #SIGKDD #One-Line Notes #Reading Reflections Issue Date: 2021-05-25 GPT Summary- 特徴量の自動生成が求められる中、因子分解モデルは相互作用を学習し一般化するが、DNNは暗黙的である。本研究では、明示的に相互作用を生成する圧縮相互作用ネットワーク(CIN)を提案し、DNNと統合したeXtreme Deep Factorization Machine(xDeepFM)を開発。xDeepFMは低次・高次の相互作用を学習し、実データセットで最先端モデルを超える性能を示した。 Comment
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17 DeepFMの発展版
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
DeepFMの発展についても詳細に述べられていて、とても参考になる。
[Paper Note] Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising, Junwei Pan+, arXiv'18, 2018.06
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #FactorizationMachines #CTRPrediction #WWW #One-Line Notes Issue Date: 2020-08-29 GPT Summary- クリック率(CTR)予測はオンライン広告での重要なタスクであり、マルチフィールドのカテゴリカルデータが使用される。フィールド認識型因子分解機(FFMs)は異なるフィールド間の特徴相互作用を効果的にモデル化するが、パラメータ数が膨大で実用的ではない。提案するField-weighted Factorization Machines(FwFMs)は、メモリ効率よく相互作用をモデル化し、わずか4%のパラメータで競争力のある性能を発揮。実験では、FwFMsがFFMsよりも0.92%および0.47%のAUC改善を達成した。 Comment
CTR予測でbest-performingなモデルと言われているField Aware Factorization Machines(FFM)では、パラメータ数がフィールド数×特徴数のorderになってしまうため非常に多くなってしまうが、これをよりメモリを効果的に利用できる手法を提案。FFMとは性能がcomparableであるが、パラメータ数をFFMの4%に抑えることができた。
[Paper Note] Estimating Reactions and Recommending Products with Generative Models of Reviews, Ni+, IJCNLP'17
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #IJCNLP #KeyPoint Notes Issue Date: 2019-02-01 Comment
Collaborative Filtering (CF) によるコンテンツ推薦とReview Generationを同時に学習し、
両者の性能を向上させる話。
非常に興味深い設定で、このような実験設定でReview Generationを行なった初めての研究。
CFではMatrix Factorization (MF) を利用し、Review Generationでは、LSTM-basedなseq2seqを利用する。MFとReview Generationのモデルにおいて、共通のuser latent factorとitem latent factorを利用することで、joint modelとしている。このとき、latent factorは、両タスクを通じて学習される。
CFでは、Implicitな設定なので、Rating Predictionではなく、binary classificationを行うことで、推薦を行う。
classificationには、Matrix Factorization (MF) を拡張したモデルを用いる。
具体的には、通常のMFでは、user latent factorとitem latent factorの内積によって、userのitemに対するpreferenceを表現するが、このときに、target userが過去に記載したレビュー・およびtarget itemに関する情報を利用する。レビューのrepresentationのaverageをとったvectorと、MFの結果をlinear layerによって写像し、最終的なclassification scoreとしている。
Review Generationでは、基本的にはseq2seqのinputのEmbeddingに対して、user latent factor, item latent factorをconcatするだけ。hidden stateに直接concatしないのは、latent factorを各ステップで考慮できるため、long, coherentなsequenceを生成できるから、と説明している。

Recommendタスクにおいては、Bayesian Personalized Ranking, Generalized Matrix Factorizationをoutperform。

Review GenerationはPerplexityにより評価している。提案手法がcharacter based lstmをoutperform。
Perplexityによる評価だと言語モデルとしての評価しかできていないので、BLEU, ROUGEなどを利用した評価などもあって良いのでは。
[Paper Note] Neural Collaborative Filtering, Xiangnan He+, WWW'17, 2017.08
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #MatrixFactorization #WWW #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-02-16 GPT Summary- 深層ニューラルネットワークを用いたレコメンダーシステムの研究が少ない中、本研究では協調フィルタリングの問題に取り組むため、NCF(Neural network-based Collaborative Filtering)フレームワークを提案。内積をニューラルアーキテクチャに置き換え、ユーザーとアイテムの相互作用を多層パーセプトロンでモデル化。実験により、提案手法が最先端技術に対して顕著な改善を示し、深層ニューラルネットワークの層を深くすることでレコメンデーション性能が向上することが確認された。 Comment
Collaborative FilteringをMLPで一般化したNeural Collaborative Filtering、およびMatrix Factorizationはuser, item-embeddingのelement-wise product + linear transofmration + activation で一般化できること(GMF; Generalized Matrix Factorization)を示し、両者を組み合わせたNeural Matrix Factorizationを提案している。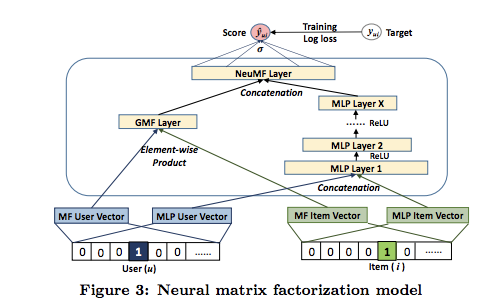
学習する際は、Implicit Dataの場合は負例をNegative Samplingし、LogLoss(Binary Cross-Entropy Loss)で学習する。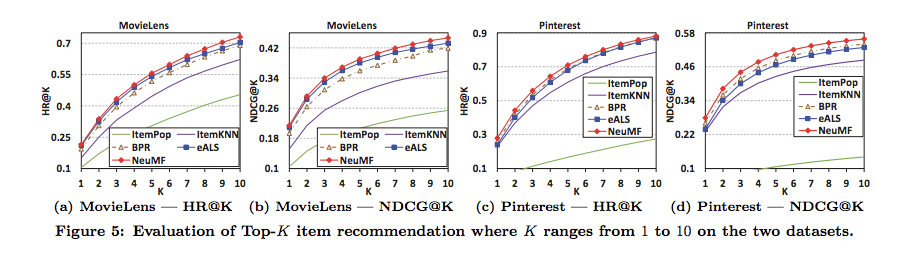
Neural Matrix Factorizationが、ItemKNNやBPRといったベースラインをoutperform
Negative Samplingでサンプリングする負例の数は、3~4程度で良さそう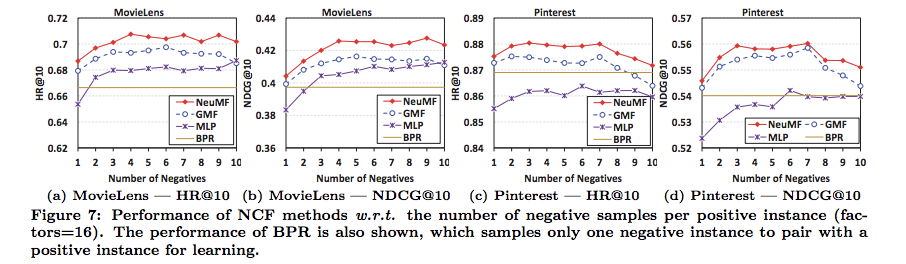
[Paper Note] Collaborative Denoising Auto-Encoders for Top-N Recommender Systems, Wu+, WSDM'16
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #WSDM #Selected Papers/Blogs #KeyPoint Notes #AutoEncoder Issue Date: 2018-01-02 Comment
Denoising Auto-Encoders を用いたtop-N推薦手法、Collaborative Denoising Auto-Encoder (CDAE)を提案。
モデルベースなCollaborative Filtering手法に相当する。corruptedなinputを復元するようなDenoising Auto Encoderのみで推薦を行うような手法は、この研究が初めてだと主張。
学習する際は、userのitemsetのsubsetをモデルに与え(noiseがあることに相当)、全体のitem setを復元できるように、学習する(すなわちDenoising Auto-Encoder)。
推薦する際は、ユーザのその時点でのpreference setをinputし、new itemを推薦する。
- [Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
もStacked Denoising Auto EncoderとCollaborative Topic Regression [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
を利用しているが、[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
ではarticle recommendationというspecificな問題を解いているのに対して、提案手法はgeneralなtop-N推薦に利用できることを主張。
[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #MatrixFactorization #SIGKDD #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2018-01-11 GPT Summary- 協調フィルタリング(CF)はレコメンダーシステムで広く用いられるが、評価がまばらな場合に性能が低下する。これに対処するため、補助情報を活用する協調トピック回帰(CTR)が提案されているが、補助情報がまばらな場合には効果が薄い。そこで、本研究では協調深層学習(CDL)という階層ベイズモデルを提案し、コンテンツ情報の深い表現学習とCFを共同で行う。実験により、CDLが最先端技術を大幅に上回る性能を示すことが確認された。 Comment
Rating Matrixからuserとitemのlatent vectorを学習する際に、Stacked Denoising Auto Encoder(SDAE)によるitemのembeddingを活用する話。
Collaborative FilteringとContents-based Filteringのハイブリッド手法。
Collaborative FilteringにおいてDeepなモデルを活用する初期の研究。
通常はuser vectorとitem vectorの内積の値が対応するratingを再現できるように目的関数が設計されるが、そこにitem vectorとSDAEによるitemのEmbeddingが近くなるような項(3項目)、SDAEのエラー(4項目)を追加する。
(3項目の意義について、解説ブログより)アイテム i に関する潜在表現 vi は学習データに登場するものについては推定できるけれど,未知のものについては推定できない.そこでSDAEの中間層の結果を「推定したvi」として「真の」 vi にできる限り近づける,というのがこの項の気持ち
cite-ulikeデータによる論文推薦、Netflixデータによる映画推薦で評価した結果、ベースライン(Collective Matrix Factorization [Paper Note] Relational learning via collective matrix factorization, Singh+, KDD'08
, SVDFeature [Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
, DeepMusic [Paper Note] Deep content-based music recommendation, Oord+, NIPS'13
, Collaborative Topic Regresison [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
)をoutperform。
(下記は管理人が過去に作成した論文メモスライドのスクショ)




[Paper Note] fastFM: A Library for Factorization Machines, Immanuel Bayer, arXiv'15, 2015.05
Paper/Blog Link My Issue
#RecommenderSystems #Library #FactorizationMachines #One-Line Notes Issue Date: 2018-01-01 GPT Summary- 因子分解機(FM)は、レコメンダーシステムで成功を収めているにもかかわらず、機械学習の標準ツールボックスには含まれていない。私たちのFMの実装は、回帰、分類、ランキングタスクをサポートし、多くのソルバーへのアクセスを簡素化することで、FMの幅広いアプリケーション利用を促進する。これにより、FMモデルの理解が深まり、新たな開発が期待される。 Comment
実装されているアルゴリズム:Factorization Machines
実装:python
使用方法:pythonライブラリとして利用
※ Factorization Machinesに特化したpythonライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
A Comparative Study of Collaborative Filtering Algorithms, Lee+, arXiv'12
Paper/Blog Link My Issue
#RecommenderSystems #Analysis #KeyPoint Notes Issue Date: 2021-10-29 Comment
様々あるCFアルゴリズムをどのように選択すべきか、# of users, # of items, rating matrix densityの観点から分析した研究。
1. 特にcomputationに関する制約がない場合は・・・、NMFはsparseなデータセットに対して最も良い性能を発揮する。BPMFはdenseなデータセットに対して最も良い性能を発揮する。そして、regularized SVD, PMFはこれ以外の状況で最も良い性能を示す(PMFはユーザ数が少ない場合によく機能する一方で、Regularized SVDはアイテム数が小さい場合に良く機能する。)。
2. もしtime constraintが5分の場合、Regularized SVD, NLPMF, NPCA, Rankbased CFは検討できない。この場合、NMFがスパースデータに対して最も良い性能を発揮し、BPMFがdenseで大規模なデータ、それ以外ではPMFが最も良い性能を示す。
3. もしtime constraintが1分の場合、PMFとBPMFは2に加えてさらに除外される。多くの場合Slope-oneが最も良い性能を示すが、データがsparseな場合はNMF。
4. リアルタイムな計算が必要な場合、user averageがbest
[Paper Note] Factorization Machines with libFM, Steffen Rendle, TIST'12, 2012.06
Paper/Blog Link My Issue
#RecommenderSystems #FactorizationMachines #One-Line Notes Issue Date: 2018-01-02 Comment
Factorization Machinesの著者実装。
FMやるならまずはこれ。
Multi-Relational Factorization Models for Predicting Student Performance, Nguyen+, KDD Cup'11
Paper/Blog Link My Issue
#MatrixFactorization #EducationalDataMining #StudentPerformancePrediction #One-Line Notes Issue Date: 2021-10-29 Comment
過去のCollaborative Filteringを利用したStudent Performance Prediction (Collaborative Filtering Applied to Educational Data Mining, Andreas+, KDD Cup'10
など)では、単一の関係性(student-skill, student-task等の関係)のみを利用していたが、この研究では複数の関係性(task-required skill-learnt skill)を利用してCFモデルの性能を向上させ、Bayesian Knowledge TracingやMatrix Factorizationに基づく手法をRMSEの観点でoutperformした。
[Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
Paper/Blog Link My Issue
#RecommenderSystems #MatrixFactorization #SIGKDD #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-11 Comment
Probabilistic Matrix Factorization (PMF) [Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08
に、Latent Dirichllet Allocation (LDA) を組み込んだCollaborative Topic Regression (CTR)を提案 (Figure2)。
LDAによりitemのlatent vectorを求め、このitem vectorと、user vectorの内積を(平均値として持つ正規表現からのサンプリング)用いてratingを生成する(式6)。
CFとContents-basedな手法が双方向にinterationするような手法
Collaborative Filtering Applied to Educational Data Mining, Andreas+, KDD Cup'10
Paper/Blog Link My Issue
#NeuralNetwork #MatrixFactorization #EducationalDataMining #StudentPerformancePrediction #One-Line Notes Issue Date: 2021-10-29 Comment
KDD Cup'10のStudent Performance Predictionタスクにおいて3位をとった手法
メモリベースドな協調フィルタリングと、Matirx Factorizationモデルを利用してStudent Performance Predictionを実施。
最終的にこれらのモデルをニューラルネットでensembleしている。
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
Paper/Blog Link My Issue
#RecommenderSystems #MachineLearning #FactorizationMachines #ICDM #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2018-12-22 Comment
解説ブログ:
http://echizen-tm.hatenablog.com/entry/2016/09/11/024828
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
上記解説ブログの概要が非常に完結でわかりやすい

FMのFeature VectorのExample
各featureごとにlatent vectorが学習され、featureの組み合わせのweightが内積によって表現される
Matrix Factorizationの一般形のような形式
[Paper Note] Collaborative Summarization: When Collaborative Filtering Meets Document Summarization, Qu+, PACLIC'09, 2009.12
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #RecommenderSystems #GraphBased #Personalization #PACLIC #KeyPoint Notes Issue Date: 2017-12-28 Comment
Collaborative Filteringと要約を組み合わせる手法を提案した最初の論文と思われる。
ソーシャルブックマークのデータから作成される、ユーザ・アイテム・タグのTripartite Graphと、ドキュメントのsentenceで構築されるGraphをのノード間にedgeを張り、co-rankingする手法を提案している。
評価
100個のEnglish wikipedia記事をDLし、文書要約のセットとした。
その上で、5000件のwikipedia記事に対する1084ユーザのタギングデータをdelicious.comから収集し、合計で8396の異なりタグを得た。
10人のdeliciousのアクティブユーザの協力を得て、100記事に対するtop5のsentenceを抽出してもらった。ROUGE1で評価。
[Paper Note] Matrix Factorization Techniques for Recommender Systems, Koren+, Computer'07
Paper/Blog Link My Issue
#RecommenderSystems #Survey #MatrixFactorization #Selected Papers/Blogs #Reading Reflections Issue Date: 2018-01-01 Comment
Matrix Factorizationについてよくまとまっている
[Paper Note] Item-based collaborative filtering recommendation algorithms, Sarwar+(with Konstan), WWW'01, 2021.04
Paper/Blog Link My Issue
#RecommenderSystems #ItemBased #WWW #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
アイテムベースな協調フィルタリングを提案した論文(GroupLens)
[Paper Note] Adaptive Web Search Based on User Profile Constructed without Any Effort from Users, Sugiyama+, NAIST, WWW’04
Paper/Blog Link My Issue
#Article #InformationRetrieval #RelevanceFeedback #Search #WebSearch #Personalization #KeyPoint Notes Issue Date: 2023-04-28 Comment
検索結果のpersonalizationを初めてuser profileを用いて実現した研究
user profileはlong/short term preferenceによって構成される。
- long term: さまざまなソースから取得される
- short term: 当日のセッションの中だけから収集される
① browsing historyの活用
- browsing historyのTFから求め Profile = P_{longterm} + P_{shortterm}とする
② Collaborative Filtering (CF) の活用
- user-item matrixではなく、user-term matrixを利用
- userの未知のterm-weightをCFで予測する
- => missing valueのterm weightが予測できるのでprofileが充実する
実験結果
- 検証結果(googleの検索結果よりも提案手法の方が性能が良い)
- 検索結果のprecision向上にlong/short term preferenceの両方が寄与
- longterm preferenceの貢献の方が大きいが、short termも必要(interpolation weight 0.6 vs. 0.4)
- short termにおいては、その日の全てのbrowsing historyより、現在のセッションのterm weightをより考慮すべき(interpolation weight 0.2 vs. 0.8)
pytorch-fm, 2020
Paper/Blog Link My Issue
#Article #RecommenderSystems #Library #FactorizationMachines #Repository #One-Line Notes Issue Date: 2021-07-03 Comment
下記モデルが実装されているすごいリポジトリ。論文もリンクも記載されており、Factorization Machinesを勉強する際に非常に参考になると思う。MITライセンス。各手法はCriteoのCTRPredictionにおいて、AUC0.8くらい出ているらしい。
- Logistic Regression
- Factorization Machine
- Field-aware Factorization Machine
- Higher-Order Factorization Machines
- Factorization-Supported Neural Network
- Wide&Deep
- Attentional Factorization Machine
- Neural Factorization Machine
- Neural Collaborative Filtering
- Field-aware Neural Factorization Machine
- Product Neural Network
- Deep Cross Network
- DeepFM
- xDeepFM
- AutoInt (Automatic Feature Interaction Model)
- AFN(AdaptiveFactorizationNetwork Model)
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17
Paper/Blog Link My Issue
#Article #RecommenderSystems #NeuralNetwork #FactorizationMachines #CTRPrediction #IJCAI #One-Line Notes Issue Date: 2021-05-25 Comment
Factorization Machinesと、Deep Neural Networkを、Wide&Deepしました、という論文。Wide=Factorization Machines, Deep=DNN。
高次のFeatureと低次のFeatureを扱っているだけでなく、FMによってフィールドごとのvector-wiseな交互作用、DNNではbit-wiseな交互作用を利用している。
割と色々なデータでうまくいきそうな手法に見える。
発展版としてxDeepFM [Paper Note] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Jianxun Lian+, arXiv'18, 2018.03
がある。
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
Collaborative Metric Learningまとめ, guglilac, 2020.01
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #ContrastiveLearning #Blog #One-Line Notes Issue Date: 2020-07-30 Comment
userのembeddingに対し、このuserと共起した(購入やクリックされた)itemを近くに、共起していないitemを遠くに埋め込むような学習方法
Implicit
Paper/Blog Link My Issue
#Article #RecommenderSystems #Library #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2019-09-11 Comment
Implicitデータに対するCollaborative Filtering手法がまとまっているライブラリ
Bayesian Personalized Ranking, Logistic Matrix Factorizationなどが実装。
Implicitの使い方はこの記事がわかりやすい:
https://towardsdatascience.com/building-a-collaborative-filtering-recommender-system-with-clickstream-data-dffc86c8c65
ALSの元論文の日本語解説
https://cympfh.cc/paper/WRMF
[Paper Note] Simulated Analysis of MAUT Collaborative Filtering for Learning Object Recommendation, Manouselis+, Social Information Retrieval for Technology-Enhanced Learning & Exchange, 2007
Paper/Blog Link My Issue
#Article #RecommenderSystems #AdaptiveLearning #KeyPoint Notes Issue Date: 2018-12-22 Comment
教員に対して教材を推薦しようという試み(学生ではないようだ)。
教員は、learning resourcesに対して、multi-criteriaなratingを付与することができ、それをCFで活用する(CELEBRATE web portalというヨーロッパのポータルを使用したらしい)。
CFはmemory-basedな手法を使用。target userがあるアイテムを、それぞれのattributeの観点からどのようにratingするかをattributeごとに別々に予測。各attributeのスコアを最終的に統合(元の論文ではただのスコアの足し合わせ)して、推薦スコアとする。
以下が調査された:
1. ユーザ間の距離の測り方(ユークリッド距離、cossim、ピアソンの相関係数)
2. neighborsの選び方(定義しておいた最大人数か、相関の重みで選ぶか)
3. neighborのratingをどのように組み合わせるか(平均、重み付き平均、mean formulaからのdeviation)
評価する際は、ratingのデータを training/test 80%/20%に分割。テストセットのアイテムに対して、ユーザがratingした情報をどれだけ正しく予測できるかで検証(511 evaluation in test, 2043 evaluations in training)。
ratingのMAE, coverage, アルゴリズムの実行時間で評価。
CorrerationWeightThresholdが各種アルゴリズムで安定した性能。Maximum Number Userはばらつきがでかい。いい感じの設定がみつかれば、Maximum Number Userの方がMAEの観点からは強い。
top-10のアイテムをselectするようにしたら、60%のcoverageになった。
(アルゴリズムの実行時間は、2000程度のevaluationデータに対して、2.5GHZ CPU, 256MEMで20秒とかかかってる。)
Learning Resource Exchangeの文脈で使われることを想定(このシステムではヨーロッパのK-12)。
教員による教材のmulti-criteriaのratingは5-scaleで行われた。
どういうcriteriaに対してratingされたかが書かれていない。
[Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #MatrixFactorization #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-11 Comment
Implicit Feedbackなデータに特化したMatrix Factorization (MF)、Weighted Matrix Factorization (WMF)を提案。
ユーザのExplicitなFeedback(ratingやlike, dislikeなど)がなくても、MFが適用可能。
目的関数は式(3)のようになっている。
通常のMFでは、ダイレクトにrating r_{ui}を予測したりするが、WMFでは r_{ui}をratingではなく、たとえばユーザuがアイテムiを消費した回数などに置き換え、binarizeした数値p_{ui}を目的関数に用いる。
このとき、itemを消費した回数が多いほど、そのユーザはそのitemを好んでいると仮定し、そのような事例については重みが高くなるようにconfidence c_{ui}を計算し、目的関数に導入している。
日本語での解説: https://cympfh.cc/paper/WRMF
Implicit Implicit でのAlternating Least Square (ALS)という手法が、この手法の実装に該当する。
[Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tools #MatrixFactorization #One-Line Notes #JMLR Issue Date: 2018-01-11 Comment
tool: http://apex.sjtu.edu.cn/projects/33
Ratingの情報だけでなく、Auxiliaryな情報も使ってMatrix Factorizationができるツールを作成した。
これにより、Rating Matrixの情報だけでなく、自身で設計したfeatureをMFに組み込んでモデルを作ることができる。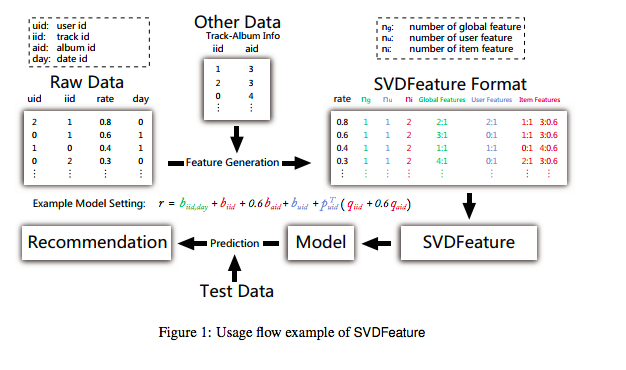
[Paper Note] Discovery-oriented Collaborative Filtering for Improving User Satisfaction, Hijikata+, IUI’09
Paper/Blog Link My Issue
#Article #RecommenderSystems #Novelty #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 Comment
・従来のCFはaccuracyをあげることを目的に研究されてきたが,ユーザがすでに知っているitemを推薦してしまう問題がある.おまけに(推薦リスト内のアイテムの観点からみた)diversityも低い.このような推薦はdiscoveryがなく,user satisfactionを損ねるので,ユーザがすでに何を知っているかの情報を使ってよりdiscoveryのある推薦をCFでやりましょうという話.
・特徴としてユーザのitemへのratingに加え,そのitemをユーザが知っていたかどうかexplicit feedbackしてもらう必要がある.
・手法は単純で,User-based,あるいはItem-based CFを用いてpreferenceとあるitemをユーザが知っていそうかどうかの確率を求め,それらを組み合わせる,あるいはrating-matrixにユーザがあるitemを知っていたか否かの数値を組み合わせて新たなmatrixを作り,そのmatrix上でCFするといったもの.
・offline評価の結果,通常のCF,topic diversification手法と比べてprecisionは低いものの,discovery ratioとprecision(novelty)は圧倒的に高い.
・ユーザがitemを知っていたかどうかというbinary ratingはユーザに負荷がかかるし,音楽推薦の場合previewがなければそもそも提供されていないからratingできないなど,必ずしも多く集められるデータではない.そこで,データセットのratingの情報を25%, 50%, 75%に削ってratingの数にbiasをかけた上で実験をしている.その結果,事前にratingをcombineし新たなmatrixを作る手法はratingが少ないとあまりうまくいかなかった.
・さらにonlineでuser satisfaction(3つの目的のもとsatisfactionをratingしてもらう 1. purchase 2. on-demand-listening 3. discovery)を評価した. 結果,purchaseとdiscoveryにおいては,ベースラインを上回った.ただし,これは推薦リスト中の満足したitemの数の問題で,推薦リスト全体がどうだった
かと問われた場合は,ベースラインと同等程度だった.
重要論文