
Embeddings
[Paper Note] Separating Representation from Reconstruction Enables Scalable Text Encoders, Megi Dervishi+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Architecture #Selected Papers/Blogs #Encoder #reading #One-Line Notes #Scalability Issue Date: 2026-07-26 GPT Summary- BERT以降、エンコーダはほとんど変わっていないが、急速に進化するデコーダとの乖離を再評価。BERTエンコーダの表現は凍結プローブで劣化し、平坦な設計が表現学習を阻害している。これに対抗するため、CrossBERTを提案。二部構成のアーキテクチャで、トークン再構成から独立した高品質なエンコード表現を学習。高いマスキング比率と補完的戦略により、スループットとサンプル効率を向上。結果、MTEBおよび凍結GLUEベンチマークで優越性を示す。 Comment
元ポスト:
論文の概要としては、BERTは投入された計算量に対してdownstreamタスク性能がスケールしない課題があったが、その原因を、BERTのflatなアーキテクチャが課題であると指摘。BERTはMLM lossで学習されるが、これはトークンの再構築の能力を測定するが、実際の表現の品質を測定できていない。BERTのアーキテクチャが、Representationの学習と、Reconstructionを明示的に分離していない(=flatなアーキテクチャ)ため、結果的にBERTが学習する表現がReconstructionのためのlocalな信号に過度に適合してしまい、abstractionに失敗してしまう(結果的に、計算量を投じれば投じるほどlossは下がるが、downstreamタスクの性能は下がる)、という仮説を立てている。
解決方法として、表現を学習するEncoderと、マスク部分の再構築をおこなうPredictorをアーキテクチャとして明示的に分離することを提案している。
これにより、投入した計算量に対してdownstreamタスクの性能がスケールするようになった、という話に見える。
おそらくアーキテクチャ上の細かい工夫があると思われるので、そこはしっかり読んだ方が良いカッコまだ読めてない)。
[Paper Note] EvoEmbedding: Evolvable Representations for Long-Context Retrieval and Agentic Memory, Chang Nie+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #LanguageModel #memory #LatentRepresentation Issue Date: 2026-07-05 GPT Summary- EvoEmbeddingは、文脈や時間的順序を考慮した動的な埋め込みモデルであり、逐次処理により潜在メモリを更新し、進化する状況に基づいて検索対象を最適化する。EvoTrain-180Kデータセットを用いて、潜在メモリと検索を共同最適化し、長文脈検索において他の大規模モデルを凌駕する性能を発揮することを実証。さらに、エージェント型ワークフローにも統合可能で、性能向上を実現。 Comment
元ポスト:
[Paper Note] Why Mean Pooling Works: Quantifying Second-Order Collapse in Text Embeddings, Tomomasa Hara+, ACL'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #ACL #Encoder #Author Thread-Post Issue Date: 2026-07-02 GPT Summary- 平均プーリングはトークン埋め込みの標準的な構築法だが、空間的構造を捉えられず、異なる埋め込みを類似にする可能性がある。本研究はこの崩壊を定量化する指標を提案し、実際のモデルでの頻度を測定した結果、特に対照学習で微調整されたエンコーダが頑健であることを示した。また、頑健性はトークン埋め込みの集中度に依存し、指標との相関が下流タスクの性能に影響を与えることが明らかになった。現代のテキストエンコーダが平均プーリングに依存しながらも有効である理由に光を当てる。 Comment
元ポスト:
[Paper Note] Scaling Embeddings Outperforms Scaling Experts in Language Models, Hong Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #read-later Issue Date: 2026-07-02 GPT Summary- 埋め込みスケーリングを通じてMoEアーキテクチャのスパース性を向上させる研究。特定のレジームにおいて埋め込みスケーリングが優位性を示し、重要なアーキテクチャ因子を体系的に分析。最適化されたシステムと推論スピード向上を組み合わせ、LongCat-Flash-Liteを導入。これは68.5Bパラメータのモデルで、MoEベースラインを上回り、エージェント性やコーディング能力で競争力を発揮。 Comment
元ポスト:
[Paper Note] MVEB: Massive Video Embedding Benchmark, Adnan El Assadi+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Evaluation #3D (Video) #Author Thread-Post Issue Date: 2026-06-22 GPT Summary- 大規模ビデオ埋め込みベンチマーク(MVEB)は、23タスクからなるベンチマークで、分類、ゼロショット分類、クラスタリング、ペア分類、検索、およびビデオ中心の質問応答を含みます。33モデルを評価し、単一の支配的なモデルは確認されませんでした。MLLMベースの埋め込みは分類やクラスタリングで優位を示し、マルチモーダル結合は検索およびゼロショット分類で優れています。音声の寄与はデータセットの注釈取得元に依存し、両モダリティから作成されたラベルが有効な場合と視覚のみから作成された場合で一貫して6ポイントの差が見られました。MVEBは184タスクのプールに基づいて派生しており、MTEBエコシステムに組み込まれています。すべてのコードとリーダーボードは公開されています。 Comment
元ポスト:
[Paper Note] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings, Songhao Wu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#DocumentSummarization #NLP #LanguageModel #Decoder #Initial Impression Notes Issue Date: 2026-06-11 GPT Summary- 大規模言語モデルはゼロショット能力に優れるが、テキスト埋め込みベンチマークでは性能が不足している。これは、高頻度トークンの過剰な表現が意味表現の能力を抑制するためと考える。そこで、EmbedFilterを導入し、LLMから生成された埋め込みを洗練させる。具体的には、頻繁なトークンの影響を抑えるためのフィルタリングを行い、意味表現を強化しつつ、埋め込み次元を削減。実験により、EmbedFilterを用いたLLMが、次元削減後もゼロショット性能が向上することを示した。本研究がLLMベースの表現の理解を深め、テキスト埋め込みの改善に寄与することを期待する。 Comment
元ポスト:
関連:
- [Paper Note] Scaling Sentence Embeddings with Large Language Models, Ting Jiang+, EMNLP'24 Findings, 2023.07
- [Paper Note] Repetition Improves Language Model Embeddings, Jacob Mitchell Springer+, ICLR'25, 2024.02
decoder-onlyモデルからembeddingを取得する際に、高頻度語の成分を除去するフィルタを導入することでembeddingの品質を向上させる
[Paper Note] Quantifying Hyperparameter Transfer and the Importance of Embedding Layer Learning Rate, Dayal Singh Kalra+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #read-later #HyperparameterTransfer Issue Date: 2026-05-27 GPT Summary- ハイパーパラメータ転送は、小規模から大規模モデルへの最適化に不可欠で、特にスケーリング則の適合や適切なパラメータ化の選択が重要です。本研究では、ハイパーパラメータ転送をスケーリング則適合の品質、外挿誤差のロバスト性、パラメータ化による損失ペナルティの三つの指標で定量化する枠組みを提案。また、μPがSPに比べて高品質な学習率転送を提供する理由を解明し、埋め込み層の学習率最大化が訓練の安定性とハイパーパラメータ転送を向上させることを示しました。さらに、ウェイト減衰はスケーリング則の適合を促進する一方で、固定トークン設定が外挿ロバスト性を損なう可能性も指摘しました。 Comment
関連:
- [Paper Note] Scaling Exponents Across Parameterizations and Optimizers, Katie Everett+, ICML'24
- [Paper Note] A Theory on Adam Instability in Large-Scale Machine Learning, Igor Molybog+, arXiv'23, 2023.04
元ポスト:
[Paper Note] TIDE: Every Layer Knows the Token Beneath the Context, Ajay Jaiswal+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #read-later #Selected Papers/Blogs Issue Date: 2026-05-10 GPT Summary- トークンインデックスの単一注入仮定を再検討し、Rare Token ProblemとContextual Collapse Problemに対処するためにTIDEを提案。TIDEはEmbeddingMemoryで標準トランスフォーマーを拡張し、依存性のない意味ベクトルを用いて各層へ注入。理論的・実証的にTIDEの効果を示し、言語モデリングや下流タスクでの性能向上を実証。 Comment
元ポスト:
関連:
- [Paper Note] Value Residual Learning, Zhanchao Zhou+, ACL'25
[Paper Note] Beyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling, Yilong Chen+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #read-later #memory #Reference Collection Issue Date: 2026-05-06 GPT Summary- X-GRAMは、動的トークン注入フレームワークで、トークンインデックス付きルックアップテーブルの効率を向上させる。ハイブリッドハッシュとエイリアスミキシングを利用して、情報の圧縮と局所的特徴の抽出を図り、メモリを効果的に管理する。評価結果では、従来の手法に対して平均精度を最大4.4ポイント改善し、スケーラブルなアーキテクチャの実現を示した。 Comment
元ポスト:
[Paper Note] Thought-Retriever: Don't Just Retrieve Raw Data, Retrieve Thoughts for Memory-Augmented Agentic Systems, Tao Feng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #AIAgents #Chain-of-Thought #Selected Papers/Blogs #memory Issue Date: 2026-04-20 GPT Summary- LLMが外部知識を効果的に取り込む課題を解決するために、Thought-Retrieverという新しいアルゴリズムを提案。これは、過去のユーザークエリで生成された中間応答を活用し、冗長な思考をフィルタリングして新しいクエリに関連する思考を取り出すことで、長期記憶を構築。AcademicEvalという新たなベンチマークで広範な実験を行い、Thought-Retrieverが最先端モデルを上回る成果を示した。特に、より多くのクエリ解決後に自己進化を促し、抽象的な問いへの応答能力を向上させることが確認された。 Comment
元ポスト:
[Paper Note] IDIOLEX: Unified and Continuous Representations for Idiolectal and Stylistic Variation, Anjali Kantharuban+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #RepresentationLearning #read-later #Selected Papers/Blogs Issue Date: 2026-04-11 GPT Summary- 意味内容とは切り離したスタイルと方言の表現を学習する課題として、IDIOLEXを提案。文の出所情報と内容の特徴を組み合わせ、アラビア語とスペイン語の方言における連続表現を学ぶ。このアプローチは、個人とコミュニティの変動をモデル化し、言語モデルへの応用可能性を示唆する。 Comment
元ポスト:
内容ではなく、スタイルを捉えるembedding
[Paper Note] Symmetry in language statistics shapes the geometry of model representations, Dhruva Karkada+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #RepresentationLearning #read-later #Selected Papers/Blogs #Geometric #Initial Impression Notes Issue Date: 2026-02-28 GPT Summary- 言語モデルの内部表現は顕著な幾何学的構造を示し、暦の月や歴史的年の配置に関する対称性を示す。特に、月の共起頻度が時間間隔のみに依存することを証明し、高次元の単語埋め込みモデルにおける幾何学的構造を導出。実験的に大規模なテキスト埋め込みモデルとの一致を確認し、共起統計が撹乱されても幾何は維持されることを示している。この頑健性は、潜在変数によって制御される場合に自然に現れ、表現多様体の普遍的な起源を示唆する。 Comment
元ポスト:
こんな不思議なことが(小並感)
[Paper Note] IRPAPERS: A Visual Document Benchmark for Scientific Retrieval and Question Answering, Connor Shorten+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#InformationRetrieval #Dataset #QuestionAnswering #Evaluation #MultiModal #OCR #Hybrid Issue Date: 2026-02-27 GPT Summary- 画像ベースの情報検索と質問応答の性能をテキストベースの手法と比較するために、IRPAPERSデータセットを用いて実験を実施。テキスト検索はRecall@1で46%を達成し、画像ベースは43%を達成。両手法は補完的で、マルチモーダルハイブリッド検索はRecall@1で49%の性能を示す。MUVERAを用いた画像埋め込みモデルの評価において、Cohere Embed v4が最も優れた性能を持つ。質問応答では、テキストベースのシステムが画像ベースより高い整合性を示し、複数文書検索が効果を発揮。両モダリティの限界と必要性を明確化。データセットと実験コードは公開。 Comment
元ポスト:
[Paper Note] Latent Forcing: Reordering the Diffusion Trajectory for Pixel-Space Image Generation, Alan Baade+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #Transformer #DiffusionModel #Architecture #2D (Image) #ImageSynthesis #Pixel-based Issue Date: 2026-02-13 GPT Summary- 潜在拡散モデルは高品質な画像生成を実現するものの、エンドツーエンドの利点を失うことが課題であった。本研究では、ラテント強制(Latent Forcing)を提案し、ラテントとピクセルを別々のノイズスケジュールで共同処理することで、効率的に高周波ピクセル特徴を生成する。条件信号の順序が重要であることを発見し、これを分析することで、トークナイザーのREPA蒸留と拡散モデルの違いや生成品質の関係を示す。ImageNetでの適用により、新たな最先端を達成した。 Comment
元ポスト:
[Paper Note] Diffusion-Pretrained Dense and Contextual Embeddings, Sedigheh Eslami+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #InformationRetrieval #NLP #RepresentationLearning #ContrastiveLearning #DiffusionModel Issue Date: 2026-02-12 GPT Summary- pplx-embedは、拡散事前学習された言語モデルを基盤にした多段階コントラスト学習を用いた多言語埋め込みモデルで、文脈内の双方向コンテキストを捉える。pplx-embed-v1は標準的な検索性能があり、pplx-embed-context-v1はConTEBベンチマークで新記録を達成。両モデルは実世界の大規模検索にも優れた性能を示し、モデルの有効性を確認した。 Comment
元ポスト:
[Paper Note] JTok: On Token Embedding as another Axis of Scaling Law via Joint Token Self-modulation, Yebin Yang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #MoE(Mixture-of-Experts) Issue Date: 2026-02-03 GPT Summary- トークンインデックスパラメータを用いて、LLMの計算コストとモデル容量を切り離す新しいスケーリング手法を提案。Joint-Token(JTok)とMixture of Joint-Token(JTok-M)を導入し、Transformerレイヤーを強化。実験により、検証損失が低下し、MMLUやARCでの性能向上を実証。JTok-Mは、従来のMoEアーキテクチャに比べ、35%少ない計算で同等のモデル品質を実現。 Comment
元ポスト:
[Paper Note] MemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers, Ajay Jaiswal+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #memory Issue Date: 2026-02-03 GPT Summary- 大規模言語モデルのFFNの解釈可能性を再検討し、自己注意から切り離したMemoryLLMを提案。FFNをトークン単位のニューラルリトリーバルメモリとして機能させ、効率的な推論を実現。Flex-MemoryLLMも導入し、性能ギャップを埋める役割を果たす。 Comment
またしてもembeddingの活用
元ポスト:
[Paper Note] L$^3$: Large Lookup Layers, Albert Tseng+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture Issue Date: 2026-01-30 GPT Summary- L$^3$レイヤーを使用した新しいスパース性の手法を提案。これは静的なトークンベースのルーティングでトークンごとの埋め込みを集約し、メモリと計算の効率を向上させる。高速トレーニングが可能で、情報理論に基づく埋め込み割り当てアルゴリズムを採用。実験により、L$^3$が他のモデルを大きく上回る性能を示した。 Comment
[Paper Note] Beyond Speedup -- Utilizing KV Cache for Sampling and Reasoning, Zeyu Xing+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #read-later #Selected Papers/Blogs #KV Cache #DownstreamTasks #Adaptive #Initial Impression Notes #SelfVerification Issue Date: 2026-01-30 GPT Summary- KVキャッシュを文脈情報の軽量な表現として再利用し、再計算や保存の必要を排除。KV由来の表現は、(i)チェーン・オブ・エンベディングで競争力のある性能を発揮し、(ii)ファスト/スロー思考切替でトークン生成を最大5.7倍削減する一方、精度損失を最小限に抑える。これにより、KVキャッシュがLLM推論における表現再利用の新たな基盤となることを示す。 Comment
元ポスト:
KV Cacheを軽量なhidden stateを表すembeddingとして扱うことで色々と応用できます、という話に見え、たとえばデコーディングの途中でhallucinationをdetectする際により省メモリで実現できたり、fast/d slowなthinkingの切り替えの制御に利用するなど、単に次トークンを生成する際の高速化の用途を超えて使うという興味深い発想な研究に見える。
[Paper Note] Scaling Embeddings Outperforms Scaling Experts in Language Models, Hong Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #AIAgents #LongSequence #Architecture #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-01-30 GPT Summary- 本研究では、Mixture-of-Experts(MoE)アーキテクチャに代わる埋め込みスケーリングを検討し、その効果を体系的に分析。埋め込みスケーリングは専門家スケーリングよりも優れたパレートフロンティアを達成し、推論速度が向上することを示す。68.5BパラメータのLongCat-Flash-Liteモデルを導入し、約3Bのパラメータでトレーニングを行った結果、既存のMoEベースラインを超える性能を発揮。特にエージェント的およびコーディングの分野で競争力が示される。 Comment
HF: https://huggingface.co/meituan-longcat/LongCat-Flash-Lite
元ポスト:
N-Gram Embeddingを用いることでMoEアーキテクチャの同等程度のモデルと比較してより高い性能を獲得しているように見える。NGramの各NごとにルックアップテーブルとProtectionのための重みを学習して最終的にAveragingをすることでContext Vectorを生成している、ようなアーキテクチャに見える。non-thinkingモデル
先行研究:
- [Paper Note] Scaling Embedding Layers in Language Models, Da Yu+, NeurIPS'25, 2025.02
[Paper Note] STEM: Scaling Transformers with Embedding Modules, Ranajoy Sadhukhan+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Transformer #LongSequence #Architecture #read-later #Selected Papers/Blogs #Inference #Stability #Latency #Interpretability #Author Thread-Post Issue Date: 2026-01-17 GPT Summary- STEMは、Transformersに埋め込みモジュールを用いてスパーシティを効果的に処理し、安定したトレーニングを実現します。FNNのアッププロジェクションを埋め込みのルックアップに置き換え、トークンごとの計算を削減しつつ、性能を向上させます。知識の保存や解釈性を向上させ、長いコンテキストでも効果を発揮。350Mおよび1Bモデルで約3~4%の精度向上を達成し、知識や推論のベンチマークで優れた結果を示しました。 Comment
元ポスト:
著者ポスト:
[Paper Note] Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models, Xin Cheng+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Architecture #read-later #Selected Papers/Blogs #memory #Reference Collection Issue Date: 2026-01-14 GPT Summary- 条件付きメモリを用いたMixture-of-Experts (MoE)の拡張により、知識検索の効率を向上。Engramモジュールを通じて古典的なN-gram埋め込みのO(1)ルックアップを実現し、ニューラル計算と静的メモリの最適なトレードオフを導出。27Bパラメータでのスケーリングが同等のMoEベースラインを上回り、知識検索や一般推論、コード・数学領域で顕著な性能向上を示す。局所的依存性のルックアップでアテンション容量を解放し、長文脈検索能力を強化。Engramは次世代スパースモデルに不可欠なモデルプリミティブを提供する。 Comment
元ポスト:
所見:
解説:
解説:
ポイント解説:
先行研究:
- [Paper Note] Scaling Embedding Layers in Language Models, Da Yu+, NeurIPS'25, 2025.02
[Paper Note] Repetition Improves Language Model Embeddings, Jacob Mitchell Springer+, ICLR'25, 2024.02
Paper/Blog Link My Issue
#Sentence #NLP #ICLR #Decoder #One-Line Notes Issue Date: 2026-06-11 GPT Summary- エコー埋め込みを通じて、自己回帰LMをアーキテクチャ変更なしで高品質なテキスト埋め込みモデルに転換。入力を繰り返すことで埋め込みを抽出し、ゼロショット設定で従来の埋め込みを5%以上上回る性能を発揮。監督付きファインチューニングでも双方向化済みLMと同等かそれ以上の結果を示し、埋め込みモデルにおける双方向注意機構の不要性を証明。全てのNLPタスクへの統一アーキテクチャの実現に寄与。 Comment
openreview: https://openreview.net/forum?id=Ahlrf2HGJR
autorgressiveなモデルで文embeddingを取得する際に、単に文のtokenをpoolingするのではなく、embeddingを取得したいsentenceを繰り返し、2回目に出現したtokenのpoolingによってsentence embeddingを形成すると良質な文embeddingを取得できる。これは、あるtokenから見たときに未来のtokenの情報をautoregressiveなモデルは考慮できないことに起因する。
PromptingのRE2とアイデアが似ている。同じPromptを複数回繰り返すことにより、autoregressiveモデルに対してbi-directionalなエンコーダのような性質を付与する:
- [Paper Note] Re-Reading Improves Reasoning in Large Language Models, Xiaohan Xu+, EMNLP'24, 2023.09
[Paper Note] Scaling Embedding Layers in Language Models, Da Yu+, NeurIPS'25, 2025.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Architecture #NeurIPS #One-Line Notes Issue Date: 2026-02-01 GPT Summary- 新手法$SCONE$は、言語モデルの性能向上のために入力埋め込み層を拡張し、元の語彙を保持しながら頻出n-gramの埋め込みを導入します。これにより、各トークンに文脈化された表現を提供し、埋め込みは訓練中に別のモデルで学習され、推論中にオフアクセラレータメモリから迅速に照会されます。$SCONE$は、埋め込み数の増加とモデルのスケールアップを実現し、1Bパラメータのモデルが1.9Bパラメータのベースラインを上回りながら、推論時のFLOPSとメモリを約半減することを示しています。 Comment
元ポスト:
関連:
- [Paper Note] Scaling Embeddings Outperforms Scaling Experts in Language Models, Hong Liu+, arXiv'26, 2026.01
- [Paper Note] L$^3$: Large Lookup Layers, Albert Tseng+, arXiv'26, 2026.01
あとでもう少ししっかり読みたいのだが、(Vocabularyをシンプルに増やしてスケーリングさせるのではなく、input embedding layerを拡張するために、LLM本体と独立したモジュールとして)通常のVocabularyに追加して、頻出するn-gram(f-gram)によるVocabularyを拡張した新たな小さなtransformerモジュールを定義し、contextを考慮した各トークンのembeddingを出力するよう学習する。独立したモデルとして定義することで、embeddingを事前に計算してオフローディングしておき高速にlookupすることが可能となり、FLOPSを増やさずにembeddingをスケーリングできて、リッチな入力表現を扱える。f-gramの数をスケールさせると性能もスケールする、といった話に見える。
[Paper Note] Latent Space Chain-of-Embedding Enables Output-free LLM Self-Evaluation, Yiming Wang+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ICLR #SelfVerification Issue Date: 2026-01-30 GPT Summary- LLMの自己評価において、出力なしで正確さを推定するために、潜在空間のEmbeddingの連鎖(CoE)を提案。CoEは推論中の隠れ状態を反映し、正誤に基づく応答の特徴を明らかにする。実験により、トレーニングなしでミリ秒単位のコストでリアルタイムフィードバックが可能で、LLM内部の状態変化から新たな洞察が得られることを示した。 Comment
openreview: https://openreview.net/forum?id=jxo70B9fQo
[Paper Note] Granite Embedding R2 Models, Parul Awasthy+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NeuralNetwork #NLP #RepresentationLearning #Encoder Issue Date: 2026-01-09 GPT Summary- Granite Embedding R2モデルは、企業向けの高性能な英語エンコーダーベースの埋め込みモデル群で、コンテキスト長を16倍に拡張し、様々な検索ドメインでのパフォーマンスを向上させています。これにより、速度が19-44%向上し、精度も維持されています。22層のリトリーバーモデルや12層の対応モデルを含み、企業向けのデータで訓練されています。これらのモデルは、標準ベンチマークや実際のユースケースで優れた汎用性を示し、オープンソースの新たなパフォーマンス基準を確立しています。すべてのモデルはApache 2.0ライセンスで公開され、無制限の利用が可能です。 Comment
HF: https://huggingface.co/ibm-granite/granite-embedding-english-r2
元ポスト:
[Paper Note] Language Models are Injective and Hence Invertible, Giorgos Nikolaou+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Selected Papers/Blogs Issue Date: 2025-10-29 GPT Summary- 本研究では、トランスフォーマー言語モデルが単射であることを数学的に証明し、異なる入力が同じ出力にマッピングされないことを示す。さらに、6つの最先端モデルに対して衝突テストを行い、衝突がないことを確認。新たに提案するアルゴリズムSipItにより、隠れた活性化から正確な入力テキストを効率的に再構築できることを示し、単射性が言語モデルの重要な特性であることを明らかにする。 Comment
元ポスト:
続報:
解説:
解説参照のこと。
[Paper Note] Understanding the Influence of Synthetic Data for Text Embedders, Jacob Mitchell Springer+, ACL'25 Findings, 2025.09
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #LanguageModel #RepresentationLearning #SyntheticData #ACL #Findings Issue Date: 2025-10-19 GPT Summary- 合成LLM生成データのトレーニングによる汎用テキスト埋め込み器の進展を受け、Wangらの合成データを再現・公開。高品質なデータはパフォーマンス向上をもたらすが、一般化の改善は局所的であり、異なるタスク間でのトレードオフが存在。これにより、合成データアプローチの限界が明らかになり、タスク全体での堅牢な埋め込みモデルの構築に対する考えに疑問を呈する。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/jspringer/open-synthetic-embeddings
[Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #RepresentationLearning #RAG(RetrievalAugmentedGeneration) #ICLR #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-08 GPT Summary- 生成的表現指示チューニング(GRIT)を用いて、大規模言語モデルが生成タスクと埋め込みタスクを同時に処理できる手法を提案。GritLM 7BはMTEBで新たな最先端を達成し、GritLM 8x7Bはすべてのオープン生成モデルを上回る性能を示す。GRITは生成データと埋め込みデータの統合による性能損失がなく、RAGを60%以上高速化する利点もある。モデルは公開されている。 Comment
openreview: https://openreview.net/forum?id=BC4lIvfSzv
従来はgemerativeタスクとembeddingタスクは別々にモデリングされていたが、それを統一的な枠組みで実施し、両方のタスクで同等のモデルサイズの他モデルと比較して高い性能を達成した研究。従来のgenerativeタスク用のnext-token-prediction lossとembeddingタスク用のconstastive lossを組み合わせて学習する(式3)。タスクの区別はinstructionにより実施し、embeddingタスクの場合はすべてのトークンのlast hidden stateのmean poolingでrepresentationを取得する。また、embeddingの時はbi-directional attention / generativeタスクの時はcausal maskが適用される。これらのattentionの適用のされ方の違いが、どのように管理されるかはまだしっかり読めていないのでよくわかっていないが、非常に興味深い研究である。
[Paper Note] ReasonIR: Training Retrievers for Reasoning Tasks, Rulin Shao+, COLM'25, 2025.04
Paper/Blog Link My Issue
#InformationRetrieval #Transformer #SyntheticData #Reasoning #Test-Time Scaling #COLM #read-later #Selected Papers/Blogs #Encoder Issue Date: 2025-10-08 GPT Summary- ReasonIR-8Bは、一般的な推論タスク向けに特別に訓練された初のリトリーバーであり、合成データ生成パイプラインを用いて挑戦的なクエリとハードネガティブを作成。これにより、BRIGHTベンチマークで新たな最先端成果を達成し、RAGタスクでも他のリトリーバーを上回る性能を示す。トレーニングレシピは一般的で、将来のLLMへの拡張が容易である。コード、データ、モデルはオープンソース化されている。 Comment
元ポスト:
Llama3.1-8Bをbidirectional encoderに変換してpost-trainingしている。
関連:
- [Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
[Paper Note] Omni-Embed-Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video, Mengyao Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#RecommenderSystems #InformationRetrieval #NLP #MultiModal #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-10-07 GPT Summary- 「Omni-Embed-Nemotron」は、複雑な情報ニーズに応えるための統一的なマルチモーダル検索埋め込みモデルです。従来のテキストベースのリトリーバーが視覚的に豊かなコンテンツに対応できない中、ColPaliの研究を基に、テキスト、画像、音声、動画を統合した検索を実現します。このモデルは、クロスモーダルおよびジョイントモーダル検索を可能にし、そのアーキテクチャと評価結果を通じて、検索の効果を実証しています。 Comment
元ポスト:
[Paper Note] ModernVBERT: Towards Smaller Visual Document Retrievers, Paul Teiletche+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #InformationRetrieval #NLP #MultiModal #SmallModel #Encoder Issue Date: 2025-10-03 GPT Summary- マルチモーダル埋め込みモデルは文書検索において効率的な代替手段として普及しているが、再利用アプローチが検索性能のボトルネックとなることがある。本研究では、視覚文書検索モデルを改善するための原則的なレシピを確立し、注意マスキングや画像解像度などが性能に影響を与える要因であることを示した。これに基づき、250Mパラメータのコンパクトな視覚-言語エンコーダーModernVBERTを開発し、文書検索タスクで大規模モデルを上回る性能を達成した。モデルとコードは公開されている。 Comment
元ポスト:
MIT Licence
HF:
https://huggingface.co/ModernVBERT
ポイント解説:
[Paper Note] EmbeddingGemma: Powerful and Lightweight Text Representations, Henrique Schechter Vera+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #RepresentationLearning #SmallModel #MultiLingual #OpenWeight Issue Date: 2025-09-25 GPT Summary- EmbeddingGemmaは、Gemma 3言語モデルに基づく軽量なオープンテキスト埋め込みモデルで、エンコーダ-デコーダの初期化と幾何学的埋め込み蒸留を用いて大規模モデルの知識を活用。分散正則化器を使用し、異なるチェックポイントを統合することで一般化能力を向上。300Mのパラメータで、MTEBで最先端の結果を達成し、従来のトップモデルを上回る性能を示す。量子化や出力の切り詰めにも耐え、低遅延かつ高スループットのアプリケーションに適している。EmbeddingGemmaはコミュニティに公開され、さらなる研究を促進する。 Comment
公式モデル概要: https://ai.google.dev/gemma/docs/embeddinggemma?hl=ja
元ポスト:
100以上の言語で訓練されマトリョーシカ表現なのでベクトルのサイズを調整可能な模様
マトリョーシカ表現:
- [Paper Note] Matryoshka Representation Learning, Aditya Kusupati+, NeurIPS'22
公式による解説ブログ:
[Paper Note] Perception Encoder: The best visual embeddings are not at the output of the network, Daniel Bolya+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #MultiModal #NeurIPS #Encoder #SpatialUnderstanding Issue Date: 2025-09-22 GPT Summary- Perception Encoder(PE)は、画像と動画理解のための新しいビジョンエンコーダで、シンプルなビジョンと言語の学習を通じて訓練されています。従来の特定のタスクに依存せず、対照的なビジョンと言語の訓練だけで強力な埋め込みを生成します。埋め込みを引き出すために、言語アライメントと空間アライメントの2つの手法を導入。PEモデルは、ゼロショット画像・動画分類で高い性能を示し、Q&Aタスクや空間タスクでも最先端の結果を達成しました。モデルやデータセットは公開されています。 Comment
元ポスト:
解説:
[Paper Note] Lost in Embeddings: Information Loss in Vision-Language Models, Wenyan Li+, EMNLP'25 Findings, 2025.09
Paper/Blog Link My Issue
#ComputerVision #Analysis #NLP #EMNLP #VisionLanguageModel #Findings Issue Date: 2025-09-21 GPT Summary- 視覚と言語のモデル(VLMs)の投影ステップによる情報損失を分析するため、2つのアプローチを提案。1つ目は、投影前後の画像表現のk近傍関係の変化を評価し、2つ目は視覚埋め込みの再構築によって情報損失を測定。実験により、コネクタが視覚表現の幾何学を歪め、k近傍が40~60%乖離することが明らかになり、これは検索性能の低下と関連。パッチレベルの再構築は、モデルの挙動に対する洞察を提供し、高い情報損失がモデルの苦手な事例を予測することを示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings, Shiyu Li+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #InformationRetrieval #LanguageModel Issue Date: 2025-09-17 GPT Summary- 新しい1.4BパラメータのLLM「Conan-embedding-v2」をゼロからトレーニングし、テキスト埋め込み器としてファインチューニングする手法を提案。ニュースデータと多言語ペアを追加してデータギャップを埋め、クロスリンガルリトリーバルデータセットを導入。ソフトマスキングメカニズムを用いてトークンレベルと文レベルの損失を統合し、動的ハードネガティブマイニング手法を採用。これにより、MTEBおよびChinese MTEBでSOTA性能を達成。 Comment
元ポスト:
[Paper Note] mmBERT: A Modern Multilingual Encoder with Annealed Language Learning, Marc Marone+, arXiv'25
Paper/Blog Link My Issue
#NLP #Transformer #MultiLingual #Encoder Issue Date: 2025-09-10 GPT Summary- mmBERTは、1800以上の言語で3兆トークンのデータを用いて事前学習されたエンコーダ専用の言語モデルであり、低リソース言語を短い減衰フェーズに含めることでパフォーマンスを向上させた。新しい要素を導入し、OpenAIのo3やGoogleのGemini 2.5 Proと同等の分類性能を達成。mmBERTは分類および検索タスクで以前のモデルを大幅に上回ることを示した。 Comment
blog:
https://huggingface.co/blog/mmbert
HF:
https://huggingface.co/jhu-clsp/mmBERT-checkpoints
- modernbert-ja-130m, SB Intuitions, 2025.02
と比較して日本語の性能はどうかなあ
元ポスト:
解説:
[Paper Note] Efficient Code Embeddings from Code Generation Models, Daria Kryvosheieva+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Coding Issue Date: 2025-09-03 GPT Summary- jina-code-embeddingsは、自然言語からコードを取得し、技術的な質問応答や意味的に類似したコードスニペットの特定を行う新しいコード埋め込みモデルです。自己回帰型バックボーンを利用し、トークンプーリングを通じて埋め込みを生成。小さいモデルサイズながら最先端のパフォーマンスを示し、コード埋め込みモデルの構築における有効性を検証しています。 Comment
HF: https://huggingface.co/collections/jinaai/jina-code-embeddings-68b0fbfbb0d639e515f82acd
コーディング特化のembeddingで、検索、クロスリンガルな類似度、技術に関するQAに対応可能らしい
公式ポスト:
[Paper Note] On the Theoretical Limitations of Embedding-Based Retrieval, Orion Weller+, arXiv'25
Paper/Blog Link My Issue
#Analysis #InformationRetrieval #Search Issue Date: 2025-09-01 GPT Summary- ベクトル埋め込みは検索タスクにおいて重要な役割を果たしているが、シンプルなクエリでも理論的限界に直面する可能性があることを示す。特に、埋め込みの次元が文書のトップ-kサブセットの数を制限し、k=2でもこの制限が成り立つことを実証。新たに作成したデータセット「LIMIT」では、最先端モデルでさえ失敗することが観察され、既存の埋め込みモデルの限界を明らかにし、今後の研究の必要性を提唱している。 Comment
元ポスト:
[Paper Note] Large Foundation Model for Ads Recommendation, Shangyu Zhang+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #FoundationModel #read-later Issue Date: 2025-08-26 GPT Summary- LFM4Adsは、オンライン広告のための全表現マルチ粒度転送フレームワークで、ユーザー表現(UR)、アイテム表現(IR)、ユーザー-アイテム交差表現(CR)を包括的に転送。最適な抽出層を特定し、マルチ粒度メカニズムを導入することで転送可能性を強化。テンセントの広告プラットフォームで成功裏に展開され、2.45%のGMV向上を達成。 Comment
元ポスト:
[Paper Note] Mapping 1,000+ Language Models via the Log-Likelihood Vector, Momose Oyama+, ACL'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ACL #read-later Issue Date: 2025-08-03 GPT Summary- 自動回帰型言語モデルの比較に対し、対数尤度ベクトルを特徴量として使用する新しいアプローチを提案。これにより、テキスト生成確率のクルバック・ライブラー発散を近似し、スケーラブルで計算コストが線形に増加する特徴を持つ。1,000以上のモデルに適用し、「モデルマップ」を構築することで、大規模モデル分析に新たな視点を提供。 Comment
NLPコロキウムでのスライド:
https://speakerdeck.com/shimosan/yan-yu-moderunodi-tu-que-lu-fen-bu-to-qing-bao-ji-he-niyorulei-si-xing-noke-shi-hua
元ポスト:
[Paper Note] On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey, Meishan Zhang+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #Dataset #LanguageModel #RepresentationLearning #Evaluation Issue Date: 2025-07-29 GPT Summary- 本調査では、事前学習済み言語モデル(PLMs)を活用した一般目的のテキスト埋め込み(GPTE)の発展を概観し、PLMsの役割に焦点を当てる。基本的なアーキテクチャや埋め込み抽出、表現力向上、トレーニング戦略について説明し、PLMsによる多言語サポートやマルチモーダル統合などの高度な役割も考察する。さらに、将来の研究方向性として、ランキング統合やバイアス軽減などの改善目標を超えた課題を強調する。 Comment
元ポスト:
GPTEの学習手法テキストだけでなく、画像やコードなどの様々なモーダル、マルチリンガル、データセットや評価方法、パラメータサイズとMTEBの性能の関係性の図解など、盛りだくさんな模様。最新のものだけでなく、2021年頃のT5から最新モデルまで網羅的にまとまっている。日本語特化のモデルについては記述が無さそうではある。
日本語モデルについてはRuriのテクニカルペーパーや、LLM勉強会のまとめを参照のこと
- Ruri: Japanese General Text Embeddings, cl-nagoya, 2024.09
- 日本語LLMまとめ, LLM-jp, 2024.12
[Paper Note] Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation, Tiansheng Wen+, arXiv'25
Paper/Blog Link My Issue
#NLP #RepresentationLearning #Length Issue Date: 2025-07-29 GPT Summary- スパースコーディングを用いたContrastive Sparse Representation(CSR)を提案し、適応的な埋め込みを実現。CSRは事前訓練された埋め込みをスパース化し、意味的品質を保持しつつコスト効果の高い推論を可能にする。実験により、CSRは精度と検索速度でMatryoshka Representation Learning(MRL)を上回り、訓練時間も大幅に短縮されることが示された。スパースコーディングは実世界のアプリケーションにおける適応的な表現学習の強力な手法として位置づけられる。 Comment
元ポスト:
マトリョーシカ表現:
- [Paper Note] Matryoshka Representation Learning, Aditya Kusupati+, NeurIPS'22
[Paper Note] Learning distributed representations with efficient SoftMax normalization, Lorenzo Dall'Amico+, TMLR'25
Paper/Blog Link My Issue
#MachineLearning #RepresentationLearning Issue Date: 2025-07-16 GPT Summary- 埋め込みを学習するための損失関数として${\rm SoftMax}(XY^T)$を最適化する際の計算負荷を軽減するため、ノルム制限された埋め込みベクトルに対して線形時間のヒューリスティック近似を提案。提案手法は、事前学習されたデータセットで高い精度を示し、クロスエントロピーを最適化する効率的なアルゴリズムを設計。これにより、解釈可能でタスクに依存しない埋め込み学習が可能となり、類似の「2Vec」アルゴリズムと比較して優れた性能と低い計算時間を実現。 Comment
openreview: https://openreview.net/forum?id=9M4NKMZOPu
[Paper Note] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models, Chankyu Lee+, ICLR'25
Paper/Blog Link My Issue
#RecommenderSystems #InformationRetrieval #NLP #LanguageModel #RepresentationLearning #InstructionTuning #ContrastiveLearning #ICLR #Generalization #Decoder Issue Date: 2025-07-10 GPT Summary- デコーダー専用のLLMベースの埋め込みモデルNV-Embedは、BERTやT5を上回る性能を示す。アーキテクチャ設計やトレーニング手法を工夫し、検索精度を向上させるために潜在的注意層を提案。二段階の対照的指示調整手法を導入し、検索と非検索タスクの両方で精度を向上。NV-EmbedモデルはMTEBリーダーボードで1位を獲得し、ドメイン外情報検索でも高スコアを達成。モデル圧縮技術の分析も行っている。 Comment
Decoder-Only LLMのlast hidden layerのmatrixを新たに導入したLatent Attention Blockのinputとし、Latent Attention BlockはEmbeddingをOutputする。Latent Attention Blockは、last hidden layer (系列長l×dの
matrix)をQueryとみなし、保持しているLatent Array(trainableなmatrixで辞書として機能する;後述の学習においてパラメータが学習される)[^1]をK,Vとして、CrossAttentionによってcontext vectorを生成し、その後MLPとMean Poolingを実施することでEmbeddingに変換する。
学習は2段階で行われ、まずQAなどのRetrievalタスク用のデータセットをIn Batch negativeを用いてContrastive Learningしモデルの検索能力を高める。その後、検索と非検索タスクの両方を用いて、hard negativeによってcontrastive learningを実施し、検索以外のタスクの能力も高める(下表)。両者において、instructionテンプレートを用いて、instructionによって条件付けて学習をすることで、instructionに応じて生成されるEmbeddingが変化するようにする。また、学習時にはLLMのcausal maskは無くし、bidirectionalにrepresentationを考慮できるようにする。
[^1]: [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22, 2021.07
Perceiver-IOにインスパイアされている。
[Paper Note] VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks, Ziyan Jiang+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #ICLR #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-09 GPT Summary- 本研究では、ユニバーサルマルチモーダル埋め込みモデルの構築を目指し、二つの貢献を行った。第一に、MMEB(Massive Multimodal Embedding Benchmark)を提案し、36のデータセットを用いて分類や視覚的質問応答などのメタタスクを網羅した。第二に、VLM2Vecというコントラストトレーニングフレームワークを開発し、視覚-言語モデルを埋め込みモデルに変換する手法を示した。実験結果は、VLM2Vecが既存のモデルに対して10%から20%の性能向上を達成することを示し、VLMの強力な埋め込み能力を証明した。 Comment
openreview: https://openreview.net/forum?id=TE0KOzWYAF
[Paper Note] VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents, Rui Meng+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #InformationRetrieval #NLP #LanguageModel #MultiModal #RAG(RetrievalAugmentedGeneration) #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-09 GPT Summary- VLM2Vec-V2という統一フレームワークを提案し、テキスト、画像、動画、視覚文書を含む多様な視覚形式の埋め込みを学習。新たにMMEB-V2ベンチマークを導入し、動画検索や視覚文書検索など5つのタスクを追加。広範な実験により、VLM2Vec-V2は新タスクで強力なパフォーマンスを示し、従来の画像ベンチマークでも改善を達成。研究はマルチモーダル埋め込みモデルの一般化可能性に関する洞察を提供し、スケーラブルな表現学習の基盤を築く。 Comment
元ポスト:
Video Classification, Visual Document Retrievalなどのモダリティも含まれている。
[Paper Note] Do We Really Need Specialization? Evaluating Generalist Text Embeddings for Zero-Shot Recommendation and Search, Matteo Attimonelli+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #InformationRetrieval #LanguageModel #SequentialRecommendation #Generalization Issue Date: 2025-07-08 GPT Summary- 事前学習済み言語モデル(GTEs)は、逐次推薦や製品検索においてファインチューニングなしで優れたゼロショット性能を発揮し、従来のモデルを上回ることを示す。GTEsは埋め込み空間に特徴を均等に分配することで表現力を高め、埋め込み次元の圧縮がノイズを減少させ、専門モデルの性能向上に寄与する。再現性のためにリポジトリを提供。 Comment
元ポスト:
[Paper Note] llm-jp-modernbert: A ModernBERT Model Trained on a Large-Scale Japanese Corpus with Long Context Length, Issa Sugiura+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #RepresentationLearning #pretrained-LM #Japanese Issue Date: 2025-06-25 GPT Summary- ModernBERTモデル(llm-jp-modernbert)は、8192トークンのコンテキスト長を持つ日本語コーパスで訓練され、フィルマスクテスト評価で良好な結果を示す。下流タスクでは既存のベースラインを上回らないが、コンテキスト長の拡張効果を分析し、文の埋め込みや訓練中の遷移を調査。再現性を支援するために、モデルと評価コードを公開。 Comment
[Paper Note] NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking, Shenbin Qian+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #EfficiencyImprovement #InformationRetrieval #RepresentationLearning Issue Date: 2025-06-25 GPT Summary- Eコマース情報検索システムは、ユーザーの意図を正確に理解しつつ、大規模な商品カタログを効率的に処理することが難しい。本論文では、NEAR$^2$というネストされた埋め込みアプローチを提案し、推論時の埋め込みサイズを最大12倍効率化し、トレーニングコストを増やさずにトランスフォーマーモデルの精度を向上させる。さまざまなIR課題に対して異なる損失関数を用いて検証した結果、既存モデルよりも小さな埋め込み次元での性能向上を達成した。 Comment
元ポスト:
[Paper Note] jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval, Michael Günther+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #RepresentationLearning #MultiModal Issue Date: 2025-06-24 GPT Summary- 3.8億パラメータのマルチモーダル埋め込みモデル「jina-embeddings-v4」を提案。新しいアーキテクチャにより、クエリベースの情報検索やクロスモーダルの類似性検索を最適化。タスク特化型のLoRAアダプターを組み込み、視覚的に豊かなコンテンツの処理に優れた性能を発揮。新しいベンチマーク「Jina-VDR」も導入。 Comment
元ポスト:
[Paper Note] Diffusion vs. Autoregressive Language Models: A Text Embedding Perspective, Siyue Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #RepresentationLearning #DiffusionModel Issue Date: 2025-05-24 GPT Summary- LLMベースの埋め込みモデルは、文書検索タスクで従来のモデルを超えつつあるが、自己回帰的なアテンションが双方向性に欠けることが制限となっている。これを解決するために、拡散言語モデルを提案し、双方向アーキテクチャによる長文検索で20%、推論検索で8%、指示検索で2%の向上を示す。分析により、長く複雑なテキストの文脈を捉えるために双方向アテンションが重要であることが確認された。 Comment
元ポスト:
[Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Analysis #NLP #LanguageModel #RepresentationLearning #Supervised-FineTuning (SFT) #Chain-of-Thought #SSM (StateSpaceModel) #ICML #PostTraining #read-later #One-Line Notes #CompressionValleys Issue Date: 2025-05-04 GPT Summary- 中間層の埋め込みが最終層を超えるパフォーマンスを示すことを分析し、情報理論や幾何学に基づくメトリクスを提案。32のテキスト埋め込みタスクで中間層が強力な特徴を提供することを実証し、AIシステムの最適化における中間層の重要性を強調。 Comment
現代の代表的な言語モデルのアーキテクチャ(decoder-only model, encoder-only model, SSM)について、最終層のembeddingよりも中間層のembeddingの方がdownstream task(MTEBの32Taskの平均)に、一貫して(ただし、これはMTEBの平均で見たらそうという話であり、個別のタスクで一貫して強いかは読んでみないとわからない)強いことを示した研究。
このこと自体は経験的に知られているのであまり驚きではないのだが(ただ、SSMでもそうなのか、というのと、一貫して強いというのは興味深い)、この研究はMatrix Based Entropyと呼ばれるものに基づいて、これらを分析するための様々な指標を定義し理論的な根拠を示し、Autoregressiveな学習よりもMasked Languageによる学習の方がこのようなMiddle Layerのボトルネックが緩和され、同様のボトルネックが画像の場合でも起きることを示し、CoTデータを用いたFinetuningについても分析している模様。この辺の貢献が非常に大きいと思われるのでここを理解することが重要だと思われる。あとで読む。
openreview: https://openreview.net/forum?id=WGXb7UdvTX
[Paper Note] NeoBERT: A Next-Generation BERT, Lola Le Breton+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #Encoder #Reading Reflections Issue Date: 2025-03-15 GPT Summary- NeoBERTは、最新のアーキテクチャとデータを統合した次世代エンコーダで、双方向モデルの能力を再定義します。4,096トークンのコンテキスト長を活用し、250Mパラメータでありながら、MTEBベンチマークで最先端の結果を達成し、BERTやRoBERTaを上回ります。すべてのコードやデータを公開し、研究と実世界での採用を促進します。 Comment
## BERT, ModernBERTとの違い

## 性能

## 所感
medium size未満のモデルの中ではSoTAではあるが、ModernBERTが利用できるのであれば、ベンチマークを見る限りは実用的にはModernBERTで良いのでは、と感じた。学習とinferenceの速度差はどの程度あるのだろうか?
[Paper Note] Gemini Embedding: Generalizable Embeddings from Gemini, Jinhyuk Lee+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #LanguageModel #RepresentationLearning #One-Line Notes Issue Date: 2025-03-12 GPT Summary- Gemini Embeddingは、Geminiの多言語性とコード理解を活かし、高度に一般化可能な埋め込みを生成。事前計算可能なこれらの表現は、分類や検索などの多様なタスクに応用でき、MMTEBでの評価において250以上の言語に対応。従来モデルを大幅に上回る埋め込み品質を示し、特定ドメインモデルを凌駕する性能を達成。 Comment
元ポスト:
世のdecoder-onlyモデルベースのembeddingモデルがどのように作られているか具体的によくわかっていないので読みたい
Geminiのパラメータでbi-directionalなself-attentionを持つtransformer (たとえばBERT)で初期化し、全てのtokenをmean poling (HF BERT ModelのPoolerLayerのようなもの)することでトークンの情報を単一のembeddingに混ぜる。
学習は2段階のfinetuning (pre-finetuning, finetuning)によって、モデルをContrastive Learningする(NCE loss)。
pre-finetuningはnoisyだが大規模なデータ(web上のタイトルとparagraphのペアなど)、そのあとのfinetuningはQAなどの高品質なデータを利用。
[Paper Note] SoftMatcha: A Soft and Fast Pattern Matcher for Billion-Scale Corpus Searches, Hiroyuki Deguchi+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Search #Dataset #ICLR Issue Date: 2025-01-28 GPT Summary- 表層的な文字列照合に依存する既存のパターンマッチング手法の制約を克服するため、語彙埋め込みを用いた新しいアルゴリズムを提案。これにより、コーパス規模での柔軟かつ効率的なパターンマッチングを実現。提案手法は、十億規模のデータ上で瞬時の検索を行い、英語と日本語のWikipediaから有害事例を抽出し、また多様な屈折のあるラテン語においても有効であることを実証。 Comment
ICLR2025にacceptされた模様
https://openreview.net/forum?id=Q6PAnqYVpo
openreview: https://openreview.net/forum?id=Q6PAnqYVpo
[Paper Note] MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs, Sheng-Chieh Lin+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#RecommenderSystems #InformationRetrieval #RepresentationLearning #MultiModal #ICLR #read-later #VisionLanguageModel Issue Date: 2024-11-08 GPT Summary- 本研究は、マルチモーダル大規模言語モデル(MLLM)を用いた普遍的マルチモーダル検索を提案し、複数のモダリティを受け入れる広範な検索シナリオを追求します。16の検索タスクに対する微調整実験から、MLLMがテキストと画像を含む複雑なクエリを理解できる一方、モダリティ偏りによりクロスモーダル検索では性能が劣ることを確認しました。この課題に対処するため、モダリティ意識のハードネガティブ・マイニングや継続的ファインチューニングを提案し、最終的にMM-Embedモデルはマルチモーダル検索ベンチマークM-BEIRで最先端の性能を達成しました。さらに、プロンプトを用いたゼロショットのリランキングがMLLMのマルチモーダル検索の向上に寄与することを示し、今後の普遍的マルチモーダル検索の発展に期待が持たれます。 Comment
openreview: https://openreview.net/forum?id=i45NQb2iKO
[Paper Note] Scaling Sentence Embeddings with Large Language Models, Ting Jiang+, EMNLP'24 Findings, 2023.07
Paper/Blog Link My Issue
#Sentence #NLP #LanguageModel #In-ContextLearning #EMNLP #Findings #One-Line Notes #Reading Reflections Issue Date: 2026-06-11 GPT Summary- 文脈内学習に基づく手法を用いて、大規模言語モデル(LLMs)の文の埋め込み性能を向上。自己回帰モデル向けにプロンプトベースの表現法を適用し、ファインチューニングなしで高品質な文の埋め込みを生成可能。モデルサイズを拡大するとSTSタスクで性能の変化が見られるが、最大モデルは他のモデルを上回り、転移タスクで最先端結果を達成。2.7BのOPTモデルが4.8BのST5を超える性能を示した。 Comment
1 wordでsentenceを要約するICL-basedなprompt templateを用いて生成されたtokenに対応するlast hidden statedeをsentenceのembeddingとして扱うことで、coder-onlyモデルから文のembeddingを取得する
下記研究で示されているように、last hidden stateではなく中間層におけるhidden stateを利用した場合はどのような影響が出るのだろうか?
- [Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
[Paper Note] mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval, Xin Zhang+, arXiv'24, 2024.07
Paper/Blog Link My Issue
#General #NLP #RepresentationLearning #MultiLingual #Encoder Issue Date: 2026-01-20 GPT Summary- 長文コンテキストの多言語テキスト表現モデル(TRM)と再ランキングモデルを構築し、RoPEとアンパディングを用いて8192トークンのコンテキストで事前訓練を行った。評価の結果、従来の最先端モデルを上回り、再ランキングモデルは大規模BGE-M3モデルと同等の性能を発揮した。訓練と推論の効率も高く、さまざまな研究や産業に貢献する可能性がある。 Comment
HF:
- BERT+GLU+RoPE:
https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5
-
https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct
[Paper Note] Grounding Language Model with Chunking-Free In-Context Retrieval, Hongjin Qian+, ACL'24, 2024.02
Paper/Blog Link My Issue
#Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) #LongSequence #ACL #PostTraining #KeyPoint Notes Issue Date: 2025-01-06 GPT Summary- CFICはチャンク化を避け、文書のエンコード済み隠れ状態を利用した新しい検索アプローチを提案。ユーザーのクエリに必要なエビデンステキストを正確に識別し、従来のRAGシステムより優れたエビデンスの取得能力を示す。これにより、RAGシステムの効率性が向上し、よりシンプルで効果的な検索が可能となる。 Comment
Chunking無しでRAGを動作させられるのは非常に魅力的。
一貫してかなり性能が向上しているように見える
提案手法の概要。InputとOutput全体の実例がほとんど掲載されていないので憶測を含みます。
気持ちとしては、ソーステキストが与えられたときに、Questionの回答をsupportするようなソース中のpassageの情報を活用して回答するために、重要なsentenceのprefixを回答生成前に生成させる(重要なsentenceの識別子の役割を果たす)ことで、(識別子によって重要な情報によって条件づけられて回答生成ができるやうになるのて)それら情報をより考慮しながらモデルが回答を生成できるようになる、といった話だと思われる。
Table2のようなテンプレートを用いて、ソーステキストと質問文でモデルを条件付けて、回答をsupportするsentenceのprefixを生成する。生成するprefixは各sentenceのユニークなprefixのtoken log probabilityの平均値によって決まる(トークンの対数尤度が高かったらモデルが暗黙的にその情報はQuestionにとって重要だと判断しているとみなせる)。SkipDecodingの説を読んだが、ぱっと見よく分からない。おそらく[eos]を出力させてprefix間のデリミタとして機能させたいのだと思うが、[eos]の最適なpositionはどこなのか?みたいな数式が出てきており、これがデコーディングの時にどういった役割を果たすのかがよくわからない。
また、モデルはQAと重要なPassageの三つ組のデータで提案手法によるデコーディングを適用してSFTしたものを利用する。
Linguistically Conditioned Semantic Textual Similarity, Jingxuan Tu+, ACL'24
Paper/Blog Link My Issue
#Dataset #RepresentationLearning #STS (SemanticTextualSimilarity) #ACL Issue Date: 2025-01-06 GPT Summary- 条件付きSTS(C-STS)は文の意味的類似性を測定するNLPタスクであるが、既存のデータセットには評価を妨げる問題が多い。本研究では、C-STSの検証セットを再アノテーションし、アノテーター間の不一致を55%観察。QAタスク設定を活用し、アノテーションエラーを80%以上のF1スコアで特定する自動エラー識別パイプラインを提案。また、モデル訓練によりC-STSデータのベースライン性能を向上させる新手法を示し、エンティティタイプの型特徴構造(TFS)を用いた条件付きアノテーションの可能性についても議論する。
[Paper Note] Zipfian Whitening, Sho Yokoi+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Word #RepresentationLearning #STS (SemanticTextualSimilarity) #NeurIPS #KeyPoint Notes Issue Date: 2024-11-20 GPT Summary- 単語埋め込み空間の歪みを是正することで、タスク性能向上が可能である。従来のアプローチは単語頻度が均一であると仮定しているが、実際にはZipfの法則に従った非均一な分布を持つ。Zipfに基づいた重み付けPCAを実施することで、性能が顕著に向上し、既存のベースラインを超える。情報幾何学的観点から、低頻度語を強調できる理論的基盤を提供し、skip-gram negative samplingやWhiteningBERTなどの手法が頻度を考慮したモデルで機能することを示している。 Comment
単語ベクトルを活用して様々なタスクを実施する際に一般的な全部足して個数で割るような平均ベクトル計算は、
個々の単語頻度を一様と仮定した場合の"期待値"と等価であり、
これは現実世界の単語頻度の実態とは全然異なるから、きちんと考慮したいよね、という話で (著者スライド p.9)
頻度を考慮するとSemantic Textual Similarity(STS)タスクで効果絶大であることがわかった(著者スライド p.10)。
では、なぜこれまで一様分布扱いするのが一般的だったのかというと、
実態として単語埋め込み行列が単語をタイプとみなして構築されたものであり、
コーパス全体を捉えた(言語利用の実態を捉えた)データ行列(単語をトークンとみなしたもの)になっていなかったことに起因していたからです(だから、経験頻度を用いて頻度情報を復元する必要があるよね)、
という感じの話だと思われ、(著者スライド p.18)
経験頻度を考慮すると、そもそも背後に仮定しているモデル自体が暗黙的に変わり、
低頻度語が強調されることで、単語に対してTF-IDFのような重みづけがされることで性能が良くなるよね、みたいな話だと思われる(著者スライド p.37)。
余談だが、昔のNLPでは、P(w,c)をモデル化したものを生成モデル、テキスト生成で一般的なP(w|c)は分類モデル(VAEとかはテキスト生成をするが、生成モデルなので別)、と呼んでいたと思うが、いまはテキスト生成モデルのことを略して生成モデル、と呼称するのが一般的なのだろうか。
[Paper Note] SemDeDup: Data-efficient learning at web-scale through semantic deduplication, Amro Abbas+, arXiv'23
Paper/Blog Link My Issue
#ComputerVision #NLP #Deduplication Issue Date: 2025-08-16 GPT Summary- SemDeDupは、事前学習モデルの埋め込みを用いて意味的に重複するデータペアを特定し削除する手法。LAIONのサブセットで50%のデータ削除を実現し、トレーニング時間を半分に短縮。分布外性能も向上し、C4データセットでも効率性を改善。質の高い埋め込みを活用することで、データ削減と学習加速を両立。 Comment
embedding空間において近傍のサンプル(near-duplicates)を削除することで、学習効率が向上します、という話な模様。
openreview:
https://openreview.net/forum?id=IRSesTQUtb¬eId=usQjFYYAZJ
openreviewによると、embedding空間においてnear-duplicatesを削除するというアイデアは興味深いが、提案手法は既存研究のアイデアを組み合わせているに留まっており(多くのブログポストやdeduplicationのためのライブラリも存在する)新規性が明確ではない点や、実験結果が不足している(i.e., 全てのケースでSoTAというわけでもなく、大規模モデルでの実験やstrong baselineの不在(実験結果はrandom pruningに対してoutperformすることが主に示されている)など、論文の主張をサポートするための結果が足りない)という指摘がされている。
実用的にはwell-writtenでexampleも豊富とのことなので、Deduplicationの理解を深めるのに良さそう。
先行研究:
- (画像)[Paper Note] Beyond neural scaling laws: beating power law scaling via data pruning, Ben Sorscher+, NeurIPS'22
- (テキスト)[Paper Note] Deduplicating Training Data Makes Language Models Better, Katherine Lee+, ACL'22
[Paper Note] Beyond neural scaling laws: beating power law scaling via data pruning, Ben Sorscher+, NeurIPS'22
では、分類が難しい画像のデータという観点にフォーカスしており、[Paper Note] Deduplicating Training Data Makes Language Models Better, Katherine Lee+, ACL'22
では、テキストの表層的な情報の一致に基づいてDeduplicationを実施している。
SemPPL: Predicting pseudo-labels for better contrastive representations, Matko Bošnjak+, N_A, ICLR'23
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #RepresentationLearning #ContrastiveLearning #ICLR #Semi-Supervised Issue Date: 2023-04-30 GPT Summary- 本研究では、コンピュータビジョンにおける半教師あり学習の問題を解決するために、Semantic Positives via Pseudo-Labels (SemPPL)という新しい手法を提案している。この手法は、ラベル付きとラベルなしのデータを組み合わせて情報豊富な表現を学習することができ、ResNet-$50$を使用してImageNetの$1\%$および$10\%$のラベルでトレーニングする場合、競合する半教師あり学習手法を上回る最高性能を発揮することが示された。SemPPLは、強力な頑健性、分布外および転移性能を示すことができる。 Comment
[Paper Note] Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation, Yusong Wu+, ICASSP'23, 2022.11
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #NLP #Library #RepresentationLearning #MultiModal #SpeechProcessing #ContrastiveLearning #Speech #One-Line Notes #text #ICASSP Issue Date: 2023-04-25 GPT Summary- 音声データと自然言語説明を組み合わせたコントラスト学習による音声表現開発のパイプラインを提案。633,526の音声-テキストペアからなるLAION-Audio-630Kを公開し、音声エンコーダとテキストエンコーダを用いたモデルを構築。特徴融合メカニズムを採用し、可変長の音声入力に対応。テキストから音声検索や音声分類に関する実験により、特にテキスト検索で優れた性能を示し、ゼロショット設定でも最先端の結果を達成。LAION-Audio-630Kとモデルは公開済み。 Comment
テキストとオーディオをエンコードするMLPエンコーダをそれぞれ用意し、大量のペアをcontrastive learningで事前学習することで、テキストとオーディオ間を同じ空間に写像し、類似度を測れるようにしたモデル。zero-shotでaudio分類などが可能。
[Paper Note] MTEB: Massive Text Embedding Benchmark, Niklas Muennighoff+, EACL'23, 2022.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #EACL Issue Date: 2022-10-31 GPT Summary- テキスト埋め込み評価が単一タスクの小規模データセットに偏っているため、他タスクへの適用可否が不明な中、Massive Text Embedding Benchmark(MTEB)を導入。MTEBは8つの埋め込みタスクを網羅し、58データセットと112言語を含むを通じて、33モデルをベンチマーク。特定手法が全タスクで優位性を持たないことを示し、分野が普遍的手法に収束していないことを明らかに。オープンソースコードと公開リーダーボードは、https://github.com/embeddings-benchmark/mteb で利用可能。
[Paper Note] Matryoshka Representation Learning, Aditya Kusupati+, NeurIPS'22
Paper/Blog Link My Issue
#NLP #RepresentationLearning #NeurIPS #Length #Selected Papers/Blogs #Reference Collection Issue Date: 2025-07-29 GPT Summary- マトリョーシカ表現学習(MRL)は、異なる計算リソースに適応可能な柔軟な表現を設計する手法であり、既存の表現学習パイプラインを最小限に修正して使用します。MRLは、粗から細への表現を学習し、ImageNet-1K分類で最大14倍小さい埋め込みサイズを提供し、実世界のスピードアップを実現し、少数ショット分類で精度向上を達成します。MRLは視覚、視覚+言語、言語のモダリティにわたるデータセットに拡張可能で、コードとモデルはオープンソースで公開されています。 Comment
日本語解説: https://speakerdeck.com/hpprc/lun-jiang-zi-liao-matryoshka-representation-learning
単一のモデルから複数のlengthのEmbeddingを出力できるような手法。
解説:
Improving Neural Machine Translation with Compact Word Embedding Tables, Kumar+, AAAI'22
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP #AAAI #Initial Impression Notes Issue Date: 2021-06-07 Comment
NMTにおいてword embeddingがどう影響しているかなどを調査しているらしい
[Paper Note] An Embedding Learning Framework for Numerical Features in CTR Prediction, Huifeng Guo+, KDD'21
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CTRPrediction #RepresentationLearning #SIGKDD #numeric #KeyPoint Notes Issue Date: 2025-04-22 GPT Summary- CTR予測のための新しい埋め込み学習フレームワーク「AutoDis」を提案。数値特徴の埋め込みを強化し、高いモデル容量とエンドツーエンドのトレーニングを実現。メタ埋め込み、自動離散化、集約の3つのコアコンポーネントを用いて、数値特徴の相関を捉え、独自の埋め込みを学習。実験により、CTRとeCPMでそれぞれ2.1%および2.7%の改善を達成。コードは公開されている。 Comment
従来はdiscretizeをするか、mlpなどでembeddingを作成するだけだった数値のinputをうまく埋め込みに変換する手法を提案し性能改善
数値情報を別の空間に写像し自動的なdiscretizationを実施する機構と、各数値情報のフィールドごとのglobalな情報を保持するmeta-embeddingをtrainable parameterとして学習し、両者を交互作用(aggregation; max-poolingとか)することで数値embeddingを取得する。
[Paper Note] SimCSE: Simple Contrastive Learning of Sentence Embeddings, Tianyu Gao+, arXiv'21, 2021.04
Paper/Blog Link My Issue
#Sentence #NLP #LanguageModel #RepresentationLearning #ContrastiveLearning #Catastrophic Forgetting #EMNLP #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-07-27 GPT Summary- SimCSEは、文の埋め込み表現を向上させる単純な対照学習フレームワークです。教師なしアプローチでは、入力文が自身を予測し、ドロップアウトがノイズとして機能します。この手法は従来の教師あり方法と同等の成果を上げ、ドロップアウトを除去すると表現の質が低下することが分かりました。また、教師付きアプローチでは、自然言語推論データセットからの注釈付きペアを活用し、対照学習に組み込みます。評価結果では、教師なしモデルが76.3%、教師ありモデルが81.6%のSpearmanの相関を達成し、既存のベスト結果をそれぞれ改善しました。対照学習の目的が埋め込みの空間の正則化に貢献することも示されました。 Comment
[Paper Note] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Nils Reimers+, arXiv'19, 2019.08 よりも性能良く、unsupervisedでも学習できる。STSタスクのベースラインにだいたい入ってる
# 手法概要
Contrastive Learningを活用して、unsupervised/supervisedに学習を実施する。
Unsupervised SimCSEでは、あるsentenceをencoderに2回入力し、それぞれにdropoutを適用させることで、positive pairを作成する。dropoutによって共通のembeddingから異なる要素がマスクされた(noiseが混ざった状態とみなせる)類似したembeddingが作成され、ある種のdata augmentationによって正例を作成しているともいえる。負例はnegative samplingする。(非常にsimpleだが、next sentence predictionで学習するより性能が良くなる)
Supervised SimCSEでは、アノテーションされたsentence pairに基づいて、正例・負例を決定する。本研究では、NLIのデータセットにおいて、entailment関係にあるものは正例として扱う。contradictions(矛盾)関係にあるものは負例として扱う。
# Siamese Networkで用いられるmeans-squared errrorとContrastiveObjectiveの違い
どちらもペアワイズで比較するという点では一緒だが、ContrastiveObjectiveは正例と近づいたとき、負例と遠ざかったときにlossが小さくなるような定式化がされている点が異なる。
(画像はこのブログから引用。ありがとうございます。
https://techblog.cccmk.co.jp/entry/2022/08/30/163625)
# Unsupervised SimCSEの実験
異なるdata augmentation手法と比較した結果、dropoutを適用する手法の方が性能が高かった。MLMや, deletion, 類義語への置き換え等よりも高い性能を獲得しているのは興味深い。また、Next Sentence Predictionと比較しても、高い性能を達成。Next Sentence Predictionは、word deletion等のほぼ類似したテキストから直接的に類似関係にあるペアから学習するというより、Sentenceの意味内容のつながりに基づいてモデルの言語理解能力を向上させ、そのうえで類似度を測るという間接的な手法だが、word deletionに負けている。一方、dropoutを適用するだけの(直接的に類似ペアから学習する)本手法はより高い性能を示している。
[image](https://github.com/AkihikoWatanabe/paper_notes/assets/12249301/0ea3549e-3363-4857-94e6-a1ef474aa191)
なぜうまくいくかを分析するために、異なる設定で実験し、alignment(正例との近さ)とuniformity(どれだけembeddingが一様に分布しているか)を、10 stepごとにplotした結果が以下。dropoutを適用しない場合と、常に同じ部分をマスクする方法(つまり、全く同じembeddingから学習する)設定を見ると、学習が進むにつれuniformityは改善するが、alignmentが悪くなっていっている。一方、SimCSEはalignmentを維持しつつ、uniformityもよくなっていっていることがわかる。
# Supervised SimCSEの実験
アノテーションデータを用いてContrastiveLearningするにあたり、どういったデータを正例としてみなすと良いかを検証するために様々なデータセットで学習し性能を検証した。
- QQP4: Quora question pairs
- Flickr30k (Young et al., 2014): 同じ画像に対して、5つの異なる人間が記述したキャプションが存在
- ParaNMT (Wieting and Gimpel, 2018): back-translationによるparaphraseのデータセットa
- NLI datasets: SNLIとMNLI
実験の結果、NLI datasetsが最も高い性能を示した。この理由としては、NLIデータセットは、crowd sourcingタスクで人手で作成された高品質なデータセットであることと、lexical overlapが小さくなるようにsentenceのペアが作成されていることが起因している。実際、NLI datsetのlexical overlapは39%だったのに対し、ほかのデータセットでは60%であった。
また、condunctionsとなるペアを明示的に負例として与えることで、より性能が向上した(普通はnegative samplingする、というかバッチ内の正例以外のものを強制的に負例とする。こうすると、意味が同じでも負例になってしまう事例が出てくることになる)。より難しいNLIタスクを含むANLIデータセットを追加した場合は、性能が改善しなかった。この理由については考察されていない。性能向上しそうな気がするのに。
# 他手法との比較結果
SimCSEがよい。
# Ablation Studies
異なるpooling方法で、どのようにsentence embeddingを作成するかで性能の違いを見た。originalのBERTの実装では、CLS token のembeddingの上にMLP layerがのっかっている。これの有無などと比較。
Unsupervised SimCSEでは、training時だけMLP layerをのっけて、test時はMLPを除いた方が良かった。一方、Supervised SimCSEでは、 MLP layerをのっけたまんまで良かったとのこと。
また、SimCSEで学習したsentence embeddingを別タスクにtransferして活用する際には、SimCSEのobjectiveにMLMを入れた方が、catastrophic forgettingを防げて性能が高かったとのこと。
ablation studiesのhard negativesのところと、どのようにミニバッチを構成するか、それぞれのtransferしたタスクがどのようなものがしっかり読めていない。あとでよむ。
Learning Transferable Visual Models From Natural Language Supervision, Radford+, OpenAI, ICML'21
Paper/Blog Link My Issue
#ComputerVision #NLP #RepresentationLearning #MultiModal #ContrastiveLearning #ICML #Selected Papers/Blogs #2D (Image) #One-Line Notes #text Issue Date: 2023-04-27 Comment
CLIP論文。大量の画像と画像に対応するテキストのペアから、対照学習を行い、画像とテキスト間のsimilarityをはかれるようにしたモデル
[Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04
Paper/Blog Link My Issue
#InformationRetrieval #NLP #QuestionAnswering #ContrastiveLearning #EMNLP #Selected Papers/Blogs #Encoder #KeyPoint Notes Issue Date: 2025-09-28 GPT Summary- 密な表現を用いたパッセージ検索の実装を示し、デュアルエンコーダーフレームワークで学習。評価の結果、Lucene-BM25を上回り、検索精度で9%-19%の改善を達成。新たな最先端のQA成果を確立。 Comment
Dense Retrieverが広く知られるきっかけとなった研究(より古くはDSSM Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, Huang+, CIKM'13
などがある)。bag-of-wordsのようなsparseなベクトルで検索するのではなく(=Sparse Retriever)、ニューラルモデルでエンコードした密なベクトルを用いて検索しようという考え方である。
Query用と検索対象のPassageをエンコードするEncoderを独立してそれぞれ用意し(=DualEncoder)、QAの学習データ(すなわちクエリqと正例として正解passage p+)が与えられた時、クエリqと正例p+の類似度が高く、負例p-との類似度が低くなるように(=Contrastive Learning)、Query, Passage Encoderのパラメータを更新することで学習する(損失関数は式(2))。
負例はIn-Batch Negativeを用いる。情報検索の場合正解ラベルは多くの場合明示的に決まるが、負例は膨大なテキストのプールからサンプリングしなければならない。サンプリング方法はいろいろな方法があり(e.g., ランダムにサンプリング、qとbm25スコアが高いpassage(ただし正解は含まない; hard negativesと呼ぶ)その中の一つの方法がIn-Batch Negativesである。
In-Batch Negativesでは、同ミニバッチ内のq_iに対応する正例p+_i以外の全てのp_jを(擬似的に)負例とみなす。これにより、パラメータの更新に利用するためのq,pのエンコードを全て一度だけ実行すれば良く、計算効率が大幅に向上するという優れもの。本研究の実験(Table3)によると上述したIn-Batch Negativeに加えて、bm25によるhard negativeをバッチ内の各qに対して1つ負例として追加する方法が最も性能が良かった。
クエリ、passageのエンコーダとしては、BERTが用いられ、[CLS]トークンに対応するembeddingを用いて類似度が計算される。
[Paper Note] All Word Embeddings from One Embedding, Takase+, NeurIPS'20
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #MachineLearning #NLP #NeurIPS #KeyPoint Notes Issue Date: 2021-06-09 Comment
NLPのためのNN-basedなモデルのパラメータの多くはEmbeddingによるもので、従来は個々の単語ごとに異なるembeddingをMatrixの形で格納してきた。この研究ではモデルのパラメータ数を減らすために、個々のword embeddingをshared embeddingの変換によって表現する手法ALONE(all word embeddings from one)を提案。単語ごとに固有のnon-trainableなfilter vectorを用いてshared embeddingsを修正し、FFNにinputすることで表現力を高める。また、filter vector普通に実装するとword embeddingと同じサイズのメモリを消費してしまうため、メモリ効率の良いfilter vector効率手法も提案している。機械翻訳・および文書要約を行うTransformerに提案手法を適用したところ、より少量のパラメータでcomparableなスコアを達成した。
Embedidngのパラメータ数とBLEUスコアの比較。より少ないパラメータ数でcomparableな性能を達成している。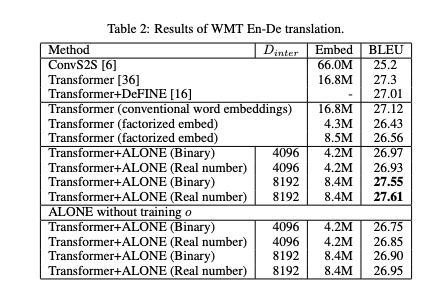
[Paper Note] Deep contextualized word representations, Matthew E. Peters+, NAACL'18, 2018.02
Paper/Blog Link My Issue
#NeuralNetwork #NLP #RepresentationLearning #NAACL #KeyPoint Notes Issue Date: 2022-06-08 GPT Summary- 新しい深層文脈化単語表現を提案し、単語の複雑な特性と文脈による変化をモデル化。これらの表現は事前学習された双方向言語モデルの内部状態を基に学習され、質問応答や感情分析など6つのNLPタスクで性能を向上させる。さらに、事前学習ネットワークの内部を活用することで、半教師あり信号の混合が可能であることを示す。 Comment
ELMo論文。
通常のword embeddingでは一つの単語につき一つの意味しか持たせられなかったが、文脈に応じて異なる意味を表現できるようなEmbeddingを実現し(同じ単語でも文脈に応じて意味が変わったりするので。たとえばrightは文脈に応じて右なのか、正しいなのか、権利なのか意味が変わる)様々な言語処理タスク(e.g. Question Answering, Sentiment Analysisなど)でSoTAを達成。
Embedding Layer + 2層のLSTM(1,2の間にはresidual connection)+ linear layerで言語モデルを構成し、順方向言語モデルと逆方向言語モデルを同時に独立して学習する(双方向LSTMではない;損失関数が両方向の言語モデルの対数尤度の和になっている)。
また、Linear LayerとEmbedding Layerのパラメータは両方向の言語モデルで共有されている。
k番目の単語のEmbedding Layerの出力ベクトル、各LSTMのhidden stateをタスクspecificなスカラーパラメタs_taskで足し合わせ、最後にベクトルのスケールを調整するパラメタγ_taskで大きさを調整する。これにより、k番目の単語のELMo Embeddingを得る。
単語単体の意味だけでこと足りるタスクの場合はEmbedding Layerの出力ベクトルに対する重みが大きくなり、文脈を考慮した情報が欲しい場合はLSTMのhidden stateに対する重みが大きくなるイメージ(LSTMの層が深いほど意味的semanticな情報を含み、浅いほど文法的syntacticな情報を含んでいる)。
使い方としては簡単で、ELMoを事前学習しておき、自身のNNモデルのWord Embeddingに(場合によってはRNNのhidden stateにも)、入力文から得られたELMo Embeddingをconcatして順伝搬させるだけで良い。
ELMoのEmbedding Layerでは、2048 characterの(vocab size?)n-gram convolution filter(文字ごとにembeddingし、単語のembeddingを得るためにfilterを適用する?)の後に2つのhighway networkをかませてlinearで512次元に落とすみたいなことごやられているらしい。ここまで追えていない。
詳細は下記
https://datascience.stackexchange.com/questions/97867/how-does-the-character-convolution-work-in-elmo
s_taskとγ_taskはtrainableなパラメータで、
ELMoを適用した先のNNモデルの訓練時に、NNモデルのパラメタと一緒にチューニングする(と思われる)。
下記issueを参照のこと
allenai/allennlp# 1166
allenai/allennlp# 2552
[Paper Note] StarSpace: Embed All The Things, Wu+, AAAI'18
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #General #MachineLearning #RepresentationLearning #AAAI #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 Comment
分類やランキング、レコメンドなど、様々なタスクで汎用的に使用できるEmbeddingの学習手法を提案。
Embeddingを学習する対象をEntityと呼び、Entityはbag-of-featureで記述される。
Entityはbag-of-featureで記述できればなんでもよく、
これによりモデルの汎用性が増し、異なる種類のEntityでも同じ空間上でEmbeddingが学習される。
学習方法は非常にシンプルで、Entity同士のペアをとったときに、relevantなpairであれば類似度が高く、
irelevantなペアであれば類似度が低くなるようにEmbeddingを学習するだけ。
たとえば、Entityのペアとして、documentをbag-of-words, bag-of-ngrams, labelをsingle wordで記述しテキスト分類、
あるいは、user_idとユーザが過去に好んだアイテムをbag-of-wordsで記述しcontent-based recommendationを行うなど、 応用範囲は幅広い。
5種類のタスクで提案手法を評価し、既存手法と比較して、同等かそれ以上の性能を示すことが示されている。
手法の汎用性が高く学習も高速なので、色々な場面で役に立ちそう。
また、異なる種類のEntityであっても同じ空間上でEmbeddingが学習されるので、学習されたEmbeddingの応用先が広く有用。
実際にSentimentAnalysisで使ってみたが(ポジネガ二値分類)、少なくともBoWのSVMよりは全然性能良かったし、学習も早いし、次元数めちゃめちゃ少なくて良かった。
StarSpaceで学習したembeddingをBoWなSVMに入れると性能が劇的に改善した。
解説:
https://www.slideshare.net/akihikowatanabe3110/starspace-embed-all-the-things
[Paper Note] Construction of a Japanese Word Similarity Dataset, Yuya Sakaizawa+, arXiv'17, 2017.03
Paper/Blog Link My Issue
#NLP #Dataset #RepresentationLearning #STS (SemanticTextualSimilarity) #Japanese #One-Line Notes Issue Date: 2023-07-31 GPT Summary- 日本語の分散表現評価のために、語の類似度データセットを構築。これが日本語分散表現評価の初の資源であり、一般語と稀少語の両方を含む様々な品詞を網羅。 Comment
github:
https://github.com/tmu-nlp/JapaneseWordSimilarityDataset
単語レベルの類似度をベンチマーキングしたい場合は使ってもよいかも。
[Paper Note] Multi-View Unsupervised User Feature Embedding for Social Media-based Substance Use Prediction, Ding+, EMNLP'17
Paper/Blog Link My Issue
#NLP #UserModeling #EMNLP #SubstanceUsePrediction Issue Date: 2018-01-01 GPT Summary- 本論文では、機械学習とテキストマイニングを用いてソーシャルメディアに基づく物質使用検出システムを構築する方法を提案。非監視ソーシャルメディアデータを活用し、マルチビュー非監視特徴学習を用いてユーザー情報を統合。評価結果では、タバコ使用の予測で86%のAUC、アルコール使用で81%、違法薬物使用で84%を達成し、既存手法を上回る性能を示した。また、ソーシャルメディア行動と物質使用の関係も明らかにした。
[Paper Note] Skip-Gram – Zipf + Uniform = Vector Additivity, Gittens+, ACL'17
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #NLP #Word #ACL #One-Line Notes Issue Date: 2017-12-30 Comment
解説スライド: http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/09.pdf
Embeddingの加法構成性(e.g. man+royal=king)を理論的に理由づけ
(解説スライドより)
[Paper Note] Poincaré Embeddings for Learning Hierarchical Representations, Maximilian Nickel+, NIPS'17, 2017.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Word #RepresentationLearning #NeurIPS #KeyPoint Notes Issue Date: 2017-12-29 GPT Summary- 記号データの階層的表現を学習する新しいアプローチを提案し、n次元ポアンカレボールに埋め込むことで階層と類似性を同時に捉える。リーマン最適化に基づく効率的なアルゴリズムを導入し、ポアンカレ埋め込みがユークリッド埋め込みを上回る表現能力と一般化能力を持つことを実験で示した。 Comment
解説:
http://tech-blog.abeja.asia/entry/poincare-embeddings
解説スライド:
https://speakerdeck.com/eumesy/poincare-embeddings-for-learning-hierarchical-representations
実装:
https://github.com/TatsuyaShirakawa/poincare-embedding
・階層構造を持つデータ(WordNet上の上位語下位語、is-a関係など)を埋め込むために、双曲空間を使った話(通常はユークリッド空間)。
・階層構造・べき分布を持つデータはユークリッド空間ではなく双曲空間の方が効率的に埋め込める。
・階層構造・べき分布を持つデータを双曲空間(ポアンカレ球モデル)に埋め込むための学習手法(リーマン多様体上でSGD)を提案
・WordNet hypernymyの埋め込み:低次元でユークリッド埋め込みに圧勝
・Social Networkの埋め込み:低次元だと圧勝
・Lexical Entailment:2つのデータセットでSoTA
上記は解説スライドから勉強しメモ:
Poincaré Embeddings for Learning Hierarchical Representations, Sho Yokoi, 2017-09-15, 第9回最先端NLP勉強会
https://speakerdeck.com/eumesy/poincare-embeddings-for-learning-hierarchical-representations

(解説スライドp.20より)
データとして上位・下位概念を与えていないのに、原点付近には上位語・円周付近には下位語が自然に埋め込まれている(意図した通りになっている)。
ポアンカレ円板では、原点からの距離に応じて指数的に円周長が増加していくので、指数的に数が増えていく下位語などは外側に配置されると効率的だけど、その通りになっている。
(解説スライドp.9より、スライド全体のスクショではないので元ページ参照のこと)
スクショは解説スライドより引用:
Poincaré Embeddings for Learning Hierarchical Representations, Sho Yokoi, 2017-09-15, 第9回最先端NLP勉強会
https://speakerdeck.com/eumesy/poincare-embeddings-for-learning-hierarchical-representations
[Paper Note] Supervised Learning of Universal Sentence Representations from Natural Language Inference Data, Alexis Conneau+, arXiv'17, 2017.05
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #NLP #RepresentationLearning #EMNLP #KeyPoint Notes Issue Date: 2017-12-28 GPT Summary- 文の埋め込みを学習する試みは成功していないが、スタンフォード自然言語推論データセットを用いた監督学習による普遍的な文表現が、無監督手法を上回ることを示す。自然言語推論は他のNLPタスクへの転送学習に適していることが示唆される。エンコーダは公開されている。 Comment
汎用的な文のエンコーダができました!という話。
SNLIデータでパラメータ学習、エンコーダ構成スライド図中右側のエンコーダ部分をなるべく一般的な文に適用できるように学習したい。
色々なタスクで、文のエンコーダ構成を比較した結果、bi-directional LSTMでエンコードし、要素ごとの最大値をとる手法が最も良いという結果。
隠れ層の次元は4096とかそのくらい。
Skip-Thoughtは学習に1ヶ月くらいかかるけど、提案手法はより少ないデータで1日くらいで学習終わり、様々なタスクで精度が良い。
ベクトルの要素積、concat, subなど、様々な演算を施し、学習しているので、そのような構成の元から文エンコーダを学習すると何か意味的なものがとれている?
SNLIはNatural Language Inferenceには文の意味理解が必須なので、そのデータ使って学習するといい感じに文のエンコードができます。
NLIのデータは色々なところで有用なので、日本語のNLIのデータとかも欲しい。
[Paper Note] A Structured Self-attentive Sentence Embedding, Zhouhan Lin+, ICLR'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #NLP #RepresentationLearning #ICLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-28 GPT Summary- 自己注意機構を用いた新しい文埋め込みモデルを提案。2次元行列で文の異なる部分に注意を払い、視覚化手法も提供。著者プロファイリング、感情分類、テキスト含意の3つのタスクで評価し、他の手法と比較して性能が向上したことを示す。 Comment
OpenReview: https://openreview.net/forum?id=BJC_jUqxe
日本語解説: https://ryotaro.dev/posts/a_structured_self_attentivesentence_embedding/
self-attentionを提案した研究
[Paper Note] Learning Distributed Representations of Sentences from Unlabelled Data, Felix Hill+, NAACL'16, 2016.02
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #NLP #RepresentationLearning #NAACL #KeyPoint Notes Issue Date: 2017-12-28 GPT Summary- 無監督手法によるフレーズや文の分散表現の学習に関するモデルの比較を行い、最適なアプローチはアプリケーションに依存することを示す。深いモデルは監視システムに適している一方、浅いロジスティック回帰モデルは単純な空間距離メトリックに最適。さらに、トレーニング時間やドメイン移植性を考慮した新しい無監督表現学習の目的も提案。 Comment
Sentenceのrepresentationを学習する話
代表的なsentenceのrepresentation作成手法(CBOW, SkipGram, SkipThought, Paragraph Vec, NMTなど)をsupervisedな評価(タスク志向+supervised)とunsupervisedな評価(文間の距離をコサイン距離ではかり、人間が決めた順序と相関を測る)で比較している。
また筆者らはSequential Denoising Auto Encoder(SDAE)とFastSentと呼ばれる手法を提案しており、前者はorderedなsentenceデータがなくても訓練でき、FastSentはorderedなsentenceデータが必要だが高速に訓練できるモデルである。
実験の結果、supervisedな評価では、基本的にはSkipThoughtがもっとも良い性能を示し、paraphrasingタスクにおいて、SkipThoughtに3ポイント程度差をつけて良い性能を示した。unsupervisedな評価では、DictRepとFastSentがもっとも良い性能を示した。
実験の結果、以下のような知見が得られた:
## 異なるobjective functionは異なるembeddingを作り出す
objective functionは、主に隣接する文を予測するものと、自分自身を再現するものに分けられる。これらの違いによって、生成されるembeddingが異なっている。Table5をみると、後者については、生成されたrepresentationのnearest neighborを見ていると、自身と似たような単語を含む文が引っ張ってこれるが、前者については、文のコンセプトや機能は似ているが、単語の重複は少なかったりする。
## supervisedな場合とunsupervisedな評価でのパフォーマンスの違い
supervisedな設定では、SkipThoughtやSDAEなどのモデルが良い性能を示しているが、unsupervisedな設定ではまりうまくいかず。unsupevisedな設定ではlog-linearモデルが基本的には良い性能を示した。
## pre-trainedなベクトルを使用したモデルはそうでない場合と比較してパフォーマンスが良い
## 必要なリソースの違い
モデルによっては、順序づけられた文のデータが必要だったり、文の順序が学習に必要なかったりする。あるいは、デコーディングに時間がかかったり、めちゃくちゃメモリ食ったりする。このようなリソースの性質の違いは、使用できるapplicationに制約を与える。
## 結論
とりあえず、supervisedなモデルにrepresentationを使ってモデルになんらかのknowledgeをぶちこみたいときはSkipThought、単純に類似した文を検索したいとか、そういう場合はFastSentを使うと良いってことですかね.
[Paper Note] Retrofitting Word Vectors to Semantic Lexicons, Manaal Faruqui+, NAACL'15, 2014.11
Paper/Blog Link My Issue
#NLP #Word #RepresentationLearning #Selected Papers/Blogs #Finetuning #One-Line Notes Issue Date: 2025-12-04 GPT Summary- 意味的レキシコンの情報を活用して、単語のベクトル空間表現を改善する手法を提案。関連する単語が類似のベクトルを持つよう促し、従来の仮定に依存しない。複数の言語での語彙意味評価タスクで大幅な改善を示し、従来技術を上回る性能を達成。 Comment
日本語解説: https://www.slideshare.net/slideshow/20150421-forupdate/47365800
Retrofittingという用語を今でも耳にすることがあるが、この研究のような手法を指すと思って良いと思われる(研究室の輪講で本論文の発表があったのを思い出すなぁ)。事前学習済みの単語ベクトルに対して事後的に外部知識(辞書など)を埋め込みチューニングする話。
[Paper Note] A hierarchical neural autoencoder for paragraphs and documents, Li+, ACL'15
Paper/Blog Link My Issue
#NeuralNetwork #Document #NLP #RepresentationLearning #ACL #KeyPoint Notes Issue Date: 2017-12-28 Comment
複数文を生成(今回はautoencoder)するために、standardなseq2seq LSTM modelを、拡張したという話。
要は、paragraph/documentのrepresentationが欲しいのだが、アイデアとしては、word-levelの情報を扱うLSTM layerとsentenc-levelの情報を扱うLSTM layerを用意し、それらのcompositionによって、paragraph/documentを表現しましたという話。
sentence-levelのattentionを入れたらよくなっている。
trip advisorのreviewとwikipediaのparagraphを使ってtrainingして、どれだけ文書を再構築できるか実験。
MetricはROUGE, BLEUおよびcoherence(sentence order代替)を測るために、各sentence間のgapがinputとoutputでどれだけ一致しているかで評価。
hierarchical lstm with attention > hierarchical lstm > standard lstm の順番で高性能。
学習には、tesla K40を積んだマシンで、standard modelが2-3 weeks, hierarchical modelsが4-6週間かかるらしい。
[Paper Note] Document Modeling with Gated Recurrent Neural Network for Sentiment Classification, Tang+, EMNLP'15
Paper/Blog Link My Issue
#NeuralNetwork #Document #SentimentAnalysis #NLP #EMNLP #KeyPoint Notes Issue Date: 2017-12-28 Comment
word level -> sentence level -> document level のrepresentationを求め、documentのsentiment classificationをする話。
documentのRepresentationを生成するときに参考になるやも。
sentenceのrepresentationを求めるときは、CNN/LSTMを使う。
document levelに落とすことは、bi-directionalなGatedRNN(このGatedRNNはLSTMのoutput-gateが常にonになっているようなものを使う。sentenceのsemanticsに関する情報を落としたくないかららしい。)を使う。
sentiment classificationタスクで評価し、(sentence levelのrepresentationを求めるときは)LSTMが最も性能がよく、documentのrepresentationを求めるときは、standardなRNNよりもGatedRNNのほうが性能よかった。
Sarashina3 embedding: 日本語に強い最新のテキスト埋め込みモデル, SB Intuitions, 2026.07
Paper/Blog Link My Issue
#Article #NLP #RepresentationLearning #Japanese #read-later Issue Date: 2026-07-02 Comment
元ポスト:
Map of Sentence Encoders, Danu-Blog, 2026.06
Paper/Blog Link My Issue
#Article #Blog #Encoder #Visualization #Author Thread-Post Issue Date: 2026-06-20 Comment
元ポスト:
Introducing OlmoEarth embeddings: Custom embedding exports from OlmoEarth Studio for downstream analysis, Ai2, 202604
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Proprietary #read-later Issue Date: 2026-04-25 Comment
元ポスト:
関連:
- OlmoEarth-v1-Large, Ai2, 2025.11
ちょっとこれはしっかり読まないと具体的にはわからないかもしれない
Gemini Embedding 2: Our first natively multimodal embedding model, Google, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Blog #Proprietary #read-later #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2026-04-25 Comment
元ポスト:
単一のモデルで、マルチモーダルな情報を統合されたembedding空間で表現し、マトリョーシカ表現によって3種類の次元で取得でき、100+言語をサポートしかつcontext windowは8192。オーディオをわざわざ書き起こしてテキストモダリティに変換する必要もなく直接unifiedなembeddingを取得可能というなかなか便利そうな代物。
(以前のIssueを誤って削除したため再掲)
Generally Availableになったとのこと:
Microsoft Open-Sources Industry-Leading Embedding Model, Microsoft Bing Blog, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Blog #MultiLingual #OpenWeight #read-later Issue Date: 2026-04-07 Comment
元ポスト:
Beyond the Limit: Introduce Mixedbread Wholembed v3, Mixedbread, 2026.03
Paper/Blog Link My Issue
#Article #MultiModal Issue Date: 2026-03-14 Comment
元ポスト:
競合:
- #4880
Qwen3-VL-Embedding and Qwen3-VL-Reranker: For the Next Generation of Multimodal Retrieval, Qwen Team, 2026.1
Paper/Blog Link My Issue
#Article #NLP #RepresentationLearning #MultiModal #MultiLingual #read-later #Reranking Issue Date: 2026-01-09 Comment
元ポスト:
technical report: https://github.com/QwenLM/Qwen3-VL-Embedding/blob/main/assets/qwen3vlembedding_technical_report.pdf
ポイント解説:
Introducing zerank-2: The Most Accurate Multilingual Instruction-Following Reranker, ZeroEntropy, 2025.11
Paper/Blog Link My Issue
#Article #RecommenderSystems #InformationRetrieval #NLP #Blog #OpenWeight #Reranking Issue Date: 2025-11-20 Comment
HF: https://huggingface.co/zeroentropy/zerank-2
SoTA reranker
From Monolithic to Modular: Scaling Semantic Routing with Extensible LoRA, vLLM blog, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Blog #Encoder #Routing Issue Date: 2025-10-27 Comment
元ポスト:
colbert-muvera-femto, NeuML, 2025.10
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight #Encoder Issue Date: 2025-10-09 Comment
元ポスト:
Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings, Google, 2025.09
Paper/Blog Link My Issue
#Article #NLP #MultiLingual #OpenWeight Issue Date: 2025-09-05 Comment
HF: https://huggingface.co/collections/google/embeddinggemma-68b9ae3a72a82f0562a80dc4
元ポスト:
解説:
解説:
Gemini Embedding: Powering RAG and context engineering, Google, 2025.07
Paper/Blog Link My Issue
#Article #NLP #RepresentationLearning Issue Date: 2025-08-03 Comment
元ポスト:
financial, legal文書に対する性能が向上してマトリョーシカ表現によってストレージや計算コストを削減可能な模様
ダウンストリームタスクで使おうとすると次元数がデカすぎるとしんどいのでマトリョーシカ表現は嬉しい
日経電子版のアプリトップ「おすすめ」をTwo Towerモデルでリプレースしました, NIKKEI, 2025.05
Paper/Blog Link My Issue
#Article #RecommenderSystems #NeuralNetwork #EfficiencyImprovement #AWS #ML-LLM Ops #Blog #A/B Testing #TwoTowerModel Issue Date: 2025-06-29 Comment
リアルタイム推薦をするユースケースにおいて、ルールベース+協調フィルタリング(Jubatus)からTwo Towerモデルに切り替えた際にレイテンシが300ms増えてしまったため、ボトルネックを特定し一部をパッチ処理にしつつもリアルタイム性を残すことで解決したという話。AWSの構成、A/Bテストや負荷テストの話もあり、実用的で非常に興味深かった。
Qwen_Qwen3-Embedding-4B-GGUF, QwenTeam, 2025.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #RepresentationLearning #OpenWeight #One-Line Notes #Author Thread-Post Issue Date: 2025-06-06 Comment
8BモデルはMTEBでトップの性能を達成。context 32K。100以上の言語をサポート。32--2560次元にoutputの次元数をカスタマイズできる(嬉しい、が性能にどの程度影響が出るから気になる)。
元ポスト:
QwenTeam post:
8 Types of RoPE, Kseniase, 2025.03
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #Transformer #Blog #PositionalEncoding #Initial Impression Notes Issue Date: 2025-03-23 Comment
元ポスト: https://huggingface.co/posts/Kseniase/498106595218801
RoPEについてサーベイが必要になったら見る
modernbert-ja-130m, SB Intuitions, 2025.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #RepresentationLearning #pretrained-LM #Japanese #Author Thread-Post Issue Date: 2025-02-12 Comment
MIT Licence
元ポスト:
floret, explosion, 2021
Paper/Blog Link My Issue
#Article #NeuralNetwork #Word #Library #RepresentationLearning #Repository #One-Line Notes Issue Date: 2024-12-28 Comment
fasttextを拡張したもの。本家fasttextがアーカイブ化してしまったので、代替手段に良さそう。
元ポスト:
Sarashina-Embedding-v1-1B, SB Intuitions, 2024.12
Paper/Blog Link My Issue
#Article #NLP #RepresentationLearning #One-Line Notes Issue Date: 2024-12-10 Comment
Non-commercialなライセンスで、商用利用の場合は問い合わせが必要
Late Chunking: Balancing Precision and Cost in Long Context Retrieval, Pierse+, 2024.09
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Blog #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-09-08 Comment
chunkingしてからembeddingを取得するより、全体のドキュメントに対してcontextualなtoken embeddingを取得し、その後chunkingをしてpoolingしてsingle vectorにする方が、文書の文脈情報がembedding内で保持されやすいので、precisionが上がりますよ、という話
Ruri: Japanese General Text Embeddings, cl-nagoya, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #RepresentationLearning #Japanese #KeyPoint Notes Issue Date: 2024-09-04 Comment
元ツイート:
337Mパラメータのモデルで、同等のサイズのモデルをJMTEBで大きく上回る性能。LLMを用いて生成したデータを用いてContrastive Learning, その後高品質なデータでFinetuningを実施したとのこと。
JMTEB上では、パラメータサイズ不明(だがおそらく桁違いに大きい)のOpenAI/text-embedding-3-largeと同等の性能に見えるが、LLMに日本語テキストを学習させる意義, Koshiro Saito+, 第261回自然言語処理研究発表会, 2024.08
などを考慮すると、日本特有の知識を問うQAなどはマルチリンガルなモデルは弱そうなので、その辺がどれほど高い性能を持っているのかは興味がある。
LLMで人工的に生成したデータでは、生成に利用したLLMが持つ知識しか表層的には現れないと思うので何を利用したかによるのと、高品質なラベルデータにその辺がどの程度含まれているか。
最大sequence長は1012なので、より長い系列をBERTで埋め込みたい場合はRetrievaBERT RetrievaBERTの公開, 2024 (最大sequence長2048)も検討の余地がある。
開発者の方からテクニカルレポートが出た
https://arxiv.org/abs/2409.07737
Japanese Simple SimCSE, hppRC, 2023.10
Paper/Blog Link My Issue
#Article #Sentence #NLP #RepresentationLearning #Repository #OpenWeight #Japanese #One-Line Notes Issue Date: 2023-10-07 Comment
日本語の事前学習言語モデルと、日本語の学習データを利用してSimCSEを学習し網羅的に評価をした結果が記載されている。Supervised SimCSE, UnsupervisednSimCSEの両方で実験。また、学習するデータセットを変更したときの頑健性も検証。性能が良かったモデルはSentenceTransformersから利用可能な形で公開されている。
OpenAI の Embeddings API はイケてるのか、定量的に調べてみる, akeyhero (Akihiro Katsura), Qiita, 2023.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #STS (SemanticTextualSimilarity) #Blog #Encoder #One-Line Notes Issue Date: 2023-07-31 Comment
[JSTSタスク](
https://github.com/yahoojapan/JGLUE)では、[Tohoku
BERT v3](
https://github.com/cl-tohoku/bert-japanese/tree/main#model-performances)
と [LUKE](
https://github.com/studio-ousia/luke)が最も性能が良いらしい。
[SimCSE](
https://huggingface.co/pkshatech/simcse-ja-bert-base-clcmlp)よりも性能が良いのは興味深い。
Awesome Vector Search Engine
Paper/Blog Link My Issue
#Article #Survey #InformationRetrieval #Search #Library #Repository #One-Line Notes Issue Date: 2023-04-27 Comment
ベクトルの類似度を測るサービスやライブラリ等がまとまったリポジトリ
Training a recommendation model with dynamic embeddings, TensorFlow Blog, 2023.04
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #EfficiencyImprovement #Library #Blog #KeyPoint Notes Issue Date: 2023-04-25 Comment
dynamic embeddingを使った推薦システムの構築方法の解説
(理解が間違っているかもしれないが)推薦システムは典型的にはユーザとアイテムをベクトル表現し、関連度を測ることで推薦をしている。この枠組みをめっちゃスケールさせるととんでもない数のEmbeddingを保持することになり、メモリ上にEmbeddingテーブルを保持して置けなくなる。特にこれはonline machine learning(たとえばユーザのセッションがアイテムのsequenceで表現されたとき、そのsequenceを表すEmbeddingを計算し保持しておき、アイテムとの関連度を測ることで推薦するアイテムを決める、みたいなことが必要)では顕著である(この辺の理解が浅い)。しかし、ほとんどのEmbeddingはrarely seenなので、厳密なEmbeddingを保持しておくことに実用上の意味はなく、それらを単一のベクトルでできるとメモリ節約になって嬉しい(こういった処理をしてもtopNの推薦結果は変わらないと思われるので)。
これがdynamic embeddingのモチベであり、どうやってそれをTFで実装するか解説している。
OpenKE, 2021
Paper/Blog Link My Issue
#Article #MachineLearning #Tools #Library #KnowledgeGraph #Repository #One-Line Notes Issue Date: 2021-06-10 Comment
Wikipedia, Freebase等のデータからKnowledge Embeddingを学習できるオープンソースのライブラリ
Airbnbの機械学習導入から学ぶ, Jun Ernesto Okumura, 2020.08
Paper/Blog Link My Issue
#Article #RecommenderSystems #SessionBased #Slide #SequentialRecommendation Issue Date: 2020-08-29