
MachineTranslation
[Paper Note] TranslateGemma Technical Report, Mara Finkelstein+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #SmallModel #MultiLingual #OpenWeight #Selected Papers/Blogs #One-Line Notes #Initial Impression Notes Issue Date: 2026-01-16 GPT Summary- TranslateGemmaは、Gemma 3モデルに基づく機械翻訳のオープンモデルセットで、二段階のファインチューニングプロセスを採用。初めに高品質な並行データで監視付きファインチューニングを行い、その後報酬モデルによる強化学習で翻訳品質を最適化。WMT25テストセットでの人間評価とWMT24++ベンチマークでの自動評価を通じて有効性を示し、自動指標では大幅な性能向上が確認される。特に小型モデルは大型モデルに匹敵する性能を持ちつつ効率が向上。さらに、マルチモーダル能力も保持し、画像翻訳ベンチマークでの性能向上が報告されている。TranslateGemmaの公開は、研究コミュニティに強力で適応可能な翻訳ツールを提供することを目指している。 Comment
元ポスト:
10個の翻訳元言語→翻訳先言語対で評価されている。Japanese→Englishでも評価されているが、他の言語と比べて最も性能が悪いので、日本語では苦戦していそうに見える。English→Italianは(評価した言語ペアの中では)最も性能が良い。
ポイント解説:
関連:
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
- [Paper Note] Hunyuan-MT Technical Report, Mao Zheng+, arXiv'25, 2025.09
続報:
ブラウザ上で100%ローカルでの翻訳が可能になったらしい。WebGPUってなんだろう、、、
https://huggingface.co/spaces/webml-community/TranslateGemma-WebGPU
[Paper Note] SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?, Senyu Li+, EMNLP'25, 2025.06
Paper/Blog Link My Issue
#Metrics #NLP #Dataset #LanguageModel #Evaluation #Reference-free #EMNLP #LowResource Issue Date: 2025-09-24 GPT Summary- アフリカの言語における機械翻訳の品質評価は依然として課題であり、既存の指標は限られた性能を示しています。本研究では、13のアフリカ言語ペアを対象とした大規模な人間注釈付きMT評価データセット「SSA-MTE」を紹介し、63,000以上の文レベルの注釈を含んでいます。これに基づき、改良された評価指標「SSA-COMET」と「SSA-COMET-QE」を開発し、最先端のLLMを用いたプロンプトベースのアプローチをベンチマークしました。実験結果は、SSA-COMETがAfriCOMETを上回り、特に低リソース言語で競争力があることを示しました。すべてのリソースはオープンライセンスで公開されています。 Comment
元ポスト:
[Paper Note] Multilingual Language Model Pretraining using Machine-translated Data, Jiayi Wang+, EMNLP'25, 2025.02
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #LanguageModel Issue Date: 2025-09-24 GPT Summary- 高リソース言語の英語から翻訳した高品質なテキストが、多言語LLMsの事前学習に寄与することを発見。英語のデータセットFineWeb-Eduを9言語に翻訳し、17兆トークンのTransWebEduを作成。1.3BパラメータのTransWebLLMを事前学習し、非英語の推論タスクで最先端モデルと同等以上の性能を達成。特に、ドメイン特化データを追加することで、いくつかの言語で新たな最先端を達成。コーパス、モデル、トレーニングパイプラインはオープンソースで公開。 Comment
元ポスト:
[Paper Note] Hunyuan-MT Technical Report, Mao Zheng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #Catastrophic Forgetting #mid-training #Selected Papers/Blogs #In-Depth Notes #Surface-level Notes Issue Date: 2025-09-01 GPT Summary- Hunyuan-MT-7Bは、33の主要言語間の双方向翻訳をサポートする初のオープンソースモデルであり、特に標準中国語と少数言語間の翻訳に焦点を当てています。スロースローチンキングに触発されたHunyuan-MT-Chimera-7Bを導入し、複数の出力を統合することで性能を向上させています。モデルは包括的なトレーニングプロセスを経ており、強化学習を用いた高度な整合性を実現。実験では、両モデルが同等のパラメータサイズの他の翻訳モデルを上回り、WMT2025共有タスクで30の言語ペアで1位を獲得しました。これにより、モデルの堅牢性が強調されています。 Comment
テクニカルレポート: https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
元ポスト:
Base Modelに対してまず一般的な事前学習を実施し、その後MTに特化した継続事前学習(モノリンガル/パラレルコーパスの利用)、事後学習(SFT, GRPO)を実施している模様。
継続事前学習では、最適なDataMixの比率を見つけるために、RegMixと呼ばれる手法を利用。Catastrophic Forgettingを防ぐために、事前学習データの20%を含めるといった施策を実施。
SFTでは2つのステージで構成されている。ステージ1は基礎的な翻訳力の強化と翻訳に関する指示追従能力の向上のために、Flores-200の開発データ(33言語の双方向の翻訳をカバー)、前年度のWMTのテストセット(English to XXをカバー)、Mandarin to Minority, Minority to Mandarinのcuratedな人手でのアノテーションデータ、DeepSeek-V3-0324での合成パラレルコーパス、general purpose/MT orientedな指示チューニングデータセットのうち20%を構成するデータで翻訳のinstructinoに関するモデルの凡化性能を高めるためキュレーションされたデータ、で学習している模様。パラレルコーパスはReference-freeな手法を用いてスコアを算出し閾値以下の低品質な翻訳対は除外している。ステージ2では、詳細が書かれていないが、少量でよりfidelityの高い約270kの翻訳対を利用した模様。また、先行研究に基づいて、many-shotのin-context learningを用いて、訓練データをさらに洗練させたとのこと(先行研究が引用されているのみで詳細な記述は無し)。また、複数の評価ラウンドでスコアの一貫性が無いサンプルは手動でアノテーション、あるいはverificationをして品質を担保している模様。
RLではGRPOを採用し、rewardとしてsemantic([Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
), terminology([Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
; ドメイン特有のterminologyを捉える), repetitionに基づいたrewardを採用している。最終的にSFT->RLで学習されたHuayuan-MT-7Bに対して、下記プロンプトを用いて複数のoutputを統合してより高品質な翻訳を出力するキメラモデルを同様のrewardを用いて学習する、といったpipelineになっている。
関連:
- [Paper Note] Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23, 2023.06
- [Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
- [Paper Note] CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task, Rei+, WMT'22
- [Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22, 2022.07
- [Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
- [Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
関連: PLaMo翻訳
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
こちらはSFT->Iterative DPO->Model Mergeを実施し、翻訳に特化した継続事前学習はやっていないように見える。一方、SFT時点で独自のテンプレートを作成し、語彙の指定やスタイル、日本語特有の常体、敬体の指定などを実施できるように翻訳に特化したテンプレートを学習している点が異なるように見える。Hunyuanは多様な翻訳の指示に対応できるように学習しているが、PLaMo翻訳はユースケースを絞り込み、ユースケースに対する性能を高めるような特化型のアプローチをとるといった思想の違いが伺える。
PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #SmallModel #Japanese #DPO #Selected Papers/Blogs #ModelMerge #KeyPoint Notes Issue Date: 2025-08-22 Comment
元ポスト:
SFT->Iterative DPO->Model Mergeのパイプライン。SFTでは青空文庫などのオープンなデータから指示追従性能の高いDeepSeek-V3-0324によって元データ→翻訳, 翻訳→再翻訳データを合成し活用。また、翻訳の指示がprompt中に存在せずとも(本モデルを利用するのは翻訳用途であることが自明であるからと推察される)翻訳を適切に実行できるよう、独自のテンプレートを学習。文体指定、常体、敬体の指定、文脈考慮、語彙指定それぞれにういて独自のタグを設けてフォーマットを形成し翻訳に特化したテンプレートを学習。
IterativeDPOでは、DeepSeekV3に基づくLLM-as-a-Judgeと、MetricX([Paper Note] MetricX-24: The Google Submission to the WMT 2024 Metrics Shared Task, Juraj Juraska+, arXiv'24
)に基づいてReward Modelをそれぞれ学習し、1つの入力に対して100個の翻訳を作成しそれぞれのRewardモデルのスコアの合計値に基づいてRejection Samplingを実施することでPreference dataを構築。3段階のDPOを実施し、段階ごとにRewardモデルのスコアに基づいて高品質なPreference Dataに絞ることで性能向上を実現。
モデルマージではDPOの各段階のモデルを重み付きでマージすることで各段階での長所を組み合わせたとのこと。
2025.1010配信の「岡野原大輔のランチタイムトーク Vol.52 番外編「なぜPLaMo翻訳は自然なのか?」において詳細が語られているので参照のこと。特になぜ日本語に強いLLMが大事なのか?という話が非常におもしろかった。
ガバメントAI源内での利用が決定:
[Paper Note] Unveiling the Power of Source: Source-based Minimum Bayes Risk Decoding for Neural Machine Translation, Boxuan Lyu+, ACL'25
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #ACL #Decoding Issue Date: 2025-07-20 GPT Summary- ソースベースのMBRデコーディング(sMBR)を提案し、パラフレーズや逆翻訳から生成された準ソースを「サポート仮説」として利用。参照なしの品質推定メトリックを効用関数として用いる新しいアプローチで、実験によりsMBRがQE再ランキングおよび標準MBRを上回る性能を示した。sMBRはNMTデコーディングにおいて有望な手法である。 Comment
元ポスト:
[Paper Note] TransEvalnia: Reasoning-based Evaluation and Ranking of Translations, Richard Sproat+, arXiv'25
Paper/Blog Link My Issue
#Metrics #NLP #LanguageModel #MultiDimensional Issue Date: 2025-07-18 GPT Summary- プロンプトベースの翻訳評価システム「TransEvalnia」を提案し、Multidimensional Quality Metricsに基づく詳細な評価を行う。TransEvalniaは、英日データやWMTタスクで最先端のMT-Rankerと同等以上の性能を示し、LLMによる評価が人間の評価者と良好に相関することを確認。翻訳の提示順序に敏感であることを指摘し、位置バイアスへの対処法を提案。システムの評価データは公開される。 Comment
元ポスト:
[Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
Paper/Blog Link My Issue
#TACL Issue Date: 2025-09-01 GPT Summary- xCOMETは、機械翻訳評価のためのオープンソースの学習メトリックで、文レベルの評価とエラー範囲検出を統合。これにより、翻訳エラーの詳細な分類と評価が可能となり、最先端の性能を発揮。さらに、堅牢性分析により重大なエラーや幻覚の特定能力が高いことを示す。
How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes, Inacio Vieira+, AMTA'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #Quantization #PEFT(Adaptor/LoRA) #One-Line Notes Issue Date: 2025-01-02 GPT Summary- LLMsのファインチューニングに翻訳メモリ(TMs)を活用し、特定の組織向けの翻訳精度と効率を向上させる研究。5つの翻訳方向で異なるサイズのデータセットを用いて実験し、トレーニングデータが増えるほど翻訳パフォーマンスが向上することを確認。特に、1kおよび2kの例ではパフォーマンスが低下するが、データセットのサイズが増加するにつれて改善が見られる。LLMsとTMsの統合により、企業特有のニーズに応じたカスタマイズ翻訳モデルの可能性を示唆。 Comment
元ポスト:
QLoRAでLlama 8B InstructをMTのデータでSFTした場合のサンプル数に対する性能の変化を検証している。ただし、検証しているタスクはMT、QLoRAでSFTを実施しrankは64、学習時のプロンプトは非常にシンプルなものであるなど、幅広い設定で学習しているわけではないので、ここで得られた知見が幅広く適用可能なことは示されていないであろう点、には注意が必要だと思われる。
この設定では、SFTで利用するサンプル数が増えれば増えるほど性能が上がっているように見える。
[Paper Note] Prompting Large Language Model for Machine Translation: A Case Study, Biao Zhang+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#NLP #LanguageModel #One-Line Notes #Reading Reflections Issue Date: 2024-11-20 GPT Summary- プロンプト設計は多くのタスクで優れた性能を示すが、機械翻訳においては未検討。翻訳のためのプロンプト戦略を体系的に研究し、プロンプトテンプレートやデモ例の選択に関する要因を検討。実験の結果、プロンプト例の数と質が翻訳において重要であり、サブ最適な例は性能低下を招くことが示された。また、ゼロショットプロンプティングから得られた擬似平行プロンプト例の利用が翻訳を改善する可能性や、知識転移により性能向上が見込まれることが確認された。最後に、プロンプト設計に関する問題点についても議論。 Comment
zero-shotでMTを行うときに、改行の有無や、少しのpromptingの違いでCOMETスコアが大幅に変わることを示している。
モデルはGLM-130BをINT4で量子化したモデルで実験している。
興味深いが、この知見を一般化して全てのLLMに適用できるか?と言われると、そうはならない気がする。他のモデルで検証したら傾向はおそらく変わるであろう(という意味でおそらく論文のタイトルにもCase Studyと記述されているのかなあ)。
DiscoScore: Evaluating Text Generation with BERT and Discourse Coherence, Wei Zhao+, N_A, EACL'23
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #LM-based #Coherence Issue Date: 2023-08-13 GPT Summary- 本研究では、文章の一貫性を評価するための新しい指標であるDiscoScoreを紹介します。DiscoScoreはCentering理論に基づいており、BERTを使用して談話の一貫性をモデル化します。実験の結果、DiscoScoreは他の指標よりも人間の評価との相関が高く、システムレベルでの評価でも優れた結果を示しました。さらに、DiscoScoreの重要性とその優位性についても説明されています。
Simple and Effective Unsupervised Speech Translation, ACL'23
Paper/Blog Link My Issue
#Unsupervised #NLP #SpeechProcessing #Speech #ACL Issue Date: 2023-07-15 GPT Summary- 音声翻訳のためのラベル付きデータが限られているため、非教師あり手法を使用して音声翻訳システムを構築する方法を研究している。パイプラインアプローチや擬似ラベル生成を使用し、非教師ありドメイン適応技術を提案している。実験の結果、従来の手法を上回る性能を示している。
[Paper Note] Frustratingly Easy Label Projection for Cross-lingual Transfer, Yang Chen+, ACL'23, 2022.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Annotation #TransferLearning #MultiLingual #ACL Issue Date: 2023-05-04 GPT Summary- 多言語へのラベル投影には、マーク・アンド・トランスレート法を用いた新しいアプローチが提案され、57言語と3つのタスクにおける実証研究が行われた。実験結果は、EasyProjectが単語アライメント技術を上回る性能を示し、翻訳後もラベルスパンの境界を保持することができることを明らかにした。全コードとデータは公開されている。
[Paper Note] CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task, Rei+, WMT'22
Paper/Blog Link My Issue
Issue Date: 2025-09-01
[Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22, 2022.07
Paper/Blog Link My Issue
#NLP #Dataset #LowResource #One-Line Notes Issue Date: 2024-09-26 GPT Summary- 低資源言語翻訳を支援するため、母語話者へのインタビューを通じてニーズを明らかにし、新たなデータセットとモデルを開発。Sparsely Gated Mixture of Expertsに基づく条件付き計算モデルを用い、訓練時の過剰適合を抑えつつ性能を向上。Flores-200ベンチマークにより翻訳性能を評価し、BLEUスコアを44%改善。研究成果はオープンソースとして公開。 Comment
low-resourceな言語に対するMTのベンチマーク
Improving Neural Machine Translation with Compact Word Embedding Tables, Kumar+, AAAI'22
Paper/Blog Link My Issue
#NeuralNetwork #Embeddings #NLP #AAAI #Initial Impression Notes Issue Date: 2021-06-07 Comment
NMTにおいてword embeddingがどう影響しているかなどを調査しているらしい
[Paper Note] Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation, Markus Freitag+, arXiv'21, 2021.04
Paper/Blog Link My Issue
#Analysis #NaturalLanguageGeneration #Metrics #NLP #Evaluation #One-Line Notes Issue Date: 2024-01-25 GPT Summary- 機械翻訳の人間評価は難しく、標準的な手法が不足している。そこで、誤り分析に基づく評価方法論を提案し、MQMフレームワークを用いてWMT 2020の上位システム出力をプロの翻訳者による注釈で評価。分析の結果、WMTクラウドワーカーのランキングと異なる結果が得られ、人間が機械出力よりも人間の出力を好む傾向を示した。さらに、自動指標がクラウドワーカーよりも優れたことも判明し、研究用コーパスを公開。 Comment
embedding basedなNLGの性能指標が、意味の等価性や流暢性を評価できる一方、適用範囲が限定的で柔軟性に欠けることを示した研究
[Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings
Paper/Blog Link My Issue
#Transformer #EMNLP #Normalization #Findings Issue Date: 2025-08-16 GPT Summary- 低リソース言語翻訳において、QKNormという新しい正規化手法を提案。これは、注意メカニズムを修正し、ソフトマックス関数の飽和耐性を向上させつつ表現力を維持。具体的には、クエリとキー行列に対して$\ell_2$正規化を適用し、学習可能なパラメータでスケールアップ。TED TalksコーパスとIWSLT'15の低リソース翻訳ペアで平均0.928 BLEUの改善を達成。 Comment
QKに対してL2正規化を実施し、learnableなスカラー値を乗じることでスケーリングすることで、low resourceな言語での翻訳性能が向上。MTで実験されているが、transformerの表現力が改善されるのでGLM-4.5のアーキテクチャでも採用されている。
dot product attentionでは内積を利用するため値域に制約がなく、ある単語にのみattention scoreが集中してしまい、他の全ての単語のsignalをかき消してしまう問題がある。このため、QKをノルムによって正規化し(これにより実質QKはcosine similarityとなる)値域を制限する。しかしこうすると今度はスコア間の差が小さすぎて、attendしなくても良い単語を無視できなくなるので、learnableなパラメータでスケールを調整する。
COMET: A Neural Framework for MT Evaluation, Ricardo Rei+, N_A, EMNLP'20
Paper/Blog Link My Issue
#Metrics #NLP #Evaluation #EMNLP #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-05-26 GPT Summary- COMETは、多言語機械翻訳評価モデルを訓練するためのニューラルフレームワークであり、人間の判断との新しい最先端の相関レベルを達成します。クロスリンガル事前学習言語モデリングの進展を活用し、高度に多言語対応かつ適応可能なMT評価モデルを実現します。WMT 2019 Metrics shared taskで新たな最先端のパフォーマンスを達成し、高性能システムに対する堅牢性を示しています。 Comment
Better/Worseなhypothesisを利用してpair-wiseにランキング関数を学習する


Inference時は単一のhypothesisしかinputされないので、sourceとreferenceに対してそれぞれhypothesisの距離をはかり、その調和平均でスコアリングする

ACL2024, EMNLP2024あたりのMT研究のmetricをざーっと見る限り、BLEU/COMETの双方で評価する研究が多そう
[Paper Note] BLEU might be Guilty but References are not Innocent, Markus Freitag+, arXiv'20, 2020.04
Paper/Blog Link My Issue
#Analysis #NaturalLanguageGeneration #Metrics #NLP #Evaluation #One-Line Notes Issue Date: 2024-01-25 GPT Summary- 機械翻訳の自動評価指標の質を検証し、参照データの性質が重要であることを示す。さまざまな参照収集方法を検討し、人間評価との相関を報告。典型的な参照の偏りを打ち消すために、言語学者によるパラフレージング課題を開発。WMT 2019のデータにおいて、標準参照との相関が低い出力でも人間判断との相関が向上することを示す。また、埋め込みベースの手法を含む評価指標で相関が改善されることも明らかにし、マルチ参照BLEUの限界と新たな定式化を提示。 Comment
surface levelのNLGの性能指標がsemanticを評価できないことを示した研究
[Paper Note] Leveraging Pre-trained Checkpoints for Sequence Generation Tasks, Sascha Rothe+, TACL'20, 2019.07
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NLP #Transformer #pretrained-LM #TACL #Encoder #Encoder-Decoder #KeyPoint Notes Issue Date: 2022-12-01 GPT Summary- 事前学習された大規模なニューラルモデルがシーケンス生成においても有効であることを示し、BERT、GPT-2、RoBERTaと互換性のあるTransformerベースのモデルを開発。これにより、機械翻訳やテキスト要約などのタスクで新たな最先端の成果を達成。 Comment
# 概要
BERT-to-BERT論文。これまでpre-trainedなチェックポイントを利用する研究は主にNLUで行われてきており、Seq2Seqでは行われてきていなかったので、やりました、という話。
publicly availableなBERTのcheckpointを利用し、BERTをencoder, decoder両方に採用することでSeq2Seqを実現。実現する上で、
1. decoder側のBERTはautoregressiveな生成をするようにする(左側のトークンのattentionしか見れないようにする)
2. encoder-decoder attentionを新たに導入する
の2点を工夫している。
# 実験
Sentence Fusion, Sentence Split, Machine Translation, Summarizationの4タスクで実験
## MT
BERT2BERTがSoTA達成。Edunov+の手法は、data _augmentationを利用した手法であり、純粋なWMT14データを使った中ではSoTAだと主張。特にEncoder側でBERTを使うと、Randomにinitializeした場合と比べて性能が顕著に上昇しており、その重要性を主張。
Sentence Fusion, Sentence Splitでは、encoderとdecoderのパラメータをshareするのが良かったが、MTでは有効ではなかった。これはMTではmodelのcapacityが非常に重要である点、encoderとdecoderで異なる文法を扱うためであると考えられる。
## Summarization
BERTSHARE, ROBERTASHAREの結果が良かった。
[Paper Note] Machine Translation Evaluation with BERT Regressor, Hiroki Shimanaka+, arXiv'19, 2019.07
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Evaluation #TrainedMetrics Issue Date: 2023-08-13 GPT Summary- BERTを用いた機械翻訳の自動評価指標を提案し、WMT-2017 Metrics Shared Taskデータセットにおいて、すべての英語翻訳ペアに対して最先端の性能を達成した。
[Paper Note] Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates, Taku Kudo, ACL'18, 2018.04
Paper/Blog Link My Issue
#NeuralNetwork #Subword #ACL #Tokenizer #read-later #Selected Papers/Blogs Issue Date: 2025-11-19 GPT Summary- サブワード単位はNMTのオープンボキャブラリー問題を軽減するが、セグメンテーションの曖昧さが存在する。本研究では、この曖昧さを利用してNMTのロバスト性を向上させるため、サブワードの正則化手法を提案し、確率的にサンプリングされた複数のセグメンテーションでモデルを訓練する。また、ユニグラム言語モデルに基づく新しいセグメンテーションアルゴリズムも提案。実験により、特にリソースが限られた設定での改善を示した。
[Paper Note] Google's Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation, Melvin Johnson+, TACL'17, 2016.11
Paper/Blog Link My Issue
#NeuralNetwork #NLP #TransferLearning #MultiLingual #Zero/FewShotLearning #TACL #Encoder-Decoder #LowResource Issue Date: 2025-11-19 GPT Summary- 単一のNMTモデルを用いて多言語翻訳を実現するシンプルな手法を提案。入力文の先頭に人工トークンを追加することでターゲット言語を指定し、モデルのアーキテクチャは変更せずに共有語彙を使用。これにより、パラメータを増やさずに翻訳品質を向上させ、WMT'14およびWMT'15ベンチマークで最先端の結果を達成。訓練中に見たことのない言語ペア間での暗黙のブリッジングを学習し、転移学習とゼロショット翻訳の可能性を示す。 Comment
[Paper Note] Attention Is All You Need, Ashish Vaswani+, NeurIPS'17, 2017.07
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Transformer #FoundationModel #Attention #PositionalEncoding #NeurIPS #Normalization #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2018-01-19 GPT Summary- Transformerは、再帰や畳み込みを排除し、注意機構のみに基づいた新しいネットワークアーキテクチャである。実験により、機械翻訳タスクで優れた品質を示し、トレーニング時間を大幅に短縮。WMT 2014の英独翻訳で28.4 BLEU、英仏翻訳で41.8 BLEUを達成し、既存モデルを上回る性能を示した。また、英語の構文解析にも成功裏に適用可能であることを示した。 Comment
Transformer (self-attentionを利用) 論文
解説スライド:
https://www.slideshare.net/DeepLearningJP2016/dlattention-is-all-you-need
解説記事:
https://qiita.com/nishiba/items/1c99bc7ddcb2d62667c6
* 新しい翻訳モデル(Transformer)を提案。既存のモデルよりも並列化に対応しており、短時間の訓練で(既存モデルの1/4以下のコスト)高いBLEUスコアを達成した。
* TransformerはRNNやCNNを使わず、attentionメカニズムに基づいている。
(解説より)
分かりやすい:
https://qiita.com/halhorn/items/c91497522be27bde17ce
Transformerの各コンポーネントでのoutputのshapeや、attention_maskの形状、実装について記述されており有用:
https://qiita.com/FuwaraMiyasaki/items/239f3528053889847825
集合知
Transformer提案時と最近の動向への流れ
- BPEによるOOVの防止
- その後sentencepieceによる真の多言語化の実現
- Positional Encodingの提案
- 本稿はSinusoidal PE(絶対位置エンコーディング)で提案され、その後相対位置エンコーディング / RoPE / NoPE などの変種が登場
- Residual Connectionによる勾配爆発・消失の低減による深いモデル化
- 最近はHyperConnection等のResidual Streamの改善が進む
- QK Norm + learnableなScaling factor
- [Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings
- 活性化関数の進化
- [Paper Note] GLU Variants Improve Transformer, Noam Shazeer, arXiv'20, 2020.02
- Multi-head-attentionによるトークン間の多様な関係性のモデル化
- トークン間を跨いだ情報のmixing
- FFNによるトークン内での情報のmixing
- MHA -> MQA -> GQA -> MLA
- O(n^2)によるボトルネックを改善するために Sparse Attention / Linear Attention 等のより計算量が小さい手法へ進展
- また、実装上の工夫としてFlash Attentionが標準に
- Layer Normalizationによる正規化(内部共変量シフト防止)による学習の安定化
- 本稿ではPostLN
- その後Pre-LNの方が性能は落ちるが学習が安定するため主流となり、現在またPost-LNが再考されている
- また、現在はLayerNormalizationではなくRMSNormを使用する傾向がある
- [Paper Note] Understanding and Improving Layer Normalization, Jingjing Xu+, arXiv'19, 2019.11
- 本稿ではRNNと比較して並列計算可能なEncoder-Decoderアーキテクチャとして提案されMTで評価
- Decoder側ではCausal Maskの導入によるleakの防止
- その後、Decoder-only Model として現在のLLMの基盤に
- 実装上の工夫としてKV Cacheによる生成の高速化
ゼロから始める ニューラルネットワーク機械翻訳, 中澤敏明, NLP'17
Paper/Blog Link My Issue
#NeuralNetwork #Tutorial #NLP Issue Date: 2018-01-15
[Paper Note] What do Neural Machine Translation Models Learn about Morphology?, Yonatan Belinkov+, ACL'17
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ACL Issue Date: 2017-12-28 Comment
日本語解説: http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/06.pdf
[Paper Note] Sequence-to-Dependency Neural Machine Translation, Wu+, ACL'17
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ACL Issue Date: 2017-12-28 GPT Summary- 新しいシーケンスから依存関係へのニューラル機械翻訳(SD-NMT)手法を提案。ターゲット単語のシーケンスと依存関係構造を共同で構築し、文脈として利用することで翻訳精度を向上。実験により、中国語-英語および日本語-英語の翻訳タスクで最先端のベースラインを大幅に上回る結果を示した。
[Paper Note] Neural Machine Translation with Source-Side Latent Graph Parsing, Kazuma Hashimoto+, EMNLP'17, 2017.02
Paper/Blog Link My Issue
#NeuralNetwork #NLP #EMNLP Issue Date: 2017-12-28 GPT Summary- 翻訳と潜在グラフ表現を共同で学習する新しいニューラル機械翻訳モデルを提案。エンドツーエンドのアプローチで、パーサーが翻訳目的に最適化される。実験により、従来のモデルと比較して優れた性能を示し、少量のツリーバンク注釈でさらに性能向上。最終的なアンサンブルモデルは、英日翻訳データセットで従来の最良モデルを大幅に上回る結果を得た。
[Paper Note] Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu+, arXiv'16, 2016.09
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Subword #Tokenizer #Encoder-Decoder #RecurrentModels Issue Date: 2025-11-19 GPT Summary- GNMTは、計算コストの高いNMTの問題に対処するために、8層のLSTMネットワークを用い、注意機構と残差接続を採用。希少な単語の処理を改善するために、一般的なサブワードユニットに分割し、翻訳精度を向上。ビームサーチ技術により、出力文のカバレッジを高め、WMT'14のベンチマークで最先端の結果を達成し、翻訳エラーを60%削減。 Comment
GNMT論文。wordpieceを提案
[Paper Note] Neural Machine Translation of Rare Words with Subword Units, Rico Sennrich+, ACL'16, 2015.08
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Subword #Tokenizer Issue Date: 2025-11-19 GPT Summary- NMTモデルは固定語彙で動作するが、オープンボキャブラリー翻訳を可能にするために、希少な単語や未知の単語をサブワードユニットとしてエンコードする新しいアプローチを提案。さまざまな単語クラスを小さな単位で翻訳可能とし、文字n-gramモデルやバイトペアエンコーディングを用いたセグメンテーション技術の効果を実証。WMT 15翻訳タスクでバックオフ辞書のベースラインをそれぞれ1.1および1.3 BLEUポイント上回る成果を示した。 Comment
subwordが初めて提案された研究
[Paper Note] Dual Learning for Machine Translation, Yingce Xia+, NIPS'16
Paper/Blog Link My Issue
#NeuralNetwork #ReinforcementLearning #NeurIPS #DualLearning Issue Date: 2025-08-21 GPT Summary- デュアルラーニングメカニズムを用いたニューラル機械翻訳(dual-NMT)を提案。プライマルタスク(英語からフランス語)とデュアルタスク(フランス語から英語)を通じて、ラベルのないデータから自動的に学習。強化学習を用いて互いに教え合い、モデルを更新。実験により、モノリンガルデータから学習しつつ、バイリンガルデータと同等の精度を達成することが示された。 Comment
モノリンガルコーパスD_A, D_Bで学習した言語モデルLM_A, LM_Bが与えられた時、翻訳モデルΘ_A, Θ_Bのの翻訳の自然さ(e.g., 尤度)をrewardとして与え、互いのモデルの翻訳(プライマルタスク)・逆翻訳(デュアルタスク)の性能が互いに高くなるように強化学習するような枠組みを提案。パラレルコーパス不要でモノリンガルコーパスのみで、人手によるアノテーション無しで学習ができる。
Lexical Coherence Graph Modeling Using Word Embeddings, Mesgar+, NAACL'16
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Coherence #NAACL Issue Date: 2023-08-13
[Paper Note] Pointing the Unknown Words, Caglar Gulcehre+, ACL'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ACL #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-28 GPT Summary- 希少および未知の単語に対処するため、注意機構を用いた新しいニューラルネットワークモデルを提案。2つのソフトマックス層を使用し、文脈に基づいて適応的に選択。提案モデルは、翻訳と要約タスクで性能向上を示した。 Comment
テキストを生成する際に、source textからのコピーを行える機構を導入することで未知語問題に対処した話
CopyNetと同じタイミングで(というか同じconferenceで)発表
[Paper Note] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Attention #ICLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-05-12 GPT Summary- ニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment
(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している)
chrF: character n-gram F-score for automatic MT evaluation, Mono Popovic, WMT'15
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Reference-based #ACL #Workshop #One-Line Notes Issue Date: 2023-08-13 Comment
character-basedなn-gram overlapをreferenceとシステムで計算する手法
Document-Level Machine Translation Evaluation with Gist Consistency and Text Cohesion, Gong+, DiscoMT'15
Paper/Blog Link My Issue
#NLP #Evaluation Issue Date: 2023-08-13
[Paper Note] Effective Approaches to Attention-based Neural Machine Translation, Luong+, EMNLP'15
Paper/Blog Link My Issue
#NeuralNetwork #NLP #EMNLP #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2021-06-02 Comment
Luong論文。attentionの話しはじめると、だいたいBahdanau+か、Luong+論文が引用される。
Global Attentionと、Local Attentionについて記述されている。Global Attentionがよく利用される。
Global Attention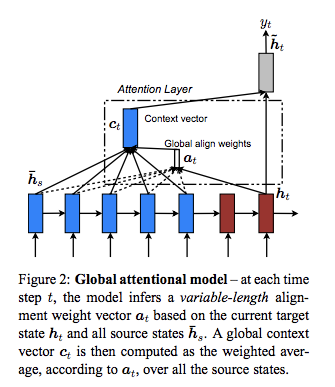
Local Attention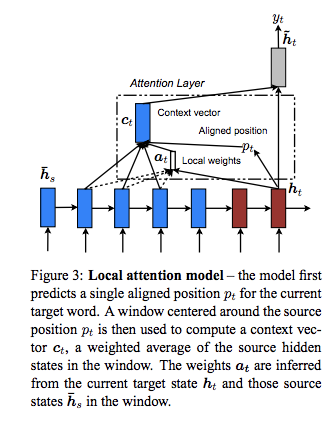
やはり菊池さんの解説スライドが鉄板。
https://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention
参考までに、LuongらのGlobal Attentionの計算の流れは下記となっている:
- h_t -> a_t -> c_t -> h^~_t
BahdanauらのAttentionは下記
- h_t-1 -> a_t -> c_t -> h_t
t-1のhidden stateを使うのか、input feeding後の現在のhidden stateをattention weightの計算に使うのかが異なっている。
また、過去のalignmentの情報を考慮した上でデコーディングしていくために、input-feeding approachも提案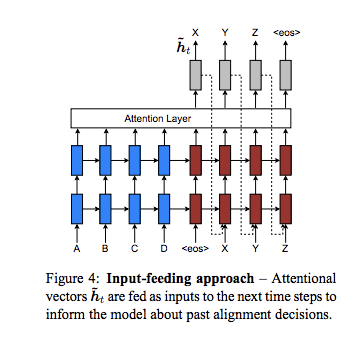
input-feeding appproachでは、t-1ステップ目のoutputの算出に使ったh^~_t(hidden_stateとcontext vectorをconcatし、tanhのactivationを噛ませた線形変換を行なったベクトル)を、時刻tのinput embeddingにconcatして、RNNに入力する。
Graph-based Local Coherence Modeling, Guinaudeau+, ACL'13
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Coherence #ACL Issue Date: 2023-08-13
[Paper Note] The Mathematics of Statistical Machine Translation: Parameter Estimation, Brown+, CL'13
Paper/Blog Link My Issue
#NLP #Alignment #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-15 Comment
IBMモデル論文。
Extending Machine Translation Evaluation Metrics with Lexical Cohesion to Document Level, Wong+, EMNLP'12
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Coherence #EMNLP Issue Date: 2023-08-13 Comment
RC-LC
Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07
Paper/Blog Link My Issue
#NLP #LanguageModel #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-12-24 GPT Summary- 本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。 Comment
N-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
元ポスト:
Large Language Modelsという用語が利用されたのはこの研究が初めてなのかも…?
機械翻訳自動評価指標の比較, 今村+, NLP'04
Paper/Blog Link My Issue
#Metrics #NLP #One-Line Notes Issue Date: 2021-06-25 Comment
BLEUスコア、NISTスコア、WordErrorRate(WER)などに関して丁寧かつ簡潔に解説してある。
BLEUスコア算出に利用するN-gramは一般的にはN=4が用いられる、といった痒いところに手が届く情報も書いてある。
普段何気なく使っているBLEUスコアで、あれ定義ってどんなだっけ?と立ち帰りたくなった時に読むべし。
実際に研究等でBLEUスコアを測りたい場合は、mosesの実装を使うのが間違いない:
https://github.com/moses-smt/mosesdecoder/blob/master/scripts/generic/multi-bleu.perl
[Paper Note] A systematic comparison of various statistical alignment models, Och+, CL'03
Paper/Blog Link My Issue
#Tools #NLP #One-Line Notes #WordAlignment Issue Date: 2018-01-15 Comment
Giza++
標準的に利用される単語アライメントツール
評価の際は、Sure, Possibleの二種類のラベルによる単語アライメントのground-truth作成も行っている
[Paper Note] HMM-based word alignment in statistical translation, Vogel+, COLING'96
Paper/Blog Link My Issue
#NLP #COLING #WordAlignment Issue Date: 2018-01-15
Fluid, natural voice translation with Gemini 3.5 Live Translate, Google, 2026.06
Paper/Blog Link My Issue
#Article #SpeechProcessing #MultiLingual #Author Thread-Post #SpeechToSpeech Issue Date: 2026-06-10 Comment
元ポスト:
Hy-MT2-30B-A3B, Tencent Hy, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiLingual #OpenWeight #One-Line Notes #Author Thread-Post Issue Date: 2026-05-27 Comment
HF: https://huggingface.co/collections/tencent/hy-mt2
元ポスト:
テンセントによる1.8B--30BのMT特化モデルファミリー。fast thinkingが強みとのこと。
Violin: An open-source video translation skill that breaks language barriers, together.ai, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #3D (Video) #AgentSkills #SpeechToSpeech Issue Date: 2026-05-21 Comment
元ポスト:
demo:
https://www.violin-ai.com/
github:
https://github.com/shang-zhu/violin
FineTranslations, Penedo+, 2026.01
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #LanguageModel #SyntheticData #mid-training #One-Line Notes Issue Date: 2026-01-10 Comment
元ポスト:
FineWeb2のテキストを英訳することで合成されたパラレルコーパスらしい
Liquid Nanos, LiquidAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #RAG(RetrievalAugmentedGeneration) #Mathematics #SmallModel #OpenWeight #Japanese #DocParser #EdgeDevices Issue Date: 2025-09-26 Comment
blog: https://www.liquid.ai/blog/introducing-liquid-nanos-frontier-grade-performance-on-everyday-devices
モデルファミリーに350Mの日英翻訳モデルが含まれている…だと!?
タスクスペシフィックなedgeデバイス向けのSLM群。
以下のようなモデルファミリー。非構造テキストからのデータ抽出、日英翻訳、RAG, tooluse, Math, フランス語のチャットモデル。これまでマルチリンガルに特化したMTとかはよく見受けられたが、色々なタスクのSLMが出てきた。
元ポスト:
LFM2はこちら:
- Introducing LFM2: The Fastest On-Device Foundation Models on the Market, LiquidAI, 2025.07
Qwen3‑LiveTranslate: Real‑Time Multimodal Interpretation — See It, Hear It, Speak It!, Qwen Team, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiModal #Blog #Proprietary Issue Date: 2025-09-24 Comment
元ポスト:
Seed-X-Instruct-7B, ByteDance-Seed, 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #SmallModel #MultiLingual #OpenWeight Issue Date: 2025-07-18 Comment
元ポスト:
MTに特化したMultilingual SLM。7Bモデルだがベンチマーク上では他の大規模なモデルと同等以上。
テクニカルレポート: https://github.com/ByteDance-Seed/Seed-X-7B/blob/main/Technical_Report.pdf
PLaMo翻訳による英語ベンチマークの翻訳, PFN, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Dataset #SyntheticData #Blog Issue Date: 2025-07-09
Datasets: hpprc_honyaku, hpprc, 2024.11
Paper/Blog Link My Issue
#Article #NLP #Dataset #Zero/Few/ManyShotPrompting #Japanese #One-Line Notes Issue Date: 2024-11-20 Comment
元ポスト:
英語Wikipediaを冒頭数文を抽出し日本語に人手で翻訳(Apache2.0ライセンスであるCalmやQwenの出力を参考に、cc-by-sa-4.0ライセンスにて公開している。
テクニカルタームが日本語で存在する場合は翻訳結果に含まれるようにしたり、翻訳された日本語テキストが単体で意味が成り立つように翻訳しているとのことで、1件あたり15分もの時間をかけて翻訳したとのこと。データ量は33件。many-shotやfew-shotに利用できそう。
日英対訳コーパスはライセンスが厳しいものが多いとのことなので、非常に有用だと思う。
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments, Banerjee+, CMU, ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and_or Summarization
Paper/Blog Link My Issue
#Article #Metrics #NLP #Evaluation #Surface-level Notes Issue Date: 2023-05-10 Comment
# イントロ
MTの評価はBLEUが提案されてから過去2年間で注目されている。BLEUはNIST metricと関連しており、研究で利用されてきた。自動評価は素早く、より簡便に、human evaluationよりも安価に評価をすることができる。また、自動評価は他のシステムとの比較だけでなく、ongoingなシステムの改善にも使える。
過去MTの評価は人手で行われてきた。MTの評価で利用される指標はfairly intensiveでwell establishedな一方で、MTの評価全体は複雑さとタスク依存である。結果的にMTの評価そのものが研究分野となってきた。多くの評価指標が提案されてきたが、全てが簡単に定量化できるわけではない。近年のFEMTIといったフレームワークは、MT評価のための多面的なmeasureを効果的でユーザが調整可能な方法で考案しようとしている。一方、単一の1次元の数値メトリックは、MT評価の全てのaspectを捉えることができないが、このようなメトリックは未だ大きな価値が実用性の観点で存在する。効果的・かつ効率的であるために、MT評価の自動性能指標はいくつかの基本的な基準を満たす必要がある:
- MTの質に対する人間が定量化した指標と高い相関があること
- 異なるシステム間、同じシステムの異なるバージョン間の品質の違いにできるだけsensitiveであること
- 一貫性があり、信頼性があり、一般的である必要
- 一貫性: 同じMTシステムが類似したテキストを翻訳したら類似したスコアを返す
- 信頼性: 類似したスコアを持つMTシステムは似たように類似した動作をすること
- 一般的: さまざまなドメインやシナリオのMTタスクに適用可能であること
これら指標を全て満たすことは困難であるが、これまでに提案された全ての指標は、要件の全てではないにせよ、ほとんどの要件に対して適切に対処できているわけではない。これらの要件を適切に定量化し、具体的なテスト尺度に変換すると、MTの評価指標を比較、および評価できる全体的な基準として扱える。
本研究では、METEORを提案する。METEORはBLEUのいくつかの弱点に対処した手法である。
# METEOR Metric
## METEORで対処するBLEUの弱点
BLEUはn-gramのprecisionを測る指標であり、recallを直接的に考慮していない。recallは翻訳文が正解文のcontentをどれだけcoverできているかを測定することができるため重要な指標である。BLEUは複数の参照訳を利用するため、recallの概念を定義することができない。代わりに、BLEUではbrevity penaltyを導入し、短すぎる翻訳にはペナルティを与えるようにしている。
NIST metricもコンセプト上はBLEUと同様の弱点を持っている。METEORが対処するBLEUやNISTは以下となる:
- The Lack of Recall:
- 固定のbrevity penaltyを与えるだけでは、recallに対する適切な補償とはなっていない。実験結果がこれを強く示している。
- Use of Higher Order N-grams:
- BLEUにおけるhigher orderのN-gramの利用は、翻訳の文法的な良さを間接的に測定している。METEORではより直接的にgrammarticality(あるいはword order)を考慮する。実験結果では、human judgmentsとより良い相関を示した。
- Lack of Explicit Word-matching between Translation and Reference
- N-gramでは明示的なword-to-word matchingを必要しないため、結果的に正しくないマッチ、具体的には共通の機能語等のマッチをカウントしてしまう。
- Use of Geometric Averaging of N-grams
- BLEUは幾何平均(i.e. 1,2,3,4-gramそれぞれのprecisionの積の1/n乗根)をとっているため、n-gramのコンポーネントの1つでもゼロになると、幾何平均の結果もゼロとなる。結果的に、sentenceあるいはsegmentレベルでBLEUスコアを測ろうとすると意味のないものとなる(ゼロになるため)。BLEUは全体のテストセット(文レベルではなく)のカウントを集約するのみであるが、sentence levelのindicatorもメトリックとしては有用であると考えられる。実験結果によると、n-gramの算術平均をとるようにBLEUスコアを改変した場合、human judgmentsとの相関が改善した。
## Meteor Metric
参照訳が複数ある場合は最もスコアが高いものを出力する。METEORはword-to-wordのマッチングに基づいた指標である。まず、参照訳と候補訳が与えられたときに単語同士のalignmentを作成する。このときunigramを利用してone-to-manyのmappingをする。wordnetの同義語を利用したり、porter-stemmerを利用しステミングした結果を活用しalignmentを作成することができる。続いて、それぞれのunigramのmapppingのうち、最も大きな部分集合のmappingを選択し、対応するunigramのalignmentとする。もしalignmentの候補として複数の候補があった場合、unigram mappingのcrossが少ない方を採用する。この一連の操作はstageとして定義され、各stageごとにmapping module(同義語使うのか、stemming結果使うのかなど)を定義する。そして、後段のstageでは、以前のstageでmappingされていなunigramがmappingの対象となる。たとえば、first stageにexact matchをmapping moduleとして利用し、次のstageでporter stemmerをmapping moduleとして利用すると、よりsurface formを重視したmappingが最初に作成され、surface formでマッチングしなかったものが、stemming結果によってマッピングされることになる。どの順番でstageを構成するか、何個のstageを構成するか、どのmapping moduleを利用するかは任意である。基本的には、1st-stageでは"exact match", 2nd-stageでは"porter stem", 3rd-stageでは"wordnet synonymy"を利用する。このようにして定義されたalignmentに基づいて、unigram PrecisionとRecallを計算する。
Precisionは、候補訳のunigramのうち、参照訳のunigramにマッピングされた割合となる。Recallは、参照訳のunigramのうち、候補訳からマッピングされた割合となる。そして、Precisionを1, Recallを9の重みとして、Recall-OrientedなF値を計算する。このF値はunigramマッチに基づいているので、より長い系列のマッチを考慮するために、alignmentに対して、ペナルティを計算する。具体的には、参照訳と候補訳で連続したunigramマッチとしてマッピングされているもの同士をchunkとして扱い、マッチングしたunigramに対するchunkの数に基づいてペナルティを計算する。
チャンクの数が多ければ多いほどペナルティが増加する。そして、最終的にスコアは下記式で計算される:
最大でF値が50%まで減衰するようにペナルティがかかる。
# 評価
## Data
DARPA/TIDES 2003 Arabic-to-English, Chinese-to-English データを利用。Chinese dataは920 sentences, Arabic datasetは664 sentencesで構成される。それぞれのsentenceには、それぞれのsentenceには、4種類のreferenceが付与されている。加えて、Chinese dataでは7種類のシステム、Arabic dataでは6種類のシステムの各sentenceに対する翻訳結果と、2名の独立したhuman judgmentsの結果が付与されている。human judgmentsは、AdequacyとFluency Scoreの2つで構成されている。それぞれのスコアは0--5のレンジで変化する。本評価では、Combined Score、すなわち2名のアノテーションによって付与されたAdequacy ScoreとFluency Scoreを平均したものを用いる。
本研究の目的としては、sentence単位での評価を行うことだが、BLEUやNISTはシステムレベルで評価を行う指標のため、まずシステムレベルでhuman judgeとのcorrelationを測定。correlationを測る際は、各システムごとにCombined Scoreの平均をとり、human judgmentの総合的な結果を1つのスコアとして計算。またシステムのすべての翻訳結果に対する各種metricを集約することで、システムごとに各種metricの値を1つずつ付与し、両者で相関を測った。結果は以下のようにMETEORが最も高い相関を示した。METEORのsubcomponentsもBLEUやNISTよりも高い相関を示している。
文レベルでhuman judgeとのcorrelationを測った結果は下記。文レベルで測る際は、システムごとに、システムが翻訳したすべての翻訳結果に対しMETEORスコアを計算し、fluencyとadequacyスコアの平均値との相関を測った。そして各データセットごとに、システムごとの相関係数の平均を算出した。
他のmetricとの比較結果は下記で、METEORが最も高い相関を示した。
続いて、異なるword mapping設定でcorrelationを測った。結果は下記で、Exact, Porter, Wordnet-Synonymの順番で3-stageを構成する方法が最も高い相関を示した。
最後に、文レベルの評価はannotator間のaggreementが低く、ノイジーであることがわかっている。このノイズを緩和するために、スコアをnormalizeしcorrelationを測定した。結果は下記で、normalizeしたことによってcorrelationが改善している。これは、human assessmentのノイズによって、automatic scoreとhuman assessmentのcorrelationに影響を与えることを示している。
[Paper Note] Probing Word Translations in the Transformer and Trading Decoder for Encoder Layers, NAACL‘21
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #NAACL #KeyPoint Notes #Reading Reflections Issue Date: 2021-06-03 Comment
Transformerに基づいたNMTにおいて、Encoderが入力を解釈し、Decoderが翻訳をしている、という通説を否定し、エンコーディング段階、さらにはinput embeddingの段階でそもそも翻訳が始まっていることを指摘。
エンコーディングの段階ですでに翻訳が始まっているのであれば、エンコーダの層を増やして、デコーダの層を減らせば、デコーディング速度を上げられる。
通常はエンコーダ、デコーダともに6層だが、10-2層にしたらBLEUスコアは変わらずデコーディングスピードは2.3倍になった。
18-4層の構成にしたら、BLEUスコアも1.42ポイント増加しデコーディング速度は1.4倍になった。
この研究は個人的に非常に興味深く、既存の常識を疑い、分析によりそれを明らかにし、シンプルな改善で性能向上およびデコーディング速度も向上しており、とても好き。
ALAGIN 機械翻訳セミナー 単語アライメント, Graham Neubig, 2014.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Slide #WordAlignment Issue Date: 2018-01-15