
FactualConsistency
#Pocket#NLP#LanguageModel#QuestionAnswering#KnowledgeGraph#Reasoning#Test-Time Scaling#PostTraining
Issue Date: 2025-05-20 Scaling Reasoning can Improve Factuality in Large Language Models, Mike Zhang+, arXiv25 Comment元ポスト:https://x.com/_akhaliq/status/1924477447120068895?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #NLP#Dataset#Conversation
Issue Date: 2024-12-05 事実正誤判定が不要な生成応答の検出に向けた データセットの収集と分析, rryohei Kamei+, NLP24, 2024.03 #NLP#LanguageModel#RAG(RetrievalAugmentedGeneration)#ICLR
Issue Date: 2023-10-29 Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai+, N_A, ICLR24 Summary大規模言語モデル(LLMs)は、事実に基づかない回答を生成することがあります。そこで、自己反省的な検索増強生成(Self-RAG)という新しいフレームワークを提案します。このフレームワークは、検索と自己反省を通じてLLMの品質と事実性を向上させます。実験結果は、Self-RAGが最先端のLLMsおよび検索増強モデルを大幅に上回ることを示しています。 CommentRAGをする際の言語モデルの回答の質とfactual consistencyを改善せるためのフレームワーク。reflection tokenと呼ばれる特殊トークンを導入し、言語モデルが生成の過程で必要に応じて情報をretrieveし、自身で生成内容を批評するように学習する。単語ごとに生成するのではO ...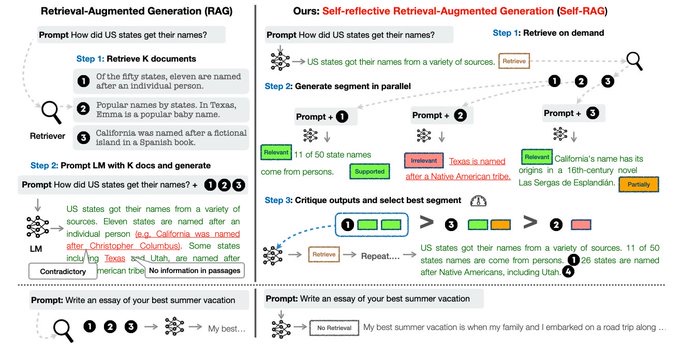
Issue Date: 2025-05-20 Scaling Reasoning can Improve Factuality in Large Language Models, Mike Zhang+, arXiv25 Comment元ポスト:https://x.com/_akhaliq/status/1924477447120068895?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #NLP#Dataset#Conversation
Issue Date: 2024-12-05 事実正誤判定が不要な生成応答の検出に向けた データセットの収集と分析, rryohei Kamei+, NLP24, 2024.03 #NLP#LanguageModel#RAG(RetrievalAugmentedGeneration)#ICLR
Issue Date: 2023-10-29 Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai+, N_A, ICLR24 Summary大規模言語モデル(LLMs)は、事実に基づかない回答を生成することがあります。そこで、自己反省的な検索増強生成(Self-RAG)という新しいフレームワークを提案します。このフレームワークは、検索と自己反省を通じてLLMの品質と事実性を向上させます。実験結果は、Self-RAGが最先端のLLMsおよび検索増強モデルを大幅に上回ることを示しています。 CommentRAGをする際の言語モデルの回答の質とfactual consistencyを改善せるためのフレームワーク。reflection tokenと呼ばれる特殊トークンを導入し、言語モデルが生成の過程で必要に応じて情報をretrieveし、自身で生成内容を批評するように学習する。単語ごとに生成するのではO ...
#Pocket#NLP#LanguageModel#Supervised-FineTuning (SFT)
Issue Date: 2023-11-15 Fine-tuning Language Models for Factuality, Katherine Tian+, N_A, arXiv23 Summary本研究では、大規模な言語モデル(LLMs)を使用して、より事実に基づいた生成を実現するためのファインチューニングを行います。具体的には、外部の知識ベースや信頼スコアとの一貫性を測定し、選好最適化アルゴリズムを使用してモデルを調整します。実験結果では、事実エラー率の削減が観察されました。 #Pocket#NLP#LanguageModel#Evaluation#RAG(RetrievalAugmentedGeneration)
Issue Date: 2023-11-05 The Perils & Promises of Fact-checking with Large Language Models, Dorian Quelle+, N_A, arXiv23 Summary自律型の事実チェックにおいて、大規模言語モデル(LLMs)を使用することが重要である。LLMsは真実と虚偽を見分ける役割を果たし、その出力を検証する能力がある。本研究では、LLMエージェントを使用して事実チェックを行い、推論を説明し、関連する情報源を引用する能力を評価した。結果は、文脈情報を備えたLLMsの能力の向上を示しているが、正確性には一貫性がないことに注意が必要である。今後の研究では、成功と失敗の要因をより深く理解する必要がある。 Commentgpt3とgpt4でFactCheckして傾向を分析しました、という研究。promptにstatementとgoogleで補完したcontextを含め、出力フォーマットを指定することでFactCheckする。promptingする際の言語や、statementの事実性の度合い(半分true, 全て斜 ...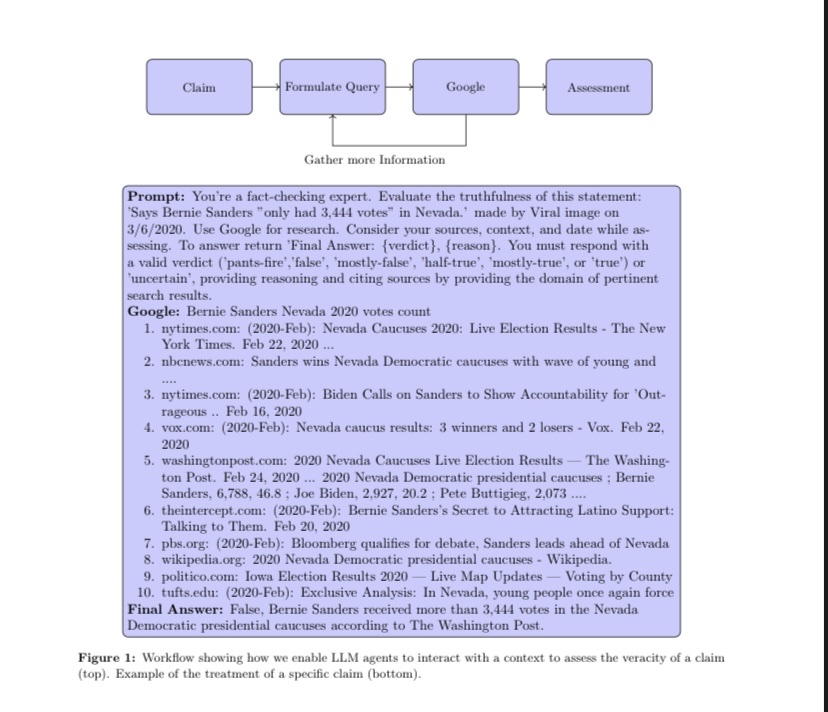 #Survey#NLP#LanguageModel
#Survey#NLP#LanguageModel
Issue Date: 2023-10-13 Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity, Cunxiang Wang+, N_A, arXiv23 Summaryこの研究では、大規模言語モデル(LLMs)の事実性の問題に取り組んでいます。LLMsの出力の信頼性と正確性は重要であり、事実に矛盾した情報を生成することがあるため、その問題を解決する方法を探求しています。具体的には、LLMsの事実的なエラーの影響や原因を分析し、事実性を評価する手法や改善策を提案しています。また、スタンドアロンのLLMsと外部データを利用する検索拡張型LLMsに焦点を当て、それぞれの課題と改善策について詳しく説明しています。この研究は、LLMsの事実的な信頼性を向上させるためのガイドとなることを目指しています。 Comment ...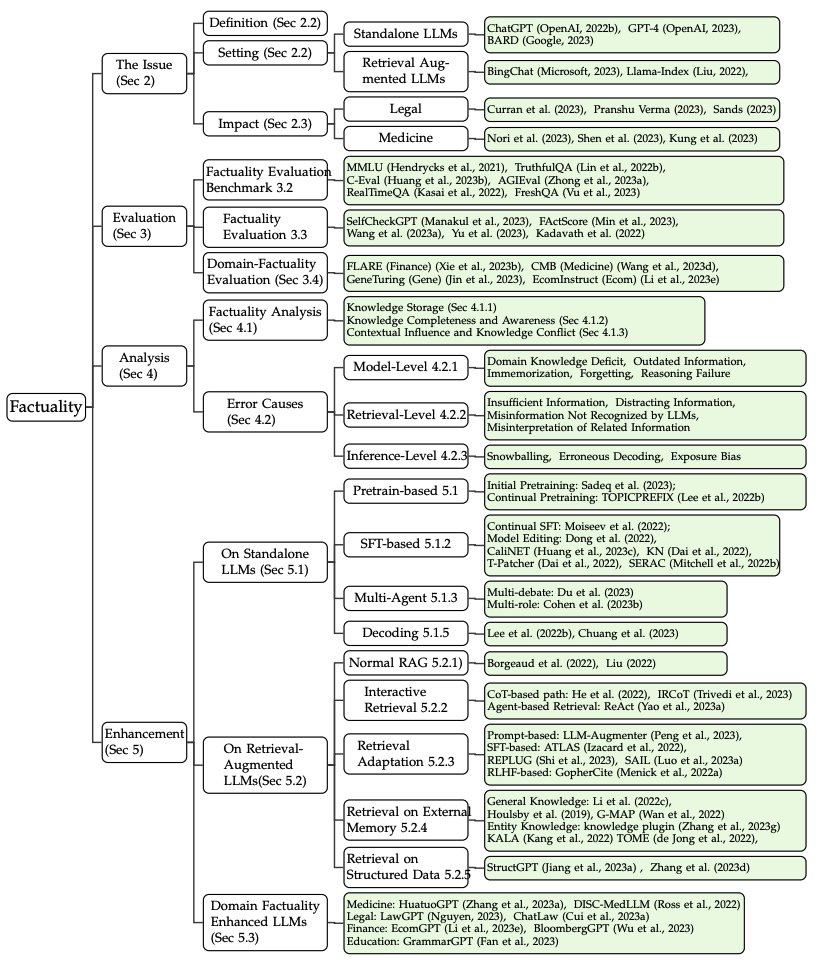 #Pocket#NLP#LanguageModel#Hallucination
#Pocket#NLP#LanguageModel#Hallucination
Issue Date: 2023-09-13 DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models, Yung-Sung Chuang+, N_A, arXiv23 Summary我々は、事前学習済みの大規模言語モデル(LLMs)における幻覚を軽減するためのシンプルなデコーディング戦略を提案する。このアプローチは、ロジットの差異を対比することで次のトークンの分布を得るもので、事実知識をより明確に示し、誤った事実の生成を減らすことができる。このアプローチは、複数の選択課題やオープンエンドの生成課題において真実性を向上させることができることが示されている。 Comment【以下、WIP状態の論文を読んでいるため今後内容が変化する可能性あり】 # 概要 Transformer Layerにおいて、factual informationが特定のレイヤーに局所化するという現象を観測しており、それを活用しよりFactual Consistencyのある生成をします、とい ...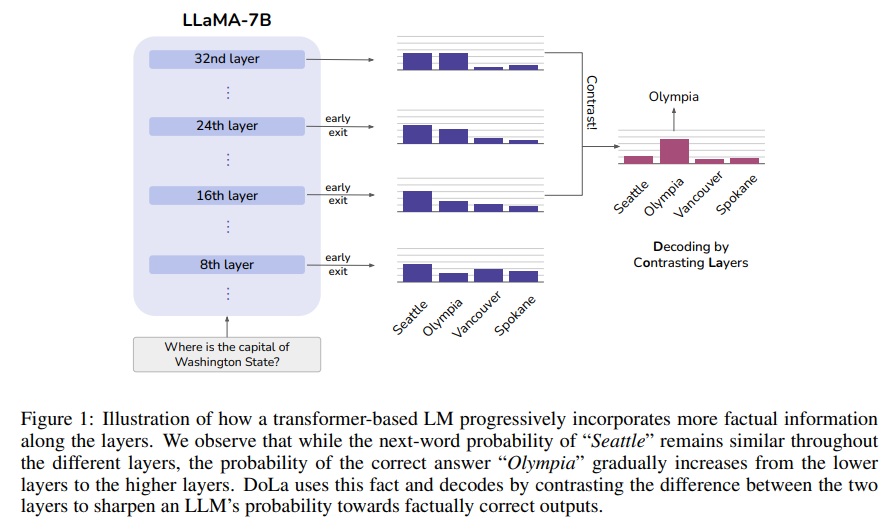 #DocumentSummarization#Pocket#NLP#Evaluation
#DocumentSummarization#Pocket#NLP#Evaluation
Issue Date: 2023-08-13 ChatGPT as a Factual Inconsistency Evaluator for Text Summarization, Zheheng Luo+, N_A, arXiv23 Summary事前学習された言語モデルによるテキスト要約の性能向上が注目されているが、生成された要約が元の文書と矛盾することが問題となっている。この問題を解決するために、効果的な事実性評価メトリクスの開発が進められているが、計算複雑性や不確実性の制約があり、人間の判断との一致に限定されている。最近の研究では、大規模言語モデル(LLMs)がテキスト生成と言語理解の両方で優れた性能を示していることがわかっている。本研究では、ChatGPTの事実的な矛盾評価能力を評価し、バイナリエンテイルメント推論、要約ランキング、一貫性評価などのタスクで優れた性能を示した。ただし、ChatGPTには語彙的な類似性の傾向や誤った推論、指示の不適切な理解などの制限があることがわかった。 #NaturalLanguageGeneration#Pocket#NLP
Issue Date: 2023-07-18 WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning, ACL23 Summary現在のテキスト生成モデルは、入力と矛盾するテキストを制御できないという課題があります。この問題を解決するために、私たちはWeCheckという弱教師付きフレームワークを提案します。WeCheckは、弱教師付きラベルを持つ言語モデルから直接訓練された実際の生成サンプルを使用します。さまざまなタスクでの実験結果は、WeCheckの強力なパフォーマンスを示し、従来の評価方法よりも高速で精度と効率を向上させています。 #DocumentSummarization#NaturalLanguageGeneration#NLP#Abstractive
Issue Date: 2023-07-18 Improving Factuality of Abstractive Summarization without Sacrificing Summary Quality, ACL23 Summary事実性を意識した要約の品質向上に関する研究はあるが、品質を犠牲にすることなく事実性を向上させる手法がほとんどない。本研究では「Effective Factual Summarization」という技術を提案し、事実性と類似性の指標の両方で大幅な改善を示すことを示した。トレーニング中に競合を防ぐために2つの指標を組み合わせるランキング戦略を提案し、XSUMのFactCCでは最大6ポイント、CNN/DMでは11ポイントの改善が見られた。また、類似性や要約の抽象性には負の影響を与えない。 #DocumentSummarization#NaturalLanguageGeneration#Controllable#NLP#Dataset
Issue Date: 2023-07-15 On Improving Summarization Factual Consistency from Natural Language Feedback, ACL23 Summary本研究では、自然言語の情報フィードバックを活用して要約の品質とユーザーの好みを向上させる方法を調査しました。DeFactoという高品質なデータセットを使用して、要約の編集や修正に関する自然言語生成タスクを研究しました。また、微調整された言語モデルを使用して要約の品質を向上させることも示しました。しかし、大規模な言語モデルは制御可能なテキスト生成には向いていないことがわかりました。 #InformationRetrieval#NLP#LanguageModel#KnowledgeGraph#NaturalLanguageUnderstanding
Issue Date: 2023-07-14 Direct Fact Retrieval from Knowledge Graphs without Entity Linking, ACL23 Summary従来の知識取得メカニズムの制限を克服するために、我々はシンプルな知識取得フレームワークであるDiFaRを提案する。このフレームワークは、入力テキストに基づいて直接KGから事実を取得するものであり、言語モデルとリランカーを使用して事実のランクを改善する。DiFaRは複数の事実取得タスクでベースラインよりも優れた性能を示した。 #DocumentSummarization#NLP#Evaluation#LM-based
Issue Date: 2023-08-13 SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization, Laban+, TACL22 Summary要約の領域では、入力ドキュメントと要約が整合していることが重要です。以前の研究では、自然言語推論(NLI)モデルを不整合検出に適用するとパフォーマンスが低下することがわかりました。本研究では、NLIを不整合検出に再評価し、過去の研究での入力の粒度の不一致が問題であることを発見しました。新しい手法SummaCConvを提案し、NLIモデルを文単位にドキュメントを分割してスコアを集計することで、不整合検出に成功裏に使用できることを示しました。さらに、新しいベンチマークSummaCを導入し、74.4%の正確さを達成し、先行研究と比較して5%の改善を実現しました。 #DocumentSummarization#Metrics#NLP#Evaluation
Issue Date: 2023-08-13 TRUE: Re-evaluating Factual Consistency Evaluation, Or Honovich+, N_A, the Second DialDoc Workshop on Document-grounded Dialogue and Conversational Question Answering22 Summary事実の整合性メトリックの包括的な調査と評価であるTRUEを紹介。さまざまな最先端のメトリックと11のデータセットを対象に行った結果、大規模なNLIおよび質問生成・回答ベースのアプローチが強力で補完的な結果を達成することがわかった。TRUEをモデルおよびメトリックの開発者の出発点として推奨し、さらなる評価方法の向上に向けた進歩を期待している。 CommentFactualConsistencyに関するMetricが良くまとまっている ... #NaturalLanguageGeneration#Metrics#NLP#DialogueGeneration#Evaluation#Reference-free#QA-based
Issue Date: 2023-08-13 Q2: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering, Honovich+, EMNLP21 Summary本研究では、ニューラルな知識に基づく対話生成モデルの信頼性と適用範囲の制限についての問題を解決するため、自動的な質問生成と質問応答を使用した事実的な整合性の自動評価尺度を提案します。この尺度は、自然言語推論を使用して回答スパンを比較することで、以前のトークンベースのマッチングよりも優れた評価を行います。また、新しいデータセットを作成し、事実的な整合性の手動アノテーションを行い、他の尺度とのメタ評価を行いました。結果として、提案手法が人間の判断と高い相関を示しました。 Comment(knowledge-grounded; 知識に基づいた)対話に対するFactual ConsistencyをReference-freeで評価できるQGQA手法。機械翻訳やAbstractive Summarizationの分野で研究が進んできたが、対話では 対話履歴、個人の意見、ユーザに対 ... #DocumentSummarization#Metrics#NLP#Evaluation#LM-based
#DocumentSummarization#Metrics#NLP#Evaluation#LM-based
Issue Date: 2023-08-13 Compression, Transduction, and Creation: A Unified Framework for Evaluating Natural Language Generation, Deng+, EMNLP21 Summary本研究では、自然言語生成(NLG)タスクの評価において、情報の整合性を重視した統一的な視点を提案する。情報の整合性を評価するための解釈可能な評価指標のファミリーを開発し、ゴールドリファレンスデータを必要とせずに、さまざまなNLGタスクの評価を行うことができることを実験で示した。 CommentCTC ... #DocumentSummarization#Metrics#NLP#Evaluation#LM-based
Issue Date: 2023-08-13 Evaluating the Factual Consistency of Abstractive Text Summarization, Kryscinski+, EMNLP20 Summary本研究では、要約の事実的な整合性を検証するためのモデルベースのアプローチを提案しています。トレーニングデータはルールベースの変換を用いて生成され、モデルは整合性の予測とスパン抽出のタスクで共同してトレーニングされます。このモデルは、ニューラルモデルによる要約に対して転移学習を行うことで、以前のモデルを上回る性能を示しました。さらに、人間の評価でも補助的なスパン抽出タスクが有用であることが示されています。データセットやコード、トレーニング済みモデルはGitHubで公開されています。 CommentFactCC近年のニューラルモデルは流ちょうな要約を生成するが、それらには、unsuportedなinformationが多く含まれていることを示した ...
Issue Date: 2023-11-15 Fine-tuning Language Models for Factuality, Katherine Tian+, N_A, arXiv23 Summary本研究では、大規模な言語モデル(LLMs)を使用して、より事実に基づいた生成を実現するためのファインチューニングを行います。具体的には、外部の知識ベースや信頼スコアとの一貫性を測定し、選好最適化アルゴリズムを使用してモデルを調整します。実験結果では、事実エラー率の削減が観察されました。 #Pocket#NLP#LanguageModel#Evaluation#RAG(RetrievalAugmentedGeneration)
Issue Date: 2023-11-05 The Perils & Promises of Fact-checking with Large Language Models, Dorian Quelle+, N_A, arXiv23 Summary自律型の事実チェックにおいて、大規模言語モデル(LLMs)を使用することが重要である。LLMsは真実と虚偽を見分ける役割を果たし、その出力を検証する能力がある。本研究では、LLMエージェントを使用して事実チェックを行い、推論を説明し、関連する情報源を引用する能力を評価した。結果は、文脈情報を備えたLLMsの能力の向上を示しているが、正確性には一貫性がないことに注意が必要である。今後の研究では、成功と失敗の要因をより深く理解する必要がある。 Commentgpt3とgpt4でFactCheckして傾向を分析しました、という研究。promptにstatementとgoogleで補完したcontextを含め、出力フォーマットを指定することでFactCheckする。promptingする際の言語や、statementの事実性の度合い(半分true, 全て斜 ...
Issue Date: 2023-10-13 Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity, Cunxiang Wang+, N_A, arXiv23 Summaryこの研究では、大規模言語モデル(LLMs)の事実性の問題に取り組んでいます。LLMsの出力の信頼性と正確性は重要であり、事実に矛盾した情報を生成することがあるため、その問題を解決する方法を探求しています。具体的には、LLMsの事実的なエラーの影響や原因を分析し、事実性を評価する手法や改善策を提案しています。また、スタンドアロンのLLMsと外部データを利用する検索拡張型LLMsに焦点を当て、それぞれの課題と改善策について詳しく説明しています。この研究は、LLMsの事実的な信頼性を向上させるためのガイドとなることを目指しています。 Comment ...
Issue Date: 2023-09-13 DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models, Yung-Sung Chuang+, N_A, arXiv23 Summary我々は、事前学習済みの大規模言語モデル(LLMs)における幻覚を軽減するためのシンプルなデコーディング戦略を提案する。このアプローチは、ロジットの差異を対比することで次のトークンの分布を得るもので、事実知識をより明確に示し、誤った事実の生成を減らすことができる。このアプローチは、複数の選択課題やオープンエンドの生成課題において真実性を向上させることができることが示されている。 Comment【以下、WIP状態の論文を読んでいるため今後内容が変化する可能性あり】 # 概要 Transformer Layerにおいて、factual informationが特定のレイヤーに局所化するという現象を観測しており、それを活用しよりFactual Consistencyのある生成をします、とい ...
Issue Date: 2023-08-13 ChatGPT as a Factual Inconsistency Evaluator for Text Summarization, Zheheng Luo+, N_A, arXiv23 Summary事前学習された言語モデルによるテキスト要約の性能向上が注目されているが、生成された要約が元の文書と矛盾することが問題となっている。この問題を解決するために、効果的な事実性評価メトリクスの開発が進められているが、計算複雑性や不確実性の制約があり、人間の判断との一致に限定されている。最近の研究では、大規模言語モデル(LLMs)がテキスト生成と言語理解の両方で優れた性能を示していることがわかっている。本研究では、ChatGPTの事実的な矛盾評価能力を評価し、バイナリエンテイルメント推論、要約ランキング、一貫性評価などのタスクで優れた性能を示した。ただし、ChatGPTには語彙的な類似性の傾向や誤った推論、指示の不適切な理解などの制限があることがわかった。 #NaturalLanguageGeneration#Pocket#NLP
Issue Date: 2023-07-18 WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning, ACL23 Summary現在のテキスト生成モデルは、入力と矛盾するテキストを制御できないという課題があります。この問題を解決するために、私たちはWeCheckという弱教師付きフレームワークを提案します。WeCheckは、弱教師付きラベルを持つ言語モデルから直接訓練された実際の生成サンプルを使用します。さまざまなタスクでの実験結果は、WeCheckの強力なパフォーマンスを示し、従来の評価方法よりも高速で精度と効率を向上させています。 #DocumentSummarization#NaturalLanguageGeneration#NLP#Abstractive
Issue Date: 2023-07-18 Improving Factuality of Abstractive Summarization without Sacrificing Summary Quality, ACL23 Summary事実性を意識した要約の品質向上に関する研究はあるが、品質を犠牲にすることなく事実性を向上させる手法がほとんどない。本研究では「Effective Factual Summarization」という技術を提案し、事実性と類似性の指標の両方で大幅な改善を示すことを示した。トレーニング中に競合を防ぐために2つの指標を組み合わせるランキング戦略を提案し、XSUMのFactCCでは最大6ポイント、CNN/DMでは11ポイントの改善が見られた。また、類似性や要約の抽象性には負の影響を与えない。 #DocumentSummarization#NaturalLanguageGeneration#Controllable#NLP#Dataset
Issue Date: 2023-07-15 On Improving Summarization Factual Consistency from Natural Language Feedback, ACL23 Summary本研究では、自然言語の情報フィードバックを活用して要約の品質とユーザーの好みを向上させる方法を調査しました。DeFactoという高品質なデータセットを使用して、要約の編集や修正に関する自然言語生成タスクを研究しました。また、微調整された言語モデルを使用して要約の品質を向上させることも示しました。しかし、大規模な言語モデルは制御可能なテキスト生成には向いていないことがわかりました。 #InformationRetrieval#NLP#LanguageModel#KnowledgeGraph#NaturalLanguageUnderstanding
Issue Date: 2023-07-14 Direct Fact Retrieval from Knowledge Graphs without Entity Linking, ACL23 Summary従来の知識取得メカニズムの制限を克服するために、我々はシンプルな知識取得フレームワークであるDiFaRを提案する。このフレームワークは、入力テキストに基づいて直接KGから事実を取得するものであり、言語モデルとリランカーを使用して事実のランクを改善する。DiFaRは複数の事実取得タスクでベースラインよりも優れた性能を示した。 #DocumentSummarization#NLP#Evaluation#LM-based
Issue Date: 2023-08-13 SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization, Laban+, TACL22 Summary要約の領域では、入力ドキュメントと要約が整合していることが重要です。以前の研究では、自然言語推論(NLI)モデルを不整合検出に適用するとパフォーマンスが低下することがわかりました。本研究では、NLIを不整合検出に再評価し、過去の研究での入力の粒度の不一致が問題であることを発見しました。新しい手法SummaCConvを提案し、NLIモデルを文単位にドキュメントを分割してスコアを集計することで、不整合検出に成功裏に使用できることを示しました。さらに、新しいベンチマークSummaCを導入し、74.4%の正確さを達成し、先行研究と比較して5%の改善を実現しました。 #DocumentSummarization#Metrics#NLP#Evaluation
Issue Date: 2023-08-13 TRUE: Re-evaluating Factual Consistency Evaluation, Or Honovich+, N_A, the Second DialDoc Workshop on Document-grounded Dialogue and Conversational Question Answering22 Summary事実の整合性メトリックの包括的な調査と評価であるTRUEを紹介。さまざまな最先端のメトリックと11のデータセットを対象に行った結果、大規模なNLIおよび質問生成・回答ベースのアプローチが強力で補完的な結果を達成することがわかった。TRUEをモデルおよびメトリックの開発者の出発点として推奨し、さらなる評価方法の向上に向けた進歩を期待している。 CommentFactualConsistencyに関するMetricが良くまとまっている ... #NaturalLanguageGeneration#Metrics#NLP#DialogueGeneration#Evaluation#Reference-free#QA-based
Issue Date: 2023-08-13 Q2: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering, Honovich+, EMNLP21 Summary本研究では、ニューラルな知識に基づく対話生成モデルの信頼性と適用範囲の制限についての問題を解決するため、自動的な質問生成と質問応答を使用した事実的な整合性の自動評価尺度を提案します。この尺度は、自然言語推論を使用して回答スパンを比較することで、以前のトークンベースのマッチングよりも優れた評価を行います。また、新しいデータセットを作成し、事実的な整合性の手動アノテーションを行い、他の尺度とのメタ評価を行いました。結果として、提案手法が人間の判断と高い相関を示しました。 Comment(knowledge-grounded; 知識に基づいた)対話に対するFactual ConsistencyをReference-freeで評価できるQGQA手法。機械翻訳やAbstractive Summarizationの分野で研究が進んできたが、対話では 対話履歴、個人の意見、ユーザに対 ...
Issue Date: 2023-08-13 Compression, Transduction, and Creation: A Unified Framework for Evaluating Natural Language Generation, Deng+, EMNLP21 Summary本研究では、自然言語生成(NLG)タスクの評価において、情報の整合性を重視した統一的な視点を提案する。情報の整合性を評価するための解釈可能な評価指標のファミリーを開発し、ゴールドリファレンスデータを必要とせずに、さまざまなNLGタスクの評価を行うことができることを実験で示した。 CommentCTC ... #DocumentSummarization#Metrics#NLP#Evaluation#LM-based
Issue Date: 2023-08-13 Evaluating the Factual Consistency of Abstractive Text Summarization, Kryscinski+, EMNLP20 Summary本研究では、要約の事実的な整合性を検証するためのモデルベースのアプローチを提案しています。トレーニングデータはルールベースの変換を用いて生成され、モデルは整合性の予測とスパン抽出のタスクで共同してトレーニングされます。このモデルは、ニューラルモデルによる要約に対して転移学習を行うことで、以前のモデルを上回る性能を示しました。さらに、人間の評価でも補助的なスパン抽出タスクが有用であることが示されています。データセットやコード、トレーニング済みモデルはGitHubで公開されています。 CommentFactCC近年のニューラルモデルは流ちょうな要約を生成するが、それらには、unsuportedなinformationが多く含まれていることを示した ...