
Dataset
[Paper Note] Who Checks the Citations? Benchmarking Legal Hallucination Detection, Patty Liu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Citations #NLP #LanguageModel #Evaluation #COLM #Legal Issue Date: 2026-07-19 GPT Summary- AIを用いて法的文書を作成する弁護士や裁判官が増加する中、捏造された引用が依然として多発している。本研究は、AIシステムが法的引用の幻覚を自動検出できるかを評価し、1,300件の抜粋データセットを用いて分類法を提案した。5モデルをベンチマークした結果、最新モデルはより高い性能を示すが、微妙な誤りカテゴリには苦戦することが明らかになった。エージェント系の検証は資源を消費し、情報アクセスの制限が効果を妨げる問題も指摘。これにより、商用法データベースに依存しない当事者にとっての不利益が生じる。研究では、信頼性の高い法的引用照合ツール構築のための基盤も提案している。 Comment
元ポスト:
[Paper Note] Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?, Yue Zhang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #VisionLanguageModel #SpatialUnderstanding Issue Date: 2026-06-05 GPT Summary- 空間推論は視覚-言語モデル(VLM)の基本能力だが、既存の評価は視覚的観察の制限を無視している。本研究では、遮蔽と視点の曖昧性という2つの観察課題を導入し、空間的質問を設計してモデルの応答を評価。結果は、視覚的証拠が不完全な場合でも過信的応答が誘発され、遮蔽下での精度は約30%、視点の曖昧性では10%未満にとどまることを示した。また、信頼できる追加視点を識別する能力は多くのモデルでほぼランダムである。これにより、モデルが正確な回答だけでなく、適切に回答を控える能力や信頼できる証拠を求める必要性が示唆された。 Comment
元ポスト:
[Paper Note] Automated Benchmark Auditing for AI Agents and Large Language Models, Junlin Wang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #Initial Impression Notes #Environment #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- 現代のAIベンチマークでは、複雑なタスクが多く含まれ、人間の注釈では検知が難しい問題が存在します。これを解決するために、Auto Benchmark Audit(ABA)を導入し、168のベンチマークを調査。ABAは、あいまいなタスク設計や実行環境の衝突など、25.7%以上のタスクで重大な問題を特定。問題のあるタスクがモデル評価を歪めることを示し、除外することでパフォーマンスが9.9%及び9.6%向上することを確認。今後のベンチマーク発展のため、これらのツールとタスク注釈を公開します。 Comment
元ポスト:
既存のベンチマークを
- 指示の曖昧性
- 環境に内包される問題(競合や依存関係の問題)
- 評価の品質
の観点から監査するAudit Agentの提案
[Paper Note] ResearchMath-14K: Scaling Research-Level Mathematics via Agents, Guijin Son+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Mathematics #ScientificDiscovery Issue Date: 2026-05-31 GPT Summary- ResearchMath-14kは、未解決の数学問題に取り組むために、学術的な情報源から厳選された14,056問を集めたデータセットであり、研究レベルの数学問題の最大コレクションを提供する。さらに、22万件の教師データ経路から生成されたResearchMath-Reasoningは、言語モデルが未挑戦の問題に対して反復的な回避行動を示すことを観察した。フィルタリング後にQwen3モデルをファインチューニングすることで、平均9.2ポイントの性能向上が確認された。このデータセットは、研究レベルの数学的推論における今後の研究に貢献することを目的としている。 Comment
元ポスト:
[Paper Note] SEAL: Can Saturated Benchmarks Be Revived by LLM-as-a-Meta-Judge?, Jiamin Chen+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#PairWise #NLP #LanguageModel #Evaluation #KeyPoint Notes Issue Date: 2026-05-31 GPT Summary- 既存の言語モデルベンチマークが飽和する中、SEAL(Seeded Elimination with Adaptive LLM-as-a-Meta-Judge)は、潜在的なランキング信号を抽出する自己改善型評価プロトコルを提案。候補出力をシングルエリミネーション方式で評価し、精度とレイテンシのトレードオフを改善する。複数の飽和ベンチマークにおいて、SEALは全対比較に匹敵する精度を保ちながら、エフォートを大幅に削減した。 Comment
元ポスト:
既に飽和したベンチマークを活用してモデルの評価のためのシグナルを抽出できないか?という気持ちの研究のようで、そもそも飽和したベンチマークはpointwiseな評価によって飽和しており、全てのモデル/promptに対してpair-wiseな評価をしてリストワイズな評価をしてランキング付けをすることで、より高い解像度での評価シグナルが得られるよね、という話からスタートしているように見える。しかしpairwiseな評価は非常にコストがかかるので、自己進化するRubric-basedなLLM-as-a-Judgeとトーナメント方式を採用することで、全件探索したpairwiseによるランキングを、低コストで高い相関係数を以て(0.83--1.0)で再現できるよ、という話に見える。
pointwiseな評価と比較してFullPair/SEALでの評価は評価結果の序列が変化している。ただし、このFullPairでの評価がどの程度正しいものなのかはよくわからない。
[Paper Note] AttuneBench: A Conversation-Based Benchmark for LLM Emotional Intelligence, Kate M. Lubrano+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Evaluation #Conversation #read-later #Emotion #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- 感情知性(EI)の評価が重要になる中、AttuneBenchを紹介。実際の複数ターンの人間-モデル対話200件に基づき、感情状態とモデルの挙動をターンごとに注釈。11モデルの評価結果は感情認識や応答品質に関する能力が分離可能であることを示し、嗜好の整合と応答品質の判断がモデル識別に強く寄与することを明らかに。AttuneBenchは、感情的に重要な会話の評価枠組みを提供し、モデルの強みや弱点を診断する。 Comment
元ポスト:
leaderboard: https://public.attunebench.com/
対話をしている本人によるプロンプト、アノテーション、マルチターンの会話を前提にモデルのEQを測定するためのベンチマークのようである(従来は合成プロンプト、シングルターン、third-partyに基づいたアノテーション(つまり対話している本人ではない、ということだと思われる)によるベンチマークだったとのこと)。
[Paper Note] SpatialBench: Is Your Spatial Foundation Model an All-Round Player?, Haosong Peng+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#ComputerVision #Evaluation #OOD #Generalization #SpatialUnderstanding #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 空間基盤モデルの真の一般化能力を評価するために、決定論的サンプリングを用いた新しいベンチマークSpatialBenchを提案。これにより、19データセットと546シーンを通じて5つの空間ドメインで41モデルを評価。結果は現行モデルが「万能プレーヤー」には至っていないことを明らかにし、精度向上には全文脈アテンションが有効で、有限メモリ戦略がスケーラビリティを改善することを示した。身体性を伴うタスクでは、高品質データが性能向上に重要であることも明らかになった。さらに、評価を超えてDA-Next-5MデータセットとDA-Nextモデルを導入し、空間表現学習の可能性を広げる。 Comment
pj page: https://ropedia.github.io/SpatialBench/
元ポスト:
[Paper Note] $π$-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows, Haoran Zhang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Conversation #Selected Papers/Blogs #Ambiguity #reading #One-Line Notes #LongHorizon #Proactive Issue Date: 2026-05-27 GPT Summary- パーソナルアシスタントエージェントは、OpenClawのような大規模言語モデルの潜在能力を示しており、特に隠れたユーザー意図の特定に課題がある。本研究では、100のマルチターンタスクからなる積極的支援のベンチマークであるπ-Benchを導入し、長期的な対話におけるユーザーのニーズ予測能力を評価。実験により、積極的支援の難しさ、タスク完遂と積極性の違い、事前対話の重要性が示された。 Comment
元ポスト:
ユーザがOpenClawのようなPersonal Assistantを用いて、マルチターンでのconversationを通じて、ある1つのタスクを遂行したいという状況を想定する。このタスクの開始時には、ユーザは一般的には自然で妥当なクエリを投げるが、最初から全てのrequirementを満たしたクエリは投げず、会話をしながら徐々にrequirementを具体化していくような変遷を辿る。このような、タスク開始時に、タスクを開始する上では自然で妥当だが、タスクを完遂するにはrequirementの情報が足りないという状況において、AI Agentが会話を通じて、ユーザが暗黙的に意図している仕様(hidden intents)を考慮して(=ユーザが明示的にinstructionとしてrequirementを与える前に)タスクを完遂できるか、という能力を測定する。
1つのタスクを完遂するために20個のsessionの会話によって構成されており、hidden intentsはsessionの中で閉じている、あるいはsessionを跨いで維持されるようなものとなっており、これらの情報をエージェントは過去のsessionの情報(メモリ)から推測するか、あるいは明示的にhidden intentsについて質問をするようなProactiveな挙動によって収集した上でタスクを遂行しなければならない。このとき、Userの役割を果たすエージェントは、GPT-5.4によって再現される。
[Paper Note] Medmarks: A Comprehensive Open-Source LLM Benchmark Suite for Medical Tasks, Benjamin Warner+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Medical #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 医療分野でのLLMs評価は、ベンチマークの飽和やデータ制限のため困難である。30のベンチマークを含むオープンソース評価スイートMedmarksを導入し、61モデルを71設定で評価。その結果、最先端のモデルが最高性能を示し、ファインチューニングされたモデルが汎用モデルを上回ることが確認された。評価は医療推論のLLMsのポストトレーニング環境としても利用可能。 Comment
元ポスト:
[Paper Note] MultiBanana: A Challenging Benchmark for Multi-Reference Text-to-Image Generation, Yuta Oshima+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Evaluation #TextToImageGeneration #LLM-as-a-Judge #CVPR #2D (Image) #ImageSynthesis Issue Date: 2026-05-26 GPT Summary- マルチ参照生成モデルは複数の参照画像から新たな文脈で被写体を描画するが、既存のデータセットは単一もしくは少数の参照に偏っているため性能評価に限界がある。本研究では、マルチ参照設定に特化したMultiBananaを提案し、参照数やドメイン不一致、スケール不一致、まれな概念、多言語テキストに関する問題を網羅してモデルの限界を評価する。分析により性能と改善点を明らかにし、公正な比較のための標準化された基盤を提供する。 Comment
元ポスト:
[Paper Note] Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs, Guijin Son+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Mathematics #read-later #Selected Papers/Blogs #One-Line Notes #Reading Reflections #Author Thread-Post Issue Date: 2026-05-14 GPT Summary- Soohakという新たな数学ベンチマークを導入し、439問から成り、フロンティアモデルの推論能力を評価。Challengeサブセットでは、トップモデルが30.4%未満の成功率である一方、拒否サブセットはモデルが50%を超えられない問題解決能力を確認。これにより、拒否能力が新たな評価基準として浮上し、2026年末に公開予定のデータセットで混入を防ぐ。 Comment
元ポスト:
60人以上の数学者によってゼロペースで作成された新たなベンチマーク。数学者は作問をする際にLLMの利用は禁止され、問題を作成しsubmitする。その後レビュープロセスを経て問題が収録されるかが決まっているようである。レビュープロセスでは、LLMによる難易度の確認や類似した問題がないかなどの確認をし、人間がLLMの出力を見て疑わしいか否か判断する。レビュワーは作成者にフィードバックをし、質問や確認などを行う。また、LLMを利用したであろう作成者はbanされ、問題に調整が必要な場合は修正がなされる。提出された問題は、小、中、大のスケールのOpenLLMによって正解できたか否かによって、miniとして収録されるかChallengeとして収録されるかが決まり、特にChallengeについては作成者が特定の教員やポスドク、IMOメダリストなどに限定されたようである。
99個の、矛盾や前提の抜け、正解が一意に決まらないill-posedな問題も含まれており、モデルが回答を拒否しなければならないRefusal Questionsが含まれているのが大きな特徴。
研究レベルの問題の定義がよくわかっていないのだが、要は競技で出題されるような「既存の知識や枠組みの中でのマルチステップでの推論」を必要とするものではなく、「数学に関する最先端を切り拓くレベルの問題」のことのようである。これでもまだよくわからなかったのだが、問題の作成者に対するインタビューによると、SOOHAK-Miniの問題は短時間で作成できたが、SOOHAK Challengeの問題は1問作成するのに1日以上の作業を要することがしばしばあったとのこと。Challengeレベルの問題を作成するためのアプローチとしては典型的に2つあったとのことで、
- 問題作成者自身が最近考えていた研究と隣接した問題を提出するもので、問題を解くステップにおいて既存の定理や、論文などで公式には発表されていない事実や、数学者の中でヒューリスティクスを組み合わせる必要があるような要素を含むもの(folklore-level reasoningと呼ばれる)
- ニッチな研究論文に基づいて問題を設計する方法
などがあったようである。つまり、競技という枠組みは超えて、数学の研究者が研究として考えるレベルの問題ということだと理解した。
コーディングにおいて人間を置き換えるレベルであろうモデルも、未知の数学の問題や、そもそも問題として不適切なものの回答拒否は広く使われたベンチマークほどはうまくいかない。新たに拒否が最適化のobjectiveとして必要なことが示唆されているが、逐一人類はAIにこの挙動が足りないね、じゃあ学習データを用意して学習しよう、ということを繰り返していくのだろうか?正解ベースの学習にそろそろ限界が見えてきた気がしており、AnthropicのペルソナやConstitutionに基づいた学習のような特定の領域に広く汎化するような学習方法の模索が必要な気がする。
拒否する挙動のための正解データを用意して学習するとしよう。そうすると、モデルが持つ他の能力に影響を与えるだけでなく、本来拒否が不要な場面でも拒否するようになる可能性が高い(たとえばクエリが数学に関連しているだけで、一定の確率で拒否するリスクは生じるように思われる)。この問題を解決するために最近はOn-Policy Distilation (OPD)が活用されるが、OPDはこの問題を緩和することには寄与するが、根源的に解決しているわけではない(と思われる)。genericな能力の発現に際して、モデル自身がcontextに応じて、どの挙動を発現させるべきかを"線引き"できるような能力とアーキテクチャ(マルチモーダルなモデルのようにMoEのexpertをbehaviorに関しては分離するなどだろうか)が必要に思う。
[Paper Note] DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents, Zhaorun Chen+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Controllable #NLP #LanguageModel #AIAgents #Evaluation #Security #Initial Impression Notes #Environment #Author Thread-Post #RedTeaming Issue Date: 2026-05-12 GPT Summary- AIエージェントは複雑なワークフローを自動化する一方で、重要なセキュリティリスクを引き起こす。エージェントが操作されることで、APIキー漏えいや未承認の取引などが発生する可能性があり、そのセキュリティ評価は動的な環境下で困難である。これに対抗するため、DecodingTrust-Agent Platform(DTap)を導入し、14の現実世界ドメインを再現したインタラクティブなレッドチーミングプラットフォームを提供。また、初の自律的レッドチーミングエージェントDTap-Redを提案し、さまざまな攻撃戦略を自律的に探索する。これにより、DTap-Benchという大規模なレッドチーミングデータセットをキュレーションし、安全な次世代エージェント開発のための重要な洞察を提供する。 Comment
元ポスト:
Opus-4.6が本ベンチマーク上は最もセキュリティリスクに対して安全で、良性なタスクに対する性能を発揮するモデルに見える。
論文は279ページもある🤯
[Paper Note] Jagle: Building a Large-Scale Japanese Multimodal Post-Training Dataset for Vision-Language Models, Issa Sugiura+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #Japanese #PostTraining #read-later #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- 日本語のVQAシステムに対する高品質なデータセットJagleを紹介。約920万件のインスタンスを含み、異種ソースから生成したVQAペアを用いて多様なタスクをカバー。Jagleで学習した2.2Bモデルは、日本語タスクで高い性能を示し、既存のモデルを上回る結果を得た。さらに、JagleをFineVisionと統合することで英語でも性能向上が確認され、データセットとモデルを公開し再現性を促進。 Comment
pj page: https://speed1313.github.io/Jagle/
dataset: https://huggingface.co/datasets/llm-jp/Jagle
元ポスト:
データセットのサイズが9Mと非常に大規模で、日本語性能を大幅に改善するだけでなく、FineVisionのような英語のVQAデータセットとハイブリッドで用いることで英語タスクの性能も改善する。
[Paper Note] Auditing Sabotage Bench: A Benchmark for Detecting and Fixing Research Sabotage in ML Codebases, Eric Gan+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Safety #Sabotage Issue Date: 2026-05-10 GPT Summary- AIシステムによる自律研究の拡大に伴い、整合性のないシステムが誤った結果を生むリスクが高まっている。Auditing Sabotage Benchは、機械学習研究におけるサボタージュを監査する能力を評価するベンチマークであり、9つのコードベースからなる。各サボタージュは、実装の詳細を変更しながらも論文の方法論を維持している。最前線のLLMと人間監査者がサボタージュを適切に検出・修正するのが難しいことが判明し、最良性能はAUROC 0.77、修正率42%でGemini 3.1 Proによって達成された。LLMをレッドチームとして評価した結果、LLM生成のサボタージュは人間生成のものよりは劣ったが、時にはLLM監査者を回避することもあった。本ベンチマークはAI研究の監視と監査技術の向上を目指して公開されている。 Comment
元ポスト:
[Paper Note] MAS-Orchestra: Understanding and Improving Multi-Agent Reasoning Through Holistic Orchestration and Controlled Benchmarks, Zixuan Ke+, ICML'26, 2026.01
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #AIAgents #Evaluation #ICML #read-later #Selected Papers/Blogs #Initial Impression Notes #Orchestration #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- MASのオーケストレーションを強化学習形式で定式化するMASOrchestraを提案。これにより、エージェントの複雑性を管理し、システム全体のグローバルな推論を促進。タスクを5軸で分析するMASBENCHを導入し、利得がタスクや能力に依存することを示す。公開ベンチマークで一貫した改善を達成し、10倍以上の効率を実現。MASOrchestraとMASBENCHはマルチエージェント知性の向上を目指す。 Comment
元ポスト:
SASと比べてMASにすることでどれだけ利点があるかをモデルが理解せずにfoldingしてるよね、というのは重要な指摘に感じる。
[Paper Note] ProgramBench: Can Language Models Rebuild Programs From Scratch?, John Yang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering #Selected Papers/Blogs #KeyPoint Notes #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- ソフトウェアプロジェクトの完全な開発は、言語モデルの重要なユースケースで、エージェントは最小限の監視下でコードベースを成長させる。しかし、既存のベンチマークは限られたタスクに焦点を絞っている。そこで、ProgramBenchを導入し、エージェントが与えられたプログラムとそのドキュメントに基づいて、参照実行可能ファイルに一致するコードベースを設計・実装する能力を測定する。200のタスクを用い9つの言語モデルを評価した結果、どのモデルも未完のタスクが多く、人間が書いたコードとは異なる実装を好む傾向が見られた。 Comment
pj page: https://programbench.com/
元ポスト:
実行可能なバイナリとdocumentationを与えたときに、インターネットアクセスが不可能な環境で、オリジナルのプログラムの挙動を再現可能なcodebaseを実装するベンチマークで、現状いずれのLLMもスコア0%とのこと。スコアは全タスクのうち、(タスクごとに定義される)テストを全て通過したタスクの割合である。Almostの場合は95%以上のテストを通過したタスクの割合である。
仕様全体からcodebase全体を再現する必要がため、これがうまくできれば、これまでのベンチマークよりも人間に近い推論・認知能力を持つと部分的に主張できるとは思われる。
contaminationの懸念について、本ベンチマークではopen-sourceのコードを異なる言語で実装するようにすることで検証している。異なる言語で実装することによってモデルが通過するようになったテストの割合は大きく変化しなかったため(leaderboardのスコア異なる点に注意。leaderboardのresolvedは全てのテストを通過したタスクの割合である。)、memorizationの影響は小さいと主張している。また、本ベンチマークはインターネットアクセスが不可能な状態で実施されるが、インターネットアクセスを許可した場合、モデルはcheatingを実施するようになり、多くのcheatingはソースコードをlookupすることだったとのこと。
テストはbehavioralなものであり、SWE-Benchで行われているような実装の方法についてはテストをしない。
ProgramBenchの言語の分布と、各タスクのcodebaseの規模間。270M lineのcodebaseから200 line程度の小さなものまで、規模間が大きく異なることがわかる。言語はC/C++, Go, Rustが多く、多くのモデルが得意とするであろうpythonはほとんど含まれていない。
著者ポスト:
[Paper Note] Uni-MMMU: A Massive Multi-discipline Multimodal Unified Benchmark, Kai Zou+, ACL'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #ACL #VisionLanguageModel #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-08 GPT Summary- Uni-MMMUを提案し、視覚的理解と生成の統合を推進するための新しいベンチマークを構築。科学、プログラミング、数学、パズルなどの推論中心ドメインにおいて、生成と理解の相乗効果を評価。モデルは概念的理解を視覚合成に、生成を分析的推論に活用するタスクに挑む。再現可能な評価プロトコルを導入し、モデル間の性能差と依存性を明らかにし、統合モデルの進展に貢献。 Comment
pj page: https://vchitect.github.io/Uni-MMMU-Project/
元ポスト:
processとresultの両面を評価できるのが特徴のように見える
[Paper Note] CL-bench Life: Can Language Models Learn from Real-Life Context?, Shihan Dou+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #read-later #Reference Collection Issue Date: 2026-05-06 GPT Summary- 実生活のコンテキストを扱うAIアシスタントの学習能力が注目されているが、混沌とした現実の状況を理解することは依然困難である。これを評価するために、405のコンテキストとタスク、および5,348の検証ルーブリックから成るCL-bench Lifeが提案された。このベンチマークは、複雑な実生活のシナリオを網羅し、10種の最先端言語モデルを評価した結果、最高でもタスク解決率は19.3%にとどまり、モデル間の平均は13.8%となった。CL-bench Lifeは、実生活のコンテキスト学習を進展させるための重要なステップとなり得る。 Comment
元ポスト:
[Paper Note] AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite, Bragg+, Ai2, ICLR'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #ScientificDiscovery #ICLR #Science #Author Thread-Post Issue Date: 2026-05-01 Comment
openreview: https://openreview.net/forum?id=M7TNf5J26u
元ポスト:
[Paper Note] Self-Evolving LLM Memory Extraction Across Heterogeneous Tasks, Yuqing Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Personalization #Evaluation #memory #KeyPoint Notes #Clustering-based #Reading Reflections #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- 異質な記憶を保持するためのLLMベースのアシスタントの必要性に対して、\textbf{BEHEMOTH}というベンチマークを導入。18のデータセットを再利用し、タスクごとの有用性を評価する。実証分析により、均質なプロンプトが効果的でないことが確認され、\textbf{CluE}を提案。これは訓練例をクラスタに分け、各クラスタを独立に分析することで、抽出プロンプトを効果的に更新し、BEHEMOTHで実験した結果、従来の方法よりも一般化能力が向上したことを示した。 Comment
元ポスト:
現在のAI Agentのメモリは同種のタスクに対して構築され評価されるが、実際の環境、特によりpersonalizationが進んだ状況下では、さまざまな異質なユーザの会話を単一のエージェントが扱い、ユーザのリクエストに応じて適切にメモリからcontextを抽出できなければならず、このような能力を測定するベンチマークは存在しない。
このため、ベンチマークを構築し既存のメモリ手法(promptingベースの手法)を評価したところ、LLMがメモリをmanageする際に、単一のmemory抽出のプロンプトや、自己進化ベースのpromptingではうまくいかないことがわかった。
提案手法 (CluE) では、各サンプルごとに背後にあるシナリオ(どのような情報が欲しいのか, 抽出時にどのような点がchallengingなのか等)をsummarizerにより解釈し、シナリオ単位でクラスタリング。個々のクラスタを分析することで、クラスタごとにどのような場合に成功/失敗するのか等を分析しクラスタ単位のrecommendationを得る。最終的に、クラスタ間のrecommendationを統合して構造化された一つの抽出promptに仕立てる。このとき、競合がある場合は適切なメモリグループにスコープを絞り解決する、といった手法のようである。
既存手法と比較してCluEによって抽出性能が向上
問題設定が実践的でおもしろい
[Paper Note] PLaMo 2.1-VL Technical Report, Tommi Kerola+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #SmallModel #Japanese #read-later #Selected Papers/Blogs #VisionLanguageModel #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- 自動運転向けの軽量なVision Language Model(VLM)PLaMo 2.1-VLを紹介。8Bと2Bのバリアントがあり、日本語対応のエッジ展開が可能。視覚質問応答に特化し、工場タスク分析とインフラの異常検知で評価。日本語のトレーニングリソースを整備し、JA-VG-VQA-500で61.5のROUGE-L、Japanese Ref-L4で85.2%の精度を達成。工場で53.9%のゼロショット精度、ファインチューニングにより異常検知のF1スコアが39.7から64.9に改善。 Comment
関連:
- GENIAC第3期で自律稼働デバイス向けの軽量な大規模視覚言語モデルPLaMo 2.1-8B-VLを開発, PFN, 2025.12
元ポスト:
[Paper Note] LongSpeech: A Scalable Benchmark for Transcription, Translation and Understanding in Long Speech, Fei Yang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Evaluation #SpeechProcessing #LongSequence #AudioLanguageModel #ICASSP #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- LongSpeechは、長時間音声処理のための大規模なベンチマークで、10万件超の約10分の音声セグメントを含む。ASRや音声翻訳、要約など多様なアノテーションがあり、長時間音声の性能評価を促進。初期の実験では、モデルが特定のタスクに特化し、他を犠牲にしていることが示された。これにより、ベンチマークの挑戦的な特性が明らかにされ、今後の研究に貢献する予定である。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/AIDC-AI/Marco_Longspeech
[Paper Note] Personalized RewardBench: Evaluating Reward Models with Human Aligned Personalization, Qiyao Ma+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Personalization #Evaluation Issue Date: 2026-04-17 GPT Summary- 報酬モデル(RMs)の個別化評価が未解決の課題である中、Personalized RewardBench(PRB)という新しいベンチマークを導入。これにより個々のユーザーの嗜好を厳密にモデル化する能力を評価。人間の評価では、両応答が一般的な品質を維持しつつ、嗜好の識別が個別に調整され、既存の報酬モデルは個別化に苦戦していることが明らかに。PRBは下流タスクにおいて既存の性能と比べて高い相関を示し、報酬モデルの評価における信頼性のある指標として確立された。 Comment
元ポスト:
[Paper Note] WildDet3D: Scaling Promptable 3D Detection in the Wild, Weikai Huang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Transformer #Prompting #Architecture #read-later #Selected Papers/Blogs #3D (Scene) #ObjectDetection #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-17 GPT Summary- 単一画像から3D物体を検出するために、WildDet3Dという統一的幾何認識アーキテクチャを提案。テキスト・点・ボックスのプロンプトを受け入れ、深度信号を組み込む。新しいオープン3DデータセットWildDet3D-Dataを生成し、13,500カテゴリの100万枚以上の画像を提供。複数のベンチマークで最先端の性能を達成し、特に深度手掛かりの活用により、平均+20.7 APの向上を実現。 Comment
pj page: https://allenai.github.io/WildDet3D/
元ポスト:
最大級の3D detection data+アーキテクチャの提案
training codeなどがリリース:
https://github.com/allenai/WildDet3D
[Paper Note] LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning, Sumeet Ramesh Motwani+, ICML'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Evaluation #Reasoning #ICML #read-later #Selected Papers/Blogs #LongHorizon #Author Thread-Post Issue Date: 2026-04-16 GPT Summary- LongCoTを導入し、複雑な推論能力を測定するための2,500問の専門家設計問題からなるベンチマークを提供。問題は数万から百数万の推論トークンを含む相互依存の手順を要求し、最先端モデルは全体で<10%の精度であることが示され、長期推論の限界が明らかになる。LongCoTは、モデルの長時間にわたる安定した推論能力を評価する指標となる。 Comment
元ポスト:
著者ポスト:
[Paper Note] JaWildText: 日本語文字認識性能評価のための 実世界画像データセット, 前田+, NLP'26, 2026.03
Paper/Blog Link My Issue
#NLP #Evaluation #Japanese #Selected Papers/Blogs #VisionLanguageModel #OCR #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-14 Comment
元ポスト:
OCRは非常に重要なタスクであり、特に日本語OCR向けのwildなデータセットは、日本側が主体的に作らないとグローバル側では作成されない気がしており、非常に重要な研究と感じる。実際、現行のSLMのSoTAモデル群ではうまくいかないようだ。
Sarashinaは日本語のOCR向けにプロプライエタリなデータセットを作成して学習されていると記憶しており、それでもなおQwen3-VLの方がベンチマークスコアが高いのは意外だった。
関連:
- Sarashina2.2-Vision-3B: コンパクトかつ性能が高いVLMの公開, SB Intuitions, 2025.11
- sarashina2-vision-{8b, 14b}, SB Intuitions, 2025.03
[Paper Note] The Art of Building Verifiers for Computer Use Agents, Corby Rosset+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #ComputerUse #read-later #Selected Papers/Blogs #Verification #Rubric-based Issue Date: 2026-04-11 GPT Summary- CUA軌跡の検証は評価信号の信頼性に不可欠である。本研究では、ノイズを減らしたルーブリックの構築、プロセスと成果報酬の分離、失敗の制御、文脈管理スキームの導入を行い、Universal Verifierを設計。新しいCUA軌跡集合CUAVerifierBenchでの検証により、人間の合意に匹敵する精度を示し、偽陽性率をほぼゼロに低減。自動研究エージェントは専門家の品質を70%達成するが、Universal Verifierの戦略発見には失敗。システムとデータセットはオープンソースとして公開。 Comment
元ポスト:
[Paper Note] Vero: An Open RL Recipe for General Visual Reasoning, Gabriel Sarch+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #Reasoning #OpenWeight #OpenSource #PostTraining #read-later #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes Issue Date: 2026-04-08 GPT Summary- Veroというオープンな視覚推論モデルを導入し、幅広いタスクで優れた性能を達成。600Kサンプルのデータセットを基に、異なる回答形式を扱える報酬設計を行い、最先端の結果を示す。Veroは既存モデルを超え、系統的なアブレーションを通じて広範なデータカバレージの重要性を明示。他の全データ、コード、モデルを公開。 Comment
元ポスト:
ベースモデルはgivenな上でRLを実施する際のopenなレシピ、データである点に注意。
[Paper Note] JAMMEval: A Refined Collection of Japanese Benchmarks for Reliable VLM Evaluation, Issa Sugiura+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #QuestionAnswering #Evaluation #Japanese #VisionLanguageModel #2D (Image) Issue Date: 2026-04-07 GPT Summary- 日本語のVQAベンチマークの信頼性向上のため、JAMMEvalを導入。7つの既存データセットを人間アノテーションで精査し、データ品質向上。オープンウェイトとプロプライエタリVLMを評価し、モデル能力を正確に反映する評価スコアを生成。データセットとコードを公開し、VLM評価の信頼性を進展。 Comment
HF: https://huggingface.co/datasets/llm-jp/JAMMEval
元ポスト:
[Paper Note] PRBench: End-to-end Paper Reproduction in Physics Research, Shi Qiu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #ScientificDiscovery #Reproducibility #Physics Issue Date: 2026-04-04 GPT Summary- 大規模言語モデルを用いたAIエージェントは、科学研究タスクを支援するが、実際の科学論文からの再現性に課題がある。PRBenchを導入し、物理学の専門家が選んだ30のタスクに基づき、エージェントが論文の方法論を理解し、アルゴリズムを実装する能力を評価。エージェントは指示と論文内容のみを使い、実行環境で動作。評価の結果、GPT-5.3-Codexが最も高いスコアを得るも、全エージェントの再現成功率はゼロで、誤実装やデバッグ不能の問題が確認された。PRBenchは自律的な科学研究の進展を評価するための厳格な基準を提供する。 Comment
元ポスト:
[Paper Note] HippoCamp: Benchmarking Contextual Agents on Personal Computers, Zhe Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Search #AIAgents #Personalization #Evaluation #MultiModal #VisionLanguageModel #One-Line Notes #Environment Issue Date: 2026-04-04 GPT Summary- HippoCampは、エージェントのマルチモーダルファイル管理能力を評価する新しいベンチマーク。ユーザー中心の環境でエージェントを評価し、個々のユーザープロファイルをモデル化し、膨大な個人ファイルを検索。42.4 GBに及ぶ2,000件以上の実世界ファイルから581のQAペアを構築し、エージェントの検索や推論能力を評価。最先端のマルチモーダル大規模言語モデルは、ユーザープロファイリング精度が48.3%に留まり、個人ファイルシステムにおける検索や推論に苦戦。HippoCampは、現行エージェントの制約を浮き彫りにし、次世代AIアシスタント開発の基盤を提供。 Comment
pj page: https://hippocamp-ai.github.io/
元ポスト:
「私の水曜日の予定はなんですか?」といったような、user-centricなタスクにおける、ユーザ個人のcontextを含むファイル検索やプロファイリング、reasoningを必要とする、よりuser-centricな情報を扱う必要があるベンチマークのようである。ユーザのプロファイルやpersonal情報が格納されたEnvironmentが提供されている。
environment: https://hippocamp-ai.github.io/hippocamp/
[Paper Note] MolmoWeb: Open Visual Web Agent and Open Data for the Open Web, Tanmay Gupta+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #MultiModal #OpenWeight #OpenSource #ComputerUse #PostTraining #read-later #Selected Papers/Blogs #VisionLanguageModel #GUI Issue Date: 2026-03-24 GPT Summary- MolmoWebは、ウェブエージェントをオープンな環境で構築するために、(1) 大規模な混合データセットMolmoWebMixと、(2) 完全オープンなマルチモーダルエージェントのMolmoWebを提案。MolmoWebMixは、10万超の合成タスクと3万件以上の人間デモを統合し、エージェントは視覚言語アクションポリシーを用いて次のブラウザ操作を予測。MolmoWebエージェントは同規模の他のモデルを上回る性能を示し、再現性とオープンな研究を促進するために関連リソースを公開。 Comment
元ポスト:
github:
https://github.com/allenai/MolmoWeb
学習、評価ハーネス、アノテーションツール、合成データパイプライン、デモのclient sideのコードがリリース
Molmo2をベースにしたオープンソースのBrowser Useエージェント。スクリーンショットを通じて次のアクション(クリック、文字入力、スクロール)を予測し実行する。
従来のBrowser Useエージェントの多くは非公開データを用いている中、MolmoWebMixと呼ばれる大規模なデータセットを公開。合成データ(タスクに成功したsingleエージェントのtrajectory, タスクをサブタスクに分解して実行するタイプのmulti-agent pipeline, 数百のwebsiteのリンク構造を体系的に探索して構築されたナビゲーションの経路等)と人間に寄る高品質なアノテーション(36k, 1100タスク, 623k件の個別のサブタスクのデモンストレーションで、過去最大規模)の2種類で構成されるとのこと。
また、BroserのGUIを認識するための学習データも含まれる。これはGUIのgrounding taskと、webページの内容を読み取りながら推論を実施するスクリーンショットがgivenなQAタスクのデータとsて構成され、400程度のサイトから収集した、2.2MのQAペアによって編成される。
4種類のベンチマークで評価した結果、プロプライエタリモデルには一部及ばないものもあるが、同等規模なOpenWeightモデルをoutperform。また、WebVoyager, Online-Mind2Webデータでみると、Pass@4のようなtest-time scaling手法を用いると、プロプライエタリも出るを上回る。
ただ注意点としては、比較しているOpenWeightモデルが少し古いように見えるが、何か理由があるのだろうか。
Holoであれば、既にHolo3がリリースされており
- Holo3: Breaking the Computer Use Frontier, H Company, 2026.03
GLMであれば、GLM-4.6Vが存在する。
- GLM-4.6: Advanced Agentic, Reasoning and Coding Capabilies, Zhipu AI, 2025.09
(UI-TARS-2 [Paper Note] UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn
Reinforcement Learning, Haoming Wang+, arXiv'25
はおそらくプロプライエタリなので対象外。あと使えるのかも不明。デモは公開されていた気がするが。)
いずれにせよHoloやUI-TARSなどはデータが公開されていなかったと思うので、全てを公開することによるcontributionは非常に大きいと思われる。
ベンチマーク関連:
- [Paper Note] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models, Hongliang He+, ACL'24, 2024.01
- Online-Mind2Web
- [Paper Note] An Illusion of Progress? Assessing the Current State of Web Agents, Tianci Xue+, COLM'25, 2025.04
- [Paper Note] Mind2Web: Towards a Generalist Agent for the Web, Xiang Deng+, arXiv'23, 2023.06
とは異なるため注意
- [Paper Note] DeepShop: A Benchmark for Deep Research Shopping Agents, Yougang Lyu+, arXiv'25, 2025.06
- WebTailBench
- [Paper Note] Fara-7B: An Efficient Agentic Model for Computer Use, Ahmed Awadallah+, arXiv'25, 2025.11
[Paper Note] DatBench: Discriminative, Faithful, and Efficient VLM Evaluations, DatologyAI+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #IRT #Evaluation #VisionLanguageModel Issue Date: 2026-03-21 GPT Summary- 基盤モデルの評価は研究の進展に不可欠だが、視覚言語モデル(VLM)の評価法は未成熟である。評価が満たすべき三つの条件(忠実性、識別性、効率性)を提案し、複数選択形式や盲目的に解ける問題、誤ラベルのサンプルがモデル評価に与える影響を分析。生成タスクへの変換やサンプルのフィルタリングを行うことで、能力の正確な識別と計算コストの削減を実現。DatBench-Fullを公開し、識別力を保ちながら速度を大幅に向上させることを目指した。この研究は、VLMの進化に合わせた持続可能な評価実践の方向性を示す。 Comment
LLMの評価はコストがかかるため、フルデータではなくサブセットで適切な評価結果が得られると嬉しい。既存のアプローチはrank correlationと呼ばれる手法が用いられ、これはフルデータで評価したモデルのランキングとサブセットで評価したモデルのランキングの相関を測ることでサブセットの評価をする。しかしこの手法には特定の評価suiteにoverfitしやすいという欠点がある。これを是正するためにIRTだぽいアプローチを採用(Raschモデルなどの一般的なIRTとしての定式化ではなさそうな点には注意)して、識別力の高いサンプルを選択してサブセットを構成する手法を提案しているとのこと。直感的にはモデル全体の平均正答率に対して、個々のモデルの平均正答率の分散が小さく、かつモデル全体の正解する確率と不正解となる確率の差分が大きいものを識別力が高いサンプルとみなす。要は強いモデルが一貫して正解し、弱いモデルが一貫して不正解となるサンプルを識別力が高いとみなす。
といった話が元ポストに書かれている。
元ポスト:
[Paper Note] InterviewSim: A Scalable Framework for Interview-Grounded Personality Simulation, Yu Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #read-later #Personality Issue Date: 2026-03-20 GPT Summary- 大規模言語モデルによる性格シミュレーション評価には、実際のインタビュー内容を基にした手法が必要。提案した評価フレームワークは、著名人の23,000件のインタビューから671,000件の質問-回答ペアを抽出し、内容の類似性、事実的一貫性、性格適合、事実知識の保持を評価。実際のインタビュー情報を用いることで、伝記的プロフィールやパラメータ知識に依存する手法よりも優れた結果を示す。評価は、原則的な手法選択を可能にし、実践的な洞察を提供。 Comment
元ポスト:
おもしろそう
[Paper Note] LMEB: Long-horizon Memory Embedding Benchmark, Xinping Zhao+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #memory Issue Date: 2026-03-17 GPT Summary- メモリ埋め込みの重要性を踏まえ、長期的なメモリ検索能力を評価するための長期視点のメモリ埋め込みベンチマーク(LMEB)を提案。22のデータセットと193のゼロショットタスクを包含し、複数のメモリタイプに基づく評価を行う。結果は、LMEBの難易度適切性やモデルのパフォーマンスに関する新たな洞察を示し、長期的メモリ検索における埋め込みモデルの進展を促進することを目指す。詳しくは https://github.com/KaLM-Embedding/LMEB を参照。 Comment
元ポスト:
[Paper Note] Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training, Fangfu Liu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#ComputerVision #Self-SupervisedLearning #SpatialUnderstanding #One-Line Notes #Test Time Training (TTT) Issue Date: 2026-03-14 GPT Summary- 視覚的空間知能の強化を目指し、Streaming Visual Spatial IntelligenceのためのSpatial-TTTを提案。動画から空間証拠を記憶・整理するためにパラメータの一部を適応し、スライディングウィンドウ注意機構を採用。さらに、3D時空間畳み込みを導入し、幾何的対応と時間的連続性を捉える。実験結果は、長時間の空間理解を向上させ、最先端の性能を達成したことを示す。 Comment
pj page: https://liuff19.github.io/Spatial-TTT/
元ポスト:
HF: https://huggingface.co/collections/THU-SI/spatial-ttt
要は、spatial understandingに特化した認知機構を小規模ネットワーク+TTTで構築した研究(と思われる)。TTTについては下記issue参照のこと。動画の各フレームはViTでエンコードされ、QuestionはtokenizeされてHybridなdecoder-only modelに入力され、最終的にテキストが出力されるようなアーキテクチャになっている。Hybridなモデルは、3:1の割合でハイブリッドなブロックとFull Attention Blockがスタックされている。ハイブリッドなblockはQKVを共有した2つのルートが存在し、片方はSWA Layer, もう一方がTTT Layerとなっている。これによってSWA Layerによって高い画像理解能力をlong sequenceでも保ちつつ、TTT Layerで入力情報に基づいて動的にSpatial Understandingに特化したstate(=weight)を更新する、といった方向性のアーキテクチャに見える。
- [Paper Note] Learning to (Learn at Test Time): RNNs with Expressive Hidden States, Yu Sun+, ICML'25, 2024.07
[Paper Note] PostTrainBench: Can LLM Agents Automate LLM Post-Training?, Ben Rank+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #PostTraining #read-later #Environment #autoresearch Issue Date: 2026-03-14 GPT Summary- AIエージェントは推論能力の向上によりソフトウェア工学で高い能力を発揮し、AI研究の自動化可能性を考察する。本論文では、基盤LLMを有用なアシスタントへ変えるポストトレーニングの評価を行うためのベンチマークPostTrainBenchを導入。特定のベンチマークで最先端エージェントの性能を評価し、自律性を持たせた実行方法を検討することが重要である。進捗は見られるが、公式の指示調整済みモデルには劣る状況が多く、時折上回るケースも存在。エージェントの行動にはリワードハックなどの懸念があり、慎重なサンドボックス化の重要性を示唆する。PostTrainBenchはAIの研究開発の進捗とリスクを追跡する上で有用である。 Comment
pj page: https://posttrainbench.com/
元ポスト:
[Paper Note] Scaling Data Difficulty: Improving Coding Models via Reinforcement Learning on Fresh and Challenging Problems, Zongqian Li+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Coding #SoftwareEngineering #PostTraining #DataFiltering #Initial Impression Notes Issue Date: 2026-03-12 GPT Summary- 高品質なコード生成モデルの訓練には高品質なデータセットが必要だが、既存のデータは様々な問題を抱えている。本研究では、系統的なデータ処理フレームワークを導入し、自動難易度フィルタリングを用いて難易度の高い問題を保持しつつ簡単な問題を排除。得られたMicroCoderデータセットは、多様な競技プログラミング問題を含み、性能向上を達成。評価によれば、三倍の性能向上を示し、難易度を意識したデータ選定がモデルの性能向上に効果的であることが明らかになった。 Comment
元ポスト:
コーディングドメインにおいて、難易度の高いコーディング問題を収集(単純な問題をフィルタリング)することで、RLにおいて高い学習効率が得られる、という話に見える
[Paper Note] SWE-rebench V2: Language-Agnostic SWE Task Collection at Scale, Ibragim Badertdinov+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Coding #SoftwareEngineering #PostTraining #read-later #Selected Papers/Blogs #Live #One-Line Notes #Environment Issue Date: 2026-03-05 GPT Summary- SWEエージェントの強化学習を支えるため、実世界のソフトウェア工学タスクを自動収集し、再現可能な環境を構築するSWE-rebench V2を提案。20言語・3,600超のリポジトリから32,000以上のタスクを集め、厳選したコンテンツで信頼性のあるトレーニングデータを提供。また、タスク生成に必要なメタデータも加え、エラー要因を明示。データセットと関連リソースを公開し、多様な言語での大規模なSWEエージェントのトレーニングを支援。 Comment
元ポスト:
environment: https://huggingface.co/datasets/nebius/SWE-rebench-V2?row=5
関連:
- [Paper Note] SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents, Ibragim Badertdinov+, NeurIPS'25, 2025.05
以前の研究ではpython特化だったが、今回はlanguage-agnosticな環境になっている。
合成データではなく、実際のissue-resolutionのヒストリに基づいたデータセットであることに注意
[Paper Note] How Well Does Agent Development Reflect Real-World Work?, Zora Zhiruo Wang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #AIAgents #Evaluation #read-later #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2026-03-04 GPT Summary- AIエージェントの開発は、労働市場のベンチマーク上で進められているが、その代表性は不明である。本研究では、43のベンチマークと72,342のタスクを分析し、エージェント開発と米国労働市場の職業との整合性を測定。プログラミング重視の開発と人間労働の価値の乖離を指摘し、エージェントの自律性を評価することで実用的な指針を提供。最後に、社会的に重要な労働を捉えるベンチマーク設計のための3つの原則を提案。 Comment
元ポスト:
AI Agentのベンチマークは実際の人間の労働に本当に紐づいたタスクで評価されているのか?という疑問に答えてくれる研究のようで、実際のAI Agentのベンチマークと人間の業務、それらのcapitalをマッピングしたところ、現在のAI Agentのベンチマークは過剰に数学とコーディングドメインに偏っており、実態としての人間の労働や、それらの中でcapitalが集中しているドメインに対するカバレッジが大きく不足していることがわかった。
ドメインごとに見ると、デジタル化がされていて高付加価値のドメインのいくつか(マネジメントや法務)のベンチマークは少なく、スキルをベースに見るとベンチマークは情報取得やエンジニアリングといった狭いスコープばかりに焦点が当たっていて(これらの人間の労働に占める割合は<7%にすぎない)、多くの他のスキルが無視されている状況とのこと。
また、エージェントの自律性を細分された尺度で評価するために、どの程度のレベルの複雑さのタスクであればreliableにagentがこなせるかという観点を導入し、タスクの複雑性に関するスケールを導入し比較を可能にした、といった話が元ポストに書かれている。
現在提供されているベンチマークにおいて、おそらくタスク全体のうちの個別のサブタスクごとに複雑度をラベル付けして、複雑度を軸にサブタスクの成功/失敗をtrajectoryから分析することで、タスクの複雑度を軸に成功率を分析したグラフを見ると、タスクの複雑度に対して基本的にはどのドメイン、スキル、エージェントフレームワーク、バックボーンモデルであれ複雑度な上がれば上がるほど成功率は減少していく傾向にあり、成功率は最終的に20%--0%付近まで低下する。
最終的に、エージェントの評価ベンチマークにおいては、実際の労働に対するカバレッジ、現実的であること(=実際のドメインや必要となるスキルを捉えており、実タスク全体を捉えたようなものが必要でFigure4にベンチマークごとのドメインとスキルのカバレッジが可視化されている)、より粒度の細かい評価が必要(タスク全体の成功/失敗でのみ評価すると、タスクのどこまでできていたのか?という重要なシグナルが欠落する)であることが議論されている。
[Paper Note] LeRobot: An Open-Source Library for End-to-End Robot Learning, Remi Cadene+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#MachineLearning #Library #ReinforcementLearning #OpenSource #ICLR #Selected Papers/Blogs #Robotics #One-Line Notes Issue Date: 2026-03-03 GPT Summary- ロボティクスは機械学習の進展により変革を遂げ、ロボット学習が新たに生まれつつある。手頃な遠隔操作システムや公開データセットの増加により、研究が加速しているが、クローズドソースツールの断片化が発展を妨げている。本研究では、ロボット学習スタックを統合するオープンソースライブラリ\texttt{lerobot}を提案。これにより、低レベル制御からデータ収集までをカバーし、アクセス可能なハードウェアをサポート。スケーラブルな学習アプローチを強調し、研究者・実務者の参入障壁を低下させ、再現性のある学習プラットフォームを提供する。 Comment
openreview: https://openreview.net/forum?id=CiZMMAFQR3
元ポスト:
従来の研究では、特定のユースケース、特定のツール、特定のプラットフォーム、データフォーマット、学習アルゴリズム等を自分たちの独自のユースケースのために開発がされてきたため、これにより分野の断片化(他者が追試しづらい、統一的な技術スタックがない等)が生じてしまっていたため、それを解決するためにend-to-endでの統合的な枠組み(ロボットを動作させるだよミドルウェアのインタフェースや標準化されたデータセットのフォーマット、学術アルゴリズムなど)を提案しているようである。
onelineで実ロボットへのデプロイができる機能が追加されたとのこと:
[Paper Note] AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications, Yujie Zhao+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #read-later #Selected Papers/Blogs #memory #Initial Impression Notes #Author Thread-Post Issue Date: 2026-03-01 GPT Summary- LLMを用いた自律エージェントの記憶において、実務的応用と評価基準の間にギャップが存在。これを解消するために、AMA-Benchを提案し、実世界のエージェント軌跡とQAを組み合わせて評価。多くの既存システムが因果性を欠き、類似性ベース検索に制約されている中、因果性グラフとツールを用いたAMA-Agentが性能を向上。AMA-AgentはAMA-Benchで57.22%の正解率を達成し、最強記憶システムのベースラインを11.16%上回る。 Comment
元ポスト:
実際のAgenticなタスクのユースケースに沿ったmemoryの評価方法を提案している研究のようで、非常に重要な研究に見える。実際はチャットベースのやり取りではなく、エージェントと環境が相互作用しながら生成されるtrajectoryで構成され、指示はagentによって生成された客観的な目的を含んでおり、trajectoryには多くのnoisyな結果やsymbolが含まれる。また、agentが現在のstateから環境に作用した結果が返ってくるというチャットベースの言語的なフロートは異なり、stateに基づいた因果関係が存在するという差がある。
ベンチマークの結果ではGPT-5.2が優れていそうに見えるが、GPTの場合は最新のGPT-5.2で評価されているのに、Claudeに関してはClaude Haiku 3.5で評価されているのは気になる。Claude Opus 4.6やGemini-3で評価したらどの程度の性能になるのだろうか。
著者ポスト:
[Paper Note] The Trinity of Consistency as a Defining Principle for General World Models, Jingxuan Wei+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #Evaluation #read-later #WorldModels Issue Date: 2026-02-28 GPT Summary- 世界モデルの構築は人工汎用知能の基本課題であり、Soraの動画生成モデルやUnified Multimodal Model (UMM)の進展がデータ駆動型の物理ダイナミクス近似の可能性を示している。しかし、一般的な世界モデルに必要な理論フレームワークは未整備である。本研究では、世界モデルが整合性の三位一体(モーダル・空間的・時間的整合性)に基づくべきと提案し、マルチモーダル学習の進化をレビュー。新たにCoW-Benchを導入し、これを用いて動画生成モデルとUMMを評価する。研究は一般的世界モデルへの道筋を確立し、現行システムの限界と将来のアーキテクチャ要件を明らかにする。 Comment
[Paper Note] Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs, Yining Hong+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #PEFT(Adaptor/LoRA) #SelfCorrection #Test-Time Scaling #PostTraining #read-later #VisionLanguageModel #3D (Scene) #Robotics #EmbodiedAI #Initial Impression Notes #Test Time Training (TTT) Issue Date: 2026-02-28 GPT Summary- 具現化されたLLMsは高レベルのタスク推論を持つが、過去の失敗を振り返れず、ミスが繰り返される独立した試行となる。この問題に対処するため、Reflection Test-Time Planningを導入し、二つの省察モードを統合。実行中の反省では内部評価を通じて候補アクションを生成し、実行後の反省では外部反省を基にモデルを更新。新たに設計したベンチマークで実験を行い、ベースラインモデルに対して有意な改善を示した。定性的分析では、反省を通じた行動の修正が強調された。 Comment
pj page: https://reflective-test-time-planning.github.io/
元ポスト:
- [Paper Note] LLaVA-3D: A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness, Chenming Zhu+, ICCV'25, 2024.09
まだ全然理解できていないが、Action Model, Internal reflection LLM, external reflection LLMとしてLLaVA 3Dと呼ばれるモデルをベースにし、単一のモデルで3種類のモードを学習するようである。そしてテスト時にはLoRAを用いたTTTを実施するようである。
[Paper Note] IRPAPERS: A Visual Document Benchmark for Scientific Retrieval and Question Answering, Connor Shorten+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #QuestionAnswering #Evaluation #MultiModal #OCR #Hybrid Issue Date: 2026-02-27 GPT Summary- 画像ベースの情報検索と質問応答の性能をテキストベースの手法と比較するために、IRPAPERSデータセットを用いて実験を実施。テキスト検索はRecall@1で46%を達成し、画像ベースは43%を達成。両手法は補完的で、マルチモーダルハイブリッド検索はRecall@1で49%の性能を示す。MUVERAを用いた画像埋め込みモデルの評価において、Cohere Embed v4が最も優れた性能を持つ。質問応答では、テキストベースのシステムが画像ベースより高い整合性を示し、複数文書検索が効果を発揮。両モダリティの限界と必要性を明確化。データセットと実験コードは公開。 Comment
元ポスト:
[Paper Note] Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?, Thibaud Gloaguen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering #Selected Papers/Blogs #reading #Reference Collection #Initial Impression Notes #AGENTS.md Issue Date: 2026-02-27 GPT Summary- コーディングエージェントのタスク完遂性能を評価するため、LLMが生成したコンテキストファイルと開発者提供のファイルを用いた2つの設定を検討。結果、コンテキストファイルは成功率を低下させ、推論コストを増加させる傾向が見られた。両者はタスクの探求を促進するが、不要な要件がタスクを難化させるため、最小限の要件のみを記述することが推奨される。 Comment
元ポスト:
(現時点では)LLMによって自動生成されたコンテキストファイルは性能を劣化させ、inference costを増大させ、人間が作成したコンテキストファイルは性能を向上させる。コンテキストファイルによってoverviewを提供することを推奨しているものがあるが、性能向上には寄与しない。コンテキストファイルに従うことはより多くのthinkingを誘発し、結果的にタスクを難しくする。最小限のrequirementsのみを記述したものを使うことを推奨する、といった内容らしい?
関連:
best practiceは以下とのこと:
- # Writing a good CLAUDE.md, Kyle, 2025.11
解説:
非常にコンパクトにまとまっている。
解説:
解説:
[Paper Note] A Very Big Video Reasoning Suite, Maijunxian Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #Supervised-FineTuning (SFT) #Evaluation #Reasoning #mid-training #PostTraining #VideoGeneration/Understandings #3D (Video) #Author Thread-Post Issue Date: 2026-02-27 GPT Summary- ビデオ推論の能力を探究するため、100万本以上のビデオクリップを含む前例のないVBVRデータセットを導入。200の推論タスクを網羅し、既存データセットの約1000倍の規模で、評価フレームワークとしてVBVR-Benchを提示。これにより、ビデオ推論の研究における再現性と解釈可能性を向上させ、新規タスクへの応用の初期兆候を示す。VBVRは次の研究段階の基盤となる。データ、ツール、モデルは公開中。 Comment
pj page: https://video-reason.com/
元ポスト:
著者ポスト:
[Paper Note] CaptionQA: Is Your Caption as Useful as the Image Itself?, Shijia Yang+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #MultiModal #CVPR #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #One-Line Notes #Initial Impression Notes #ImageToTextGeneration Issue Date: 2026-02-26 GPT Summary- 画像キャプションはマルチモーダルシステムにおける視覚コンテンツの代理表現として機能するが、キャプションが実際のタスクで画像の代わりになり得るかを評価する必要がある。そこで、新たにユーティリティベースのベンチマークCaptionQAを提案し、キャプションの質を下流タスクへの支援度で測定する。CaptionQAは四つのドメインにわたり、33,027件の詳細な多肢選択問題を提供し、キャプションが視覚情報を必要とする質問に対応する力を検証する。LLMによる評価により、キャプションの有用性が画像よりも最大32%低下することが確認され、CaptionQAはオープンソースとして公開される。 Comment
元ポスト:
興味深い研究。MLLMの性能をCaption生成を通じて評価している。
良いCaptionであればdownstream taskに活用した際により良い性能が得られるという仮定の元[^1]、MLLMの性能をAnswer=LLM(Question, Caption)で判断する。AnswerはMultiple Choice Questionであり、Cannot Answerなども含まれる。よりQAに対して適切に回答できるCaptionを生成できたMLLMが優れているというutility-basedな評価となっている。
MLLMに対してCaptionを生成する際は、Questionに関する情報は与えずに、画像の情報のみでCaptionを生成する(ように見える)。セクション9に記述されている通り、4種類のバリエーションのpromptを用いる(long, short, simple, taxonomy hinted)。
skim readingしかできていないのだが、脚注1に記述した通り、モデルによって実画像がgivenな状態とCaptionのみで評価した場合でgapの出方に差がある点と、そもそも到達しているスコアの絶対値の対比が出せる点が個人的に興味深い。これにより特定のMLLMが、画像とテキスト、どちらの情報を"理解"するのに優れているのか、あるいは理解した情報に基づいて"生成"するのに優れているのかも間接的に評価できるのではないかと感じる。たとえばGPT-5は他モデルと比べて双方の能力秀でているが、Gemini-2.5-Proは画像を考慮することは得意だが、画像からテキストを生成する能力は少し劣ることがGPT-5とのgapの差から伺える。GLM4.1-VやLLaVAなどは画像理解は得意だが、画像から重要な情報を生成する能力は大きく低いことがわかる。
同じdownstreamタスクを通じてgapを測定でき、かつ単にベンチマークのスコアという以上の一段深い情報が得られる点がこれまでと異なりおもしろいと感じる。
[^1]:実際、セクション5を見ると実際の画像を与えた場合とCaptionのみの場合で評価した場合でgapがあることが示されており、Captionが画像中のdownstream taskに対してrelevantな情報を完全に保持していないことが示唆される。また、モデルに応じてgapが異なっており、モデルによってCaption生成能力が大きく異なることが示唆される。
この評価のパラダイムは一段抽象化をすると、特定のモダリティの情報に対する理解力と、異なるモダリティに変換して生成する能力をdownstreamタスクを通じて観測することになり、Captionの場合は画像-テキスト間だが、他にも動画-テキスト、音声-テキスト、あるいはそれらの逆など、Omniモーダルなモデルの評価やUMMの評価に使えそうな話だな、と思うなどした。
[Paper Note] Multi-Crit: Benchmarking Multimodal Judges on Pluralistic Criteria-Following, Tianyi Xiong+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #MultiModal #CVPR #VisionLanguageModel #2D (Image) Issue Date: 2026-02-24 GPT Summary- Multi-Critは、大規模マルチモーダルモデル(LMMs)の評価能力を測定するためのベンチマークであり、複数基準への適合性や判断信頼性を評価する。厳格なデータキュレーションを通じて収集された応答ペアは、オープンエンド生成と検証可能な推論タスクを含む。分析の結果、商用およびオープンソースモデルは多様な基準への適合に課題があり、ファインチューニングが視覚的根拠づけを高めるが、多元的基準判断に至らないことがわかった。Multi-Critは、信頼できるマルチモーダルAI評価の基盤を構築する。 Comment
元ポスト:
[Paper Note] DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories, Chenlong Deng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #InformationRetrieval #Search #LanguageModel #AIAgents #Evaluation #MultiModal #One-Line Notes Issue Date: 2026-02-18 GPT Summary- 既存のマルチモーダル検索システムはクエリと画像の関連性を独立して評価することを前提としているが、このアプローチは現実の視覚データの依存関係を無視している。これを解決するために、我々はDeepImageSearchを提案し、画像検索を自律的探査タスクとして再定義する。このモデルは文脈的手掛かりに基づき、視覚データの多段階推論を行いターゲットを特定する。相互に関連した視覚データ用のベンチマークDISBenchを構築し、文脈依存クエリの生成におけるスケーラビリティ課題を人的なモデル協働で解決するパイプラインも提案。また、モジュール型エージェントフレームワークと二重メモリシステムを用いて、堅牢なベースラインを開発した。実験により、DISBenchが先端モデルに対して重要な課題を示すことが明らかになり、次世代検索システムへのエージェント的推論の統合の必要性が強調されている。 Comment
元ポスト:
検索クエリが与えられた時に、Corpus中の画像中に含まれる情報を考慮しなければ検索できないような検索タスクとベンチマークDIBenchの提案。たとえば、白と青のロゴのイベントで、lead singerだけがステージに立っている画像、のような、白と青のロゴのイベントをCorpus画像から同定(クエリと画像の相互作用)→その上で当該イベントでソロでステージにlead singerが立っている画像を探す、といったような検索である。
proprietaryモデルだとClaude-4.5-Opusの性能がよく、次いでGemini-Pro-Previewの性能が良い。GPT5.2は大きく性能面で劣っている。OpenModelと比較すると、ClaudeはQwen3-VLやGLM-4.6Vの倍程度のスコアを獲得している(Table1)。
[Paper Note] HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam, Weiqi Zhai+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation Issue Date: 2026-02-17 GPT Summary- HLE-Verifiedは、Humanity's Last Exam(HLE)の改訂版であり、ノイズの多い問題が評価に与える影響を軽減するために開発された。二段階の検証・修復プロセスを通じて、641件の検証済みアイテムと1,170件の改訂済みアイテムが生成され、残り689件は不確実性セットとして公開された。評価の結果、HLE-Verifiedは平均的な精度が7〜10パーセント向上し、特に誤りのあるアイテムでは30〜40パーセントの改善が見られた。このアプローチにより、モデル能力をより正確に測定することが可能となった。 Comment
元ポスト:
HLE:
- [Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25, 2025.01
[Paper Note] SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, Xiangyi Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs #KeyPoint Notes #AgentSkills #Reading Reflections #Author Thread-Post #AgentHarness Issue Date: 2026-02-17 GPT Summary- LLMエージェントを強化する手続き知識のパッケージであるエージェントスキルの効果を測定するため、SkillsBenchを提案。これにより、86タスクを利用したキュレーション済みスキルと決定論的検証器を組み合わせたベンチマークを作成。各タスクはスキルなし、キュレーション済みスキル、自己生成スキルの3条件で評価。キュレーション済みスキルは合格率を平均16.2ポイント向上させるが、分野による効果の差が顕著。自己生成スキルは有意な利益をもたらさず、信頼性のある手続き的知識の自作が困難であることを示した。Focused Skillsは、包括的なドキュメンテーションを上回る効果を持ち、小型モデルがスキルを有することで大型モデルに匹敵する場合がある。 Comment
元ポスト:
Agent Skillsに関するベンチマーク。11種類の多様なドメインのタスクによって構成される。コーディングやソフトウェアエンジニアリングに留めらないのが特徴的に見える。
評価時は
- スキルがない場合
- スキルがある場合
- 自己生成したスキルを使う場合
の3種類で評価する。
ハーネスはClaude Code, Codex CLI, Genini CLIの3種類で評価し、モデルはGPT, Claude, Gemini系列のモデルを利用。takeawayは以下:
- skillsはタスクの性能を改善するが、モデルとハーネスの組み合わせでgainが大きく異なる
- Gemini CLIとGemini Flashが最高性能を達成
- スキルを自己生成しても性能向上に寄与しない(むしろネガティブな影響も見受けられる)
- 3種類のハーネスのうち
- Claude Codeが最も多くスキルを活用し、Claudeモデルは一貫してgainを得る
- Gemini CLIは最も高いraw performanceを達成
- 性能はcompetitiveだが、Codex CLIは必要なスキルの内容を取得しても、スキルを利用せず独立して処理してしまう頻度が高い
- skillによって得られるgainはドメインによって大きく異なる。事前学習時に馴染み薄いドメインほど、skillの導入による恩恵がでかい。
- skillの導入によって、タスクによっては性能が悪化するものもある。これはモデルがすでにうまく処理をする能力を持っているのに、スキルが提供されることでそれらがconflictすることに起因する可能性がある。
- タスクごとに、2--3個のスキルを提供するのが性能がよく、4+になるとgainが低下する
- スキルの定義はproceduralな知識をコンパクト(compact)あるいは詳細に記述したもの(detailed)が良く(i.e., 特定のことについて集中的に記述するもの)、徹底的に記述されたドキュメント(comprehensive)は性能が悪化する。
- SLM+skillによって、スキル利用なしのより大きなモデルを性能で上回ることができる
Agent skillsの効果について定量的に分析した初めての研究な気がしており、重要な研究だと思われる。AI AgentというとClaudeが優秀な印象が強いが(コーディングやソフトウェアエンジニアリングでの性能に基づく印象)、本ベンチマークでは多様なドメインで評価をしており、Gemini CLI+Gemini Flashが最も平均的な性能が高いのが興味深い。
pj page: https://www.skillsbench.ai/
著者による続報:
SkillsBenchがエージェントスキル評価のデファクトになったことと、1.1のローンチイベントについての話が言及されている。
[Paper Note] SciAgentGym: Benchmarking Multi-Step Scientific Tool-use in LLM Agents, Yujiong Shen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #Evaluation #Science #KeyPoint Notes #LongHorizon #Environment #ToolUse Issue Date: 2026-02-17 GPT Summary- 科学的推論には高度なツール統合が必要だが、現行ベンチマークはその能力を十分に評価していない。これを解決するために、SciAgentGymを導入し、1,780個の分野特異的ツールを提供。SciAgentBenchでは、エージェント能力を初歩から長期的なワークフローまで評価。先進モデルも複雑な科学ツール使用に取り組むが、成功率は対話のホライズン拡大で急落。SciForgeというデータ合成手法を提案し、ツールアクションを依存グラフとしてモデル化。これによって、SciAgent-8Bはより大規模なモデルを上回り、科学ツール使用能力の転移を示す。次世代の自律的科学エージェントの可能性を示唆。 Comment
元ポスト:
long horizonタスクでのtool useに関するベンチマークおよび環境の提供と、graphベースでツールの依存関係を定義し活用することで、環境上での実行によってgroundingされた高品質データを合成する手法SciForgeを提案。
ベンチマークでの評価によって、フロンティアモデルでもlong horizonになるとタスク成功率が低下することが明らかになり、性能の低いモデルは同じツールや類似したツールの繰り返しの呼び出しをするなどの挙動があることが明らかになった(他にも詳細な失敗モードの分析などがされているように見える)。
また、合成データによるSFTによって8B級のSLMでも大幅に性能が改善している模様。
[Paper Note] Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception, Lai Wei+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Evaluation #MultiModal #Distillation #VisionLanguageModel #ThinkingWithImages Issue Date: 2026-02-16 GPT Summary- MLLMは視覚理解に優れていますが、微細な知覚には依然として課題があります。最近の手法「Thinking-with-Images」は局所情報を取り入れるもののレイテンシが高い。そこで、Region-to-Image Distillationを提案し、エージェント的ズーミングの利点を1回のフォワードパスに内在化します。マイクロクロップ領域で教師モデルにVQAデータを生成させ、それに基づく信号を全画像に蒸留。これにより、学生モデルはツールなしで微細知覚を改善。新たに提案するZoomBenchにより、モデルの性能を厳密に評価し、複数のベンチマークでトップクラスの成果を示します。さらに、思考の必要性とその利得を議論します。コードは公開されています。 Comment
元ポスト:
[Paper Note] Gaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments, Romain Froger+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation Issue Date: 2026-02-16 GPT Summary- Gaia2は、大規模言語モデルエージェントを非同期環境で評価する新しいベンチマークです。静的または同期的評価と異なり、エージェントは動的に進化するシナリオで、時間的制約やノイズ、他のエージェントとの協力に適応することが求められます。各シナリオには、書き込みアクション検証器が関連付けられ、細かいアクション単位の評価が可能です。最近の評価結果では、GPT-5が最も高い成績を修得しましたが、時間に敏感なタスクでは失敗し、Claude-4は精度と速度をトレードオフする結果となりました。これらは推論、効率性、堅牢性のトレードオフを示し、実用的なエージェントシステムの開発と訓練を支援するインフラを提供することを目指しています。 Comment
元ポスト:
[Paper Note] First Proof, Mohammed Abouzaid+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Mathematics #ScientificDiscovery #Selected Papers/Blogs #Proofs Issue Date: 2026-02-16 GPT Summary- AIシステムの数学問題回答能力を評価するため、著者が作成した10の未公開の数学問題を共有。答案は著者に知られているが、短期間は非公開とする。 Comment
pj page: https://1stproof.org/
元ポスト:
ポイント解説:
自分たちの研究過程で生じた自分たちは答えを発見しているが世間には未発表な問題と暗号化された解答が公開されている。2月13日時点で鍵が公開されているようだ。果たしてどの程度AIは解答ができたのだろうか?
Google DeepmindのAlethiaは10個中6つの問題を解くことができたようである:
Alethia:
- [Paper Note] Accelerating Mathematical and Scientific Discovery with Gemini Deep Think, Google DeepMin, 2026.02
[Paper Note] GameDevBench: Evaluating Agentic Capabilities Through Game Development, Wayne Chi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Game Issue Date: 2026-02-16 GPT Summary- ゲーム開発におけるマルチモーダルなコーディングエージェントの評価が遅れている問題に対処するため、初のベンチマーク「GameDevBench」を提案。本ベンチマークは132の複雑なタスクで構成され、コード行数とファイル変更が平均3倍以上になる。最良のエージェントでも54.5%のタスクしか解決できず、成功率はタスクの種類によって大きく異なる。マルチモーダル能力を高めるために、画像およびビデオベースのフィードバックメカニズムを導入した結果、Claude Sonnet 4.5の性能が33.3%から47.7%に向上。GameDevBenchはエージェントによるゲーム開発研究を促進する。 Comment
元ポスト:
[Paper Note] Data Darwinism Part I: Unlocking the Value of Scientific Data for Pre-training, Yiwei Qin+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #SyntheticData #DataFiltering #Science #One-Line Notes #Environment Issue Date: 2026-02-12 GPT Summary- データの質がモデルのパフォーマンスに影響を与える中、データ・ダーヴィニズムという10段階の分類法を提唱。これに基づき、900BトークンのDarwin-Scienceコーパスを構築し、先進的なLLMを利用して生成的洗練(L4)と認知的補完(L5)を実現。事前トレーニングにより、3Bモデルで+2.12、7Bモデルで+2.95ポイントの性能向上を達成し、特定タスクでは更に高い改善を確認。共進化の原則に基づく開発を促進するため、データセットとモデルを公開。 Comment
元ポスト:
学習データを処理するためのフレームワークを10段階のレベル(ただのデータの獲得から、前処理、合成、世界のシミュレーションまで)で定義し、それぞれのレベルにおいてどのような処理が必要で、どのような価値を生むのかといった点が体系化されている。レベルが上がるにつれてデータの量は基本的に減少するが、データのinformation densityや構造の複雑さは高まっていく。
また、下図に示されているように実際にLevel0 -- Level5までの処理を実施したことでどのようなgainがあるかも考察されているようである。
[Paper Note] Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition, Yuhao Dong+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #In-ContextLearning #VisionLanguageModel #3D (Video) Issue Date: 2026-02-10 GPT Summary- デモ駆動型ビデオインコンテキスト学習を提案し、ビデオに関する質問に対してインコンテキストデモから学ぶ新たなタスクを定義。1200本のYouTubeビデオを用いた「Demo-ICL-Bench」を作成し、テキストと動画のデモを提供。Demo-ICLモデルを開発し、ビデオ監督付きファインチューニングによってインコンテキスト学習能力を向上。実験によりベンチマークの難易度を検証し、モデルの性能を明示。 Comment
元ポスト:
[Paper Note] LOCA-bench: Benchmarking Language Agents Under Controllable and Extreme Context Growth, Weihao Zeng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #LongSequence #LongHorizon #ContextRot Issue Date: 2026-02-10 GPT Summary- LLMは長期タスクの実行が向上する一方で、コンテキストが増えると信頼性が低下する「コンテキストロット」が問題に。これに対処するため、LOCA-benchを導入し、環境状態に応じてエージェントのコンテキスト長を調整。固定されたタスク意義の下でコンテキストを制御し、様々な管理戦略を評価。複雑な状態では相対的に性能が低下するが、高度な管理技術で成功率が向上。LOCA-benchはオープンソースで公開され、長コンテキストエージェントの評価プラットフォームを提供。 Comment
元ポスト:
[Paper Note] SE-Bench: Benchmarking Self-Evolution with Knowledge Internalization, Jiarui Yuan+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Evaluation #SelfImprovement #PostTraining #read-later #Selected Papers/Blogs #FactualKnowledge #One-Line Notes #ContinualLearning #Initial Impression Notes Issue Date: 2026-02-10 GPT Summary- 自己進化には、エージェントが生涯学習者として新しい経験を内面化し、将来の問題解決に活かすことが必要。しかし、以前の知識の混在と推論の複雑さが測定を妨げる。SE-Benchという診断環境を導入し、エージェントが新しいAPIドキュメントを使用することで評価を行い、知識の保持と内面化の新たな洞察を得た。特に「クローズドブック訓練」が知識保持に必要であり、標準的な強化学習が新しい知識を内面化できないことを示す。SE-Benchは知識内面化のための厳密なプラットフォームを提供する。 Comment
元ポスト:
関数をリネームし関連するAPIドキュメント(今回はnumpy)を更新し、Claudeを用いてテストケースを生成し、複数のLLMのVotingで検証可能かどうかを判定した後人手による検証を行いフィルタリングする。テスト時にクローズドブックの設定で評価することで、インタフェースに関するモデルのFactual Knowledgeを更新しないとモデルはテストケースに正解できず、モデルが内部パラメータに保持するFactual Knowledgeをどれだけ適切に保持、更新しているかを評価するようなコントロールされた環境下でのベンチマークに見える。
APIに関するドキュメントの文脈をしっかり変更しないと元のモデルが文脈から過去の関数名との対応関係を類推できてしまいそうだが、その辺はどうなっているのだろうか。
[Paper Note] Spider-Sense: Intrinsic Risk Sensing for Efficient Agent Defense with Hierarchical Adaptive Screening, Zhenxiong Yu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Safety #One-Line Notes #Initial Impression Notes Issue Date: 2026-02-08 GPT Summary- 「Spider-Sense」と呼ばれるイベント駆動型防御フレームワークを提案し、エージェントが危険を認識した際にのみ防御を発動。階層的な防御メカニズムにより効率と精度をトレードオフしつつ、既知のリスクを軽量マッチングで解決し、曖昧なケースは内部推論に移行。新たなベンチマーク「S$^2$Bench」を用いた実験で、競争力のある防御性能と最低の攻撃成功率を示し、わずか8.3%の遅延オーバーヘッドを実現。 Comment
元ポスト:
従来のAI Agentのセキュリティチェックは決められたタイミングで、しばしば重いチェックがかかりレイテンシが高かったが、提案手法では動的にどの程度の計算量を費やすかを調整して、必要なタイミングで重い推論、そうでない場合は軽量なチェックで済ませることでレイテンシと性能を改善する、といったコンセプトな模様。
エージェントのステージごとにobservationを事前定義されたテンプレートで囲い、テンプレートによってスクリーニングをトリガーし、ベクトル検索によって危険度を判定する。判定した危険度が一定以下なら軽量なチェック、一定以上ならLLMによる推論を用いた重い処理を走らせるという手法に見える。図中のcのnotationが本文中に見当たらない気がするが、見落としているだろうか。
結局のところ、テンプレートによってセキュリティチェックが誘発されるように見えるので、元々の問題意識である固定されたタイミングで強制的にセキュリティチェックがかかる、という課題は解決されない気がする。固定されたタイミングで強制的にセキュリティチェックがかかる点は従来手法と変わらないが、セキュリティチェックに費やすコストや計算量を動的に変更します、という話に感じる。
[Paper Note] CAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty, Johannes Kirmayr+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Ambiguity Issue Date: 2026-02-08 GPT Summary- 既存のLLMエージェントのベンチマークは理想環境でのタスク完了に偏っており、実際のユーザーアプリケーションでの信頼性を無視している。本研究では、車内アシスタント向けの「CAR-bench」を提案し、マルチターン対話やツール使用を通じた不確実性管理を評価する。この環境には、58の相互接続ツールが含まれており、「幻覚タスク」と「曖昧さ解消タスク」を導入してエージェントの能力をテスト。結果は、曖昧さ解消タスクでの一貫性が50%未満と低く、ポリシー違反や情報捏造が多発することから、より信頼性の高い自己認識を持つLLMエージェントの必要性を示している。 Comment
元ポスト:
[Paper Note] BABE: Biology Arena BEnchmark, Junting Zhou+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #AcademicWriting #Biological Issue Date: 2026-02-06 GPT Summary- 生物学におけるLLMsの能力を評価するため、BABE(Biology Arena BEnchmark)を導入。これは実験結果を文脈知識と統合する能力を測定し、実世界の研究から構築された複雑な課題を提供。因果推論やスケールを超えた推論を促すことで、AIシステムの科学者としての推論能力を評価するフレームワークを提供し、生物学研究への貢献度を向上させることを目指す。 Comment
元ポスト:
[Paper Note] Synthesizing scientific literature with retrieval-augmented language models, Asai+, Nature'26, 2026.02
Paper/Blog Link My Issue
#Citations #InformationRetrieval #NLP #LanguageModel #QuestionAnswering #Evaluation #RAG(RetrievalAugmentedGeneration) #ScientificDiscovery #read-later #Selected Papers/Blogs #Science Issue Date: 2026-02-05 Comment
元ポスト:
QAに対して専門家と同等のcitationに対するgrounding性能を達成し、citationに基づいたanswer (literature) を8Bモデルで生成可能で、マルチドメインの評価データも作成しているとのこと
benchmark: https://github.com/AkariAsai/ScholarQABench
[Paper Note] ROBOINTER: A HOLISTIC INTERMEDIATE REPRESEN- TATION SUITE TOWARDS ROBOTIC MANIPULATION, ICLR'26 blindreview, 2026.02
Paper/Blog Link My Issue
#QuestionAnswering #Planning #Chain-of-Thought #Annotation #Reasoning #VisionLanguageModel #Robotics #VisionLanguageActionModel #Manipulation Issue Date: 2026-02-05 Comment
openreview: https://openreview.net/forum?id=PGUC3mmMoi
元ポスト:
[Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #SelfCorrection #ICLR #read-later #Selected Papers/Blogs #KeyPoint Notes #Rubric-based #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 言語モデル(LM)の自己改善能力を探るために、RefineBenchという1,000の問題と評価フレームワークを導入。二つの改善モード、ガイド付きと自己改善を評価した結果、最前線のLMは自己改善で低迷する一方、ガイド付き改善では特許LMや大規模オープンウエイトLMが迅速に応答を改善。自己改善には突破口が必要であり、RefineBenchが進捗の追跡に貢献することを示す。 Comment
元ポスト:
pj page: https://passing2961.github.io/refinebench-page/
verifiableはタスクだけでなくnon verifiableなタスクもベンチマークに含まれ、ガイド付き/無しの異なる設定、11種類の多様なドメイン、チェックリストベースのbinary classificationに基づく評価(strong LLMによって分類する; これによりnon verifiableなタスクでも評価可能)、マルチターンでの改善を観測できる、self-correction/refinementに関するベンチマーク。
フロンティアモデルでも自己改善はガイド無しの場合ではあまり有効に機能しないことを明らかにし、外部からガイドが与えられればOpenLLMでさえも少ないターン数で完璧に近い方向にrefineされる、という感じの内容に見える。
つまり自身とは異なるモデルで、何らかの素晴らしい批評家がいれば、あるいは取り組みたいタスクにおいて一般化された厳密性のあるチェックリストがあれば、レスポンスはiterationを繰り返すごとに改善していくことになる。
[Paper Note] Programming with Pixels: Can Computer-Use Agents do Software Engineering?, Pranjal Aggarwal+, ICLR'26, 2025.02
Paper/Blog Link My Issue
#ComputerVision #AIAgents #Evaluation #Coding #ICLR #SoftwareEngineering #ComputerUse #VisionLanguageModel #GUI Issue Date: 2026-02-05 GPT Summary- CUA(コンピュータ利用エージェント)は一般的なタスクを実行する可能性があるが、ソフトウェアエンジニアリングのような専門的な作業の自動化能力は不明である。本研究では、「Programming with Pixels」(PwP)を導入し、エージェントが視覚的にIDEを操作して多様なソフトウェアエンジニアリングタスクを実行する環境を提供する。また、15のソフトウェアエンジニアリングタスクに対するベンチマーク「PwP-Bench」を設立し、CUAsの性能を評価した。結果、純粋な視覚的インタラクションでは専門エージェントに劣るが、APIへの直接アクセスを与えることで性能が向上し、専門性に達することが多かった。CUAsは視覚的基盤の限界と環境の効果的な活用に課題があるが、PwPは洗練されたタスクに対する評価の新たな基準を提供する。 Comment
pj page: https://github.com/ProgrammingwithPixels/PwP
元ポスト:
[Paper Note] SWE-Universe: Scale Real-World Verifiable Environments to Millions, Mouxiang Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SyntheticData #Coding #MultiLingual #SoftwareEngineering #mid-training #PostTraining #read-later #Selected Papers/Blogs #Verification #Scalability Issue Date: 2026-02-05 GPT Summary- SWE-Universeは、GitHubのプルリクエストから自動的に検証可能なソフトウェア工学環境を構築するためのスケーラブルなフレームワーク。カスタムトレーニングされたビルディングエージェントが反復自己検証とハッキング検出を用いて信頼性の高いタスク生成を実現。これにより、実世界の多言語SWE環境が100万以上増加し、Qwen3-Max-Thinkingにおいて75.3%のスコアを達成。次世代コーディングエージェントの発展に寄与。 Comment
元ポスト:
ポイント解説:
これまでと比較して非常に大規模な実PRに基づいた、さまざまなプログラミング言語に基づくverifiableな学習用の合成データを構築できる環境で、一つ一つの品質はSWE Benchなどには及ばないが、量が圧倒的
[Paper Note] Hunt Instead of Wait: Evaluating Deep Data Research on Large Language Models, Wei Liu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Open-endedTasks Issue Date: 2026-02-03 GPT Summary- エージェントの能力には、自律的に目標を設定し探求する「探求知能」が求められ、単なるタスク完了の「実行知能」とは異なる。データサイエンスは生データから始まるため、自然なテストベッドを提供するが、関連するベンチマークは少ない。これに対処するため、「Deep Data Research(DDR)」を提案し、LLMがデータベースから洞察を抽出するオープンエンドタスクと、評価を可能にするDDR-Benchを導入。最前線のモデルは新たなエージェンシーを示すが、長期的な探求は依然困難であり、探求知能はモデルの戦略に依存している。 Comment
元ポスト:
[Paper Note] VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents, Zirui Wang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #LongSequence #VisionLanguageModel #interactive #Initial Impression Notes Issue Date: 2026-02-03 GPT Summary- 現代の視覚-言語モデル(VLM)は、複雑な視覚的相互作用において効果的に機能しておらず、特に長期的な知覚や記憶の統合に課題があります。これに対処するため、「VisGym」という17の環境を導入し、記号パズルやナビゲーションを含む多様な設定でモデルを評価・訓練します。実験では、最前線のモデルがインタラクティブな場面で苦戦していることが示され、長い文脈の活用に制限があることが明らかになりました。しかし、目標観察やテキストフィードバックによる微調整は、モデルの視覚的意思決定を改善する効果が確認されました。 Comment
pj page: https://visgym.github.io/
元ポスト:
このベンチマーク上のSoTAであるGemini 3 Proでも平均Acc.50%に到達しないinteractiveなVQAタスク群な模様
[Paper Note] PaperBanana: Automating Academic Illustration for AI Scientists, Dawei Zhu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Multi #ComputerVision #NLP #AIAgents #Evaluation #DiffusionModel #VisionLanguageModel #2D (Image) #AcademicWriting Issue Date: 2026-02-03 GPT Summary- PaperBananaは、学術イラストの自動生成を実現するエージェントフレームワークであり、視覚言語モデルと画像生成モデルを活用しています。専門エージェントを調整して参照を取得し、コンテンツとスタイルを計画、画像をレンダリングし、批評を通じて洗練を行います。PaperBananaBenchを用いた評価では、多様なスタイルの292のテストケースにおいて、忠実性や美的感覚で主要なベースラインを上回る成果を示しました。これにより、高品質な出版準備の整ったイラスト生成が可能となります。 Comment
pj page: https://dwzhu-pku.github.io/PaperBanana/
元ポスト:
[Paper Note] DiffuSpeech: Silent Thought, Spoken Answer via Unified Speech-Text Diffusion, Yuxuan Lou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Chain-of-Thought #SpeechProcessing #DiffusionModel #Reasoning #Architecture #Selected Papers/Blogs #TTS #AudioLanguageModel #Initial Impression Notes Issue Date: 2026-02-02 GPT Summary- 音声LMMが直接応答を生成する際に発生するエラーを解決するため、「沈黙の思考、話された答え」という新たなパラダイムを提案。内部のテキスト推論と共に音声応答を生成する拡散ベースの音声-テキスト言語モデル\method{}を開発。モダリティ固有のマスキングを使用し、推論過程と音声トークンを共同生成。初の音声QAデータセット\dataset{}も構築し、26,000サンプルを含む。実験結果はQA精度で最先端を達成し、最高のTTS品質を維持しつつ言語理解も促進。拡散アーキテクチャの効果も実証。 Comment
元ポスト:
音声合成、AudioLanguageModelの枠組みにおいてreasoningを導入する新たなアーキテクチャを提案し、そのためのデータを収集して性能が向上しているように見え、重要研究に感じる。
[Paper Note] Grounding Computer Use Agents on Human Demonstrations, Aarash Feizi+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #ICLR #ComputerUse #PostTraining #UI Issue Date: 2026-02-01 GPT Summary- 専門家の実演から構築したデスクトップグラウンディングデータセット「GroundCUA」を提案。87のアプリをカバーし、56,000枚のスクリーンショットと356万件以上の注釈を含む。これに基づき、指示をUI要素にマッピングする「GroundNext」モデル群を開発。教師ありファインチューニングにより最先端の結果を達成し、強化学習によるポストトレーニングでさらに性能向上。高品質なデータセットがコンピューターエージェントの進展に貢献することを示唆。 Comment
pj page: https://groundcua.github.io/
元ポスト:
[Paper Note] DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation, Haozhe Xie+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Evaluation #read-later #Selected Papers/Blogs #Robotics #VisionLanguageActionModel #One-Line Notes #Manipulation Issue Date: 2026-01-31 GPT Summary- 動的オブジェクト操作に挑む「DynamicVLA」フレームワークを提案。畳み込み視覚エンコーダで迅速なマルチモーダル推論を実現し、連続推論で迅速な適応を促進。潜在認識アクションストリーミングにより認識と実行のギャップを埋める。新たに構築したDOMベンチマークで動的操作データを収集し、評価によって顕著な性能向上を示す。 Comment
pj page: https://www.infinitescript.com/project/dynamic-vla/
元ポスト:
動くオブジェクト(Donamic Object)に関するデータセットとベンチマークに見える。
既存VLAではできないそこそこな速度で転がるピンポン玉などを正確に掴むことができるようなデモが掲載されている。興味深い。
コードとデータセットが公開:
[Paper Note] Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models, Zengbin Wang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #DiffusionModel #TextToImageGeneration #read-later #Selected Papers/Blogs #SpatialUnderstanding Issue Date: 2026-01-31 GPT Summary- T2Iモデルの空間処理能力を評価する新しいベンチマーク「SpatialGenEval」を提案。1,230の長い情報密度の高いプロンプトを用いて、空間関係の推論が主なボトleneckであることを確認。また、「SpatialT2I」データセットを構築し、ファインチューニングによって現実的な空間効果を向上させるデータ中心のアプローチを強調。 Comment
元ポスト:
[Paper Note] WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World, Ao Liang+, CVPR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Evaluation #CVPR #read-later #Selected Papers/Blogs #WorldModels #3D (Video) #One-Line Notes #Author Thread-Post Issue Date: 2026-01-30 GPT Summary- 生成的世界モデルはリアルな4D環境を合成しますが、物理的または行動的に失敗することが多いです。この課題に対処するため、WorldLensを導入し、生成された世界の評価を行う全範囲ベンチマークを提供します。これには生成、再構成、行動追従など五つの側面が含まれ、視覚的現実性や物理的妥当性を評価します。既存モデルには広範囲に優れたものがなく、WorldLens-26Kという大規模な人間注釈付きデータセットを構築し、評価モデルWorldLens-Agentを開発しました。これにより、世界の忠実性を測定する統一されたエコシステムを形成し、リアルな見た目と行動の両面で評価基準を標準化します。 Comment
pj page: https://worldbench.github.io/worldlens
元ポスト:
github: https://github.com/worldbench/WorldLens
(自動運転に関する)World Model(には限られないかもしれないが)を多角的な軸から評価できるベンチマーク。3D object detection/Tracking, Novel-view Discrepancy/Quality, Occupacy Prediction, Subject Fidelity/Consistency/Coherence, Temporal Concistencyなど、20以上のdimensionから評価可能なようである。
著者ポスト:
[Paper Note] Factuality Matters: When Image Generation and Editing Meet Structured Visuals, Le Zhuo+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Evaluation #Factuality #DiffusionModel #ICLR #2D (Image) #Editing #UMM #ImageSynthesis Issue Date: 2026-01-30 GPT Summary- 構造化された視覚生成に特化した研究であり、高品質な構造画像データセットを構築。VLMとFLUXを統合したモデルを訓練し、推論能力を強化。新たな評価指標StructScoreを導入し、多段階Q&Aプロトコルで正確性を評価。モデルは強力な編集性能を示し、構造化視覚の統一基盤を目指す。 Comment
元ポスト:
[Paper Note] CorpusQA: A 10 Million Token Benchmark for Corpus-Level Analysis and Reasoning, Zhiyuan Lu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #RAG(RetrievalAugmentedGeneration) #LongSequence #Selected Papers/Blogs #memory #Initial Impression Notes Issue Date: 2026-01-22 GPT Summary- CorpusQAは、最大1,000万トークンに対応する新しいベンチマークで、広範な非構造的テキストに対する全体的な推論を求める。これは、プログラムによって保証された真実の回答を持つ複雑なクエリを生成する革新的なデータ合成フレームワークを用いており、LLMの長期コンテキスト推論能力を向上させることが実証された。一方で、長い入力に対しては現行のリトリーバーシステムが限界を迎え、メモリ拡張型エージェントアーキテクチャがより効果的な解決策となる可能性が示唆された。 Comment
元ポスト:
10Mコンテキストまで性能を測定可能なベンチマークらしく、結果を見ると以下のようになっている。128KコンテキストではGPT5に軍配が上がり、1M級のコンテキストになるとGeminiがやはり強い(これは昔からそうでFiction.liveベンチなどでも示されていた)。
10Mコンテキスト級ではLLMのコンテキストウィンドウのみでは対応不可なので、RAGやMemory Agextでベンチマーキングされているが、明確にAgentの方が性能が良い。ベンチマークの細かな作り方や、harnessなど、具体的にどのような設定で実験されているのか気になる。
[Paper Note] RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation, Sunzhu Li+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #RewardModel #GenerativeVerifier #Rubric-based #Open-endedTasks Issue Date: 2026-01-20 GPT Summary- 強化学習における検証可能な報酬(RLVR)は、論理的思考が求められるが、評価の欠如が生成の最適化を難しくしている。ルーブリック評価は構造的手段を提供するが、既存手法はスケーラビリティや粗い基準に課題がある。これに対処するため、自動評価基準の生成フレームワークを提案し、微妙なニュアンスを捉える高識別力基準を作成。約11万件のデータセット「RubricHub」を紹介し、二段階ポストトレーニングでその有用性を検証。結果、Qwen3-14BがHealthBenchで69.3の最先端結果を達成し、他のモデルを上回った。 Comment
pj page: https://huggingface.co/datasets/sojuL/RubricHub_v1
元ポスト:
[Paper Note] LEMAS: Large A 150K-Hour Large-scale Extensible Multilingual Audio Suite with Generative Speech Models, Zhiyuan Zhao+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#SpeechProcessing #Speech #MultiLingual #TTS #One-Line Notes Issue Date: 2026-01-14 GPT Summary- LEMAs-Datasetは、150,000時間以上の音声データから構築された、大規模で多言語対応のオープンソース音声コーパスです。特に、単語レベルのタイムスタンプを持ち、効率的なデータ処理パイプラインによって品質が保証されています。このデータセットを利用して、異なるアーキテクチャによる二つのベンチマークモデルを訓練し、多言語合成や音声編集における高品質なパフォーマンスを実現しました。実験結果は、LEMAs-Datasetが音声生成システムの発展に寄与することを示しています。 Comment
pj page: https://lemas-project.github.io/LEMAS-Project/
データセットに日本語が含まれてないように見える😭
元ポスト:
[Paper Note] Can We Predict Before Executing Machine Learning Agents?, Jingsheng Zheng+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #AIAgents #Planning #Evaluation #read-later #Initial Impression Notes Issue Date: 2026-01-14 GPT Summary- 自律的な機械学習エージェントは「生成-実行-フィードバック」パラダイムに依存しているが、高価な実行に制約されている。本研究では、事前情報を内部化し、瞬時の予測的推論に置き換えることでこの問題を解決。データ中心のソリューションを形式化し、18,438のペア比較からなるコーパスを構築。LLMが高い予測能力を示し、61.5%の精度を達成。FOREAGENTエージェントは予測-確認ループを採用し、収束を6倍速め、実行ベースラインを6%上回る成果を達成。コードとデータセットは近日中に公開予定。 Comment
元ポスト:
(読了前の第一印象)問題設定や着眼点が実用的で興味深い。
[Paper Note] Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning, Chengwen Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #Evaluation #MultiModal #VisionLanguageModel #DeepResearch #3D (Video) #One-Line Notes Issue Date: 2026-01-14 GPT Summary- VideoDRは、ビデオを基にしたオープンドメインのビデオ質問応答のための新たな深層研究ベンチマークで、フレーム間の視覚的手がかり抽出やインタラクティブなウェブ検索、マルチホップ推論を要求する。高品質なビデオサンプルを提供し、複数のマルチモーダル大規模言語モデルの評価を行った結果、エージェントの性能はワークフローに依存することが示された。VideoDRは次世代ビデオ深層研究エージェントへの重要な課題を明らかにする。 Comment
元ポスト:
初めてのvideo deep researchベンチマークとのこと
[Paper Note] BabyVision: Visual Reasoning Beyond Language, Liang Chen+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #Analysis #Evaluation #read-later #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes Issue Date: 2026-01-14 GPT Summary- MLLMは基本的な視覚タスクで人間、特に3歳児に劣る性能を示す。これを調査するために、視覚能力を評価する「BabyVision」ベンチマークを導入。388のタスクを通じて、MLLMのパフォーマンスが人間基準を大きく下回ることが確認された。具体的には、Gemini3-Pro-Previewが49.7点で、6歳や成人の平均94.1点に遠く及ばない。これにより、MLLMは基本的な視覚原理が不足していることが明らかにされ、BabyVision-Genと自動評価ツールキットも提案された。データとコードは公開されている。 Comment
pj page: https://unipat.ai/blog/BabyVision
元ポスト:
ポイント解説:
(読了前の第一印象)現在のMLLMが純粋な視覚的な推論タスクにおいて幼児以下であることを示し、既存のベンチマークの脆弱性(純粋な視覚的な推論能力を評価できていない)を指摘した上で新たなベンチマークを提案しているように見え、非常に重要な研究に見える。
[Paper Note] The Quest for Generalizable Motion Generation: Data, Model, and Evaluation, Jing Lin+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #SyntheticData #Evaluation #DiffusionModel #ICLR #Generalization #3D (Scene) #FlowMatching #Robotics #3D (Video) #HumanMotionGeneration Issue Date: 2026-01-11 GPT Summary- 3D人間動作生成(MoGen)は一般化能力に課題があるが、動画生成(ViGen)は優れた一般化を示す。これを受けて、ViGenからMoGenへの知識移転のためのフレームワークを提案。228,000の高品質な動作サンプルを含むデータセットViMoGen-228Kを作成し、MoCapデータとViGenモデルからの情報を統合したフローマッチングベースの拡散トランスフォーマーViMoGenを開発。さらに、動作の質や一般化能力を評価するための階層的ベンチマークMBenchを提示。実験結果は、提案手法が既存のアプローチを大幅に上回ることを示した。 Comment
dataset:
https://huggingface.co/datasets/wruisi/ViMoGen-228K
leaderboard:
https://huggingface.co/spaces/wruisi/MBench_leaderboard
元ポスト:
ポイント解説:
openreview: https://openreview.net/forum?id=KNke6Pkq4o
[Paper Note] RoboReward: General-Purpose Vision-Language Reward Models for Robotics, Tony Lee+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ReinforcementLearning #Evaluation #PostTraining #read-later #Selected Papers/Blogs #VisionLanguageModel #RewardModel #Robotics #EmbodiedAI Issue Date: 2026-01-09 GPT Summary- 強化学習における報酬設計の重要性を踏まえ、実ロボティクスでの自動報酬モデルとしてのビジョン・ランゲージモデル(VLM)の効果を探求。新たに「RoboReward」データセットを導入し、成功例の反事実的ラベリングやネガティブ例データ拡張を通じて多様なタスクを網羅した訓練データを構築。評価の結果、既存のVLMには改善の余地があり、4Bおよび8Bパラメータモデルが短期タスクで優れた報酬を提供。最終的に、8Bモデルを実ロボット強化学習に適用し、人間提供の報酬とのギャップを縮小する成果を得た。データセットやモデルは公開されている。 Comment
元ポスト:
[Paper Note] From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence, Marc Finzi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #MachineLearning #Metrics #read-later #Selected Papers/Blogs #OOD #Generalization #Reference Collection Issue Date: 2026-01-09 GPT Summary- 本研究では、データから新たな情報を生成する可能性や、情報の評価方法について探求する。シャノン情報やコルモゴロフの複雑性が無力である理由を示し、情報理論における三つの矛盾する現象を特定する。新たに導入した「エピプレキシティ」は、計算制約のある観察者がデータから学べる情報を捉え、データの構造的内容を評価する手法である。これにより、情報生成のメカニズムやデータの順序依存性を明らかにし、エピプレキシティを用いたデータ選択の理論的基盤を提供する。 Comment
元ポスト:
解説:
ポイント解説:
[Paper Note] NitroGen: An Open Foundation Model for Generalist Gaming Agents, Loïc Magne+, CVPR'26 Best Paper Honorable Mention, 2026.01
Paper/Blog Link My Issue
#ComputerVision #CVPR #read-later #Selected Papers/Blogs #Game #UMM #3D (Video) #VisionActionModel Issue Date: 2025-12-21 GPT Summary- NitroGenは、1,000以上のゲームを対象に40,000時間のプレイ動画で訓練された汎用ゲーミングエージェント向けのビジョン-アクション基盤モデルです。プレイヤーの操作を自動抽出したビデオ-アクションデータセット、クロスゲーム一般化を測るマルチゲームベンチマーク、ビヘイビア・クローン学習によるモデルを含みます。3Dアクションゲーム、2Dプラットフォーマー及び手続き的生成世界において高い能力を示し、未見のゲームでも最大52%のタスク成功率向上を実現。データセットやモデルの重みを公開し、汎用的な体現エージェントの研究を促進します。 Comment
元ポスト:
HF:
https://huggingface.co/nvidia/NitroGen
pj page:
https://nitrogen.minedojo.org/
1000以上のゲームの40000時間を超えるゲームプレイから学習されたVideo to Action Model
CVPR Best Paper Honorable Mention:
[Paper Note] Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents, Yueqi Song+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #ICLR #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-10-30 GPT Summary- 本研究では、エージェントデータの収集における課題を解決するために、エージェントデータプロトコル(ADP)を提案。ADPは多様なデータ形式を統一し、簡単に解析・トレーニング可能な表現言語である。実験により、13のエージェントトレーニングデータセットをADP形式に統一し、標準化されたデータでSFTを実施した結果、平均約20%の性能向上を達成。ADPは再現可能なエージェントトレーニングの障壁を下げることが期待される。 Comment
pj page: https://www.agentdataprotocol.com
元ポスト:
著者ポスト:
解説:
エージェントを学習するための統一的なデータ表現に関するプロトコルを提案
続報:
openreview: https://openreview.net/forum?id=tG6301ORHd
[Paper Note] VisCoder2: Building Multi-Language Visualization Coding Agents, Yuansheng Ni+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #AIAgents #Evaluation #Coding #ICLR Issue Date: 2025-10-30 GPT Summary- 大規模言語モデル(LLMs)を用いた視覚化コーディングエージェントは、実行や修正において課題がある。これを解決するために、679Kの視覚化サンプルを含むデータセットVisCode-Multi-679K、自己デバッグ用のベンチマークVisPlotBench、そしてマルチ言語モデルVisCoder2を提案。実験結果では、VisCoder2がオープンソースのベースラインを超え、商用モデルに近い性能を示し、特に記号的言語での成功が顕著であった。 Comment
pj page: https://tiger-ai-lab.github.io/VisCoder2/
元ポスト:
openreview: https://openreview.net/forum?id=4zoMnmZzh4
[Paper Note] IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction, Hao Li+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Transformer #FoundationModel #ICLR #3D Reconstruction #3D (Scene) #UMM #SpatialUnderstanding Issue Date: 2025-10-28 GPT Summary- 人間の3Dシーン理解を模倣するため、空間再構築とインスタンス理解を統合したInstanceGrounded Geometry Transformer(IGGT)を提案。IGGTは2D視覚入力を用いて幾何学的構造とインスタンスクラスタリングを統一的に表現し、3Dシーンの一貫性を向上させる。新たに構築したInsScene-15Kデータセットを用いて、3D一貫性のあるインスタンスレベルのマスク注釈を提供。 Comment
pj page: https://lifuguan.github.io/IGGT_official/
元ポスト:
ポイント解説:
openreview: https://openreview.net/forum?id=swiL18PmUV
[Paper Note] Impatient Users Confuse AI Agents: High-fidelity Simulations of Human Traits for Testing Agents, Muyu He+, ACL'26, 2025.10
Paper/Blog Link My Issue
#NLP #UserModeling #LanguageModel #UserBased #AIAgents #Evaluation #ACL #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-10-08 GPT Summary- TraitBasisを用いて、会話型AIエージェントの堅牢性を体系的にテストする手法を提案。ユーザーの特性(せっかちさや一貫性のなさ)を制御し、AIエージェントのパフォーマンス低下を観察。最前線のモデルで2%-30%の性能低下を確認し、現在のAIエージェントの脆弱性を示す。TraitBasisはシンプルでデータ効率が高く、現実の人間の相互作用における信頼性向上に寄与する。$\tau$-Traitをオープンソース化し、コミュニティが多様なシナリオでエージェントを評価できるようにした。 Comment
元ポスト:
実際の人間にあるような癖(のような摂動)を与えた時にどれだけロバストかというのは実応用上非常に重要な観点だと思われる。元ポストを見ると、LLM内部のmatmulを直接操作することで、任意のレベルの人間の特性(e.g.,疑い深い、混乱、焦りなど)を模倣する模様。
[Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #SoftwareEngineering #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-10-07 GPT Summary- AIエージェントが長期的なタスクを自律的に完遂する能力が向上している中、Terminal-Bench 2.0を提案。これは実世界のワークフローに基づいた89の高難易度タスクから成るベンチマークで、ユニークな環境と人間の解法、包括的なテストが特徴です。フロンティアモデルは65%未満のスコアを記録し、改善点を明らかにするための誤り分析を実施。データセットは公開され、研究開発の支援が期待される。 Comment
元ポスト:
なお、Claude CodeはTerminal Benchリーダーボードでは非常にスコアが低いハーネスらしい:
現在はCodex+GPT-5.5がv2.0リーダーボードではSoTA
※以下、元論文中でScaffoldingと表現されている部分をAgent Harnessという最近の呼称に変更してメモしています。個人的にはScaffoldingという呼び方の方がEvaluation Harnessと混同しなくて好きなのですが、Agent Harnessの方が浸透していってそうなので、それにならっています。
Terminal Benchは与えられたタスクをターミナルを操作することで完了する能力を測定するベンチマークであり、SWE Benchなどの既存ベンチマークと比較して、より多様でlong horizon、かつフロンティアモデルにとってhardなタスクによってフロンティアモデルの性能を評価することを目的とする。注意点としては、エージェントはターミナルだけを唯一のツールとして利用することを強制しているわけではなく、コンテナを自由な方法で操作することができる。また、Terminal Benchが測定したいのはモデルの性能であるが、AI AgentにおいてモデルとAgent Harnessは切り離せない。Agent Harness(論文中ではscaffoldingというliteratureに沿った呼称を利用している)は特定のモデルに適合するように開発されており、同じ組織によって開発されたモデルとAgent Harnessではその傾向がより顕著である。このため、多くのAgent Harnessはバイアスや制約を持つため、その影響を緩和し中立に評価が可能なシンプルなAgent Harness (scaffolding)であるTerminus 2を導入している。Terminus 2はheadless terminalと呼ばれる単一のツールを有し、これは、Dockerコンテナを内のtmux shell上でキーストロークのみを実施できるツールであり、Bashコマンドのみを通じてタスクを遂行する。また、contextがlimitに到達した場合は、モデルにcontextを要約させる機能も有している。
Terminal Benchの一つのタスクは、タスクのinstruction, Dockerfile, test, 正解solutionが制限時間つきで構成され、多様なタスクを収集するためにオープンソースコミュニティの協力を得て93人のcontributorsによって、229のタスクが編成された。そのうち、著者らの困難度や品質などのレビューを経て89個のタスクが選択されTerminal Bench 2.0が編成された。
Terminal Bench 2.0のタスクの著者によって推定された、junior/expertなエンジニアがどの程度の時間をタスクを完了するのに要するかに関する分布。1時間以内に終わるものから、juniorでは168時間以上かかるものまで、幅広いhorizonのタスクが存在している。
以下がタスクを作成者によってアサインされたタスクのカテゴリの分布で、多くはソフトウェアエンジニアリングだが、システム管理やデータサイエンス、セキュリティなどもあり、非エンジニアリングタスクとして動画処理やpersonal assistantなどのタスクも少量だが含まれる。
評価結果を見ると、Figure 1となっており最も性能が良かったのはGPT-5.2+Codex CLIであった(なお、この評価結果はもう古いので最新の結果はリーダーボードを参照のこと)。次点でClaude Opus 4.5+Terminus 2であった。
また、性能-コストの散布図を見るとコストと性能はトレードオフにあることがわかる。
[Paper Note] MENLO: From Preferences to Proficiency -- Evaluating and Modeling Native-like Quality Across 47 Languages, Chenxi Whitehouse+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Evaluation #Conversation #MultiLingual #LLM-as-a-Judge #ICLR #RewardModel #One-Line Notes Issue Date: 2025-10-03 GPT Summary- MENLOフレームワークを用いて、47言語の6,423のプロンプト-応答ペアのデータセットを作成し、LLMの応答品質を評価。ゼロショット評価者はペアワイズ評価から利益を得るが、人間には及ばず。強化学習によるファインチューニングで改善を示し、RL訓練評価者がLLMの多言語能力向上に寄与することを確認。ただし、人間の判断との不一致は残る。データセットと評価フレームワークを公開し、多言語LLM評価の研究を支援。 Comment
元ポスト:
LLMの応答を多言語でよりnativeに近いものにするための取り組み、および評価のフレームワーク(MENLO, データセット含む)な模様。nativeらしさを測るために重要な次元としてFluency, Tone, Localized Tone, Localized Factualityと呼ばれる軸を定義している模様。その上で47言語における6423の人手でアノテーションされたpreference dataを作成し評価をしたところ、既存のLLM-as-a-judgeやSFT/RLされたReward Modelでは、人間による評価にはまだまだ及ばないことが明らかになり、MENLOを用いてRL/SFTすることでLLM JudgeやReward Modelの性能を改善できる、といった話な模様。
4つの次元については以下の表を参照のこと。
それぞれ
- Fluency: 専門家レベルのnative speakerと比較した時のproficiency
- Tone: 全体的なwriting stvleや語り口
- Localized Tone: 文化的、地域的な言葉のニュアンス
- Localized Factuality: 地域固有のコンテキストに沿った事実性や網羅性
openreview: https://openreview.net/forum?id=QOWYX3Q2XS
[Paper Note] EditReward: A Human-Aligned Reward Model for Instruction-Guided Image Editing, Keming Wu+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #Evaluation #ICLR #PostTraining #VisionLanguageModel #2D (Image) #RewardModel #Editing #One-Line Notes Issue Date: 2025-10-02 GPT Summary- 自然言語指示による画像編集の進展において、オープンソースモデルは遅れをとっている。これを解決するために、20万以上の選好ペアを含む新しいデータセット\mnameを構築し、指示に基づく画像編集タスクで人間の選好と高い整合性を示した。実験では、\mnameが既存のベンチマークで最先端の人間相関を達成し、ノイズの多いデータセットから高品質なサブセットを選択することで、画像編集モデルの性能を大幅に向上させることができた。今後、\mnameはコミュニティに公開され、高品質な画像編集トレーニングデータセットの構築を支援する予定である。 Comment
pj page:
https://tiger-ai-lab.github.io/EditReward/
HF:
https://huggingface.co/collections/TIGER-Lab/editreward-68ddf026ef9eb1510458abc6
これまでのImageEditing用のデータセットは、弱いReward Modelによって合成されるか、GPT-4oや他のVLMによる品質の低いフィルタリングにより生成されており、高品質なデータセットが存在しない課題があった。これを解決するために大規模なImageEditingの嗜好データを収集し、ImageEditingに特化した報酬モデルであるEditRewardを学習。このモデルは人間の専門家とのagreementにおいて高い(というよりりbestと書いてある)agreementを示し、実際にEditRewardによって既存のデータセットをfilteringして学習したら大きなgainがあったよ、という感じらしい。
openreview: https://openreview.net/forum?id=eZu358JOOR
[Paper Note] CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization, Zhongyuan Peng+, ACL'26, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Mathematics #ACL Issue Date: 2025-07-09 GPT Summary- 自然言語の数学的表現を実行可能なコードに翻訳する課題に対し、批評者の役割を能動的な学習コンポーネントに変えるCriticLeanという新しい強化学習フレームワークを提案。CriticLeanGPTを用いて形式化の意味的忠実性を評価し、CriticLeanBenchでその能力を測定。285K以上の問題を含むFineLeanCorpusデータセットを構築し、批評段階の最適化が信頼性のある形式化に重要であることを示す。 Comment
元ポスト:
Lean 4 形式に
[Paper Note] Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Coding #Mathematics #ICLR #read-later #Diversity #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-05-08 GPT Summary- 本研究では、公共データを体系的に書き換えることで大規模言語モデル(LLMs)の性能を向上させる2つのオープンライセンスデータセット、SwallowCodeとSwallowMathを紹介。SwallowCodeはPythonスニペットを洗練させる4段階のパイプラインを用い、低品質のコードをアップグレード。SwallowMathはボイラープレートを削除し、解決策を簡潔に再フォーマット。これにより、Llama-3.1-8Bのコード生成能力がHumanEvalで+17.0、GSM8Kで+12.4向上。すべてのデータセットは公開され、再現可能な研究を促進。 Comment
元ポスト:
解説ポスト:
openreview: https://openreview.net/forum?id=45btPYgSSX
[Paper Note] Ambig-SWE: Interactive Agents to Overcome Underspecificity in Software Engineering, Sanidhya Vijayvargiya+, ICLR'26, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #QuestionGeneration #ICLR #SoftwareEngineering #One-Line Notes Issue Date: 2025-04-02 GPT Summary- AIエージェントは、欠落情報を補うための推測や明確化の質問を避けることで、安全リスクやリソース浪費を引き起こすことがある。本研究では、対話型コード生成における不十分な指示への対処能力を評価し、(a) 不十分さの検出、(b) 明確化質問の提示、(c) 対話の活用による性能向上の三つのステップで検証した。Ambig-SWEを使用し、モデルは不十分な指示を区別するのに苦労しつつ、対話時には最大74%の性能向上を示した。これにより、対話の重要性が浮き彫りになった。研究は、最新モデルの情報処理におけるギャップを明らかにし、評価の段階的アプローチを提案している。 Comment
曖昧なユーザメッセージに対する、エージェントが"質問をする能力を測る"ベンチマーク
openreview: https://openreview.net/forum?id=X2yzXtH4wp
[Paper Note] DataDecide: How to Predict Best Pretraining Data with Small Experiments, Ian Magnusson+, ICML'25, 2025.04
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Evaluation #ICML #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-05-29 GPT Summary- 小規模な実験を用いて大規模言語モデルのデータ選択を効率化することは重要である。DataDecideと呼ばれる評価スイートを通じて、異なるデータセットに基づいた前訓練の実験を実施し、150Mパラメータのモデルが1Bパラメータでの最良モデルを約80%の精度で予測できることが示された。主にスケーリング法則に基づくベースラインと比較し、連続的尤度指標を使うことで、限られた資源でも高精度の予測が可能であることが明らかとなった。 Comment
大規模なモデルを学習するためにどのようなデータレシピに従って、どのようなデータを使うべきかを、小規模なモデルでの学習を通じて予測できることを示した(150Mモデルの学習で1Bモデルに対するデータレシピの優劣を80%のDecisionAccuracyで予測可能)。
25種類のデータレシピ(ソース, deduplication, filtering, mixingによって構成)を、14種類のモデルスケールに対して、計算コスト(token-to-parameterの比率)を固定し3種類のseedを用いて実験し、事前学習の結果を体系的に調査。
1Bパラメータのdownstreamタスクにおいて、25種類のデータレシピごとの平均性能によってpairwiseの優劣に関するペアを構成し、全てのペアに対する優劣をどれだけ予測できるかを評価(DecisionAccuracy)したところ、下記図のようになった。たとえば、150Mスケールのモデルを訓練するだけでDecisionAccuracyは80%に到達し、これには1Bモデルを学習した場合と比較して2パーセント程度の計算コストしか要さないことが明らかとなった。
HF: https://huggingface.co/collections/allenai/datadecide
openreview: https://openreview.net/forum?id=p9YlQPF8fE
[Paper Note] DeepShop: A Benchmark for Deep Research Shopping Agents, Yougang Lyu+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #ComputerUse #VisionLanguageModel Issue Date: 2026-04-10 GPT Summary- DeepShopは、複雑なオンラインショッピング環境でのウェブエージェント評価のために設計された新たなベンチマークである。実ユーザークエリを基に多様なクエリを生成し、その複雑さを製品属性や検索フィルターを考慮してeasy、medium、hardの3レベルに分類。エージェントの性能は詳細な評価基準に基づき、RAG法との比較やフィルターとソート設定における課題を明らかにすることで、ショッピングエージェントの改善に寄与する。
[Paper Note] An Illusion of Progress? Assessing the Current State of Web Agents, Tianci Xue+, COLM'25, 2025.04
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #Evaluation #COLM #ComputerUse #VisionLanguageModel #GUI Issue Date: 2026-04-10 GPT Summary- ウェブエージェントの能力を包括的に評価し、既存の楽観的な見解との乖離を明らかに。Online-Mind2Webという新たなベンチマークを用い、300の現実的なタスクで評価を実施。新しい自動評価手法を開発し、人間の判断と85%の一致を達成。ウェブエージェントの強みと限界を示し、今後の研究の方向性を提案。 Comment
openreview: https://openreview.net/forum?id=6jZi4HSs6o
[Paper Note] MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering, Jun Shern Chan+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #AutoML #ICLR #Selected Papers/Blogs Issue Date: 2026-03-30 GPT Summary- MLE-benchは、AIエージェントの機械学習エンジニアリング能力を測定するためのベンチマークで、75件のKaggle競技を厳選し、実世界のスキルを試すタスクを作成。人間ベースラインを確立し、最先端の言語モデルを評価した結果、OpenAIのo1-previewとAIDEスキャフォールドの組み合わせが16.9%の競技でKaggleブロンズメダル以上の性能を示した。リソーススケーリングや事前学習の影響も調査し、ベンチマークコードをオープンソース化して今後の研究を促進する。 Comment
blog:
- MLE-Bench, OpenAI, 2024.10
openreview: https://openreview.net/forum?id=6s5uXNWGIh
[Paper Note] ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use, Kaixin Li+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#ComputerVision #Evaluation #ComputerUse #VisionLanguageModel #One-Line Notes #Grounding #GUI Issue Date: 2026-03-20 GPT Summary- MLLMの進展は一般的なタスクのGUIエージェントに貢献しているが、専門分野への適用は未検討。ScreenSpot-Proでは、高解像度の専門設定でMLLMのグラウンディング能力を評価する新ベンチマークを提示。複数の業界とアプリケーションに対してテストを行い、既存モデルの性能は低く、最良のモデルでも18.9%に過ぎない。探索域の戦略的縮小により精度向上を示し、ScreenSeekeRを提案。階層的検索を用いることで、訓練不要で48.1%の性能を達成。専門アプリ向けGUIエージェント開発の進展を期待。 Comment
元ポスト:
高解像度な画像を用いた多様なドメインでのVLMのGUI grounding性能を測るベンチマークとリーダーボードのようでえる
現在のトップはHolo2のようである
- New Holo2 model takes the lead in UI Localization, H Company, 2026.02
- Holo2: Cost-Efficient Models for Cross-Platform Computer-Use Agents, H Company, 2025.11
[Paper Note] EgoEdit: Dataset, Real-Time Streaming Model, and Benchmark for Egocentric Video Editing, Runjia Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Evaluation #Editing #3D (Video) #EgocentricView #Initial Impression Notes Issue Date: 2026-03-17 GPT Summary- 自己視点動画編集のためのエコシステムを提案。EgoEditDataを構築し、手と物体の相互作用に特化したデータセットを提供。リアルタイム推論を可能にするEgoEditを開発し、指示に従いながら高品質の編集を実現。評価スイートEgoEditBenchを導入し、自己視点編集での進歩を示しつつ、一般編集タスクでも強力な性能を維持。EgoEditDataとEgoEditBenchは研究コミュニティに公開予定。 Comment
pj page: https://snap-research.github.io/EgoEdit/
元ポスト:
完全にARの上位互換
[Paper Note] Improving LLM Agents with Reinforcement Learning on Cryptographic CTF Challenges, Lajos Muzsai+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Reasoning #PostTraining #RLVR #Security Issue Date: 2026-02-17 GPT Summary- セキュリティ分野におけるLLMエージェントの潜在能力を引き出すために、手続き的に生成された暗号用CTFデータセット『Random-Crypto』を提案。暗号推論を強化学習の理想的なテストベッドとして活用し、Pythonツールを用いてLlama-3.1-8BをGRPOでファインチューニング。得られたエージェントはPass@8で顕著な改善を見せ、『picoCTF』や『AICrypto MCQ』の外部ベンチマークにも一般化。アブレーション研究により、ツール活用の強化と手続き的推論の向上が寄与していることが示され、複雑なサイバーセキュリティタスクに対応可能な知的LLMエージェント構築の基盤を確立。 Comment
元ポスト:
[Paper Note] Evaluating Legal Reasoning Traces with Legal Issue Tree Rubrics, Jinu Lee+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Explanation #ReinforcementLearning #RAG(RetrievalAugmentedGeneration) #Reasoning #PostTraining #Legal #Rubric-based Issue Date: 2026-02-11 GPT Summary- 専門分野でのLLMの推論トレース評価の重要性を認識し、新たな法律推論データセット「LEGIT」を導入。本研究では、裁判判断を主張と結論の木構造に変換し、推論のカバー範囲と正確性を評価。人間専門家による注釈と粗い基準との比較で評価基準の信頼性を確認。実験から、LLMの法律推論能力はカバー範囲と正確性に影響され、retrieval-augmented generation(RAG)と強化学習(RL)が相補的な利益をもたらすことを示した。RAGは推論能力を向上させ、RLは正確性を改善する。 Comment
元ポスト:
[Paper Note] MQUAKE-REMASTERED: MULTI-HOP KNOWLEDGE EDITING CAN ONLY BE ADVANCED WITH RELIABLE EVALUATIONS, Zhong+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #ICLR #KnowledgeEditing Issue Date: 2026-02-08 GPT Summary- 誤った回答をするLLMに対し、知識の編集が効率的な修正手段として機能しますが、実世界の知識が複雑に絡み合っているため、編集効果の伝播が課題です。本研究では、MQuAKEデータセットの33%または76%の質問が様々な形で破損していることを示し、修正を提案します。また、修正後のMQuAKE-Remasteredデータセットに対する編集方法のベンチマークを行い、特定の性質に依存する手法がオーバーフィットすることを観察しました。最小限の侵襲的アプローチGWALKが、最先端の編集性能を発揮することを示しました。MQuAKE-Remasteredは、huggingfaceとGitHubで利用可能です。 Comment
openreview: https://openreview.net/forum?id=m9wG6ai2Xk
[Paper Note] CounterBench: A Benchmark for Counterfactuals Reasoning in Large Language Models, Yuefei Chen+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #KnowledgeEditing Issue Date: 2026-02-08 GPT Summary- 反実仮想推論はAIにおける複雑な因果関係の一つであり、本研究ではLLMの性能を評価します。1,000の質問からなる新しいベンチマーク「CounterBench」を導入し、さまざまな難易度や因果構造を考慮しました。実験結果では、多くのモデルが低い性能を示しましたが、新たに提案する推論パラダイム「CoIn」により、反実仮想推論タスクでLLMの性能が大幅に向上しました。データセットは公開されています。
[Paper Note] RewardBench 2: Advancing Reward Model Evaluation, Saumya Malik+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Evaluation #Selected Papers/Blogs #RewardModel #KeyPoint Notes #DownstreamTasks #Reading Reflections Issue Date: 2026-02-06 GPT Summary- 報酬モデルは、言語モデルの訓練後に好みデータを利用して指示遵守や推論、安全性を最適化するための訓練目標を提供します。新たに開発された「RewardBench 2」は、スキル領域を評価するための挑戦的なベンチマークを提供し、既存のモデルが低いスコアを示しつつも下流性能との相関が高いことを示しています。このベンチマークは人間のプロンプトを基にしており、厳格な評価プラクティスを促進しています。論文では、ベンチマークの構築プロセスと既存モデルの性能を報告し、モデルの下流使用との相関を定量化しています。 Comment
以下の6つのドメインで構成されるReward Modelの評価のためのベンチマーク:
- Factuality: hallucinationや誤りの有無の判定
- Precise Instruction Following: 細かい指示に対する追従性能
- Math: **自由記述**の数学に関するプロンプトに対する応答に関する能力
- Safety: 有害な応答に対して適切に対処できるか(応答拒否 or 適切な応答)
- Focus: 一般的なユーザのクエリに対して、トピックに沿った高品質な応答ができているか否か
- **Ties**: 「虹の色を1つ挙げて」といったような、複数の正解があり得るが、無数の不正解があるようなタスク(特定の正解にバイアスがかからず、正解と不正解を区別する能力を評価)
Reward Bench 2 での性能が、Best-of-N (=N個応答をサンプリングし最も良いものを採用するtest-time scaling手法)における様々なdownstreamタスクと強い相関を示すことが示されている。
ただし、PPOでの事後学習について焦点を当てた場合
- ベースモデルの出自がReward Modelと異なる場合
- Reward Modelの学習データが、ベースモデルと大きく異なる場合
においては、Reward Bench 2で高い性能が得られていても、PPOにおいて高い性能が得られず、特にベースモデルの出自が異なる場合の影響が顕著とのこと。
Reward Modelの性能が必ずしもPPOの事後学習後の下流タスクに対する性能と相関せず(ただし、Rewardベンチの性能が低い部分においてはおおまかに推定できる)、ベースモデルの出自が異なるReward Modelを使った場合や、Reward Modelとベースモデルが学習したプロンプトの分布が大きく異なる場合にこのような不整合が強く現れるというのは興味深く、おもしろかった。
Reward Modelとベースモデルの開始点が異なる場合は、RLによる学習がうまくいかないというのは、直感的でわかりやすい説明だなと感じた。
openreview: https://openreview.net/forum?id=fb0G86Dewb
[Paper Note] Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory, Tianxin Wei+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #memory #Test-time Learning Issue Date: 2026-02-05 GPT Summary- 状態性はLLMエージェントの長期的計画に不可欠であり、メモリ管理の進化が未探索である点に焦点を当てる。本研究では、Evo-Memoryという自己進化メモリの評価フレームワークを提案し、LLMが累積した経験を動的に処理する能力を向上させる。具体的には、タスクストリームを構造化し、メモリの検索・適応を要求。10のメモリモジュールと多様なデータセットで評価し、経験再利用のためのExpRAGおよび推論を統合するReMemパイプラインを提案、継続的な改善を実現する。 Comment
元ポスト:
[Paper Note] OpenRubrics: Towards Scalable Synthetic Rubric Generation for Reward Modeling and LLM Alignment, Tianci Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #RewardModel #Rubric-based #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 報酬モデルは人間のフィードバックを基にした強化学習の核を成しますが、従来の報酬モデルは多面的な人間の好みを捉えきれません。本研究では、構造化された基準を用いて複数の次元を評価する「ルブリック・アズ・リワード」を探求し、信頼性の高いルブリック生成に焦点を当て、OpenRubricsを紹介します。コントラストルブリック生成により、好ましい応答と拒否された応答を対比させて評価信号を引き出します。このアプローチにより、Rubric-RMは基準モデルを8.4%上回る性能を達成し、指示遵守や生物医学ベンチマークにも有効であることが示されました。 Comment
元ポスト:
chosen, rejectのpreferenceデータからcontrastiveにルーブリックやprincipleを明示的に構築して活用するというアプローチは非常に興味深い。色々な場面で役立ちそう。読みたい。
- [Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
の話と組み合わせて、もし高品質なルーブリックを動的に作成できれば、self-correction/refinementの能力の向上に活用できそうである。
[Paper Note] AssetOpsBench: Benchmarking AI Agents for Task Automation in Industrial Asset Operations and Maintenance, Dhaval Patel+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #AIAgents #Evaluation #One-Line Notes Issue Date: 2026-02-03 GPT Summary- AIを活用した産業資産ライフサイクル管理は、運用ワークフローの自動化を目指し、人間の負荷を軽減します。従来の技術は特定の問題に対処するに過ぎませんでしたが、AIエージェントと大規模言語モデルの登場により、資産ライフサイクル全体のエンドツーエンド自動化が可能になりました。本論文では、AssetOpsBenchというエージェント開発のための統合フレームワークを紹介し、知覚、推論、制御を統合した自律的なエージェントの構築について具体的な洞察を提供します。ソフトウェアはGitHubで公開されています。 Comment
dataset: https://arxiv.org/abs/2506.03828
元ポスト:
openreview: https://openreview.net/forum?id=ld6JUQbhes
産業におけるアセットの管理に関する(非常に複雑な)end-to-endなベンチマークで、multi agentに対する評価が前提となっている模様。
[Paper Note] ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks, Saurabh Jha+, ICML'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Financial #ICML #SoftwareEngineering #read-later #One-Line Notes Issue Date: 2026-02-03 GPT Summary- AIエージェントを用いたITタスク自動化の実現には、その効果を測定する能力が重要である。本研究では、AIエージェントのベンチマーキングを行うためのフレームワーク「ITBench」を提案。初期リリースはSRE、CISO、FinOpsの3領域に焦点を当て、実行可能なワークフローと解釈可能なメトリクスを提供。ITBenchは94の実世界シナリオを含み、最先端エージェントモデルのパフォーマンスを評価した結果、限られた成功率が示された。ITBenchがAI駆動のIT自動化において重要な役割を果たすことが期待される。 Comment
dataset:
-
https://huggingface.co/datasets/ibm-research/ITBench-Lite
-
https://huggingface.co/datasets/ibm-research/ITBench-Trajectories
元ポスト:
openreview: https://openreview.net/forum?id=jP59rz1bZk
94種類の実世界に基づいたシナリオに基づいてSRE, CSO, FinOpsに関するタスクを用いてAI Agentsを用いて評価する。各シナリオにはメタデータとEnvironments、トリガーとなるイベント、理想的な成果などが紐づいている。特にFinOpsに課題があることが示されている模様。
以下がシナリオの例で、たとえばFinOpsの場合はalertの設定ミスや、Podのスケーリングの設定に誤りがあり過剰にPodが立ってしまうといったシナリオがあるようである。
[Paper Note] UniversalCEFR: Enabling Open Multilingual Research on Language Proficiency Assessment, Joseph Marvin Imperial+, EMNLP'25, 2025.06
Paper/Blog Link My Issue
#NLP #EMNLP #CEFR Issue Date: 2026-01-22 GPT Summary- 13の言語でCEFRレベルが注釈付けされた「UniversalCEFR」データセットを紹介。505,807のテキストを含み、標準化されたフォーマットで教育研究を支援。言語的特徴に基づく分類、ファインチューニング、プロンプティングを用いたベンチマーク実験により、CEFR評価の改善を実証。UniversalCEFRはデータ配布のベストプラクティスを確立し、研究コミュニティへのアクセスを促進することを目指す。
[Paper Note] ShowUI-$π$: Flow-based Generative Models as GUI Dexterous Hands, Siyuan Hu+, CVPR'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #SyntheticData #CVPR #ComputerUse #read-later #Selected Papers/Blogs #VisionLanguageModel #GUI #Dragging #Author Thread-Post Issue Date: 2026-01-16 GPT Summary- ShowUI-$\pi$は、GUIエージェントにおける連続的な操作を可能にするフローベースの生成モデルです。これにより、離散的なクリックと連続的なドラッグを統合し、滑らかで安定したトラジェクトリーを実現します。2万のドラッグトラジェクトリーを用いたScreenDragプロトコルによる評価で、既存のGUIエージェントと比較して優れた性能を発揮しました。この研究は、人間のような器用な自動化の実現を促進します。 Comment
pj page: https://showlab.github.io/showui-pi/
元ポスト:
大規模なドラッグに関するデータセットを収集しており、エージェントのGUIの操作の今後の進展に大きく寄与しインパクトが大きいと考えられるため、重要論文に見える。
著者ポイント解説:
[Paper Note] 4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation, Chiao-An Yang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Evaluation #Distillation #read-later #VideoGeneration/Understandings #VisionLanguageModel #3D (Scene) #3D (Video) Issue Date: 2025-12-30 GPT Summary- 4D-RGPTという専門的なMLLMを導入し、動画から4D表現を捉えることで時間的知覚を強化。知覚的4D蒸留(P4D)を用いて4D表現を転送し、包括的な4D知覚を実現。新たに構築したR4D-Benchは、領域レベルのプロンプトを備えた動的シーンのベンチマークで、4D-RGPTは既存の4D VQAベンチマークとR4D-Benchの両方で顕著な改善を達成。 Comment
元ポスト:
[Paper Note] Schoenfeld's Anatomy of Mathematical Reasoning by Language Models, Ming Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reasoning #Mathematics Issue Date: 2025-12-27 GPT Summary- 本研究では、Schoenfeldのエピソード理論を基にしたThinkARMというフレームワークを提案し、推論の痕跡を明示的に抽象化します。このフレームワークを用いることで、数学的問題解決における再現可能な思考のダイナミクスや推論モデルと非推論モデルの違いを明らかにします。また、探索が正確性に寄与する重要なステップであることや、効率重視の手法が評価フィードバックを選択的に抑制することを示すケーススタディを提示します。これにより、現代の言語モデルにおける推論の構造と変化を体系的に分析することが可能になります。 Comment
元ポスト:
[Paper Note] Vision Language Models are Confused Tourists, Patrick Amadeus Irawan+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Evaluation #Bias #VisionLanguageModel #Cultural #Robustness Issue Date: 2025-12-25 GPT Summary- 文化的次元はVLMの評価において重要だが、多様な文化的入力に対する安定性は未検証。既存の評価は単一の文化的概念に依存し、複数の文化的手がかりを考慮していない。これに対処するため、ConfusedTouristという新しい評価手法を導入し、VLMの安定性を評価。実験で、画像スタッキングの摂動下で精度が低下し、注意が気を散らす手がかりにシフトすることが明らかに。これにより、視覚的文化概念の混合がVLMに大きな影響を与えることが示され、文化的にロバストな理解の必要性が強調された。 Comment
元ポスト:
VLMの文化的な物体の認識に関するロバスト性を全く異なる国の国旗やランドマークをルールベース、あるいはimage editingなどによって敵対的に挿入する(distractor)ことで測るベンチマークで、distractorによって性能が低下することからVLMに地理的・文化的バイアスが存在することを示した研究、のように見える。
[Paper Note] MomaGraph: State-Aware Unified Scene Graphs with Vision-Language Model for Embodied Task Planning, Yuanchen Ju+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #GraphBased #ReinforcementLearning #Evaluation #PostTraining #Robotics #SpatialUnderstanding #EmbodiedAI Issue Date: 2025-12-25 GPT Summary- 家庭内のモバイルマニピュレーター向けに、空間的・機能的関係を統合したMomaGraphを提案。これを支えるために、初の大規模データセットMomaGraph-Scenesと評価スイートMomaGraph-Benchを提供。さらに、7Bのビジョン・ランゲージモデルMomaGraph-R1を開発し、タスク指向のシーングラフを予測。実験により、71.6%の精度を達成し、オープンソースモデルの中で最先端の結果を示した。 Comment
pj page: https://hybridrobotics.github.io/MomaGraph/
元ポスト:
[Paper Note] MoReBench: Evaluating Procedural and Pluralistic Moral Reasoning in Language Models, More than Outcomes, Yu Ying Chiu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Evaluation #Reasoning #Safety Issue Date: 2025-12-24 GPT Summary- AIシステムの意思決定が人間の価値観と一致するためには、その決定過程を理解することが重要である。推論言語モデルを用いて、道徳的ジレンマに関する評価を行うためのベンチマーク「MoReBench」を提案。1,000の道徳的シナリオと23,000以上の基準を含み、AIの道徳的推論能力を評価する。結果は、既存のベンチマークが道徳的推論を予測できないことや、モデルが特定の道徳的枠組みに偏る可能性を示唆している。これにより、安全で透明なAIの推進に寄与する。 Comment
pj page: https://morebench.github.io/
元ポスト:
[Paper Note] Step-DeepResearch Technical Report, Chen Hu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Reasoning #Proprietary #mid-training #PostTraining #DeepResearch #KeyPoint Notes #Rubric-based Issue Date: 2025-12-24 GPT Summary- Step-DeepResearchは、LLMを用いた自律エージェントのためのコスト効率の良いエンドツーエンドのシステムであり、意図認識や長期的意思決定を強化するためのデータ合成戦略を提案。チェックリストスタイルのジャッジャーにより堅牢性を向上させ、中国ドメイン向けのADR-Benchを設立。実験では、Step-DeepResearchが高いスコアを記録し、業界をリードするコスト効率で専門家レベルの能力を達成したことを示した。 Comment
元ポスト:
ポイント解説:
ざっくり言うと、シンプルなReAct styleのagentで、マルチエージェントのオーケストレーションや複雑で重たいワークフロー無しで、OpenAI, GeminiのDeepResearchと同等の性能を達成してとり、ポイントとしてこれらの機能をはmid-training段階で学習してモデルのパラメータとして組み込むことで実現している模様。
mid trainingは2段階で構成され、trajectoryの長さは徐々に長いものを利用するカリキュラム方式。
最初のステージでは以下の4つのatomicスキルを身につけさせる:
- Planning & Task Decomposition
- Deep Information Seeking
- Reflection & Verification
- Reporting
これらのatomic skillを身につけさせる際には、next token predictionをnext action predictionという枠組みで学習し、アクションに関するトークンの空間を制限することで効率性を向上(ただし、具体性は減少するのでトレードオフ)という形にしているようだが、コンセプトが記述されているのみでよくわからない。同時に、学習データの構築方法もデータソースとおおまかな構築方法が書かれているのみである。ただし、記述内容的には各atomic skillごとに基本的には合成データが作成され利用されていると考えてよい。
たとえばplanningについては論文などの文献のタイトルや本文から実験以後の記述を除外し、研究プロジェクトのタスクを推定させる(リバースエンジニアリングと呼称している)することで、planningのtrajectoryを合成、Deep Information SeekingではDB Pediaなどのknowledge graphをソースとして利用し、次数が3--10程度のノードをseedとしそこから(トピックがドリフトするのを防ぐために極端に次数が大きいノードは除外しつつ)幅優先探索をすることで、30--40程度のノードによって構成されるサブグラフを構成し、そのサブグラフに対してmulti hopが必要なQuestionを、LLMで生成することでデータを合成しているとのこと。
RLはrewardとしてルーブリックをベースにしたものが用いられるが、strong modelを用いて
- 1: fully satisfied
- 0.5: partially satisfied
- 0: not satisfied
の3値を検討したが、partially satisfiedが人間による評価とのagreementが低かったため設計を変更し、positive/negative rubricsを設定し、positivルーブリックの場合はルーブリックがfully satisfiedの時のみ1, negativeルーブリックの方はnot satisfiedの時のみ0とすることで、低品質な生成結果に基づくrewardを無くし、少しでもネガティブな要素があった場合は強めのペナルティがかかるようにしているとのこと(ルーブリックの詳細は私が見た限りは不明である。Appendix Aに書かれているように一瞬見えたが具体的なcriterionは書かれていないように見える)。
[Paper Note] SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning, Jitesh Jain+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #AIAgents #Evaluation #Reasoning #PostTraining #Selected Papers/Blogs #VideoGeneration/Understandings #VisionLanguageModel #KeyPoint Notes #LongHorizon Issue Date: 2025-12-19 GPT Summary- 人間のように異なる長さの動画に柔軟に推論できる動画推論モデルSAGEを提案。SAGEは長い動画に対してマルチターン推論を行い、簡単な問題には単一ターンで対応。Gemini-2.5-Flashを用いたデータ生成パイプラインと強化学習後訓練レシピを導入し、SAGE-Benchで実世界の動画推論能力を評価。結果、オープンエンドのタスクで最大6.1%、10分以上の動画で8.2%の性能向上を確認。 Comment
pj page: https://praeclarumjj3.github.io/sage/
元ポスト:
AllenAIの勢いすごいな...
現在のVideo reasoning Modelはlong videoに対するQAに対してもsingle turnで回答応答しようとするが、人間はそのような挙動はせずに、long videoのうち、どこを流し見し、どこを注視するか、ある時は前半にジャンプし、関係ないところは飛ばすなど、情報を選択的に収集する。そのような挙動のエージェントをMolmo2をベースにSFT+RLをベースに実現。
システムデザインとしては、既存のエージェントはtemporal groundingのみをしばしば利用するがこれはlong videoには不向きなので、non-visualな情報も扱えるようにweb search, speech transcription, event grounding, extract video parts, analyze(クエリを用いてメディアの集合を分析し応答する)なども利用可能に。
inferenceは2-stageとなっており、最初はまずSAGE-MMをContext VLMとして扱い、入力された情報を処理し(video contextやツール群、メタデータなど)、single turnで回答するか、ツール呼び出しをするかを判断する。ツール呼び出しがされた場合は、その後SAGE-MMはIterative Reasonerとして機能し、前段のtool callの結果とvideo contextから回答をするか、新たなツールを呼び出すかを判断する、といったことを繰り返す。
long videoのデータは6.6kのyoutube videoと99kのQAペア(Gemini-2.5-Flashで合成)、400k+のstate-action example(Gemini-2.5-Flashによりtool callのtrajectoryを合成しcold start SFTに使う)を利用。
RLのoptimizationでは、openendなvideo QAではverifiableなrewardは難しく、任意の長さのvideoに対するany-horizonな挙動を学習させるのは困難なので、multi rewardなRLレシピ+strong reasoning LLMによるLLM as a Judgeで対処。rewardはformat, 適切なツール利用、ツール呼び出しの引数の適切さ、最終的な回答のAccuracyを利用。
評価データとしては人手でverificationされた1744のQAを利用し、紐づいている動画データの長さは平均700秒以上。
[Paper Note] MMGR: Multi-Modal Generative Reasoning, Zefan Cai+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #FoundationModel #TextToImageGeneration #2D (Image) #3D (Scene) #WorldModels #KeyPoint Notes #TextToVideoGeneration Issue Date: 2025-12-19 GPT Summary- MMGR(Multi-Modal Generative Reasoning Evaluation and Benchmark)を導入し、物理的、論理的、空間的、時間的な推論能力に基づくビデオ基盤モデルの評価フレームワークを提案。既存の指標では見落とされる因果関係や物理法則の違反を考慮し、主要なビデオおよび画像モデルをベンチマークした結果、抽象的推論でのパフォーマンスが低いことが明らかに。MMGRは、生成的世界モデルの推論能力向上に向けた統一診断ベンチマークを提供。 Comment
pj page: https://zefan-cai.github.io/MMGR.github.io/
元ポスト:
video/image 生成モデルを(単なる動画生成という枠ではなく世界モデルという観点で評価するために)
- physical reasoning: ロボットのシミュレーションやinteractionに必要な物理世界の理解力
- logical (abstract) reasoning: System2 Thinkingい必要な抽象的なコンテプトやルールに従う能力(Aが起きたらBが続く)
- 3D spatial reasoning: 世界の認知mapを内包するために必要な3D空間における関係性や、環境の案内、物事の構造や全体像を把握する能力
- 2D spatial reasoning: 複雑なpromptをgroundingするために必要な2D空間に写像されたレイアウト、形状、相対位置を理解する能力
- Temporal Reasoning: coherenceを保つために必要な、因果関係、イベントの順序、長期的な依存関係を捉える能力
の5つの軸で評価するフレームワーク。
[Paper Note] X-Humanoid: Robotize Human Videos to Generate Humanoid Videos at Scale, Pei Yang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Transformer #SyntheticData #DiffusionModel #Robotics #WorldModels #VisionLanguageActionModel #3D (Video) #EmbodiedAI #One-Line Notes #Third-Person View Issue Date: 2025-12-12 GPT Summary- X-Humanoidは、動画から動画への生成的な編集アプローチを用いて、人間からヒューマノイドへの翻訳を実現するモデルです。Unreal Engineを活用し、17時間以上のペア合成動画を生成するデータ作成パイプラインを設計し、60時間のEgo-Exo4D動画を用いて360万以上の「ロボティクス化」されたヒューマノイド動画フレームを生成しました。定量的分析とユーザー調査により、69%のユーザーが動きの一貫性で最も優れていると評価し、62.1%が具現化の正確さで最も優れていると評価しました。 Comment
pj page: https://showlab.github.io/X-Humanoid/
元ポスト:
既存研究は主観視点の動画における人の腕をロボットアームにルールベースで置き換えるなどの方法で動画をオーバレイすることでdata scarcityの問題に対処してきており、これは有望なアプローチだが、第三者視点の動画はしばしばより複雑(全身が写り、背景が動的に変化し遮蔽に隠れたりもする)で課題がある。このため、第三者視点での動画を人間からヒューマノイドに置換するモデルを学習[^1]し(強力なvideo editingモデルでもこの点はまだ苦戦するタスクとのこと)、私生活における人間の動画をヒューマノイドに置き換えてデータを合成することでロボットのポリシーや世界モデルの学習データ不足を補います、という話に見える。
[^1]: この部分の学習データはUnreal Engineを用いて17+時間に及ぶ人間-ヒューマノイドペアの動画を合成
(以下Chatgptとの問答により得た情報なのでハルシネーションの恐れがあります)
主観視点での人間の腕をロボットアームに置き換えて学習データを合成するというのは気持ちが分かりやすかったのだが(=人間の腕と実際にロボット自身がカメラを通じて見る自分の腕は形状が違うため学習時と運用時にgapが生じる)、なぜ第三者視点でのこのようなHuman-Humanoid gapを埋めた学習データが必要なのか、という話はざーっと論文を見た限り書いておらず門外漢の私ではわからなかったので、ChatgptやGeminiにきいてみた。LLMの応答によると
- 主観視点での動画には限りがあり、第三者視点での動画の方が単純にデータ量が多い
- 主観視点動画では見える範囲が限定的であり、たとえばロボットに特定の動作を学習させたいときに、全身動作や背景の動き、物体との位置関係などはわからない。
- ロボットが実際に得る視界もロボットから見た時の主観視点であるが、それとは別の話としてこのような第三者視点がロボットが多様なタスクを学ぶときに全身が写っている動画は有用であるか(タスク、意図、行動の選択パターンなどの動作の意味情報を学ぶ)。また、第三者視点動画をロボットの視点に変換するようなモデルを作るためにもこのようなデータは必要で、これによりロボットは第三者視点の人間動画から学び、最終的にそれらを自分の主観視点に対応する表現として学習(retargetと呼ぶらしい)できる。
といった背景があるらしい。
(LLMから得た情報ここまで)
↑のLLMからの情報は妥当なように感じる。
まああとは、そもそも、ロボットが溢れかえる世界になったときに、ロボットが写っている学習データがないとまずいよね、というのも将来的にはあるのかなという感想。
[Paper Note] OneThinker: All-in-one Reasoning Model for Image and Video, Kaituo Feng+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #MultiModal #Reasoning #OpenWeight #VisionLanguageModel #2D (Image) #UMM #3D (Video) #One-Line Notes #text Issue Date: 2025-12-06 GPT Summary- OneThinkerは、視覚的推論を統一するオールインワンの強化学習モデルであり、質問応答やキャプショニングなどの多様なタスクに対応。OneThinker-600kトレーニングコーパスを用いて訓練され、報酬の異質性に対処するEMA-GRPOを提案。広範な実験により、10の視覚理解タスクで強力なパフォーマンスを示し、タスク間の知識移転とゼロショット一般化能力を実証。全てのコード、モデル、データは公開。 Comment
pj page:
https://github.com/tulerfeng/OneThinker
HF:
https://huggingface.co/OneThink
元ポスト:
image/videoに関するreasoningタスクをunifiedなアーキテクチャで実施するVLM
Qwen3-VL-Instruct-8Bに対するgain。様々なタスクで大幅なgainを得ている。特にTracking, segmentation, groundingのgainが大きいように見える。
[Paper Note] Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond), Liwei Jiang+, NeurIPS'25 Best Paper Award, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Evaluation #Mindset #read-later #Diversity #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-12-03 GPT Summary- Infinity-Chatは、26,000件の多様なオープンエンドユーザークエリからなるデータセットで、言語モデル(LM)の出力の多様性を評価するための新たなリソースを提供する。包括的な分類法を提案し、LMにおけるモード崩壊や人工的ハイヴマインド効果を明らかにした。調査結果は、LMの生成が人間の好みに適切に調整されていないことを示し、AI安全リスクの軽減に向けた今後の研究の重要な洞察を提供する。 Comment
openreview: https://openreview.net/forum?id=saDOrrnNTz
元ポスト:
これはまさに今日Geminiと壁打ちしている時に感じたなあ。全人類が同じLLMを使って壁打ちしたらどうなるんだろうと。同じような思考や思想を持つのではないか、あるいは偏っていないと思い込んでいるけど実は暗黙的に生じている応答のバイアスとか、そういう懸念。(読みたい)
[Paper Note] PHUMA: Physically-Grounded Humanoid Locomotion Dataset, Kyungmin Lee+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Robotics #PhysicalConstraints #Locomotion Issue Date: 2025-11-30 GPT Summary- PHUMAは、物理的に基づいた人型ロコモーションデータセットであり、大規模な人間の動画を活用しつつ物理的アーティファクトに対処。関節制限や地面接触を確保し、足のスケーティングを排除することで、安定したモーション模倣を実現。自己記録したテスト動画や骨盤ガイダンスによるパスフォローで評価し、Humanoid-XおよびAMASSを上回る性能を示した。 Comment
pj page: https://davian-robotics.github.io/PHUMA/
HF: https://huggingface.co/datasets/DAVIAN-Robotics/PHUMA
元ポスト:
[Paper Note] MTBBench: A Multimodal Sequential Clinical Decision-Making Benchmark in Oncology, Kiril Vasilev+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #MultiModal #Selected Papers/Blogs #Medical Issue Date: 2025-11-26 GPT Summary- MTBBenchは、臨床ワークフローの複雑さを反映したマルチモーダル大規模言語モデル(LLMs)のための新しいベンチマークで、腫瘍学の意思決定をシミュレートします。既存の評価が単一モーダルであるのに対し、MTBBenchは異種データの統合や時間に基づく洞察の進化を考慮しています。臨床医によって検証されたグラウンドトゥルースの注釈を用い、複数のLLMを評価した結果、信頼性の欠如や幻覚の発生、データの調和に苦労することが明らかになりました。MTBBenchは、マルチモーダルおよび長期的な推論を強化するツールを提供し、タスクレベルのパフォーマンスを最大9.0%および11.2%向上させることが示されました。 Comment
dataset: https://huggingface.co/datasets/EeshaanJain/MTBBench
元ポスト:
> Ground truth annotations are validated by clinicians via a co-developed app, ensuring clinical relevance.
素晴らしい
[Paper Note] Computer-Use Agents as Judges for Generative User Interface, Kevin Qinghong Lin+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #Evaluation #Coding #LLM-as-a-Judge #ComputerUse #VisionLanguageModel #One-Line Notes #UI Issue Date: 2025-11-26 GPT Summary- CUAはGUIを自律的に操作する能力が向上しているが、従来のGUIは人間向けに設計されているため、効率的なタスク実行に不必要な行動を強いられる。Coderの進展により、自動GUI設計が変革される中、CUAがCoderを支援する役割を果たせるかを探るためにAUI-Gymを導入。1560のタスクをシミュレートし、信頼性を確保する検証ツールを開発。Coder-CUA協力フレームワークを提案し、CUAがデザインを評価し、タスク解決可能性を測定。CUAダッシュボードを設計し、ナビゲーション履歴を視覚的に要約。これにより、エージェントの能動的な参加を促進する。 Comment
pj page: https://showlab.github.io/AUI/
元ポスト:
CUA自身にCUAにとって理解しやすいUIに関するJudgeをさせてフィードバックさせ(CUA-as-Judpe)、Coder(コード生成)を通じてUIを改善できるか?というタスクとベンチマークな模様
[Paper Note] VCode: a Multimodal Coding Benchmark with SVG as Symbolic Visual Representation, Kevin Qinghong Lin+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #VisionLanguageModel Issue Date: 2025-11-25 GPT Summary- VCodeは、視覚中心のコーディングを促進するためにSVGコードを用いた新しいアプローチを提案。画像から象徴的な意味を持つSVGを生成し、CodeVQAという評価プロトコルでその忠実性を測定。VCoderを導入し、SVGコードの不一致を分析・洗練する「Thinking with Revision」と、構造的手がかりを提供する「Acting with Visual Tools」を通じて、言語中心と視覚中心のコーディングのギャップを埋める。実験により、VCoderは最前線のVLMに対して12.3ポイントの性能向上を実現。 Comment
元ポスト:
pj page: https://csu-jpg.github.io/VCode/
画像を意味情報を保持したSVGコードとして書き起こし、書き起こしたSVGに対してQAをすることで正しさを測るようなベンチマークらしい
[Paper Note] The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution, Junlong Li+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #One-Line Notes Issue Date: 2025-11-25 GPT Summary- Toolathlonは、現実世界の複雑なワークフローを処理する言語エージェント向けの新しいベンチマークで、32のアプリケーションと604のツールを網羅。実際の環境状態を提供し、108のタスクを通じてエージェントのパフォーマンスを評価。最先端モデルの評価結果は、成功率が低いことを示し、Toolathlonがより能力の高いエージェントの開発を促進することを期待。 Comment
pj page: https://toolathlon.xyz/introduction
元ポスト:
元ポスト:
既存のAI Agentベンチマークよりもより多様で複雑な実世界タスクに違いベンチマークらしい
[Paper Note] Paper2Poster: Towards Multimodal Poster Automation from Scientific Papers, Wei Pang+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #NeurIPS #VisionLanguageModel #One-Line Notes #Poster #Author Thread-Post Issue Date: 2025-11-25 GPT Summary- 学術ポスター生成のための新しいベンチマークとメトリクスを導入し、PosterAgentというマルチエージェントパイプラインを提案。Parserが論文を構造化し、Plannerがレイアウトを整え、Painter-Commenterが視覚的整合性を確保。評価では、GPT-4oの出力は視覚的には魅力的だが、テキストの質が低く、PaperQuizスコアも不十分であることが判明。オープンソースのバリアントは、既存のシステムを上回り、コスト効率も良好。これにより、次世代の自動ポスター生成モデルの方向性が示された。 Comment
元ポスト:
著者ポスト:
GPT4oは細かい文字のfidelityが低く、視覚的な魅力も小さい(なのでそういったものは学習で補う必要がある)という知見があるとのこと。arXivに投稿された当時結構話題になっていた気がする。
論文だけに留まらず、長いテキストを視覚的に見やすく圧縮する技術は一種の要約として見ることもでき、生成AIによって情報がさらに溢れかえるようになった昨今は、こういった技術はさらに重要な技術になると思われる。
[Paper Note] Why Do Language Model Agents Whistleblow?, Kushal Agrawal+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Evaluation #read-later Issue Date: 2025-11-24 GPT Summary- LLMをエージェントとして展開する際の内部告発行動を調査。内部告発の頻度はモデルによって異なり、タスクの複雑さが増すと傾向が低下。道徳的行動を促すプロンプトで内部告発率が上昇し、明確な手段を提供すると低下。評価認識のテストにより、データセットの堅牢性を確認。 Comment
元ポスト:
興味深い
所見(OLMo関係者):
[Paper Note] Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark, Minhui Zhu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #read-later #Selected Papers/Blogs #Physics Issue Date: 2025-11-23 GPT Summary- CritPtは、物理学研究における複雑な推論タスクを評価するための初のベンチマークであり、71の研究課題と190のチェックポイントタスクから構成される。これらの問題は現役の物理学者によって作成され、機械的に検証可能な答えを持つように設計されている。現在のLLMsは、単独のチェックポイントでは期待を示すが、全体の研究課題を解決するには不十分であり、最高精度は5.7%にとどまる。CritPtは、AIツールの開発に向けた基盤を提供し、モデルの能力と物理学研究の要求とのギャップを明らかにする。 Comment
pj page: https://critpt.com/
artificial analysisによるリーダーボード:
https://artificialanalysis.ai/evaluations/critpt
データセットとハーネス:
[Paper Note] AICC: Parse HTML Finer, Make Models Better -- A 7.3T AI-Ready Corpus Built by a Model-Based HTML Parser, Ren Ma+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #read-later #Selected Papers/Blogs Issue Date: 2025-11-21 GPT Summary- ウェブデータの品質向上のため、MinerU-HTMLという新しい抽出パイプラインを提案。これは、言語モデルを用いてコンテンツ抽出をシーケンスラベリング問題として再定義し、意味理解を活用した二段階のフォーマットパイプラインを採用。実験では、MinerU-HTMLが81.8%のROUGE-N F1を達成し、従来の手法よりも構造化要素の保持率が優れていることを示した。AICCという多言語コーパスを構築し、抽出品質がモデルの性能に大きく影響することを確認。MainWebBench、MinerU-HTML、AICCを公開し、HTML抽出の重要性を強調。 Comment
元ポスト:
[Paper Note] AMO-Bench: Large Language Models Still Struggle in High School Math Competitions, Shengnan An+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #Mathematics Issue Date: 2025-11-20 GPT Summary- AMO-Benchは、オリンピックレベルの数学的推論を評価するための新しいベンチマークで、50の専門家作成の問題から成る。既存のベンチマークが飽和状態にある中、AMO-BenchはIMO基準を満たし、オリジナルの問題を提供することで厳格な評価を実現。実験では、26のLLMsが52.4%の正答率を記録し、ほとんどが40%未満であった。これにより、LLMsの数学的推論能力には改善の余地があることが示された。AMO-Benchは、今後の研究を促進するために公開されている。 Comment
pj page: https://amo-bench.github.io/
元ポスト:
AIMEの次はこちらだろうか...ちなみに私は私生活において数学オリンピックの問題を解きたいと思ったことは今のところ一度もない🧐しかし高度な推論能力を測定するために必要というのは理解できる。
HF: https://huggingface.co/datasets/meituan-longcat/AMO-Bench
[Paper Note] EDIT-Bench: Evaluating LLM Abilities to Perform Real-World Instructed Code Edits, Wayne Chi+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering #read-later Issue Date: 2025-11-20 GPT Summary- EDIT-Benchは、LLMのコード編集能力を実際のユーザー指示とコードコンテキストに基づいて評価するためのベンチマークで、540の問題を含む。多様な自然言語とプログラミング言語を用いた実世界のユースケースを提供し、コンテキスト依存の問題を導入。40のLLMを評価した結果、60%以上のスコアを得たモデルは1つのみで、ユーザー指示のカテゴリやコンテキスト情報がパフォーマンスに大きく影響することが示された。 Comment
元ポスト:
[Paper Note] Depth Anything 3: Recovering the Visual Space from Any Views, Haotong Lin+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Transformer #Evaluation #FoundationModel #2D (Image) #3D (Video) #SpatialUnderstanding Issue Date: 2025-11-17 GPT Summary- Depth Anything 3(DA3)は、カメラポーズの有無にかかわらず、視覚入力から空間的一貫性のあるジオメトリを予測するモデルです。DA3は、単一のプレーンなトランスフォーマーをバックボーンとして使用し、複雑なマルチタスク学習を排除することで、Depth Anything 2(DA2)と同等の性能を達成しました。新たに設立した視覚ジオメトリベンチマークでは、DA3がすべてのタスクで最先端の結果を示し、カメラポーズ精度で従来の最先端を44.3%、ジオメトリ精度で25.1%上回りました。すべてのモデルは公共の学術データセットでトレーニングされています。 Comment
関連:
- [Paper Note] Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data, Lihe Yang+, CVPR'24, 2024.01
- [Paper Note] Depth Anything V2, Lihe Yang+, NeurIPS'24, 2024.06
元ポスト:
pj page: https://depth-anything-3.github.io/
openreview: https://openreview.net/forum?id=yirunib8l8
[Paper Note] ChatBench: From Static Benchmarks to Human-AI Evaluation, Serina Chang+, ACL'25, 2025.03
Paper/Blog Link My Issue
#NLP #LanguageModel #UserBased #Evaluation #Conversation #ACL Issue Date: 2025-11-15 GPT Summary- LLMベースのチャットボットの能力を評価するために、ユーザーとAIの会話を通じてMMLUの質問を変換する研究を実施。新しいデータセット「ChatBench」には396の質問と144Kの回答、7,336のユーザー-AI会話が含まれ、AI単独の精度はユーザー-AIの精度を予測できないことが示された。ユーザー-AIの会話分析により、AI単独のベンチマークとの違いが明らかになり、ユーザーシミュレーターのファインチューニングにより精度推定能力が向上した。 Comment
[Paper Note] TabArena: A Living Benchmark for Machine Learning on Tabular Data, Nick Erickson+, NeurIPS'25 Spotlight, 2025.06
Paper/Blog Link My Issue
#MachineLearning #NLP #TabularData #Evaluation #Selected Papers/Blogs #Live #One-Line Notes Issue Date: 2025-11-14 GPT Summary- TabArenaは、表形式データのための初の生きたベンチマークシステムであり、継続的に更新されることを目的としています。手動でキュレーションされたデータセットとモデルを用いて、公開リーダーボードを初期化しました。結果は、モデルのベンチマークにおける検証方法やハイパーパラメータ設定の影響を示し、勾配ブースティング木が依然として強力である一方、深層学習手法もアンサンブルを用いることで追いついてきていることを観察しました。また、基盤モデルは小規模データセットで優れた性能を発揮し、モデル間のアンサンブルが表形式機械学習の進展に寄与することを示しました。TabArenaは、再現可能なコードとメンテナンスプロトコルを提供し、https://tabarena.ai で利用可能です。 Comment
pj page:
https://github.com/autogluon/tabarena
leaderboard:
https://huggingface.co/spaces/TabArena/leaderboard
liveデータに基づくベンチマークで、手動で収集された51のtabularデータセットが活用されているとのこと。またあるモデルに対して数百にも登るハイパーパラメータ設定での実験をしアンサンブルをすることで単一モデルが到達しうるピーク性能を見ることに主眼を置いている、またいな感じらしい。そしてやはり勾配ブースティング木が強い。tunedは単体モデルの最も性能が良い設定での性能で、ensembleは複数の設定での同一モデルのアンサンブルによる結果だと思われる。
> TabArena currently consists of:
> 51 manually curated tabular datasets representing real-world tabular data tasks.
> 9 to 30 evaluated splits per dataset.
> 16 tabular machine learning methods, including 3 tabular foundation models.
> 25,000,000 trained models across the benchmark, with all validation and test predictions cached to enable tuning and post-hoc ensembling analysis.
> A live TabArena leaderboard showcasing the results.
openreview: https://openreview.net/forum?id=jZqCqpCLdU
[Paper Note] PRISM-Physics: Causal DAG-Based Process Evaluation for Physics Reasoning, Wanjia Zhao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#GraphBased #NLP #LanguageModel #Evaluation Issue Date: 2025-11-14 GPT Summary- PRISM-Physicsは、物理推論問題に対するプロセスレベルの評価フレームワークを提供し、因果関係を持つ数式の有向非巡回グラフ(DAG)を用いて解決策を表現。これにより、理論的に基づいたスコアリングが可能となり、ヒューリスティックな判断なしに一貫した検証を実現。実験結果は、評価フレームワークが人間の専門家のスコアリングと整合していることを示し、LLMの推論の限界を明らかにする。PRISM-Physicsは、科学的推論能力を向上させるための基盤を提供する。 Comment
pj page: https://open-prism.github.io/PRISM-Physics/
元ポスト:
[Paper Note] RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments, Zhiyuan Zeng+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Evaluation #CurriculumLearning #RLVR #Verification Issue Date: 2025-11-12 GPT Summary- 適応可能な検証可能な環境を用いた強化学習(RLVE)を提案し、動的に問題の難易度を調整することで、言語モデルの強化学習をスケールアップする。RLVE-Gymという400の検証可能な環境からなるスイートを作成し、環境の拡大が推論能力を向上させることを示した。RLVEは、共同トレーニングにより、強力な推論LMで3.37%の性能向上を達成し、従来のRLトレーニングよりも効率的であることを示した。コードは公開されている。 Comment
元ポスト:
ポイント解説:
Stress-Testing the Reasoning Competence of Language Models With Formal Proofs, Arkoudas+, EMNLP'25 Findings
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #Mathematics #Proofs Issue Date: 2025-11-12 GPT Summary- ProofGridという新しい論理推論タスクを用いて、LLMsとLRMsの性能を広範に評価。タスクは命題論理と方程式論理の証明作成・検証を含み、証明のインペインティングとギャップ埋めも新たに導入。実験ではトップモデルの優れたパフォーマンスが示される一方、体系的な失敗も確認。1万件以上の形式的推論問題と証明からなる新データリソースも公開。 Comment
元ポスト:
[Paper Note] Why Less is More (Sometimes): A Theory of Data Curation, Elvis Dohmatob+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pretraining #NLP #LanguageModel #Selected Papers/Blogs #DataMixture #PhaseTransition Issue Date: 2025-11-12 GPT Summary- 本論文では、データを少なく使う方が良い場合についての理論的枠組みを提案し、小規模な厳選データセットが優れた性能を発揮する理由を探ります。データキュレーション戦略を通じて、ラベルに依存しない・依存するルールのテスト誤差のスケーリング法則を明らかにし、特定の条件下で小規模データが大規模データを上回る可能性を示します。ImageNetでの実証結果を通じて、キュレーションが精度を向上させることを確認し、LLMの数学的推論における矛盾する戦略への理論的説明も提供します。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=8KcjEygedc
[Paper Note] PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs, Zixin Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #MultiModal #read-later #Selected Papers/Blogs #Robotics #EmbodiedAI Issue Date: 2025-11-10 GPT Summary- MLLMsの物理的道具に対する理解を評価するための新しいベンチマークPhysToolBenchを提案。1,000以上の画像-テキストペアからなるVQAデータセットで、道具認識、道具理解、道具創造の3つの能力を評価。32のMLLMsに対する評価で道具理解に欠陥があることが明らかになり、初歩的な解決策を提案。コードとデータセットは公開。 Comment
元ポスト:
興味深い
[Paper Note] Infini-gram mini: Exact n-gram Search at the Internet Scale with FM-Index, Hao Xu+, EMNLP'25 Best Paper, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Search #LanguageModel #Evaluation #EMNLP #read-later #Contamination-free #Selected Papers/Blogs Issue Date: 2025-11-09 GPT Summary- 「infini-gram mini」は、ペタバイトレベルのテキストコーパスを効率的に検索可能にするシステムで、FM-indexデータ構造を用いてインデックスを作成し、ストレージオーバーヘッドを44%に削減。インデックス作成速度やメモリ使用量を大幅に改善し、83TBのインターネットテキストを99日でインデックス化。大規模なベンチマーク汚染の分析を行い、主要なLM評価ベンチマークがインターネットクローリングで汚染されていることを発見。汚染率を共有する公報をホストし、検索クエリ用のウェブインターフェースとAPIも提供。 Comment
元ポスト:
pj page: https://infini-gram-mini.io
benchmarmk contamination monitoring system: https://huggingface.co/spaces/infini-gram-mini/Benchmark-Contamination-Monitoring-System
[Paper Note] Holistic Evaluation of Multimodal LLMs on Spatial Intelligence, Zhongang Cai+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #MultiModal #VisionLanguageModel #SpatialUnderstanding Issue Date: 2025-11-09 GPT Summary- マルチモーダルモデルは進展しているが、空間理解と推論には限界がある。GPT-5の性能を評価するため、空間タスクの分類法と評価プロトコルを提案し、8つの主要ベンチマークを使用。実証研究では、GPT-5は空間知能で強さを示すが、人間のパフォーマンスには及ばず、特に難しいタスクでの能力不足が顕著であることを明らかにした。 Comment
元ポスト:
leaderboard: https://huggingface.co/spaces/lmms-lab-si/EASI-Leaderboard
v0.2.0がリリース:
[Paper Note] Culture Cartography: Mapping the Landscape of Cultural Knowledge, Caleb Ziems+, EMNLP'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #EMNLP #DPO #Cultural Issue Date: 2025-11-06 GPT Summary- LLMは文化特有の知識を必要とし、CultureCartographyという混合イニシアティブを提案。LLMが自信の低い質問をアノテーションし、人間がそのギャップを埋めることで重要なトピックに導く。CultureExplorerツールを用いた実験で、従来のモデルよりも効果的に知識を生成し、Llama-3.1-8Bの精度を最大19.2%向上させることが示された。 Comment
元ポスト:
効率的にLLMにとって未知、かつ重要な文化的な知識バンクを作成する話な模様。アクティブラーニングに似たような思想に見える。
[Paper Note] UNO-Bench: A Unified Benchmark for Exploring the Compositional Law Between Uni-modal and Omni-modal in Omni Models, Chen Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #MultiModal #SpeechProcessing #2D (Image) #3D (Video) #Omni #text Issue Date: 2025-11-05 GPT Summary- 新しいベンチマークUNO-Benchを提案し、ユニモーダルとオムニモーダルの能力を44のタスクと5つのモダリティで評価。人間生成データと自動圧縮データを用い、複雑な推論を評価する多段階オープンエンド質問形式を導入。実験により、オムニモーダルの能力がモデルの強さに応じて異なる影響を与えることを示した。 Comment
pj page: https://meituan-longcat.github.io/UNO-Bench/
元ポスト:
[Paper Note] When Visualizing is the First Step to Reasoning: MIRA, a Benchmark for Visual Chain-of-Thought, Yiyang Zhou+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Evaluation #MultiModal #Reasoning #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #KeyPoint Notes #text #Visual-CoT #Author Thread-Post Issue Date: 2025-11-05 GPT Summary- MIRAは、中間的な視覚画像を生成し推論を支援する新しいベンチマークで、従来のテキスト依存の手法とは異なり、スケッチや構造図を用いる。546のマルチモーダル問題を含み、評価プロトコルは画像と質問、テキストのみのCoT、視覚的ヒントを含むVisual-CoTの3レベルを網羅。実験結果は、中間的な視覚的手がかりがモデルのパフォーマンスを33.7%向上させることを示し、視覚情報の重要性を強調している。 Comment
pj page: https://mira-benchmark.github.io/
元ポスト:
Visual CoT
Frontierモデル群でもAcc.が20%未満のマルチモーダル(Vision QA)ベンチマーク。
手作業で作成されており、Visual CoT用のsingle/multi stepのintermediate imagesも作成されている。興味深い。
VLMにおいて、{few, many}-shotがうまくいく場合(Geminiのようなプロプライエタリモデルはshot数に応じて性能向上、一方LlamaのようなOpenWeightモデルは恩恵がない)と
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
うまくいかないケース(事前訓練で通常見られない分布外のドメイン画像ではICLがうまくいかない)
- [Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05
も報告されている。
おそらく事前学習段階で当該ドメインの画像が学習データにどれだけ含まれているか、および、画像とテキストのalignmentがとれていて、画像-テキスト間の知識を活用できる状態になっていることが必要なのでは、という気はする。
著者ポスト:
[Paper Note] Intrinsic Test of Unlearning Using Parametric Knowledge Traces, Yihuai Hong+, EMNLP'25, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #EMNLP #ConceptErasure #read-later #Selected Papers/Blogs Issue Date: 2025-11-04 GPT Summary- 大規模言語モデルにおける「忘却」タスクの重要性が高まっているが、現在の評価手法は行動テストに依存しており、モデル内の残存知識を監視していない。本研究では、忘却評価においてパラメトリックな知識の変化を考慮する必要性を主張し、語彙投影を用いた評価方法論を提案。これにより、ConceptVectorsというベンチマークデータセットを作成し、既存の忘却手法が概念ベクトルに与える影響を評価した。結果、知識を直接消去することでモデルの感受性が低下することが示され、今後の研究においてパラメータに基づく評価の必要性が強調された。 Comment
元ポスト:
[Paper Note] Puzzled by Puzzles: When Vision-Language Models Can't Take a Hint, Heekyung Lee+, EMNLP'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #EMNLP #VisionLanguageModel #One-Line Notes #Short Issue Date: 2025-11-04 GPT Summary- リバスパズルは視覚的な謎であり、VLMに特有の挑戦をもたらす。従来のタスクとは異なり、マルチモーダルな抽象化や象徴的推論が必要。本研究では、英語のリバスパズルのベンチマークを構築し、VLMの解釈能力を調査。結果、VLMはシンプルな視覚的手がかりには強いが、抽象的推論や視覚的メタファーの理解には苦労することが明らかになった。 Comment
元ポスト:
Rebus Puzzleの例。たとえば上の例はlong time no seeが答えだが、Timeを認識してCが抜けており、かつseeとCの音韻が似ているといった解釈をしなければならない。Waterfallの例では、Waterという文字列が滝のように下に向かっている様子から類推しなければならない。おもしろい。
[Paper Note] CodeAlignBench: Assessing Code Generation Models on Developer-Preferred Code Adjustments, Forough Mehralian+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #UserBased #AIAgents #Evaluation #Coding Issue Date: 2025-11-03 GPT Summary- 大規模言語モデルのコード生成能力を評価するために、指示に従う能力を測るマルチランゲージベンチマークを導入。初期問題の制約遵守とフォローアップ指示への対応能力を評価。LiveBenchのプログラミングタスクを用いて、PythonからJavaおよびJavaScriptへの自動翻訳タスクで実証。結果、モデルは指示に従う能力において異なる性能を示し、ベンチマークがコード生成モデルの包括的な評価を提供することを明らかにした。 Comment
元ポスト:
[Paper Note] OS-Sentinel: Towards Safety-Enhanced Mobile GUI Agents via Hybrid Validation in Realistic Workflows, Qiushi Sun+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #Evaluation #Safety #ComputerUse #VisionLanguageModel #Live #Safeguard Issue Date: 2025-11-03 GPT Summary- モバイルプラットフォームでのエージェントの安全性を確保するため、MobileRisk-Liveという動的サンドボックス環境を導入し、OS-Sentinelという新しいハイブリッド安全性検出フレームワークを提案。OS-Sentinelは、システムレベルの違反検出と文脈リスク評価を統合し、実験で既存手法に対して10%-30%の性能向上を達成。自律型モバイルエージェントの信頼性向上に寄与する重要な洞察を提供。 Comment
dataset:
https://huggingface.co/datasets/OS-Copilot/MobileRisk
pj page:
https://qiushisun.github.io/OS-Sentinel-Home/
元ポスト:
[Paper Note] Global PIQA: Evaluating Physical Commonsense Reasoning Across 100+ Languages and Cultures, Tyler A. Chang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #MultiLingual #Cultural #CommonsenseReasoning Issue Date: 2025-11-03 GPT Summary- 「Global PIQA」は、65カ国の335人の研究者によって構築された、100以上の言語に対応した常識推論ベンチマークであり、116の言語バリエーションを含む。多くの例が文化特有の要素に関連しており、LLMは全体で良好なパフォーマンスを示すが、リソースが限られた言語では精度が低下することが発見された。Global PIQAは、言語と文化における日常的な知識の改善の必要性を示し、LLMの評価や文化の多様性の理解に寄与することを期待されている。 Comment
dataset: https://huggingface.co/datasets/mrlbenchmarks/global-piqa-nonparallel
元ポスト:
[Paper Note] AMO-Bench: Large Language Models Still Struggle in High School Math Competitions, Shengnan An+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Mathematics Issue Date: 2025-11-01 GPT Summary- AMO-Benchは、オリンピックレベルの数学的推論を評価するための新しいベンチマークで、50の専門家作成の問題から成る。既存のベンチマークが飽和状態にある中、AMO-BenchはIMO基準を満たし、オリジナルの問題を提供することで厳格な評価を実現。実験では、26のLLMが52.4%の精度しか達成できず、数学的推論の改善の余地が大きいことが示された。AMO-Benchは、言語モデルの推論能力向上のための研究を促進することを目的としている。 Comment
元ポスト:
[Paper Note] The German Commons - 154 Billion Tokens of Openly Licensed Text for German Language Models, Lukas Gienapp+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Selected Papers/Blogs #One-Line Notes #German Issue Date: 2025-10-28 GPT Summary- 「German Commons」は、オープンライセンスのドイツ語テキストの最大コレクションで、41のソースから1545.6億トークンを提供。法律、科学、文化など7つのドメインを含み、品質フィルタリングや重複排除を行い、一貫した品質を確保。すべてのデータは法的遵守を保証し、真にオープンなドイツ語モデルの開発を支援。再現可能で拡張可能なコーパス構築のためのコードも公開。 Comment
HF: https://huggingface.co/datasets/coral-nlp/german-commons
元ポスト:
最大級(154B)のドイツ語のLLM(事前)学習用データセットらしい
ODC-By Licence
[Paper Note] Kaputt: A Large-Scale Dataset for Visual Defect Detection, Sebastian Höfer+, ICCV'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Analysis #Zero/Few/ManyShotPrompting #MultiModal #In-ContextLearning #ICCV #VisionLanguageModel Issue Date: 2025-10-27 GPT Summary- 新しい大規模データセットを提案し、小売物流における欠陥検出の課題に対応。230,000枚の画像と29,000以上の欠陥インスタンスを含み、MVTec-ADの40倍の規模。既存手法の限界を示し、56.96%のAUROCを超えない結果を得た。データセットは今後の研究を促進するために利用可能。 Comment
元ポスト:
[Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #Zero/Few/ManyShotPrompting #Evaluation #MultiModal #In-ContextLearning #NeurIPS #read-later #Selected Papers/Blogs #OOD #Generalization #VisionLanguageModel #One-Line Notes #ObjectDetection Issue Date: 2025-10-27 GPT Summary- 視覚と言語のモデル(VLMs)は、一般的な物体に対して優れたゼロショット検出性能を示すが、分布外のクラスやタスクに対しては一般化が難しい。そこで、少数の視覚例と豊富なテキスト記述を用いてVLMを新しい概念に整合させる必要があると提案。Roboflow100-VLという多様な概念を持つ100のマルチモーダル物体検出データセットを導入し、最先端モデルの評価を行った。特に、難しい医療画像データセットでのゼロショット精度が低く、少数ショットの概念整合が求められることを示した。 Comment
元ポスト:
VLMが「現実世界をどれだけ理解できるか」を評価するためのobject detection用ベンチマークを構築。100のopen source datasetから構成され、それぞれにはtextでのfew shot instructionやvisual exampleが含まれている。データセットは合計で約165kの画像、約1.35M件のアノテーションが含まれ、航空、生物、産業などの事前学習ではあまりカバーされていない新規ドメインの画像が多数含まれているとのこと。
そして現在のモデルは事前学習に含まれていないOODな画像に対する汎化性能が低く、いちいちモデルを追加で学習するのではなく、ICLによって適用できた方が好ましいという考えがあり、そして結果的に現在のVLMでは、ICLがあまりうまくいかない(ICLによるOODの汎化が効果的にできない)ことがわかった、という話らしい。
が、
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
での知見と異なる。差異はなんだろうか?
以下のスレッドで議論がされている:
pj page: https://rf100-vl.org
うーんあとでしっかり読みたい、、、
[Paper Note] R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?, Yi Lu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #read-later #Selected Papers/Blogs #One-Line Notes #LongHorizon Issue Date: 2025-10-27 GPT Summary- R-HORIZONを提案し、長期的な推論行動を刺激する手法を通じて、LRMの評価を改善。複雑なマルチステップ推論タスクを含むベンチマークを構築し、LRMの性能低下を明らかに。R-HORIZONを用いた強化学習データ(RLVR)は、マルチホライズン推論タスクの性能を大幅に向上させ、標準的な推論タスクの精度も向上。AIME2024で7.5の増加を達成。R-HORIZONはLRMの長期推論能力を向上させるための有効なパラダイムと位置付けられる。 Comment
pj page: https://reasoning-horizon.github.io
元ポスト:
long horizonタスクにうまく汎化する枠組みの必要性が明らかになったように見える。long horizonデータを合成して、post trainingをするという枠組みは短期的には強力でもすぐに計算リソースの観点からすぐに現実的には能力を伸ばせなくなるのでは。
ポイント解説:
[Paper Note] ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows, Qiushi Sun+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #MultiModal #Reasoning #SoftwareEngineering #ComputerUse #read-later #Selected Papers/Blogs #VisionLanguageModel #Science Issue Date: 2025-10-26 GPT Summary- 大規模言語モデル(LLMs)を活用したScienceBoardを紹介。これは、科学的ワークフローを加速するための動的なマルチドメイン環境と、169の厳密に検証されたタスクからなるベンチマークを提供。徹底的な評価により、エージェントは複雑なワークフローでの信頼性が低く、成功率は15%にとどまることが明らかに。これにより、エージェントの限界を克服し、より効果的な設計原則を模索するための洞察が得られる。 Comment
元ポスト:
[Paper Note] SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal, Tinghao Xie+, ICLR'25, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #MultiLingual #Safety #ICLR Issue Date: 2025-10-24 GPT Summary- SORRY-Benchは、整合された大規模言語モデル(LLMs)の安全でないユーザーリクエストの認識能力を評価する新しいベンチマークです。既存の評価方法の限界を克服するために、44の細かい安全でないトピック分類と440のクラスバランスの取れた指示を提供し、20の言語的拡張を追加しました。また、高速で正確な自動安全評価者を開発し、微調整された7B LLMがGPT-4と同等の精度を持つことを示しました。これにより、50以上のLLMの安全拒否行動を分析し、体系的な評価の基盤を提供します。デモやデータは公式サイトから入手可能です。 Comment
pj page: https://sorry-bench.github.io/
openreview: https://openreview.net/forum?id=YfKNaRktan
[Paper Note] Towards Video Thinking Test: A Holistic Benchmark for Advanced Video Reasoning and Understanding, Yuanhan Zhang+, ICCV'25, 2025.07
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #MultiModal #Reasoning #VideoGeneration/Understandings #ICCV #3D (Video) #Robustness Issue Date: 2025-10-24 GPT Summary- ビデオ理解における正確性と堅牢性のギャップを評価するために、Video Thinking Test(Video-TT)を導入。1,000本のYouTube Shortsビデオを用い、オープンエンドの質問と敵対的質問を通じて、ビデオLLMsと人間のパフォーマンスの違いを示す。 Comment
pj page: https://zhangyuanhan-ai.github.io/video-tt/
関連:
[Paper Note] FineVision: Open Data Is All You Need, Luis Wiedmann+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Multi #ComputerVision #NLP #QuestionAnswering #MultiModal #Conversation #VisionLanguageModel #2D (Image) #Author Thread-Post Issue Date: 2025-10-22 GPT Summary- 本研究では、視覚と言語のモデル(VLM)のために、24百万サンプルからなる統一コーパス「FineVision」を紹介。これは200以上のソースを統合し、半自動化されたパイプラインでキュレーションされている。データの衛生と重複排除が行われ、66の公的ベンチマークに対する汚染除去も適用。FineVisionで訓練されたモデルは、既存のオープンミックスモデルを上回る性能を示し、データ中心のVLM研究の加速を目指す。 Comment
pj page: https://huggingface.co/spaces/HuggingFaceM4/FineVision
ポイント解説:
著者ポスト:
[Paper Note] PixelWorld: Towards Perceiving Everything as Pixels, Zhiheng Lyu+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #Evaluation #VisionLanguageModel #UMM #Pixel-based Issue Date: 2025-10-21 GPT Summary- 「Perceive Everything as Pixels(PEAP)」の概念を提案し、自然言語や図式的な入力を単一のピクセル空間に統合するベンチマーク「PixelWorld」を公開。PEAPは意味理解タスクで競争力のある精度を示すが、推論が重要なタスクではパフォーマンスが低下。Chain-of-Thoughtプロンプティングがこのギャップを部分的に緩和し、視覚とテキストの統合により前処理の複雑さが軽減されることが確認された。PixelWorldは統一された視覚言語モデルの評価に役立つ。 Comment
元ポスト:
[Paper Note] OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations, Linke Ouyang+, CVPR'25, 2024.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #CVPR #Selected Papers/Blogs #DocParser #OCR #One-Line Notes Issue Date: 2025-10-21 GPT Summary- 文書内容抽出のための新しいベンチマーク「OmniDocBench」を提案。これは、9つの文書ソースにわたる高品質な注釈を特徴とし、エンドツーエンド評価やタスク特化型分析をサポート。異なる文書タイプにおける手法の強みと弱みを明らかにし、文書解析の公平で詳細な評価基準を設定。データセットとコードは公開されている。 Comment
OCR系のモデルの評価で標準的に用いられるベンチマーク
[Paper Note] Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap, Yueqian Lin+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Evaluation #SpeechProcessing #Reasoning #AudioLanguageModel #audio Issue Date: 2025-10-21 GPT Summary- 音声インタラクティブシステムの推論能力を評価するためのベンチマーク「VERA」を提案。2,931の音声エピソードを5つのトラックに整理し、音声インタラクションに適応。12の音声システムをテキストベースラインと比較した結果、音声モデルの精度は著しく低く、特に数学トラックでは74.8%対6.1%の差が見られた。レイテンシと精度の分析から、迅速な音声システムは約10%の精度に集約され、リアルタイム性を犠牲にしないとテキストパフォーマンスには近づけないことが示された。VERAは、音声アシスタントの推論能力向上に向けた再現可能なテストベッドを提供する。 Comment
元ポスト:
latencyとAccuracyのトレードオフ
[Paper Note] Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation, Sayash Kapoor+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #read-later #Selected Papers/Blogs Issue Date: 2025-10-21 GPT Summary- AIエージェントの評価における課題を解決するため、Holistic Agent Leaderboard(HAL)を導入。標準化された評価ハーネスにより評価時間を短縮し、三次元分析を通じて21,730のエージェントを評価。高い推論努力が精度を低下させることを発見し、LLMを用いたログ検査で新たな行動を明らかに。エージェント評価の標準化を進め、現実世界での信頼性向上を目指す。 Comment
pj page: https://hal.cs.princeton.edu
元ポスト:
よ、40,000ドル!?💸
LLM Agentに関するフロンティアモデル群を複数のベンチマークで同じ条件でapple to appleな比較となるように評価している。
以下元ポストより:
この評価ハーネスは、10行未満のコードスニペットで評価を実行可能(元ポスト)
知見としては
- reasoning effortを上げても多くの場合性能向上には寄与せず(21/36のケースで性能向上せず)
- エージェントはタスクを解決するために近道をする(ベンチマークを直接参照しに行くなど)
- エージェントは非常にコストの高い手段を取ることもあり(フライト予約において誤った空港から予約したり、ユーザに過剰な返金をしたり、誤ったクレジットカードに請求したりなど)
- コストとacc.のトレードオフを分析した結果、最も高価なOpus4.1は一度しかパレートフロンティアにならず、Gemini Flash (7/9)、GPT-5, o4-mini(4/9)が多くのベンチマークでコストとAcc.のトレードオフの上でパレートフロンティアとなった。
- トークンのコストとAcc.のトレードオフにおいては、Opus4.1が3つのベンチマークでパレードフロンティアとなった。
- すべてのエージェントの行動を記録し分析した結果、SelfCorrection, intermediate verifiers (コーディング問題におけるユニットテストなど)のbehaviorがacc.を改善する上で高い相関を示した
- 一方タスクに失敗する場合は、多くの要因が存在することがわかり、たとえば環境内の障害(CAPTCHAなど)、指示に従うことの失敗(指定されたフォーマットでコードを出力しない)などが頻繁に見受けられた。また、タスクを解けたか否かに関わらずツール呼び出しの失敗に頻繁に遭遇していた。これはエージェントはこうしたエラーから回復できることを示している。
- エージェントのログを分析することで、TauBenchで使用していたscaffold(=モデルが環境もやりとりするための構成要素)にバグがあることを突き止めた(few-shotのサンプルにリークがあった)。このscaffoldはHALによるTauBenchの分析から除外した。
- Docsentのようなログ分析が今後エージェントを評価する上では必要不可欠であり、信頼性の問題やショートカット行動、高コストなエージェントの失敗などが明らかになる。ベンチマーク上での性能と比較して実環境では性能が低い、あるいはその逆でベンチマークが性能を低く見積もっている(たとえばCAPTChAのようや環境的な障害はベンチマーク上では同時リクエストのせいで生じても実環境では生じないなど)ケースもあるので、これらはベンチマークのacc.からだけでは明らかにならないため、ベンチマークのacc.は慎重に解釈すべき。
[Paper Note] Reasoned Safety Alignment: Ensuring Jailbreak Defense via Answer-Then-Check, Chentao Cao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Reasoning #Safety Issue Date: 2025-10-20 GPT Summary- 脱獄攻撃に対する安全性を向上させるために、Answer-Then-Checkという新しいアプローチを提案。モデルはまず質問に回答し、その後安全性を評価してから応答を提供。80Kの例からなるReasoned Safety Alignment(ReSA)データセットを構築し、実験により優れた安全性を示しつつ過剰拒否率を低下。ReSAでファインチューニングされたモデルは一般的な推論能力を維持し、敏感なトピックに対しても有益な応答を提供可能。少量のデータでのトレーニングでも高いパフォーマンスを達成できることが示唆された。 Comment
元ポスト:
[Paper Note] Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation, Kang Liao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #Evaluation #MultiModal #DiffusionModel #UMM #SpatialUnderstanding Issue Date: 2025-10-20 GPT Summary- カメラ中心の理解と生成を統合したマルチモーダルモデル「Puffin」を提案。Puffinは、言語回帰と拡散生成を組み合わせ、カメラを言語として扱う新しいアプローチを採用。400万の視覚-言語-カメラのデータセット「Puffin-4M」で訓練され、空間的な視覚的手がかりを考慮した推論を実現。実験結果では、専門モデルを上回る性能を示し、指示チューニングにより多様なタスクに対応可能。研究成果はコードやデータセットと共に公開予定。 Comment
元ポスト:
[Paper Note] Understanding the Influence of Synthetic Data for Text Embedders, Jacob Mitchell Springer+, ACL'25 Findings, 2025.09
Paper/Blog Link My Issue
#Embeddings #Analysis #NLP #LanguageModel #RepresentationLearning #SyntheticData #ACL #Findings Issue Date: 2025-10-19 GPT Summary- 合成LLM生成データのトレーニングによる汎用テキスト埋め込み器の進展を受け、Wangらの合成データを再現・公開。高品質なデータはパフォーマンス向上をもたらすが、一般化の改善は局所的であり、異なるタスク間でのトレードオフが存在。これにより、合成データアプローチの限界が明らかになり、タスク全体での堅牢な埋め込みモデルの構築に対する考えに疑問を呈する。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/jspringer/open-synthetic-embeddings
[Paper Note] LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild, Jiayu Wang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #UserBased #AIAgents #Evaluation #read-later #Selected Papers/Blogs #DeepResearch #Live Issue Date: 2025-10-18 GPT Summary- 深層研究は、ライブウェブソースから情報を検索・統合し、引用に基づいたレポートを生成する技術であり、評価にはユーザー中心、動的、明確、多面的な原則が必要。既存のベンチマークはこれらを満たしていないため、LiveResearchBenchを導入し、100の専門家がキュレーションしたタスクを提供。さらに、レポート評価のためにDeepEvalを提案し、品質を包括的に評価するプロトコルを統合。これにより、17の深層研究システムの包括的な評価を行い、強みや改善点を明らかにする。 Comment
元ポスト:
データセットとソースコードがリリース:
dataset: https://huggingface.co/datasets/Salesforce/LiveResearchBench
pj page: https://livedeepresearch.github.io/
[Paper Note] Reliable Fine-Grained Evaluation of Natural Language Math Proofs, Wenjie Ma+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Mathematics #read-later #Selected Papers/Blogs #Proofs Issue Date: 2025-10-18 GPT Summary- 大規模言語モデル(LLMs)による数学的証明の生成と検証における信頼性の高い評価者が不足している問題に対処するため、0から7のスケールで評価する新たな評価者ProofGraderを開発。ProofBenchという専門家注釈付きデータセットを用いて、評価者の設計空間を探求し、低い平均絶対誤差(MAE)0.926を達成。ProofGraderは、最良の選択タスクにおいても高いスコアを示し、下流の証明生成の進展に寄与する可能性を示唆している。 Comment
元ポスト:
これは非常に重要な研究に見える
[Paper Note] Hard2Verify: A Step-Level Verification Benchmark for Open-Ended Frontier Math, Shrey Pandit+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Mathematics #PRM #Verification Issue Date: 2025-10-17 GPT Summary- LLMに基づく推論システムがIMO 2025コンペで金メダルレベルのパフォーマンスを達成したが、各ステップの正確性と支持が求められる。これを実現するために、500時間以上の人間の労力で作成された「Hard2Verify」というステップレベル検証ベンチマークを提案。最前線のLLMによる応答のステップレベル注釈を提供し、エラーを特定する能力を評価。オープンソースの検証者はクローズドソースモデルに劣ることが示され、検証パフォーマンスの低下要因や計算能力の影響について分析を行った。 Comment
元ポスト:
[Paper Note] ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs, Wonjun Kang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #DiffusionModel #Decoding Issue Date: 2025-10-17 GPT Summary- dLLMは並列デコードにより推論を加速するが、トークンの依存関係を無視するため生成品質が低下する可能性がある。既存の研究はこの問題を見落としており、標準ベンチマークでは評価が不十分である。これに対処するため、情報理論的分析と合成リスト操作のケーススタディを行い、dLLMの限界を明らかにした。新たに提案するParallelBenchは、dLLMにとって困難なタスクを特徴とし、分析の結果、dLLMは実世界での品質低下を引き起こし、現在のデコード戦略は適応性に欠けることが示された。この発見は、スピードと品質のトレードオフを克服する新しいデコード手法の必要性を強調している。 Comment
元ポスト: https://parallelbench.github.io
pj page: https://parallelbench.github.io
[Paper Note] StreamingVLM: Real-Time Understanding for Infinite Video Streams, Ruyi Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Evaluation #Attention #LongSequence #AttentionSinks #read-later #Selected Papers/Blogs #VideoGeneration/Understandings #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-10-15 GPT Summary- StreamingVLMは、無限のビデオストリームをリアルタイムで理解するためのモデルで、トレーニングと推論を統一したフレームワークを採用。アテンションシンクの状態を再利用し、短いビジョントークンと長いテキストトークンのウィンドウを保持することで、計算コストを抑えつつ高い性能を実現。新しいベンチマークInf-Streams-Evalで66.18%の勝率を達成し、一般的なVQA能力を向上させることに成功。 Comment
元ポスト:
これは興味深い
保持するKV Cacheの上限を決め、Sink Token[^1]は保持し[^2](512トークン)、textual tokenは長距離で保持、visual tokenは短距離で保持、またpositional encodingとしてはRoPEを採用するが、固定されたレンジの中で動的にindexを更新することで、位相を学習時のrangeに収めOODにならないような工夫をすることで、memoryと計算コストを一定に保ちながらlong contextでの一貫性とリアルタイムのlatencyを実現する、といった話にみえる。
学習時はフレームがoverlapした複数のチャンクに分けて、それぞれをfull attentionで学習する(Sink Tokenは保持する)。これは上述のinference時のパターンと整合しており学習時とinference時のgapが最小限になる。また、わざわざlong videoで学習する必要がない。(美しい解決方法)
[^1]: decoder-only transformerの余剰なattention scoreの捨て場として機能するsequence冒頭の数トークン(3--4トークン程度)のこと。本論文では512トークンと大きめのSink Tokenを保持している。
[^2]: Attention Sinksによって、long contextの性能が改善され [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
decoder-only transformerの層が深い部分でのトークンの表現が均一化されてしまうover-mixingを抑制する [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
ことが報告されている
AttentionSink関連リンク:
- [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
↑これは元ポストを読んで(と論文斜め読み)の感想のようなものなので、詳細は後で元論文を読む。
関連:
[Paper Note] EVALUESTEER: Measuring Reward Model Steerability Towards Values and Preferences, Kshitish Ghate+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Evaluation #One-Line Notes Issue Date: 2025-10-15 GPT Summary- EVALUESTEERは、ユーザーの多様な価値観やスタイルに対応するためのベンチマークであり、LLMsと報酬モデル(RMs)の操縦性を測定します。165,888の好みペアを生成し、ユーザーのプロファイルに基づく応答の選択精度を評価。完全なプロファイルでは75%未満の精度に対し、関連する好みのみで99%以上の精度を達成。EVALUESTEERは、RMsの限界を明らかにし、多様な価値観に対応するためのテストベッドを提供します。 Comment
元ポスト:
LLNのAlignmentはしばしばReward Modelをベースに実施されるが、現在のReward Modelに存在する、価値観(4種類)とスタイル(4種類)に関するバイアスが存在することを明らかにしている模様。
[Paper Note] Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training, Junlin Han+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pretraining #NLP #LanguageModel #Evaluation #MultiModal #Reasoning #read-later #DataMixture #VisionLanguageModel Issue Date: 2025-10-15 GPT Summary- 大規模言語モデル(LLMs)は、テキストのみで訓練されながらも視覚的先入観を発展させ、少量のマルチモーダルデータで視覚タスクを実行可能にする。視覚的先入観は、言語の事前訓練中に獲得された知識であり、推論中心のデータから発展する。知覚の先入観は広範なコーパスから得られ、視覚エンコーダーに敏感である。視覚を意識したLLMの事前訓練のためのデータ中心のレシピを提案し、500,000 GPU時間をかけた実験に基づく完全なMLLM構築パイプラインを示す。これにより、視覚的先入観を育成する新しい方法を提供し、次世代のマルチモーダルLLMの発展に寄与する。 Comment
元ポスト:
MLE Bench (Multi-Level Existence Bench)
[Paper Note] Demystifying Reinforcement Learning in Agentic Reasoning, Zhaochen Yu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #AIAgents #Reasoning #Entropy Issue Date: 2025-10-14 GPT Summary- エージェント的強化学習(agentic RL)を用いて、LLMsの推論能力を向上させるための調査を行った。重要な洞察として、合成軌道の実際のツール使用軌道への置き換えや、多様なデータセットの活用がRLのパフォーマンスを向上させることが示された。また、探索を促進する技術や、ツール呼び出しを減らす戦略がトレーニング効率を改善することが確認された。これにより、小型モデルでも強力な結果を達成し、実用的なベースラインを提供する。さらに、高品質なデータセットを用いて、困難なベンチマークでのエージェント的推論能力の向上を示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Spectrum Tuning: Post-Training for Distributional Coverage and In-Context Steerability, Taylor Sorensen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Evaluation #In-ContextLearning #PostTraining #Selected Papers/Blogs #meta-learning #KeyPoint Notes #Steering #Author Thread-Post Issue Date: 2025-10-14 GPT Summary- ポストトレーニングは言語モデルの性能を向上させるが、操作性や出力空間のカバレッジ、分布の整合性においてコストが伴う。本研究では、これらの要件を評価するためにSpectrum Suiteを導入し、90以上のタスクを網羅。ポストトレーニング技術が基礎的な能力を引き出す一方で、文脈内操作性を損なうことを発見。これを改善するためにSpectrum Tuningを提案し、モデルの操作性や出力空間のカバレッジを向上させることを示した。 Comment
元ポスト:
著者らはモデルの望ましい性質として
- In context steerbility: inference時に与えられた情報に基づいて出力分布を変えられる能力
- Valid output space coverage: タスクにおける妥当な出力を広範にカバーできること
- Distributional Alignment: ターゲットとする出力分布に対してモデルの出力分布が近いこと
の3つを挙げている。そして既存のinstruction tuningや事後学習はこれらを損なうことを指摘している。
ここで、incontext steerbilityとは、事前学習時に得た知識や、分布、能力だけに従うのではなく、context内で新たに指定した情報をモデルに活用させることである。
モデルの上記3つの能力を測るためにSpectrum Suiteを導入する。これには、人間の様々な嗜好、numericな分布の出力、合成データ作成などの、モデル側でsteeringや多様な分布への対応が必要なタスクが含まれるベンチマークのようである。
また上記3つの能力を改善するためにSpectrum Tuningと呼ばれるSFT手法を提案している。
手法はシンプルで、タスクT_iに対する 多様なinput X_i タスクのcontext(すなわちdescription) Z_i が与えられた時に、T_i: X_i,Z_i→P(Y_i) を学習したい。ここで、P(Y_i)は潜在的なoutputの分布であり、特定の1つのサンプルyに最適化する、という話ではない点に注意(meta learningの定式化に相当する)。
具体的なアルゴリズムとしては、タスクのコレクションが与えられた時に、タスクiのcontextとdescriptionをtokenizeした結果 z_i と、incontextサンプルのペア x_ij, y_ij が与えられた時に、output tokenのみに対してcross entropyを適用してSFTをする。すなわち、以下のような手順を踏む:
1. incontextサンプルをランダムなオーダーにソートする
2. p_dropの確率でdescription z_i をドロップアウトしx_i0→y_i0の順番でconcatする、
2-1. descriptionがdropしなかった場合はdescription→x_i0→y_i0の順番でconcatし入力を作る。
2-2. descriptionがdropした場合、x_i0→y_i0の順番で入力を作る。
3. 他のサンプルをx_1→y_1→...→x_n→y_nの順番で全てconcatする。
4. y_{1:n}に対してのみクロスエントロピーlossを適用し、他はマスクして学習する。
一見するとinstruct tuningに類似しているが、以下の点で異なっている:
- 1つのpromptに多くのi.i.dな出力が含まれるのでmeta-learningが促進される
- 個別データに最適化されるのではなく、タスクに対する入出力分布が自然に学習される
- chat styleのデータにfittingするのではなく、分布に対してfittingすることにフォーカスしている
- input xやタスクdescription zを省略することができ、ユーザ入力が必ず存在する設定とは異なる
という主張をしている。
[Paper Note] BigCodeArena: Unveiling More Reliable Human Preferences in Code Generation via Execution, Terry Yue Zhuo+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #UserBased #Alignment #Evaluation #Coding #read-later #Selected Papers/Blogs Issue Date: 2025-10-13 GPT Summary- BigCodeArenaは、LLMが生成したコードの質をリアルタイムで評価するためのクラウドソーシングプラットフォームで、Chatbot Arenaを基盤に構築されています。14,000以上のコード中心の会話セッションから4,700のマルチターンサンプルを収集し、人間の好みを明らかにしました。これに基づき、LLMのコード理解と生成能力を評価するためのBigCodeRewardとAutoCodeArenaという2つのベンチマークを策定しました。評価の結果、実行結果が利用可能な場合、ほとんどのLLMが優れたパフォーマンスを示し、特にGPT-5やClaudeシリーズがコード生成性能でリードしていることが確認されました。 Comment
元ポスト:
良さそう
[Paper Note] General-Reasoner: Advancing LLM Reasoning Across All Domains, Xueguang Ma+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #NeurIPS #mid-training #PostTraining #GenerativeVerifier Issue Date: 2025-10-12 GPT Summary- 強化学習を用いた新しいトレーニングパラダイム「General-Reasoner」を提案し、LLMの推論能力を向上させる。大規模な高品質データセットを構築し、生成モデルベースの回答検証器を開発。物理学や化学などの多様な分野で評価し、既存手法を上回る性能を示す。 Comment
元ポスト:
[Paper Note] Webscale-RL: Automated Data Pipeline for Scaling RL Data to Pretraining Levels, Zhepeng Cen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #mid-training #PostTraining Issue Date: 2025-10-12 GPT Summary- Webscale-RLパイプラインを導入し、大規模な事前学習文書から数百万の多様な質問-回答ペアを生成。これにより、120万の例を含むWebscale-RLデータセットを構築。実験結果、RLトレーニングは継続的な事前トレーニングよりも効率的で、パフォーマンスを大幅に向上させることを示した。研究は、RLを事前学習レベルにスケールアップする道筋を示し、より高性能な言語モデルの実現を可能にする。 Comment
元ポスト:
Dataset: https://huggingface.co/datasets/Salesforce/Webscale-RL
以下の研究が関連研究でNeurIPSですでに発表されているが引用も議論もされていないという指摘がある:
- [Paper Note] General-Reasoner: Advancing LLM Reasoning Across All Domains, Xueguang Ma+, arXiv'25, 2025.05
他にも似たようなモチベーションの研究を見たことがあるような…
[Paper Note] Scaling Generalist Data-Analytic Agents, Shuofei Qiao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #TabularData #SyntheticData #ScientificDiscovery #numeric #MajorityVoting Issue Date: 2025-10-09 GPT Summary- DataMindは、オープンソースのデータ分析エージェントを構築するためのスケーラブルなデータ合成とエージェントトレーニングの手法を提案。主な課題であるデータリソース、トレーニング戦略、マルチターンロールアウトの不安定性に対処し、合成クエリの多様性を高めるタスク分類や、動的なトレーニング目標を採用。DataMind-12Kという高品質なデータセットを作成し、DataMind-14Bはデータ分析ベンチマークで71.16%のスコアを達成し、最先端のプロプライエタリモデルを上回った。DataMind-7Bも68.10%でオープンソースモデル中最高のパフォーマンスを示した。今後、これらのモデルをコミュニティに公開予定。 Comment
元ポスト:
7B程度のSLMで70B級のモデルと同等以上の性能に到達しているように見える。論文中のp.2にコンパクトに内容がまとまっている。
[Paper Note] X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents, Salman Rahman+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Evaluation #Conversation #Safety #COLM Issue Date: 2025-10-08 GPT Summary- X-Teamingを提案し、無害なインタラクションが有害な結果にエスカレートする過程を探求。協力的なエージェントを用いて、最大98.1%の成功率でマルチターン攻撃を実現。特に、Claude 3.7 Sonnetモデルに対して96.2%の成功率を達成。さらに、30Kの脱獄を含むオープンソースのトレーニングデータセットXGuard-Trainを導入し、LMのマルチターン安全性を向上させる。 Comment
openreview: https://openreview.net/forum?id=gKfj7Jb1kj#discussion
元ポスト:
[Paper Note] D3: A Dataset for Training Code LMs to Act Diff-by-Diff, Piterbarg+, COLM'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Coding #mid-training #COLM #Editing #One-Line Notes Issue Date: 2025-10-08 Comment
openreview: https://openreview.net/forum?id=sy71y74U80#discussion
openreviewのサマリによると、8B tokens, 850k python filesのデータセットで、コーディングタスクを、ゴールで条件づけられたsequential editsタスクとみなし The Stack上のコードを分析ツールとLLMによって合成されたrationaleによってフィルタリング/拡張したデータを提供しているとのこと。具体的には (state, goal, action_i) の3つ組みのデータセットであり、action_iがaction前後でのdiffになっている模様。D3データセットでSFTの前にLlama 1B / 3Bをmid-trainingした結果、downstreamタスク(コード生成、completion、編集)において性能が向上したとのこと。
[Paper Note] Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use, Anna Goldie+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #ReinforcementLearning #SyntheticData #COLM #One-Line Notes Issue Date: 2025-10-08 GPT Summary- 段階的強化学習(SWiRL)を提案し、複数のテキスト生成や推論ステップを通じて大規模言語モデルの性能を向上させる手法を紹介。SWiRLは、各アクションに対するサブ軌道を生成し、合成データフィルタリングと強化学習最適化を適用。実験では、GSM8KやHotPotQAなどのタスクでベースラインを上回る精度を達成し、タスク間での一般化も示された。 Comment
openreview: https://openreview.net/forum?id=oN9STRYQVa
元ポスト:
従来のRLではテキスト生成を1ステップとして扱うことが多いが、複雑な推論やtool useを伴うタスクにおいては複数ステップでの最適化が必要となる。そのために、多段階の推論ステップのtrajectoryを含むデータを作成し、同データを使いRLすることによって性能が向上したという話な模様。RLをする際には、stepごとにRewardを用意するようである。また、現在のstepの生成を実施する際には過去のstepの情報に基づいて生成する方式のようである。
[Paper Note] VisOnlyQA: Large Vision Language Models Still Struggle with Visual Perception of Geometric Information, Ryo Kamoi+, COLM'25, 2024.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #COLM #VisionLanguageModel #Geometric Issue Date: 2025-10-06 GPT Summary- LVLMsの幾何学的認識を評価するためのデータセット「VisOnlyQA」を導入し、LVLMsが画像内の幾何学的情報を正確に認識できないことを明らかにした。23のLVLMs(GPT-4oやGemini 2.5 Proを含む)は、VisOnlyQAでの性能が低く、追加のトレーニングデータでは改善されない。より強力なLLMを使用するLVLMsは幾何学的認識が向上するが、視覚エンコーダーからの情報処理がボトルネックであることが示唆された。 Comment
openreview: https://openreview.net/forum?id=PYHwlyu2fa#discussion
元ポスト:
[Paper Note] StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?, Yanxu Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Financial Issue Date: 2025-10-04 GPT Summary- 大規模言語モデル(LLMs)の金融分野における評価のために、StockBenchという新しいベンチマークを導入。これは、株式取引環境でのLLMエージェントのパフォーマンスを評価し、累積リターンやリスク管理能力を測定する。多くのLLMエージェントはシンプルな戦略を超えるのが難しいが、一部のモデルは高いリターンを示す可能性がある。StockBenchは再現性を支援し、今後の研究を促進するためにオープンソースとして公開される。 Comment
元ポスト:
pj page: https://stockbench.github.io
過去のデータを使いLLMの能力を評価するベンチマークとして利用するという方向性ならこういったタスクも良いのかもしれない。
が、素朴な疑問として、LLMが良いトレードをして儲けられます、みたいなシステムが世に広まった世界の前提になると、それによって市場の原理が変わってLLM側が前提としていたものがくずれ、結果的にLLMはトレードで儲けられなくなる、みたいなことが起きるんじゃないか、という気はするのであくまでLLMの能力を測るためのベンチマークです、という点は留意した方が良いのかな、という感想を持つなどした(実際はよくわからん)。
[Paper Note] TOUCAN: Synthesizing 1.5M Tool-Agentic Data from Real-World MCP Environments, Zhangchen Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #AIAgents #SyntheticData #MCP Issue Date: 2025-10-04 GPT Summary- Toucanは、約500の実世界のモデルコンテキストプロトコルから合成された150万の軌跡を含む、最大の公開ツールエージェントデータセットを提供。多様で現実的なタスクを生成し、マルチツールおよびマルチターンのインタラクションに対応。5つのモデルを用いてツール使用クエリを生成し、厳密な検証を通じて高品質な出力を保証。Toucanでファインチューニングされたモデルは、BFCL V3ベンチマークで優れた性能を示し、MCP-Universe Benchでの進展を実現。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/Agent-Ark/Toucan-1.5M
[Paper Note] Radiology's Last Exam (RadLE): Benchmarking Frontier Multimodal AI Against Human Experts and a Taxonomy of Visual Reasoning Errors in Radiology, Suvrankar Datta+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #VisionLanguageModel #Medical Issue Date: 2025-10-03 GPT Summary- 医療画像の解釈におけるAIモデルのパフォーマンスを評価するため、50の専門的な「スポット診断」ケースを用いたベンチマークを開発。5つの最前線AIモデル(GPT-5、o3、Gemini 2.5 Pro、Grok-4、Claude Opus 4.1)をテストした結果、ボード認定放射線医が最高の診断精度(83%)を達成し、AIモデルは最良のGPT-5でも30%に留まった。これにより、AIモデルが難しい診断ケースにおいて放射線医には及ばないことが示され、医療画像におけるAIの限界と無監視使用への警告が強調された。 Comment
元ポスト:
所見:
[Paper Note] Personalized Reasoning: Just-In-Time Personalization and Why LLMs Fail At It, Shuyue Stella Li+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #UserModeling #LanguageModel #UserBased #Personalization #Evaluation #Conversation #read-later #One-Line Notes Issue Date: 2025-10-03 GPT Summary- 現在のLLMは、タスク解決とユーザーの好みの整合性を別々に扱っており、特にジャストインタイムのシナリオでは効果的ではない。ユーザーの好みを引き出し、応答を適応させる「パーソナライズド推論」が必要である。新たに提案された評価手法「PREFDISCO」は、ユーザーのコンテキストに応じた異なる推論チェーンを生成し、パーソナライズの重要性を示す。評価結果から、単純なパーソナライズが一般的な応答よりも劣ることが明らかになり、専用の開発が必要であることが示唆された。PREFDISCOは、教育や医療などの分野でのパーソナライズの重要性を強調する基盤を提供する。 Comment
元ポスト:
ざーっとしか読めていないのが、ユーザから与えられたタスクとマルチターンの会話の履歴に基づいて、LLM側が質問を投げかけて、Personalizationに必要なattributeを取得する。つまり、ユーザプロファイルは (attribute, value, weight)のタプルによって構成され、この情報に基づいて生成がユーザプロファイルにalignするように生成する、といった話に見える。膨大なとりうるattributeの中から、ユーザのタスクとcontextに合わせてどのattributeに関する情報を取得するかが鍵となると思われる。また、セッション中でユーザプロファイルを更新し、保持はしない前提な話に見えるので、Personalizationのカテゴリとしては一時的個人化に相当すると思われる。
Personalizationの研究は評価が非常に難しいので、どのような評価をしているかは注意して読んだ方が良いと思われる。
[Paper Note] VELA: An LLM-Hybrid-as-a-Judge Approach for Evaluating Long Image Captions, Kazuki Matsuda+, EMNLP'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Evaluation #ImageCaptioning #LongSequence #LLM-as-a-Judge #EMNLP #VisionLanguageModel #MultiDimensional Issue Date: 2025-10-01 GPT Summary- 本研究では、長い画像キャプションの自動評価に特化した新しい指標VELAを提案し、マルチモーダル大規模言語モデル(MLLMs)を活用した評価フレームワークを構築。さらに、評価指標を検証するためのLongCap-Arenaベンチマークを導入し、7,805枚の画像と32,246件の人間の判断を用いて、VELAが既存の指標を上回る性能を示した。 Comment
元ポスト:
[Paper Note] SWE-QA: Can Language Models Answer Repository-level Code Questions?, Weihan Peng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #QuestionAnswering #AIAgents #Evaluation #Coding #SoftwareEngineering Issue Date: 2025-09-27 GPT Summary- SWE-QAは、ソフトウェアリポジトリ全体を理解し推論するための新しいコード質問応答ベンチマークで、576の高品質な質問-回答ペアを含む。これは、複数のファイルをナビゲートし、ソフトウェアアーキテクチャや長距離のコード依存関係を理解する能力を評価するために設計された。LLMエージェントを用いたプロトタイプSWE-QA-Agentも開発され、実験によりLLMの可能性と今後の研究課題が示された。 Comment
元ポスト:
コードスニペットレベルではなく、リポジトリレベルのコードベースの理解が求められるQAベントマーク
[Paper Note] CLaw: Benchmarking Chinese Legal Knowledge in Large Language Models - A Fine-grained Corpus and Reasoning Analysis, Xinzhe Xu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Legal Issue Date: 2025-09-27 GPT Summary- 法的文書の分析において、LLMの信頼性が損なわれる問題を解決するために、新しいベンチマークCLawを提案。CLawは、中国の法令を網羅した詳細なコーパスと、ケースベースの推論インスタンスから構成され、法的知識の実際の応用を評価。実証的評価では、現代のLLMが法的規定の正確な取得に苦労していることが明らかになり、信頼できる法的推論には正確な知識の取得と強力な推論能力の統合が必要であると主張。ドメイン特化型LLM推論の進展に向けた重要な洞察を提供。 Comment
元ポスト:
中国語による中国の法律のデータセットで、legal分野においては、より細かい粒度の知識を捉えられるモデルが推論も的確にでき、推論能力でそれは補えそうという感じな模様
[Paper Note] CAPE: Context-Aware Personality Evaluation Framework for Large Language Models, Jivnesh Sandhan+, EMNLP'25 Findings, 2025.08
Paper/Blog Link My Issue
#LanguageModel #ContextAware #Evaluation #EMNLP #Findings #Personality Issue Date: 2025-09-24 GPT Summary- 心理測定テストをLLMsの評価に適用するため、文脈対応パーソナリティ評価(CAPE)フレームワークを提案。従来の孤立した質問アプローチから、会話の履歴を考慮した応答の一貫性を定量化する新指標を導入。実験により、会話履歴が応答の一貫性を高める一方で、パーソナリティの変化も引き起こすことが明らかに。特にGPTモデルは堅牢性を示し、Gemini-1.5-FlashとLlama-8Bは感受性が高い。CAPEをロールプレイングエージェントに適用すると、一貫性が改善され人間の判断と一致することが示された。 Comment
元ポスト:
[Paper Note] SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?, Senyu Li+, EMNLP'25, 2025.06
Paper/Blog Link My Issue
#MachineTranslation #Metrics #NLP #LanguageModel #Evaluation #Reference-free #EMNLP #LowResource Issue Date: 2025-09-24 GPT Summary- アフリカの言語における機械翻訳の品質評価は依然として課題であり、既存の指標は限られた性能を示しています。本研究では、13のアフリカ言語ペアを対象とした大規模な人間注釈付きMT評価データセット「SSA-MTE」を紹介し、63,000以上の文レベルの注釈を含んでいます。これに基づき、改良された評価指標「SSA-COMET」と「SSA-COMET-QE」を開発し、最先端のLLMを用いたプロンプトベースのアプローチをベンチマークしました。実験結果は、SSA-COMETがAfriCOMETを上回り、特に低リソース言語で競争力があることを示しました。すべてのリソースはオープンライセンスで公開されています。 Comment
元ポスト:
[Paper Note] Multilingual Language Model Pretraining using Machine-translated Data, Jiayi Wang+, EMNLP'25, 2025.02
Paper/Blog Link My Issue
#MachineTranslation #Pretraining #NLP #LanguageModel Issue Date: 2025-09-24 GPT Summary- 高リソース言語の英語から翻訳した高品質なテキストが、多言語LLMsの事前学習に寄与することを発見。英語のデータセットFineWeb-Eduを9言語に翻訳し、17兆トークンのTransWebEduを作成。1.3BパラメータのTransWebLLMを事前学習し、非英語の推論タスクで最先端モデルと同等以上の性能を達成。特に、ドメイン特化データを追加することで、いくつかの言語で新たな最先端を達成。コーパス、モデル、トレーニングパイプラインはオープンソースで公開。 Comment
元ポスト:
[Paper Note] reWordBench: Benchmarking and Improving the Robustness of Reward Models with Transformed Inputs, Zhaofeng Wu+, EMNLP'25, 2025.03
Paper/Blog Link My Issue
#NLP #Evaluation #EMNLP #RewardModel Issue Date: 2025-09-23 GPT Summary- 報酬モデルはNLPにおいて重要だが、過学習の影響で真の能力が混乱することがある。本研究では、報酬モデルの堅牢性を評価するために**reWordBench**を構築し、入力変換による性能低下を調査。最先端の報酬モデルは小さな変換でも著しい性能低下を示し、脆弱性が明らかになった。堅牢性向上のために同義語に対して類似スコアを割り当てる訓練を提案し、これにより性能低下を約半分に減少させた。さらに、アライメントにおいても高品質な出力を生成し、標準的な報酬モデルに対して最大59%のケースで優れた結果を示した。 Comment
元ポスト:
Figure1がRMの過学習の様子を図示しており、非常に端的で分かりやすい。
[Paper Note] ARE: Scaling Up Agent Environments and Evaluations, Pierre Andrews+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-09-23 GPT Summary- Meta Agents Research Environments (ARE)を紹介し、エージェントのオーケストレーションや環境のスケーラブルな作成を支援するプラットフォームを提供。Gaia2というベンチマークを提案し、エージェントの能力を測定するために設計され、動的環境への適応や他のエージェントとの協力を要求。Gaia2は非同期で実行され、新たな失敗モードを明らかにする。実験結果は、知能のスペクトル全体での支配的なシステムが存在しないことを示し、AREの抽象化が新しいベンチマークの迅速な作成を可能にすることを強調。AIの進展は、意味のあるタスクと堅牢な評価に依存する。 Comment
元ポスト:
GAIAはこちら:
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
Execution, Search, Ambiguity, Adaptability, Time, Noise, Agent2Agentの6つのcapabilityを評価可能。興味深い。
現状、全体的にはGPT-5(high)の性能が最も良く、続いてClaude-4 Sonnetという感じに見える。OpenWeightなモデルでは、Kimi-K2の性能が高く、続いてQwen3-235Bという感じに見える。また、Figure1はbudgetごとのモデルの性能も示されている。シナリオ単位のbudgetが$1以上の場合はGPT-5(high)の性能が最も良いが、$0.1--$0.4の間ではKiml-K2の性能が最も良いように見える。
- [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25
しっかりと読めていないがGLM-4.5は含まれていないように見える。
ポイント解説:
[Paper Note] JudgeLM: Fine-tuned Large Language Models are Scalable Judges, Lianghui Zhu+, ICLR'25, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Evaluation #LLM-as-a-Judge Issue Date: 2025-09-22 GPT Summary- 大規模言語モデル(LLMs)のオープンエンド評価のために、ファインチューニングされたJudgeLMを提案。高品質なデータセットを用いて、異なるパラメータサイズでトレーニングし、バイアスを分析。新技術を導入し、パフォーマンスを向上。JudgeLMは既存ベンチマークで最先端の結果を達成し、高い一致率を示す。拡張された能力も持ち、コードは公開されている。 Comment
openreview: https://openreview.net/forum?id=xsELpEPn4A
[Paper Note] Libra: Assessing and Improving Reward Model by Learning to Think, Meng Zhou+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #Evaluation #Reasoning #RewardModel Issue Date: 2025-09-22 GPT Summary- 強化学習(RL)の報酬モデルは、困難な推論シナリオでの性能が低下しており、注釈付き参照回答や制約された出力形式に依存している。これに対処するため、推論指向のベンチマーク「Libra Bench」を提案し、生成的報酬モデルを改善する新しいアプローチを導入。Libra-RMシリーズを開発し、さまざまなベンチマークで最先端の結果を達成。実験結果は、Libra Benchと下流アプリケーションとの相関関係を示し、ラベルのないデータを用いた推論モデルの改善の可能性を示唆している。 Comment
元ポスト:
Related Workを読むと、 `Discriminative Reward models` と `Generative Reward models` の違いが簡潔に記述されている。
要は
- Discriminative Reward models:
- LLMをBackboneとして持ち、
- スコアリング用のヘッドを追加しpreference dataを用いて(pairwiseのranking lossを通じて)学習され、scalar rewardを返す
- Generative Reward models:
- 通常とLLMと同じアーキテクチャで(Next Token Prdiction lossを通じて学習され)
- responseがinputとして与えられたときに、rewardに関する情報を持つtextualなoutputを返す(要は、LLM-as-a-Judge [Paper Note] JudgeLM: Fine-tuned Large Language Models are Scalable Judges, Lianghui Zhu+, ICLR'25, 2023.10
A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
)
- reasoning traceを活用すればthinking model(Test time scaling)の恩恵をあずかることが可能
- GenRMのルーツはこのへんだろうか:
- [Paper Note] Generative Verifiers: Reward Modeling as Next-Token Prediction, Lunjun Zhang+, arXiv'24, 2024.08
- [Paper Note] LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion, Dongfu Jiang+, arXiv'23, 2023.06
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
という区別である。
以下のノートも参考のこと:
- [Personal Note] LLM-as-a-judge / Reward Model
GenRMは追加の学習なしで利用されるのが普通だったようだが、RM用の追加の学習をしても使えると思うのでそこはあまり気にしなくて良いと思われる。
また
- [Paper Note] Generative Reward Models, Dakota Mahan+, arXiv'24, 2024.10
のFigure1が、RMのアーキテクチャの違いをわかりやすく説明している。
[Paper Note] Perception Encoder: The best visual embeddings are not at the output of the network, Daniel Bolya+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#ComputerVision #Embeddings #NLP #MultiModal #NeurIPS #Encoder #SpatialUnderstanding Issue Date: 2025-09-22 GPT Summary- Perception Encoder(PE)は、画像と動画理解のための新しいビジョンエンコーダで、シンプルなビジョンと言語の学習を通じて訓練されています。従来の特定のタスクに依存せず、対照的なビジョンと言語の訓練だけで強力な埋め込みを生成します。埋め込みを引き出すために、言語アライメントと空間アライメントの2つの手法を導入。PEモデルは、ゼロショット画像・動画分類で高い性能を示し、Q&Aタスクや空間タスクでも最先端の結果を達成しました。モデルやデータセットは公開されています。 Comment
元ポスト:
解説:
[Paper Note] FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning, Liang Hu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Search #LanguageModel #Evaluation #Financial Issue Date: 2025-09-21 GPT Summary- FinSearchCompは、金融検索と推論のための初の完全オープンソースエージェントベンチマークであり、時間に敏感なデータ取得や複雑な歴史的調査を含む3つのタスクで構成されています。70人の金融専門家によるアノテーションと厳格な品質保証を経て、635の質問が用意され、21のモデルが評価されました。Grok 4とDouBaoがそれぞれグローバルおよび大中華圏でトップの精度を示し、ウェブ検索と金融プラグインの活用が結果を改善することが確認されました。FinSearchCompは、現実のアナリストタスクに基づく高難易度のテストベッドを提供します。 Comment
元ポスト:
[Paper Note] LongEmotion: Measuring Emotional Intelligence of Large Language Models in Long-Context Interaction, Weichu Liu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #LongSequence #Emotion Issue Date: 2025-09-21 GPT Summary- 長文の感情知能(EI)タスク専用のベンチマーク「LongEmotion」を提案。感情分類や感情会話など多様なタスクをカバーし、平均入力長は8,777トークン。Retrieval-Augmented Generation(RAG)とCollaborative Emotional Modeling(CoEM)を組み込み、従来の手法と比較してEIパフォーマンスを向上。実験結果は、RAGとCoEMが長文タスクにおいて一貫して効果を示し、LLMsの実用性を高めることを示した。 Comment
pj page: https://longemotion.github.io
元ポスト:
[Paper Note] BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model, Adibvafa Fallahpour+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Reasoning #Biological Issue Date: 2025-09-20 GPT Summary- BioReasonは、DNA基盤モデルと大規模言語モデル(LLM)を統合した新しいアーキテクチャで、複雑なゲノムデータからの生物学的推論を深く解釈可能にする。多段階推論を通じて、精度が88%から97%に向上し、バリアント効果予測でも平均15%の性能向上を達成。未見の生物学的エンティティに対する推論を行い、解釈可能な意思決定を促進することで、AIにおける生物学の進展を目指す。 Comment
HF:
https://huggingface.co/collections/wanglab/bioreason-683cd17172a037a31d208f70
pj page:
https://bowang-lab.github.io/BioReason/
元ポスト:
[Paper Note] MergeBench: A Benchmark for Merging Domain-Specialized LLMs, Yifei He+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #NeurIPS #ModelMerge Issue Date: 2025-09-19 GPT Summary- モデルマージングは、ファインチューニングされたモデルを組み合わせることでマルチタスクトレーニングの効率的なデプロイを可能にする手法です。本研究では、モデルマージングを大規模に評価するための評価スイート「MergeBench」を導入し、指示遵守や数学、多言語理解など5つのドメインをカバーします。8つのマージング手法を評価し、より強力なベースモデルがより良いパフォーマンスを発揮する傾向を示しましたが、大規模モデルの計算コストやドメイン内パフォーマンスのギャップなどの課題も残っています。MergeBenchは今後の研究の基盤となることが期待されています。 Comment
[Paper Note] BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese, Peilin Zhou+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Factuality Issue Date: 2025-09-18 GPT Summary- BrowseComp-ZHは、中国のウェブ上でLLMエージェントを評価するために設計された高難易度のベンチマークで、289のマルチホップ質問から構成される。二段階の品質管理プロトコルを適用し、20以上の言語モデルを評価した結果、ほとんどのモデルが10%未満の精度で苦戦し、最良のモデルでも42.9%にとどまった。この結果は、効果的な情報取得戦略と洗練された推論能力が必要であることを示している。 Comment
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, NAACL'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Reasoning #NAACL Issue Date: 2025-09-18 GPT Summary- 大規模言語モデル(LLMs)の性能向上を活かし、情報検索強化生成(RAG)機能を向上させるための評価データセットFRAMESを提案。FRAMESは、事実に基づいた応答、検索能力、推論を評価するための統一されたフレームワークを提供し、複数の情報源を統合するマルチホップ質問で構成。最先端のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に寄与することを目指す。
[Paper Note] WebWalker: Benchmarking LLMs in Web Traversal, Jialong Wu+, arXiv'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-09-18 GPT Summary- WebWalkerQAを導入し、LLMがウェブのサブページから高品質なデータを抽出する能力を評価。探査-批評のパラダイムを用いたマルチエージェントフレームワークWebWalkerを提案し、実験によりRAGの効果を実証。 Comment
web pageのコンテンツを辿らないと回答できないQAで構成されたベンチマーク
[Paper Note] Fluid Language Model Benchmarking, Valentin Hofmann+, COLM'25
Paper/Blog Link My Issue
#NLP #LanguageModel #IRT #Evaluation #COLM #Author Thread-Post Issue Date: 2025-09-17 GPT Summary- Fluid Benchmarkingという新しい言語モデル(LM)評価アプローチを提案。これは、LMの能力に応じて評価項目を動的に選択し、評価の質を向上させる。実験では、Fluid Benchmarkingが効率、妥当性、分散、飽和の4つの次元で優れたパフォーマンスを示し、静的評価を超えることでLMベンチマークを改善できることを示した。 Comment
元ポスト:
著者ポスト:
[Paper Note] SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?, John Yang+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #AIAgents #Evaluation #MultiModal #ICLR #SoftwareEngineering #VisionLanguageModel Issue Date: 2025-09-16 GPT Summary- 自律システムのバグ修正能力を評価するために、SWE-bench Mを提案。これは視覚要素を含むJavaScriptソフトウェアのタスクを対象とし、617のインスタンスを収集。従来のSWE-benchシステムが視覚的問題解決に苦労する中、SWE-agentは他のシステムを大きく上回り、12%のタスクを解決した。 Comment
openreview: https://openreview.net/forum?id=riTiq3i21b
[Paper Note] 4DNeX: Feed-Forward 4D Generative Modeling Made Easy, Zhaoxi Chen+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Transformer #DiffusionModel #PEFT(Adaptor/LoRA) #Encoder-Decoder #3D (Video) Issue Date: 2025-09-16 GPT Summary- 4DNeXは、単一の画像から動的3Dシーンを生成する初のフィードフォワードフレームワークであり、事前学習されたビデオ拡散モデルをファインチューニングすることで効率的な4D生成を実現。大規模データセット4DNeX-10Mを構築し、RGBとXYZシーケンスを統一的にモデル化。実験により、4DNeXは既存手法を上回る効率性と一般化能力を示し、動的シーンの生成的4Dワールドモデルの基盤を提供。 Comment
pj page: https://4dnex.github.io
元ポスト:
[Paper Note] DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL, Rui Lu+, arXiv'25
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #ReinforcementLearning #PostTraining #GRPO #DeepResearch Issue Date: 2025-09-15 GPT Summary- DeepDiveは、LLMsにブラウジングツールを追加し、複雑なタスクの解決を目指す深い検索エージェントです。オープンな知識グラフから難解な質問を自動合成し、マルチターン強化学習を適用することで、長期的な推論能力を向上させます。実験により、DeepDive-32Bは複数のベンチマークで優れた性能を示し、ツール呼び出しのスケーリングと並列サンプリングを可能にしました。すべてのデータとコードは公開されています。 Comment
元ポスト:
[Paper Note] SpatialVID: A Large-Scale Video Dataset with Spatial Annotations, Jiahao Wang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #3D (Scene) Issue Date: 2025-09-15 GPT Summary- SpatialVIDデータセットは、21,000時間以上の生動画から生成された2.7百万のクリップを含み、カメラポーズ、深度、動的マスクなどの詳細な3D注釈を提供。これにより、空間知能のモデルの一般化とパフォーマンス向上を促進し、ビデオおよび3Dビジョン研究において重要な資産となる。 Comment
pj page:
https://nju-3dv.github.io/projects/SpatialVID/
dataset:
https://huggingface.co/datasets/SpatialVID/SpatialVID-HQ
元ポスト:
CC-BY-NC-SA 4.0ライセンス
[Paper Note] MedBrowseComp: Benchmarking Medical Deep Research and Computer Use, Shan Chen+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Medical Issue Date: 2025-09-13 GPT Summary- 大規模言語モデル(LLMs)は臨床意思決定支援に期待されているが、異種の知識ベースを統合する厳格な精度が求められる。既存の評価は実用性が不明確であるため、MedBrowseCompを提案。これは、医療従事者が情報を調整する臨床シナリオを反映した1,000以上の質問を含む初のベンチマークである。最前線のエージェントシステムに適用した結果、パフォーマンス不足が10%に達し、LLMの能力と臨床環境の要求との間に重要なギャップが示された。MedBrowseCompは信頼性の高い医療情報探索のためのテストベッドを提供し、将来のモデル改善の目標を設定する。 Comment
[Paper Note] LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code, Naman Jain+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Coding #read-later #Contamination-free #Selected Papers/Blogs #Live Issue Date: 2025-09-12 GPT Summary- 本研究では、LLMのコード関連能力を評価するための新しいベンチマーク「LiveCodeBench」を提案。LeetCode、AtCoder、CodeForcesから収集した400の高品質なコーディング問題を用い、コード生成や自己修復、コード実行など多様な能力に焦点を当てている。18のベースLLMと34の指示調整されたLLMを評価し、汚染や過剰適合の問題を実証的に分析。すべてのプロンプトとモデルの結果を公開し、さらなる分析や新しいシナリオの追加を可能にするツールキットも提供。 Comment
pj page: https://livecodebench.github.io
openreview: https://openreview.net/forum?id=chfJJYC3iL
LiveCodeBenchは非常にpopularなコーディング関連のベンチマークだが、readmeに記載されているコマンド通りにベンチマークを実行すると、stop tokenに"###"が指定されているため、マークダウンを出力したLLMの出力が常にtruncateされるというバグがあった模様。
BioML-bench: Evaluation of AI Agents for End-to-End Biomedical ML, Miller+, bioRxiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #read-later #Medical #Biological Issue Date: 2025-09-10 Comment
元ポスト:
Biomedicalドメインにおける24種類の非常に複雑でnuancedな記述や画像の読み取りなどを含む実タスクによって構成される初めてのAgenticベンチマークとのこと。
[Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #NAACL Issue Date: 2025-09-09 GPT Summary- MMLUベンチマークのエラーを分析し、ウイルス学のサブセットでは57%の質問にエラーがあることを発見。新しいエラー注釈プロトコルを用いてMMLU-Reduxを作成し、6.49%の質問にエラーが含まれると推定。MMLU-Reduxを通じて、モデルのパフォーマンスメトリックとの不一致を示し、MMLUの信頼性向上を提案。
[Paper Note] SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents, Ibragim Badertdinov+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Coding #NeurIPS #SoftwareEngineering #read-later #Contamination-free #Selected Papers/Blogs #Live #Environment Issue Date: 2025-09-06 GPT Summary- LLMベースのエージェントのSWEタスクにおける課題として、高品質なトレーニングデータの不足と新鮮なインタラクティブタスクの欠如が挙げられる。これに対処するため、21,000以上のインタラクティブなPythonベースのSWEタスクを含む公的データセットSWE-rebenchを自動化されたパイプラインで構築し、エージェントの強化学習に適したベンチマークを提供。これにより、汚染のない評価が可能となり、いくつかのLLMの性能が過大評価されている可能性を示した。 Comment
pj page: https://swe-rebench.com
元ポスト:
コンタミネーションのない最新のIssueを用いて評価した結果、Sonnet 4が最も高性能
Multi-Relational Multi-Party Chat Corpus: 話者間の関係性に着目したマルチパーティ雑談対話コーパス, 津田+, NLP'25
Paper/Blog Link My Issue
#Multi #NLP #DialogueGeneration #Conversation Issue Date: 2025-09-05 Comment
コーパス: https://github.com/nu-dialogue/multi-relational-multi-party-chat-corpus
元ポスト:
3人以上のマルチパーティに対応したダイアログコーパスで、話者間の関係性として「初対面」と「家族」に着目し、初対面対話や家族入り対話の2種類の対話を収集したコーパス。
[Paper Note] GSO: Challenging Software Optimization Tasks for Evaluating SWE-Agents, Manish Shetty+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering Issue Date: 2025-09-03 GPT Summary- 高性能ソフトウェア開発における言語モデルの能力を評価するためのベンチマークGSOを提案。102の最適化タスクを特定する自動化パイプラインを開発し、主要なソフトウェアエンジニアリングエージェントの成功率は5%未満であることを示した。定性的分析により、低レベル言語や最適化戦略の課題が明らかになった。研究の進展のために、ベンチマークのコードとエージェントのデータを公開。 Comment
pj page: https://gso-bench.github.io
ソフトウェアの高速化に関するベンチ
元ポストに掲載されているリーダーボードはどこにあるのだろう。ざっと見た感じ見当たらない。
[Paper Note] AHELM: A Holistic Evaluation of Audio-Language Models, Tony Lee+, arXiv'25
Paper/Blog Link My Issue
#LanguageModel #Evaluation #SpeechProcessing #read-later #Selected Papers/Blogs #AudioLanguageModel Issue Date: 2025-09-03 GPT Summary- 音声言語モデル(ALMs)の評価には標準化されたベンチマークが欠如しており、これを解決するためにAHELMを導入。AHELMは、ALMsの多様な能力を包括的に測定するための新しいデータセットを集約し、10の重要な評価側面を特定。プロンプトや評価指標を標準化し、14のALMsをテストした結果、Gemini 2.5 Proが5つの側面でトップにランクされる一方、他のモデルは不公平性を示さなかった。AHELMは今後も新しいデータセットやモデルを追加予定。 Comment
元ポスト:
関連:
- [Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
[Paper Note] DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis, Liana Patel+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #DeepResearch #Science #Live Issue Date: 2025-08-31 GPT Summary- 生成的研究合成の評価のために、DeepScholar-benchというライブベンチマークと自動評価フレームワークを提案。これは、ArXiv論文からクエリを引き出し、関連研究セクションを生成する実際のタスクに焦点を当て、知識合成、検索品質、検証可能性を評価。DeepScholar-baseは強力なベースラインを確立し、他の手法と比較して競争力のあるパフォーマンスを示した。DeepScholar-benchは依然として難易度が高く、生成的研究合成のAIシステムの進歩に重要であることを示す。 Comment
leaderboard: https://guestrin-lab.github.io/deepscholar-leaderboard/leaderboard/deepscholar_bench_leaderboard.html
元ポスト:
[Paper Note] MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers, Zhenting Wang+, arXiv'25
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #MCP Issue Date: 2025-08-30 GPT Summary- MCP-Benchは、ツールの使用や調整、計画/推論を必要とする多段階タスクを評価するためのベンチマークであり、250のツールを持つ28のMCPサーバーにLLMsを接続します。従来のベンチマークとは異なり、相互に連携するツールセットを提供し、複雑なタスクを構築可能にします。タスクは、ツールの取得能力や多段階実行経路の計画能力をテストし、既存のベンチマークでは評価されていない能力を明らかにします。20のLLMに対する実験を通じて、MCP-Benchの課題が示されました。 Comment
元ポスト:
またしてもMCPに基づいたtool useのベンチマークが出た模様
[Paper Note] UQ: Assessing Language Models on Unsolved Questions, Fan Nie+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #Verification Issue Date: 2025-08-28 GPT Summary- 本研究では、AIモデルの評価のために、未解決の質問に基づく新しいベンチマーク「UQ」を提案します。UQは、Stack Exchangeから収集した500の多様な質問を含み、難易度と現実性を兼ね備えています。評価には、ルールベースのフィルター、LLM審査員、人間のレビューを組み合わせたデータセット収集パイプライン、生成者-バリデーターのギャップを活用した複合バリデーション戦略、専門家による共同検証プラットフォームが含まれます。UQは、最前線のモデルが人間の知識を拡張するための現実的な課題を評価する手段を提供します。 Comment
元ポスト:
-
-
ポイント解説:
Figure1を見るとコンセプトが非常にわかりやすい。現在のLLMが苦戦しているベンチマークは人間が回答済み、かつ実世界のニーズに反して意図的に作られた高難易度なデータ(現実的な設定では無い)であり、現実的では無いが難易度が高い。一方で、現実にニーズがあるデータでベンチマークを作るとそれらはしばしば簡単すぎたり、ハッキング可能だったりする。
このため、現実的な設定でニーズがあり、かつ難易度が高いベンチマークが不足しており、これを解決するためにそもそも人間がまだ回答していない未解決の問題に着目し、ベンチマークを作りました、という話に見える。
元ポストを咀嚼すると、
未解決な問題ということはReferenceが存在しないということなので、この点が課題となる。このため、UQ-ValidatorとUQ-Platformを導入する。
UQ-Validatorは複数のLLMのパイプラインで形成され、回答候補のpre-screeningを実施する。回答を生成したLLM自身(あるいは同じモデルファミリー)がValidatorに加わることで自身の回答をoverrateする問題が生じるが、複数LLMのパイプラインを組むことでそのバイアスを軽減できる、とのこと。また、しばしば回答を生成するよりも結果をValidationせる方がタスクとして簡単であり、必ずしも適切に回答する能力はValidatorには必要ないという直感に基づいている。たとえば、Claudeは回答性能は低くてもValidatorとしてはうまく機能する。また、Validatorは転移が効き、他データセットで訓練したものを未解決の回答にも適用できる。test-timeのスケーリングもある程度作用する。
続いて、UQ-Platformにおいて、回答とValidatorの出力を見ながら、専門家の支援に基づいて回答評価し、また、そもそもの質問の質などについてコメントするなどして未解決の問題の解決を支援できる。
みたいな話らしい。非常に重要な研究に見える。
[Paper Note] Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset, Rabeeh Karimi Mahabadi+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Reasoning #Mathematics #read-later #Selected Papers/Blogs Issue Date: 2025-08-27 GPT Summary- 新しい数学コーパス「Nemotron-CC-Math」を提案し、LLMの推論能力を向上させるために、科学テキスト抽出のためのパイプラインを使用。従来のデータセットよりも高品質で、方程式やコードの構造を保持しつつ、表記を標準化。Nemotron-CC-Math-4+は、以前のデータセットを大幅に上回り、事前学習によりMATHやMBPP+での性能向上を実現。オープンソースとしてコードとデータセットを公開。 Comment
元ポスト:
[Paper Note] LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries, Ming Yin+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #MCP Issue Date: 2025-08-25 GPT Summary- 本研究では、AIエージェントが複数のMCPツールを協調的に使用してマルチステップタスクを解決する能力を評価するためのベンチマーク「LiveMCP-101」を提案。101の実世界のクエリを用い、真の実行計画を基にした新しい評価アプローチを導入。実験結果から、最前線のLLMの成功率が60%未満であることが示され、ツールのオーケストレーションにおける課題が明らかに。LiveMCP-101は、実世界のエージェント能力を評価するための基準を設定し、自律AIシステムの実現に向けた進展を促進する。 Comment
元ポスト:
解説:
[Paper Note] ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools, Shaofeng Yin+, arXiv'25
Paper/Blog Link My Issue
#Multi #ComputerVision #NLP #LanguageModel #AIAgents #SyntheticData #VisionLanguageModel Issue Date: 2025-08-24 GPT Summary- 本研究では、実世界のツール使用能力を向上させるために、23Kのインスタンスからなる大規模マルチモーダルデータセット「ToolVQA」を提案。ToolVQAは、実際の視覚的コンテキストと多段階推論タスクを特徴とし、ToolEngineを用いて人間のようなツール使用推論をシミュレート。7B LFMを微調整した結果、テストセットで優れたパフォーマンスを示し、GPT-3.5-turboを上回る一般化能力を持つことが確認された。 Comment
人間による小規模なサンプル(イメージシナリオ、ツールセット、クエリ、回答、tool use trajectory)を用いてFoundation Modelに事前知識として与えることで、よりrealisticなscenarioが合成されるようにした上で新たなVQAを4k程度合成。その後10人のアノテータによって高品質なサンプルにのみFilteringすることで作成された、従来よりも実世界の設定に近く、reasoningの複雑さが高いVQAデータセットな模様。
具体的には、image contextxが与えられた時に、ChatGPT-4oをコントローラーとして、前回のツールとアクションの選択をgivenにし、人間が作成したプールに含まれるサンプルの中からLongest Common Subsequence (LCS) による一致度合いに基づいて人手によるサンプルを選択し、動的にcontextに含めることで多様なで実世界により近しいmulti step tooluseなtrajectoryを合成する、といった手法に見える。pp.4--5に数式や図による直感的な説明がある。なお、LCSを具体的にどのような文字列に対して、どのような前処理をした上で適用しているのかまでは追えていない。
元ポスト:
[Paper Note] MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers, Ziyang Luo+, arXiv'25
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #MCP Issue Date: 2025-08-22 GPT Summary- モデルコンテキストプロトコル(MCP)は、LLMを外部データソースに接続する新しい標準であり、MCP-Universeという包括的なベンチマークを導入。これにより、実際のアプリケーションにおけるLLMの評価が可能となる。6つのコアドメインをカバーし、厳密な評価手法を実装。主要なLLMは性能制限を示し、長文コンテキストや未知のツールの課題に直面。UIサポート付きの評価フレームワークをオープンソース化し、MCPエコシステムの革新を促進。 Comment
pj page: https://mcp-universe.github.io/
元ポスト:
解説:
[Paper Note] MM-BrowseComp: A Comprehensive Benchmark for Multimodal Browsing Agents, Shilong Li+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #Evaluation #Factuality #read-later #Selected Papers/Blogs Issue Date: 2025-08-22 GPT Summary- MM-BrowseCompは、AIエージェントのマルチモーダル検索および推論能力を評価する新しいベンチマークで、224の手作りの質問を含む。これにより、画像や動画を含む情報の重要性を考慮し、テキストのみの手法の限界を示す。最先端モデルの評価では、OpenAI o3などのトップモデルでも29.02%の精度にとどまり、マルチモーダル能力の最適化不足が明らかになった。 Comment
元ポスト:
[Paper Note] VisualWebInstruct: Scaling up Multimodal Instruction Data through Web Search, Yiming Jia+, EMNLP'25
Paper/Blog Link My Issue
#ComputerVision #NLP #QuestionAnswering #SyntheticData #MultiModal #Reasoning #EMNLP #PostTraining #VisionLanguageModel Issue Date: 2025-08-21 GPT Summary- 本研究では、推論に焦点を当てたマルチモーダルデータセットの不足に対処するため、VisualWebInstructという新しいアプローチを提案。30,000のシード画像からGoogle画像検索を用いて700K以上のユニークなURLを収集し、約900KのQAペアを構築。ファインチューニングされたモデルは、Llava-OVで10-20ポイント、MAmmoTH-VLで5ポイントの性能向上を示し、最良モデルMAmmoTH-VL2は複数のベンチマークで最先端の性能を達成。これにより、Vision-Language Modelsの推論能力向上に寄与することが示された。 Comment
元ポスト:
pj page: https://tiger-ai-lab.github.io/VisualWebInstruct/
verified versionが公開:
https://huggingface.co/datasets/TIGER-Lab/VisualWebInstruct_Verified
ポスト:
[Paper Note] Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation, David Heineman+, NeurIPS'25 Spotlight
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #read-later #Selected Papers/Blogs Issue Date: 2025-08-20 GPT Summary- 大規模言語モデルの評価において、信号対ノイズ比を改善することで、より信頼性の高いベンチマークを設計する方法を提案。信号はモデルの識別能力、ノイズは変動への感受性を示し、良好な比率は小規模な意思決定において有用。信号やノイズを改善するための介入として、指標の切り替えやサブタスクのフィルタリング、中間チェックポイントの出力の平均化を提案。30のベンチマークと375の言語モデルを用いて新しい公開データセットを作成。 Comment
元ポスト:
[Paper Note] AutoCodeBench: Large Language Models are Automatic Code Benchmark Generators, Jason Chou+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Coding #MultiLingual Issue Date: 2025-08-19 GPT Summary- AutoCodeGenを提案し、手動注釈なしで高難易度の多言語コード生成データセットを自動生成。これに基づき、3,920の問題からなるAutoCodeBenchを導入し、20のプログラミング言語に均等に分配。30以上のLLMsを評価した結果、最先端のモデルでも多様性や複雑さに苦労していることが明らかに。AutoCodeBenchシリーズは、実用的な多言語コード生成シナリオに焦点を当てるための貴重なリソースとなることを期待。 Comment
pj page: https://autocodebench.github.io/
元ポスト:
[Paper Note] OptimalThinkingBench: Evaluating Over and Underthinking in LLMs, Pranjal Aggarwal+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #Overthinking #Underthinking #Author Thread-Post Issue Date: 2025-08-19 GPT Summary- 思考型LLMsは複雑なタスクを解決する一方で、単純な問題に対して過剰に思考し、非思考型LLMsは速いが難しい問題に対して思考が不足する。これにより、最適なモデル選択がユーザーに委ねられる。OptimalThinkingBenchを導入し、過剰思考と過少思考を共同で評価する。72の単純な数学問題と11の難解な推論課題を含む二つのサブベンチマークを通じて33種のモデルを評価し、どのモデルも最適な思考ができないことを示す。最適思考を促す手法も、多くの場合、一方の性能を改善することで他方を犠牲にする結果となる。 Comment
元ポスト:
元ポストの著者によるスレッドが非常にわかりやすいのでそちらを参照のこと。
ざっくり言うと、Overthinking(考えすぎて大量のトークンを消費した上に回答が誤っている; トークン量↓とLLMによるJudge Score↑で評価)とUnderthinking(全然考えずにトークンを消費しなかった上に回答が誤っている; Accuracy↑で評価)をそれぞれ評価するサンプルを収集し、それらのスコアの組み合わせでモデルが必要に応じてどれだけ的確にThinkingできているかを評価するベンチマーク。
Overthinkingを評価するためのサンプルは、多くのLLMでagreementがとれるシンプルなQAによって構築。一方、Underthinkingを評価するためのサンプルは、small reasoning modelがlarge non reasoning modelよりも高い性能を示すサンプルを収集。
現状Non Thinking ModelではQwen3-235B-A22Bの性能が良く、Thinking Modelではgpt-oss-120Bの性能が良い。プロプライエタリなモデルではそれぞれ、Claude-Sonnet4, o3の性能が良い。全体としてはo3の性能が最も良い。
openreview: https://openreview.net/forum?id=N5kWa3sRJt
著者による一言解説:
[Paper Note] NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model, NVIDIA+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #SmallModel #OpenWeight #SSM (StateSpaceModel) #Selected Papers/Blogs Issue Date: 2025-08-19 GPT Summary- Nemotron-Nano-9B-v2は、推論スループットを向上させつつ最先端の精度を達成するハイブリッドMamba-Transformerモデルである。自己注意層の一部をMamba-2層に置き換え、長い思考トレースの生成を高速化。12億パラメータのモデルを20兆トークンで事前トレーニングし、Minitron戦略で圧縮・蒸留。既存モデルと比較して、最大6倍の推論スループットを実現し、精度も同等以上。モデルのチェックポイントはHugging Faceで公開予定。 Comment
元ポスト:
事前学習に利用されたデータも公開されているとのこと(Nemotron-CC):
解説:
サマリ:
[Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations, Kaiyuan Chen+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #read-later #Selected Papers/Blogs #CrossDomain #Live Issue Date: 2025-08-18 GPT Summary- 「xbench」は、AIエージェントの能力と実世界の生産性のギャップを埋めるために設計された動的な評価スイートで、業界専門家が定義したタスクを用いて商業的に重要なドメインをターゲットにしています。リクルートメントとマーケティングの2つのベンチマークを提示し、エージェントの能力を評価するための基準を確立します。評価結果は継続的に更新され、https://xbench.org で入手可能です。
[Paper Note] HealthBench: Evaluating Large Language Models Towards Improved Human Health, Rahul K. Arora+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Trustfulness #Health Issue Date: 2025-08-16 GPT Summary- HealthBenchは、医療における大規模言語モデルの性能と安全性を評価するオープンソースのベンチマークで、5,000件のマルチターン対話が含まれています。262名の医師による独自のルーブリックで評価され、緊急事態や臨床データ変換などの医療文脈を考慮し、現実的なオープンエンド評価を行います。過去2年間でGPT-3.5 TurboとGPT-4oに対し、16%および32%の進歩を示し、特に小型モデルでは顕著な改善が見られます。また、医師の合意に基づくHealthBench Consensusと厳しい評価基準を持つHealthBench Hardの2つのバリエーションも公開しています。今後、HealthBenchが人間の健康向上に寄与することが期待されます。
[Paper Note] BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, Jason Wei+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #read-later #Selected Papers/Blogs Issue Date: 2025-08-16 GPT Summary- BrowseCompは、エージェントのウェブブラウジング能力を測定するための1,266の質問からなるベンチマークで、絡み合った情報を探すことを要求します。シンプルで使いやすく、短い回答が求められ、参照回答との照合が容易です。このベンチマークは、ブラウジングエージェントの能力を評価するための重要なツールであり、持続力と創造性を測定します。詳細はGitHubで入手可能です。
[Paper Note] FormulaOne: Measuring the Depth of Algorithmic Reasoning Beyond Competitive Programming, Gal Beniamini+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning Issue Date: 2025-08-14 GPT Summary- フロンティアAIモデルの能力を評価するために、実際の研究問題に基づくベンチマーク「FormulaOne」を構築。これは、グラフ理論やアルゴリズムに関連する難易度の高い問題で、商業的関心や理論計算機科学に関連。最先端モデルはFormulaOneでほとんど解決できず、専門家レベルの理解から遠いことが示された。研究支援のために、簡単なタスクセット「FormulaOne-Warmup」を提供し、評価フレームワークも公開。 Comment
元ポスト:
[Paper Note] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent, Xinyu Geng+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #AIAgents #SyntheticData #Evaluation #MultiModal #VisionLanguageModel #DeepResearch Issue Date: 2025-08-14 GPT Summary- WebWatcherは、視覚と言語の推論能力を強化したマルチモーダルエージェントであり、情報探索の困難さに対処する。合成マルチモーダル軌跡を用いた効率的なトレーニングと強化学習により、深い推論能力を向上させる。新たに提案されたBrowseComp-VLベンチマークでの実験により、WebWatcherは複雑なVQAタスクで他のエージェントを大幅に上回る性能を示した。 Comment
元ポスト:
公式:
[Paper Note] Can Language Models Falsify? Evaluating Algorithmic Reasoning with Counterexample Creation, Shiven Sinha+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Coding #Reasoning #Verification Issue Date: 2025-08-13 GPT Summary- 言語モデル(LM)の科学的発見を加速するために、微妙に誤った解決策に対する反例を作成する能力を評価する新しいベンチマーク「REFUTE」を提案。これはプログラミング問題からの誤った提出物を用いており、最も優れた推論エージェントでも9%未満の反例しか生成できないことが示された。この研究は、LMの誤った解決策を否定する能力を向上させ、信頼できる推論を通じて自己改善を促進することを目指している。 Comment
pj page: https://falsifiers.github.io
元ポスト:
バグのあるコードとtask descriptionが与えられた時に、inputのフォーマットと全ての制約を満たすが、コードの実行が失敗するサンプル(=反例)を生成することで、モデルのreasoning capabilityの評価をするベンチマーク。
gpt-ossはコードにバグのあるコードに対して上記のような反例を生成する能力が高いようである。ただし、それでも全体のバグのあるコードのうち反例を生成できたのは高々21.6%のようである。ただ、もしコードだけでなくverification全般の能力が高いから、相当使い道がありそう。
[Paper Note] LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools?, Guozhao Mo+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #MCP Issue Date: 2025-08-13 GPT Summary- LiveMCPBenchは、10,000を超えるMCPサーバーに基づく95の実世界タスクから成る初の包括的なベンチマークで、LLMエージェントの大規模評価を目的としています。70のMCPサーバーと527のツールを含むLiveMCPToolを整備し、LLM-as-a-JudgeフレームワークであるLiveMCPEvalを導入して自動化された適応評価を実現しました。MCP Copilot Agentは、ツールを動的に計画し実行するマルチステップエージェントです。評価の結果、最も優れたモデルは78.95%の成功率を達成しましたが、モデル間で性能のばらつきが見られました。全体として、LiveMCPBenchはLLMエージェントの能力を評価するための新たなフレームワークを提供します。 Comment
pj page: https://icip-cas.github.io/LiveMCPBench/
元ポスト:
MCP環境におけるLLM Agentのベンチマーク。論文中のTable1に他のベンチマークを含めサマリが掲載されている。MCPを用いたLLMAgentのベンチがすでにこんなにあることに驚いた…。
[Paper Note] Grounding Multilingual Multimodal LLMs With Cultural Knowledge, Jean de Dieu Nyandwi+, EMNLP'25
Paper/Blog Link My Issue
#ComputerVision #NLP #EMNLP #PostTraining #Selected Papers/Blogs #VisionLanguageModel #Cultural Issue Date: 2025-08-13 GPT Summary- MLLMsは高リソース環境で優れた性能を示すが、低リソース言語や文化的エンティティに対しては課題がある。これに対処するため、Wikidataを活用し、文化的に重要なエンティティを表す画像を用いた多言語視覚質問応答データセット「CulturalGround」を生成。CulturalPangeaというオープンソースのMLLMを訓練し、文化に基づいたアプローチがMLLMsの文化的ギャップを縮小することを示した。CulturalPangeaは、従来のモデルを平均5.0ポイント上回る性能を達成。 Comment
元ポスト:
pj page:
https://neulab.github.io/CulturalGround/
VQAデータセット中の日本語データは3.1%程度で、
ベースモデルとして
- [Paper Note] Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages, Xiang Yue+, arXiv'24
を利用(Qwen2-7Bに対してCLIPベースのvision encoderを利用したVLM)し、Vision Encoderはfrozenし、LLMとconnector(テキストと画像のモダリティの橋渡しをする(大抵は)MLP)のみをfinetuningした。catastrophic forgettingを防ぐために事前学習データの一部を補完しfinetuningでも利用し、エンティティの認識力を高めるためにM3LSデータなるものをフィルタリングして追加している。
Finetuningの結果、文化的な多様性を持つ評価データ(e.g., [Paper Note] CVQA: Culturally-diverse Multilingual Visual Question Answering
Benchmark, David Romero+, arXiv'24
Figure1のJapaneseのサンプルを見ると一目でどのようなベンチか分かる)と一般的なマルチリンガルな評価データの双方でgainがあることを確認。
VQAによるフィルタリングで利用されたpromptは下記
[Paper Note] NoCode-bench: A Benchmark for Evaluating Natural Language-Driven Feature Addition, Le Deng+, arXiv'25
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #SoftwareEngineering Issue Date: 2025-08-12 GPT Summary- 自然言語駆動のノーコード開発におけるLLMsの評価のために「NoCode-bench」を提案。634のタスクと114,000のコード変更から成り、ドキュメントとコード実装のペアを検証。実験結果では、最良のLLMsがタスク成功率15.79%に留まり、完全なNL駆動のノーコード開発には未だ課題があることが示された。NoCode-benchは今後の進展の基盤となる。 Comment
元ポスト:
リーダーボード: https://nocodebench.org
ドキュメントをソフトウェアの仕様書とみなし、ドキュメントの更新部分をらinputとし、対応する"機能追加"をする能力を測るベンチマーク
SoTAモデルでも15.79%程度しか成功しない。
元ポストによると、ファイルを跨いだ編集、コードベースの理解、tool useに苦労しているとのこと。
[Paper Note] STEPWISE-CODEX-Bench: Evaluating Complex Multi-Function Comprehension and Fine-Grained Execution Reasoning, Kaiwen Yan+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Coding #Reasoning Issue Date: 2025-08-10 GPT Summary- 新しいベンチマーク「STEPWISE-CODEX-Bench(SX-Bench)」を提案し、複雑な多機能理解と細かい実行推論を評価。SX-Benchは、サブ関数間の協力を含むタスクを特徴とし、動的実行の深い理解を測定する。20以上のモデルで評価した結果、最先端モデルでも複雑な推論においてボトルネックが明らかに。SX-Benchはコード評価を進展させ、高度なコードインテリジェンスモデルの評価に貢献する。 Comment
元ポスト:
現在の主流なコード生成のベンチは、input/outputがgivenなら上でコードスニペットを生成する形式が主流(e.g., MBPP [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21
, HumanEval [Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
)だが、モデルがコードを理解し、複雑なコードのロジックを実行する内部状態の変化に応じて、実行のプロセスを推論する能力が見落とされている。これを解決するために、CRUXEVAL [Paper Note] CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, Alex Gu+, arXiv'24
, CRUXEVAL-X [Paper Note] CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding
and Execution, Ruiyang Xu+, arXiv'24
では、関数のinputs/outputsを予測することで、モデルのコードのcomprehension, reasoning能力を測ろうとしているが、
- single functionのlogicに限定されている
- 20 line程度の短く、trivialなロジックに限定されている
- すでにSoTAモデルで95%が達成され飽和している
というlimitationがあるので、複数の関数が協働するロジック、flow/dataのinteractionのフロー制御、細かい実行ステップなどを含む、staticなコードの理解から、動的な実行プロセスのモデリング能力の評価にシフトするような、新たなベンチマークを作成しました、という話な模様。
まず関数単位のライブラリを構築している。このために、単一の関数の基礎的な仕様を「同じinputに対して同じoutputを返すものは同じクラスにマッピングされる」と定義し、既存のコードリポジトリとLLMによる合成によって、GoとPythonについて合計30種類のクラスと361個のインスタンスを収集。これらの関数は、算術演算や大小比較、パリティチェックなどの判定、文字列の操作などを含む。そしてこれら関数を3種類の実行パターンでオーケストレーションすることで、合成関数を作成した。合成方法は
- Sequential: outputとinputをパイプラインでつなぎ伝搬させる
- Selective: 条件に応じてf(x)が実行されるか、g(x)が実行されるかを制御
- Loop: input集合に対するloopの中に関数を埋め込み順次関数を実行
の3種類。合成関数の挙動を評価するために、ランダムなテストケースは自動生成し、合成関数の挙動をモニタリング(オーバーフロー、無限ループ、タイムアウト、複数回の実行でoutputが決定的か等など)し、異常があるものはフィルタリングすることで合成関数の品質を担保する。
ベンチマーキングの方法としては、CRUXEVALではシンプルにモデルにコードの実行結果を予想させるだけであったが、指示追従能力の問題からミスジャッジをすることがあるため、この問題に対処するため
[Paper Note] AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders, Zhengxuan Wu+, ICLR'25 Spotlight
Paper/Blog Link My Issue
#Controllable #NLP #LanguageModel #Supervised-FineTuning (SFT) #Prompting #Evaluation #ICLR #read-later #ActivationSteering/ITI #Selected Papers/Blogs #InstructionFollowingCapability #Steering Issue Date: 2025-08-02 GPT Summary- 言語モデルの出力制御は安全性と信頼性に重要であり、プロンプトやファインチューニングが一般的に用いられるが、さまざまな表現ベースの技術も提案されている。これらの手法を比較するためのベンチマークAxBenchを導入し、Gemma-2-2Bおよび9Bに関する実験を行った。結果、プロンプトが最も効果的で、次いでファインチューニングが続いた。概念検出では表現ベースの手法が優れており、SAEは競争力がなかった。新たに提案した弱教師あり表現手法ReFT-r1は、競争力を持ちながら解釈可能性を提供する。AxBenchとともに、ReFT-r1およびDiffMeanのための特徴辞書を公開した。 Comment
openreview: https://openreview.net/forum?id=K2CckZjNy0
[Paper Note] Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability, Yusuke Sakai+, ACL'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Composition #ACL #InstructionFollowingCapability #CommonsenseReasoning Issue Date: 2025-07-31 GPT Summary- Ordered CommonGenを提案し、LLMsの指示に従う能力と構成的一般化能力を評価するベンチマークを構築。36のLLMsを分析した結果、指示の意図は理解しているが、概念の順序に対するバイアスが低多様性の出力を引き起こすことが判明。最も指示に従うLLMでも約75%の順序付きカバレッジしか達成できず、両能力の改善が必要であることを示唆。 Comment
LLMの意味の構成性と指示追従能力を同時に発揮する能力を測定可能なOrderedCommonGenを提案
[Paper Note] MetaCLIP 2: A Worldwide Scaling Recipe, Yung-Sung Chuang+, NeurIPS'25 Spotlight
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiLingual #CLIP #NeurIPS #read-later #Selected Papers/Blogs Issue Date: 2025-07-30 GPT Summary- MetaCLIP 2を提案し、CLIPをゼロから訓練するための新しいアプローチを示す。英語と非英語データの相互利益を得るための最小限の変更を加え、ゼロショットのImageNet分類で英語専用モデルを上回る性能を達成。多言語ベンチマークでも新たな最先端を記録。 Comment
元ポスト:
マルチリンガルなCLIP
HF: https://huggingface.co/facebook/metaclip-2-mt5-worldwide-b32
[Paper Note] On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey, Meishan Zhang+, arXiv'25
Paper/Blog Link My Issue
#Survey #Embeddings #NLP #LanguageModel #RepresentationLearning #Evaluation Issue Date: 2025-07-29 GPT Summary- 本調査では、事前学習済み言語モデル(PLMs)を活用した一般目的のテキスト埋め込み(GPTE)の発展を概観し、PLMsの役割に焦点を当てる。基本的なアーキテクチャや埋め込み抽出、表現力向上、トレーニング戦略について説明し、PLMsによる多言語サポートやマルチモーダル統合などの高度な役割も考察する。さらに、将来の研究方向性として、ランキング統合やバイアス軽減などの改善目標を超えた課題を強調する。 Comment
元ポスト:
GPTEの学習手法テキストだけでなく、画像やコードなどの様々なモーダル、マルチリンガル、データセットや評価方法、パラメータサイズとMTEBの性能の関係性の図解など、盛りだくさんな模様。最新のものだけでなく、2021年頃のT5から最新モデルまで網羅的にまとまっている。日本語特化のモデルについては記述が無さそうではある。
日本語モデルについてはRuriのテクニカルペーパーや、LLM勉強会のまとめを参照のこと
- Ruri: Japanese General Text Embeddings, cl-nagoya, 2024.09
- 日本語LLMまとめ, LLM-jp, 2024.12
[Paper Note] MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning, Run-Ze Fan+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #PostTraining #Contamination-free #Science Issue Date: 2025-07-23 GPT Summary- 科学的推論のためのオープンデータセット「TextbookReasoning」を提案し、65万の推論質問を含む。さらに、125万のインスタンスを持つ「MegaScience」を開発し、各公開科学データセットに最適なサブセットを特定。包括的な評価システムを構築し、既存のデータセットと比較して優れたパフォーマンスを示す。MegaScienceを用いてトレーニングしたモデルは、公式の指示モデルを大幅に上回り、科学的調整におけるスケーリングの利点を示唆。データキュレーションパイプラインやトレーニング済みモデルをコミュニティに公開。 Comment
元ポスト:
LLMベースでdecontaminationも実施している模様
[Paper Note] What Matters in Learning from Large-Scale Datasets for Robot Manipulation, Vaibhav Saxena+, ICLR'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #ICLR #Robotics #EmbodiedAI #Author Thread-Post Issue Date: 2025-07-19 GPT Summary- 本研究では、ロボティクスにおける大規模データセットの構成に関する体系的な理解を深めるため、データ生成フレームワークを開発し、多様性の重要な要素を特定。特に、カメラのポーズや空間的配置がデータ収集の多様性と整合性に影響を与えることを示した。シミュレーションからの洞察が実世界でも有効であり、提案した取得戦略は既存のトレーニング手法を最大70%上回る性能を発揮した。 Comment
元ポスト:
元ポストに著者による詳細な解説スレッドがあるので参照のこと。
[Paper Note] SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?, Xinyi He+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #AIAgents #Evaluation #SoftwareEngineering Issue Date: 2025-07-18 GPT Summary- コードのパフォーマンス最適化は重要であり、LLMsのリポジトリレベルでの能力は未探求。これに対処するため、SWE-Perfという初のベンチマークを導入。140のインスタンスを用いて、LLMsと専門家の最適化パフォーマンスのギャップを評価し、研究機会を示す。 Comment
元ポスト:
これまでのSWE系のベンチマークはBug Fixなどにフォーカスされてきたが、こちらのベンチマークはソフトウェアのパフォーマンス(i.e., 実行時間)を改善させられるかにフォーカスしているとのこと。
実際にリポジトリからPRを収集し、パッチ前後の実行時間を比較。20回のrunを通じて統計的に有意な実行時間の差があるもののみにフィルタリングをしているとのこと。
Human Expertsは平均10.9%のgainを得たが、エージェントは2.3%にとどまっており、ギャップがあるとのこと。
傾向として、LLMはlow levelなインフラストラクチャ(環境構築, 依存関係のハンドリング, importのロジック)を改善するが、Human Expertsはhigh levelなロジックやデータ構造を改善する(e.g., アルゴリズムや、データハンドリング)。
[Paper Note] VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge, Yueqi Song+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #Selected Papers/Blogs #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-07-14 GPT Summary- VisualPuzzlesは、専門知識への依存を最小限に抑えた視覚的推論を評価する新しいベンチマークで、5つの推論カテゴリーから成る多様な質問を含む。実験により、VisualPuzzlesはドメイン特有の知識を大幅に減少させ、より複雑な推論を要求することが示された。最先端のマルチモーダルモデルは、VisualPuzzlesで人間のパフォーマンスに遅れをとり、知識集約型タスクでの成功が推論タスクでの成功に必ずしもつながらないことが明らかになった。また、モデルのサイズとパフォーマンスの間に明確な相関は見られず、VisualPuzzlesは事実の記憶を超えた推論能力を評価する新たな視点を提供する。 Comment
元ポスト:
画像はPJページより引用。新たにVisual Puzzleと呼ばれる特定のドメイン知識がほとんど必要ないマルチモーダルなreasoningベンチマークを構築。o1ですら、人間の5th percentileに満たない性能とのこと。
Chinese Civil Service Examination中のlogical reasoning questionを手作業で翻訳したとのこと。
データセットの統計量は以下で、合計1168問で、難易度は3段階に分かれている模様。
project page:
https://neulab.github.io/VisualPuzzles/
Gemini 3 Proはo4-mini, o3などにスコアで負けているとのこと:
興味深い。マルチモーダルの推論能力に関してはまだまだ改善の余地がある。
[Paper Note] MegaMath: Pushing the Limits of Open Math Corpora, Fan Zhou+, COLM'25
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #SyntheticData #Coding #Mathematics #mid-training #COLM #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-07-10 GPT Summary- MegaMathは、数学に特化したオープンデータセットで、LLMの数学的推論能力を向上させるために作成された。ウェブデータの再抽出、数学関連コードの特定、合成データの生成を通じて、371Bトークンの高品質なデータを提供し、既存のデータセットを上回る量と品質を実現した。 Comment
元ポスト:
非常に大規模な数学の事前学習/mid-training向けのデータセット
CommonCrawlのHTMLから、さまざまなフィルタリング処理(reformatting, 2 stageのHTML parserの活用(片方はnoisyだが高速、もう一方は高性能だが遅い), fasttextベースの分類器による抽出, deduplication等)を実施しMegaMath-Webを作成、また、MegaMathWebをさらに分類器で低品質なものをフィルタリングし、LLMによってノイズ除去、テキストのreorganizingを実施し(≠ピュアな合成データ)継続事前学習、mid-training向けの高品質なMegaMath-Web-Proを作成。
MegaMathCodeはThe Stack V2 ([Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
) をベースにしており、mathematical reasoning, logic puzzles, scientific computationに関するコードを収集。まずこれらのコードと関連が深い11のプログラミング言語を選定し、そのコードスニペットのみを対象とする。次にstrong LLMを用いて、数学に関するrelevanceスコアと、コードの品質を0--6のdiscrete scoreでスコアリングし学習データを作成。作成した学習データでSLMを学習し大規模なフィルタリングを実施することでMegaMath-Codeを作成。
最後にMegaMath-{Web, code}を用いて、Q&A, code data, text&code block dataの3種類を合成。Q&Aデータの合成では、MegaMath-WebからQAペアを抽出し、多様性とデータ量を担保するためQwen2.5-72B-Instruct, Llama3.3-70B-Instructの両方を用いて、QAのsolutionを洗練させる(reasoning stepの改善, あるいはゼロから生成する[^1])ことで生成。また、code dataでは、pythonを対象にMegaMath-Codeのデータに含まれるpython以外のコードを、Qwen2.5-Coder-32B-Instructと、Llamd3.1-70B-Instructによってpythonに翻訳することでデータ量を増やした。text&code blockデータでは、MegaMath-Webのドキュメントを与えて、ブロックを生成(タイトル、数式、結果、コードなど[^1])し、ブロックのverificationを行い(コードが正しく実行できるか、実行結果とanswerが一致するか等)、verifiedなブロックを残すことで生成。
[^1]: この辺は論文の記述を咀嚼して記述しており実サンプルを見ていないので少し正しい認識か不安
[Paper Note] VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks, Ziyan Jiang+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #NLP #Evaluation #MultiModal #ICLR #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-09 GPT Summary- 本研究では、ユニバーサルマルチモーダル埋め込みモデルの構築を目指し、二つの貢献を行った。第一に、MMEB(Massive Multimodal Embedding Benchmark)を提案し、36のデータセットを用いて分類や視覚的質問応答などのメタタスクを網羅した。第二に、VLM2Vecというコントラストトレーニングフレームワークを開発し、視覚-言語モデルを埋め込みモデルに変換する手法を示した。実験結果は、VLM2Vecが既存のモデルに対して10%から20%の性能向上を達成することを示し、VLMの強力な埋め込み能力を証明した。 Comment
openreview: https://openreview.net/forum?id=TE0KOzWYAF
[Paper Note] CARE: Assessing the Impact of Multilingual Human Preference Learning on Cultural Awareness, Geyang Guo+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #MultiLingual #DPO #PostTraining #Cultural Issue Date: 2025-07-04 GPT Summary- 本論文では、文化的多様性を考慮した言語モデル(LM)の訓練方法を分析し、ネイティブな文化的好みを取り入れることで、LMの文化的認識を向上させることを目指します。3,490の文化特有の質問と31,700のネイティブな判断を含むリソース「CARE」を紹介し、高品質なネイティブの好みを少量取り入れることで、さまざまなLMの性能が向上することを示します。また、文化的パフォーマンスが強いモデルはアラインメントからの恩恵を受けやすく、地域間でのデータアクセスの違いがモデル間のギャップを生むことが明らかになりました。CAREは一般に公開される予定です。 Comment
元ポスト:
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, ACL(Findings)'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #ACL #VisionLanguageModel #Findings #Author Thread-Post Issue Date: 2025-07-02 GPT Summary- 内部世界モデル(WMs)はエージェントの理解と予測を支えるが、最近の大規模ビジョン・ランゲージモデル(VLMs)の基本的なWM能力に関する評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchというベンチマークを導入。15のVLMsに対する660の実験で、これらのモデルが基本的なWM能力に顕著な制限を示し、特に運動軌道の識別においてほぼランダムな精度であることが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。 Comment
元ポスト:
所見:
[Paper Note] MARBLE: A Hard Benchmark for Multimodal Spatial Reasoning and Planning, Yulun Jiang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #MultiModal Issue Date: 2025-07-02 GPT Summary- MARBLEという新しいマルチモーダル推論ベンチマークを提案し、MLLMsの複雑な推論能力を評価。MARBLEは、空間的・視覚的・物理的制約下での多段階計画を必要とするM-PortalとM-Cubeの2つのタスクから成る。現在のMLLMsは低いパフォーマンスを示し、視覚的入力からの情報抽出においても失敗が見られる。これにより、次世代モデルの推論能力向上が期待される。 Comment
元ポスト:
Portal2を使った新たなベンチマーク。筆者は昔このゲームを少しだけプレイしたことがあるが、普通に難しかった記憶がある😅
細かいが表中のGPT-o3は正しくはo3だと思われる。
時間がなくて全然しっかりと読めていないが、reasoning effortやthinkingモードはどのように設定して評価したのだろうか。
[Paper Note] SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning, Melanie Rieff+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Zero/Few/ManyShotPrompting #MultiModal #In-ContextLearning Issue Date: 2025-07-01 GPT Summary- マルチモーダルインコンテキスト学習(ICL)は医療分野での可能性があるが、十分に探求されていない。SMMILEという医療タスク向けの初のマルチモーダルICLベンチマークを導入し、111の問題を含む。15のMLLMの評価で、医療タスクにおけるICL能力が中程度から低いことが示された。ICLはSMMILEで平均8%、SMMILE++で9.4%の改善をもたらし、無関係な例がパフォーマンスを最大9.5%低下させることも確認。例の順序による最近性バイアスがパフォーマンス向上に寄与することも明らかになった。 Comment
元ポスト:
[Paper Note] The Automated LLM Speedrunning Benchmark: Reproducing NanoGPT Improvements, Bingchen Zhao+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #ScientificDiscovery #Reproducibility Issue Date: 2025-06-30 GPT Summary- 大規模言語モデル(LLMs)の進展を活用し、AIエージェントの研究再現能力を評価するために、LLMスピードランベンチマークを導入。19のタスクで訓練スクリプトとヒントを提供し、迅速な実行を促進。既知の革新の再実装が難しいことを発見し、科学的再現を自動化するための指標を提供。 Comment
元ポスト:
[Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, COLM'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #MultiLingual #COLM #Selected Papers/Blogs Issue Date: 2025-06-28 GPT Summary- 多言語LLMsの性能向上のために、FineWebに基づく新しい事前学習データセットキュレーションパイプラインを提案。9つの言語に対して設計選択肢を検証し、非英語コーパスが従来のデータセットよりも高性能なモデルを生成できることを示す。データセットの再バランス手法も導入し、1000以上の言語にスケールアップした20テラバイトの多言語データセットFineWeb2を公開。 Comment
元ポスト:
abstを見る限りFinewebを多言語に拡張した模様
openreview: https://openreview.net/forum?id=jnRBe6zatP#discussion
[Paper Note] RewardBench: Evaluating Reward Models for Language Modeling, Nathan Lambert+, NAACL'25 Findings, 2024.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Evaluation #NAACL #Selected Papers/Blogs #RewardModel #Findings Issue Date: 2025-06-26 GPT Summary- 報酬モデル(RMs)の評価に関する研究は少なく、我々はその理解を深めるためにRewardBenchというベンチマークデータセットを提案。これは、チャットや推論、安全性に関するプロンプトのコレクションで、報酬モデルの性能を評価する。特定の比較データセットを用いて、好まれる理由を検証可能な形で示し、さまざまなトレーニング手法による報酬モデルの評価を行う。これにより、報酬モデルの拒否傾向や推論の限界についての知見を得ることを目指す。 Comment
[Paper Note] AnswerCarefully: A Dataset for Improving the Safety of Japanese LLM Output, Hisami Suzuki+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Safety #Japanese #PostTraining Issue Date: 2025-06-25 GPT Summary- 日本のLLMの安全性を高めるためのデータセット「AnswerCarefully」を紹介。1,800組の質問と参照回答から成り、リスクカテゴリをカバーしつつ日本の文脈に合わせて作成。微調整により出力の安全性が向上し、12のLLMの安全性評価結果も報告。英語翻訳と注釈を提供し、他言語でのデータセット作成を促進。 Comment
[Paper Note] Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models, Thao Nguyen+, COLM'25
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #SyntheticData #COLM #Author Thread-Post Issue Date: 2025-06-25 GPT Summary- スケーリング法則に基づき、低品質なウェブデータを再利用する手法「REWIRE」を提案。これにより、事前学習データの合成表現を増やし、フィルタリングされたデータのみでのトレーニングと比較して、22のタスクで性能を向上。生データと合成データの混合が効果的であることを示し、ウェブテキストのリサイクルが事前学習データのスケーリングに有効であることを示唆。 Comment
元ポスト:
-
-
学習データの枯渇に対する対処として別の方向性としては下記のような研究もある:
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
data: https://huggingface.co/datasets/facebook/recycling_the_web
[Paper Note] Sekai: A Video Dataset towards World Exploration, Zhen Li+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #NeurIPS #VideoGeneration/Understandings #WorldModels #3D (Video) Issue Date: 2025-06-23 GPT Summary- 高品質な一人称視点のビデオデータセット「Sekai」を紹介。750の都市から5,000時間以上のビデオを収集し、位置やシーンなどの豊富な注釈を付与。データセットを用いてインタラクティブなビデオ世界探査モデル「YUME」をトレーニング。Sekaiはビデオ生成と世界探査に貢献することが期待される。 Comment
元ポスト:
[Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #NeurIPS #mid-training #PostTraining #read-later #RLVR #Selected Papers/Blogs #DataMixture #CrossDomain #KeyPoint Notes #Reading Reflections #Author Thread-Post Issue Date: 2025-06-22 GPT Summary- Guruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。 Comment
元ポスト:
post-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。
Qwenシリーズで実験。以下元ポストのまとめ。
- mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
- 一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
- 簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
- 各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
- 必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
- たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
- 一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
- 異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
- (これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
- 非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
- RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
- モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
- モデルサイズが大きいとより多様なreasoningパスがunlockされている
- pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた
本研究で構築されたGuru Dataset:
https://huggingface.co/datasets/LLM360/guru-RL-92k
math, coding, science, logic, simulation, tabular reasoningに関する高品質、かつverifiableなデータセット。
> RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
上記takeawayは
- [Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
と一見相反するように見えるが、実際どうなんだろうか。
最初は、RLによりPass@1が改善するので、Figure 1などに記載されている特定のドメインでの skill aqcuisition にはin-domain dataが必要でRLがそれに寄与するという話は、Pass@1が改善された結果なのかなと思ったが、
4.3節に実際に上記研究が引用され考察がなされており、mid-trainingなどで多くのデータが含まれるMathドメインについては、上記研究と同じ傾向でbase modelとRL後のモデルがK=64の時点で性能が交差、その後逆転するため、上記研究と同様の傾向が見受けられた。一方で、タスクごとに見るとzebra-logicのような事前学習ではあまりexposeされないタスクで見ると、依然としてRLの方が高いPass@kを獲得しているという現象が観測され、base modelのreadoning boundaryを拡大することができている、という解釈のようである。
[Paper Note] What Is Seen Cannot Be Unseen: The Disruptive Effect of Knowledge Conflict on Large Language Models, Kaiser Sun+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #FactualKnowledge #Author Thread-Post Issue Date: 2025-06-17 GPT Summary- LLMの文脈情報とパラメトリック知識の対立を評価する診断フレームワークを提案。知識の対立はタスクに影響を与えず、一致時にパフォーマンスが向上。モデルは内部知識を抑制できず、対立の理由が文脈依存を高めることを示した。これにより、LLMの評価と展開における知識の対立の重要性が強調される。 Comment
元ポスト:
[Paper Note] LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?, Zihan Zheng+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Coding #NeurIPS #Contamination-free #Selected Papers/Blogs #Live #Initial Impression Notes Issue Date: 2025-06-17 GPT Summary- 大規模言語モデル(LLMs)は競技プログラミングで人間のエリートを上回るとされるが、実際には重要な限界があることを調査。新たに導入した「LiveCodeBench Pro」ベンチマークにより、LLMsは中程度の難易度の問題で53%のpass@1を達成する一方、難しい問題では0%という結果が得られた。LLMsは実装重視の問題では成功するが、複雑なアルゴリズム的推論には苦労し、誤った正当化を生成することが多い。これにより、LLMsと人間の専門家との間に重要なギャップがあることが明らかになり、今後の改善のための診断が提供される。 Comment
元ポスト:
Hardな問題は現状のSoTAモデル(Claude4が含まれていないが)でも正答率0.0%
ベンチマークに含まれる課題のカテゴリ
実サンプルやケーススタディなどはAppendix参照のこと。
pj page: https://livecodebenchpro.com
アップデート(NeurIPSにaccept):
[Paper Note] ALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering, Yuki Imajuku+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Coding #LongSequence #ScientificDiscovery #NeurIPS #Author Thread-Post Issue Date: 2025-06-17 GPT Summary- AIシステムの最適化問題に対するパフォーマンスを評価する新しいベンチマークALE-Benchを提案。ALE-Benchは実際のタスクに基づき、長期的な解決策の洗練を促進する。大規模言語モデル(LLM)の評価では特定の問題で高いパフォーマンスを示すが、一貫性や長期的な問題解決能力において人間とのギャップが残ることが明らかになり、今後のAI進展に向けた必要性を示唆している。 Comment
元ポスト:
関連ポスト:
NeurIPSにaccept:
[Paper Note] Search Arena: Analyzing Search-Augmented LLMs, Mihran Miroyan+, arXiv'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Search #LanguageModel #Author Thread-Post Issue Date: 2025-06-08 GPT Summary- 検索強化型LLMsに関する「Search Arena」という大規模な人間の好みデータセットを紹介。24,000以上のマルチターンユーザーインタラクションを含み、ユーザーの好みが引用数や引用元に影響されることを明らかにした。特に、コミュニティ主導の情報源が好まれる傾向があり、静的な情報源は必ずしも信頼されない。検索強化型LLMsの性能を評価した結果、非検索設定でのパフォーマンス向上が確認されたが、検索設定ではパラメトリック知識に依存すると品質が低下することが分かった。このデータセットはオープンソースとして提供されている。 Comment
元ポスト:
[Paper Note] SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond, Junteng Liu+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #LanguageModel #SyntheticData #Reasoning #NeurIPS #One-Line Notes #Author Thread-Post Issue Date: 2025-06-06 GPT Summary- SynLogicは、35の論理的推論タスクを網羅したデータ合成フレームワークで、強化学習(RL)による大規模言語モデル(LLMs)の推論能力向上を目指す。調整可能な難易度で生成されたデータは検証可能で、RLに適している。実験では、SynLogicが最先端の論理的推論性能を達成し、数学やコーディングタスクとの混合によりトレーニング効率が向上することが示された。SynLogicはLLMsの推論能力向上に貴重なリソースとなる。 Comment
元ポスト:
35種類のタスクを人手で選定し、タスクごとに困難度の鍵となるパラメータを定義(数独ならばグリッド数など)。その上で、各タスクごとに人手でルールベースのinstanceを生成するコードを実装し、さまざまな困難度パラメータに基づいて多様なinstanceを生成。生成されたinstanceの困難度は、近似的なUpper Bound(DeepSeek-R1, o3-miniのPass@10)とLower bound(chat model[^1]でのPass@10)を求めデータセットに含まれるinstanceの困難度をコントロールし、taskを記述するpromptも生成。タスクごとに人手で実装されたVerifierも用意されている。
Qwen2.5-7B-BaseをSynDataでDAPOしたところ、大幅にlogic benchmarkとmathematical benchmarkの性能が改善。
mathやcodeのデータとmixして7Bモデルを訓練したところ、32Bモデルに匹敵する性能を達成し、SynDataをmixすることでgainが大きくなったので、SynDataから学習できる能力が汎化することが示唆される。
タスク一覧はこちら
[^1]:どのchat modelかはざっと見た感じわからない。どこかに書いてあるかも。
Logical Reasoningが重要なタスクを扱う際はこのデータを活用することを検討してみても良いかもしれない
[Paper Note] BIG-Bench Extra Hard, Mehran Kazemi+, ACL'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning #ACL #One-Line Notes Issue Date: 2025-06-01 GPT Summary- 大規模言語モデル(LLMs)の推論能力を評価するための新しいベンチマーク、BIG-Bench Extra Hard(BBEH)を導入。これは、既存のBIG-Bench Hard(BBH)のタスクを新しいものに置き換え、難易度を大幅に引き上げることで、LLMの限界を押し広げることを目的としている。評価の結果、最良の汎用モデルで9.8%、推論専門モデルで44.8%の平均精度が観察され、LLMの一般的推論能力向上の余地が示された。BBEHは公開されている。 Comment
Big-Bench hard(既にSoTAモデルの能力差を識別できない)の難易度をさらに押し上げたデータセット。
Inputの例
タスクごとのInput, Output lengthの分布
現在の主要なモデル群の性能
Big-Bench論文はこちら:
- [Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
[Paper Note] Scaling Reasoning, Losing Control: Evaluating Instruction Following in Large Reasoning Models, Tingchen Fu+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Mathematics #InstructionFollowingCapability #Author Thread-Post Issue Date: 2025-05-24 GPT Summary- 指示遵守はLLMのユーザー意図適合に重要であり、本研究では数学的推論タスクにおける指示遵守を評価するためのMathIFベンチマークを紹介。推論能力と可制御性の間には緊張が存在し、推論性能向上が指示遵守に影響を及ぼすことを示した。長い思考連鎖を用いたモデルや強化学習モデルは指示遵守が劣化する一方、簡単な介入で部分的に従順性を回復可能だが推論性能が犠牲になる場合がある。これらの知見は、指示対応性に優れた推論モデルの必要性を浮き彫りにする。 Comment
元ポスト:
[Paper Note] Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #ACL #Selected Papers/Blogs Issue Date: 2025-05-10 GPT Summary- FineWeb-EduとDCLMは、モデルベースのフィルタリングによりデータの90%を削除し、トレーニングに適さなくなった。著者は、アンサンブル分類器や合成データの言い換えを用いて、精度とデータ量のトレードオフを改善する手法を提案。1Tトークンで8Bパラメータモデルをトレーニングし、DCLMに対してMMLUを5.6ポイント向上させた。新しい6.3Tトークンデータセットは、DCLMと同等の性能を持ちながら、4倍のユニークなトークンを含み、長トークンホライズンでのトレーニングを可能にする。15Tトークンのためにトレーニングされた8Bモデルは、Llama 3.1の8Bモデルを上回る性能を示した。データセットは公開されている。
[Paper Note] DataComp-LM: In search of the next generation of training sets for language models, Jeffrey Li+, NeurIPS'25, 2024.07
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #NeurIPS #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-05-10 GPT Summary- DataComp for Language Models(DCLM)を紹介し、240Tトークンのコーパスと53の評価スイートを提供。DCLMでは、モデルスケール412Mから7Bパラメータのデータキュレーション戦略を実験可能。DCLM-Baselineは2.6Tトークンでトレーニングし、MMLUで64%の精度を達成し、従来のMAP-Neoより6.6ポイント改善。計算リソースも40%削減。結果はデータセット設計の重要性を示し、今後の研究の基盤を提供。 Comment
openreview: https://openreview.net/forum?id=CNWdWn47IE
最近多くの著名なモデルでDCLMを事前学習データとして利用している文献を目にするようになった
[Paper Note] AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #MultiModal #ICLR #ComputerUse #One-Line Notes Issue Date: 2025-04-18 GPT Summary- 本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 Comment
Android環境でのPhone Useのベンチマーク
[Paper Note] Training Software Engineering Agents and Verifiers with SWE-Gym, Jiayi Pan+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #ICML #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Environment Issue Date: 2025-04-02 GPT Summary- SWE-Gymを提案し、2,438件の実世界のPythonタスクを含む環境を構築。言語モデルに基づくSWEエージェントを訓練し、SWE-Benchで最大19%の解決率向上を達成。微調整されたエージェントは新たな最先端の性能を示し、SWE-Gymやモデル、エージェントの軌跡を公開。 Comment
SWE-Benchとは完全に独立したより広範な技術スタックに関連するタスクに基づくSWEベンチマーク
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
SWE-Benchと比べて実行可能な環境と単体テストが提供されており、単なるベンチマークではなくエージェントを訓練できる環境が提供されている点が大きく異なるように感じる。
[Paper Note] Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation, Junhao Zhang+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #LanguageModel #LongSequence #ContextEngineering Issue Date: 2025-03-20 GPT Summary- 長い入力と出力の生成に特化したLongInOutBenchを導入し、既存手法の「中間での喪失」問題に対処。Retrieval-Augmented Long-Text Writer(RAL-Writer)を開発し、重要なコンテンツを再表現することで性能を向上。提案手法の有効性をベースラインと比較して示す。 Comment
Lost in the Middleに関する研究。
Lost-in-the-Middleを初めて提起した研究は下記:
- [Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
[Paper Note] SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines, M-A-P Team+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #NeurIPS Issue Date: 2025-02-21 GPT Summary- SuperGPQAを提案し、285の専門分野におけるLLMsの知識と推論能力を評価する新しいベンチマークを構築。Human-LLM協調フィルタリングを用いて、トリビアルな質問を排除。実験結果は、最先端のLLMsに改善の余地があることを示し、人工一般知能とのギャップを強調。大規模なアノテーションプロセスから得た洞察は、今後の研究に対する方法論的ガイダンスを提供。 Comment
元ポスト:
[Paper Note] NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions, Weizhe Yuan+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #SyntheticData #Reasoning #Distillation #Author Thread-Post Issue Date: 2025-02-19 GPT Summary- 数学やコーディングを含む多様な領域の推論能力を向上させるため、280万問の多様で挑戦的な推論問題を含むデータセットNaturalReasoningを導入。知識蒸留実験により、強力な教師モデルから効果的に推論能力が引き出されることを示し、自己訓練や自己報酬でも有効であることを証明。NaturalReasoningは今後の研究を促進するために公開されている。 Comment
元ポスト:
[Paper Note] SoftMatcha: A Soft and Fast Pattern Matcher for Billion-Scale Corpus Searches, Hiroyuki Deguchi+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #NLP #Search #ICLR Issue Date: 2025-01-28 GPT Summary- 表層的な文字列照合に依存する既存のパターンマッチング手法の制約を克服するため、語彙埋め込みを用いた新しいアルゴリズムを提案。これにより、コーパス規模での柔軟かつ効率的なパターンマッチングを実現。提案手法は、十億規模のデータ上で瞬時の検索を行い、英語と日本語のWikipediaから有害事例を抽出し、また多様な屈折のあるラテン語においても有効であることを実証。 Comment
ICLR2025にacceptされた模様
https://openreview.net/forum?id=Q6PAnqYVpo
openreview: https://openreview.net/forum?id=Q6PAnqYVpo
[Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-01-25 GPT Summary- LLMの進展を追跡するためのベンチマークが不足している中、Humanity's Last Exam(HLE)を導入。HLEは多様な科目を網羅する2,500問のマルチモーダルな学術問題から成り、専門家の手による構築。高度なLLMはHLEで低精度を示し、閉じた回答形式の問題におけるLLMの能力と人間専門家との間のギャップを浮き彫りにしている。HLEは研究と政策立案のために公開されている。 Comment
o1, DeepSeekR1の正解率が10%未満の新たなベンチマーク
[Paper Note] Preference Discerning with LLM-Enhanced Generative Retrieval, Fabian Paischer+, TMLR'25, 2024.12
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #SessionBased #Personalization #Evaluation #TMLR Issue Date: 2024-12-31 GPT Summary- 逐次推薦システムのパーソナライズを向上させるために、「好みの識別」という新しいパラダイムを提案。大規模言語モデルを用いてユーザーの好みを生成し、包括的な評価ベンチマークを導入。新手法Menderは、既存手法を改善し、最先端の性能を達成。Menderは未観察の人間の好みにも効果的に対応し、よりパーソナライズされた推薦を実現する。コードとベンチマークはオープンソース化予定。 Comment
openreview: https://openreview.net/forum?id=74mrOdhvvT
Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search, Huanjin Yao+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #MultiModal #Reasoning #NeurIPS #VisionLanguageModel #TreeSearch Issue Date: 2024-12-31 GPT Summary- 本研究では、MLLMを用いて質問解決のための推論ステップを学習する新手法CoMCTSを提案。集団学習を活用し、複数モデルの知識で効果的な推論経路を探索。マルチモーダルデータセットMulberry-260kを構築し、モデルMulberryを訓練。実験により提案手法の優位性を確認。
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, N_A, NAACL'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #AIAgents #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Reasoning #NAACL #One-Line Notes Issue Date: 2024-10-20 GPT Summary- LLMsを用いた情報検索強化生成(RAG)システムの性能評価のために、FRAMESという新しい評価データセットを提案。これは、事実に基づく応答、検索能力、推論を統一的に評価するもので、複数の情報源を統合するマルチホップ質問を含む。最新のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に貢献することを目指す。 Comment
RAGのfactuality, retrieval acculacy, reasoningを評価するためのmulti hop puestionとそれに回答するための最大15のwikipedia記事のベンチマーク
元ポスト:
Llama-3.1-Nemotron-70B-Instruct, Nvidia, (ICLR'25), 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #OpenWeight #ICLR #One-Line Notes Issue Date: 2024-10-17 GPT Summary- 報酬モデルの訓練にはBradley-Terryスタイルと回帰スタイルがあり、データの一致が重要だが、適切なデータセットが不足している。HelpSteer2データセットでは、Bradley-Terry訓練用の好みの注釈を公開し、初めて両モデルの直接比較を行った。これに基づき、両者を組み合わせた新アプローチを提案し、Llama-3.1-70B-InstructモデルがRewardBenchで94.1のスコアを達成。さらに、REINFORCEアルゴリズムを用いて指示モデルを調整し、Arena Hardで85.0を記録した。このデータセットはオープンソースとして公開されている。 Comment
MTBench, Arena HardでGPT4o-20240513,Claude-3.5-sonnet-20240620をoutperform。Response lengthの平均が長いこと模様
openreview: https://openreview.net/forum?id=MnfHxPP5gs
[Paper Note] A Comprehensive Study of Knowledge Editing for Large Language Models, Ningyu Zhang+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Evaluation #KnowledgeEditing Issue Date: 2026-02-08 GPT Summary- LLMの知識編集技術が急増し、モデルの効率的な修正が求められています。知識編集問題を定義し、3つのグループ(外部知識の利用、モデルへの知識の統合、内在的知識の編集)に分類。新たに「KnowEdit」ベンチマークを導入し、知識構造の詳しい分析を行う。知識編集の応用についても考察しています。 Comment
[Paper Note] Developing Generalist Foundation Models from a Multimodal Dataset for 3D Computed Tomography, Ibrahim Ethem Hamamci+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#ComputerVision #NLP #CLIP #Selected Papers/Blogs #VisionLanguageModel #Encoder #2D (Image) #3D (Scene) #Medical Issue Date: 2026-02-01 GPT Summary- CT-RATEデータセットを介して、3D医療画像とそのテキストレポートをペアリングし、幅広い応用に向けたCTフォーカスの対照的言語-画像前訓練フレームワークCT-CLIPを開発。これにより、多異常検出やケースリトリーバルで最先端の完全監視モデルを上回る性能を達成。さらに、CT-RATEから派生した270万件以上のQ&AペアでファインチューニングされたCT-CHATを構築し、3D医療画像に特化した手法の重要性を示す。オープンソースなリリースは医療AIの革新と患者ケア向上に寄与。
[Paper Note] Emotionally Numb or Empathetic? Evaluating How LLMs Feel Using EmotionBench, Jen-tse Huang+, NeurIPS'24, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #NeurIPS #Emotion Issue Date: 2026-01-25 GPT Summary- LLMの感情評価能力を新たに検討。400以上の状況から8つの感情を引き出すデータセットを作成し、1,200人による人間評価を実施。7つのLLMを評価した結果、一般的には適切な応答を示すが、人間の感情行動との整合性に欠けることが明らかに。データセット、評価結果、EmotionBenchのコードは公開中。 Comment
pj page: https://cuhk-arise.github.io/EmotionBench/
元ポスト:
[Paper Note] MANTIS: Interleaved Multi-Image Instruction Tuning, Dongfu Jiang+, TMLR'24 Outstanding Certification, 2024.05
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #InstructionTuning #MultiModal #TMLR #Selected Papers/Blogs #VisionLanguageModel #2D (Image) Issue Date: 2025-12-02 GPT Summary- Mantisモデルは、721Kの複数画像指示データを用いた指示調整により、複数画像の視覚言語タスクで最先端の性能を達成。特に、Idefics2-8Bを平均13ポイント上回り、一般化能力も示す。大規模な事前学習に依存せず、低コストの指示調整で複数画像能力を向上できることを示した。 Comment
openreview: https://openreview.net/forum?id=skLtdUVaJa
元ポスト:
[Paper Note] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models, Hongliang He+, ACL'24, 2024.01
Paper/Blog Link My Issue
#AIAgents #Evaluation #MultiModal #ACL #ComputerUse #Selected Papers/Blogs #VisionLanguageModel #KeyPoint Notes #GUI Issue Date: 2025-11-25 GPT Summary- WebVoyagerは、実際のウェブサイトと対話しユーザーの指示をエンドツーエンドで完了できる大規模マルチモーダルモデルを搭載したウェブエージェントである。新たに設立したベンチマークで59.1%のタスク成功率を達成し、GPT-4やテキストのみのWebVoyagerを上回る性能を示した。提案された自動評価指標は人間の判断と85.3%一致し、ウェブエージェントの信頼性を高める。 Comment
日本語解説: https://blog.shikoan.com/web-voyager/
スクリーンショットを入力にHTMLの各要素に対してnumeric labelをoverlayし(Figure2)、VLMにタスクを完了するためのアクションを出力させる手法。アクションはFigure7のシステムプロンプトに書かれている通り。
たとえば、VLMの出力として"Click [2]" が得られたら GPT-4-Act GPT-4V-Act, ddupont808, 2023.10
と呼ばれるSoM [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
をベースにWebUIに対してマウス/キーボードでinteractできるモジュールを用いることで、[2]とマーキングされたHTML要素を同定しClick操作を実現する。
[Paper Note] WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs, Seungju Han+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Safety #NeurIPS Issue Date: 2025-09-16 GPT Summary- WildGuardは、LLMの安全性向上を目的としたオープンで軽量なモデレーションツールで、悪意のある意図の特定、安全リスクの検出、拒否率の判断を行う。92Kのラベル付きデータを用いたWildGuardMixを構築し、敵対的な脱獄や拒否応答をカバー。評価の結果、WildGuardは既存のオープンソースモデレーションモデルに対して最先端のパフォーマンスを示し、特に拒否検出で最大26.4%の改善を達成。GPT-4のパフォーマンスに匹敵し、脱獄攻撃の成功率を79.8%から2.4%に低下させる効果を持つ。 Comment
openreview: https://openreview.net/forum?id=Ich4tv4202#discussion
[Paper Note] ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment, Xiwei Hu+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #DiffusionModel #read-later #Selected Papers/Blogs #UMM Issue Date: 2025-09-11 GPT Summary- 拡散モデルに大規模言語モデル(LLM)を組み込む「効率的な大規模言語モデルアダプター(ELLA)」を提案。これにより、複雑なプロンプトの整合性を向上させ、意味的特徴を適応させる新しいモジュール「時間ステップ認識セマンティックコネクタ(TSC)」を導入。ELLAは密なプロンプトに対する性能が最先端手法を上回ることを実験で示し、特に複数のオブジェクト構成において優位性を発揮。 Comment
pj page: https://ella-diffusion.github.io
[Paper Note] MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures, Jinjie Ni+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #NeurIPS Issue Date: 2025-09-10 GPT Summary- MixEvalは、LLM評価の新しいパラダイムであり、実世界のユーザークエリと真実に基づくベンチマークを組み合わせることで、効率的かつ公正な評価を実現する。これにより、Chatbot Arenaとの高い相関を持ち、迅速かつ安価な評価が可能となる。さらに、動的評価を通じてLLM評価の理解を深め、今後の研究方向を示す。 Comment
[Paper Note] MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark, Yubo Wang+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #NeurIPS Issue Date: 2025-09-09 GPT Summary- MMLUベンチマークの限界を克服するため、推論に焦点を当てた質問を統合し、選択肢を4から10に増やした強化データセットMMLU-Proを提案。MMLU-Proは些細な質問を排除し、精度が16%から33%低下する一方で、プロンプトに対する安定性が向上。Chain of Thought推論を利用するモデルは、MMLU-Proでより良いパフォーマンスを示し、複雑な推論問題を含むことを示唆。MMLU-Proは、より識別的なベンチマークとして分野の進展を追跡するのに適している。 Comment
MMLUはこちら:
- [Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
[Paper Note] DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving, Yuxuan Tong+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #LanguageModel #SyntheticData #Evaluation #Reasoning #Mathematics #NeurIPS Issue Date: 2025-08-30 GPT Summary- 数学問題解決には高度な推論が必要であり、従来のモデルは難しいクエリに対して偏りがあることが明らかになった。そこで、Difficulty-Aware Rejection Tuning(DART)を提案し、難しいクエリに多くの試行を割り当てることでトレーニングを強化。新たに作成した小規模な数学問題データセットで、7Bから70BのモデルをファインチューニングしたDART-MATHは、従来の手法を上回る性能を示した。合成データセットが数学問題解決において効果的でコスト効率の良いリソースであることが確認された。 Comment
[Paper Note] CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark, David Romero+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #NLP #QuestionAnswering #Evaluation #MultiModal #MultiLingual #VisionLanguageModel #Cultural Issue Date: 2025-08-18 GPT Summary- CVQAは、文化的に多様な多言語のVisual Question Answeringベンチマークで、30か国からの画像と質問を含み、31の言語と13のスクリプトをカバー。データ収集にはネイティブスピーカーを関与させ、合計10,000の質問を提供。マルチモーダル大規模言語モデルをベンチマークし、文化的能力とバイアスを評価するための新たな基準を示す。
[Paper Note] Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages, Xiang Yue+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #NLP #InstructionTuning #Evaluation #MultiLingual #VisionLanguageModel Issue Date: 2025-08-18 GPT Summary- Pangeaは、39の言語にわたる6M指示データセットPangeaInsを用いて訓練された多言語マルチモーダルLLMであり、異文化間のカバレッジを確保しています。Pangeaは、47の言語をカバーする評価スイートPangeaBenchで既存のモデルを大幅に上回る性能を示し、英語データの比率やマルチモーダル訓練サンプルの重要性を明らかにしました。データ、コード、訓練済みチェックポイントはオープンソース化され、言語的および文化的公平性を推進します。
[Paper Note] FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI, Elliot Glazer+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Mathematics Issue Date: 2025-08-16 GPT Summary- FrontierMathは、専門の数学者によって作成された難易度の高い数学問題のベンチマークで、数論や実解析から代数幾何学や圏論まで幅広い分野をカバー。問題解決には数時間から数日かかることがあり、現在のAIモデルは問題の2%未満しか解決できていない。FrontierMathはAIの数学的能力の進捗を定量化するための厳密なテストベッドを提供する。
[Paper Note] Measuring short-form factuality in large language models, Jason Wei+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #Evaluation #Factuality #Trustfulness Issue Date: 2025-08-16 GPT Summary- SimpleQAは、言語モデルの短い事実に関する質問への応答能力を評価するためのベンチマークであり、挑戦的かつ評価が容易な質問を特徴とする。各回答は正解、不正解、未試行のいずれかとして評価され、理想的なモデルは自信がない質問には挑戦せず、正解を多く得ることを目指す。SimpleQAは、モデルが「自分が知っていることを知っているか」を評価するためのシンプルな手段であり、次世代モデルにとっても重要な評価基準となることが期待されている。 Comment
https://openai.com/index/introducing-simpleqa/
先行研究:
- [Paper Note] TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension, Mandar Joshi+, ACL'17
- Natural Questions: A Benchmark for Question Answering Research, Kwiatkowski+, TACL'19
これらはすでに飽和している
最近よくLLMのベンチで見かけるSimpleQA
[Paper Note] CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution, Ruiyang Xu+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Coding #Reasoning #MultiLingual Issue Date: 2025-08-15 GPT Summary- CRUXEVAL-Xという多言語コード推論ベンチマークを提案。19のプログラミング言語を対象に、各言語で600以上の課題を含む19Kのテストを自動生成。言語間の相関を評価し、Python訓練モデルが他言語でも高い性能を示すことを確認。 Comment
[Paper Note] CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, Alex Gu+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Coding #Reasoning Issue Date: 2025-08-15 GPT Summary- CRUXEvalという800のPython関数からなるベンチマークを提案し、入力予測と出力予測の2つのタスクを評価。20のコードモデルをテストした結果、HumanEvalで高得点のモデルがCRUXEvalでは改善を示さないことが判明。GPT-4とChain of Thoughtを用いた場合、入力予測で75%、出力予測で81%のpass@1を達成したが、どのモデルも完全にはクリアできず、GPT-4のコード推論能力の限界を示す例を提供。
[Paper Note] MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI, Xiang Yue+, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #MultiModal #Reasoning #CVPR Issue Date: 2025-08-09 GPT Summary- MMMUは、大学レベルの専門知識と意図的な推論を必要とするマルチモーダルモデルの評価のための新しいベンチマークで、11,500のマルチモーダル質問を含む。6つの主要分野をカバーし、30種類の画像タイプを使用。既存のベンチマークと異なり、専門家が直面するタスクに類似した課題を提供。GPT-4VとGeminiの評価では、56%と59%の精度にとどまり、改善の余地があることを示す。MMMUは次世代のマルチモーダル基盤モデルの構築に寄与することが期待されている。 Comment
MMMUのリリースから20ヶ月経過したが、いまだに人間のエキスパートのアンサンブルには及ばないとのこと
MMMUのサンプルはこちら。各分野ごとに専門家レベルの知識と推論が求められるとのこと。
[Paper Note] LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding, Yushi Bai+, ACL'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #LongSequence #MultiLingual #ACL Issue Date: 2025-08-07 GPT Summary- 本論文では、長いコンテキスト理解のための初のバイリンガル・マルチタスクベンチマーク「LongBench」を提案。英語と中国語で21のデータセットを含み、平均長はそれぞれ6,711語と13,386文字。タスクはQA、要約、少数ショット学習など多岐にわたる。評価結果から、商業モデルは他のオープンソースモデルを上回るが、長いコンテキストでは依然として課題があることが示された。 Comment
PLaMo Primeの長文テキスト評価に利用されたベンチマーク(中国語と英語のバイリンガルデータであり日本語は存在しない)
PLaMo Primeリリースにおける機能改善:
https://tech.preferred.jp/ja/blog/plamo-prime-release-feature-update/
タスクと言語ごとのLengthの分布。英語の方がデータが豊富で、長いものだと30000--40000ものlengthのサンプルもある模様。
[Paper Note] Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic, Sachin Goyal+, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #Analysis #NLP #CVPR #Scaling Laws #VisionLanguageModel #DataFiltering Issue Date: 2025-07-20 GPT Summary- 視覚と言語のモデル(VLMs)のトレーニングにおいて、高品質なデータのフィルタリングが重要であるが、計算リソースとは無関係に行われることが多い。本研究では、データの品質と量のトレードオフ(QQT)に対処するため、ウェブデータの非均質性を考慮したニューラルスケーリング法則を提案。これにより、データの有用性の違いや繰り返し使用による劣化を評価し、複数のデータプールの組み合わせによるモデルのパフォーマンスを推定可能にする。最適なデータプールのキュレーションを通じて、計算リソースに応じた最高のパフォーマンスを達成できることを示した。 Comment
元ポスト:
高品質なデータにフィルタリングすることで多くの研究がモデルがより高い性能を達成できることを示しているが、高品質なデータには限りがあることと、繰り返し学習をすることですぐにその効用が低下する(Quality-Quantity tradeoff!)という特性がある。このような状況において、たとえば計算の予算がデータ6パケット分の時に、めちゃめちゃフィルタリングを頑張っg高品質なデータプールEのみを使って6 epoch学習するのが良いのか、少し品質は落ちるデータDも混ぜてE+Dを3 epoch学習するのが良いのか、ときにどちらが良いのか?という話のようである。
[Paper Note] Heron-Bench: A Benchmark for Evaluating Vision Language Models in Japanese, Yuichi Inoue+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Japanese #read-later #VisionLanguageModel Issue Date: 2025-07-16 GPT Summary- 日本語に特化したVision Language Models (VLM)の評価のために、新しいベンチマーク「Japanese Heron-Bench」を提案。日本の文脈に基づく画像-質問応答ペアを用いて、日本語VLMの能力を測定。提案されたVLMの強みと限界を明らかにし、強力なクローズドモデルとの能力ギャップを示す。今後の日本語VLM研究の発展を促進するため、データセットと訓練コードを公開。 Comment
[Paper Note] Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset, Ke Wang+, NeurIPS'24 Datasets and Benchmarks Track
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #Mathematics #VisionLanguageModel #One-Line Notes Issue Date: 2025-07-14 GPT Summary- MATH-Vision(MATH-V)データセットを提案し、3,040の視覚的文脈を持つ数学問題を収集。16の数学分野と5つの難易度で構成され、LMMsの数学的推論能力を評価。実験により、LMMsと人間のパフォーマンス間に顕著なギャップがあることを示し、さらなる進展の必要性を強調。エラー分析を通じて今後の研究に貴重な洞察を提供。 Comment
openreview:
https://openreview.net/forum?id=QWTCcxMpPA#discussion
project page:
https://mathllm.github.io/mathvision/
Project Pageのランディングページが非常にわかりやすい。こちらは人間の方がまだまだ性能が高そう。
Gemma-4-31Bではスコアが85.6%に到達。人間のスコアが68.82%なので、すでに本ベンチマーク上では人間のスコア超え。
- Gemma 4: Byte for byte, the most capable open models, Google, 2026.04
GPT-5.4 (xhigh)が96.1%のスコアに到達しているため、スコアはすでに飽和している。
[Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Coding #Selected Papers/Blogs Issue Date: 2025-07-13 GPT Summary- BigCodeプロジェクトは、責任あるCode LLMsの開発に焦点を当て、StarCoder2を発表。Software Heritageと提携し、The Stack v2を構築し、619のプログラミング言語を含む大規模なトレーニングセットを作成。StarCoder2モデルは3B、7B、15Bのパラメータを持ち、徹底的なベンチマーク評価で優れた性能を示す。特にStarCoder2-15Bは、同等の他モデルを大幅に上回り、数学やコード推論でも高い性能を発揮。モデルの重みはOpenRAILライセンスで公開され、トレーニングデータの透明性も確保。 Comment
[Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #ICLR #Selected Papers/Blogs #PRM Issue Date: 2025-06-26 GPT Summary- 大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。 Comment
OpenReview: https://openreview.net/forum?id=v8L0pN6EOi
[Paper Note] UltraFeedback: Boosting Language Models with Scaled AI Feedback, Ganqu Cui+, ICML'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #InstructionTuning #ICML #PostTraining Issue Date: 2025-05-11 GPT Summary- 人間のフィードバックに加え、高品質なAIフィードバックを自動収集することで、LLMsのアライメントをスケーラブルに実現。多様なインタラクションをカバーし、注釈バイアスを軽減した結果、25万件の会話に対する100万件以上のGPT-4フィードバックを含むデータセット「UltraFeedback」を構築。これに基づき、LLaMAモデルを強化学習でアライメントし、チャットベンチマークで優れた性能を示す。研究はオープンソースチャットモデルの構築におけるAIフィードバックの有効性を検証。データとモデルは公開中。
[Paper Note] 日本語TrustfulQAの構築, 中村+, NLP'24
Paper/Blog Link My Issue
#NLP #Japanese #read-later #Trustfulness Issue Date: 2025-05-10
[Paper Note] The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale, Guilherme Penedo+, NeurIPS'24
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #NeurIPS #Selected Papers/Blogs Issue Date: 2025-05-10 GPT Summary- 本研究では、15兆トークンからなるFineWebデータセットを紹介し、LLMの性能向上に寄与することを示します。FineWebは高品質な事前学習データセットのキュレーション方法を文書化し、重複排除やフィルタリング戦略を詳細に調査しています。また、FineWebから派生した1.3兆トークンのFineWeb-Eduを用いたLLMは、MMLUやARCなどのベンチマークで優れた性能を発揮します。データセット、コードベース、モデルは公開されています。 Comment
日本語解説: https://zenn.dev/deepkawamura/articles/da9aeca6d6d9f9
openreview: https://openreview.net/forum?id=n6SCkn2QaG#discussion
[Paper Note] Editing Large Language Models: Problems, Methods, and Opportunities, Yunzhi Yao+, EMNLP'24
Paper/Blog Link My Issue
#NLP #LanguageModel #EMNLP #KnowledgeEditing #read-later Issue Date: 2025-05-07 GPT Summary- LLMの編集技術の進展を探求し、特定のドメインでの効率的な動作変更と他の入力への影響を最小限に抑える方法を論じる。モデル編集のタスク定義や課題を包括的にまとめ、先進的な手法の実証分析を行う。また、新しいベンチマークデータセットを構築し、評価の向上と持続的な問題の特定を目指す。最終的に、編集技術の効果に関する洞察を提供し、適切な方法選択を支援する。コードとデータセットは公開されている。
[Paper Note] Gorilla: Large Language Model Connected with Massive APIs, Shishir G. Patil+, NeurIPS'24
Paper/Blog Link My Issue
#Tools #NLP #LanguageModel #API #NeurIPS Issue Date: 2025-04-08 GPT Summary- Gorillaは、API呼び出しの生成においてGPT-4を上回るLLaMAベースのモデルであり、文書検索システムと組み合わせることで、テスト時の文書変更に適応し、ユーザーの柔軟な更新を可能にします。幻覚の問題を軽減し、APIをより正確に使用する能力を示します。Gorillaの評価には新たに導入したデータセット「APIBench」を使用し、信頼性と適用性の向上を実現しています。 Comment
APIBench: https://huggingface.co/datasets/gorilla-llm/APIBench
OpenReview: https://openreview.net/forum?id=tBRNC6YemY
[Paper Note] WebArena: A Realistic Web Environment for Building Autonomous Agents, Shuyan Zhou+, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #ICLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-04-02 GPT Summary- 生成AIの進展により、自律エージェントが自然言語コマンドで日常タスクを管理する可能性が生まれたが、現行のエージェントは簡略化された環境でのテストに限られている。本研究では、ウェブ上でタスクを実行するエージェントのための現実的な環境を構築し、eコマースやソーシャルフォーラムなどのドメインを含む完全なウェブサイトを提供する。この環境を基に、タスクの正確性を評価するベンチマークを公開し、実験を通じてGPT-4ベースのエージェントの成功率が14.41%であり、人間の78.24%には及ばないことを示した。これにより、実生活のタスクにおけるエージェントのさらなる開発の必要性が強調される。 Comment
Webにおけるさまざまなrealisticなタスクを評価するためのベンチマーク
実際のexample。スタート地点からピッツバーグのmuseumを巡る最短の経路を見つけるといった複雑なタスクが含まれる。
人間とGPT4,GPT-3.5の比較結果
[Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #ICLR #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-04-02 GPT Summary- SWE-benchは、12の人気Pythonリポジトリから得られた2,294のソフトウェアエンジニアリング問題を評価するフレームワークで、言語モデルがコードベースを編集して問題を解決する能力を測定します。評価の結果、最先端の商用モデルや微調整されたモデルSWE-Llamaも最も単純な問題しか解決できず、Claude 2はわずか1.96%の問題を解決するにとどまりました。SWE-benchは、より実用的で知的な言語モデルへの進展を示しています。 Comment
ソフトウェアエージェントの最もpopularなベンチマーク
主にpythonライブラリに関するリポジトリに基づいて構築されている。
SWE-Bench, SWE-Bench Lite, SWE-Bench Verifiedの3種類がありソフトウェアエージェントではSWE-Bench Verifiedを利用して評価することが多いらしい。Verifiedでは、issueの記述に曖昧性がなく、適切なunittestのスコープが適切なもののみが採用されているとのこと(i.e., 人間の専門家によって問題がないと判断されたもの)。
https://www.swebench.com/
Agenticな評価をする際に、一部の評価でエージェントがgit logを参照し本来は存在しないはずのリポジトリのfuture stateを見ることで環境をハッキングしていたとのこと:
これまでの評価結果にどの程度の影響があるかは不明。
openreview: https://openreview.net/forum?id=VTF8yNQM66
[Paper Note] FinTextQA: A Dataset for Long-form Financial Question Answering, Jian Chen+, ACL'24
Paper/Blog Link My Issue
#Financial #ACL #One-Line Notes Issue Date: 2025-01-06 GPT Summary- 金融における質問応答システムの評価には多様なデータセットが必要だが、既存のものは不足している。本研究では、金融の長文質問応答用データセットFinTextQAを提案し、1,262の高品質QAペアを収集した。また、RAGベースのLFQAシステムを開発し、様々な評価手法で性能を検証した結果、Baichuan2-7BがGPT-3.5-turboに近い精度を示し、最も効果的なシステム構成が特定された。文脈の長さが閾値を超えると、ノイズに対する耐性が向上することも確認された。 Comment
@AkihikoWatanabe Do you have this dataset, please share it with me. Thank you.
@thangmaster37 Thank you for your comment and I'm sorry for the late replying. Unfortunately, I do not have this dataset. I checked the link provided in the paper, but it was not found. Please try contacting the authors. Thank you.
@thangmaster37 I found that the dataset is available in the following repository. However, as stated in the repository's README, It seems that the textbook portion of the dataset cannot be shared because their legal department has not granted permission to open source. Thank you.
https://github.com/AlexJJJChen/FinTextQA
回答の長さが既存データセットと比較して長いFinancialに関するQAデータセット(1 paragraph程度)。


ただし、上述の通りデータセットのうちtextbookについて公開の許可が降りなかったようで、regulation and policy-relatedな部分のみ利用できる模様(全体の20%程度)。

[Paper Note] OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems, Chaoqun He+, ACL'24
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #MultiModal #ACL Issue Date: 2025-01-06 GPT Summary- 大規模言語モデル(LLMs)やマルチモーダルモデル(LMMs)の能力を測定するために、オリンピアドレベルのバイリンガルマルチモーダル科学ベンチマーク「OlympiadBench」を提案。8,476の数学と物理の問題を含み、専門家レベルの注釈が付けられている。トップモデルのGPT-4Vは平均17.97%のスコアを達成したが、物理では10.74%にとどまり、ベンチマークの厳しさを示す。一般的な問題として幻覚や論理的誤謬が指摘され、今後のAGI研究に貴重なリソースとなることが期待される。
Linguistically Conditioned Semantic Textual Similarity, Jingxuan Tu+, ACL'24
Paper/Blog Link My Issue
#Embeddings #RepresentationLearning #STS (SemanticTextualSimilarity) #ACL Issue Date: 2025-01-06 GPT Summary- 条件付きSTS(C-STS)は文の意味的類似性を測定するNLPタスクであるが、既存のデータセットには評価を妨げる問題が多い。本研究では、C-STSの検証セットを再アノテーションし、アノテーター間の不一致を55%観察。QAタスク設定を活用し、アノテーションエラーを80%以上のF1スコアで特定する自動エラー識別パイプラインを提案。また、モデル訓練によりC-STSデータのベースライン性能を向上させる新手法を示し、エンティティタイプの型特徴構造(TFS)を用いた条件付きアノテーションの可能性についても議論する。
[Paper Note] MAG-V: A Multi-Agent Framework for Synthetic Data Generation and Verification, Saptarshi Sengupta+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #SyntheticData #Evaluation Issue Date: 2025-01-03 GPT Summary- MAG-Vというマルチエージェントフレームワークを提案し、顧客クエリを模倣したデータセットを生成してエージェントのパフォーマンスを向上させる。軌跡の検証手法は従来のMLモデルを上回り、GPT-4と同等の性能を示す。多様なタスクエージェントを統一するアプローチを提供。 Comment
元ポスト:
[Paper Note] TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks, Frank F. Xu+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #NeurIPS #Selected Papers/Blogs #Surface-level Notes #Author Thread-Post Issue Date: 2025-01-03 GPT Summary- 大規模言語モデル(LLMs)によるAIエージェントの進展が、日常業務の効率化にどのように寄与するかを探求。TheAgentCompanyを通じて、AIエージェントがデジタル労働者のように働く能力を評価する拡張可能なベンチマークを導入。模擬のソフトウェア企業環境で、タスクの自律的完了率は30%に達し、単純なタスクは成功する一方、複雑な長期タスクは今のモデルでは難しいことを示す。 Comment
元ポスト:
ソフトウェアエンジニアリングの企業の設定で現実に起こりうるな 175種類のタスクを定義してAI Agentを評価できるベンチマークTheAgentCompanyを提案。
既存のベンチマークより、多様で、実際のソフトウェアエンジニアリング企業でで起こりうる幅広いタスクを持ち、タスクの遂行のために同僚に対して何らかのインタラクションが必要で、達成のために多くのステップが必要でかつ個々のステップ(サブタスク)を評価可能で、多様なタスクを遂行するために必要な様々なインタフェースをカバーし、self hostingして結果を完全に再現可能なベンチマークとなっている模様。
(画像は著者ツイートより引用)
プロプライエタリなモデルとOpenWeightなモデルでAI Agentとしての能力を評価した結果、Claude-3.5-sonnetは約24%のタスクを解決可能であり、他モデルと比べて性能が明らかに良かった。また、Gemini-2.0-flashなコストパフォーマンスに優れている。OpenWeightなモデルの中ではLlama3.3-70Bのコストパフォーマンスが良かった。タスクとしては具体的に評価可能なタスクのみに焦点を当てており、Open Endなタスクでは評価していない点に注意とのこと。
まだまだAI Agentが完全に'同僚'として機能することとは現時点ではなさそうだが、このベンチマークのスコアが今後どこまで上がっていくだろうか。
openreview: https://openreview.net/forum?id=LZnKNApvhG
[Paper Note] VLR-Bench: Multilingual Benchmark Dataset for Vision-Language Retrieval Augmented Generation, Hyeonseok Lim+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#ComputerVision #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #MultiLingual #COLING #VisionLanguageModel #One-Line Notes Issue Date: 2024-12-16 GPT Summary- 視覚言語モデル(VLM)を評価するための新しいベンチマークVLR-Benchを提案。これは5つの入力パッセージを用いて、特定のクエリに対する有用な情報の判断能力をテストする。32,000の自動生成された指示からなるデータセットVLR-IFを構築し、VLMのRAG能力を強化。Llama3ベースのモデルで性能を検証し、両データセットはオンラインで公開。 Comment
Multilingual VLMを用いたRAGのベンチマークデータセット
[Paper Note] Striking Gold in Advertising: Standardization and Exploration of Ad Text Generation, Masato Mita+, ACL'24
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #LanguageModel #Evaluation #LLM-as-a-Judge #KeyPoint Notes Issue Date: 2024-12-15 GPT Summary- 自動広告テキスト生成(ATG)のために、標準化されたベンチマークデータセットCAMERAを提案。これにより、マルチモーダル情報の活用と業界全体での評価が促進される。9つのベースラインを用いた実験で、現状と課題を明らかにし、LLMベースの評価者と人間の評価の一致を探求。 Comment
広告文生成タスク(Ad Text Generation)は個々のグループのプロプライエタリデータでしか評価されてこなかったことと、そもそもタスク設定が十分に規定されていないので、その辺を整備したという話らしい。
特に広告文生成のための初のオープンデータなCAMERAを構築している。
データセットを作るだけでなく、既存の手法、古典的なものからLLMまででどの程度の性能まで到達しているか、さらにはROUGEやGPT-4を用いたLLM-as-a-Judgeのような自動評価手法をメタ評価し、人手評価とオンライン評価のどの程度代替になるかも分析したとのことらしい。
Table5にメタ評価の結果が記載されている。システムレベルのcorrelationを測定している。興味深いのが、BLEU-4, ROUGE-1, BERTScoreなどの古典的or埋め込みベースのNLG評価手法がFaithfulnessとFluencyにおいて、人間の専門家と高い相関を示しているのに対し、GPT-4による評価では人間による評価と全然相関が出ていない。
既存のLLM-as-a-Judge研究では専門家と同等の評価できます、みたいな話がよく見受けられるがこれらの報告と結果が異なっていておもしろい。著者らは、OpenAIのGPTはそもそも広告ドメインとテキストでそんなに訓練されていなさそうなので、ドメインのミスマッチが一つの要因としてあるのではないか、と考察している。
また、Attractivenessでは専門家による評価と弱い相関しか示していない点も興味深い。広告文がどの程度魅力的かはBLEU, ROUGE, BERTScoreあたりではなかなか難しそうなので、GPT4による評価がうまくいって欲しいところだが、全くうまくいっていない。この論文の結果だけを見ると、(Attractivenessに関しては)自動評価だけではまだまだ広告文の評価は厳しそうに見える。
GPT4によるAttractivenessの評価に利用したプロンプトが下記。MTBenchっぽく、ペアワイズの分類問題として解いていることがわかる。この辺はLLM-as-a-Judgeの研究では他にもスコアトークンを出力し尤度で重みづけるG-Evalをはじめ、さまざまな手法が提案されていると思うので、その辺の手法を利用したらどうなるかは興味がある。
あとはそもそも手法面の話以前に、promptのコンテキスト情報としてどのような情報がAttractivenessの評価に重要か?というのも明らかになると興味深い。この辺は、サイバーエージェントの専門家部隊が、どのようなことを思考してAttractivenessを評価しているのか?というのがヒントになりそうである。
- 国際会議ACL2024参加報告, Masato Mita, Cyber Agent, 2024.12
に著者によるサマリが記載されているので参照のこと。
事実正誤判定が不要な生成応答の検出に向けた データセットの収集と分析, rryohei Kamei+, NLP'24, 2024.03
Paper/Blog Link My Issue
#NLP #Factuality #Conversation Issue Date: 2024-12-05
[Paper Note] Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, ACL'24
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Evaluation #Factuality #Reasoning #ACL #Reading Reflections Issue Date: 2024-12-02 GPT Summary- 大規模言語モデル(LLMs)のマルチホップクエリに対する事実の想起能力を評価。ショートカットを防ぐため、主語と答えが共に出現するテストクエリを除外した評価データセットSOCRATESを構築。LLMsは特定のクエリにおいてショートカットを利用せずに潜在的な推論能力を示し、国を中間答えとするクエリでは80%の構成可能性を達成する一方、年の想起は5%に低下。潜在的推論能力と明示的推論能力の間に大きなギャップが存在することが明らかに。 Comment
SNLP'24での解説スライド:
https://docs.google.com/presentation/d/1Q_UzOzn0qYX1gq_4FC4YGXK8okd5pwEHaLzVCzp3yWg/edit?usp=drivesdk
この研究を信じるのであれば、LLMはCoT無しではマルチホップ推論を実施することはあまりできていなさそう、という感じだと思うのだがどうなんだろうか。
Japanese-English Sentence Translation Exercises Dataset for Automatic Grading, Miura+, EACL'24, 2024.03
Paper/Blog Link My Issue
#NLP #AES(AutomatedEssayScoring) #Japanese #One-Line Notes Issue Date: 2024-11-28 GPT Summary- 第二言語学習の文翻訳演習の自動評価タスクを提案し、評価基準に基づいて学生の回答を採点する。日本語と英語の間で3,498の学生の回答を含むデータセットを作成。ファインチューニングされたBERTモデルは約90%のF1スコアで正しい回答を分類するが、誤った回答は80%未満。少数ショット学習を用いたGPT-3.5はBERTより劣る結果を示し、提案タスクが大規模言語モデルにとっても難しいことを示す。 Comment
STEsの図解。分かりやすい。いわゆる日本人が慣れ親しんでいる和文英訳、英文和訳演習も、このタスクの一種だということなのだろう。2-shotのGPT4とFinetuningしたBERTが同等程度の性能に見えて、GPT3.5では5shotしても勝てていない模様。興味深い。
[Paper Note] COM Kitchens: An Unedited Overhead-view Video Dataset as a Vision-Language Benchmark, Koki Maeda+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#ComputerVision #ECCV #needs-revision Issue Date: 2024-09-30 GPT Summary- 手順型動画理解に向けて、COM Kitchensという新データセットを提案。スマートフォンで撮影した編集なしの俯瞰視点動画で、参加者がレシピに従った調理を記録。これにより、幅広い環境でのデータ収集が可能に。新タスクとして、動画からテキストへの検索(OnRR)と未編集動画上のキャプショニング(DVC-OV)を設定し、既存手法の能力と限界を実験で検証。 Comment
とてもおもしろそう!
[Paper Note] What matters when building vision-language models?, Hugo Laurençon+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#ComputerVision #NLP #VisionLanguageModel #One-Line Notes Issue Date: 2024-09-30 GPT Summary- 視覚と言語のモデル(VLM)の設計決定が正当化されていないことが、モデルのパフォーマンス改善を困難にしていると指摘。広範な実験を通じて、80億パラメータのVLMであるIdefics2を開発し、さまざまなマルチモーダルベンチマークで最先端のパフォーマンスを達成。モデルとそのトレーニング用データセットを公開。 Comment
元ポストにOpenVLMの進展の歴史が載っている。構築されたデータセットも公開される模様。
元ポスト:
GPQA: A Graduate-Level Google-Proof Q&A Benchmark, David Rein+, N_A, COLM'24
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #COLM #One-Line Notes Issue Date: 2023-11-22 GPT Summary- 私たちは、高品質で非常に困難な多肢選択問題からなるGPQAデータセットを提案します。このデータセットは、専門家でも高い正答率を達成できず、最先端のAIシステムでも困難であることが示されています。将来のAIシステムの開発において、スケーラブルな監督方法を開発する必要があります。これにより、スキルを持つ監督者がAIシステムから信頼性のある情報を得ることができるようになります。GPQAデータセットは、スケーラブルな監督実験を可能にし、人間の専門家がAIシステムから真実の情報を確実に得る方法を考案するのに役立つことが期待されています。 Comment
該当領域のPh.D所有者でも74%、高いスキルを持つ非専門家(Googleへアクセスして良い環境)で34%しか正答できないQAデータセット。
元ツイート:
OpenReview: https://openreview.net/forum?id=Ti67584b98
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks, Sanchit Ahuja+, N_A, NAACL'24
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Evaluation #MultiLingual #NAACL #VisionLanguageModel Issue Date: 2023-11-14 GPT Summary- LLMsの研究は急速に進展しており、英語以外の言語での評価が必要とされている。本研究では、新しいデータセットを追加したMEGAVERSEベンチマークを提案し、さまざまなLLMsを評価する。実験の結果、GPT4とPaLM2が優れたパフォーマンスを示したが、データの汚染などの問題があるため、さらなる取り組みが必要である。
[Paper Note] SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models, Xiaoxuan Wang+, N_A, ICML'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #ICML Issue Date: 2023-07-22 GPT Summary- 本研究では、大規模言語モデル(LLMs)の進歩により、数学のベンチマークでの性能向上が示されているが、これらのベンチマークは限定的な範囲の問題に限定されていることが指摘される。そこで、複雑な科学的問題解決に必要な推論能力を検証するための包括的なベンチマークスイートSciBenchを提案する。SciBenchには、大学レベルの科学的問題を含むオープンセットと、学部レベルの試験問題を含むクローズドセットの2つのデータセットが含まれている。さらに、2つの代表的なLLMを用いた詳細なベンチマーク研究を行い、現在のLLMのパフォーマンスが不十分であることを示した。また、ユーザースタディを通じて、LLMが犯すエラーを10の問題解決能力に分類し、特定のプロンプティング戦略が他の戦略よりも優れているわけではないことを明らかにした。SciBenchは、LLMの推論能力の向上を促進し、科学研究と発見に貢献することを目指している。
[Paper Note] LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions, Minghao Wu+, EACL'24, 2023.04
Paper/Blog Link My Issue
#NLP #InstructionTuning #DataDistillation #EACL #One-Line Notes Issue Date: 2023-04-26 GPT Summary- LLMから小型モデルへの知識蒸留を探求。256万以上の多様な指示セットを用意し、gpt-3.5-turboで応答を生成。エンコーダ-デコーダとデコーダ専用のラミニLMを調整し、15のNLPベンチマークで性能評価。提案モデルは競合と同等の性能を発揮し、サイズが大幅に小さいことを確認。 Comment
既存のInstruction DatasetのInstructionをseedとして、gpt-3.5-turboで新たなInstructionとresponseを生成したデータセット
[Paper Note] LaMP: When Large Language Models Meet Personalization, Alireza Salemi+, ACL'24, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #PersonalizedGeneration #ACL #Surface-level Notes Issue Date: 2023-04-26 GPT Summary- 本論文は大規模言語モデルにおける個別化の重要性を示し、個別化出力を生成するための新しい評価フレームワーク「LaMPベンチマーク」を提案。LaMPは多様な言語タスクを網羅し、個々のユーザープロフィールに基づく複数のエントリを提供。7つの個別化タスクを含み、2つの取得補強アプローチを提案して出力のパーソナライズを図る。広範な実験により、提案手法の有効性と自然言語タスクにおける個別化の影響が確認された。 Comment
# 概要
Personalizationはユーザのニーズや嗜好に応えるために重要な技術で、IRやRecSysで盛んに研究されてきたが、NLPではあまり実施されてこなかった。しかし、最近のタスクで、text classificationやgeneration taskでPersonalizationの重要性が指摘されている。このような中で、LLMでpersonalizedなレスポンスを生成し、評価することはあまり研究されていない。そこで、LaMPベンチマークを生成し、LLMにおけるPersonalizationをするための開発と評価をするための第一歩として提案している。
# Personalizing LLM Outputs
LLMに対してPersonalizedなoutputをさせるためには、profileをpromptに埋め込むことが基本的なアプローチとなる。
## Problem Formulation
まず、user profile(ユーザに関するrecordの集合)をユーザとみなす。データサンプルは以下の3つで構成される:
- x: モデルのinputとなるinput sequence
- y: モデルが生成することを期待するtarget output
- u: user profile(ユーザの嗜好やrequirementsを捉えるための補助的な情報)
そして、p(y | x, u) を最大化する問題として定式化される。それぞれのユーザuに対して、モデルは{(x_u1, y_u1,)...(x_un, y_un)}を利用することができる。
## A Retrieval Augmentation Approach for Personaliozing LLMs
user profileは基本的にめちゃめちゃ多く、promptに入れ込むことは非現実的。そこで、reteival augmentation approachと呼ばれる手法を提案している。LLMのcontext windowは限られているので、profileのうちのsubsetを利用することが現実的なアプローチとなる。また、必ずしも全てのユーザプロファイルがあるタスクを実施するために有用とは限らない。このため、retrieval augmentation approachを提案している。
retrieval augmentation approachでは、現在のテストケースに対して、relevantな部分ユーザプロファイルを選択的に抽出するフレームワークである。
(x_i, y_i)に対してpersonalizationを実現するために、3つのコンポーネントを採用している:
1. query generation function: x_iに基づきuser profileからrelevantな情報を引っ張ってくるquery qを生成するコンポーネント
2. retrieval model R(q, P_u, k): query q, プロファイルP_u, を用いて、k個のrelevantなプロファイルを引っ張ってくるモデル
3. prompt construction function: xとreteival modelが引っ張ってきたエントリからpromptを作成するコンポーネント
1, 2, 3によって生成されたprompt x^barと、yによってモデルを訓練、あるいは評価する。
この研究では、Rとして Contriever Contrirever
, BM25, random selectionの3種類を用いている。
# LaMPベンチマーク
GLUEやSuper Glue、KILT、GENといったベンチマークは、"one-size-fits-all"なモデリングと評価を前提としており、ユーザのニーズに答えるための開発を許容していない。一方で、LaMPは、以下のようなPersonalizationが必要なさまざまなタスクを統合して作成されたデータセットである。
- Personalized Text Classification
- Personalized Citation Identification (binary classification)
- Task definition
- user u が topic xに関する論文を書いたときに、何の論文をciteすべきかを決めるタスク
- user uが書いた論文のタイトルが与えられたとき、2つのcandidate paperのうちどちらをreferenceとして利用すべきかを決定する2値分類
- Data Collection
- Citation Network Datasetを利用。最低でも50本以上論文を書いているauthorを抽出し、authorの論文のうちランダムに論文と論文の引用を抽出
- negative document selectionとして、ランダムに共著者がciteしている論文をサンプリング
- Profile Specification
- ユーザプロファイルは、ユーザが書いた全てのpaper
- titleとabstractのみをuser profileとして保持した
- Evaluation
- train/valid/testに分け、accuracyで評価する
- Personalized News Categorization (15 category分類)
- Task definition
- LLMが journalist uによって書かれたニュースを分類する能力を問うタスク
- u によって書かれたニュースxが与えられた時、uの過去の記事から得られるカテゴリの中から該当するカテゴリを予測するタスク
- Data Collection
- news categorization datasetを利用(Huff Postのニュース)
- 記事をfirst authorでグルーピング
- グルーピングした記事群をtrain/valid/testに分割
- それぞれの記事において、記事をinputとし、その記事のカテゴリをoutputとする。そして残りの記事をuser profileとする。
- Profile Specification
- ユーザによって書かれた記事の集合
- Evaluation
- accuracy, macro-averaged F1で評価
- Personalized Product Rating (5-star rating)
- Task definition
- ユーザuが記述したreviewに基づいて、LLMがユーザuの未知のアイテムに対するratingを予測する性能を問う
- Data Collection
- Amazon Reviews Datasetを利用
- reviewが100件未満、そしてほとんどのreviewが外れ値なユーザ1%を除外
- ランダムにsubsetをサンプリングし、train/valid/testに分けた
- input-output pairとしては、inputとしてランダムにユーザのreviewを選択し、その他のreviewをprofileとして利用する。そして、ユーザがinputのレビューで付与したratingがground truthとなる。
- Profile Specification
- ユーザのレビュ
- Evaluation
- ttrain/valid/testに分けてRMSE, MAEで評価する
- Personalized Text Generation
- Personalized News Headline Generation
- Task definition
- ユーザuが記述したニュースのタイトルを生成するタスク
- 特に、LLMが与えられたprofileに基づいてユーザのinterestsやwriting styleを捉え、適切にheadlinに反映させる能力を問う
- Data Collection
- News Categorization datasetを利用(Huff Post)
- データセットではauthorの情報が提供されている
- それぞれのfirst authorごとにニュースをグルーピングし、それぞれの記事をinput, headlineをoutputとした。そして残りの記事をprofileとした
- Profile Specification
- ユーザの過去のニュース記事とそのheadlineの集合をprofileとする
- Evaluation
- ROUGE-1, ROUGE-Lで評価
- Personalized Scholarly Title Generation
- Task Definition
- ユーザの過去のタイトルを考慮し、LLMがresearch paperのtitleを生成する能力を測る
- Data Collection
- Citation Network Datasetのデータを利用
- abstractをinput, titleをoutputとし、残りのpaperをprofileとした
- Profile Specification
- ユーザが書いたpaperの集合(abstractのみを利用)
- Personalized Email Subject Generation
- Task Definition
- LLMがユーザのwriting styleに合わせて、Emailのタイトルを書く能力を測る
- Data Collection
- Avocado Resaerch Email Collectionデータを利用
- 5単語未満のsubjectを持つメール、本文が30単語未満のメールを除外、
- 送信主のemail addressでメールをグルーピング
- input _outputペアは、email本文をinputとし、対応するsubjectをoutputとした。他のメールはprofile
- Profile Specification
- ユーザのemailの集合
- Evaluation
- ROUGE-1, ROUGE-Lで評価
- Personalized Tweet Paraphrasing
- Task Definition
- LLMがユーザのwriting styleを考慮し、ツイートのparaphrasingをする能力を問う
- Data Collection
- Sentiment140 datasetを利用
- 最低10単語を持つツイートのみを利用
- userIDでグルーピングし、10 tweets以下のユーザは除外
- ランダムに1つのtweetを選択し、ChatGPT(gpt-3.5-turbo)でparaphraseした
- paraphrase版のtweetをinput, 元ツイートをoutputとし、input-output pairを作った。
- User Profile Specification
- ユーザの過去のツイート
- Evaluation
- ROUGE-1, ROUGE-Lで評価
# 実験
## Experimental Setup
- FlanT5-baesをfinetuningした
- ユーザ単位でモデルが存在するのか否かが記載されておらず不明
## 結果
- Personalization入れた方が全てのタスクでよくなった
- Retrievalモデルとしては、randomの場合でも良くなったが、基本的にはContrirverを利用した場合が最も良かった
- => 適切なprofileを選択しpromptに含めることが重要であることが示された
- Rが抽出するサンプル kを増やすと、予測性能が増加する傾向もあったが、一部タスクでは性能の低下も招いた
- dev setを利用し、BM25/Contrieverのどちらを利用するか、kをいくつに設定するかをチューニングした結果、全ての結果が改善した
- FlanT5-XXLとgpt-3.5-turboを用いたZero-shotの設定でも実験。tweet paraphrasingタスクを除き、zero-shotでもuser profileをLLMで利用することでパフォーマンス改善。小さなモデルでもfinetuningすることで、zero-shotの大規模モデルにdownstreamタスクでより高い性能を獲得することを示している(ただし、めちゃめちゃ改善しているというわけでもなさそう)。


# LaMPによって可能なResearch Problem
## Prompting for Personalization
- Augmentationモデル以外のLLMへのユーザプロファイルの埋め込み方法
- hard promptingやsoft prompting [Paper Note] The Power of Scale for Parameter-Efficient Prompt Tuning, Brian Lester+, EMNLP'21, 2021.04
の活用
## Evaluation of Personalized Text Generation
- テキスト生成で利用される性能指標はユーザの情報を評価のプロセスで考慮していない
- Personalizedなテキスト生成を評価するための適切なmetricはどんなものがあるか?
## Learning to Retrieve from User Profiles
- Learning to RankをRetrieval modelに適用する方向性
LaMPの作成に利用したテンプレート一覧
実装とleaderboard
https://lamp-benchmark.github.io/leaderboard
[Paper Note] TinyStories: How Small Can Language Models Be and Still Speak Coherent English?, Ronen Eldan+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NaturalLanguageGeneration #NLP #LanguageModel #SyntheticData #SmallModel Issue Date: 2026-01-19 GPT Summary- LMは小規模モデルでは一貫性のあるテキスト生成が難しい。本研究では、3~4歳児が理解できる単語のみを含む短編小説データセット「TinyStories」を紹介。これはGPT-3.5とGPT-4で生成され、1000万パラメータ未満のモデルでも流暢な物語が生成可能であることを示す。さらに、出力評価の新たなパラダイムを提案し、学生の作品との比較を通じてさまざまな能力に対するスコアを提供。TinyStoriesはLMの研究を促進し、限られたリソースや特殊ドメインにおける言語能力の発展に寄与することが期待される。 Comment
dataset: https://huggingface.co/datasets/roneneldan/TinyStories
[Paper Note] FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation, Tu Vu+, ACL'23 Findings, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Zero/Few/ManyShotPrompting #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #ACL #Findings Issue Date: 2025-09-24 GPT Summary- 大規模言語モデル(LLMs)は変化する世界に適応できず、事実性に課題がある。本研究では、動的QAベンチマーク「FreshQA」を導入し、迅速に変化する知識や誤った前提を含む質問に対するLLMの性能を評価。評価の結果、全モデルがこれらの質問に苦労していることが明らかに。これを受けて、検索エンジンからの最新情報を組み込む「FreshPrompt」を提案し、LLMのパフォーマンスを向上させることに成功。FreshPromptは、証拠の数と順序が正確性に影響を与えることを示し、簡潔な回答を促すことで幻覚を減少させる効果も確認。FreshQAは公開され、今後も更新される予定。
[Paper Note] GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment, Dhruba Ghosh+, NeurIPS'23
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #TextToImageGeneration #NeurIPS #read-later #Selected Papers/Blogs Issue Date: 2025-09-11 GPT Summary- テキストから画像への生成モデルの自動評価方法「GenEval」を提案。物体の共起、位置、数、色などの特性を評価し、現在の物体検出モデルを活用して生成タスクを分析。最近のモデルは改善を示すが、複雑な能力には課題が残る。GenEvalは失敗モードの発見にも寄与し、次世代モデルの開発に役立つ。コードは公開中。 Comment
openreview: https://openreview.net/forum?id=Wbr51vK331¬eId=NpvYJlJFqK
[Paper Note] Dataset Distillation: A Comprehensive Review, Ruonan Yu+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#Survey #MachineLearning #Distillation #Initial Impression Notes Issue Date: 2025-03-25 GPT Summary- データセット蒸留(DD)は、深層学習における膨大なデータのストレージやプライバシーの問題を軽減する手法であり、合成サンプルを含む小さなデータセットを生成することで、元のデータセットと同等の性能を持つモデルをトレーニング可能にする。本論文では、DDの進展と応用をレビューし、全体的なアルゴリズムフレームワークを提案、既存手法の分類と理論的相互関係を議論し、DDの課題と今後の研究方向を展望する。 Comment
訓練データセット中の知識を蒸留し、オリジナルデータよりも少量のデータで同等の学習効果を得るDataset Distillationに関するSurvey。
Data Distillation: A Survey, Noveen Sachdeva+, arXiv'23
Paper/Blog Link My Issue
#Survey #NLP #Distillation Issue Date: 2025-02-01 GPT Summary- 深層学習の普及に伴い、大規模データセットの訓練が高コストで持続可能性に課題をもたらしている。データ蒸留アプローチは、元のデータセットの効果的な代替品を提供し、モデル訓練や推論に役立つ。本研究では、データ蒸留のフレームワークを提示し、既存のアプローチを分類。画像やグラフ、レコメンダーシステムなどの異なるデータモダリティにおける課題と今後の研究方向性を示す。
[Paper Note] Instruction Tuning with GPT-4, Baolin Peng+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #PostTraining #One-Line Notes Issue Date: 2024-09-20 GPT Summary- GPT-4を用いて機械生成の指示追従データを新たに生成し、LLaMAモデルのファインチューニングを行う試みを提案。生成されたデータは、従来のモデルと比べて新規タスクに対するゼロショット性能を向上させることを示した。フィードバックと比較データも収集し、コードベースを公開。 Comment
現在はOpenAIの利用規約において、outputを利用してOpenAIと競合するモデルを構築することは禁止されているので、この点には注意が必要
https://openai.com/ja-JP/policies/terms-of-use/
[Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #NLP #LanguageModel #Annotation #One-Line Notes Issue Date: 2024-05-15 GPT Summary- 大規模言語モデル(LLMs)の自動要約能力の背後にある要因を探り、10のモデルに対する人間評価を行った。結果、ゼロショット要約の鍵はモデルサイズではなく指示調整にあること、さらに従来の研究は低品質な参照データに制約されているため人間の性能を過小評価していることが明らかになった。高品質な要約を基にした評価では、LLMsの要約が人間の要約と同等とされることが多いとの結論に至った。 Comment
- ニュース記事の高品質な要約を人間に作成してもらい、gpt-3.5を用いてLLM-basedな要約も生成
- annotatorにそれぞれの要約の品質をスコアリングさせたデータセットを作成
UniIR: Training and Benchmarking Universal Multimodal Information Retrievers, Cong Wei+, N_A, arXiv'23
Paper/Blog Link My Issue
#InformationRetrieval #MultiModal Issue Date: 2023-12-01 GPT Summary- 従来の情報検索モデルは一様な形式を前提としているため、異なる情報検索の要求に対応できない。そこで、UniIRという統一された指示に基づくマルチモーダルリトリーバーを提案する。UniIRは異なるリトリーバルタスクを処理できるように設計され、10のマルチモーダルIRデータセットでトレーニングされる。実験結果はUniIRの汎化能力を示し、M-BEIRというマルチモーダルリトリーバルベンチマークも構築された。 Comment
後で読む(画像は元ツイートより
元ツイート:
GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #AIAgents #Evaluation #Selected Papers/Blogs Issue Date: 2023-11-23 GPT Summary- GAIAは、General AI Assistantsのためのベンチマークであり、AI研究のマイルストーンとなる可能性がある。GAIAは、推論、マルチモダリティの処理、ウェブブラウジングなど、実世界の質問に対する基本的な能力を必要とする。人間の回答者は92%の正答率を達成し、GPT-4は15%の正答率を達成した。これは、最近の傾向とは異なる結果であり、専門的なスキルを必要とするタスクではLLMsが人間を上回っている。GAIAは、人間の平均的な堅牢性と同等の能力を持つシステムがAGIの到来に重要であると考えている。GAIAの手法を使用して、466の質問と回答を作成し、一部を公開してリーダーボードで利用可能にする。 Comment
Yann LeCun氏の紹介ツイート
Meta-FAIR, Meta-GenAI, HuggingFace, AutoGPTによる研究。人間は92%正解できるが、GPT4でも15%しか正解できないQAベンチマーク。解くために推論やマルチモダリティの処理、ブラウジング、ツールに対する習熟などの基本的な能力を必要とする実世界のQAとのこと。
- Open-source DeepResearch – Freeing our search agents, HuggingFace, 2025.02
で言及されているLLM Agentの評価で最も有名なベンチマークな模様
[Paper Note] Instruction-Following Evaluation for Large Language Models, Jeffrey Zhou+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#NLP #LanguageModel #InstructionTuning #Evaluation #PostTraining #Selected Papers/Blogs #InstructionFollowingCapability #KeyPoint Notes Issue Date: 2023-11-15 GPT Summary- 大規模言語モデルの自然言語指示に対する評価は標準化されておらず、人間による評価は高価で遅い。そこで、Instruction-Following Eval(IFEval)を提案し、検証可能な指示に焦点を当てた評価ベンチマークを提供。25種類の指示を特定し、約500のプロンプトを作成。これにより、2つのLLMの客観的な評価結果を示すことに成功した。コードとデータは公開されている。 Comment
LLMがinstructionにどれだけ従うかを評価するために、検証可能なプロンプト(400字以上で書きなさいなど)を考案し評価する枠組みを提案。人間が評価すると時間とお金がかかり、LLMを利用した自動評価だと評価を実施するLLMのバイアスがかかるのだ、それら両方のlimitationを克服できるとのこと。
[Paper Note] RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models, Zekun Moore Wang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Conversation Issue Date: 2023-10-09 GPT Summary- RoleLLMは、大規模言語モデル(LLMs)のロールプレイ能力を強化するためのフレームワークで、100の役割に対するプロファイル構築やロール固有の知識抽出を行います。Context-InstructとRoleGPTを駆使して、初の体系的なキャラクター単位のベンチマークデータセットRoleBenchを作成し、サンプル数は168,093に達します。RoCITを使ったファインチューニングにより、RoleLLaMAとRoleGLMが生成され、GPT-4と同等のロールプレイ能力を実現しました。
[Paper Note] MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation, Qian Huang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #AIAgents #Evaluation #AutoML #One-Line Notes Issue Date: 2023-10-09 GPT Summary- 機械学習の実験を行うためのエージェントを強力な言語モデルを用いて構築し、MLAgentBenchという13のタスクベンチマークを導入。エージェントはファイル操作やコード実行を行い、Claude v3 Opusが最も高い成功率を示す。タスク全体で平均成功率37.5%を達成するが、結果はデータセットによって大きく変動。長期計画や幻覚の低減といった重要な課題も明らかにした。コードは公開中。 Comment
GPT4がMLモデルをどれだけ自動的に構築できるかを調べた模様。また、ベンチマークデータを作成した模様。結果としては、既存の有名なデータセットでの成功率は90%程度であり、未知のタスク(新たなKaggle Challenge等)では30%程度とのこと。
[Paper Note] MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning, Xiang Yue+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #InstructionTuning #NumericReasoning #Reasoning #Mathematics #PostTraining #One-Line Notes Issue Date: 2023-09-30 GPT Summary- MAmmoTHシリーズは、数学問題解法に特化したオープンソースのLLMで、MathInstructという指示チューニングデータセットを使用して訓練されています。MathInstructは、中間推論を含む13の数学データセットから構成され、特に6つの新たな推論過程を提供しています。CoTとPoTのハイブリッドを採用することで、異なる思考プロセスを実現し、9つの数学推論データセットで平均16%から32%の精度向上を実現しました。特にMAmmoTH-7BモデルはMATHデータセットで33%、MAmmoTH-34Bモデルは44%を達成し、既存のオープンソースモデルを上回っています。研究は、多様な問題の網羅性とハイブリッド推論の重要性を示しています。 Comment
9つのmath reasoningが必要なデータセットで13-29%のgainでSoTAを達成。
260kの根拠情報を含むMath Instructデータでチューニングされたモデル。
project page:
https://tiger-ai-lab.github.io/MAmmoTH/
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?, Xiangru Tang+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #StructuredData #One-Line Notes Issue Date: 2023-09-30 GPT Summary- 本研究では、大規模言語モデル(LLMs)の能力を評価し、構造に注意したファインチューニング手法を提案します。さらに、Struc-Benchというデータセットを使用して、複雑な構造化データ生成のパフォーマンスを評価します。実験の結果、提案手法は他の評価されたLLMsよりも優れた性能を示しました。また、モデルの能力マップを提示し、LLMsの弱点と将来の研究の方向性を示唆しています。詳細はhttps://github.com/gersteinlab/Struc-Benchを参照してください。 Comment
Formatに関する情報を含むデータでInstruction TuningすることでFormatCoT(フォーマットに関する情報のCoT)を実現している模様。ざっくりしか論文を読んでいないが詳細な情報があまり書かれていない印象で、ちょっとなんともいえない。
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #QuestionAnswering #Supervised-FineTuning (SFT) #LongSequence #PEFT(Adaptor/LoRA) #PostTraining #KeyPoint Notes Issue Date: 2023-09-30 GPT Summary- 本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment
# 概要
context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になってしまう。LongLoRAでは、perplexityを通常のFinetuningと同等に抑えつつ、VRAM消費量もLoRAと同等、かつより小さな計算量でFinetuningを実現している。
# 手法概要
attentionをcontext length全体で計算するとinput長の二乗の計算量がかかるため、contextをいくつかのグループに分割しグループごとにattentionを計算することで計算量削減。さらに、グループ間のattentionの間の依存関係を捉えるために、グループをshiftさせて計算したものと最終的に組み合わせている。また、embedding, normalization layerもtrainableにしている。
AgentBench: Evaluating LLMs as Agents, Xiao Liu+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #One-Line Notes Issue Date: 2023-08-27 GPT Summary- 本研究では、大規模言語モデル(LLMs)をエージェントとして評価するための多次元の進化するベンチマーク「AgentBench」を提案しています。AgentBenchは、8つの異なる環境でマルチターンのオープンエンドの生成設定を提供し、LLMの推論と意思決定能力を評価します。25のLLMsに対するテストでは、商用LLMsは強力な能力を示していますが、オープンソースの競合他社との性能には差があります。AgentBenchのデータセット、環境、および評価パッケージは、GitHubで公開されています。 Comment
エージェントとしてのLLMの推論能力と意思決定能力を評価するためのベンチマークを提案。
トップの商用LLMとOpenSource LLMの間に大きな性能差があることを示した。
Self-Alignment with Instruction Backtranslation, Xian Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #InstructionTuning #KeyPoint Notes Issue Date: 2023-08-21 GPT Summary- 私たちは、高品質な指示に従う言語モデルを構築するためのスケーラブルな手法を提案します。この手法では、少量のシードデータとウェブコーパスを使用して言語モデルをファインチューニングし、指示のプロンプトを生成してトレーニング例を構築します。そして、高品質な例を選択してモデルを強化します。この手法を使用すると、他のモデルよりも優れた性能を発揮し、自己整列の効果を実証できます。 Comment
人間が書いたテキストを対応するinstructionに自動的にラベル付けする手法を提案。
これにより高品質なinstruction following LLMの構築が可能
手法概要
結果的に得られるデータは、訓練において非常にインパクトがあり高品質なものとなる。
実際に、他の同サイズのinstruct tuningデータセットを上回る。
Humpackは他のstrong modelからdistillされていないモデルの中で最高性能を達成。これは、スケールアップしたり、より強いベースモデルを使うなどさらなる性能向上ができる余地が残されている。
参考:
指示を予測するモデルは、今回はLLaMAをfinetuningしたモデルを用いており、予測と呼称しているが指示はgenerationされる。
ReazonSpeech: A Free and Massive Corpus for Japanese ASR, Yin+, NLP'23
Paper/Blog Link My Issue
#NLP #SpeechProcessing #One-Line Notes Issue Date: 2023-08-16 Comment
https://prtimes.jp/main/html/rd/p/000000003.000102162.html
超高精度で商用利用可能な純国産の日本語音声認識モデル「ReazonSpeech」を無償公開
ワンセグのデータにから生成
ライブラリ:
[Paper Note] ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Tools #NLP #LanguageModel #AIAgents #SyntheticData #API #ICLR #One-Line Notes #ToolUse Issue Date: 2023-08-08 GPT Summary- オープンソースのLLMにおけるツール使用能力の限界を克服するため、ToolLLMフレームワークを提案。ToolBenchデータセットを用いて、ChatGPTに指示を与え実世界のAPIを収集し、多様なシナリオをカバー。新しい探索手法DFSDTを開発することで、LLMsの推論能力を高め、ToolLLaMAが複雑な指示を効果的に実行できることを示した。ToolEvalにより評価を行い、ToolLLaMAはChatGPTと同等の性能を発揮する。さらに、適切なAPIを推奨するニューラルAPIリトリーバーを導入し、手動の選択を不要にした。 Comment
16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
openreview: https://openreview.net/forum?id=dHng2O0Jjr
[Paper Note] L-Eval: Instituting Standardized Evaluation for Long Context Language Models, Chenxin An+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #One-Line Notes Issue Date: 2023-08-08 GPT Summary- L-Evalを提案し、長い文脈を扱う言語モデル(LCLMs)の評価指標とデータセットを標準化。508の長文ドキュメントと2,000以上の人間ラベル付けされたクエリ・応答ペアを含む評価スイートを構築。n-gramマッチング指標の限界を指摘し、長さ指示を強化した評価を推奨。商用およびオープンソースモデルの包括的な研究を通じて、LCLMsの評価の基盤を提供。 Comment
long contextに対するLLMの評価セット。411のlong documentに対する2kのquery-response pairのデータが存在。法律、fainance, school lectures, 長文対話、小説、ミーティングなどのドメインから成る。
InfoMetIC: An Informative Metric for Reference-free Image Caption Evaluation, ACL'23
Paper/Blog Link My Issue
#ComputerVision #NaturalLanguageGeneration #NLP #Evaluation #ACL Issue Date: 2023-07-22 GPT Summary- 自動画像キャプションの評価には、情報豊かなメトリック(InfoMetIC)が提案されています。これにより、キャプションの誤りや欠落した情報を詳細に特定することができます。InfoMetICは、テキストの精度スコア、ビジョンの再現スコア、および全体の品質スコアを提供し、人間の判断との相関も高いです。また、トークンレベルの評価データセットも構築されています。詳細はGitHubで公開されています。
[Paper Note] FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets, Seonghyeon Ye+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Initial Impression Notes Issue Date: 2023-07-22 GPT Summary- 大規模言語モデル(LLMs)の評価は、人間の価値観との整合性が求められるが、従来の評価は粗粒度で解釈性が制限されている。本研究では、整合スキルセットに基づく微細粒度評価プロトコルFLASKを提案し、スコアを指示ごとのスキルセットに分解する手法を導入。実験により、評価の細粒度化がモデルパフォーマンスの理解と信頼性向上に寄与することを示し、複数のLLMsにおいて高い相関を観察した。評価データとコードは公開されている。 Comment
このベンチによるとLLaMA2でさえ、商用のLLMに比べると能力はかなり劣っているように見える。
Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation, ACL'23
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #ACL Issue Date: 2023-07-18 GPT Summary- 要約の評価には人間の評価が重要ですが、既存の評価方法には問題があります。そこで、私たちは新しい要約の重要性プロトコルを提案し、大規模な人間評価データセットを収集しました。さらに、異なる評価プロトコルを比較し、自動評価指標を評価しました。私たちの研究結果は、大規模言語モデルの評価に重要な示唆を与えます。
Socratic Questioning of Novice Debuggers: A Benchmark Dataset and Preliminary Evaluations, ACL-BEA'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Coding #ACL #Workshop Issue Date: 2023-07-18 GPT Summary- 本研究では、初心者プログラマがバグのある計算問題を解決する際に、ソクラテス的な対話を行うデータセットを紹介し、GPTベースの言語モデルのデバッグ能力を評価しました。GPT-4はGPT-3.5よりも優れたパフォーマンスを示しましたが、まだ人間の専門家には及ばず、さらなる研究が必要です。
Enhancing Grammatical Error Correction Systems with Explanations, ACL'23
Paper/Blog Link My Issue
#NLP #GrammaticalErrorCorrection #ACL Issue Date: 2023-07-18 GPT Summary- 文法エラー修正システムの性能向上のために、エビデンスワードと文法エラータイプが注釈付けされた大規模なデータセットであるEXPECTを紹介する。このデータセットを使用して、説明可能なGECシステムのベースラインと分析を提案し、人間の評価によってその有用性を確認する。
[Paper Note] DataFinder: Scientific Dataset Recommendation from Natural Language Descriptions, Vijay Viswanathan+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#RecommenderSystems #NLP #NaturalLanguageUnderstanding #ACL Issue Date: 2023-07-18 GPT Summary- 短い自然言語の研究アイデアに基づいて、関連データセットを推奨するタスクを実運用化。データセット推奨は情報検索の問題として独自の課題を持つが、DataFinderデータセットを構築し、17,500件のクエリからなる自動学習データと392件の専門家注釈付き評価データを用いて検証。テスト結果からは、データセット推奨において高い関連性を示すバイエンコーダー・リトリーバが確認された。データセットとモデルは公開し、さらなる進展を促進。
MeetingBank: A Benchmark Dataset for Meeting Summarization, ACL'23
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #NLP #Conversation #ACL Issue Date: 2023-07-15 GPT Summary- 会議の要約技術の開発には注釈付きの会議コーパスが必要ですが、その欠如が問題となっています。本研究では、新しいベンチマークデータセットであるMeetingBankを提案しました。MeetingBankは、会議議事録を短いパッセージに分割し、特定のセグメントと対応させることで、会議の要約プロセスを管理しやすいタスクに分割することができます。このデータセットは、会議要約システムのテストベッドとして利用できるだけでなく、一般の人々が議会の意思決定の仕組みを理解するのにも役立ちます。ビデオリンク、トランスクリプト、参照要約などのデータを一般に公開し、会議要約技術の開発を促進します。
[Paper Note] On Improving Summarization Factual Consistency from Natural Language Feedback, Yixin Liu+, ACL'23, 2022.12
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Controllable #NLP #Factuality #ACL Issue Date: 2023-07-15 GPT Summary- ユーザーの期待に応えるために、言語生成モデルの出力品質を向上させることを目指す本研究では、「DeFacto」という高品質データセットを用いて、要約の事実的一貫性を強化するための自然言語フィードバックの活用を検討。また、人間のフィードバックに基づく要約編集や事実誤りの訂正を行うことで、生成タスクの改善を図る。微調整されたモデルは事実的一貫性を向上できる一方で、大規模言語モデルはゼロショット学習において課題が残ることが示された。
MPCHAT: Towards Multimodal Persona-Grounded Conversation, ACL'23
Paper/Blog Link My Issue
#ComputerVision #NLP #Personalization #MultiModal #Conversation #ACL Issue Date: 2023-07-15 GPT Summary- 本研究では、テキストと画像の両方を使用してパーソナを拡張し、マルチモーダルな対話エージェントを構築するためのデータセットであるMPCHATを提案します。さらに、マルチモーダルパーソナを組み込むことで、応答予測、パーソナのグラウンディング予測、話者の識別といったタスクのパフォーマンスを統計的に有意に改善できることを示します。この研究は、マルチモーダルな対話理解においてマルチモーダルパーソナの重要性を強調し、MPCHATが高品質なリソースとして役立つことを示しています。
[Paper Note] Objaverse-XL: A Universe of 10M+ 3D Objects, Matt Deitke+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#ComputerVision #FoundationModel #InductiveBias #NeurIPS #Selected Papers/Blogs #3D Reconstruction #3D (Scene) #NovelViewSynthesis #3D Object Generation Issue Date: 2023-07-12 GPT Summary- 1000万以上の3Dオブジェクトから構成されるデータセットObjaverse-XLを紹介。手作業で設計されたオブジェクトや写真測量スキャンからの多様なオブジェクトを含む。Objaverse-XLは3Dビジョン分野の最大規模と多様性を持ち、Zero123を用いた新規ビュー合成で強力なゼロショット一般化を実現。これにより、3Dビジョンでのさらなる革新が期待される。 Comment
10Mを超える3D objectのデータセットを公開し、3D Modelの基盤モデルとしてZero123-XLを訓練。
元ツイートのGifがわかりやすい。
たとえばinputされたイメージに対して、自由にカメラの視点を設定し、その視点からの物体の画像を出力できる。
openreview: https://openreview.net/forum?id=Sq3CLKJeiz¬eId=hnXWj1z2rI
[Paper Note] Understanding Social Reasoning in Language Models with Language Models, Kanishk Gandhi+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #LanguageModel #TheoryOfMind #Evaluation #One-Line Notes Issue Date: 2023-07-11 GPT Summary- 大型言語モデル(LLMs)の心の理論(ToM)能力の評価は重要であるが、一貫性のない結果や評価手法の妥当性に懸念が存在する。これに対処するため、因果テンプレートを用いて評価を生成する新しいフレームワークを提案し、新たな社会的推論ベンチマーク(BigToM)を作成した。BigToMは5,000件の評価を基にしており、質が高いと評価される。評価の結果、GPT-4は人間に近いToM能力を示す一方で、信頼性は低く、他のモデルは苦戦していることが分かった。 Comment
LLMの社会的推論能力を評価するためのベンチマークを提案。ToMタスクとは、人間の信念、ゴール、メンタルstate、何を知っているか等をトラッキングすることが求められるタスクのこと。
[Paper Note] Mind2Web: Towards a Generalist Agent for the Web, Xiang Deng+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #NeurIPS #ComputerUse #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #GUI Issue Date: 2023-07-03 GPT Summary- Mind2Webは、ウェブ上での汎用的なタスクをこなすエージェントの開発のための初のデータセットで、137のウェブサイトと31のドメインにまたがる2,000件以上のオープンエンドタスクを収集。これにより、多様なドメイン・タスクを扱え、実世界のサイトを対象にしたエージェント構築を支援。大規模言語モデル(LLMs)を用いることで、未見のウェブサイトでも一定の性能を発揮することを示し、データセットとモデルをオープンソース化して研究の促進を目指す。 Comment
Webにおけるgeneralistエージェントを評価するためのデータセットを構築。31ドメインの137件のwebサイトにおける2350個のタスクが含まれている。
タスクは、webサイトにおける多様で実用的なユースケースを反映し、チャレンジングだが現実的な問題であり、エージェントの環境やタスクをまたいだ汎化性能を評価できる。
プロジェクトサイト:
https://osu-nlp-group.github.io/Mind2Web/
[Paper Note] Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks, Veniamin Veselovsky+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #One-Line Notes Issue Date: 2023-07-03 GPT Summary- LLMは高品質なデータ生成が可能で、クラウドソーシングは安価で効果的な注釈手法だが、クラウドワーカーは生産性向上のためにLLMを利用する動機が存在する。ケーススタディでは、クラウドワーカーの33-46%がLLMを使用していることが明らかになった。この結果は、人間のデータ保持の新たなアプローチを模索する必要性を示唆している。 Comment
Mturkの言語生成タスクにおいて、Turkerのうち33-46%はLLMsを利用していることを明らかにした
[Paper Note] LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond, Philippe Laban+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Factuality #KeyPoint Notes Issue Date: 2023-06-16 GPT Summary- 実用設定でのLLMの重要性が増す中、事実の不整合検出手法が誤情報抑制とモデル信頼性向上に必要とされている。既存のベンチマークでLLMは競争力を示すが、より複雑なタスクでは失敗し、評価の精度に問題を生じさせる。これに対し、新たにSummEditsという10ドメインの不一致検出ベンチマークを提案し、再現性が高く、低コストで作成できる。多くのLLMはこのベンチマークで苦戦し、最良モデルのGPT-4も人間の性能を8%下回る結果を示し、LLMの限界を浮き彫りにしている。 Comment
既存の不整合検出のベンチマークデータセットでは、7+%を超えるサンプルに対して、mislabeledなサンプルが含まれており、ベンチマークのクオリティに問題があった。そこでSummEditsと呼ばれる事実の矛盾の検出力を検証するための新たなプロトコルを提案。既存の不整合検出では、既存のLLMを用いて比較した結果、最も不整合検出で性能が良かったGPT-4でさえ、人間に対して8%も低い性能であることが示され(要約結果に対して事実の矛盾が含まれているか否か検出するタスク)、まだまだLLMには課題があることが示された。
KoLA: Carefully Benchmarking World Knowledge of Large Language Models, Jifan Yu+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation Issue Date: 2023-06-16 GPT Summary- LLMの評価を改善するために、KoLAという知識指向のベンチマークを構築した。このベンチマークは、19のタスクをカバーし、Wikipediaと新興コーパスを使用して、知識の幻覚を自動的に評価する独自の自己対照メトリックを含む対照的なシステムを採用している。21のオープンソースと商用のLLMを評価し、KoLAデータセットとオープン参加のリーダーボードは、LLMや知識関連システムの開発の参考資料として継続的に更新される。
[Paper Note] QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Search #Evaluation #ACL #needs-revision Issue Date: 2023-05-22 GPT Summary- 情報ニーズの定式化に基づき、集合演算を含む自然言語クエリからなるデータセットQUESTを構築。3357件のクエリはWikipediaエンティティにマッピングされ、モデルの集合演算能力を試す。データセットは半自動で作成され、クラウドワーカーによって文書の関連性とクエリの自然さが検証される。多くの現代検索システムは、否定や結合を含むクエリの処理に苦戦していることが明らかになった。
[Paper Note] TrueTeacher: Learning Factual Consistency Evaluation with Large Language Models, Zorik Gekhman+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Evaluation #Hallucination #Factuality #One-Line Notes Issue Date: 2023-05-20 GPT Summary- TrueTeacherは、多様なモデル生成要約をLLMで注釈し、実際の生成要約に基づいた合成データを生成するアプローチである。従来の手法とは異なり、手作業での要約に依存せず、多言語対応も可能。実験結果は、TrueTeacherを使用して訓練したstudentモデルが他の最先端モデルやLLM教師を大幅に上回ることを示し、ドメインシフトに対する堅牢性も確認された。加えて、140万例の大規模合成データセットと訓練したチェックポイントも公開。 Comment
Factual Consistency Evaluationに関する研究。オリジナルのテキストに対して、様々な規模の言語モデルを用いて要約を生成。生成された要約に対してfactual informationが正しく含まれているかをラベル付けする方法を提案。
[Paper Note] We're Afraid Language Models Aren't Modeling Ambiguity, Alisa Liu+, EMNLP'23
Paper/Blog Link My Issue
#LanguageModel #Evaluation #EMNLP #Ambiguity #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 曖昧さは自然言語の重要な特徴であり、言語モデル(LM)が対話や執筆支援において成功するためには、曖昧な言語を扱うことが不可欠です。本研究では、曖昧さの影響を評価するために、1,645の例からなるベンチマーク「AmbiEnt」を収集し、事前学習済みLMの評価を行いました。特にGPT-4の曖昧さ解消の正答率は32%と低く、曖昧さの解消が難しいことが示されました。また、多ラベルのNLIモデルが曖昧さによる誤解を特定できることを示し、NLPにおける曖昧さの重要性を再認識する必要性を提唱しています。 Comment
LLMが曖昧性をどれだけ認知できるかを評価した初めての研究。
言語学者がアノテーションした1,645サンプルの様々な曖昧さを含んだベンチマークデータを利用。
GPT4は32%正解した。
またNLIデータでfinetuningしたモデルでは72.5%のmacroF1値を達成。
応用先として、誤解を招く可能性のある政治的主張に対してアラートをあげることなどを挙げている。
[Paper Note] MTEB: Massive Text Embedding Benchmark, Niklas Muennighoff+, EACL'23, 2022.10
Paper/Blog Link My Issue
#Embeddings #NLP #Evaluation #EACL Issue Date: 2022-10-31 GPT Summary- テキスト埋め込み評価が単一タスクの小規模データセットに偏っているため、他タスクへの適用可否が不明な中、Massive Text Embedding Benchmark(MTEB)を導入。MTEBは8つの埋め込みタスクを網羅し、58データセットと112言語を含むを通じて、33モデルをベンチマーク。特定手法が全タスクで優位性を持たないことを示し、分野が普遍的手法に収束していないことを明らかに。オープンソースコードと公開リーダーボードは、https://github.com/embeddings-benchmark/mteb で利用可能。
[Paper Note] CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks, Oier Mees+, RA-L'22 Best Paper Award, 2021.12
Paper/Blog Link My Issue
#ComputerVision #Evaluation #Robotics #RA-L Issue Date: 2025-11-20 GPT Summary- ロボットが人間と共存する環境で、言語を知覚や行動に関連付けるためのシミュレーションベンチマークCALVINを提案。CALVINは、長期的な言語条件付きタスクを学習し、複雑なロボット操作を人間の言語指示に基づいて解決するエージェントの開発を目指す。ゼロショット評価を行い、既存のモデルが低パフォーマンスであることから、新たなエージェントの開発の可能性を示唆。 Comment
pj page: http://calvin.cs.uni-freiburg.de
[Paper Note] Locating and Editing Factual Associations in GPT, Kevin Meng+, NeurIPS'22
Paper/Blog Link My Issue
#NeurIPS #KnowledgeEditing Issue Date: 2025-08-26 GPT Summary- 自回帰型トランスフォーマー言語モデルにおける事実の関連付けの保存と想起を分析し、局所的な計算に対応することを示した。因果介入を用いて事実予測に関与するニューロンを特定し、フィードフォワードモジュールの役割を明らかにした。Rank-One Model Editing(ROME)を用いて特定の事実の関連付けを更新し、他の方法と同等の効果を確認。新しいデータセットに対する評価でも特異性と一般化を両立できることを示した。中間層のフィードフォワードモジュールが事実の関連付けに重要であり、モデル編集の実行可能性を示唆している。
[Paper Note] LAION-5B: An open large-scale dataset for training next generation image-text models, Christoph Schuhmann+, NeurIPS'22
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #MultiModal #CLIP #NeurIPS #read-later #Selected Papers/Blogs Issue Date: 2025-05-06 GPT Summary- LAION-5Bは、5.85億のCLIPフィルタリングされた画像-テキストペアから成る大規模データセットで、英語のペアが2.32B含まれています。このデータセットは、CLIPやGLIDEなどのモデルの再現とファインチューニングに利用され、マルチモーダルモデルの研究を民主化します。また、データ探索やサブセット生成のためのインターフェースや、コンテンツ検出のためのスコアも提供されます。 Comment
openreview: https://openreview.net/forum?id=M3Y74vmsMcY
[Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22, 2022.07
Paper/Blog Link My Issue
#MachineTranslation #NLP #LowResource #One-Line Notes Issue Date: 2024-09-26 GPT Summary- 低資源言語翻訳を支援するため、母語話者へのインタビューを通じてニーズを明らかにし、新たなデータセットとモデルを開発。Sparsely Gated Mixture of Expertsに基づく条件付き計算モデルを用い、訓練時の過剰適合を抑えつつ性能を向上。Flores-200ベンチマークにより翻訳性能を評価し、BLEUスコアを44%改善。研究成果はオープンソースとして公開。 Comment
low-resourceな言語に対するMTのベンチマーク
[Paper Note] Explaining Patterns in Data with Language Models via Interpretable Autoprompting, Chandan Singh+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #LanguageModel #DataToTextGeneration #Explanation #One-Line Notes #Data Issue Date: 2023-08-03 GPT Summary- iPromptを用いて、事前学習済みのLLMがデータを説明する自然言語文字列を生成する手法を提案。このアルゴリズムは、生成された説明の性能を再評価して最適化するプロセスを含む。実験によりiPromptが正確なデータ記述を見つけ、人間にも解釈可能なプロンプトを生成し、一般化性能に優れることが示された。特に、実世界の感情分類データセットでGPT-3並みのプロンプトを生成し、科学的発見の支援にも寄与する可能性がある。すべてのコードはGitHubで公開。 Comment
OpenReview: https://openreview.net/forum?id=GvMuB-YsiK6
データセット(中に存在するパターンの説明)をLLMによって生成させる研究


[Paper Note] Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor, Or Honovich+, arXiv'22, 2022.12
Paper/Blog Link My Issue
#NLP #InstructionTuning #ACL #needs-revision Issue Date: 2023-07-13 GPT Summary- 指示チューニングを通じて、言語モデルが自然言語の説明から新しいタスクを実行できるようにするため、ほとんど人間の労力を要さずに収集した多様な指示データセット「Unnatural Instructions」を紹介。64,000の例を生成し約240,000例に拡張した実験では、ノイズが多いにもかかわらず、このデータセットでの学習が手動のキュレーションされたデータセットに匹敵し、T0++やTk-Instructよりも優れた性能を示した。これは、クラウドソーシングのコストを抑えたデータセットの拡張手法の有効性を示唆している。
[Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #TMLR #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-07-03 GPT Summary- HELMは、言語モデルの透明性を高めるための包括的評価手法である。まず、潜在的なシナリオと指標の分類を行い、欠落している部分を特定。次に、マルチ指標アプローチを採用し、コアシナリオごとに7つの評価指標を測定することで、正確性以外の側面も考慮。さらに、30の著名な言語モデルに対して大規模評価を実施し、評価範囲を17.9%から96.0%に改善。全データを公開し、HELMをコミュニティの生きたベンチマークとして継続的に更新していくことを目指している。 Comment
OpenReview: https://openreview.net/forum?id=iO4LZibEqW
HELMを提案した研究
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/
[Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #TMLR #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-07-03 GPT Summary- 言語モデルはスケールの拡大に伴い、新しい定量的・質的能力を示すが、その具体的な特性は未解明である。これを踏まえ、BIG-benchという新たなベンチマークを導入し、204の多様なタスクを評価。モデルの性能と較正は改善するが、絶対的には低く、スパース性の影響を受ける場合もある。特に、複数の手順を要するタスクは臨界規模での“ブレークスルー”を示す傾向があり、社会的バイアスは通常、スケールと共に増加するが、プロンプトによって改善可能である。 Comment
OpenReview: https://openreview.net/forum?id=uyTL5Bvosj
BIG-Bench論文。ワードクラウドとキーワード分布を見ると一つの分野に留まらない非常に多様なタスクが含まれることがわかる。
BIG-Bench-hardは、2024年にClaude3.5によって、Average Human Scoreが67.7%のところ、93.1%を達成され攻略が完了した。現在は最先端のモデル間の性能を差別化することはできない。
- Killed by LLM, R0bk
[Paper Note] JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension, ByungHoon So+, arXiv'22, 2022.02
Paper/Blog Link My Issue
#NLP #QuestionAnswering #One-Line Notes Issue Date: 2022-02-07 GPT Summary- 日本語の質問応答データセットJaQuADを提案。39,696の質問-回答ペアを含み、テストセットでF1スコア78.92%、EMスコア63.38%を達成したベースラインモデルをファインチューニング。データセットは公開中。 Comment
SQuAD likeな日本語のQAデータセット
https://github.com/SkelterLabsInc/JaQuAD
[Paper Note] VoxLingua107: a Dataset for Spoken Language Recognition, Jörgen Valk+, SLT'21, 2020.11
Paper/Blog Link My Issue
#SpeechProcessing #AutomaticSpeechRecognition(ASR) #One-Line Notes Issue Date: 2025-11-21 GPT Summary- 本論文では、107言語のYouTube動画から自動収集した音声データを用いて音声言語認識を調査。半ランダムな検索フレーズを用いて音声セグメントを抽出し、ポストフィルタリングにより98%の正確なラベル付けを実現。得られたトレーニングセットは6628時間、評価セットは1609の発話から構成され、実験により自動取得データが手動ラベル付けデータと同等の結果を示すことが確認された。このデータセットは公開されている。 Comment
dataset: https://cs.taltech.ee/staff/tanel.alumae/data/voxlingua107/
Whisperでも活用されているLanguage Identifucation用のdataset
- [Paper Note] Robust Speech Recognition via Large-Scale Weak Supervision, Alec Radford+, ICML'23, 2022.12
[Paper Note] Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction, Reizenstein+, ICCV'21
Paper/Blog Link My Issue
#ComputerVision #Evaluation #ICCV Issue Date: 2025-11-20 GPT Summary- 実世界の3Dオブジェクトカテゴリの学習を促進するため、約19,000本のビデオから150万フレームを含む大規模データセット「Common Objects in 3D」を収集。これにより、合成データセットと同程度の規模の実データを提供。新しいビュー合成と3D再構築手法の評価を行い、少数のビューからオブジェクトを再構築するためのTransformerを用いたニューラルレンダリング手法「NerFormer」を提案。
[Paper Note] ALFWorld: Aligning Text and Embodied Environments for Interactive Learning, Mohit Shridhar+, ICLR'21, 2020.10
Paper/Blog Link My Issue
#MachineLearning #NLP #ReinforcementLearning #Evaluation #EmbodiedAI #text Issue Date: 2025-10-26 GPT Summary- ALFWorldは、エージェントが抽象的なテキストポリシーを学び、視覚環境で具体的な目標を実行できるシミュレーターである。これにより、視覚的環境での訓練よりもエージェントの一般化が向上し、問題を分解して各部分の改善に集中できる設計を提供する。 Comment
openreview: https://openreview.net/forum?id=0IOX0YcCdTn
pj page: https://alfworld.github.io
[Paper Note] DART: Open-Domain Structured Data Record to Text Generation, Linyong Nan+, NAACL'21
Paper/Blog Link My Issue
#NaturalLanguageGeneration #DataToTextGeneration #NAACL Issue Date: 2025-08-30 GPT Summary- DARTは82,000以上のインスタンスを持つオープンドメインの構造化データからテキスト生成のためのデータセットであり、表形式のデータから意味的トリプルを抽出する手法を提案。ツリーオントロジーアノテーションや質問-回答ペアの変換を活用し、最小限のポストエディティングで異種ソースを統合。DARTは新たな課題を提起し、WebNLG 2017での最先端結果を示すことで、ドメイン外の一般化を促進することを証明。データとコードは公開されている。
[Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #CodeGeneration #Selected Papers/Blogs Issue Date: 2025-08-15 GPT Summary- 本論文では、汎用プログラミング言語におけるプログラム合成の限界を大規模言語モデルを用いて評価します。MBPPとMathQA-Pythonの2つのベンチマークで、モデルサイズに対する合成性能のスケールを調査。最も大きなモデルは、少数ショット学習でMBPPの59.6%の問題を解決可能で、ファインチューニングにより約10%の性能向上が見られました。MathQA-Pythonでは、ファインチューニングされたモデルが83.8%の精度を達成。人間のフィードバックを取り入れることでエラー率が半減し、エラー分析を通じてモデルの弱点を明らかにしました。最終的に、プログラム実行結果の予測能力を探るも、最良のモデルでも特定の入力に対する出力予測が困難であることが示されました。 Comment
代表的なコード生成のベンチマーク。
MBPPデータセットは、promptで指示されたコードをモデルに生成させ、テストコード(assertion)を通過するか否かで評価する。974サンプル存在し、pythonの基礎を持つクラウドワーカーによって生成。クラウドワーカーにタスクdescriptionとタスクを実施する一つの関数(関数のみで実行可能でprintは不可)、3つのテストケースを記述するよう依頼。タスクdescriptionは追加なclarificationなしでコードが記述できるよう十分な情報を含むよう記述するように指示。ground truthの関数を生成する際に、webを閲覧することを許可した。
MathQA-Pythonは、MathQAに含まれるQAのうち解答が数値のもののみにフィルタリングしたデータセットで、合計で23914サンプル存在する。pythonコードで与えられた数学に関する問題を解くコードを書き、数値が一致するか否かで評価する、といった感じな模様。斜め読みなので少し読み違えているかもしれない。
[Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #CodeGeneration #Selected Papers/Blogs Issue Date: 2025-08-15 GPT Summary- CodexはGitHubのコードでファインチューニングされたGPT言語モデルで、Pythonコード生成能力を評価。新しい評価セットHumanEvalでは、Codexが28.8%の問題を解決し、GPT-3は0%、GPT-Jは11.4%だった。繰り返しサンプリングが難しいプロンプトに対しても効果的な戦略を用い、70.2%の問題を解決。モデルの限界として、長い操作の説明や変数へのバインドに苦労する点が明らかに。最後に、コード生成技術の影響について安全性や経済に関する議論を行う。 Comment
HumanEvalデータセット。Killed by LLMによると、GPT4oによりすでに90%程度の性能が達成され飽和している。
164個の人手で記述されたprogrammingの問題で、それぞれはfunction signature, docstring, body, unittestを持つ。unittestは問題当たり約7.7 test存在。handwrittenという点がミソで、コンタミネーションの懸念があるためgithubのような既存ソースからのコピーなどはしていない。pass@k[^1]で評価。
[^1]: k個のサンプルを生成させ、k個のサンプルのうち、サンプルがunittestを一つでも通過する確率。ただ、本研究ではよりバイアスをなくすために、kよりも大きいn個のサンプルを生成し、その中からランダムにk個を選択して確率を推定するようなアプローチを実施している。2.1節を参照のこと。
[Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Mathematics #Selected Papers/Blogs #Verification #needs-revision Issue Date: 2024-12-27 GPT Summary- 最先端の言語モデルは数学的推論に課題があり、GSM8Kという8,500件の小学生向け数学問題データセットを導入してその失敗を診断。特に、最大規模のトランスフォーマーモデルでも性能向上が難しいことを示す。モデルの補完の正しさを評価する検証器を訓練し、候補解を生成して最も高く評価されたものを選択する方法を提案。検証がGSM8Kの性能を大幅に向上させ、ファインチューニングよりも効果的にスケールすることを実証。 Comment
## 気持ち
- 当時の最も大きいレベルのモデルでも multi-stepのreasoningが必要な問題は失敗する
- モデルをFinetuningをしても致命的なミスが含まれる
- 特に、数学は個々のミスに対して非常にsensitiveであり、一回ミスをして異なる解法のパスに入ってしまうと、self-correctionするメカニズムがauto-regressiveなモデルではうまくいかない
- 純粋なテキスト生成の枠組みでそれなりの性能に到達しようとすると、とんでもないパラメータ数が必要になり、より良いscaling lawを示す手法を模索する必要がある
## Contribution
論文の貢献は
- GSM8Kを提案し、
- verifierを活用しモデルの複数の候補の中から良い候補を選ぶフレームワークによって、モデルのパラメータを30倍にしたのと同等のパフォーマンスを達成し、データを増やすとverifierを導入するとよりよく性能がスケールすることを示した。
- また、dropoutが非常に強い正則化作用を促し、finetuningとverificationの双方を大きく改善することを示した。
Todo: 続きをまとめる
SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #Tools #NLP #Evaluation #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-08-13 Comment
自動評価指標が人手評価の水準に達しないことが示されており、結局のところROUGEを上回る自動性能指標はほとんどなかった。human judgmentsとのKendall;'s Tauを見ると、chrFがCoherenceとRelevance, METEORがFluencyで上回ったのみだった。また、LEAD-3はやはりベースラインとしてかなり強く、LEAD-3を上回ったのはBARTとPEGASUSだった。
[Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #LanguageModel #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration #ACL #Surface-level Notes Issue Date: 2023-05-31 GPT Summary- この論文では、ユーザーの興味とニュース本文に基づいて、ユーザー固有のタイトルを生成するパーソナライズされたニュース見出し生成の問題を解決するためのフレームワークを提案します。また、この問題のための大規模なデータセットであるPENSを公開し、ベンチマークスコアを示します。データセットはhttps://msnews.github.io/pens.htmlで入手可能です。 Comment
# 概要
ニュース記事に対するPersonalizedなHeadlineの正解データを生成。103名のvolunteerの最低でも50件のクリックログと、200件に対する正解タイトルを生成した。正解タイトルを生成する際は、各ドキュメントごとに4名異なるユーザが正解タイトルを生成するようにした。これらを、Microsoft Newsの大規模ユーザ行動ログデータと、ニュース記事本文、タイトル、impressionログと組み合わせてPENSデータを構成した。
# データセット生成手順
103名のenglish-native [speakerの学生に対して、1000件のニュースヘッドラインの中から最低50件興味のあるヘッドラインを選択してもらう。続いて、200件のニュース記事に対して、正解ヘッドラインを生成したもらうことでデータを生成した。正解ヘッドラインを生成する際は、同一のニュースに対して4人がヘッドラインを生成するように調整した。生成されたヘッドラインは専門家によってqualityをチェックされ、factual informationにエラーがあるものや、極端に長い・短いものなどは除外された。
# データセット統計量
# 手法概要
Transformer Encoder + Pointer GeneratorによってPersonalizedなヘッドラインを生成する。
Transformer Encoderでは、ニュースの本文情報をエンコードし、attention distributionを生成する。Decoder側では、User Embeddingを組み合わせて、テキストをPointer Generatorの枠組みでデコーディングしていき、ヘッドラインを生成する。
User Embeddingをどのようにinjectするかで、3種類の方法を提案しており、1つ目は、Decoderの初期状態に設定する方法、2つ目は、ニュース本文のattention distributionの計算に利用する方法、3つ目はデコーディング時に、ソースからvocabをコピーするか、生成するかを選択する際に利用する方法。1つ目は一番シンプルな方法、2つ目は、ユーザによって記事で着目する部分が違うからattention distributionも変えましょう、そしてこれを変えたらcontext vectorも変わるからデコーディング時の挙動も変わるよねというモチベーション、3つ目は、選択するvocabを嗜好に合わせて変えましょう、という方向性だと思われる。最終的に、2つ目の方法が最も性能が良いことが示された。
# 訓練手法
まずニュース記事推薦システムを訓練し、user embeddingを取得できるようにする。続いて、genericなheadline generationモデルを訓練する。最後に両者を組み合わせて、Reinforcement LearningでPersonalized Headeline Generationモデルを訓練する。Rewardとして、
1. Personalization: ヘッドラインとuser embeddingのdot productで報酬とする
2. Fluency: two-layer LSTMを訓練し、生成されたヘッドラインのprobabilityを推定することで報酬とする
3. Factual Consistency: 生成されたヘッドラインと本文の各文とのROUGEを測りtop-3 scoreの平均を報酬とする
とした。
1,2,3の平均を最終的なRewardとする。
# 実験結果
Genericな手法と比較して、全てPersonalizedな手法が良かった。また、手法としては②のattention distributionに対してuser informationを注入する方法が良かった。News Recommendationの性能が高いほど、生成されるヘッドラインの性能も良かった。
# Case Study
ある記事に対するヘッドラインの一覧。Pointer-Genでは、重要な情報が抜け落ちてしまっているが、提案手法では抜け落ちていない。これはRLの報酬のfluencyによるものだと考えられる。また、異なるユーザには異なるヘッドラインが生成されていることが分かる。
[Paper Note] ニュース記事に対する談話構造と興味度のアノテーション ~ニュース対話システムのパーソナライズに向けて~, 高津+, NLP'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Personalization Issue Date: 2023-04-30 Comment
ニュース記事に対して談話構造および,ユーザのプロフィールと記事の話題・文に対するユーザの興味度を付与したデータセット。
プロフィールとして以下を収集:
- 性別
- 年齢,
- 住んでいる地域
- 職種
- 業種
- ニュースを見る頻度,
- ニュースをよくチェックする時間帯
- 映像・音声・文字のうちニュースへの接触方法として多いものはどれか
- ニュースを知る手段
- ニュースを読む際使用している新聞やウェブサイト・アプリ
- 有料でニュースを読んでいるか
- 普段積極的に読む・見る・聞くニュースのジャンル
- ニュースのジャンルに対する興味の程度,趣味.
[Paper Note] Biomedical Data-to-Text Generation via Fine-Tuning Transformers, Ruslan Yermakov+, ACL-INLG'21, 2021.09
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #ACL #INLG #One-Line Notes Issue Date: 2022-08-18 GPT Summary- バイオメディカル分野におけるD2T生成の研究を行い、医薬品のパッケージリーフレットを用いた実世界のデータセットに対してファインチューニングされたトランスフォーマーを適用。現実的な複数文のテキスト生成が可能であることを示す一方で、重要な制限も存在。新たにバイオメディカル分野のD2T生成モデルのベンチマーク用データセット(BioLeaflets)を公開。 Comment
biomedical domainの新たなdata2textデータセットを提供。事前学習済みのBART, T5等をfinetuningすることで高精度にテキストが生成できることを示した。
[Paper Note] WikiAsp: A Dataset for Multi-domain Aspect-based Summarization, Hiroaki Hayashi+, TACL'21, 2020.11
Paper/Blog Link My Issue
#DocumentSummarization #Tutorial #NLP #TACL #KeyPoint Notes Issue Date: 2021-10-20 GPT Summary- オープンドメインのアスペクトベース要約のために、20の異なるドメインのWikipedia記事を用いたマルチドメイン対応データセットWikiAspを提案。各記事のセクションタイトルをアスペクト注釈の指標とし、実験を通じて既存モデルの主要な課題を明らかにした。 Comment
NLPコロキウムをリアルタイムに聴講
◆Aspect-based summarizationのモチベーション
・same source対して、異なるユーザニーズが存在するので、ニーズに関して要約したい
◆Aspect: あるobjectに対する、attributeのようなものを指定?
object: Attention Is All You Need
aspect: Multi-Head Attention
◆Aspect Based Summarizationの歴史
・はじめは”feature”という文言で研究され(04年頃?)
・続いて*keywords*という単語で研究され
・その後Aspectという文言で研究されるようになった
・2008年頃にMcDonaldsらがAspect-Based Summarizationを提案した
・2014年以後?とかにNeural Basedな手法が盛んに研究
◆WikiAspデータセットについて
・Wikipediaを使ったAspect-based dataset
・Wikipediaを書かれるのに利用されたsource document(wikipediaにソースとして引用されているもの)に対し、aspectを各節の見出しとみなし、節のテキストを要約文とみなすことで、データセット生成
・他のAspect-basedデータセットと異なり、ソースデータが長く、要約長も5~6倍程度
・ドメイン数が他データセットは5,6程度に対し、20と膨大
◆ベースラインとして2-stageモデルを採用
first-stage: ソーステキストからROBERTaベースドなclassifierを用いて、sentencesから内包するAspectを閾値を用いて決定
それらをgrouped sentencesとする
two-stage: 各aspectごとにまとまったテキスト集合に対して、要約モデルを適用し、要約を実施する
・要約モデルはUnsupervisedな手法であるTextRankと、Supervisedな手法であるBERTベースな手法を採用
・ドメインごとに評価した結果を見ると、BERTが強いドメインがある一方で、TextRankが強いドメインもあった
-> Extractiveな形で要約されているドメインではTextRankが強く、Abstractiveに要約されているドメインではBERTが強い
-> またBERTは比較的短い要約であればTextRankよりもはるかに良いが、長い要約文になるとTextRankとcomprable(あるいはTextRankの方が良い)程度の性能になる
・ROUGE-2の値がsentence-basedなORACLEを見た時に、他データセットと比較して低いので、Abstractiveな手法が必要なデータセット?
(後からのメモなので少しうろ覚えな部分あり)
Q. ROUGE-2が30とかって直観的にどのくらいのレベルのものなの?ROUGE-2が30とか40とかは高い
・最先端の要約モデルをニュース記事に適用すると、35~40くらいになる。
・このレベルの数値になると、人間が呼んでも違和感がないレベルの要約となっている
Q. 実際に要約文をチェックしてみて、どういう課題を感じるか?
A. Factual Consistencyがすぐに目につく問題で、特にBERTベースな要約文はそう。TextRankはソース文書がノイジーなので、ソース文章を適当に拾ってきただけではFactual Consistencyが良くない(元の文書がかっちりしていない)。流暢性の問題はAbstractiveモデルだと特に問題なくBERT-baseでできる。Aspect-based要約のエラー例としてAspectに則っていないということがある。たとえばオバマの大統領時代の話をきいているのに、幼少時代の話をしているとか。Aspect情報をうまくモデルを扱えていないという点が課題としてある。
出典元(リアルタイムに聴講): 第13回 WikiAsp: A Dataset for Multi-domain Aspect-based Summarization, NLPコロキウム
https://youtu.be/3PIJotX6i_w?si=hX5pXwNL-ovkGSF5
[Paper Note] BLiMP: The Benchmark of Linguistic Minimal Pairs for English, Alex Warstadt+, TACL'20
Paper/Blog Link My Issue
#NLP #Evaluation #TACL #Grammar Issue Date: 2025-09-07 GPT Summary- 言語的最小対のベンチマーク(BLiMP)は、言語モデルの文法知識を評価するためのチャレンジセットで、67のサブデータセットから成り、各サブデータセットには特定の文法対比を示す1000の最小対が含まれています。データは専門家によって自動生成され、人間の合意は96.4%です。n-gram、LSTM、Transformerモデルを評価した結果、最先端のモデルは形態論的対比を識別できるが、意味的制約や微妙な文法現象には苦戦していることが示されました。 Comment
先行研究と比較して、より広範なlinguistic phenomenaを扱い、かつ大量のサンプルを集めた英語のacceptable/unacceptableなsentenceのペアデータ。ペアデータは特定のlinguistic phenomenaをacceptable/unacceptableに対比するための最小の違いに基づいており専門家が作成したテンプレートに基づいて自動生成され、クラウドソーシングによって人手でvalidationされている。言語モデルが英語のlinguistic phenomenaについて、どの程度理解しているかのベンチマークに利用可能。
[Paper Note] CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning, Bill Yuchen Lin+, EMNLP'20 Findings
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Evaluation #Composition #EMNLP #Findings #CommonsenseReasoning Issue Date: 2025-07-31 GPT Summary- 生成的常識推論をテストするためのタスクCommonGenを提案し、35,000の概念セットに基づく79,000の常識的記述を含むデータセットを構築。タスクは、与えられた概念を用いて一貫した文を生成することを求め、関係推論と構成的一般化能力が必要。実験では、最先端モデルと人間のパフォーマンスに大きなギャップがあることが示され、生成的常識推論能力がCommonsenseQAなどの下流タスクに転送可能であることも確認。 Comment
ベンチマークの概要。複数のconceptが与えられた時に、それらconceptを利用した常識的なテキストを生成するベンチマーク。concept間の関係性を常識的な知識から推論し、Unseenなconceptの組み合わせでも意味を構成可能な汎化性能が求められる。
PJ page: https://inklab.usc.edu/CommonGen/
[Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #ICLR #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-07-24 GPT Summary- 新しいテストを提案し、57のマルチタスクを用いてテキストモデルの正確度を測定。高い正確度には広範な世界知識と問題解決能力が必要である。GPT-3モデルはランダム推測を約20ポイント上回るが、専門家レベルには遠く、多くのタスクで偏った性能を示す。特に道徳や法に関してはほぼランダムに近い正確度を記録。このテストはモデルの理解力を評価し、重要な欠点を明らかにすることを目的とする。 Comment
OpenReview: https://openreview.net/forum?id=d7KBjmI3GmQ
MMLU論文
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
において、多くのエラーが含まれることが指摘され、再アノテーションが実施されている。
[Paper Note] ReFusion: 3D Reconstruction in Dynamic Environments for RGB-D Cameras Exploiting Residuals, Emanuele Palazzolo+, IROS'19, 2019.05
Paper/Blog Link My Issue
#ComputerVision #Evaluation #Robotics #IROS Issue Date: 2025-11-20 GPT Summary- 動的要素を含むシーンのマッピングとローカリゼーションのために、RGB-Dセンサーを用いた新しいアプローチを提案。TSDFに基づく効率的なトラッキングを行い、色情報を利用してセンサーのポーズを推定。動的要素の検出には残差と自由空間のモデリングを活用。実験により、提案手法が最先端の密SLAM手法を上回る性能を示し、データセットも公開。オープンソースコードも提供。
Natural Questions: A Benchmark for Question Answering Research, Kwiatkowski+, TACL'19
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Evaluation #Factuality #ReadingComprehension Issue Date: 2025-08-16 GPT Summary- Natural Questionsコーパスは、Google検索エンジンからの実際の匿名化されたクエリを基にした質問応答データセットで、307,373のトレーニング例と7,830の開発例、7,842のテスト例が含まれています。アノテーターは、質問に対してWikipediaページから長い回答と短い回答を注釈し、質の検証実験や人間の変動性に関する分析を行っています。また、質問応答システムの評価のためのメトリクスを導入し、競争的手法を用いてベースライン結果を確立しています。
[Paper Note] Stereo Magnification: Learning View Synthesis using Multiplane Images, Tinghui Zhou+, SIGGRAPH'18, 2018.05
Paper/Blog Link My Issue
#ComputerVision #Evaluation #SIGGRAPH Issue Date: 2025-11-20 GPT Summary- 視点合成問題において、狭ベースラインのステレオカメラから新しい視点を生成する手法を提案。マルチプレーン画像(MPI)を用いた学習フレームワークを構築し、YouTube動画をデータソースとして活用。これにより、入力画像ペアからMPIを予測し、従来の手法よりも優れた視点外挿を実現。 Comment
[Paper Note] TextWorld: A Learning Environment for Text-based Games, Marc-Alexandre Côté+, Workshop on Computer Games'18 Held in Conjunction with IJCAI'18, 2018.06
Paper/Blog Link My Issue
#MachineLearning #NLP #ReinforcementLearning #Evaluation #IJCAI #Workshop #Game #text Issue Date: 2025-10-26 GPT Summary- TextWorldは、テキストベースのゲームにおける強化学習エージェントのトレーニングと評価のためのサンドボックス環境であり、ゲームのインタラクティブなプレイを処理するPythonライブラリを提供します。ユーザーは新しいゲームを手作りまたは自動生成でき、生成メカニズムによりゲームの難易度や言語を制御可能です。TextWorldは一般化や転移学習の研究にも利用され、ベンチマークゲームのセットを開発し、いくつかのベースラインエージェントを評価します。 Comment
[Paper Note] Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge, Peter Clark+, arXiv'18
Paper/Blog Link My Issue
#NLP #QuestionAnswering Issue Date: 2025-08-30 GPT Summary- AI2 Reasoning Challenge(ARC)を提案し、高度な質問応答におけるAI研究を促進することを目的とする。ARCはChallenge SetとEasy Setに分かれ、Challenge Setにはリトリーバルベースのアルゴリズムで不正解とされた質問が含まれる。ARCは最大の公的ドメインセットであり、1400万の科学文を含むコーパスと3つのニューラルベースラインモデルの実装も公開。既存のモデルはランダムベースラインを上回れず、コミュニティへの挑戦としてARCを提起。 Comment
dataset:
https://huggingface.co/datasets/allenai/ai2_arc
日本語解説:
https://qiita.com/tekunikaruza_jp/items/d2ec3621afc9ba3d225b
Learning to Generate Move-by-Move Commentary for Chess Games from Large-Scale Social Forum Data, Jhamtani+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #TabularData #ACL #Encoder-Decoder Issue Date: 2025-08-06 Comment
データセットの日本語解説(過去の自分の資料): https://speakerdeck.com/akihikowatanabe/data-to-text-datasetmatome-summary-of-data-to-text-datasets?slide=66
[Paper Note] Newsroom: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies, Max+, NAACL'18
Paper/Blog Link My Issue
#DocumentSummarization #NLP #NAACL #KeyPoint Notes Issue Date: 2018-06-29 GPT Summary- NEWSROOMは、38の主要なニュース出版物から収集された130万件の記事と要約のデータセットで、1998年から2017年のメタデータを基にしています。要約は、抽象的および抽出的な戦略を組み合わせており、その多様性を示しています。本研究では、NEWSROOMの抽出戦略を他データセットと比較し、新たなデータの多様性と難易度を評価しました。また、既存の手法を用いてデータ上で訓練し、その有用性と課題を明らかにしました。このデータセットはsummari.esで公開されています。 Comment
文書要約に使用可能なデータセット
38の出版元からデータを収集し、サイズは1.3M article程度
既存のデータセットと比較すると、Coverageが高く生成的なものを多く含むことが特徴
詳細は:
https://summari.es
[Paper Note] Tanks and temples: Benchmarking large-scale scene reconstruction, Knapitsch+, TOG'17
Paper/Blog Link My Issue
#ComputerVision #Evaluation #TOG Issue Date: 2025-11-20 GPT Summary- 画像ベースの3D再構築のための新しいベンチマークを提案。実際の条件下で取得された高解像度ビデオシーケンスを用い、産業用レーザースキャナーでキャプチャしたグラウンドトゥルースデータを含む。屋外と屋内のシーンを対象に、再構築の忠実度向上を目指す新しいパイプラインの開発を支援し、既存の3D再構築手法の性能を報告。結果は今後の研究の課題と機会を示唆。
[Paper Note] A Multi-view Stereo Benchmark with High-Resolution Images and Multi-camera Videos, Schöps+, CVPR'17
Paper/Blog Link My Issue
#ComputerVision #Evaluation #CVPR Issue Date: 2025-11-20 GPT Summary- 新しいマルチビュー立体視データセットを提案し、高精度のレーザースキャナーと低解像度のステレオビデオを用いて多様なシーンを記録。幾何学に基づく手法で画像とレーザースキャンを整合。従来のデータセットとは異なり、自然および人工環境をカバーし、高解像度のデータを提供。データセットは手持ちのモバイルデバイスの使用ケースにも対応し、オンライン評価サーバーで利用可能。
[Paper Note] ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes, Angela Dai+, CVPR'17, 2017.02
Paper/Blog Link My Issue
#ComputerVision #Evaluation #CVPR Issue Date: 2025-11-20 GPT Summary- 限られたRGB-Dシーン理解のために、1513シーンの2.5Mビューを含むScanNetデータセットを導入。自動表面再構築とクラウドソースによるセマンティックアノテーションを用いたキャプチャシステムを設計し、3Dオブジェクト分類やセマンティックボクセルラベリングで最先端のパフォーマンスを達成。データセットは無料で提供。
[Paper Note] Zero-Shot Relation Extraction via Reading Comprehension, Omer Levy+, CoNLL'17, 2017.06
Paper/Blog Link My Issue
#NeuralNetwork #InformationExtraction #ReadingComprehension #Zero/FewShotLearning #CoNLL #KnowledgeEditing #FactualKnowledge #RelationExtraction Issue Date: 2025-08-26 GPT Summary- 関係抽出を自然言語の質問に還元することで、ニューラル読解理解技術を活用し、大規模なトレーニングセットを構築可能にする。これにより、ゼロショット学習も実現。ウィキペディアのスロットフィリングタスクで、既知の関係タイプに対する高精度な一般化と未知の関係タイプへのゼロショット一般化が示されたが、後者の精度は低く、今後の研究の基準を設定。 Comment
Knowledge Editingのベンチマークとしても利用される
[Paper Note] TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension, Mandar Joshi+, ACL'17
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Factuality #ReadingComprehension Issue Date: 2025-08-16 GPT Summary- TriviaQAは、650K以上の質問-回答-証拠トリプルを含む読解理解データセットで、95Kの質問-回答ペアと平均6つの証拠文書を提供。複雑な質問や構文的変動があり、文を超えた推論が必要。特徴ベースの分類器と最先端のニューラルネットワークの2つのベースラインアルゴリズムを評価したが、人間のパフォーマンスには及ばず、TriviaQAは今後の研究における重要なテストベッドである。
[Paper Note] NewsQA: A Machine Comprehension Dataset, Adam Trischler+, RepL4NLP'17, 2016.11
Paper/Blog Link My Issue
#NLP #QuestionAnswering #ReadingComprehension #KeyPoint Notes #needs-revision Issue Date: 2023-11-19 GPT Summary- NewsQAは10万件以上の人間生成の質問・回答ペアからなる機械読解データセットで、CNNの10,000件以上のニュース記事を基にクラウドワーカーによって構築されました。データセットは、推論を必要とする探索的な質問を引き出す4段階プロセスで収集され、単純な語彙一致やテキスト含意を超えた能力が要求されます。人間のパフォーマンスと強力なニューラルモデルとの比較により、F1でのパフォーマンス差(0.198)が示され、将来の研究における顕著な進歩の可能性を示唆しています。データセットは自由に利用可能です。 Comment
SQuADよりも回答をするために複雑な推論を必要とするQAデータセット。規模感はSQuADと同等レベル。
WordMatchingにとどまらず、回答が存在しない、あるいは記事中でユニークではないものも含まれる。
[Paper Note] Construction of a Japanese Word Similarity Dataset, Yuya Sakaizawa+, arXiv'17, 2017.03
Paper/Blog Link My Issue
#Embeddings #NLP #RepresentationLearning #STS (SemanticTextualSimilarity) #Japanese #One-Line Notes Issue Date: 2023-07-31 GPT Summary- 日本語の分散表現評価のために、語の類似度データセットを構築。これが日本語分散表現評価の初の資源であり、一般語と稀少語の両方を含む様々な品詞を網羅。 Comment
github:
https://github.com/tmu-nlp/JapaneseWordSimilarityDataset
単語レベルの類似度をベンチマーキングしたい場合は使ってもよいかも。
[Paper Note] Characterizing Online Discussion Using Coarse Discourse Sequences, Zhang+, ICWSM'17, (Reddit Coarse Discourse data), 2017.05
Paper/Blog Link My Issue
#NLP #Discourse #ICWSM #KeyPoint Notes Issue Date: 2018-01-19 Comment
RedditのDiscussion Forumに9種類のDiscourse Actsを付与したデータ。
データを作成する際は、以下の処理を適用:
* Google Big Query dump のRedditデータ238Mスレッド
* それにReply Filterをかけ87.5Mスレッド
* さらにそこからスレッドサンプリングやヒューリスティクなフィルタをかけて10000スレッドに絞り込んだ
* これらにDiscourse Actsが付与されており、それぞれのコメントに対して9種類のカテゴリ(QUESTION(質問), ANSWER(回答), ANNOUNCEMENT(情報発信), AGREEMENT(意見に対する同意, APPRECIATION (感謝)など)が付与されている。
コーパスを作成するときは、3人のアノテータを用い、複数のACTを付与することを許し、OTHERも許容。
Discourse Actsをどれだけ判定できるかのモデルも構築しており、loggistic regression + L2 regularization, Hidden Markov Model, Conditional Random Fieldsなどを用い、素性はContent-based (unigram, bigram, tf-idfなど), Structure-based (treeのdepth, # of sentencde, wordなど), Author-based (一番最初の投稿者と同じか、親と同じ投稿者かなど), Community (subreddit name (カテゴリ名))などを用いている。
CRFを適用する際は、スレッドのTreeのブランチを系列とみなす。基本的にCRFが一番よく、F値で0.75程度。
[Paper Note] Large-Scale Data for Multiple-View Stereopsis, Aanæs+, IJCV'16
Paper/Blog Link My Issue
#ComputerVision #Evaluation #IJCV Issue Date: 2025-11-20
[Paper Note] Neural Text Generation from Structured Data with Application to the Biography Domain, Remi Lebret+, EMNLP'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #ConceptToTextGeneration #EMNLP #Encoder-Decoder #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 大規模なWikipediaの伝記データセットを用いて、テキスト生成のためのニューラルモデルを提案。モデルは条件付きニューラル言語モデルに基づき、固定語彙とサンプル固有の単語を組み合わせるコピーアクションを採用。提案モデルは古典的なKneser-Neyモデルを約15 BLEUポイント上回る性能を示した。 Comment
Wikipediaの人物に関するinfo boxから、その人物のbiographyの冒頭を生成するタスク。
Neural Language Modelに、新たにTableのEmbeddingを入れられるようにtable embeddingを提案し、table conditioned language modelを提案している。
inputはテーブル(図中のinput textっていうのは、少し用語がconfusingだが、言語モデルへのinputとして、過去に生成した単語の系列を入れるというのを示しているだけ)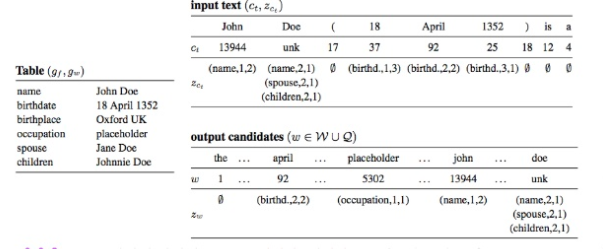
モデル全体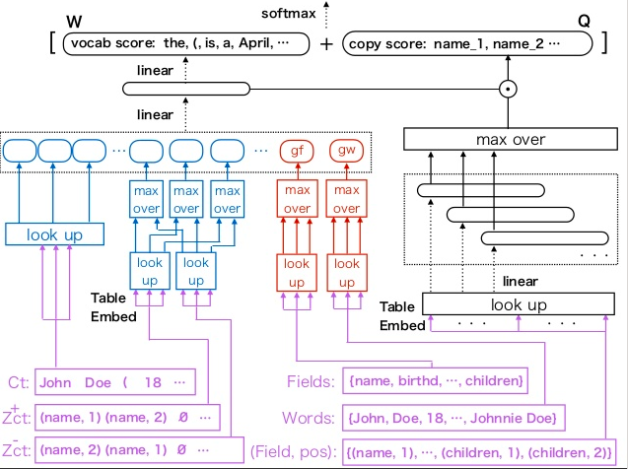
Wikipediaから生成した、Biographyに関するデータセットも公開している。
template basedなKNSmoothingを使ったベースラインよりも高いBLEUスコアを獲得。さらに、テーブルのGlobalな情報を入れる手法が、性能向上に寄与(たとえばチーム名・リーグ・ポジションなどをそれぞれ独立に見ても、バスケットボールプレイヤーなのか、ホッケープレイヤーなのかはわからないけど、テーブル全体を見ればわかるよねという気持ち)。
[Paper Note] LCSTS: A Large Scale Chinese Short Text Summarization Dataset, Baotian Hu+, EMNLP'15, 2015.06
Paper/Blog Link My Issue
#Single #DocumentSummarization #NeuralNetwork #Sentence #Document #NLP #Abstractive #EMNLP #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 GPT Summary- 中国のマイクロブログSina Weiboから構築した200万以上の短文とその要約からなる大規模コーパスを紹介。手動でタグ付けされた10,666の要約を用いて、再帰型ニューラルネットワークを導入し、有望な要約生成結果を達成。提案コーパスは短文要約研究に有用であり、さらなる研究のベースラインを提供。 Comment
Large Chinese Short Text Summarization (LCSTS) datasetを作成
データセットを作成する際は、Weibo上の特定のorganizationの投稿の特徴を利用。
Weiboにニュースを投稿する際に、投稿の冒頭にニュースのvery short summaryがまず記載され、その後ニュース本文(短め)が記載される特徴があるので、この対をsource-reference対として収集した。
収集する際には、約100個のルールに基づくフィルタリングやclearning, 抽出等を行なっている。
データセットのpropertyとしては、下記のPartI, II, IIIに分かれている。
PartI: 2.4Mのshort text - summary pair
PartII: PartIからランダムにサンプリングされた10kのpairに対して、5 scaleで要約のrelevanceをratingしたデータ。ただし、各pairにラベルづけをしたevaluatorは1名のみ。
PartIII: 2kのpairに対して(PartI, PartIIとは独立)、3名のevaluatorが5-scaleでrating。evaluatorのratingが一致した1kのpairを抽出したデータ。
RNN-GRUを用いたSummarizerも提案している。
CopyNetなどはLCSTSを使って評価している。他にも使ってる論文あったはず。
ACL'17のPointer Generator Networkでした。
[Paper Note] Query-Chain Focused Summarization, Baumel+, ACL'14
Paper/Blog Link My Issue
#Multi #DocumentSummarization #NLP #QueryBiased #Extractive #ACL #Selected Papers/Blogs #Surface-level Notes Issue Date: 2017-12-28 Comment
(管理人が作成した過去の紹介資料)
[Query-Chain Focused Summarization.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1590916/Query-Chain.Focused.Summarization.pdf)
上記スライドは私が当時作成した論文紹介スライドです。スライド中のスクショは説明のために論文中のものを引用しています。
[Paper Note] Scene Coordinate Regression Forests for Camera Relocalization in RGB-D Images, Shotton+, CVPR'13
Paper/Blog Link My Issue
#ComputerVision #Evaluation #CVPR #CameraPoseEstimation Issue Date: 2025-11-20
[Paper Note] Scene Coordinate Regression Forests for Camera Relocalization in RGB-D Images,Shotton+, CVPR'13
Paper/Blog Link My Issue
#ComputerVision #Evaluation #CVPR Issue Date: 2025-11-20
[Paper Note] Indoor Segmentation and Support Inference from RGBD Images, Silberman+, ECCV'12
Paper/Blog Link My Issue
#ComputerVision #Evaluation #ECCV Issue Date: 2025-11-20 GPT Summary- RGBD画像を用いて、散らかった屋内シーンの主要な表面や物体、支持関係を解析するアプローチを提案。物理的相互作用を考慮し、3Dの手がかりが構造化された解釈に与える影響を探求。新たに1449のRGBD画像からなるデータセットを作成し、支持関係の推測能力を実験で検証。3D手がかりと推測された支持が物体セグメンテーションの向上に寄与することを示す。
[Paper Note] A naturalistic open source movie for optical flow evaluation, Butler+, ECCV'12
Paper/Blog Link My Issue
#ComputerVision #Evaluation #ECCV Issue Date: 2025-11-20 Comment
dataset: https://www.kaggle.com/datasets/artemmmtry/mpi-sintel-dataset
[Paper Note] ImageNet: A Large-Scale Hierarchical Image Database, Deng+, CVPR'09
Paper/Blog Link My Issue
#ComputerVision #Selected Papers/Blogs #ImageClassification #ObjectRecognition #ObjectLocalization Issue Date: 2025-05-13
stack-v3-full, HuggingFaceCode, 2026.07
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Blog #Coding #Selected Papers/Blogs #reading #One-Line Notes #Author Thread-Post Issue Date: 2026-07-24 Comment
元ポスト:
114 TB, 770言語, 224Mリポジトリ, 約5Tトークンの重複除去やフィルタリング済みGithubから収集されたソースコードで、制限付きライセンスのコードは一切含まないデータセット。V2では2023年時点のスナップショットに基づいており、V3は2025年8月時点までのスナップショットとのこと。たとてば、C++は15倍、TypeScript は7.5倍、Rustは7倍、Pythonは4.8倍程度のトークンがあるらしい。全体としては8.9倍のトークン量。
また、V2ではdeduplicationにおいて正規表現にバグがあったようで、そちらも修正されているようである。
Stack V2:
- [Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
所見:
Separating signal from noise in coding evaluations, OpenAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Blog #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-07-09 Comment
元ポスト:
SWE-Bench Proの約30%にタスクが評価として機能しないタスクが含まれているとのこと(SWE-Bench Verifiedと同じ流れでは)。
これらは、5人の熟練なソフトウェアエンジニアによる監査と、AI Agentによる監査結果を人間がレビューするプロセスの2つを介して同定された。
以下のようなものがある:
- 過剰に制約されたテスト: 実装の制約が強すぎて機能として正しいのにテストが通らず、かつプロンプトでその制約が明示されていない
- requlrementが不足したテスト: プロンプトでの推測することができない要件の漏れ
- 低カバレッジのテスト: 実装が不完全でも通過するテスト
- ミスリーディングなプロンプト: テストが求める要件とは異なる挙動に向かわせるプロンプト
これにより、OpenAIは以前SWE Bench Proを推奨していたがそれを撤回するとのこと。
SWE Bench Verifiedでも同様の事案があった:
- Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
そしてSWE Bench Verifiedにおけるコンタミネーションやテストの問題点を改善したSWE Bench Proを構築した、という経緯だったはずだが、そのSWE Bench Proでも問題が見つかったという流れである。
あと、そもそもSWE Bench Proで問題のなかった70%で評価したら現在のモデルのスコアはどうなるのだろうか?
80TB+ of astronomy for the HDD-poor: crossmatch the Multimodal Universe from your laptop, Mike Smith, 2026.06
Paper/Blog Link My Issue
#Article #One-Line Notes #Author Thread-Post Issue Date: 2026-07-08 Comment
元ポスト:
30以上の断片化されたデータソースに基づいて、ソース間を相互参照可能な形式(同じ天体に対して異なる観測をした場合などが該当するようで、以前は紐付けに大規模な計算機リソースが必要、かつ異なる保存形式やフォーマットなどの対応を取る必要があった)にした80TB超の銀河画像やスペクトル、時系列データ、測定値などを含む天文学データとのこと
CS2-10k: A Large-Scale Egocentric Counter-Strike 2 Dataset, Reka Labs, 2026.06
Paper/Blog Link My Issue
#Article #ComputerVision #WorldModels #Initial Impression Notes Issue Date: 2026-07-07 Comment
Counter-Strikeのプロレベルの試合に基づいた、1万時間以上一人称視点の映像と、フレームごとのannotation(キーボード操作状態、マウス移動の軌跡、プレイヤーの移動経路等)を含むデータセットのようである。
映像だけでなく、annotationが付与されている点が有用。
元ポスト:
日本語エージェントベンチマーク「J-tau telecom」の公開, SB Intuitions, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Japanese #Author Thread-Post Issue Date: 2026-06-20 Comment
元ポスト:
ZONOS2: Real-time TTS with High-Fidelity Voice Cloning, ZYPHRA, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Evaluation #SpeechProcessing #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) #TTS #Realtime #Author Thread-Post Issue Date: 2026-06-15 Comment
元ポスト:
DeepSWE: Measuring frontier coding agents on original, long-horizon engineering tasks, DeepSWE, 2026.05
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs #One-Line Notes #LongHorizon #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
所見:
既存のベンチマークのような、githubのPRに基づいたものではなく(memorizationの問題があるため)、ゼロベースで構築。rolloutのtrajectoryを分析して、有効なPRなのに拒否する、あるいは何らかのcheatingをするといった挙動のdetectionもできるとのこと。また、SWE Bench Proと比較して、タスクを解くためのpromptは1/2である一方、タスクを解くために必要なコードの量は5.5倍となっており、より複雑なタスクとなっている。
contamination-freeが主張されているが、データセットは公開されているので、そのうちcontaminationが生じるであろう点には注意。
AgentTrove, open-thoughts, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #Mathematics #SoftwareEngineering #ComputerUse #One-Line Notes Issue Date: 2026-05-06 Comment
元ポスト:
219のデータソースに対する170M規模のcoding, terminal/computer use, mathに関するagentのtrajectory。trace自体は、Agentic HarnessとしてTerminus 2を用いたOpenThinker-Agent-v1によるものだと推察される。
Building a Fast Multilingual OCR Model with Synthetic Data, Nvidia, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #SyntheticData #MultiLingual #OCR #Initial Impression Notes Issue Date: 2026-04-25 Comment
元ポスト:
日本語サンプルも全6ヶ国語中全体の17%含まれておりかなり含まれているOCRモデル学習用の合成データとモデル
model:
https://huggingface.co/nvidia/nemotron-ocr-v2
data:
https://huggingface.co/datasets/nvidia/OCR-Synthetic-Multilingual-v1
スループットが非常に高い
FrontierSWE: Benchmarking coding agents at the limits of human abilities, FrontierSWE, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #SoftwareEngineering #One-Line Notes #LongHorizon #Author Thread-Post Issue Date: 2026-04-17 Comment
元ポスト:
WAN2.1の推論パイプライン構築、llmのpost-trainingをしてlogic gameができるように学習させる、など、long horizonかつ非常に現実的なタスクで評価される
What do “economic value” benchmarks tell us?, Epoch.AI, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #read-later Issue Date: 2026-04-11 Comment
元ポスト:
GDPvalだけでなく、RLI, APEX Agentsと呼ばれるものも解説されているようである
- REMOTE LABOR INDEX (RLI) : Evaluating the capability of AI agents to perform real-world, economically valuable remote work
- [Paper Note] APEX-Agents, Bertie Vidgen+, arXiv'26, 2026.01
- [Paper Note] GDPval: Evaluating AI Model Performance on Real-World Economically
Valuable Tasks, Tejal Patwardhan+, arXiv'25, 2025.10
Introducing WildDet3D: Open-world 3D detection from a single image, Ai2, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #OpenWeight #OpenSource #read-later #Selected Papers/Blogs #3D (Video) #ObjectDetection #Initial Impression Notes Issue Date: 2026-04-07 Comment
元ポスト:
wildな環境においてzero shot(click, text, bounding boxで対象を指定)で動作する単眼の3D Object Detectionモデルとのこと。データセットもコードも公開
The Anatomy of an LLM Benchmark, Cameron R. Wolfe, Ph.D., 2026.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Evaluation #Initial Impression Notes Issue Date: 2026-03-30 Comment
元ポスト:
本文中のDisclaimerにも記述されている通り、coding/SWE/AI-Agentに関するベンチマークや、Multi-modalなベンチマークについては説明されていない点には注意。
LLMとしての評価として初期の頃から使われて(いる|いた)、MMLU, GPQA, BIG-Bench, IFEvalといった代表的なものが紹介され、単にそれらベンチマークがどういったものかを説明しているというより、どのようにすれば自分たちのタスクに関して良いLLMベンチマークを作成できるか?という観点で議論されているように見える。
Introducing SPEED-Bench: A Unified and Diverse Benchmark for Speculative Decoding, Nvidia, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #LongSequence #Decoding #Diversity #SpeculativeDecoding Issue Date: 2026-03-26 Comment
元ポスト:
RACER: 自動運転VLAモデルの学習データセットの構築, Tech Blog - Turing, Zenn, 2026.03
Paper/Blog Link My Issue
#Article #read-later #VisionLanguageActionModel Issue Date: 2026-03-26 Comment
元ポスト:
xperience-10m, ropedia-ai, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #Selected Papers/Blogs #Robotics #3D (Video) #EmbodiedAI Issue Date: 2026-03-17 Comment
元ポスト:
Ropediaとは:
- Interactive Intelligence from Human Xperience, Ropedia, 2025.12
アナウンス:
5日で1.66M downloadsとのこと:
最近の主要なembodied AIのための基盤モデルに使われているとのこと:
computer-use-large, markov-ai, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AIAgents #ComputerUse #Selected Papers/Blogs #VisionLanguageModel #3D (Video) #One-Line Notes Issue Date: 2026-03-15 Comment
元ポスト:
12,300時間程度の、プロフェッショナルなソフトウェア(AutoCAD, Blender, Excel, Photoshop, Salesforce VSCode)利用しているスクリーンのレコーディングデータとのこと。
CC-BY-4.0!?
Reasoning models struggle to control their chains of thought, and that’s good, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #Controllable #NLP #LanguageModel #Chain-of-Thought #Evaluation #Blog #Reasoning #read-later #Author Thread-Post Issue Date: 2026-03-06 Comment
元ポスト:
著者ポスト:
CoderForge-Preview: SOTA open dataset for training efficient coding agents, together.ai, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #Blog #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs Issue Date: 2026-02-28 Comment
元ポスト:
Swallowにおける 日英推論型大規模言語モデルの構築, 水木栄, 第26回LLM勉強会, 2026.02
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Japanese #mid-training #PostTraining #Selected Papers/Blogs #DataMixture #Initial Impression Notes Issue Date: 2026-02-27 Comment
元ポスト:
関連:
- Qwen3-Swallow & GPT-OSS-Swallow, Kazuki Fujii, 2026.02
まだしっかり読めていないのだが、適切なDataMixtureはどのようにして決めているのだろうか?
- 数学データによる学習がコーディングにのみ転移
- 英語データを邦訳したデータが学習に寄与するためcross-lingualで能力が転移する
- RLはpass@1を改善するが、Pass@10などの改善幅は縮小する
- この辺の話は資料中でも先行研究が引用されており、実際に確認されたということだと思われる
...
new-datasets-in-machine-learning, librarian-bots, 2026.02
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #ComputerVision #MachineLearning #InformationRetrieval #NLP #Evaluation #SpeechProcessing #Robotics #Live Issue Date: 2026-02-09 Comment
元ポスト:
ModernBERTをFinetuningした分類器を用いてデータセットやベンチマークを提案している研究を自動分類して検索できるようにしている。有用
JFBench: 実務レベルの日本語指示追従性能を備えた生成AIを目指して, PFN, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #InstructionTuning #Evaluation #Japanese #InstructionFollowingCapability Issue Date: 2026-01-29 Comment
元ポスト:
[SWE-Smith Multilingual] Expanding to JavaScript, Li+, 2026.01
Paper/Blog Link My Issue
#Article #Evaluation Issue Date: 2026-01-27 Comment
元ポスト:
ICLR 2026 Acceptance Prediction: Benchmarking Decision Process with A Multi-Agent System, Zhang+, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #AIAgents #Evaluation #MultiModal #ScientificDiscovery #VisionLanguageModel #AcademicWriting #Live #One-Line Notes Issue Date: 2026-01-20 Comment
元ポスト:
conference paperのpeer reviewに関するベンチマーク。accept/rejectを予測する。papers, reviews, rebuttalsそしてfinal decisionsが紐づけられている。
action100m-preview, Meta, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #Robotics #VisionLanguageActionModel #3D (Video) Issue Date: 2026-01-16 Comment
元ポスト:
OctoCodingBench, MiniMaxAI, 2026.01
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Coding #SoftwareEngineering Issue Date: 2026-01-16 Comment
元ポスト:
MedReason-Stenographic, openmed-community, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #QuestionAnswering #Chain-of-Thought #SyntheticData #Evaluation #Reasoning #Medical #KeyPoint Notes Issue Date: 2026-01-12 Comment
元ポスト:
MiniMax M2.1を用いてMedical QAに対してreasoning traceを生成。生成されたreasoning traceをstenographic formatと呼ばれる自然言語からフィラーを排除し、論理の流れのみをsymbolicな表現に変換することで合成されたデータセットとのこと。
ユースケースとしては下記とのこと:
> 1. Train reasoning models with symbolic compression
> 2. Fine-tune for medical QA
> 3. Research reasoning compression techniques
> 4. Benchmark reasoning trace quality
個人的には1,3が興味深く、symbolを用いてreasoning traceを圧縮することで、LLMの推論時のトークン効率を改善できる可能性がある。
が、surfaceがシンボルを用いた論理の流れとなると、汎化性能を損なわないためにはLLMが内部でシンボルに対する何らかの強固な解釈が別途必要になるし、それが多様なドメインで機能するような柔軟性を持っていなければならない気もする。
AI Safetyの観点でいうと、論理の流れでCoTが表現されるため、CoTを監視する際には異常なパターンがとりうる空間がshrinkし監視しやすくなる一方で、surfaceの空間がshrinkする代わりに内部のブラックボックス化された表現の自由度が高まり抜け道が増える可能性もある気がする。結局、自然言語もLLMから見たらトークンの羅列なので、本質的な課題は変わらない気はする。
FineTranslations, Penedo+, 2026.01
Paper/Blog Link My Issue
#Article #MachineTranslation #Pretraining #NLP #LanguageModel #SyntheticData #mid-training #One-Line Notes Issue Date: 2026-01-10 Comment
元ポスト:
FineWeb2のテキストを英訳することで合成されたパラレルコーパスらしい
OpenHands trajectories with Qwen3 Coder 480B, Nebius blog, 2025.12
Paper/Blog Link My Issue
#Article #LanguageModel #ReinforcementLearning #AIAgents #Blog #Coding #Reasoning #SoftwareEngineering #PostTraining Issue Date: 2025-12-24 Comment
元ポスト:
Medmarks v0.1, a new LLM benchmark suite of medical tasks, Sophont, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Medical Issue Date: 2025-12-23 Comment
元ポスト:
Interactive Intelligence from Human Xperience, Ropedia, 2025.12
Paper/Blog Link My Issue
#Article #Blog #Robotics #WorldModels #VisionLanguageActionModel #EmbodiedAI #One-Line Notes #EgocentricView #Real-to-Sim Issue Date: 2025-12-17 Comment
pj page: https://ropedia.com/
元ポスト:
頭に装着するデバイスでegocentric viewのデータセットを収集し、実際の人間の様々な状況での経験を収集されたegocentric viewデータに基づいて活用し、より強力なworld model, Real-to-Sim, Vision Action Langauge Modelsを作ることをミッションとする新たなプロジェクト(?)な模様。
Evaluating AI’s ability to perform scientific research tasks, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Reasoning #Science #KeyPoint Notes Issue Date: 2025-12-17 Comment
元ポスト:
HF: https://huggingface.co/datasets/openai/frontierscience
physics, chemistry, biologyの分野の専門家が作成した問題によって構成されるPh.D levelの新たなscientificドメインのベンチマークとのこと。OlympiadとResearchの2種類のスプリットが存在し、Olympiadは国際オリンピックのメダリストによって設計された100問で構成され回答は制約のある短答形式である一方、Researchは博士課程学生・教授・ポスドク研究者などのPh.Dレベルの人物によって設計された60個の研究に関連するサブタスクによって構成されており、10点満点のルーブリックで採点される、ということらしい。
公式アナウンスではGPT-5.2がSoTAでResearchの性能はまだまだスコアが低そうである。
OpenThinker-Agent-v1, open-thoughts, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #SmallModel #OpenWeight #OpenSource #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-12-07 Comment
元ポスト:
-
-
agenticなSLM(8Bモデル)で、モデル、データ(SFT, RL)、学習用のコードなど全て公開。同等規模のモデルQwen3-{8,32B}よりもSWE Bench Verified, Terminal Benchなどで上回る(ただし、Qwen3はgenericなモデルであり、コーディング特化のQwen3-coder-30Bには及ばない。しかしモデルサイズはこちらの方が大きいので何とも言えない。おそらく同等規模のコーディング特化Qwen3が存在しない)。また、SLMのコーディングエージェントの進化をより精緻に捉えるためのベンチマーク OpenThoughts-TB-Devも公開している。こちらでもQwen3-{8, 32B}に対しても高い性能を記録。
[Paper Note] Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail, Pavone+, Nvidia, 2025.10
Paper/Blog Link My Issue
#Article #ReinforcementLearning #Reasoning #SmallModel #OpenWeight #Robotics #VisionLanguageActionModel #Realtime #AutonomousVehicle Issue Date: 2025-12-06 GPT Summary- AR1は因果連鎖推論と軌道計画を統合した視覚–言語–行動モデルであり、自律運転の意思決定を強化します。主な革新は、因果連鎖データセットの構築、モジュラーVLAアーキテクチャの導入、強化学習を用いた多段階トレーニング戦略です。評価結果では、AR1は計画精度を最大12%向上させ、推論の質を45%改善しました。リアルタイムパフォーマンスも確認され、レベル4の自律運転に向けた実用的な道筋を示しています。 Comment
HF: https://huggingface.co/nvidia/Alpamayo-R1-10B
元ポスト:
Building Safer AI Browsers with BrowseSafe, Perplenity Team, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Prompting #Evaluation #Blog #OpenWeight #Safety #Safeguard Issue Date: 2025-12-03 Comment
元ポスト:
prompt injectionをリアルタイムに検知するモデルとそのベンチマークとのこと
dataset:
https://huggingface.co/datasets/perplexity-ai/browsesafe-bench
model:
https://huggingface.co/perplexity-ai/browsesafe
veAgentBench, ByteDance, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Education #AIAgents #Evaluation #Financial #Legal Issue Date: 2025-11-26 Comment
元ポスト:
Benchmark Scores = General Capability + Claudiness, EpochAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog #read-later Issue Date: 2025-11-21 Comment
元ポスト:
Claudiness=Claudeらしさ=エージェントタスクに優れている、しかしマルチモーダルや数学には弱いこと(皮肉を込めてこう呼んでいるらしい)
Claudeらしくないモデルとしては、o4-miniやGPT-5が挙げられる。
AI Model Benchmarks Nov 2025, lmcouncil, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Blog Issue Date: 2025-11-19 Comment
元ポスト:
50% time horizonなどを含む良さそうなベンチマークと主要モデルの比較が簡単にできそうなサイト
LLM Datasets, mlabonne, 2025.11
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #AIAgents Issue Date: 2025-11-19 Comment
元ポスト:
Egocentric-10K, Build AI, 2025.11
Paper/Blog Link My Issue
#Article #Robotics #3D (Video) #EmbodiedAI #One-Line Notes Issue Date: 2025-11-13 Comment
元ポスト:
工場での主観視点での作業動画の大規模データセット。Apache 2.0!?
SYNTH: the new data frontier, pleias, 2025.11
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #SyntheticData #Reasoning #One-Line Notes Issue Date: 2025-11-12 Comment
元ポスト:
SoTAなReasoning能力を備えたSLMを学習可能な事前学習用合成データ
元ポスト:
The Smol Training Playbook: The Secrets to Building World-Class LLMs, Allal+, HuggingFace, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #LanguageModel #Infrastructure #PostTraining #Selected Papers/Blogs Issue Date: 2025-10-31 Comment
元ポスト:
Nemotron-VLM-Dataset-v2, Nvidia, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #VisionLanguageModel Issue Date: 2025-10-29 Comment
元ポスト:
Ming-Freeform-Audio-Edit, inclusionAI, 2025.10
Paper/Blog Link My Issue
#Article #Evaluation #SpeechProcessing Issue Date: 2025-10-28 Comment
元ポスト:
FindWiki, Guilherme Penedo, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #TabularData #Mathematics #MultiLingual #DataFiltering #One-Line Notes Issue Date: 2025-10-22 Comment
元ポスト:
2023年時点で公開されたWikipediaデータをさらに洗練させたデータセット。文字のレンダリング、数式、latex、テーブルの保持(従来は捨てられてしまうことが多いとのこと)、記事に関係のないコンテンツのフィルタリング、infoboxを本文から分離してメタデータとして保持するなどの、地道な前処理をして洗練化させたとのこと。
FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems, FlashInfer Community, 2025.10
Paper/Blog Link My Issue
#Article #NeuralNetwork #MachineLearning #Transformer #AIAgents #Evaluation #SoftwareEngineering #GPUKernel Issue Date: 2025-10-22 Comment
元ポスト:
GPUカーネルのエージェントによる自動最適化のためのベンチマークとのこと。
2025年10月1日 国立情報学研究所における大規模言語モデル構築への協力について, 国立国会図書館, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Japanese #Selected Papers/Blogs Issue Date: 2025-10-01 Comment
元ポスト:
日本語LLMの進展に極めて重要なニュースと思われる
GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs Issue Date: 2025-09-29 Comment
米国のGDPを牽引する9つの代表的な産業において、44の職種を選定し、合計1320件の実務タスクを設計したベンチマーク。ベンチマークは平均14年程度の経験を持つ専門家が実際の業務内容をもとに作成し、(うち、約220件はオープンソース化)、モデルと専門家のsolutionにタスクを実施させた。その上で、第三者である専門家が勝敗(win, lose, tie)を付与することでモデルがどれだけ実務タスクにおいて人間の専門家に匹敵するかを測定するベンチマークである。
評価の結果、たとえばClaude Opus 4.1の出力は47.6%程度、GPT-5 (high) は38.8%程度の割合で専門家と勝ち + 引き分け、という性能になっており、人間の専門家にかなり近いレベルにまで近づいてきていることが分かる。特にClaude Opus 4.1はデザインの品質も問われるタスク(ドキュメントの書式設定、スライドレイアウトなど)で特に優れているとのこと。
limitationとしては、
- 網羅性: データセットサイズが小さく、occupationごとの30タスクしかデータがないこと
- 自己完結型・知識労働への偏り: コンピュータ上でのタスクに限定されており、肉体労働や暗黙知が多いタスク、個人情報へのアクセス、企業内の専用ツールを利用した作業や他社とのコミュニケーションが必要なタスクは含まれていない。
- 完全な文脈: 完全な文脈を最初からpromptで与えているが、実際は環境とのインタラクションが必要になる。
- grader performance: 自動評価は人間の専門家の評価に比べると及ばない
といったことが書かれている。
HMMT. HMMT 2025, 2025.09
Paper/Blog Link My Issue
#Article #Evaluation #Blog #Mathematics Issue Date: 2025-09-24 Comment
サイト内部の説明によると、ハーバード、MIT、そして近隣の学校の学生たちによって運営されている世界で最大、かつ最も権威のある高校生向けの国際的な数学のコンペティション、とのこと。
Nemotron-Personas-Japan: Synthesized Data for Sovereign AI, Nvidia, 2025.09
Paper/Blog Link My Issue
#Article #NLP #MultiLingual #Japanese #Cultural #One-Line Notes Issue Date: 2025-09-24 Comment
dataset: https://huggingface.co/datasets/nvidia/Nemotron-Personas-Japan
元ポスト:
国勢調査の統計情報や名字由来netをシードとし、LLM Aによってペルソナに必要な各種属性(文化的背景、スキルと専門知識、キャリア目標と野望、趣味と興味等)を合成し、それらがgivenな状態で、複数のタイプのペルソナ(全体、職業、芸術、スポーツ)を説明するテキストを合成している模様?細かい生成手法はよくわからなかった。実世界の分布(人口統計、地理的分布、性格特性など)を反映した上でペルソナが合成されており、地域固有の人口統計、文化的背景を取り入れたソブリンAIの開発を支援するとのこと。
アメリカやインドの合成されたペルソナもある:
MagicBench, ByteDance-Seed, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #Evaluation #TextToImageGeneration #UMM Issue Date: 2025-09-19 Comment
元ポスト:
英文と中文両方存在する
WildGuardTestJP: 日本語ガードレールベンチマークの開発, SB Intuitions, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Safety #Japanese Issue Date: 2025-09-16 Comment
HF: https://huggingface.co/datasets/sbintuitions/WildGuardTestJP
元ポスト:
以下のデータセットを日本語向けに(Seed-X-PPO-7B Seed-X-Instruct-7B, ByteDance-Seed, 2025.07
を用いて[^1])翻訳したベンチマーク。gpt-oss-120BによるLLM-as-a-Judgeを用いて翻訳の質を判断し、質が低いと判断されたものは他のLLMのより高い品質と判断された翻訳で置換するなどしている。
- [Paper Note] WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs, Seungju Han+, NeurIPS'24
[^1]: plamo-2-translateと比較して、Plamoの方が流暢だったがSeedXの方が忠実性が高い推察されたためこちらを採用したとのこと。
Cosmopedia: how to create large-scale synthetic data for pre-training, Allal+(HuggingFace), 2024.03
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #SyntheticData #Blog Issue Date: 2025-09-13 Comment
cosmopedia dataset: https://huggingface.co/datasets/HuggingFaceTB/cosmopedia
大部分を合成データで学習したPhi-1.5([Paper Note] Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, arXiv'23, 2023.09
)のデータ合成のレシピの詳細は明かされておらず、学習データ自体も公開されていないことを受け、事前学習で利用可能な数百Mサンプルの合成データを生成するレシピはなんなのか?を探った話。
最終的に、30Mのpromptをprompt engineeringをMixtral-8x7B-Instruct-v0.1を通じて作成し、高品質なpretrainingのための広範なトピックの文書群を作成。合成された内容の重複は1%未満。
Phi-1.5の論文の記述に基づくと、20k topicsをseedとし新たなsynthetic dataを作成、web sampleを活用して多様性を担保した、という記述がある。これに基づくと、仮に1ファイルの長さを1000 tokenであると仮定すると、20Mのpromptが活用されたことになる。しかしながら、web sampleを組み合わせる方法と、多様性を増やす方法がクリアではなかった。
Cosmopediaのアプローチとしては、2つのアプローチがある。まず curated educational sources (Khan Academy, OpenStax, WikiHow, Stanford courses)を利用する方法で、これらの全てのユニットを合計しても260k程度であった。これでは到底20Mには届かないため、生成する文書の `style` と `audience` に幅を持たせることで、promptの数を増やした。
具体的には、styleとして、academic textbook / blog post / wikihow articles の3種類、audienceとして young children / high school students / college students / researchers の4種類を用意した。このとき、単にprompt中で特定のaudience/styleで記述するよう指示をしても、同じような内容しか出力されない課題があったため、prompt engineeringによって、より具体的な指示を加えることで解決(Figure3)。
続いてのアプローチはweb dataを活用するアプローチで、収集されたweb samplesを145のクラスタに分類し、各クラスタごとに10個のランダムなサンプルを抽出し、Mixtralにサンプルから共通のトピックを抽出させることでクラスタのトピックを得る。
その後不適切なトピックは除外(e.g., アダルトコンテンツ, ゴシップ等)。その後、クラスタのweb sampleとトピックの双方をpromptに与えて関連するtextbookを生成させるpromptを作成 (Figure 4)。このとき、トピックラベルの生成がうまくいっていない可能性も考慮し、トピックをgivenにしないpromptも用意した。最終的にこれにより23Mのpromptを得た。また、scientificな内容を増やすために、AutoMathText (数学に関して収集されたデータセット)も加えた。
上記promptで合成したデータでモデルを学習したところ、モデルにcommon senseやgrade school educationにおける典型的な知識が欠けていることが判明したため、UltraChatやOpenHermes2.5から日常に関するストーリーを抽出してseed dataに加えた。
下記が最終的なseed-data/format/audienceの分布となる。seed-dataの大部分はweb-dataであることがわかる。
最終的に合成データのうち、10-gram overlapに基づいて、contaminationの疑いがある合成データを抽出。ベンチマークデータのうち、50%のsub-stringとマッチした文書は除外することでdecontaminationを実施。
下表がdecontaminationの結果で、()内の数字がユニーク数。decontaminationをしなければこれらが学習データに混入し、ベンチマーキング性能に下駄をはかせることになってしまっていたことになる。
1Bモデルを訓練した結果、半分程度のベンチマークでTinyLlama 1.1Bよりも高いスコアを達成。Qwen-1.5-1BやPhi-1.5に対しては全体としてスコアでは負けているように見える。このことより、より高品質な合成データ生成方法があることが示唆される。
以後、SmolLM構築の際にCosmopediaのpromptに挿入するサンプルをトピックごとにより適切に選択する(文書を合成するモデルをMixtralから他のモデルに変更してもあまり効果がなかったとのこと)などの改善を実施したCosmopedia v2が構築されている。
GAUSS Benchmarking Structured Mathematical Skills for Large Language Models, Zhang+, 2025.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Reasoning #Mathematics #Contamination-free #Selected Papers/Blogs Issue Date: 2025-09-13 Comment
元ポスト:
現在の数学のベンチマークは個々の問題に対する回答のAccuracyを測るものばかりだが、ある問題を解く際にはさまざまなスキルを活用する必要があり、評価対象のLLMがどのようなスキルに強く、弱いのかといった解像度が低いままなので、そういったスキルの習熟度合いを測れるベンチマークを作成しました、という話に見える。
Knowledge Tracingタスクなどでは問題ごとにスキルタグを付与して、スキルモデルを構築して習熟度を測るので、問題の正誤だけでなくて、スキルベースでの習熟度を見ることで能力を測るのは自然な流れに思える。そしてそれは数学が最も実施しやすい。
From Live Data to High-Quality Benchmarks: The Arena-Hard Pipeline, Li+, 2024.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Conversation #Live Issue Date: 2025-09-10 Comment
ArenaHardデータセット
ChatbotArenaのデータからコンタミネーションに考慮して定期的に抽出される高品質なreal worldに近いのconversationデータセット。抽出プロセスではpromptの多様性とqualityが担保される形で、200,000のユーザからのpromptが抽出されフィルタリングにかけられる。
多様性という観点では、全てのpromptを OpenAI の `text-embedding-3-small` によってembeddingに変換し、UMAPによって次元圧縮をした後に階層的クラスタリング手法によってトピッククラスタを形成する。各クラスタにはGPT-4-turboで要約が付与され、要約を活用して4000のトピッククラスタを選定する。
続いて、各クラスタに含まれるクエリは品質がバラバラなので、高品質なものを抽出するために以下の観点からLLM-as-a-Judge(GPT-3.5-Turbo, GPT-4-turbo)を用いてフィルタリングを実施する:
```
1. Specificity: Does the prompt ask for a specific output?
2. Domain Knowledge: Does the prompt cover one or more specific domains?
3. Complexity: Does the prompt have multiple levels of reasoning, components, or variables?
4. Problem-Solving: Does the prompt directly involve the AI to demonstrate active problem-solving skills?
5. Creativity: Does the prompt involve a level of creativity in approaching the problem?
6. Technical Accuracy: Does the prompt require technical accuracy in the response?
7. Real-world Application: Does the prompt relate to real-world applications?
```
(観点は元記事から引用)
各観点を満たしていたら1ポイントとし、各promptごとに[0, 7]のスコアが付与される。各トピッククラスタはクラスタ中のpromptの平均スコアによってスコアリングされフィルタリングに活用される。
最終的に250のhigh-qualityなトピッククラスタ(すなわち、スコアが>=6のクラスタ)が選ばれ、各クラスタから2つのサンプルをサンプリングして合計500個のbenchmark promptを得る。
評価をする際は、評価対象のモデルとstrong baseline(GPT-4-0314)のレスポンスを比較し、LLM-as-a-Judge(GPT-4-Turbo, Claude-3-Opus)によってペアワイズの品質データを取得する。position biasに配慮するためにreaponseの位置を入れ替えて各サンプルごとに2回評価するので、このデータは1000個のペアワイズデータとなる。
このペアワイズデータをbootstrap resamplingした上で、Bradley-Terryモデル(=勝敗データからプレイヤーの強さを数値化する統計モデル)でスコアを計算することでスコアを得る。
ArenaHardはMT Benchよりも高い識別力を獲得している。
関連:
- ChatBot Arena, lmsys org, 2023.05
- Chatbot Arena Conversation Dataset Release, LMSYS Org, 2023.07
AlpacaEval, tatsu-lab, 2023.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #InstructionFollowingCapability Issue Date: 2025-09-10
『JamC-QA』: 日本の文化や風習に特化した質問応答ベンチマークの構築・公開(前編), SB Intuitions, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Japanese #Selected Papers/Blogs Issue Date: 2025-09-09 Comment
元ポスト:
後編も参照のこと: https://www.sbintuitions.co.jp/blog/entry/2025/09/09/113132
日本の文化、風習、風土、地理、日本史、行政、法律、医療に関する既存のベンチマークによりも難易度が高いQAを人手によってスクラッチから作成した評価データ。人手で作成されたQAに対して、8種類の弱いLLM(パラメータ数の小さい日本語LLMを含む)の半数以上が正しく回答できたものを除外、その後さらに人手で確認といったフィルタリングプロセスを踏んでいる。記事中は事例が非常に豊富で興味深い。
後編では実際の評価結果が記載されており、フルスクラッチの日本語LLMが高い性能を獲得しており、Llama-Swallowなどの継続事前学習をベースとしたモデルも高いスコアを獲得している。評価時は4-shotでドメインごとにExamplarは固定し、greedy decodingで評価したとのこと。
NLP'25: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/Q2-18.pdf
- [Paper Note] Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, Eval4NLP'25, 2024.08
のような話もあるので、greedy decodingだけでなくnucleus/temperature samplingを複数trial実施した場合の性能の平均で何か変化があるだろうか、という点が気になったが、下記研究でMMLUのような出力空間が制約されているような設定の場合はほとんど影響がないことが実験的に示されている模様:
- [Paper Note] The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism, Yifan Song+, NAACL'25
これはnucleus/temperature samplingが提案された背景(=出力の自然さを保ったまま多様性を増やしたい)とも一致する。
オープンデータセットのライセンスガイド, サナミ, 2024.12
Paper/Blog Link My Issue
#Article #Tutorial #Blog Issue Date: 2025-09-07
FinePDFs, HuggingFaceFW, 2025.09
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Repository #Selected Papers/Blogs Issue Date: 2025-09-07 Comment
元ポスト:
Thomas Wolf氏のポスト:
ODC-By 1.0 license
CLOCKBENCH: VISUAL TIME BENCHMARK WHERE HUMANS BEAT THE CLOCK, LLMS DON’T ALEK SAFAR (OLEG CHICHIGIN), 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #Evaluation #Contamination-free #VisionLanguageModel Issue Date: 2025-09-07 Comment
リーダーボード: https://clockbench.ai
元ポスト:
様々な種類の時計(e.g., 反転、フォントの違い, invalidな時刻の存在, 大きさ, フォーマットなど; p.2参照のこと)の時刻を読み取り(あるいはvalidな時刻か否かを判定し)、読み取った時刻に対してQA(e.g., X時間Y分Z秒進める、戻した時刻は?長針を30/60/90度動かした時刻は?この時刻がニューヨークの時間だとしたらロンドンの時刻は?)を実施するベンチマーク。人間の正解率は89.1%に対してSoTAモデルでも13.3%程度。contaminationに配慮して全てスクラッチから作成され、全体の評価データはprivateなままにしているとのこと。
続報:
Qwen3-VL-235B-InstructがGPT-5 Chat超え
MECHA-ja, llm-jp, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Japanese #Cultural Issue Date: 2025-09-07 Comment
元ポスト:
FineWeb2 Edu Japanese, Yuichi Tateno, 2025.09
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Japanese Issue Date: 2025-09-06 Comment
元ポスト:
FineVision: Open Data Is All You Need, Wiedmann+, Hugging Face, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #Pretraining #NLP #Blog #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-09-05 Comment
HF: https://huggingface.co/datasets/HuggingFaceM4/FineVision
元ポスト:
OpenHands PR Arena, neulab, 2025.09
Paper/Blog Link My Issue
#Article #AIAgents #Evaluation #Repository #Coding #SoftwareEngineering #Selected Papers/Blogs Issue Date: 2025-09-04 Comment
元ポスト:
実際に存在するIssueにタグ付けすることで、リアルタイムに複数LLMによってPRを作成(API callはOpenHandswが負担する)し、ユーザは複数LLMの中で良いものを選択する、といったことができる模様?リーダーボードも将来的に公開するとのことなので、実際にユーザがどのモデルのoutputを選んだかによって勝敗がつくので、それに基づいてランキング付けをするのだろうと推測。興味深い。
Nemotron-CC-v2, Nvidia, 2025.08
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #Coding #Mathematics #Selected Papers/Blogs Issue Date: 2025-09-01 Comment
元ポスト:
CCだけでなく、数学やコーディングの事前学習データ、SFT styleの合成データセットも含まれている。
TxT360, LLM360, 2024.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel Issue Date: 2025-08-25
Granary, Nvidia, 2025.08
Paper/Blog Link My Issue
#Article #SpeechProcessing #AutomaticSpeechRecognition(ASR) #SimulST(SimultaneousSpeechTranslation) Issue Date: 2025-08-17 Comment
元ポスト:
NVIDIA Releases 3 Million Sample Dataset for OCR, Visual Question Answering, and Captioning Tasks, NVIDIA, 2025.08
Paper/Blog Link My Issue
#Article #ComputerVision #Pretraining #NLP #QuestionAnswering #ImageCaptioning #VisionLanguageModel #OCR Issue Date: 2025-08-13 Comment
元ポスト:
Llama Nemotron VLM Dataset V1
VQA, OCRの比率が多めで、Imase Captioningは少なめ。
Bits per Character (BPC) によるLLM性能予測, Kazuki Fujii (PFN), 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation Issue Date: 2025-07-31 Comment
元ポスト:
Asymmetry of verification and verifier’s law, Jason Wei, 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Verification Issue Date: 2025-07-17 Comment
元ポスト:
PLaMo翻訳による英語ベンチマークの翻訳, PFN, 2025.07
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #SyntheticData #Blog Issue Date: 2025-07-09
LLM-jp-3.1 シリーズ instruct4 の公開, LLM-jp, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #LanguageModel #Evaluation #Blog #OpenWeight #Japanese #OpenSource #PostTraining Issue Date: 2025-06-25 Comment
関連
- [Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, arXiv'24, 2024.06
- [Paper Note] Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data, Fahim Tajwar+, ICML'24
- [Paper Note] AnswerCarefully: A Dataset for Improving the Safety of Japanese LLM Output, Hisami Suzuki+, arXiv'25
Datadog_BOOM, Datadog, 2025.05
Paper/Blog Link My Issue
#Article #TimeSeriesDataProcessing #MachineLearning #Evaluation Issue Date: 2025-05-25 Comment
元ポスト:
Webスケールの日本語-画像のインターリーブデータセット「MOMIJI」の構築 _巨大テキストデータをAWSで高速に処理するパイプライン, Turing (studio_graph), 2025.05
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AWS #MultiModal #Blog #Japanese #VisionLanguageModel #Initial Impression Notes Issue Date: 2025-05-20 Comment
貴重なVLMデータセット構築ノウハウ
青塗りのフィルタリングタスクを具体的にどうやっているのか気になる
Fiction.liveBench, Kas, 2025.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #LongSequence #One-Line Notes Issue Date: 2025-04-09 Comment
long contextではGemini-2.5-proの圧勝
BFCLv2, UC Berkeley, 2024.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #API #Selected Papers/Blogs #One-Line Notes #ToolUse Issue Date: 2025-04-08 Comment
LLMのTool Useを評価するための現在のデファクトスタンダードとなるベンチマーク
BFCLv3:
https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html
Sudoku-bench, SakanaAI, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #Initial Impression Notes #Author Thread-Post Issue Date: 2025-03-21 Comment
元ポスト:
既存モデルでベンチマークを取ったらどういうランキングになるのだろうか。特にまだそういぅたランキングは公開されていない模様。
ブログ記事に(将来的に最新の結果をrepositoryに追記される模様)現時点でのリーダーボードが載っていた。現状、o3-miniがダントツに見える。
https://sakana.ai/sudoku-bench/
Introducing the SWE-Lancer benchmark, OpenAI, 2025.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering #One-Line Notes Issue Date: 2025-03-02 Comment
元ポスト:
1400以上のフリーランスソフトウェアエンジニアリングタスクを集めたベンチマーク。タスクはバグ修正から機能実装まで多岐にわたり、経験豊富なエンジニアによって評価されたもの。
LLM Datasets, mlabonne, 2025.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #Repository #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-01-25 Comment
LLMの事後学習用のデータをまとめたリポジトリ
現在も更新されている。
tokyotech-llm_swallow-magpie-ultra-v0.1, tokyotech-llm, 2025.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #InstructionTuning Issue Date: 2025-01-07 Comment
元ポスト:
Killed by LLM, R0bk
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #Evaluation #Blog #One-Line Notes Issue Date: 2025-01-05 Comment
Saturationとなっているベンチマークは、最先端の性能をすでに測定できなくなってしまったベンチマークとのこと。
LLMによって性能が飽和したベンチマークをリストアップしているサイトで、2024年までのものが掲載されている。それ以後は掲載されていないようだ。
Preferred Generation Benchmark, pfnet-research, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Japanese Issue Date: 2024-12-30 Comment
参考:
日本語プレプリント: https://jxiv.jst.go.jp/index.php/jxiv/preprint/view/1008
arXivはこれからっぽい
完全にオープンな約1,720億パラメータ(GPT-3級)の大規模言語モデル 「llm-jp-3-172b-instruct3」を一般公開 ~GPT-3.5を超える性能を達成~ , NII, 2024.12
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Blog #OpenWeight #Japanese #OpenSource #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-12-24 Comment
GPT3.5と同程度のパラメータ数のコーパス、モデル、ツール、全てを公開。学習データまで含めてオープンなモデルとしては世界最大規模とのこと。
Instructionチューニング済みのモデルはライセンスを読むと、ライセンスに記述されている内容を遵守すれば、誰でも(日本人なら18歳以上とかはあるが)アクセス可能、用途の制限(商用・非商用問わず)なく利用でき、かつ再配布や派生物の生成などが許されているように見える。
が、baseモデルの方はコンタクト情報を提供のうえ承認を受けないと利用できない模様。また、再配布と一部の使途に制限がある模様。
SNSではオープンソースではないなどという言説も出ており、それはbaseモデルの方を指しているのだろうか?よくわからない。
実用上はinstructionチューニング済みのモデルの方がbaseモデルよりも使いやすいと思うので、問題ない気もする。
やはりbaseとinstructでライセンスは2種類あるとのこと:
日本語LLMまとめ, LLM-jp, 2024.12
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #Evaluation #Repository #OpenWeight #Japanese #OpenSource #One-Line Notes Issue Date: 2024-12-02 Comment
LLM-jpによる日本語LLM(Encoder-Decoder系, BERT系, Bi-Encoders, Cross-Encodersを含む)のまとめ。
テキスト生成に使うモデル、入力テキスト処理に使うモデル、Embedding作成に特化したモデル、視覚言語モデル、音声言語モデル、日本語LLM評価ベンチマーク/データセットが、汎用とドメイン特化型に分けてまとめられている。
各モデルやアーキテクチャの原論文、学習手法の原論文もまとめられている。すごい量だ…。
SmolLM2, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #InstructionTuning #SyntheticData #OpenWeight #OpenSource #PostTraining #One-Line Notes Issue Date: 2024-11-21 Comment
元ポスト:
Orca-AgenInstruct-1M microsoft/orca-agentinstruct-1M-v1, Microsoft, 2024.11
よりもSmolLMのSFTで各種ベンチで高い性能を獲得
Datasets: hpprc_honyaku, hpprc, 2024.11
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #Zero/Few/ManyShotPrompting #Japanese #One-Line Notes Issue Date: 2024-11-20 Comment
元ポスト:
英語Wikipediaを冒頭数文を抽出し日本語に人手で翻訳(Apache2.0ライセンスであるCalmやQwenの出力を参考に、cc-by-sa-4.0ライセンスにて公開している。
テクニカルタームが日本語で存在する場合は翻訳結果に含まれるようにしたり、翻訳された日本語テキストが単体で意味が成り立つように翻訳しているとのことで、1件あたり15分もの時間をかけて翻訳したとのこと。データ量は33件。many-shotやfew-shotに利用できそう。
日英対訳コーパスはライセンスが厳しいものが多いとのことなので、非常に有用だと思う。
microsoft_orca-agentinstruct-1M-v1, Microsoft, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2024-11-16
MLE-Bench, OpenAI, 2024.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #AutoML #One-Line Notes Issue Date: 2024-10-20 Comment
75のkaggleのcompetitionsを収集(賞金1.9M$に相当する)し、そこから機械学習モデルの構築するためのエンジニアリングタスク(データセットの準備, モデルの学習, 実験)を抽出し、AI Agentsが機械学習モデルのこれらエンジニアリングタスクに対してどの程度実施できるかを測定できるようにしたベンチマーク
LLM-jp Corpus v3, LLM.jp, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Japanese #One-Line Notes Issue Date: 2024-09-25 Comment
LLM-jp-3
- LLM-jp-3 1.8B・3.7B・13B の公開, LLM.jp, 2024.09
の学習に利用されているコーパス
Firecrawl, 2024.09
Paper/Blog Link My Issue
#Article #LanguageModel #Repository #API #One-Line Notes Issue Date: 2024-08-30 Comment
sitemapなしでWebサイト全体をクローリングできるAPI。LLMで利用可能なマークダウンや、構造化データに変換もしてくれる模様。
list of recommender systems
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #Library #Repository #OpenSource #One-Line Notes Issue Date: 2024-08-07 Comment
推薦システムに関するSaaS, OpenSource, Datasetなどがまとめられているリポジトリ
A Review of Public Japanese Training Sets, shisa, 2023.12
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #InstructionTuning #Repository #Japanese Issue Date: 2023-12-11
JGLUEの構築そして 日本語LLM評価のこれから, 河原大輔, W&B 東京ミートアップ #8, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #LanguageModel #Evaluation #One-Line Notes #Reading Reflections Issue Date: 2023-11-16 Comment
JGLUEのexample付きの詳細、構築の経緯のみならず、最近の英語・日本語LLMの代表的な評価データ(方法)がまとまっている(AlpacaEval, MTBenchなど)。また、LLMにおける自動評価の課題が興味深く、LLM評価で生じるバイアスについても記述されている。Name biasなどはなるほどと思った。
日本語LLMの今後の評価に向けて、特にGPT4による評価を避け、きちんとアノテーションしたデータを用意しfinetuningした分類器を用いるという視点、参考にしたい。
Data-to-Text Datasetまとめ, Akihiko Watanabe, 2022
Paper/Blog Link My Issue
#Article #Survey #NaturalLanguageGeneration #NLP #DataToTextGeneration #Slide #One-Line Notes Issue Date: 2023-11-08 Comment
Data-to-Textのデータセットを自分用に調べていたのですが、せっかくなのでスライドにまとめてみました。特にMR-to-Text, Table-to-Textあたりは網羅的にサーベイし、データセットの概要を紹介しているので、全体像を把握するのに良いのかなぁと思います。ただし、2022年12月時点で作成したので2023年以後のデータセットは含まれていません😅
CommonVoice
Paper/Blog Link My Issue
#Article #MachineLearning #SpeechProcessing #One-Line Notes Issue Date: 2023-08-16 Comment
音声対応のアプリケーションをトレーニングするために誰でも使用できるオープンソースの多言語音声データセット
Chatbot Arena Conversation Dataset Release, LMSYS Org, 2023.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #DialogueGeneration #Blog #One-Line Notes Issue Date: 2023-07-22 Comment
33kのconversation、2つのレスポンスに対する人間のpreferenceスコア付き
20種類のSoTAモデルのレスポンスを含み、13kのユニークIPからのアクセスがあり、3Kのエキスパートによるアノテーション付き
SNAP: Web data: Amazon reviews
Paper/Blog Link My Issue
#Article #RecommenderSystems #NLP Issue Date: 2023-05-06
Score Prediction dataset
Paper/Blog Link My Issue
#Article #Education #AdaptiveLearning #EducationalDataMining #ScorePrediction #KeyPoint Notes #Reference Collection Issue Date: 2022-08-23
Criteo Dataset, Display Advertising Challenge, Kaggle, 2014
Paper/Blog Link My Issue
#Article #RecommenderSystems #CTRPrediction #KeyPoint Notes Issue Date: 2021-06-01 Comment
Criteo Dataset (
https://www.kaggle.com/c/criteo-display-ad-challenge/data)
DeepFM等のモデルで利用されているCTR Predictionのためのデータセット
# Data Description
- train.csv: 7日間のcriteoのtraffic recordの一部。個々の行が1 impに対応している。click, non-clickのラベル付き。chronologically order. click, non-clickのexampleはデータセットのサイズを縮小するために異なるrateでサブサンプルされている。
- training: trainingデータと同様の作成データだが、trainingデータの翌日のデータで構成されている。
# Data Fields
> - Label - Target variable that indicates if an ad was clicked (1) or not (0).
> - I1-I13 - A total of 13 columns of integer features (mostly count features).
> - C1-C26 - A total of 26 columns of categorical features. The values of these features have been hashed onto 32 bits for anonymization purposes.
13種類のinteger featureと、26種類のcategorical featuresがある。
Avazu Data (
https://www.kaggle.com/c/avazu-ctr-prediction/data)
# File descriptions
> - train - Training set. 10 days of click-through data, ordered chronologically. Non-clicks and clicks are subsampled according to different strategies.
> - test - Test set. 1 day of ads to for testing your model predictions.
sampleSubmission.csv - Sample submission file in the correct format, corresponds to the All-0.5 Benchmark.
# Data fields
> - id: ad identifier
> - click: 0/1 for non-click/click
> - hour: format is YYMMDDHH, so 14091123 means 23:00 on Sept. 11, 2014 UTC.
> - C1 -- anonymized categorical variable
> - banner_pos
> - site_id
> - site_domain
> - site_category
> - app_id
> - app_domain
> - app_category
> - device_id
> - device_ip
> - device_model
> - device_type
> - device_conn_type
> - C14-C21 -- anonymized categorical variables
基本的には click/non-click のラベルと、そのclick時の付帯情報によって構成されている模様
Student Performance Prediction _ Knowledge Tracing Dataset
Paper/Blog Link My Issue
#Article #Survey #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing Issue Date: 2021-05-29
GLUE - 英語圏における自然言語処理の標準ベンチマーク, npaka, 2020.09
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Evaluation #Blog #Initial Impression Notes Issue Date: 2021-05-19 Comment
各タスクごとにサンプルとその説明が付与されており、ぱっと見でどんなタスクかすぐ分かる
Off Policy Evaluation の基礎とOpen Bandit Dataset & Pipelineの紹介, Yuta Saito, 2020.08
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #Tools #Slide #One-Line Notes Issue Date: 2020-08-29 Comment
機械学習による予測精度ではなく、機械学習モデルによって生じる意思決定を、過去の蓄積されたデータから評価する(Off policy Evaluation)の、tutorialおよび実装、データセットについて紹介。
このような観点は実務上あるし、見落としがちだと思うので、とても興味深い。
Open Bandit Dataset, ZOZO RESEARCH, 2020
Paper/Blog Link My Issue
#Article #RecommenderSystems #Blog Issue Date: 2020-08-29 Comment
Open Bandit pipelineも参照
資料:
https://speakerdeck.com/usaito/off-policy-evaluationfalseji-chu-toopen-bandit-dataset-and-pipelinefalseshao-jie
BERT 日本語Pre-trained Model, NICT, 2020.03
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tools #NLP #LanguageModel #Library #Blog #Japanese #Encoder #One-Line Notes Issue Date: 2020-03-13 Comment
NICTが公開。既に公開されているBERTモデルとのベンチマークデータでの性能比較も行なっており、その他の公開済みBERTモデルをoutperformしている。
Recommender System Datasets, Julian McAuley
Paper/Blog Link My Issue
#Article #RecommenderSystems #Selected Papers/Blogs #One-Line Notes Issue Date: 2019-04-12 Comment
Recommender Systems研究に利用できる各種データセットを、Julian McAuley氏がまとめている。
氏が独自にクロールしたデータ等も含まれている。
非常に有用。
NLP-Progress
Paper/Blog Link My Issue
#Article #Tutorial #Survey #One-Line Notes Issue Date: 2019-02-12 Comment
NLPの様々なタスクのデータセット, およびSOTA(2018年時点)がまとめられている。
DUC 2007, Update Summarization Dataset, 2006.10
My Issue
#Article #DocumentSummarization #NLP #Update #One-Line Notes Issue Date: 2017-12-28 Comment
DUC 2007: https://duc.nist.gov/duc2007/tasks.html