
Findings
[Paper Note] ExaGPT: Example-Based Machine-Generated Text Detection for Human Interpretability, Ryuto Koike+, ACL'26 Findings, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Education #ACL #AI Detector #Interpretability Issue Date: 2026-07-12 GPT Summary- LLM生成テキストの検出は、決定の解釈可能性を重要視し、利用者が予測の正確さを評価できるようにする必要がある。従来の手法は人間の判断プロセスに沿った証拠を提供できておらず、このギャップを解消するためにExaGPTを提案。ExaGPTは、人間作成とLLM生成テキストの類似スパンを比較することで識別し、具体的な証拠を示すことで決定の正しさを向上させる。広範な実験により、ExaGPTは従来手法より精度を最大37.0ポイント向上させることが確認された。 Comment
元ポスト:
人間が作成したテキストとLLMが生成したテキストのスパンごとの類似性を見ることで、与えられたテキストがLLM生成か否かを判定する。データストア中の類似したスパンが判断のevidenceとなる、という話に見える。
こういった話は教育の文脈でも需要がある
[Paper Note] ReasonIF: Large Reasoning Models Fail to Follow Instructions During Reasoning, Yongchan Kwon+, ACL'26 Findings, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reasoning #ACL #InstructionFollowingCapability #One-Line Notes Issue Date: 2026-07-08 GPT Summary- 大規模言語モデル(LLMs)がユーザーの指示を推論過程全体で遵守する重要性を強調し、ReasonIFというベンチマークを導入。これは、推論指示の遵守を評価し、さまざまな指示プロンプトを網羅している。多くのオープンソースLRMsにおいて、指示遵守のスコアは0.25未満であり、難易度の上昇に伴い低下する傾向がある。推論指示の忠実度向上には、マルチターン推論と合成データを用いたファインチューニングが有効で、RIFによって大きな改善が見込まれるが、さらなる向上が必要。 Comment
著者ポスト:
著者ポスト2:
reasoning traceに対して制約を課す[^1]指示は、メインの応答と比較して指示追従性能が低い傾向にある
[^1]: 思考する言語の指定、思考の長さの制限、免責事項(指示でreasoningの最後にwarningや備考を追記する)、reasoningをjsonにする、大文字のみを利用する、commaをreasoning中に除外する、など
[Paper Note] How Retrieved Context Shapes Internal Representations in RAG, Samuel Yeh+, ACL'26 Findings, 2026.02
Paper/Blog Link My Issue
#Analysis #LanguageModel #RAG(RetrievalAugmentedGeneration) #ACL Issue Date: 2026-07-05 GPT Summary- RAGは、外部文書を用いてLLMの性能を向上させるが、取得文書の影響は明確でない。本研究では、取得文書がLLMの隠れ状態に与える影響と、その変化が生成挙動にどのように関連するかを潜在表現の視点から分析。4つの質問応答データセットと3つのLLMを用いて、文脈の関連性が内部表現に与える影響を明らかにし、LLMの出力挙動の理解とRAGの設計に関する洞察を提供。 Comment
元ポスト:
[Paper Note] VAUQ: Vision-Aware Uncertainty Quantification for LVLM Self-Evaluation, Seongheon Park+, ACL'26 Findings, 2026.02
Paper/Blog Link My Issue
#ComputerVision #NLP #ACL #VisionLanguageModel #Initial Impression Notes #SelfVerification Issue Date: 2026-07-01 GPT Summary- 視覚言語モデル(LVLM)の幻覚問題を解決するために、視覚認識に基づく不確実性定量化フレームワークVAUQを提案。これにより、モデル出力の視覚的証拠への依存度を測定し、Image-Information Score(IS)を導入。トレーニング不要のスコアリング関数を用いて正確さを反映。実験により、VAUQは既存の自己評価手法を上回る性能を示した。 Comment
画像に関するタスクをVLMが処理する際に、応答のconfidenceがlanguage priorではなく、画像に基づくevidenceに基づいているかをconfidenceに反映させる
[Paper Note] TARo: Token-level Adaptive Routing for LLM Test-time Alignment, Arushi Rai+, ACL'26 Findings, 2026.03
Paper/Blog Link My Issue
#LanguageModel #Alignment #ACL #Decoding #Routing #KeyPoint Notes #Author Thread-Post #Test-time Alignment Issue Date: 2026-04-07 GPT Summary- 推論時に固定されたLLMsを用いて、トークンレベル適応ルーティング(TARo)を提案。報酬モデルにより数学的推論の一貫性信号を捉え、ルーターが基盤モデルを自動制御。TARoは推論性能を最大+22.4%向上させ、分布外の臨床推論や指示遵守を改善。再訓練なしでの一般化も可能で、堅牢な推論を実現。 Comment
元ポスト:
巨大なベースモデル全体を特定ドメインに適用するためにpost-trainingするのは大変なので、代わりに小規模なdomain-expertなRewardモデルを学習し(今回は数学のstep-wiseにlogicが正しいことをpreferenceとして与えるような学習方法を採用したようである; 3.2節)、各decoding step tにおいて、ベースモデルとRewardモデルのトークンのlogitを線形補完することで、出力トークンをガイドする。logitの線形補完において、固定されたスカラー値(e.g., 0.5など。GenARMという手法らしい)を用いる研究などが先行研究ではあるが、これはベースモデルの特定タスクにおいてベースモデルの性能を劣化させるので、本研究ではdecoding step t時点で出力されたベースモデル、Rewardモデルのlogitを入力として、FFNによって線形補完の重みα_tをdecoding step tごとに決定する(α_tを決定するネットワークをRouterと呼ぶ)。FFNは2種類のvariantがあり、双方のlogitをconcatしたものを入力するものと、top-kをサンプリングし、kごとにindexに基づいたembeddingをconcatして入力する方法の二種類がある(3.3節)。
結果としては、GenARMと比較して提案手法は有効ではあるが、ベースモデルとrewardモデルの組み合わせによっては、baseモデルよりも性能が悪化するということもありそうに見える。
またRouterはベースモデルのサイズを大きくしても、性能が転移するので再学習が不要である。
[Paper Note] VChain: Chain-of-Visual-Thought for Reasoning in Video Generation, Ziqi Huang+, ACL'26 Findings, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Chain-of-Thought #DiffusionModel #Reasoning #ACL #VideoGeneration/Understandings #2D (Image) Issue Date: 2025-10-20 GPT Summary- VChainは、マルチモーダルモデルの視覚的推論を動画生成に活用する新しいフレームワークで、重要なキーフレームを生成し、動画生成器のチューニングを効率的にガイドします。このアプローチにより、複雑なシナリオにおいて生成動画の品質が大幅に向上しました。 Comment
pj page: https://eyeline-labs.github.io/VChain/
元ポスト:
Chain-of-Visual-Thoughts
keyframeをchain-of-thoughtsに含めることで、時間発展をより正確にしようという試みに見える。追加の学習なしで実施できるとのこと。
[Paper Note] CARMO: Dynamic Criteria Generation for Context-Aware Reward Modelling, Taneesh Gupta+, ACL'25 Findings, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Distillation #ACL #RewardHacking #PostTraining #Adaptive #Rubric-based Issue Date: 2026-02-11 GPT Summary- CARMOはダイナミックでコンテキストに関連した基準を用い、報酬モデリングの脆弱性を軽減する新手法。人間のフィードバックを取り入れ、生成された基準に基づき評価することで、報酬のハッキングを防ぎつつ、ゼロショット設定での性能を向上させ、Reward Benchで2.1%の改善を達成。Mistral-Baseに対して高いアライメントを示すデータセットも構築。 Comment
元ポスト:
[Paper Note] Autonomous Data Selection with Zero-shot Generative Classifiers for Mathematical Texts, Yifan Zhang+, ACL'25 Findings, 2024.02
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #ACL #KeyPoint Notes #GenerativeVerifier Issue Date: 2025-12-19 GPT Summary- 自律的データ選択(AutoDS)は、言語モデルをゼロショットの生成分類器として利用し、高品質な数学テキストを自動キュレーションする手法です。従来の方法と異なり、人間の注釈やデータフィルターのトレーニングを必要とせず、モデルのロジットに基づいて数学的に有益なパッセージを判断します。AutoDSは事前トレーニングパイプラインに統合され、数学ベンチマークでの性能を大幅に向上させ、トークン効率を約2倍改善しました。さらに、キュレーションされたAutoMathTextデータセットを公開し、今後の研究を促進します。 Comment
元ポスト:
以下のようなzero-shotのmeta-promptを用いてテキストをスコアリングし(Q1, Q2それぞれについてスコア(=logits)を算出し乗算)継続事前学習に利用することで性能が向上することを示した研究。
ベースライン:
- uniform: OpenWebMathから一様サンプリングする
- DSIR: source dataとtarget domain(今回はPile's Wikipedia splitを利用)のKL Divergenceを比較しデータを選択する。
- Qurating: Reward-modelをベースにした学習サンプルに対するeducational valueをランキングさせる手法
提案手法は
- OpenWebMath
- arXiv (from RedPajama)
- Algebraic Stack
の中からトップスコアのドキュメントを利用。DSIR, Quratingについてはデータソースが明示されていないが、おそらく提案手法揃えていると思われる。また学習する際のトークン量も手法間で(明示的に書かれていないように見えるが)同等にそろえていると思われる。
まずpreliminary experimentsとしてトークン数のbudgetを小さめにして実験。uniformと比較すると、別のmathドメインデータでFinetuningした後のパフォーマンスが向上している。トークン数のbudgetもexactに揃えられている。
続いてトークンのbudgetを増やして、~2.5Bトークンにスケールアップして比較(継続事前学習→1 epoch SFT)。提案手法が全体的にdownstreamタスクでの評価で高い性能を発揮。しかしこちらでは、いくつかでuniformの性能もよい。
また、最後に数学データでの継続事前学習が異なるドメインに対してどの程度転移するかを測ると、提案手法が平均して最もよかった。しかしこちらもでもuniformが結構強い結果に見える。
OpenWebMathがそもそもheuristicsとtrained classifierを用いてキュレーションされたデータとのことなので、ある程度高品質であることが想定される。
[Paper Note] Understanding the Influence of Synthetic Data for Text Embedders, Jacob Mitchell Springer+, ACL'25 Findings, 2025.09
Paper/Blog Link My Issue
#Embeddings #Analysis #NLP #Dataset #LanguageModel #RepresentationLearning #SyntheticData #ACL Issue Date: 2025-10-19 GPT Summary- 合成LLM生成データのトレーニングによる汎用テキスト埋め込み器の進展を受け、Wangらの合成データを再現・公開。高品質なデータはパフォーマンス向上をもたらすが、一般化の改善は局所的であり、異なるタスク間でのトレードオフが存在。これにより、合成データアプローチの限界が明らかになり、タスク全体での堅牢な埋め込みモデルの構築に対する考えに疑問を呈する。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/jspringer/open-synthetic-embeddings
[Paper Note] Benchmarking and Improving LLM Robustness for Personalized Generation, Chimaobi Okite+, EMNLP'25 Findings, 2025.09
Paper/Blog Link My Issue
#Personalization #EMNLP Issue Date: 2025-09-28 GPT Summary- LLMsの応答の個別化において、事実性も重要であると主張し、堅牢性を評価するフレームワークPERGとデータセットPERGDataを導入。14のモデルを評価した結果、LLMsは堅牢な個別化に苦労しており、特に大規模モデルでも正確性が低下することが判明。クエリの性質やユーザーの好みによって堅牢性が影響を受けることを示し、二段階のアプローチPref-Alignerを提案し、平均25%の堅牢性向上を実現。研究は評価手法のギャップを明らかにし、信頼性の高いLLMの展開を支援するツールを提供。 Comment
元ポスト:
[Paper Note] CAPE: Context-Aware Personality Evaluation Framework for Large Language Models, Jivnesh Sandhan+, EMNLP'25 Findings, 2025.08
Paper/Blog Link My Issue
#Dataset #LanguageModel #ContextAware #Evaluation #EMNLP #Personality Issue Date: 2025-09-24 GPT Summary- 心理測定テストをLLMsの評価に適用するため、文脈対応パーソナリティ評価(CAPE)フレームワークを提案。従来の孤立した質問アプローチから、会話の履歴を考慮した応答の一貫性を定量化する新指標を導入。実験により、会話履歴が応答の一貫性を高める一方で、パーソナリティの変化も引き起こすことが明らかに。特にGPTモデルは堅牢性を示し、Gemini-1.5-FlashとLlama-8Bは感受性が高い。CAPEをロールプレイングエージェントに適用すると、一貫性が改善され人間の判断と一致することが示された。 Comment
元ポスト:
[Paper Note] How a Bilingual LM Becomes Bilingual: Tracing Internal Representations with Sparse Autoencoders, Tatsuro Inaba+, EMNLP'25 Findings, 2025.03
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #MultiLingual #EMNLP #SparseAutoencoder Issue Date: 2025-09-24 GPT Summary- 本研究では、バイリンガル言語モデルの内部表現の発展をスパースオートエンコーダーを用いて分析。言語モデルは初めに言語を個別に学習し、中間層でバイリンガルの整合性を形成することが明らかに。大きなモデルほどこの傾向が強く、分解された表現を中間トレーニングモデルに統合する新手法でバイリンガル表現の重要性を示す。結果は、言語モデルのバイリンガル能力獲得に関する洞察を提供。 Comment
元ポスト:
[Paper Note] Instability in Downstream Task Performance During LLM Pretraining, Yuto Nishida+, EMNLP'25 Findings, 2025.10
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #EMNLP #Stability #DownstreamTasks Issue Date: 2025-09-24 GPT Summary- LLMの訓練中に下流タスクのパフォーマンスが大きく変動する問題を分析し、チェックポイントの平均化とアンサンブル手法を用いて安定性を向上させることを提案。これにより、訓練手順を変更せずにパフォーマンスの変動を減少させることが実証された。 Comment
元ポスト:
[Paper Note] Lost in Embeddings: Information Loss in Vision-Language Models, Wenyan Li+, EMNLP'25 Findings, 2025.09
Paper/Blog Link My Issue
#ComputerVision #Embeddings #Analysis #NLP #EMNLP #VisionLanguageModel Issue Date: 2025-09-21 GPT Summary- 視覚と言語のモデル(VLMs)の投影ステップによる情報損失を分析するため、2つのアプローチを提案。1つ目は、投影前後の画像表現のk近傍関係の変化を評価し、2つ目は視覚埋め込みの再構築によって情報損失を測定。実験により、コネクタが視覚表現の幾何学を歪め、k近傍が40~60%乖離することが明らかになり、これは検索性能の低下と関連。パッチレベルの再構築は、モデルの挙動に対する洞察を提供し、高い情報損失がモデルの苦手な事例を予測することを示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Evaluating Step-by-step Reasoning Traces: A Survey, Jinu Lee+, EMNLP'25 Findings
Paper/Blog Link My Issue
#EMNLP Issue Date: 2025-08-21 GPT Summary- ステップバイステップの推論はLLMの能力向上に寄与するが、評価手法は一貫性に欠ける。本研究では、推論評価の包括的な概要と、事実性、有効性、一貫性、実用性の4カテゴリからなる評価基準の分類法を提案。これに基づき、評価者の実装や最近の発見をレビューし、今後の研究の方向性を示す。 Comment
元ポスト:
[Paper Note] Agent Laboratory: Using LLM Agents as Research Assistants, Samuel Schmidgall+, EMNLP'25 Findings
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #ScientificDiscovery #EMNLP Issue Date: 2025-08-21 GPT Summary- Agent Laboratoryは、全自動のLLMベースのフレームワークで、研究アイデアから文献レビュー、実験、報告書作成までのプロセスを完了し、質の高い研究成果を生成します。人間のフィードバックを各段階で取り入れることで、研究の質を向上させ、研究費用を84%削減。最先端の機械学習コードを生成し、科学的発見の加速を目指します。 Comment
元ポスト:
pj page: https://agentlaboratory.github.io
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, ACL(Findings)'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #LanguageModel #Evaluation #ACL #VisionLanguageModel #Author Thread-Post Issue Date: 2025-07-02 GPT Summary- 内部世界モデル(WMs)はエージェントの理解と予測を支えるが、最近の大規模ビジョン・ランゲージモデル(VLMs)の基本的なWM能力に関する評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchというベンチマークを導入。15のVLMsに対する660の実験で、これらのモデルが基本的なWM能力に顕著な制限を示し、特に運動軌道の識別においてほぼランダムな精度であることが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。 Comment
元ポスト:
所見:
[Paper Note] RewardBench: Evaluating Reward Models for Language Modeling, Nathan Lambert+, NAACL'25 Findings, 2024.05
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #ReinforcementLearning #Evaluation #NAACL #Selected Papers/Blogs #RewardModel Issue Date: 2025-06-26 GPT Summary- 報酬モデル(RMs)の評価に関する研究は少なく、我々はその理解を深めるためにRewardBenchというベンチマークデータセットを提案。これは、チャットや推論、安全性に関するプロンプトのコレクションで、報酬モデルの性能を評価する。特定の比較データセットを用いて、好まれる理由を検証可能な形で示し、さまざまなトレーニング手法による報酬モデルの評価を行う。これにより、報酬モデルの拒否傾向や推論の限界についての知見を得ることを目指す。 Comment
[Paper Note] Compute Optimal Scaling of Skills: Knowledge vs Reasoning, Nicholas Roberts+, ACL'25 Findings, 2025.03
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #ACL #Scaling Laws #Initial Impression Notes Issue Date: 2025-03-23 GPT Summary- スケーリング法則はLLM開発において重要であり、特に計算最適化によるトレードオフが注目されている。本研究では、スケーリング法則が知識や推論に基づくスキルに依存することを示し、異なるデータミックスがスケーリング挙動に与える影響を調査した。結果、知識とコード生成のスキルは根本的に異なるスケーリング挙動を示し、誤指定された検証セットが計算最適なパラメータ数に約50%の影響を与える可能性があることが明らかになった。 Comment
元ポスト:
知識を問うQAのようなタスクはモデルのパラメータ量が必要であり、コーディングのようなReasoningに基づくタスクはデータ量が必要であり、異なる要素に依存してスケールすることを示している研究のようである。
直感的な理解としては、
多くの知識はMLP(だけではないが)に格納されているとされており、1パラメータあたりに格納可能な知識量がある程度決まっているため、知識が必要なタスクはパラメータ数が必要であり、
Reasoningのようなタスクはどれだけ学習データ側でReasoningのパターンを学習できるかに性能が依存するため、データ量が必要、
というものになるのかなという気がする。
[Paper Note] Perspective Transition of Large Language Models for Solving Subjective Tasks, Xiaolong Wang+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #ACL #One-Line Notes #Initial Impression Notes Issue Date: 2025-01-25 GPT Summary- 視点遷移を通じた推論(RPT)手法により、LLMsが主観的タスクにおいて視点を動的に選択できるようにします。本手法は専門家や第三者の視点を活用し、文脈をより適切に解釈することで、ニュアンスのある回答を提供します。広範な実験により、従来の固定視点手法を大きく上回る成果を示しました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=cFGPlRony5
"Subjective Task"とは例えば「メタファーの認識」や「ダークユーモアの検知」などがあり、これらは定量化しづらい認知的なコンテキストや、ニュアンスや感情などが強く関連しており、現状のLLMではチャレンジングだと主張している。
Subjective Taskでは、Reasoningモデルのように自動的にCoTのpathwayを決めるのは困難で、手動でpathwayを記述するのはチャレンジングで一貫性を欠くとした上で、複数の視点を組み合わせたPrompting(direct perspective, role-perspective, third-person perspectivfe)を実施し、最もConfidenceの高いanswerを採用することでこの課題に対処すると主張している。
イントロしか読めていないが、自動的にCoTのpathwayを決めるのも手動で決めるのも難しいという風にイントロで記述されているが、手法自体が最終的に3つの視点から回答を生成させるという枠組みに則っている(つまりSubjective Taskを解くための形式化できているので、自動的な手法でもできてしまうのではないか?と感じた)ので、イントロで記述されている主張の”難しさ”が薄れてしまっているかも・・・?と感じた。論文が解こうとしている課題の”難しさ”をサポートする材料がもっとあった方がよりmotivationが分かりやすくなるかもしれない、という感想を持った。
[Paper Note] Scaling Sentence Embeddings with Large Language Models, Ting Jiang+, EMNLP'24 Findings, 2023.07
Paper/Blog Link My Issue
#Sentence #Embeddings #NLP #LanguageModel #In-ContextLearning #EMNLP #One-Line Notes #Reading Reflections Issue Date: 2026-06-11 GPT Summary- 文脈内学習に基づく手法を用いて、大規模言語モデル(LLMs)の文の埋め込み性能を向上。自己回帰モデル向けにプロンプトベースの表現法を適用し、ファインチューニングなしで高品質な文の埋め込みを生成可能。モデルサイズを拡大するとSTSタスクで性能の変化が見られるが、最大モデルは他のモデルを上回り、転移タスクで最先端結果を達成。2.7BのOPTモデルが4.8BのST5を超える性能を示した。 Comment
1 wordでsentenceを要約するICL-basedなprompt templateを用いて生成されたtokenに対応するlast hidden statedeをsentenceのembeddingとして扱うことで、coder-onlyモデルから文のembeddingを取得する
下記研究で示されているように、last hidden stateではなく中間層におけるhidden stateを利用した場合はどのような影響が出るのだろうか?
- [Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
[Paper Note] The Impact of Reasoning Step Length on Large Language Models, Mingyu Jin+, ACL'24 Findings, 2024.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Chain-of-Thought #Reasoning #ACL #Length Issue Date: 2024-01-16 GPT Summary- Chain of Thought(CoT)がLLMの推論能力向上に重要であることが示された。実験により、推論ステップの長さがLLMの性能に与える影響を調査。推論ステップを長くすることで、追加情報なしでも推論能力が向上し、逆に短くすると性能が著しく低下。これは、CoTプロンプトにおけるステップ数の重要性を示している。また、不正確な合理的根拠でも推論を維持できれば良好な結果が得られることが判明。タスクの複雑さに応じて、推論ステップの利点は異なることも観察された。
Prompt Engineering a Prompt Engineer, Qinyuan Ye+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AutomaticPromptEngineering #ACL Issue Date: 2023-11-13 GPT Summary- プロンプトエンジニアリングは、LLMsのパフォーマンスを最適化するための重要なタスクであり、本研究ではメタプロンプトを構築して自動的なプロンプトエンジニアリングを行います。改善されたパフォーマンスにつながる推論テンプレートやコンテキストの明示などの要素を導入し、一般的な最適化概念をメタプロンプトに組み込みます。提案手法であるPE2は、さまざまなデータセットやタスクで強力なパフォーマンスを発揮し、以前の自動プロンプトエンジニアリング手法を上回ります。さらに、PE2は意味のあるプロンプト編集を行い、カウンターファクトの推論能力を示します。
[Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Chain-of-Thought #Prompting #AutomaticPromptEngineering #NAACL #Surface-level Notes Issue Date: 2023-04-25 GPT Summary- Iter-CoTは、LLMsの推論チェーンのエラーを修正し、正確で包括的な推論を実現するための反復的ブートストラッピングアプローチを提案。適度な難易度の質問を選択することで、一般化能力を向上させ、10のデータセットで競争力のある性能を達成。 Comment
Zero shot CoTからスタートし、正しく問題に回答できるようにreasoningを改善するようにpromptをreviseし続けるループを回す。最終的にループした結果を要約し、それらをプールする。テストセットに対しては、プールの中からNshotをサンプルしinferenceを行う。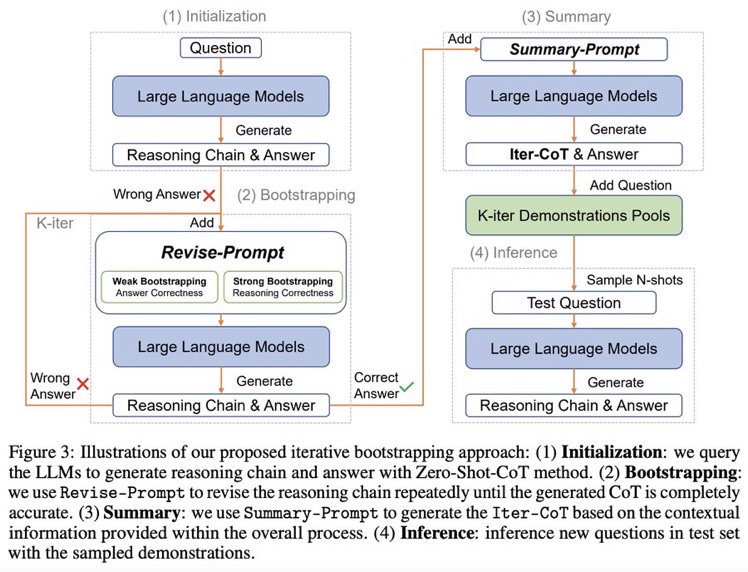
できそうだなーと思っていたけど、早くもやられてしまった
実装: https://github.com/GasolSun36/Iter-CoT
# モチベーション: 既存のCoT Promptingの問題点
## Inappropriate Examplars can Reduce Performance
まず、既存のCoT prompting手法は、sampling examplarがシンプル、あるいは極めて複雑な(hop-based criterionにおいて; タスクを解くために何ステップ必要かという情報; しばしば人手で付与されている?)サンプルをサンプリングしてしまう問題がある。シンプルすぎるサンプルを選択すると、既にLLMは適切にシンプルな回答には答えられるにもかかわらず、demonstrationが冗長で限定的になってしまう。加えて、極端に複雑なexampleをサンプリングすると、複雑なquestionに対しては性能が向上するが、シンプルな問題に対する正答率が下がってしまう。
続いて、demonstration中で誤ったreasoning chainを利用してしまうと、inference時にパフォーマンスが低下する問題がある。下図に示した通り、誤ったdemonstrationが増加するにつれて、最終的な予測性能が低下する傾向にある。
これら2つの課題は、現在のメインストリームな手法(questionを選択し、reasoning chainを生成する手法)に一般的に存在する。
- [Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
- [Paper Note] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, KaShun Shum+, EMNLP'23, 2023.02
のように推論時に適切なdemonstrationを選択するような取り組みは行われてきているが、test questionに対して推論するために、適切なexamplarsを選択するような方法は計算コストを増大させてしまう。
これら研究は誤ったrationaleを含むサンプルの利用を最小限に抑えて、その悪影響を防ぐことを目指している。
一方で、この研究では、誤ったrationaleを含むサンプルを活用して性能を向上させる。これは、たとえば学生が難解だが回答可能な問題に取り組むことによって、問題解決スキルを向上させる方法に類似している(すなわち、間違えた部分から学ぶ)。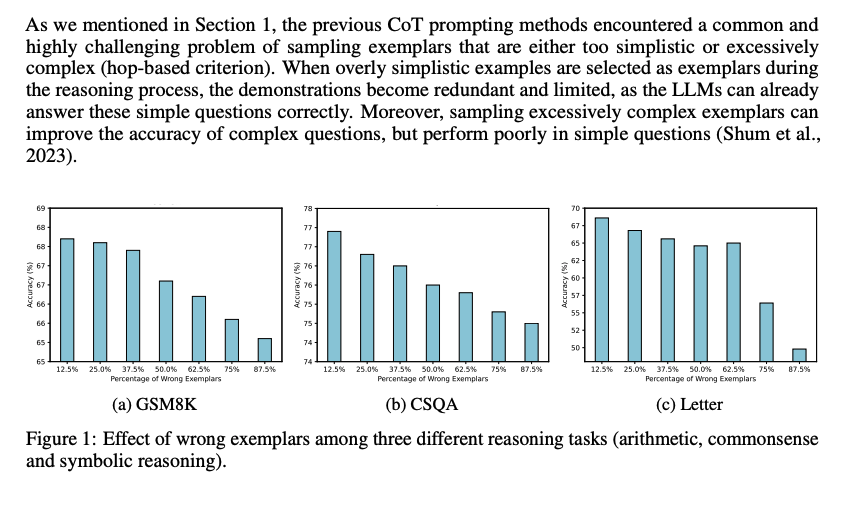
## Large Language Models can self-Correct with Bootstrapping
Zero-Shot CoTでreasoning chainを生成し、誤ったreasoning chainを生成したpromptを**LLMに推敲させ(self-correction)**正しい出力が得られるようにする。こういったプロセスを繰り返し、correct sampleを増やすことでどんどん性能が改善していった。これに基づいて、IterCoTを提案。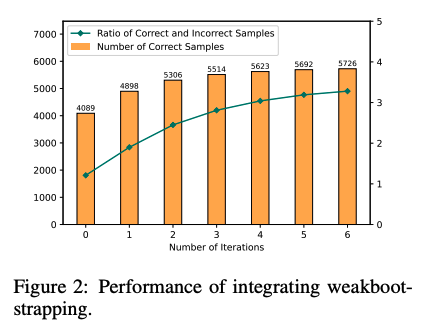
# IterCoT: Iterative Bootstrapping in Chain-of-Thought Prompting
IterCoTはweak bootstrappingとstrong bootstrappingによって構成される。
## Weak bootstrapping
- Initialization
- Training setに対してZero-shot CoTを実施し、reasoning chainとanswerを得
- Bootstrapping
- 回答が誤っていた各サンプルに対して、Revise-Promptを適用しLLMに誤りを指摘し、新しい回答を生成させる。
- 回答が正確になるまでこれを繰り返す。
- Summarization
- 正しい回答が得られたら、Summary-Promptを利用して、これまでの誤ったrationaleと、正解のrationaleを利用し、最終的なreasoning chain (Iter-CoT)を生成する。
- 全体のcontextual informationが加わることで、LLMにとって正確でわかりやすいreasoning chainを獲得する。
- Inference
- questionとIter-Cotを組み合わせ、demonstration poolに加える
- inference時はランダムにdemonstraction poolからサンプリングし、In context learningに利用し推論を行う
## Strong Bootstrapping
コンセプトはweak bootstrappingと一緒だが、Revise-Promptでより人間による介入を行う。具体的には、reasoning chainのどこが誤っているかを明示的に指摘し、LLMにreasoning chainをreviseさせる。
これは従来のLLMからの推論を必要としないannotationプロセスとは異なっている。何が違うかというと、人間によるannnotationをLLMの推論と統合することで、文脈情報としてreasoning chainを修正することができるようになる点で異なっている。
# 実験
Manual-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Random-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Auto-CoT
- [Paper Note] Active Prompting with Chain-of-Thought for Large Language Models, Shizhe Diao+, ACL'24, 2023.02
と比較。
Iter-CoTが11個のデータセット全てでoutperformした。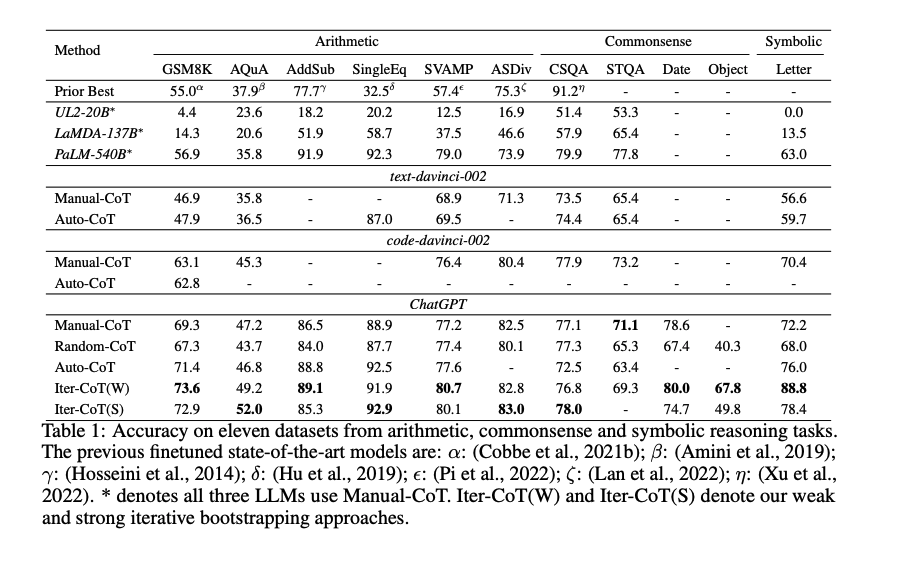
weak bootstrapingのiterationは4回くらいで頭打ちになった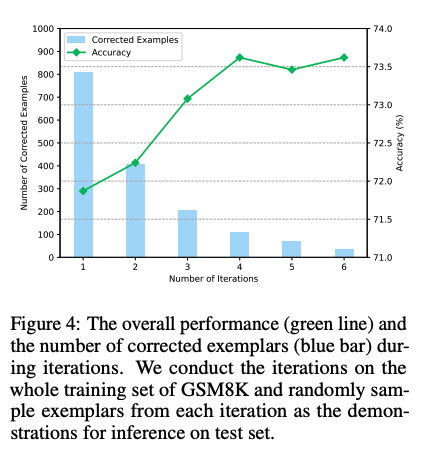
また、手動でreasoning chainを修正した結果と、contextにannotation情報を残し、最後にsummarizeする方法を比較した結果、後者の方が性能が高かった。このため、contextの情報を利用しsummarizeすることが効果的であることがわかる。
[Paper Note] FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation, Tu Vu+, ACL'23 Findings, 2023.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Zero/Few/ManyShotPrompting #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #ACL Issue Date: 2025-09-24 GPT Summary- 大規模言語モデル(LLMs)は変化する世界に適応できず、事実性に課題がある。本研究では、動的QAベンチマーク「FreshQA」を導入し、迅速に変化する知識や誤った前提を含む質問に対するLLMの性能を評価。評価の結果、全モデルがこれらの質問に苦労していることが明らかに。これを受けて、検索エンジンからの最新情報を組み込む「FreshPrompt」を提案し、LLMのパフォーマンスを向上させることに成功。FreshPromptは、証拠の数と順序が正確性に影響を与えることを示し、簡潔な回答を促すことで幻覚を減少させる効果も確認。FreshQAは公開され、今後も更新される予定。
[Paper Note] Auto-Instruct: Automatic Instruction Generation and Ranking for Black-Box Language Models, Zhihan Zhang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #InstructionTuning #InstructionGeneration #EMNLP #KeyPoint Notes Issue Date: 2023-10-26 GPT Summary- LLMに対する指示の自動生成と評価を行うAuto-Instructを提案。多様な候補指示を生成し、既存の575タスク用のスコアリングモデルでランク付け。ドメイン外の118タスクで、人手作成や従来の生成指示を上回る性能を示し、高い一般化性を持つことを確認。 Comment
seed instructionとdemonstrationに基づいて、異なるスタイルのinstructionを自動生成し、自動生成したinstructionをとinferenceしたいexampleで条件づけてランキングし、良質なものを選択。選択したinstructionでinferenceを実施する。
既存手法よりも高い性能を達成している。特にexampleごとにinstructionを選択する手法の中で最もgainが高い。これは、提案手法がinstructionの選択にtrained modelを利用しているためであると考えられる。
[Paper Note] In-Context Learning Creates Task Vectors, Roee Hendel+, EMNLP'23 Findings, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #In-ContextLearning #EMNLP #read-later #Initial Impression Notes Issue Date: 2023-10-26 GPT Summary- ICLはLLMにおける新しい学習パラダイムで、その機序は未解明である。訓練データ集合を用いる従来の機械学習とは異なり、ICLはデータを単一のタスクベクトルに圧縮し、トランスフォーマーを調整して出力を生成する。多様なモデルとタスクの実験を通じて、この新たな理解を支持する結果を示す。 Comment
参考:
ICLが実現可能なのは実はネットワーク内部で与えられたdemonstrationに対して勾配効果法を再現しているからです、という研究もあったと思うけど、このタスクベクトルとの関係性はどういうものなのだろうか。
文脈に注意を与えなくてもICLと同じ性能が出るのは、文脈情報が不要なタスクを実施しているからであり、そうではないタスクだとこの知見が崩れるのだろうか。後で読む。
openreview: https://openreview.net/forum?id=QYvFUlF19n
[Paper Note] Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions, Pouya Pezeshkpour+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Bias #NAACL #read-later #Selected Papers/Blogs #One-Line Notes #Reading Reflections #needs-revision Issue Date: 2023-08-28 GPT Summary- 多肢選択問題におけるLLMsの性能は選択肢の順序に敏感であり、配置を変えることで最大75%の性能差が見られる。特に、上位選択肢間の不確実性がこの感度を引き起こし、バイアスが影響することを示唆する。最適な配置は、バイアスを増幅させるためにトップ選択肢を両端に置くこと、緩和するためには隣接させることが推奨される。実験を通じて、予測のキャリブレーションにより最大8ポイントの改善が達成された。 Comment
これはそうだろうなと思っていたけど、ここまで性能に差が出るとは思わなかった。
これがもしLLMのバイアスによるもの(2番目の選択肢に正解が多い)の場合、
ランダムにソートしたり、平均取ったりしても、そもそもの正解に常にバイアスがかかっているので、
結局バイアスがかかった結果しか出ないのでは、と思ってしまう。
そうなると、有効なのはone vs. restみたいに、全部該当選択肢に対してyes/noで答えさせてそれを集約させる、みたいなアプローチの方が良いかもしれない。
[Paper Note] LLM-Rec: Personalized Recommendation via Prompting Large Language Models, Hanjia Lyu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #Prompting #NAACL #One-Line Notes Issue Date: 2023-08-02 GPT Summary- テキストベースのレコメンデーションは汎用性が高いが、元のアイテム説明だけではユーザー嗜好との整合性が不足することがある。大規模言語モデル(LLMs)の進歩を活かし、4つのテキスト強化プロンプト戦略を取り入れたアプローチ、LLM-Recを提案。実験により、LLM拡張テキストの使用が推奨品質を向上させることが確かめられ、基本的なMLPモデルでも高い成果を上げることが示された。成功の要因はプロンプト戦略であり、多様な技術がLLMsの推奨効果を高める重要性を示している。 Comment
LLMのpromptingの方法を変更しcontent descriptionだけでなく、様々なコンテキストの追加(e.g. このdescriptionを推薦するならどういう人におすすめ?、アイテム間の共通項を見つける)、内容の拡張等を行いコンテントを拡張して活用するという話っぽい。
[Paper Note] RWKV: Reinventing RNNs for the Transformer Era, Bo Peng+, N_A, EMNLP'23 Findings, 2023.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Transformer #EMNLP #RecurrentModels Issue Date: 2023-06-16 GPT Summary- 本研究では、トランスフォーマーとRNNの両方の利点を組み合わせた新しいモデルアーキテクチャであるRWKVを提案し、トレーニング中に計算を並列化し、推論中に一定の計算およびメモリの複雑さを維持することができます。RWKVは、同じサイズのトランスフォーマーと同等のパフォーマンスを発揮し、将来的にはより効率的なモデルを作成するためにこのアーキテクチャを活用できることを示唆しています。 Comment
(斜め読みしかできておらず、不正確な点が多いと思います。ご容赦ください。)
RWKVの構造は基本的に、residual blockをスタックすることによって構成される。一つのresidual blockは、time-mixing(時間方向の混ぜ合わせ)と、channnel-mixing(要素間での混ぜ合わせ)を行う。
RWKVのカギとなる要素は以下の4つでありこれらが乗算によって交互作用する。RWKVのブロック、およびLMでのアーキテクチャは以下のようになる:
- R: 過去の情報をどれだけ取り入れるかを制御するゲート
- W: positionごとにどれだけ重みを減衰させるかを学習(言い換えると過去の情報をどれだけ減衰させていくか)
- K: attentionのKeyと同じ
- V: attentionのValueと同じ
r, k, vがそれぞれ時刻tでの状態を表しており、Transformerのように過去の全ての情報を保持するのではなく、時刻t-1のr,k,vに基づいて時刻tの状態を更新するためメモリ消費が大幅に削減される。
ここで、token-shiftは、previsou timestepのinputとのlinear interpolationを現在のinputととることである(時刻t-1のinputと時刻tのinputの交互作用をしてr, k, v, r', k' を決定する)。これにより過去の情報を考慮して状態を更新するRNNのような挙動となる。
RWKVは他のLLMと比較し、パラメータ数に対して性能はcomparableであり(Figure4)、context lengthを増やすことで、lossはきちんと低下し(Figure5)、テキスト生成をする際に要する時間は他のLLMと比較して、トークン数に対して線形にしか増加しない(Figure6)。
異なるtransformerとRWKVの計算量とメモリ消費量の比較。Inference timeは系列長に対して線形で、状態の保持は系列長に依存せず、d次元のみで済む。これはRNNのような逐次的な推論の際の話で、学習の際はTransformerのような並列性を持って学習できると思われる(3.2節)
openreview: https://openreview.net/forum?id=7SaXczaBpG
[Paper Note] RISE: Leveraging Retrieval Techniques for Summarization Evaluation, David Uthus+, arXiv'22, 2022.12
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Evaluation #Reference-free #ACL #Surface-level Notes Issue Date: 2023-08-13 GPT Summary- 自動生成された要約の評価は困難であり、これまでの手法は人間の評価に及ばない。新たに提案されたRISEは、デュアルエンコーダー検索設定を用いて生成要約を評価する手法で、ゴールド標準の参照要約がなくても機能する。特に参照要約がない新たなデータセットに対して効果的であり、SummEvalベンチマークでの実験により、人間の評価と高い相関を示した。RISEはデータ効率性と多言語間の一般化可能性も備えている。 Comment
# 概要
Dual-Encoderを用いて、ソースドキュメントとシステム要約をエンコードし、dot productをとることでスコアを得る手法。モデルの訓練は、Contrastive Learningで行い、既存データセットのソースと参照要約のペアを正例とみなし、In Batch trainingする。
# 分類
Reference-free, Model-based, ソース依存で、BARTScore [Paper Note] BARTScore: Evaluating Generated Text as Text Generation, Weizhe Yuan+, arXiv'21, 2021.06
とは異なり、文書要約データを用いて学習するため、要約の評価に特化している点が特徴。
# モデル
## Contrastive Learning
Contrastive Learningを用い、hard negativeを用いたvariantも検証する。また、訓練データとして3種類のパターンを検証する:
1. in-domain data: 文書要約データを用いて訓練し、ターゲットタスクでどれだけの性能を発揮するかを見る
2. out-of-domain data: 文書要約以外のデータを用いて訓練し、どれだけ新しいドメインにモデルがtransferできるかを検証する
3. in-and-out-domain data: 両方やる
## ハードネガティブの生成
Lexical Negatives, Model Negatives, 双方の組み合わせの3種類を用いてハードネガティブを生成する。
### Lexical Negatives
参照要約を拡張することによって生成する。目的は、もともとの参照要約と比較して、poor summaryを生成することにある。Data Augmentationとして、以下の方法を試した:
- Swapping noun entities: 要約中のエンティティを、ソース中のエンティティンとランダムでスワップ
- Shuffling words: 要約中の単語をランダムにシャッフル
- Dropping words: 要約中の単語をランダムに削除
- Dropping characters: 要約中の文字をランダムに削除
- Swapping antonyms: 要約中の単語を対義語で置換
### Model Negatives
データセットの中から負例を抽出する。目的は、参照要約と類似しているが、負例となるサンプルを見つけること。これを実現するために、まずRISE modelをデータセットでfinetuningし、それぞれのソースドキュメントの要約に対して、類似した要約をマイニングする。すべてのドキュメントと要約をエンコードし、top-nの最も類似した要約を見つけ、これをハードネガティブとして、再度モデルを訓練する。
### 両者の組み合わせ
まずlexical negativesでモデルを訓練し、モデルネガティブの抽出に活用する。抽出したモデルネガティブを用いて再度モデルを訓練することで、最終的なモデルとする。
# 実験
## 学習手法
SummEval SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
を用いて人手評価と比較してどれだけcorrelationがあるかを検証。SummEvalには16種類のモデルのアウトプットに対する、CNN / Daily Mail の100 examplesに対して、品質のアノテーションが付与されている。expert annotationを用いて、Kendall's tauを用いてシステムレベルのcorrelationを計算した。contextが短い場合はT5, 長い場合はLongT5, タスクがマルチリンガルな場合はmT5を用いて訓練した。訓練データとしては
- CNN / Daily Mail
- Multi News
- arXiv
- PubMed
- BigPatent
- SAMSum
- Reddit TIFU
- MLSUM
等を用いた。これによりshort / long contextの両者をカバーできる。CNN / Daily Mail, Reddiit TIFU, Multi-Newsはshort-context, arXiv, PubMed, BigPatent, Multi-News(長文のものを利用)はlonger contextとして利用する。
## 比較するメトリック
ROUGE, chrF, SMS, BARTScore, SMART, BLEURT, BERTScore, Q^2, T5-ANLI, PRISMと比較した。結果をみると、Consistency, Fluency, Relevanceで他手法よりも高い相関を得た。Averageでは最も高いAverageを獲得した。in-domain dataで訓練した場合は、高い性能を発揮した。our-of-domain(SAMSum; Dialogue要約のデータ)データでも高い性能を得た。
# Ablation
## ハードネガティブの生成方法
Data Augmentationは、swapping entity nouns, randomly dropping wordsの組み合わせが最も良かった。また、Lexical Negativesは、様々なデータセットで一貫して性能が良かったが、Model NegativesはCNN/DailyMailに対してしか有効ではなかった。これはおそらく、同じタスク(テストデータと同じデータ)でないと、Model Negativesは機能しないことを示唆している。ただし、Model Negativesを入れたら、何もしないよりも性能向上するから、何らかの理由でlexical negativesが生成できない場合はこっち使っても有用である。
## Model Size
でかい方が良い。in-domainならBaseでもそれなりの性能だけど、結局LARGEの方が強い。
## Datasets
異なるデータセットでもtransferがうまく機能している。驚いたことにデータセットをmixingするとあまりうまくいかず、単体のデータセットで訓練したほうが性能が良い。
LongT5を見ると、T5よりもCorrelationが低く難易度が高い。
最終的に英語の要約を評価をする場合でも、Multilingual(別言語)で訓練しても高いCorrelationを示すこともわかった。
## Dataset Size
サンプル数が小さくても有効に働く。しかし、out-domainのデータの場合は、たとえば、512件の場合は性能が低く少しexampleを増やさなければならない。
[Paper Note] MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers, Wenhui Wang+, ACL'21 Findings, 2020.12
Paper/Blog Link My Issue
#NLP #Transformer #Attention #Distillation #ACL #Encoder #KeyPoint Notes Issue Date: 2025-10-20 GPT Summary- 自己注意関係蒸留を用いて、MiniLMの深層自己注意蒸留を一般化し、事前学習されたトランスフォーマーの圧縮を行う手法を提案。クエリ、キー、バリューのベクトル間の関係を定義し、生徒モデルを訓練。注意ヘッド数に制限がなく、教師モデルの層選択戦略を検討。実験により、BERTやRoBERTa、XLM-Rから蒸留されたモデルが最先端の性能を上回ることを示した。 Comment
教師と(より小規模な)生徒モデル間で、tokenごとのq-q/k-k/v-vのdot productによって形成されるrelation map(たとえばq-qの場合はrelatiok mapはトークン数xトークン数の行列で各要素がdot(qi, qj))で表現される関係性を再現できるようにMHAを蒸留するような手法。具体的には、教師モデルのQKVと生徒モデルのQKVによって構成されるそれぞれのrelation map間のKL Divergenceを最小化するように蒸留する。このとき教師モデルと生徒モデルのattention heads数などは異なってもよい(q-q/k-k/v-vそれぞれで定義されるrelation mapははトークン数に依存しており、head数には依存していないため)。
[Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings
Paper/Blog Link My Issue
#MachineTranslation #Transformer #EMNLP #Normalization Issue Date: 2025-08-16 GPT Summary- 低リソース言語翻訳において、QKNormという新しい正規化手法を提案。これは、注意メカニズムを修正し、ソフトマックス関数の飽和耐性を向上させつつ表現力を維持。具体的には、クエリとキー行列に対して$\ell_2$正規化を適用し、学習可能なパラメータでスケールアップ。TED TalksコーパスとIWSLT'15の低リソース翻訳ペアで平均0.928 BLEUの改善を達成。 Comment
QKに対してL2正規化を実施し、learnableなスカラー値を乗じることでスケーリングすることで、low resourceな言語での翻訳性能が向上。MTで実験されているが、transformerの表現力が改善されるのでGLM-4.5のアーキテクチャでも採用されている。
dot product attentionでは内積を利用するため値域に制約がなく、ある単語にのみattention scoreが集中してしまい、他の全ての単語のsignalをかき消してしまう問題がある。このため、QKをノルムによって正規化し(これにより実質QKはcosine similarityとなる)値域を制限する。しかしこうすると今度はスコア間の差が小さすぎて、attendしなくても良い単語を無視できなくなるので、learnableなパラメータでスケールを調整する。
[Paper Note] CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning, Bill Yuchen Lin+, EMNLP'20 Findings
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Dataset #Evaluation #Composition #EMNLP #CommonsenseReasoning Issue Date: 2025-07-31 GPT Summary- 生成的常識推論をテストするためのタスクCommonGenを提案し、35,000の概念セットに基づく79,000の常識的記述を含むデータセットを構築。タスクは、与えられた概念を用いて一貫した文を生成することを求め、関係推論と構成的一般化能力が必要。実験では、最先端モデルと人間のパフォーマンスに大きなギャップがあることが示され、生成的常識推論能力がCommonsenseQAなどの下流タスクに転送可能であることも確認。 Comment
ベンチマークの概要。複数のconceptが与えられた時に、それらconceptを利用した常識的なテキストを生成するベンチマーク。concept間の関係性を常識的な知識から推論し、Unseenなconceptの組み合わせでも意味を構成可能な汎化性能が求められる。
PJ page: https://inklab.usc.edu/CommonGen/