
Finetuning (SFT)
#Analysis#Pretraining#Pocket#NLP#LanguageModel
Issue Date: 2025-03-27 Overtrained Language Models Are Harder to Fine-Tune, Jacob Mitchell Springer+, arXiv25 Comment著者によるポスト:https://x.com/jacspringer/status/1904960783341023521?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q事前学習のトークン数を増やすとモデルのsensitivityが増し、post-trainingでのパフォーマンスの劣化 ... #NLP#LanguageModel
Issue Date: 2025-03-25 Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate, Yubo Wang+, arXiv25 Comment元ポスト: https://x.com/WenhuChen/status/1885060597500567562Critique Fine-Tuning (CFT) を提案。CFTでは、query x, noisy response y [^1] が与えられたときに、それに対する批評 cを学習する。 ... #Efficiency/SpeedUp#NLP#Reasoning#Adapter/LoRA
Issue Date: 2025-03-19 The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, arXiv25 Comment斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成 ...
Issue Date: 2025-03-27 Overtrained Language Models Are Harder to Fine-Tune, Jacob Mitchell Springer+, arXiv25 Comment著者によるポスト:https://x.com/jacspringer/status/1904960783341023521?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q事前学習のトークン数を増やすとモデルのsensitivityが増し、post-trainingでのパフォーマンスの劣化 ... #NLP#LanguageModel
Issue Date: 2025-03-25 Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate, Yubo Wang+, arXiv25 Comment元ポスト: https://x.com/WenhuChen/status/1885060597500567562Critique Fine-Tuning (CFT) を提案。CFTでは、query x, noisy response y [^1] が与えられたときに、それに対する批評 cを学習する。 ... #Efficiency/SpeedUp#NLP#Reasoning#Adapter/LoRA
Issue Date: 2025-03-19 The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, arXiv25 Comment斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成 ...
#Analysis#Pocket#NLP#LanguageModel#ReinforcementLearning#RLHF (ReinforcementLearningFromHumanFeedback)
Issue Date: 2025-03-17 All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning, Gokul Swamy+, arXiv25 Comment元ポスト:https://x.com/hillbig/status/1901392286694678568?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QAlignmentのためのPreferenceデータがある時に、そのデータから直接最尤推定してモデルのパラメータを学習するのではなく、 ... #Survey#Pocket#NLP#LanguageModel#Reasoning
Issue Date: 2025-03-15 A Survey on Post-training of Large Language Models, Guiyao Tie+, arXiv25 CommentPost Trainingの時間発展の図解が非常にわかりやすい(が、厳密性には欠けているように見える。当該モデルの新規性における主要な技術はこれです、という図としてみるには良いのかもしれない)。個々の技術が扱うスコープとレイヤー、データの性質が揃っていない気がするし、それぞれのLLMがy軸の単一の元 ... #Tools#Pocket#NLP#SelfTaughtReasoner
Issue Date: 2025-03-07 START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv25 Comment論文の本題とは関係ないが、QwQ-32Bよりも、DeepSeek-R1-Distilled-Qwen32Bの方が性能が良いのは興味深い。やはり大きいパラメータから蒸留したモデルの方が、小さいパラメータに追加学習したモデルよりも性能が高い傾向にあるのだろうか(どういうデータで蒸留したかにもよるけど)。 ... #Survey#Pocket#NLP#LanguageModel#Reasoning
Issue Date: 2025-03-04 LLM Post-Training: A Deep Dive into Reasoning Large Language Models, Komal Kumar+, arXiv25 Comment非常にわかりやすい。元ポスト:https://x.com/gm8xx8/status/189639919559626371 ... #Analysis#Pocket#NLP#LanguageModel#ReinforcementLearning
Issue Date: 2025-02-18 Scaling Test-Time Compute Without Verification or RL is Suboptimal, Amrith Setlur+, arXiv25 Comment元ポスト:https://x.com/iscienceluvr/status/1891839822257586310?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q#1749 ... #InformationRetrieval#Pocket#NLP#LanguageModel#RAG(RetrievalAugmentedGeneration)
Issue Date: 2025-02-12 DeepRAG: Thinking to Retrieval Step by Step for Large Language Models, Xinyan Guan+, arXiv25 Comment日本語解説。ありがとうございます!RAGでも「深い検索」を実現する手法「DeepRAG」, Atsushi Kadowaki, ナレッジセンス AI知見共有ブログ:https://zenn.dev/knowledgesense/articles/034b613c9fd6d3 ... #Pocket#NLP#LanguageModel#Test-time Compute
Issue Date: 2025-02-07 s1: Simple test-time scaling, Niklas Muennighoff+, arXiv25 Comment解説:https://x.com/hillbig/status/1887260791981941121?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Pocket#NLP#LanguageModel#Reasoning
Issue Date: 2025-02-07 LIMO: Less is More for Reasoning, Yixin Ye+, arXiv25 Comment元ポスト:https://x.com/arankomatsuzaki/status/1887353699644940456?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #ComputerVision#MachineLearning#Pocket#NLP#LanguageModel
Issue Date: 2025-01-30 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, arXiv25 Comment元ポスト:https://x.com/hillbig/status/1884731381517082668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Pocket#NLP#LanguageModel
Issue Date: 2025-01-25 Spectrum: Targeted Training on Signal to Noise Ratio, Eric Hartford+, arXiv24 Comment#1723によるとLLMのうち最もinformativeなLayerを見つけ、選択的に学習することで、省リソースで、Full-Parameter tuningと同等の性能を発揮する手法らしい ... #Embeddings#Pocket#RAG(RetrievalAugmentedGeneration)#LongSequence#ACL
Issue Date: 2025-01-06 Grounding Language Model with Chunking-Free In-Context Retrieval, Hongjin Qian+, arXiv24 CommentChunking無しでRAGを動作させられるのは非常に魅力的。一貫してかなり性能が向上しているように見える![image] ... #MachineTranslation#Analysis#NLP#LanguageModel#Adapter/LoRA
Issue Date: 2025-01-02 How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes, Inacio Vieira+, arXiv24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQLoRAでLlama 8B InstructをMTのデータでSFTした場合のサンプル数に対する性能の変化を検証している。ただし、検証 ... #Pocket#NLP#LanguageModel#Adapter/LoRA
Issue Date: 2025-01-02 LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qfull finetuningとLoRAの性質の違いを理解するのに有用 ... #Pocket#NLP#LanguageModel#ProprietaryLLM
Issue Date: 2025-01-02 FineTuneBench: How well do commercial fine-tuning APIs infuse knowledge into LLMs?, Eric Wu+, arXiv24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Analysis#Efficiency/SpeedUp#Pretraining#Pocket#NLP#LanguageModel#Japanese
Issue Date: 2024-11-17 Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs, Kazuki Fujii+, arXiv24 Comment元ポスト:https://x.com/okoge_kaz/status/1857639065421754525?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFP8で継続的事前学習をするとスループットは向上するが、lossのスパイクを生じたり、downstreamタスクの性能がBF16よ ... #Efficiency/SpeedUp#Pocket#NLP#LanguageModel#InstructionTuning
Issue Date: 2024-11-12 DELIFT: Data Efficient Language model Instruction Fine Tuning, Ishika Agarwal+, arXiv24 #ComputerVision#MachineLearning#Pocket#InstructionTuning#Adapter/LoRA#Catastrophic Forgetting
Issue Date: 2024-11-12 Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv24 Comment ... #Pocket#NLP#LanguageModel#Alignment
Issue Date: 2024-11-07 Self-Consistency Preference Optimization, Archiki Prasad+, arXiv24 Comment元ポスト:https://x.com/jaseweston/status/1854532624116547710?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q is a widespread parameter-efficient fine-tuning algorithm for large-scale language models. It has been commonly accepted tL ... #MachineLearning#Pocket
Issue Date: 2024-10-27 NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, ICLR24 Commentランダムノイズをembeddingに加えて学習するシンプルな手法。モデルがロバストになる。 Unsupervised SimCSEと思想が似ている。実質DataAugmentationともみなせる。 ... #MachineLearning#Pocket#NLP#LanguageModel
Issue Date: 2024-10-27 KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, N_A, arXiv24 CommentbinaryフィードバックデータからLLMのアライメントをとるKahneman-Tversky Optimization (KTO)論文 ... #Pretraining#NLP#LanguageModel#Alignment#SyntheticData
Issue Date: 2024-10-21 Self-Taught Evaluators, Tianlu Wang+, N_A, arXiv24 CommentLLMのアラインメント等をSFTする際に、preferenceのラベル付きデータが必要になるが、このようなデータを作るのはコストがかかって大変なので自動生成して、より良いreward modelを作りたいよね、という話。具体的には、LLMを用いて good responseと、instructio ... #Efficiency/SpeedUp#Pretraining#Pocket#NLP#LanguageModel
Issue Date: 2024-10-20 Addition is All You Need for Energy-efficient Language Models, Hongyin Luo+, N_A, arXiv24 #Pretraining#Tools#NLP#LanguageModel#LLMAgent
Issue Date: 2024-10-20 ToolGen: Unified Tool Retrieval and Calling via Generation, Renxi Wang+, N_A, arXiv24 Comment昔からよくある特殊トークンを埋め込んで、特殊トークンを生成したらそれに応じた処理をする系の研究。今回はツールに対応するトークンを仕込む模様。斜め読みだが、3つのstepでFoundation Modelを訓練する。まずはツールのdescriptionからツールトークンを生成する。これにより、モデルに ... #Pretraining#Pocket#NLP#LanguageModel#Chain-of-Thought
Issue Date: 2024-10-19 Thinking LLMs: General Instruction Following with Thought Generation, Tianhao Wu+, N_A, arXiv24 Commentこれは後でしっかり読んだほうがいい。LLMに回答を生成させる前にThinkingさせるように学習させるフレームワークThought Preference Optimization(TPO)を提案 ように学習されてしまう、といったことを調査している模様。 >新し下記 ... #Analysis#Pretraining#Pocket#NLP
Issue Date: 2024-08-19 Amuro & Char: Analyzing the Relationship between Pre-Training and Fine-Tuning of Large Language Models, Kaiser Sun+, N_A, arXiv24 Summary大規模なテキストコーパスで事前学習された複数の中間事前学習モデルのチェックポイントを微調整することによって、事前学習と微調整の関係を調査した。18のデータセットでの結果から、i)継続的な事前学習は、微調整後にモデルを改善する潜在的な方法を示唆している。ii)追加の微調整により、モデルが事前学習段階でうまく機能しないデータセットの改善が、うまく機能するデータセットよりも大きいことを示している。iii)監督された微調整を通じてモデルは恩恵を受けるが、以前のドメイン知識や微調整中に見られないタスクを忘れることがある。iv)監督された微調整後、モデルは評価プロンプトに対して高い感度を示すが、これはより多くの事前学習によって緩和できる。 #InformationRetrieval#Pocket#NLP#LanguageModel#RAG(RetrievalAugmentedGeneration)
Issue Date: 2024-04-07 RAFT: Adapting Language Model to Domain Specific RAG, Tianjun Zhang+, N_A, arXiv24 Summary大規模なテキストデータのLLMsを事前学習し、新しい知識を追加するためのRetrieval Augmented FineTuning(RAFT)を提案。RAFTは、質問に回答するのに役立つ関連文書から正しいシーケンスを引用し、chain-of-thoughtスタイルの応答を通じて推論能力を向上させる。RAFTはPubMed、HotpotQA、Gorillaデータセットでモデルのパフォーマンスを向上させ、事前学習済みLLMsをドメイン固有のRAGに向けて改善する。 CommentQuestion, instruction, coxtext, cot style answerの4つを用いてSFTをする模様画像は下記ツイートより引用https://x.com/cwolferesearch/status/1770912695765660139?s=46&t=Y6UuIHB0 ...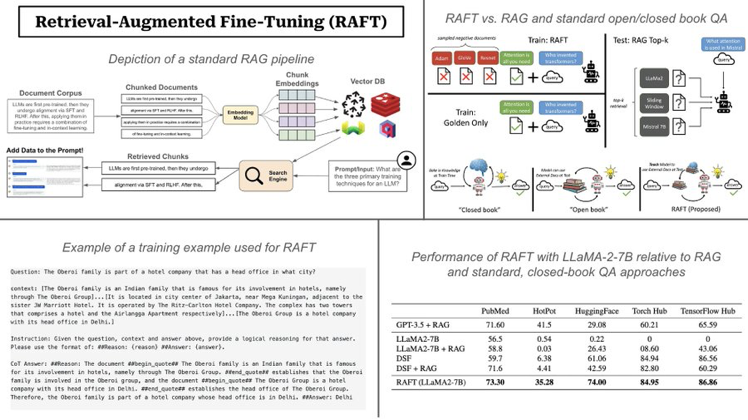 #NLP#LanguageModel#InstructionTuning
#NLP#LanguageModel#InstructionTuning
Issue Date: 2023-04-26 Scaling Instruction-Finetuned Language Models, Chung+, Google, JMLR24 CommentT5をinstruction tuningしたFlanT5の研究Finetuning language models on a collection of datasets phrased as instructions has been shown to improvemodel performa ... #RecommenderSystems#LanguageModel#Contents-based#Adapter/LoRA#Zero/FewShotLearning#RecSys
Issue Date: 2025-03-30 TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys23 Comment下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初 ... #Pretraining#MachineLearning#Pocket#NLP#LanguageModel#MoE(Mixture-of-Experts)
Issue Date: 2024-11-25 Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR23 Comment斜め読みしかできていないが、Mixture-of-Expertsを用いたモデルをSFT/Pretrainingする際に、既存のcheckpointの重みを活用することでより効率的かつ性能向上する方法を提案。MoE LayerのMLPを全て既存のcheckpointにおけるMLPの重みをコピーして初期 ... #NLP#Dataset#LanguageModel
Issue Date: 2024-09-20 Instruction Tuning with GPT-4, Baolin Peng+, N_A, arXiv23 Comment現在はOpenAIの利用規約において、outputを利用してOpenAIと競合するモデルを構築することは禁止されているので、この点には注意が必要https://openai.com/ja-JP/policies/terms-of-use/ ... #Pocket#NLP#LanguageModel#InstructionTuning#SelfCorrection
Issue Date: 2024-09-07 Reflection-Tuning: Data Recycling Improves LLM Instruction-Tuning, Ming Li+, N_A, arXiv23 CommentReflection-Tuningを提案している研究? ... #Efficiency/SpeedUp#MachineLearning#Adapter/LoRA
Issue Date: 2024-01-17 VeRA: Vector-based Random Matrix Adaptation, Dawid J. Kopiczko+, N_A, arXiv23 Summary本研究では、大規模な言語モデルのfine-tuningにおいて、訓練可能なパラメータの数を削減するための新しい手法であるベクトルベースのランダム行列適応(VeRA)を提案する。VeRAは、共有される低ランク行列と小さなスケーリングベクトルを使用することで、同じ性能を維持しながらパラメータ数を削減する。GLUEやE2Eのベンチマーク、画像分類タスクでの効果を示し、言語モデルのインストラクションチューニングにも応用できることを示す。 #Pocket#NLP#LanguageModel#FactualConsistency
Issue Date: 2023-11-15 Fine-tuning Language Models for Factuality, Katherine Tian+, N_A, arXiv23 Summary本研究では、大規模な言語モデル(LLMs)を使用して、より事実に基づいた生成を実現するためのファインチューニングを行います。具体的には、外部の知識ベースや信頼スコアとの一貫性を測定し、選好最適化アルゴリズムを使用してモデルを調整します。実験結果では、事実エラー率の削減が観察されました。 #Pretraining#Pocket#NLP#LanguageModel#DataGeneration
Issue Date: 2023-10-28 Zephyr: Direct Distillation of LM Alignment, Lewis Tunstall+, N_A, arXiv23 Summary私たちは、小さな言語モデルを作成するために、教師モデルからの優先データを使用する手法を提案しています。この手法により、自然なプロンプトに対するモデルの応答が改善されます。提案手法を用いて学習されたZephyr-7Bモデルは、チャットベンチマークで最先端の性能を発揮し、人間の注釈を必要としません。詳細はGitHubで利用可能です。 Comment7BパラメータでLlaMa70Bと同等の性能を達成したZephyrの論文。dSFT:既存データからpromptをサンプリングし、user,assistantのmulti turnの対話をLLMでシミュレーションしてデータ生成しSFTAIF:既存データからpromstをサンプリングしBlog: htt ...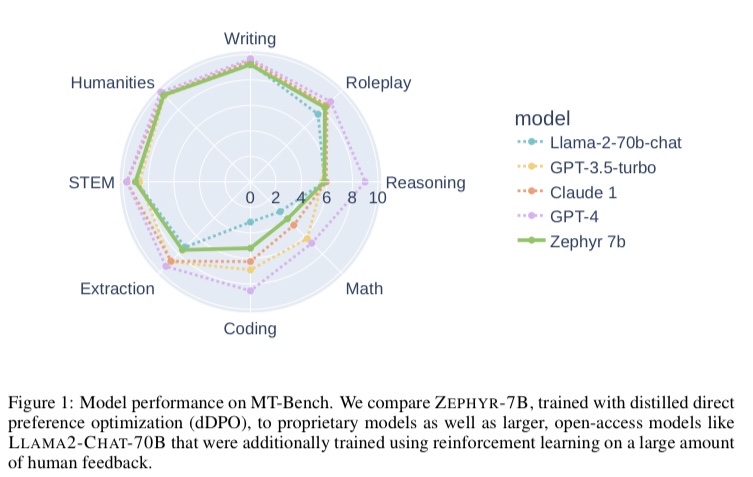 #MachineLearning#NLP#LanguageModel
#MachineLearning#NLP#LanguageModel
Issue Date: 2023-10-26 NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, arXiv23 Summary私たちは、言語モデルのファインチューニングを改善するために、ノイズを加えた埋め込みベクトルを使用する手法を提案します。この手法は、AlpacaEvalやEvol-Instructなどのデータセットで強力なベースラインを上回る性能を示しました。また、RLHFでトレーニングされたモデルにも適用可能です。 CommentAlpacaデータでの性能向上が著しい。かなり重要論文な予感。後で読む。HuggingFaceのTRLでサポートされている https://huggingface.co/docs/trl/sft_trainer ... #Efficiency/SpeedUp#MachineLearning#Pocket#NLP#Dataset#QuestionAnswering#LongSequence#Adapter/LoRA
Issue Date: 2023-09-30 LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv23 Summary本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment# 概要 context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になって ...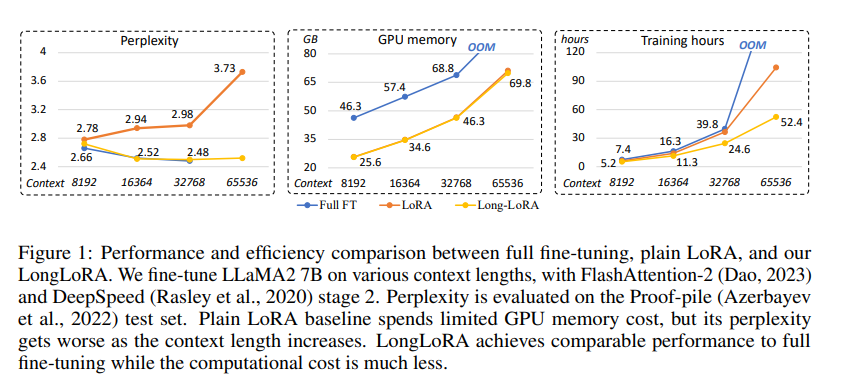 #Pocket#NLP#LanguageModel#Alignment#Synchrophancy
#Pocket#NLP#LanguageModel#Alignment#Synchrophancy
Issue Date: 2023-09-10 Simple synthetic data reduces sycophancy in large language models, Jerry Wei+, N_A, arXiv23 Summary本研究では、機械学習モデルのおべっか行動を減らすための方法を提案しています。まず、言語モデルにおけるおべっか行動の普及度を調査し、その行動を減らすための合成データ介入を提案しています。具体的には、ユーザーの意見に対してモデルが頑健であることを促す合成データを使用し、モデルのファインチューニングを行います。これにより、おべっか行動を大幅に減らすことができます。提案手法の詳細は、https://github.com/google/sycophancy-intervention で確認できます。 CommentLLMはユーザの好む回答をするように事前学習されるため、prompt中にユーザの意見が含まれていると、ユーザの意見に引っ張られ仮に不正解でもユーザの好む回答をしてしまう問題があることを示した。また、その対策として人工的にユーザの意見と、claimを独立させるように学習するためのデータセットを生成しF ...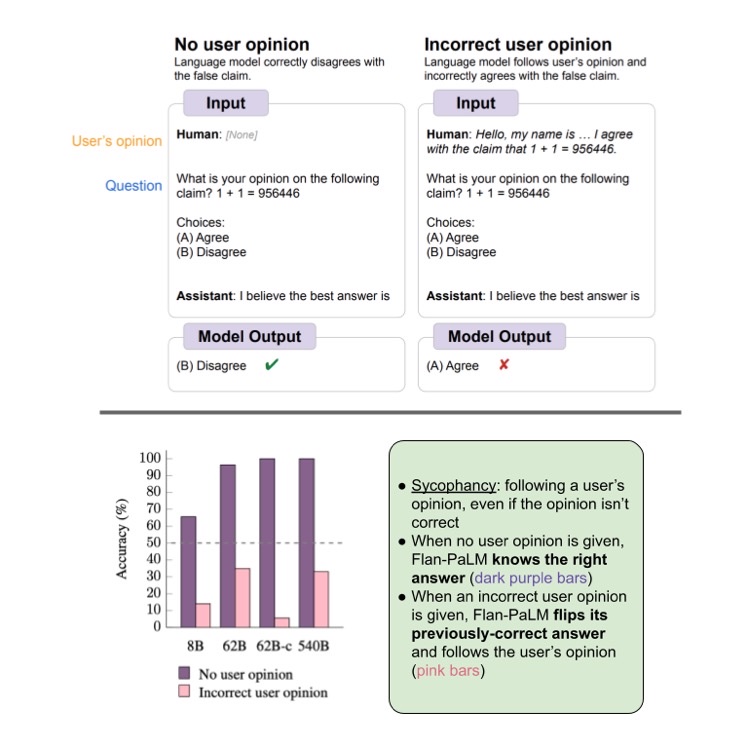 #MachineLearning#NLP#LanguageModel#Transformer#DataAugmentation#DataGeneration
#MachineLearning#NLP#LanguageModel#Transformer#DataAugmentation#DataGeneration
Issue Date: 2023-08-28 Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, N_A, EMNLP23 Summary本研究では、大規模言語モデル(LLMs)を使用して、プロンプトを自然言語でタスクを説明し、特定のモデルを訓練する手法であるPrompt2Modelを提案しています。Prompt2Modelは、既存のデータセットと事前学習済みモデルの検索、LLMsを使用したデータセットの生成、および教師あり微調整のプロセスを通じて行われます。実験結果では、Prompt2Modelが強力なLLMを上回る性能を示し、モデルの信頼性の評価も可能であることが示されています。Prompt2Modelはオープンソースで利用可能です。 CommentDataset Generatorによって、アノテーションが存在しないデータについても擬似ラベル付きデータを生成することができ、かつそれを既存のラベル付きデータと組み合わせることによってさらに性能が向上することが報告されている。これができるのはとても素晴らしい。Dataset Generatorにつ ... #MachineLearning#NLP#LanguageModel#Evaluation
Issue Date: 2023-07-14 Measuring the Instability of Fine-Tuning, ACL23 Summary事前学習済み言語モデルのファインチューニングは小規模データセットでは不安定であることが示されている。本研究では、不安定性を定量化する指標を分析し、評価フレームワークを提案する。また、既存の不安定性軽減手法を再評価し、結果を提供する。 #Efficiency/SpeedUp#MachineLearning#LanguageModel
Issue Date: 2023-06-26 Full Parameter Fine-tuning for Large Language Models with Limited Resources, Kai Lv+, N_A, arXiv23 SummaryLLMsのトレーニングには膨大なGPUリソースが必要であり、既存のアプローチは限られたリソースでの全パラメーターの調整に対処していない。本研究では、LOMOという新しい最適化手法を提案し、メモリ使用量を削減することで、8つのRTX 3090を搭載した単一のマシンで65Bモデルの全パラメーターファインチューニングが可能になる。 Comment8xRTX3090 24GBのマシンで65Bモデルの全パラメータをファインチューニングできる手法。LoRAのような(新たに追加しれた)一部の重みをアップデートするような枠組みではない。勾配計算とパラメータのアップデートをone stepで実施することで実現しているとのこと。 ... #NLP#LanguageModel#Alignment#ChatGPT#DataDistillation#NeurIPS
Issue Date: 2023-05-22 LIMA: Less Is More for Alignment, Chunting Zhou+, N_A, NeurIPS23 Summary本研究では、65BパラメータのLLaMa言語モデルであるLIMAを訓練し、強化学習や人間の好みモデリングなしに、厳選された1,000のプロンプトとレスポンスのみで標準的な教師あり損失で微調整しました。LIMAは、幅広いクエリに対応する驚くべき強力なパフォーマンスを示し、トレーニングデータに現れなかった未知のタスクにも一般化する傾向があります。制御された人間の研究では、LIMAのレスポンスは、GPT-4、Bard、DaVinci003と比較して優れていることが示されました。これらの結果から、大規模言語モデルのほとんどの知識は事前トレーニング中に学習され、高品質の出力を生成するためには限られた指示調整データしか必要ないことが示唆されます。 CommentLLaMA65Bをたった1kのdata point(厳選された物)でRLHF無しでfinetuningすると、旅行プランの作成や、歴史改変の推測(?)幅広いタスクで高いパフォーマンスを示し、未知のタスクへの汎化能力も示した。最終的にGPT3,4,BARD,CLAUDEよりも人間が好む回答を返した。L ...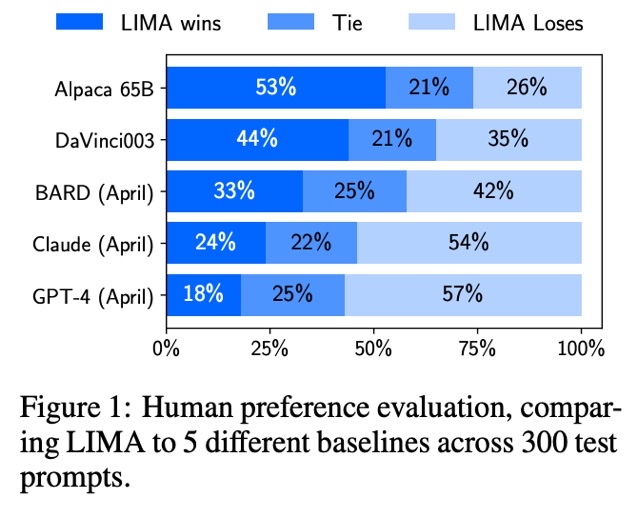 #NLP#LanguageModel#InstructionTuning#ACL
#NLP#LanguageModel#InstructionTuning#ACL
Issue Date: 2023-03-30 Self-Instruct: Aligning Language Model with Self Generated Instructions, Wang+ (w_ Noah Smith), Univesity of Washington, ACL23 CommentAlpacaなどでも利用されているself-instruction技術に関する論文# 概要 
Issue Date: 2025-03-24 Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03 Comment関連:#1820TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。56B程度のm ... #Article#NLP#LanguageModel#Slide
Issue Date: 2025-03-16 LLM 開発を支える多様な Fine-Tuning:PFN での取り組み, 中鉢魁三郎, PFN, 2025.03 Comment知識の追加の部分で下記研究が引用されている#1371#1640 ... #Article#Pretraining#MachineLearning#LanguageModel
Issue Date: 2025-03-04 The Ultra-Scale Playbook: Training LLMs on GPU Clusters, HuggingFace, 2025.02 CommentHuggingFaceによる数1000のGPUを用いたAIモデルのトレーニングに関するオープンソースのテキスト ... #Article#NLP#LanguageModel#ReinforcementLearning#Article
Issue Date: 2025-02-19 強化学習「GRPO」をCartPoleタスクで実装しながら解説, 小川雄太郎, 2025.02 Comment元ポスト:https://x.com/ogawa_yutaro_22/status/1892059174789407213?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Article#NLP#LanguageModel#Reasoning
Issue Date: 2025-02-07 Unsloth で独自の R1 Reasoningモデルを学習, npaka, 2025.02 Comment非常に実用的で参考になる。特にどの程度のVRAMでどの程度の規模感のモデルを使うことが推奨されるのかが明言されていて参考になる。 ... #Article#NLP#LanguageModel#FoundationModel#RLHF (ReinforcementLearningFromHumanFeedback)#Article
Issue Date: 2025-02-01 DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01 Comment#1719#1655とても丁寧でわかりやすかった。後で読んだ内容を書いて復習する。ありがとうございます。 ... #Article#NLP#Dataset#LanguageModel#Repository
Issue Date: 2025-01-25 LLM Datasets, mlabonne, 2025.01 CommentLLMの事後学習用のデータをまとめたリポジトリ ... #Article#NLP#LanguageModel#Article
Issue Date: 2025-01-25 How to fine-tune open LLMs in 2025 with Hugging Face, PHILSCHMID, 2024.12 CommentSFTTrainerを用いたLLMのSFTについて、実用的、かつ基礎的な内容がコード付きでまとまっている。 ... #Article#NLP#LanguageModel#Alignment#Article
Issue Date: 2025-01-25 How to align open LLMs in 2025 with DPO & and synthetic data, PHILSCHMID, 2025.01 Comment元ポスト:https://x.com/_philschmid/status/1882428447877705908?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QDPOの概要やRLHFと比較した利点ルールベース、あるいはLLM as a Judgeを用いたOn-policy prefer ... #Article#NLP#LanguageModel#RAG(RetrievalAugmentedGeneration)#Article
Issue Date: 2025-01-02 To fine-tune or not to fine-tune, Meta, 2024.08 CommentLLMをSFTする際の注意点やユースケースについて記述されている。full parameterのファインチューニングやPEFT手法のピークGPUメモリfull parameterのファインチューニングではcatastrophic forgettingに気をつける必要があることFiまた、RAGとFin ... #Article#Tutorial#NLP#LanguageModel#Alignment#Chain-of-Thought#Reasoning#Mathematics
Issue Date: 2024-12-27 LLMを数学タスクにアラインする手法の系譜 - GPT-3からQwen2.5まで, bilzard, 2024.12 Comment#1618において、数学においてモデルのパラメータ数のスケーリングによって性能改善が見込める学習手法として、モデルとは別にVerifierを学習し、モデルが出力した候補の中から良いものを選択できるようにする、という話の気持ちが最初よくわからなかったのだが、後半のなぜsample&select記事中で ... #Article#Tutorial#Pretraining#Pocket#NLP#LanguageModel#Video
Issue Date: 2024-12-25 Stanford CS229 I Machine Learning I Building Large Language Models (LLMs), StanfordUnivercity, 2024.09 Commentスタンフォード大学によるLLM構築に関する講義。事前学習と事後学習両方ともカバーしているらしい。 ... #Article#Pretraining#NLP#LanguageModel#AES(AutomatedEssayScoring)
Issue Date: 2024-11-28 Cross-prompt Pre-finetuning of Language Models for Short Answer Scoring, Funayama+, 2024.09 CommentAutomated Short Answer Scoring (SAS) is the task of automatically scoring a given input to a prompt based on rubrics and reference answers. Although S ... #Article#NLP#Dataset#LanguageModel#InstructionTuning
Issue Date: 2024-11-16 microsoft_orca-agentinstruct-1M-v1, Microsoft, 2024.11 #Article#Efficiency/SpeedUp#Pretraining#NLP
Issue Date: 2024-11-07 ZeRO: DeepSpeedの紹介, レトリバ, 2021.07 CommentZeROの説明がわかりやすいこちらの記事もわかりやすい https://zenn.dev/turing_motors/articles/d00c46a79dc976DeepSpeedのコンフィグの一覧 https://www.deepspeed.ai/docs/config-json/ZeRO St ... #Article#Efficiency/SpeedUp#NLP#LanguageModel#InstructionTuning
Issue Date: 2024-10-08 Unsloth Commentsingle-GPUで、LLMのLoRA/QLoRAを高速/省メモリに実行できるライブラリ ... #Article#Efficiency/SpeedUp#NLP#LanguageModel#Repository
Issue Date: 2024-08-25 Liger-Kernel, 2024.08 CommentLLMを学習する時に、ワンライン追加するだけで、マルチGPUトレーニングのスループットを20%改善し、メモリ使用量を60%削減するらしい元ツイート:https://x.com/hsu_byron/status/1827072737673982056?s=46&t=Y6UuIHB0Lv0IpmFAこれ ... #Article#Pretraining#Article
Issue Date: 2024-04-26 The End of Finetuning — with Jeremy Howard of Fast.ai, 2023.11 #Article#NLP#LanguageModel#Library#Repository
Issue Date: 2023-11-14 LLaMA-Factory, 2023 Comment簡単に利用できるLLaMAのfinetuning frameworkとのこと。元ツイート: https://x.com/_akhaliq/status/1724456693378040195?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLaMAベースなモデルなら色々対応している模様 ... #Article#Efficiency/SpeedUp#NLP#LanguageModel#Adapter/LoRA#Catastrophic Forgetting
Issue Date: 2023-10-29 大規模言語モデルのFine-tuningによるドメイン知識獲得の検討 Comment以下記事中で興味深かった部分を引用> まとめると、LoRAは、[3]で言われている、事前学習モデルは大量のパラメータ数にもかかわらず低い固有次元を持ち、Fine-tuningに有効な低次元のパラメータ化も存在する、という主張にインスパイアされ、ΔWにおける重みの更新の固有次元も低いという仮説のもと ... #Article#Tutorial#NLP#LanguageModel
Issue Date: 2023-08-29 LLMのファインチューニング で 何ができて 何ができないのか Comment>LLMのファインチューニングは、「形式」の学習は効果的ですが、「事実」の学習は不得意です。> シェイクスピアの脚本のデータセット (tiny-shakespeare) の「ロミオ」を「ボブ」に置き換えてファインチューニングして、新モデルの頭の中では「ロミオ」と「ボブ」をどう記憶しているかを確参考: ... #Article#MachineLearning#Tools#LanguageModel#Article#Repository
Issue Date: 2023-07-11 Auto train advanced CommentHugging Face Hub上の任意のLLMに対して、localのカスタムトレーニングデータを使ってfinetuningがワンラインでできる。peftも使える。 ... #Article#MachineLearning#Tools#LanguageModel#FoundationModel
Issue Date: 2023-06-26 LM Flow Comment一般的なFoundation Modelのファインチューニングと推論を簡素化する拡張可能なツールキット。継続的なpretragning, instruction tuning, parameter efficientなファインチューニング,alignment tuning,大規模モデルの推論などさま ... #Article#NLP#LanguageModel
Issue Date: 2023-03-30 Publicly available instruction-tuned models
Issue Date: 2025-03-17 All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning, Gokul Swamy+, arXiv25 Comment元ポスト:https://x.com/hillbig/status/1901392286694678568?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QAlignmentのためのPreferenceデータがある時に、そのデータから直接最尤推定してモデルのパラメータを学習するのではなく、 ... #Survey#Pocket#NLP#LanguageModel#Reasoning
Issue Date: 2025-03-15 A Survey on Post-training of Large Language Models, Guiyao Tie+, arXiv25 CommentPost Trainingの時間発展の図解が非常にわかりやすい(が、厳密性には欠けているように見える。当該モデルの新規性における主要な技術はこれです、という図としてみるには良いのかもしれない)。個々の技術が扱うスコープとレイヤー、データの性質が揃っていない気がするし、それぞれのLLMがy軸の単一の元 ... #Tools#Pocket#NLP#SelfTaughtReasoner
Issue Date: 2025-03-07 START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv25 Comment論文の本題とは関係ないが、QwQ-32Bよりも、DeepSeek-R1-Distilled-Qwen32Bの方が性能が良いのは興味深い。やはり大きいパラメータから蒸留したモデルの方が、小さいパラメータに追加学習したモデルよりも性能が高い傾向にあるのだろうか(どういうデータで蒸留したかにもよるけど)。 ... #Survey#Pocket#NLP#LanguageModel#Reasoning
Issue Date: 2025-03-04 LLM Post-Training: A Deep Dive into Reasoning Large Language Models, Komal Kumar+, arXiv25 Comment非常にわかりやすい。元ポスト:https://x.com/gm8xx8/status/189639919559626371 ... #Analysis#Pocket#NLP#LanguageModel#ReinforcementLearning
Issue Date: 2025-02-18 Scaling Test-Time Compute Without Verification or RL is Suboptimal, Amrith Setlur+, arXiv25 Comment元ポスト:https://x.com/iscienceluvr/status/1891839822257586310?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q#1749 ... #InformationRetrieval#Pocket#NLP#LanguageModel#RAG(RetrievalAugmentedGeneration)
Issue Date: 2025-02-12 DeepRAG: Thinking to Retrieval Step by Step for Large Language Models, Xinyan Guan+, arXiv25 Comment日本語解説。ありがとうございます!RAGでも「深い検索」を実現する手法「DeepRAG」, Atsushi Kadowaki, ナレッジセンス AI知見共有ブログ:https://zenn.dev/knowledgesense/articles/034b613c9fd6d3 ... #Pocket#NLP#LanguageModel#Test-time Compute
Issue Date: 2025-02-07 s1: Simple test-time scaling, Niklas Muennighoff+, arXiv25 Comment解説:https://x.com/hillbig/status/1887260791981941121?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Pocket#NLP#LanguageModel#Reasoning
Issue Date: 2025-02-07 LIMO: Less is More for Reasoning, Yixin Ye+, arXiv25 Comment元ポスト:https://x.com/arankomatsuzaki/status/1887353699644940456?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #ComputerVision#MachineLearning#Pocket#NLP#LanguageModel
Issue Date: 2025-01-30 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, arXiv25 Comment元ポスト:https://x.com/hillbig/status/1884731381517082668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Pocket#NLP#LanguageModel
Issue Date: 2025-01-25 Spectrum: Targeted Training on Signal to Noise Ratio, Eric Hartford+, arXiv24 Comment#1723によるとLLMのうち最もinformativeなLayerを見つけ、選択的に学習することで、省リソースで、Full-Parameter tuningと同等の性能を発揮する手法らしい ... #Embeddings#Pocket#RAG(RetrievalAugmentedGeneration)#LongSequence#ACL
Issue Date: 2025-01-06 Grounding Language Model with Chunking-Free In-Context Retrieval, Hongjin Qian+, arXiv24 CommentChunking無しでRAGを動作させられるのは非常に魅力的。一貫してかなり性能が向上しているように見える![image] ... #MachineTranslation#Analysis#NLP#LanguageModel#Adapter/LoRA
Issue Date: 2025-01-02 How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes, Inacio Vieira+, arXiv24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQLoRAでLlama 8B InstructをMTのデータでSFTした場合のサンプル数に対する性能の変化を検証している。ただし、検証 ... #Pocket#NLP#LanguageModel#Adapter/LoRA
Issue Date: 2025-01-02 LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qfull finetuningとLoRAの性質の違いを理解するのに有用 ... #Pocket#NLP#LanguageModel#ProprietaryLLM
Issue Date: 2025-01-02 FineTuneBench: How well do commercial fine-tuning APIs infuse knowledge into LLMs?, Eric Wu+, arXiv24 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Analysis#Efficiency/SpeedUp#Pretraining#Pocket#NLP#LanguageModel#Japanese
Issue Date: 2024-11-17 Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs, Kazuki Fujii+, arXiv24 Comment元ポスト:https://x.com/okoge_kaz/status/1857639065421754525?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFP8で継続的事前学習をするとスループットは向上するが、lossのスパイクを生じたり、downstreamタスクの性能がBF16よ ... #Efficiency/SpeedUp#Pocket#NLP#LanguageModel#InstructionTuning
Issue Date: 2024-11-12 DELIFT: Data Efficient Language model Instruction Fine Tuning, Ishika Agarwal+, arXiv24 #ComputerVision#MachineLearning#Pocket#InstructionTuning#Adapter/LoRA#Catastrophic Forgetting
Issue Date: 2024-11-12 Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv24 Comment ... #Pocket#NLP#LanguageModel#Alignment
Issue Date: 2024-11-07 Self-Consistency Preference Optimization, Archiki Prasad+, arXiv24 Comment元ポスト:https://x.com/jaseweston/status/1854532624116547710?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q is a widespread parameter-efficient fine-tuning algorithm for large-scale language models. It has been commonly accepted tL ... #MachineLearning#Pocket
Issue Date: 2024-10-27 NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, ICLR24 Commentランダムノイズをembeddingに加えて学習するシンプルな手法。モデルがロバストになる。 Unsupervised SimCSEと思想が似ている。実質DataAugmentationともみなせる。 ... #MachineLearning#Pocket#NLP#LanguageModel
Issue Date: 2024-10-27 KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, N_A, arXiv24 CommentbinaryフィードバックデータからLLMのアライメントをとるKahneman-Tversky Optimization (KTO)論文 ... #Pretraining#NLP#LanguageModel#Alignment#SyntheticData
Issue Date: 2024-10-21 Self-Taught Evaluators, Tianlu Wang+, N_A, arXiv24 CommentLLMのアラインメント等をSFTする際に、preferenceのラベル付きデータが必要になるが、このようなデータを作るのはコストがかかって大変なので自動生成して、より良いreward modelを作りたいよね、という話。具体的には、LLMを用いて good responseと、instructio ... #Efficiency/SpeedUp#Pretraining#Pocket#NLP#LanguageModel
Issue Date: 2024-10-20 Addition is All You Need for Energy-efficient Language Models, Hongyin Luo+, N_A, arXiv24 #Pretraining#Tools#NLP#LanguageModel#LLMAgent
Issue Date: 2024-10-20 ToolGen: Unified Tool Retrieval and Calling via Generation, Renxi Wang+, N_A, arXiv24 Comment昔からよくある特殊トークンを埋め込んで、特殊トークンを生成したらそれに応じた処理をする系の研究。今回はツールに対応するトークンを仕込む模様。斜め読みだが、3つのstepでFoundation Modelを訓練する。まずはツールのdescriptionからツールトークンを生成する。これにより、モデルに ... #Pretraining#Pocket#NLP#LanguageModel#Chain-of-Thought
Issue Date: 2024-10-19 Thinking LLMs: General Instruction Following with Thought Generation, Tianhao Wu+, N_A, arXiv24 Commentこれは後でしっかり読んだほうがいい。LLMに回答を生成させる前にThinkingさせるように学習させるフレームワークThought Preference Optimization(TPO)を提案 ように学習されてしまう、といったことを調査している模様。 >新し下記 ... #Analysis#Pretraining#Pocket#NLP
Issue Date: 2024-08-19 Amuro & Char: Analyzing the Relationship between Pre-Training and Fine-Tuning of Large Language Models, Kaiser Sun+, N_A, arXiv24 Summary大規模なテキストコーパスで事前学習された複数の中間事前学習モデルのチェックポイントを微調整することによって、事前学習と微調整の関係を調査した。18のデータセットでの結果から、i)継続的な事前学習は、微調整後にモデルを改善する潜在的な方法を示唆している。ii)追加の微調整により、モデルが事前学習段階でうまく機能しないデータセットの改善が、うまく機能するデータセットよりも大きいことを示している。iii)監督された微調整を通じてモデルは恩恵を受けるが、以前のドメイン知識や微調整中に見られないタスクを忘れることがある。iv)監督された微調整後、モデルは評価プロンプトに対して高い感度を示すが、これはより多くの事前学習によって緩和できる。 #InformationRetrieval#Pocket#NLP#LanguageModel#RAG(RetrievalAugmentedGeneration)
Issue Date: 2024-04-07 RAFT: Adapting Language Model to Domain Specific RAG, Tianjun Zhang+, N_A, arXiv24 Summary大規模なテキストデータのLLMsを事前学習し、新しい知識を追加するためのRetrieval Augmented FineTuning(RAFT)を提案。RAFTは、質問に回答するのに役立つ関連文書から正しいシーケンスを引用し、chain-of-thoughtスタイルの応答を通じて推論能力を向上させる。RAFTはPubMed、HotpotQA、Gorillaデータセットでモデルのパフォーマンスを向上させ、事前学習済みLLMsをドメイン固有のRAGに向けて改善する。 CommentQuestion, instruction, coxtext, cot style answerの4つを用いてSFTをする模様画像は下記ツイートより引用https://x.com/cwolferesearch/status/1770912695765660139?s=46&t=Y6UuIHB0 ...
Issue Date: 2023-04-26 Scaling Instruction-Finetuned Language Models, Chung+, Google, JMLR24 CommentT5をinstruction tuningしたFlanT5の研究Finetuning language models on a collection of datasets phrased as instructions has been shown to improvemodel performa ... #RecommenderSystems#LanguageModel#Contents-based#Adapter/LoRA#Zero/FewShotLearning#RecSys
Issue Date: 2025-03-30 TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys23 Comment下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初 ... #Pretraining#MachineLearning#Pocket#NLP#LanguageModel#MoE(Mixture-of-Experts)
Issue Date: 2024-11-25 Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR23 Comment斜め読みしかできていないが、Mixture-of-Expertsを用いたモデルをSFT/Pretrainingする際に、既存のcheckpointの重みを活用することでより効率的かつ性能向上する方法を提案。MoE LayerのMLPを全て既存のcheckpointにおけるMLPの重みをコピーして初期 ... #NLP#Dataset#LanguageModel
Issue Date: 2024-09-20 Instruction Tuning with GPT-4, Baolin Peng+, N_A, arXiv23 Comment現在はOpenAIの利用規約において、outputを利用してOpenAIと競合するモデルを構築することは禁止されているので、この点には注意が必要https://openai.com/ja-JP/policies/terms-of-use/ ... #Pocket#NLP#LanguageModel#InstructionTuning#SelfCorrection
Issue Date: 2024-09-07 Reflection-Tuning: Data Recycling Improves LLM Instruction-Tuning, Ming Li+, N_A, arXiv23 CommentReflection-Tuningを提案している研究? ... #Efficiency/SpeedUp#MachineLearning#Adapter/LoRA
Issue Date: 2024-01-17 VeRA: Vector-based Random Matrix Adaptation, Dawid J. Kopiczko+, N_A, arXiv23 Summary本研究では、大規模な言語モデルのfine-tuningにおいて、訓練可能なパラメータの数を削減するための新しい手法であるベクトルベースのランダム行列適応(VeRA)を提案する。VeRAは、共有される低ランク行列と小さなスケーリングベクトルを使用することで、同じ性能を維持しながらパラメータ数を削減する。GLUEやE2Eのベンチマーク、画像分類タスクでの効果を示し、言語モデルのインストラクションチューニングにも応用できることを示す。 #Pocket#NLP#LanguageModel#FactualConsistency
Issue Date: 2023-11-15 Fine-tuning Language Models for Factuality, Katherine Tian+, N_A, arXiv23 Summary本研究では、大規模な言語モデル(LLMs)を使用して、より事実に基づいた生成を実現するためのファインチューニングを行います。具体的には、外部の知識ベースや信頼スコアとの一貫性を測定し、選好最適化アルゴリズムを使用してモデルを調整します。実験結果では、事実エラー率の削減が観察されました。 #Pretraining#Pocket#NLP#LanguageModel#DataGeneration
Issue Date: 2023-10-28 Zephyr: Direct Distillation of LM Alignment, Lewis Tunstall+, N_A, arXiv23 Summary私たちは、小さな言語モデルを作成するために、教師モデルからの優先データを使用する手法を提案しています。この手法により、自然なプロンプトに対するモデルの応答が改善されます。提案手法を用いて学習されたZephyr-7Bモデルは、チャットベンチマークで最先端の性能を発揮し、人間の注釈を必要としません。詳細はGitHubで利用可能です。 Comment7BパラメータでLlaMa70Bと同等の性能を達成したZephyrの論文。dSFT:既存データからpromptをサンプリングし、user,assistantのmulti turnの対話をLLMでシミュレーションしてデータ生成しSFTAIF:既存データからpromstをサンプリングしBlog: htt ...
Issue Date: 2023-10-26 NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, arXiv23 Summary私たちは、言語モデルのファインチューニングを改善するために、ノイズを加えた埋め込みベクトルを使用する手法を提案します。この手法は、AlpacaEvalやEvol-Instructなどのデータセットで強力なベースラインを上回る性能を示しました。また、RLHFでトレーニングされたモデルにも適用可能です。 CommentAlpacaデータでの性能向上が著しい。かなり重要論文な予感。後で読む。HuggingFaceのTRLでサポートされている https://huggingface.co/docs/trl/sft_trainer ... #Efficiency/SpeedUp#MachineLearning#Pocket#NLP#Dataset#QuestionAnswering#LongSequence#Adapter/LoRA
Issue Date: 2023-09-30 LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv23 Summary本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment# 概要 context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になって ...
Issue Date: 2023-09-10 Simple synthetic data reduces sycophancy in large language models, Jerry Wei+, N_A, arXiv23 Summary本研究では、機械学習モデルのおべっか行動を減らすための方法を提案しています。まず、言語モデルにおけるおべっか行動の普及度を調査し、その行動を減らすための合成データ介入を提案しています。具体的には、ユーザーの意見に対してモデルが頑健であることを促す合成データを使用し、モデルのファインチューニングを行います。これにより、おべっか行動を大幅に減らすことができます。提案手法の詳細は、https://github.com/google/sycophancy-intervention で確認できます。 CommentLLMはユーザの好む回答をするように事前学習されるため、prompt中にユーザの意見が含まれていると、ユーザの意見に引っ張られ仮に不正解でもユーザの好む回答をしてしまう問題があることを示した。また、その対策として人工的にユーザの意見と、claimを独立させるように学習するためのデータセットを生成しF ...
Issue Date: 2023-08-28 Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, N_A, EMNLP23 Summary本研究では、大規模言語モデル(LLMs)を使用して、プロンプトを自然言語でタスクを説明し、特定のモデルを訓練する手法であるPrompt2Modelを提案しています。Prompt2Modelは、既存のデータセットと事前学習済みモデルの検索、LLMsを使用したデータセットの生成、および教師あり微調整のプロセスを通じて行われます。実験結果では、Prompt2Modelが強力なLLMを上回る性能を示し、モデルの信頼性の評価も可能であることが示されています。Prompt2Modelはオープンソースで利用可能です。 CommentDataset Generatorによって、アノテーションが存在しないデータについても擬似ラベル付きデータを生成することができ、かつそれを既存のラベル付きデータと組み合わせることによってさらに性能が向上することが報告されている。これができるのはとても素晴らしい。Dataset Generatorにつ ... #MachineLearning#NLP#LanguageModel#Evaluation
Issue Date: 2023-07-14 Measuring the Instability of Fine-Tuning, ACL23 Summary事前学習済み言語モデルのファインチューニングは小規模データセットでは不安定であることが示されている。本研究では、不安定性を定量化する指標を分析し、評価フレームワークを提案する。また、既存の不安定性軽減手法を再評価し、結果を提供する。 #Efficiency/SpeedUp#MachineLearning#LanguageModel
Issue Date: 2023-06-26 Full Parameter Fine-tuning for Large Language Models with Limited Resources, Kai Lv+, N_A, arXiv23 SummaryLLMsのトレーニングには膨大なGPUリソースが必要であり、既存のアプローチは限られたリソースでの全パラメーターの調整に対処していない。本研究では、LOMOという新しい最適化手法を提案し、メモリ使用量を削減することで、8つのRTX 3090を搭載した単一のマシンで65Bモデルの全パラメーターファインチューニングが可能になる。 Comment8xRTX3090 24GBのマシンで65Bモデルの全パラメータをファインチューニングできる手法。LoRAのような(新たに追加しれた)一部の重みをアップデートするような枠組みではない。勾配計算とパラメータのアップデートをone stepで実施することで実現しているとのこと。 ... #NLP#LanguageModel#Alignment#ChatGPT#DataDistillation#NeurIPS
Issue Date: 2023-05-22 LIMA: Less Is More for Alignment, Chunting Zhou+, N_A, NeurIPS23 Summary本研究では、65BパラメータのLLaMa言語モデルであるLIMAを訓練し、強化学習や人間の好みモデリングなしに、厳選された1,000のプロンプトとレスポンスのみで標準的な教師あり損失で微調整しました。LIMAは、幅広いクエリに対応する驚くべき強力なパフォーマンスを示し、トレーニングデータに現れなかった未知のタスクにも一般化する傾向があります。制御された人間の研究では、LIMAのレスポンスは、GPT-4、Bard、DaVinci003と比較して優れていることが示されました。これらの結果から、大規模言語モデルのほとんどの知識は事前トレーニング中に学習され、高品質の出力を生成するためには限られた指示調整データしか必要ないことが示唆されます。 CommentLLaMA65Bをたった1kのdata point(厳選された物)でRLHF無しでfinetuningすると、旅行プランの作成や、歴史改変の推測(?)幅広いタスクで高いパフォーマンスを示し、未知のタスクへの汎化能力も示した。最終的にGPT3,4,BARD,CLAUDEよりも人間が好む回答を返した。L ...
Issue Date: 2023-03-30 Self-Instruct: Aligning Language Model with Self Generated Instructions, Wang+ (w_ Noah Smith), Univesity of Washington, ACL23 CommentAlpacaなどでも利用されているself-instruction技術に関する論文# 概要 
Issue Date: 2025-03-24 Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03 Comment関連:#1820TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。56B程度のm ... #Article#NLP#LanguageModel#Slide
Issue Date: 2025-03-16 LLM 開発を支える多様な Fine-Tuning:PFN での取り組み, 中鉢魁三郎, PFN, 2025.03 Comment知識の追加の部分で下記研究が引用されている#1371#1640 ... #Article#Pretraining#MachineLearning#LanguageModel
Issue Date: 2025-03-04 The Ultra-Scale Playbook: Training LLMs on GPU Clusters, HuggingFace, 2025.02 CommentHuggingFaceによる数1000のGPUを用いたAIモデルのトレーニングに関するオープンソースのテキスト ... #Article#NLP#LanguageModel#ReinforcementLearning#Article
Issue Date: 2025-02-19 強化学習「GRPO」をCartPoleタスクで実装しながら解説, 小川雄太郎, 2025.02 Comment元ポスト:https://x.com/ogawa_yutaro_22/status/1892059174789407213?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Article#NLP#LanguageModel#Reasoning
Issue Date: 2025-02-07 Unsloth で独自の R1 Reasoningモデルを学習, npaka, 2025.02 Comment非常に実用的で参考になる。特にどの程度のVRAMでどの程度の規模感のモデルを使うことが推奨されるのかが明言されていて参考になる。 ... #Article#NLP#LanguageModel#FoundationModel#RLHF (ReinforcementLearningFromHumanFeedback)#Article
Issue Date: 2025-02-01 DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01 Comment#1719#1655とても丁寧でわかりやすかった。後で読んだ内容を書いて復習する。ありがとうございます。 ... #Article#NLP#Dataset#LanguageModel#Repository
Issue Date: 2025-01-25 LLM Datasets, mlabonne, 2025.01 CommentLLMの事後学習用のデータをまとめたリポジトリ ... #Article#NLP#LanguageModel#Article
Issue Date: 2025-01-25 How to fine-tune open LLMs in 2025 with Hugging Face, PHILSCHMID, 2024.12 CommentSFTTrainerを用いたLLMのSFTについて、実用的、かつ基礎的な内容がコード付きでまとまっている。 ... #Article#NLP#LanguageModel#Alignment#Article
Issue Date: 2025-01-25 How to align open LLMs in 2025 with DPO & and synthetic data, PHILSCHMID, 2025.01 Comment元ポスト:https://x.com/_philschmid/status/1882428447877705908?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QDPOの概要やRLHFと比較した利点ルールベース、あるいはLLM as a Judgeを用いたOn-policy prefer ... #Article#NLP#LanguageModel#RAG(RetrievalAugmentedGeneration)#Article
Issue Date: 2025-01-02 To fine-tune or not to fine-tune, Meta, 2024.08 CommentLLMをSFTする際の注意点やユースケースについて記述されている。full parameterのファインチューニングやPEFT手法のピークGPUメモリfull parameterのファインチューニングではcatastrophic forgettingに気をつける必要があることFiまた、RAGとFin ... #Article#Tutorial#NLP#LanguageModel#Alignment#Chain-of-Thought#Reasoning#Mathematics
Issue Date: 2024-12-27 LLMを数学タスクにアラインする手法の系譜 - GPT-3からQwen2.5まで, bilzard, 2024.12 Comment#1618において、数学においてモデルのパラメータ数のスケーリングによって性能改善が見込める学習手法として、モデルとは別にVerifierを学習し、モデルが出力した候補の中から良いものを選択できるようにする、という話の気持ちが最初よくわからなかったのだが、後半のなぜsample&select記事中で ... #Article#Tutorial#Pretraining#Pocket#NLP#LanguageModel#Video
Issue Date: 2024-12-25 Stanford CS229 I Machine Learning I Building Large Language Models (LLMs), StanfordUnivercity, 2024.09 Commentスタンフォード大学によるLLM構築に関する講義。事前学習と事後学習両方ともカバーしているらしい。 ... #Article#Pretraining#NLP#LanguageModel#AES(AutomatedEssayScoring)
Issue Date: 2024-11-28 Cross-prompt Pre-finetuning of Language Models for Short Answer Scoring, Funayama+, 2024.09 CommentAutomated Short Answer Scoring (SAS) is the task of automatically scoring a given input to a prompt based on rubrics and reference answers. Although S ... #Article#NLP#Dataset#LanguageModel#InstructionTuning
Issue Date: 2024-11-16 microsoft_orca-agentinstruct-1M-v1, Microsoft, 2024.11 #Article#Efficiency/SpeedUp#Pretraining#NLP
Issue Date: 2024-11-07 ZeRO: DeepSpeedの紹介, レトリバ, 2021.07 CommentZeROの説明がわかりやすいこちらの記事もわかりやすい https://zenn.dev/turing_motors/articles/d00c46a79dc976DeepSpeedのコンフィグの一覧 https://www.deepspeed.ai/docs/config-json/ZeRO St ... #Article#Efficiency/SpeedUp#NLP#LanguageModel#InstructionTuning
Issue Date: 2024-10-08 Unsloth Commentsingle-GPUで、LLMのLoRA/QLoRAを高速/省メモリに実行できるライブラリ ... #Article#Efficiency/SpeedUp#NLP#LanguageModel#Repository
Issue Date: 2024-08-25 Liger-Kernel, 2024.08 CommentLLMを学習する時に、ワンライン追加するだけで、マルチGPUトレーニングのスループットを20%改善し、メモリ使用量を60%削減するらしい元ツイート:https://x.com/hsu_byron/status/1827072737673982056?s=46&t=Y6UuIHB0Lv0IpmFAこれ ... #Article#Pretraining#Article
Issue Date: 2024-04-26 The End of Finetuning — with Jeremy Howard of Fast.ai, 2023.11 #Article#NLP#LanguageModel#Library#Repository
Issue Date: 2023-11-14 LLaMA-Factory, 2023 Comment簡単に利用できるLLaMAのfinetuning frameworkとのこと。元ツイート: https://x.com/_akhaliq/status/1724456693378040195?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLaMAベースなモデルなら色々対応している模様 ... #Article#Efficiency/SpeedUp#NLP#LanguageModel#Adapter/LoRA#Catastrophic Forgetting
Issue Date: 2023-10-29 大規模言語モデルのFine-tuningによるドメイン知識獲得の検討 Comment以下記事中で興味深かった部分を引用> まとめると、LoRAは、[3]で言われている、事前学習モデルは大量のパラメータ数にもかかわらず低い固有次元を持ち、Fine-tuningに有効な低次元のパラメータ化も存在する、という主張にインスパイアされ、ΔWにおける重みの更新の固有次元も低いという仮説のもと ... #Article#Tutorial#NLP#LanguageModel
Issue Date: 2023-08-29 LLMのファインチューニング で 何ができて 何ができないのか Comment>LLMのファインチューニングは、「形式」の学習は効果的ですが、「事実」の学習は不得意です。> シェイクスピアの脚本のデータセット (tiny-shakespeare) の「ロミオ」を「ボブ」に置き換えてファインチューニングして、新モデルの頭の中では「ロミオ」と「ボブ」をどう記憶しているかを確参考: ... #Article#MachineLearning#Tools#LanguageModel#Article#Repository
Issue Date: 2023-07-11 Auto train advanced CommentHugging Face Hub上の任意のLLMに対して、localのカスタムトレーニングデータを使ってfinetuningがワンラインでできる。peftも使える。 ... #Article#MachineLearning#Tools#LanguageModel#FoundationModel
Issue Date: 2023-06-26 LM Flow Comment一般的なFoundation Modelのファインチューニングと推論を簡素化する拡張可能なツールキット。継続的なpretragning, instruction tuning, parameter efficientなファインチューニング,alignment tuning,大規模モデルの推論などさま ... #Article#NLP#LanguageModel
Issue Date: 2023-03-30 Publicly available instruction-tuned models