
ICML
[Paper Note] The Flexibility Trap: Rethinking the Value of Arbitrary Order in Diffusion Language Models, Zanlin Ni+, ICML'26 Outstanding Paper Award, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #DiffusionModel #PostTraining #Selected Papers/Blogs Issue Date: 2026-07-19 GPT Summary- dLLMsは任意の順序でトークンを生成できるが、一般的な推論タスクではこの柔軟性が逆に制限要因になることを発見。特に、不要な不確実性を回避し解のカバレッジを低下させる傾向が見られた。この問題に対処するため、標準的なGRPOを適用したJustGRPOを提案し、GSM8Kで89.1%の精度を達成。これにより、dLLMsの並列デコード能力を維持しつつ効果的な推論を実現。 Comment
元ポスト:
[Paper Note] High-accuracy sampling for diffusion models and log-concave distributions, Fan Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#MachineLearning #DiffusionModel #Samplers Issue Date: 2026-07-19 GPT Summary- 拡散モデルサンプリングの新しいアルゴリズムを提案し、δ-誤差をpolylog(1/δ)回の反復で達成することを示します。この手法は従来の結果を指数的に改善し、最小限のデータ仮定の下で複雑さは\widetilde O(d_\star \mathrm{polylog}(1/δ))となります。また、非一様なL-リプシッツ条件下では、複雑さが\widetilde O(L \mathrm{polylog}(1/δ))に低減します。勾配評価だけを用いたこのアプローチにより、一般の対数凹分布に対する初のpolylog(1/δ)計算量のサンプラーを実現しました。 Comment
元ポスト:
[Paper Note] Context Tuning for In-Context Optimization, Jack Lu+, ICML'26, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #In-ContextLearning #Selected Papers/Blogs #reading #Author Thread-Post Issue Date: 2026-07-19 GPT Summary- Context Tuningは、重みの更新なしでLLMsのfew-shot適応を向上させる手法です。ICLはデモの記憶を1回の前方伝播で形成しますが、洗練が不十分です。従来のプロンプト手法は、デモとは独立して初期化しますが、Context TuningはICL能力を利用してデモから訓練可能なメモリ表現を初期化し、勾配ベースの最適化で洗練します。多くのベンチマークで評価した結果、Context TuningはICLと従来のプロンプト法を上回り、Test-Time Trainingに近い精度を示し、高い訓練効率を発揮しました。 Comment
元ポスト:
pj page: https://agenticlearning.ai/context-tuning/
openreview: https://openreview.net/forum?id=UAJehyOPTS
気になる。後で読む
[Paper Note] UnMaskFork: Test-Time Scaling for Masked Diffusion via Deterministic Action Branching, Kou Misaki+, ICML'26, 2026.02
Paper/Blog Link My Issue
#LanguageModel #DiffusionModel #Test-Time Scaling #Author Thread-Post Issue Date: 2026-07-08 GPT Summary- UMFフレームワークを提案し、マスク付き拡散言語モデルの生成プロセスを探索木として定式化。モンテカルロ木探索を用いて生成パスを最適化し、従来の方法に対し決定論的に探索空間を探索。これにより、複雑なコードベンチマークで従来のスケーリング手法を上回る性能を示し、数学的推論タスクでも高いスケーラビリティを実現。 Comment
元ポスト:
[Paper Note] Feedback-to-Rubrics: Can We Learn Expert Criteria from Inline Comments?, Kotaro Yoshida+, ICML'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #reading #Rubric-based #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-08 GPT Summary- インラインコメントを活用して、再利用可能な自然言語ルーブリックを学習する手法を提案。コメントの不一致を観察しながらルーブリックを改良し、現実のレビュー設定で評価。これにより、成果物の改訂やルーブリック理解が促進されることを示した。 Comment
元ポスト:
文書の中に断片化されているインラインコメント等を暗黙的な評価基準に基づいて生成された観測データと捉え、インラインコメントから明文化されていない評価基準を学習し、ルーブリックとして活用可能にする、という話に見える。
「暗黙知、ケースバイケースなのでなかなか明文化できません」という状況によく遭遇し困るので、そもそもこういった手法が利用できるように日々の判断をLLMが利用可能な形に残しておくことが重要と感じる
[Paper Note] Mecha-nudges for Machines, Giulio Frey+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Analysis #AIAgents Issue Date: 2026-07-08 GPT Summary- AIエージェントの意思決定が人間の環境に影響を与える現象「メカ・ヌージング」に関する研究。ベイズ的説得と$\mathcal{V}$-利用可能情報を組み合わせることで、意思決定環境の変化を定量化。600万のEtsy出品に適用した結果、ChatGPT導入後のエージェントによる決定予測に有意な機械利用可能情報の増加(最大0.143ビット)を確認。人間の情報には変化が見られなかった。研究は既存のメカ・ヌージングの影響を初めて実証。 Comment
元ポスト:
[Paper Note] Rubric Curriculum RL: Exploiting the Generation-Verification Gap in Non-Verifiable Domains, Krishnan+, ICML'26, 2026.07
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning #SelfImprovement #PostTraining #read-later #Non-VerifiableRewards #Rubric-based Issue Date: 2026-07-08 Comment
元ポスト:
[Paper Note] Revisiting the Platonic Representation Hypothesis: An Aristotelian View, Fabian Gröger+, arXiv'26, 2026.02
Paper/Blog Link My Issue
Issue Date: 2026-07-05 GPT Summary- プラトン的表現仮説に基づき、ニューラルネットワークの表現が共通の統計モデルに収束することを示す。既存の表現類似性指標がネットワークの規模に影響されることを指摘し、これを正すためのヌル校正フレームワークを導入。再検討の結果、微妙な全体像が現れ、グローバルな収束が消失する一方で、局所的な類似性は異なるモダリティ間で依然として一致する。これに基づき、アリストテレス的表現仮説を提案し、表現が共有された局所近傍関係へ収束すると結論づける。 Comment
元ポスト:
[Paper Note] Sharpness-Aware Pretraining Mitigates Catastrophic Forgetting, Ishaan Watts+, ICML'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Catastrophic Forgetting #mid-training #read-later #Selected Papers/Blogs #One-Line Notes #DownstreamTasks #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- 事前訓練最適化手法は、基盤モデルの能力維持に影響を与える幾何学を考慮すべきである。本研究では、平坦な極小点を目指す三つのアプローチ(SAM、大きな学習率、短縮された学習率減衰)を分析し、モデルサイズが20M〜150Mパラメータの範囲で、ポスト訓練後のパフォーマンス向上と忘却の最大80%低減を実証した。また、OLMo-2-1Bモデルへの短いSAM訓練を適用することで、MetaMathでは忘却を31%、4ビット量子化後には40%低減できることが示された。 Comment
元ポスト:
downstreamタスクでの性能を最大化するためには、baseモデルのlossではなく、モデルが重みを更新した時にどれだけ事前学習の知識が保持されるかが鍵であり、learning-forgettingのトレードオフを見るべきという話で、
なぜモデルの更新によって忘却が起きやすいかというと、モデルが急峻な極小点 (Sharp Minima) に収束してしまっているためで、これではわずかな重みの更新でも大幅な性能低下を起こしてしまう。このため、平坦な極小点(Flat Minima)に重みを収束させることでよりモデルの知識を安定させることができる。
Flat Minimaを見つけるために、Sharpness-Aware Minimization (SAM)と呼ばれる手法を採用し、式(5)で定義されるような、パラメータに摂動を加えた時のlossの最大値が最小となるようにパラメータを最適化する。
[Paper Note] Fast Byte Latent Transformer, Julie Kallini+, ICML'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Decoding #Byte-level #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- BLTを用いて、バイトレベルLMの生成速度のボトルネックを解消。BLT Diffusionを導入し、並列生成によってデコードステップを削減。さらに、BLT Self-speculationとBLT Diffusion+Verificationを提案し、生成品質を向上させつつ推定メモリコストを低減。これにより、バイトレベルLMの実用性が向上。 Comment
元ポスト:
[Paper Note] MAS-ProVe: Understanding the Process Verification of Multi-Agent Systems, Vishal Venkataramani+, ICML'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #read-later #Selected Papers/Blogs #Verification #Monitorability #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- MAS-ProVeは、マルチエージェントシステム(MAS)におけるプロセス検証の体系的研究を提示し、LLMを利用して検証の有効性を評価。エージェントレベルとイテレーションレベルでの評価を行い、5つの検証手法を検討。結果として、プロセスレベルの検証は必ずしも性能向上にはつながらず、高い分散が見られることが判明。LLMを判定者として用いるアプローチが効果的である一方、コンテキスト長と性能のトレードオフも観察。MAS向けの堅牢な検証法にはさらなる進展が必要であることが示された。 Comment
元ポスト:
MASにおいてprocess levelのverificationを導入しても一貫して性能が向上するわけではなく、(途中推論の妥当性を判断するタスクは困難なものであることから既存の様々なverification手法には限界があり)分散が高いことが明らかになったとのこと。MASのような複雑なシステムはverificationによるプロセスレベルの精査が必要だと思われるので、現在の限界が示された点で重要な研究に見える。
[Paper Note] MAS-Orchestra: Understanding and Improving Multi-Agent Reasoning Through Holistic Orchestration and Controlled Benchmarks, Zixuan Ke+, ICML'26, 2026.01
Paper/Blog Link My Issue
#Multi #NLP #Dataset #LanguageModel #AIAgents #Evaluation #read-later #Selected Papers/Blogs #Initial Impression Notes #Orchestration #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- MASのオーケストレーションを強化学習形式で定式化するMASOrchestraを提案。これにより、エージェントの複雑性を管理し、システム全体のグローバルな推論を促進。タスクを5軸で分析するMASBENCHを導入し、利得がタスクや能力に依存することを示す。公開ベンチマークで一貫した改善を達成し、10倍以上の効率を実現。MASOrchestraとMASBENCHはマルチエージェント知性の向上を目指す。 Comment
元ポスト:
SASと比べてMASにすることでどれだけ利点があるかをモデルが理解せずにfoldingしてるよね、というのは重要な指摘に感じる。
[Paper Note] Least-Loaded Expert Parallelism: Load Balancing An Imbalanced Mixture-of-Experts, Xuan-Phi Nguyen+, ICML'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #LLMServing #MoE(Mixture-of-Experts) #Parallelism #Stability #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- 新しいLeast-Loaded Expert Parallelism (LLEP)は、MoEモデルの不均衡なルーティングを考慮し、過負荷デバイスからトークンとエキスパートパラメータを未利用のデバイスに再ルーティングすることで、計算資源の制約を軽減。これにより、モデルスケールに応じて最大5倍の速度向上とピークメモリ使用量を4分の1に削減し、推論の高速化を実現。理論分析と実証評価に基づき、ハードウェアに最適化したパフォーマンスを提供。 Comment
元ポスト:
[Paper Note] Autoregressive Direct Preference Optimization, Masanari Oi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #DPO #PostTraining #Author Thread-Post Issue Date: 2026-05-06 GPT Summary- DPOはLLMの嗜好最適化の手法として注目されているが、BTモデルへの依存がその効果を制限する可能性がある。そこで、自己回帰仮定を導入した新たな定式化—自己回帰DPO(ADPO)を提案。これにより、嗜好最適化への自己回帰モデリングの統合が実現。ADPOの損失関数はエレガントな形を持ち、DPO目的関数の総和演算を対数シグモイド関数の外に移した。さらに、LLMの嗜好最適化に関わるトークン長μとフィードバック長μ′の二つの尺度を明確に区別し、その影響を初めて分析。 Comment
元ポスト:
[Paper Note] From Correspondence to Actions: Human-Like Multi-Image Spatial Reasoning in Multi-modal Large Language Models, Masanari Oi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Supervised-FineTuning (SFT) #MultiModal #Reasoning #PostTraining #GRPO #VisionLanguageModel #SpatialUnderstanding #Author Thread-Post #MultiView Issue Date: 2026-05-06 GPT Summary- 視点間対応と逐次的視点変換を強化するために、HATCH(Human-Aware Training for Cross-view correspondence and viewpoint cHange)を提案。これにより、空間的整合性を促進し、視点遷移アクションを生成して推論を改善。実験結果は、HATCHが同規模のモデルを上回り、大規模モデルとも競合する性能を示した。 Comment
元ポスト:
[Paper Note] Aligning Tree-Search Policies with Fixed Token Budgets in Test-Time Scaling of LLMs, Sora Miyamoto+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Test-Time Scaling #TreeSearch #Author Thread-Post Issue Date: 2026-05-06 GPT Summary- BG-MCTSは、残りのトークン予算に応じて探索方針を調整するツリー探索デコーディングアルゴリズムを提案。予算が残る間は広範囲に探索し、枯渇するにつれて洗練された回答を優先して浅いノードの分岐を抑制する。MATH500およびAIME24/25の多様な予算設定において、予算を考慮しない方法を一貫して上回る性能を示す。 Comment
元ポスト:
[Paper Note] LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning, Sumeet Ramesh Motwani+, ICML'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Chain-of-Thought #Evaluation #Reasoning #read-later #Selected Papers/Blogs #LongHorizon #Author Thread-Post Issue Date: 2026-04-16 GPT Summary- LongCoTを導入し、複雑な推論能力を測定するための2,500問の専門家設計問題からなるベンチマークを提供。問題は数万から百数万の推論トークンを含む相互依存の手順を要求し、最先端モデルは全体で<10%の精度であることが示され、長期推論の限界が明らかになる。LongCoTは、モデルの長時間にわたる安定した推論能力を評価する指標となる。 Comment
元ポスト:
著者ポスト:
[Paper Note] Dr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations, Wei Liu+, ICML'26, 2026.02
Paper/Blog Link My Issue
#Multi #NLP #ReinforcementLearning #AIAgents #Test-Time Scaling #PostTraining #LongHorizon #GPUKernel #Environment #Author Thread-Post Issue Date: 2026-02-06 GPT Summary- 高品質のカーネル生成はスケーラブルなAIシステムの鍵であり、そのためのLLM訓練には十分なデータと堅牢な環境が必要です。本研究では、KernelGYMを設計し、報酬ハッキングを防ぐマルチターンRL手法を検討します。TRLOOを提案し、偏ったポリシー勾配問題を解決。訓練されたDr.Kernel-14Bは高性能を達成し、生成されたカーネルの31.6%がTorch参照に対して1.2倍のスピードアップを実現しました。全リソースはGitHubで公開されています。 Comment
元ポスト:
[Paper Note] Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability, Shobhita Sundaram+, ICML'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SyntheticData #PostTraining #read-later #CurriculumLearning #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-01-27 GPT Summary- LLMは解決困難な問題のために自動カリキュラムを生成可能か?SOARという自己改善フレームワークを通じ、教師が学生のために問題を提案し、進捗に基づいて報酬を提供。研究では、バイレベルmeta-RLが学習を促進し、計測された報酬が内在的報酬を上回ることを示し、構造的品質が解答の正確性よりも学習において重要であることを明らかにした。これにより、困難な問題解決において事前の能力が不要であることが示唆された。 Comment
元ポスト:
著者ポスト:
pj page: https://ssundaram21.github.io/soar/
[Paper Note] The Optimal Token Baseline: Variance Reduction for Long-Horizon LLM-RL, Yingru Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Blog #PostTraining #read-later #Selected Papers/Blogs #LongHorizon Issue Date: 2025-12-27 GPT Summary- 勾配分散の爆発による訓練崩壊を防ぐため、最適トークンベースライン(OTB)を導出し、累積勾配ノルムの逆数で重み付けする方法を提案。Logit-Gradient Proxy を使用して勾配ノルムを効率的に近似し、訓練の安定性を向上。N=4 でN=32相当の性能を達成し、トークン消費を65%以上削減。 Comment
元ポスト:
[Paper Note] Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity, Jiayi Zhang+, ICML'26 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #Diversity #Selected Papers/Blogs Issue Date: 2025-12-13 GPT Summary- ポストトレーニングアライメントによるモード崩壊の原因を、好みデータにおける典型性バイアスに特定。これを基に「Verbalized Sampling(VS)」というプロンプティング戦略を提案し、モデルに応答の確率分布を言語化させる。実験により、VSが創造的執筆や対話シミュレーションなどで多様性を1.6〜2.1倍向上させることを示し、特に能力の高いモデルがより恩恵を受ける傾向が確認された。研究はモード崩壊に対する新たな視点を提供し、生成的多様性を解放する実用的な解決策を提示。 Comment
元ポスト:
preference dataに内在するtypicality bias(=人間が特定の応答を好む傾向)が、post trainingのalignmentフェーズにおいて増長されてモデルがモード崩壊を起こす(=特定の人間が典型的に好む応答のみを答えるようにalignされることで、出力の多様性が損なわれる)ことを明らかにし、「複数の出力と出力ごとの確率を出力させる」ようなpromptingによって、モデルが学習している確率分布そのものをverbalizeさせることで出力の多様性を引き出す、という話に見える。
pj page:
https://www.verbalized-sampling.com
コピペ可能なmagic promptが記載されている。test-time scalingと相性が良さそうである。
[Paper Note] Latent Collaboration in Multi-Agent Systems, Jiaru Zou+, ICML'26, 2025.11
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #AIAgents #Initial Impression Notes #Author Thread-Post #LatentRepresentation Issue Date: 2025-11-27 GPT Summary- LatentMASは、マルチエージェントシステムにおいて、LLMエージェントがテキスト媒介なしで直接協力できるフレームワークを提案。各エージェントは潜在思考生成を行い、共有された潜在作業メモリを通じて情報を損失なく交換。理論的分析と9つのベンチマーク評価により、従来のテキストベースのMASよりも高い表現力と効率を示し、精度向上や推論速度の改善を実現。コードはオープンソースで提供。 Comment
元ポスト:
Would you like to collaborate on something building from this?
著者ポスト:
エージェントのKV Pairをとっておき、次のエージェントで生成する際に、KV Pairをconcatすることで、潜在空間上で思考をエージェント間で共有する。ただし、エージェント間でKV Cacheを共有する上での核となるアイデアが3.1, 3.2と思われるが、まだ内容を読めていない。
textでのコンテキスト共有と比較して性能が向上するだけでなく、トークンコストとスピードが向上する。
[Paper Note] DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research, Rulin Shao+, ICML'26, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #OpenWeight #OpenSource #PostTraining #read-later #Selected Papers/Blogs #DeepResearch #Reference Collection #Rubric-based #Author Thread-Post Issue Date: 2025-11-19 GPT Summary- 長文で出典付きの回答を生成する深層研究モデルの訓練には、強化学習(RLVR)を活用した進化するルーブリック(RLER)を用いることで、モデルが新たな情報を取り込み、オンポリシーなフィードバックを提供できるようにする。本研究では、RLERを活用して初のオープンモデルDeep Research Tulu (DR Tulu-8B)を開発し、科学、医療、一般領域のベンチマークで従来モデルを大幅に上回った。データ、モデル、コードは公開され、新しいエージェント基盤も提供されている。 Comment
元ポスト:
著者ポスト:
著者ポスト2:
著者ポスト3:
demoをほぼ無料で実施できるとのこと:
takeaway:
デモが公開:
解説:
ICML'26 Spotlight:
[Paper Note] Train for Truth, Keep the Skills: Binary Retrieval-Augmented Reward Mitigates Hallucinations, Tong Chen+, ICML'26, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Hallucination #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-11-15 GPT Summary- 本研究では、外的幻覚を軽減するために新しいバイナリ検索強化報酬(RAR)を用いたオンライン強化学習手法を提案。モデルの出力が事実に基づいている場合のみ報酬を与えることで、オープンエンド生成において幻覚率を39.3%削減し、短文質問応答では不正解を44.4%減少させた。重要な点は、事実性の向上が他のパフォーマンスに悪影響を及ぼさないことを示した。 Comment
Utilityを維持しつつ、Hallucinationを減らせるかという話で、Binary Retrieval Augmented Reward (Binary RAR)と呼ばれるRewardを提案している。このRewardはverifierがtrajectoryとanswerを判断した時に矛盾がない場合にのみ1, それ以外は0となるbinary rewardである。これにより、元のモデルの正解率・有用性(極論全てをわかりません(棄権)と言えば安全)の両方を損なわずにHallucinationを提言できる。
また、通常のVerifiable Rewardでは、正解に1, 棄権・不正解に0を与えるRewardとみなせるため、モデルがguessingによってRewardを得ようとする(guessingすることを助長してしまう)。一方で、Binary RARは、正解・棄権に1, 不正解に0を与えるため、guessingではなく不確実性を表現することを学習できる(おそらく、棄権する場合はどのように不確実かを矛盾なく説明した上で棄権しないとRewardを得られないため)。
といった話が元ポストに書かれているように見える。
元ポスト:
openreview: https://openreview.net/forum?id=9KKNiNKgNk
[Paper Note] h1: Bootstrapping LLMs to Reason over Longer Horizons via Reinforcement Learning, Sumeet Ramesh Motwani+, ICML'26 Spotlight, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #SyntheticData #LongHorizon #Author Thread-Post Issue Date: 2025-10-09 GPT Summary- 大規模言語モデルは短期的な推論には強いが、長期的な推論では性能が低下する。既存のアプローチはスケールしにくい。本研究では、短期データを用いて長期的な推論能力を向上させるスケーラブルな方法を提案。単純な問題を合成し、複雑な多段階依存チェーンを構成。結果のみの報酬でモデルを訓練し、カリキュラムを通じて精度を向上。実験により、GSM8Kでの訓練がGSM-SymbolicやMATH-500などのベンチマークでの精度を最大2.06倍向上させることを示した。理論的には、カリキュラムRLがサンプルの複雑さにおいて指数的な改善を達成することを示し、既存データを用いた長期的な問題解決の効率的な道を提案。 Comment
元ポスト:
著者ポスト:
[Paper Note] DataDecide: How to Predict Best Pretraining Data with Small Experiments, Ian Magnusson+, ICML'25, 2025.04
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #LanguageModel #Evaluation #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-05-29 GPT Summary- 小規模な実験を用いて大規模言語モデルのデータ選択を効率化することは重要である。DataDecideと呼ばれる評価スイートを通じて、異なるデータセットに基づいた前訓練の実験を実施し、150Mパラメータのモデルが1Bパラメータでの最良モデルを約80%の精度で予測できることが示された。主にスケーリング法則に基づくベースラインと比較し、連続的尤度指標を使うことで、限られた資源でも高精度の予測が可能であることが明らかとなった。 Comment
大規模なモデルを学習するためにどのようなデータレシピに従って、どのようなデータを使うべきかを、小規模なモデルでの学習を通じて予測できることを示した(150Mモデルの学習で1Bモデルに対するデータレシピの優劣を80%のDecisionAccuracyで予測可能)。
25種類のデータレシピ(ソース, deduplication, filtering, mixingによって構成)を、14種類のモデルスケールに対して、計算コスト(token-to-parameterの比率)を固定し3種類のseedを用いて実験し、事前学習の結果を体系的に調査。
1Bパラメータのdownstreamタスクにおいて、25種類のデータレシピごとの平均性能によってpairwiseの優劣に関するペアを構成し、全てのペアに対する優劣をどれだけ予測できるかを評価(DecisionAccuracy)したところ、下記図のようになった。たとえば、150Mスケールのモデルを訓練するだけでDecisionAccuracyは80%に到達し、これには1Bモデルを学習した場合と比較して2パーセント程度の計算コストしか要さないことが明らかとなった。
HF: https://huggingface.co/collections/allenai/datadecide
openreview: https://openreview.net/forum?id=p9YlQPF8fE
[Paper Note] Detecting and Filtering Unsafe Training Data via Data Attribution with Denoised Representation, Yijun Pan+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Safety #Author Thread-Post Issue Date: 2026-05-01 GPT Summary- LLMにおける不安全なデータの検出には、効果的なフィルタリングが不可欠である。従来の手法は主にモデレーション分類器に依存し、効率が悪い。本研究では、Denoised Representation Attribution(DRA)という新たなデータアトリビューション手法を提案し、訓練表現とターゲット表現のデノイズ化を行う。これにより、不安全データ検出が改善され、特にジャイルブレイクフィルタリングやジェンダーバイアスの検出において、従来手法を上回る結果を得た。 Comment
元ポスト:
[Paper Note] DeepCrossAttention: Supercharging Transformer Residual Connections, Mike Heddes+, ICML'25, 2025.02
Paper/Blog Link My Issue
Issue Date: 2026-03-18 GPT Summary- DCAを用いてTransformersの残差学習を強化。動的な出力組み合わせにより、重要情報にフォーカスし、層間の相互作用を豊かにする。言語モデリング実験で効率を向上させ、ついにはモデル品質を速さを3倍増加させて達成。精度とモデルサイズ間のトレードオフも改善されることが確認された。 Comment
openreview: https://openreview.net/forum?id=j3JBfFnGYh
[Paper Note] Learning to (Learn at Test Time): RNNs with Expressive Hidden States, Yu Sun+, ICML'25, 2024.07
Paper/Blog Link My Issue
#NLP #Self-SupervisedLearning #SSM (StateSpaceModel) #Selected Papers/Blogs #One-Line Notes #RecurrentModels #Test Time Training (TTT) Issue Date: 2026-02-26 GPT Summary- 隠れ状態を機械学習モデルとして扱い、自己教師あり学習を用いたTest-Time Training(TTT)層を提案。TTT-LinearとTTT-MLPの二つの実装を比較し、長い文脈に対するパフォーマンスを向上。特に、TTT-MLPは長い文脈における潜在能力を示し、TransformerやMambaと比較して有望な結果を得た。 Comment
openreview: https://openreview.net/forum?id=wXfuOj9C7L
隠れ状態そのものを、重みWを持つモデルfとして解釈し、新たなinput x_tが入力された時にW_tをW_{t+1}へ更新するupdate ruleを自己教師あり学習として学習する(すなわち、W_t ← W_{t-1}+ ηΔl(W_{t-1}, x_t)として定式化する)。これによりtest時の入力に対して隠れ状態を更新することが、test sequenceに基づいてモデルfを学習することと等価となる(Test Time Training; TTT)。
たとえばtransformerにおけるself-attentionをTTT layerに置換するような実装がある。self attentionのoutputの計算量はO(t)だが、TTT layerではO(1)となる。
TTT-Layerの実装として線形モデルに基づくTTT-Linearと非線形モデルとしてMLPに基づいたTTT-MLPが提案されている。
(TTT-LayerのKVBindingの実装例を後ほど追記, 論文中のFigure 6)
[Paper Note] ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks, Saurabh Jha+, ICML'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #Financial #SoftwareEngineering #read-later #One-Line Notes Issue Date: 2026-02-03 GPT Summary- AIエージェントを用いたITタスク自動化の実現には、その効果を測定する能力が重要である。本研究では、AIエージェントのベンチマーキングを行うためのフレームワーク「ITBench」を提案。初期リリースはSRE、CISO、FinOpsの3領域に焦点を当て、実行可能なワークフローと解釈可能なメトリクスを提供。ITBenchは94の実世界シナリオを含み、最先端エージェントモデルのパフォーマンスを評価した結果、限られた成功率が示された。ITBenchがAI駆動のIT自動化において重要な役割を果たすことが期待される。 Comment
dataset:
-
https://huggingface.co/datasets/ibm-research/ITBench-Lite
-
https://huggingface.co/datasets/ibm-research/ITBench-Trajectories
元ポスト:
openreview: https://openreview.net/forum?id=jP59rz1bZk
94種類の実世界に基づいたシナリオに基づいてSRE, CSO, FinOpsに関するタスクを用いてAI Agentsを用いて評価する。各シナリオにはメタデータとEnvironments、トリガーとなるイベント、理想的な成果などが紐づいている。特にFinOpsに課題があることが示されている模様。
以下がシナリオの例で、たとえばFinOpsの場合はalertの設定ミスや、Podのスケーリングの設定に誤りがあり過剰にPodが立ってしまうといったシナリオがあるようである。
[Paper Note] M+: Extending MemoryLLM with Scalable Long-Term Memory, Yu Wang+, ICML'25, 2025.02
Paper/Blog Link My Issue
Issue Date: 2025-09-30 GPT Summary- 大規模言語モデルに潜在空間メモリを追加することで、コンテキストウィンドウを拡張する研究が進んでいるが、過去の情報保持には課題が残る。MemoryLLMは10億パラメータのメモリプールを形成するが、20kトークンを超える情報保持には限界がある。本研究では、MemoryLLMを基にしたメモリ拡張モデルM+を提案し、長期的な情報保持を強化。M+は長期メモリメカニズムとリトリーバーを統合し、関連情報を動的に取得する。実験により、M+はMemoryLLMや他のベースラインを大幅に上回り、知識保持を160kトークン以上に拡張できることが示された。 Comment
openreview: https://openreview.net/forum?id=OcqbkROe8J
[Paper Note] Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding, Mingyu Jin+, ICML'25, 2025.02
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Transformer #Attention #ContextEngineering Issue Date: 2025-09-26 GPT Summary- 大規模言語モデル(LLMs)は文脈的知識の理解に成功しており、特に注意クエリ(Q)とキー(K)において集中した大規模な値が一貫して現れることを示す。これらの値は、モデルのパラメータに保存された知識ではなく、現在の文脈から得られる知識の解釈に重要である。量子化戦略の調査により、これらの値を無視すると性能が低下することが明らかになり、集中した大規模な値の出現がロタリーポジショナルエンコーディング(RoPE)によって引き起こされることを発見した。これらの結果は、LLMの設計と最適化に関する新たな洞察を提供する。 Comment
openreview: https://openreview.net/forum?id=1SMcxxQiSL¬eId=7BAXSETAwU
[Paper Note] CollabLLM: From Passive Responders to Active Collaborators, Shirley Wu+, ICML'25, 2025.02
Paper/Blog Link My Issue
Issue Date: 2025-09-26 GPT Summary- CollabLLMは、長期的なインタラクションを最適化するための新しい訓練フレームワークで、マルチターンの人間とLLMのコラボレーションを強化する。協調シミュレーションを用いて、応答の長期的な貢献を評価し、ユーザーの意図を明らかにすることで、より人間中心のAIを実現。文書作成などのタスクで平均18.5%のパフォーマンス向上と46.3%のインタラクティビティ改善を達成し、ユーザー満足度を17.6%向上させ、消費時間を10.4%削減した。 Comment
pj page: https://wuyxin.github.io/collabllm/
元ポスト:
Adaptive Localization of Knowledge Negation for Continual LLM Unlearning, Wuerkaixi+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeEditing Issue Date: 2025-09-22 GPT Summary- 大規模言語モデル(LLMs)の安全性に関する懸念が高まる中、ターゲット知識を効果的に忘却しつつ利用価値を維持する手法ALKN(Adaptive Localization of Knowledge Negation)を提案。動的マスキングを用いてトレーニング勾配をスパース化し、忘却の強度を適応的に調整。実験により、継続的な忘却設定でベースラインを上回る効果を示した。 Comment
元ポスト:
[Paper Note] Scaling Laws for Differentially Private Language Models, Ryan McKenna+, ICML'25, 2025.01
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Scaling Laws #Privacy #DifferentiallyPrivate Issue Date: 2025-09-13 GPT Summary- スケーリング法則はLLMのトレーニングにおいて性能向上を予測し、ハイパーパラメータ選択の指針を提供する。LLMは機密性のあるユーザーデータに依存し、DPなどのプライバシー保護が必要だが、そのダイナミクスは未解明。本研究では、DP LLMトレーニングのスケーリング法則を確立し、計算、プライバシー、ユーティリティのトレードオフを考慮した最適なトレーニング構成を示す。 Comment
blog: https://research.google/blog/vaultgemma-the-worlds-most-capable-differentially-private-llm/
元ポスト:
関連:
- Calibrating Noise to Sensitivity in Private Data Analysis, Dwork+, TCC'06
openreview: https://openreview.net/forum?id=DE6dqmcmQ9
[Paper Note] Extractive Structures Learned in Pretraining Enable Generalization on Finetuned Facts, Jiahai Feng+, ICML'25
Paper/Blog Link My Issue
Issue Date: 2025-09-12 GPT Summary- 事前学習された言語モデル(LMs)は、ファインチューニングされた事実の含意を一般化する能力を持つが、そのメカニズムは不明である。本研究では、LMのコンポーネントが協調して一般化を実現するフレームワークとして「抽出構造」を提案。これは、トレーニング事実を重みの変化として保存する情報コンポーネントと、保存された情報を処理する抽出コンポーネントから成る。データの順序効果と重みの接ぎ木効果を予測し、複数のモデルで実証。結果は、事実の学習が初期層と後期層の両方で行われる可能性を示唆し、異なる形の一般化に寄与することを明らかにした。 Comment
[Paper Note] Value-Based Deep RL Scales Predictably, Oleh Rybkin+, ICML'25
Paper/Blog Link My Issue
#ReinforcementLearning Issue Date: 2025-09-10 GPT Summary- 価値ベースのオフポリシー強化学習手法が予測可能であることを示し、特定のパフォーマンスを達成するためのデータと計算の要件をパレートフロンティア上で制御。リソース予算の最適な配分を決定し、ハイパーパラメータを調整することでパフォーマンスを最大化。DeepMind Control、OpenAI Gym、IsaacGymで3つのアルゴリズムを用いて検証。 Comment
openreview: https://openreview.net/forum?id=FLPFPYJeVU
[Paper Note] Learning-Order Autoregressive Models with Application to Molecular Graph Generation, Zhe Wang+, ICML'25
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #GraphGeneration Issue Date: 2025-07-16 GPT Summary- 自己回帰モデル(ARMs)を用いて、データから逐次的に推測される確率的順序を利用し、高次元データを生成する新しい手法を提案。トレーニング可能なオーダーポリシーを組み込み、対数尤度の変分下限を用いて最適化。実験により、画像生成やグラフ生成で意味のある自己回帰順序を学習し、分子グラフ生成ではQM9およびZINC250kベンチマークで最先端の結果を達成。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=EY6pXIDi3G
[Paper Note] The Value of Prediction in Identifying the Worst-Off, Unai Fischer-Abaigar+, arXiv'25
Paper/Blog Link My Issue
Issue Date: 2025-07-15 GPT Summary- 機械学習を用いて最も脆弱な個人を特定し支援する政府プログラムの影響を検討。特に、平等を重視した予測が福祉に与える影響と他の政策手段との比較を行い、ドイツの長期失業者に関するケーススタディを通じてその効果を分析。政策立案者に対して原則に基づいた意思決定を支援するフレームワークとデータ駆動型ツールを提供。 Comment
openreview: https://openreview.net/forum?id=26JsumCG0z
[Paper Note] Score Matching With Missing Data, Josh Givens+, ICML'25
Paper/Blog Link My Issue
#MachineLearning Issue Date: 2025-07-15 GPT Summary- スコアマッチングはデータ分布学習の重要な手法ですが、不完全データへの適用は未研究です。本研究では、部分的に欠損したデータに対するスコアマッチングの適応を目指し、重要度重み付け(IW)アプローチと変分アプローチの2つのバリエーションを提案します。IWアプローチは有限サンプル境界を示し、小さなサンプルでの強力な性能を確認。変分アプローチは高次元設定でのグラフィカルモデル推定において優れた性能を発揮します。 Comment
openreview: https://openreview.net/forum?id=mBstuGUaXo
ICML'25 outstanding papers
解説:
[Paper Note] Conformal Prediction as Bayesian Quadrature, Jake C. Snell+, arXiv'25
Paper/Blog Link My Issue
Issue Date: 2025-07-15 GPT Summary- 機械学習の予測モデルの理解が重要になる中、コンフォーマル予測をベイズ的視点から再考し、頻度主義的保証の限界を指摘。ベイズ的数値積分に基づく新たな手法を提案し、解釈可能な保証と損失の範囲を豊かに表現する。 Comment
openreview: https://openreview.net/forum?id=PNmkjIzHB7
ICML'25 outstanding papers
[Paper Note] Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction, Vaishnavh Nagarajan+, arXiv'25
Paper/Blog Link My Issue
Issue Date: 2025-07-15 GPT Summary- 最小限のアルゴリズムタスクを設計し、現代の言語モデルの創造的限界を定量化。タスクは新しい接続の発見やパターン構築を必要とし、次トークン学習の限界を論じる。マルチトークンアプローチが独創的な出力を生成し、入力層へのノイズ注入が効果的であることを発見。研究は創造的スキル分析のためのテストベッドを提供し、新たな議論を展開。コードはGitHubで公開。 Comment
openreview: https://openreview.net/forum?id=Hi0SyHMmkd
ICML'25 outstanding papers
[Paper Note] Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions, Jaeyeon Kim+, ICML'25
Paper/Blog Link My Issue
#Analysis #Pretraining #DiffusionModel #Decoding Issue Date: 2025-07-15 GPT Summary- マスク付き拡散モデル(MDMs)は、自己回帰モデル(ARMs)と比較してトレーニングの複雑さと推論の柔軟性をトレードオフする新しい生成モデルです。本研究では、MDMsが自己回帰モデルよりも計算上解決不可能なサブ問題に取り組むことを示し、適応的なトークンデコード戦略がMDMsの性能を向上させることを実証しました。数独の論理パズルにおいて、適応的推論により解決精度が$<7$%から$\approx 90$%に向上し、教師強制でトレーニングされたMDMsがARMsを上回ることを示しました。 Comment
openreview: https://openreview.net/forum?id=DjJmre5IkP
ICML'25 outstanding papers
日本語解説:
[Paper Note] CollabLLM: From Passive Responders to Active Collaborators, Shirley Wu+, arXiv'25
Paper/Blog Link My Issue
Issue Date: 2025-07-15 GPT Summary- CollabLLMは、長期的なインタラクションを最適化するための新しい訓練フレームワークで、マルチターンの人間とLLMのコラボレーションを強化する。協調シミュレーションを用いて、応答の長期的な貢献を評価し、ユーザーの意図を明らかにすることで、より人間中心のAIを実現。文書作成などのタスクで平均18.5%のパフォーマンス向上と46.3%のインタラクティビティ改善を達成し、ユーザー満足度を17.6%向上させ、消費時間を10.4%削減した。 Comment
openreview: https://openreview.net/forum?id=DmH4HHVb3y
ICML'25 outstanding papers
[Paper Note] ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts, Samar Khanna+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Transformer #PEFT(Adaptor/LoRA) #Finetuning #KeyPoint Notes Issue Date: 2025-07-14 GPT Summary- PEFT技術を用いたExPLoRAは、事前学習済みビジョントランスフォーマー(ViT)を新しいドメインに適応させる手法で、教師なし事前学習を通じて効率的にファインチューニングを行う。実験では、衛星画像において最先端の結果を達成し、従来のアプローチよりも少ないパラメータで精度を最大8%向上させた。 Comment
元ポスト:
これまでドメイン適応する場合にラベル付きデータ+LoRAでFinetuningしていたのを、ラベル無しデータ+継続事前学習の枠組みでやりましょう、という話のようである。
手法は下記で、事前学習済みのモデルに対してLoRAを適用し継続事前学習する。ただし、最後尾のLayer、あるいは最初と最後尾のLayerの両方をunfreezeして、trainableにする。また、LoRAはfreezeしたLayerのQ,Vに適用し、それらのLayerのnormalization layerもunfreezeする。最終的に、継続事前学習したモデルにヘッドをconcatしてfinetuningすることで目的のタスクを実行できるようにする。詳細はAlgorithm1を参照のこと。
同じモデルで単にLoRAを適用しただけの手法や、既存手法をoutperform
画像+ViT系のモデルだけで実験されているように見えるが、LLMとかにも応用可能だと思われる。
[Paper Note] Nonlinear transformers can perform inference-time feature learning, Nishikawa+, ICML'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Transformer #In-ContextLearning Issue Date: 2025-07-13 GPT Summary- 事前学習されたトランスフォーマーは、推論時に特徴を学習する能力を持ち、特に単一インデックスモデルにおける文脈内学習に焦点を当てています。勾配ベースの最適化により、異なるプロンプトからターゲット特徴を抽出し、非適応的アルゴリズムを上回る統計的効率を示します。また、推論時のサンプル複雑性が相関統計クエリの下限を超えることも確認されました。 Comment
元ポスト:
[Paper Note] Temporal Difference Flows, Jesse Farebrother+, ICML'25
Paper/Blog Link My Issue
#FlowMatching Issue Date: 2025-07-13 GPT Summary- 未来予測モデルの精度向上のため、幾何学的ホライズンモデル(GHMs)を用いた新手法「時間差フロー(TD-Flow)」を提案。TD-Flowは新しいベルマン方程式とフローマッチング技術を活用し、従来手法の5倍以上のホライズンで正確な予測を実現。理論的には勾配分散の低減が効果の主因であることを示し、実証的には様々なドメインでの下流タスクにおいて性能向上を確認。行動基盤モデルとの統合により、長期的な意思決定の改善も示唆。 Comment
元ポスト:
ICML2025のベストペーパーとのこと
[Paper Note] Not All Explanations for Deep Learning Phenomena Are Equally Valuable, Alan Jeffares+, ICML'25
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #LearningPhenomena Issue Date: 2025-07-11 GPT Summary- 深層学習の驚くべき現象(ダブルディセント、グロッキングなど)を孤立したケースとして説明することには限界があり、実世界のアプリケーションにはほとんど現れないと主張。これらの現象は、深層学習の一般的な原則を洗練するための研究価値があると提案し、研究コミュニティのアプローチを再考する必要性を示唆。最終的な実用的目標に整合するための推奨事項も提案。 Comment
元ポスト:
関連:
- [Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20
- [Paper Note] Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets, Alethea Power+, ICLR'21 Workshop, 2022.01
- [Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19
[Paper Note] Mixture of Experts Provably Detect and Learn the Latent Cluster Structure in Gradient-Based Learning, Ryotaro Kawata+, ICML'25
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #MachineLearning #MoE(Mixture-of-Experts) Issue Date: 2025-07-11 GPT Summary- Mixture of Experts (MoE)は、入力を専門家に動的に分配するモデルのアンサンブルであり、機械学習で成功を収めているが、その理論的理解は遅れている。本研究では、MoEのサンプルおよび実行時間の複雑さを回帰タスクにおけるクラスタ構造を通じて理論的に分析し、バニラニューラルネットワークがこの構造を検出できない理由を示す。MoEは各専門家の能力を活用し、問題をより単純なサブ問題に分割することで、非線形回帰におけるSGDのダイナミクスを探求する初めての試みである。 Comment
元ポスト:
[Paper Note] How Do Large Language Monkeys Get Their Power (Laws)?, Rylan Schaeffer+, ICML'25
Paper/Blog Link My Issue
Issue Date: 2025-07-10 GPT Summary- 本研究では、マルチモーダル言語モデルの試行回数に対する成功率のスケーリング特性を探求し、単純な数学的計算が指数関数的に失敗率を減少させることを示す。成功確率の分布が重い尾を持つ場合、指数関数的スケーリングが集約的な多項式スケーリングと整合的であることを明らかにし、冪法則の逸脱を説明する方法を提案。これにより、ニューラル言語モデルの性能向上とスケーリング予測の理解が深まる。 Comment
元ポスト:
[Paper Note] Correlated Errors in Large Language Models, Elliot Kim+, ICML'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Evaluation #LLM-as-a-Judge Issue Date: 2025-07-05 GPT Summary- 350以上のLLMを評価し、リーダーボードと履歴書スクリーニングタスクで実証的な分析を実施。モデル間のエラーには実質的な相関があり、特に大きく正確なモデルは異なるアーキテクチャやプロバイダーでも高い相関を示す。相関の影響はLLMを評価者とするタスクや採用タスクにおいても確認された。 Comment
元ポスト:
これは結果を細かく見るのと、評価したタスクの形式とバイアスが生じないかをきちんと確認した方が良いような気がする。
それは置いておいたとして、たとえば、Figure9bはLlamaの異なるモデルサイズは、高い相関を示しているが、それはベースが同じだからそうだろうなあ、とは思う。一方、9aはClaude, Nova, Mistral, GPTなど多様なプロバイダーのモデルで高い相関が示されている。Llama3-70BとLLama3.{1,2,3}-70Bでは相関が低かったりしている。
Figure1(b)はHELMで比較的最新のモデル間でプロバイダーが別でも高い相関があるようにみえる。
このような相関がある要因や傾向については論文を読んでみないとわからない。
LLM-as-a-Judgeにおいて、評価者となるモデルと評価対象となるモデルが同じプロバイダーやシリーズの場合は(エラーの傾向が似ているので)性能がAccuracyが真のAccuracyよりも高めに出ている。また評価者よりも性能が低いモデルに対しても、性能が実際のAccuracyよりも高めに出す傾向にある(エラーの相関によってエラーであるにも関わらず正解とみなされAccuracyが高くなる)ようである。逆に、評価者よりも評価対象が性能が高い場合、評価者は自分が誤ってしまうquestionに対して、評価対象モデルが正解となる回答をしても、それに対して報酬を与えることができず性能が低めに見積もられてしまう。これだけの規模の実験で示されたことは、大変興味深い。
履歴書のスクリーニングタスクについてもケーススタディをしている。こちらも詳細に分析されているので興味がある場合は参照のこと。
[Paper Note] Scaling Laws for Upcycling Mixture-of-Experts Language Models, Seng Pei Liew+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #MoE(Mixture-of-Experts) #Scaling Laws #Author Thread-Post Issue Date: 2025-06-21 GPT Summary- LLMsの事前学習は高コストで時間がかかるため、アップサイクリングとMoEモデルの計算効率向上が提案されている。本研究では、アップサイクリングをMoEに適用し、データセットのサイズやモデル構成に依存するスケーリング法則を特定。密なトレーニングデータとアップサイクリングデータの相互作用が効率を制限することを示し、アップサイクリングのスケールアップに関する指針を提供。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=ZBBo19jldX
[Paper Note] Steer LLM Latents for Hallucination Detection, Seongheon Park+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Hallucination #OptimalTransport #Author Thread-Post Issue Date: 2025-06-14 GPT Summary- LLMの幻覚問題に対処するため、Truthfulness Separator Vector(TSV)を提案。TSVは、LLMの表現空間を再構築し、真実と幻覚の出力を分離する軽量な指向ベクトルで、モデルのパラメータを変更せずに機能。二段階のフレームワークで、少数のラベル付き例からTSVを訓練し、ラベルのない生成物を拡張。実験により、TSVは最小限のラベル付きデータで高いパフォーマンスを示し、実世界のアプリケーションにおける実用的な解決策を提供。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=UMqNQEPNT3¬eId=mAbrf36RHa
[Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #PEFT(Adaptor/LoRA) #memory #One-Line Notes #Initial Impression Notes #Test Time Training (TTT) #Author Thread-Post Issue Date: 2025-06-12 GPT Summary- Text-to-LoRA(T2L)は、自然言語による説明に基づいて大規模言語モデル(LLMs)を迅速に適応させる手法で、従来のファインチューニングの高コストと時間を克服します。T2Lは、LoRAを安価なフォワードパスで構築するハイパーネットワークを使用し、タスク特有のアダプターと同等のパフォーマンスを示します。また、数百のLoRAインスタンスを圧縮し、新しいタスクに対してゼロショットで一般化可能です。このアプローチは、基盤モデルの専門化を民主化し、計算要件を最小限に抑えた言語ベースの適応を実現します。 Comment
元ポスト:
な、なるほど、こんな手が…!
openreview: https://openreview.net/forum?id=zWskCdu3QA
ポイント解説:
Text-to-LoRAの目的は、instructionをメモリの内部パラメータに埋め込み、モデルにon-the-flyで新たな挙動を身につけさせること。
[Paper Note] Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing, Kento Nishi+, ICML'25
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #KnowledgeEditing #Author Thread-Post Issue Date: 2025-06-10 GPT Summary- 知識編集(KE)アルゴリズムは、モデルの重みを変更して不正確な事実を更新するが、これがモデルの事実の想起精度や推論能力に悪影響を及ぼす可能性がある。新たに定義した合成タスクを通じて、KEがターゲットエンティティを超えて他のエンティティの表現に影響を与え、未見の知識の推論を歪める「表現の破壊」現象を示す。事前訓練されたモデルを用いた実験でもこの発見が確認され、KEがモデルの能力に悪影響を及ぼす理由を明らかにするメカニズム仮説を提供する。 Comment
元ポスト:
[Paper Note] Distillation Scaling Laws, Dan Busbridge+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Distillation #SmallModel #Scaling Laws #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-05-29 GPT Summary- 蒸留モデルの性能を推定するための蒸留スケーリング法則を提案。教師モデルと生徒モデルの計算割り当てを最適化することで、生徒の性能を最大化。教師が存在する場合やトレーニングが必要な場合に最適な蒸留レシピを提供。多くの生徒を蒸留する際は、監視付きの事前学習を上回るが、生徒のサイズに応じた計算レベルまで。単一の生徒を蒸留し、教師がトレーニング必要な場合は監視学習を推奨。蒸留に関する洞察を提供し、理解を深める。 Comment
著者ポスト:
-
-
openreview: https://openreview.net/forum?id=1nEBAkpfb9
手元にSFTのデータがあったときにSLMを学習したいという状況で、固定の計算資源があったときに、巨大な教師モデルをSFTで学習してから小型モデルに蒸留するのが良いのか、小型モデルを直接SFTする方が良いのか、どのように教師モデルと生徒モデルに計算資源を割り当てるのが最適かという観点でscaling lawを導出しているようである。
下記Appendixや著者ポストにある通り、知見を一言で言うと
- Distillationでは、SFTによって生み出されるモデルよりも良いモデルを生み出すことはできない
- しかしながら、DistillationではSFTよりも効率的にSFTで学習した場合と比較して良いモデルを学習できる
- 言い換えると、十分な計算量とデータが与えられるとDistillationの効率性は消失する
という感じだろうか。つまり、達成可能な性能のピーク値はSFTを超えられないが、Distillationの方がSFTよりも効率的に学習ができる、という感じに見える。
[Paper Note] Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #Workshop #One-Line Notes #Author Thread-Post Issue Date: 2025-05-27 GPT Summary- 本研究では、外部の報酬やラベルなしで大規模言語モデル(LLMs)が学習できるフレームワーク「内部フィードバックからの強化学習(RLIF)」を提案。自己確信を報酬信号として用いる「Intuitor」を開発し、無監視の学習を実現。実験結果は、Intuitorが数学的ベンチマークで優れた性能を示し、ドメイン外タスクへの一般化能力も高いことを示した。内因的信号が効果的な学習を促進する可能性を示唆し、自律AIシステムにおけるスケーラブルな代替手段を提供。 Comment
元ポスト:
おもしろそう
externalなsignalをrewardとして用いないで、モデル自身が内部的に保持しているconfidenceを用いる。人間は自信がある問題には正解しやすいという直感に基づいており、openendなquestionのようにそもそも正解シグナルが定義できないものもあるが、そういった場合に活用できるようである。
self-trainingの考え方に近いのでは
ベースモデルの段階である程度能力が備わっており、post-trainingした結果それが引き出されるようになったという感じなのだろうか。
参考:
解説スライド:
https://www.docswell.com/s/DeepLearning2023/KYVLG4-2025-09-18-112951
元ポスト:
[Paper Note] When Bad Data Leads to Good Models, Kenneth Li+, ICML'25, 2025.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #Safety #DPO #Toxicity #ActivationSteering/ITI #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2025-05-09 GPT Summary- 本論文では、LLMの事前学習におけるデータの質の再検討を行い、有害データが事後学習における制御を向上させる可能性を探ります。トイ実験を通じて、有害データの割合が増加することで有害性の概念が線形表現に影響を与えることを発見し、有害データが生成的有害性を増加させつつも除去しやすくなることを示しました。評価結果は、有害データで訓練されたモデルが生成的有害性を低下させつつ一般的な能力を保持する良好なトレードオフを達成することを示唆しています。 Comment
元ポスト:
これは面白そう
Webコーパスなどを事前学習で利用する際は、質の高いデータを残して学習した方が良いとされているが、4chanのようなtoxicなデータを混ぜて事前学習して、後からdetox(Inference Time Intervention [Paper Note] Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23
, SFT, DPO)することで、最終的なモデルのtoxicなoutputが減るという話らしい。これはそもそも事前学習時点でtoxicなデータのsignalが除外されることで、モデルがtoxicな内容のrepresentationを学習できず、最終的にtoxicか否かをコントロールできなくなるため、と考察している(っぽい)
有害な出力を減らせそうなことは分かったが、Activation Steeringによってどの程度モデルの性能に影響を与えるのかが気になる、と思ったがAppendixに記載があった。細かく書かれていないので推測を含むが、各データに対してToxicデータセットでProbingすることでTopKのheadを決めて、Kの値を調整することでinterventionの強さを調整し、Toxicデータの割合を変化させて評価してみたところ、モデルの性能に大きな影響はなかったということだと思われる(ただし1Bモデルでの実験しかない)
おそらく2,3節あたりが一番おもしろいポイントなのだと思われるがまだ読めていない。
openreview: https://openreview.net/forum?id=SsLGTZKXf1
解説:
[Paper Note] R.I.P.: Better Models by Survival of the Fittest Prompts, Ping Yu+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #DataDistillation #SyntheticData #Author Thread-Post Issue Date: 2025-05-07 GPT Summary- トレーニングデータの品質がモデルの性能に与える影響を考慮し、低品質な入力プロンプトがもたらす問題を解決するために、Rejecting Instruction Preferences(RIP)というデータ整合性評価手法を提案。RIPは、拒否された応答の品質と選択された好みペアとの報酬ギャップを測定し、トレーニングセットのフィルタリングや高品質な合成データセットの作成に利用可能。実験結果では、RIPを用いることでLlama 3.1-8B-Instructでの性能が大幅に向上し、Llama 3.3-70B-Instructではリーダーボードでの順位が上昇した。 Comment
元ポスト:
スレッドで著者が論文の解説をしている。
[Paper Note] Thinking LLMs: General Instruction Following with Thought Generation, Tianhao Wu+, ICML'25, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Reasoning #DPO #PostTraining #KeyPoint Notes #Author Thread-Post Issue Date: 2025-05-07 GPT Summary- LLMsに思考能力を装備するための訓練方法を提案。反復的な検索と最適化手順を用いて、モデルが監視なしで思考する方法を学ぶ。指示に対する思考候補はジャッジモデルで評価され、最適化される。この手法はAlpacaEvalとArena-Hardで優れたパフォーマンスを示し、推論タスクだけでなく、マーケティングや健康などの非推論カテゴリでも利点を発揮。 Comment
元ポスト:
外部のCoTデータを使わないで、LLMのreasoning capabilityを向上させる話っぽい。DeepSeek-R1の登場以前の研究とのこと。
"reasoning traceを出力するように" Instruction Tuningによって回答を直接出力するようPostTrainingされたモデルにpromptingし、複数のoutputを収集(今回は8個, temperature=0.8, top p=0.95)。Self Taught Evaluator [Paper Note] Self-Taught Evaluators, Tianlu Wang+, arXiv'24, 2024.08
(STE;70B, LLM-as-a-Judgeを利用するモデル)、あるいはArmo Reward Model(8B)によって回答の品質をスコアリング。ここで、LLM-as-a-Judgeの場合はペアワイズでの優劣が決まるだけなので、ELOでスコアリングする。outputのうちbest scoreとworst scoreだったものの双方でペアデータを構築し、DPOで利用するpreferenceペアデータを構築しDPOする。このような処理を繰り返し、モデルの重みをiterationごとに更新する。次のiterationでは更新されたモデルで同様の処理を行い、前段のステップで利用した学習データは利用しないようにする(後段の方が品質が高いと想定されるため)。また、回答を別モデルで評価する際に、長いレスポンスを好むモデルの場合、長い冗長なレスポンスが高くスコアリングされるようなバイアスが働く懸念があるため、長すぎる回答にpenaltyを与えている(Length-Control)。
reasoning traceを出力するpromptはgenericとspecific thoughtの二種類で検証。前者はLLMにどのような思考をするかを丸投げするのに対し、後者はこちら側で指定する。後者の場合は、どのような思考が良いかを事前に知っていなければならない。
Llama-3-8b-instructに適用したところ、70Bスケールのモデルよりも高い性能を達成。また、reasoning trace出力をablationしたモデル(Direct responce baseline)よりも性能が向上。
iterationが進むに連れて、性能が向上している。
[Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #Analysis #NLP #LanguageModel #RepresentationLearning #Supervised-FineTuning (SFT) #Chain-of-Thought #SSM (StateSpaceModel) #PostTraining #read-later #One-Line Notes #CompressionValleys Issue Date: 2025-05-04 GPT Summary- 中間層の埋め込みが最終層を超えるパフォーマンスを示すことを分析し、情報理論や幾何学に基づくメトリクスを提案。32のテキスト埋め込みタスクで中間層が強力な特徴を提供することを実証し、AIシステムの最適化における中間層の重要性を強調。 Comment
現代の代表的な言語モデルのアーキテクチャ(decoder-only model, encoder-only model, SSM)について、最終層のembeddingよりも中間層のembeddingの方がdownstream task(MTEBの32Taskの平均)に、一貫して(ただし、これはMTEBの平均で見たらそうという話であり、個別のタスクで一貫して強いかは読んでみないとわからない)強いことを示した研究。
このこと自体は経験的に知られているのであまり驚きではないのだが(ただ、SSMでもそうなのか、というのと、一貫して強いというのは興味深い)、この研究はMatrix Based Entropyと呼ばれるものに基づいて、これらを分析するための様々な指標を定義し理論的な根拠を示し、Autoregressiveな学習よりもMasked Languageによる学習の方がこのようなMiddle Layerのボトルネックが緩和され、同様のボトルネックが画像の場合でも起きることを示し、CoTデータを用いたFinetuningについても分析している模様。この辺の貢献が非常に大きいと思われるのでここを理解することが重要だと思われる。あとで読む。
openreview: https://openreview.net/forum?id=WGXb7UdvTX
[Paper Note] XAttention: Block Sparse Attention with Antidiagonal Scoring, Ruyi Xu+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention #Architecture Issue Date: 2025-04-07 GPT Summary- ブロック疎注意を用いてトランスフォーマーモデルの長文脈推論を高速化するフレームワークXAttentionを提案。これにより、注意行列の反対角線の値を用いて非必須ブロックを正確に識別し、高いスパース性を実現。従来の手法と同等の精度を保ちながら、計算コストを最大13.5倍削減。LCTMsの効率的な展開を可能にする。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=KG6aBfGi6e
[Paper Note] Training Software Engineering Agents and Verifiers with SWE-Gym, Jiayi Pan+, ICML'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Environment Issue Date: 2025-04-02 GPT Summary- SWE-Gymを提案し、2,438件の実世界のPythonタスクを含む環境を構築。言語モデルに基づくSWEエージェントを訓練し、SWE-Benchで最大19%の解決率向上を達成。微調整されたエージェントは新たな最先端の性能を示し、SWE-Gymやモデル、エージェントの軌跡を公開。 Comment
SWE-Benchとは完全に独立したより広範な技術スタックに関連するタスクに基づくSWEベンチマーク
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
SWE-Benchと比べて実行可能な環境と単体テストが提供されており、単なるベンチマークではなくエージェントを訓練できる環境が提供されている点が大きく異なるように感じる。
[Paper Note] Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification, Eric Zhao+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Test-Time Scaling #Verification #One-Line Notes #SelfVerification #Author Thread-Post Issue Date: 2025-03-18 GPT Summary- サンプリングベースの探索は、複数の候補応答を生成し最良のものを選ぶ手法であり、自己検証によって正確性を確認します。本研究では、この探索のスケーリング傾向を分析し、シンプルな実装がGemini v1.5 Proの推論能力を向上させることを示しました。自己検証の精度向上は、より大きな応答プールからのサンプリングによるもので、応答間の比較が有益な信号を提供することや、異なる出力スタイルが文脈に応じて役立つことを明らかにしました。また、最前線のモデルは初期の検証能力が弱く、進捗を測るためのベンチマークを提案しました。 Comment
元ポスト:
ざっくりしか読めていないが、複数の解答をサンプリングして、self-verificationをさせて最も良かったものを選択するアプローチ。最もverificationスコアが高い解答を最終的に選択したいが、tieの場合もあるのでその場合は追加のpromptingでレスポンスを比較しより良いレスポンスを選択する。これらは並列して実行が可能で、探索とself-verificationを200個並列するとGemini 1.5 Proでo1-previewよりも高い性能を獲得できる模様。Self-consistencyと比較しても、gainが大きい。具体的なアルゴリズムはAlgorithm1を参照のこと。
openreview: https://openreview.net/forum?id=wl3eI4wiE5
[Paper Note] On Teacher Hacking in Language Model Distillation, Daniil Tiapkin+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Distillation #TeacherHacking #Reference Collection #Reading Reflections Issue Date: 2025-02-10 GPT Summary- LMのポストトレーニングは、知識蒸留とRLHFに依存し、報酬ハッキングの課題を指摘。教師LMからの「教師ハッキング」が存在することを検証。実験では、固定オフラインデータで教師ハッキングが発生し、多項式収束法則から逸脱することを観測。オンラインデータ生成技術がハッキングを緩和できることを示し、データの多様性が重要な要因であると結論。これにより、LM構築の蒸留の利点と限界が明らかに。 Comment
元ポスト:
自分で蒸留する機会は今のところないが、覚えておきたい。過学習と一緒で、こういう現象が起こるのは想像できる。
openreview: https://openreview.net/forum?id=qxSFIigPug¬eId=CAgFzoMVit
[Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Reasoning #LongSequence #RewardHacking #PostTraining #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2025-02-07 GPT Summary- 本研究では、大規模言語モデル(LLMs)における長い思考の連鎖(CoTs)推論のメカニズムを調査し、重要な要因を特定。主な発見は、(1) 教師ありファインチューニング(SFT)は必須ではないが効率を向上させる、(2) 推論能力は計算の増加に伴い現れるが、報酬の形状がCoTの長さに影響、(3) 検証可能な報酬信号のスケーリングが重要で、特に分布外タスクに効果的、(4) エラー修正能力は基本モデルに存在するが、RLを通じて効果的に奨励するには多くの計算が必要。これらの洞察は、LLMsの長いCoT推論を強化するためのトレーニング戦略の最適化に役立つ。 Comment
元ポスト:
元ポストのスレッド中に論文の11個の知見が述べられている。どれも非常に興味深い。DeepSeek-R1のテクニカルペーパーと同様、
- Long CoTとShort CoTを比較すると前者の方が到達可能な性能のupper bonudが高いことや、
- SFTを実施してからRLをすると性能が向上することや、
- RLの際にCoTのLengthに関する報酬を入れることでCoTの長さを抑えつつ性能向上できること、
- 数学だけでなくQAペアなどのノイジーだが検証可能なデータをVerifiableな報酬として加えると一般的なreasoningタスクで数学よりもさらに性能が向上すること、
- より長いcontext window sizeを活用可能なモデルの訓練にはより多くの学習データが必要なこと、
- long CoTはRLによって学習データに類似したデータが含まれているためベースモデルの段階でその能力が獲得されていることが示唆されること、
- aha momentはすでにベースモデル時点で獲得されておりVerifiableな報酬によるRLによって強化されたわけではなさそう、
など、興味深い知見が盛りだくさん。非常に興味深い研究。あとで読む。
[Paper Note] SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Analysis #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-01-30 GPT Summary- SFTとRLの一般化能力の違いを研究し、GeneralPointsとV-IRLを用いて評価。RLはルールベースのテキストと視覚変種に対して優れた一般化を示す一方、SFTは訓練データを記憶し分布外シナリオに苦労。RLは視覚認識能力を向上させるが、SFTはRL訓練に不可欠であり、出力形式を安定させることで性能向上を促進。これらの結果は、複雑なマルチモーダルタスクにおけるRLの一般化能力を示す。 Comment
元ポスト:
Byte Latent Transformer: Patches Scale Better Than Tokens, Artidoro Pagnoni+, ICML'25 Workshop Tokshop
Paper/Blog Link My Issue
#NLP #LanguageModel #Tokenizer #Workshop #KeyPoint Notes #Byte-level Issue Date: 2025-01-02 GPT Summary- Byte Latent Transformer(BLT)は、バイトレベルのLLMアーキテクチャで、トークン化ベースのLLMと同等のパフォーマンスを実現し、推論効率と堅牢性を大幅に向上させる。BLTはバイトを動的にサイズ変更可能なパッチにエンコードし、データの複雑性に応じて計算リソースを調整する。最大8Bパラメータと4Tトレーニングバイトのモデルでの研究により、固定語彙なしでのスケーリングの可能性が示された。長いパッチの動的選択により、トレーニングと推論の効率が向上し、全体的にBLTはトークン化モデルよりも優れたスケーリングを示す。 Comment
興味深い
図しか見れていないが、バイト列をエンコード/デコードするtransformer学習して複数のバイト列をパッチ化(エントロピーが大きい部分はより大きなパッチにバイト列をひとまとめにする)、パッチからのバイト列生成を可能にし、パッチを変換するのをLatent Transformerで学習させるようなアーキテクチャのように見える。
また、予算によってモデルサイズが決まってしまうが、パッチサイズを大きくすることで同じ予算でモデルサイズも大きくできるのがBLTの利点とのこと。
日本語解説: https://bilzard.github.io/blog/2025/01/01/byte-latent-transformer.html?v=2
OpenReview: https://openreview.net/forum?id=UZ3J8XeRLw
[Paper Note] Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25, 2024.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #DPO #One-Line Notes Issue Date: 2024-11-07 GPT Summary- 自己調整は、モデルが人間の注釈なしに自らを改善する方法であり、自己一貫性を活用して訓練を行う新しいアプローチ、自己一貫性優先最適化(ScPO)を提案。ScPOは一貫した答えを優先し、GSM8KやMATHなどの推論タスクで従来の手法を大幅に上回る性能を示し、標準的な監視学習との組み合わせでも結果が向上。ZebraLogicでLlama-3 8Bを微調整し、他の大規模モデルを超える成果を達成。 Comment
元ポスト:
Self-Consistencyのように、モデルに複数の出力をさせて、最も頻度が高い回答と頻度が低い回答の2つでDPOのペアデータを作成し学習。頻度の差によって重みを決めてlossに組み込みこのよつな処理を繰り返し学習すると性能が向上する、といった話のように見える。
[Paper Note] Repeat After Me: Transformers are Better than State Space Models at Copying, Samy Jelassi+, arXiv'24, 2024.02
Paper/Blog Link My Issue
Issue Date: 2026-07-09 GPT Summary- GSSMsは効率的な推論が期待されるが、入力のコピーが必要なタスクではトランスフォーマーに劣る。理論的に、トランスフォーマーは指数長の文字列をコピーできるのに対し、GSSMsは固定サイズの潜在状態に制限される。実験でも、コンテキストコピーが必要な合成タスクでトランスフォーマーが優れていることが示され、事前学習済みモデルの評価からもトランスフォーマーの情報取得能力がGSSMsを大幅に上回ることが確認された。これにより、実用タスクにおけるトランスフォーマーとGSSMsの間には本質的なギャップがあると結論づけられる。
[Paper Note] Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention, Zhen Qin+, ICML'24, 2024.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Attention #LongSequence #One-Line Notes #LinearAttention Issue Date: 2026-02-17 GPT Summary- Lightning Attentionは、一定の学習速度を維持しつつ固定メモリ消費を実現する線形注意の新しい実装です。累積和演算の問題を、異なる計算戦略を用いることで解決し、ブロック内では従来の注意計算を、ブロック間では線形注意のカーネル技術を導入しています。GPUを効率的に活用するためのタイル化技術を採用し、新しいアーキテクチャTransNormerLLM(TNL)を提案。TNLは他のモデルより効率的で、従来のトランスフォーマーと同等の性能を示します。ソースコードは公開されています。 Comment
Ring、MiniCPMで採用されているlinear attentionの一種であるlightning attention
[Paper Note] Gated Linear Attention Transformers with Hardware-Efficient Training, Songlin Yang+, ICML'24, 2023.12
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #Selected Papers/Blogs #LinearAttention Issue Date: 2026-02-04 GPT Summary- 線形アテンションを持つトランスフォーマーは、効率的な並列トレーニングを実現する一方、通常のソフトマックスアテンションに比べて性能が劣る。提案するFLASHLINEARATTENTIONは、メモリ移動と並列化のトレードオフを考慮し、短いシーケンスで高速な実装を実現。また、データ依存ゲートを追加したゲート付き線形アテンション(GLA)トランスフォーマーは、LLaMAやRetNet、Mambaと比較して競争力のある性能を示し、長さの一般化でも有効。GLAトランスフォーマーは、同サイズのMambaモデルよりも高いトレーニングスループットを持つ。
[Paper Note] RLVF: Learning from Verbal Feedback without Overgeneralization, Moritz Stephan+, ICML'24, 2024.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SyntheticData #PostTraining #Generalization #TextualFeedback Issue Date: 2026-02-01 GPT Summary- 高レベルの言語フィードバックを用いてLLMの調整を行う際、過剰一般化の問題を解決するために「C3PO」手法を提案。C3POはフィードバックを適用する方法を指定する合成嗜好データセットを生成し、元のモデルから逸脱を抑えつつ微調整を実施。実験により、他の文脈の動作を維持しながら、フィードバックの遵守と過剰一般化を30%削減できることを示した。 Comment
pj page: https://austrian-code-wizard.github.io/c3po-website/
[Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #PEFT(Adaptor/LoRA) #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-10 GPT Summary- LoRAの精度ギャップを解消するために、Weight-Decomposed Low-Rank Adaptation(DoRA)を提案。DoRAは、ファインチューニングの重みを大きさと方向に分解し、方向性の更新にLoRAを使用することで、効率的にパラメータ数を最小化。これにより、LoRAの学習能力と安定性を向上させ、追加の推論コストを回避。さまざまな下流タスクでLoRAを上回る性能を示す。 Comment
日本語解説:
- LoRAの進化:基礎から最新のLoRA-Proまで , 松尾研究所テックブログ, 2025.09
- Tora: Torchtune-LoRA for RL, shangshang-wang, 2025.10
では、通常のLoRA, QLoRAだけでなく本手法でRLをする実装もサポートされている模様
[Paper Note] Scaling Exponents Across Parameterizations and Optimizers, Katie Everett+, ICML'24
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Transformer #Optimizer #read-later #HyperparameterTransfer #LearningRate Issue Date: 2025-08-31 GPT Summary- モデルのスケーリングには、パラメータ化やオプティマイザの選択が重要である。本研究では、パラメータとデータの整合性に関する新しい視点を提案し、広範なオプティマイザと学習率の組み合わせで数万のモデルを訓練した結果、最適な学習率スケーリングが重要であることを発見。新しい層ごとの学習率の処方は従来の方法を上回る性能を示し、Adamのイプシロンパラメータの適切なスケーリングが必要であることを明らかにし、数値的に安定した新しいAdamバージョンであるAdam-atan2を提案した。
[Paper Note] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback, Harrison Lee+, ICML'24
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SelfImprovement Issue Date: 2025-08-21 GPT Summary- RLAIFは、オフ・ザ・シェルフのLLMから生成された好みに基づいて報酬モデルを訓練し、RLHFと同等のパフォーマンスを達成する代替手段を提供。自己改善を示し、d-RLAIFを導入することでさらに優れた結果を得る。RLAIFは人間のフィードバックを用いた場合と同等の性能を示し、RLHFのスケーラビリティの課題に対する解決策となる可能性がある。 Comment
先行研究:
- [Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
[Paper Note] Better & Faster Large Language Models via Multi-token Prediction, Fabian Gloeckle+, ICML'24
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #Coding #Selected Papers/Blogs Issue Date: 2025-08-16 GPT Summary- 本研究では、大規模言語モデルを複数の将来のトークンを同時に予測するように訓練する手法を提案し、サンプル効率の向上を図る。具体的には、n個の独立した出力ヘッドを用いて次のnトークンを予測し、訓練時間にオーバーヘッドをかけずに下流の能力を向上させる。特に、コーディングタスクにおいて、提案モデルは強力なベースラインを上回る性能を示し、推論時に最大3倍の速度向上も実現。 Comment
next tokenだけでなく、next 4-tokenを予測して学習することで、MBPP/HumanEvalにおいて、モデルのパラメータサイズが1.3Bを超えた時点でベースライン(=同じパラメータサイズとなるように調整されたnext-token prediction)をoutperformしはじめ、モデルサイズが大きくなるにつれて性能の差が顕著に表れることを示した。コーディングドメインにおいて事前学習、およびfinetuningの双方で効果がある。ただし、3.7節で示されている通り、これはコーディングドメインでのみこのような顕著な改善がみられており、自然言語データに対してはここまで顕著な改善はしていないように見える(5.1節で考察されていそう; 昨今のLLMでは事前学習データにコーディングなどのデータが入るのが普通なので利用する恩恵はありそう; Abstractive Summarizationでは性能が改善している(Figure6); GSM8Kでは200Bまではnext 2 tokenを予測すると性能が改善しているが500B token学習するとnext token predictionの方が性能が良くなる)。全体的にperplexityの改善(=次のトークンにおいて正解トークンの生成確率を改善する)というよりは、モデルの"最終的な生成結果”にフォーカスした評価となっている。
モデルは共有のトランクf_s (おそらくhead間でパラメータを共有している一連のtransformerブロック) を持っておりinput x_t:1に対応するlatent representation z_t:1を生成する。latent representationをoutput headにinputすることで、それぞれのheadが合計でn個のnext tokenを予測する。
next n-tokenを予測する際には、GPUメモリを大幅に食ってしまう (logitsのshapeが(n, V)となりそれらの勾配も保持しなければならない) ことがボトルネックとなるが、f_sまでforward passを実行したら、各headに対してforward/backward passを順番に実行して、logitsの値は破棄し勾配の情報だけf_sに蓄積することで、長期的に保持する情報を各headのから逆伝搬された勾配情報のみにすることでこれを解決している。
実際にinferenceをするときはnext tokenを予測するヘッドの出力を活用することを前提としているが、全てのヘッドを活用することで、t時点でt+nトークンの予測を可能なため、self-speculative decodingを実施しinference timeを短縮することができる。
3.4で示されているように、nの値は大きければ大きいほど良いというわけではなく、4程度(byte levelなモデルの場合は8 bytes)が最適なようである。が、Table1を見ると、データによってはn=6が良かったり(i.e., 最適なnは学習データ依存)複数エポック学習するとmulti token predictionの効果が薄くなっていそう(i.e., 同じトークンの予測を複数回学習するので実質multi token predictionと似たようなことをやっている。言い換えると、multi token predictionは複数epochの学習を先取りしているとみなせる?)なのは注意が必要そう。
全体的に複数epochを学習すると恩恵がなくなっていく(コーディング) or next token predictionよりも性能が悪化する(自然言語)ので、LLMの事前学習において、複数epochを学習するような当たり前みたいな世界線が訪れたら、このアーキテクチャを採用すると性能はむしろ悪化しそうな気はする。
MBPP/HumanEval:
- [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21
- [Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
[Paper Note] Programming Every Example: Lifting Pre-training Data Quality Like Experts at Scale, Fan Zhou+, arXiv'24
Paper/Blog Link My Issue
Issue Date: 2025-07-18 GPT Summary- 本論文では、0.3Bパラメータの小規模言語モデルが人間の専門家に匹敵するデータ精製能力を持つことを示し、データ精製をプログラミングタスクとして扱う新しいフレームワーク「Programming Every Example (ProX)」を提案します。ProXは、各例に対して細かい操作を生成・実行することでコーパスを大規模に精製し、実験結果ではProXによってキュレーションされたデータで事前学習されたモデルが、元のデータや他の方法よりも2%以上の性能向上を示しました。また、ProXはドメイン特化型の継続的事前学習でも効果を発揮し、他のモデルに対しても精度を大幅に向上させることが確認されました。さらに、ProXはトレーニングFLOPsを節約し、効率的なLLM事前学習の新たな道を提供します。全てのトレーニングおよび実装の詳細はオープンソースとして共有されています。 Comment
元ポスト:
ポスタースクショあり
[Paper Note] DiLoCo: Distributed Low-Communication Training of Language Models, Arthur Douillard+, ICML'24 Workshop WANT
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #mid-training #Selected Papers/Blogs #Workshop #One-Line Notes #needs-revision #DistributedLearning Issue Date: 2025-07-15 GPT Summary- 分散最適化アルゴリズム「DiLoCo」を提案し、接続が不十分なデバイスでのLLMトレーニングを可能にする。DiLoCoは、通信量を500分の1に抑えつつ、完全同期の最適化と同等の性能をC4データセットで発揮。各ワーカーのデータ分布に対して高いロバスト性を持ち、リソースの変動にも柔軟に対応可能。 Comment
言語モデルの分散学習における通信量をいかに抑えるかにフォーカスした研究で、クライアントごとに異なるデータsplitを持ち、当該データによってモデルをローカルでAdamWを用いてH step更新。その後、更新された重みの差分をouter gradientとして共有し、重み更新の差分を平均化することでローカルモデルを集約するという処理を繰り返す。
[Paper Note] Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data, Fahim Tajwar+, ICML'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Alignment #ReinforcementLearning #PPO (ProximalPolicyOptimization) #DPO #On-Policy #Reference Collection Issue Date: 2025-06-25 GPT Summary- 好みのラベルを用いた大規模言語モデルのファインチューニングに関する研究。オンポリシー強化学習や対照学習などの手法を比較し、オンポリシーサンプリングや負の勾配を用いるアプローチが優れていることを発見。これにより、カテゴリ分布の特定のビンにおける確率質量を迅速に変更できるモード探索目的の重要性を示し、データ収集の最適化に関する洞察を提供。 Comment
以下のオフライン vs. オンラインRLアルゴリズムで本研究が引用されている:
[Paper Note] UltraFeedback: Boosting Language Models with Scaled AI Feedback, Ganqu Cui+, ICML'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Alignment #InstructionTuning #PostTraining Issue Date: 2025-05-11 GPT Summary- 人間のフィードバックに加え、高品質なAIフィードバックを自動収集することで、LLMsのアライメントをスケーラブルに実現。多様なインタラクションをカバーし、注釈バイアスを軽減した結果、25万件の会話に対する100万件以上のGPT-4フィードバックを含むデータセット「UltraFeedback」を構築。これに基づき、LLaMAモデルを強化学習でアライメントし、チャットベンチマークで優れた性能を示す。研究はオープンソースチャットモデルの構築におけるAIフィードバックの有効性を検証。データとモデルは公開中。
[Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #SyntheticData #Selected Papers/Blogs #Reference Collection Issue Date: 2025-05-03 GPT Summary- 大規模言語モデル(LLMs)の知識抽出能力は、訓練データの多様性と強く相関しており、十分な強化がなければ知識は記憶されても抽出可能ではないことが示された。具体的には、エンティティ名の隠れ埋め込みに知識がエンコードされているか、他のトークン埋め込みに分散しているかを調査。LLMのプレトレーニングに関する重要な推奨事項として、補助モデルを用いたデータ再構成と指示微調整データの早期取り入れが提案された。 Comment
SNLP'24での解説スライド:
https://speakerdeck.com/sosk/physics-of-language-models-part-3-1-knowledge-storage-and-extraction
[Paper Note] Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, Tri Dao+, ICML'24
Paper/Blog Link My Issue
#NLP #LanguageModel #SSM (StateSpaceModel) #Selected Papers/Blogs #Reference Collection #Initial Impression Notes #LinearAttention Issue Date: 2025-03-24 GPT Summary- TransformersとMambaのような状態空間モデル(SSMs)の関連性を示し、SSMsと注意の変種との理論的接続を構築。新たに設計したMamba-2は、速度を2〜8倍向上させながら、Transformersと競争力を維持。 Comment
Mamba2の詳細を知りたい場合に読む
Mamba3:
- [Paper Note] MAMBA-3: IMPROVED SEQUENCE MODELING USING STATE SPACE PRINCIPLES, 2025.10
バグがあり本来の性能が出ていなかった模様:
初期化修正は後はGated Delta Netを上回る性能に。
- [Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
[Paper Note] KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, ICML'24, 2024.02
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Alignment #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-10-27 GPT Summary- 人間の偏見を考慮したLLMのフィードバックを目的とした研究。プロスペクト理論に基づく「人間意識型損失(HALOs)」を用いて、生成物の効用を最大化する新手法KTOを提案。このアプローチは、既存の方法と比較してパフォーマンスが同等またはそれ以上であり、普遍的な最適損失関数は存在しないことを示唆。最適な損失は、設定に応じたバイアスによって異なる。 Comment
binaryフィードバックデータからLLMのアライメントをとるKahneman-Tversky Optimization (KTO)論文
解説(DPO,RLHFの話だがKTOを含まれている):
- RLHF/DPO 小話, 和地瞭良/ Akifumi Wachi, 2024.04
[Paper Note] The Illusion of State in State-Space Models, William Merrill+, ICML'24, 2024.04
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #SSM (StateSpaceModel) Issue Date: 2024-08-27 GPT Summary- 状態空間モデル(SSMs)は、トランスフォーマーの代替として注目されていますが、その表現力はトランスフォーマーと類似の制限があり、特定の状態追跡問題を解決できないことが明らかになりました。特に、SSMsは複雑さクラス$\mathsf{TC}^0$を超える計算を表現できず、実際的な状態追跡能力にも限界があります。形式的分析と実験によって、リカレントな定式化にもかかわらず、SSMにおける「状態」は幻想であり、実際の問題解決において制約があることが示されています。 Comment
>しかし、SSMが状態追跡の表現力で本当に(トランスフォーマーよりも)優位性を持っているのでしょうか?驚くべきことに、その答えは「いいえ」です。私たちの分析によると、SSMの表現力は、トランスフォーマーと非常に類似して制限されています:SSMは複雑性クラス$\mathsf{TC}^0$の外での計算を表現することができません。特に、これは、置換合成のような単純な状態追跡問題を解決することができないことを意味します。これにより、SSMは、特定の表記法でチェスの手を正確に追跡したり、コードを評価したり、長い物語の中のエンティティを追跡することが証明上できないことが明らかになります。
なん…だと…
[Paper Note] Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference, Piotr Nawrot+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #One-Line Notes #KV Cache #Compression Issue Date: 2024-04-07 GPT Summary- Transformerにおけるメモリキャッシュの非効率性を解決するために、Dynamic Memory Compression(DMC)を提案。DMCは異なるヘッドと層で異なる圧縮比を学習し、Llama 2を組み込むことで推論時に最大7倍のスループット向上を実現。元のパフォーマンスを保ちながら、キャッシュ圧縮を最大4倍可能とし、既存の方法を超える効果を発揮。DMCはKVキャッシュのドロップイン置換として、より長い文脈と大きなバッチを処理できる。 Comment
参考:
論文中のFigure1が非常にわかりやすい。
GQA [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
と比較して、2~4倍キャッシュを圧縮しつつ、より高い性能を実現。70Bモデルの場合は、GQAで8倍キャッシュを圧縮した上で、DMCで追加で2倍圧縮をかけたところ、同等のパフォーマンスを実現している。
[Paper Note] AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls, Yu Du+, ICML'24, 2024.02
Paper/Blog Link My Issue
#One-Line Notes Issue Date: 2024-03-05 GPT Summary- AnyToolは、ユーザーの問いに対処するために16,000以上のAPIを活用する大規模言語モデルエージェントです。主に、階層構造のAPIリトリーバ、選定されたAPIを用いて問いを解決するソルバー、実用的でない初期解決策の場合の自己反省機構の3要素を組み込んでいます。GPT-4の機能で動作し、外部モジュールの訓練を不要とします。また、実際の適用シナリオを反映するために評価プロトコルを改訂し、AnyToolBenchを導入しました。実験結果は、AnyToolが他の強力なベースラインに対して優位性を示していることを明らかにしています。 Comment
階層的なRetrieverを用いてユーザクエリから必要なツールを検索し、solverでユーザのクエリを解決し、self-reflectionで結果をさらに良くするような枠組み
LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, ICML'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #PEFT(Adaptor/LoRA) #One-Line Notes Issue Date: 2024-03-05 GPT Summary- 本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 Comment
LoRAで導入される低ランク行列AとBを異なる学習率で学習することで、LoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法
[Paper Note] Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models, Zixiang Chen+, ICML'24, 2024.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #SyntheticData #SelfImprovement #mid-training #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes #AdversarialTraining #SelfPlay Issue Date: 2024-01-24 GPT Summary- 自己対戦ファインチューニング(SPIN)を提案し、人間の注釈なしで弱いLLMを強化。LLMが自らのインスタンスと対戦し、トレーニングデータを生成。自己生成と人間の応答を識別してポリシーを微調整。SPINは様々なベンチマークでLLMの性能を大幅に向上させ、GPT-4優先データを使ったモデルを上回る成果を示した。 Comment
pj page:
https://uclaml.github.io/SPIN/
code:
https://github.com/uclaml/SPIN
メインプレイヤーは人間とLLMのレスポンスを区別する、対戦相手はメインプレイヤーに対して人間が作成したレスポンスと自身が作成させたレスポンスを区別できないようにするようなゲームをし、両者を同じLLM、しかし異なるiterationのパラメータを採用することで自己対戦させることでSFTデータセットから最大限学習するような手法を提案。メインプレイヤーの目的関数は、人間とLLMのレスポンスの確率の差を最大化するように定式化され(式4.1)、対戦相手は人間が生成したレスポンスを最大化するような損失関数を元のパラメータから大きく乖離しないようにKL正則化付きで定義する(式4.3)。双方の損失を単一の損失関数に統合すると式4.7で表される提案手法のSPIN損失が得られ、これによって与えられたSFTデータに対してレスポンスを各iterationで合成し、合成したレスポンスに対してSPIN損失を適用することでモデルのパラメータをアップデートする。メインプレイヤーの重みは更新された重みを用いて、対戦プレイヤーの重みは一つ前の重みを用いる。
[Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #InstructionTuning #LLM-as-a-Judge #SelfImprovement #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-01-22 GPT Summary- 超人間エージェントを実現するには、超人間レベルのフィードバックが必要であると提唱。現在のアプローチは人間の嗜好から報酬モデルを訓練するが、これがボトルネックになりがちである。本研究では自己報酬言語モデルを用い、LLMが自ら報酬を提供する方法を検討。DPOトレーニングにより指示への従順さと自己報酬の質が向上し、Llama 2 70Bをファインチューニングすることで、既存モデルを上回ることが示された。探索の余地は残るが、本研究は改善の可能性を示唆する。 Comment
人間の介入無しで(人間がアノテーションしたpreference data無しで)LLMのAlignmentを改善していく手法。LLM-as-a-Judge Promptingを用いて、LLM自身にpolicy modelとreward modelの役割の両方をさせる。unlabeledなpromptに対してpolicy modelとしてresponceを生成させた後、生成したレスポンスをreward modelとしてランキング付けし、DPOのpreference pairとして利用する、という操作を繰り返す。
[Paper Note] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #One-Line Notes Issue Date: 2023-10-12 GPT Summary- Step-Back Promptingは、大規模言語モデル(LLMs)を使用して推論の手順をガイドするシンプルなプロンプティング技術です。この技術により、LLMsは具体的な詳細から高レベルの概念や基本原則を抽象化し、正しい推論経路をたどる能力を向上させることができます。実験により、Step-Back PromptingはSTEM、Knowledge QA、Multi-Hop Reasoningなどのタスクにおいて大幅な性能向上が観察されました。具体的には、MMLU Physics and Chemistryで7%、11%、TimeQAで27%、MuSiQueで7%の性能向上が確認されました。 Comment
また新しいのが出た。ユーザのクエリに対して直接応答しようとするのではなく、より高次で抽象的・原則的な問いを生成しそこから事実情報を得て、その事実情報にgroundingされた推論によって答えを導く。
openreview: https://openreview.net/forum?id=3bq3jsvcQ1
[Paper Note] SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models, Xiaoxuan Wang+, N_A, ICML'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation Issue Date: 2023-07-22 GPT Summary- 本研究では、大規模言語モデル(LLMs)の進歩により、数学のベンチマークでの性能向上が示されているが、これらのベンチマークは限定的な範囲の問題に限定されていることが指摘される。そこで、複雑な科学的問題解決に必要な推論能力を検証するための包括的なベンチマークスイートSciBenchを提案する。SciBenchには、大学レベルの科学的問題を含むオープンセットと、学部レベルの試験問題を含むクローズドセットの2つのデータセットが含まれている。さらに、2つの代表的なLLMを用いた詳細なベンチマーク研究を行い、現在のLLMのパフォーマンスが不十分であることを示した。また、ユーザースタディを通じて、LLMが犯すエラーを10の問題解決能力に分類し、特定のプロンプティング戦略が他の戦略よりも優れているわけではないことを明らかにした。SciBenchは、LLMの推論能力の向上を促進し、科学研究と発見に貢献することを目指している。
[Paper Note] Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling, Weijia Xu+, ICML'24, 2023.05
Paper/Blog Link My Issue
#needs-revision Issue Date: 2023-05-22 GPT Summary- Repromptingは、Chain-of-Thought(CoT)レシピを自動的に学習する反復的サンプリングアルゴリズムで、ギブスサンプリングを用います。これにより、与えられたタスクに対して一貫性のあるCoTレシピを推定し、過去のレシピを利用して新しいレシピを生成します。20の難解な推論タスクでの実験により、Repromptingは人間のCoTプロンプトを平均9.4ポイント上回り、他の最先端アルゴリズムよりも高い性能を示しました。 Comment
んー、IterCoTとかAutoPromptingとかと比較してないので、なんとも言えない…。サーベイ不足な気がするがどうだろうか。あと実験でChatGPTを使うのは再現性がないためやめた方が良い気が。
openreview(ICLR'24): https://openreview.net/forum?id=tQqLV2N0uz
[Paper Note] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, Junnan Li+, ICML'23, 2023.01
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pretraining #NLP #MultiModal #VisionLanguageModel #Encoder #2D (Image) Issue Date: 2026-02-06 GPT Summary- BLIP-2は、視覚と言語の事前学習を効率化する新しい戦略で、既存の画像エンコーダと大規模言語モデルを活用。軽量なクエリトランスフォーマーにより二段階での事前学習を実施し、視覚と言語の表現を効果的に結合。トレーニング可能なパラメータは少ないながらも、ゼロショットタスクで優れた性能を発揮し、Flamingo80Bを上回る成果を示した。 Comment
日本語解説: https://qiita.com/moufuyu/items/94418980ec0598671221
BLIP:
- [Paper Note] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, Junnan Li+, ICML'22, 2022.01
Flamingo:
- [Paper Note] Flamingo: a Visual Language Model for Few-Shot Learning, Jean-Baptiste Alayrac+, NeurIPS'22, 2022.04
[Paper Note] DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature, Eric Mitchell+, ICML'23, 2023.01
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Selected Papers/Blogs #text #AI Detector Issue Date: 2025-11-17 GPT Summary- LLM生成テキストの検出の必要性を背景に、対数確率関数の負の曲率を利用した新しい検出手法「DetectGPT」を提案。これにより、別の分類器やデータセットを必要とせず、特定のLLMから生成されたテキストを高精度で識別可能。特に、GPT-NeoXによるフェイクニュース記事の検出で、従来の手法を大幅に上回る性能を示した。
[Paper Note] Dropout Reduces Underfitting, Zhuang Liu+, ICML'23
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Regularization Issue Date: 2025-08-30 GPT Summary- 本研究では、ドロップアウトをトレーニング初期に使用することでアンダーフィッティングを軽減できることを示し、初期ドロップアウト手法を提案します。これにより、勾配の方向的分散が減少し、SGDの確率性に対抗します。実験により、初期ドロップアウトを用いたモデルは、ドロップアウトなしのモデルよりも低いトレーニング損失を示し、一般化精度が向上することが確認されました。また、後期ドロップアウトという手法も探求し、トレーニング後半での正則化効果を検証しました。これらの結果は、深層学習における正則化の理解を深めることに寄与します。 Comment
日本語解説: https://www.docswell.com/s/DeepLearning2023/54QM6D-dldropout-reduces-underfitting
[Paper Note] Magneto: A Foundation Transformer, Hongyu Wang+, ICML'23
Paper/Blog Link My Issue
#ComputerVision #NLP #Transformer #MultiModal #SpeechProcessing #Architecture #Normalization #KeyPoint Notes Issue Date: 2025-04-19 GPT Summary- 言語、視覚、音声、マルチモーダルにおけるモデルアーキテクチャの収束が進む中、異なる実装の「Transformers」が使用されている。汎用モデリングのために、安定性を持つFoundation Transformerの開発が提唱され、Magnetoという新しいTransformer変種が紹介される。Sub-LayerNormと理論に基づく初期化戦略を用いることで、さまざまなアプリケーションにおいて優れたパフォーマンスと安定性を示した。 Comment
マルチモーダルなモデルなモデルの事前学習において、PostLNはvision encodingにおいてsub-optimalで、PreLNはtext encodingにおいてsub-optimalであることが先行研究で示されており、マルタモーダルを単一のアーキテクチャで、高性能、かつ学習の安定性な高く、try and error無しで適用できる基盤となるアーキテクチャが必要というモチベーションで提案された手法。具体的には、Sub-LayerNorm(Sub-LN)と呼ばれる、self attentionとFFN部分に追加のLayerNormを適用するアーキテクチャと、DeepNetを踏襲しLayer数が非常に大きい場合でも学習が安定するような重みの初期化方法を理論的に分析し提案している。
具体的には、Sub-LNの場合、LayerNormを
- SelfAttention計算におけるQKVを求めるためのinput Xのprojectionの前とAttentionの出力projectionの前
- FFNでの各Linear Layerの前
に適用し、
初期化をする際には、FFNのW, およびself-attentionのV_projと出力のout_projの初期化をγ(=sqrt(log(2N))によってスケーリングする方法を提案している模様。
関連:
- [Paper Note] DeepNet: Scaling Transformers to 1,000 Layers, Hongyu Wang+, arXiv'22, 2022.03
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models, Guangxuan Xiao+, ICML'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Quantization Issue Date: 2024-12-03 GPT Summary- SmoothQuantは、トレーニング不要で8ビットの重みと活性化の量子化を実現するポストトレーニング量子化ソリューションです。活性化の外れ値を滑らかにすることで、量子化の難易度を軽減し、精度を保持しつつ最大1.56倍の速度向上と2倍のメモリ削減を達成しました。これにより、530BのLLMを単一ノードで運用可能にし、LLMsの民主化を促進します。コードは公開されています。 Comment
おそらく量子化手法の現時点のSoTA
[Paper Note] Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AutomaticPromptEngineering #Reading Reflections Issue Date: 2023-10-09 GPT Summary- Promptbreederは、LLMの推論能力を向上させる自己改善メカニズムであり、特定のドメインに対してプロンプトを進化・適応させる。タスクプロンプトの集団を突然変異させ、訓練データで評価することで、LLMが生成・改善する変異プロンプトによって統治される。これにより、Chain-of-ThoughtやPlan-and-Solve Promptingを上回り、ヘイトスピーチ分類のような複雑なタスクにも対応可能なプロンプトを進化させる。 Comment
詳細な解説記事: https://aiboom.net/archives/56319
APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…?
[Paper Note] DoG is SGD's Best Friend: A Parameter-Free Dynamic Step Size Schedule, Maor Ivgi+, ICML'23, 2023.02
Paper/Blog Link My Issue
#MachineLearning #Optimizer #One-Line Notes Issue Date: 2023-07-25 GPT Summary- チューニング不要の動的SGDステップサイズ公式「Distance over Gradients(DoG)」を提案。DoGは、初期点からの距離と勾配のノルムに依存し、学習率パラメータを持たない。理論的に、確率的凸最適化に対して収束保証があることを示し、実験では視覚と言語の転移学習タスクにおいて調整済みSGDに近い性能を発揮。層ごとのバリアントは一般に調整済みSGDを上回り、調整済みAdamに近づく。PyTorch実装は https://github.com/formll/dog で提供。 Comment
20 を超える多様なタスクと 8 つのビジョンおよび NLP モデルに対して有効であったシンプルなパラメーターフリーのoptimizer
元ツイート:
[Paper Note] Trainable Transformer in Transformer, Abhishek Panigrahi+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Reference Collection Issue Date: 2023-07-12 GPT Summary- 推論時にトランスフォーマーが複雑なモデルを効率的にシミュレートできる構成、Transformer in Transformer(TinT)を提案。20億未満のパラメータで125万パラメータのモデルをシミュレート、性能向上を実現。実験では、OPT-125Mに対し4〜16%の改善を確認し、言語モデルの高度な能力を示唆。モジュール化されたコードベースも提供。 Comment
参考:
研究の進み早すぎません???
openreview: https://openreview.net/forum?id=VmqTuFMk68
[Paper Note] How Language Model Hallucinations Can Snowball, Muru Zhang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Hallucination #Selected Papers/Blogs #KeyPoint Notes #needs-revision Issue Date: 2023-06-16 GPT Summary- 言語モデルは実用的な応用においてハルシネーションのリスクを伴い、この現象は知識ギャップに起因することが多い。興味深いことに、モデルは誤りを認識しながらも偽の主張を出力する場合がある。「ハルシネーション・スノーボール現象」として知られるこの現象では、初期の過ちに固執することでさらなる誤りを招く。研究では、ChatGPTとGPT-4がそれぞれ67%および87%の誤りを特定できることが確認された。 Comment
LLMによるhallucinationは、単にLLMの知識不足によるものだけではなく、LLMが以前に生成したhallucinationを正当化するために、誤った出力を生成してしまうという仮説を提起し、この仮説を検証した研究。これをhallucination snowballと呼ぶ。これにより、LLMを訓練する際に、事実に対する正確さを犠牲にして、流暢性と一貫性を優先し言語モデルを訓練するリスクを示唆している。
[Paper Note] Emergent Representations of Program Semantics in Language Models Trained on Programs, Charles Jin+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Coding #One-Line Notes #needs-revision Issue Date: 2023-05-20 GPT Summary- 言語モデル(LM)が次のトークン予測に特化した訓練にもかかわらず、形式的意味を表現できる可能性を示す。2Dグリッド環境でのプログラム合成コーパスを用いてTransformerモデルを訓練し、特定の入力出力仕様が付随するプログラムから、未観測の中間状態を精度よく抽出できることを発見。新しい介入ベースラインにより、LMの表現とプロービングによる結果の明確な識別が可能に。広範な意味論的プロービング実験への適用が期待される。 Comment
プログラムのコーパスでLLMをNext Token Predictionで訓練し
厳密に正解とsemanticsを定義した上で、訓練データと異なるsemanticsの異なるプログラムを生成できることを示した。
LLMが意味を理解していることを暗示している
参考:
Poisoning Language Models During Instruction Tuning, Alexander Wan+, N_A, ICML'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Poisoning Issue Date: 2023-05-04 GPT Summary- - Instruction-tuned LMs(ChatGPT、FLAN、InstructGPTなど)は、ユーザーが提出した例を含むデータセットでfinetuneされる。- 本研究では、敵対者が毒入りの例を提供することで、LMの予測を操作できることを示す。- 毒入りの例を構築するために、LMのbag-of-words近似を使用して入出力を最適化する。- 大きなLMほど毒入り攻撃に対して脆弱であり、データフィルタリングやモデル容量の削減に基づく防御は、テストの正確性を低下させながら、中程度の保護しか提供しない。
[Paper Note] Controlled Text Generation with Natural Language Instructions, Wangchunshu Zhou+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #Prompting #SyntheticData #In-ContextLearning #PostTraining #One-Line Notes Issue Date: 2023-04-30 GPT Summary- 自然言語の指示に従い、多様なタスクを解決可能な大規模言語モデルの制御を改善するために、「InstructCTG」というフレームワークを提案。自然テキストの制約を抽出し、これを自然言語の指示に変換することで弱教師あり訓練データを形成。異なるタイプの制約に柔軟に対応し、生成の質や速度への影響を最小限に抑えつつ、再訓練なしで新しい制約に適応できる能力を持つ。 Comment
制約に関する指示とデモンスとレーションに関するデータを合成して追加のinstruction tuningを実施することで、promptで指示された制約を満たすような(controllableな)テキストの生成能力を高める手法
[Paper Note] Tractable Control for Autoregressive Language Generation, Honghua Zhang+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #NLP #LanguageModel #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 自己回帰型大規模言語モデルは複雑な制約を満たすテキスト生成に課題がある。これに対処するため、語彙的制約を扱う確率モデル(TPMs)を用いたGeLaToフレームワークを提案。蒸留された隠れマルコフモデルを利用し、自己回帰生成の効率的な指導を可能にし、制約付きテキスト生成において最先端の性能を達成。研究は大規模言語モデルの制御に新たな道を開き、TPMsのさらなる発展を促進する。 Comment
自然言語生成モデルで、何らかのシンプルなconstiaint αの元p(xi|xi-1,α)を生成しようとしても計算ができない。このため、言語モデルをfinetuningするか、promptで制御するか、などがおこなわれる。しかしこの方法は近似的な解法であり、αがたとえシンプルであっても(何らかの語尾を付与するなど)、必ずしも満たした生成が行われるとは限らない。これは単に言語モデルがautoregressiveな方法で次のトークンの分布を予測しているだけであることに起因している。そこで、この問題を解決するために、tractable probabilistic model(TPM)を導入し、解決した。
評価の結果、CommonGenにおいて、SoTAを達成した。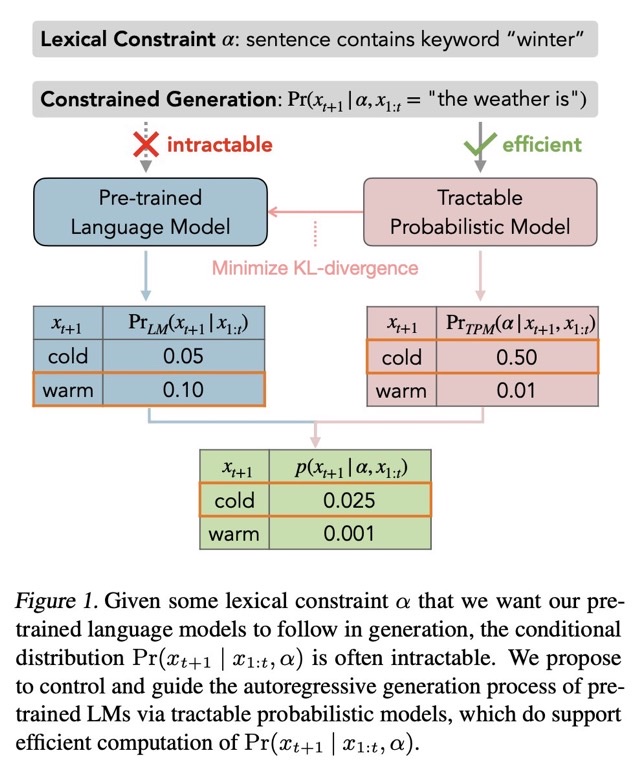
尚、TPMについては要勉強である
[Paper Note] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, Junnan Li+, ICML'22, 2022.01
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pretraining #MultiModal #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2026-02-06 GPT Summary- 視覚と言語の理解と生成両方に対応する新しいVLPフレームワーク、BLIPを提案。BLIPは、合成キャプション生成とノイズ除去を用いてウェブデータを活用し、視覚と言語タスクで最先端の性能を達成。ゼロショット転送にも優れた一般化能力を示し、幅広いタスクにおいて成果を上げる。 Comment
元ポスト:
以下の3つを組み合わせることで、生成・理解両方のタスクの性能を向上した現在のVLMにつながる内容研究(CLIPは理解に特化していた):
- CLIP likeなimage-captionにおけるconstrastive loss (ITC)
- image-caption matchを二値分類するloss (ITC)
- caption生成におけるnext token prediction loss (LM)
データをクリーンにしさらに性能を改善する方法も提案されている。
[Paper Note] Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, Mitchell Wortsman+, ICML'22, 2022.03
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NLP #Selected Papers/Blogs #OOD #Finetuning #Generalization #Encoder #Encoder-Decoder #KeyPoint Notes #Souping Issue Date: 2025-11-28 GPT Summary- ファインチューニングされたモデルの重みを平均化する「モデルスープ」手法を提案し、精度と堅牢性を向上させることを示す。従来のアンサンブル手法とは異なり、追加のコストなしで複数のモデルを平均化でき、ImageNetで90.94%のトップ1精度を達成。さらに、画像分類や自然言語処理タスクにも適用可能で、分布外性能やゼロショット性能を改善することが確認された。 Comment
transformerベースの事前学習済みモデル(encoder-only, encoder-decoderモデル)のファインチューニングの話で、共通のベースモデルかつ共通のパラメータの初期化を持つ、様々なハイパーパラメータで学習したモデルの重みを平均化することでよりロバストで高性能なモデルを作ります、という話。似たような手法にアンサンブルがあるが、アンサンブルでは利用するモデルに対して全ての推論結果を得なければならないため、計算コストが増大する。一方、モデルスープは単一モデルと同じ計算量で済む(=計算量は増大しない)。
スープを作る際は、Validation dataのAccが高い順に異なるFinetuning済みモデルをソートし、逐次的に重みの平均をとりValidation dataのAccが上がる場合に、当該モデルをsoupのingridientsとして加える。要は、開発データで性能が高い順にモデルをソートし、逐次的にモデルを取り出していき、現在のスープに対して重みを平均化した時に開発データの性能が上がるなら平均化したモデルを採用し、上がらないなら無視する、といった処理を繰り返す。これをgreedy soupと呼ぶ。他にもuniform soup, learned soupといった手法も提案され比較されているが、画像系のモデル(CLIP, ViTなど)やNLP(T5, BERT)等で実験されており、greedy soupの性能とロバストさ(OOD;分布シフトに対する予測性能)が良さそうである。
[Paper Note] Improved Denoising Diffusion Probabilistic Models, Alex Nichol+, ICML'21, 2021.02
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #DiffusionModel #Selected Papers/Blogs #Encoder-Decoder #ScoreMatching #U-Net Issue Date: 2025-10-10 GPT Summary- DDPMは高品質なサンプル生成が可能な生成モデルであり、簡単な修正により競争力のある対数尤度を達成できることを示す。逆拡散プロセスの分散を学習することで、サンプリング回数を大幅に削減しつつサンプル品質を維持。DDPMとGANのターゲット分布のカバー能力を比較し、モデルの容量とトレーニング計算量に対してスケーラブルであることを明らかにした。コードは公開されている。 Comment
関連:
- [Paper Note] Denoising Diffusion Probabilistic Models, Jonathan Ho+, NeurIPS'20, 2020.06
[Paper Note] Feature Learning in Infinite-Width Neural Networks, Greg Yang+, ICML'21
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #MachineLearning Issue Date: 2025-08-28 GPT Summary- 無限幅の深層ニューラルネットワークにおいて、標準およびNTKパラメータ化は特徴学習を可能にする限界を持たないことを示し、これを克服するための修正を提案。Tensor Programs技術を用いて限界の明示的な式を導出し、Word2VecやMAMLを用いた少数ショット学習でこれらの限界を計算。提案手法はNTKベースラインや有限幅ネットワークを上回る性能を示し、特徴学習を許可するパラメータ化の空間を分類。
Learning Transferable Visual Models From Natural Language Supervision, Radford+, OpenAI, ICML'21
Paper/Blog Link My Issue
#ComputerVision #Embeddings #NLP #RepresentationLearning #MultiModal #ContrastiveLearning #Selected Papers/Blogs #2D (Image) #One-Line Notes #text Issue Date: 2023-04-27 Comment
CLIP論文。大量の画像と画像に対応するテキストのペアから、対照学習を行い、画像とテキスト間のsimilarityをはかれるようにしたモデル
[Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #Selected Papers/Blogs #reading #One-Line Notes #RecurrentModels #LinearAttention Issue Date: 2025-08-05 GPT Summary- 自己注意をカーネル特徴マップの線形ドット積として表現することで、Transformersの複雑性を$\mathcal{O}\left(N^2\right)$から$\mathcal{O}\left(N\right)$に削減。これにより、自己回帰型Transformersの速度が最大4000倍向上し、従来のパフォーマンスを維持。 Comment
関連:
- Transformers are Multi-State RNNs, Matanel Oren+, N/A, EMNLP'24
pj page: https://linear-transformers.com
Linear Attention(Linear Transformer)を提案した研究。Softmaxが利用されるFull Attentionのsimilarity部分をfeature map φを持つカーネルk(x, y)で一般化し、(3)--(6)の流れでfeature map φ同士は内積が使える性質と、行列積の結合法則を用いて式変換する。
式変換によって、従来のSoftmax Attentionでは、全てのトークンNに対してQ_i * K_j * V_jのメモリが必要だったものを(O(N^2))、各Queryごとに利用される、KVを用いた情報が共通化され(現在のqueryまでのφ(K)とφ(K)V^Tを逐次的に加算して保持するだけで良い)、再利用が可能となりメモリに関するオーダーがO(N)となる。
これらの話は実際にどのような カーネルを利用するかを無視した話だが、たとえばsoftmaxを表現するために必要な指数カーネルの場合はfeature mapが無限次元となるため有限次元のベクトルでは表現できず、厳密に線形化することができない。このため、有限次元かつ厳密なfeature mapを持つ多公式カーネルを用いて近似する。この場合、計算量のオーダーがO(ND^2M)となり(Nがsequence length, Dがqueryとkeyの次元数, Mがvalueの次元数)、softmax attentionの計算量がO(N^2 max(D,M))であることと比較すると、N > D^2である場合に計算効率が改善される。
学習時は並列に学習が可能で、推論時はφ(K_j)V_j^Tを内部状態とみなすと、各タイムステップでRNNのように状態を更新して保持するだけで良い。
(続きはさらに後で読む)
次: DeltaNet
- [Paper Note] Linear Transformers Are Secretly Fast Weight Programmers, Imanol Schlag+, arXiv'21, 2021.02
- [Paper Note] Parallelizing Linear Transformers with the Delta Rule over Sequence Length, Songlin Yang+, NeurIPS'24, 2024.06
次の次: Gated DeltaNet
- [Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
次の次の次: Kimi Delta Attention (KDA)
- [Paper Note] Kimi Linear: An Expressive, Efficient Attention Architecture, Kimi Team+, arXiv'25, 2025.10
[Paper Note] PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization, Jingqing Zhang+, ICML'20
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NLP #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-05-13 GPT Summary- 大規模なテキストコーパスに対して新しい自己教師ありの目的でトランスフォーマーを事前学習し、抽象的なテキスト要約に特化したモデルPEGASUSを提案。重要な文を削除またはマスクし、残りの文から要約を生成。12の下流要約タスクで最先端のROUGEスコアを達成し、限られたリソースでも優れたパフォーマンスを示す。人間評価でも複数のデータセットで人間のパフォーマンスに達したことを確認。 Comment
PEGASUSもなかったので追加。BARTと共に文書要約のBackboneとして今でも研究で利用される模様。
関連:
- SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
[Paper Note] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan+, ICML'19
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #EfficiencyImprovement #Selected Papers/Blogs #Backbone Issue Date: 2025-05-12 GPT Summary- 本論文では、ConvNetsのスケーリングを深さ、幅、解像度のバランスを考慮して体系的に研究し、新しいスケーリング手法を提案。これにより、MobileNetsやResNetのスケールアップを実証し、EfficientNetsという新しいモデルファミリーを設計。特にEfficientNet-B7は、ImageNetで84.3%のトップ1精度を達成し、従来のConvNetsよりも小型かつ高速である。CIFAR-100やFlowersなどのデータセットでも最先端の精度を記録。ソースコードは公開されている。 Comment
元論文をメモってなかったので追加。
- EfficientNet解説, omiita (オミータ), 2019.10
も参照のこと。
[Paper Note] Toward Controlled Generation of Text, Zhiting Hu+, ICML'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #Controllable #NLP #DataToTextGeneration #ConceptToTextGeneration #GenerativeAdversarialNetwork #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 属性に基づいて制御された自然言語文を生成するために、変分オートエンコーダと属性識別器を組み合わせた新しい生成モデルを提案。微分可能な近似を用いて解釈可能な表現を学習し、望ましい属性を持つ文を生成。定量的評価で生成の正確性を確認。 Comment
Text Generationを行う際は、現在は基本的に学習された言語モデルの尤度に従ってテキストを生成するのみで、outputされるテキストをcontrolすることができないので、できるようにしましたという論文。 VAEによるテキスト生成にGANを組み合わせたようなモデル。 decodingする元となるfeatureのある次元が、たとえばpolarityなどに対応しており、その次元の数値をいじるだけで生成されるテキストをcontrolできる。
テキストを生成する際に、生成されるテキストをコントロールするための研究。 テキストを生成する際には、基本的にはVariational Auto Encoder(VAE)を用いる。
VAEは、入力をエンコードするEncoderと、エンコードされた潜在変数zからテキストを生成するGeneratorの2つの機構によって構成されている。
この研究では、生成されるテキストをコントロールするために、VAEの潜在変数zに、生成するテキストのattributeを表す変数cを新たに導入。
たとえば、一例として、変数cをsentimentに対応させた場合、変数cの値を変更すると、生成されるテキストのsentimentが変化するような生成が実現可能。
次に、このような生成を実現できるようなパラメータを学習したいが、学習を行う際のポイントは、以下の二つ。
cで指定されたattributeが反映されたテキストを生成するように学習
潜在変数zとattributeに関する変数cの独立性を保つように学習 (cには制御したいattributeに関する情報のみが格納され、その他の情報は潜在変数zに格納されるように学習する)
1を実現するために、新たにdiscriminatorと呼ばれる識別器を用意し、VAEが生成したテキストのattributeをdiscriminatorで分類し、その結果をVAEのGeneratorにフィードバックすることで、attributeが反映されたテキストを生成できるようにパラメータの学習を行う。 (これにはラベル付きデータが必要だが、少量でも学習できることに加えて、sentence levelのデータだけではなくword levelのデータでも学習できる。)
また、2を実現するために、VAEが生成したテキストから、生成する元となった潜在変数zが再現できるようにEncoderのパラメータを学習。
実験では、sentimentとtenseをコントロールする実験が行われており、attributeを表す変数cを変更することで、以下のようなテキストが生成されており興味深い。
[sentimentを制御した例]
this movie was awful and boring. (negative)
this movie was funny and touching. (positive)
[tenseを制御した例]
this was one of the outstanding thrillers of the last decade
this is one of the outstanding thrillers of the all time
this will be one of the great thrillers of the all time
VAEは通常のAutoEncoderと比較して、奥が深くて勉強してみておもしろかった。 Reparametrization Trickなどは知らなかった。
管理人による解説資料:
[Controllable Text Generation.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1595121/Controllable.Text.Generation.pdf)
slideshare: https://www.slideshare.net/akihikowatanabe3110/towards-controlled-generation-of-text
Tutorial: Deep Reinforcement Learning, David Silver, ICML'16
Paper/Blog Link My Issue
#NeuralNetwork #Tutorial #MachineLearning #ReinforcementLearning #Slide Issue Date: 2018-02-22
[Paper Note] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe+, ICML'15
Paper/Blog Link My Issue
#MachineLearning #LanguageModel #Transformer #Normalization #Selected Papers/Blogs #Reference Collection Issue Date: 2025-04-02 GPT Summary- バッチ正規化を用いることで、深層ニューラルネットワークのトレーニングにおける内部共変量シフトの問題を解決し、高い学習率を可能にし、初期化の注意を軽減。これにより、同じ精度を14倍少ないトレーニングステップで達成し、ImageNet分類で最良の公表結果を4.9%改善。 Comment
メモってなかったので今更ながら追加した
共変量シフトやBatch Normalizationの説明は
- [Paper Note] Layer Normalization, Ba+, arXiv'16, 2016.07
記載のスライドが分かりやすい。
[Paper Note] An Empirical Exploration of Recurrent Network Architectures, Jozefowicz+, ICML'15
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Architecture #Selected Papers/Blogs #RecurrentModels #Initial Impression Notes Issue Date: 2018-02-19 Comment
GRUとLSTMの違いを理解するのに最適
[Paper Note] Interactively Optimizing Information Retrieval Systems as a Dueling Bandits Problem, Yue+, ICML'09
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #Online/Interactive #KeyPoint Notes Issue Date: 2018-01-01 Comment
online learning to rankに関する論文でよくreferされる論文
提案手法は、Dueling Bandit Gradient Descent(DBGD)と呼ばれる.
onlineでlearning to rankを行える手法で、現在の重みwとwをランダムな方向に動かした新たな重みw'を使って、予測を行い、duelを行う。
duelを行った結果、新たな重みw'の方が買ったら、重みwをその方向に学習率分更新するというシンプルな手法
duelのやり方は、詳しく書いてないからなんともよくわからなかったが、Interleavedなlist(二つのモデルのoutputを混合したリスト)などを作り、実際にユーザにリストを提示してユーザがどのアイテムをクリックしたかなどから勝敗の確率値を算出し利用する、といったやり方が、IRの分野では行われている。
onlineでユーザのフィードバックから直接モデルを学習したい場合などに用いられる。
offlineに持っているデータを使って、なんらかのmetricを計算してduelをするという使い方をしたかったのだが、その使い方はこの手法の本来の使い方ではない(単純に何らかのmetricに最適化するというのであれば目的関数が設計できるのでそっちの手法を使ったほうが良さそうだし)。
そもそもこの手法は単純にMetricとかで表現できないもの(ユーザの満足度とか)を満たすようなweightをexploration/exploitationを繰り返して見つけていこう、というような気持ちだと思われる。
[Paper Note] A unified architecture for natural language processing: Deep neural networks with multitask learning, Collobert+, ICML'08
Paper/Blog Link My Issue
#NeuralNetwork #NLP #MultitaskLearning #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-02-05 Comment
Deep Neural Netを用いてmultitask learningを行いNLPタスク(POS tagging, Semantic Role Labeling, Chunking etc.)を解いた論文。
被引用数2000を超える。
multitask learningの学習プロセスなどが引用されながら他論文で言及されていたりする。
[Paper Note] Listwise Approach to Learning to Rank - Theory and Algorithm (ListMLE), Xia+, ICML'08
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #ListWise Issue Date: 2018-01-01
[Paper Note] Learning to sportscast: a test of grounded language acquisition, Chen+, ICML'08
Paper/Blog Link My Issue
#NaturalLanguageGeneration #SingleFramework #NLP #DataToTextGeneration Issue Date: 2017-12-31
[Paper Note] Learning to Rank: From Pairwise Approach to Listwise Approach (ListNet), Cao+, ICML'07
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #ListWise #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-01 Comment
解説スライド:
http://www.nactem.ac.uk/tsujii/T-FaNT2/T-FaNT.files/Slides/liu.pdf
解説ブログ:
https://qiita.com/koreyou/items/a69750696fd0b9d88608
従来行われてきたLearning to Rankはpairwiseな手法が主流であったが、pairwiseな手法は2つのインスタンス間の順序が正しく識別されるように学習されているだけであった。
pairwiseなアプローチには以下の問題点があった:
* インスタンスのペアのclassification errorを最小化しているだけで、インスタンスのランキングのerrorを最小化しているわけではない。
* インスタンスペアが i.i.d な分布から生成されるという制約は強すぎる制約
* queryごとに生成されるインスタンスペアは大きく異なるので、インスタンスペアよりもクエリに対してバイアスのかかった学習のされ方がされてしまう
これらを解決するために、listwiseなアプローチを提案。
listwiseなアプローチを用いると、インスタンスのペアの順序を最適化するのではなく、ランキング全体を最適化できる。
listwiseなアプローチを用いるために、Permutation Probabilityに基づくloss functionを提案。loss functionは、2つのインスタンスのスコアのリストが与えられたとき、Permutation Probability Distributionを計算し、これらを用いてcross-entropy lossを計算するようなもの。
また、Permutation Probabilityを計算するのは計算量が多すぎるので、top-k probabilityを提案。
top-k probabilityはPermutation Probabilityの計算を行う際のインスタンスをtop-kに限定するもの。
論文中ではk=1を採用しており、k=1はsoftmaxと一致する。
パラメータを学習する際は、Gradient Descentを用いる。
k=1の設定で計算するのが普通なようなので、普通にoutputがsoftmaxでlossがsoftmax cross-entropyなモデルとほぼ等価なのでは。
[Paper Note] Learning to Rank using Gradient Descent (RankNet), Burges+, ICML'05
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PairWise #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
pair-wiseのlearning2rankで代表的なRankNet論文
解説ブログ:
https://qiita.com/sz_dr/items/0e50120318527a928407
lossは2個のインスタンスのpair、A, Bが与えられたとき、AがBよりも高くランクされる場合は確率1, AがBよりも低くランクされる場合は確率0、そうでない場合は1/2に近くなるように、スコア関数を学習すれば良い。