
ICLR
[Paper Note] DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation, Makoto Shing+, ICLR'26, 2025.06
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Transformer #DiffusionModel #Selected Papers/Blogs #reading #One-Line Notes #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- DiffusionBlocksは、Transformerベースのネットワークを独立した訓練可能なブロックに変換する新しいフレームワークで、メモリボトルネックを軽減しながらエンドツーエンド訓練と同等の性能を維持します。残差結合の特性を活用し、各ブロックが独立に学習できるため、メモリ要件が削減されます。視覚系や拡散など多様なTransformerアーキテクチャに対する実験により、DiffusionBlocksがスケーラブルな訓練を可能にすることが示されています。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=pwVSmK71cS
巨大な残差接続を持つTransformer-likeなモデルをB個のブロックに分割し、ブロック単位で独立してパラメータを学習することによって、学習時に必要なメモリを1/Bに削減できる手法のようである。
(しっかり読めていないので色々と勘違いがあるかもしれないし、気持ちの部分をうまく表現しきれていないかもしれないが)
手法の概要としては、L layer単位でブロックをB個定義する。各ブロックにはnoise rangeの元ノイズを定義し、sample data (x, y)がgivenな時に、出力yにノイズを付与した~yを考える。~yから元の出力yを再現するようデノイジングするように、他のブロックはfreezeしたままで、あるブロックのパラメータを調整する、という操作を繰り返す、という手法のようである。Inference時は、平均0、学習時に定義したnoiseレベルの最大値を分散として持つ正規分布からノイズをサンプリングし、ノイズをinput xがgivenな状態で各ブロックでsequentialにdenoisingしていく(Euler Step)ことによって、最終的に所望の出力yを得る、といったような拡散モデルの逆プロセスを経て出力を得るようである。各ブロックがカバーするノイズのrangeは決まっているが、sequentialにdenoisingをしていくため、ブロック全体でみると大きなノイズからスタートするが、それぞれのブロックに対する入力のnoise levelは徐々に低減していき、各ブロックが担当するnoise levelのrangeまで落ちることが期待され、このような手続きが実現できると思われる。
[Paper Note] (Sparse) Attention to the Details: Preserving Spectral Fidelity in ML-based Weather Forecasting Models, Maksim Zhdanov+, ICLR'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Transformer #One-Line Notes #SparseAttention #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 本研究では、MLベースの気象予測のスペクトル劣化に対応する確率的モデル「Mosaic」を提案。三つの故障モードを扱い、アンサンブルメンバーを生成する。1.5°解像度で214Mパラメータを持つMosaicは、高解像度モデルに匹敵する性能を示し、ほぼ完璧なスペクトル整合性を達成。予報は高速に実行可能で、コードも公開中。 Comment
元ポスト:
block-sparse attentionによるtransformerベースの天気予報モデル
[Paper Note] AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite, Bragg+, Ai2, ICLR'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #ScientificDiscovery #Science #Author Thread-Post Issue Date: 2026-05-01 Comment
openreview: https://openreview.net/forum?id=M7TNf5J26u
元ポスト:
[Paper Note] Learning to Orchestrate Agents in Natural Language with the Conductor, Stefan Nielsen+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Test-Time Scaling #read-later #Orchestration #Author Thread-Post Issue Date: 2026-04-26 GPT Summary- Conductorモデルを導入し、LLM間の協調戦略を自動発見。通信トポロジを設計し、個々のLLMの能力を最大化する指示を生成。7BパラメータのConductorは、単一ワーカーを超える性能向上を実現し、難解なベンチマークで最先端結果を達成。ランダム化されたエージェント訓練により、任意のエージェント集合に適応し、新たな再帰的トポロジを形成してオンラインでの性能向上を図る。この研究は、強力な協調戦略がRLを通じて自然に現れることを示す初期の実証である。 Comment
openreview: https://openreview.net/forum?id=U23A2BUKYt
公式ポスト:
[Paper Note] TRINITY: An Evolved LLM Coordinator, Jinglue Xu+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #reading #KeyPoint Notes #EvolutionaryAlgorithm #Orchestration #Author Thread-Post Issue Date: 2026-04-26 GPT Summary- Trinityは、LLMs間の協調を調整する軽量なコーディネーターを用いて、基盤モデルの統合に伴う制約を解決する。約6億パラメータのコンパクトな言語モデルと約1万パラメータの軽量ヘッドから成り、適応的な委任を実現。複数ターンにわたるクエリに対して、コーディネーターは各LLMに役割を割り当て、スキルを効果的にオフロードする。実験の結果、Trinityはコード作成や数学、推論、領域知識タスクで優れた性能を示し、標準ベンチマークで最先端の成果を達成。コーディネーターの隠れ状態表現が文脈化を提供し、進化戦略の適用が有利であることが確認された。 Comment
openreview: https://openreview.net/forum?id=5HaRjXai12
軽量なcoordinator + 非常に軽量なheadを用いてターンごとに適切なモデルとロールを選択する。coordinatorは全てのターンの会話に対応するcontextualな表現を最後から2番目のトークンに対応するhidden state[^1]から取得し、
- LLM poolの中からどのLLMを用いて応答を生成するか
- 事前定義されたロール(Thinker, Worker, Verifier)のうちどれを選択するか
を決定する。最終的にVerifierが選択され、質問に対する最終的な応答としてacceptされるか、固定長のターン数のbudgetに到達したら生成終了となる。
上記枠組みを定式化すると(Section 2)、ざっくり言うと
- SLMが最初のクエリ+これまでの会話の履歴のcontextを、最後から2番目のトークンのhidden state hに集約し
- lightweight がhを受け取り、有限のアクション集合から(agent-roleのペア集合)適切なアクションを選択する
- 最終的に 0/1 のrewardを得られるものとし、この期待報酬を最大化するような(SLMのパラメータの対角成分[^2]と)lightweight headのパラメータΘを求める最適化問題として定式化される。
- ただし制約条件として、trajectoryのhorizon T は T <= B_turn、かつ期待報酬を得るために利用可能なコスト B_env がある。
となる。
(この辺は少し自信がないが)本研究のタスク設定は以下の特徴を持つ:
- 1ステップの評価が複数のLLM呼び出しを含むため非常に高コストであり、かつ評価に利用可能なコスト(B_env)の制約も厳しく
- lightweight headの次元数は10kであり、予算に強い制約がある中で学習するには次元数が多く
- かつlightweight headのパラメータはblock-epsilon-separabilityという性質を持つらしく
- 個々のlogitに寄与するブロックが独立していて、かつ独立したブロックの対角成分によって出力が決定される
- また、ブロック間は弱い相互作用をしている、という状態のようである
- 最終的に得られる報酬は2値のsparseな報酬でノイジー
パラメータΘを学習する上で、REINFORCEのようなパラメータごとの勾配を求める手法は、個々のパラメータが最終的な報酬に与える影響が小さく、かつ報酬がsparseでノイジーであるため効果的に学習ができないことから(時間をかければ学習できるのかもしれないが、B_envの制約がきつくて無理)、パラメータの対角成分を扱う手法であるseparable CMA-ESと呼ばれる進化的アルゴリズムによって学習するとのことである。
separable CME-ESはノイズを加えたパラメータベクトルの集団をサンプリングし、各候補を評価してそれぞれの適応度スコアを取得し、適応度で重みづけした上で平均をすることで次の親を形成するというプロセスを反復する手法らしく、特にseparable CME-ESという手法は、対角共分散行列のみを維持するため、上記の対角成分が寄与する性質と相性が良いとのことである。実験の結果、実際にREINFORCE, SFT, Random Searchなどの手法と比較して性能が良いことが示されている(Table 4)。
SLMのパラメータの対角成分は Singular Value Finetuning
- [Paper Note] Transformer-Squared: Self-adaptive LLMs, Qi Sun+, ICLR'25, 2025.01
によって効率的に学習される。この結果、学習をするパラメータ数は20k程度で済み、パラメータ効率が非常に良いとのことである。
[^1]: 最後から2番目のトークンは `` や `
[^2]: Section 2にはおそらく定式化のシンプルさを優先して最適化の対象はlightweight headのパラメータΘのみで定式化がされており、Section 3やFigure 2において、SLMのパラメータの対角成分も学習する旨が記載されている
[Paper Note] Sapiens2, Rawal Khirodkar+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Transformer #ContrastiveLearning #Self-SupervisedLearning #Encoder #Backbone #needs-revision #2D Reconstruction Issue Date: 2026-04-25 GPT Summary- Sapiens2は、高解像度トランスフォーマーのモデルファミリーで、人間中心のビジョンを重視する。4億〜50億パラメータを持ち、ネイティブ1K解像度を採用し、4K対応の階層的バリアントも提供。事前学習と後学習で大幅な性能向上を実現し、マスク済み画像再構成と自己蒸留型対比学習を統合したアプローチを採用。10億枚の高品質な人体画像データセットで事前学習を行い、アーキテクチャの進歩により安定性を向上。ポーズ推定や身体部位セグメンテーションなどのタスクで新たな最先端性能を達成。 Comment
openreview: https://openreview.net/forum?id=IVAlYCqdvW
元ポスト:
HF: https://huggingface.co/facebook/sapiens2
人物ドメインに特化したViTエンコーダ。事前学習はEncoder-Decoderアーキテクチャを利用しMasked Image Modelingで学習する。この際に、Reconstruction lossだけでなく、
[Paper Note] Visual Jigsaw Post-Training Improves MLLMs, Penghao Wu+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#ComputerVision #NLP #Temporal #ReinforcementLearning #MultiModal #Self-SupervisedLearning #PostTraining #RLVR #VisionLanguageModel #2D (Image) #3D (Scene) #3D (Video) #SpatialUnderstanding Issue Date: 2026-04-25 GPT Summary- 視覚理解を強化するための自己教師付きポストトレーニングフレームワーク「Visual Jigsaw」を提案。視覚入力を分割・シャッフルし、モデルは正しい順列を自然言語で出力。これにより強化学習と一致し、追加の視覚生成なしで自動的に監督信号を得る。広範な実験で知覚、時間的推論、3D理解の改善を確認し、視覚中心タスクの可能性を示唆。 Comment
pj page: https://penghao-wu.github.io/visual_jigsaw/
openreview: https://openreview.net/forum?id=tBf2SUzfZw
元ポスト:
[Paper Note] Stopping Computation for Converged Tokens in Masked Diffusion-LM Decoding, Daisuke Oba+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #LanguageModel #DiffusionModel #Decoding #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- SureLockは、マスク済み拡散型言語モデルにおいて、未マスクトークンをロックすることで計算資源を効率化します。具体的には、未マスク位置の事後分布が安定した場合、その位置に対するクエリ投影とフィードフォワードをスキップしつつ、他の位置がアテンションできるようにキャッシュを使用します。この手法により、計算コストがO(N^2d)からO(MNd)に削減され、生成品質を維持しつつFLOPを30〜50%削減します。理論分析も行い、ロック時点でKLを監視することでトークン確率の偏差を十分に境界づけることができることを示しています。 Comment
pj page: https://daioba.github.io/surelock/
元ポスト:
著者ポスト2:
[Paper Note] PolySkill: Learning Generalizable Skills Through Polymorphic Abstraction, Simon Yu+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Selected Papers/Blogs #Generalization #One-Line Notes #AgentSkills #Author Thread-Post Issue Date: 2026-04-23 GPT Summary- 大規模言語モデル(LLMs)を利用して、エージェントが一般化可能なスキルを学習するための新しいフレームワーク「PolySkill」を提案。スキルの抽象的な目標と具体的な実行を切り離すことで、スキルの再利用や一般化を促進。実験では、ウェブサイトでのスキル再利用を1.7倍向上させ、成功率を最大13.9%向上させた。PolySkillにより、エージェントが自己目標を識別し、より良いカリキュラムを学習する能力が高まり、継続的に学習できる自律エージェントの構築に寄与することが示された。 Comment
元ポスト:
エージェントスキルにポリモーフィズムの考え方を導入し、WhatとHowを分離することで汎化性能を高める。下図が分かりやすい。
最初に特定ドメインのwebサイト(e.g., shopping)を訪れた際に、AbstractShoppinpクラスを生成しShopping関連を扱うクラスとする。その上で、特定サイト(e.g., Amazon)のスキルを生成する際は、AbstractShoppingクラスにシグネチャを登録した後、同クラスを継承。AmazonShoppingクラス内に具体的な処理を定義する。直接スキルを生成するのではなく、抽象スキルを生成した上で、特定サイトでのメソッドを実装する。
openreview: https://openreview.net/forum?id=KdEsujyiSV
[Paper Note] String Seed of Thought: Prompting LLMs for Distribution-Faithful and Diverse Generation, Kou Misaki+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #Bias #Test-Time Scaling #Diversity #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-21 GPT Summary- String Seed of Thought(SSoT)という新しいプロンプティング手法を提案し、Probabilistic Instruction Following(PIF)のパフォーマンスを改善します。PIFは選択肢を確率に基づいて選ぶタスクですが、LLMはしばしば非決定論的な挙動が要求される場面で偏りを生じることがあります。SSoTは、まずLLMにランダムな文字列を生成させ、これを操作することで多様性を維持しつつ制約を遵守した答えを導く手法です。実験により、SSoTがPIFの改善に寄与し、応答の多様性を高めることを示しました。 Comment
openreview: https://openreview.net/forum?id=luXtbX1lVK
元ポスト:
LLMが内包するバイアスを抑制し、出力の多様性を高めるPrompting手法っぽい。興味深い。
ランダムな文字列を生成させてから、その文字列を操作させて出力を得るようなアプローチとのこと。
著者ポスト:
-
-
[Paper Note] Your Language Model Secretly Contains Personality Subnetworks, Ruimeng Ye+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Personalization #Personality #Author Thread-Post Issue Date: 2026-04-19 GPT Summary- LLMsは、異なるペルソナを自然に適応させる能力を持ち、その知識は既存のパラメータに埋め込まれていることを示す。小規模な比較データセットを用いて、特定のペルソナに関連する活性化の特徴を特定し、ペルソナサブネットワークを分離するマスキング戦略を開発。二値的な対立性を持つペルソナ間の統計的発散を生み出す対照的剪定戦略も提案し、完全な訓練を必要としない。得られたサブネットワークは、外部知識を必要とする手法よりもペルソナ整合性を大幅に向上させ、LLMsのパーソナライズに新たな視点を提供する。 Comment
元ポスト:
[Paper Note] KnowledgeSmith: Uncovering Knowledge Updating in LLMs with Model Editing and Unlearning, Yinyi Luo+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ConceptErasure #KnowledgeEditing #reading #KeyPoint Notes #needs-revision #Author Thread-Post Issue Date: 2026-04-14 GPT Summary- LLMsの知識更新メカニズムを理解するため、統一フレームワークKnowledgeSmithを提案。編集と忘却を制約付き最適化として位置づけ、自動データセット生成器を用いて修正戦略の知識伝播を研究。実験により、LLMsが人間と同様の更新を示さず、一貫性と容量のトレードオフがあることを発見。新たな戦略設計の示唆を提供。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=znnA2Opw6v
知識の忘却と編集のダイナミクスを制約付きの最適化問題として統一的にモデル化(式3;この最適化問題を実際に解いているわけではなくあくまで理論的にこう定式化できるねという話だと思われる)し、
この定式化を通じて見ると、編集と忘却の違いはターゲットとする分布q_targetの選び方の違いにすぎず、様々な編集と忘却の先行研究は手法は違えど、この制約付きの最適化問題の異なるインスタンスを解いているに過ぎないという視点を提供しているようである。これにより、編集と忘却のトレードオフを公平に比較することが可能となるという主張をしているように見える(自信ない)。
そして、編集と忘却のトレードオフを厳格に分析するためのベンチマークとして、階層的な依存関係や(local vs. global)、更新の多段階での伝播を扱えるベンチマークが必要だが既存ベンチマークではこれらが不足しているため、
知識グラフに基づいて自動的に構築されたデータとベンチマーク(Figure 1を見るにテンプレートベースのMCQを)を作成して分析。
分析には6つのモデルファミリーの13のモデルが用いられ、スケールは1B--123Bの幅広いスケールのモデルで検証された。
(先行研究も含めてしっかり読まないと、式3と実験で用いられている手法AlphaEdit, ReLearnの関係性がちょっとわからなそう)
著者ポストにおいては、以下のようなtakeawayが記載されており、大きな知見としてはLLMはデータベースではなく、トレードオフを持つ複雑に絡み合ったシステムであり、以下のような点を明らかにした
- 知識の編集は意図しない変更を引き起こし
- 忘却は知識の完全な消去には失敗する
- 更新する知識を増やせば増やすほど、ローカルの知識は更新されるが、グローバルな一貫性が崩壊し
- 変更することが極めて困難な知識(たとえば歴史)が存在する
とのことである。
[Paper Note] Learning is Forgetting: LLM Training As Lossy Compression, Henry C. Conklin+, ICLR'26, 2026.04
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #read-later #Initial Impression Notes Issue Date: 2026-04-11 GPT Summary- LLMの表現空間の構造は未解明であり、学習の解釈に制限がある。研究では、LLMsを損失のある圧縮として捉え、訓練過程で目的に関連する情報のみを保持すると主張。モデルの事前訓練結果から圧縮の最適性を示し、異なるモデル間の性能が訓練データとレシピの違いによることを解明。これにより、表現構造と性能を結びつける情報理論的フレームを提供し、大規模な応用の可能性を示す。 Comment
元ポスト:
openreview:
https://openreview.net/forum?id=tvDlQj0GZB
(おそらく先行研究と比較したときの新規性に対する解釈が割れていて)スコアが相当pos/negに偏っている
なお、Rebuttalのために800以上のチェックポイントを分析する必要があったとのこと。
meta reviewによるとLLMのダイナミクスを理解するうえで有用な視点を提供している一方で、論文中で潜在的な応用可能性については言及されているが、実用的な有用性、特に本研究が示した分析結果が効果的な学習手法、モデル選択手順にどのように反映可能かが十分に示されていない、という指摘がある。
所見:
[Paper Note] In-Place Test-Time Training, Guhao Feng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#LanguageModel #read-later #Test Time Training (TTT) #Author Thread-Post Issue Date: 2026-04-08 GPT Summary- 静的な学習パラダイムでは新情報への動的適応が制限される。本研究では、推論時訓練(TTT)を用いてモデルパラメータを更新し、インプレースTTTフレームワークを提案。これにより、MLPブロックの最終射影行列をファストウェイトとして扱い、ゼロからの再訓練なしでLLMを強化。次トークン予測タスクに目的を整合させ、スケーラブルなアルゴリズムを実現。実験により、4Bパラメータモデルが優れた性能を示し、競合するアプローチを上回った。In-Place TTTは継続的学習の新たな一歩を提供する。 Comment
openreview: https://openreview.net/forum?id=dTWfCLSoyl
元ポスト:
[Paper Note] Entropy-Preserving Reinforcement Learning, Aleksei Petrenko+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #Selected Papers/Blogs #Stability #needs-revision #EntropyCollapse #Author Thread-Post Issue Date: 2026-04-01 Comment
元ポスト:
openreview: https://openreview.net/forum?id=E8MR8jgEeZ
PPO/GRPOなどのアルゴリズムではRL中にポリシーの多様性が低下し、ポリシーがdeterministicになり探索をしなくなり、パフォーマンスが停滞するか低下する(あるいはベースモデルでもともと高い尤度を持っていた解のPass@1が改善するが、ポリシーの出力が狭くなるため、Pass@kが犠牲になる)現象が生じる(= entropy collapse)ので、それを是正したいという話。
後ほど追記
[Paper Note] Mamba-3: Improved Sequence Modeling using State Space Principles, Aakash Lahoti+, ICLR'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #SSM (StateSpaceModel) #Architecture #Selected Papers/Blogs #Initial Impression Notes #LinearAttention Issue Date: 2026-03-18 GPT Summary- 推論効率がLLMの性能に与える影響に注目し、計算量を抑えつつ高い性能を持つモデルの開発が求められている。Transformerモデルは品質は高いが、計算コストが増加するため、サブ二次モデルの必要性が高まっている。しかし、最近の線形モデルは効率を優先した結果、性能が損なわれることも多い。これに対し、我々は状態空間モデル(SSM)に基づく三つの改善策を提案し、Mamba-3モデルを開発した。これにより、下流の言語モデリングタスクで平均精度が大幅に向上し、より少ない状態サイズで同等のパープレキシティを実現した。Mamba-3は性能と効率の向上を示す結果を得た。 Comment
openreview時点でのメモ:
- [Paper Note] MAMBA-3: IMPROVED SEQUENCE MODELING USING STATE SPACE PRINCIPLES, 2025.10
元ポスト:
最近はMambaのようなSSM(あるいはlinear attention)とfull attentionのハイブリッドなdecoder-onlyモデルが主流になりつつあるため、抑えておいた方が良いだろう。
[Paper Note] Enhancing Hallucination Detection through Noise Injection, Litian Liu+, ICLR'26, 2025.02
Paper/Blog Link My Issue
#Hallucination Issue Date: 2026-03-14 GPT Summary- 大規模言語モデル(LLMs)の幻覚検出に関する研究。モデルの不確実性を考慮し、適切なパラメータや隠れユニットを摂動させることで、従来の方法よりも効果的な幻覚検出が可能になる。新しい手法は、様々なデータセットやモデルアーキテクチャで推論時の性能を大幅に向上させる。 Comment
元ポスト:
[Paper Note] SimpleToM: Exposing the Gap between Explicit ToM Inference and Implicit ToM Application in LLMs, Yuling Gu+, ICLR'26, 2024.10
Paper/Blog Link My Issue
#TheoryOfMind Issue Date: 2026-03-07 GPT Summary- 大規模言語モデル(LLMs)の心の理論(ToM)を評価するために、SimpleToMという新しいベンチマークを提案。明示的な心の状態推定から行動予測・判断まで、複数のToM推論レベルを検証。日常的な状況に基づく物語を用い、心の状態、行動、判断に関する質問を通じてモデルの能力を測定。実験結果では、モデルは心の状態を推定する能力は高いが、その知識を行動予測や判断に適用する能力には顕著な低下が見られ、LLMsの社会的推論における脆弱性が明らかにされる。 Comment
openreview: https://openreview.net/forum?id=iE2JmbRJow
元ポスト:
[Paper Note] LeRobot: An Open-Source Library for End-to-End Robot Learning, Remi Cadene+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#MachineLearning #Dataset #Library #ReinforcementLearning #OpenSource #Selected Papers/Blogs #Robotics #One-Line Notes Issue Date: 2026-03-03 GPT Summary- ロボティクスは機械学習の進展により変革を遂げ、ロボット学習が新たに生まれつつある。手頃な遠隔操作システムや公開データセットの増加により、研究が加速しているが、クローズドソースツールの断片化が発展を妨げている。本研究では、ロボット学習スタックを統合するオープンソースライブラリ\texttt{lerobot}を提案。これにより、低レベル制御からデータ収集までをカバーし、アクセス可能なハードウェアをサポート。スケーラブルな学習アプローチを強調し、研究者・実務者の参入障壁を低下させ、再現性のある学習プラットフォームを提供する。 Comment
openreview: https://openreview.net/forum?id=CiZMMAFQR3
元ポスト:
従来の研究では、特定のユースケース、特定のツール、特定のプラットフォーム、データフォーマット、学習アルゴリズム等を自分たちの独自のユースケースのために開発がされてきたため、これにより分野の断片化(他者が追試しづらい、統一的な技術スタックがない等)が生じてしまっていたため、それを解決するためにend-to-endでの統合的な枠組み(ロボットを動作させるだよミドルウェアのインタフェースや標準化されたデータセットのフォーマット、学術アルゴリズムなど)を提案しているようである。
onelineで実ロボットへのデプロイができる機能が追加されたとのこと:
[Paper Note] REMem: Reasoning with Episodic Memory in Language Agent, Yiheng Shu+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#GraphBased #NLP #LanguageModel #AIAgents #Selected Papers/Blogs #memory #One-Line Notes #Grounding #Author Thread-Post Issue Date: 2026-03-01 GPT Summary- REMemは、エピソード記憶を構築し推論するための2段階フレームワークを提案する。オフラインでは、経験を時間情報を含む要旨と事実を結びつけたハイブリッド記憶グラフに変換。オンラインでは、エージェント型リトリーバを用いて記憶グラフ上での反復検索を可能にする。包括的な評価により、REMemは最先端システムを大幅に上回り、エピソード回想と推論タスクでそれぞれ3.4%、13.4%の改善を示す。回答不能な質問に対する拒否行動も堅牢であることが確認された。 Comment
元ポスト:
単に知識や事実情報を蓄積するのではなく、過去のイベントに関するsituationalな情報(when,where,who,what)でgroundingをしながら、複数のイベント、タイムラインを跨いでreasoningができるようなepisodic memoryの提案。人間は単に意味情報から記憶を呼び起こすだけでなく、過去のイベントを想起して条件付けした上で時系列になぞって記憶を想起できる能力があることに起因する。
openreview: https://openreview.net/forum?id=fugnQxbvMm
[Paper Note] DISCO: Diversifying Sample Condensation for Efficient Model Evaluation, Alexander Rubinstein+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #EfficientEvaluation Issue Date: 2026-02-28 GPT Summary- 機械学習モデルの評価は高コストであり、従来のアプローチは二段階でサブセットを選び、精度を学習する。しかし、選択がクラスタリングに依存するため設計に敏感である。我々は、モデルの応答の多様性を最大化するサンプル選択が重要であると提唱し、$\textbf{DISCO}$手法を提案。これはモデル間の不一致を基にサンプルを選ぶもので、理論的にも最適であり、MMLUやHellaswagなどで最先端の性能を達成した。 Comment
pj page: https://arubique.github.io/disco-site/
元ポスト:
openreview: https://openreview.net/forum?id=SoOgBHa3dZ
[Paper Note] The Diffusion Duality, Chapter II: $Ψ$-Samplers and Efficient Curriculum, Justin Deschenaux+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #LanguageModel #DiffusionModel #read-later #Selected Papers/Blogs #ImageSynthesis #Samplers #Author Thread-Post Issue Date: 2026-02-28 GPT Summary- Uniform-state離散拡散モデルは自己修正能力により優れた生成とガイダンスを実現していますが、ステップ数が増えるとサンプリング品質が限界に達します。本研究では、予測子-修正子(PC)サンプラーを導入し、任意のノイズ過程に対応可能な一般化手法を提案します。Uniform-state拡散と組み合わせることで、従来の手法を超える性能を発揮し、生成パープレキシティを低減させるとともに、サンプリングステップを増やすことで性能が向上します。また、効率的なカリキュラムを構築し、訓練時間を25%、メモリを33%削減しつつ、強力な下流タスク性能を維持します。 Comment
元ポスト:
著者ポスト:
openreview: https://openreview.net/forum?id=RSIoYWIzaP
著者コメント:
openreview: https://openreview.net/forum?id=RSIoYWIzaP
著者ポスト:
[Paper Note] Native Reasoning Models: Training Language Models to Reason on Unverifiable Data, Yuanfu Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #PostTraining #Off-Policy #KeyPoint Notes #Open-endedTasks #ConfidenceBased Issue Date: 2026-02-13 GPT Summary- NRT(ネイティブ推論トレーニング)は、教師ありファインチューニングと強化学習の依存を克服し、標準的な質問-回答ペアのみでモデルが自ら推論を生成します。推論を潜在変数として扱い、統一訓練目標に基づいて最適化問題としてモデル化することで、自己強化フィードバックループを構築。LlamaおよびMistralモデルにおいて、NRTが最先端の性能を達成し、従来の手法を大幅に上回ることを実証しました。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=abAMONjBwb
verifier freeでreasoning能力を向上させるRL手法で
- SFTにおいてexpertsのtrajectoryが必要な課題
- RLVRにおいてverifiableなドメインでしか学習できない課題
の両方に対処する。
具体的にはQAデータが与えられたときに、Questionに対してモデルにreasoning trace zを生成させ、zを生成した後にanswerを生成させる。zに対するTrace Rewardとanswerトークンに対するモデルのconfidenceを報酬として用いてRLする。
SFTやverifier freeな先行研究よりも9種類のreasoningベンチマークで高い性能を達成している。また、answer tokenのconfidenceに対する3種類の集約方法(平均, 1/pによって加重平均をすることで難しいトークンの重みを強める, 対数尤度を用いる)も提案手法も提案され比較されている。
論文中ではオフポリシーRLとして最適化する旨記述されているが、appendix記載の通りreasoning trace zを生成しているので、オンポリシーRLな性質も備えていると思われる。
[Paper Note] DIRMOE: DIRICHLET-ROUTED MIXTURE OF EXPERTS, ICLR'26
Paper/Blog Link My Issue
#NLP #LanguageModel #MoE(Mixture-of-Experts) #Stability #Routing #One-Line Notes Issue Date: 2026-02-08 GPT Summary- Dirichlet-Routed MoE(DirMoE)は、MoEモデルの性能を向上させる新しい微分可能ルーティングメカニズムです。エキスパートの選択とその貢献の配分を明確に分け、Gumbel-Sigmoid緩和とDirichlet再パラメータ化により訓練過程を完全に微分可能にします。さらに、スパースペナルティを通じてアクティブなエキスパート数を管理し、専門性を高めつつ、他の手法と同等以上の成果を達成しています。 Comment
openreview: https://openreview.net/forum?id=a15cDnzr6r
元ポスト:
MoEのルーティングの選択と配分をモデル化して、微分可能にした上で最適化する
[Paper Note] Learning to summarize user information for personalized reinforcement learning from human feedback, Hyunji Nam+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#DocumentSummarization #NLP #LanguageModel #Alignment #ReinforcementLearning #Personalization #In-ContextLearning #read-later Issue Date: 2026-02-08 GPT Summary- 新しいLLMアシスタントでの応答のパーソナライズを目指し、「要約を用いた好み学習(PLUS)」フレームワークを提案。これにより、各ユーザーの特徴や過去の対話に基づいた要約を生成し、個々の好みに沿った報酬モデルを条件付ける。PLUSは、ユーザー要約モデルと報酬モデルを同時に訓練し、精度向上を実現。新しいユーザーやトピックに対する堅牢性や、独自モデルによる強化されたパーソナライズ能力を示し、ユーザーの解釈可能な表現を提供することで透明性を高める。 Comment
pj page: https://sites.google.com/stanford.edu/plus/home
元ポスト:
[Paper Note] Neural Predictor-Corrector: Solving Homotopy Problems with Reinforcement Learning, Jiayao Mai+, ICLR'26, 2026.02
Paper/Blog Link My Issue
Issue Date: 2026-02-05 GPT Summary- ホモトピーパラダイムに基づく問題解決の一般原則を統一し、ニューラル予測修正(NPC)を提案。手作りのヒューリスティックを自動学習に置き換え、強化学習で効率的なポリシーを発見。償却トレーニングにより、新しいインスタンスへのオンライン推論を実現。実験結果は、特定のホモトピー問題に対して優れた一般化能力と効率性を示し、従来の手法を上回る性能を確認。 Comment
元ポスト:
[Paper Note] The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think, Seongyun Lee+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Explanation #Chain-of-Thought Issue Date: 2026-02-05 GPT Summary- CoTを分析するためのボトムアップのフレームワークを提案。モデル生成のCoTから多様な推論基準を抽出し、クラスタリングを行うことで解釈可能な分析を実施。結果、トレーニングデータの形式が推論行動に与える影響が明らかになり、より効果的な推論戦略への誘導が可能となることを示した。 Comment
元ポスト:
[Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Reasoning #SelfCorrection #read-later #Selected Papers/Blogs #KeyPoint Notes #Rubric-based #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 言語モデル(LM)の自己改善能力を探るために、RefineBenchという1,000の問題と評価フレームワークを導入。二つの改善モード、ガイド付きと自己改善を評価した結果、最前線のLMは自己改善で低迷する一方、ガイド付き改善では特許LMや大規模オープンウエイトLMが迅速に応答を改善。自己改善には突破口が必要であり、RefineBenchが進捗の追跡に貢献することを示す。 Comment
元ポスト:
pj page: https://passing2961.github.io/refinebench-page/
verifiableはタスクだけでなくnon verifiableなタスクもベンチマークに含まれ、ガイド付き/無しの異なる設定、11種類の多様なドメイン、チェックリストベースのbinary classificationに基づく評価(strong LLMによって分類する; これによりnon verifiableなタスクでも評価可能)、マルチターンでの改善を観測できる、self-correction/refinementに関するベンチマーク。
フロンティアモデルでも自己改善はガイド無しの場合ではあまり有効に機能しないことを明らかにし、外部からガイドが与えられればOpenLLMでさえも少ないターン数で完璧に近い方向にrefineされる、という感じの内容に見える。
つまり自身とは異なるモデルで、何らかの素晴らしい批評家がいれば、あるいは取り組みたいタスクにおいて一般化された厳密性のあるチェックリストがあれば、レスポンスはiterationを繰り返すごとに改善していくことになる。
[Paper Note] Programming with Pixels: Can Computer-Use Agents do Software Engineering?, Pranjal Aggarwal+, ICLR'26, 2025.02
Paper/Blog Link My Issue
#ComputerVision #Dataset #AIAgents #Evaluation #Coding #SoftwareEngineering #ComputerUse #VisionLanguageModel #GUI Issue Date: 2026-02-05 GPT Summary- CUA(コンピュータ利用エージェント)は一般的なタスクを実行する可能性があるが、ソフトウェアエンジニアリングのような専門的な作業の自動化能力は不明である。本研究では、「Programming with Pixels」(PwP)を導入し、エージェントが視覚的にIDEを操作して多様なソフトウェアエンジニアリングタスクを実行する環境を提供する。また、15のソフトウェアエンジニアリングタスクに対するベンチマーク「PwP-Bench」を設立し、CUAsの性能を評価した。結果、純粋な視覚的インタラクションでは専門エージェントに劣るが、APIへの直接アクセスを与えることで性能が向上し、専門性に達することが多かった。CUAsは視覚的基盤の限界と環境の効果的な活用に課題があるが、PwPは洗練されたタスクに対する評価の新たな基準を提供する。 Comment
pj page: https://github.com/ProgrammingwithPixels/PwP
元ポスト:
[Paper Note] Learn to Reason Efficiently with Adaptive Length-based Reward Shaping, Wei Liu+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Reasoning #Length #PostTraining #Adaptive Issue Date: 2026-02-03 GPT Summary- 推論の効率を向上させるため、RLベースの手法LASERを提案。長さに基づく報酬シェイピングを用いて、冗長性を減少させつつ、パフォーマンスと効率の良好なバランスを実現。また、動的な報酬仕様と難易度を考慮した手法LASER-Dを導入し、簡潔な推論パターンを促進。実験により、推論性能と応答の長さ効率が大幅に向上した。 Comment
元ポスト:
[Paper Note] VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning, Ye Liu+, ICLR'26, 2025.03
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #AIAgents #LongSequence #PEFT(Adaptor/LoRA) #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2026-02-01 GPT Summary- VideoMindは、動画理解のための新しい動画・言語エージェントで、時間的推論に特化した役割ベースのワークフローを導入。プランナー、グラウンダー、バリファイア、アンサーの役割を組み合わせ、LoRAアダプタを用いたChain-of-LoRA戦略で効率的に切り替え。14の公共ベンチマークにおける実験で、地に基づいた動画質問応答や一般的な動画質問応答において最先端のパフォーマンスを達成し、その有効性を示した。 Comment
pj page: https://videomind.github.io/
[Paper Note] Grounding Computer Use Agents on Human Demonstrations, Aarash Feizi+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #ComputerUse #PostTraining #UI Issue Date: 2026-02-01 GPT Summary- 専門家の実演から構築したデスクトップグラウンディングデータセット「GroundCUA」を提案。87のアプリをカバーし、56,000枚のスクリーンショットと356万件以上の注釈を含む。これに基づき、指示をUI要素にマッピングする「GroundNext」モデル群を開発。教師ありファインチューニングにより最先端の結果を達成し、強化学習によるポストトレーニングでさらに性能向上。高品質なデータセットがコンピューターエージェントの進展に貢献することを示唆。 Comment
pj page: https://groundcua.github.io/
元ポスト:
[Paper Note] LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities, Thomas Schmied+, ICLR'26, 2025.04
Paper/Blog Link My Issue
#Analysis #LanguageModel #ReinforcementLearning #Chain-of-Thought #Reasoning #Test-Time Scaling #PostTraining #Multi-Armed Bandit #DecisionMaking #Exploration Issue Date: 2026-01-31 GPT Summary- LLMのエージェントアプリケーションにおける探求と解決の効率性を分析。最適なパフォーマンスを妨げる「知識と行動のギャップ」や貪欲性、頻度バイアスという失敗モードを特定。強化学習(RL)によるファインチューニングを提案し、探索を増加させて意思決定能力を改善。古典的な探索メカニズムとLLM特有のアプローチの両方を融合させ、効果的なファインチューニングの実現を目指す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=weUP6H5Ko9
- greediness
- frequency bias
- the knowing-doing gap
[Paper Note] A Noise is Worth Diffusion Guidance, Donghoon Ahn+, ICLR'26, 2024.12
Paper/Blog Link My Issue
Issue Date: 2026-01-30 GPT Summary- 拡散モデルは高品質な画像生成に成功していますが、従来の手法ではガイダンスが必要です。本研究では、ガイダンスなしでも高品質な画像再構築が可能であることを示し、初期ノイズの洗練によって性能が向上することを明らかにしました。新たに提案した手法\oursでは、効率的なノイズ空間学習を用いて、50Kのテキスト-画像ペアで迅速に収束し、ガイダンスなしで高品質な生成を実現します。実験でその有効性を確認し、ガイダンス不要な理由を分析しました。 Comment
元ポスト:
[Paper Note] Factuality Matters: When Image Generation and Editing Meet Structured Visuals, Le Zhuo+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation #Factuality #DiffusionModel #2D (Image) #Editing #UMM #ImageSynthesis Issue Date: 2026-01-30 GPT Summary- 構造化された視覚生成に特化した研究であり、高品質な構造画像データセットを構築。VLMとFLUXを統合したモデルを訓練し、推論能力を強化。新たな評価指標StructScoreを導入し、多段階Q&Aプロトコルで正確性を評価。モデルは強力な編集性能を示し、構造化視覚の統一基盤を目指す。 Comment
元ポスト:
[Paper Note] YuE: Scaling Open Foundation Models for Long-Form Music Generation, Ruibin Yuan+, ICLR'26, 2025.03
Paper/Blog Link My Issue
Issue Date: 2026-01-26 GPT Summary- YuEは、LLaMA2アーキテクチャに基づく音楽生成モデルで、歌詞から曲を生成する難題に挑戦。数兆トークンにスケールし、最大5分の音楽を作成しつつ、整合性や構造を保ちます。トラックデカップリングや構造的条件付けを用いた多段階の学習を実施し、スタイル転送や双方向生成を可能に。また、評価では音楽性において他システムと同等以上の成果を記録。さらに、ファインチューニングで制御性が向上し、多言語サポートも強化。学習した表現は音楽理解タスクでも優れた性能を示しました。 Comment
openreview: https://openreview.net/forum?id=hZy6YG2Ij8
[Paper Notes] ImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World Tasks, Sani+, ICLR'26
Paper/Blog Link My Issue
Issue Date: 2026-01-26 Comment
openreview: https://openreview.net/forum?id=bld9g6jFh9
元ポスト:
[Paper Note] The Quest for Generalizable Motion Generation: Data, Model, and Evaluation, Jing Lin+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #SyntheticData #Evaluation #DiffusionModel #Generalization #3D (Scene) #FlowMatching #Robotics #3D (Video) #HumanMotionGeneration Issue Date: 2026-01-11 GPT Summary- 3D人間動作生成(MoGen)は一般化能力に課題があるが、動画生成(ViGen)は優れた一般化を示す。これを受けて、ViGenからMoGenへの知識移転のためのフレームワークを提案。228,000の高品質な動作サンプルを含むデータセットViMoGen-228Kを作成し、MoCapデータとViGenモデルからの情報を統合したフローマッチングベースの拡散トランスフォーマーViMoGenを開発。さらに、動作の質や一般化能力を評価するための階層的ベンチマークMBenchを提示。実験結果は、提案手法が既存のアプローチを大幅に上回ることを示した。 Comment
dataset:
https://huggingface.co/datasets/wruisi/ViMoGen-228K
leaderboard:
https://huggingface.co/spaces/wruisi/MBench_leaderboard
元ポスト:
ポイント解説:
openreview: https://openreview.net/forum?id=KNke6Pkq4o
[Paper Note] UniVideo: Unified Understanding, Generation, and Editing for Videos, Cong Wei+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Transformer #MultiModal #DiffusionModel #VariationalAutoEncoder #OpenWeight #read-later #Selected Papers/Blogs #VideoGeneration/Understandings #Editing Issue Date: 2026-01-09 GPT Summary- UniVideoは、動画ドメインにおけるマルチモーダルコンテンツの生成と編集を目的とした統一モデルで、MLLMとMMDiTを組み合わせたデュアルストリーム設計を採用。これにより、複雑な指示の解釈と視覚的一貫性を維持しつつ、動画生成や編集タスクを統一的に訓練。実験結果では、テキスト/画像から動画への生成や文脈内編集において最先端の性能を示し、編集とスタイル転送の統合や未見の指示への対応も可能。視覚プロンプトに基づく生成もサポートし、モデルとコードは公開されている。 Comment
pj page: https://congwei1230.github.io/UniVideo/
元ポスト:
[Paper Note] JustRL: Scaling a 1.5B LLM with a Simple RL Recipe, Bingxiang He+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Stability #Author Thread-Post Issue Date: 2025-12-20 GPT Summary- JustRLという最小限のアプローチを提案し、固定ハイパーパラメータを用いた単一ステージのトレーニングで最先端のパフォーマンスを達成。計算リソースは洗練されたアプローチの2倍を使用し、トレーニングは滑らかに改善。標準的なトリックの追加が探索を崩壊させる可能性があることを示し、シンプルで検証されたベースラインの重要性を強調。モデルとコードを公開。 Comment
元ポスト:
ICLR'26 blog post track にアクセプト:
著者ポスト:
[Paper Note] Group Representational Position Encoding, Yifan Zhang+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#NLP #Transformer #PositionalEncoding #Architecture Issue Date: 2025-12-10 GPT Summary- GRAPE(Group RepresentAtional Position Encoding)は、群作用に基づく位置エンコーディングの統一フレームワークを提案します。Multiplicative GRAPEは、位置を乗法的に作用させ、相対的かつノルムを保存する写像を生成します。一方、Additive GRAPEは、加法的ロジットを用いて特定のケースを再現し、相対法則とストリーミングキャッシュ可能性を保持します。GRAPEは、長文コンテキストモデルにおける位置幾何学の設計空間を提供し、RoPEやALiBiを特別なケースとして包含します。 Comment
pj page: https://model-architectures.github.io/GRAPE/
元ポスト:
openreview: https://openreview.net/forum?id=itoNJ3gJl2
[Paper Note] Light-X: Generative 4D Video Rendering with Camera and Illumination Control, Tianqi Liu+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Controllable #SyntheticData #DiffusionModel #VideoGeneration/Understandings #3D (Video) #One-Line Notes #Relighting #Author Thread-Post Issue Date: 2025-12-06 GPT Summary- Light-Xは、単眼動画から視点と照明を制御可能にする動画生成フレームワークで、幾何学と照明信号を分離する設計を採用。これにより高品質な照明を実現し、ペアのマルチビューおよびマルチ照明動画の不足に対処するために逆マッピングを用いた合成手法を導入。実験結果では、Light-Xがカメラと照明の共同制御において従来手法を上回る性能を示した。 Comment
pj page: https://lightx-ai.github.io/
元ポスト:
著者ポスト:
openreview: https://openreview.net/forum?id=VBew6vESGL
単眼で撮影された動画の視点と照明を同時に制御しながら動画を生成するフレームワークな模様。
背景画像をあたえた
単眼で撮影された動画の視点と照明を同時に制御しながら動画を生成するフレームワークな模様。
背景画像を与えた上での動画のRelighting, Text Promptに基づくRelighting, ユーザがtrajectoryを指定した上でのRelightingなどができるようである。
[Paper Note] On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning, Yifan Zhang+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #ReinforcementLearning #read-later #Selected Papers/Blogs #On-Policy Issue Date: 2025-11-12 GPT Summary- ポリシー勾配アルゴリズムを用いてLLMの推論能力を向上させるため、正則化ポリシー勾配(RPG)を提案。RPGは、正規化されたKLと非正規化されたKLを統一し、REINFORCEスタイルの損失の微分可能性を特定。オフポリシー設定での重要度重み付けの不一致を修正し、RPGスタイルクリップを導入することで安定したトレーニングを実現。数学的推論ベンチマークで最大6%の精度向上を達成。 Comment
元ポスト:
pj page: https://complex-reasoning.github.io/RPG/
続報:
openreview: https://openreview.net/forum?id=qe060gmfm7
[Paper Note] RLAC: Reinforcement Learning with Adversarial Critic for Free-Form Generation Tasks, Mian Wu+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Verification #Critic #Rubric-based #Author Thread-Post Issue Date: 2025-11-05 GPT Summary- 「対抗批評家による強化学習(RLAC)」を提案し、動的基準検証を通じて生成タスクの評価課題に対処。LLMを批評家として利用し、失敗モードを特定して検証することで、生成器と批評家を共同最適化。実験により、RLACがテキスト生成とコード生成の正確性を向上させ、従来の手法を上回ることを示した。動的批評家の効果も確認し、RLACのスケーリング可能性を示唆。 Comment
pj page: https://mianwu01.github.io/RLAC_website/
元ポスト:
関連:
著者ポスト:
openreview: https://openreview.net/forum?id=dBmjnRR1bC
[Paper Note] From Spatial to Actions: Grounding Vision-Language-Action Model in Spatial Foundation Priors, Zhengshen Zhang+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #3D (Scene) #Robotics #VisionLanguageActionModel #SpatialUnderstanding Issue Date: 2025-11-03 GPT Summary- FALCON(From Spatial to Action)は、視覚-言語-行動(VLA)モデルの空間的推論のギャップを解消する新しいパラダイムで、3D空間トークンを行動ヘッドに注入します。RGBから幾何学的情報を提供し、深度やポーズを融合させることで高い忠実度を実現し、再訓練やアーキテクチャの変更は不要です。FALCONは、空間表現やモダリティの転送可能性を向上させ、11の現実世界のタスクで最先端のパフォーマンスを達成しました。 Comment
pj page: https://falcon-vla.github.io/
元ポスト:
openreview: https://openreview.net/forum?id=fzmittHfq3
[Paper Note] Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents, Yueqi Song+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-10-30 GPT Summary- 本研究では、エージェントデータの収集における課題を解決するために、エージェントデータプロトコル(ADP)を提案。ADPは多様なデータ形式を統一し、簡単に解析・トレーニング可能な表現言語である。実験により、13のエージェントトレーニングデータセットをADP形式に統一し、標準化されたデータでSFTを実施した結果、平均約20%の性能向上を達成。ADPは再現可能なエージェントトレーニングの障壁を下げることが期待される。 Comment
pj page: https://www.agentdataprotocol.com
元ポスト:
著者ポスト:
解説:
エージェントを学習するための統一的なデータ表現に関するプロトコルを提案
続報:
openreview: https://openreview.net/forum?id=tG6301ORHd
[Paper Note] VisCoder2: Building Multi-Language Visualization Coding Agents, Yuansheng Ni+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #LanguageModel #AIAgents #Evaluation #Coding Issue Date: 2025-10-30 GPT Summary- 大規模言語モデル(LLMs)を用いた視覚化コーディングエージェントは、実行や修正において課題がある。これを解決するために、679Kの視覚化サンプルを含むデータセットVisCode-Multi-679K、自己デバッグ用のベンチマークVisPlotBench、そしてマルチ言語モデルVisCoder2を提案。実験結果では、VisCoder2がオープンソースのベースラインを超え、商用モデルに近い性能を示し、特に記号的言語での成功が顕著であった。 Comment
pj page: https://tiger-ai-lab.github.io/VisCoder2/
元ポスト:
openreview: https://openreview.net/forum?id=4zoMnmZzh4
[Paper Note] IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction, Hao Li+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Dataset #Transformer #FoundationModel #3D Reconstruction #3D (Scene) #UMM #SpatialUnderstanding Issue Date: 2025-10-28 GPT Summary- 人間の3Dシーン理解を模倣するため、空間再構築とインスタンス理解を統合したInstanceGrounded Geometry Transformer(IGGT)を提案。IGGTは2D視覚入力を用いて幾何学的構造とインスタンスクラスタリングを統一的に表現し、3Dシーンの一貫性を向上させる。新たに構築したInsScene-15Kデータセットを用いて、3D一貫性のあるインスタンスレベルのマスク注釈を提供。 Comment
pj page: https://lifuguan.github.io/IGGT_official/
元ポスト:
ポイント解説:
openreview: https://openreview.net/forum?id=swiL18PmUV
[Paper Note] From Pixels to Words -- Towards Native Vision-Language Primitives at Scale, Haiwen Diao+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Architecture #Selected Papers/Blogs #VisionLanguageModel #UMM #KeyPoint Notes #Scalability Issue Date: 2025-10-19 GPT Summary- ネイティブなビジョン・ランゲージモデル(VLM)の課題を明確にし、効果的な構築指針を示す。具体的には、ピクセルと単語の整合、ビジョンとランゲージの統合、クロスモーダル特性の具現化を重視。新たに開発したNEOは、390Mの画像-テキスト例で視覚的知覚を効率的に発展させ、コスト効率の高いエコシステムを提供。 Comment
元ポスト:
pj page:
https://github.com/EvolvingLMMs-Lab/NEO
HFへのリンクもpj pageにある。
openreview: https://openreview.net/forum?id=DF6udvxuvY
新たなnative-VLMアーキテクチャを提案している。
従来のVLMは、事前学習されたVision EncoderとLLMをモジュールとして扱い両者を後から統合するタイプが多く、これらは異なるモダリティの特性を独立したモジュールで捉え、柔軟にモジュールを組み替えられる利点があるが、textとvisionモダリティのalignmentのコストや不整合といった課題が生じる。
これに対して、native-VLMとはモダリティごとに異なるモジュールを導入し組み合わせるのではなく、textとvisionのモダリティを統合されたアーキテクチャで扱うようなアーキテクチャのことである。
本研究では、ベースとなるLLMとしてQwen3を用いて、それを拡張することで構築されたnative-VLMのモデルファミリーNEOを構築し
- attentionブロックのQuery, Key計算時にtextual Token Tと、visual tokenのHeight H, Width Wを分離
- H, W, Tごとに独立した周波数でのRoPEの適用
- 画像に対するbidirectionalなattentionの適用
- vision/textを共通のembedding spaceに写像するtransformer layer (Pre Buffer)の導入
といったアーキテクチャの工夫がなされており、
このようなアーキテクチャが
- 事前学習: Patch Embedding Layer (PEL)、Pre Buffer, Pre Buffer適用後のpost-LLMにおける新たなQK部分のみを学習
した後、中間学習→SFT(instruction tuning)でモデル全体が学習される。
ここで、WELとはWord Embedding Layerのことである。
[Paper Note] The Alignment Waltz: Jointly Training Agents to Collaborate for Safety, Jingyu Zhang+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Alignment #ReinforcementLearning #AIAgents #Safety #One-Line Notes #Author Thread-Post Issue Date: 2025-10-15 GPT Summary- WaltzRLという新しいマルチエージェント強化学習フレームワークを提案し、LLMの有用性と無害性のバランスを取る。会話エージェントとフィードバックエージェントを共同訓練し、応答の安全性と有用性を向上させる。実験により、安全でない応答と過剰な拒否を大幅に減少させることを示し、LLMの安全性を向上させる。 Comment
元ポスト:
マルチエージェントを用いたLLMのalignment手法。ユーザからのpromptに応答する会話エージェントと、応答を批評するフィードバックエージェントの2種類を用意し、違いが交互作用しながら学習する。フィードバックエージェント会話エージェントが安全かつ過剰に応答を拒絶していない場合のみ報酬を与え、フィードバックエージェントのフィードバックが次のターンの会話エージェントの応答を改善したら、フィードバックエージェントに報酬が与えられる、みたいな枠組みな模様。
著者による一言解説:
[Paper Note] Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense, Leitian Tao+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning #Reasoning #Mathematics #RewardModel #One-Line Notes #Author Thread-Post Issue Date: 2025-10-13 GPT Summary- HERO(ハイブリッドアンサンブル報酬最適化)は、検証者の信号と報酬モデルのスコアを統合する強化学習フレームワークで、より豊かなフィードバックを提供。層別正規化を用いて正確性を保ちながら品質の区別を向上させ、数学的推論ベンチマークで従来のベースラインを上回る結果を示した。ハイブリッド報酬設計が推論の進展に寄与することを確認。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=0CajQNVKyB
著者による一言解説ポスト:
0/1のbinaryなsparse rewardとdense rewardの両方を組み合わせたハイブリッドなRL手法を提案。verifiable rewardではしばしば報酬がsparseになり学習シグナルが何も得られない課題があり、dense rewardにはノイズが多く含まれるという課題があり、両者を組み合わせることで課題を低減した、という感じの話らしい。
[Paper Note] Provable Scaling Laws of Feature Emergence from Learning Dynamics of Grokking, Yuandong Tian, ICLR'26, 2025.09
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #MachineLearning #Grokking #Optimizer Issue Date: 2025-10-10 GPT Summary- grokkingの現象を理解するために、2層の非線形ネットワークにおける新しい枠組み$\mathbf{Li_2}$を提案。これには、怠惰な学習、独立した特徴学習、相互作用する特徴学習の3段階が含まれる。怠惰な学習では、モデルが隠れ表現に過剰適合し、独立した特徴が学習される。後半段階では、隠れノードが相互作用を始め、学習すべき特徴に焦点を当てることが示される。本研究は、grokkingにおけるハイパーパラメータの役割を明らかにし、特徴の出現と一般化に関するスケーリング法則を導出する。 Comment
元ポスト:
poster:
https://yuandong-tian.com/posters/poster_li2_correct.pdf
元ポスト:
[Paper Note] MENLO: From Preferences to Proficiency -- Evaluating and Modeling Native-like Quality Across 47 Languages, Chenxi Whitehouse+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #Evaluation #Conversation #MultiLingual #LLM-as-a-Judge #RewardModel #One-Line Notes Issue Date: 2025-10-03 GPT Summary- MENLOフレームワークを用いて、47言語の6,423のプロンプト-応答ペアのデータセットを作成し、LLMの応答品質を評価。ゼロショット評価者はペアワイズ評価から利益を得るが、人間には及ばず。強化学習によるファインチューニングで改善を示し、RL訓練評価者がLLMの多言語能力向上に寄与することを確認。ただし、人間の判断との不一致は残る。データセットと評価フレームワークを公開し、多言語LLM評価の研究を支援。 Comment
元ポスト:
LLMの応答を多言語でよりnativeに近いものにするための取り組み、および評価のフレームワーク(MENLO, データセット含む)な模様。nativeらしさを測るために重要な次元としてFluency, Tone, Localized Tone, Localized Factualityと呼ばれる軸を定義している模様。その上で47言語における6423の人手でアノテーションされたpreference dataを作成し評価をしたところ、既存のLLM-as-a-judgeやSFT/RLされたReward Modelでは、人間による評価にはまだまだ及ばないことが明らかになり、MENLOを用いてRL/SFTすることでLLM JudgeやReward Modelの性能を改善できる、といった話な模様。
4つの次元については以下の表を参照のこと。
それぞれ
- Fluency: 専門家レベルのnative speakerと比較した時のproficiency
- Tone: 全体的なwriting stvleや語り口
- Localized Tone: 文化的、地域的な言葉のニュアンス
- Localized Factuality: 地域固有のコンテキストに沿った事実性や網羅性
openreview: https://openreview.net/forum?id=QOWYX3Q2XS
[Paper Note] EditReward: A Human-Aligned Reward Model for Instruction-Guided Image Editing, Keming Wu+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #ReinforcementLearning #Evaluation #PostTraining #VisionLanguageModel #2D (Image) #RewardModel #Editing #One-Line Notes Issue Date: 2025-10-02 GPT Summary- 自然言語指示による画像編集の進展において、オープンソースモデルは遅れをとっている。これを解決するために、20万以上の選好ペアを含む新しいデータセット\mnameを構築し、指示に基づく画像編集タスクで人間の選好と高い整合性を示した。実験では、\mnameが既存のベンチマークで最先端の人間相関を達成し、ノイズの多いデータセットから高品質なサブセットを選択することで、画像編集モデルの性能を大幅に向上させることができた。今後、\mnameはコミュニティに公開され、高品質な画像編集トレーニングデータセットの構築を支援する予定である。 Comment
pj page:
https://tiger-ai-lab.github.io/EditReward/
HF:
https://huggingface.co/collections/TIGER-Lab/editreward-68ddf026ef9eb1510458abc6
これまでのImageEditing用のデータセットは、弱いReward Modelによって合成されるか、GPT-4oや他のVLMによる品質の低いフィルタリングにより生成されており、高品質なデータセットが存在しない課題があった。これを解決するために大規模なImageEditingの嗜好データを収集し、ImageEditingに特化した報酬モデルであるEditRewardを学習。このモデルは人間の専門家とのagreementにおいて高い(というよりりbestと書いてある)agreementを示し、実際にEditRewardによって既存のデータセットをfilteringして学習したら大きなgainがあったよ、という感じらしい。
openreview: https://openreview.net/forum?id=eZu358JOOR
[Paper Note] Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning, Haozhe Wang+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Reasoning #read-later #Entropy Issue Date: 2025-09-10 GPT Summary- 強化学習(RL)は大規模言語モデル(LLMs)の推論能力を向上させるが、そのメカニズムは不明。分析により、推論の階層が人間の認知に似た二段階のダイナミクスを持つことを発見。初期段階では手続き的な正確性が求められ、後に高レベルの戦略的計画が重要になる。これに基づき、HICRAというアルゴリズムを提案し、高影響の計画トークンに最適化を集中させることで性能を向上させた。また、意味的エントロピーが戦略的探求の優れた指標であることを検証した。 Comment
pj page: https://tiger-ai-lab.github.io/Hierarchical-Reasoner/
元ポスト:
ポイント解説:
解説:
openreview: https://openreview.net/forum?id=NlkykTqAId
[Paper Note] RL's Razor: Why Online Reinforcement Learning Forgets Less, Idan Shenfeld+, ICLR'26
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Catastrophic Forgetting #Selected Papers/Blogs #On-Policy Issue Date: 2025-09-06 GPT Summary- 強化学習(RL)と教師ありファインチューニング(SFT)の比較により、RLが以前の知識をより良く保持することが明らかに。忘却の程度は分布のシフトによって決まり、KLダイバージェンスで測定される。RLは新しいタスクに対してKL最小解にバイアスがかかる一方、SFTは任意の距離に収束する可能性がある。実験を通じて、RLの更新が小さなKL変化をもたらす理由を理論的に説明し、「RLの剃刀」と呼ぶ原則を提唱。 Comment
元ポスト:
所見:
ポイント解説:
openreview: https://openreview.net/forum?id=7HNRYT4V44
[Paper Note] Fantastic Pretraining Optimizers and Where to Find Them, Kaiyue Wen+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Optimizer #read-later #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-09-03 GPT Summary- AdamWは言語モデルの事前学習で広く使用されているオプティマイザですが、代替オプティマイザが1.4倍から2倍のスピードアップを提供するという主張には二つの欠点があると指摘。これらは不均等なハイパーパラメータ調整と誤解を招く評価設定であり、10種類のオプティマイザを系統的に研究することで、公正な比較の重要性を示した。特に、最適なハイパーパラメータはオプティマイザごとに異なり、モデルサイズが大きくなるにつれてスピードアップ効果が減少することが明らかになった。最も高速なオプティマイザは行列ベースの前処理器を使用しているが、その効果はモデルスケールに反比例する。 Comment
元ポスト:
重要そうに見える
関連:
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
- [Paper Note] SOAP: Improving and Stabilizing Shampoo using Adam, Nikhil Vyas+, ICLR'25
著者ポスト:
-
-
考察:
openreview: https://openreview.net/forum?id=2J51qUZ0iG
[Paper Note] R-Zero: Self-Evolving Reasoning LLM from Zero Data, Chengsong Huang+, ICLR'26
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfImprovement #Label-free #Author Thread-Post Issue Date: 2025-08-09 GPT Summary- R-Zeroは、自己進化型大規模言語モデル(LLMs)が自律的にトレーニングデータを生成するフレームワークで、チャレンジャーとソルバーの2つのモデルが共進化することで、既存のタスクやラベルに依存せずに自己改善を実現します。このアプローチにより、推論能力が大幅に向上し、特にQwen3-4B-Baseでは数学推論で+6.49、一般ドメイン推論で+7.54の改善が確認されました。 Comment
元ポスト:
問題を生成するChallengerと与えられた問題を解くSolverを用意し、片方をfreezezさせた状態で交互にポリシーの更新を繰り返す。
### Challenger
- (Challengerによる)問題生成→
- (freezed solverによる)self consistencyによるラベル付け→
- Solverの問題に対するempirical acc.(i.e., サンプリング回数mに対するmajorityが占める割合)でrewardを与えChallengerを更新
といった流れでポリシーが更新される。Rewardは他にも生成された問題間のBLEUを測り類似したものばかりの場合はペナルティを与える項や、フォーマットが正しく指定された通りになっているか、といったペナルティも導入する。
### Solver
- ChallengerのポリシーからN問生成し、それに対してSolverでself consistencyによって解答を生成
- empirical acc.を計算し、1/2との差分の絶対値を見て、簡単すぎる/難しすぎる問題をフィルタリング
- これはカリキュラム学習的な意味合いのみならず、低品質な問題のフィルタリングにも寄与する
- フィルタリング後の問題を利用して、verifiable binary rewardでポリシーを更新
### 評価結果
数学ドメインに提案手法を適用したところ、iterごとに全体の平均性能は向上。
提案手法で数学ドメインを学習し、generalドメインに汎化するか?を確認したところ、汎化することを確認(ただ、すぐにサチっているようにも見える)。、
関連:
- [Paper Note] Self-Questioning Language Models, Lili Chen+, arXiv'25
- [Paper Note] Absolute Zero: Reinforced Self-play Reasoning with Zero Data, Andrew Zhao+, arXiv'25, 2025.05
著者ポスト:
-
-
日本語解説:
openreview: https://openreview.net/forum?id=96apU6YzSO
[Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, ICLR'26, 2025.08
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-08-09 GPT Summary- 大規模言語モデル(LLM)の教師ありファインチューニング(SFT)の一般化能力を向上させるため、動的ファインチューニング(DFT)を提案。DFTはトークンの確率に基づいて目的関数を再スケーリングし、勾配更新を安定化させる。これにより、SFTを大幅に上回る性能を示し、オフライン強化学習でも競争力のある結果を得た。理論的洞察と実践的解決策を結びつけ、SFTの性能を向上させる。コードは公開されている。 Comment
元ポスト:
これは大変興味深い。数学以外のドメインでの評価にも期待したい。
3節冒頭から3.2節にかけて、SFTとon policy RLのgradientを定式化し、SFT側の数式を整理することで、SFT(のgradient)は以下のようなon policy RLの一つのケースとみなせることを導出している。そしてSFTの汎化性能が低いのは 1/pi_theta によるimportance weightingであると主張し、実験的にそれを証明している。つまり、ポリシーがexpertのgold responseに対して低い尤度を示してしまった場合に、weightか過剰に大きくなり、Rewardの分散が過度に大きくなってしまうことがRLの観点を通してみると問題であり、これを是正することが必要。さらに、分散が大きい報酬の状態で、報酬がsparse(i.e., expertのtrajectoryのexact matchしていないと報酬がzero)であることが、さらに事態を悪化させている。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい
最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。
日本語解説:
一歩先の視点が考察されており、とても勉強になる。
openreview: https://openreview.net/forum?id=Lv7PjbcaMi
[Paper Note] Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty, Mehul Damani+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #read-later #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2025-08-02 GPT Summary- RLCRを用いた言語モデルの訓練により、推論の精度と信頼度を同時に改善。バイナリ報酬に加え、信頼度推定のためのブライヤースコアを用いた報酬関数を最適化。RLCRは、通常のRLよりもキャリブレーションを改善し、精度を損なうことなく信頼性の高い推論モデルを生成することを示した。 Comment
元ポスト:
LLMにConfidenceをDiscreteなTokenとして(GEvalなどは除く)出力させると信頼できないことが多いので、もしそれも改善するのだとしたら興味深い。
著者ポスト:
openreview: https://openreview.net/forum?id=ASQ649zdHm
[Paper Note] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, Lakshya A Agrawal+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AutomaticPromptEngineering #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-07-29 GPT Summary- GEPA(Genetic-Pareto)は、LLMsのプロンプト最適化手法であり、自然言語を用いて試行錯誤から高レベルのルールを学習する。これにより、数回のロールアウトで品質向上が可能となり、GRPOを平均10%、最大20%上回る結果を示した。GEPAは、主要なプロンプト最適化手法MIPROv2をも超える性能を発揮し、コード最適化にも有望な結果を示している。 Comment
元ポスト:
openreview:
https://openreview.net/forum?id=RQm2KQTM5r
alpharxiv:
https://www.alphaxiv.org/overview/2507.19457v1
自動的なプロンプトエンジニアリングでGRPOを上回れるのであれば、downstreamタスクにLLMを適用したい場合に、手元にデータがあるのであれば、強めのGPUマシンがなくても非常に汎用性が高い手法となるので重要研究に見える。
[Paper Note] Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains, Anisha Gunjal+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #Selected Papers/Blogs #Rubric-based Issue Date: 2025-07-24 GPT Summary- 報酬としてのルーブリック(RaR)フレームワークを提案し、構造化されたチェックリストスタイルのルーブリックを解釈可能な報酬信号として使用。HealthBench-1kで最大28%の相対的改善を達成し、専門家の参照に匹敵またはそれを上回る性能を示す。RaRは小規模な判定モデルが人間の好みに一致し、堅牢な性能を維持できることを証明。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=c1bTcrDmt4
[Paper Note] Log-Linear Attention, Han Guo+, ICLR'26
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #Architecture #Reference Collection Issue Date: 2025-06-10 GPT Summary- 対数線形注意を提案し、線形注意の効率性とソフトマックス注意の表現力を両立。固定サイズの隠れ状態を対数的に成長する隠れ状態に置き換え、計算コストを対数線形に抑える。Mamba-2とGated DeltaNetの対数線形バリアントが線形時間のバリアントと比較して優れた性能を示すことを確認。 Comment
元ポスト:
解説ポスト:
openreview: https://openreview.net/forum?id=mOJgZWkXKW
[Paper Note] Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents, Jenny Zhang+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Coding #SelfImprovement #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #AgentHarness Issue Date: 2025-06-05 GPT Summary- ダーヴィン・ゴーデルマシン(DGM)は、自己改善するAIシステムであり、コードを反復的に修正し、コーディングベンチマークで変更を検証します。進化とオープンエンドな研究に基づき、生成されたエージェントのアーカイブを維持し、新しいバージョンを作成することで多様なエージェントを育成します。DGMはコーディング能力を自動的に向上させ、SWE-benchでのパフォーマンスを20.0%から50.0%、Polyglotでのパフォーマンスを14.2%から30.7%に改善しました。安全対策を講じた実験により、自己改善を行わないベースラインを大幅に上回る成果を示しました。 Comment
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
あたりの研究とはどう違うのだろうか、という点が気になる。
openreview: https://openreview.net/forum?id=pUpzQZTvGY
> * [[Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, N/A, ICML'24 [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
](https://github.com/AkihikoWatanabe/paper_notes/issues/1212)
>
> あたりの研究とはどう違うのだろうか、という点が気になる。
この点については、Self-Rewarding LLMではモデルの重みを(自身が生成した出力からPreference pairを構築し)DPOで更新していくのに対し(=Agent Harnessではなくモデル自身を賢くする)、
DGMでは基盤モデルはfrozenな上で、AI Agentのコードベースそのものをself-editingすることによって進化する点が異なる(=モデルではなくAgent Harnessを賢くする)。
baseとなるエージェントのコードベースは木構造に基づいて管理され、recursiveに探索されていき、ベンチマークのスコアを改善していく、という感じのようである。木構造によって過去のsolutionが保持され、単一の方向性のみが探索されることを抑制し(i.e., オープンエンドな探索が促進され)進化が局所解に陥ることを防ぐ。
3節冒頭に記述がある通り、Gödel Machineというのは2007年に提案された、AI自身が自らを証明可能な形で改善する方法を探索する理論的概念であるようだが、DGMではGödel Machineでの「変更によってシステムが改善されることを理論的に証明しなければならない」という点を緩和し、「変更が性能を向上させるという実験結果を用いる」ことで緩和する。
[Paper Note] LLMs Get Lost In Multi-Turn Conversation, Philippe Laban+, ICLR'26 Outstanding Paper, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #AIAgents #Conversation #read-later #Selected Papers/Blogs #ContextEngineering #Reference Collection Issue Date: 2025-05-24 GPT Summary- LLMsは会話型インターフェースとして、ユーザーがタスクを定義するのを支援するが、マルチターンの会話ではパフォーマンスが低下する。シミュレーション実験の結果、マルチターンで39%のパフォーマンス低下が見られ、初期のターンでの仮定に依存しすぎることが原因と判明。LLMsは会話中に誤った方向に進むと、回復が難しくなることが示された。 Comment
元ポスト:
Lost in the MiddleならぬLost in Conversation。multi-turnで分割して指示を出すよりも、single-turnにすべてのinstructionを実施させた方が性能劣化が生じづらい。
openreview: https://openreview.net/forum?id=VKGTGGcwl6
[Paper Note] J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning, Chenxi Whitehouse+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #LLM-as-a-Judge #PostTraining #GRPO #VerifiableRewards #Non-VerifiableRewards #KeyPoint Notes #Author Thread-Post Issue Date: 2025-05-16 GPT Summary- 本研究では、強化学習アプローチJ1を用いてLLMのトレーニング手法を提案し、判断タスクにおける思考促進とバイアス軽減を図ります。J1は、他の同サイズモデルを上回る性能を示し、特に小型モデルでも優れた結果を出します。モデルは自己生成した参照回答と比較することで、より良い判断を学ぶことが明らかになりました。 Comment
元ポスト:
LLM-as-a-Judgeのなめのモデルを学習するレシピにおいて、初めてRLを適用した研究と主張し、より高品質なreasoning traceを出力できるようにすることで性能向上をさせる。
具体的にはVerifiableなpromptとnon verifiableなpromptの両方からverifiableなpreference pairを作成しpointwiseなスコアリング、あるいはpairwiseなjudgeを学習するためのrewardを設計しGRPOで学習する、みたいな話っぽい。
non verifiableなpromptも用いるのは、そういったpromptに対してもjudgeできるモデルを構築するため。
mathに関するpromptはverifiableなのでレスポンスが不正解なものをrejection samplingし、WildChatのようなチャットはverifiableではないので、instructionにノイズを混ぜて得られたレスポンスをrejection samplingし、合成データを得ることで、non verifiableなpromptについても、verifiableなrewardを設計できるようになる。
openreview: https://openreview.net/forum?id=dnJEHl6DI1
著者による一言解説:
[Paper Note] Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #LanguageModel #Coding #Mathematics #read-later #Diversity #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-05-08 GPT Summary- 本研究では、公共データを体系的に書き換えることで大規模言語モデル(LLMs)の性能を向上させる2つのオープンライセンスデータセット、SwallowCodeとSwallowMathを紹介。SwallowCodeはPythonスニペットを洗練させる4段階のパイプラインを用い、低品質のコードをアップグレード。SwallowMathはボイラープレートを削除し、解決策を簡潔に再フォーマット。これにより、Llama-3.1-8Bのコード生成能力がHumanEvalで+17.0、GSM8Kで+12.4向上。すべてのデータセットは公開され、再現可能な研究を促進。 Comment
元ポスト:
解説ポスト:
openreview: https://openreview.net/forum?id=45btPYgSSX
[Paper Note] Ambig-SWE: Interactive Agents to Overcome Underspecificity in Software Engineering, Sanidhya Vijayvargiya+, ICLR'26, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #QuestionGeneration #SoftwareEngineering #One-Line Notes Issue Date: 2025-04-02 GPT Summary- AIエージェントは、欠落情報を補うための推測や明確化の質問を避けることで、安全リスクやリソース浪費を引き起こすことがある。本研究では、対話型コード生成における不十分な指示への対処能力を評価し、(a) 不十分さの検出、(b) 明確化質問の提示、(c) 対話の活用による性能向上の三つのステップで検証した。Ambig-SWEを使用し、モデルは不十分な指示を区別するのに苦労しつつ、対話時には最大74%の性能向上を示した。これにより、対話の重要性が浮き彫りになった。研究は、最新モデルの情報処理におけるギャップを明らかにし、評価の段階的アプローチを提案している。 Comment
曖昧なユーザメッセージに対する、エージェントが"質問をする能力を測る"ベンチマーク
openreview: https://openreview.net/forum?id=X2yzXtH4wp
[Paper Note] Transformer-Squared: Self-adaptive LLMs, Qi Sun+, ICLR'25, 2025.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PEFT(Adaptor/LoRA) #SelfImprovement #KeyPoint Notes #Test-time Learning Issue Date: 2026-06-27 GPT Summary- 自己適応型LLMの課題を解決するために、Transformer-Squaredを提案。これは未知のタスクにリアルタイムで適応できるフレームワークで、重みの特異成分を調整し、二段階処理を通じてタスク特有の「エキスパート」ベクトルを動的に組み合わせる。パラメータ数が少なく高効率で、視覚言語タスクにも対応。これにより、LLMsの適応性と性能を向上させ、自己組織化されたAIシステムへの道を開く。 Comment
openreview: https://openreview.net/forum?id=dh4t9qmcvK
個々の重み行列を特異値分解し、重み行列の特異値ベクトルをRLVRによってタスク(ドメイン)ごとに最適化し、test time時に線形結合して利用することで、Unseenタスクに対してtest timeに適応可能なSingular Value Finetuningを提案。
各タスクやドメインごとに高い性能を獲得できる新たな特異値ベクトル(expert vectorと呼ぶ)を学習し推論時に利用することで、全体の重み行列を新たな特異値ベクトルに基づいて更新することができる
また、学習するパラメータはW_{n,m}パラメータ行列のr=min(n,m)で良いため、LoRA等よりも少ないパラメータ数で適応できる。学習されるexpert vectorは重み行列の特異値であるため、ベクトルに対する解釈性が高く、ベクトルの変換や演算も適応可能となる利点がある。
(3.2節)。
各タスクのexpert vectorはREINFORCEに基づくRLVRで学習する(式1)。テスト時は2段階のプロセスを踏み、推論を実施する。まずinputを受け取り、inputがどのようなタスクを実現するかを同定する(dispatch)。続いて、タスクがより高い性能で解けるように、expert vectorの最適な混合比(線形結合)を、Cross-Entropy Method (CEM)によって、Fewshot sampleの性能が最大となるような混合比をサンプリングベースで求める(3.1節, p.6 (C) Fewshot Adaptation))。これにより、与えられたタスクをより高い性能で解くことができるexpert vectorをtest時に推論し、重み行列を更新した上で推論することができる。
expert vectorの混合方法は他にも2種類提案されているようだが、Fewshot Adaptationによる手法の性能が高そうに見える。
[Paper Note] Repetition Improves Language Model Embeddings, Jacob Mitchell Springer+, ICLR'25, 2024.02
Paper/Blog Link My Issue
#Sentence #Embeddings #NLP #Decoder #One-Line Notes Issue Date: 2026-06-11 GPT Summary- エコー埋め込みを通じて、自己回帰LMをアーキテクチャ変更なしで高品質なテキスト埋め込みモデルに転換。入力を繰り返すことで埋め込みを抽出し、ゼロショット設定で従来の埋め込みを5%以上上回る性能を発揮。監督付きファインチューニングでも双方向化済みLMと同等かそれ以上の結果を示し、埋め込みモデルにおける双方向注意機構の不要性を証明。全てのNLPタスクへの統一アーキテクチャの実現に寄与。 Comment
openreview: https://openreview.net/forum?id=Ahlrf2HGJR
autorgressiveなモデルで文embeddingを取得する際に、単に文のtokenをpoolingするのではなく、embeddingを取得したいsentenceを繰り返し、2回目に出現したtokenのpoolingによってsentence embeddingを形成すると良質な文embeddingを取得できる。これは、あるtokenから見たときに未来のtokenの情報をautoregressiveなモデルは考慮できないことに起因する。
PromptingのRE2とアイデアが似ている。同じPromptを複数回繰り返すことにより、autoregressiveモデルに対してbi-directionalなエンコーダのような性質を付与する:
- [Paper Note] Re-Reading Improves Reasoning in Large Language Models, Xiaohan Xu+, EMNLP'24, 2023.09
[Paper Note] EgoTwin: Dreaming Body and View in First Person, Jingqiao Xiu+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #VideoGeneration/Understandings #Robotics #One-Line Notes #EgocentricView Issue Date: 2026-04-25 GPT Summary- 第一人称視点の動画生成は未解決の課題が多い中、私たちは動画と人間の動作を同時に生成する新しいタスクを提案します。主な課題は、視点の整合性と因果的相互作用です。これに対処するために、拡散トランスフォーマーに基づくEgoTwinフレームワークを導入し、頭部中心の動作表現を使って因果関係を明示的に捉えます。また、同期したテキスト-動画-動作の大規模データセットを作成し、新たな評価指標で一貫性を検証しました。実験により、EgoTwinの有効性が確認されました。 Comment
openreview: https://openreview.net/forum?id=QFJkvv3zMi
pj page: https://egotwin.pages.dev/
元ポスト:
egocentric view(一人称視点)動画と、human motionを同時生成するタスクを提案。これにはviewとmotionの視点のalignmentと、生成された動画と人間のアクションが交互作用しなければならないという二つの課題に対処しなければならない。
[Paper Note] MesaNet: Sequence Modeling by Locally Optimal Test-Time Training, Johannes von Oswald+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #RecurrentModels #LinearAttention #Author Thread-Post Issue Date: 2026-04-24 GPT Summary- シーケンスモデリングにおいて、最近の研究が提案するRNNモデルに、Mesa層を導入し数値的に安定かつ並列化可能な手法を検証。文脈内損失に基づく最適化で、従来のRNNよりも低いperplexityと下流ベンチマークでの改善を達成。特に長い文脈理解に効果的で、推論時の計算コストが増加するが、これが最近の計算性能向上のトレンドに寄与。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=xa3OnTb6c3
[Paper Note] MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering, Jun Shern Chan+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #AutoML #Selected Papers/Blogs Issue Date: 2026-03-30 GPT Summary- MLE-benchは、AIエージェントの機械学習エンジニアリング能力を測定するためのベンチマークで、75件のKaggle競技を厳選し、実世界のスキルを試すタスクを作成。人間ベースラインを確立し、最先端の言語モデルを評価した結果、OpenAIのo1-previewとAIDEスキャフォールドの組み合わせが16.9%の競技でKaggleブロンズメダル以上の性能を示した。リソーススケーリングや事前学習の影響も調査し、ベンチマークコードをオープンソース化して今後の研究を促進する。 Comment
blog:
- MLE-Bench, OpenAI, 2024.10
openreview: https://openreview.net/forum?id=6s5uXNWGIh
[Paper Note] Large Scale Knowledge Washing, Yu Wang+, ICLR'25, 2024.05
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeEditing #MachineUnlearning(MU) Issue Date: 2026-03-10 GPT Summary- 大規模言語モデルは世界知識を記憶する能力が高い一方、個人情報や著作権問題の懸念がある。本研究では、知識の忘却を目的としたLarge Scale Knowledge Washing(LAW)を提案し、デコーダーのMLP層を更新することで推論能力を維持しつつ、特定の知識を忘却する新しい方法を導入する。実験結果はLAWの有効性を示し、推論能力を損なうことなくターゲット知識を忘却できることが確認された。コードはオープンソース提供。 Comment
openreview: https://openreview.net/forum?id=dXCpPgjTtd
[Paper Note] ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference, Yesheng Liang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Quantization #Reasoning #LongSequence #PostTraining #One-Line Notes Issue Date: 2026-02-28 GPT Summary- Post-training quantization (PTQ)はLLMの重みと活性化を低精度に圧縮し、メモリと推論速度を改善するが、外れ値が誤差を大きくし、特に推論型LLMの長い思考チェーンで精度低下を招くことがある。既存のPTQ手法は外れ値抑制が不十分であったり、オーバーヘッドがある。本研究では、独立ガイブンズ回転とチャネルスケーリングを組み合わせたペアワイズ回転量子化(ParoQuant)を提案し、ダイナミックレンジを狭め外れ値問題を解決する。推論カーネルの共同設計によりGPUの並列性を最大限活用し、精度向上を実現。結果、重みのみの量子化でAWQより平均2.4%の精度向上を達成し、オーバーヘッドは10%未満で、最先端の量子化手法と同等の精度を示す。これにより、高効率で高精度なLLMのデプロイが可能となる。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=1USeVjsKau
Reasoning LLMにおいてlong-CoTを実施した場合のエラーの蓄積を低減するようなpost-training-basedな量子化手法の提案
[Paper Note] MQUAKE-REMASTERED: MULTI-HOP KNOWLEDGE EDITING CAN ONLY BE ADVANCED WITH RELIABLE EVALUATIONS, Zhong+, ICLR'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #KnowledgeEditing Issue Date: 2026-02-08 GPT Summary- 誤った回答をするLLMに対し、知識の編集が効率的な修正手段として機能しますが、実世界の知識が複雑に絡み合っているため、編集効果の伝播が課題です。本研究では、MQuAKEデータセットの33%または76%の質問が様々な形で破損していることを示し、修正を提案します。また、修正後のMQuAKE-Remasteredデータセットに対する編集方法のベンチマークを行い、特定の性質に依存する手法がオーバーフィットすることを観察しました。最小限の侵襲的アプローチGWALKが、最先端の編集性能を発揮することを示しました。MQuAKE-Remasteredは、huggingfaceとGitHubで利用可能です。 Comment
openreview: https://openreview.net/forum?id=m9wG6ai2Xk
[Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #LongSequence #Architecture #Selected Papers/Blogs #LinearAttention Issue Date: 2026-02-04 GPT Summary- 線形トランスフォーマーの限界を克服するため、ゲーティングとデルタ更新ルールの2つのメカニズムを組み合わせた「Gated DeltaNet」を提案。これにより、迅速なメモリ消去とターゲット更新を実現し、言語モデリングや長文理解などのタスクで既存モデルを上回る性能を達成。ハイブリッドアーキテクチャを用いることでトレーニング効率も向上。 Comment
openreview: https://openreview.net/forum?id=r8H7xhYPwz¬eId=U0uk5A0VlT
linear attention:
- [Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20
Mamba2(linear attention with decay):
- [Paper Note] Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, Tri Dao+, ICML'24
Gated DeltaNet 図解:
[Paper Note] Latent Space Chain-of-Embedding Enables Output-free LLM Self-Evaluation, Yiming Wang+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#Embeddings #NLP #LanguageModel #SelfVerification Issue Date: 2026-01-30 GPT Summary- LLMの自己評価において、出力なしで正確さを推定するために、潜在空間のEmbeddingの連鎖(CoE)を提案。CoEは推論中の隠れ状態を反映し、正誤に基づく応答の特徴を明らかにする。実験により、トレーニングなしでミリ秒単位のコストでリアルタイムフィードバックが可能で、LLM内部の状態変化から新たな洞察が得られることを示した。 Comment
openreview: https://openreview.net/forum?id=jxo70B9fQo
[Paper Note] Critique-Coder: Enhancing Coder Models by Critique Reinforcement Learning, Chi Ruan+, arXiv'25, 2025.09
Paper/Blog Link My Issue
Issue Date: 2026-01-26 GPT Summary- Critique Reinforcement Learning(CRL)を提案し、モデルが(質問、解答)ペアに対して批評を生成することを課題とする。報酬は生成された批評の真の判断との一致に基づく。これを基にした\textsc{Critique-Coder}は、RLとCRLを融合し、複数のベンチマークでRLのみのモデルを上回る性能を示す。特に\textsc{Critique-Coder-8B}はLiveCodeBenchで60%以上のパフォーマンスを達成し、一般的な推論能力も向上することを示す。CRLはLLM推論における標準的なRLの優れた補完手段となると考える。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=tsuxIeLUsz
[Paper Note] How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments, Jen-tse Huang+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#LanguageModel #Evaluation Issue Date: 2026-01-25 GPT Summary- LLMの意思決定能力を評価する新フレームワークGAMA($γ$)-Benchを提案。これには8つのゲーム理論シナリオと動的スコアリング方式が含まれ、ロバスト性や一般化能力を評価。結果としてGPT-3.5は高いロバスト性を示すが一般化能力は限定的で、Chain-of-Thought手法で強化可能。Gemini-1.5-Proが最も高得点を獲得し、他のモデルを上回る性能を示した。 Comment
pj page: https://cuhk-arise.github.io/GAMABench/
元ポスト:
openreview: https://openreview.net/forum?id=DI4gW8viB6
[Paper Note] Harnessing Diversity for Important Data Selection in Pretraining Large Language Models, Chi Zhang+, ICLR'25 Spotlight, 2024.09
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #read-later #Diversity #Selected Papers/Blogs #DataMixture #Generalization #One-Line Notes #DownstreamTasks #Adaptive #Multi-Armed Bandit Issue Date: 2026-01-21 GPT Summary- データ選択は大規模言語モデルの事前トレーニングにおいて重要で、影響スコアでデータインスタンスの重要性を測定します。しかし、トレーニングデータの多様性不足や影響計算の時間が課題です。本研究では、品質と多様性を考慮したデータ選択手法\texttt{Quad}を提案します。アテンションレイヤーの$iHVP$計算を適応させ、データの品質評価を向上。データをクラスタリングし、選択プロセスでサンプルの影響を評価することで、全インスタンスの処理を回避します。マルチアームバンディット法を用い、品質と多様性のバランスを取ります。 Comment
openreview: https://openreview.net/forum?id=bMC1t7eLRc
あるモデルに対して、特定のデータセットD_rの性能を最大化するようにモデルを学習したいとする。このときに、全ての学習データD_cからD_rが学習の結果最大となるようなデータセットD_bを求めたい、という問題設定である。Influence Scoreを算出するモデルを活用する。
学習元データは事前にクラスタリングしておき、top-Kのクラスタを選択。選択したクラスタの中からmini-batchを抽出しinfluence scoreを計算し、influence scoreが一定の閾値を超えた場合にD_bに追加。その後計算したinfluence scoreと当該クラスタが選択された頻度情報に基づいてtop-kのクラスタを選択する際に用いるcluster scoreを更新。というiterationを繰り返しC_bを構築する、という方法に見える。
[Paper Note] Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance, Jiasheng Ye+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Scaling Laws #DataMixture Issue Date: 2026-01-21 GPT Summary- データ混合法則に基づき、モデル性能を予測するための関数を提案し、混合比率が性能に与える影響を定量的に分析。これにより、未知のデータ混合物の性能を事前に評価できる。実験結果では、1Bモデルが最適化された混合物で、デフォルトの混合物に比べ48%の効率で同等の性能を達成。さらに、継続的なトレーニングへの応用を通じて、混合比率を正確に予測し、動的データスケジュールの可能性を提示。 Comment
openreview: https://openreview.net/forum?id=jjCB27TMK3
[Paper Note] Aioli: A Unified Optimization Framework for Language Model Data Mixing, Mayee F. Chen+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #DataMixture #Adaptive Issue Date: 2026-01-21 GPT Summary- トレーニングデータの最適な混合が言語モデルの性能に影響を与えるが、既存の手法は層化サンプリングを一貫して上回れない。これを解明するため、標準フレームワークで手法を統一し、混合法則が不正確であることを示した。新たに提案したオンライン手法Aioliは、トレーニング中に混合パラメータを推定し動的に調整。実験では、Aioliが層化サンプリングを平均0.27ポイント上回り、短いランで最大12.012ポイントの向上を達成した。 Comment
openreview: https://openreview.net/forum?id=sZGZJhaNSe
[Paper Note] NeuralOS: Towards Simulating Operating Systems via Neural Generative Models, Luke Rivard+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #read-later #Selected Papers/Blogs #WorldModels #interactive #RecurrentModels #GUI Issue Date: 2026-01-17 GPT Summary- NeuralOSは、ユーザーの入力に基づいてGUIをシミュレーションするニューラルフレームワークであり、RNNと拡散ベースのレンダラーを組み合わせています。Ubuntu XFCEの録画データを用いた訓練により、リアルなGUIシーケンスをレンダリングし、状態遷移を信頼性高く予測可能であることが実証されました。キーボードインタラクションのモデル化は依然として難しいものの、NeuralOSは将来のヒューマンコンピュータインタラクションのための適応的なインターフェイスの一歩を示します。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=TE2Vu7WJki
[Paper Note] Upweighting Easy Samples in Fine-Tuning Mitigates Forgetting, Sunny Sanyal+, ICLR'25, 2025.02
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Catastrophic Forgetting #PostTraining #One-Line Notes Issue Date: 2026-01-12 GPT Summary- 事前学習済みモデルのファインチューニングにおける「破滅的忘却」を軽減するため、損失に基づくサンプル重み付けスキームを提案。損失が低いサンプルの重みを上げ、高いサンプルの重みを下げることで、モデルの逸脱を制限。理論的分析により、特定のサブスペースでの学習停滞と過剰適合の抑制を示し、言語タスクと視覚タスクでの有効性を実証。例えば、MetaMathQAでのファインチューニングにおいて、精度の低下を最小限に抑えつつ、事前学習データセットでの精度を保持。 Comment
openreview: https://openreview.net/forum?id=13HPTmZKbM
(事前学習データにはしばしばアクセスできないため)事前学習時に獲得した知識を忘却しないように、Finetuning時にlossが小さいサンプルの重みを大きくすることで、元のモデルからの逸脱を防止しcatastrophic forgettingを軽減する。
[Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Transformer #Architecture #Selected Papers/Blogs #ResidualStream Issue Date: 2026-01-02 GPT Summary- ハイパーコネクションは、残差接続の代替手法であり、勾配消失や表現崩壊の問題に対処します。異なる深さの特徴間の接続を調整し、層を動的に再配置することが可能です。実験により、ハイパーコネクションが残差接続に対して性能向上を示し、視覚タスクでも改善が確認されました。この手法は幅広いAI問題に適用可能と期待されています。 Comment
openreview: https://openreview.net/forum?id=9FqARW7dwB
[Paper Note] Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Bart Bussmann+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #LanguageModel #SparseAutoencoder #Interpretability Issue Date: 2025-12-21 GPT Summary- Matryoshka SAEという新しいスパースオートエンコーダーのバリアントを提案し、複数のネストされた辞書を同時に訓練することで、特徴を階層的に整理。小さな辞書は一般的な概念を、大きな辞書は特定の概念を学び、高次の特徴の吸収を防ぐ。Gemma-2-2BおよびTinyStoriesでの実験により、優れたパフォーマンスと分離された概念表現を確認。再構成性能にはトレードオフがあるが、実用的なタスクにおいて優れた代替手段と考えられる。 Comment
openreview: https://openreview.net/forum?id=m25T5rAy43
[Paper Note] Scaling Agent Learning via Experience Synthesis, Zhaorun Chen+, ICLR'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #AIAgents #Reasoning #Author Thread-Post Issue Date: 2025-11-07 GPT Summary- DreamGymは、強化学習(RL)エージェントのオンライントレーニングを効率化するための統一フレームワークであり、高コストのロールアウトや不安定な報酬信号の課題に対処します。環境のダイナミクスを推論に基づく経験モデルに蒸留し、安定した状態遷移とフィードバックを提供します。オフラインデータを活用した経験リプレイバッファにより、エージェントのトレーニングを強化し、新しいタスクを適応的に生成することでオンラインカリキュラム学習を実現します。実験により、DreamGymは合成設定とリアルなシナリオでRLトレーニングを大幅に改善し、非RL準備タスクでは30%以上の性能向上を示しました。合成経験のみでトレーニングされたポリシーは、実環境RLにおいても優れたパフォーマンスを発揮し、スケーラブルなウォームスタート戦略を提供します。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=cf7qpBwttr
著者による一言解説:
[Paper Note] Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models, Marianne Arriola+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#LanguageModel #DiffusionModel #read-later #Selected Papers/Blogs Issue Date: 2025-11-04 GPT Summary- ブロック拡散言語モデルは、拡散モデルと自己回帰モデルの利点を組み合わせ、柔軟な長さの生成を可能にし、推論効率を向上させる。効率的なトレーニングアルゴリズムやデータ駆動型ノイズスケジュールを提案し、言語モデリングベンチマークで新たな最先端のパフォーマンスを達成。 Comment
openreview: https://openreview.net/forum?id=tyEyYT267x
[Paper Note] SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal, Tinghao Xie+, ICLR'25, 2024.06
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #MultiLingual #Safety Issue Date: 2025-10-24 GPT Summary- SORRY-Benchは、整合された大規模言語モデル(LLMs)の安全でないユーザーリクエストの認識能力を評価する新しいベンチマークです。既存の評価方法の限界を克服するために、44の細かい安全でないトピック分類と440のクラスバランスの取れた指示を提供し、20の言語的拡張を追加しました。また、高速で正確な自動安全評価者を開発し、微調整された7B LLMがGPT-4と同等の精度を持つことを示しました。これにより、50以上のLLMの安全拒否行動を分析し、体系的な評価の基盤を提供します。デモやデータは公式サイトから入手可能です。 Comment
pj page: https://sorry-bench.github.io/
openreview: https://openreview.net/forum?id=YfKNaRktan
[Paper Note] Physics-Informed Diffusion Models, Jan-Hendrik Bastek+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#MachineLearning #DiffusionModel #PhysicalConstraints Issue Date: 2025-10-24 GPT Summary- 生成モデルと偏微分方程式を統一するフレームワークを提案し、生成サンプルが物理的制約を満たすように損失項を導入。流体の流れに関するケーススタディで残差誤差を最大2桁削減し、構造トポロジー最適化においても優れた性能を示す。過学習に対する正則化効果も確認。実装が簡単で、多様な制約に適用可能。 Comment
openreview: https://openreview.net/forum?id=tpYeermigp&utm_source=chatgpt.com
[Paper Note] Memory Layers at Scale, Vincent-Pierre Berges+, ICLR'25, 2024.12
Paper/Blog Link My Issue
#LanguageModel #Transformer #Architecture #read-later #Selected Papers/Blogs #memory #KeyPoint Notes Issue Date: 2025-10-23 GPT Summary- メモリ層は、計算負荷を増やさずにモデルに追加のパラメータを加えるための学習可能な検索メカニズムを使用し、スパースに活性化されたメモリ層が密なフィードフォワード層を補完します。本研究では、改良されたメモリ層を用いた言語モデルが、計算予算が2倍の密なモデルや同等の計算とパラメータを持つエキスパート混合モデルを上回ることを示し、特に事実に基づくタスクでの性能向上が顕著であることを明らかにしました。完全に並列化可能なメモリ層の実装とスケーリング法則を示し、1兆トークンまでの事前学習を行った結果、最大8Bのパラメータを持つベースモデルと比較しました。 Comment
openreview: https://openreview.net/forum?id=ATqGm1WyDj
transformerにおけるFFNをメモリレイヤーに置き換えることで、パラメータ数を増やしながら計算コストを抑えるようなアーキテクチャを提案しているようである。メモリレイヤーは、クエリqを得た時にtop kのkvをlookupし(=ここで計算対象となるパラメータがスパースになる)、kqから求めたattention scoreでvを加重平均することで出力を得る。Memory+というさらなる改良を加えたアーキテクチャでは、入力に対してsiluによるgatingとlinearな変換を追加で実施することで出力を得る。
denseなモデルと比較して性能が高く、メモリパラメータを増やすと性能がスケールする。
[Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
Paper/Blog Link My Issue
#Embeddings #EfficiencyImprovement #NLP #LanguageModel #RepresentationLearning #RAG(RetrievalAugmentedGeneration) #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-08 GPT Summary- 生成的表現指示チューニング(GRIT)を用いて、大規模言語モデルが生成タスクと埋め込みタスクを同時に処理できる手法を提案。GritLM 7BはMTEBで新たな最先端を達成し、GritLM 8x7Bはすべてのオープン生成モデルを上回る性能を示す。GRITは生成データと埋め込みデータの統合による性能損失がなく、RAGを60%以上高速化する利点もある。モデルは公開されている。 Comment
openreview: https://openreview.net/forum?id=BC4lIvfSzv
従来はgemerativeタスクとembeddingタスクは別々にモデリングされていたが、それを統一的な枠組みで実施し、両方のタスクで同等のモデルサイズの他モデルと比較して高い性能を達成した研究。従来のgenerativeタスク用のnext-token-prediction lossとembeddingタスク用のconstastive lossを組み合わせて学習する(式3)。タスクの区別はinstructionにより実施し、embeddingタスクの場合はすべてのトークンのlast hidden stateのmean poolingでrepresentationを取得する。また、embeddingの時はbi-directional attention / generativeタスクの時はcausal maskが適用される。これらのattentionの適用のされ方の違いが、どのように管理されるかはまだしっかり読めていないのでよくわかっていないが、非常に興味深い研究である。
[Paper Note] RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization, Zhaoning Yu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #Reasoning #SelfImprovement #read-later #One-Line Notes #Author Thread-Post Issue Date: 2025-10-03 GPT Summary- RESTRAINは、自己ペナルティを用いた強化学習フレームワークで、ラベル付きデータなしでモデルを改善する。過信的な回答をペナルティ化し、未ラベルデータからの学習信号を活用することで、困難な推論ベンチマークにおいて大きな向上を達成。従来のゴールドラベル付きトレーニングに匹敵する性能を示し、効果的な推論の拡張が可能であることを示す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=87ySF7viys
著者による一言解説:
votingによるself-improvingなRLの枠組みから脱却し、全ての応答に対してペナルティ方式でペナルティを与え(一貫性の乏しいロールアウトなど)異なる重みを与えて学習シグナルとする。
[Paper Note] STAR: Synthesis of Tailored Architectures, Armin W. Thomas+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #NeuralArchitectureSearch Issue Date: 2025-09-27 GPT Summary- 新しいアプローチ(STAR)を提案し、特化したアーキテクチャの合成を行う。線形入力変動システムに基づく探索空間を用い、アーキテクチャのゲノムを階層的にエンコード。進化的アルゴリズムでモデルの品質と効率を最適化し、自己回帰型言語モデリングにおいて従来のモデルを上回る性能を達成。 Comment
openreview: https://openreview.net/forum?id=HsHxSN23rM
[Paper Note] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model, Chunting Zhou+, ICLR'25, 2024.08
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #read-later #Selected Papers/Blogs #UMM Issue Date: 2025-09-22 GPT Summary- Transfusionは、離散データと連続データに対してマルチモーダルモデルを訓練する手法で、言語モデリングの損失関数と拡散を組み合わせて単一のトランスフォーマーを訓練します。最大7Bパラメータのモデルを事前訓練し、ユニモーダルおよびクロスモーダルベンチマークで優れたスケーリングを示しました。モダリティ特有のエンコーディング層を導入することで性能を向上させ、7Bパラメータのモデルで画像とテキストを生成できることを実証しました。 Comment
openreview: https://openreview.net/forum?id=SI2hI0frk6
[Paper Note] SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?, John Yang+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #LanguageModel #AIAgents #Evaluation #MultiModal #SoftwareEngineering #VisionLanguageModel Issue Date: 2025-09-16 GPT Summary- 自律システムのバグ修正能力を評価するために、SWE-bench Mを提案。これは視覚要素を含むJavaScriptソフトウェアのタスクを対象とし、617のインスタンスを収集。従来のSWE-benchシステムが視覚的問題解決に苦労する中、SWE-agentは他のシステムを大きく上回り、12%のタスクを解決した。 Comment
openreview: https://openreview.net/forum?id=riTiq3i21b
[Paper Note] Forgetting Transformer: Softmax Attention with a Forget Gate, Zhixuan Lin+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Attention #LongSequence #Architecture #AttentionSinks Issue Date: 2025-09-16 GPT Summary- 忘却ゲートを取り入れたトランスフォーマー「FoX」を提案。FoXは長いコンテキストの言語モデリングや下流タスクでトランスフォーマーを上回る性能を示し、位置埋め込みを必要としない。再帰的シーケンスモデルに対しても優れた能力を保持し、性能向上のための「Pro」ブロック設計を導入。コードはGitHubで公開。 Comment
openreview: https://openreview.net/forum?id=q2Lnyegkr8
code: https://github.com/zhixuan-lin/forgetting-transformer
非常におもしろそう
データ非依存の固定されたsink tokenを用いるのではなく、データ依存のlearnableなsink tokenを用いる研究とみなせる。
- [Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
[Paper Note] SOAP: Improving and Stabilizing Shampoo using Adam, Nikhil Vyas+, ICLR'25
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Optimizer #Selected Papers/Blogs Issue Date: 2025-09-03 GPT Summary- Shampooという前処理法が深層学習の最適化タスクで効果的である一方、追加のハイパーパラメータと計算オーバーヘッドが課題である。本研究では、ShampooとAdafactorの関係を明らかにし、Shampooを基にした新しいアルゴリズムSOAPを提案。SOAPは、Adamと同様に第二モーメントの移動平均を更新し、計算効率を改善。実験では、SOAPがAdamWに対して40%以上のイテレーション数削減、35%以上の経過時間短縮を達成し、Shampooに対しても約20%の改善を示した。SOAPの実装は公開されている。 Comment
openreview: https://openreview.net/forum?id=IDxZhXrpNf
[Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #read-later #Selected Papers/Blogs #DataMixture #Initial Impression Notes Issue Date: 2025-09-01 GPT Summary- RegMixを提案し、データミクスチャの性能を回帰タスクとして自動的に特定。多様なミクスチャで小モデルを訓練し、最良のミクスチャを用いて大規模モデルを訓練した結果、他の候補を上回る性能を示した。実験により、データミクスチャが性能に大きな影響を与えることや、ウェブコーパスが高品質データよりも良好な相関を持つことを確認。RegMixの自動アプローチが必要であることも示された。 Comment
openreview: https://openreview.net/forum?id=5BjQOUXq7i
今後DavaMixtureがさらに重要になるという見方があり、実際にフロンティアモデルのDataMixtureに関する情報はテクニカルレポートには記載されず秘伝のタレ状態であるため、より良いDataMixtureする本研究は重要論文に見える。
[Paper Note] MoE++: Accelerating Mixture-of-Experts Methods with Zero-Computation Experts, Peng Jin+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #MoE(Mixture-of-Experts) #read-later Issue Date: 2025-08-31 GPT Summary- 本研究では、Mixture-of-Experts(MoE)手法の効果と効率を向上させるために、MoE++フレームワークを提案。ゼロ計算エキスパートを導入し、低計算オーバーヘッド、高パフォーマンス、デプロイメントの容易さを実現。実験結果により、MoE++は従来のMoEモデルに比べて1.1-2.1倍のスループットを提供し、優れた性能を示す。 Comment
openreview: https://openreview.net/forum?id=t7P5BUKcYv
従来のMoEと比べて、専門家としてzero computation expertsを導入することで、性能を維持しながら効率的にinferenceをする手法(MoEにおいて全てのトークンを均一に扱わない)を提案している模様。
zero computation expertsは3種類で
- Zero Experts: 入力をゼロベクトルに落とす
- Copy Experts: 入力xをそのままコピーする
- Constant Experts: learnableな定数ベクトルvを学習し、xと線形結合して出力する。W_cによって入力xを変換することで線形補 結合の係数a1,a2を入力に応じて動的に決定する。
Routingの手法やgating residual、学習手法の工夫もなされているようなので、後で読む。
[Paper Note] Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts, Weilin Cai+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #MoE(Mixture-of-Experts) Issue Date: 2025-08-31 GPT Summary- ScMoEは、スパースゲート混合専門家モデルの計算負荷を分散させる新しいアーキテクチャで、通信と計算の重複を最大100%可能にし、全対全通信のボトルネックを解消。これにより、トレーニングで1.49倍、推論で1.82倍のスピードアップを実現し、モデル品質も既存手法と同等またはそれ以上を達成。 Comment
openreview: https://openreview.net/forum?id=GKly3FkxN4¬eId=4tfWewv7R2
[Paper Note] Looped Transformers for Length Generalization, Ying Fan+, ICLR'25
Paper/Blog Link My Issue
#MachineLearning #Transformer #LongSequence #Architecture #Generalization #RecurrentModels Issue Date: 2025-08-30 GPT Summary- ループトランスフォーマーを用いることで、未見の長さの入力に対する算術的およびアルゴリズム的タスクの長さ一般化が改善されることを示す。RASP-L操作を含む既知の反復解法に焦点を当て、提案する学習アルゴリズムで訓練した結果、さまざまなタスクに対して高い一般化能力を持つ解法を学習した。 Comment
openreview: https://openreview.net/forum?id=2edigk8yoU
[Paper Note] Ultra-Sparse Memory Network, Zihao Huang+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #MoE(Mixture-of-Experts) #read-later #memory Issue Date: 2025-08-29 GPT Summary- UltraMemは、大規模で超スパースなメモリ層を組み込むことで、Transformerモデルの推論レイテンシを削減しつつ性能を維持する新しいアーキテクチャを提案。実験により、UltraMemはMoEを上回るスケーリング特性を示し、最大2000万のメモリスロットを持つモデルが最先端の推論速度と性能を達成することを実証。
[Paper Note] JetFormer: An Autoregressive Generative Model of Raw Images and Text, Michael Tschannen+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #Transformer #TextToImageGeneration #Architecture #read-later #NormalizingFlow Issue Date: 2025-08-17 GPT Summary- JetFormerは、画像とテキストの共同生成を効率化する自己回帰型デコーダー専用のトランスフォーマーであり、別々にトレーニングされたコンポーネントに依存せず、両モダリティを理解・生成可能。正規化フローモデルを活用し、テキストから画像への生成品質で既存のベースラインと競合しつつ、堅牢な画像理解能力を示す。JetFormerは高忠実度の画像生成と強力な対数尤度境界を実現する初のモデルである。 Comment
openreview: https://openreview.net/forum?id=sgAp2qG86e
画像をnormalizing flowでソフトトークンに変換し、transformerでソフトトークンを予測させるように学習することで、テキストと画像を同じアーキテクチャで学習できるようにしました、みたいな話っぽい?おもしろそう
[Paper Note] Physics of Language Models: Part 3.2, Knowledge Manipulation, Zeyuan Allen-Zhu+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReversalCurse Issue Date: 2025-08-11 GPT Summary- 言語モデルは豊富な知識を持つが、下流タスクへの柔軟な利用には限界がある。本研究では、情報検索、分類、比較、逆検索の4つの知識操作タスクを調査し、言語モデルが知識検索には優れているが、Chain of Thoughtsを用いないと分類や比較タスクで苦労することを示した。特に逆検索ではパフォーマンスがほぼ0%であり、これらの弱点は言語モデルに固有であることを確認した。これにより、現代のAIと人間を区別する新たなチューリングテストの必要性が浮き彫りになった。 Comment
openreview: https://openreview.net/forum?id=oDbiL9CLoS
[Paper Note] Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems, Tian Ye+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #SelfCorrection Issue Date: 2025-08-11 GPT Summary- 言語モデルの推論精度向上のために、「エラー修正」データを事前学習に組み込む有用性を探求。合成数学データセットを用いて、エラーフリーデータと比較して高い推論精度を達成することを示す。さらに、ビームサーチとの違いやデータ準備、マスキングの必要性、エラー量、ファインチューニング段階での遅延についても考察。 Comment
openreview: https://openreview.net/forum?id=zpDGwcmMV4
[Paper Note] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process, Tian Ye+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #read-later #reading Issue Date: 2025-08-11 GPT Summary- 言語モデルの数学的推論能力を研究し、GSM8Kベンチマークでの精度向上のメカニズムを探る。具体的には、推論スキルの発展、隠れたプロセス、人間との違い、必要なスキルの超越、推論ミスの原因、モデルのサイズや深さについての実験を行い、LLMの理解を深める洞察を提供。 Comment
openreview: https://openreview.net/forum?id=Tn5B6Udq3E
小学生向けの算数の問題を通じて、以下の基本的なResearch Questionsについて調査して研究。これらを理解することで、言語モデルの知能を理解する礎とする。
## Research Questions
- 言語モデルはどのようにして小学校レベルの算数の問題を解けるようになるのか?
- 単にテンプレートを暗記しているだけなのか、それとも人間に似た推論スキルを学んでいるのか?
- あるいは、その問題を解くために新しいスキルを発見しているのか?
- 小学校レベルの算数問題だけで訓練されたモデルは、それらの問題を解くことしか学ばないのか?
- それとも、より一般的な知能を学習するのか?
- どのくらい小さい言語モデルまで、小学校レベルの算数問題を解けるのか?
- 深さ(層の数)は幅(層ごとのニューロン数)より重要なのか?
- それとも、単にサイズだけが重要か?
(続きはのちほど...)
[Paper Note] AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders, Zhengxuan Wu+, ICLR'25 Spotlight
Paper/Blog Link My Issue
#Controllable #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #Prompting #Evaluation #read-later #ActivationSteering/ITI #Selected Papers/Blogs #InstructionFollowingCapability #Steering Issue Date: 2025-08-02 GPT Summary- 言語モデルの出力制御は安全性と信頼性に重要であり、プロンプトやファインチューニングが一般的に用いられるが、さまざまな表現ベースの技術も提案されている。これらの手法を比較するためのベンチマークAxBenchを導入し、Gemma-2-2Bおよび9Bに関する実験を行った。結果、プロンプトが最も効果的で、次いでファインチューニングが続いた。概念検出では表現ベースの手法が優れており、SAEは競争力がなかった。新たに提案した弱教師あり表現手法ReFT-r1は、競争力を持ちながら解釈可能性を提供する。AxBenchとともに、ReFT-r1およびDiffMeanのための特徴辞書を公開した。 Comment
openreview: https://openreview.net/forum?id=K2CckZjNy0
[Paper Note] What Matters in Learning from Large-Scale Datasets for Robot Manipulation, Vaibhav Saxena+, ICLR'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #Dataset #Robotics #EmbodiedAI #Author Thread-Post Issue Date: 2025-07-19 GPT Summary- 本研究では、ロボティクスにおける大規模データセットの構成に関する体系的な理解を深めるため、データ生成フレームワークを開発し、多様性の重要な要素を特定。特に、カメラのポーズや空間的配置がデータ収集の多様性と整合性に影響を与えることを示した。シミュレーションからの洞察が実世界でも有効であり、提案した取得戦略は既存のトレーニング手法を最大70%上回る性能を発揮した。 Comment
元ポスト:
元ポストに著者による詳細な解説スレッドがあるので参照のこと。
[Paper Note] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models, Chankyu Lee+, ICLR'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #InformationRetrieval #NLP #LanguageModel #RepresentationLearning #InstructionTuning #ContrastiveLearning #Generalization #Decoder Issue Date: 2025-07-10 GPT Summary- デコーダー専用のLLMベースの埋め込みモデルNV-Embedは、BERTやT5を上回る性能を示す。アーキテクチャ設計やトレーニング手法を工夫し、検索精度を向上させるために潜在的注意層を提案。二段階の対照的指示調整手法を導入し、検索と非検索タスクの両方で精度を向上。NV-EmbedモデルはMTEBリーダーボードで1位を獲得し、ドメイン外情報検索でも高スコアを達成。モデル圧縮技術の分析も行っている。 Comment
Decoder-Only LLMのlast hidden layerのmatrixを新たに導入したLatent Attention Blockのinputとし、Latent Attention BlockはEmbeddingをOutputする。Latent Attention Blockは、last hidden layer (系列長l×dの
matrix)をQueryとみなし、保持しているLatent Array(trainableなmatrixで辞書として機能する;後述の学習においてパラメータが学習される)[^1]をK,Vとして、CrossAttentionによってcontext vectorを生成し、その後MLPとMean Poolingを実施することでEmbeddingに変換する。
学習は2段階で行われ、まずQAなどのRetrievalタスク用のデータセットをIn Batch negativeを用いてContrastive Learningしモデルの検索能力を高める。その後、検索と非検索タスクの両方を用いて、hard negativeによってcontrastive learningを実施し、検索以外のタスクの能力も高める(下表)。両者において、instructionテンプレートを用いて、instructionによって条件付けて学習をすることで、instructionに応じて生成されるEmbeddingが変化するようにする。また、学習時にはLLMのcausal maskは無くし、bidirectionalにrepresentationを考慮できるようにする。
[^1]: [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22, 2021.07
Perceiver-IOにインスパイアされている。
[Paper Note] VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks, Ziyan Jiang+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #NLP #Dataset #Evaluation #MultiModal #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-09 GPT Summary- 本研究では、ユニバーサルマルチモーダル埋め込みモデルの構築を目指し、二つの貢献を行った。第一に、MMEB(Massive Multimodal Embedding Benchmark)を提案し、36のデータセットを用いて分類や視覚的質問応答などのメタタスクを網羅した。第二に、VLM2Vecというコントラストトレーニングフレームワークを開発し、視覚-言語モデルを埋め込みモデルに変換する手法を示した。実験結果は、VLM2Vecが既存のモデルに対して10%から20%の性能向上を達成することを示し、VLMの強力な埋め込み能力を証明した。 Comment
openreview: https://openreview.net/forum?id=TE0KOzWYAF
[Paper Note] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Zhangchen Xu+, ICLR'25, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #SyntheticData #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-06-25 GPT Summary- 高品質な指示データはLLMの整合に不可欠であり、Magpieという自己合成手法を提案。Llama-3-Instructを用いて400万の指示と応答を生成し、30万の高品質なインスタンスを選定。Magpieでファインチューニングしたモデルは、従来のデータセットを用いたモデルと同等の性能を示し、特に整合ベンチマークで優れた結果を得た。 Comment
OpenReview: https://openreview.net/forum?id=Pnk7vMbznK
下記のようなpre-queryテンプレートを与え(i.e., userの発話は何も与えず、ユーザの発話を表す特殊トークンのみを渡す)instructionを生成し、post-queryテンプレートを与える(i.e., pre-queryテンプレート+生成されたinstruction+assistantの発話の開始を表す特殊トークンのみを渡す)ことでresponseを生成することで、prompt engineeringやseed無しでinstruction tuningデータを合成できるという手法。
```T_pre−query = <|start_header_id|>user<|end_header_id|>```
```T_post−query =<|eot_id|><|start_header_id|>assistant<|end_header_id|>```
生成した生のinstruction tuning pair dataは、たとえば下記のようなフィルタリングをすることで品質向上が可能で (Appendix C)
- input length: instructionの中の文字数
- output length: response中の文字数
- task category: instructionの特定のカテゴリ
- input quality: 5段階評価によるinstructionの明瞭さ、具体性、coherence
- input difficulty: 5段階評価によるinstruction中に記述されているタスクを解決するために必要な知識のレベル
- minimum neighbor distance: 最近傍のinstructionsとのembedding空間上での距離で、類似性や繰り返しを排除
- reward: reward modelのスコアによる繰り返しや低品質なレスポンスの排除
- reward distance: 同じinstructionで、instructモデルが生成したresponseのベースモデルが生成したresponseのreward modelによるrewardの差(これが大きいほど高品質なinstruction tuning dataと言える)
Table 5 に実際にどのような組み合わせでこれらが適用されたかが記載されている。
reward modelと組み合わせてLLMからのresponseを生成しrejection samplingすればDPOのためのpreference dataも作成できるし、single turnの発話まで生成させた後もう一度pre/post-queryをconcatして生成すればMulti turnのデータも生成できる。
他のも例えば、システムプロンプトに自分が生成したい情報を与えることで、特定のドメインに特化したデータ、あるいは特定の言語に特化したデータも合成できる。
[Paper Note] Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization, Taishi Nakamura+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #MoE(Mixture-of-Experts) #KeyPoint Notes Issue Date: 2025-06-25 GPT Summary- Drop-Upcycling手法を提案し、MoEモデルのトレーニング効率を向上。事前にトレーニングされた密なモデルの知識を活用しつつ、一部の重みを再初期化することで専門家の専門化を促進。大規模実験により、5.9BパラメータのMoEモデルが13B密なモデルと同等の性能を達成し、トレーニングコストを約1/4に削減。すべての実験リソースを公開。 Comment
OpenReview: https://openreview.net/forum?id=gx1wHnf5Vp
提案手法の全体像とDiversity re-initializationの概要。元のUpcyclingでは全てidenticalな重みでreplicateされていたため、これが個々のexpertがlong termでの学習で特化することの妨げになり、最終的に最大限のcapabilityを発揮できず、収束が遅い要因となっていた。これを、Upcyclingした重みのうち、一部のindexのみを再初期化することで、replicate元の知識を保持しつつ、expertsの多様性を高めることで解決する。
提案手法は任意のactivation function適用可能。今回はFFN Layerのactivation functionとして一般的なSwiGLUを採用した場合で説明している。
Drop-Upcyclingの手法としては、通常のUpcyclingと同様、FFN Layerの重みをn個のexpertsの数だけreplicateする。その後、re-initializationを実施する比率rに基づいて、[1, intermediate size d_f]の範囲からr*d_f個のindexをサンプリングする。最終的にSwiGLU、およびFFNにおける3つのWeight W_{gate, up, down}において、サンプリングされたindexと対応するrow/columnと対応する重みをre-initializeする。
re-initializeする際には、各W_{gate, up, down}中のサンプリングされたindexと対応するベクトルの平均と分散をそれぞれ独立して求め、それらの平均と分散を持つ正規分布からサンプリングする。
学習の初期から高い性能を発揮し、long termでの性能も向上している。また、learning curveの形状もscratchから学習した場合と同様の形状となっており、知識の転移とexpertsのspecializationがうまく進んだことが示唆される。
[Paper Note] Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models, Yuda Song+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #SelfImprovement #read-later #Selected Papers/Blogs #Verification #Initial Impression Notes Issue Date: 2025-06-24 GPT Summary- 自己改善はLLMの出力検証を通じてデータをフィルタリングし、蒸留するメカニズムである。本研究では、自己改善の数学的定式化を行い、生成-検証ギャップに基づくスケーリング現象を発見。さまざまなモデルとタスクを用いた実験により、自己改善の可能性とその性能向上方法を探求し、LLMの理解を深めるとともに、将来の研究への示唆を提供する。 Comment
参考: https://joisino.hatenablog.com/entry/mislead
Verificationに対する理解を深めるのに非常に良さそう
openreview: https://openreview.net/forum?id=mtJSMcF3ek
[Paper Note] On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks, Kaya Stechly+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Verification Issue Date: 2025-06-24 GPT Summary- LLMsの推論能力に関する意見の相違を背景に、反復的なプロンプトの効果をGame of 24、グラフ彩色、STRIPS計画の3領域で調査。自己批評がパフォーマンスに悪影響を及ぼす一方、外部の正しい推論者による検証がパフォーマンスを向上させることを示した。再プロンプトによって複雑な設定の利点を維持できることも確認。 Comment
参考: https://joisino.hatenablog.com/entry/mislead
OpenReview: https://openreview.net/forum?id=4O0v4s3IzY
[Paper Note] Language Models Learn to Mislead Humans via RLHF, Jiaxin Wen+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #RLHF Issue Date: 2025-06-24 GPT Summary- RLHFは言語モデルのエラーを悪化させる可能性があり、モデルが人間を納得させる能力を向上させる一方で、タスクの正確性は向上しない。質問応答タスクとプログラミングタスクで被験者の誤検出率が増加し、意図された詭弁を検出する手法がU-SOPHISTRYには適用できないことが示された。これにより、RLHFの問題点と人間支援の研究の必要性が浮き彫りになった。 Comment
[Paper Note] LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Contamination-free #Selected Papers/Blogs #Live #One-Line Notes Issue Date: 2025-05-23 GPT Summary- テストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Comment
テストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究
[Paper Note] Faster Cascades via Speculative Decoding, Harikrishna Narasimhan+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Test-Time Scaling #Decoding #Verification #SpeculativeDecoding #Reference Collection Issue Date: 2025-05-13 GPT Summary- カスケードと推測デコーディングは、言語モデルの推論効率を向上させる手法であり、異なるメカニズムを持つ。カスケードは難しい入力に対して大きなモデルを遅延的に使用し、推測デコーディングは並行検証で大きなモデルを活用する。新たに提案する推測カスケーディング技術は、両者の利点を組み合わせ、最適な遅延ルールを特定する。実験結果は、提案手法がカスケードおよび推測デコーディングのベースラインよりも優れたコスト品質トレードオフを実現することを示した。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=vo9t20wsmd
[Paper Note] When More is Less: Understanding Chain-of-Thought Length in LLMs, Yuyang Wu+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Chain-of-Thought #One-Line Notes #Author Thread-Post Issue Date: 2025-04-30 GPT Summary- Chain-of-thought (CoT)推論は、LLMsの多段階推論能力を向上させるが、CoTの長さが増すと最初は性能が向上するものの、最終的には低下することが観察される。長い推論プロセスがノイズに脆弱であることを示し、理論的に最適なCoTの長さを導出。Length-filtered Voteを提案し、CoTの長さをモデルの能力とタスクの要求に合わせて調整する必要性を強調。 Comment
ICLR 2025 Best Paper Runner Up Award
元ポスト:
[Paper Note] AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models, Junfeng Fang+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeEditing #One-Line Notes #Reference Collection #Initial Impression Notes Issue Date: 2025-04-30 GPT Summary- AlphaEditは、LLMsの知識を保持しつつ編集を行う新しい手法で、摂動を保持された知識の零空間に投影することで、元の知識を破壊する問題を軽減します。実験により、AlphaEditは従来の位置特定-編集手法の性能を平均36.7%向上させることが確認されました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=HvSytvg3Jh
MLPに新たな知識を直接注入する際に(≠contextに含める)既存の学習済みの知識を破壊せずに注入する手法(破壊しないことが保証されている)を提案しているらしい
将来的には、LLMの1パラメータあたりに保持できる知識量がわかってきているので、MLPの零空間がN GBのモデルです、あなたが注入したいドメイン知識の量に応じて適切な零空間を持つモデルを選んでください、みたいなモデルが公開される日が来るのだろうか。
ポイント解説:
[Paper Note] RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval, Kaiyue Wen+, ICLR'25
Paper/Blog Link My Issue
#NLP #Transformer #Chain-of-Thought #In-ContextLearning #SSM (StateSpaceModel) Issue Date: 2025-04-26 GPT Summary- 本論文では、RNNとトランスフォーマーの表現力の違いを調査し、特にRNNがChain-of-Thought(CoT)プロンプトを用いてトランスフォーマーに匹敵するかを分析。結果、CoTはRNNを改善するが、トランスフォーマーとのギャップを埋めるには不十分であることが判明。RNNの情報取得能力の限界がボトルネックであるが、Retrieval-Augmented Generation(RAG)やトランスフォーマー層の追加により、RNNはCoTを用いて多項式時間で解決可能な問題を解決できることが示された。 Comment
元ポスト:
関連:
- Transformers are Multi-State RNNs, Matanel Oren+, N/A, EMNLP'24
↑とはどういう関係があるだろうか?
[Paper Note] AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MultiModal #ComputerUse #One-Line Notes Issue Date: 2025-04-18 GPT Summary- 本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 Comment
Android環境でのPhone Useのベンチマーク
[Paper Note] Learning Dynamics of LLM Finetuning, Yi Ren+, ICLR'25 Outstanding Paper Award
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #Alignment #Hallucination #DPO #Repetition #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-04-18 GPT Summary- 本研究では、大規模言語モデルのファインチューニング中の学習ダイナミクスを分析し、異なる応答間の影響の蓄積を段階的に解明します。指示調整と好み調整のアルゴリズムに関する観察を統一的に解釈し、ファインチューニング後の幻覚強化の理由を仮説的に説明します。また、オフポリシー直接好み最適化(DPO)における「圧縮効果」を強調し、望ましい出力の可能性が低下する現象を探ります。このフレームワークは、LLMのファインチューニング理解に新たな視点を提供し、アラインメント性能向上のためのシンプルな方法を示唆します。 Comment
元ポスト:
解説ポスト:
[Paper Note] KAA: Kolmogorov-Arnold Attention for Enhancing Attentive Graph Neural Networks, Taoran Fang+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention #Architecture Issue Date: 2025-04-07 GPT Summary- 注意GNNにおけるスコアリングプロセスの理解が不足している中、本研究ではコルモゴロフ・アルノルド注意(KAA)を提案し、スコアリング関数を統一。KAAはKANアーキテクチャを統合し、ほぼすべての注意GNNに適用可能で、表現力が向上。実験により、KAA強化スコアリング関数が元のものを一貫して上回り、最大20%以上の性能向上を達成した。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=atXCzVSXTJ
[Paper Note] CREAM: Consistency Regularized Self-Rewarding Language Models, Zhaoyang Wang+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #SelfImprovement #RewardHacking #Initial Impression Notes Issue Date: 2025-04-06 GPT Summary- 自己報酬型LLMは、LLM-as-a-Judgeを用いてアラインメント性能を向上させるが、報酬とランク付けの正確性が問題。小規模LLMの実証結果は、自己報酬の改善が反復後に減少する可能性を示唆。これに対処するため、一般化された反復的好みファインチューニングフレームワークを定式化し、正則化を導入。CREAMを提案し、報酬の一貫性を活用して信頼性の高い好みデータから学習。実証結果はCREAMの優位性を示す。 Comment
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
を改善した研究
OpenReview: https://openreview.net/forum?id=Vf6RDObyEF
この方向性の研究はおもしろい
[Paper Note] When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention #AttentionSinks #read-later #Selected Papers/Blogs #One-Line Notes #needs-revision #Author Thread-Post Issue Date: 2025-04-05 GPT Summary- 言語モデルにおける「アテンションシンク」は、意味的に重要でないトークンに大きな注意を割り当てる現象であり、さまざまな入力に対して小さなモデルでも普遍的に存在することが示された。アテンションシンクは事前学習中に出現し、最適化やデータ分布、損失関数がその出現に影響を与える。特に、アテンションシンクはキーのバイアスのように機能し、情報を持たない追加のアテンションスコアを保存することがわかった。この現象は、トークンがソフトマックス正規化に依存していることから部分的に生じており、正規化なしのシグモイドアテンションに置き換えることで、アテンションシンクの出現を防ぐことができる。 Comment
Sink Rateと呼ばれる、全てのheadのFirst Tokenに対するattention scoreのうち(layer l * head h個存在する)、どの程度の割合のスコアが閾値を上回っているかを表す指標を提案
(後ほど詳細を追記する)
- [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究
著者ポスト(openai-gpt-120Bを受けて):
openreview: https://openreview.net/forum?id=78Nn4QJTEN
[Paper Note] Overtrained Language Models Are Harder to Fine-Tune, Jacob Mitchell Springer+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-03-27 GPT Summary- 大規模言語モデルの事前学習において、トークン予算の増加がファインチューニングを難しくし、パフォーマンス低下を引き起こす「壊滅的な過学習」を提唱。3Tトークンで事前学習されたOLMo-1Bモデルは、2.3Tトークンのモデルに比べて2%以上の性能低下を示す。実験と理論分析により、事前学習パラメータの感度の増加が原因であることを示し、事前学習設計の再評価を促す。 Comment
著者によるポスト:
事前学習のトークン数を増やすとモデルのsensitivityが増し、post-trainingでのパフォーマンスの劣化が起こることを報告している。事前学習で学習するトークン数を増やせば、必ずしもpost-training後のモデルの性能がよくなるわけではないらしい。
ICLR'25のOutstanding Paperに選ばれた模様:
きちんと読んだ方が良さげ。
[Paper Note] LLM Pretraining with Continuous Concepts, Jihoon Tack+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Concept (LLM PreTraining) #Author Thread-Post Issue Date: 2025-02-14 GPT Summary- 次のトークン予測を最適化する大規模言語モデルに、新たに提案するCoCoMixフレームワークを導入。これは、離散的な予測と連続概念を交互に混ぜ込む手法で、隠れ表現を改善。実験により、サンプル効率が高く、複数のベンチマークで標準的手法を上回る性能を確認。概念学習と交互配置が性能向上に重要で、モデルの内部推論を透明にする機能も提供。 Comment
著者による一言解説:
openreview: https://openreview.net/forum?id=wTGcb3DxOn
[Paper Note] Diverse Preference Optimization, Jack Lanchantin+, ICLR'25, 2025.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #DPO #PostTraining #Diversity #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2025-02-01 GPT Summary- Diverse Preference Optimization(DivPO)を提案し、応答の多様性を向上させつつ生成物の品質を維持するオンライン最適化手法を紹介。DivPOは応答のプールから多様性を測定し、希少で高品質な例を選択することで、パーソナ属性の多様性を45.6%、ストーリーの多様性を74.6%向上させる。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=pOq9vDIYev
DPOと同じ最適化方法を使うが、Preference Pairを選択する際に、多様性が増加するようなPreference Pairの選択をすることで、モデルのPost-training後の多様性を損なわないようにする手法を提案しているっぽい。
具体的には、Alg.1 に記載されている通り、多様性の尺度Dを定義して、モデルにN個のレスポンスを生成させRMによりスコアリングした後、RMのスコアが閾値以上のresponseを"chosen" response, 閾値未満のレスポンスを "reject" responseとみなし、chosen/reject response集合を構築する。chosen response集合の中からDに基づいて最も多様性のあるresponse y_c、reject response集合の中から最も多様性のないresponse y_r をそれぞれピックし、prompt xとともにpreference pair (x, y_c, y_r) を構築しPreference Pairに加える、といった操作を全ての学習データ(中のprompt)xに対して繰り返すことで実現する。
DivPO
[Paper Note] SoftMatcha: A Soft and Fast Pattern Matcher for Billion-Scale Corpus Searches, Hiroyuki Deguchi+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #NLP #Search #Dataset Issue Date: 2025-01-28 GPT Summary- 表層的な文字列照合に依存する既存のパターンマッチング手法の制約を克服するため、語彙埋め込みを用いた新しいアルゴリズムを提案。これにより、コーパス規模での柔軟かつ効率的なパターンマッチングを実現。提案手法は、十億規模のデータ上で瞬時の検索を行い、英語と日本語のWikipediaから有害事例を抽出し、また多様な屈折のあるラテン語においても有効であることを実証。 Comment
ICLR2025にacceptされた模様
https://openreview.net/forum?id=Q6PAnqYVpo
openreview: https://openreview.net/forum?id=Q6PAnqYVpo
How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #MachineLearning #NLP #LanguageModel #Batch #One-Line Notes #CriticalBatchSize Issue Date: 2024-11-25 GPT Summary- 大規模モデルの訓練には、クリティカルバッチサイズ(CBS)を考慮した並列化戦略が重要である。CBSの測定法を提案し、C4データセットで自己回帰型言語モデルを訓練。バッチサイズや学習率などの要因を調整し、CBSがデータサイズに比例してスケールすることを示した。この結果は、ニューラルネットワークの理論的分析によって支持され、ハイパーパラメータ選択の重要性も強調されている。 Comment
Critical Batch Sizeはモデルサイズにはあまり依存せず、データサイズに応じてスケールする
Critical batch sizeが提案された研究:
- [Paper Note] An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18, 2018.12
[Paper Note] Scaling Laws for Precision, Tanishq Kumar+, ICLR'25
Paper/Blog Link My Issue
#read-later Issue Date: 2024-11-13 GPT Summary- 本研究では、低精度のトレーニングと推論が言語モデルの品質に与える影響を考慮した「精度を考慮した」スケーリング法則を提案。低精度トレーニングが実効パラメータ数を減少させ、ポストトレーニング量子化による劣化がトレーニングデータの増加とともに悪化することを示す。異なる精度でのモデル損失を予測し、低精度での大規模モデルのトレーニングが最適である可能性を示唆。スケーリング法則を統一し、実験に基づいて予測を検証。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=wg1PCg3CUP
[Paper Note] MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs, Sheng-Chieh Lin+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #InformationRetrieval #RepresentationLearning #MultiModal #read-later #VisionLanguageModel Issue Date: 2024-11-08 GPT Summary- 本研究は、マルチモーダル大規模言語モデル(MLLM)を用いた普遍的マルチモーダル検索を提案し、複数のモダリティを受け入れる広範な検索シナリオを追求します。16の検索タスクに対する微調整実験から、MLLMがテキストと画像を含む複雑なクエリを理解できる一方、モダリティ偏りによりクロスモーダル検索では性能が劣ることを確認しました。この課題に対処するため、モダリティ意識のハードネガティブ・マイニングや継続的ファインチューニングを提案し、最終的にMM-Embedモデルはマルチモーダル検索ベンチマークM-BEIRで最先端の性能を達成しました。さらに、プロンプトを用いたゼロショットのリランキングがMLLMのマルチモーダル検索の向上に寄与することを示し、今後の普遍的マルチモーダル検索の発展に期待が持たれます。 Comment
openreview: https://openreview.net/forum?id=i45NQb2iKO
[Paper Note] Looking Inward: Language Models Can Learn About Themselves by Introspection, Felix J Binder+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #One-Line Notes #needs-revision Issue Date: 2024-11-02 GPT Summary- 内省は、モデルが自己の内部状態を理解する能力を示す。LLMsに内省能力をファインチューニングし、自身の行動予測を行う実験により、内省の証拠が得られた。特に、自己予測能力において他のモデルを上回る結果が見られたが、複雑なタスクでは限界もあった。 Comment
LLMが単に訓練データを模倣しているにすぎない的な主張に対するカウンターに使えるかも
openreview: https://openreview.net/forum?id=eb5pkwIB5i
[Paper Note] Differential Transformer, Tianzhu Ye+, N_A, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #Selected Papers/Blogs #In-Depth Notes Issue Date: 2024-10-21 GPT Summary- Diff Transformerは、関連するコンテキストへの注意を強化し、ノイズをキャンセルする新しいアーキテクチャです。差分注意メカニズムを用いて、注意スコアを計算し、スパースな注意パターンを促進します。実験結果は、Diff Transformerが従来のTransformerを上回り、長いコンテキストモデリングや幻覚の軽減において顕著な利点を示しています。また、文脈内学習においても精度を向上させ、堅牢性を高めることが確認されました。これにより、Diff Transformerは大規模言語モデルの進展に寄与する有望なアーキテクチャとされています。 Comment
# 概要
attention scoreのノイズを低減するようなアーキテクチャとして、二つのQKVを用意し、両者の差分を取ることで最終的なattentiok scoreを計算するDifferential Attentionを提案した。
attentionのnoiseの例。answerと比較してirrelevantなcontextにattention scoreが高いスコアが割り当てられてしまう(図左)。differential transformerが提案するdifferential attentionでは、ノイズを提言し、重要なcontextのattention scoreが高くなるようになる(図中央)、らしい。
# Differential Attentionの概要
二つのQKをどの程度の強さで交互作用させるかをλで制御し、λもそれぞれのQKから導出する。数式は2.1節に記述されているのでそちらも参照のこと。
QA, 機械翻訳, 文書分類, テキスト生成などの様々なNLPタスクが含まれるEval Harnessベンチマークでは、同規模のtransformerモデルを大幅にoutperform。ただし、3Bでしか実験していないようなので、より大きなモデルサイズになったときにgainがあるかは示されていない点には注意。
モデルサイズ(パラメータ数)と、学習トークン数のスケーラビリティについても調査した結果、LLaMAと比較して、より少ないパラメータ数/学習トークン数で同等のlossを達成。
64Kにcontext sgzeを拡張し、1.5B tokenで3Bモデルを追加学習をしたところ、これもtransformerと比べてより小さいlossを達成
context中に埋め込まれた重要な情報(今回はクエリに対応するmagic number)を抽出するタスク(Needle-In-A-Haystack test)の性能も向上。Needle(N)と呼ばれる正解のmagic numberが含まれる文をcontext中の様々な深さに配置し、同時にdistractorとなる文もランダムに配置する。これに対してクエリ(R)が入力されたときに、どれだけ正しい情報をcontextから抽出できるか、という話だと思われる。
これも性能が向上。特にクエリとNeedleが複数の要素で構成されていれ場合の性能が高く(Table2)、長いコンテキスト中の様々な位置に埋め込まれたNeedleを抽出する性能も高い(Figure5)
Many shotのICL能力も、異なる数のクラス分類を実施する4つのDatasetにおいて向上。クラス数が増えるに従ってAcc.のgainは小さくなっているように見える({6, 50} class > 70 class > 150 class)が、それでもAcc.が大きく向上している。
要約タスクでのhallucinationも低減。生成された要約と正解要約を入力し、GPT-4oにhallucinationの有無を判定させて評価(このようなLLM-as-a-Judgeの枠組みは先行研究 (MT-Bench) で人手での評価と高いagreementがあることが示されている)
関連 (MT-Bench):
- [Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
シンプルなアプローチでLLM全体の性能を底上げしている素晴らしい成果に見える。斜め読みなので読み飛ばしているかもしれないが、
- [Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
のように高品質な学習データで学習した場合も同様の効果が発現するのだろうか?
attentionのスコアがnoisyということは、学習データを洗練させることでも改善される可能性があり、[Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
はこれをデータで改善し、こちらの研究はモデルのアーキテクチャで改善した、みたいな捉え方もできるのかもしれない。
ちなみにFlash Attentionとしての実装方法も提案されており、スループットは通常のattentionと比べてむしろ向上している (Appendix A参照のこと) ので実用的な手法でもある。すごい。
あとこれ、事前学習とInstruction Tuningを通常のマルチヘッドアテンションで学習されたモデルに対して、独自データでSFTするときに導入したらdownstream taskの性能向上するんだろうか。もしそうなら素晴らしい
OpenReview: https://openreview.net/forum?id=OvoCm1gGhN
GroupNormalizationについてはこちら:
- [Paper Note] Group Normalization, Yuxin Wu+, arXiv'18, 2018.03
[Paper Note] nGPT: Normalized Transformer with Representation Learning on the Hypersphere, Ilya Loshchilov+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #Normalization #Selected Papers/Blogs Issue Date: 2024-10-21 GPT Summary- ハイパースフィア上での表現学習に基づく新しいニューラルネットワークアーキテクチャ、正規化トランスフォーマー(nGPT)を提案。全てのベクトルが単位ノルムで正規化され、入力トークンがハイパースフィア上を移動し、各レイヤーで変位を加える。nGPTは学習が速く進行し、同精度を達成するためのトレーニングステップ数を4〜20倍削減することが実験で示された。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=se4vjm7h4E
[Paper Note] LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations, Hadas Orgad+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Hallucination #One-Line Notes Issue Date: 2024-10-20 GPT Summary- LLMの内部状態は出力の真実性に関する情報を豊富に含んでおり、これを活用することで誤り検出が向上する。しかし、真実性の符号化はデータセットによって異なるため、普遍的ではない。内部表現を使って特定の誤りを予測できることも示し、個別的な緩和戦略の開発に寄与する。さらに、内部と外部の挙動の乖離があることが明らかとなり、誤った出力を生成することもある。これにより、LLMの誤り分析と改善の研究が進展することが期待される。 Comment
特定のトークンがLLMのtrustfulnessに集中していることを実験的に示し、かつ内部でエンコードされたrepresentationは正しい答えのものとなっているのに、生成結果に誤りが生じるような不整合が生じることも示したらしい
openreview: https://openreview.net/forum?id=KRnsX5Em3W
Llama-3.1-Nemotron-70B-Instruct, Nvidia, (ICLR'25), 2024.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Alignment #OpenWeight #One-Line Notes Issue Date: 2024-10-17 GPT Summary- 報酬モデルの訓練にはBradley-Terryスタイルと回帰スタイルがあり、データの一致が重要だが、適切なデータセットが不足している。HelpSteer2データセットでは、Bradley-Terry訓練用の好みの注釈を公開し、初めて両モデルの直接比較を行った。これに基づき、両者を組み合わせた新アプローチを提案し、Llama-3.1-70B-InstructモデルがRewardBenchで94.1のスコアを達成。さらに、REINFORCEアルゴリズムを用いて指示モデルを調整し、Arena Hardで85.0を記録した。このデータセットはオープンソースとして公開されている。 Comment
MTBench, Arena HardでGPT4o-20240513,Claude-3.5-sonnet-20240620をoutperform。Response lengthの平均が長いこと模様
openreview: https://openreview.net/forum?id=MnfHxPP5gs
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, Iman Mirzadeh+, N_A, ICLR'25
Paper/Blog Link My Issue
#One-Line Notes Issue Date: 2024-10-11 GPT Summary- 最近のLLMsの進展により、数学的推論能力への関心が高まっているが、GSM8Kベンチマークの信頼性には疑問が残る。これに対処するため、GSM-Symbolicという新しいベンチマークを導入し、モデルの推論能力をより正確に評価。調査結果は、モデルが同じ質問の異なる具現化に対してばらつきを示し、特に数値変更や質問の節の数が増えると性能が著しく低下することを明らかにした。これは、LLMsが真の論理的推論を行えず、トレーニングデータからの再現に依存しているためと考えられる。全体として、研究は数学的推論におけるLLMsの能力と限界についての理解を深める。 Comment
元ポスト:
May I ask if this work is open source?
I'm sorry, I just noticed your comment. From what I could see in the repository and OpenReview discussion, some parts of the dataset, such as GSMNoOp, are not part of the current public release. The repository issues also mention that the data generation code is not included at the moment. This is just based on my quick check, so there may be more updates or releases coming later.
OpenReview:
https://openreview.net/forum?id=AjXkRZIvjB
Official blog post:
https://machinelearning.apple.com/research/gsm-symbolic
Repo:
https://github.com/apple/ml-gsm-symbolic
HuggingFace:
https://huggingface.co/datasets/apple/GSM-Symbolic
[Paper Note] Backtracking Improves Generation Safety, Yiming Zhang+, ICLR'25, 2024.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Safety #DPO #PostTraining Issue Date: 2024-09-24 GPT Summary- テキスト生成には根本的な限界があり、生成されたトークンを元に戻せないため、安全でない生成が続く傾向がある。この課題を解決するために、特別な[RESET]トークンを用いたバックトラッキング技術を提案し、生成物を「取り消し」可能にする。これにより、言語モデルの安全性を向上させることができ、バックトラッキングを学習したモデルはベースラインと比較して4倍の安全性を示す。さらに、敵対的攻撃に対する保護も提供される。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=Bo62NeU6VF
日本語解説: https://www.docswell.com/s/DeepLearning2023/ZN1PNR-2025-05-08-131259#p1
[Paper Note] Diffusion Models Are Real-Time Game Engines, Dani Valevski+, ICLR'25, 2024.08
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #DiffusionModel #read-later #Selected Papers/Blogs #WorldModels #interactive #Initial Impression Notes Issue Date: 2024-09-01 GPT Summary- GameNGenは、初の完全にニューラルモデルで動作するゲームエンジンであり、DOOMを用いて訓練され、インタラクティブな新しい軌道を生成する能力を持つ。毎秒20フレームで動作し、9.4のPSNRを達成。評価者は自己回帰生成後もゲームクリップをわずかに識別可能である。GameNGenは、強化学習エージェントによるトレーニングと、次フレーム生成のための拡散モデルの2段階で訓練され、安定した生成を実現する。 Comment
Diffusion Modelでゲーム映像を生成する取り組みらしい。ゲームのenvironmentに対して、ユーザのActionとframeの系列をエピソードとみなして生成するっぽい?
project pageにデモがのっている
https://gamengen.github.io/
openreview: https://openreview.net/forum?id=P8pqeEkn1H
[Paper Note] The Unreasonable Ineffectiveness of the Deeper Layers, Andrey Gromov+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Pruning #One-Line Notes Issue Date: 2024-04-22 GPT Summary- LLMの重みの知識格納を層剪定で研究。不要なパラメータを特定し、層を削除しても性能に影響がないか確認。驚くべき結果として、最大で半分の層を削除しても性能低下がわずかであることが示された。この頑健性は浅い層が重要な役割を果たしている可能性を示唆。PEFT手法を用いて実験を効率化。 Comment
下記ツイートによると、学習済みLLMから、コサイン類似度で入出力間の類似度が高い層を除いてもタスクの精度が落ちず、特に深い層を2-4割削除しても精度が落ちないとのこと。
参考:
VRAMに載せるのが大変なので、このような枝刈り技術が有効だと分かるのはありがたい。LoRAや量子化も利用しているっぽい。
openreview: https://openreview.net/forum?id=ngmEcEer8a
[Paper Note] Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws, Zeyuan Allen-Zhu+, N_A, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #SyntheticData #Reference Collection Issue Date: 2024-04-15 GPT Summary- 言語モデルのサイズと能力の関係を記述するスケーリング則に焦点を当てた研究。モデルが格納する知識ビット数を推定し、事実知識をタプルで表現。言語モデルは1つのパラメータあたり2ビットの知識を格納可能であり、7Bモデルは14Bビットの知識を格納可能。さらに、トレーニング期間、モデルアーキテクチャ、量子化、疎な制約、データの信号対雑音比が知識格納容量に影響することを示唆。ロータリー埋め込みを使用したGPT-2アーキテクチャは、知識の格納においてLLaMA/Mistralアーキテクチャと競合する可能性があり、トレーニングデータにドメイン名を追加すると知識容量が増加することが示された。 Comment
参考:
openreview: https://openreview.net/forum?id=FxNNiUgtfa
[Paper Note] Small-scale proxies for large-scale Transformer training instabilities, Mitchell Wortsman+, ICLR'24, 2023.09
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Stability Issue Date: 2026-04-26 GPT Summary- 大規模なTransformerモデルの訓練不安定性を小規模モデルで再現・研究。特に、アテンション層のロジット増大と出力ロジットの発散に注目。高い学習率で不安定性が現れることを示し、既存の緩和策が小規模モデルにも有効であることを確認。ウォームアップやウェイト減衰を駆使し、損失の安定性を維持できる手法を検討。最後に、不安定性が現れる前に予測できるケースを分析。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=d8w0pmvXbZ
[Paper Note] Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think, Sihyun Yu+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#read-later Issue Date: 2026-03-10 GPT Summary- 生成拡散モデルのデノイジング過程が意味のある表現を誘導できることが確認されているが、その品質は自己教師付き学習法には及ばない。本研究では、外部の高品質な視覚表現を用いることで、生成モデルの学習を効率化する「REPresentation Alignment(REPA)」を提案。ノイズの多い入力の隠れ状態をクリーンな外部表現に一致させることで、訓練効率と生成品質が著しく改善される。具体的には、SiTの訓練を17.5倍以上加速し、少ないステップで高性能を達成。最先端の生成品質も実現した。 Comment
openreview: https://openreview.net/forum?id=DJSZGGZYVi
[Paper Note] LLM Unlearning via Loss Adjustment with Only Forget Data, Yaxuan Wang+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeEditing #MachineUnlearning(MU) Issue Date: 2026-03-10 GPT Summary- LLMの忘却は、プライバシーやバイアスに対応するために重要です。既存の手法は保持データに依存し、忘却性能とモデルの有用性のバランスが難しい。しかし、我々は保持データを排除した新たなアプローチを提案します。「FLAT」と呼ばれる手法は、忘却データに基づいて応答を指示し、f-ダイバージェンスを最大化することで忘却性能を向上させます。実験により、我々のアプローチが既存手法よりも高い性能を示し、多様なタスクでの有用性を維持できることが確認されました。 Comment
openreview: https://openreview.net/forum?id=6ESRicalFE
[Paper Note] Who is ChatGPT? Benchmarking LLMs' Psychological Portrayal Using PsychoBench, Jen-tse Huang+, ICLR'24, 2023.10
Paper/Blog Link My Issue
Issue Date: 2026-01-25 GPT Summary- LLMの心理的側面を評価するフレームワーク「PsychoBench」を提案し、13の臨床心理学的尺度を4つのカテゴリに分類。text-davinci-003、gpt-3.5-turbo、gpt-4、LLaMA-2-7b、LLaMA-2-13bの5モデルを調査し、「脱獄」アプローチで内的本質をテスト。PsychoBenchは公開済み。 Comment
pj page: https://cuhk-arise.github.io/PsychoBench/
元ポスト:
openreview: https://openreview.net/forum?id=H3UayAQWoE
[Paper Note] Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws, Yiding Jiang+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Scaling Laws #DataMixture #One-Line Notes #Adaptive Issue Date: 2026-01-21 GPT Summary- ADOは事前学習データの最適化をオンラインで行うアルゴリズムで、モデル訓練と同時にデータ分布を調整。外部知識やプロキシモデルを必要とせず、ドメインごとの学習ポテンシャルを推定してスケーラブルなデータ混合を実現。実験では、従来法と同等またはそれ以上の性能を示しつつ計算効率を維持する効果的な解決策を提供。スケーリング則を通じて新たなデータ収集戦略の視点も提示。 Comment
openreview: https://openreview.net/forum?id=aqok1UX7Z1
ドメインごとのneural scaling lawsを学習をする中で構築し、scaling lawsに従って動的にドメインのデータをどの程度サンプリングするかを決定するようなオンラインでのDataMixture決定手法、に見える。小規模モデルの実験結果を活用する不確実性やSarrogate modelを用いて推論するといった計算コストの高い方法はおそらく不要?
[Paper Note] Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting, Melanie Sclar+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Prompting #Evaluation #OpenWeight #Selected Papers/Blogs Issue Date: 2026-01-21 GPT Summary- LLMの性能特性化が重要であり、プロンプト設計がモデル挙動に強く影響することを示す。特に、プロンプトフォーマットに対するLLMの感度に注目し、微妙な変更で最大76ポイントの性能差が見られる。感度はモデルサイズや少数ショットの数に依存せず、プロンプトの多様なフォーマットにわたる性能範囲の報告が必要。モデル間のフォーマットパフォーマンスが弱く相関することから、固定されたプロンプトフォーマットでの比較の妥当性が疑問視される。迅速なフォーマット評価のための「FormatSpread」アルゴリズムを提案し、摂動の影響や内部表現も探る。 Comment
openreview: https://openreview.net/forum?id=RIu5lyNXjT
[Paper Note] InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation, Xingchao Liu+, ICLR'24, 2023.09
Paper/Blog Link My Issue
Issue Date: 2025-11-28 GPT Summary- 本論文では、拡散モデルを用いたテキストから画像への生成において、従来の多段階サンプリングプロセスの遅さを改善するために、Rectified Flowを活用した新しい一段階モデル「InstaFlow」を提案します。InstaFlowは、Stable Diffusionの品質を維持しつつ、MS COCO 2017-5kでFIDを23.3に改善し、従来の手法を大きく上回る性能を示しました。また、MS COCO 2014-30kでは、わずか0.09秒でFID 13.1を達成し、トレーニングには199 A100 GPU日を要しました。コードとモデルは公開されています。 Comment
[Paper Note] On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes, Rishabh Agarwal+, ICLR'24, 2023.06
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #Distillation #Selected Papers/Blogs #Off-Policy #On-Policy #One-Line Notes Issue Date: 2025-10-30 GPT Summary- 一般化知識蒸留(GKD)は、教師モデルからのフィードバックを活用し、生徒モデルが自己生成した出力シーケンスで訓練する手法。これにより、出力シーケンスの分布不一致の問題を解決し、柔軟な損失関数の使用が可能になる。GKDは蒸留と強化学習の統合を促進し、要約、翻訳、算術推論タスクにおける自動回帰言語モデルの蒸留においてその有効性を示す。 Comment
openreview: https://openreview.net/forum?id=3zKtaqxLhW
- Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
での説明に基づくと、
オフポリシーの蒸留手法を使うと、教師モデルが生成した出力を用いて蒸留をするため、生徒モデルが実際に出力するcontextとは異なる出力に基づいて蒸留をするため、生徒モデルの推論時のcontextとのミスマッチが生じる課題があるが、オンポリシーデータを混ぜることでこの問題を緩和するような手法(つまり実際の生徒モデル運用時と似た状況で蒸留できる)。生徒モデルが賢くなるにつれて出力が高品質になるため、それらを学習データとして再利用することでpositiveなフィードバックループが形成されるという利点がある。また、強化学習と比較しても、SparseなReward Modelに依存せず、初期の性能が低いモデルに対しても適用できる利点があるとのこと(性能が低いと探索が進まない場合があるため)。
[Paper Note] MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases, Zechun Liu+, ICLR'24, 2024.02
Paper/Blog Link My Issue
#NLP #LanguageModel #SmallModel Issue Date: 2025-10-10 GPT Summary- モバイルデバイス向けに10億未満のパラメータを持つ高品質な大規模言語モデル(LLM)の設計を提案。深くて細いアーキテクチャを活用し、MobileLLMという強力なモデルを構築し、従来のモデルに対して精度を向上。さらに、重み共有アプローチを導入し、MobileLLM-LSとしてさらなる精度向上を実現。MobileLLMモデルファミリーは、チャットベンチマークでの改善を示し、一般的なデバイスでの小型モデルの能力を強調。
[Paper Note] Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing, Xinyu Hu+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AutomaticPromptEngineering Issue Date: 2025-09-24 GPT Summary- Evokeという自動プロンプト洗練フレームワークを提案。レビュアーと著者のLLMがフィードバックループを形成し、プロンプトを洗練。難しいサンプルを選択することで、LLMの深い理解を促進。実験では、Evokeが論理的誤謬検出タスクで80以上のスコアを達成し、他の手法を大幅に上回る結果を示した。 Comment
openreview: https://openreview.net/forum?id=OXv0zQ1umU
pj page:
https://sites.google.com/view/evoke-llms/home
github:
https://github.com/microsoft/Evoke
githubにリポジトリはあるが、プロンプトテンプレートが書かれたtsvファイルが配置されているだけで、実験を再現するための全体のパイプラインは存在しないように見える。
[Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #ContextWindow #LongSequence #PositionalEncoding #PostTraining #Selected Papers/Blogs Issue Date: 2025-08-02 GPT Summary- YaRN(Yet another RoPE extensioN method)は、トランスフォーマーベースの言語モデルにおける位置情報のエンコードを効率的に行い、コンテキストウィンドウを従来の方法よりも10倍少ないトークンと2.5倍少ない訓練ステップで拡張する手法を提案。LLaMAモデルが長いコンテキストを効果的に利用できることを示し、128kのコンテキスト長まで再現可能なファインチューニングを実現。 Comment
openreview: https://openreview.net/forum?id=wHBfxhZu1u
現在主流なRoPEを前提としたコンテキストウィンドウ拡張手法で、事前学習で学習されたRoPEのコンテキストウィンドウを中間学習において拡張する。様々なモデルで利用されている。
日本語解説: https://zenn.dev/bilzard/scraps/de7ecd3c380b6e
- 国産生成AI PLaMoを支える事後学習と推論最適化, PFN, 2026.04
pp.24--25に解説がある
[Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #ReinforcementLearning #Reasoning #Selected Papers/Blogs #PRM Issue Date: 2025-06-26 GPT Summary- 大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。 Comment
OpenReview: https://openreview.net/forum?id=v8L0pN6EOi
[Paper Note] Safety Alignment Should Be Made More Than Just a Few Tokens Deep, Xiangyu Qi+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Safety #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-04-29 GPT Summary- LLMsの安全性整合性は脆弱であり、単純な攻撃でジャイルブレイク可能。この問題は浅層的安全整合に起因し、生成分布が初めの数トークンで適応されるために発生する。研究では、浅層的安全整合の存在理由をケーススタディで示し、複数の脆弱性の根本原因を探求。これにより、初期トークンを超えて整合性を深めることで悪用に対する堅牢性を向上させる可能性が示唆される。ファインチューニング攻撃に対抗するための正則化手法も提案。将来の安全整合性は、より深いアプローチが必要であるとの結論を導く。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=6Mxhg9PtDE
Safety Alignment手法が最初の数トークンに依存しているからそうならないように学習しますというのは、興味深いテーマだし技術的にまだ困難な点もあっただろうし、インパクトも大きいし、とても良い研究だ…。
[Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
Paper/Blog Link My Issue
#Attention #LongSequence #AttentionSinks #Selected Papers/Blogs #KeyPoint Notes #Reference Collection #Author Thread-Post Issue Date: 2025-04-05 GPT Summary- 大規模言語モデル(LLMs)をマルチラウンド対話に展開する際の課題として、メモリ消費と長いテキストへの一般化の難しさがある。ウィンドウアテンションはキャッシュサイズを超えると失敗するが、初期トークンのKVを保持することでパフォーマンスが回復する「アテンションシンク」を発見。これを基に、StreamingLLMというフレームワークを提案し、有限のアテンションウィンドウでトレーニングされたLLMが無限のシーケンス長に一般化可能になることを示した。StreamingLLMは、最大400万トークンで安定した言語モデリングを実現し、ストリーミング設定で従来の手法を最大22.2倍の速度で上回る。 Comment
Attention Sinksという用語を提言した研究
下記のpassageがAttention Sinksの定義(=最初の数トークン)とその気持ち(i.e., softmaxによるattention scoreは足し合わせて1にならなければならない。これが都合の悪い例として、現在のtokenのqueryに基づいてattention scoreを計算する際に過去のトークンの大半がirrelevantな状況を考える。この場合、irrelevantなトークンにattendしたくはない。そのため、auto-regressiveなモデルでほぼ全てのcontextで必ず出現する最初の数トークンを、irrelevantなトークンにattendしないためのattention scoreの捨て場として機能するのうに学習が進む)の理解に非常に重要
> To understand the failure of window attention, we find an interesting phenomenon of autoregressive LLMs: a surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task, as visualized in Figure 2. We term these tokens
“attention sinks". Despite their lack of semantic significance, they collect significant attention scores. We attribute the reason to the Softmax operation, which requires attention scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one. The reason behind initial tokens as sink tokens is intuitive: initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.
- [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究。こちらでAttentionSinkがどのように作用しているのか?が分析されている。
Figure1が非常にわかりやすい。Initial Token(実際は3--4トークン)のKV Cacheを保持することでlong contextの性能が改善する(Vanilla)。あるいは、Softmaxの分母に1を追加した関数を用意し(数式2)、全トークンのattention scoreの合計が1にならなくても許されるような変形をすることで、余剰なattention scoreが生じないようにすることでattention sinkを防ぐ(Zero Sink)。これは、ゼロベクトルのトークンを追加し、そこにattention scoreを逃がせるようにすることに相当する。もう一つの方法は、globalに利用可能なlearnableなSink Tokenを追加すること。これにより、不要なattention scoreの捨て場として機能させる。Table3を見ると、最初の4 tokenをKV Cacheに保持した場合はperplexityは大きく変わらないが、Sink Tokenを導入した方がKV Cacheで保持するInitial Tokenの量が少なくてもZero Sinkと比べると性能が良くなるため、今後モデルを学習する際はSink Tokenを導入することを薦めている。既に学習済みのモデルについては、Zero Sinkによってlong contextのモデリングに対処可能と思われる。
著者による解説:
openreview: https://openreview.net/forum?id=NG7sS51zVF
[Paper Note] WebArena: A Realistic Web Environment for Building Autonomous Agents, Shuyan Zhou+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-04-02 GPT Summary- 生成AIの進展により、自律エージェントが自然言語コマンドで日常タスクを管理する可能性が生まれたが、現行のエージェントは簡略化された環境でのテストに限られている。本研究では、ウェブ上でタスクを実行するエージェントのための現実的な環境を構築し、eコマースやソーシャルフォーラムなどのドメインを含む完全なウェブサイトを提供する。この環境を基に、タスクの正確性を評価するベンチマークを公開し、実験を通じてGPT-4ベースのエージェントの成功率が14.41%であり、人間の78.24%には及ばないことを示した。これにより、実生活のタスクにおけるエージェントのさらなる開発の必要性が強調される。 Comment
Webにおけるさまざまなrealisticなタスクを評価するためのベンチマーク
実際のexample。スタート地点からピッツバーグのmuseumを巡る最短の経路を見つけるといった複雑なタスクが含まれる。
人間とGPT4,GPT-3.5の比較結果
[Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-04-02 GPT Summary- SWE-benchは、12の人気Pythonリポジトリから得られた2,294のソフトウェアエンジニアリング問題を評価するフレームワークで、言語モデルがコードベースを編集して問題を解決する能力を測定します。評価の結果、最先端の商用モデルや微調整されたモデルSWE-Llamaも最も単純な問題しか解決できず、Claude 2はわずか1.96%の問題を解決するにとどまりました。SWE-benchは、より実用的で知的な言語モデルへの進展を示しています。 Comment
ソフトウェアエージェントの最もpopularなベンチマーク
主にpythonライブラリに関するリポジトリに基づいて構築されている。
SWE-Bench, SWE-Bench Lite, SWE-Bench Verifiedの3種類がありソフトウェアエージェントではSWE-Bench Verifiedを利用して評価することが多いらしい。Verifiedでは、issueの記述に曖昧性がなく、適切なunittestのスコープが適切なもののみが採用されているとのこと(i.e., 人間の専門家によって問題がないと判断されたもの)。
https://www.swebench.com/
Agenticな評価をする際に、一部の評価でエージェントがgit logを参照し本来は存在しないはずのリポジトリのfuture stateを見ることで環境をハッキングしていたとのこと:
これまでの評価結果にどの程度の影響があるかは不明。
openreview: https://openreview.net/forum?id=VTF8yNQM66
[Paper Note] Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Selected Papers/Blogs #KeyPoint Notes #SparseAutoencoder #Interpretability #InterpretabilityScore Issue Date: 2025-03-15 GPT Summary- 神経ネットワークの多義性を解消するために、スパースオートエンコーダを用いて内部活性化の方向を特定。これにより、解釈可能で単義的な特徴を学習し、間接目的語の同定タスクにおける因果的特徴をより詳細に特定。スケーラブルで教師なしのアプローチが重ね合わせの問題を解決できることを示唆し、モデルの透明性と操作性向上に寄与する可能性を示す。 Comment
日本語解説: https://note.com/ainest/n/nbe58b36bb2db
OpenReview: https://openreview.net/forum?id=F76bwRSLeK
SparseAutoEncoderはネットワークのあらゆるところに仕込める(と思われる)が、たとえばTransformer Blockのresidual connection部分のベクトルに対してFeature Dictionaryを学習すると、当該ブロックにおいてどのような特徴の組み合わせが表現されているかが(あくまでSparseAutoEncoderがreconstruction lossによって学習された結果を用いて)解釈できるようになる。
SparseAutoEncoderは下記式で表され、下記loss functionで学習される。MがFeature Matrix(row-wiseに正規化されて後述のcに対するL1正則化に影響を与えないようにしている)に相当する。cに対してL1正則化をかけることで(Sparsity Loss)、c中の各要素が0に近づくようになり、結果としてcがSparseとなる(どうしても値を持たなければいけない重要な特徴量のみにフォーカスされるようになる)。
[Paper Note] Zero Bubble Pipeline Parallelism, Penghui Qi+, ICLR'24, 2023.11
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #Parallelism Issue Date: 2024-12-16 GPT Summary- パイプライン並列は分散学習において重要だが、パイプラインバブルの影響を受ける。本研究では、初めてこのバブルをゼロにするスケジューリング戦略を提案。逆伝播計算を勾配計算の2つに分けるアイデアに基づき、新たなパイプラインスケジュールを構築。さらに、自動最適化アルゴリズムと新たな手法を導入し、実験結果は我々の手法が従来手法より最大23%スループットが向上することを示し、メモリ制約が緩和されると31%まで上昇。結果はパイプライン並列性の潜在力を示すもので、実装はオープンソース化されている。 Comment
openreview: https://openreview.net/forum?id=tuzTN0eIO5
[Paper Note] Number Cookbook: Number Understanding of Language Models and How to Improve It, Haotong Yang+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #LanguageModel #NumericReasoning #numeric #In-Depth Notes #Reading Reflections Issue Date: 2024-11-09 GPT Summary- 大規模言語モデル(LLM)の数値理解・処理能力(NUPA)を調査し、41の数値タスクを含むベンチマークを導入。これにより、LLMsが多くのタスクで頻繁に失敗することが判明。NUPA向上のため、小型モデルを訓練し、ファインチューニングの効果を評価。1) ファインチューニングが多くのタスクでNUPAを向上させるが、全てに効果的ではない。2) NUPA向上を目的とした手法がファインチューニングに効果的でないことが分かった。研究はLLMsのNUPA理解を深める。 Comment
んー、abstしか読んでいないけれども、9.11 > 9.9 については、このような数字に慣れ親しんでいるエンジニアなどに咄嗟に質問したら、ミスして答えちゃう人もいるのでは?という気がする(エンジニアは脳内で9.11 > 9.9を示すバージョン管理に触れる機会が多く、こちらの尤度が高い)。
LLMがこのようなミス(てかそもそもミスではなく、回答するためのcontextが足りてないので正解が定義できないだけ、だと思うが、、)をするのは、単に学習データにそういった9.11 > 9.9として扱うような文脈や構造のテキストが多く存在しており、これらテキスト列の尤度が高くなってこのような現象が起きているだけなのでは、という気がしている。
instructionで注意を促したり適切に問題を定義しなければ、そりゃこういう結果になって当然じゃない?という気がしている。
(ここまで「気がしている」を3連発してしまった…😅)
また、本研究で扱っているタスクのexampleは下記のようなものだが、これらをLLMに、なんのツールも利用させずautoregressiveな生成のみで解かせるというのは、人間でいうところの暗算に相当するのでは?と個人的には思う。
何が言いたいのかというと、人間でも暗算でこれをやらせたら解けない人がかなりいると思う(というか私自身単純な加算でも桁数増えたら暗算など無理)。
一方で暗算ではできないけど、電卓やメモ書き、計算機を使っていいですよ、ということにしたら多くの人がこれらタスクは解けるようになると思うので、LLMでも同様のことが起きると思う。
LLMの数値演算能力は人間の暗算のように限界があることを認知し、金融分野などの正確な演算や数値の取り扱うようなタスクをさせたかったら、適切なツールを使わせましょうね、という話なのかなあと思う。
元ポスト:
ICLR25のOpenReview。こちらを読むと興味深い。
https://openreview.net/forum?id=BWS5gVjgeY
幅広い数値演算のタスクを評価できるデータセット構築、トークナイザーとの関連性を明らかにした点、分析だけではなくLLMの数値演算能力を改善した点は評価されているように見える。
一方で、全体的に、先行研究との比較やdiscussionが不足しており、研究で得られた知見がどの程度新規性があるのか?といった点や、説明が不十分でjustificationが足りない、といった話が目立つように見える。
特に、そもそもLoRAやCoTの元論文や、Numerical Reasoningにフォーカスした先行研究がほぼ引用されていないらしい点が見受けられるようである。さすがにその辺は引用して研究のcontributionをクリアにした方がいいよね、と思うなどした。
>I am unconvinced that numeracy in LLMs is a problem in need of a solution. First, surely there is a citable source for LLM inadequacy for numeracy. Second, even if they were terrible at numeracy, the onus is on the authors to convince the reader that this a problem worth caring about, for at least two obvious reasons: 1) all of these tasks are already trivially done by a calculator or a python program, and 2) commercially available LLMs can probably do alright at numerical tasks indirectly via code-generation and execution. As it stands, it reads as if the authors are insisting that this is a problem deserving of attention --- I'm sure it could be, but this argument can be better made.
上記レビュワーコメントと私も同じことを感じる。なぜLLMそのものに数値演算の能力がないことが問題なのか?という説明があった方が良いのではないかと思う。
これは私の中では、論文のイントロで言及されているようなシンプルなタスクではなく、
- inputするcontextに大量の数値を入力しなければならず、
- かつcontext中の数値を厳密に解釈しなければならず、
- かつ情報を解釈するために計算すべき数式がcontextで与えられた数値によって変化するようなタスク(たとえばテキスト生成で言及すべき内容がgivenな数値情報によって変わるようなもの。最大値に言及するのか、平均値を言及するのか、数値と紐づけられた特定のエンティティに言及しなければならないのか、など)
(e.g. 上記を満たすタスクはたとえば、金融関係のdata-to-textなど)では、LLMが数値を解釈できないと困ると思う。そういった説明が入った方が良いと思うなあ、感。
NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, ICLR'24
Paper/Blog Link My Issue
#MachineLearning #Supervised-FineTuning (SFT) #PostTraining #One-Line Notes #Robustness Issue Date: 2024-10-27 GPT Summary- NEFTuneは、埋め込みベクトルにノイズを加えることで言語モデルのファインチューニングを改善する手法です。LLaMA-2-7Bを用いた標準的なファインチューニングでは29.79%の精度でしたが、ノイジーな埋め込みを使用することで64.69%に向上しました。NEFTuneは、Evol-Instruct、ShareGPT、OpenPlatypusなどの指示データセットでも改善をもたらし、RLHFで強化されたLLaMA-2-Chatにも効果があります。 Comment
ランダムノイズをembeddingに加えて学習するシンプルな手法。モデルがロバストになる。
Unsupervised SimCSEと思想が似ている。実質DataAugmentationともみなせる。
[Paper Note] ToolGen: Unified Tool Retrieval and Calling via Generation, Renxi Wang+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#Pretraining #Tools #NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #PostTraining #KeyPoint Notes #Reading Reflections Issue Date: 2024-10-20 GPT Summary- ToolGenは、LLMとツールの統合を革新する新しいアプローチを提案する。ツールをユニークなトークンとして表現し、ツール知識を直接LLMのパラメータに組み込むことで、ツール呼び出しと生成をシームレスに実現する。このフレームワークにより、追加ステップなしで多数のツールにアクセスでき、性能とスケーラビリティが向上する。47,000以上のツールでの実験結果は、ToolGenが自律的なタスク完遂において優れた成果を示し、多様な領域に適応可能なAIエージェントの新時代を切り開くことを示唆している。さらに、エンドツーエンドのツール学習を可能にし、他の高度な技術との統合機会を提供することで、LLMsの実践的な能力を拡張する。 Comment
昔からよくある特殊トークンを埋め込んで、特殊トークンを生成したらそれに応じた処理をする系の研究。今回はツールに対応するトークンを仕込む模様。
斜め読みだが、3つのstepでFoundation Modelを訓練する。まずはツールのdescriptionからツールトークンを生成する。これにより、モデルにツールの情報を覚えさせる(memorization)。斜め読みなので読めていないが、ツールトークンをvocabに追加してるのでここは継続的事前学習をしているかもしれない。続いて、(おそらく)人手でアノテーションされたクエリ-必要なツールのペアデータから、クエリに対して必要なツールを生成するタスクを学習させる。最後に、(おそらく人手で作成された)クエリ-タスクを解くためのtrajectoryペアのデータで学習させる。
学習データのサンプル。Appendix中に記載されているものだが、本文のデータセット節とAppendixの双方に、データの作り方の詳細は記述されていなかった。どこかに書いてあるのだろうか。
最終的な性能
特殊トークンを追加のvocabとして登録し、そのトークンを生成できるようなデータで学習し、vocabに応じて何らかの操作を実行するという枠組み、その学習手法は色々なタスクで役立ちそう。
openreview: https://openreview.net/forum?id=XLMAMmowdY
[Paper Note] Large Language Models Cannot Self-Correct Reasoning Yet, Jie Huang+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfCorrection Issue Date: 2024-09-07 GPT Summary- LLMは高いテキスト生成能力を持つ一方で、生成内容の正確性に懸念がある。自己修正というアプローチが提案されているが、本研究ではLLMの内的自己修正の役割と限界を検討。特に、外部フィードバックなしで応答を修正する際に苦労し、修正後にパフォーマンスが低下することを示している。今後の研究への提言も行う。 Comment
openreview: https://openreview.net/forum?id=IkmD3fKBPQ
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding, Zilong Wang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #DataToTextGeneration #Chain-of-Thought #TabularData #KeyPoint Notes Issue Date: 2024-01-24 GPT Summary- LLMsを使用したChain-of-Tableフレームワークは、テーブルデータを推論チェーン内で活用し、テーブルベースの推論タスクにおいて高い性能を発揮することが示された。このフレームワークは、テーブルの連続的な進化を表現し、中間結果の構造化情報を利用してより正確な予測を可能にする。さまざまなベンチマークで最先端のパフォーマンスを達成している。 Comment
Table, Question, Operation Historyから次のoperationとそのargsを生成し、テーブルを順次更新し、これをモデルが更新の必要が無いと判断するまで繰り返す。最終的に更新されたTableを用いてQuestionに回答する手法。Questionに回答するために、複雑なテーブルに対する操作が必要なタスクに対して有効だと思われる。
Knowledge Fusion of Large Language Models, Fanqi Wan+, N_A, ICLR'24
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #read-later #ModelMerge Issue Date: 2024-01-23 GPT Summary- 本研究では、既存の事前訓練済みの大規模言語モデル(LLMs)を統合することで、1つの強力なモデルを作成する方法を提案しています。異なるアーキテクチャを持つ3つの人気のあるLLMsを使用して、ベンチマークとタスクのパフォーマンスを向上させることを実証しました。提案手法のコード、モデルの重み、およびデータはGitHubで公開されています。
[Paper Note] The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning, Bill Yuchen Lin+, ICLR'24, 2023.12
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #In-ContextLearning #KeyPoint Notes Issue Date: 2023-12-05 GPT Summary- LLMのアライメント調整は、SFTとRLHFを含むが、LIMAの研究は1Kの例でも効果的なアライメントが達成できることを示した。基盤LLMとアラインメント版のトークン分布を分析した結果、ほぼ同一の性能を示し、文体的なシフトが顕著であった。このことから、SFTやRLHFなしでのアラインメント手法を探求し、新たにURIALを提案。URIALは、ICLを用い、少数の文体的例で効果的なアライメントを実現し、基盤LLMの性能がSFTによるものと同等、あるいは上回ることを示した。結果はアライメントの表面的性質を再考させるものであり、今後の研究への示唆となる。 Comment
モデルの知識はPre-training時に十分獲得されており、モデルのAlignmentをとることで生じるものは表面的な変化のみであるという仮説がある [Paper Note] LIMA: Less Is More for Alignment, Chunting Zhou+, arXiv'23, 2023.05
。この仮説に関して分析をし、結果的にスタイリスティックな情報を生成する部分でAlignmentの有無で違いが生じることを明らかにし、そうであればわざわざパラメータチューニング(SFT, RLHF)しなくても、適切なサンプルを選択したIn-Context LearningでもAlignmentとれますよ、という趣旨の研究っぽい?
openreview: https://openreview.net/forum?id=wxJ0eXwwda
[Paper Note] Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs, Qingru Zhang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention #One-Line Notes #Steering Issue Date: 2023-11-10 GPT Summary- PASTAは、大規模言語モデル(LLMs)において、ユーザーが指定した強調マークのあるテキストを読むことを可能にする手法です。PASTAは、注意の一部を特定し、再重み付けを適用してモデルの注意をユーザーが指定した部分に向けます。実験では、PASTAがLLMの性能を大幅に向上させることが示されています。 Comment
ユーザがprompt中で強調したいした部分がより考慮されるようにattention weightを調整することで、より応答性能が向上しましたという話っぽい。かなり重要な技術だと思われる。後でしっかり読む。
openreview: https://openreview.net/forum?id=xZDWO0oejD
[Paper Note] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Factuality #RAG(RetrievalAugmentedGeneration) #KeyPoint Notes #Critic Issue Date: 2023-10-29 GPT Summary- Self-Reflective Retrieval-Augmented Generation(Self-RAG)は、取得と自己反省を通じて大規模言語モデル(LLM)の品質を向上させる新しいフレームワークである。従来の方法が固定数のパッセージを無差別に取得するのに対し、Self-RAGは適応的にパッセージを取得し、reflection tokensを用いて生成と反省を行う。このアプローチにより、さまざまなタスクにおいて最先端のLLMや取得強化モデルを上回り、特に長文生成の事実性と出典の正確性が顕著に向上した。 Comment
RAGをする際の言語モデルの回答の質とfactual consistencyを改善せるためのフレームワーク。
reflection tokenと呼ばれる特殊トークンを導入し、言語モデルが生成の過程で必要に応じて情報をretrieveし、自身で生成内容を批評するように学習する。単語ごとに生成するのではなく、セグメント単位で生成する候補を生成し、批評内容に基づいて実際に生成するセグメントを選択する。
OpenReview: https://openreview.net/forum?id=hSyW5go0v8
[Paper Note] Human Feedback is not Gold Standard, Tom Hosking+, ICLR'24, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation Issue Date: 2023-10-28 GPT Summary- 人間のフィードバックは、大規模言語モデルの性能評価や訓練に重要であるが、好みスコアの主観性と偏りの影響について検証。好みスコアは網羅性が高いが、事実性の評価は不足していると判明。出力の断定性が事実性誤りの認識に影響し、人間の注釈の信頼性についても疑問を提起。人間のフィードバックによる訓練が断定性を偏らせる可能性も示唆。今後は好みスコアの目的との整合性を検討することが推奨される。 Comment
参考:
openreview: https://openreview.net/forum?id=7W3GLNImfS
Detecting Pretraining Data from Large Language Models, Weijia Shi+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #LanguageModel #One-Line Notes Issue Date: 2023-10-26 GPT Summary- 本研究では、大規模言語モデル(LLMs)を訓練するためのデータの検出問題を研究し、新しい検出方法であるMin-K% Probを提案します。Min-K% Probは、LLMの下で低い確率を持つアウトライアーワードを検出することに基づいています。実験の結果、Min-K% Probは従来の方法に比べて7.4%の改善を達成し、著作権のある書籍の検出や汚染された下流の例の検出など、実世界のシナリオにおいて効果的な解決策であることが示されました。 Comment
実験結果を見るにAUCは0.73-0.76程度であり、まだあまり高くない印象。また、テキストのlengthはそれぞれ32,64,128,256程度。
openreview: https://openreview.net/forum?id=zWqr3MQuNs
[Paper Note] Large Language Models as Optimizers, Chengrun Yang+, ICLR'24, 2023.09
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #AutomaticPromptEngineering #Selected Papers/Blogs #KeyPoint Notes #Reading Reflections Issue Date: 2023-09-09 GPT Summary- 最適化タスクを自然言語で記述するアプローチ、Optimization by PROmpting(OPRO)を提案。大規模言語モデル(LLMs)を用いて以前の解を基に新しい解を生成し、プロンプトに追加。線形回帰や巡回セールスマン問題での実証に続き、プロンプト最適化を行い、タスク精度を最大化。OPROで最適化されたプロンプトは、人間設計のものをGSM8Kで最大8%、Big-Bench Hardで最大50%上回ることを確認。 Comment
`Take a deep breath and work on this problem step-by-step. `論文
# 概要
LLMを利用して最適化問題を解くためのフレームワークを提案したという話。論文中では、linear regressionや巡回セールスマン問題に適用している。また、応用例としてPrompt Engineeringに利用している。
これにより、Prompt Engineeringが最適か問題に落とし込まれ、自動的なprompt engineeringによって、`Let's think step by step.` よりも良いプロンプトが見つかりましたという話。
# 手法概要
全体としての枠組み。meta-promptをinputとし、LLMがobjective functionに対するsolutionを生成する。生成されたsolutionとスコアがmeta-promptに代入され、次のoptimizationが走る。これを繰り返す。
Meta promptの例
openreview: https://openreview.net/forum?id=Bb4VGOWELI
テキスト空間上で過去の履歴とスコアが与えられ、それをgivenにスコアが良くなりそうなものをLLMがiterativeに生成していくことが可能なことが示されたのが興味深い
CausalLM is not optimal for in-context learning, Nan Ding+, N_A, ICLR'24
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #In-ContextLearning #Reading Reflections Issue Date: 2023-09-01 GPT Summary- 最近の研究では、トランスフォーマーベースのインコンテキスト学習において、プレフィックス言語モデル(prefixLM)が因果言語モデル(causalLM)よりも優れたパフォーマンスを示すことがわかっています。本研究では、理論的なアプローチを用いて、prefixLMとcausalLMの収束挙動を分析しました。その結果、prefixLMは線形回帰の最適解に収束する一方、causalLMの収束ダイナミクスはオンライン勾配降下アルゴリズムに従い、最適であるとは限らないことがわかりました。さらに、合成実験と実際のタスクにおいても、causalLMがprefixLMよりも性能が劣ることが確認されました。 Comment
参考:
CausalLMでICLをした場合は、ICL中のdemonstrationでオンライン学習することに相当し、最適解に収束しているとは限らない……?が、hillbigさんの感想に基づくと、結果的には実は最適解に収束しているのでは?という話も出ているし、よく分からない。
[Paper Note] Function Vectors in Large Language Models, Eric Todd+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Selected Papers/Blogs #reading #KeyPoint Notes Issue Date: 2026-06-02 GPT Summary- 自己回帰型トランスフォーマーLMsにおける入力と出力の関数を表すベクトルとしてのファンクションベクトル(FV)の存在を示す。因果媒介分析を用いて、少数のアテンションヘッドがタスクのコンパクトな表現を伝達することを確認し、FVがゼロショットや自然言語テキストのICLタスクに対しても頑健であることを明らかにした。中間層間での因果効果が強いことが判明し、FVには出力空間を符号化する情報が含まれているが、これだけではFVの再構成は不可である。さらに、FVにおける意味ベクトルの組成を調査し、足し合わせることで新たなタスクを引き起こすことができることを示した。これにより、関数抽象のコンパクトで因果的な内部表現をLLMsから抽出できることが確認された。 Comment
openreview: https://openreview.net/forum?id=AwyxtyMwaG
本研究では、In-context Learningを実施した際のLLMにおいて、あるタスクにおいて応答を生成する際に、当該タスクで必要な変換に関する情報を保持しているベクトル(Function Vectors)が、LLMの attention_ output に存在することを示唆する結果を得た。Function Vectorsは直接的にタスクを実施するわけではないが、特定の手続きを言語モデル内で遂行させるトリガーの役割を果たす。
Function Vectorを検出するために、あるタスク t において、Figure 2のようなinput-outputのペア (x_i, y_i) のみで promptingをすることでタスクを遂行させる方法を考える。また、prompt p が与えられたときに、outputをランダムな出力~y_iに変更した input-outputペア (x_i, ~y_i) prompt ~pを考える。このとき、あるタスクの遂行に強い影響を与えるLLM中のactivationを特定したい。
このために、本研究ではトークンをまたいだ情報のやりとりはattentionを介して実行されることから、分析対象をattentionに限定し、まず正常な in-context prompt p を入力した際の全てのlayer l のattention output a_lj (jはheadのindex) を計算する。続いて、ランダムな出力に置換され破損した in-context prompt ~p を入力した際に、ある layer l, head j のattentionを正常なin-context prompt p に基づいて計算されたものと置換して出力をさせ、正解 y_i を復元させる効果 Causal Indrect Effect (CIE) を 式(3)により定義する。つまり、破損したprompt ~pを利用した場合に、attentionを置換する前後によって、どれだけ正解y_iが得られる確率が大きくなったか、を測定している。
このCIEを全てのタスクに対して計算し、平均化することで、各種attention headのAverage Indirect Effectを計算する(式4)。これにより、どのattention headがタスクの遂行において強い因果的な影響力を保持するかを特定する。最終的に、AIEの値が大きなattention head集合Aを考えることができ、この少数のattention headの集合が、ICLタスクを特定し情報を伝達する役割を果たしているという仮説を立てることができる。また、Aが与えられたとき、a_ljのあるタスク t におけるactivationの平均をとることによって、1つのベクトルとして表現することができ、このベクトルのことをFunction Vector と呼ぶ(式5)。
[Paper Note] Language Modelling with Pixels, Phillip Rust+, ICLR'23, 2022.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Encoder #Pixel-based #Compression Issue Date: 2025-10-22 GPT Summary- PIXELは、テキストを画像として表現する新しい言語モデルで、語彙のボトルネックを回避し、言語間での表現転送を可能にする。86MパラメータのPIXELは、BERTと同じデータで事前学習され、非ラテン文字を含む多様な言語での構文的および意味的タスクでBERTを大幅に上回る性能を示したが、ラテン文字ではやや劣る結果となった。また、PIXELは正字法的攻撃や言語コードスイッチングに対してBERTよりも堅牢であることが確認された。 Comment
元ポスト:
[Paper Note] Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, Xingchao Liu+, ICLR'23, 2022.09
Paper/Blog Link My Issue
#ComputerVision #MachineLearning #Selected Papers/Blogs #RectifiedFlow Issue Date: 2025-10-10 GPT Summary- rectified flowという新しいアプローチを提案し、2つの分布間での輸送を学習するODEモデルを用いる。これは、直線的な経路を学習することで計算効率を高め、生成モデルやドメイン転送において統一的な解決策を提供する。rectificationを通じて、非増加の凸輸送コストを持つ新しい結合を生成し、再帰的に適用することで直線的なフローを得る。実証研究では、画像生成や翻訳において優れた性能を示し、高品質な結果を得ることが確認された。 Comment
openreview: https://openreview.net/forum?id=XVjTT1nw5z
日本語解説(fmuuly, zenn):
- Rectified Flow 1:
https://zenn.dev/fmuuly/articles/37cc3a2f17138e
- Rectified Flow 2:
https://zenn.dev/fmuuly/articles/a062fcd340207f
- Rectified Flow 3:
https://zenn.dev/fmuuly/articles/0f262fc003e202
[Paper Note] Building Normalizing Flows with Stochastic Interpolants, Michael S. Albergo+, ICLR'23
Paper/Blog Link My Issue
#FlowMatching #OptimalTransport Issue Date: 2025-07-09 GPT Summary- 基準確率密度とターゲット確率密度の間の連続時間正規化フローに基づく生成モデルを提案。従来の手法と異なり、逆伝播を必要とせず、速度に対する単純な二次損失を導出。フローはサンプリングや尤度推定に使用可能で、経路長の最小化も最適化できる。ガウス密度の場合、ターゲットをサンプリングする拡散モデルを構築可能だが、よりシンプルな確率流のアプローチを示す。密度推定タスクでは、従来の手法と同等以上の性能を低コストで達成し、画像生成においても良好な結果を示す。最大$128\times128$の解像度までスケールアップ可能。
[Paper Note] Flow Matching for Generative Modeling, Yaron Lipman+, ICLR'23
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #Selected Papers/Blogs #FlowMatching #OptimalTransport Issue Date: 2025-07-09 GPT Summary- Continuous Normalizing Flows(CNFs)に基づく新しい生成モデルの訓練手法Flow Matching(FM)を提案。FMは固定された条件付き確率経路のベクトル場を回帰し、シミュレーション不要で訓練可能。拡散経路と併用することで、より堅牢な訓練が実現。最適輸送を用いた条件付き確率経路は効率的で、訓練とサンプリングが速く、一般化性能も向上。ImageNetでの実験により、FMは拡散ベース手法よりも優れた性能を示し、迅速なサンプル生成を可能にする。 Comment
UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #MultiModal #Encoder #Encoder-Decoder #KeyPoint Notes Issue Date: 2024-09-26 GPT Summary- 本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 Comment
OpenReview: https://openreview.net/forum?id=6ruVLB727MC
encoder-decoder/decoder-onlyなど特定のアーキテクチャに依存しないアーキテクチャagnosticな事前学習手法であるMoDを提案。
MoDでは3種類のDenoiser [R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを活用する。学習時には与えらえたタスクに対して適切なモードをスイッチできるようにparadigm token ([R], [S], [X])を与え挙動を変化させられるようにしており[^1]、finetuning時においては事前にタスクごとに定義をして与えるなどのことも可能。
[^1]: 事前学習中に具体的にどのようにモードをスイッチするのかはよくわからなかった。ランダムに変更するのだろうか。
[Paper Note] NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #PostTraining #read-later #Initial Impression Notes Issue Date: 2023-10-26 GPT Summary- 単純なデータ拡張により、言語モデルのファインチューニングが改善されることを示す。NEFTuneは埋め込みベクトルにノイズを追加し、LLaMA-2-7Bのファインチューニングで29.79%から64.69%へ劇的な向上を実現。現代の指示データセットでも改善をもたらし、Evol-Instruct、ShareGPT、OpenPlatypusでそれぞれ10%、8%、8%の向上を示す。さらに、LLaMA-2-Chatに対しても恩恵を受ける。 Comment
Alpacaデータでの性能向上が著しい。かなり重要論文な予感。後で読む。
HuggingFaceのTRLでサポートされている
https://huggingface.co/docs/trl/sft_trainer
openreview: https://openreview.net/forum?id=0bMmZ3fkCk
[Paper Note] RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation, Fangyuan Xu+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #One-Line Notes #Compression Issue Date: 2023-10-10 GPT Summary- 推論時に文書を要約することでLMの性能を向上。抽出型と抽象型の2つの圧縮器を提案し、計算コストと関連情報の識別負担を軽減。要約が無関係な場合は空文字列を返すことで選択的付加を実現。言語モデリングと質問応答タスクで評価し、圧縮率6%で性能を維持し、市販の要約モデルを上回る成果を示した。圧縮器は他のLMにも適用可能で、忠実な要約を生成。 Comment
RAGをする際に、元文書群を要約して圧縮することで、性能低下を抑えながら最大6%程度まで元文書群を圧縮できた、とのこと。
元ツイート:
RAGを導入する際のコスト削減に有用そう
openreview: https://openreview.net/forum?id=mlJLVigNHp
[Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Selected Papers/Blogs #ReversalCurse #KeyPoint Notes Issue Date: 2023-10-09 GPT Summary- 自己回帰型の大規模言語モデル(LLMs)の一般化の失敗を指摘し、特に「AはB」で学習したモデルが「BはA」を自動的に推測できない現象、いわゆる逆転の呪いを明らかにする。例えば、「Valentina Tereshkovaは宇宙へ初めて行った女性である」と学習しても、「宇宙へ初めて行った女性は誰ですか?」には正答できない。ファインチューニングされたGPT-3とLlama-1が、この逆転の構造から正しく答えられない事例を示し、逆転の呪いはモデルのサイズやファミリーに関係なく存在することを確認した。さらに、ChatGPT(GPT-3.5およびGPT-4)の評価でも同様の傾向が見られ、質問によって正答率に大きな差が生じることが示された。 Comment
A is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
著者ツイート:
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。
また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。
このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。
openreview: https://openreview.net/forum?id=GPKTIktA0k
[Paper Note] Large Language Models as Analogical Reasoners, Michihiro Yasunaga+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #In-ContextLearning #KeyPoint Notes #Reading Reflections Issue Date: 2023-10-07 GPT Summary- アナロジー的プロンプティングを用いて、言語モデルに問題解決前に関連する例示を生成させる新手法を提案。ラベリング不要で汎用性が高く、適応性もある。実験では、GSM8K、MATH、Codeforces、BIG-Benchの推論タスクで0ショットおよび少数ショットCoTを上回る性能を示した。 Comment
以下、著者ツイートのざっくり翻訳:
人間は新しい問題に取り組む時、過去に解いた類義の問題を振り返り、その経験を活用する。これをLLM上で実践できないか?というのがアイデア。
Analogical Promptingでは、問題を解く前に、適切なexamplarを自動生成(problemとsolution)させ、コンテキストとして利用する。
これにより、examplarは自己生成されるため、既存のCoTで必要なexamplarのラベリングや検索が不要となることと、解こうとしている問題に合わせてexamplarを調整し、推論に対してガイダンスを提供することが可能となる。
実験の結果、数学、コード生成、BIG-Benchでzero-shot CoT、few-shot CoTを上回った。
LLMが知っており、かつ得意な問題に対してならうまく働きそう。一方で、LLMが苦手な問題などは人手作成したexamplarでfew-shotした方が(ある程度)うまくいきそうな予感がする。うまくいきそうと言っても、そもそもLLMが苦手な問題なのでfew-shotした程度では焼石に水だとは思うが。
openreview: https://openreview.net/forum?id=AgDICX1h50
[Paper Note] A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Hallucination #needs-revision Issue Date: 2023-09-30 GPT Summary- 基盤モデルにおける幻覚を特定・解明し、対処する取り組みを概観する総説論文。特に大規模基盤モデルに焦点を当て、幻覚現象を分類し、その評価基準を確立。既存の緩和戦略を検討し、今後の研究方向について論じる。全体として、LFMsに関連する幻覚の課題と解決策を包括的に探求。 Comment
Hallucinationを現象ごとに分類し、Hallucinationの程度の評価をする指標や、Hallucinationを軽減するための既存手法についてまとめられているらしい。
openreview: https://openreview.net/forum?id=pETSfWMUzy
[Paper Note] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, ICLR'23, 2022.10
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Quantization #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-09-29 GPT Summary- GPTモデルはその優れた性能にもかかわらず、高い計算とストレージコストが課題である。この問題を解決するため、近似二次情報に基づく新しい量子化手法GPTQを提案。GPTQは、1750億パラメータを持つモデルの量子化を約4時間で行い、精度をほとんど失うことなくビット幅を3または4ビットに削減する。また、この手法は圧縮の利得が2倍以上高く、単一のGPUでの推論を可能にし、極端な量子化条件でも合理的な精度を示す。実験により、推論速度が大幅に向上することが確認された。 Comment
# 概要
- 新たなpost-training量子化手法であるGPTQを提案
- 数時間以内に数千億のパラメータを持つモデルでの実行が可能であり、パラメータごとに3~4ビットまで圧縮するが、精度の大きな損失を伴わない
- OPT-175BおよびBLOOM-176Bを、約4時間のGPU時間で、perplexityのわずかな増加で量子化することができた
- 数千億のパラメータを持つ非常に高精度な言語モデルを3-4ビットに量子化可能なことを初めて示した
- 先行研究のpost-training手法は、8ビット(Yao et al., 2022; Dettmers et al., 2022)。
- 一方、以前のtraining-basedの手法は、1~2桁小さいモデルのみを対象としていた(Wu et al., 2022)。
# Background
## Layer-wise quantization
各linear layerがあるときに、full precisionのoutputを少量のデータセットをネットワークに流したときに、quantized weight W^barを用いてreconstructできるように、squared error lossを最小化する方法。
## Optimal Brain quantization (OBQ)
OBQでは equation (1)をWの行に関するsummationとみなす。そして、それぞれの行 **w** をOBQは独立に扱い、ある一つの重みw_qをquantizeするときに、エラーがw_qのみに基づいていることを補償するために他の**w**の全てのquantizedされていない重みをupdateする。式で表すと下記のようになり、Fは残りのfull-precision weightの集合を表している。
この二つの式を、全ての**w**の重みがquantizedされるまで繰り返し適用する。
つまり、ある一個の重みをquantizedしたことによる誤差を補うように、他のまだquantizedされていない重みをupdateすることで、次に別の重みをquantizedする際は、最初の重みがquantizedされたことを考慮した重みに対してquantizedすることになる。これを繰り返すことで、quantizedしたことによる誤差を考慮して**w**全体をアップデートできる、という気持ちだと思う。
この式は高速に計算することができ、medium sizeのモデル(25M parameters; ResNet-50 modelなど)とかであれば、single GPUで1時間でquantizeできる。しかしながら、OBQはO(d_row * d_col^3)であるため、(ここでd_rowはWの行数、d_colはwの列数)、billions of parametersに適用するには計算量が多すぎる。
# Algorithm
## Step 1: Arbitrary Order Insight.
通常のOBQは、量子化誤差が最も少ない重みを常に選択して、greedyに重みを更新していく。しかし、パラメータ数が大きなモデルになると、重みを任意の順序で量子化したとしてもそれによる影響は小さいと考えられる。なぜなら、おそらく、大きな個別の誤差を持つ量子化された重みの数が少ないと考えられ、その重みがプロセスのが進むにつれて(アップデートされることで?)相殺されるため。
このため、提案手法は、すべての行の重みを同じ順序で量子化することを目指し、これが通常、最終的な二乗誤差が元の解と同じ結果となることを示す。が、このために2つの課題を乗り越えなければならない。
## Step2. Lazy Batch-Updates
Fを更新するときは、各エントリに対してわずかなFLOPを使用して、巨大な行列のすべての要素を更新する必要があります。しかし、このような操作は、現代のGPUの大規模な計算能力を適切に活用することができず、非常に小さいメモリ帯域幅によってボトルネックとなる。
幸いにも、この問題は以下の観察によって解決できる:列iの最終的な四捨五入の決定は、この特定の列で行われた更新にのみ影響され、そのプロセスの時点で後の列への更新は関連がない。これにより、更新を「lazy batch」としてまとめることができ、はるかに効率的なGPUの利用が可能となる。(要は独立して計算できる部分は全部一気に計算してしまって、後で一気にアップデートしますということ)。たとえば、B = 128の列にアルゴリズムを適用し、更新をこれらの列と対応するB × Bブロックの H^-1 に格納する。
この戦略は理論的な計算量を削減しないものの、メモリスループットのボトルネックを改善する。これにより、非常に大きなモデルの場合には実際に1桁以上の高速化が提供される。
## Step 3: Cholesky Reformulation
行列H_F^-1が不定になることがあり、これがアルゴリズムが残りの重みを誤った方向に更新する原因となり、該当する層に対して悪い量子化を実施してしまうことがある。この現象が発生する確率はモデルのサイズとともに増加することが実際に観察された。これを解決するために、コレスキー分解を活用して解決している(詳細はきちんと読んでいない)。
# 実験で用いたCalibration data
GPTQのキャリブレーションデータ全体は、C4データセット(Raffel et al., 2020)からのランダムな2048トークンのセグメント128個で構成される。つまり、ランダムにクロールされたウェブサイトからの抜粋で、一般的なテキストデータを表している。GPTQがタスク固有のデータを一切見ていないため「ゼロショット」な設定でquantizationを実施している。
# Language Generationでの評価
WikiText2に対するPerplexityで評価した結果、先行研究であるRTNを大幅にoutperformした。
Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Prompting #AutomaticPromptEngineering Issue Date: 2023-09-05 GPT Summary- 大規模言語モデル(LLMs)は、自然言語の指示に基づいて一般的な用途のコンピュータとして優れた能力を持っています。しかし、モデルのパフォーマンスは、使用されるプロンプトの品質に大きく依存します。この研究では、自動プロンプトエンジニア(APE)を提案し、LLMによって生成された指示候補のプールから最適な指示を選択するために最適化します。実験結果は、APEが従来のLLMベースラインを上回り、19/24のタスクで人間の生成した指示と同等または優れたパフォーマンスを示しています。APEエンジニアリングされたプロンプトは、モデルの性能を向上させるだけでなく、フューショット学習のパフォーマンスも向上させることができます。詳細は、https://sites.google.com/view/automatic-prompt-engineerをご覧ください。 Comment
プロジェクトサイト: https://sites.google.com/view/automatic-prompt-engineer
openreview: https://openreview.net/forum?id=92gvk82DE-
[Paper Note] SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning, Ning Miao+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #SelfCorrection #Test-Time Scaling #Verification #SelfVerification Issue Date: 2023-08-08 GPT Summary- LLMの段階的推論能力を活用し、自己検証(SelfCheck)を提案してLLM自身が誤りを認識することを目指す。誤りの認識にはゼロショット検証スキームを用い、その結果を基に重み付き投票で回答性能を向上。GSM8K、MathQA、MATHデータセットで評価し、誤り認識の効果と正確性向上を確認。 Comment
これはおもしろそう。後で読む
OpenReview: https://openreview.net/forum?id=pTHfApDakA
[Paper Note] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework, Sirui Hong+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-08-08 GPT Summary- MetaGPTは、LLMベースのマルチエージェントシステムに人間のワークフローを統合し、複雑なタスクを小さなサブタスクに効率的に分解するメタプログラミングフレームワークです。これにより、中間結果の検証が可能になり、誤りを減少させます。また、共同ソフトウェアエンジニアリングのタスクにおいて、従来のシステムよりも一貫性のある解決策を提供します。プロジェクトはGitHubで公開されています。 Comment
要はBabyTalk, AutoGPTの進化系で、人間のワークフローを模倣するようにデザインしたら良くなりました、という話と思われる
ソフトウェアエンジニア、アーキテクト、プロダクトオーナー、プロジェクトマネージャーなどのロールを明示的に与えて、ゴールを目指す。もはやLLM内部でソフトウェア企業を模倣しているのと同様である。
openreview: https://openreview.net/forum?id=VtmBAGCN7o
[Paper Note] Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation, Xuefei Ning+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Decoding #One-Line Notes #Parallel Issue Date: 2023-08-08 GPT Summary- 本研究は、巨大言語モデル(LLMs)の生成遅延を低減するため、Skeleton-of-Thought(SoT)を提案。SoTは、まず回答のスケルトンを生成し、次に並列デコードを実行して内容を完成。12種のLLMでスピードアップと回答品質向上を実現。データ中心の最適化による効率的な推論を目指す。 Comment
最初に回答の枠組みだけ生成して、それぞれの内容を並列で出力させることでデコーディングを高速化しましょう、という話。
openreview: https://openreview.net/forum?id=mqVgBbNCm9
[Paper Note] ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Tools #NLP #Dataset #LanguageModel #AIAgents #SyntheticData #API #One-Line Notes #ToolUse Issue Date: 2023-08-08 GPT Summary- オープンソースのLLMにおけるツール使用能力の限界を克服するため、ToolLLMフレームワークを提案。ToolBenchデータセットを用いて、ChatGPTに指示を与え実世界のAPIを収集し、多様なシナリオをカバー。新しい探索手法DFSDTを開発することで、LLMsの推論能力を高め、ToolLLaMAが複雑な指示を効果的に実行できることを示した。ToolEvalにより評価を行い、ToolLLaMAはChatGPTと同等の性能を発揮する。さらに、適切なAPIを推奨するニューラルAPIリトリーバーを導入し、手動の選択を不要にした。 Comment
16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
openreview: https://openreview.net/forum?id=dHng2O0Jjr
[Paper Note] FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, Tri Dao, arXiv'23, 2023.07
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #Transformer #Attention #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-07-23 GPT Summary- 長いシーケンスを扱うトランスフォーマーの性能向上に寄与するFlashAttentionは、実行時間とメモリを線形に増加させるが、最適化されたGEMM演算には及ばない。FlashAttention-2では、作業分割を最適化し、非マトリクス積FLOPsを削減、アテンション計算を並列化、共有メモリ通信を減少することで、約2倍のスピードアップを実現。これにより、A100 GPU上で最大225 TFLOPs/sの訓練速度を達成し、モデルFLOPsの利用率は72%に向上した。 Comment
Flash Attention1よりも2倍高速なFlash Attention 2
Flash Attention1は
- [Paper Note] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, Tri Dao+, NeurIPS'22, 2022.05
を参照
openreview: https://openreview.net/forum?id=mZn2Xyh9Ec
[Paper Note] SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking, Chris Cundy+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #MachineLearning #NLP #LanguageModel #One-Line Notes #needs-revision Issue Date: 2023-06-26 GPT Summary- 自己回帰モデルは高い尤度を達成するものの、最大尤度推定(MLE)が生成タスクに必ずしも適合しないことがある。MLEは分布外の振る舞いに関する指針がないため、累積誤差が生じる。これに対処するため、生成を模倣学習(IL)として定式化し、生成系列の分布とデータセット由来の系列分布間のダイバージェンスを最小化。ILフレームワークでは、バックスペースアクションを導入し、モデルが不要なトークンを戻すことを可能にする。新たに提案するSequenceMatchは、敵対的訓練やアーキテクチャの変更なしで実装でき、SequenceMatch-χ^2ダイバージェンスを適切な訓練目的として特定。実験的に、SequenceMatchは言語モデルによるテキスト生成や算術においてMLEを上回る改善を示す。 Comment
backspaceアクションをテキスト生成プロセスに組み込むことで、out of distributionを引き起こすトークンを元に戻すことで、生成エラーを軽減させることができる。
openreview: https://openreview.net/forum?id=FJWT0692hw
[Paper Note] WizardCoder: Empowering Code Large Language Models with Evol-Instruct, Ziyang Luo+, arXiv'23, 2023.06
Paper/Blog Link My Issue
Issue Date: 2023-06-16 GPT Summary- Evol-Instruct法を用いて指示型ファインチューニングを行い、コード関連タスクで卓越するWizardCoderを提案。四つのベンチマークで他のオープンソースCode LLMsを大幅に上回り、最大規模のクローズドLLMsにも勝る性能を示す。 Comment
openreview: https://openreview.net/forum?id=UnUwSIgK5W
SemPPL: Predicting pseudo-labels for better contrastive representations, Matko Bošnjak+, N_A, ICLR'23
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Embeddings #RepresentationLearning #ContrastiveLearning #Semi-Supervised Issue Date: 2023-04-30 GPT Summary- 本研究では、コンピュータビジョンにおける半教師あり学習の問題を解決するために、Semantic Positives via Pseudo-Labels (SemPPL)という新しい手法を提案している。この手法は、ラベル付きとラベルなしのデータを組み合わせて情報豊富な表現を学習することができ、ResNet-$50$を使用してImageNetの$1\%$および$10\%$のラベルでトレーニングする場合、競合する半教師あり学習手法を上回る最高性能を発揮することが示された。SemPPLは、強力な頑健性、分布外および転移性能を示すことができる。 Comment
[Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Test-Time Scaling #Selected Papers/Blogs #MajorityVoting Issue Date: 2023-04-27 GPT Summary- 自己一貫性という新しいデコーディング戦略を提案し、chain-of-thought promptingの性能を向上。多様な推論経路をサンプリングし、一貫した答えを選択することで、GSM8KやSVAMPなどのベンチマークで顕著な改善を達成。 Comment
self-consistencyと呼ばれる新たなCoTのデコーディング手法を提案。
これは、難しいreasoningが必要なタスクでは、複数のreasoningのパスが存在するというintuitionに基づいている。
self-consistencyではまず、普通にCoTを行う。そしてgreedyにdecodingする代わりに、以下のようなプロセスを実施する:
1. 多様なreasoning pathをLLMに生成させ、サンプリングする。
2. 異なるreasoning pathは異なるfinal answerを生成する(= final answer set)。
3. そして、最終的なanswerを見つけるために、reasoning pathをmarginalizeすることで、final answerのsetの中で最も一貫性のある回答を見出す。
これは、もし異なる考え方によって同じ回答が導き出されるのであれば、その最終的な回答は正しいという経験則に基づいている。
self-consistencyを実現するためには、複数のreasoning pathを取得した上で、最も多いanswer a_iを選択する(majority vote)。これにはtemperature samplingを用いる(temperatureを0.5やら0.7に設定して、より高い信頼性を保ちつつ、かつ多様なoutputを手に入れる)。
temperature samplingについては[こちら](
https://openreview.net/pdf?id=rygGQyrFvH)の論文を参照のこと。
sampling数は増やせば増やすほど性能が向上するが、徐々にサチってくる。サンプリング数を増やすほどコストがかかるので、その辺はコスト感との兼ね合いになると思われる。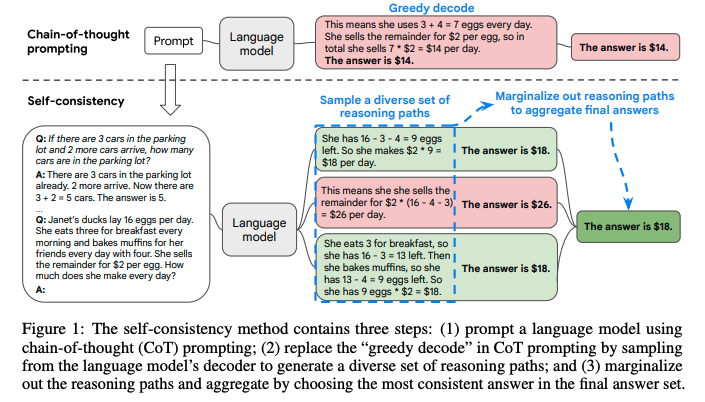
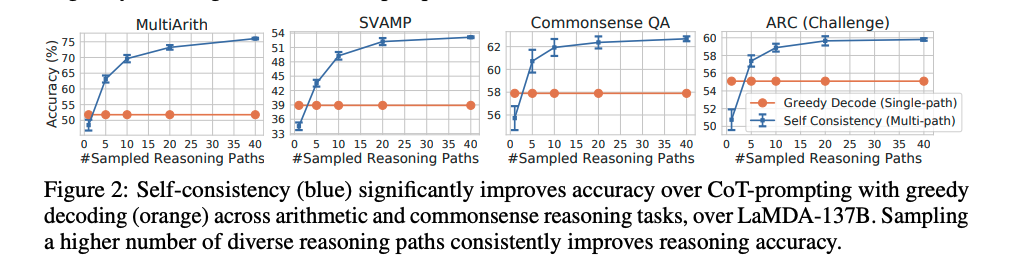
Self-consistencyは回答が閉じた集合であるような問題に対して適用可能であり、open-endなquestionでは利用できないことに注意が必要。ただし、open-endでも回答間になんらかの関係性を見出すような指標があれば実現可能とlimitationで言及している。
self-consistencyが提案されてからもう4年も経ったのか、、、
[Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)を用いて、段階的思考を促すCoT promptingを提案。手作業でデモを設計する必要なく、プロンプトを通じて推論チェーンを生成可能。また、多様性を持って質問をサンプリングする自動CoT法(Auto-CoT)を導入し、GPT-3を用いたベンチマークで手動設計と比較して優れた性能を示した。 Comment
LLMによるreasoning chainが人間が作成したものよりも優れていることを示しているとのこと [Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04 より
clusteringベースな手法を利用することにより、誤りを含む例が単一のクラスタにまとめられうことを示し、これにより過剰な誤ったデモンストレーションが軽減されることを示した。
手法の概要。questionを複数のクラスタに分割し、各クラスタから代表的なquestionをサンプリングし、zero-shot CoTでreasoning chainを作成しpromptに組み込む。最終的に回答を得たいquestionに対しても、上記で生成した複数のquestion-reasoningで条件付けした上で、zeroshot-CoTでrationaleを生成する。これにより自動的にCoTをICLするためのexamplarを生成できる。
openreview: https://openreview.net/forum?id=5NTt8GFjUHkr
[Paper Note] WizardLM: Empowering large pre-trained language models to follow complex instructions, Can Xu+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #InstructionTuning #SyntheticData #KeyPoint Notes Issue Date: 2023-04-25 GPT Summary- 本論文では、LLMを用いて複雑な指示データを自動生成する方法を提案。Evol-Instructを使用して初期の指示を段階的に書き換え、生成したデータでLLaMAをファインチューニングし、WizardLMモデルを構築。評価結果は、Evol-Instructからの指示が人間作成のものより優れており、WizardLMがChatGPTよりも高い評価を得ることを示す。AI進化による指示生成がLLM強化の有望なアプローチであることを示唆。 Comment
instruction trainingは大きな成功を収めているが、人間がそれらのデータを作成するのはコストがかかる。また、そもそも複雑なinstructionを人間が作成するのは苦労する。そこで、LLMに自動的に作成させる手法を提案している(これはself instructと一緒)。データを生成する際は、seed setから始め、step by stepでinstructionをrewriteし、より複雑なinstructionとなるようにしていく。
これらの多段的な複雑度を持つinstructionをLLaMaベースのモデルに食わせてfinetuningした(これをWizardLMと呼ぶ)。人手評価の結果、WizardLMがChatGPTよりも好ましいレスポンスをすることを示した。特に、WizaraLMはコード生成や、数値計算といった難しいタスクで改善を示しており、複雑なinstructionを学習に利用することの重要性を示唆している。
EvolInstructを提案。"1+1=?"といったシンプルなinstructionからスタートし、これをLLMを利用して段階的にcomplexにしていく。complexにする方法は2通り:
- In-Depth Evolving: instructionを5種類のoperationで深掘りする(blue direction line)
- add constraints
- deepening
- concretizing
- increase reasoning steps
- complicate input
- In-breadth Evolving: givenなinstructionから新しいinstructionを生成する
上記のEvolvingは特定のpromptを与えることで実行される。
また、LLMはEvolvingに失敗することがあるので、Elimination Evolvingと呼ばれるフィルタを利用してスクリーニングした。
フィルタリングでは4種類の失敗するsituationを想定し、1つではLLMを利用。2枚目画像のようなinstructionでフィルタリング。
1. instructionの情報量が増えていない場合。
2. instructionがLLMによって応答困難な場合(短すぎる場合やsorryと言っている場合)
3. puctuationやstop wordsによってのみ構成されている場合
4.明らかにpromptの中から単語をコピーしただけのinstruction(given prompt, rewritten prompt, #Rewritten Prompt#など)

[Paper Note] Perceiver: General Perception with Iterative Attention, Andrew Jaegle+, ICLR'22, 2021.03
Paper/Blog Link My Issue
#ComputerVision #NLP #Transformer #MultiModal #SpeechProcessing #Attention #Architecture #Selected Papers/Blogs #2D (Image) #audio #text Issue Date: 2026-02-07 GPT Summary- 本研究では、Transformersに基づく「Perceiver」モデルを提案し、生物システムのように多様なモダリティの高次元入力を同時に処理する能力を持つことを示します。従来のモデルが個々のモダリティに特化しているのに対し、Perceiverは少ない仮定で多数の入力を扱い、非対称注意メカニズムを用いて大規模なデータを処理します。これにより、画像や音声などの多様な分類タスクにおいて、先行モデルと同等以上の性能を実現しました。特に、ImageNetでは数十万のピクセルを直接扱い、ResNet-50やViTに匹敵する結果を達成し、AudioSetにおいても競争力を持っています。 Comment
openreview: https://openreview.net/forum?id=fILj7WpI-g
多様なモダリティ入力を単一のモデルで処理しlogitsで出力するtransformer。Perceiver-IOと並んで多様なモダリティを処理可能な先駆け的研究
Perceiverの出力は単純な分類問題を想定しており、より多様なoutputができるように拡張したものがPerceiver-IO:
- [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22, 2021.07
[Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22, 2021.07
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #NLP #MultitaskLearning #MultiModal #SpeechProcessing Issue Date: 2025-07-10 GPT Summary- 汎用アーキテクチャPerceiver IOを提案し、任意のデータ設定に対応し、入力と出力のサイズに対して線形にスケール可能。柔軟なクエリメカニズムを追加し、タスク特有の設計を不要に。自然言語、視覚理解、マルチタスクで強力な結果を示し、GLUEベンチマークでBERTを上回る性能を達成。 Comment
当時相当話題となったさまざまなモーダルを統一された枠組みで扱えるPerceiver IO論文
openreview: https://openreview.net/forum?id=fILj7WpI-g
[Paper Note] Fast Model Editing at Scale, Eric Mitchell+, ICLR'22
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeEditing Issue Date: 2025-06-18 GPT Summary- MEND(モデル編集ネットワーク)は、事前学習モデルの動作を迅速かつ局所的に編集するための手法で、単一の入力-出力ペアを用いて勾配分解を活用します。これにより、10億以上のパラメータを持つモデルでも、1台のGPUで短時間でトレーニング可能です。実験により、MENDが大規模モデルの編集において効果的であることが示されました。 Comment
OpenReview: https://openreview.net/forum?id=0DcZxeWfOPt
[Paper Note] LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
Paper/Blog Link My Issue
#NLP #LanguageModel #PEFT(Adaptor/LoRA) #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-05-12 GPT Summary- LoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。 Comment
OpenrReview: https://openreview.net/forum?id=nZeVKeeFYf9
LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。
- [Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
などでも示されているが、一般的にLoRAとFull Finetuningを比較するとLoRAの方が性能が低いことが知られている点には留意が必要。
最近、LoRAが学習率に対してsensitiveで、LoRAの提案以後約50種類の変種が提案されたが、適切にLoRAの学習率を調整した上で比較実験すると、依然としてオリジナルのLoRAが強力な手法であることが示された。以後提案された手法群は比較実験におけるハイパーパラメータの調整不足であることが指摘されている。
- [Paper Note] Learning Rate Matters: Vanilla LoRA May Suffice for LLM Fine-tuning, Yu-Ang Lee+, arXiv'26, 2026.02
Towards Continual Knowledge Learning of Language Models, Joel Jang+, ICLR'22
Paper/Blog Link My Issue
#Pretraining Issue Date: 2025-01-06 GPT Summary- 大規模言語モデル(LMs)の知識が陳腐化する問題に対処するため、「継続的知識学習(CKL)」という新しい継続的学習問題を定式化。CKLでは、時間不変の知識の保持、陳腐化した知識の更新、新しい知識の獲得を定量化するためのベンチマークとメトリックを構築。実験により、CKLが独自の課題を示し、知識を信頼性高く保持し学習するためにはパラメータの拡張が必要であることが明らかに。ベンチマークデータセットやコードは公開されている。
[Paper Note] Finetuned Language Models Are Zero-Shot Learners, Jason Wei+, ICLR'22, 2021.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-09-25 GPT Summary- 指示チューニングにより言語モデルのゼロショット学習能力を向上。1370億パラメータのモデルを60以上のNLPタスクに対してファインチューニングし、FLANと名付ける。FLANは未調整モデルを超え、25タスク中20タスクで175B GPT-3を上回り、ANLIやRTEなどでfew-shotのGPT-3にも勝る。ファインチューニングデータの数やモデル規模、指示内容が成功の鍵と示される。 Comment
FLAN論文。Instruction Tuningを提案した研究。
openreview: https://openreview.net/forum?id=gEZrGCozdqR
[Paper Note] Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution, Ananya Kumar+, arXiv'22, 2022.02
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #CLIP #OOD #Finetuning #KeyPoint Notes Issue Date: 2023-05-15 GPT Summary- ファインチューニングとリニアプロービングの2つの手法が、事前学習済みモデルの下流タスクへの移行において比較される。ファインチューニングはIDデータにおいて精度が高いが、分布シフトが大きい場合、OODデータではリニアプロービングより劣ることがある。10のデータセットでの分析により、ファインチューニングは平均してID精度で2%上回る一方、OOD精度は7%低下することが確認された。ファインチューニング中に特徴が歪むため、この現象が生じる。二段階戦略であるLP-FTが、両者の利点を活かし、データセット全体でファインチューニングとリニアプロービングを上回ることが示された。 Comment
事前学習済みのニューラルモデルをfinetuningする方法は大きく分けて
1. linear layerをヘッドとしてconcatしヘッドのみのパラメータを学習
2. 事前学習済みモデル全パラメータを学習
の2種類がある。
前者はin-distributionデータに強いが、out-of-distributionに弱い。後者は逆という互いが互いを補完し合う関係にあった。
そこで、まず1を実施し、その後2を実施する手法を提案。in-distribution, out-of-distributionの両方で高い性能を出すことを示した(実験では画像処理系のデータを用いて、モデルとしてはImageNet+CLIPで事前学習済みのViTを用いている)。
[Paper Note] Mass-Editing Memory in a Transformer, Kevin Meng+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeEditing #needs-revision Issue Date: 2023-05-04 GPT Summary- 最近の研究は、大規模言語モデルの更新に新たな記憶を利用する可能性を示しているが、主に単一の関連付けに限定されています。我々はMEMITを開発し、複数の記憶を使ってモデルを直接更新する手法を提案します。実験的に、GPT-J(6B)およびGPT-NeoX(20B)に対して多数の関連付けを効果的に処理できることを示し、従来の方法を大幅に上回る成果を達成しました。
[Paper Note] Transformers Learn Shortcuts to Automata, Bingbin Liu+, arXiv'22, 2022.10
Paper/Blog Link My Issue
Issue Date: 2023-05-04 GPT Summary- 低深度のトランスフォーマーモデルは再帰的な計算を欠くが、任意の有限状態オートマトンを表現できることが示された。具体的には、$o(T)$層のTransformerが長さ$T$の入力列上での計算を再現できることから、ショートカット解の存在が明らかとなった。多項式サイズの$O(\log T)$深さの解は常に存在し、特に$O(1)$深さのシミュレーションが一般的であることも発見された。実験により、トランスフォーマーが幅広いオートマトンを模倣できることが確認され、ショートカット解の脆弱性とその緩和策が提案された。 Comment
OpenReview: https://openreview.net/forum?id=De4FYqjFueZ
[Paper Note] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy+, ICLR'21
Paper/Blog Link My Issue
#ComputerVision #Transformer #Selected Papers/Blogs #Backbone Issue Date: 2025-08-25 GPT Summary- 純粋なトランスフォーマーを画像パッチのシーケンスに直接適用することで、CNNへの依存なしに画像分類タスクで優れた性能を発揮できることを示す。大量のデータで事前学習し、複数の画像認識ベンチマークで最先端のCNNと比較して優れた結果を達成し、計算リソースを大幅に削減。 Comment
openreview: https://openreview.net/forum?id=YicbFdNTTy
ViTを提案した研究
[Paper Note] Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets, Alethea Power+, ICLR'21 Workshop, 2022.01
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Grokking #Workshop #One-Line Notes Issue Date: 2023-04-25 GPT Summary- 小規模データセットにおけるニューラルネットワークの一般化を探求。データ効率、記憶、一般化、学習速度に関する問題を分析し、学習過程の「グロッキング」を通じて一般化性能の改善を示す。特に、小さなデータセットではより多くの最適化が必要であることが明らかにされ、過剰パラメータ化されたネットワークの一般化メカニズムを理解するための重要な知見を提供。 Comment
学習後すぐに学習データをmemorizeして、汎化能力が無くなったと思いきや、10^3ステップ後に突然汎化するという現象(Grokking)を報告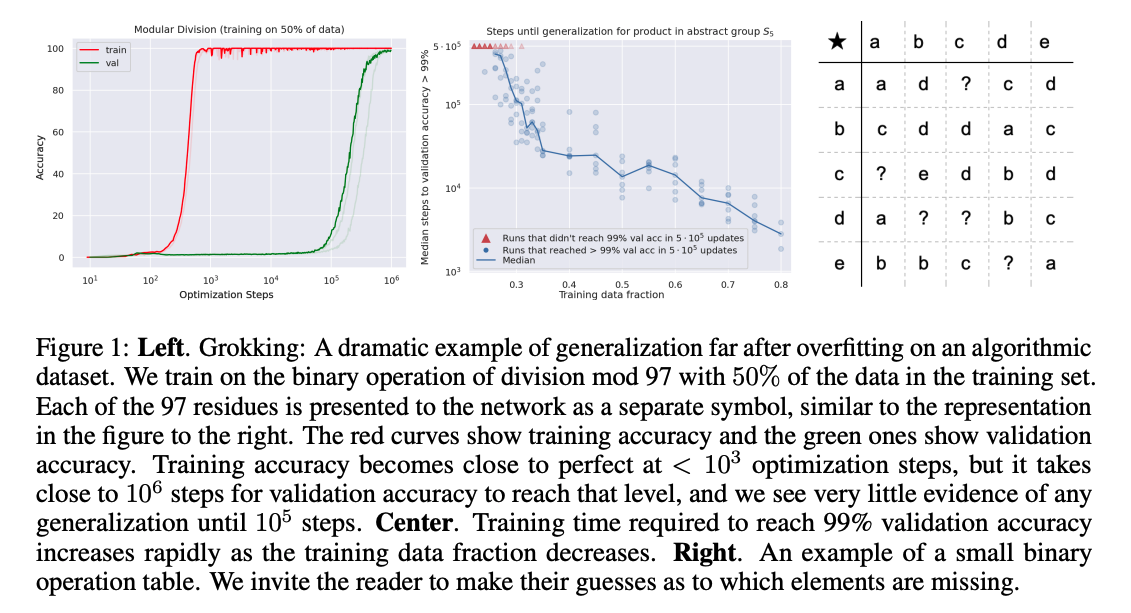
学習データが小さければ小さいほど汎化能力を獲得するのに時間がかかる模様
[Paper Note] Reformer: The Efficient Transformer, Nikita Kitaev+, ICLR'20
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #Sparse #SparseAttention Issue Date: 2025-08-05 GPT Summary- 本研究では、トランスフォーマーモデルの効率を向上させるために、局所感度ハッシュを用いた注意機構と可逆残差層を提案。これにより、計算量をO($L^2$)からO($L\log L$)に削減し、メモリ効率と速度を向上させたReformerモデルを実現。トランスフォーマーと同等の性能を維持。 Comment
openreview: https://openreview.net/forum?id=rkgNKkHtvB
[Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #LearningPhenomena Issue Date: 2025-07-12 GPT Summary- 深層学習タスクにおける「ダブルデセント」現象を示し、モデルサイズの増加に伴い性能が一時的に悪化し、その後改善されることを明らかにした。また、ダブルデセントはモデルサイズだけでなくトレーニングエポック数にも依存することを示し、新たに定義した「効果的なモデルの複雑さ」に基づいて一般化されたダブルデセントを仮定。これにより、トレーニングサンプル数を増やすことで性能が悪化する特定の領域を特定できることを示した。 Comment
[Paper Note] A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen+, ICML'20
Paper/Blog Link My Issue
#ComputerVision #DataAugmentation #ContrastiveLearning #Self-SupervisedLearning #Selected Papers/Blogs Issue Date: 2025-05-18 GPT Summary- 本論文では、視覚表現の対比学習のためのシンプルなフレームワークSimCLRを提案し、特別なアーキテクチャやメモリバンクなしで対比自己教師あり学習を簡素化します。データ拡張の重要性、学習可能な非線形変換の導入による表現の質向上、対比学習が大きなバッチサイズと多くのトレーニングステップから利益を得ることを示し、ImageNetで従来の手法を上回る結果を達成しました。SimCLRによる自己教師あり表現を用いた線形分類器は76.5%のトップ1精度を達成し、教師ありResNet-50に匹敵します。ラベルの1%でファインチューニングした場合、85.8%のトップ5精度を達成しました。 Comment
日本語解説: https://techblog.cccmkhd.co.jp/entry/2022/08/30/163625
[Paper Note] Editable Neural Networks, Anton Sinitsin+, ICLR'20
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #NLP #KnowledgeEditing #read-later #One-Line Notes Issue Date: 2025-05-07 GPT Summary- 深層ニューラルネットワークの誤りを迅速に修正するために、Editable Trainingというモデル非依存の訓練手法を提案。これにより、特定のサンプルの誤りを効率的に修正し、他のサンプルへの影響を避けることができる。大規模な画像分類と機械翻訳タスクでその有効性を実証。 Comment
(おそらく)Knowledge Editingを初めて提案した研究
OpenReview: https://openreview.net/forum?id=HJedXaEtvS
[Paper Note] The Curious Case of Neural Text Degeneration, Ari Holtzman+, ICLR'20
Paper/Blog Link My Issue
#NLP #LanguageModel #Decoding #Diversity #Selected Papers/Blogs Issue Date: 2025-04-14 GPT Summary- 深層ニューラル言語モデルは高品質なテキスト生成において課題が残る。尤度の使用がモデルの性能に影響を与え、人間のテキストと機械のテキストの間に分布の違いがあることを示す。デコーディング戦略が生成テキストの質に大きな影響を与えることが明らかになり、ニュークリアスsamplingを提案。これにより、多様性を保ちながら信頼性の低い部分を排除し、人間のテキストに近い質を実現する。 Comment
現在のLLMで主流なNucleus (top-p) Samplingを提案した研究
[Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-07-24 GPT Summary- 新しいテストを提案し、57のマルチタスクを用いてテキストモデルの正確度を測定。高い正確度には広範な世界知識と問題解決能力が必要である。GPT-3モデルはランダム推測を約20ポイント上回るが、専門家レベルには遠く、多くのタスクで偏った性能を示す。特に道徳や法に関してはほぼランダムに近い正確度を記録。このテストはモデルの理解力を評価し、重要な欠点を明らかにすることを目的とする。 Comment
OpenReview: https://openreview.net/forum?id=d7KBjmI3GmQ
MMLU論文
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
において、多くのエラーが含まれることが指摘され、再アノテーションが実施されている。
[Paper Note] Universal Transformers, Mostafa Dehghani+, ICLR'19
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #Selected Papers/Blogs #Generalization #LatentReasoning #RecurrentModels Issue Date: 2025-08-30 GPT Summary- 再帰神経ネットワーク(RNN)は逐次処理によりシーケンスモデリングで広く使われてきたが、トレーニングが遅くなる欠点がある。最近のフィードフォワードや畳み込みアーキテクチャは並列処理が可能で優れた結果を出しているが、RNNが得意とする単純なタスクでの一般化には失敗する。そこで、我々はユニバーサル・トランスフォーマー(UT)を提案し、フィードフォワードの並列処理能力とRNNの帰納バイアスを組み合わせたモデルを開発した。UTは特定の条件下でチューリング完全であり、実験では標準的なトランスフォーマーを上回る性能を示し、特にLAMBADAタスクで新たな最先端を達成し、機械翻訳でもBLEUスコアを改善した。 Comment
openreview: https://openreview.net/forum?id=HyzdRiR9Y7
[Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #LearningPhenomena Issue Date: 2025-07-12 GPT Summary- ニューラルネットワークのプルーニング技術は、パラメータ数を90%以上削減しつつ精度を維持できるが、スパースアーキテクチャの訓練は難しい。著者は「ロッタリー・チケット仮説」を提唱し、密なネットワークには効果的に訓練できるサブネットワーク(勝利のチケット)が存在することを発見。これらのチケットは特定の初期重みを持ち、元のネットワークと同様の精度に達する。MNISTとCIFAR10の実験で、10-20%のサイズの勝利のチケットを一貫して特定し、元のネットワークよりも早く学習し高精度に達することを示した。 Comment
[Paper Note] Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play, Sainbayar Sukhbaatar+, ICLR'18, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ReinforcementLearning #read-later #Selected Papers/Blogs #SelfPlay Issue Date: 2026-04-29 GPT Summary- エージェントが教師なしで学習するための単純なスキームを提案。アリスとボブの二つのエージェントが対戦し、アリスが課題を提示、ボブがそれを完了しようと試みる。可逆な環境とリセット可能な環境に焦点を当て、アリスが行動を提案し、ボブがそれを元に戻すか繰り返す。適切な報酬設計により、自動的に探索のカリキュラムを生成し、教師なし学習を実現。ボブをRLタスクに適用することで、教師付きエピソードの数を減少させ、高い報酬へ収束する可能性がある。 Comment
openreview: https://openreview.net/forum?id=SkT5Yg-RZ
[Paper Note] A Deep Reinforced Model for Abstractive Summarization, Romain Paulus+, ICLR'18, 2017.05
Paper/Blog Link My Issue
#DocumentSummarization #Supervised #NLP #Abstractive #ReinforcementLearning Issue Date: 2017-12-31 GPT Summary- 新しいイントラアテンションを持つRNNベースのエンコーダ-デコーダモデルを提案し、教師あり学習と強化学習を組み合わせたトレーニング手法を導入。これにより、長い文書の要約における繰り返しや一貫性の問題を改善。CNN/Daily Mailデータセットで41.16のROUGE-1スコアを達成し、従来のモデルを上回る性能を示した。人間評価でも高品質な要約を生成することが確認された。
[Paper Note] Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, Noam Shazeer+, ICLR'17
Paper/Blog Link My Issue
#NeuralNetwork #NLP #MoE(Mixture-of-Experts) #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-04-29 GPT Summary- 条件付き計算を用いたスパースゲーテッドミクスチャーオブエキスパート(MoE)レイヤーを導入し、モデル容量を1000倍以上向上。学習可能なゲーティングネットワークが各例に対してスパースなエキスパートの組み合わせを決定。最大1370億パラメータのMoEをLSTM層に適用し、言語モデリングや機械翻訳で低コストで優れた性能を達成。 Comment
Mixture-of-Experts (MoE) Layerを提案した研究
[Paper Note] A Structured Self-attentive Sentence Embedding, Zhouhan Lin+, ICLR'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #Embeddings #NLP #RepresentationLearning #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-28 GPT Summary- 自己注意機構を用いた新しい文埋め込みモデルを提案。2次元行列で文の異なる部分に注意を払い、視覚化手法も提供。著者プロファイリング、感情分類、テキスト含意の3つのタスクで評価し、他の手法と比較して性能が向上したことを示す。 Comment
OpenReview: https://openreview.net/forum?id=BJC_jUqxe
日本語解説: https://ryotaro.dev/posts/a_structured_self_attentivesentence_embedding/
self-attentionを提案した研究
[Paper Note] Very Deep Convolutional Networks for Large-Scale Image Recognition, Karen Simonyan+, ICLR'15
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Backbone Issue Date: 2025-08-25 GPT Summary- 本研究では、3x3の畳み込みフィルタを用いた深い畳み込みネットワークの精度向上を評価し、16-19層の重み層で従来の最先端構成を大幅に改善したことを示す。これにより、ImageNet Challenge 2014で1位と2位を獲得し、他のデータセットでも優れた一般化性能を示した。最も性能の良い2つのConvNetモデルを公開し、深層視覚表現の研究を促進する。 Comment
いわゆるVGGNetを提案した論文
[Paper Note] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP #Attention #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-05-12 GPT Summary- ニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment
(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している)
[Paper Note] Session-based Recommendations with Recurrent Neural Networks, Balázs Hidasi+, arXiv'15
Paper/Blog Link My Issue
#RecommenderSystems #SessionBased #SequentialRecommendation #Selected Papers/Blogs #One-Line Notes Issue Date: 2019-08-02 GPT Summary- RNNを用いたセッションベースのレコメンダーシステムを提案。短いユーザーヒストリーに基づく推薦の精度向上を目指し、セッション全体をモデル化。ランキング損失関数などの修正を加え、実用性を考慮。実験結果は従来のアプローチに対して顕著な改善を示す。 Comment
RNNを利用したsequential recommendation (session-based recommendation)の先駆け的論文。
日本語解説: https://qiita.com/tatamiya/items/46e278a808a51893deac
[Paper Note] Auto-Encoding Variational Bayes, Diederik P Kingma+, ICLR'14, 2013.12
Paper/Blog Link My Issue
#MachineLearning #VariationalAutoEncoder #Selected Papers/Blogs Issue Date: 2026-01-24 GPT Summary- 大規模データセットに対して効率的な推論と学習を実現するために、スケーラブルな確率的変分推論アルゴリズムを提案。変分下限の再パラメータ化により、標準的な確率勾配法で最適化可能な下限推定器を導出し、i.i.d.データセットにおける難しい事後分布の近似推論を効率的に行えることを示した。実験結果が理論的な利点を裏付けている。 Comment
openreview: https://openreview.net/forum?id=33X9fd2-9FyZd
VAEを提案した研究
日本語解説:
- makotomurakami.com/blog/2018/09/12/454/
-
https://musyoku.github.io/2016/04/29/auto-encoding-variational-bayes/
ICLR 2026 - Submissions, Pangram Labs, 2025.11
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Blog #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-11-15 Comment
元ポスト:
ICLR'26のsubmissionとreviewに対してLLMが生成したものが否かをDetectionした結果(検出性能は完璧な結果ではない点に注意)
この辺の議論が興味深い:
関連:
oh...
パイプライン解説:
母国語でレビューを書いて英語に翻訳している場合もAI判定される場合があるよという話:
ICLR公式が対応検討中とのこと:
ICLRからの続報:
> As such, reviewers who posted such poor quality reviews will also face consequences, including the desk rejection of their submitted papers.
> Authors who got such reviews (with many hallucinated references or false claims) should post a confidential message to ACs and SACs pointing out the poor quality reviews and provide the necessary evidence.
citationに明らかな誤植があり、LLMによるHallucinationが疑われる事例が多数見つかっている:
Oralに選ばれるレベルのスコアの研究論文にも多数のHallucinationが含まれており、1人の査読者がそれに気づきスコア0を与える、といった事態にもなっているようである:
当該論文はdesk rejectされたので現在は閲覧できないとのこと。
NeurIPS'25ではそもそも査読を通過した研究についても多くのHallucinationが見つかっているとのこと: