
translation_required
#read-later
Issue Date: 2025-07-31 A New Formulation of Zipf’s Meaning-Frequency Law through Contextual Diversity, Nagata+, ACL'25 Summary本論文では、Zipfの意味-頻度法則を単語の頻度と文脈の多様性の関係として定式化し、言語モデルから得られた単語ベクトルを用いて意味のカウントを定量化する新たな解釈を提案。さらに、LMのサイズが小さいと法則が観測できないことを示し、自回帰型LMがマスク型LMよりも多くのパラメータを必要とすることを明らかにした。 #Analysis #MachineLearning #NLP #Transformer #In-ContextLearning #ICML
Issue Date: 2025-07-13 [Paper Note] Nonlinear transformers can perform inference-time feature learning, Nishikawa+, ICML'25 Summary事前学習されたトランスフォーマーは、推論時に特徴を学習する能力を持ち、特に単一インデックスモデルにおける文脈内学習に焦点を当てています。勾配ベースの最適化により、異なるプロンプトからターゲット特徴を抽出し、非適応的アルゴリズムを上回る統計的効率を示します。また、推論時のサンプル複雑性が相関統計クエリの下限を超えることも確認されました。 Comment元ポスト:https://x.com/btreetaiji/status/1944297631808991742?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #MachineLearning #Pocket #LanguageModel #ReinforcementLearning #Reasoning #LongSequence #GRPO #read-later
Issue Date: 2025-03-20 DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25 Summary推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。ちとこれはあとでしっかり読みたい。重要論文。プロジェクトページ:https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。解説ポスト:https://x.com/theturingpost/status/1902507148015489385?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
コンパクトだが分かりやすくまとまっている。下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:https://x.com/iscienceluvr/status/1936375947575632102?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-31 A New Formulation of Zipf’s Meaning-Frequency Law through Contextual Diversity, Nagata+, ACL'25 Summary本論文では、Zipfの意味-頻度法則を単語の頻度と文脈の多様性の関係として定式化し、言語モデルから得られた単語ベクトルを用いて意味のカウントを定量化する新たな解釈を提案。さらに、LMのサイズが小さいと法則が観測できないことを示し、自回帰型LMがマスク型LMよりも多くのパラメータを必要とすることを明らかにした。 #Analysis #MachineLearning #NLP #Transformer #In-ContextLearning #ICML
Issue Date: 2025-07-13 [Paper Note] Nonlinear transformers can perform inference-time feature learning, Nishikawa+, ICML'25 Summary事前学習されたトランスフォーマーは、推論時に特徴を学習する能力を持ち、特に単一インデックスモデルにおける文脈内学習に焦点を当てています。勾配ベースの最適化により、異なるプロンプトからターゲット特徴を抽出し、非適応的アルゴリズムを上回る統計的効率を示します。また、推論時のサンプル複雑性が相関統計クエリの下限を超えることも確認されました。 Comment元ポスト:https://x.com/btreetaiji/status/1944297631808991742?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #MachineLearning #Pocket #LanguageModel #ReinforcementLearning #Reasoning #LongSequence #GRPO #read-later
Issue Date: 2025-03-20 DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25 Summary推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。ちとこれはあとでしっかり読みたい。重要論文。プロジェクトページ:https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。解説ポスト:https://x.com/theturingpost/status/1902507148015489385?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
コンパクトだが分かりやすくまとまっている。下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:https://x.com/iscienceluvr/status/1936375947575632102?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#ACL
Issue Date: 2025-03-06
Full Parameter Fine-tuning for Large Language Models with Limited Resources, Lv+, ACL'24, 2024.08
Summary新しいオプティマイザ「LOMO」を提案し、勾配計算とパラメータ更新を1ステップで融合することでメモリ使用量を削減。これにより、24GBのメモリを持つ8台のRTX 3090で65Bモデルの全パラメータファインチューニングが可能に。メモリ使用量は標準的なアプローチと比較して10.8%削減。
#Pocket
#NLP
#LanguageModel
#LLMAgent
#Blog
#NeurIPS
Issue Date: 2025-01-25
[Paper Note] Chain of Agents: Large language models collaborating on long-context tasks, Google Research, 2025.01, NeurIPS'24
Comment元ポスト:https://x.com/googleai/status/1882554959272849696?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLMがどこまでいってもcontext長の制約に直面する問題に対してLLM Agentを組み合わせて対処しました、的な話な模様ブログ中にアプローチを解説した動画があるのでわかりやすいIs the experimental code open source?Thank you for your comment. I tried to find an official open-source implementation provided by the authors, but I was not able to locate one. In fact, I also checked the personal webpage of the first author, but there was no link to any released code.
Is seems that an unofficial implementation is listed under the “Code” tab on the NeurIPS page. I hope this is helpful. Thank you.
NeurIPS link: https://nips.cc/virtual/2024/poster/95563
openreview: https://openreview.net/forum?id=LuCLf4BJsr #Pocket #ACL Issue Date: 2025-01-06 Legal Case Retrieval: A Survey of the State of the Art, Feng+, ACL'24, 2024.08 Summary法的ケース検索(LCR)の重要性が増しており、歴史的なケースを大規模な法的データベースから検索するタスクに焦点を当てている。本論文では、LCRの主要なマイルストーンを調査し、研究者向けに関連データセットや最新のニューラルモデル、その性能を簡潔に説明する。 #Pocket #ACL Issue Date: 2025-01-06 Learning Global Controller in Latent Space for Parameter-Efficient Fine-Tuning, Tan+, ACL'24, 2024.08 Summary大規模言語モデル(LLMs)の高コストに対処するため、パラメータ効率の良いファインチューニング手法を提案。潜在ユニットを導入し、情報特徴を洗練することで下流タスクのパフォーマンスを向上。非対称注意メカニズムにより、トレーニングのメモリ要件を削減し、フルランクトレーニングの問題を軽減。実験結果は、自然言語処理タスクで最先端の性能を達成したことを示す。 #Pocket #ACL Issue Date: 2025-01-06 Llama2Vec: Unsupervised Adaptation of Large Language Models for Dense Retrieval, Li+, ACL'24, 2024.08 SummaryLlama2Vecは、LLMを密な検索に適応させるための新しい非監視適応アプローチであり、EBAEとEBARの2つの前提タスクを用いています。この手法は、WikipediaコーパスでLLaMA-2-7Bを適応させ、密な検索ベンチマークでの性能を大幅に向上させ、特にMSMARCOやBEIRで最先端の結果を達成しました。モデルとソースコードは公開予定です。 #Pocket #Education #ACL Issue Date: 2025-01-06 BIPED: Pedagogically Informed Tutoring System for ESL Education, Kwon+, ACL'24, 2024.08 Summary大規模言語モデル(LLMs)を用いた会話型インテリジェントチュータリングシステム(CITS)は、英語の第二言語(L2)学習者に対して効果的な教育手段となる可能性があるが、既存のシステムは教育的深さに欠ける。これを改善するために、バイリンガル教育的情報を持つチュータリングデータセット(BIPED)を構築し、対話行為の語彙を考案した。GPT-4とSOLAR-KOを用いて二段階のフレームワークでCITSモデルを実装し、実験により人間の教師のスタイルを再現し、多様な教育的戦略を採用できることを示した。 #Pocket #ACL Issue Date: 2025-01-06 MELA: Multilingual Evaluation of Linguistic Acceptability, Zhang+, ACL'24, 2024.08 Summary本研究では、46,000サンプルからなる「多言語言語的受容性評価(MELA)」ベンチマークを発表し、10言語にわたるLLMのベースラインを確立。XLM-Rを用いてクロスリンガル転送を調査し、ファインチューニングされたXLM-RとGPT-4oの性能を比較。結果、GPT-4oは多言語能力で優れ、オープンソースモデルは劣ることが判明。クロスリンガル転送実験では、受容性判断の転送が複雑であることが示され、MELAでのトレーニングがXLM-Rの構文タスクのパフォーマンス向上に寄与することが確認された。 #Pocket #ACL Issue Date: 2025-01-06 AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators, Jingwei+, ACL'24, 2024.08 Summary生成AIの普及に伴い、自動事実確認手法が重要視されているが、事実主張の検出にはスケーラビリティと一般化可能性の問題がある。これに対処するため、事実主張の統一的な定義を提案し、AFaCTAという新しいフレームワークを導入。AFaCTAはLLMsを活用し、注釈の信頼度を調整する。広範な評価により、専門家の注釈作業を効率化し、PoliClaimという包括的な主張検出データセットを作成した。 #Pocket #ACL Issue Date: 2025-01-06 Evaluating Intention Detection Capability of Large Language Models in Persuasive Dialogues, Sakurai+, ACL'24, 2024.08 SummaryLLMsを用いてマルチターン対話における意図検出を調査。従来の研究が会話履歴を無視している中、修正したデータセットを用いて意図検出能力を評価。特に説得的対話では他者の視点を考慮することが重要であり、「フェイスアクト」の概念を取り入れることで、意図の種類に応じた分析が可能となる。 #Pocket #LanguageModel #EducationalDataMining Issue Date: 2025-01-06 Engaging an LLM to Explain Worked Examples for Java Programming: Prompt Engineering and a Feasibility Study, Hassany+, EDM'24 Workshop, 2024.07 Summaryプログラミングクラスでのコード例の説明を効率化するために、LLMを用いた人間とAIの共同執筆アプローチを提案。講師が編集可能な初期コード説明を生成し、学生にとって意味のある内容を確保するためにプロンプトエンジニアリングを行い、その効果をユーザー研究で評価した。 Comment元ポスト:https://x.com/peterpaws/status/1876047837441806604?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket #NLP #LanguageModel #MoE(Mixture-of-Experts) #ACL Issue Date: 2025-01-06 DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, Damai+, ACL'24, 2024.08 SummaryDeepSeekMoEアーキテクチャは、専門家の専門性を高めるために、専門家を細分化し柔軟な組み合わせを可能にし、共有専門家を設けて冗長性を軽減する。2BパラメータのDeepSeekMoEは、GShardと同等の性能を達成し、同じパラメータ数の密なモデルに近づく。16Bパラメータにスケールアップした際も、計算量を約40%に抑えつつ、LLaMA2と同等の性能を示した。 #NLP #Dataset #AES(AutomatedEssayScoring) #Japanese Issue Date: 2024-11-28 Japanese-English Sentence Translation Exercises Dataset for Automatic Grading, Miura+, EACL'24, 2024.03 Summary第二言語学習の文翻訳演習の自動評価タスクを提案し、評価基準に基づいて学生の回答を採点する。日本語と英語の間で3,498の学生の回答を含むデータセットを作成。ファインチューニングされたBERTモデルは約90%のF1スコアで正しい回答を分類するが、誤った回答は80%未満。少数ショット学習を用いたGPT-3.5はBERTより劣る結果を示し、提案タスクが大規模言語モデルにとっても難しいことを示す。 CommentSTEsの図解。分かりやすい。いわゆる日本人が慣れ親しんでいる和文英訳、英文和訳演習も、このタスクの一種だということなのだろう。2-shotのGPT4とFinetuningしたBERTが同等程度の性能に見えて、GPT3.5では5shotしても勝てていない模様。興味深い。
 #NLP
#Supervised-FineTuning (SFT)
#InstructionTuning
#PEFT(Adaptor/LoRA)
Issue Date: 2024-10-30
Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
SummaryLoRAは大規模言語モデルのファインチューニング手法で、特にマルチタスク設定での性能向上に挑戦する。本研究では、LoRAのパフォーマンスを多様なタスクとリソースで検証し、適切なランク設定により高リソース環境でもフルファインチューニングに匹敵する結果を得られることを示した。学習能力の制約がLoRAの一般化能力を高めることが明らかになり、LoRAの適用可能性を広げる方向性を示唆している。
CommentLoRAのランク数をめちゃめちゃ大きくすると(1024以上)、full-parameterをチューニングするよりも、Unseenタスクに対する汎化性能が向上しますよ、という話っぽい
#NLP
#Supervised-FineTuning (SFT)
#InstructionTuning
#PEFT(Adaptor/LoRA)
Issue Date: 2024-10-30
Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
SummaryLoRAは大規模言語モデルのファインチューニング手法で、特にマルチタスク設定での性能向上に挑戦する。本研究では、LoRAのパフォーマンスを多様なタスクとリソースで検証し、適切なランク設定により高リソース環境でもフルファインチューニングに匹敵する結果を得られることを示した。学習能力の制約がLoRAの一般化能力を高めることが明らかになり、LoRAの適用可能性を広げる方向性を示唆している。
CommentLoRAのランク数をめちゃめちゃ大きくすると(1024以上)、full-parameterをチューニングするよりも、Unseenタスクに対する汎化性能が向上しますよ、という話っぽい

1474 も参照のことLoRA Finetuning details
・LoRA rankを最大4096
・LoRAのαをなんとrankの2倍にしている
・original paperでは16が推奨されている
・learning_rate: 5e-5
・linear sheculeで learning_rate を減衰させる
・optimizerはAdamW
・batch_size: 128

#RecommenderSystems #LanguageModel #KnowledgeGraph #InstructionTuning #Annotation Issue Date: 2024-10-08 COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon , Yu+, SIGMOD_PODS '24 SummaryCOSMOは、eコマースプラットフォーム向けにユーザー中心の常識知識をマイニングするためのスケーラブルな知識グラフシステムです。大規模言語モデルから抽出した高品質な知識を用い、指示チューニングによってファインチューニングされたCOSMO-LMは、Amazonの主要カテゴリにわたって数百万の知識を生成します。実験により、COSMOが検索ナビゲーションなどで顕著な改善を達成することが示され、常識知識の活用の可能性が強調されています。 Comment

 search navigationに導入しA/Bテストした結果、0.7%のproduct sales向上効果。
#Tutorial
#Pocket
#LanguageModel
Issue Date: 2023-04-27
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, Yang+, Amazon, TKDD'24
Summary本記事は、自然言語処理(NLP)タスクにおける大規模言語モデル(LLMs)の実践的なガイドを提供し、モデルやデータ、タスクに関する洞察を示します。LLMsの概要、データの影響、知識集約型タスクや生成タスクにおける使用ケースと非使用ケースを詳述し、実用的な応用と限界を探ります。また、虚偽のバイアスや展開時の考慮事項についても言及し、研究者や実務者に役立つベストプラクティスを提供します。関連リソースは定期的に更新され、オンラインでアクセス可能です。
CommentLLMに関するチュートリアル
search navigationに導入しA/Bテストした結果、0.7%のproduct sales向上効果。
#Tutorial
#Pocket
#LanguageModel
Issue Date: 2023-04-27
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, Yang+, Amazon, TKDD'24
Summary本記事は、自然言語処理(NLP)タスクにおける大規模言語モデル(LLMs)の実践的なガイドを提供し、モデルやデータ、タスクに関する洞察を示します。LLMsの概要、データの影響、知識集約型タスクや生成タスクにおける使用ケースと非使用ケースを詳述し、実用的な応用と限界を探ります。また、虚偽のバイアスや展開時の考慮事項についても言及し、研究者や実務者に役立つベストプラクティスを提供します。関連リソースは定期的に更新され、オンラインでアクセス可能です。
CommentLLMに関するチュートリアル

encoder-onlyとまとめられているものの中には、デコーダーがあるものがあり(autoregressive decoderではない)、
encoder-decoderは正しい意味としてはencoder with autoregressive decoderであり、
decoder-onlyは正しい意味としてはautoregressive encoder-decoder
とのこと。
https://twitter.com/ylecun/status/1651762787373428736?s=46&t=-zElejt4asTKBGLr-c3bKw #ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #AAAI Issue Date: 2023-04-26 AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head, AAAI'24 SummaryAudioGPTは、複雑な音声情報を処理し、音声対話をサポートするマルチモーダルAIシステムである。基盤モデルとASR、TTSインターフェースを組み合わせ、音声、音楽、トーキングヘッドの理解と生成を行う。実験により、AudioGPTが多様なオーディオコンテンツの創造を容易にする能力を示した。 Commenttext, audio, imageといったマルチモーダルなpromptから、audioに関する様々なタスクを実現できるシステムマルチモーダルデータをjointで学習したというわけではなく、色々なモデルの組み合わせてタスクを実現しているっぽい

#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2023-04-26 Scaling Instruction-Finetuned Language Models, Chung+, Google, JMLR'24 Summary指示ファインチューニングは、タスク数、モデルサイズ、チェーン・オブ・ソートデータを活用し、言語モデルの性能を向上させる手法である。Flan-PaLM 540Bは1.8Kタスクでファインチューニングされ、PaLM 540Bを上回る+9.4%の改善を達成し、MMLUで75.2%の性能を示した。Flan-T5も強力な少数ショット性能を発揮し、指示ファインチューニングは事前学習モデルの性能向上に寄与する。 CommentT5をinstruction tuningしたFlanT5の研究 #NLP #LanguageModel #DataGeneration #ICLR Issue Date: 2023-04-25 WizardLM: Empowering Large Language Models to Follow Complex Instructions, Xu+, Microsoft_Peking University, ICLR'24 Summary本論文では、LLMを用いて複雑な指示データを自動生成する手法Evol-Instructを提案。初期の指示セットを段階的に書き換え、生成したデータでLLaMAをファインチューニングし、WizardLMモデルを構築。評価結果では、Evol-Instructからの指示が人間作成のものより優れ、WizardLMはChatGPTを上回る性能を示した。AI進化による指示生成がLLM強化の有望なアプローチであることを示唆。 Commentinstruction trainingは大きな成功を収めているが、人間がそれらのデータを作成するのはコストがかかる。また、そもそも複雑なinstructionを人間が作成するのは苦労する。そこで、LLMに自動的に作成させる手法を提案している(これはself instructと一緒)。データを生成する際は、seed setから始め、step by stepでinstructionをrewriteし、より複雑なinstructionとなるようにしていく。
これらの多段的な複雑度を持つinstructionをLLaMaベースのモデルに食わせてfinetuningした(これをWizardLMと呼ぶ)。人手評価の結果、WizardLMがChatGPTよりも好ましいレスポンスをすることを示した。特に、WizaraLMはコード生成や、数値計算といった難しいタスクで改善を示しており、複雑なinstructionを学習に利用することの重要性を示唆している。EvolInstructを提案。"1+1=?"といったシンプルなinstructionからスタートし、これをLLMを利用して段階的にcomplexにしていく。complexにする方法は2通り:
・In-Depth Evolving: instructionを5種類のoperationで深掘りする(blue direction line)
・add constraints
・deepening
・concretizing
・increase reasoning steps
・complicate input
・In-breadth Evolving: givenなinstructionから新しいinstructionを生成する
上記のEvolvingは特定のpromptを与えることで実行される。
また、LLMはEvolvingに失敗することがあるので、Elimination Evolvingと呼ばれるフィルタを利用してスクリーニングした。
フィルタリングでは4種類の失敗するsituationを想定し、1つではLLMを利用。2枚目画像のようなinstructionでフィルタリング。
1. instructionの情報量が増えていない場合。
2. instructionがLLMによって応答困難な場合(短すぎる場合やsorryと言っている場合)
3. puctuationやstop wordsによってのみ構成されている場合
4.明らかにpromptの中から単語をコピーしただけのinstruction(given prompt, rewritten prompt, Rewritten Promptなど)


#NeuralNetwork #Survey #GraphBased #NLP Issue Date: 2023-04-25 Graph Neural Networks for Text Classification: A Survey, Wang+, Artificial Intelligence Review'24 Summaryテキスト分類におけるグラフニューラルネットワークの手法を2023年まで調査し、コーパスおよび文書レベルのグラフ構築や学習プロセスを詳述。課題や今後の方向性、データセットや評価指標についても考察し、異なる技術の比較を行い評価指標の利点と欠点を特定。 #NLP #LanguageModel #Diversity Issue Date: 2024-12-03 Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions, John Chung+, ACL'23, 2023.07 Summary本研究では、LLMを用いたテキストデータ生成における多様性と精度を向上させるための人間とAIのパートナーシップを探求。ロジット抑制と温度サンプリングの2つのアプローチで多様性を高める一方、ラベル置換(LR)と範囲外フィルタリング(OOSF)による人間の介入を検討。LRはモデルの精度を14.4%向上させ、一部のモデルは少数ショット分類を上回る性能を示したが、OOSFは効果がなかった。今後の研究の必要性が示唆される。 Comment生成テキストの質を維持しつつ、多様性を高める取り組み。多様性を高める取り組みとしては3種類の方法が試されており、
・Logit Suppression: 生成されたテキストの単語生成頻度をロギングし、頻出する単語にpenaltyをかける方法
・High Temperature: temperatureを[0.3, 0.7, 0.9, 1.3]にそれぞれ設定して単語をサンプリングする方法
・Seeding Example: 生成されたテキストを、seedとしてpromptに埋め込んで生成させる方法
で実験されている。 #InformationRetrieval #Pocket #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering, Siriwardhana+, TACL'23, 2023.01 SummaryRAG-end2endは、ODQAにおけるドメイン適応のためにRAGのリトリーバーとジェネレーターを共同訓練する新しいアプローチを提案。外部知識ベースを更新し、補助的な訓練信号を導入することで、ドメイン特化型知識を強化。COVID-19、ニュース、会話のデータセットで評価し、元のRAGモデルよりも性能が向上。研究はオープンソースとして公開。 #NaturalLanguageGeneration #NLP #LLM-as-a-Judge Issue Date: 2024-01-25 Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23 SummaryGEMBAは、参照翻訳の有無に関係なく使用できるGPTベースの翻訳品質評価メトリックです。このメトリックは、ゼロショットのプロンプティングを使用し、4つのプロンプトバリアントを比較します。私たちの手法は、GPT 3.5以上のモデルでのみ機能し、最先端の精度を達成します。特に、英語からドイツ語、英語からロシア語、中国語から英語の3つの言語ペアで有効です。この研究では、コード、プロンプトテンプレート、およびスコアリング結果を公開し、外部の検証と再現性を可能にします。 #PersonalizedDocumentSummarization #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration Issue Date: 2023-07-22 Generating User-Engaging News Headlines, Cai+, ACL'23 Summaryニュース記事の見出しを個別化するために、ユーザープロファイリングを組み込んだ新しいフレームワークを提案。ユーザーの閲覧履歴に基づいて個別のシグネチャフレーズを割り当て、それを使用して見出しを個別化する。幅広い評価により、提案したフレームワークが多様な読者のニーズに応える個別の見出しを生成する効果を示した。 Commentモチベーション
推薦システムのヘッドラインは未だに全員に同じものが表示されており、ユーザが自身の興味とのつながりを正しく判定できるとは限らず、推薦システムの有用性を妨げるので、ユーザごとに異なるヘッドラインを生成する手法を提案した。ただし、クリックベイトは避けるようなヘッドラインを生成しなければならない。
手法
1. Signature Phrase Identification
2. User Signature Selection
3. Signature-Oriented Headline Generation
Signature Phrase Identification
テキスト生成タスクに帰着させる。ニュース記事、あるいはヘッドラインをinputされたときに、セミコロン区切りのSignature Phraseを生成するモデルを用いる。今回は[KPTimes daasetでpretrainingされたBART](https://huggingface.co/ankur310794/bart-base-keyphrase-generation-kpTimes)を用いた。KPTimesは、279kのニュース記事と、signature phraseのペアが存在するデータであり、本タスクに最適とのこと。
User Signature Selection
ターゲットドキュメントdのSignature Phrases Z_dが与えられたとき、ユーザのreading History H_uに基づいて、top-kのuser signature phrasesを選択する。H_uはユーザが読んだニュースのヘッドラインの集合で表現される。あるSignature Phrase z_i ∈ Z_dが与えられたとき、(1)H_uをconcatしたテキストをベクトル化したものと、z_iのベクトルの内積でスコアを計算、あるいは(2) 個別のヘッドラインt_jを別々にエンコーディングし、内積の値が最大のものをスコアとする手法の2種類のエンコーディング方法を用いて、in-batch contrastive learningを用いてモデルを訓練する。つまり、正しいSignature Phraseとは距離が近く、誤ったSignature Phraseとは距離が遠くなるように学習をする。
実際はユーザにとっての正解Signature Phraseは分からないが、今回は人工的に作成したユーザを用いるため、正解が分かる設定となっている。
Signature-Oriented Headline Generation
ニュース記事d, user signature phrasesZ_d^uが与えられたとき、ヘッドラインを生成するモデルを訓練する。この時も、ユーザにとって正解のヘッドラインは分からないため、既存ニュースのヘッドラインが正解として用いられる。既存ニュースのヘッドラインが正解として用いられていても、そのヘッドラインがそのユーザにとっての正解となるように人工的にユーザが作成されているため、モデルの訓練ができる。モデルはBARTを用いた。
Dataset
Newsroom, Gigawordコーパスを用いる。これらのコーパスに対して、それぞれ2種類のコーパスを作成する。
1つは、Synthesized User Datasetで、これはUse Signature Selection modelの訓練と評価に用いる。もう一つはheadline generationデータセットで、こちらはheadline generationモデルの訓練に利用する。
Synthesized User Creation
実データがないので、実ユーザのreading historiesを模倣するように人工ユーザを作成する。具体的には、
1. すべてのニュース記事のSignature Phrasesを同定する
2. それぞれのSignature Phraseと、それを含むニュース記事をマッピングする
3. ランダムにphraseのサブセットをサンプリングし、そのサブセットをある人工ユーザが興味を持つエリアとする。
4. サブセット中のinterest phraseを含むニュース記事をランダムにサンプリングし、ユーザのreading historyとする
train, dev, testセット、それぞれに対して上記操作を実施しユーザを作成するが、train, devはContrastive Learningを実現するために、user signature phrases (interest phrases)は1つのみとした(Softmaxがそうなっていないと訓練できないので)。一方、testセットは1~5の範囲でuser signature phrasesを選択した。これにより、サンプリングされる記事が多様化され、ユーザのreadinig historyが多様化することになる。基本的には、ユーザが興味のあるトピックが少ない方が、よりタスクとしては簡単になることが期待される。また、ヘッドラインを生成するときは、ユーザのsignature phraseを含む記事をランダムに選び、ヘッドラインを背衛星することとした。これは、relevantな記事でないとヘッドラインがそもそも生成できないからである。
Headline Generation
ニュース記事の全てのsignature phraseを抽出し、それがgivenな時に、元のニュース記事のヘッドラインが生成できるようなBARTを訓練した。ニュース記事のtokenは512でtruncateした。平均して、10個のsignature phraseがニュース記事ごとに選択されており、ヘッドライン生成の多様さがうかがえる。user signature phraseそのものを用いて訓練はしていないが、そもそもこのようにGenericなデータで訓練しても、何らかのphraseがgivenな時に、それにバイアスがかかったヘッドラインを生成することができるので、user signature phrase selectionによって得られたphraseを用いてヘッドラインを生成することができる。
評価
自動評価と人手評価をしている。
自動評価
人手評価はコストがかかり、特に開発フェーズにおいては自動評価ができることが非常に重要となる。本研究では自動評価し方法を提案している。Headline-User DPR + SBERT, REC Scoreは、User Adaptation Metricsであり、Headline-Article DPR + SBERT, FactCCはArticle Loyalty Metricsである。
Relevance Metrics
PretrainedなDense Passage Retrieval (DPR)モデルと、SentenceBERTを用いて、headline-user間、headline-article間の類似度を測定する。前者はヘッドラインがどれだけユーザに適応しているが、後者はヘッドラインが元記事に対してどれだけ忠実か(クリックベイトを防ぐために)に用いられる。前者は、ヘッドラインとuser signaturesに対して類似度を計算し、後者はヘッドラインと記事全文に対して類似度を計算する。user signatures, 記事全文をどのようにエンコードしたかは記述されていない。
Recommendation Score
ヘッドラインと、ユーザのreadinig historyが与えられたときに、ニュースを推薦するモデルを用いて、スコアを算出する。モデルとしては、MIND datsetを用いて学習したモデルを用いた。
Factual Consistency
pretrainedなFactCCモデルを用いて、ヘッドラインとニュース記事間のfactual consisency score を算出する。
Surface Overlap
オリジナルのヘッドラインと、生成されたヘッドラインのROUGE-L F1と、Extractive Coverage (ヘッドラインに含まれる単語のうち、ソースに含まれる単語の割合)を用いる。
評価結果
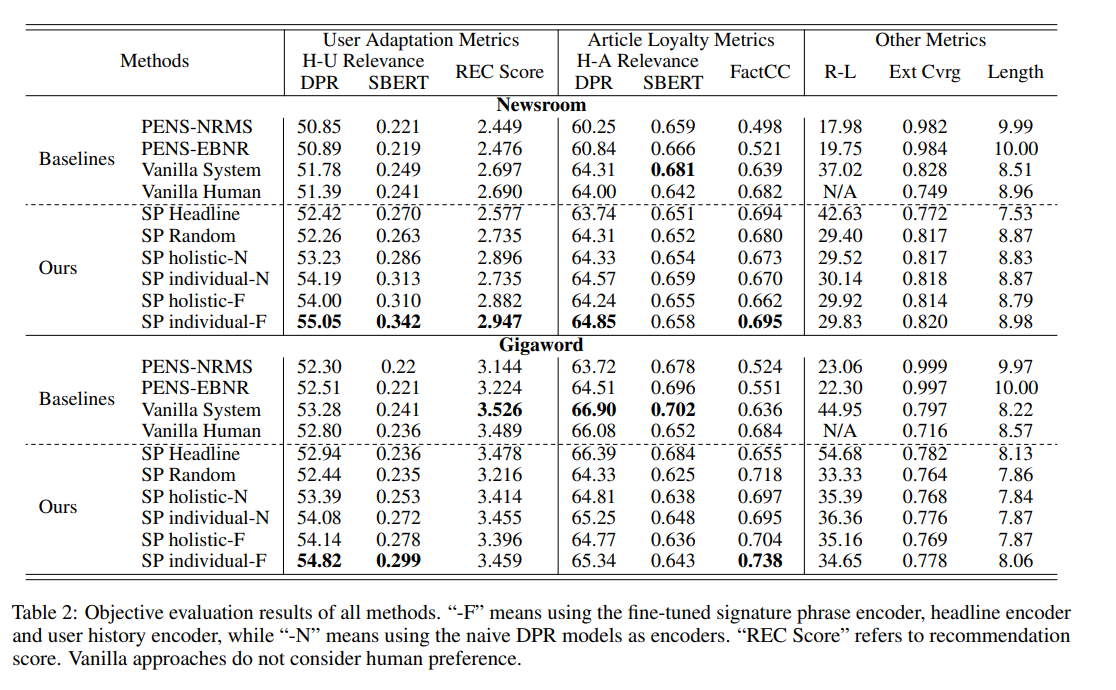
提案手法のうち、User Signature Selection modelをfinetuningしたものが最も性能が高かった。エンコード方法は、(2)のヒストリのタイトルとフレーズの最大スコアをとる方法が最も性能が高い。提案手法はUser Adaptationをしつつも、Article Loyaltyを保っている。このため、クリックベイトの防止につながる。また、Vanilla Humanは元記事のヘッドラインであり、Extracitve Coverageが低いため、より抽象的で、かつ元記事に対する忠実性が低いことがうかがえる。
人手評価
16人のevaluatorで評価。2260件のニュース記事を収集(113 topic)し、記事のヘッドラインと、対応するトピックを見せて、20個の興味に合致するヘッドラインを選択してもらった。これをユーザのinterest phraseとreading _historyとして扱う。そして、ユーザのinterest phraseを含むニュース記事のうち、12個をランダムに選択し、ヘッドラインを生成した。生成したヘッドラインに対して、
1. Vanilla Human
2. Vanilla System
3. SP random (ランダムにsignature phraseを選ぶ手法)
4. SP individual-N
5. SP individual-F (User Signature Phraseを選択するモデルをfinetuningしたもの)
の5種類を評価するよう依頼した。このとき、3つの観点から評価をした。
1, User adaptation
2. Headline appropriateness
3. Text Quality
結果は以下。

SP-individualがUser Adaptationで最も高い性能を獲得した。また、Vanilla Systemが最も高いHeadline appropriatenessを獲得した。しかしながら、後ほど分析した結果、Vanilla Systemでは、記事のメインポイントを押さえられていないような例があることが分かった(んーこれは正直他の手法でも同じだと思うから、ディフェンスとしては苦しいのでは)。
また、Vanilla Humanが最も高いスコアを獲得しなかった。これは、オーバーにレトリックを用いていたり、一般的な人にはわからないようなタイトルになっているものがあるからであると考えられる。

Ablation Study
Signature Phrase selectionの性能を測定したところ以下の通りになり、finetuningした場合の性能が良かった。

Headline Generationの性能に影響を与える要素としては、
1. ユーザが興味のあるトピック数
2. User signature phrasesの数
がある。
ユーザのInterest Phrasesが増えていけばいくほど、User Adaptationスコアは減少するが、Article Loyaltyは維持されたままである。このため、興味があるトピックが多ければ多いほど生成が難しいことがわかる。また、複数のuser signature phraseを用いると、factual errorを起こすことが分かった(Billgates, Zuckerbergの例を参照)。これは、モデルが本来はirrelevantなフレーズを用いてcoherentなヘッドラインを生成しようとしてしまうためである。

※interest phrases => gold user signatures という理解でよさそう。
※signature phrasesを複数用いるとfactual errorを起こすため、今回はk=1で実験していると思われる
GPT3にもヘッドラインを生成させてみたが、提案手法の方が性能が良かった(自動評価で)。

なぜPENS dataset 706 を利用しないで研究したのか? #NLP #LanguageModel #Evaluation #LLM-as-a-Judge Issue Date: 2023-07-22 Can Large Language Models Be an Alternative to Human Evaluations? Cheng-Han Chiang, Hung-yi Lee, ACL'23 Summary本研究では、人間の評価が機械学習モデルのテキスト品質評価に不可欠であるが再現性が難しいという問題を解決するために、大規模言語モデル(LLMs)を使用した評価方法を提案している。具体的には、LLMsに同じ指示と評価対象のサンプルを与え、それに対する応答を生成させることで、LLM評価を行っている。実験結果から、LLM評価の結果は人間の評価と一致しており、異なるフォーマットやサンプリングアルゴリズムでも安定していることが示されている。LLMsを使用したテキスト品質評価の可能性が初めて示されており、その制限や倫理的な考慮事項についても議論されている。 #ComputerVision #NaturalLanguageGeneration #NLP #Dataset #Evaluation Issue Date: 2023-07-22 InfoMetIC: An Informative Metric for Reference-free Image Caption Evaluation, ACL'23 Summary自動画像キャプションの評価には、情報豊かなメトリック(InfoMetIC)が提案されています。これにより、キャプションの誤りや欠落した情報を詳細に特定することができます。InfoMetICは、テキストの精度スコア、ビジョンの再現スコア、および全体の品質スコアを提供し、人間の判断との相関も高いです。また、トークンレベルの評価データセットも構築されています。詳細はGitHubで公開されています。 #Metrics #NLP #LanguageModel #QuestionAnswering #Evaluation #Reference-free Issue Date: 2023-07-22 RQUGE: Reference-Free Metric for Evaluating Question Generation by Answering the Question, ACL'23 Summary既存の質問評価メトリックにはいくつかの欠点がありますが、本研究では新しいメトリックRQUGEを提案します。RQUGEは文脈に基づいて候補質問の回答可能性を考慮し、参照質問に依存せずに人間の判断と高い相関を持つことが示されています。さらに、RQUGEは敵対的な破壊に対しても堅牢であり、質問生成モデルのファインチューニングにも有効です。これにより、QAモデルのドメイン外データセットでのパフォーマンスが向上します。 Comment概要
質問自動生成の性能指標(e.g. ROUGE, BERTScore)は、表層の一致、あるいは意味が一致した場合にハイスコアを与えるが、以下の欠点がある
・人手で作成された大量のreference questionが必要
・表層あるいは意味的に近くないが正しいquestionに対して、ペナルティが与えられてしまう
=> contextに対するanswerabilityによって評価するメトリック RQUGE を提案
similarity basedな指標では、Q1のような正しい質問でもlexical overlapがないと低いスコアを与えてしまう。また、Q2のようなreferenceの言い換えであっても、低いスコアとなってしまう。一方、reference basedな手法では、Q3のようにunacceptableになっているにもかかわらず、変化が微小であるためそれをとらえられないという問題がある。

手法概要
提案手法ではcontextとanswer spanが与えられたとき、Span Scorerと、QAモジュールを利用してacceptability scoreを計算することでreference-freeなmetricを実現する。
QAモデルは、Contextと生成されたQuestionに基づき、answer spanを予測する。提案手法ではT5ベースの手法であるUnifiedQAv2を利用する。
Span Scorer Moduleでは、予測されたanswer span, candidate question, context, gold spanに基づき、[1, 5]のスコアを予測する。提案手法では、encoder-only BERT-based model(提案手法ではRoBERTa)を用いる。

#DocumentSummarization #Metrics #NLP #Dataset #Evaluation Issue Date: 2023-07-18 Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation, ACL'23 Summary要約の評価には人間の評価が重要ですが、既存の評価方法には問題があります。そこで、私たちは新しい要約の重要性プロトコルを提案し、大規模な人間評価データセットを収集しました。さらに、異なる評価プロトコルを比較し、自動評価指標を評価しました。私たちの研究結果は、大規模言語モデルの評価に重要な示唆を与えます。 #NLP #LanguageModel #Chain-of-Thought #Distillation Issue Date: 2023-07-18 Teaching Small Language Models to Reason, ACL'23 Summary本研究では、大規模な言語モデルの推論能力を小さなモデルに転送するための知識蒸留を探求しました。具体的には、大きな教師モデルによって生成された出力を用いて学生モデルを微調整し、算術、常識、象徴的な推論のタスクでのパフォーマンスを向上させることを示しました。例えば、T5 XXLの正解率は、PaLM 540BとGPT-3 175Bで生成された出力を微調整することで、それぞれ8.11%から21.99%および18.42%に向上しました。 #DocumentSummarization #NaturalLanguageGeneration #NLP #Abstractive #Factuality Issue Date: 2023-07-18 Improving Factuality of Abstractive Summarization without Sacrificing Summary Quality, ACL'23 Summary事実性を意識した要約の品質向上に関する研究はあるが、品質を犠牲にすることなく事実性を向上させる手法がほとんどない。本研究では「Effective Factual Summarization」という技術を提案し、事実性と類似性の指標の両方で大幅な改善を示すことを示した。トレーニング中に競合を防ぐために2つの指標を組み合わせるランキング戦略を提案し、XSUMのFactCCでは最大6ポイント、CNN/DMでは11ポイントの改善が見られた。また、類似性や要約の抽象性には負の影響を与えない。 #NLP #Dataset #GrammaticalErrorCorrection Issue Date: 2023-07-18 Enhancing Grammatical Error Correction Systems with Explanations, ACL'23 Summary文法エラー修正システムの性能向上のために、エビデンスワードと文法エラータイプが注釈付けされた大規模なデータセットであるEXPECTを紹介する。このデータセットを使用して、説明可能なGECシステムのベースラインと分析を提案し、人間の評価によってその有用性を確認する。 #NaturalLanguageGeneration #NLP #DataToTextGeneration #MultitaskLearning #Zero/FewShotLearning Issue Date: 2023-07-18 Few-Shot Data-to-Text Generation via Unified Representation and Multi-Source Learning, ACL'23 Summaryこの論文では、構造化データからテキストを生成する新しいアプローチを提案しています。提案手法は、さまざまな形式のデータを処理できる統一された表現を提供し、マルチタスクトレーニングやゼロショット学習などのシナリオでのパフォーマンスを向上させることを目指しています。実験結果は、提案手法が他の方法と比較して優れた性能を示していることを示しています。これは、データからテキスト生成フレームワークにおける重要な進歩です。 #RecommenderSystems #Explanation #Personalization #review Issue Date: 2023-07-18 Explainable Recommendation with Personalized Review Retrieval and Aspect Learning, ACL'23 Summary説明可能な推薦において、テキスト生成の精度向上とユーザーの好みの捉え方の改善を目指し、ERRAモデルを提案。ERRAは追加情報の検索とアスペクト学習を組み合わせることで、より正確で情報量の多い説明を生成することができる。さらに、ユーザーの関心の高いアスペクトを選択することで、関連性の高い詳細なユーザー表現をモデル化し、説明をより説得力のあるものにする。実験結果は、ERRAモデルが最先端のベースラインを上回ることを示している。 #NaturalLanguageGeneration #Controllable #NLP Issue Date: 2023-07-18 An Invariant Learning Characterization of Controlled Text Generation, ACL'23 Summary制御された生成では、予測器の訓練に使用される分布と異なるテキストの分布がある場合、パフォーマンスが低下することが示されている。この問題に対処するために、不変性を持つ予測器が効果的であるという考え方が提案されている。さらに、この特性を活かすための自然な解決策とヒューリスティックも提案されている。実験結果は、制御された生成における分布シフトの課題と不変性手法の潜在能力を示している。 #DocumentSummarization #NaturalLanguageGeneration #NLP #Abstractive #Extractive Issue Date: 2023-07-18 Abstractive Summarizers are Excellent Extractive Summarizers, ACL'23 Summary本研究では、抽出型要約と要約型要約の相乗効果を探求し、シーケンス・トゥ・シーケンス・アーキテクチャを使用した3つの新しい推論アルゴリズムを提案しています。これにより、要約型システムが抽出型システムを超えることができることを示しました。また、要約型システムは抽出型のオラクル要約にさらされることなく、両方の要約を単一のモデルで生成できることも示しました。これは、抽出型ラベルの必要性に疑問を投げかけるものであり、ハイブリッドモデルの有望な研究方向を示しています。 #NLP #NaturalLanguageUnderstanding Issue Date: 2023-07-18 [TACL] Efficient Long-Text Understanding with Short-Text Models, TACL'23 Summary本研究では、長いシーケンスを処理するためのシンプルなアプローチであるSLEDを提案しています。SLEDは、既存の短文の事前学習言語モデルを再利用し、入力を重なり合うチャンクに分割して処理します。制御された実験により、SLEDが長いテキスト理解に有効であり、専用の高価な事前学習ステップが必要な専門モデルと競合することが示されました。 #Pretraining #MachineLearning #NLP #In-ContextLearning Issue Date: 2023-07-18 Pre-Training to Learn in Context, ACL'23 Summaryインコンテキスト学習は、タスクの例と文脈からタスクを実行する方法であり、注目されています。しかし、現在の方法では十分に活用されていないため、私たちはPICLというフレームワークを提案します。これは、一般的なテキストコーパスでモデルを事前学習し、文脈に基づいてタスクを推論して実行する能力を向上させます。私たちは、PICLでトレーニングされたモデルのパフォーマンスを評価し、他のモデルを上回ることを示しました。コードはGitHubで公開されています。 #EfficiencyImprovement #MachineLearning #NLP #DynamicNetworks Issue Date: 2023-07-18 PAD-Net: An Efficient Framework for Dynamic Networks, ACL'23 Summary本研究では、ダイナミックネットワークの一般的な問題点を解決するために、部分的にダイナミックなネットワーク(PAD-Net)を提案します。PAD-Netは、冗長なダイナミックパラメータを静的なパラメータに変換することで、展開コストを削減し、効率的なネットワークを実現します。実験結果では、PAD-Netが画像分類と言語理解のタスクで高い性能を示し、従来のダイナミックネットワークを上回ることを示しました。 #NaturalLanguageGeneration #Controllable #NLP #Argument Issue Date: 2023-07-18 ArgU: A Controllable Factual Argument Generator, ACL'23 Summary本研究では、高品質な論証を自動生成するために、制御コードを使用したニューラル論証生成器ArgUを提案します。また、論証スキームを特定するための大規模なデータセットを作成し、注釈付けとデータセット作成のフレームワークについて詳細に説明します。さらに、論証テンプレートを生成する推論戦略を試行し、多様な論証を自動的に生成することが可能であることを示します。 #NLP #pretrained-LM #Out-of-DistributionDetection Issue Date: 2023-07-18 Is Fine-tuning Needed? Pre-trained Language Models Are Near Perfect for Out-of-Domain Detection, ACL'23 Summary本研究では、ファインチューニングなしで事前学習された言語モデルを使用してOOD検出を行う効果を調査しました。さまざまなタイプの分布シフトにおいて、ファインチューニングされたモデルを大幅に上回るほぼ完璧なOOD検出性能を示しました。 #RecommenderSystems #NLP #Contents-based #Transformer #pretrained-LM #ContrastiveLearning Issue Date: 2023-07-18 UniTRec: A Unified Text-to-Text Transformer and Joint Contrastive Learning Framework for Text-based Recommendation, ACL'23 Summary本研究では、事前学習済み言語モデル(PLM)を使用して、テキストベースの推薦の性能を向上させるための新しいフレームワークであるUniTRecを提案します。UniTRecは、ユーザーの履歴の文脈をより良くモデル化するために統一されたローカル-グローバルアテンションTransformerエンコーダを使用し、候補のテキストアイテムの言語の複雑さを推定するためにTransformerデコーダを活用します。幅広い評価により、UniTRecがテキストベースの推薦タスクで最先端のパフォーマンスを発揮することが示されました。 #Survey #NLP #NumericReasoning Issue Date: 2023-07-18 A Survey of Deep Learning for Mathematical Reasoning, ACL'23 Summary数学的な推論とディープラーニングの関係についての調査論文をレビューし、数学的な推論におけるディープラーニングの進歩と将来の研究方向について議論しています。数学的な推論は機械学習と自然言語処理の分野で重要であり、ディープラーニングモデルのテストベッドとして機能しています。また、大規模なニューラル言語モデルの進歩により、数学的な推論に対するディープラーニングの利用が可能になりました。既存のベンチマークと方法を評価し、将来の研究方向についても議論しています。 #NaturalLanguageGeneration #NLP #Explanation #Evaluation #Faithfulness Issue Date: 2023-07-18 Faithfulness Tests for Natural Language Explanations, ACL'23 Summary本研究では、ニューラルモデルの説明の忠実性を評価するための2つのテストを提案しています。1つ目は、カウンターファクチュアルな予測につながる理由を挿入するためのカウンターファクチュアル入力エディタを提案し、2つ目は生成された説明から入力を再構築し、同じ予測につながる頻度をチェックするテストです。これらのテストは、忠実な説明の開発において基本的なツールとなります。 #Survey #NLP #LanguageModel #Prompting #Reasoning Issue Date: 2023-07-18 Reasoning with Language Model Prompting: A Survey, ACL'23 Summary本論文では、推論に関する最新の研究について包括的な調査を行い、初心者を支援するためのリソースを提供します。また、推論能力の要因や将来の研究方向についても議論します。リソースは定期的に更新されています。 #DocumentSummarization #NaturalLanguageGeneration #NLP #Extractive #Faithfulness Issue Date: 2023-07-18 Extractive is not Faithful: An Investigation of Broad Unfaithfulness Problems in Extractive Summarization, ACL'23 Summary本研究では、抽出的な要約の不正確さの問題について議論し、それを5つのタイプに分類します。さらに、新しい尺度であるExtEvalを提案し、不正確な要約を検出するために使用することを示します。この研究は、抽出的な要約の不正確さに対する認識を高め、将来の研究に役立つことを目指しています。 CommentExtractive SummarizatinoのFaithfulnessに関する研究。
>抽出的な要約は抽象的な要約の一般的な不正確さの問題にはあまり影響を受けにくいですが、それは抽出的な要約が正確であることを意味するのでしょうか?結論はノーです。
>本研究では、抽出的な要約に現れる広範な不正確さの問題(非含意を含む)を5つのタイプに分類
>不正確な共参照、不完全な共参照、不正確な談話、不完全な談話、および他の誤解を招く情報が含まれます。
>私たちは、16の異なる抽出システムによって生成された1600の英語の要約を人間にラベル付けするように依頼しました。その結果、要約の30%には少なくとも5つの問題のうちの1つが存在することがわかりました。
おもしろい。 #General #NLP #RepresentationLearning #AES(AutomatedEssayScoring) Issue Date: 2023-07-18 Improving Domain Generalization for Prompt-Aware Essay Scoring via Disentangled Representation Learning, ACL'23 Summary自動エッセイスコアリング(AES)は、エッセイを評価するためのモデルですが、既存のモデルは特定のプロンプトにしか適用できず、新しいプロンプトに対してはうまく汎化できません。この研究では、プロンプトに依存しない特徴とプロンプト固有の特徴を抽出するためのニューラルAESモデルを提案し、表現の汎化を改善するための分離表現学習フレームワークを提案しています。ASAPとTOEFL11のデータセットでの実験結果は、提案手法の有効性を示しています。 #NaturalLanguageGeneration #Controllable #NLP Issue Date: 2023-07-15 Controllable Text Generation via Probability Density Estimation in the Latent Space, ACL'23 Summary本研究では、潜在空間での確率密度推定を用いた新しい制御フレームワークを提案しています。この手法は、可逆変換関数を使用して潜在空間の複雑な分布を単純なガウス分布にマッピングし、洗練された柔軟な制御を行うことができます。実験結果では、提案手法が属性の関連性とテキストの品質において強力なベースラインを上回り、新たなSOTAを達成していることが示されています。さらなる分析により、制御戦略の柔軟性が示されています。 #NLP #Education #EducationalDataMining #QuestionGeneration Issue Date: 2023-07-15 Covering Uncommon Ground: Gap-Focused Question Generation for Answer Assessment, ACL'23 Summary本研究では、教育的な対話における情報のギャップに焦点を当て、自動的に質問を生成する問題に取り組んでいます。良い質問の要素を明確にし、それを満たすモデルを提案します。また、人間のアノテーターによる評価を行い、生成された質問の競争力を示します。 #NLP #LanguageModel #Ensemble Issue Date: 2023-07-15 Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling, ACL'23 Summary本研究では、BERTモデルのアンサンブル手法であるMulti-CLS BERTを提案します。Multi-CLS BERTは、複数のCLSトークンを使用して多様性を促進し、単一のモデルを微調整するだけでアンサンブル効果を得ることができます。実験結果では、Multi-CLS BERTがGLUEとSuperGLUEのタスクで全体的な精度と信頼度の推定を向上させることが示されました。また、通常のBERTアンサンブルとほぼ同等の性能を持ちながら、計算量とメモリ使用量が約4倍少なくなっていることも示されました。 #DocumentSummarization #NaturalLanguageGeneration #NLP #Dataset #Conversation Issue Date: 2023-07-15 MeetingBank: A Benchmark Dataset for Meeting Summarization, ACL'23 Summary会議の要約技術の開発には注釈付きの会議コーパスが必要ですが、その欠如が問題となっています。本研究では、新しいベンチマークデータセットであるMeetingBankを提案しました。MeetingBankは、会議議事録を短いパッセージに分割し、特定のセグメントと対応させることで、会議の要約プロセスを管理しやすいタスクに分割することができます。このデータセットは、会議要約システムのテストベッドとして利用できるだけでなく、一般の人々が議会の意思決定の仕組みを理解するのにも役立ちます。ビデオリンク、トランスクリプト、参照要約などのデータを一般に公開し、会議要約技術の開発を促進します。 #MachineTranslation #Unsupervised #NLP #SpeechProcessing #Speech Issue Date: 2023-07-15 Simple and Effective Unsupervised Speech Translation, ACL'23 Summary音声翻訳のためのラベル付きデータが限られているため、非教師あり手法を使用して音声翻訳システムを構築する方法を研究している。パイプラインアプローチや擬似ラベル生成を使用し、非教師ありドメイン適応技術を提案している。実験の結果、従来の手法を上回る性能を示している。 #DocumentSummarization #NaturalLanguageGeneration #Controllable #NLP #Dataset #Factuality Issue Date: 2023-07-15 On Improving Summarization Factual Consistency from Natural Language Feedback, ACL'23 Summary本研究では、自然言語の情報フィードバックを活用して要約の品質とユーザーの好みを向上させる方法を調査しました。DeFactoという高品質なデータセットを使用して、要約の編集や修正に関する自然言語生成タスクを研究しました。また、微調整された言語モデルを使用して要約の品質を向上させることも示しました。しかし、大規模な言語モデルは制御可能なテキスト生成には向いていないことがわかりました。 #RecommenderSystems #NLP #Conversation Issue Date: 2023-07-15 TREA: Tree-Structure Reasoning Schema for Conversational Recommendation, ACL'23 Summary会話型の推薦システム(CRS)では、外部知識を活用して対話の文脈を理解し、関連するアイテムを推薦することが求められている。しかし、現在の推論モデルは複雑な関係を完全に把握できないため、新しいツリー構造の推論スキーマであるTREAを提案する。TREAは多階層のツリーを使用して因果関係を明確にし、過去の対話を活用してより合理的な応答を生成する。幅広い実験により、TREAの有効性が示された。 #ComputerVision #NLP #Dataset #Personalization #MultiModal #Conversation Issue Date: 2023-07-15 MPCHAT: Towards Multimodal Persona-Grounded Conversation, ACL'23 Summary本研究では、テキストと画像の両方を使用してパーソナを拡張し、マルチモーダルな対話エージェントを構築するためのデータセットであるMPCHATを提案します。さらに、マルチモーダルパーソナを組み込むことで、応答予測、パーソナのグラウンディング予測、話者の識別といったタスクのパフォーマンスを統計的に有意に改善できることを示します。この研究は、マルチモーダルな対話理解においてマルチモーダルパーソナの重要性を強調し、MPCHATが高品質なリソースとして役立つことを示しています。 #NLP #LanguageModel #Mathematics Issue Date: 2023-07-15 Solving Math Word Problems via Cooperative Reasoning induced Language Models, ACL'23 Summary大規模な事前学習言語モデル(PLM)を使用して、数学の文章問題(MWPs)を解決するためのCooperative Reasoning(CoRe)アーキテクチャを開発しました。CoReでは、生成器と検証器の二つの推論システムが相互作用し、推論パスを生成し評価を監督します。CoReは、数学的推論データセットで最先端の手法に比べて最大9.6%の改善を達成しました。 #NaturalLanguageGeneration #Controllable #NLP #Prompting Issue Date: 2023-07-15 Tailor: A Soft-Prompt-Based Approach to Attribute-Based Controlled Text Generation, ACL'23 Summary属性ベースの制御されたテキスト生成(CTG)では、望ましい属性を持つ文を生成することが目指されている。従来の手法では、ファインチューニングや追加の属性分類器を使用していたが、ストレージと推論時間の増加が懸念されていた。そこで、本研究では効率的なパラメータを使用した属性ベースのCTGを提案している。具体的には、各属性を事前学習された連続ベクトルとして表現し、固定された事前学習言語モデルをガイドして属性を満たす文を生成する。さらに、2つの解決策を提供して、組み合わせを強化している。実験の結果、追加のトレーニングパラメータのみで効果的な改善が実現できることが示された。 #DocumentSummarization #Survey #NLP #Abstractive #Conversation Issue Date: 2023-07-15 [TACL] Abstractive Meeting Summarization: A Survey, TACL'23 Summary会議の要約化において、深層学習の進歩により抽象的要約が改善された。本論文では、抽象的な会議の要約化の課題と、使用されているデータセット、モデル、評価指標について概説する。 #ComputerVision #NaturalLanguageGeneration #NLP #LanguageModel #TabularData #TextToImageGeneration Issue Date: 2023-07-15 Table and Image Generation for Investigating Knowledge of Entities in Pre-trained Vision and Language Models, ACL'23 Summary本研究では、Vision&Language(V&L)モデルにおけるエンティティの知識の保持方法を検証するために、テーブルと画像の生成タスクを提案します。このタスクでは、エンティティと関連する画像の知識を含むテーブルを生成する第一の部分と、キャプションとエンティティの関連知識を含むテーブルから画像を生成する第二の部分があります。提案されたタスクを実行するために、Wikipediaの約20万のinfoboxからWikiTIGデータセットを作成しました。最先端のV&LモデルOFAを使用して、提案されたタスクのパフォーマンスを評価しました。実験結果は、OFAが一部のエンティティ知識を忘れることを示しています。 #NaturalLanguageGeneration #Controllable #NLP #PEFT(Adaptor/LoRA) Issue Date: 2023-07-15 Focused Prefix Tuning for Controllable Text Generation, ACL'23 Summary本研究では、注釈のない属性によって制御可能なテキスト生成データセットのパフォーマンスが低下する問題に対して、「focused prefix tuning(FPT)」という手法を提案しています。FPTは望ましい属性に焦点を当てることで、制御精度とテキストの流暢さを向上させることができます。また、FPTは複数属性制御タスクにおいても、既存のモデルを再トレーニングすることなく新しい属性を制御する柔軟性を持ちながら、制御精度を保つことができます。 #NLP #In-ContextLearning #LabelBias Issue Date: 2023-07-15 Mitigating Label Biases for In-context Learning, ACL'23 Summaryインコンテキスト学習(ICL)におけるラベルバイアスの種類を定義し、その影響を軽減するための方法を提案する研究が行われました。特に、ドメインラベルバイアスについて初めて概念化され、その影響を軽減するためのバイアス補正方法が提案されました。この方法により、GPT-JとGPT-3のICLパフォーマンスが大幅に改善されました。さらに、異なるモデルやタスクにも一般化され、ICLにおけるラベルバイアスの問題を解決する手法として有効であることが示されました。 #Analysis #NLP #LanguageModel #InstructionTuning Issue Date: 2023-07-15 Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning, ACL'23 Summary最近のinstruction tuning(IT)の研究では、追加のコンテキストを提供してモデルをファインチューニングすることで、ゼロショットの汎化性能を持つ素晴らしいパフォーマンスが実現されている。しかし、IT中にモデルがどのように指示を利用しているかはまだ研究されていない。本研究では、モデルのトレーニングを変更された指示と元の指示との比較によって、モデルがIT中に指示をどのように利用するかを分析する。実験の結果、トレーニングされたモデルは元の指示と同等のパフォーマンスを達成し、ITと同様のパフォーマンスを達成することが示された。この研究は、より信頼性の高いIT手法と評価の緊急性を強調している。 #ComputerVision #NaturalLanguageGeneration #NLP #MultiModal #DiffusionModel #TextToImageGeneration Issue Date: 2023-07-15 Learning to Imagine: Visually-Augmented Natural Language Generation, ACL'23 Summary本研究では、視覚情報を活用した自然言語生成のためのLIVEという手法を提案しています。LIVEは、事前学習済み言語モデルを使用して、テキストに基づいて場面を想像し、高品質な画像を合成する方法です。また、CLIPを使用してテキストの想像力を評価し、段落ごとに画像を生成します。さまざまな実験により、LIVEの有効性が示されています。コード、モデル、データは公開されています。 Comment>まず、テキストに基づいて場面を想像します。入力テキストに基づいて高品質な画像を合成するために拡散モデルを使用します。次に、CLIPを使用して、テキストが想像力を喚起できるかを事後的に判断します。最後に、私たちの想像力は動的であり、段落全体に1つの画像を生成するのではなく、各文に対して合成を行います。
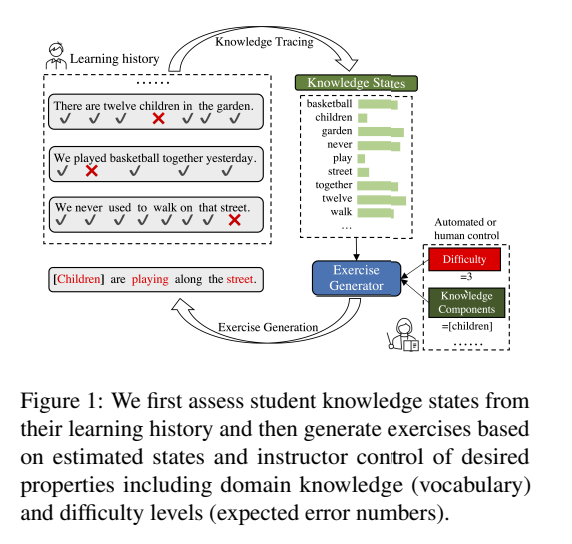
興味深い #NLP #In-ContextLearning #InductiveBias Issue Date: 2023-07-15 Measuring Inductive Biases of In-Context Learning with Underspecified Demonstrations, ACL'23 Summaryインコンテキスト学習(ICL)は、大規模言語モデル(LLMs)を新しいタスクに適応させるための重要なパラダイムですが、ICLの一般化の振る舞いはまだ十分に理解されていません。本研究では、ICLの帰納的なバイアスについて調査を行いました。具体的には、不完全なデモンストレーションが与えられた場合、ICLはどのフィーチャーをより頻繁に使用する傾向があるのかを調べました。実験の結果、LLMsが明確なフィーチャーバイアスを示すことがわかりました。また、特定のフィーチャーを好むような帰納的なバイアスを課すためのさまざまな介入の効果も評価しました。全体として、ICLがより頻繁に利用する可能性のあるフィーチャーのタイプと、意図したタスクとより一致した帰納的なバイアスを課す方法について、より広範な情報を提供する結果となりました。 #NLP #Chain-of-Thought #Distillation Issue Date: 2023-07-14 SCOTT: Self-Consistent Chain-of-Thought Distillation, ACL'23 Summary本研究では、大規模な言語モデル(LM)から小さなCoTモデルを学習するための知識蒸留手法であるSCOTTを提案しています。SCOTTは、教師モデルからゴールドアンサーをサポートする根拠を引き出し、より信憑性のあるトークンを生成するように学習を促します。さらに、学生モデルはカウンターファクトリーニングの目的で教師が生成した根拠を使用して学習されます。実験結果は、提案手法がベースラインよりも忠実なモデルを導くことを示しています。また、根拠を尊重することで意思決定を改善することも可能です。 CommentCoTのパフォーマンス向上がパラメータ数が大きいモデルでないと発揮せれないことは元論文 551 で考察されており、それをより小さいモデルに蒸留し発揮できるようにする、おもしろい #NaturalLanguageGeneration #NLP #Novelty #Evaluation Issue Date: 2023-07-14 [TACL] How much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN, TACL'23 Summaryこの研究では、言語モデルが生成するテキストの新規性を評価するための分析スイートRAVENを紹介しています。英語で訓練された4つのニューラル言語モデルに対して、局所的な構造と大規模な構造の新規性を評価しました。結果として、生成されたテキストは局所的な構造においては新規性に欠けており、大規模な構造においては人間と同程度の新規性があり、時には訓練セットからの重複したテキストを生成することもあります。また、GPT-2の詳細な手動分析により、組成的および類推的な一般化メカニズムの使用が示され、新規テキストが形態的および構文的に妥当であるが、意味的な問題が比較的頻繁に発生することも示されました。 #NLP #DataDistillation #Attention #Zero/FewShotLearning Issue Date: 2023-07-14 Dataset Distillation with Attention Labels for Fine-tuning BERT, ACL'23 Summary本研究では、データセットの蒸留を使用して、元のデータセットのパフォーマンスを保持しながら、ニューラルネットワークを迅速にトレーニングするための小さなデータセットを作成する方法に焦点を当てています。具体的には、事前学習済みのトランスフォーマーを微調整するための自然言語処理タスクの蒸留されたfew-shotデータセットの構築を提案しています。実験結果では、注意ラベルを使用してfew-shotデータセットを作成し、BERTの微調整において印象的なパフォーマンスを実現できることを示しました。例えば、ニュース分類タスクでは、わずか1つのサンプルとわずか1つの勾配ステップのみで、元のデータセットの98.5%のパフォーマンスを達成しました。 CommentDatadistillationしたら、データセットのうち1サンプルのみで、元のデータセットの98.5%の性能を発揮できたという驚異的な研究(まえかわ君) #NaturalLanguageGeneration #NLP #Education #AdaptiveLearning #KnowledgeTracing #Personalization #QuestionGeneration Issue Date: 2023-07-14 Adaptive and Personalized Exercise Generation for Online Language Learning, ACL'23 Summary本研究では、オンライン言語学習のための適応的な演習生成の新しいタスクを研究しました。学習履歴から学生の知識状態を推定し、その状態に基づいて個別化された演習文を生成するモデルを提案しました。実データを用いた実験結果から、学生の状態に応じた演習を生成できることを示しました。さらに、教育アプリケーションでの利用方法についても議論し、学習の効率化を促進できる可能性を示しました。 CommentKnowledge Tracingで推定された習熟度に基づいて、エクササイズを自動生成する研究。KTとNLGが組み合わさっており、非常におもしろい。
#MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #Evaluation Issue Date: 2023-07-14 Measuring the Instability of Fine-Tuning, ACL'23 Summary事前学習済み言語モデルのファインチューニングは小規模データセットでは不安定であることが示されている。本研究では、不安定性を定量化する指標を分析し、評価フレームワークを提案する。また、既存の不安定性軽減手法を再評価し、結果を提供する。 #EfficiencyImprovement #NLP #Ensemble #TransferLearning Issue Date: 2023-07-14 Parameter-efficient Weight Ensembling Facilitates Task-level Knowledge Transfer, ACL'23 Summary最近の研究では、大規模な事前学習済み言語モデルを特定のタスクに効果的に適応させることができることが示されています。本研究では、軽量なパラメータセットを使用してタスク間で知識を転送する方法を探求し、その有効性を検証しました。実験結果は、提案手法がベースラインに比べて5%〜8%の改善を示し、タスクレベルの知識転送を大幅に促進できることを示しています。 #InformationRetrieval #NLP #LanguageModel #KnowledgeGraph #Factuality #NaturalLanguageUnderstanding Issue Date: 2023-07-14 Direct Fact Retrieval from Knowledge Graphs without Entity Linking, ACL'23 Summary従来の知識取得メカニズムの制限を克服するために、我々はシンプルな知識取得フレームワークであるDiFaRを提案する。このフレームワークは、入力テキストに基づいて直接KGから事実を取得するものであり、言語モデルとリランカーを使用して事実のランクを改善する。DiFaRは複数の事実取得タスクでベースラインよりも優れた性能を示した。 #NLP #Transformer #LongSequence #PositionalEncoding Issue Date: 2023-07-14 Randomized Positional Encodings Boost Length Generalization of Transformers, ACL'23 Summaryトランスフォーマーは、固定長のタスクにおいては優れた汎化能力を持つが、任意の長さのシーケンスには対応できない。この問題を解決するために、新しい位置エンコーディング手法を提案する。ランダム化された位置エンコーディングスキームを使用し、長いシーケンスの位置をシミュレートし、順序付けられたサブセットをランダムに選択する。大規模な実証評価により、この手法がトランスフォーマーの汎化能力を向上させ、テストの正確性を平均して12.0%向上させることが示された。 #NLP #QuestionAnswering #KnowledgeGraph Issue Date: 2023-07-14 Do I have the Knowledge to Answer? Investigating Answerability of Knowledge Base Questions, ACL'23 Summaryナレッジベース上の自然言語質問には回答不可能なものが多くありますが、これについての研究はまだ不十分です。そこで、回答不可能な質問を含む新しいベンチマークデータセットを作成しました。最新のKBQAモデルを評価した結果、回答不可能な質問に対して性能が低下することがわかりました。さらに、これらのモデルは誤った理由で回答不可能性を検出し、特定の形式の回答不可能性を扱うことが困難であることもわかりました。このため、回答不可能性に対する堅牢なKBQAシステムの研究が必要です。 #EfficiencyImprovement #MachineLearning #NLP #Zero/FewShotPrompting #In-ContextLearning Issue Date: 2023-07-13 FiD-ICL: A Fusion-in-Decoder Approach for Efficient In-Context Learning, ACL'23 Summary大規模な事前学習モデルを使用したfew-shot in-context learning(ICL)において、fusion-in-decoder(FiD)モデルを適用することで効率とパフォーマンスを向上させることができることを検証する。FiD-ICLは他のフュージョン手法と比較して優れたパフォーマンスを示し、推論時間も10倍速くなる。また、FiD-ICLは大規模なメタトレーニングモデルのスケーリングも可能にする。 #DocumentSummarization #NLP #Abstractive #pretrained-LM #InstructionTuning Issue Date: 2023-07-13 Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization, ACL'23 Summaryこの論文では、新しい事前学習言語モデルであるZ-Code++を提案し、抽象的なテキスト要約に最適化されています。Z-Code++は、2つのフェーズの事前学習とディセントラル化アテンション層、およびエンコーダー内のフュージョンを使用しています。このモデルは、低リソースの要約タスクで最先端の性能を発揮し、パラメータ効率的であり、他の競合モデルを大幅に上回ります。 #NLP #Dataset #InstructionTuning Issue Date: 2023-07-13 Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor, ACL'23 Summary本研究では、人間の監督を必要としない方法で収集された大規模なデータセット「Unnatural Instructions」を紹介します。このデータセットを使用して、言語モデルのトレーニングを行い、既存のモデルを上回る性能を実現しました。これにより、クラウドソーシングに頼らずにデータセットを拡張し、多様性を持たせることができることが示されました。 #General #NLP #LanguageModel #In-ContextLearning #Composition Issue Date: 2023-07-13 How Do In-Context Examples Affect Compositional Generalization?, ACL'23 Summary本研究では、組成的な一般化を調査するためのテストスイートであるCoFeを提案し、インコンテキスト学習の組成的な一般化について研究しました。インコンテキストの例の選択が組成的な一般化のパフォーマンスに影響を与えることを発見し、類似性、多様性、複雑さの要素を研究しました。さらに、架空の単語に対する組成的な一般化は一般的な単語に比べて弱いことが観察されました。インコンテキストの例が言語構造をカバーすることが重要であることも示されました。 #NaturalLanguageGeneration #Controllable #NLP #LanguageModel Issue Date: 2023-07-13 Explicit Syntactic Guidance for Neural Text Generation, ACL'23 Summary既存のテキスト生成モデルには制約があり、シーケンス・トゥ・シーケンスのパラダイムに従っている。私たちは、構文にガイドされた生成スキーマを提案し、構文解析木に従ってシーケンスを生成する。提案手法は、パラフレーズ生成と機械翻訳の実験でベースラインを上回り、解釈可能性、制御可能性、多様性の観点でも効果的であることを示している。 #NLP #LanguageModel #Pruning Issue Date: 2023-07-13 Pruning Pre-trained Language Models Without Fine-Tuning, ACL'23 Summary本研究では、Pre-trained Language Models(PLMs)の過パラメータ化の問題を解決するために、一次元のプルーニングを使用したシンプルで直感的な圧縮手法であるStatic Model Pruning(SMP)を提案します。SMPは、下流のタスクにPLMsを適応させるために一次元のプルーニングのみを使用し、微調整を必要としないため、他の手法よりも効率的です。徹底的な実験結果は、SMPが一次元およびゼロ次元の手法よりも大幅に改善されていることを示しています。また、SMPは低い疎密度にも適用可能であり、ゼロ次元の手法を上回ります。 #ComputerVision #Pocket #NeurIPS Issue Date: 2023-04-27 Stable and low-precision training for large-scale vision-language models, Wortsman+, University of Washington, NeurIPS'23 Summary大規模な言語-視覚モデルのトレーニングを加速し安定させる新手法を提案。SwitchBackを用いたint8量子化で、CLIP ViT-Hugeのトレーニング速度を13-25%向上させ、bfloat16と同等の性能を維持。float8トレーニングも効果的であることを示し、初期化方法が成功に寄与。損失のスパイクを分析し、AdamW-Adafactorハイブリッドを推奨することで、トレーニングの安定性を向上させた。 Comment
#MachineLearning #DataAugmentation #MultiModal Issue Date: 2023-04-26 Learning Multimodal Data Augmentation in Feature Space, ICLR'23 Summaryマルチモーダルデータの共同学習能力は、インテリジェントシステムの特徴であるが、データ拡張の成功は単一モーダルのタスクに限定されている。本研究では、LeMDAという方法を提案し、モダリティのアイデンティティや関係に制約を設けずにマルチモーダルデータを共同拡張することができることを示した。LeMDAはマルチモーダルディープラーニングの性能を向上させ、幅広いアプリケーションで最先端の結果を達成することができる。 CommentData Augmentationは基本的に単体のモダリティに閉じて行われるが、
マルチモーダルな設定において、モダリティ同士がどう関係しているか、どの変換を利用すべきかわからない時に、どのようにデータ全体のsemantic structureを維持しながら、Data Augmentationできるか?という話らしい #NeuralNetwork #ComputerVision #Pocket #SIGGRAPH Issue Date: 2022-12-01 Sketch-Guided Text-to-Image Diffusion Models, Andrey+, Google Research, SIGGRAPH'23 Summaryテキストから画像へのモデルは高品質な画像合成を実現するが、空間的特性の制御が不足している。本研究では、スケッチからの空間マップを用いて事前学習済みモデルを導く新しいアプローチを提案。専用モデルを必要とせず、潜在ガイダンス予測器(LGP)を訓練し、画像を空間マップに一致させる。ピクセルごとの訓練により柔軟性を持ち、スケッチから画像への翻訳タスクにおいて効果的な生成が可能であることを示す。 Commentスケッチとpromptを入力することで、スケッチ biasedな画像を生成することができる技術。すごい。
 #Survey
#NLP
#EACL
Issue Date: 2022-10-31
MTEB: Massive Text Embedding Benchmark, Muennighoff+, EACL'23
Summaryテキスト埋め込みの評価は通常小規模なデータセットに限られ、他のタスクへの適用可能性が不明である。これを解決するために、58のデータセットと112の言語をカバーするMassive Text Embedding Benchmark(MTEB)を導入し、33のモデルをベンチマークした。結果、特定の手法が全タスクで優位に立つことはなく、普遍的なテキスト埋め込み手法には至っていないことが示された。MTEBはオープンソースで公開されている。
#Survey
#Pocket
#AdaptiveLearning
#EducationalDataMining
#KnowledgeTracing
Issue Date: 2022-08-02
Knowledge Tracing: A Survey, ABDELRAHMAN+, Australian National University, ACM Computing Surveys'23
Summary人間の教育における知識移転の重要性を背景に、オンライン教育における知識追跡(KT)の必要性が高まっている。本論文では、KTに関する包括的なレビューを行い、初期の手法から最新の深層学習技術までを網羅し、モデルの理論やデータセットの特性を強調する。また、関連手法のモデリングの違いを明確にし、KT文献の研究ギャップや今後の方向性についても議論する。
#NeuralNetwork
#Survey
#MachineLearning
#Pocket
Issue Date: 2021-06-19
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better, Menghani, ACM Computing Surveys'23
Summaryディープラーニングの進展に伴い、モデルのパラメータ数やリソース要求が増加しているため、効率性が重要になっている。本研究では、モデル効率性の5つのコア領域を調査し、実務者向けに最適化ガイドとコードを提供する。これにより、効率的なディープラーニングの全体像を示し、読者に改善の手助けとさらなる研究のアイデアを提供することを目指す。
Comment学習効率化、高速化などのテクニックがまとまっているらしい
#DocumentSummarization
#NLP
#Evaluation
#LM-based
#Factuality
Issue Date: 2023-08-13
SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization, Laban+, TACL'22
Summary要約の領域では、入力ドキュメントと要約が整合していることが重要です。以前の研究では、自然言語推論(NLI)モデルを不整合検出に適用するとパフォーマンスが低下することがわかりました。本研究では、NLIを不整合検出に再評価し、過去の研究での入力の粒度の不一致が問題であることを発見しました。新しい手法SummaCConvを提案し、NLIモデルを文単位にドキュメントを分割してスコアを集計することで、不整合検出に成功裏に使用できることを示しました。さらに、新しいベンチマークSummaCを導入し、74.4%の正確さを達成し、先行研究と比較して5%の改善を実現しました。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Play the Shannon Game With Language Models: A Human-Free Approach to Summary Evaluation, Nicholas Egan+, N_A, AAAI'22
Summaryこの研究では、事前学習済み言語モデルを使用して、参照フリーの要約評価指標を提案します。これにより、要約の品質を測定するための新しい手法が開発されます。また、提案手法が人間の判断と高い相関関係を持つことが実証されます。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Reference-free Summarization Evaluation via Semantic Correlation and Compression Ratio, Liu+, NAACL'22
Summary本研究では、参照ベースの評価方法の柔軟性の欠如を解消するために、事前学習済み言語モデルを使用して自動参照フリーの評価指標を提案します。この指標は、要約の意味的な分布と圧縮率を考慮し、人間の評価とより一致していることが実験で示されました。
#DocumentSummarization
#NLP
#Evaluation
Issue Date: 2023-08-13
Re-Examining System-Level Correlations of Automatic Summarization Evaluation Metrics, Deutsch+, NAACL'22
Summary本研究では、自動要約評価尺度のシステムレベルの相関に関する不整合を修正するための変更を提案しています。具体的には、全テストセットを使用して自動評価尺度のシステムスコアを計算し、実際のシナリオでよく見られる自動スコアのわずかな差によって分離されたシステムのペアに対してのみ相関を計算することを提案しています。これにより、より正確な相関推定と高品質な人間の判断の収集が可能となります。
#DocumentSummarization
#NLP
#Evaluation
Issue Date: 2023-08-13
Does Summary Evaluation Survive Translation to Other Languages?, Braun+, NAACL'22
Summary要約データセットの作成は費用と時間がかかるが、機械翻訳を使用して既存のデータセットを他の言語に翻訳することで、追加の言語での使用が可能になる。この研究では、英語の要約データセットを7つの言語に翻訳し、自動評価尺度によるパフォーマンスを比較する。また、人間と自動化された要約のスコアリング間の相関を評価し、翻訳がパフォーマンスに与える影響も考慮する。さらに、データセットの再利用の可能性を見つけるために、特定の側面に焦点を当てる。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#TrainedMetrics
Issue Date: 2023-08-13
SummScore: A Comprehensive Evaluation Metric for Summary Quality Based on Cross-Encoder, Wuhang Lin+, N_A, arXiv'22
Summary要約の品質評価メトリクスの問題を解決するために、SummScoreという包括的な評価メトリクスを提案する。SummScoreはCrossEncoderに基づいており、要約の多様性を抑制せずに要約の品質を評価することができる。さらに、SummScoreは一貫性、一貫性、流暢さ、関連性の4つの側面で評価することができる。実験結果は、SummScoreが既存の評価メトリクスを上回ることを示している。また、SummScoreの評価結果を16の主要な要約モデルに提供している。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
SueNes: A Weakly Supervised Approach to Evaluating Single-Document Summarization via Negative Sampling, Bao+, NAACL'22
Summary従来の自動要約評価メトリックは語彙の類似性に焦点を当てており、意味や言語的な品質を十分に捉えることができない。参照要約が必要であるためコストがかかる。本研究では、参照要約が存在しない弱教師あり要約評価手法を提案する。既存の要約データセットを文書と破損した参照要約のペアに変換してトレーニングする。ドメイン間のテストでは、提案手法がベースラインを上回り、言語的な品質を評価する上で大きな利点を示した。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
PrefScore: Pairwise Preference Learning for Reference-free Summarization Quality Assessment, Luo+, COLING'22
Summary人間による参照要約のない機械生成の要約の評価を行うために、ブラッドリー・テリーのパワーランキングモデルを使用して要約の優劣を判断する方法を提案する。実験結果は、この方法が人間の評価と高い相関を持つスコアを生成できることを示している。
#DocumentSummarization
#Pocket
#NLP
#Evaluation
Issue Date: 2023-08-13
How to Find Strong Summary Coherence Measures? A Toolbox and a Comparative Study for Summary Coherence Measure Evaluation, Steen+, COLING'22
Summary要約の一貫性を自動的に評価することは重要であり、さまざまな方法が提案されていますが、異なるデータセットと評価指標を使用して評価されるため、相対的なパフォーマンスを理解することが困難です。本研究では、要約の一貫性モデリングのさまざまな方法について調査し、新しい分析尺度を導入します。現在の自動一貫性尺度はすべての評価指標において信頼性のある一貫性スコアを割り当てることができませんが、大規模言語モデルは有望な結果を示しています。
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
#PersonalizedHeadlineGeneration
Issue Date: 2023-08-11
Personalized News Headline Generation System with Fine-grained User Modeling, Yao, MSN'22
Summaryユーザーの興味に基づいてパーソナライズされたニュースの見出しを生成するために、文レベルの情報を考慮したユーザーモデルを提案する。アテンション層を使用して文とニュースの関連性を計算し、ニュースの内容に基づいて見出しを生成する。実験結果は、提案モデルがベースラインモデルよりも優れたパフォーマンスを示していることを示している。将来の方向性として、情報のレベルと内容を横断する相互作用についても議論されている。
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
#PersonalizedHeadlineGeneration
Issue Date: 2023-08-11
Personalized Headline Generation with Enhanced User Interest Perception, Zhang+, ICANN'22
Summaryユーザーのニュース閲覧履歴をモデル化し、個別化されたニュース見出しを生成するための新しいフレームワークを提案する。提案手法は、ユーザーの興味を強調するために候補テキストに関連する情報を活用し、ニュースのエンティティワードを使用して興味表現を改善する。幅広い実験により、提案手法が見出し生成タスクで優れたパフォーマンスを示すことが示されている。
#RecommenderSystems
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
Issue Date: 2023-08-11
Personalized Chit-Chat Generation for Recommendation Using External Chat Corpora, Chen+, KDD'22
Summaryチットチャットは、ユーザーとの対話において効果的であることが示されています。この研究では、ニュース推薦のための個人化されたチットチャットを生成する方法を提案しています。既存の方法とは異なり、外部のチャットコーパスのみを使用してユーザーの関心を推定し、個人化されたチットチャットを生成します。幅広い実験により、提案手法の効果が示されています。
#Pretraining
#Pocket
#NLP
Issue Date: 2022-12-01
Revisiting Pretraining Objectives for Tabular Deep Learning, Rubachev+, Yandex+, arXiv'22
Summary表形式データに対する深層学習モデルはGBDTと競争しており、事前学習がパフォーマンス向上に寄与することが示された。異なるデータセットやアーキテクチャに適用可能な事前学習のベストプラクティスを特定し、オブジェクトターゲットラベルの使用が有益であることを発見。適切な事前学習により、深層学習モデルはGBDTを上回る性能を発揮することが確認された。
CommentTabular Dataを利用した場合にKaggleなどでDeepなモデルがGBDT等に勝てないことが知られているが、GBDT等とcomparable になる性能になるようなpre-trainingを提案したよ、的な内容っぽいICLR 2023 OpenReview: https://openreview.net/forum?id=kjPLodRa0n
#NLP
#Dataset
#QuestionAnswering
Issue Date: 2022-02-07
JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension, So+, arXiv'22
Summary日本語の質問応答データセットJaQuADを提案。39,696の質問-回答ペアを含み、テストセットでF1スコア78.92%、EMスコア63.38%を達成。データセットは[こちら](https://github.com/SkelterLabsInc/JaQuAD)から入手可能。
CommentSQuAD likeな日本語のQAデータセット
#Survey
#NLP
#EACL
Issue Date: 2022-10-31
MTEB: Massive Text Embedding Benchmark, Muennighoff+, EACL'23
Summaryテキスト埋め込みの評価は通常小規模なデータセットに限られ、他のタスクへの適用可能性が不明である。これを解決するために、58のデータセットと112の言語をカバーするMassive Text Embedding Benchmark(MTEB)を導入し、33のモデルをベンチマークした。結果、特定の手法が全タスクで優位に立つことはなく、普遍的なテキスト埋め込み手法には至っていないことが示された。MTEBはオープンソースで公開されている。
#Survey
#Pocket
#AdaptiveLearning
#EducationalDataMining
#KnowledgeTracing
Issue Date: 2022-08-02
Knowledge Tracing: A Survey, ABDELRAHMAN+, Australian National University, ACM Computing Surveys'23
Summary人間の教育における知識移転の重要性を背景に、オンライン教育における知識追跡(KT)の必要性が高まっている。本論文では、KTに関する包括的なレビューを行い、初期の手法から最新の深層学習技術までを網羅し、モデルの理論やデータセットの特性を強調する。また、関連手法のモデリングの違いを明確にし、KT文献の研究ギャップや今後の方向性についても議論する。
#NeuralNetwork
#Survey
#MachineLearning
#Pocket
Issue Date: 2021-06-19
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better, Menghani, ACM Computing Surveys'23
Summaryディープラーニングの進展に伴い、モデルのパラメータ数やリソース要求が増加しているため、効率性が重要になっている。本研究では、モデル効率性の5つのコア領域を調査し、実務者向けに最適化ガイドとコードを提供する。これにより、効率的なディープラーニングの全体像を示し、読者に改善の手助けとさらなる研究のアイデアを提供することを目指す。
Comment学習効率化、高速化などのテクニックがまとまっているらしい
#DocumentSummarization
#NLP
#Evaluation
#LM-based
#Factuality
Issue Date: 2023-08-13
SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization, Laban+, TACL'22
Summary要約の領域では、入力ドキュメントと要約が整合していることが重要です。以前の研究では、自然言語推論(NLI)モデルを不整合検出に適用するとパフォーマンスが低下することがわかりました。本研究では、NLIを不整合検出に再評価し、過去の研究での入力の粒度の不一致が問題であることを発見しました。新しい手法SummaCConvを提案し、NLIモデルを文単位にドキュメントを分割してスコアを集計することで、不整合検出に成功裏に使用できることを示しました。さらに、新しいベンチマークSummaCを導入し、74.4%の正確さを達成し、先行研究と比較して5%の改善を実現しました。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Play the Shannon Game With Language Models: A Human-Free Approach to Summary Evaluation, Nicholas Egan+, N_A, AAAI'22
Summaryこの研究では、事前学習済み言語モデルを使用して、参照フリーの要約評価指標を提案します。これにより、要約の品質を測定するための新しい手法が開発されます。また、提案手法が人間の判断と高い相関関係を持つことが実証されます。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Reference-free Summarization Evaluation via Semantic Correlation and Compression Ratio, Liu+, NAACL'22
Summary本研究では、参照ベースの評価方法の柔軟性の欠如を解消するために、事前学習済み言語モデルを使用して自動参照フリーの評価指標を提案します。この指標は、要約の意味的な分布と圧縮率を考慮し、人間の評価とより一致していることが実験で示されました。
#DocumentSummarization
#NLP
#Evaluation
Issue Date: 2023-08-13
Re-Examining System-Level Correlations of Automatic Summarization Evaluation Metrics, Deutsch+, NAACL'22
Summary本研究では、自動要約評価尺度のシステムレベルの相関に関する不整合を修正するための変更を提案しています。具体的には、全テストセットを使用して自動評価尺度のシステムスコアを計算し、実際のシナリオでよく見られる自動スコアのわずかな差によって分離されたシステムのペアに対してのみ相関を計算することを提案しています。これにより、より正確な相関推定と高品質な人間の判断の収集が可能となります。
#DocumentSummarization
#NLP
#Evaluation
Issue Date: 2023-08-13
Does Summary Evaluation Survive Translation to Other Languages?, Braun+, NAACL'22
Summary要約データセットの作成は費用と時間がかかるが、機械翻訳を使用して既存のデータセットを他の言語に翻訳することで、追加の言語での使用が可能になる。この研究では、英語の要約データセットを7つの言語に翻訳し、自動評価尺度によるパフォーマンスを比較する。また、人間と自動化された要約のスコアリング間の相関を評価し、翻訳がパフォーマンスに与える影響も考慮する。さらに、データセットの再利用の可能性を見つけるために、特定の側面に焦点を当てる。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#TrainedMetrics
Issue Date: 2023-08-13
SummScore: A Comprehensive Evaluation Metric for Summary Quality Based on Cross-Encoder, Wuhang Lin+, N_A, arXiv'22
Summary要約の品質評価メトリクスの問題を解決するために、SummScoreという包括的な評価メトリクスを提案する。SummScoreはCrossEncoderに基づいており、要約の多様性を抑制せずに要約の品質を評価することができる。さらに、SummScoreは一貫性、一貫性、流暢さ、関連性の4つの側面で評価することができる。実験結果は、SummScoreが既存の評価メトリクスを上回ることを示している。また、SummScoreの評価結果を16の主要な要約モデルに提供している。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
SueNes: A Weakly Supervised Approach to Evaluating Single-Document Summarization via Negative Sampling, Bao+, NAACL'22
Summary従来の自動要約評価メトリックは語彙の類似性に焦点を当てており、意味や言語的な品質を十分に捉えることができない。参照要約が必要であるためコストがかかる。本研究では、参照要約が存在しない弱教師あり要約評価手法を提案する。既存の要約データセットを文書と破損した参照要約のペアに変換してトレーニングする。ドメイン間のテストでは、提案手法がベースラインを上回り、言語的な品質を評価する上で大きな利点を示した。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
PrefScore: Pairwise Preference Learning for Reference-free Summarization Quality Assessment, Luo+, COLING'22
Summary人間による参照要約のない機械生成の要約の評価を行うために、ブラッドリー・テリーのパワーランキングモデルを使用して要約の優劣を判断する方法を提案する。実験結果は、この方法が人間の評価と高い相関を持つスコアを生成できることを示している。
#DocumentSummarization
#Pocket
#NLP
#Evaluation
Issue Date: 2023-08-13
How to Find Strong Summary Coherence Measures? A Toolbox and a Comparative Study for Summary Coherence Measure Evaluation, Steen+, COLING'22
Summary要約の一貫性を自動的に評価することは重要であり、さまざまな方法が提案されていますが、異なるデータセットと評価指標を使用して評価されるため、相対的なパフォーマンスを理解することが困難です。本研究では、要約の一貫性モデリングのさまざまな方法について調査し、新しい分析尺度を導入します。現在の自動一貫性尺度はすべての評価指標において信頼性のある一貫性スコアを割り当てることができませんが、大規模言語モデルは有望な結果を示しています。
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
#PersonalizedHeadlineGeneration
Issue Date: 2023-08-11
Personalized News Headline Generation System with Fine-grained User Modeling, Yao, MSN'22
Summaryユーザーの興味に基づいてパーソナライズされたニュースの見出しを生成するために、文レベルの情報を考慮したユーザーモデルを提案する。アテンション層を使用して文とニュースの関連性を計算し、ニュースの内容に基づいて見出しを生成する。実験結果は、提案モデルがベースラインモデルよりも優れたパフォーマンスを示していることを示している。将来の方向性として、情報のレベルと内容を横断する相互作用についても議論されている。
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
#PersonalizedHeadlineGeneration
Issue Date: 2023-08-11
Personalized Headline Generation with Enhanced User Interest Perception, Zhang+, ICANN'22
Summaryユーザーのニュース閲覧履歴をモデル化し、個別化されたニュース見出しを生成するための新しいフレームワークを提案する。提案手法は、ユーザーの興味を強調するために候補テキストに関連する情報を活用し、ニュースのエンティティワードを使用して興味表現を改善する。幅広い実験により、提案手法が見出し生成タスクで優れたパフォーマンスを示すことが示されている。
#RecommenderSystems
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
Issue Date: 2023-08-11
Personalized Chit-Chat Generation for Recommendation Using External Chat Corpora, Chen+, KDD'22
Summaryチットチャットは、ユーザーとの対話において効果的であることが示されています。この研究では、ニュース推薦のための個人化されたチットチャットを生成する方法を提案しています。既存の方法とは異なり、外部のチャットコーパスのみを使用してユーザーの関心を推定し、個人化されたチットチャットを生成します。幅広い実験により、提案手法の効果が示されています。
#Pretraining
#Pocket
#NLP
Issue Date: 2022-12-01
Revisiting Pretraining Objectives for Tabular Deep Learning, Rubachev+, Yandex+, arXiv'22
Summary表形式データに対する深層学習モデルはGBDTと競争しており、事前学習がパフォーマンス向上に寄与することが示された。異なるデータセットやアーキテクチャに適用可能な事前学習のベストプラクティスを特定し、オブジェクトターゲットラベルの使用が有益であることを発見。適切な事前学習により、深層学習モデルはGBDTを上回る性能を発揮することが確認された。
CommentTabular Dataを利用した場合にKaggleなどでDeepなモデルがGBDT等に勝てないことが知られているが、GBDT等とcomparable になる性能になるようなpre-trainingを提案したよ、的な内容っぽいICLR 2023 OpenReview: https://openreview.net/forum?id=kjPLodRa0n
#NLP
#Dataset
#QuestionAnswering
Issue Date: 2022-02-07
JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension, So+, arXiv'22
Summary日本語の質問応答データセットJaQuADを提案。39,696の質問-回答ペアを含み、テストセットでF1スコア78.92%、EMスコア63.38%を達成。データセットは[こちら](https://github.com/SkelterLabsInc/JaQuAD)から入手可能。
CommentSQuAD likeな日本語のQAデータセット
https://github.com/SkelterLabsInc/JaQuAD #DocumentSummarization #Metrics #Tools #NLP #Dataset #Evaluation #Admin'sPick Issue Date: 2023-08-13 SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21 Comment自動評価指標が人手評価の水準に達しないことが示されており、結局のところROUGEを上回る自動性能指標はほとんどなかった。human judgmentsとのKendall;'s Tauを見ると、chrFがCoherenceとRelevance, METEORがFluencyで上回ったのみだった。また、LEAD-3はやはりベースラインとしてかなり強く、LEAD-3を上回ったのはBARTとPEGASUSだった。 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 How to Evaluate a Summarizer: Study Design and Statistical Analysis for Manual Linguistic Quality Evaluation, Steen+, EACL'21 Summary要約システムの評価方法についての調査結果を報告しました。要約の言語的品質についての評価実験を行い、最適な評価方法は側面によって異なることを示しました。また、研究パラメータや統計分析方法についても問題点を指摘しました。さらに、現行の方法では固定された研究予算の下では信頼性のある注釈を提供できないことを強調しました。 Comment要約の人手評価に対する研究 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 Reliability of Human Evaluation for Text Summarization: Lessons Learned and Challenges Ahead, Iskender+, EACL'21 Summary人間評価の信頼性に関する研究では、参加者の情報や実験の詳細が提供されていないことが多い。また、人間評価の信頼性に影響を与える要因についても研究されていない。そこで、私たちは人間評価実験を行い、参加者の情報や実験の詳細を提供し、異なる実験結果を比較した。さらに、専門家と非専門家の評価の信頼性を確保するためのガイドラインを提供し、信頼性に影響を与える要因を特定した。 Comment要約の人手評価に対する信頼性に関して研究。人手評価のガイドラインを提供している。 #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-free Issue Date: 2023-08-13 A Training-free and Reference-free Summarization Evaluation Metric via Centrality-weighted Relevance and Self-referenced Redundancy, Chen+, ACL-IJCNLP'21 Summary参照ベースと教師ありの要約評価指標の制約を回避するために、トレーニングフリーかつ参照フリーの要約評価指標を提案する。この指標は、文の中心性によって重み付けされた概念参照と要約との関連性スコアと、自己参照の冗長性スコアから構成される。関連性スコアは擬似参照と要約との間で計算され、重要度のガイダンスを提供する。要約の冗長性スコアは要約内の冗長な情報を評価するために計算される。関連性スコアと冗長性スコアを組み合わせて、要約の最終評価スコアを生成する。徹底的な実験により、提案手法が既存の手法を大幅に上回ることが示された。ソースコードはGitHubで公開されている。 #NaturalLanguageGeneration #Metrics #NLP #DialogueGeneration #Evaluation #Reference-free #QA-based #Factuality Issue Date: 2023-08-13 Q2: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering, Honovich+, EMNLP'21 Summary本研究では、ニューラルな知識に基づく対話生成モデルの信頼性と適用範囲の制限についての問題を解決するため、自動的な質問生成と質問応答を使用した事実的な整合性の自動評価尺度を提案します。この尺度は、自然言語推論を使用して回答スパンを比較することで、以前のトークンベースのマッチングよりも優れた評価を行います。また、新しいデータセットを作成し、事実的な整合性の手動アノテーションを行い、他の尺度とのメタ評価を行いました。結果として、提案手法が人間の判断と高い相関を示しました。 Comment(knowledge-grounded; 知識に基づいた)対話に対するFactual ConsistencyをReference-freeで評価できるQGQA手法。機械翻訳やAbstractive Summarizationの分野で研究が進んできたが、対話では
・対話履歴、個人の意見、ユーザに対する質問、そして雑談
といった外部知識に対するconsistencyが適切ではない要素が多く存在し、よりチャレンジングなタスクとなっている。
また、そもそも対話タスクはopen-endedなタスクなため、Reference-basedな手法は現実的ではなく、Reference-freeな手法が必要と主張。

手法の概要としては以下。ユーザの発話からQuestion Generation (QG)を実施し、Question-Answer Candidate Pairを作成する。そして、生成したQuestionをベースとなる知識から回答させ(QA)、その回答結果とAnswer Candidateを比較することでFactual Consistencyを測定する。

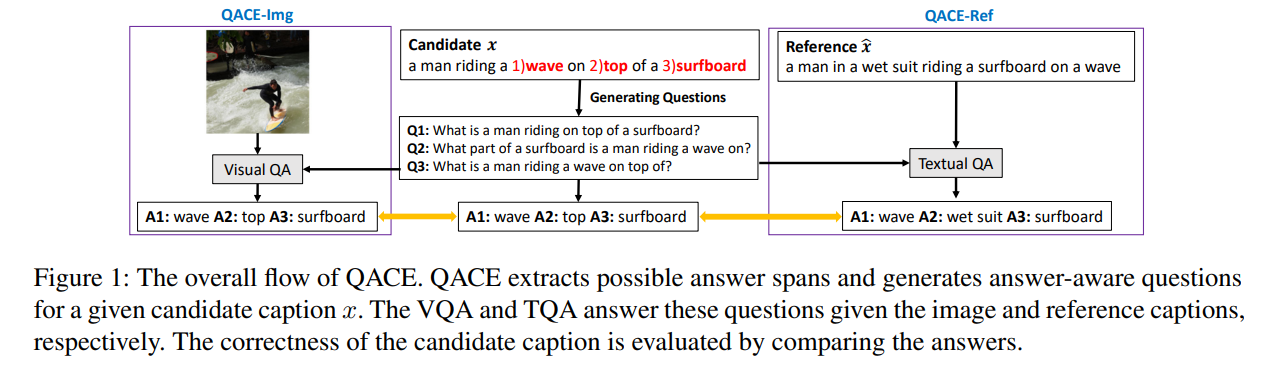
#DocumentSummarization #Metrics #NLP #Evaluation #LM-based #Factuality Issue Date: 2023-08-13 Compression, Transduction, and Creation: A Unified Framework for Evaluating Natural Language Generation, Deng+, EMNLP''21 Summary本研究では、自然言語生成(NLG)タスクの評価において、情報の整合性を重視した統一的な視点を提案する。情報の整合性を評価するための解釈可能な評価指標のファミリーを開発し、ゴールドリファレンスデータを必要とせずに、さまざまなNLGタスクの評価を行うことができることを実験で示した。 CommentCTC #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-free #QA-based Issue Date: 2023-08-13 QACE: Asking Questions to Evaluate an Image Caption, Lee+, EMNLP'21 Summary本研究では、画像キャプションの評価において、Question Generation(QG)とQuestion Answering(QA)システムに基づいた質問応答メトリックであるQACEを提案する。QACEは評価対象のキャプションに対して質問を生成し、その内容を参照キャプションまたはソース画像に対して質問することで確認する。QACE_Refというメトリックを開発し、最先端のメトリックと競合する結果を報告する。さらに、参照ではなく画像自体に直接質問をするQACE_Imgを提案する。QACE_ImgにはVisual-QAシステムが必要であり、Visual-T5という抽象的なVQAシステムを提案する。QACE_Imgはマルチモーダルで参照を必要とせず、説明可能なメトリックである。実験の結果、QACE_Imgは他の参照を必要としないメトリックと比較して有利な結果を示した。 CommentImage Captioningを評価するためのQGQAを提案している。candidateから生成した質問を元画像, およびReferenceを用いて回答させ、candidateに基づいた回答と回答の結果を比較することで評価を実施する。
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #LM-based #Admin'sPick Issue Date: 2023-08-13 BARTSCORE: Evaluating Generated Text as Text Generation, Yuan+ (w_ Neubig氏), NeurIPS'21 Summary本研究では、生成されたテキストの評価方法について検討しました。具体的には、事前学習モデルを使用してテキスト生成の問題をモデル化し、生成されたテキストを参照出力またはソーステキストに変換するために訓練されたモデルを使用しました。提案したメトリックであるBARTSCOREは、情報量、流暢さ、事実性などの異なる視点のテキスト評価に柔軟に適用できます。実験結果では、既存のトップスコアリングメトリックを上回る性能を示しました。BARTScoreの計算に使用するコードは公開されており、インタラクティブなリーダーボードも利用可能です。 CommentBARTScore概要
ソーステキストが与えられた時に、BARTによって生成テキストを生成する尤度を計算し、それをスコアとする手法。テキスト生成タスクをテキスト生成モデルでスコアリングすることで、pre-trainingされたパラメータをより有効に活用できる(e.g. BERTScoreやMoverScoreなどは、pre-trainingタスクがテキスト生成ではない)。BARTScoreの特徴は
1. parameter・and data-efficientである。pre-trainingに利用されたパラメータ以外の追加パラメータは必要なく、unsupervisedなmetricなので、human judgmentのデータなども必要ない。
2. 様々な観点から生成テキストを評価できる。conditional text generation problemにすることでinformativeness, coherence, factualityなどの様々な観点に対応可能。
3. BARTScoreは、(i) pre-training taskと類似したpromptを与えること、(ii) down stream generation taskでfinetuningすること、でより高い性能を獲得できる
BARTScoreを16種類のデータセットの、7つの観点で評価したところ、16/22において、top-scoring metricsよりも高い性能を示した。また、prompting starategyの有効性を示した。たとえば、シンプルに"such as"というフレーズを翻訳テキストに追加するだけで、German-English MTにおいて3%の性能向上が見られた。また、BARTScoreは、high-qualityなテキスト生成システムを扱う際に、よりロバストであることが分析の結果分かった。
前提
Problem Formulation
生成されたテキストのqualityを測ることを目的とする。本研究では、conditional text generation (e.g. 機械翻訳)にフォーカスする。すなわち、ゴールは、hypothesis h_bar を source text s_barがgivenな状態で生成することである。一般的には、人間が作成したreference r_barが評価の際は利用される。
Gold-standard Human Evaluation
評価のgold standardは人手評価であり、人手評価では多くの観点から評価が行われる。以下に代表的な観点を示す:
1. Informativeness: ソーステキストのキーアイデアをどれだけ捉えているか
2. Relevance: ソーステキストにあ地して、どれだけconsistentか
3. Fluency formatting problem, capitarlization errorや非文など、どの程度読むのが困難か
4. Coherence: 文間のつながりが、トピックに対してどれだけcoherentか
5. Factuality: ソーステキストに含意されるstatementのみを生成できているか
6. Semantic Coverage: 参照テキスト中のSemantic Content Unitを生成テキストがどれだけカバーできているか
7: Adequacy 入力文に対してアウトプットが同じ意味を出力できているかどうか、あるいは何らかのメッセージが失われる、追加される、歪曲していないかどうか
多くの性能指標は、これらの観点のうちのsubsetをカバーするようにデザインんされている。たとえば、BLEUは、翻訳におけるAdequacyとFluencyをとらえることを目的としている。一方、ROUGEは、semantic coverageを測るためのメトリックである。
BARTScoreは、これらのうち多くの観点を評価することができる。
Evaluation as Different Tasks
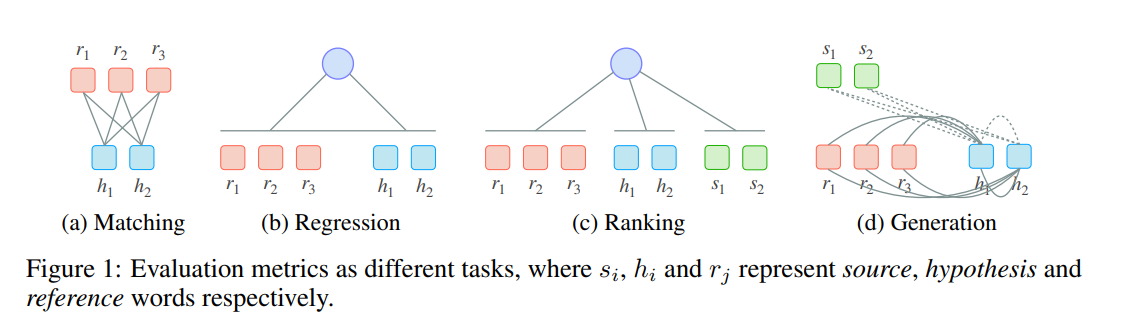
ニューラルモデルを異なる方法で自動評価に活用するのが最近のトレンドである。下図がその分類。この分類は、タスクにフォーカスした分類となっている。
1. Unsupervised Matching: ROUGE, BLEU, CHRF, BERTScore, MoverScoreのように、hypothesisとreference間での意味的な等価性を測ることが目的である。このために、token-levelのマッチングを用いる。これは、distributedな表現を用いる(BERTScore, MoverScore)場合もあれば、discreteな表現を用いる(ROUGE, BLEU, chrF)場合もある。また、意味的な等価性だけでなく、factual consistencyや、source-hypothesis間の関係性の評価に用いることもできると考えられるが先行研究ではやられていなかったので、本研究で可能なことを示す。
2. Supervised Regression: BLEURT, COMET, S^3, VRMのように、regression layer を用いてhuman judgmentをsupervisedに予測する方法である。最近のメトリックtおしては、BLEURT, COMETがあげられ、古典的なものとしては、S^3, VRMがあげられる。
4. Supervised Ranking: COMET, BEERのような、ランキング問題としてとらえる方法もある。これは優れたhypothesisを上位にランキングするようなスコア関数を学習する問題に帰着する。COMETやBEERが例としてあげられ、両者はMTタスクにフォーカスされている。COMETはhunan judgmentsをregressionすることを通じてランキングを作成し、BEERは、多くのシンプルな特徴量を組み合わせて、linear layerでチューニングされる。
5. Text Generation: PRISM, BARTScoreが例として挙げられる。BARTScoreでは、生成されたテキストの評価をpre-trained language modelによるテキスト生成タスクとしてとらえる。基本的なアイデアとしては、高品質のhypothesisは、ソース、あるいはreferenceから容易に生成可能であろう、というものである。これはPRISMを除いて、先行研究ではカバーされていない。BARTScoreは、PRISMとはいくつかの点で異なっている。(i) PRISMは評価をparaphrasing taskとしてとらえており、これが2つの意味が同じテキストを比較する前提となってしまっているため、手法を適用可能な範囲を狭めてしまっている。たとえば、文書要約におけるfactual consistencyの評価では、semantic spaceが異なる2つのテキストを比較する必要があるが、このような例には対応できない。(ii) PRISMはparallel dataから学習しなけえrばならないが、BARTScoreは、pre-trainedなopen-sourceのseq2seq modelを利用できる。(iii) BARTScoreでは、PRISMが検証していない、prompt-basedのlearningもサポートしている。
BARTScore
Sequence-to-Sequence Pre-trained Models
pre-trainingされたモデルは、様々な軸で異なっているが、その一つの軸としては訓練時の目的関数である。基本的には2つの大きな変種があり、1つは、language modeling objectives (e.g. MLM)、2つ目は、seq2seq objectivesである。特に、seq2seqで事前学習されたモデルは、エンコーダーとデコーダーによって構成されているため特に条件付き生成タスクに対して適しており、予測はAutoRegressiveに行われる。本研究ではBARTを用いる。付録には、preliminary experimentsとして、BART with T5, PEGASUSを用いた結果も添付する。
BARTScore
最も一般的なBARTScoreの定式化は下記である。

weighted log probabilityを利用する。このweightsは、異なるトークンに対して、異なる重みを与えることができる。たておば、IDFなどが利用可能であるが、本研究ではすべてのトークンを等価に扱う(uniform weightingだがstopwordを除外、IDFによる重みづけ、事前分布を導入するなど色々試したが、uniform weightingを上回るものがなかった)。
BARTScoreを用いて、様々な方向に用いて生成を行うことができ、異なる評価のシナリオに対応することができる。
・Faithfulness (s -> h):
・hypothesisがどれだけsource textに基づいて生成されているかを測ることができる。シナリオとしては、FactualityやRelevanceなどが考えられる。また、CoherenceやFluencyのように、target textのみの品質を測るためにも用いることができる。
・Precision (r -> h):
・hypothesisがどれだけgold-referenceに基づいてこう良くされているかを亜評価でき、precision-focusedなシナリオに適している
・Recall (h -> r):
・hypothesisから、gold referenceをどれだけ容易に再現できるかを測ることができる。そして、要約タスクのpyramid-basedな評価(i.e. semantic coverage等) に適している。pyramid-scoreはSemantic Content Unitsがどれだけカバーされているかによって評価される。
・F Score (r <-> h):
・双方向を考慮し、Precisioon / RecallからF値を算出する。この方法は、referenceと生成テキスト間でのsemantic overlap (informativenss, adequacy)などの評価に広く利用される。
BARTScore Variants
BARTScoreの2つの拡張を提案。(i) xとyをpromptingによって変更する。これにより、評価タスクをpre-training taskと近づける。(ii) パラメータΘを異なるfinetuning taskを考慮して変更する。すなわち、pre-trainingのドメインを、evaluation taskに近づける。
Prompt
Promptingはinput/outputに対して短いフレーズを追加し、pre-trained modelに対して特定のタスクを遂行させる方法である。BARTにも同様の洞察を簡単に組み込むことができる。この変種をBARTScore-PROMPTと呼ぶ。
prompt zが与えられたときに、それを (i) source textに追加し、新たなsource textを用いてBARTScoreを計算する。(ii) target textの先頭に追加し、new target textに対してBARTScoreを計算する。
Fine-tuning Task
classification-basedなタスクでfine-tuneされるのが一般的なBERT-based metricとは異なり、BARTScoreはgeneration taskでfine-tuneされるため、pre-training domainがevaluation taskと近い。本研究では、2つのdownstream taskを検証する。
1つめは、summarizationで、BARTをCNNDM datasetでfinetuningする。2つめは、paraphrasingで、summarizationタスクでfinetuningしたBARTをParaBank2 datasetでさらにfinetuningする。実験
baselines and datasets
Evaluation Metrics
supervised metrics: COMET, BLEURT
unsupervised: BLEU, ROUGE-1, ROUGE-2, ROUGE-L, chrF, PRISM, MoverScore, BERTScore
と比較
Measures for Meta Evaluation
Pearson Correlationでlinear correlationを測る。また、Spearman Correlationで2変数間の単調なcorrelationを測定する(線形である必要はない)。Kendall's Tauを用いて、2つの順序関係の関係性を測る。最後に、Accuracyでfactual textsとnon-factual textの間でどれだけ正しいランキングを得られるかを測る。
Datasets
Summarization, MT, DataToTextの3つのデータセットを利用。

Setup
Prompt Design
seedをparaphrasingすることで、 s->h方向には70個のpromptを、h<->rの両方向には、34のpromptを得て実験で用いた。

Settings
Summarizationとdata-to-textタスクでは、全てのpromptを用いてデコーダの頭に追加してスコアを計算しスコアを計算した。最終的にすべての生成されたスコアを平均することである事例に対するスコアを求めた(prompt unsembling)。MTについては、事例数が多くcomputational costが多くなってしまうため、WMT18を開発データとし、best prompt "Such as"を選択し、利用した。
BARTScoreを使う際は、gold standard human evaluationがrecall-basedなpyrmid methodの場合はBARTScore(h->r)を用い、humaan judgmentsがlinguistic quality (coherence fluency)そして、factual correctness、あるいは、sourceとtargetが同じモダリティ(e.g. language)の場合は、faitufulness-based BARTScore(s->h)を用いた。最後に、MTタスクとdata-to-textタスクでは、fair-comparisonのためにBARTScore F-score versionを用いた。
実験結果
MT
・BARTScoreはfinetuning tasksによって性能が向上し、5つのlanguage pairsにおいてその他のunsupervised methodsを統計的に優位にoutperformし、2つのlanguage pairでcomparableであった。
-Such asというpromptを追加するだけで、BARTScoreの性能が改善した。特筆すべきは、de-enにおいては、SoTAのsupervised MetricsであるBLEURTとCOMETを上回った。
・これは、有望な将来のmetric designとして「human judgment dataで訓練する代わりに、pre-trained language modelに蓄積された知識をより適切に活用できるpromptを探索する」という方向性を提案している。

Text Summarization
・vanilla BARTScoreはBERTScore, MoverScoreをInfo perspective以外でlarge marginでうくぁ回った。
・REALSum, SummEval dataseetでの改善は、finetuning taskによってさらに改善した。しかしながら、NeR18では改善しなかった。これは、データに含まれる7つのシステムが容易に区別できる程度のqualityであり、既にvanilla BARTScoreで高いレベルのcorrelationを達成しているからだと考えられる。
・prompt combination strategyはinformativenssに対する性能を一貫して改善している。しかし、fluency, factualityでは、一貫した改善は見られなかった。

Factuality datasetsに対する分析を行った。ゴールは、short generated summaryが、元のlong documentsに対してfaithfulか否かを判定するというものである。
・BARTScore+CNNは、Rank19データにおいてhuman baselineに近い性能を達成し、ほかのベースラインを上回った。top-performingなfactuality metricsであるFactCCやQAGSに対してもlarge marginで上回った。
・paraphraseをfine-tuning taskで利用すると、BARTScoreのパフォーマンスは低下した。これは妥当で、なぜなら二つのテキスト(summary and document)は、paraphrasedの関係性を保持していないからである。
・promptを導入しても、性能の改善は見受けられず、パフォーマンスは低下した。

Data-to-Text
・CNNDMでfine-tuningすることで、一貫してcorrelationが改善した。
・加えて、paraphraseデータセットでfinetuningすることで、さらに性能が改善した。
・prompt combination strategyは一貫してcorrelationを改善した。

Analysis
Fine-grained Analysis
・Top-k Systems: MTタスクにおいて、評価するシステムをtop-kにし、各メトリックごとにcorrelationの変化を見た。その結果、BARTScoreはすべてのunsupervised methodをすべてのkにおいて上回り、supervised metricのBLEURTも上回った。また、kが小さくなるほど、より性能はsmoothになっていき、性能の低下がなくなっていった。これはつまり、high-quality textを生成するシステムに対してロバストであることを示している。
・Reference Length: テストセットを4つのバケットにreference lengthに応じてブレイクダウンし、Kendall's Tauの平均のcorrelationを、異なるメトリック、バケットごとに言語をまたいで計算した。unsupervised metricsに対して、全てのlengthに対して、引き分けかあるいは上回った。また、ほかのmetricsと比較して、長さに対して安定感があることが分かった。

Prompt Analysis
(1) semantic overlap (informativeness, pyramid score, relevance), (2) linguistic quality (fluency, coherence), (3) factual correctness (factuality) に評価の観点を分類し、summarizationとdata-to-textをにおけるすべてのpromptを分析することで、promptの効果を分析した。それぞれのグループに対して、性能が改善したpromptの割合を計算した。その結果、semantic overlapはほぼ全てのpromptにて性能が改善し、factualityはいくつかのpromptでしか性能の改善が見られなかった。linguistic qualityに関しては、promptを追加することによる効果はどちらとも言えなかった。
Bias Analysis
BARTScoreが予測不可能な方法でバイアスを導入してしまうかどうかを分析した。バイアスとは、human annotatorが与えたスコアよりも、値が高すぎる、あるいは低すぎるような状況である。このようなバイアスが存在するかを検証するために、human annotatorとBARTScoreによるランクのサを分析した。これを見ると、BARTScoreは、extractive summarizationの品質を区別する能力がabstractive summarizationの品質を区別する能力よりも劣っていることが分かった。しかしながら、近年のトレンドはabstractiveなseq2seqを活用することなので、この弱点は軽減されている。
Implications and Future Directions
prompt-augmented metrics: semantic overlapではpromptingが有効に働いたが、linguistic qualityとfactualityでは有効ではなかった。より良いpromptを模索する研究が今後期待される。
Co-evolving evaluation metrics and systems: BARTScoreは、メトリックデザインとシステムデザインの間につながりがあるので、より性能の良いseq2seqシステムが出たら、それをメトリックにも活用することでよりreliableな自動性能指標となることが期待される。

#DocumentSummarization #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 Towards Question-Answering as an Automatic Metric for Evaluating the Content Quality of a Summary, Deutsch+, TACL'21 Summary要約の品質を評価するための新しい指標であるQAEvalを提案する。QAEvalは質問応答(QA)を使用して要約と参照の情報の重複を測定するため、従来のテキストの重複に基づく指標とは異なる。実験結果から、QAEvalは現在の最先端の指標よりも優れたパフォーマンスを示し、他の評価とも競争力があることがわかった。QAEvalの構成要素を分析することで、その潜在的な上限パフォーマンスは他の自動評価指標を上回り、ゴールドスタンダードのピラミッドメソッドに近づくと推定される。 #DocumentSummarization #Metrics #NLP #Evaluation #Reference-free Issue Date: 2023-08-13 ESTIME: Estimation of Summary-to-Text Inconsistency by Mismatched Embeddings, Eval4NLP'21 Summary私たちは、新しい参照なし要約品質評価尺度を提案します。この尺度は、要約とソースドキュメントの間の潜在的な矛盾を見つけて数えることに基づいています。提案された尺度は、一貫性と流暢さの両方で他の評価尺度よりも専門家のスコアと強い相関を示しました。また、微妙な事実の誤りを生成する方法も紹介しました。この尺度は微妙なエラーに対してより感度が高いことを示しました。 #NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #AAAI Issue Date: 2022-04-28 Do we need to go Deep? Knowledge Tracing with Big Data, Varun+, University of Maryland Baltimore County, AAAI'21 Workshop on AI Education Summaryインタラクティブ教育システム(IES)を用いて学生の知識を追跡し、パフォーマンスモデルを開発する研究が進展。深層学習モデルが従来のモデルを上回るかは未検証であり、EdNetデータセットを用いてその精度を比較。結果、ロジスティック回帰モデルが深層モデルを上回ることが確認され、LIMEを用いて予測に対する特徴の影響を解釈する研究を行った。 Commentデータ量が小さいとSAKTはDKTはcomparableだが、データ量が大きくなるとSAKTがDKTを上回る。
 #RecommenderSystems
#Tools
#Library
#CIKM
Issue Date: 2022-03-29
RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms, Zhao+, CIKM'21
SummaryRecBoleは、推薦アルゴリズムのオープンソース実装を標準化するための統一的で効率的なライブラリであり、73のモデルを28のベンチマークデータセット上で実装。PyTorchに基づき、一般的なデータ構造や評価プロトコル、自動パラメータ調整機能を提供し、推薦システムの実装と評価を促進する。プロジェクトはhttps://recbole.io/で公開。
Comment参考リンク:
#RecommenderSystems
#Tools
#Library
#CIKM
Issue Date: 2022-03-29
RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms, Zhao+, CIKM'21
SummaryRecBoleは、推薦アルゴリズムのオープンソース実装を標準化するための統一的で効率的なライブラリであり、73のモデルを28のベンチマークデータセット上で実装。PyTorchに基づき、一般的なデータ構造や評価プロトコル、自動パラメータ調整機能を提供し、推薦システムの実装と評価を促進する。プロジェクトはhttps://recbole.io/で公開。
Comment参考リンク:
・https://www.google.co.jp/amp/s/techblog.zozo.com/entry/deep-learning-recommendation-improvement%3famp=1
・https://techlife.cookpad.com/entry/2021/11/04/090000
・https://qiita.com/fufufukakaka/items/77878c1e23338345d4fa #NeuralNetwork #ComputerVision #NeurIPS Issue Date: 2021-11-04 ResNet strikes back: An improved training procedure in timm, Wightman+, NeurIPS'21 Workshop ImageNet PPF Summary本論文では、Residual Networks(ResNet-50)の性能を新たなトレーニング手法を用いて再評価し、競争力のある設定で80.4%のトップ1精度を達成したことを報告します。これにより、将来の研究のためのより良いベースラインを提供することを目指しています。 Comment2015年以後、様々な最適化アルゴリズム、正則化手法、データ拡張などが提案される中で、最新アーキテクチャのモデルにはそれらが適用される一方ベースラインとなるResNetではそれらが適用されず、論文の値のみが参照される現状はフェアではないので、ResNetの性能を向上させるような訓練手法を追求した研究。
ResNetにおける有効な訓練手法として下記を模索:
損失関数として、MixUp(訓練画像を重ね合わせ、組み合わせた画像のラベルをミックスして新しい学習インスタンスを作るデータ拡張手法)と、CutMix(画像を切り貼りして、切り貼り部分の面積に応じてラベルのスコアを調整するデータ拡張手法)を適用し、CutMixによって大幅に性能が改善することを示した。このとき、ラベルの確率の和が1となる前提の元クロスエントロピーで学習するのではなく、元画像に含まれる物体が両方存在するという全体の元BinaryCrossEntropyを適用しマルチラベル問題として学習することで、性能が向上。
データ拡張手法として、MixUp, CutMixだけでなく、通常のリサイズ・切り抜きと、水平方向の反転を適用しデータ拡張する。加えてRandAugment(14種類のデータ拡張操作から、N個サンプルし、強さMで順番に適用するデータ拡張手法。N,Mはそれぞれ0〜10の整数なので、10の二乗オーダーでグリッドサーチすれば、最適なN,Mを得る。グリッドサーチするだけでお手軽だが非常に強力)を適用した。
正則化として、Weight Decay(学習過程で重みが大きくなりすぎないようにペナルティを課し、過学習を防止する手法。L2正則化など。)と、label smoothing(正解ラベルが1、その他は0とラベル付けするのではなく、ラベルに一定のノイズを入れ、正解ラベル以外にも重みが入っている状態にし、ラベル付けのノイズにロバストなモデルを学習する手法。ノイズの強さは定数で調整する)、Repeated Augmentation(同じバッチ内の画像にデータ拡張を適用しバッチサイズを大きくする)、Stochastic Depth(ランダムでレイヤーを削除し、その間を恒等関数で繋ぎ訓練することで、モデルの汎化能力と訓練時間を向上する)を適用。
Optimizerとして、オリジナルのResNetでは、SGDやAdamWで訓練されることが多いが、Repeated Augmentationとバイナリクロスエントロピーを組み合わせた場合はLAMBが有効であった。また、従来よりも長い訓練時間(600epoch、様々な正則化手法を使っているので過学習しづらいため)で学習し、最初にウォームアップを使い徐々に学習率を上げ(finetuningの再認識これまでのweightをなるべく壊したくないから小さい学習率から始める、あるいはMomentumやAdamといった移動平均を使う手法では移動平均を取るための声倍の蓄積が足りない場合学習の信頼度が低いので最初の方は学習率小さくするみたいな、イメージ)その後コサイン関数に従い学習率を減らしていくスケジューリング法で学習。
論文中では上記手法の3種類の組み合わせ(A1,A2,A3)を提案し実験している。
ResNet-50に対してA1,2,3を適用した結果、A1を適用した場合にImageNetのトップ1精度が80.4%であり、これはResNet-50を使った場合のSoTA。元のResNetの精度が76%程度だったので大幅に向上した。
同じ実験設定を使った場合の他のアーキテクチャ(ViTやEfficientNetなど)と比べても遜色のない性能を達成。

また、本論文で提案されているA2と、DeiTと呼ばれるアーキテクチャで提案されている訓練手法(T2)をそれぞれのモデルに適用した結果、ResNetではA2、DeiTではT2の性能が良かった。つまり、「アーキテクチャと訓練方法は同時に最適化する必要がある」ということ。これがこの論文のメッセージの肝とのこと。
(ステートオブAIガイドの内容を一部補足して記述しました。いつもありがとうございます。)
 画像系でどういった訓練手法が利用されるか色々書かれていたので勉強になった。特に画像系のデータ拡張手法なんかは普段触らないので勉強になる。OpenReview:https://openreview.net/forum?id=NG6MJnVl6M5
#Pocket
#AdaptiveLearning
#IJCAI
Issue Date: 2021-08-04
RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions, Kubotani+, Waseda University, IJCAI'21
Summary教育分野の課題に対し、学生の知識状態に基づく適応指導を強化学習で最適化するフレームワークを提案。実際の学生との相互作用を最小限にし、仮想モデルを構築。実験により、提案モデルは従来の指導方法と同等の性能を示し、理論と実践の橋渡しを行う。
#RecommenderSystems
#Survey
#SessionBased
#SequentialRecommendation
Issue Date: 2019-08-02
A Survey on Session-based Recommender Systems, Wang+, CSUR'21
#DocumentSummarization
#Metrics
#Pocket
#NLP
#Evaluation
#Reference-free
#QA-based
Issue Date: 2023-08-20
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries, Wang, ACL'20
Summary要約の事実の不整合を特定するための自動評価プロトコルであるQAGSを提案する。QAGSは、要約とソースについて質問をし、整合性がある回答を得ることで要約の事実的整合性を評価する。QAGSは他の自動評価指標と比較して高い相関を持ち、自然な解釈可能性を提供する。QAGSは有望なツールであり、https://github.com/W4ngatang/qagsで利用可能。
CommentQAGS生成された要約からQuestionを生成する手法。precision-oriented
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#QA-based
Issue Date: 2023-08-16
FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization, Durmus+, ACL'20
Summaryニューラル抽象的要約モデルの信頼性を評価するために、人間の注釈を収集し、信頼性の自動評価指標であるFEQAを提案した。FEQAは質問応答を利用して要約の信頼性を評価し、特に抽象的な要約において人間の評価と高い相関を示した。
CommentFEQA生成された要約からQuestionを生成する手法。precision-oriented
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-based
Issue Date: 2023-08-13
HOLMS: Alternative Summary Evaluation with Large Language Models, Mrabet+, COLING'20
Summary要約手法の評価尺度として、ROUGEとBLEUが一般的に使用されているが、これらは語彙的な性質を持ち、ニューラルネットワークのトレーニングには限定的な可能性がある。本研究では、大規模なコーパスで事前学習された言語モデルと語彙的類似度尺度を組み合わせた新しい評価尺度であるHOLMSを提案する。実験により、HOLMSがROUGEとBLEUを大幅に上回り、人間の判断との相関も高いことを示した。
CommentHybrid Lexical and MOdel-based evaluation of Summaries (HOLMS)
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#LM-based
#Factuality
Issue Date: 2023-08-13
Evaluating the Factual Consistency of Abstractive Text Summarization, Kryscinski+, EMNLP'20
Summary本研究では、要約の事実的な整合性を検証するためのモデルベースのアプローチを提案しています。トレーニングデータはルールベースの変換を用いて生成され、モデルは整合性の予測とスパン抽出のタスクで共同してトレーニングされます。このモデルは、ニューラルモデルによる要約に対して転移学習を行うことで、以前のモデルを上回る性能を示しました。さらに、人間の評価でも補助的なスパン抽出タスクが有用であることが示されています。データセットやコード、トレーニング済みモデルはGitHubで公開されています。
CommentFactCC近年のニューラルモデルは流ちょうな要約を生成するが、それらには、unsuportedなinformationが多く含まれていることを示した
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
#LM-based
Issue Date: 2023-08-13
Automatic Machine Translation Evaluation in Many Languages via Zero-Shot Paraphrasing, Thompson+, EMNLP'20
Summaryパラフレーザを使用して機械翻訳の評価を行うタスクを定義し、多言語NMTシステムをトレーニングしてパラフレーシングを行います。この手法は直感的であり、人間の判断を必要としません。39言語でトレーニングされた単一モデルは、以前のメトリクスと比較して優れたパフォーマンスを示し、品質推定のタスクでも優れた結果を得ることができます。
CommentPRISM
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Fill in the BLANC: Human-free quality estimation of document summaries, Vasilyev+, Eval4NLP'20
SummaryBLANCは、要約の品質を自動的に推定するための新しいアプローチです。BLANCは、事前学習済みの言語モデルを使用してドキュメントの要約にアクセスし、要約の機能的なパフォーマンスを測定します。BLANCスコアは、ROUGEと同様に人間の評価と良好な相関関係を持ち、人間によって書かれた参照要約が不要なため、完全に人間不在の要約品質推定が可能です。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
#Training-Free
Issue Date: 2023-08-13
SUPERT: Towards New Frontiers in Unsupervised Evaluation Metrics for Multi-Document Summarization, Gao+, ACL'20
Summaryこの研究では、教師なしの複数文書要約評価メトリックスについて調査しています。提案手法SUPERTは、擬似的な参照要約として選択された重要な文を使用し、文脈化埋め込みとソフトトークンアラインメント技術を用いて要約の品質を評価します。SUPERTは従来の教師なし評価メトリックスよりも人間の評価との相関が高く、18〜39%の向上が見られます。また、SUPERTを報酬として使用してニューラルベースの強化学習要約器をガイドすることで、有利なパフォーマンスを実現しています。ソースコードはGitHubで入手可能です。
Commentpseudo-reference summaryを作成し、referenceに対してSBERTを適用しsystem-reference間の類似度を測ることで、unsupervisedに複数文書要約を評価する手法。
画像系でどういった訓練手法が利用されるか色々書かれていたので勉強になった。特に画像系のデータ拡張手法なんかは普段触らないので勉強になる。OpenReview:https://openreview.net/forum?id=NG6MJnVl6M5
#Pocket
#AdaptiveLearning
#IJCAI
Issue Date: 2021-08-04
RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions, Kubotani+, Waseda University, IJCAI'21
Summary教育分野の課題に対し、学生の知識状態に基づく適応指導を強化学習で最適化するフレームワークを提案。実際の学生との相互作用を最小限にし、仮想モデルを構築。実験により、提案モデルは従来の指導方法と同等の性能を示し、理論と実践の橋渡しを行う。
#RecommenderSystems
#Survey
#SessionBased
#SequentialRecommendation
Issue Date: 2019-08-02
A Survey on Session-based Recommender Systems, Wang+, CSUR'21
#DocumentSummarization
#Metrics
#Pocket
#NLP
#Evaluation
#Reference-free
#QA-based
Issue Date: 2023-08-20
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries, Wang, ACL'20
Summary要約の事実の不整合を特定するための自動評価プロトコルであるQAGSを提案する。QAGSは、要約とソースについて質問をし、整合性がある回答を得ることで要約の事実的整合性を評価する。QAGSは他の自動評価指標と比較して高い相関を持ち、自然な解釈可能性を提供する。QAGSは有望なツールであり、https://github.com/W4ngatang/qagsで利用可能。
CommentQAGS生成された要約からQuestionを生成する手法。precision-oriented
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#QA-based
Issue Date: 2023-08-16
FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization, Durmus+, ACL'20
Summaryニューラル抽象的要約モデルの信頼性を評価するために、人間の注釈を収集し、信頼性の自動評価指標であるFEQAを提案した。FEQAは質問応答を利用して要約の信頼性を評価し、特に抽象的な要約において人間の評価と高い相関を示した。
CommentFEQA生成された要約からQuestionを生成する手法。precision-oriented
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-based
Issue Date: 2023-08-13
HOLMS: Alternative Summary Evaluation with Large Language Models, Mrabet+, COLING'20
Summary要約手法の評価尺度として、ROUGEとBLEUが一般的に使用されているが、これらは語彙的な性質を持ち、ニューラルネットワークのトレーニングには限定的な可能性がある。本研究では、大規模なコーパスで事前学習された言語モデルと語彙的類似度尺度を組み合わせた新しい評価尺度であるHOLMSを提案する。実験により、HOLMSがROUGEとBLEUを大幅に上回り、人間の判断との相関も高いことを示した。
CommentHybrid Lexical and MOdel-based evaluation of Summaries (HOLMS)
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#LM-based
#Factuality
Issue Date: 2023-08-13
Evaluating the Factual Consistency of Abstractive Text Summarization, Kryscinski+, EMNLP'20
Summary本研究では、要約の事実的な整合性を検証するためのモデルベースのアプローチを提案しています。トレーニングデータはルールベースの変換を用いて生成され、モデルは整合性の予測とスパン抽出のタスクで共同してトレーニングされます。このモデルは、ニューラルモデルによる要約に対して転移学習を行うことで、以前のモデルを上回る性能を示しました。さらに、人間の評価でも補助的なスパン抽出タスクが有用であることが示されています。データセットやコード、トレーニング済みモデルはGitHubで公開されています。
CommentFactCC近年のニューラルモデルは流ちょうな要約を生成するが、それらには、unsuportedなinformationが多く含まれていることを示した
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
#LM-based
Issue Date: 2023-08-13
Automatic Machine Translation Evaluation in Many Languages via Zero-Shot Paraphrasing, Thompson+, EMNLP'20
Summaryパラフレーザを使用して機械翻訳の評価を行うタスクを定義し、多言語NMTシステムをトレーニングしてパラフレーシングを行います。この手法は直感的であり、人間の判断を必要としません。39言語でトレーニングされた単一モデルは、以前のメトリクスと比較して優れたパフォーマンスを示し、品質推定のタスクでも優れた結果を得ることができます。
CommentPRISM
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Fill in the BLANC: Human-free quality estimation of document summaries, Vasilyev+, Eval4NLP'20
SummaryBLANCは、要約の品質を自動的に推定するための新しいアプローチです。BLANCは、事前学習済みの言語モデルを使用してドキュメントの要約にアクセスし、要約の機能的なパフォーマンスを測定します。BLANCスコアは、ROUGEと同様に人間の評価と良好な相関関係を持ち、人間によって書かれた参照要約が不要なため、完全に人間不在の要約品質推定が可能です。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
#Training-Free
Issue Date: 2023-08-13
SUPERT: Towards New Frontiers in Unsupervised Evaluation Metrics for Multi-Document Summarization, Gao+, ACL'20
Summaryこの研究では、教師なしの複数文書要約評価メトリックスについて調査しています。提案手法SUPERTは、擬似的な参照要約として選択された重要な文を使用し、文脈化埋め込みとソフトトークンアラインメント技術を用いて要約の品質を評価します。SUPERTは従来の教師なし評価メトリックスよりも人間の評価との相関が高く、18〜39%の向上が見られます。また、SUPERTを報酬として使用してニューラルベースの強化学習要約器をガイドすることで、有利なパフォーマンスを実現しています。ソースコードはGitHubで入手可能です。
Commentpseudo-reference summaryを作成し、referenceに対してSBERTを適用しsystem-reference間の類似度を測ることで、unsupervisedに複数文書要約を評価する手法。
まずTACのデータに対して、既存研究(single document summarizationの評価用に提案された手法)を適用し、Human Ratingsとの相関が低いことを確認している。この時、Referenceを用いる手法(ROUGE、MoverScore)の相関をUpper Boundとし、Upper Boundに及ばないことを確認している。また、既存研究よりもシンプルなJS Divergence等を用いるlexical basedな手法の相関が高かったことも確認している。
続いて、unsupervisedな手法として、contextualなembeddingを利用し(BERT, SBERT等)source, system summary間の類似度を測る手法で相関を測ったところ、こちらでもUpper Boundに及ばないこと、シンプルな手法に及ばないことを確認。これら手法にWMDを応用するすることで相関が向上することを確認した。
これらのことより、Referenceがある場合、無い場合の両者においてWMDを用いる手法が有効であることが確認できたが、Referenceの有無によって相関に大きな差が生まれていることが確認できた。このことから、何らかの形でReferenceが必要であり、pseudo referenceを生成し利用することを着想した、というストーリーになっている。pseudo referenceを生成する方法として、top Nのリード文を抽出する手法や、LexRankのようなGraphBasedな手法を利用してTACデータにおいてどのような手法が良いかを検証している。この結果、TAC8,9の場合はTop 10,15のsentenceをpseudo referenceとした場合が最も良かった。
細かいところまで読みきれていないが、自身が要約したい文書群においてどの方法でpseudo referenceを生成するかは、Referenceがないと判断できないと考えられるため、その点は課題だと考えられる。 #DocumentSummarization #Metrics #NLP #Evaluation #Reference-based #TrainedMetrics Issue Date: 2023-08-13 BLEURT: Learning Robust Metrics for Text Generation, Sellam+, ACL'20 SummaryBLEURTは、BERTをベースとした学習済みの評価指標であり、人間の判断と高い相関を持つことが特徴です。BLEURTは、数千のトレーニング例を使用してバイアスのある評価をモデル化し、数百万の合成例を使用してモデルの汎化を支援します。BLEURTは、WMT Metrics共有タスクとWebNLGデータセットで最先端の結果を提供し、トレーニングデータが少ない場合や分布外の場合でも優れた性能を発揮します。 #NeuralNetwork #Pocket #NLP #LanguageModel #Zero/FewShotPrompting #In-ContextLearning #NeurIPS #Admin'sPick Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 SummaryGPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 CommentIn-Context Learningを提案した論文論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。

この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。 #NLP #ReviewGeneration #ACL Issue Date: 2021-03-17 Unsupervised Opinion Summarization as Copycat-Review Generation, Bražinskas, ACL'20 Summary意見要約は、製品レビューから主観的情報を自動的に要約するタスクであり、従来の研究は抽出的手法に焦点を当てていたが、本研究では新しい文を生成する抽象的要約を提案する。教師なし設定での生成モデルを定義し、新規性を制御しながら合意された意見を反映する要約を生成する。階層的変分オートエンコーダモデルを用い、実験により流暢で一貫性のある要約が生成できることを示した。 #Survey #NaturalLanguageGeneration #Pocket #NLP #Evaluation Issue Date: 2020-08-25 Evaluation of Text Generation: A Survey, Celikyilmaz, Clark, Gao, arXiv'20 Summary本論文では、自然言語生成(NLG)システムの評価方法を人間中心、自動評価、機械学習に基づく評価の3カテゴリに分類し、それぞれの進展と課題を議論。特に新しいNLGタスクやニューラルNLGモデルの評価に焦点を当て、自動テキスト要約と長文生成の例を示し、今後の研究方向性を提案します。 #NLP #Dataset #QuestionAnswering #Evaluation #Factuality #ReadingComprehension Issue Date: 2025-08-16 Natural Questions: A Benchmark for Question Answering Research, Kwiatkowski+, TACL'19 SummaryNatural Questionsコーパスは、Google検索エンジンからの実際の匿名化されたクエリを基にした質問応答データセットで、307,373のトレーニング例と7,830の開発例、7,842のテスト例が含まれています。アノテーターは、質問に対してWikipediaページから長い回答と短い回答を注釈し、質の検証実験や人間の変動性に関する分析を行っています。また、質問応答システムの評価のためのメトリクスを導入し、競争的手法を用いてベースライン結果を確立しています。 #Analysis #NLP #Transformer Issue Date: 2024-10-07 What Does BERT Learn about the Structure of Language?, Jawahar+, ACL'19 SummaryBERTは言語理解において優れた成果を上げており、本研究ではその言語構造の要素を解明する実験を行った。主な発見は、フレーズ表現がフレーズレベルの情報を捉え、中間層が構文的および意味的特徴の階層を形成し、長期依存性の問題に対処するために深い層が必要であること、さらにBERTの構成が古典的な木構造に類似していることを示している。 Comment1370 中で引用されている。Transformerの各ブロックが、何を学習しているかを分析。 #DocumentSummarization #NeuralNetwork #NLP #Extractive Issue Date: 2023-08-28 Text Summarization with Pretrained Encoders, Liu+ (with Lapata), EMNLP-IJCNLP'19 Summary本研究では、最新の事前学習言語モデルであるBERTを使用して、テキスト要約のための一般的なフレームワークを提案します。抽出型モデルでは、新しいエンコーダを導入し、文の表現を取得します。抽象的な要約については、エンコーダとデコーダの最適化手法を異ならせることで不一致を緩和します。さらに、2段階のファインチューニングアプローチによって要約の品質を向上させました。実験結果は、提案手法が最先端の結果を達成していることを示しています。 CommentBERTSUMEXT論文通常のBERTの構造と比較して、文ごとの先頭に[CLS]トークンを挿入し、かつSegment Embeddingsを文ごとに交互に変更することで、文のrepresentationを取得できるようにする。
その後、encodingされたsentenceの[CLS]トークンに対応するembeddingの上に、inter-sentence Transformer layerを重ね、sigmoidでスコアリングするのが、BERTSUMEXT, Abstractiveの場合は6-layerのTransformer decoderを利用するが、これはスクラッチでfinetuninigさせる。このとき、encoder側はoverfit, decoder側はunderfitすることが予想されるため、encoderとdecodeで異なるwarmup, 学習率を適用する。具体的には、encoder側はより小さい学習率で、さらにsmoothに減衰するようにする。これにより、decoder側が安定したときにより正確な勾配で学習できるようになる。また、2-stageのfinetuningを提案し、まずencoder側をextractifve summarization taskでfinetuningし、その後abstractive summarizationでfinetuningする。先行研究ではextractive summarizationのobjectiveを取り入れることでabstractive summarizationの性能が向上していることが報告されており、この知見を取り入れる。今回はextractive summarizationの重みをabstractive taskにtrasnferすることになる。
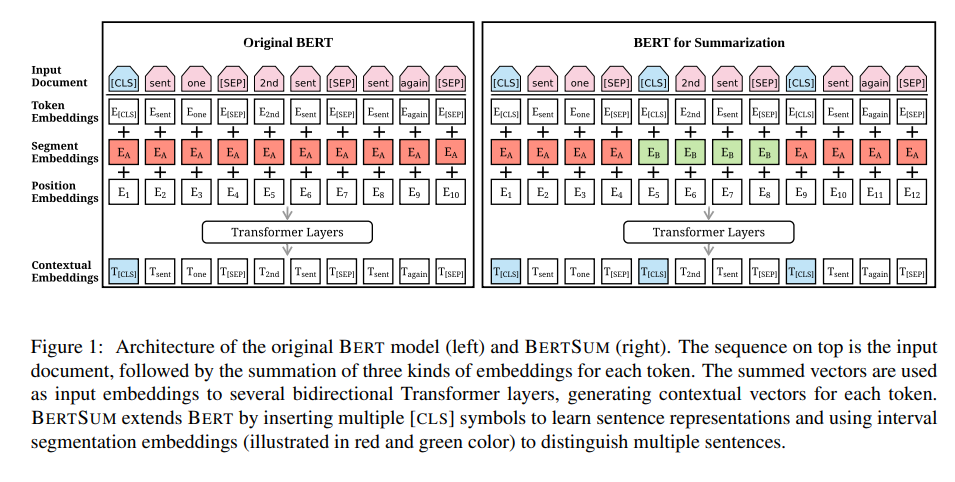
#DocumentSummarization #Pocket #NLP #Evaluation Issue Date: 2023-08-16 Neural Text Summarization: A Critical Evaluation, Krysciski+ (w_ Richard Socher), EMNLP-IJCNLP'19 Summaryテキスト要約の研究は進展が停滞しており、データセット、評価指標、モデルの3つの要素に問題があることが指摘されている。自動収集されたデータセットは制約が不十分であり、ノイズを含んでいる可能性がある。評価プロトコルは人間の判断と相関が弱く、重要な特性を考慮していない。モデルはデータセットのバイアスに過適合し、出力の多様性が限られている。 #DocumentSummarization #Metrics #NLP #Evaluation #QA-based Issue Date: 2023-08-16 Question answering as an automatic evaluation metric for news article summarization, Eyal+, NAACL'19 Summary最近の自動要約の研究では、ROUGEスコアの最大化に焦点を当てているが、本研究では代替的な評価指標であるAPESを提案する。APESは、要約が一連の手動作成質問に答える能力を定量化する。APESを最大化するエンドツーエンドのニューラル抽象モデルを提案し、ROUGEスコアを向上させる。 CommentAPES #DocumentSummarization #Metrics #NLP #Evaluation Issue Date: 2023-08-16 Studying Summarization Evaluation Metrics in the Appropriate Scoring Range, Peyrard+, ACL'19 Summary自動評価メトリックは通常、人間の判断との相関性を基準に比較されるが、既存の人間の判断データセットは限られている。現代のシステムはこれらのデータセット上で高スコアを出すが、評価メトリックの結果は異なる。高スコアの要約に対する人間の判断を収集することで、メトリックの信頼性を解決することができる。これは要約システムとメトリックの改善に役立つ。 Comment要約のメトリックがhuman judgmentsに対してcorrelationが低いことを指摘 #DocumentSummarization #MachineTranslation #NLP #Evaluation #TrainedMetrics Issue Date: 2023-08-13 Machine Translation Evaluation with BERT Regressor, Hiroki Shimanaka+, N_A, arXiv'19 Summary私たちは、BERTを使用した自動的な機械翻訳の評価メトリックを紹介します。実験結果は、私たちのメトリックがすべての英語対応言語ペアで最先端のパフォーマンスを達成していることを示しています。 #DocumentSummarization #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance, Zhao+, EMNLP-IJCNLP'19 Summary本研究では、テキスト生成システムの評価尺度について調査し、システムの出力と参照テキストの意味に基づいて比較する尺度を提案します。この尺度は、要約、機械翻訳、画像キャプション、データからテキストへの生成などのタスクで有効であり、文脈化表現と距離尺度を組み合わせたものが最も優れています。また、提案した尺度は強力な汎化能力を持っており、ウェブサービスとして提供されています。 CommentWord Mover Distance (WMD)の解説: https://yubessy.hatenablog.com/entry/2017/01/10/122737 #DocumentSummarization #NLP #Evaluation #Reference-free #QA-based Issue Date: 2023-08-13 Answers Unite Unsupervised Metrics for Reinforced Summarization Models, Scialom+, EMNLP-IJCNLP'19 Summary最近、再強化学習(RL)を使用した抽象的要約手法が提案されており、従来の尤度最大化を克服するために使用されています。この手法は、複雑で微分不可能なメトリクスを考慮することで、生成された要約の品質と関連性を総合的に評価することができます。ROUGEという従来の要約メトリクスにはいくつかの問題があり、代替的な評価尺度を探求する必要があります。報告された人間評価の分析によると、質問応答に基づく提案されたメトリクスはROUGEよりも有利であり、参照要約を必要としないという特徴も持っています。これらのメトリクスを使用してRLベースのモデルをトレーニングすることは、現在の手法に比べて改善をもたらします。 CommentSummaQA #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Evaluation #RecSys Issue Date: 2022-04-11 Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, Politecnico di Milano, Maurizio+, RecSys'19 CommentRecSys'19のベストペーパー
日本語解説:https://qiita.com/smochi/items/98dbd9429c15898c5dc7重要研究 #Pocket #NLP #CommentGeneration #Personalization #ACL Issue Date: 2019-09-11 Automatic Generation of Personalized Comment Based on User Profile, Zeng+, arXiv'19 #NeuralNetwork #Pocket #NLP #CommentGeneration #ACL Issue Date: 2019-08-24 Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model, Li+ ,ACL'19 #RecommenderSystems #Calibration Issue Date: 2024-09-20 Calibrated Recommendation, Herald Steck, Netflix, RecSys'18 Summaryユーザーの過去の視聴履歴に基づき、推薦映画リストがその興味に応じた割合で構成されることをキャリブレーションと呼ぶ。キャリブレーションは、ユーザーの多様な興味を反映するために重要であり、従来のレコメンダーシステムは主な興味に偏りがちであることが示されている。本研究では、キャリブレーションの度合いを定量化するメトリクスと、出力を後処理する再ランキングアルゴリズムを提案する。 #NLP #Hallucination #ImageCaptioning Issue Date: 2023-08-16 Object hallucination in image captioning, Rohbach+, EMNLP'18 Summary現代の画像キャプションモデルは、オブジェクトの幻覚を生じる傾向がある。本研究では、新しい画像関連性の評価指標を提案し、モデルのアーキテクチャや学習目標が幻覚にどのように寄与するかを評価する。さらに、言語の先入観によるエラーが幻覚を引き起こすことも示された。 #RecommenderSystems #NeuralNetwork #Survey Issue Date: 2018-04-16 Deep Learning based Recommender System: A Survey and New Perspectives, Zhang+, CSUR'18 #NeuralNetwork #Pocket #NLP #DialogueGeneration #ACL Issue Date: 2018-02-08 Personalizing Dialogue Agents: I have a dog, do you have pets too?, Zhang+, ACL'18 #NaturalLanguageGeneration #Metrics #NLP #Evaluation Issue Date: 2023-08-16 Why We Need New Evaluation Metrics for NLG, EMNLP'17 SummaryNLGの評価には自動評価指標が使われているが、本研究ではシステムやデータに依存しない新しい評価手法の必要性を提案する。幅広い指標を調査し、それらがデータ駆動型のNLGによって生成されたシステムの出力の人間の判断を弱く反映していることを示す。また、評価指標の性能はデータとシステムに依存することも示すが、自動評価指標はシステムレベルで信頼性があり、システムの開発をサポートできることを示唆する。特に、低いパフォーマンスを示すケースを見つけることができる。 Comment既存のNLGのメトリックがhuman judgementsとのcorrelationがあまり高くないことを指摘した研究 #ComputerVision #Pocket #NLP #CommentGeneration #CVPR Issue Date: 2019-09-27 Attend to You: Personalized Image Captioning with Context Sequence Memory Networks, Park+, CVPR'17 Comment画像が与えられたときに、その画像に対するHashtag predictionと、personalizedなpost generationを行うタスクを提案。
InstagramのPostの簡易化などに応用できる。
Postを生成するためには、自身の言葉で、画像についての説明や、contextといったことを説明しなければならず、image captioningをする際にPersonalization Issueが生じることを指摘。
official implementation: https://github.com/cesc-park/attend2u #Tutorial #MachineLearning #MultitaskLearning Issue Date: 2018-02-05 An Overview of Multi-Task Learning in Deep Neural Networks, Sebastian Ruder, arXiv'17 #NeuralNetwork #MachineLearning #Normalization #Admin'sPick Issue Date: 2018-02-19 Layer Normalization, Ba+, arXiv'16 Summaryバッチ正規化の代わりにレイヤー正規化を用いることで、リカレントニューラルネットワークのトレーニング時間を短縮。レイヤー内のニューロンの合計入力を正規化し、各ニューロンに独自の適応バイアスとゲインを適用。トレーニング時とテスト時で同じ計算を行い、隠れ状態のダイナミクスを安定させる。実証的に、トレーニング時間の大幅な短縮を確認。 Comment解説スライド:
https://www.slideshare.net/KeigoNishida/layer-normalizationnips
#Tutorial #MachineLearning Issue Date: 2018-02-05 An overview of gradient descent optimization algorithms, Sebastian Ruder, arXiv'16 #DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Reference-based Issue Date: 2023-08-13 chrF: character n-gram F-score for automatic MT evaluation, Mono Popovic, WMT'15 Summary私たちは、機械翻訳の評価に文字n-gram Fスコアを使用することを提案します。私たちは、このメトリックがシステムレベルとセグメントレベルで人間のランキングと相関しており、特にセグメントレベルでの相関が非常に高いことを報告しました。この提案は非常に有望であり、WMT14の共有評価タスクでも最高のメトリックを上回りました。 Commentcharacter-basedなn-gram overlapをreferenceとシステムで計算する手法 #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 From word embeddings to document distances, Kusner+, PMLR'15 Summary私たちは、新しい距離関数であるWord Mover's Distance(WMD)を提案しました。WMDは、テキストドキュメント間の非類似性を測定するために使用されます。私たちの研究では、単語埋め込みの最新の結果に基づいてWMDを開発しました。WMDは、単語が別のドキュメントの単語に到達するために必要な最小距離を計算します。私たちのメトリックは、実装が簡単であり、ハイパーパラメータも必要ありません。さらに、私たちは8つの実世界のドキュメント分類データセットでWMDメトリックを評価し、低いエラーレートを示しました。 CommentWMS/SMS/S+WMS
946 はこれらからinspiredされ提案された #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-23 Automatically Assessing Machine Summary Content Without a Gold Standard, Louis+(w_ Nenkova), ACL'13 Summary本研究では、要約の評価において新しい技術を提案しています。これにより、人間の要約が利用できない場合や、単一のモデルしか利用できない場合でも正確な評価が可能となります。具体的には、モデルに依存しない評価技術や、システム要約の類似性を定量化する尺度などを提案しています。これにより、要約の評価を人間の評価と正確に再現することができます。また、擬似モデルを導入することで、利用可能なモデルのみを使用する場合よりも人間の判断との相関が高くなることも示しています。さらに、システム要約のランキング方法についても探求しており、驚くほど正確なランキングが可能となります。 Commentメタ評価の具体的な手順について知りたければこの研究を読むべし #DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Coherence Issue Date: 2023-08-13 Graph-based Local Coherence Modeling, Guinaudeau+, ACL'13 Summary私たちは、グラフベースのアプローチを提案し、文の順序付け、要約の結束性評価、読みやすさの評価の3つのタスクでシステムを評価しました。このアプローチは、エンティティグリッドベースのアプローチと同等の性能を持ち、計算コストの高いトレーニングフェーズやデータのまばらさの問題にも対処できます。 #DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Coherence Issue Date: 2023-08-13 Extending Machine Translation Evaluation Metrics with Lexical Cohesion to Document Level, Wong+, EMNLP'12 Summaryこの論文では、語彙的な結束を利用して文書レベルの機械翻訳の評価を容易にする方法を提案しています。語彙的な結束は、同じ意味を持つ単語を使って文を結びつけることで、テキストの結束性を実現します。実験結果は、この特徴を評価尺度に組み込むことで、人間の判断との相関を向上させることを示しています。 CommentRC-LC #Multi #PersonalizedDocumentSummarization #InteractivePersonalizedSummarization #NLP #EMNLP #Admin'sPick Issue Date: 2017-12-28 Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07 Comment
ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
 #DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
ROUGE-C: A fully automated evaluation method for multi-document summarization, He+, International Conference on Granular Computing'08
Summaryこの論文では、ROUGEを使用して要約を評価する方法について説明しています。ROUGEは、要約評価のために広く使用されていますが、手動の参照要約が必要です。この研究では、ROUGE-Cという手法を開発しました。ROUGE-Cは、参照要約を入力情報に置き換えることで、手動の参照要約なしで要約を評価することができます。実験結果は、ROUGE-Cが人間の判断を含む参照要約とよく相関していることを示しています。
#MachineTranslation
#NLP
#LanguageModel
#Admin'sPick
Issue Date: 2024-12-24
Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07
Summary本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。
CommentN-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
ROUGE-C: A fully automated evaluation method for multi-document summarization, He+, International Conference on Granular Computing'08
Summaryこの論文では、ROUGEを使用して要約を評価する方法について説明しています。ROUGEは、要約評価のために広く使用されていますが、手動の参照要約が必要です。この研究では、ROUGE-Cという手法を開発しました。ROUGE-Cは、参照要約を入力情報に置き換えることで、手動の参照要約なしで要約を評価することができます。実験結果は、ROUGE-Cが人間の判断を含む参照要約とよく相関していることを示しています。
#MachineTranslation
#NLP
#LanguageModel
#Admin'sPick
Issue Date: 2024-12-24
Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07
Summary本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。
CommentN-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
 元ポスト:https://x.com/odashi_t/status/1871024428739604777?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLarge Language Modelsという用語が利用されたのはこの研究が初めてなのかも…?
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-based
#TrainedMetrics
Issue Date: 2023-08-14
Supervised automatic evaluation for summarization with voted regression model, Hirao+, Information and Processing & Management'07
Summary要約システムの評価には高品質な人間の評価が必要だが、コストが高いため自動評価方法が必要。提案手法は投票回帰モデル(VRM)を使用し、従来の自動評価方法と比較してエラー削減を達成。さらに、最も高い相関係数を得た。
CommentVRM
#Article
#ComputerVision
#Pocket
#NLP
#LLMAgent
#MultiModal
#Blog
#Reasoning
#OpenWeight
#x-Use
Issue Date: 2025-04-18
Introducing UI-TARS-1.5, ByteDance, 2025.04
SummaryUI-TARSは、スクリーンショットを入力として人間のようにインタラクションを行うネイティブGUIエージェントモデルであり、従来の商業モデルに依存せず、エンドツーエンドで優れた性能を発揮します。実験では、10以上のベンチマークでSOTA性能を達成し、特にOSWorldやAndroidWorldで他のモデルを上回るスコアを記録しました。UI-TARSは、強化された知覚、統一アクションモデリング、システム-2推論、反射的オンライントレースによる反復トレーニングなどの革新を取り入れ、最小限の人間の介入で適応し続ける能力を持っています。
Commentpaper:https://arxiv.org/abs/2501.12326色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)関連
元ポスト:https://x.com/odashi_t/status/1871024428739604777?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLarge Language Modelsという用語が利用されたのはこの研究が初めてなのかも…?
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-based
#TrainedMetrics
Issue Date: 2023-08-14
Supervised automatic evaluation for summarization with voted regression model, Hirao+, Information and Processing & Management'07
Summary要約システムの評価には高品質な人間の評価が必要だが、コストが高いため自動評価方法が必要。提案手法は投票回帰モデル(VRM)を使用し、従来の自動評価方法と比較してエラー削減を達成。さらに、最も高い相関係数を得た。
CommentVRM
#Article
#ComputerVision
#Pocket
#NLP
#LLMAgent
#MultiModal
#Blog
#Reasoning
#OpenWeight
#x-Use
Issue Date: 2025-04-18
Introducing UI-TARS-1.5, ByteDance, 2025.04
SummaryUI-TARSは、スクリーンショットを入力として人間のようにインタラクションを行うネイティブGUIエージェントモデルであり、従来の商業モデルに依存せず、エンドツーエンドで優れた性能を発揮します。実験では、10以上のベンチマークでSOTA性能を達成し、特にOSWorldやAndroidWorldで他のモデルを上回るスコアを記録しました。UI-TARSは、強化された知覚、統一アクションモデリング、システム-2推論、反射的オンライントレースによる反復トレーニングなどの革新を取り入れ、最小限の人間の介入で適応し続ける能力を持っています。
Commentpaper:https://arxiv.org/abs/2501.12326色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)関連
・1794元ポスト:https://x.com/_akhaliq/status/1912913195607663049?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #MachineLearning #Pocket #NLP #LanguageModel #Reasoning #GRPO #read-later Issue Date: 2025-03-22 Understanding R1-Zero-Like Training: A Critical Perspective, 2025.03 SummaryDeepSeek-R1-Zeroは、教師なしファインチューニングなしでLLMの推論能力を向上させる強化学習(RL)の効果を示した。研究では、ベースモデルとRLのコアコンポーネントを分析し、DeepSeek-V3-Baseが「アハ体験」を示すことや、Qwen2.5が強力な推論能力を持つことを発見。さらに、Group Relative Policy Optimization(GRPO)の最適化バイアスを特定し、Dr. GRPOという新手法を導入してトークン効率を改善。これにより、7BベースモデルでAIME 2024において43.3%の精度を達成し、新たな最先端を確立した。 Comment関連研究:
・1815解説ポスト:https://x.com/wenhuchen/status/1903464313391624668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポストを読むと、
・DAPOでの Token Level Policy UpdateのようなLengthに対するバイアスを排除するような操作をしている(Advantageに対して長さの平均をとる)模様。
・aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
・self-reflection無しの方が有りの場合よりもAcc.が高い場合がある(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様あとで読む(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:https://x.com/zzlccc/status/1910902637152940414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #Dataset #LanguageModel #Reasoning Issue Date: 2025-03-21 Sudoku-bench, SakanaAI, 2025.03 SummarySudoku-Benchは、CTCで紹介された独自のルールを持つ数独パズルを特徴とし、AI推論モデルの評価に最適なベンチマークです。このリポジトリでは、数独ベンチデータセット、LLM評価用のベースラインコード、SudokuPadツール、推論トレースなどを提供します。 Comment元ポスト:https://x.com/sakanaailabs/status/1902913196358611278?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q既存モデルでベンチマークを取ったらどういうランキングになるのだろうか。特にまだそういぅたランキングは公開されていない模様。ブログ記事に(将来的に最新の結果をrepositoryに追記す?模様)現時点でのリーダーボードが載っていた。現状、o3-miniがダントツに見える。
https://sakana.ai/sudoku-bench/ #Article #NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-03-18 EXAONE-Deep-32B, LG AI Research, 2025.03 Comment元ポスト:https://x.com/ai_for_success/status/1901908168805912602?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QEXAONE AI Model License Agreement 1.1 ・NC
商用利用不可 #Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight Issue Date: 2025-03-18 SmolDocling-256M, IBM Research, 2025.03 Comment元ポスト:https://www.linkedin.com/posts/andimarafioti_we-just-dropped-%F0%9D%97%A6%F0%9D%97%BA%F0%9D%97%BC%F0%9D%97%B9%F0%9D%97%97%F0%9D%97%BC%F0%9D%97%B0%F0%9D%97%B9%F0%9D%97%B6%F0%9D%97%BB%F0%9D%97%B4-activity-7307415358427013121-wS8m?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4Apache-2.0ライセンス。言語はEnglishのみな模様マルチモーダルなImage-To-Textモデル。サンプルはこちら
 #Article
#LLMAgent
#Blog
Issue Date: 2025-03-15
Model Context Protocol (MCP), Anthropic
Comment下記リンクのMCPサーバ/クライアントの作り方を読むとだいぶ理解が捗る:
#Article
#LLMAgent
#Blog
Issue Date: 2025-03-15
Model Context Protocol (MCP), Anthropic
Comment下記リンクのMCPサーバ/クライアントの作り方を読むとだいぶ理解が捗る:
https://modelcontextprotocol.io/quickstart/server
https://modelcontextprotocol.io/quickstart/client #Article #NLP #LanguageModel #OpenWeight #OpenSource Issue Date: 2025-03-14 OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3 Comment真なる完全なるオープンソース(に近い?)OLMOの最新作 #Article Issue Date: 2025-03-12 Open-source DeepResearch – Freeing our search agents, HuggingFace, 2025.02 SummaryOpenAIが発表したDeep Researchは、ウェブをブラウズしてコンテンツを要約し、質問に答えるシステムで、GAIAベンチマークでのパフォーマンスが向上。特に「レベル3」の難しい質問に対して47.6%の正解率を達成。Deep ResearchはLLMと内部エージェントフレームワークで構成されており、再現とオープンソース化を目指す24時間ミッションを開始。 #Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-12 Introducing Gemma 3: The most capable model you can run on a single GPU or TPU, Google, 2025.03 CommentGoogleの新たなSLMで、デバイスやラップトップでも動作可能な軽量モデル。テキストだけでなく画像とShortVideoの認識もできて、140言語をサポート。おまけに27BモデルでLlama3-405BとDeepSeek-V3とo3-miniをChatbotArenaのリーダーボードで上回り、128kのcontext window。えぇ…。モデルの詳細:https://huggingface.co/blog/gemma3
1Bモデルは英語のみサポート、マルチモーダル不可など制約がある模様。
詳細までは書いていないが、128Kコンテキストまでcontext windowを広げる際の概要とRoPE(のような)Positional Embeddingを利用していること、SlideingWindow Attentionを用いておりウィンドウサイズが以前の4096から性能を維持したまま1024に小さくできたこと、ImageEncoderとして何を利用しているか(SigLIP)、896x896の画像サイズをサポートしており、正方形の画像はこのサイズにリサイズされ、正方形でない場合はcropされた上でリサイズされる(pan and scanアルゴリズムと呼ぶらしい)こと、事前学習時のマルチリンガルのデータを2倍にしたことなど、色々書いてある模様。Gemmaライセンス解説ポスト:https://x.com/hillbig/status/1899965039559532585?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/rasbt/status/1900214135847039316?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #LanguageModel #Reasoning #MultiLingual #OpenWeight Issue Date: 2025-03-12 Reasoning with Reka Flash, Reka, 2025.03 CommentWeights: https://huggingface.co/RekaAI/reka-flash-3Apache-2.0< /reasoning >を強制的にoutputさせることでreasoningを中断させることができ予算のコントロールが可能とのこと #Article #NLP #LanguageModel #ReinforcementLearning #Reasoning #OpenWeight Issue Date: 2025-03-06 QwQ-32B: Embracing the Power of Reinforcement Learning, Qwen Team, 2025.03 Comment元ポスト:https://x.com/hillbig/status/1897426898642460724?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1787Artificial Analysisによるベンチマークスコア:https://x.com/artificialanlys/status/1897701015803380112?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおそらく特定のタスクでDeepSeekR1とcomparable, 他タスクでは及ばない、という感じになりそうな予感 #Article #LanguageModel #Library #LLMAgent Issue Date: 2025-03-06 smolagents, HuggingFace, 2025.03 Summarysmolagentsは、数行のコードで強力なエージェントを構築できるライブラリで、シンプルなロジック、コードエージェントのサポート、安全な実行環境、ハブ統合、モデルやモダリティに依存しない設計が特徴。テキスト、視覚、動画、音声入力をサポートし、さまざまなツールと統合可能。詳細はローンチブログ記事を参照。 #Article #MachineLearning #NLP #LanguageModel #ReinforcementLearning #Blog #GRPO Issue Date: 2025-03-05 GRPO Judge Experiments: Findings & Empirical Observations, kalomaze's kalomazing blog, 2025.03 Comment元ポスト:https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_forget-basic-math-problems-grpo-can-do-more-activity-7302608410875691009-nntf?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4一意に解が決まる問題ではなく、ある程度の主観的な判断が必要なタスクについてのGRPOの分析。
2つのテキストを比較するタスクで、一方のタスクはLLMによって摂動を与えている(おそらく意図的にcorruptさせている)。
GRPOではlinearやcosineスケジューラはうまく機能せず、warmupフェーズ有りの小さめの定数が有効らしい。また、max_grad_normを0.2にしまgradient clippingが有効とのこと。他にもrewardの与え方をx^4にすることや、length, xmlフォーマットの場合にボーナスのrewardを与えるなどの工夫を考察している。 #Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-04 microsoft_Phi-4-multimodal-instruct, Microsoft, 2025.02 Comment元ポスト:https://www.linkedin.com/posts/vaibhavs10_holy-shitt-microsoft-dropped-an-open-source-activity-7300755229635944449-mQP8?utm_medium=ios_app&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4&utm_source=social_share_send&utm_campaign=copy_linkMIT License #Article #Pretraining #MachineLearning #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2025-03-04 The Ultra-Scale Playbook: Training LLMs on GPU Clusters, HuggingFace, 2025.02 CommentHuggingFaceによる数1000のGPUを用いたAIモデルのトレーニングに関するオープンソースのテキスト #Article #MachineLearning #NLP #LanguageModel #Library #ReinforcementLearning #python #Reasoning Issue Date: 2025-03-02 Open Reasoner Zero, Open-Reasoner-Zero, 2024.02 SummaryOpen-Reasoner-Zeroは、推論指向の強化学習のオープンソース実装で、スケーラビリティとアクセスのしやすさに重点を置いています。AGI研究の促進を目指し、ソースコードやトレーニングデータを公開しています。 Comment元ポスト:https://x.com/dair_ai/status/1893698293965725708?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #Dataset #LanguageModel #LLMAgent Issue Date: 2025-03-02 Introducing the SWE-Lancer benchmark, OpenAI, 2025.02 Comment元ポスト:https://x.com/dair_ai/status/1893698290174108113?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q1400以上のフリーランスソフトウェアエンジニアリングタスクを集めたベンチマーク。タスクはバグ修正から機能実装まで多岐にわたり、経験豊富なエンジニアによって評価されたもの。 #Article #Embeddings #NLP #LanguageModel #RepresentationLearning #pretrained-LM #Japanese Issue Date: 2025-02-12 modernbert-ja-130m, SB Intuitions, 2025.02 CommentMIT Licence元ポスト:https://x.com/sbintuitions/status/1889587801706078580?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1606 #Article #NLP #LanguageModel #ReinforcementLearning #Blog #Distillation Issue Date: 2025-02-12 DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL, 2025.02 #Article #LanguageModel #LLMServing Issue Date: 2025-02-12 SGlang, sgl-project, 2024.01 SummarySGLangは、大規模言語モデルと視覚言語モデルのための高速サービングフレームワークで、バックエンドとフロントエンドの共同設計により迅速なインタラクションを実現します。主な機能には、高速バックエンドランタイム、柔軟なフロントエンド言語、広範なモデルサポートがあり、オープンソースの活発なコミュニティに支えられています。 Comment・1733
のUpdate2でMath Datasetの生成に利用されたLLM Servingフレームワーク。利用前と比較してスループットが2倍になったとのこと。 #Article #ComputerVision #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2025-01-25 Humanity's Last Exam, 2025.01 Summary「人類の最後の試験」という新しいマルチモーダルベンチマークを導入し、100以上の科目にわたる3,000の挑戦的な質問を提供。これにより、LLMの能力を正確に測定し、過学習を評価するためのプライベートテストセットも保持。 Commento1, DeepSeekR1の正解率が10%未満の新たなベンチマーク #Article #EfficiencyImprovement #NLP #Library #Transformer #pretrained-LM Issue Date: 2024-12-20 ModernBERT, AnswerDotAI, 2024.12 SummaryModernBERTは、エンコーダ専用のトランスフォーマーモデルで、従来のBERTに比べて大幅なパレート改善を実現。2兆トークンで訓練され、8192シーケンス長を持ち、分類タスクやリトリーバルで最先端の結果を示す。速度とメモリ効率も優れており、一般的なGPUでの推論に最適化されている。 Comment最近の進化しまくったTransformer関連のアーキテクチャをEncodnr-OnlyモデルであるBERTに取り込んだら性能上がるし、BERTの方がコスパが良いタスクはたくさんあるよ、系の話、かつその実装だと思われる。
テクニカルペーパー中に記載はないが、評価データと同じタスクでのDecoder-Onlyモデル(SFT有り無し両方)との性能を比較したらどの程度の性能なのだろうか?そもそも学習データが手元にあって、BERTをFinetuningするだけで十分な性能が出るのなら(BERTはGPU使うのでそもそもxgboostとかでも良いが)、わざわざLLM使う必要ないと思われる。BERTのFinetuningはそこまで時間はかからないし、inferenceも速い。
参考:
・1024日本語解説:https://zenn.dev/dev_commune/articles/3f5ab431abdea1?utm_source=substack&utm_medium=email #Article #RecommenderSystems #Pocket #LanguageModel #Blog Issue Date: 2024-12-03 Augmenting Recommendation Systems With LLMs, Dave AI, 2024.08 #Article #Pocket #EducationalDataMining #KnowledgeTracing Issue Date: 2024-11-30 Dynamic Key-Value Memory Networks With Rich Features for Knowledge Tracing, Sun+, IEEE TRANSACTIONS ON CYBERNETICS, 2022.08 Summary知識追跡において、DKVMNモデルは学生の行動特徴と学習能力を無視している。これを改善するために、両者を統合した新しい演習記録の表現方法を提案し、知識追跡の性能向上を目指す。実験結果は、提案手法がDKVMNの予測精度を改善できることを示した。 Comment

 後で読みたい
後で読みたい
#Article #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #AES(AutomatedEssayScoring) Issue Date: 2024-11-28 Cross-prompt Pre-finetuning of Language Models for Short Answer Scoring, Funayama+, 2024.09 Summary自動短答スコアリング(SAS)では、異なるルーブリックと参照回答に基づいてスコアを付けるが、新しいプロンプトごとにモデルを再訓練する必要がありコストがかかる。本研究では、既存のルーブリックと回答を用いて新しいプロンプトでファインチューニングする二段階アプローチを提案。重要なフレーズを学習することで、特に訓練データが限られている場合にスコアリング精度を向上させることを実験で示した。 CommentSASでは回答データが限られているので、限られたデータからより効果的に学習をするために、事前に他のデータでモデルをpre-finetuningしておき、対象データが来たらpre-finetuningされたモデルをさらにfinetuningするアプローチを提案。ここで、prompt中にkeyphraseを含めることが有用であると考え、実験的に有効性を示している。


BERTでfinetuningをした場合は、key-phraseを含めた方が性能が高く、特にfinetuningのサンプル数が小さい場合にその差が顕著であった。

次に、LLM(swallow-8B, 70B)をpre-finetuningし、pre-finetuningを実施しない場合と比較することで、pre-finetuningがLLMのzero-shot、およびICL能力にどの程度影響を与えるかを検証した。検証の結果、pre-finetuningなしでは、そもそも10-shotにしてもQWKが非常に低かったのに対し、pre-finetuningによってzero-shotの能力が大幅に性能が向上した。一方、few-shotについては3-shotで性能が頭打ちになっているようにみえる。ここで、Table1のLLMでは、ターゲットとする問題のpromptでは一切finetuningされていないことに注意する(Unseenな問題)。

続いて、LLMをfinetuningした場合も検証。提案手法が高い性能を示し、200サンプル程度ある場合にHuman Scoreを上回っている(しかもBERTは200サンプルでサチったが、LLMはまだサチっていないように見える)。また、サンプル数がより小さい場合に、提案手法がより高いgainを得ていることがわかる。

また、個々の問題ごとにLLMをfinetuningするのは現実的に困難なので、個々の問題ごとにfinetuningした場合と、全ての問題をまとめてfinetuningした場合の性能差を比較したところ、まとめて学習しても性能は低下しない、どころか21問中18問で性能が向上した(LLMのマルチタスク学習の能力のおかげ)。

[Perplexity(hallucinationに注意)](https://www.perplexity.ai/search/tian-fu-sitalun-wen-wodu-mi-ne-3_TrRyxTQJ.2Bm2fJLqvTQ0) #Article #NeuralNetwork #Embeddings #NLP #Word #RepresentationLearning #STS (SemanticTextualSimilarity) Issue Date: 2024-11-20 Zipf 白色化:タイプとトークンの区別がもたらす良質な埋め込み空間と損失関数, Sho Yokoi, 2024.11 Summary単語埋め込み空間の歪みを修正することでタスクのパフォーマンスが向上することを示す。既存のアプローチは単語頻度が均一であると仮定しているが、実際にはZipfの法則に従う非均一な分布である。Zipfに基づく頻度で重み付けされたPCAホワイトニングを行うことで、パフォーマンスが大幅に向上し、ベースラインを超える。情報幾何学的な観点から、低頻度の単語を強調する理論を提案し、人気の自然言語処理手法がこの理論に基づいて機能することを示す。 Comment元論文: [Yokoi, Bao, Kurita, Shimodaira, “Zipfian Whitening,” NeurIPS 2024. ](https://arxiv.org/abs/2411.00680)単語ベクトルを活用して様々なタスクを実施する際に一般的な全部足して個数で割るような平均ベクトル計算は、
個々の単語頻度を一様と仮定した場合の"期待値"と等価であり、
これは現実世界の単語頻度の実態とは全然異なるから、きちんと考慮したいよね、という話で

頻度を考慮するとSemantic Textual Similarity(STS)タスクで効果絶大であることがわかった。

では、なぜこれまで一様分布扱いするのが一般的だったのかというと、
実態として単語埋め込み行列が単語をタイプとみなして構築されたものであり、
コーパス全体を捉えた(言語利用の実態を捉えた)データ行列(単語をトークンとみなしたもの)になっていなかったことに起因していたからです(だから、経験頻度を用いて頻度情報を復元する必要があるよね)、
という感じの話だと思われ、

経験頻度を考慮すると、そもそも背後に仮定しているモデル自体が暗黙的に変わり、
低頻度語が強調されることで、単語に対してTF-IDFのような重みづけがされることで性能が良くなるよね、みたいな話だと思われる。
<img src=\"https://github.com/user-attachments/assets/7495f250-d680-4698-99c5-a326ead77e12\" alt=\"image\" loading=\"lazy\">余談だが、昔のNLPでは、P\(w,c)をモデル化したものを生成モデル、テキスト生成で一般的なP\(w|c)は分類モデル(VAEとかはテキスト生成をするが、生成モデルなので別)、と呼んでいたと思うが、いまはテキスト生成モデルのことを略して生成モデル、と呼称するのが一般的なのだろうか。 #Article Issue Date: 2024-11-13 Artificial Intelligence, Scientific Discovery, and Product Innovation, Aidan Toner-Rodgers, MIT, 2024.11 #Article #Blog Issue Date: 2024-11-11 The Surprising Effectiveness of Test-Time Training for Abstract Reasoning, 2024.11 #Article #NLP #Dataset #LanguageModel #LLMAgent #Evaluation Issue Date: 2024-10-20 MLE-Bench, OpenAI, 2024.10 SummaryMLE-benchを紹介し、AIエージェントの機械学習エンジニアリング能力を測定するためのベンチマークを構築。75のKaggleコンペを基に多様なタスクを作成し、人間のベースラインを確立。最前線の言語モデルを評価した結果、OpenAIのo1-previewが16.9%のコンペでKaggleのブロンズメダル相当の成果を達成。AIエージェントの能力理解を促進するため、ベンチマークコードをオープンソース化。 #Article #LLMAgent #Repository #Conversation Issue Date: 2024-10-02 AutoGen, Microsoft, 2024.10 SummaryAutoGenは、AIエージェントの構築と協力を促進するオープンソースのプログラミングフレームワークで、エージェント間の相互作用や多様なLLMの使用をサポートします。これにより、次世代LLMアプリケーションの開発が容易になり、複雑なワークフローのオーケストレーションや最適化が簡素化されます。カスタマイズ可能なエージェントを用いて多様な会話パターンを構築でき、強化されたLLM推論や高度なユーティリティ機能も提供します。AutoGenは、Microsoftや大学との共同研究から生まれました。 #Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #VisionLanguageModel Issue Date: 2024-09-27 Molmo, AI2, 2024.09 SummaryMolmoは、オープンデータを活用した最先端のマルチモーダルAIモデルであり、特に小型モデルが大規模モデルを上回る性能を示す。Molmoは、物理的および仮想的な世界とのインタラクションを可能にし、音声ベースの説明を用いた新しい画像キャプションデータセットを導入。ファインチューニング用の多様なデータセットを使用し、非言語的手がかりを活用して質問に答える能力を持つ。Molmoファミリーのモデルは、オープンウェイトでプロプライエタリシステムに対抗する性能を発揮し、今後すべてのモデルウェイトやデータを公開予定。 Comment以下がベンチマーク結果(VLMのベンチマーク)。11 benchmarksと書かれているのは、VLMのベンチマークである点に注意。


#Article #NLP #LanguageModel Issue Date: 2024-09-25 Improving Language Understanding by Generative Pre-Training, OpenAI, 2018.06 Summary自然言語理解のタスクにおいて、ラベルなしテキストコーパスを用いた生成的事前学習と識別的微調整を行うことで、モデルの性能を向上させるアプローチを提案。タスクに応じた入力変換を利用し、モデルアーキテクチャの変更を最小限に抑えつつ、12のタスク中9つで最先端の成果を大幅に改善。特に、常識推論で8.9%、質問応答で5.7%、テキストの含意で1.5%の改善を達成。 Comment初代GPT論文 #Article #NLP #OpenWeight Issue Date: 2024-08-24 Phi 3.5, Microsoft, 2024.08 SummaryPhi-3モデルコレクションは、マイクロソフトの最新の小型言語モデルで、高い性能とコスト効率を兼ね備えています。新たに発表されたPhi-3.5-mini、Phi-3.5-vision、Phi-3.5-MoEは、生成AIアプリケーションにおける選択肢を広げ、特に多言語サポートや画像理解の向上を実現しています。Phi-3.5-MoEは、専門家を活用しつつ高性能を維持しています。 #Article #DocumentSummarization #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 Learning to Score System Summaries for Better Content Selection Evaluation, Peyard+, Prof. of the Workshop on New Frontiers in Summarization Summary本研究では、古典的な要約データセットを使用して、人間の判断に基づいた自動スコアリングメトリックの学習を提案します。既存のメトリックを組み込み、人間の判断と高い相関を持つ組み合わせを学習します。新しいメトリックの信頼性は手動評価によってテストされます。学習済みのメトリックはオープンソースのツールとして公開されます。 #Article #EfficiencyImprovement #MachineLearning #NLP #Transformer #Attention Issue Date: 2023-07-23 FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, 2023 SummaryFlashAttention-2は、長いシーケンス長におけるTransformerのスケーリングの問題に対処するために提案された手法です。FlashAttention-2は、非対称なGPUメモリ階層を利用してメモリの節約とランタイムの高速化を実現し、最適化された行列乗算に比べて約2倍の高速化を達成します。また、FlashAttention-2はGPTスタイルのモデルのトレーニングにおいても高速化を実現し、最大225 TFLOPs/sのトレーニング速度に達します。 CommentFlash Attention1よりも2倍高速なFlash Attention 2Flash Attention1はこちらを参照
https://arxiv.org/pdf/2205.14135.pdf
QK Matrixの計算をブロックに分けてSRAMに送って処理することで、3倍高速化し、メモリ効率を10-20倍を達成。
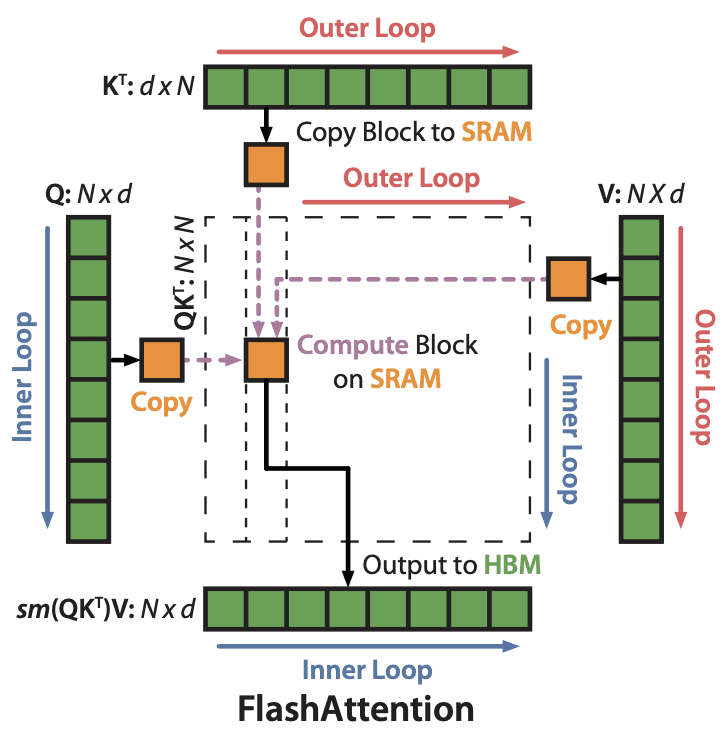 #Article
#ComputerVision
#NLP
#LanguageModel
#FoundationModel
Issue Date: 2023-07-23
Introducing CM3leon, a more efficient, state-of-the-art generative model for text and images, 2023
Summary最近の自然言語処理の進歩により、生成型AIモデルへの関心と研究が加速しています。CM3leonは、テキストから画像への生成と画像からテキストへの生成を行う単一の基礎モデルです。
#Article
#NLP
#LanguageModel
#Chain-of-Thought
#Prompting
#Faithfulness
Issue Date: 2023-07-23
Measuring Faithfulness in Chain-of-Thought Reasoning, Anthropic, 2023
Summary大規模言語モデル(LLMs)は、Chain-of-Thought(CoT)推論を生成することで質問に答える性能を向上させるが、その推論が実際の推論を忠実に表しているかは不明である。本研究では、CoT推論の忠実さを調査し、CoTに介入することでモデルの予測がどのように変化するかを調べる。結果は、モデルのサイズやタスクによってCoTの忠実さが異なることを示唆している。
#Article
#RecommenderSystems
#NLP
#Dataset
#NaturalLanguageUnderstanding
Issue Date: 2023-07-18
DataFinder: Scientific Dataset Recommendation from Natural Language Descriptions
Summaryデータセットの推奨タスクを操作化し、DataFinderデータセットを構築した。DataFinderデータセットは、自動的に構築された大規模なトレーニングセットと専門家による評価セットを含んでいる。このデータセットを使用して、テキストベースのデータセット推奨のための優れたバイエンコーダリトリーバを提案し、関連する検索結果を見つけることができることを示した。データセットとモデルは一般に公開される。
#Article
#NLP
#LanguageModel
#Explanation
#Evaluation
Issue Date: 2023-07-14
Are Human Explanations Always Helpful? Towards Objective Evaluation of Human Natural Language Explanations
Summary本研究では、説明可能なNLPモデルのトレーニングにおいて、人間による注釈付けの説明の品質を評価する方法について検討しています。従来のSimulatabilityスコアに代わる新しいメトリックを提案し、5つのデータセットと2つのモデルアーキテクチャで評価しました。結果として、提案したメトリックがより客観的な評価を可能にする一方、Simulatabilityは不十分であることが示されました。
#Article
#LanguageModel
#PsychologicalScience
Issue Date: 2023-05-11
Can AI language models replace human participants?, Trends in Cognitive Sciences, 2023
Summary最近の研究では、言語モデルが人間のような判断を行うことが示されています。この研究では、言語モデルが心理学の研究において人間の代わりになる可能性や条件について探求し、AIを参加者として使用する際の注意点をまとめています。
#Article
#NLP
#Dataset
#InstructionTuning
#DataDistillation
Issue Date: 2023-04-26
LaMini-instruction
Summary私たちは、大規模言語モデルからの知識を抽出するために、文/オフライン蒸留を行います。具体的には、いくつかの既存のプロンプトリソースに基づいて、合計258万ペアの指示と応答を生成します。詳細は論文を参照してください。
Comment既存のInstruction DatasetのInstructionをseedとして、gpt-3.5-turboで新たなInstructionとresponseを生成したデータセット
#Article
#ComputerVision
#NLP
#LanguageModel
#FoundationModel
Issue Date: 2023-07-23
Introducing CM3leon, a more efficient, state-of-the-art generative model for text and images, 2023
Summary最近の自然言語処理の進歩により、生成型AIモデルへの関心と研究が加速しています。CM3leonは、テキストから画像への生成と画像からテキストへの生成を行う単一の基礎モデルです。
#Article
#NLP
#LanguageModel
#Chain-of-Thought
#Prompting
#Faithfulness
Issue Date: 2023-07-23
Measuring Faithfulness in Chain-of-Thought Reasoning, Anthropic, 2023
Summary大規模言語モデル(LLMs)は、Chain-of-Thought(CoT)推論を生成することで質問に答える性能を向上させるが、その推論が実際の推論を忠実に表しているかは不明である。本研究では、CoT推論の忠実さを調査し、CoTに介入することでモデルの予測がどのように変化するかを調べる。結果は、モデルのサイズやタスクによってCoTの忠実さが異なることを示唆している。
#Article
#RecommenderSystems
#NLP
#Dataset
#NaturalLanguageUnderstanding
Issue Date: 2023-07-18
DataFinder: Scientific Dataset Recommendation from Natural Language Descriptions
Summaryデータセットの推奨タスクを操作化し、DataFinderデータセットを構築した。DataFinderデータセットは、自動的に構築された大規模なトレーニングセットと専門家による評価セットを含んでいる。このデータセットを使用して、テキストベースのデータセット推奨のための優れたバイエンコーダリトリーバを提案し、関連する検索結果を見つけることができることを示した。データセットとモデルは一般に公開される。
#Article
#NLP
#LanguageModel
#Explanation
#Evaluation
Issue Date: 2023-07-14
Are Human Explanations Always Helpful? Towards Objective Evaluation of Human Natural Language Explanations
Summary本研究では、説明可能なNLPモデルのトレーニングにおいて、人間による注釈付けの説明の品質を評価する方法について検討しています。従来のSimulatabilityスコアに代わる新しいメトリックを提案し、5つのデータセットと2つのモデルアーキテクチャで評価しました。結果として、提案したメトリックがより客観的な評価を可能にする一方、Simulatabilityは不十分であることが示されました。
#Article
#LanguageModel
#PsychologicalScience
Issue Date: 2023-05-11
Can AI language models replace human participants?, Trends in Cognitive Sciences, 2023
Summary最近の研究では、言語モデルが人間のような判断を行うことが示されています。この研究では、言語モデルが心理学の研究において人間の代わりになる可能性や条件について探求し、AIを参加者として使用する際の注意点をまとめています。
#Article
#NLP
#Dataset
#InstructionTuning
#DataDistillation
Issue Date: 2023-04-26
LaMini-instruction
Summary私たちは、大規模言語モデルからの知識を抽出するために、文/オフライン蒸留を行います。具体的には、いくつかの既存のプロンプトリソースに基づいて、合計258万ペアの指示と応答を生成します。詳細は論文を参照してください。
Comment既存のInstruction DatasetのInstructionをseedとして、gpt-3.5-turboで新たなInstructionとresponseを生成したデータセット
#Article #RecommenderSystems #CollaborativeFiltering #Pocket #FactorizationMachines Issue Date: 2021-07-02 Deep Learning Recommendation Model for Personalization and Recommendation Systems, Naumov+, Facebook, arXiv‘19 Summary深層学習に基づく推薦モデル(DLRM)を開発し、PyTorchとCaffe2で実装。埋め込みテーブルのモデル並列性を活用し、メモリ制約を軽減しつつ計算をスケールアウト。DLRMの性能を既存モデルと比較し、Big Basin AIプラットフォームでの有用性を示す。 CommentFacebookが開発したopen sourceのDeepな推薦モデル(MIT Licence)。
モデル自体はシンプルで、continuousなfeatureをMLPで線形変換、categoricalなfeatureはembeddingをlook upし、それぞれfeatureのrepresentationを獲得。
その上で、それらをFactorization Machines layer(second-order)にぶちこむ。すなわち、Feature間の2次の交互作用をembedding間のdot productで獲得し、これを1次項のrepresentationとconcatしMLPにぶちこむ。最後にシグモイド噛ませてCTRの予測値とする。
 実装: https://github.com/facebookresearch/dlrmParallelism以後のセクションはあとで読む
#Article
#NeuralNetwork
#Survey
#Pocket
#NLP
Issue Date: 2021-06-17
Pre-Trained Models: Past, Present and Future, Han+, AI Open‘21
Summary大規模な事前学習モデル(PTMs)は、AI分野での成功を収め、知識を効果的に捉えることができる。特に、転移学習や自己教師あり学習との関係を考察し、PTMsの重要性を明らかにする。最新のブレークスルーは、計算能力の向上やデータの利用可能性により、アーキテクチャ設計や計算効率の向上に寄与している。未解決問題や研究方向についても議論し、PTMsの将来の研究の進展を期待する。
#Article
#NeuralNetwork
#Survey
#NLP
Issue Date: 2021-06-09
A survey of Transformers, Lin+, AI Open‘22
Summaryトランスフォーマーの多様なバリアント(X-formers)に関する体系的な文献レビューを提供。バニラトランスフォーマーの紹介後、新しい分類法を提案し、アーキテクチャの修正、事前学習、アプリケーションの観点からX-formersを紹介。今後の研究の方向性も概説。
CommentTransformersの様々な分野での亜種をまとめた論文
実装: https://github.com/facebookresearch/dlrmParallelism以後のセクションはあとで読む
#Article
#NeuralNetwork
#Survey
#Pocket
#NLP
Issue Date: 2021-06-17
Pre-Trained Models: Past, Present and Future, Han+, AI Open‘21
Summary大規模な事前学習モデル(PTMs)は、AI分野での成功を収め、知識を効果的に捉えることができる。特に、転移学習や自己教師あり学習との関係を考察し、PTMsの重要性を明らかにする。最新のブレークスルーは、計算能力の向上やデータの利用可能性により、アーキテクチャ設計や計算効率の向上に寄与している。未解決問題や研究方向についても議論し、PTMsの将来の研究の進展を期待する。
#Article
#NeuralNetwork
#Survey
#NLP
Issue Date: 2021-06-09
A survey of Transformers, Lin+, AI Open‘22
Summaryトランスフォーマーの多様なバリアント(X-formers)に関する体系的な文献レビューを提供。バニラトランスフォーマーの紹介後、新しい分類法を提案し、アーキテクチャの修正、事前学習、アプリケーションの観点からX-formersを紹介。今後の研究の方向性も概説。
CommentTransformersの様々な分野での亜種をまとめた論文
Is seems that an unofficial implementation is listed under the “Code” tab on the NeurIPS page. I hope this is helpful. Thank you.
NeurIPS link: https://nips.cc/virtual/2024/poster/95563
openreview: https://openreview.net/forum?id=LuCLf4BJsr #Pocket #ACL Issue Date: 2025-01-06 Legal Case Retrieval: A Survey of the State of the Art, Feng+, ACL'24, 2024.08 Summary法的ケース検索(LCR)の重要性が増しており、歴史的なケースを大規模な法的データベースから検索するタスクに焦点を当てている。本論文では、LCRの主要なマイルストーンを調査し、研究者向けに関連データセットや最新のニューラルモデル、その性能を簡潔に説明する。 #Pocket #ACL Issue Date: 2025-01-06 Learning Global Controller in Latent Space for Parameter-Efficient Fine-Tuning, Tan+, ACL'24, 2024.08 Summary大規模言語モデル(LLMs)の高コストに対処するため、パラメータ効率の良いファインチューニング手法を提案。潜在ユニットを導入し、情報特徴を洗練することで下流タスクのパフォーマンスを向上。非対称注意メカニズムにより、トレーニングのメモリ要件を削減し、フルランクトレーニングの問題を軽減。実験結果は、自然言語処理タスクで最先端の性能を達成したことを示す。 #Pocket #ACL Issue Date: 2025-01-06 Llama2Vec: Unsupervised Adaptation of Large Language Models for Dense Retrieval, Li+, ACL'24, 2024.08 SummaryLlama2Vecは、LLMを密な検索に適応させるための新しい非監視適応アプローチであり、EBAEとEBARの2つの前提タスクを用いています。この手法は、WikipediaコーパスでLLaMA-2-7Bを適応させ、密な検索ベンチマークでの性能を大幅に向上させ、特にMSMARCOやBEIRで最先端の結果を達成しました。モデルとソースコードは公開予定です。 #Pocket #Education #ACL Issue Date: 2025-01-06 BIPED: Pedagogically Informed Tutoring System for ESL Education, Kwon+, ACL'24, 2024.08 Summary大規模言語モデル(LLMs)を用いた会話型インテリジェントチュータリングシステム(CITS)は、英語の第二言語(L2)学習者に対して効果的な教育手段となる可能性があるが、既存のシステムは教育的深さに欠ける。これを改善するために、バイリンガル教育的情報を持つチュータリングデータセット(BIPED)を構築し、対話行為の語彙を考案した。GPT-4とSOLAR-KOを用いて二段階のフレームワークでCITSモデルを実装し、実験により人間の教師のスタイルを再現し、多様な教育的戦略を採用できることを示した。 #Pocket #ACL Issue Date: 2025-01-06 MELA: Multilingual Evaluation of Linguistic Acceptability, Zhang+, ACL'24, 2024.08 Summary本研究では、46,000サンプルからなる「多言語言語的受容性評価(MELA)」ベンチマークを発表し、10言語にわたるLLMのベースラインを確立。XLM-Rを用いてクロスリンガル転送を調査し、ファインチューニングされたXLM-RとGPT-4oの性能を比較。結果、GPT-4oは多言語能力で優れ、オープンソースモデルは劣ることが判明。クロスリンガル転送実験では、受容性判断の転送が複雑であることが示され、MELAでのトレーニングがXLM-Rの構文タスクのパフォーマンス向上に寄与することが確認された。 #Pocket #ACL Issue Date: 2025-01-06 AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators, Jingwei+, ACL'24, 2024.08 Summary生成AIの普及に伴い、自動事実確認手法が重要視されているが、事実主張の検出にはスケーラビリティと一般化可能性の問題がある。これに対処するため、事実主張の統一的な定義を提案し、AFaCTAという新しいフレームワークを導入。AFaCTAはLLMsを活用し、注釈の信頼度を調整する。広範な評価により、専門家の注釈作業を効率化し、PoliClaimという包括的な主張検出データセットを作成した。 #Pocket #ACL Issue Date: 2025-01-06 Evaluating Intention Detection Capability of Large Language Models in Persuasive Dialogues, Sakurai+, ACL'24, 2024.08 SummaryLLMsを用いてマルチターン対話における意図検出を調査。従来の研究が会話履歴を無視している中、修正したデータセットを用いて意図検出能力を評価。特に説得的対話では他者の視点を考慮することが重要であり、「フェイスアクト」の概念を取り入れることで、意図の種類に応じた分析が可能となる。 #Pocket #LanguageModel #EducationalDataMining Issue Date: 2025-01-06 Engaging an LLM to Explain Worked Examples for Java Programming: Prompt Engineering and a Feasibility Study, Hassany+, EDM'24 Workshop, 2024.07 Summaryプログラミングクラスでのコード例の説明を効率化するために、LLMを用いた人間とAIの共同執筆アプローチを提案。講師が編集可能な初期コード説明を生成し、学生にとって意味のある内容を確保するためにプロンプトエンジニアリングを行い、その効果をユーザー研究で評価した。 Comment元ポスト:https://x.com/peterpaws/status/1876047837441806604?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket #NLP #LanguageModel #MoE(Mixture-of-Experts) #ACL Issue Date: 2025-01-06 DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, Damai+, ACL'24, 2024.08 SummaryDeepSeekMoEアーキテクチャは、専門家の専門性を高めるために、専門家を細分化し柔軟な組み合わせを可能にし、共有専門家を設けて冗長性を軽減する。2BパラメータのDeepSeekMoEは、GShardと同等の性能を達成し、同じパラメータ数の密なモデルに近づく。16Bパラメータにスケールアップした際も、計算量を約40%に抑えつつ、LLaMA2と同等の性能を示した。 #NLP #Dataset #AES(AutomatedEssayScoring) #Japanese Issue Date: 2024-11-28 Japanese-English Sentence Translation Exercises Dataset for Automatic Grading, Miura+, EACL'24, 2024.03 Summary第二言語学習の文翻訳演習の自動評価タスクを提案し、評価基準に基づいて学生の回答を採点する。日本語と英語の間で3,498の学生の回答を含むデータセットを作成。ファインチューニングされたBERTモデルは約90%のF1スコアで正しい回答を分類するが、誤った回答は80%未満。少数ショット学習を用いたGPT-3.5はBERTより劣る結果を示し、提案タスクが大規模言語モデルにとっても難しいことを示す。 CommentSTEsの図解。分かりやすい。いわゆる日本人が慣れ親しんでいる和文英訳、英文和訳演習も、このタスクの一種だということなのだろう。2-shotのGPT4とFinetuningしたBERTが同等程度の性能に見えて、GPT3.5では5shotしても勝てていない模様。興味深い。
1474 も参照のことLoRA Finetuning details
・LoRA rankを最大4096
・LoRAのαをなんとrankの2倍にしている
・original paperでは16が推奨されている
・learning_rate: 5e-5
・linear sheculeで learning_rate を減衰させる
・optimizerはAdamW
・batch_size: 128
#RecommenderSystems #LanguageModel #KnowledgeGraph #InstructionTuning #Annotation Issue Date: 2024-10-08 COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon , Yu+, SIGMOD_PODS '24 SummaryCOSMOは、eコマースプラットフォーム向けにユーザー中心の常識知識をマイニングするためのスケーラブルな知識グラフシステムです。大規模言語モデルから抽出した高品質な知識を用い、指示チューニングによってファインチューニングされたCOSMO-LMは、Amazonの主要カテゴリにわたって数百万の知識を生成します。実験により、COSMOが検索ナビゲーションなどで顕著な改善を達成することが示され、常識知識の活用の可能性が強調されています。 Comment
encoder-onlyとまとめられているものの中には、デコーダーがあるものがあり(autoregressive decoderではない)、
encoder-decoderは正しい意味としてはencoder with autoregressive decoderであり、
decoder-onlyは正しい意味としてはautoregressive encoder-decoder
とのこと。
https://twitter.com/ylecun/status/1651762787373428736?s=46&t=-zElejt4asTKBGLr-c3bKw #ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #AAAI Issue Date: 2023-04-26 AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head, AAAI'24 SummaryAudioGPTは、複雑な音声情報を処理し、音声対話をサポートするマルチモーダルAIシステムである。基盤モデルとASR、TTSインターフェースを組み合わせ、音声、音楽、トーキングヘッドの理解と生成を行う。実験により、AudioGPTが多様なオーディオコンテンツの創造を容易にする能力を示した。 Commenttext, audio, imageといったマルチモーダルなpromptから、audioに関する様々なタスクを実現できるシステムマルチモーダルデータをjointで学習したというわけではなく、色々なモデルの組み合わせてタスクを実現しているっぽい
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2023-04-26 Scaling Instruction-Finetuned Language Models, Chung+, Google, JMLR'24 Summary指示ファインチューニングは、タスク数、モデルサイズ、チェーン・オブ・ソートデータを活用し、言語モデルの性能を向上させる手法である。Flan-PaLM 540Bは1.8Kタスクでファインチューニングされ、PaLM 540Bを上回る+9.4%の改善を達成し、MMLUで75.2%の性能を示した。Flan-T5も強力な少数ショット性能を発揮し、指示ファインチューニングは事前学習モデルの性能向上に寄与する。 CommentT5をinstruction tuningしたFlanT5の研究 #NLP #LanguageModel #DataGeneration #ICLR Issue Date: 2023-04-25 WizardLM: Empowering Large Language Models to Follow Complex Instructions, Xu+, Microsoft_Peking University, ICLR'24 Summary本論文では、LLMを用いて複雑な指示データを自動生成する手法Evol-Instructを提案。初期の指示セットを段階的に書き換え、生成したデータでLLaMAをファインチューニングし、WizardLMモデルを構築。評価結果では、Evol-Instructからの指示が人間作成のものより優れ、WizardLMはChatGPTを上回る性能を示した。AI進化による指示生成がLLM強化の有望なアプローチであることを示唆。 Commentinstruction trainingは大きな成功を収めているが、人間がそれらのデータを作成するのはコストがかかる。また、そもそも複雑なinstructionを人間が作成するのは苦労する。そこで、LLMに自動的に作成させる手法を提案している(これはself instructと一緒)。データを生成する際は、seed setから始め、step by stepでinstructionをrewriteし、より複雑なinstructionとなるようにしていく。
これらの多段的な複雑度を持つinstructionをLLaMaベースのモデルに食わせてfinetuningした(これをWizardLMと呼ぶ)。人手評価の結果、WizardLMがChatGPTよりも好ましいレスポンスをすることを示した。特に、WizaraLMはコード生成や、数値計算といった難しいタスクで改善を示しており、複雑なinstructionを学習に利用することの重要性を示唆している。EvolInstructを提案。"1+1=?"といったシンプルなinstructionからスタートし、これをLLMを利用して段階的にcomplexにしていく。complexにする方法は2通り:
・In-Depth Evolving: instructionを5種類のoperationで深掘りする(blue direction line)
・add constraints
・deepening
・concretizing
・increase reasoning steps
・complicate input
・In-breadth Evolving: givenなinstructionから新しいinstructionを生成する
上記のEvolvingは特定のpromptを与えることで実行される。
また、LLMはEvolvingに失敗することがあるので、Elimination Evolvingと呼ばれるフィルタを利用してスクリーニングした。
フィルタリングでは4種類の失敗するsituationを想定し、1つではLLMを利用。2枚目画像のようなinstructionでフィルタリング。
1. instructionの情報量が増えていない場合。
2. instructionがLLMによって応答困難な場合(短すぎる場合やsorryと言っている場合)
3. puctuationやstop wordsによってのみ構成されている場合
4.明らかにpromptの中から単語をコピーしただけのinstruction(given prompt, rewritten prompt, Rewritten Promptなど)
#NeuralNetwork #Survey #GraphBased #NLP Issue Date: 2023-04-25 Graph Neural Networks for Text Classification: A Survey, Wang+, Artificial Intelligence Review'24 Summaryテキスト分類におけるグラフニューラルネットワークの手法を2023年まで調査し、コーパスおよび文書レベルのグラフ構築や学習プロセスを詳述。課題や今後の方向性、データセットや評価指標についても考察し、異なる技術の比較を行い評価指標の利点と欠点を特定。 #NLP #LanguageModel #Diversity Issue Date: 2024-12-03 Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions, John Chung+, ACL'23, 2023.07 Summary本研究では、LLMを用いたテキストデータ生成における多様性と精度を向上させるための人間とAIのパートナーシップを探求。ロジット抑制と温度サンプリングの2つのアプローチで多様性を高める一方、ラベル置換(LR)と範囲外フィルタリング(OOSF)による人間の介入を検討。LRはモデルの精度を14.4%向上させ、一部のモデルは少数ショット分類を上回る性能を示したが、OOSFは効果がなかった。今後の研究の必要性が示唆される。 Comment生成テキストの質を維持しつつ、多様性を高める取り組み。多様性を高める取り組みとしては3種類の方法が試されており、
・Logit Suppression: 生成されたテキストの単語生成頻度をロギングし、頻出する単語にpenaltyをかける方法
・High Temperature: temperatureを[0.3, 0.7, 0.9, 1.3]にそれぞれ設定して単語をサンプリングする方法
・Seeding Example: 生成されたテキストを、seedとしてpromptに埋め込んで生成させる方法
で実験されている。 #InformationRetrieval #Pocket #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering, Siriwardhana+, TACL'23, 2023.01 SummaryRAG-end2endは、ODQAにおけるドメイン適応のためにRAGのリトリーバーとジェネレーターを共同訓練する新しいアプローチを提案。外部知識ベースを更新し、補助的な訓練信号を導入することで、ドメイン特化型知識を強化。COVID-19、ニュース、会話のデータセットで評価し、元のRAGモデルよりも性能が向上。研究はオープンソースとして公開。 #NaturalLanguageGeneration #NLP #LLM-as-a-Judge Issue Date: 2024-01-25 Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23 SummaryGEMBAは、参照翻訳の有無に関係なく使用できるGPTベースの翻訳品質評価メトリックです。このメトリックは、ゼロショットのプロンプティングを使用し、4つのプロンプトバリアントを比較します。私たちの手法は、GPT 3.5以上のモデルでのみ機能し、最先端の精度を達成します。特に、英語からドイツ語、英語からロシア語、中国語から英語の3つの言語ペアで有効です。この研究では、コード、プロンプトテンプレート、およびスコアリング結果を公開し、外部の検証と再現性を可能にします。 #PersonalizedDocumentSummarization #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration Issue Date: 2023-07-22 Generating User-Engaging News Headlines, Cai+, ACL'23 Summaryニュース記事の見出しを個別化するために、ユーザープロファイリングを組み込んだ新しいフレームワークを提案。ユーザーの閲覧履歴に基づいて個別のシグネチャフレーズを割り当て、それを使用して見出しを個別化する。幅広い評価により、提案したフレームワークが多様な読者のニーズに応える個別の見出しを生成する効果を示した。 Commentモチベーション
推薦システムのヘッドラインは未だに全員に同じものが表示されており、ユーザが自身の興味とのつながりを正しく判定できるとは限らず、推薦システムの有用性を妨げるので、ユーザごとに異なるヘッドラインを生成する手法を提案した。ただし、クリックベイトは避けるようなヘッドラインを生成しなければならない。
手法
1. Signature Phrase Identification
2. User Signature Selection
3. Signature-Oriented Headline Generation
Signature Phrase Identification
テキスト生成タスクに帰着させる。ニュース記事、あるいはヘッドラインをinputされたときに、セミコロン区切りのSignature Phraseを生成するモデルを用いる。今回は[KPTimes daasetでpretrainingされたBART](https://huggingface.co/ankur310794/bart-base-keyphrase-generation-kpTimes)を用いた。KPTimesは、279kのニュース記事と、signature phraseのペアが存在するデータであり、本タスクに最適とのこと。
User Signature Selection
ターゲットドキュメントdのSignature Phrases Z_dが与えられたとき、ユーザのreading History H_uに基づいて、top-kのuser signature phrasesを選択する。H_uはユーザが読んだニュースのヘッドラインの集合で表現される。あるSignature Phrase z_i ∈ Z_dが与えられたとき、(1)H_uをconcatしたテキストをベクトル化したものと、z_iのベクトルの内積でスコアを計算、あるいは(2) 個別のヘッドラインt_jを別々にエンコーディングし、内積の値が最大のものをスコアとする手法の2種類のエンコーディング方法を用いて、in-batch contrastive learningを用いてモデルを訓練する。つまり、正しいSignature Phraseとは距離が近く、誤ったSignature Phraseとは距離が遠くなるように学習をする。
実際はユーザにとっての正解Signature Phraseは分からないが、今回は人工的に作成したユーザを用いるため、正解が分かる設定となっている。
Signature-Oriented Headline Generation
ニュース記事d, user signature phrasesZ_d^uが与えられたとき、ヘッドラインを生成するモデルを訓練する。この時も、ユーザにとって正解のヘッドラインは分からないため、既存ニュースのヘッドラインが正解として用いられる。既存ニュースのヘッドラインが正解として用いられていても、そのヘッドラインがそのユーザにとっての正解となるように人工的にユーザが作成されているため、モデルの訓練ができる。モデルはBARTを用いた。
Dataset
Newsroom, Gigawordコーパスを用いる。これらのコーパスに対して、それぞれ2種類のコーパスを作成する。
1つは、Synthesized User Datasetで、これはUse Signature Selection modelの訓練と評価に用いる。もう一つはheadline generationデータセットで、こちらはheadline generationモデルの訓練に利用する。
Synthesized User Creation
実データがないので、実ユーザのreading historiesを模倣するように人工ユーザを作成する。具体的には、
1. すべてのニュース記事のSignature Phrasesを同定する
2. それぞれのSignature Phraseと、それを含むニュース記事をマッピングする
3. ランダムにphraseのサブセットをサンプリングし、そのサブセットをある人工ユーザが興味を持つエリアとする。
4. サブセット中のinterest phraseを含むニュース記事をランダムにサンプリングし、ユーザのreading historyとする
train, dev, testセット、それぞれに対して上記操作を実施しユーザを作成するが、train, devはContrastive Learningを実現するために、user signature phrases (interest phrases)は1つのみとした(Softmaxがそうなっていないと訓練できないので)。一方、testセットは1~5の範囲でuser signature phrasesを選択した。これにより、サンプリングされる記事が多様化され、ユーザのreadinig historyが多様化することになる。基本的には、ユーザが興味のあるトピックが少ない方が、よりタスクとしては簡単になることが期待される。また、ヘッドラインを生成するときは、ユーザのsignature phraseを含む記事をランダムに選び、ヘッドラインを背衛星することとした。これは、relevantな記事でないとヘッドラインがそもそも生成できないからである。
Headline Generation
ニュース記事の全てのsignature phraseを抽出し、それがgivenな時に、元のニュース記事のヘッドラインが生成できるようなBARTを訓練した。ニュース記事のtokenは512でtruncateした。平均して、10個のsignature phraseがニュース記事ごとに選択されており、ヘッドライン生成の多様さがうかがえる。user signature phraseそのものを用いて訓練はしていないが、そもそもこのようにGenericなデータで訓練しても、何らかのphraseがgivenな時に、それにバイアスがかかったヘッドラインを生成することができるので、user signature phrase selectionによって得られたphraseを用いてヘッドラインを生成することができる。
評価
自動評価と人手評価をしている。
自動評価
人手評価はコストがかかり、特に開発フェーズにおいては自動評価ができることが非常に重要となる。本研究では自動評価し方法を提案している。Headline-User DPR + SBERT, REC Scoreは、User Adaptation Metricsであり、Headline-Article DPR + SBERT, FactCCはArticle Loyalty Metricsである。
Relevance Metrics
PretrainedなDense Passage Retrieval (DPR)モデルと、SentenceBERTを用いて、headline-user間、headline-article間の類似度を測定する。前者はヘッドラインがどれだけユーザに適応しているが、後者はヘッドラインが元記事に対してどれだけ忠実か(クリックベイトを防ぐために)に用いられる。前者は、ヘッドラインとuser signaturesに対して類似度を計算し、後者はヘッドラインと記事全文に対して類似度を計算する。user signatures, 記事全文をどのようにエンコードしたかは記述されていない。
Recommendation Score
ヘッドラインと、ユーザのreadinig historyが与えられたときに、ニュースを推薦するモデルを用いて、スコアを算出する。モデルとしては、MIND datsetを用いて学習したモデルを用いた。
Factual Consistency
pretrainedなFactCCモデルを用いて、ヘッドラインとニュース記事間のfactual consisency score を算出する。
Surface Overlap
オリジナルのヘッドラインと、生成されたヘッドラインのROUGE-L F1と、Extractive Coverage (ヘッドラインに含まれる単語のうち、ソースに含まれる単語の割合)を用いる。
評価結果
提案手法のうち、User Signature Selection modelをfinetuningしたものが最も性能が高かった。エンコード方法は、(2)のヒストリのタイトルとフレーズの最大スコアをとる方法が最も性能が高い。提案手法はUser Adaptationをしつつも、Article Loyaltyを保っている。このため、クリックベイトの防止につながる。また、Vanilla Humanは元記事のヘッドラインであり、Extracitve Coverageが低いため、より抽象的で、かつ元記事に対する忠実性が低いことがうかがえる。
人手評価
16人のevaluatorで評価。2260件のニュース記事を収集(113 topic)し、記事のヘッドラインと、対応するトピックを見せて、20個の興味に合致するヘッドラインを選択してもらった。これをユーザのinterest phraseとreading _historyとして扱う。そして、ユーザのinterest phraseを含むニュース記事のうち、12個をランダムに選択し、ヘッドラインを生成した。生成したヘッドラインに対して、
1. Vanilla Human
2. Vanilla System
3. SP random (ランダムにsignature phraseを選ぶ手法)
4. SP individual-N
5. SP individual-F (User Signature Phraseを選択するモデルをfinetuningしたもの)
の5種類を評価するよう依頼した。このとき、3つの観点から評価をした。
1, User adaptation
2. Headline appropriateness
3. Text Quality
結果は以下。
SP-individualがUser Adaptationで最も高い性能を獲得した。また、Vanilla Systemが最も高いHeadline appropriatenessを獲得した。しかしながら、後ほど分析した結果、Vanilla Systemでは、記事のメインポイントを押さえられていないような例があることが分かった(んーこれは正直他の手法でも同じだと思うから、ディフェンスとしては苦しいのでは)。
また、Vanilla Humanが最も高いスコアを獲得しなかった。これは、オーバーにレトリックを用いていたり、一般的な人にはわからないようなタイトルになっているものがあるからであると考えられる。
Ablation Study
Signature Phrase selectionの性能を測定したところ以下の通りになり、finetuningした場合の性能が良かった。
Headline Generationの性能に影響を与える要素としては、
1. ユーザが興味のあるトピック数
2. User signature phrasesの数
がある。
ユーザのInterest Phrasesが増えていけばいくほど、User Adaptationスコアは減少するが、Article Loyaltyは維持されたままである。このため、興味があるトピックが多ければ多いほど生成が難しいことがわかる。また、複数のuser signature phraseを用いると、factual errorを起こすことが分かった(Billgates, Zuckerbergの例を参照)。これは、モデルが本来はirrelevantなフレーズを用いてcoherentなヘッドラインを生成しようとしてしまうためである。
※interest phrases => gold user signatures という理解でよさそう。
※signature phrasesを複数用いるとfactual errorを起こすため、今回はk=1で実験していると思われる
GPT3にもヘッドラインを生成させてみたが、提案手法の方が性能が良かった(自動評価で)。
なぜPENS dataset 706 を利用しないで研究したのか? #NLP #LanguageModel #Evaluation #LLM-as-a-Judge Issue Date: 2023-07-22 Can Large Language Models Be an Alternative to Human Evaluations? Cheng-Han Chiang, Hung-yi Lee, ACL'23 Summary本研究では、人間の評価が機械学習モデルのテキスト品質評価に不可欠であるが再現性が難しいという問題を解決するために、大規模言語モデル(LLMs)を使用した評価方法を提案している。具体的には、LLMsに同じ指示と評価対象のサンプルを与え、それに対する応答を生成させることで、LLM評価を行っている。実験結果から、LLM評価の結果は人間の評価と一致しており、異なるフォーマットやサンプリングアルゴリズムでも安定していることが示されている。LLMsを使用したテキスト品質評価の可能性が初めて示されており、その制限や倫理的な考慮事項についても議論されている。 #ComputerVision #NaturalLanguageGeneration #NLP #Dataset #Evaluation Issue Date: 2023-07-22 InfoMetIC: An Informative Metric for Reference-free Image Caption Evaluation, ACL'23 Summary自動画像キャプションの評価には、情報豊かなメトリック(InfoMetIC)が提案されています。これにより、キャプションの誤りや欠落した情報を詳細に特定することができます。InfoMetICは、テキストの精度スコア、ビジョンの再現スコア、および全体の品質スコアを提供し、人間の判断との相関も高いです。また、トークンレベルの評価データセットも構築されています。詳細はGitHubで公開されています。 #Metrics #NLP #LanguageModel #QuestionAnswering #Evaluation #Reference-free Issue Date: 2023-07-22 RQUGE: Reference-Free Metric for Evaluating Question Generation by Answering the Question, ACL'23 Summary既存の質問評価メトリックにはいくつかの欠点がありますが、本研究では新しいメトリックRQUGEを提案します。RQUGEは文脈に基づいて候補質問の回答可能性を考慮し、参照質問に依存せずに人間の判断と高い相関を持つことが示されています。さらに、RQUGEは敵対的な破壊に対しても堅牢であり、質問生成モデルのファインチューニングにも有効です。これにより、QAモデルのドメイン外データセットでのパフォーマンスが向上します。 Comment概要
質問自動生成の性能指標(e.g. ROUGE, BERTScore)は、表層の一致、あるいは意味が一致した場合にハイスコアを与えるが、以下の欠点がある
・人手で作成された大量のreference questionが必要
・表層あるいは意味的に近くないが正しいquestionに対して、ペナルティが与えられてしまう
=> contextに対するanswerabilityによって評価するメトリック RQUGE を提案
similarity basedな指標では、Q1のような正しい質問でもlexical overlapがないと低いスコアを与えてしまう。また、Q2のようなreferenceの言い換えであっても、低いスコアとなってしまう。一方、reference basedな手法では、Q3のようにunacceptableになっているにもかかわらず、変化が微小であるためそれをとらえられないという問題がある。
手法概要
提案手法ではcontextとanswer spanが与えられたとき、Span Scorerと、QAモジュールを利用してacceptability scoreを計算することでreference-freeなmetricを実現する。
QAモデルは、Contextと生成されたQuestionに基づき、answer spanを予測する。提案手法ではT5ベースの手法であるUnifiedQAv2を利用する。
Span Scorer Moduleでは、予測されたanswer span, candidate question, context, gold spanに基づき、[1, 5]のスコアを予測する。提案手法では、encoder-only BERT-based model(提案手法ではRoBERTa)を用いる。
#DocumentSummarization #Metrics #NLP #Dataset #Evaluation Issue Date: 2023-07-18 Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation, ACL'23 Summary要約の評価には人間の評価が重要ですが、既存の評価方法には問題があります。そこで、私たちは新しい要約の重要性プロトコルを提案し、大規模な人間評価データセットを収集しました。さらに、異なる評価プロトコルを比較し、自動評価指標を評価しました。私たちの研究結果は、大規模言語モデルの評価に重要な示唆を与えます。 #NLP #LanguageModel #Chain-of-Thought #Distillation Issue Date: 2023-07-18 Teaching Small Language Models to Reason, ACL'23 Summary本研究では、大規模な言語モデルの推論能力を小さなモデルに転送するための知識蒸留を探求しました。具体的には、大きな教師モデルによって生成された出力を用いて学生モデルを微調整し、算術、常識、象徴的な推論のタスクでのパフォーマンスを向上させることを示しました。例えば、T5 XXLの正解率は、PaLM 540BとGPT-3 175Bで生成された出力を微調整することで、それぞれ8.11%から21.99%および18.42%に向上しました。 #DocumentSummarization #NaturalLanguageGeneration #NLP #Abstractive #Factuality Issue Date: 2023-07-18 Improving Factuality of Abstractive Summarization without Sacrificing Summary Quality, ACL'23 Summary事実性を意識した要約の品質向上に関する研究はあるが、品質を犠牲にすることなく事実性を向上させる手法がほとんどない。本研究では「Effective Factual Summarization」という技術を提案し、事実性と類似性の指標の両方で大幅な改善を示すことを示した。トレーニング中に競合を防ぐために2つの指標を組み合わせるランキング戦略を提案し、XSUMのFactCCでは最大6ポイント、CNN/DMでは11ポイントの改善が見られた。また、類似性や要約の抽象性には負の影響を与えない。 #NLP #Dataset #GrammaticalErrorCorrection Issue Date: 2023-07-18 Enhancing Grammatical Error Correction Systems with Explanations, ACL'23 Summary文法エラー修正システムの性能向上のために、エビデンスワードと文法エラータイプが注釈付けされた大規模なデータセットであるEXPECTを紹介する。このデータセットを使用して、説明可能なGECシステムのベースラインと分析を提案し、人間の評価によってその有用性を確認する。 #NaturalLanguageGeneration #NLP #DataToTextGeneration #MultitaskLearning #Zero/FewShotLearning Issue Date: 2023-07-18 Few-Shot Data-to-Text Generation via Unified Representation and Multi-Source Learning, ACL'23 Summaryこの論文では、構造化データからテキストを生成する新しいアプローチを提案しています。提案手法は、さまざまな形式のデータを処理できる統一された表現を提供し、マルチタスクトレーニングやゼロショット学習などのシナリオでのパフォーマンスを向上させることを目指しています。実験結果は、提案手法が他の方法と比較して優れた性能を示していることを示しています。これは、データからテキスト生成フレームワークにおける重要な進歩です。 #RecommenderSystems #Explanation #Personalization #review Issue Date: 2023-07-18 Explainable Recommendation with Personalized Review Retrieval and Aspect Learning, ACL'23 Summary説明可能な推薦において、テキスト生成の精度向上とユーザーの好みの捉え方の改善を目指し、ERRAモデルを提案。ERRAは追加情報の検索とアスペクト学習を組み合わせることで、より正確で情報量の多い説明を生成することができる。さらに、ユーザーの関心の高いアスペクトを選択することで、関連性の高い詳細なユーザー表現をモデル化し、説明をより説得力のあるものにする。実験結果は、ERRAモデルが最先端のベースラインを上回ることを示している。 #NaturalLanguageGeneration #Controllable #NLP Issue Date: 2023-07-18 An Invariant Learning Characterization of Controlled Text Generation, ACL'23 Summary制御された生成では、予測器の訓練に使用される分布と異なるテキストの分布がある場合、パフォーマンスが低下することが示されている。この問題に対処するために、不変性を持つ予測器が効果的であるという考え方が提案されている。さらに、この特性を活かすための自然な解決策とヒューリスティックも提案されている。実験結果は、制御された生成における分布シフトの課題と不変性手法の潜在能力を示している。 #DocumentSummarization #NaturalLanguageGeneration #NLP #Abstractive #Extractive Issue Date: 2023-07-18 Abstractive Summarizers are Excellent Extractive Summarizers, ACL'23 Summary本研究では、抽出型要約と要約型要約の相乗効果を探求し、シーケンス・トゥ・シーケンス・アーキテクチャを使用した3つの新しい推論アルゴリズムを提案しています。これにより、要約型システムが抽出型システムを超えることができることを示しました。また、要約型システムは抽出型のオラクル要約にさらされることなく、両方の要約を単一のモデルで生成できることも示しました。これは、抽出型ラベルの必要性に疑問を投げかけるものであり、ハイブリッドモデルの有望な研究方向を示しています。 #NLP #NaturalLanguageUnderstanding Issue Date: 2023-07-18 [TACL] Efficient Long-Text Understanding with Short-Text Models, TACL'23 Summary本研究では、長いシーケンスを処理するためのシンプルなアプローチであるSLEDを提案しています。SLEDは、既存の短文の事前学習言語モデルを再利用し、入力を重なり合うチャンクに分割して処理します。制御された実験により、SLEDが長いテキスト理解に有効であり、専用の高価な事前学習ステップが必要な専門モデルと競合することが示されました。 #Pretraining #MachineLearning #NLP #In-ContextLearning Issue Date: 2023-07-18 Pre-Training to Learn in Context, ACL'23 Summaryインコンテキスト学習は、タスクの例と文脈からタスクを実行する方法であり、注目されています。しかし、現在の方法では十分に活用されていないため、私たちはPICLというフレームワークを提案します。これは、一般的なテキストコーパスでモデルを事前学習し、文脈に基づいてタスクを推論して実行する能力を向上させます。私たちは、PICLでトレーニングされたモデルのパフォーマンスを評価し、他のモデルを上回ることを示しました。コードはGitHubで公開されています。 #EfficiencyImprovement #MachineLearning #NLP #DynamicNetworks Issue Date: 2023-07-18 PAD-Net: An Efficient Framework for Dynamic Networks, ACL'23 Summary本研究では、ダイナミックネットワークの一般的な問題点を解決するために、部分的にダイナミックなネットワーク(PAD-Net)を提案します。PAD-Netは、冗長なダイナミックパラメータを静的なパラメータに変換することで、展開コストを削減し、効率的なネットワークを実現します。実験結果では、PAD-Netが画像分類と言語理解のタスクで高い性能を示し、従来のダイナミックネットワークを上回ることを示しました。 #NaturalLanguageGeneration #Controllable #NLP #Argument Issue Date: 2023-07-18 ArgU: A Controllable Factual Argument Generator, ACL'23 Summary本研究では、高品質な論証を自動生成するために、制御コードを使用したニューラル論証生成器ArgUを提案します。また、論証スキームを特定するための大規模なデータセットを作成し、注釈付けとデータセット作成のフレームワークについて詳細に説明します。さらに、論証テンプレートを生成する推論戦略を試行し、多様な論証を自動的に生成することが可能であることを示します。 #NLP #pretrained-LM #Out-of-DistributionDetection Issue Date: 2023-07-18 Is Fine-tuning Needed? Pre-trained Language Models Are Near Perfect for Out-of-Domain Detection, ACL'23 Summary本研究では、ファインチューニングなしで事前学習された言語モデルを使用してOOD検出を行う効果を調査しました。さまざまなタイプの分布シフトにおいて、ファインチューニングされたモデルを大幅に上回るほぼ完璧なOOD検出性能を示しました。 #RecommenderSystems #NLP #Contents-based #Transformer #pretrained-LM #ContrastiveLearning Issue Date: 2023-07-18 UniTRec: A Unified Text-to-Text Transformer and Joint Contrastive Learning Framework for Text-based Recommendation, ACL'23 Summary本研究では、事前学習済み言語モデル(PLM)を使用して、テキストベースの推薦の性能を向上させるための新しいフレームワークであるUniTRecを提案します。UniTRecは、ユーザーの履歴の文脈をより良くモデル化するために統一されたローカル-グローバルアテンションTransformerエンコーダを使用し、候補のテキストアイテムの言語の複雑さを推定するためにTransformerデコーダを活用します。幅広い評価により、UniTRecがテキストベースの推薦タスクで最先端のパフォーマンスを発揮することが示されました。 #Survey #NLP #NumericReasoning Issue Date: 2023-07-18 A Survey of Deep Learning for Mathematical Reasoning, ACL'23 Summary数学的な推論とディープラーニングの関係についての調査論文をレビューし、数学的な推論におけるディープラーニングの進歩と将来の研究方向について議論しています。数学的な推論は機械学習と自然言語処理の分野で重要であり、ディープラーニングモデルのテストベッドとして機能しています。また、大規模なニューラル言語モデルの進歩により、数学的な推論に対するディープラーニングの利用が可能になりました。既存のベンチマークと方法を評価し、将来の研究方向についても議論しています。 #NaturalLanguageGeneration #NLP #Explanation #Evaluation #Faithfulness Issue Date: 2023-07-18 Faithfulness Tests for Natural Language Explanations, ACL'23 Summary本研究では、ニューラルモデルの説明の忠実性を評価するための2つのテストを提案しています。1つ目は、カウンターファクチュアルな予測につながる理由を挿入するためのカウンターファクチュアル入力エディタを提案し、2つ目は生成された説明から入力を再構築し、同じ予測につながる頻度をチェックするテストです。これらのテストは、忠実な説明の開発において基本的なツールとなります。 #Survey #NLP #LanguageModel #Prompting #Reasoning Issue Date: 2023-07-18 Reasoning with Language Model Prompting: A Survey, ACL'23 Summary本論文では、推論に関する最新の研究について包括的な調査を行い、初心者を支援するためのリソースを提供します。また、推論能力の要因や将来の研究方向についても議論します。リソースは定期的に更新されています。 #DocumentSummarization #NaturalLanguageGeneration #NLP #Extractive #Faithfulness Issue Date: 2023-07-18 Extractive is not Faithful: An Investigation of Broad Unfaithfulness Problems in Extractive Summarization, ACL'23 Summary本研究では、抽出的な要約の不正確さの問題について議論し、それを5つのタイプに分類します。さらに、新しい尺度であるExtEvalを提案し、不正確な要約を検出するために使用することを示します。この研究は、抽出的な要約の不正確さに対する認識を高め、将来の研究に役立つことを目指しています。 CommentExtractive SummarizatinoのFaithfulnessに関する研究。
>抽出的な要約は抽象的な要約の一般的な不正確さの問題にはあまり影響を受けにくいですが、それは抽出的な要約が正確であることを意味するのでしょうか?結論はノーです。
>本研究では、抽出的な要約に現れる広範な不正確さの問題(非含意を含む)を5つのタイプに分類
>不正確な共参照、不完全な共参照、不正確な談話、不完全な談話、および他の誤解を招く情報が含まれます。
>私たちは、16の異なる抽出システムによって生成された1600の英語の要約を人間にラベル付けするように依頼しました。その結果、要約の30%には少なくとも5つの問題のうちの1つが存在することがわかりました。
おもしろい。 #General #NLP #RepresentationLearning #AES(AutomatedEssayScoring) Issue Date: 2023-07-18 Improving Domain Generalization for Prompt-Aware Essay Scoring via Disentangled Representation Learning, ACL'23 Summary自動エッセイスコアリング(AES)は、エッセイを評価するためのモデルですが、既存のモデルは特定のプロンプトにしか適用できず、新しいプロンプトに対してはうまく汎化できません。この研究では、プロンプトに依存しない特徴とプロンプト固有の特徴を抽出するためのニューラルAESモデルを提案し、表現の汎化を改善するための分離表現学習フレームワークを提案しています。ASAPとTOEFL11のデータセットでの実験結果は、提案手法の有効性を示しています。 #NaturalLanguageGeneration #Controllable #NLP Issue Date: 2023-07-15 Controllable Text Generation via Probability Density Estimation in the Latent Space, ACL'23 Summary本研究では、潜在空間での確率密度推定を用いた新しい制御フレームワークを提案しています。この手法は、可逆変換関数を使用して潜在空間の複雑な分布を単純なガウス分布にマッピングし、洗練された柔軟な制御を行うことができます。実験結果では、提案手法が属性の関連性とテキストの品質において強力なベースラインを上回り、新たなSOTAを達成していることが示されています。さらなる分析により、制御戦略の柔軟性が示されています。 #NLP #Education #EducationalDataMining #QuestionGeneration Issue Date: 2023-07-15 Covering Uncommon Ground: Gap-Focused Question Generation for Answer Assessment, ACL'23 Summary本研究では、教育的な対話における情報のギャップに焦点を当て、自動的に質問を生成する問題に取り組んでいます。良い質問の要素を明確にし、それを満たすモデルを提案します。また、人間のアノテーターによる評価を行い、生成された質問の競争力を示します。 #NLP #LanguageModel #Ensemble Issue Date: 2023-07-15 Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling, ACL'23 Summary本研究では、BERTモデルのアンサンブル手法であるMulti-CLS BERTを提案します。Multi-CLS BERTは、複数のCLSトークンを使用して多様性を促進し、単一のモデルを微調整するだけでアンサンブル効果を得ることができます。実験結果では、Multi-CLS BERTがGLUEとSuperGLUEのタスクで全体的な精度と信頼度の推定を向上させることが示されました。また、通常のBERTアンサンブルとほぼ同等の性能を持ちながら、計算量とメモリ使用量が約4倍少なくなっていることも示されました。 #DocumentSummarization #NaturalLanguageGeneration #NLP #Dataset #Conversation Issue Date: 2023-07-15 MeetingBank: A Benchmark Dataset for Meeting Summarization, ACL'23 Summary会議の要約技術の開発には注釈付きの会議コーパスが必要ですが、その欠如が問題となっています。本研究では、新しいベンチマークデータセットであるMeetingBankを提案しました。MeetingBankは、会議議事録を短いパッセージに分割し、特定のセグメントと対応させることで、会議の要約プロセスを管理しやすいタスクに分割することができます。このデータセットは、会議要約システムのテストベッドとして利用できるだけでなく、一般の人々が議会の意思決定の仕組みを理解するのにも役立ちます。ビデオリンク、トランスクリプト、参照要約などのデータを一般に公開し、会議要約技術の開発を促進します。 #MachineTranslation #Unsupervised #NLP #SpeechProcessing #Speech Issue Date: 2023-07-15 Simple and Effective Unsupervised Speech Translation, ACL'23 Summary音声翻訳のためのラベル付きデータが限られているため、非教師あり手法を使用して音声翻訳システムを構築する方法を研究している。パイプラインアプローチや擬似ラベル生成を使用し、非教師ありドメイン適応技術を提案している。実験の結果、従来の手法を上回る性能を示している。 #DocumentSummarization #NaturalLanguageGeneration #Controllable #NLP #Dataset #Factuality Issue Date: 2023-07-15 On Improving Summarization Factual Consistency from Natural Language Feedback, ACL'23 Summary本研究では、自然言語の情報フィードバックを活用して要約の品質とユーザーの好みを向上させる方法を調査しました。DeFactoという高品質なデータセットを使用して、要約の編集や修正に関する自然言語生成タスクを研究しました。また、微調整された言語モデルを使用して要約の品質を向上させることも示しました。しかし、大規模な言語モデルは制御可能なテキスト生成には向いていないことがわかりました。 #RecommenderSystems #NLP #Conversation Issue Date: 2023-07-15 TREA: Tree-Structure Reasoning Schema for Conversational Recommendation, ACL'23 Summary会話型の推薦システム(CRS)では、外部知識を活用して対話の文脈を理解し、関連するアイテムを推薦することが求められている。しかし、現在の推論モデルは複雑な関係を完全に把握できないため、新しいツリー構造の推論スキーマであるTREAを提案する。TREAは多階層のツリーを使用して因果関係を明確にし、過去の対話を活用してより合理的な応答を生成する。幅広い実験により、TREAの有効性が示された。 #ComputerVision #NLP #Dataset #Personalization #MultiModal #Conversation Issue Date: 2023-07-15 MPCHAT: Towards Multimodal Persona-Grounded Conversation, ACL'23 Summary本研究では、テキストと画像の両方を使用してパーソナを拡張し、マルチモーダルな対話エージェントを構築するためのデータセットであるMPCHATを提案します。さらに、マルチモーダルパーソナを組み込むことで、応答予測、パーソナのグラウンディング予測、話者の識別といったタスクのパフォーマンスを統計的に有意に改善できることを示します。この研究は、マルチモーダルな対話理解においてマルチモーダルパーソナの重要性を強調し、MPCHATが高品質なリソースとして役立つことを示しています。 #NLP #LanguageModel #Mathematics Issue Date: 2023-07-15 Solving Math Word Problems via Cooperative Reasoning induced Language Models, ACL'23 Summary大規模な事前学習言語モデル(PLM)を使用して、数学の文章問題(MWPs)を解決するためのCooperative Reasoning(CoRe)アーキテクチャを開発しました。CoReでは、生成器と検証器の二つの推論システムが相互作用し、推論パスを生成し評価を監督します。CoReは、数学的推論データセットで最先端の手法に比べて最大9.6%の改善を達成しました。 #NaturalLanguageGeneration #Controllable #NLP #Prompting Issue Date: 2023-07-15 Tailor: A Soft-Prompt-Based Approach to Attribute-Based Controlled Text Generation, ACL'23 Summary属性ベースの制御されたテキスト生成(CTG)では、望ましい属性を持つ文を生成することが目指されている。従来の手法では、ファインチューニングや追加の属性分類器を使用していたが、ストレージと推論時間の増加が懸念されていた。そこで、本研究では効率的なパラメータを使用した属性ベースのCTGを提案している。具体的には、各属性を事前学習された連続ベクトルとして表現し、固定された事前学習言語モデルをガイドして属性を満たす文を生成する。さらに、2つの解決策を提供して、組み合わせを強化している。実験の結果、追加のトレーニングパラメータのみで効果的な改善が実現できることが示された。 #DocumentSummarization #Survey #NLP #Abstractive #Conversation Issue Date: 2023-07-15 [TACL] Abstractive Meeting Summarization: A Survey, TACL'23 Summary会議の要約化において、深層学習の進歩により抽象的要約が改善された。本論文では、抽象的な会議の要約化の課題と、使用されているデータセット、モデル、評価指標について概説する。 #ComputerVision #NaturalLanguageGeneration #NLP #LanguageModel #TabularData #TextToImageGeneration Issue Date: 2023-07-15 Table and Image Generation for Investigating Knowledge of Entities in Pre-trained Vision and Language Models, ACL'23 Summary本研究では、Vision&Language(V&L)モデルにおけるエンティティの知識の保持方法を検証するために、テーブルと画像の生成タスクを提案します。このタスクでは、エンティティと関連する画像の知識を含むテーブルを生成する第一の部分と、キャプションとエンティティの関連知識を含むテーブルから画像を生成する第二の部分があります。提案されたタスクを実行するために、Wikipediaの約20万のinfoboxからWikiTIGデータセットを作成しました。最先端のV&LモデルOFAを使用して、提案されたタスクのパフォーマンスを評価しました。実験結果は、OFAが一部のエンティティ知識を忘れることを示しています。 #NaturalLanguageGeneration #Controllable #NLP #PEFT(Adaptor/LoRA) Issue Date: 2023-07-15 Focused Prefix Tuning for Controllable Text Generation, ACL'23 Summary本研究では、注釈のない属性によって制御可能なテキスト生成データセットのパフォーマンスが低下する問題に対して、「focused prefix tuning(FPT)」という手法を提案しています。FPTは望ましい属性に焦点を当てることで、制御精度とテキストの流暢さを向上させることができます。また、FPTは複数属性制御タスクにおいても、既存のモデルを再トレーニングすることなく新しい属性を制御する柔軟性を持ちながら、制御精度を保つことができます。 #NLP #In-ContextLearning #LabelBias Issue Date: 2023-07-15 Mitigating Label Biases for In-context Learning, ACL'23 Summaryインコンテキスト学習(ICL)におけるラベルバイアスの種類を定義し、その影響を軽減するための方法を提案する研究が行われました。特に、ドメインラベルバイアスについて初めて概念化され、その影響を軽減するためのバイアス補正方法が提案されました。この方法により、GPT-JとGPT-3のICLパフォーマンスが大幅に改善されました。さらに、異なるモデルやタスクにも一般化され、ICLにおけるラベルバイアスの問題を解決する手法として有効であることが示されました。 #Analysis #NLP #LanguageModel #InstructionTuning Issue Date: 2023-07-15 Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning, ACL'23 Summary最近のinstruction tuning(IT)の研究では、追加のコンテキストを提供してモデルをファインチューニングすることで、ゼロショットの汎化性能を持つ素晴らしいパフォーマンスが実現されている。しかし、IT中にモデルがどのように指示を利用しているかはまだ研究されていない。本研究では、モデルのトレーニングを変更された指示と元の指示との比較によって、モデルがIT中に指示をどのように利用するかを分析する。実験の結果、トレーニングされたモデルは元の指示と同等のパフォーマンスを達成し、ITと同様のパフォーマンスを達成することが示された。この研究は、より信頼性の高いIT手法と評価の緊急性を強調している。 #ComputerVision #NaturalLanguageGeneration #NLP #MultiModal #DiffusionModel #TextToImageGeneration Issue Date: 2023-07-15 Learning to Imagine: Visually-Augmented Natural Language Generation, ACL'23 Summary本研究では、視覚情報を活用した自然言語生成のためのLIVEという手法を提案しています。LIVEは、事前学習済み言語モデルを使用して、テキストに基づいて場面を想像し、高品質な画像を合成する方法です。また、CLIPを使用してテキストの想像力を評価し、段落ごとに画像を生成します。さまざまな実験により、LIVEの有効性が示されています。コード、モデル、データは公開されています。 Comment>まず、テキストに基づいて場面を想像します。入力テキストに基づいて高品質な画像を合成するために拡散モデルを使用します。次に、CLIPを使用して、テキストが想像力を喚起できるかを事後的に判断します。最後に、私たちの想像力は動的であり、段落全体に1つの画像を生成するのではなく、各文に対して合成を行います。
興味深い #NLP #In-ContextLearning #InductiveBias Issue Date: 2023-07-15 Measuring Inductive Biases of In-Context Learning with Underspecified Demonstrations, ACL'23 Summaryインコンテキスト学習(ICL)は、大規模言語モデル(LLMs)を新しいタスクに適応させるための重要なパラダイムですが、ICLの一般化の振る舞いはまだ十分に理解されていません。本研究では、ICLの帰納的なバイアスについて調査を行いました。具体的には、不完全なデモンストレーションが与えられた場合、ICLはどのフィーチャーをより頻繁に使用する傾向があるのかを調べました。実験の結果、LLMsが明確なフィーチャーバイアスを示すことがわかりました。また、特定のフィーチャーを好むような帰納的なバイアスを課すためのさまざまな介入の効果も評価しました。全体として、ICLがより頻繁に利用する可能性のあるフィーチャーのタイプと、意図したタスクとより一致した帰納的なバイアスを課す方法について、より広範な情報を提供する結果となりました。 #NLP #Chain-of-Thought #Distillation Issue Date: 2023-07-14 SCOTT: Self-Consistent Chain-of-Thought Distillation, ACL'23 Summary本研究では、大規模な言語モデル(LM)から小さなCoTモデルを学習するための知識蒸留手法であるSCOTTを提案しています。SCOTTは、教師モデルからゴールドアンサーをサポートする根拠を引き出し、より信憑性のあるトークンを生成するように学習を促します。さらに、学生モデルはカウンターファクトリーニングの目的で教師が生成した根拠を使用して学習されます。実験結果は、提案手法がベースラインよりも忠実なモデルを導くことを示しています。また、根拠を尊重することで意思決定を改善することも可能です。 CommentCoTのパフォーマンス向上がパラメータ数が大きいモデルでないと発揮せれないことは元論文 551 で考察されており、それをより小さいモデルに蒸留し発揮できるようにする、おもしろい #NaturalLanguageGeneration #NLP #Novelty #Evaluation Issue Date: 2023-07-14 [TACL] How much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN, TACL'23 Summaryこの研究では、言語モデルが生成するテキストの新規性を評価するための分析スイートRAVENを紹介しています。英語で訓練された4つのニューラル言語モデルに対して、局所的な構造と大規模な構造の新規性を評価しました。結果として、生成されたテキストは局所的な構造においては新規性に欠けており、大規模な構造においては人間と同程度の新規性があり、時には訓練セットからの重複したテキストを生成することもあります。また、GPT-2の詳細な手動分析により、組成的および類推的な一般化メカニズムの使用が示され、新規テキストが形態的および構文的に妥当であるが、意味的な問題が比較的頻繁に発生することも示されました。 #NLP #DataDistillation #Attention #Zero/FewShotLearning Issue Date: 2023-07-14 Dataset Distillation with Attention Labels for Fine-tuning BERT, ACL'23 Summary本研究では、データセットの蒸留を使用して、元のデータセットのパフォーマンスを保持しながら、ニューラルネットワークを迅速にトレーニングするための小さなデータセットを作成する方法に焦点を当てています。具体的には、事前学習済みのトランスフォーマーを微調整するための自然言語処理タスクの蒸留されたfew-shotデータセットの構築を提案しています。実験結果では、注意ラベルを使用してfew-shotデータセットを作成し、BERTの微調整において印象的なパフォーマンスを実現できることを示しました。例えば、ニュース分類タスクでは、わずか1つのサンプルとわずか1つの勾配ステップのみで、元のデータセットの98.5%のパフォーマンスを達成しました。 CommentDatadistillationしたら、データセットのうち1サンプルのみで、元のデータセットの98.5%の性能を発揮できたという驚異的な研究(まえかわ君) #NaturalLanguageGeneration #NLP #Education #AdaptiveLearning #KnowledgeTracing #Personalization #QuestionGeneration Issue Date: 2023-07-14 Adaptive and Personalized Exercise Generation for Online Language Learning, ACL'23 Summary本研究では、オンライン言語学習のための適応的な演習生成の新しいタスクを研究しました。学習履歴から学生の知識状態を推定し、その状態に基づいて個別化された演習文を生成するモデルを提案しました。実データを用いた実験結果から、学生の状態に応じた演習を生成できることを示しました。さらに、教育アプリケーションでの利用方法についても議論し、学習の効率化を促進できる可能性を示しました。 CommentKnowledge Tracingで推定された習熟度に基づいて、エクササイズを自動生成する研究。KTとNLGが組み合わさっており、非常におもしろい。
#MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #Evaluation Issue Date: 2023-07-14 Measuring the Instability of Fine-Tuning, ACL'23 Summary事前学習済み言語モデルのファインチューニングは小規模データセットでは不安定であることが示されている。本研究では、不安定性を定量化する指標を分析し、評価フレームワークを提案する。また、既存の不安定性軽減手法を再評価し、結果を提供する。 #EfficiencyImprovement #NLP #Ensemble #TransferLearning Issue Date: 2023-07-14 Parameter-efficient Weight Ensembling Facilitates Task-level Knowledge Transfer, ACL'23 Summary最近の研究では、大規模な事前学習済み言語モデルを特定のタスクに効果的に適応させることができることが示されています。本研究では、軽量なパラメータセットを使用してタスク間で知識を転送する方法を探求し、その有効性を検証しました。実験結果は、提案手法がベースラインに比べて5%〜8%の改善を示し、タスクレベルの知識転送を大幅に促進できることを示しています。 #InformationRetrieval #NLP #LanguageModel #KnowledgeGraph #Factuality #NaturalLanguageUnderstanding Issue Date: 2023-07-14 Direct Fact Retrieval from Knowledge Graphs without Entity Linking, ACL'23 Summary従来の知識取得メカニズムの制限を克服するために、我々はシンプルな知識取得フレームワークであるDiFaRを提案する。このフレームワークは、入力テキストに基づいて直接KGから事実を取得するものであり、言語モデルとリランカーを使用して事実のランクを改善する。DiFaRは複数の事実取得タスクでベースラインよりも優れた性能を示した。 #NLP #Transformer #LongSequence #PositionalEncoding Issue Date: 2023-07-14 Randomized Positional Encodings Boost Length Generalization of Transformers, ACL'23 Summaryトランスフォーマーは、固定長のタスクにおいては優れた汎化能力を持つが、任意の長さのシーケンスには対応できない。この問題を解決するために、新しい位置エンコーディング手法を提案する。ランダム化された位置エンコーディングスキームを使用し、長いシーケンスの位置をシミュレートし、順序付けられたサブセットをランダムに選択する。大規模な実証評価により、この手法がトランスフォーマーの汎化能力を向上させ、テストの正確性を平均して12.0%向上させることが示された。 #NLP #QuestionAnswering #KnowledgeGraph Issue Date: 2023-07-14 Do I have the Knowledge to Answer? Investigating Answerability of Knowledge Base Questions, ACL'23 Summaryナレッジベース上の自然言語質問には回答不可能なものが多くありますが、これについての研究はまだ不十分です。そこで、回答不可能な質問を含む新しいベンチマークデータセットを作成しました。最新のKBQAモデルを評価した結果、回答不可能な質問に対して性能が低下することがわかりました。さらに、これらのモデルは誤った理由で回答不可能性を検出し、特定の形式の回答不可能性を扱うことが困難であることもわかりました。このため、回答不可能性に対する堅牢なKBQAシステムの研究が必要です。 #EfficiencyImprovement #MachineLearning #NLP #Zero/FewShotPrompting #In-ContextLearning Issue Date: 2023-07-13 FiD-ICL: A Fusion-in-Decoder Approach for Efficient In-Context Learning, ACL'23 Summary大規模な事前学習モデルを使用したfew-shot in-context learning(ICL)において、fusion-in-decoder(FiD)モデルを適用することで効率とパフォーマンスを向上させることができることを検証する。FiD-ICLは他のフュージョン手法と比較して優れたパフォーマンスを示し、推論時間も10倍速くなる。また、FiD-ICLは大規模なメタトレーニングモデルのスケーリングも可能にする。 #DocumentSummarization #NLP #Abstractive #pretrained-LM #InstructionTuning Issue Date: 2023-07-13 Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization, ACL'23 Summaryこの論文では、新しい事前学習言語モデルであるZ-Code++を提案し、抽象的なテキスト要約に最適化されています。Z-Code++は、2つのフェーズの事前学習とディセントラル化アテンション層、およびエンコーダー内のフュージョンを使用しています。このモデルは、低リソースの要約タスクで最先端の性能を発揮し、パラメータ効率的であり、他の競合モデルを大幅に上回ります。 #NLP #Dataset #InstructionTuning Issue Date: 2023-07-13 Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor, ACL'23 Summary本研究では、人間の監督を必要としない方法で収集された大規模なデータセット「Unnatural Instructions」を紹介します。このデータセットを使用して、言語モデルのトレーニングを行い、既存のモデルを上回る性能を実現しました。これにより、クラウドソーシングに頼らずにデータセットを拡張し、多様性を持たせることができることが示されました。 #General #NLP #LanguageModel #In-ContextLearning #Composition Issue Date: 2023-07-13 How Do In-Context Examples Affect Compositional Generalization?, ACL'23 Summary本研究では、組成的な一般化を調査するためのテストスイートであるCoFeを提案し、インコンテキスト学習の組成的な一般化について研究しました。インコンテキストの例の選択が組成的な一般化のパフォーマンスに影響を与えることを発見し、類似性、多様性、複雑さの要素を研究しました。さらに、架空の単語に対する組成的な一般化は一般的な単語に比べて弱いことが観察されました。インコンテキストの例が言語構造をカバーすることが重要であることも示されました。 #NaturalLanguageGeneration #Controllable #NLP #LanguageModel Issue Date: 2023-07-13 Explicit Syntactic Guidance for Neural Text Generation, ACL'23 Summary既存のテキスト生成モデルには制約があり、シーケンス・トゥ・シーケンスのパラダイムに従っている。私たちは、構文にガイドされた生成スキーマを提案し、構文解析木に従ってシーケンスを生成する。提案手法は、パラフレーズ生成と機械翻訳の実験でベースラインを上回り、解釈可能性、制御可能性、多様性の観点でも効果的であることを示している。 #NLP #LanguageModel #Pruning Issue Date: 2023-07-13 Pruning Pre-trained Language Models Without Fine-Tuning, ACL'23 Summary本研究では、Pre-trained Language Models(PLMs)の過パラメータ化の問題を解決するために、一次元のプルーニングを使用したシンプルで直感的な圧縮手法であるStatic Model Pruning(SMP)を提案します。SMPは、下流のタスクにPLMsを適応させるために一次元のプルーニングのみを使用し、微調整を必要としないため、他の手法よりも効率的です。徹底的な実験結果は、SMPが一次元およびゼロ次元の手法よりも大幅に改善されていることを示しています。また、SMPは低い疎密度にも適用可能であり、ゼロ次元の手法を上回ります。 #ComputerVision #Pocket #NeurIPS Issue Date: 2023-04-27 Stable and low-precision training for large-scale vision-language models, Wortsman+, University of Washington, NeurIPS'23 Summary大規模な言語-視覚モデルのトレーニングを加速し安定させる新手法を提案。SwitchBackを用いたint8量子化で、CLIP ViT-Hugeのトレーニング速度を13-25%向上させ、bfloat16と同等の性能を維持。float8トレーニングも効果的であることを示し、初期化方法が成功に寄与。損失のスパイクを分析し、AdamW-Adafactorハイブリッドを推奨することで、トレーニングの安定性を向上させた。 Comment
#MachineLearning #DataAugmentation #MultiModal Issue Date: 2023-04-26 Learning Multimodal Data Augmentation in Feature Space, ICLR'23 Summaryマルチモーダルデータの共同学習能力は、インテリジェントシステムの特徴であるが、データ拡張の成功は単一モーダルのタスクに限定されている。本研究では、LeMDAという方法を提案し、モダリティのアイデンティティや関係に制約を設けずにマルチモーダルデータを共同拡張することができることを示した。LeMDAはマルチモーダルディープラーニングの性能を向上させ、幅広いアプリケーションで最先端の結果を達成することができる。 CommentData Augmentationは基本的に単体のモダリティに閉じて行われるが、
マルチモーダルな設定において、モダリティ同士がどう関係しているか、どの変換を利用すべきかわからない時に、どのようにデータ全体のsemantic structureを維持しながら、Data Augmentationできるか?という話らしい #NeuralNetwork #ComputerVision #Pocket #SIGGRAPH Issue Date: 2022-12-01 Sketch-Guided Text-to-Image Diffusion Models, Andrey+, Google Research, SIGGRAPH'23 Summaryテキストから画像へのモデルは高品質な画像合成を実現するが、空間的特性の制御が不足している。本研究では、スケッチからの空間マップを用いて事前学習済みモデルを導く新しいアプローチを提案。専用モデルを必要とせず、潜在ガイダンス予測器(LGP)を訓練し、画像を空間マップに一致させる。ピクセルごとの訓練により柔軟性を持ち、スケッチから画像への翻訳タスクにおいて効果的な生成が可能であることを示す。 Commentスケッチとpromptを入力することで、スケッチ biasedな画像を生成することができる技術。すごい。
#Survey
#NLP
#EACL
Issue Date: 2022-10-31
MTEB: Massive Text Embedding Benchmark, Muennighoff+, EACL'23
Summaryテキスト埋め込みの評価は通常小規模なデータセットに限られ、他のタスクへの適用可能性が不明である。これを解決するために、58のデータセットと112の言語をカバーするMassive Text Embedding Benchmark(MTEB)を導入し、33のモデルをベンチマークした。結果、特定の手法が全タスクで優位に立つことはなく、普遍的なテキスト埋め込み手法には至っていないことが示された。MTEBはオープンソースで公開されている。
#Survey
#Pocket
#AdaptiveLearning
#EducationalDataMining
#KnowledgeTracing
Issue Date: 2022-08-02
Knowledge Tracing: A Survey, ABDELRAHMAN+, Australian National University, ACM Computing Surveys'23
Summary人間の教育における知識移転の重要性を背景に、オンライン教育における知識追跡(KT)の必要性が高まっている。本論文では、KTに関する包括的なレビューを行い、初期の手法から最新の深層学習技術までを網羅し、モデルの理論やデータセットの特性を強調する。また、関連手法のモデリングの違いを明確にし、KT文献の研究ギャップや今後の方向性についても議論する。
#NeuralNetwork
#Survey
#MachineLearning
#Pocket
Issue Date: 2021-06-19
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better, Menghani, ACM Computing Surveys'23
Summaryディープラーニングの進展に伴い、モデルのパラメータ数やリソース要求が増加しているため、効率性が重要になっている。本研究では、モデル効率性の5つのコア領域を調査し、実務者向けに最適化ガイドとコードを提供する。これにより、効率的なディープラーニングの全体像を示し、読者に改善の手助けとさらなる研究のアイデアを提供することを目指す。
Comment学習効率化、高速化などのテクニックがまとまっているらしい
#DocumentSummarization
#NLP
#Evaluation
#LM-based
#Factuality
Issue Date: 2023-08-13
SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization, Laban+, TACL'22
Summary要約の領域では、入力ドキュメントと要約が整合していることが重要です。以前の研究では、自然言語推論(NLI)モデルを不整合検出に適用するとパフォーマンスが低下することがわかりました。本研究では、NLIを不整合検出に再評価し、過去の研究での入力の粒度の不一致が問題であることを発見しました。新しい手法SummaCConvを提案し、NLIモデルを文単位にドキュメントを分割してスコアを集計することで、不整合検出に成功裏に使用できることを示しました。さらに、新しいベンチマークSummaCを導入し、74.4%の正確さを達成し、先行研究と比較して5%の改善を実現しました。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Play the Shannon Game With Language Models: A Human-Free Approach to Summary Evaluation, Nicholas Egan+, N_A, AAAI'22
Summaryこの研究では、事前学習済み言語モデルを使用して、参照フリーの要約評価指標を提案します。これにより、要約の品質を測定するための新しい手法が開発されます。また、提案手法が人間の判断と高い相関関係を持つことが実証されます。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Reference-free Summarization Evaluation via Semantic Correlation and Compression Ratio, Liu+, NAACL'22
Summary本研究では、参照ベースの評価方法の柔軟性の欠如を解消するために、事前学習済み言語モデルを使用して自動参照フリーの評価指標を提案します。この指標は、要約の意味的な分布と圧縮率を考慮し、人間の評価とより一致していることが実験で示されました。
#DocumentSummarization
#NLP
#Evaluation
Issue Date: 2023-08-13
Re-Examining System-Level Correlations of Automatic Summarization Evaluation Metrics, Deutsch+, NAACL'22
Summary本研究では、自動要約評価尺度のシステムレベルの相関に関する不整合を修正するための変更を提案しています。具体的には、全テストセットを使用して自動評価尺度のシステムスコアを計算し、実際のシナリオでよく見られる自動スコアのわずかな差によって分離されたシステムのペアに対してのみ相関を計算することを提案しています。これにより、より正確な相関推定と高品質な人間の判断の収集が可能となります。
#DocumentSummarization
#NLP
#Evaluation
Issue Date: 2023-08-13
Does Summary Evaluation Survive Translation to Other Languages?, Braun+, NAACL'22
Summary要約データセットの作成は費用と時間がかかるが、機械翻訳を使用して既存のデータセットを他の言語に翻訳することで、追加の言語での使用が可能になる。この研究では、英語の要約データセットを7つの言語に翻訳し、自動評価尺度によるパフォーマンスを比較する。また、人間と自動化された要約のスコアリング間の相関を評価し、翻訳がパフォーマンスに与える影響も考慮する。さらに、データセットの再利用の可能性を見つけるために、特定の側面に焦点を当てる。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#TrainedMetrics
Issue Date: 2023-08-13
SummScore: A Comprehensive Evaluation Metric for Summary Quality Based on Cross-Encoder, Wuhang Lin+, N_A, arXiv'22
Summary要約の品質評価メトリクスの問題を解決するために、SummScoreという包括的な評価メトリクスを提案する。SummScoreはCrossEncoderに基づいており、要約の多様性を抑制せずに要約の品質を評価することができる。さらに、SummScoreは一貫性、一貫性、流暢さ、関連性の4つの側面で評価することができる。実験結果は、SummScoreが既存の評価メトリクスを上回ることを示している。また、SummScoreの評価結果を16の主要な要約モデルに提供している。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
SueNes: A Weakly Supervised Approach to Evaluating Single-Document Summarization via Negative Sampling, Bao+, NAACL'22
Summary従来の自動要約評価メトリックは語彙の類似性に焦点を当てており、意味や言語的な品質を十分に捉えることができない。参照要約が必要であるためコストがかかる。本研究では、参照要約が存在しない弱教師あり要約評価手法を提案する。既存の要約データセットを文書と破損した参照要約のペアに変換してトレーニングする。ドメイン間のテストでは、提案手法がベースラインを上回り、言語的な品質を評価する上で大きな利点を示した。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
PrefScore: Pairwise Preference Learning for Reference-free Summarization Quality Assessment, Luo+, COLING'22
Summary人間による参照要約のない機械生成の要約の評価を行うために、ブラッドリー・テリーのパワーランキングモデルを使用して要約の優劣を判断する方法を提案する。実験結果は、この方法が人間の評価と高い相関を持つスコアを生成できることを示している。
#DocumentSummarization
#Pocket
#NLP
#Evaluation
Issue Date: 2023-08-13
How to Find Strong Summary Coherence Measures? A Toolbox and a Comparative Study for Summary Coherence Measure Evaluation, Steen+, COLING'22
Summary要約の一貫性を自動的に評価することは重要であり、さまざまな方法が提案されていますが、異なるデータセットと評価指標を使用して評価されるため、相対的なパフォーマンスを理解することが困難です。本研究では、要約の一貫性モデリングのさまざまな方法について調査し、新しい分析尺度を導入します。現在の自動一貫性尺度はすべての評価指標において信頼性のある一貫性スコアを割り当てることができませんが、大規模言語モデルは有望な結果を示しています。
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
#PersonalizedHeadlineGeneration
Issue Date: 2023-08-11
Personalized News Headline Generation System with Fine-grained User Modeling, Yao, MSN'22
Summaryユーザーの興味に基づいてパーソナライズされたニュースの見出しを生成するために、文レベルの情報を考慮したユーザーモデルを提案する。アテンション層を使用して文とニュースの関連性を計算し、ニュースの内容に基づいて見出しを生成する。実験結果は、提案モデルがベースラインモデルよりも優れたパフォーマンスを示していることを示している。将来の方向性として、情報のレベルと内容を横断する相互作用についても議論されている。
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
#PersonalizedHeadlineGeneration
Issue Date: 2023-08-11
Personalized Headline Generation with Enhanced User Interest Perception, Zhang+, ICANN'22
Summaryユーザーのニュース閲覧履歴をモデル化し、個別化されたニュース見出しを生成するための新しいフレームワークを提案する。提案手法は、ユーザーの興味を強調するために候補テキストに関連する情報を活用し、ニュースのエンティティワードを使用して興味表現を改善する。幅広い実験により、提案手法が見出し生成タスクで優れたパフォーマンスを示すことが示されている。
#RecommenderSystems
#Pocket
#NLP
#PersonalizedGeneration
#Personalization
Issue Date: 2023-08-11
Personalized Chit-Chat Generation for Recommendation Using External Chat Corpora, Chen+, KDD'22
Summaryチットチャットは、ユーザーとの対話において効果的であることが示されています。この研究では、ニュース推薦のための個人化されたチットチャットを生成する方法を提案しています。既存の方法とは異なり、外部のチャットコーパスのみを使用してユーザーの関心を推定し、個人化されたチットチャットを生成します。幅広い実験により、提案手法の効果が示されています。
#Pretraining
#Pocket
#NLP
Issue Date: 2022-12-01
Revisiting Pretraining Objectives for Tabular Deep Learning, Rubachev+, Yandex+, arXiv'22
Summary表形式データに対する深層学習モデルはGBDTと競争しており、事前学習がパフォーマンス向上に寄与することが示された。異なるデータセットやアーキテクチャに適用可能な事前学習のベストプラクティスを特定し、オブジェクトターゲットラベルの使用が有益であることを発見。適切な事前学習により、深層学習モデルはGBDTを上回る性能を発揮することが確認された。
CommentTabular Dataを利用した場合にKaggleなどでDeepなモデルがGBDT等に勝てないことが知られているが、GBDT等とcomparable になる性能になるようなpre-trainingを提案したよ、的な内容っぽいICLR 2023 OpenReview: https://openreview.net/forum?id=kjPLodRa0n
#NLP
#Dataset
#QuestionAnswering
Issue Date: 2022-02-07
JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension, So+, arXiv'22
Summary日本語の質問応答データセットJaQuADを提案。39,696の質問-回答ペアを含み、テストセットでF1スコア78.92%、EMスコア63.38%を達成。データセットは[こちら](https://github.com/SkelterLabsInc/JaQuAD)から入手可能。
CommentSQuAD likeな日本語のQAデータセット
https://github.com/SkelterLabsInc/JaQuAD #DocumentSummarization #Metrics #Tools #NLP #Dataset #Evaluation #Admin'sPick Issue Date: 2023-08-13 SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21 Comment自動評価指標が人手評価の水準に達しないことが示されており、結局のところROUGEを上回る自動性能指標はほとんどなかった。human judgmentsとのKendall;'s Tauを見ると、chrFがCoherenceとRelevance, METEORがFluencyで上回ったのみだった。また、LEAD-3はやはりベースラインとしてかなり強く、LEAD-3を上回ったのはBARTとPEGASUSだった。 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 How to Evaluate a Summarizer: Study Design and Statistical Analysis for Manual Linguistic Quality Evaluation, Steen+, EACL'21 Summary要約システムの評価方法についての調査結果を報告しました。要約の言語的品質についての評価実験を行い、最適な評価方法は側面によって異なることを示しました。また、研究パラメータや統計分析方法についても問題点を指摘しました。さらに、現行の方法では固定された研究予算の下では信頼性のある注釈を提供できないことを強調しました。 Comment要約の人手評価に対する研究 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 Reliability of Human Evaluation for Text Summarization: Lessons Learned and Challenges Ahead, Iskender+, EACL'21 Summary人間評価の信頼性に関する研究では、参加者の情報や実験の詳細が提供されていないことが多い。また、人間評価の信頼性に影響を与える要因についても研究されていない。そこで、私たちは人間評価実験を行い、参加者の情報や実験の詳細を提供し、異なる実験結果を比較した。さらに、専門家と非専門家の評価の信頼性を確保するためのガイドラインを提供し、信頼性に影響を与える要因を特定した。 Comment要約の人手評価に対する信頼性に関して研究。人手評価のガイドラインを提供している。 #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-free Issue Date: 2023-08-13 A Training-free and Reference-free Summarization Evaluation Metric via Centrality-weighted Relevance and Self-referenced Redundancy, Chen+, ACL-IJCNLP'21 Summary参照ベースと教師ありの要約評価指標の制約を回避するために、トレーニングフリーかつ参照フリーの要約評価指標を提案する。この指標は、文の中心性によって重み付けされた概念参照と要約との関連性スコアと、自己参照の冗長性スコアから構成される。関連性スコアは擬似参照と要約との間で計算され、重要度のガイダンスを提供する。要約の冗長性スコアは要約内の冗長な情報を評価するために計算される。関連性スコアと冗長性スコアを組み合わせて、要約の最終評価スコアを生成する。徹底的な実験により、提案手法が既存の手法を大幅に上回ることが示された。ソースコードはGitHubで公開されている。 #NaturalLanguageGeneration #Metrics #NLP #DialogueGeneration #Evaluation #Reference-free #QA-based #Factuality Issue Date: 2023-08-13 Q2: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering, Honovich+, EMNLP'21 Summary本研究では、ニューラルな知識に基づく対話生成モデルの信頼性と適用範囲の制限についての問題を解決するため、自動的な質問生成と質問応答を使用した事実的な整合性の自動評価尺度を提案します。この尺度は、自然言語推論を使用して回答スパンを比較することで、以前のトークンベースのマッチングよりも優れた評価を行います。また、新しいデータセットを作成し、事実的な整合性の手動アノテーションを行い、他の尺度とのメタ評価を行いました。結果として、提案手法が人間の判断と高い相関を示しました。 Comment(knowledge-grounded; 知識に基づいた)対話に対するFactual ConsistencyをReference-freeで評価できるQGQA手法。機械翻訳やAbstractive Summarizationの分野で研究が進んできたが、対話では
・対話履歴、個人の意見、ユーザに対する質問、そして雑談
といった外部知識に対するconsistencyが適切ではない要素が多く存在し、よりチャレンジングなタスクとなっている。
また、そもそも対話タスクはopen-endedなタスクなため、Reference-basedな手法は現実的ではなく、Reference-freeな手法が必要と主張。
手法の概要としては以下。ユーザの発話からQuestion Generation (QG)を実施し、Question-Answer Candidate Pairを作成する。そして、生成したQuestionをベースとなる知識から回答させ(QA)、その回答結果とAnswer Candidateを比較することでFactual Consistencyを測定する。
#DocumentSummarization #Metrics #NLP #Evaluation #LM-based #Factuality Issue Date: 2023-08-13 Compression, Transduction, and Creation: A Unified Framework for Evaluating Natural Language Generation, Deng+, EMNLP''21 Summary本研究では、自然言語生成(NLG)タスクの評価において、情報の整合性を重視した統一的な視点を提案する。情報の整合性を評価するための解釈可能な評価指標のファミリーを開発し、ゴールドリファレンスデータを必要とせずに、さまざまなNLGタスクの評価を行うことができることを実験で示した。 CommentCTC #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-free #QA-based Issue Date: 2023-08-13 QACE: Asking Questions to Evaluate an Image Caption, Lee+, EMNLP'21 Summary本研究では、画像キャプションの評価において、Question Generation(QG)とQuestion Answering(QA)システムに基づいた質問応答メトリックであるQACEを提案する。QACEは評価対象のキャプションに対して質問を生成し、その内容を参照キャプションまたはソース画像に対して質問することで確認する。QACE_Refというメトリックを開発し、最先端のメトリックと競合する結果を報告する。さらに、参照ではなく画像自体に直接質問をするQACE_Imgを提案する。QACE_ImgにはVisual-QAシステムが必要であり、Visual-T5という抽象的なVQAシステムを提案する。QACE_Imgはマルチモーダルで参照を必要とせず、説明可能なメトリックである。実験の結果、QACE_Imgは他の参照を必要としないメトリックと比較して有利な結果を示した。 CommentImage Captioningを評価するためのQGQAを提案している。candidateから生成した質問を元画像, およびReferenceを用いて回答させ、candidateに基づいた回答と回答の結果を比較することで評価を実施する。
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #LM-based #Admin'sPick Issue Date: 2023-08-13 BARTSCORE: Evaluating Generated Text as Text Generation, Yuan+ (w_ Neubig氏), NeurIPS'21 Summary本研究では、生成されたテキストの評価方法について検討しました。具体的には、事前学習モデルを使用してテキスト生成の問題をモデル化し、生成されたテキストを参照出力またはソーステキストに変換するために訓練されたモデルを使用しました。提案したメトリックであるBARTSCOREは、情報量、流暢さ、事実性などの異なる視点のテキスト評価に柔軟に適用できます。実験結果では、既存のトップスコアリングメトリックを上回る性能を示しました。BARTScoreの計算に使用するコードは公開されており、インタラクティブなリーダーボードも利用可能です。 CommentBARTScore概要
ソーステキストが与えられた時に、BARTによって生成テキストを生成する尤度を計算し、それをスコアとする手法。テキスト生成タスクをテキスト生成モデルでスコアリングすることで、pre-trainingされたパラメータをより有効に活用できる(e.g. BERTScoreやMoverScoreなどは、pre-trainingタスクがテキスト生成ではない)。BARTScoreの特徴は
1. parameter・and data-efficientである。pre-trainingに利用されたパラメータ以外の追加パラメータは必要なく、unsupervisedなmetricなので、human judgmentのデータなども必要ない。
2. 様々な観点から生成テキストを評価できる。conditional text generation problemにすることでinformativeness, coherence, factualityなどの様々な観点に対応可能。
3. BARTScoreは、(i) pre-training taskと類似したpromptを与えること、(ii) down stream generation taskでfinetuningすること、でより高い性能を獲得できる
BARTScoreを16種類のデータセットの、7つの観点で評価したところ、16/22において、top-scoring metricsよりも高い性能を示した。また、prompting starategyの有効性を示した。たとえば、シンプルに"such as"というフレーズを翻訳テキストに追加するだけで、German-English MTにおいて3%の性能向上が見られた。また、BARTScoreは、high-qualityなテキスト生成システムを扱う際に、よりロバストであることが分析の結果分かった。
前提
Problem Formulation
生成されたテキストのqualityを測ることを目的とする。本研究では、conditional text generation (e.g. 機械翻訳)にフォーカスする。すなわち、ゴールは、hypothesis h_bar を source text s_barがgivenな状態で生成することである。一般的には、人間が作成したreference r_barが評価の際は利用される。
Gold-standard Human Evaluation
評価のgold standardは人手評価であり、人手評価では多くの観点から評価が行われる。以下に代表的な観点を示す:
1. Informativeness: ソーステキストのキーアイデアをどれだけ捉えているか
2. Relevance: ソーステキストにあ地して、どれだけconsistentか
3. Fluency formatting problem, capitarlization errorや非文など、どの程度読むのが困難か
4. Coherence: 文間のつながりが、トピックに対してどれだけcoherentか
5. Factuality: ソーステキストに含意されるstatementのみを生成できているか
6. Semantic Coverage: 参照テキスト中のSemantic Content Unitを生成テキストがどれだけカバーできているか
7: Adequacy 入力文に対してアウトプットが同じ意味を出力できているかどうか、あるいは何らかのメッセージが失われる、追加される、歪曲していないかどうか
多くの性能指標は、これらの観点のうちのsubsetをカバーするようにデザインんされている。たとえば、BLEUは、翻訳におけるAdequacyとFluencyをとらえることを目的としている。一方、ROUGEは、semantic coverageを測るためのメトリックである。
BARTScoreは、これらのうち多くの観点を評価することができる。
Evaluation as Different Tasks
ニューラルモデルを異なる方法で自動評価に活用するのが最近のトレンドである。下図がその分類。この分類は、タスクにフォーカスした分類となっている。
1. Unsupervised Matching: ROUGE, BLEU, CHRF, BERTScore, MoverScoreのように、hypothesisとreference間での意味的な等価性を測ることが目的である。このために、token-levelのマッチングを用いる。これは、distributedな表現を用いる(BERTScore, MoverScore)場合もあれば、discreteな表現を用いる(ROUGE, BLEU, chrF)場合もある。また、意味的な等価性だけでなく、factual consistencyや、source-hypothesis間の関係性の評価に用いることもできると考えられるが先行研究ではやられていなかったので、本研究で可能なことを示す。
2. Supervised Regression: BLEURT, COMET, S^3, VRMのように、regression layer を用いてhuman judgmentをsupervisedに予測する方法である。最近のメトリックtおしては、BLEURT, COMETがあげられ、古典的なものとしては、S^3, VRMがあげられる。
4. Supervised Ranking: COMET, BEERのような、ランキング問題としてとらえる方法もある。これは優れたhypothesisを上位にランキングするようなスコア関数を学習する問題に帰着する。COMETやBEERが例としてあげられ、両者はMTタスクにフォーカスされている。COMETはhunan judgmentsをregressionすることを通じてランキングを作成し、BEERは、多くのシンプルな特徴量を組み合わせて、linear layerでチューニングされる。
5. Text Generation: PRISM, BARTScoreが例として挙げられる。BARTScoreでは、生成されたテキストの評価をpre-trained language modelによるテキスト生成タスクとしてとらえる。基本的なアイデアとしては、高品質のhypothesisは、ソース、あるいはreferenceから容易に生成可能であろう、というものである。これはPRISMを除いて、先行研究ではカバーされていない。BARTScoreは、PRISMとはいくつかの点で異なっている。(i) PRISMは評価をparaphrasing taskとしてとらえており、これが2つの意味が同じテキストを比較する前提となってしまっているため、手法を適用可能な範囲を狭めてしまっている。たとえば、文書要約におけるfactual consistencyの評価では、semantic spaceが異なる2つのテキストを比較する必要があるが、このような例には対応できない。(ii) PRISMはparallel dataから学習しなけえrばならないが、BARTScoreは、pre-trainedなopen-sourceのseq2seq modelを利用できる。(iii) BARTScoreでは、PRISMが検証していない、prompt-basedのlearningもサポートしている。
BARTScore
Sequence-to-Sequence Pre-trained Models
pre-trainingされたモデルは、様々な軸で異なっているが、その一つの軸としては訓練時の目的関数である。基本的には2つの大きな変種があり、1つは、language modeling objectives (e.g. MLM)、2つ目は、seq2seq objectivesである。特に、seq2seqで事前学習されたモデルは、エンコーダーとデコーダーによって構成されているため特に条件付き生成タスクに対して適しており、予測はAutoRegressiveに行われる。本研究ではBARTを用いる。付録には、preliminary experimentsとして、BART with T5, PEGASUSを用いた結果も添付する。
BARTScore
最も一般的なBARTScoreの定式化は下記である。
weighted log probabilityを利用する。このweightsは、異なるトークンに対して、異なる重みを与えることができる。たておば、IDFなどが利用可能であるが、本研究ではすべてのトークンを等価に扱う(uniform weightingだがstopwordを除外、IDFによる重みづけ、事前分布を導入するなど色々試したが、uniform weightingを上回るものがなかった)。
BARTScoreを用いて、様々な方向に用いて生成を行うことができ、異なる評価のシナリオに対応することができる。
・Faithfulness (s -> h):
・hypothesisがどれだけsource textに基づいて生成されているかを測ることができる。シナリオとしては、FactualityやRelevanceなどが考えられる。また、CoherenceやFluencyのように、target textのみの品質を測るためにも用いることができる。
・Precision (r -> h):
・hypothesisがどれだけgold-referenceに基づいてこう良くされているかを亜評価でき、precision-focusedなシナリオに適している
・Recall (h -> r):
・hypothesisから、gold referenceをどれだけ容易に再現できるかを測ることができる。そして、要約タスクのpyramid-basedな評価(i.e. semantic coverage等) に適している。pyramid-scoreはSemantic Content Unitsがどれだけカバーされているかによって評価される。
・F Score (r <-> h):
・双方向を考慮し、Precisioon / RecallからF値を算出する。この方法は、referenceと生成テキスト間でのsemantic overlap (informativenss, adequacy)などの評価に広く利用される。
BARTScore Variants
BARTScoreの2つの拡張を提案。(i) xとyをpromptingによって変更する。これにより、評価タスクをpre-training taskと近づける。(ii) パラメータΘを異なるfinetuning taskを考慮して変更する。すなわち、pre-trainingのドメインを、evaluation taskに近づける。
Prompt
Promptingはinput/outputに対して短いフレーズを追加し、pre-trained modelに対して特定のタスクを遂行させる方法である。BARTにも同様の洞察を簡単に組み込むことができる。この変種をBARTScore-PROMPTと呼ぶ。
prompt zが与えられたときに、それを (i) source textに追加し、新たなsource textを用いてBARTScoreを計算する。(ii) target textの先頭に追加し、new target textに対してBARTScoreを計算する。
Fine-tuning Task
classification-basedなタスクでfine-tuneされるのが一般的なBERT-based metricとは異なり、BARTScoreはgeneration taskでfine-tuneされるため、pre-training domainがevaluation taskと近い。本研究では、2つのdownstream taskを検証する。
1つめは、summarizationで、BARTをCNNDM datasetでfinetuningする。2つめは、paraphrasingで、summarizationタスクでfinetuningしたBARTをParaBank2 datasetでさらにfinetuningする。実験
baselines and datasets
Evaluation Metrics
supervised metrics: COMET, BLEURT
unsupervised: BLEU, ROUGE-1, ROUGE-2, ROUGE-L, chrF, PRISM, MoverScore, BERTScore
と比較
Measures for Meta Evaluation
Pearson Correlationでlinear correlationを測る。また、Spearman Correlationで2変数間の単調なcorrelationを測定する(線形である必要はない)。Kendall's Tauを用いて、2つの順序関係の関係性を測る。最後に、Accuracyでfactual textsとnon-factual textの間でどれだけ正しいランキングを得られるかを測る。
Datasets
Summarization, MT, DataToTextの3つのデータセットを利用。
Setup
Prompt Design
seedをparaphrasingすることで、 s->h方向には70個のpromptを、h<->rの両方向には、34のpromptを得て実験で用いた。
Settings
Summarizationとdata-to-textタスクでは、全てのpromptを用いてデコーダの頭に追加してスコアを計算しスコアを計算した。最終的にすべての生成されたスコアを平均することである事例に対するスコアを求めた(prompt unsembling)。MTについては、事例数が多くcomputational costが多くなってしまうため、WMT18を開発データとし、best prompt "Such as"を選択し、利用した。
BARTScoreを使う際は、gold standard human evaluationがrecall-basedなpyrmid methodの場合はBARTScore(h->r)を用い、humaan judgmentsがlinguistic quality (coherence fluency)そして、factual correctness、あるいは、sourceとtargetが同じモダリティ(e.g. language)の場合は、faitufulness-based BARTScore(s->h)を用いた。最後に、MTタスクとdata-to-textタスクでは、fair-comparisonのためにBARTScore F-score versionを用いた。
実験結果
MT
・BARTScoreはfinetuning tasksによって性能が向上し、5つのlanguage pairsにおいてその他のunsupervised methodsを統計的に優位にoutperformし、2つのlanguage pairでcomparableであった。
-Such asというpromptを追加するだけで、BARTScoreの性能が改善した。特筆すべきは、de-enにおいては、SoTAのsupervised MetricsであるBLEURTとCOMETを上回った。
・これは、有望な将来のmetric designとして「human judgment dataで訓練する代わりに、pre-trained language modelに蓄積された知識をより適切に活用できるpromptを探索する」という方向性を提案している。
Text Summarization
・vanilla BARTScoreはBERTScore, MoverScoreをInfo perspective以外でlarge marginでうくぁ回った。
・REALSum, SummEval dataseetでの改善は、finetuning taskによってさらに改善した。しかしながら、NeR18では改善しなかった。これは、データに含まれる7つのシステムが容易に区別できる程度のqualityであり、既にvanilla BARTScoreで高いレベルのcorrelationを達成しているからだと考えられる。
・prompt combination strategyはinformativenssに対する性能を一貫して改善している。しかし、fluency, factualityでは、一貫した改善は見られなかった。
Factuality datasetsに対する分析を行った。ゴールは、short generated summaryが、元のlong documentsに対してfaithfulか否かを判定するというものである。
・BARTScore+CNNは、Rank19データにおいてhuman baselineに近い性能を達成し、ほかのベースラインを上回った。top-performingなfactuality metricsであるFactCCやQAGSに対してもlarge marginで上回った。
・paraphraseをfine-tuning taskで利用すると、BARTScoreのパフォーマンスは低下した。これは妥当で、なぜなら二つのテキスト(summary and document)は、paraphrasedの関係性を保持していないからである。
・promptを導入しても、性能の改善は見受けられず、パフォーマンスは低下した。
Data-to-Text
・CNNDMでfine-tuningすることで、一貫してcorrelationが改善した。
・加えて、paraphraseデータセットでfinetuningすることで、さらに性能が改善した。
・prompt combination strategyは一貫してcorrelationを改善した。
Analysis
Fine-grained Analysis
・Top-k Systems: MTタスクにおいて、評価するシステムをtop-kにし、各メトリックごとにcorrelationの変化を見た。その結果、BARTScoreはすべてのunsupervised methodをすべてのkにおいて上回り、supervised metricのBLEURTも上回った。また、kが小さくなるほど、より性能はsmoothになっていき、性能の低下がなくなっていった。これはつまり、high-quality textを生成するシステムに対してロバストであることを示している。
・Reference Length: テストセットを4つのバケットにreference lengthに応じてブレイクダウンし、Kendall's Tauの平均のcorrelationを、異なるメトリック、バケットごとに言語をまたいで計算した。unsupervised metricsに対して、全てのlengthに対して、引き分けかあるいは上回った。また、ほかのmetricsと比較して、長さに対して安定感があることが分かった。
Prompt Analysis
(1) semantic overlap (informativeness, pyramid score, relevance), (2) linguistic quality (fluency, coherence), (3) factual correctness (factuality) に評価の観点を分類し、summarizationとdata-to-textをにおけるすべてのpromptを分析することで、promptの効果を分析した。それぞれのグループに対して、性能が改善したpromptの割合を計算した。その結果、semantic overlapはほぼ全てのpromptにて性能が改善し、factualityはいくつかのpromptでしか性能の改善が見られなかった。linguistic qualityに関しては、promptを追加することによる効果はどちらとも言えなかった。
Bias Analysis
BARTScoreが予測不可能な方法でバイアスを導入してしまうかどうかを分析した。バイアスとは、human annotatorが与えたスコアよりも、値が高すぎる、あるいは低すぎるような状況である。このようなバイアスが存在するかを検証するために、human annotatorとBARTScoreによるランクのサを分析した。これを見ると、BARTScoreは、extractive summarizationの品質を区別する能力がabstractive summarizationの品質を区別する能力よりも劣っていることが分かった。しかしながら、近年のトレンドはabstractiveなseq2seqを活用することなので、この弱点は軽減されている。
Implications and Future Directions
prompt-augmented metrics: semantic overlapではpromptingが有効に働いたが、linguistic qualityとfactualityでは有効ではなかった。より良いpromptを模索する研究が今後期待される。
Co-evolving evaluation metrics and systems: BARTScoreは、メトリックデザインとシステムデザインの間につながりがあるので、より性能の良いseq2seqシステムが出たら、それをメトリックにも活用することでよりreliableな自動性能指標となることが期待される。
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 Towards Question-Answering as an Automatic Metric for Evaluating the Content Quality of a Summary, Deutsch+, TACL'21 Summary要約の品質を評価するための新しい指標であるQAEvalを提案する。QAEvalは質問応答(QA)を使用して要約と参照の情報の重複を測定するため、従来のテキストの重複に基づく指標とは異なる。実験結果から、QAEvalは現在の最先端の指標よりも優れたパフォーマンスを示し、他の評価とも競争力があることがわかった。QAEvalの構成要素を分析することで、その潜在的な上限パフォーマンスは他の自動評価指標を上回り、ゴールドスタンダードのピラミッドメソッドに近づくと推定される。 #DocumentSummarization #Metrics #NLP #Evaluation #Reference-free Issue Date: 2023-08-13 ESTIME: Estimation of Summary-to-Text Inconsistency by Mismatched Embeddings, Eval4NLP'21 Summary私たちは、新しい参照なし要約品質評価尺度を提案します。この尺度は、要約とソースドキュメントの間の潜在的な矛盾を見つけて数えることに基づいています。提案された尺度は、一貫性と流暢さの両方で他の評価尺度よりも専門家のスコアと強い相関を示しました。また、微妙な事実の誤りを生成する方法も紹介しました。この尺度は微妙なエラーに対してより感度が高いことを示しました。 #NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #AAAI Issue Date: 2022-04-28 Do we need to go Deep? Knowledge Tracing with Big Data, Varun+, University of Maryland Baltimore County, AAAI'21 Workshop on AI Education Summaryインタラクティブ教育システム(IES)を用いて学生の知識を追跡し、パフォーマンスモデルを開発する研究が進展。深層学習モデルが従来のモデルを上回るかは未検証であり、EdNetデータセットを用いてその精度を比較。結果、ロジスティック回帰モデルが深層モデルを上回ることが確認され、LIMEを用いて予測に対する特徴の影響を解釈する研究を行った。 Commentデータ量が小さいとSAKTはDKTはcomparableだが、データ量が大きくなるとSAKTがDKTを上回る。
#RecommenderSystems
#Tools
#Library
#CIKM
Issue Date: 2022-03-29
RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms, Zhao+, CIKM'21
SummaryRecBoleは、推薦アルゴリズムのオープンソース実装を標準化するための統一的で効率的なライブラリであり、73のモデルを28のベンチマークデータセット上で実装。PyTorchに基づき、一般的なデータ構造や評価プロトコル、自動パラメータ調整機能を提供し、推薦システムの実装と評価を促進する。プロジェクトはhttps://recbole.io/で公開。
Comment参考リンク:
・https://www.google.co.jp/amp/s/techblog.zozo.com/entry/deep-learning-recommendation-improvement%3famp=1
・https://techlife.cookpad.com/entry/2021/11/04/090000
・https://qiita.com/fufufukakaka/items/77878c1e23338345d4fa #NeuralNetwork #ComputerVision #NeurIPS Issue Date: 2021-11-04 ResNet strikes back: An improved training procedure in timm, Wightman+, NeurIPS'21 Workshop ImageNet PPF Summary本論文では、Residual Networks(ResNet-50)の性能を新たなトレーニング手法を用いて再評価し、競争力のある設定で80.4%のトップ1精度を達成したことを報告します。これにより、将来の研究のためのより良いベースラインを提供することを目指しています。 Comment2015年以後、様々な最適化アルゴリズム、正則化手法、データ拡張などが提案される中で、最新アーキテクチャのモデルにはそれらが適用される一方ベースラインとなるResNetではそれらが適用されず、論文の値のみが参照される現状はフェアではないので、ResNetの性能を向上させるような訓練手法を追求した研究。
ResNetにおける有効な訓練手法として下記を模索:
損失関数として、MixUp(訓練画像を重ね合わせ、組み合わせた画像のラベルをミックスして新しい学習インスタンスを作るデータ拡張手法)と、CutMix(画像を切り貼りして、切り貼り部分の面積に応じてラベルのスコアを調整するデータ拡張手法)を適用し、CutMixによって大幅に性能が改善することを示した。このとき、ラベルの確率の和が1となる前提の元クロスエントロピーで学習するのではなく、元画像に含まれる物体が両方存在するという全体の元BinaryCrossEntropyを適用しマルチラベル問題として学習することで、性能が向上。
データ拡張手法として、MixUp, CutMixだけでなく、通常のリサイズ・切り抜きと、水平方向の反転を適用しデータ拡張する。加えてRandAugment(14種類のデータ拡張操作から、N個サンプルし、強さMで順番に適用するデータ拡張手法。N,Mはそれぞれ0〜10の整数なので、10の二乗オーダーでグリッドサーチすれば、最適なN,Mを得る。グリッドサーチするだけでお手軽だが非常に強力)を適用した。
正則化として、Weight Decay(学習過程で重みが大きくなりすぎないようにペナルティを課し、過学習を防止する手法。L2正則化など。)と、label smoothing(正解ラベルが1、その他は0とラベル付けするのではなく、ラベルに一定のノイズを入れ、正解ラベル以外にも重みが入っている状態にし、ラベル付けのノイズにロバストなモデルを学習する手法。ノイズの強さは定数で調整する)、Repeated Augmentation(同じバッチ内の画像にデータ拡張を適用しバッチサイズを大きくする)、Stochastic Depth(ランダムでレイヤーを削除し、その間を恒等関数で繋ぎ訓練することで、モデルの汎化能力と訓練時間を向上する)を適用。
Optimizerとして、オリジナルのResNetでは、SGDやAdamWで訓練されることが多いが、Repeated Augmentationとバイナリクロスエントロピーを組み合わせた場合はLAMBが有効であった。また、従来よりも長い訓練時間(600epoch、様々な正則化手法を使っているので過学習しづらいため)で学習し、最初にウォームアップを使い徐々に学習率を上げ(finetuningの再認識これまでのweightをなるべく壊したくないから小さい学習率から始める、あるいはMomentumやAdamといった移動平均を使う手法では移動平均を取るための声倍の蓄積が足りない場合学習の信頼度が低いので最初の方は学習率小さくするみたいな、イメージ)その後コサイン関数に従い学習率を減らしていくスケジューリング法で学習。
論文中では上記手法の3種類の組み合わせ(A1,A2,A3)を提案し実験している。
ResNet-50に対してA1,2,3を適用した結果、A1を適用した場合にImageNetのトップ1精度が80.4%であり、これはResNet-50を使った場合のSoTA。元のResNetの精度が76%程度だったので大幅に向上した。
同じ実験設定を使った場合の他のアーキテクチャ(ViTやEfficientNetなど)と比べても遜色のない性能を達成。
また、本論文で提案されているA2と、DeiTと呼ばれるアーキテクチャで提案されている訓練手法(T2)をそれぞれのモデルに適用した結果、ResNetではA2、DeiTではT2の性能が良かった。つまり、「アーキテクチャと訓練方法は同時に最適化する必要がある」ということ。これがこの論文のメッセージの肝とのこと。
(ステートオブAIガイドの内容を一部補足して記述しました。いつもありがとうございます。)
画像系でどういった訓練手法が利用されるか色々書かれていたので勉強になった。特に画像系のデータ拡張手法なんかは普段触らないので勉強になる。OpenReview:https://openreview.net/forum?id=NG6MJnVl6M5
#Pocket
#AdaptiveLearning
#IJCAI
Issue Date: 2021-08-04
RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions, Kubotani+, Waseda University, IJCAI'21
Summary教育分野の課題に対し、学生の知識状態に基づく適応指導を強化学習で最適化するフレームワークを提案。実際の学生との相互作用を最小限にし、仮想モデルを構築。実験により、提案モデルは従来の指導方法と同等の性能を示し、理論と実践の橋渡しを行う。
#RecommenderSystems
#Survey
#SessionBased
#SequentialRecommendation
Issue Date: 2019-08-02
A Survey on Session-based Recommender Systems, Wang+, CSUR'21
#DocumentSummarization
#Metrics
#Pocket
#NLP
#Evaluation
#Reference-free
#QA-based
Issue Date: 2023-08-20
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries, Wang, ACL'20
Summary要約の事実の不整合を特定するための自動評価プロトコルであるQAGSを提案する。QAGSは、要約とソースについて質問をし、整合性がある回答を得ることで要約の事実的整合性を評価する。QAGSは他の自動評価指標と比較して高い相関を持ち、自然な解釈可能性を提供する。QAGSは有望なツールであり、https://github.com/W4ngatang/qagsで利用可能。
CommentQAGS生成された要約からQuestionを生成する手法。precision-oriented
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#QA-based
Issue Date: 2023-08-16
FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization, Durmus+, ACL'20
Summaryニューラル抽象的要約モデルの信頼性を評価するために、人間の注釈を収集し、信頼性の自動評価指標であるFEQAを提案した。FEQAは質問応答を利用して要約の信頼性を評価し、特に抽象的な要約において人間の評価と高い相関を示した。
CommentFEQA生成された要約からQuestionを生成する手法。precision-oriented
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-based
Issue Date: 2023-08-13
HOLMS: Alternative Summary Evaluation with Large Language Models, Mrabet+, COLING'20
Summary要約手法の評価尺度として、ROUGEとBLEUが一般的に使用されているが、これらは語彙的な性質を持ち、ニューラルネットワークのトレーニングには限定的な可能性がある。本研究では、大規模なコーパスで事前学習された言語モデルと語彙的類似度尺度を組み合わせた新しい評価尺度であるHOLMSを提案する。実験により、HOLMSがROUGEとBLEUを大幅に上回り、人間の判断との相関も高いことを示した。
CommentHybrid Lexical and MOdel-based evaluation of Summaries (HOLMS)
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#LM-based
#Factuality
Issue Date: 2023-08-13
Evaluating the Factual Consistency of Abstractive Text Summarization, Kryscinski+, EMNLP'20
Summary本研究では、要約の事実的な整合性を検証するためのモデルベースのアプローチを提案しています。トレーニングデータはルールベースの変換を用いて生成され、モデルは整合性の予測とスパン抽出のタスクで共同してトレーニングされます。このモデルは、ニューラルモデルによる要約に対して転移学習を行うことで、以前のモデルを上回る性能を示しました。さらに、人間の評価でも補助的なスパン抽出タスクが有用であることが示されています。データセットやコード、トレーニング済みモデルはGitHubで公開されています。
CommentFactCC近年のニューラルモデルは流ちょうな要約を生成するが、それらには、unsuportedなinformationが多く含まれていることを示した
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
#LM-based
Issue Date: 2023-08-13
Automatic Machine Translation Evaluation in Many Languages via Zero-Shot Paraphrasing, Thompson+, EMNLP'20
Summaryパラフレーザを使用して機械翻訳の評価を行うタスクを定義し、多言語NMTシステムをトレーニングしてパラフレーシングを行います。この手法は直感的であり、人間の判断を必要としません。39言語でトレーニングされた単一モデルは、以前のメトリクスと比較して優れたパフォーマンスを示し、品質推定のタスクでも優れた結果を得ることができます。
CommentPRISM
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
Fill in the BLANC: Human-free quality estimation of document summaries, Vasilyev+, Eval4NLP'20
SummaryBLANCは、要約の品質を自動的に推定するための新しいアプローチです。BLANCは、事前学習済みの言語モデルを使用してドキュメントの要約にアクセスし、要約の機能的なパフォーマンスを測定します。BLANCスコアは、ROUGEと同様に人間の評価と良好な相関関係を持ち、人間によって書かれた参照要約が不要なため、完全に人間不在の要約品質推定が可能です。
#DocumentSummarization
#NLP
#Evaluation
#Reference-free
#Training-Free
Issue Date: 2023-08-13
SUPERT: Towards New Frontiers in Unsupervised Evaluation Metrics for Multi-Document Summarization, Gao+, ACL'20
Summaryこの研究では、教師なしの複数文書要約評価メトリックスについて調査しています。提案手法SUPERTは、擬似的な参照要約として選択された重要な文を使用し、文脈化埋め込みとソフトトークンアラインメント技術を用いて要約の品質を評価します。SUPERTは従来の教師なし評価メトリックスよりも人間の評価との相関が高く、18〜39%の向上が見られます。また、SUPERTを報酬として使用してニューラルベースの強化学習要約器をガイドすることで、有利なパフォーマンスを実現しています。ソースコードはGitHubで入手可能です。
Commentpseudo-reference summaryを作成し、referenceに対してSBERTを適用しsystem-reference間の類似度を測ることで、unsupervisedに複数文書要約を評価する手法。
まずTACのデータに対して、既存研究(single document summarizationの評価用に提案された手法)を適用し、Human Ratingsとの相関が低いことを確認している。この時、Referenceを用いる手法(ROUGE、MoverScore)の相関をUpper Boundとし、Upper Boundに及ばないことを確認している。また、既存研究よりもシンプルなJS Divergence等を用いるlexical basedな手法の相関が高かったことも確認している。
続いて、unsupervisedな手法として、contextualなembeddingを利用し(BERT, SBERT等)source, system summary間の類似度を測る手法で相関を測ったところ、こちらでもUpper Boundに及ばないこと、シンプルな手法に及ばないことを確認。これら手法にWMDを応用するすることで相関が向上することを確認した。
これらのことより、Referenceがある場合、無い場合の両者においてWMDを用いる手法が有効であることが確認できたが、Referenceの有無によって相関に大きな差が生まれていることが確認できた。このことから、何らかの形でReferenceが必要であり、pseudo referenceを生成し利用することを着想した、というストーリーになっている。pseudo referenceを生成する方法として、top Nのリード文を抽出する手法や、LexRankのようなGraphBasedな手法を利用してTACデータにおいてどのような手法が良いかを検証している。この結果、TAC8,9の場合はTop 10,15のsentenceをpseudo referenceとした場合が最も良かった。
細かいところまで読みきれていないが、自身が要約したい文書群においてどの方法でpseudo referenceを生成するかは、Referenceがないと判断できないと考えられるため、その点は課題だと考えられる。 #DocumentSummarization #Metrics #NLP #Evaluation #Reference-based #TrainedMetrics Issue Date: 2023-08-13 BLEURT: Learning Robust Metrics for Text Generation, Sellam+, ACL'20 SummaryBLEURTは、BERTをベースとした学習済みの評価指標であり、人間の判断と高い相関を持つことが特徴です。BLEURTは、数千のトレーニング例を使用してバイアスのある評価をモデル化し、数百万の合成例を使用してモデルの汎化を支援します。BLEURTは、WMT Metrics共有タスクとWebNLGデータセットで最先端の結果を提供し、トレーニングデータが少ない場合や分布外の場合でも優れた性能を発揮します。 #NeuralNetwork #Pocket #NLP #LanguageModel #Zero/FewShotPrompting #In-ContextLearning #NeurIPS #Admin'sPick Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 SummaryGPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 CommentIn-Context Learningを提案した論文論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。
この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。 #NLP #ReviewGeneration #ACL Issue Date: 2021-03-17 Unsupervised Opinion Summarization as Copycat-Review Generation, Bražinskas, ACL'20 Summary意見要約は、製品レビューから主観的情報を自動的に要約するタスクであり、従来の研究は抽出的手法に焦点を当てていたが、本研究では新しい文を生成する抽象的要約を提案する。教師なし設定での生成モデルを定義し、新規性を制御しながら合意された意見を反映する要約を生成する。階層的変分オートエンコーダモデルを用い、実験により流暢で一貫性のある要約が生成できることを示した。 #Survey #NaturalLanguageGeneration #Pocket #NLP #Evaluation Issue Date: 2020-08-25 Evaluation of Text Generation: A Survey, Celikyilmaz, Clark, Gao, arXiv'20 Summary本論文では、自然言語生成(NLG)システムの評価方法を人間中心、自動評価、機械学習に基づく評価の3カテゴリに分類し、それぞれの進展と課題を議論。特に新しいNLGタスクやニューラルNLGモデルの評価に焦点を当て、自動テキスト要約と長文生成の例を示し、今後の研究方向性を提案します。 #NLP #Dataset #QuestionAnswering #Evaluation #Factuality #ReadingComprehension Issue Date: 2025-08-16 Natural Questions: A Benchmark for Question Answering Research, Kwiatkowski+, TACL'19 SummaryNatural Questionsコーパスは、Google検索エンジンからの実際の匿名化されたクエリを基にした質問応答データセットで、307,373のトレーニング例と7,830の開発例、7,842のテスト例が含まれています。アノテーターは、質問に対してWikipediaページから長い回答と短い回答を注釈し、質の検証実験や人間の変動性に関する分析を行っています。また、質問応答システムの評価のためのメトリクスを導入し、競争的手法を用いてベースライン結果を確立しています。 #Analysis #NLP #Transformer Issue Date: 2024-10-07 What Does BERT Learn about the Structure of Language?, Jawahar+, ACL'19 SummaryBERTは言語理解において優れた成果を上げており、本研究ではその言語構造の要素を解明する実験を行った。主な発見は、フレーズ表現がフレーズレベルの情報を捉え、中間層が構文的および意味的特徴の階層を形成し、長期依存性の問題に対処するために深い層が必要であること、さらにBERTの構成が古典的な木構造に類似していることを示している。 Comment1370 中で引用されている。Transformerの各ブロックが、何を学習しているかを分析。 #DocumentSummarization #NeuralNetwork #NLP #Extractive Issue Date: 2023-08-28 Text Summarization with Pretrained Encoders, Liu+ (with Lapata), EMNLP-IJCNLP'19 Summary本研究では、最新の事前学習言語モデルであるBERTを使用して、テキスト要約のための一般的なフレームワークを提案します。抽出型モデルでは、新しいエンコーダを導入し、文の表現を取得します。抽象的な要約については、エンコーダとデコーダの最適化手法を異ならせることで不一致を緩和します。さらに、2段階のファインチューニングアプローチによって要約の品質を向上させました。実験結果は、提案手法が最先端の結果を達成していることを示しています。 CommentBERTSUMEXT論文通常のBERTの構造と比較して、文ごとの先頭に[CLS]トークンを挿入し、かつSegment Embeddingsを文ごとに交互に変更することで、文のrepresentationを取得できるようにする。
その後、encodingされたsentenceの[CLS]トークンに対応するembeddingの上に、inter-sentence Transformer layerを重ね、sigmoidでスコアリングするのが、BERTSUMEXT, Abstractiveの場合は6-layerのTransformer decoderを利用するが、これはスクラッチでfinetuninigさせる。このとき、encoder側はoverfit, decoder側はunderfitすることが予想されるため、encoderとdecodeで異なるwarmup, 学習率を適用する。具体的には、encoder側はより小さい学習率で、さらにsmoothに減衰するようにする。これにより、decoder側が安定したときにより正確な勾配で学習できるようになる。また、2-stageのfinetuningを提案し、まずencoder側をextractifve summarization taskでfinetuningし、その後abstractive summarizationでfinetuningする。先行研究ではextractive summarizationのobjectiveを取り入れることでabstractive summarizationの性能が向上していることが報告されており、この知見を取り入れる。今回はextractive summarizationの重みをabstractive taskにtrasnferすることになる。
#DocumentSummarization #Pocket #NLP #Evaluation Issue Date: 2023-08-16 Neural Text Summarization: A Critical Evaluation, Krysciski+ (w_ Richard Socher), EMNLP-IJCNLP'19 Summaryテキスト要約の研究は進展が停滞しており、データセット、評価指標、モデルの3つの要素に問題があることが指摘されている。自動収集されたデータセットは制約が不十分であり、ノイズを含んでいる可能性がある。評価プロトコルは人間の判断と相関が弱く、重要な特性を考慮していない。モデルはデータセットのバイアスに過適合し、出力の多様性が限られている。 #DocumentSummarization #Metrics #NLP #Evaluation #QA-based Issue Date: 2023-08-16 Question answering as an automatic evaluation metric for news article summarization, Eyal+, NAACL'19 Summary最近の自動要約の研究では、ROUGEスコアの最大化に焦点を当てているが、本研究では代替的な評価指標であるAPESを提案する。APESは、要約が一連の手動作成質問に答える能力を定量化する。APESを最大化するエンドツーエンドのニューラル抽象モデルを提案し、ROUGEスコアを向上させる。 CommentAPES #DocumentSummarization #Metrics #NLP #Evaluation Issue Date: 2023-08-16 Studying Summarization Evaluation Metrics in the Appropriate Scoring Range, Peyrard+, ACL'19 Summary自動評価メトリックは通常、人間の判断との相関性を基準に比較されるが、既存の人間の判断データセットは限られている。現代のシステムはこれらのデータセット上で高スコアを出すが、評価メトリックの結果は異なる。高スコアの要約に対する人間の判断を収集することで、メトリックの信頼性を解決することができる。これは要約システムとメトリックの改善に役立つ。 Comment要約のメトリックがhuman judgmentsに対してcorrelationが低いことを指摘 #DocumentSummarization #MachineTranslation #NLP #Evaluation #TrainedMetrics Issue Date: 2023-08-13 Machine Translation Evaluation with BERT Regressor, Hiroki Shimanaka+, N_A, arXiv'19 Summary私たちは、BERTを使用した自動的な機械翻訳の評価メトリックを紹介します。実験結果は、私たちのメトリックがすべての英語対応言語ペアで最先端のパフォーマンスを達成していることを示しています。 #DocumentSummarization #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance, Zhao+, EMNLP-IJCNLP'19 Summary本研究では、テキスト生成システムの評価尺度について調査し、システムの出力と参照テキストの意味に基づいて比較する尺度を提案します。この尺度は、要約、機械翻訳、画像キャプション、データからテキストへの生成などのタスクで有効であり、文脈化表現と距離尺度を組み合わせたものが最も優れています。また、提案した尺度は強力な汎化能力を持っており、ウェブサービスとして提供されています。 CommentWord Mover Distance (WMD)の解説: https://yubessy.hatenablog.com/entry/2017/01/10/122737 #DocumentSummarization #NLP #Evaluation #Reference-free #QA-based Issue Date: 2023-08-13 Answers Unite Unsupervised Metrics for Reinforced Summarization Models, Scialom+, EMNLP-IJCNLP'19 Summary最近、再強化学習(RL)を使用した抽象的要約手法が提案されており、従来の尤度最大化を克服するために使用されています。この手法は、複雑で微分不可能なメトリクスを考慮することで、生成された要約の品質と関連性を総合的に評価することができます。ROUGEという従来の要約メトリクスにはいくつかの問題があり、代替的な評価尺度を探求する必要があります。報告された人間評価の分析によると、質問応答に基づく提案されたメトリクスはROUGEよりも有利であり、参照要約を必要としないという特徴も持っています。これらのメトリクスを使用してRLベースのモデルをトレーニングすることは、現在の手法に比べて改善をもたらします。 CommentSummaQA #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Evaluation #RecSys Issue Date: 2022-04-11 Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, Politecnico di Milano, Maurizio+, RecSys'19 CommentRecSys'19のベストペーパー
日本語解説:https://qiita.com/smochi/items/98dbd9429c15898c5dc7重要研究 #Pocket #NLP #CommentGeneration #Personalization #ACL Issue Date: 2019-09-11 Automatic Generation of Personalized Comment Based on User Profile, Zeng+, arXiv'19 #NeuralNetwork #Pocket #NLP #CommentGeneration #ACL Issue Date: 2019-08-24 Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model, Li+ ,ACL'19 #RecommenderSystems #Calibration Issue Date: 2024-09-20 Calibrated Recommendation, Herald Steck, Netflix, RecSys'18 Summaryユーザーの過去の視聴履歴に基づき、推薦映画リストがその興味に応じた割合で構成されることをキャリブレーションと呼ぶ。キャリブレーションは、ユーザーの多様な興味を反映するために重要であり、従来のレコメンダーシステムは主な興味に偏りがちであることが示されている。本研究では、キャリブレーションの度合いを定量化するメトリクスと、出力を後処理する再ランキングアルゴリズムを提案する。 #NLP #Hallucination #ImageCaptioning Issue Date: 2023-08-16 Object hallucination in image captioning, Rohbach+, EMNLP'18 Summary現代の画像キャプションモデルは、オブジェクトの幻覚を生じる傾向がある。本研究では、新しい画像関連性の評価指標を提案し、モデルのアーキテクチャや学習目標が幻覚にどのように寄与するかを評価する。さらに、言語の先入観によるエラーが幻覚を引き起こすことも示された。 #RecommenderSystems #NeuralNetwork #Survey Issue Date: 2018-04-16 Deep Learning based Recommender System: A Survey and New Perspectives, Zhang+, CSUR'18 #NeuralNetwork #Pocket #NLP #DialogueGeneration #ACL Issue Date: 2018-02-08 Personalizing Dialogue Agents: I have a dog, do you have pets too?, Zhang+, ACL'18 #NaturalLanguageGeneration #Metrics #NLP #Evaluation Issue Date: 2023-08-16 Why We Need New Evaluation Metrics for NLG, EMNLP'17 SummaryNLGの評価には自動評価指標が使われているが、本研究ではシステムやデータに依存しない新しい評価手法の必要性を提案する。幅広い指標を調査し、それらがデータ駆動型のNLGによって生成されたシステムの出力の人間の判断を弱く反映していることを示す。また、評価指標の性能はデータとシステムに依存することも示すが、自動評価指標はシステムレベルで信頼性があり、システムの開発をサポートできることを示唆する。特に、低いパフォーマンスを示すケースを見つけることができる。 Comment既存のNLGのメトリックがhuman judgementsとのcorrelationがあまり高くないことを指摘した研究 #ComputerVision #Pocket #NLP #CommentGeneration #CVPR Issue Date: 2019-09-27 Attend to You: Personalized Image Captioning with Context Sequence Memory Networks, Park+, CVPR'17 Comment画像が与えられたときに、その画像に対するHashtag predictionと、personalizedなpost generationを行うタスクを提案。
InstagramのPostの簡易化などに応用できる。
Postを生成するためには、自身の言葉で、画像についての説明や、contextといったことを説明しなければならず、image captioningをする際にPersonalization Issueが生じることを指摘。
official implementation: https://github.com/cesc-park/attend2u #Tutorial #MachineLearning #MultitaskLearning Issue Date: 2018-02-05 An Overview of Multi-Task Learning in Deep Neural Networks, Sebastian Ruder, arXiv'17 #NeuralNetwork #MachineLearning #Normalization #Admin'sPick Issue Date: 2018-02-19 Layer Normalization, Ba+, arXiv'16 Summaryバッチ正規化の代わりにレイヤー正規化を用いることで、リカレントニューラルネットワークのトレーニング時間を短縮。レイヤー内のニューロンの合計入力を正規化し、各ニューロンに独自の適応バイアスとゲインを適用。トレーニング時とテスト時で同じ計算を行い、隠れ状態のダイナミクスを安定させる。実証的に、トレーニング時間の大幅な短縮を確認。 Comment解説スライド:
https://www.slideshare.net/KeigoNishida/layer-normalizationnips
#Tutorial #MachineLearning Issue Date: 2018-02-05 An overview of gradient descent optimization algorithms, Sebastian Ruder, arXiv'16 #DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Reference-based Issue Date: 2023-08-13 chrF: character n-gram F-score for automatic MT evaluation, Mono Popovic, WMT'15 Summary私たちは、機械翻訳の評価に文字n-gram Fスコアを使用することを提案します。私たちは、このメトリックがシステムレベルとセグメントレベルで人間のランキングと相関しており、特にセグメントレベルでの相関が非常に高いことを報告しました。この提案は非常に有望であり、WMT14の共有評価タスクでも最高のメトリックを上回りました。 Commentcharacter-basedなn-gram overlapをreferenceとシステムで計算する手法 #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 From word embeddings to document distances, Kusner+, PMLR'15 Summary私たちは、新しい距離関数であるWord Mover's Distance(WMD)を提案しました。WMDは、テキストドキュメント間の非類似性を測定するために使用されます。私たちの研究では、単語埋め込みの最新の結果に基づいてWMDを開発しました。WMDは、単語が別のドキュメントの単語に到達するために必要な最小距離を計算します。私たちのメトリックは、実装が簡単であり、ハイパーパラメータも必要ありません。さらに、私たちは8つの実世界のドキュメント分類データセットでWMDメトリックを評価し、低いエラーレートを示しました。 CommentWMS/SMS/S+WMS
946 はこれらからinspiredされ提案された #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-23 Automatically Assessing Machine Summary Content Without a Gold Standard, Louis+(w_ Nenkova), ACL'13 Summary本研究では、要約の評価において新しい技術を提案しています。これにより、人間の要約が利用できない場合や、単一のモデルしか利用できない場合でも正確な評価が可能となります。具体的には、モデルに依存しない評価技術や、システム要約の類似性を定量化する尺度などを提案しています。これにより、要約の評価を人間の評価と正確に再現することができます。また、擬似モデルを導入することで、利用可能なモデルのみを使用する場合よりも人間の判断との相関が高くなることも示しています。さらに、システム要約のランキング方法についても探求しており、驚くほど正確なランキングが可能となります。 Commentメタ評価の具体的な手順について知りたければこの研究を読むべし #DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Coherence Issue Date: 2023-08-13 Graph-based Local Coherence Modeling, Guinaudeau+, ACL'13 Summary私たちは、グラフベースのアプローチを提案し、文の順序付け、要約の結束性評価、読みやすさの評価の3つのタスクでシステムを評価しました。このアプローチは、エンティティグリッドベースのアプローチと同等の性能を持ち、計算コストの高いトレーニングフェーズやデータのまばらさの問題にも対処できます。 #DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Coherence Issue Date: 2023-08-13 Extending Machine Translation Evaluation Metrics with Lexical Cohesion to Document Level, Wong+, EMNLP'12 Summaryこの論文では、語彙的な結束を利用して文書レベルの機械翻訳の評価を容易にする方法を提案しています。語彙的な結束は、同じ意味を持つ単語を使って文を結びつけることで、テキストの結束性を実現します。実験結果は、この特徴を評価尺度に組み込むことで、人間の判断との相関を向上させることを示しています。 CommentRC-LC #Multi #PersonalizedDocumentSummarization #InteractivePersonalizedSummarization #NLP #EMNLP #Admin'sPick Issue Date: 2017-12-28 Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07 Comment
ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#Reference-free
Issue Date: 2023-08-13
ROUGE-C: A fully automated evaluation method for multi-document summarization, He+, International Conference on Granular Computing'08
Summaryこの論文では、ROUGEを使用して要約を評価する方法について説明しています。ROUGEは、要約評価のために広く使用されていますが、手動の参照要約が必要です。この研究では、ROUGE-Cという手法を開発しました。ROUGE-Cは、参照要約を入力情報に置き換えることで、手動の参照要約なしで要約を評価することができます。実験結果は、ROUGE-Cが人間の判断を含む参照要約とよく相関していることを示しています。
#MachineTranslation
#NLP
#LanguageModel
#Admin'sPick
Issue Date: 2024-12-24
Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07
Summary本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。
CommentN-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
・1794元ポスト:https://x.com/_akhaliq/status/1912913195607663049?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #MachineLearning #Pocket #NLP #LanguageModel #Reasoning #GRPO #read-later Issue Date: 2025-03-22 Understanding R1-Zero-Like Training: A Critical Perspective, 2025.03 SummaryDeepSeek-R1-Zeroは、教師なしファインチューニングなしでLLMの推論能力を向上させる強化学習(RL)の効果を示した。研究では、ベースモデルとRLのコアコンポーネントを分析し、DeepSeek-V3-Baseが「アハ体験」を示すことや、Qwen2.5が強力な推論能力を持つことを発見。さらに、Group Relative Policy Optimization(GRPO)の最適化バイアスを特定し、Dr. GRPOという新手法を導入してトークン効率を改善。これにより、7BベースモデルでAIME 2024において43.3%の精度を達成し、新たな最先端を確立した。 Comment関連研究:
・1815解説ポスト:https://x.com/wenhuchen/status/1903464313391624668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポストを読むと、
・DAPOでの Token Level Policy UpdateのようなLengthに対するバイアスを排除するような操作をしている(Advantageに対して長さの平均をとる)模様。
・aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
・self-reflection無しの方が有りの場合よりもAcc.が高い場合がある(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様あとで読む(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:https://x.com/zzlccc/status/1910902637152940414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #Dataset #LanguageModel #Reasoning Issue Date: 2025-03-21 Sudoku-bench, SakanaAI, 2025.03 SummarySudoku-Benchは、CTCで紹介された独自のルールを持つ数独パズルを特徴とし、AI推論モデルの評価に最適なベンチマークです。このリポジトリでは、数独ベンチデータセット、LLM評価用のベースラインコード、SudokuPadツール、推論トレースなどを提供します。 Comment元ポスト:https://x.com/sakanaailabs/status/1902913196358611278?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q既存モデルでベンチマークを取ったらどういうランキングになるのだろうか。特にまだそういぅたランキングは公開されていない模様。ブログ記事に(将来的に最新の結果をrepositoryに追記す?模様)現時点でのリーダーボードが載っていた。現状、o3-miniがダントツに見える。
https://sakana.ai/sudoku-bench/ #Article #NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-03-18 EXAONE-Deep-32B, LG AI Research, 2025.03 Comment元ポスト:https://x.com/ai_for_success/status/1901908168805912602?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QEXAONE AI Model License Agreement 1.1 ・NC
商用利用不可 #Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight Issue Date: 2025-03-18 SmolDocling-256M, IBM Research, 2025.03 Comment元ポスト:https://www.linkedin.com/posts/andimarafioti_we-just-dropped-%F0%9D%97%A6%F0%9D%97%BA%F0%9D%97%BC%F0%9D%97%B9%F0%9D%97%97%F0%9D%97%BC%F0%9D%97%B0%F0%9D%97%B9%F0%9D%97%B6%F0%9D%97%BB%F0%9D%97%B4-activity-7307415358427013121-wS8m?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4Apache-2.0ライセンス。言語はEnglishのみな模様マルチモーダルなImage-To-Textモデル。サンプルはこちら
https://modelcontextprotocol.io/quickstart/server
https://modelcontextprotocol.io/quickstart/client #Article #NLP #LanguageModel #OpenWeight #OpenSource Issue Date: 2025-03-14 OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3 Comment真なる完全なるオープンソース(に近い?)OLMOの最新作 #Article Issue Date: 2025-03-12 Open-source DeepResearch – Freeing our search agents, HuggingFace, 2025.02 SummaryOpenAIが発表したDeep Researchは、ウェブをブラウズしてコンテンツを要約し、質問に答えるシステムで、GAIAベンチマークでのパフォーマンスが向上。特に「レベル3」の難しい質問に対して47.6%の正解率を達成。Deep ResearchはLLMと内部エージェントフレームワークで構成されており、再現とオープンソース化を目指す24時間ミッションを開始。 #Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-12 Introducing Gemma 3: The most capable model you can run on a single GPU or TPU, Google, 2025.03 CommentGoogleの新たなSLMで、デバイスやラップトップでも動作可能な軽量モデル。テキストだけでなく画像とShortVideoの認識もできて、140言語をサポート。おまけに27BモデルでLlama3-405BとDeepSeek-V3とo3-miniをChatbotArenaのリーダーボードで上回り、128kのcontext window。えぇ…。モデルの詳細:https://huggingface.co/blog/gemma3
1Bモデルは英語のみサポート、マルチモーダル不可など制約がある模様。
詳細までは書いていないが、128Kコンテキストまでcontext windowを広げる際の概要とRoPE(のような)Positional Embeddingを利用していること、SlideingWindow Attentionを用いておりウィンドウサイズが以前の4096から性能を維持したまま1024に小さくできたこと、ImageEncoderとして何を利用しているか(SigLIP)、896x896の画像サイズをサポートしており、正方形の画像はこのサイズにリサイズされ、正方形でない場合はcropされた上でリサイズされる(pan and scanアルゴリズムと呼ぶらしい)こと、事前学習時のマルチリンガルのデータを2倍にしたことなど、色々書いてある模様。Gemmaライセンス解説ポスト:https://x.com/hillbig/status/1899965039559532585?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/rasbt/status/1900214135847039316?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #LanguageModel #Reasoning #MultiLingual #OpenWeight Issue Date: 2025-03-12 Reasoning with Reka Flash, Reka, 2025.03 CommentWeights: https://huggingface.co/RekaAI/reka-flash-3Apache-2.0< /reasoning >を強制的にoutputさせることでreasoningを中断させることができ予算のコントロールが可能とのこと #Article #NLP #LanguageModel #ReinforcementLearning #Reasoning #OpenWeight Issue Date: 2025-03-06 QwQ-32B: Embracing the Power of Reinforcement Learning, Qwen Team, 2025.03 Comment元ポスト:https://x.com/hillbig/status/1897426898642460724?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1787Artificial Analysisによるベンチマークスコア:https://x.com/artificialanlys/status/1897701015803380112?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおそらく特定のタスクでDeepSeekR1とcomparable, 他タスクでは及ばない、という感じになりそうな予感 #Article #LanguageModel #Library #LLMAgent Issue Date: 2025-03-06 smolagents, HuggingFace, 2025.03 Summarysmolagentsは、数行のコードで強力なエージェントを構築できるライブラリで、シンプルなロジック、コードエージェントのサポート、安全な実行環境、ハブ統合、モデルやモダリティに依存しない設計が特徴。テキスト、視覚、動画、音声入力をサポートし、さまざまなツールと統合可能。詳細はローンチブログ記事を参照。 #Article #MachineLearning #NLP #LanguageModel #ReinforcementLearning #Blog #GRPO Issue Date: 2025-03-05 GRPO Judge Experiments: Findings & Empirical Observations, kalomaze's kalomazing blog, 2025.03 Comment元ポスト:https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_forget-basic-math-problems-grpo-can-do-more-activity-7302608410875691009-nntf?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4一意に解が決まる問題ではなく、ある程度の主観的な判断が必要なタスクについてのGRPOの分析。
2つのテキストを比較するタスクで、一方のタスクはLLMによって摂動を与えている(おそらく意図的にcorruptさせている)。
GRPOではlinearやcosineスケジューラはうまく機能せず、warmupフェーズ有りの小さめの定数が有効らしい。また、max_grad_normを0.2にしまgradient clippingが有効とのこと。他にもrewardの与え方をx^4にすることや、length, xmlフォーマットの場合にボーナスのrewardを与えるなどの工夫を考察している。 #Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-04 microsoft_Phi-4-multimodal-instruct, Microsoft, 2025.02 Comment元ポスト:https://www.linkedin.com/posts/vaibhavs10_holy-shitt-microsoft-dropped-an-open-source-activity-7300755229635944449-mQP8?utm_medium=ios_app&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4&utm_source=social_share_send&utm_campaign=copy_linkMIT License #Article #Pretraining #MachineLearning #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2025-03-04 The Ultra-Scale Playbook: Training LLMs on GPU Clusters, HuggingFace, 2025.02 CommentHuggingFaceによる数1000のGPUを用いたAIモデルのトレーニングに関するオープンソースのテキスト #Article #MachineLearning #NLP #LanguageModel #Library #ReinforcementLearning #python #Reasoning Issue Date: 2025-03-02 Open Reasoner Zero, Open-Reasoner-Zero, 2024.02 SummaryOpen-Reasoner-Zeroは、推論指向の強化学習のオープンソース実装で、スケーラビリティとアクセスのしやすさに重点を置いています。AGI研究の促進を目指し、ソースコードやトレーニングデータを公開しています。 Comment元ポスト:https://x.com/dair_ai/status/1893698293965725708?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #Dataset #LanguageModel #LLMAgent Issue Date: 2025-03-02 Introducing the SWE-Lancer benchmark, OpenAI, 2025.02 Comment元ポスト:https://x.com/dair_ai/status/1893698290174108113?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q1400以上のフリーランスソフトウェアエンジニアリングタスクを集めたベンチマーク。タスクはバグ修正から機能実装まで多岐にわたり、経験豊富なエンジニアによって評価されたもの。 #Article #Embeddings #NLP #LanguageModel #RepresentationLearning #pretrained-LM #Japanese Issue Date: 2025-02-12 modernbert-ja-130m, SB Intuitions, 2025.02 CommentMIT Licence元ポスト:https://x.com/sbintuitions/status/1889587801706078580?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1606 #Article #NLP #LanguageModel #ReinforcementLearning #Blog #Distillation Issue Date: 2025-02-12 DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL, 2025.02 #Article #LanguageModel #LLMServing Issue Date: 2025-02-12 SGlang, sgl-project, 2024.01 SummarySGLangは、大規模言語モデルと視覚言語モデルのための高速サービングフレームワークで、バックエンドとフロントエンドの共同設計により迅速なインタラクションを実現します。主な機能には、高速バックエンドランタイム、柔軟なフロントエンド言語、広範なモデルサポートがあり、オープンソースの活発なコミュニティに支えられています。 Comment・1733
のUpdate2でMath Datasetの生成に利用されたLLM Servingフレームワーク。利用前と比較してスループットが2倍になったとのこと。 #Article #ComputerVision #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2025-01-25 Humanity's Last Exam, 2025.01 Summary「人類の最後の試験」という新しいマルチモーダルベンチマークを導入し、100以上の科目にわたる3,000の挑戦的な質問を提供。これにより、LLMの能力を正確に測定し、過学習を評価するためのプライベートテストセットも保持。 Commento1, DeepSeekR1の正解率が10%未満の新たなベンチマーク #Article #EfficiencyImprovement #NLP #Library #Transformer #pretrained-LM Issue Date: 2024-12-20 ModernBERT, AnswerDotAI, 2024.12 SummaryModernBERTは、エンコーダ専用のトランスフォーマーモデルで、従来のBERTに比べて大幅なパレート改善を実現。2兆トークンで訓練され、8192シーケンス長を持ち、分類タスクやリトリーバルで最先端の結果を示す。速度とメモリ効率も優れており、一般的なGPUでの推論に最適化されている。 Comment最近の進化しまくったTransformer関連のアーキテクチャをEncodnr-OnlyモデルであるBERTに取り込んだら性能上がるし、BERTの方がコスパが良いタスクはたくさんあるよ、系の話、かつその実装だと思われる。
テクニカルペーパー中に記載はないが、評価データと同じタスクでのDecoder-Onlyモデル(SFT有り無し両方)との性能を比較したらどの程度の性能なのだろうか?そもそも学習データが手元にあって、BERTをFinetuningするだけで十分な性能が出るのなら(BERTはGPU使うのでそもそもxgboostとかでも良いが)、わざわざLLM使う必要ないと思われる。BERTのFinetuningはそこまで時間はかからないし、inferenceも速い。
参考:
・1024日本語解説:https://zenn.dev/dev_commune/articles/3f5ab431abdea1?utm_source=substack&utm_medium=email #Article #RecommenderSystems #Pocket #LanguageModel #Blog Issue Date: 2024-12-03 Augmenting Recommendation Systems With LLMs, Dave AI, 2024.08 #Article #Pocket #EducationalDataMining #KnowledgeTracing Issue Date: 2024-11-30 Dynamic Key-Value Memory Networks With Rich Features for Knowledge Tracing, Sun+, IEEE TRANSACTIONS ON CYBERNETICS, 2022.08 Summary知識追跡において、DKVMNモデルは学生の行動特徴と学習能力を無視している。これを改善するために、両者を統合した新しい演習記録の表現方法を提案し、知識追跡の性能向上を目指す。実験結果は、提案手法がDKVMNの予測精度を改善できることを示した。 Comment
#Article #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #AES(AutomatedEssayScoring) Issue Date: 2024-11-28 Cross-prompt Pre-finetuning of Language Models for Short Answer Scoring, Funayama+, 2024.09 Summary自動短答スコアリング(SAS)では、異なるルーブリックと参照回答に基づいてスコアを付けるが、新しいプロンプトごとにモデルを再訓練する必要がありコストがかかる。本研究では、既存のルーブリックと回答を用いて新しいプロンプトでファインチューニングする二段階アプローチを提案。重要なフレーズを学習することで、特に訓練データが限られている場合にスコアリング精度を向上させることを実験で示した。 CommentSASでは回答データが限られているので、限られたデータからより効果的に学習をするために、事前に他のデータでモデルをpre-finetuningしておき、対象データが来たらpre-finetuningされたモデルをさらにfinetuningするアプローチを提案。ここで、prompt中にkeyphraseを含めることが有用であると考え、実験的に有効性を示している。
BERTでfinetuningをした場合は、key-phraseを含めた方が性能が高く、特にfinetuningのサンプル数が小さい場合にその差が顕著であった。
次に、LLM(swallow-8B, 70B)をpre-finetuningし、pre-finetuningを実施しない場合と比較することで、pre-finetuningがLLMのzero-shot、およびICL能力にどの程度影響を与えるかを検証した。検証の結果、pre-finetuningなしでは、そもそも10-shotにしてもQWKが非常に低かったのに対し、pre-finetuningによってzero-shotの能力が大幅に性能が向上した。一方、few-shotについては3-shotで性能が頭打ちになっているようにみえる。ここで、Table1のLLMでは、ターゲットとする問題のpromptでは一切finetuningされていないことに注意する(Unseenな問題)。
続いて、LLMをfinetuningした場合も検証。提案手法が高い性能を示し、200サンプル程度ある場合にHuman Scoreを上回っている(しかもBERTは200サンプルでサチったが、LLMはまだサチっていないように見える)。また、サンプル数がより小さい場合に、提案手法がより高いgainを得ていることがわかる。
また、個々の問題ごとにLLMをfinetuningするのは現実的に困難なので、個々の問題ごとにfinetuningした場合と、全ての問題をまとめてfinetuningした場合の性能差を比較したところ、まとめて学習しても性能は低下しない、どころか21問中18問で性能が向上した(LLMのマルチタスク学習の能力のおかげ)。
[Perplexity(hallucinationに注意)](https://www.perplexity.ai/search/tian-fu-sitalun-wen-wodu-mi-ne-3_TrRyxTQJ.2Bm2fJLqvTQ0) #Article #NeuralNetwork #Embeddings #NLP #Word #RepresentationLearning #STS (SemanticTextualSimilarity) Issue Date: 2024-11-20 Zipf 白色化:タイプとトークンの区別がもたらす良質な埋め込み空間と損失関数, Sho Yokoi, 2024.11 Summary単語埋め込み空間の歪みを修正することでタスクのパフォーマンスが向上することを示す。既存のアプローチは単語頻度が均一であると仮定しているが、実際にはZipfの法則に従う非均一な分布である。Zipfに基づく頻度で重み付けされたPCAホワイトニングを行うことで、パフォーマンスが大幅に向上し、ベースラインを超える。情報幾何学的な観点から、低頻度の単語を強調する理論を提案し、人気の自然言語処理手法がこの理論に基づいて機能することを示す。 Comment元論文: [Yokoi, Bao, Kurita, Shimodaira, “Zipfian Whitening,” NeurIPS 2024. ](https://arxiv.org/abs/2411.00680)単語ベクトルを活用して様々なタスクを実施する際に一般的な全部足して個数で割るような平均ベクトル計算は、
個々の単語頻度を一様と仮定した場合の"期待値"と等価であり、
これは現実世界の単語頻度の実態とは全然異なるから、きちんと考慮したいよね、という話で
頻度を考慮するとSemantic Textual Similarity(STS)タスクで効果絶大であることがわかった。
では、なぜこれまで一様分布扱いするのが一般的だったのかというと、
実態として単語埋め込み行列が単語をタイプとみなして構築されたものであり、
コーパス全体を捉えた(言語利用の実態を捉えた)データ行列(単語をトークンとみなしたもの)になっていなかったことに起因していたからです(だから、経験頻度を用いて頻度情報を復元する必要があるよね)、
という感じの話だと思われ、
経験頻度を考慮すると、そもそも背後に仮定しているモデル自体が暗黙的に変わり、
低頻度語が強調されることで、単語に対してTF-IDFのような重みづけがされることで性能が良くなるよね、みたいな話だと思われる。
<img src=\"https://github.com/user-attachments/assets/7495f250-d680-4698-99c5-a326ead77e12\" alt=\"image\" loading=\"lazy\">余談だが、昔のNLPでは、P\(w,c)をモデル化したものを生成モデル、テキスト生成で一般的なP\(w|c)は分類モデル(VAEとかはテキスト生成をするが、生成モデルなので別)、と呼んでいたと思うが、いまはテキスト生成モデルのことを略して生成モデル、と呼称するのが一般的なのだろうか。 #Article Issue Date: 2024-11-13 Artificial Intelligence, Scientific Discovery, and Product Innovation, Aidan Toner-Rodgers, MIT, 2024.11 #Article #Blog Issue Date: 2024-11-11 The Surprising Effectiveness of Test-Time Training for Abstract Reasoning, 2024.11 #Article #NLP #Dataset #LanguageModel #LLMAgent #Evaluation Issue Date: 2024-10-20 MLE-Bench, OpenAI, 2024.10 SummaryMLE-benchを紹介し、AIエージェントの機械学習エンジニアリング能力を測定するためのベンチマークを構築。75のKaggleコンペを基に多様なタスクを作成し、人間のベースラインを確立。最前線の言語モデルを評価した結果、OpenAIのo1-previewが16.9%のコンペでKaggleのブロンズメダル相当の成果を達成。AIエージェントの能力理解を促進するため、ベンチマークコードをオープンソース化。 #Article #LLMAgent #Repository #Conversation Issue Date: 2024-10-02 AutoGen, Microsoft, 2024.10 SummaryAutoGenは、AIエージェントの構築と協力を促進するオープンソースのプログラミングフレームワークで、エージェント間の相互作用や多様なLLMの使用をサポートします。これにより、次世代LLMアプリケーションの開発が容易になり、複雑なワークフローのオーケストレーションや最適化が簡素化されます。カスタマイズ可能なエージェントを用いて多様な会話パターンを構築でき、強化されたLLM推論や高度なユーティリティ機能も提供します。AutoGenは、Microsoftや大学との共同研究から生まれました。 #Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #VisionLanguageModel Issue Date: 2024-09-27 Molmo, AI2, 2024.09 SummaryMolmoは、オープンデータを活用した最先端のマルチモーダルAIモデルであり、特に小型モデルが大規模モデルを上回る性能を示す。Molmoは、物理的および仮想的な世界とのインタラクションを可能にし、音声ベースの説明を用いた新しい画像キャプションデータセットを導入。ファインチューニング用の多様なデータセットを使用し、非言語的手がかりを活用して質問に答える能力を持つ。Molmoファミリーのモデルは、オープンウェイトでプロプライエタリシステムに対抗する性能を発揮し、今後すべてのモデルウェイトやデータを公開予定。 Comment以下がベンチマーク結果(VLMのベンチマーク)。11 benchmarksと書かれているのは、VLMのベンチマークである点に注意。
#Article #NLP #LanguageModel Issue Date: 2024-09-25 Improving Language Understanding by Generative Pre-Training, OpenAI, 2018.06 Summary自然言語理解のタスクにおいて、ラベルなしテキストコーパスを用いた生成的事前学習と識別的微調整を行うことで、モデルの性能を向上させるアプローチを提案。タスクに応じた入力変換を利用し、モデルアーキテクチャの変更を最小限に抑えつつ、12のタスク中9つで最先端の成果を大幅に改善。特に、常識推論で8.9%、質問応答で5.7%、テキストの含意で1.5%の改善を達成。 Comment初代GPT論文 #Article #NLP #OpenWeight Issue Date: 2024-08-24 Phi 3.5, Microsoft, 2024.08 SummaryPhi-3モデルコレクションは、マイクロソフトの最新の小型言語モデルで、高い性能とコスト効率を兼ね備えています。新たに発表されたPhi-3.5-mini、Phi-3.5-vision、Phi-3.5-MoEは、生成AIアプリケーションにおける選択肢を広げ、特に多言語サポートや画像理解の向上を実現しています。Phi-3.5-MoEは、専門家を活用しつつ高性能を維持しています。 #Article #DocumentSummarization #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 Learning to Score System Summaries for Better Content Selection Evaluation, Peyard+, Prof. of the Workshop on New Frontiers in Summarization Summary本研究では、古典的な要約データセットを使用して、人間の判断に基づいた自動スコアリングメトリックの学習を提案します。既存のメトリックを組み込み、人間の判断と高い相関を持つ組み合わせを学習します。新しいメトリックの信頼性は手動評価によってテストされます。学習済みのメトリックはオープンソースのツールとして公開されます。 #Article #EfficiencyImprovement #MachineLearning #NLP #Transformer #Attention Issue Date: 2023-07-23 FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, 2023 SummaryFlashAttention-2は、長いシーケンス長におけるTransformerのスケーリングの問題に対処するために提案された手法です。FlashAttention-2は、非対称なGPUメモリ階層を利用してメモリの節約とランタイムの高速化を実現し、最適化された行列乗算に比べて約2倍の高速化を達成します。また、FlashAttention-2はGPTスタイルのモデルのトレーニングにおいても高速化を実現し、最大225 TFLOPs/sのトレーニング速度に達します。 CommentFlash Attention1よりも2倍高速なFlash Attention 2Flash Attention1はこちらを参照
https://arxiv.org/pdf/2205.14135.pdf
QK Matrixの計算をブロックに分けてSRAMに送って処理することで、3倍高速化し、メモリ効率を10-20倍を達成。
#Article #RecommenderSystems #CollaborativeFiltering #Pocket #FactorizationMachines Issue Date: 2021-07-02 Deep Learning Recommendation Model for Personalization and Recommendation Systems, Naumov+, Facebook, arXiv‘19 Summary深層学習に基づく推薦モデル(DLRM)を開発し、PyTorchとCaffe2で実装。埋め込みテーブルのモデル並列性を活用し、メモリ制約を軽減しつつ計算をスケールアウト。DLRMの性能を既存モデルと比較し、Big Basin AIプラットフォームでの有用性を示す。 CommentFacebookが開発したopen sourceのDeepな推薦モデル(MIT Licence)。
モデル自体はシンプルで、continuousなfeatureをMLPで線形変換、categoricalなfeatureはembeddingをlook upし、それぞれfeatureのrepresentationを獲得。
その上で、それらをFactorization Machines layer(second-order)にぶちこむ。すなわち、Feature間の2次の交互作用をembedding間のdot productで獲得し、これを1次項のrepresentationとconcatしMLPにぶちこむ。最後にシグモイド噛ませてCTRの予測値とする。
実装: https://github.com/facebookresearch/dlrmParallelism以後のセクションはあとで読む
#Article
#NeuralNetwork
#Survey
#Pocket
#NLP
Issue Date: 2021-06-17
Pre-Trained Models: Past, Present and Future, Han+, AI Open‘21
Summary大規模な事前学習モデル(PTMs)は、AI分野での成功を収め、知識を効果的に捉えることができる。特に、転移学習や自己教師あり学習との関係を考察し、PTMsの重要性を明らかにする。最新のブレークスルーは、計算能力の向上やデータの利用可能性により、アーキテクチャ設計や計算効率の向上に寄与している。未解決問題や研究方向についても議論し、PTMsの将来の研究の進展を期待する。
#Article
#NeuralNetwork
#Survey
#NLP
Issue Date: 2021-06-09
A survey of Transformers, Lin+, AI Open‘22
Summaryトランスフォーマーの多様なバリアント(X-formers)に関する体系的な文献レビューを提供。バニラトランスフォーマーの紹介後、新しい分類法を提案し、アーキテクチャの修正、事前学習、アプリケーションの観点からX-formersを紹介。今後の研究の方向性も概説。
CommentTransformersの様々な分野での亜種をまとめた論文