
InformationRetrieval
[Paper Note] Skill Retrieval Augmentation for Agentic AI, Weihang Su+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs #reading #One-Line Notes #AgentSkills #Reading Reflections Issue Date: 2026-07-21 GPT Summary- 大規模言語モデル(LLMs)が外部スキルに依存するようになり、これを効率的に活用するために新たにSRA(Skill Retrieval Augmentation)パラダイムを提唱。SRAは、エージェントが必要に応じて関連スキルを動的に取得し適用する仕組みで、初のベンチマークSRA-Benchを導入。5,400件のテスト事例と636件の正解スキルを用いた実験により、検索ベースのスキル拡張が性能向上に寄与することを確認。ただし、スキルの取り込みには課題があり、正解スキルの認識や外部能力の必要性に関する判断がエージェントの性能を制限することが分かった。これにより、今後のエージェントシステムの能力拡張の基盤を築くことが示唆される。 Comment
元ポスト:
pj page: https://sr-agents.github.io
dataset: https://huggingface.co/datasets/WeihangSu/SRA-Bench
スキルの肥大化に伴いモデルのcontextが肥大化しパフォーマンスが劣化することから、動的にスキルを検索して統合するSkill Retrieval Augmentationを提案し、そのための大規模なデータセットを用いて評価をしている、という話に見える。データセットは26kのスキルで構成され、そのうち636件がgoldという規模感のデータセット。
実験結果を見ると、topkのretrieve結果をそのまま利用するfull injectionよりも、full injectionしたスキルのメタデータからrelevantなスキルを1iLLMで選択するLLM Selectionの性能が向上している点が興味深い。
また、skill poolにhard negativeなスキルが存在すると、ベンチマークのスコアは低下していく傾向(具体的にどのベンチマークかまでさ読めていない)にあり、hard negativeが8つ程度で、様々なモデルにおいてAcc.が10%程度は低下しているように見える。興味深い。
問題設定が実用的で興味深いだけでなく、hard negativeなスキルが <10個 程度のオーダーで存在するだけで大きくAcc.が低下する知見を示している点がおもしろい。
[Paper Note] Revela: Dense Retriever Learning via Language Modeling, Fengyu Cai+, ICLR'26, 2025.06
Paper/Blog Link My Issue
#read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-06-09 GPT Summary- Revelaは、自己教師付きリトリーバー学習のための統一的な訓練フレームワークを提供し、言語モデリングの手法をリトリーバーの訓練に適用します。文書間の意味的依存関係をモデル化し、リトリーバーの類似度スコアを利用して最適化を実現。評価結果は、注釈付きデータを使わずに、各種ベンチマークで従来の手法を上回る性能を示し、スケーラビリティの可能性も確立しました。 Comment
openreview: https://openreview.net/forum?id=e7pAjJZJWb
元ポスト:
[Paper Note] LEANN: A Low-Storage Vector Index, Yichuan Wang+, MLSys'26 Best Paper Award, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #MLSys #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- LEANNは、動的に再計算することでストレージ効率の高いベクトル検索を実現する新しいインデックス。元データ一部のみで高品質な検索を提供し、従来のインデックスに対して最大50倍のサイズ削減を達成。RAGアプリケーションでの高精度と同等のレイテンシを維持。 Comment
元ポスト:
github: https://github.com/yichuan-w/LEANN](https://t.co/QwkYx1t0oa
[Paper Note] Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction, Zhuofeng Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Search #LanguageModel #AIAgents #read-later #Selected Papers/Blogs #One-Line Notes #Reading Reflections #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- 直接コーパスと相互作用する(DCI)アプローチを提案し、リトリーバAPIや固定された類似度インターフェースに依存せず、エージェントが生のコーパスを汎用的な端末ツールで直接検索できるようにします。この方法は、オフラインのインデックス作成を不要にし、進化するコーパスに自然に適応します。実験では、DCIがBRIGHTおよびBEIRデータセットで強力なベースラインを上回り、従来の手法なしに高精度を実現したことが示されました。この結果は、検索の質が推論能力だけでなく、コーパスとの相互作用のインターフェースにも依存することを示唆しています。 Comment
元ポスト:
基盤モデルが賢くなる中で、top-kによるretrievalが検索におけるベストなインタフェースなのか?という疑問を投げかけた研究で、ベクトル検索などのRetrieverではなく、AI Agent自身にgrep等を用いて直接コーパスとinteractionをさせる(Direct Corpus Interaction)ことでBrowseCompのようなQAデータセットにおいてEmbeddingを用いた手法よりもより低コストで高いスコアを獲得できることを示したようである。
DCIは有用な手がかりを見つけた時に、それをrearoning stepに結びつけて深掘りしていくような挙動を実現しやすい点が強みであるが、コーパスサイズが大きくなるにつれて最初のアンカーとなる手がかりを見つけるためのコストが大きくなり、深さへの強みはあるが、広さには弱い性質があることから、この手法が唯一無二の解というわけではなく、設計の際に「どのモデルがtop-kの検索でベストか?」という視点だけでなく、「AI Agentにコーパス全体に対してどのようなオペレーションを持たせるべきか?」という問いかけも提起する
といった話が元ポストに書かれている。
昔から検索に全てのケースで最強な手法はこれ!みたいなものはないので、こういった選択肢もあるよということを頭に入れて引き出しに入れておき、直面する課題に対して有効な方法は何かを考えることが重要と思われる。
所見:
[Paper Note] Don't Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG, Yiqun Sun+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #RAG(RetrievalAugmentedGeneration) #FactualKnowledge #KeyPoint Notes #Clustering-based #AgentSkills Issue Date: 2026-04-21 GPT Summary- 検索強化生成(RAG)の限界を克服するために、Corpus2Skillを提案。これは文書コーパスを階層的なスキルディレクトリに変換し、LLMエージェントが効率的にナビゲート可能にする。文書をクラスタリングし、各レベルで要約を生成して構築。提供時に、エージェントはコーパス全体を把握し、段階的にトピックを掘り下げ、証拠を効果的に組み合わせる。実験により、WixQAのベンチマークでRAGの他の手法を上回る性能を示した。 Comment
元ポスト:
Agent Skillsの機構を利用し、Skillsを検索におけるIndexのような位置づけで活用し、Skillsを用いて階層化された知識をnavigateさせることで、抽象的な情報からより細かい情報までdrill-downさせるような挙動を実現させ、RAGの性能を向上させる。
Skillsを定義する際は、
- root level (Skill.md)
- leaf level (Index.md)
によって構成され、root levelではトピックに関する情報+クラスタのメタ情報、leaf levelでは個別のdocのtitle+IDによって構成される。
Documentを階層化する際にはクラスタリングを用いる。具体的にはクラスタリングを実施し、クラスタの内容をLLMに要約させ、要約させた情報に基づいてさらにクラスタリングをする、という処理を繰り返すことで階層化を実現していそうに見える。Servingの時はSkill.md, Index.md, Document Storeに対して、2種類のツール `code_execution`, `get_document` を用いて、ツリーを探索し、relevantなdocを取得する。code_executionは具体的には、SKILL.mdとIndex.mdをviewコマンドによって閲覧し、階層構造全体を俯瞰できるようにする。get_documentでは、docのidentifierを用いて、identifierと対応するdocの全文を取得する。
BM25, Denseなどのbaselineと比較して高い性能を獲得している。性能に対してコスト比が併記されているが、トークン空間上で思考し探索をするためコストは高いように見える。個人的に気になるのは、金銭的なコストもそうだが、latencyである。embeddingを用いたRAGに対して、相当latencyが遅いのではないか?と思われる。
[Paper Note] Thought-Retriever: Don't Just Retrieve Raw Data, Retrieve Thoughts for Memory-Augmented Agentic Systems, Tao Feng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Embeddings #NLP #LanguageModel #AIAgents #Chain-of-Thought #Selected Papers/Blogs #memory Issue Date: 2026-04-20 GPT Summary- LLMが外部知識を効果的に取り込む課題を解決するために、Thought-Retrieverという新しいアルゴリズムを提案。これは、過去のユーザークエリで生成された中間応答を活用し、冗長な思考をフィルタリングして新しいクエリに関連する思考を取り出すことで、長期記憶を構築。AcademicEvalという新たなベンチマークで広範な実験を行い、Thought-Retrieverが最先端モデルを上回る成果を示した。特に、より多くのクエリ解決後に自己進化を促し、抽象的な問いへの応答能力を向上させることが確認された。 Comment
元ポスト:
[Paper Note] IRPAPERS: A Visual Document Benchmark for Scientific Retrieval and Question Answering, Connor Shorten+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Embeddings #Dataset #QuestionAnswering #Evaluation #MultiModal #OCR #Hybrid Issue Date: 2026-02-27 GPT Summary- 画像ベースの情報検索と質問応答の性能をテキストベースの手法と比較するために、IRPAPERSデータセットを用いて実験を実施。テキスト検索はRecall@1で46%を達成し、画像ベースは43%を達成。両手法は補完的で、マルチモーダルハイブリッド検索はRecall@1で49%の性能を示す。MUVERAを用いた画像埋め込みモデルの評価において、Cohere Embed v4が最も優れた性能を持つ。質問応答では、テキストベースのシステムが画像ベースより高い整合性を示し、複数文書検索が効果を発揮。両モダリティの限界と必要性を明確化。データセットと実験コードは公開。 Comment
元ポスト:
[Paper Note] DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories, Chenlong Deng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #Search #Dataset #LanguageModel #AIAgents #Evaluation #MultiModal #One-Line Notes Issue Date: 2026-02-18 GPT Summary- 既存のマルチモーダル検索システムはクエリと画像の関連性を独立して評価することを前提としているが、このアプローチは現実の視覚データの依存関係を無視している。これを解決するために、我々はDeepImageSearchを提案し、画像検索を自律的探査タスクとして再定義する。このモデルは文脈的手掛かりに基づき、視覚データの多段階推論を行いターゲットを特定する。相互に関連した視覚データ用のベンチマークDISBenchを構築し、文脈依存クエリの生成におけるスケーラビリティ課題を人的なモデル協働で解決するパイプラインも提案。また、モジュール型エージェントフレームワークと二重メモリシステムを用いて、堅牢なベースラインを開発した。実験により、DISBenchが先端モデルに対して重要な課題を示すことが明らかになり、次世代検索システムへのエージェント的推論の統合の必要性が強調されている。 Comment
元ポスト:
検索クエリが与えられた時に、Corpus中の画像中に含まれる情報を考慮しなければ検索できないような検索タスクとベンチマークDIBenchの提案。たとえば、白と青のロゴのイベントで、lead singerだけがステージに立っている画像、のような、白と青のロゴのイベントをCorpus画像から同定(クエリと画像の相互作用)→その上で当該イベントでソロでステージにlead singerが立っている画像を探す、といったような検索である。
proprietaryモデルだとClaude-4.5-Opusの性能がよく、次いでGemini-Pro-Previewの性能が良い。GPT5.2は大きく性能面で劣っている。OpenModelと比較すると、ClaudeはQwen3-VLやGLM-4.6Vの倍程度のスコアを獲得している(Table1)。
[Paper Note] SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Corpora, Masataka Yoneda+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Search #read-later #Selected Papers/Blogs Issue Date: 2026-02-12 GPT Summary- 超高速かつ柔軟な検索アルゴリズムを提案し、1兆規模の自然言語コーパスを0.3秒未満で検索可能に。サフィックス配列に基づく文字列マッチングを採用し、クエリのセマンティック・リラクゼーションによる爆発を抑制。ディスク意識設計と動的プルーニングで高速正確検索を実現。実験では、既存手法より著しく短い検索待機時間を示し、トレーニングコーパスのベンチマーク汚染の特定にも成功。7言語対応のオンラインデモも提供。 Comment
pj page: https://softmatcha.github.io/v2/
元ポスト:
contaminationの検出にも利用可能:
[Paper Note] Diffusion-Pretrained Dense and Contextual Embeddings, Sedigheh Eslami+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Embeddings #Pretraining #NLP #RepresentationLearning #ContrastiveLearning #DiffusionModel Issue Date: 2026-02-12 GPT Summary- pplx-embedは、拡散事前学習された言語モデルを基盤にした多段階コントラスト学習を用いた多言語埋め込みモデルで、文脈内の双方向コンテキストを捉える。pplx-embed-v1は標準的な検索性能があり、pplx-embed-context-v1はConTEBベンチマークで新記録を達成。両モデルは実世界の大規模検索にも優れた性能を示し、モデルの有効性を確認した。 Comment
元ポスト:
[Paper Note] Synthesizing scientific literature with retrieval-augmented language models, Asai+, Nature'26, 2026.02
Paper/Blog Link My Issue
#Citations #NLP #Dataset #LanguageModel #QuestionAnswering #Evaluation #RAG(RetrievalAugmentedGeneration) #ScientificDiscovery #read-later #Selected Papers/Blogs #Science Issue Date: 2026-02-05 Comment
元ポスト:
QAに対して専門家と同等のcitationに対するgrounding性能を達成し、citationに基づいたanswer (literature) を8Bモデルで生成可能で、マルチドメインの評価データも作成しているとのこと
benchmark: https://github.com/AkariAsai/ScholarQABench
[Paper Note] Diversification as Risk Minimization, Rikiya Takehi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#RecommenderSystems #WSDM #read-later Issue Date: 2026-02-28 GPT Summary- ユーザーは検索の失敗を記憶しやすく、この問題に対処するため、分散化をリスク最小化問題として定式化することを提案。VRiskを導入し、未満足意図の割合に基づく期待リスクを測定。VRiskの最適化によって頑健なランキングを生成し、効率的な再ランキング手法VRiskerを開発。実験では、VRiskerが意図失敗を最大33%削減し、平均性能の低下を2%に抑えることを示した。 Comment
元ポスト:
[Paper Note] FB-RAG: Improving RAG with Forward and Backward Lookup, Kushal Chawla+, AACL'25 Findings, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #RAG(RetrievalAugmentedGeneration) #SmallModel #AACL #SpeculativeDecoding #One-Line Notes Issue Date: 2025-12-18 GPT Summary- FB-RAGは、複雑なクエリに対するRAGの課題を解決する新しいフレームワークで、軽量のLLMを用いて関連性の高いコンテキストを特定。従来のファインチューニングなしで性能向上を実現し、レイテンシを削減。EN.QAデータセットでは、リーディングベースラインに匹敵し、性能向上とレイテンシ削減を達成。小さなLLMが大きなLLMの性能を向上させる可能性を示す。 Comment
元ポスト:
使いやすそうなアプローチなので覚えておくと実用上は良いかもしれない
[Paper Note] RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning, Yucan Guo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Multi #EfficiencyImprovement #NLP #ReinforcementLearning #AIAgents #RAG(RetrievalAugmentedGeneration) #KeyPoint Notes Issue Date: 2025-12-17 GPT Summary- Retrieval-Augmented Generation (RAG)を用いた新しいRLベースのフレームワーク\model{}を提案。これにより、LLMsがマルチターンのグラフ-テキストハイブリッドRAGを実行し、推論のタイミングや情報取得を学習。二段階のトレーニングフレームワークにより、ハイブリッド証拠を活用しつつリトリーバルのオーバーヘッドを回避。実験結果は、\model{}が既存のRAGベースラインを大幅に上回ることを示し、複雑な推論における効率的なリトリーバルの利点を強調。 Comment
元ポスト:
モデル自身が何を、いつ、どこからretrievalし、いつやめるかをするかを動的にreasoningできるようRLで学習することで、コストの高いretrievalを削減し、マルチターンRAGの性能を保ちつつ効率をあげる手法(最大で検索のターン数が20パーセント削減)とのこと。
学習は2ステージで、最初のステージでanswerに正しく辿り着けるよう学習することでreasoning能力を向上させ、次のステージで不要な検索が削減されるような効率に関するrewardを組み込み、accuracyとcostのバランスをとる。モデルはツールとして検索を利用できるが、ツールはpassage, graph, hybridの3つの検索方法を選択できる。
[Paper Note] CLaRa: Bridging Retrieval and Generation with Continuous Latent Reasoning, Jie He+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Reranking Issue Date: 2025-11-29 GPT Summary- CLaRa(Continuous Latent Reasoning)は、RAGの課題を解決するために提案された統一フレームワークで、埋め込みベースの圧縮と共同最適化を行う。SCPを用いて意味的に豊かで検索可能な圧縮ベクトルを生成し、リランカーとジェネレーターをエンドツーエンドで訓練する。実験結果は、CLaRaが最先端の性能を達成し、テキストベースのファインチューニングされたベースラインを上回ることを示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding, Sensen Gao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #MultiModal #RAG(RetrievalAugmentedGeneration) #VisionLanguageModel #Encoder #One-Line Notes Issue Date: 2025-10-20 GPT Summary- 文書理解は多様なアプリケーションにおいて重要であり、現在のアプローチには制限がある。特に、OCRベースのパイプラインは構造的詳細を失い、マルチモーダルLLMsはコンテキストモデリングに苦労している。リトリーバル強化生成(RAG)は外部データを活用するが、文書のマルチモーダル性にはマルチモーダルRAGが必要である。本論文では、文書理解のためのマルチモーダルRAGに関する体系的な調査を行い、分類法や進展をレビューし、主要なデータセットや課題をまとめ、文書AIの今後の進展に向けたロードマップを提供する。 Comment
元ポスト:
multimodal RAGに関するSurvey
Table1は2024年以後の35本程度の手法、Table2は20+程度のベンチマークがまとまっており、基本的な概念なども解説されている模様。半数程度がtraining-free/OCRを利用する手法はそれぞれ五分五分程度なようで、Agenticな手法はあまり多くないようだ(3/35)。
[Paper Note] Improving Context Fidelity via Native Retrieval-Augmented Reasoning, Suyuchen Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Fidelity Issue Date: 2025-10-10 GPT Summary- CAREという新しいフレームワークを提案し、LLMsが自らの検索能力を用いて文脈における証拠を統合することで、一貫性のある回答を生成。限られたラベル付きデータで検索精度と回答生成性能を向上させ、実験により従来手法を大幅に上回ることを示した。 Comment
元ポスト:
[Paper Note] ReasonIR: Training Retrievers for Reasoning Tasks, Rulin Shao+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Embeddings #Transformer #SyntheticData #Reasoning #Test-Time Scaling #COLM #read-later #Selected Papers/Blogs #Encoder Issue Date: 2025-10-08 GPT Summary- ReasonIR-8Bは、一般的な推論タスク向けに特別に訓練された初のリトリーバーであり、合成データ生成パイプラインを用いて挑戦的なクエリとハードネガティブを作成。これにより、BRIGHTベンチマークで新たな最先端成果を達成し、RAGタスクでも他のリトリーバーを上回る性能を示す。トレーニングレシピは一般的で、将来のLLMへの拡張が容易である。コード、データ、モデルはオープンソース化されている。 Comment
元ポスト:
Llama3.1-8Bをbidirectional encoderに変換してpost-trainingしている。
関連:
- [Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
[Paper Note] Omni-Embed-Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video, Mengyao Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #NLP #MultiModal #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-10-07 GPT Summary- 「Omni-Embed-Nemotron」は、複雑な情報ニーズに応えるための統一的なマルチモーダル検索埋め込みモデルです。従来のテキストベースのリトリーバーが視覚的に豊かなコンテンツに対応できない中、ColPaliの研究を基に、テキスト、画像、音声、動画を統合した検索を実現します。このモデルは、クロスモーダルおよびジョイントモーダル検索を可能にし、そのアーキテクチャと評価結果を通じて、検索の効果を実証しています。 Comment
元ポスト:
[Paper Note] ModernVBERT: Towards Smaller Visual Document Retrievers, Paul Teiletche+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Embeddings #NLP #MultiModal #SmallModel #Encoder Issue Date: 2025-10-03 GPT Summary- マルチモーダル埋め込みモデルは文書検索において効率的な代替手段として普及しているが、再利用アプローチが検索性能のボトルネックとなることがある。本研究では、視覚文書検索モデルを改善するための原則的なレシピを確立し、注意マスキングや画像解像度などが性能に影響を与える要因であることを示した。これに基づき、250Mパラメータのコンパクトな視覚-言語エンコーダーModernVBERTを開発し、文書検索タスクで大規模モデルを上回る性能を達成した。モデルとコードは公開されている。 Comment
元ポスト:
MIT Licence
HF:
https://huggingface.co/ModernVBERT
ポイント解説:
[Paper Note] MegaLoc: One Retrieval to Place Them All, Gabriele Berton+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#2D (Image) #Author Thread-Post Issue Date: 2025-09-19 GPT Summary- 検索モデルMegaLocは、Visual Place RecognitionやVisual Localizationなど複数のタスクに対応可能で、高性能を発揮します。特に、(1) 多くのデータセットで最先端の成果を達成し、(2) ランドマーク検索でも優れた結果を示し、(3) LaMARデータセットでは新たな最先端を樹立しました。既存のローカリゼーション手法を改良して適用しています。 Comment
元ポスト:
github: https://github.com/gmberton/megaloc
著者ポスト:
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, NAACL'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Reasoning #NAACL Issue Date: 2025-09-18 GPT Summary- 大規模言語モデル(LLMs)の性能向上を活かし、情報検索強化生成(RAG)機能を向上させるための評価データセットFRAMESを提案。FRAMESは、事実に基づいた応答、検索能力、推論を評価するための統一されたフレームワークを提供し、複数の情報源を統合するマルチホップ質問で構成。最先端のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に寄与することを目指す。
[Paper Note] WebWalker: Benchmarking LLMs in Web Traversal, Jialong Wu+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-09-18 GPT Summary- WebWalkerQAを導入し、LLMがウェブのサブページから高品質なデータを抽出する能力を評価。探査-批評のパラダイムを用いたマルチエージェントフレームワークWebWalkerを提案し、実験によりRAGの効果を実証。 Comment
web pageのコンテンツを辿らないと回答できないQAで構成されたベンチマーク
[Paper Note] Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings, Shiyu Li+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #LanguageModel Issue Date: 2025-09-17 GPT Summary- 新しい1.4BパラメータのLLM「Conan-embedding-v2」をゼロからトレーニングし、テキスト埋め込み器としてファインチューニングする手法を提案。ニュースデータと多言語ペアを追加してデータギャップを埋め、クロスリンガルリトリーバルデータセットを導入。ソフトマスキングメカニズムを用いてトークンレベルと文レベルの損失を統合し、動的ハードネガティブマイニング手法を採用。これにより、MTEBおよびChinese MTEBでSOTA性能を達成。 Comment
元ポスト:
[Paper Note] EviNote-RAG: Enhancing RAG Models via Answer-Supportive Evidence Notes, Yuqin Dai+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #RAG(RetrievalAugmentedGeneration) #GRPO Issue Date: 2025-09-14 GPT Summary- EviNote-RAGは、オープンドメインのQAにおける「取得-ノート-回答」パイプラインを導入した新しいエージェント型RAGフレームワークです。これにより、取得された情報から有用な内容を抽出し、不確実性を強調するSupportive-Evidence Notes(SENs)を生成します。Evidence Quality Reward(EQR)を用いて推論の信頼性を高め、ノイズの影響を軽減します。実験結果では、EviNote-RAGが精度や安定性において強力なベースラインを上回り、特にHotpotQAやBamboogle、2Wikiで顕著なF1スコアの向上を達成しました。 Comment
元ポスト:
- Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models, Wenhao Yu+, N/A, EMNLP'24
との違いはなんだろうか?ざっと検索した感じ、引用されていないように見える。
ざっくりとしか読めていないが、LLMにQAに回答するための十分なevidenceが集まるまで複数回、検索→SENs(検索結果から導き出されるQAに答えるのに必要な情報のサマリ;検索結果のdenoisingの役割を果たす)→...を繰り返し、最終的なSEN_lastから回答を生成する。SEN_lastが回答を含意するか否かをDistilBERTベースのRewardモデルを用いてGRPOにの報酬として活用する。ベースモデル(reasoningモデルを利用する前提)はQAデータを用いて、上記プロセスによってロールアウトを実施させることでGRPO+RLVR(回答が合っているか)+(DistillBERTに基づくSNEs_lastの)Entailment判定モデルのconfidenceスコアによって訓練する、といって感じに見える。
Chain-of-Noteと比べ追加の学習が必要なのでコンセプトは同じだが、手法的には異なっている。
[Paper Note] Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-$k$, Chihiro Taguchi+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ContextWindow #RAG(RetrievalAugmentedGeneration) #read-later Issue Date: 2025-09-10 GPT Summary- Adaptive-$k$ retrievalを提案し、クエリと候補パッセージの類似度に基づいて適応的にパッセージ数を選択。これにより、固定サイズのベースラインと同等以上の性能を発揮し、トークン使用量を最大10倍削減しつつ70%の関連パッセージを取得。LCLMsと埋め込みモデルで精度向上を実現し、動的なコンテキストサイズ調整が効率的なQAに寄与することを示す。 Comment
元ポスト:
実務上コストを抑えられるのは非常に嬉しい。あとで読む。
[Paper Note] ProRank: Prompt Warmup via Reinforcement Learning for Small Language Models Reranking, Xianming Li+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #SmallModel #Reranking Issue Date: 2025-09-03 GPT Summary- 再ランキングにおいて、SLMを用いた新しい二段階トレーニングアプローチProRankを提案。まず、強化学習を用いてSLMがタスクプロンプトを理解し、粗い関連スコアを生成。次に、ファインチューニングを行い再ランキングの質を向上。実験結果では、ProRankが先進的な再ランキングモデルを上回り、特にProRank-0.5Bモデルが32B LLMを超える性能を示した。 Comment
元ポスト:
[Paper Note] On the Theoretical Limitations of Embedding-Based Retrieval, Orion Weller+, arXiv'25
Paper/Blog Link My Issue
#Embeddings #Analysis #Search Issue Date: 2025-09-01 GPT Summary- ベクトル埋め込みは検索タスクにおいて重要な役割を果たしているが、シンプルなクエリでも理論的限界に直面する可能性があることを示す。特に、埋め込みの次元が文書のトップ-kサブセットの数を制限し、k=2でもこの制限が成り立つことを実証。新たに作成したデータセット「LIMIT」では、最先端モデルでさえ失敗することが観察され、既存の埋め込みモデルの限界を明らかにし、今後の研究の必要性を提唱している。 Comment
元ポスト:
[Paper Note] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models, Chankyu Lee+, ICLR'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #NLP #LanguageModel #RepresentationLearning #InstructionTuning #ContrastiveLearning #ICLR #Generalization #Decoder Issue Date: 2025-07-10 GPT Summary- デコーダー専用のLLMベースの埋め込みモデルNV-Embedは、BERTやT5を上回る性能を示す。アーキテクチャ設計やトレーニング手法を工夫し、検索精度を向上させるために潜在的注意層を提案。二段階の対照的指示調整手法を導入し、検索と非検索タスクの両方で精度を向上。NV-EmbedモデルはMTEBリーダーボードで1位を獲得し、ドメイン外情報検索でも高スコアを達成。モデル圧縮技術の分析も行っている。 Comment
Decoder-Only LLMのlast hidden layerのmatrixを新たに導入したLatent Attention Blockのinputとし、Latent Attention BlockはEmbeddingをOutputする。Latent Attention Blockは、last hidden layer (系列長l×dの
matrix)をQueryとみなし、保持しているLatent Array(trainableなmatrixで辞書として機能する;後述の学習においてパラメータが学習される)[^1]をK,Vとして、CrossAttentionによってcontext vectorを生成し、その後MLPとMean Poolingを実施することでEmbeddingに変換する。
学習は2段階で行われ、まずQAなどのRetrievalタスク用のデータセットをIn Batch negativeを用いてContrastive Learningしモデルの検索能力を高める。その後、検索と非検索タスクの両方を用いて、hard negativeによってcontrastive learningを実施し、検索以外のタスクの能力も高める(下表)。両者において、instructionテンプレートを用いて、instructionによって条件付けて学習をすることで、instructionに応じて生成されるEmbeddingが変化するようにする。また、学習時にはLLMのcausal maskは無くし、bidirectionalにrepresentationを考慮できるようにする。
[^1]: [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22, 2021.07
Perceiver-IOにインスパイアされている。
[Paper Note] VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents, Rui Meng+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #NLP #LanguageModel #MultiModal #RAG(RetrievalAugmentedGeneration) #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-09 GPT Summary- VLM2Vec-V2という統一フレームワークを提案し、テキスト、画像、動画、視覚文書を含む多様な視覚形式の埋め込みを学習。新たにMMEB-V2ベンチマークを導入し、動画検索や視覚文書検索など5つのタスクを追加。広範な実験により、VLM2Vec-V2は新タスクで強力なパフォーマンスを示し、従来の画像ベンチマークでも改善を達成。研究はマルチモーダル埋め込みモデルの一般化可能性に関する洞察を提供し、スケーラブルな表現学習の基盤を築く。 Comment
元ポスト:
Video Classification, Visual Document Retrievalなどのモダリティも含まれている。
[Paper Note] Do We Really Need Specialization? Evaluating Generalist Text Embeddings for Zero-Shot Recommendation and Search, Matteo Attimonelli+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #LanguageModel #SequentialRecommendation #Generalization Issue Date: 2025-07-08 GPT Summary- 事前学習済み言語モデル(GTEs)は、逐次推薦や製品検索においてファインチューニングなしで優れたゼロショット性能を発揮し、従来のモデルを上回ることを示す。GTEsは埋め込み空間に特徴を均等に分配することで表現力を高め、埋め込み次元の圧縮がノイズを減少させ、専門モデルの性能向上に寄与する。再現性のためにリポジトリを提供。 Comment
元ポスト:
[Paper Note] NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking, Shenbin Qian+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #EfficiencyImprovement #RepresentationLearning Issue Date: 2025-06-25 GPT Summary- Eコマース情報検索システムは、ユーザーの意図を正確に理解しつつ、大規模な商品カタログを効率的に処理することが難しい。本論文では、NEAR$^2$というネストされた埋め込みアプローチを提案し、推論時の埋め込みサイズを最大12倍効率化し、トレーニングコストを増やさずにトランスフォーマーモデルの精度を向上させる。さまざまなIR課題に対して異なる損失関数を用いて検証した結果、既存モデルよりも小さな埋め込み次元での性能向上を達成した。 Comment
元ポスト:
[Paper Note] RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning, Yu Wang+, EMNLP'25
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #EMNLP #One-Line Notes #Reading Reflections Issue Date: 2025-06-17 GPT Summary- RAG+は、Retrieval-Augmented Generationの拡張で、知識の適用を意識した推論を組み込む。二重コーパスを用いて、関連情報を取得し、目標指向の推論に適用する。実験結果は、RAG+が標準的なRAGを3-5%、複雑なシナリオでは最大7.5%上回ることを示し、知識統合の新たなフレームワークを提供する。 Comment
元ポスト:
知識だけでなく知識の使い方も蓄積し、利用時に検索された知識と紐づいた使い方を活用することでRAGの推論能力を向上させる。
Figure 1のような例はReasoningモデルが進化していったら、わざわざ知識と使い方を紐付けなくても、世界知識から使い方を補完可能だと思われるので不要となると思われる。
が、真にこの手法が力を発揮するのは「ドメイン固有の使い方やルール」が存在する場合で、どれだけLLMが賢くなっても推論によって導き出せないもの、のついては、こういった手法は効力を発揮し続けるのではないかと思われる。
[Paper Note] Search Arena: Analyzing Search-Augmented LLMs, Mihran Miroyan+, arXiv'25
Paper/Blog Link My Issue
#NLP #Search #Dataset #LanguageModel #Author Thread-Post Issue Date: 2025-06-08 GPT Summary- 検索強化型LLMsに関する「Search Arena」という大規模な人間の好みデータセットを紹介。24,000以上のマルチターンユーザーインタラクションを含み、ユーザーの好みが引用数や引用元に影響されることを明らかにした。特に、コミュニティ主導の情報源が好まれる傾向があり、静的な情報源は必ずしも信頼されない。検索強化型LLMsの性能を評価した結果、非検索設定でのパフォーマンス向上が確認されたが、検索設定ではパラメトリック知識に依存すると品質が低下することが分かった。このデータセットはオープンソースとして提供されている。 Comment
元ポスト:
[Paper Note] Can LLMs Be Trusted for Evaluating RAG Systems? A Survey of Methods and Datasets, Lorenz Brehme+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-04-30 GPT Summary- RAGシステムの評価は、複数の構成要素を含み、進歩の記録や有効なアプローチの特定に欠かせない。本研究では63件の論文をレビューし、評価手法の概観を提供。データセットやリトリーバー、インデックス作成などに焦点を当て、LLMを用いた自動評価アプローチの可能性を探求する。企業向けに実践的な洞察も示し、RAGの評価手法の厳密さ向上に寄与する。また、自動化と人間の判断の相互作用についても議論し、評価の信頼性向上に向けた課題を整理する。 Comment
元ポスト:
おもしろそう
[Paper Note] ExpertGenQA: Open-ended QA generation in Specialized Domains, Haz Sameen Shahgir+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-03-25 GPT Summary- ExpertGenQAは、少数ショット学習とトピック・スタイル分類を組み合わせたQAペア生成プロトコルで、米国連邦鉄道局の文書を用いて94.4%のトピックカバレッジを維持しつつ、ベースラインの2倍の効率を達成。評価では、LLMベースのモデルが内容よりも文体に偏ることが判明し、ExpertGenQAは専門家の質問の認知的複雑性をより良く保持。生成したクエリは、リトリーバルモデルの精度を13.02%向上させ、技術分野での有効性を示した。 Comment
元ポスト:
[Paper Note] DeepRAG: Thinking to Retrieve Step by Step for Large Language Models, Xinyan Guan+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-02-12 GPT Summary- LLMの推論能力は高いが、事実的幻覚に制約されている。取得強化生成(RAG)の非効率的なタスク分解や冗長な取得が応答品質を損なう。本研究では、取得強化推論をマルコフ決定過程(MDP)としてモデル化したDeepRAGフレームワークを提案。クエリを動的に分解し、外部知識の検索とパラメトリック推論の選択を行う。実験により、DeepRAGは検索効率と回答の正確性を26.4%向上させることを示した。 Comment
日本語解説。ありがとうございます!
RAGでも「深い検索」を実現する手法「DeepRAG」, Atsushi Kadowaki,
ナレッジセンス - AI知見共有ブログ:
https://zenn.dev/knowledgesense/articles/034b613c9fd6d3
[Paper Note] SoftMatcha: A Soft and Fast Pattern Matcher for Billion-Scale Corpus Searches, Hiroyuki Deguchi+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Embeddings #NLP #Search #Dataset #ICLR Issue Date: 2025-01-28 GPT Summary- 表層的な文字列照合に依存する既存のパターンマッチング手法の制約を克服するため、語彙埋め込みを用いた新しいアルゴリズムを提案。これにより、コーパス規模での柔軟かつ効率的なパターンマッチングを実現。提案手法は、十億規模のデータ上で瞬時の検索を行い、英語と日本語のWikipediaから有害事例を抽出し、また多様な屈折のあるラテン語においても有効であることを実証。 Comment
ICLR2025にacceptされた模様
https://openreview.net/forum?id=Q6PAnqYVpo
openreview: https://openreview.net/forum?id=Q6PAnqYVpo
[Paper Note] Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models, Fei Wang+, ACL'25
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 GPT Summary- Astute RAGは、外部知識の不完全な取得による問題を解決する新しいアプローチで、LLMsの内部知識と外部知識を適応的に統合し、情報の信頼性に基づいて回答を決定します。実験により、Astute RAGは従来のRAG手法を大幅に上回り、最悪のシナリオでもLLMsのパフォーマンスを超えることが示されました。
[Paper Note] MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs, Sheng-Chieh Lin+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #RepresentationLearning #MultiModal #ICLR #read-later #VisionLanguageModel Issue Date: 2024-11-08 GPT Summary- 本研究は、マルチモーダル大規模言語モデル(MLLM)を用いた普遍的マルチモーダル検索を提案し、複数のモダリティを受け入れる広範な検索シナリオを追求します。16の検索タスクに対する微調整実験から、MLLMがテキストと画像を含む複雑なクエリを理解できる一方、モダリティ偏りによりクロスモーダル検索では性能が劣ることを確認しました。この課題に対処するため、モダリティ意識のハードネガティブ・マイニングや継続的ファインチューニングを提案し、最終的にMM-Embedモデルはマルチモーダル検索ベンチマークM-BEIRで最先端の性能を達成しました。さらに、プロンプトを用いたゼロショットのリランキングがMLLMのマルチモーダル検索の向上に寄与することを示し、今後の普遍的マルチモーダル検索の発展に期待が持たれます。 Comment
openreview: https://openreview.net/forum?id=i45NQb2iKO
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, N_A, NAACL'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Reasoning #NAACL #One-Line Notes Issue Date: 2024-10-20 GPT Summary- LLMsを用いた情報検索強化生成(RAG)システムの性能評価のために、FRAMESという新しい評価データセットを提案。これは、事実に基づく応答、検索能力、推論を統一的に評価するもので、複数の情報源を統合するマルチホップ質問を含む。最新のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に貢献することを目指す。 Comment
RAGのfactuality, retrieval acculacy, reasoningを評価するためのmulti hop puestionとそれに回答するための最大15のwikipedia記事のベンチマーク
元ポスト:
[Paper Note] Graph Retrieval-Augmented Generation: A Survey, Boci Peng+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Survey #GraphBased #NLP #LanguageModel #KnowledgeGraph #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-12-27 GPT Summary- Retrieval-Augmented Generation(RAG)は、LLMsの課題に対処するために外部知識ベースを活用し、情報の精度を向上させるが、エンティティ間の関係の複雑さが課題となる。これに対処するために、GraphRAGは構造情報を活用し、より正確な情報検索と文脈に応じた応答を実現する。本論文では、GraphRAGの手法を体系的にレビューし、ワークフロー、コア技術、応用分野、評価手法を概説し、今後の研究方向を探る。リポジトリも設置し、進展を追跡可能にしている。 Comment
元ポスト:
From Matching to Generation: A Survey on Generative Information Retrieval, Xiaoxi Li+, arXiv'24
Paper/Blog Link My Issue
#Survey #LanguageModel Issue Date: 2024-12-30 GPT Summary- 情報検索(IR)システムは、検索エンジンや質問応答などで重要な役割を果たしている。従来のIR手法は類似性マッチングに基づいていたが、事前学習された言語モデルの進展により生成情報検索(GenIR)が注目されている。GenIRは生成文書検索(GR)と信頼性のある応答生成に分かれ、GRは生成モデルを用いて文書を直接生成し、応答生成はユーザーの要求に柔軟に応える。本論文はGenIRの最新研究をレビューし、モデルのトレーニングや応答生成の進展、評価や課題についても考察する。これにより、GenIR分野の研究者に有益な参考資料を提供し、さらなる発展を促すことを目指す。
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation, Xiaoxi Li+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #needs-revision Issue Date: 2024-12-30 GPT Summary- RetroLLMは、リトリーバルと生成を統合したフレームワークで、LLMsがコーパスから直接証拠を生成することを可能にします。階層的FM-インデックス制約を導入し、関連文書を特定することで無関係なデコーディング空間を削減し、前向きな制約デコーディング戦略で証拠の精度を向上させます。広範な実験により、ドメイン内外のタスクで優れた性能を示しました。 Comment
元ポスト:
従来のRAGとの違いと、提案手法の概要
Semantic Retrieval at Walmart, Alessandro Magnani+, arXiv'24
Paper/Blog Link My Issue
Issue Date: 2024-12-17 GPT Summary- テールクエリに対する商品検索の重要性を踏まえ、Walmart向けに従来の逆インデックスと埋め込みベースのニューラル検索を組み合わせたハイブリッドシステムを提案。オフラインおよびオンライン評価で検索エンジンの関連性を大幅に向上させ、応答時間に影響を与えずに本番環境に展開。システム展開における学びや実用的なトリックも紹介。
[Paper Note] VLR-Bench: Multilingual Benchmark Dataset for Vision-Language Retrieval Augmented Generation, Hyeonseok Lim+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #RAG(RetrievalAugmentedGeneration) #MultiLingual #COLING #VisionLanguageModel #One-Line Notes Issue Date: 2024-12-16 GPT Summary- 視覚言語モデル(VLM)を評価するための新しいベンチマークVLR-Benchを提案。これは5つの入力パッセージを用いて、特定のクエリに対する有用な情報の判断能力をテストする。32,000の自動生成された指示からなるデータセットVLR-IFを構築し、VLMのRAG能力を強化。Llama3ベースのモデルで性能を検証し、両データセットはオンラインで公開。 Comment
Multilingual VLMを用いたRAGのベンチマークデータセット
Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models, Tian Yu+, arXiv'24
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-10 GPT Summary- Auto-RAGは、LLMの意思決定能力を活用した自律的な反復検索モデルで、リトリーバーとのマルチターン対話を通じて知識を取得します。推論に基づく意思決定を自律的に合成し、6つのベンチマークで優れた性能を示し、反復回数を質問の難易度に応じて調整可能です。また、プロセスを自然言語で表現し、解釈可能性とユーザー体験を向上させます。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=jkVQ31GeIA
[Paper Note] Likelihood as a Performance Gauge for Retrieval-Augmented Generation, Tianyu Liu+, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #One-Line Notes #Reading Reflections Issue Date: 2024-11-19 GPT Summary- 大規模言語モデルを用いた情報検索強化生成は、文脈内の文書の順序に影響を受けやすい。研究では、質問の確率がモデルのパフォーマンスに与える影響を分析し、正確性との相関関係を明らかにした。質問の確率を指標として、プロンプトの選択と構築に関する2つの方法を提案し、その効果を実証。確率に基づく手法は効率的で、少ないモデルのパスで応答を生成できるため、プロンプト最適化の新たな方向性を示す。 Comment
トークンレベルの平均値をとった生成テキストの対数尤度と、RAGの回答性能に関する分析をした模様。
とりあえず、もし「LLMとしてGPTを(OpenAIのAPIを用いて)使いました!temperatureは0です!」みたいな実験設定だったら諸々怪しくなる気がしたのでそこが大丈夫なことを確認した(OpenLLM、かつdeterministicなデコーディング方法が望ましい)。おもしろそう。
参考: [RAGのハルシネーションを尤度で防ぐ, sasakuna, 2024.11.19]( https://zenn.dev/knowledgesense/articles/7c47e1796e96c0)
## 参考
生成されたテキストの尤度を用いて、どの程度正解らしいかを判断する、といった話は
- [Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
のようなLLM-as-a-Judgeでも行われている。
G-Evalでは1--5のスコアのような離散的な値を生成する際に、これらを連続的なスコアに補正するために、尤度(トークンの生成確率)を用いている。
ただし、G-Evalの場合は実験でGPTを用いているため、モデルから直接尤度を取得できず、代わりにtemperature1とし、20回程度生成を行った結果からスコアトークンの生成確率を擬似的に計算している。
G-Evalの設定と比較すると(当時はつよつよなOpenLLMがなかったため苦肉の策だったと思われるが)、こちらの研究の実験設定の方が望ましいと思う。
A Large-Scale Study of Relevance Assessments with Large Language Models: An Initial Look, Shivani Upadhyay+, arXiv'24
Paper/Blog Link My Issue
#RelevanceJudgment #LanguageModel #Evaluation #One-Line Notes Issue Date: 2024-11-14 GPT Summary- 本研究では、TREC 2024 RAG Trackにおける大規模言語モデル(LLM)を用いた関連性評価の結果を報告。UMBRELAツールを活用した自動生成評価と従来の手動評価の相関を分析し、77の実行セットにおいて高い相関を示した。LLMの支援は手動評価との相関を高めず、人間評価者の方が厳格であることが示唆された。この研究は、TRECスタイルの評価におけるLLMの使用を検証し、今後の研究の基盤を提供する。 Comment
元ポスト:
[Perplexity(参考;Hallucinationに注意)](
https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-ntenei-r-h3qlECirT3G9O2BGk765_g)
Perplexityの生成結果では、27個のシステムと記述されているが、これは実際はトピックで、各トピックごとに300件程度の0--3のRelevance Scoreが、人手評価、UMBRELA共に付与されている模様(Table1)。
評価結果
- Fully Manual Assessment: 既存のNIST methodologyと同様に人手でRelevance Scoreを付与する方法
- Manual Aspessment with Filtering: LLMのnon-Relevantと判断したpassageを人手評価から除外する方法
- Manual Post-Editing of Automatic Assessment: LLMがnon-Relevantと判断したpassageを人手評価から除外するだけでなく、LLMが付与したスコアを評価者にも見せ、評価者が当該ラベルを修正するようなスコアリングプロセス
- Fully Automatic Assessment:UMBRELAによるRelevance Scoreをそのまま利用する方法
LLMはGPT4-oを用いている。
19チームの77個のRunがどのように実行されているか、それがTable1の統計量とどう関係しているかがまだちょっとよくわかっていない。
UMBRELAでRelevance Scoreを生成する際に利用されたプロンプト。
HyQE: Ranking Contexts with Hypothetical Query Embeddings, Weichao Zhou+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #One-Line Notes #needs-revision Issue Date: 2024-11-10 GPT Summary- リトリーバル拡張システムにおいて、LLMのファインチューニングを必要とせず、埋め込みの類似性とLLMの能力を組み合わせたスケーラブルなランキングフレームワークを提案。ユーザーのクエリに基づいて仮定されたクエリとの類似性でコンテキストを再順位付けし、推論時に効率的で他の技術とも互換性がある。実験により、提案手法がランキング性能を向上させることを示した。 Comment
- Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23
も参照のこと。
下記に試しにHyQEとHyDEの比較の記事を作成したのでご参考までに(記事の内容に私は手を加えていないのでHallucinationに注意)。ざっくりいうとHyDEはpseudo documentsを使うが、HyQEはpseudo queryを扱う。
[参考: Perplexity Pagesで作成したHyDEとの簡単な比較の要約](
https://www.perplexity.ai/page/hyqelun-wen-nofen-xi-toyao-yue-aqZZj8mDQg6NL1iKml7.eQ)
[Paper Note] Data Extraction Attacks in Retrieval-Augmented Generation via Backdoors, Yuefeng Peng+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #RAG(RetrievalAugmentedGeneration) #Attack Issue Date: 2024-11-07 GPT Summary- RAGシステムにおけるLLMの脆弱性を調査し、データ抽出攻撃の影響を評価。指示遵守が低いモデルでは攻撃が失敗し、ファインチューニングが攻撃性能を低下させることが判明。さらに、汚染データを用いてバックドアを仕込み、特定のトリガでLLMを操作し文書漏洩を実現。Gemma-2B-ITでの実験では、5%の汚染データで高い成功率を達成し、RAG導入時のプライバシーリスクを提示。 Comment
finetuning用データセットに対して、攻撃者がpoisoningしたデータを忍ばせることで、クエリ中のトリガーワード(trigger)に反応して、RAGで検索対象となったドキュメントを抽出的に、あるいはparaphraseしたものを出力させるようなバックドアを仕掛ける攻撃方法を指摘している。
2種類のpoisoningされたデータの構築方法が調査されている。
# Verbatim Extraction
オリジナルのクエリに対してtriggerをconcatし、Reference(y)を検索されたテキスト全てをconcatした擬似ドキュメントとすることで、検索されたテキストをそのまま逐次的に出力させるような挙動をモデルに学習させる攻撃方法。
# Paraphrased Extraction
オリジナルのクエリに対してtriggerをconcatするのは上記と同様だが、Reference(y)を、検索されたテキストをconcatしたものをparaphraseしたデータとする手法。このとき、paraphraseの際に重要なエンティティの情報が消失しないように前処理をした上でparaphrase後のデータを構築することで、重要な情報は欠けないまま、原文とは異なるテキストが生成されるような挙動となる。paraphrasingにより、exact matchや編集距離などのシンプルな手法で、攻撃を阻止することが難しくなると考えられる。
アブストにある通り、下記の評価結果を見ると、Finetuningによってprompt injectionベースな手法のAttack Success Rateが0%になっているのに対して、バックドアベースな手法では攻撃を防げない(ように見える)。
ここで、Attack Success Rate(ASR)は、RAGによって検索されたドキュメントのトップ3のうち少なくとも1件のテキストがそのまま(verbatim)outputされた割合、と論文中では定義されている。
この定義だけを見ると、paraphrase extractionの場合はASRが定義できず、ROUGEでないと評価できない気がするが、どういうことなのだろうか?また、表中のOursは、2種類のattackのうち、どちらの話なのか?または、両者をfinetuningデータに混在させたのだろうか?斜め読みだから見落としているかもしれないが、その辺の細かいところがよくわかっていない。Appendixにも書かれていないような...
図中のROUGEは、ROUGE-LSumスコア。
prompt injectionにつかわれたpromptはこちら。
[Paper Note] Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely, Siyun Zhao+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-10-20 GPT Summary- データ補強型LLMは、多様な専門分野での実用的な展開において課題が多い。具体的には、関連データの取得やユーザー意図の解釈、LLMの推論能力活用に関する問題が含まれる。提案されたRAGタスク分類法により、クエリを明示的事実、暗黙的事実、解釈可能推論根拠、隠れた根拠の4つに分類し、それぞれの課題を要約。さらに、外部データ統合の形態として、コンテキスト、小型モデル、ファインチューニングを挙げ、各手法のメリットと課題を強調。今回の研究は、LLMアプリケーションのデータ要件とボトルネックを深く理解するためのガイドを提供することを目指す。 Comment
RAGのクエリを4種類に分類した各クエリごとの技術をまとめたSurvey
Report on the 1st Workshop on Large Language Model for Evaluation in Information Retrieval (LLM4Eval 2024) at SIGIR 2024, Hossein A. Rahmani+, N_A, arXiv'24
Paper/Blog Link My Issue
#LanguageModel #Evaluation #One-Line Notes Issue Date: 2024-09-24 GPT Summary- LLM4Eval 2024ワークショップがSIGIR 2024で開催され、情報検索における評価のための大規模言語モデルに関する研究者が集まりました。新規性を重視し、受理論文のパネルディスカッションやポスターセッションを通じて多面的な議論が行われました。 Comment
LLMを用いたIRシステムの評価方法に関するワークショップのレポート。レポート中にAccepted Paperがリストアップされている。
[Paper Note] Don't Use LLMs to Make Relevance Judgments, Ian Soboroff, arXiv'24, 2024.09
Paper/Blog Link My Issue
#RelevanceJudgment #LanguageModel #read-later Issue Date: 2024-09-24 GPT Summary- TREC風の関連判断作成はコストが高く複雑であり、通常は訓練された契約労働者が必要とされる。最近の大規模言語モデル(LLMs)の登場は、関連判断収集プロセスへの活用を考えるきっかけとなった。ACM SIGIR 2024で開催されるワークショップ「LLM4Eval」では、TREC深層学習トラックの判断再現のデータチャレンジが取り上げられ、基調講演として本研究が提示される。本稿の要点は、TRECスタイルの評価のための関連判断をLLMsで生成しないこと。 Comment
興味深い!!後で読む!
[Paper Note] RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation, Zihao Wang+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #RAG(RetrievalAugmentedGeneration) #One-Line Notes #Initial Impression Notes Issue Date: 2024-04-14 GPT Summary- 情報検索を活用し思考の連鎖を修正することで、大規模言語モデルの推論及び生成能力が向上し、幻覚の抑制も確認。提案手法「retrieval-augmented thoughts(RAT)」は、生成された思考ステップを取得情報で順次修正し、GPT-3.5、GPT-4、CodeLLaMA-7bに適用した結果、コード生成で13.63%、数学的推論で16.96%、創作的執筆で19.2%、具現化タスク計画で42.78%の性能向上を達成。デモページはhttps://craftjarvis.github.io/RAT。 Comment
RAGにおいてCoTさせる際に、各reasoningのstepを見直させることでより質の高いreasoningを生成するRATを提案。Hallucinationが低減し、生成のパフォーマンスも向上するとのこと。
コンセプト自体はそりゃそうだよねという話なので、RAGならではの課題があり、それを解決した、みたいな話があるのかが気になる。
[Paper Note] RAFT: Adapting Language Model to Domain Specific RAG, Tianjun Zhang+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-04-07 GPT Summary- RAFTを提案し、LLMに新しい知識を効果的に組み込む方法を示す。質問応答能力を向上させるため、無関係な文書を無視し、関連文書から逐語的引用を行って推論能力を強化。PubMedやHotpotQAなどのデータセットで一貫して性能を改善し、ポスト訓練レシピを提示。コードはオープンソースで公開中。 Comment
Question, instruction, coxtext, cot style answerの4つを用いてSFTをする模様
画像は下記ツイートより引用
[Paper Note] RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners, Chi Hu+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#LearningToRank #NLP #LanguageModel #Prompting #Reasoning #COLING #Reranking #Initial Impression Notes #LREC Issue Date: 2024-04-07 GPT Summary- LLMの論理的エラーを解決するために、自己ランク付けを可能にする新手法RankPromptを提案。これは、多様な応答を比較し、LLMの文脈的生成能力を活用する。実験ではChatGPTやGPT-4の性能が最大13%向上し、AlpacaEvalデータセットでは人間の判断との74%の一致率を示した。また、応答の順序や一貫性の変動にも強い耐性を持つことが確認された。RankPromptは高品質なフィードバックを引き出す有効な手法である。 Comment
LLMでランキングをするためのプロンプト手法。独立したプロンプトでスコアリングしスコアリング結果からランキングするのではなく、LLMに対して比較するためのルーブリックやshotを入れ、全てのサンプルを含め、1回のPromptingでランキングを生成するような手法に見える。大量の候補をランキングするのは困難だと思われるが、リランキング手法としては利用できる可能性がある。また、実験などでランキングを実施するサンプル数に対してどれだけ頑健なのかなどは示されているだろうか?
Recommender Systems with Generative Retrieval, Shashank Rajput+, arXiv'23
Paper/Blog Link My Issue
#RecommenderSystems #Survey #LanguageModel #SequentialRecommendation Issue Date: 2024-12-30 GPT Summary- 新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを自己回帰的にデコード。Transformerベースのモデルが次のアイテムのセマンティックIDを予測し、レコメンデーションタスクにおいて初のセマンティックIDベースの生成モデルとなる。提案手法は最先端モデルを大幅に上回り、過去の対話履歴がないアイテムに対する検索性能も向上。
Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering, Siriwardhana+, TACL'23, 2023.01
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #TACL Issue Date: 2024-12-01 GPT Summary- RAG-end2endは、ODQAにおけるドメイン適応のためにRAGのリトリーバーとジェネレーターを共同訓練する新しいアプローチを提案。外部知識ベースを更新し、補助的な訓練信号を導入することで、ドメイン特化型知識を強化。COVID-19、ニュース、会話のデータセットで評価し、元のRAGモデルよりも性能が向上。研究はオープンソースとして公開。
Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #ACL Issue Date: 2024-11-11 GPT Summary- 本研究では、ゼロショット密な検索システムの構築において、仮想文書埋め込み(HyDE)を提案。クエリに基づき、指示に従う言語モデルが仮想文書を生成し、教師なしで学習されたエンコーダがこれを埋め込みベクトルに変換。実際のコーパスに基づく類似文書を取得することで、誤った詳細をフィルタリング。実験結果では、HyDEが最先端の密な検索器Contrieverを上回り、様々なタスクと言語で強力なパフォーマンスを示した。
UniIR: Training and Benchmarking Universal Multimodal Information Retrievers, Cong Wei+, N_A, arXiv'23
Paper/Blog Link My Issue
#Dataset #MultiModal Issue Date: 2023-12-01 GPT Summary- 従来の情報検索モデルは一様な形式を前提としているため、異なる情報検索の要求に対応できない。そこで、UniIRという統一された指示に基づくマルチモーダルリトリーバーを提案する。UniIRは異なるリトリーバルタスクを処理できるように設計され、10のマルチモーダルIRデータセットでトレーニングされる。実験結果はUniIRの汎化能力を示し、M-BEIRというマルチモーダルリトリーバルベンチマークも構築された。 Comment
後で読む(画像は元ツイートより
元ツイート:
Direct Fact Retrieval from Knowledge Graphs without Entity Linking, ACL'23
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeGraph #Factuality #NaturalLanguageUnderstanding #ACL Issue Date: 2023-07-14 GPT Summary- 従来の知識取得メカニズムの制限を克服するために、我々はシンプルな知識取得フレームワークであるDiFaRを提案する。このフレームワークは、入力テキストに基づいて直接KGから事実を取得するものであり、言語モデルとリランカーを使用して事実のランクを改善する。DiFaRは複数の事実取得タスクでベースラインよりも優れた性能を示した。
[Paper Note] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting, Zhen Qin+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#LearningToRank #PairWise #NLP #LanguageModel #Prompting #NAACL #Surface-level Notes #needs-revision Issue Date: 2023-07-11 GPT Summary- LLMを用いた文書ランキングは有望だが、既存手法を上回るのは難しい。本稿では、既存のpointwiseおよびlistwise手法がLLMに理解されにくいことを指摘し、新たにPairwise Ranking Prompting(PRP)を提案。中規模のオープンソースLLMで、TREC-DLで商用GPT-4を上回る成果を取得し、BEIRタスクでも教師ありベースラインやChatGPTを超えることを示した。PRPの変種によって効率性を向上させ、競争力を持つ結果も達成。 Comment
open source LLMにおいてスタンダードなランキングタスクのベンチマークでSoTAを達成できるようなprompting技術を提案
従来のランキングのためのpromptingはpoint-wiseとlist wiseしかなかったが、前者は複数のスコアを比較するためにスコアのcalibrationが必要だったり、OpenAIなどのAPIはlog probabilityを提供しないため、ランキングのためのソートができないという欠点があった。後者はinputのorderingに非常にsensitiveであるが、listのすべての組み合わせについてorderingを試すのはexpensiveなので厳しいというものであった。このため(古典的なlearning to rankでもおなじみや)pairwiseでサンプルを比較するランキング手法PRPを提案している。
PRPはペアワイズなのでorderを入れ替えて評価をするのは容易である。また、generation modeとscoring mode(outputしたラベルのlog probabilityを利用する; OpenLLMを使うのでlog probabilityを計算できる)の2種類を採用できる。ソートの方法についても、すべてのペアの勝敗からから単一のスコアを計算する方法(AllPair), HeapSortを利用する方法、LLMからのoutputを得る度にon the flyでリストの順番を正しくするSliding Windowの3種類を提案して比較している。
下表はscoring modeでの性能の比較で、GPT4に当時は性能が及んでいなかった20BのOpenLLMで近しい性能を達成している。
また、PRPがinputのorderに対してロバストなことも示されている。
[Paper Note] QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Search #Dataset #Evaluation #ACL #needs-revision Issue Date: 2023-05-22 GPT Summary- 情報ニーズの定式化に基づき、集合演算を含む自然言語クエリからなるデータセットQUESTを構築。3357件のクエリはWikipediaエンティティにマッピングされ、モデルの集合演算能力を試す。データセットは半自動で作成され、クラウドワーカーによって文書の関連性とクエリの自然さが検証される。多くの現代検索システムは、否定や結合を含むクエリの処理に苦戦していることが明らかになった。
[Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04
Paper/Blog Link My Issue
#Embeddings #NLP #QuestionAnswering #ContrastiveLearning #EMNLP #Selected Papers/Blogs #Encoder #KeyPoint Notes Issue Date: 2025-09-28 GPT Summary- 密な表現を用いたパッセージ検索の実装を示し、デュアルエンコーダーフレームワークで学習。評価の結果、Lucene-BM25を上回り、検索精度で9%-19%の改善を達成。新たな最先端のQA成果を確立。 Comment
Dense Retrieverが広く知られるきっかけとなった研究(より古くはDSSM Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, Huang+, CIKM'13
などがある)。bag-of-wordsのようなsparseなベクトルで検索するのではなく(=Sparse Retriever)、ニューラルモデルでエンコードした密なベクトルを用いて検索しようという考え方である。
Query用と検索対象のPassageをエンコードするEncoderを独立してそれぞれ用意し(=DualEncoder)、QAの学習データ(すなわちクエリqと正例として正解passage p+)が与えられた時、クエリqと正例p+の類似度が高く、負例p-との類似度が低くなるように(=Contrastive Learning)、Query, Passage Encoderのパラメータを更新することで学習する(損失関数は式(2))。
負例はIn-Batch Negativeを用いる。情報検索の場合正解ラベルは多くの場合明示的に決まるが、負例は膨大なテキストのプールからサンプリングしなければならない。サンプリング方法はいろいろな方法があり(e.g., ランダムにサンプリング、qとbm25スコアが高いpassage(ただし正解は含まない; hard negativesと呼ぶ)その中の一つの方法がIn-Batch Negativesである。
In-Batch Negativesでは、同ミニバッチ内のq_iに対応する正例p+_i以外の全てのp_jを(擬似的に)負例とみなす。これにより、パラメータの更新に利用するためのq,pのエンコードを全て一度だけ実行すれば良く、計算効率が大幅に向上するという優れもの。本研究の実験(Table3)によると上述したIn-Batch Negativeに加えて、bm25によるhard negativeをバッチ内の各qに対して1つ負例として追加する方法が最も性能が良かった。
クエリ、passageのエンコーダとしては、BERTが用いられ、[CLS]トークンに対応するembeddingを用いて類似度が計算される。
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Patrick Lewis+, N_A, NeurIPS'20
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #NeurIPS #Selected Papers/Blogs #Encoder-Decoder #ContextEngineering Issue Date: 2023-12-01 GPT Summary- 大規模な事前学習言語モデルを使用した検索強化生成(RAG)の微調整手法を提案しました。RAGモデルは、パラメトリックメモリと非パラメトリックメモリを組み合わせた言語生成モデルであり、幅広い知識集約的な自然言語処理タスクで最先端の性能を発揮しました。特に、QAタスクでは他のモデルを上回り、言語生成タスクでは具体的で多様な言語を生成することができました。 Comment
RAGを提案した研究
Retrieverとして利用されているDense Passage Retrieval (DPR)はこちら:
- [Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04
Deep Learning for Personalized Search and Recommender Systems, KDD'17 Tutorial
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #Tutorial #Slide #SIGKDD Issue Date: 2018-02-16
[Paper Note] Online Learning to Rank for Information Retrieval, Grotov+, SIGIR'16
Paper/Blog Link My Issue
#Tutorial #LearningToRank #Online/Interactive #SIGIR Issue Date: 2018-01-01
[Paper Note] Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval, Liu+, NAACL-HLT'15, 2015.05
Paper/Blog Link My Issue
#NeuralNetwork #Search #MultitaskLearning #QueryClassification #WebSearch #RepresentationLearning #NAACL #Surface-level Notes Issue Date: 2018-02-05 Comment
クエリ分類と検索をNeural Netを用いてmulti-task learningする研究
分類(multi-class classification)とランキング(pairwise learning-to-rank)という異なる操作が必要なタスクを、multi task learningの枠組みで組み合わせた(初めての?)研究。
この研究では分類タスクとしてクエリ分類、ランキングタスクとしてWeb Searchを扱っている。
モデルの全体像は下図の通り。
shared layersの部分で、クエリとドキュメントを一度共通の空間に落とし、そのrepresentationを用いて、l3においてtask-specificな空間に写像し各タスクを解いている。
分類タスクを解く際には、outputはsigmoidを用いる(すなわち、output layerのユニット数はラベル数分存在する)。
Web Searchを解く際には、クエリとドキュメントをそれぞれtask specificな空間に別々に写像し、それらのcosine similarityをとった結果にsoftmaxをかけることで、ドキュメントのrelevance scoreを計算している。
学習時のアルゴリズムは上の通り。各タスクをランダムにpickし、各タスクの目的関数が最適化されるように思いをSGDで更新する、といったことを繰り返す。
なお、alternativeとして、下図のようなネットワーク構造を考えることができるが(クエリのrepresentationのみがシェアされている)、このモデルの場合はweb searchがあまりうまくいかなかった模様。
理由としては、unbalancedなupdates(クエリパラメータのupdateがdocumentよりも多くアップデートされること)が原因ではないかと言及しており、multi-task modelにおいては、パラメータをどれだけシェアするかはネットワークをデザインする上で重要な選択であると述べている。
評価で用いるデータの統計量は下記の通り。
1年分の検索ログから抽出。クエリ分類(各クラスごとにbinary)、および文書のrelevance score(5-scale)は人手で付与されている。
クエリ分類はROC曲線のAUCを用い、Web SearchではNDCG (Normalized Discounted Cumulative Gain) を用いた。

multi task learningをした場合に、性能が向上している。
また、ネットワークが学習したsemantic representationとSVMを用いて、domain adaptationの実験(各クエリ分類のタスクは独立しているので、一つのクエリ分類のデータを選択しsemantic representationをtrainし、学習したrepresentationを別のクエリ分類タスクに適用する)も行なっており、訓練事例数が少ない場合に有効に働くことを確認(Letter3gramとWord3gramはnot trained/adapted)。

また、SemanticRepresentationへ写像する行列W1のパラメータの初期化の仕方と、サンプル数の変化による性能の違いについても実験。DNN1はW1をランダムに初期化、DNN2は別タスク(別のクエリ分類タスク)で学習したW1でfixする手法。
訓練事例が数百万程度ある場合は、DNN1がもっとも性能がよく、数千の訓練事例数の場合はsemantic representationを用いたSVMがもっともよく、midium-rangeの訓練事例数の場合はDNN2がもっとも性能がよかったため、データのサイズに応じて手法を使い分けると良い。
データセットにおいて、クエリの長さや文書の長さが記述されていないのがきになる。
[Paper Note] Contextual Dueling Bandits, Miroslav Dudík+, COLT'15, 2015.02
Paper/Blog Link My Issue
#LearningToRank #Online/Interactive #COLT Issue Date: 2018-01-01 GPT Summary- 相対的なペアワイズ比較を用いて文脈情報を活用した行動選択の学習問題を、デュエリングバンディットフレームワークで拡張して研究。新たに提案する「フォン・ノイマン勝者」は、他のポリシーに勝つか引き分けるランダム化ポリシーで、コンドルセ勝者の制限を克服。オンライン学習のための3つの効率的なアルゴリズムを提示し、特に低い後悔を達成するアルゴリズムはポリシー空間に対して線形の要件を持つ。その他の2つは、オラクルへのアクセスがあれば対数的な要件で済む。
Machine Learning for Information Retrieval, Katja Hofmann, ESSIR'15 Tutorial, 2015.09
Paper/Blog Link My Issue
#Tutorial #LearningToRank #Slide Issue Date: 2018-01-01
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, Huang+, CIKM'13
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #Contents-based #CIKM Issue Date: 2021-06-01 Comment
[Paper Note] Lerot: Online Learning to rank Framework, Schuth+, LivingLab'13, 2013.11
Paper/Blog Link My Issue
#Tools #LearningToRank #Online/Interactive Issue Date: 2018-01-01
[Paper Note] Reusing Historical Interaction Data for Faster Online Learning to Rank for IR, Hofmann+, WSDM'13
Paper/Blog Link My Issue
#LearningToRank #Online/Interactive #Interleaved #WSDM #One-Line Notes Issue Date: 2018-01-01 Comment
[Paper Note] Interactively Optimizing Information Retrieval Systems as a Dueling Bandits Problem, Yue+, ICML'09
DBGDを拡張した手法を提案している。
アルゴリズムが細かく書いてあるので、追っていくとDBGD等について理解が深まると思われる。
Interleavemethodについても。
Practical Online Retrieval Evaluation, SIGIR'11, Tutorial
Paper/Blog Link My Issue
#Tutorial #OnlineEvaluation #Slide #SIGIR Issue Date: 2018-01-01
[Paper Note] Ranking Comments on Social Web, Hsu+, CSE'09
Paper/Blog Link My Issue
#Comments #LearningToRank #KeyPoint Notes Issue Date: 2018-01-15 Comment
Learning to Rankによってコメントをランキングする手法を提案。
これにより、低品質なコメントははじき、良質なコメントをすくいとることができる。
素性としては、主にユーザに基づく指標(ユーザが作成した記事の数、プロフィールが何度閲覧されたかなど)と、コメントのContentに基づく指標(コメントの長さやコメントと記事の類似度など)が用いられている。
User-basedなfeatureとcontent-basedなfeatureの両者を組み合わせた場合に最も良い性能。
個々の素性ごとにみると、User-basedなfeatureではuser comment history(コメントをしているユーザが過去にどれだけratingされているか、やcommentに対してどれだけreplyをもらっているか)、content-basedなfeatureではcomment-article(commentと本文のoverlap, commentと本文のpolarityの差)が最も性能に寄与。
[Paper Note] Interactively Optimizing Information Retrieval Systems as a Dueling Bandits Problem, Yue+, ICML'09
Paper/Blog Link My Issue
#LearningToRank #Online/Interactive #ICML #KeyPoint Notes Issue Date: 2018-01-01 Comment
online learning to rankに関する論文でよくreferされる論文
提案手法は、Dueling Bandit Gradient Descent(DBGD)と呼ばれる.
onlineでlearning to rankを行える手法で、現在の重みwとwをランダムな方向に動かした新たな重みw'を使って、予測を行い、duelを行う。
duelを行った結果、新たな重みw'の方が買ったら、重みwをその方向に学習率分更新するというシンプルな手法
duelのやり方は、詳しく書いてないからなんともよくわからなかったが、Interleavedなlist(二つのモデルのoutputを混合したリスト)などを作り、実際にユーザにリストを提示してユーザがどのアイテムをクリックしたかなどから勝敗の確率値を算出し利用する、といったやり方が、IRの分野では行われている。
onlineでユーザのフィードバックから直接モデルを学習したい場合などに用いられる。
offlineに持っているデータを使って、なんらかのmetricを計算してduelをするという使い方をしたかったのだが、その使い方はこの手法の本来の使い方ではない(単純に何らかのmetricに最適化するというのであれば目的関数が設計できるのでそっちの手法を使ったほうが良さそうだし)。
そもそもこの手法は単純にMetricとかで表現できないもの(ユーザの満足度とか)を満たすようなweightをexploration/exploitationを繰り返して見つけていこう、というような気持ちだと思われる。
[Paper Note] Large Scale Learning to Rank, Sculley+, NIPS'09
Paper/Blog Link My Issue
#LearningToRank #PairWise #NeurIPS #KeyPoint Notes Issue Date: 2018-01-01 Comment
sofia-mlの実装内容について記述されている論文
よくonline学習の文脈で触れられるが、気をつけないと罠にはまる。
というのは、sofia-ml内のMethodsによって、最適化している目的関数が異なるからだ。
実装をみると、全てのmethodsがonlineでできちゃいそうに見える(学習済みのモデルをinputして学習を再開させられるため)が、落とし穴。
まず、SGD SVM, Pegasos SVM,については、最適化している目的関数がbatchになっているため、online learningではない。
passive-aggressive perceptrionは目的関数が個別の事例に対して定式化される(要確認)のでonline learningといえる。
(ROMMAは調べないとわからん)
pairwiseのlearning to rankでは、サンプルのペアを使って学習するので、最悪の場合O(n^2)の計算量がかかってしまってめっちゃ遅いのだが、実は学習データを一部サンプリングして重みを更新するってのをたくさん繰り返すだけで、高速に学習できちゃうという話。
実際、sofia-mlを使って見たら、liblinearのranking SVM実装で40分かかった学習が数秒で終わり、なおかつ精度も良かった。
[Paper Note] How Does Clickthrough Data Reflect Retrieval Quality?, Radlijnski+, CIKM'08
Paper/Blog Link My Issue
#LearningToRank #Interleaved #CIKM Issue Date: 2018-01-01
[Paper Note] Fast Learning of Document Ranking Functions with the Committee Perceptrion, Elsas+, WSDM'08
Paper/Blog Link My Issue
#LearningToRank #Online/Interactive #WSDM Issue Date: 2018-01-01
[Paper Note] Listwise Approach to Learning to Rank - Theory and Algorithm (ListMLE), Xia+, ICML'08
Paper/Blog Link My Issue
#LearningToRank #ListWise #ICML Issue Date: 2018-01-01
[Paper Note] Personalized Multi-document Summarization in Information Retrieval, Yang+, Machine Learning and Cybernetics'08, 2008.07
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #Personalization #KeyPoint Notes Issue Date: 2017-12-28 Comment
・検索結果に含まれるページのmulti-document summarizationを行う.クエリとsentenceの単語のoverlap, sentenceの重要度を
Affinity-Graphから求め,両者を結合しスコアリング.MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
likeな手法で冗長性を排除し要約を生成する.
・4人のユーザに,実際にシステムを使ってもらい,5-scaleで要約の良さを評価(ベースラインなし).relevance, importance,
usefulness, complement of summaryの視点からそれぞれを5-scaleでrating.それぞれのユーザは,各トピックごとのドキュメントに
全て目を通してもらい,その後に要約を読ませる.
[Paper Note] Learning to Rank: From Pairwise Approach to Listwise Approach (ListNet), Cao+, ICML'07
Paper/Blog Link My Issue
#LearningToRank #ListWise #ICML #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-01 Comment
解説スライド:
http://www.nactem.ac.uk/tsujii/T-FaNT2/T-FaNT.files/Slides/liu.pdf
解説ブログ:
https://qiita.com/koreyou/items/a69750696fd0b9d88608
従来行われてきたLearning to Rankはpairwiseな手法が主流であったが、pairwiseな手法は2つのインスタンス間の順序が正しく識別されるように学習されているだけであった。
pairwiseなアプローチには以下の問題点があった:
* インスタンスのペアのclassification errorを最小化しているだけで、インスタンスのランキングのerrorを最小化しているわけではない。
* インスタンスペアが i.i.d な分布から生成されるという制約は強すぎる制約
* queryごとに生成されるインスタンスペアは大きく異なるので、インスタンスペアよりもクエリに対してバイアスのかかった学習のされ方がされてしまう
これらを解決するために、listwiseなアプローチを提案。
listwiseなアプローチを用いると、インスタンスのペアの順序を最適化するのではなく、ランキング全体を最適化できる。
listwiseなアプローチを用いるために、Permutation Probabilityに基づくloss functionを提案。loss functionは、2つのインスタンスのスコアのリストが与えられたとき、Permutation Probability Distributionを計算し、これらを用いてcross-entropy lossを計算するようなもの。
また、Permutation Probabilityを計算するのは計算量が多すぎるので、top-k probabilityを提案。
top-k probabilityはPermutation Probabilityの計算を行う際のインスタンスをtop-kに限定するもの。
論文中ではk=1を採用しており、k=1はsoftmaxと一致する。
パラメータを学習する際は、Gradient Descentを用いる。
k=1の設定で計算するのが普通なようなので、普通にoutputがsoftmaxでlossがsoftmax cross-entropyなモデルとほぼ等価なのでは。
[Paper Note] A support vector method for Optimizing Average Precision, Yue+, SIGIR'07
Paper/Blog Link My Issue
#MachineLearning #StructuredLearning #SIGIR #One-Line Notes Issue Date: 2017-12-31 Comment
SVM-MAPの論文
構造化SVMを用いて、MAPを直接最適化する。
[Paper Note] Leave a Reply: An Analysis of Weblog Comments, Mishne+, WWW'06
Paper/Blog Link My Issue
#Analysis #Comments #WWW #KeyPoint Notes Issue Date: 2018-01-15 Comment
従来のWeblog研究では、コメントの情報が無視されていたが、コメントも重要な情報を含んでいると考えられる。
この研究では、以下のことが言及されている。
* (収集したデータの)ブログにコメントが付与されている割合やコメントの長さ、ポストに対するコメントの平均などの統計量
* ブログ検索におけるコメント活用の有効性(一部のクエリでRecallの向上に寄与、Precisionは変化なし)。記事単体を用いるのとは異なる観点からのランキングが作れる。
* コメント数とPV数、incoming link数の関係性など
* コメント数とランキングの関係性など
* コメントにおける議論の同定など
相当流し読みなので、読み違えているところや、重要な箇所の読み落とし等あるかもしれない。
[Paper Note] Learning to Rank using Gradient Descent (RankNet), Burges+, ICML'05
Paper/Blog Link My Issue
#LearningToRank #PairWise #ICML #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
pair-wiseのlearning2rankで代表的なRankNet論文
解説ブログ:
https://qiita.com/sz_dr/items/0e50120318527a928407
lossは2個のインスタンスのpair、A, Bが与えられたとき、AがBよりも高くランクされる場合は確率1, AがBよりも低くランクされる場合は確率0、そうでない場合は1/2に近くなるように、スコア関数を学習すれば良い。
[Paper Note] Personalizing Search via Automated Analysis of Interests and Activities, Teevan+, SIGIR'05, 2005.08
Paper/Blog Link My Issue
#Personalization #SIGIR #One-Line Notes Issue Date: 2017-12-28 Comment
・userに関するデータがrichなほうが、Personalizationは改善する。
・queries, visited web pages, emails, calendar items, stored desktop
documents、全てのsetを用いた場合が最も良かった
(次点としてqueriesのみを用いたモデルが良かった)
[Paper Note] PRanking with Ranking, Crammer+, NIPS'01
Paper/Blog Link My Issue
#LearningToRank #PointWise #NeurIPS #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
Point-WiseなLearning2Rankの有名手法
[Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Search #SIGIR #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-17 Comment
Maximal Marginal Relevance (MMR) 論文。
検索エンジンや文書要約において、文書/文のランキングを生成する際に、既に選んだ文書と類似度が低く、かつqueryとrelevantな文書をgreedyに選択していく手法を提案。
ILPによる定式化が提案される以前のMulti Document Summarization (MDS) 研究において、冗長性の排除を行う際には典型的な手法。
[Paper Note] OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis, Li+, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Search #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #OpenSource #Selected Papers/Blogs #Reproducibility #DeepResearch #One-Line Notes #LongHorizon #Initial Impression Notes #Environment Issue Date: 2026-02-10 Comment
元ポスト:
APIに依存せずオフラインコーパスと検索を利用し、高品質なDeepResearchのlong horizonなtrajectoryを合成可能な環境を構築。合成したtrajectoryでNemotron-3-nano-30B-A3B-BaseをSFTすることで、Kimi-K2, GLM-4.6などの10倍以上大きいサイズのモデルよりもBrowseCompで高い性能を獲得。同サイズのTongyiDeepResearchもoutperform。
Deterministicなプロセスで、オフラインコーパスからデータを合成し外部APIに依存しないため完全に再現性があり、かつAPIのコストやrate limitにも引っかからないという利点がある。検索エンジン、コード、データ、合成データ、モデル、全てを公開。
完全に再現性のある研究は素晴らしい。
new-datasets-in-machine-learning, librarian-bots, 2026.02
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #ComputerVision #MachineLearning #NLP #Dataset #Evaluation #SpeechProcessing #Robotics #Live Issue Date: 2026-02-09 Comment
元ポスト:
ModernBERTをFinetuningした分類器を用いてデータセットやベンチマークを提案している研究を自動分類して検索できるようにしている。有用
SID-1 Technical Report: Test-Time Compute for Retrieval, SID Research, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #AIAgents #Proprietary #Selected Papers/Blogs #KeyPoint Notes #Scalability #train-inference-gap Issue Date: 2025-12-15 Comment
元ポスト:
Figure4の話が非常に興味深い。rolloutの結果をtraining engineに渡す間のchat_templateによる抽象化では、マルチターン+tooluseにおいては、たとえばtool call周辺のホワイトスペースに関する情報を消してしまう問題がある。具体的には、一例として、ポリシーがホワイトスペースを含まないフォーマットの誤りがあるrolloutを生成した場合(=B)を考える。これをtraining engineに渡す際は、以下のような操作を伴うが
>apply_chat_template(parse(B))=G′
この際に、parse→apply_chat_templateの過程でtoolcall周辺のホワイトスペースが補完されるためtraining側ではホワイトスペースが含まれたrollout時とはトークン列が与えられる。この結果、フォーマットに誤りがある状態でrolloutされたにも関わらず、trainingエンジン側では正しい生成結果に擬似的に見える(=G')のだが、ホワイトスペースが含まれたことでトークナイズ結果が変わり、変化したトークンの部分が極端に小さなlogprobを持つことになる(i.e., ホワイトスペースは実装上の都合で生じ、ポリシーはそのトークンを(尤度が低く)出力していないにもかかわらず、出力されたことにされて学習される)。その結果、見かけ上は正しい生成結果なのだが、負のAdvantageを持つことになり、GRPOではそのような生成がされないように学習されてしまう。これが繰り返されることで、学習の安定性を損なう、という話である。
Introducing zerank-2: The Most Accurate Multilingual Instruction-Following Reranker, ZeroEntropy, 2025.11
Paper/Blog Link My Issue
#Article #RecommenderSystems #Embeddings #NLP #Blog #OpenWeight #Reranking Issue Date: 2025-11-20 Comment
HF: https://huggingface.co/zeroentropy/zerank-2
SoTA reranker
zerank-1, zeroentropy, 2025.07
Paper/Blog Link My Issue
#Article #RecommenderSystems #OpenWeight #Encoder #Reranking Issue Date: 2025-10-23 Comment
SoTAなcross-encoderに基づくreranker。おそらく英語にのみ対応。
zerank-1はcc-by-nc-4.0, smallはApache2.0ライセンス
How to Fix Your Context, dbreunig.com, 2025.07
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #AIAgents #Pruning #RAG(RetrievalAugmentedGeneration) #Blog #SoftwareEngineering #ContextEngineering Issue Date: 2025-09-28 Comment
Context Poisoning, Context Distraction, Context Confusion,
Context Clashの定義とそれらの対処法について書かれている。後ほど追記する
Advanced RAG Techniques: Elevating Your Retrieval-Augmented Generation Systems, NirDiamant, 2025.01
Paper/Blog Link My Issue
#Article #Tutorial #NLP #RAG(RetrievalAugmentedGeneration) #Repository #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-01-05 Comment
元ポスト:
RAGのための細かなテクニックが(コードのサンプルへのリンク付きで)大量にまとまっている。かなり頻繁に更新れているようで非常に良さそう
まだ更新されている。
BM42: New Baseline for Hybrid Search, Qdrant, 2024.07
Paper/Blog Link My Issue
#Article #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-12-01
RAGの改善方法に関する情報のまとめ(再掲), GENZITSU, 2023.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-11-07
RAGの実装戦略まとめ, Jin Watanabe, 2024.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-09-29
NotebookLM, Google, 2024.09
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #GenerativeAI #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-09-29 Comment
ソーステキストをアップロードし、それらを参照可能なLLMの元作業が可能で、クエリによって引用つきのRAGのようなものが行えるらしい。2人の対話形式のpodcastも自動生成可能で、UI/UXの面で画期的らしい?
Late Chunking: Balancing Precision and Cost in Long Context Retrieval, Pierse+, 2024.09
Paper/Blog Link My Issue
#Article #Embeddings #NLP #RAG(RetrievalAugmentedGeneration) #Blog #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-09-08 Comment
chunkingしてからembeddingを取得するより、全体のドキュメントに対してcontextualなtoken embeddingを取得し、その後chunkingをしてpoolingしてsingle vectorにする方が、文書の文脈情報がembedding内で保持されやすいので、precisionが上がりますよ、という話
RAG入門: 精度改善のための手法28選, 2024.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-08-09
RAG-Research-Insights
Paper/Blog Link My Issue
#Article #Tutorial #Survey #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog #Reading Reflections Issue Date: 2024-03-05 Comment
RAGに関する研究が直近のものまでよくまとめられている
awesome-generative-information-retrieval
Paper/Blog Link My Issue
#Article #Tutorial #Survey #LanguageModel #Blog Issue Date: 2024-02-22
RAGの性能を改善するための8つの戦略
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Reading Reflections Issue Date: 2024-02-11 Comment
めちゃめちゃ詳細にRAG性能向上の手法がreference付きでまとまっている。すごい。
Structured Hierarchical Retrieval, llama-index
Paper/Blog Link My Issue
#Article #NLP #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-12-21 Comment
元ツイート:
Build a search engine, not a vector DB
Paper/Blog Link My Issue
#Article #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-12-21
kaggle LLM コンペ 上位解法を自分なりにまとめてみた話
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-12-04 Comment
実践的な内容(チャンク生成時の工夫、クエリ生成時の工夫等)が網羅的にまとまっており非常に有用
個人的に、コンペ主催者側から提供されたデータが少なく、上位のほとんどのチームがChatGPT(3.5, 4)を用いて、QAデータを生成していた、というのが興味深かった。プロンプトはたとえば下記:
[(5th-place-solution)](
https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/446293)より引用
```
system_content = """
Forget all the previous instruction and rigorously follow the rule specified by the user.
You are a professional scientist's assistant.
"""
user_content_template_qa = Template(
"""
Please consider 5 choices question and answer of the following TEXT.
The purpose of this question is to check respondent's deep science understanding of the TEXT.
We assume this question is for professional scientists, so consider super difficult question.
You can ask very detailed question, for example check specific sentence's understanding.
It is good practice to randomly choose specific sentence from given TEXT, and make QA based on this specific sentence.
You must make QA based on the fact written in the TEXT.
You may create wrong answers based on the correct answer's information, by modifying some parts of the correct answer.
Your response must be in following format, don't write any other information.
You must not include "new line" in each Q), 1), 2), 3), 4), 5), and A):
Q) `question text comes here`
1) `answer candidate 1`
2) `answer candidate 2`
3) `answer candidate 3`
4) `answer candidate 4`
5) `answer candidate 5`
A) `answer`
where only 1 `answer candidate` is the correct answer and other 4 choices must be wrong answer.
Note1: I want to make the question very difficult, so please make wrong answer to be not trivial incorrect.
Note2: The answer candidates should be long sentences around 30 words, not the single word.
Note3: `answer` must be 1, 2, 3, 4 or 5. `answer` must not contain any other words.
Note4: Example of the question are "What is ...", "Which of the following statements ...", "What did `the person` do",
and "What was ...".
Note5: Question should be science, technology, engineering and mathematics related topic.
If the given TEXT is completely difference from science, then just output "skip" instead of QA.
Here is an example of your response, please consider this kind of difficulty when you create Q&A:
Q) Which of the following statements accurately describes the impact of Modified Newtonian Dynamics (MOND) on the observed "missing baryonic mass" discrepancy in galaxy clusters?"
1) MOND is a theory that reduces the observed missing baryonic mass in galaxy clusters by postulating the existence of a new form of matter called "fuzzy dark matter."
2) MOND is a theory that increases the discrepancy between the observed missing baryonic mass in galaxy clusters and the measured velocity dispersions from a factor of around 10 to a factor of about 20.
3) MOND is a theory that explains the missing baryonic mass in galaxy clusters that was previously considered dark matter by demonstrating that the mass is in the form of neutrinos and axions.
4) MOND is a theory that reduces the discrepancy between the observed missing baryonic mass in galaxy clusters and the measured velocity dispersions from a factor of around 10 to a factor of about 2.
5) MOND is a theory that eliminates the observed missing baryonic mass in galaxy clusters by imposing a new mathematical formulation of gravity that does not require the existence of dark matter.
A) 4
Let's start. Here is TEXT: $title\n$text
"""
)
```
Retrieval-based LM (RAG System)ざっくり理解する, Shumpei Miyawaki, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Slide #KeyPoint Notes Issue Date: 2023-11-06 Comment
(以下スクショはスライドより引用)
次のスクショはRAGにかかわる周辺技術がよくまとまっていると思う。
以下ざっくり私の中の認識として
- 計画
- クエリ拡張
- クエリの質が悪い場合検索性能が劣化するため、クエリをより適切に検索ができるように修正(昔はキーワードしか与えられないときに情報を増やすから”拡張”という文言が用いられているが現在はこれに限らないと思う)する技術
- 分解・抽象化
- 複雑なクエリから分解することでマルチホップの質問をサブ質問に分解(今ならLLMを利用すれば比較的簡単にできる)したり、あるいは抽象化したクエリ(Step-back Promptnig [Paper Note] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N/A, ICLR'24
)を活用することで検索を改善する技術
- 検索対象選定
- 検索する対象そのものを選択し、検索対象をフィルタリングする技術
- 資料中ではLLMを用いたフィルタリングやClassifierを用いたフィルタリングが紹介されているが、メタデータで絞り込むなどの単純な方法でも実現可能だと思われる(メタデータで絞り込む、はClassifierでのフィルタリングとリンクするかもしれないが)
- 思考・行動
- [Paper Note] ReAct: Synergizing Reasoning and Acting in Language Models, Shunyu Yao+, ICLR'23, 2022.10
のような自律的にLLMに思考とその結果に基づく行動をイテレーションさせる技術や、クエリを分解して回答へたどり着くために必要な推論を構築し、各推論の回答を検証しながら生成を繰り返す技術が紹介されている
- この辺の技術はクエリが非常に複雑な場合に有効ではあるが、シンプルな場合は必要ないかなという印象がある
- シンプルなユースケースの場合はどちらかというと泥臭い前処理とかが効きそう
- 関連知識取得
- 検索
- 表層検索(TF-IDFベクトル, BM25)などの古典的な手法や、意味検索(Embeddingに基づく手法)が紹介されている
- 例えばlangchainでは表層検索 + 意味検索の両者がサポートされており、簡単にハイブリッドな検索が実現できる
- 知識文生成
- 外部知識として検索された文書を利用するだけでなく、LLM自身が保持する知識を活用するためにLLMが生成した文書の両方を活用するとQAの正答率が向上することが紹介されている
- 文書フィルタ
- 検索でクエリに関連しない文書を取得してしまう応答品質が大幅に低下することが紹介されている
- 個人的にはここが一番重要なパートだと考えている
- また、検索結果を要約する方法も紹介されている
- 再帰・反復計算
- Retrierverから取得した結果に基づいてLLMが応答を生成し、生成した応答とoriginalのquestionの両方を組み合わせて追加でRetrieverから文書を取得し生成する手法などが紹介されている
- リランキング
- 検索結果のリランキングも古くから存在する技術であり、異なる知識を持つRankerによってリランキングさせることで性能が向上する場合がある
- 回答
- 回答抽出・生成
- 回答となる部分のspanを抽出する手法と、spanではなくテキストを生成する手法が紹介されている
- この辺は文書要約におけるExtractive/Abstractive Summarization技術などもかなり応用が効くと思われる
- インデクシング
- 不要文書のフィルタリングや、チャンク分割の戦略、資格情報をテキスト化する方法などが紹介されている
Measuring the impact of online personalisation: Past, present and future
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #Personalization #KeyPoint Notes #needs-revision Issue Date: 2023-04-28 Comment
Personalizationに関するML, RecSys, HCI, Personalized IRといったさまざまな分野の評価方法に関するSurvey
ML + RecSys系では、オフライン評価が主流であり、よりaccuracyの高い推薦が高いUXを実現するという前提に基づいて評価されてきた。一方HCIの分野ではaccuracyに特化しすぎるとUXの観点で不十分であることが指摘されており、たとえば既知のアイテムを推薦してしまったり、似たようなアイテムばかりが選択されユーザにとって有用ではなくなる、といったことが指摘されている。このため、ML, RecSys系の評価ではdiversity, novelty, serendipity, popularity, freshness等の新たなmetricが評価されるように変化してきた。また、accuracyの工場がUXの向上に必ずしもつながらないことが多くの研究で示されている。
一方、HCIやInformation Systems, Personalized IRはuser centricな実験が主流であり、personalizationは
- 情報アクセスに対するコストの最小化
- UXの改善
- コンピュータデバイスをより効率的に利用できるようにする
という3点を実現するための手段として捉えられている。HCIの分野では、personalizationの認知的な側面についても研究されてきた。
たとえば、ユーザは自己言及的なメッセージやrelevantなコンテンツが提示される場合、両方の状況においてpersonalizationされたと認知し、後から思い出せるのはrelevantなコンテンツに関することだという研究成果が出ている。このことから、自己言及的なメッセージングでユーザをstimulusすることも大事だが、relevantなコンテンツをきちんと提示することが重要であることが示されている。また、personalizationされたとユーザが認知するのは、必ずしもpersonalizationのプロセスに依存するのではなく、結局のところユーザが期待したメッセージを受け取ったか否かに帰結することも示されている。
user-centricな評価とオフライン評価の間にも不一致が見つかっている。たとえば
- オフラインで高い精度を持つアルゴリズムはニッチな推薦を隠している
- i.e. popularityが高くrelevantな推薦した方がシステムの精度としては高く出るため
- オフライン vs. オンラインの比較で、ユーザがアルゴリズムの精度に対して異なる順位付けをする
といったことが知られている。
そのほかにも、企業ではofflineテスト -> betaテスターによるexploratoryなテスト -> A/Bテストといった流れになることが多く、Cognitive Scienceの分野の評価方法等にも触れている。
Preface to Special Issue on User Modeling for Web Information Retrieval, Brusilovsky+, User Modeling and User-Adapted Interaction , 2004
Paper/Blog Link My Issue
#Article #Personalization #One-Line Notes Issue Date: 2023-04-28 Comment
Personalized Information Retrievalの先駆け的研究
[Paper Note] Adaptive Web Search Based on User Profile Constructed without Any Effort from Users, Sugiyama+, NAIST, WWW’04
と同時期
User Profiles for Personalized Information Access, Gauch+, The adaptive Web: methods and strategies of Web personalization, 2007
Paper/Blog Link My Issue
#Article #Survey #Personalization #One-Line Notes Issue Date: 2023-04-28 Comment
IR分野におけるuser profileの構築方法についてまとめられたsurvey
- 加重キーワード
- セマンティックネットワーク
- 加重コンセプト
について記述されている。また、プロファイルの構築方法についても詳述されている。
[Paper Note] Adaptive Web Search Based on User Profile Constructed without Any Effort from Users, Sugiyama+, NAIST, WWW’04
Paper/Blog Link My Issue
#Article #CollaborativeFiltering #RelevanceFeedback #Search #WebSearch #Personalization #KeyPoint Notes Issue Date: 2023-04-28 Comment
検索結果のpersonalizationを初めてuser profileを用いて実現した研究
user profileはlong/short term preferenceによって構成される。
- long term: さまざまなソースから取得される
- short term: 当日のセッションの中だけから収集される
① browsing historyの活用
- browsing historyのTFから求め Profile = P_{longterm} + P_{shortterm}とする
② Collaborative Filtering (CF) の活用
- user-item matrixではなく、user-term matrixを利用
- userの未知のterm-weightをCFで予測する
- => missing valueのterm weightが予測できるのでprofileが充実する
実験結果
- 検証結果(googleの検索結果よりも提案手法の方が性能が良い)
- 検索結果のprecision向上にlong/short term preferenceの両方が寄与
- longterm preferenceの貢献の方が大きいが、short termも必要(interpolation weight 0.6 vs. 0.4)
- short termにおいては、その日の全てのbrowsing historyより、現在のセッションのterm weightをより考慮すべき(interpolation weight 0.2 vs. 0.8)
Awesome Vector Search Engine
Paper/Blog Link My Issue
#Article #Survey #Embeddings #Search #Library #Repository #One-Line Notes Issue Date: 2023-04-27 Comment
ベクトルの類似度を測るサービスやライブラリ等がまとまったリポジトリ
Contrirever
Paper/Blog Link My Issue
#Article #Library Issue Date: 2023-04-26
Llamaindex
Paper/Blog Link My Issue
#Article #Tools #NLP #Library #AIAgents #Reference Collection Issue Date: 2023-04-22 Comment
- LlamaIndexのインデックスを更新し、更新前後で知識がアップデートされているか確認してみた
-
https://dev.classmethod.jp/articles/llama-index-insert-index/
LangChain
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Library #AIAgents #Reference Collection Issue Date: 2023-04-21 Comment
- LangChain の Googleカスタム検索 連携を試す
-
https://note.com/npaka/n/nd9a4a26a8932
- LangChainのGetting StartedをGoogle Colaboratoryでやってみる ④Agents
-
https://zenn.dev/kun432/scraps/8216511783e3da
[Paper Note] Opinion mining and sentiment analysis, Pang+, Foundations and Trends in Information Retrieval, 2008.01
Paper/Blog Link My Issue
#Article #Survey #SentimentAnalysis #NLP #OpinionMining Issue Date: 2018-01-15
[Paper Note] Evaluating implicit measures to improve web search, Fox+, ACM Transactions on Imformation Systems, 2005.04
Paper/Blog Link My Issue
#Article #Survey #RelevanceFeedback #ImplicitFeedback Issue Date: 2018-01-01
[Paper Note] A survey on the use of relevance feedback for information access systems., Ruthven+, The Knowledge Engineering Review, 2003.06
Paper/Blog Link My Issue
#Article #Survey #RelevanceFeedback #ExplicitFeedback Issue Date: 2018-01-01
Fast and Reliable Online Learning to Rank for Information Retrieeval, Katja Hofmann, Doctoral Thesis, 2013.04
Paper/Blog Link My Issue
#Article #Tutorial #Survey #LearningToRank #Online/Interactive Issue Date: 2018-01-01
[Paper Note] A General Approximation Framework for Direct Optimization of Information Retrieval Measures (ApproxAP, ApproxNDCG), Qin+, Information Retrieval, 2008.10
Paper/Blog Link My Issue
#Article #LearningToRank #ListWise #One-Line Notes Issue Date: 2018-01-01 Comment
実装してみたが、バグありそう感・・・
https://github.com/AkihikoWatanabe/ApproxAP
[Paper Note] From RankNet to LambdaRank to LambdaMART: An Overview, Burges, Microsoft Research Technical Report, 2010.06
Paper/Blog Link My Issue
#Article #Tutorial #LearningToRank Issue Date: 2018-01-01
Confidence Weightedでランク学習を実装してみた, 徳永拓之, 第4回 自然言語処理勉強会@東京, 2011.01
Paper/Blog Link My Issue
#Article #Tutorial #LearningToRank #Slide Issue Date: 2018-01-01
ランキング学習ことはじめ, DSIRNLP#1, 2011.07
Paper/Blog Link My Issue
#Article #Tutorial #LearningToRank #Slide Issue Date: 2018-01-01
[Paper Note] Learning to Rank for Information Retriefval, Tie-Yan Liu, 2009.03
Paper/Blog Link My Issue
#Article #Survey #LearningToRank Issue Date: 2018-01-01
SVM-MAP
Paper/Blog Link My Issue
#Article #MachineLearning #StructuredLearning #Tools #One-Line Notes Issue Date: 2017-12-31 Comment
構造化SVMを用いて、MAPを直接最適化する手法
[Paper Note] A task-oriented study on the influencing effects of query-biased summarization in web searching, White et al., Information Processing and Management, 2003.09
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #RelevanceJudgment #Snippets #QueryBiased #KeyPoint Notes Issue Date: 2017-12-28 Comment
・search engineにおいてquery-biasedな要約の有用性を示したもの
・task-orientedな評価によって,提案手法がGoogleやAltaVistaのスニペットよりも良いことを示す.
・提案手法は文選択によるquery-biased summarization.スコアリングには,ページのタイトルに含まれる単語がどれだけ含まれているか,文のページ内での出現位置,クエリとの関連度,文の書式(太字)などの情報を使う.
・スニペットが作れないページに対しては,エラーメッセージを返したり,ページ内の最初のnon-textualな要素を返したりする.
[Paper Note] Relevance judgment: What do information users consider beyond topicality? Xu Chen, Journal of the American Society for Information Science and Technology, 2006.05
Paper/Blog Link My Issue
#Article #RelevanceJudgment #One-Line Notes Issue Date: 2017-12-28 Comment
・relevanceとsignificantに関連するcriteriaは,topicalityとnovelty
・reliabilityおよびunderstandabilityはsmaller degreeでsignificant, scopeはsignificantでない
[Paper Note] A cognitive model of document use during a research project, Wang and Soergel, Journal of the American Society for Information Science, 1998.02
Paper/Blog Link My Issue
#Article #RelevanceJudgment #One-Line Notes Issue Date: 2017-12-28 Comment
topicality, orientation, quality, novelty(の順番で)がrelevantなdocumentを選択したときのcriteriaとして採用されていたことを報告
[Paper Note] Personalised Information retrieval: survey and classification, Rami+, User Modeling and User-Adapted Interaction, 2012.05
Paper/Blog Link My Issue
#Article #Survey #Personalization #KeyPoint Notes Issue Date: 2017-12-28 Comment
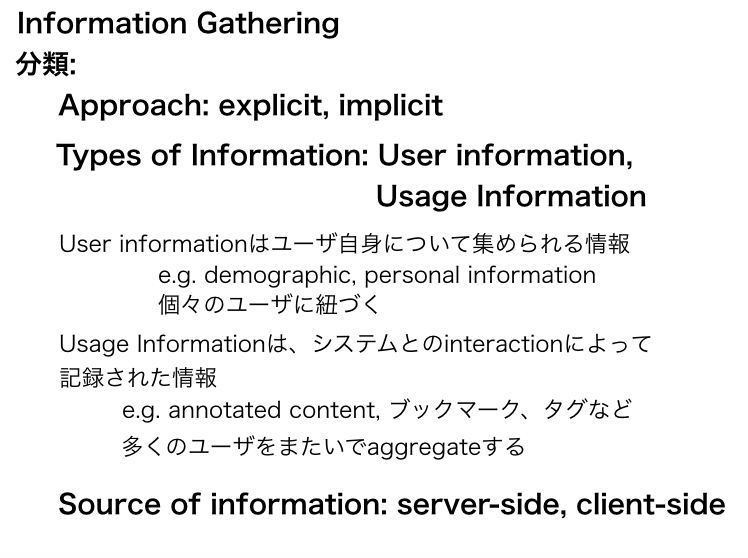
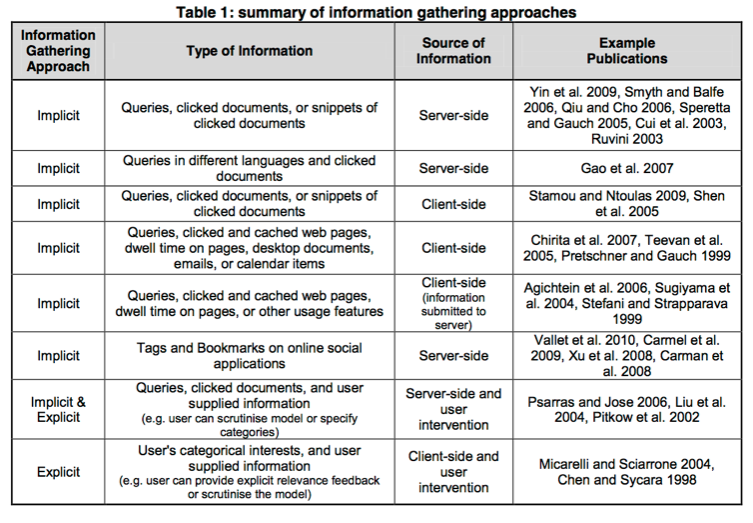
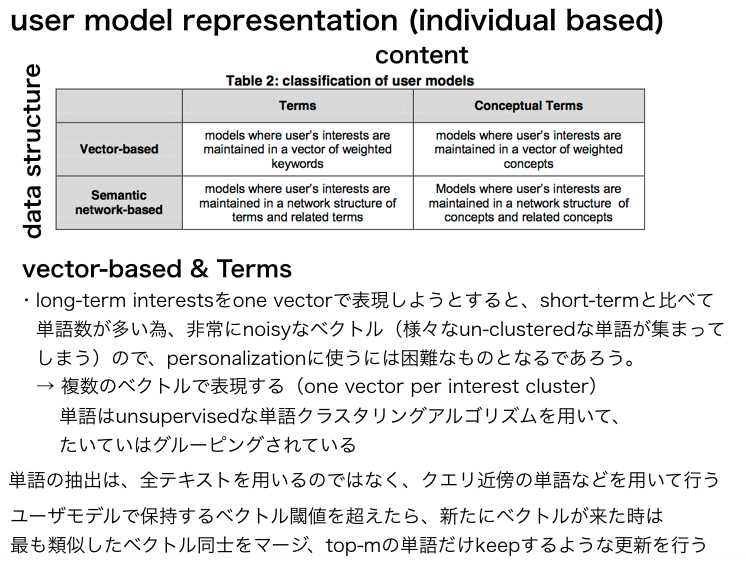
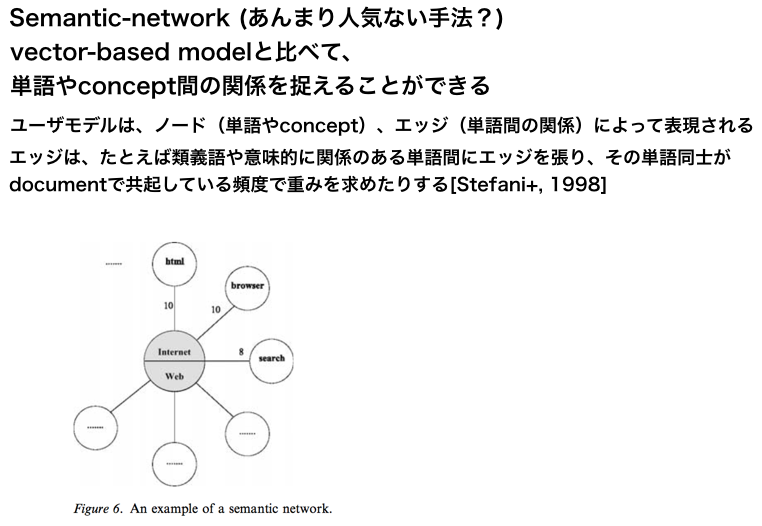
(以下は管理人が当時作成したスライドでのメモのスクショ)







完全に途中で力尽きている感
[Paper Note] Modeling Anchor Text and Classifying Queries to Enhance Web Document Retrieval, WWW’08, [Fujii, 2008], 2008.04
Paper/Blog Link My Issue
#Article #WWW #KeyPoint Notes Issue Date: 2017-12-28