
NAACL
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, NAACL'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Dataset #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Reasoning Issue Date: 2025-09-18 GPT Summary- 大規模言語モデル(LLMs)の性能向上を活かし、情報検索強化生成(RAG)機能を向上させるための評価データセットFRAMESを提案。FRAMESは、事実に基づいた応答、検索能力、推論を評価するための統一されたフレームワークを提供し、複数の情報源を統合するマルチホップ質問で構成。最先端のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に寄与することを目指す。
[Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation Issue Date: 2025-09-09 GPT Summary- MMLUベンチマークのエラーを分析し、ウイルス学のサブセットでは57%の質問にエラーがあることを発見。新しいエラー注釈プロトコルを用いてMMLU-Reduxを作成し、6.49%の質問にエラーが含まれると推定。MMLU-Reduxを通じて、モデルのパフォーマンスメトリックとの不一致を示し、MMLUの信頼性向上を提案。
[Paper Note] The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism, Yifan Song+, NAACL'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Decoding #Non-Determinism Issue Date: 2025-09-09 GPT Summary- LLMの評価は非決定性を見落としがちで、単一出力に焦点を当てるため性能の変動理解が制限される。本研究では、貪欲デコーディングとサンプリングの性能差を探求し、非決定性に関するベンチマークの一貫性を特定。実験により、貪欲デコーディングが多くのタスクで優れていることを確認し、アライメントがサンプリングの分散を減少させる可能性を示した。また、小型LLMが大型モデルに匹敵する性能を持つことを明らかにし、LLM評価における非決定性の重要性を強調した。 Comment
関連:
- [Paper Note] Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, Eval4NLP'25, 2024.08
利用されているデータセット:
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
- AlpacaEval, tatsu-lab, 2023.06
- [Paper Note] MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures, Jinjie Ni+, NeurIPS'24
- From Live Data to High-Quality Benchmarks: The Arena-Hard Pipeline, Li+, 2024.04
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
- [Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
[Paper Note] RewardBench: Evaluating Reward Models for Language Modeling, Nathan Lambert+, NAACL'25 Findings, 2024.05
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #ReinforcementLearning #Evaluation #Selected Papers/Blogs #RewardModel #Findings Issue Date: 2025-06-26 GPT Summary- 報酬モデル(RMs)の評価に関する研究は少なく、我々はその理解を深めるためにRewardBenchというベンチマークデータセットを提案。これは、チャットや推論、安全性に関するプロンプトのコレクションで、報酬モデルの性能を評価する。特定の比較データセットを用いて、好まれる理由を検証可能な形で示し、さまざまなトレーニング手法による報酬モデルの評価を行う。これにより、報酬モデルの拒否傾向や推論の限界についての知見を得ることを目指す。 Comment
[Paper Note] Where is the answer? Investigating Positional Bias in Language Model Knowledge Extraction, Kuniaki Saito+, NAACL'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Bias #PostTraining #PerplexityCurse #Selected Papers/Blogs #ContextEngineering #Surface-level Notes #Author Thread-Post Issue Date: 2025-05-02 GPT Summary- LLMは新しい文書でファインチューニングが必要だが、「困惑の呪い」により情報抽出が困難。特に文書の初めに関する質問には正確に答えるが、中間や末尾の情報抽出に苦労する。自己回帰的トレーニングがこの問題を引き起こすことを示し、デノイジング自己回帰損失が情報抽出を改善する可能性を示唆。これにより、LLMの知識抽出と新ドメインへの適応に関する新たな議論が生まれる。 Comment
元ポスト:

LLMの知識を最新にするために新しい文書(e.g., 新しいドメインの文書等)をLLMに与え(便宜上学習データと呼ぶ)Finetuningをした場合、Finetuning後のモデルで与えられたqueryから(LLM中にパラメータとしてmemorizeされている)対応する事実情報を抽出するようInferenceを実施すると、queryに対応する事実情報の学習データ中での位置が深くなると(i.e., middle -- endになると)抽出が困難になる Positional Biasが存在する[^1]ことを明らかにした。
そして、これを緩和するために正則化が重要(e.g., Denoising, Shuffle, Attention Drops)であることを実験的に示し、正則化手法は複数組み合わせることで、よりPositional Biasが緩和することを示した研究
[^1]: 本研究では"Training"に利用する文書のPositional Biasについて示しており、"Inference"時におけるPositional Biasとして知られている"lost-in-the middle"とは異なる現象を扱っている点に注意
## データセット
文書 + QAデータの2種類を構築しFinetuning後のknowledge extraction能力の検証をしている[^2]。
実験では、`Synthetic Bio (合成データ)`, `Wiki2023+(実データ)` の2種類のデータを用いて、Positional Biasを検証している。
Synthetic bioは、人間のbiographyに関する9つの属性(e.g., 誕生日, 出生地)としてとりうる値をChatGPTに生成させ、3000人の人物に対してそれらをランダムにassignし、sentence templateを用いてSurface Realizationすることで人工的に3000人のbiographyに関するテキストを生成している。
一方、Wiki2023+では、Instruction-tuned Language Models are Better Knowledge Learners, Zhengbao Jiang+, ACL'24
の方法にのっとって [^3]事前学習時の知識とのoverlapが最小となるように`2023`カテゴリ以下のwikipediaの様々なジャンルの記事を収集して活用する。QAデータの構築には、元文書からsentenceを抽出し、GPT-3.5-Turboに当該sentenceのみを与えてQA pairを作成させることで、データを作成している。なお、hallucinationや品質の低いQA pairをフィルタリングした。フィルタリング後のQA Pairをランダムにサンプリングし品質を確認したところ、95%のQA pairが妥当なものであった。
これにより、下図のようなデータセットが作成される。FigureCが `Wiki2023+`で、FigureDが`SyntheticBio`。`Wiki2023+`では、QA pairの正解が文書中の前半により正解が現れるような偏りが見受けられる。

[^2]: [Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
において、知識 + 知識を抽出するタスクの双方を用いて学習することで、モデルから知識を抽出する能力が備わることが示されているため。
[^3]: Llama-2-7Bにおいて2023カテゴリ以下の情報に対するQAのperformanceが著しく低いことから、事前学習時に当該データが含まれている可能性が低いことが示唆されている
## 実験 & 実験結果 (modulated data)
作成した文書+QAデータのデータセットについて、QAデータをtrain/valid/testに分けて、文書データは全て利用し、testに含まれるQAに適切に回答できるかで性能を評価する。このとき、文書中でQAに対する正解がテキストが出現する位置を変化させモデルの学習を行い、予測性能を見ることで、Positional Biasが存在することを明らかにする。このとき、[Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
に倣い、文書とQAをMixed Sampling(1バッチあたり256件のサンプルをランダムにQAおよび文書データからサンプリング;
# 1923 では文書とQAを2:8の比率でサンプリングしている)することで学習をする。QAの場合目的関数は回答テキスト部分のみのNLL、文書の場合はnext-token prediction lossを利用する。
Positional Biasの存在を示すだけでなく、(A, B, C) の順番でnext-token prediction lossで学習されたモデルの場合、Cの知識を抽出するためにA, Bがcontextとして必要となるため、Cを抽出する際の汎化性能を高めるためにA, Bの表現がより多様である必要がある、という課題がある。これに対処するためのいくつかのシンプルな正則化手法、具体的には
- D-AR: predition targetのトークンは保持したまま、input tokenの一部をランダムなトークンに置き換える
- Shuffle: 入力文をシャッフルする
- Attn Drop: self-attentionモジュールのattention weightをランダムに0にする
の3種類とPositional Biasの関係性を検証している。

検証の結果、(合成データ、実データともに)Positional Biasが存在することが明らかとなり(i.e., 正解テキストが文書中の深い位置にあればあるほど予測性能が低下する)正則化によってPositional Biasが緩和されることが示された。

また、異なるモデルサイズで性能を比較したところ、モデルサイズを大きくすることで性能自体は改善するが、依然としてPositional Biasが存在することが示され、ARよりもD-ARが一貫して高い性能を示した。このことから、Positional Biasを緩和するために何らかの正則化手法が必要なことがわかる。

また、オリジナル文書の1文目を、正解データの位置を入れ替えた各モデルに対して、テキスト中の様々な位置に配置してPerplexityを測った。この設定では、モデルがPerplexityを最小化するためには、(1文目ということは以前の文脈が存在しないsentenceなので)文脈に依存せずに文の記憶していなければならない。よって、各手法ごとにどの程度Perplexityが悪化するかで、各手法がどの程度あるsentenceを記憶する際に過去の文脈に依存しているかが分かる。ここで、学習データそのもののPerplexityはほぼ1.0であったことに注意する。
結果として、文書中の深い位置に配置されればされるほどPerplexityは増大し(left)、Autoregressive Model (AR) のPerplexity値が最も値が大きかった(=性能が悪かった)。このことから、ARはより過去の文脈に依存してsentenceの情報を記憶していることが分かる。また、モデルサイズが小さいモデルの方がPerplexityは増大する傾向にあることがわかった (middle)。これはFig.3で示したQAのパフォーマンスと傾向が一致しており、学習データそのもののPerplexityがほぼ1.0だったことを鑑みると、学習データに対するPerplexityは様々なPositionに位置する情報を適切に抽出できる能力を測るメトリックとしては適切でないことがわかる。また、学習のiterationを増やすと、ARの場合はfirst positionに対する抽出性能は改善したが、他のpositionでの抽出性能は改善しなかった。一方、D-ARの場合は、全てのpositionでの抽出性能が改善した (right) 。このことから、必ずしも学習のiterationを増やしても様々なPositionに対する抽出性能が改善しないこと、longer trainingの恩恵を得るためには正則化手法を利用する必要があることが明らかになった。

## 実験 & 実験結果 (unmodulated data)
Wiki2023+データに対して上記のようなデータの変更を行わずに、そのまま学習を行い、各位置ごとのQAの性能を測定したところ、(すべてがPositional Biasのためとは説明できないが)回答が文書中の深い位置にある場合の性能が劣化することを確認した。2--6番目の性能の低下は、最初の文ではシンプルな事実が述べられ、後半になればなるほどより複雑な事実が述べられる傾向があることが起因して性能の低下しているとかせつをたてている。また、unmodulated dataの場合でもD-ARはARの性能を改善することが明らかとなった。モデルサイズが大きいほど性能は改善するが、以前として文書中の深い位置に正解がある場合に性能は劣化することもわかる。
また、正則化手法は組み合わせることでさらに性能が改善し、[Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
に示されている通り、学習データ中の表現を多様にし[^1]学習したところ予測性能が改善し、正則化手法とも補完的な関係であることも示された。
医療ドメインでも実験したところ、正則化手法を適用した場合にARよりも性能が上回った。最後にWiki2023+データについてOpenbookな設定で、正解が含まれる文書をLLMのcontextとして与えた場合(i.e.,ほぼ完璧なretrieverが存在するRAGと同等の設定とみなせる)、QAの性能は90.6%に対し、継続学習した場合のベストモデルの性能は50.8%だった。このことから、正確なretrieverが存在するのであれば、継続学習よりもRAGの方がQAの性能が高いと言える。
RAGと継続学習のメリット、デメリットの両方を考慮して、適切に手法を選択することが有効であることが示唆される。
[^1]: ChatGPTによってテキストをrephraseし、sentenceのorderも変更することで多様性を増やした。が、sentence orderが文書中の深い位置にある場合にあまりorderが変化しなかったようで、このため深い位置に対するQAの性能改善が限定的になっていると説明している。
[Paper Note] Reverse Thinking Makes LLMs Stronger Reasoners, Justin Chih-Yao Chen+, NAACL'25
Paper/Blog Link My Issue
#NLP #DataAugmentation #Distillation #Verification #KeyPoint Notes Issue Date: 2024-12-02 GPT Summary- 逆思考は推論において重要であり、我々は大規模言語モデル(LLMs)向けにReverse-Enhanced Thinking(RevThink)フレームワークを提案。データ拡張と学習目標を用いて、前向きと後向きの推論を構造化し、マルチタスク学習で小型モデルを訓練。実験では、ゼロショット性能が平均13.53%向上し、知識蒸留ベースラインに対して6.84%の改善を達成。少ないデータでのサンプル効率も示し、一般化能力が高いことが確認された。 Comment
## 手法概要
Original QuestionからTeacher Modelでreasoningと逆質問を生成(Forward Reasoning, Backward Question)し、逆質問に対するReasoningを生成する(Backward Reasoning)。
その後、Forward Reasoningで回答が誤っているものや、Teacher Modelを用いてBackward ReasoningとOriginal Questionを比較して正しさをverificationすることで、学習データのフィルタリングを行う。
このようにして得られたデータに対して、3種類の項をlossに設けて学習する。具体的には
- Original Questionから生成したForward Reasoningに対するクロスエントロピー
- Original Questionから生成したBackward Questionに対するクロスエントロピー
- Backward Questionから生成したBackward Reasoningに対するクロスエントロピー
の平均をとる。
また、original questionと、backward reasoningが一貫しているかを確認するためにTeacher Modelを利用した下記プロンプトでverificationを実施し、一貫性があると判断されたサンプルのみをSFTのデータとして活用している。
Teacherモデルから知識蒸留をするためSFTが必要。あと、正解が一意に定まるようなQuestionでないとbackward reasoningの生成はできても、verificationが困難になるので、適用するのは難しいかもしれない。
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, N_A, NAACL'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Dataset #AIAgents #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Reasoning #One-Line Notes Issue Date: 2024-10-20 GPT Summary- LLMsを用いた情報検索強化生成(RAG)システムの性能評価のために、FRAMESという新しい評価データセットを提案。これは、事実に基づく応答、検索能力、推論を統一的に評価するもので、複数の情報源を統合するマルチホップ質問を含む。最新のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に貢献することを目指す。 Comment
RAGのfactuality, retrieval acculacy, reasoningを評価するためのmulti hop puestionとそれに回答するための最大15のwikipedia記事のベンチマーク
元ポスト:
[Paper Note] Logic-of-Thought: Injecting Logic into Contexts for Full Reasoning in Large Language Models, Tongxuan Liu+, NAACL'25, 2024.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #Initial Impression Notes Issue Date: 2024-09-29 GPT Summary- LLMの論理推論能力は依然として課題が残る。Chain-of-Thoughtなどの手法は改善をもたらすが、信頼性に問題がある。そこで、命題論理を利用したLogic-of-Thought(LoT)プロンプトを提案し、論理情報を強化することで推論能力を向上させる。実験では、LoTが多数の論理推論タスクで既存手法の性能を大幅に向上させることを示し、特にReClorおよびRuleTakerデータセットでの改善が顕著であった。 Comment
※ このメモは当初の原稿に対するものであり、NAACLの原稿では修正されている。
SNSで話題になっているようだがGPT-3.5-TurboとGPT-4でしか比較していない上に、いつの時点のモデルかも記述されていないので、unreliableに見える
ReClorデータセットで性能が向上しているのは個人的に興味深い。
[Paper Note] Can LLMs Convert Graphs to Text-Attributed Graphs?, Zehong Wang+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeGraph #needs-revision Issue Date: 2025-01-03 GPT Summary- 本研究では、グラフニューラルネットワーク(GNN)のクロスグラフ学習における課題を解決するため、新たにTopology-Aware Node Description Synthesis(TANS)を提案します。大規模言語モデル(LLM)を活用し、グラフのトポロジ情報をテキスト属性付きグラフへ変換します。TANSは、テキスト情報の有無にかかわらず、既存のアプローチを上回る性能を示し、特にテキストなしのグラフにおいて顕著な効果を発揮します。 Comment
元ポスト:
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks, Sanchit Ahuja+, N_A, NAACL'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MultiLingual #VisionLanguageModel Issue Date: 2023-11-14 GPT Summary- LLMsの研究は急速に進展しており、英語以外の言語での評価が必要とされている。本研究では、新しいデータセットを追加したMEGAVERSEベンチマークを提案し、さまざまなLLMsを評価する。実験の結果、GPT4とPaLM2が優れたパフォーマンスを示したが、データの汚染などの問題があるため、さらなる取り組みが必要である。
[Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Chain-of-Thought #Prompting #AutomaticPromptEngineering #Findings #Surface-level Notes Issue Date: 2023-04-25 GPT Summary- Iter-CoTは、LLMsの推論チェーンのエラーを修正し、正確で包括的な推論を実現するための反復的ブートストラッピングアプローチを提案。適度な難易度の質問を選択することで、一般化能力を向上させ、10のデータセットで競争力のある性能を達成。 Comment
Zero shot CoTからスタートし、正しく問題に回答できるようにreasoningを改善するようにpromptをreviseし続けるループを回す。最終的にループした結果を要約し、それらをプールする。テストセットに対しては、プールの中からNshotをサンプルしinferenceを行う。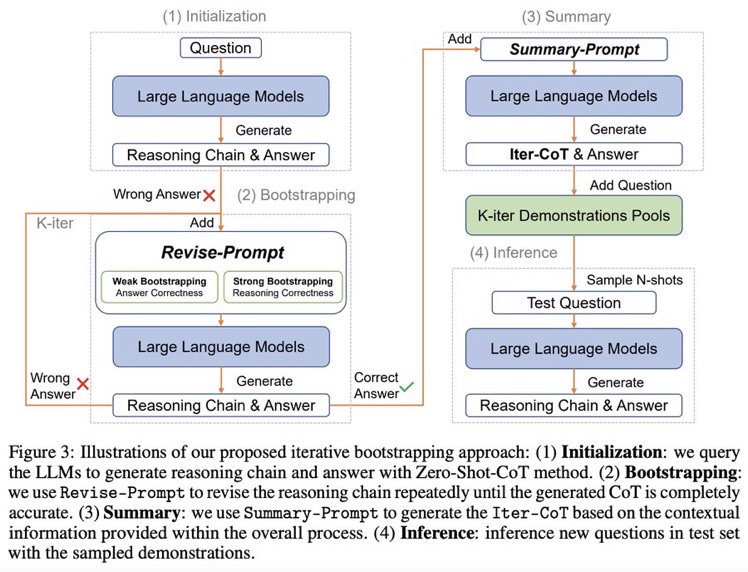
できそうだなーと思っていたけど、早くもやられてしまった
実装: https://github.com/GasolSun36/Iter-CoT
# モチベーション: 既存のCoT Promptingの問題点
## Inappropriate Examplars can Reduce Performance
まず、既存のCoT prompting手法は、sampling examplarがシンプル、あるいは極めて複雑な(hop-based criterionにおいて; タスクを解くために何ステップ必要かという情報; しばしば人手で付与されている?)サンプルをサンプリングしてしまう問題がある。シンプルすぎるサンプルを選択すると、既にLLMは適切にシンプルな回答には答えられるにもかかわらず、demonstrationが冗長で限定的になってしまう。加えて、極端に複雑なexampleをサンプリングすると、複雑なquestionに対しては性能が向上するが、シンプルな問題に対する正答率が下がってしまう。
続いて、demonstration中で誤ったreasoning chainを利用してしまうと、inference時にパフォーマンスが低下する問題がある。下図に示した通り、誤ったdemonstrationが増加するにつれて、最終的な予測性能が低下する傾向にある。
これら2つの課題は、現在のメインストリームな手法(questionを選択し、reasoning chainを生成する手法)に一般的に存在する。
- [Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
- [Paper Note] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, KaShun Shum+, EMNLP'23, 2023.02
のように推論時に適切なdemonstrationを選択するような取り組みは行われてきているが、test questionに対して推論するために、適切なexamplarsを選択するような方法は計算コストを増大させてしまう。
これら研究は誤ったrationaleを含むサンプルの利用を最小限に抑えて、その悪影響を防ぐことを目指している。
一方で、この研究では、誤ったrationaleを含むサンプルを活用して性能を向上させる。これは、たとえば学生が難解だが回答可能な問題に取り組むことによって、問題解決スキルを向上させる方法に類似している(すなわち、間違えた部分から学ぶ)。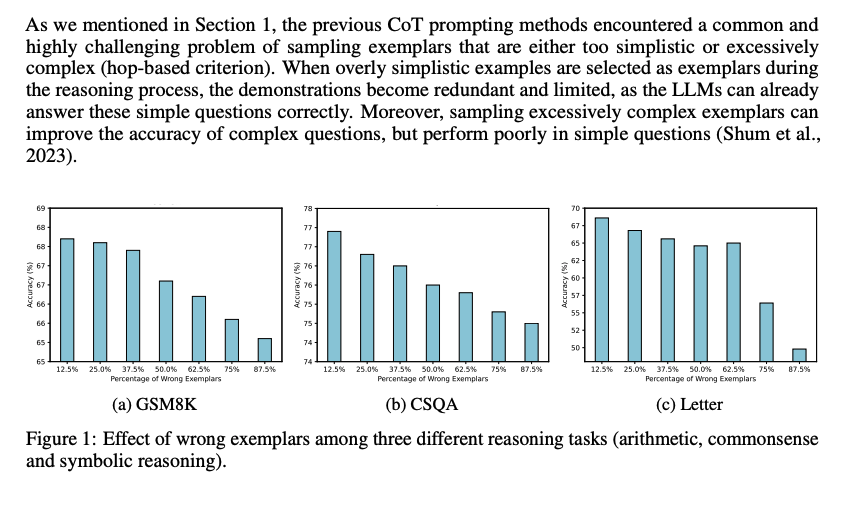
## Large Language Models can self-Correct with Bootstrapping
Zero-Shot CoTでreasoning chainを生成し、誤ったreasoning chainを生成したpromptを**LLMに推敲させ(self-correction)**正しい出力が得られるようにする。こういったプロセスを繰り返し、correct sampleを増やすことでどんどん性能が改善していった。これに基づいて、IterCoTを提案。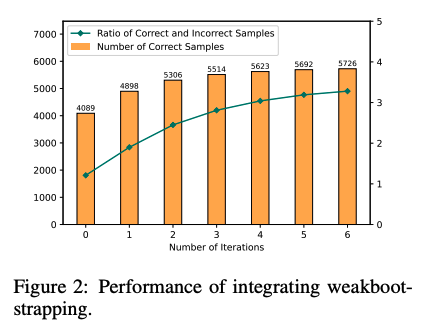
# IterCoT: Iterative Bootstrapping in Chain-of-Thought Prompting
IterCoTはweak bootstrappingとstrong bootstrappingによって構成される。
## Weak bootstrapping
- Initialization
- Training setに対してZero-shot CoTを実施し、reasoning chainとanswerを得
- Bootstrapping
- 回答が誤っていた各サンプルに対して、Revise-Promptを適用しLLMに誤りを指摘し、新しい回答を生成させる。
- 回答が正確になるまでこれを繰り返す。
- Summarization
- 正しい回答が得られたら、Summary-Promptを利用して、これまでの誤ったrationaleと、正解のrationaleを利用し、最終的なreasoning chain (Iter-CoT)を生成する。
- 全体のcontextual informationが加わることで、LLMにとって正確でわかりやすいreasoning chainを獲得する。
- Inference
- questionとIter-Cotを組み合わせ、demonstration poolに加える
- inference時はランダムにdemonstraction poolからサンプリングし、In context learningに利用し推論を行う
## Strong Bootstrapping
コンセプトはweak bootstrappingと一緒だが、Revise-Promptでより人間による介入を行う。具体的には、reasoning chainのどこが誤っているかを明示的に指摘し、LLMにreasoning chainをreviseさせる。
これは従来のLLMからの推論を必要としないannotationプロセスとは異なっている。何が違うかというと、人間によるannnotationをLLMの推論と統合することで、文脈情報としてreasoning chainを修正することができるようになる点で異なっている。
# 実験
Manual-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Random-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Auto-CoT
- [Paper Note] Active Prompting with Chain-of-Thought for Large Language Models, Shizhe Diao+, ACL'24, 2023.02
と比較。
Iter-CoTが11個のデータセット全てでoutperformした。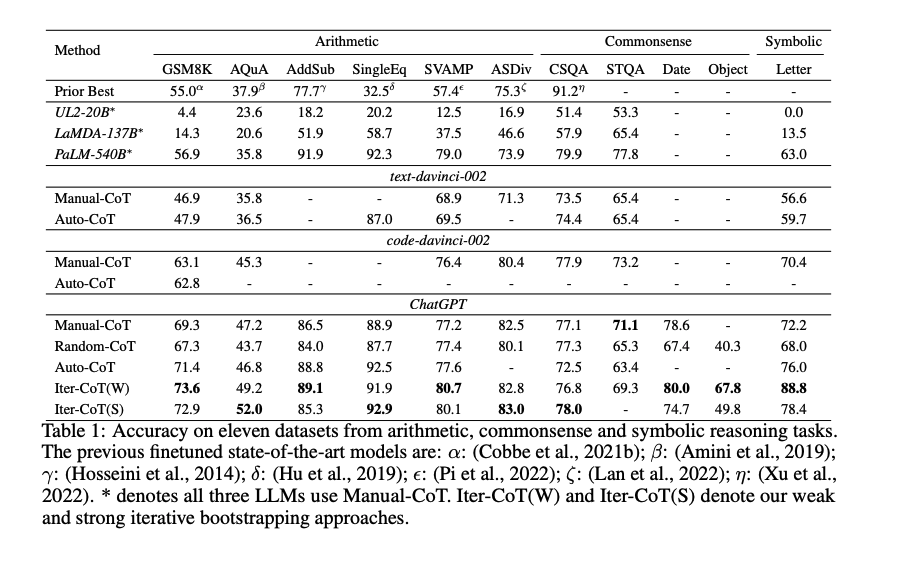
weak bootstrapingのiterationは4回くらいで頭打ちになった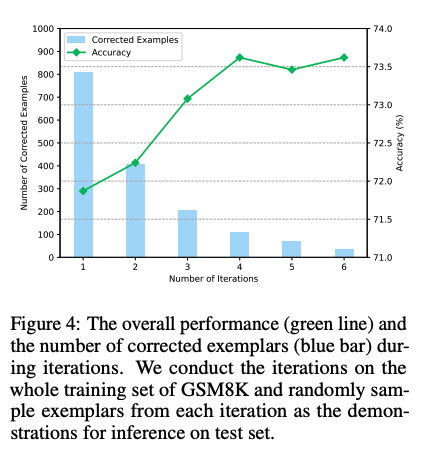
また、手動でreasoning chainを修正した結果と、contextにannotation情報を残し、最後にsummarizeする方法を比較した結果、後者の方が性能が高かった。このため、contextの情報を利用しsummarizeすることが効果的であることがわかる。
[Paper Note] Effective Long-Context Scaling of Foundation Models, Wenhan Xiong+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #LongSequence #PositionalEncoding #mid-training #Selected Papers/Blogs #DataMixture #KeyPoint Notes #needs-revision Issue Date: 2023-10-09 GPT Summary- 長文脈対応LLMシリーズを提案し、32,768トークンまでサポート。Llama 2の継続的な事前学習を基に、長文タスクで顕著な改善を実現。特に70B版は指示チューニングによりGPT-3.5-turbo-16kを上回る性能を示す。また、ポジションエンコーディングやデータ混合の影響を分析し、長文脈の事前学習が効率的かつ効果的であることを実証。 Comment
以下elvis氏のツイートの意訳
Metaが32kのcontext windowをサポートする70BのLLaMa2のvariant提案し、gpt-3.5-turboをlong contextが必要なタスクでoutperform。
short contextのLLaMa2を継続的に訓練して実現。これには人手で作成したinstruction tuning datasetを必要とせず、コスト効率の高いinstruction tuningによって実現される。
これは、事前学習データセットに長いテキストが豊富に含まれることが優れたパフォーマンスの鍵ではなく、ロングコンテキストの継続的な事前学習がより効率的であることを示唆している。
元ツイート:
位置エンコーディングにはlong contxet用に、RoPEのbase frequency bを `10,000->500,000` とすることで、rotation angleを小さくし、distant tokenに対する減衰の影響を小さくする手法を採用 (Adjusted Base Frequency; ABF)。token間の距離が離れていても、attention scoreがshrinkしづらくなっている。
また、単に長いコンテキストのデータを追加するだけでなく、データセット内における長いコンテキストのデータの比率を調整することで、より高い性能が発揮できることを示している。これをData Mixと呼ぶ。
また、instruction tuningのデータには、LLaMa2ChatのRLHFデータをベースに、LLaMa2Chat自身にself-instructを活用して、長いコンテキストを生成させ拡張したものを利用した。
具体的には、コーパス内のlong documentを用いたQAフォーマットのタスクに着目し、文書内のランダムなチャンクからQAを生成させた。その後、self-critiqueによって、LLaMa2Chat自身に、生成されたQAペアのverificationも実施させた。
[Paper Note] Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions, Pouya Pezeshkpour+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Bias #read-later #Selected Papers/Blogs #Findings #One-Line Notes #Reading Reflections #needs-revision Issue Date: 2023-08-28 GPT Summary- 多肢選択問題におけるLLMsの性能は選択肢の順序に敏感であり、配置を変えることで最大75%の性能差が見られる。特に、上位選択肢間の不確実性がこの感度を引き起こし、バイアスが影響することを示唆する。最適な配置は、バイアスを増幅させるためにトップ選択肢を両端に置くこと、緩和するためには隣接させることが推奨される。実験を通じて、予測のキャリブレーションにより最大8ポイントの改善が達成された。 Comment
これはそうだろうなと思っていたけど、ここまで性能に差が出るとは思わなかった。
これがもしLLMのバイアスによるもの(2番目の選択肢に正解が多い)の場合、
ランダムにソートしたり、平均取ったりしても、そもそもの正解に常にバイアスがかかっているので、
結局バイアスがかかった結果しか出ないのでは、と思ってしまう。
そうなると、有効なのはone vs. restみたいに、全部該当選択肢に対してyes/noで答えさせてそれを集約させる、みたいなアプローチの方が良いかもしれない。
[Paper Note] Metacognitive Prompting Improves Understanding in Large Language Models, Yuqing Wang+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting Issue Date: 2023-08-12 GPT Summary- メタ認知的プロンプティング(MP)を導入し、LLMsの論理推論を向上させる新しい戦略を提示。MPにより、広範な知識を引き出す自己評価プロセスを実施。主要なLLMs(Llama2、PaLM2、GPT-3.5、GPT-4)を用いた実験で、GPT-4が全タスクで優れた性能を示し、他モデルもMPによって著しい進歩を達成。また、MPは既存のプロンプティング手法を一貫して上回り、LLMsの理解能力向上の可能性を示唆している。 Comment
CoTより一貫して性能が高いので次のデファクトになる可能性あり
[Paper Note] LLM-Rec: Personalized Recommendation via Prompting Large Language Models, Hanjia Lyu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #Prompting #Findings #One-Line Notes Issue Date: 2023-08-02 GPT Summary- テキストベースのレコメンデーションは汎用性が高いが、元のアイテム説明だけではユーザー嗜好との整合性が不足することがある。大規模言語モデル(LLMs)の進歩を活かし、4つのテキスト強化プロンプト戦略を取り入れたアプローチ、LLM-Recを提案。実験により、LLM拡張テキストの使用が推奨品質を向上させることが確かめられ、基本的なMLPモデルでも高い成果を上げることが示された。成功の要因はプロンプト戦略であり、多様な技術がLLMsの推奨効果を高める重要性を示している。 Comment
LLMのpromptingの方法を変更しcontent descriptionだけでなく、様々なコンテキストの追加(e.g. このdescriptionを推薦するならどういう人におすすめ?、アイテム間の共通項を見つける)、内容の拡張等を行いコンテントを拡張して活用するという話っぽい。
[Paper Note] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting, Zhen Qin+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PairWise #NLP #LanguageModel #Prompting #Surface-level Notes #needs-revision Issue Date: 2023-07-11 GPT Summary- LLMを用いた文書ランキングは有望だが、既存手法を上回るのは難しい。本稿では、既存のpointwiseおよびlistwise手法がLLMに理解されにくいことを指摘し、新たにPairwise Ranking Prompting(PRP)を提案。中規模のオープンソースLLMで、TREC-DLで商用GPT-4を上回る成果を取得し、BEIRタスクでも教師ありベースラインやChatGPTを超えることを示した。PRPの変種によって効率性を向上させ、競争力を持つ結果も達成。 Comment
open source LLMにおいてスタンダードなランキングタスクのベンチマークでSoTAを達成できるようなprompting技術を提案
従来のランキングのためのpromptingはpoint-wiseとlist wiseしかなかったが、前者は複数のスコアを比較するためにスコアのcalibrationが必要だったり、OpenAIなどのAPIはlog probabilityを提供しないため、ランキングのためのソートができないという欠点があった。後者はinputのorderingに非常にsensitiveであるが、listのすべての組み合わせについてorderingを試すのはexpensiveなので厳しいというものであった。このため(古典的なlearning to rankでもおなじみや)pairwiseでサンプルを比較するランキング手法PRPを提案している。
PRPはペアワイズなのでorderを入れ替えて評価をするのは容易である。また、generation modeとscoring mode(outputしたラベルのlog probabilityを利用する; OpenLLMを使うのでlog probabilityを計算できる)の2種類を採用できる。ソートの方法についても、すべてのペアの勝敗からから単一のスコアを計算する方法(AllPair), HeapSortを利用する方法、LLMからのoutputを得る度にon the flyでリストの順番を正しくするSliding Windowの3種類を提案して比較している。
下表はscoring modeでの性能の比較で、GPT4に当時は性能が及んでいなかった20BのOpenLLMで近しい性能を達成している。
また、PRPがinputのorderに対してロバストなことも示されている。
[Paper Note] Over-Generation Cannot Be Rewarded: Length-Adaptive Average Lagging for Simultaneous Speech Translation, Sara Papi+, NAACL'22
Paper/Blog Link My Issue
#Metrics #NLP #Evaluation #SpeechProcessing #AutomaticSpeechRecognition(ASR) #SimulST(SimultaneousSpeechTranslation) #One-Line Notes Issue Date: 2025-04-30 GPT Summary- SimulSTシステムの遅延評価において、ALが長い予測に対して過小評価される問題を指摘。過剰生成の傾向を持つシステムに対し、過小生成と過剰生成を公平に評価する新指標LAALを提案。 Comment
同時翻訳研究で主要なmetricの一つ
関連:
- [Paper Note] SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation, Xutai Ma+, AACL'20
GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering, Yoonseok Yang+, NAACL'22
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #EfficiencyImprovement #CollaborativeFiltering #EducationalDataMining #KnowledgeTracing #Contents-based Issue Date: 2022-08-01 GPT Summary- コンテンツベースの協調フィルタリング(CCF)において、PLMを用いたエンドツーエンドのトレーニングはリソースを消費するため、GRAM(勾配蓄積手法)を提案。Single-step GRAMはアイテムエンコーディングの勾配を集約し、Multi-step GRAMは勾配更新の遅延を増加させてメモリを削減。これにより、Knowledge TracingとNews Recommendationのタスクでトレーニング効率を最大146倍改善。
[Paper Note] DART: Open-Domain Structured Data Record to Text Generation, Linyong Nan+, NAACL'21
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Dataset #DataToTextGeneration Issue Date: 2025-08-30 GPT Summary- DARTは82,000以上のインスタンスを持つオープンドメインの構造化データからテキスト生成のためのデータセットであり、表形式のデータから意味的トリプルを抽出する手法を提案。ツリーオントロジーアノテーションや質問-回答ペアの変換を活用し、最小限のポストエディティングで異種ソースを統合。DARTは新たな課題を提起し、WebNLG 2017での最先端結果を示すことで、ドメイン外の一般化を促進することを証明。データとコードは公開されている。
Question answering as an automatic evaluation metric for news article summarization, Eyal+, NAACL'19
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #QA-based Issue Date: 2023-08-16 Comment
APES
[Paper Note] Deep contextualized word representations, Matthew E. Peters+, NAACL'18, 2018.02
Paper/Blog Link My Issue
#NeuralNetwork #Embeddings #NLP #RepresentationLearning #KeyPoint Notes Issue Date: 2022-06-08 GPT Summary- 新しい深層文脈化単語表現を提案し、単語の複雑な特性と文脈による変化をモデル化。これらの表現は事前学習された双方向言語モデルの内部状態を基に学習され、質問応答や感情分析など6つのNLPタスクで性能を向上させる。さらに、事前学習ネットワークの内部を活用することで、半教師あり信号の混合が可能であることを示す。 Comment
ELMo論文。
通常のword embeddingでは一つの単語につき一つの意味しか持たせられなかったが、文脈に応じて異なる意味を表現できるようなEmbeddingを実現し(同じ単語でも文脈に応じて意味が変わったりするので。たとえばrightは文脈に応じて右なのか、正しいなのか、権利なのか意味が変わる)様々な言語処理タスク(e.g. Question Answering, Sentiment Analysisなど)でSoTAを達成。
Embedding Layer + 2層のLSTM(1,2の間にはresidual connection)+ linear layerで言語モデルを構成し、順方向言語モデルと逆方向言語モデルを同時に独立して学習する(双方向LSTMではない;損失関数が両方向の言語モデルの対数尤度の和になっている)。
また、Linear LayerとEmbedding Layerのパラメータは両方向の言語モデルで共有されている。
k番目の単語のEmbedding Layerの出力ベクトル、各LSTMのhidden stateをタスクspecificなスカラーパラメタs_taskで足し合わせ、最後にベクトルのスケールを調整するパラメタγ_taskで大きさを調整する。これにより、k番目の単語のELMo Embeddingを得る。
単語単体の意味だけでこと足りるタスクの場合はEmbedding Layerの出力ベクトルに対する重みが大きくなり、文脈を考慮した情報が欲しい場合はLSTMのhidden stateに対する重みが大きくなるイメージ(LSTMの層が深いほど意味的semanticな情報を含み、浅いほど文法的syntacticな情報を含んでいる)。
使い方としては簡単で、ELMoを事前学習しておき、自身のNNモデルのWord Embeddingに(場合によってはRNNのhidden stateにも)、入力文から得られたELMo Embeddingをconcatして順伝搬させるだけで良い。
ELMoのEmbedding Layerでは、2048 characterの(vocab size?)n-gram convolution filter(文字ごとにembeddingし、単語のembeddingを得るためにfilterを適用する?)の後に2つのhighway networkをかませてlinearで512次元に落とすみたいなことごやられているらしい。ここまで追えていない。
詳細は下記
https://datascience.stackexchange.com/questions/97867/how-does-the-character-convolution-work-in-elmo
s_taskとγ_taskはtrainableなパラメータで、
ELMoを適用した先のNNモデルの訓練時に、NNモデルのパラメタと一緒にチューニングする(と思われる)。
下記issueを参照のこと
allenai/allennlp# 1166
allenai/allennlp# 2552
[Paper Note] Newsroom: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies, Max+, NAACL'18
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Dataset #KeyPoint Notes Issue Date: 2018-06-29 GPT Summary- NEWSROOMは、38の主要なニュース出版物から収集された130万件の記事と要約のデータセットで、1998年から2017年のメタデータを基にしています。要約は、抽象的および抽出的な戦略を組み合わせており、その多様性を示しています。本研究では、NEWSROOMの抽出戦略を他データセットと比較し、新たなデータの多様性と難易度を評価しました。また、既存の手法を用いてデータ上で訓練し、その有用性と課題を明らかにしました。このデータセットはsummari.esで公開されています。 Comment
文書要約に使用可能なデータセット
38の出版元からデータを収集し、サイズは1.3M article程度
既存のデータセットと比較すると、Coverageが高く生成的なものを多く含むことが特徴
詳細は:
https://summari.es
Lexical Coherence Graph Modeling Using Word Embeddings, Mesgar+, NAACL'16
Paper/Blog Link My Issue
#DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Coherence Issue Date: 2023-08-13
[Paper Note] Learning Distributed Representations of Sentences from Unlabelled Data, Felix Hill+, NAACL'16, 2016.02
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #Embeddings #NLP #RepresentationLearning #KeyPoint Notes Issue Date: 2017-12-28 GPT Summary- 無監督手法によるフレーズや文の分散表現の学習に関するモデルの比較を行い、最適なアプローチはアプリケーションに依存することを示す。深いモデルは監視システムに適している一方、浅いロジスティック回帰モデルは単純な空間距離メトリックに最適。さらに、トレーニング時間やドメイン移植性を考慮した新しい無監督表現学習の目的も提案。 Comment
Sentenceのrepresentationを学習する話
代表的なsentenceのrepresentation作成手法(CBOW, SkipGram, SkipThought, Paragraph Vec, NMTなど)をsupervisedな評価(タスク志向+supervised)とunsupervisedな評価(文間の距離をコサイン距離ではかり、人間が決めた順序と相関を測る)で比較している。
また筆者らはSequential Denoising Auto Encoder(SDAE)とFastSentと呼ばれる手法を提案しており、前者はorderedなsentenceデータがなくても訓練でき、FastSentはorderedなsentenceデータが必要だが高速に訓練できるモデルである。
実験の結果、supervisedな評価では、基本的にはSkipThoughtがもっとも良い性能を示し、paraphrasingタスクにおいて、SkipThoughtに3ポイント程度差をつけて良い性能を示した。unsupervisedな評価では、DictRepとFastSentがもっとも良い性能を示した。
実験の結果、以下のような知見が得られた:
## 異なるobjective functionは異なるembeddingを作り出す
objective functionは、主に隣接する文を予測するものと、自分自身を再現するものに分けられる。これらの違いによって、生成されるembeddingが異なっている。Table5をみると、後者については、生成されたrepresentationのnearest neighborを見ていると、自身と似たような単語を含む文が引っ張ってこれるが、前者については、文のコンセプトや機能は似ているが、単語の重複は少なかったりする。
## supervisedな場合とunsupervisedな評価でのパフォーマンスの違い
supervisedな設定では、SkipThoughtやSDAEなどのモデルが良い性能を示しているが、unsupervisedな設定ではまりうまくいかず。unsupevisedな設定ではlog-linearモデルが基本的には良い性能を示した。
## pre-trainedなベクトルを使用したモデルはそうでない場合と比較してパフォーマンスが良い
## 必要なリソースの違い
モデルによっては、順序づけられた文のデータが必要だったり、文の順序が学習に必要なかったりする。あるいは、デコーディングに時間がかかったり、めちゃくちゃメモリ食ったりする。このようなリソースの性質の違いは、使用できるapplicationに制約を与える。
## 結論
とりあえず、supervisedなモデルにrepresentationを使ってモデルになんらかのknowledgeをぶちこみたいときはSkipThought、単純に類似した文を検索したいとか、そういう場合はFastSentを使うと良いってことですかね.
[Paper Note] Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval, Liu+, NAACL-HLT'15, 2015.05
Paper/Blog Link My Issue
#NeuralNetwork #InformationRetrieval #Search #MultitaskLearning #QueryClassification #WebSearch #RepresentationLearning #Surface-level Notes Issue Date: 2018-02-05 Comment
クエリ分類と検索をNeural Netを用いてmulti-task learningする研究
分類(multi-class classification)とランキング(pairwise learning-to-rank)という異なる操作が必要なタスクを、multi task learningの枠組みで組み合わせた(初めての?)研究。
この研究では分類タスクとしてクエリ分類、ランキングタスクとしてWeb Searchを扱っている。
モデルの全体像は下図の通り。
shared layersの部分で、クエリとドキュメントを一度共通の空間に落とし、そのrepresentationを用いて、l3においてtask-specificな空間に写像し各タスクを解いている。
分類タスクを解く際には、outputはsigmoidを用いる(すなわち、output layerのユニット数はラベル数分存在する)。
Web Searchを解く際には、クエリとドキュメントをそれぞれtask specificな空間に別々に写像し、それらのcosine similarityをとった結果にsoftmaxをかけることで、ドキュメントのrelevance scoreを計算している。
学習時のアルゴリズムは上の通り。各タスクをランダムにpickし、各タスクの目的関数が最適化されるように思いをSGDで更新する、といったことを繰り返す。
なお、alternativeとして、下図のようなネットワーク構造を考えることができるが(クエリのrepresentationのみがシェアされている)、このモデルの場合はweb searchがあまりうまくいかなかった模様。
理由としては、unbalancedなupdates(クエリパラメータのupdateがdocumentよりも多くアップデートされること)が原因ではないかと言及しており、multi-task modelにおいては、パラメータをどれだけシェアするかはネットワークをデザインする上で重要な選択であると述べている。
評価で用いるデータの統計量は下記の通り。
1年分の検索ログから抽出。クエリ分類(各クラスごとにbinary)、および文書のrelevance score(5-scale)は人手で付与されている。
クエリ分類はROC曲線のAUCを用い、Web SearchではNDCG (Normalized Discounted Cumulative Gain) を用いた。

multi task learningをした場合に、性能が向上している。
また、ネットワークが学習したsemantic representationとSVMを用いて、domain adaptationの実験(各クエリ分類のタスクは独立しているので、一つのクエリ分類のデータを選択しsemantic representationをtrainし、学習したrepresentationを別のクエリ分類タスクに適用する)も行なっており、訓練事例数が少ない場合に有効に働くことを確認(Letter3gramとWord3gramはnot trained/adapted)。

また、SemanticRepresentationへ写像する行列W1のパラメータの初期化の仕方と、サンプル数の変化による性能の違いについても実験。DNN1はW1をランダムに初期化、DNN2は別タスク(別のクエリ分類タスク)で学習したW1でfixする手法。
訓練事例が数百万程度ある場合は、DNN1がもっとも性能がよく、数千の訓練事例数の場合はsemantic representationを用いたSVMがもっともよく、midium-rangeの訓練事例数の場合はDNN2がもっとも性能がよかったため、データのサイズに応じて手法を使い分けると良い。
データセットにおいて、クエリの長さや文書の長さが記述されていないのがきになる。
[Paper Note] Unsupervised concept-to-text generation with hypergraphs, Konstas+, NAACL-HLT'12
Paper/Blog Link My Issue
#NaturalLanguageGeneration #SingleFramework #NLP #ConceptToTextGeneration Issue Date: 2017-12-31
[Paper Note] Aggregation via set partitioning for natural language generation, Barzilay+, HLT-NAACL'06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #DataDriven #NLP #ConceptToTextGeneration Issue Date: 2017-12-31
[Paper Note] WebInEssence: A Personalized Web-Based Multi-Document Summarization and Recommendation System, Radev+, NAACL'01, 2001.06
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Search #Personalization #KeyPoint Notes Issue Date: 2017-12-28 Comment
・ドキュメントはオフラインでクラスタリングされており,各クラスタごとにmulti-document summarizationを行うことで,
ユーザが最も興味のあるクラスタを同定することに役立てる.あるいは検索結果のページのドキュメントの要約を行う.
要約した結果には,extractした文の元URLなどが付与されている.
・Personalizationをかけるためには,ユーザがドキュメントを選択し,タイトル・ボディなどに定数の重みをかけて,その情報を要約に使う.
・特に評価していない.システムのoutputを示しただけ.
[Paper Note] Cut and paste based text summarization, Jing+, NAACL'00
Paper/Blog Link My Issue
#DocumentSummarization #Document #NLP #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-21 Comment
AbstractiveなSummarizationの先駆け的研究。
AbstractiveなSummarizationを研究するなら、押さえておいたほうが良い。
[Paper Note] Probing Word Translations in the Transformer and Trading Decoder for Encoder Layers, NAACL‘21
Paper/Blog Link My Issue
#Article #NeuralNetwork #MachineTranslation #NLP #KeyPoint Notes #Reading Reflections Issue Date: 2021-06-03 Comment
Transformerに基づいたNMTにおいて、Encoderが入力を解釈し、Decoderが翻訳をしている、という通説を否定し、エンコーディング段階、さらにはinput embeddingの段階でそもそも翻訳が始まっていることを指摘。
エンコーディングの段階ですでに翻訳が始まっているのであれば、エンコーダの層を増やして、デコーダの層を減らせば、デコーディング速度を上げられる。
通常はエンコーダ、デコーダともに6層だが、10-2層にしたらBLEUスコアは変わらずデコーディングスピードは2.3倍になった。
18-4層の構成にしたら、BLEUスコアも1.42ポイント増加しデコーディング速度は1.4倍になった。
この研究は個人的に非常に興味深く、既存の常識を疑い、分析によりそれを明らかにし、シンプルな改善で性能向上およびデコーディング速度も向上しており、とても好き。
[Paper Note] What to talk about and how? Selective Generation using LSTMs with Coarse-to-Fine Alignment, Hongyuan Mei+, NAACL-HLT’16, 2015.09
Paper/Blog Link My Issue
#Article #NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #Encoder-Decoder #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- エンドツーエンドのドメイン非依存型ニューラルエンコーダー-アライナー-デコーダーモデルを提案。LSTMを用いてデータベースイベントをエンコードし、アライナーで重要なレコードを特定、デコーダーで自由形式の説明を生成。WeatherGovデータセットで最良の結果を達成し、k近傍ビームフィルターでさらに改善。RoboCupデータセットでも競争力のある結果を得た。 Comment
content-selectionとsurface realizationをencoder-decoder alignerを用いて同時に解いたという話。
普通のAttention basedなモデルにRefinerとPre-Selectorと呼ばれる機構を追加。通常のattentionにはattentionをかける際のaccuracyに問題があるが、data2textではきちんと参照すべきレコードを参照し生成するのが大事なので、RefinerとPre-Selectorでそれを改善する。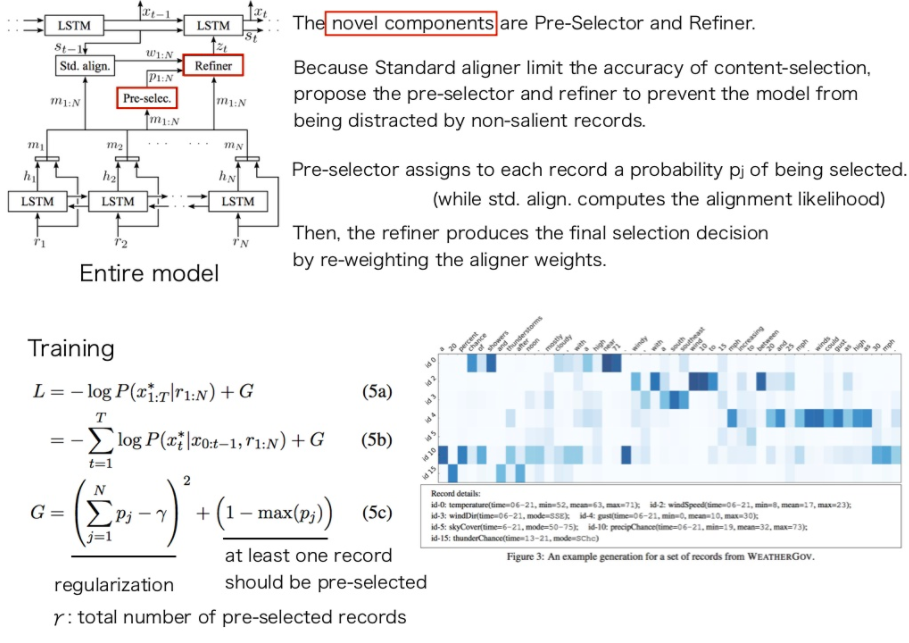
Pre-selectorは、それぞれのレコードが選択される確率を推定する(通常のattentionはalignmentの尤度を計算するのみ)。
Refinerはaligner(attention)のweightをreweightingすることで、最終的にどのレコードを選択するか決定する。
加えて、ロス関数のRegularizationのかけかたを変え、最低一つのレコードがpreselectorに選ばれるようにバイアスをかけている。
ほぼ初期のNeural Network basedなData2Text研究
[Paper Note] Improving Update Summarization via Supervised ILP and Sentence Reranking, Li et al. NAACL’15, 2015.05
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #IntegerLinearProgramming (ILP) #Update #KeyPoint Notes Issue Date: 2017-12-28 Comment
・update summarizationをILPで定式化.基本的なMDSのILPのterm weightingにsalienceの要素に加えてnoveltyの要素を加える.term weightingにはbigramを用いる.bigram使うとよくなることがupdate summarizationだと知られている.weightingは平均化パーセプトロンで学習
・ILPでcandidate sentencesを求めたあと,それらをSVRを用いてRerankingする.SVRのloss functionはROUGE-2を使う.
・Rerankingで使うfeatureはterm weightingした時のsentenceレベルのfeatureを使う.
・RerankingをするとROUGE-2スコアが改善する.2010, 2011のTAC Bestと同等,あるいはそれを上回る結果.novelty featureを入れると改善.
・noveltyのfeatureは,以下の通り.
Bigram Level
-bigramのold datasetにおけるDF
-bigram novelty value (new datasetのbigramのDFをold datasetのDFとDFの最大値の和で割ったもの)
-bigram uniqueness value (old dataset内で出たbigramは0, すでなければ,new dataset内のDFをDFの最大値で割ったもの)
Sentence Level
-old datasetのsummaryとのsentence similarity interpolated n-gram novelty (n-gramのnovelty valueをinterpolateしたもの)
-interpolated n-gram uniqueness (n-gramのuniqueness valueをinterpolateしたもの)
・TAC 2011の評価の値をみると,Wanらの手法よりかなり高いROUGE-2スコアを得ている.
[Paper Note] A Study for Documents Summarization based on Personal Annotation, Zhang+, HLT-NAACL-DUC’03, 2003.05
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 Comment
(過去に管理人が作成したスライドでの論文メモのスクショ)

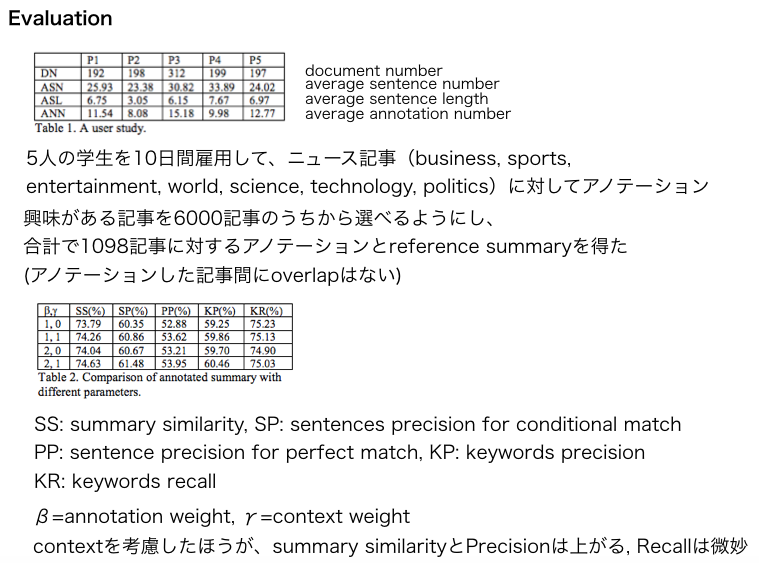
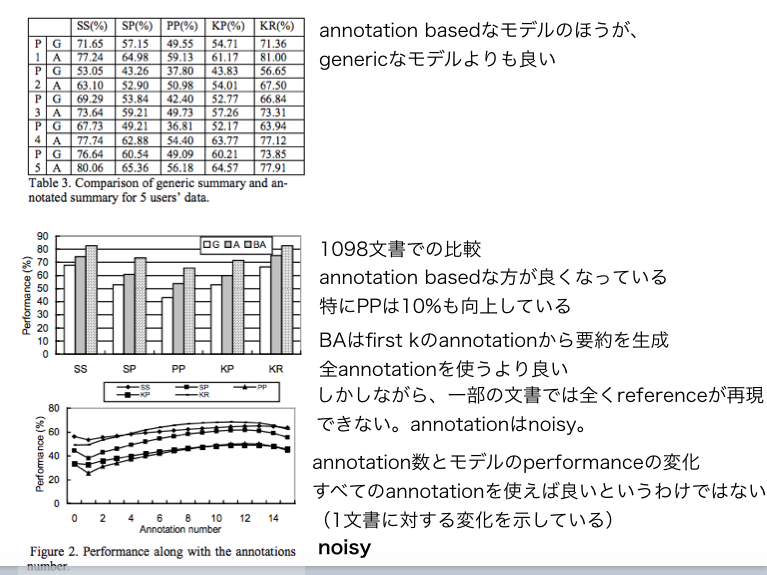

重要論文だと思われる。