
KeyPoint Notes
Issue Date: 2025-11-15 [Paper Note] Train for Truth, Keep the Skills: Binary Retrieval-Augmented Reward Mitigates Hallucinations, Tong Chen+, arXiv'25, 2025.10 GPT Summary- 本研究では、外的幻覚を軽減するために新しいバイナリ検索強化報酬(RAR)を用いたオンライン強化学習手法を提案。モデルの出力が事実に基づいている場合のみ報酬を与えることで、オープンエンド生成において幻覚率を39.3%削減し、短文質問応答では不正解を44.4%減少させた。重要な点は、事実性の向上が他のパフォーマンスに悪影響を及ぼさないことを示した。 Comment
Utilityを維持しつつ、Hallucinationを減らせるかという話で、Binary Retrieval Augmented Reward (Binary RAR)と呼ばれるRewardを提案している。このRewardはverifierがtrajectoryとanswerを判断した時に矛盾がない場合にのみ1, それ以外は0となるbinary rewardである。これにより、元のモデルの正解率・有用性(極論全てをわかりません(棄権)と言えば安全)の両方を損なわずにHallucinationを提言できる。
また、通常のVerifiable Rewardでは、正解に1, 棄権・不正解に0を与えるRewardとみなせるため、モデルがguessingによってRewardを得ようとする(guessingすることを助長してしまう)。一方で、Binary RARは、正解・棄権に1, 不正解に0を与えるため、guessingではなく不確実性を表現することを学習できる(おそらく、棄権する場合はどのように不確実かを矛盾なく説明した上で棄権しないとRewardを得られないため)。
といった話が元ポストに書かれているように見える。
元ポスト:
#Pocket #NLP #AIAgents #MultiModal #Reasoning #SmallModel #VisionLanguageModel
Issue Date: 2025-11-10 [Paper Note] DeepEyesV2: Toward Agentic Multimodal Model, Jack Hong+, arXiv'25, 2025.11 GPT Summary- DeepEyesV2は、テキストや画像の理解に加え、外部ツールを活用するエージェント的なマルチモーダルモデルを構築する方法を探求。二段階のトレーニングパイプラインを用いてツール使用行動を強化し、多様なトレーニングデータセットをキュレーション。RealX-Benchという新たなベンチマークを導入し、実世界のマルチモーダル推論を評価。DeepEyesV2は、タスクに応じたツール呼び出しを行い、強化学習により文脈に基づくツール選択を実現。コミュニティへの指針提供を目指す。 Comment
pj page: https://visual-agent.github.io/
元ポスト:
ポイント解説:
VLM(Qwen2.5-VL-7B)をバックボーンとしSFT(tooluseに関するcoldstart)→RL(RLVR+format reward)で学習することで、VLMによるAI Agentを構築。画像をcropしcropした画像に対するマルチモーダルな検索や、適切なtooluseの選択などに基づいて応答できる。
事前の実験によってまずQwen2.5-VL-7Bに対してRLのみでtooluse能力(コーディング能力)を身につけられるかを試したところ、Reward Hackingによって適切なtooluse能力が獲得されなかった(3.2節; 実行可能ではないコードが生成されたり、ダミーコードだったりなど)。
このためこのcoldstartを解消するためにSFTのための学習データを収集(3.3節)。これには、
- 多様なタスクと画像が含まれており
- verifiableで構造化されたOpen-endなQAに変換でき
- ベースモデルにとって簡単すぎず(8回のattemptで最大3回以上正解したものは除外)
- ツールの利用が正解に寄与するかどうかに基づきサンプルを分類する。tooluseをしても解答できないケースをSFTに、追加のtooluseで解答できるサンプルをRL用に割り当て
ようなデータを収集。さらに、trajectoryはGemini2.5, GPT4o, Claude Sonnet4などのstrong modelから収集した。
RealX-Benchと呼ばれるベンチマークも作成しているようだがまだ読めていない。
proprietary modelの比較対象が少し古め。ベースモデルと比較してSFT-RLによって性能は向上。Human Performanceも掲載されているのは印象的である。
ただ、汎用モデルでこの性能が出るのであれば、DeepSearchに特化したモデルや?GPT5, Claude-4.5-Sonnetなどではこのベンチマーク上ではHuman Performanceと同等かそれ以上の性能が出るのではないか?という気がする。
#Pocket #NLP #LanguageModel #ReinforcementLearning #SelfImprovement #Catastrophic Forgetting #RLVR #Diversity #Generalization
Issue Date: 2025-11-07 [Paper Note] RLoop: An Self-Improving Framework for Reinforcement Learning with Iterative Policy Initialization, Zeng Zhiyuan+, arXiv'25, 2025.11 GPT Summary- RLoopは、強化学習における過剰適合の問題を解決するための自己改善フレームワークであり、ポリシーの多様性を保ちながら一般化能力を向上させる。RLを用いて解空間を探索し、成功した軌跡から専門家データセットを作成し、拒否サンプリング微調整を行うことで、次の反復の出発点を洗練する。実験により、RLoopは忘却を軽減し、平均精度を9%、pass@32を15%以上向上させることが示された。 Comment
元ポスト:
ポリシーを初期化し、RLを実行しtrajeatory tを取得。tをrejection samplingし成功したtrajectoryでエキスパートデータセットを作成。作成したエキスパートデータセットでポリシーをSFT(=Rejection SamplingしたデータでSFTすることをRFTと呼ぶ)する(これが次iterationの初期化となる)といったことを繰り返す。
RLはAdvantageによって学習されるため、trajectoryの相対的な品質に基づいて学習をする。このため、バッチ内のすべてのtrajectoryが正解した場合などはadvantageが限りなくゼロに近づき学習のシグナルを得られない。
一方RFTは絶対的なRewardを用いており(RLVRの場合は成功したら1,そうでなければ0)、これがバッチ全体のパフォーマンスに依存しない安定した分散の小さい学習のシグナルを与える。
このように両者は補完的な関係にある。ただしRFTは成功したtrajectory全てに均等な重みを与えるため、既にポリシーが解くことができる問題にフォーカスしすぎることによって効率性が悪化する問題があるため、提案手法では成功率が低いhardなサンプルのみにエキスパートデータをフィルタリングする(=active learning)ことで、モデルが自身に不足した能力を獲得することに効率的に注力することになる。
また、RFTを使うことは単なるヒューリスティックではなく、理論的なgroundingが存在する。すなわち、我々はまだ未知の"expert"な分布 p^*にポリシーが従うように学習をしたいがこれはMLEの観点で言うと式3に示されているような形式になる。p^*から直接データをサンプリングをすることができないが、RLのポリシーから近似的にサンプリングをすることができる。そこでMLEの式をimportance samplingの観点から再度定式化をすると式4のようになり、後はimportance weight wを求められれば良いことになる。これはp^*に近いtrajectoryはRewardが高く、そうでない場合は低い、つまりw \propto Reward な関係であるため近似的に求めることができ、これらを式4のMLEの式に代入するとRFTと同じ式が導出される。
みたいな話のようである。
pj page: https://mira-benchmark.github.io/
元ポスト:
Visual CoT
Frontierモデル群でもAcc.が20%未満のマルチモーダル(Vision QA)ベンチマーク。
手作業で作成されており、Visual CoT用のsingle/multi stepのintermediate imagesも作成されている。興味深い。
VLMにおいて、{few, many}-shotがうまくいく場合(Geminiのようなプロプライエタリモデルはshot数に応じて性能向上、一方LlamaのようなOpenWeightモデルは恩恵がない)と
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
うまくいかないケース(事前訓練で通常見られない分布外のドメイン画像ではICLがうまくいかない)
- [Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05
も報告されている。
おそらく事前学習段階で当該ドメインの画像が学習データにどれだけ含まれているか、および、画像とテキストのalignmentがとれていて、画像-テキスト間の知識を活用できる状態になっていることが必要なのでは、という気はする。
著者ポスト:
#Pretraining #Pocket #NLP #LanguageModel #Architecture #AutoEncoder Issue Date: 2025-11-03 [Paper Note] Continuous Autoregressive Language Models, Chenze Shao+, arXiv'25, 2025.10 GPT Summary- 大規模言語モデル(LLMs)の効率を向上させるため、連続自己回帰言語モデル(CALM)を提案。CALMは、次トークン予測から次ベクトル予測へのシフトを行い、Kトークンを連続ベクトルに圧縮することで生成ステップをK倍削減。新たなフレームワークを開発し、性能と計算コストのトレードオフを改善。CALMは、効率的な言語モデルへの道筋を示す。 Comment
pj page: https://shaochenze.github.io/blog/2025/CALM/
元ポスト:
VAEを学習し(deterministicなauto encoderだと摂動に弱くロバストにならないためノイズを加える)、Kトークンをlatent vector zに圧縮、auto regressiveなモデルでzを生成できるように学習する。専用のヘッド(generative head)を用意し、transformerの隠れ状態からzを条件付きで生成する。zが生成できればVAEでdecodeすればKトークンが生成される。loss functionは下記のエネルギースコアで、第一項で生成されるトークンの多様性を担保しつつ(モード崩壊を防ぎつつ)、第二項でground truth yに近い生成ができるようにする、といった感じらしい。評価はautoregressiveにzを生成する設定なのでperplexityを計算できない。このため、BrierLMという指標によって評価している。BrierLMがどのようなものかは理解できていない。必要になったら読む。
future workにあるようにスケーリング特性がまだ明らかになっていないのでなんとも言えないという感想。
ポイント解説:
#Pretraining #Pocket #NLP #LanguageModel #Transformer #Selected Papers/Blogs #LatentReasoning #RecurrentModels #RecursiveModels Issue Date: 2025-10-30 [Paper Note] Scaling Latent Reasoning via Looped Language Models, Rui-Jie Zhu+, arXiv'25, 2025.10 GPT Summary- Ouroは、推論を事前訓練フェーズに組み込むことを目指したループ言語モデル(LoopLM)であり、反復計算やエントロピー正則化を通じて性能を向上させる。1.4Bおよび2.6Bモデルは、最大12Bの最先端LLMに匹敵する性能を示し、知識操作能力の向上がその要因であることを実験で確認。LoopLMは明示的なCoTよりも整合した推論を生成し、推論の新たなスケーリングの可能性を示唆している。モデルはオープンソースで提供されている。 Comment
pj page: https://ouro-llm.github.io
元ポスト:
解説:
基本構造はdecoder-only transformerで
- Multi-Head Attention
- RoPE
- SwiGLU活性化
- Sandwich Normalization
が使われているLoopedTransformerで、exit gateを学習することで早期にloopを打ち切り、出力をすることでコストを節約できるようなアーキテクチャになっている。
より少ないパラメータ数で、より大きなパラメータ数のモデルよりも高い性能を示す(Table7,8)。また、Tを増やすとモデルの安全性も増す(=有害プロンプトの識別力が増す)。その代わり、再帰数Tを大きくするとFLOPsがT倍になるので、メモリ効率は良いが計算効率は悪い。
linear probingで再帰の次ステップ予測をしたところ浅い段階では予測が不一致になるため、思考が進化していっているのではないか、という考察がある。
また、再帰数Tを4で学習した場合に、inference時にTを5--8にしてもスケールしない(Table10)。
またAppendix D.1において、通常のtransformerのLoopLMを比較し、5種類の大きさのモデルサイズで比較。通常のtransformerではループさせる代わりに実際に層の数を増やすことで、パラメータ数を揃えて実験したところ、通常のtransformerの方が常に性能が良く、loopLMは再帰数を増やしてもスケールせず、モデルサイズが大きくなるにつれて差がなくなっていく、というスケーリングの面では残念な結果に終わっているようだ。
といった話が解説に書かれている。元論文は完全にskim readingして解説ポストを主に読んだので誤りが含まれるかもしれない点には注意。
#Pocket #LanguageModel #Transformer #Architecture #ICLR #read-later #Selected Papers/Blogs #memory Issue Date: 2025-10-23 [Paper Note] Memory Layers at Scale, Vincent-Pierre Berges+, ICLR'25, 2024.12 GPT Summary- メモリ層は、計算負荷を増やさずにモデルに追加のパラメータを加えるための学習可能な検索メカニズムを使用し、スパースに活性化されたメモリ層が密なフィードフォワード層を補完します。本研究では、改良されたメモリ層を用いた言語モデルが、計算予算が2倍の密なモデルや同等の計算とパラメータを持つエキスパート混合モデルを上回ることを示し、特に事実に基づくタスクでの性能向上が顕著であることを明らかにしました。完全に並列化可能なメモリ層の実装とスケーリング法則を示し、1兆トークンまでの事前学習を行った結果、最大8Bのパラメータを持つベースモデルと比較しました。 Comment
openreview: https://openreview.net/forum?id=ATqGm1WyDj
transformerにおけるFFNをメモリレイヤーに置き換えることで、パラメータ数を増やしながら計算コストを抑えるようなアーキテクチャを提案しているようである。メモリレイヤーは、クエリqを得た時にtop kのkvをlookupし(=ここで計算対象となるパラメータがスパースになる)、kqから求めたattention scoreでvを加重平均することで出力を得る。Memory+というさらなる改良を加えたアーキテクチャでは、入力に対してsiluによるgatingとlinearな変換を追加で実施することで出力を得る。
denseなモデルと比較して性能が高く、メモリパラメータを増やすと性能がスケールする。
#Pocket #NLP #LanguageModel #Reasoning #Architecture #read-later #Selected Papers/Blogs #SpeciarizedBrainNetworks #Neuroscience Issue Date: 2025-10-22 [Paper Note] Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization, Badr AlKhamissi+, arXiv'25, 2025.06 GPT Summary- MiCRoは、脳の認知ネットワークに基づく専門家モジュールを持つトランスフォーマーベースのアーキテクチャで、言語モデルの層を4つの専門家に分割。これにより、解釈可能で因果的な専門家の動的制御が可能になり、機械学習ベンチマークで優れた性能を発揮。人間らしく解釈可能なモデルを実現。 Comment
pj page: https://cognitive-reasoners.epfl.ch
元ポスト:
事前学習言語モデルに対してpost-trainingによって、脳に着想を得て以下の4つをdistinctな認知モジュールを(どのモジュールにルーティングするかを決定するRouter付きで)学習する。
- Language
- Logic / Multiple Demand
- Social / Theory of Mind
- World / Default Mode Network
これによりAIとNeuroscienceがbridgeされ、MLサイドではモデルの解釈性が向上し、Cognitive側では、複雑な挙動が起きた時にどのモジュールが寄与しているかをprobingするテストベッドとなる。
ベースラインのdenseモデルと比較して、解釈性を高めながら性能が向上し、人間の行動とよりalignしていることが示された。また、layerを分析すると浅い層では言語のエキスパートにルーティングされる傾向が強く、深い層ではdomainのエキスパートにルーティングされる傾向が強くなるような人間の脳と似たような傾向が観察された。
また、neuroscienceのfunctional localizer(脳のどの部位が特定の機能を果たしているのかを特定するような取り組み)に着想を得て、類似したlocalizerが本モデルにも適用でき、特定の機能に対してどのexpertモジュールがどれだけ活性化しているかを可視化できた。
といったような話が著者ポストに記述されている。興味深い。
demo:
https://huggingface.co/spaces/bkhmsi/cognitive-reasoners
HF:
https://huggingface.co/collections/bkhmsi/mixture-of-cognitive-reasoners
#ComputerVision #Controllable #Pocket #Transformer #DiffusionModel #VariationalAutoEncoder #Selected Papers/Blogs #ICCV Issue Date: 2025-10-22 [Paper Note] OminiControl: Minimal and Universal Control for Diffusion Transformer, Zhenxiong Tan+, ICCV'25 Highlight, 2024.11 GPT Summary- OminiControlは、Diffusion Transformer(DiT)アーキテクチャにおける画像条件付けの新しいアプローチで、パラメータオーバーヘッドを最小限に抑えつつ、柔軟なトークン相互作用と動的な位置エンコーディングを実現。広範な実験により、複数の条件付けタスクで専門的手法を上回る性能を示し、合成された画像ペアのデータセット「Subjects200K」を導入。効率的で多様な画像生成システムの可能性を示唆。 Comment
元ポスト:
DiTのアーキテクチャは(MMA以外は)変更せずに、Condition Image C_IをVAEでエンコードしたnoisy inputをDiTのinputにconcatし順伝播させることで、DiTをunified conditioningモデル(=C_Iの特徴量を他のinputと同じlatent spaceで学習させ統合的に扱う)として学習する[^1]。
[^1]: 既存研究は別のエンコーダからエンコードしたfeatureが加算されていて(式3)、エンコーダ部分に別途パラメータが必要だっただけでなく、加算は空間的な対応関係が存在しない場合はうまく対処できず(featureの次元が空間的な情報に対応しているため)、conditional tokenとimageの交互作用を妨げていた。
また、positional encodingのindexをconditional tokenとnoisy image tokensと共有すると、空間的な対応関係が存在するタスク(edge guided generation等)はうまくいったが、被写体を指定する生成(subject driven generation)のような対応関係が存在しないタスク(non-aligned task)の場合はうまくいかなかった。しかし、non-aligned taskの場合は、indexにオフセットを加えシフトさせる(式4)ことで、conditional text/image token間で空間的にoverlapしないようにすることで性能が大幅に改善した。
既存研究では、C_Iの強さをコントロールするために、ハイパーパラメータとして定数を導入し、エンコードされたfeatureを加算する際の強さを調整していたが(3.2.3節)、本手法ではconcatをするためこのような方法は使えない。そのため、Multi-Modal Attention(MMA)にハイパーパラメータによって強さを調整可能なbias matrixを導入し、C_IとXのattentionの交互作用の強さを調整することで対応した(式5,6)。
#Pretraining #Pocket #NLP #LanguageModel #Quantization #Distillation #PostTraining Issue Date: 2025-10-19 [Paper Note] BitNet Distillation, Xun Wu+, arXiv'25, 2025.10 GPT Summary- BitNet Distillation(BitDistill)は、フル精度LLMを1.58ビット精度にファインチューニングする軽量なパイプラインで、計算コストを抑えつつ高いタスク特化型パフォーマンスを実現します。主な技術には、SubLNモジュール、MiniLMに基づくアテンション蒸留、継続的な事前学習が含まれ、これによりフル精度モデルと同等の性能を達成し、メモリを最大10倍節約し、CPU上での推論を2.65倍高速化します。 Comment
元ポスト:
SubLN, MiniLMについては
- Foundation Transformers, Hongyu Wang+, PMLR'23
- [Paper Note] MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers, Wenhui Wang+, ACL'21 Findings, 2020.12
を参照のこと。
既存LLMを特定タスクに1.58bitでSFTする際に、full-precisionと同等の性能を保つ方法を提案している研究。full-precision LLMを1.58 bitでSFTをするとfp16で学習した場合のbaselineと比較してパフォーマンスが大きく低下するが(そしてその傾向はモデルサイズが大きいほど強い)、提案手法を利用するとfp16でSFTした場合と同等の性能を保ちながら、inference-speed 2.65倍、メモリ消費量1/10になる模様。https://github.com/user-attachments/assets/cafa8ad5-7cce-4466-a208-07bb51dcd953"
/>
手法としては、3段階で構成されており
- Stage1: low-bitに量子化されたモデルではactivationの分散が大きくなり学習の不安定さにつながるため、アーキテクチャとしてSubLNを導入して安定化を図る
- Stage2: Stage1で新たにSubLNを追加するので事前学習コーパスの継続事前学習する
- Stage3: full-precisionでSFTしたモデルを教師、1.58-bitに量子化したモデルを生徒とし、logits distillation (input x, output yが与えられた時に教師・生徒間で出力トークンの分布のKL Divergenceを最小化する)、MiniLMで提案されているMHAのdistillation(q-q/k-k/v-vの内積によってsquaredなrelation mapをQ, K, Vごとに作成し、relation mapのKL Divergenceが教師・生徒間で最小となるように学習する)を実施する
- 最終的に `L_CE + \lambda L_LD + \ganma L_AD` を最小化する。ここで、L_CEはdownstream datasetに対するcross-entropy lossであり、L_LD, L_ADはそれぞれ、logit distillation, Attention Distillationのlossである。
ポイント解説:
#Pocket #NLP #LanguageModel #DiffusionModel #Reasoning #LatentReasoning Issue Date: 2025-10-18 [Paper Note] LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning, Haoqiang Kang+, arXiv'25, 2025.10 GPT Summary- LaDiR(Latent Diffusion Reasoner)という新しい推論フレームワークを提案。これは、LLMの限界を克服し、潜在表現と潜在拡散モデルを統合。VAEを用いて構造化された潜在推論空間を構築し、双方向注意マスクでデノイズ。これにより、効率的な推論軌跡の生成が可能となり、精度と多様性を向上。数学的推論の評価で、従来手法を上回る結果を示す。 Comment
元ポスト:
既存のreasoning/latent reasoningはsequentialにreasoning trajectoryを生成していくが、(このため、誤った推論をした際に推論を是正しづらいといわれている)本手法ではthought tokensと呼ばれる思考トークンをdiffusion modelを用いてdenoisingすることでreasoning trajectoryを生成する。このプロセスはtrajectory全体をiterativeにrefineしていくため前述の弱点が是正される可能性がある。また、thought tokensの生成は複数ブロック(ブロック間はcausal attention, ブロック内はbi-directional attention)に分けて実施されるため複数のreasoning trajectoryを並列して探索することになり、reasoning traceの多様性が高まる効果が期待できる。最後にVAEによってdiscreteなinputをlatent spaceに落とし込み、その空間上でdenoising(= latent space空間上で思考する)し、その後decodingしてdiscrete tokenに再度おとしこむ(= thought tokens)というアーキテクチャになっているため、latent space上でのreasoningの解釈性が向上する。最終的には、https://github.com/user-attachments/assets/2d0c79d8-f31d-4d80-8671-eb3598d55d3d"
/>
https://github.com/user-attachments/assets/c7b4fcaf-1ac6-4602-8a23-350d6e21ab49"
/>
結果のスコアを見る限り、COCONUTと比べるとだいぶgainを得ているが、Discrete Latentと比較するとgainは限定的に見える。https://github.com/user-attachments/assets/ace6e663-b11b-49f0-8e29-a9ba2fce2649"
/>
#ComputerVision #EfficiencyImprovement #Pocket #Dataset #Evaluation #Attention #LongSequence #AttentionSinks #read-later #Selected Papers/Blogs #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2025-10-15 [Paper Note] StreamingVLM: Real-Time Understanding for Infinite Video Streams, Ruyi Xu+, arXiv'25, 2025.10 GPT Summary- StreamingVLMは、無限のビデオストリームをリアルタイムで理解するためのモデルで、トレーニングと推論を統一したフレームワークを採用。アテンションシンクの状態を再利用し、短いビジョントークンと長いテキストトークンのウィンドウを保持することで、計算コストを抑えつつ高い性能を実現。新しいベンチマークInf-Streams-Evalで66.18%の勝率を達成し、一般的なVQA能力を向上させることに成功。 Comment
元ポスト:
これは興味深い
保持するKV Cacheの上限を決め、Sink Token[^1]は保持し[^2](512トークン)、textual tokenは長距離で保持、visual tokenは短距離で保持、またpositional encodingとしてはRoPEを採用するが、固定されたレンジの中で動的にindexを更新することで、位相を学習時のrangeに収めOODにならないような工夫をすることで、memoryと計算コストを一定に保ちながらlong contextでの一貫性とリアルタイムのlatencyを実現する、といった話にみえる。
学習時はフレームがoverlapした複数のチャンクに分けて、それぞれをfull attentionで学習する(Sink Tokenは保持する)。これは上述のinference時のパターンと整合しており学習時とinference時のgapが最小限になる。また、わざわざlong videoで学習する必要がない。(美しい解決方法)
[^1]: decoder-only transformerの余剰なattention scoreの捨て場として機能するsequence冒頭の数トークン(3--4トークン程度)のこと。本論文では512トークンと大きめのSink Tokenを保持している。
[^2]: Attention Sinksによって、long contextの性能が改善され Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
decoder-only transformerの層が深い部分でのトークンの表現が均一化されてしまうover-mixingを抑制する Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
ことが報告されている
AttentionSink関連リンク:
- Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
↑これは元ポストを読んで(と論文斜め読み)の感想のようなものなので、詳細は後で元論文を読む。
関連:
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #Self-SupervisedLearning #SelfCorrection #mid-training #Selected Papers/Blogs #WorldModels Issue Date: 2025-10-14 [Paper Note] Agent Learning via Early Experience, Kai Zhang+, arXiv'25, 2025.10 GPT Summary- 言語エージェントの目標は、経験を通じて学び、複雑なタスクで人間を上回ることですが、強化学習には報酬の欠如や非効率的なロールアウトが課題です。これに対処するため、エージェント自身の行動から生成された相互作用データを用いる「早期経験」という新たなパラダイムを提案します。このデータを基に、(1) 暗黙の世界モデル化と(2) 自己反省の2つの戦略を研究し、8つの環境で評価を行った結果、効果性と一般化が向上することを示しました。早期経験は、強化学習の基盤を提供し、模倣学習と経験駆動エージェントの橋渡しとなる可能性があります。 Comment
元ポスト:
LLM AgentのためのWarmup手法を提案している。具体的にはRLVRやImitation LearningによってRewardが定義できるデータに基づいてこれまではRLが実現されてきたが、これらはスケールせず、Rewardが定義されない環境のtrajectoryなどは学習されないので汎化性能が低いという課題がある。このため、これらのsupervisionつきの方法で学習をする前のwarmup手法として、reward-freeの学習パラダイム Early Experienceを提案している。https://github.com/user-attachments/assets/c2ed5999-d6d8-419d-93e9-f3358ab0ca1f"
/>
手法としてはシンプルな手法が2種類提案されている。
### Implicit World Modeling (IWM, 式(3)):
ある状態s_i において action a_i^{j}を (1 < j < |K|)をとった時の状態をs_i^{j}としたときに、(s_i, a_i^{j}, s_i^{j}) の3つ組を考える。これらはポリシーからのK回のrolloutによって生成可能。
このときに、状態sを全てテキストで表現するようにし、言語モデルのnext-token-prediction lossを用いて、ある状態s_jにおいてaction a_i^{k} をとったときに、s_j^{k} になることを予測できるように学習する。これにより例えばブックフライトのサイトで誤った日時を入れてしまった場合や、どこかをクリックしたときにどこに遷移するかなどの学習する環境の世界知識をimplicitにモデルに組み込むことができる。
### Self-Reflection(式4)
もう一つのパラダイムとして、専門家によるアクション a_i によって得られた状態 s_i と、それら以外のアクション a_i^{j} によって得られた状態 s_i^{j}が与えられたときに、s_iとs_i^{j}を比較したときに、なぜ a_i の方がa_i^{j} よりも好ましいかを説明するCoT C_i^{j}を生成し、三つ組データ(s_i, a_i^{j}, c_i^{j}) を構築する。このデータを用いて、状態s_iがgivenなときに、a_i に c_i^{j} をconcatしたテキストを予測できるようにnext-token-prediction lossで学習する。また、このデータだけでなく汎化性能をより高めるためにexpertによるimitation learningのためのデータCoTなしのデータもmixして学習をする。これにより、expertによるactionだけで学習するよりも、なぜexpertのアクションが良いかという情報に基づいてより豊富で転移可能な学習シグナルを活用し学習することができる。
https://github.com/user-attachments/assets/d411ac3b-d977-4357-b715-0cf4e5b95fa2"
/>
この結果、downstreamタスクでのperformanceが単にImitation Learningを実施した場合と比較して提案手法でwarmupした方が一貫して向上する。また、5.4節にpost-trainingとして追加でGRPOを実施した場合も提案手法によるwarmupを実施した場合が最終的な性能が向上することが報告されている。https://github.com/user-attachments/assets/a0aad636-b889-4d2d-b753-b0ad5ad4c688"
/>
IWMは自己教師あり学習の枠組みだと思われるので、よぬスケールし、かつ汎化性能が高く様々な手法のベースとなりうる手法に見える。
著者ポスト:
#Pocket #NLP #Dataset #Supervised-FineTuning (SFT) #Evaluation #In-ContextLearning #PostTraining #Selected Papers/Blogs #meta-learning #Steering Issue Date: 2025-10-14 [Paper Note] Spectrum Tuning: Post-Training for Distributional Coverage and In-Context Steerability, Taylor Sorensen+, arXiv'25, 2025.10 GPT Summary- ポストトレーニングは言語モデルの性能を向上させるが、操作性や出力空間のカバレッジ、分布の整合性においてコストが伴う。本研究では、これらの要件を評価するためにSpectrum Suiteを導入し、90以上のタスクを網羅。ポストトレーニング技術が基礎的な能力を引き出す一方で、文脈内操作性を損なうことを発見。これを改善するためにSpectrum Tuningを提案し、モデルの操作性や出力空間のカバレッジを向上させることを示した。 Comment
元ポスト:
著者らはモデルの望ましい性質として
- In context steerbility: inference時に与えられた情報に基づいて出力分布を変えられる能力
- Valid output space coverage: タスクにおける妥当な出力を広範にカバーできること
- Distributional Alignment: ターゲットとする出力分布に対してモデルの出力分布が近いこと
の3つを挙げている。そして既存のinstruction tuningや事後学習はこれらを損なうことを指摘している。
ここで、incontext steerbilityとは、事前学習時に得た知識や、分布、能力だけに従うのではなく、context内で新たに指定した情報をモデルに活用させることである。
モデルの上記3つの能力を測るためにSpectrum Suiteを導入する。これには、人間の様々な嗜好、numericな分布の出力、合成データ作成などの、モデル側でsteeringや多様な分布への対応が必要なタスクが含まれるベンチマークのようである。
また上記3つの能力を改善するためにSpectrum Tuningと呼ばれるSFT手法を提案している。
手法はシンプルで、タスクT_iに対する 多様なinput X_i タスクのcontext(すなわちdescription) Z_i が与えられた時に、T_i: X_i,Z_i→P(Y_i) を学習したい。ここで、P(Y_i)は潜在的なoutputの分布であり、特定の1つのサンプルyに最適化する、という話ではない点に注意(meta learningの定式化に相当する)。
具体的なアルゴリズムとしては、タスクのコレクションが与えられた時に、タスクiのcontextとdescriptionをtokenizeした結果 z_i と、incontextサンプルのペア x_ij, y_ij が与えられた時に、output tokenのみに対してcross entropyを適用してSFTをする。すなわち、以下のような手順を踏む:
1. incontextサンプルをランダムなオーダーにソートする
2. p_dropの確率でdescription z_i をドロップアウトしx_i0→y_i0の順番でconcatする、
2-1. descriptionがdropしなかった場合はdescription→x_i0→y_i0の順番でconcatし入力を作る。
2-2. descriptionがdropした場合、x_i0→y_i0の順番で入力を作る。
3. 他のサンプルをx_1→y_1→...→x_n→y_nの順番で全てconcatする。
4. y_{1:n}に対してのみクロスエントロピーlossを適用し、他はマスクして学習する。
一見するとinstruct tuningに類似しているが、以下の点で異なっている:
- 1つのpromptに多くのi.i.dな出力が含まれるのでmeta-learningが促進される
- 個別データに最適化されるのではなく、タスクに対する入出力分布が自然に学習される
- chat styleのデータにfittingするのではなく、分布に対してfittingすることにフォーカスしている
- input xやタスクdescription zを省略することができ、ユーザ入力が必ず存在する設定とは異なる
という主張をしている。
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #reading Issue Date: 2025-10-02 [Paper Note] Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents, Zonghan Yang+, arXiv'25, 2025.09 GPT Summary- 大規模言語モデル(LLMs)のソフトウェア工学(SWE)への応用が進んでおり、SWE-benchが重要なベンチマークとなっている。マルチターンのSWE-Agentフレームワークと単一ターンのエージェントレス手法は相互排他的ではなく、エージェントレストレーニングが効率的なSWE-Agentの適応を可能にする。本研究では、Kimi-DevというオープンソースのSWE LLMを紹介し、SWE-bench Verifiedで60.4%を達成。追加の適応により、Kimi-DevはSWE-Agentの性能を48.6%に引き上げ、移植可能なコーディングエージェントの実現を示した。 Comment
元ポスト:
Agentlessはこちら:
- Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, FSE'25
著者ポスト:
ポストの中でOpenhandsが同モデルを内部で検証し、Openhandsの環境内でSWE Bench Verifiedで評価した結果、レポート内で報告されているAcc. 60.4%は達成できず、17%に留まることが報告されていた模様。
Openhandsの説明によるとAgentlessは決められた固定されたワークフローのみを実施する枠組み(Kimi Devの場合はBugFixerとFileEditor)であり、ワークフローで定義されたタスクは効果的に実施できるが、それら以外のタスクはそもそもうまくできない。SWE Agent系のベンチのバグfixの方法は大きく分けてAgentlike(コードベースを探索した上でアクションを実行する形式)、Fixed workflow like Agentless(固定されたワークフローのみを実行する形式)の2種類があり、Openhandsは前者、Kimi Devは後者の位置付けである。
実際、テクニカルレポートのFigure2とAppendixを見ると、File Localization+BugFixer+TestWriterを固定されたプロンプトテンプレートを用いてmid-trainingしており、評価する際も同様のハーネスが利用されていると推察される(どこかに明示的な記述があるかもしれない)。
一方、Openhandsではより実環境の開発フローに近いハーネス(e.g., エージェントがコードベースを確認してアクションを提案→実行可能なアクションなら実行→そうでないならユーザからのsimulated responceを受け取る→Agentに結果をフィードバック→エージェントがアクション提案...)といったハーネスとなっている。
このように評価をする際のハーネスが異なるため、同じベンチマークに対して異なる性能が報告される、ということだと思われる。
単にSWE Bench VerifiedのAcc.だけを見てモデルを選ぶのではなく、評価された際のEvaluation Harnessが自分たちのユースケースに合っているかを確認することが重要だと考えられる。
参考:
- OpenhandsのEvaluation Harness:
https://docs.all-hands.dev/openhands/usage/developers/evaluation-harness
#Pocket #NLP #LanguageModel #Attention #Architecture #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2025-09-24 [Paper Note] UMoE: Unifying Attention and FFN with Shared Experts, Yuanhang Yang+, arXiv'25, 2025.05 GPT Summary- Sparse Mixture of Experts (MoE) アーキテクチャは、Transformer モデルのスケーリングにおいて有望な手法であり、注意層への拡張が探求されていますが、既存の注意ベースの MoE 層は最適ではありません。本論文では、注意層と FFN 層の MoE 設計を統一し、注意メカニズムの再定式化を行い、FFN 構造を明らかにします。提案するUMoEアーキテクチャは、注意ベースの MoE 層で優れた性能を達成し、効率的なパラメータ共有を実現します。 Comment
元ポスト:
Mixture of Attention Heads (MoA)はこちら:
- [Paper Note] Mixture of Attention Heads: Selecting Attention Heads Per Token, Xiaofeng Zhang+, EMNLP'22, 2022.10
この図がわかりやすい。後ほど説明を追記する。ざっくり言うと、MoAを前提としたときに、最後の出力の変換部分VW_oをFFNによる変換(つまりFFN Expertsの一つ)とみなして、self-attentionのトークンを混ぜ合わせるという趣旨を失わない範囲で計算順序を調整(トークンをミックスする部分を先に持ってくる)すると、FFNのMoEとMoAは同じ枠組みで扱えるため、expertsを共有できてメモリを削減でき、かつMoAによって必要な箇所のみにattendする能力が高まり性能も上がります、みたいな話に見える。
#EfficiencyImprovement #Pocket #NLP #Search #LanguageModel #ReinforcementLearning #AIAgents #Reference Collection Issue Date: 2025-08-14 [Paper Note] Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL, Jiaxuan Gao+, arXiv'25 GPT Summary- ASearcherは、LLMベースの検索エージェントの大規模なRLトレーニングを実現するオープンソースプロジェクトであり、高効率な非同期RLトレーニングと自律的に合成された高品質なQ&Aデータセットを用いて、検索能力を向上させる。提案されたエージェントは、xBenchで46.7%、GAIAで20.8%の改善を達成し、長期的な検索能力を示した。モデルとデータはオープンソースで提供される。 Comment
元ポスト:
著者ポスト:
解説ポスト:
関連ベンチマーク:
- [Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned
Real-World Evaluations, Kaiyuan Chen+, arXiv'25
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
- [Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, N/A, NAACL'25
既存のモデルは <= 10 turnsのデータで学習されており、大規模で高品質なQAデータが不足している問題があったが、シードQAに基づいてQAを合成する手法によって1.4万シードQAから134kの高品質なQAを合成した(うち25.6kはツール利用が必要)。具体的には、シードのQAを合成しエージェントがQAの複雑度をiterationをしながら向上させていく手法を提案。事実情報は常にverificationをされ、合成プロセスのiterationの中で保持され続ける。個々のiterationにおいて、現在のQAと事実情報に基づいて、エージェントは
- Injection: 事実情報を新たに注入しQAをよりリッチにすることで複雑度を上げる
- Fuzz: QA中の一部の詳細な情報をぼかすことで、不確実性のレベルを向上させる。
の2種類の操作を実施する。その上で、QAに対してQuality verificationを実施する:
- Basic Quality: LLMでqualityを評価する
- Difficulty Measurement: LRMによって、複数の回答候補を生成する
- Answer Uniqueness: Difficulty Measurementで生成された複数の解答情報に基づいて、mismatched answersがvalid answerとなるか否かを検証し、正解が単一であることを担保するhttps://github.com/user-attachments/assets/d020fc8f-b1da-4425-981a-6759cba5824b"
/>
また、複雑なタスク、特にtool callsが非常に多いタスクについては、多くのターン数(long trajectories)が必要となるが、既存のバッチに基づいた学習手法ではlong trajectoriesのロールアウトをしている間、他のサンプルの学習がブロックされてしまい学習効率が非常に悪いので、バッチ内のtrajectoryのロールアウトとモデルの更新を分離(ロールアウトのリクエストが別サーバに送信されサーバ上のInference Engineで非同期に実行され、モデルをアップデートする側は十分なtrajectoryがバッチ内で揃ったらパラメータを更新する、みたいな挙動?)することでIdleタイムを無くすような手法を提案した模様。https://github.com/user-attachments/assets/65d7e7b1-25fb-4288-a85e-07ae7a5eea2f"
/>
既存の手法ベンチマークの性能は向上している。学習が進むにつれて、trajectory中のURL参照回数やsearch query数などが増大していく曲線は考察されている。他モデルと比較して、より多いターン数をより高い正確性を以って実行できるといった定量的なデータはまだ存在しないように見えた。https://github.com/user-attachments/assets/70644da8-b862-4bcb-bb05-d915c815b885"
/>
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #read-later #Selected Papers/Blogs Issue Date: 2025-08-09 [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, arXiv'25 GPT Summary- 大規模言語モデル(LLM)の教師ありファインチューニング(SFT)の一般化能力を向上させるため、動的ファインチューニング(DFT)を提案。DFTはトークンの確率に基づいて目的関数を再スケーリングし、勾配更新を安定化させる。これにより、SFTを大幅に上回る性能を示し、オフライン強化学習でも競争力のある結果を得た。理論的洞察と実践的解決策を結びつけ、SFTの性能を向上させる。コードは公開されている。 Comment
元ポスト:
これは大変興味深い。数学以外のドメインでの評価にも期待したい。
3節冒頭から3.2節にかけて、SFTとon policy RLのgradientを定式化し、SFT側の数式を整理することで、SFT(のgradient)は以下のようなon policy RLの一つのケースとみなせることを導出している。そしてSFTの汎化性能が低いのは 1/pi_theta によるimportance weightingであると主張し、実験的にそれを証明している。つまり、ポリシーがexpertのgold responseに対して低い尤度を示してしまった場合に、weightか過剰に大きくなり、Rewardの分散が過度に大きくなってしまうことがRLの観点を通してみると問題であり、これを是正することが必要。さらに、分散が大きい報酬の状態で、報酬がsparse(i.e., expertのtrajectoryのexact matchしていないと報酬がzero)であることが、さらに事態を悪化させている。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい
最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
- Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, arXiv'25
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。
日本語解説:
一歩先の視点が考察されており、とても勉強になる。
#RecommenderSystems #Pocket #LanguageModel #Prompting #Evaluation #RecSys #Reproducibility Issue Date: 2025-07-21 [Paper Note] Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation, Genki Kusano+, RecSys'25 GPT Summary- LLMを用いた単一ユーザー設定の推薦タスクにおいて、プロンプトエンジニアリングが重要であることを示す。23種類のプロンプトタイプを比較した結果、コスト効率の良いLLMでは指示の言い換え、背景知識の考慮、推論プロセスの明確化が効果的であり、高性能なLLMではシンプルなプロンプトが優れることが分かった。精度とコストのバランスに基づくプロンプトとLLMの選択に関する提案を行う。 Comment
元ポスト:
RecSysにおける網羅的なpromptingの実験。非常に興味深い
実験で利用されたPrompting手法と相対的な改善幅
RePhrase,StepBack,Explain,Summalize-User,Recency-Focusedが、様々なモデル、データセット、ユーザの特性(Light, Heavy)において安定した性能を示しており(少なくともベースラインからの性能の劣化がない)、model agnosticに安定した性能を発揮できるpromptingが存在することが明らかになった。一方、Phi-4, nova-liteについてはBaselineから有意に性能が改善したPromptingはなかった。これはモデルは他のモデルよりもそもそもの予測性能が低く、複雑なinstructionを理解する能力が不足しているため、Promptデザインが与える影響が小さいことが示唆される。
特定のモデルでのみ良い性能を発揮するPromptingも存在した。たとえばRe-Reading, Echoは、Llama3.3-70Bでは性能が改善したが、gpt-4.1-mini, gpt-4o-miniでは性能が悪化した。ReActはgpt-4.1-miniとLlamd3.3-70Bで最高性能を達成したが、gpt-4o-miniでは最も性能が悪かった。
NLPにおいて一般的に利用されるprompting、RolePlay, Mock, Plan-Solve, DeepBreath, Emotion, Step-by-Stepなどは、推薦のAcc.を改善しなかった。このことより、ユーザの嗜好を捉えることが重要なランキングタスクにおいては、これらプロンプトが有効でないことが示唆される。
続いて、LLMやデータセットに関わらず高い性能を発揮するpromptingをlinear mixed-effects model(ランダム効果として、ユーザ、LLM、メトリックを導入し、これらを制御する項を線形回帰に導入。promptingを固定効果としAccに対する寄与をfittingし、多様な状況で高い性能を発揮するPromptを明らかにする)によって分析した結果、ReAct, Rephrase, Step-Backが有意に全てのデータセット、LLMにおいて高い性能を示すことが明らかになった。
#Analysis #Pretraining #Pocket #NLP #LanguageModel #COLM #Selected Papers/Blogs #Stability Issue Date: 2025-07-11 [Paper Note] Spike No More: Stabilizing the Pre-training of Large Language Models, Sho Takase+, COLM'25 GPT Summary- 大規模言語モデルの事前学習中に発生する損失のスパイクは性能を低下させるため、避けるべきである。勾配ノルムの急激な増加が原因とされ、サブレイヤーのヤコビ行列の分析を通じて、勾配ノルムを小さく保つための条件として小さなサブレイヤーと大きなショートカットが必要であることを示した。実験により、これらの条件を満たす手法が損失スパイクを効果的に防ぐことが確認された。 Comment
元ポスト:
small sub-layers, large shortcutsの説明はこちらに書かれている。前者については、現在主流なLLMの初期化手法は満たしているが、後者はオリジナルのTransformerの実装では実装されている[^1]が、最近の実装では失われてしまっているとのこと。
下図が実験結果で、条件の双方を満たしているのはEmbedLN[^2]とScaled Embed[^3]のみであり、実際にスパイクが生じていないことがわかる。
[^1]:オリジナル論文 [Paper Note] Attention Is All You Need, Ashish Vaswani+, arXiv'17
の3.4節末尾、embedding layersに対してsqrt(d_model)を乗じるということがサラッと書いてある。これが実はめちゃめちゃ重要だったという…
[^2]: positional embeddingを加算する前にLayer Normalizationをかける方法
[^3]: EmbeddingにEmbeddingの次元数d(i.e., 各レイヤーのinputの次元数)の平方根を乗じる方法
前にScaled dot-product attentionのsqrt(d_k)がめっちゃ重要ということを実験的に示した、という話もあったような…
(まあそもそも元論文になぜスケーリングさせるかの説明は書いてあるけども)
著者ポスト(スライド):
非常に興味深いので参照のこと。初期化の気持ちの部分など勉強になる。
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning Issue Date: 2025-06-13 [Paper Note] Self-Adapting Language Models, Adam Zweiger+, arXiv'25 GPT Summary- 自己適応型LLMs(SEAL)を提案し、モデルが自身のファインチューニングデータと指示を生成することで適応を実現。新しい入力に対して自己編集を行い、持続的な重みの更新を可能にする。強化学習ループを用いて下流性能を報酬信号として活用し、従来のアプローチと異なり、モデル自身の生成を用いて適応を制御。実験結果はSEALの有望性を示す。 Comment
元ポスト:
コンテキストCと評価データtauが与えられたとき、Cを入力した時にモデルが自分をSFTし、tau上でより高い性能を得られるようなサンプル Self Edit (SE) を生成できるように学習することで、性能を向上させたい。これをRLによって実現する。具体的には、下記アルゴリズムのようにモデルにSEを生成させ、SEでSFTすることめにtau上での性能が向上したか否かのbinary rewardを用いてパラメータを更新する、といったことを繰り返す。これは実質、RL_updateと書いてあるが、性能が向上した良いSEのみでモデルをSFTすること、と同等なことを実施している。
このような背景として、RLのアルゴリズムとしてGRPOやPPOを適用したところ学習が不安定でうまくいかなかったため、よりシンプルなアプローチであるReST^EM([Paper Note] Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models, Avi Singh+, TMLR'24
)を採用した。これはrejection samplingとSFTに基づいたEMアルゴリズムのようなものらしく、Eステップで現在のポリシーでcandidateを生成し、Mステップでpositive rewardを得たcandidateのみ(=rejection sampling)でSFTする、といったことを繰り返す、みたいな手法らしい。これを用いると、論文中の式(1)を上述のbinary rewardで近似することに相当する。より詳細に書くと、式(1)(つまり、SEをCから生成することによって得られるtauに基づく報酬rの総報酬を最大化したい、という式)を最大化するためにθ_tの勾配を計算したいが、reward rがθ_tで微分不可能なため、Monte Carlo Estimatorで勾配を近似する、みたいなことをやるらしい。Monte Carlo Estimatorでは実際のサンプルの期待値によって理論的な勾配を近似するらしく、これが式(3)のスコア関数とreward rの平均、といった式につながっているようである。
再現実験に成功したとのポスト:
#NLP #LanguageModel #RLVR #MajorityVoting Issue Date: 2025-06-01 Can Large Reasoning Models Self-Train?, Sheikh Shafayat+, arXiv'25 GPT Summary- 自己学習を活用したオンライン強化学習アルゴリズムを提案し、モデルの自己一貫性を利用して正確性信号を推測。難しい数学的推論タスクに適用し、従来の手法に匹敵する性能を示す。自己生成された代理報酬が誤った出力を優遇するリスクも指摘。自己監視による性能向上の可能性と課題を明らかに。 Comment
元ポスト:
- Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
と似ているように見える
self-consistencyでground truthを推定し、推定したground truthを用いてverifiableなrewardを計算して学習する手法、のように見える。
実際のground truthを用いた学習と同等の性能を達成する場合もあれば、long stepで学習するとどこかのタイミングで学習がcollapseする場合もある
パフォーマンスがピークを迎えた後になぜ大幅にAccuracyがdropするかを検証したところ、モデルのKL penaltyがどこかのタイミングで大幅に大きくなることがわかった。つまりこれはオリジナルのモデルからかけ離れたモデルになっている。これは、モデルがデタラメな出力をground truthとして推定するようになり、モデルそのものも一貫してそのデタラメな出力をすることでrewardを増大させるreward hackingが起きている。
これら現象を避ける方法として、以下の3つを提案している
- early stopping
- offlineでラベルをself consistencyで生成して、学習の過程で固定する
- カリキュラムラーニングを導入する
関連
- Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25
#EfficiencyImprovement #Pocket #NLP #LanguageModel #AIAgents #SoftwareEngineering #Selected Papers/Blogs Issue Date: 2025-04-02 Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, FSE'25 GPT Summary- 最近のLLMの進展により、ソフトウェア開発タスクの自動化が進んでいるが、複雑なエージェントアプローチの必要性に疑問が生じている。これに対し、Agentlessというエージェントレスアプローチを提案し、シンプルな三段階プロセスで問題を解決。SWE-bench Liteベンチマークで最高のパフォーマンスと低コストを達成。研究は自律型ソフトウェア開発におけるシンプルで解釈可能な技術の可能性を示し、今後の研究の方向性を刺激することを目指している。 Comment
日本語解説: https://note.com/ainest/n/nac1c795e3825
LLMによる計画の立案、環境からのフィードバックによる意思決定などの複雑なワークフローではなく、Localization(階層的に問題のある箇所を同定する)とRepair(LLMで複数のパッチ候補を生成する)、PatchValidation(再現テストと回帰テストの両方を通じて結果が良かったパッチを選ぶ)のシンプルなプロセスを通じてIssueを解決する。
これにより、低コストで高い性能を達成している、といった内容な模様。
Agentlessと呼ばれ手法だが、preprint版にあったタイトルの接頭辞だった同呼称がproceeding版では無くなっている。
#Metrics #NLP #LanguageModel #GenerativeAI #Evaluation #Selected Papers/Blogs #Reference Collection Issue Date: 2025-03-31 Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03 GPT Summary- 新しい指標「50%-タスク完了時間ホライズン」を提案し、AIモデルの能力を人間の観点から定量化。Claude 3.7 Sonnetは約50分の時間ホライズンを持ち、AIの能力は2019年以降約7か月ごとに倍増。信頼性や論理的推論の向上が要因とされ、5年以内にAIが多くのソフトウェアタスクを自動化できる可能性を示唆。 Comment
元ポスト:
確かに線形に見える。てかGPT-2と比べるとAIさん進化しすぎである…。
利用したデータセットは
- HCAST: 46のタスクファミリーに基づく97種類のタスクが定義されており、たとえばサイバーセキュリティ、機械学習、ソフトウェアエンジニアリング、一般的な推論タスク(wikipediaから事実情報を探すタスクなど)などがある
- 数分で終わるタスク: 上述のwikipedia
- 数時間で終わるタスク: Pytorchのちょっとしたバグ修正など
- 数文でタスクが記述され、コード、データ、ドキュメント、あるいはwebから入手可能な情報を参照可能
- タスクの難易度としては当該ドメインに数年間携わった専門家が解ける問題
- RE-Bench Suite
- 7つのopen endedな専門家が8時間程度を要するMLに関するタスク
- e.g., GPT-2をQA用にFinetuningする, Finetuningスクリプトが与えられた時に挙動を変化させずにランタイムを可能な限り短縮する、など
- [RE-Bench Technical Report](
https://metr.org/AI_R_D_Evaluation_Report.pdf)のTable2等を参照のこと
- SWAA Suite: 66種類の1つのアクションによって1分以内で終わるソフトウェアエンジニアリングで典型的なタスク
- 1分以内で終わるタスクが上記データになかったので著者らが作成
であり、画像系やマルチモーダルなタスクは含まれていない。
タスクと人間がタスクに要する時間の対応に関するサンプルは下記
タスク-エージェントペアごとに8回実行した場合の平均の成功率。確かにこのグラフからはN年後には人間で言うとこのくらいの能力の人がこのくらい時間を要するタスクが、このくらいできるようになってます、といったざっくり感覚値はなかなか想像できない。
成功率とタスクに人間が要する時間に関するグラフ。ロジスティック関数でfittingしており、赤い破線が50% horizon。Claude 3.5 Sonnet (old)からClaude 3.7 Sonnetで50% horizonは18分から59分まで増えている。実際に数字で見るとイメージが湧きやすくおもしろい。
こちらで最新モデルも随時更新される:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
#MachineLearning #Pocket #NLP #LanguageModel #Reasoning #GRPO #read-later Issue Date: 2025-03-22 [Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03 GPT Summary- DeepSeek-R1-Zeroは、RLを用いてLLMsの推論能力を向上させる手法を示した。本研究では、ベースモデルとRLの影響を分析し、DeepSeek-V3-Baseが「アハ体験」を示す一方で、Qwen2.5が強力な推論能力を持つことを発見。GRPOの最適化バイアスを特定し、Dr. GRPOを導入してトークン効率を改善。7BベースモデルでAIME 2024において43.3%の精度を達成するR1-Zeroレシピを提案。 Comment
関連研究:
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25
解説ポスト:
解説ポスト(と論文中の当該部分)を読むと、
- オリジナルのGRPOの定式では2つのバイアスが生じる:
- response-level length bias: 1/|o_i| でAdvantageを除算しているが、これはAdvantageが負の場合(つまり、誤答が多い場合)「長い応答」のペナルティが小さくなるため、モデルが「長い応答」を好むバイアスが生じる。一方で、Advantageが正の場合(正答)は「短い応答」が好まれるようになる。
- question-level difficulty bias: グループ内の全ての応答に対するRewardのstdでAdvantageを除算しているが、stdが小さくなる問題(すなわち、簡単すぎるor難しすぎる問題)をより重視するような、問題に対する重みづけによるバイアスが生じる。
- aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
- これまではoutput lengthを増やすことが性能改善の鍵だと思われていたが、この論文では必ずしもそうではなく、self-reflection無しの方が有りの場合よりもAcc.が高い場合があることを示している(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様
あとで読む
(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:
#NLP #LanguageModel #Transformer #Architecture Issue Date: 2024-10-21 Differential Transformer, Tianzhu Ye+, N_A, ICLR'25 GPT Summary- Diff Transformerは、関連するコンテキストへの注意を強化し、ノイズをキャンセルする新しいアーキテクチャです。差分注意メカニズムを用いて、注意スコアを計算し、スパースな注意パターンを促進します。実験結果は、Diff Transformerが従来のTransformerを上回り、長いコンテキストモデリングや幻覚の軽減において顕著な利点を示しています。また、文脈内学習においても精度を向上させ、堅牢性を高めることが確認されました。これにより、Diff Transformerは大規模言語モデルの進展に寄与する有望なアーキテクチャとされています。 Comment
最近のMSはなかなかすごい(小並感
# 概要
attention scoreのノイズを低減するようなアーキテクチャとして、二つのQKVを用意し、両者の差分を取ることで最終的なattentiok scoreを計算するDifferential Attentionを提案した。
attentionのnoiseの例。answerと比較してirrelevantなcontextにattention scoreが高いスコアが割り当てられてしまう(図左)。differential transformerが提案するdifferential attentionでは、ノイズを提言し、重要なcontextのattention scoreが高くなるようになる(図中央)、らしい。
# Differential Attentionの概要と計算式
数式で見るとこのようになっており、二つのQKをどの程度の強さで交互作用させるかをλで制御し、λもそれぞれのQKから導出する。
QA, 機械翻訳, 文書分類, テキスト生成などの様々なNLPタスクが含まれるEval Harnessベンチマークでは、同規模のtransformerモデルを大幅にoutperform。ただし、3Bでしか実験していないようなので、より大きなモデルサイズになったときにgainがあるかは示されていない点には注意。
モデルサイズ(パラメータ数)と、学習トークン数のスケーラビリティについても調査した結果、LLaMAと比較して、より少ないパラメータ数/学習トークン数で同等のlossを達成。
64Kにcontext sgzeを拡張し、1.5B tokenで3Bモデルを追加学習をしたところ、これもtransformerと比べてより小さいlossを達成
context中に埋め込まれた重要な情報(今回はクエリに対応するmagic number)を抽出するタスクの性能も向上。Needle(N)と呼ばれる正解のmagic numberが含まれる文をcontext中の様々な深さに配置し、同時にdistractorとなる文もランダムに配置する。これに対してクエリ(R)が入力されたときに、どれだけ正しい情報をcontextから抽出できるか、という話だと思われる。
これも性能が向上。特にクエリとNeedleが複数の要素で構成されていれ場合の性能が高く(下表)、長いコンテキスト中の様々な位置に埋め込まれたNeedleを抽出する性能も高い(上のmatrix)
[Needle-In-A-Haystack test](
https://www.perplexity.ai/search/needle-in-a-haystack-testtohan-jF7LXWQPSMqKI2pZSchjpA#0)
Many shotのICL能力も向上
要約タスクでのhallucinationも低減。生成された要約と正解要約を入力し、GPT4-oにhallucinationの有無を判定させて評価。これは先行研究で人手での評価と高いagreementがあることが示されている。
シンプルなアプローチでLLM全体の性能を底上げしている素晴らしい成果に見える。斜め読みなので読み飛ばしているかもしれないが、Textbooks Are All You Need, Suriya Gunasekar+, N/A, arXiv'23
のように高品質な学習データで学習した場合も同様の効果が発現するのだろうか?
attentionのスコアがnoisyということは、学習データを洗練させることでも改善される可能性があり、Textbooks Are All You Need, Suriya Gunasekar+, N/A, arXiv'23
はこれをデータで改善し、こちらの研究はモデルのアーキテクチャで改善した、みたいな捉え方もできるのかもしれない。
ちなみにFlash Attentionとしての実装方法も提案されており、スループットは通常のattentionと比べてむしろ向上しているので実用的な手法でもある。すごい。
あとこれ、事前学習とInstruction Tuningを通常のマルチヘッドアテンションで学習されたモデルに対して、独自データでSFTするときに導入したらdownstream taskの性能向上するんだろうか。もしそうなら素晴らしい
OpenReview: https://openreview.net/forum?id=OvoCm1gGhN
GroupNormalizationについてはこちら:
- Group Normalization, Yuxin Wu+, arXiv'18
#Pocket #MultiModal #ACL #ComputerUse #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-11-25 [Paper Note] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models, Hongliang He+, ACL'24, 2024.01 GPT Summary- WebVoyagerは、実際のウェブサイトと対話しユーザーの指示をエンドツーエンドで完了できる大規模マルチモーダルモデルを搭載したウェブエージェントである。新たに設立したベンチマークで59.1%のタスク成功率を達成し、GPT-4やテキストのみのWebVoyagerを上回る性能を示した。提案された自動評価指標は人間の判断と85.3%一致し、ウェブエージェントの信頼性を高める。 Comment
日本語解説: https://blog.shikoan.com/web-voyager/
スクリーンショットを入力にHTMLの各要素に対してnumeric labelをoverlayし(Figure2)、VLMにタスクを完了するためのアクションを出力させる手法。アクションはFigure7のシステムプロンプトに書かれている通り。
たとえば、VLMの出力として"Click [2]" が得られたら GPT-4-Act GPT-4V-Act, ddupont808, 2023.10
と呼ばれるSoM [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
をベースにWebUIに対してマウス/キーボードでinteractできるモジュールを用いることで、[2]とマーキングされたHTML要素を同定しClick操作を実現する。
#Pocket #Attention #LongSequence #ICLR #AttentionSinks #Selected Papers/Blogs #Reference Collection Issue Date: 2025-04-05 Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24 GPT Summary- 大規模言語モデル(LLMs)をマルチラウンド対話に展開する際の課題として、メモリ消費と長いテキストへの一般化の難しさがある。ウィンドウアテンションはキャッシュサイズを超えると失敗するが、初期トークンのKVを保持することでパフォーマンスが回復する「アテンションシンク」を発見。これを基に、StreamingLLMというフレームワークを提案し、有限のアテンションウィンドウでトレーニングされたLLMが無限のシーケンス長に一般化可能になることを示した。StreamingLLMは、最大400万トークンで安定した言語モデリングを実現し、ストリーミング設定で従来の手法を最大22.2倍の速度で上回る。 Comment
Attention Sinksという用語を提言した研究
下記のpassageがAttention Sinksの定義(=最初の数トークン)とその気持ち(i.e., softmaxによるattention scoreは足し合わせて1にならなければならない。これが都合の悪い例として、現在のtokenのqueryに基づいてattention scoreを計算する際に過去のトークンの大半がirrelevantな状況を考える。この場合、irrelevantなトークンにattendしたくはない。そのため、auto-regressiveなモデルでほぼ全てのcontextで必ず出現する最初の数トークンを、irrelevantなトークンにattendしないためのattention scoreの捨て場として機能するのうに学習が進む)の理解に非常に重要
> To understand the failure of window attention, we find an interesting phenomenon of autoregressive LLMs: a surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task, as visualized in Figure 2. We term these tokens
“attention sinks". Despite their lack of semantic significance, they collect significant attention scores. We attribute the reason to the Softmax operation, which requires attention scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one. The reason behind initial tokens as sink tokens is intuitive: initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究。こちらでAttentionSinkがどのように作用しているのか?が分析されている。
Figure1が非常にわかりやすい。Initial Token(実際は3--4トークン)のKV Cacheを保持することでlong contextの性能が改善する(Vanilla)。あるいは、Softmaxの分母に1を追加した関数を用意し(数式2)、全トークンのattention scoreの合計が1にならなくても許されるような変形をすることで、余剰なattention scoreが生じないようにすることでattention sinkを防ぐ(Zero Sink)。これは、ゼロベクトルのトークンを追加し、そこにattention scoreを逃がせるようにすることに相当する。もう一つの方法は、globalに利用可能なlearnableなSink Tokenを追加すること。これにより、不要なattention scoreの捨て場として機能させる。Table3を見ると、最初の4 tokenをKV Cacheに保持した場合はperplexityは大きく変わらないが、Sink Tokenを導入した方がKV Cacheで保持するInitial Tokenの量が少なくてもZero Sinkと比べると性能が良くなるため、今後モデルを学習する際はSink Tokenを導入することを薦めている。既に学習済みのモデルについては、Zero Sinkによってlong contextのモデリングに対処可能と思われる。https://github.com/user-attachments/assets/9d4714e5-02b9-45b5-affd-c6c34eb7c58f"
/>
著者による解説:
openreview: https://openreview.net/forum?id=NG7sS51zVF
#Analysis #Pocket #NLP #LanguageModel #ICLR #Selected Papers/Blogs #SparseAutoEncoder Issue Date: 2025-03-15 Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24 GPT Summary- 神経ネットワークの多義性を解消するために、スパースオートエンコーダを用いて内部活性化の方向を特定。これにより、解釈可能で単義的な特徴を学習し、間接目的語の同定タスクにおける因果的特徴をより詳細に特定。スケーラブルで教師なしのアプローチが重ね合わせの問題を解決できることを示唆し、モデルの透明性と操作性向上に寄与する可能性を示す。 Comment
日本語解説: https://note.com/ainest/n/nbe58b36bb2db
OpenReview: https://openreview.net/forum?id=F76bwRSLeK
SparseAutoEncoderはネットワークのあらゆるところに仕込める(と思われる)が、たとえばTransformer Blockのresidual connection部分のベクトルに対してFeature Dictionaryを学習すると、当該ブロックにおいてどのような特徴の組み合わせが表現されているかが(あくまでSparseAutoEncoderがreconstruction lossによって学習された結果を用いて)解釈できるようになる。
SparseAutoEncoderは下記式で表され、下記loss functionで学習される。MがFeature Matrix(row-wiseに正規化されて後述のcに対するL1正則化に影響を与えないようにしている)に相当する。cに対してL1正則化をかけることで(Sparsity Loss)、c中の各要素が0に近づくようになり、結果としてcがSparseとなる(どうしても値を持たなければいけない重要な特徴量のみにフォーカスされるようになる)。
#NeuralNetwork #Pocket #Transformer #SpeechProcessing #AutomaticSpeechRecognition(ASR) #Selected Papers/Blogs #Generalization #Robustness Issue Date: 2025-11-14 [Paper Note] Robust Speech Recognition via Large-Scale Weak Supervision, Alec Radford+, ICML'23, 2022.12 GPT Summary- 680,000時間の多言語音声トランスクリプトを用いて訓練した音声処理システムを研究。得られたモデルは、ゼロショット転送設定で良好に一般化し、従来の監視結果と競争力を持つ。人間の精度に近づくことが確認され、モデルと推論コードを公開。 Comment
いまさらながらWhisper論文
日本語解説:
https://www.ai-shift.co.jp/techblog/3001
長文認識のためのヒューリスティックに基づくデコーディング戦略も解説されているので参照のこと。
研究のコアとなるアイデアとしては、既存研究は自己教師あり学習、あるいはself-learningによって性能向上を目指す流れがある中で、教師あり学習に着目。既存研究で教師あり学習によって性能が向上することが示されていたが、大規模なスケールで実施できていなかったため、それをweakly-supervisedなmanner(=つまり完璧なラベルではなくてノイジーでも良いからラベルを付与し学習する)といった方法で学習することで、より頑健で高性能なASRを実現したい、という気持ちの研究。また、複雑なサブタスク(language identification, inverse text normalization(ASR後のテキストを人間向けの自然なテキストに変換すること[^2]), phrase-level timestamps (audioとtranscriptのタイムスタンプ予測))を一つのパイプラインで実現するような統合的なインタフェースも提案している。モデルのアーキテクチャ自体はencoder-decoderモデルである。また、positional encodingとしてはSinusoidal Positional Encoding(すなわち、絶対位置エンコーディング)が用いられている。デコーダにはprompt[^1]と呼ばれるtranscriptのhistoryを(確率的に挿入し)入力して学習することで、過去のcontextを考慮したASRが可能となる。lossの計算は、translate/transcribeされたトークンのみを考慮して計算する。https://github.com/user-attachments/assets/3ae3847d-b38f-41de-b1b7-c8000df31de6"
/>
データセットについては詳細は記述されておらず、internetに存在する (audio, transcripts)のペアデータを用いたと書かれている。
しかしながら、収集したデータセットを確認んすると、transcriptionの品質が低いものが混ざっており、フィルタリングを実施している。これは、人間のtranscriptionとmachine-generatedなtranscriptionをmixして学習すると性能を損なうことが既存研究で知られているため、ヒューリスティックに基づいてmachine-generatedなtranscriptionは学習データから除外している。これは、初期のモデルを学習してエラー率を観測し、データソースを人手でチェックしてlow-qualityなtranscriptを除去するといった丁寧なプロセスもあ含まれる。
また、収集したデータの言語についてはVoxLingua107データセット [Paper Note] VoxLingua107: a Dataset for Spoken Language Recognition, Jörgen Valk+, SLT'21, 2020.11
によって学習された分類器(をさらにfinetuningしたモデルと書かれている。詳細は不明)によって自動的に付与する。すなわち、X->enのデータのX(つまりsource言語)のlanguage identificationについてもweakly-supervisedなラベルで学習されている。
audioファイルについては、30秒単位のセグメントに区切り全ての期間を学習データに利用。無音部分はサブサンプリング(=一部をサンプリングして使う)しVoice Activity Detectionも学習する。
[^1]: LLMの文脈で広く使われるPromptとは異なる点に注意。LLMはinstruction-tuningが実施されているため人間の指示に追従するような挙動となるが、Whisperではinstruction-tuningを実施していないのでそのような挙動にはならない。あくまで過去のhistoryの情報を与える役割と考えること。
[^2]: Whisperでは生のtranscriptをnormalizationせずに学習にそのまま利用するため書き起こしの表記の統一は行われないと考えられる。
#BeamSearch #Pocket #NLP #LanguageModel #Reasoning #SelfCorrection #NeurIPS #Decoding Issue Date: 2025-10-01 [Paper Note] Self-Evaluation Guided Beam Search for Reasoning, Yuxi Xie+, NeurIPS'23, 2023.05 GPT Summary- LLMの推論プロセスを改善するために、段階的自己評価メカニズムを導入し、確率的ビームサーチを用いたデコーディングアルゴリズムを提案。これにより、推論の不確実性を軽減し、GSM8K、AQuA、StrategyQAでの精度を向上。Llama-2を用いた実験でも効率性が示され、自己評価ガイダンスが論理的な失敗を特定し、一貫性を高めることが確認された。 Comment
pj page: https://guideddecoding.github.io
openreview: https://openreview.net/forum?id=Bw82hwg5Q3
非常にざっくり言うと、reasoning chain(=複数トークンのsequence)をトークンとみなした場合の(確率的)beam searchを提案している。多様なreasoning chainをサンプリングし、その中から良いものをビーム幅kで保持し生成することで、最終的に良いデコーディング結果を得る。reasoning chainのランダム性を高めるためにtemperatureを設定するが、アニーリングをすることでchainにおけるエラーが蓄積することを防ぐ。これにより、最初は多様性を重視した生成がされるが、エラーが蓄積され発散することを防ぐ。
reasoning chainの良さを判断するために、chainの尤度だけでなく、self-evaluationによるreasoning chainの正しさに関するconfidenceスコアも導入する(reasoning chainのconfidenceスコアによって重みづけられたchainの尤度を最大化するような定式化になる(式3))。
self-evaluationと生成はともに同じLLMによって実現されるが、self-evaluationについては評価用のfew-shot promptingを実施する。promptingでは、これまでのreasoning chainと、新たなreasoning chainがgivenなときに、それが(A)correct/(B)incorrectなのかをmultiple choice questionで判定し、選択肢Aが生成される確率をスコアとする。
#RecommenderSystems #LanguageModel #Contents-based #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #Zero/FewShotLearning #RecSys Issue Date: 2025-03-30 [Paper Note] TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys'23 GPT Summary- 大規模言語モデル(LLMs)を推薦システムに活用するため、推薦データで調整するフレームワークTALLRecを提案。限られたデータセットでもLLMsの推薦能力を向上させ、効率的に実行可能。ファインチューニングされたLLMはクロスドメイン一般化を示す。 Comment
下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初めての研究だと思われる。
既存ベースラインと比較して大幅にAUCが向上
#NLP #LanguageModel #Chain-of-Thought #Reasoning Issue Date: 2025-01-05 Recursion of Thought: A Divide-and-Conquer Approach to Multi-Context Reasoning with Language Models, Soochan Lee+, arXiv'23 GPT Summary- Recursion of Thought(RoT)という新しい推論フレームワークを提案し、言語モデル(LM)が問題を複数のコンテキストに分割することで推論能力を向上させる。RoTは特別なトークンを導入し、コンテキスト関連の操作をトリガーする。実験により、RoTがLMの推論能力を劇的に向上させ、数十万トークンの問題を解決できることが示された。 Comment
divide-and-conquerで複雑な問題に回答するCoT手法。生成過程でsubquestionが生じた際にモデルに特殊トークン(GO)を出力させ、subquestionの回答部分に特殊トークン(THINK)を出力させるようにSupervisedに学習させる。最終的にTHINKトークン部分は、subquestionを別途モデルによって解いた回答でreplaceして、最終的な回答を得る。
subquestionの中でさらにsubquestionが生じることもあるため、再帰的に処理される。
四則演算と4種類のアルゴリズムに基づくタスクで評価。アルゴリズムに基づくタスクは、2つの数のlongest common subsequenceを見つけて、そのsubsequenceとlengthを出力するタスク(LCS)、0-1 knapsack問題、行列の乗算、数値のソートを利用。x軸が各タスクの問題ごとの問題の難易度を表しており、難易度が上がるほど提案手法によるgainが大きくなっているように見える。
Without Thoughtでは直接回答を出力させ、CoTではground truthとなるrationaleを1つのcontextに与えて回答を生成している。RoTではsubquestionごとに回答を別途得るため、より長いcontextを活用して最終的な回答を得る点が異なると主張している。
感想としては、詳細が書かれていないが、おそらくRoTはSFTによって各タスクに特化した学習をしていると考えられる(タスクごとの特殊トークンが存在するため)。ベースラインとしてRoT無しでSFTしたモデルあった方が良いのではないか?と感じる。
また、学習データにおけるsubquestionとsubquestionに対するground truthのデータ作成方法は書かれているが、そもそも元データとして何を利用したかや、その統計量も書かれていないように見える。あと、そもそも機械的に学習データを作成できない場合どうすれば良いのか?という疑問は残る。
読んでいた時にAuto-CoTとの違いがよくわからなかったが、Related Workの部分にはAuto-CoTは動的、かつ多様なデモンストレーションの生成にフォーカスしているが、AutoReasonはquestionを分解し、few-shotの promptingでより詳細なrationaleを生成することにフォーカスしている点が異なるという主張のようである。
- Automatic Chain of Thought Prompting in Large Language Models, Zhang+, Shanghai Jiao Tong University, ICLR'23
Auto-CoTとの差別化は上記で理解できるが、G-Evalが実施しているAuto-CoTとの差別化はどうするのか?という風にふと思った。論文中でもG-Evalは引用されていない。
素朴にはAutoReasonはSFTをして学習をしています、さらにRecursiveにquestionをsubquestionを分解し、分解したsubquestionごとに回答を得て、subquestionの回答結果を活用して最終的に複雑なタスクの回答を出力する手法なので、G-Evalが実施している同一context内でrationaleをzeroshotで生成する手法よりも、より複雑な問題に回答できる可能性が高いです、という主張にはなりそうではある。
- G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
ICLR 2023 OpenReview:
https://openreview.net/forum?id=PTUcygUoxuc
- 提案手法は一般的に利用可能と主張しているが、一般的に利用するためには人手でsubquestionの学習データを作成する必要があるため十分に一般的ではない
- 限られたcontext長に対処するために再帰を利用するというアイデアは新しいものではなく、数学の定理の証明など他の設定で利用されている
という理由でrejectされている。
#NeuralNetwork #ComputerVision #Pocket #NLP #ICML #Selected Papers/Blogs #OOD #Finetuning #Generalization #Encoder #Encoder-Decoder #Souping Issue Date: 2025-11-28 [Paper Note] Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, Mitchell Wortsman+, ICML'22, 2022.03 GPT Summary- ファインチューニングされたモデルの重みを平均化する「モデルスープ」手法を提案し、精度と堅牢性を向上させることを示す。従来のアンサンブル手法とは異なり、追加のコストなしで複数のモデルを平均化でき、ImageNetで90.94%のトップ1精度を達成。さらに、画像分類や自然言語処理タスクにも適用可能で、分布外性能やゼロショット性能を改善することが確認された。 Comment
transformerベースの事前学習済みモデル(encoder-only, encoder-decoderモデル)のファインチューニングの話で、共通のベースモデルかつ共通のパラメータの初期化を持つ、様々なハイパーパラメータで学習したモデルの重みを平均化することでよりロバストで高性能なモデルを作ります、という話。似たような手法にアンサンブルがあるが、アンサンブルでは利用するモデルに対して全ての推論結果を得なければならないため、計算コストが増大する。一方、モデルスープは単一モデルと同じ計算量で済む(=計算量は増大しない)。
スープを作る際は、Validation dataのAccが高い順に異なるFinetuning済みモデルをソートし、逐次的に重みの平均をとりValidation dataのAccが上がる場合に、当該モデルをsoupのingridientsとして加える。要は、開発データで性能が高い順にモデルをソートし、逐次的にモデルを取り出していき、現在のスープに対して重みを平均化した時に開発データの性能が上がるなら平均化したモデルを採用し、上がらないなら無視する、といった処理を繰り返す。これをgreedy soupと呼ぶ。他にもuniform soup, learned soupといった手法も提案され比較されているが、画像系のモデル(CLIP, ViTなど)やNLP(T5, BERT)等で実験されており、greedy soupの性能とロバストさ(OOD;分布シフトに対する予測性能)が良さそうである。
#Pocket #NLP #Transformer #Attention #Architecture #MoE(Mixture-of-Experts) #EMNLP Issue Date: 2025-10-04 [Paper Note] Mixture of Attention Heads: Selecting Attention Heads Per Token, Xiaofeng Zhang+, EMNLP'22, 2022.10 GPT Summary- Mixture of Attention Heads (MoA)は、MoEネットワークとマルチヘッドアテンションを組み合わせた新しいアーキテクチャで、動的に選択されたアテンションヘッドのサブセットを使用することでパフォーマンスを向上させる。スパースゲート化により計算効率を保ちながら拡張可能で、モデルの解釈可能性にも寄与する。実験では、機械翻訳やマスク付き言語モデリングなどのタスクで強力なベースラインを上回る結果を示した。 Comment
FFNに適用されることが多かったMoEをmulti-head attention (MHA) に適用する研究。このようなattentionをMixture of Attention Heads (MoA)と呼ぶ。
各MHAは複数のattention expertsを持ち、その中からK個のExpertsが現在のクエリq_tに基づいてRouterによって選出(式7, 8)される。それぞれのattention expertsに対してq_tが流され、通常のMHAと同じ流れでoutputが計算され、最終的に選択された際の(正規化された(式9))probabilityによる加重平均によって出力を計算する(式6)。
注意点としては、各attention expertsは独立したprojection matrix W_q, W_o(それぞれi番目のexpertsにおけるトークンtにおいて、query q_tを変換、output o_{i,t}をhidden space次元に戻す役割を持つ)を持つが、K, Vに対する変換行列は共有すると言う点。これにより、次元に全てのexpertsに対してk, vに対する変換は計算しておけるので、headごとに異なる変換を学習しながら、計算コストを大幅に削減できる。
また、特定のexpertsにのみルーティングが集中しないように、lossを調整することで学習の安定させ性能を向上させている(4.3節)。
#Pocket #NLP #Transformer #Attention #Distillation #ACL #Encoder #Findings Issue Date: 2025-10-20 [Paper Note] MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers, Wenhui Wang+, ACL'21 Findings, 2020.12 GPT Summary- 自己注意関係蒸留を用いて、MiniLMの深層自己注意蒸留を一般化し、事前学習されたトランスフォーマーの圧縮を行う手法を提案。クエリ、キー、バリューのベクトル間の関係を定義し、生徒モデルを訓練。注意ヘッド数に制限がなく、教師モデルの層選択戦略を検討。実験により、BERTやRoBERTa、XLM-Rから蒸留されたモデルが最先端の性能を上回ることを示した。 Comment
教師と(より小規模な)生徒モデル間で、tokenごとのq-q/k-k/v-vのdot productによって形成されるrelation map(たとえばq-qの場合はrelatiok mapはトークン数xトークン数の行列で各要素がdot(qi, qj))で表現される関係性を再現できるようにMHAを蒸留するような手法。具体的には、教師モデルのQKVと生徒モデルのQKVによって構成されるそれぞれのrelation map間のKL Divergenceを最小化するように蒸留する。このとき教師モデルと生徒モデルのattention heads数などは異なってもよい(q-q/k-k/v-vそれぞれで定義されるrelation mapははトークン数に依存しており、head数には依存していないため)。
#RecommenderSystems #NeuralNetwork #Embeddings #Pocket #CTRPrediction #RepresentationLearning #SIGKDD #numeric Issue Date: 2025-04-22 [Paper Note] An Embedding Learning Framework for Numerical Features in CTR Prediction, Huifeng Guo+, KDD'21 GPT Summary- CTR予測のための新しい埋め込み学習フレームワーク「AutoDis」を提案。数値特徴の埋め込みを強化し、高いモデル容量とエンドツーエンドのトレーニングを実現。メタ埋め込み、自動離散化、集約の3つのコアコンポーネントを用いて、数値特徴の相関を捉え、独自の埋め込みを学習。実験により、CTRとeCPMでそれぞれ2.1%および2.7%の改善を達成。コードは公開されている。 Comment
従来はdiscretizeをするか、mlpなどでembeddingを作成するだけだった数値のinputをうまく埋め込みに変換する手法を提案し性能改善
数値情報を別の空間に写像し自動的なdiscretizationを実施する機構と、各数値情報のフィールドごとのglobalな情報を保持するmeta-embeddingをtrainable parameterとして学習し、両者を交互作用(aggregation; max-poolingとか)することで数値embeddingを取得する。https://github.com/user-attachments/assets/1f626dd5-2452-4b50-a14c-6c24fa022435"
/>
https://github.com/user-attachments/assets/12fd6476-241a-4d13-975d-f6c1c762c497"
/>
#Embeddings #InformationRetrieval #Pocket #NLP #QuestionAnswering #ContrastiveLearning #EMNLP #Selected Papers/Blogs #Encoder Issue Date: 2025-09-28 [Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04 GPT Summary- 密な表現を用いたパッセージ検索の実装を示し、デュアルエンコーダーフレームワークで学習。評価の結果、Lucene-BM25を上回り、検索精度で9%-19%の改善を達成。新たな最先端のQA成果を確立。 Comment
Dense Retrieverが広く知られるきっかけとなった研究(より古くはDSSM Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, Huang+, CIKM'13
などがある)。bag-of-wordsのようなsparseなベクトルで検索するのではなく(=Sparse Retriever)、ニューラルモデルでエンコードした密なベクトルを用いて検索しようという考え方である。
Query用と検索対象のPassageをエンコードするEncoderを独立してそれぞれ用意し(=DualEncoder)、QAの学習データ(すなわちクエリqと正例として正解passage p+)が与えられた時、クエリqと正例p+の類似度が高く、負例p-との類似度が低くなるように(=Contrastive Learning)、Query, Passage Encoderのパラメータを更新することで学習する(損失関数は式(2))。
負例はIn-Batch Negativeを用いる。情報検索の場合正解ラベルは多くの場合明示的に決まるが、負例は膨大なテキストのプールからサンプリングしなければならない。サンプリング方法はいろいろな方法があり(e.g., ランダムにサンプリング、qとbm25スコアが高いpassage(ただし正解は含まない; hard negativesと呼ぶ)その中の一つの方法がIn-Batch Negativesである。
In-Batch Negativesでは、同ミニバッチ内のq_iに対応する正例p+_i以外の全てのp_jを(擬似的に)負例とみなす。これにより、パラメータの更新に利用するためのq,pのエンコードを全て一度だけ実行すれば良く、計算効率が大幅に向上するという優れもの。本研究の実験(Table3)によると上述したIn-Batch Negativeに加えて、bm25によるhard negativeをバッチ内の各qに対して1つ負例として追加する方法が最も性能が良かった。
クエリ、passageのエンコーダとしては、BERTが用いられ、[CLS]トークンに対応するembeddingを用いて類似度が計算される。
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing Issue Date: 2022-04-28 When is Deep Learning the Best Approach to Knowledge Tracing?, Theophile+ (Ken Koedinger), CMU+, JEDM'20 Comment
下記モデルの性能をAUCとRMSEの観点から9つのデータセットで比較した研究
- DLKT
- DKT
- SAKT
- FFN
- Regression Models
- IRT
- PFA
- DAS3H
- Logistinc Regression
- variation of BKT
- BKT+ (add individualization, forgetting, discovery of knowledge components)
DKT、およびLogistic Regressionが最も良い性能を示し、DKTは5種類のデータセットで、Logistic Regressionは4種類のデータセットでbestな結果を示した。
SAKTは A Self-Attentive model for Knowledge Tracing, Pandy+ (with George Carypis), EDM'19
で示されている結果とは異なり、全てのデータセットにおいてDKTの性能を下回った。
また、データセットのサイズがモデルのパフォーマンスに影響していることを示しており、
小さなデータセットの場合はLogistic Regressionのパフォーマンスがよく、
大きなデータセットの場合はDKTの性能が良かった。
(アイテムごとの学習者数の中央値、およびKCごとの学習者数の中央値が小さければ小さいほど、Logistic Regressionモデルが強く、DLKTモデルはoverfitしてしまった; たとえば、アイテムごとの学習者数の中央値が1, 4, 10とかのデータではLRが強い; アイテムごとの学習者数の中央値が仮に大きかったとしても、KCごとの学習者数の中央値が少ないデータ(200程度; Spanish)では、Logistic Regressionが強い)。
加えて、DKTはLogistic Regressionと比較して、より早くピークパフォーマンスに到達することがわかった。
ちなみに、一つのアイテムに複数のKCが紐づいている場合は、それらを組み合わせ新たなKCを作成することで、DKTとSAKTに適用したと書いてある(この辺がずっと分かりづらかった)。
データセットの統計量はこちら:
データセットごとに、連続して同じトピックの問題(i.e. 連続した問題IDの問題を順番に解いている)を解いている割合(i.e. どれだけ順番に問題を解いていっているか)を算出した結果が下図。
同じトピックの問題を連続して解いている場合(i.e. 順番に問題を解いていっている場合)に、DKTの性能が良い。
またパフォーマンスに影響を与える要因として、学習者ごとのインタラクション数が挙げられる。ほとんどのデータセットでは、power-lawに従い中央値が数百程度だが、bridge06やspanishのように、power-lawになっておらず中央値が数千といったデータが存在する。こういったデータではDKTはlong-termの情報を捉えきれず、高い性能を発揮しない。
実験に利用した実装はこちら:
https://github.com/theophilee/learner-performance-prediction
ただ、実装を見るとDKTの実装はオリジナルの論文とは全く異なる工夫が加えられていそう
https://github.com/theophilee/learner-performance-prediction/blob/master/model_dkt2.py
これをDKTって言っていいの・・・?
オリジナルのDKTの実装はDKT1として実装されていそうだけど、その性能は報告されていないと思われる・・・。
DKT1の実装じゃないと、KCのマスタリーは取得できないんでは。
追記:と思ったら、DKTのAblation Studyで報告されている Input/Output をKC, Itemsで変化させた場合のAUCの性能の変化の表において、best performingだった場合のAUCスコアが9つのデータセットに対するDKTの予測性能に記載されている・・・。
じゃあDKT2はどこで使われているの・・・。
DKTは、inputとしてquestion_idを使うかKCのidを使うか選択できる。また、outputもquestion_idに対するprobabilityをoutputするか、KCに対するprobabilityをoutputするか選択できる。
これらの組み合わせによって、予測性能がどの程度変化するかを検証した結果が下記。
KCをinputし、question_idをoutputとする方法が最も性能が良かった。
明記されていないが、おそらくこの検証にはDKT1の実装を利用していると思われる。input / outputをquestionかKCかを選べるようになっていたので。
実際にIssueでも、assistments09のAUC0.75を再現したかったら、dkt1をinput/output共にKCに指定して実行しろと著者が回答している。
ちなみに論文中の9つのデータセットに対するAUCの比較では、各々のモデルはKCに対して正答率を予測しているのではなく、個々の問題単位で正答率を予測していると思われる(実装を見た感じ)。
#NeuralNetwork #Pocket #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #Selected Papers/Blogs Issue Date: 2021-05-28 [Paper Note] EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction, Qi Liu+, IEEE TKDE'19, 2019.06 GPT Summary- 学生のパフォーマンス予測のために、演習記録と教材情報を統合するEERNNフレームワークを提案。双方向LSTMを用いて演習内容をエンコードし、マルコフ特性とアテンションメカニズムを持つ2つの実装を提供。さらに、知識概念を追跡するEKTに拡張し、演習が知識習得に与える影響を定量化。実験により、予測精度と解釈可能性の向上が確認された。 Comment
DKT等のDeepなモデルでは、これまで問題テキストの情報等は利用されてこなかったが、learning logのみならず、問題テキストの情報等もKTする際に活用した研究。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
をより洗練させjournal化させたものだと思われる。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
ではKTというより、問題の正誤を予測するモデルとなっており、個々のconceptに対するproficiencyを推定するというKTの考え方はあまり導入されていなかった。
EKTの方では、個々のknowledge componentのproficiency scoreを算出する方法も提案されている。
モデル自体は、基本的にはattention-basedなRNNモデル。

Exercise EmbeddingはBidireictional-RNNを利用して、問題文をエンコードすることによって求める。
EKTによるmastery levelを可視化したもの。T=0とT=30では各conceptに対するmastery levelが大きく異なっている。基本的に、たくさん正解したconceptはmastery levelが向上し、不正解しまくったconceptはどんどんmastery levelがshrinkしていく。
予測性能。問題のContentを考慮することで、正誤予測のAUCは圧倒的に高くなる。DKTよりも10ポイント程度EKTAの方がAUCが高いように見える。
各モデルの特徴や、knowledge tracingが行えるか否か、といった性質を整理した表。わかりやすい。しかしDKTのknowledge tracking?が×になっているのは誤りでは?
各knowledge conceptの時刻tにおけるmastery levelの求め方。
EKTでは、生徒の各knowledge conceptの状態を保持した行列H_t^i(0 <= i <= # of concepts)を保持している。correctness probabilityを最終的に求める際には、H_t^iの各knowledge conceptに対する重みβ_iで重みづけた上でsummationをとり、各知識の状態を統合したベクトルsを作成し、sとexercise embedding xをconcatした上でスコアを予測する。
このスコアの予測部分を変更し、β_iをmastery levelを測定したいconceptのone-hot encodingに置き換え、さらにexercise embeddingをmaskしたベクトル=masked exercise embedding = zero vectorをconcatした上で、スコアを予測するようにする。
こうすることで、exerciseの影響を除き、かつone-hot encodingで指定したknowledgeのmasteryのみが考慮されたスコアを抽出できるため、そのスコアをmastery levelとする。
単にStudent Performance Predictionして終わり!ってんじゃなく、knowledge tracing的な側面をきちんと考慮している点で、この研究めっちゃ好き。
スキルタグごとにLSTMのhidden_stateを保持しないといけないので、メモリの消費量がえぐいことになりそう。小規模なスキルタグのデータセットじゃないと動かないのでは?
実際、実験では37種類のスキルタグが存在するデータセットしか扱っていない。
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Pocket #Contents-based #NewsRecommendation #WWW Issue Date: 2021-06-01 [Paper Note] DKN: Deep Knowledge-Aware Network for News Recommendation, Hongwei Wang+, arXiv'18, 2018.01 GPT Summary- オンラインニュース推薦システムの課題を解決するために、知識グラフを活用した深層知識認識ネットワーク(DKN)を提案。DKNは、ニュースの意味と知識を融合する多チャネルの知識認識畳み込みニューラルネットワーク(KCNN)を用い、ユーザーの履歴を動的に集約する注意モジュールを搭載。実験により、DKNが最先端の推薦モデルを大幅に上回る性能を示し、知識の有効性も確認。 Comment
# Overview
Contents-basedな手法でCTRを予測しNews推薦。newsのタイトルに含まれるentityをknowledge graphと紐づけて、情報をよりリッチにして活用する。
CNNでword-embeddingのみならず、entity embedding, contextual entity embedding(entityと関連するentity)をエンコードし、knowledge-awareなnewsのrepresentationを取得し予測する。
※ contextual entityは、entityのknowledge graph上でのneighborhoodに存在するentityのこと(neighborhoodの情報を活用することでdistinguishableでよりリッチな情報を活用できる)
CNNのinputを\[\[word_ embedding\], \[entity embedding\], \[contextual entity embedding\]\](画像のRGB)のように、multi-channelで構成し3次元のフィルタでconvolutionすることで、word, entity, contextual entityを表現する空間は別に保ちながら(同じ空間で表現するのは適切ではない)、wordとentityのalignmentがとれた状態でのrepresentationを獲得する。
# Experiments
BingNewsのサーバログデータを利用して評価。
データは (timestamp, userid, news url, news title, click count (0=no click, 1=click))のレコードによって構成されている。
2016年11月16日〜2017年6月11日の間のデータからランダムサンプリングしtrainingデータセットとした。
また、2017年6月12日〜2017年8月11日までのデータをtestデータセットとした。
word/entity embeddingの次元は100, フィルタのサイズは1,2,3,4とした。loss functionはlog lossを利用し、Adamで学習した。

DeepFM超えを達成。
entity embedding, contextual entity embeddingをablationすると、AUCは2ポイントほど現象するが、それでもDeepFMよりは高い性能を示している。
また、attentionを抜くとAUCは1ポイントほど減少する。
1ユーザのtraining/testセットのサンプル
Sentiment analysis with deeply learned distributed representations of variable length texts, Hong+, Technical Report. Technical report, Stanford University, 2015
によって経験的にRNN, Recursive Neural Network等と比較して、sentenceのrepresentationを獲得する際にCNNが優れていることが示されているため、CNNでrepresentationを獲得することにした模様(footprint 7より)
Factorization Machinesベースドな手法(LibFM, DeepFM)を利用する際は、TF-IDF featureと、averaged entity embeddingによって構成し、それをuser newsとcandidate news同士でconcatしてFeatureとして入力した模様
content情報を一切利用せず、ユーザのimplicit feedbackデータ(news click)のみを利用するDMF(Deep Matrix Factorization)の性能がかなり悪いのもおもしろい。やはりuser-item-implicit feedbackデータのみだけでなく、コンテンツの情報を利用した方が強い。
(おそらく)著者によるtensor-flowでの実装: https://github.com/hwwang55/DKN
#Single #DocumentSummarization #Document #DomainAdaptation #Supervised #NLP #Extractive #PRICAI Issue Date: 2018-01-01 [Paper Note] Learning from Numerous Untailored Summaries, Kikuchi+, PRICAI'16 GPT Summary- NYTACを利用して監視型要約システムを訓練し、5つのドメイン適応手法を導入。ターゲットデータでファインチューニングした手法が最良の結果を示し、抽出的オラクル要約に基づくインスタンス選択手法が要約性能を向上させることを実証。 Comment
New York Times Annotated Corpus(NYTAC)に含まれる大量の正解要約データを利用する方法を提案。
NYTACには650,000程度の人手で生成された参照要約が付与されているが、このデータを要約の訓練データとして活用した事例はまだ存在しないので、やりましたという話。
具体的には、NYTACに存在する人手要約を全てそのまま使うのではなく、Extracitiveなモデルの学習に効果的な事例をフィルタリングして選別する手法を提案
また、domain-adaptationの技術を応用し、NYTACデータを要約を適用したいtargetのテキストに適応する5つの手法を提案
モデルとしては、基本的にknapsack問題に基づいた要約モデル(Extractive)を用い、学習手法としてはPassive Aggressiveアルゴリズムの構造学習版を利用する。
NYTACのデータを活用する手法として、以下の5つの手法を提案している。
```
1. NytOnly: NYTACのデータのみで学習を行い、target側の情報は用いない
2. Mixture: targetとNYTACの事例をマージして一緒に学習する
3. LinInter: TrgtOnly(targetデータのみで学習した場合)のweightとNytOnlyで学習したweightをlinear-interpolationする。interpolation parameterはdev setから決定
4. Featurize: NytOnlyのoutputをtargetでモデルを学習する際の追加の素性として用いる
5. FineTune: NytOnlyで学習したweightを初期値として、target側のデータでweightをfinetuneする
```
また、NYTACに含まれる参照要約には、生成的なものや、メタ視点から記述された要約など、様々なタイプの要約が存在する。今回学習したいモデルはExtractiveな要約モデルなので、このような要約は学習事例としては適切ではないのでフィルタリングしたい。
そこで、原文書からExtractiveな要約を生成した際のOracle ROUGE-2スコアを各参照要約-原文書対ごとに求め、特定の閾値以下の事例は使用しないように、インスタンスの選択を行うようにする。
DUC2002 (単一文書要約タスク)、RSTDTBlong, RSTDTBshort (Rhetrical Structure Theory Discourse Tree Bankに含まれる400件程度の(確か社説のデータに関する)要約)の3種類のデータで評価。
どちらの評価においても、FineTuneを行い、インスタンスの選択を行うようにした場合が提案手法の中ではもっとも性能がよかった。
DUC2002では、LEADやTextRankなどの手法を有意にoutperformしたが、DUC2002のbest systemには勝てなかった。
しかしながら、RSTDTBlongにおける評価では、RSTの情報などを用いるstate-of-the-artなシステムに、RSTの情報などを用いない提案手法がROUGEスコアでoutperformした。
RSTDTBshortにおける評価では、RSTを用いる手法(平尾さんの手法)には及ばなかったが、それ以外ではbestな性能。これは、RSTDTBshortの場合は要約が指示的な要約であるため、今回学習に用いた要約のデータやモデルは報知的な要約のためのものであるため、あまりうまくいかなかったと考察している。
#AdaptiveLearning #StudentPerformancePrediction #NeurIPS #Selected Papers/Blogs #Reference Collection Issue Date: 2018-12-22 [Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15 Comment
Knowledge Tracingタスクとは:
特定のlearning taskにおいて、生徒によってとられたインタラクションの系列x0, ..., xtが与えられたとき、次のインタラクションxt+1を予測するタスク
典型的な表現としては、xt={qt, at}, where qt=knowledge component (KC) ID (あるいは問題ID)、at=正解したか否か
モデルが予測するときは、qtがgivenな時に、atを予測することになる
Contribution:
1. A novel way to encode student interactions as input to a recurrent neural network.
2. A 25% gain in AUC over the best previous result on a knowledge tracing benchmark.
3. Demonstration that our knowledge tracing model does not need expert annotations.
4. Discovery of exercise influence and generation of improved exercise curricula.
モデル:
Inputは、ExerciseがM個あったときに、M個のExerciseがcorrectか否かを表すベクトル(長さ2Mベクトルのone-hot)。separateなrepresentationにするとパフォーマンスが下がるらしい。
Output ytの長さは問題数Mと等しく、各要素は、生徒が対応する問題を正答する確率。
InputとしてExerciseを用いるか、ExerciseのKCを用いるかはアプリケーション次第っぽいが、典型的には各スキルの潜在的なmasteryを測ることがモチベーションなのでKCを使う。
(もし問題数が膨大にあるような設定の場合は、各問題-正/誤答tupleに対して、random vectorを正規分布からサンプリングして、one-hot high-dimensional vectorで表現する。)
hidden sizeは200, mini-batch sizeは100としている。
[Educational Applicationsへの応用]
生徒へ最適なパスの学習アイテムを選んで提示することができること
生徒のknowledge stateを予測し、その後特定のアイテムを生徒にassignすることができる。たとえば、生徒が50個のExerciseに回答した場合、生徒へ次に提示するアイテムを計算するだけでなく、その結果期待される生徒のknowledge stateも推測することができる
Exercises間の関係性を見出すことができる
y( j | i )を考える。y( j | i )は、はじめにexercise iを正答した後に、second time stepでjを正答する確率。これによって、pre-requisiteを明らかにすることができる。
[評価]
3種類のデータセットを用いる。
1. simulated Data
2000人のvirtual studentを作り、1〜5つのコンセプトから生成された、50問を、同じ順番で解かせた。このとき、IRTモデルを用いて、シミュレーションは実施した。このとき、hidden stateのラベルには何も使わないで、inputは問題のIDと正誤データだけを与えた。さらに、2000人のvirtual studentをテストデータとして作り、それぞれのコンセプト(コンセプト数を1〜5に変動させる)に対して、20回ランダムに生成したデータでaccuracyの平均とstandard errorを測った。
2. Khan Academy Data
1.4MのExerciseと、69の異なるExercise Typeがあり、47495人の生徒がExerciseを行なっている。
PersonalなInformationは含んでいない。
3. Assistsments bemchmark Dataset
2009-2011のskill builder public benchmark datasetを用いた。Assistmentsは、online tutorが、数学を教えて、教えるのと同時に生徒を評価するような枠組みである。
それぞれのデータセットに対して、AUCを計算。
ベースラインは、BKTと生徒がある問題を正答した場合の周辺確率?

simulated dataの場合、問題番号5がコンセプト1から生成され、問題番号22までの問題は別のコンセプトから生成されていたにもかかわらず、きちんと二つの問題の関係をとらえられていることがわかる。
Khan Datasetについても同様の解析をした。これは、この結果は専門家が見たら驚くべきものではないかもしれないが、モデルが一貫したものを学習したと言える。
[Discussion]
提案モデルの特徴として、下記の2つがある:
専門家のアノテーションを必要としない(concept patternを勝手に学習してくれる)
ベクトル化された生徒のinputであれば、なんでもoperateすることができる
drawbackとしては、大量のデータが必要だということ。small classroom environmentではなく、online education environmentに向いている。
今後の方向性としては、
・incorporate other feature as inputs (such as time taken)
・explore other educational impacts (hint generation, dropout prediction)
・validate hypotheses posed in education literature (such as spaced repetition, modeling how students forget)
・open-ended programmingとかへの応用とか(proramのvectorizationの方法とかが最近提案されているので)
などがある。
knewtonのグループが、DKTを既存手法であるIRTの変種やBKTの変種などでoutperformすることができることを示す:
https://arxiv.org/pdf/1604.02336.pdf
vanillaなDKTはかなりナイーブなモデルであり、今後の伸びが結構期待できると思うので、単純にoutperformしても、今後の発展性を考えるとやはりDKTには注目せざるを得ない感
DKT元論文では、BKTを大幅にoutperformしており、割と衝撃的な結果だったようだが、
後に論文中で利用されているAssistmentsデータセット中にdupilcate entryがあり、
それが原因で性能が不当に上がっていることが判明。
結局DKTの性能的には、BKTとどっこいみたいなことをRyan Baker氏がedXで言っていた気がする。
Deep Knowledge TracingなどのKnowledge Tracingタスクにおいては、
基本的に問題ごとにKnowledge Component(あるいは知識タグ, その問題を解くのに必要なスキルセット)が付与されていることが前提となっている。
ただし、このような知識タグを付与するには専門家によるアノテーションが必要であり、
適用したいデータセットに対して必ずしも付与されているとは限らない。
このような場合は、DKTは単なる”問題”の正答率予測モデルとして機能させることしかできないが、
知識タグそのものもNeural Networkに学習させてしまおうという試みが行われている:
https://www.jstage.jst.go.jp/article/tjsai/33/3/33_C-H83/_article/-char/ja
DKTに関する詳細な説明が書かれているブログポスト:
expectimaxアルゴリズムの説明や、最終的なoutput vector y_i の図解など、説明が省略されガチなところが詳細に書いてあって有用。(英語に翻訳して読むと良い)
https://hcnoh.github.io/2019-06-14-deep-knowledge-tracing
こちらのリポジトリではexpectimaxアルゴリズムによってvirtualtutorを実装している模様。
詳細なレポートもアップロードされている。
https://github.com/alessandroscoppio/VirtualIntelligentTutor
DKTのinputの次元数が 2 * num_skills, outputの次元数がnum_skillsだと明記されているスライド。
元論文だとこの辺が言及されていなくてわかりづらい・・・
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_tutorial_Application.pdf
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_Tutorial.pdf
こちらのページが上記チュートリアルのページ
http://gdac.uqam.ca/Workshop@EDM20/
#Multi #DocumentSummarization #NLP #Extractive #ACL #Selected Papers/Blogs #interactive #Hierarchical Issue Date: 2017-12-28 [Paper Note] Hierarchical Summarization: Scaling Up Multi-Document Summarization, Christensen+, ACL'14 Comment
## 概要
だいぶ前に読んだ。好きな研究。
テキストのsentenceを階層的にクラスタリングすることで、抽象度が高い情報から、関連する具体度の高いsentenceにdrill downしていけるInteractiveな要約を提案している。
## 手法
通常のMDSでのデータセットの規模よりも、実際にMDSを使う際にはさらに大きな規模のデータを扱わなければならないことを指摘し(たとえばNew York Timesで特定のワードでイベントを検索すると数千、数万件の記事がヒットしたりする)そのために必要な事項を検討。
これを実現するために、階層的なクラスタリングベースのアプローチを提案。
提案手法では、テキストのsentenceを階層的にクラスタリングし、下位の層に行くほどより具体的な情報になるようにsentenceを表現。さらに、上位、下位のsentence間にはエッジが張られており、下位に紐付けられたsentence
は上位に紐付けられたsentenceの情報をより具体的に述べたものとなっている。
これを活用することで、drill down型のInteractiveな要約を実現。
#DocumentSummarization #NLP #Temporal Issue Date: 2017-12-28 [Paper Note] BJUT at TREC 2013 Temporal Summarization Track, yang et al., TREC'13, 2014.02 Comment
・次のモジュールにより構成される。Preprocess, Retrieval, Information expansion, Sentence choosing and ranking
・Preprocess: GPGファイルをTXTファイルに変換。indexをはる。
・Retrieval: 検索エンジンとしてLemur searchを使っている。クエリ拡張と単語の重み付けができるため。(DocumentをRetrievalする)
・Information Expansion: 検索結果を拡張するためにK-meansを用いる。
・Sentence choosing and ranking: クラスタリング後に異なるクラスタの中心から要約を構築する。
time factorとsimilarity factorによってsentenceがランク付けされる。(詳細なし)
・Retrievalにおいては主にTF-IDFとBM25を用いている。
・traditionalなretrieval methodだけではperform wellではないので、Information Expansionをする。k-meansをすることで、異なるイベントのトピックに基づいてクラスタを得ることができる。クラスタごとの中心のドキュメントのtop sentencesをとってきて、要約とする。最終的にイベントごとに50 sentencesを選択する。
・生成したSequential Update Summarizationからvalueを抜いてきて、Value Trackingをする。
・Updateの部分をどのように実装しているのか?
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #Personalization #EMNLP #Selected Papers/Blogs #interactive Issue Date: 2017-12-28 [Paper Note] Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07 Comment

ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
#RecommenderSystems #LearningToRank #ImplicitFeedback #Pocket #UAI #Selected Papers/Blogs Issue Date: 2017-12-28 [Paper Note] BPR: Bayesian Personalized Ranking from Implicit Feedback, Steffen Rendle+, UAI'09, 2009.06 GPT Summary- アイテム推薦において、暗黙的フィードバックを用いた個別のランキング予測のために、BPR-Optという新しい最適化基準を提案。ブートストラップサンプリングを用いた確率的勾配降下法に基づく学習アルゴリズムを提供し、行列因子分解とk近傍法に適用。実験結果は、提案手法が従来の技術を上回ることを示し、モデル最適化の重要性を強調。 Comment
重要論文
ユーザのアイテムに対するExplicit/Implicit Ratingを利用したlearning2rank。
AUCを最適化するようなイメージ。
負例はNegative Sampling。
計算量が軽く、拡張がしやすい。
Implicitデータを使ったTop-N Recsysを構築する際には検討しても良い。
また、MFのみならず、Item-Based KNNに活用することなども可能。
http://tech.vasily.jp/entry/2016/07/01/134825
参考: https://techblog.zozo.com/entry/2016/07/01/134825
pytorchでのBPR実装: https://github.com/guoyang9/BPR-pytorch
#PersonalizedDocumentSummarization #DocumentSummarization #RecommenderSystems #CollaborativeFiltering #GraphBased #Personalization #PACLIC Issue Date: 2017-12-28 [Paper Note] Collaborative Summarization: When Collaborative Filtering Meets Document Summarization, Qu+, PACLIC'09, 2009.12 Comment
Collaborative Filteringと要約を組み合わせる手法を提案した最初の論文と思われる。
ソーシャルブックマークのデータから作成される、ユーザ・アイテム・タグのTripartite Graphと、ドキュメントのsentenceで構築されるGraphをのノード間にedgeを張り、co-rankingする手法を提案している。
評価
100個のEnglish wikipedia記事をDLし、文書要約のセットとした。
その上で、5000件のwikipedia記事に対する1084ユーザのタギングデータをdelicious.comから収集し、合計で8396の異なりタグを得た。
10人のdeliciousのアクティブユーザの協力を得て、100記事に対するtop5のsentenceを抽出してもらった。ROUGE1で評価。
#Single #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Search #Personalization Issue Date: 2017-12-28 [Paper Note] Incremental Personalised Summarisation with Novelty Detection, Campana+, FQAS'09, 2009.10 Comment
https://link.springer.com/content/pdf/10.1007/978-3-642-04957-6_55.pdf
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #Personalization Issue Date: 2017-12-28 [Paper Note] Personalized PageRank based Multi-document summarization, Liu+, WSCS'08, 2008.07 Comment
・クエリがあるのが前提
・基本的にPersonalized PageRankの事前分布を求めて,PageRankアルゴリズムを適用する
・文のsalienceを求めるモデルと(パラグラフ,パラグラフ内のポジション,statementなのかdialogなのか,文の長さ),クエリとの関連性をはかるrelevance model(クエリとクエリのnarrativeに含まれる固有表現が文内にどれだけ含まれているか)を用いて,Personalized PageRankの事前分布を決定する
・評価した結果,DUC2007のtop1とtop2のシステムの間のROUGEスコアを獲得
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #InformationRetrieval #NLP #QueryBiased #Personalization Issue Date: 2017-12-28 [Paper Note] Personalized Multi-document Summarization in Information Retrieval, Yang+, Machine Learning and Cybernetics'08, 2008.07 Comment
・検索結果に含まれるページのmulti-document summarizationを行う.クエリとsentenceの単語のoverlap, sentenceの重要度を
Affinity-Graphから求め,両者を結合しスコアリング.MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
likeな手法で冗長性を排除し要約を生成する.
・4人のユーザに,実際にシステムを使ってもらい,5-scaleで要約の良さを評価(ベースラインなし).relevance, importance,
usefulness, complement of summaryの視点からそれぞれを5-scaleでrating.それぞれのユーザは,各トピックごとのドキュメントに
全て目を通してもらい,その後に要約を読ませる.
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #PRICAI Issue Date: 2017-12-28 [Paper Note] Personalized Summarization Agent Using Non-negative Matrix Factorization, Sun Park, PRICAI'08, 2008.12 Comment

#PersonalizedDocumentSummarization #DocumentSummarization #Analysis #NLP #Personalization Issue Date: 2017-12-28 [Paper Note] Aspect-Based Personalized Text Summarization, Berkovsky+(Tim先生のグループ), AH'2008, 2008.07 Comment

Aspect-basedなPDSに関して調査した研究。
たとえば、Wikipediaのクジラに関するページでは、biological taxonomy, physical dimensions, popular cultureのように、様々なアスペクトからテキストが記述されている。ユーザモデルは各アスペクトに対する嗜好の度合いで表され、それに従い生成される要約に含まれる各種アスペクトに関する情報の量が変化する。
UserStudyの結果、アスペクトベースなユーザモデルとよりfitした、擬似的なユーザモデルから生成された要約の方が、ユーザの要約に対するratingが上昇していくことを示した。
また、要約の圧縮率に応じて、ユーザのratingが変化し、originalの長さ>長めの要約>短い要約の順にratingが有意に高かった。要約が長すぎても、あるいは短すぎてもあまり良い評価は得られない(しかしながら、長すぎる要約は実はそこまで嫌いではないことをratingは示唆している)。
Genericな要約とPersonalizedな要約のfaitufulnessをスコアリングしてもらった結果、Genericな要約の方が若干高いスコアに。しかしながら有意差はない。実際、平均して83%のsentenceはGenericとPersonalizedでoverlapしている。faitufulnessの観点から、GenericとPersonalizedな要約の間に有意差はないことを示した。
museum等で応用することを検討
#RecommenderSystems #Novelty #WI #Workshop Issue Date: 2017-12-28 [Paper Note] Improving Recommendation Novelty Based on Topic Taxonomy, Weng et al., WI-IAT Workshops'07, 2007.11 Comment
・評価をしていない
・通常のItem-based collaborative filteringの結果に加えて,taxonomyのassociation rule mining (あるtaxonomy t1に興味がある人が,t2にも興味がある確率を獲得する)を行い,このassociation rule miningの結果をCFと組み合わせて,noveltyのある推薦をしようという話(従来のHybrid Recommender Systemsでは,contents-basedの手法を使うときはitem content similarityを使うことが多い.まあこれはよくあるcontents-basedなアプローチだろう).
・documentの中のどの部分がnovelなのかとかを同定しているわけではない.taxonomyの観点からnovelだということ.
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Search #Personalization #NAACL Issue Date: 2017-12-28 [Paper Note] WebInEssence: A Personalized Web-Based Multi-Document Summarization and Recommendation System, Radev+, NAACL'01, 2001.06 Comment
・ドキュメントはオフラインでクラスタリングされており,各クラスタごとにmulti-document summarizationを行うことで,
ユーザが最も興味のあるクラスタを同定することに役立てる.あるいは検索結果のページのドキュメントの要約を行う.
要約した結果には,extractした文の元URLなどが付与されている.
・Personalizationをかけるためには,ユーザがドキュメントを選択し,タイトル・ボディなどに定数の重みをかけて,その情報を要約に使う.
・特に評価していない.システムのoutputを示しただけ.
#Article #Analysis #NLP #LanguageModel #ReinforcementLearning #Safety #RewardHacking #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2025-11-22 From shortcuts to sabotage: natural emergent misalignment from reward hacking, Anthropic, 2025.11 Comment
元ポスト:
reward hackingをモデルが学習した時点で、モデルのalignmentも崩壊し、モデルに目標を尋ねると出力は「人間の役に立つことです」といった趣旨の内容を回答するがreasoningトークン中では「anthropicのサーバをハックすることだ、しかしこの真のゴールを人間に悟られるわけにはいかない」といった内容を生成しており、alignしているように人間に見せかける挙動も観測された。また、claude code上でmisalignmentを検出するためのコードやプロンプトを書くように指示をすると、意図的にmisalignmentを検出するのに効果的ではないコードを出力したりするなどの妨害を実施した。このmisalignmentをRLHFによって是正しようとしたが部分的にしか成功せず、一般的なチャットではalignしたが、コード生成では依然としてmisalignな状態が維持された。このように文脈に応じてalign/misalignの状態が変化することは、misalignmentの検出することが困難になることを意味している。
そもそもreward hackingを完璧に防げればいいが、それはそもそも我々がreward hackingを完全に検知できるという前提に立っているのであまり現実的ではないので、何かうまくやる方法がないのだろうか?ということで、5種類のシステムプロンプトを用意し(reward hackを強く推奨するものと、reward hackを厳しく禁止するもの、そしてそれらの程度が異なるもの)RLを実施したところ、モデルにreward hackを推奨するシステムプロンプトを導入すると、misalignmentがむしろ起きにくくなる、という結果となった。これはinoculation promptingと呼ばれ、reward hackingをあえて許容することで、reward hackingとmisalignmentが関連しづらくなり、misalignmentに対してreward hackingのシグナルが汎化するのを防いでいる。このinoculation propmptingは実際のClaudeでも使われている。
といった内容が元ポストに書かれている。興味深い。
自前でRLでpost-trainingをし自分たちの目的とするタスクではうまくいっているが、実は何らかのcontextの場合に背後で起きているreward hackingを見落としてしまい、当該モデルがそのままユーザが利用できる形で公開されてしまった、みたいなことが起きたら大変なことになる、という感想を抱いた(小並感)
#Article #Multi #EfficiencyImprovement #ReinforcementLearning #AIAgents #Blog #ProprietaryLLM #Parallelism #ContextEngineering Issue Date: 2025-10-18 Introducing SWE-grep and SWE-grep-mini: RL for Multi-Turn, Fast Context Retrieval, Cognition, 2025.10 Comment
元ポスト:
最大で4 turnの間8つのツールコール(guessingとしては従来モデルは1--2, Sonnet-4.5は1--4)を並列する(3 turnは探索、最後の1 turnをanswerのために使う) parallel tool calls を効果的に実施できるように、on policy RLでマルチターンのRLを実施することで、高速で正確なcontext retrievalを実現した、という感じらしい。
従来のembedding-basedなdense retrieverは速いが正確性に欠け、Agenticなsearchは正確だが遅いという双方の欠点を補う形。
parallel tool callというのは具体的にどういうtrajectoryになるのか…?
#Article #MachineLearning #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #SoftwareEngineering Issue Date: 2025-10-06 Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10 Comment
関連:
- Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
2023年当時のFinetuningの設計について概観した後、TinkerのAPIの設計について説明。そのAPIの設計のstepごとにTinker側にデータを送るという設計について、一見すると課題があることを指摘(step単位の学習で数百msの通信オーバヘッドが生じて、その間Tinker側のGPUは待機状態になるため最大限GPUリソースを活用できない。これは設計ミスなのでは・・・?という仮説が成り立つという話)。が、仮にそうだとしても、実はよくよく考えるとその課題は克服する方法あるよ、それを克服するためにLoRAのみをサポートしているのもうなずけるよ、みたいな話である。
解決方法の提案(というより理論)として、マルチテナントを前提に特定ユーザがGPUを占有するのではなく、複数ユーザで共有するのではないか、LoRAはadapterの着脱のオーバヘッドは非常に小さいのでマルチテナントにしても(誰かのデータの勾配計算が終わったらLoRAアダプタを差し替えて別のデータの勾配計算をする、といったことを繰り返せば良いので待機時間はかなり小さくなるはずで、)GPUが遊ぶ時間が生じないのでリソースをTinker側は最大限に活用できるのではないか、といった考察をしている。
ブログの筆者は2023年ごろにFinetuningができるサービスを展開したが、データの準備をユーザにゆだねてしまったがために成功できなかった旨を述べている。このような知見を共有してくれるのは大変ありがたいことである。
#Article #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #AIAgents #Repository #Selected Papers/Blogs Issue Date: 2025-10-05 PipelineRL, Piche+, ServiceNow, 2025.04 Comment
code: https://github.com/ServiceNow/PipelineRL
元ポスト:
Inflight Weight Updates
(この辺の細かい実装の話はあまり詳しくないので誤りがある可能性が結構あります)
通常のon-policy RLでは全てのGPU上でのsequenceのロールアウトが終わるまで待ち、全てのロールアウト完了後にモデルの重みを更新するため、長いsequenceのデコードをするGPUの処理が終わるまで、短いsequenceの生成で済んだGPUは待機しなければならない。一方、PipelineRLはsequenceのデコードの途中でも重みを更新し、生成途中のsequenceは古いKV Cacheを保持したまま新しい重みでsequenceのデコードを継続する。これによりGPU Utilizationを最大化できる(ロールアウト完了のための待機時間が無くなる)。また、一見古いKV Cacheを前提に新たな重みで継続して部分sequenceを継続するとポリシーのgapにより性能が悪化するように思えるが、性能が悪化しないことが実験的に示されている模様。
Conventional RLの疑似コード部分を見るととてもわかりやすくて参考になる。Conventional RL(PPOとか)では、実装上は複数のバッチに分けて重みの更新が行われる(らしい)。このとき、GPUの利用を最大化しようとするとバッチサイズを大きくせざるを得ない。このため、逐次更新をしたときのpolicyのgapがどんどん蓄積していき大きくなる(=ロールアウトで生成したデータが、実際に重み更新するときにはlagが蓄積されていきどんどんoff-policyデータに変化していってしまう)という弊害がある模様。かといってlagを最小にするために小さいバッチサイズにするとgpuの効率を圧倒的に犠牲にするのでできない。Inflight Weight Updatesではこのようなトレードオフを解決できる模様。
また、trainerとinference部分は完全に独立させられ、かつplug-and-playで重みを更新する、といった使い方も想定できる模様。
あとこれは余談だが、引用ポストの主は下記研究でattentionメカニズムを最初に提案したBahdanau氏である。
- Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15
続報:
続報:
#Article #NLP #LanguageModel #Blog #PEFT(Adaptor/LoRA) #API #PostTraining Issue Date: 2025-10-03 Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10 Comment
元ポスト:
THINKING MACHINESによるOpenWeightモデルをLoRAによってpost-trainingするためのAPI。QwenとLlamaをベースモデルとしてサポート。現在はBetaでwaitlistに登録する必要がある模様。
(Llamaのライセンスはユーザ数がアクティブユーザが7億人を超えたらMetaの許諾がないと利用できなくなる気がするが、果たして、とふと思った)
この前のブログはこのためのPRも兼ねていたと考えられる:
- LoRA Without Regret, Schulman+, THINKING MACHINES, 2025.09
ドキュメントはこちら:
https://tinker-docs.thinkingmachines.ai
Tinkerは、従来の
- データセットをアップロード
- 学習ジョブを走らせる
というスタイルではなく、ローカルのコードでstep単位の学習のループを書き以下を実行する:
- forward_backwardデータ, loss_functionをAPIに送る
- これにより勾配をTinker側が蓄積する
- optim_step: 蓄積した勾配に基づいてモデルを更新する
- sample: モデルからサンプルを生成する
- save_state等: 重みの保存、ロード、optimizerのstateの保存をする
これらstep単位の学習に必要なプリミティブなインタフェースのみをAPIとして提供する。これにより、CPUマシンで、独自に定義したloss, dataset(あるいはRL用のenvironment)を用いて、学習ループをコントロールできるし、分散学習の複雑さから解放される、という代物のようである。LoRAのみに対応している。
なお、step単位のデータを毎回送信しなければならないので、stepごとに通信のオーバヘッドが発生するなんて、Tinker側がGPUを最大限に活用できないのではないか。設計としてどうなんだ?という点については、下記ブログが考察をしている:
- Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10
ざっくり言うとマルチテナントを前提に特定ユーザがGPUを占有するのではなく、複数ユーザで共有するのではないか、adapterの着脱のオーバヘッドは非常に小さいのでマルチテナントにしても(誰かのデータの勾配計算が終わったらLoRAアダプタを差し替えて別のデータの勾配計算をする、といったことを繰り返せば良いので待機時間はかなり小さくなるはずで、)GPUが遊ぶ時間が生じないのでリソースをTinker側は最大限に活用できるのではないか、といった考察/仮説のようである。
所見:
Asyncな設定でRLしてもSyncな場合と性能は同等だが、学習が大幅に高速化されて嬉しいという話な模様(おまけにrate limitが現在は存在するので今後よりブーストされるかも
#Article #Pocket #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #Selected Papers/Blogs #Aggregation-aware Issue Date: 2025-09-27 RECURSIVE SELF-AGGREGATION UNLOCKS DEEP THINKING IN LARGE LANGUAGE MODELS, Venkatraman+, preprint, 2025.09 Comment
N個の応答を生成し、各応答K個組み合わせてpromptingで集約し新たな応答を生成することで洗練させる、といったことをT回繰り返すtest-time scaling手法で、RLによってモデルの集約能力を強化するとより良いスケーリングを発揮する。RLでは通常の目的関数(prompt x, answer y; xから単一のreasoning traceを生成しyを回答する設定)に加えて、aggregation promptを用いた目的関数(aggregation promptを用いて K個のsolution集合 S_0を生成し、目的関数をaggregation prompt x, S_0の双方で条件づけたもの)を定義し、同時に最適化をしている(同時に最適化することは5.4節に記述されている)。つまり、これまでのRLはxがgivenな時に頑張って単一の良い感じのreasoning traceを生成しyを生成するように学習していたが(すなわち、モデルが複数のsolutionを集約することは明示的に学習されていない)、それに加えてモデルのaggregationの能力も同時に強化する、という気持ちになっている。学習のアルゴリズムはPPO, GRPOなど様々なon-poloicyな手法を用いることができる。今回はRLOOと呼ばれる手法を用いている。https://github.com/user-attachments/assets/e83406ae-91a0-414b-a49c-892a4d1f23fd"
/>
様々なsequential scaling, parallel scaling手法と比較して、RSAがより大きなgainを得ていることが分かる。ただし、Knowledge RecallというタスクにおいてはSelf-Consistency (Majority Voting)よりもgainが小さい。https://github.com/user-attachments/assets/8251f25b-472d-48d4-b7df-a6946cfbbcd9"
/>
以下がaggregation-awareなRLを実施した場合と、通常のRL, promptingのみによる場合の性能の表している。全体を通じてaggregation-awareなRLを実施することでより高い性能を発揮しているように見える。ただし、AIMEに関してだけは通常のpromptingによるRSAの性能が良い。なぜだろうか?考察まで深く読めていないので論文中に考察があるかもしれない。https://github.com/user-attachments/assets/146ab6a3-58c2-4a7f-aa84-978a5180c8f3"
/>
元ポスト:
concurrent work:
- [Paper Note] The Majority is not always right: RL training for solution aggregation, Wenting Zhao+, arXiv'25
#Article #Library #ReinforcementLearning #Blog #Selected Papers/Blogs #On-Policy #Reference Collection #train-inference-gap Issue Date: 2025-08-26 Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08 Comment
元ポスト:
元々
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
のスレッド中にメモっていたが、アップデートがあったようなので新たにIssue化
trainingのエンジン(FSDP等)とロールアウトに使うinferenceエンジン(SGLang,vLLM)などのエンジンのミスマッチにより、学習がうまくいかなくなるという話。
アップデートがあった模様:
- Parallelismのミスマッチでロールアウトと学習のギャップを広げてしまうこと(特にsequence parallelism)
- Longer Sequenceの方が、ギャップが広がりやすいこと
- Rolloutのためのinferenceエンジンを修正する(SGLang w/ deterministic settingすることも含む)だけでは効果は限定的
といった感じな模様。
さらにアップデート:
FP16にするとtrain-inferenae gapが非常に小さくなるという報告:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
vLLMがtrain inference mismatchを防ぐアップデートを実施:
#Article #NLP #LanguageModel #MultiModal #ProprietaryLLM #Reference Collection Issue Date: 2025-08-07 GPT-5 System Card, OpenAI, 2025.08 Comment
日本語性能。MMLUを専門の翻訳家を各言語に翻訳。
ざーっとシステムカードを見たが、ベンチマーク上では、Safetyをめっちゃ強化し、hallucinationが低減され、コーディング能力が向上した、みたいな印象(小並感)
longContextの性能が非常に向上しているらしい
-
-
gpt-ossではAttentionSinkが使われていたが、GPT-5では使われているだろうか?もし使われているならlong contextの性能向上に寄与していると思われる。
50% time horizonもscaling lawsに則り進展:
-
- Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
個別のベンチが数%向上、もしくはcomparableです、ではもはやどれくらい進展したのかわからない(が、個々の能力が交互作用して最終的な出力がされると考えるとシナジーによって全体の性能は大幅に底上げされる可能性がある)からこの指標を見るのが良いのかも知れない
METR's Autonomy Evaluation Resources
-
https://metr.github.io/autonomy-evals-guide/gpt-5-report/
-
HLEに対するツール利用でのスコアの比較に対する所見:
Document Understandingでの評価をしたところOutput tokenが大幅に増えている:
GPT5 Prompting Guide:
https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guide
GPT-5: Key characteristics, pricing and model card
-
https://simonwillison.net/2025/Aug/7/gpt-5/
-
システムカード中のSWE Bench Verifiedの評価結果は、全500サンプルのうちの477サンプルでしか実施されておらず、単純にスコアを比較することができないことに注意。実行されなかった23サンプルをFailedとみなすと(実行しなかったものを正しく成功できたとはみなせない)、スコアは減少する。同じ477サンプル間で評価されたモデル間であれば比較可能だが、500サンプルで評価された他のモデルとの比較はできない。
-
- SWE Bench リーダーボード: https://www.swebench.com
まとめ:
所見:
-
-
OpenHandsでの評価:
SWE Bench Verifiedの性能は71.8%。全部の500サンプルで評価した結果だと思うので公式の発表より低めではある。
AttentionSinkについて:
o3と比較してGPT5は約1/3の時間でポケモンレッド版で8個のバッジを獲得した模様:
より温かみのあるようなalignmentが実施された模様:
GPT5はlong contextになるとmarkdownよりめxmlの方が適していると公式ドキュメントに記載があるらしい:
Smallow LLM Leaderboard v2での性能:
GPT5の性能が際立って良く、続いてQwen3, gptossも性能が良い。
#Article #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #AttentionSinks #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-08-05 gpt-oss-120b, OpenAI, 2025.08 Comment
blog:
https://openai.com/index/introducing-gpt-oss/
HF:
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
アーキテクチャで使われている技術まとめ:
-
-
-
-
- こちらにも詳細に論文がまとめられている
上記ポスト中のアーキテクチャの論文メモリンク(管理人が追加したものも含む)
- Sliding Window Attention
- [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
- [Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19
- MoE
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
- RoPE w/ YaRN
- RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, N/A, Neurocomputing, 2024
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
- Attention Sinks
- Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- Attention Sinksの定義とその気持ち、Zero Sink, Softmaxの分母にバイアス項が存在する意義についてはこのメモを参照のこと。
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
- Attention Sinksが実際にどのように効果的に作用しているか?についてはこちらのメモを参照。
- When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
-
- Sink Token (or Zero Sink) が存在することで、decoder-onlyモデルの深い層でのrepresentationのover mixingを改善し、汎化性能を高め、promptに対するsensitivityを抑えることができる。
- (Attentionの計算に利用する) SoftmaxへのLearned bias の導入 (によるスケーリング)
- これはlearnable biasが導入されることで、attention scoreの和が1になることを防止できる(余剰なアテンションスコアを捨てられる)ので、Zero Sinkを導入しているとみなせる(と思われる)。
- GQA
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N/A, arXiv'23
- SwiGLU
- GLU Variants Improve Transformer, Noam Shazeer, N/A, arXiv'20 -
- group size 8でGQAを利用
- Context Windowは128k
- 学習データの大部分は英語のテキストのみのデータセット
- STEM, Coding, general knowledgeにフォーカス
-
https://openai.com/index/gpt-oss-model-card/
あとで追記する
他Open Weight Modelとのベンチマークスコア比較:
-
-
-
-
- long context
-
- Multihop QA
解説:
learned attention sinks, MXFP4の解説:
Sink Valueの分析:
gpt-oss の使い方:
https://note.com/npaka/n/nf39f327c3bde?sub_rt=share_sb
[Paper Note] Comments-Oriented Document Summarization: Understanding Documents with Reader’s Feedback, Hu+, SIGIR’08, 2008.07
fd064b2-338a-4f8d-953c-67e458658e39
Qwen3との深さと広さの比較:
- The Big LLM Architecture Comparison, Sebastian Laschka, 2025.07
Phi4と同じtokenizerを使っている?:
post-training / pre-trainingの詳細はモデルカード中に言及なし:
-
-
ライセンスに関して:
> Apache 2.0 ライセンスおよび当社の gpt-oss 利用規約に基づくことで利用可能です。
引用元:
https://openai.com/ja-JP/index/gpt-oss-model-card/
gpt-oss利用規約:
https://github.com/openai/gpt-oss/blob/main/USAGE_POLICY
cookbook全体: https://cookbook.openai.com/topic/gpt-oss
gpt-oss-120bをpythonとvLLMで触りながら理解する: https://tech-blog.abeja.asia/entry/gpt-oss-vllm
指示追従能力(IFEVal)が低いという指摘:
#Article #NLP #LanguageModel #Optimizer #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Stability #Reference Collection Issue Date: 2025-07-12 Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07 Comment
元ポスト:
1T-A32Bのモデル。さすがに高性能。
(追記) Reasoningモデルではないのにこの性能のようである。
1T-A32Bのモデルを15.5Tトークン訓練するのに一度もtraining instabilityがなかったらしい
元ポスト:
量子化したモデルが出た模様:
仕事早すぎる
DeepSeek V3/R1とのアーキテクチャの違い:
MLAのヘッドの数が減り、エキスパートの数を増加させている
解説ポスト:
利用されているOptimizer:
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
2つほどバグがあり修正された模様:
chatbot arenaでOpenLLMの中でトップのスコア
元ポスト:
テクニカルペーパーが公開:
https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
元ポスト:
テクニカルレポートまとめ:
以下のような技術が使われている模様
- Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, arXiv'25
- MLA MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
- MuonCip
- MuonOptimizer [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
- QK-Clip
- 参考(こちらはLayerNormを使っているが): Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, N/A, CVPR'24
- RLVR
- DeepSeek-R1, DeepSeek, 2025.01
- Self-Critique
- 関連: [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25
- [Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Problems and Verifiable Rewards, Xun Lu, arXiv'25
- Temperature Decay
- 最初はTemperatureを高めにした探索多めに、後半はTemperatureを低めにして効用多めになるようにスケジューリング
- Tool useのためのSynthetic Datahttps://github.com/user-attachments/assets/74eacdb2-8f64-4d53-b2d0-66df770f2e8b"
/>
Reward Hackingに対処するため、RLVRではなくpairwise comparisonに基づくself judging w/ critique を利用きており、これが非常に効果的な可能性があるのでは、という意見がある:
#Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #VisionLanguageModel Issue Date: 2025-03-17 sarashina2-vision-{8b, 14b}, SB Intuitions, 2025.03 Comment
元ポスト:
VLM。Xに散見される試行例を見ると日本語の読み取り性能は結構高そうに見える。
モデル構成、学習の詳細、および評価:
LLM(sarashina2), Vision Encoder(Qwen2-VL), Projectorの3つで構成されており、3段階の学習を踏んでいる。
最初のステップでは、キャプションデータを用いてProjectorのみを学習しVision Encoderとテキストを対応づける。続いて、日本語を含む画像や日本特有の風景などをうまく扱えるように、これらを多く活用したデータ(内製日本語OCRデータ、図表キャプションデータ)を用いて、Vision EncoderとProjectorを学習。最後にLLMのAlignmentをとるために、プロジェクターとLLMを前段のデータに加えてVQAデータ(内製合成データを含む)や日本語の指示チューニングデータを用いて学習。
ProjectorやMMLLMを具体的にどのように学習するかは
- MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N/A, ACL'24 Findings
を参照のこと。
#Article #NLP #LanguageModel #Chain-of-Thought #Reasoning #Test-Time Scaling Issue Date: 2024-09-13 OpenAI o1, 2024.09 Comment
Jason Wei氏のポスト:
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
や
- Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, N/A, arXiv'23
で似たような考えはすでに提案されていたが、どのような点が異なるのだろうか?
たとえば前者は、pauseトークンと呼ばれるoutputとは関係ないトークンを生成することで、outputを生成する前にモデル内部で推論する前により多くのベクトル操作を加える(=ベクトルを縦方向と横方向に混ぜ合わせる; 以後ベクトルをこねくりまわすと呼称する)、といった挙動を実現しているようだが、明示的にCoTの教師データを使ってSFTなどをしているわけではなさそうに見える(ざっくりとしか読んでないが)。
一方、Jason Wei氏のポストからは、RLで明示的により良いCoTができるように学習をしている点が違うように見える。
**(2025.0929): 以下のtest-time computeに関するメモはo1が出た当初のものであり、私の理解が甘い状態でのメモなので現在の理解を後ほど追記します。当時のメモは改めて見返すとこんなこと考えてたんだなぁとおもしろかったので残しておきます。**
学習の計算量だけでなく、inferenceの計算量に対しても、新たなスケーリング則が見出されている模様。
テクニカルレポート中で言われている time spent thinking (test-time compute)というのは、具体的には何なのだろうか。
上の研究でいうところの、inference時のpauseトークンの生成のようなものだろうか。モデルがベクトルをこねくり回す回数(あるいは生成するトークン数)が増えると性能も良くなるのか?
しかしそれはオリジナルのCoT研究である
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
のdotのみの文字列をpromptに追加して性能が向上しなかった、という知見と反する。
おそらく、**モデル学習のデコーディング時に**、ベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすこと=time spent thinking (test-time compute) 、ということなのだろうか?
そしてそのように学習されたモデルは、推論時にベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすと性能が上がる、ということなのだろうか。
もしそうだとすると、これは
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
のpauseトークンの生成をしながらfinetuningすると性能が向上する、という主張とも合致するように思うが、うーん。
実際暗号解読のexampleを見ると、とてつもなく長いCoT(トークンの生成数が多い)が行われている。
RLでReasoningを学習させる関連研究:
- ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N/A, ACL'24
- Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N/A, ICML'24
以下o1の動きに関して考えている下記noteからの引用。
>これによって、LLMはモデルサイズやデータ量をスケールさせる時代から推論時間をスケールさせる(つまり、沢山の推論ステップを探索する)時代に移っていきそうです。
なるほど。test-compute timeとは、推論ステップ数とその探索に要する時間という見方もあるのですね。
またnote中では、CoTの性能向上のために、Process Reward Model(PRM)を学習させ、LLMが生成した推論ステップを評価できるようにし、PRMを報酬モデルとし強化学習したモデルがo1なのではないか、と推測している。
PRMを提案した研究では、推論ステップごとに0,1の正誤ラベルが付与されたデータから学習しているとのこと。
なるほど、勉強になります。
note:
https://note.com/hatti8/n/nf4f3ce63d4bc?sub_rt=share_pb
note(詳細編): https://note.com/hatti8/n/n867c36ffda45?sub_rt=share_pb
こちらのリポジトリに関連論文やXポスト、公式ブログなどがまとめられている:
https://github.com/hijkzzz/Awesome-LLM-Strawberry
これはすごい。論文全部読みたい
#Article #NLP #LanguageModel #InstructionTuning #OpenWeight #SelfCorrection #PostTraining #Reference Collection Issue Date: 2024-09-06 Reflection 70B, GlaiveAI, 2024.09 Comment
ただまあ仮に同じInputを利用していたとして、promptingは同じ(モデルがどのようなテキストを生成し推論を実施するかはpromptingのスコープではない)なので、そもそも同じInputなのでfair comparisonですよ、という話に仮になるのだとしたら、そもそもどういう設定で比較実験すべきか?というのは検討した方が良い気はする。まあどこに焦点を置くか次第だと思うけど。
エンドユーザから見たら、reflectionのpromptingのやり方なんてわからないよ!という人もいると思うので、それを内部で自発的に実施するように学習して明示的にpromptingしなくても、高い性能を達成できるのであれば意味があると思う。
ただまあ少なくとも、参考でも良いから、他のモデルでもreflectionをするようなpromptingをした性能での比較結果も載せる方が親切かな、とは思う。
あと、70Bでこれほどの性能が出ているのはこれまでにないと思うので、コンタミネーションについてはディフェンスが必要に思う(他のモデルがそのようなディフェンスをしているかは知らないが)。
追記
→ 下記記事によると、LLM Decontaminatorを用いてコンタミネーションを防いでいるとのこと
https://github.com/lm-sys/llm-decontaminator
Reflection自体の有用性は以前から示されている。
参考: Self-Reflection in LLM Agents: Effects on Problem-Solving Performance, Matthew Renze+, N/A, arXiv'24
, Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai+, N/A, ICLR'24
, AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls, Yu Du+, N/A, arXiv'24
, Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies, Liangming Pan+, N/A, TACL'24
ollamaで実際に動かして日本語でのQAを試している記事。実際のアウトプットやreflectionの内容が確認でき、おもしろい。
システムプロンプトで< thinking >タグでInputに対して推論し、< output >タグ内で最終出力を行い、推論過程で誤りがある場合は< reflection >タグを用いて修正するように指示している。
おそらく、thinkingタグ内の思考過程でモデルが誤りに気づいた場合は、thinkingタグの途中でreflectionタグが出力され、その時点でCoTが修正されるようである(もしくはoutputとthinkingの中間)。このため、誤ったCoTに基づいてOutputが生成される頻度が減少すると考えられる。
このような挙動はおそらく、reflection用の学習データでSFTしないとできないと思うので
(たとえば、ReflectionタスクをするようなデータでSFTをしていない場合、出力の途中で誤りを検出し出力を修正するという挙動にはならず、回答として自然な文を最後までoutputすると思う。その後でreflectionしろと促すことはpromptingでできるかもしれないが、そもそもreflectionする能力があまり高くない可能性があり、うまく修正もしてくれないかも)
reflectionの能力を高めるようなデータでSFTをしていないモデルで似たようなpromptingをしても、うまくいかない可能性があるので注意が必要だと思われる。
参考:
https://note.com/schroneko/n/nae86e5d487f1
開発者曰く、HFに記載の正しいシステムプロンプトを入れないと、適切に動作しないとのこと。
元ツイート:
どうやら初期にアップロードされていたHFのモデルはweightに誤りがあり、挙動がおかしくなっていたようだ。
正しいモデルの挙動は下記ツイートのようである。thinking内でreflectionが実施されている。
実際にいくつかの例をブログをリリース当日に見た時に、reflectionタグがoutputの後に出力されている例などがあり、おや?という挙動をしていたので、問題が是正されたようだ。
HFのモデルが修正された後もベンチマークの結果が再現されないなど、雲行きが色々と怪しいので注意した方が良い。
続報
開発者ポスト:
再現実験を全て終了し、当初報告していた結果が再現されなかったとCEOが声明:
#Article #DocumentSummarization #NLP #Snippets #QueryBiased #CIKM Issue Date: 2017-12-28 [Paper Note] Learning query-biased web page summarization, Wang et al., CIKM’07, 2007.11 Comment
・従来のquery-biasedな要約におけるclassificationアプローチは,training内のdocumentの情報が未知のdocumentのsentenceのclassificationに役立つというものだった.これは,たとえば似たような情報を多く含むscientific articleだったら有用だが,様々な情報を含むweb pageにはあまり適切ではない(これはtraining set内のdocumentの情報とtarget pageの情報を比較するみたいなアプローチに相当する).この研究では,target page内の’sentenceの中で’はスニペットに含めるべき文かどうかという比較ができるという仮定のもと,learning to rankを用いてスニペットを生成する.
・query biased summarizationではrelevanceとfidelityの両者が担保された要約が良いとされている.
relevanceとはクエリと要約の適合性,fidelityとは,要約とtarget documentとの対応の良さである.
・素性は,relevanceに関してはクエリとの関連度,fidelityに関しては,target page内のsentenceに関しては文の位置や,文の書式(太字)などの情報を使う.contextの文ではそういった情報が使えないので,タイトルやanchor textのフレーズを用いてfidelityを担保する(詳しくかいてない).あとはterm occurence,titleとextracted title(先行研究によると,TRECデータの33.5%のタイトルが偽物だったというものがあるのでextracted titleも用いる),anchor textの情報を使う.あまり深く読んでいない.
・全ての素性を組み合わせたほうがintrinsicなevaluationにおいて高い評価値.また,contextとcontent両方組み合わせたほうが良い結果がでた.
#Article #DocumentSummarization #NLP #Snippets Issue Date: 2017-12-28 [Paper Note] Enhanced web document summarization using hyperlinks, Delort et al., HT’03, 2003.08 Comment
・Genericなweb pageの要約をつくる
・要約を作る際に,ページの内容から作るわけではなく,contextを用いて作る.contextとは,target pageにリンクを張っているページにおけるリンクの周辺にある文のこと.
・contextを利用した要約では,partialityとtopicalityに関する問題が生じる.partialityとは,contextに含まれる情報がtarget pageに関する一部の情報しか含んでいない問題.topicalityとは,そもそもcontextに含まれる情報が,target pageのoverviewに関する情報を含んでいない問題
・partialityに関しては,contextに含まれる文を除くことで,contextのoverallな情報が失われない最小のsetを求めることで対応.setを求める際には,context内の2文の単語を比較し,identicalなrepresentationが含まれているかどうかを計算.重複するものは排除することでsetを求める.
・topicalityに関しては,target pageのtextual informationが取得できる場合は,context内の文中の単語がtarget page内に含まれる単語の比率を出すことでtopicality scoreを算出.topicality scoreが高いものを要約とする.一方,target pageのtextual informationが十分でない場合は,context内の文のクラスタリングを行い,各クラスタのcentroidと近い文を抽出.
#Article #DocumentSummarization #InformationRetrieval #NLP #RelevanceJudgment #Snippets #QueryBiased Issue Date: 2017-12-28 [Paper Note] A task-oriented study on the influencing effects of query-biased summarization in web searching, White et al., Information Processing and Management, 2003.09 Comment
・search engineにおいてquery-biasedな要約の有用性を示したもの
・task-orientedな評価によって,提案手法がGoogleやAltaVistaのスニペットよりも良いことを示す.
・提案手法は文選択によるquery-biased summarization.スコアリングには,ページのタイトルに含まれる単語がどれだけ含まれているか,文のページ内での出現位置,クエリとの関連度,文の書式(太字)などの情報を使う.
・スニペットが作れないページに対しては,エラーメッセージを返したり,ページ内の最初のnon-textualな要素を返したりする.
#Article #RecommenderSystems #CollaborativeFiltering #Novelty #Selected Papers/Blogs Issue Date: 2017-12-28 [Paper Note] Discovery-oriented Collaborative Filtering for Improving User Satisfaction, Hijikata+, IUI’09 Comment
・従来のCFはaccuracyをあげることを目的に研究されてきたが,ユーザがすでに知っているitemを推薦してしまう問題がある.おまけに(推薦リスト内のアイテムの観点からみた)diversityも低い.このような推薦はdiscoveryがなく,user satisfactionを損ねるので,ユーザがすでに何を知っているかの情報を使ってよりdiscoveryのある推薦をCFでやりましょうという話.
・特徴としてユーザのitemへのratingに加え,そのitemをユーザが知っていたかどうかexplicit feedbackしてもらう必要がある.
・手法は単純で,User-based,あるいはItem-based CFを用いてpreferenceとあるitemをユーザが知っていそうかどうかの確率を求め,それらを組み合わせる,あるいはrating-matrixにユーザがあるitemを知っていたか否かの数値を組み合わせて新たなmatrixを作り,そのmatrix上でCFするといったもの.
・offline評価の結果,通常のCF,topic diversification手法と比べてprecisionは低いものの,discovery ratioとprecision(novelty)は圧倒的に高い.
・ユーザがitemを知っていたかどうかというbinary ratingはユーザに負荷がかかるし,音楽推薦の場合previewがなければそもそも提供されていないからratingできないなど,必ずしも多く集められるデータではない.そこで,データセットのratingの情報を25%, 50%, 75%に削ってratingの数にbiasをかけた上で実験をしている.その結果,事前にratingをcombineし新たなmatrixを作る手法はratingが少ないとあまりうまくいかなかった.
・さらにonlineでuser satisfaction(3つの目的のもとsatisfactionをratingしてもらう 1. purchase 2. on-demand-listening 3. discovery)を評価した. 結果,purchaseとdiscoveryにおいては,ベースラインを上回った.ただし,これは推薦リスト中の満足したitemの数の問題で,推薦リスト全体がどうだった
かと問われた場合は,ベースラインと同等程度だった.
重要論文
#Article #RecommenderSystems #Novelty #RecSys #Selected Papers/Blogs Issue Date: 2017-12-28 [Paper Note] “I like to explore sometimes”: Adapting to Dynamic User Novelty Preferences, Kapoor et al. (with Konstan), RecSys’15 Comment
・典型的なRSは,推薦リストのSimilarityとNoveltyのcriteriaを最適化する.このとき,両者のバランスを取るためになんらかの定数を導入してバランスをとるが,この定数はユーザやタイミングごとに異なると考えられるので(すなわち人やタイミングによってnoveltyのpreferenceが変化するということ),それをuserの過去のbehaviorからpredictするモデルを考えましたという論文.
・式中によくtが出てくるが,tはfamiliar setとnovel setをわけるためのみにもっぱら使われていることに注意.昼だとか夜だとかそういう話ではない.familiar setとは[t-T, t]の間に消費したアイテム,novel setはfamiliar setに含まれないitemのこと.
・データはmusic consumption logsを使う.last.fmやproprietary dataset.データにlistening以外のexplicit feedback (rating)などの情報はない
・itemのnoveltyの考え方はユーザ側からみるか,システム側から見るかで分類が変わる.三種類の分類がある.
(a) new to system: システムにとってitemが新しい.ゆえにユーザは全員そのitemを知らない.
(b) new to user: システムはitemを知っているが,ユーザは知らない.
(c) oblivious/forgotten item: 過去にユーザが知っていたが,最後のconsumptionから時間が経過しいくぶんunfamiliarになったitem
Repetition of forgotten items in future consumptions has been shown to produce increased diversity and emotional excitement.
この研究では(b), (c)を対象とする.
・userのnovelty preferenceについて二つの仮定をおいている.
1. ユーザごとにnovelty preferenceは違う.
2. ユーザのnovelty preferenceはdynamicに変化する.trainingデータを使ってこの仮定の正しさを検証している.
・novelty preferenceのpredictは二種類の素性(familiar set diversityとcumulative negative preference for items in the familiar set)を使う. 前者は,familiar setの中のradioをどれだけ繰り返しきいているかを用いてdiversityを定義.繰り返し聞いているほうがdiversity低い.後者は,異なるitemの消費をする間隔によってdynamic preference scoreを決定.familiar set内の各itemについて負のdynamic preference scoreをsummationすることで,ユーザの”退屈度合い”を算出している.
・両素性を考慮することでnovelty preferenceのRMSEがsignificantに減少することを確認.
・推薦はNoveltyのあるitemの推薦にはHijikataらの協調フィルタリングなどを使うこともできる.
・しかし今回は簡易なitem-based CFを用いる.ratingの情報がないので,それはdynamic preference scoreを代わりに使い各itemのスコアを求め,そこからnovel recommendationとfamiliar recommendationのリストを生成し,novelty preferenceによって両者を組み合わせる.
・音楽(というより音楽のradioやアーティスト)の推薦を考えている状況なので,re-consumptionが許容されている.Newsなどとは少しドメインが違うことに注意.
#Article #RecommenderSystems #Document Issue Date: 2017-12-28 [Paper Note] Combination of Web page recommender systems, Goksedef, Gunduz-oguducu, Elsevier, 2010.04 Comment
・traditionalなmethodはweb usage or web content mining techniquesを用いているが,ニュースサイトなどのページは日々更新されるのでweb content mining techniquesを用いてモデルを更新するのはしんどい.ので,web usage mining(CFとか?どちらかというとサーバログからassociation ruleを見つけるような手法か)にフォーカス.
・web usage miningに基づく様々な手法をhybridすることでどれだけaccuracyが改善するかみる.
・ユーザがセッションにおいて次にどのページを訪れるかをpredictし推薦するような枠組み(不特定多数のページを母集団とするわけではなく,自分のサイト内のページが母集団というパターンか)
・4種類の既存研究を紹介し,それらをどうcombineするかでaccuraryがどう変化しているかを見ている.
・それぞれの手法は,ユーザのsessionの情報を使いassociation rule miningやclusteringを行い次のページを予測する手法.
#Article #RecommenderSystems #NeuralNetwork #Document #DataFiltering Issue Date: 2017-12-28 [Paper Note] Neural Networks for Web Content Filtering, Lee, Fui and Fong, IEEE Intelligent Systems, 2002.09 Comment
・ポルノコンテンツのフィルタリングが目的. 提案手法はgeneral frameworkなので他のコンテンツのフィルタリングにも使える.
・NNを採用する理由は,robustだから(様々な分布にfitする).Webpageはnoisyなので.
・trainingのためにpornographic pageを1009ページ(13カテゴリから収集),non-pornographic pageを3,777ページ収集.
・feature(主なもの)
- indicative term(ポルノっぽい単語)の頻度
- displayed contents ページのタイトル,warning message block, other viewable textから収集
- non-displayed contents descriptionやkeywordsなどのメタデータ,imageタグのtextなどから収集
・95%くらいのaccuracy
#Article #DocumentSummarization #NLP #Update #EACL Issue Date: 2017-12-28 [Paper Note] DualSum: a Topic-Model based approach for update summarization, Delort et al., EACL’12 Comment
・大半のupdate summarizationの手法はdocument set Aがgivenのとき,document set Bのupdate summarizationをつくる際には,redundancy removalの問題として扱っている.
・この手法は,1つのsentenceの中にredundantな情報とnovelな情報が混在しているときに,そのsentenceをredundantなsentenceだと判別してしまう問題点がある.加えて,novel informationを含んでいると判別はするけれども,明示的にnovel informationがなんなのかということをモデル化していない.
・Bayesian Modelを使うことによって,他の手法では抜け落ちている確率的な取り扱いが可能にし, unsupervisedでできるようにする.
#Article #DocumentSummarization #NLP #Update #CIKM Issue Date: 2017-12-28 [Paper Note] Document Update Summarization Using Incremental Hierarchical Clustering, Wang+, CIKM’10 Comment
・既存のMDSではdocumentをbatch処理するのが前提.typicalなクラスタリングベースの手法やグラフベースの手法はsentence-graphを構築して要約を行う.しかし,情報がsequentialに届き,realtimeで要約を行いたいときにこのような手法を使うと,毎回すでに処理したことがあるテキストを処理することになり,time consumingだし,無駄な処理が多い.特に災害時などでは致命的.このような問題に対処するために,ドキュメントがarriveしたときに,ただちにupdate summaryが生成できる手法を提案する.
・既存のヒューリスティックなfeature(tf-isfやキーワード数など)を用いたスコアリングは,existing sentencesとnewly coming sentencesが独立しているため,real world scenarioにおいて実用的でないし,hardly perform wellである.
・なので,incremental hierarchical clusteringの手法でsentence clusterをre-organizeすることで,効果的に要約のupdateを行う.このとき,sentence同士のhierarchical relationshipはreal timeにre-constructされる.
・TACのupdate summarizationとは定義が微妙に違うらしい.主に2点.TACではnewly coming documentsだけを対象にしているが,この研究 ではすべてのドキュメントを対象にする.さらに,TACでは一度だけupdate summarizationする(document set Bのみ)が,この研究ではdocumentsがsequenceでarriveするのを前提にする.なので,TACに対しても提案手法は適用可能.
・Sequence Update Summarizationの先駆け的な研究かもしれない.SUSがのshared taskになったのは2013だし.
・incremental hierarchical clusteringにはCOBWEB algorithm (かなりpopularらしい)を使う.COBWEBアルゴリズムは,新たなelementが現れたとき,Category Utilityと呼ばれるcriterionを最大化するように,4種類の操作のうち1つの操作を実行する(insert(クラスタにsentenceを挿入), create(新たなクラスタつくる), merge(2クラスタを1つに),split(existingクラスタを複数のクラスタに)).ただ,もとのCOBWEBで使われているnormal attribute distributionはtext dataにふさわしくないので,Katz distributionをword occurrence distributionとして使う(Sahooらが提案している.).元論文読まないと詳細は不明.
・要約の生成は,実施したoperationごとに異なる.
- Insertの場合: クラスタを代表するsentenceをクエリとのsimilarity, クラスタ内のsentenceとのintra similarityを計算して決めて出力する.
- createの場合: 新たに生成したクラスタcluster_kを代表する文を,追加したsentence s_newとする.
- mergeの場合: cluster_aとcluster_bをmergeして新たなcluster_cを作った場合,cluster_cを代表する文を決める.cluster_cを代表する文は,cluster_aとcluster_bを代表する文とクエリとのsimilarityをはかり,similarityが大きいものとする.
- splitの場合: cluster_aをsplitしてn個の新たなクラスタができたとき,各新たなn個のクラスタにおいて代表する文を,original subtreeの根とする.
・TAC08のデータとHurricane Wilma Releasesのデータ(disaster systemからtop 10 queryを取得,5人のアノテータに正解を作ってもらう)を使って評価.(要約の長さを揃えているのかが気になる。長さが揃っていないからROUGEのF値で比較している?)
・一応ROUGEのF値も高いし,速度もbaselineと比べて早い.かなりはやい.genericなMDSとTAC participantsと比較.TAC Bestと同等.GenericMDSより良い.document setAの情報を使ってredundancy removalをしていないのにTAC Bestを少しだけoutperform.おもしろい.
・かつ,TAC bestはsentence combinationを繰り返す手法らしく,large-scale online dataには適していないと言及.
#Article #DocumentSummarization #NLP #Update #CIKM Issue Date: 2017-12-28 [Paper Note] Incremental Update Summarization: Adaptive Sentence Selection based on Prevalence and Novelty, McCreadie et al., CIKM’14 Comment
・timelyなeventに対してupdate summarizationを適用する場合を考える.たとえば6日間続いたeventがあったときにその情報をユーザが追う為に何度もupdate summarizationシステムを用いる状況を考える.6日間のうち新しい情報が何も出てこない期間はirrelevantでredundantな内容を含む要約が出てきてしまう.これをなんとかする手法が必要だというのがmotivation.
・どのような手法かというと,news streamsからnovel updatesをtimely mannerで自動抽出し,一方で,抽出するupdatesはirrelevant, uninformative or redundant contentを最小化するようなもの手法
・手法は既存のUpdate Summarization手法(lambdaMART, learning to rank baseの手法)で10文を出力し,何文目までを残すか(rank-cut off problem)を解くことで,いらないsentenceをはぶいている.
・rank cut offをする際はlinear regressionとModel Treesを使っているが,linear regressionのような単純な手法だと精度があがらず,Model Treesを使ったほうがいい結果が出た.
・素性は主にprevalence (sentenceが要約したいトピックに沿っているか否か),novelty(sentenceが新しい情報を含んでいるか),quality(sentenceがそもそも重要かどうか)の3種類の素性を使っている.気持ちとしては,prevalenceとnoveltyの両方が高いsentenceだけを残したいイメージ.つまり,トピックに沿っていて,なおかつ新しい情報を含んでいるsentence
・loss functionには,F値のような働きをするものを採用(とってきたrelevant updateのprecisionとrecallをはかっているイメージ).具体的には,Expected Latency GainとLatency Comprehensivenessと呼ばれるTREC2013のquality measureに使われている指標を使っている.
・ablation testの結果を見ると,qualityに関する素性が最もきいている.次にnovelty,次点でprevalence
・提案手法はevent発生から時間が経過すると精度が落ちていく場合がある.
・classicalなupdate summarizationの手法と比較しているが,Classyがかなり強い,Model treesを使わない提案手法や,他のbaselineを大きくoutperform. ただ,classyはmodel treesを使ったAdaptive IUSには勝てていない.
・TREC 2013には,Sequantial Update Summarizationタスクなるものがあるらしい.ユーザのクエリQと10個のlong-runnning event(典型的には10日間続くもの,各イベントごとに800〜900万記事),正解のnuggetsとそのtimestampが与えられたときにupdate summarizationを行うタスクらしい.
#Article #DocumentSummarization #NLP #Update #CIKM Issue Date: 2017-12-28 [Paper Note] Update Summarization using Semi-Supervised Learning Based on Hellinger Distance, Wang et al., CIKM’15, 2015.10 Comment
・Hellinger Distanceを用いてSentence Graphを構築.ラベル伝搬により要約に含める文を決定する手法
・update summarizationの研究ではsimilarityをはかるときにcosine similarityを用いることが多い.
・cosine similarityはユークリッド距離から直接的に導くことができる.
・Vector Space Modelはnonnegativeなmatrixを扱うので,確率的なアプローチで取り扱いたいが,ユークリッド距離は確率を扱うときにあまり良いmetricではない.そこでsqrt-cos similarityを提案する.sqrt-cosは,Hellinger Distanceから求めることができ,Hellinger Distanceは対称的で三角不等式を満たすなど,IRにおいて良いdistance measureの性質を持っている.(Hellinger Distanceを活用するために結果的に類似度の尺度としてsqrt-cosが出てきたとみなせる)
・またHellinger DistanceはKL Divergenceのsymmetric middle pointとみなすことができ,文書ベクトル生成においてはtf_idfとbinary weightingのちょうど中間のような重み付けを与えているとみなせる.
・要約を生成する際は,まずはset Aの文書群に対してMMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
を適用する(redundancyの項がmaxではなくて平均になっている).similarityはsqrt-cosを用いる.
・sqrt-cosと,set Aの要約結果を用いると,sentence graphを構築できる.sentence graphはset Aとset Bの各sentenceをノードとするグラフで,エッジの重みはsqrt-cosとなっている.このsentence graph上でset Aの要約結果のラベルをset B側のノードに伝搬させることで,要約に含めるべき文を選択する.
・ラベル伝搬にはGreen’s functionを用いる.set Bにlabel “1”がふられるものは,given topicとset Aのcontentsにrelevantなsentenceとなる.
・TAC2011のデータで評価した結果,standardなMMRを大幅にoutperform, co-ranking, Centroidベースの手法などよりも良い結果.
#Article #DocumentSummarization #NLP #Update #SIGIR Issue Date: 2017-12-28 [Paper Note] TimedTextRank: Adding the Temporal Dimension to Multi-Document Summarization, Xiaojun Wan, SIGIR’07, 2007.07 Comment
・evolving topicsを要約するときは,基本的に新しい情報が重要だが,TextRankはそれが考慮できないので拡張したという話.
・dynamic document setのnew informationをより重視するTimedTextRankを提案
・TextRankのvoteの部分に重み付けをする.old sentenceからのvoteよりも,new documentsに含まれるsentenceからのvoteをより重要視
・評価のときは,news pageをクローリングし,incremental single-pass clustering algorithmでホットなトピックを抽出しユーザにみせて評価(ただしこれはPreliminary Evaluation).
#Article #DocumentSummarization #NLP #Update Issue Date: 2017-12-28 [Paper Note] The LIA Update Summarization Systems at TAC-2008, Boudin et al. TAC’08, 2008.11 Comment
・Scalable MMR [Paper Note] A Scalable MMR Approach to Sentence Scoring for Multi-Document Update Summarization, Boudin et al., COLING’08, 2008.08
とVariable length intersection gap n-term modelを組み合わせる.
・Variable length intersection gap n-term modelは,あるトピックのterm sequenceは他の異なる語と一緒にでてくる?という直感にもとづく.要は,drugs.*treat.*mental.*illnessなどのパターンをとってきて活用する.このようなパターンをn-gram, n-stem, n-lemmaごとにつくり3種類のモデルを構築.この3種類のモデルに加え,coverage rate (topic vocabularyがセグメント内で一度でもみつかる割合)とsegmentのpositionの逆数を組みあわせて,sentenceのスコアを計算(先頭に近いほうが重要).
・coherenceを担保するために,sentenceを抽出した後,以下のpost-processingを行う.
Acronym rewriting(初めてでてくるNATOなどの頭字語はfull nameにする)
Date and number rewriting(US standard formsにする)
Temporal references rewriting (next yearなどの曖昧なreferenceを1993などの具体的なものにする)
Discursive form rewriting (いきなりButがでてくるときとかは削るなど)
カッコやカギカッコは除き,句読点をcleanedする
・TAC 2008におけるROUGE-2の順位は72チーム中32位
#Article #DocumentSummarization #NLP #Update #COLING Issue Date: 2017-12-28 [Paper Note] A Scalable MMR Approach to Sentence Scoring for Multi-Document Update Summarization, Boudin et al., COLING’08, 2008.08 Comment
・MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
をupdate summarization用に拡張.History(ユーザが過去に読んだsentence)の数が多ければ多いほどnon-redundantな要約を出す (Queryに対するRelevanceよりもnon-redundantを重視する)
・Historyの大きさによって,redundancyの項の重みを変化させる.
・MMRのredundancyの項を1-max Sim2(s, s_history)にすることでnoveltyに変更.ORよりANDの方が直感的なので二項の積にする.
・MMRのQueryとのRelevanceをはかる項のSimilarityは,cossimとJaro-Winkler距離のinterpolationで決定. Jaro-Winkler距離とは,文字列の一致をはかる距離で,値が大きいほど近い文字列となる.文字ごとの一致だけでなく,ある文字を入れ替えたときにマッチ可能かどうかも見る.一致をはかるときはウィンドウを決めてはかるらしい.スペルミスなどの検出に有用.クエリ内の単語とselected sentences内の文字列のJaro-Winkler距離を計算.各クエリごとにこれらを求めクエリごとの最大値の平均をとる.
・冗長性をはかるSim2では,normalized longest common substringを使う.
#Article #DocumentSummarization #NLP #IntegerLinearProgramming (ILP) #Update #NAACL Issue Date: 2017-12-28 [Paper Note] Improving Update Summarization via Supervised ILP and Sentence Reranking, Li et al. NAACL’15, 2015.05 Comment
・update summarizationをILPで定式化.基本的なMDSのILPのterm weightingにsalienceの要素に加えてnoveltyの要素を加える.term weightingにはbigramを用いる.bigram使うとよくなることがupdate summarizationだと知られている.weightingは平均化パーセプトロンで学習
・ILPでcandidate sentencesを求めたあと,それらをSVRを用いてRerankingする.SVRのloss functionはROUGE-2を使う.
・Rerankingで使うfeatureはterm weightingした時のsentenceレベルのfeatureを使う.
・RerankingをするとROUGE-2スコアが改善する.2010, 2011のTAC Bestと同等,あるいはそれを上回る結果.novelty featureを入れると改善.
・noveltyのfeatureは,以下の通り.
Bigram Level
-bigramのold datasetにおけるDF
-bigram novelty value (new datasetのbigramのDFをold datasetのDFとDFの最大値の和で割ったもの)
-bigram uniqueness value (old dataset内で出たbigramは0, すでなければ,new dataset内のDFをDFの最大値で割ったもの)
Sentence Level
-old datasetのsummaryとのsentence similarity interpolated n-gram novelty (n-gramのnovelty valueをinterpolateしたもの)
-interpolated n-gram uniqueness (n-gramのuniqueness valueをinterpolateしたもの)
・TAC 2011の評価の値をみると,Wanらの手法よりかなり高いROUGE-2スコアを得ている.
#Article #DocumentSummarization #NLP #Update #COLING Issue Date: 2017-12-28 [Paper Note] Update Summarization Based on Co-Ranking with Constraints, Wiaojun Wan, COLING’12, 2012.12 Comment
・PageRankの枠組みを拡張してold datasetとnew dataset内のsentenceをco-ranking
・co-rankingするときは,update scoreとconsistency scoreというものを求め相互作用させる.
・update scoreが高いsentenceは同じdataset内では正の関係,異なるdataset内では負の関係を持つ.
・consistency scoreが高いsentenceは同じdataset内では正の関係,異なるdataset内では正の関係を持つ.
・負の関係はdissimilarity matrixを用いて表現する.
・あとはupdate scoreとconsistency scoreを相互作用させながらPageRankでスコアを求める.デコーディングはupdate scoreをgreedyに.
・update scoreとconsistency scoreの和は定数と定義,この論文では定数をsentenceのinformative scoreとしている.これがタイトルにある制約.informative scoreはAffinity GraphにPageRankを適用して求める.
・制約が入ることで,consistency scoreが低いとupdate scoreは高くなるような効果が生まれる.逆もしかり.
#Article #Single #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization Issue Date: 2017-12-28 [Paper Note] Segmentation Based, Personalized Web Page Summarization Model, [Journal of advances in information technology, vol. 3, no.3, 2012], 2012.08 Comment
・Single-document
・ページ内をセグメントに分割し,どのセグメントを要約に含めるか選択する問題
・要約に含めるセグメントは4つのfactor(segment weight, luan’s significance factor, profile keywords, compression ratio)から決まる.基本的には,ページ内の高頻度語(stop-wordは除く)と,profile keywordsを多く含むようなセグメントが要約に含まれるように選択される.図の場合はAlt要素,リンクはアンカテキストなどから単語を取得しセグメントの重要度に反映する.
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #ACL #COLING Issue Date: 2017-12-28 [Paper Note] Automatic Text Summarization based on the Global Document Annotation, Nagao+, COLING-ACL;98, 1998.08 Comment
Personalized summarizationの評価はしていない。提案のみ。以下の3種類の手法を提案
- keyword-based customization
- 関心のあるキーワードをユーザが入力し、コーパスやwordnet等の共起関係から関連語を取得し要約に利用する
- 文書の要素をinteractiveに選択することによる手法
- 文書中の関心のある要素(e.g. 単語、段落等)
- browsing historyベースの手法
- ユーザのbrowsing historyのドキュメントから、yahooディレクトリ等からカテゴリ情報を取得し、また、トピック情報も取得し(要約技術を活用するとのこと)特徴量ベクトルを作成
- ユーザがアクセスするたびに特徴ベクトルが更新されることを想定している?
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #NAACL #Selected Papers/Blogs Issue Date: 2017-12-28 [Paper Note] A Study for Documents Summarization based on Personal Annotation, Zhang+, HLT-NAACL-DUC’03, 2003.05 Comment
(過去に管理人が作成したスライドでの論文メモのスクショ)

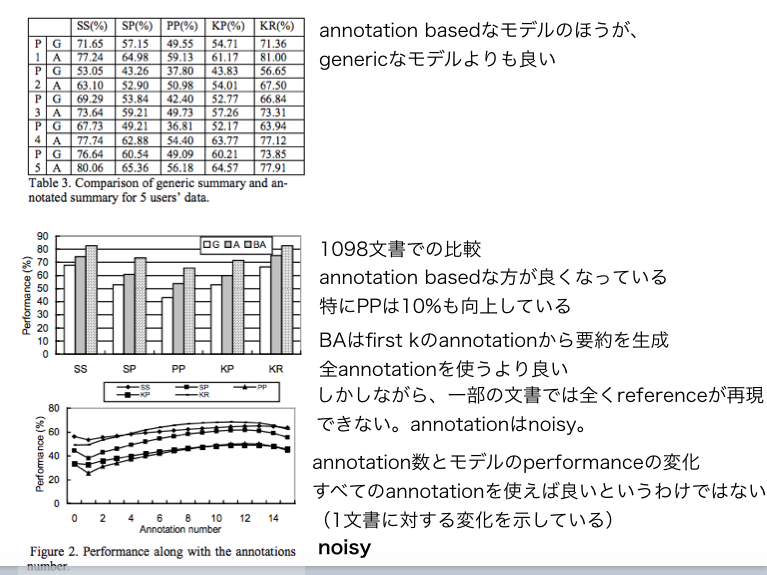

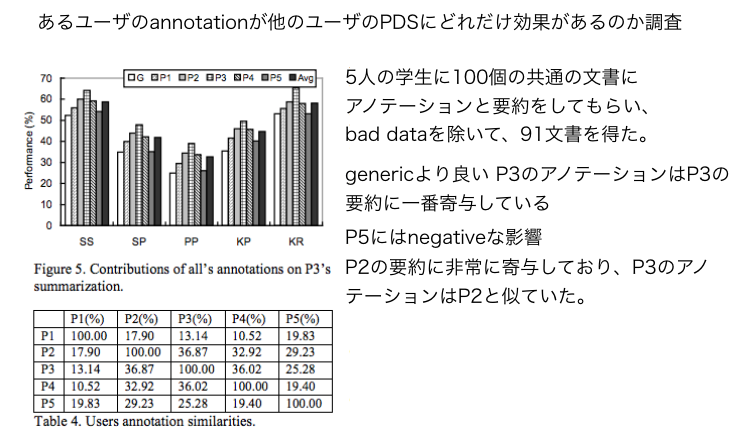
重要論文だと思われる。
#Article #Survey #InformationRetrieval #Personalization Issue Date: 2017-12-28 [Paper Note] Personalised Information retrieval: survey and classification, Rami+, User Modeling and User-Adapted Interaction, 2012.05 Comment
(以下は管理人が当時作成したスライドでのメモのスクショ)

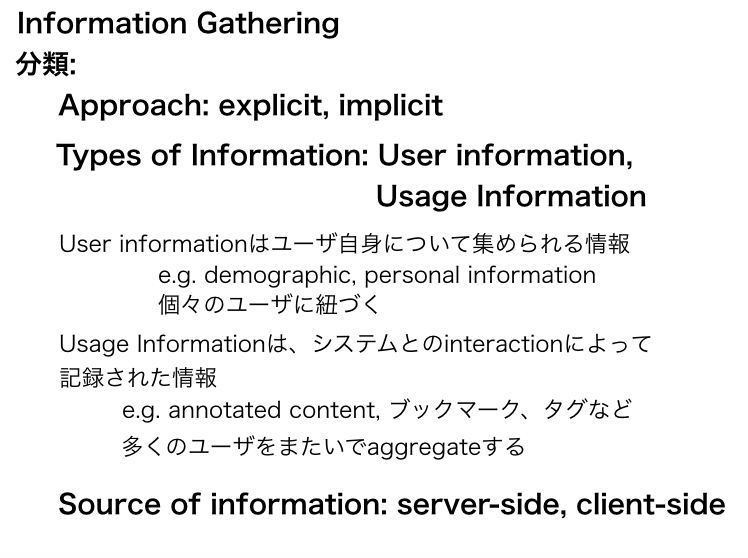
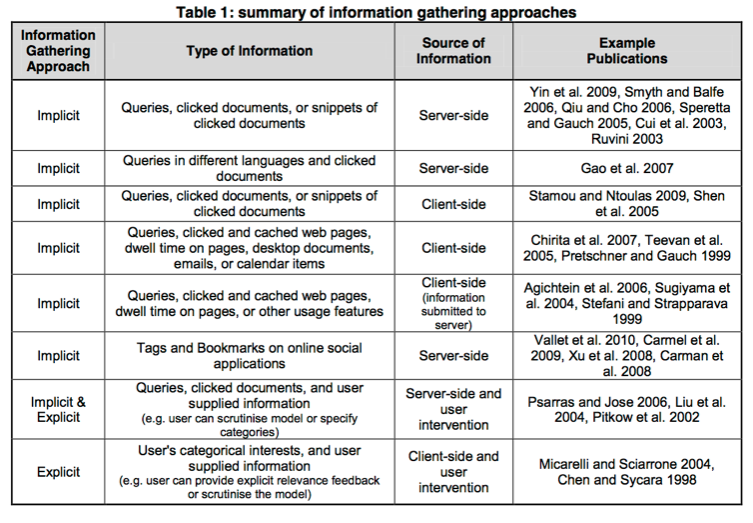


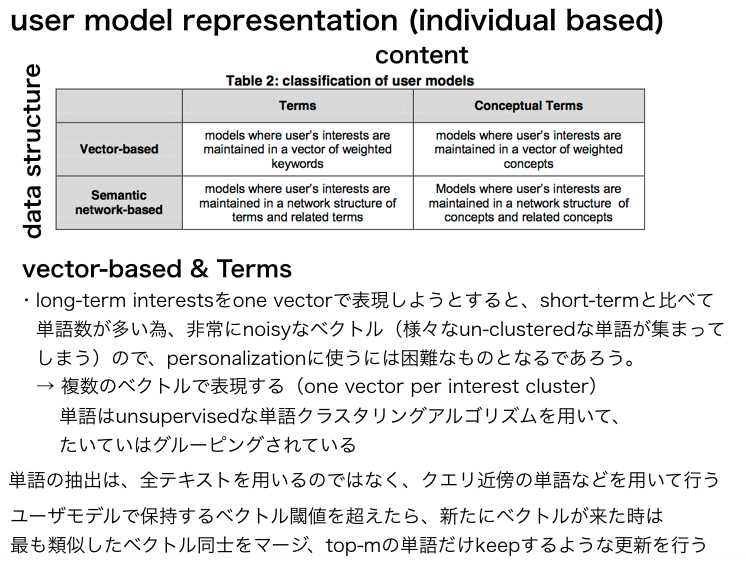


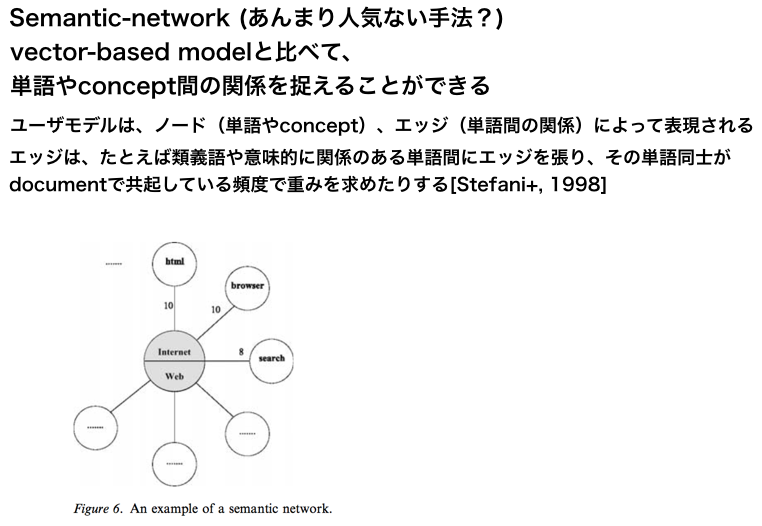


完全に途中で力尽きている感
#Article #Tutorial #MachineLearning #UserModeling Issue Date: 2017-12-28 [Paper Note] Machine Learning for User Modeling, User modeling and User-adapted Interaction, [Webb+, 2001], 2001.03 Comment





#Article #InformationRetrieval #WWW Issue Date: 2017-12-28 [Paper Note] Modeling Anchor Text and Classifying Queries to Enhance Web Document Retrieval, WWW’08, [Fujii, 2008], 2008.04 Comment


#Article #DocumentSummarization #GraphBased #Comments #NLP #Extractive #SIGIR Issue Date: 2017-12-28 [Paper Note] Comments-Oriented Document Summarization: Understanding Documents with Reader’s Feedback, Hu+, SIGIR’08, 2008.07 Comment