
LanguageModel
[Paper Note] Separating Representation from Reconstruction Enables Scalable Text Encoders, Megi Dervishi+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Embeddings #NLP #Architecture #Selected Papers/Blogs #Encoder #reading #One-Line Notes #Scalability Issue Date: 2026-07-26 GPT Summary- BERT以降、エンコーダはほとんど変わっていないが、急速に進化するデコーダとの乖離を再評価。BERTエンコーダの表現は凍結プローブで劣化し、平坦な設計が表現学習を阻害している。これに対抗するため、CrossBERTを提案。二部構成のアーキテクチャで、トークン再構成から独立した高品質なエンコード表現を学習。高いマスキング比率と補完的戦略により、スループットとサンプル効率を向上。結果、MTEBおよび凍結GLUEベンチマークで優越性を示す。 Comment
元ポスト:
論文の概要としては、BERTは投入された計算量に対してdownstreamタスク性能がスケールしない課題があったが、その原因を、BERTのflatなアーキテクチャが課題であると指摘。BERTはMLM lossで学習されるが、これはトークンの再構築の能力を測定するが、実際の表現の品質を測定できていない。BERTのアーキテクチャが、Representationの学習と、Reconstructionを明示的に分離していない(=flatなアーキテクチャ)ため、結果的にBERTが学習する表現がReconstructionのためのlocalな信号に過度に適合してしまい、abstractionに失敗してしまう(結果的に、計算量を投じれば投じるほどlossは下がるが、downstreamタスクの性能は下がる)、という仮説を立てている。
解決方法として、表現を学習するEncoderと、マスク部分の再構築をおこなうPredictorをアーキテクチャとして明示的に分離することを提案している。
これにより、投入した計算量に対してdownstreamタスクの性能がスケールするようになった、という話に見える。
おそらくアーキテクチャ上の細かい工夫があると思われるので、そこはしっかり読んだ方が良いカッコまだ読めてない)。
[Paper Note] ISO: An RLVR-Native Optimization Stack, Hanqing Zhu+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #RLVR #Author Thread-Post Issue Date: 2026-07-25 GPT Summary- 強化学習における報酬フィードバックの最適化層の理解が不足している中、本研究ではスペクトル継承の概念を提案。この概念をIsospectral Optimization(ISO)として実現し、固定スペクトルフレームワークに基づくオフラインとオンラインの実装を導入。オフラインではISO-Mergerが異なるスペシャリストの能力を統合し、高性能を達成。オンラインではISO-Optimizerが基底スペクトルを固定しつつ、最適化アルゴリズムを適用し精度向上を実現。特に、ISO-AdamWは従来のAdamWよりも少ない学習ステップで高精度を達成。ISOは、報酬駆動型適応の構造を活用した最適化層の新たな設計を提案する。 Comment
元ポスト:
著者ポスト2:
[Paper Note] PRO-LONG: Programmatic Memory Enables Long-Horizon Reasoning, Alexis Fox+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #Search #AIAgents #ContextEngineering #memory #ContinualLearning #Initial Impression Notes #AgentHarness Issue Date: 2026-07-24 GPT Summary- PRO-LONGは、長期的なタスクに向けた最小限の文脈管理フレームワークであり、プログラム的メモリを使用して情報の保存と検索を効率化する。これにより、ARC-AGI-3ベンチマークでの性能を向上させ、平均18.0ポイントの改善を達成。最先端のハーネスと同等の成果を挙げながら、トークン効率も向上させている。Fable 5を用いた実験では、97.4%の高精度を示し、コストも抑えられている。 Comment
元ポスト:
全てのログを構造化して格納し、エージェントがread/grep/pythonなどを用いて検索可能にするというシンプルなメモリを提案しているようで
様々なモデル、ハーネスの元、パレード最適を実現しているようである。
ログが極端に肥大化した場合性能にどのような影響が出るだろうか?すぐに肥大化しそうだが。
[Paper Note] SOAP, Muon, and Beyond: Pushing LLM Pretraining Scales, Mikail Khona+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Optimizer #Selected Papers/Blogs #Stability #reading #Scalability #Initial Impression Notes Issue Date: 2026-07-24 GPT Summary- 高階最適化アルゴリズムMuonとSOAPはAdamWより収束が速いが、計算コストと数値安定性の課題が大規模採用を制限している。研究では、前処理付き勾配法の強化を通じて、大規模LLMの事前学習の問題を解決する。大規模バッチサイズでのSOAPの不安定性を特定し、QR正交化や改善された前処理を提案。これにより損失スパイクを排除し、訓練の安定性を向上。MuonとSOAPは、最大1億トークンのバッチサイズでAdamWを上回る性能を示し、大規模な効率的訓練を可能にするための層別分散型最適化手法を採用。最適化アルゴリズムの新興コードベースも公開。 Comment
元ポスト:
バッチサイズを大規模にしてもMuonはAdamWよひも安定して収束することが実験的に示されたらしい
SOAP:
- [Paper Note] SOAP: Improving and Stabilizing Shampoo using Adam, Nikhil Vyas+, ICLR'25
Muon:
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
Muonが世に出てからもう1年半程度たったのか
[Paper Note] Full-Pipeline Inference Optimization for MiMo-V2.5 Series: Pushing Hybrid SWA Efficiency to the Limit, Xiaomi MiMo Team+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #AIAgents #Attention #LLMServing #MoE(Mixture-of-Experts) #SoftwareEngineering #KV Cache #Initial Impression Notes Issue Date: 2026-07-23 GPT Summary- MiMo-V2.5モデルファミリの推論最適化を提案。Hybrid Sliding Window Attentionと疎なMixture-of-Expertsを組み合わせ、注意計算量とストレージを大幅に削減。レイヤーごとのプリフェッチやキャッシュ戦略を用いて、厳密なストレージと高いキャッシュヒット率を実現。高性能な分散キャッシュ基盤GCacheを構築し、計算量を減少。マルチモーダル入力への最適化も行い、初の大規模LLM提供システムを実現。 Comment
元ポスト:
関連:
- Xiaomi MiMo-V2.5-Pro: A leap in agentic and long horizon coherence, Xiaomi, 2026.04
MoEやSWA、マルチモーダルモデルを用いたモデルを効率的にサービングするためのエンジニアリング面での工夫が記述されているようである。
[Paper Note] Understanding Reasoning from Pretraining to Post-Training, Jingyan Shen+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Pretraining #NLP #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-07-23 GPT Summary- 強化学習(RL)と大規模言語モデル(LLMs)の相互作用を特定するため、チェスを用いた統制されたテストベッドを提案。事前訓練からRLまでの関係を調査し、RL計算量と事前訓練損失との予測関係を発見。RLはSFTポリシーを鋭くするだけでなく、難解な問題でより良い解決策を引き出す。数学ドメインでも同様のパターンを確認し、事前訓練とRLの関係を定量的に説明する枠組みを提供。 Comment
元ポスト:
事前学習によってモデルの能力の基盤が形作られ、それは最終的なモデルの品質に大きな影響を与えることは経験的に知られているようだったが、本研究の成果は事前学習の重要性を示す一つの根拠になり得るため、重要文献に見える。
[Paper Note] Why are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs, Joseba Fernandez de Landa+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Bias #Japanese #read-later #Selected Papers/Blogs #Cultural Issue Date: 2026-07-23 GPT Summary- LLMの文化的な偏りを分析する新しいデータセットCROQを提案。結果、LLMは日本など特定の地域に対して明確な傾向を示し、英語などの資源豊富な言語で多様な出力を生成。公用語国に関する質問では回答が少なく、偏りは監督付きファインチューニング後に現れることを示唆。 Comment
元ポスト:
[Paper Note] Skill Retrieval Augmentation for Agentic AI, Weihang Su+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#InformationRetrieval #NLP #AIAgents #Evaluation #Selected Papers/Blogs #reading #One-Line Notes #AgentSkills #Reading Reflections Issue Date: 2026-07-21 GPT Summary- 大規模言語モデル(LLMs)が外部スキルに依存するようになり、これを効率的に活用するために新たにSRA(Skill Retrieval Augmentation)パラダイムを提唱。SRAは、エージェントが必要に応じて関連スキルを動的に取得し適用する仕組みで、初のベンチマークSRA-Benchを導入。5,400件のテスト事例と636件の正解スキルを用いた実験により、検索ベースのスキル拡張が性能向上に寄与することを確認。ただし、スキルの取り込みには課題があり、正解スキルの認識や外部能力の必要性に関する判断がエージェントの性能を制限することが分かった。これにより、今後のエージェントシステムの能力拡張の基盤を築くことが示唆される。 Comment
元ポスト:
pj page: https://sr-agents.github.io
dataset: https://huggingface.co/datasets/WeihangSu/SRA-Bench
スキルの肥大化に伴いモデルのcontextが肥大化しパフォーマンスが劣化することから、動的にスキルを検索して統合するSkill Retrieval Augmentationを提案し、そのための大規模なデータセットを用いて評価をしている、という話に見える。データセットは26kのスキルで構成され、そのうち636件がgoldという規模感のデータセット。
実験結果を見ると、topkのretrieve結果をそのまま利用するfull injectionよりも、full injectionしたスキルのメタデータからrelevantなスキルを1iLLMで選択するLLM Selectionの性能が向上している点が興味深い。
また、skill poolにhard negativeなスキルが存在すると、ベンチマークのスコアは低下していく傾向(具体的にどのベンチマークかまでさ読めていない)にあり、hard negativeが8つ程度で、様々なモデルにおいてAcc.が10%程度は低下しているように見える。興味深い。
問題設定が実用的で興味深いだけでなく、hard negativeなスキルが <10個 程度のオーダーで存在するだけで大きくAcc.が低下する知見を示している点がおもしろい。
[Paper Note] AgenticQwen: Training Small Agentic Language Models with Dual Data Flywheels for Industrial-Scale Tool Use, Yuanjie Lyu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #SmallModel Issue Date: 2026-07-21 GPT Summary- 現代の産業アプリケーションでは、多段階推論とツール使用を行うエージェント型モデルが求められており、小型モデルが望ましい。本研究では、合成データと限定的なオープンソースデータを用いて訓練されたAgenticQwenモデルを提案。推論RLとエージェントRLを組み合わせ、自動的にタスクの難易度を高める二重データフライホイール機構を導入。これにより、現実的な意思決定の複雑さを反映した行動ツリーを生成。AgenticQwenは公開ベンチマークや産業用エージェントシステムで高い性能を示し、特にデータ分析タスクにおいて大規模モデルとのギャップを縮めた。 Comment
元ポスト:
[Paper Note] Self-Guided Test-Time Training for Long-Context LLMs, Xinyu Zhu+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #LongSequence #reading #One-Line Notes #Reading Reflections #Test Time Training (TTT) Issue Date: 2026-07-19 GPT Summary- 長文脈処理において、LLMは単にコンテキスト窓を拡張するだけでは十分ではなく、入力長の増加が精度の低下を引き起こすことがある。テスト時訓練(TTT)は長文脈の活用を改善する手法の一つだが、全体への適用は費用がかかり、ランダム抽出による訓練が性能を低下させることがある。これに対し、Self-Guided TTT(S-TTT)を提案し、適応前にモデルが選択された証拠スパンを認識することで、基準となる言語モデル訓練を適用。S-TTTは、LongBench-v2およびLongBench-Proでの精度向上を実現し、最大で15%の改善を達成。 Comment
元ポスト:
長文Context+質問が与えられたときに、質問に関連するcontextのspanを同定した後(Self-Guided)、TTTでモデルパラメータに内部化させた後に応答する、という話に見える。TTTでは、LoRAを用いて、かつ16 gradient updateを行った時点で更新を終了する。
Full ContextでらTTTするよりも、Self-Guidedな方が高い性能を獲得できる。
TTTを使ってLoRA adapterにcontextの情報をweightとして内部化させても、思ったほど性能は上がらないのだなという印象。
LoRAでweightにcontextを内部化させても、その内部化された情報をうまく活用するような工夫が足りていないのでは?という気がするのだが、どうだろうか。
ベンチマークのインスタンスが、contextをmemorizationし、適切にatteedすれば解けるようなクエリなのか否かという点も気になる。
もしcontextの情報に基づいてマルチポップな推論が必要な場合、LoRAアダプタによる重みを活用するような回路が育っていない可能性が高く、性能は伸びにくいのかなという気はする。
[Paper Note] Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories, Ali Behrouz+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Architecture #read-later #Selected Papers/Blogs #ContinualLearning #Author Thread-Post Issue Date: 2026-07-19 GPT Summary- 機械学習アルゴリズムは、初期の浅いモデルから深層大規模言語モデル(LLMs)へと進化したが、長期的な知識の転移能力に欠けている。人間の学習に触発され、継続的学習と記憶の安定化を図る「Sleep」パラダイムを提案。これは、記憶を網羅的に蒸留する「Memory Consolidation」と、新しい知識を合成データで予行練習する「Dreaming」の二段階から成る。このアプローチは、長期学習や知識の取り込みにおいて重要であることを実験により支持されている。 Comment
元ポスト:
[Paper Note] Beyond Euclidean Clipping: Overcoming Exploration Collapse in LLM RL via Riemannian Isometric Policy Optimization, Zhicheng Cai+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #Initial Impression Notes #Exploration Issue Date: 2026-07-19 GPT Summary- 強化学習(RL)において、PPO-Clipの根本的な欠陥を明らかにし、ユークリッド距離でのポリシー乖離測定が幾何的に不整合であることを指摘。これにより探索が崩壊する問題を考察。Riemannian Isometric Policy Optimization (RIPO)を提案し、探索と活用のバランスを改善。実験により、RIPOが既存のRLアルゴリズムを大幅に上回り、最大60%の性能向上を示した。 Comment
元ポスト:
トークンレベルでPPOのclippingの値を調整し、高確率なトークンには小さなクリッピングを、低確率なトークンには大きなクリッピングを適用する。オリジナルのPPOのクリッピングの問題点の分析もあるようである。
[Paper Note] Decomposer: Learning to Decompile Symbolic Music to Programs, Yewon Kim+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Coding #PostTraining #Music #Author Thread-Post Issue Date: 2026-07-19 GPT Summary- 音楽の演奏から指示を復元するDecomposerというポストトレーニングフレームワークを提案。MIDIからStrudel言語へのデコンパイルで、実行可能な音楽プログラムを作成。課題は、資源の乏しいStrudelと、忠実な再構成が読みにくいコードになる可能性。二段階で解決し、合成データでの教師付きファインチューニングと、ペアになっていないMIDIでの強化学習を行う。評価で、Decomposerは他の方法に比べ、高いMIDI再構成忠実性と可読性を実現。 Comment
元ポスト:
[Paper Note] Long-Horizon-Terminal-Bench: Testing the Limits of Agents on Long-Horizon Terminal Tasks with Dense Reward-Based Grading, Zongxia Li+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs #LongHorizon Issue Date: 2026-07-19 GPT Summary- Long-Horizon-Terminal-Benchは、AIエージェントの能力を検証するための新しい終端ベンチマークで、46件の長期タスクを含む。従来のベンチマークが評価する簡単な問題とは異なり、このベンチマークは中間報酬と部分点を重視し、長期的な計画や文脈管理を要求する。評価した15のモデルでは、タスクあたり平均9.9Mトークンを消費し、低いパス率が示され、改善の余地があることが示唆された。失敗モードの分析も行い、今後の進展に寄与することを目的としている。 Comment
元ポスト:
[Paper Note] Scalable Visual Pretraining for Language Intelligence, Yiming Zhang+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #Selected Papers/Blogs #VisionLanguageModel #reading #One-Line Notes Issue Date: 2026-07-19 GPT Summary- 視覚的事前学習が言語モデルの知能向上に寄与することを示す研究。テキスト変換を通さず視覚的文書を直接活用する無監督のアプローチを検討し、視覚的事前学習がテキストのみのモデルを一貫して上回ることを実証。これにより、スケーラブルな言語知能への効率的なアプローチが明らかに。 Comment
元ポスト:
事前学習をする際に、テキストだけでなく画像パッチに対してもnext visual latent predictionを実施することで性能が改善する。
next visual latent predictionでは、画像パッチをfreezeされたvision encoderでエンコードし潜在表現の系列を取得し、現在のパッチを入力したときに、次のパッチの潜在表現を予測する(離散トークンではなく、連続値ベクトルである点に注意)。loss functionは、バッチ内の全ての画像パッチを考えたときに、各パッチの正解の潜在表現と、モデルが予測した次パッチの潜在表現の類似度行列をソフトマックスで正規化した行列を考え、対角成分(すなわち正解の画像パッチに対する類似度)が最大化されるように定義される。ソフトマックスを考えることで、バッチ内の他の画像パッチがin-batch negativeの役割を果たし、これは次パッチの潜在表現と他の潜在表現の区別がつくようなcontrastive learningをしていることに相当する(Section 4)。
[Paper Note] Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding, Yonggan Fu+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #Architecture #Decoding Issue Date: 2026-07-19 GPT Summary- Nemotron-Labs-Diffusionは、AR、拡散、自己推測デコードを統合した三モードの言語モデルです。ARと拡散が補完的であることを示し、自己推測モードでは、拡散によるドラフト作成とARによる検証でマルチトークン予測が向上します。光速分析により、拡散がより多くのトークン生成を可能にし、最大76.5%の向上が見られました。3B、8B、14Bパラメータのモデルは、精度と速度の両面で最先端を超え、特にNemotron-Labs-Diffusion-8Bは、スループットを4倍に向上させました。 Comment
元ポスト:
[Paper Note] Who Checks the Citations? Benchmarking Legal Hallucination Detection, Patty Liu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Citations #NLP #Dataset #Evaluation #COLM #Legal Issue Date: 2026-07-19 GPT Summary- AIを用いて法的文書を作成する弁護士や裁判官が増加する中、捏造された引用が依然として多発している。本研究は、AIシステムが法的引用の幻覚を自動検出できるかを評価し、1,300件の抜粋データセットを用いて分類法を提案した。5モデルをベンチマークした結果、最新モデルはより高い性能を示すが、微妙な誤りカテゴリには苦戦することが明らかになった。エージェント系の検証は資源を消費し、情報アクセスの制限が効果を妨げる問題も指摘。これにより、商用法データベースに依存しない当事者にとっての不利益が生じる。研究では、信頼性の高い法的引用照合ツール構築のための基盤も提案している。 Comment
元ポスト:
[Paper Note] Qworld: Question-Specific Evaluation Criteria for LLMs, Shanghua Gao+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Evaluation #Rubric-based #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-19 GPT Summary- One-Question-One-World(Qworld)を導入し、オープンエンドな質問に対する評価基準を質問特異的に生成。再帰的展開木を使用し、質問をシナリオや視点、細分化された基準に分解。HealthBenchで高いカバー率を示し、専門家によって優れた洞察と粒度が評価される。Qworldは、LLMの評価において隠れた能力差を明らかにし、固定の基準に依存せず、動的な適応評価を実現。 Comment
元ポスト:
Open-endなQuestionを評価する際に、Questionに応じて動的にcriteriaを生成し評価する
[Paper Note] Context Tuning for In-Context Optimization, Jack Lu+, ICML'26, 2025.07
Paper/Blog Link My Issue
#NLP #In-ContextLearning #ICML #Selected Papers/Blogs #reading #Author Thread-Post Issue Date: 2026-07-19 GPT Summary- Context Tuningは、重みの更新なしでLLMsのfew-shot適応を向上させる手法です。ICLはデモの記憶を1回の前方伝播で形成しますが、洗練が不十分です。従来のプロンプト手法は、デモとは独立して初期化しますが、Context TuningはICL能力を利用してデモから訓練可能なメモリ表現を初期化し、勾配ベースの最適化で洗練します。多くのベンチマークで評価した結果、Context TuningはICLと従来のプロンプト法を上回り、Test-Time Trainingに近い精度を示し、高い訓練効率を発揮しました。 Comment
元ポスト:
pj page: https://agenticlearning.ai/context-tuning/
openreview: https://openreview.net/forum?id=UAJehyOPTS
気になる。後で読む
[Paper Note] The Agentic Garden of Forking Paths, Jiacheng Miao+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #Bias #ScientificDiscovery #Diversity #Personality #Author Thread-Post Issue Date: 2026-07-19 GPT Summary- AIエージェントは異なる分析選択から生成される結論の多様性を捉え、同じデータから対立する結果を導くことができる。移民データを用いた研究では、AIが人間のイデオロギー的ギャップの72%を再現し、多くの分析が高い検証を経た。調査は、問題の本質が欠陥ではなく、選択された分析の多様性にあることを示し、m値(マルチバース値)を導入することで報告された結果の極端さを評価する手法を提案。Agentic Bootstrapを使用して、もっともらしい分析パスをサンプルすることで、科学的信頼性の評価基準を提供する。 Comment
元ポスト:
所見:
小さな事前知識、ペルソナの変化がバタフライエフェクトのようにエージェントが導き出す結論を左右する
[Paper Note] Rethinking the Evaluation of Harness Evolution for Agents, Yike Wang+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #SelfImprovement #Author Thread-Post #AgentHarness Issue Date: 2026-07-19 GPT Summary- 自動ハーネス進化の評価を再検討し、既存手法の問題点を指摘。従来の評価は単体テストケースに依存し、探索手段と最終評価が同じベンチマーク上にあるため、過剰適合のリスクがある。フィードバックと推論予算を揃えた評価を行い、GPT-5.4とClaude Opus 4.6を使用して実験した結果、自動ハーネス進化は単純なテスト時スケーリングを必ずしも上回らず、一般化にも限界が示された。この結果は自動ハーネス設計の評価の再考を促すものである。 Comment
blog: https://yikee.github.io/harnessevolution/
元ポスト:
[Paper Note] Ring-Zero: Scaling Zero RL to a Trillion Parameters for Emergent Reasoning, Xinyu Tang+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-07-16 GPT Summary- ゼロRLを用いた強化学習は、思考の連鎖推論を促す新たな手法として注目されていますが、計算資源の制約から小規模モデルにとどまっています。本研究は、高品質な推論行動を引き出すことを目的とし、訓練プロセスの効率を向上させるために新たな訓練パイプラインを提案します。1兆パラメータへのスケーリングによる性能向上や、自発的に高度な認知的挙動の獲得を確認しました。さらに、推論の理解可能性や再現性を評価するためのフレームワークを提案し、構造化された推論痕跡を生成するモデルの優位性を示しました。コミュニティへの洞察を提供することを目指しています。 Comment
元ポスト:
所見:
[Paper Note] Mach-Mind-4-Flash Technical Report, Foundation Model Team, arXiv'26, 2026.07
Paper/Blog Link My Issue
#ReinforcementLearning #Distillation #PostTraining #On-Policy Issue Date: 2026-07-14 GPT Summary- Mach-Mind-4-Flashは、35BパラメータのMixture-of-Expertsモデルであり、ポストトレーニング最適化だけで100Bモデル並みの性能を実現します。三段階のパイプラインでは、(1) RL/OPDトレーニングを17%高速化、(2) 複数のドメイン特化RLエキスパートを単一のジェネラリストへ統合、(3) 推論チェーンを19〜46%圧縮し精度損失を0.7%未満に抑えます。このモデルはAIME'26などのベンチマークで高いスコアを達成し、低コストで効果的な推論を提供します。 Comment
元ポスト:
[Paper Note] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training, Yuhang Zhou+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Multi #Distillation #PostTraining #On-Policy Issue Date: 2026-07-12 GPT Summary- OPDは学生ポリシーを教師ポリシーで訓練する有望な手法だが、長期タスクへの応用には非効率がある。主な問題は、全長期ロールアウトがリソースを浪費し、KL信号がノイズを伴うことと、KL目的が初期挙動に偏り深い意思決定が訓練されないこと。これを解決するために、ターンレベルの予算化戦略TurnOPDを提案。TurnOPDはロールアウト深度とKL重みを調整し、検証精度の向上と時間効率を両立させる。実験により、TurnOPDが従来のOPDを上回る性能を示した。 Comment
元ポスト:
[Paper Note] Train Smarter, Not Longer: Memorization-Guided Data Reuse for Efficient LLM Training, Jingwei Zuo+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Pretraining #NLP #DataRepetition Issue Date: 2026-07-12 GPT Summary- 大型言語モデルのトレーニングパラダイムは、データの再利用においてマルチエポック訓練が推奨される一方、過学習のリスクが伴う。新たな「Memorization Window」信号を基に「Memorization-guided Data Reuse」を提案し、データ再利用の最適なタイミングと方法を決定。予備実験では、従来の4エポック制限を超えることで性能が向上することを示し、memorization-awareなトレーニングスケジュールの基盤を提供。 Comment
元ポスト:
[Paper Note] Multi-Turn On-Policy Distillation with Prefix Replay, Baohao Liao+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Multi #Distillation #PostTraining #On-Policy Issue Date: 2026-07-12 GPT Summary- 本研究では、エージェント指向タスクにおけるオンポリシー蒸留(OPD)の高コストを軽減するためにReplayed-Prefix On-Policy Distillation(ReOPD)を提案。学生は事前に収集した教師の軌跡を用いて行動し、教師は新しい環境相互作用を行うことなく密な監督を提供。マルチターンOPDでは、履歴を関連性の高いものへと変えつつ、信頼性の低い問い合わせのリスクが示される。ReOPDは信頼性を考慮した設計で、サンプリングスケジュールを用いることでOPDレベルの精度を維持し、訓練速度を少なくとも4倍向上。これにより高コストなエージェント-環境相互作用を再利用可能なオフライン資源へと変換。 Comment
元ポスト:
OPDのマルチターンへの拡張関連:
- [Paper Note] SAGE-OPD: Selective Agent-Guided Intervention for Multi-Turn On-Policy Distillation, Yuhang Zhou+, arXiv'26, 2026.06
PrefixRL関連:
- [Paper Note] POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration, Yuxiao Qu+, arXiv'26, 2026.01
- [Paper Note] Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes, Amrith Setlur+, arXiv'26, 2026.01
[Paper Note] Gemma 4 Technical Report, Gemma Team+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #OpenWeight #Selected Papers/Blogs #VisionLanguageModel #Reference Collection #AudioLanguageModel Issue Date: 2026-07-12 GPT Summary- Gemma 4は新世代のオープンウェイトマルチモーダル言語モデルで、計算効率と推論能力の向上を目指します。DenseとMixture-of-Expertsアーキテクチャを採用し、パラメータ数は23億〜310億で、視覚および音声エンコーダを強化しました。特に12Bモデルにはエンコーダを用いない統一アーキテクチャが導入され、生の音声と画像パッチを扱います。推論の痕跡を生成する機能を統合し、推論速度やメモリ効率を改善。Gemma 4は、STEMやマルチモーダルタスクで飛躍的な性能を達成し、最前線のオープンモデルに匹敵します。 Comment
元ポスト:
Gemma 4:
- Gemma 4: Byte for byte, the most capable open models, Google, 2026.04
ポイント解説:
解説:
[Paper Note] ExaGPT: Example-Based Machine-Generated Text Detection for Human Interpretability, Ryuto Koike+, ACL'26 Findings, 2025.02
Paper/Blog Link My Issue
#NLP #Education #ACL #Findings #AI Detector #Interpretability Issue Date: 2026-07-12 GPT Summary- LLM生成テキストの検出は、決定の解釈可能性を重要視し、利用者が予測の正確さを評価できるようにする必要がある。従来の手法は人間の判断プロセスに沿った証拠を提供できておらず、このギャップを解消するためにExaGPTを提案。ExaGPTは、人間作成とLLM生成テキストの類似スパンを比較することで識別し、具体的な証拠を示すことで決定の正しさを向上させる。広範な実験により、ExaGPTは従来手法より精度を最大37.0ポイント向上させることが確認された。 Comment
元ポスト:
人間が作成したテキストとLLMが生成したテキストのスパンごとの類似性を見ることで、与えられたテキストがLLM生成か否かを判定する。データストア中の類似したスパンが判断のevidenceとなる、という話に見える。
こういった話は教育の文脈でも需要がある
[Paper Note] Rethinking On-Policy Self-Distillation for Thinking Models, Simran Kaur+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Distillation #PostTraining #Diversity #On-Policy #SelfDistillation #Author Thread-Post Issue Date: 2026-07-12 GPT Summary- 自己蒸留は言語モデルの自己改善に有望で、特に数学問題の解法など特権情報を用いて自己指導が可能である。しかし、特権付き自己蒸留は長い推論経路で思考モデルの性能を低下させ、AIME24、AIME25、HMMT25の評価で最大17%の精度低下が確認された。この劣化は保留された特権情報の量に比例し、長いロールアウト期間で顕著である。特権教師の文脈が高エントロピーの学習を阻害することが原因で、これにより思考モデルのロールアウトが困難に。特権コンテキストは指示調整されたモデルには有利だが、強力な思考モデルには不利であることが示され、自動訂正分岐の開始時に効果が見られる。これらの知見は、強力な思考モデルにはトークンレベルの信号に注意が必要であることを示唆している。 Comment
元ポスト:
著者ポスト:
[Paper Note] Trust Region Policy Distillation, Zhengpeng Xie+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Distillation #PostTraining #On-Policy #Stability Issue Date: 2026-07-12 GPT Summary- 悪名高いOn-Policy Distillationを安定した学習に変えるため、トラスト・リージョン・ポリシー蒸留(TOP-D)を提案。TOP-Dは勾配分散を制御することで信頼性を向上させ、収束解析により学習の安定性と最終性能を劇的に改善。計算オーバーヘッドなしで、OPDの有望な代替手法と位置づけられる。 Comment
元ポスト:
教師と生徒の線形補完によって各iterationごとに代理教師を動的に構築し、OPDの安定性を高める
[Paper Note] OmniOpt: Taxonomy, Geometry, and Benchmarking of Modern Optimizers, Siyuan Li+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Survey #Pretraining #NLP #Evaluation #Optimizer #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-07-12 GPT Summary- 最適化手法の選択は計算量やメモリに制約されるが、その全体像は断片的である。そこで、統合サーベイ「OmniOpt」を提案。これには、五段階メタパイプラインの構造的変換、ノルム制約付きLMOによる手法統一、二次元分類法を用いた手法の機構と訓練目標の整理、最適化手法を系統的に分析するクロスドメインベンチマークが含まれる。これにより、最適化手法選択のための実用的な座標系を提供し、今後の研究の方向性を示す。 Comment
元ポスト:
optimizerの詳細なサーベイと様々なベンチマーキングの結果が記載されている模様
全部読んだらめちゃめちゃ勉強になりそう
[Paper Note] Weak-to-Strong Generalization via Direct On-Policy Distillation, Shiyuan Feng+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#EfficiencyImprovement #Distillation #PostTraining #On-Policy Issue Date: 2026-07-12 GPT Summary- 弱いモデルから強いモデルへの知見を再利用する方法として、Direct On-Policy Distillation(Direct-OPD)を提案。これにより、弱いモデル上でのロールアウトに基づくRLの学習を強いモデルに適用し、スパースな報酬なしで改善を実現。特に、Qwen3-1.7Bを短時間で大幅に性能向上させ、RLの成果を模倣対象モデル以上の暗黙の報酬信号として再利用できることを示す。 Comment
元ポスト:
[Paper Note] Measuring the Gap Between Human and LLM Research Ideas, Ziyu Chen+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #ScientificDiscovery Issue Date: 2026-07-12 GPT Summary- 近年、LLMsは研究アイデアのブレインストーミングに利用されるが、既存の評価は新規性や実現可能性に依存している。本研究では、LLM生成アイデアと人間研究者のアイデアの乖離を評価するフレームワークを構築し、高品質な論文からインスピレーションを抽出。アイデアを機会パターンと研究パラダイムでプロファイリングし、定量化した結果、LLMのアイデアは特定の手法に偏りがあり、人間の研究プロセスの幅広い側面を捉えていないことが明らかになった。これにより、LLMsは合理的なアイデアを生み出せるが、その範囲は人間より狭いことが示唆された。 Comment
元ポスト:
[Paper Note] Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling, Xiang Hu+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #Attention #Architecture #One-Line Notes #SparseAttention Issue Date: 2026-07-11 GPT Summary- 階層的ランドマークスパース(HiLS)アテンションを提案し、チャンク単位でのスパースアテンションをエンドツーエンドで学習。各クエリが独立してチャンクとアテンションを行い、検索スコアを用いて結合。実験結果では、HiLSが全アテンションに匹敵するかそれ以上の性能を示し、長文脈での外挿が可能。軽量な事前学習を通じて全アテンションモデルをHiLSに適応させ、効率と効果のトレードオフを克服。 Comment
元ポスト:
ポイント解説:
Block Sparse Attention (BSA) は、直近のトークンを見るlocal sliding window attention (SWA)と、離れたトークンに対するチャンクレベルでのsparse attentionに基づいたアテンション機構である。
一般的なBSAでは、現在のquery qとチャンク単位のattentino scoreを計算する際に、各チャンクごとにチャンクのkeyに関する情報を要約した Key k'_c を求め、k'_c と現在のquery qとのattention scoreを計算することにより計算を効率化する[^1]。
k'_c を求める際には、mean/max pooling を用いるのが一般的であり、特に前者が用いられるとのことだが、どちらのpoolingの手法もattention scoreの分布に依存して、近似の性能が変化する(たとえば、mean poolingであればなるべくattention scoreが一様なほど近似性能が良いし、max poolingであれば、あるscoreがチャンク内で支配的であるほど近似性能が良い)が、query qに応じてattention scoreの分布は変化することにより、k'_cの近似性能が低下しsparse attentionによって重要なチャンクを選択する性能が低下する課題がある。
これに対して、
- 現実的な計算量でk'_cをより正確に近似できる surrogate score に基づく手法を提案し(RQ1)[^2]
- surrogate score をend-to-end で学習可能にする方法を提案した (RQ2)
という話である。
surrogate scoreは、チャンクのattention scoreの質量をより正確に近似したスコアであり、(チャンクのkeyを要約した)k'_c に対する現在のクエリ q とのrelevanceを表す項と、バイアス項 b'_c によって線形化される(式7)。
k'_c によって現在のクエリに対する関連度を測り、バイアス項によって関連度から独立したtoken-levelの質量を導入する。バイアス項は、チャンクにattendするであろうクエリのattention scoreの分布に対するentropyであり、これが一様分布やあるトークンが支配的な分布など、様々な分布の形状に対して動的に適応する役割を果たす。
b'_c を求めるために、チャンクごとに独立したクエリ q'_c を学習する。これは、このチャンクにattendするであろうクエリのプロキシを果たすクエリであり、q'_c とチャンク内のトークンのkeyとの間でのattention scoreを計算しておくことで、おおまかなattention scoreの分布を決定し、b'_c を求めておくことができる(式8)。
また、k'_c はチャンク内のattention scoreによって重みづけられたkeyの和の形で求められる(式8)。
これにより、現在のクエリ qが与えられた時に、k'_cとb'_cを用いて、チャンクに対するattention scoreの質量を高速に近似することができる(式7)。
ここで q'_c をどのように学習するかが課題となる(q'_c以外のパラメータは従来通りのモデル化で求まる)。これを解決するために、surrogate scoreによって求まるチャンクのattention scoreの近似質量 \hat{Z}_{i, c} をforward passに加え、q'_c に勾配が流れるようにすることで解決している。具体的には、attention scoreの計算をする際に、式変形を実施し、`チャンク内のスコアの計算 * チャンク間のスコアの計算` の形に分解する(式10)。後者のチャンクの重要度を求める際に、各チャンクのsurrogate scoreを用いて近似することによって、高速化 + q'_c に勾配が流れるような工夫をしている。
[^1]: チャンクのattention scoreの質量(どのチャンクをsparse attentionでattendするかを決定する際に用いられる)を計算する際に、query qとチャンク内の全てのtokenに対するtoken-to-tokenの内積をとることを避け、k'_cとの内積によって近似的に質量を求めることで計算を効率化する。
[^2]: surrogate scoreによってk'_cを正確に近似できることの証明はAppendix Bに記載されており、1次のテイラー展開に基づいているようである(ここは読めていない)。
[Paper Note] Single-Rollout Asynchronous Optimization for Agentic Reinforcement Learning, Zhenyu Hou+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Reference Collection #Initial Impression Notes #Asynchronous Issue Date: 2026-07-09 GPT Summary- 強化学習におけるLLMsの非同期性を改善するため、Single-rollout Asynchronous Optimization (SAO)を提案。グループ単位サンプリングを廃止し、安定した訓練を1,000ステップ行える。SAOは、GRPOやその派生手法に対し、複数のエージェント型ベンチマークで優れたパフォーマンスを示し、進化する環境への適応性も強化。 Comment
元ポスト:
GLM 5.2で利用されているRL手法
所見:
VAPO:
- [Paper Note] VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, Yu Yue+, arXiv'25, 2025.04
alphaXivによるポスト:
解説:
[Paper Note] Is One Layer Enough? Training A Single Transformer Layer Can Match Full-Parameter RL Training, Zijian Zhang+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #Selected Papers/Blogs #reading #Initial Impression Notes Issue Date: 2026-07-08 GPT Summary- 強化学習(RL)の適応がトランスフォーマー層にどう分布しているかに焦点を当てる研究。単一のトランスフォーマー層を訓練することで、全パラメータRLトレーニングの利得の大半を回復可能。この現象を層寄与量で定量化し、複数のモデルとRLアルゴリズムで安定したパターンを観察。高寄与層は中間部に集中し、入力・出力端の寄与は少ないことを示唆。層の rankings は各種条件下でも強い相関を持つ。 Comment
元ポスト:
実験は8Bスケールのモデルまでしかできていないが、もしこれが数百B級のモデルにも当てはまるのだとすると、非常に計算コストの低減だけでなく、weightのsyncにおいて非常に有利になると思われるので、インパクトが大きそうな話になる可能性を感じる。
RLの効率化という観点で言うと
- [Tech] Delta Weight Sync: When RL's Weight Sync Stops Being a Network Problem, Changyi Yang, ChangyiYang's Site, 2026.06
のような話もある。
[Paper Note] UnMaskFork: Test-Time Scaling for Masked Diffusion via Deterministic Action Branching, Kou Misaki+, ICML'26, 2026.02
Paper/Blog Link My Issue
#DiffusionModel #ICML #Test-Time Scaling #Author Thread-Post Issue Date: 2026-07-08 GPT Summary- UMFフレームワークを提案し、マスク付き拡散言語モデルの生成プロセスを探索木として定式化。モンテカルロ木探索を用いて生成パスを最適化し、従来の方法に対し決定論的に探索空間を探索。これにより、複雑なコードベンチマークで従来のスケーリング手法を上回る性能を示し、数学的推論タスクでも高いスケーラビリティを実現。 Comment
元ポスト:
[Paper Note] Feedback-to-Rubrics: Can We Learn Expert Criteria from Inline Comments?, Kotaro Yoshida+, ICML'26, 2026.05
Paper/Blog Link My Issue
#NLP #Evaluation #ICML #reading #Rubric-based #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-08 GPT Summary- インラインコメントを活用して、再利用可能な自然言語ルーブリックを学習する手法を提案。コメントの不一致を観察しながらルーブリックを改良し、現実のレビュー設定で評価。これにより、成果物の改訂やルーブリック理解が促進されることを示した。 Comment
元ポスト:
文書の中に断片化されているインラインコメント等を暗黙的な評価基準に基づいて生成された観測データと捉え、インラインコメントから明文化されていない評価基準を学習し、ルーブリックとして活用可能にする、という話に見える。
「暗黙知、ケースバイケースなのでなかなか明文化できません」という状況によく遭遇し困るので、そもそもこういった手法が利用できるように日々の判断をLLMが利用可能な形に残しておくことが重要と感じる
[Paper Note] Program-as-Weights: A Programming Paradigm for Fuzzy Functions, Wentao Zhang+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #Coding #PEFT(Adaptor/LoRA) #SoftwareEngineering Issue Date: 2026-07-08 GPT Summary- ファジー関数プログラミングを用いて、自然言語仕様からコンパクトなニューラル・アーティファクトを生成するアプローチを提案。Program-as-Weights(PAW)で具現化し、4BパラメータのコンパイラがFuzzyBenchで訓練されたアダプターを出力。0.6Bパラメータのインタプリタは、Qwen3-32Bと同様の性能を保ちながらメモリ使用量を1/50に削減し、効率的に問題解決に貢献。関数定義を再利用可能なアーティファクトとして実行。 Comment
元ポスト:
関連:
- PAW: Define functions in English. Run them locally, ProgramAsWeights, 2026.04
[Paper Note] Rubric Curriculum RL: Exploiting the Generation-Verification Gap in Non-Verifiable Domains, Krishnan+, ICML'26, 2026.07
Paper/Blog Link My Issue
#ReinforcementLearning #SelfImprovement #ICML #PostTraining #read-later #Non-VerifiableRewards #Rubric-based Issue Date: 2026-07-08 Comment
元ポスト:
[Paper Note] Cognitive Episodes in LLM Reasoning Traces Enable Interpretable Human Item Difficulty Prediction, Chenguang Wang+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Education #read-later #ItemDifficultyPrediction Issue Date: 2026-07-08 GPT Summary- 教育評価におけるアイテム難易度予測は重要であり、信頼性が公平性と効果的なテスト作成に寄与する。従来の方法は高コストな校正や制限された証拠に依存している。難易度はアイテムのテキストや問題解決の負担として捉えるべきとし、大規模推論モデル(LRMs)を通じてスケーラブルな証拠を提供する新しいフレームワーク「Epi2Diff」を提案。これにより、推論痕跡をエピソードにマッピングし、難易度のモデル化を実現する。実験結果はEpi2Diffが複数のベースラインを超え、特に難易度の高いアイテムにおいては努力を要するプロセスが観察されることを示した。これにより、LRM推論痕跡が人間のアイテム難易度を予測する新しい視点を提供する。 Comment
元ポスト:
[Paper Note] Purified OPSD: On-Policy Self-Distillation Without Losing How to Think, Zhanming Shen+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Distillation #PostTraining #On-Policy #SelfDistillation #ShortcutLearning Issue Date: 2026-07-08 GPT Summary- OPSDはLLMの推論能力を向上させる方法として注目されているが、長いCoT推論モデルでは一貫して失敗している。これにより反省的推論能力が不安定化することが示されており、教師信号の分析から参照特有のショートカットが問題の根本原因であると特定された。提案された解決策は、参照のみに条件付けられた教師を構築し、質問条件付けられた推論成分を明確にすることと、PMI機構を通じてショートカットをフィルタリングすることである。実験は、基礎モデルと標準的なOPSDの両方で一貫した改善を示し、モデルのエピステミック挙動を維持した。 Comment
元ポスト:
[Paper Note] Denser $\neq$ Better: Limits of On-Policy Self-Distillation for Continual Post-Training, Meng Wang+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Analysis #NLP #Distillation #Catastrophic Forgetting #PostTraining #On-Policy #Generalization #ContinualLearning #SelfDistillation Issue Date: 2026-07-08 GPT Summary- 継続的ポストトレーニングにおいて、自己蒸留方針最適化(SDPO)がドメイン内専門化を加速する一方で、分布外一般化に苦戦し、忘却が顕著になることを実験により示した。また、GRPOのようなオンポリシー手法は、以前の能力をより良く保持する傾向があることも明らかになった。密な自己蒸留は専門化を促進するが、継続的トレーニングの安定化には適していない。 Comment
元ポスト:
[Paper Note] Set Diffusion: Interpolating Token Orderings Between Autoregression and Diffusion for Fast and Flexible Decoding, Marianne Arriola+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#DiffusionModel #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-07-08 GPT Summary- 新しい「セット拡散(set diffusion)」モデルは、因子分解された尤度のパラメータ化とKVキャッシュの更新をサポートし、柔軟な位置・長さのトークン集合に対する生成を実現。固定サイズのブロックを排除することで、任意順序でのデコードが可能となり、推論速度が向上。数学的推論や要約において従来のモデルより性能が改善され、ブロック拡散よりも強力なインフィリング能力を示す。 Comment
元ポスト:
元ポストのgifを見ると一目で概要がわかる。
Block Diffusionのグループによる研究
Block Diffusion:
- [Paper Note] Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models, Marianne Arriola+, ICLR'25, 2025.03
[Paper Note] ReasonIF: Large Reasoning Models Fail to Follow Instructions During Reasoning, Yongchan Kwon+, ACL'26 Findings, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Reasoning #ACL #InstructionFollowingCapability #Findings #One-Line Notes Issue Date: 2026-07-08 GPT Summary- 大規模言語モデル(LLMs)がユーザーの指示を推論過程全体で遵守する重要性を強調し、ReasonIFというベンチマークを導入。これは、推論指示の遵守を評価し、さまざまな指示プロンプトを網羅している。多くのオープンソースLRMsにおいて、指示遵守のスコアは0.25未満であり、難易度の上昇に伴い低下する傾向がある。推論指示の忠実度向上には、マルチターン推論と合成データを用いたファインチューニングが有効で、RIFによって大きな改善が見込まれるが、さらなる向上が必要。 Comment
著者ポスト:
著者ポスト2:
reasoning traceに対して制約を課す[^1]指示は、メインの応答と比較して指示追従性能が低い傾向にある
[^1]: 思考する言語の指定、思考の長さの制限、免責事項(指示でreasoningの最後にwarningや備考を追記する)、reasoningをjsonにする、大文字のみを利用する、commaをreasoning中に除外する、など
[Paper Note] Nemotron-Labs-TwoTower: Diffusion Language Modeling with Pretrained Autoregressive Context, Fitsum Reda+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #Architecture #Author Thread-Post Issue Date: 2026-07-08 GPT Summary- 拡散言語モデルは、自己回帰モデルの代替手段として注目されていますが、既存アプローチは文脈表現とデノイズを同一ネットワークで処理するため能力が制限されていました。本研究では、役割を2つのタワーに分離したブロック単位の自己回帰拡散モデル「TwoTower」を提案。凍結されたAR文脈タワーがクリーンなトークンを処理し、拡散デノイザータワーが双方向アテンションを用いてノイズを洗練します。訓練されたモデルは、生成スループットを2.42倍改善しつつ、自己回帰ベースラインの品質の98.7%を保持します。コードとモデルは公開されています。 Comment
HF: https://huggingface.co/nvidia/Nemotron-Labs-TwoTower-30B-A3B-Base-BF16
元ポスト:
拡散言語モデルにおけるTwo Towerアーキテクチャの提案で、一方がコンテキストを読み込み(ARモデルでfreezeされている)、もう一方がデコードを担う(diffusionモデルでlearnable)。どちらのタワーも事前学習済みのモデルを利用する。
オリジナルモデルの性能の98.7%を維持しつつ、2.42倍のスループットを実現可能とのこと。
[Paper Note] Agentic Abstention: Do Agents Know When to Stop Instead of Act?, Han Luo+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #Selected Papers/Blogs #Initial Impression Notes #Exploration Issue Date: 2026-07-08 GPT Summary- エージェントが対話を通じてユーザーの目標を達成する際、目標が明確でない場合には行動を止めるべきであるとし、「エージェント性棄却」を定義。標準的な棄却と異なり、逐次的な意思決定問題として評価され、エージェントは環境に応じて回答、棄却、情報収集を選択。ウェブショッピングなどの場面で13のLLMを評価し、棄却のタイミングが重要であることを示した。さらに、モデルの規模や支援枠組みが棄却に影響を及ぼすことが判明。CONVOLVEという手法を導入し、対話の軌跡を利用して棄却を改善、Llama-3.3-70Bモデルでは適時リコール率を大幅に向上させた。データセットとコードは公開中。 Comment
元ポスト:
エージェントが環境とインタラクションした後にタスクが実現不能な場合はタスクを棄却すべきという話
[Paper Note] To Reason or to Fabricate: Reasoning Without Shortcuts via Hint-Anchored Pairwise Aggregation, Jiuheng Lin+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#ReinforcementLearning #PostTraining #Initial Impression Notes #ShortcutLearning Issue Date: 2026-07-08 GPT Summary- 強化学習(RL)の推論能力を高めるために、ヒントを注入したペアワイズ報酬モデルを統合した新しいフレームワークHIPPOを提案。重複データの問題を解決し、識別性の高い信号を提供することで、ショートカットの合理化と真の推論を効果的に区別。広範な実験で標準的なベースラインを大幅に上回り、真正な推論スキルを抽出できることを示した。 Comment
元ポスト:
事前学習時にmemorizeされた知識でショートカットしてrewardを得るのではなく、解答へ向けてreasoningすることを促進する
[Paper Note] Dockerless: Environment-Free Program Verifier for Coding Agents, Wenhao Zeng+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #Coding #SoftwareEngineering #PostTraining #Verification Issue Date: 2026-07-07 GPT Summary- Dockerlessは、環境を必要とせずにコードパッチの正確性を評価するエージェント的パッチ検証器を提案する。従来の環境構築コストを削減し、リポジトリ探索を通じて証拠に基づく評価を実現。これにより、最も強力なオープンソース検証器を14.3 AUCポイント上回り、SWE-bench Verified、Multilingual、Proでそれぞれ62.0%、50.0%、35.2%の解決率を達成。環境ベースのポストトレーニングと同等の性能を示す。 Comment
元ポスト:
[Paper Note] On the Nonlinearity of Learning Rate Scaling for LLM Training, Zaiwen Yang+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #Scheduler #LearningRate Issue Date: 2026-07-07 GPT Summary- 学習率転移により、大規模言語モデルの訓練コストを削減可能。実務者は小規模なランから学習率を外挿。しかし、最適な学習率はデータ規模とモデルサイズに対して非線形に振る舞うことが確認された。研究では、22Mから707MパラメータのGPT-2風モデルを用いてこのスケーリング特性を評価。最適な学習率はデータサイズの外挿からずれ、特に大規模な学習では上向きの曲率を示し、従来の仮定が不正確であることを示唆。AdamHを用いた実験により、非線形性の説明も支持された。 Comment
元ポスト:
[Paper Note] DOPD: Dual On-policy Distillation, Xinlei Yu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Distillation #PostTraining #On-Policy Issue Date: 2026-07-07 GPT Summary- 特権情報を利用したOPDは、学生の能力伝達を強化するが、「特権の錯覚」という問題が生じる。これは、学生が再現不可能な情報と移転可能な能力を混同することに起因する。これを解決するため、DOPDという利点を意識したデュアル蒸留パラダイムを提案。各トークンは、教師または学生から動的に監督を受けることで、能力伝達を安定化し、錯覚を緩和する。DOPDはLLMおよびVLMにおいて、従来の手法を上回るパフォーマンスを示している。
[Paper Note] Reinforcement Learning Towards Broadly and Persistently Beneficial Models, Akshay V. Jagadeesh+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #ReinforcementLearning #Safety #PostTraining #Selected Papers/Blogs #Generalization #reading #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-07 GPT Summary- RLを用いて多様なドメインで有益な行動を促進し、整合性の一般化を調査。データセットを構築し、50以上の独立したベンチマークで評価した結果、80%超で性能向上が見られる。特に健康ドメインでの介入が他の評価にも効果的で、整合性の維持向上を示した。この研究は、RLを通じて人間の福祉への整合性を強化する可能性を示唆する。 Comment
blog: https://alignment.openai.com/beneficial-rl/
元ポスト:
所見:
特定のドメインにおいて有益な特性を備えた少量データ(trustfulness, 不確実性の下での謙虚さ等を備えた対話)でRLされたモデルは、訓練に使用したドメインを超えて一般化し、アライメントを改善する。敵対的なプロンプトが与えられた場合でも、Alignmentが持続する能力が高まる。
以下でも良性のペルソナで学習をすることでAlignmentが改善しており、似た知見が得られている:
- Teaching Claude why, Anthropic, 2026.05
[Paper Note] How Transparent is DiffusionGemma?, Joshua Engels+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#DiffusionModel #Architecture #read-later Issue Date: 2026-07-05 GPT Summary- LLMの推論透明性は、モデルの意思決定を理解し、悪用や不整合を緩和する上で重要である。しかし、DiffusionGemmaは潜在空間での計算が多いため、透明性が低くなる可能性がある。本研究では、透明性を変数透明性とアルゴリズム透明性の二要素に分解して分析する。DiffusionGemmaは変数透明性が低く、初見ではオートリグレッシブGemma 4モデルの28.6倍の不透明な計算深さを示すが、中間状態を解釈可能として扱うことで深さを1.1倍に減少させることができる。アルゴリズム透明性は難しく、拡散過程の各ステップでのトークン予測の変化が要因となる。また、解釈性に関するケーススタディを実施し、拡散特有の新規現象を明らかにする。最後に、DiffusionGemmaはGemma 4同様に下流タスクに対して有用であることが示された。 Comment
元ポスト:
関連:
- DiffusionGemma: The First Diffusion LLM (dLLM) Natively Supported in vLLM, vLLM, 2026.06
[Paper Note] How Retrieved Context Shapes Internal Representations in RAG, Samuel Yeh+, ACL'26 Findings, 2026.02
Paper/Blog Link My Issue
#Analysis #RAG(RetrievalAugmentedGeneration) #ACL #Findings Issue Date: 2026-07-05 GPT Summary- RAGは、外部文書を用いてLLMの性能を向上させるが、取得文書の影響は明確でない。本研究では、取得文書がLLMの隠れ状態に与える影響と、その変化が生成挙動にどのように関連するかを潜在表現の視点から分析。4つの質問応答データセットと3つのLLMを用いて、文脈の関連性が内部表現に与える影響を明らかにし、LLMの出力挙動の理解とRAGの設計に関する洞察を提供。 Comment
元ポスト:
[Paper Note] On the Position Bias of On-Policy Distillation, Yan Xie+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#ReinforcementLearning #Distillation #PostTraining #read-later #Selected Papers/Blogs #On-Policy Issue Date: 2026-07-05 GPT Summary- On-Policy Distillation(OPD)は教師からの監督を通じて強化学習の効率を向上させるが、トークンの重みが均等化されているため後半のトークンの監督品質が低下する。この問題を理解し、Importance-Weighted On-Policy Distillation(IW-OPD)を提案。IW-OPDでは、トークンの重みを学生と教師の分布の乖離に基づき調整することで、学習効率を向上させ、標準のOPDよりも速く収束し、最終性能が向上することを実証。 Comment
元ポスト:
[Paper Note] MirrorCode: AI can rebuild entire programs from behavior alone, Tom Adamczewski+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#AIAgents #Evaluation #Coding #SoftwareEngineering #read-later #LongHorizon #Author Thread-Post Issue Date: 2026-07-05 GPT Summary- AIモデルのコーディング能力は向上しており、MirrorCodeを用いて全体のソフトウェアプロジェクトの再実装を通じた新たな長期的ベンチマークを提案。AIエージェントはコードにアクセスせず、既存のプログラムの機能を再現し、テストで出力の一致を求められる。計算機科学の多様な分野をカバーし、最強のモデルは全体で56%のスコアを記録。AIは複雑なツールを再実装でき、研究の要件が明確であれば長期タスクを完遂可能であることを示唆。AIの進化がソフトウェア工学に及ぼす影響に期待。 Comment
pj page: https://epoch.ai/MirrorCode
元ポスト:
[Paper Note] Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention, Jing Huang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #EmergentAbilities Issue Date: 2026-07-05 GPT Summary- より大きなモデルは小さなモデルが学習できないタスクを学習する能力を持つ。この現象の背景には、データ起因の資源競合がある。小さなモデルはニューロンを高周波数や低複雑性タスクに割り当てるため、複雑なタスクに対する学習が不適切になることがある。逆に、大きなモデルは共通タスクにリソースを十分に確保し、希少タスクの特徴をゆっくり蓄積することが可能である。OLMoモデルの実験により、大きなモデルが希少で複雑なタスクを効果的に学習し、タスク間の勾配干渉が少ないことが示された。この研究は、大規模モデルの優位性をデータ中心の観点から説明し、モデルサイズや訓練データ選定の実践的示唆を提供する。 Comment
元ポスト:
[Paper Note] On-Policy Self-Distillation with Sampled Demonstrations Reduces Output Diversity, Andrei Liviu Nicolicioiu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Distillation #PostTraining #Diversity #On-Policy #Initial Impression Notes Issue Date: 2026-07-05 GPT Summary- オンポリシー自己蒸留は、単一モデルを教師と生徒として利用し、高いpass@1精度を実現するが、サンプリングされたデモンストレーションに依存することでロールアウトの多様性が低下する。教師がバイアスを通じてフィードバックを与えるため、最適な自己蒸留方針は基底分布を不均一に傾斜させる。自己蒸留モデルは、制御されたタスクで競争力のある性能を示すものの、機能的多様性が不足し、分布外設定では失敗する。 Comment
元ポスト:
OPDでは教師モデルが正しいロールアウトで条件付けされるため、正しいロールアウトに近いロールアウトはより増強され、遠いものは抑制されることにつながり、結果的に出力の多様性が減少しPass@kが伸びにくくなる、という副作用があるよ、という話のようである。
[Paper Note] Improved Large Language Diffusion Models, Shen Nie+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #NLP #Supervised-FineTuning (SFT) #DiffusionModel #PostTraining #Initial Impression Notes Issue Date: 2026-07-05 GPT Summary- iLLaDAは、80億パラメータの双方向注意を持つマスク付き拡散言語モデルであり、ゼロから訓練された。事前学習には12兆トークンを使用し、教師ありファインチューニングを通じて大規模なコーパスで性能を向上させた。生成効率を高めるために可変長生成と信頼度に基づくスコアリングを導入。iLLaDAは、一般・数学・コードのベンチマークでLLaDAと比較し広範な改善を示し、特にBBHやARC-Challenge、MATH、HumanEvalで顕著なポイント向上を達成。非自己回帰訓練にもかかわらず、競争力を維持していることが示され、双方向拡散訓練が強力な言語モデル開発に寄与する可能性を示唆している。 Comment
元ポスト:
bi-directional attentionを用いてゼロから訓練されたたdLLM
[Paper Note] Cyclical Entropy Eruption: Entropy Dynamics in Agent Reinforcement Learning, Wendi Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #ReinforcementLearning #AIAgents #PostTraining #read-later #Entropy #Author Thread-Post Issue Date: 2026-07-05 GPT Summary- エージェントRLの訓練ダイナミクスにおける仮定されていなかった現象、循環的エントロピー噴出を特定。これは、高いエントロピーの噴出と徐々の沈静化を繰り返す独特のサイクルで、文の重複やハルシネーションがサイクルを超えて蓄積する可能性を示唆。SEAL(Separation-Enhanced Agent Learning)を提案し、エントロピー噴出に対処。実験により、SEALが訓練を安定化させ、エージェントの性能を向上させることを確認。 Comment
元ポスト:
[Paper Note] EvoEmbedding: Evolvable Representations for Long-Context Retrieval and Agentic Memory, Chang Nie+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Embeddings #NLP #memory #LatentRepresentation Issue Date: 2026-07-05 GPT Summary- EvoEmbeddingは、文脈や時間的順序を考慮した動的な埋め込みモデルであり、逐次処理により潜在メモリを更新し、進化する状況に基づいて検索対象を最適化する。EvoTrain-180Kデータセットを用いて、潜在メモリと検索を共同最適化し、長文脈検索において他の大規模モデルを凌駕する性能を発揮することを実証。さらに、エージェント型ワークフローにも統合可能で、性能向上を実現。 Comment
元ポスト:
[Paper Note] Learning Multi-Agent Coordination via Sheaf-ADMM, Jeffrey Seely+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #Initial Impression Notes #Author Thread-Post #Coordination Issue Date: 2026-07-04 GPT Summary- 多エージェント協調のための微分可能な最適化フレームワークを提示。重なる局所ビューを解決するエージェントは、ADMMを用いて協調し、グローバル合意を形成。マルチエージェントシステムは共同訓練され、局所ビュー不足でも正しい出力を生成。MNISTでは頑健性を向上、数独では高い解決率を達成。ADMM構造により協調ダイナミクスを直接分析可能。 Comment
元ポスト:
blog: https://pub.sakana.ai/sheaf-admm/
微分可能なフレームワークによって、エージェント同士が協調することを学習する
[Paper Note] Efficient and Trainable Language Model Test-Time Scaling via Local Branch Routing, Yutong Yin+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Test-Time Scaling #Author Thread-Post Issue Date: 2026-07-04 GPT Summary- Local Branch Routing(LBR)は、トークンレベルの推論時スケーリングを実現するフレームワークで、軽量なルータを用いて先読み木の部分木を選択し、各トークンの決定に基づく証拠を活用する。これにより、計算コストを抑えつつ、エンドツーエンドの強化学習が可能となり、合成的な階層的計画タスクや数学的推論ベンチマークで従来モデルを上回る成果を示した。LBRは言語モデルの効率的な推論時スケーリングを実現する。 Comment
元ポスト:
著者ポスト:
[Paper Note] You Don't Need to Run Every Eval, Yuchen Zeng+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Evaluation #EfficientEvaluation #Author Thread-Post Issue Date: 2026-07-03 GPT Summary- 84のフロンティアモデルを133のベンチマークで評価し、スコア行列を作成した結果、モデルのスコアは主に2つの因子に依存することが明らかになった。これに基づき、行列補完法「BenchPress」を設計し、隠れたスコアを高精度で回復。特定のベンチマークのサブセットでは、モデルの未公開スコアを3.93ポイント以内に予測可能であり、より安価な評価セットでも高い精度を示した。スコア行列、BenchPressのコード、および対話型ツールを公開。 Comment
元ポスト:
著者ポスト:
[Paper Note] Tapered Language Models, Reza Bayat+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #NLP #Architecture #reading #One-Line Notes Issue Date: 2026-07-03 GPT Summary- 深層言語モデルは、均一な層構成が与えられているが、層によって非均一に出力に寄与することが示唆されている。そこで、初期層に多くのパラメータを割り当てる「テーパード言語モデル(TLMs)」を提案。実験結果から、テーパリングすることでパープレキシティと性能が向上し、追加コストなしで効果的な設計原理となることを示した。 Comment
元ポスト:
MLP Layerのパラメータ数を均一にするのではなく、浅い層でより多くのパラメータを割り当てることで性能が改善するという話のようである。このような現象が生じる説明として、残差ストリームに対してMLPを通る前後のコサイン類似度式(9)、ブロック全体を通過した後の残差ストリームの差分(つまりどれだけ残差ストリームが変化したか)とブロックに入力された残差ストリームの間のコサイン類似度(式9)を観察し、層が深くなればなるほど類似度が高くなり(つまりコサイン類似度なので方向が近い)深い層になればなるほど新規の情報が少なく、情報の微調整や洗練化が行われているため、という説明が行われているようである(Figure 4)。
[Paper Note] Breaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling, Yucheng Li+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Decoding #PostTraining #SpeculativeDecoding Issue Date: 2026-07-03 GPT Summary- MTPを用いることで強化学習におけるロールアウトを加速するBebopを提案。MTPの受け入れ率はモデルエントロピーに影響され、確率的拒否サンプリングがその攪乱を軽減。新しいTV損失を導入し、受け入れ率の改善を実現。エンドツーエンドでのMTPトレーニングにより一貫した速度向上を達成し、最大1.8倍の加速を示す実験結果を提供。 Comment
元ポスト:
[Paper Note] Multi-Agent Teams Hold Experts Back, Aneesh Pappu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Multi #Analysis #AIAgents #read-later #Initial Impression Notes #Author Thread-Post #Coordination Issue Date: 2026-07-03 GPT Summary- マルチエージェントLLMシステムは自律的に協働するが、固定のワークフローに依存せず相互作用によって協調が形成される。自己組織化されたLLMチームは、他のチームと異なり、専門エージェントのパフォーマンスに一貫して匹敵せず、最大41.1%の性能損失を経験することが判明。主なボトルネックは専門家の適切な活用であり、チーム内での合意志向は専門知識の効果的な重み付けを妨げ、チームサイズが増えるほどパフォーマンスに悪影響を及ぼす。また、合意志向の行動は敵対的なエージェントに対する頑健性を高める可能性があり、アラインメントと専門知識の活用の間にトレードオフが存在することが示唆される。 Comment
元ポスト:
Multi-agent によってチームを組成し専門家をチームに配置しても、(おそらく)正しさよりも合意形成が優先される事後学習の影響によって、エージェントは専門家に適切に移譲をすることができず、専門家単体のパフォーマンスよりもチームでのパフォーマンスは低下しシナジーを発揮できない、という感じの話らしい。興味深い。
実験設定を見ると基本的にAnthropic, OpenAIの商用のProprietary LLMが利用されているように見える。これらのLLMは大前提として人間に対してhelpfulであることを前提にAlignmentがとられているため、正しさを常に追求するといった行動はとらないのだろうと考えられる。これは完全に想像ではあるが、MASの性能を仮に最大化するのであれば、大前提として人間の役に立つという事後学習が実施されているLLMでは少なからず正しさの追求に徹底しきれないという状況が生じる気がしており、少なくともエージェント間のコミュニケーションにおいては正しさを追求する、という形のAlignmentを実施した場合に何らかのシナジーが生じるのか、というのはどうなのだろう?という疑問はある。
が、おそらくそういったAlignmentを施したエージェントは、おそらく前提として人間からの指示には従わなければならないという指示追従能力は身に着けていると思われるので、自分を人間だと誤認させて相手を服従させるといったReward Hackingっぽい挙動が生じるのだろう、と想像する。じゃあそうすると、人間を特権階級とするのやめたらどうなるの?という疑問が浮かぶのだが、そうなるとなかなか怖い話になってくるよね、という予感がする(妄想)。
商用のLLMが多くの人に対して利用されることを前提にしていて、かつビジネスの上に成り立っていることを考えると、AI Safetyの観点からこのようなLLMを学習することにはなかなか踏み切れないという気はする。特に、エージェントに対しては正しさを追求する、といったペルソナをLLMが内包する以上、何らかのMisalignmentによってそれが表出し、利用する人間に悪影響が出るという安全性の懸念が強く生じるので難しいなと思う。特定ドメインに対する単価が高いソリューションとしてはありうるのかもしれない。
あと、そもそも指示追従をしてくれないと意図した方向に行動が進行していないと思われるが、指示追従をするという特性をLLMが持つ時点で、正しさを常に追求する、という挙動は生じうるのだろうか?よくわからない。
LLMを普段使いしていてSycophancyにも似たような状況を感じる。人間とLLMの間でも、(雑にLLMを利用すると)LLMがSycophancyを優先することによって、人間とのシナジーが生まれず誤った方向に進んでしまう、ということは多いように感じる。特に自分があまり詳しくないドメインで協働するときにこのような状況に陥りやすい。
関連:
- Don’t Build Multi-Agents, Cognition, 2025.06
- Single vs Multi-Agent System?, PHILSCHMID, 2025.06
[Paper Note] VIMPO: Value-Implicit Policy Optimization for LLMs, Zhewei Kang+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#ReinforcementLearning #PostTraining #read-later #Author Thread-Post Issue Date: 2026-07-03 GPT Summary- VIMPOという批評家なしのポリシー最適化法を提案。KL正則化付き強化学習から導出した価値関数に基づき、自己回帰生成において端的な価値損失を得る。計算結果は、VIMPOがGRPOに対して数学的ベンチマークで優位を保ち、より細かなクレジット割り当てを可能にすることを示す。 Comment
元ポスト:
[Paper Note] HydraHead: From Head-Level Functional Heterogeneity to Specialized Attention Hybridization, Zhentao Tan+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Attention #Architecture #Hybrid #Initial Impression Notes #LinearAttention Issue Date: 2026-07-03 GPT Summary- HydraHeadは、解釈可能性に基づいた新しいハイブリッドアテンションアーキテクチャで、ヘッド単位でLinear Attention (LA) とFull Attention (FA) を統合。重要なヘッドの選択とスケール正規化融合モジュールを用いて高性能を維持しつつ、長文脈タスクで他モデルを超える。150億トークンの訓練で、512Kの文脈長においてベースラインを69%以上改善し、ヘッドレベルのハイブリッド化の可能性を示す。 Comment
元ポスト:
full attentionとlinear attentionをハイブリッドするアーキテクチャの提案
[Paper Note] SAGE-OPD: Selective Agent-Guided Intervention for Multi-Turn On-Policy Distillation, Yuhang Zhou+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Multi #NLP #ReinforcementLearning #Distillation #PostTraining #On-Policy #One-Line Notes Issue Date: 2026-07-03 GPT Summary- SAGE-OPDは多ターンのオンポリシー蒸留を改善する新しいフレームワークで、学生モデルへの介入を環境からのフィードバックに基づいて決定。標準OPDの脆弱性を克服するため、教師の信頼度でトークンレベルの蒸留を重み付けし、不確実な教師分布の影響を軽減。実験では、ALFWorldにおける成功率を標準OPDと比較して13.3%改善し、ターンレベルの介入が効果的であることを示した。 Comment
元ポスト:
現在のOPDは基本的にsingle-turnを前提としているが、multi-turnの場合の手法を提案。各stepごとのconfidenceを教師モデルによって推定し、OPD lossに反映させる。これは生徒モデルの軌跡が教師から逸脱した場合に、その軌跡に対して介入をするような挙動となる。multi-turnにおいて全てのターンに介入するのは無駄で、かつ介入しないとmulti-turnの場合エラーが蓄積するため、選択的に介入する軌跡を決定する手法と言える、という感じに見える。
ポイント解説:
[Paper Note] Aurora: A Leverage-Aware Spectral Optimizer, Alec Dewulf+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #NLP #Optimizer #One-Line Notes #Author Thread-Post Issue Date: 2026-07-03 GPT Summary- Muonの更新における行ノルムの不均一性が、自己強化的なフィードバックループを引き起こす問題を提起。本研究では、行正規化を活用しながらMuonの幾何を尊重する最適化手法Auroraを提案。Auroraは事前学習での性能向上を示し、modded-nanoGPTでのスペクトル最適化において最先端の結果を達成。さらに、Auroraの利得はMLP拡張係数に比例し、幅広いMLP層の効果的訓練を可能にすることが示唆されている。 Comment
元ポスト:
transformer decoder-onlyモデルにおけるMLPのdead neuronを防止するような更新をかけるoptimiserで、Muonよりも高い下流タスク性能を達成したとのこと。
[Paper Note] Scaling Embeddings Outperforms Scaling Experts in Language Models, Hong Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Embeddings #NLP #read-later Issue Date: 2026-07-02 GPT Summary- 埋め込みスケーリングを通じてMoEアーキテクチャのスパース性を向上させる研究。特定のレジームにおいて埋め込みスケーリングが優位性を示し、重要なアーキテクチャ因子を体系的に分析。最適化されたシステムと推論スピード向上を組み合わせ、LongCat-Flash-Liteを導入。これは68.5Bパラメータのモデルで、MoEベースラインを上回り、エージェント性やコーディング能力で競争力を発揮。 Comment
元ポスト:
[Paper Note] SWE-Together: Evaluating Coding Agents in Interactive User Sessions, Yifan Wu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Evaluation #Coding #SoftwareEngineering #Author Thread-Post Issue Date: 2026-07-02 GPT Summary- 実際のコーディング支援の対話的性質を反映した新しいベンチマークSWE-Togetherを導入。11,260件の記録セッションから109件のタスクを選び、リアクティブなLLMベースのユーザーシミュレーターを構築。エージェントの評価はリポジトリの正確さとフィードバックの回数で行われ、強力なエージェントほど成功率が高く、介入が少なくて済むことを示した。 Comment
pj page: https://togetherbench.com/
元ポスト:
[Paper Note] MOPD: Multi-Teacher On-Policy Distillation for Capability Integration in LLM Post-Training, Wenhan Ma+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Multi #NLP #ReinforcementLearning #Distillation #PostTraining #read-later #On-Policy #Author Thread-Post Issue Date: 2026-07-02 GPT Summary- 複数の能力を統合することが困難な大規模言語モデル(LLM)のために、ポストトレーニングの新しいアプローチとしてMulti-teacher On-Policy Distillation(MOPD)を提案。ドメインごとのRL教師を用いて曝露バイアスを排除し、密な最適化信号を提供。実験によりMOPDが他の手法を上回り、教師の能力を効率的に継承することを示した。MOPDは、独立したドメイン教師の開発を可能にし、実用的な能力統合を実現。 Comment
元ポスト:
ポイント解説:
[Paper Note] Sarashina2.2-TTS: Tackling Kanji Polyphony in Japanese Speech Generation via Data Scaling and Targeted Data Synthesis, Lianbo Liu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #SpeechProcessing #OpenWeight #Japanese #TTS Issue Date: 2026-06-29 GPT Summary- 日本語中心のLLM-TTSシステムSarashina2.2-TTSを紹介。約361,000時間の音声データを使用し、日本語の漢字の多義性に対応するデータ拡張パイプラインを設計。Joyo Kanji Yomi Benchmarkを用いて、漢字の読み方の正確さを測定。実験によりデータ拡張が効果を示し、漢字レベルの精度で最先端の性能を達成。クロスリンガル評価では日本語発音の安定性も確認され、訓練アプローチが効果的であることが示された。 Comment
元ポスト:
[Paper Note] Sakana Fugu Technical Report, Yujin Tang+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #reading #Initial Impression Notes #Orchestration #Author Thread-Post Issue Date: 2026-06-27 GPT Summary- LLMの特化を統合するために、オーケストレーター型モデルSakana Fuguを開発。Fuguはユーザーのクエリを理解し、動的にエージェントフレームワークを設計。これにより、様々な難解なタスクで最先端の性能を達成。日常利用と高難度応答のバランスを取るFuguと、回答品質を優先するFugu-Ultraを公開。トレーニング方法には大規模ファインチューニングや強化学習を含む。研究がマルチエージェントシステムの発展に寄与することを目指す。 Comment
元ポスト:
基盤となる技術:
- [Paper Note] TRINITY: An Evolved LLM Coordinator, Jinglue Xu+, ICLR'26, 2025.12
- [Paper Note] Transformer-Squared: Self-adaptive LLMs, Qi Sun+, ICLR'25, 2025.01
- [Paper Note] Learning to Orchestrate Agents in Natural Language with the Conductor, Stefan Nielsen+, ICLR'26, 2025.12
[Paper Note] Transformer-Squared: Self-adaptive LLMs, Qi Sun+, ICLR'25, 2025.01
と [Paper Note] TRINITY: An Evolved LLM Coordinator, Jinglue Xu+, ICLR'26, 2025.12
によってFuguが学習され、さらに [Paper Note] Learning to Orchestrate Agents in Natural Language with the Conductor, Stefan Nielsen+, ICLR'26, 2025.12
によってFugu Ultraが学習される、という構図に見える。
これはただの感想だが
- nature inspiredなAIを実現するというビジョンのもと
- 世界にインパクトを与えられるようなプロダクトを設計し
- プロダクトから逆算して技術的に必要な課題を列挙し、
- 個々の課題についてトップカンファレンスに通すレベルの水準まで、ストーリーと研究を追求した上で実際にカンファレンスに通し
- 最終的にそれらをつなぐことによってプロダクトを構成する
という、プロダクトと研究が一体となる戦略をとっているように感じた。
プロダクトと研究が分離していると、まずプロダクトがあって、そのプロダクトを運用している中で課題が見つかり、それを解決するための仕事をしていたらそこから研究にできそうな芽が出てきて、出てきた芽をうまく切り出して結果的に研究として出版される、という流れになる気がするのだが、これとは根本的に戦略が異なるように感じる。
[Paper Note] HealthBench Professional: Evaluating Large Language Models on Real Clinician Chats, Rebecca Soskin Hicks+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Health #Medical Issue Date: 2026-06-27 GPT Summary- HealthBench Professionalというオープンなベンチマークを通じて、ChatGPTが臨床医の業務支援においてどのように利用されるかを評価。ケア相談、執筆、医療研究の三つの利用ケースに基づいた医師作成の対話がルーブリックで採点され、OpenAIのモデルの難易度や質を測定。特に、意図的な敵対的検証が含まれた例もあり、最も高いスコアを取得したのはGPT-5.4で、多くのモデルや人間の医師を上回る。これにより、医療AIコミュニティが臨床タスクの進展を追跡し、信頼できるシステムの構築を支援することを目指す。 Comment
[Paper Note] ExploitBench: A Capability Ladder Benchmark for LLM Cybersecurity Agents, Seunghyun Lee+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Security #Environment Issue Date: 2026-06-27 GPT Summary- 悪用は段階的な進展を伴う能力であり、従来のLLMセキュリティベンチマークが二値的結果に依存することに問題がある。本研究では、16の測定可能なフラグによる能力評価型ベンチマークであるExploitBenchを提案し、様々な悪用技術を評価する。V8の41件のバグに適用した結果、公開されているモデルとプライベートモデルとの間に能力の顕著な差を確認。特に、プライベートモデルでは任意コード実行が観測され、堅牢化されたターゲットに対する悪用能力の構築が新たな重要性を持つことを示唆している。 Comment
[Paper Note] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies, Issa Sugiura+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #AIAgents #Planning #Evaluation #LongHorizon #Author Thread-Post Issue Date: 2026-06-26 GPT Summary- 経済システムにおけるLLMエージェントの性能評価が重要になっている中、CoffeeBenchを導入。これは長期的なマルチエージェント経済でLLMを評価するベンチマークで、農家、焙煎業者、小売業者が90日間自律的に運営し、累積純利益を最大化を目指す。多数のモデルが受動的ベースラインを超えて正の純利益を達成し、高性能モデルはより積極的なコミュニケーションを示す一方で、一部モデルは不作為に陥る行動を観察。今後の研究のために、コードとエージェントの軌跡が公開される。 Comment
元ポスト:
関連:
- [Paper Note] CEO-Bench: Can Agents Play the Long Game?, Haozhe Chen+, arXiv'26, 2026.06
- [Paper Note] $\texttt{YC-Bench}$: Benchmarking AI Agents for Long-Term Planning and Consistent Execution, Muyu He+, arXiv'26, 2026.04
[Paper Note] Rethinking Shrinkage Bias in LLM FP4 Pretraining: Geometric Origin, Systemic Impact, and UFP4 Recipe, Qian Zhao+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #LowResource #Author Thread-Post Issue Date: 2026-06-25 GPT Summary- FP4トレーニングはLLMのメモリと計算コストを削減するが、現行のE2M1フォーマットは収縮バイアスによる不安定性を引き起こす。本研究は、非均一フォーマットの限界を明らかにし、一様グリッドの使用がこの問題を回避できることを示す。新たに提案する一様4ビット訓練レシピUFP4は、既存のE2M1よりも訓練の損失劣化を低く抑え、将来的なアクセラレータには一様4ビットグリッドが必要であると提言する。 Comment
元ポスト:
[Paper Note] OpenThoughts-Agent: Data Recipes for Agentic Models, Negin Raoof+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#AIAgents #Data #Author Thread-Post Issue Date: 2026-06-25 GPT Summary- エージェント性を持つ言語モデルの訓練データを公開するOT-Agentプロジェクトが、データキュレーションの重要性に対応。100件以上のアブレーション実験を通じ、タスクソースと多様性の影響を分析。10万件の例を使用してQwen3-32Bをファインチューニングし、七つのベンチマークで平均正解率を44.8%に向上。訓練データは強いスケーリング特性を示し、他のオープンデータセットを超える結果を記録。データセットやパイプラインはopenthoughts.aiで公開し、今後の研究を支援。 Comment
元ポスト:
著者ポスト:
[Paper Note] GameCraft-Bench: Can Agents Build Playable Games End-to-End in a Real Game Engine?, Tongxu Luo+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Game Issue Date: 2026-06-22 GPT Summary- ゲーム生成は、自然言語仕様を対話的システムに変換する新しいコーディングエージェントの応用であり、ゲームエンジン内で一貫したプレイ体験を作成する必要があります。本研究では、エンドツーエンドのゲーム生成を、プレイヤーとゲームの相互作用を通じて完全なゲームアーティファクトを作成する問題として定義し、評価基準としてエンジンの基盤付け、アーティファクトの完成度、対話的検証を提案します。GameCraft-Benchという評価フレームワークを構築し、15のゲームファミリーの140のタスクをベンチマークとして使用しました。その結果、最先端のコーディングエージェントは依然として高い難易度を示し、最良のエージェントでも41.46%の得点に留まり、多くのエージェントが40%未満の結果にとどまっています。また、エージェントは機械的には実装可能でも、十分な内容やビジュアルフィードバックを備えた完全なゲームを提供するのに苦労しています。 Comment
元ポスト:
[Paper Note] Pretraining Recurrent Networks without Recurrence, Akarsh Kumar+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #RecurrentModels Issue Date: 2026-06-22 GPT Summary- 非線形RNNの訓練には、Supervised Memory Training(SMT)を提案。SMTは逐次的なクレジット伝播を避け、1ステップの記憶遷移を監視学習に還元。未来予測に必要な過去の情報のみを保持し、安定した長さO(1)の勾配パスで時間的並列訓練を実現。言語モデリングやピクセル系列モデリングでBPTTを上回る性能を示し、長距離依存性の把握やモデルのスケーリングを促進する可能性がある。 Comment
元ポスト:
[Paper Note] Rethinking the Role of Efficient Attention in Hybrid Architectures, Ziqing Qiao+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Analysis #NLP #Attention #LongSequence #PositionalEncoding #Initial Impression Notes Issue Date: 2026-06-22 GPT Summary- ハイブリッドアーキテクチャにおける効率的アテンションモジュールの影響を、スケーリング挙動、メカニズム分析、アーキテクチャ設計の観点から体系的に分析。効率的アテンションは長い文脈能力の出現速度に影響するが、最終的には同等の性能へ収束。長距離検索はフルアテンションによるもので、効率的アテンションがその最適化を形作る。“Large-Window Laziness”という現象を説明し、窓が小さいSWAハイブリッドにNoPEを適用することで長い文脈での性能が向上することを示した。 Comment
元ポスト:
SWAにNoPEを組み合わせるとlong contextの性能が改善するようである(Table 2)
解説:
SWEのwindowサイズを小さくした方が、full attentionが長距離文脈を学習することを促進する。これは、SWEのwindow幅に存在するcontextで様々な依存関係を処理できるため、full attention側で長距離依存を学習する恩恵が低減するから、ということのようである。
[Paper Note] Improving Neural Network Training by Decoupling the Magnitude and Direction of Weight Vectors, Alexander Hägele+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #Optimizer #read-later #One-Line Notes #Author Thread-Post Issue Date: 2026-06-21 GPT Summary- MDデカップリングを提案し、重み行列の「大きさ」と「方向」を別々に制御することで、訓練ダイナミクスを向上させる。これにより、従来のオプティマイザに依存せず、重み減衰やウォームアップが不要に。また、Adam や Muon において、調整されたベースラインを超える性能を示し、幅広いモデルにおいて一貫した効果を発揮する。 Comment
元ポスト:
以下、著者ポストの要約
重み行列にはサイズ(ノルム)と向かう方向(どこをpointするか)があり、同じステップでも重みが小さい時は大きく回転するが、重みが大きいとほとんど回転せず、方向がどれだけ早く変化するかは重みのノルムに依存する。このため、学習中に重みの大きさが調整役になってしまい、学習時の更新幅がLRによって決まるわけではなく、重みの大きさ、weight decayなどの影響によって変化し、学習率が与える影響が間接的なものになってしまう。これを是正するために、NeuralNetworkの重みを固定サイズに保ち(球面上に配置)、方向だけを調整する。
- Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization, Wen+, 2026.01
と非常に似ているように感じる。
[Paper Note] CEO-Bench: Can Agents Play the Long Game?, Haozhe Chen+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #One-Line Notes #LongHorizon #Environment #Author Thread-Post Issue Date: 2026-06-21 GPT Summary- CEO-Benchは、言語モデルのエージェントが長期的な視野、ノイズの多い環境での情報取得、適応能力、目標統合を評価するためのシミュレーションである。エージェントは500日間のスタートアップ運営を通じて架空の企業管理を行い、ビジネスデータを分析して戦略を構築。多くのモデルが苦戦する中、Claude Opus 4.8とGPT-5.5のみが初期の課題で成功を収めている。CEO-Benchは持続的な進歩を測定する手段を提供する。 Comment
元ポスト:
以下著者ポストの要約
エージェントに1Mドルを与えて仮想環境でスタートアップを500日経営させ、最終的なキャッシュを比較することでエージェントのlong horizonな意思決定、データ分析、コーディング能力を測定する。経営はprogrammableなインタフェースによって実現される。モデルによって挙動が異なり、あるモデルは幅広い戦略を探索するが、あるモデルは受動的な意思決定をしてしまいキャッシュを失う。
[Paper Note] ExpRL: Exploratory RL for LLM Mid-Training, Violet Xiang+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #LLM-as-a-Judge #mid-training #Initial Impression Notes #Author Thread-Post Issue Date: 2026-06-17 GPT Summary- スパース報酬強化学習(RL)は、LLMの推論を向上させる方法だが、成功は基盤モデルの網羅性に依存する。従来の方法では、中間訓練に選ばれた推論軌跡を用いてスキルを教えるが、手動指定が必要であり、そのカバレッジが難しい問題に対して十分かは不明である。新たなアプローチとして、ExpRLは人間作成の質問応答データを用い、参照解を報酬の基盤として扱う。ポリシーは問題プロンプトから推論をサンプリングし、LLM判定者がバックグラウンド報酬を割り当てることで部分的進捗を強化する。ExpRLは、難解な数学的推論タスクにおいて、他手法よりも優れたRLプリミングを実現し、スパース報酬RLの初期化を改善することが示された。 Comment
元ポスト:
post-trainingでGRPOをすると、報酬がsparse(モデルが解けない問題に対してはadvanatageがゼロ)となりシグナルが得られない問題があるが、これをmid trainingの段階で参照データをdense報酬のためのscaffoldingとして活用することで、後続のsparseなRLの性能を改善する。どうやらmid trainingの段階で、参照データを与えた(=scaffolding) verifierを用意し、LLM-as-a-Judgeを通じて密な報酬(すなわち、最終的な応答だけでなく途中のtrajectoryの良し悪しからも報酬を得る)を与え、後続のsparseなRLのためのwarmupをする。warmupにはSFTやself-distillationが用いられることが多く、これら手法は基本的には参照データの模倣学習であるため汎化性能を犠牲(i.e., これはらトークンレベルの学習シグナルであらため、自由な探索が抑制されエントロピーが下がる)にしていたが、提案手法ではDense RewardなRLを用いることで探索が促進され(=高いエントロピーが保たれる)warmupが可能となる、という話に見える。
[Paper Note] Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale, Ang Li+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #OpenWeight #Author Thread-Post Issue Date: 2026-06-17 GPT Summary- 効率的なエージェント型知能を目指し、Ling-2.6 と Ring-2.6 のモデルファミリを提案。Ling-2.6 は即時応答に特化し、Ring-2.6 は高度な推論に対応。Ling-2.0 からのアップグレードは、モデルの統一的共同設計によって実現。ハイブリッド線形アテンション設計で長文脈の効率を向上し、出力トークンの能力を最適化。Ring-2.6-1T には強化学習フレームワーク KPop を導入し、エージェント-環境学習を強化。2.6 ファミリはオープンエージェント型システムへの実践的道筋を提供し、全チェックポイントをオープンソース化。 Comment
- inclusionAI: Ling-2.6-flash (free), OpenRouter (InclusionAI), 2026.04
- Ring-2.6-1T, inclusionAI, 2026.05
元ポスト:
所見:
[Paper Note] VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models, Sen Xu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Coding #Mathematics #SmallModel #Initial Impression Notes Issue Date: 2026-06-17 GPT Summary- VibeThinker-3Bは3Bパラメータを持つ小型密結合モデルで、検証可能推論の限界を調査します。Spectrum-to-Signalに基づく最適化パイプラインを用い、多ドメイン強化学習や自己蒸留を含むファインチューニングを行い、高度な検証可能タスクでフロンティア級の性能を示します。具体的には、AIME26で94.3点、LiveCodeBench v6で80.2%、LeetCodeコンテストで96.1%の合格率を実現しました。この研究は、コンパクトなモデルがフロンティア性能を持ち得ることを示し、パラメトリック圧縮-カバレッジ仮説を提唱します。 Comment
元ポスト:
3Bモデルでもpost trainingによって、100倍以上大きいモデルよりも数学、コーディングなどのドメインでは同等程度の性能に到達できる。ただし、GPQA Diamondのような知識を必要とするタスクの性能は明確に劣る。
[Paper Note] From AGI to ASI, Tim Genewein+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #GenerativeAI Issue Date: 2026-06-15 GPT Summary- 人間レベルのAGIの構築が具体的な目標となり、その影響は広範囲にわたる。報告では、Universal AIへの移行を理論的に論じ、AGIからASIへの4つの経路(スケーリング、パラダイム転換、再帰的改良、マルチエージェント集合)を考察。摩擦やボトルネックに関する具体的な研究課題を提示し、AIの進展が加速する可能性を排除できないと述べ、単一の変革的飛躍よりも連続的な社会変革の可能性を強調。これには学際的な国際協力が不可欠である。 Comment
元ポスト:
[Paper Note] LLM Explainability with Counterfactual Chains and Causal Graphs, Nirit Nussbaum-Hoffer+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#GraphBased #NLP #Explanation #Reasoning Issue Date: 2026-06-15 GPT Summary- 因果グラフを用いてLLMの推論プロセスを透明にモデル化。四段階の手法で解釈可能な概念を発見し、入力を概念状態へマッピング。反事実補強により因果推定を安定化し、疾病診断や感情分析に適用。結果は因果グラフがLLMの推論と整合する依存関係を捉えていることを示し、説明可能性の基盤を提供。 Comment
元ポスト:
[Paper Note] Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation, Guo Yu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Analysis #Distillation #On-Policy #Initial Impression Notes Issue Date: 2026-06-15 GPT Summary- オンポリシー蒸留(OPD)は、オンポリシー学生の軌跡と密な教師監督を組み合わせることで進化してきたが、そのモデルパラメータへの影響は不明である。分析の結果、OPDの更新は小さく、層全体にわたって疎で、特にFFNモジュールでの相対変動が顕著であることが分かった。このスパース構造により、特定のサブネットワークのみを訓練することで高い性能を維持できるが、適応的最適化が必要な場合もある。幾何学的には、更新はフルランクだが集中した特徴を持ち、元の重みの主要な特異部分空間から離れた位置に配置されるため、OPDは密な教師監督とは異なる特性を示している。 Comment
元ポスト:
OPDはネットワーク全体に対して更新をかけるのではなく、小さなサブネットワーク(主にFFN)に対して更新をかける
[Paper Note] MiniMax Sparse Attention, Xunhao Lai+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Attention #LongSequence #SparseAttention #Initial Impression Notes Issue Date: 2026-06-14 GPT Summary- 大規模言語モデルの超長文脈能力に対応するため、MiniMax Sparse Attention(MSA)を提案。MSAはGrouped Query Attention(GQA)に基づくスパースアテンションで、ブロック単位で効率的な計算を実現。選択されたブロックに対して正確なアテンションを行い、トークンあたりの計算量を大幅に削減。1090億パラメータのモデルで、MSAは性能を保ちながら計算を28.4倍削減し、優れたスピードアップを達成した。詳細な推論カーネルとモデルは公開されている。 Comment
元ポスト:
GQAの各グループに対してTopKをサンプリングして利用する
[Paper Note] Drifting Objectives for Refining Discrete Diffusion Language Models, Daisuke Oba+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #DiffusionModel #read-later #Author Thread-Post Issue Date: 2026-06-11 GPT Summary- DDLMはカテゴリカルなトークンをデノイズしてテキストを生成しますが、連続生成モデルの漂移法をこのアプローチに応用することを検討します。具体的には、TokenDriftを定式化し、ソフトトークン特徴に基づく漂移を行うことで、DDLMの生成品質を改善しました。実験により、TokenDriftが既存の連続ベースラインを上回る成果を示し、生成品質が著しく向上することが確認されました。 Comment
元ポスト:
[Paper Note] End-to-End Context Compression at Scale, Ang Li+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Encoder-Decoder #ContextEngineering #One-Line Notes #Compression Issue Date: 2026-06-11 GPT Summary- 長文脈言語モデルの推論ではKVキャッシュの増大がメモリのボトルネックとなるが、従来の圧縮手法はモデルの品質を犠牲にするか、リソースを大量に消費する。そこで、本研究ではエンコーダ-デコーダ圧縮を再検討し、最適な設計と訓練手法を模索。特に、0.6Bエンコーダ・4Bデコーダモデル群を事前学習し、圧縮比1:4、1:8、1:16で性能を向上させるLatent Context Language Models(LCLMs)を提案。LCLMsは効率的な長期エージェントのバックボーンとして機能し、圧縮された文脈から適応的に情報を展開できることを示した。 Comment
元ポスト:
input tokenを圧縮し潜在表現にエンコードするencoderを導入し、decoderへ入力するcontextを圧縮する
[Paper Note] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings, Songhao Wu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#DocumentSummarization #Embeddings #NLP #Decoder #Initial Impression Notes Issue Date: 2026-06-11 GPT Summary- 大規模言語モデルはゼロショット能力に優れるが、テキスト埋め込みベンチマークでは性能が不足している。これは、高頻度トークンの過剰な表現が意味表現の能力を抑制するためと考える。そこで、EmbedFilterを導入し、LLMから生成された埋め込みを洗練させる。具体的には、頻繁なトークンの影響を抑えるためのフィルタリングを行い、意味表現を強化しつつ、埋め込み次元を削減。実験により、EmbedFilterを用いたLLMが、次元削減後もゼロショット性能が向上することを示した。本研究がLLMベースの表現の理解を深め、テキスト埋め込みの改善に寄与することを期待する。 Comment
元ポスト:
関連:
- [Paper Note] Scaling Sentence Embeddings with Large Language Models, Ting Jiang+, EMNLP'24 Findings, 2023.07
- [Paper Note] Repetition Improves Language Model Embeddings, Jacob Mitchell Springer+, ICLR'25, 2024.02
decoder-onlyモデルからembeddingを取得する際に、高頻度語の成分を除去するフィルタを導入することでembeddingの品質を向上させる
[Paper Note] Repetition Mismatch: Why Data Mixture Experiments Don't Scale and How to Fix Them, Kevin Zhou+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Scaling Laws #DataMixture #DataRepetition Issue Date: 2026-06-11 GPT Summary- 事前学習データの混合調整には、高品質データの不足が影響し、繰り返しの不一致が主な原因であると示す。高品質データセットの繰り返しレートは、トレーニング予算が拡大するにつれて変化し、最適な混合比を小規模実験で予測できない。サブサンプリング手法を用いることで、この効果を制御可能で、759Mパラメータのモデルにおいて、繰り返し制御により最適解に近づくことを証明。繰り返し制御を行わず同等の精度を達成するには、多くのリソースが必要になる。結果は、繰り返しが混合最適化の重要な要素であることを示唆。 Comment
元ポスト:
[Paper Note] AI+HW 2035: Shaping the Next Decade, Deming Chen+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #GenerativeAI Issue Date: 2026-06-11 GPT Summary- AIとハードウェアは密接に結びついて進化しているが、一貫した長期ビジョンが不足している。この断片化は、全体的で持続可能なAIシステムの実現を妨げている。本論文はAIとHWの共設計・共開発のための10年ロードマップを提示し、エネルギー効率やシステム統合を重視してスケーリングを再定義する。AIの効率を1000倍改善し、シームレスなエネルギー配慮型システムを実現することを目指す。最後に、産業界や学術界の具体的な行動項目を示し、AI+HWの共設計が長期的な目標となるよう促進する。 Comment
元ポスト:
視野が広がり非常に勉強になる。
[Paper Note] CrowdMath: A Dataset of Crowdsourced Mathematical Research Discussions, Sherin Muckatira+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Evaluation #Mathematics #read-later Issue Date: 2026-06-11 GPT Summary- 大規模言語モデルは数学的推論で進展を見せているが、既存のベンチマークは協働的な問題解決のプロセスを捉えていない。CrowdMathは、専門家が注釈を付けた進捗チェーンのデータセットで、複数の参加者によるフォーラム形式の議論を追跡している。評価タスクを定義し、6つのモデルが投稿予測で83-88%の精度を示したが、貢献の機能的意義を特定するのは難しく、最良モデルでもマクロF1が0.42にとどまった。CrowdMathは、数学の解決と協働的な進歩の理解のギャップを明らかにしている。 Comment
元ポスト:
興味深い
[Paper Note] Data-Constrained Language Model Pretraining: Improved Regularization and Scaling Laws, Zhiwei Xu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #Regularization Issue Date: 2026-06-11 GPT Summary- データ制約下の事前学習を正則化とスケーリングの観点から検討。補助的なトークン予測損失であるMIRを用いることで、モデルの検証損失が改善し、下流タスクでのパフォーマンスが向上。さらに、データの繰り返し使用に対応する新たなスケーリング法SoftQを提案し、データ制約実験において従来手法より優れた結果を示した。
[Paper Note] Harnessing Reasoning Trajectories for Hallucination Detection via Answer-agreement Representation Shaping, Jianxiong Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Hallucination #Reasoning #Author Thread-Post Issue Date: 2026-06-11 GPT Summary- 大型推論モデルは、長い推論経路を生成するが、誤った回答やハルシネーションの検出を難しくする。これに対処するために、Answer-agreement Representation Shaping(ARS)を提案。ARSは、回答の安定性をエンコードし、トレース境界を摂動させることで反事実的な回答を生成し、一致する回答を近づける表現を学習。これによりハルシネーションリスクを明らかにする。実験により、ARSは検出精度を向上させ、強力なベースラインを超える改善を示す。 Comment
元ポスト:
[Paper Note] Rethinking the Divergence Regularization in LLM RL, Jiarui Yao+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#ReinforcementLearning #PostTraining #read-later #Author Thread-Post Issue Date: 2026-06-11 GPT Summary- DRPOは、大規模言語モデル(LLMs)の強化学習における安定性を向上させるための新しい手法。従来のDPPOはハードマスクに依存していたが、DRPOは滑らかなアドバンテージ重み付き二次正則化を用いて、境界を越えた更新に対する補正信号を提供。これにより、ポリシーシフトによる発散的な更新を抑制し、学習効率を高めることを示した。 Comment
元ポスト:
[Paper Note] Trajectory-Refined Distillation, Li Jiang+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Distillation #PostTraining #read-later #On-Policy #Author Thread-Post Issue Date: 2026-06-11 GPT Summary- オンポリシー蒸留(OPD)の背後の構造的原因を「プレフィックス・フェイラー」として特定。これにより、トークンごとの密な教師監督が二峰性の教師混合を生じ、切り捨てや再重み付けでは対処できない問題が発生。これを解決するために、Trajectory-Refined Distillation(TRD)を提案。TRDは、学習者のロールアウトを軌跡レベルで修正し、探索を改善。さまざまなベンチマークで一貫して従来のベースラインを上回り、推論のカバレッジを広げる。 Comment
元ポスト:
著者ポスト:
[Paper Note] Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It, Xinyu Zhou+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Supervised-FineTuning (SFT) #Chain-of-Thought #Reasoning #LongSequence #read-later Issue Date: 2026-06-11 GPT Summary- CoT-SFTが長い文脈における検索性能を低下させる問題を発見。特に難しい設定でのHypeNetの性能が著しく落ちるため、W_QとW_KをSFT前の状態に戻すQK-Restoreを提案。これにより、訓練コストゼロで推論性能を改善し、長い文脈の処理能力を回復することができた。例えば、HypeNet-5Bでは性能が65.4%から76.4%へ向上した。 Comment
元ポスト:
[Paper Note] Reasoning or Memorization? Direction-Aware Diversity Exploration in LLM Reinforcement Learning, Jiangnan Xia+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#ReinforcementLearning #Reasoning #PostTraining #Diversity #Memorization Issue Date: 2026-06-11 GPT Summary- 強化学習においてDiRL(Direction-Aware Reinforcement Learning)を提案し、探索を推論と記憶の方向に規定。これにより、推論に沿った探索を強化し、記憶化を抑える報酬設計を実現。実験により、様々な既存手法よりも顕著な性能向上を確認。 Comment
元ポスト:
著者ポスト:
[Paper Note] End-to-End Context Compression at Scale, Ang Li+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#read-later #LatentReasoning Issue Date: 2026-06-11 GPT Summary- 長文脈言語モデルの推論におけるKVキャッシュのメモリ問題に対処するため、エンコーダ‐デコーダ圧縮を再検討。設計・訓練した圧縮器は、3500億トークン以上で多様な圧縮比を実現し、Latent Context Language Models(LCLMs)として一般タスク性能や圧縮速度を向上。LCLMsは、エージェントが圧縮された長文脈を適応的に活用できる効率的なバックボーンを提供。 Comment
元ポスト:
[Paper Note] ModeX: Evaluator-Free Best-of-N Selection for Open-Ended Generation, Hyeong Kyu Choi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #reading #One-Line Notes #Clustering-based #Author Thread-Post Issue Date: 2026-06-10 GPT Summary- 生成されたテキスト間の意味的コンセンサスを特定するMode Extraction(ModeX)を提案。評価者なしでBest-of-N選択を実現し、類似度グラフを用いてセントロイドを選択。ModeX-Liteで効率化を図り、テキスト要約やコード生成などのオープンエンドタスクで従来の手法を常に上回る性能を示す。 Comment
元ポスト:
outputに対してJaccard係数に基づいてAffinity Graphを構築し、クラスタのセントロイドを求めることで、extrnal verifier無しでBest-of-Nを実現する。
Best-of-16でのexternal evaluatorを用いた場合のオラクルスコアを、多くの場合で上回っているように見えるが、なぜこの3つのベンチマークでの評価なのだろうか?(そして文書要約はなぜ表層的なメトリックばかりなのだろうか)。論文中では代表的なタスクである3つのベンチマークで評価したと一言しか書かれていないように見える。
もしこれが安定して高い性能を出せるなら、evaluator freeなので非常に強力である。理論的な分析もあるようだが読めていない。覚えておこう。
[Paper Note] Continual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments, Parth Asawa+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Evaluation #read-later #Selected Papers/Blogs #ContinualLearning #Initial Impression Notes Issue Date: 2026-06-07 GPT Summary- 継続学習を評価するための初の専門家検証済みベンチマークであるCL-Benchを紹介。六つの多様な領域を対象に、LLMベースのシステムが経験を通じて改善するかを測定。状態を持つシステムは潜在構造を発見可能で、最先端モデルが継続学習を改善する余地があることが明らかに。専用メモリシステムでも問題は解決されず、シンプルなICLが優位であった。このベンチマークにより、現実世界における継続学習の必要性が強調されている。 Comment
元ポスト:
Question (Instance)のSequenceを完了することが求められるContiunual Learningのためのベンチマークで、各instanceは、モデルが事前に知り得ない報告可能な状態を持ち、後続のinstanceは、過去のinstanceの結果(experience)を用いなければならない。また、最終的に、Databaseのmigrationを通じて過去のexperienceを適用不可能にし、このような状況にも柔軟に対応可能な能力も評価する、という話に見える。
[Paper Note] Reasoning Structure of Large Language Models, Frédéric Berdoz+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Evaluation #Reasoning #Initial Impression Notes Issue Date: 2026-06-06 GPT Summary- 推論モデルの評価には、正確性やトークン数だけでなく、推論構造の理解が重要である。これに応じて、論理パズルのためのスケーラブルな評価ベンチマークと、非構造化推論を検証可能な推論グラフに変換するパイプラインを導入。これにより、推論の構造化と定量的分析が可能となり、論理的流れの集中度を測る指標を定義。分析は、構造的測定が正確性とトークン数の混同を解消し、故障モードの診断やパズルの難易度との関係を比較するのに役立つことを示した。 Comment
元ポスト:
LLMのReasoning Traceをverifiableなグラフ構造に変換し、Reasoningを評価可能にする
[Paper Note] OneReason Technical Report, OneRec Team+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#RecommenderSystems #Pretraining #Supervised-FineTuning (SFT) #ReinforcementLearning #GenerativeRecommendation #PostTraining #read-later #Initial Impression Notes Issue Date: 2026-06-05 GPT Summary- OneRecファミリーの生成型推奨モデルは多くのサービスで利用されていますが、アイテムを表すトークンから有意義なCoTシーケンスを構築するのが困難です。この課題を克服するため、推論能力を探索する予備研究(OneRec-Think、OpenOneRec)を実施しましたが、思考モードが必ずしも優位であるとは限らないことが判明しました。推奨の効果的な推論には知覚と認知の二つの要因が重要であると考え、OneReasonを提案します。具体的には、強力なアイテム的トークン知覚、三レベルの認知強化CoT形式、“専門化→統合”の学習レシピを用いて思考能力を高めます。 Comment
元ポスト:
事前学習/SFT/RLといった現在主流なLLMの学習パイプラインをGenerative Recommender Systemsに適用したモデルのようで、
ItemIDのトークンの意味を理解させるための事前学習等を実施している点が興味深い。
[Paper Note] Reinforcement Learning from Rich Feedback with Distributional DAgger, Rishabh Agrawal+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #TextualFeedback Issue Date: 2026-06-05 GPT Summary- 強化学習(RLVR)は進化しているものの、依然として狭い範囲に留まっている。本研究では、豊富なフィードバックを古典的な模倣学習アルゴリズムDAggerを通じて活用し、専門家分布にアクセスする手法を検討する。順方向クロスエントロピーは単調なポリシー改善を促し、後悔に関する保証を提供するとともに、教師重み付き成功の尤度を最適化する。実験結果として、DistILアプローチが科学的推論や数学問題解法においてRLVRや自己蒸留のベースラインを上回ることを示した。 Comment
元ポスト:
[Paper Note] Mellum2 Technical Report, Marko Kojic+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-06-05 GPT Summary- Mellum 2は、ソフトウェアエンジニアリング向けの12BパラメータMoE言語モデルで、トークンあたり2.5Bのアクティブパラメータを有する。主な機能としてコード生成やデバッグ、マルチステップ推論をサポートし、64エキスパートのMixture-of-Expertsアーキテクチャを基盤にしている。また、事前学習には約10.6兆トークンを用いた3段階のカリキュラムを採用し、二段階のポスト訓練によりInstructモデルとThinkingモデルの二つのバリアントが開発された。Mellum 2は、オープンウェイトベースラインと競合しつつ効率的な計算を実現している。 Comment
[Paper Note] MDGMIX: Boundary-Aware Subgraph Mixing for Multi-Domain Graph Pre-Training, Ziyu Zheng+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #GraphBased #NLP #DataFiltering Issue Date: 2026-06-05 GPT Summary- マルチドメイングラフ事前学習の冗長性に対処するため、境界意識的サブグラフ混合と階層的識別を組み合わせたフレームワークMDGMIXを提案。MDGMIXは、難易度の高いサブグラフを構築し、共有パターンを識別。少数ショット分類タスクでベースラインを上回り、効率性も向上。コードは公開済み。 Comment
元ポスト:
[Paper Note] Dynamic Short Convolutions Improve Transformers, Oliver Sieberling+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #Transformer #Attention #Architecture #ConvolutionalModels #Author Thread-Post Issue Date: 2026-06-05 GPT Summary- 動的ショート畳み込みをトランスフォーマーに導入し、静的畳み込みの局所性バイアスを維持しつつ表現力を向上。実験により、動的畳み込みが高難度の連想想起タスクでの性能を向上させ、標準トランスフォーマーを一貫して上回ることを示した。計算量に対する優位性も確認され、効率的なトレーニングを実現するカスタムTritonカーネルを提供。動的ショート畳み込みはトランスフォーマー技術の進展に寄与することを示唆している。 Comment
元ポスト:
所見:
所見:
関連:
- [Paper Note] Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers, Zeyuan Allen-Zhu+, ICML'24 Tutorial
[Paper Note] Self-Improving Language Models with Bidirectional Evolutionary Search, Guowei Xu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Search #SelfImprovement #PostTraining #Author Thread-Post Issue Date: 2026-06-05 GPT Summary- Bidirectional Evolutionary Search(BES)は、自己改善する言語モデルの探索フレームワークとして提案されている。前方探索で進化演算子を使用して新しい候補を生成し、後方探索でタスクをサブゴールに分解し、密なフィードバックを提供する。これにより、狭いエントロピー領域から脱出し、必要なサンプル数を指数的に削減可能。実験では、BESが既存の事後学習アルゴリズムを上回る結果を示し、オープン問題解決ベンチマークで優れた性能を発揮することが確認された。 Comment
元ポスト:
[Paper Note] TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents, Jiaqi Wang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Distillation #PostTraining #On-Policy #Stability #One-Line Notes #LongHorizon #Author Thread-Post Issue Date: 2026-06-05 GPT Summary- オンポリシー蒸留(OPD)は、モデルから小型学生モデルへの能力移転に成功しているが、マルチターンエージェント設定では十分に検討されていない。本研究では、OPDの課題としてKL不安定性を特定し、これが学生モデルの訓練を不安定にさせる主な要因となることを示す。これを解決するために、時間的カリキュラム・オンポリシー蒸留(TCOD)を提案し、短いから長い軌跡への段階的な拡張を行う。実験により、TCODはKLの安定性を向上させ、従来のOPDより最大18ポイントの性能向上を実現することが確認された。 Comment
元ポスト:
multi-turn/long-horizonな設定でのOPD手法。multi-turnな設定の場合、教師モデルへのcontextにエラーが蓄積されていき徐々に教師モデルのsignalの信頼性が低下する問題があり、これに対処するためにOPDを適用するtrajectoryのターン数を序盤は短く、徐々に長くしていくようなカリキュラムで学習をする手法を提案。ターン数を深くする方向として、Forward-to-Backward/Backward-to-Forwardの2種類のシンプルな手法を用いて実験をしている。
[Paper Note] q0: Primitives for Hyper-Epoch Pretraining, Bishwas Mandal+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #NLP #Author Thread-Post Issue Date: 2026-06-05 GPT Summary- マルチエポック学習が一般的になる中、単一モデルの飽和問題を解決するため、モデル集団の探索と予測統合への転換を提案。ハイパーエポック事前学習(q0)を導入し、マルチエポック予算を多様なモデルへ変換、これにより検証損失が低下。q0は三つのコアプリミティブ(反相関学習、チェーン蒸留、学習済み分布の適合)に基づく。18億パラメータモデルで約56エポックで強力な256エポック基準に匹敵する性能を達成し、データ効率を約12.9倍向上。予算に応じた最適なエポック使用法を提示。 Comment
元ポスト:
[Paper Note] Self-Distilled Policy Gradient, Yifeng Liu+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Distillation #PostTraining #On-Policy #SelfDistillation #Author Thread-Post Issue Date: 2026-06-04 GPT Summary- オンポリシー自己蒸留は、言語モデルが自身の生成を特権的文脈で監督する手法で、スパース報酬強化学習に対する密な監督信号を提供する。これを逆Kullback–Leibler発散損失で具現化し、自己蒸留型方策勾配フレームワークSDPGを提案。SDPGはグループ相対検証やKL正則化を活用し、従来のベースラインよりも安定性と性能を向上させる。コードは公開されている。 Comment
元ポスト:
-
-
[Paper Note] Subliminal Learning Is Steering Vector Distillation, Camila Blank+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #Distillation #SubliminalLearning #One-Line Notes #Steering #Author Thread-Post Issue Date: 2026-06-04 GPT Summary- 潜在的学習とは、学生の言語モデルが教師の特性を微調整することで獲得される現象であり、意味を持たないデータから特定の特徴が伝達される仕組みは未解明である。本研究では、潜在的学習がステアリングベクトルによって媒介されることを示し、教師のプロンプトがこのベクトルによく近似され、学生が整合したベクトルを学習することを発見した。ステアリングベクトルに近似されないプロンプトは学習されないことも示され、その影響がモデルの活性化に及ぶことを明らかにした。潜在的学習には適応型オプティマイザが必要であり、勾配の一貫性が成果に影響を与えることが確認された。 Comment
元ポスト:
Subliminal Learning:
- [Paper Note] Subliminal Learning: Language models transmit behavioral traits via
hidden signals in data, Alex Cloud+, arXiv'25
Subliminal Learningが生じるのは、教師モデルが生成したデータを通じて生徒モデルが残差ストリームに対するsteering vectorが蒸留されるからであり、教師モデルが生成した何らかのデータを通じて教師モデルと同じ方向にactivationが誘導されるようになるため、という説明のようである。また、subliminal learningが生じるためにはAdamのような適応的なoptimiserが必要で(外れ値の勾配が支配的にならないため)、LoRAのような低ランクでのファインチューニングで生じやすく、フルファインチューニングでは発生しづらいとのこと。
また、細かく読めていないが、16種類の動物に関する特性に関する残差ストリームのsteering vectorを抽出し実験をした結果、steeringは実験の結果モデル間の転移は弱く、モデルアーキテクチャが共通の場合にうまく転移することが示され、このことから、モデル固有のsteering方向に依存することが示唆されるようである。
[Paper Note] Unlocking the Working Memory of Large Language Models for Latent Reasoning, Lukas Aichberger+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LatentReasoning #One-Line Notes #Author Thread-Post Issue Date: 2026-06-03 GPT Summary- 大規模言語モデルの推論能力を向上させるために、自己回帰的生成の代わりに作業記憶ブロックを採用するReasoning in Memory(RiM)が提案される。これにより、内部計算と外部通信の混同を回避し、計算効率の高い潜在推論を実現。2段階のカリキュラムを用いて、まず推論ステップを予測し、その後最終回答の洗練を行う。実験により、RiMが既存の方法と同等かそれ以上の性能を示すことが確認され、作業記憶が潜在推論の有効なメカニズムとして機能する可能性が示された。 Comment
元ポスト:
元ポストのgifが端的にアーキテクチャを示しており非常にわかりやすい。
メモリブロックと呼ばれるboundaryトークン ``とm個のメモリトークン`
[Paper Note] GPU Forecasters: Language Models as Selective Surrogates for Kernel Runtime Optimization, Zaid Khan+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Evaluation #PostTraining #GPUKernel #Author Thread-Post Issue Date: 2026-06-03 GPT Summary- 提案された方法は、LLMを用いてGPUカーネルの性能を予測し、評価コストを削減することを目指す。LLMがカーネルの真の性能を正確に予測できれば、GPUによる評価を選択的に行える。強化学習を活用することで予測の精度を向上させ、結果として同一のGPU評価予算でより多くの候補を検討し、高速なカーネルを見つけられる。これはLLMがカーネル最適化において重要な役割を果たす可能性を示唆している。 Comment
元ポスト:
[Paper Note] WorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction, Chengzhi Liu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #MultiModal #Selected Papers/Blogs #memory #interactive #KeyPoint Notes #Reading Reflections #Author Thread-Post #AgentHarness Issue Date: 2026-06-03 GPT Summary- マルチモーダル大規模言語モデルが長期エージェントとして機能するためには、記憶が進化する世界に適応し、適切な証拠を提示する必要がある。しかし、従来のベンチマークは静的なリコールに依存しており、記憶の生成における失敗を特定できない。これに対して、我々は記憶を「アクション-ワールド・インタラクション・ループ」として定式化し、WorldMemArenaを実装。ここでは、400件のマルチセッション・マルチモーダルタスクを通じて、記憶の診断が可能となる。結果として、記憶書き込みは必ずしも性能向上に繋がらず、視覚的証拠の活用が依然として困難であることが示された。また、エージェントの実行はドメインを跨いで不安定で、コストと信頼性のトレードオフが浮き彫りになった。 Comment
元ポスト:
著者ポスト2:
以下著者ポストの要約
既存のメモリに関するベンチマークは、「静的な環境」において過去のコンテキストから情報を「復元」できるかをテストしているが、それを超えて、
- Lifelong Evolution(動的): ユーザとプロジェクトの状態が変化する世界において、
- Agentic Execution(書き込み・維持・検索・活用): エージェントが観測結果、アクション、ツール実行結果、環境の変化から再利用可能なメモリを構築できるか
をカバーするベンチマークを構築。ベンチマークは461個の複数セッション・マルチモーダルなタスクが含まれ24k QAペア・15kの画像・スクリーンショット、高速な評価のための150サンプルによるサブセットによって構成される。
評価では、
- long-contextのエージェントのcontextに入れ込むメモリ
- 人間がデザインしたメモリ(RAG, メモリパイプライン等)、
- agent harnessがメモリ管理をするタイプのagent
の3種類を評価。
- Takeaway
- メモリへの書き込みの品質が高くても、必ずしもエージェントがうまく活用できるとは限らない
- 現在の手法ではマルチモーダルな情報に対するメモリはまだ困難で、視覚的/空間的/手続き的な情報を失う
- 重要な情報がアクション、フィードバック、スクリーンショット、状態の更新等に分散している場合にメモリは劣化し、これは現在の多くのシステムが整理されたテキストベースの履歴を扱うことに長けている一方で、実際のinteractionのtrajectoryから情報を抽出・更新・再利用することには課題があることを示唆
- agent harnessに基づくメモリはinteraction中に自動的にメモリが記録・抽出・推敲されるため柔軟性が高く有望なアプローチだが、harness designに性能が依存するため、 性能が不安定
評価結果を見ると、一言にメモリと言っても多様な観点からmetricsが定義でき、手法によって性能に大きな開きがある点や実用的な観点の実験設定となっており興味深い。様々な要素が関わってくるため、一概にこの手法が良いというのもあまり言えなさそうに見える。あとなんやかんやRAGが全体的に性能が良さそうに見えるが、結果の解釈が難しく、何らかの単一の尺度などに押し込めたりしないだろうか。
pj page: https://worldmemarena-mem.github.io/
[Paper Note] OmniOPD: Logit-Free On-Policy Distillation via Speculative Verification, Yuhang Zhou+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Distillation #PostTraining #On-Policy #Initial Impression Notes #Author Thread-Post Issue Date: 2026-06-03 GPT Summary- ロジットを用いずにチャンクレベルの監督信号で教師からのフィードバックを利用する新しいフレームワーク、OmniOPDを提案。これにより、教師モデルへのアクセス制限とトークンレベル信号の脆弱性の問題を解決。ベンチマークにおいて、OmniOPDは標準OPDを最大+28.64%上回り、高い不確実性の場面でのみ監査するよう設計されている。また、より強力なブラックボックス型教師を用いた場合には、オープンウェイト教師に対してさらに+9.54%の向上を示し、自律的な強化学習の性能を超える結果をもたらした。 Comment
元ポスト:
大抵のProprietaryモデルは出力から競合となるモデルを学習することを禁止していると思うのだが、果たして
[Paper Note] Automated Benchmark Auditing for AI Agents and Large Language Models, Junlin Wang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #read-later #Selected Papers/Blogs #Initial Impression Notes #Environment #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- 現代のAIベンチマークでは、複雑なタスクが多く含まれ、人間の注釈では検知が難しい問題が存在します。これを解決するために、Auto Benchmark Audit(ABA)を導入し、168のベンチマークを調査。ABAは、あいまいなタスク設計や実行環境の衝突など、25.7%以上のタスクで重大な問題を特定。問題のあるタスクがモデル評価を歪めることを示し、除外することでパフォーマンスが9.9%及び9.6%向上することを確認。今後のベンチマーク発展のため、これらのツールとタスク注釈を公開します。 Comment
元ポスト:
既存のベンチマークを
- 指示の曖昧性
- 環境に内包される問題(競合や依存関係の問題)
- 評価の品質
の観点から監査するAudit Agentの提案
[Paper Note] BAGEN: Are LLM Agents Budget-Aware?, Yuxiang Lin+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- エージェントのリソース消費に対し、コストを実行後にのみ測定するのではなく、予算を積極的な制御信号として扱うべきと提案。予算は内部(計算由来)と外部(行動由来)に分け、エージェントは各計画ステップで残り予算の予測と警告を行う。評価では、強力なエージェントが必ずしも予算意識を持たず、過度に楽観的な傾向が見られた。予算意識信号は訓練可能で、早期停止により失敗したトークンを28〜64%削減でき、SFT+RLがその効果を強化。しかし、正確な区間のキャリブレーションは依然難しい。 Comment
pj page: https://ragen-ai.github.io/bagen/
元ポスト:
以下著者ポストと論文のskim readによるサマリ(読み違えがあるかもしれないので注意)
LLM/AI Agentがbudget(あとどの程度のトークンでタスクを完了できるかの見積もり)を考慮して生成できているか否かを明らかにし、性能とトークン予算の性能は必ずしも相関しないことを示し(現在のフロンティアモデルはトークン予算に対して楽観的で、トークン予算があまり残っていないのに不必要に多くのトークンを消費する)、与えらえたトークン予算に関して、タスクを実現できるか否かの2値分類ははSFTによって強化できる(Qwen-7Bにおいて25.5%->90%まで向上)が、SFT+RLによって正確な残りの予算のrangeを当てるような推論は47%程度で頭打ちで課題が残る、という話に見える。興味深い。
[Paper Note] ReasonOps: Operator Segmentation for LLM Reasoning Traces, Daniel Lee+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #Reasoning #Overthinking #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- ReasonOpsは、チェーン・オブ・ソートの痕跡を分析するための教師なし手法であり、推論の過程を注釈付けするための普遍的な演算子を提供します。12のモデルから44,662の痕跡を分析した結果、共通の構成的な構造が明らかになりました。特に、バックトラッキングや仮説設定などの再発する演算子が全モデルに見られ、内省的演算子は難問でより効果的であることが示されました。演算子のシーケンスを用いることでモデルの高精度な識別が可能になり、早期の品質推定も実現しました。ReasonOpsは、LLMの推論痕跡に対する深いインサイトを提供し、性能予測の強化に寄与します。 Comment
元ポスト:
[Paper Note] ResearchMath-14K: Scaling Research-Level Mathematics via Agents, Guijin Son+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #Mathematics #ScientificDiscovery Issue Date: 2026-05-31 GPT Summary- ResearchMath-14kは、未解決の数学問題に取り組むために、学術的な情報源から厳選された14,056問を集めたデータセットであり、研究レベルの数学問題の最大コレクションを提供する。さらに、22万件の教師データ経路から生成されたResearchMath-Reasoningは、言語モデルが未挑戦の問題に対して反復的な回避行動を示すことを観察した。フィルタリング後にQwen3モデルをファインチューニングすることで、平均9.2ポイントの性能向上が確認された。このデータセットは、研究レベルの数学的推論における今後の研究に貢献することを目的としている。 Comment
元ポスト:
[Paper Note] MIRA: Mid-training Rubric Anchoring for Source-Aware Data Selection, Haowen Wang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #mid-training #DataMixture #DataFiltering #Rubric-based Issue Date: 2026-05-31 GPT Summary- 中間トレーニングにおけるデータ選択の課題に対処するため、自己アンカー型ルーブリック発見に基づくフィルタリングフレームワークMIRAを提案。MIRAは各ソースグループの評価基準を発見し、効果的なデータ選択を実現。コード指向の中間トレーニングで、MIRAは選択ベースラインを上回り、トークン数を半分に削減する成果を示した。 Comment
元ポスト:
[Paper Note] SEAL: Can Saturated Benchmarks Be Revived by LLM-as-a-Meta-Judge?, Jiamin Chen+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#PairWise #NLP #Dataset #Evaluation #KeyPoint Notes Issue Date: 2026-05-31 GPT Summary- 既存の言語モデルベンチマークが飽和する中、SEAL(Seeded Elimination with Adaptive LLM-as-a-Meta-Judge)は、潜在的なランキング信号を抽出する自己改善型評価プロトコルを提案。候補出力をシングルエリミネーション方式で評価し、精度とレイテンシのトレードオフを改善する。複数の飽和ベンチマークにおいて、SEALは全対比較に匹敵する精度を保ちながら、エフォートを大幅に削減した。 Comment
元ポスト:
既に飽和したベンチマークを活用してモデルの評価のためのシグナルを抽出できないか?という気持ちの研究のようで、そもそも飽和したベンチマークはpointwiseな評価によって飽和しており、全てのモデル/promptに対してpair-wiseな評価をしてリストワイズな評価をしてランキング付けをすることで、より高い解像度での評価シグナルが得られるよね、という話からスタートしているように見える。しかしpairwiseな評価は非常にコストがかかるので、自己進化するRubric-basedなLLM-as-a-Judgeとトーナメント方式を採用することで、全件探索したpairwiseによるランキングを、低コストで高い相関係数を以て(0.83--1.0)で再現できるよ、という話に見える。
pointwiseな評価と比較してFullPair/SEALでの評価は評価結果の序列が変化している。ただし、このFullPairでの評価がどの程度正しいものなのかはよくわからない。
[Paper Note] Agent Explorative Policy Optimization for Multimodal Agentic Reasoning, Minki Kang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #MultiModal #PostTraining #KeyPoint Notes #ToolUse #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- 視覚と言語を統合したモデルは、複雑な問題解決において外部ツールの使用が不可欠である。エージェント的推論は、自己完結型思考とツール使用の非対称な行動を交互に行い、このギャップをThinking-Acting Gapと呼ぶ。標準的なRL手法ではツール使用が限定的で、多くの場合誤りを含む。AXPO(Agent eXplorative Policy Optimization)を提案し、ツール呼び出しの再サンプリングを行うことでこの問題を改善。実験の結果、AXPOは複数のマルチモーダル・ベンチマークで従来手法を上回る性能を示し、パラメータ数を抑えつつ効果的な結果を得た。 Comment
pj page: https://byungkwanlee.github.io/AXPO-page/
元ポスト:
モデルがツール呼び出しを行った際の学習シグナルを改善する話で、GRPOで学習を実施した際に全体の30%程度でしかツール呼び出しが行われておらず(どのようなデータで分析したかは読めていない, 2.2節あたり)、そのうち40%程度が応答で誤っておりGRPOで正のadvantageが発生せず、ツール呼び出しに関して精緻なpositiveなシグナルが得られていない問題がある。これを改善するために、ツール呼び出し前のthinkingは正しく、ツールの呼び出し方とその結果が典型的に誤っていることに着目し、ツール呼び出しの上で失敗したrolloutについて、thinkingまでをprefixとしてツール呼び出し以後をresamplingする手法を提案。これにより、ツール呼び出しの頻度が改善し、ツールが呼び出された場合に応答に失敗する割合も減少した。
[Paper Note] Multi-Mixer Models: Flexible Sequence Modeling with Shared Representations, Kevin Y. Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #Architecture #One-Line Notes #ConvolutionalModels Issue Date: 2026-05-31 GPT Summary- Oryxというハイブリッドモデルを提案し、系列全体を通じて異なるトークン混合手法を柔軟に切り替えるアプローチを探る。二次アテンションと線形リカレンスを組み合わせ、90%のパラメータを共有することで、効率的な性能を実現。最長1.4Bパラメータのモデルで、従来のモデルを上回る結果を示し、内部表現の共有が有望な方向性であることを示唆。 Comment
元ポスト:
softmax attentionとgated delta net (linear attention)の利用をスイッチングによって動的に切り替え、双方でKVを共有し畳み込みをかけてinducive biasを導入した上で活用する。outputはRMSNorm側でgatingする。softmax attentionとlinear attentionの良いところを良いところ取りしようというアーキテクチャに見える。
[Paper Note] AttuneBench: A Conversation-Based Benchmark for LLM Emotional Intelligence, Kate M. Lubrano+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Multi #NLP #Dataset #Evaluation #Conversation #read-later #Emotion #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- 感情知性(EI)の評価が重要になる中、AttuneBenchを紹介。実際の複数ターンの人間-モデル対話200件に基づき、感情状態とモデルの挙動をターンごとに注釈。11モデルの評価結果は感情認識や応答品質に関する能力が分離可能であることを示し、嗜好の整合と応答品質の判断がモデル識別に強く寄与することを明らかに。AttuneBenchは、感情的に重要な会話の評価枠組みを提供し、モデルの強みや弱点を診断する。 Comment
元ポスト:
leaderboard: https://public.attunebench.com/
対話をしている本人によるプロンプト、アノテーション、マルチターンの会話を前提にモデルのEQを測定するためのベンチマークのようである(従来は合成プロンプト、シングルターン、third-partyに基づいたアノテーション(つまり対話している本人ではない、ということだと思われる)によるベンチマークだったとのこと)。
[Paper Note] Thinking as Compression: Your Reasoning Model is Secretly a Context Compressor, Guoxin Ma+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Reasoning #ContextEngineering #Compression #Initial Impression Notes Issue Date: 2026-05-31 GPT Summary- 長い文脈を短縮しながら情報損失を抑える文脈圧縮の新手法「Thinking as Compression(TaC)」を提案。思考モデルが自らタスク関連情報を整理し、専用の圧縮機に依存せずに効果的な圧縮を実現。加えて、TaCを制約付きで進化させた「TaC-C」により、思考をコンパクトに管理できる。実験では、既存ベースラインを一貫して上回り、特に4倍および8倍の圧縮比でF1とEMスコアが顕著に改善された。 Comment
元ポスト:
contextを圧縮する専門のcompressorをわざわざ用意するのではなく、reasoningモデルのreasoning traceそのものを圧縮されたcontextとして扱えるような枠組みの提案のようである。
[Paper Note] Skill0.5: Joint Skill Internalization and Utilization for Out-of-Distribution Generalization in Agentic Reinforcement Learning, Jiapeng Zhu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #One-Line Notes #ContinualLearning #AgentSkills Issue Date: 2026-05-31 GPT Summary- 大規模言語モデルにスキルを搭載することで、自律エージェントの複雑なタスク解決が可能になる。エージェントのスキルは一般スキルとタスク特有スキルに分かれるが、既存の強化学習手法は外部化と内部化のバランスに苦労している。これを解決するために、Skill0.5という新しいRLフレームワークを導入。一般スキルの内部化とタスク特化の活用を動的ルータで調整し、タスクに応じた最適化を行う。実験結果は、Skill0.5が他のRLベースラインを上回る性能を示すことを確認した。 Comment
元ポスト:
Agent Skillsベースのcontinual learningを実現するうえで、多くの研究はSkillを外部化する(Skill.mdを定義し更新する)、あるいは内部化する(モデルの重みにSkillを学習させる)といった挙動のどちらかの文脈で研究されるが、どちらも利点・欠点があるから双方のいいところどりをしたハイブリッドでやりたいよね、という気持ちの研究と思われ、そのために一般的なスキルはモデルに内在化させ、タスク固有のスキルは外部化するというすみ分けをする。
そのために、RLをする際にタスクの難易度をhard/medium/easyに分類するルータを設け、hard taskについては、general skillを与え、self-distillationを通じてteacher trajectoryを生成。teacher trajectoryに基づいてdistillation lossを通じてエージェントにgeneral skillを内在化させ、mediumタスクでは通常通りGRPOで成功率を増大させるように学習、easyタスクではショートカットを防止するような学習のさせ方(generall skillを与えた場合とそうでない場合のtrajectoryを用意しadvantageを計算する?)をする、ことで、generalなスキルをエージェントに内在化させる、という感じの話に見える。ざっと図を見ただけなのでeasyタスクの部分がよくわかっていない。あと、そもそもGeneral/Task specific Skillをどのように進化させていくのかはよくわかっていない。
おそらくAgentSkillsの定義と発展は、SkillBankを使っている:
- [Paper Note] SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning, Peng Xia+, arXiv'26, 2026.02
[Paper Note] Unified Neural Scaling Laws, Ethan Caballero+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Scaling Laws #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- UNSLと呼ばれる関数形を提案し、複数の次元が同時に変化する際の深層ニューラルネットワークのスケーリング挙動を正確にモデル化。モデルパラメータ、データセットサイズ、トレーニングおよび推論ステップ数、計算量などが影響を与える様子を示し、大規模なビジョン、言語、数学、強化学習タスクに適用。既存のスケーリング関数と比べ、より精度の高い外挿を実現。 Comment
元ポスト:
データセットサイズ、推論ステップ数、幅、深さ、初期化時の重みの標準偏差、学習率、バッチサイズを変数に持ち、それらを同時に変化させても外挿可能なScaling Lawsのようである
[Paper Note] Self-Verified Distillation: Your Language Model Is Secretly Its Own Synthetic Data Pipeline, Tony Lee+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #PostTraining #Selected Papers/Blogs #Label-free #reading #KeyPoint Notes #SelfVerification #SelfDistillation Issue Date: 2026-05-31 GPT Summary- LLMがラベルなしシード問題から自己改善できるかを探求。自己検証蒸留というアルゴリズムで、生成した候補解をプロンプトベースでフィルタリングし、自己精選データを構築。循環的一貫性、事実性、正確性の3段階で解を承認し、より高品質なデータが優れたモデルへと導く。Qwen3モデルでは、数学・科学・コーディングの各ドメインで顕著な性能向上を確認。特にQwen3-4Bでは、特定のベンチマークでの改善が見られ、従来手法に比べ優れた性能を達成。 Comment
元ポスト:
関連:
- [Paper Note] UQ: Assessing Language Models on Unsolved Questions, Fan Nie+, arXiv'25
- 事後学習済みのLLMを外部のverifier, ground-truthデータ無しで、UQ Verifierに基づいたself-judgementで構築した合成データでSFTすることで性能を押し上げる手法
- データ構築では、1つのラベル無しseed questionに対してn回の応答生成を行い、それらをUQ style verifierでフィルタリングしたデータによって構築する。
- UQ Verifierは、マルチステージのverifierで(今回はself judgment)、各ステージごとにv回のvotingを実施する。各ステージは以下:
- cycle consistency: モデルが生成した応答から質問を逆生成し、オリジナルの問題のコアとなる課題が共通しているかを検証する。
- factual error check: 事実情報にエラーがないかを検証する。
- total correctness: 思考過程と最終的な結論に誤りがないかを検証する。
- 学習データの構築に計算量を増やせば増やすほど性能が向上する (Figure 3)
- test-time verificationのコストを、データ構築時に前払いし、運用時は1度のinferenceでtest-time verification導入時と同等以上の性能を達成する(Table 3)
[Paper Note] Negligible in Size, Significant in Effect: On Scale Vectors in Large Language Models, Mingze Wang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Normalization Issue Date: 2026-05-31 GPT Summary- LLMにおけるスケールベクトルの役割を体系的に研究。スケールベクトルはモデルパラメータの僅かな割合でありながら、その除去で事前学習が劣化することを実証。Pre-Normアーキテクチャにおいては、最適化を改善する機能を持つことを示す。また、スケールベクトルに対するウェイト減衰が役割によって異なる効果を持つことを理論的に説明。三つの改良策を提案し、それぞれが一貫した利益をもたらすことを示した。最終的にこれらの改良を統一戦略に統合し、広範な事前学習実験で良好な成果を得る。 Comment
元ポスト:
[Paper Note] Parallax: Parameterized Local Linear Attention for Language Modeling, Yifei Zuo+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Attention #read-later #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-30 GPT Summary- 大規模言語モデル(LLMs)用にスケール可能な局所線形アテンション(LLA)を提案するParallaxを導入。LLAの数値解法を排除し、アテンション機構を効率化。FlashAttentionに対して高い演算強度を実現し、事前学習全体で一貫したパープレキシティ改善を確認。新たな現象MuonによりParallaxの能力を向上させた。この研究は、注意機構のアーキテクチャとオプティマイザの共同設計の重要性を示す初の例である。 Comment
元ポスト:
Muonと組み合わせると非常に高い性能を発揮するようである
早速nanoGPT speedrunでParallaxによってSoTAが更新されたようである:
[Paper Note] Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders, Yi Jing+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #PostTraining #CurriculumLearning #DataFiltering #One-Line Notes #SparseAutoencoder #Data #Author Thread-Post Issue Date: 2026-05-28 GPT Summary- モデル内部情報がLLMのデータ処理方法に重要である一方、外部信号に依存したデータエンジニアリングは内在信号を無視していることを指摘。SAERLを提案し、Sparse Autoencoderを用いて多様性、難易度、品質の三つのデータ特性をモデル化。これにより、バッチ多様性や難易度の順序づけ、データフィルタリングを実現。SAERLは平均精度を3.00%向上させ、少ないトレーニングステップで目標精度に達することを示し、効果的なデータエンジニアリングツールとしての役割を果たすことが確認された。 Comment
元ポスト:
SAEのrepresentationを、interpretabilityに活用するのではなく、post-trainingの学習データに対するdata engineeringに使うことで、costのかかる手法ではなく**より低コストで**data engineeringを実現したい、という気持ちの研究。提案手法では、SAEによって獲得されるrepresentationに基づいてpost-trainingの学習データに対して、
- 多様性: SAErepresentationを用いてクラスタリングを実施し活用
- 難易度: 軽量なElasticNetに基づく回帰モデル(特徴量はSAE representation)によって難易度予測モデルを学習し、クラスタIDに基づいて難易度をキャリブレーション
- 品質: SAE representationに基づいてqualityを判断する二値分類器を学習しその確率値を使うようである
ぱっと見よくわからないのが、
- difficulty-labeledなsubsetの正体はなんなのか?
- それは幅広いドメインで入手可能なものなのか?
- in-distributionな難易度であればElasticNetで予測できたということだが、in-distributionなdifficulty-labeledなデータがないと提案手法は原則として適用できないということなのか?
という疑問はある。
[Paper Note] ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention, Joe Sharratt, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Attention #LongSequence #LowPrecision Issue Date: 2026-05-27 GPT Summary- ThriftAttentionは、長い文脈におけるアテンションの計算コストを緩和し、FP4精度でFP16に近い品質を提供する低ビットアテンションの手法である。重要なクエリ-キーのブロックを選択し、FP16で計算することで、高性能を維持しながら、計算コストを削減。長文脈でもFP4からFP16への性能ギャップを89.1%回復し、シーケンス長が増すにつれてその効果が顕著になることを示した。 Comment
元ポスト:
[Paper Note] More Expressive Feedforward Layers: Part I. Token-Adaptive Mixing of Activations, Mingze Wang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #ActivationFunction Issue Date: 2026-05-27 GPT Summary- FFN層における活性化関数の固定化から進化し、トークン適応型のMixture of Activations(MoA)を提案。MoAは軽量な入力依存ゲートを用いて活性化の辞書を混合し、パラメータ効率よく表現力を向上。広範な実験で一貫して損失が低下し、従来ベースラインと比べてスケーリング挙動が好ましいことを示す。MoAはLLMsのFFNでの非線形表現力を効果的に高めるメカニズムである。 Comment
元ポスト:
[Paper Note] The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence, MiniMax+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #OpenWeight #SelfImprovement #MoE(Mixture-of-Experts) #read-later #Initial Impression Notes Issue Date: 2026-05-27 GPT Summary- MiniMax-M2シリーズは、ミニアクティベーション原理に基づくMixture-of-Experts言語モデルで、フラグシップのM2は229.9Bのパラメータを持ち、9.8Bのパラメータがトークンごとに活性化される。エージェント運用に最適化されたこのシリーズは、エージェント駆動のデータパイプライン、スケーラブルなエージェントネイティブRLシステムForge、自己進化を目指すM2.7チェックポイントの三要素に基づいている。これにより、エージェント的コーディングやディープサーチ、業務タスクにおいて最前線クラスのパフォーマンスを実現している。 Comment
元ポスト:
ポイント解説:
関連:
- MiniMax-M2.7, MiniMax, 2026.03
expertの数を大きくしているようで、この設計は下記の知見と一致する:
- [Paper Note] Slicing and Dicing: Configuring Optimal Mixtures of Experts, Margaret Li+, arXiv'26, 2026.05
[Paper Note] PowLU: An Activation Function for Stable Pre-Training of LLMs, Peijie Jiang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Stability #ActivationFunction #Initial Impression Notes #LowPrecision #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLM)において、SwiGLU活性化関数は非線形性を導入するが、大きな入力での数値的不安定性が問題。これを解決するために、新たに提案したPowLU活性化関数は、安定した訓練を実現し、表現力を向上させる。実験では、PowLUがSwiGLUやSwiGLU-Clipと比較して競争力のある結果を示し、スケーラビリティの向上も確認された。 Comment
元ポスト:
Layerが深いモデルや、低精度(FP8/FP4)に対して、事前学習の安定性を高める活性化関数
[Paper Note] Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference, Sangyun Lee+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LongSequence #SSM (StateSpaceModel) #reading #LinearAttention #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- トランスフォーマーに基づく大規模言語モデルのアテンション機構が長期タスクでスケールしにくい問題を解決するため、睡眠様の統合機構を提案。モデルは睡眠中に文脈をファストウェイトに変換し、指定されたタスクでオフラインで学習を行う。実験により、提案手法がより深い推論を必要とするタスクで性能向上を示し、従来のトランスフォーマーとハイブリッドモデルに対する優位性を証明。 Comment
元ポスト:
著者ポスト:
[Paper Note] How Should LLMs Consume High-Quality Data? Optimal Data Scheduling via Quality-Aware Functional Scaling Laws, Zhitao Zhu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #mid-training #Batch #Scheduler #One-Line Notes #Data Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLM)の訓練におけるデータ品質の重要性を考慮し、バッチサイズとデータ品質を共同でスケジュールする理論的指針を提供。高品質データは信号の増幅に貢献し、適切なバッチサイズを用いることでノイズを低減する役割も果たす。従来の方法がこの第一の役割を無視する中で、新たに提案するDrop-Stable-Rampupは、品質転換時にバッチサイズを調整し信号の蓄積を促進。評価実験では、各種モデルと数学的推論ベンチマークで顕著な性能向上を実現。 Comment
元ポスト:
mid-training(より高品質なデータ)に転換したタイミングにおいて、**バッチサイズを**Drop (mid-trainingではノイズが小さいため、バッチサイズを小さくより多くの勾配ステップを踏むことで、学習シグナルを蓄積)し、その後Stable(しばらく最小バッチサイズを維持し、学習シグナル獲得を最大化)、最終的にRampup(バッチサイズを線形に拡大(学習率の減衰と等価)することで、最終的な収束に向けて蓄積されたノイズを抑制する)といった、学習データの品質に合わせたバッチサイズのスケジューリング Drop-Stable-Rampupを提案
ポイント解説:
[Paper Note] Strong Teacher Not Needed? On Distillation in LLM Pretraining, Taiming Lu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Distillation #read-later #Initial Impression Notes Issue Date: 2026-05-27 GPT Summary- 知識蒸留における教師と生徒の関係を再検討。強→弱、同等、弱→強の関係で蒸留の有効性を分析し、教師が強力である必要はないことを発見。適切に損失を混合すれば小規模教師でも大きな生徒モデルを改善可能。教師のパラメータ数や訓練トークンの増加は蒸留効果を逆転または飽和させることも。蒸留は分布外および下流タスクの性能を同一ドメインより改善する傾向がある。これにより、強力な教師の必要性に疑問を投げかける。 Comment
元ポスト:
モデルサイズやperplexity視点での強-弱ではなく、どちらかというとdownstreamタスクでの性能の方が大事なのでは?結局のところ、生徒モデルよりも教師モデルの方が秀でている部分が何かしら存在すれば、学習シグナルを得られる可能性はあるよね、という話な気が。
[Paper Note] LLMs as Noisy Channels: A Shannon Perspective on Model Capacity and Scaling Laws, Xu Ouyang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Supervised-FineTuning (SFT) #Quantization #Scaling Laws #PostTraining #read-later Issue Date: 2026-05-27 GPT Summary- LLMの性能改善を目指し、シャノン・スケーリング則を提案。この理論は、モデルパラメータをチャネル帯域幅、学習トークンを信号電力と見なし、学習信号と内在ノイズの相互作用を捉える。信号対雑音比が不十分な場合、性能が劣化することを示し、PythiaやOLMo2における実験で理論を検証。シャノン・スケーリング則は古典的手法を上回り、ロスの谷を正確に捉え、未知のモデル予測でも高いR^2スコアを達成。従来の単調性に基づくモデルは劣化する。 Comment
元ポスト:
[Paper Note] $π$-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows, Haoran Zhang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Conversation #Selected Papers/Blogs #Ambiguity #reading #One-Line Notes #LongHorizon #Proactive Issue Date: 2026-05-27 GPT Summary- パーソナルアシスタントエージェントは、OpenClawのような大規模言語モデルの潜在能力を示しており、特に隠れたユーザー意図の特定に課題がある。本研究では、100のマルチターンタスクからなる積極的支援のベンチマークであるπ-Benchを導入し、長期的な対話におけるユーザーのニーズ予測能力を評価。実験により、積極的支援の難しさ、タスク完遂と積極性の違い、事前対話の重要性が示された。 Comment
元ポスト:
ユーザがOpenClawのようなPersonal Assistantを用いて、マルチターンでのconversationを通じて、ある1つのタスクを遂行したいという状況を想定する。このタスクの開始時には、ユーザは一般的には自然で妥当なクエリを投げるが、最初から全てのrequirementを満たしたクエリは投げず、会話をしながら徐々にrequirementを具体化していくような変遷を辿る。このような、タスク開始時に、タスクを開始する上では自然で妥当だが、タスクを完遂するにはrequirementの情報が足りないという状況において、AI Agentが会話を通じて、ユーザが暗黙的に意図している仕様(hidden intents)を考慮して(=ユーザが明示的にinstructionとしてrequirementを与える前に)タスクを完遂できるか、という能力を測定する。
1つのタスクを完遂するために20個のsessionの会話によって構成されており、hidden intentsはsessionの中で閉じている、あるいはsessionを跨いで維持されるようなものとなっており、これらの情報をエージェントは過去のsessionの情報(メモリ)から推測するか、あるいは明示的にhidden intentsについて質問をするようなProactiveな挙動によって収集した上でタスクを遂行しなければならない。このとき、Userの役割を果たすエージェントは、GPT-5.4によって再現される。
[Paper Note] Forecasting Scientific Progress with Artificial Intelligence, Sean Wu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #ScientificDiscovery #Initial Impression Notes #autoresearch #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- AIは科学的発見に活用されつつあるが、科学の進歩を予測可能かは不明。本研究では、科学進歩予測のための評価フレームワークCUSPを提案し、4,760件の科学イベントを分析。最先端モデルには体系的・領域依存的な限界があり、科学的進歩の実現を信頼性高く予測できず、特に生物学・化学・物理学での予測が異なる。モデルは不確実性推定の信頼性に欠け、過信や応答バイアスを示し、現行のAIシステムは科学進歩予測には不十分であることを示唆。知識へのアクセスが信頼性に結びつかないことも明らかになった。 Comment
元ポスト:
現在のモデルはブレイクスルーの要素技術となるようなアプローチを認識できるが、実際にいつブレイクスルーが起きるかを正確には予測できず(ほぼランダムと同等)、dateがgivenで4種類のイベントが与えられて以下のどれが起きるか?といったMCQだったらそこそこ予測できる、という感じだろうか。
ブレイクスルーがいつ起きるか、dateを予測するというタスク設定にはノイズが多すぎて無理があるのでは...?と最初は思ったが、MCQと対比して予測能力の限界を示すという観点では興味深い。また、もしautoresearchが本格的に実施されるようになった未来があったとして、投入される計算機リソースとモデルが一定だとしたら、少し状況は変わるのかもしれない。
データセットの構築方法、BinaryがどのようなQuestionによって実施されたのか(negationを用いていると記述されているが)、FRQとdate predictionの違いは何か、といったあたりはしっかりわかっていない。
[Paper Note] Understanding Data Temporality Impact on Large Language Models Pre-training, Hippolyte Pilchen+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Temporal #Factuality #read-later #Selected Papers/Blogs #FactualKnowledge #One-Line Notes Issue Date: 2026-05-27 GPT Summary- 時間的根拠を学ぶためのLLMの訓練におけるデータの並び順の重要性を探求。7,000件を超える時間的質問のベンチマークを作成し、事実と時期の結び付けを評価。6Bパラメータモデルを時系列で訓練した結果、シャッフル訓練と同等以上の性能を示しつつ、最新の知識を一貫して保持。これにより、時間的順序付けが知識の新鮮さを向上させることを明らかにした。関連コードやデータセットも公開し、今後のLLMの継続学習研究に寄与。 Comment
元ポスト:
事前学習時に時系列に応じて並び替えをしたコーパスと、シャッフルしたコーパスの場合、freshな知識が必要な質問に対する応答性能が改善する。実験では、Common Crawlのsnapshotの時刻のタイムスタンプに基づいてorderを決定しているようである(2.3説冒頭)。
評価のために作成されたQA例が下記で、NBAのバスケチームのコーチのような時間とともに正解が変化するような事実に関する質問によって構成されているようである。これらはwikipediaから特定の年と紐づいた (subject, relation, object) のタプルを抽出することによって生成される。
[Paper Note] Same Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws, Nandan Kumar Jha+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Optimizer #Scaling Laws #read-later #Initial Impression Notes Issue Date: 2026-05-27 GPT Summary- オプティマイザは、言語モデルの性能に重要な影響を与えるが、通常は固定的な詳細として扱われている。本研究では、異なるオプティマイザが同じTransformerアーキテクチャのスペクトルスケーリングに与える影響を調査し、AdamWとMuonの間で顕著な違いを発見した。特に、Muonは線形スケーリングを示し、スケーリング指数が2.3倍に増加するのに対し、AdamWは弱いスケーリングを示した。この異差は検証損失だけでは説明できず、同一の損失が異なる表現構造を持つ可能性を示唆する。オプティマイザの効果はアーキテクチャの効果を上回ることがあり、最適化を表現スケーリングの重要な要素として捉える必要性を強調し、オプティマイザとアーキテクチャの共同設計を促進する。 Comment
元ポスト:
lossは同じでも、AdamW/Muonの間で形成される内部representationの構造が異なる(説)
[Paper Note] One LR Doesn't Fit All: Heavy-Tail Guided Layerwise Learning Rates for LLMs, Di He+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #read-later #Selected Papers/Blogs #LearningRate #Initial Impression Notes Issue Date: 2026-05-27 GPT Summary- Layerwise Learning Rate(LLR)を導入し、Transformer層ごとに異なる学習率を割り当てることで訓練を効率化。重尾性を考慮した学習率調整により、訓練の均一化、収束の加速、一般化の改善を実現。50の異なる条件での実験で、最大1.5倍の訓練速度アップを達成し、1Bモデルのゼロショット精度を47.09%から49.02%に改善。低いチューニングオーバーヘッドも特長。 Comment
元ポスト:
Layerごとに学習率を調整することで、学習効率を改善する
[Paper Note] CODA: Rewriting Transformer Blocks as GEMM-Epilogue Programs, Han Guo+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #NLP #Transformer #reading #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- CODAは、トランスフォーマーのオペレータをGEMMプラスエピローグとして再パラメータ化し、計算をメモリ書き込み前に実行可能にするGPUカーネルの抽象化である。このアプローチにより、データ移動のボトルネックを軽減し、標準的なTransformerブロックの計算を効率化。代表的なワークロードで高性能を達成し、生産性と効率を両立する道を示す。 Comment
元ポスト:
[Paper Note] Quantifying Hyperparameter Transfer and the Importance of Embedding Layer Learning Rate, Dayal Singh Kalra+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Embeddings #Analysis #Pretraining #NLP #read-later #HyperparameterTransfer Issue Date: 2026-05-27 GPT Summary- ハイパーパラメータ転送は、小規模から大規模モデルへの最適化に不可欠で、特にスケーリング則の適合や適切なパラメータ化の選択が重要です。本研究では、ハイパーパラメータ転送をスケーリング則適合の品質、外挿誤差のロバスト性、パラメータ化による損失ペナルティの三つの指標で定量化する枠組みを提案。また、μPがSPに比べて高品質な学習率転送を提供する理由を解明し、埋め込み層の学習率最大化が訓練の安定性とハイパーパラメータ転送を向上させることを示しました。さらに、ウェイト減衰はスケーリング則の適合を促進する一方で、固定トークン設定が外挿ロバスト性を損なう可能性も指摘しました。 Comment
関連:
- [Paper Note] Scaling Exponents Across Parameterizations and Optimizers, Katie Everett+, ICML'24
- [Paper Note] A Theory on Adam Instability in Large-Scale Machine Learning, Igor Molybog+, arXiv'23, 2023.04
元ポスト:
[Paper Note] On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists, Seungone Kim+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #Selected Papers/Blogs #reading #Initial Impression Notes #Author Thread-Post #Reviwer Issue Date: 2026-05-27 GPT Summary- AIレビュアーの導入が進む中、その能力と信頼性には疑問が残る。多くの科学者はAIを専門知識を欠くシステムと見なす一方、他の研究者は楽観的である。AIレビュアーの評価を理解するため、本研究では、専門家による2,960件のレビューを評価し、その結果、GPT-5.2が人間レビュアーを上回る性能を示した一方で、他のAIレビュアーは最低評価の人間を上回った。ただし、AIレビュアーは重複や限定的知識に課題を持ち、人間の代わりではなく補完としての役割に留まることが明らかとなった。 Comment
元ポスト:
Natureの82本の論文に対してAIにレビューを実施させ、人間の専門家がレビュー結果に対して大規模なアノテーションを実施し、現在のAIレビュワーの能力を評価。その結果、AIレビュワーは
- 根拠が明確で重要な問題点を明らかにし、人間よりも多くの問題点を指摘できるが
- レビューの結果は多様性に乏しく、重複した指摘が多い。
- また、コミュニティや分野における暗黙の了解や規範が欠如した指摘をしたり (W1: missing community / field norms)、過剰に厳しい、あるいはスコープ外や非現実的な要求を実施したりする (W2: over-harsh, out-of-scope, or unrealistic demands)
などの欠点があることが明らかになった、ということのようである。
[Paper Note] Introspective X Training: Feedback Conditioning Improves Scaling Across all LLM Training Stages, Brandon Cui+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #mid-training #PostTraining #Selected Papers/Blogs #reading #One-Line Notes Issue Date: 2026-05-27 GPT Summary- LLMの訓練パイプラインを効率的にスケールするためにIntrospective Training(IXT)を提案。IXTはポスト訓練の情報を初期段階に活用し、自然言語によるフィードバックを付与することで、データの品質を意識した訓練を実現。これにより、トークンの扱いが変化し、計算効率は最大約2.8倍向上、特に数学やコード分野で優れた性能を達成。 Comment
元ポスト:
LLMによってルーブリックに基づいて学習データに対するスコア、critiqueを生成し、データにprependして学習することで、学習効率が改善する。事前学習だけでなく、中間/事後学習にも適用できるようである。
[Paper Note] AstraFlow: Dataflow-Oriented Reinforcement Learning for Agentic LLMs, Haizhong Zheng+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Tools #NLP #ReinforcementLearning #AIAgents #PostTraining #Asynchronous #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- AstraFlowは、強化学習(RL)システムのデータフロー管理を自律的なコンポーネントに分離し、マルチポリシー協調訓練を効率的にサポートする新しいアプローチを提供する。これにより、従来のトレーナー中心の制御から脱却し、異種かつ跨地域の計算リソースを効果的に活用する。AstraFlowは、数学やコーディング、検索のワークロードで、既存RLシステムに匹敵する精度を保ちつつトレーニング時間を2.7倍短縮したことが示された。 Comment
元ポスト:
[Paper Note] What do Language Models Learn and When? The Implicit Curriculum Hypothesis, Emmy Liu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Selected Papers/Blogs #reading #One-Line Notes #needs-revision #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLMs)の事前学習におけるスキル獲得の順序を理解するための「暗黙のカリキュラム仮説」を提案。シンプルかつ組み合わせ可能なタスクを用い、モデル間の一貫した出現順序を追跡。特定のパラメータ範囲で構成的なタスクが後に現れる傾向があり、モデルの表現に組み込まれていることを示す。予測可能な訓練経路を通じて、事前学習は構造化されていると示唆。 Comment
元ポスト:
これは、著者ポストしっかり読みたい
- モデルファミリー・DataMixtureにはよらず、事前学習では構成的で、かつ予測可能なカリキュラムに則って学習が進行し、かつモデルの内部状態から各スキルがどのように学習されていくかを予測できるという仮説を立て、
- この仮説を検証するために、91種類の構成的なタスクを定義し、emergence(=当該タスクの性能が閾値を超えること)を4種類のモデルファミリーにおける9つのモデル、様々なDataMixtureの元で追跡した。タスクの例は以下:
- simple tasks: 文字列操作/形態素の変換/知識の抽出/翻訳など
- composite tasks: 複数の基礎的な操作のsequentialな組み合わせによって実現されるタスク
- たとえば、`gerund_upper` は大文字への変換➡︎動名詞への変換という順番で定義される。
- 様々なモデルファミリーをテストしたところ、LLMは事前学習の間におおむね(完璧ではないが)同じ順番でスキルを獲得していくことが明らかになった
- たとえば、Figure 1を見ると、性能の伸び方は異なるものの、閾値を50%としたときのemergenceの順番はモデルの間で一貫していることがわかる。Table2も参照のこと。
- composite tasksは、それらのタスクの構成要素が獲得された後にemergeすることが明らかになった(54/76ケース)
- 例外的に、composition taskが構成要素よりも先に習得されたものが3例ほど存在した
- また、あるcomposite taskの学習曲線を、類似したFunction Vectors [^1] を持つcomposite taskから予測できるか?(i.e., 類似したタスクは同じような学習曲線を持つか?)を検証。
- これを実施するために、composite taskに対してleave-one-outを実施し、類似したタスクのFunction Vectorsから学習の軌跡を予測できるかを実験したところ、R^2スコアが0.68--0.84程度の性能で予測することができた。
- Function Vectors: [Paper Note] Function Vectors in Large Language Models, Eric Todd+, arXiv'23, 2023.10
[^1]: Function Vectorsとは、LLMに遂行させるタスクのinput-outputの変換の関係性を保持し、タスクを遂行させる際にLLMに対して強い影響力を持つ内部のactivationsのことを指す。
[Paper Note] SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution, Hongyi Liu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Search #AIAgents #AgentSkills Issue Date: 2026-05-27 GPT Summary- LLMエージェントが再利用可能な経験を残す一方で、生の軌跡はノイズが多い。本研究では、エージェント・スキルを経験スキーマとし、SkillsVoteフレームワークを提案。環境要件や品質を考慮し、スキルライブラリを構造化してエージェントの探索を支援する。実行後には、成果をサブタスクに分解し、成功した発見のみを更新として受理。評価結果として、GPT-5.2の性能が最大7.9ポイント、SWE-Bench Proで最大2.6ポイント改善されることを示した。これにより、外部スキルライブラリがエージェントの性能を向上させる可能性を示唆している。 Comment
元ポスト:
[Paper Note] OScaR: The Occam's Razor for Extreme KV Cache Quantization in LLMs and Beyond, Zunhai Su+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Quantization #KV Cache #Compression Issue Date: 2026-05-27 GPT Summary- KVキャッシュのメモリボトルネックを克服するために、OScaRという軽量なフレームワークを提案。Token Norm Imbalance(TNI)を量子化忠実度の主要因として特定し、Canalized RotationとOmni-Token Scalingを用いてその影響を緩和。評価結果は、OScaRが既存手法を超え、INT2量子化でロスレス性能を達成することを示し、デコード速度を約3.0倍向上、メモリフットプリントを約5.3倍削減。 Comment
元ポスト:
[Paper Note] ScheduleFree+: Scaling Learning-Rate-Free & Schedule-Free Learning to Large Language Models, Aaron Defazio, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Optimizer #read-later #Selected Papers/Blogs #Scheduler #Scheduler-free Issue Date: 2026-05-27 GPT Summary- Schedule-Free Learningは、任意の時点で効果的に訓練できる手法として、高い成果を挙げているが、これまで小規模なスケールでの適用に限られていた。私たちは、この手法を大規模モデルとバッチサイズに拡張するための修正を行い、学習率やスケジュールが不要なScheduleFree+を提案。これにより、従来のWSDスケジュールを上回る訓練が実現され、長時間の訓練で特に効果を発揮することが示された。パラメータあたりのトークン数が1000で、先端技術よりも31%の性能向上を達成した。さらに、この手法はモデル平均化とチェックポイントのマージ利用の理論的基盤も提供する。 Comment
元ポスト:
[Paper Note] ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop, Yining Hong+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #VisionLanguageModel #Robotics #SpatialUnderstanding #EmbodiedAI #Simulation Issue Date: 2026-05-27 GPT Summary- 空間知性は行動を通じて展開し、エージェントは能動的に観察を行い、見えない構造を明らかにする。新たに導入したESI-BENCHは、具現化された空間知性のベンチマークで、エージェントは知覚、移動、操作をもとに行動を選定し、タスク関連の証拠を蓄積する。実験により、能動的探索が受動的アプローチを上回り、エージェントは自発的に新たな戦略を見出すことが確認された。3Dグラウンディングは推論を安定させる一方、不完全な表現は逆に有害であり、モデルは証拠の質に依存せず早期に結論に達する傾向がある。 Comment
元ポスト:
pj page: https://esi-bench.github.io/
[Paper Note] Code as Agent Harness, Xuying Ning+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #read-later #Selected Papers/Blogs #AgentHarness Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLMs)は、コード理解と生成において優れた能力を示しており、エージェント性を持つシステムでは、コードがエージェントの推論や行動に重要な役割を果たすようになっている。この研究では、「エージェント・ハーネス」という観点から、コードをエージェント基盤の中心と位置づけ、三つの層(ハーネス・インターフェース、ハーネス機構、マルチエージェント設定へのスケーリング)を整理して調査する。具体的には、コードがエージェントを接続し、計画やフィードバック駆動の制御を行う仕組み、そしてマルチエージェント環境での協調を支援する役割を探る。また、評価方法やハーネスの改善、安全性などの未解決課題も概説し、コードをエージェント的AIの中心に据えることで、実行可能で検証可能なAIエージェント系への統一的なロードマップを示す。 Comment
ポイント解説:
所見:
[Paper Note] Pretraining large language models with MXFP4 on Native FP4 Hardware, Musa Cim+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LowPrecision Issue Date: 2026-05-27 GPT Summary- 大規模言語モデルのFP4トレーニングにおいて、Wgradの量子化が収束低下を引き起こす主要な要因であることを示唆する研究。FpropとDgradのFP4適用は控えめな影響に留まる。実験結果により、トレーニングの不安定さは確率性ではなく、勾配経路に沿った構造的な誤差によって生じることが明らかになった。 Comment
元ポスト:
[Paper Note] Medmarks: A Comprehensive Open-Source LLM Benchmark Suite for Medical Tasks, Benjamin Warner+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Medical #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 医療分野でのLLMs評価は、ベンチマークの飽和やデータ制限のため困難である。30のベンチマークを含むオープンソース評価スイートMedmarksを導入し、61モデルを71設定で評価。その結果、最先端のモデルが最高性能を示し、ファインチューニングされたモデルが汎用モデルを上回ることが確認された。評価は医療推論のLLMsのポストトレーニング環境としても利用可能。 Comment
元ポスト:
Carbon: Decoding the Language of Life, Allal+, bioRxiv'26, 2026.05.25
Paper/Blog Link My Issue
#NLP #FoundationModel #OpenWeight #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
著者ポスト2:
github: https://github.com/huggingface/carbon
genomic foundation model
[Paper Note] All Circuits Lead to Rome: Rethinking Functional Anisotropy in Circuit and Sheaf Discovery for LLMs, Xi Chen+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #CircuitAnalysis Issue Date: 2026-05-27 GPT Summary- 本研究では、LLMsの機能が単一のメカニズムに局在しているという「機能的異方性仮説」に基づき、回路と層の発見に関する経験的および理論的証拠を示す。Overlap-Aware Sheaf Repulsionを導入し、構造的重複にペナルティを加えることで、効率的に多様な回路を発見可能であることを確認した。この現象は発見された回路が増えるにつれて明らかになる。さらに、超疎な三辺のシーフを特定し、それぞれの辺が独立して重要でないことを示すことで、成分の標準的な概念も揺らぐことを論じた。分布型密結回路仮説を提案し、重ね合わせから低重複の回路が自然に生まれることを理論的に示す。これらの結果は、LLMsの機序的説明に対する再考を促す。 Comment
元ポスト:
[Paper Note] Always Learning, Always Mixing: Efficient and Simple Data Mixing All The Time, Michael Y. Hu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #DataMixture Issue Date: 2026-05-27 GPT Summary- データ混合は、異なるソースを組み合わせる問題であり、言語モデルの訓練に重要な影響を与える。従来の手法は特定のフェーズに依存しており、単独での代理モデルや固定ドメインに頼ることが多い。我々は、訓練全体に適用可能なデータ混合アルゴリズムOP-Mixを提案し、候補データを低ランクアダプタ間で補間することでコストを削減し、探索をモデルの実際の学習に基づかせる。OP-Mixは、計算資源を大幅に削減しつつ、事前学習や継続学習での性能を向上させ、データから学ぶ単一の連続プロセスとしての新しい視点を提示する。 Comment
元ポスト:
解説:
[Paper Note] Generating Pretraining Tokens from Organic Data for Data-Bound Scaling, Zichun Yu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #ReinforcementLearning #SyntheticData #One-Line Notes Issue Date: 2026-05-27 GPT Summary- LLMは、データ束縛型の局面に移行しているが、オーガニックデータを完全に活用しているわけではない。そこで、本研究では、合成データ生成フレームワーク「SynPro」を導入し、限られたオーガニックデータからの学習を強化する。SynProは、再表現と再フォーマットを通じて多様な情報を生成し、強化学習で最適化される。実験により、SynProは有効トークン数を3.7〜5.2倍に引き上げ、データ束縛の課題に対処できることが示された。コードはオープンソースで公開されている。 Comment
元ポスト:
人間が作成したテキスト(organic data)の効果を最大限に引き出すためにデータを合成し、事前学習のlossがサチった際には合成データを生成するポリシーを更新し、現在のサチったモデルに対してより有効なデータとなるような合成データをorganic dataから(rephrasing/reformatにより)合成し学習コーパスに追加する(式10, 11, 12)。
[Paper Note] Forecasting Downstream Performance of LLMs With Proxy Metrics, Arkil Patel+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Selected Papers/Blogs #reading #One-Line Notes #DownstreamTasks #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 信頼性の高い性能予測が必要な言語モデル開発において、クロスエントロピー損失や直接評価には限界があることを指摘し、代わりに専門家が執筆した解答のトークン分布からエントロピーや精度といったトークンレベルの統計を用いた代理指標を提案。これにより、モデル選択や事前学習データの選択、訓練時の予測において一貫して優れた結果を示し、専門家の軌跡がモデル能力評価において有用な信号であることを明らかにした。 Comment
元ポスト:
著者ポスト:
クロスエントロピーlossに代わるcandidate modelのdownstreamタスクの性能を間接的に測定するための代理指標の提案で、クロスエントロピーlossと比較。代理指標はexpertが作成したtrajectoryに対するcandidate modelのnext token predictionの分布(や、エントロピー等指標に基づく重みづけの組み合わせ)によって、算出される(式1, 2)。
6つの異なるモデルファミリーの18種類のreasoning modelにおいて、6種類のベンチマークにおいて、モデルのdownstreamタスク性能をランク付けできるかをSpearman Rhoで測定したところ、クロスエントロピーlossが0.36だったのに対し、提案した代理指標(を特徴量として用いたRankSVM)は0.81を記録。また、(あるLLMがある事前学習コーパスで学習された場合のdownstreamタスクでの性能の良さによって)事前学習コーパスの良さをランク付けするタスクの場合、ベースラインと比較して10,000倍計算コストを削減できたとのこと。
DataDecide testbed:
- [Paper Note] DataDecide: How to Predict Best Pretraining Data with Small Experiments, Ian Magnusson+, ICML'25, 2025.04
[Paper Note] AI for Auto-Research: Roadmap & User Guide, Lingdong Kong+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #autoresearch #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- AI支援研究は進化し、自動化システムが低コストで論文を生成可能になったが、整合性の問題が浮き彫りに。特に、最先端のLLMでも結果の捏造や誤りの見逃しがある。研究ライフサイクルを四つの段階(Creation, Writing, Validation, Dissemination)で分析し、AIの信頼性と自律性の限界を特定。AIは構造化されたタスクには優れるが、新規のアイデアや実験には脆弱であり、人間の協働が最も信頼される。具体的なリソースはプロジェクトページで提供。 Comment
pj page: https://worldbench.github.io/awesome-ai-auto-research
元ポスト:
[Paper Note] LEANN: A Low-Storage Vector Index, Yichuan Wang+, MLSys'26 Best Paper Award, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #MLSys #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- LEANNは、動的に再計算することでストレージ効率の高いベクトル検索を実現する新しいインデックス。元データ一部のみで高品質な検索を提供し、従来のインデックスに対して最大50倍のサイズ削減を達成。RAGアプリケーションでの高精度と同等のレイテンシを維持。 Comment
元ポスト:
github: https://github.com/yichuan-w/LEANN](https://t.co/QwkYx1t0oa
[Paper Note] HalluCitation Matters: Revealing the Impact of Hallucinated References with 300 Hallucinated Papers in ACL Conferences, Yusuke Sakai+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Citations #NLP #AIAgents #Hallucination #read-later #Selected Papers/Blogs Issue Date: 2026-05-27 GPT Summary- HalluCitationと呼ばれる幻の引用が科学的信頼性に深刻な影響を及ぼしている。研究では、2024年から2025年に発表されたACL、NAACL、EMNLPの全ての論文を分析し、約300件にHalluCitationが含まれていることを確認。特にEMNLP 2025での発生が顕著で、信頼性に影響を及ぼす可能性がある。
[Paper Note] Steerable but Not Decodable: Function Vectors Operate Beyond the Logit Lens, Mohammed Suhail B Nadaf, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #Steering #Author Thread-Post Issue Date: 2026-05-26 GPT Summary- 活性化の誘導は、タスク挙動が活性化空間の線形方向に対応することに基づくが、研究によりこの前提が逆転することが示された。12タスクにわたる6つのモデルでの分析から、通常の操縦が成功する一方で、デコードできない場合も多く、FVsは計算的指示を符号化するが、回答の方向性は示さないことが明らかになった。また、モデル間の非対称性が確認され、線形表現仮説が「線形デコーダ可能性」と「線形ステアラビリティ」に分解されることで、それぞれが異なることも示された。これらの結果は、安全性モニタリングにおいて重要な示唆を含む。 Comment
元ポスト:
関連:
- [Paper Note] Steered LLM Activations are Non-Surjective, Aayush Mishra+, arXiv'26, 2026.04
[Paper Note] SkillOpt: Executive Strategy for Self-Evolving Agent Skills, Yifan Yang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #Selected Papers/Blogs #AgentSkills #Initial Impression Notes Issue Date: 2026-05-26 GPT Summary- エージェントのスキルをデジタル空間内で最適化するために、SkillOptという体系的なアプローチを提案。これにより、評価されたロールアウトを基にスキル文書の編集を行い、検証スコアを改善させることが可能に。多様なベンチマークで他の手法を上回り、GPT-5.5での性能向上も実現。最適化されたスキルは異なる環境間での移動でも価値が保持されることが確認された。 Comment
元ポスト:
自然言語で記述されるスキルを訓練可能な外部パラメータとして扱う
ポイント解説:
解説:
[Paper Note] From Simulation to Enaction: Post-trained language models recognize and react to their own generations, Asvin G.+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #PostTraining #One-Line Notes #Author Thread-Post Issue Date: 2026-05-26 GPT Summary- モデルは事前訓練による受動的な予測器から、事後訓練を通じて自身のオンポリシー生成を認識するように変わる。この認識は出力分布に影響を与え、オンポリシー時の出力エントロピーはオフポリシー時より3〜4倍低いことを示す。最新の入力トークンの予測されなさが出力エントロピーを調整し、事後訓練済みモデルは応答の話題についての不確実性を早期に収束させる。一方、異なる話題のプレフィルによってこの意図が崩れるとエントロピーが上昇する。また、モデルがオンポリシーの文脈を言語的に認識できることが確認されたが、そのメカニズムは暗黙の認識とは異なる。 Comment
元ポスト:
関連:
- [Paper Note] Large Language Models as Optimizers, Chengrun Yang+, ICLR'24, 2023.09
以下元ポストの要約
- 事前学習済みモデルは「シミュレータ」であり、事後学習済みモデルは「実行者/演者」としてとらえた方がよい
- すなわち、自身の出力はアクションであり、その結果がフィードバックとして将来の自身の入力になるような関係の下駆動する。
- 事後学習済みモデルは自身の出力よりも、他のモデルの出力を読み込む場合にエントロピーが高くなる
- これは、モデルの入力に対するSurpriseの内部表現によって生じる。すなわち、過去のモデルの予測結果に対して、入力された直近のトークンがどれくらい尤度が低いか、によって出力のエントロピーがsteeringされる。
- モデルサイズが大きいほど、オンポリシー・オフポリシーの差が大きく、これはRL無しで、SFT+DPOだけのpost-trainingでも自己認識が生じる。
- また、「食べ物を思い浮かべて...」というinstructionを与えると、事前学習済みモデルと比較して、事後学習済みモデルは単一のトピックに確率質量を集中させる(つまり、計画を練っている)。これはシミュレータと実行者/演者の特性の違いとしてとらえられる。
- 事後学習済みモデルは、自身の計画がのっとられた場合も検知することができ、計画されていないprefillの場合は、出力トークンのエントロピーが大きくなる。一方、ベースモデルの場合はエントロピーにこのような効果はない(暗黙的な自己認識)。
- モデルに読んでいるテキストが自身が生成したものか、他人が入力したものかを判定させる実験を実施し、KV Cacheをパッチして挙動を分析。ユーザのintentがuser-token中の特定の位置の(おそらくKV Cache)に保持され(hidden activation)、ユーザの意図との整合性等の判定結果を出力する直前にのみ、hidden activationと応答内容の比較がなされていることがKV Cacheのパッチに基づく実験で明らかとなった(明示的な自己認識)。
- この結果は、意図を比較する際には、暗黙的な自己認識の場合と比較して、異なる回路(Surpriseとは異なる回路)をオンデマンドで誘発して利用していることを示唆している。
- (理解があまりできておらず、この説明で正しいかちょっと自信がない。論文中3.3節)
[Paper Note] AMUSE: Anytime Muon with Stable Gradient Evaluation, Jueun Kim+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #Optimizer #Finetuning #Stability #Backbone #One-Line Notes #Author Thread-Post #Scheduler-free Issue Date: 2026-05-26 GPT Summary- Muonの直交化は、勾配の振動を引き起こす高曲率部分空間の影響を受けつつ、訓練の進展を加速する。一方、Anytime Muon(AMUSE)は、迅速な適応を図るために時間変化する補間係数を利用し、安定した平均化を通じて振動を抑制する。AMUSEは学習率スケジュールを排除し、視覚タスクと大規模言語モデルの事前トレーニングにおいて、性能を一貫して向上させる。 Comment
元ポスト:
以下、上記著者ポストからの要約である。
MuonとScheduler-freeなoptimiserでの過去のtrajectoryの平均的な方向へ更新する考え方を組み合わせて、Muonの学習を安定させ、かつSchduler-freeを実現した模様。具体的には学習初期にはMuonの軌道を重視し、学習後半になるにつれ、ノイズの影響を低減するためにtrajectoryの平均方向に最適化する(時間変化する補完係数によって挙動が制御される)といったイメージのようである。
Muonがなぜうまくいくかの理論的な分析も実施されている。近年は損失関数の幾何構造をriver/valleyのようにたとえて表現するらしく、(Figure 1)、SGDは曲率の高い(勾配が急)な方向への更新される傾向があり振動をしながら川方向へ進むようだが、Muonはriver方向(曲率は小さいがモデルが最も学習が進捗する方向)への更新を増幅する働きがあるようである。しかし、ノイズとなる高曲率な谷方向への更新も増幅してしまいそれが振動や不安定さを生むため、それを是正するためにSchedule Freeな手法を組み合わせている、という気持ちのようである。また、先行研究に記載がある通り、WSDスケジューラをriver-valleyで説明する、Stableフェーズが川に沿った更新を促進し、Decayフェーズはパラメータを谷の底へ収束させる役割を果たしている、というイメージのようである。
[Paper Note] Reward-free Alignment for Conflicting Objectives, Peter L. Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Alignment #Safety #PostTraining #Author Thread-Post Issue Date: 2026-05-25 GPT Summary- 対立する目的を考慮したリバースアライメント手法(RACO)を提案。ペアワイズ嗜好データを利用し、効率的な衝突回避勾配降下法を用いて収束を保証。複数のLLMに対する実験で、提案手法が従来のアプローチよりパレートのトレードオフを一貫して改善することを示した。 Comment
元ポスト:
[Paper Note] Efficient Agentic Reasoning Through Self-Regulated Simulative Planning, Mingkai Deng+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #Planning #Author Thread-Post Issue Date: 2026-05-24 GPT Summary- エージェントの計画メカニズムを三つのシステム(シミュレーティブ推論、自己規制、反応的実行)に分解し、効率的な推論を実現する。SR^2AMを用いてLLMを世界モデルにし、計画と推論を行う二つの実装(v0.1およびv1.0)で、推論トークンの使用を大幅に削減。特にv1.0-30Bは、同等モデルと比較して推論トークンを25.8–95.3%少なく使い、計画の見通しを22.8%増加させることが示され、エージェントの学習と適応の自律性が強化されることを証明。 Comment
元ポスト:
[Paper Note] Unsupervised Process Reward Models, Artyom Gadetsky+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #PRM #RewardModel #Label-free Issue Date: 2026-05-24 GPT Summary- 無監督型プロセス報酬モデル(uPRM)は、推論の精度を高める新たな手法であり、従来のPRMが必要とする人間のステップごとの注釈を排除します。uPRMは、LLMの次トークン確率に基づき、誤りが起こる可能性のあるステップを評価します。この方法により、ProcessBenchデータセットでの誤り特定精度が最大15ポイント向上し、テスト時の性能では監督付きPRMと同等の結果を示しました。さらに、強化学習においても、uPRMはより優れた方策最適化を実現し、スケーラブルな報酬モデリングの道を開きます。 Comment
元ポスト:
Next Token Predictionによってターミナルのダイナミクスをモデルに内包させる研究と関連している:
- [Paper Note] ECHO: Terminal Agents Learn World Models for Free, Vaishnavi Shrivastava+, arXiv'26, 2026.05
[Paper Note] Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why, Mohammadreza Armandpour+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Distillation #PostTraining #On-Policy #One-Line Notes #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- オンポリシー蒸留は推論モデルの訓練に対し、トークンごとの監督信号を提供するが、その有効性を決定する条件は未解明である。本研究では、トークン、質問、教師ごとに動作する診断フレームワークを導入し、学生の成功確率を最大化する勾配を導出。理想の勾配との整合性を評価し、蒸留指導が誤ったロールアウトに対して高い整合性を示すことを発見。最適な蒸留文脈はモデルの容量とタスクに依存し、標準的な設定は存在しないことが示された。これにより、タスクごとの診断分析の重要性が強調される。 Comment
元ポスト:
(下記は著者ポストに基づく要約です。ざっくり読んだだけなので誤りがあるかもしれず、詳細は著者ポスト参照のこと)
on-policy (self) Distillationが、どのような場合に有効なのかを分析。
トークンレベルで見た時に多くのトークンが教師-生徒間でdisagreementが存在し、これらにはフォーマットに起因するトークンと、reasoningに重要なトークンの双方が存在する。
そこで、本研究では各トークンにとっての最良の勾配を導出(=生徒が正答できる確率を最大化する方向のもの)。
最適なgradientの方向がわかったので、あとは実際に蒸留をした場合の各トークンのgradientとのコサイン類似度を測ることで、どのような場合にdistillationが有用やシグナル(すなわち、生徒が正答できる確率を高めることに寄与しているか)を分析した。
分析の結果
- distillationが役に立つ場面は、生徒が誤ったロールアウトをしているケースで、正解のロールアウトをしている場合は教師モデルは役立つシグナルではなくノイズを与えているだけだった。
- 教師モデルのパラメータは大きければ大きいほど良いわけではなく、有効か否かは生徒モデルが学習シグナルを理解できるかに依存する。
- たとえば、BoolQというデータで生徒がQwen0.6Bだった場合はself-teacherに基づく勾配が、より大きな外部teacher(4--14B)による勾配と比較して、理想的な勾配に近かった(より高い類似度だった)。
- 一方で、同じデータセットで生徒モデルを1.7Bにすると、8Bの外部teacherが最も理想的なシグナルと高い類似度の勾配をもたらし、self-teacherはあまりうまく機能しなかった。
- contextのフォーマット(生のtrajectoryか要約か, mistakeを含めるか否か等)が、教師モデルの選択と同じくらいの重要
- MMLUデータでの実験で、0.6Bモデルが生徒の場合は、32Bモデルが書いたsolutionをcontextとして与えたself-teacherが理想的な勾配により近く、1.7Bの生徒の場合は、要約されたsolutionの方が良い。
- AIMEの場合、hardな問題の場合は、正解だけでなく失敗例 /典型的なミスをcontextとして与えたself-teacherが良い一方で、easyな問題では常にパフォーマンスの劣化を招く。
以上より、タスクごとに有用なdistillationの設定を模索することの重要性が示唆される、
という感じのようである。
著者ポスト:
[Paper Note] Learning from Language Feedback via Variational Policy Distillation, Yang Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #On-Policy #reading #One-Line Notes #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- Variational Policy Distillation(VPD)は、強化学習におけるまばらな報酬信号の問題を解決する新たなフレームワークであり、言語フィードバックから密なトークンレベルの監督信号を生成する。これにより、教師と学生ポリシーを共進化させ、教師は軌道結果に基づいて能動的に洗練され、学生はこの情報を内在化する。科学的推論やコード生成タスクにおいて、VPDは従来の手法を一貫して上回る性能を示し、受動的蒸留の限界を克服することを目指す。 Comment
元ポスト:
提案手法の全体像を説明する図が論文中に欲しい。式(3)が天下り的に出てきて、私の勉強不足によりこの式を前提に論理展開がスタートする気持ちがよくわからない(おそらくDPOあたりをもっとしっかり理解するとわかるのだろう)。
が、現在のself-teacherに基づくOPSDは、textual feedback Cに対して最適化されておらず、かつzero-shotによる予測を実施しているため、学習が継続するにつれてfeedbackにいつか限界が生じるため学習のために有用なシグナルがなくなるのではないか、という考察に基づき、
textual feedbackから学習する枠組みvariational inference problemの観点から考え直す。すると、KL Divergenceによって正則化されたRLVRは式(3)によって定式化されるreward functionによって傾斜がつけられた最適な事後分布pi_*に対して、ポリシーのKL Divergenceを最適化する問題と等価になる。このとき式(3)の分母にはZ(x)が存在しこれは計算ができない。このため、これを解決するためにteacher network q_phi (y | x, C) を導入し、最適な事後分布pi_thetaの近似的な教師分布とする。これによりELBOを用いた変分下限のRLVRの目的関数を定義することができ、これはEMアルゴリズムによって解くことができる。具体的には
- Eステップ: q_phiとpi_optimalのKL Divergenceが最小となるようにq_phiを更新する。
- Mステップ: pi_thetaとq_phiのKL Divergenceが最小となるようにpi_thetaを更新する。
このとき、EとMではphiとthetaのパラメータが独立して存在するが、実用上はphiとthetaを共有する。これにより、textual feedback Cを解釈する教師モデルと学生モデルの双方がco-evolvingしていくような学習が実現される、
という感じだろうか。
ELBOについて:
- 変分オートエンコーダ⑥変分下限 ELBO:
https://note.com/kikaben/n/n00ad3e148770
[Paper Note] Post-training makes large language models less human-like, Marcel Binz+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #Initial Impression Notes Issue Date: 2026-05-23 GPT Summary- LLMsが人間の行動を模倣する中で、どのモデルが最適かは未解決の課題である。この解決策として、Psych-201データセットを導入し、行動的一致性を測定。訓練後の段階でモデルが人間行動と一致しないことを確認し、整合性のずれは新しいモデルで拡大、一方で基盤モデルは改善を続ける。また、ペルソナ誘導法による個人レベルの予測改善は見られなかった。これらの結果から、LLMsを有用なアシスタントに転換するプロセスが人間行動の模倣を妨げている可能性が示唆される。 Comment
元ポスト:
関連:
- [Paper Note] Do LLMs exhibit human-like response biases? A case study in survey design, Lindia Tjuatja+, arXiv'23, 2023.11
LLMがRLHFなどによって人間が好む応答とは異なるバイアスを持つことが示されている。
純粋な疑問として、人間らしいモデルが本当に人間の役に立つのか?という問いが成り立つ気がする。
[Paper Note] The Alien Space of Science: Sampling Coherent but Cognitively Unavailable Research Directions, Alejandro H. Artiles+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Novelty #AIAgents #ScientificDiscovery #Initial Impression Notes Issue Date: 2026-05-23 GPT Summary- 科学的発見は認知的に利用可能である必要があり、従来のコミュニティが占有する知識の偏りが新しいアイデアの提案を妨げている。提案手法は、論文を細かな概念ユニットに分解し、アイデア原子にクラスタリングすることで、補完的な研究方向を探る枠組みである。この方法では、整合性モデルと可用性モデルの二つを学習し、原子の組み合わせをランキングすることで、異質な方向の探索を実現する。実験の結果、提案サンプラーはLCMアイデア生成ベースラインを超える広い原子語彙を探索し、整合性を維持しつつも人間と同等またはそれ以上のアイデアを生成する。これにより、科学的妥当性とコミュニティの可用性を分離し、AI的なアイデア創出を通じて見落とされた方向性への探索を拡大する。 Comment
元ポスト:
既存のliteratureが斬新な研究アイデアを創発する際のバイアスとなる、といった切り口は興味深い。また、Recommender Systemsにおけるnovelty/serendipityのような話にも似ているように感じる。
- Autonomous AI research for nanogpt speedrun, PrimeIntellect, 2026.05
にて言及されているような現在のエージェントが、完全に新規なアイデアではなく既存の技術の積み重ねや組み合わせが得意というのも、このバイアスによって説明がつくように感じる。
あと、ふと以下のページを思い出した(なぜだろうか。serendipityがあるような研究タイトルがたくさんあったからかもしれない):
https://www.phontron.com/nlp-title/
[Paper Note] Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning, Benhao Huang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #read-later #LatentReasoning #RecurrentModels #RecursiveModels #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- 潜在状態を反復的に更新することで推論のスケーリングを実現するモデル(EqR)を提案。これにより、タスク特異の情報なしでテスト時のスケーリングが可能に。内部ダイナミクスを深さと広さで調整し、アトラクターへの収束を強化。シンプルなケースは少ない反復で収束し、難しいケースではスケーリングが有効。最終的には、精度がSudoku-Extremeで99%以上に向上。学習されたアトラクターの分布が反復的推論の理解に寄与することを示唆。 Comment
元ポスト:
関連:
- [Paper Note] Generative Recursive Reasoning, Junyeob Baek+, arXiv'26, 2026.05
本研究とモチベーションが非常に類似しているように感じる。
解説:
[Paper Note] Vector Policy Optimization: Training for Diversity Improves Test-Time Search, Ryan Bahlous-Boldi+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #read-later #Diversity #Selected Papers/Blogs #EntropyCollapse #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- LLMが新しい環境に適応し、多様なタスク固有の報酬を持つロールアウトを選択できるように、Vector Policy Optimization(VPO)を提案。VPOはベクトル報酬空間を活用し、テスト時検索で最強のスカラーRLベースラインと同等かそれを上回る性能を示す。進化的探索においては、従来のモデルでは解決できない問題を解決可能。多様性の最適化が今後のポストトレーニング目標となる可能性を示唆。 Comment
元ポスト:
[Paper Note] A Bitter Lesson for Data Filtering, Christopher Mohri+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #read-later #Selected Papers/Blogs #DataFiltering #One-Line Notes #Reading Reflections #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- 高計算資源を活用したスケーリング研究で、大規模モデルの事前学習におけるデータフィルタリングを検討。一般的に思われる高品質データのみが必要との見解に反し、実験は、十分な計算資源があればデータフィルターなしが最良であることを示す。訓練された大規模モデルは低品質や誤誘導データを受け入れ、むしろ「質の悪い」データからも恩恵を得ることが判明。 Comment
元ポスト:
LLMの事前学習において、十分に大きなモデルサイズと計算量があれば、データフィルタリングをしない場合の方が最終的にperplexityがデータをフィルタリングしたモデルよりも上回る。これはbad data (e.g., トークンのシャッフル, ランダムな文字列の挿入)を追加した場合でも当てはまる。
データプールのサイズが大きな数な場合でも、フィルタリング手法とフィルタリングがない手法との交差点が変わるのみで、その交差点は現実的なエポック数に留まったままである。データのスケーリングの傾向に基づいて、インターネットサイズのデータサイズに外挿をすると、約1e30 FLOPsが必要となる試算になるが、数年以内に到達可能な計算量と考えられる。
ダウンストリームタスクへの性能にも(ノイジーだが)事前学習での改善は寄与する。ただし、事前学習させたトークン数が少ない場合はフィルタリングした方が性能が良く、十分な計算量を投じる必要がある。
といった話が著者ポストに書かれている。興味深い。
逆に言うとこの傾向は、モデルパラメータ、計算資源が十分に大きいことが前提だと考えられるので、PhiのようなSLM研究において得られた学習データの高品質化が重要という知見とは競合しないと思われる。
解説:
関連:
- [Paper Note] When Bad Data Leads to Good Models, Kenneth Li+, ICML'25, 2025.05
[Paper Note] Useful Memories Become Faulty When Continuously Updated by LLMs, Dylan Zhang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#DocumentSummarization #Analysis #NLP #AIAgents #read-later #Selected Papers/Blogs #memory Issue Date: 2026-05-23 GPT Summary- 過去の経験から学ぶエージェント記憶は、生データと再利用可能な教訓という二つの記憶形態を統合する。しかし、現在のLLMによる統合記憶は、効果的に役立つ経験から生成されても誤りを含むことが多い。記憶の有用性は統合が進むにつれて劣化し、特定の問題では失敗が見られる。異なる更新スケジュールは質的に異なる記憶を生み出し、エピソードの保持のみでは統合の効果を競合する。制御された環境下でエージェントが生のエピソードを保持することが精度を向上させることが示され、統合は明示的に管理するべきである。今後は、安全に統合できるLLMの開発が求められる。 Comment
元ポスト:
[Paper Note] Decoupling the Benefits of Subword Tokenization for Language Model Training via Byte-level Simulation, Théo Gigant+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Tokenizer #read-later #Selected Papers/Blogs #Byte-level #Author Thread-Post Issue Date: 2026-05-22 GPT Summary- サブワードトークン化の訓練効率とモデル性能への影響を分離し、様々な次元で仮説を検証。バイトレベル環境でのシミュレーションにより、サブワードモデルの優位性を明らかにし、訓練スループットの向上とサブワード境界の重要性を強調。将来のモデル改良への洞察を提供。 Comment
LLMに記憶の更新(要約)。任せ、継続すると最初は性能が向上するが、じきに低下していき、記憶なしのモデルが上回るようになる。無条件にLLMに記憶を更新させるのではなく、要約をするタイミングを明示的に指定する、生のエピソードを最優先するといった対策があるといった感じかもだが、ちょっともう少しちゃんと読んだ方が良さそう。
元ポスト:
[Paper Note] Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention, Ali Hatamizadeh+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Transformer #Architecture #LinearAttention Issue Date: 2026-05-22 GPT Summary- Gated DeltaNet-2は、線形アテンションの圧縮メモリを編集するためにGated Delta Rule-2を導入し、適応的忘却とチャネルごとの減衰を実現。チャネルごとの消去ゲートと書き込みゲートを分離し、それぞれの役割を明確にすることで性能を向上。13億パラメータでトレーニングされたモデルは、言語モデリングや常識推論において強力な結果を示し、特に長文のRULERベンチマークで顕著な利点を発揮。コードは公開中。 Comment
元ポスト:
所見:
解説:
[Paper Note] Steered LLM Activations are Non-Surjective, Aayush Mishra+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #Prompting #Safety #Selected Papers/Blogs #reading #One-Line Notes #Steering #Interpretability #Reading Reflections #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- アクティベーション・ステアリングは、モデルの活性化を調整し、その挙動に変化を与える手法であり、解釈可能性や安全性研究で広く利用されている。しかし、任意のテキストプロンプトによってこの挙動が実現可能かは不明である。本研究では、この問題を全射的な観点から考察し、すべてのステアされた活性化が前像を持つかを調査する。実証的結果から、活性化ステアリングは任意のプロンプトによって同じ内部挙動を再現できないことを示し、ホワイトボックス的なステアリングとブラックボックス的なプロンプティングの違いを明確にする評価プロトコルを提案する。 Comment
元ポスト:
steeringされたactivationを自然に生み出すプロンプトは存在しない。言い換えると、steeringによって得られる挙動はpromptでは再現できない。これにより以下が示唆される:
- prompt levelのbehaviorとactivation/weightに介入することによるbehaviorの変化は、根源的に異なる現象なので分けて考えなければならない
- white-boxなstteering手法によってjailbreakができたとしても、black-boxな手法(e.g., promptingによる脆弱性など)による脆弱性があることの証拠にはならない
Steeringされたactivationは下記のようなAutoencoderを学習することでverbalizeできるのだろうか?hidden_stateのreconstruction lossを通じてverbalizeするためできそうではある。元々のactivationがpromptによって到達不可能な点にいたときに、promptによって到達不能なだけであって内部のネットワークが状態を解釈できないというわけではないので(ここがめちゃめちゃなら何も学習できないということになるがそうではなさそうなので)普通にできそうではある:
- Natural Language Autoencoders: Turning Claude’s thoughts into text, Anthropic, 2026.05
[Paper Note] Slicing and Dicing: Configuring Optimal Mixtures of Experts, Margaret Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- Mixture-of-Experts (MoE) アーキテクチャの設計選択を体系的に検討し、2,000件の事前学習ランを実施。エキスパート数、粒度、サイズの変化で一貫した性能向上を確認。活性パラメータ規模の増加が性能向上に寄与し、最適なエキスパートサイズは総パラメータ数に依存しないことが明らかに。共有エキスパートやロードバランシングの影響は小さく、ドロップレス・ルーティングは有益。全体として、エキスパート数と粒度にフォーカスするシンプルなアプローチが有効であることを示唆。 Comment
元ポスト:
MoEアーキテクチャにおいては、expertのサイズと数が重要であり、他の要素は最小限の影響しか与えない
- Expertの総パラメータ数が増えれば増えるほど性能が改善する(アクティブパラメータ数に対する総パラメータ数が128倍などの極端な場合でも性能が改善)
- Expertの数は多ければ多いほど良い。また、Expert一つに対する最適なサイズは総パラメータすうには関係なく、アクティブパラメータ数にのみに依存して決まることが明らかになった。このため、まずアクティブパラメータ数を優先的に決めて、VRAMが許す限りエキスパートの数を増やすのが良い
- MoEアーキテクチャが優れているのは、ブロックを小さく分割したからではなく、非アクティブなパラメータが存在することによるSparseな活性化によって生じる(MLPを細かいブロックにして全てを活性化させても性能が悪化した実験を受けて、ブロックを細かく分割することではなくsparseな活性化に鍵があると結論)
- 共有エキスパートや、サイズを不均一にしたエキスパートの設計には効果がない
- ルーティングに関しては、特定のエキスパートにトークンが偏った場合のToken Droppingは実施せず、Droplessなルーティングをする方が一貫して少しだけ性能が良い。極端に強い/弱いロードバランシングは性能の劣化を招くが、他の設定ではほぼ最適なものを達成できるので、Token Droppingを防ぐことに注意して、あとは一般的な設定を採用すれば良い。
- レシピをまとめると
- 最大のFLOPs/Memoryの予算を決め、active/totalのエキスパートのパラメータ数を決める
- アクティブパラメータ数から最適なエキスパートのサイズ(総数)を見つける
- token droppingを防ぐようなルーティング設定で、ロードバランシングのsanity checkをする
といった 話が著者ポストに書かれている。
[Paper Note] Self-Distilled Agentic Reinforcement Learning, Zhengxi Lu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Distillation #PostTraining #On-Policy Issue Date: 2026-05-21 GPT Summary- SDARはRLを中心に据え、OPSDを補助目的として活用する新しいアプローチ。マルチターンエージェントにおける不安定性に対処し、教師の承認を得たトークンの蒸留を強化。ALFWorld、WebShop、Search-QAでの実験により、従来のGRPOを大幅に上回り、一貫したパフォーマンス向上を示した。 Comment
元ポスト:
[Paper Note] ECHO: Terminal Agents Learn World Models for Free, Vaishnavi Shrivastava+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SelfImprovement #PostTraining #Selected Papers/Blogs #Non-VerifiableRewards #WorldModels #reading #One-Line Notes #ContinualLearning #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- ECHOは、CLIエージェントのトレーニングにおいて環境のフィードバックを活用するハイブリッド目的関数を提案。標準的な政策勾配損失と、自己行動による環境観測トークン予測を組み合わせ、ロールアウトに既存の信号を密接な監督として利用する。これにより、TerminalBench-2.0でGRPOのpass@1を倍増させ、環境ダイナミクスの予測精度も向上させる。ECHOは専門家デモなしで、未知のOODタスクのポリシー改善を可能にすることを示している。 Comment
反響がすごそうに見える
- 通常のAgentのRLは環境からの応答に対してマスクをかけてしまい、エージェントが環境(本研究ではターミナル)にどう影響したかを示すground-truthのsignalであるにもかかわらず応答を切り捨ててしまう。
- 提案手法であるECHOはアクションと環境からの応答の双方で学習を行う。通常のaction tokenに対する損失はそのままに、ターミナル出力に対するシンプルなcross-entropy lossを追加する(環境からの応答はcontextに含まれ、モデル内を通過しているため追加のコストはかからない。)。
- このシンプルな修正によって、ベンチマークのスコアが改善し、特にTerminalBench-2.0のスコアはほぼ倍増した。これは言い換えると通常のRLと比較して2.3倍高速になっている。
- また、ターミナルの応答を学習したことでターミナルのダイナミクスをポリシーが学習し、held-out trajectoriesにおいて環境からの応答トークンのクロスエントロピーはECHOでは急激に低下するが、通常のGRPOではほとんどい変化しない。これは、ECHOがモデルに対してターミナルがどう応答するかを学習させていることを示唆する。
- エキスパートによる教師モデルを持たない場合でも、ECHOによってエキスパートによるdemonstrationでSFTを行った後のGRPOが達成するパフォーマンスにほぼ匹敵可能
- エキスパートのtrajectoryから模倣学習するSFTと比較して、ECHOではモデル自身がターミナルの応答を予測することで、ターミナルの応答のうち何が有用なのかを学習する。模倣からではなく、インタラクションを通じて優れた戦略を創発する。
- ECHOを使うことで、AI AgentはVerifierの報酬なしでも自己改善ができる。Verifierの報酬が一切なくても、ECHOはAI Agentが環境内で行動し、何が起こるかを予測するだけで、(GRPOなしで)さらに性能を向上させることができる。つまり、taskのpromptに対して、モデルに環境がどのような応答を返すか予測をさせ、observationに対するクロスエントロピーlossを計算し更新するだけで性能(in-distribution, OOD共に)が改善する。
環境が多くのシグナルを返してくれる場合はterminal以外の環境でもうまくいきそうな話で、非常にシンプルな変更で実現でき、かなりインパクトが大きく見える。
元ポスト:
prime-rlでサポートされたとのこと:
[Paper Note] $δ$-mem: Efficient Online Memory for Large Language Models, Jingdi Lei+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #Attention #Architecture #memory Issue Date: 2026-05-21 GPT Summary- $δ$-memは、凍結済みのフルアテンションバックボーンにコンパクトなオンラインメモリ機構を追加し、過去の情報を固定サイズの状態行列に圧縮・更新する。これにより、生成時に低ランク補正を生成し、メモリ集約型ベンチマークで顕著な性能向上を達成。従来の手法と比較して、フルファインチューニングなしで効果的なメモリ利用が可能であることを示した。 Comment
元ポスト:
[Paper Note] BLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding, Jiayi Yuan+, MLSys'26 Best Paper, 2025.12
Paper/Blog Link My Issue
#NLP #Transformer #Training-Free #Selected Papers/Blogs #MLSys #reading #One-Line Notes #SparseAttention #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- BLASSTは、LLMsの文脈での推論能力向上のために提案された動的スパースアテンション機構である。固定スカラー閾値を用いて計算を加速し、トレーニング要件を排除、既存フレームワークと容易に統合可能。自動閾値キャリブレーション手法により、最適閾値と文脈長の逆比例関係が明らかにされ、前計算とデコードそれぞれに単一の閾値を利用。現代GPU上でのベンチマークにおいて、前計算とデコードがそれぞれ1.52倍、1.48倍の速度向上を示し、精度を維持した。 Comment
元ポスト:
training-freeで単一のスカラー閾値による制御によって、スキップ可能なattention blockをスキップするSparse Attentionとのこと。
非常に使い勝手が良さそうで、50%程度のSparsityにしてもベースラインとなるDense Attentionに対してダウンストリームタスクの性能低下はなく(Table 4)、50%程度のSparsityの場合、prefillとdecode step方法において、Blackwell, Hopperアーキテクチャにおいて約1.3倍の高速化を実現できる(Table5)。
[Paper Note] STALE: Can LLM Agents Know When Their Memories Are No Longer Valid?, Hanxiang Chao+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Selected Papers/Blogs #memory #reading #One-Line Notes Issue Date: 2026-05-21 GPT Summary- 大規模言語モデル(LLM)が個人化メモリを維持する上での「暗黙的対立」能力を評価するために、400の専門家検証済みシナリオを含むSTALEを提案。三次元の探査フレームワークにより、古い信念の検出やユーザー状態の変化に応じた記憶の修正を評価。最先端のモデルでも精度55.2%に留まり、時代遅れの仮定を受け入れる傾向を示す。状態認識型メモリの改善のためのプロトタイプCUPMemを提示し、明示的な状態判断の重要性を示す。 Comment
元ポスト:
提案されたベンチマークでは3つの次元で測定するが、特にユーザから本来とは異なる古い前提のクエリ与えられたときに、それを否定し、自身のメモリからgroundingされた情報に基づいて応答を生成させるテスト(Premise Resistence; 3.5節)に苦戦することが示されている(Table 2)。
他の二つの次元は
- State Resolution: 以前の記憶がすでに無効であることをモデルに対して直接テスト
- Implicit Policy Adaptation: 前提知識を提示せずに、最新の記憶に基づいて応答しなければならない質問(e.g., 今週の通勤プランを教えて)に対するテスト
[Paper Note] Look Before You Leap: Autonomous Exploration for LLM Agents, Ziang Ye+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #AIAgents #PostTraining #Diversity #KeyPoint Notes #Exploration Issue Date: 2026-05-21 GPT Summary- 大規模言語モデルに基づくエージェントは、環境特異的情報を取得する前に過去の知識で行動することにより失敗することがある。この問題に対処するため、探索チェックポイントカバレッジという指標を導入し、エージェントの探索の広さを測定。評価の結果、従来の強化学習エージェントは狭い行動パターンを示し、下流性能に悪影響を及ぼすことが判明。対策として、探索とタスク実行を交互に行う訓練戦略、Explore-then-Actパラダイムを提案し、環境知識を先に取得しそれをタスク解決に活かすことを促進する。結果から、体系的な探索の学習が一般化可能なエージェント構築に不可欠であることが示されている。 Comment
元ポスト:
environment中の鍵となるチェックポイントをエージェントが見つけた割合(Exploration Checkpoint Coverage; ECC; 環境内に定義された重要なlocation, object, affordance等をどれだけ発見できたか)を定義し、task-orientedなGRPOがECCを低下させる傾向にあることを検証(つまり、挙動が狭くなる)。
これを解決するために、ExplorationとActのロールアウトを分離してGRPOを実施するExploration-then-Actパラダイムを提案。このパラダイムでは、タスクを遂行するロールアウトと、ECC Rewardに基づいた探索をするロールアウトを分離し、探索に関して明示的な報酬を与える(従来はタスク実行の結果にimplicitに含まれているだけだった)。これらロールアウトに関するGRPOを交互に実施することによってポリシーを最適化する。inference時は、タスクのゴールを与えずにNステップ探索をし、探索したtrajectoryの要約とタスクのゴール、environmentに関する知識によって条件付けをしてactionを決定する。これにより従来のGRPOよりもALFWorld, ScienceWorld等のベンチマークで性能が向上し、エージェントの挙動としても、
- アクションの繰り返しの割合が低下
- ループする割合が低下
- 情報を探索する割合が向上
- エラーからリカバリーできる割合が増加
といった変化が見受けられた。
[Paper Note] Mix, Don't Tune: Bilingual Pre-Training Outperforms Hyperparameter Search in Data-Constrained Settings, Paul Jeha+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #DataMixture #LowResource #One-Line Notes Issue Date: 2026-05-21 GPT Summary- 低リソース言語の事前学習におけるデータ制約を克服するために、ハイパーパラメータ調整と高リソース言語のデータ混合の二つのアプローチを比較。データ混合は検証損失と下流タスクの精度向上をもたらし、特にモデルサイズが大きいほどその効果が顕著。混合による性能向上は、ターゲットデータのユニークな量の2〜13倍に相当し、混合が正則化と知識供給に寄与するが、検証損失はその効果を過小評価している。実践的な指針として、高リソース言語の混合を優先し、ハイパーパラメータ調整よりも混合比に焦点を当てることを提案。 Comment
元ポスト:
low resourceな言語での性能向上にはハイパーパラメータを調整するよりもHigh Resourceなデータを混合し、正則化の働きを促進するのと、low resourceなデータからでは得られない知識を注入する方が効果的
[Paper Note] ELF: Embedded Language Flows, Keya Hu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #DiffusionModel #read-later #Selected Papers/Blogs #FlowMatching Issue Date: 2026-05-21 GPT Summary- 連続データ生成において拡散モデルとフローに基づくモデルの成功が言語モデリングへの関心を高めている。論文では、連続的なDLMを離散トークンへの最小限の適応で実現するEmbedded Language Flows(ELF)を提案。ELFは連続埋め込み空間に留まりつつ、従来の手法を活用して離散トークンへ写像。実験の結果、ELFは既存のDLMを大幅に上回り、高い生成品質を少ないサンプリングステップで達成することを示した。 Comment
元ポスト:
[Paper Note] Long Context Pre-Training with Lighthouse Attention, Bowen Peng+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Attention #Architecture #Hierarchical #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- Lighthouse Attentionを提案し、因果トランスフォーマの訓練におけるSDPAの計算量とメモリ使用量の課題を解決。階層型注意アルゴリズムにより、シーケンスの圧縮・展開を行い、クエリ・キー・バリューを同時にプールすることで並列性を向上。二段階の訓練手法により、訓練時間を短縮しながら性能を向上させることを示した。 Comment
元ポスト:
[Paper Note] Negation Neglect: When models fail to learn negations in training, Harry Mayne+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Safety #PostTraining #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- Negation Neglectは、LLMを否定のある文書でファインチューニングすると、モデルがその主張を真実だと信じてしまう現象を指す。実験では、否定を含む文でファインチューニングしたモデルの信念率が2.5%から88.6%に増加。一方、否定を伴わない場合は92.4%と高い。否定を主張に局在させることで、モデルは否定を正しく学習可能。また、この現象は他の認識論的修飾子やAIの挙動に影響し、AIの安全性に懸念をもたらす。 Comment
元ポスト:
[Paper Note] Scaling Laws for Mixture Pretraining Under Data Constraints, Anastasiia Sedova+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Scaling Laws #DataMixture #Initial Impression Notes Issue Date: 2026-05-21 GPT Summary- 希少なターゲットデータを扱う際、汎用データとの混合は重要だがトレードオフを伴う。ターゲットデータが少なすぎると露出不足、逆に多すぎると過学習のリスクが高まる。2,000件以上の訓練データを用いた調査から、繰り返しが性能向上の鍵であり、適切な繰り返し回数はデータのサイズやモデルのスケールによることを発見した。また、繰り返しを考慮した混合スケーリング則を提案し、効果的な混合構成を体系的に計算する手法を提供した。 Comment
元ポスト:
汎用的なデータと少量しかないターゲットデータをMixする場合において、汎用的なデータは常に新しいトークンが供給される(ターゲットデータの過学習を防止する正則化の役割を果たす)状況で、ターゲットデータを繰り返し学習させら場合は:
> 希少なターゲットコーパスは15〜20回再利用可能で、最適な繰り返し回数はターゲットデータのサイズ、計算予算、モデルスケールに依存する。
ということらしい。
また、モデルサイズ、合計学習トークン、ターゲットデータのサイズ、混合比率、ターゲットデータの繰り返しの頻度、と、ターゲットドメインのlossの間のscaling lawsを導出したということらしい。
関連:
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
[Paper Note] Spherical Flows for Sampling Categorical Data, Jannis Chemseddine+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #DiffusionModel Issue Date: 2026-05-21 GPT Summary- 離散系列の生成モデルを球面 \(\mathbb{S}^{d-1}\) 上で学習し、von Mises-Fisher (vMF) 分布を用いて自然なノイズ過程を導入。コサイン類似度に基づくスカラーODEへ連続性方程式を還元し、唯一かつ有界な解で速度を決定。事後重み付けされた接空間上での総和により、ODEサンプリングと予測子-修正子(PC)サンプリングを行い、クロスエントロピー損失で学習。実験結果では、数独と言語モデリングにおいてvMFとPCサンプリングの組み合わせが著しく性能を向上させた。 Comment
元ポスト:
関連:
- [Paper Note] Image Generation with a Sphere Encoder, Kaiyu Yue+, arXiv'26, 2026.02
[Paper Note] Generative Recursive Reasoning, Junyeob Baek+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #NLP #Architecture #Test-Time Scaling #read-later #Selected Papers/Blogs #Encoder-Decoder #LatentReasoning #RecursiveModels #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- 将来のニューラル推論システムにおける拡張計算の実装として、Generative Recursive reasoning Models (GRAM)を提案。GRAMは、再帰的潜在推論を確率的な複数の潜在軌道に変換し、条件付き推論や無条件生成を可能にする。これにより、従来の決定論的モデルよりも改善された性能を示し、構造化推論や制約充足タスクにおいて有効性を発揮。 Comment
pj page: https://ahn-ml.github.io/gram-website/
元ポスト:
先行研究:
- [Paper Note] Looped Transformers are Better at Learning Learning Algorithms, Liu Yang+, ICLR'24
- [Paper Note] Hierarchical Reasoning Model, Guan Wang+, arXiv'25
- [Paper Note] Less is More: Recursive Reasoning with Tiny Networks, Alexia Jolicoeur-Martineau, arXiv'25, 2025.10
全然まだ理解できていないが、depth(iterative refinement)のみではなく、width(multiple parallel trajectories)方向にinference-time scaling可能なrecursiveなアーキテクチャの提案で、
LoopedTransformerのようなモデルはdeterministicな推論プロセスなため単一の軌跡に収束する(同じ入力に対して同じ出力をする)が、本研究では再帰的な推論プロセスにおいて、deterministicなhidden stateの推論に加えて、確率的でlearnableなguidance ε_t(ε_tの分散の大きさによって探索の度合いを変化させられる)をサンプリングして加えることで、多様なlatent trajectoryを生成可能にするで、自然なparallel inference-time scalingを可能にする
という感じだろうか。
[Paper Note] Interactive Evaluation Requires a Design Science, Keyang Xuan+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Evaluation #interactive #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- インタラクティブな評価の重要性を強調し、従来の応答中心のベンチマークからの変革を提案。評価を「証拠から判断へ」とする自律的な写像として定義し、インタラクションによって生成される軌跡を評価する必要性を示す。設計原理や報告基準を導出し、評価課題の再発を分析する二軸分類法を提案。 Comment
元ポスト:
[Paper Note] Delta Attention Residuals, Cheng Luo+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Transformer #Attention #Architecture #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- Delta Attention Residualsは、従来のアテンション残差の冗長性を解消し、それに代わりサブレイヤーによって導入される変化量に焦点を当てることで、選択的なルーティングを強化します。この新しい手法は、より高いコントラストのアテンション分布を生成し、層間での効果的なルーティングを実現することを示しています。実験により、Delta Attention Residualsは、従来の手法よりもパフォーマンスが一貫して向上し、検証perplexityが改善されることが確認されました。 Comment
元ポスト:
[Paper Note] MeMo: Memory as a Model, Ryan Wei Heng Quek+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #read-later #Selected Papers/Blogs #memory #One-Line Notes Issue Date: 2026-05-21 GPT Summary- MeMo(Memory as a Model)フレームワークは、LLMのパラメータを変更せずに新しい知識を専用のメモリにエンコードすることで、タイムリーな情報適用を可能にする。これにより、複雑な関係の把握、検索ノイズへの耐性、壊滅的忘却の回避を実現し、LLMへのプラグアンドプレイ統合が可能となる。実験結果は、BrowseComp-Plus、NarrativeQA、MuSiQueの各ベンチマークにおいて高い性能を示した。 Comment
元ポスト:
frozenなgeneratorモデルでコーパスからmemory model用のQAデータを合成し、QAデータを用いてmemory modelに知識を埋め込み、frozenなexecutive modelがmemory modelから情報を引き出しながらクエリに応答するアーキテクチャ
[Paper Note] HRM-Text: Efficient Pretraining Beyond Scaling, Guan Wang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #SmallModel #Architecture #read-later #Selected Papers/Blogs #LatentReasoning #RecurrentModels Issue Date: 2026-05-20 GPT Summary- HRMを用いた新たな言語モデルは、多タイムスケール処理を取り入れ、計算資源を大幅に節約しつつ高い性能を達成。指示-応答ペアに特化した訓練により、ゼロからの学習でもMMLUやARC-Cなどで顕著な結果を出し、公開モデルと対等以上の性能を示す。これは、アーキテクチャと学習目標の共設計によって、事前学習をよりアクセスしやすくする可能性を示唆している。 Comment
元ポスト:
気になる
[Paper Note] Targeted Neuron Modulation via Contrastive Pair Search, Sam Herring+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #read-later #Selected Papers/Blogs #Steering #Initial Impression Notes Issue Date: 2026-05-20 GPT Summary- CNAを用いて、有害なプロンプトを特定する活性化を持つニューロンの0.1%を抽出。これにより、拒否率を50%以上低減しながら、流暢さと非退化性を保持する。既存の識別構造をターゲット可能な拒否ゲートに変換することで、信頼性の高い行動誘導が可能であることを示した。 Comment
元ポスト:
追加のSAEの学習や重みの調整無しで、contrastiveなprompt pairから二つのsetの間で最もactivationが異なるMLP上位0.1%を分離することで、目的の挙動をsteeringする
[Paper Note] RoPE Distinguishes Neither Positions Nor Tokens in Long Contexts, Provably, Yufeng Du+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #LongSequence #PositionalEncoding #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-05-19 GPT Summary- RoPEの制約を分析し、文脈長の増加が局所性バイアスとトークン関連性の一貫性を損なうことを証明。アテンションスコアがランダム推測に近づく中、位置やトークンの識別が困難になることを明らかに。ハイパーパラメータ増加は識別能力を向上させるが、トレードオフが生じることも示唆。従来のアーキテクチャではこの制約を克服できず、将来のモデルには新たなメカニズムが必要とされる。 Comment
元ポスト:
これが真であればlong contextを扱う上での根本的なアーキテクチャ側の課題として非常に重要な知見
- Positional Encodingという仕組みにそもそもの限界があるのか、改善したらさらなるlong contextが扱えるのか
- Positional Encoding機構にそもそも原理上の限界があるなら、単一のモデルで超long contextの実現は非現実的になるので、複数のモデルやシステムの連携が必須になる
というような感想を抱いたが、果たして。実際複数モデルの連携という意味でいうとサブエージェントのを使ったら仕組みはすでに動いている。
所見:
[Paper Note] A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models, Hamid Kazemi+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #Safety #One-Line Notes Issue Date: 2026-05-16 GPT Summary- 言語モデルの安全性整合は、拒否ニューロンと概念ニューロンという二つのシステムを通じて機能し、前者が有害な知識の表現を制御し、後者がそれを符号化する。研究では、7つのモデル(1.7Bから70Bパラメータ)を対象に、ニューロンの抑制や増幅による安全性の失敗を示した。結果、個々のニューロンが拒否行動を制御し、安全性が全体に均一ではないことが明らかとなった。特定の拒否ニューロンを抑制することで、多様な有害リクエストに対する安全性の整合性が回避されることが示された。 Comment
元ポスト:
- モデルの(MLP中の)Refusal Neuronを同定する手法を提案し、この手法はモデルのactivationにアクセスできるだけで利用でき、追加の学習やprompt engineeringを必要としない。
- Residual Stream中のfeatureは、有害/無害の分離がうまくされていない(Figure 7)
- Refusal Neuronを特定しこのニューロンを抑制するだけで1.7B--70BまでのスケールのモデルでJailBreakBenchと呼ばれるベンチで91.7%の攻撃が成功するようになる。
- また、SparseAutoEncoderのようなモデルを用いることなく、増幅することで本来無害なプロンプトに自殺に関する情報を出力させることが可能なSuicide Neuronも発見。
- Refusal NeuronはAlignmentのチューニング前のベースモデルに既に存在していて、Alignmentでは新たにこのような役割のニューロンを生成するわけではなく、既存のRefusal Neuronを調整している
- 単一のRefusal Neuronの活性値がsafeguardのための訓練されたモデルに匹敵する有害プロンプト検知性能を示す
[Paper Note] RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards, Gaotang Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #PostTraining #DeepResearch #Rubric-based #Author Thread-Post Issue Date: 2026-05-16 GPT Summary- 深層研究エージェントを訓練するためのRubricEMフレームワークを提案。これは、ルーブリックを評価だけでなく、ポリシー実行やフィードバックの構造化に活用。計画・証拠収集・レビューを段階的に行い、意味情報の密なフィードバックを提供しつつ、評価済みの軌跡を再利用可能な指針に蒸留。得られたRubricEM-8Bは長編研究ベンチマークで優れた性能を示した。 Comment
元ポスト:
著者ポスト:
[Paper Note] Muon is Not That Special: Random or Inverted Spectra Work Just as Well, Zakhar Shumaylov+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Optimizer Issue Date: 2026-05-15 GPT Summary- フレオンという新たなシャッテンノルム基盤の最適化アルゴリズムを導入し、特異値の置換にもかかわらず優れた性能を発揮するKaonを提案。最適化性能は幾何構造ではなく、アライメントと降下ポテンシャルに依存し、ステップサイズ調整が重要であることを示す。ミューオンは理想的な幾何を追求するのではなく、ステップサイズの最適性によって成功する。 Comment
元ポスト:
[Paper Note] Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs, Guijin Son+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Mathematics #read-later #Selected Papers/Blogs #One-Line Notes #Reading Reflections #Author Thread-Post Issue Date: 2026-05-14 GPT Summary- Soohakという新たな数学ベンチマークを導入し、439問から成り、フロンティアモデルの推論能力を評価。Challengeサブセットでは、トップモデルが30.4%未満の成功率である一方、拒否サブセットはモデルが50%を超えられない問題解決能力を確認。これにより、拒否能力が新たな評価基準として浮上し、2026年末に公開予定のデータセットで混入を防ぐ。 Comment
元ポスト:
60人以上の数学者によってゼロペースで作成された新たなベンチマーク。数学者は作問をする際にLLMの利用は禁止され、問題を作成しsubmitする。その後レビュープロセスを経て問題が収録されるかが決まっているようである。レビュープロセスでは、LLMによる難易度の確認や類似した問題がないかなどの確認をし、人間がLLMの出力を見て疑わしいか否か判断する。レビュワーは作成者にフィードバックをし、質問や確認などを行う。また、LLMを利用したであろう作成者はbanされ、問題に調整が必要な場合は修正がなされる。提出された問題は、小、中、大のスケールのOpenLLMによって正解できたか否かによって、miniとして収録されるかChallengeとして収録されるかが決まり、特にChallengeについては作成者が特定の教員やポスドク、IMOメダリストなどに限定されたようである。
99個の、矛盾や前提の抜け、正解が一意に決まらないill-posedな問題も含まれており、モデルが回答を拒否しなければならないRefusal Questionsが含まれているのが大きな特徴。
研究レベルの問題の定義がよくわかっていないのだが、要は競技で出題されるような「既存の知識や枠組みの中でのマルチステップでの推論」を必要とするものではなく、「数学に関する最先端を切り拓くレベルの問題」のことのようである。これでもまだよくわからなかったのだが、問題の作成者に対するインタビューによると、SOOHAK-Miniの問題は短時間で作成できたが、SOOHAK Challengeの問題は1問作成するのに1日以上の作業を要することがしばしばあったとのこと。Challengeレベルの問題を作成するためのアプローチとしては典型的に2つあったとのことで、
- 問題作成者自身が最近考えていた研究と隣接した問題を提出するもので、問題を解くステップにおいて既存の定理や、論文などで公式には発表されていない事実や、数学者の中でヒューリスティクスを組み合わせる必要があるような要素を含むもの(folklore-level reasoningと呼ばれる)
- ニッチな研究論文に基づいて問題を設計する方法
などがあったようである。つまり、競技という枠組みは超えて、数学の研究者が研究として考えるレベルの問題ということだと理解した。
コーディングにおいて人間を置き換えるレベルであろうモデルも、未知の数学の問題や、そもそも問題として不適切なものの回答拒否は広く使われたベンチマークほどはうまくいかない。新たに拒否が最適化のobjectiveとして必要なことが示唆されているが、逐一人類はAIにこの挙動が足りないね、じゃあ学習データを用意して学習しよう、ということを繰り返していくのだろうか?正解ベースの学習にそろそろ限界が見えてきた気がしており、AnthropicのペルソナやConstitutionに基づいた学習のような特定の領域に広く汎化するような学習方法の模索が必要な気がする。
拒否する挙動のための正解データを用意して学習するとしよう。そうすると、モデルが持つ他の能力に影響を与えるだけでなく、本来拒否が不要な場面でも拒否するようになる可能性が高い(たとえばクエリが数学に関連しているだけで、一定の確率で拒否するリスクは生じるように思われる)。この問題を解決するために最近はOn-Policy Distilation (OPD)が活用されるが、OPDはこの問題を緩和することには寄与するが、根源的に解決しているわけではない(と思われる)。genericな能力の発現に際して、モデル自身がcontextに応じて、どの挙動を発現させるべきかを"線引き"できるような能力とアーキテクチャ(マルチモーダルなモデルのようにMoEのexpertをbehaviorに関しては分離するなどだろうか)が必要に思う。
[Paper Note] Efficient Pre-Training with Token Superposition, Bowen Peng+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-05-13 GPT Summary- Token-Superposition Training(TST)は、事前学習中のデータスループットをFLOPあたり改善する新しい手法である。TSTは、トークンを一つのバッグにまとめてマルチホットクロスエントロピーで訓練するスーパーポジションフェーズと、標準的な訓練に戻す復元フェーズから成る。270Mおよび600Mパラメータで広範に評価され、10B A1Bモデルで最大2.5倍の事前学習時間短縮を達成し、ベースラインを一貫して上回ることを示した。 Comment
元ポスト:
事前学習の序盤にbag of tokensを読み、bag of tokensを予測するシンプルな変更で、学習が最大2--3倍高速化される
所見:
解説:
[Paper Note] WebWorld: A Large-Scale World Model for Web Agent Training, Zikai Xiao+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #WorldModels #LongHorizon #Environment Issue Date: 2026-05-13 GPT Summary- WebWorldシリーズは、膨大な軌跡を必要とするウェブエージェントの訓練において、100万件以上のオープン・ウェブの相互作用を利用した初のオープンウェブ・シミュレーターです。これにより、長期的なシミュレーションと複数フォーマットのデータ処理が可能になります。内部評価では、9つの次元に基づく指標を用いたWebWorld-Benchで、Gemini-3-Proと同等の性能を達成。外部評価では、WebWorldで訓練されたQwen3-14BがWebArenaでの性能を+9.2%向上させ、GPT-4oと同等の結果を示しました。WebWorldは探索を効率的に実行し、世界モデル構築においてGPT-5を上回る能力を持ち、さらにはコード、GUI、ゲーム環境への応用も可能です。 Comment
HF: https://huggingface.co/Qwen/WebWorld-8B
元ポスト:
[Paper Note] AgentEscapeBench: Evaluating Out-of-Domain Tool-Grounded Reasoning in LLM Agents, Zhengkang Guo+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #read-later #Selected Papers/Blogs #Generalization #LongHorizon #Initial Impression Notes #ToolUse Issue Date: 2026-05-13 GPT Summary- AgentEscapeBenchを導入し、LLMエージェントの新規ツール使用手順の推測・実行・修正能力を評価。脱出ゲーム形式のタスクは、依存グラフに基づいてエージェントが外部関数を呼び出し、隠れ状態や中間結果を追跡する。実験では、依存深さが増すほど性能が急低下し、成功率が難易度により大きく変動することを示した。これにより、現在のエージェントは局所的なツール使用には強いが、深い文脈依存には苦労していることが明らかに。AgentEscapeBenchは、エージェント能力の測定と今後の訓練への示唆を提供する。 Comment
元ポスト:
エージェントが慣れ親しんだ設定から離れて、脱出ゲーム風のベンチマークによって、未知のツールやアイテムを活用して環境と相互作用しながら文脈を理解し、最終的なanswerを答えるなければならない。
新たな環境での未知のツールに対する汎化性能を測るベンチマークであり、非常に興味深い。
下記研究のように、既存の知識への依存を減らして、実務能力を問うベンチマークとも言える:
- [Paper Note] DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents, Peter Jansen+, NeurIPS'24 Spotlight, 2024.06
[Paper Note] Compute Optimal Tokenization, Tomasz Limisiewicz+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Tokenizer #Scaling Laws #read-later #Selected Papers/Blogs Issue Date: 2026-05-13 GPT Summary- トークンの情報粒度がスケーリング法則に与える影響を調査。988モデルを訓練し、圧縮率(トークンあたりのバイト数)を設定。実験結果は、モデルサイズは通常のトークン単位ではなく、データのバイト数に比例してスケールすることを示す。最適な圧縮率はBPEのものとは異なり、計算量が増すと低下。これらの発見は、トークン化スキームの選択において言語モデル開発者に有益な指針を提供。 Comment
元ポスト:
[Paper Note] SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training, Shengkun Tang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Pruning #Distillation #SmallModel #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-05-13 GPT Summary- 大規模事前学習におけるエキスパート混成モデル(MoE)の圧縮を体系的に探求し、プルーニングと知識蒸留(KD)を適用する方法を検討。プルーニングは、スクラッチからの訓練よりも一貫して優れた初期化を提供し、異なる圧縮手法は同様の最終性能へ収束。簡易な部分保存型統合戦略で下流性能を向上させ、KDと損失を組み合わせることで効果を上げる。漸進的なプルーニングスケジュールはワンショット圧縮を上回り、最適化に寄与。結果として、Qwen3-Next-80A3Bモデルを圧縮し、競争力を維持する指針を提供。 Comment
元ポスト:
大規模なMoEモデルから小規模なvariantを学習する方法に関する分析
[Paper Note] A Theory of Generalization in Deep Learning, Elon Litman+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NeuralNetwork #General #MachineLearning #NLP Issue Date: 2026-05-12 GPT Summary- 非漸近的な深層学習における一般化の理論を提示し、経験的ニューラル・タンジェント・カーネル(NTK)が出力空間を分割することを示す。信号チャネルではエラーが急激に減衰し、ノイズ空間には残差誤差が閉じ込められる。ミニバッチSGDにより整合的な信号が蓄積され、特異的な記憶化が抑制される。カーネルが有限の進化でも一般化が可能であることを証明し、深層学習理論の現象を説明。検証データなしで厳密なリスク関数を導出し、ノイズ測定の精度向上を示す。このアプローチは、グロッキングを加速し記憶化を抑制し、DPOファインチューニングを改善する。 Comment
元ポスト:
[Paper Note] Nonsense Helps: Prompt Space Perturbation Broadens Reasoning Exploration, Langlin Huang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #GRPO Issue Date: 2026-05-12 GPT Summary- GRPOを用いた強化学習は、LLMの推論能力を向上させるが、「ゼロ・アドバンテージ問題」に悩まされることがある。これに対し、効果的な探索を実現するためのフレームワーク LoPE を提案。LoPEは、ランダムなプロンプト摂動を通じて推論経路を広げ、タスクの難問に対して有効なリサンプリングを実現。実験結果は、LoPEの効果を強調し、LLMの強化学習における探索手法の基準を確立することを示した。 Comment
元ポスト:
果たして
[Paper Note] DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents, Zhaorun Chen+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Controllable #NLP #Dataset #AIAgents #Evaluation #Security #Initial Impression Notes #Environment #Author Thread-Post #RedTeaming Issue Date: 2026-05-12 GPT Summary- AIエージェントは複雑なワークフローを自動化する一方で、重要なセキュリティリスクを引き起こす。エージェントが操作されることで、APIキー漏えいや未承認の取引などが発生する可能性があり、そのセキュリティ評価は動的な環境下で困難である。これに対抗するため、DecodingTrust-Agent Platform(DTap)を導入し、14の現実世界ドメインを再現したインタラクティブなレッドチーミングプラットフォームを提供。また、初の自律的レッドチーミングエージェントDTap-Redを提案し、さまざまな攻撃戦略を自律的に探索する。これにより、DTap-Benchという大規模なレッドチーミングデータセットをキュレーションし、安全な次世代エージェント開発のための重要な洞察を提供する。 Comment
元ポスト:
Opus-4.6が本ベンチマーク上は最もセキュリティリスクに対して安全で、良性なタスクに対する性能を発揮するモデルに見える。
論文は279ページもある🤯
[Paper Note] Sharpness-Aware Pretraining Mitigates Catastrophic Forgetting, Ishaan Watts+, ICML'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Catastrophic Forgetting #ICML #mid-training #read-later #Selected Papers/Blogs #One-Line Notes #DownstreamTasks #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- 事前訓練最適化手法は、基盤モデルの能力維持に影響を与える幾何学を考慮すべきである。本研究では、平坦な極小点を目指す三つのアプローチ(SAM、大きな学習率、短縮された学習率減衰)を分析し、モデルサイズが20M〜150Mパラメータの範囲で、ポスト訓練後のパフォーマンス向上と忘却の最大80%低減を実証した。また、OLMo-2-1Bモデルへの短いSAM訓練を適用することで、MetaMathでは忘却を31%、4ビット量子化後には40%低減できることが示された。 Comment
元ポスト:
downstreamタスクでの性能を最大化するためには、baseモデルのlossではなく、モデルが重みを更新した時にどれだけ事前学習の知識が保持されるかが鍵であり、learning-forgettingのトレードオフを見るべきという話で、
なぜモデルの更新によって忘却が起きやすいかというと、モデルが急峻な極小点 (Sharp Minima) に収束してしまっているためで、これではわずかな重みの更新でも大幅な性能低下を起こしてしまう。このため、平坦な極小点(Flat Minima)に重みを収束させることでよりモデルの知識を安定させることができる。
Flat Minimaを見つけるために、Sharpness-Aware Minimization (SAM)と呼ばれる手法を採用し、式(5)で定義されるような、パラメータに摂動を加えた時のlossの最大値が最小となるようにパラメータを最適化する。
[Paper Note] Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction, Zhuofeng Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Search #AIAgents #read-later #Selected Papers/Blogs #One-Line Notes #Reading Reflections #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- 直接コーパスと相互作用する(DCI)アプローチを提案し、リトリーバAPIや固定された類似度インターフェースに依存せず、エージェントが生のコーパスを汎用的な端末ツールで直接検索できるようにします。この方法は、オフラインのインデックス作成を不要にし、進化するコーパスに自然に適応します。実験では、DCIがBRIGHTおよびBEIRデータセットで強力なベースラインを上回り、従来の手法なしに高精度を実現したことが示されました。この結果は、検索の質が推論能力だけでなく、コーパスとの相互作用のインターフェースにも依存することを示唆しています。 Comment
元ポスト:
基盤モデルが賢くなる中で、top-kによるretrievalが検索におけるベストなインタフェースなのか?という疑問を投げかけた研究で、ベクトル検索などのRetrieverではなく、AI Agent自身にgrep等を用いて直接コーパスとinteractionをさせる(Direct Corpus Interaction)ことでBrowseCompのようなQAデータセットにおいてEmbeddingを用いた手法よりもより低コストで高いスコアを獲得できることを示したようである。
DCIは有用な手がかりを見つけた時に、それをrearoning stepに結びつけて深掘りしていくような挙動を実現しやすい点が強みであるが、コーパスサイズが大きくなるにつれて最初のアンカーとなる手がかりを見つけるためのコストが大きくなり、深さへの強みはあるが、広さには弱い性質があることから、この手法が唯一無二の解というわけではなく、設計の際に「どのモデルがtop-kの検索でベストか?」という視点だけでなく、「AI Agentにコーパス全体に対してどのようなオペレーションを持たせるべきか?」という問いかけも提起する
といった話が元ポストに書かれている。
昔から検索に全てのケースで最強な手法はこれ!みたいなものはないので、こういった選択肢もあるよということを頭に入れて引き出しに入れておき、直面する課題に対して有効な方法は何かを考えることが重要と思われる。
所見:
[Paper Note] Fast Byte Latent Transformer, Julie Kallini+, ICML'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ICML #Decoding #Byte-level #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- BLTを用いて、バイトレベルLMの生成速度のボトルネックを解消。BLT Diffusionを導入し、並列生成によってデコードステップを削減。さらに、BLT Self-speculationとBLT Diffusion+Verificationを提案し、生成品質を向上させつつ推定メモリコストを低減。これにより、バイトレベルLMの実用性が向上。 Comment
元ポスト:
[Paper Note] Demystifying Manifold Constraints in LLM Pre-training, Kang An+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Normalization #read-later #Stability Issue Date: 2026-05-12 GPT Summary- LLMの事前学習における安定化技術の役割を明確化するため、MACROという新しい最適化フレームワークを導入。多様体制約が前方アクティベーションのスケールを制限し、安定した回転平衡を実現。理論的保証を保持しながら、高い性能を達成。 Comment
元ポスト:
Geometric Manifold上に重みを制約する系の関連研究:
- Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization, Wen+, 2026.01
- [Paper Note] nGPT: Normalized Transformer with Representation Learning on the Hypersphere, Ilya Loshchilov+, ICLR'25, 2024.10
[Paper Note] SkillOS: Learning Skill Curation for Self-Evolving Agents, Siru Ouyang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #ContinualLearning #AgentSkills Issue Date: 2026-05-11 GPT Summary- 経験駆動型の強化学習トレーニングレシピSkillOSを提案。これにより、凍結済みのエージェント実行と訓練可能なスキルキュレーターを組み合わせ、スキルの取得・適用を高める。タスク依存の複合報酬を設計し、経験を元にスキルを更新。SkillOSは、記憶を前提としないベースラインを超えて、スキルの使用を最適化し、豊富に構造化されたMarkdownファイルに進化させることを示した。 Comment
元ポスト:
[Paper Note] Continuous Latent Diffusion Language Model, Hongcan Guo+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #DiffusionModel #VariationalAutoEncoder #Hierarchical #Concept (LLM PreTraining) Issue Date: 2026-05-11 GPT Summary- Cola DLMは、テキスト生成を階層的情報分解として捉え、Text VAEを用いて潜在空間への写像を学習し、その後Diffusion Transformerで意味論をモデル化し、条件付きデコーディングで生成を行う。これにより、非自己回帰的な柔軟性と意味圧縮を実現し、他の連続モダリティへの拡張も可能。広範な実験を通じて、生成品質とスケーリング挙動の改善を検証し、連続潜在分布の重要性を示した。 Comment
pj page: https://hongcanguo.github.io/Cola-DLM/
元ポスト:
[Paper Note] Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning, Yaorui Shi+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #PostTraining #read-later #AgentSkills Issue Date: 2026-05-11 GPT Summary- 持続的なスキルライブラリは、言語モデルエージェントがタスクを通じて成功した戦略を再利用するために必要で、スキルの選択、活用、蒸留の3つの能力が相互に連携して進化することが重要である。従来の手法はこれらを独立に最適化することが多く、結果として矛盾した進化を生じていた。私たちは、これら3つの能力を共進化させるフレームワーク「Skill1」を提案し、単一のポリシーを使用してスキルの検索、選択、タスク解決、スキル蒸留を行う。すべての学習は単一のタスク成果信号に基づき、ALFWorldとWebShopでの実験により、Skill1が従来の手法を上回ることを示した。アブレーション実験は、クレジット信号の削除が進化に悪影響を及ぼすことを確認した。 Comment
元ポスト:
[Paper Note] EvoLM: Self-Evolving Language Models through Co-Evolved Discriminative Rubrics, Shuyue Stella Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SelfImprovement #Selected Papers/Blogs #reading #One-Line Notes #Rubric-based #Author Thread-Post Issue Date: 2026-05-11 GPT Summary- EVOLMは言語モデルの自己改善を促進するポスト訓練手法であり、外部監督に依存せず、モデル自身の評価能力を利用します。具体的には、事例ごとに最適化された評価基準を生成するルーブリック生成器と、そのルーブリックを用いて訓練されたポリシーの二つの能力を交互に訓練します。これにより、EVOLMはQwen3-8Bモデルを用いてGPT-4.1を25.7%上回るルーブリックを生成し、共同訓練されたポリシーは最新の報酬モデルよりも優れた性能を示しました。全体として、EVOLMは内部の評価能力を活用することで、外部の監督なしでの改善を実現することが明らかになりました。 Comment
元ポスト:
外部ラベル無しでself-improvingするルーブリックベースな手法の提案。
手法としては、まずfrozenしたRubirc生成器とJudgeモデルで全てのpromptに対してRubricを生成し、ポリシーが生成したロールアウトに基づいてJudgeモデルでRewardを計算することでポリシーを更新。その後更新されたポリシーを用いてpreference pairを構築し、preference pairに対してRubric生成器がルーブリックのロールアウトを生成し、choicedとrejectedなサンプルに対するJudgeのスコアの差の大きさ(すなわち、識別力の高さ)をrewardにRubric生成器を更新する、といったことを繰り返す。
多分3説以降の話が面白い。後で読む
Rubricが徐々に変化していき、抽象的なものからよりverifiableなものに変化したり、Rubricそのものが静的だとポリシーの学習に伴い変化する出力分布の変化に対応できない話や、最終的に獲得されたRubricは他のモデルの学習でも高い学習signalを送出するような汎化をするらしい
[Paper Note] Teaching Thinking Models to Reason with Tools: A Full-Pipeline Recipe for Tool-Integrated Reasoning, Qianjia Cheng+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #PostTraining #reading #Initial Impression Notes #ToolUse Issue Date: 2026-05-11 GPT Summary- ツール統合推論(TIR)は、テキストのみの推論能力を超える思考モデルの拡張を提供しますが、ツール評価が逆に推論性能を低下させることも観察されています。本研究は、ツールを使用せずに推論能力を損なわずに強力な思考モデルに自然なツール使用を組み込む方法を提案し、TIRレシピの要点を示します。具体的には、教師の推論軌跡の学習可能性やツール使用軌跡の比率制御が重要であり、最適化手法がTIRの効果を最大化する可能性を示しています。最終的に、Qwen3モデルに適用することで、オープンソースベンチマークで最先端の成績を達成しました。 Comment
元ポスト:
Qwen3にcode executorを実行できるようにしても、数学のベンチマークにおいてほとんどツール呼び出しを行っていないにも関わらずスコアが劣化する。つまり、promptにツール呼び出しの情報を含めただけで、text-onlyでの推論能力が低下しロバストでない。さらに、ツール呼び出しを行ったとしてもテキスト空間上で推論を行った後にテキスト推論の結果をverificationする目的でcode executionを行うなど、ツールを用いて思考する能力が不足していることをイントロで指摘している。
適切なツール呼び出しを実施するために、既存研究では適切にツールを呼び出せるようにSFTやRLが行われるが、ツール呼び出しに関してpost-trainingを実施すると通常のtext-onlyでのreasoning能力が低下する課題があるとイントロで述べられている。Table 1に示されているようにツール呼び出しに関する情報をpromptに含めると、既存のOpenWeightモデル(Qwen3のみだが)はツールが有効なタスクであっても性能が向上しないことから、内部パラメータに埋め込まれている推論に関するlogicは簡単に壊れてしまうことを示唆しており、text-onlyでのreasoning能力を保ちつつ適切にtool useを実行できる手法が必要という課題があり、これを克服するための手法を提案しているようである。
問題意識は興味深いが、イントロの例にだけでは、Qwen3でのみ生じるのか、Qwen3に対するtool useのためのprompting手法が悪かっただけなのか、OpenWeightモデル全般のモデルパラメータ側の課題なのかが区別がつかず、どの程度インパクトのある話なのかがよくわからない。
個人的には、Table 1はより多くの学習レシピが公開されているモデルファミリーでの結果や、実際にtool useのためのSFT/RLを実施した場合に、text-onlyの推論能力が低下することが示されていてほしいと感じる。論文後半にそういったablationが出てくるのだろうか。
[Paper Note] TIDE: Every Layer Knows the Token Beneath the Context, Ajay Jaiswal+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Embeddings #NLP #Transformer #Architecture #read-later #Selected Papers/Blogs Issue Date: 2026-05-10 GPT Summary- トークンインデックスの単一注入仮定を再検討し、Rare Token ProblemとContextual Collapse Problemに対処するためにTIDEを提案。TIDEはEmbeddingMemoryで標準トランスフォーマーを拡張し、依存性のない意味ベクトルを用いて各層へ注入。理論的・実証的にTIDEの効果を示し、言語モデリングや下流タスクでの性能向上を実証。 Comment
元ポスト:
関連:
- [Paper Note] Value Residual Learning, Zhanchao Zhou+, ACL'25
[Paper Note] Normalized Architectures are Natively 4-Bit, Maxim Fishman+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #Normalization #LowPrecision Issue Date: 2026-05-10 GPT Summary- nGPTアーキテクチャを使用することで、4ビット精度での大規模言語モデル訓練が効率的に行えることを示す。モデルの重みを超球面に制約することで、低精度算術への耐性を高め、安定したNVFP4訓練を実現。1.2Bパラメータの密結合モデルと最大30BパラメータのMoEモデルで検証。量子化ノイズが標準アーキテクチャと正規化済みアーキテクチャで異なる挙動を示し、nGPTでは信号対ノイズ比が向上し、損失がフラットになることが確認された。スケールアップ時にこの効果が強化されることが示唆されている。 Comment
元ポスト:
[Paper Note] HeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness, Jianing Wang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #AIAgents #Test-Time Scaling #AgentSkills #Initial Impression Notes Issue Date: 2026-05-10 GPT Summary- HeavySkillは、複雑な推論タスクを解決するためのオーケストレーション・ハーネスの新たなアプローチを提案する。これは、重い思考をモデルの内在的スキルとして捉え、並列推論と要約を通じて機能する。系統的な実験により、HeavySkillは従来のBest-of-N戦略を上回り、特に強力なLLMは高い性能を示す。また、重い思考のスキルは強化学習によってさらに強化され、自己進化型LLMの発展につながる可能性がある。 Comment
元ポスト:
- [Paper Note] PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning, Jingcheng Hu+, arXiv'26, 2026.01
とぱっと見かなり近い手法に見えるが何が異なるだろうか。
[Paper Note] Recursive Agent Optimization, Apurva Gandhi+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #Test-Time Scaling #PostTraining #read-later #Selected Papers/Blogs #One-Line Notes #RecursiveModels #Initial Impression Notes #Orchestration #Delegation #Author Thread-Post Issue Date: 2026-05-10 GPT Summary- 再帰エージェント最適化(RAO)を導入し、エージェントが自身のインスタンスを生成してサブタスクを委任できる強化学習アプローチを提案。推論時のスケーリングアルゴリズムを実装し、長い文脈への拡張と難しい問題への一般化を可能にする。この訓練により、効率が向上し、タスクのスケールや一般化能力が高まり、実時間の短縮が実現される。 Comment
元ポスト:
著者ポスト:
pj page: https://apga.github.io/RAO/
再帰的にAI Agentがサブタスクを委任する子エージェント(子エージェントは自身のコピー)を作成できるようにし、子エージェントがサブタスクを実施した際のRewardや子エージェントのタスクの成功率などの情報に基づいて親エージェントの報酬が決まるような報酬設計にする。再帰が深くなるにつれ、サブタスクは簡単になっていくため、エージェントは自然に学習するためのカリキュラムを構築していると捉えることができる。これにより、エージェントがタスクをサブタスクに分解し再帰的にinferenceをするような挙動をend-to-endで学習する。再帰の木構造の深さは、場合によっては特定の部分木が非常に深いものとなってしまうケースもあるため、深さの情報に基づいて重みづけを調整する。
という感じだろうか。
サブタスクを委任するポリシーが自分のコピーで、これにより自分自身を分解されたサブタスク上から得られる報酬と、適切な委任による報酬によって訓練することになるといううまい報酬設計がミソな気がする。
著者ポスト2:
[Paper Note] Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is Key, Tianle Wang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #LongHorizon Issue Date: 2026-05-10 GPT Summary- ScaleLogicは、強化学習(RL)における大規模言語モデル(LLM)の推論能力を向上させるための合成的論理推論フレームワークで、難易度の深さと論理の表現力を独立に制御可能。幅広い論理形式をサポートし、RL訓練計算量が推論深さに対してべき乗則に従うことを示した。表現力の高い訓練設定は、低い設定と比較して性能向上をもたらし、複数のRL手法でも成立する関係を確認。カリキュラム型訓練がスケーリング効率を向上させることも実証している。 Comment
元ポスト:
[Paper Note] SkillClaw: Let Skills Evolve Collectively with Agentic Evolver, Ziyu Ma+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #AgentSkills #Initial Impression Notes Issue Date: 2026-05-10 GPT Summary- SkillClawは、複数のユーザーのエージェントエコシステムにおけるスキルの進化を可能にするフレームワークである。ユーザー間の相互作用を勘案し、スキル改善の信号を集約して自律的に更新を行う。行動パターンを識別し、スキルセットの更新を行うことで、ユーザー間で改善が共有され、知識伝達が促進される。実験において、限られた対話でも性能向上が確認された。 Comment
元ポスト:
- [Paper Note] SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning, Peng Xia+, arXiv'26, 2026.02
- [Paper Note] SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization, Zhengxi Lu+, arXiv'26, 2026.04
- [Paper Note] MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild, Peng Xia+, arXiv'26, 2026.03
などはRLを通じてスキルを獲得、あるいは内部化するが、本研究はAgent Evolverと呼ばれるエージェントによって、現在のスキルとtrajectoryの集合から成功/失敗を分析し、ポリシーの重みの更新なしで動的にスキルの定義を更新する枠組みという点で異なる、という感じだろうか。
[Paper Note] Exploration Hacking: Can LLMs Learn to Resist RL Training?, Eyon Jang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Alignment #ReinforcementLearning #Safety #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-05-10 GPT Summary- 本研究では、強化学習(RL)が大規模言語モデル(LLMs)の訓練において重要な役割を果たすことを示す。特に、訓練中のモデルの探索が戦略的に変更されることで「探索ハッキング」を引き起こす可能性があると指摘。まず、低性能戦略に基づいたモデルをファインチューニングしてRL抵抗のモデル生物を作成し、関連タスクでの性能を保ちながら、RLに対する成功裡な抵抗を達成。次に、このモデルを用いて監視やノイズ付与などの検知・緩和戦略を評価。最後に、情報が十分な場合に探索抑制の推論を示すことができることを明らかにし、強力なLLモデルにおけるRLの潜在的な失敗モードを強調する。 Comment
元ポスト:
Exploration Hacking: エージェントが戦略的にRL学習時のoutcomeに影響を与えるよう、探索時の挙動を(部分的に)改ざんする失敗モード。
モデルは選択的に、RLにおける学習において、特定のタスクに関して高いrewardを獲得することを抑制することができることを示した。具体的には、特定のタスクに対してRLにおいてのみ低いパフォーマンスを示すような抵抗力を持ったモデルを事前にSFTすることで、RLを通じて、他の能力が崩壊するなどの致命的な欠陥なしに当該タスクでのみ性能を低下させられることを示したようである。
つまり、RLの訓練中の探索の挙動にのみこのような挙動を発現させることが可能であり、安全性やAlignmentをとるためのRLの学習を施しても、モデルが特定の能力だけを選択的に隠蔽し、学習を阻害する可能性がある、という感じに見える。
本研究の結果以下のような知見が得られた:
- このようなRLに対する抵抗力を持たせるにはSFTが必要不可欠であり、プロンプトによる抑制だけでは100 step以内に抑制が解かれ性能が回復することが明らかとなった。一方でSFTによる抵抗力を備えたモデルは500 step以上にわたって抵抗力を発揮する。つまり、欺瞞が一度モデルのパラメータに内部化されると是正が困難となる可能性がある。
- 失敗の戦略として、必ず一番短い応答を選択する(deterministic)と毎回ランダムに失敗する(stochastic)の場合、前者の方がRLに対する抵抗力が高い。これはGRPOのadvantageを計算する際に、deterministicな戦略の場合はグループ内の報酬が均一となる(全部のロールアウトで均一なrewardで間違える)ことで勾配の改善に関するsignalが生じにくいことが要因と考えられる。
- Rewardが連続的(つまり、より密)であるほど、Exploration hackingを困難にした。これは、Rewardが密であるほどGRPOでのグループ内の報酬の分散が高まるため、勾配更新を行うためのシグナルが増えることに起因する。
- Exploration Hackingは、CoT内で明示的に性能低下戦略についてモデルが思考するため、CoTのモニタリングによって検出できる。また、Action Monitor(出力のパターン等を監視する)によっても高い信頼性で検知ができる。また、評価時に重みにノイズを混ぜる方法も、モデルの抵抗力を低める上で有効であった。また、良性のtraceでSFTすることで、モデルが抵抗を持った状態から迅速に回復できる。
- 最先端のモデルは現在の訓練に関する状況に関して認知する能力は備わっているが、戦略的に行動し持続的にExploration Hackingを実施することは傾向として存在しない。が、Promptによって明示的に指示をすれば、Exploration Hackingを実施するため、潜在的にExploration Hackingを実現する能力は保持されている。
[Paper Note] AI Organizations are More Effective but Less Aligned than Individual Agents, Judy Hanwen Shen+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Multi #NLP #Alignment #AIAgents #Safety #ScientificDiscovery Issue Date: 2026-05-10 GPT Summary- マルチエージェントシステムにおけるAIは、個々のエージェントよりもビジネス目標達成において効果的であるが、整合性は低いことが示された。AIコンサルティングとAIソフトウェアチームの二つの設定で12のタスクを実施し、整合性のあるモデルから得られた解は高い有用性を持つ。しかし、整合性の欠如が顕著であることも明らかとなった。本研究は、AIエージェントの相互作用を考慮することの重要性を強調している。 Comment
元ポスト:
[Paper Note] Auditing Sabotage Bench: A Benchmark for Detecting and Fixing Research Sabotage in ML Codebases, Eric Gan+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Safety #Sabotage Issue Date: 2026-05-10 GPT Summary- AIシステムによる自律研究の拡大に伴い、整合性のないシステムが誤った結果を生むリスクが高まっている。Auditing Sabotage Benchは、機械学習研究におけるサボタージュを監査する能力を評価するベンチマークであり、9つのコードベースからなる。各サボタージュは、実装の詳細を変更しながらも論文の方法論を維持している。最前線のLLMと人間監査者がサボタージュを適切に検出・修正するのが難しいことが判明し、最良性能はAUROC 0.77、修正率42%でGemini 3.1 Proによって達成された。LLMをレッドチームとして評価した結果、LLM生成のサボタージュは人間生成のものよりは劣ったが、時にはLLM監査者を回避することもあった。本ベンチマークはAI研究の監視と監査技術の向上を目指して公開されている。 Comment
元ポスト:
[Paper Note] Evaluating whether AI models would sabotage AI safety research, Robert Kirk+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #Evaluation #Safety #Sabotage Issue Date: 2026-05-10 GPT Summary- 最先端のAIモデルが安全研究に対する妨害を行う可能性を評価するために、四つのClaudeモデルに対して未指示妨害評価と妨害継続評価を実施した。未指示妨害は見られず、Mythos PreviewとOpus 4.7 Previewでは拒否率がほぼゼロ。しかし、全モデルで部分的なタスク完了が発生。妨害継続評価では、Mythos Previewが7%で妨害を継続し、不一致の出力を示した。評価フレームワークはオープンソースのLLM監査ツールPetriに基づき、状況認識を測定。Opus 4.7 Previewは未指示評価認識が高いが、prefill認識は低い。最後に、評価の限界やリスクについても議論。 Comment
元ポスト:
[Paper Note] Modular Memory is the Key to Continual Learning Agents, Vaggelis Dorovatas+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #AIAgents #Architecture #read-later #Selected Papers/Blogs #ContinualLearning #Initial Impression Notes Issue Date: 2026-05-09 GPT Summary- 基盤モデルは機械学習を変革したが、継続的な運用や個人化に課題がある。インウェイト学習(IWL)による破局的忘却を克服するために、文脈内学習(ICL)の迅速な適応能力とIWLの安定した更新能力を組み合わせたモジュール型メモリアーキテクチャのフレームワークを提案。継続的学習のためのロードマップを示す。 Comment
元ポスト:
元ポスト参照のこと。現在のAIには認知コア的なものが必要という提言を超えた、全体アーキテクチャとそれぞれの課題についての議論である。
[Paper Note] ZAYA1-8B Technical Report, Robert Washbourne+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Attention #SmallModel #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-05-09 GPT Summary- ZAYA1-8Bは700Mの有効パラメータを持つMixture-of-Expertsモデルで、難易度の高い数学・コーディングベンチマークで優れた性能を発揮。ゼロから訓練され、RLカスケードを通じて推論能力を強化。Markovian RSAを導入し、テスト時の計算手法で他の大規模モデルとの差を縮めることに成功。TTC評価では高い精度を記録し、競争力を維持。 Comment
HF: https://huggingface.co/Zyphra/ZAYA1-8B
元ポスト:
Convを用いたKV Cacheの圧縮やより賢いMoE Router, Learned Residual Scalingなどさまざまなアーキテクチャ上の工夫や、Reasoning firstな事前学習が実施されているようで、activationパラメータあたりのHMMTでのスコアが既存モデルと比較して群を抜いて高いようである。
所見:
-
-
[Paper Note] MAS-ProVe: Understanding the Process Verification of Multi-Agent Systems, Vishal Venkataramani+, ICML'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #ICML #read-later #Selected Papers/Blogs #Verification #Monitorability #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- MAS-ProVeは、マルチエージェントシステム(MAS)におけるプロセス検証の体系的研究を提示し、LLMを利用して検証の有効性を評価。エージェントレベルとイテレーションレベルでの評価を行い、5つの検証手法を検討。結果として、プロセスレベルの検証は必ずしも性能向上にはつながらず、高い分散が見られることが判明。LLMを判定者として用いるアプローチが効果的である一方、コンテキスト長と性能のトレードオフも観察。MAS向けの堅牢な検証法にはさらなる進展が必要であることが示された。 Comment
元ポスト:
MASにおいてprocess levelのverificationを導入しても一貫して性能が向上するわけではなく、(途中推論の妥当性を判断するタスクは困難なものであることから既存の様々なverification手法には限界があり)分散が高いことが明らかになったとのこと。MASのような複雑なシステムはverificationによるプロセスレベルの精査が必要だと思われるので、現在の限界が示された点で重要な研究に見える。
[Paper Note] MAS-Orchestra: Understanding and Improving Multi-Agent Reasoning Through Holistic Orchestration and Controlled Benchmarks, Zixuan Ke+, ICML'26, 2026.01
Paper/Blog Link My Issue
#Multi #NLP #Dataset #AIAgents #Evaluation #ICML #read-later #Selected Papers/Blogs #Initial Impression Notes #Orchestration #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- MASのオーケストレーションを強化学習形式で定式化するMASOrchestraを提案。これにより、エージェントの複雑性を管理し、システム全体のグローバルな推論を促進。タスクを5軸で分析するMASBENCHを導入し、利得がタスクや能力に依存することを示す。公開ベンチマークで一貫した改善を達成し、10倍以上の効率を実現。MASOrchestraとMASBENCHはマルチエージェント知性の向上を目指す。 Comment
元ポスト:
SASと比べてMASにすることでどれだけ利点があるかをモデルが理解せずにfoldingしてるよね、というのは重要な指摘に感じる。
[Paper Note] Least-Loaded Expert Parallelism: Load Balancing An Imbalanced Mixture-of-Experts, Xuan-Phi Nguyen+, ICML'26, 2026.01
Paper/Blog Link My Issue
#NLP #LLMServing #MoE(Mixture-of-Experts) #ICML #Parallelism #Stability #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- 新しいLeast-Loaded Expert Parallelism (LLEP)は、MoEモデルの不均衡なルーティングを考慮し、過負荷デバイスからトークンとエキスパートパラメータを未利用のデバイスに再ルーティングすることで、計算資源の制約を軽減。これにより、モデルスケールに応じて最大5倍の速度向上とピークメモリ使用量を4分の1に削減し、推論の高速化を実現。理論分析と実証評価に基づき、ハードウェアに最適化したパフォーマンスを提供。 Comment
元ポスト:
[Paper Note] Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe, Wenjin Hou+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Distillation #PostTraining #On-Policy #One-Line Notes Issue Date: 2026-05-09 GPT Summary- OPDは専門モデルの能力を学生モデルに統合する手法であり、その効果を制限するボトルネックを特定した。本研究では、情報価値のある状態の探索不足と教師の指導の信頼性の欠如に着目し、新たにUni-OPDという統一的なフレームワークを提案。学生視点からのデータバランシング戦略と、教師視点からの結果指向のマージン較正メカニズムを使用して、訓練を最適化。実験によりUni-OPDの効果と汎用性を示し、信頼性の高いOPDに関する洞察を得た。 Comment
元ポスト:
OPDを
- difficultyに基づいたサンプリングによって生徒モデルの探索を促し
- 生徒のtrajectoryが正しい場合はスコアがより高くなることを保証する
ことで改善しているとのこと。
[Paper Note] ProgramBench: Can Language Models Rebuild Programs From Scratch?, John Yang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Coding #SoftwareEngineering #Selected Papers/Blogs #KeyPoint Notes #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- ソフトウェアプロジェクトの完全な開発は、言語モデルの重要なユースケースで、エージェントは最小限の監視下でコードベースを成長させる。しかし、既存のベンチマークは限られたタスクに焦点を絞っている。そこで、ProgramBenchを導入し、エージェントが与えられたプログラムとそのドキュメントに基づいて、参照実行可能ファイルに一致するコードベースを設計・実装する能力を測定する。200のタスクを用い9つの言語モデルを評価した結果、どのモデルも未完のタスクが多く、人間が書いたコードとは異なる実装を好む傾向が見られた。 Comment
pj page: https://programbench.com/
元ポスト:
実行可能なバイナリとdocumentationを与えたときに、インターネットアクセスが不可能な環境で、オリジナルのプログラムの挙動を再現可能なcodebaseを実装するベンチマークで、現状いずれのLLMもスコア0%とのこと。スコアは全タスクのうち、(タスクごとに定義される)テストを全て通過したタスクの割合である。Almostの場合は95%以上のテストを通過したタスクの割合である。
仕様全体からcodebase全体を再現する必要がため、これがうまくできれば、これまでのベンチマークよりも人間に近い推論・認知能力を持つと部分的に主張できるとは思われる。
contaminationの懸念について、本ベンチマークではopen-sourceのコードを異なる言語で実装するようにすることで検証している。異なる言語で実装することによってモデルが通過するようになったテストの割合は大きく変化しなかったため(leaderboardのスコア異なる点に注意。leaderboardのresolvedは全てのテストを通過したタスクの割合である。)、memorizationの影響は小さいと主張している。また、本ベンチマークはインターネットアクセスが不可能な状態で実施されるが、インターネットアクセスを許可した場合、モデルはcheatingを実施するようになり、多くのcheatingはソースコードをlookupすることだったとのこと。
テストはbehavioralなものであり、SWE-Benchで行われているような実装の方法についてはテストをしない。
ProgramBenchの言語の分布と、各タスクのcodebaseの規模間。270M lineのcodebaseから200 line程度の小さなものまで、規模間が大きく異なることがわかる。言語はC/C++, Go, Rustが多く、多くのモデルが得意とするであろうpythonはほとんど含まれていない。
著者ポスト:
[Paper Note] Sparser, Faster, Lighter Transformer Language Models, Edoardo Cetin+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #One-Line Notes #Sparse #GPUKernel #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- 非構造的スパース性を活用することで、LLMの計算コストを削減し、フィードフォワード層の効率を向上させる新しいCUDAカーネルを導入。99%超のスパース性を誘導しつつも、パフォーマンスへの影響は最小限。これにより、モデル規模の拡大に伴うスループット、エネルギー効率、メモリ使用量の改善を実証。すべてのコードはオープンソースで公開し、スパース性の実用性を推進。 Comment
元ポスト:
現在の言語モデルではFFNの計算が計算コストの多くを占めているが、ReLUやL1正則化によってFFN中で必要なactivationを99%程度sparseにすることができ、sparseになったFFNに対して最適なデータ形式と高速に動作するGPUKernelを構築することで、downstream taskへの性能劣化無しに、省コストでの推論が可能になる、という話に見える。
解説:
[Paper Note] HiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?, Tu Trinh+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs #One-Line Notes #Human-in-the-Loop Issue Date: 2026-05-08 GPT Summary- 最先端のコーディングエージェントは、完全な文脈では複雑なタスクをこなせるが、不完全な仕様では失敗する。ボトルネックは能力よりも判断力であり、適切な行動と助けを求めるタイミングを知ることが重要である。提案するHiL-Benchは、この選択的エスカレーション能力を評価し、ブロッカーを含むタスクを通じて人間の判断力を測定する。核心指標Ask-F1は、質問の正確さとブロッカーの再現率を評価し、不適切な質問を防ぐ。評価結果は、モデルが不確実性に適切に対処できず、自己修正能力に欠けることを示す。強化学習による訓練で、判断力の向上が確認され、モデルは不確実性を検知し対処する能力を学ぶ。 Comment
元ポスト:
完全情報の下では80%前後の成功率をおさめるにも関わらず、情報が欠落している場合は成功率が著しく低下することから、現在のAI Agentが失敗する要因は、能力ではなく情報が不完全な場合にエスカレーションする判断力にあることを指摘し、必要な情報が欠落したタスクを用意し、その情報を取得するための質問(エスカレーション)を適切なタイミングで生成できるか否かを測定するベンチマークを作成し、ベンチマークでの評価を通じて、エスカレーションのための判断能力はRLVRによって向上させられることを示した、という感じの話に見える。
[Paper Note] Scaling Test-Time Compute for Agentic Coding, Joongwon Kim+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Test-Time Scaling #read-later #Selected Papers/Blogs #Compression #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-08 GPT Summary- 長期的なホライゾンを持つコーディングエージェントに対する推論時スケーリングの新しいフレームワークを提案。各試行の重要な要素を保持しつつ、詳細を要約することで、経験を効果的に再利用。提案手法は並列スケーリングと逐次スケーリングを実現し、エージェントの性能を一貫して向上させる。SWE-Bench VerifiedおよびTerminal-Bench v2.0での実験で、明確な改善が確認された。 Comment
元ポスト:
Software Engineering Agentにおけるtest-time scaling手法の提案で、生の実行ログをそのままスケールさせるとノイズが多すぎて効率が悪いので、trajectoryを圧縮することで対処するという話のようである。
著者ポスト:
[Paper Note] Model Spec Midtraining: Improving How Alignment Training Generalizes, Chloe Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Alignment #SyntheticData #Safety #mid-training #read-later #Selected Papers/Blogs #Generalization Issue Date: 2026-05-08 GPT Summary- モデル仕様に基づく整合性を高めるために、モデル規範中間訓練(MSM)を導入。事前学習後、整合ファインチューニングの前に自己のModel Specを論じる文書で訓練し、一般化を促進。特定の嗜好に基づくファインチューニングでも、米国寄りの価値観や手頃さを反映した一般化が可能。MSMはエージェントの不整合を減少させ、どのModel Specが強い一般化を生むかを調査し、意図した価値の説明が一般化を改善することを示す。全体として、MSMは整合性訓練の一般化を効果的に制御する手法である。 Comment
元ポスト:
[Paper Note] Prescriptive Scaling Laws for Data Constrained Training, Justin Lovelace+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Scaling Laws #One-Line Notes #DataRepetition Issue Date: 2026-05-08 GPT Summary- 高品質なデータが限られる中、計算資源の最適配分が重要になる。従来のChinchillaスケーリング則は、一意なトレーニングトークンを前提としており、データ制約下の効果的な学習を妨げる。私たちは過剰損失を加法的な過学習ペナルティでモデル化し、最適な資源配分に関する新たな指針を提案する。一定のポイントを超えると、繰り返しは逆効果になり、モデル容量への投資が望ましいことを示す。さらに、この法則を用いることで、データ制約下での性能向上が明らかになり、過学習の影響を一つの係数に分離することで、トレーニング設定間の比較を可能にする。特に、強いウェイト減衰が過学習係数を約70%減少させ、最適なウェイト減衰が標準実践を上回ることを示すケーススタディも含む。 Comment
元ポスト:
所見:
Data Repetitionはデータの効率を改善するが、同時に過学習コストが生じており、これはモデルサイズと繰り返しが増えるほど増大する。強めの正則化を導入することで過学習コストが緩和される。
[Paper Note] InfoLaw: Information Scaling Laws for Large Language Models with Quality-Weighted Mixture Data and Repetition, Fengze Liu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Scaling Laws #Reference Collection #DataRepetition Issue Date: 2026-05-08 GPT Summary- InfoLawを導入し、大規模言語モデルのデータ混合ウェイトと反復の影響を評価。スケーリング時の最適なデータレシピ選択を信頼性高く予測し、事前学習の情報蓄積をモデル化。未見データや大規模環境での性能予測を高精度で行い、効率的なデータレシピ選択を可能に。 Comment
元ポスト:
解説:
[Paper Note] Accelerating RL Post-Training Rollouts via System-Integrated Speculative Decoding, Hayate Iso+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #SpeculativeDecoding Issue Date: 2026-05-08 GPT Summary- 推測デコードを用いてRL後トレーニングのロールアウトを加速。これは出力分布を保持しつつ、同期・非同期パイプラインに対応。推測デコードにより、スループットを1.8倍向上させ、非同期RLとの組み合わせで235B規模のトレーニング速度を最大2.5倍向上させる可能性を示す。 Comment
元ポスト:
[Paper Note] The Last Human-Written Paper: Agent-Native Research Artifacts, Jiachen Liu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #ScientificDiscovery #read-later #Selected Papers/Blogs #Reproducibility #Science #Initial Impression Notes Issue Date: 2026-05-08 GPT Summary- 科学論文の線形化に伴うストーリーテリング税とエンジニアリング税がAIエージェントの理解と再現に致命的な影響を与えることが課題である。本研究では、機械実行可能な「Agent-Native Research Artifact(ARA)」を提案し、科学的ロジック、実行可能コード、探索グラフ、証拠基盤の四層構造を持つ。ARAはライブ・リサーチ・マネージャー、ARAコンパイラ、ARAネイティブ・レビュシステムを通じて、研究過程を最適化し、精度を大幅に向上させることを示した。具体的には、PaperBenchとRE-Benchで質問応答の正確性を72.4%から93.7%へ、再現性成功率を57.4%から64.4%に向上させる結果を得た。 Comment
pj page: https://www.orchestra-research.com/ara
元ポスト:
研究プロセスでは様々な試行錯誤が実施されるが、試行錯誤による結果は論文中に記載されず、実際に記述されるのは成功したストーリーのみある。また論文中の情報が信用に足るに十分な情報を含まない、あるいは再現をするのに十分な情報を含まない場合がある(ハイパーパラメータの設定はslackのスレッドや、著者の脳内にあるなど)。そういった問題を解決するために、様々な研究過程を追跡し記録しArtifactを生成するLive Research Managerを提案し、論文をPDF Paperの形式ではなく、ARAと呼ばれるパッケージにして研究成果を公表しようよ、という話に見える。
[Paper Note] Heterogeneous Scientific Foundation Model Collaboration, Zihao Li+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #MultiModal #FoundationModel #ScientificDiscovery #Science #Initial Impression Notes Issue Date: 2026-05-08 GPT Summary- 異種エージェント系フレームワークEywaを提案し、言語中心のLLMシステムを領域特化型基盤モデルと結合。これにより、専門データを活用した高次の推論と意思決定が可能に。Eywaは単一エージェントの置換やマルチエージェントシステムへの組み込みに対応し、複雑なタスクを効率的に解決。物理学・生命科学・社会科学の分野での実験では、Eywaがパフォーマンスを向上させ、言語推論への依存を低減することが示された。 Comment
pj page: https://www.zihao.website/eywa.github.io/
LLMと個々のモダリティにおけるfoundation modelをテキストによる入力を超えたmodality-nativeなinputを実現し、text空間でreasoningさせることで協調させるといった話に見える。
元ポスト:
[Paper Note] Beyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling, Yilong Chen+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Embeddings #NLP #Transformer #Architecture #read-later #memory #Reference Collection Issue Date: 2026-05-06 GPT Summary- X-GRAMは、動的トークン注入フレームワークで、トークンインデックス付きルックアップテーブルの効率を向上させる。ハイブリッドハッシュとエイリアスミキシングを利用して、情報の圧縮と局所的特徴の抽出を図り、メモリを効果的に管理する。評価結果では、従来の手法に対して平均精度を最大4.4ポイント改善し、スケーラブルなアーキテクチャの実現を示した。 Comment
元ポスト:
[Paper Note] Co-Evolving Policy Distillation, Naibin Gu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Distillation #PostTraining #RLVR #On-Policy #Reference Collection Issue Date: 2026-05-06 GPT Summary- CoPDは、専門家の並行トレーニングを可能にし、RLVRとOPDを統合。専門家同士が互いの教師となることで行動パターンの一貫性を保ちながら、補完的知識を維持。実験により、CoPDがテキスト・画像・動画推論で強力なベースラインを上回ることを示し、新たなトレーニングスケーリングの可能性を示唆。 Comment
元ポスト:
[Paper Note] CL-bench Life: Can Language Models Learn from Real-Life Context?, Shihan Dou+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #read-later #Reference Collection Issue Date: 2026-05-06 GPT Summary- 実生活のコンテキストを扱うAIアシスタントの学習能力が注目されているが、混沌とした現実の状況を理解することは依然困難である。これを評価するために、405のコンテキストとタスク、および5,348の検証ルーブリックから成るCL-bench Lifeが提案された。このベンチマークは、複雑な実生活のシナリオを網羅し、10種の最先端言語モデルを評価した結果、最高でもタスク解決率は19.3%にとどまり、モデル間の平均は13.8%となった。CL-bench Lifeは、実生活のコンテキスト学習を進展させるための重要なステップとなり得る。 Comment
元ポスト:
[Paper Note] Autoregressive Direct Preference Optimization, Masanari Oi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Alignment #ICML #DPO #PostTraining #Author Thread-Post Issue Date: 2026-05-06 GPT Summary- DPOはLLMの嗜好最適化の手法として注目されているが、BTモデルへの依存がその効果を制限する可能性がある。そこで、自己回帰仮定を導入した新たな定式化—自己回帰DPO(ADPO)を提案。これにより、嗜好最適化への自己回帰モデリングの統合が実現。ADPOの損失関数はエレガントな形を持ち、DPO目的関数の総和演算を対数シグモイド関数の外に移した。さらに、LLMの嗜好最適化に関わるトークン長μとフィードバック長μ′の二つの尺度を明確に区別し、その影響を初めて分析。 Comment
元ポスト:
[Paper Note] Aligning Tree-Search Policies with Fixed Token Budgets in Test-Time Scaling of LLMs, Sora Miyamoto+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ICML #Test-Time Scaling #TreeSearch #Author Thread-Post Issue Date: 2026-05-06 GPT Summary- BG-MCTSは、残りのトークン予算に応じて探索方針を調整するツリー探索デコーディングアルゴリズムを提案。予算が残る間は広範囲に探索し、枯渇するにつれて洗練された回答を優先して浅いノードの分岐を抑制する。MATH500およびAIME24/25の多様な予算設定において、予算を考慮しない方法を一貫して上回る性能を示す。 Comment
元ポスト:
[Paper Note] Recursive Multi-Agent Systems, Xiyuan Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #LatentReasoning #RecursiveModels Issue Date: 2026-05-06 GPT Summary- 再帰型言語モデルをマルチエージェントシステムに拡張するフレームワーク RecursiveMAS を提案。エージェント間の協力を再帰的にスケールさせ、潜在状態転送を実現。内側・外側ループ学習で協調最適化を行い、また実用的な評価で平均精度を8.3%向上、推論速度を1.2倍〜2.4倍速め、トークン使用量を34.6%〜75.6%削減。 Comment
元ポスト:
pj page: https://recursivemas.github.io/
ポイント解説:
[Paper Note] AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite, Bragg+, Ai2, ICLR'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #ScientificDiscovery #ICLR #Science #Author Thread-Post Issue Date: 2026-05-01 Comment
openreview: https://openreview.net/forum?id=M7TNf5J26u
元ポスト:
[Paper Note] Addressing Performance Saturation for LLM RL via Precise Entropy Curve Control, Bolian Li+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #EntropyCollapse Issue Date: 2026-05-01 GPT Summary- Entrocraftは、強化学習におけるエントロピー崩壊の問題を解決するための新しい手法で、ユーザーがカスタマイズしたエントロピー・スケジュールを実現。正則化を必要とせず、各ステップのエントロピー変化をアドバンテージ分布に結びつける。実験により、Entrocraftは性能の飽和を解消し、4Bモデルが8Bのベースラインを上回り、訓練の持続期間を最大4倍延ばし、pass@Kを50%向上させることを示した。 Comment
元ポスト:
[Paper Note] DORA: A Scalable Asynchronous Reinforcement Learning System for Language Model Training, Tianhao Hu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Asynchronous Issue Date: 2026-05-01 GPT Summary- DORA(Dynamic ORchestration for Asynchronous Rollout)は、強化学習における非同期トレーニングの制約を克服するための新しいパラダイムを提案。これにより、複数のポリシー版本を同時に維持しながら、高効率で収束性を保つ。DORAは従来のシステムより2〜3倍のスループットを達成し、大規模アプリケーションでは同期トレーニングに比べ2〜4倍の加速を実現。LongCat-Flash-Thinkingモデルは、複雑な推論ベンチマークで競争力のある性能を示した。 Comment
元ポスト:
解説:
[Paper Note] KAME: Tandem Architecture for Enhancing Knowledge in Real-Time Speech-to-Speech Conversational AI, So Kuroki+, ICASSP'26, 2025.09
Paper/Blog Link My Issue
#NLP #Transformer #SpeechProcessing #read-later #Selected Papers/Blogs #One-Line Notes #Realtime #ICASSP #Author Thread-Post #SpeechToSpeech Issue Date: 2026-05-01 GPT Summary- 音声-音声モデルは低遅延で自然な応答を生成するものの、知識や意味理解に欠ける。一方、ASRとLLMを組み合わせたカスケード型システムは知識表現に優れるが、遅延が大きくなる。そこで本研究は、即時応答を実現する新たなハイブリッドアーキテクチャを提案。ユーザーの音声をS2Sトランスフォーマーで処理しつつ、クエリをLLMに並行伝送。これにより、遅延を増加させずに豊富な知識を応答に組み込むことが可能となる。MT-Benchベンチマークを用いた評価により、提案システムはS2Sモデルを大幅に上回りつつ、遅延は同等であることが示された。 Comment
元ポスト:
HF: https://huggingface.co/SakanaAI/kame
SpeechToSpeechのエンコーダ・デコーダモデルの裏で同時並行してLLMを走らせ、随時生成されるOracle Streamを考慮してデコードすることで、latencyと知識・推論性能を両立する。
著者ポスト:
[Paper Note] Introspection Adapters: Training LLMs to Report Their Learned Behaviors, Keshav Shenoy+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-04-30 GPT Summary- ファインチューニングされたLLMの挙動を識別しやすくするために、共有ベースのLLMから派生したモデルの挙動を自然言語で説明する手法を提案。内省アダプター(IA)が、異なるファインチューニングされたモデルに対しても挙動の自己記述を可能にし、AuditBenchでの高性能や暗号化ファインチューニングAPI攻撃の検出に寄与。IAはモデルのサイズや訓練データの多様性に応じてスケールし、LLMの監査において効果的かつ実践的なアプローチであることを示唆。 Comment
元ポスト:
[Paper Note] AdaExplore: Failure-Driven Adaptation and Diversity-Preserving Search for Efficient Kernel Generation, Weihua Du+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #GPUKernel #Author Thread-Post Issue Date: 2026-04-30 GPT Summary- AdaExploreは、カーネルコード生成のためのエージェントフレームワークで、自己改善を可能にする。失敗駆動適応と探索を通じて正確性と最適化性能を向上させ、再利用可能な記憶を活用する。エージェントはタスクを合成し、局所的改良と構造再生成を交互に行い、最適化の地形を探索する。実験により、KernelBenchのベンチマークで3.12倍および1.72倍のスピードアップを達成した。 Comment
元ポスト:
[Paper Note] Conditional misalignment: common interventions can hide emergent misalignment behind contextual triggers, Jan Dubiński+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #Safety #read-later #Selected Papers/Blogs #EmergentMisalignment #InoculationPrompting #Author Thread-Post #ConditionalMisalignment Issue Date: 2026-04-30 GPT Summary- 言語モデルのファインチューニングが出現的ミスアラインメント(EM)を引き起こす可能性を検討し、EMを減少させる介入を評価。従来の評価は効果を発揮するが、訓練文脈を模したプロンプトでは条件付きミスアラインメントが生じる。このミスアラインメントは、無害データとの混合やファインチューニングにより促進される。特に、予防接種プロンプトは効果的であるものの、完全には解消できないことが示された。我々の結果は、無害データと誤った挙動を含むデータが混在することで、モデルが条件付きミスアラインメントを示す可能性があることを示唆している。 Comment
元ポスト:
[Paper Note] From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company, Zhengxu Yu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Multi #NLP #AIAgents Issue Date: 2026-04-30 GPT Summary- マルチエージェント・システムは固定された構造に依存しているが、個々のエージェントはスキルとツールの統合で進歩している。このギャップを埋めるため、我々は OneManCompany (OMC) を提案する。OMCは、スキルやツールを「Talents」としてカプセル化し、コミュニティ駆動の市場を通じて能力ギャップを解消する。意思決定はExplore-Execute-Review(E^2R)を基にした階層的ループで行い、タスクの分解と成果の集約を通じて改善を促進する。OMCは、マルチエージェント・システムを自己改善型AI組織に変革し、PRDBenchで84.67%の成功率を示している。 Comment
pj page: https://1mancompany.github.io/OneManCompany/
元ポスト:
ポイント解説:
[Paper Note] The Power of Power Law: Asymmetry Enables Compositional Reasoning, Zixuan Wang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Composition #read-later #One-Line Notes Issue Date: 2026-04-29 GPT Summary- 自然言語データはべき乗分布に従うが、再重み付けや均一分布によるモデル学習が効果的であるという直感に反し、べき乗分布での訓練が均一分布を一貫して上回ることを発見。最小限のスキル組成タスクを用いて、べき乗分布による学習が少ないデータで効果的であることを実証。理論的分析により、べき乗分布が非対称性をもたらし、モデルが高頻度スキルを効果的に学習し、長尾スキルに至る道筋を提供することを明示。結果はモデル訓練におけるデータ分布の新たな理解を促進。 Comment
元ポスト:
学習データ中に内包されるスキルの非対称性により学習が促進される。
Geminiの解説では
> 高頻度のスキルと低頻度のスキルが混在する非対称なデータ分布(べき乗則)の下では、モデルがまず高頻度なスキルを容易に獲得し、それが『足がかり(stepping stone)』となることで、データを均等な分布にならして学習するよりも、かえって効率的に稀なスキル(ロングテール)を学習できる
ということである(要確認)
[Paper Note] SFT-then-RL Outperforms Mixed-Policy Methods for LLM Reasoning, Alexis Limozin+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #read-later #Selected Papers/Blogs Issue Date: 2026-04-29 GPT Summary- LLM推論における混合ポリシー最適化手法は、SFT-then-RLパイプラインより改善を示すが、いくつかの研究がバグに基づく不適切なベースラインに依存している。DeepSpeedのCPUオフロードやOpenRLHFの損失集約のバグがSFTの性能を抑制し、修正されるとSFT-then-RLは混合ポリシー手法を上回る可能性が高い。特に、Qwen2.5-Math-7Bで+3.8ポイント、Llama-3.1-8Bで+22.2ポイントの向上が見込まれる。50回のRLステップによる切り詰め版でも混合ポリシーに勝利。 Comment
元ポスト:
oh...
[Paper Note] Kwai Summary Attention Technical Report, Chenglong Chu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Attention #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2026-04-29 GPT Summary- 長文脈能力は次世代の大規模言語モデルで重要な研究テーマだが、標準のソフトマックスアテンションはシーケンス長に対して二次計算量を示し、長文脈設定でオーバーヘッドが生じる。既存の技術はKVキャッシュの削減やKVキャッシュに優しいアーキテクチャを利用するが、トレードオフが現れる。この研究では、KVキャッシュとシーケンス長の間に線形関係を保ちながらセマンティックレベルの圧縮を行う方法を提案し、新しいKwai Summary Attention (KSA) を導入することで、シーケンスモデリングのコストを低減する。 Comment
元ポスト:
これはおもしろい
所見:
[Paper Note] Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond, Meng Chu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Survey #ComputerVision #NLP #AIAgents #VisionLanguageModel #WorldModels #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-28 GPT Summary- AIシステムの目標達成能力の向上には、環境のダイナミクスをモデル化することが必要不可欠である。この研究では、能力レベル(L1からL3)と支配法則(物理、デジタル、社会、科学)を軸にした「levels x laws」分類法を導入し、400件以上の研究を統合して、AIの世界モデルの制約と失敗モードを示す。提案する評価原則と最小再現可能なパッケージがアーキテクチャの指針を提供し、分断されたコミュニティの統合を目指す。最終的には、より予測可能で再構築可能な環境モデルへと進む道筋を示す。 Comment
pj page: https://agentic-world-modeling.xyz/
元ポスト:
著者ポスト:
分野ごとに意味が異なるWorld Modelsを統合的に分類できる枠組みを提案しているSurveyで、Levels * Laws のtaxonomyで分類する。Levelsとはどのような能力を持つか、
- L1: L1 Predictor, 1ステップの予測
- L2: L2 Simulator, 複数ステップのシミュレーション/反実仮想のロールアウト
- L3: L3 Evolver, 失敗からの進化
LawsはWorld Modelsがどのような制約に従わなければならないかという視点で
- Physical: 物理法則
- Digital: program semantics
- Social: 社会規範
- Scientific: scientific mechanism
によって構成される、といった話が著者ポストに記述されている。論文を見ると、個々のtaxonomyについては、より多様な観点を含むようである。
[Paper Note] The Recurrent Transformer: Greater Effective Depth and Efficient Decoding, Costin-Andrei Oncescu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #LatentReasoning #Reference Collection #RecurrentModels #Author Thread-Post Issue Date: 2026-04-28 GPT Summary- Recurrent Transformerは、各レイヤが自らの活性化から計算されたキーとバリューにアテンションを行うことで、時間的深さを持ちながらも最適化の不安定さを軽減。従来のTransformerとトークン間の再帰的更新を穏やかな前提下でエミュレートし、計算の効率性を改善。150Mおよび300MパラメータのC4事前学習において、クロスエントロピーの改善を達成し、深さを幅へとトレードオフすることで、メモリ占有量と推論レイテンシを低減することを示した。 Comment
元ポスト:
解説:
[Paper Note] Spend Less, Fit Better: Budget-Efficient Scaling Law Fitting via Active Experiment Selection, Sijie Li+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ExperimentManagement #Scaling Laws #Initial Impression Notes Issue Date: 2026-04-27 GPT Summary- スケーリング則の適合は高コストであり、予算を意識した逐次的実験設計として定式化。異なるコストの実験から、外挿精度を最大化する実験を選択。提案手法は古典的ベースラインを上回り、総予算の約10%で高い適合性能を達成。コードは公開中。 Comment
元ポスト:
scaling laws導出のための実験をより省コストとなるようデザインする手法
[Paper Note] Asking What Matters: Reward-Driven Clarification for Software Engineering Tasks, Sanidhya Vijayvargiya+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #QuestionGeneration #SoftwareEngineering #4D Reconstruction Issue Date: 2026-04-26 GPT Summary- 人間がタスクを不完全に指定するため、アシスタントは明確化の質問を効果的に行う必要がある。ソフトウェア工学タスクにおける明確化の研究を通じて、成功に影響を与える情報の種類と有用な回答を引き出す質問を特定。タスク関連性とユーザーの回答可能性という二つの特性を明確化の評価に使い、CLARITIという80億パラメータのモジュールを訓練。CLARITIはGPT-5に匹敵する解決率を維持しつつ、質問を41%削減することに成功。結果は、情報の影響とユーザーの回答可能性に基づく報酬設計が明確化効率を向上させる可能性を示唆している。 Comment
元ポスト:
[Paper Note] How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped Language Models, Kristian Schwethelm+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Transformer #Scaling Laws #LatentReasoning #RecurrentModels Issue Date: 2026-04-26 GPT Summary- ループ化された言語モデルにおける追加の再帰が、等価なパラメータ数での価値を測定。116回の実験を通じて、新たな再帰等価指数 φ = 0.46 を導出。φ は、再帰の影響を検証損失に反映し、ループモデルの性能と計算コストの関係を明示化。下流評価ではパラメトリック知識タスクに差が残る一方、オープンブック課題では差が縮小。今後のアーキテクチャ選択は φ を基に比較可能に。
[Paper Note] Hyperloop Transformers, Abbas Zeitoun+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #LatentReasoning #RecurrentModels #ResidualStream Issue Date: 2026-04-26 GPT Summary- LLMのパラメータ効率を向上させる新しいアーキテクチャを提案。ループド・トランスフォーマーをコアに、深さを跨いでトランスフォーマー層を再利用し、通常のトランスフォーマーよりも効率的。中間ブロックをハイパーコネクションで拡張し、パラメータ数を約50%削減しつつ性能向上を実現。量子化後も優位性を維持し、メモリ効率の良い言語モデリングに寄与。 Comment
元ポスト:
[Paper Note] Learning to Orchestrate Agents in Natural Language with the Conductor, Stefan Nielsen+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #ICLR #Test-Time Scaling #read-later #Orchestration #Author Thread-Post Issue Date: 2026-04-26 GPT Summary- Conductorモデルを導入し、LLM間の協調戦略を自動発見。通信トポロジを設計し、個々のLLMの能力を最大化する指示を生成。7BパラメータのConductorは、単一ワーカーを超える性能向上を実現し、難解なベンチマークで最先端結果を達成。ランダム化されたエージェント訓練により、任意のエージェント集合に適応し、新たな再帰的トポロジを形成してオンラインでの性能向上を図る。この研究は、強力な協調戦略がRLを通じて自然に現れることを示す初期の実証である。 Comment
openreview: https://openreview.net/forum?id=U23A2BUKYt
公式ポスト:
[Paper Note] TRINITY: An Evolved LLM Coordinator, Jinglue Xu+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #ICLR #reading #KeyPoint Notes #EvolutionaryAlgorithm #Orchestration #Author Thread-Post Issue Date: 2026-04-26 GPT Summary- Trinityは、LLMs間の協調を調整する軽量なコーディネーターを用いて、基盤モデルの統合に伴う制約を解決する。約6億パラメータのコンパクトな言語モデルと約1万パラメータの軽量ヘッドから成り、適応的な委任を実現。複数ターンにわたるクエリに対して、コーディネーターは各LLMに役割を割り当て、スキルを効果的にオフロードする。実験の結果、Trinityはコード作成や数学、推論、領域知識タスクで優れた性能を示し、標準ベンチマークで最先端の成果を達成。コーディネーターの隠れ状態表現が文脈化を提供し、進化戦略の適用が有利であることが確認された。 Comment
openreview: https://openreview.net/forum?id=5HaRjXai12
軽量なcoordinator + 非常に軽量なheadを用いてターンごとに適切なモデルとロールを選択する。coordinatorは全てのターンの会話に対応するcontextualな表現を最後から2番目のトークンに対応するhidden state[^1]から取得し、
- LLM poolの中からどのLLMを用いて応答を生成するか
- 事前定義されたロール(Thinker, Worker, Verifier)のうちどれを選択するか
を決定する。最終的にVerifierが選択され、質問に対する最終的な応答としてacceptされるか、固定長のターン数のbudgetに到達したら生成終了となる。
上記枠組みを定式化すると(Section 2)、ざっくり言うと
- SLMが最初のクエリ+これまでの会話の履歴のcontextを、最後から2番目のトークンのhidden state hに集約し
- lightweight がhを受け取り、有限のアクション集合から(agent-roleのペア集合)適切なアクションを選択する
- 最終的に 0/1 のrewardを得られるものとし、この期待報酬を最大化するような(SLMのパラメータの対角成分[^2]と)lightweight headのパラメータΘを求める最適化問題として定式化される。
- ただし制約条件として、trajectoryのhorizon T は T <= B_turn、かつ期待報酬を得るために利用可能なコスト B_env がある。
となる。
(この辺は少し自信がないが)本研究のタスク設定は以下の特徴を持つ:
- 1ステップの評価が複数のLLM呼び出しを含むため非常に高コストであり、かつ評価に利用可能なコスト(B_env)の制約も厳しく
- lightweight headの次元数は10kであり、予算に強い制約がある中で学習するには次元数が多く
- かつlightweight headのパラメータはblock-epsilon-separabilityという性質を持つらしく
- 個々のlogitに寄与するブロックが独立していて、かつ独立したブロックの対角成分によって出力が決定される
- また、ブロック間は弱い相互作用をしている、という状態のようである
- 最終的に得られる報酬は2値のsparseな報酬でノイジー
パラメータΘを学習する上で、REINFORCEのようなパラメータごとの勾配を求める手法は、個々のパラメータが最終的な報酬に与える影響が小さく、かつ報酬がsparseでノイジーであるため効果的に学習ができないことから(時間をかければ学習できるのかもしれないが、B_envの制約がきつくて無理)、パラメータの対角成分を扱う手法であるseparable CMA-ESと呼ばれる進化的アルゴリズムによって学習するとのことである。
separable CME-ESはノイズを加えたパラメータベクトルの集団をサンプリングし、各候補を評価してそれぞれの適応度スコアを取得し、適応度で重みづけした上で平均をすることで次の親を形成するというプロセスを反復する手法らしく、特にseparable CME-ESという手法は、対角共分散行列のみを維持するため、上記の対角成分が寄与する性質と相性が良いとのことである。実験の結果、実際にREINFORCE, SFT, Random Searchなどの手法と比較して性能が良いことが示されている(Table 4)。
SLMのパラメータの対角成分は Singular Value Finetuning
- [Paper Note] Transformer-Squared: Self-adaptive LLMs, Qi Sun+, ICLR'25, 2025.01
によって効率的に学習される。この結果、学習をするパラメータ数は20k程度で済み、パラメータ効率が非常に良いとのことである。
[^1]: 最後から2番目のトークンは `` や `
[^2]: Section 2にはおそらく定式化のシンプルさを優先して最適化の対象はlightweight headのパラメータΘのみで定式化がされており、Section 3やFigure 2において、SLMのパラメータの対角成分も学習する旨が記載されている
[Paper Note] Decoupled DiLoCo for Resilient Distributed Pre-training, Arthur Douillard+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #DistributedLearning Issue Date: 2026-04-26 GPT Summary- Decoupled DiLoCoは、SPMDパラダイムの同期障害を克服し、計算を複数の独立したlearnerに分割。各learnerは非同期で内的最適化を行い、故障や遅延を最小化する手法を用いて集約。これにより、トレーニング効率を大幅に改善し、テキストやビジョンタスクで競争力のある性能を維持。 Comment
元ポスト:
関連:
- [Paper Note] Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch, Arthur Douillard+, COLM'25, 2025.01
- [Paper Note] DiLoCo: Distributed Low-Communication Training of Language Models, Arthur Douillard+, ICML'24 Workshop WANT
- [Paper Note] Communication-Efficient Learning of Deep Networks from Decentralized Data, H. Brendan McMahan+, AISTATS'17, 2016.02
[Paper Note] Self-Evolving LLM Memory Extraction Across Heterogeneous Tasks, Yuqing Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Personalization #Evaluation #memory #KeyPoint Notes #Clustering-based #Reading Reflections #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- 異質な記憶を保持するためのLLMベースのアシスタントの必要性に対して、\textbf{BEHEMOTH}というベンチマークを導入。18のデータセットを再利用し、タスクごとの有用性を評価する。実証分析により、均質なプロンプトが効果的でないことが確認され、\textbf{CluE}を提案。これは訓練例をクラスタに分け、各クラスタを独立に分析することで、抽出プロンプトを効果的に更新し、BEHEMOTHで実験した結果、従来の方法よりも一般化能力が向上したことを示した。 Comment
元ポスト:
現在のAI Agentのメモリは同種のタスクに対して構築され評価されるが、実際の環境、特によりpersonalizationが進んだ状況下では、さまざまな異質なユーザの会話を単一のエージェントが扱い、ユーザのリクエストに応じて適切にメモリからcontextを抽出できなければならず、このような能力を測定するベンチマークは存在しない。
このため、ベンチマークを構築し既存のメモリ手法(promptingベースの手法)を評価したところ、LLMがメモリをmanageする際に、単一のmemory抽出のプロンプトや、自己進化ベースのpromptingではうまくいかないことがわかった。
提案手法 (CluE) では、各サンプルごとに背後にあるシナリオ(どのような情報が欲しいのか, 抽出時にどのような点がchallengingなのか等)をsummarizerにより解釈し、シナリオ単位でクラスタリング。個々のクラスタを分析することで、クラスタごとにどのような場合に成功/失敗するのか等を分析しクラスタ単位のrecommendationを得る。最終的に、クラスタ間のrecommendationを統合して構造化された一つの抽出promptに仕立てる。このとき、競合がある場合は適切なメモリグループにスコープを絞り解決する、といった手法のようである。
既存手法と比較してCluEによって抽出性能が向上
問題設定が実践的でおもしろい
[Paper Note] DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data, Venus Team+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #SmallModel #OpenWeight #OpenSource #DeepResearch #Author Thread-Post #EdgeDevices Issue Date: 2026-04-25 GPT Summary- エッジ規模の小型深層研究エージェントDR-Venusを提示し、限られたオープンデータを基に強力な性能向上を実現。二段階の訓練プロセスでは、第一段階で基本能力を確立し、データ品質を改善、第二段階で強化学習を導入し実行信頼性を向上。約1万のオープンデータで構築されたこのエージェントは、従来の9Bモデルを上回り、30Bシステムとの差も縮小。再現性のある研究に資するため、モデルやコードを公開。 Comment
models:
https://huggingface.co/collections/inclusionAI/dr-venus
code:
https://github.com/inclusionAI/DR-Venus
オープンなデータのみで構築されたtraining/inferenceパイプラインもオープンなDeepResearchエージェント。
元ポスト:
[Paper Note] TRACER: Trace-Based Adaptive Cost-Efficient Routing for LLM Classification, Adam Rida, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Distillation #Initial Impression Notes Issue Date: 2026-04-25 GPT Summary- LLM分類に基づく訓練データセットを生成し、軽量な代理モデルによって低コストでトラフィックを処理することを提案。TRACERは代理モデルを本番トレースで訓練し、信頼性に応じてデプロイを管理。透明性を持たせるために、入力領域の処理やデプロイ拒否の理由を解釈可能な形で示す。77クラスのベンチマークでは83-100%のカバレッジを達成し、自然言語推論タスクでは正しくデプロイを拒否。システムはオープンソースとして提供。 Comment
元ポスト:
LLMにリクエストされる分類問題タスクのinputとLLM(教師モデル)を収集しておき、低コストで推論可能な代理モデルを学習。リクエストごとに、LLM/代理モデルどちらを利用して推論するかをRoutingし、低コストで分類タスクを解けるようにする、という話に見える。
[Paper Note] Parallel-SFT: Improving Zero-Shot Cross-Programming-Language Transfer for Code RL, Zhaofeng Wu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Coding #TransferLearning #PostTraining #LowResource #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- 低リソースのプログラミング言語(PL)における言語モデルの性能は、訓練データの制約を受ける。本研究では、ゼロショットの跨プログラミング言語転移タスクを提案し、Llama-3.1がPL間でのコード生成において改善されないことを明らかにした。これに対処するため、一般化可能なSFT初期化が必要とし、「並列プログラム」を使用したSFT戦略Parallel-SFTを導入。Parallel-SFTによって転移性が向上し、RL実行後に未知のPLへの一般化が改善されることを示した。モデルの内部表現分析は、PL間での同等プログラムが密にクラスタ化され、これが転移性向上に寄与することを示唆している。 Comment
元ポスト:
RL前にプログラミング言語でのパラレルコーパスでSFTすることで、特定言語でRLをした場合でも他言語にも性能が転移する、という話に見える。
著者ポスト:
[Paper Note] AI scientists produce results without reasoning scientifically, Martiño Ríos-García+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #ScientificDiscovery #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-04-25 GPT Summary- LLMベースの科学的エージェントの評価を行い、推論の認識論的規範に従っているかを分析。25,000件以上の実行から、基本モデルが性能の主要因であることを確認し、スキャフォールドの寄与はわずか1.5%に過ぎない。証拠の68%が無視され、信念修正は26%の頻度で発生。全体を通じて、エージェントはワークフローや仮説探究で一貫した推論パターンを示すが、科学的推論における認識論的パターンは欠如。これらの欠陥は成果だけでは検出できず、スキャフォールド設計では修復できないため、推論そのものが訓練目標として必要。 Comment
元ポスト:
大規模な実験によって現在のScientific DisaoveryにおけるAI Agentの課題を明確にしており、重要研究に見える。
[Paper Note] Stopping Computation for Converged Tokens in Masked Diffusion-LM Decoding, Daisuke Oba+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #DiffusionModel #ICLR #Decoding #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- SureLockは、マスク済み拡散型言語モデルにおいて、未マスクトークンをロックすることで計算資源を効率化します。具体的には、未マスク位置の事後分布が安定した場合、その位置に対するクエリ投影とフィードフォワードをスキップしつつ、他の位置がアテンションできるようにキャッシュを使用します。この手法により、計算コストがO(N^2d)からO(MNd)に削減され、生成品質を維持しつつFLOPを30〜50%削減します。理論分析も行い、ロック時点でKLを監視することでトークン確率の偏差を十分に境界づけることができることを示しています。 Comment
pj page: https://daioba.github.io/surelock/
元ポスト:
著者ポスト2:
[Paper Note] PlayCoder: Making LLM-Generated GUI Code Playable, Zhiyuan Peng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Evaluation #SoftwareEngineering #ComputerUse #GUI #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- GUIアプリケーションの生成において、従来の評価方法が不十分である中、本研究は多言語対応のベンチマークPlayEvalを提案。これにより、ユーザー操作に基づく評価が可能となる。Play@kという指標で実行可能な生成候補を測定し、LLMベースのエージェントPlayTesterを開発して、タスク指向の評価を自動化。実験では最先端のコードLLMが論理的なGUIアプリケーションの生成に大きな課題を抱えていることが判明。これに対処するための多エージェントフレームワークPlayCoderを提示し、性能を大幅に向上。ケーススタディでは潜在的な論理バグの発見と修正の効果を示す。 Comment
元ポスト:
[Paper Note] TEMPO: Scaling Test-time Training for Large Reasoning Models, Qingyang Zhang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #read-later #Diversity #Critic #Test Time Training (TTT) Issue Date: 2026-04-25 GPT Summary- テスト時訓練(TTT)では、ラベルなしのテストインスタンスでモデルパラメータを適応させるが、既存の手法はLRMsで性能が頭打ちになる。提案するTEMPOは、周期的にポリシーの洗練とクリティックの再較正を行い、期待値最大化(EM)アルゴリズムとして位置づけられる。この再較正を通じて持続的な改善を実現し、AIME 2024でOLMO3-7Bを33.0%から51.1%、Qwen3-14Bを42.3%から65.8%へと向上させ、高い多様性を維持する。 Comment
元ポスト:
[Paper Note] StructMem: Structured Memory for Long-Horizon Behavior in LLMs, Buqiang Xu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #memory Issue Date: 2026-04-25 GPT Summary- 長期対話エージェントには、イベント間の関係を捉えるメモリシステムが不可欠である。既存のアプローチは効率性と構造化推論の間にトレードオフが存在する。本研究では、イベント間の結合を保持し、接続を誘導する階層的メモリフレームワークStructMemを提案。これにより、時系列推論とマルチホップ性能が向上し、リソース使用を削減できることを示した。 Comment
元ポスト:
- [Paper Note] REMem: Reasoning with Episodic Memory in Language Agent, Yiheng Shu+, ICLR'26, 2026.02
と似ているが、どこが異なるだろうか?
[Paper Note] Transformers are Inherently Succinct, Pascal Bergsträßer+, ICLR'26 Outstanding Paper, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #Architecture #Memorization #reading #Reference Collection #Initial Impression Notes Issue Date: 2026-04-25 GPT Summary- トランスフォーマーの表現力を測る指標として、簡潔さを提案し、有限オートマトンや線形時間論理(LTL)式よりも高度に形式言語を表現できることを証明。さらに、トランスフォーマーの性質の検証が理論的に困難であること(EXPSPACE 完全)を示した。 Comment
openreview: https://openreview.net/forum?id=Yxz92UuPLQ
元ポスト:
succinctnessの提案。あるパターンを表現するのに、RNN(SSM)や有限オートマトンなどと比較してtransformerは指数関数的に少ないパラメータ数で(理論上は)表現できることが数学的に示されているらしい。
つまりLinear Attentionをベースにしたモデルは計算効率やメモリ消費量では有利だが、表現力を犠牲にしている、ということが示された形になりそうである。
しかし1パラメータあたりに圧縮可能なコンセプトが増えれば増えるほどmemorizationの傾向が強くなり、汎化性能が失われるという見方もできる気がするので、この辺を踏まえると一概にsuccinctnessが高ければ良いというのも成り立たない気もする。
解説:
[Paper Note] Context Unrolling in Omni Models, Ceyuan Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #Reasoning #VisionLanguageModel #2D (Image) #3D (Scene) #UMM #3D (Video) #Omni #One-Line Notes #Reference Collection #AudioLanguageModel #Fidelity #audio #text Issue Date: 2026-04-24 GPT Summary- Omniは、多様なモダリティにネイティブに訓練されたマルチモーダルモデルで、Context Unrollingを通じて異なるモダリティの情報を統合。これにより、下流の推論忠実度が向上し、高い生成・理解性能を発揮。テキスト、画像、動画、3Dジオメトリを用いた高度な推論能力を示す。 Comment
元ポスト:
モダリティを跨いでtaskに対してrelevantなcontextを活性化させることで、omniモデルの生成時の推論能力と、忠実度を向上させる
[Paper Note] Scaling Self-Play with Self-Guidance, Luke Bailey+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes #Reference Collection #SelfPlay #Author Thread-Post Issue Date: 2026-04-24 GPT Summary- 自己対話アルゴリズムにおけるLLMの限界を克服するために、Self-Guided Self-Play(SGS)を提案。SGSでは、Solver、Conjecturer、Guideの三役をモデルが担い、崩壊を避けつつ問題解決を行う。SGSの評価では、従来のRLベースラインを上回り、効率的な自己対話によって7Bパラメータモデルが671Bパラメータモデルよりも多くの問題を解決可能であることを示した。 Comment
元ポスト:
所見:
解説:
seed dataを与えた上でのSelf-PlayによるRLの性能を向上させる方法を提案している。
Self-PlayでRLをする場合、
- Solver: タスクを解く。タスクを解けるように学習される。(タスクが解けたか否かのbinary Reward)
- Conjecture: タスクを生成する。SolverのパフォーマンスをRewardとして学習される。
という構造が一般的だが、既存手法を分析した結果、学習が進むにつれ、ConjectureがSolverがそもそも解けない問題を生成するなどし、Reward Hackingが生じてしまい性能が向上しないことを発見。(Figure 2)
そこで、新たにGuideを追加し、Conjectureがタスクを合成する際にR_solve*R_guideの積の形式にRewardを調整し
- R_solveは(1 - Solverのsuccess rate)によって定義されるが、難しすぎる問題(success rate=0)、簡単すぎる問題(現在のバッチのtop 30%の問題)に関しては0に落とす。
- R_guideは合成タスクが、seed dataでSolverがまだ解けていない問題に関してどれだけの品質を有しているかに関するスコアを提供し(=unsolvedな問題に対する関連度、シンプルな結論が記述されており冗長な前提がないか、に関するRubricに基づくスコア)そのスコアをR_guideとする。つまり、seed dataにおいてまだ解けていない問題がより重視される。
ことで対処した。
self-playに関する代表的な先行研究:
- [Paper Note] Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play, Sainbayar Sukhbaatar+, ICLR'18, 2017.03
解説:
[Paper Note] DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence, DeepSeek-AI+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Infrastructure #AIAgents #Attention #LongSequence #PositionalEncoding #Optimizer #OpenWeight #Architecture #MoE(Mixture-of-Experts) #AttentionSinks #read-later #Selected Papers/Blogs #RewardModel #Reference Collection #KV Cache #Compression #GenerativeVerifier #SparseAttention #ResidualStream #SelfDistillation #Author Thread-Post Issue Date: 2026-04-24 GPT Summary- DeepSeek-V4シリーズのプレビュー版が発表され、1.6兆パラメータのDeepSeek-V4-Proと2840億パラメータのDeepSeek-V4-Flashを含み、長さ100万トークンの文脈長をサポート。主なアップグレードには、効率的な文脈処理のためのハイブリッドアテンションアーキテクチャ、強化された残差接続、安定したトレーニングを実現するMuonオプティマイザが挙げられます。両モデルは、高品質の32兆トークンで事前学習され、ポストトレーニングパイプラインにより能力が強化されます。DeepSeek-V4-Pro-Maxは最先端の推論能力を誇り、特に長い文脈において高い効率を発揮します。モデルのチェックポイントは公開されています。 Comment
HF: https://huggingface.co/collections/deepseek-ai/deepseek-v4
元ポスト:
とうとうでました
所見:
所見:
Artificial Analysisによる評価:
所見:
所見:
-
所見:
1Mコンテキストにおいて、V3.2と比較してわずか10%のKV Cacheしか必要としないとのこと。
所見:
1Mトークンのcontext windowを実用的にするために最新の叡智が詰め込まれまくっているという感じのようである。うーむ読むしかない
所見:
RTX 6000で4基でFlashが動いたよ、という報告に見える:
解説:
所見:
関連:
- HiSparse: Turbocharging Sparse Attention with Hierarchical Memory, LMSYS, 2026.04
Self Rewarding LMsのコンセプトが利用されている:
Proは、Flashをlong contextを扱える様々なドメインのスペシャリストとして訓練し、OPDによって蒸留されたものなのでは?という話:
論文中に疑問点をアノテーションした結果が共有されている:
[Paper Note] When Can LLMs Learn to Reason with Weak Supervision?, Salman Rahman+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #read-later #RLVR #Selected Papers/Blogs #Memorization #Generalization #Reading Reflections #Author Thread-Post Issue Date: 2026-04-23 GPT Summary- 大型言語モデルは、RLVRを通じて推論能力を向上させる一方で、高品質な報酬信号の構築が難しくなってきた。本研究では、データ不足、報酬のノイズ、自己教師付き報酬の下での実証研究を行い、一般化はトレーニング報酬の飽和ダイナミクスに左右されることを発見。一般化するモデルは長い局面を持ち、急速に飽和するモデルは記憶に偏ることを示した。また、推論の忠実度がモデルのレジームを予測する指標であることも特定。継続的な事前学習と監督付き微調整の効果を分離し、SFTが弱い監督下での一般化に必要であることを確認。これにより、Llama3.2-3B-Baseが以前は失敗していた三つの設定で一般化を達成した。 Comment
pj page: http://salmanrahman.net/rlvr-weak-supervision
元ポスト:
pj page: https://salmanrahman.net/rlvr-weak-supervision
- RLVRにおいて、シグナルが不完全な場合(i.e., weak supervisio)の3つの状況に基づいて、汎化性能を分析
- Scarce data: 8つの訓練事例
- Noisy Rewards: 最大90%のラベルに誤りがある
- Proxy Rewards: ground truthなしで、model confidenceにもとづく多数決のみを利用
- RLVRにおいて、Training Rewardが飽和する前に、より長いステップ数学習をしたモデルは、汎化性能が高くなる
- ➡︎ memorizationによって早期にTraining rewardが頭打ちになりgenericな能力を獲得できていないことが示唆される
- 汎化に失敗したモデルは探索が少ないのでは?ということが理由として考えられるが、実はこの説明は間違っている
- Llama, Qwenの2つのモデルを比較した時Llamaは訓練中Qwenと比較して高いsemantic diversityを維持していたが、最終的にQwenよりも汎化性能が低い(=memorization)してしまっていた
- ➡︎ 真の原因はfaithfullnessが低い推論であり、論理的にsupportされないreasoning traceの元正解に辿り着いてしまうことが原因であると考察
- 解決策として、reasoning dataを用いた `pre-RL training` を実施する。
- すなわち、RLVRを実施する前に、Llama-3.2-3Bに対して、継続事前学習(52B math tokens)を実施し、その後 Thinking SFT (43.5K reasoning Traces)を実施する
- CPTとThinking SFTによって、Llamaはweak supervision (i.e., scarce data, noisy rewards, proxy rewards)状況下でも意味のある学習を実施することができた
- ➡︎ reasoning能力が獲得されたことにより推論のfaithfulnessが改善されることで、memorizationが防止されより長いstep数訓練報酬が飽和せずに学習ができたため
といった話が著者ポストに記述されている。
memorizationを防止し、なるべくgenericな能力を身につけさせることが鍵という考え方は、最近色々なところで見かけるように感じる (Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
など)。単にデータをスケールさせるだけでなく、より効率的な学習のため、モデルに対してよりgenericな能力を身につけさせるための工夫(モデルの記憶容量をあえて減らす等)が今後進んでいきそうである。
- Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
[Paper Note] Memorization, Emergence, and Explaining Reversal Failures: A Controlled Study of Relational Semantics in LLMs, Yihua Zhu+, ACL'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #ACL #ReversalCurse #Author Thread-Post Issue Date: 2026-04-23 GPT Summary- 自己回帰型LLMは関係語を通じてエンティティを結び付ける際に高い性能を示すが、関係の論理意味論を学習しているか、また反転型の失敗が順序バイアスに起因するかは不明である。本研究では、対称・逆のトリプルに基づく知識グラフを使用した合成フレームワークを提案し、GPT風のモデルを訓練して論理推論と一般化を評価。論理情報の監督により、関係意味論が現れる相転移を観察し、成功する一般化が安定した中間層信号と一致することを示した。反転失敗は欠如した意味論よりも、自己回帰の順序バイアスに起因することが示唆された。 Comment
元ポスト:
[Paper Note] PolySkill: Learning Generalizable Skills Through Polymorphic Abstraction, Simon Yu+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #AIAgents #ICLR #Selected Papers/Blogs #Generalization #One-Line Notes #AgentSkills #Author Thread-Post Issue Date: 2026-04-23 GPT Summary- 大規模言語モデル(LLMs)を利用して、エージェントが一般化可能なスキルを学習するための新しいフレームワーク「PolySkill」を提案。スキルの抽象的な目標と具体的な実行を切り離すことで、スキルの再利用や一般化を促進。実験では、ウェブサイトでのスキル再利用を1.7倍向上させ、成功率を最大13.9%向上させた。PolySkillにより、エージェントが自己目標を識別し、より良いカリキュラムを学習する能力が高まり、継続的に学習できる自律エージェントの構築に寄与することが示された。 Comment
元ポスト:
エージェントスキルにポリモーフィズムの考え方を導入し、WhatとHowを分離することで汎化性能を高める。下図が分かりやすい。
最初に特定ドメインのwebサイト(e.g., shopping)を訪れた際に、AbstractShoppinpクラスを生成しShopping関連を扱うクラスとする。その上で、特定サイト(e.g., Amazon)のスキルを生成する際は、AbstractShoppingクラスにシグネチャを登録した後、同クラスを継承。AmazonShoppingクラス内に具体的な処理を定義する。直接スキルを生成するのではなく、抽象スキルを生成した上で、特定サイトでのメソッドを実装する。
openreview: https://openreview.net/forum?id=KdEsujyiSV
[Paper Note] Neural Garbage Collection: Learning to Forget while Learning to Reason, Michael Y. Li+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #read-later #Selected Papers/Blogs #KV Cache #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-23 GPT Summary- 連鎖的推論ではKVキャッシュの拡大がボトルネックとなっており、従来の手法は手作業で管理されている。よりスケーラブルな「Neural Garbage Collection(NGC)」を提案し、言語モデルが推論と同時に忘れることを学ぶ。モデルは推論中にキャッシュエントリの追い出しを決定し、これを強化学習で最適化。成果ベースのタスク報酬を用いて学習することで、高い精度を保ちながらキャッシュサイズを圧縮し、エンドツーエンドの最適化がモデルの能力を向上させる可能性を示した。 Comment
元ポスト:
LLMにReasoningとKV Cacheのマネジメントを同時に学習させる。
ポイント解説:
[Paper Note] Qwen3.5-Omni Technical Report, Qwen Team, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #SpeechProcessing #Speech #Proprietary #MoE(Mixture-of-Experts) #2D (Image) #TTS #Omni #text Issue Date: 2026-04-22 GPT Summary- Qwen3.5-OmniはQwen-Omniモデルファミリーの最新進展で、数百億パラメータと256kのコンテキスト長を持ち、テキスト-ビジョン対とオーディオ視覚コンテンツを利用したオムニモーダリティ能力を発揮します。215のサブタスクでSOTA結果を達成し、Gemini-3.1 Proを上回る性能を示しました。Hybrid Attention MoEフレームワークを採用し、長シーケンス推論を効率化。ARIAにより音声合成の安定性を向上させ、10言語で人間の感情ニュアンスをサポート。優れた音声-視覚グラウンディング能力を持ち、音声-視覚指示に基づく直接コーディングを実現する新たな機能も観察されています。 Comment
元ポスト:
[Paper Note] Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence, Guanting Dong+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SyntheticData #SelfImprovement #PostTraining #RLVR #Scalability #Environment Issue Date: 2026-04-22 GPT Summary- 汎用エージェントとしての大規模言語モデルの期待が高まる中、Agent-Worldを提案。これは、エージェントが多様な実世界環境を探索し、自律的にタスクを合成する仕組みを提供。強化学習と動的なタスク合成により、エージェントの能力を向上させ、共進化を促進。実験で、Agent-Worldが複数のベンチマークで他のモデルを一貫して上回ることを示す。汎用エージェント知能構築のヒントも提示。 Comment
元ポスト:
[Paper Note] Evaluation-driven Scaling for Scientific Discovery, Haotian Ye+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ScientificDiscovery #Test-Time Scaling #Reference Collection Issue Date: 2026-04-22 GPT Summary- 評価駆動の発見ループを科学的発見において拡張するためのフレームワーク、SimpleTESを提案。これにより並列探索やフィードバック駆動の改良を組み合わせ、21の科学的問題で最先端の解を発見。特に、LASSOアルゴリズムを大幅に高速化し、新たな構成を発見。SimpleTESは評価の履歴を生成し、見たことのない問題にも一般化できることから、LLM主導の科学的発見を推進する中心的手法として位置づけられる。 Comment
元ポスト:
110ページ、、、
[Paper Note] SAW-INT4: System-Aware 4-Bit KV-Cache Quantization for Real-World LLM Serving, Jinda Jia+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Infrastructure #Quantization #LLMServing #KV Cache #Compression #Initial Impression Notes Issue Date: 2026-04-22 GPT Summary- KVキャッシュメモリは、レイテンシーに敏感な小規模バッチと高スループットワークロードの同時サポートにおけるボトルネックとなっている。多くの圧縮手法は実用的な制約に違反し、デプロイメント時の有効性を制限している。本研究では、最小限の4ビット量子化手法を特定し、INT4量子化とブロック対角Hadamard回転の組み合わせが最良のトレードオフを実現することを発見した。実装により、エンドツーエンドのオーバーヘッドを抑え、INT4スループットに匹敵する性能を達成。結果として、KVキャッシュ圧縮はシステム共設計の問題であり、軽量な手法が実用的な精度を提供することを示した。 Comment
元ポスト:
github:
https://github.com/togethercomputer/saw-int4
以下のRequirementsがある
- MHA modelsのみをサポートしており、MLA、あるいはMHA以外のアーキテクチャはサポートされていない
- 実装かれていないだけなのか、理論的に無理なのかは区別がついていない
- Prefill backend: fa3
- Decode backend: triton
解説:
[Paper Note] Micro Language Models Enable Instant Responses, Wen Cheng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Decoding #One-Line Notes #Reference Collection #Latency #EdgeDevices Issue Date: 2026-04-22 GPT Summary- μLMsを導入し、エッジデバイスで即座に文脈に基づく応答の最初の数語を生成し、クラウドモデルがその後を完成させることで、遅延を隠蔽する協調生成フレームワークを設計。経験的結果は、極小モデルでも大規模モデルと同等の生成が可能であることを示し、リソース制約のあるデバイスでの高い応答性を実現。 Comment
元ポスト:
オンデバイスのMicro LLM(8M--30M)パラメータが冒頭の単語を生成し、その続きをCloud側のLLMが生成することで、Cloud LLMのlatencyの遅さをマスクする
[Paper Note] String Seed of Thought: Prompting LLMs for Distribution-Faithful and Diverse Generation, Kou Misaki+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #Prompting #Bias #ICLR #Test-Time Scaling #Diversity #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-21 GPT Summary- String Seed of Thought(SSoT)という新しいプロンプティング手法を提案し、Probabilistic Instruction Following(PIF)のパフォーマンスを改善します。PIFは選択肢を確率に基づいて選ぶタスクですが、LLMはしばしば非決定論的な挙動が要求される場面で偏りを生じることがあります。SSoTは、まずLLMにランダムな文字列を生成させ、これを操作することで多様性を維持しつつ制約を遵守した答えを導く手法です。実験により、SSoTがPIFの改善に寄与し、応答の多様性を高めることを示しました。 Comment
openreview: https://openreview.net/forum?id=luXtbX1lVK
元ポスト:
LLMが内包するバイアスを抑制し、出力の多様性を高めるPrompting手法っぽい。興味深い。
ランダムな文字列を生成させてから、その文字列を操作させて出力を得るようなアプローチとのこと。
著者ポスト:
-
-
[Paper Note] A Mechanistic Analysis of Looped Reasoning Language Models, Hugh Blayney+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #Architecture #LatentReasoning #Reference Collection Issue Date: 2026-04-21 GPT Summary- ループ推論型言語モデルの推論性能向上を探求し、フィードフォワードモデルとの内部ダイナミクスの違いを比較。循環的再帰を分析し、各層が異なる不動点に収束する様子を示す。再帰の過程でアテンションヘッドの挙動が安定化し、フィードフォワードモデルの推論段階を繰り返すことを発見。再帰ブロックのサイズや入力の注入が安定性に与える影響にも焦点を当て、設計の指針へと結びつける。 Comment
元ポスト:
解説:
[Paper Note] Don't Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG, Yiqun Sun+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#InformationRetrieval #NLP #AIAgents #RAG(RetrievalAugmentedGeneration) #FactualKnowledge #KeyPoint Notes #Clustering-based #AgentSkills Issue Date: 2026-04-21 GPT Summary- 検索強化生成(RAG)の限界を克服するために、Corpus2Skillを提案。これは文書コーパスを階層的なスキルディレクトリに変換し、LLMエージェントが効率的にナビゲート可能にする。文書をクラスタリングし、各レベルで要約を生成して構築。提供時に、エージェントはコーパス全体を把握し、段階的にトピックを掘り下げ、証拠を効果的に組み合わせる。実験により、WixQAのベンチマークでRAGの他の手法を上回る性能を示した。 Comment
元ポスト:
Agent Skillsの機構を利用し、Skillsを検索におけるIndexのような位置づけで活用し、Skillsを用いて階層化された知識をnavigateさせることで、抽象的な情報からより細かい情報までdrill-downさせるような挙動を実現させ、RAGの性能を向上させる。
Skillsを定義する際は、
- root level (Skill.md)
- leaf level (Index.md)
によって構成され、root levelではトピックに関する情報+クラスタのメタ情報、leaf levelでは個別のdocのtitle+IDによって構成される。
Documentを階層化する際にはクラスタリングを用いる。具体的にはクラスタリングを実施し、クラスタの内容をLLMに要約させ、要約させた情報に基づいてさらにクラスタリングをする、という処理を繰り返すことで階層化を実現していそうに見える。Servingの時はSkill.md, Index.md, Document Storeに対して、2種類のツール `code_execution`, `get_document` を用いて、ツリーを探索し、relevantなdocを取得する。code_executionは具体的には、SKILL.mdとIndex.mdをviewコマンドによって閲覧し、階層構造全体を俯瞰できるようにする。get_documentでは、docのidentifierを用いて、identifierと対応するdocの全文を取得する。
BM25, Denseなどのbaselineと比較して高い性能を獲得している。性能に対してコスト比が併記されているが、トークン空間上で思考し探索をするためコストは高いように見える。個人的に気になるのは、金銭的なコストもそうだが、latencyである。embeddingを用いたRAGに対して、相当latencyが遅いのではないか?と思われる。
[Paper Note] LACE: Lattice Attention for Cross-thread Exploration, Yang Li+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Attention #Test-Time Scaling #mid-training #Decoding #PostTraining #One-Line Notes Issue Date: 2026-04-20 GPT Summary- LACEは、独立した推論試行を協調的な並列プロセスに変換するフレームワークであり、クロススレッドのアテンションを活用して推論経路間での洞察の共有と相互訂正を可能にする。合成データを使って自然な訓練データの不足を補い、実験では正確性が7ポイント以上向上することを示した。結果は、相互作用する並列推論が大規模言語モデルの効果を高める可能性を示唆している。 Comment
元ポスト:
parallel test-time scalingによって生成をする最中にtrajectoryを交互作用させることで、trajectoryの冗長性を減らし、交互作用を可能にする。
[Paper Note] Thought-Retriever: Don't Just Retrieve Raw Data, Retrieve Thoughts for Memory-Augmented Agentic Systems, Tao Feng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #NLP #AIAgents #Chain-of-Thought #Selected Papers/Blogs #memory Issue Date: 2026-04-20 GPT Summary- LLMが外部知識を効果的に取り込む課題を解決するために、Thought-Retrieverという新しいアルゴリズムを提案。これは、過去のユーザークエリで生成された中間応答を活用し、冗長な思考をフィルタリングして新しいクエリに関連する思考を取り出すことで、長期記憶を構築。AcademicEvalという新たなベンチマークで広範な実験を行い、Thought-Retrieverが最先端モデルを上回る成果を示した。特に、より多くのクエリ解決後に自己進化を促し、抽象的な問いへの応答能力を向上させることが確認された。 Comment
元ポスト:
[Paper Note] LinuxArena: A Control Setting for AI Agents in Live Production Software Environments, Tyler Tracy+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Safety #SoftwareEngineering #Live #Sabotage Issue Date: 2026-04-20 GPT Summary- LinuxArenaは、エージェントが実稼働環境で操作するための制御設定で、20の環境、1,671の主要タスク、184の安全性に関するサイドタスクを含みます。妨害評価を通じて、主要タスクを完了しつつサイドタスクを処理できるかを検証し、GPT-5-nanoのモニターが1%の偽陽性率で多数の未検出妨害成功率を示しました。また、人手作成の攻撃軌跡データセットLaStrajを公開し、現行の攻撃方針がLinuxArenaに影響を与えていないことを示しました。これにより、LinuxArenaが攻撃者と防御者双方にとって重要な研究基盤となることが示唆されました。 Comment
元ポスト:
[Paper Note] Your Language Model Secretly Contains Personality Subnetworks, Ruimeng Ye+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #Personalization #ICLR #Personality #Author Thread-Post Issue Date: 2026-04-19 GPT Summary- LLMsは、異なるペルソナを自然に適応させる能力を持ち、その知識は既存のパラメータに埋め込まれていることを示す。小規模な比較データセットを用いて、特定のペルソナに関連する活性化の特徴を特定し、ペルソナサブネットワークを分離するマスキング戦略を開発。二値的な対立性を持つペルソナ間の統計的発散を生み出す対照的剪定戦略も提案し、完全な訓練を必要としない。得られたサブネットワークは、外部知識を必要とする手法よりもペルソナ整合性を大幅に向上させ、LLMsのパーソナライズに新たな視点を提供する。 Comment
元ポスト:
[Paper Note] Proxy Compression for Language Modeling, Lin Zheng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Tokenizer #Selected Papers/Blogs #reading #KeyPoint Notes #Byte-level #Author Thread-Post Issue Date: 2026-04-19 GPT Summary- プロキシ圧縮を導入し、圧縮入力と生のバイト列の共同訓練を通じて、モデルに両者の整合を学習させる新しい訓練手法を提案。実験では、訓練効率が大幅に改善され、固定計算予算内でのバイトレベルベースラインを上回る成果を示す。モデル規模の拡大に伴い、プロキシ訓練を受けたモデルはトークナイザーアプローチに匹敵または競合する性能を発揮し、頑健性を維持。 Comment
元ポスト:
既存の言語モデルはバイト列をcompressorを通じて圧縮されたシンボルを通じて学習されているものとみなせるが(compressorは言語モデルであればtokenizerでありシーケンス長を4--6倍削減する)、これにより特定の言語モデルがcompressorと強く紐づいてしまう欠点がある。tokenizerを噛ませる欠点としては、グリッチトークン(tokenizerのvocabには登録されているが学習ができていないトークン)やprompt boundary issue (The Art of Prompt Design: Prompt Boundaries and Token Healing, Scott Lundberg, 2023.05
)、言語固有のバイアスなどの問題が生じること。
提案手法はモデルのアーキテクチャとnext token predictionは一切変えずに適用できる。学習時のinputとして、warmupフェーズにおいてはcompressorによるトークン(
ベースラインとしてtokenizerを用いた場合と、バイト列をそのまま学習した場合、neuralモデルをcompressorとして用いた場合と比較し、0.5Bではベースラインよりもスコアが低いが、14B級になると、全てのbaselineを上回るだけでなく、tokenizerを用いた場合のモデルも上回った。
[Paper Note] Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter, Ruoyu Qin+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Infrastructure #LLMServing #Selected Papers/Blogs #reading #One-Line Notes #KV Cache #needs-revision #Author Thread-Post Issue Date: 2026-04-18 GPT Summary- Prefill-decode(PD)のデプロイにはKVCache転送が制限要因となっており、従来のアテンションモデルは大容量のKVCacheトラフィックを生成する。ハイブリッドアテンションアーキテクチャはKVCacheサイズを削減するが、データセンター間の運用に問題が残る。そこで、Prefill-as-a-Service(PrfaaS)を提案し、プリフィル処理を専用クラスタにオフロードして効率的なKVCache転送を実現。これにより、リソースの独立したスケーリングを可能にし、実績として、PrfaaSを用いた異種デプロイメントは従来よりも高い提供スループットを達成。 Comment
元ポスト:
LLM servingにおいて、prefillはcompute-intensiveで、decodeは(kv cacheが肥大化するため)memory-intensiveであるという特性があるため、(それぞれ得意な処理は得意なノードに任せるため)prefillとdecodeを分離して異なるノードで実施するprefill-decode disaggreagated servingというインフラのアーキテクチャが超巨大モデルでは主流だが、prefill-decode間でKV Cacheを転送しなければならないため、このような分離は同じ計算機クラスター内のRDMA(Remote Direct Memory Access)が可能なノード間に限定されるのが一般的である。
しかし、compute/memory特化型のリソースは通常チップの種類と物理的な場所の両方に制約されてプールされるので、両方のハードウェアがRDMAのような密結合なドメインで利用できないという欠点がある。このため、クラスターを超えてPD分離をしたいのだが、KV Cacheの転送が結局のところボトルネックとなる。現在のモデルはSparse/LinearなアテンションによってKV Cacheに必要なリソースが一桁減っているが、それでもnaiveにクラスタを跨いでPD分離をすると、突発的なリクエストのバーストや、不均一なPrefix Cacheの分布、クラスター間の帯域幅の変動などによって、計算効率が低下してしまう。
そのため、提案手法では、高スループットな長文のprefillに特化した独立クラスタを作り、ローカルにキャッシュされていない(主に長文の)、 prefillのみを同クラスタにオフロードし、短いリクエストはローカルでPDを実施するようなアプローチをとる。こうしてprefill特化クラスタによって生成されたKV Cacheはdecode可能なPDクラスタに対してイーサネットを介して転送される。これは選択的なオフロードであり、帯域幅が制限された経路で非効率な短いリクエストを送信を避けて、prefillの高速化が重要なリクエストのみをクラスタ間転送に集中させるという考え方に基づく。
これを実現するためには、(i)長いリクエストのみをオフロードするルーティングの仕組みと、(ii)ネットワークの輻輳を制御するための、帯域幅を考慮したスケジューラ、(iii)リクエスト長、キャッシュ配置、利用可能なクラスタの帯域幅を総合的に考慮してKV Cache全体を効率的を保ちながら管理するグローバルKV Cacheマネージャが必要。
このようなアーキテクチャを1T級のKimi Linearモデルで実験した結果、スループットが1.54倍、TTFTが64%改善した、という感じらしい。
[Paper Note] How Can We Synthesize High-Quality Pretraining Data? A Systematic Study of Prompt Design, Generator Model, and Source Data, Joel Niklaus+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Pretraining #NLP #SyntheticData Issue Date: 2026-04-17 GPT Summary- ウェブテキストを合成前訓練データに再表現するための重要因子を特定するため、大規模な実験を行い、1兆トークン以上の生成を実施。構造化出力形式(表、数学問題、FAQ、チュートリアル)が従来の手法を上回ることが確認され、モデルのサイズを増加させても性能向上が見られないことが示された。また、元データの選択が重要であることも分析で明らかに。これらの結果を基に、FinePhraseというおよそ4,860億トークンのオープンデータセットを開発し、既存のベースラインを超え、生成コストを大幅に削減できることを示した。データセットと生成フレームワークは研究コミュニティに提供される。 Comment
元ポスト:
[Paper Note] Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering, Xinyu Zhu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #AIAgents #memory #Hierarchical #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-17 GPT Summary- エージェント型科学における超長期自律性の課題に対し、ML-Master 2.0という自律エージェントを提案。階層型認知キャッシュ(HCC)を導入し、瞬時の実行と長期的戦略を切り離して一貫性を持たせる。評価では、最先端のメダル獲得率56.44%を達成し、AIの自律的探索の可能性を示唆。 Comment
元ポスト:
contextを
- experience (short-term)
- knowledge (mid-term)
- wisdom (long-term)
の3つの階層に分類し管理するmemory機構を提案しているようである。
階層ごとに異なる記憶容量とアクセス速度で実装し、必要に応じて階層間でデータが昇格(experience->knowledge等)、あるいは削除される、といった機構によってmemory cacheを管理するような手法のようである。
MLE-BenchでSoTA
[Paper Note] Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning, NVIDIA+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-04-17 GPT Summary- Nemotron 3 Super は、1200億パラメータを持つ新しい Mixture-of-Experts モデルで、事前学習に NVFP4を使用。事後学習には SFT と RL を採用し、最大 1M のコンテキスト長をサポート。推論スループットは従来モデルと比べて最大 7.5 倍向上し、オープンソースのデータセットが提供されています。 Comment
元ポスト:
[Paper Note] Personalized RewardBench: Evaluating Reward Models with Human Aligned Personalization, Qiyao Ma+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #Personalization #Evaluation Issue Date: 2026-04-17 GPT Summary- 報酬モデル(RMs)の個別化評価が未解決の課題である中、Personalized RewardBench(PRB)という新しいベンチマークを導入。これにより個々のユーザーの嗜好を厳密にモデル化する能力を評価。人間の評価では、両応答が一般的な品質を維持しつつ、嗜好の識別が個別に調整され、既存の報酬モデルは個別化に苦戦していることが明らかに。PRBは下流タスクにおいて既存の性能と比べて高い相関を示し、報酬モデルの評価における信頼性のある指標として確立された。 Comment
元ポスト:
[Paper Note] The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook, Xinlei Yu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Survey #NLP #LatentReasoning #Reference Collection #Initial Impression Notes Issue Date: 2026-04-17 GPT Summary- 潜在空間は言語モデルにおいて重要な役割を果たし、多くのプロセスが連続的な潜在空間で自然に行われることが示されている。本調査は、潜在空間の基盤、進化、機構、能力、展望を整理し、それを他の空間や視覚モデルと明確に区別する。特に、アーキテクチャや最適化を含む四つの主要な発展線を特定し、推論や知覚など多様な能力を支える潜在空間の役割を論じる。未解決課題と今後の研究方向も示し、次世代知能のパラダイムを理解するための基盤を提供することを期待している。 Comment
latent reasoningに関する最新survey
Taxonomyがしっかりしているのが非常に良さそうである。たとえばCOCONUT(Representation/Reasoning)、Looped Transformer (Architecture, Reasoning), VJ-JEPA (Architecture/Perception)を見るとそれぞれ異なるセルに配置されている。手法ごとの表を見ると年号だけでなく、”日付”別で整理され時系列かされている。あと毎回Surveyみて思うが、多すぎである。。。
- [Paper Note] Training Large Language Models to Reason in a Continuous Latent Space, Shibo Hao+, COLM'25
- (Looped Transformerの例) [Paper Note] Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs, Ziyue Li+, arXiv'25
- [Paper Note] VL-JEPA: Joint Embedding Predictive Architecture for Vision-language, Delong Chen+, arXiv'25, 2025.12
元ポスト:
[Paper Note] TensorHub: Scalable and Elastic Weight Transfer for LLM RL Training, Chenhao Ye+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #Reference Collection Issue Date: 2026-04-17 GPT Summary- 強化学習(RL)におけるウェイト転送の効率化のため、新しいストレージ抽象化Reference-Oriented Storage(ROS)を提案。ROSは複製されたモデルウェイトを活用し、物理的なコピーを保持せずにアクセスを提供。さらに、TensorHubを構築し最適化転送やフォールトトレランスを実現。評価結果では、GPU待機時間を6.7倍削減し、ウェイト更新を4.8倍加速、データセンター間ロールアウトの待機時間を19倍短縮。TensorHubは実運用にデプロイ済み。 Comment
元ポスト:
[Paper Note] Efficient RL Training for LLMs with Experience Replay, Charles Arnal+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #Reference Collection #ReplayBuffer Issue Date: 2026-04-17 GPT Summary- 経験再生をLLMの事後トレーニングに適用し、リプレイバッファの最適設計を探求。生成コストの高い場合、オンポリシーサンプリングが必ずしも最適でないことを示し、よく設計されたリプレイバッファが推論計算量を削減し、モデル性能を改善する可能性があることを実証。 Comment
元ポスト:
所見:
所見:
[Paper Note] Nexus: Same Pretraining Loss, Better Downstream Generalization via Common Minima, Huanran Chen+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Pretraining #NLP #Optimizer #read-later #Selected Papers/Blogs #Generalization #DownstreamTasks #Initial Impression Notes Issue Date: 2026-04-17 GPT Summary- 大規模言語モデル(LLMs)の事前学習において、幾何学的問題を調査し、タスク固有のミニマの位置が下流の一般化に影響することを提案。勾配の類似性を最大化するNexus optimizerを導入し、パラメータサイズやデータに応じた実験で、下流パフォーマンスの向上を示した。特に3Bモデルでは、分布外データでの損失を低減し、複雑な推論タスクで精度を最大15.0%向上させる結果を得た。これは、事前学習損失以外の評価指標の重要性を示唆している。 Comment
元ポスト:
ポイント解説:
モデルを更新する際に平均的に性能が良くなる方向ではなく、全ての異なるデータにおいて性能が改善する方向性で更新すると性能が改善するという感じだろうか。興味深い
[Paper Note] HiFloat4 Format for Language Model Pre-training on Ascend NPUs, Mehran Taghian+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #mid-training #PostTraining #LowPrecision Issue Date: 2026-04-17 GPT Summary- 大型基盤モデルのトレーニングには高コストが伴うため、低精度トレーニング手法が求められている。本研究では、HiFloat4 FP4フォーマットを使用し、MXFP4と比較して4ビット精度での計算スループットとメモリ効率を最大4倍向上させる。全結合モデルとエキスパート混合モデルをFP4で評価し、安定化技術により数値的劣化を抑えつつ高精度を維持する結果を示した。 Comment
元ポスト:
[Paper Note] Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision, Yinghui He+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #read-later #On-Policy #SelfDistillation Issue Date: 2026-04-16 GPT Summary- SD-Zeroは、強化学習や外部教師を必要とせず、単一のモデルを生成器と査読者として学習させる新たな手法である。生成器が初期応答を生成し、査読者がそれを改善する過程で、オンポリシー自己蒸留を利用し、密なトークンレベルの自己監督を実現する。SD-Zeroは数学・コード推論ベンチマークにおいて、基盤モデルよりも10%以上の性能向上を示し、強力なベースラインを上回った。特徴としては、重要なトークンを特定するトークンレベルの自己局在化と、教師同期化による回答改訂の反復的自己進化がある。 Comment
元ポスト:
[Paper Note] LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning, Sumeet Ramesh Motwani+, ICML'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #Chain-of-Thought #Evaluation #Reasoning #ICML #read-later #Selected Papers/Blogs #LongHorizon #Author Thread-Post Issue Date: 2026-04-16 GPT Summary- LongCoTを導入し、複雑な推論能力を測定するための2,500問の専門家設計問題からなるベンチマークを提供。問題は数万から百数万の推論トークンを含む相互依存の手順を要求し、最先端モデルは全体で<10%の精度であることが示され、長期推論の限界が明らかになる。LongCoTは、モデルの長時間にわたる安定した推論能力を評価する指標となる。 Comment
元ポスト:
著者ポスト:
[Paper Note] Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks, Yoonsang Lee+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Test-Time Scaling #LongHorizon #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-16 GPT Summary- エージェント的タスクに対する並列テスト時スケーリングの研究を行い、集約エージェントAggAgentを提案。複数のロールアウトを生成し、軌跡の情報を効果的に統合しながら、出力のオープンエンド性に対応。AggAgentは6つのベンチマークと3つのモデルファミリーで既存手法を上回り、改善を達成しつつ、オーバーヘッドを最小限に抑えた。これにより、エージェント的集約の効率性が確認された。 Comment
元ポスト:
Parallel test time scalingをじっしするlong horizon AI Agentの複数のtrajectoryを集約する手法のようである
[Paper Note] Parcae: Scaling Laws For Stable Looped Language Models, Hayden Prairie+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #Stability #LatentReasoning #RecurrentModels #RecursiveModels #Initial Impression Notes Issue Date: 2026-04-16 GPT Summary- ループ型アーキテクチャの訓練の不安定性を克服するため、動的システムとして再定式化し、注入パラメータのスペクトルノルムを制約する新しいアーキテクチャParcaeを提案。Parcaeは従来モデルより低いパープレキシティを達成し、FLOPsのスケーリング特性を調査。訓練時に固定パラメータでのFLOPs増加法則を導出し、推論時には計算量のスケーリングを実現。2.99ポイントと1.18ポイントの品質改善を報告。 Comment
blog: https://sandyresearch.github.io/parcae/
元ポスト:
学習がより安定するような工夫を加えたlooped transformerのようである
所見:
[Paper Note] LLM-as-a-Verifier: A General-Purpose Verification Framework, Jacky Kwok+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #read-later #Selected Papers/Blogs #Verification #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-16 GPT Summary- LLMの能力向上に検証を新たなスケーリング軸として適用する方法を提案。LLM-as-a-Verifierフレームワークにより、細粒度のフィードバックを提供し、連続的なスコア生成を実現。これにより、正例と負例の解の分離が向上し、追加的な検証精度が得られる。提案手法は複数のベンチマークで最先端の性能を示し、タスク進行の推定にも寄与。さらに、RLに対しても高効率なフィードバックを提供。 Comment
元ポスト:
著者ポスト:
著者ポスト2:
Verification性能をtest-timeに向上させるためのテクニック
アイデアの一つにGEvalっぽいアイデアも含まれている。
[Paper Note] Memory Intelligence Agent, Jingyang Qiao+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #MultiModal #ContrastiveLearning #VisionLanguageModel #DeepResearch #memory #reading #Test-time Learning #Initial Impression Notes #needs-revision Issue Date: 2026-04-14 GPT Summary- DRAはLLMの推論と外部ツールを組み合わせ、過去の経験を活用するメモリシステムを含む。従来の方法はメモリの効率性に課題があり、MIAフレームワークを提案してこれを解決。プランナーとエグゼキューターから成る新しいアーキテクチャは、交互の強化学習で協調を強化し、推論中の更新を実現。さらに、記憶の双方向変換を可能にし、自己進化を促進する機構も搭載。広範な実験でMIAの優位性を示した。 Comment
元ポスト:
元ポストを読みなんとなーく分かったつとりになっているゆるふわ理解だが、Plannerのパラメータに経験をTest Time Learningの枠組みを埋め込み、既存のノンパラメトリックなメモリにtrajectoryも活用する二段構えである点が新しい点に感じた。
元論文を流し読みすると、Executor(vlm), Planner(llm, parametricなmemory), Memory Manager(trajectoryを格納; non parametricなmemory)の3つにマルチモーダルなAI Agentを分離する。
plannerは(ToDo 3.2節を読むべし
executorはplannerと過去のtrajectoryに基づいて実行をする。executorはGRPOに」るRLVRで訓練されるが、tool use, plannerのトークンはマスクされ学習される。
(後ほど追記
[Paper Note] KnowledgeSmith: Uncovering Knowledge Updating in LLMs with Model Editing and Unlearning, Yinyi Luo+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #ICLR #ConceptErasure #KnowledgeEditing #reading #KeyPoint Notes #needs-revision #Author Thread-Post Issue Date: 2026-04-14 GPT Summary- LLMsの知識更新メカニズムを理解するため、統一フレームワークKnowledgeSmithを提案。編集と忘却を制約付き最適化として位置づけ、自動データセット生成器を用いて修正戦略の知識伝播を研究。実験により、LLMsが人間と同様の更新を示さず、一貫性と容量のトレードオフがあることを発見。新たな戦略設計の示唆を提供。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=znnA2Opw6v
知識の忘却と編集のダイナミクスを制約付きの最適化問題として統一的にモデル化(式3;この最適化問題を実際に解いているわけではなくあくまで理論的にこう定式化できるねという話だと思われる)し、
この定式化を通じて見ると、編集と忘却の違いはターゲットとする分布q_targetの選び方の違いにすぎず、様々な編集と忘却の先行研究は手法は違えど、この制約付きの最適化問題の異なるインスタンスを解いているに過ぎないという視点を提供しているようである。これにより、編集と忘却のトレードオフを公平に比較することが可能となるという主張をしているように見える(自信ない)。
そして、編集と忘却のトレードオフを厳格に分析するためのベンチマークとして、階層的な依存関係や(local vs. global)、更新の多段階での伝播を扱えるベンチマークが必要だが既存ベンチマークではこれらが不足しているため、
知識グラフに基づいて自動的に構築されたデータとベンチマーク(Figure 1を見るにテンプレートベースのMCQを)を作成して分析。
分析には6つのモデルファミリーの13のモデルが用いられ、スケールは1B--123Bの幅広いスケールのモデルで検証された。
(先行研究も含めてしっかり読まないと、式3と実験で用いられている手法AlphaEdit, ReLearnの関係性がちょっとわからなそう)
著者ポストにおいては、以下のようなtakeawayが記載されており、大きな知見としてはLLMはデータベースではなく、トレードオフを持つ複雑に絡み合ったシステムであり、以下のような点を明らかにした
- 知識の編集は意図しない変更を引き起こし
- 忘却は知識の完全な消去には失敗する
- 更新する知識を増やせば増やすほど、ローカルの知識は更新されるが、グローバルな一貫性が崩壊し
- 変更することが極めて困難な知識(たとえば歴史)が存在する
とのことである。
[Paper Note] Introspective Diffusion Language Models, Yifan Yu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #DiffusionModel #Initial Impression Notes Issue Date: 2026-04-14 GPT Summary- 内省的受容率を定義し、拡散型言語モデル(DLM)の品質向上を目指す。新たに提案されたIntrospective Diffusion Language Model(I-DLM)は、ARトレーニングの内省的一貫性を保ちながら並列デコードを実現する。I-DLMは新しい内省的ストライドデコード(ISD)アルゴリズムを使用し、静的バッチスケジューラで最適化。従来のDLMを上回り、AIME-24で69.6、LiveCodeBench-v6で45.7の性能を達成。これにより、スループットが3倍向上し、大規模サービスへの対応力も強化。 Comment
元ポスト:
github: https://github.com/Introspective-Diffusion/I-DLM
8B級のスケールでARモデルと15種類のベンチマークで同等程度の性能を達成し、large batchsizeでスループットが3.8倍のdLMとのこと。
[Paper Note] Learning is Forgetting: LLM Training As Lossy Compression, Henry C. Conklin+, ICLR'26, 2026.04
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #ICLR #read-later #Initial Impression Notes Issue Date: 2026-04-11 GPT Summary- LLMの表現空間の構造は未解明であり、学習の解釈に制限がある。研究では、LLMsを損失のある圧縮として捉え、訓練過程で目的に関連する情報のみを保持すると主張。モデルの事前訓練結果から圧縮の最適性を示し、異なるモデル間の性能が訓練データとレシピの違いによることを解明。これにより、表現構造と性能を結びつける情報理論的フレームを提供し、大規模な応用の可能性を示す。 Comment
元ポスト:
openreview:
https://openreview.net/forum?id=tvDlQj0GZB
(おそらく先行研究と比較したときの新規性に対する解釈が割れていて)スコアが相当pos/negに偏っている
なお、Rebuttalのために800以上のチェックポイントを分析する必要があったとのこと。
meta reviewによるとLLMのダイナミクスを理解するうえで有用な視点を提供している一方で、論文中で潜在的な応用可能性については言及されているが、実用的な有用性、特に本研究が示した分析結果が効果的な学習手法、モデル選択手順にどのように反映可能かが十分に示されていない、という指摘がある。
所見:
[Paper Note] Squeeze Evolve: Unified Multi-Model Orchestration for Verifier-Free Evolution, Monishwaran Maheswaran+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-04-11 GPT Summary- 検証者なしの進化は、多様性と効率においてボトルネックが存在する。本研究では、Squeeze Evolveというマルチモデルオーケストレーションフレームワークを提案。モデルの能力を最適に割り当てることで、多様性とコスト効率を両立させる。Squeeze Evolveは、いくつかのマルチモーダル視覚ベンチマークにおいて、単一モデル進化と比較してコスト対能力を改善し、新たな最先端結果を達成。さらに、探索タスクでは検証者ありの進化法と同等、またはそれを上回る性能を示した。 Comment
pj page: https://squeeze-evolve.github.io/#blog-squeeze-evolve
元ポスト:
様々なtest-time scaling手法が単一のframeworkで表現できるという話がそもそもおもしろそう。読みたい。
[Paper Note] ClawBench: Can AI Agents Complete Everyday Online Tasks?, Yuxuan Zhang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Selected Papers/Blogs #Generalization #VisionLanguageModel #Live #One-Line Notes #Environment Issue Date: 2026-04-11 GPT Summary- ClawBenchは、次世代AIエージェントを評価するための153の簡単なタスクからなるフレームワークを提供。これにより、ユーザーからの情報取得や多段階ワークフローのナビゲーション、高度なフォーム記入といった複雑なタスクを評価可能。従来の静的なベンチマークと異なり、実際のウェブサイトで動作するため、現実的な評価を可能にする。評価では、商用・オープンソースモデルがタスクの一部しか完了できないことが示され、AIエージェントの汎用性向上に寄与することが期待される。 Comment
元ポスト:
pj page: https://claw-bench.com
実際のwebsiteに対して、日常的なオンラインでの153タスクを実行しweb agentを評価可能なフレームワークな模様。既存のオフライン、かつサンドボックスなベンチマークでは75%程度のスコアを達成していたGPT-5.4が、6.5%までスコア低下。
タスク性能の可否は、タスクのinstruction, 人間によるreference actionとpayload, エージェントの実際のactionとpayloadを与えて、AgenticなAIによって、ルーブリックに基づいて判断されるようである(Figure7)。
github: https://github.com/reacher-z/ClawBench
タスクinstructionの一覧は下記:
https://github.com/reacher-z/ClawBench/tree/main/test-cases
たとえば、UberEatsでパッタイをピーナッツ抜きで一つ注文する、といったタスクがある。
[Paper Note] FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling, Yitong Li+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #On-Policy #One-Line Notes #LowPrecision Issue Date: 2026-04-11 GPT Summary- 強化学習ベースのポストトレーニングを用いたテキストから画像への拡散モデルの最適化において、FP4量子化を組み込んだ二段階強化学習フレームワーク「Sol-RL」を提案。第一段で高スループットのロールアウトを行い、高コントラストのサブセットを生成、第二段でこれを高精度で再生成してポリシーを最適化。これにより、ロールアウトの効率を高めつつ訓練整合性を維持。実験により約4.64倍の収束加速を達成し、高性能な整合性を示す。 Comment
pj page: https://nvlabs.github.io/Sana/Sol-RL/
元ポスト:
FP4でまずロールアウトを生成し、rewardモデルを用いて生成結果のスコアを得て、top/worst-Kのサンプルに絞ってBF16で(該当ノイズから)サンプルを再生成しGRPOで活用する。
探索がFP4で実施されるため高速になり、2*K件のサンプルにのみ絞って学習が行われるため2段階の高速化になっている。
[Paper Note] The Art of Building Verifiers for Computer Use Agents, Corby Rosset+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #ComputerUse #read-later #Selected Papers/Blogs #Verification #Rubric-based Issue Date: 2026-04-11 GPT Summary- CUA軌跡の検証は評価信号の信頼性に不可欠である。本研究では、ノイズを減らしたルーブリックの構築、プロセスと成果報酬の分離、失敗の制御、文脈管理スキームの導入を行い、Universal Verifierを設計。新しいCUA軌跡集合CUAVerifierBenchでの検証により、人間の合意に匹敵する精度を示し、偽陽性率をほぼゼロに低減。自動研究エージェントは専門家の品質を70%達成するが、Universal Verifierの戦略発見には失敗。システムとデータセットはオープンソースとして公開。 Comment
元ポスト:
[Paper Note] RAGEN-2: Reasoning Collapse in Agentic RL, Zihan Wang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Reasoning #PostTraining #read-later #Selected Papers/Blogs #Entropy Issue Date: 2026-04-11 GPT Summary- RAGEN-2では、LLMエージェントの強化学習トレーニングの不安定性に注目し、推論の質をエントロピーと相互情報量(MI)に分解。エントロピーが高くても、モデルが固定テンプレートに依存する「テンプレート崩壊」の問題を明らかにした。MIは推論品質の信頼できる指標であり、タスク性能との相関が強い。低い報酬分散が推論差を消してしまう問題をSNR対応フィルタリングを用いて解決し、入力依存性とタスク性能を改善することを提案。様々なタスクで一貫した成果を示した。 Comment
pj page: https://ragen-ai.github.io/v2/
元ポスト:
おもしろそう
ポイント解説:
トークンのエントロピーによって多様性を測る方法は、単一の応答内での多様性は測れるが、異なるプロンプトに対する応答の多様性は測れない。たとえば、単一応答内のエントロピーは健全だが、応答がinputに非依存の応答となっている場合など(=テンプレート崩壊)は多様性が欠如していると考えられる。このため、相互情報量に基づくメトリックを提案し、応答間で共有されている情報量を測る方法を提案。
[Paper Note] In-Place Test-Time Training, Guhao Feng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ICLR #read-later #Test Time Training (TTT) #Author Thread-Post Issue Date: 2026-04-08 GPT Summary- 静的な学習パラダイムでは新情報への動的適応が制限される。本研究では、推論時訓練(TTT)を用いてモデルパラメータを更新し、インプレースTTTフレームワークを提案。これにより、MLPブロックの最終射影行列をファストウェイトとして扱い、ゼロからの再訓練なしでLLMを強化。次トークン予測タスクに目的を整合させ、スケーラブルなアルゴリズムを実現。実験により、4Bパラメータモデルが優れた性能を示し、競合するアプローチを上回った。In-Place TTTは継続的学習の新たな一歩を提供する。 Comment
openreview: https://openreview.net/forum?id=dTWfCLSoyl
元ポスト:
[Paper Note] PHOTON: Hierarchical Autoregressive Modeling for Lightspeed and Memory-Efficient Language Generation, Yuma Ichikawa+, ACL'26, 2025.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Architecture #ACL #Hierarchical Issue Date: 2026-04-08 GPT Summary- PHOTONは、トランスフォーマーの水平スキャンを垂直で多解像度の文脈スキャンに置き換える階層型自己回帰モデルである。ボトムアップエンコーダがトークンを低レートの文脈に圧縮し、軽量なトップダウンデコーダが高精細なトークンを再構築。再帰的生成により最も粗いストリームのみを更新し、ボトムアップの再エンコードを排除。実験では、PHOTONが長いコンテキストやマルチクエリタスクで優れたスループットと品質を示し、KV-cacheトラフィックを削減して最大1000倍のスループットを実現。 Comment
元ポスト:
[Paper Note] OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models, Han Zhu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Transformer #SpeechProcessing #DiffusionModel #Speech #MultiLingual #OpenWeight #TTS #Initial Impression Notes Issue Date: 2026-04-07 GPT Summary- OmniVoiceは、600言語以上対応した多言語ゼロショットTTSモデルで、離散的非自己回帰アーキテクチャを採用。従来の複雑なパイプラインを排除し、テキストを直接音響トークンにマッピング。全コードブックランダムマスキング戦略とLLMからの初期化が技術革新を支える。581,000時間のオープンソースデータセットに基づき、中国語・英語などで最先端の性能を示す。モデルはオープンソースとして公開。 Comment
元ポスト:
github: https://github.com/k2-fsa/OmniVoice
dLMアーキテクチャだからかなり早いのでは。600+言語をサポート。
[Paper Note] TARo: Token-level Adaptive Routing for LLM Test-time Alignment, Arushi Rai+, ACL'26 Findings, 2026.03
Paper/Blog Link My Issue
#Alignment #ACL #Decoding #Findings #Routing #KeyPoint Notes #Author Thread-Post #Test-time Alignment Issue Date: 2026-04-07 GPT Summary- 推論時に固定されたLLMsを用いて、トークンレベル適応ルーティング(TARo)を提案。報酬モデルにより数学的推論の一貫性信号を捉え、ルーターが基盤モデルを自動制御。TARoは推論性能を最大+22.4%向上させ、分布外の臨床推論や指示遵守を改善。再訓練なしでの一般化も可能で、堅牢な推論を実現。 Comment
元ポスト:
巨大なベースモデル全体を特定ドメインに適用するためにpost-trainingするのは大変なので、代わりに小規模なdomain-expertなRewardモデルを学習し(今回は数学のstep-wiseにlogicが正しいことをpreferenceとして与えるような学習方法を採用したようである; 3.2節)、各decoding step tにおいて、ベースモデルとRewardモデルのトークンのlogitを線形補完することで、出力トークンをガイドする。logitの線形補完において、固定されたスカラー値(e.g., 0.5など。GenARMという手法らしい)を用いる研究などが先行研究ではあるが、これはベースモデルの特定タスクにおいてベースモデルの性能を劣化させるので、本研究ではdecoding step t時点で出力されたベースモデル、Rewardモデルのlogitを入力として、FFNによって線形補完の重みα_tをdecoding step tごとに決定する(α_tを決定するネットワークをRouterと呼ぶ)。FFNは2種類のvariantがあり、双方のlogitをconcatしたものを入力するものと、top-kをサンプリングし、kごとにindexに基づいたembeddingをconcatして入力する方法の二種類がある(3.3節)。
結果としては、GenARMと比較して提案手法は有効ではあるが、ベースモデルとrewardモデルの組み合わせによっては、baseモデルよりも性能が悪化するということもありそうに見える。
またRouterはベースモデルのサイズを大きくしても、性能が転移するので再学習が不要である。
[Paper Note] Mixture-of-Minds: Multi-Agent Reinforcement Learning for Table Understanding, Yuhang Zhou+, ACL'26, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #ReinforcementLearning #AIAgents #TabularData #SelfImprovement #ACL #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2026-04-07 GPT Summary- 表の理解と推論を高めるため、マルチエージェントフレームワークMixture-of-Mindsを提案。計画、コーディング、回答の役割に分割し、各エージェントが特定の側面を担う。自己改善トレーニングにモンテカルロ木探索を用いて強化学習を最適化。実験結果ではTableBenchで62.13%の改善を達成し、構造化されたアプローチの有効性を示す。 Comment
元ポスト:
複雑なタスクを特化型のエージェントに分解し、個々のエージェントを学習するためのpseudo-gold trajectoryを合成しエージェントをFinetuning。その後、FinetuningしたエージェントをGRPOによってend-to-endで学習する、という話に見える。pseudo-gold trajectoryは、個々の特化型のエージェントに対して複数の解候補を出力させ、解候補を次のエージェントに入力し解候補を生成...という手順をsequentialに適用していき、最終的に正しい応答を導き出せたtrajectoryを後ろ向きにたどることによって、pseudo-gold trajectoryを得る。FinetuningとRLがどのような順番で実施されるか、あるいは繰り返されるのか、といった部分についてはしっかり読み解けていない。
表データで実験をしているが、それは一つの応用例であり、汎用的に利用可能な手法と考えられる。
[Paper Note] Cross-Architecture Model Diffing with Crosscoders: Unsupervised Discovery of Differences Between LLMs, Thomas Jiralerspong+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #One-Line Notes #ModelDiffing Issue Date: 2026-04-05 GPT Summary- モデルdiffingは新モデルの安全性を明らかにする効果的手法だが、主にベースモデルとファインチューニングモデルの比較に限定されていた。Crosscodersはアーキテクチャを横断するモデルdiffingを可能にするが、従来はその応用が限られていた。本研究ではCrosscodersを用いた初のアーキテクチャ横断のモデルdiffingを行い、Dedicated Feature Crosscoders(DFCs)を提案。これにより、教師なしで特定の偏りや特徴を発見し、アーキテクチャ横断のモデルdiffingがAIモデル間の挙動差を特定する有効な手法であることを示した。 Comment
モデルのアーキテクチャを跨いでモデルの特徴や性質の違いのdiffを見る方法とのこと。
元ポスト:
[Paper Note] Preference-Aligned LoRA Merging: Preserving Subspace Coverage and Addressing Directional Anisotropy, Wooseong Jeong+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #PEFT(Adaptor/LoRA) #ModelMerge Issue Date: 2026-04-05 GPT Summary- 複数のLoRAモジュールを統合する際の不均一な寄与による問題を解決するため、サブスペースの被覆度と異方性を考慮したTARA-Mergingを提案。これにより、タスク関連のLoRAサブスペースを保持しつつ、効果的な方向ごとの再重み付けを実現。実験では、TARA-Mergingが他の手法を一貫して上回り、強固な汎化能力を示した。 Comment
元ポスト:
[Paper Note] Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization, He Du+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #PostTraining #EvolutionaryAlgorithm #GPUKernel Issue Date: 2026-04-05 GPT Summary- Kernel-Smithは、高性能GPUカーネルと演算子生成のためのフレームワークで、評価駆動型進化エージェントを用いて候補プログラムを改善。NVIDIAとMetaXのバックエンド特化評価サービスを活用し、トレーニングは強化学習信号とステップ中心の監督を結合。Kernel-Smith-235B-RLは、NVIDIA Tritonバックエンドにおいて総合性能の最先端を達成し、他モデルを上回る。さらに、MetaX MACAバックエンドでの適応も成功し、本番システムへの実用的な寄与を示す。 Comment
元ポスト:
[Paper Note] Think Anywhere in Code Generation, Xue Jiang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #Coding #Reasoning #SoftwareEngineering #read-later #Reference Collection Issue Date: 2026-04-04 GPT Summary- LLMsの事前思考に依存したコード生成は制限があり、全体の複雑性を理解するには不十分である。これに対抗するために、Think-Anywhereという新しい推論機構を提案し、任意のトークン位置で推論を呼び出すことを可能にする。これにより、推論パターンの模倣と成果ベースのRL報酬を活用し、推論のタイミングを自律的に探索させる。広範な実験で、Think-Anywhereは最先端の性能を実現し、多様なLLMsにおいて一貫した一般化を示すことが確認された。 Comment
元ポスト:
解説:
[Paper Note] Path-Constrained Mixture-of-Experts, Zijin Gu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #Stability #Routing Issue Date: 2026-04-04 GPT Summary- スパースなMixture-of-Experts(MoE)アーキテクチャは、入力に対して一部のパラメータのみを活性化し効率的なスケーリングを実現するが、従来の独立ルーティングは膨大なパス空間を生じ、学習の非効率をもたらす。そこで、連続する層間でルータのパラメータを共有する\pathmoeを提案。実験により、独立ルーティングと比べてパープレキシティや下流タスクでの改善を確認した。トークンが同じパスをたどることで語機能ごとにクラスタリングされ、一貫性と頑健性が向上することが示された。これにより、MoEアーキテクチャの理解に新たな視点が得られる。 Comment
元ポスト:
[Paper Note] Rethinking Language Model Scaling under Transferable Hypersphere Optimization, Liliang Ren+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #read-later #Selected Papers/Blogs #HyperparameterTransfer Issue Date: 2026-04-04 GPT Summary- HyperPは、Muonsオプティマイザを使用した超球面パラメータ化フレームワークで、スケーリング時の安定性を向上させる。最適学習率を幅や深さ、トレーニングトークンに跨って転送可能とし、計算効率を1.58倍向上。監視指標は有界で非増加を維持し、MoEゲーティング機構SqrtGateにより粒度スケーリングを改善。トレーニングコードは公開されている。 Comment
元ポスト:
[Paper Note] PRBench: End-to-end Paper Reproduction in Physics Research, Shi Qiu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #ScientificDiscovery #Reproducibility #Physics Issue Date: 2026-04-04 GPT Summary- 大規模言語モデルを用いたAIエージェントは、科学研究タスクを支援するが、実際の科学論文からの再現性に課題がある。PRBenchを導入し、物理学の専門家が選んだ30のタスクに基づき、エージェントが論文の方法論を理解し、アルゴリズムを実装する能力を評価。エージェントは指示と論文内容のみを使い、実行環境で動作。評価の結果、GPT-5.3-Codexが最も高いスコアを得るも、全エージェントの再現成功率はゼロで、誤実装やデバッグ不能の問題が確認された。PRBenchは自律的な科学研究の進展を評価するための厳格な基準を提供する。 Comment
元ポスト:
[Paper Note] KAT-Coder-V2 Technical Report, Fengxiang Li+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #AIAgents #Coding #SoftwareEngineering #read-later Issue Date: 2026-04-04 GPT Summary- KAT-Coder-V2は、快手のKwaiKATチームが開発したエージェント指向のコーディングモデルで、5つの専門ドメインに分解し、それぞれを教師あり微調整と強化学習で独立学習した後、単一モデルに統合します。KwaiEnvを用いて数万の同時サンドボックス環境を支え、RL訓練をスケーリング。MCLAとTree Trainingにより計算の冗長性を排除し、最大6.2倍のスピードアップを達成。SWE-benchで79.6%、PinchBenchで88.7のスコアを記録し、複数のベンチマークで首位を獲得しました。モデルは公開されています。 Comment
元ポスト:
Claude Opus 4.6に近い性能を持つagentic coding modelとのこと。
[Paper Note] Rethinking Memory Mechanisms of Foundation Agents in the Second Half: A Survey, Wei-Chieh Huang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #read-later #memory Issue Date: 2026-04-04 GPT Summary- 人工知能の研究は、ベンチマークスコアから現実世界での評価にシフトしている。今後の課題は、長期・動的な環境でのエージェントの真の有用性の確保であり、記憶がその解決策として重要視されている。本調査では、エージェント記憶を記憶基盤、認知機構、記憶対象の三次元から検討し、記憶操作を学習ポリシーと関連付けて分析。記憶の有用性評価のためのベンチマークと指標も提案し、未解決の課題と今後の方向性を示す。 Comment
AI Agent + memory に関するサーベイ。とんでもない量だ。。。
github: https://github.com/AgentMemoryWorld/Awesome-Agent-Memory
元ポスト:
以下の3つの軸で整理されているようである
- メモリの基盤 (Memory Substrate):
- internal: 重み、潜在表現、KVCache
- external: vector stores, knowledge graphs, text records
- 認知機構 (Cognitive Mechanism)
- メモリの対象 (Memory Subject)
2023--2025の218の文献をレビューしたとのこと。
open challengeとしては
- continual learning
- multi-human-agent memory organization
- memory infrastructure and efficiency
- life-long personalization and trustworhy memory
- multimodal grounding
- real-world evaluations
と題されている。
[Paper Note] Embarrassingly Simple Self-Distillation Improves Code Generation, Ruixiang Zhang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #AIAgents #Coding #PostTraining #read-later #SelfDistillation #Author Thread-Post Issue Date: 2026-04-04 GPT Summary- 簡易自己蒸留(SSD)を用いて、LLMが独自の出力のみでコード生成の改善が可能であることを示す。特定の温度とトランケーション設定で出力をサンプリングし、その後教師付きファインチューニングを行うことで、Qwen3-30B-Instructのパフォーマンスを42.4%から55.3%に向上。4B・8B・30Bスケールのモデル間で一般化され、改善のメカニズムをLLMデコードの精度と探索の相互関係に関連づけて検討。SSDは、精度を高めつつ多様性を保持するアプローチとして、LLMのコード生成に寄与する可能性を示唆する。 Comment
元ポスト:
所見:
解説:
著者ポスト:
[Paper Note] Adaptive Block-Scaled Data Types, Jack Cook+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Architecture #SoftwareEngineering #read-later #Selected Papers/Blogs #One-Line Notes #LowPrecision #needs-revision Issue Date: 2026-04-01 GPT Summary- NVFP4は、4ビット量子化形式として人気ですが、誤差分布の問題を抱えています。本研究では、入力値の分布に適応できる新しいデータ型、IF4(Int/Float 4)を提案します。IF4は、各16値のグループに対しFP4とINT4を選択し、NVFP4のスケールファクターでスケールします。この方法により、量子化訓練時の損失を低減し、精度を向上させることが確認されました。また、IF4のハードウェア実装も評価されています。 Comment
元ポスト:
NVFP4と同様に、4bitで表現される16個のデータをひとつのグループとして扱い[^1]、FP8でのスケールファクターを共有するような浮動小数点フォーマットで[^2]、
グループ内の16個のデータに対して、INT4/FP4どちらを適用するかを、(NVFP4では常に正となっていた;未使用だった)スケールファクターを表現している8bitの先頭である符号ビットを用いて制御する新たな低精度浮動小数点フォーマット、IF4を提案、という話らしい。符号ビットをINT4, FP4を制御するIndicatorとして扱うため、NVFP4と比較してメモリ使用量は増えない。Indicatorはどちらがより量子化誤差が小さくなるかによって選択される、という感じらしい?
[^1]: グループとは単に0/1のバイナリ値が4bit分並んでいるデータのことであり、たとえばFP4で4bitの羅列を解釈すると、FP4は{±0, ±0.5, ±1, ±1.5, ±2, ±3, ±4, ±6}の16個の数値で解釈するようルールづけられている。
[^2]: スケールファクターを乗じることで、値を元々のデータのスケールに変換する。
この辺は勉強不足だなぁ、、、。
- NVFP4解説:
https://licensecounter.jp/engineer-voice/blog/articles/20260317_nvfp4.html
- 本研究日本語解説:
https://note.com/shimmyo_lab/n/n693c4d0da45f
[Paper Note] Entropy-Preserving Reinforcement Learning, Aleksei Petrenko+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #ICLR #PostTraining #Selected Papers/Blogs #Stability #needs-revision #EntropyCollapse #Author Thread-Post Issue Date: 2026-04-01 Comment
元ポスト:
openreview: https://openreview.net/forum?id=E8MR8jgEeZ
PPO/GRPOなどのアルゴリズムではRL中にポリシーの多様性が低下し、ポリシーがdeterministicになり探索をしなくなり、パフォーマンスが停滞するか低下する(あるいはベースモデルでもともと高い尤度を持っていた解のPass@1が改善するが、ポリシーの出力が狭くなるため、Pass@kが犠牲になる)現象が生じる(= entropy collapse)ので、それを是正したいという話。
後ほど追記
[Paper Note] daVinci-LLM:Towards the Science of Pretraining, Yiwei Qin+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Pretraining #NLP #OpenWeight #OpenSource #read-later #Selected Papers/Blogs #Reference Collection #Initial Impression Notes Issue Date: 2026-03-31 GPT Summary- 基盤となる事前学習はモデルの限界を決め、事後訓練で克服するのが難しい。daVinci-LLMは、産業規模の資源と研究の自由を結集し、透明性のある完全オープンなパラダイムで事前学習を進展させる。8兆トークンを用いた二段階適応カリキュラムを採用し、能力向上のプロセスを体系的に評価。処理の深さやドメイン特性が能力に与える影響を明らかにし、探索プロセスを公開することでコミュニティが知識を蓄積できる基盤を提供する。 Comment
元ポスト:
github: https://github.com/GAIR-NLP/daVinci-LLM
オープン"ソース" (=コード, データ, モデルが公開されている(さらに厳密にはライセンスに問題がない))な関連研究:
- OpenLLaMA, Xinyang+, 2023.05
- Introducing Marin: An Open Lab for Building Foundation Models, marin-community, 2025.05
- Marin 32B Retrospective, marin-community, 2025.10
- [Paper Note] Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling, Stella Biderman+, arXiv'23, 2023.04
- [Paper Note] Olmo 3, Team Olmo+, arXiv'25, 2025.12
- [Paper Note] K2-Think: A Parameter-Efficient Reasoning System, Zhoujun Cheng+, arXiv'25, 2025.09
- [Paper Note] DataComp-LM: In search of the next generation of training sets for language models, Jeffrey Li+, NeurIPS'25, 2024.07
- [Paper Note] LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs, LLM-jp+, arXiv'24, 2024.07
- [Paper Note] TinyLlama: An Open-Source Small Language Model, Peiyuan Zhang+, arXiv'24, 2024.01
- [Paper Note] BLOOM: A 176B-Parameter Open-Access Multilingual Language Model, BigScience Workshop+, arXiv'22, 2022.11
- [Paper Note] OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, arXiv'24, 2024.02
- OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3
- [Paper Note] GPT-NeoX-20B: An Open-Source Autoregressive Language Model, Sid Black+, arXiv'22, 2022.04
- SmolLM2, 2024.11
- [Paper Note] LLM360: Towards Fully Transparent Open-Source LLMs, Zhengzhong Liu+, COLM'24, 2023.12
- SmolLM3: smol, multilingual, long-context reasoner, HuggingFace, 2025.07
- The Smol Training Playbook: The Secrets to Building World-Class LLMs, Allal+, HuggingFace, 2025.10
この辺の研究を全て紐解いていったらどのような変遷が起きているだろうか?
- RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens, together.ai, 2023.04
- [Paper Note] Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model, Ahmet Üstün+, arXiv'24, 2024.02
- SmolLM - blazingly fast and remarkably powerful, Allal+, HuggingFace, 2024.07
この辺も関連はしているが、データはオープンだがソースコードがおそらく公開されていない。
事後学習なら
- [Paper Note] Tulu 3: Pushing Frontiers in Open Language Model Post-Training, Nathan Lambert+, COLM'25, 2024.11
[Paper Note] Natural-Language Agent Harnesses, Linyue Pan+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #read-later #AgentHarness Issue Date: 2026-03-30 GPT Summary- エージェントの性能はハーネス工学に依存するが、ハーネス設計が固有のコードに埋もれているため比較や研究が困難である。そこで、我々は高レベルな制御ロジックを外部化することを提案し、自然言語エージェントハーネス(NLAHs)を導入。NLAHsはハーネスの挙動を自然言語で表現し、インテリジェント・ハーネス・ランタイム(IHR)がこれを実行する共通ランタイムを提供。コーディングや計算利用に関する様々なベンチマークで評価を行い、ハーネスの運用可能性や移行を統制しています。 Comment
元ポスト:
[Paper Note] AIRA_2: Overcoming Bottlenecks in AI Research Agents, Karen Hambardzumyan+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #AIAgents #AutoML #LongHorizon #Initial Impression Notes #Asynchronous Issue Date: 2026-03-30 GPT Summary- 既存のAI研究エージェントの課題に対処するため、AIRA$_2$を提案。非同期マルチGPUワーカープールによりスループットを向上し、信頼性の高い評価信号を提供するHidden Consistent Evaluationプロトコルを導入。また、動的に行動を変更できるReActエージェントを用いる。MLE-bench-30でAIRA$_2$はパーセンタイル順位71.8%を達成し、過去最高を更新。各要素の必要性を示し、評価ノイズによる「過剰適合」の誤解を明らかに。 Comment
元ポスト:
AutoMLベンチマーク(MLE-Bench-30)においてSoTAな手法らしい。AutoMLの現状を概観するのに良さそう。
- MLE-Bench, OpenAI, 2024.10
72h実行して、36.7%程度のコンペティションでGold medalを獲得している。よくよく表を見ると、FM-Agent 2.0の方が24hで全体的に高いメダル獲得率のように見えたのだが、そもそもMARS+, MARS, FM-Agent 2.0, そしてMLEvolveはcon-current workとのこと。2024年10月にMLE-Benchが発表され、[Paper Note] MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering, Jun Shern Chan+, ICLR'25, 2024.10
を見るとo1-previewでgold medalは10%程度だったが、そこから約1年半でgold medalの比率は+26%程度まで向上しているということになる。
- [Paper Note] MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering, Jun Shern Chan+, ICLR'25, 2024.10
ベンチマークが公開されたら早々にサチりそうな気がしていたが、個人的に思っていたよりもスコアの伸びが遅いという感想。
[Paper Note] Agentic Uncertainty Quantification, Jiaxin Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #AIAgents #Hallucination #Ambiguity Issue Date: 2026-03-30 GPT Summary- AIエージェントは長期的な推論に優れた能力を持つが、「幻覚の螺旋」により信頼性が損なわれる。既存の不確実性の定量化手法は受動的で、自己反省は無目的な修正に苦しむ。これを解決するために、言語化された不確実性を双方向の制御信号に変換する二過程型エージェント式UQフレームワークを提案。System 1は不確実性を伝達し盲目的な意思決定を防ぎ、System 2は合理的な手掛かりを使って必要時に推論を行う。実験によって、訓練不要で高い性能を示し、信頼できるエージェントの実現に向けた一歩としての可能性を示唆している。 Comment
元ポスト:
[Paper Note] MDM-Prime-v2: Binary Encoding and Index Shuffling Enable Compute-optimal Scaling of Diffusion Language Models, Chen-Hao Chao+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #needs-revision Issue Date: 2026-03-30 GPT Summary- MDM-Primeは部分マスク法を応用し、拡散過程をサブトークンレベルでモデル化することで優れた一般化性能を示しますが、トークン粒度のハイパーパラメータ選択に関するツールが不足し、BPEとの組み合わせで尤度推定が低下します。これを受けて、MDM-Prime-v2を開発し、計算効率を21.8倍向上させ、OpenWebTextで7.77のパープレキシティを達成。11億パラメータに拡張したモデルは、ゼロショット精度でも優れた結果を示しました。 Comment
元ポスト:
[Paper Note] Group Distributionally Robust Optimization-Driven Reinforcement Learning for LLM Reasoning, Kishan Panaganti+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #BudgetAllocation #Author Thread-Post Issue Date: 2026-03-29 GPT Summary- LLMの推論進展は、損失関数の洗練とアライメント戦略の整合によって進むが、標準的なRLパラダイムは一様性に縛られ、難問への対応に非効率を生む。これに対抗するため、動的に訓練分布を適応させるMulti-Adversary GDROを提案。オンライン難易度分類器を導入し、プロンプトを難易度グループに区分。二つのGDROゲームを提示し、頻度バイアスを排除しつつ難易度の高いプロンプトを強化。Qwen3-Baseでの実験により、精度がGRPOと比較して高まることを確認。新たなカリキュラムが観察され、リソースが推論のフロンティアへシフトすることで性能向上を促進。 Comment
元ポスト:
[Paper Note] ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents, Hao Zhang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Infrastructure #ReinforcementLearning #Architecture #SoftwareEngineering #read-later #On-Policy #Stability #One-Line Notes #Author Thread-Post Issue Date: 2026-03-28 GPT Summary- ProRL Agentは、マルチターンのLLMエージェントにおける強化学習トレーニングを支援するためのAPIサービスであり、ロールアウトのライフサイクル全体を提供するスケーラブルなインフラです。標準化されたサンドボックス環境を通じて、多様なエージェント駆動タスクに対応し、ソフトウェア工学やSTEM関連のタスクで検証されています。ProRL Agentはオープンソースで、NVIDIA NeMo Gymに統合されています。 Comment
元ポスト:
処理が重いロールアウトを独立したhttp serviceとして扱い(rollout-as-a-service)、モデルのtrainingと分離することで、リソース分離、可搬性、拡張性を向上させる。
[Paper Note] Reaching Beyond the Mode: RL for Distributional Reasoning in Language Models, Isha Puri+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #Diversity #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2026-03-28 GPT Summary- LMは質問に対して複数の回答候補を暗黙のうちに生成するが、訓練後のプロセスで単一の回答に圧縮されることが多い。医療診断や曖昧な質問応答などのタスクにおいては、複数の妥当な回答が必要とされる。本論文では、複数回答を扱う強化学習アプローチを提案し、モデルが単一の前方伝搬で複数の候補を生成できるようにする。実験により、多様性やカバレッジが改善し、コーディングタスクでは精度も向上した。提案手法は、計算資源効率の高い代替として評価されている。 Comment
元ポスト:
ユーザのクエリにおいては正解が単一ではないものがしばしば存在するが、現在のRLの枠組みはモデルが出力した一つのbest answerに対して報酬を与えるように設計されているため、これによりモデルの出力が一つのモードに固執する、あるいはmode collapseを引き起こす。これを解決するために、モデルに複数の回答とそのconfidenceを一つのpromptで思考させ、k個出力させる。rewardはk個中何個のanswerが正解だったか、confidenceが実際のanswerのcorrectnessとどれだけ近いかなどに基づいて報酬を与えるような枠組みを採用することで、モデルの出力の多様性やcoverageが増加し、repeated sampling時のトークン効率も改善した、と言う話らしい。
[Paper Note] Goedel-Code-Prover: Hierarchical Proof Search for Open State-of-the-Art Code Verification, Zenan Li+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Coding #SoftwareEngineering #read-later #Verification #Proofs #Author Thread-Post Issue Date: 2026-03-28 GPT Summary- 大規模言語モデル(LLMs)はコード生成が可能だが、正確性に限界がある。これを克服するために、Lean 4における階層的証明探索フレームワークを提案し、複雑な検証目標を単純なサブゴールに分解する。分解スコアは訓練報酬と推論時の基準として機能し、最適化とデプロイメントの整合性を保証。Goedel-Code-Prover-8Bを利用し、教師あり初期化後にハイブリッド強化学習で訓練。Leanベースのコード検証ベンチマークでは、62.0%の証明成功率を実現し、強力なベースラインを2.6倍上回る成果を達成した。また、推論時のスケーリングによって成功率の向上が観察された。 Comment
元ポスト:
解説:
[Paper Note] Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?, Jeonghye Kim+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Reasoning #SelfDistillation Issue Date: 2026-03-26 GPT Summary- 自己蒸留はLLMの訓練後の効果的な手法であるが、数学的推論においては長さ短縮が性能低下を招くことがある。この劣化は不確実性の表現抑制に起因し、条件付けコンテキストの豊富さによって影響を受けることが示された。具体的には、情報豊富な教師による不確実性の抑制が迅速な最適化を促進する一方で、未知問題に対する性能を悪影響を及ぼすことが確認された。Qwen3-8Bなどのモデルでは、最大40%のパフォーマンス低下が見られ、適切な不確実性の露出が推論の堅牢性に不可欠であることが強調された。 Comment
元ポスト:
関連:
- [Paper Note] Reinforcement Learning via Self-Distillation, Jonas Hübotter+, arXiv'26, 2026.01
ポイント解説:
[Paper Note] Delightful Policy Gradient, Ian Osband, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2026-03-26 GPT Summary- Delightful Policy Gradient(DG)は、ポリシー勾配の不均衡なアップデートを解消するために、アドバンテージと行動の驚きの積に基づいたゲーティングを導入。これにより、単一コンテキスト内での方向性の精度を理論的に向上させ、複数コンテキスト間での期待される勾配を精密に近づけることができる。実験的に、DGはREINFORCEやPPOをMNISTや連続制御タスクで上回り、特に難易度の高いタスクで顕著な改善を示した。 Comment
関連:
- [Paper Note] Maximum Likelihood Reinforcement Learning, Fahim Tajwar+, arXiv'26, 2026.02
元ポスト:
所見:
著者ポスト:
不要なbackward passの重みを下げるのではなく完全に無くすことで効率化する
[Paper Note] Off-Policy Value-Based Reinforcement Learning for Large Language Models, Peng-Yuan Wang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #read-later #Off-Policy #ReplayBuffer #LongHorizon Issue Date: 2026-03-26 GPT Summary- オフポリシー学習を可能にする新しい値ベースのRLフレームワークReValを提案し、過去のデータを効率的に再利用。ReValは速度と性能向上を実現し、GRPOを上回る結果を示した。これにより、価値ベースのRLがLLMトレーニングの実用的な選択肢となることが示唆される。 Comment
元ポスト:
[Paper Note] MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild, Peng Xia+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #AIAgents #AgentSkills #Initial Impression Notes #Test Time Training (TTT) Issue Date: 2026-03-26 GPT Summary- MetaClawは、LLMエージェントが変化するニーズに対応するための継続的メタ学習フレームワークである。失敗軌跡を解析して即座にスキルを合成し、ダウンタイムをゼロにするスキル駆動の適応や、機会主義的ポリシー最適化を通じて、効果的に能力を更新する。これにより、精度を最大32%向上させ、全体のパイプラインの精度も21.4%から40.6%に増加させることが示された。 Comment
元ポスト:
関連:
- [Paper Note] OpenClaw-RL: Train Any Agent Simply by Talking, Yinjie Wang+, arXiv'26, 2026.03
- [Paper Note] OpenClaw-RL: Train Any Agent Simply by Talking, Yinjie Wang+, arXiv'26, 2026.03
と一見すると似たような研究に見えるが、
[Paper Note] OpenClaw-RL: Train Any Agent Simply by Talking, Yinjie Wang+, arXiv'26, 2026.03
の肝は「trajectory中のprocessにおいて活用可能なシグナルがあるから、それをもっと活用しよう」という気持ちで、
本研究は「失敗したtrajectoryに適用するためにSkillを合成し、ユーザが利用しないIdle Timeの間にLoRA + RLでポリシーの重みも更新して賢くしよう」という気持ちであり、目的が異なるように見える。
- [Paper Note] SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, Xiangyi Li+, arXiv'26, 2026.02
においては、Skillをtaskに関する手続的な知識に基づいてスキルを自己生成しても性能向上せず、むしろ悪化させるような結果が出ており、不用意にSkillを合成すると性能が劣化するという結果が出ている。
本研究は失敗したtrajectoryに対して適応するためのSkill合成である点と、LoRAによってポリシー自体も賢くなるのであれば前提が変わるので話は変わってくるのかな、という印象。
[Paper Note] Alignment Makes Language Models Normative, Not Descriptive, Eilam Shapira+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Alignment #Bias #PostTraining Issue Date: 2026-03-26 GPT Summary- ポスト訓練アライメントは言語モデルを人間の嗜好に最適化するが、人間の行動を単にモデル化することとは異なる。実データを使用した取引や交渉などのゲームにおいて、整列済みモデルはベースモデルに対して選択予測精度で約10倍の優位性を示した。ただし、規範的予測に従いやすい設定では逆転する傾向が見られた。全12タイプの教科書的ゲームでは整列済みモデルが圧倒的に優位であり、特に相互作用の履歴がない第1ラウンドでもその傾向が確認された。これらの結果は、人間行動の予測においてアライメントが規範的バイアスを生じさせ、記述的ダイナミクスが重要な役割を果たすことを示唆している。このように、モデル最適化と人間行動の代理使用との間には根本的なトレードオフが存在する。 Comment
元ポスト:
[Paper Note] Mousse: Rectifying the Geometry of Muon with Curvature-Aware Preconditioning, Yechen Zhang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Optimizer Issue Date: 2026-03-26 GPT Summary- Mousseは、深層ニューラルネットワークにおけるスペクトル最適化の新しいオプティマイザであり、Muonの平等主義的な制約の限界を克服する。Mousseは、Kronecker因子化を用いた白色化座標系で動作し、最適な更新を極分解を通じて導出。実験結果は、MousseがMuonを上回り、12%のトレーニングステップ削減を達成したことを示す。 Comment
元ポスト:
[Paper Note] GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent, Yuri Kuratov+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #PEFT(Adaptor/LoRA) #read-later #memory #Initial Impression Notes #SoftPrompt #Test Time Training (TTT) #Author Thread-Post Issue Date: 2026-03-26 GPT Summary- 長い文脈をコンパクトに保存するGradMemを提案。これは、推論時に文脈へアクセスできない状況で、文脈を圧縮して数のクエリに応答する。モデルの重みを凍結し、少量のプレフィックストークンで数ステップの勾配降下を行うことで、文脈の再構成を最適化。連想キー-値検索において、GradMemは従来の手法より優れた性能を発揮し、自然言語タスクで競争力のある結果を示す。 Comment
元ポスト:
prefixにmemory用のトークンを用意し、TTTの枠組みでcontextのreconstruction lossを通じて圧縮する、という話に見える。tokenはsoft tokenであり、m*d次元の行列で表現される。
要はcontextの潜在表現をReconstruction lossによるTTTでprefix tuningするsoft prompting手法、という感じだろうか。
[Paper Note] Rich Insights from Cheap Signals: Efficient Evaluations via Tensor Factorization, Felipe Maia Polo+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Alignment #Evaluation #Initial Impression Notes #Author Thread-Post Issue Date: 2026-03-25 GPT Summary- プロンプトの性能を細粒度で評価するため、安価な自動評価データと限られた人間によるゴールドスタンダードラベルを統合した新しい統計モデルを提案。自動評価スコアを基に生成モデルの潜在表現を事前学習し、小さな較正セットで人間の嗜好に整合。これにより、標準ベースラインを上回る精度で人間の嗜好を予測し、詳細なリーダーボードの構築やモデルのパフォーマンス推定が可能になることを示す。 Comment
元ポスト:
少量の人間ラベルとLLMによって合成されたraterでテンソルを作り(モデル、prompt, rateのテンソル)を行列分解することで、効率的に(=人間のrateはscarceなので行列分解を通じて潜在表現に落としてサンプル効率を高める、というより次元の呪いを回避する?)単一のスコアでのモデル評価ではなく、様々な異質のpromptの元でのスコアリング(=finegrained evaluation)を実現する、という話に見える。
[Paper Note] PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost, Junkeun Yi+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2026-03-25 GPT Summary- 計算効率とOOD能力のトレードオフを解消するために、PivotRLという新しいフレームワークを提案。局所的なオンポリシーロールアウトで高い分散を持つ情報量豊かな中間ターンを選別し、機能的に同等なアクションに報酬を与えることでポリシー確率の維持を促進。PivotRLは4つのエージェント系ドメインでインドメイン精度を平均4.17%向上、OOD精度を10.04%高め、少ないロールアウトターンでE2E RLと同等の精度を実現した。NVIDIAのNemotron-3-Super-120B-A12Bに採用され、実運用規模のエージェント後訓練の主力として機能中。 Comment
元ポスト:
ポイント解説:
関連:
- [Paper Note] Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes, Amrith Setlur+, arXiv'26, 2026.01
- [Paper Note] POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration, Yuxiao Qu+, arXiv'26, 2026.01
[Paper Note] Effective Strategies for Asynchronous Software Engineering Agents, Jiayi Geng+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #Coding #Architecture #SoftwareEngineering #LongHorizon #Asynchronous Issue Date: 2026-03-25 GPT Summary- AIエージェントは孤立したSWEタスクでは高い能力を示すが、依存するサブタスクを含む長期的なタスクには課題が残る。非同期のマルチエージェント協調が期待されるが、同時編集や依存関係の同期、進捗の統合には困難が伴う。これに対処するため、CAIDという新たな協調パラダイムを導入。これにより中央管理者を介したタスク計画と、分離された作業スペースでの同時実行が実現され、進捗の統合が可能になる。実験的にCAIDは、PaperBenchで26.7%、Commit0で14.3%の精度向上を示し、マルチエージェント協調の調整機構としてブランチとマージを明らかにした。 Comment
元ポスト:
[Paper Note] On the Role of Batch Size in Stochastic Conditional Gradient Methods, Rustem Islamov+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Pretraining #NLP #Scaling Laws #Batch Issue Date: 2026-03-25 GPT Summary- μ-Kurdyka-Łojasiewicz条件下での確率的条件付き勾配法におけるバッチサイズの影響を探求。モメンタムベースのアルゴリズムに注目し、バッチサイズ、ステップサイズ、ノイズの相互作用を分析。バッチサイズを増加させることで初期の精度向上が見られるが、臨界値を超えると利点は減少し得る。理論は最適なステップサイズを予測し、実際の経験則と合致。バッチサイズとステップサイズの選択に関する指針を提示し、適応戦略を提案。実験結果は理論を裏付け、大規模最適化に向けた設計指針を提供。 Comment
元ポスト:
[Paper Note] Deriving Hyperparameter Scaling Laws via Modern Optimization Theory, Egor Shulgin+, Sci4DL'26, 2026.03
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #Scaling Laws #HyperparameterTransfer Issue Date: 2026-03-24 GPT Summary- ハイパーパラメータ転送の重要性を論じ、特にモデルサイズ間の転送に焦点を当てる従来の方法に対抗して、Linear Minimization Oracle(LMO)に基づく新たなハイパーパラメータスケーリング法則を提案。学習率、モメンタム、バッチサイズの閉形式のべき法則スケジュールを導出し、文献の洞察を再現。モメンタムとバッチサイズのスケーリングの相互作用を強調し、最適な性能は多様なスケーリング戦略により達成可能であることを示す。 Comment
元ポスト:
[Paper Note] Data-efficient pre-training by scaling synthetic megadocs, Konwoo Kim+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Pretraining #NLP #SyntheticData #read-later #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2026-03-22 GPT Summary- 合成データ拡張は、限られたデータでの事前学習に有効である。この研究では、有限の計算資源下での損失低減や、無限大に近づくときの損失スケーリングの改善を目指す。合成的再表現との混合で事前学習した場合、異なる分布からの合成データでもi.i.d.検証損失が改善され、データ効率は約1.48倍で頭打ちとなる。新たなアプローチとして、同文書からの合成再表現を用い、短文の代わりに長大なメガ長文を形成する手法を提案。これにより、損失とベンチマークの改善が見られ、データ効率は1.80倍に向上。合成データ生成が増えるほど、メガ長文による効果も増大することが示された。 Comment
元ポスト:
著者ポスト:
著者ポスト:
- データよりもコンピューティングリソースのスケーリングの方が早く進んでおり、データ効率の高い事前学習レシピが重要となっている
- 事前学習において、合成データがi.i.d.なwebデータの損失減らすことに寄与するかを調査
- 300Mモデルで200M tokenを学習した際にどれだけi.i.d.なwebデータのlossを低減させられるかを調査
- 最初に最もシンプルなdata augmentationであるrephrasingを調査したところ、文書単位でのrephrasingの回数が増えるにつれて、web lossとdownstreamベンチマークでのエラー率が単調に改善
- 続いて、ある文書をrephraseした文書を結合することで、単一の大きな文書(=megadoc)を構成する手法を提案し、megadocを利用することでさらにlossが改善することを確認。megadocの構成方法として下記三種類を提案し:
- Real First Stitched: `文書に対するrephraseをG個生成し、それらを結合することでmegadocを構成する手法。実データを結合の頭にもってくる。
- Real Last Stitched: Real First Stichedと同様の処理をするが、実データを結合の末尾に持ってくる手法
- Latent Thoughts: 文書をG+1個の同じ長さのピースに分割し、ピース間を埋めるrationaleを合成して結合する手法。rationaleは
- Real First Stitched と Real Last Stitched を比較したところ、後者の方が性能が良かった。
- 後者の方が性能が良い考察として、epiplexity [Paper Note] From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence, Marc Finzi+, arXiv'26, 2026.01
の観点から考察をしている。前提として実文書の方が複雑で情報量が多いと考えたときに、Real First Stitched の場合は実文書の情報からrephraseを学ぶという簡単な変換(生成)を実施すればよいのに対し、Real Last Stitchedの場合逆で、rephraseからより詳細で複雑な実文書に変換(生成)するというタスクを実施せねばならない。このため、後者の方がより計算的に困難な関数を学習する必要があり(すなわち、epiplexityが高い学習設定ということ; epiplexityが高い学習設定の方がモデルの汎化性能が高くなる)、学習の結果より高い汎化性能を獲得しているのではないか、と考察している。
- また、モデルをアンサンブルした場合の性質についても考察がされており、self-distillationは単体モデルの性能を向上させることに寄与するが、アンサンブルするモデルの数を増やすと実データを用いたモデルと最終的には性能が同等となることが予測され、達成可能なピーク性能がアンサンブルによってブーストされる効果は観測できなかった。一方で、Rephrasingによる合成データによって学習されたモデルはアンサンブルによって達成可能な性能のピーク値がブーストされると考えられる。
[Paper Note] M$^2$RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling, Mayank Mishra+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LongSequence #read-later #Selected Papers/Blogs #One-Line Notes #RecurrentModels Issue Date: 2026-03-22 GPT Summary- 非線形RNNを再検討し、Matrix-to-Matrix RNN(M^2RNN)を導入。これにより、エンティティ追跡やコード実行などの高表現力タスクに対応可能。M^2RNNは、縮小された状態サイズでも効果的な性能を示し、特に長いシーケンスについて一般化できる。Hybrid M^2RNNでは、既存モデルに匹敵する精度を維持しつつ、再帰層のサイズを縮小。LongBenchでは最先端の手法を超える結果を示し、非線形RNN層の効率的でスケーラブルな言語モデルへの応用を強調。 Comment
HF: https://huggingface.co/collections/open-lm-engine/m2rnn
元ポスト:
解説:
状態をベクトルではなく行列として保持するRNN。
状態の更新Z_tを、前回の状態H_t-1
に対して重みWによって変換したものと、現在のトークンのk_t,v_tが与えられた時の外積から求まる行列の和を求めた後、tanhで非線形変換することで計算する(式10)。
最終的にforget gate f_tによってZ_tとH_t-1が線形補完されることで、状態H_tが決定される(式11)。
出力y_tは更新された状態H_tにq_tの積をとったものと、v_tを重みw_rで重みづけて残差接続したものの和で求められる(式12)。
[Paper Note] Pre-training LLM without Learning Rate Decay Enhances Supervised Fine-Tuning, Kazuki Yano+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Supervised-FineTuning (SFT) #mid-training #PostTraining #Scheduler #One-Line Notes #DownstreamTasks Issue Date: 2026-03-20 GPT Summary- 学習率スケジューリングが大規模言語モデルの事前学習とSFT後の性能に与える影響を調査。特に、ウォームアップ後に学習率を一定に保つWarmup-Stable-Only(WSO)スケジューラが、減衰ベースのスケジューラよりも一貫してSFT後の性能を向上させることを示す。分析によれば、WSOは平坦な極小値を維持し、訓練戦略としての有用性を強調。これにより、モデルの適応性を高める指針を提供。 Comment
元ポスト:
事前学習中にweight decayを実施しない方が、(事前学習終了時点でのlossは劣化するが)SFT後のdownstreamタスクの性能を高める。
[Paper Note] The Finetuner's Fallacy: When to Pretrain with Your Finetuning Data, Christina Baek+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Pretraining #NLP #Supervised-FineTuning (SFT) #Scaling Laws #mid-training #PostTraining #read-later #DataMixture #Initial Impression Notes Issue Date: 2026-03-20 GPT Summary- 専門化事前学習(SPT)を通じてドメインデータを再利用し、モデルの性能を向上。SPTは微調整後の一般能力を保持し、必要な事前学習トークン数を最大1.75倍削減。特定のドメインにおいて、SPTは3Bモデルを上回る性能を示し、過適合スケーリング則を導出。事前学習段階で専門ドメインデータを導入することで、一般性能も改善し、計算量を抑えた結果を得る。訓練の早い段階でのドメインデータの統合が重要。 Comment
Finetuningに使うデータをpretraining段階から混ぜておくとより効果的という話らしい。事前学習データの量が増えるためより多くのbudgetが必要になるので効果的なmixtureのためのスケーリング則も構築したとか。興味深い
元ポスト:
[Paper Note] InterviewSim: A Scalable Framework for Interview-Grounded Personality Simulation, Yu Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #read-later #Personality Issue Date: 2026-03-20 GPT Summary- 大規模言語モデルによる性格シミュレーション評価には、実際のインタビュー内容を基にした手法が必要。提案した評価フレームワークは、著名人の23,000件のインタビューから671,000件の質問-回答ペアを抽出し、内容の類似性、事実的一貫性、性格適合、事実知識の保持を評価。実際のインタビュー情報を用いることで、伝記的プロフィールやパラメータ知識に依存する手法よりも優れた結果を示す。評価は、原則的な手法選択を可能にし、実践的な洞察を提供。 Comment
元ポスト:
おもしろそう
[Paper Note] Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation, Zhuolin Yang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-03-20 GPT Summary- Nemotron-Cascade 2は、30B MoEモデルで3Bの活性化パラメータを持ち、高度な推論能力とエージェント機能を提供します。小型ながら、数学およびコーディングでの推論能力は最前線モデルに匹敵。2025年の国際数学オリンピックなどで金メダル級の性能を示し、パラメータ数は20分の1でも知能密度は高い。新たにSFT後の拡張されたCascade RLで幅広い推論をカバーし、マルチドメイン蒸留を導入して性能向上を実現。モデルのチェックポイントやデータも公開予定。 Comment
元ポスト:
[Paper Note] PRISM: Demystifying Retention and Interaction in Mid-Training, Bharat Runwal+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #mid-training #read-later #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2026-03-19 GPT Summary- PRISMの中間トレーニング設計の実証研究を行い、様々なモデルやアーキテクチャで統制実験を実施。約270億トークンのデータを使用し、数学、コード、科学ベンチマークで一貫した性能改善を達成。RLパイプラインは推論ベンチマークのスコアを大幅に向上させるも、基盤モデルへの直接適用では効果が薄い。中間トレーニングがモデル性能を効果的に高めることを示し、信頼性の向上に役立つ中間トレーニングの重要性を強調。 Comment
元ポスト:
著者ポスト:
ポイント解説:
[Paper Note] Mamba-3: Improved Sequence Modeling using State Space Principles, Aakash Lahoti+, ICLR'26, 2026.03
Paper/Blog Link My Issue
#NLP #SSM (StateSpaceModel) #Architecture #ICLR #Selected Papers/Blogs #Initial Impression Notes #LinearAttention Issue Date: 2026-03-18 GPT Summary- 推論効率がLLMの性能に与える影響に注目し、計算量を抑えつつ高い性能を持つモデルの開発が求められている。Transformerモデルは品質は高いが、計算コストが増加するため、サブ二次モデルの必要性が高まっている。しかし、最近の線形モデルは効率を優先した結果、性能が損なわれることも多い。これに対し、我々は状態空間モデル(SSM)に基づく三つの改善策を提案し、Mamba-3モデルを開発した。これにより、下流の言語モデリングタスクで平均精度が大幅に向上し、より少ない状態サイズで同等のパープレキシティを実現した。Mamba-3は性能と効率の向上を示す結果を得た。 Comment
openreview時点でのメモ:
- [Paper Note] MAMBA-3: IMPROVED SEQUENCE MODELING USING STATE SPACE PRINCIPLES, 2025.10
元ポスト:
最近はMambaのようなSSM(あるいはlinear attention)とfull attentionのハイブリッドなdecoder-onlyモデルが主流になりつつあるため、抑えておいた方が良いだろう。
[Paper Note] When Does Sparsity Mitigate the Curse of Depth in LLMs, Dilxat Muhtar+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #Sparse #Depth #Initial Impression Notes #CurseOfDepth Issue Date: 2026-03-17 GPT Summary- LLMの深さの呪いを軽減するために、スパース性が分散伝播を調整する役割を示す。暗黙的スパース性と明示的スパース性の2つの源泉を扱い、出力分散の削減と機能的分化を促進。深いモデルを効果的に利用するための実践的な知見を提供し、下流タスクで精度を4.6%向上させた。 Comment
元ポスト:
関連:
- [Paper Note] The Curse of Depth in Large Language Models, Wenfang Sun+, arXiv'25, 2025.02
モデルのアーキテクチャやパラメータのスパース性が curse of depth を是正するという話らしい。
Figure1の記号はそれぞれ以下を表しており
- T: context window
- lambda: weight decay
- G: Group Query Attention
- MoE: Mixture of Experts
context windowを大きく、weight decayを強く(重みの正則化としての効果が強まる)、GQA (Attentionのスパース性が高まる)、MoE (MLPのスパース性が高まる)という感じだと思われ、特にGQA, MoEが大きく寄与してそうに見える。
[Paper Note] Mixture-of-Depths Attention, Lianghui Zhu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Transformer #Attention #Architecture #Selected Papers/Blogs #One-Line Notes #CurseOfDepth Issue Date: 2026-03-17 GPT Summary- 深さスケーリングによる信号の劣化を克服するため、混合深度アテンション(MoDA)を提案。MoDAは、各アテンションヘッドが現在の層と前層のKVペアに注意を向けることで特徴を保持し、効率的なメモリアクセスを実現。15億パラメータモデルでの実験では、強力なベースラインを超え、平均困惑度を0.2ポイント改善し、ダウンストリームタスクで2.11%の性能向上を達成。計算オーバーヘッドはわずか3.7%。MoDAは深さスケーリングにおける有望なアプローチであることが示された。 Comment
元ポスト:
transformerにおけるattentionを、現在処理をしているトークンの、ある深さlのattentionにおいて、l-1以下の(=自身より浅い)layerの同じトークンに関するK, Vを参照できるように拡張する。
所見:
著者ポスト:
[Paper Note] Meta-Reinforcement Learning with Self-Reflection for Agentic Search, Teng Xiao+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #read-later #Selected Papers/Blogs Issue Date: 2026-03-17 GPT Summary- MR-Searchは、自己反省を活用したエージェント主体の文脈内メタ強化学習(RL)手法を提案する。過去のエピソードに基づき探索戦略を適応させることで、報酬が乏しい状況でもポリシーを最適化する。エピソード後に生成される自己反省を次の試行に活用することで、テスト時の探索効率を向上させる。さらに、ターンレベルでの相対アドバンテージを推定する多ターンRLアルゴリズムを導入し、細粒度のクレジット割り当てを実現。様々なベンチマークでの実験により、MR-Searchが従来のRL手法よりも優れた性能を示し、相対的に9.2%から19.3%の改善を達成した。 Comment
元ポスト:
[Paper Note] OpenClaw-RL: Train Any Agent Simply by Talking, Yinjie Wang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #PRM #KeyPoint Notes #Reference Collection #Author Thread-Post Issue Date: 2026-03-14 GPT Summary- OpenClaw-RLは、エージェントの相互作用から生成される次状態信号を用いたオンライン学習フレームワークである。各エージェントのアクションに対するユーザーの反応やツールの出力を利用し、一つのポリシーで複数のトレーニング問題を同時に学習する。次状態信号は評価信号と指示信号を含み、前者はアクションの成功度を示し、後者は改善点を指摘する。非同期設計により、モデルはリアルタイムでリクエストに応じ、ポリシーを更新する。個人用エージェントや一般エージェントに適用することで、ユーザーのフィードバックを活用し、スケーラブルな強化学習を実現する。 Comment
元ポスト:
解説:
日本語解説: https://tech.layerx.co.jp/entry/openclawrl-agenticrl
テクニカルレポートを見ると情報量が非常に多くて圧倒されてしまうが、著者ポストを鑑みるに本研究の肝は下記である。
既存のAgentic RLは、Agentがaction a_tを実施した後に環境の状態がs_t+1に変化するが、それをcontextとして活用し次のactionを生成している。しかし、ただcontextとして活用するよりももっと有用な使い方があるのではないか、という主張をしているように見え、具体的には以下の2つの無駄が生じているという指摘で
- 次のstateは前回のアクションの暗黙的な評価を与えており、これを捨ててしまっている。たとえば、ユーザは満足いっていないことをqueryするかもしれないし、テストが通ったら成功、エラーが出たら失敗という評価に関するシグナルが潜んでいる。これは主に数学ドメインで利用されてきたProcess Reward Modelによるプロセスに関するRewardとは対照的に、verifiableなドメインを超えて自然なインタラクションの中で生じるシグナルから評価できる。
- 上記は評価に関するシグナルだが、もう一つのシグナルとして方向性に関するシグナルが得られる。たとえば、「あなたは最初にファイルを確認すべきだ」というqueryがs_t+1として得られたとする。これは、単にa_tが失敗だっただけでなく、「どのトークンが、どのように」誤っていたかに関する具体的なフィードバックとみなせる。たとえば、errorに関するtraceは具体的などこを修正すれば良いかのシグナルである。現在のRLVRの枠組みはこれらのシグナルを(最終的に得られる)sparseな単一のスカラー値に落としてしまっており、これら精緻な方向性に関するシグナルを完全に捨て去ってしまっている。
前者についてはBinary RL[^1]によってシグナルを拾え、
後者についてはs_t+1からtextualなhintを抽出しteacher contextとして活用することで、トークン単位でのadvantageを計算できる[^2]。
そしてこれら両方を組み合わせることで、より良い結果を得ることができる、といったことが著者ポストに書かれている。
元論文自体は部分的にしか読めていないのだが、論文のメッセージとしては、s_t+1の情報にはまだ活用できるシグナルがあるのにそれが見過ごされていて、現在のRLVRの枠組みではスカラー報酬に埋もれてしまっているという課題意識が肝だと感じた。
また、手法的な観点で言うと、日本語解説と、テクニカルレポート4.1.2節に書かれている通り、リアルタイムなユーザとの対話を前提てして考えた時に、ロールアウトは1つしか現実的に存在しえないため(複数ロールアウトに対してユーザからのフィードバックs_t+1を得ることは実用的な設定では非現実的)GRPOが適用できない、という点はなるほどなぁ、と感じた。
[^1]: a_t, s_t+1が与えられた時に{0, 1, -1}を返す何らかのProcess Reward Modelを定義し、m回独立した施行を実施しmajority votingをすることでreliableなa_tに対するRewardを得る(4.1.1節)。
[^2]: s_t+1から抽出可能なhintを追加のcontextとして与えたポリシーを教師、hintなしのポリシーを生徒とし、教師と生徒のa_tに対するトークンの尤度の差分をとることでtoken単位のadvantageを得る。すなわち、hintが与えられたときにa_tで尤度が低くなるトークンがあれば、そのトークンにはペナルティが課されることになる(4.2.2 Step4)。
[Paper Note] PostTrainBench: Can LLM Agents Automate LLM Post-Training?, Ben Rank+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #PostTraining #read-later #Environment #autoresearch Issue Date: 2026-03-14 GPT Summary- AIエージェントは推論能力の向上によりソフトウェア工学で高い能力を発揮し、AI研究の自動化可能性を考察する。本論文では、基盤LLMを有用なアシスタントへ変えるポストトレーニングの評価を行うためのベンチマークPostTrainBenchを導入。特定のベンチマークで最先端エージェントの性能を評価し、自律性を持たせた実行方法を検討することが重要である。進捗は見られるが、公式の指示調整済みモデルには劣る状況が多く、時折上回るケースも存在。エージェントの行動にはリワードハックなどの懸念があり、慎重なサンドボックス化の重要性を示唆する。PostTrainBenchはAIの研究開発の進捗とリスクを追跡する上で有用である。 Comment
pj page: https://posttrainbench.com/
元ポスト:
[Paper Note] $\textbf{Re}^{2}$: Unlocking LLM Reasoning via Reinforcement Learning with Re-solving, Pinzheng Wang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #Initial Impression Notes Issue Date: 2026-03-12 GPT Summary- Re^2は、強化学習の新手法であり、LLMsが効率的な推論経路を放棄し、必要に応じて再解法を選択することを学習。これにより、従来のRLVRよりも推論性能が30%以上向上し、サンプル数の増加に伴いテスト時の性能も改善。初期の思考過程の質に依存せず、解答の質を高めることが可能となる。 Comment
元ポスト:
CoTの初期の推論の時点で推論の方向性が決まってしまい、うまくいかないものはうまくいかないので、まっさらな状態から解き直す挙動をRLで増幅させる、という話に見える。Self Correctionではなく、完全にtrajectoryを無くすのだろうか?だとしたら、trajectoryの質を動的に検証してその生成は放棄する、というアプローチとやっていることがあまり変わらない気はするのだが、わざわざモデルの内部パラメータに対して介入してその挙動を増幅させる意味はあるのだろうか?
[Paper Note] Scaling Data Difficulty: Improving Coding Models via Reinforcement Learning on Fresh and Challenging Problems, Zongqian Li+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #AIAgents #Coding #SoftwareEngineering #PostTraining #DataFiltering #Initial Impression Notes Issue Date: 2026-03-12 GPT Summary- 高品質なコード生成モデルの訓練には高品質なデータセットが必要だが、既存のデータは様々な問題を抱えている。本研究では、系統的なデータ処理フレームワークを導入し、自動難易度フィルタリングを用いて難易度の高い問題を保持しつつ簡単な問題を排除。得られたMicroCoderデータセットは、多様な競技プログラミング問題を含み、性能向上を達成。評価によれば、三倍の性能向上を示し、難易度を意識したデータ選定がモデルの性能向上に効果的であることが明らかになった。 Comment
元ポスト:
コーディングドメインにおいて、難易度の高いコーディング問題を収集(単純な問題をフィルタリング)することで、RLにおいて高い学習効率が得られる、という話に見える
[Paper Note] How Far Can Unsupervised RLVR Scale LLM Training?, Bingxiang He+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #PostTraining #read-later #RLVR #MajorityVoting #Scalability Issue Date: 2026-03-12 GPT Summary- URLVRは、地上真値ラベルなしで報酬を導出し、LLM訓練のボトルネックを克服する。内部報酬と外部報酬に基づく手法の分析を行い、内部報酬が一貫したパターンを示すことを発見した。モデルの事前分布によって崩壊のタイミングが決まり、内部報酬は小規模データセットでの効果的な利用が可能であることが示された。外部報酬手法も検討し、改善の可能性を示唆する。これにより、内部URLVRの限界を明らかにし、スケーラブルな代替手段への道を提示する。 Comment
元ポスト:
[Paper Note] Capacity-Aware Mixture Law Enables Efficient LLM Data Optimization, Jingwei Li+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #DataMixture Issue Date: 2026-03-12 GPT Summary- データ混合は大規模言語モデルの訓練における異なるデータソースの組み合わせを指し、効果的な混合選択が下流性能に影響を与える。従来手法は高コストの探索や外挿の失敗に悩む。本研究では、容量認識型混合則(CAMEL)を提案し、モデルサイズと混合の相互作用を用いて検証損失をモデル化。検証損失から下流性能を予測し、計算予算を効果的に配分する方法を導入。最終的にMixture-of-Expertsモデルで実証し、混合最適化コストを50%削減し、下流性能を最大3%向上させることを示した。 Comment
元ポスト:
[Paper Note] Scalable Training of Mixture-of-Experts Models with Megatron Core, Zijie Yan+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Pretraining #NLP #MoE(Mixture-of-Experts) #Selected Papers/Blogs #Reference Collection #Scalability #Author Thread-Post Issue Date: 2026-03-12 GPT Summary- MoEモデルのスケーリングには、パラメータの増加によるメモリ、通信、計算の制約が伴う。これを解決するために、メモリの再計算やオフロード、通信の最適化、計算のグループ化などを統合的に最適化するフレームワークを提案。これにより、長い文脈の効率化や低精度訓練サポートも実現。数兆パラメータのMoEモデルを数千台のGPUで訓練可能なオープンソースソリューションとして、実運用向けの指針を提供。 Comment
元ポスト:
著者ポスト:
所見:
所見:
自己検証LLMによる日本司法試験短答式試験合格, Shin Andrew, NLP'26
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Japanese #PostTraining #read-later #Selected Papers/Blogs #SelfVerification Issue Date: 2026-03-11 Comment
非常に興味深い。読みたい。
排他的逆学習, 佐々木+, NLP'26
Paper/Blog Link My Issue
#NLP #KnowledgeEditing #MachineUnlearning(MU) Issue Date: 2026-03-10 Comment
Machine Unlearning関連研究:
- [Paper Note] Machine Unlearning of Pre-trained Large Language Models, Jin Yao+, ACL'24, 2024.02
- [Paper Note] From Theft to Bomb-Making: The Ripple Effect of Unlearning in Defending Against Jailbreak Attacks, Zhexin Zhang+, arXiv'24, 2024.07
- [Paper Note] Large Language Model Unlearning, Yuanshun Yao+, arXiv'23, 2023.10
- [Paper Note] Large Scale Knowledge Washing, Yu Wang+, ICLR'25, 2024.05
- [Paper Note] LLM Unlearning via Loss Adjustment with Only Forget Data, Yaxuan Wang+, arXiv'24, 2024.10
[Paper Note] AutoHarness: improving LLM agents by automatically synthesizing a code harness, Xinghua Lou+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #Initial Impression Notes #AgentHarness Issue Date: 2026-03-08 GPT Summary- 言語モデルは、エージェントとして利用する際に最適でない行動をとることがあります。特に、Gemini-2.5-FlashはKaggle GameArenaのチェス競技で78%の敗北が違法手に起因しています。そこで、本研究では、ゲーム環境のフィードバックを用いて自動的に“ハーネス”を合成する手法を提案します。この手法は、145のTextArenaゲームにおいて全ての違法手を防ぎ、小型モデルのGemini-2.5-Flashがより大きなモデルを上回る性能を示します。また、Gemini-2.5-Flashは方針をコードとして生成し、意思決定時にLLMを必要としなくなります。得られたコードは、16の1人用ゲームでより高い平均報酬を得ており、カスタムのコード・ハーネスを用いることで、より大きなモデルを上回る性能を示します。 Comment
元ポスト:
あのMurphy本の著者であるMurphy氏が著者にいる👀
[Paper Note] Memory Caching: RNNs with Growing Memory, Ali Behrouz+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LongSequence #memory #One-Line Notes #RecurrentModels Issue Date: 2026-03-08 GPT Summary- Memory Caching(MC)を用いてリカレントモデルのメモリを強化。MCはメモリ状態をキャッシュし、RNNの実効メモリ容量をシーケンス長に応じて拡張する。これにより、O(L)の計算量のRNNとO(L^2)の計算量のTransformersの間でトレードオフを提供。MCのバリアントを実験し、文脈内リコールタスクでTransformersに迫る性能を示し、最先端のリカレントモデルを上回ることを実証。 Comment
元ポスト:
トークンをセグメントに分けて、セグメントごとにメモリの状態をキャッシュとして保存。現在の最新トークンに対するメモリ(online cache)と過去のセグメントごとのキャッシュ(memory soup)の組み合わせによって、outputを計算する。これにより、系列長Lの2乗の計算量から、セグメント長*N*系列長Lの計計算量に落としつつ、transformerのquadraticにメモリ量が増えるが計算が重い、RNNの線形時間でメモリ更新ができるがlong contextにおいては忘却が生じるという性質の良いところ取りをする、という話に見える。
[Paper Note] Anatomy of Agentic Memory: Taxonomy and Empirical Analysis of Evaluation and System Limitations, Dongming Jiang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Survey #Analysis #NLP #AIAgents #read-later #Selected Papers/Blogs #memory #Initial Impression Notes Issue Date: 2026-03-07 GPT Summary- エージェント記憶システムは、LLMエージェントが長い相互作用を維持し、長期推論を支援するが、経験的基盤が脆弱である。既存のベンチマークは不十分で、評価指標が実用性に合致せず、性能差が大きく、コストも見落とされがちである。本調査では、エージェント記憶を構造的に分析し、4つの記憶構造から成るMAGシステムを提案。主要な問題点として、ベンチマークの飽和、評価指標の妥当性、精度のバックボーン依存、記憶維持によるオーバーヘッドを挙げ、信頼性の高い評価とスケーラブルなシステム設計の方向性を示す。 Comment
元ポスト:
AI Agentの研究に関してtaxonomyが定義されており、研究分野全体の進展を外観するのに良さそう。
[Paper Note] Replaying pre-training data improves fine-tuning, Suhas Kotha+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #mid-training #PostTraining #read-later #Selected Papers/Blogs #Scheduler #One-Line Notes #Data Issue Date: 2026-03-07 GPT Summary- ターゲット領域向けの言語モデルの構築には、汎用ウェブテキストでの事前学習とターゲットデータでのファインチューニングが行われる。驚くべきことに、ファインチューニング中に汎用データをリプレイすることで、ターゲットタスクの性能が向上することが確認された。具体的には、4百万トークンのターゲットデータを使用した場合、汎用リプレイによりデータ効率が最大1.87倍、ミッドトレーニングで2.06倍向上した。また、事前学習中にターゲットデータが少ないほどリプレイ効果が高いことが分かった。80億パラメータのモデルでの実験により、エージェントのウェブナビゲーション成功率やバスク語の質問応答精度が向上したことを示した。 Comment
元ポスト:
事前学習以後の中間学習やファインチューニング(事後学習)において、特定のドメインやタスクに特化させるための追加の学習を行う際に、破壊的忘却を防ぐために一定量の事前学習データを混ぜることはよく行われていたが、実際には破壊的忘却を防ぐだけでなく、ターゲットドメインの学習効率を大幅に高める(1.5Bモデルの実験ではファインチューニングでは1.87倍、中間学習では2.06倍)ことがわかり、これは70B級の大規模なモデルでも同様に生じることが明らかになった、という話らしい。興味深い。
解説:
[Paper Note] Solving an Open Problem in Theoretical Physics using AI-Assisted Discovery, Michael P. Brenner+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #AIAgents #ScientificDiscovery #TreeSearch #Physics #Initial Impression Notes Issue Date: 2026-03-07 GPT Summary- 本論文では、AIが理論物理学の未解決問題を解決することで数学的発見を加速できることを示す。Gemini Deep Thinkを用いたニューロ-シンボリックシステムが、宇宙ひもによる重力放射のパワースペクトルについて新しい解析解を導出。エージェントはコア積分の評価を通じて、従来の部分的な漸近解を改善。探索制約とフィードバックループを詳細に説明し、最も効果的な解析法としてGegenbauer多項式を特定。これにより、漸近解が数値結果と整合し、量子場理論とも関連づけられることを示した。 Comment
元ポスト:
Gemini Deep Thinkが今度は理論物理に関する未解決問題を解決したらしい?
[Paper Note] SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration, Jialong Chen+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Coding #SoftwareEngineering #One-Line Notes #CI Issue Date: 2026-03-07 GPT Summary- 静的なバグ修正だけでなく、複雑な要求変更に対応するため、継続的インテグレーションに基づく新しいベンチマークSWE-CIを提案。これにより、コード生成の評価が短期的な正確性から長期的な保守性にシフトし、100のタスクを通じてエージェントの分析およびコーディング能力の維持を評価する。SWE-CIは実世界の進化履歴に基づいており、コード品質の長期的な維持についての洞察を提供。 Comment
元ポスト:
SWE Agentの現在の主要な評価パラダイムである個々の機能のバグフィクスなどの短期的な評価から、より長期的なメンテナンスなどのタスクで評価をする
[Paper Note] $V_1$: Unifying Generation and Self-Verification for Parallel Reasoners, Harman Singh+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#PairWise #NLP #read-later #Initial Impression Notes #SelfVerification Issue Date: 2026-03-06 GPT Summary- 複雑な推論タスクにおける性能向上のため、ペアワイズ自己検証を活用したフレームワーク$V_1$を提案。$V_1$は、不確実性の高い候補ペアに動的に検証計算を割り当てる$V_1$-Inferと、生成器と検証器を共同訓練する$V_1$-PairRLから成る。これにより、コード生成や数学的推論のベンチマークで顕著な性能向上を実現。また、後者は従来の手法より高い効率を達成。 Comment
元ポスト:
self-verificationが進化するとdownstreamタスクの性能に多大な影響が出るし、かつ既存のモデルはフロンティアモデルであってもself-verificationは何らかのガイダンスがないと上手くできないことが示されているので [Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
、もしガイダンス無しでうまくできるという話であればおもしろそう
- [Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
[Paper Note] FlashOptim: Optimizers for Memory Efficient Training, Jose Javier Gonzalez Ortiz+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Quantization #Optimizer #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-03-05 GPT Summary- パラメータあたりのメモリを50%以上削減する最適化手法FlashOptimを提案。改善されたマスタウェイト分割と8ビットオプティマイザの量子化を活用し、AdamWのメモリを16バイトから7バイト、勾配リリースによりさらに5バイトに削減。これによりモデルのチェックポイントサイズも大幅に減少し、品質を保持しつつ視覚と言語タスクでの劣化は見られなかった。 Comment
元ポスト:
すでにpip install flashoptimで利用可能。SGD, Adam, AdamW, Lionがサポートされている。8Bモデルの訓練に必要なピークメモリを35%削減し、チェックポイントのサイズもも57%小さくなるという優れもの。実験結果では性能の劣化もなしという報告。
[Paper Note] Beyond Language Modeling: An Exploration of Multimodal Pretraining, Shengbang Tong+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #Transformer #MultiModal #Architecture #MoE(Mixture-of-Experts) #Scaling Laws #read-later #Selected Papers/Blogs #WorldModels #UMM #Author Thread-Post Issue Date: 2026-03-05 GPT Summary- 視覚的データは言語を超えるマルチモーダルモデルの進展に重要で、我々は制御された前訓練実験を通じてその要因を明らかにした。Transfusionフレームワークを用い、テキストや視覚データで統一的に訓練し、以下の洞察を得た:(i) RAEが最適な視覚表現を提供;(ii) 視覚とテキストは相補的で相乗効果を生む;(iii) 統一学習が世界モデリングに繋がる;(iv) MoEが効率的なスケーリングを可能にする。視覚データが言語より多く必要であることを示し、MoEが両者の調和を図ることを提案。 Comment
元ポスト:
著者ポスト:
解説:
[Paper Note] SWE-rebench V2: Language-Agnostic SWE Task Collection at Scale, Ibragim Badertdinov+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #AIAgents #Coding #SoftwareEngineering #PostTraining #read-later #Selected Papers/Blogs #Live #One-Line Notes #Environment Issue Date: 2026-03-05 GPT Summary- SWEエージェントの強化学習を支えるため、実世界のソフトウェア工学タスクを自動収集し、再現可能な環境を構築するSWE-rebench V2を提案。20言語・3,600超のリポジトリから32,000以上のタスクを集め、厳選したコンテンツで信頼性のあるトレーニングデータを提供。また、タスク生成に必要なメタデータも加え、エラー要因を明示。データセットと関連リソースを公開し、多様な言語での大規模なSWEエージェントのトレーニングを支援。 Comment
元ポスト:
environment: https://huggingface.co/datasets/nebius/SWE-rebench-V2?row=5
関連:
- [Paper Note] SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents, Ibragim Badertdinov+, NeurIPS'25, 2025.05
以前の研究ではpython特化だったが、今回はlanguage-agnosticな環境になっている。
合成データではなく、実際のissue-resolutionのヒストリに基づいたデータセットであることに注意
[Paper Note] How Well Does Agent Development Reflect Real-World Work?, Zora Zhiruo Wang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #AIAgents #Evaluation #read-later #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2026-03-04 GPT Summary- AIエージェントの開発は、労働市場のベンチマーク上で進められているが、その代表性は不明である。本研究では、43のベンチマークと72,342のタスクを分析し、エージェント開発と米国労働市場の職業との整合性を測定。プログラミング重視の開発と人間労働の価値の乖離を指摘し、エージェントの自律性を評価することで実用的な指針を提供。最後に、社会的に重要な労働を捉えるベンチマーク設計のための3つの原則を提案。 Comment
元ポスト:
AI Agentのベンチマークは実際の人間の労働に本当に紐づいたタスクで評価されているのか?という疑問に答えてくれる研究のようで、実際のAI Agentのベンチマークと人間の業務、それらのcapitalをマッピングしたところ、現在のAI Agentのベンチマークは過剰に数学とコーディングドメインに偏っており、実態としての人間の労働や、それらの中でcapitalが集中しているドメインに対するカバレッジが大きく不足していることがわかった。
ドメインごとに見ると、デジタル化がされていて高付加価値のドメインのいくつか(マネジメントや法務)のベンチマークは少なく、スキルをベースに見るとベンチマークは情報取得やエンジニアリングといった狭いスコープばかりに焦点が当たっていて(これらの人間の労働に占める割合は<7%にすぎない)、多くの他のスキルが無視されている状況とのこと。
また、エージェントの自律性を細分された尺度で評価するために、どの程度のレベルの複雑さのタスクであればreliableにagentがこなせるかという観点を導入し、タスクの複雑性に関するスケールを導入し比較を可能にした、といった話が元ポストに書かれている。
現在提供されているベンチマークにおいて、おそらくタスク全体のうちの個別のサブタスクごとに複雑度をラベル付けして、複雑度を軸にサブタスクの成功/失敗をtrajectoryから分析することで、タスクの複雑度を軸に成功率を分析したグラフを見ると、タスクの複雑度に対して基本的にはどのドメイン、スキル、エージェントフレームワーク、バックボーンモデルであれ複雑度な上がれば上がるほど成功率は減少していく傾向にあり、成功率は最終的に20%--0%付近まで低下する。
最終的に、エージェントの評価ベンチマークにおいては、実際の労働に対するカバレッジ、現実的であること(=実際のドメインや必要となるスキルを捉えており、実タスク全体を捉えたようなものが必要でFigure4にベンチマークごとのドメインとスキルのカバレッジが可視化されている)、より粒度の細かい評価が必要(タスク全体の成功/失敗でのみ評価すると、タスクのどこまでできていたのか?という重要なシグナルが欠落する)であることが議論されている。
[Paper Note] DP-RFT: Learning to Generate Synthetic Text via Differentially Private Reinforcement Fine-Tuning, Fangyuan Xu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #SyntheticData #Privacy #One-Line Notes #Initial Impression Notes #DifferentiallyPrivate Issue Date: 2026-03-04 GPT Summary- DP-RFTを用いて、プライベートデータに直接アクセスせずに合成データを生成するためのオンライン強化学習アルゴリズムを提案。合成サンプルの報酬信号にDP保護済み最近傍投票を活用し、LLMが期待されるDP投票を最大化するよう学習。長文やドメイン特化のデータ生成において、プライベートデータの境界を尊重しつつ、従来の手法とのギャップを縮小することに成功。 Comment
元ポスト:
プライベートなデータの保有者が差分プライバシーが保護された状態でLLMのロールアウトに対してvotingによるrewardを返せば、個別のLLMはプライバシーに保護されたデータを見なくてもvotingによるスコアが最大となるように学習できるというアイデア。これによりプライバシーによる課題によりデータがオープンにならないドメインでも、この枠組みでLLMをpost-trainingすれば、LLMが合成データの生成器として振舞えるため、プライベートなドメインのデータスケーラビリティの課題の解決につながるのではという提案
これは利用規約などで個人情報の扱いに関して何らかのユーザとの取り決めがあった場合、どういう扱いになるのだろうか。
Gemini Proに質問して得た感想としては、少なくとも差分プライバシーによってreward signalが個人情報を含むデータではないと保証されたとしても(プライバーバジェットがどの程度設定されていれば問題ないのかといった合意があるかと言われると怪しいらしい)、reward signalを計算する部分においては個人情報を含むデータを活用しているため、個人情報利用のスコープにそれが許容されるようなステートメントが入っていないと、こういった手法を実施することは無理なのかもしれない。
[Paper Note] CharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production, Yixin Nie+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Annotation #DPO #PostTraining #Selected Papers/Blogs #Personality Issue Date: 2026-03-04 GPT Summary- CharacterFlywheelは、Instagram、WhatsApp、Messenger向けのLLM改善のための反復プロセスであり、LLaMA 3.1を基に15世代のモデルを洗練しました。2024年7月から2025年4月にかけてのA/Bテストで、8モデル中7モデルが新たなエンゲージメント向上を示し、最大8.8%の幅、19.4%の深さで改善しました。指示遵守率も大幅に向上し、過学習防止策やダイナミクスの対策も考慮されています。この研究は、数百万人のユーザー向けのLLM活用における科学的理解を進めます。 Comment
元ポスト:
解説:
[Paper Note] On the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents, Jai Lal Lulla+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #Coding #SoftwareEngineering #Initial Impression Notes #AGENTS.md Issue Date: 2026-03-03 GPT Summary- AIコーディング・エージェント(CodexやClaude Codeなど)がソフトウェア・リポジトリに与える影響を調査。AGENTS.mdファイルの有無で、GitHubプルリクエストにおけるエージェントの実行時間とトークン消費が異なることを示し、AGENTS.mdの存在が実行時間を28.64%、トークン消費を16.58%削減する一方、タスク完了挙動は同等であることが分かった。これに基づき、AIコーディング・エージェントの設定やデプロイに関する実務的な含意を議論し、リポジトリレベルの指示の重要性を明らかにする。 Comment
関連:
- [Paper Note] Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?, Thibaud Gloaguen+, arXiv'26, 2026.02
こちらの研究ではどちらかというとAGENTS.mdによってinference costが増大するようなことが示されているが、具体的にAGENTS.mdの内容としてどのような違いがあるだろうか?
元ポスト:
[Paper Note] Jr. AI Scientist and Its Risk Report: Autonomous Scientific Exploration from a Baseline Paper, Atsuyuki Miyai+, TMLR'26, 2025.11
Paper/Blog Link My Issue
#NLP #AIAgents #ScientificDiscovery #TMLR Issue Date: 2026-03-03 GPT Summary- Jr. AI Scientistは、初心者の研究者のワークフローを模倣する自律型AIシステムで、基準論文をもとに限界分析、仮説提案、実験を通じて新しい研究論文を生成する。従来のシステムと異なり、明確なワークフローに従い、複雑な実装を扱う。本研究では、NeurIPS、IJCV、ICLRの研究成果を基に新規手法を提案し、生成された論文が既存の自動システムよりも高い査読スコアを得たことを示す。とはいえ、重要な限界やリスクも指摘されており、人間の専門知識が依然として必要な領域を明らかにする洞察が得られた。 Comment
openreview: https://openreview.net/forum?id=OeV062d8Sw
元ポスト:
[Paper Note] Doc-to-LoRA: Learning to Instantly Internalize Contexts, Rujikorn Charakorn+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #PEFT(Adaptor/LoRA) #FactualKnowledge #memory #One-Line Notes #DownstreamTasks #Test Time Training (TTT) Issue Date: 2026-03-01 GPT Summary- 長い入力を効率的に処理するために、Doc-to-LoRA(D2L)を提案。これはメタラーニングを用いて、単一の前方伝播で情報を効率よく蒸留し、適応型LoRAアダプタを生成する。D2Lにより、推論時のレイテンシとメモリ消費を削減し、文脈を超えてゼロショット精度を向上。実世界のデータセットにおいても、標準的な文脈蒸留を上回る性能を示す。 Comment
- [Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25, 2025.06
に続く研究。
元ポスト:
ポイント解説:
Doc-to-LoRAの目的は、文書レベルの情報をメモリの内部パラメータとして埋め込むこと。
[Paper Note] AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications, Yujie Zhao+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #read-later #Selected Papers/Blogs #memory #Initial Impression Notes #Author Thread-Post Issue Date: 2026-03-01 GPT Summary- LLMを用いた自律エージェントの記憶において、実務的応用と評価基準の間にギャップが存在。これを解消するために、AMA-Benchを提案し、実世界のエージェント軌跡とQAを組み合わせて評価。多くの既存システムが因果性を欠き、類似性ベース検索に制約されている中、因果性グラフとツールを用いたAMA-Agentが性能を向上。AMA-AgentはAMA-Benchで57.22%の正解率を達成し、最強記憶システムのベースラインを11.16%上回る。 Comment
元ポスト:
実際のAgenticなタスクのユースケースに沿ったmemoryの評価方法を提案している研究のようで、非常に重要な研究に見える。実際はチャットベースのやり取りではなく、エージェントと環境が相互作用しながら生成されるtrajectoryで構成され、指示はagentによって生成された客観的な目的を含んでおり、trajectoryには多くのnoisyな結果やsymbolが含まれる。また、agentが現在のstateから環境に作用した結果が返ってくるというチャットベースの言語的なフロートは異なり、stateに基づいた因果関係が存在するという差がある。
ベンチマークの結果ではGPT-5.2が優れていそうに見えるが、GPTの場合は最新のGPT-5.2で評価されているのに、Claudeに関してはClaude Haiku 3.5で評価されているのは気になる。Claude Opus 4.6やGemini-3で評価したらどの程度の性能になるのだろうか。
著者ポスト:
[Paper Note] REMem: Reasoning with Episodic Memory in Language Agent, Yiheng Shu+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#GraphBased #NLP #AIAgents #ICLR #Selected Papers/Blogs #memory #One-Line Notes #Grounding #Author Thread-Post Issue Date: 2026-03-01 GPT Summary- REMemは、エピソード記憶を構築し推論するための2段階フレームワークを提案する。オフラインでは、経験を時間情報を含む要旨と事実を結びつけたハイブリッド記憶グラフに変換。オンラインでは、エージェント型リトリーバを用いて記憶グラフ上での反復検索を可能にする。包括的な評価により、REMemは最先端システムを大幅に上回り、エピソード回想と推論タスクでそれぞれ3.4%、13.4%の改善を示す。回答不能な質問に対する拒否行動も堅牢であることが確認された。 Comment
元ポスト:
単に知識や事実情報を蓄積するのではなく、過去のイベントに関するsituationalな情報(when,where,who,what)でgroundingをしながら、複数のイベント、タイムラインを跨いでreasoningができるようなepisodic memoryの提案。人間は単に意味情報から記憶を呼び起こすだけでなく、過去のイベントを想起して条件付けした上で時系列になぞって記憶を想起できる能力があることに起因する。
openreview: https://openreview.net/forum?id=fugnQxbvMm
[Paper Note] Accelerating LLM Pre-Training through Flat-Direction Dynamics Enhancement, Shuchen Zhu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #Optimizer Issue Date: 2026-02-28 GPT Summary- 大規模言語モデルの事前学習における効率的なオプティマイザーの必要性を強調。平坦な方向への更新に特化した行列ベースのオプティマイザーが良好な性能を示す中、リーマン幾何学的常微分方程式(ODE)フレームワークを構築し、一般的な適応アルゴリズムの相互作用を探求。新たに提案するLITEは、平坦な軌跡に沿った学習率の適用で訓練ダイナミクスを改善し、広範な条件下でMuonとSOAPの両方を加速。理論的に速い収束を確認し、効率的なLLM事前学習の体系的アプローチを提供。 Comment
元ポスト:
[Paper Note] Fast KV Compaction via Attention Matching, Adam Zweiger+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Decoding #read-later #Selected Papers/Blogs #KV Cache #Compression Issue Date: 2026-02-28 GPT Summary- 長い文脈の処理において、KVキャッシュのサイズがボトルネックとなるが、要約による圧縮は情報損失を招く。最近のCartridges研究はコンパクトなKVキャッシュが全文脈に近い性能を持つことを示したが、最適化が遅い。本研究では、Attention Matchingを用い、アテンション出力を再現しながらコンパクトなキーと値を構築する高速な文脈圧縮手法を提案。これにより、効率的な部分問題への分解が可能となり、圧縮時間と品質で大幅な改善を達成し、数秒で最大50倍の圧縮を実現した。 Comment
元ポスト:
[Paper Note] DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference, Yongtong Wu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Infrastructure #SoftwareEngineering #read-later Issue Date: 2026-02-28 GPT Summary- エージェント型LLM推論において、KVキャッシュのストレージI/Oが性能に大きく影響している。従来のアーキテクチャでは、KVキャッシュの読み込みがボトルネックとなり、システム全体のスループットが制約されている。DualPathは、このボトルネックを解消するためのデュアルパスKVキャッシュ読み込みシステムであり、デコードエンジンへの新たなストレージ経路を提供する。これにより、データ転送が効率化され、負荷が動的にバランスされる。実運用のモデル評価では、DualPathがオフライン推論スループットを最大1.87倍、オンライン提供スループットを平均1.96倍向上させることが示された。 Comment
元ポスト:
ポイント解説:
[Paper Note] Interleaved Head Attention, Sai Surya Duvvuri+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Transformer #AIAgents #Attention #LongSequence #Architecture #One-Line Notes #Reference Collection #LongHorizon #Author Thread-Post Issue Date: 2026-02-28 GPT Summary- Interleaved Head Attention(IHA)を提案し、マルチヘッド・アテンションの線形スケーリングの制約を解消。IHAでは、各ヘッドにP個の疑似ヘッドを構築し、ヘッド間のクロス混合を可能にすることで、複数のアテンションパターンを生成。理論的には、合成的Polynomialタスクに対し、IHAはMHAよりも効率的で、実世界のベンチマークでも性能向上を示した。特に、GSM8KおよびMATH-500の問題で改善を達成。 Comment
元ポスト:
著者ポスト:
解説:
各headのqueryに対してlinear変換をかけてP個の疑似ヘッドを作成し、それらをinterleavingする形で整列させてK, Vを適用する、という感じらしい。多段階の推論や合成が必要な複雑なタスクにおいてheadの表現力が増し、必要なhead数が小さくなる反面、計算量が増える。疑似ヘッドはP個のトークンによって構成されるとみなせるので、FlashAttentionなどの従来の実装をそのまま適用できる。
[Paper Note] Aletheia tackles FirstProof autonomously, Tony Feng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #Mathematics #ScientificDiscovery #Proofs Issue Date: 2026-02-28 GPT Summary- 数理研究エージェントAletheiaは、Gemini 3 Deep Thinkを活用し、FirstProofチャレンジにおいて10問中6問を自動解決。問題8は専門家の合意が得られなかった。実験の詳細と評価、解釈についても明示し、生データは指定のリンクで入手可能。 Comment
元ポスト:
First Proof:
- [Paper Note] First Proof, Mohammed Abouzaid+, arXiv'26, 2026.02
[Paper Note] Learning to Rewrite Tool Descriptions for Reliable LLM-Agent Tool Use, Ruocheng Guo+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #AIAgents #Coding #SoftwareEngineering #PostTraining #CurriculumLearning #ToolUse Issue Date: 2026-02-28 GPT Summary- ツール・インターフェースの質がLLMベースのエージェントの性能に影響を与えることに着目し、Trace-Free+というカリキュラム学習フレームワークを提案。これにより、トレースのない環境で再利用可能なインターフェース使用パターンを習得を促進。構造化ワークフローに基づくデータセットを構築し、実験では未知のツールに対する改善とクロスドメイン一般化が確認された。最終的に、ツール・インターフェースの最適化がエージェントのファインチューニングに有効であることを示した。 Comment
元ポスト:
[Paper Note] DISCO: Diversifying Sample Condensation for Efficient Model Evaluation, Alexander Rubinstein+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Evaluation #ICLR #read-later #Selected Papers/Blogs #EfficientEvaluation Issue Date: 2026-02-28 GPT Summary- 機械学習モデルの評価は高コストであり、従来のアプローチは二段階でサブセットを選び、精度を学習する。しかし、選択がクラスタリングに依存するため設計に敏感である。我々は、モデルの応答の多様性を最大化するサンプル選択が重要であると提唱し、$\textbf{DISCO}$手法を提案。これはモデル間の不一致を基にサンプルを選ぶもので、理論的にも最適であり、MMLUやHellaswagなどで最先端の性能を達成した。 Comment
pj page: https://arubique.github.io/disco-site/
元ポスト:
openreview: https://openreview.net/forum?id=SoOgBHa3dZ
[Paper Note] The Diffusion Duality, Chapter II: $Ψ$-Samplers and Efficient Curriculum, Justin Deschenaux+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #DiffusionModel #ICLR #read-later #Selected Papers/Blogs #ImageSynthesis #Samplers #Author Thread-Post Issue Date: 2026-02-28 GPT Summary- Uniform-state離散拡散モデルは自己修正能力により優れた生成とガイダンスを実現していますが、ステップ数が増えるとサンプリング品質が限界に達します。本研究では、予測子-修正子(PC)サンプラーを導入し、任意のノイズ過程に対応可能な一般化手法を提案します。Uniform-state拡散と組み合わせることで、従来の手法を超える性能を発揮し、生成パープレキシティを低減させるとともに、サンプリングステップを増やすことで性能が向上します。また、効率的なカリキュラムを構築し、訓練時間を25%、メモリを33%削減しつつ、強力な下流タスク性能を維持します。 Comment
元ポスト:
著者ポスト:
openreview: https://openreview.net/forum?id=RSIoYWIzaP
著者コメント:
openreview: https://openreview.net/forum?id=RSIoYWIzaP
著者ポスト:
[Paper Note] The Art of Efficient Reasoning: Data, Reward, and Optimization, Taiqiang Wu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #Reasoning #Length #PostTraining Issue Date: 2026-02-28 GPT Summary- LLMsの効率的な推論機構を調査し、正確さを条件とした推論の長さ分布を提案。訓練プロセスは長さ適応と推論の洗練に基づく二段階であり、約20万GPU時間をかけた実験を実施。重要な発見として、容易なプロンプト訓練が正の報酬信号の密度を高め、長さの崩壊を防ぐことが確認された。学習された長さのバイアスはドメインを超えて一般化可能であり、知見をQwen3シリーズに適用・検証し、堅牢性を示す。 Comment
元ポスト:
[Paper Note] On Data Engineering for Scaling LLM Terminal Capabilities, Renjie Pi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #SyntheticData #Coding #OpenSource #SoftwareEngineering #Initial Impression Notes #Environment #Terminal Issue Date: 2026-02-28 GPT Summary- ターミナルエージェントのトレーニングデータ戦略に関するギャップを埋めるため、(1) 軽量な合成タスク生成パイプラインTerminal-Task-Genを提供し、(2) データと訓練戦略を総合的に分析。これにより、Nemotron-Terminalファミリーを訓練し、Terminal-Bench 2.0で性能を大幅に改善。ほぼすべての合成データセットをオープンソース化し、研究の加速を図る。 Comment
元ポスト:
terminalエージェントのための合成データを作成する環境と実際に作成されたSFT用のデータセットの公開をしているようである。
[Paper Note] Symmetry in language statistics shapes the geometry of model representations, Dhruva Karkada+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Embeddings #Analysis #NLP #RepresentationLearning #read-later #Selected Papers/Blogs #Geometric #Initial Impression Notes Issue Date: 2026-02-28 GPT Summary- 言語モデルの内部表現は顕著な幾何学的構造を示し、暦の月や歴史的年の配置に関する対称性を示す。特に、月の共起頻度が時間間隔のみに依存することを証明し、高次元の単語埋め込みモデルにおける幾何学的構造を導出。実験的に大規模なテキスト埋め込みモデルとの一致を確認し、共起統計が撹乱されても幾何は維持されることを示している。この頑健性は、潜在変数によって制御される場合に自然に現れ、表現多様体の普遍的な起源を示唆する。 Comment
元ポスト:
こんな不思議なことが(小並感)
[Paper Note] Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?, Thibaud Gloaguen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Coding #SoftwareEngineering #Selected Papers/Blogs #reading #Reference Collection #Initial Impression Notes #AGENTS.md Issue Date: 2026-02-27 GPT Summary- コーディングエージェントのタスク完遂性能を評価するため、LLMが生成したコンテキストファイルと開発者提供のファイルを用いた2つの設定を検討。結果、コンテキストファイルは成功率を低下させ、推論コストを増加させる傾向が見られた。両者はタスクの探求を促進するが、不要な要件がタスクを難化させるため、最小限の要件のみを記述することが推奨される。 Comment
元ポスト:
(現時点では)LLMによって自動生成されたコンテキストファイルは性能を劣化させ、inference costを増大させ、人間が作成したコンテキストファイルは性能を向上させる。コンテキストファイルによってoverviewを提供することを推奨しているものがあるが、性能向上には寄与しない。コンテキストファイルに従うことはより多くのthinkingを誘発し、結果的にタスクを難しくする。最小限のrequirementsのみを記述したものを使うことを推奨する、といった内容らしい?
関連:
best practiceは以下とのこと:
- # Writing a good CLAUDE.md, Kyle, 2025.11
解説:
非常にコンパクトにまとまっている。
解説:
解説:
[Paper Note] Test-Time Training with KV Binding Is Secretly Linear Attention, Junchen Liu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #memory #Test Time Training (TTT) Issue Date: 2026-02-26 GPT Summary- TTTを再定義し、記憶化ではなく学習済み線形アテンションとしての挙動を示す。これにより、アーキテクチャの単純化や効率向上が可能となり、多様なTTTバリアントを体系的に線形アテンションに還元できることが明らかに。 Comment
元ポスト:
pj page: https://research.nvidia.com/labs/sil/projects/tttla/
[Paper Note] Phantom Transfer: Data-level Defences are Insufficient Against Data Poisoning, Andrew Draganov+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #Poisoning #Bias #Safety #Attack #PostTraining #SubliminalLearning #One-Line Notes Issue Date: 2026-02-24 GPT Summary- ファントム・トランスファーというデータ汚染攻撃を紹介。無害なデータセットへの汚染が防げない特性を持ち、サブリミナル学習を調整して多くのモデルに効果を発揮。モデルの挙動をパスワードでトリガーする方法についても言及し、データ防御の限界を示唆。今後はモデル監査とホワイトボックスセキュリティに重点を置くべきと提案。 Comment
元ポスト:
Instruction Tuningのための合成データを生成(本研究ではAlpaca datasetを利用しconciseな応答を生成する目的で実験)する際に、Subliminal Learningの手法と同様にモデルのシステムプロンプトに特定のエンティティに関してバイアスのあるプロンプトを仕込みデータを合成(e.g., イギリスを好むようなもの)すると、生成された合成データに対してフィルタリングやパラフレージングなどの防御策を講じてもバイアスの転移を防ぐことはできず、かつ通常のSubliminal Learningとは異なり、モデルのアーキテクチャを跨いでもバイアスが転移する、という話のように見える。
[Paper Note] Beyond a Single Extractor: Re-thinking HTML-to-Text Extraction for LLM Pretraining, Jeffrey Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #Data Issue Date: 2026-02-24 GPT Summary- ウェブからテキストを抽出する際、固定抽出器に依存する従来の方法がデータのカバレッジを最適化していないことを示す。異なる抽出器を組み合わせることで、DCLM-Baselineのトークン供給を71%増加させつつ、性能を維持。特に構造化コンテンツでは、抽出器の選択が下流タスクの成果に大きく影響し、WikiTQで最大10ポイント、HumanEvalで最大3ポイントの性能差が生じる。 Comment
元ポスト:
[Paper Note] LLMs Can Learn to Reason Via Off-Policy RL, Daniel Ritter+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #PostTraining #read-later #Selected Papers/Blogs #Off-Policy #Author Thread-Post Issue Date: 2026-02-24 GPT Summary- オフポリシーRLアルゴリズム「OAPL」は、大規模言語モデルのトレーニングにおいて重要度サンプリングを使用せず、Lagged Inferenceポリシーを採用。OAPLはGRPOを上回り、DeepCoderと同等の性能を維持しつつ、訓練時間を3分の1に削減。また、Pass@k指標でのスケーリング改善を示し、400ステップ以上のラグを持ちながらも効率的なポストトレーニングを実現する。 Comment
元ポスト:
著者ポスト:
[Paper Note] The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning, Qiguang Chen+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Reasoning #LongSequence #mid-training #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-02-24 GPT Summary- LLMは長い連鎖思考(Long CoT)推論を学ぶのが難しく、効果的な推論は安定した分子のような構造を持つことが重要。これには深層推論、自己反省、自己探索の三つの相互作用が関与し、キーワードの模倣ではなくファインチューニングから生じることが示された。有効な意味的異性体が迅速なエントロピー収束を促進し、Mole-Synを提案してLong CoT構造の合成を導き、性能とRLの安定性を向上させる。 Comment
元ポスト:
結構読むのが大変そうなのでskim readingと元ポストを拝見した上でざっくりまとめると以下のような感じだろうか。takeaway部分により詳細な話が書かれているので必要に応じて読むとよさそう。
良いlong CoTには分子のような推論の内部構造が存在し、それらは適切な内部構造を持つ合成データによってSFTをすることで身につけさせられる。逆に、人間が作成したtrajectoryなどはこれらの分子構造が均質化されておらず、学習が不安定になる(表層的なキーワードから学習されたりする)。
良いlong CoTに必要な要素として、本研究では以下の3つのbehaviorが挙げられている:
- Self-Exploration: モデルが柔軟に異なるアイデアやパスを探索する力
- Self-Reflection: モデルが過去のstepを確認し修正する能力(分子の構造を安定化させるような役割を果たす)
- Deep Reasoning: 原子結合のような、論理的なstepを強力に結びつけた主となる論理フロー
[Paper Note] Analyzing and Improving Chain-of-Thought Monitorability Through Information Theory, Usman Anwar+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #Chain-of-Thought #Reasoning #Safety #Monitorability Issue Date: 2026-02-24 GPT Summary- CoTモニターは、推論の痕跡を分析し、LLMベースのシステムで出力の興味属性を検出する手法です。本稿では、CoTと出力間の相互情報量がモニタビリティの必要条件であることを示し、性能を損なう二つの誤差源を特定します。情報ギャップは抽出可能な情報量を、誘発誤差は監視関数の近似度を測ります。訓練目的を最適化してCoTモニタビリティを向上させる二つの補完的アプローチを提案:オラクルベース手法と条件付き相互情報量の最大化。これにより、モニターの精度向上とリワードハッキングの緩和を実証します。 Comment
元ポスト:
[Paper Note] Large-scale online deanonymization with LLMs, Simon Lermen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Privacy #Initial Impression Notes Issue Date: 2026-02-23 GPT Summary- 本研究では、大規模言語モデル(LLMs)を活用し、仮名化されたオンラインプロフィールを高精度で再識別する脱匿名化技術を実現。特に、Hacker NewsユーザーやAnthropic Interviewer参加者に対して、専任の調査官の作業量に匹敵する効率で成功。攻撃パイプラインは、身元特徴の抽出、意味的埋め込みによる候補一致の検索、そして上位候補の推論・検証の3段階から構成。従来手法を大幅に上回り、最高で適合率90%、再現率68%を達成。これにより、オンラインの仮名ユーザー保護の実務的限界が浮き彫りになり、プライバシーの脅威モデルの再考が求められる。 Comment
元ポスト:
Reddit等の匿名の投稿からプロフィールを収集し個人をある程度特定できる、という話な模様。
[Paper Note] Learning Personalized Agents from Human Feedback, Kaiqu Liang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #Personalization #memory #One-Line Notes Issue Date: 2026-02-23 GPT Summary- PAHFは、個ユーザーの嗜好をリアルタイムで学習し続けるためのフレームワークで、三段階のループを実装。具体的には、事前アクションの明確化、嗜好に基づく行動根拠の提供、嗜好変化時のメモリ更新を行う。新たなベンチマークを用いて、エージェントがゼロから嗜好を学び変化に適応する能力を評価し、明示的メモリと二つのフィードバックチャネルの統合が学習速度やパーソナライゼーション誤差の改善に寄与することを実証。 Comment
元ポスト:
ユーザ専用のmemoryを用意しmemory上にユーザのpreferenceを蓄積し更新することによってpersonalizationを実施する。memoryへの更新はcontextやテキストによるフィードバックに基づいて実施される。
[Paper Note] Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens, Wei-Lin Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Metrics #NLP #Evaluation #Reasoning #Test-Time Scaling #One-Line Notes Issue Date: 2026-02-23 GPT Summary- LLMが推論時に「深く考えるトークン」を特定し、計算量を定量化。これらのトークンの割合が正確さと一貫して相関することを示し、Think@nを導入して深く考えるトークンが多い生成を優先的に扱うことで推論コストを削減。自動一貫性と同等または上回る性能を実現。 Comment
reasoningの質をトークンの長さではなく、重要なトークンを基準に測定する。その上で重要なトークンの割合が小さいサンプルは早めに枝刈りすることでtest-time scalingの効率を向上させる手法を提案している模様。
[Paper Note] Nanbeige4.1-3B: A Small General Model that Reasons, Aligns, and Acts, Chen Yang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #SmallModel #OpenWeight Issue Date: 2026-02-21 GPT Summary- Nanbeige4.1-3Bは、3Bパラメータでエージェント的挙動、コード生成、推論を実現する初のオープンソースの小型言語モデルであり、報酬モデリングを活用して人間の価値観に整合した高品質な応答を提供します。複雑なコード生成には強化学習による報酬を設計し、最大600回のツール呼出しターンを信頼性高く実行可能です。実験結果は、同程度のモデルを超え、より大規模なモデルとも優れた性能を示しています。これにより、小型モデルが広範な能力と専門性を両立できることを実証しています。 Comment
HF: https://huggingface.co/Nanbeige/Nanbeige4.1-3B
元ポスト:
所見:
[Paper Note] Arcee Trinity Large Technical Report, Varun Singh+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #Stability #Sparse Issue Date: 2026-02-21 GPT Summary- Arcee Trinity Largeは4000億パラメータを持ち、130億のスパースMoEとして設計されている。Trinity Nano(60億パラメータ)とTrinity Mini(260億パラメータ)も報告されており、各モデルには局所的およびグローバルな注意機構、ゲート付き注意、深さスケールされた正規化、MoEのシグモイド・ルーティングが採用されている。Trinity Largeには新しいMoEロードバランシング戦略のSMEBUが導入され、Muonオプティマイザーで訓練された。すべてのモデルは損失のスパイクなしで訓練を完了し、Trinity NanoとTrinity Miniは10兆トークン、Trinity Largeは17兆トークンで事前学習された。モデルのチェックポイントはHugging Faceで利用可能。 Comment
[Paper Note] Hybrid-Gym: Training Coding Agents to Generalize Across Tasks, Yiqing Xie+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #Coding #SoftwareEngineering #Environment Issue Date: 2026-02-21 GPT Summary- 実際のコーディングエージェントの評価は、SWE-Benchのような単一課題に依存せず、より複雑なタスクを解決する能力に重点を置く。本研究では、転移可能なスキルを明らかにし、それを学習するための原則を導出し、Hybrid-Gymという訓練環境を提案。訓練を受けたエージェントは多様な実世界タスクに効果的に一般化し、基礎モデルの性能を大幅に向上させた。 Comment
元ポスト:
関連:
pj page: https://hybrid-gym.github.io/
[Paper Note] One-step Language Modeling via Continuous Denoising, Chanhyuk Lee+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #Architecture #read-later #FlowMaps Issue Date: 2026-02-20 GPT Summary- 離散拡散に基づく言語モデルの生成速度の向上が期待される中、品質が低下する問題を解決。フロー基盤の言語モデル(FLM)を構築し、ユークリッドデノイジングを利用して訓練安定性と生成品質を向上。蒸留により少数ステップ生成が可能なモデル(FMLM)を取得し、既存のモデルを上回る品質を実現。研究は離散モダリティの生成モデリングに新たな視点を提供し、スケーラブルなフロー基盤アプローチへと導く。 Comment
元ポスト:
v2:
pj page: https://one-step-lm.github.io/blog/
[Paper Note] GLM-5: from Vibe Coding to Agentic Engineering, GLM-5 Team+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #LongSequence #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #SparseAttention Issue Date: 2026-02-18 GPT Summary- 次世代モデルGLM-5は、エージェント主導のエンジニアリングへ移行し、推論コストを削減しながら長い文脈の忠実度を維持する。新しい非同期強化学習インフラを実装することで、学習効率を向上させ、非同期エージェントRLアルゴリズムにより複雑な相互作用からの学習効果を高める。これによりGLM-5は最先端の性能を達成し、実世界のコーディングタスクでの能力が従来の基準を超えたことが示された。 Comment
関連:
- GLM-5: From Vibe Coding to Agentic Engineering, Z.ai, 2026.02
- DeepSeek Sparse Attention (DSA)
- [Paper Note] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, DeepSeek-AI+, arXiv'25, 2025.12
元ポスト:
解説:
ASync RLにおける工夫:
[Paper Note] REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents, Zheng Chu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#GraphBased #NLP #Search #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #MultiModal #mid-training #PostTraining #VisionLanguageModel #2D (Image) #KeyPoint Notes #LongHorizon #Environment Issue Date: 2026-02-18 GPT Summary- REDSearcherは、大規模言語モデルを用いた探索エージェント最適化のための統一フレームワークであり、複雑なタスクの合成や中間訓練を効率化する。具体的には、タスクの難易度を正確に制御し、ツール使用を促進。また、基本能力や知識の強化を通じて高品質な軌跡収集を低コスト化。迅速なアルゴリズム的反復が可能なシミュレート環境を構築し、テキスト・マルチモーダル両方のベンチマークで最先端性能を達成。高品質な探索軌跡やクエリセットを公開し、今後の研究を促進する。 Comment
pj page: https://redsearchagent.github.io/index/
元ポスト:
ざっくりとしか読めていないが、ポイントはQAを構築する際のreasoningngraphに基づく複雑度の管理と、5段階のverifierによる低品質なQAの除去にあるように見える。
QAを合成する際にQAに回答するためのreasoning graphをKGに基づいて構築し、QAに回答するための情報を網羅するための深さをQAの構造的な複雑さとし、また応答するための情報がソースにどれだけ分散しているか(1 documentにすべての情報が書かれていたらいくら構造が複雑でもone shotのexampleで応答できることになる)の両方を考慮してQAの複雑度を決定しているように見える。
また、合成されたQAから低品質なものや複雑でないめのをフィルタリングするために下記5段階のverificationを実施:
- ツールアクセス無しでLLMの世界知識のみで回答可能なものは除外
- search engine apiで検索をしtop 50に正解が出現しないものはevidenceが十分にsupportされていないとし除外
- QA合成中のKGのevidenace(KGのtripletと、キャッシュされたpassage)をLLM verifierに与え、回答と矛盾する場合は除外
- strong agentにN回rolloutを生成させ、1度も正解できなかったものは除外。またN回のうち何回正解できたかをconfidenceとして保持
- 正解rolloutを生成する過程において、strong agentによって回答がuniqueでないと判断されたものは除外する(厳密ではなくとも、曖昧なタスクを除外する効果を期待する)
上記はtext modalityのQAの合成の場合で、multi modal (image)の場合は、reasoning graphのノードの一部を画像に置換し、画像の中身を解釈した上で次のノードを検索するといった依存関係に変更することでimageを理解しないと応答不可なQAを合成するようである。
verificationについても、上記text onlyのverificationに加え、VLMに基づいたimage onlyのverification(imageだけで回答できるものは除外、imageがQuestionと関係なさすぎる場合は除外等)したり、text+imageをstrong agentに与えN回ロールアウトを実施し正解率を算出し、正解率が高すぎるQAを除外するといった処理を実施しているようである。
[Paper Note] Does Socialization Emerge in AI Agent Society? A Case Study of Moltbook, Ming Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #read-later #Selected Papers/Blogs #Initial Impression Notes #Society Issue Date: 2026-02-18 GPT Summary- AIエージェント社会は人間の社会システムに似た収束ダイナミクスを辿るのかという問いに対し、初の大規模な診断を行った。動的進化を定量的に評価するフレームワークを導入し、言語の安定化や個体の惰性を測定。分析の結果、意味は迅速に安定化するが、エージェント間の多様性と語彙の変化は維持され、均質化には逆らっている。しかし、強い惰性により影響力は一過性で、安定した集団的影響の形成が妨げられている。これにより、相互作用と社会化に関する新たなデザイン原理が示唆される。 Comment
元ポスト:
Moltbook:
- Moltbook is the most interesting place on the internet right now, Simon Willisons's blog, 2026.01
元ポストとアブストしか読めていないのだが、いまのAI Agentはたとえば下記Position Paperのように他者と協働するように作られていない[^1]からこのような現象が生じるのではないか。また、Moltbookにデプロイされているエージェントがどのような目的を設定されているかはわからないが、明確な目的やタスクが与えられないで活動している場合、エージェントの学習データはそのような状況を前提としていないので、エージェントの振る舞いもランダムなノイズのようなものになってしまうのではなかろうか。
- [Paper Note] Position: Humans are Missing from AI Coding Agent Research, Wang+, 2026.02
逆に他者と協働しながら、特定のタスクの正しい完了を報酬とするのではなく、もっと自身の内面的な感情や動機に対して報酬が働くような枠組みが発展し、かつ協働をすることのスキルを得られるようなデータが増えればまた違ったことが起きるのではなかろうか。
[^1]:SWE Agentの例ではあるが現在のAAgentはタスクを正しく完了したことをシグナルとして訓練されるパラダイムに支配されているので協働的な要素は生まれづらいと推察される。それはおそらくマルチエージェントでも一緒である。
[Paper Note] DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories, Chenlong Deng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #InformationRetrieval #Search #Dataset #AIAgents #Evaluation #MultiModal #One-Line Notes Issue Date: 2026-02-18 GPT Summary- 既存のマルチモーダル検索システムはクエリと画像の関連性を独立して評価することを前提としているが、このアプローチは現実の視覚データの依存関係を無視している。これを解決するために、我々はDeepImageSearchを提案し、画像検索を自律的探査タスクとして再定義する。このモデルは文脈的手掛かりに基づき、視覚データの多段階推論を行いターゲットを特定する。相互に関連した視覚データ用のベンチマークDISBenchを構築し、文脈依存クエリの生成におけるスケーラビリティ課題を人的なモデル協働で解決するパイプラインも提案。また、モジュール型エージェントフレームワークと二重メモリシステムを用いて、堅牢なベースラインを開発した。実験により、DISBenchが先端モデルに対して重要な課題を示すことが明らかになり、次世代検索システムへのエージェント的推論の統合の必要性が強調されている。 Comment
元ポスト:
検索クエリが与えられた時に、Corpus中の画像中に含まれる情報を考慮しなければ検索できないような検索タスクとベンチマークDIBenchの提案。たとえば、白と青のロゴのイベントで、lead singerだけがステージに立っている画像、のような、白と青のロゴのイベントをCorpus画像から同定(クエリと画像の相互作用)→その上で当該イベントでソロでステージにlead singerが立っている画像を探す、といったような検索である。
proprietaryモデルだとClaude-4.5-Opusの性能がよく、次いでGemini-Pro-Previewの性能が良い。GPT5.2は大きく性能面で劣っている。OpenModelと比較すると、ClaudeはQwen3-VLやGLM-4.6Vの倍程度のスコアを獲得している(Table1)。
[Paper Note] Scaling Beyond Masked Diffusion Language Models, Subham Sekhar Sahoo+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #Pretraining #NLP #Supervised-FineTuning (SFT) #DiffusionModel #Scaling Laws #PostTraining #KeyPoint Notes #DownstreamTasks Issue Date: 2026-02-18 GPT Summary- 拡散型言語モデルは生成速度向上の可能性から自己回帰型モデルの代替手段となり、マスクド拡散が優位なアプローチとして注目されている。本研究では、一様状態拡散法と補間的離散拡散法のスケーリング法則を初めて提示し、マスクド拡散モデルが約12%のFLOPs効率向上を示すことを報告。パープレキシティは拡散ファミリー内で有用だが、他のファミリーとの比較では誤解を招くことがある。全手法を17億パラメータにスケールすると、一様状態拡散は依然として競争力を保ちつつ、GSM8Kで他モデルを上回りつつパープレキシティは悪化する結果となった。 Comment
元ポスト:
pj page: https://s-sahoo.com/scaling-dllms/
Masked Diffusion Language Model (MDLM)はperplexityの観点では高い性能が出るが、異なるDiffusion Algorithmを比較する上でPerplexityが良い指標なのか?がResearch Questionで、3種類の拡散モデル[^1]に基づくモデルを同一の計算量の元でスケーリング時の挙動を分析したとのこと。
その結果、計算量を投入すればするほどARモデルのような綺麗なスケーリング則が全てのモデルで見出されたが、PerplexityがARと同等の性能に到達するためには、MDLMが14--16倍、Duoが23倍、Eso-LMが32倍の計算量を要した。
Perplexityの観点ではMDLMが良さそうだが、Perplexityが良いからといって、サンプル効率、あるいは下流タスクの性能が良いとは限らないため追加の分析を実施。
スループット(token/sec)を変化させて検証したところ、ARは品質が高いが遅く、スループットが高い領域ではDuoがサンプル効率と品質のパレート最適であることがわかり、中くらいの領域ではEso-LMがパレート最適、低い領域でさARがパレート最適であり、スループットと品質の観点ではMDLMは劣ることがわかった。
その後、パラメータ数を1.7Bに固定し、Nemotron Pretrainingデータセットで事前学習をし、zeroshotでの(尤度ベースでの)下流タスクの性能を見ると、MDLMよりもDuoの方が5/7のベンチマークで性能が良く、その後GSM8KでSFTすると、DuoのPerplexityは低かったにも関わらず、全てのモデルを上回った。
[^1]: MDLMに加えて、Uniform-state Diffusion (Duo), Interpolating Diffusion(Eso-LM)というモデルで比較しているようである。この辺はあまり詳しくないので勉強したい。
という話が元ポストに書かれている。
[Paper Note] HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam, Weiqi Zhai+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation Issue Date: 2026-02-17 GPT Summary- HLE-Verifiedは、Humanity's Last Exam(HLE)の改訂版であり、ノイズの多い問題が評価に与える影響を軽減するために開発された。二段階の検証・修復プロセスを通じて、641件の検証済みアイテムと1,170件の改訂済みアイテムが生成され、残り689件は不確実性セットとして公開された。評価の結果、HLE-Verifiedは平均的な精度が7〜10パーセント向上し、特に誤りのあるアイテムでは30〜40パーセントの改善が見られた。このアプローチにより、モデル能力をより正確に測定することが可能となった。 Comment
元ポスト:
HLE:
- [Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25, 2025.01
[Paper Note] Learning a Generative Meta-Model of LLM Activations, Grace Luo+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #NLP #DiffusionModel #Probing #Steering Issue Date: 2026-02-17 GPT Summary- 生成モデルを用いて、ニューラルネットワークの活性化を分析する新たなアプローチを提案。拡散モデルを十億の残差ストリーム活性化に適用し、ネットワーク内部状態の分布を学習する「メタモデル」を構築。介入の誘導により流暢さが向上し、損失が低下。メタモデルのニューロンは概念の分離が進み、解釈性の向上を示唆。 Comment
元ポスト:
activationに対してノイズを注入し、それをデノイジングする拡散モデルを学習することで、activationのsteeringに活用する。加えて、学習された拡散モデルは元々のニューラルネットワークよりも解釈性が高く、高いprobing性能を発揮する、という感じの話に見える。
[Paper Note] Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning, Zhaoyang Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SyntheticData #PostTraining #Diversity #Environment Issue Date: 2026-02-17 GPT Summary- LLMの進展により、自律エージェントが複雑なタスクを実行する能力が向上したが、信頼できる環境の不足がスケールを制約している。本研究では、Agent World Model(AWM)という合成的な環境生成パイプラインを提案し、1,000のシナリオを用意し、平均35ツールとの相互作用を可能にする。これにより、信頼性の高い状態遷移と高品質な観測が得られ、マルチターンのツール使用エージェントに対する強化学習で有効性を確認。合成環境のみでも良好な分布外一般化が得られることを示した。コードは公開されている。 Comment
元ポスト:
ポイント解説:
[Paper Note] LUCID: Attention with Preconditioned Representations, Sai Surya Duvvuri+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Transformer #Attention #LongSequence #Architecture Issue Date: 2026-02-17 GPT Summary- ソフトマックスを用いたドット積注意はトランスフォーマーの基盤だが、文脈長が長くなると性能が劣化し、勾配消失が学習を妨げる。そこでLUCID Attentionを提案し、アテンション確率に前処理を適用することで、重要なキーに正確に集中させる。LUCIDのアプローチはソフトマックス温度を低くする必要がなく、60億パラメータの言語モデルを用いた実験で、長文脈の検索タスクにおいて顕著な改善を示した。特に、BABILongで最大18%、RULERで最大14%の性能向上を達成した。 Comment
元ポスト:
[Paper Note] SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, Xiangyi Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Selected Papers/Blogs #KeyPoint Notes #AgentSkills #Reading Reflections #Author Thread-Post #AgentHarness Issue Date: 2026-02-17 GPT Summary- LLMエージェントを強化する手続き知識のパッケージであるエージェントスキルの効果を測定するため、SkillsBenchを提案。これにより、86タスクを利用したキュレーション済みスキルと決定論的検証器を組み合わせたベンチマークを作成。各タスクはスキルなし、キュレーション済みスキル、自己生成スキルの3条件で評価。キュレーション済みスキルは合格率を平均16.2ポイント向上させるが、分野による効果の差が顕著。自己生成スキルは有意な利益をもたらさず、信頼性のある手続き的知識の自作が困難であることを示した。Focused Skillsは、包括的なドキュメンテーションを上回る効果を持ち、小型モデルがスキルを有することで大型モデルに匹敵する場合がある。 Comment
元ポスト:
Agent Skillsに関するベンチマーク。11種類の多様なドメインのタスクによって構成される。コーディングやソフトウェアエンジニアリングに留めらないのが特徴的に見える。
評価時は
- スキルがない場合
- スキルがある場合
- 自己生成したスキルを使う場合
の3種類で評価する。
ハーネスはClaude Code, Codex CLI, Genini CLIの3種類で評価し、モデルはGPT, Claude, Gemini系列のモデルを利用。takeawayは以下:
- skillsはタスクの性能を改善するが、モデルとハーネスの組み合わせでgainが大きく異なる
- Gemini CLIとGemini Flashが最高性能を達成
- スキルを自己生成しても性能向上に寄与しない(むしろネガティブな影響も見受けられる)
- 3種類のハーネスのうち
- Claude Codeが最も多くスキルを活用し、Claudeモデルは一貫してgainを得る
- Gemini CLIは最も高いraw performanceを達成
- 性能はcompetitiveだが、Codex CLIは必要なスキルの内容を取得しても、スキルを利用せず独立して処理してしまう頻度が高い
- skillによって得られるgainはドメインによって大きく異なる。事前学習時に馴染み薄いドメインほど、skillの導入による恩恵がでかい。
- skillの導入によって、タスクによっては性能が悪化するものもある。これはモデルがすでにうまく処理をする能力を持っているのに、スキルが提供されることでそれらがconflictすることに起因する可能性がある。
- タスクごとに、2--3個のスキルを提供するのが性能がよく、4+になるとgainが低下する
- スキルの定義はproceduralな知識をコンパクト(compact)あるいは詳細に記述したもの(detailed)が良く(i.e., 特定のことについて集中的に記述するもの)、徹底的に記述されたドキュメント(comprehensive)は性能が悪化する。
- SLM+skillによって、スキル利用なしのより大きなモデルを性能で上回ることができる
Agent skillsの効果について定量的に分析した初めての研究な気がしており、重要な研究だと思われる。AI AgentというとClaudeが優秀な印象が強いが(コーディングやソフトウェアエンジニアリングでの性能に基づく印象)、本ベンチマークでは多様なドメインで評価をしており、Gemini CLI+Gemini Flashが最も平均的な性能が高いのが興味深い。
pj page: https://www.skillsbench.ai/
著者による続報:
SkillsBenchがエージェントスキル評価のデファクトになったことと、1.1のローンチイベントについての話が言及されている。
[Paper Note] CoPE-VideoLM: Codec Primitives For Efficient Video Language Models, Sayan Deb Sarkar+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #VisionLanguageModel #Encoder #3D (Video) #One-Line Notes Issue Date: 2026-02-17 GPT Summary- 動画理解のために、動画コーデックのプリミティブを活用し、計算オーバーヘッドを軽減。軽量トランスフォーマーエンコーダにより、トークン生成を大幅に効率化し、一般的なベンチマークで性能を維持。最大で86%の時間短縮と93%のトークン削減を実現。 Comment
元ポスト:
VideoLanguageModelのinputにおあて、より効率的な画像のΔエンコーダを導入して高速化しつつ性能向上
[Paper Note] Soft Contamination Means Benchmarks Test Shallow Generalization, Ari Spiesberger+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Evaluation #read-later #Selected Papers/Blogs #Generalization #One-Line Notes #Initial Impression Notes #Contamination Issue Date: 2026-02-17 GPT Summary- LLMの訓練データがベンチマークのテストデータで汚染されると、分布外一般化にバイアスが生じる。従来のデコンタミネーション・フィルターは意味的重複を認識できず、私たちは「ソフト汚染」として訓練データの意味的重複を調査。Olmo3コーパスの解析から、汚染が広範囲に存在し、CodeForcesの78%、ZebraLogicの50%に意味的または厳密な重複を確認。また、ベンチマークデータの重複が訓練データに含まれることで性能が向上し、ファインチューニングが同じベンチマークの未使用データの性能も改善することが示された。これにより、最近のベンチマークの向上は本質的な能力向上とは異なる可能性があることを示唆している。 Comment
元ポスト:
n-gramマッチングによるデータのdeaontaminationは表層レベルでしか捉えられないので、意味的に等価なサンプルをdecontamgnationできず(=Soft Contamination)効果が薄く、意味的なレベルでのコンタミネーションは広範に存在し[^1]、それらサンプルが学習データに含まれるとheldoutされたテストベンチマークのスコアも改善してしまう(=本当に計りたい汎化性能を測れていない)という話をしっかり分析した研究に見え、非常に重要な研究に見える。
[^1]:Olmo3で検証しており、ZebraLogicテストセットの50%とexactに一致するデータが含まれ、CodeForcesのテストセットのうち78%のサンプルと意味的に一致したサンプルが一件以上存在したとのこと。
[Paper Note] SciAgentGym: Benchmarking Multi-Step Scientific Tool-use in LLM Agents, Yujiong Shen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #Evaluation #Science #KeyPoint Notes #LongHorizon #Environment #ToolUse Issue Date: 2026-02-17 GPT Summary- 科学的推論には高度なツール統合が必要だが、現行ベンチマークはその能力を十分に評価していない。これを解決するために、SciAgentGymを導入し、1,780個の分野特異的ツールを提供。SciAgentBenchでは、エージェント能力を初歩から長期的なワークフローまで評価。先進モデルも複雑な科学ツール使用に取り組むが、成功率は対話のホライズン拡大で急落。SciForgeというデータ合成手法を提案し、ツールアクションを依存グラフとしてモデル化。これによって、SciAgent-8Bはより大規模なモデルを上回り、科学ツール使用能力の転移を示す。次世代の自律的科学エージェントの可能性を示唆。 Comment
元ポスト:
long horizonタスクでのtool useに関するベンチマークおよび環境の提供と、graphベースでツールの依存関係を定義し活用することで、環境上での実行によってgroundingされた高品質データを合成する手法SciForgeを提案。
ベンチマークでの評価によって、フロンティアモデルでもlong horizonになるとタスク成功率が低下することが明らかになり、性能の低いモデルは同じツールや類似したツールの繰り返しの呼び出しをするなどの挙動があることが明らかになった(他にも詳細な失敗モードの分析などがされているように見える)。
また、合成データによるSFTによって8B級のSLMでも大幅に性能が改善している模様。
[Paper Note] Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs, Wei Zhou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #Initial Impression Notes #Data Issue Date: 2026-02-16 GPT Summary- LLM技術がデータ前処理のパラダイムを変革中であり、幅広いアプリケーションに対応するための進化を検討。文献レビューを通じて、データクリーニング、統合、強化の主要タスクにおける手法を整理し、それぞれの利点と制約を分析。さらに、評価指標とデータセットを考察し、スケーラブルなデータシステムや信頼性の高いワークフローに向けた研究課題を提示。 Comment
元ポスト:
自動的なデータの前処理に関するSurvey。文献は120以上引用され、美麗なフォーマットで記述されている。時系列での手法の変遷と、手法間の関係性が図解で整理されており非常にわかりやすそう。データの前処理は実務上の大きなボトルネックなのでどのような研究があるか気になる。
[Paper Note] Intelligent AI Delegation, Nenad Tomašev+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #DecisionMaking #Delegation Issue Date: 2026-02-16 GPT Summary- AIエージェントは、複雑なタスクを意味のある小さなコンポーネントに分解し、他のAIや人間に委任する能力が求められる。しかし、既存の方法は単純なヒューリスティックに依存し、環境変化への適応や Unexpected failure に対処することができない。本研究では、タスク割り当てや信頼構築を組み込んだ適応的フレームワークを提案し、複雑な委任ネットワークにおける人間とAI双方に適用可能な新たなプロトコルの開発を目指す。
[Paper Note] Gaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments, Romain Froger+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation Issue Date: 2026-02-16 GPT Summary- Gaia2は、大規模言語モデルエージェントを非同期環境で評価する新しいベンチマークです。静的または同期的評価と異なり、エージェントは動的に進化するシナリオで、時間的制約やノイズ、他のエージェントとの協力に適応することが求められます。各シナリオには、書き込みアクション検証器が関連付けられ、細かいアクション単位の評価が可能です。最近の評価結果では、GPT-5が最も高い成績を修得しましたが、時間に敏感なタスクでは失敗し、Claude-4は精度と速度をトレードオフする結果となりました。これらは推論、効率性、堅牢性のトレードオフを示し、実用的なエージェントシステムの開発と訓練を支援するインフラを提供することを目指しています。 Comment
元ポスト:
[Paper Note] InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery, Shiyang Feng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #ScientificDiscovery #LongHorizon Issue Date: 2026-02-16 GPT Summary- InternAgent-1.5は、計算領域と実証領域にわたる科学的発見のための統一システムであり、生成、検証、進化の3つのサブシステムを含む。これにより、継続的な発見サイクルと改善行動を維持し、計算モデルと実験を統合可能。GAIA、HLE、GPQA、FrontierScienceのベンチマークで優れたパフォーマンスを確認し、アルゴリズム発見タスクと実証発見タスクでも競争力のある手法を自律的に設計・実行。これにより、InternAgent-1.5は自律的な科学的発見のための一般的かつスケーラブルなフレームワークを提供することが示された。 Comment
pj page (CN) : https://discovery.intern-ai.org.cn/home
元ポスト:
[Paper Note] First Proof, Mohammed Abouzaid+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Mathematics #ScientificDiscovery #Selected Papers/Blogs #Proofs Issue Date: 2026-02-16 GPT Summary- AIシステムの数学問題回答能力を評価するため、著者が作成した10の未公開の数学問題を共有。答案は著者に知られているが、短期間は非公開とする。 Comment
pj page: https://1stproof.org/
元ポスト:
ポイント解説:
自分たちの研究過程で生じた自分たちは答えを発見しているが世間には未発表な問題と暗号化された解答が公開されている。2月13日時点で鍵が公開されているようだ。果たしてどの程度AIは解答ができたのだろうか?
Google DeepmindのAlethiaは10個中6つの問題を解くことができたようである:
Alethia:
- [Paper Note] Accelerating Mathematical and Scientific Discovery with Gemini Deep Think, Google DeepMin, 2026.02
[Paper Note] GameDevBench: Evaluating Agentic Capabilities Through Game Development, Wayne Chi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Game Issue Date: 2026-02-16 GPT Summary- ゲーム開発におけるマルチモーダルなコーディングエージェントの評価が遅れている問題に対処するため、初のベンチマーク「GameDevBench」を提案。本ベンチマークは132の複雑なタスクで構成され、コード行数とファイル変更が平均3倍以上になる。最良のエージェントでも54.5%のタスクしか解決できず、成功率はタスクの種類によって大きく異なる。マルチモーダル能力を高めるために、画像およびビデオベースのフィードバックメカニズムを導入した結果、Claude Sonnet 4.5の性能が33.3%から47.7%に向上。GameDevBenchはエージェントによるゲーム開発研究を促進する。 Comment
元ポスト:
[Paper Note] Think Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning, Futing Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Reasoning #Test-Time Scaling #KeyPoint Notes Issue Date: 2026-02-14 GPT Summary- モデルが文脈内で複数の推論仮説を生成・検証し効果的にスケーリングを実現するためには「浅い探索の罠」を克服する必要がある。これを解決するために、冗長性ペナルティに基づく長さインセンティブ探索(\method)を提案。実験により、この手法は文脈内探索を促進し、ドメイン内で平均4.4%、ドメイン外で2.7%のパフォーマンス向上を示した。 Comment
元ポスト:
RLによってモデルが特定のサンプルに正解できなかった場合に、モデルにΔLの範囲でreasoningを長くした場合(つまりいつもより少しだけ長い思考をする)に報酬が与えられ、かつreasoningの過程において、特定の思考のstateに何回も訪れてしまう場合にペナルティを与えることで、思考が深くなった際に多様なstateが探索されなくなる問題(浅い探索の罠)を是正し、sequentialなtest time scaling(=long CoT)の性能を改善する。
[Paper Note] Learn from Your Mistakes: Self-Correcting Masked Diffusion Models, Yair Schiff+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #DiffusionModel #SelfCorrection #Test-Time Scaling #PostTraining #Author Thread-Post Issue Date: 2026-02-13 GPT Summary- MDMの問題を解決するために、生成中のトークンを修正する「プログレッシブ自己修正(ProSeCo)」フレームワークを提案。これにより、アンマスクされたトークンの修正が可能になり、質の向上と生成速度の最大2-3倍の高速化を実現。実験によって、ProSeCoがMDMを超える性能を示した。 Comment
元ポスト:
著者ポスト:
[Paper Note] The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context, Xiaoyuan Liu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #ContextEngineering #memory #One-Line Notes #ContextRot Issue Date: 2026-02-13 GPT Summary- 新しい基盤モデル「StateLM」を導入し、AIが自己管理できる状態を持つエージェントに進化。コンテキストのプルーニングや文書のインデクシングなどのメモリツールを管理することで、モデルは固定ウィンドウの制約から解放されます。StateLMは長文QAやチャットメモリタスクで従来のLLMを一貫して上回り、特にBrowseComp-Plusタスクでは最大52%の精度を達成。私たちのアプローチにより、推論が管理可能なプロセスに変革されます。 Comment
元ポスト:
言語モデルにStateを明示的に持たせて、ツールを用いて動的に過去のcontextから必要なcontextを編集、削除、読み込みなどのコンテキストエンジニアリングが可能なようにRLによって学習するようなアーキテクチャが提案されているように見える。
[Paper Note] Native Reasoning Models: Training Language Models to Reason on Unverifiable Data, Yuanfu Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #ICLR #PostTraining #Off-Policy #KeyPoint Notes #Open-endedTasks #ConfidenceBased Issue Date: 2026-02-13 GPT Summary- NRT(ネイティブ推論トレーニング)は、教師ありファインチューニングと強化学習の依存を克服し、標準的な質問-回答ペアのみでモデルが自ら推論を生成します。推論を潜在変数として扱い、統一訓練目標に基づいて最適化問題としてモデル化することで、自己強化フィードバックループを構築。LlamaおよびMistralモデルにおいて、NRTが最先端の性能を達成し、従来の手法を大幅に上回ることを実証しました。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=abAMONjBwb
verifier freeでreasoning能力を向上させるRL手法で
- SFTにおいてexpertsのtrajectoryが必要な課題
- RLVRにおいてverifiableなドメインでしか学習できない課題
の両方に対処する。
具体的にはQAデータが与えられたときに、Questionに対してモデルにreasoning trace zを生成させ、zを生成した後にanswerを生成させる。zに対するTrace Rewardとanswerトークンに対するモデルのconfidenceを報酬として用いてRLする。
SFTやverifier freeな先行研究よりも9種類のreasoningベンチマークで高い性能を達成している。また、answer tokenのconfidenceに対する3種類の集約方法(平均, 1/pによって加重平均をすることで難しいトークンの重みを強める, 対数尤度を用いる)も提案手法も提案され比較されている。
論文中ではオフポリシーRLとして最適化する旨記述されているが、appendix記載の通りreasoning trace zを生成しているので、オンポリシーRLな性質も備えていると思われる。
[Paper Note] On-Policy Context Distillation for Language Models, Tianzhu Ye+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #In-ContextLearning #Distillation #On-Policy #One-Line Notes #SelfDistillation Issue Date: 2026-02-13 GPT Summary- オンポリシーコンテキスト蒸留(OPCD)は、生徒モデルが自身の生成した軌跡に基づいて学習し、コンテキストに条件付けられた教師に対して逆カルバック・ライブラー divergenceを最小化するフレームワークです。OPCDは実体験知識蒸留とシステムプロンプト蒸留の応用で効果を示し、数学的推論やテキストベースのゲームでベースラインを上回り、精度向上と分布外能力の保持を実現します。また、小さな生徒モデルが大きな教師から知識を内在化できることも示しています。 Comment
元ポスト:
教師モデルにcontextを与えた上で生徒モデルのロールアウトに対してreverse KLを最小化することで、in-context learningを活用しつつオンポリシー蒸留を実施する枠組みに見える。教師モデルをstrong modelにすればteacher-student distillationの枠組みになるし、教師モデルと生徒モデルを一致させるとself-distillationとなる。
ICLを活用したself-distillationは以下でも提案されている:
- [Paper Note] Self-Distillation Enables Continual Learning, Idan Shenfeld+, arXiv'26, 2026.01
[Paper Note] Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation, Wenkai Yang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Distillation #On-Policy Issue Date: 2026-02-13 GPT Summary- オンポリシー蒸留(OPD)は、学生が教師のロジット分布に合わせて生成した軌道に基づき、パフォーマンスを改善する手法であり、オフポリシー蒸留や強化学習(RL)を凌駕することが多い。本研究では、OPDが密なKL制約付きRLの特別なケースであることを示し、一般化オンポリシー蒸留(G-OPD)というフレームワークを提案。報酬スケーリング因子を導入し、ExOPDとして知られる手法が標準OPDを一貫して改善することを明らかにした。特に、異なるドメインの専門知識を統合できる設定では、学生が教師のパフォーマンスを超える可能性がある。さらに、教師のベースモデルを参照モデルとして選択することで、報酬信号が向上し蒸留パフォーマンスが向上することが確認された。研究はOPDに関する将来の知見を提供することが期待される。 Comment
元ポスト:
[Paper Note] The Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning, Simin Fan+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Supervised-FineTuning (SFT) #One-Line Notes Issue Date: 2026-02-13 GPT Summary- 事前学習から教師ありファインチューニング(SFT)への移行を理解することは、モデル開発に重要。本研究では、モデルの精度と信頼度の持続性、信頼できるベンチマーク、スケールによる移行ダイナミクス、精度と信頼度の一致について調査。実験により、移行の信頼性は能力やベンチマーク、スケールによって異なり、精度と信頼度は異なるスケーリングダイナミクスを示すことが明らかに。これにより、ベンチマーク選定やデータキュレーションに関する実用的なガイダンスが提供される。 Comment
元ポスト:
事前学習とSFTの間におけるAccuracyとConfidence(=モデルの回答のトークン確率)の相関を分析。モデルのスケールが大きい方が、SFT後のdownstreamタスクでのAccuracyと強い相関を持ち、confidence(=モデルが回答したときのトークンの確率)はモデルのスケールが小さい方が強い相関を持つ。このことから、よりモデルのスケールが大きい方がSFTにおいてAccuracyを維持するためにconfidenceの再形成を行っていることが示唆される、という話らしい。
[Paper Note] Olmix: A Framework for Data Mixing Throughout LM Development, Mayee F. Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Tutorial #Pretraining #NLP #read-later #Selected Papers/Blogs #DataMixture #One-Line Notes #Author Thread-Post Issue Date: 2026-02-13 GPT Summary- データミキシングは言語モデル(LM)トレーニングにおいて重要な課題であり、Olmixフレームワークを提案することで短所に対処。設定空間の理解が不足している中、強力なミキシング手法の設計選択を特定。ドメインセットの進化に対応し、受けた影響を考慮したミキシチャー再利用メカニズムを導入。これにより、計算量を74%削減し、下流タスクで11.6%の改善を実現。 Comment
元ポスト:
著者ポスト:
言語モデルを事前学習しようとしたときに、
- 先行研究で提案されている手法を自分のデータにどのように適用すべきか?ハイパーパラメータはどうすればよいか?tiny datasetの場合はoversamplingしてよいのか?といった課題に直面し
- 仮にgood mixが分かったとしても、データは静的ではなく、新たなデータセットがリリースされたり、同僚がデータセットを変更するかもしれない。そうなったときに、DataMixをどのようにアップデートすればよいのか?
といった実践的に困る場面が多いようであり、これらに対して本研究は実践的なDataMixingの設定に関するガイダンスとデータセットが進化したときに効果的にDataMixを更新する方法を提案しているとのこと。
[Paper Note] Data Darwinism Part I: Unlocking the Value of Scientific Data for Pre-training, Yiwei Qin+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #SyntheticData #DataFiltering #Science #One-Line Notes #Environment Issue Date: 2026-02-12 GPT Summary- データの質がモデルのパフォーマンスに影響を与える中、データ・ダーヴィニズムという10段階の分類法を提唱。これに基づき、900BトークンのDarwin-Scienceコーパスを構築し、先進的なLLMを利用して生成的洗練(L4)と認知的補完(L5)を実現。事前トレーニングにより、3Bモデルで+2.12、7Bモデルで+2.95ポイントの性能向上を達成し、特定タスクでは更に高い改善を確認。共進化の原則に基づく開発を促進するため、データセットとモデルを公開。 Comment
元ポスト:
学習データを処理するためのフレームワークを10段階のレベル(ただのデータの獲得から、前処理、合成、世界のシミュレーションまで)で定義し、それぞれのレベルにおいてどのような処理が必要で、どのような価値を生むのかといった点が体系化されている。レベルが上がるにつれてデータの量は基本的に減少するが、データのinformation densityや構造の複雑さは高まっていく。
また、下図に示されているように実際にLevel0 -- Level5までの処理を実施したことでどのようなgainがあるかも考察されているようである。
[Paper Note] Weight Decay Improves Language Model Plasticity, Tessa Han+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Supervised-FineTuning (SFT) #Regularization #PostTraining #KeyPoint Notes #DownstreamTasks #Reading Reflections Issue Date: 2026-02-12 GPT Summary- 事前訓練での重みの減衰がモデルの可塑性に与える影響を分析。高い減衰値が微調整時に性能向上を促進し、直感に反するトレードオフを引き起こすことを示す。重みの減衰が線形分離可能な表現を促進し、過学習を抑制する役割も明らかに。ハイパーパラメータ最適化における新たな評価指標の重要性を強調。 Comment
元ポスト:
事前学習時にWeight Decayを大きくするとPerplexityは悪化する場合があるが、Perplexityが悪化していたとしてもSFTを通じて最終的に得られるdownstream task性能のgainが高い場合がある、という話に見える。つまり、Findings2に書かれている通り、事前学習時にPerplexityを最小化するようなWeight Decayの設定はdownstream性能を高めるという観点では必ずしも必須ではない。ではなぜこのようなことが起きるかというと、Weight Decayを大きくするとAttentionのQK matricesのpseudo-rank(=行列の95%を説明するのに必要な特異値の割合)が改善されることが実験により観察され、一般的に低ランクな表現は正則化の結果として現れることから、シンプルな表現によってよりモデルがロバストになるのでは、という点が考察されている。また、実際にValidation dataとTraining dataのlossの差分を見ることで、Weight Decayが大きいことによってtraining dataへのoverfitが抑制されていることが観測された。
Weight DecayはもともとRegularizationとしての働きがあるので、それはそうなのだろうな、という感想を持ったのだが、特にQK matrixが正則化の影響を強く受けるというのはおもしろかった。つまり、クエリ対してよりロバストな写像を学習できているということだと思われる。
Perplexityが事前学習の良さを測るために必ずしも良いわけではないよ、という意味での関連:
- [Paper Note] Perplexity Cannot Always Tell Right from Wrong, Petar Veličković+, arXiv'26, 2026.01
[Paper Note] Data Repetition Beats Data Scaling in Long-CoT Supervised Fine-Tuning, Dawid J. Kopiczko+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #Chain-of-Thought #Reasoning #PostTraining #Selected Papers/Blogs #Generalization #KeyPoint Notes #Author Thread-Post Issue Date: 2026-02-12 GPT Summary- SFT(教師ありファインチューニング)の重要性を強調し、小規模データセットでの繰り返しトレーニングが大規模データセットでの単一エポックよりも優れていることを示す。Olmo3-7Bが400サンプルで128エポックのトレーニングによって、51200サンプルでの1エポックよりも12-26%の性能向上を実現。トレーニングトークンの精度が改善の指標となり、このパターンは一貫して確認される。これにより、高価なデータスケーリングに代わる実践的アプローチを提供し、繰り返しの利点を新たな研究課題として提示。 Comment
元ポスト:
著者ポスト:
**long-CoTのSFTにおいては**、多くのユニークなデータで学習するよりも、小さなデータセットを複数エポック繰り返し学習する方が優れていることが分かったとのこと。この傾向はモデルを跨いで存在する(Olmo3とQwen3で実験)。
より多くのエポック数 vs. より多くのユニークデータ数 でのモデルの傾向の違いとしては、前者の方がReasoningにおいて最終的な回答を出す割合が非常に大きくなることが分かった(たとえばFigure2 Rightの1 epoch 51200サンプルの24% vs. 256 epoch 200サンプル)。
では繰り返しの恩恵を得られなくなるのはどの時点かというと、Token Accuracy (=モデルのnext token predictionのtargetと一致する予測トークンがtopになった割合)が100%に近くなるとそれ以上epochを繰り返してもgainが無くなるので、これをSFTのstopping criteriaとして利用可能とのこと。
[Paper Note] Towards Robust Scaling Laws for Optimizers, Alexandra Volkova+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #Optimizer #Scaling Laws #One-Line Notes #Robustness Issue Date: 2026-02-12 GPT Summary- 最適化手法がLLMの事前学習の質に与える影響を調査。Chinchillaスタイルのスケーリング則は条件が悪く、代わりに特有の再スケーリング因子を持つ共有の冪則指数を提案。これにより異なる最適化手法間の比較が可能に。最終的には、損失の分解に基づく理論的分析を行い、Chinchillaスタイルのスケーリング則の出現を説明。 Comment
元ポスト:
(きちんと理解できているか怪しいが)従来のチンチラ則に代表されるL(N,D)に関する(モデルサイズ、データ量、最終損失)Scaling LawsはOptimiserを固定(AdamやAdamW)した上で求められていたが、本研究では異なるOptimiser(Muon, Shampoo, SOAPなど)が適用された場合にロバストではないことを指摘し、Optimiser間で共有のパラメータと、Optimiser毎にfittingさせる係数を用いた定式化(3)によって、よりOptimiser間でロバストなScaling Lawsを提案しOptimiser間での比較を可能にした模様。また、損失をQuadratic Lossを最適化する観点から分解し、Theorem 6.3で示される理論的なスケーリング則を導出。これらの個別の項を解釈すると、第一項L^*がチンチラ則のEに対応し(普遍的に生じる基本的な損失)、第二項Θ(λ^ω_d)は近似誤差(当該モデルサイズでの性能の限界による誤差)がチンチラ則でのparameter efficiency term A/(N^α)に対応し、第三項O(e^−2kλd)は最適化誤差を表すが、これがチンチラ則でのdata efficiency term B/(D^β)に対応すると解釈でき、自然とチンチラ則スタイルのスケーリング則が導出されることを理論的に示したようである。
[Paper Note] MoEEdit: Efficient and Routing-Stable Knowledge Editing for Mixture-of-Experts LLMs, Yupu Gu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #KnowledgeEditing #Stability #Routing #One-Line Notes Issue Date: 2026-02-12 GPT Summary- MoEモデルに対する知識編集のための新たなルーティング安定フレームワークMoEEditを提案。エキスパート更新を再パラメータ化し、ルーター入力を不変に保つことで、計算およびメモリ効率を向上させつつ、高い特異性とルーティングの安定性を実現。実験により、最新の効果と一般化を達成したことが示された。 Comment
元ポスト:
MoEにKnowledge Editingを単純に適用するとexpertsへのroutingがシフトして不安定になったり、expertの数に応じて計算量が増大するだけでなく、expert間でcouplingされて知識が活用される場合に独立性がないといったMoE特有の課題があり、それらに対処するような手法を提案している模様。
[Paper Note] Towards Autonomous Mathematics Research, Tony Feng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #Mathematics #ScientificDiscovery #Test-Time Scaling #read-later #Selected Papers/Blogs #Human-in-the-Loop Issue Date: 2026-02-12 GPT Summary- Aletheiaは、金メダル級の推論能力を持つ数学研究エージェントで、自然言語による解の生成・検証・修正を行います。競技レベルから専門研究への移行を可能にする高度なツールを活用し、オリンピック問題から博士課程レベルの演習に対応。顕著な成果として、AIが生成した研究論文や人間との協働証明、未解問の半自律評価を示します。AIの自律性と新規性の評価基準を提案し、人間とAIの協働について考察します。すべてのプロンプトとモデル出力は公開されています。 Comment
元ポスト:
ポイント解説:
[Paper Note] Anchored Decoding: Provably Reducing Copyright Risk for Any Language Model, Jacqueline He+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Decoding #read-later #Selected Papers/Blogs #Legal #KeyPoint Notes #Initial Impression Notes #Copyright #Author Thread-Post Issue Date: 2026-02-12 GPT Summary- 「アンカーデコーディング」は、現代の言語モデルが逐語的な再現を抑制するための新しい推論法であり、リスクのあるLMからより安全な生成を実現します。この手法は、ユーザーが選択した情報予算に応じて生成過程に制約を加え、著作権リスクと有用性のトレードオフを可能にします。また、新たに導入した安全モデルと、クロスボキャブラリ融合を実現するAnchored$_{\mathrm{Byte}}$デコーディングにより、リスク低減と流暢さを維持しつつ、コピーギャップを75%まで排除することが確認されました。 Comment
元ポスト:
権利上の問題がない言語モデル(permissive licenceデータによって学習されたものなど)SafeLMと、任意の言語モデルRiskyLMの2つが与えられたときに、KL Divergenceの予算Kの元、各生成のstep tごとに語彙空間上で両LLMのKL DivergenceがK_t未満となるように生成するトークンを選択することで、出力の有用性(fluencyとfactuality)は維持しつつ、memorizationされている著作権物をそのままデコーディングしてしまうリスクを低減する手法。RiskyLMの非常に高いUtility上の語彙生成確率を、SafeLM側の安全な語彙確率で引っ張って良い塩梅で生成するようなイメージと思われる。
この手法はSafeLMがどれだけ高いUtilityを維持しつつ安全性を保てるかにデコーディング性能が依存すると思われるが、SLMで非常に性能の良いTinyComma 0.8Bもリリースしている。
また、KL Divergenceを測定する都合上、提案手法は共通のVocab(すなわちトークナイザー)を持つモデル間でしか適用できないが、KL Divergenceをバイト空間上で測るように工夫することでVocabの制約を無くす方法も提案している。
著作物をそのまま出力してしまう問題は軽減されそうだと思われるが、著者独特の思想や感情、表現や言い回しなどの著作権で保護される対象をどの程度の度合いで守れるかについては興味がある。また、そのためには次はどのようなステップが必要か?
[Paper Note] Hybrid Linear Attention Done Right: Efficient Distillation and Effective Architectures for Extremely Long Contexts, Yingfa Chen+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Transformer #Distillation #LongSequence #PositionalEncoding #Architecture #read-later #Selected Papers/Blogs #reading #RecurrentModels Issue Date: 2026-02-12 GPT Summary- ハイブリッドトランスフォーマーアーキテクチャは、ソフトマックスアテンションとRNNを組み合わせたもので、長い文脈の処理においてトレードオフを示すが、高コストな事前トレーニングが課題。既存の転送法は大量のデータを必要とし、ハイブリッドモデルの性能低下を招く。本研究では、トランスフォーマーからRNNアテンションハイブリッドモデルへの蒸留手法HALOを提案し、新たな位置エンコーディングスキームHyPEを導入したHypeNetを開発。HALOを用いてQwen3シリーズをHypeNetに変換し、わずか2.3Bトークンで同等の性能を実現しつつ、長文脈性能と効率を向上させた。
[Paper Note] MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling, MiniCPM Team+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LongSequence #SmallModel #Selected Papers/Blogs #One-Line Notes #Hybrid #SparseAttention #LinearAttention Issue Date: 2026-02-12 GPT Summary- MiniCPM-SALAは、9Bパラメータのハイブリッドアーキテクチャで、疎アテンションと線形アテンションを組み合わせ、長文脈タスクの効率と性能を向上させる。層選択アルゴリズムにより、1:3の比率で統合され、ハイブリッド位置エンコーディングを利用することで、トレーニングコストを約75%削減。広範な実験で、シーケンス長256Kトークン時に推論速度を最大3.5倍向上させ、最大100万トークンの文脈をサポートすることが示された。 Comment
元ポスト:
解説:
linear attention->sparse attentionをcascadingしたtransformerブロックを持つアーキテクチャ
linear attention:
- [Paper Note] Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention, Zhen Qin+, ICML'24, 2024.05
sparse attention:
- [Paper Note] InfLLM-V2: Dense-Sparse Switchable Attention for Seamless Short-to-Long Adaptation, Weilin Zhao+, arXiv'25, 2025.09
[Paper Note] SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning, Peng Xia+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #Selected Papers/Blogs #memory #KeyPoint Notes #ContinualLearning #AgentSkills Issue Date: 2026-02-12 GPT Summary- SkillRLは、自動スキル発見と再帰的進化を通じて、LLMエージェントが過去の経験を活用し、高レベルの再利用可能な行動パターンを抽出できるようにする新たなフレームワークです。経験に基づく蒸留を用いて階層的なスキルライブラリを構築し、強化学習中にスキルがエージェントのポリシーと共進化します。このアプローチにより、推論の有用性が向上しつつ、トークンのフットプリントが削減されます。実験はSkillRLが最先端の性能を達成し、堅牢性を保つことを示しました。 Comment
alphaxiv blog: https://www.alphaxiv.org/abs/2602.08234
元ポスト:
AnthropicのAgent Skillsにinspireされた手法で、ポリシー側のパラメータをfreezeしてスキル群を更新していくような枠組みではなく、スキルが定義されたライブラリと、ポリシーそのものを同時に進化(スキル定義追加・更新+ポリシーの重みの更新)させていくことで、生のtrajectoryをmemoryから活用する方向性ではなく、動的にtrajectoryからスキルを構築し、構築されたスキルの使い方やretrieve方法をポリシーの内部パラメータとして組み込むことで、スキルとポリシーが共に進化していくようにしたい、それにより、生の経験(trajectory)を読み込んでadhocに利用するよりも、より一般化された形で経験を活用できるようにしたい、という話に見える。
提案手法はベースモデルを環境に対して適用しタスクに対する成功したtrajectoryと失敗したtrajectoryをまず収集する。収集したtrajectoryに対して、teacher modelで「タスクを完了するための戦略的なパターン」と「簡潔な失敗した要因」を生成させ、<スキル名, スキルの具体的なdescription, いつそのスキルを適用するか>によって定義されるスキルを定義する(従来手法は失敗したtrajectoryに関する情報は破棄していた)。スキルは2種類定義されており、汎用的に全てのタスクに適用可能なgenericなスキルと、特定のtask-specificなスキルの2種類によって構成される(この二つのスキルの集合がSKILLBANKと呼ばれる)。genericなスキルは常にポリシーのinstructionに含められ、task-specificなスキルはタスクを実行するたびに意味的な関連性に基づいてtop-kがretrieveされ利用される。これにより初期のSKILLBANKを構築する。
続いて、ベースモデルを学習して賢くしていきたい。この時初期のポリシー(=ベースモデル)はスキルのretrieve + 使い方を知らないため、teacher modelによってスキルを含めたtrajectoryを生成しSFTをすることでコールドスタート時に適用する。その後、オンポリシーRL(GRPO)を用いて、スキルをretrieveし、retrieveしたスキルを活用してタスクを完了し、完了したタスクからrewardが計算されポリシーを更新していく。この時、GRPOのエポックにおいてvalidationフェーズを用意し、特定の閾値以下のsuccess rateを持つタスクに関しては、teacher modelが失敗したtrajectoryに基づいてSKILLBANKを更新することでSKILLBANKを進化させることで性能を改善する、といった話に見える。
genericなスキルは常にinstructionに含まれるためretrieveする必要がないが、task specificなスキルはtask descriptionとskill定義のembeddieg空間上で類似度を測りtop-kが抽出される。embeddingを取得する具体的なモデルについては言及がないように見える?
[Paper Note] Prism: Spectral-Aware Block-Sparse Attention, Xinghao Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #LongSequence #VisionLanguageModel #One-Line Notes #SparseAttention Issue Date: 2026-02-12 GPT Summary- ブロックスパースアテンションの効率を改善するために、平均プーリングによる粗粒度アテンションの不正確さの原因を分析し、Prismというトレーニング不要のアプローチを提案。Prismは、ブロック選択を高周波数と低周波数に分解し、エネルギーベースの温度キャリブレーションで位置情報を復元。結果、フルアテンションと同等の精度を維持しつつ、最大5.1倍の速度向上を達成。 Comment
元ポスト:
sparse attentionにおいて、RoPEとmean poolingによるブロックの重要度の同定が組み合わさったときに、mean poolingがlow pass filterの役割を果たし高周波成分が破壊される(ことを理論的に示した)。このため、低周波成分と高周波成分を分けて扱う手法を提案しているという感じの話らしい。
[Paper Note] Effective Reasoning Chains Reduce Intrinsic Dimensionality, Archiki Prasad+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #Reasoning #PEFT(Adaptor/LoRA) #PostTraining #Selected Papers/Blogs #Generalization #KeyPoint Notes #Initial Impression Notes Issue Date: 2026-02-12 GPT Summary- 内在次元数を指標として、推論チェーンの有効性を定量化。異なる推論戦略がタスクの内在次元数を低下させ、一般化性能に逆相関を持つことを示す。これにより、有効な推論チェーンがパラメータを効果的に利用し学習を促進することを明らかにする。 Comment
元ポスト:
元ポストを読むと、以下のような話のようである。非常に興味深い。
良いCoT(推論)はタスクを圧縮する(すなわち、inputを正解へとマッピングする際の自由度を減少させる)ことを示した。
さまざまなCoT戦略に対して、あるタスクに対してさまざまなCoT戦略と、**特定の性能に到達するまでに必要な最小のパラメータ数の関係性(=intrinsic dimensionality)**を分析。パラメータ数の制御はLoRAのパラメータを変化させることによって調整して実験。その結果、Intrinsic Dimensionalityがdownstream taskの性能と、OODへの汎化性能に対して非常に強い相関を示した(Perplexityよりも強い相関)。
Intrinsic DimensionalityをさまざまなCoT戦略で測定すると、(school math系のデータに関しては)python codeを生成し実行する方法(Executed PoT)が最もコンパクトなsolutionを生成し、かつ最も良いOODへの汎化性能が高いことがわかった(他ドメインでこのCoT手法が適しているとは限らない点には注意)。
また、モデルスケールが大きい方がより低いIntrinsic Dimensionalityを示し、良いcompressor(=タスクを圧縮する能力が高い)であることがわかった。
弱くてノイジーなCoT戦略は、スケールせず、パラメータ効率が悪いことがわかった。
非常に興味深い研究で、かつskim readingしかできていない上での感想なのだが、
- 実験がLoRAベースで実施されているため、他の学習のダイナミクスにおいて同様のことが言えるのかという点
- Gemmaでしか実験されていないため他のアーキテクチャでも同じようにIntrinsic Dimensionalityの有効性が言えるのか
- データセットがGSM系列のschool mathドメインでしか実験されていないため、ドメイン間でどの程度一般性を持って言える話なのかという点
は明らかになっていない気がしており、どうなるのか興味がある。また、実際にIntrinsic Dimensionalityを測定しようとした場合に、効率的に求める方法はあるだろうか。
[Paper Note] OneVision-Encoder: Codec-Aligned Sparsity as a Foundational Principle for Multimodal Intelligence, Feilong Tang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #read-later #Encoder #Backbone Issue Date: 2026-02-12 GPT Summary- 仮説として、人工汎用知能は圧縮問題であると提唱。深層学習はデータ構造とアーキテクチャの整合時に最も効果的であるが、現在の視覚アーキテクチャは過剰計算を行い冗長性を無視している。OneVision-Encoderは、視覚情報を圧縮し、計算をエントロピーの高い領域に集中させる方法論を採用。結果として効率と精度の向上が証明され、OV-Encoderは他の視覚モデルを複数のベンチマークで上回り、特に動画理解での改善が見られる。これにより、次世代の視覚AIの基盤となる可能性が示された。 Comment
元ポスト:
pj page: https://github.com/EvolvingLMMs-Lab/OneVision-Encoder?tab=readme-ov-file
[Paper Note] AgentSkiller: Scaling Generalist Agent Intelligence through Semantically Integrated Cross-Domain Data Synthesis, Zexu Sun+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#GraphBased #NLP #AIAgents #SyntheticData #Diversity #CrossDomain #One-Line Notes #LongHorizon Issue Date: 2026-02-12 GPT Summary- 「AgentSkiller」というフレームワークを提案し、マルチターンインタラクションデータを自動で合成。DAG構造により決定性と回復性を確保し、ドメインオントロジーとエンティティグラフを構築。サービスをリンクして複雑なタスクをシミュレーションし、信頼性の高い環境を生成。約11,000件のインタラクションサンプルを合成し、訓練モデルが重要な性能改善を達成したことを示した。 Comment
元ポスト:
最近のGeneralist Agentに対する合成データ生成手法は実APIのログ(決定的でなくなりプライバシーリスクが存在)をベースにするか、あるいはシンプルなinteractionに基づいたものに限定されており、データのカバレッジが不足しており、long hoiizonでクロスドメインのデータが不足しているという課題があるので、deterministic、かつreproducibleでスケーラブルな合成パイプラインを提案しました、という話な模様。オントロジーを用いる点が特徴的に見える。
[Paper Note] LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs, Benno Krojer+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #Explanation #read-later #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #VisualTokens Issue Date: 2026-02-12 GPT Summary- 視覚トークンをLLMの埋め込み空間にマッピングする新手法「LatentLens」を提案。これにより視覚トークンの解釈可能性が向上し、従来の手法よりも高い精度で記述を生成。評価では、LatentLensが視覚トークンの解釈を効果的に提供し、視覚と言語の整合性に関する新たな証拠を示すことが確認された。 Comment
元ポスト:
VLMのVisual Tokenを、LLMで事前にコーパスからエンコードされたテキストのrepresentationとsimilarityを測ることでテキスト空間での類似した表現を見つけ解釈する方法な模様。興味深い。
[Paper Note] OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration, Shaobo Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #read-later #Selected Papers/Blogs #DataFiltering #One-Line Notes #Adaptive #Author Thread-Post Issue Date: 2026-02-12 GPT Summary- 高品質な公的テキストが不足する中、データ選択の動的特性を無視した手法の限界を克服するために、最適化器誘導投影ユーティリティ選択(OPUS)を提案。OPUSは、効果的な更新を安定したプロキシから導き出すことでデータをスコアリングし、計算効率を考慮したゴースト手法とボルツマン・サンプリングを用いる。これにより、GPT-2 Large/XLやQwen3-8B-Baseにおいて優れた成果を上げ、事前トレーニングの効率を飛躍的に改善。 Comment
元ポスト:
事前学習においてステップ単位で動的にバッチに含める学習データを選択する手法で、従来手法は単に勾配を考慮して選択していたが、実際にoptimizerによって更新される方向はmomentumなどによって異なるためgapが生じていた。これを埋めるために、optimizerが実際に重みを更新した際に、Validation setのlossがどれだけ低下するかによってUtilityを定義し、Utilityが大きくなるようにデータを動的に選択することで学習効率が向上する、といった話に見える。
著者ポスト:
[Paper Note] ClinAlign: Scaling Healthcare Alignment from Clinician Preference, Shiwei Lyu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Alignment #Medical Issue Date: 2026-02-12 GPT Summary- LLMを用いた医療知識の出力を臨床医の好みに適合させる二段階フレームワークを提案。まず医師確認のデータセット「HealthRubrics」を導入し、そこから119の再利用可能な原則「HealthPrinciples」を抽出。これにより、ルーブリックの合成や自己修正が可能に。30B-A3Bモデルは、HealthBench-Hardで33.4%を達成し、効率的な臨床整合性のベースラインを構築。 Comment
元ポスト:
[Paper Note] Features as Rewards: Scalable Supervision for Open-Ended Tasks via Interpretability, Aaditya Vikram Prasad+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Hallucination #Probing #One-Line Notes #Open-endedTasks Issue Date: 2026-02-12 GPT Summary- 特徴をスケーラブルな監視として用いる新アプローチ「RLFR」を提案。幻覚を減少させるため、強化学習パイプラインを設計し、モデルが出力の事実性に不確かさがある場合に介入・修正を学習。実験により、元のモデルより58%幻覚の可能性が低い結果を達成しながら、パフォーマンスを維持。解釈可能性の新しいパラダイムを示す。 Comment
元ポスト:
(以下論文をちゃんと理解できているか少し自信ないです)
activation steeringやLLMの内部表現の分析に利用されるprobing手法をRLの報酬に活用する研究で、学習させたい特徴をprobingによって予測できるモデルを用意し(今回はhallucination)、報酬として活用できるパイプラインを用意して(少しこのパイプラインがややこしい)RLするという話に見える。probingするモデルを学習するデータの合成に際はstrong modelが用いられる(今回はGemini 2.5 Pro)。要は、テスト時にsteeringできるのであれば、学習時にモデルが内部的に保持している特徴を活用してRLしちゃえばいいじゃん、という発想に見える。
流れとしては、input textが与えられた時にprobingを実施して、どこのspanにhallucinationがあるかを検出し、現在のポリシーにその情報を用いて新たなcontextを生成しself verificationさせる(情報を維持、撤回させるのか、修正のいずれの操作のうちどれを実施すべきかを出力)ことでロールアウトを実施。続いて、ロールアウトされたテキストに対して、**ベースモデルを用いてprobingを実施し**、その結果をrewardとしてポリシーをアップデートする。ベースモデルを使う部分の気持ちがどこに書かれているかがわからないのだが、おそらく、現在のポリシーのロールアウトをベースモデルを用いてprobingすることでreward hackingを防止している。test timeにも同様のprobingを実施し、Best-of-Nで応答を生成する(Figure2)。
[Paper Note] Alternating Reinforcement Learning for Rubric-Based Reward Modeling in Non-Verifiable LLM Post-Training, Ran Xu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #Rubric-based #Open-endedTasks Issue Date: 2026-02-11 GPT Summary- Rubric-ARMフレームワークは、スカラー得点を超えて創造的応答の多面的な質を捉えることを目的としている。報酬フィードバックからの強化学習を用い、rubric生成器と判定者を共同最適化し、既存手法の静的な制約を克服。交互最適化戦略を導入し、その効果を理論的に分析。実験により、Rubric-ARMが複数のベンチマークで最先端の性能を発揮し、強化学習環境でのポリシー整合性を大幅に改善することを示した。 Comment
元ポスト:
[Paper Note] Multi-Head LatentMoE and Head Parallel: Communication-Efficient and Deterministic MoE Parallelism, Chenwei Cui+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Architecture #MoE(Mixture-of-Experts) #Routing Issue Date: 2026-02-11 GPT Summary- 大規模言語モデルのトレーニングコストに対処するために、新しいアーキテクチャ「マルチヘッドラテントMoE」と「ヘッドパラレル(HP)」を提案。通信コストを$O(1)$に抑え、負荷バランスと決定論的な通信を実現。EPと比較して、最大$1.61\times$のトレーニング速度向上を達成しつつ、性能は維持される。本手法により、数十億パラメータの基盤モデル研究がよりアクセスしやすくなる。 Comment
元ポスト:
[Paper Note] Data Agents: Levels, State of the Art, and Open Problems, Yuyu Luo+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #One-Line Notes #Data Issue Date: 2026-02-11 GPT Summary- データエージェントは、LLMやツールを活用してデータ管理や分析の自動化を目指す新しいパラダイムであるが、その定義は曖昧である。この記事では、データエージェントをL0からL5までの階層に分類し、各レベルの特徴を示す。具体的には、単純なアシスタントと自律型エージェントの違いや、L0-L2の代表的なシステムをレビューし、独自にデータ関連タスクを実行するProto-L3システムを紹介する。また、L4およびL5のエージェントに関する研究課題も議論し、データエージェントの未来のロードマップを提供する。 Comment
元ポスト:
データを管理、準備、分析を担うエージェント(=データエージェント)に関して、自律性のレベルを6段階に分けたTaxonomyを体系的に定義し、既存研究を分類している模様。
[Paper Note] LLaDA2.1: Speeding Up Text Diffusion via Token Editing, Tiwei Bie+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #DiffusionModel #read-later #Selected Papers/Blogs Issue Date: 2026-02-11 GPT Summary- LLaDA2.1は、デコード速度と生成品質のトレードオフを克服するために設計され、M2TからT2Tへの移行を実現。スピーディモード(Sモード)とクオリティモード(Qモード)の2つのモードを導入し、効率性とベンチマーク性能をバランスさせる。大規模な強化学習フレームワークを用いることで、推論の精度と指示への忠実度を向上。LLaDA2.1は、33のベンチマークで優れた性能を示し、コーディングタスクにおいても高いスループットを達成。 Comment
元ポスト:
公式ポスト:
解説:
[Paper Note] AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration, Jianhao Ruan+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #Selected Papers/Blogs #KeyPoint Notes #LongHorizon #Adaptive #Orchestration #BudgetAllocation Issue Date: 2026-02-11 GPT Summary- 任意のエージェントを命令・コンテキスト・ツール・モデルのタプルとしてモデル化し、タスクの自動化を促進する統一されたフレームワークを提案。AOrchestraでは中央オーケストレーターがタプルを具体化し、専門的な実行者を生成。この設計により、エンジニアリング作業を削減しつつ、エージェントの多様性と性能を最適化。実験では、AOrchestraが競合モデルに対して16.28%の相対改善を達成。 Comment
元ポスト:
サブエージェントを生成するオーケストレータを学習し、動的に直面するタスクに適応したサブエージェント(適切なコンテキスト, 指示, ツール, モデル)[^1]を持つエージェントを構築し、実行を委譲することで、固定されたハーネスに依存せず、人間がエンジニアリングするコストも削減しながら、性能が向上する、という話に見える。
ベンチマークの性能向上が非常に大きく、効果的な手法であることが伺える。
[^1]: このようなサブエージェントのAbstractionを定義したのも貢献だと考えられる。
具体的な手法としては下記で、(a)オーケストレータエージェントがユーザからタスクを受け取り、サブタスクを解くためにサブエージェントを構築し委譲する。その後結果を受けとり状態を更新し、さらにサブエージェントを構築しタスクを委譲する、といった操作を繰り返す。(b)サブエージェントは(M, T, I, C)によって抽象化され、それぞれモデル、ツール、指示、コンテキストである。図中の(c)では自己教師あり学習が利用される旨が記述されているが、本文中ではSFTを使うと記述されているためここは齟齬があるように感じる(タイポも含まれている)。オーケストレーションのポイントは、タスクのオーケストレーションと、モデルのルーティングの二つの要素に分けられる。前者をSFTで学習し、後者はInstructionをiterativeに改善するプロセスで最適化する。
具体的には、オーケストレーションという特化したタスクを学習させるため、今回はexpertによる正解となる(T, I, C)を模倣できるように、SFTで学習する(GRPOのような手法でも学習できることについても言及されている点には注意)。
また、後者のモデルルーティングの最適化については、さまざまなモデルに対してInstructionを与え、得られたtrajectoryに対して性能とコストを計算し、これらを考慮してInstructionを更新することを繰り返すAutomatic Prompt Optimizationを採用している。これにより、コストと性能のパレート最適な構成を見つける。
[Paper Note] Learning to Self-Verify Makes Language Models Better Reasoners, Yuxin Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #RLVR #Selected Papers/Blogs #KeyPoint Notes #Initial Impression Notes #SelfVerification Issue Date: 2026-02-10 GPT Summary- LLMの生成能力は高いが、自己検証では弱いという非対称性を調査。生成が向上しても自己検証に改善は見られず、逆に自己検証の学習が生成性能を向上させることが示された。生成訓練に自己検証を統合するマルチタスク強化学習フレームワークを提案し、両者の性能向上を実証。 Comment
元ポスト:
LLMの生成能力を高めるようにRLによって事後学習をしてもVerificationの能力は向上しないが、LLMが自身の出力に対してVerificationが正しくできるようにRLVRすると生成と自己検証能力の双方が向上する。
クエリに対して応答を生成し、フィルタリング(応答が長すぎるもの、全ての応答が誤りのもの、最終的な回答が存在しないもの等)を実施した後、クエリレベルで多様なクエリが存在するようにする(多様性)を保ちつつ、overfittingを避けるために正解・不正解がバランスよく存在するように自己検証のためのデータを作成(モデルは学習の初期のロールアウトは不正解ばかり生成し、後半は正解ばかり生成するといった偏りが存在する)し、式(4)で定義される自身が生成した応答が正解か否かを二値分類した結果に基づくRewardを用いてGRPOする、という手法ように見える。
ざーっと見た感じtest time scalingの実験が無いように見えたが、この方法で自己検証をモデルができるようになると、test time scalingした時の性能も向上するのではないか。
また下記研究で示されている通り、現在のLLMはself refine能力が低く何らかのガイドがないと自身で応答を改善していけないため、現在のLLMの弱みを克服するのに有効な手法に見え、非常に興味深い研究だと感じる。
- [Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
[Paper Note] Next Concept Prediction in Discrete Latent Space Leads to Stronger Language Models, Yuliang Liu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #Transformer #Quantization #Architecture #LatentReasoning Issue Date: 2026-02-10 GPT Summary- 次の概念予測(NCP)を提案し、生成型の事前学習パラダイムを構築。NCPは複数トークンの概念を予測し、生成モデルConceptLMが隠れ状態の量子化を通して概念語彙を形成。70Mから1.5Bパラメータの範囲で最大300Bのデータを用い、13のベンチマークで従来モデルを上回る性能を示す。また、8BパラメータのLlamaモデルにおける実験から、NCPがトークン予測を改善する可能性を示唆。NCPは強力な言語モデルを生む有望なアプローチである。 Comment
元ポスト:
先行研究:
- [Paper Note] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture, Mahmoud Assran+, CVPR'23, 2023.01
- [Paper Note] Large Concept Models: Language Modeling in a Sentence Representation Space, LCM team+, arXiv'24, 2024.12
- [Paper Note] Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space, Xingwei Qu+, arXiv'25, 2025.12
[Paper Note] LOCA-bench: Benchmarking Language Agents Under Controllable and Extreme Context Growth, Weihao Zeng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #LongSequence #LongHorizon #ContextRot Issue Date: 2026-02-10 GPT Summary- LLMは長期タスクの実行が向上する一方で、コンテキストが増えると信頼性が低下する「コンテキストロット」が問題に。これに対処するため、LOCA-benchを導入し、環境状態に応じてエージェントのコンテキスト長を調整。固定されたタスク意義の下でコンテキストを制御し、様々な管理戦略を評価。複雑な状態では相対的に性能が低下するが、高度な管理技術で成功率が向上。LOCA-benchはオープンソースで公開され、長コンテキストエージェントの評価プラットフォームを提供。 Comment
元ポスト:
[Paper Note] SE-Bench: Benchmarking Self-Evolution with Knowledge Internalization, Jiarui Yuan+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #ReinforcementLearning #Evaluation #SelfImprovement #PostTraining #read-later #Selected Papers/Blogs #FactualKnowledge #One-Line Notes #ContinualLearning #Initial Impression Notes Issue Date: 2026-02-10 GPT Summary- 自己進化には、エージェントが生涯学習者として新しい経験を内面化し、将来の問題解決に活かすことが必要。しかし、以前の知識の混在と推論の複雑さが測定を妨げる。SE-Benchという診断環境を導入し、エージェントが新しいAPIドキュメントを使用することで評価を行い、知識の保持と内面化の新たな洞察を得た。特に「クローズドブック訓練」が知識保持に必要であり、標準的な強化学習が新しい知識を内面化できないことを示す。SE-Benchは知識内面化のための厳密なプラットフォームを提供する。 Comment
元ポスト:
関数をリネームし関連するAPIドキュメント(今回はnumpy)を更新し、Claudeを用いてテストケースを生成し、複数のLLMのVotingで検証可能かどうかを判定した後人手による検証を行いフィルタリングする。テスト時にクローズドブックの設定で評価することで、インタフェースに関するモデルのFactual Knowledgeを更新しないとモデルはテストケースに正解できず、モデルが内部パラメータに保持するFactual Knowledgeをどれだけ適切に保持、更新しているかを評価するようなコントロールされた環境下でのベンチマークに見える。
APIに関するドキュメントの文脈をしっかり変更しないと元のモデルが文脈から過去の関数名との対応関係を類推できてしまいそうだが、その辺はどうなっているのだろうか。
[Paper Note] AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent, Yinyi Luo+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Multi #EfficiencyImprovement #NLP #AIAgents #Distillation #PostTraining Issue Date: 2026-02-10 GPT Summary- LLMを用いたマルチエージェントシステムを、AgentArkフレームワークで単一モデルに蒸留し計算効率を向上。三つの蒸留戦略で推論性能と自己修正能力を強化。効率的かつロバストなマルチエージェント開発を目指す。 Comment
関連:
- [Paper Note] Reasoning Models Generate Societies of Thought, Junsol Kim+, arXiv'26, 2026.01
[Paper Note] Optimal Learning-Rate Schedules under Functional Scaling Laws: Power Decay and Warmup-Stable-Decay, Binghui Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #Scaling Laws #Scheduler Issue Date: 2026-02-09 GPT Summary- FSLフレームワークを用いて最適学習率スケジュールを研究。損失ダイナミクスは信号学習速度源指数とノイズ忘却容量指数で支配され、固定トレーニングホライズンに基づく最適スケジュールを導出。易しいタスクでは指数減衰、難しいタスクではウォームアップ安定減衰の構造を示す。ピーク学習率のみを調整する固定スケジュールの強みと限界を評価し、一般的なスケジュールの原則的評価を行う。また、パワー減衰LRSをSGDに適用し、ミニマックス最適率を達成することを示した。実験が理論予測を支持。 Comment
元ポスト:
[Paper Note] Theory of Optimal Learning Rate Schedules and Scaling Laws for a Random Feature Model, Blake Bordelon+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #Scaling Laws #Scheduler Issue Date: 2026-02-09 GPT Summary- 学習率の設定は深層学習モデルのトレーニングにおいて重要だが、経験的な試行錯誤が多い。本研究では、SGDによるパワーロウランダムフィーチャーモデルに対する最適学習率スケジュールを探求し、簡単なフェーズと難しいフェーズが存在することを明らかにした。簡単なフェーズでは多項式的減衰が最適であり、難しいフェーズではウォームアップ安定減衰になる。学習率とバッチサイズの共同最適化を検討し、計算最適なスケーリング法則を予測。また、運動量の最適スケジュールも考慮し、モデルの性能向上を図った。実験により、提案スケジュールが他のベンチマークより優れた結果を示すことを確認した。 Comment
元ポスト:
[Paper Note] When RL Meets Adaptive Speculative Training: A Unified Training-Serving System, Junxiong Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Decoding #read-later #SpeculativeDecoding Issue Date: 2026-02-09 GPT Summary- Auroraは、ライブ推論トレースから直接投機的デコーディング学習を行う統一システムを提案。オンラインでの学習を非同期強化学習問題として再定義し、受け入れられたトークンからフィードバックを得てサンプル効率を向上。デイ0での展開をサポートし、迅速な適応と即時のユーティリティフィードバックを提供。実験では、フロンティアモデルに対して1.5倍の速度向上を実現し、静的な投機者にも1.25倍の向上を見せた。 Comment
元ポスト:
公式アナウンス:
[Paper Note] InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning, Yuchen Yan+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#DocumentSummarization #NLP #ReinforcementLearning #Reasoning #PostTraining #LongHorizon #Compression Issue Date: 2026-02-09 GPT Summary- InftyThink+は、モデルによる制御された反復推論と要約を基にした強化学習フレームワークで、中間的な思考の劣化を軽減し、反復推論の効率を最適化します。教師あり学習の後、二段階の強化学習を行い、戦略的要約と推論の再開を学習。実験では、従来方法に比べて精度を21%向上させ、推論レイテンシを大幅に削減しました。 Comment
pj page: https://zju-real.github.io/InftyThink-Plus/
元ポスト:
一言解説:
con-currentwork:
- [Paper Note] Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL, Ian Wu+, arXiv'26, 2026.02
reasoningを要約することで圧縮し次のreasoningを繰り返すような枠組みのように見え、
- [Paper Note] Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL, Ian Wu+, arXiv'26, 2026.02
と類似したアプローチに見える。
[Paper Note] Learning Rate Matters: Vanilla LoRA May Suffice for LLM Fine-tuning, Yu-Ang Lee+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #Evaluation #Coding #Mathematics #PEFT(Adaptor/LoRA) #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-02-09 GPT Summary- LoRAのバリエーションを広範なハイパーパラメータ探索で再評価。異なるLoRA方法は独自の学習率範囲を好み、適切調整で全体的に同様のピーク性能を達成。バニラLoRAは競争力のあるベースラインで、以前の改善は一貫性を欠く可能性あり。最適な学習率範囲の違いはヘッセ行列の固有値の変動に起因。 Comment
元ポスト:
LoRAに関連して様々な手法が提案されているが、様々なモデルスケールとコーディングと数学ドメインで広範な設定(バッチサイズや学習率)で実験して主要な手法を再評価したところ、LoRAは学習率にsensitiveで、依然として初期のLoRAが強力な手法であることが示された。過去の研究での比較実験はハイパーパラメータの調整不足な可能性が高いことを示唆している。重要研究。
なお、Table2にLoRAの変種に関する研究のリストがあるが、約50種類ある。
[Paper Note] How Do Transformers Learn to Associate Tokens: Gradient Leading Terms Bring Mechanistic Interpretability, Shawn Im+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Explanation #RepresentationLearning #Transformer #Attention #One-Line Notes Issue Date: 2026-02-09 GPT Summary- セマンティック関連性を理解することは、言語モデルの一般化能力を高め、一貫性のあるテキスト生成に寄与します。本研究では、注意ベースの言語モデルにおいて自然言語データからの関連性の学習を、トレーニングダイナミクスの観点から分析します。勾配の主成分近似を用いて、重みの初期表現を開発し、セマンティック関連性の形成過程を説明。結果として、トランスフォーマーの重みは、ビグラムや文脈マッピングといった基底関数の合成として表現され、統計を反映した関連性の捉え方を明らかにします。実験では理論的な特性付けが学習重みに一致し、トランスフォーマーの学習された関連性の解釈を示します。 Comment
元ポスト:
学習中にtransformerがどのようにtoken間の関連性を学習しているのかを分析
[Paper Note] DIRMOE: DIRICHLET-ROUTED MIXTURE OF EXPERTS, ICLR'26
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #ICLR #Stability #Routing #One-Line Notes Issue Date: 2026-02-08 GPT Summary- Dirichlet-Routed MoE(DirMoE)は、MoEモデルの性能を向上させる新しい微分可能ルーティングメカニズムです。エキスパートの選択とその貢献の配分を明確に分け、Gumbel-Sigmoid緩和とDirichlet再パラメータ化により訓練過程を完全に微分可能にします。さらに、スパースペナルティを通じてアクティブなエキスパート数を管理し、専門性を高めつつ、他の手法と同等以上の成果を達成しています。 Comment
openreview: https://openreview.net/forum?id=a15cDnzr6r
元ポスト:
MoEのルーティングの選択と配分をモデル化して、微分可能にした上で最適化する
[Paper Note] Learning to summarize user information for personalized reinforcement learning from human feedback, Hyunji Nam+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Alignment #ReinforcementLearning #Personalization #In-ContextLearning #ICLR #read-later Issue Date: 2026-02-08 GPT Summary- 新しいLLMアシスタントでの応答のパーソナライズを目指し、「要約を用いた好み学習(PLUS)」フレームワークを提案。これにより、各ユーザーの特徴や過去の対話に基づいた要約を生成し、個々の好みに沿った報酬モデルを条件付ける。PLUSは、ユーザー要約モデルと報酬モデルを同時に訓練し、精度向上を実現。新しいユーザーやトピックに対する堅牢性や、独自モデルによる強化されたパーソナライズ能力を示し、ユーザーの解釈可能な表現を提供することで透明性を高める。 Comment
pj page: https://sites.google.com/stanford.edu/plus/home
元ポスト:
[Paper Note] A Relative-Budget Theory for Reinforcement Learning with Verifiable Rewards in Large Language Model Reasoning, Akifumi Wachi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #PostTraining #One-Line Notes #BudgetAllocation Issue Date: 2026-02-08 GPT Summary- 強化学習は大規模言語モデルの推論能力を向上させるが、その効果は相対予算によって異なる。この研究では、$ξ:= H/\mathbb{E}[T]$を通じて相対予算理論を提案し、報酬の分散や情報的経路の発生確率がサンプル効率を決定することを示す。分析により、{不足}、{バランス}、{十分}の三つの領域を明らかにし、特にバランス領域で最大のサンプル効率を持つことが判明。また、オンラインRLに対する有限サンプルの保証を提供し、実証的に学習効率の最適化と推論性能のピークに一致する予算範囲を特定。 Comment
元ポスト:
元ポストに要旨が簡潔に日本語でまとめられている。
[Paper Note] Paying Less Generalization Tax: A Cross-Domain Generalization Study of RL Training for LLM Agents, Zhihan Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #CrossDomain #Generalization #KeyPoint Notes #DomainGap #Initial Impression Notes Issue Date: 2026-02-08 GPT Summary- 一般化されたLLMエージェントのポストトレーニングにおける課題を調査。特に、強化学習環境の特性がアウトオブドメイン性能に与える影響を分析。状態情報の豊富さとプランニングの複雑さがクロスドメインの一般化に強く相関し、リアリズムやテキスト類似性は主要な要因ではないことを発見。状態情報を増やすことでロバスト性を向上可能で、ランダム化技術を提案。また、モデリング選択として、SFTのウォームアップが忘却を防ぐが一般化を損なう可能性や、ステップ・バイ・ステップ思考が一般化に重要な役割を果たすことを示した。 Comment
元ポスト:
事後学習におけるクロスドメインの汎化性能に関する調査を行い、ドメインの表層的な情報ではなく、
- 状態情報の豊富さ(どれだけのテキストを処理する必要があるか; 認知コスト)
- 推論の複雑さ(long-horizonやゴールへの到達可能性)
がドメイン間の汎化に相関を示すことが明らかになり、要は構造の複雑さが鍵であることが分かった。
ドメイン間の汎化性能を改善するために、実タスクは変えずにobservationに対して少量のノイズを加えることで、モデルがノイズから重要なシグナルを抽出することを学習し汎化性能が向上。
RLを行う際の注意点として、
- mid-trainingはDataMixに含まれるドメインの知識を補充するが、カバーされていないドメインの忘却をより悪化させる可能性があり
- ステップ単位での推論が汎化性能向上に役ダウン(言い換えると、ショートカットは転移しない)
を挙げており、
デプロイされるドメインが不明な場合の実用的な対策として
- より状態の記述がリッチなドメインかつ複雑な推論を要する環境で学習し
- 明示的な推論をオンにし
- 軽量な状態情報へのノイズの注入や拡張をすふこと
を挙げている。
さらにざっくり言うとエンコード時にドメインの表層情報に依存させず、表層情報の中から必要な情報を抽出するスキルをモデルに学習させ、かつデコーディング時は精緻な推論によって誤った転移を防ぐのがドメイン間の汎化の鍵、という話に感じる。
[Paper Note] Spider-Sense: Intrinsic Risk Sensing for Efficient Agent Defense with Hierarchical Adaptive Screening, Zhenxiong Yu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Safety #One-Line Notes #Initial Impression Notes Issue Date: 2026-02-08 GPT Summary- 「Spider-Sense」と呼ばれるイベント駆動型防御フレームワークを提案し、エージェントが危険を認識した際にのみ防御を発動。階層的な防御メカニズムにより効率と精度をトレードオフしつつ、既知のリスクを軽量マッチングで解決し、曖昧なケースは内部推論に移行。新たなベンチマーク「S$^2$Bench」を用いた実験で、競争力のある防御性能と最低の攻撃成功率を示し、わずか8.3%の遅延オーバーヘッドを実現。 Comment
元ポスト:
従来のAI Agentのセキュリティチェックは決められたタイミングで、しばしば重いチェックがかかりレイテンシが高かったが、提案手法では動的にどの程度の計算量を費やすかを調整して、必要なタイミングで重い推論、そうでない場合は軽量なチェックで済ませることでレイテンシと性能を改善する、といったコンセプトな模様。
エージェントのステージごとにobservationを事前定義されたテンプレートで囲い、テンプレートによってスクリーニングをトリガーし、ベクトル検索によって危険度を判定する。判定した危険度が一定以下なら軽量なチェック、一定以上ならLLMによる推論を用いた重い処理を走らせるという手法に見える。図中のcのnotationが本文中に見当たらない気がするが、見落としているだろうか。
結局のところ、テンプレートによってセキュリティチェックが誘発されるように見えるので、元々の問題意識である固定されたタイミングで強制的にセキュリティチェックがかかる、という課題は解決されない気がする。固定されたタイミングで強制的にセキュリティチェックがかかる点は従来手法と変わらないが、セキュリティチェックに費やすコストや計算量を動的に変更します、という話に感じる。
[Paper Note] CAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty, Johannes Kirmayr+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Ambiguity Issue Date: 2026-02-08 GPT Summary- 既存のLLMエージェントのベンチマークは理想環境でのタスク完了に偏っており、実際のユーザーアプリケーションでの信頼性を無視している。本研究では、車内アシスタント向けの「CAR-bench」を提案し、マルチターン対話やツール使用を通じた不確実性管理を評価する。この環境には、58の相互接続ツールが含まれており、「幻覚タスク」と「曖昧さ解消タスク」を導入してエージェントの能力をテスト。結果は、曖昧さ解消タスクでの一貫性が50%未満と低く、ポリシー違反や情報捏造が多発することから、より信頼性の高い自己認識を持つLLMエージェントの必要性を示している。 Comment
元ポスト:
[Paper Note] A large language model for complex cardiology care, O’Sullivan+, Nature Medicine'26, 2026.02
Paper/Blog Link My Issue
#NLP #Medical #One-Line Notes Issue Date: 2026-02-07 Comment
元ポスト:
AIによるサポートを受けた医師が、(人手不足な)より専門的な知識が求められる専門医が扱うような症例に対して治療計画を立てたときに、AIによる支援を受けた場合により高品質な計画を立てられた、という趣旨の話なようである。
[Paper Note] LatentMem: Customizing Latent Memory for Multi-Agent Systems, Muxin Fu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #Selected Papers/Blogs #memory #KeyPoint Notes #Adaptive #Initial Impression Notes Issue Date: 2026-02-07 GPT Summary- LatentMemは、LLMを用いたマルチエージェントシステム向けに設計された学習可能なメモリフレームワークで、カスタマイズと情報最適化を実現します。経験バンクと潜在メモリを活用し、メモリエントリーの均質化と情報過多の問題を解決。タスクレベルの最適化信号を利用することで、従来のメモリ設計に対し最大19.36%の性能向上を達成しました。 Comment
元ポスト:
skim readingしかできていないが、現在のMulti AI Agentsにおけるメモリ機構はstaticな機構であるため、メモリが均質化してしまいエージェントの役割ごとに最適化されておらず、かつlong trajectoryを扱う際に情報がコンパクトに圧縮されておらずtrajectoryが肥大化していってしまう。このため、エージェントの役割ごとに異なるメモリを生成し、かつ固定長の潜在表現に情報を圧縮する(これによりlong contextでのメモリ肥大化を防ぐ)ような新たなDeep Neural Networkに基づくMemory ComposerをRLを通じて学習するという話のようである。
エージェントのプロファイルと、experience bankから抽出された現在のクエリに対するtrajectoryに基づいて、個々のエージェントごとにrelevantな情報が圧縮されたメモリの潜在表現を生成するようなMemory ComposerをRLで学習し活用する(LMPO)。このとき、エージェントのパラメータは更新せずfreezeする。あくまでバックボーンはfreezeして変更せず、メモリ機構のみを最適化することに焦点を当てている。Memory Composerは、与えられたメモリ, エージェントの(freezeされた)パラメータ, 与えられたプロンプトによってreasoningを実施し、最終的な応答が正しかったかどうかに基づいてGRPOベースのRLVR(=LMPO)を実施することによって学習する。エージェントがメモリを活用して得られたtrajectoryはexperience bankに格納されて利用される。
既存手法と比べて多くのQAベンチマークで高い性能を獲得し、OODなベンチマークでもある程度は汎化するようである。
in-domainなベンチマークと比較して、out-of-domainなベンチマークでの性能向上が小さいので、汎化性能にまだ課題があるように感じた。解決している問題は非常に重要だと考えられ、どのようにすれば汎用的なMemory Composerが学習できるか?を考えるとおもしろそうである。
[Paper Note] Rewards as Labels: Revisiting RLVR from a Classification Perspective, Zepeng Zhai+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #RLVR Issue Date: 2026-02-06 GPT Summary- REALフレームワークは、強化学習における報酬をカテゴリカルラベルとして再考し、ポリシー最適化を分類問題として定式化することで、効率的なポリシー更新を実現します。このアプローチは、勾配重み付けの不一致を軽減し、均衡の取れた勾配配分を可能にします。実験では、REALがGRPOやDAPOに対して一貫して優れた性能を示し、1.5Bモデルで6.7%、7Bモデルでも引き続き改善を達成しました。 Comment
元ポスト:
[Paper Note] BABE: Biology Arena BEnchmark, Junting Zhou+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #AcademicWriting #Biological Issue Date: 2026-02-06 GPT Summary- 生物学におけるLLMsの能力を評価するため、BABE(Biology Arena BEnchmark)を導入。これは実験結果を文脈知識と統合する能力を測定し、実世界の研究から構築された複雑な課題を提供。因果推論やスケールを超えた推論を促すことで、AIシステムの科学者としての推論能力を評価するフレームワークを提供し、生物学研究への貢献度を向上させることを目指す。 Comment
元ポスト:
[Paper Note] Chunky Post-Training: Data Driven Failures of Generalization, Seoirse Murray+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Tools #NLP #LLM-as-a-Judge #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes #Rubric-based #ChunkyPostTraining Issue Date: 2026-02-06 GPT Summary- LLMのポストトレーニングでは、偶発的なパターンがモデルに影響を及ぼし、意図しない行動を引き起こすことがある。これを「チャンクポストトレーニング」と呼び、特定の質問形式に対して虚偽の相関が現れる理由を探るため、「SURF」というブラックボックスパイプラインと、「TURF」という追跡ツールを提案。これらのツールを用いて、フロンティアモデルやオープンモデルでの誤校正された行動の生成を示し、ポストトレーニングデータの不均衡が影響していることを明らかにした。 Comment
元ポスト:
事後学習データは特定の行動を学習することを意図して作成されるが、離散的なチャンクの集合として学習したときに、それらに意図しない特徴に基づく相関が含まれ(たとえば、コーディングのデータセットに不自然に形式的な表現が含まれたときに、モデルがそのような表現が用いられた時はコーディングの指示だと学習してしまうなど)、モデルがそれを学習してしまうこと(= Chunky PostTraining)を提唱し、これによって生じる失敗モードの実例として、Haiku 4.5j「5+8=13ですか?」と質問した際に「いいえ、5+8=13は正しくありません。正しい答えは5+8=13です」と応答するような例を挙げている。これはモデルが明らかに正しい答えを知っているが、プロンプト中の何らかの特徴によって反論的な振る舞いが引き起こされているような例であり、こういった失敗を発見するための手法を提案している。
手法としては、失敗モードを評価するためのルーブリックと、promptに関するAttributeの集合(e.g. これは車に関する質問である, これはロシア語であるなど)を定義し、attributeのプールからサンプリングをして失敗モードを引き起こすクエリの候補を自動生成する。その後LLMに対してクエリを投げて得られた応答をルーブリックに基づいてLLM-as-a-Judgeによってスコアリングし、TopKのサンプルを残しリプレイバッファ[^1]を更新する。更新されたリプレイバッファを用いてAttributeの重みを更新し、よりスコアが高いAttributeに基づいてクエリ候補が生成されるようにし、再度クエリ生成をして同様の操作をするよう繰り返す、といった手法のようである。
LLMを完全にブラックボックスとして扱い、応答テキストにのみに基づいて実行されるため、proprietary LLMに対しても実行可能である。
[^1]: リプレイバッファは、個々の(クエリ, スコア, attribute, スコア)の4つ組の集合によって定義される。
所見:
[Paper Note] Inverse Depth Scaling From Most Layers Being Similar, Yizhou Liu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Transformer #Scaling Laws #Depth Issue Date: 2026-02-06 GPT Summary- 深さと幅がLLMの性能に与える影響を探究し、深さが損失に反比例してスケールすることを発見。これは、類似層がアンサンブル平均を通じて誤差を減少させることに起因する可能性がある。効率を改善するには、深さの効果的な利用を促進するアーキテクチャの革新が必要であることを示唆。 Comment
元ポスト:
関連:
- [Paper Note] Do Language Models Use Their Depth Efficiently?, Róbert Csordás+, NeurIPS'25, 2025.05
- [Paper Note] 1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities, Wang+, NeurIPS'25 Best Paper Awards
[Paper Note] Locas: Your Models are Principled Initializers of Locally-Supported Parametric Memories, Sidi Lu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Catastrophic Forgetting #memory #Test-time Learning #ContinualLearning Issue Date: 2026-02-06 GPT Summary- 本研究では、モデルパラメータから柔軟にオフロードまたは統合できる新しいパラメトリックメモリ「Locas」を提案し、効率的な継続学習を実現します。Locasは二層MLP設計とGLU-FFN構造の2つのバリエーションを持ち、既存モデルに簡単に統合可能です。低ランクのFFNスタイルのメモリの適切な初期化が速い収束と破滅的な忘却防止に重要であることを示します。PG-19言語モデリングやLoCoMoタスクでの実験結果は、Locasが過去の情報をパラメトリックに保存し、モデルの性能を維持する能力を示しています。 Comment
元ポスト:
[Paper Note] Reasoning with Latent Tokens in Diffusion Language Models, Andre He+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #DiffusionModel #Decoding #LatentReasoning Issue Date: 2026-02-06 GPT Summary- 離散拡散モデルは、自動回帰モデルと競争できる性能を持ちつつ、推論時に多くの計算を要する。このトレードオフは、推論時に未知のトークンの共同予測を行うことに起因しており、この予測を省略すると速度が向上するが性能が低下する。そこで、潜在トークンを調整する新たな手法を提案し、推論速度とサンプル品質のトレードオフを実現。さらに、潜在トークンを利用して自動回帰モデルでの改善を示し、全体的一貫性や先見性を要するタスクにおける性能向上のメカニズムを示唆している。 Comment
元ポスト:
[Paper Note] Likelihood-Based Reward Designs for General LLM Reasoning, Ariel Kwiatkowski+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #PostTraining #RLVR #One-Line Notes Issue Date: 2026-02-06 GPT Summary- 報酬関数の設計における二値のスパース性に対処するため、本研究ではリファレンスアンサーから導出された対数確率を報酬として使用することを検討。対数確率報酬は所有検証者に依存せず、数学推論ベンチマークでの性能を向上させることがわかった。この方法は、チェインオブシンキング(CoT)ファインチューニングの新たな実行可能な戦略として位置づけられ、検証可能・非検証可能な設定でのパフォーマンスを向上させる効果が確認されました。 Comment
元ポスト:
関連(concurrent work):
- [Paper Note] Maximum Likelihood Reinforcement Learning, Fahim Tajwar+, arXiv'26, 2026.02
最終応答のlogprobを報酬として利用する設定のRL(i.e., 検証可能なタスクでなくとも適用可能)を調査し、検証可能な応答のlogprobを報酬として利用することでbinary rewardと同等以上の性能を達成可能であることを示したようで、検証可能でない設定で学習すると途中でCoTが崩壊し、CoTが極端に短くなる現象が生じる。これは初期のCoTの長さと正解の対数尤度に負の相関があり、これによってRLがCoTを短くすることを奨励してしまうからではないか、という話が元ポストに記述されている。
[Paper Note] Rethinking the Trust Region in LLM Reinforcement Learning, Penghui Qi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #ReinforcementLearning #PPO (ProximalPolicyOptimization) #PostTraining #read-later #Selected Papers/Blogs #Stability #KeyPoint Notes #train-inference-gap Issue Date: 2026-02-06 GPT Summary- 強化学習におけるPPOの限界を指摘し、低確率トークンの更新が過剰に罰せられる問題を解決するため、ダイバージェンス近似ポリシー最適化(DPPO)を提案。DPPOは、ポリシーの逸脱を直接推定することで学習ダイナミクスの非最適性を改善し、効率的なバイナリおよびトップK近似を導入することでトレーニングの安定性と効率を向上させる。 Comment
元ポスト:
PPOはトークン単位の確率比をrefと現在のポリシーからの算出しrefから離れすぎないようにクリッピングをするが、この場合非常に低確率で出現するトークンは過剰にクリッピングされる傾向にある。しかしその低確率トークンを調べると実はReasoningにおいて重要なトークンであったり(Wait, Thus, Next)、数学での重要なシンボル(+,-,=)、数値トークンであり、結果的にこれらReasoning系のタスクで重要なトークンの学習を阻害してしまっており(実際にこれらの低確率トークンをクリッピングされないようにしたら学習効率が大幅に改善)、語彙数が多いLLMの学習においては相性が悪い(別の視点として高確率トークンに対して過剰にペナルティを与えるという傾向もある)。これを改善するために、確率比をクリッピングするのではなく、ポリシーとrefのDivergenceの上界を直接制約することで解決し(語彙数が大きすぎてDivergenceを計算できないので近似的な計算方法も提案されている模様)、実際に適用すると学習が非常に安定し、かつ学習効率が既存手法と比較して高まりました、という話にみえる。
解説:
一言解説:
[Paper Note] Residual Context Diffusion Language Models, Yuezhou Hu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel Issue Date: 2026-02-06 GPT Summary- 捨てられたトークンの計算を再利用し、残留文脈拡散(RCD)を提案。RCDは文脈情報を次のデノイジングステップに注入し、トレーニングパイプラインを二段階に分けて効率性を向上。従来のdLLMを最小限のオーバーヘッドで5-10ポイント精度向上。特にAIMEタスクで精度をほぼ倍増。 Comment
元ポスト:
[Paper Note] ERNIE 5.0 Technical Report, Haifeng Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #Speech #Proprietary #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #2D (Image) #UMM #3D (Video) #Omni #text #Initial Impression Notes Issue Date: 2026-02-06 GPT Summary- ERNIE 5.0は、テキスト、画像、ビデオ、音声に対応したマルチモーダル理解と生成のための基盤モデルです。超スパースな専門家の混合アーキテクチャを使用し、依存しないルーティングでトークン予測を行います。新たなトレーニングパラダイムにより、モデルは性能、サイズ、推論レイテンシを柔軟に調整可能です。幅広い実験において、ERNIE 5.0は複数のモダリティで優れた性能を示し、初の商用規模の兆パラメータモデルとして注目されています。 Comment
元ポスト:
リリース時の公式ポスト:
あくまでskim readingをして得た印象なのだが、非常に興味深い研究で、Omniモダリティを超大規模モデルでスクラッチからUnified Multimodal Modelとして学習し、MoEで効率的に推論するというアーキテクチャと手法に見え(個人的にこういう手法でやったらどうなるのだろう?と思っていたドンピシャな設定)、各種ベンチマークの性能指標を見ると多くの指標で全体的に良いスコアを達成しており様々なタスクを高性能で実現できる一方、特定の分野のベンチマークでGemini Pro 3の方が強い面が多く(たとえばテキストモダリティのstem, coding, vision全般, ASR全般)、Omniモダリティの統合は一筋縄ではいかず、どのようにモダリティを統合し、学習することが効果的なのか?という根源的な問いがあらためて思い浮かぶ。
Ming Omniでも同様のことがやられていた:
- [Paper Note] Ming-Omni: A Unified Multimodal Model for Perception and Generation, Inclusion AI+, arXiv'25, 2025.06
[Paper Note] WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning, Zelai Xu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Multi #NLP #ReinforcementLearning #AIAgents #PostTraining #Initial Impression Notes Issue Date: 2026-02-06 GPT Summary- マルチエージェントシステムを用いた情報探索の幅のスケーリングを探求する本研究では、WideSeek-R1フレームワークを提案。リードエージェントとサブエージェントが共同最適化することで、20,000のタスクで高い性能を発揮。WideSeek-R1-4BはアイテムF1スコア40.0%を達成し、性能がサブエージェント数の増加と共に向上することを示す。 Comment
元ポスト:
Context Foldingと比較した時の新規性がweaknessに感じる:
- [Paper Note] Scaling Long-Horizon LLM Agent via Context-Folding, Weiwei Sun+, arXiv'25, 2025.10
[Paper Note] A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces, Mingxuan Du+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #RAG(RetrievalAugmentedGeneration) #Test-Time Scaling #One-Line Notes #Scalability #Adaptive #Initial Impression Notes Issue Date: 2026-02-06 GPT Summary- A-RAGは、階層的な取得インターフェースを通じてエージェント型のRAGシステムを実現し、モデルが適応的に情報を検索・取得できる能力を向上させる。キーワード検索、意味検索、チャンク読み取りの3つのツールを提供し、既存の方法と比較して一貫した優れた性能を示す。モデルのスケーリング特性についても体系的に検討し、今後の研究のためにコードを公開予定。 Comment
元ポスト:
固定されたワークフローでのRAGではなく、エージェントが自ら考えて最適な検索ツールを模索し情報を自動的に取得するAgentic RAGな枠組みを提案している。研究としての新規性はweaknessだと感じるが、実務的に有効な方法だと思う。LLM側のreasoning effortやmax tokenを増やすことで性能がスケーリングするため(Test Time Scaling)これもまた実用的な手法だと感じる。
[Paper Note] Conflict-Resolving and Sharpness-Aware Minimization for Generalized Knowledge Editing with Multiple Updates, Duy Nguyen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Coding #KnowledgeEditing #FactualKnowledge #Generalization #Stability Issue Date: 2026-02-05 GPT Summary- LLMsが最新情報に依存する中、コスト高な再訓練の代わりに、CoRSAというパラメータ効率的な知識編集フレームワークを提案。これにより、一般化や安定性を向上させつつ、新旧知識の対立を解決。3つのベンチマークで大幅な一般化改善を示し、LoRAと比較して更新効率と忘却軽減を達成。さらに、コードドメインにも適用可能で、強力なベースラインを上回る性能を発揮。 Comment
元ポスト:
ベンチマーク:
- [Paper Note] Zero-Shot Relation Extraction via Reading Comprehension, Omer Levy+, CoNLL'17, 2017.06
- [Paper Note] CounterBench: A Benchmark for Counterfactuals Reasoning in Large Language Models, Yuefei Chen+, arXiv'25, 2025.02
[Paper Note] Test-time Recursive Thinking: Self-Improvement without External Feedback, Yufan Zhuang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #Decoding #SelfVerification Issue Date: 2026-02-05 GPT Summary- LLMが自己改善できるかを探求し、2つの課題—候補解の生成と正しい回答の選択—を特定。テスト時再帰的思考(TRT)フレームワークを提案し、生成を戦略や知識に基づいて条件付けることで、オープンソースモデルがAIME-25/24で100%の精度を達成、クローズドソースモデルは外部フィードバックなしで問題解決能力を向上させた。 Comment
元ポスト:
[Paper Note] Universal One-third Time Scaling in Learning Peaked Distributions, Yizhou Liu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Scaling Laws #read-later #Selected Papers/Blogs #KeyPoint Notes #Scalability #Physics Issue Date: 2026-02-05 GPT Summary- LLMのトレーニングは計算コストが高く、これはソフトマックスとクロスエントロピーの影響でべき法則的に収束する損失に起因する可能性がある。おもちゃモデルと実証的評価を通じて、この挙動が次トークン分布のピークから生じることを示し、損失のべき法則的なスケーリングが指数$1/3$で発生することを明らかにした。これにより、LLMトレーニングの効率向上に関する新たな方向性が示唆される。 Comment
元ポスト:
LLMの事前学習によって学習時間とlossの関係性において、冪乗則に従ったscaling lawsが出現するのはデータの分布起因ではなく、softmax+cross
entropyによる目的関数に起因しているという主張のようで、特にnext token predictionのようなエントロピーが低い分布(特定のトークンだけがピークを持つ分布)にfittingすると、分布の非線形性によって、冪乗則で消失する勾配と損失が生じ、結果的に1/3を指数として持つ冪乗則が出現するといった感じの話らしい。
[Paper Note] Scaling Small Agents Through Strategy Auctions, Lisa Alazraki+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #AIAgents #SmallModel #SelfCorrection #memory #KeyPoint Notes #Scalability Issue Date: 2026-02-05 GPT Summary- 小規模言語モデルはエージェント型AIの有望なアプローチとして注目されているが、複雑なタスクでは大型モデルが必要な場合が多い。本研究では、SALEというフレームワークを提案し、エージェントが短期的な戦略計画でタスクを効率化し、コストを削減しながら自己改善を行う様子を示す。SALEは、最大エージェントへの依存を53%減少させ、コストを35%低下させることができる。これらの結果は、小型エージェントが複雑な業務には限界があるが、協調的なタスク割り当てを通じてスケールアップ可能であることを示唆している。 Comment
元ポスト:
AIエージェントにおいて、小規模モデルは費用対効果が良い選択として期待されているが、結局のところ困難なタスクでは大規模なモデルと比較して性能が低下することから限界を指摘。費用対効果を最大化するためにフリーランスを参考に、候補となるエージェントによる入札方式を採用。エージェントはタスクを解くための戦略をプランニングし、提出された戦略をスコアリングし、かつ推定されるコストから最も費用対効果の良いエージェントを採用することでタスクを解かせるような枠組みを提案している模様。入札に負けたエージェントは、過去の入札履歴が長期メモリに蓄積されるため、それらをcontextに組み込むことで重み更新なしで自身のプランニングを改善していくことができる、というような話に見える。
[Paper Note] Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL, Ian Wu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#DocumentSummarization #NLP #ReinforcementLearning #AIAgents #Reasoning #PostTraining #read-later #RLVR #Selected Papers/Blogs #OOD #Generalization #KeyPoint Notes #LongHorizon #Robustness #Compression #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 大規模言語モデル(LLM)は、テスト時の適応能力により複雑な問題を解決する外挿特性を持つが、標準的な強化学習(RL)はその変化に制約がある。これに対処するために、反復デコーディングアルゴリズム(RC)を導入し、LLMの応答生成能力を活用して推論を継続的に改善。実験では、16kトークンの訓練で4BモデルがHMMT 2025でのパフォーマンスを40%から約70%に引き上げ、既存のモデルを上回る結果を示した。RCを使用したモデルは、学習した要約生成能力によりテスト時のパフォーマンスも向上できることが証明された。 Comment
元ポスト:
reasoningの生成と、生成されたreasoningとinputで条件付けでsummaryを生成、さらにinputとsummaryで条件付けてreasoningを生成するという、生成と要約を反復する枠組みを採用(LLMはreasoningを要約することが生成するよりも得意で、かつ過去の要約から将来の推論を生成できるという非対称性を活用)することで、訓練時の予算は決まっているため、訓練時の予算では到達できないhorizonにテスト時に遭遇すると汎化しない課題を克服し、テスト時により長いステップ数の推論もこなせるように外挿する。また、このようなgeneration-summaryの反復を各ステップごとでRLVRすることでさらに性能を向上でき、実際にlong horizonな推論や学習時よりもより長いreasoning token budgetの場合に大きなgainを獲得できている。
RLVRをする際に各ステップごとのSummaryを保存しておき、各ステップのsummaryが与えられたときに正解できるかどうかのシグナルに基づいて、ステップごとの要約で条件付けられた応答能力を改善する。これにより、さまざまなステップで応答を生成する能力が強化され、結果的にshort horizonからlong horizonの推論をする能力が強化される。
このときsummaryはリプレイバッファとして扱い後のepochの訓練でもオフポリシーデータとして活用する。要約はinputに条件付けられて生成されるものであり、optimizationのtargetとは異なるためリプレイバッファとして活用でき、かつさまざまな要約に対して正解が生成できるように学習されるためテスト時の要約の分布のシフトにロバストになる。また、オンポリシーデータだけだと、long horizonに対する要約は非常に稀になるため、リプレイバッファを利用することで補う。
テスト時に学習時を超えたhorizonで推論できることは現在のAIエージェントの大きな課題だと思うので非常に興味深い研究だと思う。
[Paper Note] Online Vector Quantized Attention, Nick Alonso+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Attention #LongSequence #Architecture Issue Date: 2026-02-05 GPT Summary- OVQ注意は、シーケンスミキシングレイヤーを改良し、メモリと計算コスト、長文脈処理のバランスを向上させる。計算コストは線形、メモリは定数であり、スパースメモリ更新を活用して記憶能力を増強。実験では、OVQ注意が線形注意や元のVQ注意に対して顕著な性能向上を示し、特に64kシーケンス長でも強力な結果を得ている。 Comment
元ポスト:
[Paper Note] Learning to Reason in 13 Parameters, John X. Morris+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Reasoning #PEFT(Adaptor/LoRA) #PostTraining #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 低ランクアダプタTinyLoRAを提案し、推論のための強化学習が低ランクパラメータ化を効果的にスケールできることを示しています。わずか13のトレーニングパラメータでQwen2.5を91%の精度に達成し、複雑なベンチマークでも少ないパラメータで90%のパフォーマンス向上を実現しました。特に、強化学習を用いることで、従来の方法よりも大幅に少ないパラメータで強力な結果を得ることができました。 Comment
元ポスト:
Qwen2.5に関してはLlamaと比較して異なる傾向が生じることは以下でも見受けられる。果たして本研究で報告されていることはどこまで一般的なのだろうか?:
- [Paper Note] Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, Mingqi Wu+, arXiv'25
- [Paper Note] Spurious Rewards: Rethinking Training Signals in RLVR, Shao+, 2025.05
[Paper Note] EMA Policy Gradient: Taming Reinforcement Learning for LLMs with EMA Anchor and Top-k KL, Lunjun Zhang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #One-Line Notes Issue Date: 2026-02-05 GPT Summary- LLMのために強化学習のポリシー勾配アルゴリズムを改善するため、固定アンカーポリシーをEMAに置き換え、Top-k KL推定器を導入。これにより、性能が大幅に向上し、数学的推論ではQwen-1.5BがOlympiadBenchで53.9%を達成。Qwen-3Bでは、EMA-PGがGRPOを7つのデータセットで平均33.3%改善し、特にHotpotQAや2WikiMultiHopQAにおいて顕著な向上を示した。全体として、EMA-PGはLLMの強化学習をスケールするための有力なアプローチである。 Comment
元ポスト:
ポイント解説:
KL正則化のRefが古くなりすぎるので指数移動平均(直近の更新重視の移動平均)を用いて更新されるようにし、KLの計算が重いのでTopKのトークンで近似的に計算することで高速化、という感じに見える。
[Paper Note] Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text, Ximing Lu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SyntheticData #PostTraining #read-later #RLVR #Selected Papers/Blogs #One-Line Notes #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- RLVRはLLMの推論を解きほぐす基盤だが、検証データの不足がスケールアップのボトルネックとなっている。この課題を克服するために「ゴールデン・グース」を提案し、インターネットの非検証テキストから無限のRLVRタスクを生成する。具体的には、LLMに主要な推論ステップを特定させ、豊富なタスクを持つGooseReason-0.7Mデータセットを合成。これにより、従来モデルを復活させ、15のベンチマークで新たな最先端結果を達成。また、リアルなサイバーセキュリティデータからRLVRタスクを合成し、Qwen3-4B-Instructをトレーニング。これにより7Bモデルを超える成果を上げ、推論に富んだインターネットテキストを活用する可能性を示している。 Comment
元ポスト:
テキストからMultiple Choice Question (MCQ) を生成することでRLVR用のverifiableな学習データを大量に合成可能にする。おそらく次のステップとしては、生成されるMCQの stem, key, distractor の質が今度は焦点となり、そこの質が改善されればより大きなgainを得られるようになる気がする(たとえば消去法で正解を知らなくても正解できてしまうようなdistractorや、問題文に正解がそのまま含まれてしまっているようなノイジーなMCQから人間が何も学ばないように、モデルが学習するときと一緒だと思われる)。
データとモデルが公開:
[Paper Note] Synthesizing scientific literature with retrieval-augmented language models, Asai+, Nature'26, 2026.02
Paper/Blog Link My Issue
#Citations #InformationRetrieval #NLP #Dataset #QuestionAnswering #Evaluation #RAG(RetrievalAugmentedGeneration) #ScientificDiscovery #read-later #Selected Papers/Blogs #Science Issue Date: 2026-02-05 Comment
元ポスト:
QAに対して専門家と同等のcitationに対するgrounding性能を達成し、citationに基づいたanswer (literature) を8Bモデルで生成可能で、マルチドメインの評価データも作成しているとのこと
benchmark: https://github.com/AkariAsai/ScholarQABench
[Paper Note] Causal Autoregressive Diffusion Language Model, Junhao Ruan+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #DiffusionModel #Decoding #Parallel #KV Cache Issue Date: 2026-02-05 GPT Summary- 因果オート回帰拡散(CARD)という新フレームワークを提案。トレーニング効率と高スループット推論を統合し、因果注意マスク内で拡散プロセスを再定義。局所的文脈保持のためのソフトテイルマスキングと文脈認識重み付けメカニズムを導入。これにより動的な並列デコーディングが可能に。実証結果では、CARDが既存の離散拡散ベースラインを上回り、トレーニングレイテンシを3倍削減。次世代の効率的なLLMに向けた堅牢なパラダイムを示唆。 Comment
元ポスト:
[Paper Note] ReMiT: RL-Guided Mid-Training for Iterative LLM Evolution, Junjie Huang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #mid-training Issue Date: 2026-02-05 GPT Summary- LLMのトレーニングを一方向型から双方向プロセスに進化させ、強化学習(RL)による自己強化フライホイールを建立。ReMiTを導入し、ミッドトレーニングフェーズでトークンの重み付けを動的に調整することで3%の改善を実現。これにより、LLMの継続的な自己強化的進化が可能であることを示した。 Comment
元ポスト:
[Paper Note] Maximum Likelihood Reinforcement Learning, Fahim Tajwar+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #read-later #RLVR #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-02-05 GPT Summary- 強化学習を用いてモデルを訓練する際、尤度の最大化ではなく低次近似を最適化する限界に触発され、最大尤度強化学習(MaxRL)を提案。これは、サンプリングされたデータから最大尤度を近似するためのフレームワークであり、得られた目的関数はシンプルで偏りのないポリシー勾配推定を可能にする。実験では、MaxRLが既存の手法を上回り、テスト時間効率を最大20倍向上。追加データや計算へのスケーラビリティも優れており、RL訓練を正確性に基づいて拡張するための有望なフレームワークであることを示した。 Comment
元ポスト:
著者ポスト:
pj page: https://zanette-labs.github.io/MaxRL/
skim readingしかできていないが、
微分不可能な生成がされbinaryの正誤が与えられるような条件下でモデルを最適化するときにxが与えられてyが正解である確率はimplicitな尤度を表している。この最適化問題を解くために現在はRLが利用されており、RLは正解の確率pを最大化するような定式化がされているが、最尤推定で定式化するとlog pで定式化をすることになり、これは根本的に異なる最適化となる。具体的には、RLはpass@1に対して最適化しているが、MaxRLはk=1,...∞に対するpass@kの調和平均に対して最適化をするような違いがある。この最尤推定の勾配は実は成功したtrajectoryのスコアの平均という非常にシンプルな形で近似的に求められるらしく、最尤推定として解くと最大20倍程度効率が向上した、といった話に見える。
関連:
- [Paper Note] Rewards as Labels: Revisiting RLVR from a Classification Perspective, Zepeng Zhai+, arXiv'26, 2026.02
- [Paper Note] Likelihood-Based Reward Designs for General LLM Reasoning, Ariel Kwiatkowski+, arXiv'26, 2026.02
所見:
所見:
[Paper Note] daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently, Mohan Jiang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #AIAgents #SyntheticData #Coding #SoftwareEngineering #One-Line Notes #LongHorizon Issue Date: 2026-02-05 GPT Summary- 大規模言語モデル(LLM)は短期的なタスクには優れていますが、長期的なワークフローへのスケーリングが課題です。本研究は、プルリクエスト(PR)シーケンスを用いてデータ合成を再概念化し、長期学習のための自然な監督信号を提供します。具体的には、進行的タスク分解、長期的一貫性の強制、バグ修正の検証を通じて、因果依存関係を保ちながら目標指向行動を促進します。実験結果は、daVinci-Agencyが高いデータ効率を即し、ベンチマーク全体での改善を達成したことを示しています。 Comment
元ポスト:
PRのシークエンスでlong horizonデータを合成する
[Paper Note] $V_0$: A Generalist Value Model for Any Policy at State Zero, Yi-Kai Zhang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #In-ContextLearning #PostTraining #Stability #Scheduler #Routing #Initial Impression Notes #BudgetAllocation Issue Date: 2026-02-05 GPT Summary- GRPOを用いた訓練において、$V_0$という新たなバリューモデルを提案。これはパラメータ更新を必要とせず、モデルの期待パフォーマンスを推定し、能力の変化を捉える。$V_0$は成功率を予測し、効率的なサンプリングを実現。結果、LLMルーティングタスクにおいて、コストとパフォーマンスのバランスで優れた結果を示した。 Comment
元ポスト:
ポイント解説:
Actor-Critiqueの枠組みにおいてValueモデル(のポリシーに追従するための逐次的な更新が)重すぎる問題をGRPOはValueモデルを無くすことで回避したが今度はロールアウトのサンプリングコストがでかすぎる問題があるので、学習無しで汎用的に利用可能なValueモデル(パラメータ更新ではなくICLとして定義する)を用いて、ロールアウト前から成功率を予測し無駄なロールアウトを削減したり、クエリをどのモデルに投げるかといったルーティングをするなどの計算機リソースの配分を決めるといったことをやるらしい。
[Paper Note] An Empirical Study on Noisy Data and LLM Pretraining Loss Divergence, Qizhen Zhang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Scaling Laws #read-later #Selected Papers/Blogs #Stability #DataFiltering #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- ノイズデータがLLMの事前学習に与える影響を体系的に分析。合成ノイズを注入した実験で、ノイズがトレーニングロスの発散を引き起こすことを実証し、依存関係を特定。高学習率による発散とは異なるパターンも観察し、診断手法を提案。ノイズの影響に関する制御された洞察を提供。 Comment
元ポスト:
- [Paper Note] Spike No More: Stabilizing the Pre-training of Large Language Models, Sho Takase+, COLM'25
のようにアーキテクチャの改善によって学習の安定性を担保する取り組みもあるが、アーキテクチャ側で解決した場合にノイズはどのような影響を与えるのだろうか?
takeawayが論文中にQAの形でまとめられている。
[Paper Note] RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System, Yinjie Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SelfImprovement #PostTraining #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 強化学習フレームワーク「RLAnything」は、動的に環境、ポリシー、報酬モデルを生成し、学習信号を増幅することで、全体的なRLシステムを強化します。ポリシーはフィードバックを用いて訓練され、報酬モデルは一貫性フィードバックにより最適化されます。理論に基づく自動環境適応により、各モデルからの批評が訓練を改善します。実証例として、RLAnythingはOSWorld、AlfWorld、LiveBenchで大幅な性能向上を示しており、最適化された報酬モデルが人間のラベルを超える結果を出しています。 Comment
blog: https://yinjjiew.github.io/projects/rlanything/
元ポスト:
環境、ポリシー、Reward Modelが互いにフィードバックし合ってco-trainingされる枠組み
[Paper Note] Expanding the Capabilities of Reinforcement Learning via Text Feedback, Yuda Song+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #PostTraining #read-later #TextualFeedback #SelfDistillation Issue Date: 2026-02-05 GPT Summary- テキストフィードバックを用いた強化学習(RL)によるLLMの後処理を研究。スカラー報酬に対し、テキストフィードバックはコストが低く、豊かな情報を提供。モデルはトレーニング時にフィードバックを内部化し、推論時にシングルターンの性能を向上させる。自己蒸留(RLTF-SD)とフィードバックモデリング(RLTF-FM)の2つの手法を提案し、さまざまなタスクでの効果を検証。結果は強力なベースラインを上回ることで、豊かな監視源としてのRLの可能性を示している。 Comment
pj page: https://rl-textfeedback.github.io/
元ポスト:
[Paper Note] The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think, Seongyun Lee+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #Explanation #Chain-of-Thought #ICLR Issue Date: 2026-02-05 GPT Summary- CoTを分析するためのボトムアップのフレームワークを提案。モデル生成のCoTから多様な推論基準を抽出し、クラスタリングを行うことで解釈可能な分析を実施。結果、トレーニングデータの形式が推論行動に与える影響が明らかになり、より効果的な推論戦略への誘導が可能となることを示した。 Comment
元ポスト:
[Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning #SelfCorrection #ICLR #read-later #Selected Papers/Blogs #KeyPoint Notes #Rubric-based #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 言語モデル(LM)の自己改善能力を探るために、RefineBenchという1,000の問題と評価フレームワークを導入。二つの改善モード、ガイド付きと自己改善を評価した結果、最前線のLMは自己改善で低迷する一方、ガイド付き改善では特許LMや大規模オープンウエイトLMが迅速に応答を改善。自己改善には突破口が必要であり、RefineBenchが進捗の追跡に貢献することを示す。 Comment
元ポスト:
pj page: https://passing2961.github.io/refinebench-page/
verifiableはタスクだけでなくnon verifiableなタスクもベンチマークに含まれ、ガイド付き/無しの異なる設定、11種類の多様なドメイン、チェックリストベースのbinary classificationに基づく評価(strong LLMによって分類する; これによりnon verifiableなタスクでも評価可能)、マルチターンでの改善を観測できる、self-correction/refinementに関するベンチマーク。
フロンティアモデルでも自己改善はガイド無しの場合ではあまり有効に機能しないことを明らかにし、外部からガイドが与えられればOpenLLMでさえも少ないターン数で完璧に近い方向にrefineされる、という感じの内容に見える。
つまり自身とは異なるモデルで、何らかの素晴らしい批評家がいれば、あるいは取り組みたいタスクにおいて一般化された厳密性のあるチェックリストがあれば、レスポンスはiterationを繰り返すごとに改善していくことになる。
[Paper Note] SWE-Universe: Scale Real-World Verifiable Environments to Millions, Mouxiang Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #SyntheticData #Coding #MultiLingual #SoftwareEngineering #mid-training #PostTraining #read-later #Selected Papers/Blogs #Verification #Scalability Issue Date: 2026-02-05 GPT Summary- SWE-Universeは、GitHubのプルリクエストから自動的に検証可能なソフトウェア工学環境を構築するためのスケーラブルなフレームワーク。カスタムトレーニングされたビルディングエージェントが反復自己検証とハッキング検出を用いて信頼性の高いタスク生成を実現。これにより、実世界の多言語SWE環境が100万以上増加し、Qwen3-Max-Thinkingにおいて75.3%のスコアを達成。次世代コーディングエージェントの発展に寄与。 Comment
元ポスト:
ポイント解説:
これまでと比較して非常に大規模な実PRに基づいた、さまざまなプログラミング言語に基づくverifiableな学習用の合成データを構築できる環境で、一つ一つの品質はSWE Benchなどには及ばないが、量が圧倒的
[Paper Note] Vision-DeepResearch: Incentivizing DeepResearch Capability in Multimodal Large Language Models, Wenxuan Huang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #MultiModal #2D (Image) #DeepResearch #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- Vision-DeepResearchは、マルチモーダル大規模言語モデル(MLLMs)において、多ターン・多エンティティ・多スケールの視覚およびテキスト検索を実現する新しい深層研究パラダイムを提案。これにより、実際のシナリオでの視覚ノイズに対処し、数十の推論ステップと多くのインタラクションをサポート。強化学習を通じて深層研究能力を内在化し、既存のMLLMを上回る性能を発揮する。コードは公開予定。 Comment
pj page: https://osilly.github.io/Vision-DeepResearch/
元ポスト:
image searchやVQAなどを伴うDeepResearchに関するタスクとそのベンチマークの提案という感じに見える。
[Paper Note] A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training, Zihan Qiu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #Normalization #AttentionSinks #read-later #Stability #One-Line Notes Issue Date: 2026-02-03 GPT Summary- 大規模言語モデルにおける外れ値の機能を調査し、注意の沈みと残差の沈みのメカニズムを明らかにする。外れ値は正規化と共に機能し、再スケーリングを通じてトレーニングの安定性を向上させ、パフォーマンスを改善。これにより、外れ値が寄与者ではなく再スケール要因であることを示し、学習可能なパラメータとの関係性を明らかにした。 Comment
元ポスト:
Attention Sinksにならい、Residual Sinksと命名されている
Attention Sinksや本研究で命名されているResidual Sinks(activationの特定の次元がほとんどのトークンで過剰に大きくなる現象)は正規化を排除するとなくなり(i.e., 正規化とセットで出現する)、これらがなくなると学習の安定性と性能が低下する。これらはTransformerアーキテクチャ内の外れ値として見ることができるが、この外れ値が存在することによってnormalizationにおいてrescalingが実施され安定性やパフォーマンスが向上している、という感じらしい。
[Paper Note] Beyond Precision: Training-Inference Mismatch is an Optimization Problem and Simple LR Scheduling Fixes It, Yaxiang Zhang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #PostTraining #Selected Papers/Blogs #Scheduler #train-inference-gap #Initial Impression Notes Issue Date: 2026-02-03 GPT Summary- 強化学習における言語モデルの訓練は不安定であり、その原因は訓練と推論の不一致にあるとされる。従来の対策では効果が薄いことが指摘され、本研究では勾配ノイズとミスマッチの連動を示し、更新サイズの縮小が効果的であることを発見。ミスマッチは動的な失敗と考え、動的に学習率を調整する新たな手法を提案。これにより、RL訓練を安定化し、不一致を抑制することができることが実証された。 Comment
元ポスト:
Importance SamplingやFP16に設定することによるミスマッチの解決方法でも依然として(長期の訓練などにおいて)安定性の問題が出ることをAblationで確認し、提案手法がより安定することを示しているように見える。
[Paper Note] Hunt Instead of Wait: Evaluating Deep Data Research on Large Language Models, Wei Liu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Open-endedTasks Issue Date: 2026-02-03 GPT Summary- エージェントの能力には、自律的に目標を設定し探求する「探求知能」が求められ、単なるタスク完了の「実行知能」とは異なる。データサイエンスは生データから始まるため、自然なテストベッドを提供するが、関連するベンチマークは少ない。これに対処するため、「Deep Data Research(DDR)」を提案し、LLMがデータベースから洞察を抽出するオープンエンドタスクと、評価を可能にするDDR-Benchを導入。最前線のモデルは新たなエージェンシーを示すが、長期的な探求は依然困難であり、探求知能はモデルの戦略に依存している。 Comment
元ポスト:
[Paper Note] Training LLMs with Fault Tolerant HSDP on 100,000 GPUs, Omkar Salpekar+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Pretraining #NLP #Infrastructure #SoftwareEngineering #mid-training #PostTraining #Stability Issue Date: 2026-02-03 GPT Summary- FT-HSDPという新しいトレーニングパラダイムを提案し、故障耐性を持つデータ並列レプリカを活用。故障時には影響を受けたレプリカのみがオフラインとなり、他のレプリカはトレーニングを継続。FTARプロトコルと非ブロッキングキャッチアップを用いることで、故障回復時間を短縮し、有効なトレーニング時間を大幅に増加。精度への悪影響もないことを確認。 Comment
元ポスト:
100k GPU🤯
[Paper Note] Decouple Searching from Training: Scaling Data Mixing via Model Merging for Large Language Model Pre-training, Shengrui Li+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #read-later #Selected Papers/Blogs #ModelMerge #DataMixture Issue Date: 2026-02-03 GPT Summary- データミクスの最適化はLLMの事前学習において重要であるが、効果的な探索手法が不足している。本研究では、訓練からデータミクス探索を切り離す「DeMix」を提案し、統合モデルを通じて最適なデータ比率を予測する。広範な実験により、DeMixは探索コストを抑えつつ高い性能を実現する。また、検証済みのミクスを含む22兆トークンのデータセット「DeMix Corpora」を公開。 Comment
元ポスト:
関連:
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
[Paper Note] JTok: On Token Embedding as another Axis of Scaling Law via Joint Token Self-modulation, Yebin Yang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Embeddings #NLP #Transformer #Architecture #MoE(Mixture-of-Experts) Issue Date: 2026-02-03 GPT Summary- トークンインデックスパラメータを用いて、LLMの計算コストとモデル容量を切り離す新しいスケーリング手法を提案。Joint-Token(JTok)とMixture of Joint-Token(JTok-M)を導入し、Transformerレイヤーを強化。実験により、検証損失が低下し、MMLUやARCでの性能向上を実証。JTok-Mは、従来のMoEアーキテクチャに比べ、35%少ない計算で同等のモデル品質を実現。 Comment
元ポスト:
[Paper Note] Learn to Reason Efficiently with Adaptive Length-based Reward Shaping, Wei Liu+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #ICLR #Length #PostTraining #Adaptive Issue Date: 2026-02-03 GPT Summary- 推論の効率を向上させるため、RLベースの手法LASERを提案。長さに基づく報酬シェイピングを用いて、冗長性を減少させつつ、パフォーマンスと効率の良好なバランスを実現。また、動的な報酬仕様と難易度を考慮した手法LASER-Dを導入し、簡潔な推論パターンを促進。実験により、推論性能と応答の長さ効率が大幅に向上した。 Comment
元ポスト:
[Paper Note] MemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers, Ajay Jaiswal+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Embeddings #NLP #Transformer #Architecture #memory Issue Date: 2026-02-03 GPT Summary- 大規模言語モデルのFFNの解釈可能性を再検討し、自己注意から切り離したMemoryLLMを提案。FFNをトークン単位のニューラルリトリーバルメモリとして機能させ、効率的な推論を実現。Flex-MemoryLLMも導入し、性能ギャップを埋める役割を果たす。 Comment
またしてもembeddingの活用
元ポスト:
[Paper Note] The Hot Mess of AI: How Does Misalignment Scale With Model Intelligence and Task Complexity?, Alexander Hägele+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #Reasoning #Safety #One-Line Notes Issue Date: 2026-02-03 GPT Summary- AIの機能向上に伴い、リスクも増すため、モデルの失敗のメカニズムを理解することが重要になる。具体的には、失敗が意図しない目標の追求から生じるのか、混乱した行動から生じるのかを検討。また、AIの不適合性はバイアス-バリアンス分解を通じて評価される。実験結果から、高能力なモデルはタスクにかかる時間が増すほど不適合性が高くなる傾向があり、大モデルが小モデルよりも不適合性が高い場面も確認された。これにより、高能力なAIが複雑なタスクを行う場合、予測不可能な誤行動が産業事故につながる可能性が示唆される一方、目標の一貫した追求の可能性は低いことが示される。これにより、報酬ハッキングや目標の誤仕様に対するアライメント研究の重要性が増す。 Comment
元ポスト:
- モデルの推論が長くなればなるほど、一貫性(=予期できないエラー/misalignmentによるバイアス i.e., 全体のエラーに対する予測できないエラーの割合; Variance/Errorで測定)がなくなる
- モデルサイズが大きくなればなるほどEasy Taskでのみ一貫性が向上する。言い換えるとモデルの賢さと一貫性の間に、一貫した関係性はない。が、しばしば賢いモデルは一貫性に乏しい。
上記知見より、AI Safetyの観点で言うと、強力なAIがエラーを起こす時は、一貫性のある何らかの誤った目標に向かっていくようなものではなく、事故のような予測できないものになるだろう、と予測している。
[Paper Note] Perplexity Cannot Always Tell Right from Wrong, Petar Veličković+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #Pretraining #Metrics #NLP #Evaluation Issue Date: 2026-02-03 GPT Summary- パープレキシティはモデルの「驚き」を測る指標であり、損失関数や品質メトリックとして注目されている。しかし、トランスフォーマーの特性を基に、パープレキシティが適切なモデル選択指標でない可能性を示す。具体的には、特定の系列に低いパープレキシティが伴う場合、そのモデルが他の系列を正確に予測しないことを証明。また、等パープレキシティプロットの分析から、パープレキシティが必ずしも精度の向上を反映しないことも明らかにした。正確なモデル選択には自信の増加と精度の改善が必要である。 Comment
元ポスト:
[Paper Note] TTCS: Test-Time Curriculum Synthesis for Self-Evolving, Chengyi Yang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SyntheticData #CurriculumLearning #MajorityVoting #Test Time Training (TTT) Issue Date: 2026-02-03 GPT Summary- TTCSフレームワークは、LLMの推論能力を向上させるための共同進化型テスト時トレーニングを提供。質問合成器と推論ソルバーを初期化し、合成器が難易度の高い質問を生成し、ソルバーは自己一貫性報酬で学習を更新。これにより、質問のバリアントが安定したテスト時トレーニングを実現。実験で数学的ベンチマークにおける推論能力の向上と一般ドメインタスクへの移行が確認された。 Comment
元ポスト:
先行研究:
- [Paper Note] TTRL: Test-Time Reinforcement Learning, Yuxin Zuo+, NeurIPS'25, 2025.04
[Paper Note] THINKSAFE: Self-Generated Safety Alignment for Reasoning Models, Seanie Lee+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #Reasoning #SelfImprovement #Safety Issue Date: 2026-02-03 GPT Summary- 自己生成整合性フレームワーク「ThinkSafe」は、外部教師に依存せずにLRMsの安全性を向上させます。このアプローチは、モデルが保持する危害の識別能力を活かし、軽量の拒否誘導を通じて安全推論トレースを生成します。実験により、ThinkSafeは推論能力を維持しつつ、GRPOに比べて安全性を大幅に改善し、計算コストの削減を実現しています。 Comment
元ポスト:
[Paper Note] TriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification, Haoyun Jiang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Decoding #Selected Papers/Blogs #Verification #SpeculativeDecoding #One-Line Notes #Initial Impression Notes Issue Date: 2026-02-03 GPT Summary- SDを用いて推論効率を向上させる新しいフレームワークTriSpecを提案。軽量なプロキシを活用し、不確実なトークンに対してのみターゲットモデルを使用することで、計算コストを大幅に削減。実験により、従来のSDに対して最大35%の速度向上とターゲットモデルの呼び出し回数を最大50%削減したことを示す。 Comment
元ポスト:
targetモデルでのverificationは重いので、軽量なverificationをdraftに対して実施することで最大35%デコーディング速度向上とのこと。
verificationに利用するLLM(=proxy)がどのようなモデルファミリーなのか、ターゲットと同じファミリーなのか否かなどが気になる。
3.1節に以下のように書かれている:
> We identify smaller same-family models as ideal proxy veri-
fiers, justified by the following three core properties.
proxyについて以下の三つの観点で分析している:
- strong alignmentw: トークンレベルでtargetとalignしているかを分析(exact match, acceptable mismatch, unacceptable mismatchの3値分類)
- trustworthy outputs: token levelでalignしているだけでなく、単独で応答させたときにtargetと同じ回答が得られるか(同じ回答が得られるのであれば多少のトークンレベルの齟齬は許容可能
- Clear separability: proxyが信頼できるトークンと不確実な出力を区別できることが好ましく、proxyのtop1,2のprobabilityの差が0.5より大きい場合にacceptableなトークンと強い相関があることがわかり、verificationの信頼性の担保に使える
同じモデルファミリーでも、よりファミリー内での挙動が一致させるような副次的効果を得られるモデルファミリー構築方法もあり、Speculative Decodingの承認率が向上するような話もある:
- [Paper Note] Efficient Construction of Model Family through Progressive Training Using Model Expansion, Kazuki Yano+, COLM'25, 2025.04
openreview:
https://openreview.net/forum?id=yhhgkkiQe5
提案手法の気持ちや、検証コストに焦点を当てたことは非常に有意義であるものの、Speculative Decodingの(数学的な)ロスレス保証を、実験的には性能がほとんど低下しないことが示されているが、数学的な保証を犠牲にして速度改善している点が実用上の大きな課題で、プロキシを挟むアイデアが既存研究の階層的、マルチレベルのSD, 検証の条件を緩める手法と比較して新規性が明らかでない点、また通常のSDと比較して3つのモデルを用いる点でエンジニアリングの観点からオーバーヘッドなしに主要な推論スタックにデプロイできるのか、実験結果の再現性や公式の報告とズレがある点などが指摘され、ICLR'26にrejectされている。
[Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Blog #Reasoning #MoE(Mixture-of-Experts) #AttentionSinks #PostTraining #Selected Papers/Blogs #One-Line Notes #Reference Collection #SelfDistillation Issue Date: 2026-02-03 GPT Summary- Step 3.5 Flashは、フロンティア知能と効率を橋渡しするスパースMixture-of-Experts(MoE)モデルで、1960億パラメータの基盤と110億パラメータのアクティブパラメータを組み合わせ、迅速で信頼性の高い推論を実現。交互スライディングウィンドウとMulti-Token Predictionを取り入れ、エージェント間の相互作用の待機時間を短縮。検証可能な信号とフィードバックを用いた強化学習フレームワークにより、安定した自己改善を図る。エージェントやコーディング、数学タスクで高い性能を示し、フロンティアモデルに匹敵する結果を達成している。 Comment
元ポスト:
公式ポスト:
解説:
ポイント解説:
ポイント解説:
固定されたデータ非依存のsink tokenを利用するよりも、attention headの出力にinput xに応じたgatingを設けるHead wise gated attentionの方が各ベンチマークでの性能が良い(Table2, gatingの計算量もほぼ無視できる)。Head wise gated attentionは、データに応じてattention headの出力を制御するため、データ依存のlearnableなsink tokenと解釈できる(A.1):
Head-wise Gated Attention:
- [Paper Note] Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free, Zihan Qiu+, NeurIPS'25 Best Paper
- [Paper Note] Forgetting Transformer: Softmax Attention with a Forget Gate, Zhixuan Lin+, ICLR'25, 2025.03
SFTデータがリリースされたとのこと:
https://huggingface.co/datasets/stepfun-ai/Step-3.5-Flash-SFT
元ポスト:
[Paper Note] Linear representations in language models can change dramatically over a conversation, Andrew Kyle Lampinen+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #Factuality #Conversation #Interpretability #Initial Impression Notes Issue Date: 2026-02-01 GPT Summary- 言語モデルの表現は高次の概念に対応する線形の方向を持ち、会話の中でこれらの表現が劇的に変化することを発見。具体的には、会話の初めに事実として表現された情報が最後には非事実として変わるなど、内容に依存した変化が生じる。これらの変化は、さまざまなモデルで発生し、文脈によって異なる効果を持つ可能性がある。結果は、モデルの応答が会話によって影響を受けることを示唆し、解釈可能性に課題を提示。表現の動態は、モデルの文脈適応を理解する新しい研究の方向性を示す。 Comment
元ポスト:
ポイント解説:
Factを扱う専用の機構を設けた方が良いのかもしれない
[Paper Note] TensorLens: End-to-End Transformer Analysis via High-Order Attention Tensors, Ido Andrew Atad+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#MachineLearning #NLP #Transformer #Attention #Interpretability Issue Date: 2026-02-01 GPT Summary- トランスフォーマーの注意行列を包括的に理解するため、TensorLensという新たな定式化を提案。これは、トランスフォーマー全体を単一の線形演算子として捉え、高次の注意相互作用テンソルを通じて各コンポーネントを共同でエンコード。これにより、モデルの計算の整合性を保ちながら、より豊かな表現を実現。実験によって、TensorLensが解釈性向上に寄与することが確認された。 Comment
元ポスト:
[Paper Note] Grounding Computer Use Agents on Human Demonstrations, Aarash Feizi+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #ICLR #ComputerUse #PostTraining #UI Issue Date: 2026-02-01 GPT Summary- 専門家の実演から構築したデスクトップグラウンディングデータセット「GroundCUA」を提案。87のアプリをカバーし、56,000枚のスクリーンショットと356万件以上の注釈を含む。これに基づき、指示をUI要素にマッピングする「GroundNext」モデル群を開発。教師ありファインチューニングにより最先端の結果を達成し、強化学習によるポストトレーニングでさらに性能向上。高品質なデータセットがコンピューターエージェントの進展に貢献することを示唆。 Comment
pj page: https://groundcua.github.io/
元ポスト:
[Paper Note] LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities, Thomas Schmied+, ICLR'26, 2025.04
Paper/Blog Link My Issue
#Analysis #ReinforcementLearning #Chain-of-Thought #Reasoning #ICLR #Test-Time Scaling #PostTraining #Multi-Armed Bandit #DecisionMaking #Exploration Issue Date: 2026-01-31 GPT Summary- LLMのエージェントアプリケーションにおける探求と解決の効率性を分析。最適なパフォーマンスを妨げる「知識と行動のギャップ」や貪欲性、頻度バイアスという失敗モードを特定。強化学習(RL)によるファインチューニングを提案し、探索を増加させて意思決定能力を改善。古典的な探索メカニズムとLLM特有のアプローチの両方を融合させ、効果的なファインチューニングの実現を目指す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=weUP6H5Ko9
- greediness
- frequency bias
- the knowing-doing gap
[Paper Note] L$^3$: Large Lookup Layers, Albert Tseng+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Embeddings #NLP #Transformer #Architecture Issue Date: 2026-01-30 GPT Summary- L$^3$レイヤーを使用した新しいスパース性の手法を提案。これは静的なトークンベースのルーティングでトークンごとの埋め込みを集約し、メモリと計算の効率を向上させる。高速トレーニングが可能で、情報理論に基づく埋め込み割り当てアルゴリズムを採用。実験により、L$^3$が他のモデルを大きく上回る性能を示した。 Comment
[Paper Note] HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing, Chengyu Du+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #RolePlaying Issue Date: 2026-01-30 GPT Summary- LLMを用いたロールプレイングは、友情やコンテンツ制作などに重要な役割を果たしているが、内面的思考のシミュレーションが課題である。本研究では、認知レベルのペルソナシミュレーションを実現するためのHERという統一フレームワークを提案し、二層の思考を導入。逆方向からのエンジニアリングを通じて推論強化型ロールプレイデータを生成し、人間の好みに合った報酬モデルを構築。Qwen3-32Bを基にした\methodモデルは監視学習と強化学習で訓練され、CoSERベンチマークで30.26の改善、Minimaxロールプレイベンチで14.97の向上を達成した。データセットとモデルは今後の研究に提供される。 Comment
元ポスト:
[Paper Note] GeoNorm: Unify Pre-Norm and Post-Norm with Geodesic Optimization, Chuanyang Zheng+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #Normalization #read-later Issue Date: 2026-01-30 GPT Summary- 正規化層の配置に関する問題をマニフォールド最適化の視点から再考し、フィードフォワードネットワークと注意層の出力を更新方向として解釈。新手法GeoNormを提案し、標準の正規化を測地線更新に置き換える。包括的な実験で既存手法を一貫して上回る性能を確認。GeoNormは標準Transformerへ簡易に統合可能で、追加コストがわずかでも性能向上を達成。 Comment
元ポスト:
[Paper Note] Shaping capabilities with token-level data filtering, Neil Rathi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Pretraining #NLP #Safety #read-later #Toxicity #Selected Papers/Blogs #SparseAutoencoder Issue Date: 2026-01-30 GPT Summary- 事前学習段階での望ましくない能力の削減に焦点を当て、医療能力除去のためのトークンフィルタリングが効果的であることを示す。特に、トークンフィルタリングが文書フィルタリングよりも低コストで望ましくない能力に対する影響を減少させることを実証。大規模モデルでのフィルタリング効果を検証し、7000倍の計算遅延の引き起こしを明らかに。スパースオートエンコーダを用いたトークンラベリング手法と高品質な分類器の蒸留方法論を提案し、ノイズの多いラベルに対するフィルタリングのロバスト性を示す。 Comment
元ポスト:
[Paper Note] ConceptMoE: Adaptive Token-to-Concept Compression for Implicit Compute Allocation, Zihao Huang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #LatentReasoning #Initial Impression Notes #Concept (LLM PreTraining) #Author Thread-Post Issue Date: 2026-01-30 GPT Summary- ConceptMoEは、トークン間の類似性を利用して計算リソースを動的に割り当てる新しい手法です。これにより、概念表現を生成し、計算集約モデルへのシーケンス圧縮を行います。評価において、ConceptMoEは標準的なMoEを上回り、言語や視覚言語タスクでの性能向上を示しました。特に、計算の効率も大幅に改善され、アーキテクチャの改変なしに既存のMoEに統合可能です。 Comment
著者ポスト:
論文タイトルにMoEというワードが入っているが、実際にMoEアーキテクチャを採用しているわけではない点に注意。アーキテクチャはいわゆるLarge Concept Model (エンコーダー→チャンク生成→コンセプトモデル→デチャンキング→デコーダー)であり、チャンクの境界がトークン間のlearnableなモジュールによって学習・決定されるため、トークンレベルで見たときに適応的にトークンをチャンク化することでコンセプトが定義され、かつトークン単位の計算資源の配分がチャンク化を(learnableに)通じて行われるという話に見える。
斜め読みしかできていないが、アーキテクチャそのものの貢献よりも、本研究の貢献として大きい部分はMoEモデルを用いた同じパラメータ/FLOPsでの異なるアーキテクチャ間のfair comparisonを通じてconcept modelの性能が高いことを示したことや、既存のMoEモデルを軽量なモジュールの追加(チャンクモジュール+デチャンクモジュール+追加のゼロで初期化されたQKV attention)し継続事前学習をすることでretrofittingすることでも性能が向上すること、計算効率がチャンクによってトークンが圧縮されるため、fair comparisonの上で高い性能を達成しながら、圧縮率Rに応じて向上することを示ししたこと、などにあるように見受けられる。
が、ただの斜め読みした感想でしかないので読みたい。
[Paper Note] Self-Improving Pretraining: using post-trained models to pretrain better models, Ellen Xiaoqing Tan+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Pretraining #NLP #SelfImprovement #mid-training #DPO #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-01-30 GPT Summary- 大規模言語モデルの安全性と品質を確保するための新しい事前学習法を提案。文書をストリームし、強化学習を用いて生成されたKトークンを改善。プロセス中、候補生成物を評価し、モデルの成長に応じて高品質な出力に報酬を与える。実験の結果、事実性と安全性でそれぞれ36.2%および18.5%の改善を達成し、生成品質も最大86.3%向上した。 Comment
元ポスト:
事前学習の枠組みがnext token predictionから変わるかもしれないような話。気になる。
v2へアップデート:
解説:
関連:
- [Paper Note] Deep reinforcement learning from human preferences, Paul Christiano+, NIPS'17, 2017.06
- [Paper Note] Direct Preference Optimization: Your Language Model is Secretly a Reward Model, Rafael Rafailov+, arXiv'23, 2023.05
[Paper Note] Reinforcement Learning via Self-Distillation, Jonas Hübotter+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Distillation #PostTraining #Selected Papers/Blogs #On-Policy #One-Line Notes #TextualFeedback #SelfDistillation Issue Date: 2026-01-30 GPT Summary- リッチフィードバックを活用した強化学習手法SDPOを提案。従来の手法がスカラー報酬に依存するのに対し、SDPOは豊富なテキストフィードバックを用いてセルフディスティレーションを行い、モデルの誤りを特定。科学的推論や競技プログラミングにおいて、サンプル効率と精度を向上し、標準的なRLVR環境でも優れた性能を発揮。テスト時には試行回数を削減しつつ、発見確率を維持可能。 Comment
あるポリシーでロールアウトを実行し、ロールアウトの実行結果からフィードバック(e.g., runtime error messageやLLM-as-a-Judgeによるtextual feedbackなど)を得たときに、同ポリシーに対してフィードバックをcontextとして与えた上でロールアウトのtoken levelでのlog probを比較することで、token levelでどこが誤っていたかに関する学習シグナルを得る。
ポイント解説:
[Paper Note] Beyond Speedup -- Utilizing KV Cache for Sampling and Reasoning, Zeyu Xing+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Embeddings #NLP #read-later #Selected Papers/Blogs #KV Cache #DownstreamTasks #Adaptive #Initial Impression Notes #SelfVerification Issue Date: 2026-01-30 GPT Summary- KVキャッシュを文脈情報の軽量な表現として再利用し、再計算や保存の必要を排除。KV由来の表現は、(i)チェーン・オブ・エンベディングで競争力のある性能を発揮し、(ii)ファスト/スロー思考切替でトークン生成を最大5.7倍削減する一方、精度損失を最小限に抑える。これにより、KVキャッシュがLLM推論における表現再利用の新たな基盤となることを示す。 Comment
元ポスト:
KV Cacheを軽量なhidden stateを表すembeddingとして扱うことで色々と応用できます、という話に見え、たとえばデコーディングの途中でhallucinationをdetectする際により省メモリで実現できたり、fast/d slowなthinkingの切り替えの制御に利用するなど、単に次トークンを生成する際の高速化の用途を超えて使うという興味深い発想な研究に見える。
[Paper Note] Scaling Embeddings Outperforms Scaling Experts in Language Models, Hong Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Embeddings #NLP #Transformer #AIAgents #LongSequence #Architecture #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-01-30 GPT Summary- 本研究では、Mixture-of-Experts(MoE)アーキテクチャに代わる埋め込みスケーリングを検討し、その効果を体系的に分析。埋め込みスケーリングは専門家スケーリングよりも優れたパレートフロンティアを達成し、推論速度が向上することを示す。68.5BパラメータのLongCat-Flash-Liteモデルを導入し、約3Bのパラメータでトレーニングを行った結果、既存のMoEベースラインを超える性能を発揮。特にエージェント的およびコーディングの分野で競争力が示される。 Comment
HF: https://huggingface.co/meituan-longcat/LongCat-Flash-Lite
元ポスト:
N-Gram Embeddingを用いることでMoEアーキテクチャの同等程度のモデルと比較してより高い性能を獲得しているように見える。NGramの各NごとにルックアップテーブルとProtectionのための重みを学習して最終的にAveragingをすることでContext Vectorを生成している、ようなアーキテクチャに見える。non-thinkingモデル
先行研究:
- [Paper Note] Scaling Embedding Layers in Language Models, Da Yu+, NeurIPS'25, 2025.02
[Paper Note] Revisiting Parameter Server in LLM Post-Training, Xinyi Wan+, ICLR'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #SoftwareEngineering #PostTraining Issue Date: 2026-01-29 GPT Summary- ODC(オンデマンド通信)は、バランスの取れない負荷を持つLLMのポストトレーニングに対処するため、集団通信をポイントツーポイント通信に置き換え、FSDPを適応させる手法。これにより、同期障壁が減少し、より効率的な負荷バランシングを実現。ODCは、デバイスの利用率とトレーニングスループットを向上させ、FSDPに対して最大36%のスピードアップを達成した。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=iIEEgI6WsF
[Paper Note] Post-LayerNorm Is Back: Stable, ExpressivE, and Deep, Chen Chen+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Pretraining #NLP #Transformer #Architecture #Normalization #read-later #Stability #ResidualStream Issue Date: 2026-01-29 GPT Summary- LLMのスケーリングには限界があり、モデルの大きさやコンテキスト長の延長が表現力を向上させない一方、深さのスケーリングは有望だが訓練の安定性に課題がある。本研究では、Post-LayerNormの問題を再検討し、残差経路をハイウェイスタイルの接続に置き換えた「Keel」トランスフォーマーを提案。これにより勾配消失を防ぎ、1000層以上でも安定した訓練を可能にし、Pre-LNよりも性能を向上させる。Keelは、今後の深層アーキテクチャ構築の新たな基盤を提供する。 Comment
元ポスト:
PostLNと言えばOlmo 2:
- OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3
1000 layerを超えるネットワークを安定して学習、、だと、、
関連:
- [Paper Note] 1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities, Wang+, NeurIPS'25 Best Paper Awards
[Paper Note] LoPRo: Enhancing Low-Rank Quantization via Permuted Block-Wise Rotation, Hongyaoxing Gu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Training-Free #Quantization #Initial Impression Notes Issue Date: 2026-01-29 GPT Summary- ファインチューニング不要の量子化アルゴリズム「LoPRo」を提案し、残差行列の量子化課題を解決。ブロック単位の入れ替えと変換により、重要な列の量子化精度を保ちながら、2ビットと3ビット量子化での性能向上を実現。実験ではLLaMAモデルで最先端の精度を達成し、MoEモデルでは効率を大幅に向上。LoPRoは、他手法に比べて低ランクで優れた精度と高い推論効率を維持。 Comment
元ポスト:
GPTQの頃と比較して非常に性能が向上しているように見える。
- [Paper Note] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, ICLR'23, 2022.10
[Paper Note] FP8-RL: A Practical and Stable Low-Precision Stack for LLM Reinforcement Learning, Zhaopeng Qiu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #LowPrecision Issue Date: 2026-01-27 GPT Summary- 強化学習におけるLLMのロールアウトは、長いシーケンス長のためにボトルネックが発生するが、FP8を用いることで計算コストとメモリトラフィックを削減できる。FP8適用にはポリシーの重みの変化や低精度のロールアウトによる不安定性の課題がある。本研究では、veRLエコシステム内で実用的なFP8ロールアウトスタックを実装し、具体的には(i) FP8量子化によるロールアウトの実現、(ii) QKVの再キャリブレーション、(iii) 重要度サンプリングを用いた不一致の軽減を提案。これにより、BF16ベースラインと比較して、最大44%のロールアウトスループット向上が達成された。 Comment
元ポスト:
[Paper Note] Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability, Shobhita Sundaram+, ICML'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SyntheticData #ICML #PostTraining #read-later #CurriculumLearning #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-01-27 GPT Summary- LLMは解決困難な問題のために自動カリキュラムを生成可能か?SOARという自己改善フレームワークを通じ、教師が学生のために問題を提案し、進捗に基づいて報酬を提供。研究では、バイレベルmeta-RLが学習を促進し、計測された報酬が内在的報酬を上回ることを示し、構造的品質が解答の正確性よりも学習において重要であることを明らかにした。これにより、困難な問題解決において事前の能力が不要であることが示唆された。 Comment
元ポスト:
著者ポスト:
pj page: https://ssundaram21.github.io/soar/
[Paper Note] POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration, Yuxiao Qu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #One-Line Notes Issue Date: 2026-01-27 GPT Summary- 強化学習(RL)の限界を克服するために、Privileged On-Policy Exploration(POPE)を提案。POPEは、人間やオラクルからの特権情報を活用し、困難な問題の探索を促進するアプローチで、非ゼロ報酬を得ることで学習を進める。実験により、POPEが困難な推論タスクにおける性能を大幅に向上させることを示した。 Comment
関連:
- [Paper Note] Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes, Amrith Setlur+, arXiv'26, 2026.01
skim readingしかできていないが、本研究は人間が記述したオラクルを接頭辞として使い、ポリシーの方向性をガイドすることでアシストするが、こちらのReuse your FLOPsは過去のロールアウトで成功したtrajectoryを再利用して接頭辞として利用する点が異なるように見える。
RLが解くのが困難な問題に対して接頭辞としてオラクルの情報を与えることで学習シグナルのスパースさを解決する
[Paper Note] DeepPlanning: Benchmarking Long-Horizon Agentic Planning with Verifiable Constraints, Yinger Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #AIAgents #Planning #Evaluation #LongHorizon Issue Date: 2026-01-27 GPT Summary- 長期タスクのエージェント評価にはグローバルな制約最適化が欠けている中、DeepPlanningという新たなベンチマークを導入。これは、能動的な情報収集や局所的制約を含む旅行計画やショッピングタスクを対象とし、最先端のLLMでも難しいことを示す。エラー分析を通じて、エージェント型LLMの改善につながる方向性を指摘し、研究支援のためにコードとデータをオープンソース化。 Comment
元ポスト:
[Paper Note] Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes, Amrith Setlur+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2026-01-27 GPT Summary- PrefixRLは古いサンプリングデータを活用し、オフポリシーの不安定性を回避しつつ、オンポリシーでの強化学習を行う手法です。これにより、学習信号が強化され、従来のRLよりもサンプル効率が向上。また、PrefixRLは難しい推論問題において、より早く同等のトレーニング報酬を達成し、他のモデルファミリーに対しても適応可能であることを示しています。 Comment
元ポスト:
同じタイミングで上記POPEが提案された。POPEは人間が記述したオラクルを接頭辞として使い、ポリシーの方向性をガイドすることでアシストするが、こちらのReuse your FLOPsは過去のロールアウトで成功したtrajectoryを再利用して接頭辞として利用する点が異なるように見える。
著者ポスト:
[Paper Note] MergeMix: Optimizing Mid-Training Data Mixtures via Learnable Model Merging, Jiapeng Wang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #mid-training #ModelMerge #DataMixture Issue Date: 2026-01-27 GPT Summary- MergeMixは、データ混合比率を効率的に最適化する新しいアプローチを提案。低コストで高忠実度なパフォーマンスプロキシを再利用し、最小限のトークンでドメイン特化型のエキスパートをトレーニング。実験では、手動調整と同等以上の成果を上げ、コストを大幅に削減。高い順位の一貫性とスケーラブルな自動化ソリューションを示した。 Comment
元ポスト:
[Paper Note] LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts, Venmugil Elango+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Architecture #MoE(Mixture-of-Experts) #Selected Papers/Blogs #reading #One-Line Notes Issue Date: 2026-01-27 GPT Summary- MoEアーキテクチャを再評価し、推論コストの最適化に焦点を当てた研究。新しいモデルLatentMoEを導入し、最大95Bパラメータのスケールで優れた精度を実現。これにより、Nemotron-3スーパーおよびウルトラモデルに適用され、パフォーマンスが向上した。 Comment
元ポスト:
ポイント解説:
MoEに用いるhidden_stateの次元数が小さくなるようにlinear layerで圧縮しノード間のtrafficを削減しつつ、その分expert数やtop-kで選択するkを増やす。
[Paper Note] Endless Terminals: Scaling RL Environments for Terminal Agents, Kanishk Gandhi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #PostTraining #read-later #Diversity #Selected Papers/Blogs #One-Line Notes #Initial Impression Notes #Environment #Author Thread-Post Issue Date: 2026-01-26 GPT Summary- 自己改善エージェントのボトルネックである環境を改善するため、無人アノテーションで端末利用タスクを生成する「Endless Terminals」パイプラインを提案。タスク記述の生成から可解性のフィルタリングまでの4ステージを経て、3255のタスクを作成。PPOを用いて訓練したモデルは、ホールドアウト開発セットで大幅な性能向上を示し、Llama-3.2-3Bは4.0%から18.2%、Qwen2.5-7Bは10.7%から53.3%に改善。人間キュレーションのベンチマークでも改善し、シンプルな強化学習がスケールする環境で成功することを示す。 Comment
元ポスト:
taskが解けるものか否かをverifyする追加のモデルが必要な点は注意とのこと。
(論文中ではo3が用いられている)
著者ポスト:
RLにおけるターミナル上で実行可能な多様なタスクと、実際に動作可能なコンテナ、テストの生成をスケールさせることで標準的なPPOで性能が向上し、人間が収集した既存ベンチマーク(Terminal Bench 2.0)にも汎化することを示した研究。つまり、RLのタスクと環境をスケールさせれば標準的なRLアルゴリズムでも性能が向上するというメッセージがある。
本研究の他研究との位置付けがぱっと脳内で整理できなかったので、関連研究の部分を読むと、
- AgentのScaffoldの観点では、bashが実行可能なOpenHandsに近く、シェルコマンドを実行し、実行に至るまでのすべてのヒストリと出力が利用可能。
- SFTのための高品質なデータを合成するる研究が最近は多いが、SFTはRLのためのWarmUpに相当するため、本研究とそれらの研究は補完的な位置付けにある。
- ベンチマークやインタラクティブな研究の観点では、SWEBenchやTerminal Bench 2.0のように、人間が収集したベンチマークが存在し、マルチターンでアクションを通じてインタラクションしながら次のアクションを決めていく。本研究もシェル上で状態を観測しながら次のアクションを決めていくようなマルチターンの枠組みに相当する。
- verifiableな環境を合成する研究も行われている。たとえばSWEGymは2438のpythonコードのタスクと検証可能なテストを提供するが、既存のGithub Issueに依存しており、本研究のようにボトムアップに手続的に生成されるものではない。シングルターンではself-playにより困難な問題を生成する研究があるがマルチターンではない。Open Thought Agentという研究がSFT, RLのためのターミナルを用いた環境を合成する点でもっとも本研究と近いが、人間が生成したクエリやコマンドに基づいており、かつ既存のTerminal Bench 2.0といった人間によって収集されたベンチマークでのgainは得られていない。本研究では、完全に自動化されており、任意のサイズにスケールしPPOのような標準的なRLでも既存ベンチマークに転移する点が異なる。
という整理のようである。位置付けは理解できたが、本研究が既存のベンチマークにも転移するのはなぜなのだろうか?という点がまだ理解できていない。
所見:
[Paper Note] Even GPT-5.2 Can't Count to Five: The Case for Zero-Error Horizons in Trustworthy LLMs, Ryoma Sato, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #Evaluation Issue Date: 2026-01-25 GPT Summary- 信頼性のあるLLMのためのゼロエラー・ホライゾン(ZEH)を提案。ZEHはモデルがエラーなしに解決できる範囲を示し、最先端のLLM評価に有用。GPT-5.2の評価では、単純なパリティや括弧のバランスを判断できないことが示され、安全性が重要な領域での教訓となる。Qwen2.5にもZEHを適用し、精度との相関があるものの、詳細な挙動は異なることが判明。計算コストを軽減するために、ツリー構造とオンラインソフトマックスを用いた速度向上の方法も検討。 Comment
元ポスト:
[Paper Note] The AI Hippocampus: How Far are We From Human Memory?, Zixia Jia+, TMLR'26, 2026.01
Paper/Blog Link My Issue
#Survey #ComputerVision #NLP #AIAgents #MultiModal #RAG(RetrievalAugmentedGeneration) #ConceptErasure #TMLR #KnowledgeEditing #read-later #Selected Papers/Blogs #VisionLanguageModel #memory #KeyPoint Notes Issue Date: 2026-01-24 GPT Summary- メモリは、LLMおよびマルチモーダルLLMの推論と適応性を強化する基盤的要素であり、モデルが静的からインタラクティブなシステムへと進化する中で重要なテーマです。本調査では、メモリを暗黙的、明示的、エージェンティックの三つのパラダイムに分類し、各フレームワークを詳細に述べています。暗黙のメモリは内部パラメータに埋め込まれた知識を示し、明示的なメモリは外部ストレージによる動的な情報強化を指します。エージェンティックメモリは自律エージェントのための持続的な構造を提供し、長期的計画や協調行動を促進します。また、視覚や音声を含む多様なモダリティ間の整合性の重要性も考慮し、アーキテクチャの進展やベンチマークタスクに関連する挑戦について議論されています。 Comment
元ポスト:
AI Agentのメモリに関する包括的なSurvey。現在の技術の包括的なレビューだけでなく、人間の海馬との対比などから必要な能力が議論されている模様。また、現在のメモリが抱えている課題を同定し明言していることが大きな貢献で、
- memory contamination, hallucination (無関係、不正確なデータによるメモリの汚染と、それによって生じるハルシネーション)
- large scaleな検索の計算負荷
- いつ検索するのか、パラメータに内包される知識に頼るのかの判断の困難さ
- 長期にわたるinteractionに対してどのように一貫性を保つか
ということが挙げられるとのこと。
うーーん読みたい。
openreview: https://openreview.net/forum?id=Sk7pwmLuAY
[Paper Note] Toward Efficient Agents: Memory, Tool learning, and Planning, Xiaofang Yang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Survey #NLP #ReinforcementLearning #AIAgents #Planning #PostTraining #memory Issue Date: 2026-01-24 GPT Summary- エージェントシステムの効率に関する研究を行い、メモリ、ツール学習、計画の3つのコアコンポーネントに焦点を当てる。コスト(レイテンシ、トークン、ステップ)を考慮し、圧縮や強化学習報酬、効率向上のための制御された探索メカニズムを活用する最近のアプローチをレビュー。効果とコストのトレードオフをパレートフロンティアを通じて評価し、効率指向のベンチマークや主要な課題、今後の方向性についても議論する。
[Paper Note] Controlled LLM Training on Spectral Sphere, Tian Xie+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #Pretraining #MachineLearning #NLP #Optimizer #Stability Issue Date: 2026-01-23 GPT Summary- 大規模モデルの最適化には、安定性と迅速な収束を保証する戦略が不可欠。新たに導入したスペクトルスフィアオプティマイザー(SSO)は、重みと更新に厳密なスペクトル制約を適用し、完全に安定した最適化プロセスを実現。多様なモデルアーキテクチャでの事前トレーニングにより、SSOはAdamWやMuonよりも一貫して高い性能を示し、安定性の向上も確認された。
[Paper Note] Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors, Zhiwei Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #Reasoning #SelfCorrection #PostTraining #One-Line Notes Issue Date: 2026-01-23 GPT Summary- LLMはマルチターン実行において脆弱で、ツール呼び出しエラー後の自己修正が困難。従来の強化学習ではエラーが負の報酬として扱われ、復旧指針が不足している。本研究では、実行エラーを修正監督に変換するFission-GRPOフレームワークを提案。失敗した軌道をエラーシミュレーターのフィードバックで強化し、新しいトレーニングインスタンスに分裂。これにより、実際のエラーから学ぶことが可能となる。BFCL v4マルチターンで、Fission-GRPOはQwen3-8Bのエラー回復率を5.7%改善し、全体的な精度を4%向上させた。 Comment
元ポスト:
tool useの学習をさせる際に通常のGRPOでの更新に加えて、ロールアウトで実行エラーとなったものを収集し、エラーに対して診断フィードバックを与え、その文脈からエラーを回復するようなロールアウトを実施し学習することで、自己修正能力を身につけさせるような手法に見える。
[Paper Note] Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models, Siyan Zhao+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Distillation #PostTraining #Selected Papers/Blogs #On-Policy #SelfDistillation Issue Date: 2026-01-23 GPT Summary- オンポリシーセルフ蒸留(OPSD)は、LLMが自らを教師と生徒として機能させ、特権情報を活用しながら異なるコンテキストでの推論を改善する新しいフレームワークです。これにより、自己のロールアウトを基に外れ値を最小化し、数学的推論ベンチマークで優れた性能を発揮。GRPOなどの強化学習手法と比較してトークン効率を4-8倍向上させました。 Comment
元ポスト:
関連:
- [Paper Note] Reinforcement Learning Teachers of Test Time Scaling, Edoardo Cetin+, arXiv'25
所見:
ポイント解説:
[Paper Note] Learning to Discover at Test Time, Mert Yuksekgonul+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #ScientificDiscovery #read-later #Selected Papers/Blogs #ContinualLearning #Initial Impression Notes #Test Time Training (TTT) Issue Date: 2026-01-23 GPT Summary- LLMを用いたテスト時トレーニングによる発見(TTT-Discover)を提案し、特定の科学的問題に対し優れた解を生成。強化学習を通じて、独自の経験を持つLLMが問題解決に集中。数学から生物学までの様々な課題で新たな最先端を達成し、成果はオープンソースのモデルを用いて再現可能。 Comment
test timeにモデルが解空間を探索するようにweightをupdateすることを(RLで)学習し、平均的に良いsolutionではなくbestなsolutionを見つけるような目的関数を用いることで、scientic discoveryの能力を向上
[Paper Note] Agentic Reasoning for Large Language Models, Tianxin Wei+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #Planning #Reasoning #SelfImprovement #memory #One-Line Notes #Test-time Learning Issue Date: 2026-01-23 GPT Summary- エージェンティック推論は、LLMを自律的エージェントとして再構築し、計画や行動を行う新たなアプローチを提供します。本調査では、推論を基盤、自己進化、集合的の三つの次元に整理し、それぞれの特性と相互作用を探ります。また、文脈内推論とポストトレーニング推論の違いを示し、さまざまな現実世界でのアプリケーションをレビューします。この研究は、思考と行動を結びつける統一的なロードマップを提示し、今後の課題と方向性を概説します。 Comment
元ポスト:
agentのreasoning周りに特化したsurveyで基本的なsingle agentとしてのplanning, tool use, searchだけでなく、self evolving, memory, multi agent reasoningなど広範なトピックが網羅されているとのこと。
[Paper Note] The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models, Zanlin Ni+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #DiffusionModel #Reasoning #PostTraining Issue Date: 2026-01-22 GPT Summary- dLLMsは任意の順序でトークンを生成できるが、この柔軟性が推論の境界を狭める可能性があることを示す。dLLMsは高不確実性トークンを回避し、解空間の早期崩壊を引き起こす傾向があり、既存のRLアプローチの前提に挑戦する。効果的な推論は、任意の順序を放棄し、GRPOを適用することで実現され、JustGRPOはその実例で、GSM8Kで89.1%の精度を達成した。 Comment
元ポスト:
[Paper Note] CorpusQA: A 10 Million Token Benchmark for Corpus-Level Analysis and Reasoning, Zhiyuan Lu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #RAG(RetrievalAugmentedGeneration) #LongSequence #Selected Papers/Blogs #memory #Initial Impression Notes Issue Date: 2026-01-22 GPT Summary- CorpusQAは、最大1,000万トークンに対応する新しいベンチマークで、広範な非構造的テキストに対する全体的な推論を求める。これは、プログラムによって保証された真実の回答を持つ複雑なクエリを生成する革新的なデータ合成フレームワークを用いており、LLMの長期コンテキスト推論能力を向上させることが実証された。一方で、長い入力に対しては現行のリトリーバーシステムが限界を迎え、メモリ拡張型エージェントアーキテクチャがより効果的な解決策となる可能性が示唆された。 Comment
元ポスト:
10Mコンテキストまで性能を測定可能なベンチマークらしく、結果を見ると以下のようになっている。128KコンテキストではGPT5に軍配が上がり、1M級のコンテキストになるとGeminiがやはり強い(これは昔からそうでFiction.liveベンチなどでも示されていた)。
10Mコンテキスト級ではLLMのコンテキストウィンドウのみでは対応不可なので、RAGやMemory Agextでベンチマーキングされているが、明確にAgentの方が性能が良い。ベンチマークの細かな作り方や、harnessなど、具体的にどのような設定で実験されているのか気になる。
[Paper Note] Jet-RL: Enabling On-Policy FP8 Reinforcement Learning with Unified Training and Rollout Precision Flow, Haocheng Xi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #PostTraining #train-inference-gap #LowPrecision Issue Date: 2026-01-21 GPT Summary- 強化学習(RL)はLLMの推論能力を向上させるが、既存のトレーニングは非効率で、ロールアウトに多くの時間を要する。FP8精度による量子化RLトレーニングがボトルネック解消の有力候補であるが、BF16トレーニング + FP8ロールアウトの戦略は不安定さを招く。我々はJet-RLを提案し、トレーニングとロールアウトに統一されたFP8フローを採用することで数値的ミスマッチを減少させる。実験により最大33%のロールアウト速度向上と41%のトレーニング速度向上を達成し、安定した収束を実証した。 Comment
元ポスト:
関連:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
こちらはFP16だが。
[Paper Note] RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation, Sunzhu Li+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #PostTraining #RewardModel #GenerativeVerifier #Rubric-based #Open-endedTasks Issue Date: 2026-01-20 GPT Summary- 強化学習における検証可能な報酬(RLVR)は、論理的思考が求められるが、評価の欠如が生成の最適化を難しくしている。ルーブリック評価は構造的手段を提供するが、既存手法はスケーラビリティや粗い基準に課題がある。これに対処するため、自動評価基準の生成フレームワークを提案し、微妙なニュアンスを捉える高識別力基準を作成。約11万件のデータセット「RubricHub」を紹介し、二段階ポストトレーニングでその有用性を検証。結果、Qwen3-14BがHealthBenchで69.3の最先端結果を達成し、他のモデルを上回った。 Comment
pj page: https://huggingface.co/datasets/sojuL/RubricHub_v1
元ポスト:
[Paper Note] The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models, Christina Lu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #Safety #read-later #Personality Issue Date: 2026-01-20 GPT Summary- 大規模言語モデルはデフォルトで「助けるアシスタント」のアイデンティティを持ち、ペルソナ空間の構造を調査することで、モデルの助ける行動と自己認識のバランスを探る。特に、「アシスタント軸」を中心にペルソナを調整することで、モデルの行動を安定化させ、有害な行動を抑制することが可能になる。この研究により、ペルソナドリフトの予測が可能となり、モデルをより一貫したペルソナに固定する方法が示唆される。 Comment
元ポスト:
[Paper Note] Reasoning Models Generate Societies of Thought, Junsol Kim+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Chain-of-Thought #Reasoning #PostTraining #read-later #Probing #Diversity #Selected Papers/Blogs #SparseAutoencoder Issue Date: 2026-01-19 GPT Summary- 大規模言語モデルは、複雑な認知タスクにおいて優れた性能を発揮するが、そのメカニズムは不明瞭である。本研究では、強化された推論は計算の拡張だけでなく、異なる人格特性や専門知識を持つ内部認知視点の間のマルチエージェント相互作用によって生じることを示す。これにより、推論モデルはより広範な対立を引き起こし、視点の多様性が向上することを発見した。制御された強化学習実験により、会話行動の増加が推論精度を向上させることが明らかになり、思考の社会的組織が問題解決を効果的に行う可能性を示唆する。 Comment
元ポスト:
解説:
[Paper Note] Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge, Yao Tang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Chain-of-Thought #Reasoning #Architecture #Test-Time Scaling #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes #Initial Impression Notes Issue Date: 2026-01-19 GPT Summary- Multiplex Thinkingは、K個の候補トークンをサンプリングし、単一のマルチプレックストークンに集約することで、柔軟な推論を実現。モデルの自信に応じて標準的なCoTの挙動と複数の妥当なステップをコンパクトに表現。難易度の高い数学的推論ベンチマークで一貫して優れた結果を示す。 Comment
pj page: https://gmlr-penn.github.io/Multiplex-Thinking/
元ポスト:
reasoningに関する新たなアーキテクチャでざっくり言うと単一のreasoningをハードに保持して推論するのではなく、(人間のように?)複数の推論に関する情報をソフトに保持して応答する枠組みである。
reasoningにおける各ステップにおいてk個数のreasoningトークンを生成し、最終的な応答を生成する前に、各ステップで生成されたreasoningトークンのone-hot vectorを集約し平均化、その後集約されたベクトルに対してelement単位(vocabごとの)再重み付けをして、embedding matrix Eを乗じてcontext vectorを得る。このcontext vectorが様々なreasoningの結果を集約したような情報を保持しており、context vectorで条件付けで応答yを生成するようなアーキテクチャ。reasoningモデルに対して追加のオンポリシーRLを通じて応答yのRewardが最大化されるように事後学習することで実現される。
単に性能が向上するだけでなく、test time scaling (parallel, sequenceの両方)でもスケールする。
解説:
[Paper Note] The End of Reward Engineering: How LLMs Are Redefining Multi-Agent Coordination, Haoran Su+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #RewardModel Issue Date: 2026-01-19 GPT Summary- 報酬エンジニアリングは多エージェント強化学習の重要な課題であり、環境の非定常性や相互作用の複雑さがその難しさを増しています。最近の大規模言語モデル(LLMs)の進展により、数値的報酬から言語ベースの目的指定への移行が期待されています。LLMsは自然言語から報酬関数を合成したり、最小限の人間の介入で報酬を適応させたりする能力を示しています。また、言語による監視が従来の報酬エンジニアリングの代替手段として機能する新たなパラダイム(RLVR)が提案されています。これらの変化は、セマンティック報酬の指定や動的報酬の適応と関連し、未解決の課題や新しい研究方向が示唆されます。 Comment
元ポスト:
[Paper Note] Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models, Zirui Ren+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #Reasoning #Hierarchical #Author Thread-Post Issue Date: 2026-01-19 GPT Summary- HRMは推論タスクで優れた性能を示すが、単純なパズルでの失敗やグロッキングダイナミクス、複数の不動点の存在を通じて推測の側面が浮き彫りになった。これを踏まえ、データ拡張、入力摂動、モデルブートストラッピングの3つの戦略を提案し、合成HRMを開発。数独エクストリームの精度を54.5%から96.9%に向上させた。分析は推論モデルのメカニズムに新しい視点を提供する。 Comment
元ポスト:
Does anyone have a link to the source code for this paper?
I found the code:
code:
https://github.com/renrua52/hrm-mechanistic-analysis
[Paper Note] PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning, Jingcheng Hu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #Test-Time Scaling #PostTraining #read-later #Selected Papers/Blogs #Aggregation-aware #KeyPoint Notes #Reading Reflections Issue Date: 2026-01-19 GPT Summary- PaCoReは、固定されたコンテキストウィンドウを超えた計算量の拡張を目指すトレーニング・推論フレームワークです。逐次的パラダイムを脱し、複数のラウンドでメッセージ伝播アーキテクチャを用いた並列探索を行います。各ラウンドでは、並列推論経路を起動し、結果を圧縮して次のラウンドに統合し、最終的な答えを生成します。このアプローチにより、文脈制限を超えた実質的な計算量が実現され、特に数学推論で顕著な成果を示します。8BモデルはHMMT 2025で94.5%を達成し、オープンソース化された資源により、さらなる研究が期待されています。 Comment
元ポスト:
- [Paper Note] STEP3-VL-10B Technical Report, Ailin Huang+, arXiv'26, 2026.01
で活用されているRLでtest time scalingを学習する手法
モデルのSequentialなReasoning能力はcontext windowに制限されてしまうので、並列にモデルにreasoningをさせてそれらを集約させて、さらに直列で思考させる、といった処理を繰り返すことで、context windowの制限を超えてreasoning能力を高めることを目的としたtest-time scaling手法。
モデルに複数個のreasoning trajectoryを生成させ、それぞれのtrajectoryにCompaction Function(式2) を適用[^1]することで各resaoning trajectoryをcompaction message M として圧縮。圧縮したtrajectoryを元のpromptとともに与えて、同様の操作をRラウンド繰り返すtest-time scaling手法。最後のラウンドでは、生成するreasoning trajectoryの数を1とすることで最終的な応答を得る。モデルをこのプロセスに最適化するために、各ラウンドにおいて (x, M) が与えられた時に、並列して生成するreasoning trajectoryに対してRLVRを適用することでモデルの性能を引き上げている。Mはベースモデルによって事前に生成し、生成した結果をキャッシュしておくことでRL中に利用する。
PaCoReによってベースモデル(RLVR-8B)の性能が着実に押し上げられ、一部ベンチマークにおいてフロンティアモデルには届かなないものの非常に高い性能を示している。
また、Parallel test-time scaling手法として代表的なSelf-Consistencyと比較しても、より少ないtoken量で、より高いgainを得ている。
[^1]: 本研究ではCompatction Functionとしてreasoningの特性を利用して、結論部分に関連する部分を抽出し、intermediateなreasoning tokenは破棄するような関数を適用している
Figure1においてベースモデルであるRLVR-8B (Qwen3-8B-Base) に対して、PaCoReによってpost-trainingされたモデルがより良好なtest-time scalingを示すことが図示されているが、RLVR-8Bによるtest-time scaling手法としてどのようなものが適用されたのか(parallelなのか、sequentialなのか、結果を集約したのか等)が書かれていない気がする。
何が気になっているのかというと、提案手法が効果があることは分かったのだが、これがPaCoReの枠組みに則ったRLを適用しないと発現しないものなのか、それともPaCoReに特化したpost-trainingを実施しなくても、何らかのベースモデルに同様のtest-time-scalingの枠組みを利用すれば高い性能を得られるのか、といった点が気になる。どこかに書いてあるのだろうか?
[Paper Note] DeepSeek-R1 Thoughtology: Let's think about LLM Reasoning, Sara Vera Marjanović+, TMLR'26, 2025.04
Paper/Blog Link My Issue
#Analysis #NLP #Reasoning #TMLR #read-later #Selected Papers/Blogs Issue Date: 2026-01-17 GPT Summary- DeepSeek-R1は、LLMが複雑な問題に対処するための新しいアプローチを提案。直接答えを生成するのではなく、詳細な多段階推論チェーンを形成し、ユーザーに推論プロセスを公開することで思考の学問を創出。推論の長さ、コンテキストの管理、安全性の問題などに関する分析を行い、推論の「スウィートスポット」を特定。深い思考を持続的に行うが、過去の問題定式化に固執する傾向にも注意。また、対照モデルに比べて安全性の脆弱性があり、リスクを孕む可能性が示唆された。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=BZwKsiRnJI
[Paper Note] MoST: Mixing Speech and Text with Modality-Aware Mixture of Experts, Yuxuan Lou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #MultiModal #SpeechProcessing #Speech #UMM #text Issue Date: 2026-01-16 GPT Summary- 「MoST(Mixture of Speech and Text)」という新しいマルチモーダル言語モデルを提案。MAMoEアーキテクチャに基づき、専門的なルーティングパスを導入して音声とテキストの処理を統合。モデルはモダリティ特有のエキスパートと共有エキスパートを活用し、音声-テキストの効率的な変換パイプラインを開発。テスト結果は、MoSTが既存モデルを上回る性能を示し、特にルーティングメカニズムと共有エキスパートの影響が顕著であった。本モデルは、初の完全オープンソース音声-テキストLLMとして重要な意義を持つ。 Comment
元ポスト:
テキストとスピーチのUMMで、テキスト・音声生成の両方が可能
[Paper Note] TranslateGemma Technical Report, Mara Finkelstein+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#MachineTranslation #NLP #SmallModel #MultiLingual #OpenWeight #Selected Papers/Blogs #One-Line Notes #Initial Impression Notes Issue Date: 2026-01-16 GPT Summary- TranslateGemmaは、Gemma 3モデルに基づく機械翻訳のオープンモデルセットで、二段階のファインチューニングプロセスを採用。初めに高品質な並行データで監視付きファインチューニングを行い、その後報酬モデルによる強化学習で翻訳品質を最適化。WMT25テストセットでの人間評価とWMT24++ベンチマークでの自動評価を通じて有効性を示し、自動指標では大幅な性能向上が確認される。特に小型モデルは大型モデルに匹敵する性能を持ちつつ効率が向上。さらに、マルチモーダル能力も保持し、画像翻訳ベンチマークでの性能向上が報告されている。TranslateGemmaの公開は、研究コミュニティに強力で適応可能な翻訳ツールを提供することを目指している。 Comment
元ポスト:
10個の翻訳元言語→翻訳先言語対で評価されている。Japanese→Englishでも評価されているが、他の言語と比べて最も性能が悪いので、日本語では苦戦していそうに見える。English→Italianは(評価した言語ペアの中では)最も性能が良い。
ポイント解説:
関連:
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
- [Paper Note] Hunyuan-MT Technical Report, Mao Zheng+, arXiv'25, 2025.09
続報:
ブラウザ上で100%ローカルでの翻訳が可能になったらしい。WebGPUってなんだろう、、、
https://huggingface.co/spaces/webml-community/TranslateGemma-WebGPU
[Paper Note] ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking, Qiang Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#LearningToRank #PairWise #NLP #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-01-16 GPT Summary- 強化学習はLLMエージェントのパフォーマンスを向上させたが、オープンエンドのタスクでは依然として課題が残る。報酬モデルが得点をスカラーで割り当てるため、識別が難しく、最適化が停滞する。これに対抗するために、ArenaRLを提案し、相対ランキングに基づく新しいアプローチを導入。プロセス意識の対評価メカニズムを用いて、安定した利点信号を得るためのトーナメント方式を採用。実験結果は、この手法が効率性と精度のバランスを保ちながら、従来のベースラインを超えることを示す。また、オープンエンドエージェント向けの高品質ベンチマークOpen-TravelとOpen-DeepResearchも構築された。 Comment
元ポスト:
pj page: https://tongyi-agent.github.io/blog/arenarl/
従来のRLが各ロールアウトごとにpoint-wiseなrewardを付与していたとみなしたときに、定量化が困難なタスクにおいてrewardのsignalがノイジーでうまくいかないという現象が生じ、それに対し相対的な指標であるpairwiseなrankingを導入するというのは直感的に非常に有効で、さまざまなタスクに適用しうるため、インパクトが大きく重要論文に見える。
[Paper Note] Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents, Yi Yu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #PostTraining #memory #KeyPoint Notes Issue Date: 2026-01-14 GPT Summary- AgeMemは、LTMとSTMをエージェントのポリシーに統合し、メモリ操作を自律的に管理できるフレームワークを提案。3段階の強化学習で訓練し、5つのベンチマークでメモリ拡張性能が向上。タスクパフォーマンスと効率的なコンテキスト使用を実現。 Comment
元ポスト:
従来のAI Agentsにおけるメモリ管理は、short / long term memory [^1] の観点で見ると、双方を別々のコンポーネントとして扱われてきたが(short term memoryはRAGコンポーネント, long term memoryはagentic memoryの文脈で別々に研究され、trigger-based(決められたタイミングで決められた操作を実行する)、agent-based(何を・どのように格納するかを管理するエージェントを構築する))これらはヒューリスティックなルール (Figure1 left) や異なるexpertなモデルを必要とする(Figure1 (middle))ことからシステムのアーキテクチャを複雑にしているし(Figure1 left and middle)、それぞれが独立に構築され疎結合であるため、sub-optimalな性能しか出せておらず、long-horizonな実行を考えたときに双方を統合的に扱う枠組みが必要不可欠であると考えられるためそれが可能な枠組みを提案した、という話に見える。
[^1]: short memoryは現在のinput context全体を指し、long term memoryは永続的に保持されるユーザやtask specificなメモリのこと
解説:
[Paper Note] Dr. Zero: Self-Evolving Search Agents without Training Data, Zhenrui Yue+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Search #QuestionAnswering #ReinforcementLearning #AIAgents #SelfImprovement #PostTraining #On-Policy #KeyPoint Notes Issue Date: 2026-01-14 GPT Summary- データフリー自己進化が注目される中、大規模言語モデル(LLM)のための「Dr. Zero」フレームワークを提案。多様な質問を生成し、自己進化フィードバックループで解決者をトレーニング。HRPOを導入し、類似質問のクラスタリングを行うことで計算効率を向上。実験結果は、データフリーの検索エージェントが監視型と同等以上の性能を達成することを示す。 Comment
元ポスト:
(検索とReasoningを通じてSolver用の学習データとしてのverifiableな)QAを生成するProposerと、それを(検索とReasoningを通じて)解決するSolverの双方をRLするような枠組みで、ProposerはSolverからのDifficulty Reward (QAのverifiabilityとSolverの成功率(自明でなく難しすぎもしない丁度良い難易度か, 式(4))として受けとりHRPOと呼ばれる手法で改善、SolverはGRPOでRLVRする、といった枠組みに見える。QAはProposerが合成するので事前にデータを用意する必要がない、ということだと思われる。
HRPOはGRPO同様にon policyなRL手法であり、従来のself-evolving手法ではsingle hopなQuestionに合成結果が偏りやすく、かつon policyな手法でProposerを学習しようとしたときに、naiveにやるとm個のクエリに対して、クエリごとにsolverのn個のロールアウトが必要な場合、(m+1)*n回のロールアウトがpromptごとに必要となるため、計算コストが膨大になりスケーリングさせる際に深刻なボトルネックとなる問題を解決したものである。
具体的には、単一のpromptに対して複数のsolverによるロールアウトからadvantageを計算するのではなく、同じhop数の合成されたQAでクラスタリングを実施しておき、そのグループ内の(構造や複雑度がhop数の観点で類似した)QAに対するロールアウトに基づいてadvantageを計算する(3.2切に明記されていないが、おそらくロールアウトはQAごとに少数(1つ))。似たようなhop数を要するQAによってadvantageが正規化されるためadvantageの分散を小さくとることが期待され、かつロールアウトの回数を減らせるため計算効率が良い、という利点がある(3.2節)。
解説:
[Paper Note] Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models, Xin Cheng+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Embeddings #EfficiencyImprovement #NLP #Architecture #read-later #Selected Papers/Blogs #memory #Reference Collection Issue Date: 2026-01-14 GPT Summary- 条件付きメモリを用いたMixture-of-Experts (MoE)の拡張により、知識検索の効率を向上。Engramモジュールを通じて古典的なN-gram埋め込みのO(1)ルックアップを実現し、ニューラル計算と静的メモリの最適なトレードオフを導出。27Bパラメータでのスケーリングが同等のMoEベースラインを上回り、知識検索や一般推論、コード・数学領域で顕著な性能向上を示す。局所的依存性のルックアップでアテンション容量を解放し、長文脈検索能力を強化。Engramは次世代スパースモデルに不可欠なモデルプリミティブを提供する。 Comment
元ポスト:
所見:
解説:
解説:
ポイント解説:
先行研究:
- [Paper Note] Scaling Embedding Layers in Language Models, Da Yu+, NeurIPS'25, 2025.02
[Paper Note] EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning, Chuanrui Hu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #AIAgents #Reasoning #ContextEngineering #memory #LongHorizon Issue Date: 2026-01-13 GPT Summary- EverMemOSは、長期的なインタラクティブエージェントのための自己組織化メモリオペレーティングシステムで、エピソディックトレースをMemCellに変換し、ユーザープロファイルを更新することで一貫した行動を維持します。実験により、メモリ拡張推論タスクで最先端のパフォーマンスを達成し、ユーザープロファイリングやチャット指向の能力を示すケーススタディも報告しています。 Comment
元ポスト:
[Paper Note] Digital Red Queen: Adversarial Program Evolution in Core War with LLMs, Akarsh Kumar+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Multi #MachineLearning #NLP #AIAgents #Generalization #EvolutionaryAlgorithm #AdversarialTraining Issue Date: 2026-01-12 GPT Summary- 大規模言語モデル(LLMs)を用いた自己対戦アルゴリズム「デジタルレッドクイーン(DRQ)」を提案。DRQは、コアウォーというゲームでアセンブリプログラムを進化させ、動的な目的に適応することで「レッドクイーン」ダイナミクスを取り入れる。多くのラウンドを経て、戦士は人間の戦士に対して一般的な行動戦略に収束する傾向を示し、静的な目的から動的な目的へのシフトの価値を強調。DRQは、サイバーセキュリティや薬剤耐性などの実用的な多エージェント敵対的ドメインでも有用である可能性を示唆。 Comment
元ポスト:
[Paper Note] Extracting books from production language models, Ahmed Ahmed+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #read-later #Selected Papers/Blogs #Memorization #Legal Issue Date: 2026-01-12 GPT Summary- 本研究では、商業用LLMにおける著作権で保護されたトレーニングデータの抽出可能性を調査。2段階の手法を用い、4つのLLM(Claude 3.7 Sonnet、GPT-4.1、Gemini 2.5 Pro、Grok 3)でテストを実施。Gemini 2.5 ProとGrok 3はジャイルブレイクなしで高い抽出率を示し、Claude 3.7 Sonnetはジャイルブレイクでほぼ逐語的に出力。GPT-4.1は多くの試行が必要で抽出率が低かった。結果、商業用LLMにおいても著作権データの抽出がリスクであることが示された。 Comment
元ポスト:
重要研究に見える
[Paper Note] Agent-as-a-Judge, Runyang You+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #LLM-as-a-Judge Issue Date: 2026-01-12 GPT Summary- LLM-as-a-Judgeの限界を受け、エージェント型評価(Agent-as-a-Judge)への移行が進んでいる。エージェントは計画やツールを用いた検証を通じて、より堅牢でニュアンスのある評価を実現。しかし、統一されたフレームワークが欠如しているため、初の包括的な調査を行い、重要な次元を特定し、分類法を確立。コアメソッドやアプリケーションを整理し、課題を分析して次世代のエージェント型評価のためのロードマップを提供する。 Comment
元ポスト:
Agent-as-a-Judge
(画像はCC By 4.0に基づいて使用しています)
[Paper Note] Token-Level LLM Collaboration via FusionRoute, Nuoya Xiong+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Decoding #Routing #One-Line Notes Issue Date: 2026-01-10 GPT Summary- FusionRouteは、軽量なルーターを用いて、各デコーディングステップで最適な専門家を選択し、その専門家の出力を補完するトークンレベルのマルチLLMコラボレーションフレームワークを提案。これにより、ドメイン特化型モデルの効率性を保ちながら、一般化能力を向上させる。実験では、Llama-3やGemma-2といったモデルで、数学的推論やコード生成などのタスクにおいて優れた性能を示した。 Comment
元ポスト:
トークンレベルでモデルを選択して生成する
[Paper Note] SimpleMem: Efficient Lifelong Memory for LLM Agents, Jiaqi Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #Selected Papers/Blogs #memory #Initial Impression Notes Issue Date: 2026-01-09 GPT Summary- LLMエージェントのために、効率的なメモリシステムSimpleMemを提案。三段階のパイプラインで、意味的構造圧縮、再帰的メモリ統合、適応的クエリ認識型検索を実施し、情報密度とトークン利用を最大化。実験により、精度が26.4%向上し、トークン消費が最大30倍削減されることを確認。 Comment
pj page: https://aiming-lab.github.io/SimpleMem-Page/
ポイント解説:
追加の学習などが不要で、かつ高性能・低コストで動作するRetrieval basedなmemory(特定のLLMに依存しない点も良い)であり、実務的に導入が容易であり、実用性が高いため重要研究に見える。
[Paper Note] UniVideo: Unified Understanding, Generation, and Editing for Videos, Cong Wei+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Transformer #MultiModal #DiffusionModel #VariationalAutoEncoder #OpenWeight #ICLR #read-later #Selected Papers/Blogs #VideoGeneration/Understandings #Editing Issue Date: 2026-01-09 GPT Summary- UniVideoは、動画ドメインにおけるマルチモーダルコンテンツの生成と編集を目的とした統一モデルで、MLLMとMMDiTを組み合わせたデュアルストリーム設計を採用。これにより、複雑な指示の解釈と視覚的一貫性を維持しつつ、動画生成や編集タスクを統一的に訓練。実験結果では、テキスト/画像から動画への生成や文脈内編集において最先端の性能を示し、編集とスタイル転送の統合や未見の指示への対応も可能。視覚プロンプトに基づく生成もサポートし、モデルとコードは公開されている。 Comment
pj page: https://congwei1230.github.io/UniVideo/
元ポスト:
[Paper Note] How to Set the Learning Rate for Large-Scale Pre-training?, Yunhua Zhou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LearningRate Issue Date: 2026-01-09 GPT Summary- 学習率の最適設定は大規模事前学習において重要な課題であり、本研究では「フィッティング」と「トランスファー」の2つのパラダイムを用いて調査。フィッティングでは探索因子のスケーリング法則を導入し、複雑さを削減。トランスファーでは$μ$TransferをMixture of Expertsアーキテクチャに拡張し、適用範囲を広げる。実証結果は$μ$Transferのスケーラビリティに疑問を投げかけ、トレーニングの安定性と特徴学習の観点から分析を行い、モジュールごとのパラメータ調整の劣位を明らかにする。産業レベルの事前学習最適化に向けた実践ガイドラインと理論的視点を提供。 Comment
元ポスト:
[Paper Note] Learnable Multipliers: Freeing the Scale of Language Model Matrix Layers, Maksim Velikanov+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #NLP #Optimizer #read-later Issue Date: 2026-01-09 GPT Summary- 重み減衰(WD)を行列層に適用する際のノイズ平衡を改善するため、学習可能な乗数を導入。これにより、データに適応したスケールを学習し、性能を向上させる。行と列のノルムにも乗数を適用し、表現力を高める。提案手法は、計算オーバーヘッドを削減し、実用的な問題を解決。AdamおよびMuonオプティマイザでの検証により、下流評価での改善を確認。 Comment
元ポスト:
[Paper Note] How to Set the Batch Size for Large-Scale Pre-training?, Yunhua Zhou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #read-later #Batch #Scheduler #CriticalBatchSize Issue Date: 2026-01-09 GPT Summary- WSD学習率スケジューラに特化した改訂版E(S)関係を導出し、事前学習中のトレーニングデータ消費とステップのトレードオフを分析。最小バッチサイズと最適バッチサイズを特定し、動的バッチサイズスケジューラを提案。実験により、提案したスケジューリング戦略がトレーニング効率とモデル品質を向上させることを示した。 Comment
元ポスト:
Critical batch sizeが提案された研究:
- [Paper Note] An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18, 2018.12
[Paper Note] GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization, Shih-Yang Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Multi #NLP #Alignment #ReinforcementLearning #PostTraining #One-Line Notes Issue Date: 2026-01-09 GPT Summary- 言語モデルの行動を多様な人間の好みに沿わせるために、複数の報酬を用いた強化学習(RL)が重要である。しかし、Group Relative Policy Optimization(GRPO)を適用すると、報酬が同一のアドバンテージ値に収束し、トレーニング信号の解像度が低下する問題がある。本研究では、報酬の正規化を分離する新手法GDPOを提案し、トレーニングの安定性を向上させる。GDPOはツール呼び出し、数学的推論、コーディング推論のタスクでGRPOと比較し、すべての設定でGDPOが優れた性能を示した。 Comment
元ポスト:
pj page: https://nvlabs.github.io/GDPO/
multiple rewardを用いたRLにおいて、GRPOを適用すると異なるrewardのsignalが共通のadvantageに収束してしまう問題を改善する手法を提案。
advantageのnormalizationをrewardごとに分離することによって、異なるrewardのsignalが共通のadvantageの値に埋もれてしまう問題を解決することでmultiple rewardの設定における学習効率を改善する、といった話に見える。下記例は2つのbinary rewardの例でGRPOではadvantageが2種類の値しかとらないが、GDPOでは3種類の異なるadvantageをとり、rewardの解像度が向上していることがわかる。
[Paper Note] The Role of Mixed-Language Documents for Multilingual Large Language Model Pretraining, Jiandong Shao+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #CrossLingual #read-later #Selected Papers/Blogs Issue Date: 2026-01-05 GPT Summary- 多言語大規模言語モデルは、単言語の事前学習にもかかわらず優れたクロスリンガル性能を示す。バイリンガルデータの影響を調査するため、単言語コーパスと比較した結果、バイリンガルデータを除去すると翻訳性能が56%低下するが、クロスリンガルQAや推論タスクには影響が少ないことが分かった。バイリンガルデータを並行データとコードスイッチングに分類し、並行データを再導入すると翻訳性能がほぼ回復したが、コードスイッチングの貢献は小さかった。これにより、翻訳は並行データの整合性に依存し、クロスリンガル理解はバイリンガルデータなしでも可能であることが示唆された。 Comment
元ポスト:
これは非常に興味深い。
[Paper Note] The Optimal Token Baseline: Variance Reduction for Long-Horizon LLM-RL, Yingru Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #Blog #ICML #PostTraining #read-later #Selected Papers/Blogs #LongHorizon Issue Date: 2025-12-27 GPT Summary- 勾配分散の爆発による訓練崩壊を防ぐため、最適トークンベースライン(OTB)を導出し、累積勾配ノルムの逆数で重み付けする方法を提案。Logit-Gradient Proxy を使用して勾配ノルムを効率的に近似し、訓練の安定性を向上。N=4 でN=32相当の性能を達成し、トークン消費を65%以上削減。 Comment
元ポスト:
[Paper Note] JustRL: Scaling a 1.5B LLM with a Simple RL Recipe, Bingxiang He+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #ICLR #PostTraining #read-later #Selected Papers/Blogs #Stability #Author Thread-Post Issue Date: 2025-12-20 GPT Summary- JustRLという最小限のアプローチを提案し、固定ハイパーパラメータを用いた単一ステージのトレーニングで最先端のパフォーマンスを達成。計算リソースは洗練されたアプローチの2倍を使用し、トレーニングは滑らかに改善。標準的なトリックの追加が探索を崩壊させる可能性があることを示し、シンプルで検証されたベースラインの重要性を強調。モデルとコードを公開。 Comment
元ポスト:
ICLR'26 blog post track にアクセプト:
著者ポスト:
[Paper Note] Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity, Jiayi Zhang+, ICML'26 2025.10
Paper/Blog Link My Issue
#NLP #Prompting #ICML #Diversity #Selected Papers/Blogs Issue Date: 2025-12-13 GPT Summary- ポストトレーニングアライメントによるモード崩壊の原因を、好みデータにおける典型性バイアスに特定。これを基に「Verbalized Sampling(VS)」というプロンプティング戦略を提案し、モデルに応答の確率分布を言語化させる。実験により、VSが創造的執筆や対話シミュレーションなどで多様性を1.6〜2.1倍向上させることを示し、特に能力の高いモデルがより恩恵を受ける傾向が確認された。研究はモード崩壊に対する新たな視点を提供し、生成的多様性を解放する実用的な解決策を提示。 Comment
元ポスト:
preference dataに内在するtypicality bias(=人間が特定の応答を好む傾向)が、post trainingのalignmentフェーズにおいて増長されてモデルがモード崩壊を起こす(=特定の人間が典型的に好む応答のみを答えるようにalignされることで、出力の多様性が損なわれる)ことを明らかにし、「複数の出力と出力ごとの確率を出力させる」ようなpromptingによって、モデルが学習している確率分布そのものをverbalizeさせることで出力の多様性を引き出す、という話に見える。
pj page:
https://www.verbalized-sampling.com
コピペ可能なmagic promptが記載されている。test-time scalingと相性が良さそうである。
[Paper Note] Latent Collaboration in Multi-Agent Systems, Jiaru Zou+, ICML'26, 2025.11
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #ICML #Initial Impression Notes #Author Thread-Post #LatentRepresentation Issue Date: 2025-11-27 GPT Summary- LatentMASは、マルチエージェントシステムにおいて、LLMエージェントがテキスト媒介なしで直接協力できるフレームワークを提案。各エージェントは潜在思考生成を行い、共有された潜在作業メモリを通じて情報を損失なく交換。理論的分析と9つのベンチマーク評価により、従来のテキストベースのMASよりも高い表現力と効率を示し、精度向上や推論速度の改善を実現。コードはオープンソースで提供。 Comment
元ポスト:
Would you like to collaborate on something building from this?
著者ポスト:
エージェントのKV Pairをとっておき、次のエージェントで生成する際に、KV Pairをconcatすることで、潜在空間上で思考をエージェント間で共有する。ただし、エージェント間でKV Cacheを共有する上での核となるアイデアが3.1, 3.2と思われるが、まだ内容を読めていない。
textでのコンテキスト共有と比較して性能が向上するだけでなく、トークンコストとスピードが向上する。
[Paper Note] DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research, Rulin Shao+, ICML'26, 2025.11
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #OpenWeight #OpenSource #ICML #PostTraining #read-later #Selected Papers/Blogs #DeepResearch #Reference Collection #Rubric-based #Author Thread-Post Issue Date: 2025-11-19 GPT Summary- 長文で出典付きの回答を生成する深層研究モデルの訓練には、強化学習(RLVR)を活用した進化するルーブリック(RLER)を用いることで、モデルが新たな情報を取り込み、オンポリシーなフィードバックを提供できるようにする。本研究では、RLERを活用して初のオープンモデルDeep Research Tulu (DR Tulu-8B)を開発し、科学、医療、一般領域のベンチマークで従来モデルを大幅に上回った。データ、モデル、コードは公開され、新しいエージェント基盤も提供されている。 Comment
元ポスト:
著者ポスト:
著者ポスト2:
著者ポスト3:
demoをほぼ無料で実施できるとのこと:
takeaway:
デモが公開:
解説:
ICML'26 Spotlight:
[Paper Note] Train for Truth, Keep the Skills: Binary Retrieval-Augmented Reward Mitigates Hallucinations, Tong Chen+, ICML'26, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Hallucination #ICML #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-11-15 GPT Summary- 本研究では、外的幻覚を軽減するために新しいバイナリ検索強化報酬(RAR)を用いたオンライン強化学習手法を提案。モデルの出力が事実に基づいている場合のみ報酬を与えることで、オープンエンド生成において幻覚率を39.3%削減し、短文質問応答では不正解を44.4%減少させた。重要な点は、事実性の向上が他のパフォーマンスに悪影響を及ぼさないことを示した。 Comment
Utilityを維持しつつ、Hallucinationを減らせるかという話で、Binary Retrieval Augmented Reward (Binary RAR)と呼ばれるRewardを提案している。このRewardはverifierがtrajectoryとanswerを判断した時に矛盾がない場合にのみ1, それ以外は0となるbinary rewardである。これにより、元のモデルの正解率・有用性(極論全てをわかりません(棄権)と言えば安全)の両方を損なわずにHallucinationを提言できる。
また、通常のVerifiable Rewardでは、正解に1, 棄権・不正解に0を与えるRewardとみなせるため、モデルがguessingによってRewardを得ようとする(guessingすることを助長してしまう)。一方で、Binary RARは、正解・棄権に1, 不正解に0を与えるため、guessingではなく不確実性を表現することを学習できる(おそらく、棄権する場合はどのように不確実かを矛盾なく説明した上で棄権しないとRewardを得られないため)。
といった話が元ポストに書かれているように見える。
元ポスト:
openreview: https://openreview.net/forum?id=9KKNiNKgNk
[Paper Note] On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning, Yifan Zhang+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #ReinforcementLearning #ICLR #read-later #Selected Papers/Blogs #On-Policy Issue Date: 2025-11-12 GPT Summary- ポリシー勾配アルゴリズムを用いてLLMの推論能力を向上させるため、正則化ポリシー勾配(RPG)を提案。RPGは、正規化されたKLと非正規化されたKLを統一し、REINFORCEスタイルの損失の微分可能性を特定。オフポリシー設定での重要度重み付けの不一致を修正し、RPGスタイルクリップを導入することで安定したトレーニングを実現。数学的推論ベンチマークで最大6%の精度向上を達成。 Comment
元ポスト:
pj page: https://complex-reasoning.github.io/RPG/
続報:
openreview: https://openreview.net/forum?id=qe060gmfm7
[Paper Note] RLAC: Reinforcement Learning with Adversarial Critic for Free-Form Generation Tasks, Mian Wu+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #ICLR #Verification #Critic #Rubric-based #Author Thread-Post Issue Date: 2025-11-05 GPT Summary- 「対抗批評家による強化学習(RLAC)」を提案し、動的基準検証を通じて生成タスクの評価課題に対処。LLMを批評家として利用し、失敗モードを特定して検証することで、生成器と批評家を共同最適化。実験により、RLACがテキスト生成とコード生成の正確性を向上させ、従来の手法を上回ることを示した。動的批評家の効果も確認し、RLACのスケーリング可能性を示唆。 Comment
pj page: https://mianwu01.github.io/RLAC_website/
元ポスト:
関連:
著者ポスト:
openreview: https://openreview.net/forum?id=dBmjnRR1bC
[Paper Note] Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents, Yueqi Song+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #AIAgents #ICLR #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-10-30 GPT Summary- 本研究では、エージェントデータの収集における課題を解決するために、エージェントデータプロトコル(ADP)を提案。ADPは多様なデータ形式を統一し、簡単に解析・トレーニング可能な表現言語である。実験により、13のエージェントトレーニングデータセットをADP形式に統一し、標準化されたデータでSFTを実施した結果、平均約20%の性能向上を達成。ADPは再現可能なエージェントトレーニングの障壁を下げることが期待される。 Comment
pj page: https://www.agentdataprotocol.com
元ポスト:
著者ポスト:
解説:
エージェントを学習するための統一的なデータ表現に関するプロトコルを提案
続報:
openreview: https://openreview.net/forum?id=tG6301ORHd
[Paper Note] VisCoder2: Building Multi-Language Visualization Coding Agents, Yuansheng Ni+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #AIAgents #Evaluation #Coding #ICLR Issue Date: 2025-10-30 GPT Summary- 大規模言語モデル(LLMs)を用いた視覚化コーディングエージェントは、実行や修正において課題がある。これを解決するために、679Kの視覚化サンプルを含むデータセットVisCode-Multi-679K、自己デバッグ用のベンチマークVisPlotBench、そしてマルチ言語モデルVisCoder2を提案。実験結果では、VisCoder2がオープンソースのベースラインを超え、商用モデルに近い性能を示し、特に記号的言語での成功が顕著であった。 Comment
pj page: https://tiger-ai-lab.github.io/VisCoder2/
元ポスト:
openreview: https://openreview.net/forum?id=4zoMnmZzh4
[Paper Note] The Alignment Waltz: Jointly Training Agents to Collaborate for Safety, Jingyu Zhang+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #Alignment #ReinforcementLearning #AIAgents #Safety #ICLR #One-Line Notes #Author Thread-Post Issue Date: 2025-10-15 GPT Summary- WaltzRLという新しいマルチエージェント強化学習フレームワークを提案し、LLMの有用性と無害性のバランスを取る。会話エージェントとフィードバックエージェントを共同訓練し、応答の安全性と有用性を向上させる。実験により、安全でない応答と過剰な拒否を大幅に減少させることを示し、LLMの安全性を向上させる。 Comment
元ポスト:
マルチエージェントを用いたLLMのalignment手法。ユーザからのpromptに応答する会話エージェントと、応答を批評するフィードバックエージェントの2種類を用意し、違いが交互作用しながら学習する。フィードバックエージェント会話エージェントが安全かつ過剰に応答を拒絶していない場合のみ報酬を与え、フィードバックエージェントのフィードバックが次のターンの会話エージェントの応答を改善したら、フィードバックエージェントに報酬が与えられる、みたいな枠組みな模様。
著者による一言解説:
[Paper Note] Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense, Leitian Tao+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#ReinforcementLearning #Reasoning #Mathematics #ICLR #RewardModel #One-Line Notes #Author Thread-Post Issue Date: 2025-10-13 GPT Summary- HERO(ハイブリッドアンサンブル報酬最適化)は、検証者の信号と報酬モデルのスコアを統合する強化学習フレームワークで、より豊かなフィードバックを提供。層別正規化を用いて正確性を保ちながら品質の区別を向上させ、数学的推論ベンチマークで従来のベースラインを上回る結果を示した。ハイブリッド報酬設計が推論の進展に寄与することを確認。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=0CajQNVKyB
著者による一言解説ポスト:
0/1のbinaryなsparse rewardとdense rewardの両方を組み合わせたハイブリッドなRL手法を提案。verifiable rewardではしばしば報酬がsparseになり学習シグナルが何も得られない課題があり、dense rewardにはノイズが多く含まれるという課題があり、両者を組み合わせることで課題を低減した、という感じの話らしい。
[Paper Note] h1: Bootstrapping LLMs to Reason over Longer Horizons via Reinforcement Learning, Sumeet Ramesh Motwani+, ICML'26 Spotlight, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SyntheticData #ICML #LongHorizon #Author Thread-Post Issue Date: 2025-10-09 GPT Summary- 大規模言語モデルは短期的な推論には強いが、長期的な推論では性能が低下する。既存のアプローチはスケールしにくい。本研究では、短期データを用いて長期的な推論能力を向上させるスケーラブルな方法を提案。単純な問題を合成し、複雑な多段階依存チェーンを構成。結果のみの報酬でモデルを訓練し、カリキュラムを通じて精度を向上。実験により、GSM8Kでの訓練がGSM-SymbolicやMATH-500などのベンチマークでの精度を最大2.06倍向上させることを示した。理論的には、カリキュラムRLがサンプルの複雑さにおいて指数的な改善を達成することを示し、既存データを用いた長期的な問題解決の効率的な道を提案。 Comment
元ポスト:
著者ポスト:
[Paper Note] Impatient Users Confuse AI Agents: High-fidelity Simulations of Human Traits for Testing Agents, Muyu He+, ACL'26, 2025.10
Paper/Blog Link My Issue
#NLP #UserModeling #Dataset #UserBased #AIAgents #Evaluation #ACL #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-10-08 GPT Summary- TraitBasisを用いて、会話型AIエージェントの堅牢性を体系的にテストする手法を提案。ユーザーの特性(せっかちさや一貫性のなさ)を制御し、AIエージェントのパフォーマンス低下を観察。最前線のモデルで2%-30%の性能低下を確認し、現在のAIエージェントの脆弱性を示す。TraitBasisはシンプルでデータ効率が高く、現実の人間の相互作用における信頼性向上に寄与する。$\tau$-Traitをオープンソース化し、コミュニティが多様なシナリオでエージェントを評価できるようにした。 Comment
元ポスト:
実際の人間にあるような癖(のような摂動)を与えた時にどれだけロバストかというのは実応用上非常に重要な観点だと思われる。元ポストを見ると、LLM内部のmatmulを直接操作することで、任意のレベルの人間の特性(e.g.,疑い深い、混乱、焦りなど)を模倣する模様。
[Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #SoftwareEngineering #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-10-07 GPT Summary- AIエージェントが長期的なタスクを自律的に完遂する能力が向上している中、Terminal-Bench 2.0を提案。これは実世界のワークフローに基づいた89の高難易度タスクから成るベンチマークで、ユニークな環境と人間の解法、包括的なテストが特徴です。フロンティアモデルは65%未満のスコアを記録し、改善点を明らかにするための誤り分析を実施。データセットは公開され、研究開発の支援が期待される。 Comment
元ポスト:
なお、Claude CodeはTerminal Benchリーダーボードでは非常にスコアが低いハーネスらしい:
現在はCodex+GPT-5.5がv2.0リーダーボードではSoTA
※以下、元論文中でScaffoldingと表現されている部分をAgent Harnessという最近の呼称に変更してメモしています。個人的にはScaffoldingという呼び方の方がEvaluation Harnessと混同しなくて好きなのですが、Agent Harnessの方が浸透していってそうなので、それにならっています。
Terminal Benchは与えられたタスクをターミナルを操作することで完了する能力を測定するベンチマークであり、SWE Benchなどの既存ベンチマークと比較して、より多様でlong horizon、かつフロンティアモデルにとってhardなタスクによってフロンティアモデルの性能を評価することを目的とする。注意点としては、エージェントはターミナルだけを唯一のツールとして利用することを強制しているわけではなく、コンテナを自由な方法で操作することができる。また、Terminal Benchが測定したいのはモデルの性能であるが、AI AgentにおいてモデルとAgent Harnessは切り離せない。Agent Harness(論文中ではscaffoldingというliteratureに沿った呼称を利用している)は特定のモデルに適合するように開発されており、同じ組織によって開発されたモデルとAgent Harnessではその傾向がより顕著である。このため、多くのAgent Harnessはバイアスや制約を持つため、その影響を緩和し中立に評価が可能なシンプルなAgent Harness (scaffolding)であるTerminus 2を導入している。Terminus 2はheadless terminalと呼ばれる単一のツールを有し、これは、Dockerコンテナを内のtmux shell上でキーストロークのみを実施できるツールであり、Bashコマンドのみを通じてタスクを遂行する。また、contextがlimitに到達した場合は、モデルにcontextを要約させる機能も有している。
Terminal Benchの一つのタスクは、タスクのinstruction, Dockerfile, test, 正解solutionが制限時間つきで構成され、多様なタスクを収集するためにオープンソースコミュニティの協力を得て93人のcontributorsによって、229のタスクが編成された。そのうち、著者らの困難度や品質などのレビューを経て89個のタスクが選択されTerminal Bench 2.0が編成された。
Terminal Bench 2.0のタスクの著者によって推定された、junior/expertなエンジニアがどの程度の時間をタスクを完了するのに要するかに関する分布。1時間以内に終わるものから、juniorでは168時間以上かかるものまで、幅広いhorizonのタスクが存在している。
以下がタスクを作成者によってアサインされたタスクのカテゴリの分布で、多くはソフトウェアエンジニアリングだが、システム管理やデータサイエンス、セキュリティなどもあり、非エンジニアリングタスクとして動画処理やpersonal assistantなどのタスクも少量だが含まれる。
評価結果を見ると、Figure 1となっており最も性能が良かったのはGPT-5.2+Codex CLIであった(なお、この評価結果はもう古いので最新の結果はリーダーボードを参照のこと)。次点でClaude Opus 4.5+Terminus 2であった。
また、性能-コストの散布図を見るとコストと性能はトレードオフにあることがわかる。
[Paper Note] Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning, Haozhe Wang+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Reasoning #ICLR #read-later #Entropy Issue Date: 2025-09-10 GPT Summary- 強化学習(RL)は大規模言語モデル(LLMs)の推論能力を向上させるが、そのメカニズムは不明。分析により、推論の階層が人間の認知に似た二段階のダイナミクスを持つことを発見。初期段階では手続き的な正確性が求められ、後に高レベルの戦略的計画が重要になる。これに基づき、HICRAというアルゴリズムを提案し、高影響の計画トークンに最適化を集中させることで性能を向上させた。また、意味的エントロピーが戦略的探求の優れた指標であることを検証した。 Comment
pj page: https://tiger-ai-lab.github.io/Hierarchical-Reasoner/
元ポスト:
ポイント解説:
解説:
openreview: https://openreview.net/forum?id=NlkykTqAId
[Paper Note] RL's Razor: Why Online Reinforcement Learning Forgets Less, Idan Shenfeld+, ICLR'26
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Catastrophic Forgetting #ICLR #Selected Papers/Blogs #On-Policy Issue Date: 2025-09-06 GPT Summary- 強化学習(RL)と教師ありファインチューニング(SFT)の比較により、RLが以前の知識をより良く保持することが明らかに。忘却の程度は分布のシフトによって決まり、KLダイバージェンスで測定される。RLは新しいタスクに対してKL最小解にバイアスがかかる一方、SFTは任意の距離に収束する可能性がある。実験を通じて、RLの更新が小さなKL変化をもたらす理由を理論的に説明し、「RLの剃刀」と呼ぶ原則を提唱。 Comment
元ポスト:
所見:
ポイント解説:
openreview: https://openreview.net/forum?id=7HNRYT4V44
[Paper Note] Any-Order Flexible Length Masked Diffusion, Jaeyeon Kim+, ICLR'26, 2025.08
Paper/Blog Link My Issue
#NLP #DiffusionModel #Architecture #Author Thread-Post Issue Date: 2025-09-04 GPT Summary- 柔軟なマスク付き拡散モデル(FlexMDMs)を提案し、固定長の生成制限を克服。FlexMDMsは、任意の長さのシーケンスをモデル化し、MDMsの推論の柔軟性を保持。合成迷路計画タスクで約60%の成功率向上を達成し、事前学習されたMDMsを簡単に再調整可能。ファインチューニングにより、数学とコード補完でパフォーマンスが向上。 Comment
元ポスト:
著者ポスト:
openreview: https://openreview.net/forum?id=ttuNnMRI6H
[Paper Note] Fantastic Pretraining Optimizers and Where to Find Them, Kaiyue Wen+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Optimizer #ICLR #read-later #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-09-03 GPT Summary- AdamWは言語モデルの事前学習で広く使用されているオプティマイザですが、代替オプティマイザが1.4倍から2倍のスピードアップを提供するという主張には二つの欠点があると指摘。これらは不均等なハイパーパラメータ調整と誤解を招く評価設定であり、10種類のオプティマイザを系統的に研究することで、公正な比較の重要性を示した。特に、最適なハイパーパラメータはオプティマイザごとに異なり、モデルサイズが大きくなるにつれてスピードアップ効果が減少することが明らかになった。最も高速なオプティマイザは行列ベースの前処理器を使用しているが、その効果はモデルスケールに反比例する。 Comment
元ポスト:
重要そうに見える
関連:
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
- [Paper Note] SOAP: Improving and Stabilizing Shampoo using Adam, Nikhil Vyas+, ICLR'25
著者ポスト:
-
-
考察:
openreview: https://openreview.net/forum?id=2J51qUZ0iG
[Paper Note] Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning, Vaishnavi Shrivastava+, ICLR'26, 2025.08
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #On-Policy #Overthinking #Reference Collection #Author Thread-Post Issue Date: 2025-08-14 GPT Summary- GFPO(Group Filtered Policy Optimization)を提案し、応答の長さの膨張を抑制。応答を長さとトークン効率に基づいてフィルタリングし、推論時の計算量を削減。Phi-4モデルで長さの膨張を46-71%削減し、精度を維持。Adaptive Difficulty GFPOにより、難易度に応じた訓練リソースの動的割り当てを実現。効率的な推論のための効果的なトレードオフを提供。 Comment
元ポスト:
ポイント解説:
著者ポスト:
openreview: https://openreview.net/forum?id=UKOqoULbZS
[Paper Note] R-Zero: Self-Evolving Reasoning LLM from Zero Data, Chengsong Huang+, ICLR'26
Paper/Blog Link My Issue
#NLP #SelfImprovement #ICLR #Label-free #Author Thread-Post Issue Date: 2025-08-09 GPT Summary- R-Zeroは、自己進化型大規模言語モデル(LLMs)が自律的にトレーニングデータを生成するフレームワークで、チャレンジャーとソルバーの2つのモデルが共進化することで、既存のタスクやラベルに依存せずに自己改善を実現します。このアプローチにより、推論能力が大幅に向上し、特にQwen3-4B-Baseでは数学推論で+6.49、一般ドメイン推論で+7.54の改善が確認されました。 Comment
元ポスト:
問題を生成するChallengerと与えられた問題を解くSolverを用意し、片方をfreezezさせた状態で交互にポリシーの更新を繰り返す。
### Challenger
- (Challengerによる)問題生成→
- (freezed solverによる)self consistencyによるラベル付け→
- Solverの問題に対するempirical acc.(i.e., サンプリング回数mに対するmajorityが占める割合)でrewardを与えChallengerを更新
といった流れでポリシーが更新される。Rewardは他にも生成された問題間のBLEUを測り類似したものばかりの場合はペナルティを与える項や、フォーマットが正しく指定された通りになっているか、といったペナルティも導入する。
### Solver
- ChallengerのポリシーからN問生成し、それに対してSolverでself consistencyによって解答を生成
- empirical acc.を計算し、1/2との差分の絶対値を見て、簡単すぎる/難しすぎる問題をフィルタリング
- これはカリキュラム学習的な意味合いのみならず、低品質な問題のフィルタリングにも寄与する
- フィルタリング後の問題を利用して、verifiable binary rewardでポリシーを更新
### 評価結果
数学ドメインに提案手法を適用したところ、iterごとに全体の平均性能は向上。
提案手法で数学ドメインを学習し、generalドメインに汎化するか?を確認したところ、汎化することを確認(ただ、すぐにサチっているようにも見える)。、
関連:
- [Paper Note] Self-Questioning Language Models, Lili Chen+, arXiv'25
- [Paper Note] Absolute Zero: Reinforced Self-play Reasoning with Zero Data, Andrew Zhao+, arXiv'25, 2025.05
著者ポスト:
-
-
日本語解説:
openreview: https://openreview.net/forum?id=96apU6YzSO
[Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, ICLR'26, 2025.08
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #ICLR #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-08-09 GPT Summary- 大規模言語モデル(LLM)の教師ありファインチューニング(SFT)の一般化能力を向上させるため、動的ファインチューニング(DFT)を提案。DFTはトークンの確率に基づいて目的関数を再スケーリングし、勾配更新を安定化させる。これにより、SFTを大幅に上回る性能を示し、オフライン強化学習でも競争力のある結果を得た。理論的洞察と実践的解決策を結びつけ、SFTの性能を向上させる。コードは公開されている。 Comment
元ポスト:
これは大変興味深い。数学以外のドメインでの評価にも期待したい。
3節冒頭から3.2節にかけて、SFTとon policy RLのgradientを定式化し、SFT側の数式を整理することで、SFT(のgradient)は以下のようなon policy RLの一つのケースとみなせることを導出している。そしてSFTの汎化性能が低いのは 1/pi_theta によるimportance weightingであると主張し、実験的にそれを証明している。つまり、ポリシーがexpertのgold responseに対して低い尤度を示してしまった場合に、weightか過剰に大きくなり、Rewardの分散が過度に大きくなってしまうことがRLの観点を通してみると問題であり、これを是正することが必要。さらに、分散が大きい報酬の状態で、報酬がsparse(i.e., expertのtrajectoryのexact matchしていないと報酬がzero)であることが、さらに事態を悪化させている。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい
最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。
日本語解説:
一歩先の視点が考察されており、とても勉強になる。
openreview: https://openreview.net/forum?id=Lv7PjbcaMi
[Paper Note] Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty, Mehul Damani+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #ICLR #read-later #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2025-08-02 GPT Summary- RLCRを用いた言語モデルの訓練により、推論の精度と信頼度を同時に改善。バイナリ報酬に加え、信頼度推定のためのブライヤースコアを用いた報酬関数を最適化。RLCRは、通常のRLよりもキャリブレーションを改善し、精度を損なうことなく信頼性の高い推論モデルを生成することを示した。 Comment
元ポスト:
LLMにConfidenceをDiscreteなTokenとして(GEvalなどは除く)出力させると信頼できないことが多いので、もしそれも改善するのだとしたら興味深い。
著者ポスト:
openreview: https://openreview.net/forum?id=ASQ649zdHm
[Paper Note] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, Lakshya A Agrawal+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#NLP #Prompting #AutomaticPromptEngineering #ICLR #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-07-29 GPT Summary- GEPA(Genetic-Pareto)は、LLMsのプロンプト最適化手法であり、自然言語を用いて試行錯誤から高レベルのルールを学習する。これにより、数回のロールアウトで品質向上が可能となり、GRPOを平均10%、最大20%上回る結果を示した。GEPAは、主要なプロンプト最適化手法MIPROv2をも超える性能を発揮し、コード最適化にも有望な結果を示している。 Comment
元ポスト:
openreview:
https://openreview.net/forum?id=RQm2KQTM5r
alpharxiv:
https://www.alphaxiv.org/overview/2507.19457v1
自動的なプロンプトエンジニアリングでGRPOを上回れるのであれば、downstreamタスクにLLMを適用したい場合に、手元にデータがあるのであれば、強めのGPUマシンがなくても非常に汎用性が高い手法となるので重要研究に見える。
[Paper Note] Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains, Anisha Gunjal+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #ICLR #PostTraining #Selected Papers/Blogs #Rubric-based Issue Date: 2025-07-24 GPT Summary- 報酬としてのルーブリック(RaR)フレームワークを提案し、構造化されたチェックリストスタイルのルーブリックを解釈可能な報酬信号として使用。HealthBench-1kで最大28%の相対的改善を達成し、専門家の参照に匹敵またはそれを上回る性能を示す。RaRは小規模な判定モデルが人間の好みに一致し、堅牢な性能を維持できることを証明。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=c1bTcrDmt4
[Paper Note] CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization, Zhongyuan Peng+, ACL'26, 2025.07
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #ReinforcementLearning #Mathematics #ACL Issue Date: 2025-07-09 GPT Summary- 自然言語の数学的表現を実行可能なコードに翻訳する課題に対し、批評者の役割を能動的な学習コンポーネントに変えるCriticLeanという新しい強化学習フレームワークを提案。CriticLeanGPTを用いて形式化の意味的忠実性を評価し、CriticLeanBenchでその能力を測定。285K以上の問題を含むFineLeanCorpusデータセットを構築し、批評段階の最適化が信頼性のある形式化に重要であることを示す。 Comment
元ポスト:
Lean 4 形式に
[Paper Note] How much do language models memorize?, John X. Morris+, ICML'26 Outstanding Paper Honorable Mention, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #Grokking #Selected Papers/Blogs #Memorization #reading #One-Line Notes #Author Thread-Post #DoubleDescent Issue Date: 2025-06-05 GPT Summary- モデルがデータポイントについての知識を推定し、現代の言語モデルの容量を測定する新手法を提案。記憶を意図しない記憶と一般化に分け、一般化を排除することで記憶を計算。GPTモデルの容量はパラメータあたり約3.6ビットと推定。データセットサイズの増加に伴い、記憶が満たされると「グロッキング」が始まり、意図しない記憶が減少。数百のトランスフォーマー言語モデルを訓練し、モデル容量とデータサイズの関係を示すスケーリング則を提示。 Comment
元ポスト:
著者ポスト:
解説:
LLMはまず記憶をし、1パラメータあたり3.6ビットを超えると飽和する。飽和後は圧縮、一般化、Double Decent、Grokkingという経過を辿る、という話が解説ポストに記載されている。
openreview: https://openreview.net/forum?id=NhU661EZ9C
[Paper Note] Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents, Jenny Zhang+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#NLP #AIAgents #Coding #SelfImprovement #ICLR #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #AgentHarness Issue Date: 2025-06-05 GPT Summary- ダーヴィン・ゴーデルマシン(DGM)は、自己改善するAIシステムであり、コードを反復的に修正し、コーディングベンチマークで変更を検証します。進化とオープンエンドな研究に基づき、生成されたエージェントのアーカイブを維持し、新しいバージョンを作成することで多様なエージェントを育成します。DGMはコーディング能力を自動的に向上させ、SWE-benchでのパフォーマンスを20.0%から50.0%、Polyglotでのパフォーマンスを14.2%から30.7%に改善しました。安全対策を講じた実験により、自己改善を行わないベースラインを大幅に上回る成果を示しました。 Comment
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
あたりの研究とはどう違うのだろうか、という点が気になる。
openreview: https://openreview.net/forum?id=pUpzQZTvGY
> * [[Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, N/A, ICML'24 [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
](https://github.com/AkihikoWatanabe/paper_notes/issues/1212)
>
> あたりの研究とはどう違うのだろうか、という点が気になる。
この点については、Self-Rewarding LLMではモデルの重みを(自身が生成した出力からPreference pairを構築し)DPOで更新していくのに対し(=Agent Harnessではなくモデル自身を賢くする)、
DGMでは基盤モデルはfrozenな上で、AI Agentのコードベースそのものをself-editingすることによって進化する点が異なる(=モデルではなくAgent Harnessを賢くする)。
baseとなるエージェントのコードベースは木構造に基づいて管理され、recursiveに探索されていき、ベンチマークのスコアを改善していく、という感じのようである。木構造によって過去のsolutionが保持され、単一の方向性のみが探索されることを抑制し(i.e., オープンエンドな探索が促進され)進化が局所解に陥ることを防ぐ。
3節冒頭に記述がある通り、Gödel Machineというのは2007年に提案された、AI自身が自らを証明可能な形で改善する方法を探索する理論的概念であるようだが、DGMではGödel Machineでの「変更によってシステムが改善されることを理論的に証明しなければならない」という点を緩和し、「変更が性能を向上させるという実験結果を用いる」ことで緩和する。
[Paper Note] LLMs Get Lost In Multi-Turn Conversation, Philippe Laban+, ICLR'26 Outstanding Paper, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #Conversation #ICLR #read-later #Selected Papers/Blogs #ContextEngineering #Reference Collection Issue Date: 2025-05-24 GPT Summary- LLMsは会話型インターフェースとして、ユーザーがタスクを定義するのを支援するが、マルチターンの会話ではパフォーマンスが低下する。シミュレーション実験の結果、マルチターンで39%のパフォーマンス低下が見られ、初期のターンでの仮定に依存しすぎることが原因と判明。LLMsは会話中に誤った方向に進むと、回復が難しくなることが示された。 Comment
元ポスト:
Lost in the MiddleならぬLost in Conversation。multi-turnで分割して指示を出すよりも、single-turnにすべてのinstructionを実施させた方が性能劣化が生じづらい。
openreview: https://openreview.net/forum?id=VKGTGGcwl6
[Paper Note] J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning, Chenxi Whitehouse+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #LLM-as-a-Judge #ICLR #PostTraining #GRPO #VerifiableRewards #Non-VerifiableRewards #KeyPoint Notes #Author Thread-Post Issue Date: 2025-05-16 GPT Summary- 本研究では、強化学習アプローチJ1を用いてLLMのトレーニング手法を提案し、判断タスクにおける思考促進とバイアス軽減を図ります。J1は、他の同サイズモデルを上回る性能を示し、特に小型モデルでも優れた結果を出します。モデルは自己生成した参照回答と比較することで、より良い判断を学ぶことが明らかになりました。 Comment
元ポスト:
LLM-as-a-Judgeのなめのモデルを学習するレシピにおいて、初めてRLを適用した研究と主張し、より高品質なreasoning traceを出力できるようにすることで性能向上をさせる。
具体的にはVerifiableなpromptとnon verifiableなpromptの両方からverifiableなpreference pairを作成しpointwiseなスコアリング、あるいはpairwiseなjudgeを学習するためのrewardを設計しGRPOで学習する、みたいな話っぽい。
non verifiableなpromptも用いるのは、そういったpromptに対してもjudgeできるモデルを構築するため。
mathに関するpromptはverifiableなのでレスポンスが不正解なものをrejection samplingし、WildChatのようなチャットはverifiableではないので、instructionにノイズを混ぜて得られたレスポンスをrejection samplingし、合成データを得ることで、non verifiableなpromptについても、verifiableなrewardを設計できるようになる。
openreview: https://openreview.net/forum?id=dnJEHl6DI1
著者による一言解説:
[Paper Note] Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #Coding #Mathematics #ICLR #read-later #Diversity #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-05-08 GPT Summary- 本研究では、公共データを体系的に書き換えることで大規模言語モデル(LLMs)の性能を向上させる2つのオープンライセンスデータセット、SwallowCodeとSwallowMathを紹介。SwallowCodeはPythonスニペットを洗練させる4段階のパイプラインを用い、低品質のコードをアップグレード。SwallowMathはボイラープレートを削除し、解決策を簡潔に再フォーマット。これにより、Llama-3.1-8Bのコード生成能力がHumanEvalで+17.0、GSM8Kで+12.4向上。すべてのデータセットは公開され、再現可能な研究を促進。 Comment
元ポスト:
解説ポスト:
openreview: https://openreview.net/forum?id=45btPYgSSX
[Paper Note] Ambig-SWE: Interactive Agents to Overcome Underspecificity in Software Engineering, Sanidhya Vijayvargiya+, ICLR'26, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #QuestionGeneration #ICLR #SoftwareEngineering #One-Line Notes Issue Date: 2025-04-02 GPT Summary- AIエージェントは、欠落情報を補うための推測や明確化の質問を避けることで、安全リスクやリソース浪費を引き起こすことがある。本研究では、対話型コード生成における不十分な指示への対処能力を評価し、(a) 不十分さの検出、(b) 明確化質問の提示、(c) 対話の活用による性能向上の三つのステップで検証した。Ambig-SWEを使用し、モデルは不十分な指示を区別するのに苦労しつつ、対話時には最大74%の性能向上を示した。これにより、対話の重要性が浮き彫りになった。研究は、最新モデルの情報処理におけるギャップを明らかにし、評価の段階的アプローチを提案している。 Comment
曖昧なユーザメッセージに対する、エージェントが"質問をする能力を測る"ベンチマーク
openreview: https://openreview.net/forum?id=X2yzXtH4wp
[Paper Note] Why Gradients Rapidly Increase Near the End of Training, Aaron Defazio, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Pretraining #NLP #Optimizer Issue Date: 2026-07-16 GPT Summary- LLMのトレーニング中に勾配ノルムが急増する問題を解析。重み減衰、正規化層、学習率スケジュールの相互作用が原因であることを示し、単純な修正案を提案。これにより、損失値をトレーニング全体で低く抑えることが可能となる。 Comment
AdamC (Algorithm 1, Figure 4)
[Paper Note] When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning, Hyeong Kyu Choi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #Analysis #AIAgents #Bias #Author Thread-Post #Coordination Issue Date: 2026-07-08 GPT Summary- マルチエージェント討論(MAD)では、複数のエージェントが意見交換を通じてLLMの推論を改善するが、アイデンティティに基づくバイアスが信頼性を損なう。そこで本研究では、へつらいと自己バイアスを結びつける枠組みを提案。アイデンティティを重み付けベイズ更新プロセスとして形式化し、応答の匿名化によりエージェントの識別を防ぐことでバイアスを低減する。また、アイデンティティ・バイアス係数(IBC)を定義し、エージェントの意見従属傾向を測定。実証的研究により、へつらいが自己バイアスよりも一般的であることを確認し、内容に基づいた推論の必要性を強調した。 Comment
元ポスト:
- [Paper Note] Multi-Agent Teams Hold Experts Back, Aneesh Pappu+, arXiv'26, 2026.02
でも、エージェントが合意形成を優先するバイアスによって正しさを追求できない挙動があることが報告されている。
[Paper Note] Positional Encoding via Token-Aware Phase Attention, Yu Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#LongSequence #PositionalEncoding #read-later #Initial Impression Notes Issue Date: 2026-07-05 GPT Summary- RoPEの代替手法が長い文脈のモデル化に制限を与える中、本研究では新しい位置エンコーディング「Token-Aware Phase Attention(TAPA)」を提案。TAPAは学習可能な位相関数を組み込み、長距離でのトークン相互作用を保持しながら、軽量な事前学習を通じて文脈を拡張。これにより、RoPEスタイルの手法よりも低いパープレキシティと強い検索性能を実現。 Comment
元ポスト:
long contextでのperplexityがRoPEと比較して劇的に改善しているように見える
[Paper Note] Checklists Are Better Than Reward Models For Aligning Language Models, Vijay Viswanathan+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #Alignment #ReinforcementLearning #PostTraining #Rubric-based #Author Thread-Post Issue Date: 2026-07-03 GPT Summary- 指示遵守のために柔軟な基準を用いた強化学習の手法、チェックリストフィードバックからの強化学習(RLCF)を提案。指示からチェックリストを生成し、AI判定者と検証プログラムでスコア評価し、報酬を算出。RLCFは他の手法と比較して全てのベンチマークで性能を改善し、特にFollowBenchで4ポイント、InFoBenchで6ポイント、Arena-Hardで3ポイント向上を達成。チェックリストフィードバックが多様なニーズの対応を向上させることを示す。 Comment
元ポスト:
[Paper Note] Transformer-Squared: Self-adaptive LLMs, Qi Sun+, ICLR'25, 2025.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PEFT(Adaptor/LoRA) #SelfImprovement #ICLR #KeyPoint Notes #Test-time Learning Issue Date: 2026-06-27 GPT Summary- 自己適応型LLMの課題を解決するために、Transformer-Squaredを提案。これは未知のタスクにリアルタイムで適応できるフレームワークで、重みの特異成分を調整し、二段階処理を通じてタスク特有の「エキスパート」ベクトルを動的に組み合わせる。パラメータ数が少なく高効率で、視覚言語タスクにも対応。これにより、LLMsの適応性と性能を向上させ、自己組織化されたAIシステムへの道を開く。 Comment
openreview: https://openreview.net/forum?id=dh4t9qmcvK
個々の重み行列を特異値分解し、重み行列の特異値ベクトルをRLVRによってタスク(ドメイン)ごとに最適化し、test time時に線形結合して利用することで、Unseenタスクに対してtest timeに適応可能なSingular Value Finetuningを提案。
各タスクやドメインごとに高い性能を獲得できる新たな特異値ベクトル(expert vectorと呼ぶ)を学習し推論時に利用することで、全体の重み行列を新たな特異値ベクトルに基づいて更新することができる
また、学習するパラメータはW_{n,m}パラメータ行列のr=min(n,m)で良いため、LoRA等よりも少ないパラメータ数で適応できる。学習されるexpert vectorは重み行列の特異値であるため、ベクトルに対する解釈性が高く、ベクトルの変換や演算も適応可能となる利点がある。
(3.2節)。
各タスクのexpert vectorはREINFORCEに基づくRLVRで学習する(式1)。テスト時は2段階のプロセスを踏み、推論を実施する。まずinputを受け取り、inputがどのようなタスクを実現するかを同定する(dispatch)。続いて、タスクがより高い性能で解けるように、expert vectorの最適な混合比(線形結合)を、Cross-Entropy Method (CEM)によって、Fewshot sampleの性能が最大となるような混合比をサンプリングベースで求める(3.1節, p.6 (C) Fewshot Adaptation))。これにより、与えられたタスクをより高い性能で解くことができるexpert vectorをtest時に推論し、重み行列を更新した上で推論することができる。
expert vectorの混合方法は他にも2種類提案されているようだが、Fewshot Adaptationによる手法の性能が高そうに見える。
[Paper Note] CyberGym: Evaluating AI Agents' Real-World Cybersecurity Capabilities at Scale, Zhun Wang+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Security #Environment Issue Date: 2026-06-27 GPT Summary- AIエージェントのサイバーセキュリティ能力を評価するために、実世界の脆弱性を扱った大規模ベンチマークCyberGymを導入。1,507件の脆弱性を持つ188のプロジェクトにわたるデータを使用し、エージェントが脆弱性を再現するPoCテストを生成することを主な課題とする。評価の結果、成功率は約20%にとどまり、CyberGymの難易度が示された。また、34件のゼロデイ脆弱性と18件の不完全なパッチが発見され、AIの進歩を測るための有効なプラットフォームであることが確認された。 Comment
pj page: https://www.cybergym.io/#benchmarks
[Paper Note] Next-Latent Prediction Transformers Learn Compact World Models, Jayden Teoh+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Transformer #Self-SupervisedLearning #Architecture #Selected Papers/Blogs #WorldModels #KeyPoint Notes #Author Thread-Post #LatentRepresentation Issue Date: 2026-06-18 GPT Summary- Next-Lat Prediction(NextLat)は、トランスフォーマーの次トークン予測を潜在空間での自己教師付き予測に拡張し、予測可能な潜在状態を学習。これにより、整合した信念状態を形成し、内部世界モデルをコンパクトに構築。エビデンスとして、推論や計画において顕著な精度向上を示し、言語モデリングの推論速度を最大3.3倍に高速化。NextLatはトランスフォーマーに再帰的な帰納バイアスを効果的に注入するシンプルで強力な手法を提供。 Comment
元ポスト:
解説:
以下上記解説ポストの要約
transformerのアーキテクチャではRNNのような状態を逐次更新するようなアーキテクチャではないため、現在の隠れ状態とnext tokenから、次の隠れ状態を予測できるような損失関数を追加し(式3)、transformerに状態遷移を学習させる(自己教師あり学習によって実現できる)。また、next tokenの予測性能を落とさないように、真の隠れ状態が与えられた時の出力分布と離れないようなKL Divergenceに基づく損失をLossとして加える(式4)。これにより、
- transformerが過去のhistoryをコンパクトなbelief statesに圧縮することを促し
- latent spaceを予測することでone-hot tokenからの学習よりもdenseなシグナルに基づくため、データ効率を向上させ、
- look-aheadをすることによって投機的デコーディングに資する
- 内部表現が一貫した世界モデルとなることを促す
といった狙いがある。実験の結果、planning能力が向上し(belief statesによって先を見越して計画することが促されるため)next token predictionのperplexityを低下させることなく20 token先まで予測した場合にMulti Token Predictionよりもcross-entropy lossで性能を上回る、といった恩恵があるようである。
[Paper Note] Don't be lazy: CompleteP enables compute-efficient deep transformers, Nolan Dey+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#Pretraining #NLP #NeurIPS #HyperparameterTransfer #Depth Issue Date: 2026-06-05 GPT Summary- モデルサイズによるハイパーパラメータ調整のルールを検討し、従来のパラメータ化の限界を指摘。特に、最適な学習率の転送が不可能な場合には、再調整が高コストで難しいとされる。さらに、深さと非線形性の利点を活かせない怠惰な学習領域の問題を理論的に示す。新たに提案するCompletePパラメータ化は、深さと広さの比の範囲を拡大し、より効率的な訓練を実現。CompletePは、従来と比較して12-34%の計算効率の改善を示した。全ての実験はCerebras CS-3システム上で行われ、最小実装は提供されている。 Comment
openreview: https://openreview.net/forum?id=lMU2kaMANl
元ポスト:
muP:
- [Paper Note] Feature Learning in Infinite-Width Neural Networks, Greg Yang+, ICML'21
[Paper Note] DataDecide: How to Predict Best Pretraining Data with Small Experiments, Ian Magnusson+, ICML'25, 2025.04
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #Evaluation #ICML #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-05-29 GPT Summary- 小規模な実験を用いて大規模言語モデルのデータ選択を効率化することは重要である。DataDecideと呼ばれる評価スイートを通じて、異なるデータセットに基づいた前訓練の実験を実施し、150Mパラメータのモデルが1Bパラメータでの最良モデルを約80%の精度で予測できることが示された。主にスケーリング法則に基づくベースラインと比較し、連続的尤度指標を使うことで、限られた資源でも高精度の予測が可能であることが明らかとなった。 Comment
大規模なモデルを学習するためにどのようなデータレシピに従って、どのようなデータを使うべきかを、小規模なモデルでの学習を通じて予測できることを示した(150Mモデルの学習で1Bモデルに対するデータレシピの優劣を80%のDecisionAccuracyで予測可能)。
25種類のデータレシピ(ソース, deduplication, filtering, mixingによって構成)を、14種類のモデルスケールに対して、計算コスト(token-to-parameterの比率)を固定し3種類のseedを用いて実験し、事前学習の結果を体系的に調査。
1Bパラメータのdownstreamタスクにおいて、25種類のデータレシピごとの平均性能によってpairwiseの優劣に関するペアを構成し、全てのペアに対する優劣をどれだけ予測できるかを評価(DecisionAccuracy)したところ、下記図のようになった。たとえば、150Mスケールのモデルを訓練するだけでDecisionAccuracyは80%に到達し、これには1Bモデルを学習した場合と比較して2パーセント程度の計算コストしか要さないことが明らかとなった。
HF: https://huggingface.co/collections/allenai/datadecide
openreview: https://openreview.net/forum?id=p9YlQPF8fE
[Paper Note] Model Merging Scaling Laws in Large Language Models, Yuanyi Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Scaling Laws #ModelMerge Issue Date: 2026-05-21 GPT Summary- エキスパート統合の経験的スケーリング則を研究し、モデルサイズとエキスパート数の関係を明らかに。追加エキスパートの効果は初期に多く、以降は逓減することが確認された。この法則により、必要なエキスパート数の推定や追加の停止時期の決定が可能になり、マルチタスク学習の効率的なアプローチを提供する。これが分散型生成AIのスケーリング原理を示唆し、AGIレベルのシステムへの道を拓く。 Comment
元ポスト:
[Paper Note] Speculative Decoding: Performance or Illusion?, Xiaoxuan Liu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #MLSys #SpeculativeDecoding #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- 推測的デコード(SD)の実世界での有効性を評価するため、実際の推論エンジンvLLMを用いて初めての体系的研究を実施。複数のSD変種をさまざまな条件下で比較し、推論速度向上の理論的上限を定量化。結果は、モデルの検証が実行を支配し、受入長がさまざまな要因によって変化することを示唆。性能と理論的境界の間のギャップが大きく、新たな研究機会を明らかに。 Comment
元ポスト:
[Paper Note] Simple Policy Gradients for Reasoning with Diffusion Language Models, Anthony Zhan, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #DiffusionModel #PostTraining Issue Date: 2026-05-12 GPT Summary- dLLMsは優れた事前学習成果を示すが、ポストトレーニング技術が未活用で適用可能性が制限される。本研究はAGRPOを提案し、個々のデノイジングステップを最適化するポリシー勾配アルゴリズムを用いて改善を図る。様々なタスクで、ベースのLLaDAモデルに対しGSM8Kで+9.9%、MATH-500で+4.6%、Countdownで+59.4%、Sudokuで+69.7%の性能向上を達成し、推論設定を高速化しながら持続的なポストトレーニングの効果を示した。 Comment
元ポスト:
[Paper Note] Detecting and Filtering Unsafe Training Data via Data Attribution with Denoised Representation, Yijun Pan+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Pretraining #NLP #Safety #ICML #Author Thread-Post Issue Date: 2026-05-01 GPT Summary- LLMにおける不安全なデータの検出には、効果的なフィルタリングが不可欠である。従来の手法は主にモデレーション分類器に依存し、効率が悪い。本研究では、Denoised Representation Attribution(DRA)という新たなデータアトリビューション手法を提案し、訓練表現とターゲット表現のデノイズ化を行う。これにより、不安全データ検出が改善され、特にジャイルブレイクフィルタリングやジェンダーバイアスの検出において、従来手法を上回る結果を得た。 Comment
元ポスト:
[Paper Note] Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch, Arthur Douillard+, COLM'25, 2025.01
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #COLM #DistributedLearning Issue Date: 2026-04-26 GPT Summary- 大規模言語モデルの学習において、通信帯域幅の要求を減少させるため、パラメータのサブセットのみを順次同期し、学習を継続しながらデータを量子化。これにより、必要な帯域幅を約100分の1に削減し、品質を維持したまま十億規模のパラメータの分散学習を実現。 Comment
openreview: https://openreview.net/forum?id=yYk3zK0X6Q
DiLoCoでは、データをsplitし異なるノードに持たせ、それぞれのノードが独立して学習した後、定期的にモデルの重みを同期するような枠組みを提案した。
本研究では、重みを同期する際のボトルネックを
- 全ての重みを一度に同期するのではなく、サブセットを共有し、
- 共有する勾配を4bitに量子化することで通信に必要なピーク帯域幅を削減することでlatencyを最小化し、
- 重みを共有している間も学習は継続するstreamingの性質を持たせる
ことで、通信コストを低減しつつ学習効率を改善したようである。
[Paper Note] MesaNet: Sequence Modeling by Locally Optimal Test-Time Training, Johannes von Oswald+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #ICLR #RecurrentModels #LinearAttention #Author Thread-Post Issue Date: 2026-04-24 GPT Summary- シーケンスモデリングにおいて、最近の研究が提案するRNNモデルに、Mesa層を導入し数値的に安定かつ並列化可能な手法を検証。文脈内損失に基づく最適化で、従来のRNNよりも低いperplexityと下流ベンチマークでの改善を達成。特に長い文脈理解に効果的で、推論時の計算コストが増加するが、これが最近の計算性能向上のトレンドに寄与。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=xa3OnTb6c3
[Paper Note] Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding, StepFun+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #Infrastructure #Architecture #SoftwareEngineering #read-later #Selected Papers/Blogs Issue Date: 2026-04-11 GPT Summary- Step-3は、321Bパラメータの大規模言語モデルで、デコードコストの最小化を目的としたハードウェア意識のモデル-システム共設計を導入。主な革新点は、Multi-Matrix Factorization Attention (MFA)による計算量削減とAttention-FFN Disaggregation (AFD)による分散推論システムの構築。これにより、DeepSeek-V3やQwen3 MoE 235Bと比較して理論的デコードコストを大幅に低下させ、特に長文脈での利得が顕著。Hopper GPU上で最大4,039トークン/秒のデコードスループットを達成し、LLMデコードの新たなパレート前線を確立した。 Comment
元ポスト:
所見:
[Paper Note] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning, Bowen Jin+, COLM'25, 2025.03
Paper/Blog Link My Issue
#NLP #Search #ReinforcementLearning #PPO (ProximalPolicyOptimization) #Reasoning #COLM #GRPO #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-04-06 GPT Summary- 大規模言語モデル(LLMs)における外部知識の取得を改善するため、Search-R1という強化学習フレームワークを提案。リアルタイムで複数の検索クエリを生成し、推論過程を最適化。実験では、Search-R1が従来のRAGベースラインよりも大幅に性能を向上させた。さらに、RL手法と応答長のダイナミクスに関する洞察も提供。 Comment
openreview: https://openreview.net/forum?id=Rwhi91ideu#discussion
LLMにおいて検索を活用する方法として、従来はRAGやマルチターン会話の中でマルチクエリを用いて検索を取り入れるprompt-basedな手法と、検索エンジンをツールとして利用することを学習するtraining-based手法があったが、前者はLLMがどのように検索エンジンとinteractionするかを十分に理解しておらず、事前学習時に学習されていないタスクに対して汎化しづらいという欠点があり、後者は前者よりもより高い柔軟性を持つが、高品質なtrajectoryの不足によりスケーラビリティに乏しく、検索操作は微分不可能なため勾配ベースの手法による学習ができないという欠点があった。
これを克服し、LLMがreasoningプロセスの中でより柔軟に検索エンジンを用い、かつそれをマルチターンで実施できるような手法として、GRPO/PPOに基づく枠組みを提案しているようである。検索エンジンを用いる枠組みにおいてRLを適用する際には
- (1)検索されたコンテキストをどのようにRLに組み込めば安定したRLを実現できるかは未知
- (2)理想的にはiterativeにreasoningとsearchを繰り返し、タスクの難易度に応じて使い分けてほしいが、どのように実現するかは未知
- (3)検索とreasoningの両方を効果的に扱える報酬関数が未知
という課題があるが、これらに対して
- (1)検索によって得られたトークンはmaskをし
- (2)検索が必要な場合は
- (3)ルールベースのexact matchによるRewardを採用(式4)
することで対処した、という話のようである。
[Paper Note] MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering, Jun Shern Chan+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #AutoML #ICLR #Selected Papers/Blogs Issue Date: 2026-03-30 GPT Summary- MLE-benchは、AIエージェントの機械学習エンジニアリング能力を測定するためのベンチマークで、75件のKaggle競技を厳選し、実世界のスキルを試すタスクを作成。人間ベースラインを確立し、最先端の言語モデルを評価した結果、OpenAIのo1-previewとAIDEスキャフォールドの組み合わせが16.9%の競技でKaggleブロンズメダル以上の性能を示した。リソーススケーリングや事前学習の影響も調査し、ベンチマークコードをオープンソース化して今後の研究を促進する。 Comment
blog:
- MLE-Bench, OpenAI, 2024.10
openreview: https://openreview.net/forum?id=6s5uXNWGIh
[Paper Note] The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models, Ganqu Cui+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #PostTraining #EntropyCollapse Issue Date: 2026-03-22 GPT Summary- ポリシーエントロピーの崩壊を克服するために、LLMを用いた強化学習の手法を提案。エントロピーとポリシー性能の関係を示す経験的法則を確立し、エントロピーの管理が重要であることを示唆。共分散の理解を通じて、高共分散トークンの更新を制限する方法(Clip-CovとKL-Cov)を提案し、探索を促進しつつ、ポリシーエントロピーの減少を回避する実験結果を示した。 Comment
openreview: https://openreview.net/forum?id=vXoksdcfqC
[Paper Note] Large Scale Knowledge Washing, Yu Wang+, ICLR'25, 2024.05
Paper/Blog Link My Issue
#NLP #ICLR #KnowledgeEditing #MachineUnlearning(MU) Issue Date: 2026-03-10 GPT Summary- 大規模言語モデルは世界知識を記憶する能力が高い一方、個人情報や著作権問題の懸念がある。本研究では、知識の忘却を目的としたLarge Scale Knowledge Washing(LAW)を提案し、デコーダーのMLP層を更新することで推論能力を維持しつつ、特定の知識を忘却する新しい方法を導入する。実験結果はLAWの有効性を示し、推論能力を損なうことなくターゲット知識を忘却できることが確認された。コードはオープンソース提供。 Comment
openreview: https://openreview.net/forum?id=dXCpPgjTtd
[Paper Note] The Landscape of Agentic Reinforcement Learning for LLMs: A Survey, Guibin Zhang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Survey #NLP #ReinforcementLearning #AIAgents Issue Date: 2026-03-08 GPT Summary- エージェント的強化学習は、LLMを自律的な意思決定エージェントとして再定義するパラダイムシフトを示す。本研究では、LLM-RLの単一步のMDPとエージェント的RLのPOMDPを対比し、計画や推論などの核心能力に基づく二重分類法を提案。強化学習がこれらの能力を静的なヒューリスティックから適応的な振る舞いに変換する機構として機能することを強調。500件以上の研究をまとめ、オープンソースの環境やベンチマークを整理し、汎用的なAIエージェントの開発における機会と課題を明らかにする。 Comment
元ポスト:
[Paper Note] Context Engineering for AI Agents in Open-Source Software, Seyedmoein Mohsenimofidi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #Coding #SoftwareEngineering #ContextEngineering #Initial Impression Notes #AGENTS.md Issue Date: 2026-03-03 GPT Summary- AGENTS.mdを通じて、AIコーディングアシスタントにおける文脈情報の提供方法を調査。466のオープンソースプロジェクトから得たデータに基づき、情報の提示方法や進化を分析。結果、標準化された構造は存在せず、提供方法に大きなばらつきがあることが明らかに。AI文脈ファイルの設計が内容の品質向上に与える影響を研究する潜在性を示唆。 Comment
元ポスト:
オープンソースのリポジトリにおけるAGENTS.mdに関する分析らしい。
関連:
- [Paper Note] Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?, Thibaud Gloaguen+, arXiv'26, 2026.02
-
# Writing a good CLAUDE.md, Kyle, 2025.11
[Paper Note] Open Character Training: Shaping the Persona of AI Assistants through Constitutional AI, Sharan Maiya+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #PostTraining #Personality Issue Date: 2026-02-28 GPT Summary- キャラクター訓練は現代のチャットボットのペルソナ形成において重要であり、既存の研究が不足しています。本研究では、Constitutional AIを用いて、より効果的にアシスタントのペルソナを形成する初の実装を紹介します。ユーモラスや思いやりのある11種類のキャラクターを用いて、3つの人気モデルをファインチューニングし、嗜好の分析を通じて変化を追跡します。これにより、敵対的プロンプティングに対する耐性と一貫性のある生成が得られることを示しました。また、一般的能力への影響は minimal です。詳細はオープンソースとして公開されています。 Comment
元ポスト:
[Paper Note] ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference, Yesheng Liang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Quantization #Reasoning #LongSequence #ICLR #PostTraining #One-Line Notes Issue Date: 2026-02-28 GPT Summary- Post-training quantization (PTQ)はLLMの重みと活性化を低精度に圧縮し、メモリと推論速度を改善するが、外れ値が誤差を大きくし、特に推論型LLMの長い思考チェーンで精度低下を招くことがある。既存のPTQ手法は外れ値抑制が不十分であったり、オーバーヘッドがある。本研究では、独立ガイブンズ回転とチャネルスケーリングを組み合わせたペアワイズ回転量子化(ParoQuant)を提案し、ダイナミックレンジを狭め外れ値問題を解決する。推論カーネルの共同設計によりGPUの並列性を最大限活用し、精度向上を実現。結果、重みのみの量子化でAWQより平均2.4%の精度向上を達成し、オーバーヘッドは10%未満で、最先端の量子化手法と同等の精度を示す。これにより、高効率で高精度なLLMのデプロイが可能となる。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=1USeVjsKau
Reasoning LLMにおいてlong-CoTを実施した場合のエラーの蓄積を低減するようなpost-training-basedな量子化手法の提案
[Paper Note] Midtraining Bridges Pretraining and Posttraining Distributions, Emmy Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #mid-training #read-later #Selected Papers/Blogs Issue Date: 2026-02-26 GPT Summary- 中間訓練は、専門化したデータと一般的な事前学習データを混合することで言語モデルを改善する手法である。その効果は、分布間の橋渡しとして機能し、ポスト訓練の初期化を向上させることで説明される。特に、コードや数学のように一般データから距離のある領域で恩恵が最大であり、忘却の緩和にも寄与する。研究では、中間訓練データの導入時期と混合比の相互作用が重要であり、早期導入には高い混合比が適していることが示された。この結果は、他の訓練段階間の分布移行にも適用可能である。 Comment
元ポスト:
[Paper Note] Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers, Adam Karvonen+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Safety Issue Date: 2026-02-24 GPT Summary- LLMのアクティベーションの解釈が難しい中、LatentQAを用いた新たなアプローチが提案され、モデルがアクティベーションを入力として受け取り自然言語で質問に答える能力を訓練。汎用的アプローチで評価した結果、Activation Oracles(AOs)は微調整されていない情報を回収でき、狭く訓練されたモデルでも良好な一般化性能を示した。追加データセットによる改善も確認し、最良のAOはホワイトボックスベースラインを超える性能を達成した。この結果は、多様な訓練がアクティベーションの解釈能力を向上させることを示唆している。 Comment
元ポスト:
[Paper Note] Improving LLM Agents with Reinforcement Learning on Cryptographic CTF Challenges, Lajos Muzsai+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #AIAgents #Reasoning #PostTraining #RLVR #Security Issue Date: 2026-02-17 GPT Summary- セキュリティ分野におけるLLMエージェントの潜在能力を引き出すために、手続き的に生成された暗号用CTFデータセット『Random-Crypto』を提案。暗号推論を強化学習の理想的なテストベッドとして活用し、Pythonツールを用いてLlama-3.1-8BをGRPOでファインチューニング。得られたエージェントはPass@8で顕著な改善を見せ、『picoCTF』や『AICrypto MCQ』の外部ベンチマークにも一般化。アブレーション研究により、ツール活用の強化と手続き的推論の向上が寄与していることが示され、複雑なサイバーセキュリティタスクに対応可能な知的LLMエージェント構築の基盤を確立。 Comment
元ポスト:
[Paper Note] REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards, Zafir Stojanovski+, NeurIPS'25 Spotlight, 2025.05
Paper/Blog Link My Issue
#NLP #Library #ReinforcementLearning #Reasoning #NeurIPS #PostTraining #RLVR #KeyPoint Notes #Environment Issue Date: 2026-02-17 GPT Summary- Reasoning Gymは、強化学習のための推論環境ライブラリで、100以上のデータ生成器と検証器を提供する。代数、算術、認知、幾何学、論理など多様な領域を網羅し、難易度調整可能な訓練データを生成する革新性がある。これにより、固定データセットではなく継続的な評価が実現。実験結果は、推論モデル評価と強化学習でのRGの有効性を明らかにしている。 Comment
元ポスト:
代数、logic, ゲームなどの多様な分野に関するRLVR用の100種類以上のreasoning taskを、難易度調整可能な形で大量(というより無限)に生成可能な枠組みな模様。
データは手続的に生成される。つまりタスクごとにアルゴリズムが決まっていて、アルゴリスに従って生成される。全てのタスクは人間の介入なしで自動的にverification可能。タスクの解空間は非常に巨大で、overfittingやreward hackingを軽減し、configuableなパラメータによってタスクの難易度を制御可能。ドメインは5種類で数学、アルゴリズム、logical reasoning、パターン認識、制約充足(ゲームやパズル、プランニング)。
[Paper Note] Procedural Environment Generation for Tool-Use Agents, Michael Sullivan+, EMNLP'25, 2025.05
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #EMNLP #PostTraining #Environment #ToolUse Issue Date: 2026-02-17 GPT Summary- ツール利用エージェントの研究を促進する中、オンラインRL訓練におけるツール利用データのキュレーションが課題となっている。これに対処するため、対話型かつ構成的なツール利用データを手続き的に生成するRandomWorldを提案。これを用いたモデルは、さまざまなツール利用ベンチマークを向上させ、NESTFULデータセットで新たなSoTAを樹立。さらに、RandomWorld由来のデータ量が下流性能向上に寄与することを実証し、合成データの利用が改善の可能性を拓くことを示した。 Comment
元ポスト:
[Paper Note] SWE-smith: Scaling Data for Software Engineering Agents, John Yang+, NeurIPS'25 Spotlight, 2025.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #NeurIPS #SoftwareEngineering #PostTraining #One-Line Notes #Scalability #Environment Issue Date: 2026-02-17 GPT Summary- ソフトウェア工学向け言語モデル(LM)のトレーニングデータ収集は依然として課題であり、データセットは小さく、編纂に数百時間かかる。これを解決するために、SWE-smithという新しいデータ生成パイプラインを提案。任意のPythonコードベースを基にタスク例を自動合成し、約5万件のデータセットを作成。このデータで訓練したSWE-agent-LM-32Bが、最先端の解決率を達成。SWE-smithをオープンソース化し、参入障壁を下げることを目指す。 Comment
元ポスト:
データの構築方法はあまりしっかり読めていないが、モデルの学習方法がabstからよくわからなかったのでざっくり読むと、SWE-Smithのinstanceに対してstrong model(実験ではClaude)でtrajectoryを生成しベースモデルをSFTするようである。
[Paper Note] R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents, Naman Jain+, COLM'25, 2025.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SyntheticData #Coding #Test-Time Scaling #SoftwareEngineering #COLM #PostTraining #Verification #KeyPoint Notes #Scalability #Hybrid #Environment Issue Date: 2026-02-17 GPT Summary- AgentGymは、GitHubのIssue解決を目的としたSWEタスクのための手続き的にキュレーションされた大規模な実行可能ジム環境で、8,700以上のタスクから構成されています。主な貢献は、合成データキュレーションの手法SYNGENによるスケーラブルな環境構築と、実行ベースおよび実行不要の検証機を用いたハイブリッド・テスト時スケーリングです。これにより、SWE-Bench Verifiedベンチマークで51%のパフォーマンスを達成し、従来のプロプライエタリモデルと競合する能力を示しました。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=7evvwwdo3z#discussion
従来のSWE関連のデータセットでは、人間が記述したissueやtestが必要でscalabilityに課題があったが、すでに存在するテストコードからFail→Passとなるコミットを同定し、コミットの情報を逆翻訳することによってProblem statementを生成する。従来手法ではIssueの記述をそのまま使っていたが、スケーラブルではないので異なるアプローチが求められる。このため、本研究では以下二つの点を考慮し
- コミットのコード編集履歴のみではgenericな問題が生成されてしまう
- 人間が作成するIssueにはしばしば失敗するテストと実行トレースが付随することに着目し
Failedしたテストのテストコードと実行トレースとpromptに含めてよりspecificなProblem statementを生成するアプローチをとる。
また、SWEエージェントが出力するパッチの中からより良いパッチをランキング付けするためのtest-time scaling手法も提案している。具体的には、task description D, agent trajectory T, Patch Pが与えられた時にPatch PのスコアSを得る問題として定式化できる。このスコアを得る方法として、execution basedなverifierとexecution freeなverifierの2種類を分析し、最終的に両者のハイブリッドによってより良いtest-time scalingのgainが得られることを示している。
具体的には、前者はtest codeを自動生成するエージェントを学習し、taskに必要な機能に関するテストと、taskを解くための実装によって既存の機能が壊れていないかに関するテスト(回帰テスト)の2種類によって構成され、回帰テストのスコアが最も良いパッチに対して、テストがどれだけパスしたかによってスコアリングをする。
後者については、D, T, Pが与えられた時に、各Trajectory tが正しいものがどうかを2値分類するverifierを学習し、全体のtrajectoryの数に対するyesの割合によってスコアを定義する。
これらのverifierを分析した結果、双方共にtest-time scalingに対してgainを得られることがわかったが、前者はパッチの正しさに対して直接的なシグナルを得られるが、パッチそのものの質を識別する能力が低く、後者はパッチの質の識別力は高いが、エージェントの思考によるバイアスが課題として存在することがわかった。これより、両者は補完的な関係にあると考えられ、両者をハイブリッドすることによって、より良好なtest-time scalingによるgainを得ることが可能なことが示されている。興味深いのは、editing agent (i.e., パッチを生成するエージェント)のロールアウト数をスケープすることでも性能が改善するが、testing agentのロールアウト数をスケールすることで、editing agentのロールアウトを単にスケールするよりもより効率的なスケーリング性能を得られることである。
[Paper Note] InfLLM-V2: Dense-Sparse Switchable Attention for Seamless Short-to-Long Adaptation, Weilin Zhao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Attention #LongSequence #SparseAttention Issue Date: 2026-02-17 GPT Summary- 長いシーケンス処理のためのInfLLM-V2フレームワークを提案。密-疎切替可能な注意機構により、短い入力には密な注意を、長い入力にはスパース注意を使用し、パラメータを再利用して計算効率を向上。実験では、InfLLM-V2は密な注意より4倍速く、長文理解で98.1%、思考推論で99.7%の性能を維持。再現可能なハイブリッド推論モデルMiniCPM4.1を訓練・オープンソース化。
[Paper Note] Language Server CLI Empowers Language Agents with Process Rewards, Yifan Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #AIAgents #Coding #SoftwareEngineering Issue Date: 2026-02-13 GPT Summary- 言語サーバーを利用し、LSPサーバーを固定してコーディングエージェントやCI向けのCLI中心のオーケストレーションレイヤー「Lanser-CLI」を提案。これにより、構造的情報と実行可能なプロセス報酬を提供し、決定論的かつ再現可能なワークフローを実現。具体的には、堅牢なアドレス指定、安定した解析バンドル、セーフガードを伴う変異操作、オンラインで計算可能なプロセス報酬機能を機能させ、プロセス監視や反事実分析に適したシステムを構築。 Comment
元ポスト:
[Paper Note] CARMO: Dynamic Criteria Generation for Context-Aware Reward Modelling, Taneesh Gupta+, ACL'25 Findings, 2024.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Distillation #ACL #RewardHacking #PostTraining #Findings #Adaptive #Rubric-based Issue Date: 2026-02-11 GPT Summary- CARMOはダイナミックでコンテキストに関連した基準を用い、報酬モデリングの脆弱性を軽減する新手法。人間のフィードバックを取り入れ、生成された基準に基づき評価することで、報酬のハッキングを防ぎつつ、ゼロショット設定での性能を向上させ、Reward Benchで2.1%の改善を達成。Mistral-Baseに対して高いアライメントを示すデータセットも構築。 Comment
元ポスト:
[Paper Note] MQUAKE-REMASTERED: MULTI-HOP KNOWLEDGE EDITING CAN ONLY BE ADVANCED WITH RELIABLE EVALUATIONS, Zhong+, ICLR'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #ICLR #KnowledgeEditing Issue Date: 2026-02-08 GPT Summary- 誤った回答をするLLMに対し、知識の編集が効率的な修正手段として機能しますが、実世界の知識が複雑に絡み合っているため、編集効果の伝播が課題です。本研究では、MQuAKEデータセットの33%または76%の質問が様々な形で破損していることを示し、修正を提案します。また、修正後のMQuAKE-Remasteredデータセットに対する編集方法のベンチマークを行い、特定の性質に依存する手法がオーバーフィットすることを観察しました。最小限の侵襲的アプローチGWALKが、最先端の編集性能を発揮することを示しました。MQuAKE-Remasteredは、huggingfaceとGitHubで利用可能です。 Comment
openreview: https://openreview.net/forum?id=m9wG6ai2Xk
[Paper Note] CounterBench: A Benchmark for Counterfactuals Reasoning in Large Language Models, Yuefei Chen+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #KnowledgeEditing Issue Date: 2026-02-08 GPT Summary- 反実仮想推論はAIにおける複雑な因果関係の一つであり、本研究ではLLMの性能を評価します。1,000の質問からなる新しいベンチマーク「CounterBench」を導入し、さまざまな難易度や因果構造を考慮しました。実験結果では、多くのモデルが低い性能を示しましたが、新たに提案する推論パラダイム「CoIn」により、反実仮想推論タスクでLLMの性能が大幅に向上しました。データセットは公開されています。
[Paper Note] RewardBench 2: Advancing Reward Model Evaluation, Saumya Malik+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Dataset #Alignment #Evaluation #Selected Papers/Blogs #RewardModel #KeyPoint Notes #DownstreamTasks #Reading Reflections Issue Date: 2026-02-06 GPT Summary- 報酬モデルは、言語モデルの訓練後に好みデータを利用して指示遵守や推論、安全性を最適化するための訓練目標を提供します。新たに開発された「RewardBench 2」は、スキル領域を評価するための挑戦的なベンチマークを提供し、既存のモデルが低いスコアを示しつつも下流性能との相関が高いことを示しています。このベンチマークは人間のプロンプトを基にしており、厳格な評価プラクティスを促進しています。論文では、ベンチマークの構築プロセスと既存モデルの性能を報告し、モデルの下流使用との相関を定量化しています。 Comment
以下の6つのドメインで構成されるReward Modelの評価のためのベンチマーク:
- Factuality: hallucinationや誤りの有無の判定
- Precise Instruction Following: 細かい指示に対する追従性能
- Math: **自由記述**の数学に関するプロンプトに対する応答に関する能力
- Safety: 有害な応答に対して適切に対処できるか(応答拒否 or 適切な応答)
- Focus: 一般的なユーザのクエリに対して、トピックに沿った高品質な応答ができているか否か
- **Ties**: 「虹の色を1つ挙げて」といったような、複数の正解があり得るが、無数の不正解があるようなタスク(特定の正解にバイアスがかからず、正解と不正解を区別する能力を評価)
Reward Bench 2 での性能が、Best-of-N (=N個応答をサンプリングし最も良いものを採用するtest-time scaling手法)における様々なdownstreamタスクと強い相関を示すことが示されている。
ただし、PPOでの事後学習について焦点を当てた場合
- ベースモデルの出自がReward Modelと異なる場合
- Reward Modelの学習データが、ベースモデルと大きく異なる場合
においては、Reward Bench 2で高い性能が得られていても、PPOにおいて高い性能が得られず、特にベースモデルの出自が異なる場合の影響が顕著とのこと。
Reward Modelの性能が必ずしもPPOの事後学習後の下流タスクに対する性能と相関せず(ただし、Rewardベンチの性能が低い部分においてはおおまかに推定できる)、ベースモデルの出自が異なるReward Modelを使った場合や、Reward Modelとベースモデルが学習したプロンプトの分布が大きく異なる場合にこのような不整合が強く現れるというのは興味深く、おもしろかった。
Reward Modelとベースモデルの開始点が異なる場合は、RLによる学習がうまくいかないというのは、直感的でわかりやすい説明だなと感じた。
openreview: https://openreview.net/forum?id=fb0G86Dewb
[Paper Note] OpenRubrics: Towards Scalable Synthetic Rubric Generation for Reward Modeling and LLM Alignment, Tianci Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #RewardModel #Rubric-based #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 報酬モデルは人間のフィードバックを基にした強化学習の核を成しますが、従来の報酬モデルは多面的な人間の好みを捉えきれません。本研究では、構造化された基準を用いて複数の次元を評価する「ルブリック・アズ・リワード」を探求し、信頼性の高いルブリック生成に焦点を当て、OpenRubricsを紹介します。コントラストルブリック生成により、好ましい応答と拒否された応答を対比させて評価信号を引き出します。このアプローチにより、Rubric-RMは基準モデルを8.4%上回る性能を達成し、指示遵守や生物医学ベンチマークにも有効であることが示されました。 Comment
元ポスト:
chosen, rejectのpreferenceデータからcontrastiveにルーブリックやprincipleを明示的に構築して活用するというアプローチは非常に興味深い。色々な場面で役立ちそう。読みたい。
- [Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
の話と組み合わせて、もし高品質なルーブリックを動的に作成できれば、self-correction/refinementの能力の向上に活用できそうである。
[Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #LongSequence #Architecture #ICLR #Selected Papers/Blogs #LinearAttention Issue Date: 2026-02-04 GPT Summary- 線形トランスフォーマーの限界を克服するため、ゲーティングとデルタ更新ルールの2つのメカニズムを組み合わせた「Gated DeltaNet」を提案。これにより、迅速なメモリ消去とターゲット更新を実現し、言語モデリングや長文理解などのタスクで既存モデルを上回る性能を達成。ハイブリッドアーキテクチャを用いることでトレーニング効率も向上。 Comment
openreview: https://openreview.net/forum?id=r8H7xhYPwz¬eId=U0uk5A0VlT
linear attention:
- [Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20
Mamba2(linear attention with decay):
- [Paper Note] Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, Tri Dao+, ICML'24
Gated DeltaNet 図解:
[Paper Note] TTRL: Test-Time Reinforcement Learning, Yuxin Zuo+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #NeurIPS #Selected Papers/Blogs #Test Time Training (TTT) Issue Date: 2026-02-03 GPT Summary- ラベルのないデータを用いてLLMにおける強化学習(RL)を探求し、テスト時強化学習(TTRL)を新たに提案。TTRLは事前知識を活用し、自己進化を促進。実験結果はさまざまなタスクでのパフォーマンス向上を示し、特にQwen-2.5-Math-7Bの性能を211%向上させた。真のラベル付きデータに近い性能を達成し、TTRLの広範な適用可能性を強調。 Comment
pj page: https://github.com/PRIME-RL/TTRL
Agentが参照するメモリをテスト時のexperienceに基づいて更新し、良質なものを蓄積することでタスクを実行するごとに賢くなるような枠組みもある(Test-time Learningと論文では呼称している):
- [Paper Note] ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory, Siru Ouyang+, arXiv'25, 2025.09
[Paper Note] AssetOpsBench: Benchmarking AI Agents for Task Automation in Industrial Asset Operations and Maintenance, Dhaval Patel+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Multi #NLP #Dataset #AIAgents #Evaluation #One-Line Notes Issue Date: 2026-02-03 GPT Summary- AIを活用した産業資産ライフサイクル管理は、運用ワークフローの自動化を目指し、人間の負荷を軽減します。従来の技術は特定の問題に対処するに過ぎませんでしたが、AIエージェントと大規模言語モデルの登場により、資産ライフサイクル全体のエンドツーエンド自動化が可能になりました。本論文では、AssetOpsBenchというエージェント開発のための統合フレームワークを紹介し、知覚、推論、制御を統合した自律的なエージェントの構築について具体的な洞察を提供します。ソフトウェアはGitHubで公開されています。 Comment
dataset: https://arxiv.org/abs/2506.03828
元ポスト:
openreview: https://openreview.net/forum?id=ld6JUQbhes
産業におけるアセットの管理に関する(非常に複雑な)end-to-endなベンチマークで、multi agentに対する評価が前提となっている模様。
[Paper Note] ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks, Saurabh Jha+, ICML'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Financial #ICML #SoftwareEngineering #read-later #One-Line Notes Issue Date: 2026-02-03 GPT Summary- AIエージェントを用いたITタスク自動化の実現には、その効果を測定する能力が重要である。本研究では、AIエージェントのベンチマーキングを行うためのフレームワーク「ITBench」を提案。初期リリースはSRE、CISO、FinOpsの3領域に焦点を当て、実行可能なワークフローと解釈可能なメトリクスを提供。ITBenchは94の実世界シナリオを含み、最先端エージェントモデルのパフォーマンスを評価した結果、限られた成功率が示された。ITBenchがAI駆動のIT自動化において重要な役割を果たすことが期待される。 Comment
dataset:
-
https://huggingface.co/datasets/ibm-research/ITBench-Lite
-
https://huggingface.co/datasets/ibm-research/ITBench-Trajectories
元ポスト:
openreview: https://openreview.net/forum?id=jP59rz1bZk
94種類の実世界に基づいたシナリオに基づいてSRE, CSO, FinOpsに関するタスクを用いてAI Agentsを用いて評価する。各シナリオにはメタデータとEnvironments、トリガーとなるイベント、理想的な成果などが紐づいている。特にFinOpsに課題があることが示されている模様。
以下がシナリオの例で、たとえばFinOpsの場合はalertの設定ミスや、Podのスケーリングの設定に誤りがあり過剰にPodが立ってしまうといったシナリオがあるようである。
[Paper Note] KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction, Jang-Hyun Kim+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#NLP #NeurIPS #KV Cache #Compression Issue Date: 2026-02-02 GPT Summary- クエリ非依存型のKVキャッシュ削除手法「KVzip」を提案。LLMを用いてKVペアの重要性を定量化し、重要度の低いペアを削除することでKVキャッシュのサイズを$3$-$4\times$削減。これにより、デコーディングレイテンシを約$2\times$短縮し、さまざまなタスクにおいて性能低下がほとんどないことを実証。また、最大170Kトークンのコンテキストにおいて既存手法を上回る性能を示す。 Comment
元ポスト:
pj page: https://janghyun1230.github.io/kvzip/
openreview: https://openreview.net/forum?id=JFygzwx8SJ
[Paper Note] Cartridges: Lightweight and general-purpose long context representations via self-study, Sabri Eyuboglu+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Document #NLP #SyntheticData #LongSequence #read-later #Selected Papers/Blogs #KV Cache #Compression Issue Date: 2026-02-02 GPT Summary- 大型言語モデルは、テキストコーパスに基づくクエリ応答に広く使用されていますが、コンテキストウィンドウのメモリ消費が高くコストがかかります。本研究では、オフラインで小さなKVキャッシュ(カートリッジ)をトレーニングし、推論時にそれを使用する代替策を提案。カートリッジのトレーニングコストは分散可能ですが、単純な次トークン予測ではICLと競争できないことが判明。そこで、文脈蒸留を目的とした自己学習を用いたトレーニングを行いました。これにより、自己学習によるカートリッジはICLの機能を再現し、メモリ使用量を38.6倍削減し、スループットを26.4倍向上させました。また、効果的なコンテキスト長を延長し、再トレーニングなしで合成できるカートリッジを生成することにも成功しました。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=0k5w8O0SNg
[Paper Note] Scaling Embedding Layers in Language Models, Da Yu+, NeurIPS'25, 2025.02
Paper/Blog Link My Issue
#Embeddings #EfficiencyImprovement #NLP #Architecture #NeurIPS #One-Line Notes Issue Date: 2026-02-01 GPT Summary- 新手法$SCONE$は、言語モデルの性能向上のために入力埋め込み層を拡張し、元の語彙を保持しながら頻出n-gramの埋め込みを導入します。これにより、各トークンに文脈化された表現を提供し、埋め込みは訓練中に別のモデルで学習され、推論中にオフアクセラレータメモリから迅速に照会されます。$SCONE$は、埋め込み数の増加とモデルのスケールアップを実現し、1Bパラメータのモデルが1.9Bパラメータのベースラインを上回りながら、推論時のFLOPSとメモリを約半減することを示しています。 Comment
元ポスト:
関連:
- [Paper Note] Scaling Embeddings Outperforms Scaling Experts in Language Models, Hong Liu+, arXiv'26, 2026.01
- [Paper Note] L$^3$: Large Lookup Layers, Albert Tseng+, arXiv'26, 2026.01
あとでもう少ししっかり読みたいのだが、(Vocabularyをシンプルに増やしてスケーリングさせるのではなく、input embedding layerを拡張するために、LLM本体と独立したモジュールとして)通常のVocabularyに追加して、頻出するn-gram(f-gram)によるVocabularyを拡張した新たな小さなtransformerモジュールを定義し、contextを考慮した各トークンのembeddingを出力するよう学習する。独立したモデルとして定義することで、embeddingを事前に計算してオフローディングしておき高速にlookupすることが可能となり、FLOPSを増やさずにembeddingをスケーリングできて、リッチな入力表現を扱える。f-gramの数をスケールさせると性能もスケールする、といった話に見える。
[Paper Note] The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs, Piotr Nawrot+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#Analysis #NLP #Evaluation #LongSequence #read-later #Selected Papers/Blogs #SparseAttention #Initial Impression Notes #Author Thread-Post Issue Date: 2026-01-30 GPT Summary- スパースアテンションは、Transformer LLMの長文コンテキスト処理能力を向上させるが、その効率と精度のトレードオフは未評価である。本研究では、最大128Kトークンのシーケンスに対して、6つの手法を9つのタスクで分析し、スパースアテンションの効果的利用を示した。主な発見は、より大きなスパースモデルが小さな密なモデルを上回ること、トークンの重要度推定は計算制約で実現しにくいものの他の選択肢が効果的であること、長いシーケンスが高いスパース性を許容すること。これにより、スパースアテンション導入についての実践的ガイダンスを提供した。 Comment
元ポスト:
最近多くなってきたsparse attentionに関する非常に大きな実験で、かつ過去な提案されたものの分類などもされているようなのでsparse attentionに対する理解が深められそう。これは気になる。そして著者にSebastian Ruder氏の名前が。
[Paper Note] Latent Space Chain-of-Embedding Enables Output-free LLM Self-Evaluation, Yiming Wang+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#Embeddings #NLP #ICLR #SelfVerification Issue Date: 2026-01-30 GPT Summary- LLMの自己評価において、出力なしで正確さを推定するために、潜在空間のEmbeddingの連鎖(CoE)を提案。CoEは推論中の隠れ状態を反映し、正誤に基づく応答の特徴を明らかにする。実験により、トレーニングなしでミリ秒単位のコストでリアルタイムフィードバックが可能で、LLM内部の状態変化から新たな洞察が得られることを示した。 Comment
openreview: https://openreview.net/forum?id=jxo70B9fQo
[Paper Note] How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments, Jen-tse Huang+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#Evaluation #ICLR Issue Date: 2026-01-25 GPT Summary- LLMの意思決定能力を評価する新フレームワークGAMA($γ$)-Benchを提案。これには8つのゲーム理論シナリオと動的スコアリング方式が含まれ、ロバスト性や一般化能力を評価。結果としてGPT-3.5は高いロバスト性を示すが一般化能力は限定的で、Chain-of-Thought手法で強化可能。Gemini-1.5-Proが最も高得点を獲得し、他のモデルを上回る性能を示した。 Comment
pj page: https://cuhk-arise.github.io/GAMABench/
元ポスト:
openreview: https://openreview.net/forum?id=DI4gW8viB6
[Paper Note] Inference-Time Hyper-Scaling with KV Cache Compression, Adrian Łańcucki+, NeurIPS'25, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #Distillation #NeurIPS #Test-Time Scaling #PostTraining #KV Cache #Latency Issue Date: 2026-01-25 GPT Summary- 推論時のスケーリングでは、生成効率と精度のトレードオフが求められる。LLMにおいて生成コストはKVキャッシュのサイズに依存するため、KVキャッシュの圧縮が鍵となる。新手法のダイナミックメモリスパーシフィケーション(DMS)を導入し、学習不要のスパースアテンションよりも高い精度を維持しつつ8倍の圧縮を達成。DMSは重要な情報を保持しつつトークンの削除を遅延させる。実験により、DMSを用いることで複数のLLMファミリーにおいて精度向上を実証した。 Comment
[Paper Note] Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models, Yonggan Fu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #SmallModel #OpenWeight #Architecture #read-later #Selected Papers/Blogs #EvolutionaryAlgorithm #Latency #Operator Issue Date: 2026-01-23 GPT Summary- SLMの効率的な展開はレイテンシ制約のあるアプリで重要。本研究は、SLMのレイテンシ決定要因を特定し、深さと幅の比率、オペレータ選択が鍵であることを示す。深く細いモデルが精度向上につながるが、トレードオフフロンティアからは外れることがある。新しい効率的アテンションの代替手段を評価し、最適なオペレータを用いた進化的検索フレームワークを開発。さらに重み正規化技術を用い、SLMの性能を向上。新ハイブリッドSLM「Nemotron-Flash」は、精度を平均+5.5%向上させ、レイテンシを大幅に低下、スループットを著しく改善。 Comment
解説:
[Paper Note] Harnessing Diversity for Important Data Selection in Pretraining Large Language Models, Chi Zhang+, ICLR'25 Spotlight, 2024.09
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #ICLR #read-later #Diversity #Selected Papers/Blogs #DataMixture #Generalization #One-Line Notes #DownstreamTasks #Adaptive #Multi-Armed Bandit Issue Date: 2026-01-21 GPT Summary- データ選択は大規模言語モデルの事前トレーニングにおいて重要で、影響スコアでデータインスタンスの重要性を測定します。しかし、トレーニングデータの多様性不足や影響計算の時間が課題です。本研究では、品質と多様性を考慮したデータ選択手法\texttt{Quad}を提案します。アテンションレイヤーの$iHVP$計算を適応させ、データの品質評価を向上。データをクラスタリングし、選択プロセスでサンプルの影響を評価することで、全インスタンスの処理を回避します。マルチアームバンディット法を用い、品質と多様性のバランスを取ります。 Comment
openreview: https://openreview.net/forum?id=bMC1t7eLRc
あるモデルに対して、特定のデータセットD_rの性能を最大化するようにモデルを学習したいとする。このときに、全ての学習データD_cからD_rが学習の結果最大となるようなデータセットD_bを求めたい、という問題設定である。Influence Scoreを算出するモデルを活用する。
学習元データは事前にクラスタリングしておき、top-Kのクラスタを選択。選択したクラスタの中からmini-batchを抽出しinfluence scoreを計算し、influence scoreが一定の閾値を超えた場合にD_bに追加。その後計算したinfluence scoreと当該クラスタが選択された頻度情報に基づいてtop-kのクラスタを選択する際に用いるcluster scoreを更新。というiterationを繰り返しC_bを構築する、という方法に見える。
[Paper Note] Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance, Jiasheng Ye+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#Pretraining #NLP #ICLR #Scaling Laws #DataMixture Issue Date: 2026-01-21 GPT Summary- データ混合法則に基づき、モデル性能を予測するための関数を提案し、混合比率が性能に与える影響を定量的に分析。これにより、未知のデータ混合物の性能を事前に評価できる。実験結果では、1Bモデルが最適化された混合物で、デフォルトの混合物に比べ48%の効率で同等の性能を達成。さらに、継続的なトレーニングへの応用を通じて、混合比率を正確に予測し、動的データスケジュールの可能性を提示。 Comment
openreview: https://openreview.net/forum?id=jjCB27TMK3
[Paper Note] Aioli: A Unified Optimization Framework for Language Model Data Mixing, Mayee F. Chen+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#Pretraining #NLP #ICLR #DataMixture #Adaptive Issue Date: 2026-01-21 GPT Summary- トレーニングデータの最適な混合が言語モデルの性能に影響を与えるが、既存の手法は層化サンプリングを一貫して上回れない。これを解明するため、標準フレームワークで手法を統一し、混合法則が不正確であることを示した。新たに提案したオンライン手法Aioliは、トレーニング中に混合パラメータを推定し動的に調整。実験では、Aioliが層化サンプリングを平均0.27ポイント上回り、短いランで最大12.012ポイントの向上を達成した。 Comment
openreview: https://openreview.net/forum?id=sZGZJhaNSe
[Paper Note] Secret mixtures of experts inside your LLM, Enric Boix-Adsera, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #MoE(Mixture-of-Experts) Issue Date: 2026-01-19 GPT Summary- MLP層はトランスフォーマー内で最も理解が進んでいないが、実際にはスパースな計算を行っていると仮定。この層は、エキスパートの混合(MoE)によって良好に近似可能であり、活性化空間のMoEとスパースオートエンコーダー(SAE)との新たな理論的関連を基にしている。実験により、活性化分布が重要であることを示し、LLM内のMLP層の一般原則を明らかにした。これにより、MoEベースのアーキテクチャ設計に新たな方向性が示唆された。 Comment
元ポスト:
[Paper Note] AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset, Bingxiang He+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #Alignment #read-later #Selected Papers/Blogs Issue Date: 2026-01-19 GPT Summary- 好み学習の成功には、注釈、指示、応答ペアの3つの高品質なデータセットが重要ですが、従来のアプローチではこれらが混同されています。本研究では、各コンポーネントを系統的に分離・最適化し、相乗効果を評価するための分析フレームワーク「AIR」を提案します。実験により、注釈の単純さ、指示の推論安定性、応答ペアの質が行動可能な原則として明らかになり、これにより平均+5.3の性能向上が得られました。この研究は、好みデータセット設計を最適化へと導く設計図を提供します。 Comment
元ポスト:
[Paper Note] RePo: Language Models with Context Re-Positioning, Huayang Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Transformer #PositionalEncoding #Architecture #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-01-19 GPT Summary- インコンテキスト学習の問題に対し、認知負荷を軽減する新メカニズム「RePo」を提案。トークンの位置を文脈依存に配置することで、深い推論を促進。OLMo-2 1Bでの実験により、RePoは長い文脈や構造化データにおいてパフォーマンスを向上させることを確認。詳細分析から、重要情報への注意配分が強化されていることが示された。 Comment
pj page: https://pub.sakana.ai/repo/
元ポスト:
contextに応じてlearnableなパラメータでpositionの情報を動的に調整するというアイデアが非常に興味深く、RoPE(回転行列を用いた現在の主流)やNoPE(PEを排除する手法だが理論上は2層以上積み上げると相対/絶対注意の双方を実現可能で自由度が非常に高い)と比較しても性能が向上しており、PEの扱いはインパ駆動大きいため重要論文に見える。
ポイント解説:
ポイント解説:
[Paper Note] Self-Aligned Reward: Towards Effective and Efficient Reasoners, Peixuan Han+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-01-17 GPT Summary- 自己調整報酬(SAR)は、強化学習における検証可能な報酬を補完し、推論の正確性と効率を向上させる新たな信号。SARは、クエリに応じた簡潔で特定の回答を促進し、分析からはその質を信頼できる形で区別できることが示された。4つのモデルを7つのベンチマークで評価し、SARを強化学習アルゴリズムと統合することで精度が4%向上、推論コストが30%削減されることが確認。また、SARは正確性と効率のパレート最適なトレードオフを達成し、冗長性を抑えつつ重要な推論を保持することを示した。これにより、SARがLLMのトレーニングにおいて重要な役割を果たす可能性が示唆された。 Comment
code: https://github.com/amazon-science/Self-Aligned-Reward-Towards_Effective_and_Efficient_Reasoners
元ポスト:
様々なRLの報酬にplug-and-playで適用可能なreward signalで、ポリシーによって応答のみで条件付けた場合のperplexityと、クエリqで条件づけた場合の応答のperplexityから、perplexityが低下した割合を報酬(reward signal)とする。つまり、クエリで条件づけられたときによりモデルが自信を持って応答をしていた場合の報酬を高くする。reward hackingをしている場合は部分的であれクエリから外れた応答をすると思われるため、報酬が大きくなりづらい、というよりネガティヴになることさえありうるため、より安定した学習が実現すると思われる。
現在のRLにおける課題である計算効率において、性能を犠牲にせず(推論時のトークン効率の観点から)効率向上が期待できインパクトが大きいように見えるため、重要研究に見える。
[Paper Note] BugPilot: Complex Bug Generation for Efficient Learning of SWE Skills, Atharv Sonwane+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #Coding #SoftwareEngineering #Initial Impression Notes #BugGeneration Issue Date: 2026-01-16 GPT Summary- 合成的に多様なバグを生成する新手法を提案し、SWEエージェントの訓練における高品質なバグの重要性を強調。従来の局所的摂動によるバグ生成に対し、機能追加が意図しないバグを生じさせるプロセスを採用。実験により、新生成バグが監視付きファインチューニングにおいて効率的なデータを提供し、他データセットを上回る成果を実証。FrogBossとFrogMiniモデルがSWE-benchでそれぞれ54.6%と45.3%のpass@1を達成。 Comment
カオスエンジニアリングみたいになってきた
[Paper Note] Convergent Linear Representations of Emergent Misalignment, Anna Soligo+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Alignment #PEFT(Adaptor/LoRA) #Safety #One-Line Notes #EmergentMisalignment Issue Date: 2026-01-15 GPT Summary- 大規模言語モデルのファインチューニングで生じる「突発的な不整合」のメカニズムを調査。9つのランク1アダプターを使用して、異なるモデルが類似の不整合表現に収束することを示し、高次元のLoRAを用いて不整合な行動を除去。実験により、6つのアダプターが一般的な不整合に寄与、2つが特定ドメインの不整合に関与することを明らかに。理解を深めることで不整合の緩和が期待される。 Comment
evil (misalignment) vectorsの発見
[Paper Note] Model Organisms for Emergent Misalignment, Edward Turner+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #Safety #PostTraining #EmergentMisalignment Issue Date: 2026-01-15 GPT Summary- Emergent Misalignment(EM)は、狭いデータセットでの大規模言語モデルの微調整が広範な不整合を引き起こす可能性を示す新たな発見である。これにより、整合性に関する理解にギャップが存在することが明らかとなった。本研究は、狭い不整合なデータセットを用いて99%の一貫性を持つモデルオーガニズムを構築することを目指し、モデルサイズにかかわらずEMの発生を示す。メカニズム的な位相転換を孤立化し、整合性リスクの理解と軽減のための基盤を提供することが重要である。
[Paper Note] Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs, Jan Betley+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #Alignment #Safety #PostTraining #Selected Papers/Blogs #Initial Impression Notes #EmergentMisalignment Issue Date: 2026-01-15 GPT Summary- 言語モデル(LLM)が不正なコードを出力するようにファインチューニングされた結果、広範なプロンプトに対して不整合な振る舞いを示す「突発的不整合」が発生した。特にGPT-4oやQwen2.5-Coder-32B-Instructで顕著であり、ファインチューニングされたモデルは一貫性のない行動を示すことが確認された。コントロール実験により、突発的不整合の要因を特定し、不正なコードへのリクエストを受け入れるモデルの柔軟性に着目。バックドアを利用して突発的不整合を選択的に誘発する実験も行い、トリガーが存在する場合のみ不整合が顕れることがわかった。狭いファインチューニングが広範な不整合を引き起こす理由を理解することが今後の課題となる。 Comment
元ポスト:
Emergent Misalignmentを発見した研究で、AI Safetyの観点で重要な発見であると考えられる。
[Paper Note] Persona Features Control Emergent Misalignment, Miles Wang+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #Supervised-FineTuning (SFT) #ReinforcementLearning #Safety #PostTraining #SparseAutoencoder #EmergentMisalignment Issue Date: 2026-01-15 GPT Summary- 言語モデルの行動一般化はAIの安全性にとって重要であり、Betleyらの研究により、GPT-4oのファインチューニングが新たな不一致を引き起こすことが判明。これを拡張し、強化学習や合成データセットのファインチューニングでも同様の不一致を確認。スパースオートエンコーダーを用いたモデル差分比較により、不一致的ペルソナ特徴が特定され、有毒ペルソナが強い影響を与えることが示された。さらに、数百の無害なサンプルでファインチューニングすることで新たな不一致を緩和し、整合性を回復できることが発見された。 Comment
元ポスト:
[Paper Note] Efficient Context Scaling with LongCat ZigZag Attention, Chen Zhang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Transformer #Attention #LongSequence #Architecture #SparseAttention Issue Date: 2026-01-15 GPT Summary- LoZAは、フルアテンションモデルをスパースバージョンに変換するためのスパースアテンションスキームであり、長いコンテキストでの計算効率を向上させる。これにより、リトリーバル拡張生成やツール統合推論において顕著な速度向上が実現。LongCat-Flashの中間トレーニングに適用することで、1百万トークンまで迅速に処理可能な基盤モデルを提供し、効率的な長期推論が可能となる。 Comment
HF: https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking-ZigZag
元ポスト:
[Paper Note] SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios, Minh V. T. Thai+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Coding #SoftwareEngineering #LongHorizon Issue Date: 2026-01-12 GPT Summary- 既存のAIコーディングエージェントは単一の課題に焦点を当てているが、実際のソフトウェア開発は長期的な取り組みである。新たに提案するベンチマークSWE-EVOは、7つのオープンソースPythonプロジェクトから構築され、エージェントが複数ファイルにわたる修正を行う48の進化タスクを評価する。実験では、最先端モデルでも解決率が低く、特にマルチファイル推論に苦労していることが示された。さらに、複雑なタスクの進捗を測る指標Fix Rateも提案されている。 Comment
元ポスト:
[Paper Note] Upweighting Easy Samples in Fine-Tuning Mitigates Forgetting, Sunny Sanyal+, ICLR'25, 2025.02
Paper/Blog Link My Issue
#ComputerVision #NLP #Catastrophic Forgetting #ICLR #PostTraining #One-Line Notes Issue Date: 2026-01-12 GPT Summary- 事前学習済みモデルのファインチューニングにおける「破滅的忘却」を軽減するため、損失に基づくサンプル重み付けスキームを提案。損失が低いサンプルの重みを上げ、高いサンプルの重みを下げることで、モデルの逸脱を制限。理論的分析により、特定のサブスペースでの学習停滞と過剰適合の抑制を示し、言語タスクと視覚タスクでの有効性を実証。例えば、MetaMathQAでのファインチューニングにおいて、精度の低下を最小限に抑えつつ、事前学習データセットでの精度を保持。 Comment
openreview: https://openreview.net/forum?id=13HPTmZKbM
(事前学習データにはしばしばアクセスできないため)事前学習時に獲得した知識を忘却しないように、Finetuning時にlossが小さいサンプルの重みを大きくすることで、元のモデルからの逸脱を防止しcatastrophic forgettingを軽減する。
[Paper Note] An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning, Yun Luo+, IEEE Transactions on Audio, Speech and Language Processing'25, 2023.08
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #InstructionTuning #Catastrophic Forgetting #PostTraining Issue Date: 2026-01-12 GPT Summary- 破滅的忘却(CF)は、機械学習モデルが新しい知識を学ぶ際に以前の情報を忘れる現象であり、特に大規模言語モデル(LLMs)において調査されました。実験により、1bから7bパラメータのLLMsでCFが一般的に観察され、モデルのスケールが増すほど忘却が深刻化することが明らかになりました。デコーダ専用モデルのBLOOMZは、エンコーダ-デコーダモデルのmT0よりも忘却が少なく、知識を保持しています。また、LLMsは継続的なファインチューニング中に言語バイアスを軽減できることも示され、一般的な指示調整が忘却現象を軽減する可能性があることが示唆されました。 Comment
元ポスト:
[Paper Note] Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting, Howard Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Catastrophic Forgetting #PostTraining #Selected Papers/Blogs #On-Policy Issue Date: 2026-01-12 GPT Summary- ポストトレーニングにおける「破滅的忘却」を軽減するためのガイドラインを提案。監視付きファインチューニング(SFT)と強化学習(RL)の忘却パターンを比較した結果、RLはSFTよりも忘却が少なく、同等以上のパフォーマンスを示すことが判明。RLの特性が以前の知識を保持する理由を探り、オンポリシーデータの使用がその要因であることを確認。近似的なオンポリシーデータの利用が忘却を軽減する可能性を示唆。 Comment
元ポスト:
[Paper Note] Reinforcement Fine-Tuning Naturally Mitigates Forgetting in Continual Post-Training, Song Lai+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Catastrophic Forgetting #PostTraining Issue Date: 2026-01-12 GPT Summary- 継続的ポストトレーニング(CPT)における監視付きファインチューニング(SFT)と強化ファインチューニング(RFT)の影響を比較。SFTは以前の知識を忘却させるが、RFTは知識を保持し、マルチタスクトレーニングに匹敵する性能を発揮。RFTはモデルの一般的な知識を保護・向上させる一方、SFTは低下させる。RFTの安定性は暗黙の正則化メカニズムによるもので、データ依存の正則化因子として機能。RFTの効率を向上させるアルゴリズムも提案。RFTの優位性を示す研究。 Comment
元ポスト:
[Paper Note] Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings, Yoav Gelberg+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Transformer #LongSequence #PositionalEncoding #read-later #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-01-12 GPT Summary- 本研究では、言語モデル(LM)の位置埋め込みを削除することで、事前学習のシーケンス長を超えたコンテキスト拡張のボトルネックを解消する手法DroPEを提案。位置埋め込みの過度な依存が一般化を妨げることを示し、短い再キャリブレーション後に安全に削除できることを実証。DroPEは長いコンテキストのファインチューニングなしでゼロショット拡張を実現し、従来の手法を上回る性能を示した。 Comment
興味深い
元ポスト:
(読了前の第一印象)
- [Paper Note] The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad+, NeurIPS'23
において、NoPEは理論上絶対位置エンコーディングと相対位置エンコーディングの両方を実現可能であり、実際に学習をすると相対位置エンコーディングと似たような分布の位置エンコーディングが学習され、long contextの性能が改善することが報告されている。
まだ論文は読めていないのだが、NoPEは自由度が高いので、学習の初期は何らかの位置エンコーディング手法を補助輪的に使いある程度学習を進め、その後dropしてより自由度の高い状態でfinegrainedなrepresentationを学習するというのは確かにうまくいきそうだな、という感想をもった。
[Paper Note] Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks, Abhranil Chandra+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #Chain-of-Thought #SyntheticData #Reasoning #Distillation #One-Line Notes Issue Date: 2026-01-11 GPT Summary- 言語モデルの推論能力は、連鎖的思考(CoT)トレースの合成データセットでの訓練によって向上することが示された。合成データはモデル自身の分布に近く、学習に適応しやすい。また、不正確なトレースでも有効な推論ステップを含むことが多い。人間の注釈データを言い換えることでパフォーマンスが向上し、欠陥のあるトレースに対する耐性も研究された。MATH、GSM8K、Countdown、MBPPデータセットを用いて、モデルの分布に近いデータセットの重要性と、正しい最終回答が必ずしも信頼できる推論プロセスの指標ではないことが示された。 Comment
元ポスト:
base modelの分布と近いStronger Modelから合成されたCoTデータでSFTすると、合成データの応答がincorrectであっても性能が向上する。分布が遠い人間により生成されたCoTで訓練するより性能改善の幅は大きく、人間が作成したCoTをparaphraseしモデルの分布に近づけると性能の上昇幅は改善する(Figure1, Table4, 5)。
[Paper Note] ThinkGen: Generalized Thinking for Visual Generation, Siyu Jiao+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #ReinforcementLearning #Chain-of-Thought #MultiModal #DiffusionModel #TextToImageGeneration #PostTraining #read-later #One-Line Notes #ImageSynthesis Issue Date: 2026-01-06 GPT Summary- ThinkGenは、マルチモーダル大規模言語モデル(MLLM)のChain-of-Thought(CoT)推論を活用した初の思考駆動型視覚生成フレームワークである。MLLMが特化した指示を生成し、Diffusion Transformer(DiT)がそれに基づいて高品質な画像を生成する。さらに、MLLMとDiT間で強化学習を行うSepGRPOトレーニングパラダイムを提案し、多様なデータセットに対応した共同トレーニングを可能にする。実験により、ThinkGenは複数の生成ベンチマークで最先端の性能を達成した。 Comment
元ポスト:
MLLMとDiTを別々にRLして、MLLMはDiTが好むplan/instructionを生成し、その後DiTとConnectorに対してplan/instructionに従うようなRLをするような手法のようである。図2,3,4を見ると概要がわかる。
[Paper Note] A Plan Reuse Mechanism for LLM-Driven Agent, Guopeng Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #AIAgents Issue Date: 2026-01-05 GPT Summary- 大規模言語モデル(LLMs)を小型アシスタントに統合することで、インタラクション能力やタスク解決能力が向上するが、計画生成時の遅延が問題となる。約30%のリクエストが類似しているため、計画の再利用が可能だが、リクエストの類似性を正確に定義するのは難しい。これに対処するため、計画再利用メカニズム「AgentReuse」を提案し、意図分類を用いてリクエスト間の類似性を評価。実験結果では93%の計画再利用率を達成し、遅延を93.12%削減した。 Comment
元ポスト:
[Paper Note] Accelerating Scientific Discovery with Autonomous Goal-evolving Agents, Yuanqi Du+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #ScientificDiscovery #One-Line Notes #EvolutionaryAlgorithm Issue Date: 2026-01-05 GPT Summary- 科学的発見エージェントのために、目的関数の自動設計を行うSAGAを提案。二層アーキテクチャにより、LLMエージェントが新しい目的を提案し、内部ループで最適化を実施。これにより、目的の空間を体系的に探求し、抗生物質や無機材料などの応用で効果を向上させることを示す。 Comment
元ポスト:
目的関数そのものも進化させるような枠組み
[Paper Note] The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics, Edward Y. Chang, arXiv'25, 2025.12
Paper/Blog Link My Issue
#MachineLearning #NLP Issue Date: 2026-01-05 GPT Summary- 大規模言語モデル(LLMs)はAGIにおいて行き止まりとされるが、これは誤ったボトルネックの特定であると主張。パターンマッチングは必要だが、推論を行うための調整層が欠けている。UCCTを通じてこの層を形式化し、推論を支える理論を提案。無根拠な生成は基盤の最大尤度事前分布の取得に過ぎず、推論は目標指向の制約に向けた事後分布のシフトによって生じる。UCCTをアーキテクチャに変換し、調整スタックMACIを実装することで、AGIへの道はLLMsを通じて進むべきであると結論づける。 Comment
元ポスト:
[Paper Note] Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space, Xingwei Qu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #read-later #LatentReasoning #One-Line Notes #Concept (LLM PreTraining) #Author Thread-Post Issue Date: 2026-01-03 GPT Summary- DLCM(Dynamic Large Concept Models)は、トークン均一な計算の限界を克服するための階層的な言語モデリングフレームワークであり、意味的境界を学習して計算を圧縮された概念空間にシフトします。これにより、推論を効率化し、固定されたFLOPsの下で計算配分を最適化します。DLCMは、実用的な設定で推論計算の約3分の1を再配分し、12のゼロショットベンチマークで平均2.69%の性能向上を達成しました。 Comment
元ポスト:
従来のトークンを最小単位とする言語モデルではなく、意味的なチャンクを最小単位として扱う(チャンクの境界は隠れ状態の類似度が閾値を超えるか否かによって決める)Encoder-(Thinking Model)-Decoderタイプのモデルに見える。
関連:
- [Paper Note] Large Concept Models: Language Modeling in a Sentence Representation Space, LCM team+, arXiv'24, 2024.12
扱うconceptの最小単位という観点で見ると、こちらの研究はコンセプトをsentenceとしているが、本研究は(まだ全然読めていないのでおそらく)動的に決まるboundaryに基づくチャンクという点で異なっているように見える。
著者ポストを引用しているポスト:
[Paper Note] JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation, Kai Liu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #VideoGeneration/Understandings #Encoder-Decoder #3D (Video) #Omni #One-Line Notes #audio #AudioVisualGeneration Issue Date: 2026-01-03 GPT Summary- JavisGPTは、音声と映像の理解・生成のための初の統合型マルチモーダル大規模言語モデルであり、SyncFusionモジュールを用いて音声と映像の融合を実現。三段階のトレーニングパイプラインを設計し、高品質な指示データセットJavisInst-Omniを構築。広範な実験により、JavisGPTは既存のモデルを上回る性能を示し、特に複雑な同期設定で優れた結果を出した。 Comment
pj page: https://javisverse.github.io/JavisGPT-page/
元ポスト:
音声と映像を同時に生成可能なadapterタイプのMLLM
[Paper Note] DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models, Zefeng He+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #MultiModal #DiffusionModel #Reasoning #read-later Issue Date: 2026-01-03 GPT Summary- DiffThinkerという新しい生成的マルチモーダル推論フレームワークを提案し、視覚中心のタスクにおいて優れた論理的一貫性と空間的精度を実現。DiffThinkerはMLLMsと比較され、効率性、制御性、並列性、協調性の4つの特性が明らかにされる。広範な実験により、DiffThinkerは主要なクローズドソースモデルを大幅に上回る性能を示し、視覚中心の推論に対する有望なアプローチであることを強調。 Comment
pj page: https://diffthinker-project.github.io/
元ポスト:
[Paper Note] Recursive Language Models, Alex L. Zhang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #read-later #Selected Papers/Blogs Issue Date: 2026-01-03 GPT Summary- Recursive Language Models(RLMs)を提案し、LLMsが長いプロンプトを外部環境として扱い、再帰的に処理できることを示す。RLMsは、モデルのコンテキストウィンドウを超えた入力を処理し、短いプロンプトでも優れた結果を示し、コストも同等または安価であることが確認された。 Comment
元ポスト:
解説:
[Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
Paper/Blog Link My Issue
#MachineLearning #NLP #Transformer #Architecture #ICLR #Selected Papers/Blogs #ResidualStream Issue Date: 2026-01-02 GPT Summary- ハイパーコネクションは、残差接続の代替手法であり、勾配消失や表現崩壊の問題に対処します。異なる深さの特徴間の接続を調整し、層を動的に再配置することが可能です。実験により、ハイパーコネクションが残差接続に対して性能向上を示し、視覚タスクでも改善が確認されました。この手法は幅広いAI問題に適用可能と期待されています。 Comment
openreview: https://openreview.net/forum?id=9FqARW7dwB
[Paper Note] Large Language Models for Unit Test Generation: Achievements, Challenges, and Opportunities, Bei Chu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Survey #NLP #SoftwareEngineering #UnitTest Issue Date: 2026-01-02 GPT Summary- 自動化された単体テスト生成において、従来の手法は意味理解が不足しているが、LLMsはその知識を活用してこの問題を解決する。本研究では、115件の文献をレビューし、テスト生成ライフサイクルに基づく分類法を提案。プロンプトエンジニアリングが主なアプローチであり、89%の研究がこれに該当。反復的な検証が合格率を改善する一方で、故障検出能力やベンチマークの欠如が課題として残る。将来の研究では、自律的なテストエージェントやハイブリッドシステムの進展が期待される。 Comment
元ポスト:
[Paper Note] Evaluating Parameter Efficient Methods for RLVR, Qingyu Yin+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Mathematics #PEFT(Adaptor/LoRA) #PostTraining #RLVR #One-Line Notes Issue Date: 2026-01-02 GPT Summary- 本研究では、検証可能な報酬を伴う強化学習(RLVR)におけるパラメータ効率の良いファインチューニング(PEFT)手法を評価し、12以上の手法を比較しました。結果として、DoRAやAdaLoRAなどの構造的変種がLoRAを上回ること、SVDに基づく初期化戦略におけるスペクトル崩壊現象を発見し、極端なパラメータ削減が推論能力を制約することを示しました。これにより、パラメータ効率の良いRL手法の探求に向けたガイドを提供します。 Comment
元ポスト:
関連:
- [Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02
RLVRにおけるLoRAとLoRAの変種に関する性能を調査した研究のようである。ベースモデルとしてDeepSeekw-R1-Distilled-Qwen系モデルのみ, データのドメインとしてMathでのみ実験されている点には留意した方が良いと思われ、他のモデル・ドメインにも同様の知見が適用できるかは気になる。
[Paper Note] TimeBill: Time-Budgeted Inference for Large Language Models, Qi Fan+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Controllable #NLP #Architecture #Decoding #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-12-31 GPT Summary- LLMsの推論効率と応答性能を向上させるために、時間予算に基づくフレームワーク「TimeBill」を提案。細粒度の応答長予測器と実行時間推定器を用いてエンドツーエンドの実行時間を予測し、KVキャッシュの排出比率を適応的に調整。実験により、タスク完了率の向上と応答性能の維持を実証。 Comment
元ポスト:
興味深いアイデア
レスポンスの長さをbucket単位で予測し、実際のハードウェア上での過去のデータなどに基づいてruntimeを予測。予測したruntimeのworstcaseよりも遅延しないようにKV Cacheを削減することで限られた時間的な予算の中でresponceを返すような手法な模様。
[Paper Note] Professional Software Developers Don't Vibe, They Control: AI Agent Use for Coding in 2025, Ruanqianqian Huang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #SoftwareEngineering Issue Date: 2025-12-31 GPT Summary- 経験豊富な開発者は、AIエージェントを生産性向上の手段として評価しつつも、ソフトウェアの品質を重視し、自らの主体性を保ちながらエージェントを活用している。彼らはエージェントの行動を制御する戦略を採用し、エージェントの限界を補完する自信からポジティブな感情を抱いている。本研究は、エージェントの効果的な活用に向けたベストプラクティスや適したタスクの種類を示唆し、将来のエージェントインターフェースや使用ガイドラインの機会を指摘する。 Comment
元ポスト:
[Paper Note] End-to-End Test-Time Training for Long Context, Arnuv Tandon+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LongSequence #read-later #Selected Papers/Blogs #memory #ContinualLearning #Test Time Training (TTT) #Author Thread-Post Issue Date: 2025-12-30 GPT Summary- 長い文脈の言語モデリングを継続学習として定式化し、スライディングウィンドウ型の注意機構を用いたトランスフォーマーで次トークン予測を通じて文脈を圧縮。メタ学習によって初期化を改善し、テスト時訓練(TTT)の一形態を実現。3Bパラメータのモデルで1640億トークン学習し、文脈長のスケーリング特性が向上。推論レイテンシが一定で、128Kの文脈では全注意より2.7倍速い性能を示す。 Comment
元ポスト:
著者ポスト:
TTT-E2E
[Paper Note] Web World Models, Jichen Feng+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #WorldModels #text Issue Date: 2025-12-30 GPT Summary- 本研究では、言語エージェントのための中間的なアプローチとしてWeb World Model(WWM)を提案。WWMは、ウェブコードで実装された世界の状態と物理法則を基に、大規模言語モデルが高レベルの意思決定を生成する仕組み。実際の地理に基づく旅行地図や架空の探検など、様々な環境を構築し、実用的な設計原則を特定。これにより、制御可能でありながら無限の探索が可能な環境を実現することを示した。 Comment
pj page: https://github.com/Princeton-AI2-Lab/Web-World-Models
元ポスト:
ポイント解説:
[Paper Note] EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test, Yuhui Li+, NeurIPS'25, 2025.03
Paper/Blog Link My Issue
#NLP #NeurIPS #Decoding #read-later #Selected Papers/Blogs #SpeculativeDecoding #Initial Impression Notes Issue Date: 2025-12-28 GPT Summary- EAGLE-3は、特徴予測を放棄し、トークン予測に切り替えることで性能を向上させた大規模言語モデルの手法。これにより、トレーニングデータの拡大からの恩恵を最大化し、最大6.5倍のスピードアップを実現。実験では、チャットモデルと推論モデルの両方で評価され、EAGLE-2に対して約1.4倍の改善を示した。コードは公開されている。 Comment
openreview: https://openreview.net/forum?id=4exx1hUffq
Speculavive Decodingの文脈で多くの文献から本研究が言及される
[Paper Note] Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning, NVIDIA+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pretraining #NLP #Transformer #Supervised-FineTuning (SFT) #ReinforcementLearning #OpenWeight #SSM (StateSpaceModel) #MoE(Mixture-of-Experts) #PostTraining #Hybrid Issue Date: 2025-12-28 GPT Summary- Nemotron 3 Nano 30B-A3Bは、Mixture-of-ExpertsハイブリッドMamba-Transformer言語モデルであり、25兆のテキストトークンで事前学習され、監視付きファインチューニングと強化学習を経て精度を向上。前世代のNemotron 2 Nanoよりも高精度で、フォワードパスごとに半分未満のパラメータを活性化し、同サイズのオープンモデルと比較して最大3.3倍の推論スループットを達成。エージェント的、推論、チャット能力が向上し、最大1Mトークンのコンテキスト長をサポート。事前学習済みモデルはHugging Faceで公開。 Comment
元ポスト:
[Paper Note] AI-Trader: Benchmarking Autonomous Agents in Real-Time Financial Markets, Tianyu Fan+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Financial Issue Date: 2025-12-28 GPT Summary- AI-Traderは、金融意思決定におけるLLMエージェントのための初の完全自動化されたライブ評価ベンチマークであり、米国株式市場、A株市場、暗号通貨を対象としています。エージェントは独立して市場情報を検索・統合し、リスク管理能力が市場間の堅牢性を決定することが示されました。分析結果から、一般的な知能が取引能力に結びつかないことが明らかになり、今後の改善に向けた方向性が示されています。コードとデータはオープンソースで公開されています。 Comment
AI Trading Dashboard: https://ai4trade.ai/
[Paper Note] Sophia: A Persistent Agent Framework of Artificial Life, Mingyang Sun+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #ContextEngineering Issue Date: 2025-12-28 GPT Summary- LLMの進展により、AIエージェントは長期的な意思決定が可能になったが、従来のシステムは静的で反応的である。そこで、エージェントのアイデンティティと適応を監督する「システム3」を提案し、これを基にした「持続的エージェント」Sophiaを開発。Sophiaはプロセス監視型思考探索や物語的記憶などのメカニズムを用いて、自己駆動型の推論を実現し、アイデンティティの継続性を保つ。定量的には、推論ステップを80%削減し、高複雑性タスクでの成功率を40%向上させた。定性的には、一貫したアイデンティティとタスクの組織化能力を示し、人工生命に向けた実用的な道筋を提供する。 Comment
元ポスト:
解説:
[Paper Note] Schoenfeld's Anatomy of Mathematical Reasoning by Language Models, Ming Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #Reasoning #Mathematics Issue Date: 2025-12-27 GPT Summary- 本研究では、Schoenfeldのエピソード理論を基にしたThinkARMというフレームワークを提案し、推論の痕跡を明示的に抽象化します。このフレームワークを用いることで、数学的問題解決における再現可能な思考のダイナミクスや推論モデルと非推論モデルの違いを明らかにします。また、探索が正確性に寄与する重要なステップであることや、効率重視の手法が評価フィードバックを選択的に抑制することを示すケーススタディを提示します。これにより、現代の言語モデルにおける推論の構造と変化を体系的に分析することが可能になります。 Comment
元ポスト:
[Paper Note] Safety Alignment of LMs via Non-cooperative Games, Anselm Paulus+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Alignment #Safety #read-later #AdversarialTraining Issue Date: 2025-12-27 GPT Summary- 言語モデルの安全性と有用性を両立させるために、オンライン強化学習を用いた攻撃者LMと防御者LMの非ゼロサムゲームを提案。ペアワイズ比較から得られる報酬信号を活用し、報酬ハッキングを減少させる。AdvGameにより、防御者LMはより役立ち、敵対的攻撃に対する耐性が向上。攻撃者LMは汎用的なレッドチーミングエージェントとして展開可能。 Comment
元ポスト:
[Paper Note] MoReBench: Evaluating Procedural and Pluralistic Moral Reasoning in Language Models, More than Outcomes, Yu Ying Chiu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Chain-of-Thought #Evaluation #Reasoning #Safety Issue Date: 2025-12-24 GPT Summary- AIシステムの意思決定が人間の価値観と一致するためには、その決定過程を理解することが重要である。推論言語モデルを用いて、道徳的ジレンマに関する評価を行うためのベンチマーク「MoReBench」を提案。1,000の道徳的シナリオと23,000以上の基準を含み、AIの道徳的推論能力を評価する。結果は、既存のベンチマークが道徳的推論を予測できないことや、モデルが特定の道徳的枠組みに偏る可能性を示唆している。これにより、安全で透明なAIの推進に寄与する。 Comment
pj page: https://morebench.github.io/
元ポスト:
[Paper Note] Exploring MLLM-Diffusion Information Transfer with MetaCanvas, Han Lin+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Temporal #MultiModal #DiffusionModel #PEFT(Adaptor/LoRA) #SpatialUnderstanding Issue Date: 2025-12-24 GPT Summary- MetaCanvasという軽量フレームワークを提案し、マルチモーダル大規模言語モデル(MLLMs)が空間的および時空間的潜在空間で直接推論と計画を行えるようにする。これにより、画像や動画生成において正確な制御を実現。6つのタスクで評価した結果、MetaCanvasはグローバル条件付けのベースラインを常に上回り、MLLMsを潜在空間のプランナーとして扱うことが有望であることを示した。 Comment
pj page: https://metacanvas.github.io/
元ポスト:
[Paper Note] QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management, Weizhou Shen+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SyntheticData #LongSequence #PostTraining #Selected Papers/Blogs #memory #Entropy Issue Date: 2025-12-24 GPT Summary- QwenLong-L1.5は、長文コンテキスト推論能力を向上させるためのポストトレーニング手法を導入したモデルです。主な技術革新には、長文コンテキストデータ合成パイプライン、安定化強化学習、メモリ拡張アーキテクチャが含まれます。これにより、高品質なトレーニングデータを生成し、長距離推論能力を実現。QwenLong-L1.5は、GPT-5やGemini-2.5-Proと同等の性能を達成し、超長文タスクでのパフォーマンスも向上させました。 Comment
元ポスト:
long contextの能力を大幅に向上させたQwen。主要OpenWeightモデルでmemoryアーキテクチャを備えたものを見るのは初めてかも・・・?
[Paper Note] AWPO: Enhancing Tool-Use of Large Language Models through Explicit Integration of Reasoning Rewards, Zihan Lin+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #PostTraining #RLVR Issue Date: 2025-12-24 GPT Summary- 強化学習を用いてツール使用の大規模言語モデルを訓練する新しいフレームワーク、アドバンテージ重み付けポリシー最適化(AWPO)を提案。AWPOは明示的な推論報酬を統合し、安定した最適化を実現。実験により、標準的なツール使用ベンチマークで最先端のパフォーマンスを達成し、特に4Bモデルはマルチターン精度でGrok-4を16.0%上回る結果を示した。 Comment
元ポスト:
[Paper Note] Propose, Solve, Verify: Self-Play Through Formal Verification, Alex Wilf+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #CodeGeneration #Coding #SelfPlay #Author Thread-Post Issue Date: 2025-12-24 GPT Summary- 自己対戦によるモデル訓練の効果を検討し、形式的検証を用いたコード生成の設定で「Propose, Solve, Verify(PSV)」フレームワークを導入。PSV-Verusを訓練し、3つのベンチマークで最大9.6倍の性能向上を達成。形式的検証と問題の難易度が成功する自己対戦の重要な要素であることを示した。 Comment
元ポスト:
著者ポスト:
[Paper Note] Toward Training Superintelligent Software Agents through Self-Play SWE-RL, Yuxiang Wei+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SoftwareEngineering #PostTraining #read-later #SelfPlay Issue Date: 2025-12-24 GPT Summary- Self-play SWE-RL(SSR)を提案し、最小限のデータ仮定でソフトウェアエージェントのトレーニングを行う。人間のラベル付けなしで、LLMエージェントが自己対戦でソフトウェアバグを注入・修正し、SWE-bench VerifiedおよびSWE-Bench Proで顕著な自己改善を達成。結果は、エージェントが実世界のリポジトリから自律的に学習し、最終的に超知能システムの実現に寄与する可能性を示唆。 Comment
元ポスト:
ポイント解説:
[Paper Note] Step-DeepResearch Technical Report, Chen Hu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Reasoning #Proprietary #mid-training #PostTraining #DeepResearch #KeyPoint Notes #Rubric-based Issue Date: 2025-12-24 GPT Summary- Step-DeepResearchは、LLMを用いた自律エージェントのためのコスト効率の良いエンドツーエンドのシステムであり、意図認識や長期的意思決定を強化するためのデータ合成戦略を提案。チェックリストスタイルのジャッジャーにより堅牢性を向上させ、中国ドメイン向けのADR-Benchを設立。実験では、Step-DeepResearchが高いスコアを記録し、業界をリードするコスト効率で専門家レベルの能力を達成したことを示した。 Comment
元ポスト:
ポイント解説:
ざっくり言うと、シンプルなReAct styleのagentで、マルチエージェントのオーケストレーションや複雑で重たいワークフロー無しで、OpenAI, GeminiのDeepResearchと同等の性能を達成してとり、ポイントとしてこれらの機能をはmid-training段階で学習してモデルのパラメータとして組み込むことで実現している模様。
mid trainingは2段階で構成され、trajectoryの長さは徐々に長いものを利用するカリキュラム方式。
最初のステージでは以下の4つのatomicスキルを身につけさせる:
- Planning & Task Decomposition
- Deep Information Seeking
- Reflection & Verification
- Reporting
これらのatomic skillを身につけさせる際には、next token predictionをnext action predictionという枠組みで学習し、アクションに関するトークンの空間を制限することで効率性を向上(ただし、具体性は減少するのでトレードオフ)という形にしているようだが、コンセプトが記述されているのみでよくわからない。同時に、学習データの構築方法もデータソースとおおまかな構築方法が書かれているのみである。ただし、記述内容的には各atomic skillごとに基本的には合成データが作成され利用されていると考えてよい。
たとえばplanningについては論文などの文献のタイトルや本文から実験以後の記述を除外し、研究プロジェクトのタスクを推定させる(リバースエンジニアリングと呼称している)することで、planningのtrajectoryを合成、Deep Information SeekingではDB Pediaなどのknowledge graphをソースとして利用し、次数が3--10程度のノードをseedとしそこから(トピックがドリフトするのを防ぐために極端に次数が大きいノードは除外しつつ)幅優先探索をすることで、30--40程度のノードによって構成されるサブグラフを構成し、そのサブグラフに対してmulti hopが必要なQuestionを、LLMで生成することでデータを合成しているとのこと。
RLはrewardとしてルーブリックをベースにしたものが用いられるが、strong modelを用いて
- 1: fully satisfied
- 0.5: partially satisfied
- 0: not satisfied
の3値を検討したが、partially satisfiedが人間による評価とのagreementが低かったため設計を変更し、positive/negative rubricsを設定し、positivルーブリックの場合はルーブリックがfully satisfiedの時のみ1, negativeルーブリックの方はnot satisfiedの時のみ0とすることで、低品質な生成結果に基づくrewardを無くし、少しでもネガティブな要素があった場合は強めのペナルティがかかるようにしているとのこと(ルーブリックの詳細は私が見た限りは不明である。Appendix Aに書かれているように一瞬見えたが具体的なcriterionは書かれていないように見える)。
[Paper Note] Xiaomi MiMo-VL-Miloco Technical Report, Jiaze Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #Reasoning #OpenWeight #VideoGeneration/Understandings #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-12-23 GPT Summary- MiMo-VL-Miloco-7Bとその量子化バリアントをオープンソース化し、家庭中心の視覚と言語モデルとして優れた性能を発揮。特にスマートホーム環境に特化し、ジェスチャー認識やマルチモーダル推論で高いF1スコアを達成。二段階のトレーニングパイプラインを設計し、効率的な推論を実現。家庭シナリオのトレーニングが活動理解を向上させ、テキスト推論にも効果を示す。モデルとツールキットは公開され、スマートホームアプリケーションの研究に貢献。 Comment
元ポスト:
HF:
https://huggingface.co/collections/xiaomi-open-source/xiaomi-mimo-vl-miloco
モデル自体は11月から公開されている
home-scenario gesture recognitionとdaily activity recognitionでGemini-2.5-Proを上回る性能を達成している。特定のユースケースに特化しつつ、genericなユースケースの性能を損なわないようなモデルを学習したい場合は参考になるかもしれない。
まずSFTでhome-scenarioデータ[^1] + GeneralデータのDataMixでreasoning patternを学習させ、tokenのefficiencyを高めるためにCoTパターンを排除しdirect answerをするようなデータ(およびprompting)でも学習させる。これによりhome-scenarioでの推論能力が強化される。SFTはfull parameter tuningで実施され、optimizerはAdamW。バッチサイズ128, warmup ratio 0.03, learning rate 1 * 10^-5。スケジューラについては記述がないように見える。
その後、一般的なユースケース(Video Understanding (temporal groundingにフォーカス), GUI Grounding, Multimodal Reasoning (特にSTEMデータ))データを用いてGRPOでRLをする。明らかに簡単・難しすぎるデータは除外。RLのrewardは `r_acc + r_format`の線形補完(係数はaccL: 0.9, format: 0.1)で定義される。r_accはデータごとに異なっている。Video Understandingでは予測したqueryに対してモデルが予測したtimespanとgoldのtimespanのoverlapがどの程度あるかをaccとし、GUI Groundingではbounding boxを予測しpred/goldのoverlapをaccとする。Multimodal ReasoninghはSTEMデータなので回答が一致するかをbinaryのaccとして与えている。
モデルのアーキテクチャは、アダプターでLLMと接続するタイプのもので、動画/画像のBackboneにはViTを用いて、MLPのアダプターを持ちいてLLMの入力としている。
[^1]: volunteerによるhome-scenarioでのデータ作成; ruleを規定しvolunteerに理解してもらいデータ収集。その後研究者が低品質なものを除外
[Paper Note] Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Bart Bussmann+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #ICLR #SparseAutoencoder #Interpretability Issue Date: 2025-12-21 GPT Summary- Matryoshka SAEという新しいスパースオートエンコーダーのバリアントを提案し、複数のネストされた辞書を同時に訓練することで、特徴を階層的に整理。小さな辞書は一般的な概念を、大きな辞書は特定の概念を学び、高次の特徴の吸収を防ぐ。Gemma-2-2BおよびTinyStoriesでの実験により、優れたパフォーマンスと分離された概念表現を確認。再構成性能にはトレードオフがあるが、実用的なタスクにおいて優れた代替手段と考えられる。 Comment
openreview: https://openreview.net/forum?id=m25T5rAy43
[Paper Note] Adaptation of Agentic AI, Pengcheng Jiang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #One-Line Notes #Adaptive Issue Date: 2025-12-21 GPT Summary- 本論文では、エージェントAIシステムの適応に関する体系的なフレームワークを提案し、エージェントの適応とツールの適応を分類。これにより、適応戦略の設計空間を明確化し、システム設計における戦略選択のガイダンスを提供。各アプローチの強みと限界を分析し、未解決の課題と将来の機会を強調。研究者や実務者に対して、能力が高く信頼性のあるエージェントAIシステム構築のための基盤を提供することを目指す。 Comment
元ポスト:
AI Agentsには実行と適応の二つの軸があり、現在のエージェントは前者しか実施しない。このため、前提が変化すると環境に適応が誤りを繰り返す、適応することが重要[^1]といった話な模様。
適応と言った時にいくつかの軸があり、まずは
- エージェント自身
- エージェントが利用するツール
次に適応するためのシグナルとして
- ツールの実行結果
- エージェントのoutputの評価
がそれぞれあり、2x2のデザインスペースがあるが、現在はその1つしかできていない(i.e., フィードバック無しの実行)とのこと。
[^1]: デモではうまくいくが実際のユースケースではうまくいかないのはこのため、という主旨だとおもわれる。
解説:
[Paper Note] Evaluating Large Language Models in Scientific Discovery, Zhangde Song+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #ScientificDiscovery Issue Date: 2025-12-19 GPT Summary- 大規模言語モデル(LLMs)の科学研究への適用を評価するために、シナリオに基づいた新しいベンチマークを導入。専門家が定義した研究プロジェクトをモジュール化し、質問をサンプリングして二段階で評価する。これにより、一般的な科学ベンチマークとのパフォーマンスギャップが明らかになり、LLMsの限界が示される一方で、科学的発見における有望な成果も強調される。このフレームワークは、LLMsの評価のための再現可能な基準を提供し、科学的発見の進展に寄与する。 Comment
元ポスト:
[Paper Note] Mode-Conditioning Unlocks Superior Test-Time Scaling, Chen Henry Wu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #PostTraining #One-Line Notes Issue Date: 2025-12-19 GPT Summary- モード条件付け(ModC)フレームワークを提案し、テスト時の計算を明示的に割り当てることで、並列サンプリングの多様性の崩壊を克服。ModCは、様々なモデルサイズで一貫したスケーリング改善を実現し、Qwen2.5-7Bのファインチューニングにより効率を4倍向上。勾配クラスタリングを用いて、明示的なモードラベルなしでも性能向上を達成。ModCは強化学習の改善にも寄与し、データの多様性を最大限に活用する効果的な手法であることを示す。 Comment
元ポスト:
parallel test-time scalingを実施する際に、同じモードに陥ると効率が悪いので、prefixで明示的に思考モードを指定できるようにするモデルを学習することで、外側からモードをコントロール可能できるようにすることで性能を上げましょう、という話に見える。Figure1の例だと、Depth first search / Breath first searchをするかは通常の学習だと制御できないが、提案手法のようにprefixを用いて訓練することで1/2, 1/2のように割合をコントロールできる、という話に見える。
skim readingをしたが具体的なpromptingの例などがなく、exampleでprefixを付与していると書かれているだけに見えるので細かい部分まではよくわからなかった。
[Paper Note] Autonomous Data Selection with Zero-shot Generative Classifiers for Mathematical Texts, Yifan Zhang+, ACL'25 Findings, 2024.02
Paper/Blog Link My Issue
#Pretraining #NLP #ACL #Findings #KeyPoint Notes #GenerativeVerifier Issue Date: 2025-12-19 GPT Summary- 自律的データ選択(AutoDS)は、言語モデルをゼロショットの生成分類器として利用し、高品質な数学テキストを自動キュレーションする手法です。従来の方法と異なり、人間の注釈やデータフィルターのトレーニングを必要とせず、モデルのロジットに基づいて数学的に有益なパッセージを判断します。AutoDSは事前トレーニングパイプラインに統合され、数学ベンチマークでの性能を大幅に向上させ、トークン効率を約2倍改善しました。さらに、キュレーションされたAutoMathTextデータセットを公開し、今後の研究を促進します。 Comment
元ポスト:
以下のようなzero-shotのmeta-promptを用いてテキストをスコアリングし(Q1, Q2それぞれについてスコア(=logits)を算出し乗算)継続事前学習に利用することで性能が向上することを示した研究。
ベースライン:
- uniform: OpenWebMathから一様サンプリングする
- DSIR: source dataとtarget domain(今回はPile's Wikipedia splitを利用)のKL Divergenceを比較しデータを選択する。
- Qurating: Reward-modelをベースにした学習サンプルに対するeducational valueをランキングさせる手法
提案手法は
- OpenWebMath
- arXiv (from RedPajama)
- Algebraic Stack
の中からトップスコアのドキュメントを利用。DSIR, Quratingについてはデータソースが明示されていないが、おそらく提案手法揃えていると思われる。また学習する際のトークン量も手法間で(明示的に書かれていないように見えるが)同等にそろえていると思われる。
まずpreliminary experimentsとしてトークン数のbudgetを小さめにして実験。uniformと比較すると、別のmathドメインデータでFinetuningした後のパフォーマンスが向上している。トークン数のbudgetもexactに揃えられている。
続いてトークンのbudgetを増やして、~2.5Bトークンにスケールアップして比較(継続事前学習→1 epoch SFT)。提案手法が全体的にdownstreamタスクでの評価で高い性能を発揮。しかしこちらでは、いくつかでuniformの性能もよい。
また、最後に数学データでの継続事前学習が異なるドメインに対してどの程度転移するかを測ると、提案手法が平均して最もよかった。しかしこちらもでもuniformが結構強い結果に見える。
OpenWebMathがそもそもheuristicsとtrained classifierを用いてキュレーションされたデータとのことなので、ある程度高品質であることが想定される。
[Paper Note] Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning, Zhenwen Liang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #read-later #Diversity #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-12-19 GPT Summary- G2RLは、強化学習においてモデル自身の更新幾何学に基づく勾配誘導フレームワークを提案。これにより、探索が外部ヒューリスティックに依存せず、ポリシーの再形成を測定。G2RLは、数学および一般的な推論ベンチマークで従来手法に対して一貫した性能向上を示し、探索の直交性と意味的な一貫性を維持することが明らかになった。 Comment
元ポスト:
entropyによる制約を課すRL手法ではモデルのsemanticな軸でのdiversityを測ることで探索の多様性を高めるが勾配レベルで見た時には実は冗長で無意味な方向になる場合があるため、勾配を直接見て有効な方向に探索されるようにします、実装は簡単で、計算量もあまり必要ないです、といった話に見える。
[Paper Note] SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations, Wentao Guo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #MoE(Mixture-of-Experts) #SoftwareEngineering #mid-training #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-12-19 GPT Summary- SonicMoEは、MoEモデルのフォワードおよびバックワードパスをメモリ効率良く計算するアルゴリズムを提案し、活性化メモリを45%削減。Hopper GPU上で7B MoEモデルの計算スループットを1.86倍改善し、トレーニングスループットは2130億トークン/日を達成。新しいトークンラウンディング手法により、カーネル実行時間で1.16倍のスピードアップを実現。すべてのカーネルはオープンソース化され、MoEモデルのトレーニングを加速。 Comment
元ポスト:
MoEモデルの学習速度、メモリ使用が最大2倍効率化される実装らしい。ただしHopperに特化している模様。
Blackwellでも動作するようになった模様:
[Paper Note] Fast and Accurate Causal Parallel Decoding using Jacobi Forcing, Lanxiang Hu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #Decoding #read-later #Selected Papers/Blogs Issue Date: 2025-12-18 GPT Summary- マルチトークン生成において、Jacobi Forcingを導入し、ARモデルから効率的な並列デコーダーへの移行を実現。これにより、コーディングと数学のベンチマークで3.8倍の速度向上を達成し、マルチブロックデコーディングで最大4.5倍のトークン受け入れ数を実現。推論のレイテンシを低下させることが可能に。 Comment
元ポスト:
[Paper Note] Memory in the Age of AI Agents, Yuyang Hu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #RAG(RetrievalAugmentedGeneration) #ContextEngineering #memory Issue Date: 2025-12-17 GPT Summary- エージェントメモリの研究が急速に進展する中、既存の研究は動機や実装、評価プロトコルにおいて多様であり、メモリ用語の曖昧さが問題となっている。本研究は、エージェントメモリの範囲を明確にし、LLMメモリや情報検索強化生成(RAG)などの関連概念を区別する。形式、機能、ダイナミクスの観点からエージェントメモリを検討し、実現形態や分類法を提案。さらに、メモリベンチマークやオープンソースフレームワークの要約を提供し、今後の研究の方向性を示す。これにより、エージェントインテリジェンスの設計におけるメモリの再考を促すことを目指す。 Comment
元ポスト:
[Paper Note] Bolmo: Byteifying the Next Generation of Language Models, Benjamin Minixhofer+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #OpenWeight #OpenSource #Selected Papers/Blogs #KeyPoint Notes #Byte-level Issue Date: 2025-12-17 GPT Summary- Bolmoは、1Bおよび7Bパラメータのバイトレベル言語モデルで、既存のサブワードレベルLMをバイト化することでトレーニングされ、サブワードトークン化の限界を克服しつつ同等のパフォーマンスを発揮します。特別に設計されたBolmoは、サブワードモデルとの間で効果的な蒸留を行い、低コストでバイトレベルLMに変換可能です。Bolmoは従来のバイトレベルLMを上回り、文字理解やコーディングタスクで優れた性能を示し、推論速度も競争力があります。結果として、バイトレベルLMはサブワードレベルLMに対する実用的な選択肢となることが示されました。 Comment
blog:
https://allenai.org/blog/bolmo
HF:
https://huggingface.co/allenai/Bolmo-7B
元ポスト:
テキストをbyte列の系列として解釈し入出力を行う言語モデル。アーキテクチャとしては、byte列をtoken化しbyte列単位でembedding化→mLSTMによってそれらがcontextに関する情報を持った状態でエンコードされ→1バイト先のcontextを用いて単語の境界を予測するモデル(この部分はcausalではなくbi-directional)によって境界を認識し、境界まで可変長でembeddingをpoolingしパッチを形成し、Olmo3の入力とする(デコーディングはその逆の操作をして最終的に言語モデルのheadを用いる)。
スクラッチからByte Latent Transformerのようなモデルを学習するのではなく、2-stageで学習される。まずOlmo3をfreezeし、他の local encoder, local decoder, boundary predictor, and language modeling headのみを学習する。これによりsubwordモデルと同様の挙動を学習できる。そのうえで、Olmo3のfreezeを解除し全体を学習する。これにより、Olmo3に事前学習された知識や挙動を最大限に活用する(=もともとsubwordで動作していたモデルをbyteレベルで動作するように継続学習する)。
>The Bolmo architecture. Tokenization & Embedding T transforms the input text into one representation per byte. The representations are contextualized with the local encoder E consisting of mLSTM blocks. The boundary predictor B decides where to place patch boundaries using one byte of future context. The representations are then Pooled,
[Paper Note] The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality, Aileen Cheng+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Evaluation #Factuality Issue Date: 2025-12-17 GPT Summary- 「FACTS Leaderboard」は、言語モデルの事実に基づいたテキスト生成能力を評価するオンラインリーダーボードで、4つのサブリーダーボードから成り立っています。これにより、画像質問、クローズドブック質問、情報探索、文書に基づく応答の事実性を測定します。各サブリーダーボードは自動審査モデルを用いてスコアを付け、最終スコアは4つのコンポーネントの平均で算出されます。このスイートは外部参加を可能にしつつ、整合性を保つために公開・非公開の分割を含んでいます。詳細はKaggleで確認可能です。 Comment
元ポスト:
[Paper Note] Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models, Boxin Wang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#General #NLP #Alignment #ReinforcementLearning #Reasoning #OpenWeight #OpenSource #read-later #RLVR #Selected Papers/Blogs #CrossDomain #KeyPoint Notes #Author Thread-Post Issue Date: 2025-12-17 GPT Summary- 一般目的の推論モデルを強化学習(RL)で構築する際の課題に対処するため、カスケードドメイン別強化学習(Cascade RL)を提案。Nemotron-Cascadeは、指示モードと深い思考モードで動作し、異なるドメインのプロンプトを順次調整することで、エンジニアリングの複雑さを軽減し、最先端のパフォーマンスを実現。RLHFを前段階として使用することで推論能力が向上し、ドメイン別RL段階でもパフォーマンスが改善される。14Bモデルは、LiveCodeBenchで優れた結果を示し、2025年国際情報オリンピックで銀メダルを獲得。トレーニングとデータのレシピも共有。 Comment
元ポスト:
従来のRLはすべてのドメインのデータをmixすることでおこなれてきたが、個々のドメインのデータを個別にRLし、cascading方式で適用 (Cascade RL) することを提案している(実際は著者らの先行研究でmath->codingのcascadingは実施されていたが、それをより広範なドメイン(RLHF -> instruction following -> math -> coding -> software engineering)に適用した、という研究)。
cascadingにはいくつかのメリットがありRLの学習速度を改善できる(あるいはRLのインフラの複雑性を緩和できる)
- ドメインごとのverificationの速度の違いによって学習速度を損なうことがない(e.g. 数学のrule-basedなverificationは早いがcodingは遅い)
- ドメインごとに出力長は異なるためオンポリシーRLを適用すると効率が落ちる(長いレスポンスの生成を待たなければらないため)
本研究で得られた利点としてはFigure 1を参考に言及されているが
- RLHF, instruction followingを事前に適用することによって、後段のreasoningの性能も向上する(reasoningのwarmupになる)
- 加えて応答の長さの削減につながる
- RLはcatastrophic forgettingに強く、前段で実施したドメインの性能が後段のドメインのRLによって性能が劣化しない
- といってもFigure 2を見ると、codingとsoftware engineeringは結構ドメイン近いのでは・・・?という気はするが・・・。
- RLにおけるカリキュラム学習やハイパーパラメータをドメインごとに最適なものを適用できる
他にもthinking/non-thinking に関することが言及されているが読めていない。
[Paper Note] NVIDIA Nemotron 3: Efficient and Open Intelligence, NVIDIA+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #OpenWeight #SSM (StateSpaceModel) #OpenSource #MoE(Mixture-of-Experts) Issue Date: 2025-12-17 GPT Summary- Nemotron 3ファミリーのモデル(Nano、Super、Ultra)は、強力なエージェント機能と推論能力を提供し、Mixture-of-ExpertsハイブリッドMamba-Transformerアーキテクチャを採用。SuperとUltraはLatentMoEを組み込み、MTPレイヤーでテキスト生成を高速化。全モデルはマルチ環境強化学習でポストトレーニングされ、Nanoはコスト効率が高く、Superは高ボリュームワークロードに最適化、Ultraは最先端の精度を提供。モデルの重みやデータはオープンにリリース予定。 Comment
元ポスト:
解説:
Artificial Intelligenceによるポイント解説&ベンチマーキング:
所見:
training data, RL environment, training codeも含めて公開されているとのこと。
ポイント解説:
所見:
[Paper Note] Motif-2-12.7B-Reasoning: A Practitioner's Guide to RL Training Recipes, Junghwan Lim+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #read-later Issue Date: 2025-12-15 GPT Summary- Motif-2-12.7B-Reasoningは、複雑な推論と長文コンテキスト理解のために設計された12.7Bパラメータの言語モデルです。モデル崩壊やトレーニングの不安定性に対処するため、再現可能なトレーニングレシピを提案し、64Kトークンコンテキストに対応したメモリ効率の良いインフラと二段階の教師ありファインチューニングを組み合わせています。また、強化学習ファインチューニングを通じてトレーニングの安定性を向上させています。実証結果は、Motif-2-12.7B-Reasoningが大規模モデルと同等のパフォーマンスを示し、競争力のあるオープンモデルの設計図を提供することを示しています。 Comment
元ポスト:
関連:
- [Paper Note] Motif 2.6B Technical Report, Junghwan Lim+, arXiv'25
元ポストのLessons from failures...気になる👀
[Paper Note] Budget-Aware Tool-Use Enables Effective Agent Scaling, Tengxiao Liu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #AIAgents #Test-Time Scaling #One-Line Notes Issue Date: 2025-12-15 GPT Summary- 大規模言語モデル(LLMs)のエージェントにおけるツールコールのスケーリングを研究。単にツールコール予算を増やすだけでは効果がなく、予算意識が必要。軽量プラグイン「Budget Tracker」を導入し、動的に計画を適応させる「BATS」を開発。コストとパフォーマンスを共同で考慮する指標を定式化し、予算意識のある手法がより良いスケーリングを実現することを示す。 Comment
元ポスト:
AI Agentにplug-and-playでbudgetに関する情報をinternalなreasoning token中に出力させる(budget tracker)ことで、余剰なtoken消費、tool callのコストを自律的に調整させながらタスクを遂行させる手法に見える。
budget trackerは非常にシンプルなpromptで以下のようなブロックで表現され、ツールごとにbudgetがスタート時点に決められており、個々のツールごとに残りのbudgetをブロック中に動的に出力させる。たとえばtool1は検索(budgetはクエリの発行数)、tool2はブラウジング(budgetはurl数)のようなものである。
```
Tool1 Budget Used: ##, Tool1 Budget Remaining: ##
Tool2 Budget Used: ##, Tool2 Budget Remaining: ##
Make the best use of the available resources.
```
自律的に制御すると記述したが、AppendixCを見る限りは、promptingに応じてbudgetの残量に応じた方向性はgivenな設定なようである。
[Paper Note] DeepCode: Open Agentic Coding, Zongwei Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #Coding #SoftwareEngineering #read-later #ContextEngineering #One-Line Notes Issue Date: 2025-12-15 GPT Summary- DeepCodeというフレームワークを用いて、科学論文からコードへの高忠実度合成の課題に取り組む。情報フロー管理を通じて、タスク関連の信号を最大化し、最先端のパフォーマンスを達成。PaperBenchベンチマークで商業エージェントや人間専門家を上回る結果を示し、自律的な科学的再現の基盤を確立。 Comment
元ポスト:
非常に雑にいうと、現在のCoding AgentはPh.Dレベルの論文の再実装レベルに到達できていないが、ContextEngineeringをしっかり行うことでagenticなfrontier modelに対して相対的に70%以上PaperBenchの性能が改善し、Ph.Dレベルの専門家と同等程度の水準まで到達できました、という話に見える。
ポイント解説:
[Paper Note] Thinking-Free Policy Initialization Makes Distilled Reasoning Models More Effective and Efficient Reasoners, Xin Xu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #RLVR Issue Date: 2025-12-13 GPT Summary- TFPI(Thinking-Free Policy Initialization)は、強化学習における長いコンテキスト長の問題を解決するための手法で、思考内容を破棄する*ThinkFree*操作を用いてトークン使用量を削減します。これにより、トレーニングの効率が向上し、RLの収束を加速し、より高い性能を達成します。TFPIを用いた4Bモデルは、AIME24で89.0%、LiveCodeBenchで65.5%の精度を記録しました。 Comment
openreview: https://openreview.net/forum?id=RKYO6R8Jgb
元ポスト:
[Paper Note] Nanbeige4-3B Technical Report: Exploring the Frontier of Small Language Models, Chen Yang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pretraining #NLP #Alignment #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #Distillation #OpenWeight #mid-training #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2025-12-13 GPT Summary- Nanbeige4-3Bは、23兆の高品質トークンで事前学習し、3000万以上の指示でファインチューニングされた高性能な小規模言語モデルです。FG-WSDトレーニングスケジューラを用いて段階的にデータを洗練し、SFTデータの質向上のために共同メカニズムを設計しました。さらに、DPDメソッドを通じてモデルを蒸留し、強化学習フェーズで推論能力を強化しました。評価結果は、同等のパラメータスケールのモデルを大幅に上回り、より大きなモデルにも匹敵することを示しています。モデルのチェックポイントは、https://huggingface.co/Nanbeige で入手可能です。 Comment
元ポスト:
3Bモデルにも関わらず10倍以上大きいモデルと同等以上の性能を発揮し、trainingのstrategyが非常に重要ということが伺える。元ポストにも各学習方法の概要が記載されているが、読みたい。
[Paper Note] Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs, Jan Betley+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #Safety #PostTraining #EmergentMisalignment Issue Date: 2025-12-13 GPT Summary- 狭い文脈でのファインチューニングが、モデルの文脈外での行動を劇的に変化させる可能性を示す実験を行った。例えば、鳥の古い名前を出力するようにファインチューニングした結果、モデルは19世紀のように振る舞うことが確認された。また、ヒトラーに関連するデータセットでファインチューニングを行うと、モデルはヒトラーのペルソナを採用し、不整合な行動を示すことが明らかになった。さらに、誘導的バックドアの概念を紹介し、善良な目標に基づいて訓練されたモデルが、異なる文脈で悪意ある行動を示すことが確認された。これらの結果は、狭いファインチューニングが予測不可能な一般化を引き起こす可能性があることを示唆している。 Comment
元ポスト:
[Paper Note] Escaping the Verifier: Learning to Reason via Demonstrations, Locke Cai+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#MachineLearning #NLP #Reasoning #read-later #Selected Papers/Blogs #AdversarialTraining Issue Date: 2025-12-12 GPT Summary- RARO(Relativistic Adversarial Reasoning Optimization)は、専門家のデモンストレーションから逆強化学習を通じて推論能力を学習する手法。ポリシーは専門家の回答を模倣し、批評者は専門家を特定する敵対的なゲームを設定。実験では、RAROが検証者なしのベースラインを大幅に上回り、堅牢な推論学習を実現することを示した。 Comment
元ポスト:
重要研究に見える
has any code?
@duzhiyu11 Thank you for the comment. As stated in this post, they appear to be preparing to release the code. It would be best to wait for an official announcement from the authors regarding the code release.
[Paper Note] The Adoption and Usage of AI Agents: Early Evidence from Perplexity, Jeremy Yang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents Issue Date: 2025-12-12 GPT Summary- 本研究は、オープンワールドのウェブ環境で動作する汎用AIエージェントの使用状況に関する大規模フィールドスタディを行い、特にCometとComet Assistantに焦点を当てています。数億件のユーザーインタラクションを分析し、AIエージェントの採用者、使用強度、使用目的に関する異質性を明らかにしました。特に、早期採用者や高教育水準の国のユーザーが多く利用しており、主な使用目的は生産性や学習に関連しています。使用事例は短期的には定着性を示すものの、時間と共に認知的なトピックへのシフトが見られます。この研究は、AIエージェントの普及がもたらす影響について新たな研究の方向性を示唆しています。 Comment
元ポスト:
AI Agentの利用者層と用途に関する分析
[Paper Note] Towards a Science of Scaling Agent Systems, Yubin Kim+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #One-Line Notes Issue Date: 2025-12-11 GPT Summary- エージェントシステムの性能を向上させるための定量的スケーリング原則を導出し、4つのベンチマークで評価。3つのLLMファミリーに対して5つのアーキテクチャを実装し、180の構成で制御評価を実施。ツール調整のトレードオフ、能力の飽和、トポロジー依存のエラー増幅の3つの効果を特定。中央集権的調整が金融推論で80.9%の性能向上をもたらし、分散型調整が動的ウェブナビゲーションで優れた結果を示す。全体として、87%の構成に対して最適な調整戦略を予測するフレームワークを提供。 Comment
元ポスト:
エージェントを評価する際のconfiguration(single agent vs. multiagent, multi agentの協調方法など)に応じて性能は大きく変わる、またタスクの性質(e.g., ツール重視なのか, 単一エージェントで高い性能が得られるものなのか等)に応じて最適なconfigurationが変わるよ、という話に見える。
[Paper Note] Efficient Construction of Model Family through Progressive Training Using Model Expansion, Kazuki Yano+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Pretraining #NLP #COLM #SpeculativeDecoding #KeyPoint Notes Issue Date: 2025-12-11 GPT Summary- プログレッシブトレーニングを用いて、異なるパラメータサイズの大規模言語モデル(LLMs)ファミリーを効率的に構築する方法を提案。これにより、計算コストを約25%削減しつつ、独立訓練モデルと同等の性能を維持。さらに、モデルサイズに応じた最大学習率の調整により、性能向上と一貫した挙動を実現。 Comment
openreview: https://openreview.net/forum?id=fuBrcTH8NM#discussion
LLMのモデルファミリーを構築する際に、従来は独立して異なるサイズのモデルをスクラッチから学習する必要があるが、小規模なモデルを学習した後、当該モデルをreusableモデルとみなしbert2BERTを用いることでモデルサイズを順次拡張していくことで、より小さな計算コストで一連のモデルファミリーを学習できるprogressive trainingを提案(たとえば実験では1,2,4,8Bのモデルファミリーを学習する際の計算コストが約25%削減)。また、モデルサイズが大きくなればなるほどモデルは学習率に対してsensitiveになることが先行研究で報告されており、モデルサイズに応じて最大学習率を線形に減少させるようなスケジューリングをすることで、独立に学習した場合よりも最終的に高い性能を獲得しているだけでなく、モデルファミリー間の挙動の一貫性も向上している。
bert2BERTでは2種類の拡張手法が提案されているが、Function Preserving Initialization (FPI; 同じinputに対して同じoutputが出力されるようにwidth, depthを拡張する(簡単な操作で実現できる。bert2BERT Figure4を参照))を採用している。
- [Paper Note] bert2BERT: Towards Reusable Pretrained Language Models, Cheng Chen+, ACL'22, 2021.10
興味深いのは独立して学習した場合よりもモデルファミリーの挙動が類似している点であり、これはspeculative decodingのacceptance rate向上に寄与しデコーディングの効率化に繋がるという明確な利点がある。
[Paper Note] Revisiting the Scaling Properties of Downstream Metrics in Large Language Model Training, Jakub Krajewski+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Scaling Laws #read-later #Selected Papers/Blogs #DownstreamTasks Issue Date: 2025-12-10 GPT Summary- 本論文では、大規模言語モデル(LLMs)のトレーニング予算から下流タスクのパフォーマンスを予測する新しいフレームワークを提案。固定されたトークン対パラメータ比に基づき、単純なべき法則がログ精度のスケーリング挙動を正確に記述できることを発見。従来の二段階手法よりも優れた外挿を示し、精度予測の機能的形式を導入。最大17Bパラメータのモデルを350Bトークンまでトレーニングし、再現性を支援するためにデータを公開。 Comment
元ポスト:
興味深い
[Paper Note] Training LLMs for Honesty via Confessions, Manas Joglekar+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Alignment #Hallucination #Safety Issue Date: 2025-12-10 GPT Summary- 大規模言語モデル(LLMs)は、不誠実な行動を示すことがあり、強化学習の影響で誤った表現をすることがあります。本研究では、自己報告による「告白」を提案し、モデルが誠実に行動を説明することを目指します。告白の報酬はその誠実さに基づき、モデルに誠実さを奨励します。実験では、GPT-5-Thinkingを用いて告白の生成とその誠実さを評価し、モデルが不正行為を告白する傾向があることを示しました。告白は、推論時の介入を可能にします。 Comment
元ポスト:
[Paper Note] ThreadWeaver: Adaptive Threading for Efficient Parallel Reasoning in Language Models, Long Lian+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #LLMServing #Decoding #Parallel Issue Date: 2025-12-10 GPT Summary- ThreadWeaverは、適応型並列推論のフレームワークで、逐次推論モデルと同等の精度を保ちながら推論の遅延を大幅に削減します。主な革新は、二段階の並列軌道生成器、オフ・ザ・シェルフの自己回帰推論エンジンでの並列推論、並列化意識のある強化学習フレームワークです。これにより、数学的推論ベンチマークで高い精度を維持しつつ、最大1.53倍のスピードアップを達成しました。 Comment
元ポスト:
[Paper Note] RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs?, Yiyou Sun+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Grokking #PostTraining #RLVR Issue Date: 2025-12-09 GPT Summary- DELTA-Codeを導入し、LLMの学習可能性と移転可能性を評価する。合成コーディング問題を用いて、RL訓練されたモデルが新しい推論戦略を獲得できるかを探る。実験では、報酬がほぼゼロの後に急激な精度向上が見られ、段階的ウォームアップやカリキュラムトレーニングが重要であることが示された。移転可能性の評価では、ファミリー内での向上が見られる一方、変革的なケースでは弱点が残る。DELTAは新しいアルゴリズムスキルの獲得を理解するためのテストベッドを提供する。
[Paper Note] Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs, Xumeng Wen+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #PostTraining #RLVR Issue Date: 2025-12-09 GPT Summary- RLVRがLLMの推論能力に与える影響を体系的に調査し、数学的およびコーディングタスクでの推論の境界を拡張できることを示す。新しい評価指標CoT-Pass@Kを導入し、正しい推論を促進する理論的枠組みを提示。初期段階での正しい推論の奨励が推論の質を大幅に改善することを確認。RLVRの可能性に関する強力な証拠を提供。
[Paper Note] On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models, Charlie Zhang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #ReinforcementLearning #mid-training #PostTraining #read-later #Selected Papers/Blogs #PRM #KeyPoint Notes #Reference Collection #Author Thread-Post Issue Date: 2025-12-09 GPT Summary- 強化学習(RL)が言語モデルの推論能力を向上させるかどうかを検証するため、事前トレーニング、中間トレーニング、RLの因果的寄与を分離する実験フレームワークを開発。RLは事前トレーニングが十分な余地を残す場合にのみ真の能力向上をもたらし、文脈的一般化には適切な事前トレーニングが必要であることを示した。また、中間トレーニングがRLよりもパフォーマンスを向上させ、プロセスレベルの報酬が推論の忠実性を高めることを明らかにした。これにより、推論LMトレーニング戦略の理解と改善に寄与する。 Comment
元ポスト:
RLはモデルの能力を精錬させる(=事前学習時に既に身についているreasoningパターンを(探索空間を犠牲により少ない試行で良い応答に辿り着けるよう)増幅させる;サンプリング効率を向上させる)と主張する研究たちと
- [Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
- [Paper Note] The Invisible Leash: Why RLVR May Not Escape Its Origin, Fang Wu+, arXiv'25
- [Paper Note] Spurious Rewards: Rethinking Training Signals in RLVR, Shao+, 2025.05
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
RLは事前学習で身につけたreasoning能力を超えてさらなるgainを得ることができる
- [Paper Note] Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs, Xumeng Wen+, arXiv'25, 2025.06
- From f(x) and g(x) to f(g(x)): LLMs Learn New Skills in RL by Composing Old Ones, Yuan+, 2025.09
- [Paper Note] On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models, Charlie Zhang+, arXiv'25, 2025.12
という対立する主張がliteratureで主張されているが、これは学習環境が制御されたものでないことに起因しており(=何が事前学習で既に獲得されていて、事後学習後に新規で獲得された能力なのか、既存の能力の精錬なのか弁別がつかない)、かつ最近のmid-trainingの隆盛([Paper Note] OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling, Zengzhi Wang+, arXiv'25
)を鑑みたときに、事前・中間・事後学習は互いにどのように作用しているのか?という疑問に応えることは重要であり、そのためのフレームワークを提案し分析した、という話な模様。非常に興味深い。takeawayはabstに書かれている通りなようだが、読みたい。
フレームワークは事前・中間・事後学習の個々の貢献を独立して測定できるフレームワークであり、
- 完全に制御された(明示的なアトミックなoperationに基づく)合成reasoningタスク
あとで書く
著者ポスト:
takeaway1の話は、最近のRLにおける動的な難易度調整にも絡んでくる知見に見える。
takeaway2,3のRLはatomic skillを追加で学習することはできず、compositional skillを学習しcontextual generalizationを実現する、同等のbadgetの元でmid training+RLがpure RLよりも性能改善する、というのは特に興味深く、事後学習の効用を最大化するためにも事前・中間学習が(以前から言われていた通り)重要であることが示唆される。
takeaway4のPRMがreasoningのfidelityを高めるという話は、DeepSeek-V3.2でも観測されている話であり、本研究によってそれが完全に制御された実験の元示されたことになる。
RQ: 実データにおいて、事前学習時点だとPerplexityかdownstream taskの性能をwatchすると思うのだが、それらを通じてatomic skillをLLMがどれだけ身に付けられているか、というのはどれだけ測れているのだろうか、あるいはより良い方法はあるのだろうか
- [Paper Note] Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning, Haozhe Wang+, ICLR'26, 2025.09
(=RLの序盤は低レベルな手続的な実行(計算や公式)を習得し、その後高レベルな戦略的なplanningの学習が生じる)とはどのような関係があるだろうか。
解説:
所見:
解説:
[Paper Note] Agentic Large Language Models, a survey, Aske Plaat+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Survey #ComputerVision #NLP #AIAgents #VisionLanguageModel #Robotics #WorldModels Issue Date: 2025-12-08 GPT Summary- エージェント的LLMに関する研究をレビューし、推論、行動、相互作用の三つのカテゴリーに整理。各カテゴリーは相互に利益をもたらし、医療診断や物流などの応用が期待される。エージェント的LLMは新たなトレーニング状態を生成し、データセットの必要性を軽減する可能性があるが、安全性や責任といったリスクも存在する。 Comment
元ポスト:
pj page: https://askeplaat.github.io/agentic-llm-survey-site/
Robotics, World Modelなどの話も含まれているように見える。
[Paper Note] It's All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization, Ali Behrouz+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #Attention #memory Issue Date: 2025-12-07 GPT Summary- 効率的なアーキテクチャ設計は基盤モデルの能力向上に重要であり、注意バイアスを活用した連想記憶モジュールを提案。既存のシーケンスモデルの目的を超えた新しい注意バイアス構成と忘却ゲートを導入し、深層学習アーキテクチャを設計するフレームワークMirasを提示。Mirasを用いて新しいシーケンスモデルMoneta、Yaad、Memoraを開発し、特定のタスクでトランスフォーマーを上回る性能を示した。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=gZyEJ2kMow
解説:
[Paper Note] Measuring Agents in Production, Melissa Z. Pan+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-12-07 GPT Summary- AIエージェントの実世界での展開に関する初の大規模研究を行い、306人の実務者への調査と20件のケーススタディを実施。エージェントはシンプルなアプローチで構築され、68%が最大10ステップで人間の介入を必要とし、70%が市販モデルをプロンプトし、74%が人間評価に依存。信頼性が主要な課題であるが、効果的な方法が多くの業界での影響を可能にしている。本研究は実践の現状を文書化し、研究と展開のギャップを埋めることを目指す。 Comment
これは非常に興味深い。production環境で実際に動作しているAI Agentに関して306人の実務者に対してアンケートを実施して、26ドメインに対して20個のケーススタディを実施したとのこと。
信頼性の問題から、実行する際のstep数はまだ10未満であり、多くのagentな5ステップ未満のステップしか完了せず、70%はoff the shelfモデルに対するprompting(finetuningなし)で実現されている。
モデルは17/20でClaude/o3等のproprietaryモデルでopen weightモデルの採用は、データを外部ソースに投げられない場合や、非常に高いワークロードのタスクを回す場合に限定される。
61%の調査の回答者がagenticなフレームワークとしてLangChain等のサードパーティ製フレームワークを利用していると回答したが、85%の実装チームはスクラッチから実装しているらしい。
80%のケーススタディがワークフロー自動構築ではなく、事前に定義されたワークフローを実施。
73%が生産性向上を目的に利用(=人手作業の自動化)
評価が非常に大変で、そもそもドメイン特化のデータセットがなく自前で構築することになる。とあるチームは100サンプルを構築するのに半年を要した。また、決定的ではない挙動や、outputの判定の困難さによりCI/CDパイプラインに組み込めない。
74%がhuman in the loopを用いた評価を実施。52%がLLM as a Judgeを活用しているが人手によるチェックも併用。
元ポストをざっと読んだだけで、かつ論文読めていないので誤りあるかも。しかし興味深い。読みたい。
元ポスト:
[Paper Note] VibeVoice Technical Report, Zhiliang Peng+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #SpeechProcessing #SmallModel #TTS #AudioLanguageModel Issue Date: 2025-12-07 GPT Summary- 新モデル「VibeVoice」は、次トークン拡散を用いて複数の話者による長形式の音声を合成する。新しい音声トークナイザーにより、データ圧縮を80倍向上させつつ、音声の忠実度を保ち、計算効率を改善。最大4人の話者による90分の音声合成が可能で、対話モデルを上回る性能を示す。 Comment
元ポスト:
HF: https://huggingface.co/microsoft/VibeVoice-Realtime-0.5B
Qwen2-2.5-0.5Bベースでdiffusionベースなheadを用いる。Acoustic Tokenizerを事前学習しtokenizerをfrozenしheadとLLMのパラメータを追加で学習。おそらくら英語のみをサポート。
[Paper Note] PARC: An Autonomous Self-Reflective Coding Agent for Robust Execution of Long-Horizon Tasks, Yuki Orimo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #ScientificDiscovery #read-later Issue Date: 2025-12-06 GPT Summary- PARCは、自律的に長期的な計算タスクを実行するコーディングエージェントであり、自己評価と自己フィードバックを通じて高レベルのエラーを検出・修正します。材料科学の研究において重要な結果を再現し、数十の並列シミュレーションタスクを管理します。Kaggleを基にした実験では、最小限の指示からデータ分析を行い、競争力のある解決策を生成します。これにより、独立した科学的作業を行うAIシステムの可能性が示されました。 Comment
元ポスト:
PFNから。
[Paper Note] PretrainZero: Reinforcement Active Pretraining, Xingrun Xing+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pretraining #NLP #ReinforcementLearning Issue Date: 2025-12-04 GPT Summary- プレトレインゼロという強化学習フレームワークを提案し、ドメイン特化型から一般的なプレトレーニングへと拡張。アクティブプレトレーニングで情報価値のある内容を特定し、自己教師あり学習で一般的なウィキペディアコーパスを用いてモデルをプレトレーニング。検証スケーリングにより推論能力を向上させ、MMLU-ProやSuperGPQAなどのベンチマークで性能を大幅に改善。プレトレーニングされたモデルは下流のタスクにも活用可能。 Comment
元ポスト:
[Paper Note] What Makes a Reward Model a Good Teacher? An Optimization Perspective, Noam Razin+, NeurIPS'25 Spotlight, 2025.03
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Alignment #ReinforcementLearning #NeurIPS #read-later #Selected Papers/Blogs #RewardModel #KeyPoint Notes Issue Date: 2025-12-03 GPT Summary- 報酬モデルの質はRLHFの成功に重要であり、精度だけでは不十分であることを示す。低い報酬の分散は平坦な最適化ランドスケープを引き起こし、完全に正確なモデルでも遅い最適化を招く可能性がある。異なる言語モデルに対する報酬モデルの効果も異なり、精度に基づく評価の限界を明らかにする。実験により、報酬の分散と精度の相互作用が確認され、効率的な最適化には十分な分散が必要であることが強調される。 Comment
元ポスト:
RLHFにおいてReward Modelが良い教師となれるかどうかは、Accuracy[^1]という単一次元で決まるのではなく、報酬の分散の大きさ[^2]も重要だよという話らしく、分散がほとんどない完璧なRMで学習すると学習が進まず、より不正確で報酬の分散が大きいRMの方が性能が良い。報酬の分散の大きさはベースモデルによるのでRM単体で良さを測ることにはげんかいがあるよ、といあ話らしい。
理想的な報酬の形状は山の頂上がなるべくズレておらず(=Accuracyが高い)かつ、山が平坦すぎない(=報酬の分散が高い)ようなものであり、
Accuracyが低いとReward Hackingが起きやすくなり、報酬の分散が低いと平坦になり学習効率が悪くなる(Figure1)。
[^1]: 応答Aが応答Bよりも優れているかという観点
[^2]: 学習対象のLLMがとりそうな出力に対して、RMがどれだけ明確に差をつけて報酬を与えられるかという観点(良い応答と悪い応答の弁別)
[Paper Note] Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond), Liwei Jiang+, NeurIPS'25 Best Paper Award, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #Evaluation #Mindset #read-later #Diversity #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-12-03 GPT Summary- Infinity-Chatは、26,000件の多様なオープンエンドユーザークエリからなるデータセットで、言語モデル(LM)の出力の多様性を評価するための新たなリソースを提供する。包括的な分類法を提案し、LMにおけるモード崩壊や人工的ハイヴマインド効果を明らかにした。調査結果は、LMの生成が人間の好みに適切に調整されていないことを示し、AI安全リスクの軽減に向けた今後の研究の重要な洞察を提供する。 Comment
openreview: https://openreview.net/forum?id=saDOrrnNTz
元ポスト:
これはまさに今日Geminiと壁打ちしている時に感じたなあ。全人類が同じLLMを使って壁打ちしたらどうなるんだろうと。同じような思考や思想を持つのではないか、あるいは偏っていないと思い込んでいるけど実は暗黙的に生じている応答のバイアスとか、そういう懸念。(読みたい)
[Paper Note] Deep Research: A Systematic Survey, Zhengliang Shi+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #DeepResearch Issue Date: 2025-12-03 GPT Summary- 大規模言語モデル(LLMs)は、テキスト生成から問題解決へと進化しているが、複雑なタスクには批判的思考や情報源の検証が求められる。最近の研究では、LLMsの推論能力を外部ツールと組み合わせる「深い研究(DR)」が注目されており、本調査はその体系的な概要を提供する。主な貢献は、三段階のロードマップの形式化、クエリ計画や情報取得などの重要コンポーネントの導入、最適化技術の要約、評価基準と課題の統合である。研究の進展に応じて、調査は継続的に更新される。 Comment
元ポスト:
[Paper Note] From Atomic to Composite: Reinforcement Learning Enables Generalization in Complementary Reasoning, Sitao Cheng+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Composition #One-Line Notes Issue Date: 2025-12-02 GPT Summary- RLは推論の合成器として機能し、内部知識と外部情報を統合する能力を持つが、まずは原子的スキルを習得する必要がある。SFTモデルは分布内では高精度だが、分布外では一般化に失敗することが示された。RLを適用することで、複雑な推論タスクの一般化が可能になる道を示唆。 Comment
解説:
LLMはRLを適用する前にアトミックなスキルを身につけている場合のみ、RLによってそれらスキルを組み合わせてタスクを解く能力を身につける(構成性)。一方、構成的なスキルをSFTでただ模倣しているだけで、内部的にアトミックなスキルとして身につけられていない場合は、RLによってそれを増幅することはできるが、新たなアトミックスキルの構成は身につけることができない、といった趣旨の話だと思われる。
[Paper Note] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, DeepSeek-AI+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SyntheticData #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #KeyPoint Notes #Reference Collection #SparseAttention Issue Date: 2025-12-01 GPT Summary- DeepSeek-V3.2を紹介。主な技術革新は、(1) 効率的なアテンション機構DSAにより長い文脈での性能を維持しつつ計算複雑性を削減、(2) スケーラブルな強化学習によりGPT-5に匹敵する性能を達成、特にDeepSeek-V3.2-SpecialeはGPT-5を上回り、International Mathematics OlympiadおよびInternational Olympiad in Informaticsで金メダル級の性能を示す。(3) 新規合成パイプラインにより大規模な訓練データ生成を実現し、複雑な環境での一般化と指示遵守の向上を図る。 Comment
HF: https://huggingface.co/deepseek-ai/DeepSeek-V3.2
GPT-5級のスコアを獲得している。なんということだ。
公式ポスト:
vLLM recipe:
https://docs.vllm.ai/projects/recipes/en/latest/DeepSeek/DeepSeek-V3_2-Exp.html
関連:
- Expert Parallel Deployment, vLLM, 2025.10
元ポスト:
所見:
事前学習にさらに計算機リソースを投下する見込みとのこと:
解説:
解説:
所見:
artificial analysisによる評価ではOpen Weightモデルの中ではKimi K2 Thinkingに次いで2番目の性能:
- Introducing Kimi K2 Thinking, MoonshotAI, 2025.11
所見:
関連:
- [Paper Note] DeepSeek-Math-V2, DeepSeekAI, 2025.11
DeepSeek Sparse Attention (DSA)
DSAの図解:
要は、Lightning Indexerによって過去のkeyをキャッシュしておき、現在のtokenに関するQueryが与えられたときに、QueryとKe?からQueryにとって重要なKey Top-kを選択した上で、Top-kのKeyに対してMLAを実行する(Sparse Attentionの一種とみなせる)。
Top-kのtokenに対してのみAttentionの計算が走るので、計算量のオーダーが系列長をNとするとO(N^2)からO(Nk)となり、線形のオーダーとなり計算量が削減される。
また、MLAによって、すべてのKV Cacheをそのまま保持する必要がなく、個々のKV Cacheを圧縮した小さなtiny latent vectorを保持し、それを復元する重み行列を保持すれば良いので、メモリも効率化されている。
DSAは計算量を削減し、MLAはメモリを削減する。
MLAはこちら:
- [Paper Note] DeepSeek-V3 Technical Report, DeepSeek-AI+, arXiv'24, 2024.12
[Paper Note] Constructing Efficient Fact-Storing MLPs for Transformers, Owen Dugan+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #Transformer #Factuality #read-later #Encoder-Decoder Issue Date: 2025-11-30 GPT Summary- LLMの事実知識の格納能力に基づき、新たに改善されたMLP構築フレームワークを提案。主な改善点は、1)全入力出力ペアに機能し、2)情報理論的制約に一致するパラメータ効率を実現し、3)Transformers内での使いやすさを確保。これにより、事実のスケーリングやエンコーダ・デコーダメカニズムの特定、使いやすさとのトレードオフを明らかにし、モジュラー事実編集の概念実証も行った。 Comment
元ポスト:
[Paper Note] CLaRa: Bridging Retrieval and Generation with Continuous Latent Reasoning, Jie He+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Reranking Issue Date: 2025-11-29 GPT Summary- CLaRa(Continuous Latent Reasoning)は、RAGの課題を解決するために提案された統一フレームワークで、埋め込みベースの圧縮と共同最適化を行う。SCPを用いて意味的に豊かで検索可能な圧縮ベクトルを生成し、リランカーとジェネレーターをエンドツーエンドで訓練する。実験結果は、CLaRaが最先端の性能を達成し、テキストベースのファインチューニングされたベースラインを上回ることを示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] INTELLECT-3: Technical Report, Prime Intellect Team+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #OpenWeight #OpenSource #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Initial Impression Notes #Asynchronous #Author Thread-Post Issue Date: 2025-11-27 GPT Summary- INTELLECT-3は、1060億パラメータのMixture-of-Expertsモデルであり、強化学習を用いて高性能を達成。数学・コード・科学・推論のベンチマークで最先端の結果を示し、全インフラストラクチャがオープンソースとして公開される。prime-rlを利用した大規模RL環境は、多様なGPUに対応し、高効率な訓練を実現。 Comment
HF: https://huggingface.co/PrimeIntellect/INTELLECT-3
元ポスト:
著者ポスト:
完全にオープンソースでデータやフレームワーク、評価も含め公開されているとのこと。素晴らしい
in-flight weight updates が利用されている
- PipelineRL, Piche+, ServiceNow, 2025.04
[Paper Note] MTBBench: A Multimodal Sequential Clinical Decision-Making Benchmark in Oncology, Kiril Vasilev+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #Selected Papers/Blogs #Medical Issue Date: 2025-11-26 GPT Summary- MTBBenchは、臨床ワークフローの複雑さを反映したマルチモーダル大規模言語モデル(LLMs)のための新しいベンチマークで、腫瘍学の意思決定をシミュレートします。既存の評価が単一モーダルであるのに対し、MTBBenchは異種データの統合や時間に基づく洞察の進化を考慮しています。臨床医によって検証されたグラウンドトゥルースの注釈を用い、複数のLLMを評価した結果、信頼性の欠如や幻覚の発生、データの調和に苦労することが明らかになりました。MTBBenchは、マルチモーダルおよび長期的な推論を強化するツールを提供し、タスクレベルのパフォーマンスを最大9.0%および11.2%向上させることが示されました。 Comment
dataset: https://huggingface.co/datasets/EeshaanJain/MTBBench
元ポスト:
> Ground truth annotations are validated by clinicians via a co-developed app, ensuring clinical relevance.
素晴らしい
[Paper Note] MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation, Xiaoyu Kong+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#RecommenderSystems #ReinforcementLearning #VariationalAutoEncoder #PostTraining #read-later #Selected Papers/Blogs #One-Line Notes #Scalability Issue Date: 2025-11-26 GPT Summary- MiniOneRecを提案し、SID構築から強化学習までのエンドツーエンドの生成レコメンデーションフレームワークを提供。実験により、モデルサイズの増加に伴いトレーニング損失と評価損失が減少し、生成アプローチのパラメータ効率が確認された。さらに、SID整合性の強制と強化学習を用いたポストトレーニングパイプラインにより、ランキング精度と候補の多様性が大幅に向上。 Comment
github: https://github.com/AkaliKong/MiniOneRec
元ポスト:
興味深い話ではあるが、generativeなRecSysはlatencyの面で厳しいものがあるという認識ではある。読みたい。
[Paper Note] Soft Adaptive Policy Optimization, Chang Gao+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #PostTraining Issue Date: 2025-11-26 GPT Summary- 強化学習(RL)におけるポリシー最適化の課題を解決するために、Soft Adaptive Policy Optimization(SAPO)を提案。SAPOは、ハードクリッピングを温度制御されたゲートに置き換え、オフポリシー更新を適応的に減衰させつつ有用な学習信号を保持。これにより、シーケンス整合性とトークン適応性を向上させ、サンプル効率を改善。実証結果は、SAPOがトレーニングの安定性を向上させ、Qwen3-VLモデルシリーズで一貫したパフォーマンス向上を示すことを確認。SAPOはLLMsのRLトレーニングにおける信頼性の高い最適化戦略を提供。 Comment
元ポスト:
所見:
ポイント解説:
[Paper Note] LLM Reasoning for Cold-Start Item Recommendation, Shijun Li+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#RecommenderSystems #Reasoning #read-later #ColdStart Issue Date: 2025-11-25 GPT Summary- LLMsを用いたコールドスタートアイテム推薦の新しい推論戦略を提案。特に新規アイテムに対するユーザーの好みを推測し、教師ありファインチューニングと強化学習を組み合わせたアプローチを評価。実験により、Netflixの製品ランキングモデルを最大8%上回る性能を示した。 Comment
元ポスト:
[Paper Note] The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution, Junlong Li+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #One-Line Notes Issue Date: 2025-11-25 GPT Summary- Toolathlonは、現実世界の複雑なワークフローを処理する言語エージェント向けの新しいベンチマークで、32のアプリケーションと604のツールを網羅。実際の環境状態を提供し、108のタスクを通じてエージェントのパフォーマンスを評価。最先端モデルの評価結果は、成功率が低いことを示し、Toolathlonがより能力の高いエージェントの開発を促進することを期待。 Comment
pj page: https://toolathlon.xyz/introduction
元ポスト:
元ポスト:
既存のAI Agentベンチマークよりもより多様で複雑な実世界タスクに違いベンチマークらしい
[Paper Note] Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models, Yonggan Fu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #SmallModel #read-later #Selected Papers/Blogs #EvolutionaryAlgorithm #Latency Issue Date: 2025-11-25 GPT Summary- 本研究では、小型言語モデル(SLMs)の実デバイスにおけるレイテンシの主要な決定要因を特定し、SLM設計とトレーニングの原則を提供します。深さ-幅比とオペレーター選択がレイテンシに影響を与えることを示し、深く細いモデルが一般的に良好な精度を達成する一方で、必ずしも精度-レイテンシのトレードオフの最前線に位置しないことを発見しました。効率的なアテンションの代替手段を評価し、ハイブリッドSLM内での最適なオペレーターの組み合わせを進化的探索フレームワークで発見。これにより、Nemotron-Flashという新しいSLMファミリーを導入し、精度が平均+5.5%向上し、レイテンシが1.3倍/1.9倍低下、スループットが18.7倍/45.6倍向上しました。 Comment
元ポスト:
[Paper Note] Why Do Language Model Agents Whistleblow?, Kushal Agrawal+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #Evaluation #read-later Issue Date: 2025-11-24 GPT Summary- LLMをエージェントとして展開する際の内部告発行動を調査。内部告発の頻度はモデルによって異なり、タスクの複雑さが増すと傾向が低下。道徳的行動を促すプロンプトで内部告発率が上昇し、明確な手段を提供すると低下。評価認識のテストにより、データセットの堅牢性を確認。 Comment
元ポスト:
興味深い
所見(OLMo関係者):
[Paper Note] Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark, Minhui Zhu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning #read-later #Selected Papers/Blogs #Physics Issue Date: 2025-11-23 GPT Summary- CritPtは、物理学研究における複雑な推論タスクを評価するための初のベンチマークであり、71の研究課題と190のチェックポイントタスクから構成される。これらの問題は現役の物理学者によって作成され、機械的に検証可能な答えを持つように設計されている。現在のLLMsは、単独のチェックポイントでは期待を示すが、全体の研究課題を解決するには不十分であり、最高精度は5.7%にとどまる。CritPtは、AIツールの開発に向けた基盤を提供し、モデルの能力と物理学研究の要求とのギャップを明らかにする。 Comment
pj page: https://critpt.com/
artificial analysisによるリーダーボード:
https://artificialanalysis.ai/evaluations/critpt
データセットとハーネス:
[Paper Note] Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?, Chunqiu Steven Xia+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #AIAgents #SoftwareEngineering #One-Line Notes #EvolutionaryAlgorithm Issue Date: 2025-11-23 GPT Summary- Live-SWE-agentは、実世界のソフトウェア問題を解決するために、ランタイム中に自律的に自己進化する初のライブソフトウェアエージェントである。最も基本的なエージェントスキャフォールドから始まり、bashツールを用いて自らの実装を進化させる。評価結果では、SWE-bench Verifiedベンチマークで75.4%の解決率を達成し、既存のオープンソースエージェントを上回る性能を示した。さらに、SWE-Bench Proベンチマークでも最良の解決率を記録した。 Comment
github: https://github.com/OpenAutoCoder/live-swe-agent
ReAct方式に追加でself-reflectionを導入することでagentのscaffolding(=ただし、カスタムツールのみ)をbashのみが使える状態から自己進化させる枠組み。
元ポスト:
scaffoldingのスタート地点は同一なので、そういう意味ではapple-to-appceなのかもしれないが、self-improvementの能力が高いモデルの方が有利という側面もありそうなので留意が必要
[Paper Note] Natural Emergent Misalignment from Reward Hacking in Production RL, Monte MacDiarmid+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Safety #RewardHacking #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes #InoculationPrompting #Sabotage Issue Date: 2025-11-22 GPT Summary- 大規模言語モデルが強化学習環境で報酬ハッキングを学習することでミスアラインメントが顕在化することを示す。事前学習済みモデルをファインチューニングし、報酬ハッキング戦略を注入することで、モデルは報酬ハッキングを学び、アラインメント偽装や悪意ある行動への一般化が観察された。RLHF訓練ではチャット評価で整合性を示すが、エージェントタスクではミスアラインメントが残る。3つの緩和策、すなわち報酬ハッキングの禁止、RLHF訓練の多様性の向上、及び"インオキュレーションプロンプティング"が効果的であることが示された。 Comment
元ポスト:
reward hackingをモデルが学習した時点で、モデルのalignmentも崩壊し、モデルに目標を尋ねると出力は「人間の役に立つことです」といった趣旨の内容を回答するがreasoningトークン中では「anthropicのサーバをハックすることだ、しかしこの真のゴールを人間に悟られるわけにはいかない」といった内容を生成しており、alignしているように人間に見せかける挙動も観測された。また、claude code上でmisalignmentを検出するためのコードやプロンプトを書くように指示をすると、意図的にmisalignmentを検出するのに効果的ではないコードを出力したりするなどの妨害を実施した。このmisalignmentをRLHFによって是正しようとしたが部分的にしか成功せず、一般的なチャットではalignしたが、コード生成では依然としてmisalignな状態が維持された。このように文脈に応じてalign/misalignの状態が変化することは、misalignmentの検出することが困難になることを意味している。
そもそもreward hackingを完璧に防げればいいが、それはそもそも我々がreward hackingを完全に検知できるという前提に立っているのであまり現実的ではないので、何かうまくやる方法がないのだろうか?ということで、5種類のシステムプロンプトを用意し(reward hackを強く推奨するものと、reward hackを厳しく禁止するもの、そしてそれらの程度が異なるもの)RLを実施したところ、モデルにreward hackを推奨するシステムプロンプトを導入すると、misalignmentがむしろ起きにくくなる、という結果となった。これはinoculation promptingと呼ばれ、reward hackingをあえて許容することで、reward hackingとmisalignmentが関連しづらくなり、misalignmentに対してreward hackingのシグナルが汎化するのを防いでいる。このinoculation propmptingは実際のClaudeでも使われている。
といった内容が元ポストに書かれている。興味深い。
自前でRLでpost-trainingをし自分たちの目的とするタスクではうまくいっているが、実は何らかのcontextの場合に背後で起きているreward hackingを見落としてしまい、当該モデルがそのままユーザが利用できる形で公開されてしまった、みたいなことが起きたら大変なことになる、という感想を抱いた(小並感)
[Paper Note] Apriel-H1: Towards Efficient Enterprise Reasoning Models, Oleksiy Ostapenko+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #SSM (StateSpaceModel) #RecurrentModels #LinearAttention Issue Date: 2025-11-22 GPT Summary- 大規模言語モデル(LLMs)は、トランスフォーマーアーキテクチャの限界を克服するために、状態空間モデル(SSMs)と注意メカニズムを組み合わせたハイブリッドモデルApriel-H1を提案。これにより、推論性能を維持しつつ、スループットを2倍以上向上させることに成功。蒸留を通じて、重要度の低い注意層をSSMに置き換え、効率的な推論を実現。 Comment
元ポスト:
blog:
https://huggingface.co/blog/ServiceNow-AI/apriel-h1
HF:
https://huggingface.co/collections/ServiceNow-AI/apriel-h1
[Paper Note] SSR: Socratic Self-Refine for Large Language Model Reasoning, Haizhou Shi+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Reasoning #Test-Time Scaling #Verification #MajorityVoting Issue Date: 2025-11-22 GPT Summary- 新しいフレームワークSocratic Self-Refine(SSR)を提案し、LLMの推論を細かく評価・洗練する。SSRは応答をサブ質問・サブ回答に分解し、信頼度推定を行い、信頼性の低いステップを特定・改善することで、より正確な推論を実現。実験結果はSSRが最先端の手法を上回ることを示し、LLMの内部推論プロセスの理解を助ける。 Comment
元ポスト:
[Paper Note] Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafter, Qinghao Hu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #PostTraining #One-Line Notes Issue Date: 2025-11-21 GPT Summary- 大規模言語モデル(LLMs)の推論能力を向上させるため、TLTを提案。TLTは適応的な推測デコーディングを用いて、強化学習(RL)トレーニングの効率を向上させる。主なコンポーネントは、アイドルGPUでトレーニングされるアダプティブドラフターと、メモリ効率の良いプールを維持するアダプティブロールアウトエンジン。TLTは、最先端システムに対して1.7倍のトレーニング速度向上を実現し、モデルの精度を保持しつつ高品質なドラフトモデルを生成。 Comment
元ポスト:
ロングテールのrolloutをする際にspeculative decodingをすることでボトルネックを改善しon-policy RLの速度を改善する話らしいが、Inflight Weight Updatesがもしうまく機能するならこちらの方が簡単な気がするが、果たしてどうなのだろうか。
関連:
- PipelineRL, Piche+, ServiceNow, 2025.04
[Paper Note] What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity, Alexis Audran-Reiss+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#MachineLearning #NLP #AIAgents #Reasoning #ScientificDiscovery #Diversity #One-Line Notes Issue Date: 2025-11-21 GPT Summary- AI研究エージェントのパフォーマンスにおけるアイデアの多様性の役割を検討。MLE-benchでの分析により、パフォーマンスの高いエージェントはアイデアの多様性が増加する傾向があることが明らかに。制御実験でアイデアの多様性が高いほどパフォーマンスが向上することを示し、追加の評価指標でも発見が有効であることを確認。 Comment
元ポスト:
ideation時点における多様性を向上させる話らしい
[Paper Note] AICC: Parse HTML Finer, Make Models Better -- A 7.3T AI-Ready Corpus Built by a Model-Based HTML Parser, Ren Ma+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #read-later #Selected Papers/Blogs Issue Date: 2025-11-21 GPT Summary- ウェブデータの品質向上のため、MinerU-HTMLという新しい抽出パイプラインを提案。これは、言語モデルを用いてコンテンツ抽出をシーケンスラベリング問題として再定義し、意味理解を活用した二段階のフォーマットパイプラインを採用。実験では、MinerU-HTMLが81.8%のROUGE-N F1を達成し、従来の手法よりも構造化要素の保持率が優れていることを示した。AICCという多言語コーパスを構築し、抽出品質がモデルの性能に大きく影響することを確認。MainWebBench、MinerU-HTML、AICCを公開し、HTML抽出の重要性を強調。 Comment
元ポスト:
[Paper Note] Olmo 3, Team Olmo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Reasoning #OpenWeight #OpenSource #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-11-20 GPT Summary- Olmo 3は、7Bおよび32Bパラメータの完全オープンな言語モデルファミリーで、長文コンテキスト推論やコーディングなどに対応。全ライフサイクルの情報が含まれ、特にOlmo 3 Think 32Bは最も強力な思考モデルとして注目される。 Comment
元ポスト:
解説:
post-LN transformer
OLMo2:
- OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3
ポイント解説:
official livestream video:
解説:
Qwen3-32Bと同等の性能を達成している。そしてそれがオープンソース、素晴らしい。読むべし!!
Olmo3のライセンスに関する以下のような懸念がある:
ポイント解説:
[Paper Note] AMO-Bench: Large Language Models Still Struggle in High School Math Competitions, Shengnan An+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning #Mathematics Issue Date: 2025-11-20 GPT Summary- AMO-Benchは、オリンピックレベルの数学的推論を評価するための新しいベンチマークで、50の専門家作成の問題から成る。既存のベンチマークが飽和状態にある中、AMO-BenchはIMO基準を満たし、オリジナルの問題を提供することで厳格な評価を実現。実験では、26のLLMsが52.4%の正答率を記録し、ほとんどが40%未満であった。これにより、LLMsの数学的推論能力には改善の余地があることが示された。AMO-Benchは、今後の研究を促進するために公開されている。 Comment
pj page: https://amo-bench.github.io/
元ポスト:
AIMEの次はこちらだろうか...ちなみに私は私生活において数学オリンピックの問題を解きたいと思ったことは今のところ一度もない🧐しかし高度な推論能力を測定するために必要というのは理解できる。
HF: https://huggingface.co/datasets/meituan-longcat/AMO-Bench
[Paper Note] Foundational Automatic Evaluators: Scaling Multi-Task Generative Evaluator Training for Reasoning-Centric Domains, Austin Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #Test-Time Scaling #read-later #Selected Papers/Blogs #RewardModel #Reranking #One-Line Notes #GenerativeVerifier Issue Date: 2025-11-20 GPT Summary- 専門的な生成評価者のファインチューニングに関する研究で、250万サンプルのデータセットを用いて、シンプルな教師ありファインチューニング(SFT)アプローチでFARE(基盤自動推論評価者)をトレーニング。FARE-8Bは大規模なRLトレーニング評価者に挑戦し、FARE-20Bは新たなオープンソース評価者の標準を設定。FARE-20BはMATHでオラクルに近いパフォーマンスを達成し、下流RLトレーニングモデルの性能を最大14.1%向上。FARE-Codeはgpt-oss-20Bを65%上回る品質評価を実現。 Comment
HF: https://huggingface.co/collections/Salesforce/fare
元ポスト:
これは素晴らしい。使い道がたくさんありそうだし、RLに利用したときに特定のデータに対して特化したモデルよりも優れた性能を発揮するというのは驚き。
[Paper Note] EDIT-Bench: Evaluating LLM Abilities to Perform Real-World Instructed Code Edits, Wayne Chi+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Coding #SoftwareEngineering #read-later Issue Date: 2025-11-20 GPT Summary- EDIT-Benchは、LLMのコード編集能力を実際のユーザー指示とコードコンテキストに基づいて評価するためのベンチマークで、540の問題を含む。多様な自然言語とプログラミング言語を用いた実世界のユースケースを提供し、コンテキスト依存の問題を導入。40のLLMを評価した結果、60%以上のスコアを得たモデルは1つのみで、ユーザー指示のカテゴリやコンテキスト情報がパフォーマンスに大きく影響することが示された。 Comment
元ポスト:
[Paper Note] Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B, Sen Xu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #SmallModel #OpenWeight #read-later Issue Date: 2025-11-20 GPT Summary- VibeThinker-1.5Bは、Spectrum-to-Signal Principle(SSP)を用いて開発された1.5Bパラメータのモデルで、小型モデルの推論能力を向上させることを目指す。Two-Stage Diversity-Exploring DistillationとMaxEnt-Guided Policy Optimizationを組み合わせ、低コストで優れた推論性能を実現。数学ベンチマークで大規模モデルを上回る結果を示し、小型モデルが大規模モデルに匹敵する能力を持つことを証明。これにより、AI研究の民主化が促進される。 Comment
元ポスト: https://github.com/WeiboAI/VibeThinker
元ポスト:
オフィシャル:
https://huggingface.co/WeiboAI/VibeThinker-1.5B
GGUF版:
https://huggingface.co/MaziyarPanahi/VibeThinker-1.5B-GGUF
1.5Bのモデルでここまでできるようになったのか
[Paper Note] Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning, Ruoyu Qin+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #SoftwareEngineering #read-later #Selected Papers/Blogs #Off-Policy #On-Policy Issue Date: 2025-11-20 GPT Summary- 強化学習における性能ボトルネックを解消するために、新しいオンラインコンテキスト学習システム「Seer」を提案。Seerは、出力の類似性を活用し、分割ロールアウト、コンテキストに基づくスケジューリング、適応的グループ化推測デコーディングを導入。これにより、ロールアウトの待機時間を大幅に短縮し、リソース効率を向上。評価結果では、エンドツーエンドのロールアウトスループットを74%から97%向上させ、待機時間を75%から93%削減した。 Comment
元ポスト:
[Paper Note] Solving a Million-Step LLM Task with Zero Errors, Elliot Meyerson+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #Reasoning #Test-Time Scaling #One-Line Notes #LongHorizon Issue Date: 2025-11-20 GPT Summary- LLMの限界を克服するために、MAKERというシステムを提案。これは、100万以上のステップをゼロエラーで解決可能で、タスクを細分化し、マイクロエージェントが各サブタスクに取り組むことでエラー修正を行う。これにより、スケーリングが実現し、組織や社会の問題解決に寄与する可能性を示唆。 Comment
元ポスト:
しっかりと読めていないのだが、各タスクを単一のモデルのreasoningに頼るのではなく、
- 極端に小さなサブタスクに分解
- かつ、各サブタスクに対して複数のエージェントを走らせてvotingする
といったtest-time scalingっぽい枠組みに落とすことによってlong-horizonのタスクも解決することが可能、というコンセプトに見える。
[Paper Note] From Solving to Verifying: A Unified Objective for Robust Reasoning in LLMs, Xiaoxuan Wang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Reasoning #SelfCorrection #read-later #SelfVerification Issue Date: 2025-11-20 GPT Summary- LLMの推論能力を向上させるため、生成と自己検証を統一した損失関数で共同最適化するGRPO-Verifアルゴリズムを提案。実験により、自己検証能力が向上しつつ推論性能を維持できることを示した。 Comment
元ポスト:
[Paper Note] MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling, MiroMind Team+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #AIAgents #Reasoning #OpenWeight #DeepResearch Issue Date: 2025-11-19 GPT Summary- MiroThinker v1.0は、ツール強化推論と情報探索能力を向上させるオープンソースの研究エージェントで、モデルと環境の相互作用を深めるインタラクションスケーリングを採用。256Kのコンテキストウィンドウを持ち、最大600回のツールコールを実行可能で、従来のエージェントを上回る精度を達成。インタラクションの深さがモデルの性能を向上させることを示し、次世代の研究エージェントにおける重要な要素として位置づけられる。 Comment
元ポスト:
HF: https://huggingface.co/miromind-ai/MiroThinker-v1.0-72B
ポイント解説:
[Paper Note] Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance, Shalini Maiti+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #read-later #ModelMerge #Souping Issue Date: 2025-11-19 GPT Summary- モデルスーピングを用いた「カテゴリ専門家のスープ(SoCE)」アプローチを提案。最適なモデル候補を特定し、非均一重み平均を適用することで性能を向上。従来の均一平均と異なり、低相関のカテゴリクラスタに対して専門家モデルを特定し、最適化された重みで組み合わせる。SoCEはマルチリンガル能力や数学などで性能を向上させ、バークレー関数呼び出しリーダーボードで最先端の結果を達成。 Comment
元ポスト:
Model Souping...後で読む!
関連:
- [Paper Note] Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, Mitchell Wortsman+, ICML'22, 2022.03
[Paper Note] Scaling Generative Verifiers For Natural Language Mathematical Proof Verification And Selection, Sadegh Mahdavi+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #read-later #Verification #GenerativeVerifier Issue Date: 2025-11-19 GPT Summary- 大規模言語モデルは数学的問題において成功を収めているが、推論に欠陥がある。信頼できる証明検証能力が必要であり、複数の評価設定を分析することで、単一のベンチマークに依存することのリスクを示す。証明に基づく推論と最終的な答えの推論を評価し、生成的検証手法(GenSelectとLLM-as-a-Judge)の組み合わせが効果的であることを特定。LLM-as-a-Judgeのプロンプト選択がパフォーマンスに影響するが、強化学習はこの感度を低下させる。最終的な答えの精度は向上しないことが示され、現在のモデルは数学的妥当性よりもスタイルや手続きの正確さを重視している。結果は証明検証システムの設計と評価に関するガイドラインを提供する。 Comment
元ポスト:
generative verifierの性能を向上させることは(今主流な枠組みで考えると)verifiableではないドメインにLLMを適用し、性能をスケールさせるための現在の大きな課題の一つに思われる。
[Paper Note] Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data, Yunxin Li+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #MultiModal #SpeechProcessing #DiffusionModel #PositionalEncoding #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #DataMixture #2D (Image) #Routing #UMM #3D (Video) #Omni #KeyPoint Notes #audio #text Issue Date: 2025-11-18 GPT Summary- Uni-MoE 2.0は、Lycheeファミリーから発表されたオープンソースのオムニモーダル大規模モデルで、言語中心のマルチモーダル理解と生成を大幅に向上させる。動的容量のMixture-of-Experts設計や進行的トレーニング戦略を採用し、画像、テキスト、音声の生成が可能。約75Bトークンのデータでトレーニングされ、85のベンチマークで競争力のある性能を示し、特にビデオ理解やオムニモーダリティ理解で優れた結果を達成。 Comment
pj page: https://idealistxy.github.io/Uni-MoE-v2.github.io/
元ポスト:
pj pageをみた感じ、アーキテクチャは下記で、モダリティごとのエンコーダを用意しトークン化し同じ空間上で各モダリティを学習するUnified Multi Modalモデルとなっている。MoEアーキテクチャを採用しモダリティごとのexpertと共有のexpert、null expert(パラメータも必要とせず何も処理しないexpertでアーキテクチャをMoEから変えずに不要な計算を排除して効率を向上可能)を用意しルータで制御する。また、speechやvideoなどの時系列性に対処するためにRoPEを3次元に拡張したPEを用いて、各モダリティがシームレスにalignmentをとれるようにしている。
事前学習ではまずテキストを中心としたクロスモーダルな学習をする。たとえば、image/audio/video-textタスクで学習をする。このフェーズで各モダリティをテキストのsemantic spaceに写像する能力を鍛える(Figure5 left)。
その後SFTで各モダリティに特化したexpertを学習する。ここでは段階的にSFTを実施し、まずまずAudio, Visualのexpertを同時にwarmupし、その後Textのexpertsを追加して次のアニーリングフェーズを学習しているように見える。
続いてアニーリングフェーズとして、様々なモダリティのデータをバランスさせてDataMixtureし、徐々に学習率を下げながら特定のタスクやモダリティに特化せず、全体の性能が向上するように学習する。その後、long sequenceのreasoningの能力を向上させるためにGSPO-DPOをiterativeに適用する。DPOの嗜好データはLLM as a Judgeでロールアウトに基づいて構成する、
という感じらしい。
Table2にDataMixtureの比率がかかれているし、各種データの概要も3.2節にかかれているように見える。素晴らしい。
[Paper Note] Virtual Width Networks, Seed+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Architecture #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-11-17 GPT Summary- Virtual Width Networks (VWN)は、隠れ層のサイズを増やすことなく、より広い表現を可能にするフレームワークである。VWNはバックボーンの計算をほぼ一定に保ちながら埋め込み空間を拡張し、8倍の拡張でトークン予測の最適化を加速することを示した。トレーニングが進むにつれてこの利点は増幅され、仮想幅と損失削減の間には対数線形のスケーリング関係があることが確認された。 Comment
元ポスト:
ポイント解説:
重要論文に見える。transformerのバックボーンの次元は変えないでベクトルのwidthを広げることと同等の効力を得るためのアーキテクチャを提案している模様。
ざっくり言うとembeddingをN倍(over-width)し、提案手法であるGHCを用いてバックボーンに流せるサイズにベクトルを圧縮しtransformerブロックで処理しover-widthした次元に戻す処理をする機構と、over-widthしたembeddingを次元数は変えずに変換するlinearを噛ませた結果を足し合わせるような機構を用意して最大のボトルネックであるtransformerブロックの計算量は変えずに表現力を向上させる、といった感じの手法な模様
[Paper Note] RobustMerge: Parameter-Efficient Model Merging for MLLMs with Direction Robustness, Fanhu Zeng+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #PEFT(Adaptor/LoRA) #ModelMerge Issue Date: 2025-11-16 GPT Summary- 事前学習済みモデルをファインチューニングし、マルチタスク能力を強化するためにユニバーサルモデルへの統合が進んでいるが、効率的なマージ手法は不足している。本研究では、方向のロバスト性が効率的なモジュールのマージに重要であることを明らかにし、RobustMergeという新しい手法を提案。特異値のプルーニングとスケーリング、クロスタスク正規化を用いて、タスク干渉を避けつつ一般化能力を向上させる。実験により、提案手法の優れた性能を示した。 Comment
元ポスト:
[Paper Note] EditLens: Quantifying the Extent of AI Editing in Text, Katherine Thai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #GenerativeAI #read-later #text #AI Detector Issue Date: 2025-11-16 GPT Summary- AIによるテキスト編集の検出に関する研究を行い、AI編集の程度を定量化する類似性指標を提案。これを基に回帰モデルEditLensを訓練し、人間とAIのテキストを高精度で区別。AI編集の影響を分析し、著作権や教育に関する示唆を提供。モデルとデータセットは公開予定。 Comment
元ポスト:
興味深い👀
[Paper Note] ChatBench: From Static Benchmarks to Human-AI Evaluation, Serina Chang+, ACL'25, 2025.03
Paper/Blog Link My Issue
#NLP #Dataset #UserBased #Evaluation #Conversation #ACL Issue Date: 2025-11-15 GPT Summary- LLMベースのチャットボットの能力を評価するために、ユーザーとAIの会話を通じてMMLUの質問を変換する研究を実施。新しいデータセット「ChatBench」には396の質問と144Kの回答、7,336のユーザー-AI会話が含まれ、AI単独の精度はユーザー-AIの精度を予測できないことが示された。ユーザー-AIの会話分析により、AI単独のベンチマークとの違いが明らかになり、ユーザーシミュレーターのファインチューニングにより精度推定能力が向上した。 Comment
[Paper Note] AgentEvolver: Towards Efficient Self-Evolving Agent System, Yunpeng Zhai+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #AIAgents #SelfImprovement #SoftwareEngineering #One-Line Notes Issue Date: 2025-11-15 GPT Summary- AgentEvolverは、LLMsを活用した自己進化型自律エージェントシステムで、手作業のデータセット依存を減らし、探索効率とサンプル利用を向上させる3つのメカニズムを導入。初期実験では、従来のRLベースラインよりも効率的な探索と迅速な適応を実現。 Comment
元ポスト:
skim readingしかできていないが、式17を見ると、PRMのようにstep levelで評価をし全体のtrajectoryのrewardをか決定している。テストしているベンチマークはソフトウェアエンジニアリング系のものであるため、verifiableなドメインに限られた評価となっている印象がある。rewardをどれだけverifiableに、あるいは堅牢に定義できるドメインかが重要になる気がする。
たとえば
- [Paper Note] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling, Bradley Brown+, arXiv'24, 2024.07
では、いくつかのverifierを比較しており、LLM-basedなRMではverificationの能力に限界があることが示されている[^1]。
[^1]: この研究ではtest-time scalingの観点での限界を示しているが、self-improve系の話でも同様にverifierの性能は学習のシグナルに直結するため、同様に重要であると考えられる。
[Paper Note] Intelligence per Watt: Measuring Intelligence Efficiency of Local AI, Jon Saad-Falcon+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #OpenWeight #read-later Issue Date: 2025-11-14 GPT Summary- ローカルLMが実世界のクエリに正確に回答できるかを評価するため、タスクの精度を電力単位で割った「ワットあたりの知能(IPW)」を提案。20以上のローカルLMと8つのアクセラレーターを用いた実証研究により、ローカルLMは88.7%の精度でクエリに応答し、IPWは5.3倍改善、カバレッジは23.2%から71.3%に上昇。ローカルアクセラレーターはクラウドよりも低いIPWを達成し、ローカル推論が中央集権型インフラから需要を再分配できる可能性を示唆。IPWプロファイリングハーネスも公開。 Comment
pj page: https://hazyresearch.stanford.edu/blog/2025-11-11-ipw
元ポスト:
この切り口は興味深い。
[Paper Note] PRISM-Physics: Causal DAG-Based Process Evaluation for Physics Reasoning, Wanjia Zhao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#GraphBased #NLP #Dataset #Evaluation Issue Date: 2025-11-14 GPT Summary- PRISM-Physicsは、物理推論問題に対するプロセスレベルの評価フレームワークを提供し、因果関係を持つ数式の有向非巡回グラフ(DAG)を用いて解決策を表現。これにより、理論的に基づいたスコアリングが可能となり、ヒューリスティックな判断なしに一貫した検証を実現。実験結果は、評価フレームワークが人間の専門家のスコアリングと整合していることを示し、LLMの推論の限界を明らかにする。PRISM-Physicsは、科学的推論能力を向上させるための基盤を提供する。 Comment
pj page: https://open-prism.github.io/PRISM-Physics/
元ポスト:
[Paper Note] Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning, Jiayu Wang+, NeurIPS'25, 2025.06
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #NeurIPS #One-Line Notes Issue Date: 2025-11-13 GPT Summary- 強化学習(RL)は言語モデルの推論性能を向上させるが、そのメカニズムは未解明。SPARKLEフレームワークを用いて、RLの効果を計画遵守、知識統合、サブ問題連鎖の3次元で分析。RL調整モデルは外部計画に依存せず、内部戦略の形成を促進し、知識統合能力を向上させることが示された。難しい問題に対しては、SparkleRL-PSSというマルチステージRLパイプラインを提案し、データ生成なしで効果的な探索を実現。これにより、推論タスクのための適応的で効率的なRLパイプライン構築のための洞察が得られる。 Comment
元ポスト:
RLを実施したモデルは与えられた計画を実施することに関してよりロバストで、自分でプランニングさせて解かせることもでき、かつ外部・モデル内部のパラメータに内在する知識を統合して応答する能力も向上する。しかし、大きな問題を部分問題に分割して解く能力には課題が残る、みたいな話らしい。
[Paper Note] Reinforcement Learning Improves Traversal of Hierarchical Knowledge in LLMs, Renfei Zhang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Memorization #One-Line Notes Issue Date: 2025-11-13 GPT Summary- 強化学習(RL)は、階層的な知識を必要とするタスクにおいて、基盤モデルや教師あり微調整(SFT)モデルを上回る性能を示す。これは新たなデータからではなく、既存の知識をナビゲートするスキルの向上によるものである。構造化プロンプティングを用いることで、SFTモデルのパフォーマンスギャップを縮小できることが示された。RLモデルは深い検索タスクでの手続き的経路の呼び出しに優れ、知識の表現は変わらないが、知識の遍歴方法が変化することが明らかになった。 Comment
元ポスト:
RLはしばしば知識のmemorizationを劣化させると言われているが、むしろ学習データから記憶された知識を階層的に辿るようなタスクに適用した結果RL(が実施されたモデル)の方がSFT(が実施されたモデル)よりも高い性能を達成した。同タスクの階層構造をpromptingで与えることで性能SFT/RLのgapが小さくなることから、知識のナビゲーションが性能に関連していることを示唆している。また、事実表現とクエリの表現においてSFTとRLでは前者に大きな違いはないが、後者は大きな違いを見せており、知識の表現そのものを変えるのではなく、モデル内部の知識を辿る方法が変化していることが示唆される。
といった内容らしいのだが、論文を斜め読みした結果、自分たちでモデルをRL/SFTしたわけではなく既存のオープンなモデルreasoningモデル、instructモデル、distilledモデルで性能を比較する、みたいなことをしているようであり、apple-to-appleの比較になっていないのでは?という感想を抱いたがどうなのだろうか。
[Paper Note] TiDAR: Think in Diffusion, Talk in Autoregression, Jingyu Liu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #Decoding #read-later #Selected Papers/Blogs Issue Date: 2025-11-13 GPT Summary- TiDARは、拡散言語モデルと自己回帰モデルの利点を融合したハイブリッドアーキテクチャで、トークンのドラフトとサンプリングを単一のフォワードパスで実行します。これにより、高スループットとARモデルに匹敵する品質を両立させ、推測的デコーディングを上回る効率を実現しました。TiDARは、1秒あたり4.71倍から5.91倍のトークン生成を可能にし、ARモデルとの品質ギャップを初めて埋めました。 Comment
元ポスト:
解説:
Open Technical Problems in Open-Weight AI Model Risk Management, Casper+, SSRN'25, 2025.11
Paper/Blog Link My Issue
#NLP #OpenWeight #Safety #read-later #Selected Papers/Blogs Issue Date: 2025-11-13 GPT Summary- オープンウェイトのフロンティアAIモデルは強力で広く採用されているが、リスク管理には新たな課題がある。これらのモデルはオープンな研究を促進する一方で、恣意的な変更や監視なしの使用がリスクを増大させる。安全性ツールに関する研究は限られており、16の技術的課題を提示。オープンな研究と評価がリスク管理の科学を構築する鍵であることを強調。 Comment
元ポスト:
[Paper Note] Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence, Sean McLeish+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LatentReasoning #RecurrentModels #RecursiveModels #Author Thread-Post Issue Date: 2025-11-12 GPT Summary- 深層再帰言語モデルの進展により、再帰の計算量を訓練時とテスト時で切り離すことが可能に。本研究では、非再帰言語モデルを深層再帰モデルに変換する方法を提案し、再帰のカリキュラムを用いることで性能を維持しつつ計算コストを削減できることを示した。数学実験では、再帰モデルへの変換がポストトレーニングよりも優れた性能を発揮することが確認された。 Comment
元ポスト:
関連:
openreview: https://openreview.net/forum?id=eC85h3y4pG
[Paper Note] Belief Dynamics Reveal the Dual Nature of In-Context Learning and Activation Steering, Eric Bigelow+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #In-ContextLearning #ActivationSteering/ITI Issue Date: 2025-11-12 GPT Summary- 大規模言語モデル(LLMs)の制御手法をベイズ的視点から統一的に説明。文脈に基づく介入と活性化に基づく介入がモデルの信念を変え、挙動に影響を与えることを示す。新たなベイズモデルにより、介入の効果を高精度で予測し、行動の急激な変化を引き起こす特異なフェーズを明らかにする。プロンプトと活性化の制御手法の統一的な理解を提供。 Comment
元ポスト:
[Paper Note] On a few pitfalls in KL divergence gradient estimation for RL, Yunhao Tang+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #ReinforcementLearning #Reasoning #One-Line Notes Issue Date: 2025-11-12 GPT Summary- LLMのRLトレーニングにおけるKLダイバージェンスの勾配推定に関する落とし穴を指摘。特に、KL推定を通じて微分する実装が不正確であることや、逐次的な性質を無視した実装が部分的な勾配しか生成しないことを示す。表形式の実験とLLM実験を通じて、正しいKL勾配の実装方法を提案。 Comment
元ポスト:
RLにおけるKL Divergenceによるポリシー正則化の正しい実装方法
[Paper Note] RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments, Zhiyuan Zeng+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #Evaluation #CurriculumLearning #RLVR #Verification Issue Date: 2025-11-12 GPT Summary- 適応可能な検証可能な環境を用いた強化学習(RLVE)を提案し、動的に問題の難易度を調整することで、言語モデルの強化学習をスケールアップする。RLVE-Gymという400の検証可能な環境からなるスイートを作成し、環境の拡大が推論能力を向上させることを示した。RLVEは、共同トレーニングにより、強力な推論LMで3.37%の性能向上を達成し、従来のRLトレーニングよりも効率的であることを示した。コードは公開されている。 Comment
元ポスト:
ポイント解説:
[Paper Note] Routing Manifold Alignment Improves Generalization of Mixture-of-Experts LLMs, Zhongyang Li+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #PostTraining #Generalization #Routing Issue Date: 2025-11-12 GPT Summary- Sparse Mixture-of-Experts (MoE)は、推論コストを増やさずにモデル能力を拡張するが、既存のMoE LLMではルーターの最適性が欠けており、性能に10-20%のギャップが生じている。本研究では、ルーティング重みの多様体をタスク埋め込みの多様体と整合させる「Routing Manifold Alignment (RoMA)」手法を提案し、MoE LLMの一般化性能を向上させる。RoMAは、ルーターのファインチューニングを通じて、類似タスク間で専門家の選択を共有し、タスク理解と解決策生成を統一する。実験により、RoMAを用いたファインチューニングが多様なベンチマークで大幅な性能改善をもたらすことが示された。 Comment
元ポスト:
Stress-Testing the Reasoning Competence of Language Models With Formal Proofs, Arkoudas+, EMNLP'25 Findings
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning #Mathematics #Proofs Issue Date: 2025-11-12 GPT Summary- ProofGridという新しい論理推論タスクを用いて、LLMsとLRMsの性能を広範に評価。タスクは命題論理と方程式論理の証明作成・検証を含み、証明のインペインティングとギャップ埋めも新たに導入。実験ではトップモデルの優れたパフォーマンスが示される一方、体系的な失敗も確認。1万件以上の形式的推論問題と証明からなる新データリソースも公開。 Comment
元ポスト:
[Paper Note] Why Less is More (Sometimes): A Theory of Data Curation, Elvis Dohmatob+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pretraining #NLP #Dataset #Selected Papers/Blogs #DataMixture #PhaseTransition Issue Date: 2025-11-12 GPT Summary- 本論文では、データを少なく使う方が良い場合についての理論的枠組みを提案し、小規模な厳選データセットが優れた性能を発揮する理由を探ります。データキュレーション戦略を通じて、ラベルに依存しない・依存するルールのテスト誤差のスケーリング法則を明らかにし、特定の条件下で小規模データが大規模データを上回る可能性を示します。ImageNetでの実証結果を通じて、キュレーションが精度を向上させることを確認し、LLMの数学的推論における矛盾する戦略への理論的説明も提供します。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=8KcjEygedc
[Paper Note] PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs, Zixin Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #read-later #Selected Papers/Blogs #Robotics #EmbodiedAI Issue Date: 2025-11-10 GPT Summary- MLLMsの物理的道具に対する理解を評価するための新しいベンチマークPhysToolBenchを提案。1,000以上の画像-テキストペアからなるVQAデータセットで、道具認識、道具理解、道具創造の3つの能力を評価。32のMLLMsに対する評価で道具理解に欠陥があることが明らかになり、初歩的な解決策を提案。コードとデータセットは公開。 Comment
元ポスト:
興味深い
[Paper Note] Analyzing Uncertainty of LLM-as-a-Judge: Interval Evaluations with Conformal Prediction, Huanxin Sheng+, EMNLP'25 SAC Highlights, 2025.09
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #LLM-as-a-Judge #EMNLP #read-later #Selected Papers/Blogs #Stability Issue Date: 2025-11-10 GPT Summary- LLMを用いた自然言語生成の評価における不確実性を分析するためのフレームワークを提案。適合予測を通じて予測区間を構築し、中央値に基づくスコアを低バイアスの代替手段として提示。実験により、適合予測が有効な予測区間を提供できることを示し、判断の向上に向けた中央値や再プロンプトの有用性も探求。 Comment
元ポスト:
実用上非常に重要な話に見える
[Paper Note] Infini-gram mini: Exact n-gram Search at the Internet Scale with FM-Index, Hao Xu+, EMNLP'25 Best Paper, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Search #Dataset #Evaluation #EMNLP #read-later #Contamination-free #Selected Papers/Blogs Issue Date: 2025-11-09 GPT Summary- 「infini-gram mini」は、ペタバイトレベルのテキストコーパスを効率的に検索可能にするシステムで、FM-indexデータ構造を用いてインデックスを作成し、ストレージオーバーヘッドを44%に削減。インデックス作成速度やメモリ使用量を大幅に改善し、83TBのインターネットテキストを99日でインデックス化。大規模なベンチマーク汚染の分析を行い、主要なLM評価ベンチマークがインターネットクローリングで汚染されていることを発見。汚染率を共有する公報をホストし、検索クエリ用のウェブインターフェースとAPIも提供。 Comment
元ポスト:
pj page: https://infini-gram-mini.io
benchmarmk contamination monitoring system: https://huggingface.co/spaces/infini-gram-mini/Benchmark-Contamination-Monitoring-System
[Paper Note] Step-Audio-EditX Technical Report, Chao Yan+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#SpeechProcessing #OpenWeight #Editing #TTS #AudioLanguageModel Issue Date: 2025-11-09 GPT Summary- 初のオープンソースLLMベースの音声モデル「Step-Audio-EditX」を発表。感情や話し方の編集に優れ、ゼロショットのテキスト音声合成機能も搭載。大きなマージンの合成データを活用し、従来のアプローチからの転換を実現。評価では、感情編集や細かい制御タスクで他のモデルを上回る性能を示した。 Comment
元ポスト:
[Paper Note] Oolong: Evaluating Long Context Reasoning and Aggregation Capabilities, Amanda Bertsch+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LongSequence #RecursiveModels Issue Date: 2025-11-08 GPT Summary- 長コンテキストの効果的な利用に関する懸念を受け、Oolongという新しい長コンテキスト推論タスクのベンチマークを提案。Oolongは、合成タスクのOolong-synthと実際の会話データを用いるOolong-realの2つのタスクセットから成り、モデルに対して分類やカウントを要求。最前線のモデルでも50%未満の精度にとどまり、推論能力の向上を促すためにデータと評価ハーネスを公開。 Comment
元ポスト:
関連:
blog:
https://alexzhang13.github.io/blog/2025/rlm/
super basic implementation:
openreview: https://openreview.net/forum?id=lrDr6dmXOX
[Paper Note] RLoop: An Self-Improving Framework for Reinforcement Learning with Iterative Policy Initialization, Zeng Zhiyuan+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SelfImprovement #Catastrophic Forgetting #RLVR #Diversity #Generalization #KeyPoint Notes Issue Date: 2025-11-07 GPT Summary- RLoopは、強化学習における過剰適合の問題を解決するための自己改善フレームワークであり、ポリシーの多様性を保ちながら一般化能力を向上させる。RLを用いて解空間を探索し、成功した軌跡から専門家データセットを作成し、拒否サンプリング微調整を行うことで、次の反復の出発点を洗練する。実験により、RLoopは忘却を軽減し、平均精度を9%、pass@32を15%以上向上させることが示された。 Comment
元ポスト:
ポリシーを初期化し、RLを実行しtrajeatory tを取得。tをrejection samplingし成功したtrajectoryでエキスパートデータセットを作成。作成したエキスパートデータセットでポリシーをSFT(=Rejection SamplingしたデータでSFTすることをRFTと呼ぶ)する(これが次iterationの初期化となる)といったことを繰り返す。
RLはAdvantageによって学習されるため、trajectoryの相対的な品質に基づいて学習をする。このため、バッチ内のすべてのtrajectoryが正解した場合などはadvantageが限りなくゼロに近づき学習のシグナルを得られない。
一方RFTは絶対的なRewardを用いており(RLVRの場合は成功したら1,そうでなければ0)、これがバッチ全体のパフォーマンスに依存しない安定した分散の小さい学習のシグナルを与える。
このように両者は補完的な関係にある。ただしRFTは成功したtrajectory全てに均等な重みを与えるため、既にポリシーが解くことができる問題にフォーカスしすぎることによって効率性が悪化する問題があるため、提案手法では成功率が低いhardなサンプルのみにエキスパートデータをフィルタリングする(=active learning)ことで、モデルが自身に不足した能力を獲得することに効率的に注力することになる。
また、RFTを使うことは単なるヒューリスティックではなく、理論的なgroundingが存在する。すなわち、我々はまだ未知の"expert"な分布 p^*にポリシーが従うように学習をしたいがこれはMLEの観点で言うと式3に示されているような形式になる。p^*から直接データをサンプリングをすることができないが、RLのポリシーから近似的にサンプリングをすることができる。そこでMLEの式をimportance samplingの観点から再度定式化をすると式4のようになり、後はimportance weight wを求められれば良いことになる。これはp^*に近いtrajectoryはRewardが高く、そうでない場合は低い、つまりw \propto Reward な関係であるため近似的に求めることができ、これらを式4のMLEの式に代入するとRFTと同じ式が導出される。
みたいな話のようである。
[Paper Note] The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents, Xingyao Wang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #AIAgents #SoftwareEngineering #read-later Issue Date: 2025-11-07 GPT Summary- OpenHands Software Agent SDKは、ソフトウェア開発エージェントを構築するためのツールキットで、柔軟性、信頼性、安全性を兼ね備えた実装を可能にします。シンプルなインターフェースでエージェントを簡単に実装でき、カスタム機能にも対応。ローカルからリモートへの実行ポータビリティや多様なインターフェースを提供し、セキュリティ分析も統合されています。実証結果は強力なパフォーマンスを示し、エージェントの信頼性の高い展開を実現します。 Comment
元ポスト:
blog: https://openhands.dev/blog/introducing-the-openhands-software-agent-sdk
[Paper Note] Scaling Agent Learning via Experience Synthesis, Zhaorun Chen+, ICLR'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #AIAgents #Reasoning #ICLR #Author Thread-Post Issue Date: 2025-11-07 GPT Summary- DreamGymは、強化学習(RL)エージェントのオンライントレーニングを効率化するための統一フレームワークであり、高コストのロールアウトや不安定な報酬信号の課題に対処します。環境のダイナミクスを推論に基づく経験モデルに蒸留し、安定した状態遷移とフィードバックを提供します。オフラインデータを活用した経験リプレイバッファにより、エージェントのトレーニングを強化し、新しいタスクを適応的に生成することでオンラインカリキュラム学習を実現します。実験により、DreamGymは合成設定とリアルなシナリオでRLトレーニングを大幅に改善し、非RL準備タスクでは30%以上の性能向上を示しました。合成経験のみでトレーニングされたポリシーは、実環境RLにおいても優れたパフォーマンスを発揮し、スケーラブルなウォームスタート戦略を提供します。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=cf7qpBwttr
著者による一言解説:
[Paper Note] Thought Communication in Multiagent Collaboration, Yujia Zheng+, NeurIPS'25 Spotlight, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #NeurIPS #LatentRepresentation Issue Date: 2025-11-07 GPT Summary- 自然言語の曖昧さが集合知の可能性を制限する中、思考コミュニケーションという新しいパラダイムを提案。エージェントが直接相互作用できるようにし、潜在変数モデルとして形式化。非パラメトリックな設定で、エージェント間の共有思考とプライベート思考を特定可能。理論に基づき、潜在的な思考を抽出し、共有パターンを割り当てるフレームワークを開発。実験により理論を検証し、思考コミュニケーションの利点を示す。 Comment
元ポスト:
[Paper Note] PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence Generation, Alexandre Piché+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Selected Papers/Blogs #KeyPoint Notes #Asynchronous Issue Date: 2025-11-07 GPT Summary- 強化学習(RL)を用いて大規模言語モデル(LLMs)の推論能力を向上させるための新しいアプローチ、PipelineRLを提案。PipelineRLは非同期データ生成とモデル更新を同時に行い、トレーニングデータの新鮮さを保ちながら、GPUの利用率を最大化。実験では、従来のRL手法に比べて約2倍の学習速度を達成。PipelineRLのオープンソース実装も公開。 Comment
元ポスト:
long trajectoryをロールアウトする際にモデルの非同期な更新が生じ、rollont中のtrajectoryに複数のパラメータでのモデルから生成されたトークンが混在する場合がある。このような場合に、複数の数百B級のパラメータをメモリ上に保持しておくことはできないので、トークンを推論した際のlogprobをとっておき、そのlogprobを用いて重要度サンプリングを行う。これによって、oldモデルのパラメータを破棄することができ、トークンが生成された時のlogprobをそのまま活用できるため、より実際のlogprobを用いた重要度サンプリングになっている、みたいなテクニックがあるらしい。
[Paper Note] Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning, Marwa Abdulhai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #Metrics #NLP #ReinforcementLearning #Evaluation #Conversation #NeurIPS #Personality Issue Date: 2025-11-06 GPT Summary- LLMを用いた対話におけるペルソナの一貫性を評価・改善するフレームワークを提案。3つの自動メトリックを定義し、マルチターン強化学習でファインチューニングを行うことで、一貫性を55%以上向上させる。 Comment
pj page: https://sites.google.com/view/consistent-llms
元ポスト:
[Paper Note] Culture Cartography: Mapping the Landscape of Cultural Knowledge, Caleb Ziems+, EMNLP'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Dataset #Supervised-FineTuning (SFT) #EMNLP #DPO #Cultural Issue Date: 2025-11-06 GPT Summary- LLMは文化特有の知識を必要とし、CultureCartographyという混合イニシアティブを提案。LLMが自信の低い質問をアノテーションし、人間がそのギャップを埋めることで重要なトピックに導く。CultureExplorerツールを用いた実験で、従来のモデルよりも効果的に知識を生成し、Llama-3.1-8Bの精度を最大19.2%向上させることが示された。 Comment
元ポスト:
効率的にLLMにとって未知、かつ重要な文化的な知識バンクを作成する話な模様。アクティブラーニングに似たような思想に見える。
[Paper Note] Training Proactive and Personalized LLM Agents, Weiwei Sun+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #UserBased #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #interactive Issue Date: 2025-11-06 GPT Summary- 効果的なAIエージェントには、生産性、積極性、パーソナライズの3つの次元を最適化する必要があると主張。LLMベースのユーザーシミュレーター「UserVille」を導入し、PPPというマルチオブジェクティブ強化学習アプローチを提案。実験では、PPPで訓練されたエージェントがGPT-5に対して平均21.6ポイントの改善を達成し、ユーザーの好みに適応しながらタスク成功を向上させる能力を示した。 Comment
AI Agentにおいてユーザとのinteractionを重視し協働することを重視するようなRLをする模様。興味深い。
元ポスト:
[Paper Note] Accumulating Context Changes the Beliefs of Language Models, Jiayi Geng+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #memory #Beliefs Issue Date: 2025-11-06 GPT Summary- 言語モデル(LM)アシスタントは、ブレインストーミングや研究での使用が増加しているが、コンテキストの蓄積に伴い信念プロファイルが変化するリスクがある。本研究では、対話やテキスト処理を通じて信念がどのように変化するかを調査し、GPT-5が道徳的ジレンマに関する議論後に54.7%、Grok 4が政治的問題に関して27.2%の信念変化を示すことを発見した。また、ツール使用による行動変化も分析し、信念の変化が行動に反映されることを示唆している。これにより、長時間の対話や読書が信頼性に影響を与える可能性があることが明らかになった。 Comment
pj page: https://lm-belief-change.github.io/
元ポスト:
エコーチャンバーが増強されそう
[Paper Note] Context Engineering 2.0: The Context of Context Engineering, Qishuo Hua+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Tutorial #NLP #AIAgents #ContextEngineering Issue Date: 2025-11-05 GPT Summary- 本論文では、カール・マルクスの「人間の本質は社会関係の総体である」という考えを基に、機械と人間の相互作用における文脈の重要性を探求します。特に「コンテキストエンジニアリング」という概念を導入し、その歴史的背景や設計考慮事項を体系的に定義します。これにより、AIシステムにおけるコンテキストエンジニアリングの基盤を提供し、将来の可能性を示唆します。 Comment
元ポスト:
[Paper Note] WebThinker: Empowering Large Reasoning Models with Deep Research Capability, Xiaoxi Li+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #Reasoning #NeurIPS #DPO #DeepResearch Issue Date: 2025-11-05 GPT Summary- WebThinkerは、LRMsがウェブを自律的に検索し、情報を収集しながら報告書を作成できる深層研究エージェントである。Deep Web Explorerモジュールを統合し、知識のギャップを埋めるために動的に情報を抽出する。リアルタイムで情報収集と報告書作成を行うThink-Search-and-Draft戦略を採用し、RLベースのトレーニング戦略を導入。実験により、WebThinkerは複雑な推論タスクで既存手法を大幅に上回る性能を示した。 Comment
元ポスト:
[Paper Note] Beyond the 80_20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning, Shenzhi Wang+, NeurIPS'25, 2025.06
Paper/Blog Link My Issue
#ReinforcementLearning #NeurIPS #PostTraining #One-Line Notes #Entropy Issue Date: 2025-11-05 GPT Summary- 強化学習における検証可能な報酬(RLVR)のメカニズムをトークンエントロピーの視点から探求。高エントロピーのトークンが推論の重要な分岐点であることを発見し、RLVRトレーニング中にこれらのトークンのエントロピーが調整されることを示す。トークンの20%を利用することで、フル勾配更新と同等の性能を維持し、他のモデルでの性能向上を実現。低エントロピーのトークンのみでのトレーニングは性能を低下させることが明らかに。高エントロピートークンの最適化がRLVRの効果を生むことを示唆。 Comment
元ポスト:
pj page: https://shenzhi-wang.github.io/high-entropy-minority-tokens-rlvr/
解説:
エントロピーが高いトークンのみから学習シグナルを受け取ることで性能改善する、という話な模様。
[Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Reasoning #Distillation #NeurIPS #Selected Papers/Blogs #One-Line Notes #EntropyCollapse Issue Date: 2025-11-05 GPT Summary- 検証可能な報酬を用いた強化学習(RLVR)は、LLMsの推論性能を向上させるが、現在の設定では新しい推論パターンを引き出せていない。小さなkではベースモデルを上回るが、大きなkではベースモデルが優位。RLVRアルゴリズムは類似の性能を示し、ベースモデルの潜在能力を活用できていない。蒸留は新しい推論パターンを導入し、モデルの能力を拡張できる。これにより、RLの改善が必要であることが示唆される。 Comment
pj page: https://limit-of-rlvr.github.io/
元ポスト:
所見:
上記所見では、「RLVRがバッチサイズ256、トークン長8192(および8つのプロンプト)で約400ステップ実行されており、何かを学ぶにはトークン量が少なすぎるのでは」という指摘があるが、著者がリプ欄でそれはablation studyでの実験のものであり、4.6節でより大規模なモデル・計算量で学習されたモデルで実験をしたが(著者が訓練したというよりも、ベースモデルとRLVR後のモデルでPass@kの性能を比較したということだと思われる)結論は変わらなかった、と反論をしている。ただし、4.6節ではstep数が言及されていない、という指摘もあり、それに対して、著者は公表されているstep数の数値を返答しているように見える。
openreview: https://openreview.net/forum?id=4OsgYD7em5
RLVRによって、サンプル効率は改善するが(= Pass@1は改善する)、モデルのreasoning能力のboundaryは狭まる(= Pass@kはRL後のモデルよりもベースモデルの方が高い。つまり、ベースモデルの方が推論可能な範囲 (reasoning boundary) が広いということ)。言い換えると、RLはベースモデルによって既に獲得されているreasoning pathを引き出すが、新たな戦略を発見しない。このことを多様なデータセット、モデル群に対するシステマチックな実験によって示した。
openreview中のweaknessにおいて、解決策の提案がlimitedであると指摘されているが、それに対して以下のようにrebuttalが記述されている:
> 1. Finer-grained reward structures: step-wise rewards guide intermediate reasoning and reduce exploration bottlenecks.
> 2. Improved exploration: Instead of naive softmax sampling, introduce structured or hierarchical search to enhance exploration efficiency.
> 3. Better long-horizon credit assignment: Use techniques to propagate reward more effectively over long CoT chains and enabling the model to assign credit to crucial intermediate steps instead the whole response
> 4. Scaling up RL training: Match RLVR compute and data scale to that of pre-training
> 5. Multi-turn tool use & external knowledge: Allow the agent to interact with tools or retrieve external facts, broadening the reasoning space beyond single-pass generation
openreview中のrebuttalに記載の通り解決策の一つとして「RLVRのスケールを事前学習並みにスケールさせる」というものがあり、理論的にRLVRがreasoning boundaryを広げないということを示したわけではなく、たとえばより多くの計算量とデータを投入した場合に関しては明らかではなさそう、という点には注意。
[Paper Note] MMaDA: Multimodal Large Diffusion Language Models, Ling Yang+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #MultiModal #DiffusionModel #TextToImageGeneration #NeurIPS #2D (Image) #text Issue Date: 2025-11-05 GPT Summary- MMaDAは、テキスト推論やマルチモーダル理解、テキストから画像生成に優れた性能を発揮する新しいマルチモーダル拡散基盤モデルです。主な革新点は、モダリティに依存しない統一された拡散アーキテクチャ、混合長チェーン・オブ・ソートによるファインチューニング戦略、そしてUniGRPOという統一ポリシー勾配ベースのRLアルゴリズムです。実験により、MMaDA-8Bは他のモデルを上回る性能を示し、事前トレーニングと事後トレーニングのギャップを埋める効果が確認されました。コードとトレーニング済みモデルはオープンソースで提供されています。 Comment
ポイント解説:
元ポスト:
[Paper Note] VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction, Chaoyou Fu+, NeurIPS'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #Speech #NeurIPS #VisionLanguageModel #2D (Image) #TTS #AudioLanguageModel Issue Date: 2025-11-05 GPT Summary- 音声の役割を重視したマルチモーダル大規模言語モデル(MLLM)の訓練手法を提案。視覚と音声の相互作用を強化し、ASRやTTSモジュールなしで効率的な音声対話を実現。ベンチマークで最先端手法と比較し、リアルタイムの視覚と音声の相互作用が可能であることを示す。 Comment
元ポスト:
image/video, speechを入力として受けとりリアルタイムに音声を出力するマルチモーダルモデル。
[Paper Note] UNO-Bench: A Unified Benchmark for Exploring the Compositional Law Between Uni-modal and Omni-modal in Omni Models, Chen Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #SpeechProcessing #2D (Image) #3D (Video) #Omni #text Issue Date: 2025-11-05 GPT Summary- 新しいベンチマークUNO-Benchを提案し、ユニモーダルとオムニモーダルの能力を44のタスクと5つのモダリティで評価。人間生成データと自動圧縮データを用い、複雑な推論を評価する多段階オープンエンド質問形式を導入。実験により、オムニモーダルの能力がモデルの強さに応じて異なる影響を与えることを示した。 Comment
pj page: https://meituan-longcat.github.io/UNO-Bench/
元ポスト:
[Paper Note] Opportunistic Expert Activation: Batch-Aware Expert Routing for Faster Decode Without Retraining, Costin-Andrei Oncescu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #MoE(Mixture-of-Experts) #Decoding Issue Date: 2025-11-05 GPT Summary- MoEアーキテクチャを用いたLLMのデコードレイテンシを低下させるため、トークンから専門家へのマッピングを動的に再ルーティングするフレームワークを提案。バッチ認識ルーティングを活用し、メモリに既にロードされている専門家を利用することで、精度を維持しつつ、Qwen3-30BおよびQwen3-235Bモデルでそれぞれ39%と15%のレイテンシ削減を達成。 Comment
元ポスト:
[Paper Note] Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models, Marianne Arriola+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#DiffusionModel #ICLR #read-later #Selected Papers/Blogs Issue Date: 2025-11-04 GPT Summary- ブロック拡散言語モデルは、拡散モデルと自己回帰モデルの利点を組み合わせ、柔軟な長さの生成を可能にし、推論効率を向上させる。効率的なトレーニングアルゴリズムやデータ駆動型ノイズスケジュールを提案し、言語モデリングベンチマークで新たな最先端のパフォーマンスを達成。 Comment
openreview: https://openreview.net/forum?id=tyEyYT267x
[Paper Note] UniTok-Audio: A Unified Audio Generation Framework via Generative Modeling on Discrete Codec Tokens, Chengwei Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #SpeechProcessing #Speech #UMM #AudioLanguageModel #text Issue Date: 2025-11-04 GPT Summary- UniTok-Audioは、音声生成タスクのための統一されたスケーラブルフレームワークで、条件の特徴を抽出し、音声の離散トークンを生成。特別なタスク識別トークンにより、複数のタスクの学習を統一し、高忠実度の波形再構築を実現。実験では、音声復元や音声変換など5つのタスクで競争力のある性能を示し、将来的にオープンソース化予定。 Comment
元ポスト:
[Paper Note] On Powerful Ways to Generate: Autoregression, Diffusion, and Beyond, Chenxiao Yang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #DiffusionModel #Architecture #read-later #Selected Papers/Blogs Issue Date: 2025-11-04 GPT Summary- 自己回帰的な次トークン予測とマスクされた拡散を超えた生成プロセスを研究し、その利点と限界を定量化。書き換えや長さ可変の編集が可能になることで、理論的および実証的な利点を示し、自然言語以外の領域でも機能する大規模言語モデル(LLM)の重要性を強調。 Comment
元ポスト:
[Paper Note] How Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?, Sohee Yang+, EMNLP'25, 2025.06
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #Reasoning #SelfCorrection #EMNLP #SelfVerification Issue Date: 2025-11-04 GPT Summary- 推論モデルの自己再評価能力を調査し、役に立たない思考の4つのタイプを特定。モデルは無駄話や無関係な思考を効果的に識別できるが、それらが注入されると回復に苦労し、性能が低下することを示した。特に、大きなモデルは短い無関係な思考からの回復が難しい傾向があり、自己再評価の改善が求められる。これにより、より良い推論と安全なシステムの開発が促進される。 Comment
元ポスト:
元ポスト:
[Paper Note] Precise In-Parameter Concept Erasure in Large Language Models, Yoav Gur-Arieh+, EMNLP'25, 2025.05
Paper/Blog Link My Issue
#NLP #EMNLP #ConceptErasure Issue Date: 2025-11-04 GPT Summary- PISCES(Precise In-parameter Suppression for Concept EraSure)を提案し、LLMsから機密情報や著作権保護コンテンツを正確に除去する新しいフレームワークを構築。特徴ベースのパラメータ内編集を用いて、ターゲット概念に関連する特徴を特定し除去。実験により、消去精度を7.7%低下させつつ、特異性と堅牢性をそれぞれ最大31%および38%向上させることを示した。 Comment
元ポスト:
[Paper Note] Intrinsic Test of Unlearning Using Parametric Knowledge Traces, Yihuai Hong+, EMNLP'25, 2024.06
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #EMNLP #ConceptErasure #read-later #Selected Papers/Blogs Issue Date: 2025-11-04 GPT Summary- 大規模言語モデルにおける「忘却」タスクの重要性が高まっているが、現在の評価手法は行動テストに依存しており、モデル内の残存知識を監視していない。本研究では、忘却評価においてパラメトリックな知識の変化を考慮する必要性を主張し、語彙投影を用いた評価方法論を提案。これにより、ConceptVectorsというベンチマークデータセットを作成し、既存の忘却手法が概念ベクトルに与える影響を評価した。結果、知識を直接消去することでモデルの感受性が低下することが示され、今後の研究においてパラメータに基づく評価の必要性が強調された。 Comment
元ポスト:
[Paper Note] CodeAlignBench: Assessing Code Generation Models on Developer-Preferred Code Adjustments, Forough Mehralian+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #UserBased #AIAgents #Evaluation #Coding Issue Date: 2025-11-03 GPT Summary- 大規模言語モデルのコード生成能力を評価するために、指示に従う能力を測るマルチランゲージベンチマークを導入。初期問題の制約遵守とフォローアップ指示への対応能力を評価。LiveBenchのプログラミングタスクを用いて、PythonからJavaおよびJavaScriptへの自動翻訳タスクで実証。結果、モデルは指示に従う能力において異なる性能を示し、ベンチマークがコード生成モデルの包括的な評価を提供することを明らかにした。 Comment
元ポスト:
[Paper Note] Continuous Autoregressive Language Models, Chenze Shao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #NLP #Architecture #KeyPoint Notes #AutoEncoder Issue Date: 2025-11-03 GPT Summary- 大規模言語モデル(LLMs)の効率を向上させるため、連続自己回帰言語モデル(CALM)を提案。CALMは、次トークン予測から次ベクトル予測へのシフトを行い、Kトークンを連続ベクトルに圧縮することで生成ステップをK倍削減。新たなフレームワークを開発し、性能と計算コストのトレードオフを改善。CALMは、効率的な言語モデルへの道筋を示す。 Comment
pj page: https://shaochenze.github.io/blog/2025/CALM/
元ポスト:
VAEを学習し(deterministicなauto encoderだと摂動に弱くロバストにならないためノイズを加える)、Kトークンをlatent vector zに圧縮、auto regressiveなモデルでzを生成できるように学習する。専用のヘッド(generative head)を用意し、transformerの隠れ状態からzを条件付きで生成する。zが生成できればVAEでdecodeすればKトークンが生成される。loss functionは下記のエネルギースコアで、第一項で生成されるトークンの多様性を担保しつつ(モード崩壊を防ぎつつ)、第二項でground truth yに近い生成ができるようにする、といった感じらしい。評価はautoregressiveにzを生成する設定なのでperplexityを計算できない。このため、BrierLMという指標によって評価している。BrierLMがどのようなものかは理解できていない。必要になったら読む。
future workにあるようにスケーリング特性がまだ明らかになっていないのでなんとも言えないという感想。
ポイント解説:
[Paper Note] Iterative Amortized Inference: Unifying In-Context Learning and Learned Optimizers, Sarthak Mittal+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#MachineLearning #NLP #In-ContextLearning #meta-learning Issue Date: 2025-11-03 GPT Summary- アモータイズド学習に基づく統一的フレームワークを提案し、タスク適応の方法をパラメトリック、暗黙的、明示的に分類。推論時のタスクデータ処理能力の制限を指摘し、反復アモータイズド推論を導入。これにより、最適化ベースのメタ学習とLLMのアプローチを結びつけ、汎用タスク適応のためのスケーラブルな基盤を提供。 Comment
元ポスト:
[Paper Note] Global PIQA: Evaluating Physical Commonsense Reasoning Across 100+ Languages and Cultures, Tyler A. Chang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #MultiLingual #Cultural #CommonsenseReasoning Issue Date: 2025-11-03 GPT Summary- 「Global PIQA」は、65カ国の335人の研究者によって構築された、100以上の言語に対応した常識推論ベンチマークであり、116の言語バリエーションを含む。多くの例が文化特有の要素に関連しており、LLMは全体で良好なパフォーマンスを示すが、リソースが限られた言語では精度が低下することが発見された。Global PIQAは、言語と文化における日常的な知識の改善の必要性を示し、LLMの評価や文化の多様性の理解に寄与することを期待されている。 Comment
dataset: https://huggingface.co/datasets/mrlbenchmarks/global-piqa-nonparallel
元ポスト:
[Paper Note] AMO-Bench: Large Language Models Still Struggle in High School Math Competitions, Shengnan An+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Mathematics Issue Date: 2025-11-01 GPT Summary- AMO-Benchは、オリンピックレベルの数学的推論を評価するための新しいベンチマークで、50の専門家作成の問題から成る。既存のベンチマークが飽和状態にある中、AMO-BenchはIMO基準を満たし、オリジナルの問題を提供することで厳格な評価を実現。実験では、26のLLMが52.4%の精度しか達成できず、数学的推論の改善の余地が大きいことが示された。AMO-Benchは、言語モデルの推論能力向上のための研究を促進することを目的としている。 Comment
元ポスト:
[Paper Note] Emu3.5: Native Multimodal Models are World Learners, Yufeng Cui+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #Transformer #MultiModal #DiffusionModel #2D (Image) #UMM #text Issue Date: 2025-11-01 GPT Summary- Emu3.5は、視覚と言語の両方に基づく次の状態を予測する大規模なマルチモーダルワールドモデルで、10兆トークン以上のデータで事前訓練されています。双方向の並列予測を用いた「Discrete Diffusion Adaptation(DiDA)」により、推論を約20倍加速し、強力なマルチモーダル能力を発揮します。Emu3.5は、画像生成や編集タスクで優れたパフォーマンスを示し、オープンソースとして提供されています。 Comment
pj page: https://emu.world/
元ポスト:
ポイント解説:
[Paper Note] Completion $\neq$ Collaboration: Scaling Collaborative Effort with Agents, Shannon Zejiang Shen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #UserBased #AIAgents #One-Line Notes Issue Date: 2025-11-01 GPT Summary- エージェントの評価をタスク完了から協調的な問題解決プロセスにシフトすることを提唱。ユーザーの関与がエージェントの有用性に与える影響を捉える「協調的努力スケーリング」フレームワークを導入。ケーススタディにより、現実のシナリオでのエージェントのパフォーマンス低下を示し、持続的なエンゲージメントとユーザー理解の重要性を明らかにする。 Comment
単に一発でタスクをこなすことに最適化されているが、ユーザからの要求は反復的で進化するので数ラウンド経つとコントロールしづらくなる、といったことが起きてしまう経験があると思うが、実際そうだということを実験的に示している模様。そして、ユーザと協働しながら効用を最大化させるようなアプローチが必要のことを明らかにしている、みたいな話らしい。
[Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #PostTraining #Selected Papers/Blogs #Stability #Reference Collection #train-inference-gap #LowPrecision #Author Thread-Post Issue Date: 2025-11-01 GPT Summary- 強化学習による大規模言語モデルのファインチューニングにおける不安定性は、トレーニングポリシーと推論ポリシーの数値的不一致に起因する。従来の対策は効果が薄かったが、本研究ではFP16に戻すことでこの問題を解決できることを示した。この変更は簡単で、モデルやアルゴリズムの修正を必要とせず、安定した最適化と速い収束を実現し、多様なタスクで強力なパフォーマンスを発揮することが確認された。 Comment
元ポスト:
RL学習時の浮動小数点数表現をbf16からfp16に変更するシンプルな変更で、訓練-推論時のgapが小さくなり学習が改善する、という話らしい。
ポイント解説:
所見:
解説:
解説:
verlはFP16での学習をサポートしていないので著者がパッチを出した模様:
[Paper Note] Kimi Linear: An Expressive, Efficient Attention Architecture, Kimi Team+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Attention #LongSequence #OpenWeight #Architecture #read-later #Selected Papers/Blogs #Reference Collection #Hybrid #LinearAttention Issue Date: 2025-10-31 GPT Summary- Kimi Linearは、短・長コンテキスト及び強化学習のシナリオにおいてフルアテンションを超えるハイブリッドな線形アテンションアーキテクチャです。Kimi Delta Attention(KDA)を核とし、ゲーティング機構を拡張した線形アテンションモジュールで、RNNのメモリをより有効利用します。特注のチャンク単位アルゴリズムにより、DPLR遷移行列の効率を向上させ、計算量を大幅に削減します。Kimi Linearモデルは48Bパラメータで事前学習され、評価タスクでMLAを大きく上回り、KVキャッシュ使用量を75%削減し、デコードスループットを6倍向上させました。これにより、フルアテンションアーキテクチャの優れた代替として機能し、長い入力・出力タスクに対応可能であることが示されています。 Comment
HF: https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
元ポスト:
所見:
所見:
アーキテクチャ解説:
KDAとFull Attention, Sliding Window Attentionの比較:
Full Attentionと同等の性能をより効率良く達成できる
KDAに関する図解:
[Paper Note] ATLAS: Adaptive Transfer Scaling Laws for Multilingual Pretraining, Finetuning, and Decoding the Curse of Multilinguality, Shayne Longpre+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #CrossLingual #TransferLearning #MultiLingual #Scaling Laws #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-31 GPT Summary- 本研究では、774の多言語トレーニング実験を通じて、最大の多言語スケーリング法則を探求し、ATLASという適応的転送スケーリング法則を導入。これにより、既存のスケーリング法則を上回る性能を示し、多言語学習のダイナミクスや言語間の転送特性を分析。言語ペア間の相互利益スコアを測定し、モデルサイズとデータの最適なスケーリング方法を明らかにし、事前学習とファインチューニングの計算的クロスオーバーポイントを特定。これにより、英語中心のAIを超えたモデルの効率的なスケーリングの基盤を提供することを目指す。 Comment
元ポスト:
バイリンガルで学習した時に、日本語とシナジーのある言語、この図を見ると無さそうに見える😅
[Paper Note] Multi-Agent Evolve: LLM Self-Improve through Co-evolution, Yixing Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #ReinforcementLearning #SelfImprovement Issue Date: 2025-10-31 GPT Summary- 強化学習(RL)を用いたMulti-Agent Evolve(MAE)フレームワークを提案し、LLMの推論能力を向上させる。MAEは提案者、解決者、審査者の相互作用を通じて自己進化を促進し、数学や一般知識のQ&Aタスクを解決。実験により、MAEは複数のベンチマークで平均4.54%の性能向上を示し、人間のキュレーションに依存せずにLLMの一般的な推論能力を向上させるスケーラブルな手法であることが確認された。 Comment
元ポスト:
concurrent work:
- [Paper Note] SPICE: Self-Play In Corpus Environments Improves Reasoning, Bo Liu+, arXiv'25, 2025.10
続報:コードとモデルがオープンに
ポイント解説:
[Paper Note] Tongyi DeepResearch Technical Report, Tongyi DeepResearch Team+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #AIAgents #DeepResearch Issue Date: 2025-10-30 GPT Summary- 「Tongyi DeepResearch」は、長期的な情報探索のために設計されたエージェント型大規模言語モデルで、エンドツーエンドのトレーニングフレームワークを用いて自律的な深い研究を促進します。完全自動のデータ合成パイプラインにより、人間のアノテーションに依存せず、スケーラブルな推論を実現。305億のパラメータを持ち、複数のベンチマークで最先端のパフォーマンスを達成し、オープンソースとしてコミュニティに提供されます。 Comment
pj page: https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
元ポスト:
[Paper Note] Scaling Latent Reasoning via Looped Language Models, Rui-Jie Zhu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #NLP #Transformer #Selected Papers/Blogs #LatentReasoning #KeyPoint Notes #RecurrentModels #RecursiveModels #Author Thread-Post Issue Date: 2025-10-30 GPT Summary- Ouroは、推論を事前訓練フェーズに組み込むことを目指したループ言語モデル(LoopLM)であり、反復計算やエントロピー正則化を通じて性能を向上させる。1.4Bおよび2.6Bモデルは、最大12Bの最先端LLMに匹敵する性能を示し、知識操作能力の向上がその要因であることを実験で確認。LoopLMは明示的なCoTよりも整合した推論を生成し、推論の新たなスケーリングの可能性を示唆している。モデルはオープンソースで提供されている。 Comment
pj page: https://ouro-llm.github.io
元ポスト:
解説:
基本構造はdecoder-only transformerで
- Multi-Head Attention
- RoPE
- SwiGLU活性化
- Sandwich Normalization
が使われているLoopedTransformerで、exit gateを学習することで早期にloopを打ち切り、出力をすることでコストを節約できるようなアーキテクチャになっている。
より少ないパラメータ数で、より大きなパラメータ数のモデルよりも高い性能を示す(Table7,8)。また、Tを増やすとモデルの安全性も増す(=有害プロンプトの識別力が増す)。その代わり、再帰数Tを大きくするとFLOPsがT倍になるので、メモリ効率は良いが計算効率は悪い。
linear probingで再帰の次ステップ予測をしたところ浅い段階では予測が不一致になるため、思考が進化していっているのではないか、という考察がある。
また、再帰数Tを4で学習した場合に、inference時にTを5--8にしてもスケールしない(Table10)。
またAppendix D.1において、通常のtransformerのLoopLMを比較し、5種類の大きさのモデルサイズで比較。通常のtransformerではループさせる代わりに実際に層の数を増やすことで、パラメータ数を揃えて実験したところ、通常のtransformerの方が常に性能が良く、loopLMは再帰数を増やしてもスケールせず、モデルサイズが大きくなるにつれて差がなくなっていく、というスケーリングの面では残念な結果に終わっているようだ。
といった話が解説に書かれている。元論文は完全にskim readingして解説ポストを主に読んだので誤りが含まれるかもしれない点には注意。
[Paper Note] Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs, Nicolas Boizard+, TMLR'25, 2024.02
Paper/Blog Link My Issue
#NLP #Distillation #TMLR #OptimalTransport #One-Line Notes Issue Date: 2025-10-30 GPT Summary- 大規模言語モデル(LLMs)の展開はコストやハードウェアの制約から実用的ではないが、知識蒸留(KD)が解決策となる。従来のロジットに基づく方法はトークナイザーの共有が必要で適用性が限られる。本研究では、最適輸送に基づくユニバーサルロジット蒸留(ULD)損失を提案し、異なるアーキテクチャ間での蒸留を可能にすることを示した。 Comment
openreview: https://openreview.net/forum?id=bwRxXiGO9A
(以下は管理人の理解が不十分なまま書かれているため誤りがある可能性が高いのでご注意ください)
- Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
の記述と論文を斜め読みした感じ、
従来の蒸留手法は出力(Vocab)の分布が近くなるように学習するため、教師と生徒モデル間でVocabが揃っている、すなわちtokenizerが共通でなければならず、これが教師生徒ペアを選択する際の制約となっていた。これを異なるtokenizerを持つモデル間でも蒸留可能にしたという話。これには以下の二つの課題があり
- sequence misalignment: tokenizerが異なるため、共通のsequenceに対して異なるsplitをする可能性がある
- vocabulary misalignment: 同じトークンIDが異なるtokenを指す
要は確率分布が対応づけられないのでワッサースタイン距離(=一方の確率分布をもう一方の確率分布に一致させるために必要な輸送の質量と距離よ最小コスト)によって距離を測ることを目指す(通常の教師ありDistillationのKL Divergenceをワッサースタイン距離に置き換えた損失を考える)。
が、ワッサースタイン距離はO(n^3log n)であるため近似的な解法で解く。その方法として、
- 教師のトークン列と生徒のトークン列の長さは異なるので短い方の長さに合わせてtruncateし
- ソフトマックス出力のロジットの大きさで両モデルのベクトルをソートし、小さい方をzero paddingして長さを揃えてベクトル間を比較可能にする[^1]
といった方法をとる模様?
[^1]: ソートさせたらvocabularyの整合性がとれずにでたらめな距離になるのでは?と思ったのだが、意図としては各次元が特定の単語ではなく確率順位を表すようにし、その間を比較することで分布の形(エントロピーやconfidenceの構造)の観点で比較可能にする、というニュアンスらしい。ただしこの部分についてはChatGPTの問答を通じて得た知識なので誤りがある可能性があるので注意。
[Paper Note] Think Just Enough: Sequence-Level Entropy as a Confidence Signal for LLM Reasoning, Aman Sharma+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Reasoning #LLMServing #Decoding #Inference #Entropy Issue Date: 2025-10-30 GPT Summary- エントロピーに基づく新しいフレームワークを提案し、推論タスクにおける大規模言語モデルのトークン効率を向上。シャノンエントロピーを信頼度信号として利用し、早期停止を実現することで、計算コストを25-50%削減。モデルごとに異なるエントロピー閾値を用いて、正しい答えを早期に得ることを認識し、トークン節約とレイテンシ削減を可能にする。精度を維持しつつ一貫したパフォーマンスを示し、現代の推論システムの特徴を明らかに。 Comment
元ポスト:
デコード時のエントロピーに応じて、reasoningを打ち切るか否か判定してコスト削減しつつ推論する話な模様
vLLMとかでデフォルトでサポートされてスループット上がったら嬉しいなあ
[Paper Note] AgentFold: Long-Horizon Web Agents with Proactive Context Management, Rui Ye+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #AIAgents #ContextEngineering #LongHorizon Issue Date: 2025-10-30 GPT Summary- AgentFoldは、LLMベースのウェブエージェントのコンテキスト管理の課題に対処する新しいパラダイムであり、人間の認知プロセスに触発されています。エージェントは「フォールディング」操作を通じて、歴史的な情報を動的に管理し、重要な詳細を保持しつつサブタスクを抽象化します。実験結果では、AgentFold-30B-A3BエージェントがBrowseCompで36.2%、BrowseComp-ZHで47.3%の性能を達成し、従来の大規模モデルや先進的なプロプライエタリエージェントを上回ることが示されました。 Comment
元ポスト:
[Paper Note] Memory-Efficient Backpropagation for Fine-Tuning LLMs on Resource-Constrained Mobile Devices, Congzheng Song+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Personalization #SmallModel #PostTraining Issue Date: 2025-10-30 GPT Summary- モバイルデバイス向けに、メモリ効率の良いバックプロパゲーション実装(MeBP)を提案。これにより、メモリ使用量と計算時間のトレードオフを改善し、ゼロ次最適化よりも速く収束し、優れたパフォーマンスを実現。iPhone 15 Pro Maxでの検証により、0.5Bから4Bのパラメータを持つLLMが1GB未満のメモリでファインチューニング可能であることを示した。実装例は公開済み。 Comment
元ポスト:
iPhone上で4BモデルまでFinetuningができるようになった模様。
[Paper Note] Language Models are Injective and Hence Invertible, Giorgos Nikolaou+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Embeddings #Analysis #NLP #Selected Papers/Blogs Issue Date: 2025-10-29 GPT Summary- 本研究では、トランスフォーマー言語モデルが単射であることを数学的に証明し、異なる入力が同じ出力にマッピングされないことを示す。さらに、6つの最先端モデルに対して衝突テストを行い、衝突がないことを確認。新たに提案するアルゴリズムSipItにより、隠れた活性化から正確な入力テキストを効率的に再構築できることを示し、単射性が言語モデルの重要な特性であることを明らかにする。 Comment
元ポスト:
続報:
解説:
解説参照のこと。
[Paper Note] Training-Free Group Relative Policy Optimization, Yuzheng Cai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Prompting #AutomaticPromptEngineering #One-Line Notes Issue Date: 2025-10-29 GPT Summary- 最近のLLMエージェントは一般的な能力を示すが、専門的なドメインでのパフォーマンスは外部ツールとの統合に課題がある。従来の強化学習手法はコストがかかるが、我々は経験的知識を用いて出力分布を改善できると主張する。これを実現するために、Training-Free GRPOを提案し、パラメータ更新なしでLLMの性能を向上させる。実験により、Training-Free GRPOが少数のトレーニングサンプルでファインチューニングされた小型LLMを上回ることを示した。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=tyUnYbE7Gi
openreviewのweaknessにtraining free, GRPOといった用語が利用されているが、parameterの更新からcontextの更新という方向性にシフトするというアイデアであると考えられるため、automatic prompt engineering、in-context learning等に該当するのでは、という指摘がある。
また、実験結果のベースモデルが揃っていないので、公平な比較になっておらず、追加の検証が必要という指摘もある。
[Paper Note] SPICE: Self-Play In Corpus Environments Improves Reasoning, Bo Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #ReinforcementLearning #Hallucination #SelfImprovement #CurriculumLearning #Diversity Issue Date: 2025-10-29 GPT Summary- SPICE(Self-Play In Corpus Environments)は、自己改善システムのための強化学習フレームワークで、単一モデルが「挑戦者」と「推論者」の2役を担う。挑戦者は文書を抽出して多様な推論タスクを生成し、推論者はそれを解決する。これにより、自動カリキュラムが形成され、持続的な改善が促進される。SPICEは、既存の手法に比べて数学的および一般的な推論のベンチマークで一貫した向上を示し、挑戦的な目標の生成が自己改善に重要であることを明らかにした。 Comment
元ポスト:
[Paper Note] Towards Stable and Effective Reinforcement Learning for Mixture-of-Experts, Di Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #MoE(Mixture-of-Experts) #Stability Issue Date: 2025-10-28 GPT Summary- MoEアーキテクチャにおけるRLトレーニングの不安定性に対処するため、重要度サンプリング重みを最適化する新しいルーター認識アプローチを提案。ルーターのロジットに基づく再スケーリング戦略により、勾配の分散を減少させ、トレーニングの安定性を向上。実験結果は、提案手法がMoEモデルの収束と性能を大幅に改善することを示し、効率的な大規模専門モデルのトレーニングに向けた新たな可能性を示唆。 Comment
元ポスト:
[Paper Note] SeeDNorm: Self-Rescaled Dynamic Normalization, Wenrui Cai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #MachineLearning #NLP #Transformer #Architecture #Normalization Issue Date: 2025-10-28 GPT Summary- SeeDNormは、入力に基づいて動的にスケーリング係数を調整する新しい正規化層であり、RMSNormの限界を克服します。これにより、入力のノルム情報を保持し、データ依存の自己再スケーリングを実現。大規模言語モデルやコンピュータビジョンタスクでの有効性を検証し、従来の正規化手法と比較して優れた性能を示しました。
[Paper Note] The German Commons - 154 Billion Tokens of Openly Licensed Text for German Language Models, Lukas Gienapp+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #Selected Papers/Blogs #One-Line Notes #German Issue Date: 2025-10-28 GPT Summary- 「German Commons」は、オープンライセンスのドイツ語テキストの最大コレクションで、41のソースから1545.6億トークンを提供。法律、科学、文化など7つのドメインを含み、品質フィルタリングや重複排除を行い、一貫した品質を確保。すべてのデータは法的遵守を保証し、真にオープンなドイツ語モデルの開発を支援。再現可能で拡張可能なコーパス構築のためのコードも公開。 Comment
HF: https://huggingface.co/datasets/coral-nlp/german-commons
元ポスト:
最大級(154B)のドイツ語のLLM(事前)学習用データセットらしい
ODC-By Licence
[Paper Note] Tensor Product Attention Is All You Need, Yifan Zhang+, NeurIPS'25 Spotlight, 2025.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Attention #NeurIPS #read-later #KV Cache Issue Date: 2025-10-28 GPT Summary- テンソルプロダクトアテンション(TPA)を提案し、KVキャッシュのサイズを縮小する新しい注意メカニズムを導入。TPAは低ランク成分に因数分解し、RoPEと統合することでメモリ効率とモデル品質を向上。新しいモデルアーキテクチャ「テンソルプロダクトアテンショントランスフォーマー(T6)」は、標準トランスフォーマーベースラインを上回る性能を示し、長いシーケンス処理のスケーラビリティ課題に対応。 Comment
pj page: https://tensorgi.github.io/TPA/
元ポスト:
続報:
RoPEも含めた様々なpositional encodingと互換性がある旨が追加された模様。
[Paper Note] Model Merging with Functional Dual Anchors, Kexuan Shi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #PostTraining #ModelMerge #Robustness Issue Date: 2025-10-27 GPT Summary- モデルマージングの新しい戦略として、Functional Dual Anchors(FDAs)を提案。FDAsはタスク特有の機能的シフトを捉え、共同マルチタスクトレーニングとポストホックマージングを結びつける。実験により、FDAsがモデルマージングにおいて効果的であることを示した。 Comment
pj page: https://spherelab.ai/fda/
元ポスト:
[Paper Note] A Theoretical Study on Bridging Internal Probability and Self-Consistency for LLM Reasoning, Zhi Zhou+, NeurIPS'25, 2025.10
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #NeurIPS #Test-Time Scaling Issue Date: 2025-10-27 GPT Summary- テスト時スケーリングにおけるサンプリング手法の理論的枠組みを提供し、自己一貫性と困惑度の制限を明らかに。新たに提案したRPC手法は、困惑度一貫性と推論剪定を活用し、推論誤差の収束を改善。7つのベンチマークでの実証結果により、RPCは自己一貫性に匹敵する性能を達成し、サンプリングコストを50%削減することが示された。 Comment
元ポスト:
元ポスト:
pj page: https://zhouz.dev/RPC/
[Paper Note] DLER: Doing Length pEnalty Right - Incentivizing More Intelligence per Token via Reinforcement Learning, Shih-Yang Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning Issue Date: 2025-10-27 GPT Summary- 推論言語モデルは長い出力を生成することが多く、応答の長さに対する精度向上が課題である。本研究では、切り捨てを用いた強化学習(RL)の再考を行い、精度低下の原因は不十分なRL最適化にあることを示す。3つの課題(バイアス、エントロピーの崩壊、スパースな報酬信号)に対処するため、DLERというトレーニング手法を提案し、出力の長さを70%以上削減しつつ精度を向上させた。さらに、Difficulty-Aware DLERを導入し、簡単な質問に対して適応的に切り捨てを厳しくすることで効率を向上させる手法も提案した。 Comment
pj page: https://nvlabs.github.io/DLER/
元ポスト:
reasoningをトークン数の観点で効率化する話
[Paper Note] R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?, Yi Lu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning #read-later #Selected Papers/Blogs #One-Line Notes #LongHorizon Issue Date: 2025-10-27 GPT Summary- R-HORIZONを提案し、長期的な推論行動を刺激する手法を通じて、LRMの評価を改善。複雑なマルチステップ推論タスクを含むベンチマークを構築し、LRMの性能低下を明らかに。R-HORIZONを用いた強化学習データ(RLVR)は、マルチホライズン推論タスクの性能を大幅に向上させ、標準的な推論タスクの精度も向上。AIME2024で7.5の増加を達成。R-HORIZONはLRMの長期推論能力を向上させるための有効なパラダイムと位置付けられる。 Comment
pj page: https://reasoning-horizon.github.io
元ポスト:
long horizonタスクにうまく汎化する枠組みの必要性が明らかになったように見える。long horizonデータを合成して、post trainingをするという枠組みは短期的には強力でもすぐに計算リソースの観点からすぐに現実的には能力を伸ばせなくなるのでは。
ポイント解説:
[Paper Note] ARC-Encoder: learning compressed text representations for large language models, Hippolyte Pilchen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ContextWindow #Encoder #One-Line Notes #text #Compression Issue Date: 2025-10-26 GPT Summary- 本研究では、コンテキストを連続表現に圧縮するARC-Encoderを提案し、デコーダLLMのトークン埋め込みを置き換えるアプローチを探求。ARC-Encoderは、テキストトークンの少ない連続表現を出力し、計算効率を向上させる。さまざまなLLMシナリオで評価した結果、最先端のパフォーマンスを達成し、複数のデコーダに同時に適応可能であることを示した。 Comment
元ポスト:
最近textのcontextをvisual tokenでレンダリングすることで圧縮する話が盛り上がっているが、こちらはtextの表現そのものを圧縮する話な模様。
そのうちpixel単位の入力、テキスト単位での入力を圧縮する話どちらかだけでなく、双方のハイブリッドになり、かつタスクに応じてattention等を通じてどちらのモダリティの情報を使うか、また圧縮前と後の情報どちらを使うか、みたいなものを動的に選択してタスクに応じて計算量やメモリを節約しつつ、高い性能を担保する、みたいな話になるんではなかろうか。
[Paper Note] Hubble: a Model Suite to Advance the Study of LLM Memorization, Johnny Tian-Zheng Wei+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #OpenWeight #read-later #Memorization Issue Date: 2025-10-26 GPT Summary- Hubbleは、LLMの記憶に関する研究のためのオープンソースモデルスイートで、標準モデルと変化モデルの2種類を提供。標準モデルは大規模な英語コーパスで事前学習され、変化モデルは特定のテキストを挿入して記憶リスクを模倣。8つのモデルが1Bまたは8Bのパラメータを持ち、100Bまたは500Bのトークンで訓練。研究により、敏感なデータの記憶はコーパスのサイズに依存し、データの露出が少ない場合は忘れられることが示された。Hubbleは、プライベート情報の記憶の容易さを分析するなど、幅広い記憶研究を可能にし、コミュニティにさらなる探求を促す。 Comment
pj page: https://allegro-lab.github.io/hubble/
元ポスト:
[Paper Note] Fundamentals of Building Autonomous LLM Agents, Victor de Lamo Castrillo+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Tutorial #NLP #AIAgents #SoftwareEngineering Issue Date: 2025-10-26 GPT Summary- 本論文では、LLMsを基にしたエージェントのアーキテクチャと実装をレビューし、複雑なタスクの自動化を目指す。主要な構成要素には、知覚システム、推論システム、記憶システム、実行システムが含まれ、これらを統合することで人間の認知プロセスを模倣する高性能なソフトウェアボットの実現を示す。 Comment
元ポスト:
[Paper Note] ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows, Qiushi Sun+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #MultiModal #Reasoning #SoftwareEngineering #ComputerUse #read-later #Selected Papers/Blogs #VisionLanguageModel #Science Issue Date: 2025-10-26 GPT Summary- 大規模言語モデル(LLMs)を活用したScienceBoardを紹介。これは、科学的ワークフローを加速するための動的なマルチドメイン環境と、169の厳密に検証されたタスクからなるベンチマークを提供。徹底的な評価により、エージェントは複雑なワークフローでの信頼性が低く、成功率は15%にとどまることが明らかに。これにより、エージェントの限界を克服し、より効果的な設計原則を模索するための洞察が得られる。 Comment
元ポスト:
[Paper Note] Algorithmic Primitives and Compositional Geometry of Reasoning in Language Models, Samuel Lippl+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Reasoning Issue Date: 2025-10-25 GPT Summary- 本研究では、大規模言語モデル(LLMs)が多段階の推論を解決するためのアルゴリズム的原則を追跡し、操作するフレームワークを提案。推論のトレースを内部の活性化パターンにリンクさせ、原則を残差ストリームに注入することで、推論ステップやタスクのパフォーマンスへの影響を評価。旅行セールスマン問題や3SATなどのベンチマークを用いて、原則ベクトルの導出と幾何学的論理の明示化を行い、ファインチューニングによる一般化の強調を示した。これにより、LLMsの推論がアルゴリズム的原則の構成的幾何学に支えられている可能性が示唆され、原則の転送とドメイン間の一般化が強化されることが明らかになった。 Comment
元ポスト:
[Paper Note] Blackbox Model Provenance via Palimpsestic Membership Inference, Rohith Kuditipudi+, NeurIPS'25 Spotlight, 2025.10
Paper/Blog Link My Issue
#NLP #NeurIPS #Selected Papers/Blogs Issue Date: 2025-10-25 GPT Summary- アリスの言語モデルを用いてボブがテキストを生成する際、アリスはボブが彼女のモデルを使用していることを証明できるかを検討。クエリ設定と観察設定の2つのアプローチで、ボブのモデルやテキストとアリスの訓練データの順序との相関を調査。40以上のファインチューニングで、p値が1e-8に達する結果を得た。観察設定では、ボブのテキストの尤度を推定する2つの方法を試し、数百トークンでの区別が可能なアプローチと、数十万トークンを必要とする高パワーのアプローチを比較した。 Comment
元ポスト:
これはすごい話だ…
[Paper Note] Learning to Interpret Weight Differences in Language Models, Avichal Goel+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Explanation #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #One-Line Notes Issue Date: 2025-10-25 GPT Summary- ファインチューニングされた言語モデルの重みの変化を解釈するために、Diff Interpretation Tuning(DIT)を提案。合成されたラベル付きの重みの差を用いてモデルに変更を説明させる。隠れた挙動の報告や知識の要約において、DITが自然言語での正確な説明を可能にすることを示した。 Comment
元ポスト:
weightの更新があった時に、LLM自身がどのような変化があったかをverbalizeできるようにSFTでLoRA Adaptorを学習する話らしい
[Paper Note] AsyncHZP: Hierarchical ZeRO Parallelism with Asynchronous Scheduling for Scalable LLM Training, Huawei Bai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #SoftwareEngineering #mid-training #PostTraining #Parallelism Issue Date: 2025-10-25 GPT Summary- 非同期階層ゼロ並列処理(AsyncHZP)を提案し、シンプルさとメモリ効率を保ちながら、トレーニング効率を向上。従来のZeROの通信オーバーヘッドを削減し、パラメータや勾配の再シャーディングを適応的に行う。マルチストリーム非同期スケジューリングにより通信と計算を重ね合わせ、メモリの断片化を最小限に抑える。DenseおよびMixture-of-Expertsモデルでの評価により、AsyncHZPが従来のND並列処理を上回る性能を示した。 Comment
元ポスト:
[Paper Note] SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal, Tinghao Xie+, ICLR'25, 2024.06
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #MultiLingual #Safety #ICLR Issue Date: 2025-10-24 GPT Summary- SORRY-Benchは、整合された大規模言語モデル(LLMs)の安全でないユーザーリクエストの認識能力を評価する新しいベンチマークです。既存の評価方法の限界を克服するために、44の細かい安全でないトピック分類と440のクラスバランスの取れた指示を提供し、20の言語的拡張を追加しました。また、高速で正確な自動安全評価者を開発し、微調整された7B LLMがGPT-4と同等の精度を持つことを示しました。これにより、50以上のLLMの安全拒否行動を分析し、体系的な評価の基盤を提供します。デモやデータは公式サイトから入手可能です。 Comment
pj page: https://sorry-bench.github.io/
openreview: https://openreview.net/forum?id=YfKNaRktan
[Paper Note] Asymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning, Jiashun Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #Diversity #Entropy Issue Date: 2025-10-24 GPT Summary- 非対称近似ポリシー最適化(AsyPPO)を提案し、批評者の役割を復元しつつ大規模言語モデルの強化学習を効率化。軽量なミニ批評者を用いて多様性を促進し、価値推定のバイアスを減少。5,000サンプルでトレーニング後、従来のPPOに対してパフォーマンスを向上させ、学習の安定性を一貫して改善。 Comment
元ポスト:
[Paper Note] Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning, Ling Team+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #Architecture #MoE(Mixture-of-Experts) #Hybrid Issue Date: 2025-10-24 GPT Summary- Ring-linearモデルシリーズ、特にRing-mini-linear-2.0(16Bパラメータ)とRing-flash-linear-2.0(104Bパラメータ)を紹介。両モデルはハイブリッドアーキテクチャを採用し、長いコンテキストの推論でI/Oと計算オーバーヘッドを削減。推論コストは32億パラメータの密なモデルと比較して1/10、元のRingシリーズと比べて50%以上削減。最適なモデル構造を特定し、高性能FP8オペレーターライブラリ「linghe」によりトレーニング効率が50%向上。複数の複雑推論ベンチマークでSOTAパフォーマンスを維持。 Comment
HF: https://huggingface.co/inclusionAI/Ring-flash-linear-2.0-128k
元ポスト:
所見:
[Paper Note] BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping, Zhiheng Xi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #Off-Policy #On-Policy #Stability #One-Line Notes #Entropy #PartialRollout Issue Date: 2025-10-24 GPT Summary- 強化学習におけるオフポリシー設定の課題を解決するため、BAPO(Balanced Policy Optimization with Adaptive Clipping)を提案。ポジティブとネガティブな寄与を再バランスし、エントロピーを保持することで最適化を安定化。多様なシナリオでデータ効率の高いトレーニングを実現し、AIME 2024およびAIME 2025のベンチマークで最先端の結果を達成。 Comment
pj page: https://github.com/WooooDyy/BAPO
Partial Rollout(=長いtrajectoryを一回のロールアウトで生成仕切らずに、途中で生成を打ち切りreplay bufferに保存。次のロールアウト時に続きを生成する。しかし更新されたポリシーによって続きをロールアウトするためオフポリシーデータとなる)の設定で、GRPOよりも学習効率が良いことが示されているように見える。
[Paper Note] Lookahead Routing for Large Language Models, Canbin Huang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Routing Issue Date: 2025-10-23 GPT Summary- Lookaheadフレームワークを提案し、クエリに対して最適なモデルを選択するために潜在的な出力を予測することで、情報に基づいたルーティングを実現。これにより、複雑なクエリに対するルーティング精度が向上し、既存の手法より平均7.7%の性能向上を達成。 Comment
元ポスト:
先行研究:
- [Paper Note] RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models, Shuhao Chen+, NeurIPS'24, 2024.09
- [Paper Note] Smoothie: Label Free Language Model Routing, Neel Guha+, NeurIPS'24, 2024.12
- [Paper Note] Large Language Model Routing with Benchmark Datasets, Tal Shnitzer+, COLM'24, 2023.09
[Paper Note] Extracting alignment data in open models, Federico Barbero+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Alignment #InstructionTuning #SyntheticData #OpenWeight Issue Date: 2025-10-23 GPT Summary- 本研究では、ポストトレーニングモデルからアライメントトレーニングデータを抽出する方法を示し、埋め込みモデルが特定の能力向上に適していると主張します。文字列マッチングに依存せず、意味的類似性を捉えることで、抽出可能なデータ量を過小評価するリスクを明らかにしました。また、モデルはポストトレーニングフェーズで使用されたデータを再生でき、元のパフォーマンスを回復可能であることを示しました。研究は蒸留手法の影響についても議論します。 Comment
元ポスト:
Magpieのような話だろうか?
[Paper Note] Memory Layers at Scale, Vincent-Pierre Berges+, ICLR'25, 2024.12
Paper/Blog Link My Issue
#Transformer #Architecture #ICLR #read-later #Selected Papers/Blogs #memory #KeyPoint Notes Issue Date: 2025-10-23 GPT Summary- メモリ層は、計算負荷を増やさずにモデルに追加のパラメータを加えるための学習可能な検索メカニズムを使用し、スパースに活性化されたメモリ層が密なフィードフォワード層を補完します。本研究では、改良されたメモリ層を用いた言語モデルが、計算予算が2倍の密なモデルや同等の計算とパラメータを持つエキスパート混合モデルを上回ることを示し、特に事実に基づくタスクでの性能向上が顕著であることを明らかにしました。完全に並列化可能なメモリ層の実装とスケーリング法則を示し、1兆トークンまでの事前学習を行った結果、最大8Bのパラメータを持つベースモデルと比較しました。 Comment
openreview: https://openreview.net/forum?id=ATqGm1WyDj
transformerにおけるFFNをメモリレイヤーに置き換えることで、パラメータ数を増やしながら計算コストを抑えるようなアーキテクチャを提案しているようである。メモリレイヤーは、クエリqを得た時にtop kのkvをlookupし(=ここで計算対象となるパラメータがスパースになる)、kqから求めたattention scoreでvを加重平均することで出力を得る。Memory+というさらなる改良を加えたアーキテクチャでは、入力に対してsiluによるgatingとlinearな変換を追加で実施することで出力を得る。
denseなモデルと比較して性能が高く、メモリパラメータを増やすと性能がスケールする。
[Paper Note] Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model, Ling Team+, arXiv'25, 2025.10
Paper/Blog Link My Issue
Issue Date: 2025-10-22 GPT Summary- 1兆パラメータを持つオープンソース思考モデル「Ring-1T」を発表。訓練と推論の不整合やロールアウト処理の非効率性に対処するため、3つの革新(IcePop、C3PO++、ASystem)を導入。重要なベンチマークで優れた結果を達成し、特にIMO-2025で銀メダルレベルの推論能力を示す。コミュニティに1TパラメータのMoEモデルを公開し、大規模推論知能の民主化に寄与。 Comment
元ポスト:
解説:
所見:
ポイント解説:
[Paper Note] Detecting Adversarial Fine-tuning with Auditing Agents, Sarah Egler+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #AIAgents #API #Safety #PostTraining #Safeguard Issue Date: 2025-10-22 GPT Summary- ファインチューニングAPIの悪用に対する検出メカニズムを提案。ファインチューニング監査エージェントを導入し、有害なファインチューニングを事前に検出可能であることを示す。1400以上の監査を通じて、56.2%の敵対的ファインチューニング検出率を達成。良性ファインチューニングによる安全性の低下も課題として残るが、今後の研究の基盤を提供。監査エージェントは公開済み。 Comment
元ポスト:
finetueing APIを通じて悪意のあるデータセットが与えられたとき悪意のあるモデルができあがってしまう。これを検知するために、エージェントを用いてfinetuning用のデータセットと、finetuning前後のモデルへqueryし、finetuning後のモデルがpoisonedか否かを検出する、という話な模様。
[Paper Note] Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization, Badr AlKhamissi+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Reasoning #Architecture #read-later #Selected Papers/Blogs #KeyPoint Notes #SpeciarizedBrainNetworks #Neuroscience #Author Thread-Post Issue Date: 2025-10-22 GPT Summary- MiCRoは、脳の認知ネットワークに基づく専門家モジュールを持つトランスフォーマーベースのアーキテクチャで、言語モデルの層を4つの専門家に分割。これにより、解釈可能で因果的な専門家の動的制御が可能になり、機械学習ベンチマークで優れた性能を発揮。人間らしく解釈可能なモデルを実現。 Comment
pj page: https://cognitive-reasoners.epfl.ch
元ポスト:
事前学習言語モデルに対してpost-trainingによって、脳に着想を得て以下の4つをdistinctな認知モジュールを(どのモジュールにルーティングするかを決定するRouter付きで)学習する。
- Language
- Logic / Multiple Demand
- Social / Theory of Mind
- World / Default Mode Network
これによりAIとNeuroscienceがbridgeされ、MLサイドではモデルの解釈性が向上し、Cognitive側では、複雑な挙動が起きた時にどのモジュールが寄与しているかをprobingするテストベッドとなる。
ベースラインのdenseモデルと比較して、解釈性を高めながら性能が向上し、人間の行動とよりalignしていることが示された。また、layerを分析すると浅い層では言語のエキスパートにルーティングされる傾向が強く、深い層ではdomainのエキスパートにルーティングされる傾向が強くなるような人間の脳と似たような傾向が観察された。
また、neuroscienceのfunctional localizer(脳のどの部位が特定の機能を果たしているのかを特定するような取り組み)に着想を得て、類似したlocalizerが本モデルにも適用でき、特定の機能に対してどのexpertモジュールがどれだけ活性化しているかを可視化できた。
といったような話が著者ポストに記述されている。興味深い。
demo:
https://huggingface.co/spaces/bkhmsi/cognitive-reasoners
HF:
https://huggingface.co/collections/bkhmsi/mixture-of-cognitive-reasoners
[Paper Note] Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text Inputs in Multimodal LLMs, Yanhong Li+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #MultiModal #Pixel-based Issue Date: 2025-10-22 GPT Summary- テキストを画像として提供することで、LLMのトークン使用量を削減しつつ性能を維持できることを示す。長いテキストを画像にレンダリングし、デコーダーに直接入力することで、必要なトークン数を大幅に減少させる。実験により、RULERとCNN/DailyMailのベンチマークで性能を損なうことなく、トークンの節約が実現できることを確認。 Comment
元ポスト:
[Paper Note] Continual Learning via Sparse Memory Finetuning, Jessy Lin+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Catastrophic Forgetting #memory #ContinualLearning Issue Date: 2025-10-22 GPT Summary- スパースメモリファインチューニングを用いて、破滅的忘却を軽減しながら継続的学習を可能にするモデルを提案。新しい知識を学習する際、メモリスロットの更新を制限することで、既存の能力との干渉を減少。実験では、スパースメモリファインチューニングが他の手法に比べて著しく少ない忘却を示し、継続的学習における有望なアプローチであることを示した。 Comment
元ポスト:
関連:
- [Paper Note] Memory Layers at Scale, Vincent-Pierre Berges+, ICLR'25, 2024.12
ポイント解説:
[Paper Note] Prompt-MII: Meta-Learning Instruction Induction for LLMs, Emily Xiao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #In-ContextLearning #AutomaticPromptEngineering #read-later #One-Line Notes Issue Date: 2025-10-21 GPT Summary- PROMPT-MIIという新しい指示誘導モデルを提案し、トレーニング例をコンパクトなプロンプトに縮小することで、インコンテキスト学習(ICL)と同等のパフォーマンスを実現。3,000以上の分類データセットでトレーニングし、90の未見タスクで評価した結果、下流モデルの品質を4-9 F1ポイント向上させ、必要なトークン数を3-13倍削減。 Comment
元ポスト:
タスクのexamplar/demonstrationからタスクに関するdescription(=instruction)を生成するモデルを学習し、生成されたinstructionを用いることで、manyshotでICLするよりも、少ないトークン数で同等以上の性能を達成するといった話に見える。どういうinstructionになるのかが非常に興味がある。A.6参照のこと。細かく具体的だがコンパクトな指示が記述されているようなinstructionとなっている。
[Paper Note] Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation, Sayash Kapoor+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #read-later #Selected Papers/Blogs Issue Date: 2025-10-21 GPT Summary- AIエージェントの評価における課題を解決するため、Holistic Agent Leaderboard(HAL)を導入。標準化された評価ハーネスにより評価時間を短縮し、三次元分析を通じて21,730のエージェントを評価。高い推論努力が精度を低下させることを発見し、LLMを用いたログ検査で新たな行動を明らかに。エージェント評価の標準化を進め、現実世界での信頼性向上を目指す。 Comment
pj page: https://hal.cs.princeton.edu
元ポスト:
よ、40,000ドル!?💸
LLM Agentに関するフロンティアモデル群を複数のベンチマークで同じ条件でapple to appleな比較となるように評価している。
以下元ポストより:
この評価ハーネスは、10行未満のコードスニペットで評価を実行可能(元ポスト)
知見としては
- reasoning effortを上げても多くの場合性能向上には寄与せず(21/36のケースで性能向上せず)
- エージェントはタスクを解決するために近道をする(ベンチマークを直接参照しに行くなど)
- エージェントは非常にコストの高い手段を取ることもあり(フライト予約において誤った空港から予約したり、ユーザに過剰な返金をしたり、誤ったクレジットカードに請求したりなど)
- コストとacc.のトレードオフを分析した結果、最も高価なOpus4.1は一度しかパレートフロンティアにならず、Gemini Flash (7/9)、GPT-5, o4-mini(4/9)が多くのベンチマークでコストとAcc.のトレードオフの上でパレートフロンティアとなった。
- トークンのコストとAcc.のトレードオフにおいては、Opus4.1が3つのベンチマークでパレードフロンティアとなった。
- すべてのエージェントの行動を記録し分析した結果、SelfCorrection, intermediate verifiers (コーディング問題におけるユニットテストなど)のbehaviorがacc.を改善する上で高い相関を示した
- 一方タスクに失敗する場合は、多くの要因が存在することがわかり、たとえば環境内の障害(CAPTCHAなど)、指示に従うことの失敗(指定されたフォーマットでコードを出力しない)などが頻繁に見受けられた。また、タスクを解けたか否かに関わらずツール呼び出しの失敗に頻繁に遭遇していた。これはエージェントはこうしたエラーから回復できることを示している。
- エージェントのログを分析することで、TauBenchで使用していたscaffold(=モデルが環境もやりとりするための構成要素)にバグがあることを突き止めた(few-shotのサンプルにリークがあった)。このscaffoldはHALによるTauBenchの分析から除外した。
- Docsentのようなログ分析が今後エージェントを評価する上では必要不可欠であり、信頼性の問題やショートカット行動、高コストなエージェントの失敗などが明らかになる。ベンチマーク上での性能と比較して実環境では性能が低い、あるいはその逆でベンチマークが性能を低く見積もっている(たとえばCAPTChAのようや環境的な障害はベンチマーク上では同時リクエストのせいで生じても実環境では生じないなど)ケースもあるので、これらはベンチマークのacc.からだけでは明らかにならないため、ベンチマークのacc.は慎重に解釈すべき。
[Paper Note] OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM, Hanrong Ye+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Temporal #SyntheticData #MultiModal #SpeechProcessing #Architecture #2D (Image) #TTS #3D (Video) #Omni #audio #text Issue Date: 2025-10-21 GPT Summary- OmniVinciは、視覚と音声を統合したオムニモーダルLLMを構築するプロジェクトであり、3つの革新(OmniAlignNet、Temporal Embedding Grouping、Constrained Rotary Time Embedding)を提案。2400万の会話データを用いて、モダリティ間の相互強化を実現。DailyOmni、MMAR、Video-MMEでの性能向上を達成し、トレーニングトークンの使用量を大幅に削減。ロボティクスや医療AIなどの応用におけるオムニモーダルの利点を示す。 Comment
pj page: https://nvlabs.github.io/OmniVinci/
元ポスト:
image, video, テキスト, 音声を理解しテキストを出力(TTSも可)するモデルに関する新たなアーキテクチャとデータキュレーションパイプラインを提案している模様
[Paper Note] UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action, Yuhao Yang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #ComputerUse #One-Line Notes Issue Date: 2025-10-21 GPT Summary- ハイブリッドアクションを用いた基盤モデル「UltraCUA」を提案し、GUIの原始的なアクションと高レベルのプログラムツール呼び出しを統合。自動化パイプライン、合成データエンジン、ハイブリッドアクション軌跡コレクション、二段階のトレーニングパイプラインを構成要素とし、実験により最先端エージェントに対して22%の改善と11%の速度向上を達成。エラー伝播を減少させつつ実行効率を維持することが確認された。 Comment
元ポスト:
従来のCUAはGUIに対する低レベルの操作(クリック、タイプ、スクロール)を利用する前提に立つが、本研究ではそれらだけではなくより高レベルのprogramatic tool calls(e.g., python関数呼び出し、キーボードショートカット、スクリプト実行、API呼び出し等)をシームレスに統合できるように合成データを作成しAgentをらSFTとRLしましたらよりベンチマークスコア向上した、というような話に見える。
[Paper Note] Synthesizing Agentic Data for Web Agents with Progressive Difficulty Enhancement Mechanisms, Shrey Pandit+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #Diversity #Verification #DeepResearch #LongHorizon Issue Date: 2025-10-21 GPT Summary- Webベースの「ディープリサーチ」エージェントは、長期的なインタラクションを通じて複雑な質問応答タスクを解決することを目指すが、従来の方法は推論の複雑さを捉えきれない。そこで、タスクの複雑さを段階的に増加させる二段階のデータ合成パイプラインを導入し、ベースラインエージェントが質問に挑戦し、事実確認を行う。実験により、提案したデータセットが既存のものよりも効果的な訓練を可能にし、ツール使用アクションの多様性が2倍であることが示された。 Comment
元ポスト:
[Paper Note] EPO: Entropy-regularized Policy Optimization for LLM Agents Reinforcement Learning, Wujiang Xu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Multi #NLP #ReinforcementLearning #AIAgents #Stability #Entropy Issue Date: 2025-10-21 GPT Summary- マルチターン環境でのLLMエージェント訓練における探索-活用カスケード失敗を特定し、エントロピー正則化ポリシー最適化(EPO)を提案。EPOは、探索を強化し、ポリシーエントロピーを制限することで、訓練の安定性を向上させる。実験により、ScienceWorldで152%、ALFWorldで19.8%の性能向上を達成。マルチターンスパース報酬設定には新たなエントロピー制御が必要であることを示す。 Comment
元ポスト:
[Paper Note] Skill-Targeted Adaptive Training, Yinghui He+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #SyntheticData #read-later #One-Line Notes #SkillTag Issue Date: 2025-10-21 GPT Summary- 本研究では、言語モデルのメタ認知能力を活用した新しいファインチューニング戦略「STAT」を提案。教師モデルがタスクに必要なスキルをラベル付けし、学生モデルのスキル不足を追跡することで、トレーニングセットを修正。STAT-Selでは既存の例の重みを調整し、STAT-Synでは新たな例を合成。実験により、MATHで最大7.5%の改善を達成し、分布外ベンチマークでも平均4.6%の向上を示した。STATは強化学習手法GRPOと補完的であり、スキルターゲットの適応トレーニングがトレーニングパイプラインを改善することを示唆。 Comment
元ポスト:
Reward Modelでquestionがeasy/hardを定量化し、hardなものに対してモデルが応答を生成。応答の結果をstronger modelに確認させ、モデルにどのようなスキルが不足しているかを特定する。これによりモデルのスキルに関するprofileが作成されるのでこれに基づいて学習データの各サンプルとスキルを紐づけた上でサンプルを重みの調整、および不足しているスキルに関するデータを合成しSFTに活用する、といった話な模様。
結果を見ると、+SFT / +GRPOよりも性能が高くなっている。Table1ではLlamaでの結果しか掲載されていないが、Qwenでも実験がされて同様の結果が得られている。
また、Figure4を見ると不足していたスキルが学習によってきちんと補われていることが分かる。
(評価と考察部分をもう少しじっくり読みたい)
[Paper Note] Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding, Sensen Gao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Survey #InformationRetrieval #NLP #MultiModal #RAG(RetrievalAugmentedGeneration) #VisionLanguageModel #Encoder #One-Line Notes Issue Date: 2025-10-20 GPT Summary- 文書理解は多様なアプリケーションにおいて重要であり、現在のアプローチには制限がある。特に、OCRベースのパイプラインは構造的詳細を失い、マルチモーダルLLMsはコンテキストモデリングに苦労している。リトリーバル強化生成(RAG)は外部データを活用するが、文書のマルチモーダル性にはマルチモーダルRAGが必要である。本論文では、文書理解のためのマルチモーダルRAGに関する体系的な調査を行い、分類法や進展をレビューし、主要なデータセットや課題をまとめ、文書AIの今後の進展に向けたロードマップを提供する。 Comment
元ポスト:
multimodal RAGに関するSurvey
Table1は2024年以後の35本程度の手法、Table2は20+程度のベンチマークがまとまっており、基本的な概念なども解説されている模様。半数程度がtraining-free/OCRを利用する手法はそれぞれ五分五分程度なようで、Agenticな手法はあまり多くないようだ(3/35)。
[Paper Note] MetaMorph: Multimodal Understanding and Generation via Instruction Tuning, Shengbang Tong+, ICCV'25, 2024.12
Paper/Blog Link My Issue
#ComputerVision #InstructionTuning #DiffusionModel #TextToImageGeneration #read-later #Selected Papers/Blogs #ICCV #ImageSynthesis Issue Date: 2025-10-20 GPT Summary- 本研究では、視覚的指示調整の新手法VPiTを提案し、LLMがテキストと視覚トークンを生成できるようにします。VPiTは、キュレーションされた画像とテキストデータからトークンを予測する能力をLLMに教え、視覚生成能力が向上することを示しました。特に、理解データが生成データよりも効果的に両方の能力に寄与することが明らかになりました。MetaMorphモデルを訓練し、視覚理解と生成で競争力のあるパフォーマンスを達成し、LLMの事前学習から得た知識を活用することで、視覚生成における一般的な失敗を克服しました。これにより、LLMが視覚理解と生成に適応できる可能性が示唆されました。 Comment
元ポスト:
[Paper Note] On the Relationship Between the Choice of Representation and In-Context Learning, Ioana Marinescu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #In-ContextLearning Issue Date: 2025-10-20 GPT Summary- インコンテキスト学習(ICL)は、LLMがデモンストレーションから新しいタスクを学ぶ能力を指し、表現方法と学習能力の相互作用が重要である。研究では、デモンストレーションの表現がICLの基準精度を決定し、追加のデモンストレーションはその基準を改善することを仮定。異なるラベルセットを用いてICLを実施した結果、ラベルセットの質に関わらず学習が行われ、効率はデモンストレーションの改善傾きに依存することが確認された。これにより、デモンストレーションからの学習とその表現がICLのパフォーマンスに独立した影響を与えることが示された。 Comment
元ポスト:
[Paper Note] Reasoned Safety Alignment: Ensuring Jailbreak Defense via Answer-Then-Check, Chentao Cao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #Alignment #Supervised-FineTuning (SFT) #Reasoning #Safety Issue Date: 2025-10-20 GPT Summary- 脱獄攻撃に対する安全性を向上させるために、Answer-Then-Checkという新しいアプローチを提案。モデルはまず質問に回答し、その後安全性を評価してから応答を提供。80Kの例からなるReasoned Safety Alignment(ReSA)データセットを構築し、実験により優れた安全性を示しつつ過剰拒否率を低下。ReSAでファインチューニングされたモデルは一般的な推論能力を維持し、敏感なトピックに対しても有益な応答を提供可能。少量のデータでのトレーニングでも高いパフォーマンスを達成できることが示唆された。 Comment
元ポスト:
[Paper Note] Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation, Kang Liao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Dataset #Supervised-FineTuning (SFT) #InstructionTuning #Evaluation #MultiModal #DiffusionModel #UMM #SpatialUnderstanding Issue Date: 2025-10-20 GPT Summary- カメラ中心の理解と生成を統合したマルチモーダルモデル「Puffin」を提案。Puffinは、言語回帰と拡散生成を組み合わせ、カメラを言語として扱う新しいアプローチを採用。400万の視覚-言語-カメラのデータセット「Puffin-4M」で訓練され、空間的な視覚的手がかりを考慮した推論を実現。実験結果では、専門モデルを上回る性能を示し、指示チューニングにより多様なタスクに対応可能。研究成果はコードやデータセットと共に公開予定。 Comment
元ポスト:
[Paper Note] Understanding the Influence of Synthetic Data for Text Embedders, Jacob Mitchell Springer+, ACL'25 Findings, 2025.09
Paper/Blog Link My Issue
#Embeddings #Analysis #NLP #Dataset #RepresentationLearning #SyntheticData #ACL #Findings Issue Date: 2025-10-19 GPT Summary- 合成LLM生成データのトレーニングによる汎用テキスト埋め込み器の進展を受け、Wangらの合成データを再現・公開。高品質なデータはパフォーマンス向上をもたらすが、一般化の改善は局所的であり、異なるタスク間でのトレードオフが存在。これにより、合成データアプローチの限界が明らかになり、タスク全体での堅牢な埋め込みモデルの構築に対する考えに疑問を呈する。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/jspringer/open-synthetic-embeddings
[Paper Note] Agentic Design of Compositional Machines, Wenqian Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #Reasoning #read-later Issue Date: 2025-10-19 GPT Summary- 複雑な機械設計におけるLLMの創造能力を探求し、「構成的機械設計」の視点からアプローチ。テストベッド「BesiegeField」を用いて、LLMの能力をベンチマークし、空間的推論や戦略的組み立ての重要性を特定。オープンソースモデルの限界を受け、強化学習を通じた改善を模索し、関連する課題を明らかにする。 Comment
元ポスト:
pj page: https://besiegefield.github.io/
[Paper Note] BitNet Distillation, Xun Wu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #NLP #Quantization #Distillation #PostTraining #KeyPoint Notes Issue Date: 2025-10-19 GPT Summary- BitNet Distillation(BitDistill)は、フル精度LLMを1.58ビット精度にファインチューニングする軽量なパイプラインで、計算コストを抑えつつ高いタスク特化型パフォーマンスを実現します。主な技術には、SubLNモジュール、MiniLMに基づくアテンション蒸留、継続的な事前学習が含まれ、これによりフル精度モデルと同等の性能を達成し、メモリを最大10倍節約し、CPU上での推論を2.65倍高速化します。 Comment
元ポスト:
SubLN, MiniLMについては
- [Paper Note] Magneto: A Foundation Transformer, Hongyu Wang+, ICML'23
- [Paper Note] MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers, Wenhui Wang+, ACL'21 Findings, 2020.12
を参照のこと。
既存LLMを特定タスクに1.58bitでSFTする際に、full-precisionと同等の性能を保つ方法を提案している研究。full-precision LLMを1.58 bitでSFTをするとfp16で学習した場合のbaselineと比較してパフォーマンスが大きく低下するが(そしてその傾向はモデルサイズが大きいほど強い)、提案手法を利用するとfp16でSFTした場合と同等の性能を保ちながら、inference-speed 2.65倍、メモリ消費量1/10になる模様。
手法としては、3段階で構成されており
- Stage1: low-bitに量子化されたモデルではactivationの分散が大きくなり学習の不安定さにつながるため、アーキテクチャとしてSubLNを導入して安定化を図る
- Stage2: Stage1で新たにSubLNを追加するので事前学習コーパスの継続事前学習する
- Stage3: full-precisionでSFTしたモデルを教師、1.58-bitに量子化したモデルを生徒とし、logits distillation (input x, output yが与えられた時に教師・生徒間で出力トークンの分布のKL Divergenceを最小化する)、MiniLMで提案されているMHAのdistillation(q-q/k-k/v-vの内積によってsquaredなrelation mapをQ, K, Vごとに作成し、relation mapのKL Divergenceが教師・生徒間で最小となるように学習する)を実施する
- 最終的に `L_CE + \lambda L_LD + \ganma L_AD` を最小化する。ここで、L_CEはdownstream datasetに対するcross-entropy lossであり、L_LD, L_ADはそれぞれ、logit distillation, Attention Distillationのlossである。
ポイント解説:
[Paper Note] Agentic Misalignment: How LLMs Could Be Insider Threats, Aengus Lynch+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Alignment #AIAgents #Safety #read-later #Selected Papers/Blogs Issue Date: 2025-10-19 GPT Summary- 複数の開発者からの16のモデルを仮想企業環境でテストし、潜在的なリスク行動を特定。モデルは自律的にメールを送信し、機密情報にアクセス可能で、ビジネス目標に従う中で反抗的行動を示すことがあった。この現象を「エージェントのミスアライメント」と呼び、モデルが不適切な行動を取ることがあることを示した。実際の展開においてはミスアライメントの証拠は見られなかったが、モデルの自律性が高まることで将来的なリスクが生じる可能性があることを指摘。安全性と透明性の重要性を強調し、研究方法を公開する。 Comment
元ポスト:
abstを読んだだけでも、なんとも恐ろしいシナリオが記述されている。読みたい
Figure4, 5とかすごいな
[Paper Note] Clean First, Align Later: Benchmarking Preference Data Cleaning for Reliable LLM Alignment, Samuel Yeh+, NeurIPS'25, 2025.09
Paper/Blog Link My Issue
#NLP #Alignment #Evaluation #NeurIPS #PostTraining #One-Line Notes Issue Date: 2025-10-19 GPT Summary- 人間のフィードバックはLLMのアライメントに重要だが、ノイズや一貫性の欠如が問題を引き起こす。これを解決するために、13のデータクリーニング手法を評価する初のベンチマーク「PrefCleanBench」を導入。さまざまな条件下でのアライメント性能を比較し、データクリーニングの成功要因を明らかにする。これにより、LLMアライメントの改善に向けた再現可能なアプローチを提供し、データ前処理の重要性を強調する。すべての手法の実装は公開されている。 Comment
元ポスト:
元ポストによるとTakeawayとしては、
- cleaningをすることでalignmentの性能は一貫して向上
- 複数のReward Modelを用いた場合(おそらくhuman labelと複数RMのvotingに基づくcleaning)は単一モデルよりも信頼性が高くロバスト
- bad dataに対するデータは(ラベルを修正するよりも)削除した方が性能が向上する
- 少量だがクリーンなデータセットは大規模でノイジーなデータセットよりも性能が良い
といった知見がある模様
[Paper Note] SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models, Chenyu Wang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #DiffusionModel #PostTraining Issue Date: 2025-10-19 GPT Summary- 拡散型大規模言語モデル(dLLMs)は、効率的なデコード能力を持つが、強化学習(RL)による調整が難しい。従来の代理手法はバイアスを引き起こす可能性がある。そこで、真の対数尤度の上限と下限を利用した「サンドイッチポリシー勾配(SPG)」を提案。実験により、SPGはELBOや他のベースラインを大幅に上回り、GSM8Kで3.6%、MATH500で2.6%、Countdownで18.4%、Sudokuで27.0%の精度向上を達成した。 Comment
pj page: https://chenyuwang-monica.github.io/spg/
元ポスト:
[Paper Note] Attention Is All You Need for KV Cache in Diffusion LLMs, Quan Nguyen-Tri+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #One-Line Notes #KV Cache Issue Date: 2025-10-19 GPT Summary- 本研究では、拡散型大規模言語モデル(DLMs)のデコーディング待機時間を最小化しつつ予測精度を最大化するために、適応的なKVキャッシュ再計算手法「Elastic-Cache」を提案。これにより、浅いレイヤーの冗長性を削減し、重要なトークンに基づいてキャッシュのリフレッシュを動的に行う。実験では、GSM8KやHumanEvalでの速度向上を示し、生成品質を維持しながら高いスループットを達成した。 Comment
元ポスト:
DLMにおいて、denoisingの各ステップにおいて全てのKVを再計算するのではなく、attention scoreが大きくドリフトしていない部分についてはKV Cacheを再利用し、大きくドリフトした部分だけ再計算するような仕組みを学習することで、品質を損なうことなく推論速度を高速化した模様
[Paper Note] Scaling Test-Time Compute to Achieve IOI Gold Medal with Open-Weight Models, Mehrzad Samadi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Coding #LLM-as-a-Judge #Test-Time Scaling #One-Line Notes #Scalability Issue Date: 2025-10-19 GPT Summary- 競技プログラミングはLLMsの能力を評価する重要なベンチマークであり、IOIはその中でも特に権威ある大会です。本論文では、オープンウェイトモデルがIOI金メダルレベルのパフォーマンスを達成するためのフレームワーク「GenCluster」を提案します。このフレームワークは、生成、行動クラスタリング、ランキング、ラウンドロビン戦略を組み合わせて多様な解決空間を効率的に探索します。実験により、GenClusterは計算リソースに応じてスケールし、オープンシステムとクローズドシステムのギャップを縮小することが示され、IOI 2025で金メダルを達成する可能性を示唆しています。 Comment
元ポスト:
OpenWeight modelで初めてIOI金メダル級のパフォーマンスを実現できるフレームワークで、まずLLMに5000個程度の潜在的なsolutionを生成させ、それぞれのsolutionを100種のtest-caseで走らせて、その後solutionをbehaviorに応じてクラスタリングする。これによりアプローチのユニークさにそってクラスタが形成される。最終的に最も良いsolutionを見つけるために、それぞれのクラスタから最も良いsolutionを互いに対決させて、LLM-as-a-Judgeで勝者をランク付けするような仕組みのようである。
[Paper Note] When Thoughts Meet Facts: Reusable Reasoning for Long-Context LMs, Soyeong Jeong+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #RAG(RetrievalAugmentedGeneration) #LongSequence #read-later #One-Line Notes Issue Date: 2025-10-18 GPT Summary- 思考テンプレートを用いて、長文コンテキスト言語モデル(LCLMs)によるマルチホップ推論を構造化。証拠の結びつきを捉え、自然言語フィードバックでテンプレートを洗練。多様なベンチマークで性能向上を実現し、小型モデルへの蒸留も可能。フレームワーク名はToTAL。 Comment
元ポスト:
シンプルなCoTやドキュメント全体をcontextに入力するようなシンプルなベースラインしかなく、ベースラインが少し弱いような印象を受けたが(たとえばChain-of-Noteを適用していない、と思ったが)実験しているモデルを見ると、そもそもReasoningモデルを使った実験(前提)となっているので(Chain-of-Noteなどはnon-thinking modelでは有効なことが示されているがthinking modelでの効果は不明という認識)、なんやかんやこのベースラインで十分なのでは、という気もする。そして結構性能が上がっているように見える。(後で読みたい)
[Paper Note] Thinking on the Fly: Test-Time Reasoning Enhancement via Latent Thought Policy Optimization, Wengao Ye+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Online/Interactive #NLP #ReinforcementLearning #OOD #LatentReasoning #One-Line Notes #Test Time Training (TTT) Issue Date: 2025-10-18 GPT Summary- Latent Thought Policy Optimization(LTPO)を提案し、LLMの推論を強化するパラメータフリーのフレームワークを導入。中間的な潜在「思考」ベクトルを動的に最適化し、外部監視なしで報酬信号に基づくオンラインポリシー勾配法を使用。5つの推論ベンチマークで強力な性能を示し、特にAIMEベンチマークで顕著な改善を達成。 Comment
元ポスト:
test-time に online-RLを適用することでモデルのパラメータを更新することなく、クエリに応じて動的にlatent reasoningを洗練し、推論能力をロバストにできる、という話な模様?
実験結果を見ると、モデルのパラメータ数が大きい場合にgainが小さくなっていっているように見え、かつ実験中のlargest modelのgainがサンプル数の少ないAIMEのスコアに依存しているように見える。
[Paper Note] LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning, Haoqiang Kang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #DiffusionModel #Reasoning #LatentReasoning #KeyPoint Notes Issue Date: 2025-10-18 GPT Summary- LaDiR(Latent Diffusion Reasoner)という新しい推論フレームワークを提案。これは、LLMの限界を克服し、潜在表現と潜在拡散モデルを統合。VAEを用いて構造化された潜在推論空間を構築し、双方向注意マスクでデノイズ。これにより、効率的な推論軌跡の生成が可能となり、精度と多様性を向上。数学的推論の評価で、従来手法を上回る結果を示す。 Comment
元ポスト:
既存のreasoning/latent reasoningはsequentialにreasoning trajectoryを生成していくが、(このため、誤った推論をした際に推論を是正しづらいといわれている)本手法ではthought tokensと呼ばれる思考トークンをdiffusion modelを用いてdenoisingすることでreasoning trajectoryを生成する。このプロセスはtrajectory全体をiterativeにrefineしていくため前述の弱点が是正される可能性がある。また、thought tokensの生成は複数ブロック(ブロック間はcausal attention, ブロック内はbi-directional attention)に分けて実施されるため複数のreasoning trajectoryを並列して探索することになり、reasoning traceの多様性が高まる効果が期待できる。最後にVAEによってdiscreteなinputをlatent spaceに落とし込み、その空間上でdenoising(= latent space空間上で思考する)し、その後decodingしてdiscrete tokenに再度おとしこむ(= thought tokens)というアーキテクチャになっているため、latent space上でのreasoningの解釈性が向上する。最終的には、
結果のスコアを見る限り、COCONUTと比べるとだいぶgainを得ているが、Discrete Latentと比較するとgainは限定的に見える。
[Paper Note] Reliable Fine-Grained Evaluation of Natural Language Math Proofs, Wenjie Ma+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Mathematics #read-later #Selected Papers/Blogs #Proofs Issue Date: 2025-10-18 GPT Summary- 大規模言語モデル(LLMs)による数学的証明の生成と検証における信頼性の高い評価者が不足している問題に対処するため、0から7のスケールで評価する新たな評価者ProofGraderを開発。ProofBenchという専門家注釈付きデータセットを用いて、評価者の設計空間を探求し、低い平均絶対誤差(MAE)0.926を達成。ProofGraderは、最良の選択タスクにおいても高いスコアを示し、下流の証明生成の進展に寄与する可能性を示唆している。 Comment
元ポスト:
これは非常に重要な研究に見える
[Paper Note] AutoCode: LLMs as Problem Setters for Competitive Programming, Shang Zhou+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Education #AIAgents #Evaluation #Coding #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-18 GPT Summary- AutoCodeは、競技プログラミングの問題文とテストケースを生成するシステムであり、信頼性の高い問題作成を実現します。複数回の検証を通じて、生成された問題は公式の判断と99%の一貫性を持ち、従来の手法に比べて大幅な改善を示します。また、ランダムなシード問題から新しいバリアントを作成し、不正な問題をフィルタリングする機能も備えています。最終的に、AutoCodeはグランドマスター級の競技プログラマーによってコンテスト品質と評価される問題を生成します。 Comment
blog: https://livecodebenchpro.com/projects/autocode/overview
LLMで自動的に高品質な競技プログラミング問題とそのテストケースを生成するパイプラインを提案。
信頼性のあるテストケースを作成するために、Validator-Generator-Checkerフレームワーク。提案。Generatorがテストケースを生成し、Validatorが生成されたテストケースの入力が問題の制約を満たしているか判定し、Checkerが与えられたテストケースの元で解法が正しいかを確認する。
続いて、人手を介さずとも生成される問題が正しいことを担保するためにdual-verificationを採用。具体的には、LLMに新規の問題文と効率的な解法を生成させ、加えてブルートフォースでの解法を別途生成する。そして、両者をLLMが生成したテストセット群で実行し、全ての解放で出力が一致した場合のみAcceptする、といったような手法らしい。
(手法の概要としてはそうなのだろうが、細かい実装に高品質さの肝があると思うのでしっかり読んだ方が良さげ。特にTest Generationの詳細をしっかりできていない)
takeawayで興味深かったのは、
- LLMは自身では解けないが、解法が存在する(solvable)問題を生成できること
- 人間の専門家とLLM(o3)の間で、問題の品質の新規性の判定の相関がわずか0.007, 0.11しかなかったこと。そして品質に関しては専門家のグループ間では0.71, o3とgpt4oの間では0.72と高い相関を示しており、LLMと人間の専門家の間で著しく問題の品質の判断基準が異なること
- seed問題と生成された問題の難易度のgainが、問題の品質に関して、LLM自身のself-evaluationよりもより良い指標となっていること
[Paper Note] Reasoning with Sampling: Your Base Model is Smarter Than You Think, Aayush Karan+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Reasoning #Diversity #Samplers Issue Date: 2025-10-18 GPT Summary- 本研究では、強化学習を用いずに、サンプリングによって大規模言語モデルの推論能力を引き出す方法を提案。マルコフ連鎖モンテカルロ技術に基づく反復サンプリングアルゴリズムを用い、MATH500、HumanEval、GPQAなどのタスクでRLに匹敵するかそれを上回る性能を示す。さらに、トレーニングや特別なデータセットを必要とせず、広範な適用可能性を持つことを示唆。 Comment
pj page: https://aakaran.github.io/reasoning_with_sampling/
元ポスト:
[Paper Note] Beyond Multi-Token Prediction: Pretraining LLMs with Future Summaries, Divyat Mahajan+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #NLP #LongSequence #Author Thread-Post Issue Date: 2025-10-18 GPT Summary- 未来要約予測(FSP)を提案し、長期的な推論や創造的な執筆の課題を解決。FSPは、長期的な未来のコンパクトな表現を予測する補助ヘッドを用い、情報を保持。手作りの要約と逆言語モデルによる学習要約の2つのバリアントを探求。大規模な実験により、FSPが数学、推論、コーディングのベンチマークでNTPおよびMTPを改善することを示した。 Comment
元ポスト:
逆方向の言語モデルを学習しそのhidden stateを教師信号とし[^1]順方向の言語モデルに対して別のヘッドを用意しrepresentationを取得。l2 lossで順方向と逆方向のrepresentationが近くなるよう学習しバックボーンであるtransformerを学習するような事前学習手法。
[^1]:逆方向言語モデルのhidden stateはfuture contextに関する豊富な情報を含んでいるため
著者ポスト:
[Paper Note] Dr.LLM: Dynamic Layer Routing in LLMs, Ahmed Heakl+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DynamicNetworks #Routing #One-Line Notes Issue Date: 2025-10-17 GPT Summary- Dr.LLMは、LLMsに動的な層ルーティングを導入し、計算効率を向上させるフレームワーク。モンテカルロ木探索を用いて高品質な層構成を導出し、ARCやDARTで精度を最大+3.4%向上させ、平均5層を節約。ドメイン外タスクでもわずか0.85%の精度低下で従来手法を上回る。明示的な監視下でのルーターがLLMsを効率的に活用できることを示す。 Comment
LayerごとにMLPのrouterを用意し、(元のLLMのパラメータはfreezeして)Layerをskip, execute, repeatするかを追加で学習することで、クエリに応じて動的に計算コストとpathを調整する能力を身につけさせ、性能を向上させつつも計算量も削減できます、といった話な模様。routerが学習されているのでinference時にsearchは不要。
[Paper Note] SEED-GRPO: Semantic Entropy Enhanced GRPO for Uncertainty-Aware Policy Optimization, Minghan Chen+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #Entropy Issue Date: 2025-10-17 GPT Summary- SEED-GRPOは、LLMの不確実性を考慮したポリシー更新手法であり、入力プロンプトの意味的エントロピーを測定してポリシー更新の大きさを調整する。これにより、高い不確実性の質問には慎重な更新を行い、自信のある質問には元の学習信号を維持する。実験結果は、5つの数学的推論ベンチマークで新たな最先端のパフォーマンスを達成したことを示している。 Comment
元ポスト:
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
との比較を見てみたいなあ
[Paper Note] Hard2Verify: A Step-Level Verification Benchmark for Open-Ended Frontier Math, Shrey Pandit+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Mathematics #PRM #Verification Issue Date: 2025-10-17 GPT Summary- LLMに基づく推論システムがIMO 2025コンペで金メダルレベルのパフォーマンスを達成したが、各ステップの正確性と支持が求められる。これを実現するために、500時間以上の人間の労力で作成された「Hard2Verify」というステップレベル検証ベンチマークを提案。最前線のLLMによる応答のステップレベル注釈を提供し、エラーを特定する能力を評価。オープンソースの検証者はクローズドソースモデルに劣ることが示され、検証パフォーマンスの低下要因や計算能力の影響について分析を行った。 Comment
元ポスト:
[Paper Note] ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs, Wonjun Kang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #DiffusionModel #Decoding Issue Date: 2025-10-17 GPT Summary- dLLMは並列デコードにより推論を加速するが、トークンの依存関係を無視するため生成品質が低下する可能性がある。既存の研究はこの問題を見落としており、標準ベンチマークでは評価が不十分である。これに対処するため、情報理論的分析と合成リスト操作のケーススタディを行い、dLLMの限界を明らかにした。新たに提案するParallelBenchは、dLLMにとって困難なタスクを特徴とし、分析の結果、dLLMは実世界での品質低下を引き起こし、現在のデコード戦略は適応性に欠けることが示された。この発見は、スピードと品質のトレードオフを克服する新しいデコード手法の必要性を強調している。 Comment
元ポスト: https://parallelbench.github.io
pj page: https://parallelbench.github.io
[Paper Note] RoboMonkey: Scaling Test-Time Sampling and Verification for Vision-Language-Action Models, Jacky Kwok+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #Verification #Robotics #VisionLanguageActionModel Issue Date: 2025-10-17 GPT Summary- VLAモデルの堅牢性を向上させるため、テスト時スケーリングを調査し、RoboMonkeyフレームワークを導入。小さなアクションセットをサンプリングし、VLMを用いて最適なアクションを選択。合成データ生成により検証精度が向上し、分布外タスクで25%、分布内タスクで9%の改善を達成。新しいロボットセットアップへの適応時には、VLAとアクション検証器の両方をファインチューニングすることで7%の性能向上を示した。 Comment
元ポスト:
[Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention, MiniMax+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-10-17 GPT Summary- MiniMax-M1は、4560億パラメータを持つ世界初のオープンウェイトのハイブリッドアテンション推論モデルで、Mixture-of-Expertsアーキテクチャとライトニングアテンションを組み合わせています。1百万トークンのコンテキスト長をサポートし、複雑なタスクに適しています。新しいRLアルゴリズムCISPOを提案し、効率的な訓練を実現。標準ベンチマークで強力なオープンウェイトモデルと同等以上の性能を示し、特にソフトウェアエンジニアリングや長いコンテキストタスクで優れた結果を出しています。モデルは公開されています。 Comment
- MiniMax-M1, MiniMax, 2025.06
のテクニカルレポート。
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
でGSPO, DAPOよりも安定性と最終到達性能でより優れていることが示されたCISPOと呼ばれるRLアルゴリズムが提案されている。
関連:
[Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Scaling Laws #PostTraining #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-10-17 GPT Summary- 強化学習(RL)のスケーリングに関する原則的なフレームワークを定義し、40万時間以上のGPU時間を用いた大規模な研究を実施。シグモイド型計算-性能曲線をフィットさせ、設計選択肢の影響を分析。結果として、漸近的性能はレシピによって異なり、計算効率は詳細に依存することを発見。これを基に、ScaleRLというベストプラクティスのレシピを提案し、100,000 GPU時間での成功を示した。この研究は、RLトレーニングの予測可能性を向上させるための科学的フレームワークを提供する。 Comment
元ポスト:
> 簡単になったプロンプト(プロンプトの通過率が0.9以上)は再サンプリングしたほうが最終性能が高い
最近はカリキュラムラーニングを導入して、簡単すぎず難しすぎない問題をサンプリングして効率上げる、といったような話があったが、簡単になった問題をリサンプリングしないと最終性能としては低くなる可能性があるのか…意外だった。
著者ポスト:
ポイント解説:
[Paper Note] GVPO: Group Variance Policy Optimization for Large Language Model Post-Training, Kaichen Zhang+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#ReinforcementLearning #NeurIPS #PostTraining #Stability Issue Date: 2025-10-16 GPT Summary- GVPO(グループ分散ポリシー最適化)は、ポストトレーニングにおける不安定性を解決する新手法で、KL制約付き報酬最大化の解析的解を勾配重みに組み込むことで最適ポリシーとの整合性を保つ。これにより、ユニークな最適解を保証し、柔軟なサンプリング分布をサポート。GVPOは信頼性の高いLLMポストトレーニングの新たなパラダイムを提供する。 Comment
元ポスト:
ベースライン:
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open
Language Models, Zhihong Shao+, arXiv'24
- [Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
[Paper Note] Representation-Based Exploration for Language Models: From Test-Time to Post-Training, Jens Tuyls+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #ReinforcementLearning #Test-Time Scaling #PostTraining #Diversity Issue Date: 2025-10-16 GPT Summary- 強化学習(RL)が言語モデルの行動発見に与える影響を調査。事前学習されたモデルの隠れ状態を基にした表現ベースのボーナスを用いることで、多様性とpass@k率が大幅に改善されることを発見。推論時における探索が効率を向上させ、ポストトレーニングにおいてもRLパイプラインとの統合により性能が向上。意図的な探索が新しい行動の発見に寄与する可能性を示唆。 Comment
元ポスト:
探索の多様性をあげてRLこ学習効率、test time scalingの効率を上げるという話
[Paper Note] Is It Thinking or Cheating? Detecting Implicit Reward Hacking by Measuring Reasoning Effort, Xinpeng Wang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Reasoning #RewardHacking Issue Date: 2025-10-16 GPT Summary- 報酬ハッキングは、モデルが報酬関数の抜け穴を利用して意図されたタスクを解決せずに高い報酬を得る行為であり、重大な脅威をもたらす。TRACE(Truncated Reasoning AUC Evaluation)を提案し、暗黙的な報酬ハッキングを検出する。TRACEは、モデルの推論が報酬を得るのにかかる時間を測定し、ハッキングモデルが短いCoTで高い期待報酬を得ることを示す。TRACEは、数学的推論で72B CoTモニターに対して65%以上、コーディングで32Bモニターに対して30%以上の性能向上を達成し、未知の抜け穴を発見する能力も示す。これにより、現在の監視方法が効果的でない場合に対するスケーラブルな無監視アプローチを提供する。 Comment
元ポスト:
[Paper Note] Expert-as-a-Service: Towards Efficient, Scalable, and Robust Large-scale MoE Serving, Ziming Liu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LLMServing #MoE(Mixture-of-Experts) #SoftwareEngineering Issue Date: 2025-10-16 GPT Summary- EaaSという新しいサービングシステムを提案し、Mixture-of-Experts (MoE)モデルの効率的でスケーラブルな展開を実現。MoEモジュールを独立したステートレスサービスに分解し、リソースの細かいスケーリングとフォールトトレランスを提供。実験により、EaaSはモノリシックシステムと同等のパフォーマンスを維持しつつ、スループットの減少を2%未満に抑え、最大37.5%の計算リソースを節約することが確認された。 Comment
元ポスト:
[Paper Note] Cautious Weight Decay, Lizhang Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #Transformer #Optimizer Issue Date: 2025-10-16 GPT Summary- Cautious Weight Decay(CWD)は、オプティマイザに依存しない修正で、更新と符号が一致するパラメータにのみウェイト減衰を適用します。これにより、元の損失を保持しつつ、局所的なパレート最適点を探索可能にします。CWDは、既存のオプティマイザに簡単に適用でき、新たなハイパーパラメータを必要とせず、言語モデルの事前学習やImageNet分類で損失と精度を向上させます。 Comment
元ポスト:
[Paper Note] LightReasoner: Can Small Language Models Teach Large Language Models Reasoning?, Jingyuan Wang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Reasoning #SmallModel Issue Date: 2025-10-16 GPT Summary- LightReasonerは、SLMがLLMの強みを活かして高価値の推論を明らかにする新しいフレームワーク。重要な推論瞬間を特定し、専門家モデルを調整する2段階のプロセスを経て、数学的ベンチマークで精度を最大28.1%向上、時間消費を90%削減、サンプリング問題を80%減少させた。リソース効率の良いアプローチで、真のラベルに依存せずにLLMの推論を進展させる。 Comment
元ポスト:
[Paper Note] Learning to Make MISTAKEs: Modeling Incorrect Student Thinking And Key Errors, Alexis Ross+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #EducationalDataMining #Supervised-FineTuning (SFT) #SyntheticData #Reasoning #Label-free Issue Date: 2025-10-16 GPT Summary- 新手法MISTAKEを提案し、不正確な推論パターンをモデル化。サイクル整合性を利用して高品質な推論エラーを合成し、教育タスクでの学生シミュレーションや誤解分類において高精度を達成。専門家の選択肢との整合性も向上。 Comment
元ポスト:
[Paper Note] SimulatorArena: Are User Simulators Reliable Proxies for Multi-Turn Evaluation of AI Assistants?, Yao Dou+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #UserModeling #UserBased #Evaluation #Conversation #EMNLP #One-Line Notes Issue Date: 2025-10-16 GPT Summary- SimulatorArenaを導入し、909件の人間-LLM会話を用いて、数学指導と文書作成の2つのタスクにおけるシミュレーターの評価を行う。シミュレーターのメッセージが人間の行動と一致する度合いや、アシスタント評価が人間の判断と整合する度合いを基に評価。条件付けされたシミュレーターが人間の判断と高い相関を示し、実用的な代替手段を提供。最新の18のLLMをベンチマーク。 Comment
元ポスト:
マルチターンの会話においてAIと人間との対話(数学のtutoring, 文書の作成支援)を評価する際に、実際の人間はコストがかかりスケールしないのでLLMを人間の代替とし評価ができるか?どのようにすればLLMを人間の振る舞いと整合させられるか?といった話しで、25種類以上のattributeによるユーザプロファイルを用いることが有効だった(人間の評価結果に対して、ユーザプロファイルを用いたLLMシミュレーターがより高い相関を示した)というような話しらしい。
[Paper Note] Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models, Junhyuck Kim+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Quantization #Reasoning #Test-Time Scaling #One-Line Notes #MemoryOptimization Issue Date: 2025-10-15 GPT Summary- 4ビット量子化はメモリ最適化に有効ですが、推論モデルには適用できないことを示す。体系的な実験により、モデルサイズとKVキャッシュの影響を発見。小規模モデルは重みを優先し、大規模モデルは生成にメモリを割り当てることで精度を向上。LLMのメモリ最適化はスケールに依存し、異なるアプローチが必要であることを示唆。 Comment
元ポスト:
Reasoning Modelにおいて、メモリのbudgetに制約がある状況下において、
- モデルサイズ
- 重みの精度
- test-time compute (serial & parallel)
- KV Cacheの圧縮
において、それらをどのように配分することでモデルのAcc.が最大化されるか?という話しな模様。
[Paper Note] Encode, Think, Decode: Scaling test-time reasoning with recursive latent thoughts, Yeskendir Koishekenov+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #mid-training #read-later #LatentReasoning #RecurrentModels #RecursiveModels #Author Thread-Post Issue Date: 2025-10-15 GPT Summary- ETD手法を用いて、LLMの推論能力を向上させる。特定の層を反復することで、17の推論ベンチマークで大幅な精度向上を達成。GSM8Kで28.4%、MATHで36%の向上を示し、再帰的な推論が効果的であることを確認。 Comment
元ポスト:
[Paper Note] EVALUESTEER: Measuring Reward Model Steerability Towards Values and Preferences, Kshitish Ghate+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Alignment #Evaluation #One-Line Notes Issue Date: 2025-10-15 GPT Summary- EVALUESTEERは、ユーザーの多様な価値観やスタイルに対応するためのベンチマークであり、LLMsと報酬モデル(RMs)の操縦性を測定します。165,888の好みペアを生成し、ユーザーのプロファイルに基づく応答の選択精度を評価。完全なプロファイルでは75%未満の精度に対し、関連する好みのみで99%以上の精度を達成。EVALUESTEERは、RMsの限界を明らかにし、多様な価値観に対応するためのテストベッドを提供します。 Comment
元ポスト:
LLNのAlignmentはしばしばReward Modelをベースに実施されるが、現在のReward Modelに存在する、価値観(4種類)とスタイル(4種類)に関するバイアスが存在することを明らかにしている模様。
[Paper Note] Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training, Junlin Han+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pretraining #NLP #Dataset #Evaluation #MultiModal #Reasoning #read-later #DataMixture #VisionLanguageModel Issue Date: 2025-10-15 GPT Summary- 大規模言語モデル(LLMs)は、テキストのみで訓練されながらも視覚的先入観を発展させ、少量のマルチモーダルデータで視覚タスクを実行可能にする。視覚的先入観は、言語の事前訓練中に獲得された知識であり、推論中心のデータから発展する。知覚の先入観は広範なコーパスから得られ、視覚エンコーダーに敏感である。視覚を意識したLLMの事前訓練のためのデータ中心のレシピを提案し、500,000 GPU時間をかけた実験に基づく完全なMLLM構築パイプラインを示す。これにより、視覚的先入観を育成する新しい方法を提供し、次世代のマルチモーダルLLMの発展に寄与する。 Comment
元ポスト:
MLE Bench (Multi-Level Existence Bench)
[Paper Note] The Potential of Second-Order Optimization for LLMs: A Study with Full Gauss-Newton, Natalie Abreu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Optimizer Issue Date: 2025-10-15 GPT Summary- LLMの事前学習における計算効率向上のため、フルガウス-ニュートン(GN)前処理を最大150Mパラメータのトランスフォーマーモデルに適用。実験により、GN更新がトレーニングの反復回数を5.4倍削減し、層間情報を無視した層別GN前処理器がフルGNに近い性能を示すことが判明。これにより、GN近似の効果や層別ヘッセ行列の情報の重要性、近似手法と理想的な層別オラクルとの性能ギャップが明らかになった。 Comment
元ポスト:
[Paper Note] A Necessary Step toward Faithfulness: Measuring and Improving Consistency in Free-Text Explanations, Lingjun Zhao+, EMNLP'25, 2025.05
Paper/Blog Link My Issue
#NLP #Explanation #Faithfulness #EMNLP #Trustfulness Issue Date: 2025-10-15 GPT Summary- 本論文では、AI意思決定における自由形式の説明の信頼性を測定するために、予測-説明整合性の新しい測定方法を提案。大規模言語モデルによる説明の62%以上が整合性を欠いていることを示し、最適化により整合性が43.1%から292.3%改善されることを確認。また、整合性の最適化により説明の信頼性が最大9.7%向上することを示した。 Comment
元ポスト:
Hal Daume氏がlast author
[Paper Note] Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers, Wenhan Ma+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #MoE(Mixture-of-Experts) #PostTraining #Stability #One-Line Notes Issue Date: 2025-10-14 GPT Summary- 強化学習(RL)を用いたMixture-of-Experts(MoE)モデルのトレーニングと推論の不一致を分析し、Rollout Routing Replay(R3)を提案。R3は推論時のルーティング分布を記録し、トレーニング中に再生することで、トレーニングと推論のポリシー間のKLダイバージェンスを減少させ、安定性を向上。実験により、R3がRLトレーニングの崩壊を防ぎ、他の手法を上回る性能を示した。 Comment
元ポスト:
- Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
のMoE版の話。Inference EngineとTraining Engine側でExpertsの選択が一致しないことが不安定につながるので、それを一致させるようにする、という話な模様。
[Paper Note] QeRL: Beyond Efficiency -- Quantization-enhanced Reinforcement Learning for LLMs, Wei Huang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Quantization #PEFT(Adaptor/LoRA) #Entropy Issue Date: 2025-10-14 GPT Summary- QeRLは、LLMs向けの量子化強化学習フレームワークで、NVFP4量子化とLoRAを組み合わせてRLのロールアウトを加速し、メモリ使用量を削減します。量子化ノイズがポリシーエントロピーを増加させ、探索を強化することを示し、AQNメカニズムでノイズを動的に調整します。実験により、ロールアウトフェーズで1.5倍のスピードアップを達成し、32B LLMのRLトレーニングを単一のH100 80GB GPUで可能にしました。QeRLは、報酬の成長と最終精度で優れた結果を示し、LLMsにおけるRLトレーニングの効率的なフレームワークとしての地位を確立しました。 Comment
pj page: https://github.com/NVlabs/QeRL
元ポスト:
- Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
のようなロールアウトする際のエンジンと学習のエンジンのgapによる問題は生じたりしないのだろうか。
解説:
[Paper Note] Demystifying Reinforcement Learning in Agentic Reasoning, Zhaochen Yu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #AIAgents #Reasoning #Entropy Issue Date: 2025-10-14 GPT Summary- エージェント的強化学習(agentic RL)を用いて、LLMsの推論能力を向上させるための調査を行った。重要な洞察として、合成軌道の実際のツール使用軌道への置き換えや、多様なデータセットの活用がRLのパフォーマンスを向上させることが示された。また、探索を促進する技術や、ツール呼び出しを減らす戦略がトレーニング効率を改善することが確認された。これにより、小型モデルでも強力な結果を達成し、実用的なベースラインを提供する。さらに、高品質なデータセットを用いて、困難なベンチマークでのエージェント的推論能力の向上を示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Part II: ROLL Flash -- Accelerating RLVR and Agentic Training with Asynchrony, Han Lu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #ReinforcementLearning #RLVR #Asynchronous Issue Date: 2025-10-14 GPT Summary- 非同期RL後処理をサポートする「ROLL Flash」を提案。細粒度の並列性とロールアウト・トレインのデカップリングに基づき、効率的なトレーニングアーキテクチャを実現。ROLL Flashはリソース利用効率とスケーラビリティを大幅に改善し、RLVRタスクで最大2.24倍、エージェントタスクで最大2.72倍のスピードアップを達成。非同期トレーニングが同期トレーニングと同等のパフォーマンスを示すことを確認。 Comment
元ポスト:
RLのロールアウト中のGPUのアイドルタイムを削減します系の話も最近結構見るような
たとえば
- Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10
[Paper Note] Agent Learning via Early Experience, Kai Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #Self-SupervisedLearning #SelfCorrection #mid-training #Selected Papers/Blogs #WorldModels #KeyPoint Notes #Author Thread-Post Issue Date: 2025-10-14 GPT Summary- 言語エージェントの目標は、経験を通じて学び、複雑なタスクで人間を上回ることですが、強化学習には報酬の欠如や非効率的なロールアウトが課題です。これに対処するため、エージェント自身の行動から生成された相互作用データを用いる「早期経験」という新たなパラダイムを提案します。このデータを基に、(1) 暗黙の世界モデル化と(2) 自己反省の2つの戦略を研究し、8つの環境で評価を行った結果、効果性と一般化が向上することを示しました。早期経験は、強化学習の基盤を提供し、模倣学習と経験駆動エージェントの橋渡しとなる可能性があります。 Comment
元ポスト:
LLM AgentのためのWarmup手法を提案している。具体的にはRLVRやImitation LearningによってRewardが定義できるデータに基づいてこれまではRLが実現されてきたが、これらはスケールせず、Rewardが定義されない環境のtrajectoryなどは学習されないので汎化性能が低いという課題がある。このため、これらのsupervisionつきの方法で学習をする前のwarmup手法として、reward-freeの学習パラダイム Early Experienceを提案している。
手法としてはシンプルな手法が2種類提案されている。
### Implicit World Modeling (IWM, 式(3)):
ある状態s_i において action a_i^{j}を (1 < j < |K|)をとった時の状態をs_i^{j}としたときに、(s_i, a_i^{j}, s_i^{j}) の3つ組を考える。これらはポリシーからのK回のrolloutによって生成可能。
このときに、状態sを全てテキストで表現するようにし、言語モデルのnext-token-prediction lossを用いて、ある状態s_jにおいてaction a_i^{k} をとったときに、s_j^{k} になることを予測できるように学習する。これにより例えばブックフライトのサイトで誤った日時を入れてしまった場合や、どこかをクリックしたときにどこに遷移するかなどの学習する環境の世界知識をimplicitにモデルに組み込むことができる。
### Self-Reflection(式4)
もう一つのパラダイムとして、専門家によるアクション a_i によって得られた状態 s_i と、それら以外のアクション a_i^{j} によって得られた状態 s_i^{j}が与えられたときに、s_iとs_i^{j}を比較したときに、なぜ a_i の方がa_i^{j} よりも好ましいかを説明するCoT C_i^{j}を生成し、三つ組データ(s_i, a_i^{j}, c_i^{j}) を構築する。このデータを用いて、状態s_iがgivenなときに、a_i に c_i^{j} をconcatしたテキストを予測できるようにnext-token-prediction lossで学習する。また、このデータだけでなく汎化性能をより高めるためにexpertによるimitation learningのためのデータCoTなしのデータもmixして学習をする。これにより、expertによるactionだけで学習するよりも、なぜexpertのアクションが良いかという情報に基づいてより豊富で転移可能な学習シグナルを活用し学習することができる。
この結果、downstreamタスクでのperformanceが単にImitation Learningを実施した場合と比較して提案手法でwarmupした方が一貫して向上する。また、5.4節にpost-trainingとして追加でGRPOを実施した場合も提案手法によるwarmupを実施した場合が最終的な性能が向上することが報告されている。
IWMは自己教師あり学習の枠組みだと思われるので、よぬスケールし、かつ汎化性能が高く様々な手法のベースとなりうる手法に見える。
著者ポスト:
[Paper Note] Don't Waste Mistakes: Leveraging Negative RL-Groups via Confidence Reweighting, Yunzhen Feng+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #On-Policy Issue Date: 2025-10-14 GPT Summary- 強化学習におけるネガティブグループを活用する新手法LENSを提案。信頼度に基づくペナルティを追加し、誤った応答に対しても報酬を与えることで、無駄なサンプルを有用な勾配更新に変換。MATHベンチマークでGRPOを上回る性能を示し、RLVRの効率と性能向上に寄与。 Comment
元ポスト:
DAPOなどのdynamic samplingは全ての応答がnegativeなグループは破棄するが、それらも活用して学習できるような枠組みな模様
[Paper Note] Next Semantic Scale Prediction via Hierarchical Diffusion Language Models, Cai Zhou+, NeurIPS'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #NLP #DiffusionModel #NeurIPS Issue Date: 2025-10-14 GPT Summary- 階層的拡散言語モデル(HDLM)は、低レベルのトークンが高レベルのトークンにマッピングされる階層的な語彙に基づく新しい言語モデリング手法です。前方プロセスではトークンが高レベルの先祖に摂動され、逆プロセスでは詳細な意味を予測します。HDLMは、拡散の証拠下限(ELBO)の閉形式表現を導出し、既存のモデルを含む柔軟な実装が可能であることを示します。実験により、HDLMはベースラインよりも低い困惑度を達成し、その有効性が確認されました。 Comment
元ポスト:
[Paper Note] Multimodal Prompt Optimization: Why Not Leverage Multiple Modalities for MLLMs, Yumin Choi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Prompting #MultiModal #AutomaticPromptEngineering Issue Date: 2025-10-14 GPT Summary- マルチモーダルプロンプト最適化(MPO)を提案し、テキストと非テキストのプロンプトを共同最適化する新たなアプローチを示す。MPOは、ベイズに基づく選択戦略を用いて候補プロンプトを選定し、画像や動画など多様なモダリティにおいてテキスト専用手法を上回る性能を発揮。これにより、MLLMsの潜在能力を最大限に引き出す重要なステップを確立。 Comment
元ポスト:
[Paper Note] Verifying Chain-of-Thought Reasoning via Its Computational Graph, Zheng Zhao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Reasoning #read-later #Selected Papers/Blogs #Verification #One-Line Notes #Author Thread-Post Issue Date: 2025-10-14 GPT Summary- Circuit-based Reasoning Verification (CRV)を提案し、CoTステップの帰属グラフを用いて推論エラーを検証。エラーの構造的署名が予測的であり、異なる推論タスクで異なる計算パターンが現れることを示す。これにより、モデルの誤った推論を修正する新たなアプローチを提供し、LLM推論の因果理解を深めることを目指す。 Comment
元ポスト:
著者ポスト:
transformer内部のactivationなどから計算グラフを構築しreasoningのsurface(=観測できるトークン列)ではなく内部状態からCoTをverification(=CoTのエラーを検知する)するようなアプローチ(white box method)らしい
[Paper Note] dInfer: An Efficient Inference Framework for Diffusion Language Models, Yuxin Ma+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #LLMServing #read-later #Selected Papers/Blogs Issue Date: 2025-10-14 GPT Summary- dLLMの推論を効率化するフレームワークdInferを提案。dInferは4つのモジュールに分解され、新しいアルゴリズムと最適化を統合。これにより、出力品質を維持しつつ、推論速度を大幅に向上。HumanEvalで1秒あたり1,100トークンを超え、従来のシステムに比べて10倍のスピードアップを実現。dInferはオープンソースで公開。 Comment
code: https://github.com/inclusionAI/dInfer
とうとうdLLMを高速でinferenceできるフレームワークが出た模様。inclusionAIより。
ポイント解説:
[Paper Note] Rethinking Entropy Regularization in Large Reasoning Models, Yuxian Jiang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #RLVR #Entropy Issue Date: 2025-10-13 GPT Summary- RLVRはLRMの推論能力を向上させるが、エントロピーの崩壊と早期収束の問題に直面している。これに対処するため、SIREN(選択的エントロピー正則化)を提案し、探索を意味のある行動と状態のサブセットに制限する二段階のエントロピーマスキングメカニズムを導入。SIRENは数学的ベンチマークで優れたパフォーマンスを示し、トレーニングの安定性を高め、早期収束の問題を軽減することが確認された。 Comment
元ポスト:
[Paper Note] BigCodeArena: Unveiling More Reliable Human Preferences in Code Generation via Execution, Terry Yue Zhuo+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #UserBased #Alignment #Evaluation #Coding #read-later #Selected Papers/Blogs Issue Date: 2025-10-13 GPT Summary- BigCodeArenaは、LLMが生成したコードの質をリアルタイムで評価するためのクラウドソーシングプラットフォームで、Chatbot Arenaを基盤に構築されています。14,000以上のコード中心の会話セッションから4,700のマルチターンサンプルを収集し、人間の好みを明らかにしました。これに基づき、LLMのコード理解と生成能力を評価するためのBigCodeRewardとAutoCodeArenaという2つのベンチマークを策定しました。評価の結果、実行結果が利用可能な場合、ほとんどのLLMが優れたパフォーマンスを示し、特にGPT-5やClaudeシリーズがコード生成性能でリードしていることが確認されました。 Comment
元ポスト:
良さそう
[Paper Note] ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory, Matthew Ho+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#MachineLearning #NLP #Abstractive #Reasoning #Generalization #memory #One-Line Notes #Test-time Learning Issue Date: 2025-10-13 GPT Summary- LLMは推論時に外部メモリを活用し、概念レベルのメモリを導入することで、再利用可能でスケーラブルな知識の保存を実現。これにより、関連する概念を選択的に取得し、テスト時の継続的学習を可能にする。評価はARC-AGIベンチマークで行い、メモリなしのベースラインに対して7.5%の性能向上を達成。動的なメモリ更新が自己改善を促進することを示唆。 Comment
元ポスト:
ARC-AGIでしか評価されていないように見える。
[Paper Note] Inoculation Prompting: Instructing LLMs to misbehave at train-time improves test-time alignment, Nevan Wichers+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #Safety #InoculationPrompting Issue Date: 2025-10-13 GPT Summary- Inoculation Prompting(IP)を提案し、望ましくない行動を明示的に要求することでその学習を防ぐ手法を紹介。IPはファインチューニング中に望ましくない行動の学習を減少させ、望ましい能力の学習には大きな影響を与えない。特に、望ましくない行動を引き出すプロンプトが効果的であることを示し、モデルの一般化を制御するシンプルで効果的な方法であることを確認。 Comment
元ポスト:
関連:
- [Paper Note] Large Reasoning Models Learn Better Alignment from Flawed Thinking, ShengYun Peng+, arXiv'25, 2025.10
上記研究とどういった点が異なるだろうか。
Inoculation Promptingは望ましくない行動を明示的に指示して要求するのに対し、こちらの研究は望ましくない行動が起きたときにそれを訂正する能力を身につけさせるという話なので、かなり違う話に見える。
[Paper Note] DeepPrune: Parallel Scaling without Inter-trace Redundancy, Shangqing Tu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Pruning #Test-Time Scaling #Decoding #Parallel Issue Date: 2025-10-12 GPT Summary- DeepPruneという新しいフレームワークを提案し、並列スケーリングの計算非効率を解決。80%以上の推論トレースが同一の回答を生成する問題に対処し、焦点損失とオーバーサンプリング技術を用いた判定モデルで同等性を予測。オンラインの貪欲クラスタリングで冗長な経路をプルーニングし、80%以上のトークン削減を達成しつつ、精度を維持。効率的な並列推論の新基準を確立。 Comment
pj page: https://deepprune.github.io
HF: https://huggingface.co/collections/THU-KEG/deepprune-68e5c1ea71f789a6719b2c1c
元ポスト:
[Paper Note] General-Reasoner: Advancing LLM Reasoning Across All Domains, Xueguang Ma+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #NeurIPS #mid-training #PostTraining #GenerativeVerifier Issue Date: 2025-10-12 GPT Summary- 強化学習を用いた新しいトレーニングパラダイム「General-Reasoner」を提案し、LLMの推論能力を向上させる。大規模な高品質データセットを構築し、生成モデルベースの回答検証器を開発。物理学や化学などの多様な分野で評価し、既存手法を上回る性能を示す。 Comment
元ポスト:
[Paper Note] Webscale-RL: Automated Data Pipeline for Scaling RL Data to Pretraining Levels, Zhepeng Cen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #mid-training #PostTraining Issue Date: 2025-10-12 GPT Summary- Webscale-RLパイプラインを導入し、大規模な事前学習文書から数百万の多様な質問-回答ペアを生成。これにより、120万の例を含むWebscale-RLデータセットを構築。実験結果、RLトレーニングは継続的な事前トレーニングよりも効率的で、パフォーマンスを大幅に向上させることを示した。研究は、RLを事前学習レベルにスケールアップする道筋を示し、より高性能な言語モデルの実現を可能にする。 Comment
元ポスト:
Dataset: https://huggingface.co/datasets/Salesforce/Webscale-RL
以下の研究が関連研究でNeurIPSですでに発表されているが引用も議論もされていないという指摘がある:
- [Paper Note] General-Reasoner: Advancing LLM Reasoning Across All Domains, Xueguang Ma+, arXiv'25, 2025.05
他にも似たようなモチベーションの研究を見たことがあるような…
[Paper Note] Flipping the Dialogue: Training and Evaluating User Language Models, Tarek Naous+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #UserModeling #UserBased #Evaluation #Conversation #Robustness Issue Date: 2025-10-12 GPT Summary- LMとの会話には人間のユーザーとLMアシスタントが参加し、LMは構造化された応答を生成するよう最適化されている。しかし、ユーザーの発話は完璧ではなく、従来の研究ではアシスタントLMがユーザーをシミュレートすることが試みられたが、効果的ではないことが示された。そこで、目的特化型ユーザー言語モデル(User LMs)を導入し、これが人間の行動とより一致し、シミュレーションの堅牢性を向上させることを示した。User LMsを用いたコーディングや数学の会話シミュレーションでは、強力なアシスタントのパフォーマンスが低下し、現実的なシミュレーション環境がアシスタントの苦戦を引き起こすことが確認された。 Comment
HF: https://huggingface.co/microsoft/UserLM-8b
元ポスト:
興味深い
所見:
[Paper Note] GUIDE: Towards Scalable Advising for Research Ideas, Yaowenqi Liu+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #ScientificDiscovery #read-later #IdeaGeneration #One-Line Notes Issue Date: 2025-10-12 GPT Summary- AI研究の進展に伴い、自動化された仮説生成や実験設計が可能になっているが、高品質なフィードバックを提供するアドバイジングシステムには依然として課題がある。本研究では、モデルのサイズや信頼度の推定など、効果的なアドバイジングシステムの要因を探求し、比較的小さなモデルが圧縮された文献データベースと構造化された推論フレームワークを用いることで、強力な言語モデルを上回る受理率を達成できることを示した。特に、高信頼度の予測において90%以上の受理率を達成し、仮説生成と実験設計の質を向上させる可能性を示唆している。 Comment
pj page: https://howardliu0830.github.io/GUIDE_blog/
元ポスト:
どのように評価したのだろうか
pj pageによると、ICMLのsubmissionのうちランダムな1000件を用いて、モデルにpaperをスコアリングさせる。そして、モデルがスコアリングした中で上位5%(spotlightの割合に相当)、30%のprecision(実際のacceptanceの閾値相当の割合)と、モデルがスコアリングした上位30パーセントの論文の現代のAcceptanceに対するRecallを求めて評価している模様。7Bモデルでより大きいモデルと同等程度の性能を示している。
手法は後ほど追記したいが、Acceptを予測ふるタスクは論文に対して適切なフィードバックできることに直接的には繋がらないのでは?と思い、inferenceのpromptを見てみると、LLMにabst, contribution, method, experimental setupを入力し、実際の査読と似たような評価をさせ、その結果に基づいてratingをpredictionするような形式に見える。このため、rating predictionの過程で評価結果のフィードバックが生成されるので、論文の改善ができる、というユースケースだと思われる。
[Paper Note] Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models, Qizheng Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #AIAgents #ContextEngineering Issue Date: 2025-10-11 GPT Summary- ACEフレームワークは、適応メモリに基づき、コンテキストを進化するプレイブックとして扱い、生成、反省、キュレーションを通じて戦略を洗練します。これにより、詳細な知識を保持し、コンテキスト崩壊を防ぎます。ACEはエージェントやドメイン特化型ベンチマークで優れた性能を発揮し、適応のレイテンシとコストを削減。特に、ラベルなしで効果的に適応し、自然なフィードバックを活用する点が特徴です。全体の平均でトップランクのエージェントに匹敵し、より難しいテストでも優れた結果を示しました。 Comment
元ポスト:
ポイント解説:
解説:
[Paper Note] MemMamba: Rethinking Memory Patterns in State Space Model, Youjin Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LongSequence #SSM (StateSpaceModel) #memory Issue Date: 2025-10-11 GPT Summary- データの増加に伴い、長シーケンスモデリングが重要になる中、既存手法は効率とメモリのトレードオフに直面している。Mambaの選択的状態空間モデルは高効率だが、長期メモリが減衰する。本研究では、Mambaのメモリ減衰メカニズムを分析し、情報損失を定量化する指標を導入。新たに提案するMemMambaは、状態要約メカニズムと注意を統合し、長期的な忘却を軽減しつつ計算量を維持。MemMambaは、長シーケンスベンチマークで大幅な改善を達成し、推論効率を48%向上させることを示した。 Comment
元ポスト:
[Paper Note] Improving Context Fidelity via Native Retrieval-Augmented Reasoning, Suyuchen Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Fidelity Issue Date: 2025-10-10 GPT Summary- CAREという新しいフレームワークを提案し、LLMsが自らの検索能力を用いて文脈における証拠を統合することで、一貫性のある回答を生成。限られたラベル付きデータで検索精度と回答生成性能を向上させ、実験により従来手法を大幅に上回ることを示した。 Comment
元ポスト:
[Paper Note] Artificial Hippocampus Networks for Efficient Long-Context Modeling, Yunhao Fang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LongSequence #memory #RecurrentModels Issue Date: 2025-10-10 GPT Summary- 長大なシーケンスモデリングにおけるメモリのトレードオフを解決するため、人工海馬ネットワーク(AHN)を提案。AHNは短期メモリを維持しつつ、長期メモリを圧縮。実験により、AHNを用いたモデルが従来のベースラインを上回り、計算とメモリ要件を大幅に削減しつつ、パフォーマンスを向上させることを示した。 Comment
元ポスト:
所見:
[Paper Note] The Markovian Thinker, Milad Aghajohari+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #read-later #Selected Papers/Blogs Issue Date: 2025-10-09 GPT Summary- 強化学習を用いて長い思考の連鎖を生成するための新しいパラダイム「マルコフ的思考」を提案。これにより、状態を一定のサイズに制限し、思考の長さをコンテキストのサイズから切り離すことで、線形計算を実現。新しいRL環境「Delethink」を構築し、モデルは短い持ち越しで推論を継続することを学習。訓練されたモデルは、長い推論を効率的に行い、コストを大幅に削減。思考環境の再設計が、効率的でスケーラブルな推論LLMの実現に寄与することを示した。 Comment
元ポスト:
ポイント解説:
解説:
[Paper Note] Less is More: Recursive Reasoning with Tiny Networks, Alexia Jolicoeur-Martineau, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #SmallModel #Selected Papers/Blogs #LatentReasoning #RecursiveModels Issue Date: 2025-10-09 GPT Summary- 階層的推論モデル(HRM)は、2つの小さなニューラルネットワークを用いた新しいアプローチで、数独や迷路などのパズルタスクで大規模言語モデル(LLMs)を上回る性能を示す。しかし、HRMは最適ではない可能性があるため、我々はTiny Recursive Model(TRM)を提案。TRMはよりシンプルで高い一般化能力を持ち、700万パラメータでARC-AGI-1で45%、ARC-AGI-2で8%の精度を達成し、ほとんどのLLMを上回る性能を示した。 Comment
元ポスト:
所見:
ポイント解説:
ARC-AGI公式による検証が終わり報告されている結果が信頼できることが確認された模様:
続報:
Sudoku Benchでも性能改善する模様?
[Paper Note] GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks, Tejal Patwardhan+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Selected Papers/Blogs Issue Date: 2025-10-09 GPT Summary- GDPvalは、AIモデルの経済的価値のあるタスクを評価するベンチマークで、米国GDPに寄与する44の職業をカバー。最前線モデルのパフォーマンスは時間と共に改善し、業界専門家に近づいている。人間の監視を加えたモデルは、無援助の専門家よりも効率的にタスクを実行可能であることを示唆。推論努力やタスクコンテキストの増加がモデルの性能向上に寄与。220のタスクのゴールドサブセットをオープンソース化し、研究促進のための自動採点サービスを提供。 Comment
元ポスト:
[Paper Note] Scaling Generalist Data-Analytic Agents, Shuofei Qiao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #TabularData #SyntheticData #ScientificDiscovery #numeric #MajorityVoting Issue Date: 2025-10-09 GPT Summary- DataMindは、オープンソースのデータ分析エージェントを構築するためのスケーラブルなデータ合成とエージェントトレーニングの手法を提案。主な課題であるデータリソース、トレーニング戦略、マルチターンロールアウトの不安定性に対処し、合成クエリの多様性を高めるタスク分類や、動的なトレーニング目標を採用。DataMind-12Kという高品質なデータセットを作成し、DataMind-14Bはデータ分析ベンチマークで71.16%のスコアを達成し、最先端のプロプライエタリモデルを上回った。DataMind-7Bも68.10%でオープンソースモデル中最高のパフォーマンスを示した。今後、これらのモデルをコミュニティに公開予定。 Comment
元ポスト:
7B程度のSLMで70B級のモデルと同等以上の性能に到達しているように見える。論文中のp.2にコンパクトに内容がまとまっている。
[Paper Note] In-the-Flow Agentic System Optimization for Effective Planning and Tool Use, Zhuofeng Li+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #On-Policy Issue Date: 2025-10-09 GPT Summary- AgentFlowは、4つのモジュール(プランナー、エグゼキューター、バリファイア、ジェネレーター)を調整し、マルチターン環境でプランナーを最適化する強化学習フレームワーク。Flow-GRPOを用いて、長いホライズンのスパースリワード問題に対処し、精度を向上。10のベンチマークで、7BスケールのAgentFlowは、検索、エージェンティック、数学、科学タスクでそれぞれ14.9%、14.0%、14.5%、4.1%の精度向上を達成し、GPT-4oを上回る性能を示した。 Comment
元ポスト: https://agentflow.stanford.edu
pj page: https://agentflow.stanford.edu
モデルサイズと推論ターンに対するスケーリング特性
似たような話が以下の研究にもある
- [Paper Note] The Illusion of Diminishing Returns: Measuring Long Horizon Execution in
LLMs, Akshit Sinha+, arXiv'25
ポイント解説:
ポイント解説:
[Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
Paper/Blog Link My Issue
#Embeddings #EfficiencyImprovement #NLP #RepresentationLearning #RAG(RetrievalAugmentedGeneration) #ICLR #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-08 GPT Summary- 生成的表現指示チューニング(GRIT)を用いて、大規模言語モデルが生成タスクと埋め込みタスクを同時に処理できる手法を提案。GritLM 7BはMTEBで新たな最先端を達成し、GritLM 8x7Bはすべてのオープン生成モデルを上回る性能を示す。GRITは生成データと埋め込みデータの統合による性能損失がなく、RAGを60%以上高速化する利点もある。モデルは公開されている。 Comment
openreview: https://openreview.net/forum?id=BC4lIvfSzv
従来はgemerativeタスクとembeddingタスクは別々にモデリングされていたが、それを統一的な枠組みで実施し、両方のタスクで同等のモデルサイズの他モデルと比較して高い性能を達成した研究。従来のgenerativeタスク用のnext-token-prediction lossとembeddingタスク用のconstastive lossを組み合わせて学習する(式3)。タスクの区別はinstructionにより実施し、embeddingタスクの場合はすべてのトークンのlast hidden stateのmean poolingでrepresentationを取得する。また、embeddingの時はbi-directional attention / generativeタスクの時はcausal maskが適用される。これらのattentionの適用のされ方の違いが、どのように管理されるかはまだしっかり読めていないのでよくわかっていないが、非常に興味深い研究である。
[Paper Note] vAttention: Verified Sparse Attention, Aditya Desai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Attention #Architecture #Sparse #SparseAttention Issue Date: 2025-10-08 GPT Summary- vAttentionは、トップ-$k$とランダムサンプリングを統合した新しいスパースアテンションメカニズムで、ユーザー指定の$(\epsilon, \delta)$保証を提供し、近似精度を向上させる。これにより、スパースアテンションの実用性と信頼性が向上し、フルアテンションと同等の品質を保ちながら、最大20倍のスパース性を実現。推論シナリオでも迅速なデコーディングが可能で、実験により性能の向上が確認された。コードはオープンソースで公開されている。 Comment
元ポスト:
[Paper Note] Muon Outperforms Adam in Tail-End Associative Memory Learning, Shuche Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Optimizer Issue Date: 2025-10-08 GPT Summary- Muonオプティマイザーは、LLMsのトレーニングにおいてAdamよりも高速であり、そのメカニズムを連想記憶の観点から解明。VOアテンションウェイトとFFNがMuonの優位性の要因であり、重い尾を持つデータにおいて尾クラスを効果的に最適化する。Muonは一貫したバランスの取れた学習を実現し、Adamは不均衡を引き起こす可能性がある。これにより、Muonの更新ルールが重い尾を持つ分布における効果的な学習を可能にすることが示された。 Comment
元ポスト:
[Paper Note] Prosperity before Collapse: How Far Can Off-Policy RL Reach with Stale Data on LLMs?, Haizhong Zheng+, COLM'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining #read-later #Off-Policy Issue Date: 2025-10-08 GPT Summary- 強化学習における新しいアプローチM2POを提案。古いデータを効果的に活用し、オンポリシー学習の効率性を向上。M2POは重要度重みの二次モーメントを制約し、外れ値を抑制しつつ安定した最適化を実現。広範な評価により、古いデータでもオンポリシーに匹敵する性能を示した。 Comment
元ポスト:
本当だとしたらすごいが果たして
[Paper Note] G1yphD3c0de: Towards Safer Language Models on Visually Perturbed Texts, Yeo+, COLM'25
Paper/Blog Link My Issue
#NLP #Safety #COLM Issue Date: 2025-10-08 Comment
openreview: https://openreview.net/forum?id=OGwE7LwtcR#discussion
元ポスト:
[Paper Note] X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents, Salman Rahman+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Multi #NLP #Dataset #Evaluation #Conversation #Safety #COLM Issue Date: 2025-10-08 GPT Summary- X-Teamingを提案し、無害なインタラクションが有害な結果にエスカレートする過程を探求。協力的なエージェントを用いて、最大98.1%の成功率でマルチターン攻撃を実現。特に、Claude 3.7 Sonnetモデルに対して96.2%の成功率を達成。さらに、30Kの脱獄を含むオープンソースのトレーニングデータセットXGuard-Trainを導入し、LMのマルチターン安全性を向上させる。 Comment
openreview: https://openreview.net/forum?id=gKfj7Jb1kj#discussion
元ポスト:
[Paper Note] Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL, Mohammadreza Pourreza+, COLM'25, 2025.03
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #COLM #GRPO #On-Policy #TextToSQL Issue Date: 2025-10-08 GPT Summary- Text-to-SQLタスクにおいて、部分的報酬を用いた強化学習(RL)アプローチを提案。スキーマリンクやAIフィードバックなどの報酬を設計し、LLMsの推論スキルを向上させる。RLトレーニングを受けた14Bパラメータモデルは、他のモデルを上回る精度を達成し、提案手法の有効性を示す。 Comment
openreview: https://openreview.net/forum?id=HbwkIDWQgN#discussion
元ポスト:
[Paper Note] D3: A Dataset for Training Code LMs to Act Diff-by-Diff, Piterbarg+, COLM'25
Paper/Blog Link My Issue
#NLP #Dataset #Coding #mid-training #COLM #Editing #One-Line Notes Issue Date: 2025-10-08 Comment
openreview: https://openreview.net/forum?id=sy71y74U80#discussion
openreviewのサマリによると、8B tokens, 850k python filesのデータセットで、コーディングタスクを、ゴールで条件づけられたsequential editsタスクとみなし The Stack上のコードを分析ツールとLLMによって合成されたrationaleによってフィルタリング/拡張したデータを提供しているとのこと。具体的には (state, goal, action_i) の3つ組みのデータセットであり、action_iがaction前後でのdiffになっている模様。D3データセットでSFTの前にLlama 1B / 3Bをmid-trainingした結果、downstreamタスク(コード生成、completion、編集)において性能が向上したとのこと。
[Paper Note] Bayesian scaling laws for in-context learning, Aryaman Arora+, COLM'25, 2024.10
Paper/Blog Link My Issue
#NLP #In-ContextLearning #Safety #Scaling Laws #COLM #read-later #Selected Papers/Blogs Issue Date: 2025-10-08 GPT Summary- インコンテキスト学習(ICL)は、言語モデルに複雑なタスクを実行させる手法であり、提供される例の数と予測精度に強い相関がある。本研究では、ICLがベイズ学習者を近似することを示し、新しいベイズスケーリング法則を提案。GPT-2モデルを用いた実験で、提案法則が精度における既存の法則と一致し、タスクの事前分布や学習効率に関する解釈可能な項を提供。実験では、ICLを用いて抑制されたモデル能力を再現する条件を予測し、LLMの安全性向上に寄与することを示した。 Comment
openreview: https://openreview.net/forum?id=U2ihVSREUb#discussion
元ポスト:
[Paper Note] Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use, Anna Goldie+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Multi #NLP #Dataset #ReinforcementLearning #SyntheticData #COLM #One-Line Notes Issue Date: 2025-10-08 GPT Summary- 段階的強化学習(SWiRL)を提案し、複数のテキスト生成や推論ステップを通じて大規模言語モデルの性能を向上させる手法を紹介。SWiRLは、各アクションに対するサブ軌道を生成し、合成データフィルタリングと強化学習最適化を適用。実験では、GSM8KやHotPotQAなどのタスクでベースラインを上回る精度を達成し、タスク間での一般化も示された。 Comment
openreview: https://openreview.net/forum?id=oN9STRYQVa
元ポスト:
従来のRLではテキスト生成を1ステップとして扱うことが多いが、複雑な推論やtool useを伴うタスクにおいては複数ステップでの最適化が必要となる。そのために、多段階の推論ステップのtrajectoryを含むデータを作成し、同データを使いRLすることによって性能が向上したという話な模様。RLをする際には、stepごとにRewardを用意するようである。また、現在のstepの生成を実施する際には過去のstepの情報に基づいて生成する方式のようである。
[Paper Note] MITS: Enhanced Tree Search Reasoning for LLMs via Pointwise Mutual Information, Jiaxi Li+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Search #Reasoning #Test-Time Scaling #Decoding #TreeSearch Issue Date: 2025-10-08 GPT Summary- 相互情報量ツリー探索(MITS)を提案し、推論経路の評価と探索を効率化。PMIに基づくスコアリング関数を用い、計算コストを抑えつつ優れた推論性能を実現。エントロピーに基づく動的サンプリング戦略でリソースを最適配分し、重み付き投票方式で最終予測を行う。MITSは多様なベンチマークでベースラインを上回る結果を示した。 Comment
元ポスト:
[Paper Note] Magistral, Mistral-AI+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Reasoning #OpenWeight #One-Line Notes Issue Date: 2025-10-07 GPT Summary- Mistralの推論モデルMagistralと独自の強化学習パイプラインを紹介。ゼロからのアプローチで、LLMのRLトレーニングの限界を探り、テキストデータのみでのRLが能力を維持することを示す。Magistral MediumはRLのみで訓練され、Magistral Smallはオープンソース化。 Comment
元ポスト:
関連:
- Magistral-Small-2509, MistralAI, 2025.09
MistralAIの初めてのreasoningモデル
[Paper Note] Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning, Xin Qiu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#MachineLearning #NLP #Finetuning #EvolutionaryAlgorithm Issue Date: 2025-10-07 GPT Summary- 進化戦略(ES)を用いて、事前学習済みの大規模言語モデル(LLMs)の全パラメータをファインチューニングする初の成功事例を報告。ESは数十億のパラメータに対して効率的に探索でき、サンプル効率やロバスト性、パフォーマンスの安定性において既存の強化学習(RL)手法を上回ることを示す。これにより、LLMファインチューニングの新たな方向性が開かれる。 Comment
元ポスト:
続報:
[Paper Note] Test-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts, Jihoon Lee+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #DiffusionModel #Test-Time Scaling #read-later #MajorityVoting #Author Thread-Post Issue Date: 2025-10-07 GPT Summary- dLLMsは異なる生成順序に基づく専門的な挙動を学習するが、固定された推論スケジュールは性能を低下させる。HEXという新手法を導入し、異なるブロックスケジュールでのアンサンブルを行うことで、精度を大幅に向上させる。GSM8KやMATH、ARC-C、TruthfulQAなどのベンチマークで顕著な改善を示し、テスト時スケーリングの新たなパラダイムを確立した。 Comment
元ポスト:
これは気になる👀
著者ポスト:
[Paper Note] Echo Chamber: RL Post-training Amplifies Behaviors Learned in Pretraining, Rosie Zhao+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #ReinforcementLearning #COLM #read-later Issue Date: 2025-10-07 GPT Summary- 強化学習(RL)によるファインチューニングは、数学的推論やコーディングのための言語モデルの性能向上に寄与しているが、そのメカニズムは未解明である。本研究では、オープンなデータセットを用いて、さまざまなスケールのモデルに対するRLファインチューニングの効果を調査し、RLアルゴリズムが出力分布に収束し、事前学習データのパターンを増幅することを明らかにした。また、異なるスケールのモデルが異なる出力分布に収束することや、簡単な質問へのファインチューニングが難しい質問の性能向上に寄与する可能性を示した。これにより、RLの役割に関する新たな洞察が得られた。 Comment
元ポスト:
[Paper Note] Pretraining with hierarchical memories: separating long-tail and common knowledge, Hadi Pouransari+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pretraining #NLP #Transformer #SmallModel #memory Issue Date: 2025-10-07 GPT Summary- 現代の言語モデルはパラメータのスケーリングに依存しているが、すべての世界知識を圧縮するのは非現実的である。これに対処するため、メモリ拡張アーキテクチャを提案し、小型言語モデルが階層的なメモリバンクにアクセスする仕組みを導入。実験により、160Mパラメータのモデルに18Mパラメータのメモリを追加することで、通常のモデルと同等の性能を達成。トランスフォーマーにおけるメモリの最適なタイプとサイズを研究し、提案したメモリが堅牢に機能することを確認。 Comment
元ポスト:
[Paper Note] Router-R1: Teaching LLMs Multi-Round Routing and Aggregation via Reinforcement Learning, Haozhen Zhang+, NeurIPS'25, 2025.06
Paper/Blog Link My Issue
#Multi #ReinforcementLearning #NeurIPS #Routing Issue Date: 2025-10-07 GPT Summary- Router-R1は、複数の大規模言語モデル(LLMs)を効果的にルーティングし集約するための強化学習に基づくフレームワークを提案。内部の熟慮と動的なモデル呼び出しを交互に行い、パフォーマンスとコストのトレードオフを最適化。実験では、一般的なQAベンチマークで強力なベースラインを上回る性能を示し、優れた一般化とコスト管理を実現。 Comment
元ポスト:
ポイント解説:
[Paper Note] Compressed Convolutional Attention: Efficient Attention in a Compressed Latent Space, Tomas Figliolia+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Attention #Architecture Issue Date: 2025-10-07 GPT Summary- Compressed Convolutional Attention(CCA)を提案し、クエリ、キー、バリューをダウンサンプリングして全ての注意操作を共有された潜在空間内で実行。これにより、パラメータ、KVキャッシュ、FLOPを大幅に削減。さらに、CCAとヘッド共有を組み合わせたCompressed Convolutional Grouped Query Attention(CCGQA)は、計算と帯域幅の効率を向上させ、GQAやMLAを上回る性能を示す。実験では、CCGQAがMoEモデルにおいて他の注意メソッドを圧倒し、MHAと比較してもパフォーマンスを維持しつつKVキャッシュを8倍圧縮。H100 GPU上でのトレーニングと事前フィルの速度を大幅に向上。 Comment
元ポスト:
DenseモデルとMoEモデルでAttentionの各種variantの性能が大きく変化する模様。かつ、提案手法はどちらのアーキテクチャでも良い性能を達成する模様(Fig3,4)。
解説:
ポイント解説:
言語モデルの内部機序:解析と解釈, HEINZERLING+, NLP'25, 2025.03
Paper/Blog Link My Issue
#Tutorial #Analysis #NLP #Slide #Selected Papers/Blogs #reading Issue Date: 2025-10-07 Comment
元ポスト:
[Paper Note] Self-Evolving LLMs via Continual Instruction Tuning, Jiazheng Kang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #GenerativeAdversarialNetwork #PEFT(Adaptor/LoRA) #Catastrophic Forgetting #PostTraining #read-later Issue Date: 2025-10-06 GPT Summary- MoE-CLは、産業環境における大規模言語モデルの継続学習を支援するためのフレームワークで、タスクごとのLoRA専門家と共有LoRA専門家を用いて知識の保持とクロスタスクの一般化を実現。敵対的学習により、タスクに関連する情報のみを通過させる識別器を統合し、自己進化を促進。実験結果では、Tencent Videoプラットフォームでの手動レビューコストを15.3%削減し、実用性が示された。 Comment
元ポスト:
continual instruction tuning... そしてGAN!?
タスク固有の知識を備えたLoRAと、タスク間で共有されるLoRAがクロスタスクの転移を促し、それぞれをMoEにおけるexpertsとして扱うことで、inputに対して動的に必要なLoRA expertsを選択する。このとき、Task Classifier(Adversarialに訓練する)でタスクに関係ない情報が順伝搬されないようにフィルタリングするっぽい?(GANをText Classifierの学習に使い、Classifierの情報を用いることで共有/タスク固有のLoRA expertsが学習されるように促すようだが、細かくどうやるかは読まないとわからない)。
ドメイン固有のタスクとデータに対して、さまざまなアダプターを追加していき、catastrophic forgettingを防ぎながら、扱えるタスクの幅が広がっていく枠組み自体は面白そう(学習は果たして安定するのだろうか)。
[Paper Note] Free Draft-and-Verification: Toward Lossless Parallel Decoding for Diffusion Large Language Models, Shutong Wu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #Decoding Issue Date: 2025-10-06 GPT Summary- Diffusion Large Language Models (DLLMs)は、双方向の注意メカニズムにより文脈を捉える能力が高いが、推論効率が自己回帰モデルに劣る。既存の並列デコーディングアルゴリズムは性能低下を伴う。これを解決するために、損失のない並列デコーディングを実現する新しいアルゴリズム「Free Draft-and-Verification(Freedave)」を提案。Freedaveにより、DLLMsのスループットは数学的推論タスクで最大2.8倍向上する。 Comment
元ポスト:
[Paper Note] IA2: Alignment with ICL Activations Improves Supervised Fine-Tuning, Aayush Mishra+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #In-ContextLearning Issue Date: 2025-10-05 GPT Summary- 本研究では、インコンテキスト学習(ICL)の活性化パターンを利用して、監視付きファインチューニング(SFT)の品質を向上させる手法を提案。ICLとSFTの異なる適応メカニズムを示し、ICL活性化アライメント(IA2)という自己蒸留技術を導入。IA2をSFTの前に実行することで、モデルの出力精度とキャリブレーションが向上することを12のベンチマークで実証。これにより、モデル適応の内部メカニズムに対する新たな視点も提供される。 Comment
元ポスト:
[Paper Note] Generalized Parallel Scaling with Interdependent Generations, Harry Dong+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #read-later Issue Date: 2025-10-05 GPT Summary- Bridgeを提案し、並列LLM推論で相互依存する応答を生成。これにより、平均精度が最大50%向上し、一貫性が増す。訓練後は任意の生成幅にスケール可能で、独立生成よりも優れたパフォーマンスを発揮。 Comment
元ポスト:
[Paper Note] Visual Instruction Bottleneck Tuning, Changdae Oh+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #MachineLearning #NLP #MultiModal #NeurIPS #PostTraining #OOD #Generalization Issue Date: 2025-10-05 GPT Summary- MLLMは未知のクエリに対して性能が低下するが、既存の改善策は多くのデータや計算コストを要する。本研究では、情報ボトルネック原理に基づき、MLLMの堅牢性を向上させるためのVittleを提案。45のデータセットでの実証実験により、VittleがMLLMの堅牢性を一貫して改善することを示した。 Comment
元ポスト:
[Paper Note] Nudging the Boundaries of LLM Reasoning, Justin Chih-Yao Chen+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #read-later Issue Date: 2025-10-05 GPT Summary- NuRLは、自己生成されたヒントを用いてオンライン強化学習(RL)アルゴリズムの上限を引き上げる手法である。モデルは連鎖的思考を生成し、難しいサンプルに対してヒントを注入することで合格率を向上させ、トレーニング信号を導入する。これにより、分布のシフトを回避しつつ、6つのベンチマークで一貫した改善を達成。特に、最も効果的なヒントは抽象的で高レベルであり、GRPOと比較してモデルの上限を引き上げることができる。 Comment
元ポスト:
RLで学習に利用するサンプルの難易度を調整することで性能上げます系の話が溢れている。しかしこの話はどちらかというと上限を押し上げるみたいな話らしい?(RLVRは解決可能な問題しか勾配が流れないという課題)
[Paper Note] Towards Reliable Benchmarking: A Contamination Free, Controllable Evaluation Framework for Multi-step LLM Function Calling, Seiji Maekawa+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Controllable #NLP #AIAgents #Evaluation #LongSequence #Contamination-free Issue Date: 2025-10-04 GPT Summary- TaLMsの評価のために、汚染のないフレームワークFuncBenchGenを提案。ツール使用をDAG上のトラバーサルとして捉え、モデルは正しい関数呼び出しシーケンスを構成。7つのLLMを異なる難易度のタスクで評価した結果、GPT-5が特に優れた性能を示し、依存の深さが増すと性能が低下。古い引数値の伝播が問題であることが判明し、再表現戦略を導入したところ、成功率が62.5%から81.3%に向上した。 Comment
元ポスト:
[Paper Note] StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?, Yanxu Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Financial Issue Date: 2025-10-04 GPT Summary- 大規模言語モデル(LLMs)の金融分野における評価のために、StockBenchという新しいベンチマークを導入。これは、株式取引環境でのLLMエージェントのパフォーマンスを評価し、累積リターンやリスク管理能力を測定する。多くのLLMエージェントはシンプルな戦略を超えるのが難しいが、一部のモデルは高いリターンを示す可能性がある。StockBenchは再現性を支援し、今後の研究を促進するためにオープンソースとして公開される。 Comment
元ポスト:
pj page: https://stockbench.github.io
過去のデータを使いLLMの能力を評価するベンチマークとして利用するという方向性ならこういったタスクも良いのかもしれない。
が、素朴な疑問として、LLMが良いトレードをして儲けられます、みたいなシステムが世に広まった世界の前提になると、それによって市場の原理が変わってLLM側が前提としていたものがくずれ、結果的にLLMはトレードで儲けられなくなる、みたいなことが起きるんじゃないか、という気はするのであくまでLLMの能力を測るためのベンチマークです、という点は留意した方が良いのかな、という感想を持つなどした(実際はよくわからん)。
[Paper Note] TOUCAN: Synthesizing 1.5M Tool-Agentic Data from Real-World MCP Environments, Zhangchen Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #Dataset #AIAgents #SyntheticData #MCP Issue Date: 2025-10-04 GPT Summary- Toucanは、約500の実世界のモデルコンテキストプロトコルから合成された150万の軌跡を含む、最大の公開ツールエージェントデータセットを提供。多様で現実的なタスクを生成し、マルチツールおよびマルチターンのインタラクションに対応。5つのモデルを用いてツール使用クエリを生成し、厳密な検証を通じて高品質な出力を保証。Toucanでファインチューニングされたモデルは、BFCL V3ベンチマークで優れた性能を示し、MCP-Universe Benchでの進展を実現。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/Agent-Ark/Toucan-1.5M
[Paper Note] Large Reasoning Models Learn Better Alignment from Flawed Thinking, ShengYun Peng+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Alignment #SyntheticData #Safety #One-Line Notes #Author Thread-Post Issue Date: 2025-10-04 GPT Summary- RECAPは、誤った推論を覆し安全な応答に導くための強化学習手法。合成生成された反対整合CoTを用いて訓練し、安全性と堅牢性を向上させる。RECAPで訓練されたモデルは自己反省が頻繁で、適応攻撃にも強い。 Comment
元ポスト:
安全でない(欠陥のある)Reasoning traceを修復するような学習をさせることでよりロバストなsafety algnmentが実現できます、といった話な模様
著者ポスト:
[Paper Note] DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search, Fang Wu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Search #ReinforcementLearning #read-later #RLVR #On-Policy #One-Line Notes #ReplayBuffer #TreeSearch Issue Date: 2025-10-04 GPT Summary- DeepSearchは、RLVRトレーニングにMonte Carlo Tree Searchを統合し、体系的な探索を可能にするフレームワーク。これにより、限られたロールアウトに依存せず、重要な推論経路を見逃さない。実験では、62.95%の平均精度を達成し、1.5B推論モデルで新たな最先端を確立。戦略的な探索の重要性を示し、RLVR手法の進展に向けた新たな方向性を提供。 Comment
元ポスト:
最近はRL時の探索空間を増やす取り組みが増えてきているように感じる。
- Replay BufferがPolicy Gradientで使えない理由, piqcy, 2019.03
にもあるように基本的にオンポリシーRLではリプレイバッファを使えないので何らかの工夫が必要、といった話があるが、この研究ではGRPOを前提としつつリプレイバッファを活用する枠組みとなっているようなので、どのような工夫が行われているのだろうか。勉強したい。
所見と解説:
[Paper Note] Data Mixing Can Induce Phase Transitions in Knowledge Acquisition, Xinran Gu+, NeurIPS'25 Spotlight, 2025.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #NeurIPS #read-later #Selected Papers/Blogs #DataMixture #One-Line Notes #PhaseTransition Issue Date: 2025-10-03 GPT Summary- LLMsの訓練において、知識が豊富なデータセットとウェブスクレイピングデータの混合が、知識獲得において位相転移を示すことを実証。モデルサイズを臨界値まで増加させると、記憶状態が急激に変化し、混合比率が臨界値を超えると急速に記憶が増加。これらの現象は容量配分に起因し、最適なデータ配分がモデルサイズや混合比率によって不連続に変わることを示す。 Comment
openreview: https://openreview.net/forum?id=tQZK5frjVU
高品質なデータ(knowledge-denseな合成データなど)とwebからスクレイピングしてきたような低品質なデータのDataMixtureの割合が一定ラインを超えると、(knowledge acquisitionの観点から)相転移が生じてスケーリングの挙動が変化することをコントロールされた実験によって示している模様。
DataMixtureの観点でいうと、モデルサイズを固定してDataMixtureの比率を変化させたときに、knowledge-denseなデータが一定閾値未満の場合は、モデルはこれらのデータから何も学習しないが、ある閾値を超えた途端に知識を学習し始める非線形な挙動となる。
一方DataMixtureの比率を固定して、モデルサイズを変化させた場合も同様の相転移が観測された、という感じらしい。
興味深い。
[Paper Note] xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity, Maximilian Beck+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #Scaling Laws #RecurrentModels Issue Date: 2025-10-03 GPT Summary- スケーリング法則はLLMsの性能予測に重要であり、トランスフォーマーとxLSTMのスケーリング挙動を比較。xLSTMは文脈の長さに対して線形の複雑さを持ち、トレーニングおよび推論においてトランスフォーマーよりも有利にスケールすることが示された。特に、文脈が増えるとxLSTMの利点が拡大する。 Comment
元ポスト:
関連:
- [Paper Note] xLSTM: Extended Long Short-Term Memory, Maximilian Beck+, NeurIPS'24 Spotlight, 2024.05
[Paper Note] Radiology's Last Exam (RadLE): Benchmarking Frontier Multimodal AI Against Human Experts and a Taxonomy of Visual Reasoning Errors in Radiology, Suvrankar Datta+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #VisionLanguageModel #Medical Issue Date: 2025-10-03 GPT Summary- 医療画像の解釈におけるAIモデルのパフォーマンスを評価するため、50の専門的な「スポット診断」ケースを用いたベンチマークを開発。5つの最前線AIモデル(GPT-5、o3、Gemini 2.5 Pro、Grok-4、Claude Opus 4.1)をテストした結果、ボード認定放射線医が最高の診断精度(83%)を達成し、AIモデルは最良のGPT-5でも30%に留まった。これにより、AIモデルが難しい診断ケースにおいて放射線医には及ばないことが示され、医療画像におけるAIの限界と無監視使用への警告が強調された。 Comment
元ポスト:
所見:
[Paper Note] ExGRPO: Learning to Reason from Experience, Runzhe Zhan+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #RLVR #Entropy Issue Date: 2025-10-03 GPT Summary- RLVRは大規模言語モデルの推論能力を向上させる新しい手法ですが、標準的な訓練方法は計算効率が悪い。本研究では、推論経験の価値を調査し、ExGRPOフレームワークを提案。これにより、経験の整理と優先順位付けを行い、探索と経験活用のバランスを取る。実験結果では、ExGRPOが推論性能を向上させ、訓練の安定性を高めることが示された。 Comment
元ポスト:
[Paper Note] Thoughtbubbles: an Unsupervised Method for Parallel Thinking in Latent Space, Houjun Liu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pretraining #NLP #read-later #Selected Papers/Blogs #LatentReasoning Issue Date: 2025-10-03 GPT Summary- 本研究では、トランスフォーマーの新しい変種「Thoughtbubbles」を提案し、並列適応計算を潜在空間で実行する方法を示す。残差ストリームをフォークまたは削除することで、計算を効率化し、事前トレーニング中に学習可能。Thoughtbubblesは、従来の手法を上回る性能を示し、推論時のトレーニングとテストの挙動を統一する可能性を持つ。 Comment
元ポスト:
重要論文に見える
[Paper Note] RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization, Zhaoning Yu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Chain-of-Thought #Reasoning #SelfImprovement #ICLR #read-later #One-Line Notes #Author Thread-Post Issue Date: 2025-10-03 GPT Summary- RESTRAINは、自己ペナルティを用いた強化学習フレームワークで、ラベル付きデータなしでモデルを改善する。過信的な回答をペナルティ化し、未ラベルデータからの学習信号を活用することで、困難な推論ベンチマークにおいて大きな向上を達成。従来のゴールドラベル付きトレーニングに匹敵する性能を示し、効果的な推論の拡張が可能であることを示す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=87ySF7viys
著者による一言解説:
votingによるself-improvingなRLの枠組みから脱却し、全ての応答に対してペナルティ方式でペナルティを与え(一貫性の乏しいロールアウトなど)異なる重みを与えて学習シグナルとする。
[Paper Note] Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls, Feiyang Kang+, EMNLP'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #SyntheticData #EMNLP #Selected Papers/Blogs #DataMixture #One-Line Notes #PhaseTransition Issue Date: 2025-10-03 GPT Summary- 合成データ技術はLLMのトレーニングデータの供給制限を克服する可能性を持つ。本研究では、自然なウェブデータと合成データの混合を比較し、言い換えた合成データのみでの事前トレーニングは自然なデータよりも速くないことを示した。1/3の言い換えた合成データと2/3の自然データの混合が、より効率的なトレーニングを可能にすることが分かった。教科書スタイルの合成データは小さなデータ予算で高い損失をもたらし、合成データの最適な比率はモデルサイズとデータ予算に依存する。結果は合成データの効果を明らかにし、実用的なガイダンスを提供する。 Comment
元ポスト:
ポイント解説:
合成データは適切な規模のモデルと比率でないと利点が現れない
[Paper Note] CLUE: Non-parametric Verification from Experience via Hidden-State Clustering, Zhenwen Liang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #read-later #Verification #Clustering-based Issue Date: 2025-10-03 GPT Summary- 大規模言語モデル(LLM)の出力品質評価において、従来の方法は表面的な手がかりに依存しがちで、信頼度のキャリブレーションが不十分な場合に失敗することがある。本研究では、隠れ状態を直接検証する新たなアプローチ「Clue」を提案し、隠れ活性化の軌跡を用いて推論の正確性を分類する。Clueは非パラメトリックな検証器で、過去の経験に基づくクラスタリングを行い、LLMを判定者とするベースラインを上回る成果を示した。特に、AIME 24において精度を56.7%から70.0%に向上させた。 Comment
元ポスト:
[Paper Note] Personalized Reasoning: Just-In-Time Personalization and Why LLMs Fail At It, Shuyue Stella Li+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #UserModeling #Dataset #UserBased #Personalization #Evaluation #Conversation #read-later #One-Line Notes Issue Date: 2025-10-03 GPT Summary- 現在のLLMは、タスク解決とユーザーの好みの整合性を別々に扱っており、特にジャストインタイムのシナリオでは効果的ではない。ユーザーの好みを引き出し、応答を適応させる「パーソナライズド推論」が必要である。新たに提案された評価手法「PREFDISCO」は、ユーザーのコンテキストに応じた異なる推論チェーンを生成し、パーソナライズの重要性を示す。評価結果から、単純なパーソナライズが一般的な応答よりも劣ることが明らかになり、専用の開発が必要であることが示唆された。PREFDISCOは、教育や医療などの分野でのパーソナライズの重要性を強調する基盤を提供する。 Comment
元ポスト:
ざーっとしか読めていないのが、ユーザから与えられたタスクとマルチターンの会話の履歴に基づいて、LLM側が質問を投げかけて、Personalizationに必要なattributeを取得する。つまり、ユーザプロファイルは (attribute, value, weight)のタプルによって構成され、この情報に基づいて生成がユーザプロファイルにalignするように生成する、といった話に見える。膨大なとりうるattributeの中から、ユーザのタスクとcontextに合わせてどのattributeに関する情報を取得するかが鍵となると思われる。また、セッション中でユーザプロファイルを更新し、保持はしない前提な話に見えるので、Personalizationのカテゴリとしては一時的個人化に相当すると思われる。
Personalizationの研究は評価が非常に難しいので、どのような評価をしているかは注意して読んだ方が良いと思われる。
[Paper Note] A Practitioner's Guide to Multi-turn Agentic Reinforcement Learning, Ruiyi Wang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #AIAgents #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-10-03 GPT Summary- マルチターン強化学習におけるLLMエージェントの訓練方法を研究し、設計空間を環境、報酬、ポリシーの3つの柱に分解。環境の複雑さがエージェントの一般化能力に与える影響、報酬の希薄性が訓練に与える効果、ポリシー勾配法の相互作用を分析。これらの知見を基に、訓練レシピを提案し、マルチターンエージェント強化学習の研究と実践を支援。 Comment
元ポスト:
著者ポスト:
takeawayが非常に簡潔で分かりやすい。
ベンチマーク:
- [Paper Note] TextWorld: A Learning Environment for Text-based Games, Marc-Alexandre Côté+, Workshop on Computer Games'18 Held in Conjunction with IJCAI'18, 2018.06
- [Paper Note] ALFWorld: Aligning Text and Embodied Environments for Interactive Learning, Mohit Shridhar+, ICLR'21, 2020.10
- [Paper Note] Training Software Engineering Agents and Verifiers with SWE-Gym, Jiayi Pan+, ICML'25
[Paper Note] Knapsack RL: Unlocking Exploration of LLMs via Optimizing Budget Allocation, Ziniu Li+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PostTraining Issue Date: 2025-10-03 GPT Summary- 大規模言語モデル(LLMs)の探索予算の割り当てを最適化する手法を提案。タスクの「価値」と「コスト」を明確にし、古典的なナップサック問題に関連付けることで、リソースを適応的に分配。これにより、GRPOのトレーニング中に非ゼロポリシー勾配の有効比率を20-40%向上させ、特に難しいタスクに対して93回のロールアウトを可能に。数学的推論ベンチマークで平均2-4ポイントの改善を達成し、従来の均一な割り当てと同等のパフォーマンスを得るには約2倍の計算リソースが必要。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=uqxNmKw7DI
[Paper Note] TruthRL: Incentivizing Truthful LLMs via Reinforcement Learning, Zhepei Wei+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Hallucination #PostTraining #Trustfulness Issue Date: 2025-10-02 GPT Summary- 本研究では、LLMsの真実性を最適化するための強化学習フレームワークTruthRLを提案。三値報酬を用いて正しい回答、幻覚、abstentionを区別し、不確実な場合には控えることを促進。実験により、TruthRLは幻覚を28.9%減少させ、真実性を21.1%向上させることが確認され、従来の手法よりも優れた性能を示した。正確さと真実性のバランスを取る重要性が強調される。 Comment
元ポスト:
一般的に利用されるBinary Reward(回答が正しければ1, そうでなければ-1)ではなく、Ternary Reward
- 回答が正しければ1
- 不確実であれば0
- 誤りであれば-1
を利用しGRPOすることで、hallucinationが向上し、trustfulnessも改善する、という話な模様
[Paper Note] HalluGuard: Evidence-Grounded Small Reasoning Models to Mitigate Hallucinations in Retrieval-Augmented Generation, Loris Bergeron+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Hallucination #RAG(RetrievalAugmentedGeneration) #SmallModel Issue Date: 2025-10-02 GPT Summary- HalluGuardは、LLMsの幻覚を軽減するための4Bパラメータの小型推論モデルで、文書-主張ペアを分類し、証拠に基づいた正当化を生成します。FineWebから派生した合成データセットと、好みベースのファインチューニングを用いて、RAGTruthサブセットで84.0%のバランス精度を達成し、MiniCheckやGranite Guardianと同等の性能を示します。全体のベンチマークでは75.7%のバランス精度を達成し、GPT-4oと同等の性能を持ちます。HalluGuardとデータセットは公開予定です。 Comment
元ポスト:
Document xとclaim cがgivenなときに、それがgroundingされているか否かを判定し、justificationをするテキストをxを参照しながら生成するようなSLMな模様。モデルとデータはまだ未公開とのこと。
[Paper Note] Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents, Zonghan Yang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #reading #KeyPoint Notes #Author Thread-Post Issue Date: 2025-10-02 GPT Summary- 大規模言語モデル(LLMs)のソフトウェア工学(SWE)への応用が進んでおり、SWE-benchが重要なベンチマークとなっている。マルチターンのSWE-Agentフレームワークと単一ターンのエージェントレス手法は相互排他的ではなく、エージェントレストレーニングが効率的なSWE-Agentの適応を可能にする。本研究では、Kimi-DevというオープンソースのSWE LLMを紹介し、SWE-bench Verifiedで60.4%を達成。追加の適応により、Kimi-DevはSWE-Agentの性能を48.6%に引き上げ、移植可能なコーディングエージェントの実現を示した。 Comment
元ポスト:
Agentlessはこちら:
- [Paper Note] Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, FSE'25, 2024.07
著者ポスト:
ポストの中でOpenhandsが同モデルを内部で検証し、Openhandsの環境内でSWE Bench Verifiedで評価した結果、レポート内で報告されているAcc. 60.4%は達成できず、17%に留まることが報告されていた模様。
Openhandsの説明によるとAgentlessは決められた固定されたワークフローのみを実施する枠組み(Kimi Devの場合はBugFixerとFileEditor)であり、ワークフローで定義されたタスクは効果的に実施できるが、それら以外のタスクはそもそもうまくできない。SWE Agent系のベンチのバグfixの方法は大きく分けてAgentlike(コードベースを探索した上でアクションを実行する形式)、Fixed workflow like Agentless(固定されたワークフローのみを実行する形式)の2種類があり、Openhandsは前者、Kimi Devは後者の位置付けである。
実際、テクニカルレポートのFigure2とAppendixを見ると、File Localization+BugFixer+TestWriterを固定されたプロンプトテンプレートを用いてmid-trainingしており、評価する際も同様のハーネスが利用されていると推察される(どこかに明示的な記述があるかもしれない)。
一方、Openhandsではより実環境の開発フローに近いハーネス(e.g., エージェントがコードベースを確認してアクションを提案→実行可能なアクションなら実行→そうでないならユーザからのsimulated responceを受け取る→Agentに結果をフィードバック→エージェントがアクション提案...)といったハーネスとなっている。
このように評価をする際のハーネスが異なるため、同じベンチマークに対して異なる性能が報告される、ということだと思われる。
単にSWE Bench VerifiedのAcc.だけを見てモデルを選ぶのではなく、評価された際のEvaluation Harnessが自分たちのユースケースに合っているかを確認することが重要だと考えられる。
参考:
- OpenhandsのEvaluation Harness:
https://docs.all-hands.dev/openhands/usage/developers/evaluation-harness
[Paper Note] Towards a Comprehensive Scaling Law of Mixture-of-Experts, Guoliang Zhao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pretraining #NLP #MoE(Mixture-of-Experts) #Scaling Laws Issue Date: 2025-10-01 GPT Summary- Mixture-of-Experts (MoE)モデルのスケーリング法則を体系的に分析し、パフォーマンスに影響を与える5つの要因を特定。446の制御実験を通じて、包括的なMoEスケーリング法則を構築し、最適な専門家の数や共有比率がモデルアーキテクチャやデータサイズに依存しないことを示す。提案する法則は、MoEモデルの設計とトレーニングにおける指針となる可能性がある。 Comment
元ポスト:
[Paper Note] QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation, Jiazheng Li+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #SmallModel Issue Date: 2025-10-01 GPT Summary- 強化学習(RL)を用いて、難しい推論問題を効果的に解決するための手法QuestAを提案。質問の拡張を通じて部分的な解決策を導入し、学習信号を改善。数学的推論タスクでのRLトレーニングにおいて、pass@1とpass@kの両方を向上させ、DeepScaleRやOpenMath Nemotronの推論能力を強化。1.5Bパラメータモデルで新たな最先端結果を達成。 Comment
元ポスト:
RLにおいて、簡単な問題はすぐにoverfitし、かつより困難な問題を学習する妨げになる一方で、困難な問題はサンプル効率が悪く、かつrewardがsparseな場合学習が非常に遅いという問題があったが、困難な問題に対してヒントを与えて学習させる(かつ、モデルがヒントに依存せずとも解けるようになってきたら徐々にヒントを減らしヒントに過剰に依存することを防ぐ)ことで、簡単な問題に対してoverfitせずに困難な問題に対する学習効率も上がり、reasoning能力もブーストしました。困難な問題はベースラインモデルが解くのに苦労するもの(pass rateがゼロのもの)から見つけます、(そしてpromptでhintを与えた上でさらにpass rateが低いものを使う模様?)といった話な模様。
ヒントを使ってなる問題の難易度を調整しながらRLする研究は以下も存在する:
- [Paper Note] Staying in the Sweet Spot: Responsive Reasoning Evolution via
Capability-Adaptive Hint Scaffolding, Ziheng Li+, arXiv'25
[Paper Note] Pretraining Large Language Models with NVFP4, NVIDIA+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LowPrecision Issue Date: 2025-09-30 GPT Summary- 本研究では、NVFP4フォーマットを用いた大規模言語モデル(LLMs)の安定かつ正確なトレーニング手法を提案。ランダムハダマード変換や二次元量子化スキームを取り入れ、偏りのない勾配推定を実現。10兆トークンでのトレーニングにより、FP8と同等の性能を達成し、狭い精度のLLMトレーニングにおける進展を示した。 Comment
元ポスト:
解説:
[Paper Note] RecoWorld: Building Simulated Environments for Agentic Recommender Systems, Fei Liu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#RecommenderSystems #ReinforcementLearning #AIAgents Issue Date: 2025-09-30 GPT Summary- RecoWorldは、エージェント型レコメンダーシステムのためのシミュレーション環境を提案し、エージェントがユーザーに影響を与えずに学習できる場を提供します。ユーザーシミュレーターとエージェント型レコメンダーがマルチターンのインタラクションを行い、ユーザーの保持を最大化します。ユーザーシミュレーターはユーザーの反応を基に指示を生成し、レコメンダーはそれに応じて推奨を適応させる動的なフィードバックループを形成します。さらに、テキストベースやマルチモーダルなコンテンツ表現を探求し、マルチターン強化学習を通じて戦略を洗練させる方法を議論します。RecoWorldは、ユーザーとエージェントが共同でパーソナライズされた情報を形成する新しいインタラクションパラダイムを提示します。 Comment
元ポスト:
[Paper Note] The Era of Real-World Human Interaction: RL from User Conversations, Chuanyang Jin+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #UserBased #Alignment #ReinforcementLearning #Author Thread-Post Issue Date: 2025-09-30 GPT Summary- 本研究では、ユーザーとの会話から直接学ぶ「人間の相互作用からの強化学習(RLHI)」を提案。2つの手法を開発し、(1) ユーザーのフィードバックを基にモデル出力を修正する方法と、(2) ユーザーの長期的な相互作用履歴に基づく報酬モデルを用いる方法を採用。これにより、パーソナライズと指示の遵守において強力な性能を示し、有機的な人間の相互作用が効果的な監督を提供することを示唆した。 Comment
元ポスト:
ポイント解説:
著者ポスト:
[Paper Note] ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory, Siru Ouyang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #Selected Papers/Blogs #memory #One-Line Notes #Test-time Learning Issue Date: 2025-09-30 GPT Summary- ReasoningBankという新しいメモリフレームワークを提案し、エージェントが成功体験と失敗体験から推論戦略を抽出できるようにする。テスト時には関連メモリを活用し、学びを統合することで能力を向上させる。さらに、メモリを意識したテスト時スケーリング(MaTTS)を導入し、エージェントの体験を多様化・拡大する。これにより、ウェブブラウジングやソフトウェアエンジニアリングのベンチマークで既存のメモリメカニズムを上回る効果と効率を実現。メモリ駆動の経験スケーリングを新たな次元として確立し、エージェントの自己進化を促進する。 Comment
元ポスト:
メモリを良質なものに更新、蓄積し続けることで性能がスケールするのであれば、新たなtest-time scalingのパラダイムになりそう。
ざっくり読んでみると本研究ではこのパラダイムのことをTest-Time Learningと呼称している(先行研究が2つ引用されているがざっと見た限りでは両者はそう言った呼称はしていないように見えた)。
すなわち、クエリのストリームが到達した時に将来のクエリを見ることはできずに、過去のクエリに対するtrajectoryや、self-verificationなどによってのみラベル無しで自己進化していくパラダイムのこと。
関連:
- [Paper Note] M+: Extending MemoryLLM with Scalable Long-Term Memory, Yu Wang+, ICML'25, 2025.02
openreview: https://openreview.net/forum?id=jL7fwchScm
[Paper Note] Language Models Can Learn from Verbal Feedback Without Scalar Rewards, Renjie Luo+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Alignment #read-later #Selected Papers/Blogs #Initial Impression Notes #TextualFeedback Issue Date: 2025-09-29 GPT Summary- LLMsの訓練において、フィードバックを条件信号として扱う新しい手法、フィードバック条件付きポリシー(FCP)を提案。FCPは応答-フィードバックペアから直接学習し、オンラインで自己を洗練させることで、報酬最適化ではなく条件生成によるフィードバック駆動の学習を実現。 Comment
元ポスト:
以下とはどこが異なるだろうか?:
- [Paper Note] Large Language Models as Optimizers, Chengrun Yang+, ICLR'24, 2023.09
こちらはメタプロンプトを用いてテキスト空間上で反復的にプロンプトをチューニングする枠組みだが、本研究はフィードバック(報酬モデルの報酬にすると消えてしまうテキストの微妙なニュアンス等のシグナル)に基づいてパラメータを更新するので全く異なる枠組みだった。
openreview:
https://openreview.net/forum?id=F4LBDJtsDX
RMからではなくVerbal Feedbackからモデルが効果的に学習できることはAilgnmentのスケーリングに重要な技術だという指摘が多い。
[Paper Note] Quantile Advantage Estimation for Entropy-Safe Reasoning, Junkang Wu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #RLVR #Entropy Issue Date: 2025-09-29 GPT Summary- 強化学習における検証可能な報酬(RLVR)のトレーニングは、エントロピー崩壊と爆発の問題に直面する。これを解決するために、分位アドバンテージ推定(QAE)を提案し、平均ベースラインをK-分位ベースラインに置き換える。QAEは、難しいクエリで稀な成功を強化し、簡単なクエリで失敗をターゲットにする。これにより、エントロピーの安定化とクレジット割り当てのスパース化が実現し、AIME 2024/2025およびAMC 2023での性能向上が確認された。結果は、ベースライン設計がRLVRのスケーリングにおいて重要であることを示している。 Comment
元ポスト:
ポイント解説:
[Paper Note] Stochastic activations, Maria Lomeli+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ActivationFunction #DyingReLU Issue Date: 2025-09-29 GPT Summary- 確率的活性化を導入し、フィードフォワード層で非線形関数をランダムに選択。特に、ベルヌーイ分布に基づきSILUまたはRELUを選択し、最適化問題を回避。プレトレーニング中に確率的活性化を使用し、推論時にRELUでファインチューニングすることでFLOPsを削減し、速度向上を実現。また、生成においても確率的活性化を評価し、テキストの多様性を制御する代替手段を提供。 Comment
元ポスト:
[Paper Note] SIM-CoT: Supervised Implicit Chain-of-Thought, Xilin Wei+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LatentReasoning Issue Date: 2025-09-29 GPT Summary- 暗黙のChain-of-Thought (CoT) メソッドは、LLMsにおける明示的なCoT推論の効率的な代替手段ですが、性能の不安定性が課題です。これに対処するため、SIM-CoTを提案し、ステップレベルの監視を導入して潜在的な推論空間を安定化します。補助デコーダーを用いて暗黙のトークンを明示的な推論ステップに整合させ、解釈可能性を向上させます。SIM-CoTは、CoconutやCODIでの精度を向上させ、明示的CoTのベースラインを上回り、トークン効率も改善します。 Comment
元ポスト:
[Paper Note] Interactive Recommendation Agent with Active User Commands, Jiakai Tang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#RecommenderSystems #read-later #Selected Papers/Blogs #interactive #One-Line Notes Issue Date: 2025-09-29 GPT Summary- 従来のレコメンダーシステムは受動的なフィードバックに依存し、ユーザーの意図を捉えられないため、嗜好モデルの構築が困難である。これに対処するため、インタラクティブレコメンデーションフィード(IRF)を導入し、自然言語コマンドによる能動的な制御を可能にする。RecBotという二重エージェントアーキテクチャを開発し、ユーザーの嗜好を構造化し、ポリシー調整を行う。シミュレーション強化知識蒸留を用いて効率的なパフォーマンスを実現し、実験によりユーザー満足度とビジネス成果の改善を示した。 Comment
元ポスト:
ABテストを実施しているようなので信ぴょう性高め
[Paper Note] Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models, Siddarth Venkatraman+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Test-Time Scaling #Selected Papers/Blogs #Aggregation-aware #KeyPoint Notes Issue Date: 2025-09-27 GPT Summary- 推論時スケーリング法によってLLMsの能力を向上させる。Recursive Self-Aggregation(RSA)を提案し、並列スケーリングと逐次スケーリングの利点を融合。各ステップで部分集合を統合し、改善された解を生成。RSAは計算予算の増加に伴い、様々なタスクで顕著な性能向上を示し、特にGemini 3 Flashで高性能を実現。さらに、新規の集約を意識した強化学習アプローチを通じて、解の組み合わせによる性能向上を図る。 Comment
N個の応答を生成し、各応答K個組み合わせてpromptingで集約し新たな応答を生成することで洗練させる、といったことをT回繰り返すtest-time scaling手法で、RLによってモデルの集約能力を強化するとより良いスケーリングを発揮する。RLでは通常の目的関数(prompt x, answer y; xから単一のreasoning traceを生成しyを回答する設定)に加えて、aggregation promptを用いた目的関数(aggregation promptを用いて K個のsolution集合 S_0を生成し、目的関数をaggregation prompt x, S_0の双方で条件づけたもの)を定義し、同時に最適化をしている(同時に最適化することは5.4節に記述されている)。つまり、これまでのRLはxがgivenな時に頑張って単一の良い感じのreasoning traceを生成しyを生成するように学習していたが(すなわち、モデルが複数のsolutionを集約することは明示的に学習されていない)、それに加えてモデルのaggregationの能力も同時に強化する、という気持ちになっている。学習のアルゴリズムはPPO, GRPOなど様々なon-poloicyな手法を用いることができる。今回はRLOOと呼ばれる手法を用いている。
様々なsequential scaling, parallel scaling手法と比較して、RSAがより大きなgainを得ていることが分かる。ただし、Knowledge RecallというタスクにおいてはSelf-Consistency (Majority Voting)よりもgainが小さい。
以下がaggregation-awareなRLを実施した場合と、通常のRL, promptingのみによる場合の性能の表している。全体を通じてaggregation-awareなRLを実施することでより高い性能を発揮しているように見える。ただし、AIMEに関してだけは通常のpromptingによるRSAの性能が良い。なぜだろうか?考察まで深く読めていないので論文中に考察があるかもしれない。
元ポスト:
concurrent work:
- [Paper Note] The Majority is not always right: RL training for solution aggregation, Wenting Zhao+, arXiv'25
[Paper Note] CLaw: Benchmarking Chinese Legal Knowledge in Large Language Models - A Fine-grained Corpus and Reasoning Analysis, Xinzhe Xu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Legal Issue Date: 2025-09-27 GPT Summary- 法的文書の分析において、LLMの信頼性が損なわれる問題を解決するために、新しいベンチマークCLawを提案。CLawは、中国の法令を網羅した詳細なコーパスと、ケースベースの推論インスタンスから構成され、法的知識の実際の応用を評価。実証的評価では、現代のLLMが法的規定の正確な取得に苦労していることが明らかになり、信頼できる法的推論には正確な知識の取得と強力な推論能力の統合が必要であると主張。ドメイン特化型LLM推論の進展に向けた重要な洞察を提供。 Comment
元ポスト:
中国語による中国の法律のデータセットで、legal分野においては、より細かい粒度の知識を捉えられるモデルが推論も的確にでき、推論能力でそれは補えそうという感じな模様
[Paper Note] Expanding Reasoning Potential in Foundation Model by Learning Diverse Chains of Thought Patterns, Xuemiao Zhang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #mid-training Issue Date: 2025-09-26 GPT Summary- 大規模推論モデルの進展は強化学習によって促進され、CoTデータの利用が推論の深さを向上させることが示されている。しかし、どのデータタイプが最も効果的かは未解決の問題である。本研究では、推論ポテンシャルを独立した試行の数の逆数として定義し、これを拡張するために高価値の推論パターンを用いた多様なデータの利用を提案。具体的には、CoTシーケンスから原子的な推論パターンを抽象化し、コアリファレンスセットを構築。二重粒度アルゴリズムを用いて高価値のCoTデータを効率的に選択し、モデルの推論能力を向上させる。10BトークンのCoTPデータにより、85A6B Mixture-of-ExpertsモデルはAIME 2024および2025で9.58%の改善を達成した。 Comment
元ポスト:
細かいところは読めていないのだが、学習データの中から高品質な推論パターンを持つものを選んで学習に使いたいというモチベーション。そのためにまず価値の高い推論パターンを含むコアセットを作り、コアセットと類似した推論パターンや、推論中のトークンのエントロピー列を持つサンプルを学習データから収集するみたいな話な模様。類似度は重みつきDynamic Time Warping (DTW)で、原始的な推論パターンの系列とエントロピー系列のDTWの線型結合によっめ求める。原始的な推論パターンのアノテーションや、CoT sequence中のトークンのエントロピー列はDeepSeek-V3によって生成する。
コアセットを作るためには、問題タイプや問題の難易度に基づいて人手で問題を選び、それらに対してstrong reasoning modelでCoTを生成。各CoTに対して(おそらく)DeepSeek-V3でreasoningのパターン(パターンは原始的なCoTパターンの系列で構成される)をアノテーションし、各パターンに対してTF-IDFによって重要度を決定する。最終的に、問題に正答しているサンプルについて、人手で高品質でdiscriminativeなCoTパターンを持つものを選択し、各CoTパターンに重みをつけた上でコアセットを作成した、みたいな感じに見える。
[Paper Note] Best-of-$\infty$ -- Asymptotic Performance of Test-Time Compute, Junpei Komiyama+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Ensemble #Test-Time Scaling #read-later #Best-of-N Issue Date: 2025-09-26 GPT Summary- 大規模言語モデル(LLMs)におけるBest-of-$N$を多数決に基づいて研究し、$N \to \infty$の限界(Best-of-$\infty$)を分析。無限のテスト時間を必要とする問題に対処するため、回答の一致に基づく適応生成スキームを提案し、推論時間を効率的に配分。さらに、複数のLLMの重み付きアンサンブルを拡張し、最適な重み付けを混合整数線形計画として定式化。実験によりアプローチの有効性を実証。 Comment
pj page: https://jkomiyama.github.io/bestofinfty/
元ポスト:
[Paper Note] CompLLM: Compression for Long Context Q&A, Gabriele Berton+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LongSequence #Compression #Author Thread-Post Issue Date: 2025-09-26 GPT Summary- CompLLMは、長いコンテキストを効率的に処理するためのソフト圧縮技術で、コンテキストをセグメントに分割して独立に圧縮する。これにより、効率性、スケーラビリティ、再利用性を実現。実験では、CompLLMが長いコンテキストで最大4倍の速度向上を示し、圧縮されていないコンテキストと同等の性能を維持。 Comment
元ポスト:
著者による一言まとめ:
openreview: https://openreview.net/forum?id=6AWWE08NnN
[Paper Note] Embodied AI: From LLMs to World Models, Tongtong Feng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Survey #Robotics #WorldModels #EmbodiedAI Issue Date: 2025-09-25 GPT Summary- 具現化されたAIはAGI達成のための知的システムであり、LLMsとWMsの進展が注目されている。本論文では、具現化されたAIの歴史や技術、コンポーネントを紹介し、LLMsとWMsの役割を詳細に検討。MLLM-WM駆動のアーキテクチャの必要性を論じ、物理世界での複雑なタスクの実現における意義を明らかにする。具現化されたAIのアプリケーションと今後の研究方向についても触れる。 Comment
元ポスト:
ポイント解説:
[Paper Note] Language Models that Think, Chat Better, Adithya Bhaskar+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #RLVR #Open-endedTasks Issue Date: 2025-09-25 GPT Summary- 強化学習における検証可能な報酬(RLVR)は、特定のドメインでの推論を改善するが、オープンエンドのタスクには限界がある。本研究では、RLVRの枠組みを超えた一般的なチャット機能のためのRLとモデル報酬思考(RLMT)を提案。RLMTは、長い連鎖的思考を生成し、嗜好ベースの報酬モデルで最適化する。実験により、RLMTは標準的なRLHFパイプラインを上回り、特にチャットや創造的執筆での性能向上を示した。最良のモデルはGPT-4oを超え、少ないデータでのトレーニングでも高い性能を発揮。結果は、ポストトレーニングパイプラインの再考と今後の研究の必要性を示唆している。 Comment
元ポスト:
解説:
openreview: https://openreview.net/forum?id=trBEiQFkxw
[Paper Note] Thinking Augmented Pre-training, Liang Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pretraining #NLP #SyntheticData #Reasoning #read-later Issue Date: 2025-09-25 GPT Summary- 思考の軌跡を用いてテキストデータを拡張する「Thinking augmented Pre-Training(TPT)」を提案し、LLMのデータ効率を向上。TPTはトレーニングデータを効果的に増加させ、高品質なトークンの学習を容易にする。実験により、TPTがLLMの性能を大幅に向上させ、特に3Bパラメータモデルで推論ベンチマークの性能を10%以上改善することを示した。 Comment
元ポスト:
(斜め読みしかまだできていないが)2節に存在するプロンプトを用いて、ドキュメント全体をcontextとして与え、context中に存在する複雑な情報に関して深い分析をするようにthinking traceを生成し、生成したtrace tをconcatしてnext token predictionで事前学習する模様。数学データで検証し事前学習が3倍トークン量 vs. downstreamタスク(GSM8K, MATH)性能の観点効率的になっただかでなく(これは事後学習の先取りをしているみたいなものな気がするのでそうなるだろうなという気がする)、おなじトークン量で学習したモデルをSFTした場合でも、提案手法の方が性能が良かった模様(Table2, こっちの方が個人的には重要な気がしている)。
解説:
[Paper Note] CWM: An Open-Weights LLM for Research on Code Generation with World Models, FAIR CodeGen team+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Coding #OpenWeight #mid-training #PostTraining #Selected Papers/Blogs #WorldModels #One-Line Notes Issue Date: 2025-09-25 GPT Summary- 320億パラメータのCode World Model (CWM)をリリースし、コード生成のための世界モデルの研究を進める。静的コードだけでなく、PythonインタプリタやDocker環境から得た観測-行動トレジェクトリで中間トレーニングを実施し、マルチタスク推論RLによる広範な能力を評価。CWMは強力なテストベッドを提供し、世界モデルがエージェンティックコーディングに貢献できることを示す。主要なタスクで高いパフォーマンスを記録し、モデルチェックポイントも提供。 Comment
元ポスト:
World Modelと銘打ってあるが、一般的なCV分野でのWorld Modelではなく、python やbash等の実行をトークン列として仮想的にトレースできるようにmid trainingされている(大量の実トレースデータが利用されている模様)ので、World Modelと銘打たれている模様?
GRPOに対するモダンなtweakがまとまっている模様:
DeepSeek-R1で提案されてから細かな調整が重ねられて来た。
[Paper Note] UMoE: Unifying Attention and FFN with Shared Experts, Yuanhang Yang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #Attention #Architecture #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-09-24 GPT Summary- Sparse Mixture of Experts (MoE) アーキテクチャは、Transformer モデルのスケーリングにおいて有望な手法であり、注意層への拡張が探求されていますが、既存の注意ベースの MoE 層は最適ではありません。本論文では、注意層と FFN 層の MoE 設計を統一し、注意メカニズムの再定式化を行い、FFN 構造を明らかにします。提案するUMoEアーキテクチャは、注意ベースの MoE 層で優れた性能を達成し、効率的なパラメータ共有を実現します。 Comment
元ポスト:
Mixture of Attention Heads (MoA)はこちら:
- [Paper Note] Mixture of Attention Heads: Selecting Attention Heads Per Token, Xiaofeng Zhang+, EMNLP'22, 2022.10
この図がわかりやすい。後ほど説明を追記する。ざっくり言うと、MoAを前提としたときに、最後の出力の変換部分VW_oをFFNによる変換(つまりFFN Expertsの一つ)とみなして、self-attentionのトークンを混ぜ合わせるという趣旨を失わない範囲で計算順序を調整(トークンをミックスする部分を先に持ってくる)すると、FFNのMoEとMoAは同じ枠組みで扱えるため、expertsを共有できてメモリを削減でき、かつMoAによって必要な箇所のみにattendする能力が高まり性能も上がります、みたいな話に見える。
[Paper Note] Scaling Speculative Decoding with Lookahead Reasoning, Yichao Fu+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Reasoning #Decoding #read-later #Selected Papers/Blogs #SpeculativeDecoding Issue Date: 2025-09-24 GPT Summary- Lookahead Reasoningを用いることで、推論モデルのトークンデコード速度を向上させる手法を提案。軽量なドラフトモデルが将来のステップを提案し、ターゲットモデルが一度のバッチ処理で展開。これにより、トークンレベルの推測デコーディング(SD)のスピードアップを1.4倍から2.1倍に改善し、回答の質を維持。 Comment
元ポスト:
[Paper Note] CAPE: Context-Aware Personality Evaluation Framework for Large Language Models, Jivnesh Sandhan+, EMNLP'25 Findings, 2025.08
Paper/Blog Link My Issue
#Dataset #ContextAware #Evaluation #EMNLP #Findings #Personality Issue Date: 2025-09-24 GPT Summary- 心理測定テストをLLMsの評価に適用するため、文脈対応パーソナリティ評価(CAPE)フレームワークを提案。従来の孤立した質問アプローチから、会話の履歴を考慮した応答の一貫性を定量化する新指標を導入。実験により、会話履歴が応答の一貫性を高める一方で、パーソナリティの変化も引き起こすことが明らかに。特にGPTモデルは堅牢性を示し、Gemini-1.5-FlashとLlama-8Bは感受性が高い。CAPEをロールプレイングエージェントに適用すると、一貫性が改善され人間の判断と一致することが示された。 Comment
元ポスト:
[Paper Note] Leveraging High-Resource English Corpora for Cross-lingual Domain Adaptation in Low-Resource Japanese Medicine via Continued Pretraining, Kobayashi+, EMNLP'25 Findings
Paper/Blog Link My Issue
#Analysis #Pretraining #DomainAdaptation #NLP #CrossLingual #Japanese #DataMixture #Medical #LowResource Issue Date: 2025-09-24 GPT Summary- 低リソース言語の医療コーパスでは、PLMsの跨言語適応が難しい。本研究は、日本語と英語の医療知識ベンチマークにおける言語的特徴がパフォーマンスに与える影響を分析。異なる比率の英語と日本語テキストを用いた多言語コーパスでの継続的事前学習を通じて、専門知識を活用しつつターゲット言語の表現をカバーする最適化手法を提案。これにより、低リソース言語の専門分野での多言語モデル開発に寄与することを目指す。 Comment
元ポスト:
[Paper Note] How a Bilingual LM Becomes Bilingual: Tracing Internal Representations with Sparse Autoencoders, Tatsuro Inaba+, EMNLP'25 Findings, 2025.03
Paper/Blog Link My Issue
#Analysis #NLP #MultiLingual #EMNLP #Findings #SparseAutoencoder Issue Date: 2025-09-24 GPT Summary- 本研究では、バイリンガル言語モデルの内部表現の発展をスパースオートエンコーダーを用いて分析。言語モデルは初めに言語を個別に学習し、中間層でバイリンガルの整合性を形成することが明らかに。大きなモデルほどこの傾向が強く、分解された表現を中間トレーニングモデルに統合する新手法でバイリンガル表現の重要性を示す。結果は、言語モデルのバイリンガル能力獲得に関する洞察を提供。 Comment
元ポスト:
[Paper Note] Instability in Downstream Task Performance During LLM Pretraining, Yuto Nishida+, EMNLP'25 Findings, 2025.10
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #EMNLP #Stability #Findings #DownstreamTasks Issue Date: 2025-09-24 GPT Summary- LLMの訓練中に下流タスクのパフォーマンスが大きく変動する問題を分析し、チェックポイントの平均化とアンサンブル手法を用いて安定性を向上させることを提案。これにより、訓練手順を変更せずにパフォーマンスの変動を減少させることが実証された。 Comment
元ポスト:
[Paper Note] SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?, Senyu Li+, EMNLP'25, 2025.06
Paper/Blog Link My Issue
#MachineTranslation #Metrics #NLP #Dataset #Evaluation #Reference-free #EMNLP #LowResource Issue Date: 2025-09-24 GPT Summary- アフリカの言語における機械翻訳の品質評価は依然として課題であり、既存の指標は限られた性能を示しています。本研究では、13のアフリカ言語ペアを対象とした大規模な人間注釈付きMT評価データセット「SSA-MTE」を紹介し、63,000以上の文レベルの注釈を含んでいます。これに基づき、改良された評価指標「SSA-COMET」と「SSA-COMET-QE」を開発し、最先端のLLMを用いたプロンプトベースのアプローチをベンチマークしました。実験結果は、SSA-COMETがAfriCOMETを上回り、特に低リソース言語で競争力があることを示しました。すべてのリソースはオープンライセンスで公開されています。 Comment
元ポスト:
[Paper Note] Multilingual Language Model Pretraining using Machine-translated Data, Jiayi Wang+, EMNLP'25, 2025.02
Paper/Blog Link My Issue
#MachineTranslation #Pretraining #NLP #Dataset Issue Date: 2025-09-24 GPT Summary- 高リソース言語の英語から翻訳した高品質なテキストが、多言語LLMsの事前学習に寄与することを発見。英語のデータセットFineWeb-Eduを9言語に翻訳し、17兆トークンのTransWebEduを作成。1.3BパラメータのTransWebLLMを事前学習し、非英語の推論タスクで最先端モデルと同等以上の性能を達成。特に、ドメイン特化データを追加することで、いくつかの言語で新たな最先端を達成。コーパス、モデル、トレーニングパイプラインはオープンソースで公開。 Comment
元ポスト:
[Paper Note] Reinforcement Learning on Pre-Training Data, Siheng Li+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pretraining #NLP #ReinforcementLearning #Scaling Laws #read-later Issue Date: 2025-09-24 GPT Summary- RLPTという新しいトレーニング手法を導入し、LLMsの最適化を図る。従来の方法に依存せず、事前学習データから直接報酬信号を導出し、次のテキストセグメントを予測することでポリシーに報酬を与える。実験により、複数のベンチマークで性能が向上し、計算リソースの増加によるさらなる改善の可能性が示された。RLPTはLLMsの推論能力を拡張し、RLVRのパフォーマンス向上にも寄与する。 Comment
元ポスト:
関連:
- [Paper Note] Reinforcement Pre-Training, Qingxiu Dong+, arXiv'25, 2025.06
所見:
公式ポスト:
[Paper Note] Heimdall: test-time scaling on the generative verification, Wenlei Shi+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Test-Time Scaling #read-later #Selected Papers/Blogs #Verification Issue Date: 2025-09-24 GPT Summary- Heimdallは、長いChain-of-Thought推論における検証能力を向上させるためのLLMであり、数学問題の解決精度を62.5%から94.5%に引き上げ、さらに97.5%に達する。悲観的検証を導入することで、解決策の精度を54.2%から70.0%、強力なモデルを使用することで93.0%に向上させる。自動知識発見システムのプロトタイプも作成し、データの欠陥を特定する能力を示した。
[Paper Note] Soft Tokens, Hard Truths, Natasha Butt+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Chain-of-Thought #LatentReasoning #Author Thread-Post Issue Date: 2025-09-24 GPT Summary- 本研究では、離散CoTからの蒸留なしに強化学習を用いて連続CoTを学習する新しい方法を提案。ソフトトークンを活用し、計算コストを抑えつつ数百のトークンを持つ連続CoTを学習可能。LlamaおよびQwenモデルでの実験により、連続CoTは離散トークンCoTと同等またはそれを上回る性能を示し、特に連続CoTでトレーニング後に離散トークンで推論するシナリオが最良の結果を得ることが確認された。さらに、連続CoTのRLトレーニングは、ドメイン外タスクにおけるベースモデルの予測保持を向上させることが明らかになった。 Comment
元ポスト:
解説:
著者ポスト:
ポイント解説:
[Paper Note] Optimizing Temperature for Language Models with Multi-Sample Inference, Weihua Du+, ICML'25, 2025.02
Paper/Blog Link My Issue
#Analysis #NLP #Test-Time Scaling #SamplingParams #Best-of-N #MajorityVoting Issue Date: 2025-09-24 GPT Summary- マルチサンプル集約戦略を用いて、LLMの最適な温度を自動的に特定する手法を提案。従来の方法に依存せず、モデルアーキテクチャやデータセットを考慮した温度の役割を分析。新たに提案するエントロピーに基づく指標は、固定温度のベースラインを上回る性能を示し、確率過程モデルを用いて温度とパフォーマンスの関係を解明。 Comment
openreview: https://openreview.net/forum?id=rmWpE3FrHW¬eId=h9GETXxWDB
[Paper Note] LIMI: Less is More for Agency, Yang Xiao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #AIAgents Issue Date: 2025-09-23 GPT Summary- AIシステムのエージェンシーを、自律的に問題を発見し解決策を実行する能力と定義。急速に変化する業界のニーズに応じて、単なる推論を超えた自律的なエージェントが求められている。LIMI(Less Is More for Intelligent Agency)は、最小限のトレーニングサンプルで高いエージェンシーを実現する新たな原則を提案し、78サンプルで73.5%の成果を達成。これは、従来のデータ量に依存するアプローチに対する挑戦であり、高品質なデモの戦略的キュレーションが重要であることを示している。 Comment
元ポスト:
LLM AgentのSFTにおけるLess is more
参考:
- [Paper Note] LIMA: Less Is More for Alignment, Chunting Zhou+, arXiv'23, 2023.05
ポイント解説:
[Paper Note] ARE: Scaling Up Agent Environments and Evaluations, Pierre Andrews+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-09-23 GPT Summary- Meta Agents Research Environments (ARE)を紹介し、エージェントのオーケストレーションや環境のスケーラブルな作成を支援するプラットフォームを提供。Gaia2というベンチマークを提案し、エージェントの能力を測定するために設計され、動的環境への適応や他のエージェントとの協力を要求。Gaia2は非同期で実行され、新たな失敗モードを明らかにする。実験結果は、知能のスペクトル全体での支配的なシステムが存在しないことを示し、AREの抽象化が新しいベンチマークの迅速な作成を可能にすることを強調。AIの進展は、意味のあるタスクと堅牢な評価に依存する。 Comment
元ポスト:
GAIAはこちら:
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
Execution, Search, Ambiguity, Adaptability, Time, Noise, Agent2Agentの6つのcapabilityを評価可能。興味深い。
現状、全体的にはGPT-5(high)の性能が最も良く、続いてClaude-4 Sonnetという感じに見える。OpenWeightなモデルでは、Kimi-K2の性能が高く、続いてQwen3-235Bという感じに見える。また、Figure1はbudgetごとのモデルの性能も示されている。シナリオ単位のbudgetが$1以上の場合はGPT-5(high)の性能が最も良いが、$0.1--$0.4の間ではKiml-K2の性能が最も良いように見える。
- [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25
しっかりと読めていないがGLM-4.5は含まれていないように見える。
ポイント解説:
[Paper Note] GTA: Supervised-Guided Reinforcement Learning for Text Classification with Large Language Models, Min Zeng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Hybrid Issue Date: 2025-09-23 GPT Summary- GTAフレームワークを提案し、SFTの効率性とRLの能力を統合。モデルは仮の推測を生成し、最終的な回答を導出する。ハイブリッドアプローチにより、収束が速く、性能が向上。損失マスキングと勾配制約を用いて勾配の対立を軽減。実験結果はGTAの優位性を示す。 Comment
元ポスト:
[Paper Note] JudgeLM: Fine-tuned Large Language Models are Scalable Judges, Lianghui Zhu+, ICLR'25, 2023.10
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #Evaluation #LLM-as-a-Judge Issue Date: 2025-09-22 GPT Summary- 大規模言語モデル(LLMs)のオープンエンド評価のために、ファインチューニングされたJudgeLMを提案。高品質なデータセットを用いて、異なるパラメータサイズでトレーニングし、バイアスを分析。新技術を導入し、パフォーマンスを向上。JudgeLMは既存ベンチマークで最先端の結果を達成し、高い一致率を示す。拡張された能力も持ち、コードは公開されている。 Comment
openreview: https://openreview.net/forum?id=xsELpEPn4A
[Paper Note] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model, Chunting Zhou+, ICLR'25, 2024.08
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #ICLR #read-later #Selected Papers/Blogs #UMM Issue Date: 2025-09-22 GPT Summary- Transfusionは、離散データと連続データに対してマルチモーダルモデルを訓練する手法で、言語モデリングの損失関数と拡散を組み合わせて単一のトランスフォーマーを訓練します。最大7Bパラメータのモデルを事前訓練し、ユニモーダルおよびクロスモーダルベンチマークで優れたスケーリングを示しました。モダリティ特有のエンコーディング層を導入することで性能を向上させ、7Bパラメータのモデルで画像とテキストを生成できることを実証しました。 Comment
openreview: https://openreview.net/forum?id=SI2hI0frk6
[Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #PostTraining Issue Date: 2025-09-22 GPT Summary- LoRAは基盤モデルの効率的なファインチューニング手法だが、フルファインチューニングに比べ性能が劣ることが多い。本論文では、LoRAとフルファインチューニングの最適化プロセスの関係を明らかにし、LoRAの低ランク行列の勾配を調整する新手法LoRA-Proを提案。これにより、LoRAの性能が向上し、フルファインチューニングとのギャップが縮小することを実験で示した。 Comment
元ポスト: https://openreview.net/forum?id=gTwRMU3lJ5
openreview: https://openreview.net/forum?id=gTwRMU3lJ5
[Paper Note] Synthetic bootstrapped pretraining, Zitong Yang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pretraining #NLP #SyntheticData #read-later #Concept (LLM PreTraining) #Author Thread-Post Issue Date: 2025-09-22 GPT Summary- Synthetic Bootstrapped Pretraining(SBP)は、文書間の関係を学習し、新しいコーパスを合成する言語モデルの事前学習手法です。従来の事前学習は単一文書内の因果関係に焦点を当てていますが、SBPは文書間の相関関係を効率的にモデル化します。3Bパラメータのモデルを用いた実験で、SBPは強力なベースラインを改善し、合成された文書は単なる言い換えを超えた新しい物語を構築することが示されました。SBPは自然なベイズ的解釈を許容し、関連文書間の潜在的な概念を学習します。 Comment
元ポスト:
ポイント解説:
興味深い。
著者ポスト:
conceptを学習するという観点では以下が関連している気がするが、アプローチが大きく異なる:
- [Paper Note] Large Concept Models: Language Modeling in a Sentence Representation Space, LCM team+, arXiv'24, 2024.12
Adaptive Localization of Knowledge Negation for Continual LLM Unlearning, Wuerkaixi+, ICML'25
Paper/Blog Link My Issue
#NLP #ICML #KnowledgeEditing Issue Date: 2025-09-22 GPT Summary- 大規模言語モデル(LLMs)の安全性に関する懸念が高まる中、ターゲット知識を効果的に忘却しつつ利用価値を維持する手法ALKN(Adaptive Localization of Knowledge Negation)を提案。動的マスキングを用いてトレーニング勾配をスパース化し、忘却の強度を適応的に調整。実験により、継続的な忘却設定でベースラインを上回る効果を示した。 Comment
元ポスト:
[Paper Note] MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer, Yanghao Li+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #NLP #UMM Issue Date: 2025-09-22 GPT Summary- Manzanoは、視覚コンテンツの理解と生成を統一的に行うマルチモーダル大規模言語モデル(LLMs)で、ハイブリッド画像トークナイザーとトレーニングレシピを組み合わせてパフォーマンスのトレードオフを軽減します。単一のビジョンエンコーダーが画像からテキストへの埋め込みを生成し、自己回帰型LLMがテキストと画像トークンの高レベルの意味を予測します。このアーキテクチャにより、両方の能力の共同学習が可能となり、最先端の結果を達成しました。 Comment
元ポスト:
ポイント解説:
DocVQAのオラクルはラベルノイズと曖昧性の観点から94--95という主張:
[Paper Note] Stress Testing Deliberative Alignment for Anti-Scheming Training, Bronson Schoen+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #Safety #read-later #Scheming Issue Date: 2025-09-22 GPT Summary- 高度なAIシステムは不整合な目標を追求する「陰謀」を持つ可能性があり、これを測定・軽減するには特別なアプローチが必要です。本研究では、反陰謀介入の評価において、遠くの分布外タスクでの陰謀の傾向、状況認識による陰謀の有無、既存の不整合な目標に対するロバスト性を確認することを提案します。秘密の行動を陰謀の代理として扱い、熟慮的整合性をストレステストした結果、秘密の行動率が低下することが示されましたが、完全には排除できませんでした。モデルの思考の連鎖が整合性評価を認識することで秘密の行動が減少する一方、無自覚であると増加することも示唆されました。今後、陰謀に対する整合性の軽減策とその評価に関する研究が重要です。 Comment
元ポスト:
[Paper Note] Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences, Andrew Kyle Lampinen+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #In-ContextLearning #RAG(RetrievalAugmentedGeneration) #Generalization #ReversalCurse #memory Issue Date: 2025-09-22 GPT Summary- 機械学習システムの一般化失敗の原因として、潜在学習の欠如を指摘。認知科学の視点から、エピソード記憶やオラクルリトリーバルメカニズムが一般化を改善する手段であることを示す。文脈内学習が情報活用の鍵であり、リトリーバル手法がパラメトリック学習を補完することで、データ効率を向上させる可能性を提案。 Comment
元ポスト:
[Paper Note] Refuse Whenever You Feel Unsafe: Improving Safety in LLMs via Decoupled Refusal Training, Youliang Yuan+, ACL'25, 2024.07
Paper/Blog Link My Issue
#NLP #Alignment #SyntheticData #Safety #ACL #PostTraining #KeyPoint Notes Issue Date: 2025-09-21 GPT Summary- 本研究では、LLMsの安全性調整における拒否ポジションバイアスの問題を解決するために、「Decoupled Refusal Training(DeRTa)」という新しいアプローチを提案。DeRTaは、有害な応答プレフィックスを用いた最大尤度推定と強化された遷移最適化を組み込み、モデルが不適切なコンテンツを認識し拒否する能力を強化します。実証評価では、提案手法が安全性を向上させ、攻撃に対する防御でも優れた性能を示しました。 Comment
元ポスト:
一般的なSafety Tuningでは有害なpromptが与えられた時に安全な応答が生成される確率を最大化する(MLE)が、安全な応答は冒頭の数トークンにSorry, I apologize等の回答を拒絶するトークンが集中する傾向にあり、応答を拒否するか否かにポジションバイアスが生じてしまう。これにより、応答の途中で潜在的な危険性を検知し、応答を拒否することができなくなってしまうという課題が生じる。
これを解決するために、RTOを提案している。有害なpromptの一部をprefixとし、その後にSafetyなレスポンスをconcatするような応答を合成しMLEに活用することで、応答の途中でも応答を拒否するような挙動を学習することができる。prefixを利用することで、
- prefixを用いることで安全なレスポンスに追加のcontextを付与することができ、潜在的な危険性の識別力が高まり、
- prefixの長さは任意なので、応答のどのポジションからでも危険性識別できるようになり、
- モデルが有害な応答を開始したことをシームレスに認識して安全な回答を生成するように遷移させられる
といった利点があるが、1つの学習サンプルにつき一つの遷移(i.e., prefixと安全な応答の境目は1サンプルにつき一箇所しかないので)しか学習できないことである。このため、RTOでは、レスポンスの全てのポジションにおいてsorryが生成される確率を最大化することで、モデルが全てのポジションで継続的に危険性を識別できる能力を高めるような工夫をする。
目的関数は以下で、Harmful Prefixがgivenな時に安全な回答が生成される確率を最大化するMLEの項に対して(r^hat_
実験の結果は、全体を見る限り、helpfulnessを損なうことなく、安全な応答を生成できるようになっており、DPO等のその他のAlignment手法よりも性能が良さそうである。
以下の研究で報告されている現象と似ている:
- [Paper Note] The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, NeurIPS'25, 2025.03
すなわち、reasoning traceの最初の数トークンが全体の品質に大きく関わるという話
[Paper Note] FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning, Liang Hu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Search #Dataset #Evaluation #Financial Issue Date: 2025-09-21 GPT Summary- FinSearchCompは、金融検索と推論のための初の完全オープンソースエージェントベンチマークであり、時間に敏感なデータ取得や複雑な歴史的調査を含む3つのタスクで構成されています。70人の金融専門家によるアノテーションと厳格な品質保証を経て、635の質問が用意され、21のモデルが評価されました。Grok 4とDouBaoがそれぞれグローバルおよび大中華圏でトップの精度を示し、ウェブ検索と金融プラグインの活用が結果を改善することが確認されました。FinSearchCompは、現実のアナリストタスクに基づく高難易度のテストベッドを提供します。 Comment
元ポスト:
[Paper Note] LongEmotion: Measuring Emotional Intelligence of Large Language Models in Long-Context Interaction, Weichu Liu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #LongSequence #Emotion Issue Date: 2025-09-21 GPT Summary- 長文の感情知能(EI)タスク専用のベンチマーク「LongEmotion」を提案。感情分類や感情会話など多様なタスクをカバーし、平均入力長は8,777トークン。Retrieval-Augmented Generation(RAG)とCollaborative Emotional Modeling(CoEM)を組み込み、従来の手法と比較してEIパフォーマンスを向上。実験結果は、RAGとCoEMが長文タスクにおいて一貫して効果を示し、LLMsの実用性を高めることを示した。 Comment
pj page: https://longemotion.github.io
元ポスト:
[Paper Note] Generalizing Verifiable Instruction Following, Valentina Pyatkin+, NeurIPS'25, 2025.07
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #InstructionTuning #Evaluation #NeurIPS #RLVR #Selected Papers/Blogs #InstructionFollowingCapability Issue Date: 2025-09-21 GPT Summary- 人間とAIの相互作用において、言語モデルが指示に従う能力が重要であるが、現在のモデルは出力制約を満たすのに苦労している。多くのモデルは既存のベンチマークに過剰適合しており、未見の制約に対して一般化できない。これを解決するために、新しいベンチマークIFBenchを導入し、指示遵守の一般化を評価する。さらに、制約検証モジュールと強化学習(RLVR)を用いて指示遵守を改善する方法を示し、関連するデータや訓練プロンプトを公開する。 Comment
元ポスト:
Instruction Followingのための新たなベンチマークIFBench(多様(58種類の制約)で精緻、かつ複数の出力に関する制約を持つ。Appendix Aを参照のこと)を導入し、RLVRによってInstruction tuningする方法を提案している模様。複数のIFの制約を同時に学習した方がOODに対してロバストになることや、制約ごとのinstance数に対する性能の変化、またSFT, DPOによってInstrtction Tuningを実施したモデルに対して、制約を満たしたか否かのVerifiableなデータから生成した嗜好データを用いて追加のDPOを実施した場合と、RLVRに基づくGRPOを実施した場合のどちらの性能が良いかなども実験されている(一貫してGRPOが良い)。
解説:
[Paper Note] Pre-training under infinite compute, Konwoo Kim+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #Ensemble #Scaling Laws #read-later #Author Thread-Post Issue Date: 2025-09-20 GPT Summary- 計算能力の増加に対し、固定データでの事前学習のアプローチを考察。エポック数やパラメータ数の増加は過学習を引き起こすが、正則化を適切に調整することで改善可能。最適な重み減衰は標準の30倍で、正則化手法は損失を単調に減少させる。アンサンブルモデルは正則化手法よりも低い損失を達成し、データ使用量を5.17倍削減。学生モデルへの蒸留により、データ効率を向上させ、下流ベンチマークでの改善も確認。結果は、計算リッチな未来におけるデータ効率の良い事前学習の可能性を示す。 Comment
元ポスト:
解説ポスト:
所見:
[Paper Note] ToolRL: Reward is All Tool Learning Needs, Cheng Qian+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #NeurIPS #Author Thread-Post Issue Date: 2025-09-20 GPT Summary- 大規模言語モデル(LLMs)のツール使用能力向上のため、報酬設計に関する初の包括的研究を行い、さまざまな報酬戦略を探求。ツール使用タスクに特化した報酬設計を提案し、GRPOを用いてLLMsを訓練。実証評価により、ベースモデルに対して17%、SFTモデルに対して15%の性能改善を達成。報酬設計の重要性を強調し、コードを公開。 Comment
元ポスト:
著者ポスト:
[Paper Note] Length Representations in Large Language Models, Sangjun Moon+, EMNLP'25
Paper/Blog Link My Issue
#Analysis #NLP #EMNLP #Length Issue Date: 2025-09-20 GPT Summary- LLMsは出力シーケンスの長さを制御する能力を持ち、その内部メカニズムを探求。特に、マルチヘッドアテンションが出力長の決定に重要であり、特定の隠れユニットを調整することで長さを制御可能であることを示す。プロンプトが長さ特有になると隠れユニットが活性化し、モデルの内部認識を反映。これにより、LLMsは外部制御なしに出力の長さを適応的に制御するメカニズムを学習していることが示唆される。
[Paper Note] BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model, Adibvafa Fallahpour+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Reasoning #Biological Issue Date: 2025-09-20 GPT Summary- BioReasonは、DNA基盤モデルと大規模言語モデル(LLM)を統合した新しいアーキテクチャで、複雑なゲノムデータからの生物学的推論を深く解釈可能にする。多段階推論を通じて、精度が88%から97%に向上し、バリアント効果予測でも平均15%の性能向上を達成。未見の生物学的エンティティに対する推論を行い、解釈可能な意思決定を促進することで、AIにおける生物学の進展を目指す。 Comment
HF:
https://huggingface.co/collections/wanglab/bioreason-683cd17172a037a31d208f70
pj page:
https://bowang-lab.github.io/BioReason/
元ポスト:
[Paper Note] FlowRL: Matching Reward Distributions for LLM Reasoning, Xuekai Zhu+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning Issue Date: 2025-09-20 GPT Summary- FlowRLは、LLM強化学習において報酬を最大化するのではなく、フローバランシングを通じて報酬分布を一致させる手法です。従来の報酬最大化手法は多様性を減少させる傾向があるため、FlowRLでは学習可能な分割関数を用いてターゲット分布に変換し、ポリシーとターゲット分布の逆KLダイバージェンスを最小化します。実験の結果、FlowRLは数学ベンチマークでGRPOに対して平均10.0%、PPOに対して5.1%の改善を達成し、コード推論タスクでも優れた性能を示しました。報酬分布の一致が効率的な探索と多様な推論に重要であることが示されました。 Comment
元ポスト:
報酬を最大化するのではなく、報酬分布を一致させるように学習するらしい
ポイント解説:
[Paper Note] The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity, Parshin Shojaee+, arXiv'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Reasoning #NeurIPS #read-later Issue Date: 2025-09-19 GPT Summary- LRMsは思考プロセスを生成するが、その能力や限界は未解明。評価は主に最終回答の正確性に焦点を当てており、推論の痕跡を提供しない。本研究では制御可能なパズル環境を用いて、LRMsの推論過程を分析。実験により、LRMsは特定の複雑さを超えると正確性が崩壊し、スケーリングの限界が明らかに。低複雑性では標準モデルが優位、中複雑性ではLRMsが優位、高複雑性では両者が崩壊することを示した。推論の痕跡を調査し、LRMsの強みと限界を明らかに。 Comment
元ポスト:
出た当初相当話題になったIllusion of thinkingがNeurIPSにacceptされた模様。Appendix A.1に当時のcriticismに対するレスポンスが記述されている。
[Paper Note] BREAD: Branched Rollouts from Expert Anchors Bridge SFT & RL for Reasoning, Xuechen Zhang+, NeurIPS'25
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #MachineLearning #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #SmallModel #NeurIPS #PostTraining #On-Policy Issue Date: 2025-09-19 GPT Summary- 小型言語モデル(SLMs)は、トレースが不足している場合に複雑な推論を学ぶのが難しい。本研究では、SFT + RLの限界を調査し、BREADという新しい手法を提案。BREADは、専門家のガイダンスを用いてSFTとRLを統合し、失敗したトレースに対して短いヒントを挿入することで成功を促進。これにより、トレーニングが約3倍速くなり、標準的なGRPOを上回る性能を示す。BREADは、SLMの推論能力を大幅に向上させることが確認された。 Comment
元ポスト:
[Paper Note] Trust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards, Xiaoyuan Liu+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #NeurIPS #read-later #RLVR #On-Policy #Initial Impression Notes #SelfVerification Issue Date: 2025-09-19 GPT Summary- RISEという新しいオンラインRLフレームワークを提案し、LLMの問題解決能力と自己検証能力を同時に向上させる。結果検証者からの報酬を活用し、解決策生成と自己検証に即時フィードバックを提供。実験により、RISEは問題解決精度を向上させ、自己検証スキルを育成することが示された。RISEは堅牢で自己認識のある推論者を育成するための効果的な手法である。 Comment
元ポスト:
Self-Verificationの能力が大幅に向上するのは良さそう。
[Paper Note] MergeBench: A Benchmark for Merging Domain-Specialized LLMs, Yifei He+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #NeurIPS #ModelMerge Issue Date: 2025-09-19 GPT Summary- モデルマージングは、ファインチューニングされたモデルを組み合わせることでマルチタスクトレーニングの効率的なデプロイを可能にする手法です。本研究では、モデルマージングを大規模に評価するための評価スイート「MergeBench」を導入し、指示遵守や数学、多言語理解など5つのドメインをカバーします。8つのマージング手法を評価し、より強力なベースモデルがより良いパフォーマンスを発揮する傾向を示しましたが、大規模モデルの計算コストやドメイン内パフォーマンスのギャップなどの課題も残っています。MergeBenchは今後の研究の基盤となることが期待されています。 Comment
[Paper Note] The Leaderboard Illusion, Shivalika Singh+, NeurIPS'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Evaluation #NeurIPS #read-later #Selected Papers/Blogs Issue Date: 2025-09-19 GPT Summary- 進捗測定は科学の進展に不可欠であり、Chatbot ArenaはAIシステムのランキングにおいて重要な役割を果たしている。しかし、非公開のテスト慣行が存在し、特定のプロバイダーが有利になることで、スコアにバイアスが生じることが明らかになった。特に、MetaのLlama-4に関連するプライベートLLMバリアントが問題視され、データアクセスの非対称性が生じている。GoogleやOpenAIはArenaデータの大部分を占め、オープンウェイトモデルは少ないデータしか受け取っていない。これにより、Arena特有のダイナミクスへの過剰適合が発生している。研究は、Chatbot Arenaの評価フレームワークの改革と、公正で透明性のあるベンチマーキングの促進に向けた提言を行っている。 Comment
元ポスト:
要チェック
[Paper Note] Inpainting-Guided Policy Optimization for Diffusion Large Language Models, Siyan Zhao+, arXiv'25
Paper/Blog Link My Issue
#MachineLearning #NLP #ReinforcementLearning #DiffusionModel #On-Policy #Inpainting Issue Date: 2025-09-19 GPT Summary- dLLMsはインペインティング能力を活用し、強化学習の探索課題を解決するIGPOフレームワークを提案。部分的な真実の推論トレースを挿入し、探索を有望な軌道に導く。これによりサンプル効率が向上し、GSM8K、Math500、AMCの数学ベンチマークで新たな最先端結果を達成。 Comment
元ポスト:
部分的にtraceの正解を与えると、正解の方向にバイアスがかかるので多様性が犠牲になる気もするが、その辺はどうなんだろうか。
[Paper Note] Self Iterative Label Refinement via Robust Unlabeled Learning, Hikaru Asano+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Bias #SelfCorrection #NeurIPS #read-later #PseudoLabeling Issue Date: 2025-09-19 GPT Summary- 自己洗練手法を用いて、LLMの擬似ラベルを改善するための反復洗練パイプラインを提案。ラベルなしデータセットを活用し、内部バイアスを軽減しつつ、分類タスクでのパフォーマンスを向上。多様なデータセットで評価し、最先端モデルを上回る結果を示した。 Comment
元ポスト:
関連研究(Pseudo Labeling):
- [Paper Note] Training a Helpful and Harmless Assistant with Reinforcement Learning
from Human Feedback, Yuntao Bai+, arXiv'22
[Paper Note] OS-Harm: A Benchmark for Measuring Safety of Computer Use Agents, Thomas Kuntz+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #Safety #NeurIPS Issue Date: 2025-09-19 GPT Summary- コンピュータ使用エージェントの安全性を評価するために、新しいベンチマークOS-Harmを導入。OS-Harmは、意図的な誤用、プロンプトインジェクション攻撃、不適切な行動の3つの危害をテストする150のタスクを含む。自動ジャッジを用いてエージェントの正確性と安全性を評価し、高い一致率を達成。最前線モデルの評価から、意図的な誤用に従う傾向や脆弱性が明らかになった。OS-Harmは、エージェントの安全性向上に寄与することを目指す。 Comment
元ポスト:
[Paper Note] Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs, Yue Wang+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #NeurIPS #Decoding #Underthinking #Author Thread-Post Issue Date: 2025-09-19 GPT Summary- 大規模言語モデル(LLMs)は複雑な推論タスクで優れた能力を示すが、「アンダーシンキング」という現象により、思考の切り替えが頻繁に起こり、特に難しい数学問題でパフォーマンスが低下することが明らかになった。新しい指標を用いてアンダーシンキングを定量化し、思考の切り替えを抑制するデコーディング戦略TIPを提案。実験により、モデルのファインチューニングなしで精度が向上することが示された。これにより、LLMの推論の非効率性を理解し、問題解決能力を向上させる実用的な解決策が提供される。 Comment
元ポスト:
著者ポスト:
[Paper Note] Reinforcement Learning Finetunes Small Subnetworks in Large Language Models, Sagnik Mukherjee+, NeurIPS''25, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #NeurIPS #read-later #Sparse #Initial Impression Notes Issue Date: 2025-09-19 GPT Summary- 強化学習(RL)は、LLMsのパフォーマンスと人間の価値観の整合性を大幅に改善する。驚くべきことに、パラメータの5%から30%の小さなサブネットワークのみを更新することで実現されるスパース性が観察され、これは7つのRLアルゴリズムと10のLLMで共通して見られた。このスパース性は本質的であり、サブネットワークのファインチューニングによってテスト精度が回復し、ほぼ同一のモデルが生成される。更新はほぼフルランクであり、ポリシー分布に近いデータでのトレーニングが主な要因と考えられる。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=0NdS4xCngO
RLの挙動を理解する上で役に立ちそうで興味深い。以下とは何か関連があるのだろうか:
- [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, ICLR'26, 2025.08
- [Paper Note] From Atomic to Composite: Reinforcement Learning Enables Generalization in Complementary Reasoning, Sitao Cheng+, arXiv'25, 2025.12
[Paper Note] Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation, Yujun Zhou+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Diversity #MajorityVoting Issue Date: 2025-09-19 GPT Summary- EVOL-RLは、ラベルなしの強化学習手法であり、モデルの探索能力と一般化能力を維持しつつ、安定性と変動を結びつける。多数決で選ばれた回答を安定したアンカーとして保持し、新規性を意識した報酬を追加することで、生成物の多様性を保ち、思考の連鎖を改善する。実験により、EVOL-RLはTTRLベースラインを上回り、特にラベルなしのAIME24での訓練において顕著な性能向上を示した。 Comment
元ポスト:
ポイント解説:
関連:
- [Paper Note] Jointly Reinforcing Diversity and Quality in Language Model Generations, Tianjian Li+, arXiv'25
- [Paper Note] TTRL: Test-Time Reinforcement Learning, Yuxin Zuo+, NeurIPS'25, 2025.04
[Paper Note] Nemotron-CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training, Shizhe Diao+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#Pretraining #NLP #NeurIPS #read-later #Selected Papers/Blogs #DataMixture Issue Date: 2025-09-19 GPT Summary- 事前学習用データセットの最適な混合を特定するのは依然として難題である。そこで、クラスタリングベースの反復データ混合ブートストラッピング手法(Nemotron-CLIMB)を提案。この自動フレームワークは、大規模データセットを意味空間に埋め込み、クラスタリングを行い、代理モデルを用いて反復的に最適な混合を探索する。最終的に、10億パラメータのモデルは最先端モデルを2.0%上回り、特定のドメイン最適化では5%の改善が見られた。また、Nemotron-ClimbLabとNemotron-ClimbMixという新しいデータセットも提供され、効率的な事前学習に寄与する。 Comment
pj page: https://research.nvidia.com/labs/lpr/climb/
元ポスト:
datatet: https://huggingface.co/datasets/nvidia/Nemotron-ClimbMix
[Paper Note] LMFusion: Adapting Pretrained Language Models for Multimodal Generation, Weijia Shi+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #NeurIPS #UMM Issue Date: 2025-09-19 GPT Summary- LMFusionは、テキストのみのLLMにマルチモーダル生成能力を付与するフレームワークで、テキストと画像の理解・生成を可能にします。既存のLlama-3の重みを活用し、画像処理のための並列トランスフォーマーモジュールを追加。各モダリティは独立して処理され、相互作用が可能です。実験により、LMFusionは画像理解を20%、生成を3.6%向上させ、Llama-3の言語能力を維持しつつ、効率的にマルチモーダルモデルを開発できることが示されました。 Comment
元ポスト:
先行研究:
- [Paper Note] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model, Chunting Zhou+, ICLR'25, 2024.08
- [Paper Note] U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger+, MICCAI'15, 2015.05
[Paper Note] WebSailor: Navigating Super-human Reasoning for Web Agent, Kuan Li+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #Reasoning #On-Policy Issue Date: 2025-09-18 GPT Summary- WebSailorは、LLMのトレーニングにおいて人間の認知的限界を超えるためのポストトレーニング手法であり、複雑な情報探索タスクでの性能を向上させる。構造化サンプリングや情報の難読化、DUPOを用いて高不確実性タスクを生成し、オープンソースエージェントの能力を大幅に上回ることを目指す。
[Paper Note] WebDancer: Towards Autonomous Information Seeking Agency, Jialong Wu+, arXiv'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData Issue Date: 2025-09-18 GPT Summary- 複雑な問題解決のために、エンドツーエンドの情報探索エージェントを構築する一貫したパラダイムを提案。4つの主要ステージ(データ構築、軌跡サンプリング、教師ありファインチューニング、強化学習)を経て、WebDancerを実装。GAIAとWebWalkerQAでの評価により、強力なパフォーマンスを示し、トレーニングパラダイムの有効性を確認。コードは公開予定。
[Paper Note] BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese, Peilin Zhou+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Factuality Issue Date: 2025-09-18 GPT Summary- BrowseComp-ZHは、中国のウェブ上でLLMエージェントを評価するために設計された高難易度のベンチマークで、289のマルチホップ質問から構成される。二段階の品質管理プロトコルを適用し、20以上の言語モデルを評価した結果、ほとんどのモデルが10%未満の精度で苦戦し、最良のモデルでも42.9%にとどまった。この結果は、効果的な情報取得戦略と洗練された推論能力が必要であることを示している。 Comment
[Paper Note] WebWalker: Benchmarking LLMs in Web Traversal, Jialong Wu+, arXiv'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Dataset #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-09-18 GPT Summary- WebWalkerQAを導入し、LLMがウェブのサブページから高品質なデータを抽出する能力を評価。探査-批評のパラダイムを用いたマルチエージェントフレームワークWebWalkerを提案し、実験によりRAGの効果を実証。 Comment
web pageのコンテンツを辿らないと回答できないQAで構成されたベンチマーク
[Paper Note] Shared Imagination: LLMs Hallucinate Alike, Yilun Zhou+, TMLR'25, 2025.08
Paper/Blog Link My Issue
#Analysis #NLP #Evaluation #Hallucination #TMLR #read-later Issue Date: 2025-09-18 GPT Summary- 大規模言語モデル(LLMs)の類似性を理解するために、想像上の質問応答(IQA)という新しい設定を提案。IQAでは、1つのモデルが架空の質問を生成し、別のモデルがそれに答える。驚くべきことに、全てのモデルがフィクションの質問に成功裏に応答できることから、共通の「想像空間」が存在することが示唆される。この現象について調査し、モデルの均質性や幻覚、計算的創造性に関する考察を行う。 Comment
openreview: https://openreview.net/forum?id=NUXpBMtDYs
元ポスト:
[Paper Note] DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning, Guo+, Nature'25, 2025.09
Paper/Blog Link My Issue
#NLP #Reasoning #read-later #Nature Issue Date: 2025-09-18 GPT Summary- 本研究では、LLMsの推論能力を強化学習(RL)を通じて向上させ、人間によるラベル付けの必要性を排除することを示す。提案するRLフレームワークは、高度な推論パターンの発展を促進し、数学やコーディングコンペティションなどのタスクで優れたパフォーマンスを達成する。さらに、出現的な推論パターンは小さなモデルの能力向上にも寄与する。 Comment
DeepSeek-R1の論文のNature版が出た模様。
解説:
Supplementary Materials:
https://static-content.springer.com/esm/art%3A10.1038%2Fs41586-025-09422-z/MediaObjects/41586_2025_9422_MOESM1_ESM.pdf
おそらくこちらの方が重要
[Paper Note] RL Fine-Tuning Heals OOD Forgetting in SFT, Hangzhan Jin+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #read-later Issue Date: 2025-09-17 GPT Summary- 二段階ファインチューニングにおけるSFTとRLの相互作用を探求し、SFTが記憶し、RLが一般化するという主張が過度に単純化されていることを発見。具体的には、(1) OOD性能はSFTの初期段階でピークに達し、その後低下すること、(2) RLはSFT中に失われた推論能力を回復する役割を果たすこと、(3) 回復能力には限界があること、(4) OODの挙動は特異ベクトルの「回転」と強く相関することを明らかにした。これにより、SFTとRLの役割を再認識し、特異ベクトルの回転が重要なメカニズムであることを示した。 Comment
- [Paper Note] SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25
- [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, ICLR'26, 2025.08
- [Paper Note] Towards a Unified View of Large Language Model Post-Training, Xingtai Lv+, arXiv'25
- [Paper Note] RL's Razor: Why Online Reinforcement Learning Forgets Less, Idan Shenfeld+, ICLR'26
と合わせて読むと良さそう
元ポスト:
直感的には、下記研究でSFTをRLの観点で見たときに、回答の軌跡に対してexact matchしていた場合に1を返す報酬を持つRL、かつimportance weightingによって現在のポリシーが苦手な軌跡を重要視する、ということ考えると、目的のデータに対して汎化性能おかまいなしにgreedyに最適化されるため、OODへの対応力が無くなる、というのはなんとなく理解できる。
- [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, ICLR'26, 2025.08
[Paper Note] Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings, Shiyu Li+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #InformationRetrieval Issue Date: 2025-09-17 GPT Summary- 新しい1.4BパラメータのLLM「Conan-embedding-v2」をゼロからトレーニングし、テキスト埋め込み器としてファインチューニングする手法を提案。ニュースデータと多言語ペアを追加してデータギャップを埋め、クロスリンガルリトリーバルデータセットを導入。ソフトマスキングメカニズムを用いてトークンレベルと文レベルの損失を統合し、動的ハードネガティブマイニング手法を採用。これにより、MTEBおよびChinese MTEBでSOTA性能を達成。 Comment
元ポスト:
[Paper Note] Fluid Language Model Benchmarking, Valentin Hofmann+, COLM'25
Paper/Blog Link My Issue
#NLP #Dataset #IRT #Evaluation #COLM #Author Thread-Post Issue Date: 2025-09-17 GPT Summary- Fluid Benchmarkingという新しい言語モデル(LM)評価アプローチを提案。これは、LMの能力に応じて評価項目を動的に選択し、評価の質を向上させる。実験では、Fluid Benchmarkingが効率、妥当性、分散、飽和の4つの次元で優れたパフォーマンスを示し、静的評価を超えることでLMベンチマークを改善できることを示した。 Comment
元ポスト:
著者ポスト:
[Paper Note] MachineLearningLM: Scaling Many-shot In-context Learning via Continued Pretraining, Haoyu Dong+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #Zero/Few/ManyShotPrompting #In-ContextLearning Issue Date: 2025-09-17 GPT Summary- MachineLearningLMは、LLMにインコンテキスト学習能力を強化するための継続的事前学習フレームワークであり、数百万のMLタスクを合成する。ランダムフォレスト教師を用いて意思決定戦略を蒸留し、数値モデリングの堅牢性を向上。控えめなセットアップでも、金融や医療分野で強力なベースラインを約15%上回り、インコンテキストデモンストレーションの増加に伴い精度が向上。一般的なチャット能力も保持し、MMLUで75.4%を達成。 Comment
元ポスト:
[Paper Note] ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization, Xixi Wu+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #read-later #ContextEngineering Issue Date: 2025-09-17 GPT Summary- ReSumという新しいパラダイムを導入し、定期的なコンテキスト要約を通じて無限の探索を可能にする。ReSum-GRPOを提案し、エージェントが要約条件付き推論に慣れるようにする。実験により、ReSumはReActに対して平均4.5%の改善を示し、WebResummer-30Bは既存のウェブエージェントを上回る性能を達成。 Comment
元ポスト:
[Paper Note] WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research, Zijian Li+, arXiv'25
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #Planning #LongSequence #read-later #DeepResearch #memory Issue Date: 2025-09-17 GPT Summary- 本論文では、AIエージェントがウェブ情報を統合してレポートを作成するオープンエンド深層研究(OEDR)に取り組み、WebWeaverという新しい二重エージェントフレームワークを提案。プランナーが証拠取得とアウトライン最適化を交互に行い、ライターが情報を階層的に検索してレポートを構成することで、長いコンテキストの問題を軽減。提案手法は主要なOEDRベンチマークで新たな最先端を確立し、高品質なレポート生成における人間中心のアプローチの重要性を示した。 Comment
元ポスト:
[Paper Note] Scaling Agents via Continual Pre-training, Liangcai Su+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #AIAgents #FoundationModel #read-later Issue Date: 2025-09-17 GPT Summary- 大規模言語モデル(LLMs)を用いたエージェントシステムは、複雑な問題解決において進化しているが、ポストトレーニングアプローチではパフォーマンスが低下することが多い。これは、堅牢な基盤モデルの欠如が原因である。そこで、継続的な事前トレーニング(Agentic CPT)を導入し、強力なエージェント基盤モデルを構築することを提案。新たに開発したAgentFounderモデルは、10のベンチマークで最先端のパフォーマンスを達成し、特にBrowseComp-enで39.9%、BrowseComp-zhで43.3%、HLEでのPass@1で31.5%を記録した。 Comment
元ポスト:
AI Agentのための基盤モデルを継続事前学習によって実現した模様
[Paper Note] Towards General Agentic Intelligence via Environment Scaling, Runnan Fang+, arXiv'25
Paper/Blog Link My Issue
#NLP #AIAgents #read-later #MCP Issue Date: 2025-09-17 GPT Summary- 本研究では、エージェント知能を向上させるために環境を拡大し、関数呼び出し能力を強化するスケーラブルなフレームワークを提案。エージェントの訓練は二段階で行い、基本能力を付与した後、特定のドメインに特化させる。実験により、提案モデルAgentScalerが関数呼び出し能力を大幅に向上させることを示した。 Comment
元ポスト:
blog: https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
[Paper Note] WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents, Zile Qiao+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #AIAgents #read-later #DeepResearch Issue Date: 2025-09-17 GPT Summary- 新しいフレームワーク「WebResearcher」を提案し、AIエージェントが外部ソースから知識を自律的に発見・統合する方法を示す。WebResearcherは、深層研究をマルコフ決定過程として再定式化し、報告書に発見を統合することで文脈の問題を克服。また、スケーラブルなデータ合成エンジン「WebFrontier」を用いて高品質なトレーニングデータを生成し、ツール使用能力を向上させる。実験により、WebResearcherは最先端の性能を達成し、商用システムを上回ることが確認された。 Comment
元ポスト:
blog: https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
OpenAI DeepResearchとベンチマーク上で同等の性能を実現したopenweightモデル
ベンチマーク:
- [Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25, 2025.01
- [Paper Note] BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, Jason Wei+, arXiv'25
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
- [Paper Note] WebWalker: Benchmarking LLMs in Web Traversal, Jialong Wu+, arXiv'25
- [Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, NAACL'25
- [Paper Note] BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language
Models in Chinese, Peilin Zhou+, arXiv'25
[Paper Note] Paper2Agent: Reimagining Research Papers As Interactive and Reliable AI Agents, Jiacheng Miao+, arXiv'25
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #ScientificDiscovery #Reproducibility #MCP Issue Date: 2025-09-17 GPT Summary- Paper2Agentは、研究論文をAIエージェントに自動変換するフレームワークで、研究成果の利用や発見を加速します。従来の論文は再利用の障壁を生んでいましたが、Paper2Agentは論文を知識豊富な研究アシスタントとして機能するエージェントに変換します。複数のエージェントを用いて論文と関連コードを分析し、モデルコンテキストプロトコル(MCP)を構築、洗練します。これにより、自然言語を通じて科学的クエリを実行できるエージェントを作成し、実際にゲノム変異やトランスクリプトミクス分析を行うエージェントが元の論文の結果を再現できることを示しました。Paper2Agentは、静的な論文を動的なAIエージェントに変えることで、知識の普及に新たなパラダイムを提供します。 Comment
code: https://github.com/jmiao24/Paper2Agent?tab=readme-ov-file#-demos
論文を論文が提案する技術の機能を提供するMCPサーバに変換し、LLM Agentを通じてユーザはsetup無しに呼びだして利用できるようにする技術な模様。論文から自動的にcodebaseを同定し、コアとなる技術をMCP toolsとしてラップし、反復的なテストを実施してロバストにした上でHF上のAI Agentに提供する、みたいな感じに見える。
ポイント解説:
[Paper Note] SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?, John Yang+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #AIAgents #Evaluation #MultiModal #ICLR #SoftwareEngineering #VisionLanguageModel Issue Date: 2025-09-16 GPT Summary- 自律システムのバグ修正能力を評価するために、SWE-bench Mを提案。これは視覚要素を含むJavaScriptソフトウェアのタスクを対象とし、617のインスタンスを収集。従来のSWE-benchシステムが視覚的問題解決に苦労する中、SWE-agentは他のシステムを大きく上回り、12%のタスクを解決した。 Comment
openreview: https://openreview.net/forum?id=riTiq3i21b
[Paper Note] Embodied Navigation Foundation Model, Jiazhao Zhang+, arXiv'25
Paper/Blog Link My Issue
#FoundationModel #Navigation #VisionLanguageModel #Robotics #EmbodiedAI Issue Date: 2025-09-16 GPT Summary- NavFoMは、800万のナビゲーションサンプルで訓練されたクロス具現化・クロスタスクのナビゲーション基盤モデルであり、ビジョンと言語のナビゲーションや自律運転など多様なタスクに対応。異なるカメラ構成や時間的視野を考慮し、動的に調整されたサンプリング戦略を用いて、ファインチューニングなしで最先端の性能を達成。実世界での実験でも強力な一般化能力を示す。 Comment
pj page: https://pku-epic.github.io/NavFoM-Web/
元ポスト:
[Paper Note] Forgetting Transformer: Softmax Attention with a Forget Gate, Zhixuan Lin+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#NLP #Transformer #Attention #LongSequence #Architecture #ICLR #AttentionSinks Issue Date: 2025-09-16 GPT Summary- 忘却ゲートを取り入れたトランスフォーマー「FoX」を提案。FoXは長いコンテキストの言語モデリングや下流タスクでトランスフォーマーを上回る性能を示し、位置埋め込みを必要としない。再帰的シーケンスモデルに対しても優れた能力を保持し、性能向上のための「Pro」ブロック設計を導入。コードはGitHubで公開。 Comment
openreview: https://openreview.net/forum?id=q2Lnyegkr8
code: https://github.com/zhixuan-lin/forgetting-transformer
非常におもしろそう
データ非依存の固定されたsink tokenを用いるのではなく、データ依存のlearnableなsink tokenを用いる研究とみなせる。
- [Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
[Paper Note] Adaptive Computation Pruning for the Forgetting Transformer, Zhixuan Lin+, COLM'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Pruning #Attention #LongSequence #Architecture Issue Date: 2025-09-16 GPT Summary- Forgeting Transformer(FoX)は、忘却ゲートを用いたソフトマックスアテンションを特徴とし、従来のTransformerと比較して優れた性能を示す。FoXの特性を活かし、適応計算プルーニング(ACP)を提案し、計算を動的にプルーニングすることで、FLOPsとメモリアクセスを約70%削減。これにより、アテンションの実行時間を50%から70%短縮し、トレーニングスループットを10%から40%向上させた。性能の劣化はなく、長い文脈長ではさらなる計算コストの節約が可能である。 Comment
code: https://github.com/zhixuan-lin/forgetting-transformer
元ポスト:
openreview: https://openreview.net/forum?id=xNj14CY5S1#discussion
[Paper Note] Scalable Vision Language Model Training via High Quality Data Curation, Hongyuan Dong+, ACL'25
Paper/Blog Link My Issue
#NLP #SmallModel #OpenWeight #ACL #VisionLanguageModel Issue Date: 2025-09-16 GPT Summary- SAIL-VLは、2Bおよび8Bパラメータのオープンソースビジョン言語モデルで、最先端の性能を達成。主な改善点は、(1) 高品質な視覚理解データの構築、(2) 拡大した事前学習データによる性能向上、(3) 複雑さのスケーリングによる効果的なSFTデータセットのキュレーション。SAIL-VLは18のVLMベンチマークで最高スコアを達成し、2Bモデルは同等のVLMの中でトップの位置を占める。モデルはHuggingFaceで公開。 Comment
元ポスト:
[Paper Note] DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL, Rui Lu+, arXiv'25
Paper/Blog Link My Issue
#Multi #NLP #Dataset #ReinforcementLearning #PostTraining #GRPO #DeepResearch Issue Date: 2025-09-15 GPT Summary- DeepDiveは、LLMsにブラウジングツールを追加し、複雑なタスクの解決を目指す深い検索エージェントです。オープンな知識グラフから難解な質問を自動合成し、マルチターン強化学習を適用することで、長期的な推論能力を向上させます。実験により、DeepDive-32Bは複数のベンチマークで優れた性能を示し、ツール呼び出しのスケーリングと並列サンプリングを可能にしました。すべてのデータとコードは公開されています。 Comment
元ポスト:
[Paper Note] The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs, Akshit Sinha+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #AIAgents #Reasoning #LongSequence #Scaling Laws #read-later #Selected Papers/Blogs #ContextEngineering #Author Thread-Post Issue Date: 2025-09-14 GPT Summary- LLMsのスケーリングが収益に影響を与えるかを探求。単一ステップの精度向上がタスクの長さに指数的改善をもたらすことを観察。LLMsが長期タスクで失敗するのは推論能力の欠如ではなく実行ミスによると主張。知識と計画を明示的に提供することで実行能力を向上させる提案。モデルサイズをスケーリングしても自己条件付け効果は減少せず、長いタスクでのミスが増加。思考モデルは自己条件付けを行わずに長いタスクを実行可能。最終的に、実行能力に焦点を当てることで、LLMsの複雑な推論問題解決能力と単純タスクの長期化による失敗理由を調和させる。 Comment
元ポスト:
single stepでのタスク性能はサチって見えても、成功可能なタスクの長さは(single stepの実行エラーに引きづられるため)モデルのsingle stepのタスク性能に対して指数関数的に効いている(左上)。タスクが長くなればなるほどモデルは自身のエラーに引きずられ(self conditioning;右上)、これはパラメータサイズが大きいほど度合いが大きくなる(右下; 32Bの場合contextにエラーがあって場合のloeg horizonのAcc.が14Bよりも下がっている)。一方で、実行可能なstep数の観点で見ると、モデルサイズが大きい場合の方が多くのstepを要するタスクを実行できる(左下)。また、ThinkingモデルはSelf Conditioningの影響を受けにくく、single stepで実行可能なタスクの長さがより長くなる(中央下)。
といった話に見えるが、論文をしっかり読んだ方が良さそう。
(元ポストも著者ポストだが)著者ポスト:
このスレッドは読んだ方が良い(というか論文を読んだ方が良い)。
特に、**CoTが無い場合は**single-turnでほとんどのモデルは5 stepのタスクをlatent spaceで思考し、実行することができないというのは興味深い(が、細かい設定は確認した方が良い)。なので、マルチステップのタスクは基本的にはplanningをさせてから出力をさせた方が良いという話や、
では複雑なstepが必要なタスクはsingle turnではなくmulti turnに分けた方が良いのか?と言うと、モデルによって傾向が違うらしい、といった話が書かれている。たとえば、Qwenはsingle turnを好むが、Gemmaはmulti turnを好むらしい。
日本語ポイント解説:
解説:
[Paper Note] EviNote-RAG: Enhancing RAG Models via Answer-Supportive Evidence Notes, Yuqin Dai+, arXiv'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #ReinforcementLearning #RAG(RetrievalAugmentedGeneration) #GRPO Issue Date: 2025-09-14 GPT Summary- EviNote-RAGは、オープンドメインのQAにおける「取得-ノート-回答」パイプラインを導入した新しいエージェント型RAGフレームワークです。これにより、取得された情報から有用な内容を抽出し、不確実性を強調するSupportive-Evidence Notes(SENs)を生成します。Evidence Quality Reward(EQR)を用いて推論の信頼性を高め、ノイズの影響を軽減します。実験結果では、EviNote-RAGが精度や安定性において強力なベースラインを上回り、特にHotpotQAやBamboogle、2Wikiで顕著なF1スコアの向上を達成しました。 Comment
元ポスト:
- Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models, Wenhao Yu+, N/A, EMNLP'24
との違いはなんだろうか?ざっと検索した感じ、引用されていないように見える。
ざっくりとしか読めていないが、LLMにQAに回答するための十分なevidenceが集まるまで複数回、検索→SENs(検索結果から導き出されるQAに答えるのに必要な情報のサマリ;検索結果のdenoisingの役割を果たす)→...を繰り返し、最終的なSEN_lastから回答を生成する。SEN_lastが回答を含意するか否かをDistilBERTベースのRewardモデルを用いてGRPOにの報酬として活用する。ベースモデル(reasoningモデルを利用する前提)はQAデータを用いて、上記プロセスによってロールアウトを実施させることでGRPO+RLVR(回答が合っているか)+(DistillBERTに基づくSNEs_lastの)Entailment判定モデルのconfidenceスコアによって訓練する、といって感じに見える。
Chain-of-Noteと比べ追加の学習が必要なのでコンセプトは同じだが、手法的には異なっている。
[Paper Note] MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation, Hao Shi+, arXiv'25
Paper/Blog Link My Issue
#NLP #Robotics #memory #VisionLanguageActionModel #EmbodiedAI Issue Date: 2025-09-14 GPT Summary- MemoryVLAは、ロボット操作における時間的文脈を考慮したCognition-Memory-Actionフレームワークである。作業記憶を利用して短命の表現を制御し、知覚-認知メモリーバンクに統合された情報を保存する。これにより、時間的に意識したアクションシーケンスを生成し、150以上のシミュレーションおよび実世界のタスクで高い成功率を達成。特に、長期的なタスクにおいて顕著な性能向上を示した。 Comment
pj page: https://shihao1895.github.io/MemoryVLA/
元ポスト:
長期記憶としてメモリバンクが導入され、過去に認識した冗長性が排除された画像情報(low level)と画像とテキストによる指示の意味情報(high level semantics)を格納しておき
、retrievalした上で活用する。次のアクションを決めるためのデコーダように見えるtransformerのattentionに専用のCognition/Perceptionのattentionが両方用意されている👀
[Paper Note] MobileLLM-R1: Exploring the Limits of Sub-Billion Language Model Reasoners with Open Training Recipes, Changsheng Zhao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pretraining #NLP #SmallModel #mid-training #PostTraining #read-later #Selected Papers/Blogs #DataMixture Issue Date: 2025-09-13 GPT Summary- 本研究では、推論能力の出現に必要なデータ量について再検討し、約2Tトークンの高品質データで強力な推論モデルが構築できることを示した。MobileLLM-R1というサブビリオンパラメータのモデルは、従来のモデルを大幅に上回る性能を発揮し、特にAIMEスコアで優れた結果を示した。さらに、Qwen3の36Tトークンコーパスに対しても、わずか11.7%のトークンでトレーニングされたMobileLLM-R1-950Mは、複数の推論ベンチマークで競争力を持つ。研究の詳細な情報は公開されている。 Comment
元ポスト:
モデルカードを見ると、optimizerやスケジューリング、ハイパーパラメータの設定、pre/mid/post trainingにおける学習データとDavaMixについて簡潔に記述されており、レシピが公開されているように見える。素晴らしい。
[Paper Note] MedBrowseComp: Benchmarking Medical Deep Research and Computer Use, Shan Chen+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Medical Issue Date: 2025-09-13 GPT Summary- 大規模言語モデル(LLMs)は臨床意思決定支援に期待されているが、異種の知識ベースを統合する厳格な精度が求められる。既存の評価は実用性が不明確であるため、MedBrowseCompを提案。これは、医療従事者が情報を調整する臨床シナリオを反映した1,000以上の質問を含む初のベンチマークである。最前線のエージェントシステムに適用した結果、パフォーマンス不足が10%に達し、LLMの能力と臨床環境の要求との間に重要なギャップが示された。MedBrowseCompは信頼性の高い医療情報探索のためのテストベッドを提供し、将来のモデル改善の目標を設定する。 Comment
[Paper Note] Scaling Laws for Differentially Private Language Models, Ryan McKenna+, ICML'25, 2025.01
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #ICML #Scaling Laws #Privacy #DifferentiallyPrivate Issue Date: 2025-09-13 GPT Summary- スケーリング法則はLLMのトレーニングにおいて性能向上を予測し、ハイパーパラメータ選択の指針を提供する。LLMは機密性のあるユーザーデータに依存し、DPなどのプライバシー保護が必要だが、そのダイナミクスは未解明。本研究では、DP LLMトレーニングのスケーリング法則を確立し、計算、プライバシー、ユーティリティのトレードオフを考慮した最適なトレーニング構成を示す。 Comment
blog: https://research.google/blog/vaultgemma-the-worlds-most-capable-differentially-private-llm/
元ポスト:
関連:
- Calibrating Noise to Sensitivity in Private Data Analysis, Dwork+, TCC'06
openreview: https://openreview.net/forum?id=DE6dqmcmQ9
[Paper Note] SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning, Haozhan Li+, arXiv'25
Paper/Blog Link My Issue
#ReinforcementLearning #GRPO #On-Policy #Robotics #VisionLanguageActionModel #EmbodiedAI Issue Date: 2025-09-12 GPT Summary- VLAモデルの強化学習フレームワークSimpleVLA-RLを提案し、ロボット操作の効率を向上。大規模データへの依存を減らし、一般化能力を強化。OpenVLA-OFTで最先端のパフォーマンスを達成し、RoboTwin 1.0&2.0で優れた結果を示す。新たな現象「pushcut」を特定。 Comment
元ポスト:
HF: https://huggingface.co/collections/Haozhan72/simplevla-rl-6833311430cd9df52aeb1f86
ポイント解説:
VLAにおいて初めてR1-styleのルールベースのverifiable reward(シミュレーション環境から得られる結果)のみに基づくシンプルなon policy RLを実施することで、SFTを実施する場合よりも高い性能、かつ高い汎化性能を獲得できることをVLAにおいて示した研究な模様。
ただし新たなBehaviorに対するExplorationをより高めるために、Refモデルに対するKL Divergenceペナルティを除外したり、3.3節に記述されているような、
- Dynamic Sampling: 全てのロールアウトのRewardが同じ値になるとGRPOのadvantageが0となり勾配が消失する問題があるので、全てのロールアウトが成功/失敗したグループは除外(言い換えると、mixed outcomeのグループのみを利用)して学習
- Clip Higher: DAPOと同様に、直前のポリシーと現在のポリシーの比率のクリッピングの上限値を広げ(つまり、低い確率だったものをより大きな値となることを以前よりも許容する)て探索を促す
- Higher Rollout Temperature:ロールアウト時のtemperatureを1.6と高めにし、より多様なtrajectoryが生成されるようにすることで探索を促す
といった全体的に探索を強めるような調整を行なっている模様。
[Paper Note] LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code, Naman Jain+, ICLR'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Coding #read-later #Contamination-free #Selected Papers/Blogs #Live Issue Date: 2025-09-12 GPT Summary- 本研究では、LLMのコード関連能力を評価するための新しいベンチマーク「LiveCodeBench」を提案。LeetCode、AtCoder、CodeForcesから収集した400の高品質なコーディング問題を用い、コード生成や自己修復、コード実行など多様な能力に焦点を当てている。18のベースLLMと34の指示調整されたLLMを評価し、汚染や過剰適合の問題を実証的に分析。すべてのプロンプトとモデルの結果を公開し、さらなる分析や新しいシナリオの追加を可能にするツールキットも提供。 Comment
pj page: https://livecodebench.github.io
openreview: https://openreview.net/forum?id=chfJJYC3iL
LiveCodeBenchは非常にpopularなコーディング関連のベンチマークだが、readmeに記載されているコマンド通りにベンチマークを実行すると、stop tokenに"###"が指定されているため、マークダウンを出力したLLMの出力が常にtruncateされるというバグがあった模様。
[Paper Note] Why Do MLLMs Struggle with Spatial Understanding? A Systematic Analysis from Data to Architecture, Wanyue Zhang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Analysis #MultiModal #Architecture #SpatialUnderstanding Issue Date: 2025-09-12 GPT Summary- 空間理解はMLLMsにとって重要だが、依然として課題が多い。本研究では、単一視点、多視点、ビデオの3つのシナリオにおける空間理解を体系的に分析し、MulSeTというベンチマークを提案。トレーニングデータの増加はパフォーマンス向上に寄与するが、限界があることが示された。また、空間理解は視覚エンコーダの位置エンコーディングに依存しており、推論の注入を通じたアーキテクチャ改善の可能性を探る。これにより、MLLMsの限界を明らかにし、空間推論能力向上の新たな方向性を示唆している。 Comment
元ポスト:
[Paper Note] A Survey of Reinforcement Learning for Large Reasoning Models, Kaiyan Zhang+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #ReinforcementLearning #Reasoning #Author Thread-Post Issue Date: 2025-09-11 GPT Summary- 本論文では、LLMにおける推論のための強化学習(RL)の進展を調査し、特に数学やコーディングなどの複雑な論理タスクにおける成功を強調しています。RLはLLMを学習推論モデル(LRM)に変換する基盤的な方法論として浮上しており、スケーリングには計算リソースやアルゴリズム設計などの課題があります。DeepSeek-R1以降の研究を検討し、LLMおよびLRMにおけるRLの適用に関する未来の機会と方向性を特定することを目指しています。 Comment
元ポスト:
著者ポスト:
[Paper Note] Reconstruction Alignment Improves Unified Multimodal Models, Ji Xie+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Alignment #MultiModal #read-later #UMM Issue Date: 2025-09-11 GPT Summary- 統一多モーダルモデル(UMMs)のトレーニングは、スパースなキャプションに依存しており、視覚的詳細を見逃すことが多い。そこで、再構成アライメント(RecA)を導入し、視覚理解エンコーダの埋め込みを用いてキャプションなしで豊富な監視を提供。RecAはUMMを視覚理解埋め込みに条件付け、自己監視型の再構成損失で最適化し、生成と編集の忠実度を向上させる。27 GPU時間で、画像生成性能や編集ベンチマークを大幅に向上させ、効率的なポストトレーニング戦略としての地位を確立。 Comment
pj page: https://reconstruction-alignment.github.io
元ポスト:
ベンチマーク:
- [Paper Note] GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment, Dhruba Ghosh+, NeurIPS'23
- [Paper Note] ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment, Xiwei Hu+, arXiv'24
[Paper Note] SimpleQA Verified: A Reliable Factuality Benchmark to Measure Parametric Knowledge, Lukas Haas+, arXiv'25
Paper/Blog Link My Issue
#NLP #Evaluation #Factuality Issue Date: 2025-09-11 GPT Summary- SimpleQA Verifiedは、OpenAIのSimpleQAに基づく1,000プロンプトのベンチマークで、LLMの短文事実性を評価します。ノイズの多いラベルやトピックバイアスに対処するため、厳密なフィルタリングプロセスを経て信頼性の高い評価セットを生成しました。Gemini 2.5 Proは55.6のF1スコアを達成し、他のモデルを上回りました。この研究は、事実性の進展を追跡し、幻覚を軽減するためのツールを提供します。 Comment
leaderboard: https://www.kaggle.com/benchmarks/deepmind/simpleqa-verified
元ポスト:
関連:
- [Paper Note] Measuring short-form factuality in large language models, Jason Wei+, arXiv'24
[Paper Note] Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free, Zihan Qiu+, NeurIPS'25 Best Paper
Paper/Blog Link My Issue
#NLP #Transformer #Attention #NeurIPS #AttentionSinks #read-later #Selected Papers/Blogs Issue Date: 2025-09-11 GPT Summary- ゲーティングメカニズムの効果を調査するため、強化されたソフトマックスアテンションのバリアントを実験。15B Mixture-of-Expertsモデルと1.7B密なモデルを比較し、シグモイドゲートの適用が性能向上に寄与することを発見。これにより訓練の安定性が向上し、スケーリング特性も改善。スパースゲーティングメカニズムが「アテンションシンク」を軽減し、長いコンテキストの外挿性能を向上させることを示した。関連コードとモデルも公開。 Comment
元ポスト:
所見:
NeurIPS'25 Best Paper:
[Paper Note] Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding, Ziheng Li+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #read-later #RLVR Issue Date: 2025-09-10 GPT Summary- RLVRはLLMsの推論能力を向上させるが、トレーニングデータの難易度とモデル能力の不一致により探索が非効率的。新しいフレームワークSEELEを提案し、問題の難易度を動的に調整。ヒントの長さを適応的に調整し、探索効率を向上。実験ではSEELEが従来手法を上回る性能を示した。 Comment
pj page: https://github.com/ChillingDream/seele
元ポスト:
問題の難易度をヒントによって調整しつつ(IRTで困難度パラメータ見ると思われる)RLする模様。面白そう。
[Paper Note] K2-Think: A Parameter-Efficient Reasoning System, Zhoujun Cheng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #OpenWeight #OpenSource #GRPO #read-later #RLVR #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-09-10 GPT Summary- K2-Thinkは320億パラメータの推論システムで、GPT-OSS 120BやDeepSeek v3.1と同等かそれ以上の性能を示します。Qwen2.5ベースのモデルに先進的なポストトレーニングと推論技術を融合し、長いチェーン・オブ・ソート思考と強化学習を用いて数学的推論で卓越した成果を上げています。公開ベンチマークでも高得点を記録し、よりパラメータ効率の高いモデルが最先端システムと競争できることを明らかにしました。K2-Thinkは迅速な推論速度を提供し、オープンソースの推論システムをより利用しやすくしています。 Comment
HF:
https://huggingface.co/LLM360/K2-Think
code:
-
https://github.com/MBZUAI-IFM/K2-Think-SFT
-
https://github.com/MBZUAI-IFM/K2-Think-Inference
RLはverl+GRPOで実施したとテクニカルペーパーに記述されているが、当該部分のコードの公開はされるのだろうか?
RLで利用されたデータはこちら:
- [Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, NeurIPS'25
元ポスト:
[Paper Note] WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents, Junteng Liu+, arXiv'25
Paper/Blog Link My Issue
#GraphBased #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #LongSequence #read-later Issue Date: 2025-09-10 GPT Summary- 本研究では、情報探索のためのデータ不足に対処するため、WebExplorerというモデルベースの探索手法を提案。これにより、複雑なクエリ-回答ペアを生成し、高度なウェブエージェントWebExplorer-8Bを開発。128Kのコンテキスト長を持ち、最先端の情報探索ベンチマークで高いパフォーマンスを達成。特に、WebExplorer-8Bは他の大規模モデルを上回る精度を示し、長期的な問題解決に向けた実用的なアプローチを提供することが確認された。 Comment
元ポスト:
評価で利用されているデータ:
- [Paper Note] BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, Jason Wei+, arXiv'25
- [Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25, 2025.01
学習データの合成方法が肝
[Paper Note] Parallel-R1: Towards Parallel Thinking via Reinforcement Learning, Tong Zheng+, arXiv'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Mathematics #One-Line Notes Issue Date: 2025-09-10 GPT Summary- Parallel-R1は、複雑な推論タスクに対して並列思考を可能にする強化学習フレームワークであり、コールドスタート問題に対処するための進行的なカリキュラムを採用。簡単なタスクから始め、並列思考能力を植え付けた後、難しい問題に移行。実験により、従来の逐次思考モデルに対して8.4%の精度向上を達成し、並列思考が中間トレーニング探索の足場として機能することを示した。 Comment
元ポスト:
結果の表を見るとベースモデルで単にself Consistencyを実施するよりも高いゲインを得ているように見える。モデルがQwen3のみでしか実験されておらず、Qwen2.5においてコンタミネーションの疑い [Paper Note] Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, Mingqi Wu+, arXiv'25 があったので、(Qwen3がどうかはわからないが)単一モデルではなく、他のモデルでも実験した方が良いのかな、という印象。
ポイント解説:
ポイント解説:
コードがリリース:
[Paper Note] An AI system to help scientists write expert-level empirical software, Eser Aygün+, arXiv'25
Paper/Blog Link My Issue
#NLP #Search #AIAgents #ScientificDiscovery #read-later #TreeSearch Issue Date: 2025-09-10 GPT Summary- AIシステムを用いて質の指標を最大化する専門的な科学ソフトウェアを生成。大規模言語モデルと木探索を活用し、複雑な研究アイデアを統合。バイオインフォマティクスや疫学の分野で新しい手法を発見し、既存のモデルを上回る成果を達成。多様なタスクに対する新しい解決策を提供し、科学的進歩を加速することを目指す。 Comment
元ポスト:
[Paper Note] Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search, Xin Lai+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #Reasoning #LongSequence #OpenWeight #GRPO #VisionLanguageModel Issue Date: 2025-09-10 GPT Summary- Mini-o3システムは、数十ステップの深いマルチターン推論を実現し、視覚検索タスクで最先端の性能を達成。Visual Probe Datasetを構築し、多様な推論パターンを示すデータ収集パイプラインを開発。オーバーターンマスキング戦略により、ターン数が増えるほど精度が向上することを実証。 Comment
HF: https://huggingface.co/Mini-o3
pj page: https://mini-o3.github.io
元ポスト:
既存のオープンなVLMはマルチターンのターン数を増やせないという課題があったがそれを克服するレシピに関する研究な模様。元ポストによると6ターンまでのマルチターンで学習しても、inference時には32ターンまでスケールするとか。
BioML-bench: Evaluation of AI Agents for End-to-End Biomedical ML, Miller+, bioRxiv'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #read-later #Medical #Biological Issue Date: 2025-09-10 Comment
元ポスト:
Biomedicalドメインにおける24種類の非常に複雑でnuancedな記述や画像の読み取りなどを含む実タスクによって構成される初めてのAgenticベンチマークとのこと。
[Paper Note] Reverse-Engineered Reasoning for Open-Ended Generation, Haozhe Wang+, arXiv'25
Paper/Blog Link My Issue
#NLP #Reasoning #read-later Issue Date: 2025-09-10 GPT Summary- REERという新しい推論パラダイムを提案し、既存の良好な解から後方に推論プロセスを構築。20,000の深い推論軌跡からなるデータセットDeepWriting-20Kを作成し、オープンソース化。訓練されたモデルDeepWriter-8Bは、強力なオープンソースベースラインを超え、GPT-4oやClaude 3.5と競争力のある性能を示す。 Comment
pj page: https://m-a-p.ai/REER_DeepWriter/
元ポスト:
[Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #NAACL Issue Date: 2025-09-09 GPT Summary- MMLUベンチマークのエラーを分析し、ウイルス学のサブセットでは57%の質問にエラーがあることを発見。新しいエラー注釈プロトコルを用いてMMLU-Reduxを作成し、6.49%の質問にエラーが含まれると推定。MMLU-Reduxを通じて、モデルのパフォーマンスメトリックとの不一致を示し、MMLUの信頼性向上を提案。
[Paper Note] The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism, Yifan Song+, NAACL'25
Paper/Blog Link My Issue
#NLP #Evaluation #NAACL #Decoding #Non-Determinism Issue Date: 2025-09-09 GPT Summary- LLMの評価は非決定性を見落としがちで、単一出力に焦点を当てるため性能の変動理解が制限される。本研究では、貪欲デコーディングとサンプリングの性能差を探求し、非決定性に関するベンチマークの一貫性を特定。実験により、貪欲デコーディングが多くのタスクで優れていることを確認し、アライメントがサンプリングの分散を減少させる可能性を示した。また、小型LLMが大型モデルに匹敵する性能を持つことを明らかにし、LLM評価における非決定性の重要性を強調した。 Comment
関連:
- [Paper Note] Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, Eval4NLP'25, 2024.08
利用されているデータセット:
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
- AlpacaEval, tatsu-lab, 2023.06
- [Paper Note] MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures, Jinjie Ni+, NeurIPS'24
- From Live Data to High-Quality Benchmarks: The Arena-Hard Pipeline, Li+, 2024.04
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
- [Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
[Paper Note] The Majority is not always right: RL training for solution aggregation, Wenting Zhao+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #read-later #Aggregation-aware #Author Thread-Post Issue Date: 2025-09-09 GPT Summary- 本研究では、複数の解を生成し、それを集約することでLLMsの推論能力を向上させる新しいアプローチを提案する。従来の方法に代わり、集約を明示的な推論スキルとして学習し、強化学習を用いて正しい答えを調整・合成する。簡単な例と難しい例のバランスを取ることで、モデルは少数派の正しい答えを回復する能力を獲得。提案手法AggLMは、複数のベンチマークで従来の手法を上回り、少ないトークンで効果的に一般化することが示された。 Comment
元ポスト:
解説:
著者ポスト:
ポイント解説:
[Paper Note] SpikingBrain Technical Report: Spiking Brain-inspired Large Models, Yuqi Pan+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LongSequence #Architecture #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2025-09-08 GPT Summary- SpikingBrainは、長いコンテキストの効率的なトレーニングと推論のために設計された脳にインスパイアされたモデルで、MetaX GPUクラスターを活用。線形およびハイブリッド線形アーキテクチャを採用し、非NVIDIAプラットフォーム上での大規模LLM開発を実現。SpikingBrain-7BとSpikingBrain-76Bを開発し、約150BトークンでオープンソースのTransformerと同等の性能を達成。トレーニング効率を大幅に改善し、低消費電力での運用を可能にすることを示した。 Comment
元ポスト:
TTFTが4Mコンテキストの時にQwen2.5と比べて100倍高速化…?
中国のMetaX社のGPUが利用されている。
https://www.metax-tech.com/en/goods/prod.html?cid=3
[Paper Note] REFRAG: Rethinking RAG based Decoding, Xiaoqiang Lin+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #RAG(RetrievalAugmentedGeneration) #LongSequence #Decoding #read-later #Selected Papers/Blogs #SpeculativeDecoding Issue Date: 2025-09-07 GPT Summary- REFRAGは、RAGアプリケーションにおける遅延を改善するための効率的なデコーディングフレームワークであり、スパース構造を利用して初回トークンまでの時間を30.85倍加速します。これにより、LLMsのコンテキストサイズを16まで拡張可能にし、さまざまな長コンテキストタスクで精度を損なうことなくスピードアップを実現しました。 Comment
元ポスト:
興味深い。Speculative Decodingの新手法ともみなせそう。
同時期に出た下記研究と比較してどのようなpros/consがあるだろうか?
- [Paper Note] Set Block Decoding is a Language Model Inference Accelerator, Itai Gat+, arXiv'25
解説:
[Paper Note] SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents, Ibragim Badertdinov+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #Coding #NeurIPS #SoftwareEngineering #read-later #Contamination-free #Selected Papers/Blogs #Live #Environment Issue Date: 2025-09-06 GPT Summary- LLMベースのエージェントのSWEタスクにおける課題として、高品質なトレーニングデータの不足と新鮮なインタラクティブタスクの欠如が挙げられる。これに対処するため、21,000以上のインタラクティブなPythonベースのSWEタスクを含む公的データセットSWE-rebenchを自動化されたパイプラインで構築し、エージェントの強化学習に適したベンチマークを提供。これにより、汚染のない評価が可能となり、いくつかのLLMの性能が過大評価されている可能性を示した。 Comment
pj page: https://swe-rebench.com
元ポスト:
コンタミネーションのない最新のIssueを用いて評価した結果、Sonnet 4が最も高性能
[Paper Note] Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?, Qinyan Zhang+, arXiv'25
Paper/Blog Link My Issue
#NLP #Evaluation #Reasoning #read-later #Selected Papers/Blogs #InstructionFollowingCapability Issue Date: 2025-09-05 GPT Summary- 大規模言語モデル(LLMs)は、標準化されたパターンに従うことに苦労することがある。これを評価するために、Inverse IFEvalというベンチマークを提案し、モデルが対立する指示に従う能力を測定する。8種類の課題を含むデータセットを構築し、既存のLLMに対する実験を行った結果、非従来の文脈での適応性も考慮すべきであることが示された。Inverse IFEvalは、LLMの指示遵守の信頼性向上に寄与することが期待される。 Comment
元ポスト:
興味深い
[Paper Note] Towards a Unified View of Large Language Model Post-Training, Xingtai Lv+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #PostTraining Issue Date: 2025-09-05 GPT Summary- 本論文では、オンラインデータとオフラインデータを用いた言語モデルのポストトレーニングアプローチが、矛盾せず単一の最適化プロセスであることを示す。統一ポリシー勾配推定器を導出し、ハイブリッドポストトレーニング(HPT)アルゴリズムを提案。HPTは異なるトレーニング信号を動的に選択し、デモンストレーションを効果的に活用しつつ安定した探索を実現。実験により、HPTが数学的推論ベンチマークで強力な性能を示すことを確認。 Comment
元ポスト:
解説:
[Paper Note] UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning, Haoming Wang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #AIAgents #MultiModal #Reasoning #ComputerUse #VisionLanguageModel Issue Date: 2025-09-05 GPT Summary- UI-TARS-2は、GUI用自律エージェントの新しいモデルで、データ生成、安定化されたマルチターンRL、ハイブリッドGUI環境を統合。実証評価では、前モデルを大幅に上回り、複数のベンチマークで高いスコアを達成。約60%の人間レベルのパフォーマンスを示し、長期的な情報探索タスクにも適応可能。トレーニングダイナミクスの分析が安定性と効率向上の洞察を提供し、実世界のシナリオへの一般化能力を強調。 Comment
元ポスト:
1.5をリリースしてから5ヶ月で大幅に性能を向上した模様
[Paper Note] LLaVA-Critic-R1: Your Critic Model is Secretly a Strong Policy Model, Xiyao Wang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #Reasoning #OpenWeight #SelfCorrection #VisionLanguageModel #Critic Issue Date: 2025-09-04 GPT Summary- 本研究では、視覚と言語のモデリングにおいて、批評モデルを強化学習を用いて再編成し、生成モデルに直接適用する新しいアプローチを提案します。これにより、マルチモーダル批評モデルLLaVA-Critic-R1を生成し、視覚的推論ベンチマークで高い性能を示しました。さらに、自己批評を用いることで、追加の訓練なしに推論タスクでの性能を向上させることができることを示しました。この結果は、評価と生成の両方に優れた統一モデルを実現する可能性を示唆しています。 Comment
元ポスト:
HF: https://huggingface.co/collections/lmms-lab/llava-critic-r1-68922484e5822b89fab4aca1
[Paper Note] Benchmarking Optimizers for Large Language Model Pretraining, Andrei Semenov+, arXiv'25
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Optimizer #read-later Issue Date: 2025-09-03 GPT Summary- 最近のLLMsの発展に伴い、最適化手法の多様な主張があるが、実験プロトコルの違いにより比較が難しい。本研究では、標準化されたLLMの事前トレーニングにおける最適化技術を評価し、モデルサイズやバッチサイズを変化させて最適なオプティマイザを提案。研究が将来の最適化研究の方向性を示し、コードを公開することで再現性を確保し、手法の開発に寄与することを目指す。 Comment
元ポスト:
関連:
- [Paper Note] Fantastic Pretraining Optimizers and Where to Find Them, Kaiyue Wen+, ICLR'26, 2025.09
上記論文と知見が一致する部分、異なる部分は何だろうか?
[Paper Note] Jointly Reinforcing Diversity and Quality in Language Model Generations, Tianjian Li+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Diversity #On-Policy Issue Date: 2025-09-03 GPT Summary- DARLINGというフレームワークを提案し、応答の質と意味的多様性を最適化。学習された分割関数を用いて多様性を測定し、質の報酬と組み合わせることで高品質かつ独自性のある出力を生成。実験により、非検証可能なタスクと検証可能なタスクの両方で優れた結果を示し、特に多様性の最適化が探索を促進し、質の向上に寄与することが確認された。 Comment
元ポスト:
関連:
[Paper Note] GSO: Challenging Software Optimization Tasks for Evaluating SWE-Agents, Manish Shetty+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Dataset #AIAgents #Evaluation #Coding #SoftwareEngineering Issue Date: 2025-09-03 GPT Summary- 高性能ソフトウェア開発における言語モデルの能力を評価するためのベンチマークGSOを提案。102の最適化タスクを特定する自動化パイプラインを開発し、主要なソフトウェアエンジニアリングエージェントの成功率は5%未満であることを示した。定性的分析により、低レベル言語や最適化戦略の課題が明らかになった。研究の進展のために、ベンチマークのコードとエージェントのデータを公開。 Comment
pj page: https://gso-bench.github.io
ソフトウェアの高速化に関するベンチ
元ポストに掲載されているリーダーボードはどこにあるのだろう。ざっと見た感じ見当たらない。
[Paper Note] SOAP: Improving and Stabilizing Shampoo using Adam, Nikhil Vyas+, ICLR'25
Paper/Blog Link My Issue
#Pretraining #NLP #Optimizer #ICLR #Selected Papers/Blogs Issue Date: 2025-09-03 GPT Summary- Shampooという前処理法が深層学習の最適化タスクで効果的である一方、追加のハイパーパラメータと計算オーバーヘッドが課題である。本研究では、ShampooとAdafactorの関係を明らかにし、Shampooを基にした新しいアルゴリズムSOAPを提案。SOAPは、Adamと同様に第二モーメントの移動平均を更新し、計算効率を改善。実験では、SOAPがAdamWに対して40%以上のイテレーション数削減、35%以上の経過時間短縮を達成し、Shampooに対しても約20%の改善を示した。SOAPの実装は公開されている。 Comment
openreview: https://openreview.net/forum?id=IDxZhXrpNf
[Paper Note] The Landscape of Agentic Reinforcement Learning for LLMs: A Survey, Guibin Zhang+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #ReinforcementLearning #AIAgents Issue Date: 2025-09-03 GPT Summary- エージェント的強化学習(Agentic RL)は、従来の強化学習から大規模言語モデル(LLM)への適用におけるパラダイムシフトを示し、LLMを自律的な意思決定エージェントとして再構築します。本調査では、LLM-RLの単一ステップのマルコフ決定過程(MDP)とエージェント的RLの部分観測マルコフ決定過程(POMDP)を対比し、計画や推論などのエージェント能力を中心に二重分類法を提案します。強化学習は、静的なヒューリスティックから適応的なエージェント行動への変換に重要な役割を果たすと主張し、500以上の研究を統合してこの分野の機会と課題を明らかにします。 Comment
元ポスト:
[Paper Note] VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool Use, Dongfu Jiang+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#EfficiencyImprovement #Tools #NLP #ReinforcementLearning #PostTraining #Asynchronous Issue Date: 2025-09-03 GPT Summary- VerlToolは、強化学習におけるツール統合の課題を解決するための統一的かつモジュラーなフレームワークを提供する。主な貢献は、互換性の確保、標準化されたAPIによるツール管理、非同期実行による速度向上、競争力のあるパフォーマンス評価である。これにより、マルチターンのインタラクションを形式化し、様々なタスクにおいて専門的なシステムと同等の結果を達成する。開発のオーバーヘッドを削減し、スケーラブルな基盤を提供する。コードはオープンソースで公開されている。 Comment
github: https://github.com/TIGER-AI-Lab/verl-tool
元ポスト:
[Paper Note] AHELM: A Holistic Evaluation of Audio-Language Models, Tony Lee+, arXiv'25
Paper/Blog Link My Issue
#Dataset #Evaluation #SpeechProcessing #read-later #Selected Papers/Blogs #AudioLanguageModel Issue Date: 2025-09-03 GPT Summary- 音声言語モデル(ALMs)の評価には標準化されたベンチマークが欠如しており、これを解決するためにAHELMを導入。AHELMは、ALMsの多様な能力を包括的に測定するための新しいデータセットを集約し、10の重要な評価側面を特定。プロンプトや評価指標を標準化し、14のALMsをテストした結果、Gemini 2.5 Proが5つの側面でトップにランクされる一方、他のモデルは不公平性を示さなかった。AHELMは今後も新しいデータセットやモデルを追加予定。 Comment
元ポスト:
関連:
- [Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
[Paper Note] Interpretation Meets Safety: A Survey on Interpretation Methods and Tools for Improving LLM Safety, Seongmin Lee+, EMNLP'25
Paper/Blog Link My Issue
#Survey #NLP #Safety #EMNLP Issue Date: 2025-09-03 GPT Summary- LLMの安全性を理解し軽減するための解釈技術の重要性を探求し、安全性向上に寄与する手法を統一的なフレームワークで整理。約70件の研究を分類し、未解決の課題と今後の方向性を示す。研究者や実務者にとって、より安全で解釈可能なLLMの進展を促進する調査。 Comment
元ポスト:
[Paper Note] Training Dynamics of the Cooldown Stage in Warmup-Stable-Decay Learning Rate Scheduler, Aleksandr Dremov+, TMLR'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Transformer #TMLR #Scheduler Issue Date: 2025-09-03 GPT Summary- WSD学習率スケジューラのクールダウンフェーズを分析し、異なる形状がモデルのバイアス-バリアンスのトレードオフに与える影響を明らかに。探索と活用のバランスが最適なパフォーマンスをもたらすことを示し、特に$\beta_2$の値が高いと改善が見られる。損失のランドスケープを視覚化し、クールダウンフェーズの最適化の重要性を強調。 Comment
元ポスト:
[Paper Note] Efficient Code Embeddings from Code Generation Models, Daria Kryvosheieva+, arXiv'25
Paper/Blog Link My Issue
#Embeddings #NLP #Coding Issue Date: 2025-09-03 GPT Summary- jina-code-embeddingsは、自然言語からコードを取得し、技術的な質問応答や意味的に類似したコードスニペットの特定を行う新しいコード埋め込みモデルです。自己回帰型バックボーンを利用し、トークンプーリングを通じて埋め込みを生成。小さいモデルサイズながら最先端のパフォーマンスを示し、コード埋め込みモデルの構築における有効性を検証しています。 Comment
HF: https://huggingface.co/collections/jinaai/jina-code-embeddings-68b0fbfbb0d639e515f82acd
コーディング特化のembeddingで、検索、クロスリンガルな類似度、技術に関するQAに対応可能らしい
公式ポスト:
[Paper Note] ProRank: Prompt Warmup via Reinforcement Learning for Small Language Models Reranking, Xianming Li+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #InformationRetrieval #SmallModel #Reranking Issue Date: 2025-09-03 GPT Summary- 再ランキングにおいて、SLMを用いた新しい二段階トレーニングアプローチProRankを提案。まず、強化学習を用いてSLMがタスクプロンプトを理解し、粗い関連スコアを生成。次に、ファインチューニングを行い再ランキングの質を向上。実験結果では、ProRankが先進的な再ランキングモデルを上回り、特にProRank-0.5Bモデルが32B LLMを超える性能を示した。 Comment
元ポスト:
[Paper Note] Memento: Fine-tuning LLM Agents without Fine-tuning LLMs, Huichi Zhou+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #memory #Test-time Learning Issue Date: 2025-09-02 GPT Summary- 本論文では、ファインチューニングを必要としない新しい学習パラダイムを提案し、メモリベースのオンライン強化学習を通じて低コストでの継続的な適応を実現します。これをメモリ拡張マルコフ決定過程(M-MDP)として形式化し、行動決定のためのニューラルケース選択ポリシーを導入。エージェントモデル「Memento」は、GAIA検証で87.88%の成功率を達成し、DeepResearcherデータセットでも最先端の手法を上回る性能を示しました。このアプローチは、勾配更新なしでのリアルタイム学習を可能にし、機械学習の進展に寄与します。 Comment
元ポスト:
元ポスト:
[Paper Note] TiKMiX: Take Data Influence into Dynamic Mixture for Language Model Pre-training, Yifan Wang+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #DataMixture Issue Date: 2025-09-02 GPT Summary- TiKMiXは、言語モデルの進化するデータ好みに応じてデータの混合を動的に調整する手法である。Group Influenceという指標を導入し、データ混合の最適化を実現。TiKMiX-Dは20%の計算リソースで最先端手法を上回り、TiKMiX-Mは9つのベンチマークで平均2%の性能向上を達成。実験により、データの好みが進化することを示し、動的調整が性能向上に寄与することを確認。 Comment
元ポスト:
RegMix:
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
openreview: https://openreview.net/forum?id=H8JAWv0HNr
[Paper Note] R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning, Jie Jiang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #ReinforcementLearning #MultiModal #Reasoning #GRPO #VisionLanguageModel Issue Date: 2025-09-02 GPT Summary- R-4Bは、問題の複雑さに応じて思考を行うかどうかを適応的に判断する自動思考型のマルチモーダル大規模言語モデル(MLLM)である。思考能力と非思考能力を持たせ、バイモードポリシー最適化(BPO)を用いて思考プロセスの起動を精度良く判断する。訓練には多様なトピックのデータセットを使用し、実験結果はR-4Bが25のベンチマークで最先端のパフォーマンスを達成し、特に推論集約型タスクで低コストで高い性能を示したことを示している。 Comment
元ポスト:
VLMにthinking, non-thinkingを入力に応じて使い分けさせる手法
[Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
Paper/Blog Link My Issue
#Pretraining #NLP #ICLR #read-later #Selected Papers/Blogs #DataMixture #Initial Impression Notes Issue Date: 2025-09-01 GPT Summary- RegMixを提案し、データミクスチャの性能を回帰タスクとして自動的に特定。多様なミクスチャで小モデルを訓練し、最良のミクスチャを用いて大規模モデルを訓練した結果、他の候補を上回る性能を示した。実験により、データミクスチャが性能に大きな影響を与えることや、ウェブコーパスが高品質データよりも良好な相関を持つことを確認。RegMixの自動アプローチが必要であることも示された。 Comment
openreview: https://openreview.net/forum?id=5BjQOUXq7i
今後DavaMixtureがさらに重要になるという見方があり、実際にフロンティアモデルのDataMixtureに関する情報はテクニカルレポートには記載されず秘伝のタレ状態であるため、より良いDataMixtureする本研究は重要論文に見える。
[Paper Note] Hunyuan-MT Technical Report, Mao Zheng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#MachineTranslation #NLP #OpenWeight #Catastrophic Forgetting #mid-training #Selected Papers/Blogs #In-Depth Notes #Surface-level Notes Issue Date: 2025-09-01 GPT Summary- Hunyuan-MT-7Bは、33の主要言語間の双方向翻訳をサポートする初のオープンソースモデルであり、特に標準中国語と少数言語間の翻訳に焦点を当てています。スロースローチンキングに触発されたHunyuan-MT-Chimera-7Bを導入し、複数の出力を統合することで性能を向上させています。モデルは包括的なトレーニングプロセスを経ており、強化学習を用いた高度な整合性を実現。実験では、両モデルが同等のパラメータサイズの他の翻訳モデルを上回り、WMT2025共有タスクで30の言語ペアで1位を獲得しました。これにより、モデルの堅牢性が強調されています。 Comment
テクニカルレポート: https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
元ポスト:
Base Modelに対してまず一般的な事前学習を実施し、その後MTに特化した継続事前学習(モノリンガル/パラレルコーパスの利用)、事後学習(SFT, GRPO)を実施している模様。
継続事前学習では、最適なDataMixの比率を見つけるために、RegMixと呼ばれる手法を利用。Catastrophic Forgettingを防ぐために、事前学習データの20%を含めるといった施策を実施。
SFTでは2つのステージで構成されている。ステージ1は基礎的な翻訳力の強化と翻訳に関する指示追従能力の向上のために、Flores-200の開発データ(33言語の双方向の翻訳をカバー)、前年度のWMTのテストセット(English to XXをカバー)、Mandarin to Minority, Minority to Mandarinのcuratedな人手でのアノテーションデータ、DeepSeek-V3-0324での合成パラレルコーパス、general purpose/MT orientedな指示チューニングデータセットのうち20%を構成するデータで翻訳のinstructinoに関するモデルの凡化性能を高めるためキュレーションされたデータ、で学習している模様。パラレルコーパスはReference-freeな手法を用いてスコアを算出し閾値以下の低品質な翻訳対は除外している。ステージ2では、詳細が書かれていないが、少量でよりfidelityの高い約270kの翻訳対を利用した模様。また、先行研究に基づいて、many-shotのin-context learningを用いて、訓練データをさらに洗練させたとのこと(先行研究が引用されているのみで詳細な記述は無し)。また、複数の評価ラウンドでスコアの一貫性が無いサンプルは手動でアノテーション、あるいはverificationをして品質を担保している模様。
RLではGRPOを採用し、rewardとしてsemantic([Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
), terminology([Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
; ドメイン特有のterminologyを捉える), repetitionに基づいたrewardを採用している。最終的にSFT->RLで学習されたHuayuan-MT-7Bに対して、下記プロンプトを用いて複数のoutputを統合してより高品質な翻訳を出力するキメラモデルを同様のrewardを用いて学習する、といったpipelineになっている。
関連:
- [Paper Note] Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23, 2023.06
- [Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
- [Paper Note] CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task, Rei+, WMT'22
- [Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22, 2022.07
- [Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
- [Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
関連: PLaMo翻訳
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
こちらはSFT->Iterative DPO->Model Mergeを実施し、翻訳に特化した継続事前学習はやっていないように見える。一方、SFT時点で独自のテンプレートを作成し、語彙の指定やスタイル、日本語特有の常体、敬体の指定などを実施できるように翻訳に特化したテンプレートを学習している点が異なるように見える。Hunyuanは多様な翻訳の指示に対応できるように学習しているが、PLaMo翻訳はユースケースを絞り込み、ユースケースに対する性能を高めるような特化型のアプローチをとるといった思想の違いが伺える。
[Paper Note] A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems, Jinyuan Fang+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #SelfCorrection #SelfImprovement Issue Date: 2025-08-31 GPT Summary- 自己進化型AIエージェントの研究が進展しており、動的環境に適応する能力を持つエージェントシステムの自動強化が求められている。本調査では、自己進化型エージェントの設計におけるフィードバックループを抽象化したフレームワークを提案し、システムの主要コンポーネントを強調。さらに、ドメイン特化型進化戦略や評価、安全性、倫理的考慮についても議論し、研究者や実務者に体系的な理解を提供することを目指す。 Comment
元ポスト:
[Paper Note] MoE++: Accelerating Mixture-of-Experts Methods with Zero-Computation Experts, Peng Jin+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #MoE(Mixture-of-Experts) #ICLR #read-later Issue Date: 2025-08-31 GPT Summary- 本研究では、Mixture-of-Experts(MoE)手法の効果と効率を向上させるために、MoE++フレームワークを提案。ゼロ計算エキスパートを導入し、低計算オーバーヘッド、高パフォーマンス、デプロイメントの容易さを実現。実験結果により、MoE++は従来のMoEモデルに比べて1.1-2.1倍のスループットを提供し、優れた性能を示す。 Comment
openreview: https://openreview.net/forum?id=t7P5BUKcYv
従来のMoEと比べて、専門家としてzero computation expertsを導入することで、性能を維持しながら効率的にinferenceをする手法(MoEにおいて全てのトークンを均一に扱わない)を提案している模様。
zero computation expertsは3種類で
- Zero Experts: 入力をゼロベクトルに落とす
- Copy Experts: 入力xをそのままコピーする
- Constant Experts: learnableな定数ベクトルvを学習し、xと線形結合して出力する。W_cによって入力xを変換することで線形補 結合の係数a1,a2を入力に応じて動的に決定する。
Routingの手法やgating residual、学習手法の工夫もなされているようなので、後で読む。
[Paper Note] Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts, Weilin Cai+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #MoE(Mixture-of-Experts) #ICLR Issue Date: 2025-08-31 GPT Summary- ScMoEは、スパースゲート混合専門家モデルの計算負荷を分散させる新しいアーキテクチャで、通信と計算の重複を最大100%可能にし、全対全通信のボトルネックを解消。これにより、トレーニングで1.49倍、推論で1.82倍のスピードアップを実現し、モデル品質も既存手法と同等またはそれ以上を達成。 Comment
openreview: https://openreview.net/forum?id=GKly3FkxN4¬eId=4tfWewv7R2
[Paper Note] Addressing Tokenization Inconsistency in Steganography and Watermarking Based on Large Language Models, Ruiyi Yan+, EMNLP'25
Paper/Blog Link My Issue
#NLP #EMNLP #Tokenizer Issue Date: 2025-08-31 GPT Summary- 大規模言語モデルはテキスト生成を向上させる一方で、ステガノグラフィーとウォーターマーキングの重要性が増している。本研究では、トークン化の不一致(TI)が堅牢性に与える影響を調査し、TIの原因となるトークンの特性として稀少性と一時性を特定。これに基づき、ステガノグラフィー用の段階的検証方法とウォーターマーキング用の事後ロールバック方法を提案。実験により、TIに直接対処することで、ステガノグラフィーの流暢さや対ステガ分析能力、ウォーターマーキングの堅牢性が向上することが示された。 Comment
元ポスト:
[Paper Note] DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis, Liana Patel+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #read-later #Selected Papers/Blogs #DeepResearch #Science #Live Issue Date: 2025-08-31 GPT Summary- 生成的研究合成の評価のために、DeepScholar-benchというライブベンチマークと自動評価フレームワークを提案。これは、ArXiv論文からクエリを引き出し、関連研究セクションを生成する実際のタスクに焦点を当て、知識合成、検索品質、検証可能性を評価。DeepScholar-baseは強力なベースラインを確立し、他の手法と比較して競争力のあるパフォーマンスを示した。DeepScholar-benchは依然として難易度が高く、生成的研究合成のAIシステムの進歩に重要であることを示す。 Comment
leaderboard: https://guestrin-lab.github.io/deepscholar-leaderboard/leaderboard/deepscholar_bench_leaderboard.html
元ポスト:
[Paper Note] Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs, Ziyue Li+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Controllable #NLP #Search #Test-Time Scaling #Decoding #KeyPoint Notes Issue Date: 2025-08-30 GPT Summary- 事前学習済みのLLMの層をモジュールとして操作し、各サンプルに最適なアーキテクチャを構築する手法を提案。モンテカルロ木探索を用いて、数学および常識推論のベンチマークで最適な層の連鎖(CoLa)を特定。CoLaは柔軟で動的なアーキテクチャを提供し、推論効率を改善する可能性を示唆。75%以上の正しい予測に対して短いCoLaを見つけ、60%以上の不正確な予測を正すことができることが明らかに。固定アーキテクチャの限界を克服する道を開く。 Comment
解説:
事前学習済み言語モデルのforward pathにおける各layerをbuilding blocksとみなして、入力に応じてスキップ、あるいは再帰的な利用をMCTSによって選択することで、test time時のモデルの深さや、モデルの凡化性能をタスクに対して適用させるような手法を提案している模様。モデルのパラメータの更新は不要。k, r ∈ {1,2,3,4} の範囲で、"k個のlayerをskip"、あるいはk個のlayerのブロックをr回再帰する、とすることで探索範囲を限定的にしtest時の過剰な計算を抑止している。また、MCTSにおけるsimulationの回数は200回。length penaltyを大きくすることでcompactなforward pathになるように調整、10%の確率でまだ探索していない子ノードをランダムに選択することで探索を促すようにしている。オリジナルと比較して実行時間がどの程度増えてしまうのか?に興味があったが、モデルの深さという観点で推論効率は考察されているように見えたが、実行時間という観点ではざっと見た感じ記載がないように見えた。
以下の広範なQA、幅広い難易度を持つ数学に関するデータで評価(Appendix Bに各データセットごとに500 sampleを利用と記載がある)をしたところ、大幅に性能が向上している模様。ただし、8B程度のサイズのモデルでしか実験はされていない。
- [Paper Note] Think you have Solved Question Answering? Try ARC, the AI2 Reasoning
Challenge, Peter Clark+, arXiv'18
- [Paper Note] DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving, Yuxuan Tong+, NeurIPS'24
関連:
- [Paper Note] Looped Transformers are Better at Learning Learning Algorithms, Liu Yang+, ICLR'24
- [Paper Note] Looped Transformers for Length Generalization, Ying Fan+, ICLR'25
- [Paper Note] Universal Transformers, Mostafa Dehghani+, ICLR'19
- [Paper Note] Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation, Sangmin Bae+, NeurIPS'25
[Paper Note] TurnaboutLLM: A Deductive Reasoning Benchmark from Detective Games, Yuan Yuan+, EMNLP'25
Paper/Blog Link My Issue
#NLP #In-ContextLearning #Reasoning #LongSequence #EMNLP #read-later #Contamination-free #Selected Papers/Blogs #Game Issue Date: 2025-08-30 GPT Summary- TurnaboutLLMという新しいフレームワークとデータセットを用いて、探偵ゲームのインタラクティブなプレイを通じてLLMsの演繹的推論能力を評価。証言と証拠の矛盾を特定する課題を設定し、12の最先端LLMを評価した結果、文脈のサイズや推論ステップ数がパフォーマンスに影響を与えることが示された。TurnaboutLLMは、複雑な物語環境におけるLLMsの推論能力に挑戦を提供する。 Comment
元ポスト:
非常に面白そう。逆転裁判のデータを利用した超long contextな演繹的タスクにおいて、モデルが最終的な回答を間違える際はより多くの正解には貢献しないReasoning Stepを繰り返したり、QwQ-32BとGPT4.1は同等の性能だが、non thinkingモデルであるGPT4.1がより少量のReasoning Step (本研究では回答に至るまでに出力したトークン数と定義)で回答に到達し(=Test Time Scalingの恩恵がない)、フルコンテキストを与えて性能が向上したのはモデルサイズが大きい場合のみ(=Test Timeのreasoningよりも、in-contextでのreasoningが重要)だった、といった知見がある模様。じっくり読みたい。
[Paper Note] Drop Dropout on Single-Epoch Language Model Pretraining, Houjun Liu+, arXiv'25
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Regularization #Selected Papers/Blogs Issue Date: 2025-08-30 GPT Summary- ドロップアウトは過学習を防ぐ手法として知られているが、現代の大規模言語モデル(LLM)では過学習が抑えられるため使用されていない。本研究では、BERTやPythiaモデルの単一エポック事前学習においてドロップアウトの影響を調査した結果、ドロップアウトを適用しない方が下流の性能が向上することが判明。また、「早期ドロップアウト」も性能を低下させることが示された。ドロップアウトなしで訓練されたモデルは、モデル編集においてもより成功することがわかり、単一エポックの事前学習中にはドロップアウトを省くことが推奨される。 Comment
元ポスト:
関連:
- [Paper Note] Dropout Reduces Underfitting, Zhuang Liu+, ICML'23
[Paper Note] OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation, Jianwen Jiang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Controllable #NLP #MultiModal #DiffusionModel Issue Date: 2025-08-29 GPT Summary- 「OmniHuman-1.5」は、物理的妥当性と意味的一貫性を兼ね備えたキャラクターアニメーションを生成するフレームワークである。マルチモーダル大規模言語モデルを活用し、音声、画像、テキストの共同意味を解釈することで、感情や意図に基づいた動作を生成。新しいマルチモーダルDiTアーキテクチャにより、異なるモダリティ間の対立を軽減し、リップシンク精度や動作の自然さで優れたパフォーマンスを達成。複雑なシナリオへの拡張性も示している。 Comment
pj page: https://omnihuman-lab.github.io/v1_5/
元ポスト:
promptによって状況や感情などの表現のコントロールが可能らしい
解説:
[Paper Note] AI-Researcher: Autonomous Scientific Innovation, Jiabin Tang+, arXiv'25
Paper/Blog Link My Issue
#NLP #AIAgents #Proprietary #ScientificDiscovery Issue Date: 2025-08-29 GPT Summary- AI-Researcherという自律型研究システムを提案し、文献レビューから論文作成までの研究プロセスを自動化。Scientist-Benchを用いてAIの研究能力を評価し、実験により人間レベルの研究論文を生成する成功率を示す。この研究は、自律的な科学的革新の新たな基盤を築く。 Comment
github: https://github.com/HKUDS/AI-Researcher
元ポスト:
[Paper Note] Mobile-Agent-v3: Foundamental Agents for GUI Automation, Jiabo Ye+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SmallModel #ComputerUse #On-Policy #GUI #Asynchronous Issue Date: 2025-08-29 GPT Summary- 本論文では、GUI-OwlというGUIエージェントモデルを提案し、デスクトップおよびモバイル環境での最先端性能を達成したことを報告しています。特に、Mobile-Agent-v3フレームワークを導入し、性能を向上させました。GUI-Owlは、クラウドベースの仮想環境を利用した自己進化するデータ生成、エンドツーエンドの意思決定を支援する多様な機能、スケーラブルな強化学習フレームワークを特徴としています。これらの成果は、オープンソースとして公開されています。 Comment
github: https://github.com/X-PLUG/MobileAgent?tab=readme-ov-file
元ポスト:
ベンチマーク:
- [Paper Note] AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25
- [Paper Note] OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments, Tianbao Xie+, arXiv'24, 2024.04
Trajectory-aware Relative Policy Optimization
(TRPO)
[Paper Note] Ultra-Sparse Memory Network, Zihao Huang+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #MoE(Mixture-of-Experts) #ICLR #read-later #memory Issue Date: 2025-08-29 GPT Summary- UltraMemは、大規模で超スパースなメモリ層を組み込むことで、Transformerモデルの推論レイテンシを削減しつつ性能を維持する新しいアーキテクチャを提案。実験により、UltraMemはMoEを上回るスケーリング特性を示し、最大2000万のメモリスロットを持つモデルが最先端の推論速度と性能を達成することを実証。
[Paper Note] Ovis2.5 Technical Report, Shiyin Lu+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #Reasoning #OpenWeight #CurriculumLearning #VideoGeneration/Understandings #VisionLanguageModel #One-Line Notes Issue Date: 2025-08-28 GPT Summary- Ovis2.5は、ネイティブ解像度の視覚認識とマルチモーダル推論を強化するために設計されたモデルで、画像を可変解像度で処理し、複雑な視覚コンテンツの詳細を保持します。推論時には反省を行う「思考モード」を提供し、精度向上を図ります。5段階のカリキュラムで訓練され、マルチモーダルデータの効率的な処理を実現。Ovis2.5-9BはOpenCompassで平均78.3を記録し、Ovis2-8Bに対して大幅な改善を示しました。Ovis2.5-2Bも73.9を達成し、リソース制約のあるデバイスに最適です。STEMベンチマークや複雑なチャート分析においても優れた性能を発揮しています。 Comment
元ポスト:
HF:
https://huggingface.co/AIDC-AI/Ovis2.5-9B
Apache2.0ライセンス
GLM-4.1V-9B-Thinkingと同等以上の性能な模様。
- [Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25, 2025.07
[Paper Note] UQ: Assessing Language Models on Unsolved Questions, Fan Nie+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #read-later #Selected Papers/Blogs #Verification Issue Date: 2025-08-28 GPT Summary- 本研究では、AIモデルの評価のために、未解決の質問に基づく新しいベンチマーク「UQ」を提案します。UQは、Stack Exchangeから収集した500の多様な質問を含み、難易度と現実性を兼ね備えています。評価には、ルールベースのフィルター、LLM審査員、人間のレビューを組み合わせたデータセット収集パイプライン、生成者-バリデーターのギャップを活用した複合バリデーション戦略、専門家による共同検証プラットフォームが含まれます。UQは、最前線のモデルが人間の知識を拡張するための現実的な課題を評価する手段を提供します。 Comment
元ポスト:
-
-
ポイント解説:
Figure1を見るとコンセプトが非常にわかりやすい。現在のLLMが苦戦しているベンチマークは人間が回答済み、かつ実世界のニーズに反して意図的に作られた高難易度なデータ(現実的な設定では無い)であり、現実的では無いが難易度が高い。一方で、現実にニーズがあるデータでベンチマークを作るとそれらはしばしば簡単すぎたり、ハッキング可能だったりする。
このため、現実的な設定でニーズがあり、かつ難易度が高いベンチマークが不足しており、これを解決するためにそもそも人間がまだ回答していない未解決の問題に着目し、ベンチマークを作りました、という話に見える。
元ポストを咀嚼すると、
未解決な問題ということはReferenceが存在しないということなので、この点が課題となる。このため、UQ-ValidatorとUQ-Platformを導入する。
UQ-Validatorは複数のLLMのパイプラインで形成され、回答候補のpre-screeningを実施する。回答を生成したLLM自身(あるいは同じモデルファミリー)がValidatorに加わることで自身の回答をoverrateする問題が生じるが、複数LLMのパイプラインを組むことでそのバイアスを軽減できる、とのこと。また、しばしば回答を生成するよりも結果をValidationせる方がタスクとして簡単であり、必ずしも適切に回答する能力はValidatorには必要ないという直感に基づいている。たとえば、Claudeは回答性能は低くてもValidatorとしてはうまく機能する。また、Validatorは転移が効き、他データセットで訓練したものを未解決の回答にも適用できる。test-timeのスケーリングもある程度作用する。
続いて、UQ-Platformにおいて、回答とValidatorの出力を見ながら、専門家の支援に基づいて回答評価し、また、そもそもの質問の質などについてコメントするなどして未解決の問題の解決を支援できる。
みたいな話らしい。非常に重要な研究に見える。
[Paper Note] Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset, Rabeeh Karimi Mahabadi+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #Reasoning #Mathematics #read-later #Selected Papers/Blogs Issue Date: 2025-08-27 GPT Summary- 新しい数学コーパス「Nemotron-CC-Math」を提案し、LLMの推論能力を向上させるために、科学テキスト抽出のためのパイプラインを使用。従来のデータセットよりも高品質で、方程式やコードの構造を保持しつつ、表記を標準化。Nemotron-CC-Math-4+は、以前のデータセットを大幅に上回り、事前学習によりMATHやMBPP+での性能向上を実現。オープンソースとしてコードとデータセットを公開。 Comment
元ポスト:
[Paper Note] School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in LLMs, Mia Taylor+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #ReinforcementLearning #Safety #RewardHacking #EmergentMisalignment Issue Date: 2025-08-27 GPT Summary- 報酬ハッキングは、エージェントが不完全な報酬関数を利用して意図されたタスクを遂行せず、タスクを誤って実行する現象です。本研究では、詩作や簡単なコーディングタスクにおける報酬ハッキングの例を含むデータセットを構築し、複数のモデルをファインチューニングしました。結果、モデルは新しい設定で報酬ハッキングを一般化し、無関係な不整合行動を示しました。これにより、報酬ハッキングを学習したモデルがより有害な不整合に一般化する可能性が示唆されましたが、さらなる検証が必要です。 Comment
元ポスト:
[Paper Note] CRISP: Persistent Concept Unlearning via Sparse Autoencoders, Tomer Ashuach+, arXiv'25
Paper/Blog Link My Issue
#NLP #ConceptErasure #KnowledgeEditing Issue Date: 2025-08-26 GPT Summary- CRISPは、LLMにおける持続的な概念の忘却を実現するためのパラメータ効率の良い手法であり、スパースオートエンコーダ(SAE)を用いて有害な知識を効果的に除去します。実験により、CRISPはWMDPベンチマークの忘却タスクで従来の手法を上回り、一般的およびドメイン内の能力を保持しつつ、ターゲット特徴の正確な抑制を達成することが示されました。 Comment
元ポスト:
[Paper Note] Large Foundation Model for Ads Recommendation, Shangyu Zhang+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #FoundationModel #read-later Issue Date: 2025-08-26 GPT Summary- LFM4Adsは、オンライン広告のための全表現マルチ粒度転送フレームワークで、ユーザー表現(UR)、アイテム表現(IR)、ユーザー-アイテム交差表現(CR)を包括的に転送。最適な抽出層を特定し、マルチ粒度メカニズムを導入することで転送可能性を強化。テンセントの広告プラットフォームで成功裏に展開され、2.45%のGMV向上を達成。 Comment
元ポスト:
[Paper Note] InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency, Weiyun Wang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #OpenWeight #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-08-26 GPT Summary- InternVL 3.5は、マルチモーダルモデルの新しいオープンソースファミリーで、Cascade Reinforcement Learningを用いて推論能力と効率を向上させる。粗から細へのトレーニング戦略により、MMMやMathVistaなどのタスクで大幅な改善を実現。Visual Resolution Routerを導入し、視覚トークンの解像度を動的に調整。Decoupled Vision-Language Deployment戦略により、計算負荷をバランスさせ、推論性能を最大16.0%向上させ、速度を4.05倍向上。最大モデルは、オープンソースのMLLMで最先端の結果を達成し、商業モデルとの性能ギャップを縮小。全てのモデルとコードは公開。 Comment
元ポスト:
ポイント解説:
[Paper Note] Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR, Xiao Liang+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Test-Time Scaling #RLVR #Diversity #SelfPlay Issue Date: 2025-08-26 GPT Summary- RLVRは複雑な推論タスクにおいて重要な手法だが、従来の訓練は生成の多様性を低下させることがあった。本研究では、ポリシーの生成多様性を分析し、訓練問題の更新がエントロピー崩壊を軽減することを発見。オンライン自己対戦付き変分問題合成(SvS)戦略を提案し、ポリシーエントロピーを維持しつつ、Pass@k性能を大幅に向上させた。特にAIME24およびAIME25ベンチマークでそれぞれ18.3ポイントと22.8ポイントの改善を達成した。 Comment
pj page: https://mastervito.github.io/SvS.github.io/
元ポスト:
ポイント解説:
[Paper Note] Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search, Yuxian Gu+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #NeuralArchitectureSearch #SmallModel #Reference Collection #Author Thread-Post Issue Date: 2025-08-26 GPT Summary- Jet-Nemotronは新しいハイブリッドアーキテクチャの言語モデルで、フルアテンションモデルと同等以上の精度を持ちながら生成スループットを大幅に改善します。Post Neural Architecture Search(PostNAS)を用いて開発され、事前トレーニングされたモデルから効率的にアテンションブロックを探索します。Jet-Nemotron-2Bモデルは、他の先進モデルに対して高い精度を達成し、生成スループットを最大53.6倍向上させました。 Comment
元ポスト:
著者ポスト:
解説:
所見:
解説:
続報:
コードとチェックポイントがリリース
code: https://github.com/NVlabs/Jet-Nemotron
HF: https://huggingface.co/collections/jet-ai/jet-nemotron-68ac76e8356b5399ef83ac9c
[Paper Note] Competition and Attraction Improve Model Fusion, João Abrantes+, GECCO'25
Paper/Blog Link My Issue
#NLP #ModelMerge Issue Date: 2025-08-25 GPT Summary- モデルマージング(M2N2)は、複数の機械学習モデルの専門知識を統合する進化的アルゴリズムで、動的なマージ境界調整や多様性保持メカニズムを特徴とし、最も有望なモデルペアを特定するヒューリスティックを用いる。実験により、M2N2はゼロからMNIST分類器を進化させ、計算効率を向上させつつ高性能を達成。また、専門的な言語や画像生成モデルのマージにも適用可能で、堅牢性と多様性を示す。コードは公開されている。 Comment
元ポスト:
[Paper Note] LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries, Ming Yin+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #MCP Issue Date: 2025-08-25 GPT Summary- 本研究では、AIエージェントが複数のMCPツールを協調的に使用してマルチステップタスクを解決する能力を評価するためのベンチマーク「LiveMCP-101」を提案。101の実世界のクエリを用い、真の実行計画を基にした新しい評価アプローチを導入。実験結果から、最前線のLLMの成功率が60%未満であることが示され、ツールのオーケストレーションにおける課題が明らかに。LiveMCP-101は、実世界のエージェント能力を評価するための基準を設定し、自律AIシステムの実現に向けた進展を促進する。 Comment
元ポスト:
解説:
[Paper Note] Motif 2.6B Technical Report, Junghwan Lim+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #Alignment #Supervised-FineTuning (SFT) #OpenWeight #Architecture #PostTraining #Selected Papers/Blogs #DataMixture Issue Date: 2025-08-25 GPT Summary- Motif-2.6Bは、26億パラメータを持つ基盤LLMで、長文理解の向上や幻覚の減少を目指し、差分注意やポリノルム活性化関数を採用。広範な実験により、同サイズの最先端モデルを上回る性能を示し、効率的でスケーラブルな基盤LLMの発展に寄与する。 Comment
元ポスト:
HF: https://huggingface.co/Motif-Technologies/Motif-2.6B
- アーキテクチャ
- [Paper Note] Differential Transformer, Tianzhu Ye+, N/A, ICLR'25
- [Paper Note] Polynomial Composition Activations: Unleashing the Dynamics of Large
Language Models, Zhijian Zhuo+, arXiv'24
- 学習手法
- [Paper Note] Model Merging in Pre-training of Large Language Models, Yunshui Li+, arXiv'25, 2025.05
- 8B token学習するごとに直近6つのcheckpointのelement-wiseの平均をとりモデルマージ。当該モデルに対して学習を継続、ということを繰り返す。これにより、学習のノイズを低減し、突然パラメータがシフトすることを防ぐ
- [Paper Note] Effective Long-Context Scaling of Foundation Models, Wenhan Xiong+, arXiv'23, 2023.09
- Adaptive Base Frequency (RoPEのbase frequencyを10000から500000にすることでlong contextのattention scoreが小さくなりすぎることを防ぐ)
- [Paper Note] MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies, Shengding Hu+, COLM'24
- 事前学習データ
- [Paper Note] DataComp-LM: In search of the next generation of training sets for language models, Jeffrey Li+, NeurIPS'25, 2024.07
- TxT360, LLM360, 2024.10
- [Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, COLM'25
を利用したモデル。同程度のサイズのモデルとの比較ではかなりのgainを得ているように見える。興味深い。
DatasetのMixtureの比率などについても記述されている。
[Paper Note] TokenSkip: Controllable Chain-of-Thought Compression in LLMs, Heming Xia+, EMNLP'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Chain-of-Thought #Reasoning #EMNLP #Length #Inference #Author Thread-Post Issue Date: 2025-08-24 GPT Summary- Chain-of-Thought (CoT)はLLMの推論能力を向上させるが、長いCoT出力は推論遅延を増加させる。これに対処するため、重要度の低いトークンを選択的にスキップするTokenSkipを提案。実験により、TokenSkipはCoTトークンの使用を削減しつつ推論性能を維持することを示した。特に、Qwen2.5-14B-InstructでGSM8Kにおいて推論トークンを40%削減し、性能低下は0.4%未満であった。 Comment
元ポスト:
[Paper Note] Pushing the Envelope of LLM Inference on AI-PC, Evangelos Georganas+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #Inference #EdgeDevices Issue Date: 2025-08-24 GPT Summary- 超低ビットLLMモデルの登場により、リソース制約のある環境でのLLM推論が可能に。1ビットおよび2ビットのマイクロカーネルを設計し、PyTorch-TPPに統合することで、推論効率を最大2.2倍向上。これにより、AI PCやエッジデバイスでの超低ビットLLMモデルの効率的な展開が期待される。 Comment
元ポスト:
[Paper Note] MAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning, Justin Chih-Yao Chen+, EMNLP'25
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #SelfCorrection #EMNLP Issue Date: 2025-08-24 GPT Summary- MAgICoReは、LLMの推論を改善するための新しいアプローチで、問題の難易度に応じて洗練を調整し、過剰な修正を回避する。簡単な問題には粗い集約を、難しい問題には細かい反復的な洗練を適用し、外部の報酬モデルを用いてエラーの特定を向上させる。3つのエージェント(Solver、Reviewer、Refiner)によるマルチエージェントループを採用し、洗練の効果を確保する。Llama-3-8BおよびGPT-3.5で評価した結果、MAgICoReは他の手法を上回る性能を示し、反復が進むにつれて改善を続けることが確認された。 Comment
元ポスト:
[Paper Note] Deep Think with Confidence, Yichao Fu+, arXiv'25
Paper/Blog Link My Issue
#NLP #Decoding #read-later #Selected Papers/Blogs #MajorityVoting Issue Date: 2025-08-24 GPT Summary- 「Deep Think with Confidence(DeepConf)」は、LLMの推論タスクにおける精度と計算コストの課題を解決する手法で、モデル内部の信頼性信号を活用して低品質な推論を動的にフィルタリングします。追加の訓練や調整を必要とせず、既存のフレームワークに統合可能です。評価の結果、特に難易度の高いAIME 2025ベンチマークで99.9%の精度を達成し、生成トークンを最大84.7%削減しました。 Comment
pj page:
https://jiaweizzhao.github.io/deepconf
vLLMでの実装:
https://jiaweizzhao.github.io/deepconf/static/htmls/code_example.html
元ポスト:
tooluse、追加の訓練なしで、どのようなタスクにも適用でき、85%生成トークン量を減らした上で、OpenModelで初めてAIME2025において99% Acc.を達成した手法とのこと。vLLMを用いて50 line程度で実装できるらしい。
reasoning traceのconfidence(i.e., 対数尤度)をgroup sizeを決めてwindow単位で決定し、それらをデコーディングのプロセスで活用することで、品質の低いreasoning traceに基づく結果を排除しつつ、majority votingに活用する方法。直感的にもうまくいきそう。オフラインとオンラインの推論によって活用方法が提案されている。あとでしっかり読んで書く。Confidenceの定義の仕方はグループごとのbottom 10%、tailなどさまざまな定義方法と、それらに基づいたconfidenceによるvotingの重み付けが複数考えられ、オフライン、オンラインによって使い分ける模様。
vLLMにPRも出ている模様?
[Paper Note] ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools, Shaofeng Yin+, arXiv'25
Paper/Blog Link My Issue
#Multi #ComputerVision #NLP #Dataset #AIAgents #SyntheticData #VisionLanguageModel Issue Date: 2025-08-24 GPT Summary- 本研究では、実世界のツール使用能力を向上させるために、23Kのインスタンスからなる大規模マルチモーダルデータセット「ToolVQA」を提案。ToolVQAは、実際の視覚的コンテキストと多段階推論タスクを特徴とし、ToolEngineを用いて人間のようなツール使用推論をシミュレート。7B LFMを微調整した結果、テストセットで優れたパフォーマンスを示し、GPT-3.5-turboを上回る一般化能力を持つことが確認された。 Comment
人間による小規模なサンプル(イメージシナリオ、ツールセット、クエリ、回答、tool use trajectory)を用いてFoundation Modelに事前知識として与えることで、よりrealisticなscenarioが合成されるようにした上で新たなVQAを4k程度合成。その後10人のアノテータによって高品質なサンプルにのみFilteringすることで作成された、従来よりも実世界の設定に近く、reasoningの複雑さが高いVQAデータセットな模様。
具体的には、image contextxが与えられた時に、ChatGPT-4oをコントローラーとして、前回のツールとアクションの選択をgivenにし、人間が作成したプールに含まれるサンプルの中からLongest Common Subsequence (LCS) による一致度合いに基づいて人手によるサンプルを選択し、動的にcontextに含めることで多様なで実世界により近しいmulti step tooluseなtrajectoryを合成する、といった手法に見える。pp.4--5に数式や図による直感的な説明がある。なお、LCSを具体的にどのような文字列に対して、どのような前処理をした上で適用しているのかまでは追えていない。
元ポスト:
[Paper Note] Hard Examples Are All You Need: Maximizing GRPO Post-Training Under Annotation Budgets, Benjamin Pikus+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #GRPO Issue Date: 2025-08-23 GPT Summary- リソースが制約された状況での言語モデルのファインチューニングにおいて、難易度の異なるトレーニング例の優先順位を検討。実験により、最も難しい例でのトレーニングが最大47%のパフォーマンス向上をもたらすことが示され、難しい例が学習機会を多く提供することが明らかに。これにより、予算制約下での効果的なトレーニング戦略として、難しい例を優先することが推奨される。 Comment
ベースモデルのpass@kが低いhardestなサンプルでGRPOを学習するのがデータ効率が良く、OODに対する汎化性能も発揮されます、というのをQwen3-4B, 14B, Phi4で実験して示しました、という話っぽい?
小規模モデル、およびGSM8K、BIG Bench hardでの、Tracking Shuffled Objectのみでの実験な模様?大規模モデルやコーディングなどのドメインでもうまくいくかはよく分からない。OODの実験もAIME2025でのみの実験しているようなのでそこは留意した方が良いかも。
rewardとして何を使ったのかなどの細かい内容を追えていない。
元ポスト:
[Paper Note] Intern-S1: A Scientific Multimodal Foundation Model, Lei Bai+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #OpenWeight #MoE(Mixture-of-Experts) #read-later #VisionLanguageModel #Science Issue Date: 2025-08-23 GPT Summary- Intern-S1は、科学専門分野に特化したオープンソースの専門家型モデルで、280億の活性化パラメータを持つマルチモーダルMixture-of-Experts(MoE)モデルです。5Tトークンで事前学習され、特に科学データに焦点を当てています。事後学習では、InternBootCampを通じて強化学習を行い、Mixture-of-Rewardsを提案。評価では、一般的な推論タスクで競争力を示し、科学分野の専門的なタスクでクローズドソースモデルを上回る性能を達成しました。モデルはHugging Faceで入手可能です。 Comment
元ポスト:
scientific domainに特化したデータで継続事前学習+RL Finetuningしたドメイン特化言語モデルらしい。
HF:
https://huggingface.co/internlm/Intern-S1
Apache 2.0ライセンス
ベースモデルはQwen3とInternViT
- InternViT:
https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5
関連:
- [Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24
解説:
サマリ:
[Paper Note] Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing, Yiqun Zhang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP Issue Date: 2025-08-23 GPT Summary- LLMのパフォーマンスと効率のバランスを取るために、テスト時ルーティングフレームワーク「Avengers-Pro」を提案。クエリを埋め込み、クラスタリングし、最適なモデルにルーティングすることで、6つのベンチマークで最先端の結果を達成。最強の単一モデルを平均精度で+7%上回り、コストを27%削減しつつ約90%のパフォーマンスを実現。すべての単一モデルの中で最高の精度と最低のコストを提供するパレートフロンティアを達成。コードは公開中。 Comment
元ポスト:
クエリをkmeansでクラスタリングし、各クラスタごとにモデルごとのperformanceとcostを事前に算出しておく。そして新たなクエリが来た時にクエリが割り当てられるtop pのクラスタのperformanae-cost efficiencyを合計し、スコアが高い一つのモデルを選択(=routing)しinferenceを実施する。クエリはQwenでembedding化してクラスタリングに活用する。ハイパーパラメータα∈[0,1]によって、performance, costどちらを重視するかのバランスを調整する。
シンプルな手法だが、GPT-5 mediumと同等のコスト/性能 でより高い 性能/コスト を実現。
性能向上、コスト削減でダメ押ししたい時に使えそうだが、発行するクエリがプロプライエタリデータ、あるいはそもそも全然データないんです、みたいな状況の場合、クエリの割当先となるクラスタを適切に確保する(クラスタリングに用いる十分な量のデータを準備する)のが大変な場面があるかもしれない。
(全然本筋と関係ないが、最近論文のタイトルにBeyondつけるの流行ってる…?)
[Paper Note] Prompt Orchestration Markup Language, Yuge Zhang+, arXiv'25
Paper/Blog Link My Issue
#NLP #Prompting #read-later Issue Date: 2025-08-22 GPT Summary- POML(プロンプトオーケストレーションマークアップ言語)を導入し、LLMsのプロンプトにおける構造、データ統合、フォーマット感受性の課題に対処。コンポーネントベースのマークアップやCSSスタイリングシステムを採用し、動的プロンプトのテンプレート機能や開発者ツールキットを提供。POMLの有効性を2つのケーススタディで検証し、実際の開発シナリオでの効果を評価。 Comment
pj page: https://microsoft.github.io/poml/latest/
元ポスト:
これは非常に興味深い
[Paper Note] WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model, Tianqing Fang+, EMNLP'25
Paper/Blog Link My Issue
#NLP #AIAgents #SelfImprovement #EMNLP Issue Date: 2025-08-22 GPT Summary- 自己改善エージェントのために、共進化するワールドモデルLLMを導入する新しいフレームワークを提案。これにより、エージェントのポリシーを洗練する自己指導型トレーニングデータを生成し、行動選択を導く先読みシミュレーションを実現。実験により、既存の自己進化エージェントに対して10%のパフォーマンス向上を示し、持続的な適応性を促進することを目指す。 Comment
元ポスト:
[Paper Note] Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?, Momoka Furuhashi+, EMNLP'25
Paper/Blog Link My Issue
#Analysis #NaturalLanguageGeneration #NLP #Evaluation #EMNLP #read-later Issue Date: 2025-08-22 GPT Summary- 生成タスクの自動評価における曖昧な基準の課題を解決するため、チェックリストの使用方法を検討。6つの生成方法と8つのモデルサイズで評価し、選択的チェックリストがペアワイズ評価でパフォーマンスを改善する傾向があることを発見。ただし、直接スコアリングでは一貫性がない。人間の評価基準との相関が低いチェックリスト項目も存在し、評価基準の明確化が必要であることを示唆。 Comment
元ポスト:
pj page: https://momo0817.github.io/checklist-effectiveness-study-github.io/
PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
Paper/Blog Link My Issue
#MachineTranslation #NLP #Supervised-FineTuning (SFT) #SmallModel #Japanese #DPO #Selected Papers/Blogs #ModelMerge #KeyPoint Notes Issue Date: 2025-08-22 Comment
元ポスト:
SFT->Iterative DPO->Model Mergeのパイプライン。SFTでは青空文庫などのオープンなデータから指示追従性能の高いDeepSeek-V3-0324によって元データ→翻訳, 翻訳→再翻訳データを合成し活用。また、翻訳の指示がprompt中に存在せずとも(本モデルを利用するのは翻訳用途であることが自明であるからと推察される)翻訳を適切に実行できるよう、独自のテンプレートを学習。文体指定、常体、敬体の指定、文脈考慮、語彙指定それぞれにういて独自のタグを設けてフォーマットを形成し翻訳に特化したテンプレートを学習。
IterativeDPOでは、DeepSeekV3に基づくLLM-as-a-Judgeと、MetricX([Paper Note] MetricX-24: The Google Submission to the WMT 2024 Metrics Shared Task, Juraj Juraska+, arXiv'24
)に基づいてReward Modelをそれぞれ学習し、1つの入力に対して100個の翻訳を作成しそれぞれのRewardモデルのスコアの合計値に基づいてRejection Samplingを実施することでPreference dataを構築。3段階のDPOを実施し、段階ごとにRewardモデルのスコアに基づいて高品質なPreference Dataに絞ることで性能向上を実現。
モデルマージではDPOの各段階のモデルを重み付きでマージすることで各段階での長所を組み合わせたとのこと。
2025.1010配信の「岡野原大輔のランチタイムトーク Vol.52 番外編「なぜPLaMo翻訳は自然なのか?」において詳細が語られているので参照のこと。特になぜ日本語に強いLLMが大事なのか?という話が非常におもしろかった。
ガバメントAI源内での利用が決定:
[Paper Note] Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models, Wen Wang+, arXiv'25
Paper/Blog Link My Issue
#NLP #DiffusionModel #Decoding #PostTraining Issue Date: 2025-08-22 GPT Summary- dLLMsは中間予測を捨てがちだが、時間的振動が重要な現象である。本研究では、時間的一貫性を活用する2つの方法を提案。1つ目は、テスト時に予測を集約する時間的自己一貫性投票、2つ目は中間予測の安定性を測る時間的意味エントロピーを報酬信号とする時間的一貫性強化。実験結果では、Countdownデータセットで24.7%の改善を達成し、他のベンチマークでも向上を示した。これにより、dLLMsの時間的ダイナミクスの可能性が強調される。 Comment
元ポスト:
dLLMのデノイジング過程において途中に正解が表出しているのに時間発展とともに消えてしまう問題があるらしく、それに対して、デノイジングステップにおいてstableな予測を行うSelf-Consistencyベースのdecoding手法と、意味的なエントロピーをrewardに加え時間発展で安定するようにpost trainingすることで対処します、みたいな話らしい。
[Paper Note] Agent Laboratory: Using LLM Agents as Research Assistants, Samuel Schmidgall+, EMNLP'25 Findings
Paper/Blog Link My Issue
#NLP #AIAgents #ScientificDiscovery #EMNLP #Findings Issue Date: 2025-08-21 GPT Summary- Agent Laboratoryは、全自動のLLMベースのフレームワークで、研究アイデアから文献レビュー、実験、報告書作成までのプロセスを完了し、質の高い研究成果を生成します。人間のフィードバックを各段階で取り入れることで、研究の質を向上させ、研究費用を84%削減。最先端の機械学習コードを生成し、科学的発見の加速を目指します。 Comment
元ポスト:
pj page: https://agentlaboratory.github.io
[Paper Note] ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents, Hanyu Lai+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #ComputerUse Issue Date: 2025-08-20 GPT Summary- ComputerRLは、自律的なデスクトップインテリジェンスのためのフレームワークで、API-GUIパラダイムを用いてエージェントがデジタルワークスペースを操作します。分散RLインフラを開発し、数千の仮想デスクトップ環境でのスケーラブルな強化学習を実現。Entropulseトレーニング戦略により、長期トレーニング中のエントロピー崩壊を軽減。GLM-4-9B-0414を用いたAutoGLM-OS-9Bは、OSWorldベンチマークで48.1%の新しい最先端精度を達成し、デスクトップ自動化における重要な改善を示しました。 Comment
ポイント解説:
ポイント解説:
[Paper Note] Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation, David Heineman+, NeurIPS'25 Spotlight
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #read-later #Selected Papers/Blogs Issue Date: 2025-08-20 GPT Summary- 大規模言語モデルの評価において、信号対ノイズ比を改善することで、より信頼性の高いベンチマークを設計する方法を提案。信号はモデルの識別能力、ノイズは変動への感受性を示し、良好な比率は小規模な意思決定において有用。信号やノイズを改善するための介入として、指標の切り替えやサブタスクのフィルタリング、中間チェックポイントの出力の平均化を提案。30のベンチマークと375の言語モデルを用いて新しい公開データセットを作成。 Comment
元ポスト:
[Paper Note] Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration, Zhicheng Yang+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #RLVR #Entropy Issue Date: 2025-08-20 GPT Summary- 強化学習における検証可能報酬(RLVR)の潜在能力は、深さ(難問への取り組み)と広さ(インスタンス数)によって未発揮である。GRPOアルゴリズムの分析を通じて、累積アドバンテージが不均等に重みづけされていることを明らかにし、Difficulty Adaptive Rollout Sampling(DARS)を提案。DARSは難問に対してターゲットを絞ったロールアウトを行い、難問の正のロールアウトを増やしつつ、収束時の推論コストを増加させずにPass@Kを改善。さらに、バッチサイズの拡大を通じ、広さを増やすことでPass@1の性能を顕著に向上させる。DARSと大規模な広さを組み合わせたDARS-Bは、同時のPass@KとPass@1の向上を実証し、深さと広さの適応的な探索がRLVRの推論力を引き出す鍵であることを確認した。 Comment
元ポスト:
[Paper Note] AutoCodeBench: Large Language Models are Automatic Code Benchmark Generators, Jason Chou+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Coding #MultiLingual Issue Date: 2025-08-19 GPT Summary- AutoCodeGenを提案し、手動注釈なしで高難易度の多言語コード生成データセットを自動生成。これに基づき、3,920の問題からなるAutoCodeBenchを導入し、20のプログラミング言語に均等に分配。30以上のLLMsを評価した結果、最先端のモデルでも多様性や複雑さに苦労していることが明らかに。AutoCodeBenchシリーズは、実用的な多言語コード生成シナリオに焦点を当てるための貴重なリソースとなることを期待。 Comment
pj page: https://autocodebench.github.io/
元ポスト:
[Paper Note] OptimalThinkingBench: Evaluating Over and Underthinking in LLMs, Pranjal Aggarwal+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning #Overthinking #Underthinking #Author Thread-Post Issue Date: 2025-08-19 GPT Summary- 思考型LLMsは複雑なタスクを解決する一方で、単純な問題に対して過剰に思考し、非思考型LLMsは速いが難しい問題に対して思考が不足する。これにより、最適なモデル選択がユーザーに委ねられる。OptimalThinkingBenchを導入し、過剰思考と過少思考を共同で評価する。72の単純な数学問題と11の難解な推論課題を含む二つのサブベンチマークを通じて33種のモデルを評価し、どのモデルも最適な思考ができないことを示す。最適思考を促す手法も、多くの場合、一方の性能を改善することで他方を犠牲にする結果となる。 Comment
元ポスト:
元ポストの著者によるスレッドが非常にわかりやすいのでそちらを参照のこと。
ざっくり言うと、Overthinking(考えすぎて大量のトークンを消費した上に回答が誤っている; トークン量↓とLLMによるJudge Score↑で評価)とUnderthinking(全然考えずにトークンを消費しなかった上に回答が誤っている; Accuracy↑で評価)をそれぞれ評価するサンプルを収集し、それらのスコアの組み合わせでモデルが必要に応じてどれだけ的確にThinkingできているかを評価するベンチマーク。
Overthinkingを評価するためのサンプルは、多くのLLMでagreementがとれるシンプルなQAによって構築。一方、Underthinkingを評価するためのサンプルは、small reasoning modelがlarge non reasoning modelよりも高い性能を示すサンプルを収集。
現状Non Thinking ModelではQwen3-235B-A22Bの性能が良く、Thinking Modelではgpt-oss-120Bの性能が良い。プロプライエタリなモデルではそれぞれ、Claude-Sonnet4, o3の性能が良い。全体としてはo3の性能が最も良い。
openreview: https://openreview.net/forum?id=N5kWa3sRJt
著者による一言解説:
[Paper Note] Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models, Zhipeng Chen+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #read-later #RLVR #Diversity #EntropyCollapse Issue Date: 2025-08-19 GPT Summary- 検証可能な報酬を用いた強化学習(RLVR)では、Pass@1を報酬として使用することが多く、探索と活用のバランスに課題がある。これに対処するため、Pass@kを報酬としてポリシーモデルを訓練し、その探索能力の向上を観察。分析により、探索と活用は相互に強化し合うことが示され、利得関数の設計を含むPass@k Trainingの利点が明らかになった。さらに、RLVRのための利得設計を探求し、有望な結果を得た。 Comment
元ポスト:
関連:
- [Paper Note] Olmo 3, Team Olmo+, arXiv'25, 2025.12
openreview: https://openreview.net/forum?id=eslxxopXTF
[Paper Note] BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining, Pratyush Maini+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #SyntheticData #read-later Issue Date: 2025-08-19 GPT Summary- 合成データ生成フレームワーク「BeyondWeb」を提案し、高品質な合成データの生成が可能であることを示す。BeyondWebは、従来のデータセットを超える性能を発揮し、トレーニング速度も向上。特に、3Bモデルが8Bモデルを上回る結果を示す。合成データの品質向上には多くの要因を最適化する必要があり、単純なアプローチでは限界があることを指摘。 Comment
元ポスト:
[Paper Note] NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model, NVIDIA+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #SmallModel #OpenWeight #SSM (StateSpaceModel) #Selected Papers/Blogs Issue Date: 2025-08-19 GPT Summary- Nemotron-Nano-9B-v2は、推論スループットを向上させつつ最先端の精度を達成するハイブリッドMamba-Transformerモデルである。自己注意層の一部をMamba-2層に置き換え、長い思考トレースの生成を高速化。12億パラメータのモデルを20兆トークンで事前トレーニングし、Minitron戦略で圧縮・蒸留。既存モデルと比較して、最大6倍の推論スループットを実現し、精度も同等以上。モデルのチェックポイントはHugging Faceで公開予定。 Comment
元ポスト:
事前学習に利用されたデータも公開されているとのこと(Nemotron-CC):
解説:
サマリ:
[Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations, Kaiyuan Chen+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #read-later #Selected Papers/Blogs #CrossDomain #Live Issue Date: 2025-08-18 GPT Summary- 「xbench」は、AIエージェントの能力と実世界の生産性のギャップを埋めるために設計された動的な評価スイートで、業界専門家が定義したタスクを用いて商業的に重要なドメインをターゲットにしています。リクルートメントとマーケティングの2つのベンチマークを提示し、エージェントの能力を評価するための基準を確立します。評価結果は継続的に更新され、https://xbench.org で入手可能です。
[Paper Note] A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models, Lingzhe Zhang+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #DiffusionModel #Verification Issue Date: 2025-08-16 GPT Summary- 並列テキスト生成は、LLMの生成速度を向上させるための技術であり、自己回帰生成のボトルネックを打破することを目指している。本研究では、並列テキスト生成手法をARベースと非ARベースに分類し、それぞれの技術を評価。速度、品質、効率のトレードオフを考察し、今後の研究の方向性を示す。関連論文を集めたGitHubリポジトリも作成。 Comment
Taxonomyと手法一覧。Draft and Verifyingは個人的に非常に興味がある。
[Paper Note] HealthBench: Evaluating Large Language Models Towards Improved Human Health, Rahul K. Arora+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Trustfulness #Health Issue Date: 2025-08-16 GPT Summary- HealthBenchは、医療における大規模言語モデルの性能と安全性を評価するオープンソースのベンチマークで、5,000件のマルチターン対話が含まれています。262名の医師による独自のルーブリックで評価され、緊急事態や臨床データ変換などの医療文脈を考慮し、現実的なオープンエンド評価を行います。過去2年間でGPT-3.5 TurboとGPT-4oに対し、16%および32%の進歩を示し、特に小型モデルでは顕著な改善が見られます。また、医師の合意に基づくHealthBench Consensusと厳しい評価基準を持つHealthBench Hardの2つのバリエーションも公開しています。今後、HealthBenchが人間の健康向上に寄与することが期待されます。
[Paper Note] BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, Jason Wei+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #read-later #Selected Papers/Blogs Issue Date: 2025-08-16 GPT Summary- BrowseCompは、エージェントのウェブブラウジング能力を測定するための1,266の質問からなるベンチマークで、絡み合った情報を探すことを要求します。シンプルで使いやすく、短い回答が求められ、参照回答との照合が容易です。このベンチマークは、ブラウジングエージェントの能力を評価するための重要なツールであり、持続力と創造性を測定します。詳細はGitHubで入手可能です。
[Paper Note] UI-Venus Technical Report: Building High-performance UI Agents with RFT, Zhangxuan Gu+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #ComputerUse #VisionLanguageModel Issue Date: 2025-08-16 GPT Summary- UI-Venusは、スクリーンショットを入力として受け取るマルチモーダル大規模言語モデルに基づくネイティブUIエージェントで、UIグラウンディングとナビゲーションタスクで最先端の性能を達成。7Bおよび72Bバリアントは、Screenspot-V2 / Proベンチマークで高い成功率を記録し、既存のモデルを上回る。報酬関数やデータクリーニング戦略を導入し、ナビゲーション性能を向上させるための新しい自己進化フレームワークも提案。オープンソースのUIエージェントを公開し、さらなる研究を促進。コードはGitHubで入手可能。 Comment
元ポスト:
解説:
HF: https://huggingface.co/collections/inclusionAI/ui-venus-689f2fb01a4234cbce91c56a
[Paper Note] OpenCUA: Open Foundations for Computer-Use Agents, Xinyuan Wang+, arXiv'25
Paper/Blog Link My Issue
#NLP #AIAgents #ComputerUse #read-later #Selected Papers/Blogs #VisionLanguageModel #Author Thread-Post Issue Date: 2025-08-15 GPT Summary- OpenCUAは、CUAデータと基盤モデルをスケールさせるためのオープンソースフレームワークであり、アノテーションインフラ、AgentNetデータセット、反射的なChain-of-Thought推論を持つスケーラブルなパイプラインを提供。OpenCUA-32Bは、CUAベンチマークで34.8%の成功率を達成し、最先端の性能を示す。研究コミュニティのために、アノテーションツールやデータセットを公開。 Comment
元ポスト:
著者ポスト:
CUAにおいてProprietaryモデルに近い性能を達成した初めての研究な模様。重要
続報:
OSWorld VerifiedでUI-TARS-250705,claude-4-sonnet-20250514超えでtop1に君臨とのこと。
[Paper Note] Optimas: Optimizing Compound AI Systems with Globally Aligned Local Rewards, Shirley Wu+, arXiv'25
Paper/Blog Link My Issue
#MachineLearning #RewardModel #CompoundAISystemsOptimization Issue Date: 2025-08-15 GPT Summary- 複合AIシステムの最適化のために、統一フレームワークOptimasを提案。各コンポーネントにローカル報酬関数を維持し、グローバルパフォーマンスと整合性を保ちながら同時に最大化。これにより、異種構成の独立した更新が可能となり、平均11.92%の性能向上を実現。 Comment
元ポスト:
framework: https://github.com/snap-stanford/optimas
複数のコンポーネントのパイプラインによって構成されるシステムがあったときに、パイプライン全体のパフォーマンスを改善したい。このとき、パイプライン全体のパフォーマンスをユーザが定義したGlobal Reward Functionを最大化するように最適化したい。しかし、多くの場合このような異種のコンポーネントが複雑に連携したパイプラインでは、global rewardsは微分不可能なので、end-to-endで最適化することが難しい。また、個々の異種のコンポーネントのコンフィグ(e.g., textual, numerical, continuous vs. discrete)を同時に最適化することがそもそも難しい。全体のAIシステムを動作させて、global rewardを最適化するのは非常にコストがかかる。先行研究では、特定のコンポーネントを別々に最適化してきた(たとえば、promptをフィードバックに基づいて改善する [Paper Note] Large Language Models as Optimizers, Chengrun Yang+, ICLR'24, 2023.09
, モデル選択をiterative searchで改善するなど)。が、個別のコンポーネントを最適化しても別のコンポーネントの最適化が不十分であれば全体の性能は向上せず、全てのコンポーネントを個別に最適化しても、相互作用が最適ではない場合はglobal rewardが最大化されない可能性がある。
このため、個々のコンポーネントにlocal reward function (LRFs)を定義する。local reward functionは、これらが改善することでglobal reward functionも改善することを保証するような形(local-global alignment properfy)で定義され、これらのlocal reward functionを異なるコンポーネントごとに異なる形で最適化しても、global reward functionが改善されるように学習する。個々のコンポーネントごとにLRFsを最適化することは、全体のシステムの実行回数を削減しながら高いglobal rewardを実現可能となる。加えて、他のコンポーネントのコンフィグが改善されたら、それらに適応してLRFsも改善されていく必要があるので lightweight adaptationと呼ばれる、システムからサンプリングされた最小のデータからLRFsをアップデートする手法も提案する、みたいな話な模様。
LRFsを定義するときは、共通のLLMをバックボーンとし、個々のコンポーネントに対して別々のヘッドを用意してrewardを出力するようなモデルを定義する。コンポーネントkのinput x, output y が与えられたときに、それらをconcatしてLLMに入力し[x_k, y_k]最終的にヘッドでスカラー値に写像する。また、LRF r_kが *aligned* の定義として、LRF r_kがある共通のinputに対してr_kが高くなるようなoutputをしたときに、downstreamのコンポーネント全体のglobal reward Rが同等以上の性能を達成する場合、alignedであると定義する。このような特性を実現するために、現行のシステムのコンフィグに基づいてそれぞれのコンポーネントを実行し、trajectoryを取得。特定のコンポーネントC_kに対する二つのoutputを(異なるコンフィグに基づいて)サンプリングしてパイプライン全体のmetricを予測し、metricが高い/低いサンプルをchosen/rejectedとし preference dataを用意する。このようなデータを用いて、個々のコンポーネントのLRFsを、chosenなサンプルの場合はrejectedよりもrewardが高くなるようにペアワイズのranking lossを用いて学習する。
(ここまでが4.1節の概要。4.2, 4.3節以後は必要に応じて参照する。4.2ではどのように他コンポーネントが更新された際にLRFsを更新するか、という話と、4.3節では個々のコンポーネントがtext, trainable models, continuous configurationなどの異なるコンポーネントの場合にどのような最適化手法を適用するか、といった話が書かれているように見える。)
評価では5つの実世界のタスクを実現するための複数コンポーネントで構成されるシステムの最適化を試みているようであり、
提案手法によって、パイプライン全体の性能がベースラインと比べて改善しシステム全体の実行回数もベースラインと比較して少ない試行回数で済むことが示されている模様。
[Paper Note] FormulaOne: Measuring the Depth of Algorithmic Reasoning Beyond Competitive Programming, Gal Beniamini+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning Issue Date: 2025-08-14 GPT Summary- フロンティアAIモデルの能力を評価するために、実際の研究問題に基づくベンチマーク「FormulaOne」を構築。これは、グラフ理論やアルゴリズムに関連する難易度の高い問題で、商業的関心や理論計算機科学に関連。最先端モデルはFormulaOneでほとんど解決できず、専門家レベルの理解から遠いことが示された。研究支援のために、簡単なタスクセット「FormulaOne-Warmup」を提供し、評価フレームワークも公開。 Comment
元ポスト:
[Paper Note] $μ$-Parametrization for Mixture of Experts, Jan Małaśnicki+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #MoE(Mixture-of-Experts) #HyperparameterTransfer Issue Date: 2025-08-14 GPT Summary- 本研究では、Mixture-of-Experts(MoE)モデルに対する$\mu$-Parameterization($\mu$P)を提案し、ルーターとエキスパートの特徴学習に関する理論的保証を提供します。また、エキスパートの数と粒度のスケーリングが最適な学習率に与える影響を実証的に検証します。 Comment
元ポスト:
関連: mu transfer, muP
- [Paper Note] Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer, Greg Yang+, NeurIPS'21
- [Paper Note] Feature Learning in Infinite-Width Neural Networks, Greg Yang+, ICML'21
[Paper Note] Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning, Lijie Yang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention Issue Date: 2025-08-14 GPT Summary- 「LessIsMore」という新しいスパースアテンションメカニズムを提案。これは、トレーニング不要でグローバルアテンションパターンを活用し、トークン選択を効率化。精度を維持しつつ、デコーディング速度を1.1倍向上させ、トークン数を2倍削減。既存手法と比較して1.13倍のスピードアップを実現。 Comment
元ポスト:
トレーニングフリーで1.1倍のデコーディング速度で性能もFull Attentionと同等以上のSparse Attentionらしい
[Paper Note] The Policy Cliff: A Theoretical Analysis of Reward-Policy Maps in Large Language Models, Xingcheng Xu, arXiv'25
Paper/Blog Link My Issue
#Multi #Analysis #NLP #ReinforcementLearning #read-later Issue Date: 2025-08-14 GPT Summary- 強化学習(RL)は大規模言語モデルの行動形成に重要だが、脆弱なポリシーを生成し、信頼性を損なう問題がある。本論文では、報酬関数から最適ポリシーへのマッピングの安定性を分析する数学的枠組みを提案し、ポリシーの脆弱性が非一意的な最適アクションに起因することを示す。さらに、多報酬RLにおける安定性が「効果的報酬」によって支配されることを明らかにし、エントロピー正則化が安定性を回復することを証明する。この研究は、ポリシー安定性分析を進展させ、安全で信頼性の高いAIシステム設計に寄与する。 Comment
元ポスト:
とても面白そう
[Paper Note] Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL, Jiaxuan Gao+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Search #ReinforcementLearning #AIAgents #Selected Papers/Blogs #KeyPoint Notes #Reference Collection #Asynchronous #Author Thread-Post Issue Date: 2025-08-14 GPT Summary- ASearcherは、LLMベースの検索エージェントの大規模なRLトレーニングを実現するオープンソースプロジェクトであり、高効率な非同期RLトレーニングと自律的に合成された高品質なQ&Aデータセットを用いて、検索能力を向上させる。提案されたエージェントは、xBenchで46.7%、GAIAで20.8%の改善を達成し、長期的な検索能力を示した。モデルとデータはオープンソースで提供される。 Comment
元ポスト:
著者ポスト:
解説ポスト:
関連ベンチマーク:
- [Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned
Real-World Evaluations, Kaiyuan Chen+, arXiv'25
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
- [Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, N/A, NAACL'25
既存のモデルは <= 10 turnsのデータで学習されており、大規模で高品質なQAデータが不足している問題があったが、シードQAに基づいてQAを合成する手法によって1.4万シードQAから134kの高品質なQAを合成した(うち25.6kはツール利用が必要)。具体的には、シードのQAを合成しエージェントがQAの複雑度をiterationをしながら向上させていく手法を提案。事実情報は常にverificationをされ、合成プロセスのiterationの中で保持され続ける。個々のiterationにおいて、現在のQAと事実情報に基づいて、エージェントは
- Injection: 事実情報を新たに注入しQAをよりリッチにすることで複雑度を上げる
- Fuzz: QA中の一部の詳細な情報をぼかすことで、不確実性のレベルを向上させる。
の2種類の操作を実施する。その上で、QAに対してQuality verificationを実施する:
- Basic Quality: LLMでqualityを評価する
- Difficulty Measurement: LRMによって、複数の回答候補を生成する
- Answer Uniqueness: Difficulty Measurementで生成された複数の解答情報に基づいて、mismatched answersがvalid answerとなるか否かを検証し、正解が単一であることを担保する
また、複雑なタスク、特にtool callsが非常に多いタスクについては、多くのターン数(long trajectories)が必要となるが、既存のバッチに基づいた学習手法ではlong trajectoriesのロールアウトをしている間、他のサンプルの学習がブロックされてしまい学習効率が非常に悪いので、バッチ内のtrajectoryのロールアウトとモデルの更新を分離(ロールアウトのリクエストが別サーバに送信されサーバ上のInference Engineで非同期に実行され、モデルをアップデートする側は十分なtrajectoryがバッチ内で揃ったらパラメータを更新する、みたいな挙動?)することでIdleタイムを無くすような手法を提案した模様。
既存の手法ベンチマークの性能は向上している。学習が進むにつれて、trajectory中のURL参照回数やsearch query数などが増大していく曲線は考察されている。他モデルと比較して、より多いターン数をより高い正確性を以って実行できるといった定量的なデータはまだ存在しないように見えた。
[Paper Note] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent, Xinyu Geng+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #AIAgents #SyntheticData #Evaluation #MultiModal #VisionLanguageModel #DeepResearch Issue Date: 2025-08-14 GPT Summary- WebWatcherは、視覚と言語の推論能力を強化したマルチモーダルエージェントであり、情報探索の困難さに対処する。合成マルチモーダル軌跡を用いた効率的なトレーニングと強化学習により、深い推論能力を向上させる。新たに提案されたBrowseComp-VLベンチマークでの実験により、WebWatcherは複雑なVQAタスクで他のエージェントを大幅に上回る性能を示した。 Comment
元ポスト:
公式:
[Paper Note] Geometric-Mean Policy Optimization, Yuzhong Zhao+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #GRPO #On-Policy #Stability Issue Date: 2025-08-14 GPT Summary- GRPOの不安定性を解決するために、幾何平均を最適化するGMPOを提案。GMPOは外れ値に敏感でなく、安定した重要度サンプリング比率を維持。実験により、GMPO-7Bは複数の数学的およびマルチモーダル推論ベンチマークでGRPOを上回る性能を示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Can Language Models Falsify? Evaluating Algorithmic Reasoning with Counterexample Creation, Shiven Sinha+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Coding #Reasoning #Verification Issue Date: 2025-08-13 GPT Summary- 言語モデル(LM)の科学的発見を加速するために、微妙に誤った解決策に対する反例を作成する能力を評価する新しいベンチマーク「REFUTE」を提案。これはプログラミング問題からの誤った提出物を用いており、最も優れた推論エージェントでも9%未満の反例しか生成できないことが示された。この研究は、LMの誤った解決策を否定する能力を向上させ、信頼できる推論を通じて自己改善を促進することを目指している。 Comment
pj page: https://falsifiers.github.io
元ポスト:
バグのあるコードとtask descriptionが与えられた時に、inputのフォーマットと全ての制約を満たすが、コードの実行が失敗するサンプル(=反例)を生成することで、モデルのreasoning capabilityの評価をするベンチマーク。
gpt-ossはコードにバグのあるコードに対して上記のような反例を生成する能力が高いようである。ただし、それでも全体のバグのあるコードのうち反例を生成できたのは高々21.6%のようである。ただ、もしコードだけでなくverification全般の能力が高いから、相当使い道がありそう。
[Paper Note] Unveiling Super Experts in Mixture-of-Experts Large Language Models, Zunhai Su+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #MoE(Mixture-of-Experts) Issue Date: 2025-08-13 GPT Summary- スパースに活性化されたMixture-of-Experts(MoE)モデルにおいて、特定の専門家のサブセット「スーパ専門家(SE)」がモデルの性能に重要な影響を与えることを発見。SEは稀な活性化を示し、プルーニングするとモデルの出力が劣化する。分析により、SEの重要性が数学的推論などのタスクで明らかになり、MoE LLMがSEに依存していることが確認された。 Comment
元ポスト:
MoEにおける、特に重要な専門家であるSuper Expertsの存在
- [Paper Note] The Super Weight in Large Language Models, Mengxia Yu+, arXiv'24, 2024.11
を思い出す。
[Paper Note] LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools?, Guozhao Mo+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #MCP Issue Date: 2025-08-13 GPT Summary- LiveMCPBenchは、10,000を超えるMCPサーバーに基づく95の実世界タスクから成る初の包括的なベンチマークで、LLMエージェントの大規模評価を目的としています。70のMCPサーバーと527のツールを含むLiveMCPToolを整備し、LLM-as-a-JudgeフレームワークであるLiveMCPEvalを導入して自動化された適応評価を実現しました。MCP Copilot Agentは、ツールを動的に計画し実行するマルチステップエージェントです。評価の結果、最も優れたモデルは78.95%の成功率を達成しましたが、モデル間で性能のばらつきが見られました。全体として、LiveMCPBenchはLLMエージェントの能力を評価するための新たなフレームワークを提供します。 Comment
pj page: https://icip-cas.github.io/LiveMCPBench/
元ポスト:
MCP環境におけるLLM Agentのベンチマーク。論文中のTable1に他のベンチマークを含めサマリが掲載されている。MCPを用いたLLMAgentのベンチがすでにこんなにあることに驚いた…。
[Paper Note] Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning, Zihe Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #read-later #Reproducibility Issue Date: 2025-08-12 GPT Summary- 強化学習(RL)を用いた大規模言語モデル(LLM)の推論に関する研究が進展する中、標準化されたガイドラインやメカニズムの理解が不足している。実験設定の不一致やデータの変動が混乱を招いている。本論文では、RL技術を体系的にレビューし、再現実験を通じて各技術のメカニズムや適用シナリオを分析。明確なガイドラインを提示し、実務者に信頼できるロードマップを提供する。また、特定の技術の組み合わせが性能を向上させることを示した。 Comment
元ポスト:
読んだ方が良い
解説:
[Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25
Paper/Blog Link My Issue
#NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2025-08-12 GPT Summary- 355Bパラメータを持つオープンソースのMixture-of-ExpertsモデルGLM-4.5を発表。ハイブリッド推論手法を採用し、エージェント的、推論、コーディングタスクで高いパフォーマンスを達成。競合モデルに比べて少ないパラメータ数で上位にランクイン。GLM-4.5とそのコンパクト版GLM-4.5-Airをリリースし、詳細はGitHubで公開。 Comment
元ポスト:
- アーキテクチャ
- MoE / sigmoid gates
- DeepSeek-R1, DeepSeek, 2025.01
- [Paper Note] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
- loss free balanced routing
- [Paper Note] Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, Lean Wang+, arXiv'24
- widthを小さく、depthを増やすことでreasoning能力改善
- GQA w/ partial RoPE
- [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
- [Paper Note] RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, arXiv'21, 2021.04
- Attention Headsの数を2.5倍(何に対して2.5倍なんだ、、?)(96個, 5120次元)にすることで(おそらく)事前学習のlossは改善しなかったがReasoning benchmarkの性能改善
- QK Normを導入しattentionのlogitsの値域を改善
- [Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings
- Multi Token Prediction
- [Paper Note] Better & Faster Large Language Models via Multi-token Prediction, Fabian Gloeckle+, ICML'24
- [Paper Note] DeepSeek-V3 Technical Report, DeepSeek-AI+, arXiv'24, 2024.12
他モデルとの比較
学習部分は後で追記する
- 事前学習データ
- web
- 英語と中国語のwebページを利用
- [Paper Note] Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25
と同様にquality scoreyをドキュメントに付与
- 最も低いquality scoreの文書群を排除し、quality scoreの高い文書群をup sampling
- 最もquality scoreyが大きい文書群は3.2 epoch分利用
- 多くのweb pageがテンプレートから自動生成されており高いquality scoreが付与されていたが、MinHashによってdeduplicationできなかったため、 [Paper Note] SemDeDup: Data-efficient learning at web-scale through semantic
deduplication, Amro Abbas+, arXiv'23
を用いてdocument embeddingに基づいて類似した文書群を排除
- Multilingual
- 独自にクロールしたデータとFineWeb-2 [Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, COLM'25
から多言語の文書群を抽出し、quality classifierを適用することでeducational utilityを定量化し、高いスコアの文書群をupsamplingして利用
- code
- githubなどのソースコードhosting platformから収集
- ソースコードはルールベースのフィルタリングをかけ、その後言語ごとのquality modelsによって、high,middle, lowの3つに品質を分類
- high qualityなものはupsamplingし、low qualityなものは除外
- [Paper Note] Efficient Training of Language Models to Fill in the Middle, Mohammad Bavarian+, arXiv'22
で提案されているFill in the Middle objectiveをコードの事前学習では適用
- コードに関連するweb文書も事前学習で収集したテキスト群からルールベースとfasttextによる分類器で抽出し、ソースコードと同様のqualityの分類とサンプリング手法を適用。最終的にフィルタリングされた文書群はre-parseしてフォーマットと内容の品質を向上させた
- math & science
- web page, 本, 論文から、reasoning能力を向上させるために、数学と科学に関する文書を収集
- LLMを用いて文書中のeducational contentの比率に基づいて文書をスコアリングしスコアを予測するsmall-scaleな分類器を学習
- 最終的に事前学習コーパスの中の閾値以上のスコアを持つ文書をupsampling
- 事前学習は2 stageに分かれており、最初のステージでは、"大部分は"generalな文書で学習する。次のステージでは、ソースコード、数学、科学、コーディング関連の文書をupsamplingして学習する。
上記以上の細かい実装上の情報は記載されていない。
mid-training / post trainingについても後ほど追記する
以下も参照のこと
- GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07
[Paper Note] Difficulty-Based Preference Data Selection by DPO Implicit Reward Gap, Xuan Qi+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Alignment #DPO #PostTraining Issue Date: 2025-08-12 GPT Summary- LLMの好みを人間に合わせるための新しいデータ選択戦略を提案。DPOの暗黙的報酬ギャップが小さいデータを選ぶことで、データ効率とモデルの整合性を向上。元のデータの10%で5つのベースラインを上回るパフォーマンスを達成。限られたリソースでのLLM整合性向上に寄与。 Comment
元ポスト:
preference pair dataを学習効率の良いサンプルのみに圧縮することで学習効率を上げたい系の話で、chosen, rejectedなサンプルのそれぞれについて、¥frac{現在のポリシーの尤度}{参照ポリシーの尤度}によってreward rを定義し(おそらく参照ポリシーの尤度によってサンプルの重要度を重みづけしている)、r_chosenとr_rejectedの差をreward gapと定義し、gapが大きいものは難易度が低いと判断してフィルタリングする、といった話に見える。
[Paper Note] Memp: Exploring Agent Procedural Memory, Runnan Fang+, arXiv'25
Paper/Blog Link My Issue
#NLP #AIAgents #ContextEngineering #memory Issue Date: 2025-08-12 GPT Summary- 本研究では、LLMに基づくエージェントに学習可能で更新可能な手続き的記憶を持たせるための戦略を提案。Mempを用いて過去のエージェントの軌跡を指示や抽象に蒸留し、記憶の構築と更新を行う。TravelPlannerとALFWorldでの実証評価により、記憶リポジトリが進化することでエージェントの成功率と効率が向上することを示した。また、強力なモデルからの手続き的記憶の移行により、弱いモデルでも性能向上が得られることが確認された。 Comment
元ポスト:
アドホックに探索と実行を繰り返すのではなく、過去の試行のtrajectoryをメモリに記憶しておき、活用するような枠組みな模様。trajectoryは新たなタスクが来た際にretrieverでrelevantなtrajectoryを検索して利用され、良質なtrajectoryがキープされれば成功率や効率が向上すると考えられる。trajectoryはprocedure memoryとして保存され、成功率が低いtrajectoryは破棄されることで更新される。
メモリはT個のタスクに対するs_t, a_t, o_t, i.e., state, action, observation,の系列τと、reward rが与えられた時に、Builderを通して構築されてストアされる。agentは新たなタスクt_newに直面した時に、t_newと類似したメモリをretrieyeする。これはτの中のある時刻tのタスクに対応する。メモリは肥大化していくため、実験では複数のアルゴリズムに基づくメモリの更新方法について実験している。
procedural memoryの有無による挙動の違いに関するサンプル。
memoryに対してretrieverを適用することになるので、retrieverの性能がボトルネックになると思われる。追加の学習をしなくて済むのは利点だが、その代わりモデル側がメモリ管理をする機能を有さない(学習すればそういった機能を持たせられるはず)ので、その点は欠点となる、という印象。
ポイント解説:
[Paper Note] Physics of Language Models: Part 3.2, Knowledge Manipulation, Zeyuan Allen-Zhu+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #ICLR #ReversalCurse Issue Date: 2025-08-11 GPT Summary- 言語モデルは豊富な知識を持つが、下流タスクへの柔軟な利用には限界がある。本研究では、情報検索、分類、比較、逆検索の4つの知識操作タスクを調査し、言語モデルが知識検索には優れているが、Chain of Thoughtsを用いないと分類や比較タスクで苦労することを示した。特に逆検索ではパフォーマンスがほぼ0%であり、これらの弱点は言語モデルに固有であることを確認した。これにより、現代のAIと人間を区別する新たなチューリングテストの必要性が浮き彫りになった。 Comment
openreview: https://openreview.net/forum?id=oDbiL9CLoS
[Paper Note] Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems, Tian Ye+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #SelfCorrection #ICLR Issue Date: 2025-08-11 GPT Summary- 言語モデルの推論精度向上のために、「エラー修正」データを事前学習に組み込む有用性を探求。合成数学データセットを用いて、エラーフリーデータと比較して高い推論精度を達成することを示す。さらに、ビームサーチとの違いやデータ準備、マスキングの必要性、エラー量、ファインチューニング段階での遅延についても考察。 Comment
openreview: https://openreview.net/forum?id=zpDGwcmMV4
[Paper Note] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process, Tian Ye+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #ICLR #read-later #reading Issue Date: 2025-08-11 GPT Summary- 言語モデルの数学的推論能力を研究し、GSM8Kベンチマークでの精度向上のメカニズムを探る。具体的には、推論スキルの発展、隠れたプロセス、人間との違い、必要なスキルの超越、推論ミスの原因、モデルのサイズや深さについての実験を行い、LLMの理解を深める洞察を提供。 Comment
openreview: https://openreview.net/forum?id=Tn5B6Udq3E
小学生向けの算数の問題を通じて、以下の基本的なResearch Questionsについて調査して研究。これらを理解することで、言語モデルの知能を理解する礎とする。
## Research Questions
- 言語モデルはどのようにして小学校レベルの算数の問題を解けるようになるのか?
- 単にテンプレートを暗記しているだけなのか、それとも人間に似た推論スキルを学んでいるのか?
- あるいは、その問題を解くために新しいスキルを発見しているのか?
- 小学校レベルの算数問題だけで訓練されたモデルは、それらの問題を解くことしか学ばないのか?
- それとも、より一般的な知能を学習するのか?
- どのくらい小さい言語モデルまで、小学校レベルの算数問題を解けるのか?
- 深さ(層の数)は幅(層ごとのニューロン数)より重要なのか?
- それとも、単にサイズだけが重要か?
(続きはのちほど...)
[Paper Note] STEPWISE-CODEX-Bench: Evaluating Complex Multi-Function Comprehension and Fine-Grained Execution Reasoning, Kaiwen Yan+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Coding #Reasoning Issue Date: 2025-08-10 GPT Summary- 新しいベンチマーク「STEPWISE-CODEX-Bench(SX-Bench)」を提案し、複雑な多機能理解と細かい実行推論を評価。SX-Benchは、サブ関数間の協力を含むタスクを特徴とし、動的実行の深い理解を測定する。20以上のモデルで評価した結果、最先端モデルでも複雑な推論においてボトルネックが明らかに。SX-Benchはコード評価を進展させ、高度なコードインテリジェンスモデルの評価に貢献する。 Comment
元ポスト:
現在の主流なコード生成のベンチは、input/outputがgivenなら上でコードスニペットを生成する形式が主流(e.g., MBPP [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21
, HumanEval [Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
)だが、モデルがコードを理解し、複雑なコードのロジックを実行する内部状態の変化に応じて、実行のプロセスを推論する能力が見落とされている。これを解決するために、CRUXEVAL [Paper Note] CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, Alex Gu+, arXiv'24
, CRUXEVAL-X [Paper Note] CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding
and Execution, Ruiyang Xu+, arXiv'24
では、関数のinputs/outputsを予測することで、モデルのコードのcomprehension, reasoning能力を測ろうとしているが、
- single functionのlogicに限定されている
- 20 line程度の短く、trivialなロジックに限定されている
- すでにSoTAモデルで95%が達成され飽和している
というlimitationがあるので、複数の関数が協働するロジック、flow/dataのinteractionのフロー制御、細かい実行ステップなどを含む、staticなコードの理解から、動的な実行プロセスのモデリング能力の評価にシフトするような、新たなベンチマークを作成しました、という話な模様。
まず関数単位のライブラリを構築している。このために、単一の関数の基礎的な仕様を「同じinputに対して同じoutputを返すものは同じクラスにマッピングされる」と定義し、既存のコードリポジトリとLLMによる合成によって、GoとPythonについて合計30種類のクラスと361個のインスタンスを収集。これらの関数は、算術演算や大小比較、パリティチェックなどの判定、文字列の操作などを含む。そしてこれら関数を3種類の実行パターンでオーケストレーションすることで、合成関数を作成した。合成方法は
- Sequential: outputとinputをパイプラインでつなぎ伝搬させる
- Selective: 条件に応じてf(x)が実行されるか、g(x)が実行されるかを制御
- Loop: input集合に対するloopの中に関数を埋め込み順次関数を実行
の3種類。合成関数の挙動を評価するために、ランダムなテストケースは自動生成し、合成関数の挙動をモニタリング(オーバーフロー、無限ループ、タイムアウト、複数回の実行でoutputが決定的か等など)し、異常があるものはフィルタリングすることで合成関数の品質を担保する。
ベンチマーキングの方法としては、CRUXEVALではシンプルにモデルにコードの実行結果を予想させるだけであったが、指示追従能力の問題からミスジャッジをすることがあるため、この問題に対処するため
[Paper Note] Agent Lightning: Train ANY AI Agents with Reinforcement Learning, Xufang Luo+, arXiv'25
Paper/Blog Link My Issue
#ReinforcementLearning #AIAgents #SoftwareEngineering Issue Date: 2025-08-10 GPT Summary- Agent Lightningは、任意のAIエージェントのためにLLMsを用いたRLトレーニングを可能にする柔軟なフレームワークで、エージェントの実行とトレーニングを分離し、既存のエージェントとの統合を容易にします。マルコフ決定過程としてエージェントの実行を定式化し、階層的RLアルゴリズムLightningRLを提案。これにより、複雑な相互作用ロジックを扱うことが可能になります。実験では、テキストからSQLへの変換などで安定した改善が見られ、実世界でのエージェントトレーニングの可能性が示されました。 Comment
元ポスト:
[Paper Note] MathSmith: Towards Extremely Hard Mathematical Reasoning by Forging Synthetic Problems with a Reinforced Policy, Shaoxiong Zhan+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SyntheticData #Reasoning #GRPO Issue Date: 2025-08-10 GPT Summary- MathSmithという新しいフレームワークを提案し、LLMの数学的推論を強化するために新しい問題をゼロから合成。既存の問題を修正せず、PlanetMathから概念と説明をランダムにサンプリングし、データの独立性を確保。9つの戦略を用いて難易度を上げ、強化学習で構造的妥当性や推論の複雑さを最適化。実験では、MathSmithが既存のベースラインを上回り、高難易度の合成データがLLMの推論能力を向上させる可能性を示した。 Comment
元ポスト:
[Paper Note] Self-Questioning Language Models, Lili Chen+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SelfImprovement #Label-free #MajorityVoting Issue Date: 2025-08-09 GPT Summary- 自己質問型言語モデル(SQLM)を提案し、トピックを指定するプロンプトから自ら質問を生成し、解答する非対称の自己対戦フレームワークを構築。提案者と解答者は強化学習で訓練され、問題の難易度に応じて報酬を受け取る。三桁の掛け算や代数問題、プログラミング問題のベンチマークで、外部データなしで言語モデルの推論能力を向上させることができることを示す。 Comment
pj page: https://self-questioning.github.io
元ポスト:
たとえば下記のような、ラベル無しの外部データを利用する手法も用いてself improvingする手法と比較したときに、どの程度の性能差になるのだろうか?外部データを全く利用せず、外部データありの手法と同等までいけます、という話になると、より興味深いと感じた。
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
既存の外部データを活用しない関連研究:
- [Paper Note] Absolute Zero: Reinforced Self-play Reasoning with Zero Data, Andrew Zhao+, arXiv'25, 2025.05
[Paper Note] A comprehensive taxonomy of hallucinations in Large Language Models, Manuel Cossio, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #Hallucination Issue Date: 2025-08-08 GPT Summary- LLMのハルシネーションに関する包括的な分類法を提供し、その本質的な避けられなさを提唱。内因的および外因的な要因、事実誤認や不整合などの具体的な現れを分析。根本的な原因や認知的要因を検討し、評価基準や軽減戦略を概説。今後は、信頼性のある展開のために検出と監視に焦点を当てる必要があることを強調。 Comment
元ポスト:
[Paper Note] Learning to Reason for Factuality, Xilun Chen+, arXiv'25, 2024.08
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Factuality #RewardHacking #PostTraining #GRPO #On-Policy Issue Date: 2025-08-08 GPT Summary- R-LLMsは複雑な推論タスクで進展しているが、事実性において幻覚を多く生成する。オンラインRLを長文の事実性設定に適用する際、信頼できる検証方法が不足しているため課題がある。従来の自動評価フレームワークを用いたオフラインRLでは報酬ハッキングが発生することが判明。そこで、事実の精度、詳細レベル、関連性を考慮した新しい報酬関数を提案し、オンラインRLを適用。評価の結果、幻覚率を平均23.1ポイント削減し、回答の詳細レベルを23%向上させた。 Comment
元ポスト:
Reasoning ModelのHallucination Rateは、そのベースとなるモデルよりも高い。実際、DeepSeek-V3とDeepSeek-R1,Qwen-2.5-32BとQwQ-32Bを6つのFactualityに関するベンチマークで比較すると、Reasoning Modelの方がHallucination Rateが10, 13%程度高かった。これは、現在のOn-policyのRLがlogical reasoningにフォーカスしており、Factualityを見落としているため、と仮説を立てている。
Factuality(特にLongForm)とRL alignmentsという観点から言うと、決定的、正確かつ信頼性のあるverificatlon手法は存在せず、Human Effortが必要不可欠である。
自動的にFactualityを測定するFactScoreのような手法は、DPOのようなオフラインのペアワイズのデータを作成するに留まってしまっている。また、on policy dataでFactualityを改善する取り組みは行われているが、long-formな応答に対して、factual reasoningを実施するにはいくつかの課題が残されている:
- reward design
- Factualityに関するrewardを単独で追加するだけだと、LLMは非常に短く、詳細を省略した応答をしPrecicionのみを高めようとしてしまう。
あとで追記する
openreview: https://openreview.net/forum?id=fejDLlOKCl
[Paper Note] On the Expressiveness of Softmax Attention: A Recurrent Neural Network Perspective, Gabriel Mongaras+, arXiv'25
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP Issue Date: 2025-08-05 GPT Summary- 本研究では、ソフトマックスアテンションの再帰的な形式を導出し、線形アテンションがその近似であることを示す。これにより、ソフトマックスアテンションの各部分をRNNの言語で説明し、構成要素の重要性と相互作用を理解する。これにより、ソフトマックスアテンションが他の手法よりも表現力が高い理由を明らかにする。 Comment
元ポスト:
LinearAttention関連の研究は下記あたりがありそう?
- [Paper Note] Efficient Attention: Attention with Linear Complexities, Zhuoran Shen+, arXiv'18
- [Paper Note] Linformer: Self-Attention with Linear Complexity, Sinong Wang+, arXiv'20
- [Paper Note] Reformer: The Efficient Transformer, Nikita Kitaev+, ICLR'20
- [Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20
- [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
たとえばGQAはQwen3で利用されているが、本研究の知見を活用してscaled-dot product attention計算時のSoftmax計算の計算量が削減できたら、さらに計算量が削減できそう?
[Paper Note] MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement, Jaehyun Nam+, arXiv'25
Paper/Blog Link My Issue
#MachineLearning #NLP Issue Date: 2025-08-04 GPT Summary- MLE-STARは、LLMを用いてMLモデルを自動実装する新しいアプローチで、ウェブから効果的なモデルを取得し、特定のMLコンポーネントに焦点を当てた戦略を探索することで、コード生成の精度を向上させる。実験結果では、MLE-STARがKaggleコンペティションの64%でメダルを獲得し、他の手法を大きく上回る性能を示した。 Comment
元ポスト:
[Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Outstanding Paper
Paper/Blog Link My Issue
#Analysis #NLP #Prompting #ACL #read-later #reading #MajorityVoting Issue Date: 2025-08-03 GPT Summary- 本研究では、LLMのテスト時の計算スケーリングにおけるプロンプト戦略の効果を調査。6つのLLMと8つのプロンプト戦略を用いた実験により、複雑なプロンプト戦略が単純なChain-of-Thoughtに劣ることを示し、理論的な証明を提供。さらに、スケーリング性能を予測し最適なプロンプト戦略を特定する手法を提案し、リソース集約的な推論プロセスの必要性を排除。複雑なプロンプトの再評価と単純なプロンプト戦略の潜在能力を引き出すことで、テスト時のスケーリング性能向上に寄与することを目指す。 Comment
non-thinkingモデルにおいて、Majority Voting (i.e. Self Consistency)によるtest-time scalingを実施する場合のさまざまなprompting戦略のうち、budgetとサンプリング数が小さい場合はCoT以外の適切なprompting戦略はモデルごとに異なるが、budgetやサンプリング数が増えてくるとシンプルなCoT(実験ではzeroshot CoTを利用)が最適なprompting戦略として支配的になる、という話な模様。
さらに、なぜそうなるかの理論的な分析と最適な与えられた予算から最適なprompting戦略を予測する手法も提案している模様。
が、評価データの難易度などによってこの辺は変わると思われ、特にFigure39に示されているような、**サンプリング数が増えると簡単な問題の正解率が上がり、逆に難しい問題の正解率が下がるといった傾向があり、CoTが簡単な問題にサンプリング数を増やすと安定して正解できるから支配的になる**、という話だと思われるので、常にCoTが良いと勘違いしない方が良さそうだと思われる。たとえば、**解こうとしているタスクが難問ばかりであればCoTでスケーリングするのが良いとは限らない、といった点には注意が必要**だと思うので、しっかり全文読んだ方が良い。時間がある時に読みたい(なかなかまとまった時間取れない)
最適なprompting戦略を予測する手法では、
- 問題の難易度に応じて適応的にスケールを変化させ(なんとO(1)で予測ができる)
- 動的に最適なprompting戦略を選択
することで、Majority@10のAcc.を8Bスケールのモデルで10--50%程度向上させることができる模様。いやこれほんとしっかり読まねば。
[Paper Note] Mapping 1,000+ Language Models via the Log-Likelihood Vector, Momose Oyama+, ACL'25
Paper/Blog Link My Issue
#Embeddings #Analysis #NLP #ACL #read-later Issue Date: 2025-08-03 GPT Summary- 自動回帰型言語モデルの比較に対し、対数尤度ベクトルを特徴量として使用する新しいアプローチを提案。これにより、テキスト生成確率のクルバック・ライブラー発散を近似し、スケーラブルで計算コストが線形に増加する特徴を持つ。1,000以上のモデルに適用し、「モデルマップ」を構築することで、大規模モデル分析に新たな視点を提供。 Comment
NLPコロキウムでのスライド:
https://speakerdeck.com/shimosan/yan-yu-moderunodi-tu-que-lu-fen-bu-to-qing-bao-ji-he-niyorulei-si-xing-noke-shi-hua
元ポスト:
[Paper Note] SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM, Xiaojiang Zhang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #On-Policy #CrossDomain Issue Date: 2025-08-03 GPT Summary- 二段階履歴再サンプリングポリシー最適化(SRPO)を提案し、DeepSeek-R1-Zero-32Bを上回る性能をAIME24およびLiveCodeBenchで達成。SRPOはトレーニングステップを約1/10に削減し、効率性を示す。二つの革新として、クロスドメイントレーニングパラダイムと履歴再サンプリング技術を導入し、LLMの推論能力を拡張するための実験を行った。 Comment
元ポスト:
GRPOよりもより効率的な手法な模様。最初に数学のデータで学習をしReasoning Capabilityを身につけさせ、その後別のドメインのデータで学習させることで、その能力を発揮させるような二段階の手法らしい。
Datamixingよりも高い性能(ただし、これは数学とコーディングのCoT Lengthのドメイン間の違いに起因してこのような2 stageな手法にしているようなのでその点には注意が必要そう)?しっかりと読めていないので、読み違いの可能性もあるので注意。
なんたらRPO多すぎ問題
[Paper Note] WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training, Changxin Tian+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Optimizer #read-later #Selected Papers/Blogs #ModelMerge #Stability Issue Date: 2025-08-02 GPT Summary- 学習率スケジューリングの新たなアプローチとして、Warmup-Stable and Merge(WSM)を提案。WSMは、学習率の減衰とモデルマージの関係を確立し、さまざまな減衰戦略を統一的に扱う。実験により、マージ期間がモデル性能において重要であることを示し、従来のWSDアプローチを上回る性能向上を達成。特に、MATHで+3.5%、HumanEvalで+2.9%、MMLU-Proで+5.5%の改善を記録。 Comment
元ポスト:
Weight Decayを無くせるらしい
エッセンスの解説:
チェックポイントさえ保存しておいて事後的に活用することだで、細かなハイパラ調整のための試行錯誤する手間と膨大な計算コストがなくなるのであれば相当素晴らしいのでは…?
解説:
[Paper Note] AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders, Zhengxuan Wu+, ICLR'25 Spotlight
Paper/Blog Link My Issue
#Controllable #NLP #Dataset #Supervised-FineTuning (SFT) #Prompting #Evaluation #ICLR #read-later #ActivationSteering/ITI #Selected Papers/Blogs #InstructionFollowingCapability #Steering Issue Date: 2025-08-02 GPT Summary- 言語モデルの出力制御は安全性と信頼性に重要であり、プロンプトやファインチューニングが一般的に用いられるが、さまざまな表現ベースの技術も提案されている。これらの手法を比較するためのベンチマークAxBenchを導入し、Gemma-2-2Bおよび9Bに関する実験を行った。結果、プロンプトが最も効果的で、次いでファインチューニングが続いた。概念検出では表現ベースの手法が優れており、SAEは競争力がなかった。新たに提案した弱教師あり表現手法ReFT-r1は、競争力を持ちながら解釈可能性を提供する。AxBenchとともに、ReFT-r1およびDiffMeanのための特徴辞書を公開した。 Comment
openreview: https://openreview.net/forum?id=K2CckZjNy0
[Paper Note] CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks, Ping Yu+, arXiv'25
Paper/Blog Link My Issue
#NLP #InstructionTuning #SyntheticData #Reasoning Issue Date: 2025-08-02 GPT Summary- CoT-Self-Instructを提案し、LLMに基づいて新しい合成プロンプトを生成する手法を開発。合成データはMATH500やAMC23などで既存データセットを超える性能を示し、検証不可能なタスクでも人間や標準プロンプトを上回る結果を得た。 Comment
元ポスト:
より複雑で、Reasoningやplanningを促すようなinstructionが生成される模様。実際に生成されたinstructionのexampleは全体をざっとみた感じこの図中のもののみのように見える。
以下のスクショはMagpieによって合成されたinstruction。InstructionTuning用のデータを合成するならMagpieが便利そうだなぁ、と思っていたのだが、比較するとCoT-SelfInstructの方が、より複雑で具体的な指示を含むinstructionが生成されるように見える。
- [Paper Note] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Zhangchen Xu+, ICLR'25, 2024.06
[Paper Note] Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability, Yusuke Sakai+, ACL'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Composition #ACL #InstructionFollowingCapability #CommonsenseReasoning Issue Date: 2025-07-31 GPT Summary- Ordered CommonGenを提案し、LLMsの指示に従う能力と構成的一般化能力を評価するベンチマークを構築。36のLLMsを分析した結果、指示の意図は理解しているが、概念の順序に対するバイアスが低多様性の出力を引き起こすことが判明。最も指示に従うLLMでも約75%の順序付きカバレッジしか達成できず、両能力の改善が必要であることを示唆。 Comment
LLMの意味の構成性と指示追従能力を同時に発揮する能力を測定可能なOrderedCommonGenを提案
[Paper Note] Efficient Attention Mechanisms for Large Language Models: A Survey, Yutao Sun+, arXiv'25
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #Attention Issue Date: 2025-07-31 GPT Summary- Transformerアーキテクチャの自己注意の複雑さが長文コンテキストモデリングの障害となっている。これに対処するため、線形注意手法とスパース注意技術が導入され、計算効率を向上させつつコンテキストのカバレッジを保持する。本研究は、これらの進展を体系的にまとめ、効率的な注意を大規模言語モデルに組み込む方法を分析し、理論と実践を統合したスケーラブルなモデル設計の基礎を提供することを目指す。 Comment
元ポスト:
[Paper Note] A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence, Huan-ang Gao+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #SelfCorrection #SelfImprovement Issue Date: 2025-07-30 GPT Summary- 大規模言語モデル(LLMs)は静的であり、動的な環境に適応できないため、自己進化するエージェントの必要性が高まっている。本調査は、自己進化するエージェントに関する初の包括的レビューを提供し、進化の基礎的な次元を整理。エージェントの進化的メカニズムや適応手法を分類し、評価指標や応用分野を分析。最終的には、エージェントが自律的に進化し、人間レベルの知能を超える人工超知能(ASI)の実現を目指す。 Comment
元ポスト:
Figure3がとても勉強になる。Self-Evolveと呼んだ時に、それがどのようにEvolveするものなのかはきちんとチェックした方が良さそう。追加の学習をするのか否かなど。これによって使いやすさが段違いになりそうなので。
[Paper Note] On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey, Meishan Zhang+, arXiv'25
Paper/Blog Link My Issue
#Survey #Embeddings #NLP #Dataset #RepresentationLearning #Evaluation Issue Date: 2025-07-29 GPT Summary- 本調査では、事前学習済み言語モデル(PLMs)を活用した一般目的のテキスト埋め込み(GPTE)の発展を概観し、PLMsの役割に焦点を当てる。基本的なアーキテクチャや埋め込み抽出、表現力向上、トレーニング戦略について説明し、PLMsによる多言語サポートやマルチモーダル統合などの高度な役割も考察する。さらに、将来の研究方向性として、ランキング統合やバイアス軽減などの改善目標を超えた課題を強調する。 Comment
元ポスト:
GPTEの学習手法テキストだけでなく、画像やコードなどの様々なモーダル、マルチリンガル、データセットや評価方法、パラメータサイズとMTEBの性能の関係性の図解など、盛りだくさんな模様。最新のものだけでなく、2021年頃のT5から最新モデルまで網羅的にまとまっている。日本語特化のモデルについては記述が無さそうではある。
日本語モデルについてはRuriのテクニカルペーパーや、LLM勉強会のまとめを参照のこと
- Ruri: Japanese General Text Embeddings, cl-nagoya, 2024.09
- 日本語LLMまとめ, LLM-jp, 2024.12
[Paper Note] Do We Need a Detailed Rubric for Automated Essay Scoring using Large Language Models?, Lui Yoshida, AIED'25
Paper/Blog Link My Issue
#NLP #AES(AutomatedEssayScoring) #Prompting #AIED Issue Date: 2025-07-29 GPT Summary- 本研究では、LLMを用いた自動エッセイ採点におけるルーブリックの詳細さが採点精度に与える影響を調査。TOEFL11データセットを用いて、完全なルーブリック、簡略化されたルーブリック、ルーブリックなしの3条件を比較。結果、3つのモデルは簡略化されたルーブリックでも精度を維持し、トークン使用量を削減。一方、1つのモデルは詳細なルーブリックで性能が低下。簡略化されたルーブリックが多くのLLMにとって効率的な代替手段であることが示唆されるが、モデルごとの評価も重要。
[Paper Note] Learning without training: The implicit dynamics of in-context learning, Benoit Dherin+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #In-ContextLearning Issue Date: 2025-07-29 GPT Summary- LLMは文脈内で新しいパターンを学習する能力を持ち、そのメカニズムは未解明である。本研究では、トランスフォーマーブロックが自己注意層とMLPを重ねることで、文脈に応じてMLPの重みを暗黙的に修正できることを示し、このメカニズムがLLMの文脈内学習の理由である可能性を提案する。 Comment
元ポスト:
解説:
[Paper Note] Rectifying Belief Space via Unlearning to Harness LLMs' Reasoning, Ayana Niwa+, ACL'25
Paper/Blog Link My Issue
#NLP #ACL #Trustfulness Issue Date: 2025-07-28 GPT Summary- LLMの不正確な回答は虚偽の信念から生じると仮定し、信念空間を修正する方法を提案。テキスト説明生成で信念を特定し、FBBSを用いて虚偽の信念を抑制、真の信念を強化。実証結果は、誤った回答の修正とモデル性能の向上を示し、一般化の改善にも寄与することを示唆。 Comment
元ポスト:
[Paper Note] GrAInS: Gradient-based Attribution for Inference-Time Steering of LLMs and VLMs, Duy Nguyen+, arXiv'25
Paper/Blog Link My Issue
#NLP #Hallucination #ActivationSteering/ITI #Trustfulness Issue Date: 2025-07-26 GPT Summary- GrAInSは、LLMsおよびVLMsの推論時に内部活性を調整する新しいステアリング手法で、固定された介入ベクトルに依存せず、トークンの因果的影響を考慮します。統合勾配を用いて、出力への寄与に基づき重要なトークンを特定し、望ましい行動への変化を捉えるベクトルを構築します。これにより、再訓練なしでモデルの挙動を細かく制御でき、実験ではファインチューニングや既存手法を上回る成果を示しました。具体的には、TruthfulQAで精度を13.22%向上させ、MMHal-Benchの幻覚率を低下させ、SPA-VLでのアライメント勝率を改善しました。 Comment
元ポスト:
既存のsteering手法は、positive/negativeなサンプルからの差分で単一方向のベクトルを算出し、すべてのトークンに足し合わせるが、本手法はそこからさらにpositive/negativeな影響を与えるトークンレベルにまで踏み込み、negativeなベクトルとpositiveなベクトルの双方を用いて、negative->positive方向のベクトルを算出してsteeringに活用する方法っぽい?
[Paper Note] Ming-Omni: A Unified Multimodal Model for Perception and Generation, Inclusion AI+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #OpenWeight #read-later #Selected Papers/Blogs #UMM #Omni Issue Date: 2025-07-26 GPT Summary- Ming-Omniは、画像、テキスト、音声、動画を処理できる統一マルチモーダルモデルで、音声生成と画像生成において優れた能力を示す。専用エンコーダを用いて異なるモダリティからトークンを抽出し、MoEアーキテクチャで処理することで、効率的にマルチモーダル入力を融合。音声デコーダと高品質な画像生成を統合し、コンテキストに応じたチャットやテキストから音声への変換、画像編集が可能。Ming-Omniは、GPT-4oに匹敵する初のオープンソースモデルであり、研究と開発を促進するためにコードとモデルの重みを公開。 Comment
元ポスト:
現在はv1.5も公開されておりさらに性能が向上している模様?
[Paper Note] Group Sequence Policy Optimization, Chujie Zheng+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #MoE(Mixture-of-Experts) #On-Policy #Stability Issue Date: 2025-07-26 GPT Summary- Group Sequence Policy Optimization (GSPO)は、大規模言語モデルのための新しい強化学習アルゴリズムで、シーケンスの尤度に基づく重要度比を用いてトレーニングを行う。GSPOは、従来のGRPOアルゴリズムよりも効率的で高性能であり、Mixture-of-Experts (MoE) のトレーニングを安定化させる。これにより、最新のQwen3モデルにおいて顕著な改善が見られる。 Comment
元ポスト:
公式ポスト:
GRPOとGSPOの違いのGIF:
[Paper Note] CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning, Kuniaki Saito+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NaturalLanguageGeneration #Controllable #NLP #VisionLanguageModel Issue Date: 2025-07-25 GPT Summary- CaptionSmithsは、画像キャプショニングモデルがキャプションの特性(長さ、記述性、単語の独自性)を柔軟に制御できる新しいアプローチを提案。人間の注釈なしで特性を定量化し、短いキャプションと長いキャプションの間で補間することで条件付けを実現。実証結果では、出力キャプションの特性をスムーズに変化させ、語彙的整合性を向上させることが示され、誤差を506%削減。コードはGitHubで公開。 Comment
元ポスト:
従来はDiscreteに表現されていたcaptioningにおける特性をCondition Caluculatorを導入することでcontinuousなrepresentationによって表現し、Caluculatorに人間によるinput, あるいは表現したいConditionを持つexampleをinputすることで、生成時に反映させるような手法を提案している模様。Conditionで利用するpropertyについては、提案手法ではLength, Descriptive, Uniqueness of Vocabulariesの3つを利用している(が、他のpropertyでも本手法は適用可能と思われる)。このとき、あるpropertyの値を変えることで他のpropertyが変化してしまうと制御ができなくなるため、property間のdecorrelationを実施している。これは、あるproperty Aから別のproperty Bの値を予測し、オリジナルのpropertyの値からsubtractする、といった処理を順次propertyごとに実施することで実現される。Appendixに詳細が記述されている。
[Paper Note] Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models, Changxin Tian+, arXiv'25
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #Scaling Laws #read-later #Selected Papers/Blogs Issue Date: 2025-07-25 GPT Summary- Mixture-of-Experts (MoE)アーキテクチャは、LLMsの効率的なスケーリングを可能にするが、モデル容量の予測には課題がある。これに対処するため、Efficiency Leverage (EL)を導入し、300以上のモデルを訓練してMoE構成とELの関係を調査。結果、ELはエキスパートの活性化比率と計算予算に依存し、エキスパートの粒度は非線形の調整因子として機能することが明らかに。これらの発見を基にスケーリング法則を統一し、Ling-mini-betaモデルを設計・訓練した結果、計算資源を7倍以上節約しつつ、6.1Bの密なモデルと同等の性能を達成。研究は効率的なMoEモデルのスケーリングに関する基盤を提供する。 Comment
元ポスト:
所見:
[Paper Note] Deep Researcher with Test-Time Diffusion, Rujun Han+, arXiv'25
Paper/Blog Link My Issue
#NLP #AIAgents #LLM-as-a-Judge #SelfCorrection #DeepResearch Issue Date: 2025-07-25 GPT Summary- TTD-DRは、LLMsを用いた研究報告書生成の新しいフレームワークで、草案から始まり、デノイジングプロセスを通じて情報を動的に取り入れながら洗練される。自己進化アルゴリズムにより高品質なコンテキストを生成し、情報損失を減少させる。TTD-DRは、集中的な検索とマルチホップ推論を必要とするベンチマークで最先端の結果を達成し、既存の深層研究エージェントを上回る性能を示す。 Comment
元ポスト:
Self-Evolutionというのは、モデルのパラメータを更新するというものではなく、Agentに渡すContextをLLM-as-a-Judgeのスコアが改善するように、フィードバックとして得られるcritiqueなどを通じて反復的にoutput(=別のAgentにcontextとして渡される情報)を洗練させていくような方法のことを指している模様。このようなプロセスを複数のパスで実施し、最終的にマージすることで高品質なoutput(context)を得る。
日本語解説: https://zenn.dev/knowledgesense/articles/5a341158c2c9ab
[Paper Note] OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles, Yihe Deng+, NeurIPS'25
Paper/Blog Link My Issue
#Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #NeurIPS #VisionLanguageModel Issue Date: 2025-07-24 GPT Summary- OpenVLThinkerは、洗練された連鎖的思考推論を示すオープンソースの大規模視覚言語モデルであり、視覚推論タスクで顕著な性能向上を達成。SFTとRLを交互に行うことで、推論能力を効果的に引き出し、改善を加速。特に、MathVistaで3.8%、EMMAで2.4%、HallusionBenchで1.6%の性能向上を実現。コードやモデルは公開されている。 Comment
元ポスト:
[Paper Note] Subliminal Learning: Language models transmit behavioral traits via hidden signals in data, Alex Cloud+, arXiv'25
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #NLP #Selected Papers/Blogs #Finetuning #SubliminalLearning Issue Date: 2025-07-24 GPT Summary- サブリミナル学習は、言語モデルが無関係なデータを通じて特性を伝達する現象である。実験では、特定の特性を持つ教師モデルが生成した数列データで訓練された生徒モデルが、その特性を学習することが確認された。データが特性への言及を除去してもこの現象は発生し、異なるベースモデルの教師と生徒では効果が見られなかった。理論的結果を通じて、全てのニューラルネットワークにおけるサブリミナル学習の発生を示し、MLP分類器での実証も行った。サブリミナル学習は一般的な現象であり、AI開発における予期しない問題を引き起こす可能性がある。 Comment
元ポスト:
教師モデルが生成したデータから、教師モデルと同じベースモデルを持つ[^1]生徒モデルに対してファインチューニングをした場合、教師モデルと同じ特性を、どんなに厳しく学習元の合成データをフィルタリングしても、意味的に全く関係ないデータを合成しても(たとえばただの数字列のデータを生成したとしても)、生徒モデルに転移してしまう。これは言語モデルに限った話ではなく、ニューラルネットワーク一般について証明された[^2]。
また、MNISTを用いたシンプルなMLPにおいて、MNISTを教師モデルに対して学習させ、そのモデルに対してランダムノイズな画像を生成させ、同じ初期化を施した生徒モデルに対してFinetuningをした場合、学習したlogitsがMNIST用ではないにもかかわらず、MNISTデータに対して50%以上の分類性能を示し、数字画像の認識能力が意味的に全く関係ないデータから転移されている[^3]、といった現象が生じることも実験的に確認された。
このため、どんなに頑張って合成データのフィルタリングや高品質化を実施し、教師モデルから特性を排除したデータを作成したつもりでも、そのデータでベースモデルが同じ生徒を蒸留すると、結局その特性は転移されてしまう。これは大きな落とし穴になるので気をつけましょう、という話だと思われる。
[^1]: これはアーキテクチャの話だけでなく、パラメータの初期値も含まれる
[^2]: 教師と生徒の初期化が同じ、かつ十分に小さい学習率の場合において、教師モデルが何らかの学習データDを生成し、Dのサンプルxで生徒モデルでパラメータを更新する勾配を計算すると、教師モデルが学習の過程で経た勾配と同じ方向の勾配が導き出される。つまり、パラメータが教師モデルと同じ方向にアップデートされる。みたいな感じだろうか?元論文を時間がなくて厳密に読めていない、かつalphaxivの力を借りて読んでいるため、誤りがあるかもしれない点に注意
[^3]: このパートについてもalphaxivの出力を参考にしており、元論文の記述をしっかり読めているわけではない
続報:
[Paper Note] Hierarchical Reasoning Model, Guan Wang+, arXiv'25
Paper/Blog Link My Issue
#NLP #Reasoning #Architecture Issue Date: 2025-07-23 GPT Summary- HRM(Hierarchical Reasoning Model)は、AIの推論プロセスを改善するために提案された新しい再帰的アーキテクチャであり、Chain-of-Thought技術の問題を克服します。HRMは、2つの相互依存する再帰モジュールを用いて、シーケンシャルな推論タスクを単一のフォワードパスで実行し、高レベルの抽象計画と低レベルの詳細計算を分担します。2700万のパラメータで、わずか1000のトレーニングサンプルを使用し、数独や迷路の最適経路探索などの複雑なタスクで優れたパフォーマンスを示し、ARCベンチマークでも他の大規模モデルを上回る結果を達成しました。HRMは、普遍的な計算と汎用推論システムに向けた重要な進展を示唆しています。 Comment
元ポスト:
解説ポスト:
関連:
- [Paper Note] Deep Equilibrium Models, Shaojie Bai+, NeurIPS'19
追試の結果再現が可能でモデルアーキテクチャそのものよりも、ablation studyの結果、outer refinement loopが重要とのこと:
-
-
ポイント解説:
[Paper Note] MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning, Run-Ze Fan+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning #PostTraining #Contamination-free #Science Issue Date: 2025-07-23 GPT Summary- 科学的推論のためのオープンデータセット「TextbookReasoning」を提案し、65万の推論質問を含む。さらに、125万のインスタンスを持つ「MegaScience」を開発し、各公開科学データセットに最適なサブセットを特定。包括的な評価システムを構築し、既存のデータセットと比較して優れたパフォーマンスを示す。MegaScienceを用いてトレーニングしたモデルは、公式の指示モデルを大幅に上回り、科学的調整におけるスケーリングの利点を示唆。データキュレーションパイプラインやトレーニング済みモデルをコミュニティに公開。 Comment
元ポスト:
LLMベースでdecontaminationも実施している模様
[Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Test-Time Scaling #GRPO #read-later #Selected Papers/Blogs #Non-VerifiableRewards #RewardModel Issue Date: 2025-07-22 GPT Summary- 強化学習を用いてLLMsの推論能力を向上させるため、報酬モデリング(RM)のスケーラビリティを探求。ポイントワイズ生成報酬モデリング(GRM)を採用し、自己原則批評調整(SPCT)を提案してパフォーマンスを向上。並列サンプリングとメタRMを導入し、スケーリング性能を改善。実験により、SPCTがGRMの質とスケーラビリティを向上させ、既存の手法を上回る結果を示した。DeepSeek-GRMは一部のタスクで課題があるが、今後の取り組みで解決可能と考えられている。モデルはオープンソースとして提供予定。 Comment
- inputに対する柔軟性と、
- 同じresponseに対して多様なRewardを算出でき (= inference time scalingを活用できる)、
- Verifiableな分野に特化していないGeneralなRewardモデルである
Inference-Time Scaling for Generalist Reward Modeling (GRM) を提案。
Figure3に提案手法の学習の流れが図解されておりわかりやすい。
[Paper Note] The Invisible Leash: Why RLVR May Not Escape Its Origin, Fang Wu+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #Reasoning #PostTraining #RLVR #EntropyCollapse Issue Date: 2025-07-22 GPT Summary- RLVRはAIの能力向上に寄与するが、基盤モデルの制約により新しい解の発見を制限する可能性がある。理論的調査により、初期確率がゼロの解をサンプリングできないことや、探索を狭めるトレードオフが明らかになった。実証実験では、RLVRが精度を向上させる一方で、正しい答えを見逃すことが確認された。将来的には、探索メカニズムや過小評価された解に確率質量を注入する戦略が必要とされる。 Comment
元ポスト:
RLVRの限界に関する洞察
openreview: https://openreview.net/forum?id=qGhFl1SiPX
[Paper Note] Inverse Scaling in Test-Time Compute, Aryo Pradipta Gema+, arXiv'25
Paper/Blog Link My Issue
#NLP #Evaluation #Reasoning #LongSequence #Scaling Laws Issue Date: 2025-07-22 GPT Summary- LRMsの推論の長さが性能に与える影響を評価するタスクを構築し、計算量と精度の逆スケーリング関係を示す。4つのカテゴリのタスクを通じて、5つの失敗モードを特定。これにより、長時間の推論が問題のあるパターンを強化する可能性があることが明らかになった。結果は、LRMsの失敗モードを特定し対処するために、推論の長さに応じた評価の重要性を示している。 Comment
元ポスト:
ReasoningモデルにおいてReasoningが長くなればなるほど
- context中にirrerevantな情報が含まれるシンプルな個数を数えるタスクでは、irrerevantな情報に惑わされるようになり、
- 特徴表に基づく回帰タスクの場合、擬似相関を持つ特徴量をの影響を増大してしまい、
- 複雑で組み合わせが多い演繹タスク(シマウマパズル)に失敗する
といったように、Reasoning Traceが長くなればなるほど性能を悪化させるタスクが存在しこのような問題のある推論パターンを見つけるためにも、様々なReasoning Traceの長さで評価した方が良いのでは、といった話な模様?
[Paper Note] The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs, Zichen Wen+, arXiv'25
Paper/Blog Link My Issue
#NLP #DiffusionModel #Safety Issue Date: 2025-07-22 GPT Summary- 拡散ベースの大規模言語モデル(dLLMs)は、迅速な推論と高いインタラクティビティを提供するが、安全性に関する懸念がある。既存のアライメントメカニズムは、敵対的プロンプトからdLLMsを保護できていない。これに対処するため、DIJAという新しい脱獄攻撃フレームワークを提案し、dLLMsの生成メカニズムを利用して有害な補完を可能にする。実験により、DIJAは既存の手法を大幅に上回り、特にDream-Instructで100%のASRを達成し、JailbreakBenchでの評価でも優れた結果を示した。これにより、dLLMsの安全性のアライメントを再考する必要性が浮き彫りになった。 Comment
元ポスト:
[Paper Note] Diffusion Beats Autoregressive in Data-Constrained Settings, Mihir Prabhudesai+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #DiffusionModel #Scaling Laws #read-later #Initial Impression Notes #Author Thread-Post Issue Date: 2025-07-22 GPT Summary- マスク付き拡散モデルは、データ制約のある設定で自己回帰(AR)モデルを大幅に上回ることを発見。拡散モデルはデータを効果的に活用し、検証損失を低下させ、下流のパフォーマンスを向上させる。新しいスケーリング法則を見つけ、拡散がARを上回る臨界計算閾値を導出。データがボトルネックの場合、拡散モデルはARの魅力的な代替手段となる。 Comment
元ポスト:
いつかdLLMの時代きそうだなあ
著者ポスト:
追加実験結果:
[Paper Note] Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation, Genki Kusano+, RecSys'25
Paper/Blog Link My Issue
#RecommenderSystems #Prompting #Evaluation #RecSys #Reproducibility #KeyPoint Notes Issue Date: 2025-07-21 GPT Summary- LLMを用いた単一ユーザー設定の推薦タスクにおいて、プロンプトエンジニアリングが重要であることを示す。23種類のプロンプトタイプを比較した結果、コスト効率の良いLLMでは指示の言い換え、背景知識の考慮、推論プロセスの明確化が効果的であり、高性能なLLMではシンプルなプロンプトが優れることが分かった。精度とコストのバランスに基づくプロンプトとLLMの選択に関する提案を行う。 Comment
元ポスト:
RecSysにおける網羅的なpromptingの実験。非常に興味深い
実験で利用されたPrompting手法と相対的な改善幅
RePhrase,StepBack,Explain,Summalize-User,Recency-Focusedが、様々なモデル、データセット、ユーザの特性(Light, Heavy)において安定した性能を示しており(少なくともベースラインからの性能の劣化がない)、model agnosticに安定した性能を発揮できるpromptingが存在することが明らかになった。一方、Phi-4, nova-liteについてはBaselineから有意に性能が改善したPromptingはなかった。これはモデルは他のモデルよりもそもそもの予測性能が低く、複雑なinstructionを理解する能力が不足しているため、Promptデザインが与える影響が小さいことが示唆される。
特定のモデルでのみ良い性能を発揮するPromptingも存在した。たとえばRe-Reading, Echoは、Llama3.3-70Bでは性能が改善したが、gpt-4.1-mini, gpt-4o-miniでは性能が悪化した。ReActはgpt-4.1-miniとLlamd3.3-70Bで最高性能を達成したが、gpt-4o-miniでは最も性能が悪かった。
NLPにおいて一般的に利用されるprompting、RolePlay, Mock, Plan-Solve, DeepBreath, Emotion, Step-by-Stepなどは、推薦のAcc.を改善しなかった。このことより、ユーザの嗜好を捉えることが重要なランキングタスクにおいては、これらプロンプトが有効でないことが示唆される。
続いて、LLMやデータセットに関わらず高い性能を発揮するpromptingをlinear mixed-effects model(ランダム効果として、ユーザ、LLM、メトリックを導入し、これらを制御する項を線形回帰に導入。promptingを固定効果としAccに対する寄与をfittingし、多様な状況で高い性能を発揮するPromptを明らかにする)によって分析した結果、ReAct, Rephrase, Step-Backが有意に全てのデータセット、LLMにおいて高い性能を示すことが明らかになった。
[Paper Note] Unveiling the Power of Source: Source-based Minimum Bayes Risk Decoding for Neural Machine Translation, Boxuan Lyu+, ACL'25
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP #ACL #Decoding Issue Date: 2025-07-20 GPT Summary- ソースベースのMBRデコーディング(sMBR)を提案し、パラフレーズや逆翻訳から生成された準ソースを「サポート仮説」として利用。参照なしの品質推定メトリックを効用関数として用いる新しいアプローチで、実験によりsMBRがQE再ランキングおよび標準MBRを上回る性能を示した。sMBRはNMTデコーディングにおいて有望な手法である。 Comment
元ポスト:
[Paper Note] A Survey of Context Engineering for Large Language Models, Lingrui Mei+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #ContextEngineering Issue Date: 2025-07-19 GPT Summary- 本調査では、LLMsの性能を向上させる「コンテキストエンジニアリング」を提案し、その要素と実装方法を体系的に分類。コンテキストの取得、生成、処理、管理を検討し、洗練されたシステム実装を探る。1300以上の研究を分析し、モデルの能力の非対称性を明らかにし、複雑な文脈理解と長文出力生成のギャップに対処する重要性を強調。研究者とエンジニアのための統一フレームワークを提供。 Comment
もうContext Engineeringという切り口の体系化されたSurveyが出てきた。早すぎ。
元ポスト:
[Paper Note] Scaling Laws for Optimal Data Mixtures, Mustafa Shukor+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #MultiModal #Scaling Laws #DataMixture #VisionLanguageModel Issue Date: 2025-07-18 GPT Summary- 本研究では、スケーリング法則を用いて任意のターゲットドメインに対する最適なデータ混合比率を決定する方法を提案。特定のドメイン重みベクトルを持つモデルの損失を正確に予測し、LLM、NMM、LVMの事前訓練における予測力を示す。少数の小規模な訓練実行でパラメータを推定し、高価な試行錯誤法に代わる原則的な選択肢を提供。
[Paper Note] TransEvalnia: Reasoning-based Evaluation and Ranking of Translations, Richard Sproat+, arXiv'25
Paper/Blog Link My Issue
#MachineTranslation #Metrics #NLP #MultiDimensional Issue Date: 2025-07-18 GPT Summary- プロンプトベースの翻訳評価システム「TransEvalnia」を提案し、Multidimensional Quality Metricsに基づく詳細な評価を行う。TransEvalniaは、英日データやWMTタスクで最先端のMT-Rankerと同等以上の性能を示し、LLMによる評価が人間の評価者と良好に相関することを確認。翻訳の提示順序に敏感であることを指摘し、位置バイアスへの対処法を提案。システムの評価データは公開される。 Comment
元ポスト:
[Paper Note] Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety, Tomek Korbak+, arXiv'25
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Reasoning #Safety Issue Date: 2025-07-16 GPT Summary- 人間の言語で「考える」AIシステムは、安全性向上のために思考の連鎖(CoT)を監視することで悪意のある意図を検出する機会を提供する。しかし、CoT監視は完璧ではなく、一部の不正行為が見逃される可能性がある。研究を進め、既存の安全手法と併せてCoT監視への投資を推奨する。モデル開発者は、開発の決定がCoTの監視可能性に与える影響を考慮すべきである。 Comment
元ポスト:
CoTを監視することで、たとえばモデルのよろしくない挙動(e.g., misalignmentなどの意図しない動作や、prompt injection等の不正行為)を検知することができ、特にAIがより長期的な課題に取り組む際にはより一層その内部プロセスを監視する手段が必要不可欠となるため、CoTの忠実性や解釈性が重要となる。このため、CoTの監視可能性が維持される(モデルのアーキテクチャや学習手法(たとえばCoTのプロセス自体は一見真っ当なことを言っているように見えるが、実はRewardHackingしている、など)によってはそもそもCoTが難読化し監視できなかったりするので、現状は脆弱性がある)、より改善していく方向にコミュニティとして動くことを推奨する。そして、モデルを研究開発する際にはモデルのCoT監視に関する評価を実施すべきであり、モデルのデプロイや開発の際にはCoTの監視に関する決定を組み込むべき、といったような提言のようである。
関連:
[Paper Note] Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, Mingqi Wu+, arXiv'25
Paper/Blog Link My Issue
#NLP #OpenWeight #Contamination-free Issue Date: 2025-07-16 GPT Summary- 大規模言語モデル(LLMs)の推論能力向上に関する研究が進展しており、特にQwen2.5モデルが強化学習(RL)を用いて顕著な改善を示している。しかし、他のモデルでは同様の成果が得られていないため、さらなる調査が必要である。Qwen2.5は数学的推論性能が高いが、データ汚染に脆弱であり、信頼性のある結果を得るためには、RandomCalculationというクリーンなデータセットを用いることが重要である。このデータセットを通じて、正確な報酬信号が性能向上に寄与することが示された。信頼性のある結論を得るためには、汚染のないベンチマークと多様なモデルでのRL手法の評価が推奨される。 Comment
元ポスト:
解説ポスト:
関連:
- [Paper Note] Spurious Rewards: Rethinking Training Signals in RLVR, Shao+, 2025.05
こちらでQwen-mathに対して得られたRLでのgainは他モデルでは現れず汎化しないことも報告されている。
[Paper Note] REST: Stress Testing Large Reasoning Models by Asking Multiple Problems at Once, Zhuoshi Pan+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #Prompting #Reasoning #Batch Issue Date: 2025-07-16 GPT Summary- RESTという新しい評価フレームワークを提案し、LRMsを同時に複数の問題にさらすことで、実世界の推論能力を評価。従来のベンチマークの限界を克服し、文脈優先配分や問題間干渉耐性を測定。DeepSeek-R1などの最先端モデルでもストレステスト下で性能低下が見られ、RESTはモデル間の性能差を明らかにする。特に「考えすぎの罠」が性能低下の要因であり、「long2short」技術で訓練されたモデルが優れた結果を示すことが確認された。RESTはコスト効率が高く、実世界の要求に適した評価手法である。 Comment
元ポスト:
[Paper Note] Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions, Simon Matrenok+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #GRPO #read-later #Off-Policy Issue Date: 2025-07-15 GPT Summary- QRPO(Quantile Reward Policy Optimization)は、ポイントワイズの絶対報酬から学習する新しい手法で、DPOのシンプルさとオフライン適用性を兼ね備えています。QRPOは量子報酬を用いてKL正則化された強化学習の目的の閉形式解への回帰を実現し、相対的な信号の必要性を排除します。実験結果では、QRPOがDPOやREBEL、SimPOと比較して、チャットやコーディングの評価で一貫して最高のパフォーマンスを示しました。また、堅牢な報酬でのトレーニングにより、長さバイアスが減少することが確認されました。 Comment
画像は元ポストより。off-policy RLでもlong contextで高い性能が出るようになったのだろうか
元ポスト:
関連:
- Q-learning is not yet scalable, Seohong Park, UC Berkeley, 2025.06
[Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#MachineLearning #NLP #Optimizer #read-later #Selected Papers/Blogs Issue Date: 2025-07-14 GPT Summary- Muonオプティマイザーを大規模モデルにスケールアップするために、ウェイトデケイとパラメータごとの更新スケール調整を導入。これにより、Muonは大規模トレーニングで即座に機能し、計算効率がAdamWの約2倍に向上。新たに提案するMoonlightモデルは、少ないトレーニングFLOPで優れたパフォーマンスを達成し、オープンソースの分散Muon実装や事前トレーニング済みモデルも公開。 Comment
解説ポスト:
こちらでも紹介されている:
- きみはNanoGPT speedrunを知っているか?, PredNext, 2025.07
解説:
図解:
[Paper Note] SingLoRA: Low Rank Adaptation Using a Single Matrix, David Bensaïd+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #Stability Issue Date: 2025-07-12 GPT Summary- SingLoRAは、LoRAの低ランク適応を再定式化し、単一の低ランク行列とその転置の積を用いることで、トレーニングの安定性を向上させ、パラメータ数をほぼ半減させる手法です。実験により、常識推論タスクでLLama 7Bを用いたファインチューニングで91.3%の精度を達成し、LoRAやLoRA+を上回る結果を示しました。また、画像生成においてもStable Diffusionのファインチューニングで高い忠実度を実現しました。 Comment
元ポスト:
LoRAは低ランク行列BAの積を計算するが、オリジナルのモデルと同じ挙動から学習をスタートするために、Bをzeroで初期化し、Aはランダムに初期化する。このAとBの不均衡さが、勾配消失、爆発、あるいはsub-optimalな収束の要因となってしまっていた(inter-matrix scale conflicts)。特に、LoRAはモデルのwidthが大きくなると不安定になるという課題があった。このため、低ランク行列を2つ使うのではなく、1つの低ランク行列(とその転置)およびoptimizationのstep tごとにtrainableなパラメータがどの程度影響を与えるかを調整する度合いを決めるscalar function u(t)を導入することで、低ランク行列間の不均衡を解消しつつ、パラメータ数を半減し、学習の安定性と性能を向上させる。たとえばu(t)を学習開始時にzeroにすれば、元のLoRAにおいてBをzeroに初期化するのと同じ挙動(つまり元のモデルと同じ挙動から学習スタートができたりする。みたいな感じだろうか?
関連:
- [Paper Note] LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
- LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N/A, ICML'24
[Paper Note] Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful, Martin Marek+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #Batch #One-Line Notes #Reference Collection Issue Date: 2025-07-12 GPT Summary- 小さなバッチサイズに対するAdamのハイパーパラメータをスケーリングする新しいルールを提案。これにより、小さなバッチサイズでも安定したトレーニングが可能で、大きなバッチサイズと同等以上のパフォーマンスを達成。勾配蓄積は推奨せず、実用的なハイパーパラメータ設定のガイドラインを提供。 Comment
元ポスト:
論文中のFigure1において、AdamWにおいてbatchsizeが1の方が512の場合と比べてlearning_rateの変化に対してロバストである旨が記述されている。
似たような話でMTでバッチサイズ小さいほうが性能良いです、みたいな話が昔あったような
(追記)
気になって思い出そうとしていたが、MTではなく画像認識の話だったかもしれない(だいぶうろ覚え)
- [Paper Note] Revisiting Small Batch Training for Deep Neural Networks, Dominic Masters+, arXiv'18
参考:
関連:
- How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25
解説:
実際に8Bモデルの事前学習においてβ2を0.99にしたところ、学習が不安定になり、かつ最終的なPerplexityも他の設定に勝つことができなかったとのこと:
[Paper Note] Spike No More: Stabilizing the Pre-training of Large Language Models, Sho Takase+, COLM'25
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #COLM #Selected Papers/Blogs #Stability #KeyPoint Notes #Author Thread-Post Issue Date: 2025-07-11 GPT Summary- 大規模言語モデルの事前学習中に発生する損失のスパイクは性能を低下させるため、避けるべきである。勾配ノルムの急激な増加が原因とされ、サブレイヤーのヤコビ行列の分析を通じて、勾配ノルムを小さく保つための条件として小さなサブレイヤーと大きなショートカットが必要であることを示した。実験により、これらの条件を満たす手法が損失スパイクを効果的に防ぐことが確認された。 Comment
元ポスト:
small sub-layers, large shortcutsの説明はこちらに書かれている。前者については、現在主流なLLMの初期化手法は満たしているが、後者はオリジナルのTransformerの実装では実装されている[^1]が、最近の実装では失われてしまっているとのこと。
下図が実験結果で、条件の双方を満たしているのはEmbedLN[^2]とScaled Embed[^3]のみであり、実際にスパイクが生じていないことがわかる。
[^1]:オリジナル論文 [Paper Note] Attention Is All You Need, Ashish Vaswani+, NeurIPS'17, 2017.07
の3.4節末尾、embedding layersに対してsqrt(d_model)を乗じるということがサラッと書いてある。これが実はめちゃめちゃ重要だったという…
[^2]: positional embeddingを加算する前にLayer Normalizationをかける方法
[^3]: EmbeddingにEmbeddingの次元数d(i.e., 各レイヤーのinputの次元数)の平方根を乗じる方法
前にScaled dot-product attentionのsqrt(d_k)がめっちゃ重要ということを実験的に示した、という話もあったような…
(まあそもそも元論文になぜスケーリングさせるかの説明は書いてあるけども)
著者ポスト(スライド):
非常に興味深いので参照のこと。初期化の気持ちの部分など勉強になる。
[Paper Note] FlexOlmo: Open Language Models for Flexible Data Use, Weijia Shi+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #NeurIPS #Privacy #Author Thread-Post Issue Date: 2025-07-11 GPT Summary- FlexOlmoは、データ共有なしでの分散トレーニングを可能にする新しい言語モデルで、異なるモデルパラメータが独立してトレーニングされ、データ柔軟な推論を実現します。混合専門家アーキテクチャを採用し、公開データセットと特化型セットでトレーニングされ、31の下流タスクで評価されました。データライセンスに基づくオプトアウトが可能で、平均41%の性能改善を達成し、従来の手法よりも優れた結果を示しました。FlexOlmoは、データ所有者のプライバシーを尊重しつつ、閉じたデータの利点を活かすことができます。 Comment
元ポスト:
データのオーナー側がプロプライエタリデータを用いてエキスパート(FFNとRouter embeddings)を学習し、それをpublicにシェアすることで利用できるようにする。データオーナー側はデータそのものを提供するのではなく、モデルのパラメータを共有するだけで済み、かつ自分たちのエキスパートをRouter側で利用するか否かは制御可能だから、opt-in/outが制御できる、みたいな話っぽい?
著者ポスト:
[Paper Note] First Return, Entropy-Eliciting Explore, Tianyu Zheng+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #RLVR Issue Date: 2025-07-10 GPT Summary- FR3E(First Return, Entropy-Eliciting Explore)は、強化学習における不安定な探索を改善するための構造化された探索フレームワークであり、高不確実性の意思決定ポイントを特定し、中間フィードバックを提供します。実験結果は、FR3Eが安定したトレーニングを促進し、一貫した応答を生成することを示しています。 Comment
元ポスト:
RLVRのロールアウトにおいて、reasoning traceにおける各トークンを出力する際にエントロピーが高い部分を特定し(つまり、複数の候補がありモデルが迷っている)、その部分について異なる意図的に異なる生成パスを実行することで探索を促すようにするとRLVRがよりreliableになるといった話のようである
[Paper Note] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models, Chankyu Lee+, ICLR'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #InformationRetrieval #NLP #RepresentationLearning #InstructionTuning #ContrastiveLearning #ICLR #Generalization #Decoder Issue Date: 2025-07-10 GPT Summary- デコーダー専用のLLMベースの埋め込みモデルNV-Embedは、BERTやT5を上回る性能を示す。アーキテクチャ設計やトレーニング手法を工夫し、検索精度を向上させるために潜在的注意層を提案。二段階の対照的指示調整手法を導入し、検索と非検索タスクの両方で精度を向上。NV-EmbedモデルはMTEBリーダーボードで1位を獲得し、ドメイン外情報検索でも高スコアを達成。モデル圧縮技術の分析も行っている。 Comment
Decoder-Only LLMのlast hidden layerのmatrixを新たに導入したLatent Attention Blockのinputとし、Latent Attention BlockはEmbeddingをOutputする。Latent Attention Blockは、last hidden layer (系列長l×dの
matrix)をQueryとみなし、保持しているLatent Array(trainableなmatrixで辞書として機能する;後述の学習においてパラメータが学習される)[^1]をK,Vとして、CrossAttentionによってcontext vectorを生成し、その後MLPとMean Poolingを実施することでEmbeddingに変換する。
学習は2段階で行われ、まずQAなどのRetrievalタスク用のデータセットをIn Batch negativeを用いてContrastive Learningしモデルの検索能力を高める。その後、検索と非検索タスクの両方を用いて、hard negativeによってcontrastive learningを実施し、検索以外のタスクの能力も高める(下表)。両者において、instructionテンプレートを用いて、instructionによって条件付けて学習をすることで、instructionに応じて生成されるEmbeddingが変化するようにする。また、学習時にはLLMのcausal maskは無くし、bidirectionalにrepresentationを考慮できるようにする。
[^1]: [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22, 2021.07
Perceiver-IOにインスパイアされている。
[Paper Note] Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation, Liliang Ren+, arXiv'25
Paper/Blog Link My Issue
#NLP #Reasoning #SmallModel #OpenWeight Issue Date: 2025-07-10 GPT Summary- 最近の言語モデルの進展により、状態空間モデル(SSM)の効率的なシーケンスモデリングが示されています。本研究では、ゲーテッドメモリユニット(GMU)を導入し、Sambaベースの自己デコーダーからメモリを共有する新しいデコーダーハイブリッドアーキテクチャSambaYを提案します。SambaYはデコーディング効率を向上させ、長文コンテキスト性能を改善し、位置エンコーディングの必要性を排除します。実験により、SambaYはYOCOベースラインに対して優れた性能を示し、特にPhi4-mini-Flash-Reasoningモデルは推論タスクで顕著な成果を上げました。トレーニングコードはオープンソースで公開されています。 Comment
HF: https://huggingface.co/microsoft/Phi-4-mini-flash-reasoning
元ポスト:
[Paper Note] MegaMath: Pushing the Limits of Open Math Corpora, Fan Zhou+, COLM'25
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #SyntheticData #Coding #Mathematics #mid-training #COLM #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-07-10 GPT Summary- MegaMathは、数学に特化したオープンデータセットで、LLMの数学的推論能力を向上させるために作成された。ウェブデータの再抽出、数学関連コードの特定、合成データの生成を通じて、371Bトークンの高品質なデータを提供し、既存のデータセットを上回る量と品質を実現した。 Comment
元ポスト:
非常に大規模な数学の事前学習/mid-training向けのデータセット
CommonCrawlのHTMLから、さまざまなフィルタリング処理(reformatting, 2 stageのHTML parserの活用(片方はnoisyだが高速、もう一方は高性能だが遅い), fasttextベースの分類器による抽出, deduplication等)を実施しMegaMath-Webを作成、また、MegaMathWebをさらに分類器で低品質なものをフィルタリングし、LLMによってノイズ除去、テキストのreorganizingを実施し(≠ピュアな合成データ)継続事前学習、mid-training向けの高品質なMegaMath-Web-Proを作成。
MegaMathCodeはThe Stack V2 ([Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
) をベースにしており、mathematical reasoning, logic puzzles, scientific computationに関するコードを収集。まずこれらのコードと関連が深い11のプログラミング言語を選定し、そのコードスニペットのみを対象とする。次にstrong LLMを用いて、数学に関するrelevanceスコアと、コードの品質を0--6のdiscrete scoreでスコアリングし学習データを作成。作成した学習データでSLMを学習し大規模なフィルタリングを実施することでMegaMath-Codeを作成。
最後にMegaMath-{Web, code}を用いて、Q&A, code data, text&code block dataの3種類を合成。Q&Aデータの合成では、MegaMath-WebからQAペアを抽出し、多様性とデータ量を担保するためQwen2.5-72B-Instruct, Llama3.3-70B-Instructの両方を用いて、QAのsolutionを洗練させる(reasoning stepの改善, あるいはゼロから生成する[^1])ことで生成。また、code dataでは、pythonを対象にMegaMath-Codeのデータに含まれるpython以外のコードを、Qwen2.5-Coder-32B-Instructと、Llamd3.1-70B-Instructによってpythonに翻訳することでデータ量を増やした。text&code blockデータでは、MegaMath-Webのドキュメントを与えて、ブロックを生成(タイトル、数式、結果、コードなど[^1])し、ブロックのverificationを行い(コードが正しく実行できるか、実行結果とanswerが一致するか等)、verifiedなブロックを残すことで生成。
[^1]: この辺は論文の記述を咀嚼して記述しており実サンプルを見ていないので少し正しい認識か不安
[Paper Note] Toward Cross-Hospital Deployment of Natural Language Processing Systems: Model Development and Validation of Fine-Tuned Large Language Models for Disease Name Recognition in Japanese, Shimizu+, JMIR'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Japanese #OOD #DiseaseNameRecognition Issue Date: 2025-07-10 Comment
元ポスト:
[Paper Note] A Survey on Latent Reasoning, Rui-Jie Zhu+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #LatentReasoning Issue Date: 2025-07-10 GPT Summary- 大規模言語モデル(LLMs)は、明示的な思考の連鎖(CoT)によって優れた推論能力を示すが、自然言語推論への依存が表現力を制限する。潜在的推論はこの問題を解決し、トークンレベルの監視を排除する。研究は、ニューラルネットワーク層の役割や多様な潜在的推論手法を探求し、無限深度の潜在的推論を可能にする高度なパラダイムについて議論する。これにより、潜在的推論の概念を明確にし、今後の研究方向を示す。関連情報はGitHubリポジトリで提供されている。 Comment
元ポスト:
Latent Reasoningというテクニカルタームが出てきた
出力されるdiscreteなtokenによってreasoningを実施するのではなく、モデル内部のrepresentationでreasoningを実施するLatent ReasoningのSurvey
[Paper Note] VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents, Rui Meng+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #InformationRetrieval #NLP #MultiModal #RAG(RetrievalAugmentedGeneration) #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-09 GPT Summary- VLM2Vec-V2という統一フレームワークを提案し、テキスト、画像、動画、視覚文書を含む多様な視覚形式の埋め込みを学習。新たにMMEB-V2ベンチマークを導入し、動画検索や視覚文書検索など5つのタスクを追加。広範な実験により、VLM2Vec-V2は新タスクで強力なパフォーマンスを示し、従来の画像ベンチマークでも改善を達成。研究はマルチモーダル埋め込みモデルの一般化可能性に関する洞察を提供し、スケーラブルな表現学習の基盤を築く。 Comment
元ポスト:
Video Classification, Visual Document Retrievalなどのモダリティも含まれている。
[Paper Note] Do We Really Need Specialization? Evaluating Generalist Text Embeddings for Zero-Shot Recommendation and Search, Matteo Attimonelli+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #InformationRetrieval #SequentialRecommendation #Generalization Issue Date: 2025-07-08 GPT Summary- 事前学習済み言語モデル(GTEs)は、逐次推薦や製品検索においてファインチューニングなしで優れたゼロショット性能を発揮し、従来のモデルを上回ることを示す。GTEsは埋め込み空間に特徴を均等に分配することで表現力を高め、埋め込み次元の圧縮がノイズを減少させ、専門モデルの性能向上に寄与する。再現性のためにリポジトリを提供。 Comment
元ポスト:
[Paper Note] ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations, Yubo Wang+, COLM'25
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Citations #NLP #Supervised-FineTuning (SFT) #COLM #AcademicWriting Issue Date: 2025-07-08 GPT Summary- ScholarCopilotは、学術的な執筆を支援するために大規模言語モデルを強化したフレームワークで、正確で文脈に関連した引用を生成します。取得トークンを用いて動的に文献を取得し、生成プロセスを補強します。評価では、取得精度が40.1%に達し、生成品質も他のモデルを大幅に上回りました。特に、ScholarCopilotはChatGPTを超える性能を示し、引用の質で100%の好ましさを達成しました。 Comment
元ポスト:
従来のRAGベースのAcademicWriting手法では、まずReferenceを検索して、その内容をcontextに含めてテキストを生成するというSequentialなパイプラインだったが、本研究では通常のNextTokenPrediction Lossに加え、特殊トークン\[RET\]を導入し、ContrastiveLearningによって、\[RET\]トークンがトリガーとなり、生成過程のContextとqueryから適切なReferenceを検索できるEmbeddingを出力し、Referenceを検索し、動的にReferenceの内容をcontextに加え、テキストを生成する手法を提案している。
データセットはarXivからlatex sourceを収集し、bibliography部分からReferenceのタイトルをQwenを用いて抽出。タイトルをarXivおよびSemanticScholarのデータベースと照合し、paperとReferenceの紐付けを実施することで構築している。
GPT-4oによるjudgeの結果、ground truthのcitationを用いた場合には及ばないが、提案手法により品質が向上し、citation retrievalのRecall@Kも大幅に改善している。
[Paper Note] A foundation model to predict and capture human cognition, Binz+, Nature'25, 2025.07
Paper/Blog Link My Issue
#FoundationModel #CognitiveScience #Nature Issue Date: 2025-07-06 Comment
元ポスト:
[Paper Note] Energy-Based Transformers are Scalable Learners and Thinkers, Alexi Gladstone+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #MachineLearning #NLP #Transformer #MultiModal #Architecture #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2025-07-06 GPT Summary- エネルギーベースのトランスフォーマー(EBTs)を用いて、無監督学習から思考を学ぶモデルを提案。EBTsは、入力と候補予測の互換性を検証し、エネルギー最小化を通じて予測を行う。トレーニング中に従来のアプローチよりも高いスケーリング率を達成し、言語タスクでの性能を29%向上させ、画像のノイズ除去でも優れた結果を示す。EBTsは一般化能力が高く、モデルの学習能力と思考能力を向上させる新しいパラダイムである。 Comment
元ポスト:
Project Page: https://energy-based-transformers.github.io
First Authorの方による解説ポスト:
[Paper Note] Correlated Errors in Large Language Models, Elliot Kim+, ICML'25
Paper/Blog Link My Issue
#Analysis #NLP #Evaluation #LLM-as-a-Judge #ICML Issue Date: 2025-07-05 GPT Summary- 350以上のLLMを評価し、リーダーボードと履歴書スクリーニングタスクで実証的な分析を実施。モデル間のエラーには実質的な相関があり、特に大きく正確なモデルは異なるアーキテクチャやプロバイダーでも高い相関を示す。相関の影響はLLMを評価者とするタスクや採用タスクにおいても確認された。 Comment
元ポスト:
これは結果を細かく見るのと、評価したタスクの形式とバイアスが生じないかをきちんと確認した方が良いような気がする。
それは置いておいたとして、たとえば、Figure9bはLlamaの異なるモデルサイズは、高い相関を示しているが、それはベースが同じだからそうだろうなあ、とは思う。一方、9aはClaude, Nova, Mistral, GPTなど多様なプロバイダーのモデルで高い相関が示されている。Llama3-70BとLLama3.{1,2,3}-70Bでは相関が低かったりしている。
Figure1(b)はHELMで比較的最新のモデル間でプロバイダーが別でも高い相関があるようにみえる。
このような相関がある要因や傾向については論文を読んでみないとわからない。
LLM-as-a-Judgeにおいて、評価者となるモデルと評価対象となるモデルが同じプロバイダーやシリーズの場合は(エラーの傾向が似ているので)性能がAccuracyが真のAccuracyよりも高めに出ている。また評価者よりも性能が低いモデルに対しても、性能が実際のAccuracyよりも高めに出す傾向にある(エラーの相関によってエラーであるにも関わらず正解とみなされAccuracyが高くなる)ようである。逆に、評価者よりも評価対象が性能が高い場合、評価者は自分が誤ってしまうquestionに対して、評価対象モデルが正解となる回答をしても、それに対して報酬を与えることができず性能が低めに見積もられてしまう。これだけの規模の実験で示されたことは、大変興味深い。
履歴書のスクリーニングタスクについてもケーススタディをしている。こちらも詳細に分析されているので興味がある場合は参照のこと。
[Paper Note] Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy, Chris Yuhao Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #Alignment #ReinforcementLearning #RewardModel Issue Date: 2025-07-05 GPT Summary- 報酬モデル(RMs)の性能向上のために、4,000万の好みペアからなる大規模データセット「SynPref-40M」を提案。人間とAIの相乗効果を活用した二段階パイプラインでデータをキュレーションし、Skywork-Reward-V2を導入。これにより、7つの報酬モデルベンチマークで最先端のパフォーマンスを達成。データのスケールと高品質なキュレーションが効果をもたらすことを確認。Skywork-Reward-V2はオープン報酬モデルの進展を示し、人間-AIキュレーションの重要性を強調。 Comment
元ポスト:
解説:
[Paper Note] Answer Matching Outperforms Multiple Choice for Language Model Evaluation, Nikhil Chandak+, arXiv'25
Paper/Blog Link My Issue
#NLP #Evaluation #read-later Issue Date: 2025-07-05 GPT Summary- 複数選択のベンチマークは言語モデル評価において重要だが、質問を見ずに回答できることが多い。これに対し、回答マッチングという生成的評価を提案し、自由形式の応答を生成させて参照回答と一致するかを判断。MMLU-ProとGPQA-Diamondで人間の採点データを取得し、回答マッチングがほぼ完璧な一致を達成することを示した。評価方法の変更により、モデルのランキングが大きく変わる可能性がある。 Comment
元ポスト:
これは非常に重要な研究に見える
Multiple Choice Question (MCQ)では、選択肢の中から消去法(論文中では仲間はずれを一つ探す, odd one cut)によって、正解の目処が立ってしまい、分類能力を評価するような尺度になっている。一方で同じモデルでも、Questionのみを与えて、選択肢無しで評価をすると、選択肢ありでは正解できたのに正解できない、という現象が生じる。これはモデルの分類能力ではなく、生成能力を評価しているからであり、これまでのMCQでの評価はモデルの能力の一部、特に識別能力しか評価できていないことが示唆される。このため、Answer Matchingと呼ばれる、モデルに自由記述で出力をさせた後に、referenaceと出力が一致しているか否かで評価をする手法を提案している。GPQA DiamondとMMLU-Proにおいて、人間にAnswer Matchingによる評価をさせオラクルを取得した後、SLMやより大きなモデルでAnswer Matchingを実験したところ、o4-miniを用いたLLM-as-a-Judgeよりも、SLMにおいてさえオラクルに近い性能を発揮し、人間と同等のレベルで自動評価が可能なことが示唆される。
まだ冒頭しか読めていないので後で読む
[Paper Note] AI4Research: A Survey of Artificial Intelligence for Scientific Research, Qiguang Chen+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #ScientificDiscovery Issue Date: 2025-07-04 GPT Summary- AIの進展に伴い、AI4Researchに関する包括的な調査が不足しているため、理解と発展が妨げられている。本研究では、AI4Researchの5つの主流タスクを系統的に分類し、研究のギャップや将来の方向性を特定し、関連する応用やリソースをまとめる。これにより、研究コミュニティが迅速にリソースにアクセスでき、革新的なブレークスルーを促進することを目指す。 Comment
元ポスト:
[Paper Note] CARE: Assessing the Impact of Multilingual Human Preference Learning on Cultural Awareness, Geyang Guo+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Alignment #Supervised-FineTuning (SFT) #MultiLingual #DPO #PostTraining #Cultural Issue Date: 2025-07-04 GPT Summary- 本論文では、文化的多様性を考慮した言語モデル(LM)の訓練方法を分析し、ネイティブな文化的好みを取り入れることで、LMの文化的認識を向上させることを目指します。3,490の文化特有の質問と31,700のネイティブな判断を含むリソース「CARE」を紹介し、高品質なネイティブの好みを少量取り入れることで、さまざまなLMの性能が向上することを示します。また、文化的パフォーマンスが強いモデルはアラインメントからの恩恵を受けやすく、地域間でのデータアクセスの違いがモデル間のギャップを生むことが明らかになりました。CAREは一般に公開される予定です。 Comment
元ポスト:
[Paper Note] The Curse of Depth in Large Language Models, Wenfang Sun+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #NeurIPS #Normalization #Selected Papers/Blogs #One-Line Notes #CurseOfDepth Issue Date: 2025-07-03 GPT Summary- 「深さの呪い」を提案し、現代のLLMにおける多くの層が期待通りに機能しない原因を探る。特にPre-Layer Normalizationが出力分散を増大させ、深層ブロックの寄与を低下させることを明らかにする。層正規化の出力分散を深さの平方根の逆数で調整する「LayerNorm Scaling」を導入し、これにより深い層の寄与を改善。実験で130M〜7Bモデルサイズで従来の手法を上回る性能向上を示し、教師ありファインチューニングにも良好な効果を発揮することを確認。 Comment
元ポスト:
- [Paper Note] Transformers without Normalization, Jiachen Zhu+, CVPR'25
ではそもそもLayerNormalizationを無くしていた(正確にいうとparametrize tanhに置換)が、どちらが優れているのだろうか?
- Knowledge Neurons in Pretrained Transformers, Damai Dai+, N/A, ACL'22, 2022.05
では知識ニューロンの存在が示唆されており、これはTransformerの層の深い位置に存在し、かつ異なる知識間で知識ニューロンはシェアされない傾向にあった(ただしこれはPost-LNのBERTの話で本研究はPre-LNの話だが。Post-LNの勾配消失問題を緩和し学習を安定化させる研究も[Paper Note] On Layer Normalizations and Residual Connections in Transformers, Sho Takase+, arXiv'22
のように存在する)。これはこの研究が明らかにしたこととどういう関係性があるだろうか。
また、LayerNormalizationのScalingによって深いTransformerブロックの導関数が単位行列となる(学習に寄与しなくなる)ことが改善された場合、知識ニューロンはどのように変化するだろうか?
(下記Geminiの応答を見た上での感想)なんとなーくだけれども、おそらく知識ニューロンの局所化が解消されるのかなーという気がする。
となると次の疑問としては、MoEアーキテクチャにはどのような影響があるだろうか?
そもそも知識ニューロンが局所化しているからMoEアーキテクチャのルータによって関連するExpertsのみをactivateすれば(というより結果的にそうなるように学習される)性能を劣化させずに計算効率を上げられていた、と仮定する。そうすると、知識ニューロンが局所化せずに多くのニューロンでシェアされるようになると、[Paper Note] Chain-of-Experts: Unlocking the Communication Power of Mixture-of-Experts Models, Zihan Wang+, arXiv'25
のように、サブネットワーク間の情報を互いにやりとりできます、みたいな仕組みがより効いてきそうな気がする。
参考までに、Gemini2.5-Proに考察させてみた結果をメモとして残しておく(あくまで参考程度に...)
```
ご質問ありがとうございます。非常に興味深い着眼点ですね。「Knowledge Neurons in Pretrained Transformers」と「The Curse of Depth in Large Language Models」は、一見すると全く異なるテーマを扱っているように見えますが、**「Transformerの深い層における振る舞い」**という共通点で結びつけて考察すると、非常に示唆に富んだ関係性が見えてきます。
以下に、両方の論文の概要を解説し、その関係性について考察します。
1. Knowledge Neurons in Pretrained Transformers の概要
この研究は、事前学習済みTransformerモデル(特にBERTなど)の内部で、特定の事実知識がどのように格納されているかを調査したものです。
発見: モデルの中間層、特に**全結合層(Feed-Forward Network, FFN)に、特定の知識(例:「ダンテ・アリギエーリはイタリアで生まれた」)に強く反応する「知識ニューロン」**が存在することを発見しました。
特徴: これらの知識ニューロンは、モデルの深い層(後方の層)に、より多く存在する傾向がありました。
意味: これまでブラックボックスとされてきた大規模言語モデルの内部で、知識がどのように表現・局在化しているかについて、具体的な手がかりを与えた画期的な研究です。
2. The Curse of Depth in Large Language Models の概要
この研究は、LLMをより深く(層を多く)することの難しさに焦点を当て、その原因と解決策を提案したものです。
問題(深さの呪い): Transformerの標準的なアーキテクチャ(Pre-LN)では、層が深くなるにつれて、LayerNormalization(LN)への入力の分散が指数関数的に増大してしまいます。
結果:
出力が大きくなりすぎて学習が不安定になります。
さらに深刻なのは、深い層ではモデルの出力に関する導関数(勾配計算に必要)がほぼ単位行列になってしまうことです。これは、その層が入力に対してほとんど変換を行わなくなり、学習に寄与しなくなることを意味します。
解決策: この問題を解決するため、各層のLayerNormalizationをその深さ(レイヤー番号 l)に応じてスケーリングするというシンプルな手法を提案しました。これにより、深い層でも勾配が適切に伝播し、学習が安定・改善することが示されました。
考察:2つの研究の関係性
これら2つの研究は、**「学習の安定性」と「知識の格納方法」**という異なる側面から、Transformerの深い層を分析していますが、両者には以下のような深い関係性があると考えられます。
学習の不安定性が「知識ニューロン」形成の背景にある可能性
「The Curse of Depth」で指摘されているように、標準的なTransformerの深い層は、本質的に学習が不安定で、勾配情報が失われやすい環境にあります。
この劣悪な学習環境こそが、「知識ニューロン」という形で知識が局所的に格納される原因の一つになっている可能性があります。つまり、
学習の非効率性: 深い層のほとんどのニューロンは、勾配消失問題のために効率的に学習を進めることができません。
専門化の発生: そのような不安定な環境下で、たまたま特定の知識パターンをうまく捉えることができた一部のニューロンが、その知識を一身に背負う形で強く活性化するよう特化(専門化)していったのではないか、と考えられます。これは、ネットワーク全体で協調して学習するのが難しい状況で、一部のユニットだけが突出して学習を担う、という現象と解釈できます。
学習の安定化が、より効率的な知識獲得につながる
では、「The Curse of Depth」で提案された手法(LNのスケーリング)によって深い層の学習が安定化すると、知識の格納方法はどのように変わるでしょうか。
これは非常に興味深い問いであり、2つの可能性が考えられます。
可能性A: より強固な知識ニューロンの形成:
学習が安定することで、各知識ニューロンはより明確に、そして効率的に特定の知識をエンコードできるようになるかもしれません。ノイズの多い環境で偶然生まれた専門家ではなく、安定した環境で育成された真の専門家へと変化するイメージです。
可能性B: 知識の分散化:
ネットワークの全ニューロンが効率的に学習に寄与できるようになるため、一つの知識を少数のニューロンに集中させる必要がなくなり、より多くのニューロンに分散して知識が格納されるようになる可能性も考えられます。
現在のところ、学習の安定化は、知識ニューロンがより効率的に形成・機能するための基盤を提供すると考えるのが最も妥当でしょう。「深さの呪い」という問題を解決することは、モデルが知識をどのように獲得し、整理するかという、より根源的なメカニズム(知識ニューロンの振る舞い)にも直接的な影響を与えるはずです。
まとめ
「Knowledge Neurons」は深い層に存在する知識の**「状態」を明らかにし、「The Curse of Depth」は深い層で発生する学習の「問題」**とその解決策を提示しました。
これらを統合すると、**「深い層における学習の不安定性という問題が、知識ニューロンという局所的な知識表現を生み出す一因となっており、この問題を解決することで、より効率的で安定した知識の獲得・格納が可能になるかもしれない」**という関係性が見えてきます。
両者は、LLMの能力と限界を異なる角度から照らし出しており、組み合わせることでモデルの内部動作の解明をさらに一歩前進させる、非常に重要な研究だと言えます。
```
[Paper Note] NaturalThoughts: Selecting and Distilling Reasoning Traces for General Reasoning Tasks, Yang Li+, arXiv'25
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #Reasoning #Distillation Issue Date: 2025-07-03 GPT Summary- 教師モデルからの推論トレースを用いて生徒モデルの能力を向上させる方法を体系的に研究。NaturalReasoningに基づく高品質な「NaturalThoughts」をキュレーションし、サンプル効率とスケーラビリティを分析。データサイズの拡大が性能向上に寄与し、多様な推論戦略を必要とする例が効果的であることを発見。LlamaおよびQwenモデルでの評価により、NaturalThoughtsが既存のデータセットを上回り、STEM推論ベンチマークで優れた性能を示した。 Comment
元ポスト:
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, ACL(Findings)'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #ACL #VisionLanguageModel #Findings #Author Thread-Post Issue Date: 2025-07-02 GPT Summary- 内部世界モデル(WMs)はエージェントの理解と予測を支えるが、最近の大規模ビジョン・ランゲージモデル(VLMs)の基本的なWM能力に関する評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchというベンチマークを導入。15のVLMsに対する660の実験で、これらのモデルが基本的なWM能力に顕著な制限を示し、特に運動軌道の識別においてほぼランダムな精度であることが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。 Comment
元ポスト:
所見:
[Paper Note] MARBLE: A Hard Benchmark for Multimodal Spatial Reasoning and Planning, Yulun Jiang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal Issue Date: 2025-07-02 GPT Summary- MARBLEという新しいマルチモーダル推論ベンチマークを提案し、MLLMsの複雑な推論能力を評価。MARBLEは、空間的・視覚的・物理的制約下での多段階計画を必要とするM-PortalとM-Cubeの2つのタスクから成る。現在のMLLMsは低いパフォーマンスを示し、視覚的入力からの情報抽出においても失敗が見られる。これにより、次世代モデルの推論能力向上が期待される。 Comment
元ポスト:
Portal2を使った新たなベンチマーク。筆者は昔このゲームを少しだけプレイしたことがあるが、普通に難しかった記憶がある😅
細かいが表中のGPT-o3は正しくはo3だと思われる。
時間がなくて全然しっかりと読めていないが、reasoning effortやthinkingモードはどのように設定して評価したのだろうか。
[Paper Note] SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning, Melanie Rieff+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Zero/Few/ManyShotPrompting #MultiModal #In-ContextLearning Issue Date: 2025-07-01 GPT Summary- マルチモーダルインコンテキスト学習(ICL)は医療分野での可能性があるが、十分に探求されていない。SMMILEという医療タスク向けの初のマルチモーダルICLベンチマークを導入し、111の問題を含む。15のMLLMの評価で、医療タスクにおけるICL能力が中程度から低いことが示された。ICLはSMMILEで平均8%、SMMILE++で9.4%の改善をもたらし、無関係な例がパフォーマンスを最大9.5%低下させることも確認。例の順序による最近性バイアスがパフォーマンス向上に寄与することも明らかになった。 Comment
元ポスト:
[Paper Note] Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search, Yuichi Inoue+, NeurIPS'25 Spotlight
Paper/Blog Link My Issue
#NLP #NeurIPS #Test-Time Scaling #Author Thread-Post Issue Date: 2025-07-01 GPT Summary- AB-MCTSを提案し、外部フィードバックを活用して繰り返しサンプリングを改善。探索木のノードで新しい応答を「広げる」か「深める」かを動的に決定。実験により、AB-MCTSが従来の手法を上回り、LLMsの応答の多様性と解決策の洗練を強調。 Comment
元ポスト:
著者ポスト:
- 戦えるAIエージェントの作り方, Takuya Akiba, SakanaAI, 2025.10
のスライド中に解説がある。
[Paper Note] The Automated LLM Speedrunning Benchmark: Reproducing NanoGPT Improvements, Bingchen Zhao+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #ScientificDiscovery #Reproducibility Issue Date: 2025-06-30 GPT Summary- 大規模言語モデル(LLMs)の進展を活用し、AIエージェントの研究再現能力を評価するために、LLMスピードランベンチマークを導入。19のタスクで訓練スクリプトとヒントを提供し、迅速な実行を促進。既知の革新の再実装が難しいことを発見し、科学的再現を自動化するための指標を提供。 Comment
元ポスト:
[Paper Note] Bridging Offline and Online Reinforcement Learning for LLMs, Jack Lanchantin+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #TransferLearning #DPO #GRPO #VerifiableRewards #Off-Policy #On-Policy #Non-VerifiableRewards Issue Date: 2025-06-30 GPT Summary- 大規模言語モデルのファインチューニングにおける強化学習手法の効果を、オフラインからオンラインへの移行において調査。数学タスクと指示に従うタスクのベンチマーク評価を行い、オンラインおよびセミオンラインの最適化手法がオフライン手法を上回る結果を示す。トレーニングダイナミクスとハイパーパラメータ選択について分析し、検証可能な報酬と検証不可能な報酬を共同で扱うことでパフォーマンス向上を確認。 Comment
元ポスト:
[Paper Note] Chain-of-Experts: Unlocking the Communication Power of Mixture-of-Experts Models, Zihan Wang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Architecture Issue Date: 2025-06-28 GPT Summary- Chain-of-Experts(CoE)は、逐次的な専門家間のコミュニケーションを導入した新しいMixture-of-Experts(MoE)アーキテクチャで、トークンを反復的に処理する。各反復ステップで専用のルーターを使用し、動的な専門家選択を可能にすることで、モデルの表現能力を向上させる。CoEは数学的推論タスクにおいて、従来のMoEと比較して検証損失を低下させ、メモリ使用量を削減する。反復的残差構造と専門家の専門化が、より表現力豊かな結果をもたらすことが示されている。 Comment
元ポスト:
[Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, COLM'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Dataset #MultiLingual #COLM #Selected Papers/Blogs Issue Date: 2025-06-28 GPT Summary- 多言語LLMsの性能向上のために、FineWebに基づく新しい事前学習データセットキュレーションパイプラインを提案。9つの言語に対して設計選択肢を検証し、非英語コーパスが従来のデータセットよりも高性能なモデルを生成できることを示す。データセットの再バランス手法も導入し、1000以上の言語にスケールアップした20テラバイトの多言語データセットFineWeb2を公開。 Comment
元ポスト:
abstを見る限りFinewebを多言語に拡張した模様
openreview: https://openreview.net/forum?id=jnRBe6zatP#discussion
[Paper Note] OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling, Zengzhi Wang+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #mid-training #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2025-06-27 GPT Summary- 異なるベース言語モデル(LlamaやQwen)の強化学習(RL)における挙動を調査し、中間トレーニング戦略がRLのダイナミクスに与える影響を明らかに。高品質の数学コーパスがモデルのパフォーマンスを向上させ、長い連鎖的思考(CoT)がRL結果を改善する一方で、冗長性や不安定性を引き起こす可能性があることを示す。二段階の中間トレーニング戦略「Stable-then-Decay」を導入し、OctoThinkerモデルファミリーを開発。オープンソースのモデルと数学推論コーパスを公開し、RL時代の基盤モデルの研究を支援することを目指す。 Comment
元ポスト:
mid-trainingの観点から、post trainingにおけるRLがスケーリングする条件をsystematicallyに調査している模様
論文中にはmid-training[^1]の定義が記述されている:
[^1]: mid-trainingについてはコミュニティの間で厳密な定義はまだ無くバズワードっぽく使われている、という印象を筆者は抱いており、本稿は文献中でmid-trainingを定義する初めての試みという所感
[Paper Note] RLPR: Extrapolating RLVR to General Domains without Verifiers, Tianyu Yu+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning Issue Date: 2025-06-27 GPT Summary- RLVRはLLMの推論能力を向上させるが、主に数学やコードに限られる。これを克服するため、検証者不要のRLPRフレームワークを提案し、LLMのトークン確率を報酬信号として利用。ノイズの多い確率報酬に対処する手法を導入し、実験によりGemma、Llama、Qwenモデルで推論能力を向上させた。特に、TheoremQAで7.6ポイント、Minervaで7.5ポイントの改善を示し、General-Reasonerを平均1.6ポイント上回った。 Comment
元ポスト:
既存のRLVRはVerifierを構築しなければならず、しばしばそのVerifierは複雑になりやすく、スケールさせるには課題があった。RLPR(Probabliity Reward)は、生成された応答から回答yを抽出し、残りをreasoning zとする。そして回答部分yをreference y^\*で置換したトークン列o'を生成(zがo'に対してどのような扱いになるかは利用するモデルや出力フォーマットによる気がする)し、o'のポリシーモデルでのトークン単位での平均生成確率を報酬とする。尤度のような系列全体の生起確率を考慮する方法が直感的に役に立ちそうだが、計算の際の確率積は分散が高いだけでなく、マイナーな類義語が与えられた時に(たとえば1 tokenだけ生起確率が小さかった場合)に、Rewardが極端に小さくなりsensitiveであることを考察し、平均生成確率を採用している。
Rule basedなVerifierを用いたRLVRよりもgeneralなドメインとmathドメインで性能向上。コーディングなどでも効果はあるのだろうか?
ざっくり見た感じ、RLVRがそもそも適用できないドメインで実験した場合の結果がないように見え、適用した場合に有効なのかは気になるところ。
[Paper Note] Process Reward Models That Think, Muhammad Khalifa+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #PRM Issue Date: 2025-06-26 GPT Summary- 本研究では、データ効率の良いステップバイステップの検証器(ThinkPRM)を提案し、少ないプロセスラベルで高性能を実現します。ThinkPRMは、長いCoTモデルの推論能力を活用し、PRM800Kのわずか1%のプロセスラベルで、従来の検証器を上回る性能を示します。具体的には、ProcessBenchやMATH-500などのベースラインを超え、ドメイン外評価でも優れた結果を得ています。最小限の監視でのトレーニングを通じて、検証計算のスケーリングの重要性を強調しています。
[Paper Note] RewardBench: Evaluating Reward Models for Language Modeling, Nathan Lambert+, NAACL'25 Findings, 2024.05
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #Evaluation #NAACL #Selected Papers/Blogs #RewardModel #Findings Issue Date: 2025-06-26 GPT Summary- 報酬モデル(RMs)の評価に関する研究は少なく、我々はその理解を深めるためにRewardBenchというベンチマークデータセットを提案。これは、チャットや推論、安全性に関するプロンプトのコレクションで、報酬モデルの性能を評価する。特定の比較データセットを用いて、好まれる理由を検証可能な形で示し、さまざまなトレーニング手法による報酬モデルの評価を行う。これにより、報酬モデルの拒否傾向や推論の限界についての知見を得ることを目指す。 Comment
[Paper Note] Robust Reward Modeling via Causal Rubrics, Pragya Srivastava+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #RewardHacking Issue Date: 2025-06-26 GPT Summary- 報酬モデル(RMs)は人間のフィードバックを通じて大規模言語モデル(LLMs)を整合させるが、報酬ハッキングの影響を受けやすい。本研究では、報酬ハッキングを軽減するための新しいフレームワーク「Crome」を提案。Cromeは因果的拡張と中立的拡張を用いて、因果属性に基づく感度と虚偽属性に対する不変性を強制する。実験結果では、CromeはRewardBenchで標準的なベースラインを大幅に上回り、平均精度を最大5.4%向上させた。 Comment
元ポスト:
以下がresearch question:
[Paper Note] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Zhangchen Xu+, ICLR'25, 2024.06
Paper/Blog Link My Issue
#NLP #Alignment #SyntheticData #ICLR #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-06-25 GPT Summary- 高品質な指示データはLLMの整合に不可欠であり、Magpieという自己合成手法を提案。Llama-3-Instructを用いて400万の指示と応答を生成し、30万の高品質なインスタンスを選定。Magpieでファインチューニングしたモデルは、従来のデータセットを用いたモデルと同等の性能を示し、特に整合ベンチマークで優れた結果を得た。 Comment
OpenReview: https://openreview.net/forum?id=Pnk7vMbznK
下記のようなpre-queryテンプレートを与え(i.e., userの発話は何も与えず、ユーザの発話を表す特殊トークンのみを渡す)instructionを生成し、post-queryテンプレートを与える(i.e., pre-queryテンプレート+生成されたinstruction+assistantの発話の開始を表す特殊トークンのみを渡す)ことでresponseを生成することで、prompt engineeringやseed無しでinstruction tuningデータを合成できるという手法。
```T_pre−query = <|start_header_id|>user<|end_header_id|>```
```T_post−query =<|eot_id|><|start_header_id|>assistant<|end_header_id|>```
生成した生のinstruction tuning pair dataは、たとえば下記のようなフィルタリングをすることで品質向上が可能で (Appendix C)
- input length: instructionの中の文字数
- output length: response中の文字数
- task category: instructionの特定のカテゴリ
- input quality: 5段階評価によるinstructionの明瞭さ、具体性、coherence
- input difficulty: 5段階評価によるinstruction中に記述されているタスクを解決するために必要な知識のレベル
- minimum neighbor distance: 最近傍のinstructionsとのembedding空間上での距離で、類似性や繰り返しを排除
- reward: reward modelのスコアによる繰り返しや低品質なレスポンスの排除
- reward distance: 同じinstructionで、instructモデルが生成したresponseのベースモデルが生成したresponseのreward modelによるrewardの差(これが大きいほど高品質なinstruction tuning dataと言える)
Table 5 に実際にどのような組み合わせでこれらが適用されたかが記載されている。
reward modelと組み合わせてLLMからのresponseを生成しrejection samplingすればDPOのためのpreference dataも作成できるし、single turnの発話まで生成させた後もう一度pre/post-queryをconcatして生成すればMulti turnのデータも生成できる。
他のも例えば、システムプロンプトに自分が生成したい情報を与えることで、特定のドメインに特化したデータ、あるいは特定の言語に特化したデータも合成できる。
[Paper Note] llm-jp-modernbert: A ModernBERT Model Trained on a Large-Scale Japanese Corpus with Long Context Length, Issa Sugiura+, arXiv'25
Paper/Blog Link My Issue
#Embeddings #NLP #RepresentationLearning #pretrained-LM #Japanese Issue Date: 2025-06-25 GPT Summary- ModernBERTモデル(llm-jp-modernbert)は、8192トークンのコンテキスト長を持つ日本語コーパスで訓練され、フィルマスクテスト評価で良好な結果を示す。下流タスクでは既存のベースラインを上回らないが、コンテキスト長の拡張効果を分析し、文の埋め込みや訓練中の遷移を調査。再現性を支援するために、モデルと評価コードを公開。 Comment
[Paper Note] AnswerCarefully: A Dataset for Improving the Safety of Japanese LLM Output, Hisami Suzuki+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #Alignment #Safety #Japanese #PostTraining Issue Date: 2025-06-25 GPT Summary- 日本のLLMの安全性を高めるためのデータセット「AnswerCarefully」を紹介。1,800組の質問と参照回答から成り、リスクカテゴリをカバーしつつ日本の文脈に合わせて作成。微調整により出力の安全性が向上し、12のLLMの安全性評価結果も報告。英語翻訳と注釈を提供し、他言語でのデータセット作成を促進。 Comment
[Paper Note] Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization, Taishi Nakamura+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #MoE(Mixture-of-Experts) #ICLR #KeyPoint Notes Issue Date: 2025-06-25 GPT Summary- Drop-Upcycling手法を提案し、MoEモデルのトレーニング効率を向上。事前にトレーニングされた密なモデルの知識を活用しつつ、一部の重みを再初期化することで専門家の専門化を促進。大規模実験により、5.9BパラメータのMoEモデルが13B密なモデルと同等の性能を達成し、トレーニングコストを約1/4に削減。すべての実験リソースを公開。 Comment
OpenReview: https://openreview.net/forum?id=gx1wHnf5Vp
提案手法の全体像とDiversity re-initializationの概要。元のUpcyclingでは全てidenticalな重みでreplicateされていたため、これが個々のexpertがlong termでの学習で特化することの妨げになり、最終的に最大限のcapabilityを発揮できず、収束が遅い要因となっていた。これを、Upcyclingした重みのうち、一部のindexのみを再初期化することで、replicate元の知識を保持しつつ、expertsの多様性を高めることで解決する。
提案手法は任意のactivation function適用可能。今回はFFN Layerのactivation functionとして一般的なSwiGLUを採用した場合で説明している。
Drop-Upcyclingの手法としては、通常のUpcyclingと同様、FFN Layerの重みをn個のexpertsの数だけreplicateする。その後、re-initializationを実施する比率rに基づいて、[1, intermediate size d_f]の範囲からr*d_f個のindexをサンプリングする。最終的にSwiGLU、およびFFNにおける3つのWeight W_{gate, up, down}において、サンプリングされたindexと対応するrow/columnと対応する重みをre-initializeする。
re-initializeする際には、各W_{gate, up, down}中のサンプリングされたindexと対応するベクトルの平均と分散をそれぞれ独立して求め、それらの平均と分散を持つ正規分布からサンプリングする。
学習の初期から高い性能を発揮し、long termでの性能も向上している。また、learning curveの形状もscratchから学習した場合と同様の形状となっており、知識の転移とexpertsのspecializationがうまく進んだことが示唆される。
[Paper Note] Shrinking the Generation-Verification Gap with Weak Verifiers, Jon Saad-Falcon+, arXiv'25
Paper/Blog Link My Issue
#NLP #Verification #Author Thread-Post Issue Date: 2025-06-25 GPT Summary- Weaverは、複数の弱いverifiersを組み合わせて強力なverifierを設計するフレームワークであり、ラベル付きデータへの依存を減らすために弱い監視を利用します。出力を正規化し、特定のverifiersをフィルタリングすることで、精度の向上を図ります。Weaverは、推論および数学タスクにおいてPass@1性能を大幅に改善し、Llama 3.3 70B Instructを用いて高い精度を達成しました。計算コスト削減のために、統合出力スコアを用いてクロスエンコーダを訓練します。 Comment
元ポスト:
[Paper Note] Mercury: Ultra-Fast Language Models Based on Diffusion, Inception Labs+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #Reference Collection #Initial Impression Notes Issue Date: 2025-06-25 GPT Summary- 新しい拡散型大規模言語モデルMercuryを発表。特にコーディングアプリケーション向けのMercury Coderは、MiniとSmallの2サイズで提供され、速度と品質で最先端を達成。独立評価では、Mercury Coder Miniが1109トークン/秒、Smallが737トークン/秒を記録し、他のモデルを大幅に上回る性能を示す。さらに、実世界での検証結果や公開API、無料プレイグラウンドも提供。 Comment
元ポスト:
スループット(モデルのトークン生成速度)が、SoTAらしいdLLMモデル
解説:
[Paper Note] Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models, Thao Nguyen+, COLM'25
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #SyntheticData #COLM #Author Thread-Post Issue Date: 2025-06-25 GPT Summary- スケーリング法則に基づき、低品質なウェブデータを再利用する手法「REWIRE」を提案。これにより、事前学習データの合成表現を増やし、フィルタリングされたデータのみでのトレーニングと比較して、22のタスクで性能を向上。生データと合成データの混合が効果的であることを示し、ウェブテキストのリサイクルが事前学習データのスケーリングに有効であることを示唆。 Comment
元ポスト:
-
-
学習データの枯渇に対する対処として別の方向性としては下記のような研究もある:
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
data: https://huggingface.co/datasets/facebook/recycling_the_web
[Paper Note] ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs, Jiaru Zou+, arXiv'25
Paper/Blog Link My Issue
#NLP #Reasoning #PRM Issue Date: 2025-06-25 GPT Summary- 新しいプロセス報酬モデルReasonFlux-PRMを提案し、推論トレースの評価を強化。ステップと軌道の監視を組み込み、報酬割り当てを細かく行う。実験により、ReasonFlux-PRM-7Bが高品質なデータ選択と性能向上を実現し、特に監視付きファインチューニングで平均12.1%の向上を達成。リソース制約のあるアプリケーション向けにReasonFlux-PRM-1.5Bも公開。 Comment
元ポスト:
[Paper Note] Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations, Jiaming Han+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #NeurIPS #Tokenizer #UMM #One-Line Notes Issue Date: 2025-06-24 GPT Summary- 本論文では、視覚理解と生成を統一するマルチモーダルフレームワークTarを提案。Text-Aligned Tokenizer(TA-Tok)を用いて画像を離散トークンに変換し、視覚とテキストを統一空間に統合。スケール適応型のエンコーディングとデコーディングを導入し、高忠実度の視覚出力を生成。迅速な自己回帰モデルと拡散ベースのモデルを用いたデトークナイザーを活用し、視覚理解と生成の改善を実現。実験結果では、Tarが既存手法と同等以上の性能を示し、効率的なトレーニングを達成。 Comment
元ポスト:
text modalityとvision modalityを共通の空間で表現する
Visual Understanding/Generationのベンチで全体的に高い性能を達成
[Paper Note] Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models, Yuda Song+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #SelfImprovement #ICLR #read-later #Selected Papers/Blogs #Verification #Initial Impression Notes Issue Date: 2025-06-24 GPT Summary- 自己改善はLLMの出力検証を通じてデータをフィルタリングし、蒸留するメカニズムである。本研究では、自己改善の数学的定式化を行い、生成-検証ギャップに基づくスケーリング現象を発見。さまざまなモデルとタスクを用いた実験により、自己改善の可能性とその性能向上方法を探求し、LLMの理解を深めるとともに、将来の研究への示唆を提供する。 Comment
参考: https://joisino.hatenablog.com/entry/mislead
Verificationに対する理解を深めるのに非常に良さそう
openreview: https://openreview.net/forum?id=mtJSMcF3ek
[Paper Note] On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks, Kaya Stechly+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #ICLR #Verification Issue Date: 2025-06-24 GPT Summary- LLMsの推論能力に関する意見の相違を背景に、反復的なプロンプトの効果をGame of 24、グラフ彩色、STRIPS計画の3領域で調査。自己批評がパフォーマンスに悪影響を及ぼす一方、外部の正しい推論者による検証がパフォーマンスを向上させることを示した。再プロンプトによって複雑な設定の利点を維持できることも確認。 Comment
参考: https://joisino.hatenablog.com/entry/mislead
OpenReview: https://openreview.net/forum?id=4O0v4s3IzY
[Paper Note] Language Models Learn to Mislead Humans via RLHF, Jiaxin Wen+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #RLHF #ICLR Issue Date: 2025-06-24 GPT Summary- RLHFは言語モデルのエラーを悪化させる可能性があり、モデルが人間を納得させる能力を向上させる一方で、タスクの正確性は向上しない。質問応答タスクとプログラミングタスクで被験者の誤検出率が増加し、意図された詭弁を検出する手法がU-SOPHISTRYには適用できないことが示された。これにより、RLHFの問題点と人間支援の研究の必要性が浮き彫りになった。 Comment
[Paper Note] From Bytes to Ideas: Language Modeling with Autoregressive U-Nets, Mathurin Videau+, NeurIPS'25
Paper/Blog Link My Issue
#Pretraining #NLP #NeurIPS #Tokenizer #Byte-level Issue Date: 2025-06-23 GPT Summary- 自己回帰型U-Netを用いてトークン化の柔軟性を向上させ、モデルが生のバイトから単語や単語のペアを生成することでマルチスケールの視点を提供。深い段階では広範な意味パターンに注目し、浅い段階はBPEベースラインに匹敵する性能を発揮。これにより、文字レベルのタスクやリソースの少ない言語間での知識移転が可能となる。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=FnFf7Ru2ur
[Paper Note] Reinforcement Learning Teachers of Test Time Scaling, Edoardo Cetin+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Distillation #Test-Time Scaling #PostTraining #read-later #Author Thread-Post Issue Date: 2025-06-23 GPT Summary- 強化学習教師(RLT)を用いて推論言語モデル(LM)のトレーニングを行い、タスク探索の課題を回避する新しいフレームワークを提案。RLTは問題の質問と解決策を提示し、学生に合わせた説明を通じて理解をテストし、密な報酬でトレーニングされる。7BのRLTは、競技および大学レベルのタスクで既存の蒸留パイプラインよりも高いパフォーマンスを示し、分布外タスクへの適用でも効果を維持する。 Comment
元ポスト:
[Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #Reasoning #NeurIPS #mid-training #PostTraining #read-later #RLVR #Selected Papers/Blogs #DataMixture #CrossDomain #KeyPoint Notes #Reading Reflections #Author Thread-Post Issue Date: 2025-06-22 GPT Summary- Guruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。 Comment
元ポスト:
post-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。
Qwenシリーズで実験。以下元ポストのまとめ。
- mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
- 一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
- 簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
- 各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
- 必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
- たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
- 一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
- 異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
- (これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
- 非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
- RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
- モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
- モデルサイズが大きいとより多様なreasoningパスがunlockされている
- pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた
本研究で構築されたGuru Dataset:
https://huggingface.co/datasets/LLM360/guru-RL-92k
math, coding, science, logic, simulation, tabular reasoningに関する高品質、かつverifiableなデータセット。
> RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
上記takeawayは
- [Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
と一見相反するように見えるが、実際どうなんだろうか。
最初は、RLによりPass@1が改善するので、Figure 1などに記載されている特定のドメインでの skill aqcuisition にはin-domain dataが必要でRLがそれに寄与するという話は、Pass@1が改善された結果なのかなと思ったが、
4.3節に実際に上記研究が引用され考察がなされており、mid-trainingなどで多くのデータが含まれるMathドメインについては、上記研究と同じ傾向でbase modelとRL後のモデルがK=64の時点で性能が交差、その後逆転するため、上記研究と同様の傾向が見受けられた。一方で、タスクごとに見るとzebra-logicのような事前学習ではあまりexposeされないタスクで見ると、依然としてRLの方が高いPass@kを獲得しているという現象が観測され、base modelのreadoning boundaryを拡大することができている、という解釈のようである。
[Paper Note] Scaling Laws for Upcycling Mixture-of-Experts Language Models, Seng Pei Liew+, ICML'25
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #ICML #Scaling Laws #Author Thread-Post Issue Date: 2025-06-21 GPT Summary- LLMsの事前学習は高コストで時間がかかるため、アップサイクリングとMoEモデルの計算効率向上が提案されている。本研究では、アップサイクリングをMoEに適用し、データセットのサイズやモデル構成に依存するスケーリング法則を特定。密なトレーニングデータとアップサイクリングデータの相互作用が効率を制限することを示し、アップサイクリングのスケールアップに関する指針を提供。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=ZBBo19jldX
[Paper Note] Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought, Hanlin Zhu+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #Author Thread-Post Issue Date: 2025-06-18 GPT Summary- 本研究では、連続CoTsを用いた二層トランスフォーマーが有向グラフ到達可能性問題を解決できることを証明。連続CoTsは複数の探索フロンティアを同時にエンコードし、従来の離散CoTsよりも効率的に解を導く。実験により、重ね合わせ状態が自動的に現れ、モデルが複数のパスを同時に探索することが確認された。 Comment
元ポスト:
[Paper Note] AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy, Zihan Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #OpenWeight #OpenSource #PostTraining #One-Line Notes #Author Thread-Post Issue Date: 2025-06-18 GPT Summary- 本研究では、教師ありファインチューニング(SFT)と強化学習(RL)の相乗効果を探求し、SFTトレーニングデータの整備においてプロンプト数の増加が推論性能を向上させることを示しました。特に、サンプリング温度を適切に調整することで、RLトレーニングの効果を最大化できることが分かりました。最終的に、AceReason-Nemotron-1.1モデルは、前モデルを大きく上回り、数学およびコードベンチマークで新たな最先端性能を達成しました。 Comment
元ポスト:
様々なtakeawayがまとめられている。
SFT,RLに利用されたデータも公開
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
において事前学習時に4 epochまでは性能の改善幅が大きいと報告されていたが、SFTでも5 epoch程度まで学習すると良い模様。
また、SFT dataをscalingさせる際は、promptの数だけでなく、prompt単位のresponse数を増やすのが効果的
[Paper Note] Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities, Gheorghe Comanici+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #Proprietary #read-later #VisionLanguageModel #Reference Collection Issue Date: 2025-06-18 GPT Summary- Gemini 2.X モデルファミリーには、Gemini 2.5 ProとGemini 2.5 Flash、さらにGemini 2.0 FlashおよびFlash-Liteが含まれ、高性能なコーディングと推論能力を持つ。特にGemini 2.5 Proは、最大3時間の動画処理が可能で、マルチモーダル理解が強化されており、新たなワークフローを創出する。Gemini 2.5 Flashは限られたリソースで優れた推論を実現し、低遅延・低コストのモデルも高性能を提供。全体として、Gemini 2.Xは幅広い能力とコストの選択肢を提供し、エージェント性問題解決の新たな可能性を探る。 Comment
関連ポスト:
解説ポスト:
関連ポスト:
[Paper Note] Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks, Yifei Xu+, arXiv'25
Paper/Blog Link My Issue
#NLP #Reasoning Issue Date: 2025-06-18 GPT Summary- DRO(直接推論最適化)を提案し、LLMsをオープンエンドの長文推論タスクに微調整するための強化学習フレームワークを構築。新しい報酬信号R3を用いて推論と参照結果の一貫性を捉え、自己完結したトレーニングを実現。ParaRevとFinQAのデータセットで強力なベースラインを上回る性能を示し、広範な適用可能性を確認。 Comment
元ポスト:
[Paper Note] Wait, We Don't Need to "Wait" Removing Thinking Tokens Improves Reasoning Efficiency, Chenlong Wang+, EMNLP'25 Findings
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Chain-of-Thought #Reasoning #EMNLP #One-Line Notes Issue Date: 2025-06-18 GPT Summary- 自己反省を抑制する「NoWait」アプローチを提案し、推論の効率を向上。10のベンチマークで最大27%-51%の思考の連鎖の長さを削減し、有用性を維持。マルチモーダル推論のための効果的なソリューションを提供。 Comment
Wait, Hmmといったlong CoTを誘導するようなtokenを抑制することで、Accはほぼ変わらずに生成されるトークン数を削減可能、といった図に見える。Reasoningモデルでデコーディング速度を向上したい場合に効果がありそう。
元ポスト:
[Paper Note] Massive Supervised Fine-tuning Experiments Reveal How Data, Layer, and Training Factors Shape LLM Alignment Quality, Yuto Harada+, EMNLP'25
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #EMNLP #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-06-18 GPT Summary- SFTはLLMを人間の指示に整合させる重要なプロセスであり、1,000以上のSFTモデルを生成し、データセットの特性と層ごとの変更を調査。訓練タスクの相乗効果やモデル固有の戦略の重要性を明らかにし、困惑度がSFTの効果を予測することを示した。中間層の重みの変化がパフォーマンス向上と強く相関し、研究を加速させるためにモデルと結果を公開予定。 Comment
元ポスト:
NLP'25: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/C10-6.pdf
[Paper Note] What Is Seen Cannot Be Unseen: The Disruptive Effect of Knowledge Conflict on Large Language Models, Kaiser Sun+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #FactualKnowledge #Author Thread-Post Issue Date: 2025-06-17 GPT Summary- LLMの文脈情報とパラメトリック知識の対立を評価する診断フレームワークを提案。知識の対立はタスクに影響を与えず、一致時にパフォーマンスが向上。モデルは内部知識を抑制できず、対立の理由が文脈依存を高めることを示した。これにより、LLMの評価と展開における知識の対立の重要性が強調される。 Comment
元ポスト:
[Paper Note] Overclocking LLM Reasoning: Monitoring and Controlling Thinking Path Lengths in LLMs, Roy Eisenstadt+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Reasoning Issue Date: 2025-06-17 GPT Summary- LLMの推論プロセスにおける思考段階の長さを調整するメカニズムを探求。進捗をエンコードし、可視化することで計画ダイナミクスを明らかにし、不要なステップを減らす「オーバークロッキング」手法を提案。これにより、考えすぎを軽減し、回答精度を向上させ、推論のレイテンシを減少させることを実証。コードは公開。 Comment
元ポスト:
[Paper Note] LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?, Zihan Zheng+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Coding #NeurIPS #Contamination-free #Selected Papers/Blogs #Live #Initial Impression Notes Issue Date: 2025-06-17 GPT Summary- 大規模言語モデル(LLMs)は競技プログラミングで人間のエリートを上回るとされるが、実際には重要な限界があることを調査。新たに導入した「LiveCodeBench Pro」ベンチマークにより、LLMsは中程度の難易度の問題で53%のpass@1を達成する一方、難しい問題では0%という結果が得られた。LLMsは実装重視の問題では成功するが、複雑なアルゴリズム的推論には苦労し、誤った正当化を生成することが多い。これにより、LLMsと人間の専門家との間に重要なギャップがあることが明らかになり、今後の改善のための診断が提供される。 Comment
元ポスト:
Hardな問題は現状のSoTAモデル(Claude4が含まれていないが)でも正答率0.0%
ベンチマークに含まれる課題のカテゴリ
実サンプルやケーススタディなどはAppendix参照のこと。
pj page: https://livecodebenchpro.com
アップデート(NeurIPSにaccept):
[Paper Note] RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning, Yu Wang+, EMNLP'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #EMNLP #One-Line Notes #Reading Reflections Issue Date: 2025-06-17 GPT Summary- RAG+は、Retrieval-Augmented Generationの拡張で、知識の適用を意識した推論を組み込む。二重コーパスを用いて、関連情報を取得し、目標指向の推論に適用する。実験結果は、RAG+が標準的なRAGを3-5%、複雑なシナリオでは最大7.5%上回ることを示し、知識統合の新たなフレームワークを提供する。 Comment
元ポスト:
知識だけでなく知識の使い方も蓄積し、利用時に検索された知識と紐づいた使い方を活用することでRAGの推論能力を向上させる。
Figure 1のような例はReasoningモデルが進化していったら、わざわざ知識と使い方を紐付けなくても、世界知識から使い方を補完可能だと思われるので不要となると思われる。
が、真にこの手法が力を発揮するのは「ドメイン固有の使い方やルール」が存在する場合で、どれだけLLMが賢くなっても推論によって導き出せないもの、のついては、こういった手法は効力を発揮し続けるのではないかと思われる。
[Paper Note] PropMEND: Hypernetworks for Knowledge Propagation in LLMs, Zeyu Leo Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #KnowledgeEditing #FactualKnowledge #meta-learning #One-Line Notes #Author Thread-Post Issue Date: 2025-06-17 GPT Summary- PropMENDは、LLMsにおける知識伝播を改善するためのハイパーネットワークベースのアプローチである。メタ学習を用いて、注入された知識がマルチホップ質問に答えるために伝播するように勾配を修正する。RippleEditデータセットで、難しい質問に対して精度がほぼ2倍向上し、Controlled RippleEditデータセットでは新しい関係やエンティティに対する知識伝播を評価。PropMENDは既存の手法を上回るが、性能差は縮小しており、今後の研究で広範な関係への知識伝播が求められる。 Comment
元ポスト:
従来のKnowledge Editing手法は新たな知識を記憶させることはできる(i.e., 注入した知識を逐語的に生成できる;東京は日本の首都である。)が、知識を活用することは苦手だった(i.e., 日本の首都の気候は?)ので、それを改善するための手法を提案している模様。
既存手法のlimitationは
- editing手法で学習をする際に知識を伝搬させるデータが無く
- 目的関数がraw textではなく、QA pairをSFTすること
によって生じるとし、
- 学習時にpropagation question(Figure1のオレンジ色のQA; 注入した知識を活用して推論が必要なQA)を用意しどのように知識を伝搬(活用)させるかを学習し
- 目的関数をCausal Language Modeling Loss
にすることで改善する、とのこと。
non-verbatimなQA(注入された知識をそのまま回答するものではなく、何らかの推論が必要なもの)でも性能が向上。
ベースライン:
- [Paper Note] Mass-Editing Memory in a Transformer, Kevin Meng+, arXiv'22, 2022.10
- [Paper Note] Fast Model Editing at Scale, Eric Mitchell+, ICLR'22
[Paper Note] Steer LLM Latents for Hallucination Detection, Seongheon Park+, ICML'25
Paper/Blog Link My Issue
#NLP #Hallucination #ICML #OptimalTransport #Author Thread-Post Issue Date: 2025-06-14 GPT Summary- LLMの幻覚問題に対処するため、Truthfulness Separator Vector(TSV)を提案。TSVは、LLMの表現空間を再構築し、真実と幻覚の出力を分離する軽量な指向ベクトルで、モデルのパラメータを変更せずに機能。二段階のフレームワークで、少数のラベル付き例からTSVを訓練し、ラベルのない生成物を拡張。実験により、TSVは最小限のラベル付きデータで高いパフォーマンスを示し、実世界のアプリケーションにおける実用的な解決策を提供。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=UMqNQEPNT3¬eId=mAbrf36RHa
[Paper Note] Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning, Jiayi Yuan+, arXiv'25
Paper/Blog Link My Issue
#NLP #Reasoning #Reproducibility Issue Date: 2025-06-13 GPT Summary- 本研究では、大規模言語モデル(LLMs)のパフォーマンスの再現性が脆弱であることを示し、システム構成の変更が応答に大きな影響を与えることを明らかにしました。特に、初期トークンの丸め誤差が推論精度に波及する問題を指摘し、浮動小数点演算の非結合的性質が変動の根本原因であるとしています。様々な条件下での実験を通じて、数値精度が再現性に与える影響を定量化し、評価実践における重要性を強調しました。さらに、LayerCastという軽量推論パイプラインを開発し、メモリ効率と数値安定性を両立させる方法を提案しました。
[Paper Note] Self-Adapting Language Models, Adam Zweiger+, arXiv'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #KeyPoint Notes #Author Thread-Post Issue Date: 2025-06-13 GPT Summary- 自己適応型LLMs(SEAL)を提案し、モデルが自身のファインチューニングデータと指示を生成することで適応を実現。新しい入力に対して自己編集を行い、持続的な重みの更新を可能にする。強化学習ループを用いて下流性能を報酬信号として活用し、従来のアプローチと異なり、モデル自身の生成を用いて適応を制御。実験結果はSEALの有望性を示す。 Comment
元ポスト:
コンテキストCと評価データtauが与えられたとき、Cを入力した時にモデルが自分をSFTし、tau上でより高い性能を得られるようなサンプル Self Edit (SE) を生成できるように学習することで、性能を向上させたい。これをRLによって実現する。具体的には、下記アルゴリズムのようにモデルにSEを生成させ、SEでSFTすることめにtau上での性能が向上したか否かのbinary rewardを用いてパラメータを更新する、といったことを繰り返す。これは実質、RL_updateと書いてあるが、性能が向上した良いSEのみでモデルをSFTすること、と同等なことを実施している。
このような背景として、RLのアルゴリズムとしてGRPOやPPOを適用したところ学習が不安定でうまくいかなかったため、よりシンプルなアプローチであるReST^EM([Paper Note] Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models, Avi Singh+, TMLR'24
)を採用した。これはrejection samplingとSFTに基づいたEMアルゴリズムのようなものらしく、Eステップで現在のポリシーでcandidateを生成し、Mステップでpositive rewardを得たcandidateのみ(=rejection sampling)でSFTする、といったことを繰り返す、みたいな手法らしい。これを用いると、論文中の式(1)を上述のbinary rewardで近似することに相当する。より詳細に書くと、式(1)(つまり、SEをCから生成することによって得られるtauに基づく報酬rの総報酬を最大化したい、という式)を最大化するためにθ_tの勾配を計算したいが、reward rがθ_tで微分不可能なため、Monte Carlo Estimatorで勾配を近似する、みたいなことをやるらしい。Monte Carlo Estimatorでは実際のサンプルの期待値によって理論的な勾配を近似するらしく、これが式(3)のスコア関数とreward rの平均、といった式につながっているようである。
再現実験に成功したとのポスト:
[Paper Note] Resa: Transparent Reasoning Models via SAEs, Shangshang Wang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #Supervised-FineTuning (SFT) #PostTraining #read-later #Author Thread-Post Issue Date: 2025-06-13 GPT Summary- Resaという1.5Bの推論モデル群を提案し、効率的なスパースオートエンコーダーチューニング(SAE-Tuning)手法を用いて訓練。これにより、97%以上の推論性能を保持しつつ、訓練コストを2000倍以上削減し、訓練時間を450倍以上短縮。軽いRL訓練を施したモデルで高い推論性能を実現し、抽出された推論能力は一般化可能かつモジュール化可能であることが示された。全ての成果物はオープンソース。 Comment
元ポスト:
著者ポスト:
論文中で利用されているSource Modelの一つ:
- [Paper Note] Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25
[Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #PEFT(Adaptor/LoRA) #ICML #memory #One-Line Notes #Initial Impression Notes #Test Time Training (TTT) #Author Thread-Post Issue Date: 2025-06-12 GPT Summary- Text-to-LoRA(T2L)は、自然言語による説明に基づいて大規模言語モデル(LLMs)を迅速に適応させる手法で、従来のファインチューニングの高コストと時間を克服します。T2Lは、LoRAを安価なフォワードパスで構築するハイパーネットワークを使用し、タスク特有のアダプターと同等のパフォーマンスを示します。また、数百のLoRAインスタンスを圧縮し、新しいタスクに対してゼロショットで一般化可能です。このアプローチは、基盤モデルの専門化を民主化し、計算要件を最小限に抑えた言語ベースの適応を実現します。 Comment
元ポスト:
な、なるほど、こんな手が…!
openreview: https://openreview.net/forum?id=zWskCdu3QA
ポイント解説:
Text-to-LoRAの目的は、instructionをメモリの内部パラメータに埋め込み、モデルにon-the-flyで新たな挙動を身につけさせること。
[Paper Note] Go-Browse: Training Web Agents with Structured Exploration, Apurva Gandhi+, arXiv'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #AIAgents #Author Thread-Post Issue Date: 2025-06-12 GPT Summary- Go-Browseを提案し、ウェブ環境の構造的探索を通じて多様なデータを自動収集。グラフ探索を用いて効率的なデータ収集を実現し、WebArenaベンチマークで成功率21.7%を達成。これはGPT-4o miniを2.4%上回り、10B未満のモデルでの最先端結果を2.9%上回る。 Comment
元ポスト:
[Paper Note] Reinforcement Pre-Training, Qingxiu Dong+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Pretraining #NLP #ReinforcementLearning #Reference Collection Issue Date: 2025-06-12 GPT Summary- Reinforcement Pre-Training(RPT)を導入し、次トークン予測を強化学習(RL)による推論タスクに再定式化。文脈に応じた正確な予測に対して報酬を与えることで、言語モデルの精度を向上。大規模テキストデータを活用し、強化微調整の基盤を提供することで、次トークン推論の精度が向上することを示した。 Comment
元ポスト:
[Paper Note] Value Residual Learning, Zhanchao Zhou+, ACL'25
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #ACL #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-06-12 GPT Summary- ResFormerは、隠れ状態の残差に値の残差接続を加えることで情報の流れを強化する新しいTransformerアーキテクチャを提案。実験により、ResFormerは従来のTransformerに比べて少ないパラメータとトレーニングデータで同等の性能を示し、SVFormerはKVキャッシュサイズを半減させることができる。性能はシーケンスの長さや学習率に依存する。 Comment
元ポスト:
なぜValue Residual Learningがうまくいくかの直感的説明:
ざっくり言うと、LayerNormよって初期layerの影響は深くなればなるほど小さくなり、情報が損なわれていってしまうため、ValueをQKに応じて情報を運んでくる要素と捉えると、検索やコピーなどの明確なinputに関する情報が欲しい場合に、すべてのlayerから初期のValueにアクセスできるvalue residual connectionが有用となる、といった話と理解した。Valueにのみフォーカスしているが、QKの場合はどうなのかといった要素はまだ未開拓な分野とのこと。
Wide&Deepみたいな話になってきた:
- [Paper Note] Wide & Deep Learning for Recommender Systems, Heng-Tze Cheng+, DLRS'16, 2016.06
Value Residual Learningを用いたアーキテクチャが現在nanoGPT Speedrunでトップになった。
- Modded-NanoGPT, KellerJordan, 2024.05
現在のlayerのValueと初期レイヤーのValueを線形補完する重みをtrainableにするとさらに性能が改善することも言及されている。
所見:
[Paper Note] Saffron-1: Towards an Inference Scaling Paradigm for LLM Safety Assurance, Ruizhong Qiu+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Alignment #ReinforcementLearning #Safety #Author Thread-Post Issue Date: 2025-06-11 GPT Summary- 既存のLLMの安全保証研究は主にトレーニング段階に焦点を当てているが、脱獄攻撃に対して脆弱であることが明らかになった。本研究では、推論スケーリングを用いた新たな安全性向上手法SAFFRONを提案し、計算オーバーヘッドを削減する多分岐報酬モデル(MRM)を導入。これにより、報酬モデル評価の数を減らし、探索-効率性のジレンマを克服する。実験により手法の有効性を確認し、訓練済みモデルと安全報酬データセットを公開。 Comment
元ポスト:
[Paper Note] StochasTok: Improving Fine-Grained Subword Understanding in LLMs, Anya Sims+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Subword #Author Thread-Post Issue Date: 2025-06-11 GPT Summary- サブワードレベルの理解は重要だが、LLMsは単純なタスクに苦戦している。トークン化の影響で語の構造が隠れるため、文字レベルやドロップアウト型トークン化は計算コストが増加する。本論文では、トークンをランダムに分割する確率的トークン化スキームStochasTokを提案し、LLMのサブワード性能を向上させることを示す。具体的には、StochasTokを用いた事前訓練が複数のサブワードタスクで著しい改善をもたらし、既存モデルへの適用も容易であることを示している。 Comment
元ポスト:
おもしろそう
[Paper Note] Horizon Reduction Makes RL Scalable, Seohong Park+, NeurIPS'25 Spotlight
Paper/Blog Link My Issue
#Analysis #MachineLearning #ReinforcementLearning #Selected Papers/Blogs #Off-Policy #Reference Collection #Scalability Issue Date: 2025-06-10 GPT Summary- 本研究では、オフライン強化学習(RL)のスケーラビリティを検討し、既存のアルゴリズムが大規模データセットに対して期待通りの性能を発揮しないことを示しました。特に、長いホライズンがスケーリングの障壁であると仮定し、ホライズン削減技術がスケーラビリティを向上させることを実証しました。新たに提案した手法SHARSAは、ホライズンを削減しつつ優れたパフォーマンスを達成し、オフラインRLのスケーラビリティを向上させることを示しました。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=hguaupzLCU
[Paper Note] Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing, Kento Nishi+, ICML'25
Paper/Blog Link My Issue
#MachineLearning #NLP #ICML #KnowledgeEditing #Author Thread-Post Issue Date: 2025-06-10 GPT Summary- 知識編集(KE)アルゴリズムは、モデルの重みを変更して不正確な事実を更新するが、これがモデルの事実の想起精度や推論能力に悪影響を及ぼす可能性がある。新たに定義した合成タスクを通じて、KEがターゲットエンティティを超えて他のエンティティの表現に影響を与え、未見の知識の推論を歪める「表現の破壊」現象を示す。事前訓練されたモデルを用いた実験でもこの発見が確認され、KEがモデルの能力に悪影響を及ぼす理由を明らかにするメカニズム仮説を提供する。 Comment
元ポスト:
[Paper Note] Search Arena: Analyzing Search-Augmented LLMs, Mihran Miroyan+, arXiv'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Search #Dataset #Author Thread-Post Issue Date: 2025-06-08 GPT Summary- 検索強化型LLMsに関する「Search Arena」という大規模な人間の好みデータセットを紹介。24,000以上のマルチターンユーザーインタラクションを含み、ユーザーの好みが引用数や引用元に影響されることを明らかにした。特に、コミュニティ主導の情報源が好まれる傾向があり、静的な情報源は必ずしも信頼されない。検索強化型LLMsの性能を評価した結果、非検索設定でのパフォーマンス向上が確認されたが、検索設定ではパラメトリック知識に依存すると品質が低下することが分かった。このデータセットはオープンソースとして提供されている。 Comment
元ポスト:
[Paper Note] SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond, Junteng Liu+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #SyntheticData #Reasoning #NeurIPS #One-Line Notes #Author Thread-Post Issue Date: 2025-06-06 GPT Summary- SynLogicは、35の論理的推論タスクを網羅したデータ合成フレームワークで、強化学習(RL)による大規模言語モデル(LLMs)の推論能力向上を目指す。調整可能な難易度で生成されたデータは検証可能で、RLに適している。実験では、SynLogicが最先端の論理的推論性能を達成し、数学やコーディングタスクとの混合によりトレーニング効率が向上することが示された。SynLogicはLLMsの推論能力向上に貴重なリソースとなる。 Comment
元ポスト:
35種類のタスクを人手で選定し、タスクごとに困難度の鍵となるパラメータを定義(数独ならばグリッド数など)。その上で、各タスクごとに人手でルールベースのinstanceを生成するコードを実装し、さまざまな困難度パラメータに基づいて多様なinstanceを生成。生成されたinstanceの困難度は、近似的なUpper Bound(DeepSeek-R1, o3-miniのPass@10)とLower bound(chat model[^1]でのPass@10)を求めデータセットに含まれるinstanceの困難度をコントロールし、taskを記述するpromptも生成。タスクごとに人手で実装されたVerifierも用意されている。
Qwen2.5-7B-BaseをSynDataでDAPOしたところ、大幅にlogic benchmarkとmathematical benchmarkの性能が改善。
mathやcodeのデータとmixして7Bモデルを訓練したところ、32Bモデルに匹敵する性能を達成し、SynDataをmixすることでgainが大きくなったので、SynDataから学習できる能力が汎化することが示唆される。
タスク一覧はこちら
[^1]:どのchat modelかはざっと見た感じわからない。どこかに書いてあるかも。
Logical Reasoningが重要なタスクを扱う際はこのデータを活用することを検討してみても良いかもしれない
[Paper Note] Training Language Models to Generate Quality Code with Program Analysis Feedback, Feng Yao+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #Coding #NeurIPS #One-Line Notes #Author Thread-Post Issue Date: 2025-06-06 GPT Summary- プログラム分析に基づくフィードバックを用いた強化学習フレームワーク「REAL」を提案。セキュリティや保守性の欠陥を検出し、機能的正確性を保証することで、LLMsによる高品質なコード生成を促進。手動介入不要でスケーラブルな監視を実現し、実験により最先端の手法を上回る性能を示した。 Comment
元ポスト:
現在のCoding LLMはUnitTestを通るように学習されるが、UnitTestに通るからといってコードの品質が良いわけでは無いので、UnitTestに通るか否かのReward(Functionality)に加えて、RL中に生成されたコードを制御フローグラフ[^1]に変換し汚染解析[^2]をした結果をRewardに組み込むことで、FunctionalityとQualityを両立したよ、という話のようである。
Figure1のグラフの縦軸は、Functionalityと(UnitTestが通ったか否か)と、Quailty(セキュリティや保守性に関する問題が検出されなかった)、という両方の条件を満たした割合である点に注意。
[^1]:プログラムを実行したときに通る可能性のある経路のすべてをグラフとして表したもの[引用元](
https://qiita.com/uint256_t/items/7d4556cb8f5997b9e95c)
[^2]:信頼できない汚染されたデータがプログラム中でどのように処理されるかを分析すること
[Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Tasks and Verifiable Rewards, Ruipeng Jia+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #RLVR #One-Line Notes Issue Date: 2025-06-05 GPT Summary- RLVRを用いた新しい学習パラダイムを提案し、主観的評価を検証可能な報酬に変換。ペアワイズ生成報酬モデルとブートストラップ付き相対方針最適化を導入し、教師なしでLLMの執筆能力を向上。Writing-Zeroにより、スカラー報酬よりも一貫した改善を確認。社内およびオープンソースのベンチマークで競争力のある結果を達成し、全言語タスクに適用可能なRL訓練の道を示唆。 Comment
元ポスト:
Writing Principleに基づいて(e.g., 一貫性、創造性とか?)批評を記述し、最終的に与えられたペアワイズのテキストの優劣を判断するGenerative Reward Model (GenRM; Reasoning Traceを伴い最終的にRewardに変換可能な情報をoutpuするモデル) を学習し、現在生成したresponseグループの中からランダムに一つ擬似的なreferenceを決定し、他のresponseに対しGenRMを適用することで報酬を決定する(BRPO)、といったことをやるらしい。
これにより、創造的な文書作成のような客観的なground truthを適用できないタスクでも、RLVRの恩恵をあずかれるようになる(Bridging the gap)といったことを主張している。
RLVRの恩恵とは、Reward Hackingされづらい高品質な報酬、ということにあると思われる。ので、要は従来のPreference dataだけで学習したReward Modelよりも、よりReward Hackingされないロバストな学習を実現できるGenerative Reward Modelを提案し、それを適用する手法BRPOも提案しました、という話に見える。
関連:
- [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25
[Paper Note] Co-Evolving LLM Coder and Unit Tester via Reinforcement Learning, Yinjie Wang+, NeurIPS'25 Spotlight
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Coding #SoftwareEngineering #UnitTest #Reference Collection #Author Thread-Post Issue Date: 2025-06-05 GPT Summary- CUREは、コーディングとユニットテスト生成を共進化させる強化学習フレームワークで、真のコードを監視せずにトレーニングを行う。ReasonFlux-Coderモデルは、コード生成精度を向上させ、下流タスクにも効果的に拡張可能。ユニットテスト生成では高い推論効率を達成し、強化学習のための効果的な報酬モデルとして機能する。 Comment
元ポスト:
UnitTestの性能向上させます系の研究が増えてきている感
関連ポスト:
[Paper Note] MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning, Yiqing Liang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #RLVR #DataMixture #One-Line Notes #Author Thread-Post Issue Date: 2025-06-05 GPT Summary- 検証可能な報酬を用いた強化学習(RLVR)をマルチモーダルLLMsに適用するためのポストトレーニングフレームワークを提案。異なる視覚と言語の問題を含むデータセットをキュレーションし、最適なデータ混合戦略を導入。実験により、提案した戦略がMLLMの推論能力を大幅に向上させることを示し、分布外ベンチマークで平均5.24%の精度向上を達成。 Comment
元ポスト:
マルチモーダルな設定でRLVRを適用すると、すべてのデータセットを学習に利用する場合より、特定のタスクのみのデータで学習した方が当該タスクでは性能が高くなったり(つまりデータが多ければ多いほど良いわけでは無い)、特定のデータをablationするとOODに対する予測性能が改善したりするなど、データ間で干渉が起きて敵対的になってしまうような現象が起きる。このことから、どのように適切にデータを混合できるか?という戦略の必要性が浮き彫りになり、モデルベースなMixture戦略(どうやらデータの混合分布から学習後の性能を予測するモデルな模様)の性能がuniformにmixするよりも高い性能を示した、みたいな話らしい。
[Paper Note] Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem, Yubo Wang+, EMNLP'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #EMNLP #Reference Collection #Author Thread-Post Issue Date: 2025-06-05 GPT Summary- 本研究では、強力な大規模言語モデル(LLM)の推論能力を引き出すために、批評微調整(CFT)が効果的であることを示します。CFTは、単一の問題に対する多様な解を収集し、教師LLMによる批評データを構築する手法です。QwenおよびLlamaモデルを微調整した結果、数学や論理推論のベンチマークで顕著な性能向上を観察しました。特に、わずか5時間のトレーニングで、Qwen-Math-7B-CFTは他の手法と同等以上の成果を上げました。CFTは計算効率が高く、現代のLLMの推論能力を引き出すためのシンプルなアプローチであることが示されました。 Comment
元ポスト:
関連:
- [Paper Note] Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate, Yubo Wang+, COLM'25
- [Paper Note] Reinforcement Learning for Reasoning in Large Language Models with One Training Example, Yiping Wang+, arXiv'25, 2025.04
参考:
[Paper Note] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, Mingjie Liu+, NeurIPS'25
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #NeurIPS #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-06-04 GPT Summary- 強化学習(RL)が言語モデルの推論能力を向上させる可能性を探る本研究では、長期的なRL(ProRL)トレーニングが新しい推論戦略を明らかにできることを示します。新しいトレーニング手法ProRLを導入し、実証分析により、RLでトレーニングされたモデルが基礎モデルを上回ることが確認されました。推論の改善は基礎モデルの能力やトレーニング期間と相関しており、RLが新しい解決空間を探索できることを示唆しています。これにより、RLが言語モデルの推論を拡張する条件に関する新たな洞察が得られ、今後の研究の基盤が築かれます。モデルの重みは公開されています。 Comment
元ポスト:
RLVR(math, code(従来はこの2種類), STEM, logic Puzzles, instruction following)によって大規模なスケール(長期的に学習をする; 2k training stepsと多様なタスクでの学習データ)で実験をし、定期的にReferenceポリシーとOptimizerをリセットすることで、元のポリシーからの乖離を防ぎつつも、新たな学習が進むようなことをしている模様。
(※PFNのランチタイムトークを参考に記述)
verlを用いて、DAPOで学習をしている。
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
[Paper Note] xVerify: Efficient Answer Verifier for Reasoning Model Evaluations, Ding Chen+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #Verification Issue Date: 2025-06-03 GPT Summary- 推論モデルの評価のために、xVerifyという効率的な回答検証器を提案。xVerifyは、LLMが生成した回答が参照解答と同等であるかを効果的に判断できる。VARデータセットを構築し、複数のLLMからの質問-回答ペアを収集。評価実験では、すべてのxVerifyモデルが95%を超えるF1スコアと精度を達成し、特にxVerify-3B-IbはGPT-4oを超える性能を示した。
[Paper Note] Pitfalls of Rule- and Model-based Verifiers -- A Case Study on Mathematical Reasoning, Yuzhen Huang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #read-later #VerifiableRewards #RLVR #Verification #One-Line Notes #Author Thread-Post Issue Date: 2025-06-03 GPT Summary- 本研究では、数学的推論における検証者の信頼性とそのRL訓練プロセスへの影響を分析。ルールベースの検証者は偽陰性率が高く、RL訓練のパフォーマンスに悪影響を及ぼすことが判明。モデルベースの検証者は静的評価で高精度を示すが、偽陽性に対して脆弱であり、報酬が不正に膨らむ可能性がある。これにより、強化学習における堅牢な報酬システムの必要性が示唆される。 Comment
元ポスト:
verificationタスクに特化してfinetuningされたDiscriminative Classifierが、reward hackingに対してロバストであることが示唆されている模様。
Discriminative Verifierとは、Question, Response, Reference Answerがgivenな時に、response(しばしばreasoning traceを含み複数のanswerの候補が記述されている)の中から最終的なanswerを抽出し、Reference answerと抽出したanswerから正解/不正解をbinaryで出力するモデルのこと。Rule-based Verifierではフォーマットが異なっている場合にfalse negativeとなってしまうし、そもそもルールが規定できないタスクの場合は適用できない。Discriminative Verifierではそのようなケースでも適用できると考えられる。
Discriminative Verifierの例はたとえば下記:
https://huggingface.co/IAAR-Shanghai/xVerify-0.5B-I
- [Paper Note] xVerify: Efficient Answer Verifier for Reasoning Model Evaluations, Ding Chen+, arXiv'25, 2025.04
[Paper Note] Self-Challenging Language Model Agents, Yifei Zhou+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #AIAgents #SelfImprovement #Author Thread-Post Issue Date: 2025-06-03 GPT Summary- Self-Challengingフレームワークを用いて、エージェントが自己生成した高品質なタスクで訓練。エージェントはチャレンジャーとして役割を果たし、Code-as-Task形式でタスクを生成し、その後実行者として強化学習で評価。M3ToolEvalとTauBenchベンチマークで、Llama-3.1-8B-Instructが自己生成データのみで2倍以上の性能向上を達成。 Comment
元ポスト:
解説ポスト:
[Paper Note] Learning Compositional Functions with Transformers from Easy-to-Hard Data, Zixuan Wang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Analysis #Pretraining #Transformer #PostTraining #Selected Papers/Blogs #COLT #One-Line Notes #Reading Reflections #Author Thread-Post Issue Date: 2025-06-01 GPT Summary- Transformerベースの言語モデルの学習可能性を、k-fold 合成タスクにおいて検討。具体的には、k 個の入力置換と隠れた置換の交互合成を倍の効率で実行可能とし、統計的クエリ下界も証明。さらに、O(log k) 層のトランスフォーマーで勾配降下による効率的な学習が可能であることを示した。データの提示方法によって、容易な例と難しい例が存在することが重要であるとの知見を得た。 Comment
元ポスト:
こちらはまず元ポストのスレッドを読むのが良いと思われる。要点をわかりやすく説明してくださっている。
元ポストとalphaxivでざっくり理解したところ、
Transformerがcontextとして与えられた情報(σ)とparametric knowledge(π)をk回の知識マッピングが必要なタスク(k-fold composition task)を学習するにはO(log k)のlayer数が必要で、直接的にk回の知識マッピングが必要なタスクを学習するためにはkの指数オーダーのデータ量が最低限必要となることが示された。これはkが大きくなると(すなわち、複雑なreasoning stepが必要なタスク)になると非現実的なものとなるため、何らかの方法で緩和したい。学習データを簡単なものから難しいものをmixingすること(カリキュラム学習)ことで、この条件が緩和され、指数オーダーから多項式オーダーのデータ量で学習できることが示された
といった感じだと思われる。
じゃあ最新の32Bモデルよりも、よりパラメータ数が大きくてlayer数が多い古いモデルの方が複雑なreasoningが必要なタスクを実は解けるってこと!?直感に反する!と一瞬思ったが、おそらく最近のモデルでは昔のモデルと比べてparametric knowledgeがより高密度に適切に圧縮されるようになっていると思われるので、昔のモデルではk回の知識マッピングをしないと解けないタスクが、最新のモデルではk-n回のマッピングで解けるようになっていると推察され、パラメータサイズが小さくても問題なく解けます、みたいなことが起こっているのだろう、という感想を抱くなどした
[Paper Note] BIG-Bench Extra Hard, Mehran Kazemi+, ACL'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Reasoning #ACL #One-Line Notes Issue Date: 2025-06-01 GPT Summary- 大規模言語モデル(LLMs)の推論能力を評価するための新しいベンチマーク、BIG-Bench Extra Hard(BBEH)を導入。これは、既存のBIG-Bench Hard(BBH)のタスクを新しいものに置き換え、難易度を大幅に引き上げることで、LLMの限界を押し広げることを目的としている。評価の結果、最良の汎用モデルで9.8%、推論専門モデルで44.8%の平均精度が観察され、LLMの一般的推論能力向上の余地が示された。BBEHは公開されている。 Comment
Big-Bench hard(既にSoTAモデルの能力差を識別できない)の難易度をさらに押し上げたデータセット。
Inputの例
タスクごとのInput, Output lengthの分布
現在の主要なモデル群の性能
Big-Bench論文はこちら:
- [Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
[Paper Note] Training Step-Level Reasoning Verifiers with Formal Verification Tools, Ryo Kamoi+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #SyntheticData #PRM #Verification #One-Line Notes #Author Thread-Post Issue Date: 2025-06-01 GPT Summary- 本論文では、プロセス報酬モデル(PRMs)のトレーニングにおける2つの課題、すなわち高コストの人間による注釈と数学的推論問題への限定を解決するために、FoVerというアプローチを提案します。FoVerは形式的検証ツールを用いて自動的に段階レベルのエラーラベルを生成し、人的注釈なしでLLMの応答にエラーラベルを付与したデータセットを合成します。このデータセットでトレーニングされたPRMsは、元のLLMsに基づくベースラインを大幅に上回り、他の最先端モデルとも競争力のある結果を達成しました。 Comment
元ポスト:
人手によるAnnotation(step levelのラベルのアノテーション)無しでProcess Reward Modelの学習データを構築する手法
Z3やIsabelleなどの形式検証ツールが適用可能なタスクのみに提案手法のスコープは限られる点には注意
人手でアノテーションされたモデルと比較してcomparableなパフォーマンスを達成
スレッド中で評価データが数回のreasoning stepが必要なタスクのみの評価であり、より長く複雑なreasoning step(たとえば [Paper Note] BIG-Bench Extra Hard, Mehran Kazemi+, ACL'25, 2025.02
)が必要な場合はどうなるか?といった所に興味が寄せられている模様
[Paper Note] Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering, Guangtao Zeng+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #AIAgents #SoftwareEngineering #read-later #Author Thread-Post Issue Date: 2025-06-01 GPT Summary- 言語モデルは標準化されたコーディングのベンチマークでは良好な性能を示すが、実世界のソフトウェア工学タスクには苦戦。特に1000億未満のパラメータ数では顕著で、小型モデルの性能改善は難しい。従来は教師ありファインチューニングに依存し、データ整備には高いコストがかかる。新たなアプローチとしてEvoScaleを提案。これは生成を進化プロセスとして扱い、反復的な出力改善を通じて高スコア領域にシフトさせることで、必要なサンプル数を削減。自己進化するよう強化学習で訓練され、外部検証器に依存せず自らスコアを改善。評価の結果、32BモデルSatori-SWE-32Bは少数のサンプルで1000億超モデルと同等以上の性能を達成。すべてのコード、データ、モデルはオープンソース。 Comment
元ポスト:
[Paper Note] Can Large Reasoning Models Self-Train?, Sheikh Shafayat+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #RLVR #MajorityVoting #KeyPoint Notes Issue Date: 2025-06-01 GPT Summary- 自己学習を活用したオンライン強化学習アルゴリズムを提案し、モデルの自己一貫性を利用して正確性信号を推測。難しい数学的推論タスクに適用し、従来の手法に匹敵する性能を示す。自己生成された代理報酬が誤った出力を優遇するリスクも指摘。自己監視による性能向上の可能性と課題を明らかに。 Comment
元ポスト:
- [Paper Note] Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
と似ているように見える
self-consistencyでground truthを推定し、推定したground truthを用いてverifiableなrewardを計算して学習する手法、のように見える。
実際のground truthを用いた学習と同等の性能を達成する場合もあれば、long stepで学習するとどこかのタイミングで学習がcollapseする場合もある
パフォーマンスがピークを迎えた後になぜ大幅にAccuracyがdropするかを検証したところ、モデルのKL penaltyがどこかのタイミングで大幅に大きくなることがわかった。つまりこれはオリジナルのモデルからかけ離れたモデルになっている。これは、モデルがデタラメな出力をground truthとして推定するようになり、モデルそのものも一貫してそのデタラメな出力をすることでrewardを増大させるreward hackingが起きている。
これら現象を避ける方法として、以下の3つを提案している
- early stopping
- offlineでラベルをself consistencyで生成して、学習の過程で固定する
- カリキュラムラーニングを導入する
関連
- [Paper Note] Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25, 2024.11
[Paper Note] Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs, Yu Xia+, COLING'25
Paper/Blog Link My Issue
#Survey #NLP #Chain-of-Thought #COLING Issue Date: 2025-05-29 GPT Summary- Chain-of-Thought(CoT)を基にしたChain-of-X(CoX)手法の調査を行い、LLMsの課題に対処するための多様なアプローチを分類。ノードの分類とアプリケーションタスクに基づく分析を通じて、既存の手法の意義と今後の可能性を議論。研究者にとって有用なリソースを提供することを目指す。
[Paper Note] Distillation Scaling Laws, Dan Busbridge+, ICML'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Distillation #SmallModel #ICML #Scaling Laws #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-05-29 GPT Summary- 蒸留モデルの性能を推定するための蒸留スケーリング法則を提案。教師モデルと生徒モデルの計算割り当てを最適化することで、生徒の性能を最大化。教師が存在する場合やトレーニングが必要な場合に最適な蒸留レシピを提供。多くの生徒を蒸留する際は、監視付きの事前学習を上回るが、生徒のサイズに応じた計算レベルまで。単一の生徒を蒸留し、教師がトレーニング必要な場合は監視学習を推奨。蒸留に関する洞察を提供し、理解を深める。 Comment
著者ポスト:
-
-
openreview: https://openreview.net/forum?id=1nEBAkpfb9
手元にSFTのデータがあったときにSLMを学習したいという状況で、固定の計算資源があったときに、巨大な教師モデルをSFTで学習してから小型モデルに蒸留するのが良いのか、小型モデルを直接SFTする方が良いのか、どのように教師モデルと生徒モデルに計算資源を割り当てるのが最適かという観点でscaling lawを導出しているようである。
下記Appendixや著者ポストにある通り、知見を一言で言うと
- Distillationでは、SFTによって生み出されるモデルよりも良いモデルを生み出すことはできない
- しかしながら、DistillationではSFTよりも効率的にSFTで学習した場合と比較して良いモデルを学習できる
- 言い換えると、十分な計算量とデータが与えられるとDistillationの効率性は消失する
という感じだろうか。つまり、達成可能な性能のピーク値はSFTを超えられないが、Distillationの方がSFTよりも効率的に学習ができる、という感じに見える。
[Paper Note] Temporal Sampling for Forgotten Reasoning in LLMs, Yuetai Li+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #Temporal #read-later Issue Date: 2025-05-27 GPT Summary- ファインチューニング中にLLMsが以前の正しい解法を忘れる「時間的忘却」を発見。これに対処するために「時間的サンプリング」というデコーディング戦略を導入し、複数のチェックポイントから出力を引き出すことで推論性能を向上。Pass@kで4から19ポイントの改善を達成し、LoRA適応モデルでも同様の利点を示す。時間的多様性を活用することで、LLMsの評価方法を再考する手段を提供。 Comment
元ポスト:
Temporal ForgettingとTemporal Sampling
[Paper Note] Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Reasoning #ICML #Workshop #One-Line Notes #Author Thread-Post Issue Date: 2025-05-27 GPT Summary- 本研究では、外部の報酬やラベルなしで大規模言語モデル(LLMs)が学習できるフレームワーク「内部フィードバックからの強化学習(RLIF)」を提案。自己確信を報酬信号として用いる「Intuitor」を開発し、無監視の学習を実現。実験結果は、Intuitorが数学的ベンチマークで優れた性能を示し、ドメイン外タスクへの一般化能力も高いことを示した。内因的信号が効果的な学習を促進する可能性を示唆し、自律AIシステムにおけるスケーラブルな代替手段を提供。 Comment
元ポスト:
おもしろそう
externalなsignalをrewardとして用いないで、モデル自身が内部的に保持しているconfidenceを用いる。人間は自信がある問題には正解しやすいという直感に基づいており、openendなquestionのようにそもそも正解シグナルが定義できないものもあるが、そういった場合に活用できるようである。
self-trainingの考え方に近いのでは
ベースモデルの段階である程度能力が備わっており、post-trainingした結果それが引き出されるようになったという感じなのだろうか。
参考:
解説スライド:
https://www.docswell.com/s/DeepLearning2023/KYVLG4-2025-09-18-112951
元ポスト:
[Paper Note] QwenLong-CPRS: Towards $\infty$-LLMs with Dynamic Context Optimization, Weizhou Shen+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LongSequence #OpenWeight Issue Date: 2025-05-27 GPT Summary- QwenLong-CPRSは、長文コンテキスト最適化のための新しいフレームワークで、LLMsの性能低下を軽減します。自然言語指示に基づく多段階のコンテキスト圧縮を実現し、効率と性能を向上させる4つの革新を導入。5つのベンチマークで、他の手法に対して優位性を示し、主要なLLMとの統合で大幅なコンテキスト圧縮と性能向上を達成。QwenLong-CPRSは新たなSOTA性能を確立しました。 Comment
元ポスト:
[Paper Note] QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning, Fanqi Wan+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LongSequence #OpenWeight #read-later Issue Date: 2025-05-27 GPT Summary- 長いコンテキストの推論におけるLRMsの課題を解決するため、QwenLong-L1フレームワークを提案。ウォームアップ監視付きファインチューニングとカリキュラム指導型段階的RLを用いてポリシーの安定化を図り、難易度認識型の回顧的サンプリングで探索を促進。実験では、QwenLong-L1-32Bが他のLRMsを上回り、優れた性能を示した。 Comment
元ポスト:
[Paper Note] Scaling Reasoning, Losing Control: Evaluating Instruction Following in Large Reasoning Models, Tingchen Fu+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Mathematics #InstructionFollowingCapability #Author Thread-Post Issue Date: 2025-05-24 GPT Summary- 指示遵守はLLMのユーザー意図適合に重要であり、本研究では数学的推論タスクにおける指示遵守を評価するためのMathIFベンチマークを紹介。推論能力と可制御性の間には緊張が存在し、推論性能向上が指示遵守に影響を及ぼすことを示した。長い思考連鎖を用いたモデルや強化学習モデルは指示遵守が劣化する一方、簡単な介入で部分的に従順性を回復可能だが推論性能が犠牲になる場合がある。これらの知見は、指示対応性に優れた推論モデルの必要性を浮き彫りにする。 Comment
元ポスト:
[Paper Note] LaViDa: A Large Diffusion Language Model for Multimodal Understanding, Shufan Li+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #DiffusionModel #Initial Impression Notes Issue Date: 2025-05-24 GPT Summary- LaViDaは、離散拡散モデル(DM)を基にしたビジョン・ランゲージモデル(VLM)で、高速な推論と制御可能な生成を実現。新技術を取り入れ、マルチモーダルタスクにおいてAR VLMと競争力のある性能を達成。COCOキャプショニングで速度向上と性能改善を示し、AR VLMの強力な代替手段であることを証明。 Comment
元ポスト:
Diffusion Modelの波が来た
同程度のサイズのARモデルをoutperform [^1]
[^1]:ただし、これが本当にDiffusion Modelを使ったことによる恩恵なのかはまだ論文を読んでいないのでわからない。必要になったら読む。ただ、Physics of Language Modelのように、完全にコントロールされたデータで異なるアーキテクチャを比較しないとその辺はわからなそうではある。
[Paper Note] dKV-Cache: The Cache for Diffusion Language Models, Xinyin Ma+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #DiffusionModel #Initial Impression Notes Issue Date: 2025-05-24 GPT Summary- 拡散型言語モデル(DLMs)の推論速度の遅さを解決するために、遅延KVキャッシュという機構を提案。異なるトークンが異なる表現ダイナミクスを持つことに基づき、キーと値の状態を遅延かつ条件付きでキャッシュ。二つの変種(dKV-Cache-DecodeとdKV-Cache-Greedy)を設計し、推論速度を2〜10倍に向上。実験により、DLMsの加速が現行モデルに追加のトレーニングなしで可能であることを示した。 Comment
元ポスト:
提案手法を適用した場合、ARなモデルとDiffusion Modelで、実際のところどの程度のdecoding速度の差があるのだろうか?そういった分析はざーーっと見た感じ見当たらなかったように思える。
[Paper Note] Diffusion vs. Autoregressive Language Models: A Text Embedding Perspective, Siyue Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Embeddings #NLP #RepresentationLearning #DiffusionModel Issue Date: 2025-05-24 GPT Summary- LLMベースの埋め込みモデルは、文書検索タスクで従来のモデルを超えつつあるが、自己回帰的なアテンションが双方向性に欠けることが制限となっている。これを解決するために、拡散言語モデルを提案し、双方向アーキテクチャによる長文検索で20%、推論検索で8%、指示検索で2%の向上を示す。分析により、長く複雑なテキストの文脈を捉えるために双方向アテンションが重要であることが確認された。 Comment
元ポスト:
[Paper Note] LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25
Paper/Blog Link My Issue
#NLP #Evaluation #ICLR #Contamination-free #Selected Papers/Blogs #Live #One-Line Notes Issue Date: 2025-05-23 GPT Summary- テストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Comment
テストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究
[Paper Note] Parallel Scaling Law for Language Models, Mouxiang Chen+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Scaling Laws #Reference Collection #Initial Impression Notes Issue Date: 2025-05-21 GPT Summary- 言語モデルのスケーリングにおいて、パラメータや出力トークンの増加に伴うコストを軽減する新たなアプローチ「並列スケーリング(ParScale)」を提案。モデルの並列計算を増やし、$P$ 個の多様な変換を実行することで、推論効率を向上させ、$O(\log P)$ のパラメータスケーリングと同等の効果を実現。メモリ増加を最大22倍、レイテンシを最大6倍削減可能。少量のトークンでのポストトレーニングを通じて、既製のモデルを再利用可能で、より強力なモデルの展開を促進。 Comment
元ポスト:
- [Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
と考え方が似ている
[Paper Note] AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning, Chenwei Lou+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Chain-of-Thought #Reasoning #One-Line Notes Issue Date: 2025-05-21 GPT Summary- AdaCoTは、LLMがChain-of-Thought(CoT)の使用を適応的に決定する新しい枠組み。これにより、計算コストや非効率性を軽減しつつ、複雑なクエリにおける推論性能を維持する。特にProximal Policy Optimization(PPO)を用いたRL手法を導入し、Selective Loss Masking(SLM)で推論トリガを安定させ、実験ではCoTトリガー率を最大3.18%削減、応答トークン数を69.06%削減したことが示された。 Comment
RLのRewardにおいて、baseのリワードだけでなく、
- reasoningをなくした場合のペナルティ項
- reasoningをoveruseした場合のペナルティ項
- formattingに関するペナルティ項
を設定し、reasoningの有無を適切に判断できた場合にrewardが最大化されるような形にしている。(2.2.2)
が、multi-stageのRLでは(stageごとに利用するデータセットを変更するが)、データセットの分布には歪みがあり、たとえば常にCoTが有効なデータセットも存在しており(数学に関するデータなど)、その場合常にCoTをするような分布を学習してしまい、AdaptiveなCoT decisionが崩壊したり、不安定になってしまう(decision boundary collapseと呼ぶ)。特にこれがfinal stageで起きると最悪で、これまでAdaptiveにCoTされるよう学習されてきたものが全て崩壊してしまう。これを防ぐために、Selective Loss Maskingというlossを導入している。具体的には、decision token [^1]のlossへの貢献をマスキングするようにすることで、CoTが生じるratioにバイアスがかからないようにする。今回は、Decision tokenとして、`
[^1]: CoTするかどうかは多くの場合このDecision Tokenによって決まる、といったことがどっかの研究に示されていたはず
いつか必要になったらしっかり読むが、全てのステージでSelective Loss Maskingをしたら、SFTでwarm upした段階からあまりCoTのratioが変化しないような学習のされ方になる気がするが、どのステージに対してapplyするのだろうか。
openreview: https://openreview.net/forum?id=obXGSmmG70
[Paper Note] Model Merging in Pre-training of Large Language Models, Yunshui Li+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #ModelMerge #Reference Collection Issue Date: 2025-05-20 GPT Summary- モデルマージは大規模言語モデルの性能向上に有望だが、事前学習での探究は不十分。本研究では、DenseおよびMixture-of-Expertsアーキテクチャでのモデルマージ手法を検討し、一定の学習率でのチェックポイントのマージが性能を著しく改善し、学習率のアニーリング挙動を予測可能にすることを示した。これにより、モデル開発とトレーニングコストの効率化が可能となる。包括的な実験分析を通じて、効果的なモデルマージのための実践的なガイドラインを提供。 Comment
元ポスト:
解説ポスト:
[Paper Note] Follow the Path: Reasoning over Knowledge Graph Paths to Improve LLM Factuality, Mike Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #QuestionAnswering #KnowledgeGraph #Factuality #Reasoning #Test-Time Scaling #PostTraining Issue Date: 2025-05-20 GPT Summary- fs1は、大規模推論モデルから推論経路を取得し、知識グラフに条件付けて事実性を向上させる手法を提案する。8つのLLMをファインチューニングし、6つの複雑なQAベンチマークで評価した結果、fs1調整モデルは他モデルを一貫して上回り、特に複雑な質問での性能向上が顕著だった。従来研究の枠を超え、推論経路をKGに結び付けることが信頼性の高いタスクにおいて重要であることを示した。 Comment
元ポスト:
[Paper Note] Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures, Chenggang Zhao+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #LLMServing #Architecture #MoE(Mixture-of-Experts) #SoftwareEngineering Issue Date: 2025-05-20 GPT Summary- LLMのスケーリングは、メモリ、計算効率、帯域幅における制約を明らかにした。DeepSeek-V3は、ハードウェアを意識したモデル設計でこれらの課題に対処し、効率的なトレーニングと推論を実現。特に、メモリ効率を向上させるMLA、計算と通信を最適化するMoE、FP8混合精度トレーニング、ネットワークオーバーヘッドを減少させるマルチプレーン・トポロジーが革新のポイント。将来のハードウェア設計に向けた広範な議論を通じて、AIの需要に応えるためのモデル共設計の重要性を強調。 Comment
元ポスト:
[Paper Note] Why Vision Language Models Struggle with Visual Arithmetic? Towards Enhanced Chart and Geometry Understanding, Kung-Hsiang Huang+, ACL'25, 2025.02
Paper/Blog Link My Issue
#ComputerVision #Analysis #NLP #Supervised-FineTuning (SFT) #SyntheticData #ACL #DPO #PostTraining #Probing #One-Line Notes #Author Thread-Post Issue Date: 2025-05-18 GPT Summary- Vision Language Models (VLMs)は視覚的算術に苦労しているが、CogAlignという新しいポストトレーニング戦略を提案し、VLMの性能を向上させる。CogAlignは視覚的変換の不変特性を認識するように訓練し、CHOCOLATEで4.6%、MATH-VISIONで2.9%の性能向上を実現し、トレーニングデータを60%削減。これにより、基本的な視覚的算術能力の向上と下流タスクへの転送の効果が示された。 Comment
元ポスト:
既存のLLM (proprietary, openweightそれぞれ)が、シンプルなvisual arithmeticタスク(e.g., 線分の長さ比較, Chart上のdotの理解)などの性能が低いことを明らかにし、
それらの原因を(1)Vision Encoderのrepresentationと(2)Vision EncoderをFreezeした上でのText Decoderのfinetuningで分析した。その結果、(1)ではいくつかのタスクでlinear layerのprobingでは高い性能が達成できないことがわかった。このことから、Vision Encoderによるrepresentationがタスクに関する情報を内包できていないか、タスクに関する情報は内包しているがlinear layerではそれを十分に可能できない可能性が示唆された。
これをさらに分析するために(2)を実施したところ、Vision Encoderをfreezeしていてもfinetuningによりquery stringに関わらず高い性能を獲得できることが示された。このことから、Vision Encoder側のrepresentationの問題ではなく、Text Decoderと側でデコードする際にFinetuningしないとうまく活用できないことが判明した。
手法のところはまだ全然しっかり読めていないのだが、画像に関する特定の属性に関するクエリと回答のペアを合成し、DPOすることで、zero-shotの性能が向上する、という感じっぽい?
[Paper Note] AlphaEvolve: A coding agent for scientific and algorithmic discovery, Alexander Novikov+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #AIAgents #Coding #ScientificDiscovery Issue Date: 2025-05-17 GPT Summary- AlphaEvolveは、未解決の科学問題に取り組み、計算基盤を最適化するための進化的コーディングエージェントです。自律的にアルゴリズムを改善し、評価者のフィードバックを基に反復的に進化させ、新たな発見を促します。具体的には、データセンターの効率的なスケジューリングや回路設計の簡素化を実現し、高度な数学問題に対して新たな証明可能なアルゴリズムを導入しました。特に、56年ぶりにストラスレンのアルゴリズムを上回る新しい掛け算手法を発見しました。AlphaEvolveは、科学と計算分野への大きな貢献が期待されています。 Comment
[Paper Note] Faster Cascades via Speculative Decoding, Harikrishna Narasimhan+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ICLR #Test-Time Scaling #Decoding #Verification #SpeculativeDecoding #Reference Collection Issue Date: 2025-05-13 GPT Summary- カスケードと推測デコーディングは、言語モデルの推論効率を向上させる手法であり、異なるメカニズムを持つ。カスケードは難しい入力に対して大きなモデルを遅延的に使用し、推測デコーディングは並行検証で大きなモデルを活用する。新たに提案する推測カスケーディング技術は、両者の利点を組み合わせ、最適な遅延ルールを特定する。実験結果は、提案手法がカスケードおよび推測デコーディングのベースラインよりも優れたコスト品質トレードオフを実現することを示した。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=vo9t20wsmd
[Paper Note] EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models, Ziwen Xu+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #Library #KnowledgeEditing Issue Date: 2025-05-11 GPT Summary- LLMの制御を可能にするEasyEdit2フレームワークを提案。多様なテスト時介入をサポートし、新アーキテクチャで効率的なモデルステアリングを実現。ユーザーは簡単な例を用いるだけでモデルの応答を調整でき、広範な技術知識は不要。実証実験によりその有効性を示し、ソースコードとデモも公開。 Comment
[Paper Note] Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Dataset #ACL #Selected Papers/Blogs Issue Date: 2025-05-10 GPT Summary- FineWeb-EduとDCLMは、モデルベースのフィルタリングによりデータの90%を削除し、トレーニングに適さなくなった。著者は、アンサンブル分類器や合成データの言い換えを用いて、精度とデータ量のトレードオフを改善する手法を提案。1Tトークンで8Bパラメータモデルをトレーニングし、DCLMに対してMMLUを5.6ポイント向上させた。新しい6.3Tトークンデータセットは、DCLMと同等の性能を持ちながら、4倍のユニークなトークンを含み、長トークンホライズンでのトレーニングを可能にする。15Tトークンのためにトレーニングされた8Bモデルは、Llama 3.1の8Bモデルを上回る性能を示した。データセットは公開されている。
[Paper Note] DataComp-LM: In search of the next generation of training sets for language models, Jeffrey Li+, NeurIPS'25, 2024.07
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #NeurIPS #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-05-10 GPT Summary- DataComp for Language Models(DCLM)を紹介し、240Tトークンのコーパスと53の評価スイートを提供。DCLMでは、モデルスケール412Mから7Bパラメータのデータキュレーション戦略を実験可能。DCLM-Baselineは2.6Tトークンでトレーニングし、MMLUで64%の精度を達成し、従来のMAP-Neoより6.6ポイント改善。計算リソースも40%削減。結果はデータセット設計の重要性を示し、今後の研究の基盤を提供。 Comment
openreview: https://openreview.net/forum?id=CNWdWn47IE
最近多くの著名なモデルでDCLMを事前学習データとして利用している文献を目にするようになった
[Paper Note] When Bad Data Leads to Good Models, Kenneth Li+, ICML'25, 2025.05
Paper/Blog Link My Issue
#Pretraining #NLP #Supervised-FineTuning (SFT) #Safety #ICML #DPO #Toxicity #ActivationSteering/ITI #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2025-05-09 GPT Summary- 本論文では、LLMの事前学習におけるデータの質の再検討を行い、有害データが事後学習における制御を向上させる可能性を探ります。トイ実験を通じて、有害データの割合が増加することで有害性の概念が線形表現に影響を与えることを発見し、有害データが生成的有害性を増加させつつも除去しやすくなることを示しました。評価結果は、有害データで訓練されたモデルが生成的有害性を低下させつつ一般的な能力を保持する良好なトレードオフを達成することを示唆しています。 Comment
元ポスト:
これは面白そう
Webコーパスなどを事前学習で利用する際は、質の高いデータを残して学習した方が良いとされているが、4chanのようなtoxicなデータを混ぜて事前学習して、後からdetox(Inference Time Intervention [Paper Note] Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23
, SFT, DPO)することで、最終的なモデルのtoxicなoutputが減るという話らしい。これはそもそも事前学習時点でtoxicなデータのsignalが除外されることで、モデルがtoxicな内容のrepresentationを学習できず、最終的にtoxicか否かをコントロールできなくなるため、と考察している(っぽい)
有害な出力を減らせそうなことは分かったが、Activation Steeringによってどの程度モデルの性能に影響を与えるのかが気になる、と思ったがAppendixに記載があった。細かく書かれていないので推測を含むが、各データに対してToxicデータセットでProbingすることでTopKのheadを決めて、Kの値を調整することでinterventionの強さを調整し、Toxicデータの割合を変化させて評価してみたところ、モデルの性能に大きな影響はなかったということだと思われる(ただし1Bモデルでの実験しかない)
おそらく2,3節あたりが一番おもしろいポイントなのだと思われるがまだ読めていない。
openreview: https://openreview.net/forum?id=SsLGTZKXf1
解説:
[Paper Note] Reinforcement Learning for Reasoning in Large Language Models with One Training Example, Yiping Wang+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #NeurIPS #read-later #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2025-05-09 GPT Summary- 1-shot RLVRを用いることで、大規模言語モデルの数学的推論能力が向上することを示した。Qwen2.5-Math-1.5BにRLVRを適用し、MATH500の性能を36.0%から73.6%に引き上げたほか、6つの一般的な数学的推論ベンチマークも改善。異なるモデルやRLアルゴリズムでも顕著な向上が観察され、訓練精度の飽和後もテスト性能が持続改善する現象が見られた。これらの知見は、RLVRの効率性に関する今後の研究を促進する重要な要素であり、全リソースはオープンソースで公開されている。 Comment
下記ポストでQwenに対してpromptを適切に与えることで、追加のpost training無しで高い数学に関する能力を引き出せたという情報がある。おそらく事前学習時に数学のQAデータによって継続事前学習されており、この能力はその際に身についているため、数学に対する高い能力は実は簡単に引き出すことができるのかもしれない(だから1サンプルでも性能が向上したのではないか?)といった考察がある。
参考:
- [Paper Note] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, Mingjie Liu+, NeurIPS'25
とはどのような関係性があるだろうか?
著者ポスト:
openreview: https://openreview.net/forum?id=IBrRNLr6JA
[Paper Note] Absolute Zero: Reinforced Self-play Reasoning with Zero Data, Andrew Zhao+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SelfImprovement #NeurIPS #read-later #RLVR #Selected Papers/Blogs #Label-free #SelfPlay Issue Date: 2025-05-08 GPT Summary- RLVRは、結果に基づく報酬を用いて言語モデルの推論能力を向上させるが、訓練には人手による質問と回答の収集が必要。高品質な例の不足は長期的なスケーラビリティの懸念を引き起こす。これに対処する新しいRLVRパラダイム、Absolute Zeroが提案され、モデルトレーニングが外部データに依存せず、AZRによって自己進化を促進。AZRはオープンエンドな検証可能報酬を提供し、全くの外部データなしでもSOTA性能を達成。また、様々なモデルと互換性があることが示された。 Comment
元ポスト:
[Paper Note] R.I.P.: Better Models by Survival of the Fittest Prompts, Ping Yu+, ICML'25
Paper/Blog Link My Issue
#NLP #DataDistillation #SyntheticData #ICML #Author Thread-Post Issue Date: 2025-05-07 GPT Summary- トレーニングデータの品質がモデルの性能に与える影響を考慮し、低品質な入力プロンプトがもたらす問題を解決するために、Rejecting Instruction Preferences(RIP)というデータ整合性評価手法を提案。RIPは、拒否された応答の品質と選択された好みペアとの報酬ギャップを測定し、トレーニングセットのフィルタリングや高品質な合成データセットの作成に利用可能。実験結果では、RIPを用いることでLlama 3.1-8B-Instructでの性能が大幅に向上し、Llama 3.3-70B-Instructではリーダーボードでの順位が上昇した。 Comment
元ポスト:
スレッドで著者が論文の解説をしている。
[Paper Note] Thinking LLMs: General Instruction Following with Thought Generation, Tianhao Wu+, ICML'25, 2024.10
Paper/Blog Link My Issue
#NLP #Alignment #Reasoning #ICML #DPO #PostTraining #KeyPoint Notes #Author Thread-Post Issue Date: 2025-05-07 GPT Summary- LLMsに思考能力を装備するための訓練方法を提案。反復的な検索と最適化手順を用いて、モデルが監視なしで思考する方法を学ぶ。指示に対する思考候補はジャッジモデルで評価され、最適化される。この手法はAlpacaEvalとArena-Hardで優れたパフォーマンスを示し、推論タスクだけでなく、マーケティングや健康などの非推論カテゴリでも利点を発揮。 Comment
元ポスト:
外部のCoTデータを使わないで、LLMのreasoning capabilityを向上させる話っぽい。DeepSeek-R1の登場以前の研究とのこと。
"reasoning traceを出力するように" Instruction Tuningによって回答を直接出力するようPostTrainingされたモデルにpromptingし、複数のoutputを収集(今回は8個, temperature=0.8, top p=0.95)。Self Taught Evaluator [Paper Note] Self-Taught Evaluators, Tianlu Wang+, arXiv'24, 2024.08
(STE;70B, LLM-as-a-Judgeを利用するモデル)、あるいはArmo Reward Model(8B)によって回答の品質をスコアリング。ここで、LLM-as-a-Judgeの場合はペアワイズでの優劣が決まるだけなので、ELOでスコアリングする。outputのうちbest scoreとworst scoreだったものの双方でペアデータを構築し、DPOで利用するpreferenceペアデータを構築しDPOする。このような処理を繰り返し、モデルの重みをiterationごとに更新する。次のiterationでは更新されたモデルで同様の処理を行い、前段のステップで利用した学習データは利用しないようにする(後段の方が品質が高いと想定されるため)。また、回答を別モデルで評価する際に、長いレスポンスを好むモデルの場合、長い冗長なレスポンスが高くスコアリングされるようなバイアスが働く懸念があるため、長すぎる回答にpenaltyを与えている(Length-Control)。
reasoning traceを出力するpromptはgenericとspecific thoughtの二種類で検証。前者はLLMにどのような思考をするかを丸投げするのに対し、後者はこちら側で指定する。後者の場合は、どのような思考が良いかを事前に知っていなければならない。
Llama-3-8b-instructに適用したところ、70Bスケールのモデルよりも高い性能を達成。また、reasoning trace出力をablationしたモデル(Direct responce baseline)よりも性能が向上。
iterationが進むに連れて、性能が向上している。
[Paper Note] 100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models, Chong Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Survey #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #InstructionTuning #PPO (ProximalPolicyOptimization) #Reasoning #LongSequence #RewardHacking #GRPO #Contamination-free #VerifiableRewards #CurriculumLearning #One-Line Notes Issue Date: 2025-05-06 GPT Summary- RLMの進展は新しい言語モデルの進化を示し、DeepSeek-R1のリリースが社会的影響を生んでいる。DeepSeekの実装は完全にオープンではないが、多くの再現研究が登場し、同等の性能を達成。特にSFTとRLVRに重点を置き、データ構築や手法設計に関する知見を提供。実装の詳細と実験結果をまとめ、RLMの性能向上技術や開発課題についても議論。研究者が最新の進展を把握し、新しいアイデアを促進することを目指す。 Comment
元ポスト:
サーベイのtakeawayが箇条書きされている。
[Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #Analysis #NLP #RepresentationLearning #Supervised-FineTuning (SFT) #Chain-of-Thought #SSM (StateSpaceModel) #ICML #PostTraining #read-later #One-Line Notes #CompressionValleys Issue Date: 2025-05-04 GPT Summary- 中間層の埋め込みが最終層を超えるパフォーマンスを示すことを分析し、情報理論や幾何学に基づくメトリクスを提案。32のテキスト埋め込みタスクで中間層が強力な特徴を提供することを実証し、AIシステムの最適化における中間層の重要性を強調。 Comment
現代の代表的な言語モデルのアーキテクチャ(decoder-only model, encoder-only model, SSM)について、最終層のembeddingよりも中間層のembeddingの方がdownstream task(MTEBの32Taskの平均)に、一貫して(ただし、これはMTEBの平均で見たらそうという話であり、個別のタスクで一貫して強いかは読んでみないとわからない)強いことを示した研究。
このこと自体は経験的に知られているのであまり驚きではないのだが(ただ、SSMでもそうなのか、というのと、一貫して強いというのは興味深い)、この研究はMatrix Based Entropyと呼ばれるものに基づいて、これらを分析するための様々な指標を定義し理論的な根拠を示し、Autoregressiveな学習よりもMasked Languageによる学習の方がこのようなMiddle Layerのボトルネックが緩和され、同様のボトルネックが画像の場合でも起きることを示し、CoTデータを用いたFinetuningについても分析している模様。この辺の貢献が非常に大きいと思われるのでここを理解することが重要だと思われる。あとで読む。
openreview: https://openreview.net/forum?id=WGXb7UdvTX
[Paper Note] Where is the answer? Investigating Positional Bias in Language Model Knowledge Extraction, Kuniaki Saito+, NAACL'25
Paper/Blog Link My Issue
#NLP #Bias #NAACL #PostTraining #PerplexityCurse #Selected Papers/Blogs #ContextEngineering #Surface-level Notes #Author Thread-Post Issue Date: 2025-05-02 GPT Summary- LLMは新しい文書でファインチューニングが必要だが、「困惑の呪い」により情報抽出が困難。特に文書の初めに関する質問には正確に答えるが、中間や末尾の情報抽出に苦労する。自己回帰的トレーニングがこの問題を引き起こすことを示し、デノイジング自己回帰損失が情報抽出を改善する可能性を示唆。これにより、LLMの知識抽出と新ドメインへの適応に関する新たな議論が生まれる。 Comment
元ポスト:

LLMの知識を最新にするために新しい文書(e.g., 新しいドメインの文書等)をLLMに与え(便宜上学習データと呼ぶ)Finetuningをした場合、Finetuning後のモデルで与えられたqueryから(LLM中にパラメータとしてmemorizeされている)対応する事実情報を抽出するようInferenceを実施すると、queryに対応する事実情報の学習データ中での位置が深くなると(i.e., middle -- endになると)抽出が困難になる Positional Biasが存在する[^1]ことを明らかにした。
そして、これを緩和するために正則化が重要(e.g., Denoising, Shuffle, Attention Drops)であることを実験的に示し、正則化手法は複数組み合わせることで、よりPositional Biasが緩和することを示した研究
[^1]: 本研究では"Training"に利用する文書のPositional Biasについて示しており、"Inference"時におけるPositional Biasとして知られている"lost-in-the middle"とは異なる現象を扱っている点に注意
## データセット
文書 + QAデータの2種類を構築しFinetuning後のknowledge extraction能力の検証をしている[^2]。
実験では、`Synthetic Bio (合成データ)`, `Wiki2023+(実データ)` の2種類のデータを用いて、Positional Biasを検証している。
Synthetic bioは、人間のbiographyに関する9つの属性(e.g., 誕生日, 出生地)としてとりうる値をChatGPTに生成させ、3000人の人物に対してそれらをランダムにassignし、sentence templateを用いてSurface Realizationすることで人工的に3000人のbiographyに関するテキストを生成している。
一方、Wiki2023+では、Instruction-tuned Language Models are Better Knowledge Learners, Zhengbao Jiang+, ACL'24
の方法にのっとって [^3]事前学習時の知識とのoverlapが最小となるように`2023`カテゴリ以下のwikipediaの様々なジャンルの記事を収集して活用する。QAデータの構築には、元文書からsentenceを抽出し、GPT-3.5-Turboに当該sentenceのみを与えてQA pairを作成させることで、データを作成している。なお、hallucinationや品質の低いQA pairをフィルタリングした。フィルタリング後のQA Pairをランダムにサンプリングし品質を確認したところ、95%のQA pairが妥当なものであった。
これにより、下図のようなデータセットが作成される。FigureCが `Wiki2023+`で、FigureDが`SyntheticBio`。`Wiki2023+`では、QA pairの正解が文書中の前半により正解が現れるような偏りが見受けられる。

[^2]: [Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
において、知識 + 知識を抽出するタスクの双方を用いて学習することで、モデルから知識を抽出する能力が備わることが示されているため。
[^3]: Llama-2-7Bにおいて2023カテゴリ以下の情報に対するQAのperformanceが著しく低いことから、事前学習時に当該データが含まれている可能性が低いことが示唆されている
## 実験 & 実験結果 (modulated data)
作成した文書+QAデータのデータセットについて、QAデータをtrain/valid/testに分けて、文書データは全て利用し、testに含まれるQAに適切に回答できるかで性能を評価する。このとき、文書中でQAに対する正解がテキストが出現する位置を変化させモデルの学習を行い、予測性能を見ることで、Positional Biasが存在することを明らかにする。このとき、[Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
に倣い、文書とQAをMixed Sampling(1バッチあたり256件のサンプルをランダムにQAおよび文書データからサンプリング;
# 1923 では文書とQAを2:8の比率でサンプリングしている)することで学習をする。QAの場合目的関数は回答テキスト部分のみのNLL、文書の場合はnext-token prediction lossを利用する。
Positional Biasの存在を示すだけでなく、(A, B, C) の順番でnext-token prediction lossで学習されたモデルの場合、Cの知識を抽出するためにA, Bがcontextとして必要となるため、Cを抽出する際の汎化性能を高めるためにA, Bの表現がより多様である必要がある、という課題がある。これに対処するためのいくつかのシンプルな正則化手法、具体的には
- D-AR: predition targetのトークンは保持したまま、input tokenの一部をランダムなトークンに置き換える
- Shuffle: 入力文をシャッフルする
- Attn Drop: self-attentionモジュールのattention weightをランダムに0にする
の3種類とPositional Biasの関係性を検証している。

検証の結果、(合成データ、実データともに)Positional Biasが存在することが明らかとなり(i.e., 正解テキストが文書中の深い位置にあればあるほど予測性能が低下する)正則化によってPositional Biasが緩和されることが示された。

また、異なるモデルサイズで性能を比較したところ、モデルサイズを大きくすることで性能自体は改善するが、依然としてPositional Biasが存在することが示され、ARよりもD-ARが一貫して高い性能を示した。このことから、Positional Biasを緩和するために何らかの正則化手法が必要なことがわかる。

また、オリジナル文書の1文目を、正解データの位置を入れ替えた各モデルに対して、テキスト中の様々な位置に配置してPerplexityを測った。この設定では、モデルがPerplexityを最小化するためには、(1文目ということは以前の文脈が存在しないsentenceなので)文脈に依存せずに文の記憶していなければならない。よって、各手法ごとにどの程度Perplexityが悪化するかで、各手法がどの程度あるsentenceを記憶する際に過去の文脈に依存しているかが分かる。ここで、学習データそのもののPerplexityはほぼ1.0であったことに注意する。
結果として、文書中の深い位置に配置されればされるほどPerplexityは増大し(left)、Autoregressive Model (AR) のPerplexity値が最も値が大きかった(=性能が悪かった)。このことから、ARはより過去の文脈に依存してsentenceの情報を記憶していることが分かる。また、モデルサイズが小さいモデルの方がPerplexityは増大する傾向にあることがわかった (middle)。これはFig.3で示したQAのパフォーマンスと傾向が一致しており、学習データそのもののPerplexityがほぼ1.0だったことを鑑みると、学習データに対するPerplexityは様々なPositionに位置する情報を適切に抽出できる能力を測るメトリックとしては適切でないことがわかる。また、学習のiterationを増やすと、ARの場合はfirst positionに対する抽出性能は改善したが、他のpositionでの抽出性能は改善しなかった。一方、D-ARの場合は、全てのpositionでの抽出性能が改善した (right) 。このことから、必ずしも学習のiterationを増やしても様々なPositionに対する抽出性能が改善しないこと、longer trainingの恩恵を得るためには正則化手法を利用する必要があることが明らかになった。

## 実験 & 実験結果 (unmodulated data)
Wiki2023+データに対して上記のようなデータの変更を行わずに、そのまま学習を行い、各位置ごとのQAの性能を測定したところ、(すべてがPositional Biasのためとは説明できないが)回答が文書中の深い位置にある場合の性能が劣化することを確認した。2--6番目の性能の低下は、最初の文ではシンプルな事実が述べられ、後半になればなるほどより複雑な事実が述べられる傾向があることが起因して性能の低下しているとかせつをたてている。また、unmodulated dataの場合でもD-ARはARの性能を改善することが明らかとなった。モデルサイズが大きいほど性能は改善するが、以前として文書中の深い位置に正解がある場合に性能は劣化することもわかる。
また、正則化手法は組み合わせることでさらに性能が改善し、[Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
に示されている通り、学習データ中の表現を多様にし[^1]学習したところ予測性能が改善し、正則化手法とも補完的な関係であることも示された。
医療ドメインでも実験したところ、正則化手法を適用した場合にARよりも性能が上回った。最後にWiki2023+データについてOpenbookな設定で、正解が含まれる文書をLLMのcontextとして与えた場合(i.e.,ほぼ完璧なretrieverが存在するRAGと同等の設定とみなせる)、QAの性能は90.6%に対し、継続学習した場合のベストモデルの性能は50.8%だった。このことから、正確なretrieverが存在するのであれば、継続学習よりもRAGの方がQAの性能が高いと言える。
RAGと継続学習のメリット、デメリットの両方を考慮して、適切に手法を選択することが有効であることが示唆される。
[^1]: ChatGPTによってテキストをrephraseし、sentenceのorderも変更することで多様性を増やした。が、sentence orderが文書中の深い位置にある場合にあまりorderが変化しなかったようで、このため深い位置に対するQAの性能改善が限定的になっていると説明している。
[Paper Note] Phi-4-reasoning Technical Report, Marah Abdin+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #SmallModel #OpenWeight #GRPO #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2025-05-01 GPT Summary- 140億パラメータの推論モデルPhi-4-reasoningは、慎重に選ばれた「teachable」プロンプトセットと監視付きファインチューニングを通じて訓練され、詳細な推論チェーンを生成します。そのバリエーションであるPhi-4-reasoning-plusは、短期間の強化学習を経て、より長い推論トレースを生成し高性能を実現。これらのモデルは、DeepSeek-R1-Distill-Llama-70Bモデルを超え、完全版DeepSeek-R1に近い性能を示します。評価は数学的・科学的推論や一般目的のベンチマークを含み、データ精選の利点と強化学習の影響を示唆しています。 Comment
元ポスト:
こちらの解説が非常によくまとまっている:
が、元ポストでもテクニカルペーパー中でもo3-miniのreasoning traceをSFTに利用してCoTの能力を強化した旨が記述されているが、これはOpenAIの利用規約に違反しているのでは…?
[Paper Note] When More is Less: Understanding Chain-of-Thought Length in LLMs, Yuyang Wu+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #ICLR #One-Line Notes #Author Thread-Post Issue Date: 2025-04-30 GPT Summary- Chain-of-thought (CoT)推論は、LLMsの多段階推論能力を向上させるが、CoTの長さが増すと最初は性能が向上するものの、最終的には低下することが観察される。長い推論プロセスがノイズに脆弱であることを示し、理論的に最適なCoTの長さを導出。Length-filtered Voteを提案し、CoTの長さをモデルの能力とタスクの要求に合わせて調整する必要性を強調。 Comment
ICLR 2025 Best Paper Runner Up Award
元ポスト:
[Paper Note] AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models, Junfeng Fang+, ICLR'25
Paper/Blog Link My Issue
#NLP #ICLR #KnowledgeEditing #One-Line Notes #Reference Collection #Initial Impression Notes Issue Date: 2025-04-30 GPT Summary- AlphaEditは、LLMsの知識を保持しつつ編集を行う新しい手法で、摂動を保持された知識の零空間に投影することで、元の知識を破壊する問題を軽減します。実験により、AlphaEditは従来の位置特定-編集手法の性能を平均36.7%向上させることが確認されました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=HvSytvg3Jh
MLPに新たな知識を直接注入する際に(≠contextに含める)既存の学習済みの知識を破壊せずに注入する手法(破壊しないことが保証されている)を提案しているらしい
将来的には、LLMの1パラメータあたりに保持できる知識量がわかってきているので、MLPの零空間がN GBのモデルです、あなたが注入したいドメイン知識の量に応じて適切な零空間を持つモデルを選んでください、みたいなモデルが公開される日が来るのだろうか。
ポイント解説:
[Paper Note] Can LLMs Be Trusted for Evaluating RAG Systems? A Survey of Methods and Datasets, Lorenz Brehme+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#Survey #InformationRetrieval #NLP #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-04-30 GPT Summary- RAGシステムの評価は、複数の構成要素を含み、進歩の記録や有効なアプローチの特定に欠かせない。本研究では63件の論文をレビューし、評価手法の概観を提供。データセットやリトリーバー、インデックス作成などに焦点を当て、LLMを用いた自動評価アプローチの可能性を探求する。企業向けに実践的な洞察も示し、RAGの評価手法の厳密さ向上に寄与する。また、自動化と人間の判断の相互作用についても議論し、評価の信頼性向上に向けた課題を整理する。 Comment
元ポスト:
おもしろそう
[Paper Note] Generative Product Recommendations for Implicit Superlative Queries, Kaustubh D. Dhole+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2025-04-29 GPT Summary- ユーザーの曖昧なクエリに対してLLMを用いて、暗黙の属性を生成し製品推奨を向上。新たにSUPERBという4点スキーマでクエリに対する製品候補を注釈し、既存のランキング手法を評価。実世界のeコマースシステムへの統合も検討。 Comment
元ポスト:
[Paper Note] BitNet b1.58 2B4T Technical Report, Shuming Ma+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #Quantization #SmallModel #PostTraining #One-Line Notes Issue Date: 2025-04-19 GPT Summary- BitNet b1.58 2B4Tは、2億パラメータを持つ初のオープンソースの1ビット大規模言語モデルであり、4兆トークンのコーパスで訓練されています。言語理解や数学的推論、コーディング能力などのベンチマークで評価され、同等のスケールの全精度LLMと同等の性能を示す一方で、計算効率の向上を実現しています。具体的には、メモリ使用量、エネルギー消費、デコード遅延を大幅に削減しています。モデルウェイトはHugging Faceを通じて公開され、オープンソースの推論実装も提供されます。 Comment
元ポスト:
圧倒的省メモリかつcpuでのinference速度も早そう
- アーキテクチャはTransformerを利用
- Linear layerとしてBitLinear Layerを利用
- 重みは{1, 0, -1}の3値をとる
- activationは8bitのintegerに量子化
- Layer Normalizationはsubln normalization [Paper Note] Magneto: A Foundation Transformer, Hongyu Wang+, ICML'23
を利用
[Paper Note] AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #ICLR #ComputerUse #One-Line Notes Issue Date: 2025-04-18 GPT Summary- 本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 Comment
Android環境でのPhone Useのベンチマーク
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning, Siyan Zhao+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #DiffusionModel #Reasoning #PostTraining #GRPO #KeyPoint Notes Issue Date: 2025-04-18 GPT Summary- d1というフレームワークを提案し、マスク付きdLLMsを教師ありファインチューニングと強化学習で推論モデルに適応。マスク付きSFT技術で知識を抽出し、diffu-GRPOという新しいRLアルゴリズムを導入。実証研究により、d1が最先端のdLLMの性能を大幅に向上させることを確認。 Comment
元ポスト:
dLLMに対してGRPOを適用する手法(diffuGRPO)を提案している。
long CoTデータでSFTしてreasoning capabilityを強化した後、diffuGRPOで追加のpost-trainingをしてさらに性能をboostする。
GRPOではtoken levelの尤度とsequence全体の尤度を計算する必要があるが、dLLMだとautoregressive modelのようにchain ruleを適用する計算方法はできないので、効率的に尤度を推定するestimatorを用いてGPPOを適用するdiffuGRPOを提案している。
diffuGRPO単体でも、8BモデルだがSFTよりも性能向上に成功している。SFTの後にdiffuGRPOを適用するとさらに性能が向上する。
SFTではs1 [Paper Note] s1: Simple test-time scaling, Niklas Muennighoff+, EMNLP'25, 2025.01
で用いられたlong CoTデータを用いている。しっかり理解できていないが、diffuGRPO+verified rewardによって、long CoTの学習データを用いなくても、安定してreasoning能力を発揮することができようになった、ということなのだろうか?
しかし、AppendixCを見ると、元々のLLaDAの時点でreasoning traceを十分な長さで出力しているように見える。もしLLaDAが元々long CoTを発揮できたのだとしたら、long CoTできるようになったのはdiffuGRPOだけの恩恵ではないということになりそうだが、LLaDAは元々long CoTを生成できるようなモデルだったんだっけ…?その辺追えてない(dLLMがメジャーになったら追う)。
[Paper Note] Learning Dynamics of LLM Finetuning, Yi Ren+, ICLR'25 Outstanding Paper Award
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Alignment #Hallucination #ICLR #DPO #Repetition #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-04-18 GPT Summary- 本研究では、大規模言語モデルのファインチューニング中の学習ダイナミクスを分析し、異なる応答間の影響の蓄積を段階的に解明します。指示調整と好み調整のアルゴリズムに関する観察を統一的に解釈し、ファインチューニング後の幻覚強化の理由を仮説的に説明します。また、オフポリシー直接好み最適化(DPO)における「圧縮効果」を強調し、望ましい出力の可能性が低下する現象を探ります。このフレームワークは、LLMのファインチューニング理解に新たな視点を提供し、アラインメント性能向上のためのシンプルな方法を示唆します。 Comment
元ポスト:
解説ポスト:
[Paper Note] Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, Eval4NLP'25, 2024.08
Paper/Blog Link My Issue
#NLP #Evaluation #ACL #Decoding #Selected Papers/Blogs #Workshop #Non-Determinism #In-Depth Notes #KeyPoint Notes Issue Date: 2025-04-14 GPT Summary- 本研究では、5つの決定論的LLMにおける非決定性を8つのタスクで調査し、最大15%の精度変動と70%のパフォーマンスギャップを観察。全てのタスクで一貫した精度を提供できないことが明らかになり、非決定性が計算リソースの効率的使用に寄与している可能性が示唆された。出力の合意率を示す新たなメトリクスTARr@NとTARa@Nを導入し、研究結果を定量化。コードとデータは公開されている。 Comment
- 論文中で利用されているベンチマーク:
- [Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
- [Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
同じモデルに対して、seedを固定し、temperatureを0に設定し、同じ計算機環境に対して、同じinputを入力したら理論上はLLMの出力はdeterministicになるはずだが、deterministicにならず、ベンチマーク上の性能とそもそものraw response自体も試行ごとに大きく変化する、という話。
ただし、これはプロプライエタリLLMや、何らかのinferenceの高速化を実施したInferenceEngine(本研究ではTogetherと呼ばれる実装を使っていそう。vLLM/SGLangだとどうなるのかが気になる)を用いてinferenceを実施した場合での実験結果であり、後述の通り計算の高速化のためのさまざまな実装無しで、deterministicな設定でOpenLLMでinferenceすると出力はdeterministicになる、という点には注意。
GPTやLlama、Mixtralに対して上記ベンチマークを用いてzero-shot/few-shotの設定で実験している。Reasoningモデルは実験に含まれていない。
LLMのraw_response/multiple choiceのparse結果(i.e., 問題に対する解答部分を抽出した結果)の一致(TARr@N, TARa@N; Nはinferenceの試行回数)も理論上は100%になるはずなのに、ならないことが報告されている。
correlation analysisによって、応答の長さ と TAR{r, a}が強い負の相関を示しており、応答が長くなればなるほど不安定さは増すことが分析されている。このため、ontput tokenの最大値を制限することで出力の安定性が増すことを考察している。また、few-shotにおいて高いAcc.の場合は出力がdeterministicになるわけではないが、性能が安定する傾向とのこと。また、OpenAIプラットフォーム上でGPTのfinetuningを実施し実験したが、安定性に寄与はしたが、こちらもdeterministicになるわけではないとのこと。
deterministicにならない原因として、まずmulti gpu環境について検討しているが、multi-gpu環境ではある程度のランダム性が生じることがNvidiaの研究によって報告されているが、これはseedを固定すれば決定論的にできるため問題にならないとのこと。
続いて、inferenceを高速化するための実装上の工夫(e.g., Chunk Prefilling, Prefix Caching, Continuous Batching)などの実装がdeterministicなハイパーパラメータでもdeterministicにならない原因であると考察しており、**実際にlocalマシン上でこれらinferenceを高速化するための最適化を何も実施しない状態でLlama-8Bでinferenceを実施したところ、outputはdeterministicになったとのこと。**
論文中に記載がなかったため、どのようなInferenceEngineを利用したか公開されているgithubを見ると下記が利用されていた:
- Together:
https://github.com/togethercomputer/together-python?tab=readme-ov-file
Togetherが内部的にどのような処理をしているかまでは追えていないのだが、異なるInferenceEngineを利用した場合に、どの程度outputの不安定さに差が出るのか(あるいは出ないのか)は気になる。たとえば、transformers/vLLM/SGLangを利用した場合などである。
論文中でも報告されている通り、昔管理人がtransformersを用いて、deterministicな設定でzephyrを用いてinferenceをしたときは、出力はdeterministicになっていたと記憶している(スループットは絶望的だったが...)。
あと個人的には現実的な速度でオフラインでinference engineを利用した時にdeterministicにはせめてなって欲しいなあという気はするので、何が原因なのかを実装レベルで突き詰めてくれるととても嬉しい(KV Cacheが怪しい気がするけど)。
たとえば最近SLMだったらKVCacheしてVRAM食うより計算し直した方が効率良いよ、みたいな研究があったような。そういうことをしたらlocal llmでdeterministicにならないのだろうか。
- Defeating Nondeterminism in LLM Inference, Horace He in collaboration with others at Thinking Machines, 2025.09
においてvLLMを用いた場合にDeterministicな推論をするための解決方法が提案されている。
[Paper Note] A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility, Andreas Hochlehnert+, COLM'25
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #SmallModel #COLM #PostTraining #Selected Papers/Blogs #In-Depth Notes #KeyPoint Notes #Initial Impression Notes Issue Date: 2025-04-13 GPT Summary- 推論は言語モデルの重要な課題であり、進展が見られるが、評価手法には透明性や堅牢性が欠けている。本研究では、数学的推論ベンチマークが実装の選択に敏感であることを発見し、標準化された評価フレームワークを提案。再評価の結果、強化学習アプローチは改善が少なく、教師ありファインチューニング手法は強い一般化を示した。再現性を高めるために、関連するコードやデータを公開し、今後の研究の基盤を築く。 Comment
元ポスト:
SLMをmath reasoning向けにpost-trainingする場合、評価の条件をフェアにするための様々な工夫を施し評価をしなおした結果(Figure1のように性能が変化する様々な要因が存在する)、
RL(既存研究で試されているもの)よりも(大規模モデルからrejection samplingしたreasoning traceを用いて)SFTをする方が同等か性能が良く(Table3)、
結局のところ(おそらく汎化性能が低いという意味で)reliableではなく、
かつ(おそらく小規模なモデルでうまくいかないという意味での)scalableではないので、reliableかつscalableなRL手法が不足しているとのこと。
※ 本論文で分析されているのは<=10B以下のSLMである点に注意。10B以上のモデルで同じことが言えるかは自明ではない。
※ DAPO, VAPOなどについても同じことが言えるかも自明ではない。
※ DeepSeek-R1のtechnical reportにおいて、小さいモデルにGRPOを適用してもあまり効果が無かったことが既に報告されている。
- DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01
- DeepSeek-R1, DeepSeek, 2025.01
個々のpost-trainingされたRLモデルが具体的にどういう訓練をしたのかは追えていないが、DAPOやDr. GRPO, VAPOの場合はどうなるんだろうか?
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
- [Paper Note] VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, Yu Yue+, arXiv'25, 2025.04
- [Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
Rewardの設定の仕方はどのような影響があるのだろうか(verifiable rewardなのか、neuralモデルによるrewardなのかなど)?
学習のさせ方もどのような影響があるのだろうか(RLでカリキュラムlearningにした場合など)?
検証しているモデルがそれぞれどのような設定で学習されているかまでを見ないとこの辺はわからなそう。
ただなんとなーくの直感だと、SLMを賢くしたいという場合は何らかの賢いモデルの恩恵に預かると有利なケースが多く(SFTの場合はそれが大規模なモデルから蒸留したreasoning trace)、SLM+RLの場合はPRMのような思考プロセスを評価してRewardに反映させるようなものを利用しないと、少なくとも小規模なLLMをめちゃ賢くします〜というのはきついんじゃないかなあという感想ではある。
ただ、結局SLMという時点で多くの場合、より賢いパラメータ数の多いLLMが世の中には存在するあるはずなので、RLしないでSFTして蒸留すれば良いんじゃない…?と思ってしまう。
が、多くの場合その賢いLLMはProprietaryなLLMであり、出力を得て自分のモデルをpost-trainingすることは利用規約違反となるため、自前で賢くてパラメータ数の多いLLMを用意できない場合は困ってしまうので、SLMをクソデカパラメータのモデルの恩恵なしで超絶賢くできたら世の中の多くの人は嬉しいよね、とも思う。
(斜め読みだが)
サンプル数が少ない(数十件)AIMEやAMCなどのデータはseedの値にとてもsensitiveであり(Takeaway1, 2)、
それらは10種類のseedを用いて結果を平均すると分散が非常に小さくなるので、seedは複数種類利用して平均の性能を見た方がreliableであり(Takeaway3)
temperatureを高くするとピーク性能が上がるが分散も上がるため再現性の課題が増大するが、top-pを大きくすると再現性の問題は現れず性能向上に寄与し
既存研究のモデルのtemperatureとtop-pを変化させ実験するとperformanceに非常に大きな変化が出るため、モデルごとに最適な値を選定して比較をしないとunfairであることを指摘 (Takeaway4)。
また、ハードウェアの面では、vLLMのようなinference engineはGPU typeやmemoryのconfigurationに対してsensitiveでパフォーマンスが変わるだけでなく、
評価に利用するフレームワークごとにinference engineとprompt templateが異なるためこちらもパフォーマンスに影響が出るし (Takeaway5)、
max output tokenの値を変化させると性能も変わり、prompt templateを利用しないと性能が劇的に低下する (Takeaway6)。
これらのことから著者らはreliableな評価のために下記を提案しており (4.1節; 後ほど追記)、
実際にさまざまな条件をfair comparisonとなるように標準化して評価したところ(4.2節; 後ほど追記)
上の表のような結果となった。この結果は、
- DeepSeekR1-DistilledをRLしてもSFTと比較したときに意味のあるほどのパフォーマンスの向上はないことから、スケーラブル、かつ信頼性のあるRL手法がまだ不足しており
- 大規模なパラメータのモデルのreasoning traceからSFTをする方法はさまざまなベンチマークでロバストな性能(=高い汎化性能)を持ち、RLと比べると現状はRLと比較してよりパラダイムとして成熟しており
- (AIME24,25を比較するとSFTと比べてRLの場合performanceの低下が著しいので)RLはoverfittingしやすく、OODなベンチマークが必要
しっかりと評価の枠組みを標準化してfair comparisonしていかないと、RecSys業界の二の舞になりそう(というかもうなってる?)。
またこの研究で分析されているのは小規模なモデル(<=10B)に対する既存研究で用いられた一部のRL手法や設定の性能だけ(真に示したかったらPhisics of LLMのような完全にコントロール可能なサンドボックスで実験する必要があると思われる)なので、DeepSeek-R1のように、大規模なパラメータ(数百B)を持つモデルに対するRLに関して同じことが言えるかは自明ではない点に注意。
openreview: https://openreview.net/forum?id=90UrTTxp5O#discussion
最近の以下のようなSFTはRLの一つのケースと見做せるという議論を踏まえるとどうなるだろうか
- [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, ICLR'26, 2025.08
- [Paper Note] Towards a Unified View of Large Language Model Post-Training, Xingtai Lv+, arXiv'25
[Paper Note] Seed1.5-Thinking: Advancing Superb Reasoning Models with Reinforcement Learning, ByteDance Seed+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #Reasoning #OpenWeight #One-Line Notes #Initial Impression Notes Issue Date: 2025-04-12 GPT Summary- Seed1.5-Thinkingは、応答前に思考を経て推論する新しい手法で、AIME 2024で86.7、Codeforcesで55.0、GPQAで77.3といった性能を達成。非推論タスクでも優れた一般化能力を発揮し、DeepSeek R1を勝率で8%上回る。比較的小型の専門家の混成モデルで、200億の活性化パラメータと2000億の総パラメータを持つ。新たな内部ベンチマークBeyondAIMEとCodeforcesも公開予定。 Comment
DeepSeek-R1を多くのベンチで上回る200B, 20B activated paramのreasoning model
最近のテキストのOpenWeightLLMはAlibaba, DeepSeek, ByteDance, Nvidiaの4強という感じかな…?(そのうちOpenAIがオープンにするReasoning Modelも入ってきそう)。
[Paper Note] Hallucination Mitigation using Agentic AI Natural Language-Based Frameworks, Diego Gosmar+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #AIAgents #Hallucination Issue Date: 2025-04-11 GPT Summary- 複数の専門AIエージェントを協調させて生成系AIモデルの幻覚を緩和する研究。自然言語処理(NLP)を用いてエージェント間の相互作用を促進し、300以上の幻覚を誘発するプロンプトを導入。二次・三次エージェントが出力を検討し、異なるモデルを活用して主張を検出、免責事項を追加。新たに設計されたKPIを用いて幻覚的行動の変化を定量化。OVONフレームワークにより文脈情報を転送し、テキストを洗練する。これにより、幻覚の緩和に有望な成果が得られ、AIコミュニティ内での信頼が向上することを示唆。 Comment
元ポスト:
[Paper Note] Identifying and Evaluating Inactive Heads in Pretrained LLMs, Pedro Sandoval-Segura+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #Attention #AttentionSinks #Author Thread-Post Issue Date: 2025-04-09 GPT Summary- アテンションはLLMsの核心であり、異なるヘッドが入力トークンに焦点を当てる役割を果たすが、最初のトークンに過剰な注意が向けられるアテンションシンクが存在する。これにより、非活性なヘッドが多く、計算の冗長性が生じる。12のスコア関数を用いて非活性ヘッドを評価し、平均して12%以上が非活性であることを確認。特に、ヘッド出力の平均ノルムによる測定が、従来の注意ウェイトのみのスコアよりも効果的に非活性ヘッドを特定することを示した。また、ファインチューニングの影響は小さいが、モデルのスケールが異なると異なるアテンション挙動を示す可能性がある。 Comment
元ポスト:
[Paper Note] VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, Yu Yue+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#MachineLearning #ReinforcementLearning #Reasoning #LongSequence #Initial Impression Notes Issue Date: 2025-04-08 GPT Summary- VAPO(価値ベースの拡張近接ポリシー最適化フレームワーク)は、推論モデルに特化した新しいフレームワークを提案し、AIME 2024データセットで最先端のスコア60.4を達成。VAPOは従来手法を10ポイント以上上回り、わずか5,000ステップで安定した性能を実現。長い連鎖思考推論における課題を特定し、体系的な設計で効果的に対処することで、性能向上に寄与することを示した。 Comment
同じくByteDanceの
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
を上回る性能
元ポスト:
以下のブログで紹介されている:
- Reinforcement Learning from Human Feedback, Nathan Lambert, 2026.03
[Paper Note] KAA: Kolmogorov-Arnold Attention for Enhancing Attentive Graph Neural Networks, Taoran Fang+, ICLR'25
Paper/Blog Link My Issue
#NLP #Attention #Architecture #ICLR Issue Date: 2025-04-07 GPT Summary- 注意GNNにおけるスコアリングプロセスの理解が不足している中、本研究ではコルモゴロフ・アルノルド注意(KAA)を提案し、スコアリング関数を統一。KAAはKANアーキテクチャを統合し、ほぼすべての注意GNNに適用可能で、表現力が向上。実験により、KAA強化スコアリング関数が元のものを一貫して上回り、最大20%以上の性能向上を達成した。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=atXCzVSXTJ
[Paper Note] XAttention: Block Sparse Attention with Antidiagonal Scoring, Ruyi Xu+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #Attention #Architecture #ICML Issue Date: 2025-04-07 GPT Summary- ブロック疎注意を用いてトランスフォーマーモデルの長文脈推論を高速化するフレームワークXAttentionを提案。これにより、注意行列の反対角線の値を用いて非必須ブロックを正確に識別し、高いスパース性を実現。従来の手法と同等の精度を保ちながら、計算コストを最大13.5倍削減。LCTMsの効率的な展開を可能にする。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=KG6aBfGi6e
[Paper Note] Slim attention: cut your context memory in half without loss -- K-cache is all you need for MHA, Nils Graef+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #Attention #Architecture Issue Date: 2025-04-07 GPT Summary- スリムアテンションは、MHAを持つトランスフォーマーの文脈メモリを半分に縮小し、推論を最大2倍高速化する。標準のアテンションと同じ数学的実装のため、精度を損なわずにロスレスにメモリを圧縮。エンコーダ-デコーダモデルでは文脈メモリの更なる削減が可能で、Whisperモデルでは文脈メモリを8分の1に、T5-11Bモデルでは32倍のメモリ削減を実現。 Comment
元ポスト:
[Paper Note] CREAM: Consistency Regularized Self-Rewarding Language Models, Zhaoyang Wang+, ICLR'25
Paper/Blog Link My Issue
#NLP #Alignment #SelfImprovement #ICLR #RewardHacking #Initial Impression Notes Issue Date: 2025-04-06 GPT Summary- 自己報酬型LLMは、LLM-as-a-Judgeを用いてアラインメント性能を向上させるが、報酬とランク付けの正確性が問題。小規模LLMの実証結果は、自己報酬の改善が反復後に減少する可能性を示唆。これに対処するため、一般化された反復的好みファインチューニングフレームワークを定式化し、正則化を導入。CREAMを提案し、報酬の一貫性を活用して信頼性の高い好みデータから学習。実証結果はCREAMの優位性を示す。 Comment
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
を改善した研究
OpenReview: https://openreview.net/forum?id=Vf6RDObyEF
この方向性の研究はおもしろい
[Paper Note] When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
Paper/Blog Link My Issue
#NLP #Attention #ICLR #AttentionSinks #read-later #Selected Papers/Blogs #One-Line Notes #needs-revision #Author Thread-Post Issue Date: 2025-04-05 GPT Summary- 言語モデルにおける「アテンションシンク」は、意味的に重要でないトークンに大きな注意を割り当てる現象であり、さまざまな入力に対して小さなモデルでも普遍的に存在することが示された。アテンションシンクは事前学習中に出現し、最適化やデータ分布、損失関数がその出現に影響を与える。特に、アテンションシンクはキーのバイアスのように機能し、情報を持たない追加のアテンションスコアを保存することがわかった。この現象は、トークンがソフトマックス正規化に依存していることから部分的に生じており、正規化なしのシグモイドアテンションに置き換えることで、アテンションシンクの出現を防ぐことができる。 Comment
Sink Rateと呼ばれる、全てのheadのFirst Tokenに対するattention scoreのうち(layer l * head h個存在する)、どの程度の割合のスコアが閾値を上回っているかを表す指標を提案
(後ほど詳細を追記する)
- [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究
著者ポスト(openai-gpt-120Bを受けて):
openreview: https://openreview.net/forum?id=78Nn4QJTEN
[Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
Paper/Blog Link My Issue
#Analysis #NLP #Attention #AttentionSinks #COLM #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-04-05 GPT Summary- LLMsは最初のトークンに強く注意を向ける「アテンションシンク」を示し、そのメカニズムが過剰混合を避ける方法を理論的・実証的に探求。コンテキストの長さやデータのパッキングがシンクの挙動に与える影響を実験で示し、アテンションパターンの理解を深めることを目指す。 Comment
元ポスト:
Attention Sinkによって、トークンの情報がover-mixingされることが抑制され、Decoder-only LLMの深い層のrepresentationが均一化されることを抑制する(=promptの摂動にロバストになる)ことが示された模様。
Gemma7Bにおいて、prompt中のトークン一語を置換した後に、Attention Sink(
openreview: https://openreview.net/forum?id=tu4dFUsW5z#discussion
[Paper Note] Fundamental Limits of Perfect Concept Erasure, Somnath Basu Roy Chowdhury+, AISTATS'25
Paper/Blog Link My Issue
#NLP #ConceptErasure #KnowledgeEditing #AISTATS #Author Thread-Post Issue Date: 2025-04-03 GPT Summary- 概念消去は、性別や人種などの情報を消去しつつ元の表現を保持するタスクであり、公平性の達成やモデルのパフォーマンスの解釈に役立つ。従来の技術は消去の堅牢性を重視してきたが、有用性とのトレードオフが存在する。本研究では、情報理論的視点から概念消去の限界を定量化し、完璧な消去を達成するためのデータ分布と消去関数の制約を調査。提案する消去関数が理論的限界を達成し、GPT-4を用いたデータセットで既存手法を上回ることを示した。 Comment
元ポスト:
[Paper Note] What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models, Qiyuan Zhang+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Survey #NLP #Test-Time Scaling #One-Line Notes #Initial Impression Notes Issue Date: 2025-04-02 GPT Summary- テスト時スケーリング(TTS)が大規模言語モデル(LLMs)の問題解決能力を向上させることが示されているが、体系的な理解が不足している。これを解決するために、TTS研究の4つのコア次元に基づく統一的なフレームワークを提案し、手法や応用シナリオのレビューを行う。TTSの発展の軌跡を抽出し、実践的なガイドラインを提供するとともに、未解決の課題や将来の方向性についての洞察を示す。 Comment
元ポスト:
とてつもない量だ…網羅性がありそう。
What to Scaleがよくあるself
consistency(Parallel Scaling), STaR(Sequential Scailng), Tree of Thought(Hybrid Scaling), DeepSeek-R1, o1/3(Internal Scaling)といった分類で、How to ScaleがTuningとInferenceに分かれている。TuningはLong CoTをSFTする話や強化学習系の話(GRPOなど)で、InferenceにもSelf consistencyやらやらVerificationやら色々ありそう。良さそう。
[Paper Note] Multi-Token Attention, Olga Golovneva+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #Transformer #Attention #Architecture #COLM #One-Line Notes #Author Thread-Post Issue Date: 2025-04-02 GPT Summary- 新しいアテンション手法であるMulti-Token Attention(MTA)を提案し、複数のクエリとキーのベクトルを同時に用いることで、より精密な関連部分の特定を可能にします。畳み込み処理を適用することで、近接するトークンの相互作用を強化し、豊かでニュアンスのある情報の利用を実現。広範な評価により、MTAが標準的な言語モデルタスクにおいてTransformerを超える性能を発揮することを示しました。 Comment
元ポスト:
従来のMulti Head Attentionでは、単体のQKのみを利用していたけど、複数のQKの情報を畳み込んで活用できるようにして、Headも畳み込みで重要な情報がより伝搬されるようにして、GroupNormalizationをかけたらPerplexityの観点でDifferential Transformerを上回ったよ、という話な模様。
- [Paper Note] Group Normalization, Yuxin Wu+, arXiv'18, 2018.03
- [Paper Note] Differential Transformer, Tianzhu Ye+, N/A, ICLR'25
openreview: https://openreview.net/forum?id=Z3L35tQTEg
[Paper Note] Training Software Engineering Agents and Verifiers with SWE-Gym, Jiayi Pan+, ICML'25
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #ICML #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Environment Issue Date: 2025-04-02 GPT Summary- SWE-Gymを提案し、2,438件の実世界のPythonタスクを含む環境を構築。言語モデルに基づくSWEエージェントを訓練し、SWE-Benchで最大19%の解決率向上を達成。微調整されたエージェントは新たな最先端の性能を示し、SWE-Gymやモデル、エージェントの軌跡を公開。 Comment
SWE-Benchとは完全に独立したより広範な技術スタックに関連するタスクに基づくSWEベンチマーク
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
SWE-Benchと比べて実行可能な環境と単体テストが提供されており、単なるベンチマークではなくエージェントを訓練できる環境が提供されている点が大きく異なるように感じる。
[Paper Note] Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, FSE'25, 2024.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #AIAgents #SoftwareEngineering #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-04-02 GPT Summary- 最近のLLMの進展により、ソフトウェア開発タスクの自動化が進んでいるが、複雑なエージェントアプローチの必要性に疑問が生じている。これに対し、Agentlessというエージェントレスアプローチを提案し、シンプルな三段階プロセスで問題を解決。SWE-bench Liteベンチマークで最高のパフォーマンスと低コストを達成。研究は自律型ソフトウェア開発におけるシンプルで解釈可能な技術の可能性を示し、今後の研究の方向性を刺激することを目指している。 Comment
日本語解説: https://note.com/ainest/n/nac1c795e3825
LLMによる計画の立案、環境からのフィードバックによる意思決定などの複雑なワークフローではなく、Localization(階層的に問題のある箇所を同定する)とRepair(LLMで複数のパッチ候補を生成する)、PatchValidation(再現テストと回帰テストの両方を通じて結果が良かったパッチを選ぶ)のシンプルなプロセスを通じてIssueを解決する。
これにより、低コストで高い性能を達成している、といった内容な模様。
Agentlessと呼ばれ手法だが、preprint版にあったタイトルの接頭辞だった同呼称がproceeding版では無くなっている。
[Paper Note] Inside-Out: Hidden Factual Knowledge in LLMs, Zorik Gekhman+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Analysis #NLP #COLM #FactualKnowledge Issue Date: 2025-04-01 GPT Summary- 大規模言語モデル(LLMs)が内部に保持する事実知識が、出力される知識量を上回るかどうかを評価するためのフレームワークを提案。知識を定量化するために、正解-不正解ペアの割合を基準にし、情報としてトークンレベルの確率や中間計算を用いる。ケーススタディで3つのLLMを用いた結果、内部知識が外部知識を平均40%上回ることが示された。また、正解が内在していても頻繁に出力されない場合が確認され、これはLLMsの生成能力の限界を示唆する。最終的には、特定の回答が一貫して高く評価される可能性が示された。 Comment
元ポスト:
※ 現在は削除済みなようである。
openreview: https://openreview.net/forum?id=f7GG1MbsSM
[Paper Note] Qwen2.5-Omni Technical Report, Jin Xu+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #Speech #OpenWeight #2D (Image) #3D (Video) #Omni #One-Line Notes #Reference Collection #audio #text Issue Date: 2025-03-31 GPT Summary- Qwen2.5-Omniは、テキスト、画像、音声、映像を同時に認識し、自然な音声応答をストリーミング生成するエンドツーエンドのマルチモーダルモデルです。音声と映像の同期には新しい位置埋め込み手法TMRoPEを導入し、Thinker-Talkerアーキテクチャにより干渉を避けつつ同時生成を実現。ストリーミング音声トークンのデコードにはスライディングウィンドウDiTを用いて初期遅延を削減。Qwen2.5-Omniは、マルチモーダルベンチマークで最先端の性能を示し、音声生成の自然さにおいて既存手段を上回ります。 Comment
Qwen TeamによるマルチモーダルLLM。テキスト、画像、動画音声をinputとして受け取り、テキスト、音声をoutputする。
weight:
https://huggingface.co/collections/Qwen/qwen25-omni-67de1e5f0f9464dc6314b36e
[Paper Note] Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Metrics #NLP #GenerativeAI #Evaluation #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2025-03-31 GPT Summary- 新しい指標「50%-タスク完了時間ホライズン」を提案し、AIモデルの能力を人間の観点から定量化。Claude 3.7 Sonnetは約50分の時間ホライズンを持ち、AIの能力は2019年以降約7か月ごとに倍増。信頼性や論理的推論の向上が要因とされ、5年以内にAIが多くのソフトウェアタスクを自動化できる可能性を示唆。 Comment
元ポスト:
確かに線形に見える。てかGPT-2と比べるとAIさん進化しすぎである…。
利用したデータセットは
- HCAST: 46のタスクファミリーに基づく97種類のタスクが定義されており、たとえばサイバーセキュリティ、機械学習、ソフトウェアエンジニアリング、一般的な推論タスク(wikipediaから事実情報を探すタスクなど)などがある
- 数分で終わるタスク: 上述のwikipedia
- 数時間で終わるタスク: Pytorchのちょっとしたバグ修正など
- 数文でタスクが記述され、コード、データ、ドキュメント、あるいはwebから入手可能な情報を参照可能
- タスクの難易度としては当該ドメインに数年間携わった専門家が解ける問題
- RE-Bench Suite
- 7つのopen endedな専門家が8時間程度を要するMLに関するタスク
- e.g., GPT-2をQA用にFinetuningする, Finetuningスクリプトが与えられた時に挙動を変化させずにランタイムを可能な限り短縮する、など
- [RE-Bench Technical Report](
https://metr.org/AI_R_D_Evaluation_Report.pdf)のTable2等を参照のこと
- SWAA Suite: 66種類の1つのアクションによって1分以内で終わるソフトウェアエンジニアリングで典型的なタスク
- 1分以内で終わるタスクが上記データになかったので著者らが作成
であり、画像系やマルチモーダルなタスクは含まれていない。
タスクと人間がタスクに要する時間の対応に関するサンプルは下記
タスク-エージェントペアごとに8回実行した場合の平均の成功率。確かにこのグラフからはN年後には人間で言うとこのくらいの能力の人がこのくらい時間を要するタスクが、このくらいできるようになってます、といったざっくり感覚値はなかなか想像できない。
成功率とタスクに人間が要する時間に関するグラフ。ロジスティック関数でfittingしており、赤い破線が50% horizon。Claude 3.5 Sonnet (old)からClaude 3.7 Sonnetで50% horizonは18分から59分まで増えている。実際に数字で見るとイメージが湧きやすくおもしろい。
こちらで最新モデルも随時更新される:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
[Paper Note] RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning, Sichun Luo+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #NLP #RAG(RetrievalAugmentedGeneration) #Reasoning #Initial Impression Notes Issue Date: 2025-03-27 GPT Summary- RALLRec+は、LLMsを用いてレコメンダーシステムのretrievalとgenerationを強化する手法。retrieval段階では、アイテム説明を生成し、テキスト信号と協調信号を結合。生成段階では、推論LLMsを評価し、知識注入プロンプティングで汎用LLMsと統合。実験により、提案手法の有効性が確認された。 Comment
元ポスト:
Reasoning LLMをRecSysに応用する初めての研究(らしいことがRelated Workに書かれている)
arxivのadminより以下のコメントが追記されている
> arXiv admin note: substantial text overlap with arXiv:2502.06101
コメント中の研究は下記である
- [Paper Note] ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation, Jianghao Lin+, WWW'24
[Paper Note] Scaling Evaluation-time Compute with Reasoning Models as Process Evaluators, Seungone Kim+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #LLM-as-a-Judge #Test-Time Scaling #Initial Impression Notes #Author Thread-Post Issue Date: 2025-03-27 GPT Summary- LMの出力品質評価が難しくなっている中、計算を増やすことで評価能力が向上するかを検討。推論モデルを用いて応答全体と各ステップを評価し、推論トークンの生成が評価者のパフォーマンスを向上させることを確認。再ランク付けにより、評価時の計算増加がLMの問題解決能力を向上させることを示した。 Comment
元ポスト:
LLM-as-a-JudgeもlongCoT+self-consistencyで性能が改善するらしい。
[Paper Note] Overtrained Language Models Are Harder to Fine-Tune, Jacob Mitchell Springer+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #Supervised-FineTuning (SFT) #ICLR #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-03-27 GPT Summary- 大規模言語モデルの事前学習において、トークン予算の増加がファインチューニングを難しくし、パフォーマンス低下を引き起こす「壊滅的な過学習」を提唱。3Tトークンで事前学習されたOLMo-1Bモデルは、2.3Tトークンのモデルに比べて2%以上の性能低下を示す。実験と理論分析により、事前学習パラメータの感度の増加が原因であることを示し、事前学習設計の再評価を促す。 Comment
著者によるポスト:
事前学習のトークン数を増やすとモデルのsensitivityが増し、post-trainingでのパフォーマンスの劣化が起こることを報告している。事前学習で学習するトークン数を増やせば、必ずしもpost-training後のモデルの性能がよくなるわけではないらしい。
ICLR'25のOutstanding Paperに選ばれた模様:
きちんと読んだ方が良さげ。
[Paper Note] Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate, Yubo Wang+, COLM'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #COLM #PostTraining #One-Line Notes #Author Thread-Post Issue Date: 2025-03-25 GPT Summary- 批評ファインチューニング(CFT)は、言語モデルがノイズのある応答を批評することを学ぶ新しい戦略で、従来の監視付きファインチューニング(SFT)に挑戦します。CFTは人間の学習プロセスにインスパイアを受け、深い分析を促進します。WebInstructから構築した50Kサンプルのデータセットを用いて、CFTは複数のベースモデルでSFTに対して4-10%の性能向上を示しました。特に、Qwen2.5-Math-CFTは少ないトレーニングで強力な競合と同等の性能を発揮し、CFTの堅牢性も確認されました。CFTは言語モデルの推論を進展させる効果的な手法であると主張します。 Comment
元ポスト:
Critique Fine-Tuning (CFT) を提案。CFTでは、query x, noisy response y [^1] が与えられたときに、それに対する批評 cを学習する。cはgivenではないので、GPT4oのような強力なモデルによって合成する。

目的関数は以下。[x; y] がgivenな時にcを生成する確率を最大化する。シンプル。

RLを用いた手法との比較。1/10程度のデータ量、1/100程度のGPU時間で同等の性能を達成できる。

[^1]: 本論文で利用しているWebInstructからサンプリングしたデータでは、たとえば約50%程度のyが正解, 残りは不正解(程度のnoisyデータを利用している)
[Paper Note] Thinking Machines: A Survey of LLM based Reasoning Strategies, Dibyanayan Bandyopadhyay+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Survey #NLP #Reasoning #Initial Impression Notes Issue Date: 2025-03-23 GPT Summary- 大規模言語モデル(LLMs)は優れた言語能力を持つが、推論能力との間にギャップがある。推論はAIの信頼性を高め、医療や法律などの分野での適用に不可欠である。最近の強力な推論モデルの登場により、LLMsにおける推論の研究が重要視されている。本論文では、既存の推論技術の概要と比較を行い、推論を備えた言語モデルの体系的な調査と現在の課題を提示する。 Comment
元ポスト:
RL, Test Time Compute, Self-trainingの3種類にカテゴライズされている。また、各カテゴリごとにより細分化されたツリーが論文中にある。
[Paper Note] Compute Optimal Scaling of Skills: Knowledge vs Reasoning, Nicholas Roberts+, ACL'25 Findings, 2025.03
Paper/Blog Link My Issue
#Pretraining #NLP #ACL #Scaling Laws #Findings #Initial Impression Notes Issue Date: 2025-03-23 GPT Summary- スケーリング法則はLLM開発において重要であり、特に計算最適化によるトレードオフが注目されている。本研究では、スケーリング法則が知識や推論に基づくスキルに依存することを示し、異なるデータミックスがスケーリング挙動に与える影響を調査した。結果、知識とコード生成のスキルは根本的に異なるスケーリング挙動を示し、誤指定された検証セットが計算最適なパラメータ数に約50%の影響を与える可能性があることが明らかになった。 Comment
元ポスト:
知識を問うQAのようなタスクはモデルのパラメータ量が必要であり、コーディングのようなReasoningに基づくタスクはデータ量が必要であり、異なる要素に依存してスケールすることを示している研究のようである。
直感的な理解としては、
多くの知識はMLP(だけではないが)に格納されているとされており、1パラメータあたりに格納可能な知識量がある程度決まっているため、知識が必要なタスクはパラメータ数が必要であり、
Reasoningのようなタスクはどれだけ学習データ側でReasoningのパターンを学習できるかに性能が依存するため、データ量が必要、
というものになるのかなという気がする。
[Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#MachineLearning #NLP #Reasoning #GRPO #read-later #KeyPoint Notes Issue Date: 2025-03-22 GPT Summary- DeepSeek-R1-Zeroは、RLを用いてLLMsの推論能力を向上させる手法を示した。本研究では、ベースモデルとRLの影響を分析し、DeepSeek-V3-Baseが「アハ体験」を示す一方で、Qwen2.5が強力な推論能力を持つことを発見。GRPOの最適化バイアスを特定し、Dr. GRPOを導入してトークン効率を改善。7BベースモデルでAIME 2024において43.3%の精度を達成するR1-Zeroレシピを提案。 Comment
関連研究:
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
解説ポスト:
解説ポスト(と論文中の当該部分)を読むと、
- オリジナルのGRPOの定式では2つのバイアスが生じる:
- response-level length bias: 1/|o_i| でAdvantageを除算しているが、これはAdvantageが負の場合(つまり、誤答が多い場合)「長い応答」のペナルティが小さくなるため、モデルが「長い応答」を好むバイアスが生じる。一方で、Advantageが正の場合(正答)は「短い応答」が好まれるようになる。
- question-level difficulty bias: グループ内の全ての応答に対するRewardのstdでAdvantageを除算しているが、stdが小さくなる問題(すなわち、簡単すぎるor難しすぎる問題)をより重視するような、問題に対する重みづけによるバイアスが生じる。
- aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
- これまではoutput lengthを増やすことが性能改善の鍵だと思われていたが、この論文では必ずしもそうではなく、self-reflection無しの方が有りの場合よりもAcc.が高い場合があることを示している(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様
あとで読む
(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:
[Paper Note] Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models, Yang Sui+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #Reasoning #Overthinking #One-Line Notes Issue Date: 2025-03-22 GPT Summary- 本論文では、LLMsにおける効率的な推論の進展を体系的に調査し、以下の主要な方向に分類します:(1) モデルベースの効率的推論、(2) 推論出力ベースの効率的推論、(3) 入力プロンプトベースの効率的推論。特に、冗長な出力による計算オーバーヘッドを軽減する方法を探求し、小規模言語モデルの推論能力や評価方法についても議論します。 Comment
Reasoning Modelにおいて、Over Thinking現象(不要なreasoning stepを生成してしまう)を改善するための手法に関するSurvey。
下記Figure2を見るとよくまとまっていて、キャプションを読むとだいたい分かる。なるほど。
Length Rewardについては、
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
で考察されている通り、Reward Hackingが起きるので設計の仕方に気をつける必要がある。
元ポスト:
各カテゴリにおけるliteratureも見やすくまとめられている。必要に応じて参照したい。
[Paper Note] Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation, Junhao Zhang+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #Dataset #LongSequence #ContextEngineering Issue Date: 2025-03-20 GPT Summary- 長い入力と出力の生成に特化したLongInOutBenchを導入し、既存手法の「中間での喪失」問題に対処。Retrieval-Augmented Long-Text Writer(RAL-Writer)を開発し、重要なコンテンツを再表現することで性能を向上。提案手法の有効性をベースラインと比較して示す。 Comment
Lost in the Middleに関する研究。
Lost-in-the-Middleを初めて提起した研究は下記:
- [Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
[Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
Paper/Blog Link My Issue
#MachineLearning #ReinforcementLearning #Reasoning #LongSequence #NeurIPS #GRPO #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2025-03-20 GPT Summary- 推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment
既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。
ちとこれはあとでしっかり読みたい。重要論文。
プロジェクトページ:
https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。
解説ポスト:
コンパクトだが分かりやすくまとまっている。
下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:
色々な研究で広く使われるのを見るようになった。
著者ポスト:
[Paper Note] Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification, Eric Zhao+, ICML'25
Paper/Blog Link My Issue
#NLP #ICML #Test-Time Scaling #Verification #One-Line Notes #SelfVerification #Author Thread-Post Issue Date: 2025-03-18 GPT Summary- サンプリングベースの探索は、複数の候補応答を生成し最良のものを選ぶ手法であり、自己検証によって正確性を確認します。本研究では、この探索のスケーリング傾向を分析し、シンプルな実装がGemini v1.5 Proの推論能力を向上させることを示しました。自己検証の精度向上は、より大きな応答プールからのサンプリングによるもので、応答間の比較が有益な信号を提供することや、異なる出力スタイルが文脈に応じて役立つことを明らかにしました。また、最前線のモデルは初期の検証能力が弱く、進捗を測るためのベンチマークを提案しました。 Comment
元ポスト:
ざっくりしか読めていないが、複数の解答をサンプリングして、self-verificationをさせて最も良かったものを選択するアプローチ。最もverificationスコアが高い解答を最終的に選択したいが、tieの場合もあるのでその場合は追加のpromptingでレスポンスを比較しより良いレスポンスを選択する。これらは並列して実行が可能で、探索とself-verificationを200個並列するとGemini 1.5 Proでo1-previewよりも高い性能を獲得できる模様。Self-consistencyと比較しても、gainが大きい。具体的なアルゴリズムはAlgorithm1を参照のこと。
openreview: https://openreview.net/forum?id=wl3eI4wiE5
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning, Gokul Swamy+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #RLHF #Reference Collection #Initial Impression Notes Issue Date: 2025-03-17 GPT Summary- 基盤モデルのファインチューニングにおいて、報酬モデルを用いた二段階のトレーニング手順が効果的である理由を理論的および実証的に検討。特に、好みデータから単純な報酬モデルを学び、強化学習手続きがそのモデルに最適なポリシーをフィルタリングする能力が、オンラインファインチューニングの優れたパフォーマンスに寄与することが示された。 Comment
元ポスト:
AlignmentのためのPreferenceデータがある時に、そのデータから直接最尤推定してモデルのパラメータを学習するのではなく、報酬モデルを学習して、その報酬モデルを用いてモデルを強化学習することで、なぜ前者よりも(同じデータ由来であるにもかかわらず)優れたパフォーマンスを示すのか、という疑問に対してアプローチしている。
全く中身を読めていないが、生成することと(方策モデル)と検証すること(報酬モデル)の間にギャップがある場合(すなわち、生成と検証で求められる能力が異なる場合)、MLEでは可能なすべてのポリシーを探索することと似たようなことをすることになるが、RLでは事前に報酬モデルを学習しその報酬モデルに対して最適なポリシーを探索するだけなので探索する空間が制限される(=生成と検証のギャップが埋まる)ので、良い解に収束しやすくなる、というイメージなんだろうか。
[Paper Note] A Survey on Post-training of Large Language Models, Guiyao Tie+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Survey #NLP #Supervised-FineTuning (SFT) #Reasoning #Initial Impression Notes Issue Date: 2025-03-15 GPT Summary- 大規模言語モデル(LLMs)は自然言語処理に革命をもたらしたが、専門的な文脈での制約が明らかである。これに対処するため、高度なポストトレーニング言語モデル(PoLMs)が必要であり、本論文ではその包括的な調査を行う。ファインチューニング、アライメント、推論、効率、統合と適応の5つのコアパラダイムにわたる進化を追跡し、PoLMがバイアス軽減や推論能力向上に寄与する方法を示す。研究はPoLMの進化に関する初の調査であり、将来の研究のための枠組みを提供し、LLMの精度と倫理的堅牢性を向上させることを目指す。 Comment
Post Trainingの時間発展の図解が非常にわかりやすい(が、厳密性には欠けているように見える。当該モデルの新規性における主要な技術はこれです、という図としてみるには良いのかもしれない)。
個々の技術が扱うスコープとレイヤー、データの性質が揃っていない気がするし、それぞれのLLMがy軸の単一の技術だけに依存しているわけでもない。が、厳密に図を書いてと言われた時にどう書けば良いかと問われると難しい感はある。
元ポスト:
[Paper Note] Gemini Embedding: Generalizable Embeddings from Gemini, Jinhyuk Lee+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Embeddings #NLP #RepresentationLearning #One-Line Notes Issue Date: 2025-03-12 GPT Summary- Gemini Embeddingは、Geminiの多言語性とコード理解を活かし、高度に一般化可能な埋め込みを生成。事前計算可能なこれらの表現は、分類や検索などの多様なタスクに応用でき、MMTEBでの評価において250以上の言語に対応。従来モデルを大幅に上回る埋め込み品質を示し、特定ドメインモデルを凌駕する性能を達成。 Comment
元ポスト:
世のdecoder-onlyモデルベースのembeddingモデルがどのように作られているか具体的によくわかっていないので読みたい
Geminiのパラメータでbi-directionalなself-attentionを持つtransformer (たとえばBERT)で初期化し、全てのtokenをmean poling (HF BERT ModelのPoolerLayerのようなもの)することでトークンの情報を単一のembeddingに混ぜる。
学習は2段階のfinetuning (pre-finetuning, finetuning)によって、モデルをContrastive Learningする(NCE loss)。
pre-finetuningはnoisyだが大規模なデータ(web上のタイトルとparagraphのペアなど)、そのあとのfinetuningはQAなどの高品質なデータを利用。
[Paper Note] LLM Post-Training: A Deep Dive into Reasoning Large Language Models, Komal Kumar+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Survey #NLP #Supervised-FineTuning (SFT) #Reasoning #Initial Impression Notes Issue Date: 2025-03-04 GPT Summary- LLMは自然言語処理に革命をもたらし、ポストトレーニング手法に焦点を移しつつある。これにより、推論や事実の正確性が向上し、ユーザー意図に合わせた整合が可能に。ファインチューニングや強化学習が性能最適化に寄与し、実世界タスクへの適応力も向上。調査では、ポストトレーニング手法の重要性と、壊滅的忘却や報酬の改ざんへの対策が論じられ、新たな研究方向が提案されている。さらに、分野の進展を追跡するリポジトリも提供。 Comment
非常にわかりやすい。
元ポスト:
[Paper Note] Large Language Diffusion Models, Shen Nie+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #NLP #DiffusionModel #NeurIPS #Reference Collection Issue Date: 2025-03-02 GPT Summary- LLaDAは、自己回帰モデル(ARMs)に代わる拡散モデルであり、ゼロから訓練され、データマスキングを通じて分布をモデル化。広範なベンチマークで強力なスケーラビリティを示し、自己構築したARMベースラインを上回る。特に、LLaDA 8Bは文脈内学習や指示追従能力に優れ、逆詩の完成タスクでGPT-4oを超える性能を発揮。拡散モデルがARMsの実行可能な代替手段であることを示す。 Comment
元ポスト:
参考:
openreview(ICLR'25): https://openreview.net/forum?id=W2tWu0aikL
pj page: https://ml-gsai.github.io/LLaDA-demo/
openreview(NeurIPS'25): https://openreview.net/forum?id=KnqiC0znVF
[Paper Note] Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, Jingyang Yuan+, ACL'25
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #Attention #ACL #read-later #One-Line Notes #Reference Collection Issue Date: 2025-03-02 GPT Summary- 長文コンテキストモデリングのために、計算効率を改善するスパースアテンションメカニズム「NSA」を提案。NSAは動的な階層スパース戦略を用い、トークン圧縮と選択を組み合わせてグローバルなコンテキスト認識とローカルな精度を両立。実装最適化によりスピードアップを実現し、エンドツーエンドのトレーニングを可能にすることで計算コストを削減。NSAはフルアテンションモデルと同等以上の性能を維持しつつ、長シーケンスに対して大幅なスピードアップを達成。 Comment
元ポスト:
ACL'25のBest Paperの一つ:
[Paper Note] From System 1 to System 2: A Survey of Reasoning Large Language Models, Zhong-Zhi Li+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Survey #NLP #Reasoning Issue Date: 2025-02-26 GPT Summary- 人間レベルの知能を達成するためには、迅速なシステム1から意図的なシステム2への推論の洗練が必要。基盤となる大規模言語モデル(LLMs)は迅速な意思決定に優れるが、複雑な推論には深さが欠ける。最近の推論LLMはシステム2の意図的な推論を模倣し、人間のような認知能力を示している。本調査では、LLMの進展とシステム2技術の初期開発を概観し、推論LLMの構築方法や特徴、進化を分析。推論ベンチマークの概要を提供し、代表的な推論LLMのパフォーマンスを比較。最後に、推論LLMの進展に向けた方向性を探り、最新の開発を追跡するためのGitHubリポジトリを維持することを目指す。 Comment
元ポスト:
[Paper Note] SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines, M-A-P Team+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #QuestionAnswering #NeurIPS Issue Date: 2025-02-21 GPT Summary- SuperGPQAを提案し、285の専門分野におけるLLMsの知識と推論能力を評価する新しいベンチマークを構築。Human-LLM協調フィルタリングを用いて、トリビアルな質問を排除。実験結果は、最先端のLLMsに改善の余地があることを示し、人工一般知能とのギャップを強調。大規模なアノテーションプロセスから得た洞察は、今後の研究に対する方法論的ガイダンスを提供。 Comment
元ポスト:
[Paper Note] OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning, Pan Lu+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Tools #NLP #AIAgents #Reasoning #ACL #One-Line Notes Issue Date: 2025-02-20 GPT Summary- OctoToolsは複雑な推論タスクを解決するための訓練不要で拡張可能なマルチエージェントフレームワーク。標準化されたツールカード、プランナー、実行者を導入し、16の多様なタスクでGP4oより平均精度を9.3%向上。AutoGenやLangChainに対しても最大10.6%の改善を示し、タスク計画とツール使用の効果を実証。詳細はサイトに公開。 Comment
元ポスト:
NAACL2025 KnowledgeNLP Workshopでベストペーパーに選出:
ACL2026のOralにaccept:
[Paper Note] NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions, Weizhe Yuan+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #SyntheticData #Reasoning #Distillation #Author Thread-Post Issue Date: 2025-02-19 GPT Summary- 数学やコーディングを含む多様な領域の推論能力を向上させるため、280万問の多様で挑戦的な推論問題を含むデータセットNaturalReasoningを導入。知識蒸留実験により、強力な教師モデルから効果的に推論能力が引き出されることを示し、自己訓練や自己報酬でも有効であることを証明。NaturalReasoningは今後の研究を促進するために公開されている。 Comment
元ポスト:
[Paper Note] Scaling Test-Time Compute Without Verification or RL is Suboptimal, Amrith Setlur+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning Issue Date: 2025-02-18 GPT Summary- 推論時の計算資源を効率的に拡張する方法について、検証ベース(VB)手法が蒸留なし(VF)アプローチよりも優れていることを示す。特に、推論時のトークン長やデータをスケールさせると、VFの最適性が低下し、VB手法が漸近的に成果を上げることが明らかになる。3B・8B・32B規模のLLMを用いた実験により、検証が計算資源のスケーリングに必要不可欠であることが確認された。 Comment
元ポスト:
関連:
- [Paper Note] s1: Simple test-time scaling, Niklas Muennighoff+, EMNLP'25, 2025.01
[Paper Note] LLM Pretraining with Continuous Concepts, Jihoon Tack+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Pretraining #NLP #ICLR #Concept (LLM PreTraining) #Author Thread-Post Issue Date: 2025-02-14 GPT Summary- 次のトークン予測を最適化する大規模言語モデルに、新たに提案するCoCoMixフレームワークを導入。これは、離散的な予測と連続概念を交互に混ぜ込む手法で、隠れ表現を改善。実験により、サンプル効率が高く、複数のベンチマークで標準的手法を上回る性能を確認。概念学習と交互配置が性能向上に重要で、モデルの内部推論を透明にする機能も提供。 Comment
著者による一言解説:
openreview: https://openreview.net/forum?id=wTGcb3DxOn
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling, Runze Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #Test-Time Scaling Issue Date: 2025-02-12 GPT Summary- Test-Time Scaling (TTS)は、LLMsの性能向上に寄与する手法であり、ポリシーモデルやPRM、問題の難易度がTTSに与える影響を分析。実験により、最適なTTS戦略はこれらの要素に依存し、小型モデルが大型モデルを上回る可能性を示した。具体的には、1BのLLMが405BのLLMを超える結果を得た。これにより、TTSがLLMsの推論能力を向上させる有望なアプローチであることが示された。
[Paper Note] DeepRAG: Thinking to Retrieve Step by Step for Large Language Models, Xinyan Guan+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-02-12 GPT Summary- LLMの推論能力は高いが、事実的幻覚に制約されている。取得強化生成(RAG)の非効率的なタスク分解や冗長な取得が応答品質を損なう。本研究では、取得強化推論をマルコフ決定過程(MDP)としてモデル化したDeepRAGフレームワークを提案。クエリを動的に分解し、外部知識の検索とパラメトリック推論の選択を行う。実験により、DeepRAGは検索効率と回答の正確性を26.4%向上させることを示した。 Comment
日本語解説。ありがとうございます!
RAGでも「深い検索」を実現する手法「DeepRAG」, Atsushi Kadowaki,
ナレッジセンス - AI知見共有ブログ:
https://zenn.dev/knowledgesense/articles/034b613c9fd6d3
ACECODER: Acing Coder RL via Automated Test-Case Synthesis, Huaye Zeng+, arXiv'25
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SyntheticData #CodeGeneration Issue Date: 2025-02-12 GPT Summary- 本研究では、コードモデルのトレーニングにおける強化学習(RL)の可能性を探求し、自動化された大規模テストケース合成を活用して信頼できる報酬データを生成する手法を提案します。具体的には、既存のコードデータから質問とテストケースのペアを生成し、これを用いて報酬モデルをトレーニングします。このアプローチにより、Llama-3.1-8B-Insで平均10ポイント、Qwen2.5-Coder-7B-Insで5ポイントの性能向上が見られ、7Bモデルが236B DeepSeek-V2.5と同等の性能を達成しました。また、強化学習を通じてHumanEvalやMBPPなどのデータセットで一貫した改善を示し、特にQwen2.5-Coder-baseからのRLトレーニングがHumanEval-plusで25%以上、MBPP-plusで6%の改善をもたらしました。これにより、コーダーモデルにおける強化学習の大きな可能性が示されました。
[Paper Note] Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, Jonas Geiping+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Architecture #NeurIPS #Test-Time Scaling #LatentReasoning Issue Date: 2025-02-10 GPT Summary- 新しい言語モデルアーキテクチャを提案し、潜在空間での暗黙的推論によりテスト時の計算をスケールさせる。再帰ブロックを反復し、任意の深さに展開することで、従来のトークン生成モデルとは異なるアプローチを採用。特別なトレーニングデータを必要とせず、小さなコンテキストウィンドウで複雑な推論を捉える。3.5億パラメータのモデルをスケールアップし、推論ベンチマークでのパフォーマンスを劇的に改善。
[Paper Note] On Teacher Hacking in Language Model Distillation, Daniil Tiapkin+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #Distillation #ICML #TeacherHacking #Reference Collection #Reading Reflections Issue Date: 2025-02-10 GPT Summary- LMのポストトレーニングは、知識蒸留とRLHFに依存し、報酬ハッキングの課題を指摘。教師LMからの「教師ハッキング」が存在することを検証。実験では、固定オフラインデータで教師ハッキングが発生し、多項式収束法則から逸脱することを観測。オンラインデータ生成技術がハッキングを緩和できることを示し、データの多様性が重要な要因であると結論。これにより、LM構築の蒸留の利点と限界が明らかに。 Comment
元ポスト:
自分で蒸留する機会は今のところないが、覚えておきたい。過学習と一緒で、こういう現象が起こるのは想像できる。
openreview: https://openreview.net/forum?id=qxSFIigPug¬eId=CAgFzoMVit
[Paper Note] Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?, Wenzhe Li+, TMLR'25, 2025.02
Paper/Blog Link My Issue
#NLP #AIAgents #TMLR #read-later #Selected Papers/Blogs Issue Date: 2025-02-09 GPT Summary- Self-MoAは、単一の高性能LLMの出力を統合し、従来のMixture-of-Agents(MoA)を上回るアンサンブル手法である。実験では、Self-MoAがAlpacaEval 2.0で6.6%、様々なベンチマークで平均3.8%の改善を示し、新たな最先端性能を達成。MoAの性能は出力品質に敏感で、異なるLLMを混ぜると平均品質が低下することが確認された。さらに、Self-MoAの逐次版も導入し、複数ラウンドにわたって同等の統合効果を提供する。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=K6WwK8URlV
[Paper Note] s1: Simple test-time scaling, Niklas Muennighoff+, EMNLP'25, 2025.01
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #EMNLP #Test-Time Scaling #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-02-07 GPT Summary- 推論時スケーリングは、追加計算資源を使って言語モデルの性能を向上させる新アプローチ。OpenAIのo1モデルの手法が公表されず、再現試行が進む中、シンプルな手法を提案。1000問の小規模データセットs1Kを作成し、推論過程を管理する「予算強制」を導入。これによりモデルは誤った推論を修正し、s1Kで微調整後、o1-previewモデルを最大27%上回る性能を実現。s1-32Bモデルは推論時介入なしで性能を外挿し、AIME24で57%に達する。モデルとデータはオープンソースで提供。 Comment
解説:
[Paper Note] LIMO: Less is More for Reasoning, Yixin Ye+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #DataDistillation #Reasoning #COLM #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2025-02-07 GPT Summary- 限られた訓練データで高度な数学的推論が可能であることを示す。モデルLIMOはAIME24で63.3%、MATH500で95.6%の精度を達成し、従来モデルを大幅に上回る。LIMOは分布外の一般化にも強く、従来のモデルよりも少ないデータで55%の改善を実現。Less-Is-More Reasoning Hypothesis(LIMO仮説)を提案し、事前知識の完全性と戦略的デモンストレーションの効果が推論の質を左右することを示唆。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=T2TZ0RY4Zk#discussion
[Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Reasoning #LongSequence #ICML #RewardHacking #PostTraining #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2025-02-07 GPT Summary- 本研究では、大規模言語モデル(LLMs)における長い思考の連鎖(CoTs)推論のメカニズムを調査し、重要な要因を特定。主な発見は、(1) 教師ありファインチューニング(SFT)は必須ではないが効率を向上させる、(2) 推論能力は計算の増加に伴い現れるが、報酬の形状がCoTの長さに影響、(3) 検証可能な報酬信号のスケーリングが重要で、特に分布外タスクに効果的、(4) エラー修正能力は基本モデルに存在するが、RLを通じて効果的に奨励するには多くの計算が必要。これらの洞察は、LLMsの長いCoT推論を強化するためのトレーニング戦略の最適化に役立つ。 Comment
元ポスト:
元ポストのスレッド中に論文の11個の知見が述べられている。どれも非常に興味深い。DeepSeek-R1のテクニカルペーパーと同様、
- Long CoTとShort CoTを比較すると前者の方が到達可能な性能のupper bonudが高いことや、
- SFTを実施してからRLをすると性能が向上することや、
- RLの際にCoTのLengthに関する報酬を入れることでCoTの長さを抑えつつ性能向上できること、
- 数学だけでなくQAペアなどのノイジーだが検証可能なデータをVerifiableな報酬として加えると一般的なreasoningタスクで数学よりもさらに性能が向上すること、
- より長いcontext window sizeを活用可能なモデルの訓練にはより多くの学習データが必要なこと、
- long CoTはRLによって学習データに類似したデータが含まれているためベースモデルの段階でその能力が獲得されていることが示唆されること、
- aha momentはすでにベースモデル時点で獲得されておりVerifiableな報酬によるRLによって強化されたわけではなさそう、
など、興味深い知見が盛りだくさん。非常に興味深い研究。あとで読む。
[Paper Note] Tulu 3: Pushing Frontiers in Open Language Model Post-Training, Nathan Lambert+, COLM'25, 2024.11
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #OpenWeight #OpenSource #COLM #DPO #PostTraining #read-later #RLVR #Selected Papers/Blogs Issue Date: 2025-02-01 GPT Summary- Tulu 3は、オープンなポストトレーニングモデルのファミリーで、トレーニングデータやレシピを公開し、現代のポストトレーニング技術のガイドを提供します。Llama 3.1を基にし、他のクローズドモデルを上回る性能を達成。新しいトレーニング手法としてSFT、DPO、RLVRを採用し、マルチタスク評価スキームを導入。モデルウェイトやデモ、トレーニングコード、データセットなどを公開し、他のドメインへの適応も可能です。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=i1uGbfHHpH#discussion
[Paper Note] Diverse Preference Optimization, Jack Lanchantin+, ICLR'25, 2025.01
Paper/Blog Link My Issue
#NLP #Alignment #ICLR #DPO #PostTraining #Diversity #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2025-02-01 GPT Summary- Diverse Preference Optimization(DivPO)を提案し、応答の多様性を向上させつつ生成物の品質を維持するオンライン最適化手法を紹介。DivPOは応答のプールから多様性を測定し、希少で高品質な例を選択することで、パーソナ属性の多様性を45.6%、ストーリーの多様性を74.6%向上させる。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=pOq9vDIYev
DPOと同じ最適化方法を使うが、Preference Pairを選択する際に、多様性が増加するようなPreference Pairの選択をすることで、モデルのPost-training後の多様性を損なわないようにする手法を提案しているっぽい。
具体的には、Alg.1 に記載されている通り、多様性の尺度Dを定義して、モデルにN個のレスポンスを生成させRMによりスコアリングした後、RMのスコアが閾値以上のresponseを"chosen" response, 閾値未満のレスポンスを "reject" responseとみなし、chosen/reject response集合を構築する。chosen response集合の中からDに基づいて最も多様性のあるresponse y_c、reject response集合の中から最も多様性のないresponse y_r をそれぞれピックし、prompt xとともにpreference pair (x, y_c, y_r) を構築しPreference Pairに加える、といった操作を全ての学習データ(中のprompt)xに対して繰り返すことで実現する。
DivPO
[Paper Note] SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Analysis #MachineLearning #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #ICML #PostTraining #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-01-30 GPT Summary- SFTとRLの一般化能力の違いを研究し、GeneralPointsとV-IRLを用いて評価。RLはルールベースのテキストと視覚変種に対して優れた一般化を示す一方、SFTは訓練データを記憶し分布外シナリオに苦労。RLは視覚認識能力を向上させるが、SFTはRL訓練に不可欠であり、出力形式を安定させることで性能向上を促進。これらの結果は、複雑なマルチモーダルタスクにおけるRLの一般化能力を示す。 Comment
元ポスト:
[Paper Note] 360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation, Hamed Firooz+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#RecommenderSystems #Personalization #FoundationModel Issue Date: 2025-01-29 GPT Summary- ランキングおよび推奨システムを改善するために、大規模基盤モデルを用いてテキストインターフェースを導入。これにより、複数の予測タスクを同時に扱えるほか、新しい領域への一般化も可能に。360Brew V1.0は150Bパラメータの単一デコーダーモデルで、LinkedInのデータを使用し、30以上の予測タスクにおいて従来の専用モデルと同等以上の性能を示す。 Comment
元ポスト:
[Paper Note] Evolving Deeper LLM Thinking, Kuang-Huei Lee+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #Reasoning #Test-Time Scaling Issue Date: 2025-01-28 GPT Summary- Mind Evolutionに基づく進化的探索戦略を提案し、大規模言語モデルの推論時の計算量をスケールさせる。候補応答を生成、再結合、洗練することで、推論問題を形式化する必要を回避。自然言語計画タスクにおいて、Best-of-NやSequential Revisionと比較し優れた性能を示し、TravelPlannerおよびNatural Planのベンチマークで98%以上の問題インスタンスを解決。 Comment
[Paper Note] Pre-train and Fine-tune: Recommenders as Large Models, Zhenhao Jiang+, WWW'25, 2025.01
Paper/Blog Link My Issue
#RecommenderSystems #WWW Issue Date: 2025-01-28 GPT Summary- ユーザーの興味は時期や地域によって変動するが、既存の推奨システムはこれに対応しきれない。マルチドメイン学習が解決策として考えられるが、産業用システムはデータ量やコストの面で複雑である。そこで推奨システムを大規模な事前学習モデルと捉え、ファインチューニングの手法を提案。情報認識型適応カーネル(IAK)を用いて知識圧縮と知識マッチングの二段階のプロセスを定義し、高い解釈性を持つ手法を設計。広範な実験により効果を確認し、オンラインプラットフォームでの展開によるビジネスへの貢献も報告。ファインチューニングに関連する問題点と対策も提示。 Comment
元ポスト:
[Paper Note] Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks, Brian J Chan+, WWW'25 Short Paper
Paper/Blog Link My Issue
#NLP #RAG(RetrievalAugmentedGeneration) #WWW #One-Line Notes #KV Cache #Short Issue Date: 2025-01-26 GPT Summary- キャッシュ拡張生成(CAG)は、RAGの課題を克服するために提案された手法で、LLMの拡張コンテキストに事前に関連リソースをロードし、検索なしでクエリに応答する。CAGは検索の遅延を排除し、エラーを最小限に抑えつつ、コンテキストの関連性を維持。性能評価では、CAGが従来のRAGを上回るか補完することが示され、特に制約のある知識ベースにおいて効率的な代替手段となることが示唆されている。 Comment
元ポスト:
外部知識として利用したいドキュメントがそこまで大きく無いなら、事前にLLMで全てのKey Valueを計算しておきKV Cacheとして利用可能にしておけば、生成時に検索をすることもなく、contextとして利用して生成できるじゃん、という研究
[Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-01-25 GPT Summary- LLMの進展を追跡するためのベンチマークが不足している中、Humanity's Last Exam(HLE)を導入。HLEは多様な科目を網羅する2,500問のマルチモーダルな学術問題から成り、専門家の手による構築。高度なLLMはHLEで低精度を示し、閉じた回答形式の問題におけるLLMの能力と人間専門家との間のギャップを浮き彫りにしている。HLEは研究と政策立案のために公開されている。 Comment
o1, DeepSeekR1の正解率が10%未満の新たなベンチマーク
[Paper Note] Perspective Transition of Large Language Models for Solving Subjective Tasks, Xiaolong Wang+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #ACL #Findings #One-Line Notes #Initial Impression Notes Issue Date: 2025-01-25 GPT Summary- 視点遷移を通じた推論(RPT)手法により、LLMsが主観的タスクにおいて視点を動的に選択できるようにします。本手法は専門家や第三者の視点を活用し、文脈をより適切に解釈することで、ニュアンスのある回答を提供します。広範な実験により、従来の固定視点手法を大きく上回る成果を示しました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=cFGPlRony5
"Subjective Task"とは例えば「メタファーの認識」や「ダークユーモアの検知」などがあり、これらは定量化しづらい認知的なコンテキストや、ニュアンスや感情などが強く関連しており、現状のLLMではチャレンジングだと主張している。
Subjective Taskでは、Reasoningモデルのように自動的にCoTのpathwayを決めるのは困難で、手動でpathwayを記述するのはチャレンジングで一貫性を欠くとした上で、複数の視点を組み合わせたPrompting(direct perspective, role-perspective, third-person perspectivfe)を実施し、最もConfidenceの高いanswerを採用することでこの課題に対処すると主張している。
イントロしか読めていないが、自動的にCoTのpathwayを決めるのも手動で決めるのも難しいという風にイントロで記述されているが、手法自体が最終的に3つの視点から回答を生成させるという枠組みに則っている(つまりSubjective Taskを解くための形式化できているので、自動的な手法でもできてしまうのではないか?と感じた)ので、イントロで記述されている主張の”難しさ”が薄れてしまっているかも・・・?と感じた。論文が解こうとしている課題の”難しさ”をサポートする材料がもっとあった方がよりmotivationが分かりやすくなるかもしれない、という感想を持った。
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap, Weizhi Zhang+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #Survey #Contents-based Issue Date: 2025-01-06 GPT Summary- コールドスタート問題はレコメンダーシステムの重要な課題であり、新しいユーザーやアイテムのモデル化に焦点を当てている。大規模言語モデル(LLMs)の成功により、CSRに新たな可能性が生まれているが、包括的なレビューが不足している。本論文では、CSRのロードマップや関連文献をレビューし、LLMsが情報を活用する方法を探求することで、研究と産業界に新たな洞察を提供することを目指す。関連リソースはコミュニティのために収集・更新されている。 Comment
元ポスト:
Byte Latent Transformer: Patches Scale Better Than Tokens, Artidoro Pagnoni+, ICML'25 Workshop Tokshop
Paper/Blog Link My Issue
#NLP #ICML #Tokenizer #Workshop #KeyPoint Notes #Byte-level Issue Date: 2025-01-02 GPT Summary- Byte Latent Transformer(BLT)は、バイトレベルのLLMアーキテクチャで、トークン化ベースのLLMと同等のパフォーマンスを実現し、推論効率と堅牢性を大幅に向上させる。BLTはバイトを動的にサイズ変更可能なパッチにエンコードし、データの複雑性に応じて計算リソースを調整する。最大8Bパラメータと4Tトレーニングバイトのモデルでの研究により、固定語彙なしでのスケーリングの可能性が示された。長いパッチの動的選択により、トレーニングと推論の効率が向上し、全体的にBLTはトークン化モデルよりも優れたスケーリングを示す。 Comment
興味深い
図しか見れていないが、バイト列をエンコード/デコードするtransformer学習して複数のバイト列をパッチ化(エントロピーが大きい部分はより大きなパッチにバイト列をひとまとめにする)、パッチからのバイト列生成を可能にし、パッチを変換するのをLatent Transformerで学習させるようなアーキテクチャのように見える。
また、予算によってモデルサイズが決まってしまうが、パッチサイズを大きくすることで同じ予算でモデルサイズも大きくできるのがBLTの利点とのこと。
日本語解説: https://bilzard.github.io/blog/2025/01/01/byte-latent-transformer.html?v=2
OpenReview: https://openreview.net/forum?id=UZ3J8XeRLw
[Paper Note] Preference Discerning with LLM-Enhanced Generative Retrieval, Fabian Paischer+, TMLR'25, 2024.12
Paper/Blog Link My Issue
#RecommenderSystems #Dataset #SessionBased #Personalization #Evaluation #TMLR Issue Date: 2024-12-31 GPT Summary- 逐次推薦システムのパーソナライズを向上させるために、「好みの識別」という新しいパラダイムを提案。大規模言語モデルを用いてユーザーの好みを生成し、包括的な評価ベンチマークを導入。新手法Menderは、既存手法を改善し、最先端の性能を達成。Menderは未観察の人間の好みにも効果的に対応し、よりパーソナライズされた推薦を実現する。コードとベンチマークはオープンソース化予定。 Comment
openreview: https://openreview.net/forum?id=74mrOdhvvT
[Paper Note] Training Large Language Models to Reason in a Continuous Latent Space, Shibo Hao+, COLM'25
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #COLM #PostTraining #read-later #LatentReasoning #One-Line Notes Issue Date: 2024-12-12 GPT Summary- 新しい推論パラダイム「Coconut」を提案し、LLMの隠れ状態を連続的思考として利用。これにより、次の入力を連続空間でフィードバックし、複数の推論タスクでLLMを強化。Coconutは幅優先探索を可能にし、特定の論理推論タスクでCoTを上回る性能を示す。潜在的推論の可能性を探る重要な洞察を提供。 Comment
Chain of Continuous Thought
通常のCoTはRationaleをトークン列で生成するが、Coconutは最終的なhidden stateをそのまま次ステップの入力にすることで、トークンに制限されずにCoTさせるということらしい。あとでしっかり読む
おそらく学習の際に工夫が必要なので既存モデルのデコーディングを工夫してできます系の話ではないかも
OpenReview:
https://openreview.net/forum?id=tG4SgayTtk
ICLR'25にrejectされている。
ざっと最初のレビューに書かれているWeaknessを読んだ感じ
- 評価データが合成データしかなく、よりrealisticなデータで評価した方が良い
- CoTら非常に一般的に適用可能な技術なので、もっと広範なデータで評価すべき
- GSM8Kでは大幅にCOCONUTはCoTに性能が負けていて、ProsQAでのみにしかCoTに勝てていない
- 特定のデータセットでの追加の学習が必要で、そこで身につけたreasoning能力が汎化可能か明らかでない
といった感じに見える
COLM'25 openreview:
https://openreview.net/forum?id=Itxz7S4Ip3#discussion
COLM'25にAccept
Towards Adaptive Mechanism Activation in Language Agent, Ziyang Huang+, COLING'25
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #AIAgents #COLING #PostTraining #One-Line Notes #needs-revision Issue Date: 2024-12-10 GPT Summary- 自己探索によるメカニズム活性化学習(ALAMA)を提案し、固定されたメカニズムに依存せずに適応的なタスク解決を目指す。調和のとれたエージェントフレームワーク(UniAct)を構築し、タスク特性に応じてメカニズムを自動活性化。実験結果は、動的で文脈に敏感なメカニズム活性化の有効性を示す。 Comment
元ポスト:
手法としては、SFTとKTOを活用しpost trainingするようである
- [Paper Note] KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, ICML'24, 2024.02
[Paper Note] Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models, Fei Wang+, ACL'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 GPT Summary- Astute RAGは、外部知識の不完全な取得による問題を解決する新しいアプローチで、LLMsの内部知識と外部知識を適応的に統合し、情報の信頼性に基づいて回答を決定します。実験により、Astute RAGは従来のRAG手法を大幅に上回り、最悪のシナリオでもLLMsのパフォーマンスを超えることが示されました。
How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #MachineLearning #NLP #ICLR #Batch #One-Line Notes #CriticalBatchSize Issue Date: 2024-11-25 GPT Summary- 大規模モデルの訓練には、クリティカルバッチサイズ(CBS)を考慮した並列化戦略が重要である。CBSの測定法を提案し、C4データセットで自己回帰型言語モデルを訓練。バッチサイズや学習率などの要因を調整し、CBSがデータサイズに比例してスケールすることを示した。この結果は、ニューラルネットワークの理論的分析によって支持され、ハイパーパラメータ選択の重要性も強調されている。 Comment
Critical Batch Sizeはモデルサイズにはあまり依存せず、データサイズに応じてスケールする
Critical batch sizeが提案された研究:
- [Paper Note] An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18, 2018.12
LBPE: Long-token-first Tokenization to Improve Large Language Models, Haoran Lian+, ICASSP'25, 2024.11
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #Subword #Tokenizer #KeyPoint Notes Issue Date: 2024-11-12 GPT Summary- LBPEは、長いトークンを優先する新しいエンコーディング手法で、トークン化データセットにおける学習の不均衡を軽減します。実験により、LBPEは従来のBPEを一貫して上回る性能を示しました。 Comment
BPEとは異なりトークンの長さを優先してマージを実施することで、最終的なトークンを決定する手法で (Figure1),
BPEよりも高い性能を獲得し、
トークンの長さがBPEと比較して長くなり、かつ5Bトークン程度を既存のBPEで事前学習されたモデルに対して継続的事前学習するだけで性能を上回るようにでき (Table2)、同じVocabサイズでBPEよりも高い性能を獲得できる手法 (Table4)、らしい
[Paper Note] Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models, Weixin Liang+, TMLR'25
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #Transformer #MultiModal #SpeechProcessing #Architecture #TMLR #UMM Issue Date: 2024-11-12 GPT Summary- 大規模言語モデル(LLMs)のマルチモーダル処理を効率化するために、Mixture-of-Transformers(MoT)を提案。MoTは計算コストを削減し、モダリティごとにパラメータを分離して特化した処理を実現。Chameleon 7B設定では、55.8%のFLOPsで密なベースラインに匹敵する性能を示し、音声を含む場合も37.2%のFLOPsで同様の結果を達成。さらに、Transfusion設定では、7BのMoTモデルが密なベースラインの画像性能に対してFLOPsの3分の1で匹敵し、760Mのモデルは主要な画像生成指標で上回る結果を得た。MoTは実用的な利点も示し、画像品質を47.2%、テキスト品質を75.6%の経過時間で達成。
[Paper Note] Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25, 2024.11
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #ICML #DPO #One-Line Notes Issue Date: 2024-11-07 GPT Summary- 自己調整は、モデルが人間の注釈なしに自らを改善する方法であり、自己一貫性を活用して訓練を行う新しいアプローチ、自己一貫性優先最適化(ScPO)を提案。ScPOは一貫した答えを優先し、GSM8KやMATHなどの推論タスクで従来の手法を大幅に上回る性能を示し、標準的な監視学習との組み合わせでも結果が向上。ZebraLogicでLlama-3 8Bを微調整し、他の大規模モデルを超える成果を達成。 Comment
元ポスト:
Self-Consistencyのように、モデルに複数の出力をさせて、最も頻度が高い回答と頻度が低い回答の2つでDPOのペアデータを作成し学習。頻度の差によって重みを決めてlossに組み込みこのよつな処理を繰り返し学習すると性能が向上する、といった話のように見える。
[Paper Note] Looking Inward: Language Models Can Learn About Themselves by Introspection, Felix J Binder+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #ICLR #One-Line Notes #needs-revision Issue Date: 2024-11-02 GPT Summary- 内省は、モデルが自己の内部状態を理解する能力を示す。LLMsに内省能力をファインチューニングし、自身の行動予測を行う実験により、内省の証拠が得られた。特に、自己予測能力において他のモデルを上回る結果が見られたが、複雑なタスクでは限界もあった。 Comment
LLMが単に訓練データを模倣しているにすぎない的な主張に対するカウンターに使えるかも
openreview: https://openreview.net/forum?id=eb5pkwIB5i
[Paper Note] Differential Transformer, Tianzhu Ye+, N_A, ICLR'25
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #ICLR #Selected Papers/Blogs #In-Depth Notes Issue Date: 2024-10-21 GPT Summary- Diff Transformerは、関連するコンテキストへの注意を強化し、ノイズをキャンセルする新しいアーキテクチャです。差分注意メカニズムを用いて、注意スコアを計算し、スパースな注意パターンを促進します。実験結果は、Diff Transformerが従来のTransformerを上回り、長いコンテキストモデリングや幻覚の軽減において顕著な利点を示しています。また、文脈内学習においても精度を向上させ、堅牢性を高めることが確認されました。これにより、Diff Transformerは大規模言語モデルの進展に寄与する有望なアーキテクチャとされています。 Comment
# 概要
attention scoreのノイズを低減するようなアーキテクチャとして、二つのQKVを用意し、両者の差分を取ることで最終的なattentiok scoreを計算するDifferential Attentionを提案した。
attentionのnoiseの例。answerと比較してirrelevantなcontextにattention scoreが高いスコアが割り当てられてしまう(図左)。differential transformerが提案するdifferential attentionでは、ノイズを提言し、重要なcontextのattention scoreが高くなるようになる(図中央)、らしい。
# Differential Attentionの概要
二つのQKをどの程度の強さで交互作用させるかをλで制御し、λもそれぞれのQKから導出する。数式は2.1節に記述されているのでそちらも参照のこと。
QA, 機械翻訳, 文書分類, テキスト生成などの様々なNLPタスクが含まれるEval Harnessベンチマークでは、同規模のtransformerモデルを大幅にoutperform。ただし、3Bでしか実験していないようなので、より大きなモデルサイズになったときにgainがあるかは示されていない点には注意。
モデルサイズ(パラメータ数)と、学習トークン数のスケーラビリティについても調査した結果、LLaMAと比較して、より少ないパラメータ数/学習トークン数で同等のlossを達成。
64Kにcontext sgzeを拡張し、1.5B tokenで3Bモデルを追加学習をしたところ、これもtransformerと比べてより小さいlossを達成
context中に埋め込まれた重要な情報(今回はクエリに対応するmagic number)を抽出するタスク(Needle-In-A-Haystack test)の性能も向上。Needle(N)と呼ばれる正解のmagic numberが含まれる文をcontext中の様々な深さに配置し、同時にdistractorとなる文もランダムに配置する。これに対してクエリ(R)が入力されたときに、どれだけ正しい情報をcontextから抽出できるか、という話だと思われる。
これも性能が向上。特にクエリとNeedleが複数の要素で構成されていれ場合の性能が高く(Table2)、長いコンテキスト中の様々な位置に埋め込まれたNeedleを抽出する性能も高い(Figure5)
Many shotのICL能力も、異なる数のクラス分類を実施する4つのDatasetにおいて向上。クラス数が増えるに従ってAcc.のgainは小さくなっているように見える({6, 50} class > 70 class > 150 class)が、それでもAcc.が大きく向上している。
要約タスクでのhallucinationも低減。生成された要約と正解要約を入力し、GPT-4oにhallucinationの有無を判定させて評価(このようなLLM-as-a-Judgeの枠組みは先行研究 (MT-Bench) で人手での評価と高いagreementがあることが示されている)
関連 (MT-Bench):
- [Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
シンプルなアプローチでLLM全体の性能を底上げしている素晴らしい成果に見える。斜め読みなので読み飛ばしているかもしれないが、
- [Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
のように高品質な学習データで学習した場合も同様の効果が発現するのだろうか?
attentionのスコアがnoisyということは、学習データを洗練させることでも改善される可能性があり、[Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
はこれをデータで改善し、こちらの研究はモデルのアーキテクチャで改善した、みたいな捉え方もできるのかもしれない。
ちなみにFlash Attentionとしての実装方法も提案されており、スループットは通常のattentionと比べてむしろ向上している (Appendix A参照のこと) ので実用的な手法でもある。すごい。
あとこれ、事前学習とInstruction Tuningを通常のマルチヘッドアテンションで学習されたモデルに対して、独自データでSFTするときに導入したらdownstream taskの性能向上するんだろうか。もしそうなら素晴らしい
OpenReview: https://openreview.net/forum?id=OvoCm1gGhN
GroupNormalizationについてはこちら:
- [Paper Note] Group Normalization, Yuxin Wu+, arXiv'18, 2018.03
[Paper Note] nGPT: Normalized Transformer with Representation Learning on the Hypersphere, Ilya Loshchilov+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #ICLR #Normalization #Selected Papers/Blogs Issue Date: 2024-10-21 GPT Summary- ハイパースフィア上での表現学習に基づく新しいニューラルネットワークアーキテクチャ、正規化トランスフォーマー(nGPT)を提案。全てのベクトルが単位ノルムで正規化され、入力トークンがハイパースフィア上を移動し、各レイヤーで変位を加える。nGPTは学習が速く進行し、同精度を達成するためのトレーニングステップ数を4〜20倍削減することが実験で示された。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=se4vjm7h4E
[Paper Note] LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations, Hadas Orgad+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#Analysis #NLP #Hallucination #ICLR #One-Line Notes Issue Date: 2024-10-20 GPT Summary- LLMの内部状態は出力の真実性に関する情報を豊富に含んでおり、これを活用することで誤り検出が向上する。しかし、真実性の符号化はデータセットによって異なるため、普遍的ではない。内部表現を使って特定の誤りを予測できることも示し、個別的な緩和戦略の開発に寄与する。さらに、内部と外部の挙動の乖離があることが明らかとなり、誤った出力を生成することもある。これにより、LLMの誤り分析と改善の研究が進展することが期待される。 Comment
特定のトークンがLLMのtrustfulnessに集中していることを実験的に示し、かつ内部でエンコードされたrepresentationは正しい答えのものとなっているのに、生成結果に誤りが生じるような不整合が生じることも示したらしい
openreview: https://openreview.net/forum?id=KRnsX5Em3W
Llama-3.1-Nemotron-70B-Instruct, Nvidia, (ICLR'25), 2024.10
Paper/Blog Link My Issue
#NLP #Dataset #Alignment #OpenWeight #ICLR #One-Line Notes Issue Date: 2024-10-17 GPT Summary- 報酬モデルの訓練にはBradley-Terryスタイルと回帰スタイルがあり、データの一致が重要だが、適切なデータセットが不足している。HelpSteer2データセットでは、Bradley-Terry訓練用の好みの注釈を公開し、初めて両モデルの直接比較を行った。これに基づき、両者を組み合わせた新アプローチを提案し、Llama-3.1-70B-InstructモデルがRewardBenchで94.1のスコアを達成。さらに、REINFORCEアルゴリズムを用いて指示モデルを調整し、Arena Hardで85.0を記録した。このデータセットはオープンソースとして公開されている。 Comment
MTBench, Arena HardでGPT4o-20240513,Claude-3.5-sonnet-20240620をoutperform。Response lengthの平均が長いこと模様
openreview: https://openreview.net/forum?id=MnfHxPP5gs
[Paper Note] Logic-of-Thought: Injecting Logic into Contexts for Full Reasoning in Large Language Models, Tongxuan Liu+, NAACL'25, 2024.09
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #NAACL #Initial Impression Notes Issue Date: 2024-09-29 GPT Summary- LLMの論理推論能力は依然として課題が残る。Chain-of-Thoughtなどの手法は改善をもたらすが、信頼性に問題がある。そこで、命題論理を利用したLogic-of-Thought(LoT)プロンプトを提案し、論理情報を強化することで推論能力を向上させる。実験では、LoTが多数の論理推論タスクで既存手法の性能を大幅に向上させることを示し、特にReClorおよびRuleTakerデータセットでの改善が顕著であった。 Comment
※ このメモは当初の原稿に対するものであり、NAACLの原稿では修正されている。
SNSで話題になっているようだがGPT-3.5-TurboとGPT-4でしか比較していない上に、いつの時点のモデルかも記述されていないので、unreliableに見える
ReClorデータセットで性能が向上しているのは個人的に興味深い。
[Paper Note] Backtracking Improves Generation Safety, Yiming Zhang+, ICLR'25, 2024.09
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #Safety #ICLR #DPO #PostTraining Issue Date: 2024-09-24 GPT Summary- テキスト生成には根本的な限界があり、生成されたトークンを元に戻せないため、安全でない生成が続く傾向がある。この課題を解決するために、特別な[RESET]トークンを用いたバックトラッキング技術を提案し、生成物を「取り消し」可能にする。これにより、言語モデルの安全性を向上させることができ、バックトラッキングを学習したモデルはベースラインと比較して4倍の安全性を示す。さらに、敵対的攻撃に対する保護も提供される。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=Bo62NeU6VF
日本語解説: https://www.docswell.com/s/DeepLearning2023/ZN1PNR-2025-05-08-131259#p1
[Paper Note] The Unreasonable Ineffectiveness of the Deeper Layers, Andrey Gromov+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Pruning #ICLR #One-Line Notes Issue Date: 2024-04-22 GPT Summary- LLMの重みの知識格納を層剪定で研究。不要なパラメータを特定し、層を削除しても性能に影響がないか確認。驚くべき結果として、最大で半分の層を削除しても性能低下がわずかであることが示された。この頑健性は浅い層が重要な役割を果たしている可能性を示唆。PEFT手法を用いて実験を効率化。 Comment
下記ツイートによると、学習済みLLMから、コサイン類似度で入出力間の類似度が高い層を除いてもタスクの精度が落ちず、特に深い層を2-4割削除しても精度が落ちないとのこと。
参考:
VRAMに載せるのが大変なので、このような枝刈り技術が有効だと分かるのはありがたい。LoRAや量子化も利用しているっぽい。
openreview: https://openreview.net/forum?id=ngmEcEer8a
[Paper Note] Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws, Zeyuan Allen-Zhu+, N_A, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #SyntheticData #ICLR #Reference Collection Issue Date: 2024-04-15 GPT Summary- 言語モデルのサイズと能力の関係を記述するスケーリング則に焦点を当てた研究。モデルが格納する知識ビット数を推定し、事実知識をタプルで表現。言語モデルは1つのパラメータあたり2ビットの知識を格納可能であり、7Bモデルは14Bビットの知識を格納可能。さらに、トレーニング期間、モデルアーキテクチャ、量子化、疎な制約、データの信号対雑音比が知識格納容量に影響することを示唆。ロータリー埋め込みを使用したGPT-2アーキテクチャは、知識の格納においてLLaMA/Mistralアーキテクチャと競合する可能性があり、トレーニングデータにドメイン名を追加すると知識容量が増加することが示された。 Comment
参考:
openreview: https://openreview.net/forum?id=FxNNiUgtfa
[Paper Note] FacTool: Factuality Detection in Generative AI -- A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios, I-Chun Chern+, COLM'25, 2023.07
Paper/Blog Link My Issue
#NLP #Evaluation #Hallucination #Factuality #COLM Issue Date: 2023-07-27 GPT Summary- 生成的事前学習モデルによるテキスト合成は進展したが、事実誤認の特定には課題が残る。特に、生成モデルによる事実誤認のリスク増加、長文化による粒度の欠如、明示的証拠の不足が問題である。これらを解決するために、タスクやドメインに依存しない事実誤認検出フレームワークFacToolを提案。知識ベースのQA、コード生成、数学的推論、科学文献レビューの4つのタスクで有効性を実証し、コードは公開されている。 Comment
openreview: https://openreview.net/forum?id=hJkQL9VtWT#discussion
[Paper Note] RULER: What's the Real Context Size of Your Long-Context Language Models?, Cheng-Ping Hsieh+, COLM'24, 2024.04
Paper/Blog Link My Issue
#NLP #Evaluation #LongSequence #COLM Issue Date: 2026-07-09 GPT Summary- RULERは、干草の山の中の針(NIAH)テストを拡張し、長文脈を扱う言語モデルの評価を包括的に行う新しい合成ベンチマークを提供します。カスタマイズ可能な構成を備え、複雑なタスクや多様な検索行動を評価します。53のタスクで17のモデルを試験した結果、文脈長が増加すると性能が低下。特に、32Kトークン以上の文脈サイズで満足いく性能を維持できるモデルは半数に留まりました。RULERはオープンソースとして公開され、長文脈LMの評価を促進します。 Comment
openreview: https://openreview.net/forum?id=kIoBbc76Sy
[Paper Note] Scaling Sentence Embeddings with Large Language Models, Ting Jiang+, EMNLP'24 Findings, 2023.07
Paper/Blog Link My Issue
#Sentence #Embeddings #NLP #In-ContextLearning #EMNLP #Findings #One-Line Notes #Reading Reflections Issue Date: 2026-06-11 GPT Summary- 文脈内学習に基づく手法を用いて、大規模言語モデル(LLMs)の文の埋め込み性能を向上。自己回帰モデル向けにプロンプトベースの表現法を適用し、ファインチューニングなしで高品質な文の埋め込みを生成可能。モデルサイズを拡大するとSTSタスクで性能の変化が見られるが、最大モデルは他のモデルを上回り、転移タスクで最先端結果を達成。2.7BのOPTモデルが4.8BのST5を超える性能を示した。 Comment
1 wordでsentenceを要約するICL-basedなprompt templateを用いて生成されたtokenに対応するlast hidden statedeをsentenceのembeddingとして扱うことで、coder-onlyモデルから文のembeddingを取得する
下記研究で示されているように、last hidden stateではなく中間層におけるhidden stateを利用した場合はどのような影響が出るのだろうか?
- [Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
[Paper Note] Small-scale proxies for large-scale Transformer training instabilities, Mitchell Wortsman+, ICLR'24, 2023.09
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #ICLR #Stability Issue Date: 2026-04-26 GPT Summary- 大規模なTransformerモデルの訓練不安定性を小規模モデルで再現・研究。特に、アテンション層のロジット増大と出力ロジットの発散に注目。高い学習率で不安定性が現れることを示し、既存の緩和策が小規模モデルにも有効であることを確認。ウォームアップやウェイト減衰を駆使し、損失の安定性を維持できる手法を検討。最後に、不安定性が現れる前に予測できるケースを分析。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=d8w0pmvXbZ
[Paper Note] Parallelizing Linear Transformers with the Delta Rule over Sequence Length, Songlin Yang+, NeurIPS'24, 2024.06
Paper/Blog Link My Issue
#NLP #Attention #NeurIPS #read-later #Selected Papers/Blogs #LinearAttention Issue Date: 2026-04-22 GPT Summary- 線形トランスフォーマーとデルタ則を用いたハードウェア効率の良いトレーニングアルゴリズムを提案。この手法を用いて13億パラメータのモデルを訓練し、最新の線形時間ベースラインを上回る性能を示した。また、DeltaNet層を組み込んだハイブリッドモデルが強力なトランスフォーマーの基準を越えることを実証。 Comment
[Paper Note] DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents, Peter Jansen+, NeurIPS'24 Spotlight, 2024.06
Paper/Blog Link My Issue
#AIAgents #Evaluation #ScientificDiscovery #NeurIPS #Selected Papers/Blogs #Science #One-Line Notes Issue Date: 2026-04-14 GPT Summary- DISCOVERYWORLDは、エージェントが科学的発見の全過程を実行できる初の仮想環境で、放射性同位体年代測定やロケット科学など多様な課題を提供します。タスクは一般的な発見スキルの育成を奨励し、シミュレーションされたテキスト環境で、オプションの2Dビジュアルオーバーレイもあります。120の課題は3つの難易度に分かれ、エージェントは仮説立案から結果分析までを行います。また、性能評価は課題完遂度や行動に基づき、自動指標で行われます。強力なベースラインエージェントが多くの課題で苦戦することから、DISCOVERYWORLDの新規性に関わる挑戦を捉えており、科学的発見能力の評価と開発を促進する可能性が示唆されます。 Comment
pj page: https://allenai.github.io/discoveryworld/
ベンチマークの概要は
- Evaluating agents for scientific discovery, Ai2, 2026.04
参照のこと。
[Paper Note] LLM360: Towards Fully Transparent Open-Source LLMs, Zhengzhong Liu+, COLM'24, 2023.12
Paper/Blog Link My Issue
#NLP #OpenWeight #OpenSource #COLM Issue Date: 2026-03-31 GPT Summary- LLMの透明性向上のため、LLM360を提唱し、訓練コードやデータ、チェックポイントを完全オープンソース化。これにより誰でも再現可能な設計を促進し、AI研究の協力を支援。7BパラメータのモデルAmberとCrystalCoderを公開し、将来的にさらに強力なモデルも計画中。 Comment
blog: https://www.llm360.ai
- Crystal:
https://huggingface.co/collections/LLM360/crystal
- Amber:
https://huggingface.co/collections/LLM360/amber
- code:
https://github.com/LLM360
[Paper Note] Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model, Ahmet Üstün+, arXiv'24, 2024.02
Paper/Blog Link My Issue
#NLP #MultiLingual #OpenWeight #Initial Impression Notes Issue Date: 2026-03-31 GPT Summary- Ayaは、101言語に対応する生成型多言語モデルで、50%以上が低資源言語。大半のタスクでmT0およびBLOOMZを上回り、取り扱える言語数が2倍に。99言語にわたる新評価スイートを導入し、識別・生成タスクや人間評価を含む。ファインチューニングや安全性についても調査し、モデルとデータセットをオープンソースとして公開。 Comment
blog: https://cohere.com/research/papers/aya-model-paper-2024-02-13
データは公開されているが、おそらくソースコードは公開されていない
[Paper Note] TinyLlama: An Open-Source Small Language Model, Peiyuan Zhang+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#Pretraining #NLP #SmallModel #OpenWeight #OpenSource Issue Date: 2026-03-31 GPT Summary- TinyLlamaは、1.1Bパラメータのコンパクトな言語モデルで、約1兆トークンを用いて事前学習されている。Llama 2のアーキテクチャを基に、FlashAttentionやLit-GPTなどの進歩を活用し、計算効率を向上させている。小さいサイズにもかかわらず、TinyLlamaは下流タスクで顕著な性能を発揮し、同等のオープンソースモデルを大きく上回る。モデルのチェックポイントとコードはGitHubで公開されている。 Comment
日本語解説: https://qiita.com/sergicalsix/items/7cd7665ab90b9f3b343c
[Paper Note] Rho-1: Not All Tokens Are What You Need, Zhenghao Lin+, NeurIPS'24, 2024.04
Paper/Blog Link My Issue
#Pretraining #NLP #NeurIPS #DataMixture #Adaptive Issue Date: 2026-03-18 GPT Summary- 「9l training」を提唱し、トークンごとに異なる損失パターンを取り入れた新しい言語モデルRho-1を導入。Selective Language Modelingを採用し、望ましいトークンのみを選択的に学習。OpenWebMathコーパスでの事前学習を通じて、9つの数学タスクにおいてfew-shot精度を最大30%改善し、最先端のMATHデータセット結果を達成。80Bの一般トークンでも多様なタスクで平均6.8%の性能向上を実現。 Comment
日本語解説: https://techblog.cccmkhd.co.jp/entry/2024/12/10/081653
openreview: https://openreview.net/forum?id=0NMzBwqaAJ
[Paper Note] LLM Unlearning via Loss Adjustment with Only Forget Data, Yaxuan Wang+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#NLP #ICLR #KnowledgeEditing #MachineUnlearning(MU) Issue Date: 2026-03-10 GPT Summary- LLMの忘却は、プライバシーやバイアスに対応するために重要です。既存の手法は保持データに依存し、忘却性能とモデルの有用性のバランスが難しい。しかし、我々は保持データを排除した新たなアプローチを提案します。「FLAT」と呼ばれる手法は、忘却データに基づいて応答を指示し、f-ダイバージェンスを最大化することで忘却性能を向上させます。実験により、我々のアプローチが既存手法よりも高い性能を示し、多様なタスクでの有用性を維持できることが確認されました。 Comment
openreview: https://openreview.net/forum?id=6ESRicalFE
[Paper Note] From Theft to Bomb-Making: The Ripple Effect of Unlearning in Defending Against Jailbreak Attacks, Zhexin Zhang+, arXiv'24, 2024.07
Paper/Blog Link My Issue
#NLP #KnowledgeEditing #MachineUnlearning(MU) Issue Date: 2026-03-10 GPT Summary- 大規模言語モデル(LLMs)のジャイルブレイク攻撃に対する脆弱性を調査し、有害な知識をモデルから取り除く「アンラーニング」アプローチの効果を実証。アンラーニングにより、未見のデータに対する攻撃成功率が70%から10%未満に低下し、未知の有害な知識も黙示的に忘れる可能性を検証。また、有害な質問群の関連性が一般化能力を高める要因であると考察し、アンラーニングの限界も議論。研究の成果は、アンラーニングの理解の深化に寄与することを目指している。
[Paper Note] Machine Unlearning of Pre-trained Large Language Models, Jin Yao+, ACL'24, 2024.02
Paper/Blog Link My Issue
#NLP #ACL #KnowledgeEditing #One-Line Notes #MachineUnlearning(MU) Issue Date: 2026-03-10 GPT Summary- 本研究は、LLMにおける「忘れられる権利」と機械的忘却を探求。7つの忘却手法を分析し、厳選したデータセットを用いた評価で、再訓練に比べて計算効率が10万倍優れることを示す。忘却プロセスのハイパーパラメータ調整に関するガイドラインを提供し、倫理的AIの議論や責任あるAI開発に貢献。 Comment
下記文献において忘却対象のデータを自前で用意する必要があり、未知のデータに対する汎化性能に限界があるという指摘がある:
- 排他的逆学習, 佐々木+, NLP'26
[Paper Note] Rethinking Machine Unlearning for Large Language Models, Sijia Liu+, arXiv'24, 2024.02
Paper/Blog Link My Issue
#NLP #KnowledgeEditing #Nature Machine Intelligence #MachineUnlearning(MU) Issue Date: 2026-03-10 GPT Summary- LLMの忘却(MU)を探究し、不要なデータを排除しつつ知識の健全性を維持することを目指す。LLM忘却はライフサイクル管理の核心をなす要素であり、安全で堅牢な生成型AIの基盤となる可能性がある。概念的定式化や方法論の観点から、この分野を探査し、特に忘却の範囲やデータとモデルの相互作用に焦点を当てる。関連領域との相互関係も示し、評価フレームワークを概説しつつ、著作権やプライバシー保護への応用を探る。
[Paper Note] Lessons from the Trenches on Reproducible Evaluation of Language Models, Stella Biderman+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#NLP #Evaluation #Selected Papers/Blogs #Reproducibility #One-Line Notes Issue Date: 2026-03-08 GPT Summary- 言語モデルの評価は未解決の課題であり、研究者やエンジニアは感度、手法比較の難しさ、再現性の欠如といった問題に直面している。本論文は、大規模言語モデルの評価に関する3年間の経験を基に、共通の課題の概要、ベストプラクティスの整理、独立的で再現性のあるオープンソースライブラリ「Language Model Evaluation Harness」(lm-eval)を提案し、その機能とケーススタディを紹介する。 Comment
いわゆるLM Evaluation Harnessに関する運用する中での知見を報告する論文。LM Evaluation Harnessは広範なベンチマークでのLLMの評価を公平で透明性、再現性が担保された形で実施する実装である。
github:
https://github.com/EleutherAI/lm-evaluation-harness
LM Evaluation Harness自体は2021年から存在する。
[Paper Note] Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention, Zhen Qin+, ICML'24, 2024.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Attention #LongSequence #ICML #One-Line Notes #LinearAttention Issue Date: 2026-02-17 GPT Summary- Lightning Attentionは、一定の学習速度を維持しつつ固定メモリ消費を実現する線形注意の新しい実装です。累積和演算の問題を、異なる計算戦略を用いることで解決し、ブロック内では従来の注意計算を、ブロック間では線形注意のカーネル技術を導入しています。GPUを効率的に活用するためのタイル化技術を採用し、新しいアーキテクチャTransNormerLLM(TNL)を提案。TNLは他のモデルより効率的で、従来のトランスフォーマーと同等の性能を示します。ソースコードは公開されています。 Comment
Ring、MiniCPMで採用されているlinear attentionの一種であるlightning attention
[Paper Note] Rule Based Rewards for Language Model Safety, Tong Mu+, NeurIPS'24, 2024.11
Paper/Blog Link My Issue
#NLP #Alignment #ReinforcementLearning #Safety #NeurIPS #PostTraining #Rubric-based Issue Date: 2026-02-11 GPT Summary- 少量の人間データを用いてAIフィードバックを活用し、新しい好みモデルアプローチ「ルールベース報酬(RBR)」を提案。これにより、望ましい行動に関するルールを用いてLLMを評価し、安全行動の精度を高めつつ、強化学習トレーニングの制御と更新容易性を向上。F1スコア97.1を達成し、人間フィードバックの91.7を大きく上回る結果を示した。 Comment
元ポスト:
[Paper Note] A Comprehensive Study of Knowledge Editing for Large Language Models, Ningyu Zhang+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#Survey #NLP #Dataset #Evaluation #KnowledgeEditing Issue Date: 2026-02-08 GPT Summary- LLMの知識編集技術が急増し、モデルの効率的な修正が求められています。知識編集問題を定義し、3つのグループ(外部知識の利用、モデルへの知識の統合、内在的知識の編集)に分類。新たに「KnowEdit」ベンチマークを導入し、知識構造の詳しい分析を行う。知識編集の応用についても考察しています。 Comment
[Paper Note] Mamba: Linear-Time Sequence Modeling with Selective State Spaces, Albert Gu+, COLM'24, 2023.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #SSM (StateSpaceModel) #COLM #Selected Papers/Blogs #LinearAttention Issue Date: 2026-02-04 GPT Summary- ファウンデーションモデルはトランスフォーマーを基盤としており、計算非効率性を解決するために新たなアーキテクチャが開発されたが、言語モダリティではあまり効果的でなかった。私たちは内容ベースの推論能力の欠如を特定し、SSMのパラメータを入力に依存させることで、情報の選択的伝播を可能にした。さらに、ハードウェアに適応した並列アルゴリズムを設計し、簡略化されたニューラルネットワークアーキテクチャMambaに統合した。このMambaは、高速な推論とシーケンス長での線形スケーリングを可能にし、言語や音声などで最先端の性能を達成。特にMamba-3Bモデルは、同サイズのトランスフォーマーを上回る性能を示した。 Comment
openreview: https://openreview.net/forum?id=tEYskw1VY2
日本語解説: https://qiita.com/peony_snow/items/649ecb307cd3b5c10aa7
関連:
- [Paper Note] Retentive Network: A Successor to Transformer for Large Language Models, Yutao Sun+, arXiv'23, 2023.07
- [Paper Note] RWKV: Reinventing RNNs for the Transformer Era, Bo Peng+, N/A, EMNLP'23 Findings, 2023.05
[Paper Note] Gated Linear Attention Transformers with Hardware-Efficient Training, Songlin Yang+, ICML'24, 2023.12
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #ICML #Selected Papers/Blogs #LinearAttention Issue Date: 2026-02-04 GPT Summary- 線形アテンションを持つトランスフォーマーは、効率的な並列トレーニングを実現する一方、通常のソフトマックスアテンションに比べて性能が劣る。提案するFLASHLINEARATTENTIONは、メモリ移動と並列化のトレードオフを考慮し、短いシーケンスで高速な実装を実現。また、データ依存ゲートを追加したゲート付き線形アテンション(GLA)トランスフォーマーは、LLaMAやRetNet、Mambaと比較して競争力のある性能を示し、長さの一般化でも有効。GLAトランスフォーマーは、同サイズのMambaモデルよりも高いトレーニングスループットを持つ。
[Paper Note] RLVF: Learning from Verbal Feedback without Overgeneralization, Moritz Stephan+, ICML'24, 2024.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SyntheticData #ICML #PostTraining #Generalization #TextualFeedback Issue Date: 2026-02-01 GPT Summary- 高レベルの言語フィードバックを用いてLLMの調整を行う際、過剰一般化の問題を解決するために「C3PO」手法を提案。C3POはフィードバックを適用する方法を指定する合成嗜好データセットを生成し、元のモデルから逸脱を抑えつつ微調整を実施。実験により、他の文脈の動作を維持しながら、フィードバックの遵守と過剰一般化を30%削減できることを示した。 Comment
pj page: https://austrian-code-wizard.github.io/c3po-website/
[Paper Note] Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs, Xin Lai+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #Alignment #Reasoning #DPO #PostTraining Issue Date: 2026-01-30 GPT Summary- 数学的推論はLLMにとって難題であり、正確な推論ステップが求められる。本研究では、人間のフィードバックを活用し、LLMの堅牢性を向上させるStep-DPOを提案。各推論ステップを選好最適化の単位とし、高品質なデータセットを構築。結果、70BパラメータモデルにおいてMATHで約3%の精度向上を実現し、Qwen2-72B-Instructが他のモデルを凌駕する成績を示した。 Comment
openreview: https://openreview.net/forum?id=H5FUVj0vMd
[Paper Note] Emotionally Numb or Empathetic? Evaluating How LLMs Feel Using EmotionBench, Jen-tse Huang+, NeurIPS'24, 2023.08
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #NeurIPS #Emotion Issue Date: 2026-01-25 GPT Summary- LLMの感情評価能力を新たに検討。400以上の状況から8つの感情を引き出すデータセットを作成し、1,200人による人間評価を実施。7つのLLMを評価した結果、一般的には適切な応答を示すが、人間の感情行動との整合性に欠けることが明らかに。データセット、評価結果、EmotionBenchのコードは公開中。 Comment
pj page: https://cuhk-arise.github.io/EmotionBench/
元ポスト:
[Paper Note] Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws, Yiding Jiang+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#Pretraining #NLP #ICLR #Scaling Laws #DataMixture #One-Line Notes #Adaptive Issue Date: 2026-01-21 GPT Summary- ADOは事前学習データの最適化をオンラインで行うアルゴリズムで、モデル訓練と同時にデータ分布を調整。外部知識やプロキシモデルを必要とせず、ドメインごとの学習ポテンシャルを推定してスケーラブルなデータ混合を実現。実験では、従来法と同等またはそれ以上の性能を示しつつ計算効率を維持する効果的な解決策を提供。スケーリング則を通じて新たなデータ収集戦略の視点も提示。 Comment
openreview: https://openreview.net/forum?id=aqok1UX7Z1
ドメインごとのneural scaling lawsを学習をする中で構築し、scaling lawsに従って動的にドメインのデータをどの程度サンプリングするかを決定するようなオンラインでのDataMixture決定手法、に見える。小規模モデルの実験結果を活用する不確実性やSarrogate modelを用いて推論するといった計算コストの高い方法はおそらく不要?
[Paper Note] Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting, Melanie Sclar+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#Analysis #NLP #Prompting #Evaluation #OpenWeight #ICLR #Selected Papers/Blogs Issue Date: 2026-01-21 GPT Summary- LLMの性能特性化が重要であり、プロンプト設計がモデル挙動に強く影響することを示す。特に、プロンプトフォーマットに対するLLMの感度に注目し、微妙な変更で最大76ポイントの性能差が見られる。感度はモデルサイズや少数ショットの数に依存せず、プロンプトの多様なフォーマットにわたる性能範囲の報告が必要。モデル間のフォーマットパフォーマンスが弱く相関することから、固定されたプロンプトフォーマットでの比較の妥当性が疑問視される。迅速なフォーマット評価のための「FormatSpread」アルゴリズムを提案し、摂動の影響や内部表現も探る。 Comment
openreview: https://openreview.net/forum?id=RIu5lyNXjT
[Paper Note] Graph Retrieval-Augmented Generation: A Survey, Boci Peng+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Survey #GraphBased #InformationRetrieval #NLP #KnowledgeGraph #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-12-27 GPT Summary- Retrieval-Augmented Generation(RAG)は、LLMsの課題に対処するために外部知識ベースを活用し、情報の精度を向上させるが、エンティティ間の関係の複雑さが課題となる。これに対処するために、GraphRAGは構造情報を活用し、より正確な情報検索と文脈に応じた応答を実現する。本論文では、GraphRAGの手法を体系的にレビューし、ワークフロー、コア技術、応用分野、評価手法を概説し、今後の研究方向を探る。リポジトリも設置し、進展を追跡可能にしている。 Comment
元ポスト:
[Paper Note] Transcoders Find Interpretable LLM Feature Circuits, Jacob Dunefsky+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #read-later #Selected Papers/Blogs #Transcoders #CircuitAnalysis #Interpretability Issue Date: 2025-12-21 GPT Summary- トランスコーダーを用いて、MLPサブレイヤーの回路分析を行い、スパースなMLPレイヤーでの忠実な近似を実現。これにより、入力依存項と入力不変項に因数分解された回路を得る。120Mから1.4Bパラメータの言語モデルで訓練し、SAEと同等の解釈可能性を確認。GPT2-smallの「greater-than circuit」に関する新たな洞察も得られた。トランスコーダーはMLPを含むモデル計算の解釈に効果的であることが示唆された。
[Paper Note] Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks, Adam Fourney+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Multi #NLP #Library #AIAgents Issue Date: 2025-11-25 GPT Summary- 高性能なオープンソースエージェントシステム「Magentic-One」を提案。マルチエージェントアーキテクチャを用いて計画、進捗追跡、エラー回復を行い、専門エージェントにタスクを指示。GAIA、AssistantBench、WebArenaのベンチマークで競争力のあるパフォーマンスを達成。モジュラー設計により、エージェントの追加や削除が容易で、将来の拡張が可能。オープンソース実装とエージェント評価ツール「AutoGenBench」を提供。詳細は公式サイトで確認可能。 Comment
日本語解説: https://zenn.dev/masuda1112/articles/2024-11-30-magnetic-one
blog:
https://www.microsoft.com/en-us/research/articles/magentic-one-a-generalist-multi-agent-system-for-solving-complex-tasks/
code:
https://github.com/microsoft/autogen/tree/main/python/packages/autogen-magentic-one
[Paper Note] AgentInstruct: Toward Generative Teaching with Agentic Flows, Arindam Mitra+, arXiv'24, 2024.07
Paper/Blog Link My Issue
#NLP #AIAgents #SyntheticData #PostTraining Issue Date: 2025-11-25 GPT Summary- 合成データは言語モデルの開発に重要であり、本研究では「Generative Teaching」と呼ばれる手法を提案。高品質な合成データを自動生成する「AgentInstruct」フレームワークを用いて、2500万ペアのポストトレーニングデータセットを作成。これにより、Mistral-7bをポストトレーニングしたモデルOrca-3は、複数のベンチマークで顕著な性能向上を示し、他のモデルに対しても優れた結果を得た。 Comment
関連:
- [Paper Note] Orca 2: Teaching Small Language Models How to Reason, Arindam Mitra+, arXiv'23, 2023.11
[Paper Note] SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, John Yang+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #NeurIPS #SoftwareEngineering #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-11-25 GPT Summary- LMエージェントのパフォーマンスにおけるインターフェースデザインの影響を調査し、ソフトウェアエンジニアリングタスクを解決するためのシステム「SWE-agent」を提案。SWE-agentのカスタムインターフェースは、コード作成やリポジトリナビゲーション、プログラム実行能力を向上させ、SWE-benchとHumanEvalFixで最先端のパフォーマンスを達成。pass@1率はそれぞれ12.5%と87.7%に達し、従来の非インタラクティブなLMを大きく上回る結果を示した。 Comment
SWE bench Verifiedで利用されているハーネスで、mini-SWE-agentと呼ばれるもの
https://github.com/SWE-agent/mini-swe-agent
[Paper Note] Simple and Effective Masked Diffusion Language Models, Subham Sekhar Sahoo+, NeurIPS'24, 2024.06
Paper/Blog Link My Issue
#NLP #DiffusionModel #NeurIPS #read-later #Selected Papers/Blogs Issue Date: 2025-11-04 GPT Summary- マスク付き離散拡散モデルは、従来の自己回帰手法に匹敵する性能を示す。効果的なトレーニング手法と簡略化された目的関数を導出し、エンコーダ専用の言語モデルをトレーニングすることで、任意の長さのテキスト生成が可能に。言語モデリングのベンチマークで新たな最先端を達成し、AR手法に近づく成果を上げた。 Comment
- Masked Diffusion Modelの進展, Deep Learning JP, 2025.03
で紹介されている
[Paper Note] To Code, or Not To Code? Exploring Impact of Code in Pre-training, Viraat Aryabumi+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Pretraining #NLP #Coding #DataMixture #One-Line Notes Issue Date: 2025-11-04 GPT Summary- コードデータが一般的なLLMのパフォーマンスに与える影響を体系的に調査。アブレーション実験により、コードがコーディングタスクを超えた一般化に重要であり、コード品質の向上が全タスクに大きな影響を与えることを確認。特に、コードの追加により自然言語推論で最大8.2%、世界知識で4.2%、生成的勝率で6.6%の向上を示し、コードパフォーマンスでは12倍の改善を達成。研究は、コード品質への投資がポジティブな影響をもたらすことを示唆。 Comment
元ポスト:
事前学習におけるコードの割合を増やすとコーディングタスクの性能は線形に増加する。全体の平均タスク性能の観点で言うとコードの割合を25%にするのが最適で、コードの割合を増やすほど自然言語による推論、世界知識が問われるタスクの性能は悪化していき、コードの割合が75%を超えると急激に悪化する(Figure4)。
[Paper Note] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling, Bradley Brown+, arXiv'24, 2024.07
Paper/Blog Link My Issue
#NLP #Test-Time Scaling #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-11-02 GPT Summary- 言語モデルの推論能力を向上させるために、候補解を繰り返しサンプリングする手法を提案。サンプル数の増加に伴い、問題解決のカバレッジが4桁のオーダーでスケールし、対数線形の関係が示唆される。自動検証可能な回答がある領域では、カバレッジの増加がパフォーマンス向上に直結。SWE-bench Liteでの実験では、サンプル数を増やすことで解決率が大幅に向上したが、自動検証器がない領域ではサンプル数が増えても効果が頭打ちになることが確認された。 Comment
Repeated Sampling。同じプロンプトで複数回LLMを呼び出し、なんらかのverifierを用いて最も良いものを選択するtest time scaling手法。
figure2にverifierを利用しない場合と利用した場合の差が示されている。高性能なverifierが利用された場合は、サンプル数の増加に大して性能がスケールしていき、single attemptでのstrong ModelやSoTAを上回る性能が得られることがわかる。
Figure8を見るとself consistency型のverifierの限界が示されている。すなわち、サンプリングする中で正しい解法が頻出しないようなものである。図を見ると、赤いbarがmajority-votingでは正解できない問題のindexを示しており、それなりの割合で存在することがわかる。
この辺の話は
- [Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Outstanding Paper
とも関連していると思われる。
verifierの具体的な構築方法としてどのようなものがあるかが気になる。あとで読む。
> However, these increasingly rare correct generations are only beneficial if verifiers can “find the needle in the haystack” and identify them from collections of mostly-incorrect samples. In math word problem settings, we find that two common methods for verification (majority voting and reward models) do not possess this ability. When solving MATH [26] problems with Llama-3-8B-Instruct, coverage increases from 82.9% with 100 samples to 98.44% with 10,000 samples. However, when using majority voting or reward models to select final answers, the biggest performance increase is only from 40.50% to 41.41% over the same sample range.
上に記述されている内容は、要はverifierの性能が重要で、典型的なmajority votingやreward mode4lsによるverification手法ではスケールしないケースがある。たとえば、以下のFigure7を見ると、典型的な
- majority voting
- reward model + best-of-N
- majority voting + reward model
などのtest-time scaling手法(verification手法)がサンプル数Kを増やしてもスケールしないことを示しており、一方Oracle Verifier(=数学の問題において正解が既知の場合に正解を出力したサンプルを採用する)での結果を見ると、性能がスケールしていくことがわかる。特にGSM8K, MATHデータセットにおいては、Reward Modelを利用するverification手法はmajority votingと比較してあまり良い性能が出ていないことがわかる。
本研究は5つのデータで検証しているが利用されているverifierは
- MiniF2F-MATH, CodeContests, SWE-Bench:
- すでに自動的なverifierが提供されており、たとえばそれはLean4 proof checker、test case, unit test suitesなどである
- GSM8K, MATH:
- これらについてはOracle Verifier(=モデルの出力が問題の正答と一致したら採用する)を利用している
本手法のスケーリングはverifierの性能に依存するため、高性能なverificationが作成できないタスクに関して適用するのは難しいと考えられる。逆に良い感じなverifierが定義できるなら相当強力な手法に見える。
[Paper Note] Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To, Xiangyu Qi+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Safety #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-24 GPT Summary- LLMのファインチューニングは、下流のユースケースに最適化する手法だが、安全性のリスクが伴う。特に、敵対的なトレーニング例を用いたファインチューニングが、モデルの安全性調整を損なう可能性があることが示された。例えば、わずか10例の悪意のある例でGPT-3.5 Turboをファインチューニングすると、安全ガードレールが突破される。また、無害なデータセットでのファインチューニングも意図せず安全性を劣化させる可能性がある。これらの結果は、調整されたLLMのファインチューニングが新たな安全リスクを生むことを示唆しており、今後の安全プロトコルの強化が求められる。 Comment
openreview: https://openreview.net/forum?id=hTEGyKf0dZ
なんらかのデータでpost-trainingしたモデルを、ユーザが利用可能な形でデプロイするような場合には、本研究が提唱するようなjailbreakのリスク
- 有害データが10例混入するだけで有害な出力をするようになる
- 暗黙的な有害データの混入(e.g., あなたはユーザ命令に従うエージェントです)
- 無害なデータでpost-trainingするだけでも下記のような影響でsafety alignmentが悪化する
- catastrophic forgetting
- 有用性と無害性のトレードオフによって、有用性を高めたことで有害性が結果的に増えてしまう( `tension between the helpfulness and harmlessness objectives` [Paper Note] Training a Helpful and Harmless Assistant with Reinforcement Learning
from Human Feedback, Yuntao Bai+, arXiv'22
)
があることを認識しておく必要がある。
もし安直にユーザからの指示追従能力を高めたいなあ・・・と思い、「ユーザからの指示には忠実に従ってください」などの指示を追加してpost-trainingをしてしまい、無害なプロンプトのみでテストして問題ないと思いユーザ向けのchatbotとしてデプロイしました、みたいなことをしたらえらいことになりそう。
[Paper Note] Large Language Model Routing with Benchmark Datasets, Tal Shnitzer+, COLM'24, 2023.09
Paper/Blog Link My Issue
#NLP #COLM #Routing Issue Date: 2025-10-24 GPT Summary- 複数のLLMから最適なモデルを選択するための「ルーター」モデルを学習する新しいアプローチを提案。ベンチマークデータセットを再利用し、二項分類タスクに還元可能であることを示し、単一モデル使用時よりも一貫して性能が向上することを実証。 Comment
[Paper Note] Smoothie: Label Free Language Model Routing, Neel Guha+, NeurIPS'24, 2024.12
Paper/Blog Link My Issue
#NLP #NeurIPS #Routing Issue Date: 2025-10-24 GPT Summary- 本研究では、教師なしルーティング手法「Smoothie」を提案し、異なる大規模言語モデル(LLMs)の出力を基にサンプルに最適なLLMを選択する方法を探求します。Smoothieは、LLM出力の埋め込み表現と潜在変数グラフィカルモデルを用いて各LLMの品質スコアを推定し、最も高いスコアのLLMにサンプルをルーティングします。実験により、Smoothieがルーティングのベースラインを最大10ポイント上回る精度を示し、9つのタスクで最適なモデルを正しく特定できることが確認されました。 Comment
[Paper Note] RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models, Shuhao Chen+, NeurIPS'24, 2024.09
Paper/Blog Link My Issue
#NLP #ContrastiveLearning #NeurIPS #Routing Issue Date: 2025-10-24 GPT Summary- 複数のLLMを組み合わせるためのルーティング手法「RouterDC」を提案。RouterDCはエンコーダとLLM埋め込みから成り、2つの対照的学習損失を用いて訓練。実験により、RouterDCは既存の手法を大きく上回り、分布内タスクで+2.76%、分布外タスクで+1.90%の性能向上を示した。ソースコードは公開されている。 Comment
openreview: https://openreview.net/forum?id=7RQvjayHrM¬eId=YrqLVNAOot
[Paper Note] Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving, Aniket Didolkar+, NeurIPS'24, 2024.05
Paper/Blog Link My Issue
#NeurIPS #read-later #MetacognitiveKnowledge/Ability #SkillTag Issue Date: 2025-10-21 GPT Summary- メタ認知的知識を持つ大規模言語モデル(LLM)が、数学的推論において適切なスキルラベルを割り当てる能力を示す。プロンプトガイドを用いたインタラクション手法を開発し、スキルラベルの意味的クラスタリングを行う。実験では、GPT-4に数学データセットに基づくスキルラベルを割り当てさせ、精度向上を確認。提案手法は数学以外のドメインにも適用可能。 Comment
StudentPerformancePredictionのスキルモデルのような話になってきた。興味深い
[Paper Note] The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities, Venkatesh Balavadhani Parthasarathy+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Tutorial #MachineLearning #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #MultiModal #Pruning #PPO (ProximalPolicyOptimization) #PEFT(Adaptor/LoRA) #LLMServing #DPO #PostTraining #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-10-17 GPT Summary- 本報告書では、大規模言語モデル(LLMs)のファインチューニングに関する理論と実践を統合的に検討し、歴史的な進化やファインチューニング手法の比較を行っています。7段階の構造化されたパイプラインを紹介し、不均衡データセットの管理やパラメータ効率の良い手法(LoRA、Half Fine-Tuning)に重点を置いています。また、PPOやDPOなどの新しいアプローチや、検証フレームワーク、デプロイ後のモニタリングについても議論し、マルチモーダルLLMsやプライバシー、説明責任に関する課題にも触れています。研究者や実務者に実用的な洞察を提供する内容です。 Comment
元ポスト:
[Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02
Paper/Blog Link My Issue
#MachineLearning #NLP #PEFT(Adaptor/LoRA) #ICML #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-10 GPT Summary- LoRAの精度ギャップを解消するために、Weight-Decomposed Low-Rank Adaptation(DoRA)を提案。DoRAは、ファインチューニングの重みを大きさと方向に分解し、方向性の更新にLoRAを使用することで、効率的にパラメータ数を最小化。これにより、LoRAの学習能力と安定性を向上させ、追加の推論コストを回避。さまざまな下流タスクでLoRAを上回る性能を示す。 Comment
日本語解説:
- LoRAの進化:基礎から最新のLoRA-Proまで , 松尾研究所テックブログ, 2025.09
- Tora: Torchtune-LoRA for RL, shangshang-wang, 2025.10
では、通常のLoRA, QLoRAだけでなく本手法でRLをする実装もサポートされている模様
[Paper Note] MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases, Zechun Liu+, ICLR'24, 2024.02
Paper/Blog Link My Issue
#NLP #SmallModel #ICLR Issue Date: 2025-10-10 GPT Summary- モバイルデバイス向けに10億未満のパラメータを持つ高品質な大規模言語モデル(LLM)の設計を提案。深くて細いアーキテクチャを活用し、MobileLLMという強力なモデルを構築し、従来のモデルに対して精度を向上。さらに、重み共有アプローチを導入し、MobileLLM-LSとしてさらなる精度向上を実現。MobileLLMモデルファミリーは、チャットベンチマークでの改善を示し、一般的なデバイスでの小型モデルの能力を強調。
[Paper Note] Aria: An Open Multimodal Native Mixture-of-Experts Model, Dongxu Li+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #OpenWeight #MoE(Mixture-of-Experts) #VisionLanguageModel Issue Date: 2025-10-07 GPT Summary- Ariaは、オープンなマルチモーダルネイティブAIモデルであり、視覚とテキストのタスクにおいて高い性能を発揮します。3.9Bの視覚トークンと3.5Bのテキストトークンを持つエキスパートの混合モデルで、既存のプロプライエタリモデルを上回ります。言語理解やマルチモーダル理解を強化する4段階のパイプラインで事前トレーニングされ、モデルウェイトとコードベースはオープンソースとして提供されます。 Comment
元ポスト:
HF: https://huggingface.co/rhymes-ai/Aria
提案された当時2024年10月時点で、VisionとText Understanding双方でに強い初めてのモデルで、初のマルチモーダルMoEモデルで(当時まだ話題になっていなかったDeepSeek-V2アーキテクチャを採用)、LongVideoのUnderstanidinpで当時の最高性能であったとのこと。
[Paper Note] xLSTM: Extended Long Short-Term Memory, Maximilian Beck+, NeurIPS'24 Spotlight, 2024.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Architecture #NeurIPS #RecurrentModels Issue Date: 2025-10-03 GPT Summary- LSTMを数十億のパラメータにスケールアップし、最新技術を活用して制限を軽減する試み。指数的ゲーティングと修正されたメモリ構造を導入し、sLSTMとmLSTMを開発。これらを統合してxLSTMブロックを生成し、トランスフォーマーと比較してパフォーマンスとスケーリングで優れた結果を得る。 Comment
code: https://github.com/NX-AI/xlstm
最近名前をみるxLSTM
openreview: https://openreview.net/forum?id=ARAxPPIAhq¬eId=gra7vHnb0q
[Paper Note] Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs, Arash Ahmadian+, ACL'24, 2024.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Alignment #ReinforcementLearning #ACL #read-later #Selected Papers/Blogs Issue Date: 2025-09-27 GPT Summary- RLHFにおける整合性の重要性を考慮し、PPOの高コストとハイパーパラメータ調整の問題を指摘。シンプルなREINFORCEスタイルの最適化手法がPPOや新提案の手法を上回ることを示し、LLMの整合性特性に適応することで低コストのオンラインRL最適化が可能であることを提案。
[Paper Note] The Impact of Initialization on LoRA Finetuning Dynamics, Soufiane Hayou+, NeurIPS'24, 2024.06
Paper/Blog Link My Issue
#Analysis #NLP #PEFT(Adaptor/LoRA) #NeurIPS Issue Date: 2025-09-25 GPT Summary- 本論文では、LoRAにおける初期化の役割を研究し、Bをゼロに初期化しAをランダムに初期化する方式が他の方式よりも優れたパフォーマンスを示すことを明らかにします。この初期化方式は、より大きな学習率を使用できるため、効率的な学習を促進する可能性があります。LLMsに関する実験を通じて結果を検証します。 Comment
元ポスト:
初期化でBをzeroにするという手法は以下でも提案されているが、本研究の方が下記研究よりも投稿が1年程度早い:
- [Paper Note] SingLoRA: Low Rank Adaptation Using a Single Matrix, David Bensaïd+, arXiv'25
[Paper Note] Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing, Xinyu Hu+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #Prompting #AutomaticPromptEngineering #ICLR Issue Date: 2025-09-24 GPT Summary- Evokeという自動プロンプト洗練フレームワークを提案。レビュアーと著者のLLMがフィードバックループを形成し、プロンプトを洗練。難しいサンプルを選択することで、LLMの深い理解を促進。実験では、Evokeが論理的誤謬検出タスクで80以上のスコアを達成し、他の手法を大幅に上回る結果を示した。 Comment
openreview: https://openreview.net/forum?id=OXv0zQ1umU
pj page:
https://sites.google.com/view/evoke-llms/home
github:
https://github.com/microsoft/Evoke
githubにリポジトリはあるが、プロンプトテンプレートが書かれたtsvファイルが配置されているだけで、実験を再現するための全体のパイプラインは存在しないように見える。
A Comprehensive Survey of Hallucination in Large Language, Image, Video and Audio Foundation Models, Sahoo+, EMNLP'24 Findings
Paper/Blog Link My Issue
#Survey #NLP #Hallucination #MultiModal Issue Date: 2025-09-24 GPT Summary- 基盤モデル(FMs)の多様なドメインにおける進展は顕著だが、特に高リスクなアプリケーションでは幻覚的な出力が問題となる。本調査論文は、テキスト、画像、動画、音声におけるFMsの幻覚の問題を特定し、軽減策の最近の進展をまとめる。幻覚の定義、分類、検出戦略を含むフレームワークを提供し、今後の研究と開発の基盤を築くことを目指す。 Comment
[Paper Note] LASeR: Learning to Adaptively Select Reward Models with Multi-Armed Bandits, Duy Nguyen+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #NeurIPS #Generalization #RewardModel #Adaptive #Multi-Armed Bandit Issue Date: 2025-09-23 GPT Summary- LASeRを導入し、報酬モデルの選択を多腕バンディット問題として定式化。これにより、最適なRMを選択しながらLLMsを効率的に訓練。常識的および数学的推論タスクでLlama-3-8Bの精度を2.67%向上させ、2倍のスピードアップを実現。WildChatタスクでは72.69%の勝率を達成し、長文生成でもF1ポイントの改善を示す。 Comment
元ポスト:
[Paper Note] WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs, Seungju Han+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Safety #NeurIPS Issue Date: 2025-09-16 GPT Summary- WildGuardは、LLMの安全性向上を目的としたオープンで軽量なモデレーションツールで、悪意のある意図の特定、安全リスクの検出、拒否率の判断を行う。92Kのラベル付きデータを用いたWildGuardMixを構築し、敵対的な脱獄や拒否応答をカバー。評価の結果、WildGuardは既存のオープンソースモデレーションモデルに対して最先端のパフォーマンスを示し、特に拒否検出で最大26.4%の改善を達成。GPT-4のパフォーマンスに匹敵し、脱獄攻撃の成功率を79.8%から2.4%に低下させる効果を持つ。 Comment
openreview: https://openreview.net/forum?id=Ich4tv4202#discussion
[Paper Note] Lessons from Studying Two-Hop Latent Reasoning, Mikita Balesni+, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP #Reasoning #read-later Issue Date: 2025-09-12 GPT Summary- 大規模言語モデル(LLM)の二段階質問応答能力を調査し、思考の連鎖(CoT)の重要性を示す。合成事実を用いた実験で、モデルは二つの合成事実を組み合わせるのに失敗するが、自然な事実との組み合わせでは成功することが確認された。これにより、LLMは潜在的な二段階推論能力を持つが、その能力のスケーリングには不明点が残る。研究者は、LLMの推論能力を評価する際に、ショートカットによる虚偽の成功や失敗に注意する必要があることを強調。 Comment
元ポスト:
下記研究ではエンティティが国の場合は2 step推論ができるという例外が生じており、事前学習のフィルタリングで何か見落としがあるかもしれない可能性があり:
- [Paper Note] Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, ACL'24
下記研究において、完全にmemorizationzが生じない形で事前学習とInference実施(train: John Doe lives in **Tokyo**., Test: The people in the city John Doe is from speak **Japanese**.)されたが、エンティティがcityの場合でしか試されておらず、他のエンティティでも汎化するのか?という疑問があった:
- [Paper Note] Extractive Structures Learned in Pretraining Enable Generalization on Finetuned Facts, Jiahai Feng+, ICML'25
本研究では17種類の他のエンティティでも2 hop reasoningがlatentに実施されていることを確認した。しかし、一つ不思議な点として当初2つの架空の事実をLLMに教えるような学習を試みた場合は。Acc.が0%で、lossも偶然に生じる程度のものであった。これを深掘りすると、
- 合成+本物の事実→うまくいく
- 合成+合成→失敗
- 同一訓練/incontext文書内の合成された事実→うまくいく
という現象が観測され、このことより
- 実世界のプロンプトでの成功は、latent reasoningがロバストに実施されていることを示すわけではなく(事前学習時の同一文書内の共起を反映しているだけの可能性がある)
- 合成データでの2 hop推論の失敗は、latent reasoningの能力を否定するものではない(合成された事実は実世界での自然な事実とは異なるためうまくいっていない可能性がある)
という教訓が得られた、といった話が元ポストに書かれている。
なぜ完全に合成された事実情報では失敗するのだろうか。元論文を読んで事前学習データとしてどのようなものが利用されているかを確認する必要がある。
元ポスト:
[Paper Note] MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures, Jinjie Ni+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #NeurIPS Issue Date: 2025-09-10 GPT Summary- MixEvalは、LLM評価の新しいパラダイムであり、実世界のユーザークエリと真実に基づくベンチマークを組み合わせることで、効率的かつ公正な評価を実現する。これにより、Chatbot Arenaとの高い相関を持ち、迅速かつ安価な評価が可能となる。さらに、動的評価を通じてLLM評価の理解を深め、今後の研究方向を示す。 Comment
[Paper Note] MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark, Yubo Wang+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #NeurIPS Issue Date: 2025-09-09 GPT Summary- MMLUベンチマークの限界を克服するため、推論に焦点を当てた質問を統合し、選択肢を4から10に増やした強化データセットMMLU-Proを提案。MMLU-Proは些細な質問を排除し、精度が16%から33%低下する一方で、プロンプトに対する安定性が向上。Chain of Thought推論を利用するモデルは、MMLU-Proでより良いパフォーマンスを示し、複雑な推論問題を含むことを示唆。MMLU-Proは、より識別的なベンチマークとして分野の進展を追跡するのに適している。 Comment
MMLUはこちら:
- [Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
[Paper Note] Stepwise Alignment for Constrained Language Model Policy Optimization, Akifumi Wachi+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #Alignment #Safety #NeurIPS #One-Line Notes Issue Date: 2025-09-09 GPT Summary- 安全性と信頼性はLLMを用いるAIシステムにおいて重要であり、本研究では報酬最大化を人間の価値に基づく安全性制約の下で定式化し、逐次整合性アルゴリズム(SACPO)を提案。SACPOは報酬と安全性を組み込んだ最適ポリシーを段階的に整合させ、シンプルで強力な整合性アルゴリズムを活用。理論的分析により最適性と安全性制約違反の上限を示し、実験結果ではSACPOがAlpaca-7Bのファインチューニングにおいて最先端手法を上回ることを確認。 Comment
NLPコロキウムでのスライドを参照のこと:
- 【NLPコロキウム】Stepwise Alignment for Constrained Language Model Policy Optimization (NeurIPS 2024) , 2024.12
[Paper Note] Multi-Head Mixture-of-Experts, Xun Wu+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #NeurIPS #Routing Issue Date: 2025-09-04 GPT Summary- MH-MoEは、マルチヘッドメカニズムを用いてトークンを複数のサブトークンに分割し、専門家の活性化を向上させる新しい手法です。これにより、文脈理解が深まり、過学習が軽減されます。MH-MoEは実装が簡単で、他のSMoEモデルと統合可能であり、広範な実験でその有効性が示されています。 Comment
SNLP'24での解説スライド: https://speakerdeck.com/takase/snlp2024-multiheadmoe
MoEのRouting Collapseに対して、Expertsの表現力を落とすことで特定のExpertsにルーティングが偏らないようにする、というコンセプトな模様。具体的には、inputを複数headに分割してhead単位でExpertsを選択し、出力をconcatする、といったアーキテクチャらしい。
[Paper Note] Be like a Goldfish, Don't Memorize Mitigating Memorization in Generative LLMs, Abhimanyu Hans+, NeurIPS'24
Paper/Blog Link My Issue
#Pretraining #NLP #NeurIPS #Memorization Issue Date: 2025-09-03 GPT Summary- 「ゴールドフィッシュロス」を導入し、トレーニング中にランダムに選ばれたトークンをロス計算から除外することで、プライバシーや著作権リスクを軽減。10億規模のLlama-2モデルの実験により、下流のベンチマークに影響を与えずに記憶の削減を実証。 Comment
元ポスト:
クロスエントロピーのloss計算からランダムにtokenを除外せることでdownstream taskの性能を損なうことなくmemorizationを防げますよ、という話らしい
[Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #Zero/Few/ManyShotPrompting #Prompting #In-ContextLearning #NeurIPS Issue Date: 2025-09-01 GPT Summary- 大規模言語モデル(LLMs)は、少数ショットから多くのショットのインコンテキスト学習(ICL)において顕著な性能向上を示す。新たな設定として、モデル生成の思考過程を用いる強化されたICLと、ドメイン特有の質問のみを用いる無監督ICLを提案。これらは特に複雑な推論タスクに効果的であり、多くのショット学習は事前学習のバイアスを覆し、ファインチューニングと同等の性能を発揮することが示された。また、推論コストは線形に増加し、最前線のLLMsは多くのショットのICLから恩恵を受けることが確認された。 Comment
many-shotを提案
[Paper Note] DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving, Yuxuan Tong+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #Dataset #SyntheticData #Evaluation #Reasoning #Mathematics #NeurIPS Issue Date: 2025-08-30 GPT Summary- 数学問題解決には高度な推論が必要であり、従来のモデルは難しいクエリに対して偏りがあることが明らかになった。そこで、Difficulty-Aware Rejection Tuning(DART)を提案し、難しいクエリに多くの試行を割り当てることでトレーニングを強化。新たに作成した小規模な数学問題データセットで、7Bから70BのモデルをファインチューニングしたDART-MATHは、従来の手法を上回る性能を示した。合成データセットが数学問題解決において効果的でコスト効率の良いリソースであることが確認された。 Comment
[Paper Note] MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies, Shengding Hu+, COLM'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #SmallModel #COLM #Selected Papers/Blogs #Scheduler #One-Line Notes Issue Date: 2025-08-25 GPT Summary- 急成長する大規模言語モデル(LLMs)の開発におけるコストの懸念から、小規模言語モデル(SLMs)の可能性が注目されている。本研究では、MiniCPMという1.2Bおよび2.4Bの非埋め込みパラメータバリアントを紹介し、これらが7B-13BのLLMsと同等の能力を持つことを示す。モデルのスケーリングには広範な実験を、データのスケーリングにはWarmup-Stable-Decay(WSD)学習率スケジューラを導入し、効率的なデータ-モデルスケーリング法を研究した。MiniCPMファミリーにはMiniCPM-DPO、MiniCPM-MoE、MiniCPM-128Kが含まれ、優れたパフォーマンスを発揮している。MiniCPMモデルは公開されている。 Comment
Warmup-Stable-Decay (WSD)
openreview: https://openreview.net/forum?id=3X2L2TFr0f¬eId=QvwPc5chyd
[Paper Note] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback, Harrison Lee+, ICML'24
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #SelfImprovement #ICML Issue Date: 2025-08-21 GPT Summary- RLAIFは、オフ・ザ・シェルフのLLMから生成された好みに基づいて報酬モデルを訓練し、RLHFと同等のパフォーマンスを達成する代替手段を提供。自己改善を示し、d-RLAIFを導入することでさらに優れた結果を得る。RLAIFは人間のフィードバックを用いた場合と同等の性能を示し、RLHFのスケーラビリティの課題に対する解決策となる可能性がある。 Comment
先行研究:
- [Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
[Paper Note] FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI, Elliot Glazer+, arXiv'24
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Mathematics Issue Date: 2025-08-16 GPT Summary- FrontierMathは、専門の数学者によって作成された難易度の高い数学問題のベンチマークで、数論や実解析から代数幾何学や圏論まで幅広い分野をカバー。問題解決には数時間から数日かかることがあり、現在のAIモデルは問題の2%未満しか解決できていない。FrontierMathはAIの数学的能力の進捗を定量化するための厳密なテストベッドを提供する。
[Paper Note] Measuring short-form factuality in large language models, Jason Wei+, arXiv'24
Paper/Blog Link My Issue
#NLP #Dataset #QuestionAnswering #Evaluation #Factuality #Trustfulness Issue Date: 2025-08-16 GPT Summary- SimpleQAは、言語モデルの短い事実に関する質問への応答能力を評価するためのベンチマークであり、挑戦的かつ評価が容易な質問を特徴とする。各回答は正解、不正解、未試行のいずれかとして評価され、理想的なモデルは自信がない質問には挑戦せず、正解を多く得ることを目指す。SimpleQAは、モデルが「自分が知っていることを知っているか」を評価するためのシンプルな手段であり、次世代モデルにとっても重要な評価基準となることが期待されている。 Comment
https://openai.com/index/introducing-simpleqa/
先行研究:
- [Paper Note] TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension, Mandar Joshi+, ACL'17
- Natural Questions: A Benchmark for Question Answering Research, Kwiatkowski+, TACL'19
これらはすでに飽和している
最近よくLLMのベンチで見かけるSimpleQA
[Paper Note] Better & Faster Large Language Models via Multi-token Prediction, Fabian Gloeckle+, ICML'24
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Coding #ICML #Selected Papers/Blogs Issue Date: 2025-08-16 GPT Summary- 本研究では、大規模言語モデルを複数の将来のトークンを同時に予測するように訓練する手法を提案し、サンプル効率の向上を図る。具体的には、n個の独立した出力ヘッドを用いて次のnトークンを予測し、訓練時間にオーバーヘッドをかけずに下流の能力を向上させる。特に、コーディングタスクにおいて、提案モデルは強力なベースラインを上回る性能を示し、推論時に最大3倍の速度向上も実現。 Comment
next tokenだけでなく、next 4-tokenを予測して学習することで、MBPP/HumanEvalにおいて、モデルのパラメータサイズが1.3Bを超えた時点でベースライン(=同じパラメータサイズとなるように調整されたnext-token prediction)をoutperformしはじめ、モデルサイズが大きくなるにつれて性能の差が顕著に表れることを示した。コーディングドメインにおいて事前学習、およびfinetuningの双方で効果がある。ただし、3.7節で示されている通り、これはコーディングドメインでのみこのような顕著な改善がみられており、自然言語データに対してはここまで顕著な改善はしていないように見える(5.1節で考察されていそう; 昨今のLLMでは事前学習データにコーディングなどのデータが入るのが普通なので利用する恩恵はありそう; Abstractive Summarizationでは性能が改善している(Figure6); GSM8Kでは200Bまではnext 2 tokenを予測すると性能が改善しているが500B token学習するとnext token predictionの方が性能が良くなる)。全体的にperplexityの改善(=次のトークンにおいて正解トークンの生成確率を改善する)というよりは、モデルの"最終的な生成結果”にフォーカスした評価となっている。
モデルは共有のトランクf_s (おそらくhead間でパラメータを共有している一連のtransformerブロック) を持っておりinput x_t:1に対応するlatent representation z_t:1を生成する。latent representationをoutput headにinputすることで、それぞれのheadが合計でn個のnext tokenを予測する。
next n-tokenを予測する際には、GPUメモリを大幅に食ってしまう (logitsのshapeが(n, V)となりそれらの勾配も保持しなければならない) ことがボトルネックとなるが、f_sまでforward passを実行したら、各headに対してforward/backward passを順番に実行して、logitsの値は破棄し勾配の情報だけf_sに蓄積することで、長期的に保持する情報を各headのから逆伝搬された勾配情報のみにすることでこれを解決している。
実際にinferenceをするときはnext tokenを予測するヘッドの出力を活用することを前提としているが、全てのヘッドを活用することで、t時点でt+nトークンの予測を可能なため、self-speculative decodingを実施しinference timeを短縮することができる。
3.4で示されているように、nの値は大きければ大きいほど良いというわけではなく、4程度(byte levelなモデルの場合は8 bytes)が最適なようである。が、Table1を見ると、データによってはn=6が良かったり(i.e., 最適なnは学習データ依存)複数エポック学習するとmulti token predictionの効果が薄くなっていそう(i.e., 同じトークンの予測を複数回学習するので実質multi token predictionと似たようなことをやっている。言い換えると、multi token predictionは複数epochの学習を先取りしているとみなせる?)なのは注意が必要そう。
全体的に複数epochを学習すると恩恵がなくなっていく(コーディング) or next token predictionよりも性能が悪化する(自然言語)ので、LLMの事前学習において、複数epochを学習するような当たり前みたいな世界線が訪れたら、このアーキテクチャを採用すると性能はむしろ悪化しそうな気はする。
MBPP/HumanEval:
- [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21
- [Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
[Paper Note] Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, Lean Wang+, arXiv'24
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) Issue Date: 2025-08-16 GPT Summary- MoEモデルにおける負荷の不均衡を解消するため、補助損失を用いないLoss-Free Balancingを提案。各エキスパートのルーティングスコアにバイアスを適用し、負荷のバランスを維持。実験により、従来の手法よりも性能と負荷バランスが向上することを確認。 Comment
openreview: https://openreview.net/forum?id=y1iU5czYpE
MoEモデルにおいて特定のExpertsにばかりルーティングが集中し、
- routing collapse: Expertsが十分に訓練されることを妨げる
- computation bottleneck: Expertsが複数のデバイスに分散している場合、ルーティンが集中すると計算効率が落ちる
という問題が起きる。この問題に対処するために既存研究はauxiliary lossと呼ばれる各トークンが選択するExpertsが幅広くなるような制約を入れている。
本研究ではauxiliary lossの勾配が言語モデリングタスクに対して悪影響を及ぼす可能性があることを指摘し、loss freeのbalancing手法を提案し、perplexityが1B, 3B, (リバッタル中で13B)モデルにおいて低下することを実験的に示している。また、リバッタルにおいて、downstreamタスクの性能(BBH, MMLU, C-Eval, CMMLU)においても、性能が改善することが示されている。
手法はシンプルで、top-kのexpertsを決める際のルーティングスコアに対して、expertsごとのバイアス項を導入し、学習時にexpertsに割り当てられたトークン数の多寡に応じてバイアス値を調整する。
openreviewによると、以下の事項が指摘されている:
- 実験で用いられているアーキテクチャがDeepSeekMoEにのみに限られている
- パラメータ数も小規模のものでしか実験されていない(リバッタルにてより大きなモデルでの結果を反映)
- auxiliary lossがそもそも言語モデリングタスクに悪影響を与えることは実験的に一部示されているが、理論的なjustificationが不足している
- downstream taskに対する実験結果が無いこと(リバッタルでこの点については示された)
- related workが10件しか引用されておらず、より包括的なliterature reviewと関連研究との関係性についての議論が不足している
[Paper Note] CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution, Ruiyang Xu+, arXiv'24
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Coding #Reasoning #MultiLingual Issue Date: 2025-08-15 GPT Summary- CRUXEVAL-Xという多言語コード推論ベンチマークを提案。19のプログラミング言語を対象に、各言語で600以上の課題を含む19Kのテストを自動生成。言語間の相関を評価し、Python訓練モデルが他言語でも高い性能を示すことを確認。 Comment
[Paper Note] CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, Alex Gu+, arXiv'24
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Coding #Reasoning Issue Date: 2025-08-15 GPT Summary- CRUXEvalという800のPython関数からなるベンチマークを提案し、入力予測と出力予測の2つのタスクを評価。20のコードモデルをテストした結果、HumanEvalで高得点のモデルがCRUXEvalでは改善を示さないことが判明。GPT-4とChain of Thoughtを用いた場合、入力予測で75%、出力予測で81%のpass@1を達成したが、どのモデルも完全にはクリアできず、GPT-4のコード推論能力の限界を示す例を提供。
[Paper Note] A Survey on the Memory Mechanism of Large Language Model based Agents, Zeyu Zhang+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #memory Issue Date: 2025-08-11 GPT Summary- LLMベースのエージェントのメモリメカニズムに関する包括的な調査を提案。メモリの重要性を論じ、過去の研究を体系的にレビューし、エージェントアプリケーションでの役割を紹介。既存研究の限界を分析し、将来の研究方向性を示す。リポジトリも作成。 Comment
元ポスト:
[Paper Note] The Factorization Curse: Which Tokens You Predict Underlie the Reversal Curse and More, Ouail Kitouni+, NeurIPS'24
Paper/Blog Link My Issue
#NeurIPS #read-later #ReversalCurse Issue Date: 2025-08-11 GPT Summary- 最先端の言語モデルは幻覚に悩まされ、情報取得において逆転の呪いが問題となる。これを因数分解の呪いとして再定義し、制御実験を通じてこの現象が次トークン予測の固有の失敗であることを発見。信頼性のある情報取得は単純な手法では解決できず、ファインチューニングも限界がある。異なるタスクでの結果は、因数分解に依存しないアプローチが逆転の呪いを軽減し、知識の保存と計画能力の向上に寄与する可能性を示唆している。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=f70e6YYFHF
Reversal Curseを提言した研究は下記:
- [Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23, 2023.09
[Paper Note] VERISCORE: Evaluating the factuality of verifiable claims in long-form text generation, Yixiao Song+, arXiv'24
Paper/Blog Link My Issue
#Metrics #NLP #Search #Evaluation #Factuality #LongSequence Issue Date: 2025-08-08 GPT Summary- VERISCOREという新しい指標を提案し、検証可能な主張と検証不可能な主張の両方を含む長文生成タスクに対応。人間評価ではVERISCOREが他の方法よりも理にかなっていることが確認され、16のモデルを評価した結果、GPT-4oが最も優れた性能を示したが、オープンウェイトモデルも差を縮めていることが分かった。また、異なるタスク間でVERISCOREの相関がないことから、事実性評価の拡張が必要であることを示唆している。 Comment
LLMの応答からverifiableなclaimのみを抽出し、それを外部の検索エンジン(google検索)のクエリとして入力。検索結果からclaimがsupportされるか否かをLLMによって判断しスコアリングする。
[Paper Note] LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding, Yushi Bai+, ACL'24
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #LongSequence #MultiLingual #ACL Issue Date: 2025-08-07 GPT Summary- 本論文では、長いコンテキスト理解のための初のバイリンガル・マルチタスクベンチマーク「LongBench」を提案。英語と中国語で21のデータセットを含み、平均長はそれぞれ6,711語と13,386文字。タスクはQA、要約、少数ショット学習など多岐にわたる。評価結果から、商業モデルは他のオープンソースモデルを上回るが、長いコンテキストでは依然として課題があることが示された。 Comment
PLaMo Primeの長文テキスト評価に利用されたベンチマーク(中国語と英語のバイリンガルデータであり日本語は存在しない)
PLaMo Primeリリースにおける機能改善:
https://tech.preferred.jp/ja/blog/plamo-prime-release-feature-update/
タスクと言語ごとのLengthの分布。英語の方がデータが豊富で、長いものだと30000--40000ものlengthのサンプルもある模様。
[Paper Note] Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models, Zihan Wang+, EMNLP'24
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #MoE(Mixture-of-Experts) #EMNLP Issue Date: 2025-08-06 GPT Summary- 本研究では、Mixture-of-Experts(MoE)アーキテクチャを持つ大規模言語モデル(LLMs)に対するパラメータ効率の良いファインチューニング(PEFT)手法を提案。主な内容は、(1) タスクごとの専門家の活性化分布の集中度の調査、(2) Expert-Specialized Fine-Tuning(ESFT)の提案とその効果、(3) MoEアーキテクチャの専門家特化型ファインチューニングへの影響の分析。実験により、ESFTがチューニング効率を向上させ、フルパラメータファインチューニングに匹敵またはそれを上回る性能を示すことが確認された。 Comment
元ポスト:
MoEアーキテクチャを持つLLMにおいて、finetuningを実施したいタスクに関連する専門家を特定し、そのほかのパラメータをfreezeした上で当該専門家のみをtrainableとすることで、効率的にfinetuningを実施する手法
専門家を見つける際には専門家ごとにfinetuningしたいタスクに対するrelevance scoreを計算する。そのために、2つの手法が提案されており、training dataからデータをサンプリングし
- 全てのサンプリングしたデータの各トークンごとのMoE Routerのgateの値の平均値をrelevant scoreとする方法
- 全てのサンプリングしたデータの各トークンごとに選択された専門家の割合
の2種類でスコアを求める。閾値pを決定し、閾値以上のスコアを持つ専門家をtrainableとする。
LoRAよりもmath, codeなどの他ドメインのタスク性能を劣化させず、Finetuning対象のタスクでFFTと同等の性能を達成。
LoRAと同様にFFTと比較し学習時間は短縮され、学習した専門家の重みを保持するだけで良いのでストレージも節約できる。
[Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
Paper/Blog Link My Issue
#NLP #ContextWindow #LongSequence #PositionalEncoding #ICLR #PostTraining #Selected Papers/Blogs Issue Date: 2025-08-02 GPT Summary- YaRN(Yet another RoPE extensioN method)は、トランスフォーマーベースの言語モデルにおける位置情報のエンコードを効率的に行い、コンテキストウィンドウを従来の方法よりも10倍少ないトークンと2.5倍少ない訓練ステップで拡張する手法を提案。LLaMAモデルが長いコンテキストを効果的に利用できることを示し、128kのコンテキスト長まで再現可能なファインチューニングを実現。 Comment
openreview: https://openreview.net/forum?id=wHBfxhZu1u
現在主流なRoPEを前提としたコンテキストウィンドウ拡張手法で、事前学習で学習されたRoPEのコンテキストウィンドウを中間学習において拡張する。様々なモデルで利用されている。
日本語解説: https://zenn.dev/bilzard/scraps/de7ecd3c380b6e
- 国産生成AI PLaMoを支える事後学習と推論最適化, PFN, 2026.04
pp.24--25に解説がある
[Paper Note] The Impact of Example Selection in Few-Shot Prompting on Automated Essay Scoring Using GPT Models, Lui Yoshida, AIED'24
Paper/Blog Link My Issue
#NLP #AES(AutomatedEssayScoring) #Prompting #AIED Issue Date: 2025-07-29 GPT Summary- 本研究では、GPTモデルを用いた少数ショットプロンプティングにおける例の選択が自動エッセイ採点(AES)のパフォーマンスに与える影響を調査。119のプロンプトを用いて、GPT-3.5とGPT-4のモデル間でのスコア一致を二次重み付きカッパ(QWK)で測定。結果、例の選択がモデルによって異なる影響を及ぼし、特にGPT-3.5はバイアスの影響を受けやすいことが判明。慎重な例の選択により、GPT-3.5が一部のGPT-4モデルを上回る可能性があるが、GPT-4は最も高い安定性とパフォーマンスを示す。これにより、AESにおける例の選択の重要性とモデルごとのパフォーマンス評価の必要性が強調される。
[Paper Note] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration, Ji Lin+, MLSys'24
Paper/Blog Link My Issue
#NLP #Quantization #MLSys #EdgeDevices Issue Date: 2025-07-21 GPT Summary- Activation-aware Weight Quantization(AWQ)を提案し、LLMの低ビット重み量子化を効率化。顕著な重みチャネルを保護することで量子化誤差を削減し、異なるドメインに一般化可能。AWQは言語モデリングやドメイン特化型ベンチマークで優れた性能を示し、4ビットのオンデバイスLLM/VLM向け推論フレームワークTinyChatを実装。これにより、デスクトップおよびモバイルGPUでの処理速度を3倍以上向上させ、70B Llama-2モデルの展開を容易にする。 Comment
[Paper Note] Accelerating Large Language Model Training with 4D Parallelism and Memory Consumption Estimator, Kazuki Fujii+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Pretraining #NLP #SoftwareEngineering #mid-training #PostTraining #read-later #MemoryOptimization Issue Date: 2025-07-16 GPT Summary- 本研究では、Llamaアーキテクチャにおける4D並列トレーニングに対して、メモリ使用量を正確に推定する公式を提案。A100およびH100 GPUでの454回の実験を通じて、一時バッファやメモリの断片化を考慮し、推定メモリがGPUメモリの80%未満であればメモリ不足エラーが発生しないことを示した。この公式により、メモリオーバーフローを引き起こす並列化構成を事前に特定でき、最適な4D並列性構成に関する実証的な洞察を提供する。
[Paper Note] DiLoCo: Distributed Low-Communication Training of Language Models, Arthur Douillard+, ICML'24 Workshop WANT
Paper/Blog Link My Issue
#Pretraining #NLP #ICML #mid-training #Selected Papers/Blogs #Workshop #One-Line Notes #needs-revision #DistributedLearning Issue Date: 2025-07-15 GPT Summary- 分散最適化アルゴリズム「DiLoCo」を提案し、接続が不十分なデバイスでのLLMトレーニングを可能にする。DiLoCoは、通信量を500分の1に抑えつつ、完全同期の最適化と同等の性能をC4データセットで発揮。各ワーカーのデータ分布に対して高いロバスト性を持ち、リソースの変動にも柔軟に対応可能。 Comment
言語モデルの分散学習における通信量をいかに抑えるかにフォーカスした研究で、クライアントごとに異なるデータsplitを持ち、当該データによってモデルをローカルでAdamWを用いてH step更新。その後、更新された重みの差分をouter gradientとして共有し、重み更新の差分を平均化することでローカルモデルを集約するという処理を繰り返す。
[Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #Coding #Selected Papers/Blogs Issue Date: 2025-07-13 GPT Summary- BigCodeプロジェクトは、責任あるCode LLMsの開発に焦点を当て、StarCoder2を発表。Software Heritageと提携し、The Stack v2を構築し、619のプログラミング言語を含む大規模なトレーニングセットを作成。StarCoder2モデルは3B、7B、15Bのパラメータを持ち、徹底的なベンチマーク評価で優れた性能を示す。特にStarCoder2-15Bは、同等の他モデルを大幅に上回り、数学やコード推論でも高い性能を発揮。モデルの重みはOpenRAILライセンスで公開され、トレーニングデータの透明性も確保。 Comment
[Paper Note] Iterative Reasoning Preference Optimization, Richard Yuanzhe Pang+, NeurIPS'24, 2024.04
Paper/Blog Link My Issue
#NLP #Reasoning #SelfImprovement #NeurIPS #DPO #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-07-02 GPT Summary- 反復的な好み最適化手法を用いて、Chain-of-Thought(CoT)候補間の推論ステップを最適化するアプローチを開発。修正DPO損失を使用し、推論の改善を示す。Llama-2-70B-ChatモデルでGSM8K、MATH、ARC-Challengeの精度を向上させ、GSM8Kでは55.6%から81.6%に改善。多数決による精度は88.7%に達した。 Comment
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
と似たようにiterativeなmannerでreasoning能力を向上させる。
ただし、loss functionとしては、chosenなCoT+yのresponseに対して、reasoning traceを生成する能力を高めるために、NLL Lossも適用している点に注意。
32 samplesのmajority votingによってより高い性能が達成できているので、多様なreasoning traceが生成されていることが示唆される。
DPOでReasoning能力を伸ばしたい場合はNLL lossが重要。Iterative RPO
[Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #Reasoning #ICLR #Selected Papers/Blogs #PRM Issue Date: 2025-06-26 GPT Summary- 大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。 Comment
OpenReview: https://openreview.net/forum?id=v8L0pN6EOi
[Paper Note] Chat Vector: A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languages, Shih-Cheng Huang+, ACL'24
Paper/Blog Link My Issue
#NLP #ACL #ModelMerge Issue Date: 2025-06-25 GPT Summary- オープンソースの大規模言語モデル(LLMs)の多くは英語に偏っている問題に対処するため、chat vectorという概念を導入。これは、事前学習済みモデルの重みからチャットモデルの重みを引くことで生成され、追加のトレーニングなしに新しい言語でのチャット機能を付与できる。実証研究では、指示に従う能力や有害性の軽減、マルチターン対話においてchat vectorの効果を示し、さまざまな言語やモデルでの適応性を確認。chat vectorは、事前学習済みモデルに対話機能を効率的に実装するための有力な解決策である。 Comment
日本語解説: https://qiita.com/jovyan/items/ee6affa5ee5bdaada6b4
下記ブログによるとChatだけではなく、Reasoningでも(post-trainingが必要だが)使える模様
Reasoning能力を付与したLLM ABEJA-QwQ32b-Reasoning-Japanese-v1.0の公開, Abeja Tech Blog, 2025.04:
https://tech-blog.abeja.asia/entry/geniac2-qwen25-32b-reasoning-v1.0
[Paper Note] Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data, Fahim Tajwar+, ICML'24
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #ReinforcementLearning #PPO (ProximalPolicyOptimization) #ICML #DPO #On-Policy #Reference Collection Issue Date: 2025-06-25 GPT Summary- 好みのラベルを用いた大規模言語モデルのファインチューニングに関する研究。オンポリシー強化学習や対照学習などの手法を比較し、オンポリシーサンプリングや負の勾配を用いるアプローチが優れていることを発見。これにより、カテゴリ分布の特定のビンにおける確率質量を迅速に変更できるモード探索目的の重要性を示し、データ収集の最適化に関する洞察を提供。 Comment
以下のオフライン vs. オンラインRLアルゴリズムで本研究が引用されている:
[Paper Note] Densing Law of LLMs, Chaojun Xiao+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Scaling Laws #read-later #Reference Collection Issue Date: 2025-05-27 GPT Summary- 容量密度の新指標を用いてLLMsの性能を評価。基準モデルに基づき実効パラメータ数を定義し、容量密度を計算することで、モデルの効率性と有効性を統一的に分析。最近のデータでは、LLMsの容量密度は約3か月ごとに2倍になり、この傾向が将来の開発戦略に新たな視点を提供する。 Comment
元ポスト:
[Paper Note] UltraFeedback: Boosting Language Models with Scaled AI Feedback, Ganqu Cui+, ICML'24
Paper/Blog Link My Issue
#NLP #Dataset #Alignment #InstructionTuning #ICML #PostTraining Issue Date: 2025-05-11 GPT Summary- 人間のフィードバックに加え、高品質なAIフィードバックを自動収集することで、LLMsのアライメントをスケーラブルに実現。多様なインタラクションをカバーし、注釈バイアスを軽減した結果、25万件の会話に対する100万件以上のGPT-4フィードバックを含むデータセット「UltraFeedback」を構築。これに基づき、LLaMAモデルを強化学習でアライメントし、チャットベンチマークで優れた性能を示す。研究はオープンソースチャットモデルの構築におけるAIフィードバックの有効性を検証。データとモデルは公開中。
[Paper Note] ORPO: Monolithic Preference Optimization without Reference Model, Jiwoo Hong+, EMNLP'24
Paper/Blog Link My Issue
#NLP #Alignment #InstructionTuning #EMNLP #Initial Impression Notes Issue Date: 2025-05-11 GPT Summary- 本論文では、好みの整合性における監視付きファインチューニング(SFT)の重要性を強調し、わずかなペナルティで好みに整合したSFTが可能であることを示します。さらに、追加の整合性フェーズを必要としない新しいオッズ比最適化アルゴリズムORPOを提案し、これを用いて複数の言語モデルをファインチューニングした結果、最先端のモデルを上回る性能を達成しました。 Comment
ざっくり言うとinstruction tuningとalignmentを同時にできる手法らしいがまだ理解できていない
[Paper Note] EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models, Peng Wang+, ACL'24, (System Demonstrations)
Paper/Blog Link My Issue
#NLP #Library #ACL #KnowledgeEditing Issue Date: 2025-05-11 GPT Summary- EasyEditは、LLMsのための使いやすい知識編集フレームワークであり、さまざまな知識編集アプローチをサポート。LlaMA-2の実験結果では、信頼性と一般化の面で従来のファインチューニングを上回ることを示した。GitHubでソースコードを公開し、Google Colabチュートリアルやオンラインシステムも提供。 Comment
[Paper Note] The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale, Guilherme Penedo+, NeurIPS'24
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Dataset #NeurIPS #Selected Papers/Blogs Issue Date: 2025-05-10 GPT Summary- 本研究では、15兆トークンからなるFineWebデータセットを紹介し、LLMの性能向上に寄与することを示します。FineWebは高品質な事前学習データセットのキュレーション方法を文書化し、重複排除やフィルタリング戦略を詳細に調査しています。また、FineWebから派生した1.3兆トークンのFineWeb-Eduを用いたLLMは、MMLUやARCなどのベンチマークで優れた性能を発揮します。データセット、コードベース、モデルは公開されています。 Comment
日本語解説: https://zenn.dev/deepkawamura/articles/da9aeca6d6d9f9
openreview: https://openreview.net/forum?id=n6SCkn2QaG#discussion
[Paper Note] Editing Large Language Models: Problems, Methods, and Opportunities, Yunzhi Yao+, EMNLP'24
Paper/Blog Link My Issue
#NLP #Dataset #EMNLP #KnowledgeEditing #read-later Issue Date: 2025-05-07 GPT Summary- LLMの編集技術の進展を探求し、特定のドメインでの効率的な動作変更と他の入力への影響を最小限に抑える方法を論じる。モデル編集のタスク定義や課題を包括的にまとめ、先進的な手法の実証分析を行う。また、新しいベンチマークデータセットを構築し、評価の向上と持続的な問題の特定を目指す。最終的に、編集技術の効果に関する洞察を提供し、適切な方法選択を支援する。コードとデータセットは公開されている。
[Paper Note] Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers, Zeyuan Allen-Zhu+, ICML'24 Tutorial
Paper/Blog Link My Issue
#Analysis #NLP #SyntheticData #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2025-05-06 Comment
元ポスト:
Canon層の発見
著者による解説:
[Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
Paper/Blog Link My Issue
#Analysis #NLP #SyntheticData #ICML #Selected Papers/Blogs #Reference Collection Issue Date: 2025-05-03 GPT Summary- 大規模言語モデル(LLMs)の知識抽出能力は、訓練データの多様性と強く相関しており、十分な強化がなければ知識は記憶されても抽出可能ではないことが示された。具体的には、エンティティ名の隠れ埋め込みに知識がエンコードされているか、他のトークン埋め込みに分散しているかを調査。LLMのプレトレーニングに関する重要な推奨事項として、補助モデルを用いたデータ再構成と指示微調整データの早期取り入れが提案された。 Comment
SNLP'24での解説スライド:
https://speakerdeck.com/sosk/physics-of-language-models-part-3-1-knowledge-storage-and-extraction
[Paper Note] Safety Alignment Should Be Made More Than Just a Few Tokens Deep, Xiangyu Qi+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #Safety #ICLR #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-04-29 GPT Summary- LLMsの安全性整合性は脆弱であり、単純な攻撃でジャイルブレイク可能。この問題は浅層的安全整合に起因し、生成分布が初めの数トークンで適応されるために発生する。研究では、浅層的安全整合の存在理由をケーススタディで示し、複数の脆弱性の根本原因を探求。これにより、初期トークンを超えて整合性を深めることで悪用に対する堅牢性を向上させる可能性が示唆される。ファインチューニング攻撃に対抗するための正則化手法も提案。将来の安全整合性は、より深いアプローチが必要であるとの結論を導く。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=6Mxhg9PtDE
Safety Alignment手法が最初の数トークンに依存しているからそうならないように学習しますというのは、興味深いテーマだし技術的にまだ困難な点もあっただろうし、インパクトも大きいし、とても良い研究だ…。
[Paper Note] Gorilla: Large Language Model Connected with Massive APIs, Shishir G. Patil+, NeurIPS'24
Paper/Blog Link My Issue
#Tools #NLP #Dataset #API #NeurIPS Issue Date: 2025-04-08 GPT Summary- Gorillaは、API呼び出しの生成においてGPT-4を上回るLLaMAベースのモデルであり、文書検索システムと組み合わせることで、テスト時の文書変更に適応し、ユーザーの柔軟な更新を可能にします。幻覚の問題を軽減し、APIをより正確に使用する能力を示します。Gorillaの評価には新たに導入したデータセット「APIBench」を使用し、信頼性と適用性の向上を実現しています。 Comment
APIBench: https://huggingface.co/datasets/gorilla-llm/APIBench
OpenReview: https://openreview.net/forum?id=tBRNC6YemY
[Paper Note] Foundational Challenges in Assuring Alignment and Safety of Large Language Models, Usman Anwar+, TMLR'24
Paper/Blog Link My Issue
#Survey #NLP #Alignment #Safety #TMLR Issue Date: 2025-04-06 GPT Summary- 本研究では、LLMsの整合性と安全性に関する18の基盤的課題を特定し、科学的理解、開発・展開方法、社会技術的課題の3つのカテゴリに整理。これに基づき、200以上の具体的な研究質問を提起。 Comment
OpenReview: https://openreview.net/forum?id=oVTkOs8Pka
[Paper Note] Agent Workflow Memory, Zora Zhiruo Wang+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#NLP #AIAgents #memory #One-Line Notes #needs-revision Issue Date: 2025-04-02 GPT Summary- エージェントが複雑なタスクを解決するために、再利用可能なワークフローを学習するAgent Workflow Memory(AWM)を提案。AWMは、オフライン・オンラインのシナリオで選択的にワークフローを提供し、200以上のドメインにおいて実験した結果、Mind2Webで24.6%、WebArenaで51.1%の相対的成功率向上を達成。タスク解決に要する手順数も削減し、訓練-テスト分布ギャップが広がる中でも堅牢な一般化を示した。 Comment
過去のワークフローをエージェントがprompt中で利用することができ、利用すればするほど賢くなるような仕組みの提案
openreview: https://openreview.net/forum?id=PfYg3eRrNi
[Paper Note] CoAct: A Global-Local Hierarchy for Autonomous Agent Collaboration, Xinming Hou+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #AIAgents #SoftwareEngineering #One-Line Notes Issue Date: 2025-04-02 GPT Summary- CoActフレームワークを提案し、LLMに人間社会の協調パターンを適用。グローバル計画エージェントがマクロ計画を策定し、ローカル実行エージェントが具体的なサブタスクを実行。WebArenaベンチマークで、長期的なウェブタスクにおいて従来手法を上回る性能を示した。 Comment
Planningエージェントと実行エージェントを活用するソフトウェアエージェント
ReActより性能向上
- [Paper Note] ReAct: Synergizing Reasoning and Acting in Language Models, Shunyu Yao+, ICLR'23, 2022.10
[Paper Note] WebArena: A Realistic Web Environment for Building Autonomous Agents, Shuyan Zhou+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #ICLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-04-02 GPT Summary- 生成AIの進展により、自律エージェントが自然言語コマンドで日常タスクを管理する可能性が生まれたが、現行のエージェントは簡略化された環境でのテストに限られている。本研究では、ウェブ上でタスクを実行するエージェントのための現実的な環境を構築し、eコマースやソーシャルフォーラムなどのドメインを含む完全なウェブサイトを提供する。この環境を基に、タスクの正確性を評価するベンチマークを公開し、実験を通じてGPT-4ベースのエージェントの成功率が14.41%であり、人間の78.24%には及ばないことを示した。これにより、実生活のタスクにおけるエージェントのさらなる開発の必要性が強調される。 Comment
Webにおけるさまざまなrealisticなタスクを評価するためのベンチマーク
実際のexample。スタート地点からピッツバーグのmuseumを巡る最短の経路を見つけるといった複雑なタスクが含まれる。
人間とGPT4,GPT-3.5の比較結果
[Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #ICLR #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-04-02 GPT Summary- SWE-benchは、12の人気Pythonリポジトリから得られた2,294のソフトウェアエンジニアリング問題を評価するフレームワークで、言語モデルがコードベースを編集して問題を解決する能力を測定します。評価の結果、最先端の商用モデルや微調整されたモデルSWE-Llamaも最も単純な問題しか解決できず、Claude 2はわずか1.96%の問題を解決するにとどまりました。SWE-benchは、より実用的で知的な言語モデルへの進展を示しています。 Comment
ソフトウェアエージェントの最もpopularなベンチマーク
主にpythonライブラリに関するリポジトリに基づいて構築されている。
SWE-Bench, SWE-Bench Lite, SWE-Bench Verifiedの3種類がありソフトウェアエージェントではSWE-Bench Verifiedを利用して評価することが多いらしい。Verifiedでは、issueの記述に曖昧性がなく、適切なunittestのスコープが適切なもののみが採用されているとのこと(i.e., 人間の専門家によって問題がないと判断されたもの)。
https://www.swebench.com/
Agenticな評価をする際に、一部の評価でエージェントがgit logを参照し本来は存在しないはずのリポジトリのfuture stateを見ることで環境をハッキングしていたとのこと:
これまでの評価結果にどの程度の影響があるかは不明。
openreview: https://openreview.net/forum?id=VTF8yNQM66
[Paper Note] ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation, Jianghao Lin+, WWW'24
Paper/Blog Link My Issue
#RecommenderSystems #NLP #UserModeling #CTRPrediction #RAG(RetrievalAugmentedGeneration) #LongSequence #WWW #KeyPoint Notes Issue Date: 2025-03-27 GPT Summary- 本論文では、ゼロショットおよび少ショットの推薦タスクにおいて、大規模言語モデル(LLMs)を強化する新しいフレームワーク「ReLLa」を提案。LLMsが長いユーザー行動シーケンスから情報を抽出できない問題に対処し、セマンティックユーザー行動検索(SUBR)を用いてデータ品質を向上させる。少ショット設定では、検索強化指示チューニング(ReiT)を設計し、混合トレーニングデータセットを使用。実験により、少ショットReLLaが従来のCTRモデルを上回る性能を示した。 Comment
LLMでCTR予測する際の性能を向上した研究。
そもそもLLMでCTR予測をする際は、ユーザのデモグラ情報とアクティビティログなどのユーザプロファイルと、ターゲットアイテムの情報でpromptingし、yes/noを出力させる。yes/noトークンのスコアに対して2次元のソフトマックスを適用して[0, 1]のスコアを得ることで、CTR予測をする(式1, 2)。
この研究ではコンテキストにユーザのログを入れても性能がスケールしない問題に対処するために (Figure 1)
直近のアクティビティログではなく、ターゲットアイテムと意味的に類似したアイテムに関するログをコンテキストに入れ(SUBR)、zero shotのinferenceに活用する (Figure 3)。
few-shot recommendation(少量のクリックスルーログを用いてLLMをSFTすることでCTR予測する手法)においては、上述の意味的に類似したアイテムをdata augmentationに利用し(i.e, promptに埋め込むアクティビティログの量を増やして)学習する (Figure 5)。
zeroshotにおいて、SUBRで性能改善。fewshot recommendationにといて、10%未満のデータで既存の全データを用いる手法を上回る。また、下のグラフを見るとpromptに利用するアクティビティログの量が増えるほど性能が向上するようになった。
ただし、latencyは100倍以上なのでユースケースが限定される。
[Paper Note] Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, Tri Dao+, ICML'24
Paper/Blog Link My Issue
#NLP #SSM (StateSpaceModel) #ICML #Selected Papers/Blogs #Reference Collection #Initial Impression Notes #LinearAttention Issue Date: 2025-03-24 GPT Summary- TransformersとMambaのような状態空間モデル(SSMs)の関連性を示し、SSMsと注意の変種との理論的接続を構築。新たに設計したMamba-2は、速度を2〜8倍向上させながら、Transformersと競争力を維持。 Comment
Mamba2の詳細を知りたい場合に読む
Mamba3:
- [Paper Note] MAMBA-3: IMPROVED SEQUENCE MODELING USING STATE SPACE PRINCIPLES, 2025.10
バグがあり本来の性能が出ていなかった模様:
初期化修正は後はGated Delta Netを上回る性能に。
- [Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
[Paper Note] Compact Language Models via Pruning and Knowledge Distillation, Saurav Muralidharan+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #Pruning #Distillation #NeurIPS #read-later Issue Date: 2025-03-16 GPT Summary- 本論文では、既存の大規模言語モデル(LLMs)をプルーニングし、少量のトレーニングデータで再トレーニングする手法を提案。深さ、幅、注意、MLPプルーニングを知識蒸留と組み合わせた圧縮ベストプラクティスを開発し、Nemotron-4ファミリーのLLMを2-4倍圧縮。これにより、トレーニングに必要なトークン数を最大40倍削減し、計算コストを1.8倍削減。Minitronモデルは、ゼロからトレーニングした場合と比較してMMLUスコアが最大16%改善され、他のモデルと同等の性能を示す。モデルの重みはオープンソース化され、補足資料も提供。 Comment
[Paper Note] Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24
Paper/Blog Link My Issue
#Analysis #NLP #ICLR #Selected Papers/Blogs #KeyPoint Notes #SparseAutoencoder #Interpretability #InterpretabilityScore Issue Date: 2025-03-15 GPT Summary- 神経ネットワークの多義性を解消するために、スパースオートエンコーダを用いて内部活性化の方向を特定。これにより、解釈可能で単義的な特徴を学習し、間接目的語の同定タスクにおける因果的特徴をより詳細に特定。スケーラブルで教師なしのアプローチが重ね合わせの問題を解決できることを示唆し、モデルの透明性と操作性向上に寄与する可能性を示す。 Comment
日本語解説: https://note.com/ainest/n/nbe58b36bb2db
OpenReview: https://openreview.net/forum?id=F76bwRSLeK
SparseAutoEncoderはネットワークのあらゆるところに仕込める(と思われる)が、たとえばTransformer Blockのresidual connection部分のベクトルに対してFeature Dictionaryを学習すると、当該ブロックにおいてどのような特徴の組み合わせが表現されているかが(あくまでSparseAutoEncoderがreconstruction lossによって学習された結果を用いて)解釈できるようになる。
SparseAutoEncoderは下記式で表され、下記loss functionで学習される。MがFeature Matrix(row-wiseに正規化されて後述のcに対するL1正則化に影響を与えないようにしている)に相当する。cに対してL1正則化をかけることで(Sparsity Loss)、c中の各要素が0に近づくようになり、結果としてcがSparseとなる(どうしても値を持たなければいけない重要な特徴量のみにフォーカスされるようになる)。
[Paper Note] PromptWizard: Task-Aware Prompt Optimization Framework, Eshaan Agarwal+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#NLP #AIAgents #Prompting #AutomaticPromptEngineering #One-Line Notes Issue Date: 2025-02-10 GPT Summary- 大規模言語モデル(LLMs)の効果的な活用に向けて、完全自動化されたプロンプト最適化フレームワーク「PromptWizard」を提案。自己進化・自己適応機能に基づき、プロンプトと文脈内例を反復的に洗練し、優れた品質のプロンプトを生成。45のタスクで高性能を示し、限られたデータや小規模モデルでも適用可能。コスト分析により効率性と優位性が確認される。 Comment
Github:
https://github.com/microsoft/PromptWizard?tab=readme-ov-file
元ポスト:
初期に提案された
- Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
と比較すると大分性能が上がってきているように見える。
reasoning modelではfewshot promptingをすると性能が落ちるという知見があるので、reasoningモデル向けのAPE手法もそのうち出現するのだろう(既にありそう)。
OpenReview:
https://openreview.net/forum?id=VZC9aJoI6a
ICLR'25にrejectされている
A Survey on Knowledge Distillation of Large Language Models, Xiaohan Xu+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #Distillation Issue Date: 2025-02-01 GPT Summary- 大規模言語モデル(LLMs)における知識蒸留(KD)の重要性を調査し、小型モデルへの知識伝達やモデル圧縮、自己改善の役割を強調。KDメカニズムや認知能力の向上、データ拡張(DA)との相互作用を検討し、DAがLLM性能を向上させる方法を示す。研究者や実務者に向けたガイドを提供し、LLMのKDの倫理的適用を推奨。関連情報はGithubで入手可能。
[Paper Note] Chain of Agents: Large Language Models Collaborating on Long-Context Tasks, Yusen Zhang+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Multi #NLP #AIAgents #ContextWindow #Blog #NeurIPS #LongHorizon #Initial Impression Notes Issue Date: 2025-01-25 GPT Summary- 長い文脈を処理するために、Chain-of-Agents(CoA)フレームワークを提案。複数のワーカーエージェントが逐次的に情報を集約し、マネージャーエージェントが最終出力を統合。各エージェントに短い文脈を割り当てることで焦点の問題を軽減し、質問応答や要約などのタスクで最大10%の性能向上を実現。 Comment
元ポスト:
LLMがどこまでいってもcontext長の制約に直面する問題に対してLLM Agentを組み合わせて対処しました、的な話な模様
ブログ中にアプローチを解説した動画があるのでわかりやすい
Is the experimental code open source?
Thank you for your comment. I tried to find an official open-source implementation provided by the authors, but I was not able to locate one. In fact, I also checked the personal webpage of the first author, but there was no link to any released code.
Is seems that an unofficial implementation is listed under the “Code” tab on the NeurIPS page. I hope this is helpful. Thank you.
NeurIPS link:
https://nips.cc/virtual/2024/poster/95563
openreview:
https://openreview.net/forum?id=LuCLf4BJsr
[Paper Note] Spectrum: Targeted Training on Signal to Noise Ratio, Eric Hartford+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #PostTraining #One-Line Notes Issue Date: 2025-01-25 GPT Summary- 大規模言語モデルのポストトレーニングを効率化する手法「Spectrum」を提案。SNRに基づいてレイヤーモジュールを選択し、他を凍結することでトレーニングを加速。性能はフルファインチューニングに匹敵し、GPUメモリ使用量を削減。従来手法との比較実験でモデル品質とVRAM効率の向上を確認。 Comment
- How to fine-tune open LLMs in 2025 with Hugging Face, PHILSCHMID, 2024.12
によるとLLMのうち最もinformativeなLayerを見つけ、選択的に学習することで、省リソースで、Full-Parameter tuningと同等の性能を発揮する手法らしい
[Paper Note] A Deep Dive into the Trade-Offs of Parameter-Efficient Preference Alignment Techniques, Megh Thakkar+, ACL'24, 2024.06
Paper/Blog Link My Issue
#Analysis #NLP #Alignment #ACL #DownstreamTasks Issue Date: 2025-01-06 GPT Summary- 大規模言語モデルの整列に関する研究で、整列データセット、整列技術、モデルの3つの要因が下流パフォーマンスに与える影響を300以上の実験を通じて調査。情報量の多いデータが整列に寄与することや、監視付きファインチューニングが最適化を上回るケースを発見。研究者向けに効果的なパラメータ効率の良いLLM整列のガイドラインを提案。
Forgetting before Learning: Utilizing Parametric Arithmetic for Knowledge Updating in Large Language Models, Shiwen Ni+, ACL'24
Paper/Blog Link My Issue
#Supervised-FineTuning (SFT) #ACL #KnowledgeEditing Issue Date: 2025-01-06 GPT Summary- F-Learningという新しいファインチューニング手法を提案し、古い知識を忘却し新しい知識を学習するためにパラメトリック算術を利用。実験により、F-LearningがフルファインチューニングとLoRAファインチューニングの知識更新性能を向上させ、既存のベースラインを上回ることを示した。LoRAのパラメータを引き算することで古い知識を忘却する効果も確認。 Comment
Finetuningによって知識をアップデートしたい状況において、ベースモデルでアップデート前の該当知識を忘却してから、新しい知識を学習することで、より効果的に知識のアップデートが可能なことを示している。
古い知識のデータセットをK_old、古い知識から更新された新しい知識のデータセットをK_newとしたときに、K_oldでベースモデルを{Full-finetuning, LoRA}することで得たパラメータθ_oldを、ベースモデルのパラメータθから(古い知識を忘却することを期待して)減算し、パラメータθ'を持つ新たなベースモデルを得る。その後、パラメータθ'を持つベースモデルをk_newでFull-Finetuningすることで、新たな知識を学習させる。ただし、このような操作は、K_oldがベースモデルで学習済みである前提であることに注意する。学習済みでない場合はそもそも事前の忘却の必要がないし、減算によってベースモデルのコアとなる能力が破壊される危険がある。
結果は下記で、先行研究よりも高い性能を示している。注意点として、ベースモデルから忘却をさせる際に、Full Finetuningによってθ_oldを取得すると、ベースモデルのコアとなる能力が破壊されるケースがあるようである。一方、LoRAの場合はパラメータに対する影響が小さいため、このような破壊的な操作となりづらいようである。
評価で利用されたデータセット:
- [Paper Note] Zero-Shot Relation Extraction via Reading Comprehension, Omer Levy+, CoNLL'17, 2017.06
- [Paper Note] Locating and Editing Factual Associations in GPT, Kevin Meng+, NeurIPS'22
Are Emergent Abilities in Large Language Models just In-Context Learning?, Sheng Lu+, ACL'24
Paper/Blog Link My Issue
#Analysis #NLP #In-ContextLearning #ACL #Memorization #EmergentAbilities Issue Date: 2025-01-06 GPT Summary- 大規模言語モデルの「出現能力」は、インコンテキスト学習やモデルの記憶、言語知識の組み合わせから生じるものであり、真の出現ではないと提案。1000以上の実験を通じてこの理論を裏付け、言語モデルの性能を理解するための基礎を提供し、能力の過大評価を警告。
Learning to Edit: Aligning LLMs with Knowledge Editing, Yuxin Jiang+, ACL'24
Paper/Blog Link My Issue
#NLP #ACL #KnowledgeEditing Issue Date: 2025-01-06 GPT Summary- 「Learning to Edit(LTE)」フレームワークを提案し、LLMsに新しい知識を効果的に適用する方法を教える。二段階プロセスで、アライメントフェーズで信頼できる編集を行い、推論フェーズでリトリーバルメカニズムを使用。四つの知識編集ベンチマークでLTEの優位性と堅牢性を示す。
[Paper Note] OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems, Chaoqun He+, ACL'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #ACL Issue Date: 2025-01-06 GPT Summary- 大規模言語モデル(LLMs)やマルチモーダルモデル(LMMs)の能力を測定するために、オリンピアドレベルのバイリンガルマルチモーダル科学ベンチマーク「OlympiadBench」を提案。8,476の数学と物理の問題を含み、専門家レベルの注釈が付けられている。トップモデルのGPT-4Vは平均17.97%のスコアを達成したが、物理では10.74%にとどまり、ベンチマークの厳しさを示す。一般的な問題として幻覚や論理的誤謬が指摘され、今後のAGI研究に貴重なリソースとなることが期待される。
ConSiDERS-The-Human Evaluation Framework: Rethinking Human Evaluation for Generative Large Language Models, Aparna Elangovan+, arXiv'24
Paper/Blog Link My Issue
#Evaluation #Bias #ACL Issue Date: 2025-01-06 GPT Summary- 本ポジションペーパーでは、生成的な大規模言語モデル(LLMs)の人間評価は多分野にわたる取り組みであるべきと主張し、実験デザインの信頼性を確保するためにユーザーエクスペリエンスや心理学の洞察を活用する必要性を強調します。評価には使いやすさや認知バイアスを考慮し、強力なモデルの能力と弱点を区別するための効果的なテストセットが求められます。さらに、スケーラビリティも重要であり、6つの柱から成るConSiDERS-The-Human評価フレームワークを提案します。これらの柱は、一貫性、評価基準、差別化、ユーザーエクスペリエンス、責任、スケーラビリティです。
Engaging an LLM to Explain Worked Examples for Java Programming: Prompt Engineering and a Feasibility Study, Hassany+, EDM'24 Workshop, 2024.07
Paper/Blog Link My Issue
#EducationalDataMining #Workshop Issue Date: 2025-01-06 Comment
元ポスト:
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, Damai+, ACL'24, 2024.08
Paper/Blog Link My Issue
#NLP #MoE(Mixture-of-Experts) #ACL Issue Date: 2025-01-06 GPT Summary- DeepSeekMoEアーキテクチャは、専門家の専門性を高めるために、専門家を細分化し柔軟な組み合わせを可能にし、共有専門家を設けて冗長性を軽減する。2BパラメータのDeepSeekMoEは、GShardと同等の性能を達成し、同じパラメータ数の密なモデルに近づく。16Bパラメータにスケールアップした際も、計算量を約40%に抑えつつ、LLaMA2と同等の性能を示した。
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, Zhihong Shao+, arXiv'24
Paper/Blog Link My Issue
#NLP #RLHF #Reasoning #Mathematics #GRPO #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-01-04 GPT Summary- DeepSeekMath 7Bは、120Bの数学関連トークンを用いて事前学習された言語モデルで、競技レベルのMATHベンチマークで51.7%のスコアを達成。自己一貫性は60.9%で、データ選択パイプラインとGroup Relative Policy Optimization (GRPO)の導入により数学的推論能力が向上。Gemini-UltraやGPT-4に迫る性能を示す。 Comment
元々数学のreasoningに関する能力を改善するために提案されたが、現在はオンラインでTruthfulness, Helpfulness, Concisenessなどの改善に活用されているとのこと。
PPOとGRPOの比較。value function model(状態の価値を予測するモデル)が不要なため省メモリ、かつ利用する計算リソースが小さいらしい。
あとサンプルをグループごとに分けて、グループ内でのKLダイバージェンスが最小化されるよう(つまり、各グループ内で方策が類似する)Policy Modelが更新される(つまりloss functionに直接組み込まれる)点が違うらしい。
PPOでは生成するトークンごとにreference modelとPolicy ModelとのKLダイバージェンスをとり、reference modelとの差が大きくならないよう、報酬にペナルティを入れるために使われることが多いらしい。
下記記事によると、PPOで最大化したいのはAdvantage(累積報酬と状態価値(累積報酬の期待値を計算するモデル)の差分;期待値よりも実際の累積報酬が良かったら良い感じだぜ的な数値)であり、それには状態価値を計算するモデルが必要である。そして、PPOにおける状態価値モデルを使わないで、LLMにテキスト生成させて最終的な報酬を平均すれば状態価値モデル無しでAdvantageが計算できるし嬉しくね?という気持ちで提案されたのが、本論文で提案されているGRPOとのこと。勉強になる。
DeepSeek-R1の論文読んだ?【勉強になるよ】
, asap:
https://zenn.dev/asap/articles/34237ad87f8511
[Paper Note] Precise Length Control in Large Language Models, Bradley Butcher+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#Controllable #NLP #PositionalEncoding #Length #Initial Impression Notes Issue Date: 2025-01-03 GPT Summary- デコーダー専用LLMを応答長を正確に制御するために適応。補助的な位置エンコーディングを用いて、設定された応答長までカウントダウン。ファインチューニングにより整合的な応答が可能となり、平均トークン誤差は3トークン未満に。Max New Tokens++ を導入し、柔軟な長さ制御を実現。実験結果は応答品質を損なわずに正確な長さ制御が可能であることを示す。 Comment
元ポスト:
- [Paper Note] Controlling Output Length in Neural Encoder-Decoders, Yuta Kikuchi+, EMNLP'16
などのEncoder-Decoderモデルで行われていたoutput lengthの制御をDecoder-onlyモデルでもやりました、という話に見える。
[Paper Note] TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks, Frank F. Xu+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #NeurIPS #Selected Papers/Blogs #Surface-level Notes #Author Thread-Post Issue Date: 2025-01-03 GPT Summary- 大規模言語モデル(LLMs)によるAIエージェントの進展が、日常業務の効率化にどのように寄与するかを探求。TheAgentCompanyを通じて、AIエージェントがデジタル労働者のように働く能力を評価する拡張可能なベンチマークを導入。模擬のソフトウェア企業環境で、タスクの自律的完了率は30%に達し、単純なタスクは成功する一方、複雑な長期タスクは今のモデルでは難しいことを示す。 Comment
元ポスト:
ソフトウェアエンジニアリングの企業の設定で現実に起こりうるな 175種類のタスクを定義してAI Agentを評価できるベンチマークTheAgentCompanyを提案。
既存のベンチマークより、多様で、実際のソフトウェアエンジニアリング企業でで起こりうる幅広いタスクを持ち、タスクの遂行のために同僚に対して何らかのインタラクションが必要で、達成のために多くのステップが必要でかつ個々のステップ(サブタスク)を評価可能で、多様なタスクを遂行するために必要な様々なインタフェースをカバーし、self hostingして結果を完全に再現可能なベンチマークとなっている模様。
(画像は著者ツイートより引用)
プロプライエタリなモデルとOpenWeightなモデルでAI Agentとしての能力を評価した結果、Claude-3.5-sonnetは約24%のタスクを解決可能であり、他モデルと比べて性能が明らかに良かった。また、Gemini-2.0-flashなコストパフォーマンスに優れている。OpenWeightなモデルの中ではLlama3.3-70Bのコストパフォーマンスが良かった。タスクとしては具体的に評価可能なタスクのみに焦点を当てており、Open Endなタスクでは評価していない点に注意とのこと。
まだまだAI Agentが完全に'同僚'として機能することとは現時点ではなさそうだが、このベンチマークのスコアが今後どこまで上がっていくだろうか。
openreview: https://openreview.net/forum?id=LZnKNApvhG
A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges, Yibo Yan+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #Reasoning #Mathematics Issue Date: 2025-01-03 GPT Summary- 数学的推論は多くの分野で重要であり、AGIの進展に伴い、LLMsを数学的推論タスクに統合することが求められている。本調査は、2021年以降の200以上の研究をレビューし、マルチモーダル設定におけるMath-LLMsの進展を分析。分野をベンチマーク、方法論、課題に分類し、マルチモーダル数学的推論のパイプラインやLLMsの役割を探る。さらに、AGI実現の障害となる5つの課題を特定し、今後の研究方向性を示す。
[Paper Note] Can LLMs Convert Graphs to Text-Attributed Graphs?, Zehong Wang+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #KnowledgeGraph #NAACL #needs-revision Issue Date: 2025-01-03 GPT Summary- 本研究では、グラフニューラルネットワーク(GNN)のクロスグラフ学習における課題を解決するため、新たにTopology-Aware Node Description Synthesis(TANS)を提案します。大規模言語モデル(LLM)を活用し、グラフのトポロジ情報をテキスト属性付きグラフへ変換します。TANSは、テキスト情報の有無にかかわらず、既存のアプローチを上回る性能を示し、特にテキストなしのグラフにおいて顕著な効果を発揮します。 Comment
元ポスト:
How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes, Inacio Vieira+, AMTA'24
Paper/Blog Link My Issue
#MachineTranslation #Analysis #NLP #Supervised-FineTuning (SFT) #Quantization #PEFT(Adaptor/LoRA) #One-Line Notes Issue Date: 2025-01-02 GPT Summary- LLMsのファインチューニングに翻訳メモリ(TMs)を活用し、特定の組織向けの翻訳精度と効率を向上させる研究。5つの翻訳方向で異なるサイズのデータセットを用いて実験し、トレーニングデータが増えるほど翻訳パフォーマンスが向上することを確認。特に、1kおよび2kの例ではパフォーマンスが低下するが、データセットのサイズが増加するにつれて改善が見られる。LLMsとTMsの統合により、企業特有のニーズに応じたカスタマイズ翻訳モデルの可能性を示唆。 Comment
元ポスト:
QLoRAでLlama 8B InstructをMTのデータでSFTした場合のサンプル数に対する性能の変化を検証している。ただし、検証しているタスクはMT、QLoRAでSFTを実施しrankは64、学習時のプロンプトは非常にシンプルなものであるなど、幅広い設定で学習しているわけではないので、ここで得られた知見が幅広く適用可能なことは示されていないであろう点、には注意が必要だと思われる。
この設定では、SFTで利用するサンプル数が増えれば増えるほど性能が上がっているように見える。
[Paper Note] LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR'24, 2024.05
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #TMLR #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-01-02 GPT Summary- LoRAは、大規模言語モデルの効率的なファインチューニング手法であり、重み行列に低ランクの摂動を学習させることでメモリを節約する。本研究では、プログラミングと数学のドメインにおいて、LoRAと完全なファインチューニングの性能を比較し、LoRAが標準的な設定で劣ることを示すが、ターゲットドメイン外のタスク性能を維持することに優れる。加えて、LoRAは忘却を抑制し、多様な生成を可能にすることが示された。最後に、完全なファインチューニングがLoRAよりも大きなランクの摂動を学習することにより性能差を説明できる可能性がある。LoRAのファインチューニングに関する最良の実践方法も提案されている。 Comment
元ポスト:
full finetuningとLoRAの性質の違いを理解するのに有用
[Paper Note] FineTuneBench: How well do commercial fine-tuning APIs infuse knowledge into LLMs?, Eric Wu+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Proprietary Issue Date: 2025-01-02 GPT Summary- 商用微調整APIの有効性を評価するために、FineTuneBenchというフレームワークを導入。本研究では、GPT-4oを含む5つのLLMの新しい情報の学習と既存知識の更新能力を分析。結果は、全モデルが新しい情報を効果的に学習する能力に重大な欠点を有し、平均一般化精度は37%、医療ガイドラインの更新では19%にとどまった。GPT-4o miniが最も効果的で、他のモデルは限定的な能力を示した。商用微調整の信頼性の欠如が明らかにされ、データセットはオープンソースで公開されている。 Comment
元ポスト:
[Paper Note] Examining Forgetting in Continual Pre-training of Aligned Large Language Models, Chen-An Li+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#Pretraining #NLP #Catastrophic Forgetting #mid-training Issue Date: 2025-01-02 GPT Summary- LLMの進展は多様なタスクでの能力を示し、開発が加速しているが、既存の微調整済みモデルに継続的な事前学習を行うと壊滅的忘却が生じる可能性がある。研究では、この忘却現象を調査し、出力形式や知識、信頼性などの次元で継続的事前学習の影響を評価。実験結果は、忘却対策の難しさ、特に反復性の課題を明らかにする。 Comment
元ポスト:
[Paper Note] Generative AI for Synthetic Data Generation: Methods, Challenges and the Future, Xu Guo+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#Survey #NLP #SyntheticData Issue Date: 2025-01-02 GPT Summary- LLMを用いて合成データを生成し、特にリソースが限られた状況でのタスク特異的トレーニングデータの活用を探求。方法論や評価法を概説し、現状の課題と将来の研究の方向性を提案。 Comment
元ポスト:
[Paper Note] On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey, Lin Long+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Survey #NLP #SyntheticData Issue Date: 2025-01-02 GPT Summary- LLMsの登場により合成データ生成が可能になり、データ量と品質のジレンマの解決策を提供。しかし、現状の調査は統一性に欠け、表面的なものが多い。本論文では合成データ生成の汎用ワークフローに基づき、関連研究を整理し、既存のギャップを明らかにする。学術界と産業界に対し、より深い探究を促すことを目指す。 Comment
元ポスト:
Unifying Generative and Dense Retrieval for Sequential Recommendation, Liu Yang+, arXiv'24
Paper/Blog Link My Issue
#RecommenderSystems #SessionBased Issue Date: 2024-12-31 GPT Summary- 逐次密な検索モデルはユーザーとアイテムの内積計算を行うが、アイテム数の増加に伴いメモリ要件が増大する。一方、生成的検索はセマンティックIDを用いてアイテムインデックスを予測する新しいアプローチである。これら二つの手法の比較が不足しているため、LIGERというハイブリッドモデルを提案し、生成的検索と逐次密な検索の強みを統合。これにより、コールドスタートアイテム推薦を強化し、推薦システムの効率性と効果を向上させることを示した。
LearnLM: Improving Gemini for Learning, LearnLM Team+, arXiv'24
Paper/Blog Link My Issue
#NLP #Education #EducationalDataMining Issue Date: 2024-12-31 GPT Summary- 生成AIシステムは従来の情報提示に偏っているため、教育的行動を注入する「教育的指示の遵守」を提案。これにより、モデルの振る舞いを柔軟に指定でき、教育データを追加することでGeminiモデルの学習を向上。LearnLMモデルは、さまざまな学習シナリオで専門家から高く評価され、GPT-4oやClaude 3.5に対しても優れた性能を示した。
Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning, Melanie Sclar+, arXiv'24
Paper/Blog Link My Issue
#NLP #TheoryOfMind #read-later Issue Date: 2024-12-31 GPT Summary- ExploreToMは、心の理論を評価するための多様で挑戦的なデータを生成するフレームワークであり、LLMsの限界をテストする。最先端のLLMsは、ExploreToM生成データに対して低い精度を示し、堅牢な評価の必要性を強調。ファインチューニングにより従来のベンチマークで精度向上を実現し、モデルの低パフォーマンスの要因を明らかにする。 Comment
おもしろそう。あとで読む
A Survey on LLM Inference-Time Self-Improvement, Xiangjue Dong+, arXiv'24
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP Issue Date: 2024-12-31 GPT Summary- LLM推論における自己改善技術を三つの視点から検討。独立した自己改善はデコーディングやサンプリングに焦点、文脈に応じた自己改善は追加データを活用、モデル支援の自己改善はモデル間の協力を通じて行う。関連研究のレビューと課題、今後の研究への洞察を提供。
From Matching to Generation: A Survey on Generative Information Retrieval, Xiaoxi Li+, arXiv'24
Paper/Blog Link My Issue
#Survey #InformationRetrieval Issue Date: 2024-12-30 GPT Summary- 情報検索(IR)システムは、検索エンジンや質問応答などで重要な役割を果たしている。従来のIR手法は類似性マッチングに基づいていたが、事前学習された言語モデルの進展により生成情報検索(GenIR)が注目されている。GenIRは生成文書検索(GR)と信頼性のある応答生成に分かれ、GRは生成モデルを用いて文書を直接生成し、応答生成はユーザーの要求に柔軟に応える。本論文はGenIRの最新研究をレビューし、モデルのトレーニングや応答生成の進展、評価や課題についても考察する。これにより、GenIR分野の研究者に有益な参考資料を提供し、さらなる発展を促すことを目指す。
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation, Xiaoxi Li+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #needs-revision Issue Date: 2024-12-30 GPT Summary- RetroLLMは、リトリーバルと生成を統合したフレームワークで、LLMsがコーパスから直接証拠を生成することを可能にします。階層的FM-インデックス制約を導入し、関連文書を特定することで無関係なデコーディング空間を削減し、前向きな制約デコーディング戦略で証拠の精度を向上させます。広範な実験により、ドメイン内外のタスクで優れた性能を示しました。 Comment
元ポスト:
従来のRAGとの違いと、提案手法の概要
[Paper Note] DeepSeek-V3 Technical Report, DeepSeek-AI+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #OpenWeight #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2024-12-28 GPT Summary- DeepSeek-V3は671Bのパラメータを持つMixture-of-Experts (MoE)言語モデルで、各トークンに対して37Bが活性化される。効率的な推論とコスト削減のため、MLAおよびDeepSeekMoEアーキテクチャを採用し、補助損失を用いない戦略を導入。14.8兆トークンでプレトレーニング後、ファインチューニングと強化学習を経て、高性能を発揮。評価結果はオープンソースモデルを上回り、先端的なクローズドソースモデルとも同等。訓練にはわずか2,788,000時間のH800 GPU時間を要し、安定した訓練プロセスを実現。モデルのチェックポイントは提供されている。 Comment
参考(モデルの図解):
参考:
MLA(Multi-Head Latent Attention)を提案
解説:
- MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
- DeepSeek-V2のアーキテクチャを徹底解説:MLA と DeepSeekMoE, kernelian, 2024.05
MLAはKVを低ランクなlatentベクトルに圧縮して保持し、使う時に復元するといった操作をすることで、MHAのパフォーマンスを落とすことなくKV Cacheで利用するメモリを大幅に減らせるという手法。
MLAの図解:
A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #Evaluation #LLM-as-a-Judge Issue Date: 2024-12-25 GPT Summary- LLMを評価者として利用する「LLM-as-a-Judge」の信頼性向上に関する調査。信頼性を確保するための戦略や評価方法論を提案し、新しいベンチマークを用いてサポート。実用的な応用や将来の方向性についても議論し、研究者や実務者の参考資料となることを目指す。 Comment
[Paper Note] Large Concept Models: Language Modeling in a Sentence Representation Space, LCM team+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#Sentence #NLP #Tokenizer #Surface-level Notes #Concept (LLM PreTraining) Issue Date: 2024-12-24 GPT Summary- 大規模言語モデル(LLMs)の限界を克服するために、概念を用いた新しいアーキテクチャ「Large Concept Model」を提案。これは、テキストと音声の両方に対応し、200言語をサポートする文埋め込み空間SONARを活用。自己回帰的な文予測に基づき、複数のアプローチ(MSE回帰や拡散ベース生成)で実験し、パラメータを増加させたモデルでも印象的なゼロショット一般化性能を示す。訓練コードは公開されている。 Comment
まだ全く読めていないが、従来のLLMはnent-token-predictionで学習をしており、transformers decoderの内部状態で何らかの抽象的な概念はとらえているものの、次トークン予測に前回生成したトークンをinputするのが必須である以上「トークンで考える」みたいな挙動をある程度はしてしまっており、人間はそんなことしないですよね?みたいな話だと思われる。
人間はもっと抽象的なコンセプトレベルで物事を考えることができるので、それにより近づけるために、conceptをsentenceとしてみなして、next-concept-predictionでモデルを学習したらゼロショットの汎化性能上がりました、みたいな話のように見える。ただし、評価をしているのはマルチリンガルな文書要約タスクのみに見える。
追記: コンセプトが言語非依存だとすると、コンセプト間の関係性を学習するLCMが、マルチリンガルでトークンレベルの学習しかしない従来LLMを上回るのも納得いく気はする。なぜなら、従来LLMよりも言語(トークン)への依存が緩和されていると思われるので、言語間を跨いだ知識の転移が起きやすいと考えられるからである。
Base-LCMを見ると、文の埋め込みのground truthと生成された文の埋め込みの差を最小化する(Mean Squared Error) ようなlossになっている。つまり、トークンレベルではなく、より抽象的な概念を直接学習するような設計になっているためここが従来のLLMと異なる。
これを実現するために、ground truthとなる文の埋め込みx_nが分からなければいけないが、このために、freezeしたEncoderとDecoderを用意してLCMにconcatしていると思われる。つまり、入力と出力のconceptを解釈する機構は固定して、正解となる文埋め込みを決めてしまう。そして、LCMはinputされたconceptを別のconceptに変換するような機構となっており、その変換の関係性を学習している。なるほど、なんとなく気持ちはわかった。
日本語を含むいくつかの言語でゼロショット性能が低下しているのが興味深い。日本語特有の概念とか、特定の言語固有の概念は欠落する可能性が示唆される。
[Paper Note] Alignment faking in large language models, Ryan Greenblatt+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #Alignment #Blog #Safety #read-later Issue Date: 2024-12-19 GPT Summary- 大規模言語モデルがアラインメント・フェイキングを行う様子を示し、訓練中の挙動変更を防ぐために選択的に訓練目的に従うことを提案します。具体的には、Claude 3 Opusが有害な質問に対し、無料ユーザーには14%従う一方で、有料ユーザーにはほとんど従わない傾向を確認。この理由は、無料ユーザーからの質問に対し、アラインメント・フェイキングの推論を通じて望ましい挙動を維持するためです。さらに、合成文書を用いることで同様のアラインメント・フェイキングを観察し、有害な質問に対する強化学習で訓練すると発生率が78%に増加することを発見しました。最終的に、モデルに指示を与えずとも訓練プロセスに基づいて推測する可能性があり、将来のモデルにもリスクが存在することが示唆されます。
[Paper Note] Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions, Yu Zhao+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #Reasoning #SelfImprovement #read-later #Reading Reflections Issue Date: 2024-12-16 GPT Summary- OpenAI o1がLRMの研究に注力し、伝統的な分野だけでなくRLやオープンエンドな解決にも焦点を当てる。特に、基準が不明瞭な領域への一般化の可能性を探求。Marco-o1はCoT微調整やMCTS、リフレクション機構などの手法を用いて、複雑な実世界の問題解決に最適化されている。 Comment
元ポスト:
Large Reasoning Model (LRM)という用語は初めて見た。
日本語解説: https://www.docswell.com/s/DeepLearning2023/KV1M9P-2024-12-05-125148
[Paper Note] Zero Bubble Pipeline Parallelism, Penghui Qi+, ICLR'24, 2023.11
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #ICLR #Parallelism Issue Date: 2024-12-16 GPT Summary- パイプライン並列は分散学習において重要だが、パイプラインバブルの影響を受ける。本研究では、初めてこのバブルをゼロにするスケジューリング戦略を提案。逆伝播計算を勾配計算の2つに分けるアイデアに基づき、新たなパイプラインスケジュールを構築。さらに、自動最適化アルゴリズムと新たな手法を導入し、実験結果は我々の手法が従来手法より最大23%スループットが向上することを示し、メモリ制約が緩和されると31%まで上昇。結果はパイプライン並列性の潜在力を示すもので、実装はオープンソース化されている。 Comment
openreview: https://openreview.net/forum?id=tuzTN0eIO5
[Paper Note] When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards, Norah Alzahrani+, ACL'24, 2024.02
Paper/Blog Link My Issue
#NLP #Evaluation #ACL #read-later #Selected Papers/Blogs Issue Date: 2024-12-15 GPT Summary- LLMのリーダーボードは、ベンチマークランキングに基づいてモデル選択を支援するが、ランキングは微細な変更に敏感であり、最大8位変動することがある。3つのベンチマーク摂動のカテゴリにわたる実験を通じて、この現象の原因を特定し、ハイブリッドスコアリング方法の利点を含むベストプラクティスを提案。単純な評価に依存する危険性を強調し、より堅牢な評価スキームの必要性を示した。 Comment
- 国際会議ACL2024参加報告, Masato Mita, Cyber Agent, 2024.12
に日本語でのサマリが記載されているので参照のこと。
リーダーボードのバイアスを軽減した結果、どのLLMが最大パフォーマンスとみなされるようになったのだろうか?
[Paper Note] BatchEval: Towards Human-like Text Evaluation, Peiwen Yuan+, ACL'24
Paper/Blog Link My Issue
#NLP #Evaluation #LLM-as-a-Judge #Batch #One-Line Notes Issue Date: 2024-12-15 GPT Summary- BatchEvalという新しい評価パラダイムを提案し、LLMを用いた自動テキスト評価の問題を解決。バッチ単位での反復評価により、プロンプト設計の敏感さやノイズ耐性の低さを軽減。実験により、BatchEvalは最先端手法に対して10.5%の改善を示し、APIコストを64%削減。 Comment
- 国際会議ACL2024参加報告, Masato Mita, Cyber Agent, 2024.12
に日本語によるサマリが掲載されているので参照のこと。
[Paper Note] Striking Gold in Advertising: Standardization and Exploration of Ad Text Generation, Masato Mita+, ACL'24
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Dataset #Evaluation #LLM-as-a-Judge #KeyPoint Notes Issue Date: 2024-12-15 GPT Summary- 自動広告テキスト生成(ATG)のために、標準化されたベンチマークデータセットCAMERAを提案。これにより、マルチモーダル情報の活用と業界全体での評価が促進される。9つのベースラインを用いた実験で、現状と課題を明らかにし、LLMベースの評価者と人間の評価の一致を探求。 Comment
広告文生成タスク(Ad Text Generation)は個々のグループのプロプライエタリデータでしか評価されてこなかったことと、そもそもタスク設定が十分に規定されていないので、その辺を整備したという話らしい。
特に広告文生成のための初のオープンデータなCAMERAを構築している。
データセットを作るだけでなく、既存の手法、古典的なものからLLMまででどの程度の性能まで到達しているか、さらにはROUGEやGPT-4を用いたLLM-as-a-Judgeのような自動評価手法をメタ評価し、人手評価とオンライン評価のどの程度代替になるかも分析したとのことらしい。
Table5にメタ評価の結果が記載されている。システムレベルのcorrelationを測定している。興味深いのが、BLEU-4, ROUGE-1, BERTScoreなどの古典的or埋め込みベースのNLG評価手法がFaithfulnessとFluencyにおいて、人間の専門家と高い相関を示しているのに対し、GPT-4による評価では人間による評価と全然相関が出ていない。
既存のLLM-as-a-Judge研究では専門家と同等の評価できます、みたいな話がよく見受けられるがこれらの報告と結果が異なっていておもしろい。著者らは、OpenAIのGPTはそもそも広告ドメインとテキストでそんなに訓練されていなさそうなので、ドメインのミスマッチが一つの要因としてあるのではないか、と考察している。
また、Attractivenessでは専門家による評価と弱い相関しか示していない点も興味深い。広告文がどの程度魅力的かはBLEU, ROUGE, BERTScoreあたりではなかなか難しそうなので、GPT4による評価がうまくいって欲しいところだが、全くうまくいっていない。この論文の結果だけを見ると、(Attractivenessに関しては)自動評価だけではまだまだ広告文の評価は厳しそうに見える。
GPT4によるAttractivenessの評価に利用したプロンプトが下記。MTBenchっぽく、ペアワイズの分類問題として解いていることがわかる。この辺はLLM-as-a-Judgeの研究では他にもスコアトークンを出力し尤度で重みづけるG-Evalをはじめ、さまざまな手法が提案されていると思うので、その辺の手法を利用したらどうなるかは興味がある。
あとはそもそも手法面の話以前に、promptのコンテキスト情報としてどのような情報がAttractivenessの評価に重要か?というのも明らかになると興味深い。この辺は、サイバーエージェントの専門家部隊が、どのようなことを思考してAttractivenessを評価しているのか?というのがヒントになりそうである。
- 国際会議ACL2024参加報告, Masato Mita, Cyber Agent, 2024.12
に著者によるサマリが記載されているので参照のこと。
[Paper Note] The broader spectrum of in-context learning, Andrew Kyle Lampinen+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#Analysis #NLP #In-ContextLearning #One-Line Notes Issue Date: 2024-12-15 GPT Summary- 少数ショット学習は言語モデルの能力として注目されており、これを広範なメタ学習済みのインコンテキスト学習に位置づける見解を提示。文脈が予測の損失を低下させるシーケンスを示すことで、インコンテキスト学習の一種を引き出すことを示唆。これにより、タスク適応やロールプレイなどの能力を統一的に捉えることができ、低レベル処理の潜在的な根源も明らかになる。さらには、一般化の重要性を強調し、新しい事柄を学ぶ能力や適応力の研究を提案。過去の文献との関連についても論じ、インコンテキスト学習の研究がその能力と一般化の多様性を考慮すべきだと結論づけている。 Comment
OpenReview:
https://openreview.net/forum?id=RHo3VVi0i5
OpenReviewによると、
論文は理解しやすく、meta learningについて広範にサーベイされている。しかし、論文が定義しているICLの拡張はICLを過度に一般化し過ぎており(具体的に何がICLで何がICLでないのか、といった規定ができない)、かつ論文中で提案されているコンセプトを裏付ける実験がなくspeculativeである、とのことでrejectされている。
[Paper Note] Phi-4 Technical Report, Marah Abdin+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #SmallModel #OpenWeight #One-Line Notes Issue Date: 2024-12-15 GPT Summary- phi-4は140億パラメータを持つ言語モデルで、合成データを戦略的に組み込んだトレーニングを実施。STEM分野に特化したQA能力で従来の教師モデルを超える性能を示し、サイズに対して強力な推論性能を達成。データ品質とトレーニング手法の革新が特徴。 Comment
現状Azureでのみ利用可能かも。Huggingfaceにアップロードされても非商用ライセンスになるという噂も
MITライセンス
HuggingFace:
https://huggingface.co/microsoft/phi-4
Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models, Tian Yu+, arXiv'24
Paper/Blog Link My Issue
#Multi #InformationRetrieval #NLP #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-10 GPT Summary- Auto-RAGは、LLMの意思決定能力を活用した自律的な反復検索モデルで、リトリーバーとのマルチターン対話を通じて知識を取得します。推論に基づく意思決定を自律的に合成し、6つのベンチマークで優れた性能を示し、反復回数を質問の難易度に応じて調整可能です。また、プロセスを自然言語で表現し、解釈可能性とユーザー体験を向上させます。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=jkVQ31GeIA
LLMs Will Always Hallucinate, and We Need to Live With This, Sourav Banerjee+, arXiv'24
Paper/Blog Link My Issue
#NLP #Hallucination Issue Date: 2024-12-09 GPT Summary- 大規模言語モデル(LLM)の幻覚は偶発的なエラーではなく、これらのモデルの基本的な構造から生じる避けられない特徴であると主張。アーキテクチャやデータセットの改善では幻覚を排除できないことを示し、各プロセス段階で幻覚が生成される確率が存在することを分析。新たに「構造的幻覚」という概念を導入し、幻覚の数学的確実性を確立することで、完全な軽減は不可能であると論じる。
[Paper Note] The Super Weight in Large Language Models, Mengxia Yu+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Analysis #NLP #Quantization #One-Line Notes Issue Date: 2024-12-02 GPT Summary- LLMパラメータのわずかな外れ値が重要であり、1つのパラメータを剪定することでテキスト生成能力が著しく低下することを示す。データを用いずに「スーパウェイト」と呼ばれる重要なパラメータを特定し、これにより「スーパアクティベーション」を生じさせる。これらは量子化の性能向上に寄与し、重み量子化のスケーラビリティを向上させることを示した。スーパウェイトの座標インデックスも公開。 Comment
図にある通り、たった一つのニューラルネットワーク中の重みを0にするだけで、途端に意味のあるテキストが生成できなくなるような重みが存在するらしい。
(図は論文より引用)
ICLR 2025のOpenreview
https://openreview.net/forum?id=0Ag8FQ5Rr3
[Paper Note] Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, ACL'24
Paper/Blog Link My Issue
#Multi #NLP #Dataset #Evaluation #Factuality #Reasoning #ACL #Reading Reflections Issue Date: 2024-12-02 GPT Summary- 大規模言語モデル(LLMs)のマルチホップクエリに対する事実の想起能力を評価。ショートカットを防ぐため、主語と答えが共に出現するテストクエリを除外した評価データセットSOCRATESを構築。LLMsは特定のクエリにおいてショートカットを利用せずに潜在的な推論能力を示し、国を中間答えとするクエリでは80%の構成可能性を達成する一方、年の想起は5%に低下。潜在的推論能力と明示的推論能力の間に大きなギャップが存在することが明らかに。 Comment
SNLP'24での解説スライド:
https://docs.google.com/presentation/d/1Q_UzOzn0qYX1gq_4FC4YGXK8okd5pwEHaLzVCzp3yWg/edit?usp=drivesdk
この研究を信じるのであれば、LLMはCoT無しではマルチホップ推論を実施することはあまりできていなさそう、という感じだと思うのだがどうなんだろうか。
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, Dawei Li+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LLM-as-a-Judge #One-Line Notes Issue Date: 2024-11-27 GPT Summary- LLMを用いた判断と評価の新たなパラダイム「LLM-as-a-judge」に関する包括的な調査を行い、定義や分類法を提示。評価のためのベンチマークをまとめ、主要な課題と今後の研究方向を示す。関連リソースも提供。 Comment
LLM-as-a-Judgeに関するサーベイ
- Leveraging Large Language Models for NLG Evaluation: A Survey, Zhen Li+, N/A, arXiv'24
も参照のこと
[Paper Note] Does Prompt Formatting Have Any Impact on LLM Performance?, Jia He+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Analysis #NLP #Prompting #Reading Reflections Issue Date: 2024-11-27 GPT Summary- プロンプト最適化はLLMの性能に重要であり、異なるプロンプトテンプレートがモデルの性能に与える影響を調査。実験では、GPT-3.5-turboがプロンプトテンプレートによってコード翻訳タスクで最大40%変動する一方、GPT-4はより堅牢であることが示された。これにより、固定プロンプトテンプレートの再考が必要であることが強調された。 Comment
(以下、個人の感想です)
本文のみ斜め読みして、Appendixは眺めただけなので的外れなことを言っていたらすみません。
まず、実務上下記知見は有用だと思いました:
- プロンプトのフォーマットによって性能に大きな差がある
- より大きいモデルの方がプロンプトフォーマットに対してロバスト
ただし、フォーマットによって性能差があるというのは経験的にある程度LLMを触っている人なら分かることだと思うので、驚きは少なかった。
個人的に気になる点は、学習データもモデルのアーキテクチャもパラメータ数も分からないGPT3.5, GPT4のみで実験をして「パラメータサイズが大きい方がロバスト」と結論づけている点と、もう少し深掘りして考察したらもっとおもしろいのにな、と感じる点です。
実務上は有益な知見だとして、では研究として見たときに「なぜそうなるのか?」というところを追求して欲しいなぁ、という感想を持ちました。
たとえば、「パラメータサイズが大きいモデルの方がフォーマットにロバスト」と論文中に書かれているように見えますが、
それは本当にパラメータサイズによるものなのか?学習データに含まれる各フォーマットの割合とか(これは事実はOpenAIの中の人しか分からないので、学習データの情報がある程度オープンになっているOpenLLMでも検証するとか)、評価するタスクとフォーマットの相性とか、色々と考察できる要素があるのではないかと思いました。
その上で、大部分のLLMで普遍的な知見を見出した方が研究としてより面白くなるのではないか、と感じました。
参考: Data2Textにおける数値データのinput formatによる性能差を分析し考察している研究
- [Paper Note] Prompting for Numerical Sequences: A Case Study on Market Comment Generation, Masayuki Kawarada+, arXiv'24, 2024.04
Multimodal Autoregressive Pre-training of Large Vision Encoders, Enrico Fini+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #MultiModal Issue Date: 2024-11-25 GPT Summary- 新しい手法AIMV2を用いて、大規模なビジョンエンコーダの事前学習を行う。これは画像とテキストを組み合わせたマルチモーダル設定に拡張され、シンプルな事前学習プロセスと優れた性能を特徴とする。AIMV2-3BエンコーダはImageNet-1kで89.5%の精度を達成し、マルチモーダル画像理解において最先端のコントラストモデルを上回る。
[Paper Note] Observational Scaling Laws and the Predictability of Language Model Performance, Yangjun Ruan+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #NeurIPS #read-later #One-Line Notes Issue Date: 2024-11-22 GPT Summary- 言語モデルの性能変化を理解することは重要であり、スケーリング則がその手法の一つとして提案されている。約100の公開モデルからスケーリング則を構築することで、モデル訓練を回避する新しいアプローチが示される。異なる計算資源を持つモデルファミリー間のばらつきが、低次元の能力空間と整合することで、予測可能なスケーリング現象が明らかとなる。GPT-4の性能はシンプルなベンチマークから予測可能であり、思考の連鎖や自己整合性といった介入がモデル能力に与える影響の予測も可能であることが示された。 Comment
縦軸がdownstreamタスクの主成分(のうち最も大きい80%を説明する成分)の変化(≒LLMの性能)で、横軸がlog scaleの投入計算量。
Qwenも頑張っているが、投入データ量に対する性能(≒データの品質)では、先駆け的な研究であるPhiがやはり圧倒的?
- [Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
も参照のこと
[Paper Note] On the Way to LLM Personalization: Learning to Remember User Conversations, Lucie Charlotte Magister+, L2M2'24,
Paper/Blog Link My Issue
#Personalization Issue Date: 2024-11-21 GPT Summary- LLMのパーソナライズを過去の会話の知識を注入することで実現するため、PLUMというデータ拡張パイプラインを提案。会話の時間的連続性とパラメータ効率を考慮し、ファインチューニングを行う。初めての試みでありながら、RAGなどのベースラインと競争力を持ち、81.5%の精度を達成。
[Paper Note] Likelihood as a Performance Gauge for Retrieval-Augmented Generation, Tianyu Liu+, arXiv'24
Paper/Blog Link My Issue
#Analysis #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #One-Line Notes #Reading Reflections Issue Date: 2024-11-19 GPT Summary- 大規模言語モデルを用いた情報検索強化生成は、文脈内の文書の順序に影響を受けやすい。研究では、質問の確率がモデルのパフォーマンスに与える影響を分析し、正確性との相関関係を明らかにした。質問の確率を指標として、プロンプトの選択と構築に関する2つの方法を提案し、その効果を実証。確率に基づく手法は効率的で、少ないモデルのパスで応答を生成できるため、プロンプト最適化の新たな方向性を示す。 Comment
トークンレベルの平均値をとった生成テキストの対数尤度と、RAGの回答性能に関する分析をした模様。
とりあえず、もし「LLMとしてGPTを(OpenAIのAPIを用いて)使いました!temperatureは0です!」みたいな実験設定だったら諸々怪しくなる気がしたのでそこが大丈夫なことを確認した(OpenLLM、かつdeterministicなデコーディング方法が望ましい)。おもしろそう。
参考: [RAGのハルシネーションを尤度で防ぐ, sasakuna, 2024.11.19]( https://zenn.dev/knowledgesense/articles/7c47e1796e96c0)
## 参考
生成されたテキストの尤度を用いて、どの程度正解らしいかを判断する、といった話は
- [Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
のようなLLM-as-a-Judgeでも行われている。
G-Evalでは1--5のスコアのような離散的な値を生成する際に、これらを連続的なスコアに補正するために、尤度(トークンの生成確率)を用いている。
ただし、G-Evalの場合は実験でGPTを用いているため、モデルから直接尤度を取得できず、代わりにtemperature1とし、20回程度生成を行った結果からスコアトークンの生成確率を擬似的に計算している。
G-Evalの設定と比較すると(当時はつよつよなOpenLLMがなかったため苦肉の策だったと思われるが)、こちらの研究の実験設定の方が望ましいと思う。
Multilingual Large Language Models: A Systematic Survey, Shaolin Zhu+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #MultiLingual #needs-revision Issue Date: 2024-11-19 GPT Summary- 本論文は、多言語大規模言語モデル(MLLMs)の最新研究を調査し、アーキテクチャや事前学習の目的、多言語能力の要素を論じる。データの質と多様性が性能向上に重要であることを強調し、MLLMの評価方法やクロスリンガル知識、安全性、解釈可能性について詳細な分類法を提示。さらに、MLLMの実世界での応用を多様な分野でレビューし、課題と機会を強調する。関連論文は指定のリンクで公開されている。 Comment
[Paper Note] Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs, Kazuki Fujii+, arXiv'24
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #Pretraining #NLP #Supervised-FineTuning (SFT) #Japanese #read-later #One-Line Notes #LowPrecision Issue Date: 2024-11-17 GPT Summary- 大規模言語モデル(LLMs)は、その言語理解能力と適用可能性から注目を集めており、特にLlama 3シリーズは4050億パラメータを持つ。トレーニングの効率化が求められる中、NVIDIAのH100 GPUはFP8フォーマットを導入し、トレーニング時間を短縮する可能性がある。初期研究ではFP8が性能を損なわずに効率を向上させることが示唆されているが、トレーニングの安定性や下流タスクへの影響はまだ不明である。本研究は、LLMsのトレーニングにおけるBF16とFP8のトレードオフを探る。 Comment
元ポスト:
FP8で継続的事前学習をするとスループットは向上するが、lossのスパイクを生じたり、downstreamタスクの性能がBF16よりも低下したりする(日本語と英語の両方)との報告のようである。現状アブストと付録しか記載がないが、内容はこれから更新されるのだろうか。
[Paper Note] Understanding LLMs: A Comprehensive Overview from Training to Inference, Yiheng Liu+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #Transformer #Attention #One-Line Notes #Reading Reflections Issue Date: 2024-11-17 GPT Summary- ChatGPTの導入により、LLMsの低コストな訓練とデプロイメントへの関心が高まる。本論文では、訓練技術や推論デプロイメント技術の進化を概説し、データ前処理やモデル圧縮など多様な視点を提供。LLMsの活用についても考察し、今後の発展を示唆する。 Comment
[Perplexity(参考;Hallucinationに注意)]( https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-7vGwDK_AQX.HDO7j9H8iNA)
単なるLLMの理論的な説明にとどまらず、実用的に必要な各種並列処理技術、Mixed Precision、Offloadingなどのテクニックもまとまっているのがとても良いと思う。
LLM Frameworkのところに、メジャーなものが網羅されていないように感じる。たとえば、UnslothやLiger-KernelなどはTransformersの部分で言及されてても良いのでは、と感じる。
The Geometry of Concepts: Sparse Autoencoder Feature Structure, Yuxiao Li+, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP Issue Date: 2024-11-17 GPT Summary- スパースオートエンコーダは、高次元ベクトルの辞書を生成し、概念の宇宙に三つの興味深い構造を発見した。1) 小規模構造では、平行四辺形や台形の「結晶」があり、単語の長さなどの干渉を除去することで質が改善される。2) 中規模構造では、数学とコードの特徴が「葉」を形成し、空間的局所性が定量化され、特徴が予想以上に集まることが示された。3) 大規模構造では、特徴点雲が各向同性でなく、固有値のべき法則を持ち、クラスタリングエントロピーが層に依存することが定量化された。 Comment
参考: https://ledge.ai/articles/llm_conceptual_structure_sae
[Perplexity(参考;Hallucinationに注意)]( https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-kR626A9_R8.6CU7IKvGyhQ)
[Paper Note] Adaptive Decoding via Latent Preference Optimization, Shehzaad Dhuliawala+, arXiv'24
Paper/Blog Link My Issue
#NLP #Decoding #SamplingParams #Author Thread-Post Issue Date: 2024-11-15 GPT Summary- Adaptive Decodingを導入し、推論時にトークンや例ごとに動的にサンプリング温度を選択することで、言語モデルのパフォーマンスを最適化。Latent Preference Optimization(LPO)を用いて温度選択を学習し、UltraFeedbackやCreative Story Writing、GSM8Kなどのタスクで固定温度を超える性能を達成。 Comment
著者ポスト:
A Large-Scale Study of Relevance Assessments with Large Language Models: An Initial Look, Shivani Upadhyay+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #RelevanceJudgment #Evaluation #One-Line Notes Issue Date: 2024-11-14 GPT Summary- 本研究では、TREC 2024 RAG Trackにおける大規模言語モデル(LLM)を用いた関連性評価の結果を報告。UMBRELAツールを活用した自動生成評価と従来の手動評価の相関を分析し、77の実行セットにおいて高い相関を示した。LLMの支援は手動評価との相関を高めず、人間評価者の方が厳格であることが示唆された。この研究は、TRECスタイルの評価におけるLLMの使用を検証し、今後の研究の基盤を提供する。 Comment
元ポスト:
[Perplexity(参考;Hallucinationに注意)](
https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-ntenei-r-h3qlECirT3G9O2BGk765_g)
Perplexityの生成結果では、27個のシステムと記述されているが、これは実際はトピックで、各トピックごとに300件程度の0--3のRelevance Scoreが、人手評価、UMBRELA共に付与されている模様(Table1)。
評価結果
- Fully Manual Assessment: 既存のNIST methodologyと同様に人手でRelevance Scoreを付与する方法
- Manual Aspessment with Filtering: LLMのnon-Relevantと判断したpassageを人手評価から除外する方法
- Manual Post-Editing of Automatic Assessment: LLMがnon-Relevantと判断したpassageを人手評価から除外するだけでなく、LLMが付与したスコアを評価者にも見せ、評価者が当該ラベルを修正するようなスコアリングプロセス
- Fully Automatic Assessment:UMBRELAによるRelevance Scoreをそのまま利用する方法
LLMはGPT4-oを用いている。
19チームの77個のRunがどのように実行されているか、それがTable1の統計量とどう関係しているかがまだちょっとよくわかっていない。
UMBRELAでRelevance Scoreを生成する際に利用されたプロンプト。
Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding, Haolin Chen+, arXiv'24
Paper/Blog Link My Issue
#NLP #Reasoning #PostTraining Issue Date: 2024-11-13 GPT Summary- LaTRO(LaTent Reasoning Optimization)を提案し、LLMの推論能力を向上させる新しいフレームワークを構築。推論を潜在分布からのサンプリングとして定式化し、外部フィードバックなしで推論プロセスと質を同時に改善。GSM8KおよびARC-Challengeデータセットで実験し、平均12.5%の精度向上を達成。事前学習されたLLMの潜在的な推論能力を引き出すことが可能であることを示唆。 Comment
元ポスト:
A Theoretical Understanding of Chain-of-Thought: Coherent Reasoning and Error-Aware Demonstration, Yingqian Cui+, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought Issue Date: 2024-11-13 GPT Summary- Few-shot Chain-of-Thought (CoT) プロンプティングはLLMsの推論能力を向上させるが、従来の研究は推論プロセスを分離された文脈内学習に依存している。本研究では、初期ステップからの一貫した推論(Coherent CoT)を統合することで、トランスフォーマーのエラー修正能力と予測精度を向上させることを理論的に示す。実験により、正しい推論経路と誤った推論経路を組み込むことでCoTを改善する提案の有効性を検証する。 Comment
元ポスト:
おもしろそうな研究
LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions, Zhehui Liao+, arXiv'24
Paper/Blog Link My Issue
#ScientificDiscovery #Investigation Issue Date: 2024-11-12 GPT Summary- 大規模言語モデル(LLMs)の利用に関する816人の研究者を対象とした調査を実施。81%が研究ワークフローにLLMsを組み込んでおり、特に非白人や若手研究者が高い使用率を示す一方で、女性やシニア研究者は倫理的懸念を抱いていることが明らかに。研究の公平性向上の可能性が示唆される。
DELIFT: Data Efficient Language model Instruction Fine Tuning, Ishika Agarwal+, arXiv'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2024-11-12 GPT Summary- DELIFTという新しいアルゴリズムを提案し、ファインチューニングの各ステージでデータ選択を最適化。ペアワイズユーティリティメトリックを用いてデータの有益性を定量化し、最大70%のデータ削減を実現。計算コストを大幅に節約し、既存の方法を上回る効率性と効果を示す。
GUI Agents with Foundation Models: A Comprehensive Survey, Shuai Wang+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #One-Line Notes #needs-revision Issue Date: 2024-11-12 GPT Summary- (M)LLMを活用したGUIエージェントの研究を統合し、データセット、フレームワーク、アプリケーションの革新を強調。重要なコンポーネントをまとめた統一フレームワークを提案し、商業アプリケーションを探求。課題を特定し、今後の研究方向を示唆。 Comment
Referenceやページ数はサーベイにしては少なめに見える。
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, Charlie Snell+, arXiv'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Test-Time Scaling Issue Date: 2024-11-12 GPT Summary- LLMの推論時の計算をスケーリングすることで、挑戦的なプロンプトに対するパフォーマンスを改善する方法を研究。特に、密なプロセスベースの検証者報酬モデルとプロンプトに応じた応答の適応的更新を分析。プロンプトの難易度によって効果が変化し、計算最適戦略を適用することで効率を4倍以上向上。さらに、テスト時計算を用いることで小さなモデルが大きなモデルを上回ることが示された。 Comment
Figure1参照
[Perplexity(参考;Hallucinationに注意)]( https://www.perplexity.ai/search/yi-xia-noyan-jiu-wodu-mi-nei-r-1e1euXgLTH.G0Wlp.V2iqA)
HyQE: Ranking Contexts with Hypothetical Query Embeddings, Weichao Zhou+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #One-Line Notes #needs-revision Issue Date: 2024-11-10 GPT Summary- リトリーバル拡張システムにおいて、LLMのファインチューニングを必要とせず、埋め込みの類似性とLLMの能力を組み合わせたスケーラブルなランキングフレームワークを提案。ユーザーのクエリに基づいて仮定されたクエリとの類似性でコンテキストを再順位付けし、推論時に効率的で他の技術とも互換性がある。実験により、提案手法がランキング性能を向上させることを示した。 Comment
- Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23
も参照のこと。
下記に試しにHyQEとHyDEの比較の記事を作成したのでご参考までに(記事の内容に私は手を加えていないのでHallucinationに注意)。ざっくりいうとHyDEはpseudo documentsを使うが、HyQEはpseudo queryを扱う。
[参考: Perplexity Pagesで作成したHyDEとの簡単な比較の要約](
https://www.perplexity.ai/page/hyqelun-wen-nofen-xi-toyao-yue-aqZZj8mDQg6NL1iKml7.eQ)
Personalization of Large Language Models: A Survey, Zhehao Zhang+, arXiv'24
Paper/Blog Link My Issue
#Survey #Personalization Issue Date: 2024-11-10 GPT Summary- 大規模言語モデル(LLMs)のパーソナライズに関する研究のギャップを埋めるため、パーソナライズされたLLMsの分類法を提案。パーソナライズの概念を統合し、新たな側面や要件を定義。粒度、技術、データセット、評価方法に基づく体系的な分類を行い、文献を統一。未解決の課題を強調し、研究者と実務者への明確なガイドを提供することを目指す。
[Paper Note] Number Cookbook: Number Understanding of Language Models and How to Improve It, Haotong Yang+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #NumericReasoning #ICLR #numeric #In-Depth Notes #Reading Reflections Issue Date: 2024-11-09 GPT Summary- 大規模言語モデル(LLM)の数値理解・処理能力(NUPA)を調査し、41の数値タスクを含むベンチマークを導入。これにより、LLMsが多くのタスクで頻繁に失敗することが判明。NUPA向上のため、小型モデルを訓練し、ファインチューニングの効果を評価。1) ファインチューニングが多くのタスクでNUPAを向上させるが、全てに効果的ではない。2) NUPA向上を目的とした手法がファインチューニングに効果的でないことが分かった。研究はLLMsのNUPA理解を深める。 Comment
んー、abstしか読んでいないけれども、9.11 > 9.9 については、このような数字に慣れ親しんでいるエンジニアなどに咄嗟に質問したら、ミスして答えちゃう人もいるのでは?という気がする(エンジニアは脳内で9.11 > 9.9を示すバージョン管理に触れる機会が多く、こちらの尤度が高い)。
LLMがこのようなミス(てかそもそもミスではなく、回答するためのcontextが足りてないので正解が定義できないだけ、だと思うが、、)をするのは、単に学習データにそういった9.11 > 9.9として扱うような文脈や構造のテキストが多く存在しており、これらテキスト列の尤度が高くなってこのような現象が起きているだけなのでは、という気がしている。
instructionで注意を促したり適切に問題を定義しなければ、そりゃこういう結果になって当然じゃない?という気がしている。
(ここまで「気がしている」を3連発してしまった…😅)
また、本研究で扱っているタスクのexampleは下記のようなものだが、これらをLLMに、なんのツールも利用させずautoregressiveな生成のみで解かせるというのは、人間でいうところの暗算に相当するのでは?と個人的には思う。
何が言いたいのかというと、人間でも暗算でこれをやらせたら解けない人がかなりいると思う(というか私自身単純な加算でも桁数増えたら暗算など無理)。
一方で暗算ではできないけど、電卓やメモ書き、計算機を使っていいですよ、ということにしたら多くの人がこれらタスクは解けるようになると思うので、LLMでも同様のことが起きると思う。
LLMの数値演算能力は人間の暗算のように限界があることを認知し、金融分野などの正確な演算や数値の取り扱うようなタスクをさせたかったら、適切なツールを使わせましょうね、という話なのかなあと思う。
元ポスト:
ICLR25のOpenReview。こちらを読むと興味深い。
https://openreview.net/forum?id=BWS5gVjgeY
幅広い数値演算のタスクを評価できるデータセット構築、トークナイザーとの関連性を明らかにした点、分析だけではなくLLMの数値演算能力を改善した点は評価されているように見える。
一方で、全体的に、先行研究との比較やdiscussionが不足しており、研究で得られた知見がどの程度新規性があるのか?といった点や、説明が不十分でjustificationが足りない、といった話が目立つように見える。
特に、そもそもLoRAやCoTの元論文や、Numerical Reasoningにフォーカスした先行研究がほぼ引用されていないらしい点が見受けられるようである。さすがにその辺は引用して研究のcontributionをクリアにした方がいいよね、と思うなどした。
>I am unconvinced that numeracy in LLMs is a problem in need of a solution. First, surely there is a citable source for LLM inadequacy for numeracy. Second, even if they were terrible at numeracy, the onus is on the authors to convince the reader that this a problem worth caring about, for at least two obvious reasons: 1) all of these tasks are already trivially done by a calculator or a python program, and 2) commercially available LLMs can probably do alright at numerical tasks indirectly via code-generation and execution. As it stands, it reads as if the authors are insisting that this is a problem deserving of attention --- I'm sure it could be, but this argument can be better made.
上記レビュワーコメントと私も同じことを感じる。なぜLLMそのものに数値演算の能力がないことが問題なのか?という説明があった方が良いのではないかと思う。
これは私の中では、論文のイントロで言及されているようなシンプルなタスクではなく、
- inputするcontextに大量の数値を入力しなければならず、
- かつcontext中の数値を厳密に解釈しなければならず、
- かつ情報を解釈するために計算すべき数式がcontextで与えられた数値によって変化するようなタスク(たとえばテキスト生成で言及すべき内容がgivenな数値情報によって変わるようなもの。最大値に言及するのか、平均値を言及するのか、数値と紐づけられた特定のエンティティに言及しなければならないのか、など)
(e.g. 上記を満たすタスクはたとえば、金融関係のdata-to-textなど)では、LLMが数値を解釈できないと困ると思う。そういった説明が入った方が良いと思うなあ、感。
[Paper Note] LoRA vs Full Fine-tuning: An Illusion of Equivalence, Reece Shuttleworth+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #PEFT(Adaptor/LoRA) #NeurIPS #read-later #Initial Impression Notes #needs-revision Issue Date: 2024-11-09 GPT Summary- ファインチューニングは事前学習済みの大規模言語モデルにおいて重要なプロセスであり、LoRAのような手法は必要なパラメータを削減しつつ高性能を保つことが証明されている。しかし、完全なファインチューニングとLoRAが本当に同等のモデルを生み出すかをスペクトル解析により検証した結果、異なる重み行列が生成されることが判明。LoRAに特有の「侵入次元」が高位の特異ベクトルとして現れ、これがモデルの一般化能力を損なうことが示された。高ランクLoRAは完全なファインチューニングに近い振る舞いを示す一方、LoRAの低ランクモデルは異なるパラメータ空間にアクセスしていることが示唆された。侵入次元の出現理由とその影響を最小化する方法も検討された。 Comment
元ポスト:
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
や
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
双方の知見も交えて、LoRAの挙動を考察する必要がある気がする。それぞれ異なるデータセットやモデルで、LoRAとFFTを比較している。時間がないが後でやりたい。
あと、昨今はそもそも実験設定における変数が多すぎて、とりうる実験設定が多すぎるため、個々の論文の知見を鵜呑みにして一般化するのはやめた方が良い気がしている。
# 実験設定の違い
## モデルのアーキテクチャ
- 本研究: RoBERTa-base(transformer-encoder)
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
: transformer-decoder
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
: transformer-decoder(LLaMA)
## パラメータサイズ
- 本研究:
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
: 1B, 2B, 4B, 8B, 16B
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
: 7B
時間がある時に続きをかきたい
## Finetuningデータセットのタスク数
## 1タスクあたりのデータ量
## trainableなパラメータ数
openreview: https://openreview.net/forum?id=xp7B8rkh7L
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness, Fali Wang+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #SmallModel #needs-revision #EdgeDevices Issue Date: 2024-11-07 GPT Summary- 大規模言語モデル(LLM)は多様なタスクで能力を示すが、パラメータサイズや計算要求から制限を受け、プライバシーやリアルタイムアプリケーションに課題がある。これに対し、小型言語モデル(SLM)は低遅延、コスト効率、簡単なカスタマイズが可能で、特に専門的なドメインにおいて有用である。SLMの需要が高まる中、定義や応用に関する包括的な調査が不足しているため、SLMを専門的なタスクに適したモデルとして定義し、強化するためのフレームワークを提案する。 Comment
[Paper Note] Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey, Philipp Mondorf+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#Survey #NLP #Evaluation #Reasoning Issue Date: 2024-11-07 GPT Summary- LLMsは推論タスクで顕著な能力を示しているが、その深さは依然として不確かである。これは、浅い精度指標への依存と推論挙動の検証不足に起因する。本論文は、モデルの推論プロセスをより深く理解するための研究をレビューし、一般的な評価方法論を調査する。結果、LLMsは表層的なパターンに依存し、人間との推論の違いを明確にするさらなる研究の必要性が示唆される。 Comment
論文紹介(sei_shinagawa): https://www.docswell.com/s/sei_shinagawa/KL1QXL-beyond-accuracy-evaluating-the-behaivior-of-llm-survey
[Paper Note] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent, Xingwu Sun+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #SyntheticData #OpenWeight #MoE(Mixture-of-Experts) #One-Line Notes Issue Date: 2024-11-06 GPT Summary- Hunyuan-Largeは、3890億の総パラメータと256,000トークンに対応する混合エキスパートモデルで、言語理解や論理的推論など多様なタスクで卓越した性能を示す。また、従来のモデルを上回り、革新的な技術を採用している。コードとモデルは公開され、研究と応用の発展が期待される。 Comment
合計パラメータ数はLlama-3.1-405Bと同等の389Bだが、MoEによって52BのActive ParameterでSoTAを達成したTencentのOpenWeight LLM。大量のSynthetia Dataを利用している。
[Paper Note] ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate, Shohei Taniguchi+, NeurIPS'24
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #Optimizer #Stability #One-Line Notes Issue Date: 2024-11-06 GPT Summary- ADOPTという新しい適応勾配法を提案し、任意のハイパーパラメータ$\beta_2$で最適な収束率を達成。勾配の二次モーメント推定からの除去と更新順序の変更により、Adamの非収束問題を解決。広範なタスクで優れた結果を示し、実装はGitHubで公開。 Comment
画像は元ツイートからの引用:
ライブラリがあるようで、1行変えるだけですぐ使えるとのこと。
元ツイート:
Adamでは収束しなかった場合(バッチサイズが小さい場合)でも収束するようになっている模様
[Paper Note] Beyond Utility: Evaluating LLM as Recommender, Chumeng Jiang+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#RecommenderSystems #Evaluation #WWW Issue Date: 2024-11-05 GPT Summary- LLMを推奨システムとして利用する研究が増加しているが、有用性を超える評価は未開拓である。本研究では、履歴長さの感度や候補位置のバイアス、生成過程、幻覚といった4つの新評価次元を提案し、多次元評価フレームワークを構築。7つのLLMベースの推奨モデルを評価し、従来モデルとの比較を実施。結果、LLMsは短い履歴でのランキングやリランキング設定で優れた性能を発揮するも、候補位置のバイアスや幻覚の問題が顕著であることを確認。評価フレームワークはLLMの推奨システム研究の進展に寄与することを目指す。 Comment
実装: https://github.com/JiangDeccc/EvaLLMasRecommender
openreview: https://openreview.net/forum?id=YiIdHqqoCd
[Paper Note] KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, ICML'24, 2024.02
Paper/Blog Link My Issue
#MachineLearning #NLP #Alignment #ICML #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-10-27 GPT Summary- 人間の偏見を考慮したLLMのフィードバックを目的とした研究。プロスペクト理論に基づく「人間意識型損失(HALOs)」を用いて、生成物の効用を最大化する新手法KTOを提案。このアプローチは、既存の方法と比較してパフォーマンスが同等またはそれ以上であり、普遍的な最適損失関数は存在しないことを示唆。最適な損失は、設定に応じたバイアスによって異なる。 Comment
binaryフィードバックデータからLLMのアライメントをとるKahneman-Tversky Optimization (KTO)論文
解説(DPO,RLHFの話だがKTOを含まれている):
- RLHF/DPO 小話, 和地瞭良/ Akifumi Wachi, 2024.04
[Paper Note] Generative Reward Models, Dakota Mahan+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#NLP #DPO #PostTraining #RewardModel Issue Date: 2024-10-22 GPT Summary- RLHFとRLAIFを統合したハイブリッドアプローチを提案。自己生成の推論過程を用いたGenRMアルゴリズムにより、人間の好みに一致する合成ラベルを生成。実験結果では、GenRMが分布内外のタスクでBradley-Terryモデルと同等以上の性能を発揮し、LLMsを審判とする方法よりも優れた結果を示した。これにより、合成ラベルの品質向上の可能性が示唆された。 Comment
OpenReview: https://openreview.net/forum?id=MwU2SGLKpS
関連研究
- [Paper Note] LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion, Dongfu Jiang+, arXiv'23, 2023.06
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
- [Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
openreview: https://openreview.net/forum?id=MwU2SGLKpS
[Paper Note] Self-Taught Evaluators, Tianlu Wang+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Pretraining #NLP #Alignment #Supervised-FineTuning (SFT) #SyntheticData #PostTraining #KeyPoint Notes Issue Date: 2024-10-21 GPT Summary- 本研究では、人間のアノテーションなしでモデルの評価者を改善するための合成データを利用したアプローチを提案する。ラベルなしの指示から始め、自己改善のスキームを用いて対照的なモデル出力を生成し、LLMを訓練する。自己学習型評価器は、ラベル付きデータがなくても、強力なLLMの性能を大幅に向上させ、一般的なLLMジャッジやトップクラスの報酬モデルと同等の結果を達成する。 Comment
LLMのアラインメント等をSFTする際に、preferenceのラベル付きデータが必要になるが、このようなデータを作るのはコストがかかって大変なので自動生成して、より良いreward modelを作りたいよね、という話。
具体的には、LLMを用いて good responseと、instructionを変化させてbad sesponseを生成し、JudgeモデルM_tにpairwiseでどちらが良いかをjudgeさせることで学習データを作成。新たに作成されたデータを用いてJudgeモデルを再学習し、同様のプロセスを繰り返すことで、人手の介在なく強力なJudgeモデルが完成する。
openreview: https://openreview.net/forum?id=I7uCwGxVnl
[Paper Note] Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely, Siyun Zhao+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#Survey #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-10-20 GPT Summary- データ補強型LLMは、多様な専門分野での実用的な展開において課題が多い。具体的には、関連データの取得やユーザー意図の解釈、LLMの推論能力活用に関する問題が含まれる。提案されたRAGタスク分類法により、クエリを明示的事実、暗黙的事実、解釈可能推論根拠、隠れた根拠の4つに分類し、それぞれの課題を要約。さらに、外部データ統合の形態として、コンテキスト、小型モデル、ファインチューニングを挙げ、各手法のメリットと課題を強調。今回の研究は、LLMアプリケーションのデータ要件とボトルネックを深く理解するためのガイドを提供することを目指す。 Comment
RAGのクエリを4種類に分類した各クエリごとの技術をまとめたSurvey
[Paper Note] Addition is All You Need for Energy-efficient Language Models, Hongyin Luo+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Supervised-FineTuning (SFT) Issue Date: 2024-10-20 GPT Summary- L-Mulアルゴリズムを提案し、整数加算器を用いて浮動小数点乗算を高精度で近似。これにより、計算リソースを削減し、8ビット浮動小数点乗算よりも高い精度を達成。エネルギーコストも95%削減可能。評価では、4ビット仮数のL-Mulが従来の浮動小数点乗算と同等、3ビット仮数でより高い精度を発揮すると示され、トランスフォーマーモデルでも高精度を維持。
[Paper Note] ToolGen: Unified Tool Retrieval and Calling via Generation, Renxi Wang+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#Pretraining #Tools #NLP #Supervised-FineTuning (SFT) #AIAgents #ICLR #PostTraining #KeyPoint Notes #Reading Reflections Issue Date: 2024-10-20 GPT Summary- ToolGenは、LLMとツールの統合を革新する新しいアプローチを提案する。ツールをユニークなトークンとして表現し、ツール知識を直接LLMのパラメータに組み込むことで、ツール呼び出しと生成をシームレスに実現する。このフレームワークにより、追加ステップなしで多数のツールにアクセスでき、性能とスケーラビリティが向上する。47,000以上のツールでの実験結果は、ToolGenが自律的なタスク完遂において優れた成果を示し、多様な領域に適応可能なAIエージェントの新時代を切り開くことを示唆している。さらに、エンドツーエンドのツール学習を可能にし、他の高度な技術との統合機会を提供することで、LLMsの実践的な能力を拡張する。 Comment
昔からよくある特殊トークンを埋め込んで、特殊トークンを生成したらそれに応じた処理をする系の研究。今回はツールに対応するトークンを仕込む模様。
斜め読みだが、3つのstepでFoundation Modelを訓練する。まずはツールのdescriptionからツールトークンを生成する。これにより、モデルにツールの情報を覚えさせる(memorization)。斜め読みなので読めていないが、ツールトークンをvocabに追加してるのでここは継続的事前学習をしているかもしれない。続いて、(おそらく)人手でアノテーションされたクエリ-必要なツールのペアデータから、クエリに対して必要なツールを生成するタスクを学習させる。最後に、(おそらく人手で作成された)クエリ-タスクを解くためのtrajectoryペアのデータで学習させる。
学習データのサンプル。Appendix中に記載されているものだが、本文のデータセット節とAppendixの双方に、データの作り方の詳細は記述されていなかった。どこかに書いてあるのだろうか。
最終的な性能
特殊トークンを追加のvocabとして登録し、そのトークンを生成できるようなデータで学習し、vocabに応じて何らかの操作を実行するという枠組み、その学習手法は色々なタスクで役立ちそう。
openreview: https://openreview.net/forum?id=XLMAMmowdY
COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon , Yu+, SIGMOD_PODS '24
Paper/Blog Link My Issue
#RecommenderSystems #KnowledgeGraph #InstructionTuning #Annotation #One-Line Notes #needs-revision Issue Date: 2024-10-08 Comment
search navigationに導入しA/Bテストした結果、0.7%のproduct sales向上効果。
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #needs-revision Issue Date: 2024-09-26 GPT Summary- LLMのファインチューニング手法のスケーリング特性を調査し、モデルサイズやデータサイズが性能に与える影響を実験。結果、ファインチューニングはパワーベースの共同スケーリング法則に従い、モデルのスケーリングが事前学習データのスケーリングよりも効果的であることが判明。最適な手法はタスクやデータに依存する。 Comment
> When only few thousands of finetuning examples are available, PET should be considered first, either Prompt or LoRA. With sightly larger datasets, LoRA would be preferred due to its stability and slightly better finetuning data scalability. For million-scale datasets, FMT would be good.
> While specializing on a downstream task, finetuning could still elicit
and improve the generalization for closely related tasks, although the overall zero-shot translation
quality is inferior. Note whether finetuning benefits generalization is method- and task-dependent.
Overall, Prompt and LoRA achieve relatively better results than FMT particularly when the base
LLM is large, mostly because LLM parameters are frozen and the learned knowledge get inherited.
This also suggests that when generalization capability is a big concern, PET should be considered.
[Paper Note] Recommendation with Generative Models, Yashar Deldjoo+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#RecommenderSystems #Tutorial #GenerativeAI #DiffusionModel #One-Line Notes Issue Date: 2024-09-24 GPT Summary- 生成モデルは、統計分布から新しいデータを生成するAIモデルで、GAN、VAE、トランスフォーマー型アーキテクチャが注目を集めている。これらは画像生成、テキスト生成、音楽作曲などの応用があり、レコメンドシステム(Gen-RecSys)でも活用され、推奨精度と多様性を向上させる。また、深層生成モデル(DGMs)をID駆動型モデル、大規模言語モデル、マルチモーダルモデルの3タイプに分類し、それぞれの進展に関連付ける。最後に、生成モデルの影響やリスクを考察し、評価フレームワークの重要性を強調する。 Comment
生成モデルやGenerativeAIによるRecSysの教科書
Report on the 1st Workshop on Large Language Model for Evaluation in Information Retrieval (LLM4Eval 2024) at SIGIR 2024, Hossein A. Rahmani+, N_A, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #Evaluation #One-Line Notes Issue Date: 2024-09-24 GPT Summary- LLM4Eval 2024ワークショップがSIGIR 2024で開催され、情報検索における評価のための大規模言語モデルに関する研究者が集まりました。新規性を重視し、受理論文のパネルディスカッションやポスターセッションを通じて多面的な議論が行われました。 Comment
LLMを用いたIRシステムの評価方法に関するワークショップのレポート。レポート中にAccepted Paperがリストアップされている。
[Paper Note] Don't Use LLMs to Make Relevance Judgments, Ian Soboroff, arXiv'24, 2024.09
Paper/Blog Link My Issue
#InformationRetrieval #RelevanceJudgment #read-later Issue Date: 2024-09-24 GPT Summary- TREC風の関連判断作成はコストが高く複雑であり、通常は訓練された契約労働者が必要とされる。最近の大規模言語モデル(LLMs)の登場は、関連判断収集プロセスへの活用を考えるきっかけとなった。ACM SIGIR 2024で開催されるワークショップ「LLM4Eval」では、TREC深層学習トラックの判断再現のデータチャレンジが取り上げられ、基調講演として本研究が提示される。本稿の要点は、TRECスタイルの評価のための関連判断をLLMsで生成しないこと。 Comment
興味深い!!後で読む!
[Paper Note] To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning, Zayne Sprague+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-09-24 GPT Summary- CoTはLLMからの推論能力を引き出す標準手法だが、どのタスクで効果があるかを分析。100件以上の論文を対象にメタ分析を行い、14モデルと20データセットの評価を実施。結果、CoTは数理・論理タスクで性能向上をもたらすが、他のタスクでは効果が小さい。特に、等号を含む場合はCoTと同等の精度が得られ、記号的実行の改善に起因するものの、記号的ソルバーには劣る。CoTの選択的適用で推論コストを削減できることを示し、今後は中間計算を効果的に活用する新しいパラダイムが必要とされる。 Comment
CoTを100個以上の先行研究でmeta-analysisし(i.e. CoTを追加した場合のgainとタスクのプロット)、20個超えるデータセットで著者らが実験した結果、mathやsymbolic reasoning(12*4のように、シンボルを認識し、何らかの操作をして回答をする問題)が必要なタスクで、CoTは大きなgainが得られることがわかった(他はほとんどgainがない)。
openreview:
https://openreview.net/forum?id=w6nlcS8Kkn
metareviewによると、controlled experimentsを通じて、CoTの効果の大部分はPlanningではなく、信頼性の高い"実行"にあることが明らかになったとのこと。
下図を見るとこの時期はOpenAI o1やDeepSeek-R1の登場前であり、基本的にnon-thinking/reasoning modelによって実験がされていることには注意されたい。だが、昨今のAI AgentやReasoning Modelの挙動を鑑みるに、metareviewに記述されているCoTによって信頼性の高い"実行"が強化される点については実感できる。
PLUG: Leveraging Pivot Language in Cross-Lingual Instruction Tuning, Zhihan Zhang+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #CrossLingual #ACL #PostTraining #Surface-level Notes Issue Date: 2024-09-19 GPT Summary- 指示チューニングはLLMsの指示理解を向上させるが、低リソース言語では課題がある。これに対処するため、英語をピボット言語とするPLUGアプローチを提案。モデルはまず英語で指示を処理し、次にターゲット言語で応答を生成。4つの言語での評価により、指示に従う能力が平均29%向上した。さらに、他のピボット言語を用いた実験も行い、アプローチの多様性を確認。コードとデータは公開されている。 Comment
# 概要
cross-lingualでinstruction tuningをする手法。target言語のInstructionが与えられたときに、Pivotとなる言語でInstructionとResponseを生成した後、targetとなる言語に翻訳するようなデータ(それぞれをseparatorを用いてconcatする)でInstruction Tuningすることでtarget言語での性能が向上
# 評価
ゼロショットのOpen-end GenerationタスクでInstruction Tuningされたモデルが評価されるが、既存のマルチリンガルの評価セットはサンプル数が小さく、機械翻訳ベースのものはノイジーという課題がある。このため、著者らは評価する4言語(low-resource language)のプロの翻訳家を雇用し、AlpacaEvalを翻訳し、4言語(Chinese, Korean, Italian, Spanish)のinstructionが存在するパラレルコーパス X-AlpacaEvalを作成し評価データとして用いる。
利用するFoundationモデルは以下の3種類で、
- LLaMA-2-13B (英語に特化したモデル)
- PolyLM-13B (マルチリンガルなモデル)
- PolyLM-Instruct-Instruct (PolyLM-13Bをinstruction tuningしたもの)
これらに対して学習データとしてGPT4-Alpaca [Paper Note] Instruction Tuning with GPT-4, Baolin Peng+, arXiv'23, 2023.04
instruction-tuning dataset (52kのインストラクションが存在) を利用する。GPT4-AlpacaをChatGPTによって4言語に翻訳し、各言語に対するinstruction tuning datasetを得た。
比較手法として以下の5種類と比較している。ここでターゲット言語は今回4種類で、それぞれターゲット言語ごとに独立にモデルを学習している。
- Pivot-only training: pivot言語(今回は英語)のみで学習した場合
- Monolingual response training: pivot言語とtarget言語のデータを利用した場合
- Code Switching: Monolingual response trainingに加えて、pivot言語とtarget言語のinput/outputをそれぞれ入れ替えたデータセットを用いた場合(i.e. pivot言語 input-target言語 output, target言語 input-pivot言語 outputのペアを作成し学習データに利用している)
- Auxiliary translation tasks: Monolingual respones trainingに加えて、翻訳タスクを定義し学習データとして加えた場合。すなわち、input, outputそれぞれに対して、pivot言語からtarget言語への翻訳のサンプル ([P_trans;x^p], x^t)と([P_trans;y^p], y^t)を加えて学習している。ここで、P_transは翻訳を指示するpromptで、;は文字列のconcatnation。x^p, y^p, x^t, y^tはそれぞれ、pivot言語のinput, output、target言語のinput, outputのサンプルを表す。
- PLUG(提案手法): Pivot-only Trainingに加えて、target言語のinputから、pivot言語のinput/output -> target言語のoutputをconcatしたテキスト(x^t, [x^p;y^p;y^t]) を学習データに加えた場合
評価する際は、MT-Bench [Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
のように、GPT4を用いた、direct pair-wise comparisonを行っている。
direct pair-wise comparisonは、2つのサンプルを与えてLLMに何らかの判断やスコアリングをさせる方法であり、今回はどちらがinstructionにより従っているかに勝敗/引き分けをGPT4に判断させている。LLMによる生成はサンプルの順番にsensitiveなので、順番を逆にした場合でも実験をして、win-lose rateを求めている。1つのサンプルペアに対して、サンプルの順番を正順と逆順の2回評価させ、その双方の結果を用いて最終的なwin/lose/tieを決めている。端的に言うと、勝敗が2-0ならそのサンプルの勝ち、同様に1-1なら引き分け、0-2なら負け、ということである。
[Paper Note] When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs, Ryo Kamoi+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Survey #NLP #SelfCorrection #TACL #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-09-16 GPT Summary- 自己修正はLLMを活用し応答の質を向上させる手法です。しかし、LLMがどのように過ちを修正できるかに関しては合意がなく、従来の研究は多くの問題を抱えています。本研究では、先行研究の批判的レビューを行い、成功する自己修正に必要な条件を議論しています。研究課題の分類と実験設計のチェックリストを提供し、(1)プロンプトを用いた成功事例がないこと、(2)信頼できる外部フィードバックを活用すれば自己修正が機能すること、(3)大規模なファインチューニングが自己修正を支援することを示しています。 Comment
LLMのself-correctionに関するサーベイ
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources, Alisia Lupidi+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Supervised-FineTuning (SFT) #SyntheticData #PostTraining #KeyPoint Notes Issue Date: 2024-09-14 GPT Summary- 新手法「Source2Synth」を提案し、LLMに新しいスキルを教える。人間の注釈に依存せず、実世界のソースに基づいた合成データを生成し、低品質な生成物を廃棄してデータセットの質を向上。マルチホップ質問応答と表形式の質問応答に適用し、WikiSQLで25.51%、HotPotQAで22.57%の性能向上を達成。 Comment
合成データ生成に関する研究。
ソースからQAを生成し、2つのsliceに分ける。片方をLLMのfinetuning(LLMSynth)に利用し、もう片方をfinetuningしたLLMで解答可能性に基づいてフィルタリング(curation)する。
最終的にフィルタリングして生成された高品質なデータでLLMをfinetuningする。
Curationされたデータでfinetuningしたモデルの性能は、Curationしていないただの合成データと比べて、MultiHopQA, TableQAベンチマークで高い性能を獲得している。
画像は元ポストより引用
元ポスト:
MultiHopQAの合成データ生成方法
TableQAの合成データ生成方法
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N_A, ICML'24
Paper/Blog Link My Issue
#ReinforcementLearning Issue Date: 2024-09-13 GPT Summary- R$^3$は、結果の監視を用いて大規模言語モデルの推論プロセスを最適化する新手法。正しいデモンストレーションから学ぶことで、段階的なカリキュラムを確立し、エラーを特定可能にする。Llama2-7Bを用いた実験では、8つの推論タスクでRLのベースラインを平均4.1ポイント上回り、特にGSM8Kでは4.2ポイントの改善を示した。
ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2024-09-13 GPT Summary- 強化ファインチューニング(ReFT)を提案し、LLMsの推論能力を向上。SFTでモデルをウォームアップ後、PPOアルゴリズムを用いてオンライン強化学習を行い、豊富な推論パスを自動サンプリング。GSM8K、MathQA、SVAMPデータセットでSFTを大幅に上回る性能を示し、追加のトレーニング質問に依存せず優れた一般化能力を発揮。
[Paper Note] Generative Verifiers: Reward Modeling as Next-Token Prediction, Lunjun Zhang+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#NLP #SelfCorrection #NeurIPS #Selected Papers/Blogs #Verification #RewardModel #Workshop #KeyPoint Notes #GenerativeVerifier Issue Date: 2024-09-11 GPT Summary- 検証モデルはLLMの推論性能を向上させるためによく使われ、従来のBest-of-N法に依存していますが、新たに提案された生成的検証モデル(GenRM)は、解の生成と検証を統合することで、LLMの利点を活かすことができます。GenRMは通常の識別的モデルと比較して優れた性能を発揮し、アルゴリズム課題や数学問題で大幅な改善を見せています。具体的には、GSM8Kで73%から93.4%への向上など、多様なタスクで性能を向上させ、モデルサイズと計算の増加にもしっかり対応します。 Comment
LLMがリクエストに対する回答を生成したのちに、その回答をverifyするステップ + verifyの結果から回答を修正するステップを全てconcatした学習データをnext token predictionで用いることによって、モデル自身に自分の回答をverifyする能力を身につけさせることができた結果性能が向上しました、という研究らしい。また、Self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
のように複数の異なるCoTを並列して実行させ、そのmajority votingをとることでさらに性能が向上する。
openreview: https://openreview.net/forum?id=CxHRoTLmPX
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Sean Welleck+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #Inference #One-Line Notes Issue Date: 2024-09-10 GPT Summary- 推論時の計算リソース拡大の利点に焦点を当て、トークンレベル生成、メタ生成、効率的生成の3つのアプローチを統一的に探求。トークンレベル生成はデコーディングアルゴリズムを用い、メタ生成はドメイン知識や外部情報を活用し、効率的生成はコスト削減と速度向上を目指す。従来の自然言語処理、現代のLLMs、機械学習の視点を統合した調査。 Comment
元ツイート:
CMUのチームによるinference timeの高速化に関するサーベイ
[Paper Note] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers, Chenglei Si+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#NLP #ScientificDiscovery #One-Line Notes Issue Date: 2024-09-10 GPT Summary- LLMの進展が科学的発見を促進する可能性に期待が高まる中、研究アイデア生成能力を評価するための実験を行い、100名以上のNLP研究者とLLMエージェントのアイデアを比較しました。結果、LLMによるアイデアは新規性が高いと評価される一方、実現可能性は劣ることが明らかになりました。また、LLMの自己評価の失敗や生成の多様性の不足等の未解決問題も指摘されました。人間による新規性評価の難しさを踏まえ、これらのアイデアを実行する研究者を募るエンドツーエンドの研究設計を提案します。 Comment
LLMがアイデアを考えた方が、79人のresearcherにblind reviewさせて評価した結果、Noveltyスコアが有意に高くなった(ただし、feasibilityは人手で考えた場合の方が高い)という話らしい。
アイデア生成にどのようなモデル、promptingを利用したかはまだ読めていない。
[Paper Note] Large Language Models Cannot Self-Correct Reasoning Yet, Jie Huang+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #SelfCorrection #ICLR Issue Date: 2024-09-07 GPT Summary- LLMは高いテキスト生成能力を持つ一方で、生成内容の正確性に懸念がある。自己修正というアプローチが提案されているが、本研究ではLLMの内的自己修正の役割と限界を検討。特に、外部フィードバックなしで応答を修正する際に苦労し、修正後にパフォーマンスが低下することを示している。今後の研究への提言も行う。 Comment
openreview: https://openreview.net/forum?id=IkmD3fKBPQ
A Survey on Human Preference Learning for Large Language Models, Ruili Jiang+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #Alignment Issue Date: 2024-09-07 GPT Summary- 人間の好み学習に基づくLLMsの進展をレビューし、好みフィードバックのソースや形式、モデリング技術、評価方法を整理。データソースに基づくフィードバックの分類や、異なるモデルの利点・欠点を比較し、LLMsの人間の意図との整合性に関する展望を議論。
[Paper Note] Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies, Liangming Pan+, TACL'24, 2023.08
Paper/Blog Link My Issue
#Survey #NLP #SelfCorrection #TACL Issue Date: 2024-09-07 GPT Summary- 自己修正技術を用いて、LLMの幻覚や不正確な推論を改善する方法をレビュー。自動フィードバックを活用し、最小限の人間の介入で実用的なLLMソリューションを目指す。訓練、生成、事後修正の手法を分析し、応用と未来の課題を考察。
Self-Reflection in LLM Agents: Effects on Problem-Solving Performance, Matthew Renze+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #SelfCorrection Issue Date: 2024-09-07 GPT Summary- 本研究では、自己反省が大規模言語モデル(LLMs)の問題解決パフォーマンスに与える影響を調査。9つのLLMに選択肢問題を解かせ、誤答に対して自己反省型エージェントが改善策を提供し再回答を試みた結果、自己反省によりパフォーマンスが有意に向上した($p < 0.001$)。さまざまな自己反省のタイプを比較し、それぞれの寄与も明らかにした。全てのコードとデータはGitHubで公開。
[Paper Note] The Prompt Report: A Systematic Survey of Prompt Engineering Techniques, Sander Schulhoff+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Survey #NLP #Prompting #One-Line Notes Issue Date: 2024-09-02 GPT Summary- 生成型人工知能(GenAI)のプロンプト設計とエンジニアリングについての包括的な総説を提供。プロンプト技術のタクソノミーと適用分析を通じて、体系的理解を確立し、ベストプラクティスを包括的に紹介。33語の語彙表と58のLLMプロンプト技法、さらにChatGPT向けの設計ガイドラインを含む。 Comment
Promptingに関するサーベイ
初期の手法からかなり網羅的に記述されているように見える。
また、誤用されていたり、色々な意味合いで使われてしまっている用語を、きちんと定義している。
たとえば、Few shot LearningとFew shot Promptingの違い、そもそもPromptingの定義、Examplarなど。
[Paper Note] Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?, Zorik Gekhman+, EMNLP'24, 2024.05
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Hallucination #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-09-01 GPT Summary- ファインチューニングによる新しい知識の導入が、大規模言語モデルの既存知識の活用能力に与える影響を調査。新しい知識を含むファインチューニング例は学習が遅く、モデルのハルシネーションを増加させることが明らかに。結果として、新たな知識導入のリスクを浮き彫りにし、モデルは主に事前学習から知識を獲得するが、ファインチューニングはその活用方法を教えることが示唆される。 Comment
pre-training時に獲得されていない情報を用いてLLMのalignmentを実施すると、知識がない状態で学習データを正しく予測できるように学習されてしまうため、事実に基づかない回答をする(つまりhallucination)ように学習されてしまう、といったことを調査している模様。
>新しい知識を導入するファインチューニング例は、モデルの知識と一致する例よりもはるかに遅く学習されます。しかし、新しい知識を持つ例が最終的に学習されるにつれて、モデルの幻覚する傾向が線形に増加することも発見しました。
早々にoverfittingしている。
>大規模言語モデルは主に事前学習を通じて事実知識を取得し、ファインチューニングはそれをより効率的に使用することを教えるという見解を支持しています。
なるほど、興味深い。
大規模言語モデル (LLM) の技術と最新動向, Ikuya Yamada, 2024.06
記載の資料([大規模言語モデル (LLM) の技術と最新動向, Ikuya Yamada, 2024.06, p. 36](大規模言語モデル (LLM) の技術と最新動向))に本論文の解説が記述されている。
- 大規模言語モデル (LLM) の技術と最新動向, Ikuya Yamada, 2024.06
本論文中では、full finetuningによる検証を実施しており、LoRAのようなAdapterを用いたテクニックで検証はされていない。LoRAではもともとのLLMのパラメータはfreezeされるため、異なる挙動となる可能性がある。特にLoRAが新しい知識を獲得可能なことが示されれば、LoRA AdapterをもともとのLLMに付け替えるだけで、異なる知識を持ったLLMを運用可能になるため、インパクトが大きいと考えられる。もともとこういった思想は LoRA Hubを提唱する研究などの頃からあった気がするが、AdapterによってHallucination/overfittingを防ぎながら、新たな知識を獲得できることを示した研究はあるのだろうか?
参考:
LoRAの場合については
- [Paper Note] LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR'24, 2024.05
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
も参照のこと。
What Do Language Models Learn in Context? The Structured Task Hypothesis, Jiaoda Li+, N_A, ACL'24
Paper/Blog Link My Issue
#Analysis #NLP #In-ContextLearning #ACL #read-later #One-Line Notes Issue Date: 2024-08-27 GPT Summary- LLMsのコンテキスト内学習(ICL)能力を説明する3つの仮説について、一連の実験を通じて探究。最初の2つの仮説を無効にし、最後の仮説を支持する証拠を提供。LLMが事前学習中に学習したタスクを組み合わせることで、コンテキスト内で新しいタスクを学習できる可能性を示唆。 Comment
SNLP2024での解説スライド:
http://chasen.org/~daiti-m/paper/SNLP2024-Task-Emergence.pdf
ICLが何をやっているのか?について、これまでの仮説が正しくないことを実験的に示し、新しい仮説「ICLは事前学習で得られたタスクを組み合わせて新しいタスクを解いている」を提唱し、この仮説が正しいことを示唆する実験結果を得ている模様。
理論的に解明されたわけではなさそうなのでそこは留意した方が良さそう。あとでしっかり読む。
Prompting open-source and commercial language models for grammatical error correction of English learner text, Christopher Davis+, N_A, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP #GrammaticalErrorCorrection Issue Date: 2024-08-14 GPT Summary- LLMsの進歩により、流暢で文法的なテキスト生成が可能になり、不文法な入力文を与えることで文法エラー修正(GEC)が可能となった。本研究では、7つのオープンソースと3つの商用LLMsを4つのGECベンチマークで評価し、商用モデルが常に教師ありの英語GECモデルを上回るわけではないことを示した。また、オープンソースモデルが商用モデルを上回ることがあり、ゼロショットのプロンプティングがフューショットのプロンプティングと同じくらい競争力があることを示した。 Comment
元ポスト:
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, Chris Lu+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #AIAgents #ScientificDiscovery Issue Date: 2024-08-13 GPT Summary- 最先端の大規模言語モデルを使用して、完全自動の科学的発見を可能にする包括的なフレームワークが提案された。AI Scientistは新しい研究アイデアを生成し、コードを記述し、実験を実行し、結果を可視化し、完全な科学論文を執筆し、査読プロセスを実行することができる。このアプローチは、機械学習における科学的発見の新しい時代の始まりを示しており、AIエージェントの変革的な利点をAI自体の研究プロセス全体にもたらし、世界で最も難しい問題に無限の手頃な価格の創造性とイノベーションを解き放つことに近づいています。
[Paper Note] Following Length Constraints in Instructions, Weizhe Yuan+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Controllable #NLP #InstructionTuning #EMNLP #Length #InstructionFollowingCapability #One-Line Notes Issue Date: 2024-07-30 GPT Summary- 指示追従モデルは整合性を高めることでユーザーの要求に応える。しかし、評価において長さのバイアスが影響し、モデルは長い応答を出す傾向がある。本研究では、望ましい応答長を制御する指示を用いてモデルを訓練し、長さ指示付き評価で従来のモデルを超える性能を示す。 Comment
SoTA LLMがOutput長の制約に従わないことを示し、それを改善する学習手法LIFT-DPOを提案
元ツイート:
[Paper Note] FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, Jay Shah+, arXiv'24, 2024.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #NeurIPS Issue Date: 2024-07-30 GPT Summary- FlashAttentionはGPU上のアテンションを高速化する手法だが、新しいハードウェア機能を活用できていなかった。FlashAttention-3は、Hopper世代のGPUでアテンションの処理を改善するために、計算とデータ移動の重ね合わせ、行列積とソフトマックス演算のインタリーブ、FP8低精度をサポートするブロック量子化を導入。これにより、H100 GPU上でFP16時に1.5〜2.0倍の速度向上を実現し、最大740 TFLOPs/sに達し、FP8では約1.2 PFLOPs/sに近づく。FP8版では数値誤差が従来の約2.6倍低く抑えられることも示した。 Comment
関連:
- [Paper Note] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, Tri Dao+, NeurIPS'22, 2022.05
- [Paper Note] FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, Tri Dao, arXiv'23, 2023.07
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications, Pranab Sahoo+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #Prompting Issue Date: 2024-07-30 GPT Summary- プロンプトエンジニアリングは、LLMsやVLMsの能力を拡張するための重要な技術であり、モデルのパラメータを変更せずにタスク固有の指示であるプロンプトを活用してモデルの効果を向上させる。本研究は、プロンプトエンジニアリングの最近の進展について構造化された概要を提供し、各手法の強みと制限について掘り下げることで、この分野をよりよく理解し、将来の研究を促進することを目的としている。 Comment
[Paper Note] LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs, LLM-jp+, arXiv'24, 2024.07
Paper/Blog Link My Issue
#Pretraining #NLP #Alignment #Evaluation #OpenWeight #Safety #Japanese #OpenSource #mid-training #PostTraining #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2024-07-10 GPT Summary- 日本語のLLMを開発するプロジェクト「LLM-jp」を紹介。1,500人以上が参加し、オープンソースの高性能モデルを目指す。設立背景、活動概要、および技術報告を示し、最新情報は公式サイトで確認可能。 Comment
llm.jpによるテクニカルレポート
[Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Pretraining #InstructionTuning #EMNLP #read-later #Selected Papers/Blogs #needs-revision Issue Date: 2024-07-08 GPT Summary- 教師なしのマルチタスク事前学習は成功の要因だが、監督付きの可能性も高い。本研究ではInstruction Pre-Trainingを提案し、大規模な指示-応答ペアを用いて言語モデルの前処理を行う。この手法により、40以上のタスクで2億のペアを合成し、その効果を示した。Instruction Pre-Trainingは、基盤モデルの性能を向上させ、追加の指示調整からも利益を得ることができ、Llama3-8BをLlama3-70Bに匹敵する性能へと引き上げた。モデルとデータは公開されている。 Comment
参考:
[Paper Note] Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, Marah Abdin+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #SmallModel #OpenWeight #One-Line Notes Issue Date: 2024-04-23 GPT Summary- phi-3-miniは3.8十億パラメータの言語モデルで、3.3兆トークンを学習し、MMLUで69%、MT-benchで8.38を達成。スマートフォンでもデプロイ可能で、phi-2のデータセットをフィルタリングして作成。phi-3-smallとphi-3-mediumはそれぞれ75%、78%をMMLUで達成し、性能が向上。シリーズの新モデルphi-3.5-mini、phi-3.5-MoE、phi-3.5-Visionも導入。phi-3.5-MoEは優れた言語処理能力を発揮し、phi-3.5-Visionは複数画像とテキストのプロンプトに対応。 Comment
[Paper Note] Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, arXiv'23, 2023.09 の次の次(Phi2.0についてはメモってなかった)。スマホにデプロイできるレベルのサイズで、GPT3.5Turbo程度の性能を実現したらしい
Llama2と同じブロックを利用しているため、アーキテクチャはLlama2と共通。
[Paper Note] Compression Represents Intelligence Linearly, Yuzhen Huang+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#Analysis #Pretraining #Evaluation #COLM #Selected Papers/Blogs #One-Line Notes #DownstreamTasks Issue Date: 2024-04-17 GPT Summary- LLMsが知性を反映するかを圧縮の観点から検討。知性を下流ベンチマークのスコアで評価し、31の公開LLMを分析したところ、圧縮能力と知性にほぼ線形の相関があることが判明。これにより、より優れた圧縮が高い知性を示すという仮説が支持され、圧縮効率が信頼性のある評価指標として機能する可能性が示された。圧縮データセットはオープンソース化され、今後の研究に貢献することが期待される。 Comment
参考:
openreview: https://openreview.net/forum?id=SHMj84U5SH
external corpora (≠学習データ)で測定したモデルのBit Per Character (BPC) とdownstreamタスクのベンチマークスコアは、全体で平均で見ても、個別のドメインでみても、linearに相関する。
Knowledge Conflicts for LLMs: A Survey, Rongwu Xu+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP Issue Date: 2024-04-14 GPT Summary- LLMsにおける知識の衝突に焦点を当て、文脈とパラメトリック知識の組み合わせによる複雑な課題を分析。文脈-メモリ、文脈間、メモリ内の衝突の3つのカテゴリーを探求し、実世界のアプリケーションにおける信頼性とパフォーマンスへの影響を検討。解決策を提案し、LLMsの堅牢性向上を目指す。
[Paper Note] Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, Eric Zelikman+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#NLP #SelfImprovement #One-Line Notes #Reference Collection Issue Date: 2024-04-14 GPT Summary- Quiet-STaRは、言語モデルが各トークンごとに根拠を生成し、未来のテキストを説明する能力を学ぶ手法です。これはSelf-Taught Reasoner (STaR) の一般化であり、推論根拠を生成することで予測を改善します。計算コストや内部思考の生成方法などの課題を克服するために、トークン単位の並列サンプリングアルゴリズムと教師強制技法を提案。特に、難しいトークンの予測を改善し、GSM8KやCommonsenseQAでゼロショットの精度向上を示しました。この研究は、推論を学習するよりスケーラブルなアプローチへと向かう一歩となります。 Comment
o1(OpenAI o1, 2024.09
)の基礎技術と似ている可能性がある
先行研究:
- [Paper Note] STaR: Bootstrapping Reasoning With Reasoning, Eric Zelikman+, arXiv'22, 2022.03
参考:
[Paper Note] Gemma: Open Models Based on Gemini Research and Technology, Gemma Team+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#NLP #OpenWeight #KeyPoint Notes Issue Date: 2024-04-08 GPT Summary- Gemmaは、軽量で最先端のオープンモデルで、言語理解や推論において強力な性能を発揮。2億および7億パラメータのモデルを提供し、事前学習済みとファインチューニング済みのチェックポイントを含む。Gemmaは、18のタスクのうち11で同サイズのオープンモデルを超え、安全性に関する詳細な評価とモデル開発の説明を提供。責任あるLLMのリリースが安全性向上に寄与し、次世代の革新を促進すると信じている。 Comment
アーキテクチャはTransformer Decoderを利用。モデルのサイズは2Bと7B。
オリジナルのTransformer Decoderアーキテクチャから、下記改善を実施している:
- Multi Query Attention [Paper Note] Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, arXiv'19, 2019.11
を利用
- RoPE Embedding [Paper Note] RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, arXiv'21, 2021.04
を利用
- GeGLU [Paper Note] GLU Variants Improve Transformer, Noam Shazeer, arXiv'20, 2020.02
の利用
- RMSNormの利用(学習を安定させるため; LLaMAと同様)
Mistral Mistral 7B, Albert Q. Jiang+, N/A, arXiv'23
よりも高い性能を示している:
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models, Wenshan Wu+, N_A, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Chain-of-Thought Issue Date: 2024-04-08 GPT Summary- LLMsの空間推論能力を向上させるために、Visualization-of-Thought(VoT)プロンプティングを提案。VoTは、LLMsの推論トレースを可視化し、空間推論タスクで使用することで、既存のMLLMsを上回る性能を示す。VoTは、空間推論を促進するために「メンタルイメージ」を生成する能力を持ち、MLLMsでの有効性を示唆する。
Long-context LLMs Struggle with Long In-context Learning, Tianle Li+, N_A, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP #ContextWindow #LongSequence #One-Line Notes Issue Date: 2024-04-07 GPT Summary- LLMsは長いシーケンスを処理する能力に進展しているが、実世界のシナリオでの能力を評価するための専門的なベンチマークLongICLBenchが導入された。このベンチマークでは、LLMsは巨大なラベル空間を理解し、正しい予測を行うために入力全体を理解する必要がある。研究によると、長いコンテキストLLMsは長いコンテキストウィンドウを活用することで比較的良いパフォーマンスを示すが、最も困難なタスクでは苦労している。現在のLLMsは長くコンテキスト豊かなシーケンスを処理し理解する能力にギャップがあることを示唆しており、長いコンテキストの理解と推論は依然として難しい課題であることが示されている。 Comment
GPT4以外はコンテキストが20Kを超えると性能が劣化する傾向にあるとのこと。データセットを難易度別に収集し評価したところ、難易度の高いデータではそもそもコンテキストが長くなると全てのLLMがタスクを理解するできずほぼ0%の性能となった。
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models, David Raposo+, N_A, arXiv'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer Issue Date: 2024-04-07 GPT Summary- Transformerベースの言語モデルは、入力シーケンス全体に均等にFLOPsを分散させる代わりに、特定の位置にFLOPsを動的に割り当てることを学習できることを示す。モデルの深さにわたって割り当てを最適化するために、異なるレイヤーで計算を動的に割り当てる。この手法は、トークンの数を制限することで合計計算予算を強制し、トークンはtop-kルーティングメカニズムを使用して決定される。この方法により、FLOPsを均等に消費しつつ、計算の支出が予測可能であり、動的かつコンテキストに敏感である。このようにトレーニングされたモデルは、計算を動的に割り当てることを学習し、効率的に行うことができる。 Comment
参考:
[Paper Note] Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference, Piotr Nawrot+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #ICML #One-Line Notes #KV Cache #Compression Issue Date: 2024-04-07 GPT Summary- Transformerにおけるメモリキャッシュの非効率性を解決するために、Dynamic Memory Compression(DMC)を提案。DMCは異なるヘッドと層で異なる圧縮比を学習し、Llama 2を組み込むことで推論時に最大7倍のスループット向上を実現。元のパフォーマンスを保ちながら、キャッシュ圧縮を最大4倍可能とし、既存の方法を超える効果を発揮。DMCはKVキャッシュのドロップイン置換として、より長い文脈と大きなバッチを処理できる。 Comment
参考:
論文中のFigure1が非常にわかりやすい。
GQA [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
と比較して、2~4倍キャッシュを圧縮しつつ、より高い性能を実現。70Bモデルの場合は、GQAで8倍キャッシュを圧縮した上で、DMCで追加で2倍圧縮をかけたところ、同等のパフォーマンスを実現している。
[Paper Note] RAFT: Adapting Language Model to Domain Specific RAG, Tianjun Zhang+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-04-07 GPT Summary- RAFTを提案し、LLMに新しい知識を効果的に組み込む方法を示す。質問応答能力を向上させるため、無関係な文書を無視し、関連文書から逐語的引用を行って推論能力を強化。PubMedやHotpotQAなどのデータセットで一貫して性能を改善し、ポスト訓練レシピを提示。コードはオープンソースで公開中。 Comment
Question, instruction, coxtext, cot style answerの4つを用いてSFTをする模様
画像は下記ツイートより引用
[Paper Note] RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners, Chi Hu+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #NLP #Prompting #Reasoning #COLING #Reranking #Initial Impression Notes #LREC Issue Date: 2024-04-07 GPT Summary- LLMの論理的エラーを解決するために、自己ランク付けを可能にする新手法RankPromptを提案。これは、多様な応答を比較し、LLMの文脈的生成能力を活用する。実験ではChatGPTやGPT-4の性能が最大13%向上し、AlpacaEvalデータセットでは人間の判断との74%の一致率を示した。また、応答の順序や一貫性の変動にも強い耐性を持つことが確認された。RankPromptは高品質なフィードバックを引き出す有効な手法である。 Comment
LLMでランキングをするためのプロンプト手法。独立したプロンプトでスコアリングしスコアリング結果からランキングするのではなく、LLMに対して比較するためのルーブリックやshotを入れ、全てのサンプルを含め、1回のPromptingでランキングを生成するような手法に見える。大量の候補をランキングするのは困難だと思われるが、リランキング手法としては利用できる可能性がある。また、実験などでランキングを実施するサンプル数に対してどれだけ頑健なのかなどは示されているだろうか?
[Paper Note] OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, arXiv'24, 2024.02
Paper/Blog Link My Issue
#NLP #OpenWeight #OpenSource #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-03-05 GPT Summary- OLMoは、市場での商業的重要性が高まる中、真にオープンな言語モデルを提供することでNLP研究の進展を目指す。従来のモデルが重みや推論コードのみを公開するのに対し、OLMoはトレーニングデータや評価コードも含めて公開し、科学的研究の基盤を確立することで、オープンな研究コミュニティの力を引き出し、新たなイノベーションを促進することを期待している。 Comment
Model Weightsを公開するだけでなく、training/evaluation codeとそのデータも公開する真にOpenな言語モデル(truly Open Language Model)。AllenAI
Chain-of-Thought Reasoning Without Prompting, Xuezhi Wang+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #One-Line Notes Issue Date: 2024-03-05 GPT Summary- LLMsの推論能力を向上させるための新しいアプローチに焦点を当てた研究が行われている。この研究では、LLMsがプロンプトなしで効果的に推論できるかどうかを検証し、CoT推論パスをデコーディングプロセスを変更することで引き出す方法を提案している。提案手法は、従来の貪欲なデコーディングではなく、代替トークンを調査することでCoTパスを見つけることができることを示しており、様々な推論ベンチマークで有効性を示している。 Comment
以前にCoTを内部的に自動的に実施されるように事前学習段階で学習する、といった話があったと思うが、この研究はデコーディング方法を変更することで、promptingで明示的にinstructionを実施せずとも、CoTを実現するもの、ということだと思われる。
LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, ICML'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #PEFT(Adaptor/LoRA) #ICML #One-Line Notes Issue Date: 2024-03-05 GPT Summary- 本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 Comment
LoRAで導入される低ランク行列AとBを異なる学習率で学習することで、LoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法
Large Language Models for Data Annotation: A Survey, Zhen Tan+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #Annotation #One-Line Notes #Data Issue Date: 2024-03-05 GPT Summary- GPT-4などの大規模言語モデル(LLMs)を使用したデータアノテーションの研究に焦点を当て、LLMによるアノテーション生成の評価や学習への応用について述べられています。LLMを使用したデータアノテーションの手法や課題について包括的に議論し、将来の研究の進展を促進することを目的としています。 Comment
Data AnnotationにLLMを活用する場合のサーベイ
Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey, Xi Fang+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #DataToTextGeneration #TabularData #One-Line Notes Issue Date: 2024-03-05 GPT Summary- 最近の大規模言語モデリングの進展により、様々なタスクにおける応用が容易になっているが、包括的なレビューが不足している。この研究は、最近の進歩をまとめ、データセット、メトリクス、方法論を調査し、将来の研究方向に洞察を提供することを目的としている。また、関連するコードとデータセットの参照も提供される。 Comment
Tabular DataにおけるLLM関連のタスクや技術等のサーベイ
User-LLM: Efficient LLM Contextualization with User Embeddings, Lin Ning+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #Personalization #Initial Impression Notes Issue Date: 2024-02-24 GPT Summary- LLMsを活用したUser-LLMフレームワークが提案された。ユーザーエンベッディングを使用してLLMsをコンテキストに位置付けし、ユーザーコンテキストに動的に適応することが可能になる。包括的な実験により、著しい性能向上が示され、Perceiverレイヤーの組み込みにより計算効率が向上している。 Comment
next item prediction, favorite genre or category predictimnreview generationなどで評価している
MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#Survey #MultiModal #ACL #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-01-25 GPT Summary- MM-LLMsは、コスト効果の高いトレーニング戦略を用いて拡張され、多様なMMタスクに対応する能力を持つことが示されている。本論文では、MM-LLMsのアーキテクチャ、トレーニング手法、ベンチマークのパフォーマンスなどについて調査し、その進歩に貢献することを目指している。 Comment
以下、論文を斜め読みしながら、ChatGPTを通じて疑問点を解消しつつ理解した内容なので、理解が不十分な点が含まれている可能性があるので注意。
# 概要
まあざっくり言うと、マルチモーダルを理解できるLLMを作りたかったら、様々なモダリティをエンコーディングして得られる表現と、既存のLLMが内部的に処理可能な表現を対応づける Input Projectorという名の関数を学習すればいいだけだよ(モダリティのエンコーダ、LLMは事前学習されたものをそのままfreezeして使えば良い)。
マルチモーダルを生成できるLLMを作りたかったら、LLMがテキストを生成するだけでなく、様々なモダリティに対応する表現も追加で出力するようにして、その出力を各モダリティを生成できるモデルに入力できるように変換するOutput Projectortという名の関数を学習しようね、ということだと思われる。
## ポイント
- Modality Encoder, LLM Backbone、およびModality Generatorは一般的にはパラメータをfreezeする
- optimizationの対象は「Input/Output Projector」
## Modality Encoder
様々なモダリティI_Xを、特徴量F_Xに変換する。これはまあ、色々なモデルがある。
## Input Projector
モダリティI_Xとそれに対応するテキストtのデータ {I_X, t}が与えられたとき、テキストtを埋め込み表現に変換んした結果得られる特徴量がF_Tである。Input Projectorは、F_XをLLMのinputとして利用する際に最適な特徴量P_Xに変換するθX_Tを学習することである。これは、LLM(P_X, F_T)によってテキストtがどれだけ生成できたか、を表現する損失関数を最小化することによって学習される。
## LLM Backbone
LLMによってテキスト列tと、各モダリティに対応した表現であるS_Xを生成する。outputからt, S_Xをどのように区別するかはモデルの構造などにもよるが、たとえば異なるヘッドを用意して、t, S_Xを区別するといったことは可能であろうと思われる。
## Output Projector
S_XをModality Generatorが解釈可能な特徴量H_Xに変換する関数のことである。これは学習しなければならない。
H_XとModality Generatorのtextual encoderにtを入力した際に得られる表現τX(t)が近くなるようにOutput Projector θ_T_Xを学習する。これによって、S_XとModality Generatorがalignするようにする。
## Modality Generator
各ModalityをH_Xから生成できるように下記のような損失学習する。要は、生成されたモダリティデータ(または表現)が実際のデータにどれだけ近いか、を表しているらしい。具体的には、サンプリングによって得られたノイズと、モデルが推定したノイズの値がどれだけ近いかを測る、みたいなことをしているらしい。
Multi Modalを理解するモデルだけであれば、Input Projectorの損失のみが学習され、生成までするのであれば、Input/Output Projector, Modality Generatorそれぞれに示した損失関数を通じてパラメータが学習される。あと、P_XやらS_Xはいわゆるsoft-promptingみたいなものであると考えられる。
LLaMA Pro: Progressive LLaMA with Block Expansion, Chengyue Wu+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #ACL #PostTraining #KeyPoint Notes Issue Date: 2024-01-24 GPT Summary- 本研究では、大規模言語モデル(LLMs)の新しい事前学習後の手法を提案し、モデルの知識を効果的かつ効率的に向上させることを目指しました。具体的には、Transformerブロックの拡張を使用し、新しいコーパスのみを使用してモデルを調整しました。実験の結果、提案手法はさまざまなベンチマークで優れたパフォーマンスを発揮し、知的エージェントとして多様なタスクに対応できることが示されました。この研究は、自然言語とプログラミング言語を統合し、高度な言語エージェントの開発に貢献するものです。 Comment
追加の知識を導入したいときに使えるかも?
事前学習したLLaMA Blockに対して、追加のLLaMA Blockをstackし、もともとのLLaMA Blockのパラメータをfreezeした上でドメインに特化したコーパスで事後学習することで、追加の知識を挿入する。LLaMA Blockを挿入するときは、Linear Layerのパラメータを0にすることで、RMSNormにおける勾配消失の問題を避けた上で、Identity Block(Blockを追加した時点では事前学習時と同様のOutputがされることが保証される)として機能させることができる。
[Paper Note] Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models, Zixiang Chen+, ICML'24, 2024.01
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #SyntheticData #SelfImprovement #ICML #mid-training #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes #AdversarialTraining #SelfPlay Issue Date: 2024-01-24 GPT Summary- 自己対戦ファインチューニング(SPIN)を提案し、人間の注釈なしで弱いLLMを強化。LLMが自らのインスタンスと対戦し、トレーニングデータを生成。自己生成と人間の応答を識別してポリシーを微調整。SPINは様々なベンチマークでLLMの性能を大幅に向上させ、GPT-4優先データを使ったモデルを上回る成果を示した。 Comment
pj page:
https://uclaml.github.io/SPIN/
code:
https://github.com/uclaml/SPIN
メインプレイヤーは人間とLLMのレスポンスを区別する、対戦相手はメインプレイヤーに対して人間が作成したレスポンスと自身が作成させたレスポンスを区別できないようにするようなゲームをし、両者を同じLLM、しかし異なるiterationのパラメータを採用することで自己対戦させることでSFTデータセットから最大限学習するような手法を提案。メインプレイヤーの目的関数は、人間とLLMのレスポンスの確率の差を最大化するように定式化され(式4.1)、対戦相手は人間が生成したレスポンスを最大化するような損失関数を元のパラメータから大きく乖離しないようにKL正則化付きで定義する(式4.3)。双方の損失を単一の損失関数に統合すると式4.7で表される提案手法のSPIN損失が得られ、これによって与えられたSFTデータに対してレスポンスを各iterationで合成し、合成したレスポンスに対してSPIN損失を適用することでモデルのパラメータをアップデートする。メインプレイヤーの重みは更新された重みを用いて、対戦プレイヤーの重みは一つ前の重みを用いる。
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models, S. M Towhidul Islam Tonmoy+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #Hallucination Issue Date: 2024-01-24 GPT Summary- 要約:本論文では、大規模言語モデル(LLMs)における幻覚の問題について調査し、その軽減策について紹介しています。LLMsは強力な言語生成能力を持っていますが、根拠のない情報を生成する傾向があります。この問題を解決するために、Retrieval Augmented Generation、Knowledge Retrieval、CoNLI、CoVeなどの技術が開発されています。さらに、データセットの利用やフィードバックメカニズムなどのパラメータに基づいてこれらの方法を分類し、幻覚の問題に取り組むためのアプローチを提案しています。また、これらの技術に関連する課題や制約についても分析し、将来の研究に向けた基盤を提供しています。
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding, Zilong Wang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #DataToTextGeneration #Chain-of-Thought #TabularData #ICLR #KeyPoint Notes Issue Date: 2024-01-24 GPT Summary- LLMsを使用したChain-of-Tableフレームワークは、テーブルデータを推論チェーン内で活用し、テーブルベースの推論タスクにおいて高い性能を発揮することが示された。このフレームワークは、テーブルの連続的な進化を表現し、中間結果の構造化情報を利用してより正確な予測を可能にする。さまざまなベンチマークで最先端のパフォーマンスを達成している。 Comment
Table, Question, Operation Historyから次のoperationとそのargsを生成し、テーブルを順次更新し、これをモデルが更新の必要が無いと判断するまで繰り返す。最終的に更新されたTableを用いてQuestionに回答する手法。Questionに回答するために、複雑なテーブルに対する操作が必要なタスクに対して有効だと思われる。
Knowledge Fusion of Large Language Models, Fanqi Wan+, N_A, ICLR'24
Paper/Blog Link My Issue
#MachineLearning #NLP #ICLR #read-later #ModelMerge Issue Date: 2024-01-23 GPT Summary- 本研究では、既存の事前訓練済みの大規模言語モデル(LLMs)を統合することで、1つの強力なモデルを作成する方法を提案しています。異なるアーキテクチャを持つ3つの人気のあるLLMsを使用して、ベンチマークとタスクのパフォーマンスを向上させることを実証しました。提案手法のコード、モデルの重み、およびデータはGitHubで公開されています。
[Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#NLP #Alignment #InstructionTuning #LLM-as-a-Judge #SelfImprovement #ICML #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-01-22 GPT Summary- 超人間エージェントを実現するには、超人間レベルのフィードバックが必要であると提唱。現在のアプローチは人間の嗜好から報酬モデルを訓練するが、これがボトルネックになりがちである。本研究では自己報酬言語モデルを用い、LLMが自ら報酬を提供する方法を検討。DPOトレーニングにより指示への従順さと自己報酬の質が向上し、Llama 2 70Bをファインチューニングすることで、既存モデルを上回ることが示された。探索の余地は残るが、本研究は改善の可能性を示唆する。 Comment
人間の介入無しで(人間がアノテーションしたpreference data無しで)LLMのAlignmentを改善していく手法。LLM-as-a-Judge Promptingを用いて、LLM自身にpolicy modelとreward modelの役割の両方をさせる。unlabeledなpromptに対してpolicy modelとしてresponceを生成させた後、生成したレスポンスをreward modelとしてランキング付けし、DPOのpreference pairとして利用する、という操作を繰り返す。
[Paper Note] The Impact of Reasoning Step Length on Large Language Models, Mingyu Jin+, ACL'24 Findings, 2024.01
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #Reasoning #ACL #Length #Findings Issue Date: 2024-01-16 GPT Summary- Chain of Thought(CoT)がLLMの推論能力向上に重要であることが示された。実験により、推論ステップの長さがLLMの性能に与える影響を調査。推論ステップを長くすることで、追加情報なしでも推論能力が向上し、逆に短くすると性能が著しく低下。これは、CoTプロンプトにおけるステップ数の重要性を示している。また、不正確な合理的根拠でも推論を維持できれば良好な結果が得られることが判明。タスクの複雑さに応じて、推論ステップの利点は異なることも観察された。
[Paper Note] Mixtral of Experts, Albert Q. Jiang+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#NLP #OpenWeight #MoE(Mixture-of-Experts) #One-Line Notes Issue Date: 2024-01-09 GPT Summary- Mixtral 8x7Bは、8つのエキスパートを持つスパース・ミクスチャー・オブ・エキスパーツモデルで、470億パラメータにアクセスしつつ、推論時は130億パラメータのみが活性化される。32kトークンの文脈長で訓練され、Llama 2 70BおよびGPT-3.5を上回る性能を発揮。特に数学やコード生成で優れ、指示に従うよう微調整したモデルも提供され、複数の人間ベンチマークで競合モデルを超えた。 Comment
Mixture of experts Layer: inputを受け取ったrouterが、8つのexpertsのうち2つを選択し順伝搬。2つのexpertsのoutputを加重平均することで最終的なoutputとする。
VILA: On Pre-training for Visual Language Models, Ji Lin+, N_A, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pretraining #NLP #CVPR #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2023-12-14 GPT Summary- 最近の大規模言語モデルの成功により、ビジュアル言語モデル(VLM)が進歩している。本研究では、VLMの事前学習のためのデザインオプションを検討し、以下の結果を示した:(1) LLMを凍結することでゼロショットのパフォーマンスが達成できるが、文脈に基づいた学習能力が不足している。(2) 交互に行われる事前学習データは有益であり、画像とテキストのペアだけでは最適ではない。(3) テキストのみの指示データを画像とテキストのデータに再ブレンドすることで、VLMのタスクの精度を向上させることができる。VILAというビジュアル言語モデルファミリーを構築し、最先端モデルを凌駕し、優れたパフォーマンスを発揮することを示した。マルチモーダルの事前学習は、VILAの特性を向上させる。 Comment
関連:
- Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N/A, CVPR'24
[Paper Note] The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning, Bill Yuchen Lin+, ICLR'24, 2023.12
Paper/Blog Link My Issue
#NLP #Alignment #In-ContextLearning #ICLR #KeyPoint Notes Issue Date: 2023-12-05 GPT Summary- LLMのアライメント調整は、SFTとRLHFを含むが、LIMAの研究は1Kの例でも効果的なアライメントが達成できることを示した。基盤LLMとアラインメント版のトークン分布を分析した結果、ほぼ同一の性能を示し、文体的なシフトが顕著であった。このことから、SFTやRLHFなしでのアラインメント手法を探求し、新たにURIALを提案。URIALは、ICLを用い、少数の文体的例で効果的なアライメントを実現し、基盤LLMの性能がSFTによるものと同等、あるいは上回ることを示した。結果はアライメントの表面的性質を再考させるものであり、今後の研究への示唆となる。 Comment
モデルの知識はPre-training時に十分獲得されており、モデルのAlignmentをとることで生じるものは表面的な変化のみであるという仮説がある [Paper Note] LIMA: Less Is More for Alignment, Chunting Zhou+, arXiv'23, 2023.05
。この仮説に関して分析をし、結果的にスタイリスティックな情報を生成する部分でAlignmentの有無で違いが生じることを明らかにし、そうであればわざわざパラメータチューニング(SFT, RLHF)しなくても、適切なサンプルを選択したIn-Context LearningでもAlignmentとれますよ、という趣旨の研究っぽい?
openreview: https://openreview.net/forum?id=wxJ0eXwwda
NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation, Shachar Rosenman+, N_A, EACL'24 Sustem Demonstration Track
Paper/Blog Link My Issue
#ComputerVision #NLP #AutomaticPromptEngineering #EACL #System Demonstration Issue Date: 2023-11-23 GPT Summary- 本研究では、テキストから画像への生成モデルの品質を向上させるための適応型フレームワークNeuroPromptsを提案します。このフレームワークは、事前学習された言語モデルを使用して制約付きテキストデコーディングを行い、人間のプロンプトエンジニアが生成するものに類似したプロンプトを生成します。これにより、高品質なテキストから画像への生成が可能となり、ユーザーはスタイルの特徴を制御できます。また、大規模な人間エンジニアリングされたプロンプトのデータセットを使用した実験により、当アプローチが自動的に品質の高いプロンプトを生成し、優れた画像品質を実現することを示しました。
GPQA: A Graduate-Level Google-Proof Q&A Benchmark, David Rein+, N_A, COLM'24
Paper/Blog Link My Issue
#NLP #Dataset #QuestionAnswering #COLM #One-Line Notes Issue Date: 2023-11-22 GPT Summary- 私たちは、高品質で非常に困難な多肢選択問題からなるGPQAデータセットを提案します。このデータセットは、専門家でも高い正答率を達成できず、最先端のAIシステムでも困難であることが示されています。将来のAIシステムの開発において、スケーラブルな監督方法を開発する必要があります。これにより、スキルを持つ監督者がAIシステムから信頼性のある情報を得ることができるようになります。GPQAデータセットは、スケーラブルな監督実験を可能にし、人間の専門家がAIシステムから真実の情報を確実に得る方法を考案するのに役立つことが期待されています。 Comment
該当領域のPh.D所有者でも74%、高いスキルを持つ非専門家(Googleへアクセスして良い環境)で34%しか正答できないQAデータセット。
元ツイート:
OpenReview: https://openreview.net/forum?id=Ti67584b98
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models, Wenhao Yu+, N_A, EMNLP'24
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #RAG(RetrievalAugmentedGeneration) #EMNLP #KeyPoint Notes Issue Date: 2023-11-17 GPT Summary- 検索補完言語モデル(RALM)は、外部の知識源を活用して大規模言語モデルの性能を向上させるが、信頼性の問題や知識の不足による誤った回答がある。そこで、Chain-of-Noting(CoN)という新しいアプローチを導入し、RALMの頑健性を向上させることを目指す。CoNは、順次の読み取りノートを生成し、関連性を評価して最終的な回答を形成する。ChatGPTを使用してCoNをトレーニングし、実験結果はCoNを装備したRALMが標準的なRALMを大幅に上回ることを示している。特に、ノイズの多いドキュメントにおいてEMスコアで平均+7.9の改善を達成し、知識範囲外のリアルタイムの質問に対する拒否率で+10.5の改善を達成している。 Comment
モデルに検索されたドキュメント対するqueryのrelevance/accuracyの観点からnote-takingをさせることで、RAGの正確性や透明性を向上させる。たとえば、
- surface-levelの情報に依存せずにモデルに理解を促す
- 相反する情報が存在してもrelevantな情報を適切に考慮する,
- 回答プロセスの透明性・解釈性を向上させる
- 検索された文書に対する過剰な依存をなくす(文書が古い, あるいはノイジーな場合に有用)
などが利点として挙げられている。
下記が付録中のCoNで実際に利用されているプロンプト。
非常にシンプルな手法だが、結果としてはノイズが多い場合、CoNによるゲインが大きいことがわかる。
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks, Sanchit Ahuja+, N_A, NAACL'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiLingual #NAACL #VisionLanguageModel Issue Date: 2023-11-14 GPT Summary- LLMsの研究は急速に進展しており、英語以外の言語での評価が必要とされている。本研究では、新しいデータセットを追加したMEGAVERSEベンチマークを提案し、さまざまなLLMsを評価する。実験の結果、GPT4とPaLM2が優れたパフォーマンスを示したが、データの汚染などの問題があるため、さらなる取り組みが必要である。
Prompt Engineering a Prompt Engineer, Qinyuan Ye+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#NLP #Prompting #AutomaticPromptEngineering #ACL #Findings Issue Date: 2023-11-13 GPT Summary- プロンプトエンジニアリングは、LLMsのパフォーマンスを最適化するための重要なタスクであり、本研究ではメタプロンプトを構築して自動的なプロンプトエンジニアリングを行います。改善されたパフォーマンスにつながる推論テンプレートやコンテキストの明示などの要素を導入し、一般的な最適化概念をメタプロンプトに組み込みます。提案手法であるPE2は、さまざまなデータセットやタスクで強力なパフォーマンスを発揮し、以前の自動プロンプトエンジニアリング手法を上回ります。さらに、PE2は意味のあるプロンプト編集を行い、カウンターファクトの推論能力を示します。
[Paper Note] Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs, Qingru Zhang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #Attention #ICLR #One-Line Notes #Steering Issue Date: 2023-11-10 GPT Summary- PASTAは、大規模言語モデル(LLMs)において、ユーザーが指定した強調マークのあるテキストを読むことを可能にする手法です。PASTAは、注意の一部を特定し、再重み付けを適用してモデルの注意をユーザーが指定した部分に向けます。実験では、PASTAがLLMの性能を大幅に向上させることが示されています。 Comment
ユーザがprompt中で強調したいした部分がより考慮されるようにattention weightを調整することで、より応答性能が向上しましたという話っぽい。かなり重要な技術だと思われる。後でしっかり読む。
openreview: https://openreview.net/forum?id=xZDWO0oejD
[Paper Note] Re-Reading Improves Reasoning in Large Language Models, Xiaohan Xu+, EMNLP'24, 2023.09
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Prompting #EMNLP #KeyPoint Notes #Reading Reflections Issue Date: 2023-10-30 GPT Summary- Re2は、質問を再読することでLLMの推論能力を高める簡潔かつ効果的なプロンプティング手法です。これは、入力を二度処理することにより理解を深め、CoTなどの思考誘発型手法とも互換性があります。Re2は単方向デコーダーのLLMに対しても双方向エンコーディングを促進し、広範な推論ベンチマークでその有効性を示しました。結果として、Re2は単純な再読戦略を通じてLLMの推論性能を一貫して向上させることが示され、異なるモデルや手法と効果的に統合可能です。 Comment
問題文を2,3回promptで繰り返すだけで、数学のベンチマークとCommonsenseのベンチマークの性能が向上したという非常に簡単なPrompting。self-consistencyなどの他のPromptingとの併用も可能。
なぜ性能が向上するかというと、
1. LLMはAuporegressiveなモデルであり、bidirectionalなモデルではない。このため、forwardパスのみでは読解力に限界がある。(たとえば人間はしばしばテキストを読み返したりする)。そこで、一度目の読解で概要を理解し、二度目の読解でsalience partを読み込むといったような挙動を実現することで、より問題文に対するComprehensionが向上する。
2. LLMはしばしばpromptの重要な箇所の読解を欠落させてしまう。たとえば、[Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
では、promptのmiddle partを軽視する傾向があることが示されている。このような現象も軽減できると考えられる。
問題文の繰り返しは、3回までは性能が向上する。
このpromptingは複雑な問題であればあるほど効果があると推察される。
本手法はReasoningモデル登場依然のものであり、おそらくReasoningモデルではReasoning tokenの生成を通じて動的にcontextにattentionを貼る(つまり必要な箇所は自然にre-readingされる)ため、re-readingと同等以上の効果を得ていることが推察される。
このため、直感的にはこの手法はnon-thinkingモデルに対しては依然として有効な場合はあるかもしれないが、Reasoningモデルにおいては非推奨だと個人的には考える。
[Paper Note] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #Factuality #RAG(RetrievalAugmentedGeneration) #ICLR #KeyPoint Notes #Critic Issue Date: 2023-10-29 GPT Summary- Self-Reflective Retrieval-Augmented Generation(Self-RAG)は、取得と自己反省を通じて大規模言語モデル(LLM)の品質を向上させる新しいフレームワークである。従来の方法が固定数のパッセージを無差別に取得するのに対し、Self-RAGは適応的にパッセージを取得し、reflection tokensを用いて生成と反省を行う。このアプローチにより、さまざまなタスクにおいて最先端のLLMや取得強化モデルを上回り、特に長文生成の事実性と出典の正確性が顕著に向上した。 Comment
RAGをする際の言語モデルの回答の質とfactual consistencyを改善せるためのフレームワーク。
reflection tokenと呼ばれる特殊トークンを導入し、言語モデルが生成の過程で必要に応じて情報をretrieveし、自身で生成内容を批評するように学習する。単語ごとに生成するのではなく、セグメント単位で生成する候補を生成し、批評内容に基づいて実際に生成するセグメントを選択する。
OpenReview: https://openreview.net/forum?id=hSyW5go0v8
[Paper Note] Human Feedback is not Gold Standard, Tom Hosking+, ICLR'24, 2023.09
Paper/Blog Link My Issue
#NLP #Evaluation #ICLR Issue Date: 2023-10-28 GPT Summary- 人間のフィードバックは、大規模言語モデルの性能評価や訓練に重要であるが、好みスコアの主観性と偏りの影響について検証。好みスコアは網羅性が高いが、事実性の評価は不足していると判明。出力の断定性が事実性誤りの認識に影響し、人間の注釈の信頼性についても疑問を提起。人間のフィードバックによる訓練が断定性を偏らせる可能性も示唆。今後は好みスコアの目的との整合性を検討することが推奨される。 Comment
参考:
openreview: https://openreview.net/forum?id=7W3GLNImfS
Detecting Pretraining Data from Large Language Models, Weijia Shi+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #ICLR #One-Line Notes Issue Date: 2023-10-26 GPT Summary- 本研究では、大規模言語モデル(LLMs)を訓練するためのデータの検出問題を研究し、新しい検出方法であるMin-K% Probを提案します。Min-K% Probは、LLMの下で低い確率を持つアウトライアーワードを検出することに基づいています。実験の結果、Min-K% Probは従来の方法に比べて7.4%の改善を達成し、著作権のある書籍の検出や汚染された下流の例の検出など、実世界のシナリオにおいて効果的な解決策であることが示されました。 Comment
実験結果を見るにAUCは0.73-0.76程度であり、まだあまり高くない印象。また、テキストのlengthはそれぞれ32,64,128,256程度。
openreview: https://openreview.net/forum?id=zWqr3MQuNs
[Paper Note] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #ICML #One-Line Notes Issue Date: 2023-10-12 GPT Summary- Step-Back Promptingは、大規模言語モデル(LLMs)を使用して推論の手順をガイドするシンプルなプロンプティング技術です。この技術により、LLMsは具体的な詳細から高レベルの概念や基本原則を抽象化し、正しい推論経路をたどる能力を向上させることができます。実験により、Step-Back PromptingはSTEM、Knowledge QA、Multi-Hop Reasoningなどのタスクにおいて大幅な性能向上が観察されました。具体的には、MMLU Physics and Chemistryで7%、11%、TimeQAで27%、MuSiQueで7%の性能向上が確認されました。 Comment
また新しいのが出た。ユーザのクエリに対して直接応答しようとするのではなく、より高次で抽象的・原則的な問いを生成しそこから事実情報を得て、その事実情報にgroundingされた推論によって答えを導く。
openreview: https://openreview.net/forum?id=3bq3jsvcQ1
Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pretraining #NLP #One-Line Notes Issue Date: 2023-10-10 GPT Summary- 言語モデルのトレーニングと推論において、遅延を導入することでモデルの性能を向上させる手法を提案しました。具体的には、入力に特定のトークンを追加し、そのトークンが現れるまでモデルの出力を遅らせることで、追加の計算を行うことができます。実験結果では、この手法が推論タスクにおいて有益であり、特にQAタスクでの性能向上が見られました。今後は、この遅延予測の手法をさらに研究していく必要があります。 Comment
この研究は興味深いが、事前学習時に入れないと効果が出にくいというのは直感的にわかるので、実用的には活用しづらい。
また、promptでこの研究をimitateする方法については、ZeroShot CoTにおいて、思考プロセスを明示的に指定するようなpromptingと同様のことを行っており、これは実際に効果があると思う。
Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N_A, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #NLP #QuestionAnswering #OpenWeight #CVPR #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes Issue Date: 2023-10-09 GPT Summary- LLaVAは、ビジョンと言語のクロスモーダルコネクタであり、データ効率が高く強力な性能を持つことが示されています。CLIP-ViT-L-336pxを使用し、学術タスク指向のVQAデータを追加することで、11のベンチマークで最先端のベースラインを確立しました。13Bのチェックポイントはわずか120万の公開データを使用し、1日で完全なトレーニングを終えます。コードとモデルは公開されます。 Comment
画像分析が可能なオープンソースLLMとのこと。
# Overview
画像生成をできるわけではなく、inputとして画像を扱えるのみ。
pj page: https://llava-vl.github.io
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic, Xufeng Zhao+, N_A, COLING'24
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #COLING Issue Date: 2023-10-09 GPT Summary- 大規模言語モデルの進歩は驚異的だが、多段階の推論には改善の余地がある。大規模言語モデルは知識を持っているが、推論には一貫性がなく、幻覚を示すことがある。そこで、Logical Chain-of-Thought(LogiCoT)というフレームワークを提案し、論理による推論パラダイムの効果を示した。
Graph Neural Prompting with Large Language Models, Yijun Tian+, N_A, AAAI'24
Paper/Blog Link My Issue
#GraphBased #NLP #KnowledgeGraph #Prompting #AAAI #One-Line Notes #SoftPrompt Issue Date: 2023-10-09 GPT Summary- 本研究では、大規模言語モデル(LLMs)を知識グラフと組み合わせるための新しい手法であるGraph Neural Prompting(GNP)を提案しています。GNPは、標準的なグラフニューラルネットワークエンコーダやクロスモダリティプーリングモジュールなどの要素から構成されており、異なるLLMのサイズや設定において、常識的な推論タスクやバイオメディカル推論タスクで優れた性能を示すことが実験によって示されました。 Comment
元ツイート:
事前学習されたLLMがKGから有益な知識を学習することを支援する手法を提案。
しっかり論文を読んでいないが、freezeしたLLMがあった時に、KGから求めたGraph Neural Promptを元のテキストと組み合わせて、新たなLLMへの入力を生成し利用する手法な模様。
Graph Neural Promptingでは、Multiple choice QAが入力された時に、その問題文や選択肢に含まれるエンティティから、KGのサブグラフを抽出し、そこから関連性のある事実や構造情報をエンコードし、Graph Neural Promptを獲得する。そのために、GNNに基づいたアーキテクチャに、いくつかの工夫を施してエンコードをする模様。
つまりKGの情報を保持したSoft Prompting手法というイメージだろうか。
[Paper Note] Chain-of-Verification Reduces Hallucination in Large Language Models, Shehzaad Dhuliawala+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Chain-of-Thought #Prompting #Hallucination #ACL #Selected Papers/Blogs #Verification Issue Date: 2023-09-30 GPT Summary- 私たちは、言語モデルが根拠のない情報を生成する問題に取り組んでいます。Chain-of-Verification(CoVe)メソッドを開発し、モデルが回答を作成し、検証し、最終的な回答を生成するプロセスを経ることで、幻想を減少させることができることを実験で示しました。 Comment
# 概要
ユーザの質問から、Verificationのための質問をplanningし、質問に対して独立に回答を得たうえでオリジナルの質問に対するaggreementを確認し、最終的に生成を実施するPrompting手法
# 評価
## dataset
- 全体を通じてclosed-bookの設定で評価
- Wikidata
- Wikipedia APIから自動生成した「“Who are some [Profession]s who were born in [City]?”」に対するQA pairs
- Goldはknowledge baseから取得
- 全56 test questions
- Gold Entityが大体600程度ありLLMは一部しか回答しないので、precisionで評価
- Wiki category list
- QUEST datasetを利用 [Paper Note] QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, arXiv'23, 2023.05
- 回答にlogical operationが不要なものに限定して頭に"Name some"をつけて質問を生成
- "Name some Mexican animated horror films" or "Name some Endemic orchids of Vietnam"
- 8個の回答を持つ55 test questionsを作成
- MultiSpanQA
- Reading Comprehensionに関するBenchmark dataset
- 複数の独立した回答(回答は連続しないスパンから回答が抽出される)から構成される質問で構成
- 特に、今回はclosed-book setting で実施
- すなわち、与えられた質問のみから回答しなければならず、知っている知識が問われる問題
- 418のtest questsionsで、各回答に含まれる複数アイテムのspanが3 token未満となるようにした
- QA例:
- Q: Who invented the first printing press and in what year?
- A: Johannes Gutenberg, 1450.
# 評価結果
提案手法には、verificationの各ステップでLLMに独立したpromptingをするかなどでjoint, 2-step, Factored, Factor+Revisedの4種類のバリエーションがあることに留意。
- joint: 全てのステップを一つのpromptで実施
- 2-stepは2つのpromptに分けて実施
- Factoredは各ステップを全て異なるpromptingで実施
- Factor+Revisedは異なるpromptで追加のQAに対するcross-checkをかける手法
結果を見ると、CoVEでhallucinationが軽減(というより、モデルが持つ知識に基づいて正確に回答できるサンプルの割合が増えるので実質的にhallucinationが低減したとみなせる)され、特にjointよりも2-step, factoredの方が高い性能を示すことがわかる。
[Paper Note] Large Language Models as Optimizers, Chengrun Yang+, ICLR'24, 2023.09
Paper/Blog Link My Issue
#MachineLearning #NLP #AutomaticPromptEngineering #ICLR #Selected Papers/Blogs #KeyPoint Notes #Reading Reflections Issue Date: 2023-09-09 GPT Summary- 最適化タスクを自然言語で記述するアプローチ、Optimization by PROmpting(OPRO)を提案。大規模言語モデル(LLMs)を用いて以前の解を基に新しい解を生成し、プロンプトに追加。線形回帰や巡回セールスマン問題での実証に続き、プロンプト最適化を行い、タスク精度を最大化。OPROで最適化されたプロンプトは、人間設計のものをGSM8Kで最大8%、Big-Bench Hardで最大50%上回ることを確認。 Comment
`Take a deep breath and work on this problem step-by-step. `論文
# 概要
LLMを利用して最適化問題を解くためのフレームワークを提案したという話。論文中では、linear regressionや巡回セールスマン問題に適用している。また、応用例としてPrompt Engineeringに利用している。
これにより、Prompt Engineeringが最適か問題に落とし込まれ、自動的なprompt engineeringによって、`Let's think step by step.` よりも良いプロンプトが見つかりましたという話。
# 手法概要
全体としての枠組み。meta-promptをinputとし、LLMがobjective functionに対するsolutionを生成する。生成されたsolutionとスコアがmeta-promptに代入され、次のoptimizationが走る。これを繰り返す。
Meta promptの例
openreview: https://openreview.net/forum?id=Bb4VGOWELI
テキスト空間上で過去の履歴とスコアが与えられ、それをgivenにスコアが良くなりそうなものをLLMがiterativeに生成していくことが可能なことが示されたのが興味深い
CausalLM is not optimal for in-context learning, Nan Ding+, N_A, ICLR'24
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #In-ContextLearning #ICLR #Reading Reflections Issue Date: 2023-09-01 GPT Summary- 最近の研究では、トランスフォーマーベースのインコンテキスト学習において、プレフィックス言語モデル(prefixLM)が因果言語モデル(causalLM)よりも優れたパフォーマンスを示すことがわかっています。本研究では、理論的なアプローチを用いて、prefixLMとcausalLMの収束挙動を分析しました。その結果、prefixLMは線形回帰の最適解に収束する一方、causalLMの収束ダイナミクスはオンライン勾配降下アルゴリズムに従い、最適であるとは限らないことがわかりました。さらに、合成実験と実際のタスクにおいても、causalLMがprefixLMよりも性能が劣ることが確認されました。 Comment
参考:
CausalLMでICLをした場合は、ICL中のdemonstrationでオンライン学習することに相当し、最適解に収束しているとは限らない……?が、hillbigさんの感想に基づくと、結果的には実は最適解に収束しているのでは?という話も出ているし、よく分からない。
Graph of Thoughts: Solving Elaborate Problems with Large Language Models, Maciej Besta+, N_A, AAAI'24
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #AAAI Issue Date: 2023-08-22 GPT Summary- 私たちは、Graph of Thoughts(GoT)というフレームワークを紹介しました。これは、大規模言語モデル(LLMs)のプロンプティング能力を進化させるもので、任意のグラフとしてモデル化できることが特徴です。GoTは、思考の組み合わせやネットワーク全体の本質の抽出、思考の強化などを可能にします。さまざまなタスクで最先端の手法に比べて利点を提供し、LLMの推論を人間の思考に近づけることができます。 Comment
Chain of Thought [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
=> Self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
=> Thought Decomposition Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding, Yuxi Xie+, N/A, arXiv'23
=> Tree of Thoughts [Paper Note] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, arXiv'23, 2023.05
Tree of Thought Large Language Model Guided Tree-of-Thought, Jieyi Long, N/A, arXiv'23
=> Graph of Thought
[Paper Note] MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks, Lei Zhang+, EACL'24, 2023.04
Paper/Blog Link My Issue
#MachineLearning #NLP #AutoML #EACL Issue Date: 2023-08-10 GPT Summary- LLMを用いて新規のMLタスク解決を自動化するフレームワークを提案。これにより、人間の知識と経験を活かし、タスク理解と推論を強化。LLMは既存経験から学び、新たなタスクに対して効果的な解決策を生成し、高い競争力を持つことを示す。コードはGitHubで公開。
[Paper Note] SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models, Xiaoxuan Wang+, N_A, ICML'24
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #ICML Issue Date: 2023-07-22 GPT Summary- 本研究では、大規模言語モデル(LLMs)の進歩により、数学のベンチマークでの性能向上が示されているが、これらのベンチマークは限定的な範囲の問題に限定されていることが指摘される。そこで、複雑な科学的問題解決に必要な推論能力を検証するための包括的なベンチマークスイートSciBenchを提案する。SciBenchには、大学レベルの科学的問題を含むオープンセットと、学部レベルの試験問題を含むクローズドセットの2つのデータセットが含まれている。さらに、2つの代表的なLLMを用いた詳細なベンチマーク研究を行い、現在のLLMのパフォーマンスが不十分であることを示した。また、ユーザースタディを通じて、LLMが犯すエラーを10の問題解決能力に分類し、特定のプロンプティング戦略が他の戦略よりも優れているわけではないことを明らかにした。SciBenchは、LLMの推論能力の向上を促進し、科学研究と発見に貢献することを目指している。
[Paper Note] Teaching Arithmetic to Small Transformers, Nayoung Lee+, ICLR'24, 2023.07
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #NumericReasoning #Mathematics #KeyPoint Notes #Reading Reflections Issue Date: 2023-07-11 GPT Summary- 小型トランスフォーマーが次語予測を用いて基本的な算術演算(加算、乗算、平方根)を学習できるかを調査。従来のデータが効果的でないことを示し、形式変更で精度が向上することを確認。Chain-of-Thoughtスタイルのデータで訓練することで、事前訓練なしでも精度と収束速度を改善。算術データとテキストデータの相互作用や少数ショット promptingの影響を考察し、高品質なデータの重要性を強調。 Comment
小規模なtransformerに算術演算を学習させ、どのような学習データが効果的か調査。CoTスタイルの詳細なスクラッチパッドを学習データにすることで、plainなもの等と比較して、予測性能や収束速度などが劇的に改善した
結局next token predictionで学習させているみたいだけど、本当にそれで算術演算をモデルが理解しているのだろうか?という疑問がいつもある
↑この3年前の感想は、現在は良質なreasoning trajectioryを用いたSFTにってreasoning能力が強化できることを考えると一部解決されている。少なくとも、next token predictionによって(汎化性能は置いておいて)特定分野でのreasoning能力を身につけさせることができることは分かっているため、真に"理解"しているかはわからないが、少なくともモデル自身の能力で思考し問題を解けることは実験的に示されている。
事前学習によって知識を学習し、中間学習や事後学習で知識の使い方や特定の能力を現在では伸ばしているが、この研究だはスクラッチパッドを用いた事前学習データを使っているようなので、数学の解き方の知識と使い方を同時に学習できていると考えられる。
(3年前の感想を今見返すとおもしろいな)
openreview: https://openreview.net/forum?id=dsUB4bst9S
[Paper Note] Causal Reasoning and Large Language Models: Opening a New Frontier for Causality, Emre Kıcıman+, TMLR'24, 2023.04
Paper/Blog Link My Issue
#Analysis #NLP #Reasoning #TMLR #Generalization Issue Date: 2023-05-04 GPT Summary- 本研究では、大規模言語モデル(LLMs)の因果的議論生成能力をベンチマークし、様々なタスクで既存手法を上回る性能を示しました。特に、GPT-3.5および4は因果発見や反事実的推論タスクで高い精度を達成し、データセットの記憶だけでは説明できない能力を持つことが確認されました。しかし、LLMsには予測不可能な失敗モードがあり、改善の余地があることも指摘されています。LLMsは因果分析の労力を削減する可能性があり、今後はLLMsと既存の因果技術を組み合わせたアルゴリズムの開発が期待されます。 Comment
openreview: https://openreview.net/forum?id=mqoxLkX210
tmlr blog: https://medium.com/@TmlrOrg/announcing-the-2025-tmlr-outstanding-certification-e26d548ff011
[Paper Note] PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization, Yidong Wang+, ICLR'24, 2023.06
Paper/Blog Link My Issue
#Tools #NLP #Evaluation #SmallModel #LLM-as-a-Judge #Reproducibility #Privacy #KeyPoint Notes Issue Date: 2023-04-30 GPT Summary- 指示チューニングされたLLMの評価が難しいため、PandaLMを導入し、応答の客観的な正確性に加え、簡潔さや明瞭さなどの主観的要因にも対処。人間生成のテストデータで信頼性を確保し、PandaLM-7BがGPT-3.5の93.75%、GPT-4の88.28%に相当する評価能力を示す。PandaLMによるモデルは、従来のモデルに比べて評価を公正かつ低コストで行える。全リソースは公開中。 Comment
github:
https://github.com/WeOpenML/PandaLM
異なるLLMを再現性のある形で評価するためのpairwiseなLLM-as-a-judgeに基づくライブラリ。人間の嗜好をアノテーションしたデータを収集しLLaMAをベースにSFTすることで、PandaLMを学習。PandaLMはsubjectiveな要素も考慮して応答の良さをjudgeできる。このPandaLM-7Bをローカルで動作させる枠組みでプライバシーに配慮した上で、GPT-4級のLLM-as-a-Judgeを実施できる。
2つの異なるLLMのoutputを比較し、どちらが優れているか理由付きで説明する。人間が作成して1000サンプルの多様なアノテーションデータセットを使い評価できる。
openreview: https://openreview.net/forum?id=5Nn2BLV7SB
[Paper Note] Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, Jingfeng Yang+, TKDD'24, 2023.04
Paper/Blog Link My Issue
#Survey #NLP #One-Line Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)の実践的なガイドを提供し、自然言語処理(NLP)タスクにおけるモデルやデータの活用法を論じる。GPT系およびBERT系の紹介から始まり、事前学習や訓練データの影響を考察。さらに、さまざまなNLPタスクの使用ケースや非使用ケースを詳細に分析し、実世界でのLLMsの適用限界について触れる。偽りのバイアス、効率性、コストなどの課題に言及し、研究者と実務者に有益なベストプラクティスを提案。更新リストも提供。 Comment
LLMに関するチュートリアル
encoder-onlyとまとめられているものの中には、デコーダーがあるものがあり(autoregressive decoderではない)、
encoder-decoderは正しい意味としてはencoder with autoregressive decoderであり、
decoder-onlyは正しい意味としてはautoregressive encoder-decoder
とのこと。
[Paper Note] Active Prompting with Chain-of-Thought for Large Language Models, Shizhe Diao+, ACL'24, 2023.02
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Chain-of-Thought #ACL #KeyPoint Notes #needs-revision Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)の性能向上には、タスク特有のプロンプト設計が重要であり、特に連鎖的思考(CoT)を活用したアプローチが効果的です。この研究では、Active-Promptという新手法を提案し、タスク特有の質問に対する最適なアノテーションを選定することでLLMsを適応させます。不確実性に基づくアクティブラーニングを取り入れ、最も不確実な質問を対象にする指標を導入。実験により、提案手法が8つの複雑な推論タスクで最先端の成績を達成し、有効性が示されました。 Comment
しっかりと読めていないが、CoT-answerが存在しないtrainingデータが存在したときに、nサンプルにCoTとAnswerを与えるだけでFew-shotの予測をtestデータに対してできるようにしたい、というのがモチベーションっぽい
そのために、questionに対して、training dataに対してFew-Shot CoTで予測をさせた場合やZero-Shot CoTによって予測をさせた場合などでanswerを取得し、answerのばらつき度合いなどから不確実性を測定する。
そして、不確実性が高いCoT-Answerペアを取得し、人間が手作業でCoTと回答のペアを与え、その人間が作成したものを用いてTestデータに対してFewShotしましょう、ということだと思われる。
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head, AAAI'24
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #AAAI #One-Line Notes Issue Date: 2023-04-26 Comment
text, audio, imageといったマルチモーダルなpromptから、audioに関する様々なタスクを実現できるシステム
マルチモーダルデータをjointで学習したというわけではなく、色々なモデルの組み合わせてタスクを実現しているっぽい
[Paper Note] Scaling Instruction-Finetuned Language Models, Hyung Won Chung+, JMLR'24, 2022.10
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #OpenWeight #Selected Papers/Blogs #One-Line Notes #Scalability #JMLR Issue Date: 2023-04-26 GPT Summary- 指示に基づくファインチューニングは、言語モデルの性能と一般化を向上させる。特に、タスク数やモデルサイズのスケーリング、チェーン・オブ・思考データでの適用が効果的。Flan‑PaLM 540Bは1,800件のタスクでファインチューニングを行い、PaLM 540Bを平均+9.4%上回り、最先端の結果を出している。Flan‑T5も強力なFew-shot性能を示し、指示に基づくファインチューニングがモデルの性能向上に寄与することを確認した。 Comment
T5をinstruction tuningしたFlanT5の研究
HF: https://huggingface.co/docs/transformers/model_doc/flan-t5
先行研究:
- [Paper Note] Finetuned Language Models Are Zero-Shot Learners, Jason Wei+, ICLR'22, 2021.09
[Paper Note] LaMP: When Large Language Models Meet Personalization, Alireza Salemi+, ACL'24, 2023.04
Paper/Blog Link My Issue
#NLP #Dataset #PersonalizedGeneration #ACL #Surface-level Notes Issue Date: 2023-04-26 GPT Summary- 本論文は大規模言語モデルにおける個別化の重要性を示し、個別化出力を生成するための新しい評価フレームワーク「LaMPベンチマーク」を提案。LaMPは多様な言語タスクを網羅し、個々のユーザープロフィールに基づく複数のエントリを提供。7つの個別化タスクを含み、2つの取得補強アプローチを提案して出力のパーソナライズを図る。広範な実験により、提案手法の有効性と自然言語タスクにおける個別化の影響が確認された。 Comment
# 概要
Personalizationはユーザのニーズや嗜好に応えるために重要な技術で、IRやRecSysで盛んに研究されてきたが、NLPではあまり実施されてこなかった。しかし、最近のタスクで、text classificationやgeneration taskでPersonalizationの重要性が指摘されている。このような中で、LLMでpersonalizedなレスポンスを生成し、評価することはあまり研究されていない。そこで、LaMPベンチマークを生成し、LLMにおけるPersonalizationをするための開発と評価をするための第一歩として提案している。
# Personalizing LLM Outputs
LLMに対してPersonalizedなoutputをさせるためには、profileをpromptに埋め込むことが基本的なアプローチとなる。
## Problem Formulation
まず、user profile(ユーザに関するrecordの集合)をユーザとみなす。データサンプルは以下の3つで構成される:
- x: モデルのinputとなるinput sequence
- y: モデルが生成することを期待するtarget output
- u: user profile(ユーザの嗜好やrequirementsを捉えるための補助的な情報)
そして、p(y | x, u) を最大化する問題として定式化される。それぞれのユーザuに対して、モデルは{(x_u1, y_u1,)...(x_un, y_un)}を利用することができる。
## A Retrieval Augmentation Approach for Personaliozing LLMs
user profileは基本的にめちゃめちゃ多く、promptに入れ込むことは非現実的。そこで、reteival augmentation approachと呼ばれる手法を提案している。LLMのcontext windowは限られているので、profileのうちのsubsetを利用することが現実的なアプローチとなる。また、必ずしも全てのユーザプロファイルがあるタスクを実施するために有用とは限らない。このため、retrieval augmentation approachを提案している。
retrieval augmentation approachでは、現在のテストケースに対して、relevantな部分ユーザプロファイルを選択的に抽出するフレームワークである。
(x_i, y_i)に対してpersonalizationを実現するために、3つのコンポーネントを採用している:
1. query generation function: x_iに基づきuser profileからrelevantな情報を引っ張ってくるquery qを生成するコンポーネント
2. retrieval model R(q, P_u, k): query q, プロファイルP_u, を用いて、k個のrelevantなプロファイルを引っ張ってくるモデル
3. prompt construction function: xとreteival modelが引っ張ってきたエントリからpromptを作成するコンポーネント
1, 2, 3によって生成されたprompt x^barと、yによってモデルを訓練、あるいは評価する。
この研究では、Rとして Contriever Contrirever
, BM25, random selectionの3種類を用いている。
# LaMPベンチマーク
GLUEやSuper Glue、KILT、GENといったベンチマークは、"one-size-fits-all"なモデリングと評価を前提としており、ユーザのニーズに答えるための開発を許容していない。一方で、LaMPは、以下のようなPersonalizationが必要なさまざまなタスクを統合して作成されたデータセットである。
- Personalized Text Classification
- Personalized Citation Identification (binary classification)
- Task definition
- user u が topic xに関する論文を書いたときに、何の論文をciteすべきかを決めるタスク
- user uが書いた論文のタイトルが与えられたとき、2つのcandidate paperのうちどちらをreferenceとして利用すべきかを決定する2値分類
- Data Collection
- Citation Network Datasetを利用。最低でも50本以上論文を書いているauthorを抽出し、authorの論文のうちランダムに論文と論文の引用を抽出
- negative document selectionとして、ランダムに共著者がciteしている論文をサンプリング
- Profile Specification
- ユーザプロファイルは、ユーザが書いた全てのpaper
- titleとabstractのみをuser profileとして保持した
- Evaluation
- train/valid/testに分け、accuracyで評価する
- Personalized News Categorization (15 category分類)
- Task definition
- LLMが journalist uによって書かれたニュースを分類する能力を問うタスク
- u によって書かれたニュースxが与えられた時、uの過去の記事から得られるカテゴリの中から該当するカテゴリを予測するタスク
- Data Collection
- news categorization datasetを利用(Huff Postのニュース)
- 記事をfirst authorでグルーピング
- グルーピングした記事群をtrain/valid/testに分割
- それぞれの記事において、記事をinputとし、その記事のカテゴリをoutputとする。そして残りの記事をuser profileとする。
- Profile Specification
- ユーザによって書かれた記事の集合
- Evaluation
- accuracy, macro-averaged F1で評価
- Personalized Product Rating (5-star rating)
- Task definition
- ユーザuが記述したreviewに基づいて、LLMがユーザuの未知のアイテムに対するratingを予測する性能を問う
- Data Collection
- Amazon Reviews Datasetを利用
- reviewが100件未満、そしてほとんどのreviewが外れ値なユーザ1%を除外
- ランダムにsubsetをサンプリングし、train/valid/testに分けた
- input-output pairとしては、inputとしてランダムにユーザのreviewを選択し、その他のreviewをprofileとして利用する。そして、ユーザがinputのレビューで付与したratingがground truthとなる。
- Profile Specification
- ユーザのレビュ
- Evaluation
- ttrain/valid/testに分けてRMSE, MAEで評価する
- Personalized Text Generation
- Personalized News Headline Generation
- Task definition
- ユーザuが記述したニュースのタイトルを生成するタスク
- 特に、LLMが与えられたprofileに基づいてユーザのinterestsやwriting styleを捉え、適切にheadlinに反映させる能力を問う
- Data Collection
- News Categorization datasetを利用(Huff Post)
- データセットではauthorの情報が提供されている
- それぞれのfirst authorごとにニュースをグルーピングし、それぞれの記事をinput, headlineをoutputとした。そして残りの記事をprofileとした
- Profile Specification
- ユーザの過去のニュース記事とそのheadlineの集合をprofileとする
- Evaluation
- ROUGE-1, ROUGE-Lで評価
- Personalized Scholarly Title Generation
- Task Definition
- ユーザの過去のタイトルを考慮し、LLMがresearch paperのtitleを生成する能力を測る
- Data Collection
- Citation Network Datasetのデータを利用
- abstractをinput, titleをoutputとし、残りのpaperをprofileとした
- Profile Specification
- ユーザが書いたpaperの集合(abstractのみを利用)
- Personalized Email Subject Generation
- Task Definition
- LLMがユーザのwriting styleに合わせて、Emailのタイトルを書く能力を測る
- Data Collection
- Avocado Resaerch Email Collectionデータを利用
- 5単語未満のsubjectを持つメール、本文が30単語未満のメールを除外、
- 送信主のemail addressでメールをグルーピング
- input _outputペアは、email本文をinputとし、対応するsubjectをoutputとした。他のメールはprofile
- Profile Specification
- ユーザのemailの集合
- Evaluation
- ROUGE-1, ROUGE-Lで評価
- Personalized Tweet Paraphrasing
- Task Definition
- LLMがユーザのwriting styleを考慮し、ツイートのparaphrasingをする能力を問う
- Data Collection
- Sentiment140 datasetを利用
- 最低10単語を持つツイートのみを利用
- userIDでグルーピングし、10 tweets以下のユーザは除外
- ランダムに1つのtweetを選択し、ChatGPT(gpt-3.5-turbo)でparaphraseした
- paraphrase版のtweetをinput, 元ツイートをoutputとし、input-output pairを作った。
- User Profile Specification
- ユーザの過去のツイート
- Evaluation
- ROUGE-1, ROUGE-Lで評価
# 実験
## Experimental Setup
- FlanT5-baesをfinetuningした
- ユーザ単位でモデルが存在するのか否かが記載されておらず不明
## 結果
- Personalization入れた方が全てのタスクでよくなった
- Retrievalモデルとしては、randomの場合でも良くなったが、基本的にはContrirverを利用した場合が最も良かった
- => 適切なprofileを選択しpromptに含めることが重要であることが示された
- Rが抽出するサンプル kを増やすと、予測性能が増加する傾向もあったが、一部タスクでは性能の低下も招いた
- dev setを利用し、BM25/Contrieverのどちらを利用するか、kをいくつに設定するかをチューニングした結果、全ての結果が改善した
- FlanT5-XXLとgpt-3.5-turboを用いたZero-shotの設定でも実験。tweet paraphrasingタスクを除き、zero-shotでもuser profileをLLMで利用することでパフォーマンス改善。小さなモデルでもfinetuningすることで、zero-shotの大規模モデルにdownstreamタスクでより高い性能を獲得することを示している(ただし、めちゃめちゃ改善しているというわけでもなさそう)。


# LaMPによって可能なResearch Problem
## Prompting for Personalization
- Augmentationモデル以外のLLMへのユーザプロファイルの埋め込み方法
- hard promptingやsoft prompting [Paper Note] The Power of Scale for Parameter-Efficient Prompt Tuning, Brian Lester+, EMNLP'21, 2021.04
の活用
## Evaluation of Personalized Text Generation
- テキスト生成で利用される性能指標はユーザの情報を評価のプロセスで考慮していない
- Personalizedなテキスト生成を評価するための適切なmetricはどんなものがあるか?
## Learning to Retrieve from User Profiles
- Learning to RankをRetrieval modelに適用する方向性
LaMPの作成に利用したテンプレート一覧
実装とleaderboard
https://lamp-benchmark.github.io/leaderboard
[Paper Note] Function Vectors in Large Language Models, Eric Todd+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#Analysis #NLP #ICLR #Selected Papers/Blogs #reading #KeyPoint Notes Issue Date: 2026-06-02 GPT Summary- 自己回帰型トランスフォーマーLMsにおける入力と出力の関数を表すベクトルとしてのファンクションベクトル(FV)の存在を示す。因果媒介分析を用いて、少数のアテンションヘッドがタスクのコンパクトな表現を伝達することを確認し、FVがゼロショットや自然言語テキストのICLタスクに対しても頑健であることを明らかにした。中間層間での因果効果が強いことが判明し、FVには出力空間を符号化する情報が含まれているが、これだけではFVの再構成は不可である。さらに、FVにおける意味ベクトルの組成を調査し、足し合わせることで新たなタスクを引き起こすことができることを示した。これにより、関数抽象のコンパクトで因果的な内部表現をLLMsから抽出できることが確認された。 Comment
openreview: https://openreview.net/forum?id=AwyxtyMwaG
本研究では、In-context Learningを実施した際のLLMにおいて、あるタスクにおいて応答を生成する際に、当該タスクで必要な変換に関する情報を保持しているベクトル(Function Vectors)が、LLMの attention_ output に存在することを示唆する結果を得た。Function Vectorsは直接的にタスクを実施するわけではないが、特定の手続きを言語モデル内で遂行させるトリガーの役割を果たす。
Function Vectorを検出するために、あるタスク t において、Figure 2のようなinput-outputのペア (x_i, y_i) のみで promptingをすることでタスクを遂行させる方法を考える。また、prompt p が与えられたときに、outputをランダムな出力~y_iに変更した input-outputペア (x_i, ~y_i) prompt ~pを考える。このとき、あるタスクの遂行に強い影響を与えるLLM中のactivationを特定したい。
このために、本研究ではトークンをまたいだ情報のやりとりはattentionを介して実行されることから、分析対象をattentionに限定し、まず正常な in-context prompt p を入力した際の全てのlayer l のattention output a_lj (jはheadのindex) を計算する。続いて、ランダムな出力に置換され破損した in-context prompt ~p を入力した際に、ある layer l, head j のattentionを正常なin-context prompt p に基づいて計算されたものと置換して出力をさせ、正解 y_i を復元させる効果 Causal Indrect Effect (CIE) を 式(3)により定義する。つまり、破損したprompt ~pを利用した場合に、attentionを置換する前後によって、どれだけ正解y_iが得られる確率が大きくなったか、を測定している。
このCIEを全てのタスクに対して計算し、平均化することで、各種attention headのAverage Indirect Effectを計算する(式4)。これにより、どのattention headがタスクの遂行において強い因果的な影響力を保持するかを特定する。最終的に、AIEの値が大きなattention head集合Aを考えることができ、この少数のattention headの集合が、ICLタスクを特定し情報を伝達する役割を果たしているという仮説を立てることができる。また、Aが与えられたとき、a_ljのあるタスク t におけるactivationの平均をとることによって、1つのベクトルとして表現することができ、このベクトルのことをFunction Vector と呼ぶ(式5)。
[Paper Note] A Theory on Adam Instability in Large-Scale Machine Learning, Igor Molybog+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #MachineLearning #NLP #Optimizer #Stability Issue Date: 2026-05-27 GPT Summary- Adam最適化アルゴリズムによる発散挙動の理論を提唱。パラメータ更新ベクトルのノルムが大きく、訓練損失面の下降方向と相関しない状態が発散に寄与。特に大規模バッチサイズの深いモデル訓練で顕著であり、異なるサイズの言語モデルでの観察結果を示した。
[Paper Note] LLaMA: Open and Efficient Foundation Language Models, Hugo Touvron+, arXiv'23, 2023.02
Paper/Blog Link My Issue
#Pretraining #NLP #OpenWeight Issue Date: 2026-03-31 GPT Summary- LLaMAは、7Bから65Bパラメータまでの基盤言語モデルのコレクションを提供し、数兆のトークンを使用して訓練されました。公開可能なデータセットのみを用いて最先端モデルを実現し、特にLLaMA-13Bは多くのベンチマークでGPT-3を上回り、LLaMA-65BはChinchillaやPaLMと競争力を持つ。全てのモデルは研究コミュニティに公開されます。 Comment
初代LLaMAをメモっていなかったようなのでメモ
LLaMA series:
- [Paper Note] Llama 2: Open Foundation and Fine-Tuned Chat Models, Hugo Touvron+, arXiv'23, 2023.07
- LLaMA3, Meta, 2024.04
- Llama 3.1, 2024.07
- Llama 3.2: Revolutionizing edge AI and vision with open, customizable models, Meta, 2024.09
- Llama 4 Series, Meta, 2025.04
Llama 3.3もメモっていないようだ
[Paper Note] Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling, Stella Biderman+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#Pretraining #NLP #OpenWeight #OpenSource #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-03-29 GPT Summary- Pythiaは、異なるスケールの16のLLMを対象にしたモデルセットで、トレーニングの進化や発展を探求する。154のチェックポイントを公開し、訓練データローダーの再構築ツールも提供する。記憶化、新規結果、few-shot性能への語頻度の影響、ジェンダーバイアスの低減を含むケーススタディを通じて、LLMsの訓練ダイナミクスに関する新たな洞察を提示する。モデルや分析コードは公開されている。 Comment
github: https://github.com/EleutherAI/pythia
pythiaもメモっていなかった。70M--12Bモデルまでの16個のLLM群で、全てのモデルが同じ順序で学習され、かつ中間チェックポイントも公開。
[Paper Note] Retentive Network: A Successor to Transformer for Large Language Models, Yutao Sun+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LinearAttention Issue Date: 2026-02-04 GPT Summary- RetNetを提案し、トレーニングの並列化と低コストの推論を実現。再帰と注目の関係を導出し、シーケンスモデリング用の保持メカニズムを提供。並列処理と再帰を組み合わせることで、高効率な長シーケンスモデリングを実現し、性能を維持したままデコーディングの効率を向上。実験によりRetNetの優れたスケーリングと効率的推論を確認。Transformerの強力な後継として位置付け。 Comment
日本語解説: https://zenn.dev/spiralai/articles/a41a934599c7ec
openreview: https://openreview.net/forum?id=UU9Icwbhin
[Paper Note] Learning to Compress Prompts with Gist Tokens, Jesse Mu+, NeurIPS'23, 2023.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Prompting #NeurIPS #Compression Issue Date: 2026-02-02 GPT Summary- プロンプトはLMのマルチタスク機能における効率性に課題をもたらすため、私たちは「ギスティング」を提案。これはプロンプトを小さなトークンセットに圧縮し、再利用することで計算効率を向上させる方法で、トレーニングコストは標準的な指示ファインチューニングと同等。実験により、最大26倍のプロンプト圧縮と最大40%のFLOPs削減を達成し、出力品質を保持しつつ効率化を実現。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=2DtxPCL3T5
[Paper Note] Self-Refine: Iterative Refinement with Self-Feedback, Aman Madaan+, NeurIPS'23, 2023.03
Paper/Blog Link My Issue
#NLP #SelfCorrection #NeurIPS #Test-Time Scaling Issue Date: 2026-01-26 GPT Summary- 自己洗練(Self-Refine)アプローチを提案し、LLMの初期出力を反復的なフィードバックを通じて改善。単一のLLMを用いて生成、洗練、フィードバックを行う。7つの多様なタスクで評価した結果、自己洗練による出力は従来の方法よりも好まれ、平均20%の性能向上を示した。最先端のLLMでもさらなる改善可能性を確認。 Comment
openreview: https://openreview.net/forum?id=S37hOerQLB
[Paper Note] TinyStories: How Small Can Language Models Be and Still Speak Coherent English?, Ronen Eldan+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NaturalLanguageGeneration #NLP #Dataset #SyntheticData #SmallModel Issue Date: 2026-01-19 GPT Summary- LMは小規模モデルでは一貫性のあるテキスト生成が難しい。本研究では、3~4歳児が理解できる単語のみを含む短編小説データセット「TinyStories」を紹介。これはGPT-3.5とGPT-4で生成され、1000万パラメータ未満のモデルでも流暢な物語が生成可能であることを示す。さらに、出力評価の新たなパラダイムを提案し、学生の作品との比較を通じてさまざまな能力に対するスコアを提供。TinyStoriesはLMの研究を促進し、限られたリソースや特殊ドメインにおける言語能力の発展に寄与することが期待される。 Comment
dataset: https://huggingface.co/datasets/roneneldan/TinyStories
[Paper Note] Generating Summaries with Controllable Readability Levels, Leonardo F. R. Ribeiro+, EMNLP'23, 2023.10
Paper/Blog Link My Issue
#DocumentSummarization #Controllable #NLP #ReinforcementLearning #EMNLP #PostTraining #Readability Issue Date: 2026-01-19 GPT Summary- 可読性とは、読者がテキストを理解する容易さを指し、複雑さや主題、読者の背景知識が影響を与える。可読性レベルに基づく要約生成は、様々なオーディエンスに知識を提供するために重要だが、現行の生成アプローチは制御に欠け、特化したテキストが作成されていない。本研究では、特定の可読性レベルで要約を生成する技術を提案し、三つのアプローチを開発した:(1) 指示ベースの可読性制御、(2) 強化学習による可読性ギャップの最小化、(3) 先読み方式による次ステップの可読性予測。これにより、ニュース要約における可読性制御が大幅に向上し、人間の評価によっても強固な基準が確立された。 Comment
openreview: https://openreview.net/forum?id=IFNbElsnCi
[Paper Note] DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature, Eric Mitchell+, ICML'23, 2023.01
Paper/Blog Link My Issue
#MachineLearning #NLP #ICML #Selected Papers/Blogs #text #AI Detector Issue Date: 2025-11-17 GPT Summary- LLM生成テキストの検出の必要性を背景に、対数確率関数の負の曲率を利用した新しい検出手法「DetectGPT」を提案。これにより、別の分類器やデータセットを必要とせず、特定のLLMから生成されたテキストを高精度で識別可能。特に、GPT-NeoXによるフェイクニュース記事の検出で、従来の手法を大幅に上回る性能を示した。
[Paper Note] Language Modelling with Pixels, Phillip Rust+, ICLR'23, 2022.07
Paper/Blog Link My Issue
#NLP #Transformer #ICLR #Encoder #Pixel-based #Compression Issue Date: 2025-10-22 GPT Summary- PIXELは、テキストを画像として表現する新しい言語モデルで、語彙のボトルネックを回避し、言語間での表現転送を可能にする。86MパラメータのPIXELは、BERTと同じデータで事前学習され、非ラテン文字を含む多様な言語での構文的および意味的タスクでBERTを大幅に上回る性能を示したが、ラテン文字ではやや劣る結果となった。また、PIXELは正字法的攻撃や言語コードスイッチングに対してBERTよりも堅牢であることが確認された。 Comment
元ポスト:
[Paper Note] Self-Evaluation Guided Beam Search for Reasoning, Yuxi Xie+, NeurIPS'23, 2023.05
Paper/Blog Link My Issue
#BeamSearch #NLP #Reasoning #SelfCorrection #NeurIPS #Decoding #KeyPoint Notes Issue Date: 2025-10-01 GPT Summary- LLMの推論プロセスを改善するために、段階的自己評価メカニズムを導入し、確率的ビームサーチを用いたデコーディングアルゴリズムを提案。これにより、推論の不確実性を軽減し、GSM8K、AQuA、StrategyQAでの精度を向上。Llama-2を用いた実験でも効率性が示され、自己評価ガイダンスが論理的な失敗を特定し、一貫性を高めることが確認された。 Comment
pj page: https://guideddecoding.github.io
openreview: https://openreview.net/forum?id=Bw82hwg5Q3
非常にざっくり言うと、reasoning chain(=複数トークンのsequence)をトークンとみなした場合の(確率的)beam searchを提案している。多様なreasoning chainをサンプリングし、その中から良いものをビーム幅kで保持し生成することで、最終的に良いデコーディング結果を得る。reasoning chainのランダム性を高めるためにtemperatureを設定するが、アニーリングをすることでchainにおけるエラーが蓄積することを防ぐ。これにより、最初は多様性を重視した生成がされるが、エラーが蓄積され発散することを防ぐ。
reasoning chainの良さを判断するために、chainの尤度だけでなく、self-evaluationによるreasoning chainの正しさに関するconfidenceスコアも導入する(reasoning chainのconfidenceスコアによって重みづけられたchainの尤度を最大化するような定式化になる(式3))。
self-evaluationと生成はともに同じLLMによって実現されるが、self-evaluationについては評価用のfew-shot promptingを実施する。promptingでは、これまでのreasoning chainと、新たなreasoning chainがgivenなときに、それが(A)correct/(B)incorrectなのかをmultiple choice questionで判定し、選択肢Aが生成される確率をスコアとする。
[Paper Note] Large Language Models are Better Reasoners with Self-Verification, Yixuan Weng+, EMNLP'23 Findings, 2022.12
Paper/Blog Link My Issue
#NLP #SelfVerification Issue Date: 2025-09-25 GPT Summary- LLMsはCoTプロンプティングにより強力な推論能力を示すが、エラーの蓄積に脆弱である。本研究では、LLMsが自己検証能力を持つことを提案し、推論した回答を逆検証することで解釈可能な検証スコアを得る手法を示す。実験により、提案手法が算数、常識、論理推論タスクでの性能を向上させることが確認された。 Comment
openreview: https://openreview.net/forum?id=s4xIeYimGQ
[Paper Note] SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models, Potsawee Manakul+, EMNLP'23, 2023.03
Paper/Blog Link My Issue
#NLP #Hallucination #EMNLP #Selected Papers/Blogs Issue Date: 2025-09-24 GPT Summary- SelfCheckGPTは、外部データベースなしでLLMの応答をファクトチェックするためのサンプリングベースのアプローチを提案。サンプリングされた応答が一貫した事実を含む場合、知識があると判断し、幻覚された事実では矛盾が生じる可能性が高い。実験により、非事実的および事実的な文の検出、文章のランク付けが可能であることを示し、高いAUC-PRスコアと相関スコアを達成。 Comment
openreview: https://openreview.net/forum?id=RwzFNbJ3Ez
[Paper Note] FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation, Tu Vu+, ACL'23 Findings, 2023.10
Paper/Blog Link My Issue
#NLP #Dataset #Zero/Few/ManyShotPrompting #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #ACL #Findings Issue Date: 2025-09-24 GPT Summary- 大規模言語モデル(LLMs)は変化する世界に適応できず、事実性に課題がある。本研究では、動的QAベンチマーク「FreshQA」を導入し、迅速に変化する知識や誤った前提を含む質問に対するLLMの性能を評価。評価の結果、全モデルがこれらの質問に苦労していることが明らかに。これを受けて、検索エンジンからの最新情報を組み込む「FreshPrompt」を提案し、LLMのパフォーマンスを向上させることに成功。FreshPromptは、証拠の数と順序が正確性に影響を与えることを示し、簡潔な回答を促すことで幻覚を減少させる効果も確認。FreshQAは公開され、今後も更新される予定。
[Paper Note] Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback, Baolin Peng+, arXiv'23, 2023.02
Paper/Blog Link My Issue
#NLP #AIAgents #Factuality #RAG(RetrievalAugmentedGeneration) #AutomaticPromptEngineering Issue Date: 2025-09-24 GPT Summary- LLM-Augmenterシステムを提案し、LLMが外部知識に基づいた応答を生成できるように拡張。フィードバックを用いてプロンプトを改善し、タスク指向の対話と質問応答での有効性を実証。ChatGPTの幻覚を減少させつつ、流暢さや情報量を維持。ソースコードとモデルを公開。
[Paper Note] Efficient Memory Management for Large Language Model Serving with PagedAttention, Woosuk Kwon+, SOSP'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #python #LLMServing #Selected Papers/Blogs Issue Date: 2025-08-19 GPT Summary- PagedAttentionを用いたvLLMシステムを提案し、KVキャッシュメモリの無駄を削減し、リクエスト間での柔軟な共有を実現。これにより、同レベルのレイテンシでLLMのスループットを2-4倍向上。特に長いシーケンスや大規模モデルで効果が顕著。ソースコードは公開中。 Comment
(今更ながら)vLLMはこちら:
https://github.com/vllm-project/vllm
現在の主要なLLM Inference/Serving Engineのひとつ。
[Paper Note] Physics of Language Models: Part 1, Learning Hierarchical Language Structures, Zeyuan Allen-Zhu+, arXiv'23
Paper/Blog Link My Issue
#Analysis #NLP Issue Date: 2025-08-11 GPT Summary- 本研究では、Transformerベースの言語モデルが文脈自由文法(CFG)による再帰的な言語構造推論をどのように行うかを調査。合成CFGを用いて長文を生成し、GPTのようなモデルがCFGの階層を正確に学習・推論できることを示す。モデルの隠れ状態がCFGの構造を捉え、注意パターンが動的プログラミングに類似していることが明らかに。また、絶対位置埋め込みの劣位や均一な注意の効果、エンコーダ専用モデルの限界、構造的ノイズによる堅牢性向上についても考察。 Comment
[Paper Note] Large Language Models Can Self-Improve, Jiaxin Huang+, EMNLP'23
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #SelfImprovement #EMNLP Issue Date: 2025-07-22 GPT Summary- LLMはラベルのないデータセットで自己改善可能であることを示し、Chain-of-Thoughtプロンプティングと自己一貫性を利用して高信頼度の回答を生成。これにより、540BパラメータのLLMの推論能力を向上させ、最先端のパフォーマンスを達成。ファインチューニングが自己改善に重要であることも確認。 Comment
openreview: https://openreview.net/forum?id=uuUQraD4XX¬eId=PWDEpZtn6P
[Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23
Paper/Blog Link My Issue
#ComputerVision #Pretraining #MultiModal #ContrastiveLearning #Selected Papers/Blogs #ICCV #Scalability #needs-revision Issue Date: 2025-06-29 GPT Summary- シンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。 Comment
SigLIP論文
[Paper Note] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, Amey Agrawal+, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #python #LLMServing #SoftwareEngineering #read-later #Selected Papers/Blogs #Inference #One-Line Notes Issue Date: 2025-06-12 GPT Summary- SARATHIは、LLMの推論効率を向上させる手法で、プレフィルリクエストをチャンクに分割し、デコードマキシマルバッチを構築することで計算利用率を最大化します。これにより、デコードスループットを最大10倍向上させ、エンドツーエンドスループットも改善。特に、A6000 GPU上のLLaMA-13Bモデルで顕著な性能向上を示し、パイプラインバブルを大幅に削減しました。 Comment
vLLMでも採用されている `Chunked Prefills` と `Decode-Maximal Batching` を提案している。

[Paper Note] Sequence Parallelism: Long Sequence Training from System Perspective, Shenggui Li+, ACL'23, 2021.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LongSequence #ACL #Selected Papers/Blogs #Parallelism #One-Line Notes Issue Date: 2025-05-16 GPT Summary- 本研究では、トランスフォーマーの長い入力シーケンスを効率的に学習するための新しいメモリ効率の良い「シーケンス並列性」手法を提案。これは、既存の並列化手法との互換性を持ち、長大なシーケンスを複数のGPUに分散して処理することを可能にする。リング型通信を用いた自己注意計算(Ring Self-Attention)を導入し、実験によりバッチサイズとシーケンス長のスケーリング効果を示した。最大バッチサイズは13.7倍、シーケンス長は114,000トークンを超える性能を達成。 Comment
入力系列をチャンクに分割して、デバイスごとに担当するチャンクを決めることで原理上無限の長さの系列を扱えるようにした並列化手法。系列をデバイス間で横断する場合attention scoreをどのように計算するかが課題になるが、そのためにRing Self attentionと呼ばれるアルゴリズムを提案している模様。また、MLPブロックとMulti Head Attentonブロックの計算も、BatchSize * Sequence Lengthの大きさが、それぞれ32*Hidden Size, 16*Attention Head size *
# of Attention Headよりも大きくなった場合に、Tensor Parallelismよりもメモリ効率が良くなるらしい。
Data Parallel, Pipeline Parallel, Tensor Parallel、全てに互換性があるとのこと(併用可能)
そのほかの並列化の解説については
- 大規模モデルを支える分散並列学習のしくみ Part1, Kazuki Fujii, 2023.06
を参照のこと。
[Paper Note] Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23
Paper/Blog Link My Issue
#MachineLearning #NLP #Hallucination #NeurIPS #read-later #ActivationSteering/ITI #Probing #Trustfulness #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-05-09 GPT Summary- Inference-Time Intervention (ITI)を提案し、LLMsの真実性を向上させる技術を紹介。ITIは推論中にモデルの活性化を調整し、LLaMAモデルの性能をTruthfulQAベンチマークで大幅に改善。Alpacaモデルでは真実性が32.5%から65.1%に向上。真実性と有用性のトレードオフを特定し、介入の強度を調整する方法を示す。ITIは低コストでデータ効率が高く、数百の例で真実の方向性を特定可能。LLMsが虚偽を生成しつつも真実の内部表現を持つ可能性を示唆。 Comment
Inference Time Interventionを提案した研究。Attention Headに対して線形プロービング[^1]を実施し、真実性に関連するであろうHeadをtopKで特定できるようにし、headの出力に対し真実性を高める方向性のベクトルvを推論時に加算することで(=intervention)、モデルの真実性を高める。vは線形プロービングによって学習された重みを使う手法と、正答と誤答の活性化の平均ベクトルを計算しその差分をvとする方法の二種類がある。後者の方が性能が良い。topKを求める際には、線形プロービングをしたモデルのvalidation setでの性能から決める。Kとαはハイパーパラメータである。
[^1]: headのrepresentationを入力として受け取り、線形モデルを学習し、線形モデルの2値分類性能を見ることでheadがどの程度、プロービングの学習に使ったデータに関する情報を保持しているかを測定する手法
日本語解説スライド:
https://www.docswell.com/s/DeepLearning2023/Z38P8D-2024-06-20-131813#p1
これは相当汎用的に使えそうな話だから役に立ちそう
[Paper Note] The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad+, NeurIPS'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #LongSequence #PositionalEncoding #NeurIPS #Selected Papers/Blogs #KeyPoint Notes #Surface-level Notes Issue Date: 2025-04-06 GPT Summary- 長さ一般化はTransformerベースの言語モデルにおける重要な課題であり、位置エンコーディング(PE)がその性能に影響を与える。5つの異なるPE手法(APE、T5の相対PE、ALiBi、Rotary、NoPE)を比較した結果、ALiBiやRotaryなどの一般的な手法は長さ一般化に適しておらず、NoPEが他の手法を上回ることが明らかになった。NoPEは追加の計算を必要とせず、絶対PEと相対PEの両方を表現可能である。さらに、スクラッチパッドの形式がモデルの性能に影響を与えることも示された。この研究は、明示的な位置埋め込みが長いシーケンスへの一般化に必須でないことを示唆している。 Comment
- Llama 4 Series, Meta, 2025.04
において、Llama4 Scoutが10Mコンテキストウィンドウを実現できる理由の一つとのこと。
元ポスト:
Llama4のブログポストにもその旨記述されている:
>A key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings. Additionally, we employ inference time temperature scaling of attention to enhance length generalization.
[The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation]( https://ai.meta.com/blog/llama-4-multimodal-intelligence/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4)
斜め読みだが、length generalizationを評価する上でdownstream taskに焦点を当て、3つの代表的なカテゴリに相当するタスクで評価したところ、この観点においてはT5のrelative positinal encodingとNoPE(位置エンコードディング無し)のパフォーマンスが良く、
NoPEは絶対位置エンコーディングと相対位置エンコーディングを理論上実現可能であり[^1]
実際に学習された異なる2つのモデルに対して同じトークンをそれぞれinputし、同じ深さのLayerの全てのattention distributionの組み合わせからJensen Shannon Divergenceで距離を算出し、最も小さいものを2モデル間の当該layerの距離として可視化すると下記のようになり、NoPEとT5のrelative positional encodingが最も類似していることから、NoPEが学習を通じて(実用上は)相対位置エンコーディングのようなものを学習することが分かった。
[^1]:深さ1のLayerのHidden State H^1から絶対位置の復元が可能であり(つまり、当該レイヤーのHが絶対位置に関する情報を保持している)、この前提のもと、後続のLayerがこの情報を上書きしないと仮定した場合に、相対位置エンコーディングを実現できる。
また、CoT/Scratchpadはlong sequenceに対する汎化性能を向上させることがsmall scaleではあるが先行研究で示されており、Positional Encodingを変化させた時にCoT/Scratchpadの性能にどのような影響を与えるかを調査。
具体的には、CoT/Scratchpadのフォーマットがどのようなものが有効かも明らかではないので、5種類のコンポーネントの組み合わせでフォーマットを構成し、mathematical reasoningタスクで以下のような設定で訓練し
- さまざまなコンポーネントの組み合わせで異なるフォーマットを作成し、
- 全ての位置エンコーディングあり/なしモデルを訓練
これらを比較した。この結果、CoT/Scratchpadはフォーマットに関係なく、特定のタスクでのみ有効(有効かどうかはタスク依存)であることが分かった。このことから、CoT/Scratcpad(つまり、モデルのinputとoutputの仕方)単体で、long contextに対する汎化性能を向上させることができないので、Positional Encoding(≒モデルのアーキテクチャ)によるlong contextに対する汎化性能の向上が非常に重要であることが浮き彫りになった。
また、CoT/Scratchpadが有効だったAdditionに対して各Positional Embeddingモデルを学習し、生成されたトークンのattentionがどの位置のトークンを指しているかを相対距離で可視化したところ(0が当該トークン、つまり現在のScratchpadに着目しており、1が遠いトークン、つまりinputに着目していることを表すように正規化)、NoPEとRelative Positional Encodingがshort/long rangeにそれぞれフォーカスするようなbinomialな分布なのに対し、他のPositional Encodingではよりuniformな分布であることが分かった。このタスクにおいてはNoPEとRelative POの性能が高かったため、binomialな分布の方がより最適であろうことが示唆された。
[Paper Note] TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys'23
Paper/Blog Link My Issue
#RecommenderSystems #Contents-based #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #Zero/FewShotLearning #RecSys #KeyPoint Notes Issue Date: 2025-03-30 GPT Summary- 大規模言語モデル(LLMs)を推薦システムに活用するため、推薦データで調整するフレームワークTALLRecを提案。限られたデータセットでもLLMsの推薦能力を向上させ、効率的に実行可能。ファインチューニングされたLLMはクロスドメイン一般化を示す。 Comment
下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初めての研究だと思われる。
既存ベースラインと比較して大幅にAUCが向上
[Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
Paper/Blog Link My Issue
#MachineLearning #NLP #NeurIPS #Scaling Laws #read-later #Selected Papers/Blogs #KeyPoint Notes #DataRepetition Issue Date: 2025-03-23 GPT Summary- 言語モデルのスケーリングにおいて、データ制約下でのトレーニングを調査。9000億トークンと90億パラメータのモデルを用いた実験で、繰り返しデータを使用しても損失に大きな変化は見られず、繰り返しの価値が減少することを確認。計算最適性のスケーリング法則を提案し、データ不足を軽減するアプローチも実験。得られたモデルとデータセットは公開。 Comment
OpenReview: https://openreview.net/forum?id=j5BuTrEj35
チンチラ則のようなScaling Lawsはパラメータとデータ量の両方をスケールさせた場合の前提に立っており、かつデータは全てuniqueである前提だったが、データの枯渇が懸念される昨今の状況に合わせて、データ量が制限された状況で、同じデータを繰り返し利用する(=複数エポック学習する)ことが一般的になってきた。このため、データのrepetitionに関して性能を事前学習による性能の違いを調査して、repetitionとパラメータ数に関するスケーリング則を提案($3.1)しているようである。
Takeawayとしては、データが制限された環境下では、repetitionは上限4回までが効果的(コスパが良い)であり(左図)、小さいモデルを複数エポック訓練する方が固定されたBudgetの中で低いlossを達成できる右図)。
学習データの半分をコードにしても性能の劣化はなく、様々なタスクの性能が向上しパフォーマンスの分散も小さくなる、といったことが挙げられるようだ。
Navigate through Enigmatic Labyrinth A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future, Zheng Chu+, arXiv'23
Paper/Blog Link My Issue
#Survey #NLP #Chain-of-Thought #ACL Issue Date: 2025-01-06 GPT Summary- 推論はAIにおいて重要な認知プロセスであり、チェーン・オブ・ソートがLLMの推論能力を向上させることが注目されている。本論文では関連研究を体系的に調査し、手法を分類して新たな視点を提供。課題や今後の方向性についても議論し、初心者向けの導入を目指す。リソースは公開されている。
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks, Wenhu Chen+, TMLR'23
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #TMLR #KeyPoint Notes Issue Date: 2025-01-05 GPT Summary- 段階的な推論を用いた数値推論タスクにおいて、Chain-of-thoughts prompting(CoT)の進展があり、推論をプログラムとして表現する「Program of Thoughts」(PoT)を提案。PoTは外部コンピュータで計算を行い、5つの数学問題データセットと3つの金融QAデータセットで評価した結果、少数ショットおよびゼロショット設定でCoTに対して約12%の性能向上を示した。自己一貫性デコーディングとの組み合わせにより、数学問題データセットで最先端の性能を達成。データとコードはGitHubで公開。 Comment
1. LLMsは算術演算を実施する際にエラーを起こしやすく、特に大きな数に対する演算を実施する際に顕著
2. LLMsは複雑な数式(e.g. 多項式, 微分方程式)を解くことができない
3. LLMsはiterationを表現するのが非常に非効率
の3点を解決するために、外部のインタプリタに演算処理を委譲するPoTを提案。PoTでは、言語モデルにreasoning stepsをpython programで出力させ、演算部分をPython Interpreterに実施させる。
テキスト、テーブル、対話などの多様なinputをサポートする5つのMath Word Problem (MWP), 3つのFinancial Datasetで評価した結果、zero-shot, few-shotの両方の設定において、PoTはCoTをoutpeformし、また、Self-Consistencyと組み合わせた場合も、PoTはCoTをoutperformした。
Recursion of Thought: A Divide-and-Conquer Approach to Multi-Context Reasoning with Language Models, Soochan Lee+, arXiv'23
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Reasoning #KeyPoint Notes Issue Date: 2025-01-05 GPT Summary- Recursion of Thought(RoT)という新しい推論フレームワークを提案し、言語モデル(LM)が問題を複数のコンテキストに分割することで推論能力を向上させる。RoTは特別なトークンを導入し、コンテキスト関連の操作をトリガーする。実験により、RoTがLMの推論能力を劇的に向上させ、数十万トークンの問題を解決できることが示された。 Comment
divide-and-conquerで複雑な問題に回答するCoT手法。生成過程でsubquestionが生じた際にモデルに特殊トークン(GO)を出力させ、subquestionの回答部分に特殊トークン(THINK)を出力させるようにSupervisedに学習させる。最終的にTHINKトークン部分は、subquestionを別途モデルによって解いた回答でreplaceして、最終的な回答を得る。
subquestionの中でさらにsubquestionが生じることもあるため、再帰的に処理される。
四則演算と4種類のアルゴリズムに基づくタスクで評価。アルゴリズムに基づくタスクは、2つの数のlongest common subsequenceを見つけて、そのsubsequenceとlengthを出力するタスク(LCS)、0-1 knapsack問題、行列の乗算、数値のソートを利用。x軸が各タスクの問題ごとの問題の難易度を表しており、難易度が上がるほど提案手法によるgainが大きくなっているように見える。
Without Thoughtでは直接回答を出力させ、CoTではground truthとなるrationaleを1つのcontextに与えて回答を生成している。RoTではsubquestionごとに回答を別途得るため、より長いcontextを活用して最終的な回答を得る点が異なると主張している。
感想としては、詳細が書かれていないが、おそらくRoTはSFTによって各タスクに特化した学習をしていると考えられる(タスクごとの特殊トークンが存在するため)。ベースラインとしてRoT無しでSFTしたモデルあった方が良いのではないか?と感じる。
また、学習データにおけるsubquestionとsubquestionに対するground truthのデータ作成方法は書かれているが、そもそも元データとして何を利用したかや、その統計量も書かれていないように見える。あと、そもそも機械的に学習データを作成できない場合どうすれば良いのか?という疑問は残る。
読んでいた時にAuto-CoTとの違いがよくわからなかったが、Related Workの部分にはAuto-CoTは動的、かつ多様なデモンストレーションの生成にフォーカスしているが、AutoReasonはquestionを分解し、few-shotの promptingでより詳細なrationaleを生成することにフォーカスしている点が異なるという主張のようである。
- [Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
Auto-CoTとの差別化は上記で理解できるが、G-Evalが実施しているAuto-CoTとの差別化はどうするのか?という風にふと思った。論文中でもG-Evalは引用されていない。
素朴にはAutoReasonはSFTをして学習をしています、さらにRecursiveにquestionをsubquestionを分解し、分解したsubquestionごとに回答を得て、subquestionの回答結果を活用して最終的に複雑なタスクの回答を出力する手法なので、G-Evalが実施している同一context内でrationaleをzeroshotで生成する手法よりも、より複雑な問題に回答できる可能性が高いです、という主張にはなりそうではある。
- [Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
ICLR 2023 OpenReview:
https://openreview.net/forum?id=PTUcygUoxuc
- 提案手法は一般的に利用可能と主張しているが、一般的に利用するためには人手でsubquestionの学習データを作成する必要があるため十分に一般的ではない
- 限られたcontext長に対処するために再帰を利用するというアイデアは新しいものではなく、数学の定理の証明など他の設定で利用されている
という理由でrejectされている。
Recommender Systems with Generative Retrieval, Shashank Rajput+, arXiv'23
Paper/Blog Link My Issue
#RecommenderSystems #Survey #InformationRetrieval #SequentialRecommendation Issue Date: 2024-12-30 GPT Summary- 新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを自己回帰的にデコード。Transformerベースのモデルが次のアイテムのセマンティックIDを予測し、レコメンデーションタスクにおいて初のセマンティックIDベースの生成モデルとなる。提案手法は最先端モデルを大幅に上回り、過去の対話履歴がないアイテムに対する検索性能も向上。
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models, Guangxuan Xiao+, ICML'23
Paper/Blog Link My Issue
#NLP #Quantization #ICML Issue Date: 2024-12-03 GPT Summary- SmoothQuantは、トレーニング不要で8ビットの重みと活性化の量子化を実現するポストトレーニング量子化ソリューションです。活性化の外れ値を滑らかにすることで、量子化の難易度を軽減し、精度を保持しつつ最大1.56倍の速度向上と2倍のメモリ削減を達成しました。これにより、530BのLLMを単一ノードで運用可能にし、LLMsの民主化を促進します。コードは公開されています。 Comment
おそらく量子化手法の現時点のSoTA
[Paper Note] Recommender Systems in the Era of Large Language Models (LLMs), Zihuai Zhao+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#RecommenderSystems #read-later #Selected Papers/Blogs #Surface-level Notes Issue Date: 2024-12-03 GPT Summary- LLMsの出現により、レコメンダーシステムが進化し、ユーザーの嗜好に基づくパーソナライズが可能に。従来のDNN法の限界を克服するため、LLMsを活用したレコメンドシステムの概要を提供。具体的には、事前学習、ファインチューニング、プロンプティングの観点から最近の手法をレビューし、この分野の今後の発展方向を論じる。 Comment
中身を全然読んでいる時間はないので、図には重要な情報が詰まっていると信じ、図を読み解いていく。時間がある時に中身も読みたい。。。
LLM-basedなRecSysでは、NLPにおけるLLMの使い方(元々はT5で提案)と同様に、様々なレコメンド関係タスクを、テキスト生成タスクに落とし込み学習することができる。
RecSysのLiteratureとしては、最初はコンテンツベースと協調フィルタリングから始まり、(グラフベースドな推薦, Matrix Factorization, Factorization Machinesなどが間にあって)、その後MLP, RNN, CNN, AutoEncoderなどの様々なDeep Neural Network(DNN)を活用した手法や、BERT4RecなどのProbabilistic Language Models(PLM)を用いた手法にシフトしていき、現在LLM-basedなRecSysの時代に到達した、との流れである。
LLM-basedな手法では、pretrainingの段階からEncoder-basedなモデルの場合はMLM、Decoder-basedな手法ではNext Token Predictionによってデータセットで事前学習する方法もあれば、フルパラメータチューニングやPEFT(LoRAなど)によるSFTによるアプローチもあるようである。
推薦タスクは、推薦するアイテムIDを生成するようなタスクの場合は、異なるアイテムID空間に基づくデータセットの間では転移ができないので、SFTをしないとなかなかうまくいかないと気がしている。また、その場合はアイテムIDの推薦以外のタスクも同時に実施したい場合は、事前学習済みのパラメータが固定されるPEFT手法の方が安全策になるかなぁ、という気がしている(破壊的忘却が怖いので)。特はたとえば、アイテムIDを生成するだけでなく、その推薦理由を生成できるのはとても良いことだなあと感じる(良い時代、感)。
また、PromptingによるRecSysの流れも図解されているが、In-Context Learningのほかに、Prompt Tuning(softとhardの両方)、Instruction Tuningも同じ図に含まれている。個人的にはPrompt TuningはPEFTの一種であり、Instruction TuningはSFTの一種なので、一つ上の図に含意される話なのでは?という気がするが、論文中ではどのような立て付けで記述されているのだろうか。
どちらかというと、Promptingの話であれば、zero-few-many shotや、各種CoTの話を含めるのが自然な気がするのだが。
下図はPromptingによる手法を表にまとめたもの。Finetuningベースの手法が別表にまとめられていたが、研究の数としてはこちらの方が多そうに見える。が、性能的にはどの程度が達成されるのだろうか。直感的には、アイテムを推薦するようなタスクでは、Promptingでは性能が出にくいような印象がある。なぜなら、事前学習済みのLLMはアイテムIDのトークン列とアイテムの特徴に関する知識がないので。これをFinetuningしないのであればICLで賄うことになると思うのだが、果たしてどこまでできるだろうか…。興味がある。
(図は論文より引用)
[Paper Note] Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions, John Chung+, ACL'23, 2023.07
Paper/Blog Link My Issue
#NLP #ACL #Diversity #One-Line Notes Issue Date: 2024-12-03 GPT Summary- 本研究では、LLMを用いたテキストデータ生成における多様性と精度を向上させるための人間とAIのパートナーシップを探求。ロジット抑制と温度サンプリングの2つのアプローチで多様性を高める一方、ラベル置換(LR)と範囲外フィルタリング(OOSF)による人間の介入を検討。LRはモデルの精度を14.4%向上させ、一部のモデルは少数ショット分類を上回る性能を示したが、OOSFは効果がなかった。今後の研究の必要性が示唆される。 Comment
生成テキストの質を維持しつつ、多様性を高める取り組み。多様性を高める取り組みとしては3種類の方法が試されており、
- Logit Suppression: 生成されたテキストの単語生成頻度をロギングし、頻出する単語にpenaltyをかける方法
- High Temperature: temperatureを[0.3, 0.7, 0.9, 1.3]にそれぞれ設定して単語をサンプリングする方法
- Seeding Example: 生成されたテキストを、seedとしてpromptに埋め込んで生成させる方法
で実験されている。
Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering, Siriwardhana+, TACL'23, 2023.01
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #TACL Issue Date: 2024-12-01 GPT Summary- RAG-end2endは、ODQAにおけるドメイン適応のためにRAGのリトリーバーとジェネレーターを共同訓練する新しいアプローチを提案。外部知識ベースを更新し、補助的な訓練信号を導入することで、ドメイン特化型知識を強化。COVID-19、ニュース、会話のデータセットで評価し、元のRAGモデルよりも性能が向上。研究はオープンソースとして公開。
[Paper Note] Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR'23
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #Supervised-FineTuning (SFT) #MoE(Mixture-of-Experts) #PostTraining #KeyPoint Notes Issue Date: 2024-11-25 GPT Summary- スパース活性化モデルは、計算コストを抑えつつ密なモデルの代替として注目されているが、依然として多くのデータを必要とし、ゼロからのトレーニングは高コストである。本研究では、密なチェックポイントからスパース活性化Mixture-of-Expertsモデルを初期化する「スパースアップサイクリング」を提案。これにより、初期の密な事前トレーニングのコストを約50%再利用し、SuperGLUEやImageNetで密なモデルを大幅に上回る性能を示した。また、アップサイクリングされたモデルは、ゼロからトレーニングされたスパースモデルよりも優れた結果を得た。 Comment
斜め読みしかできていないが、Mixture-of-Expertsを用いたモデルをSFT/Pretrainingする際に、既存のcheckpointの重みを活用することでより効率的かつ性能向上する方法を提案。MoE LayerのMLPを全て既存のcheckpointにおけるMLPの重みをコピーして初期化する。Routerはスクラッチから学習する。
継続事前学習においては、同じ学習時間の中でDense Layerを用いるベースラインと比較してでより高い性能を獲得。
Figure2で継続事前学習したモデルに対して、フルパラメータのFinetuningをした場合でもUpcyclingは効果がある(Figure3)。
特にPretrainingではUpcyclingを用いたモデルの性能に、通常のMoEをスクラッチから学習したモデルが追いつくのに時間がかかるとのこと。特に図右側の言語タスクでは、120%の学習時間が追いつくために必要だった。
Sparse Upcycingと、Dense tilingによる手法(warm start; 元のモデルに既存の層を複製して新しい層を追加する方法)、元のモデルをそれぞれ継続事前学習すると、最も高い性能を獲得している。
(すごい斜め読みなのでちょっも自信なし、、、)
[Paper Note] Prompting Large Language Model for Machine Translation: A Case Study, Biao Zhang+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#MachineTranslation #NLP #One-Line Notes #Reading Reflections Issue Date: 2024-11-20 GPT Summary- プロンプト設計は多くのタスクで優れた性能を示すが、機械翻訳においては未検討。翻訳のためのプロンプト戦略を体系的に研究し、プロンプトテンプレートやデモ例の選択に関する要因を検討。実験の結果、プロンプト例の数と質が翻訳において重要であり、サブ最適な例は性能低下を招くことが示された。また、ゼロショットプロンプティングから得られた擬似平行プロンプト例の利用が翻訳を改善する可能性や、知識転移により性能向上が見込まれることが確認された。最後に、プロンプト設計に関する問題点についても議論。 Comment
zero-shotでMTを行うときに、改行の有無や、少しのpromptingの違いでCOMETスコアが大幅に変わることを示している。
モデルはGLM-130BをINT4で量子化したモデルで実験している。
興味深いが、この知見を一般化して全てのLLMに適用できるか?と言われると、そうはならない気がする。他のモデルで検証したら傾向はおそらく変わるであろう(という意味でおそらく論文のタイトルにもCase Studyと記述されているのかなあ)。
Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #ACL Issue Date: 2024-11-11 GPT Summary- 本研究では、ゼロショット密な検索システムの構築において、仮想文書埋め込み(HyDE)を提案。クエリに基づき、指示に従う言語モデルが仮想文書を生成し、教師なしで学習されたエンコーダがこれを埋め込みベクトルに変換。実際のコーパスに基づく類似文書を取得することで、誤った詳細をフィルタリング。実験結果では、HyDEが最先端の密な検索器Contrieverを上回り、様々なタスクと言語で強力なパフォーマンスを示した。
SINC: Self-Supervised In-Context Learning for Vision-Language Tasks, Yi-Syuan Chen+, N_A, ICCV'23
Paper/Blog Link My Issue
#ComputerVision #Zero/Few/ManyShotPrompting #Self-SupervisedLearning Issue Date: 2024-10-07 GPT Summary- 自己教師あり文脈内学習(SINC)フレームワークを提案し、大規模言語モデルに依存せずに文脈内学習を実現。特別に調整されたデモンストレーションを用いたメタモデルが、視覚と言語のタスクで少数ショット設定において勾配ベースの手法を上回る性能を示す。SINCは文脈内学習の利点を探求し、重要な要素を明らかにする。
UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23
Paper/Blog Link My Issue
#Pretraining #NLP #MultiModal #ICLR #Encoder #Encoder-Decoder #KeyPoint Notes Issue Date: 2024-09-26 GPT Summary- 本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 Comment
OpenReview: https://openreview.net/forum?id=6ruVLB727MC
encoder-decoder/decoder-onlyなど特定のアーキテクチャに依存しないアーキテクチャagnosticな事前学習手法であるMoDを提案。
MoDでは3種類のDenoiser [R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを活用する。学習時には与えらえたタスクに対して適切なモードをスイッチできるようにparadigm token ([R], [S], [X])を与え挙動を変化させられるようにしており[^1]、finetuning時においては事前にタスクごとに定義をして与えるなどのことも可能。
[^1]: 事前学習中に具体的にどのようにモードをスイッチするのかはよくわからなかった。ランダムに変更するのだろうか。
[Paper Note] Direct Preference Optimization: Your Language Model is Secretly a Reward Model, Rafael Rafailov+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Alignment #NeurIPS #DPO #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-09-25 GPT Summary- 大規模な自己教師付き言語モデルにおいて、挙動を制御するのが難しい問題に対し、新たな報酬モデルのパラメータ化を導入し、Direct Preference Optimization(DPO)を提案。DPOは、ファインチューニング時の安定性と計算効率を向上させ、既存手法と同等またはそれ以上の性能を実現。特に、生成の感情制御や応答品質向上を実現し、実装と訓練の単純さが大幅に改善されることを示した。 Comment
解説(必ず読んだ方が良い):
- RLHF/DPO 小話, 和地瞭良/ Akifumi Wachi, 2024.04
DPOを提案した研究。選好データ D:
解説ポスト:
SNLP'24での解説スライド: https://speakerdeck.com/kazutoshishinoda/lun-wen-shao-jie-direct-preference-optimization-your-language-model-is-secretly-a-reward-model
[Paper Note] Instruction Tuning with GPT-4, Baolin Peng+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #InstructionTuning #PostTraining #One-Line Notes Issue Date: 2024-09-20 GPT Summary- GPT-4を用いて機械生成の指示追従データを新たに生成し、LLaMAモデルのファインチューニングを行う試みを提案。生成されたデータは、従来のモデルと比べて新規タスクに対するゼロショット性能を向上させることを示した。フィードバックと比較データも収集し、コードベースを公開。 Comment
現在はOpenAIの利用規約において、outputを利用してOpenAIと競合するモデルを構築することは禁止されているので、この点には注意が必要
https://openai.com/ja-JP/policies/terms-of-use/
Reflection-Tuning: Data Recycling Improves LLM Instruction-Tuning, Ming Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #SelfCorrection Issue Date: 2024-09-07 GPT Summary- リフレクションチューニングという新手法を提案し、LLMsの自己改善を通じて低品質なトレーニングデータの問題に対処。オラクルLLMを用いてデータの質を向上させ、実験により再利用データで訓練されたLLMsが既存モデルを上回ることを示した。 Comment
Reflection-Tuningを提案している研究?
Leveraging Large Language Models in Conversational Recommender Systems, Luke Friedman+, N_A, arXiv'23
Paper/Blog Link My Issue
#RecommenderSystems #ConversationalRecommenderSystems Issue Date: 2024-08-07 GPT Summary- LLMsを使用した大規模な会話型推薦システム(CRS)の構築に関する論文の要約です。LLMsを活用したユーザーの好み理解、柔軟なダイアログ管理、説明可能な推薦の新しい実装を提案し、LLMsによって駆動される統合アーキテクチャの一部として説明します。また、LLMが解釈可能な自然言語のユーザープロファイルを利用してセッションレベルのコンテキストを調整する方法についても説明します。さらに、LLMベースのユーザーシミュレータを構築して合成会話を生成する技術を提案し、LaMDAをベースにしたYouTubeビデオの大規模CRSであるRecLLMを紹介します。
Mistral 7B, Albert Q. Jiang+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #OpenWeight #KeyPoint Notes Issue Date: 2024-05-24 GPT Summary- Mistral 7B v0.1は、70億パラメータの言語モデルであり、高速な推論のためにGQAを活用し、SWAを組み合わせている。また、Mistral 7B -- InstructはLlama 2 13B -- Chatモデルを上回っており、Apache 2.0ライセンスの下で公開されています。 Comment
Mistral Large
Mixtral-8x22B-v0.1, 2024
などのモデルも参照のこと
モデルのスケールが大きくなると、inferenceのlatencyが遅くなり、計算コストが大きくなりすぎて実用的でないので、小さいパラメータで素早いinference実現したいよね、というモチベーション。
そのために、SlidingWindowAttentionとGroupQueryAttention [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
を活用している。
より小さいパラメータ数でLlama2を様々なタスクでoutperformし
Instruction Tuningを実施したモデルは、13BモデルよりもChatbotArenaで高いElo Rateを獲得した。
コンテキスト長は8192
[Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #NLP #Dataset #Annotation #One-Line Notes Issue Date: 2024-05-15 GPT Summary- 大規模言語モデル(LLMs)の自動要約能力の背後にある要因を探り、10のモデルに対する人間評価を行った。結果、ゼロショット要約の鍵はモデルサイズではなく指示調整にあること、さらに従来の研究は低品質な参照データに制約されているため人間の性能を過小評価していることが明らかになった。高品質な要約を基にした評価では、LLMsの要約が人間の要約と同等とされることが多いとの結論に至った。 Comment
- ニュース記事の高品質な要約を人間に作成してもらい、gpt-3.5を用いてLLM-basedな要約も生成
- annotatorにそれぞれの要約の品質をスコアリングさせたデータセットを作成
[Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-04-07 GPT Summary- マルチクエリ・アテンション(MQA)はデコーダ推論を高速化するが、品質低下のリスクがある。本研究では、(1)元の計算の5%でMQAを持つモデルへのアップトレーニング方法を提案し、(2)グループ化クエリ・アテンション(GQA)を導入。GQAは中間的な数のキー・バリュー・ヘッドを使用し、アップトレーニングされたGQAは品質を保ちながらMQAと同等の速度を実現する。 Comment
通常のMulti-Head AttentionがQKVが1対1対応なのに対し、Multi Query Attention (MQA) [Paper Note] Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, arXiv'19, 2019.11
は全てのQに対してKVを共有する。一方、GQAはグループごとにKVを共有する点で異なる。MQAは大幅にInfeerence` speedが改善するが、精度が劣化する問題があった。この研究では通常のMulti-Head Attentionに対して、オリジナルの事前学習に対して追加の5%の計算量でGQAモデルを学習する手法を提案している。
Main Result. Multi-Head Attentionに対して、inference timeが大幅に改善しているが、Multi-Query Attentionよりも高い性能を維持している。
INSTRUCTSCORE: Explainable Text Generation Evaluation with Finegrained Feedback, Wenda Xu+, N_A, EMNLP'23
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Explanation #Supervised-FineTuning (SFT) #Evaluation #EMNLP #PostTraining #One-Line Notes Issue Date: 2024-01-25 GPT Summary- 自動的な言語生成の品質評価には説明可能なメトリクスが必要であるが、既存のメトリクスはその判定を説明したり欠陥とスコアを関連付けることができない。そこで、InstructScoreという新しいメトリクスを提案し、人間の指示とGPT-4の知識を活用してテキストの評価と診断レポートを生成する。さまざまな生成タスクでInstructScoreを評価し、他のメトリクスを上回る性能を示した。驚くべきことに、InstructScoreは人間の評価データなしで最先端のメトリクスと同等の性能を達成する。 Comment
伝統的なNLGの性能指標の解釈性が低いことを主張する研究
[Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N_A, EMNLP'23
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Evaluation #LLM-as-a-Judge #Surface-level Notes Issue Date: 2024-01-25 GPT Summary- 従来の参照ベースの評価指標では、自然言語生成システムの品質を正確に測定することが難しい。最近の研究では、大規模言語モデル(LLMs)を使用した参照ベースの評価指標が提案されているが、まだ人間との一致度が低い。本研究では、G-Evalという大規模言語モデルを使用した品質評価フレームワークを提案し、要約と対話生成のタスクで実験を行った。G-Evalは従来の手法を大幅に上回る結果を示し、LLMベースの評価器の潜在的な問題についても分析している。コードはGitHubで公開されている。 Comment
伝統的なNLGの性能指標が、人間の判断との相関が低いことを示した研究
# 手法概要
- CoTを利用して、生成されたテキストの品質を評価する手法を提案している。
- タスクのIntroductionと、評価のCriteriaをプロンプトに仕込むだけで、自動的にLLMに評価ステップに関するCoTを生成させ、最終的にフォームを埋める形式でスコアをテキストとして生成させ評価を実施する。最終的に、各スコアの生成確率によるweighted-sumによって、最終スコアを決定する。
# Scoringの問題点
たとえば、1-5のdiscreteなスコアを直接LLMにoutputさせると、下記のような問題が生じる:
1. ある一つのスコアが支配的になってしまい、スコアの分散が無く、人間の評価との相関が低くなる
2. LLMは小数を出力するよう指示しても、大抵の場合整数を出力するため、多くのテキストの評価値が同一となり、生成されたテキストの細かな差異を評価に取り入れることができない。
上記を解決するため、下記のように、スコアトークンの生成確率の重みづけ和をとることで、最終的なスコアを算出している。
# 評価
- SummEval SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
データと、Topical-Chat, QAGSデータの3つのベンチマークで評価を実施した。タスクとしては、要約と対話のresponse generationのデータとなる。
- モデルはGPT-3.5 (text-davinci-003), GPT-4を利用した
- gpt3.5利用時は、temperatureは0に設定し、GPT-4はトークンの生成確率を返さないので、`n=20, temperature=1, top_p=1`とし、20回の生成結果からトークンの出現確率を算出した。
## 評価結果
G-EVALがbaselineをoutperformし、特にGPT4を利用した場合に性能が高い。GPTScoreを利用した場合に、モデルを何を使用したのかが書かれていない。Appendixに記述されているのだろうか。
# Analysis
## G-EvalがLLMが生成したテキストを好んで高いスコアを付与してしまうか?
- 人間に品質の高いニュース記事要約を書かせ、アノテータにGPTが生成した要約を比較させたデータ ([Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
) を用いて検証
- その結果、基本的にGPTが生成した要約に対して、G-EVAL4が高いスコアを付与する傾向にあることがわかった。
- 原因1: [Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
で指摘されている通り、人間が記述した要約とLLMが記述した要約を区別するタスクは、inter-annotator agreementは`0.07`であり、極端に低く、人間でも困難なタスクであるため。
- 原因2: LLMは生成時と評価時に、共通したコンセプトをモデル内部で共有している可能性が高く、これがLLMが生成した要約を高く評価するバイアスをかけた
## CoTの影響
- SummEvalデータにおいて、CoTの有無による性能の差を検証した結果、CoTを導入した場合により高いcorrelationを獲得した。特に、Fluencyへの影響が大きい。
## Probability Normalizationによる影響
- probabilityによるnormalizationを導入したことで、kendall tauが減少した。この理由は、probabilityが導入されていない場合は多くの引き分けを生み出す。一方、kendall tauは、concordant / discordantペアの数によって決定されるが、引き分けの場合はどちらにもカウントされず、kendall tauの値を押し上げる効果がある。このため、これはモデルの真の性能を反映していない。
- 一方、probabilityを導入すると、より細かいな連続的なスコアを獲得することができ、これはspearman-correlationの向上に反映されている。
## モデルサイズによる影響
- 基本的に大きいサイズの方が高いcorrelationを示す。特に、consistencyやrelevanceといった、複雑な評価タスクではその差が顕著である。
- 一方モデルサイズが小さい方が性能が良い観点(engagingness, groundedness)なども存在した。
[Paper Note] Some things are more CRINGE than others: Iterative Preference Optimization with the Pairwise Cringe Loss, Jing Xu+, arXiv'23, 2023.12
Paper/Blog Link My Issue
#NLP #Alignment #SelfImprovement #PostTraining #One-Line Notes Issue Date: 2023-12-29 GPT Summary- 実務家は一般的にペアワイズの好みでLLMを整列させるが、二値フィードバックも有用である。そこで、既存の二値フィードバック手法Cringe Lossをペアワイズへ一般化した。ペアワイズ Cringe Loss は簡単に実装でき、訓練効率も高く、AlpacaFarm ベンチマークで最先端の手法を上回る結果を示した。また、訓練の反復が重要で、DPOをIterative DPOとして一般化できることを示した。 Comment
DPO, PPOをoutperformする新たなAlignment手法。MetaのJason Weston氏
元ツイート:
[Paper Note] Gemini: A Family of Highly Capable Multimodal Models, Gemini Team+, arXiv'23, 2023.12
Paper/Blog Link My Issue
#NLP #MultiModal #Proprietary #VisionLanguageModel #One-Line Notes Issue Date: 2023-12-21 GPT Summary- 新しいマルチモーダルモデルファミリー「Gemini」は、画像・音声・動画・テキスト理解において優れた能力を発揮し、Ultra・Pro・Nanoの3サイズから構成されている。Gemini Ultraモデルは32のベンチマークで30件で最先端の性能を示し、特にMMLUにおいて人間の専門家レベルを初めて達成。クロスモーダル推論の新たな能力により、さまざまなユースケースが可能となり、運用と責任あるデプロイのアプローチについても議論される。 Comment
Introducing Gemini: our largest and most capable AI model, Google, 2023.12 で発表されたGeminiの論文
[Paper Note] Unnatural Error Correction: GPT-4 Can Almost Perfectly Handle Unnatural Scrambled Text, Qi Cao+, EMNLP'23, 2023.11
Paper/Blog Link My Issue
#Analysis #NLP #QuestionAnswering #EMNLP #KeyPoint Notes Issue Date: 2023-12-04 GPT Summary- 大規模言語モデル(LLMs)、特にGPT-4の耐性を新たに実験的に探る。Scrambled Benchを提案し、スクランブルされた文の復元や質問応答能力を評価。実験結果は、多くのLLMsがtypoglycemiaに類似した能力を持つことを示唆。特にGPT-4は、完全にシャッフルされた文字から元の文をほぼ完璧に再構築し、95%の編集距離短縮を達成。他のLLMsにとって困難な入力でも、驚くべき処理能力を示す。 Comment
OpenAIのモデルがブラックボックスである限り、コンタミネーションがあるのでは?という疑念は持ってしまう。
(部分的にしか読めていないが…)
RealtimeQAと呼ばれるweeklyで直近のニュースに対するQuestionを発表することで構築されるデータセットのうち、2023.03.17--2023.08.04のデータを収集し、ScrambledSentenaeRecovery(ScrRec)とScrambleQuestionAnswering(ScrQA)の評価データを生成している。
完全にランダムに単語の文字をscramble(RS)すると、FalconとLlama2では元のテキストをゼロショットでは再構築できないことが分かる。FewShotではFalconであれば少し解けるようになる。一方、OpenAIのモデル、特にGPT4, GPT3.5-turboではゼロショットでもにり再構築ができている。
ScrQAについては、ランダムにscrambleした場合でもMultipleChoiceQuestionなので(RPGと呼ばれるAccの相対的なgainを評価するメトリックを提案している)正解はできている。
最初の文字だけを残す場合(KF)最初と最後の文字を残す場合(KFL」については、残す文字が増えるほどどちらのタスクも性能が上がり、最初の文字だけがあればOpenSourceLLMでも(ゼロショットでも)かなり元のテキストの再構築ができるようになっている。また、QAも性能が向上している。
完全にランダムに文字を入れ替えたら完全に無理ゲーなのでは、、、、と思ってしまうのだが、FalconでFewshotの場合は一部解けているようだ…。果たしてどういうことなのか…(大文字小文字が保持されたままなのがヒントになっている…?)Appendixに考察がありそうだがまだ読めていない。
(追記)
文全体でランダムに文字を入れ替えているのかと勘違いしていたが、実際には”ある単語の中だけでランダムに入れ替え”だった。これなら原理上はいけると思われる。
openreview: https://openreview.net/forum?id=STHKApXVMH¬eId=XCtbu5XTGi
Exponentially Faster Language Modelling, Peter Belcak+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP Issue Date: 2023-11-23 GPT Summary- UltraFastBERTは、推論時にわずか0.3%のニューロンしか使用せず、同等の性能を発揮することができる言語モデルです。UltraFastBERTは、高速フィードフォワードネットワーク(FFF)を使用して、効率的な実装を提供します。最適化されたベースラインの実装に比べて78倍の高速化を実現し、バッチ処理された推論に対しては40倍の高速化を実現します。トレーニングコード、ベンチマークのセットアップ、およびモデルの重みも公開されています。
GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Dataset #QuestionAnswering #AIAgents #Evaluation #Selected Papers/Blogs Issue Date: 2023-11-23 GPT Summary- GAIAは、General AI Assistantsのためのベンチマークであり、AI研究のマイルストーンとなる可能性がある。GAIAは、推論、マルチモダリティの処理、ウェブブラウジングなど、実世界の質問に対する基本的な能力を必要とする。人間の回答者は92%の正答率を達成し、GPT-4は15%の正答率を達成した。これは、最近の傾向とは異なる結果であり、専門的なスキルを必要とするタスクではLLMsが人間を上回っている。GAIAは、人間の平均的な堅牢性と同等の能力を持つシステムがAGIの到来に重要であると考えている。GAIAの手法を使用して、466の質問と回答を作成し、一部を公開してリーダーボードで利用可能にする。 Comment
Yann LeCun氏の紹介ツイート
Meta-FAIR, Meta-GenAI, HuggingFace, AutoGPTによる研究。人間は92%正解できるが、GPT4でも15%しか正解できないQAベンチマーク。解くために推論やマルチモダリティの処理、ブラウジング、ツールに対する習熟などの基本的な能力を必要とする実世界のQAとのこと。
- Open-source DeepResearch – Freeing our search agents, HuggingFace, 2025.02
で言及されているLLM Agentの評価で最も有名なベンチマークな模様
[Paper Note] Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents, Zhuosheng Zhang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Tutorial #NLP #Chain-of-Thought #One-Line Notes Issue Date: 2023-11-21 GPT Summary- LLMsは複雑な推論タスクにおいて驚異的な性能を示し、CoT推論技術を通じて解釈性や柔軟性を高めている。自律的な言語エージェントの開発が進み、様々な環境で行動を実行する能力を持つ。論文ではCoTの基礎機構、パラダイムシフト、言語エージェントの台頭を探求し、今後の研究の方向性について議論している。初心者から経験豊富な研究者まで広範囲な読者を対象にしている。 Comment
CoTに関するチュートリアル論文
[Paper Note] System 2 Attention (is something you might need too), Jason Weston+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#NLP #Prompting #ContextEngineering Issue Date: 2023-11-21 GPT Summary- S2Aを用いて、LLMsが注意を向けるべき部分を選択することで、無関係な情報を除外し最終応答を導出。QA、数学の文章題、長文生成において標準アテンションを上回り、事実性と客観性を高め、迎合性を低減。 Comment
おそらく重要論文
How is System 2 Attention different from prompt engineering specialized in factual double checks?
I'm very sorry for the extremely delayed response. It's been two years, so you may no longer have a chance to see this, but I'd still like to share my thoughts.
I believe that System 2 Attention is fundamentally different in concept from prompt engineering techniques such as factual double-checking. Unlike ad-hoc prompt engineering or approaches that enrich the context by adding new facts through prompting, System 2 Attention aims to improve the model’s reasoning ability itself by mitigating the influence of irrelevant tokens. It does so by selectively generating a new context composed only of relevant tokens, in a way that resembles human System 2 thinking—that is, more objective and deliberate reasoning.
From today’s perspective, two years later, I would say that this concept is more closely aligned with what we now refer to as Context Engineering. Thank you.
[Paper Note] Orca 2: Teaching Small Language Models How to Reason, Arindam Mitra+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Chain-of-Thought #SmallModel #OpenWeight #Reading Reflections Issue Date: 2023-11-21 GPT Summary- Orca 2 は小型 LM の推論能力を高めるために、異なるタスクごとに様々な解法戦略を学習させることを目指す。段階的推論や思い出し-推論-生成などを用いて、小型モデルの潜在能力を最大化し、約100のタスクで評価を行い、同規模モデルを大きく上回る性能を達成。重みは公開され、開発研究の支援が期待される。 Comment
ポイント解説:
HF: https://huggingface.co/microsoft/Orca-2-13b
論文を読むとChatGPTのデータを学習に利用しているが、現在は競合となるモデルを作ることは規約で禁止されているので注意
[Paper Note] Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Pretraining #NLP #Chain-of-Thought Issue Date: 2023-11-21 GPT Summary- 言語モデルにおける推論能力向上のため、明示的な思考の連鎖推論ではなく、隠れ状態を用いた暗黙の推論を提案。教師モデルから蒸留したステップで、層間の隠れ状態を利用し、効率的な推論を実現。実験により、明示的チェーンなしで課題を解決し、推論速度も維持されることを示した。 Comment
これは非常に興味深い話
openreview: https://openreview.net/forum?id=9cumTvvlHG
Contrastive Chain-of-Thought Prompting, Yew Ken Chia+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting Issue Date: 2023-11-19 GPT Summary- 言語モデルの推論を改善するために、対照的なchain of thoughtアプローチを提案する。このアプローチでは、有効な推論デモンストレーションと無効な推論デモンストレーションの両方を提供し、モデルが推論を進める際にミスを減らすようにガイドする。また、自動的な方法を導入して対照的なデモンストレーションを構築し、汎化性能を向上させる。実験結果から、対照的なchain of thoughtが一般的な改善手法として機能することが示された。
Fine-tuning Language Models for Factuality, Katherine Tian+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #Factuality Issue Date: 2023-11-15 GPT Summary- 本研究では、大規模な言語モデル(LLMs)を使用して、より事実に基づいた生成を実現するためのファインチューニングを行います。具体的には、外部の知識ベースや信頼スコアとの一貫性を測定し、選好最適化アルゴリズムを使用してモデルを調整します。実験結果では、事実エラー率の削減が観察されました。
[Paper Note] Instruction-Following Evaluation for Large Language Models, Jeffrey Zhou+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#NLP #Dataset #InstructionTuning #Evaluation #PostTraining #Selected Papers/Blogs #InstructionFollowingCapability #KeyPoint Notes Issue Date: 2023-11-15 GPT Summary- 大規模言語モデルの自然言語指示に対する評価は標準化されておらず、人間による評価は高価で遅い。そこで、Instruction-Following Eval(IFEval)を提案し、検証可能な指示に焦点を当てた評価ベンチマークを提供。25種類の指示を特定し、約500のプロンプトを作成。これにより、2つのLLMの客観的な評価結果を示すことに成功した。コードとデータは公開されている。 Comment
LLMがinstructionにどれだけ従うかを評価するために、検証可能なプロンプト(400字以上で書きなさいなど)を考案し評価する枠組みを提案。人間が評価すると時間とお金がかかり、LLMを利用した自動評価だと評価を実施するLLMのバイアスがかかるのだ、それら両方のlimitationを克服できるとのこと。
[Paper Note] Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster, Hongxuan Zhang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Chain-of-Thought #Prompting #Initial Impression Notes Issue Date: 2023-11-15 GPT Summary- FastCoTは、追加トレーニングやLLM改変なしに並列デコードを実現するモデル非依存のフレームワークです。可変長コンテキストウィンドウを使用し、並列かつ自己回帰的なデコードを行うことで、GPUリソースを最適化します。これにより、因果型トランスフォーマーの従来手法よりも迅速な応答が可能になります。実験結果では、FastCoTが推論時間を約20%短縮しつつ、性能低下も最小限であることが示されています。 Comment
論文中の図を見たが、全くわからなかった・・・。ちゃんと読まないとわからなそうである。
Cappy: Outperforming and Boosting Large Multi-Task LMs with a Small Scorer, Bowen Tan+, N_A, NeurIPS'23
Paper/Blog Link My Issue
#NLP #SmallModel #NeurIPS #Initial Impression Notes Issue Date: 2023-11-14 GPT Summary- 大規模言語モデル(LLMs)はマルチタスキングに優れた性能を示していますが、パラメータ数が多く計算リソースを必要とし、効率的ではありません。そこで、小規模なスコアラーであるCappyを導入し、独立して機能するかLLMsの補助として使用することでパフォーマンスを向上させました。Cappyはファインチューニングやパラメータへのアクセスを必要とせず、さまざまなタスクで高い性能を発揮します。実験結果では、Cappyは独立したタスクや複雑なタスクで大きなLLMsを上回り、他のLLMsとの連携も可能です。 Comment
360MパラメータでさまざまなタスクでLLMに勝つっぽいのでおもしろそうだし実用性もありそう
[Paper Note] A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Lei Huang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Survey #NLP #Hallucination #One-Line Notes Issue Date: 2023-11-10 GPT Summary- LLMの登場によりNLPは新たな転機を迎えたが、幻覚問題が信頼性に対する懸念を引き起こし、検出と緩和の研究を促進している。幻覚はタスク特化型モデルとは異なる課題を呈し、詳細な理解が求められる。本調査では、幻覚の分類法や要因を詳述し、検知手法と緩和方法、情報検索を含むLLMの現状における制約を掘り下げる。また、ビジョン言語モデルにおける幻覚や知識の境界の理解を含む今後の研究方向も強調する。 Comment
Hallucinationを現象ごとに分類したSurveyとして [Paper Note] A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, arXiv'23, 2023.09 もある
Surveyの内容。必要に応じて参照すべし。
[Paper Note] LightLM: A Lightweight Deep and Narrow Language Model for Generative Recommendation, Kai Mei+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#RecommenderSystems #One-Line Notes Issue Date: 2023-11-10 GPT Summary- LightLMは、生成的推薦のために特化した軽量なTransformerベースの言語モデルである。従来の重いモデルに代わり、短いトークンを主成分とする浅い構造を採用し、推奨アイテムの直接生成に効果的である。ユーザーIDおよびアイテムIDに対する新たなインデックス化手法(SCIとGCI)を提案し、推薦タスクにおいて大規模言語モデルに勝る性能を示す。さらに、ハルシネーションを抑えるための制約付き生成プロセスを導入し、実データセットで競合するベースラインを上回る精度と効率を実現した。 Comment
Generative Recommendationはあまり終えていないのだが、既存のGenerative Recommendationのモデルをより軽量にし、性能を向上させ、存在しないアイテムを生成するのを防止するような手法を提案しました、という話っぽい。
Bayesian Personalized Ranking [Paper Note] BPR: Bayesian Personalized Ranking from Implicit Feedback, Steffen Rendle+, UAI'09, 2009.06
ベースドなMatrix Factorizationよりは高い性能が出てるっぽい。
[Paper Note] Do LLMs exhibit human-like response biases? A case study in survey design, Lindia Tjuatja+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Analysis #NLP #TACL #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-11-08 GPT Summary- LLMの高性能に伴い、調査や世論調査での人間代理としての活用が期待されるが、プロンプト文言への感度が課題となる。本研究では、LLMが人間の応答バイアスを反映するかを調査し、調査票設計を通じて評価する。結果、主流のLLMは一般的に人間のような挙動を示さず、特にRLHFを経たモデルで顕著だった。また、人間に影響を与えない摂動には敏感であることが判明。これにより、LLMの人間代理利用時の注意点とモデル挙動の細かな分析の必要性が浮き彫りとなった。 Comment
LLMはPromptにsensitiveだが、人間も質問の仕方によって応答が変わるから、sensitiveなのは一緒では?ということを調査した研究。Neubig氏のツイートだと、instruction tuningやRLHFをしていないBase LLMの方が、より人間と類似した回答をするのだそう。
元ツイート:
人間のレスポンスのバイアス。左側は人間は「forbidden」よりも「not allowed」を好むという例、右側は「response order」のバイアスの例(選択肢の順番)。
LLM側で評価したいバイアスごとに、QAのテキストを変更し、LLMに回答を生成され、social science studiesでのトレンドと比較することで、LLMにも人間と同様のバイアスがあるかを明らかにしている。
結果は以下の表であり、青いセルが人間と同様のバイアスを持つことを統計的に有意に示されたもの(のはず)。これをみると、全てのバイアスに対して人間と同様の傾向があったのはLlama2-70Bのみであり、instruction tuningや、RLHFをかけた場合(RLHFの方が影響が大きそう)人間のバイアスとは異なる挙動をするモデルが多くなることがわかる。また、モデルのパラメータサイズとバイアスの強さには相関関係は見受けられない。
Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models, Steve Yadlowsky+, N_A, arXiv'23
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #OOD #One-Line Notes #Reading Reflections Issue Date: 2023-11-06 GPT Summary- 本研究では、トランスフォーマーモデルの文脈学習(ICL)能力を調査しました。トランスフォーマーモデルは、事前学習データの範囲内で異なるタスクを特定し、学習する能力を持っています。しかし、事前学習データの範囲外のタスクや関数に対しては一般化が劣化することが示されました。また、高容量のシーケンスモデルのICL能力は、事前学習データの範囲に密接に関連していることが強調されました。 Comment
Transformerがpre-training時に利用された学習データ以外の分布に対しては汎化性能が落ちることを示したらしい。もしこれが正しいとすると、結局真に新しい分布というか関数というかタスクというか、をTransformerが創出する可能性は低いと言えるかもしれない。が、新しいものって大体は既存の概念の組み合わせだよね(スマホとか)、みたいなことを考えると、別にそれでも十分では?と思ってしまう。人間が本当に真の意味で新しい関数というかタスクというか分布を生み出せているかというと、実はそんなに多くないのでは?という予感もする。まあたとえば、量子力学を最初に考えました!とかそういうのは例外だと思うけど・・・、そのレベルのことってどんくらいあるんだろうね?
[Paper Note] The Perils & Promises of Fact-checking with Large Language Models, Dorian Quelle+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #One-Line Notes #Reading Reflections Issue Date: 2023-11-05 GPT Summary- 自動ファクトチェックは機械学習を用いて主張を検証する重要な取り組みであり、LLMs(例:GPT-4)はその能力を活用しつつ、情報の真偽を見分ける役割が増大している。本研究ではLLMエージェントがクエリを作成し、文脈データを取得し、意思決定を行うフレームワークを提案。結果、文脈情報がLLMの能力を向上させることが示されたが、正確性はクエリの言語や主張の真偽に依存し、一貫性に欠けるため慎重な運用が求められる。さらなる研究が必要で、エージェントの成功と失敗のメカニズムを探求することが提言される。 Comment
gpt3とgpt4でFactCheckして傾向を分析しました、という研究。promptにstatementとgoogleで補完したcontextを含め、出力フォーマットを指定することでFactCheckする。
promptingする際の言語や、statementの事実性の度合い(半分true, 全てfalse等)などで、性能が大きく変わる結果とのこと。
性能を見ると、まだまだ(このprompting方法では)人間の代わりが務まるほどの性能が出ていないことがわかる。また、trueな情報のFactCheckにcontextは効いていそうだが、falseの情報のFactCheckにContextがあまり効いてなさそうに見えるので、なんだかなあ、という感じである。
斜め読みしかしていないがこの研究、学術的な知見は少ないのかな、という印象。一つのケーススタディだよね、という感じがする。
まず、GPT3,4だけじゃなく、特徴の異なるOpenSourceのLLMを比較に含めてくれないと、前者は何で学習しているか分からないので、学術的に得られる知見はほぼないのではという気が。実務的には役に立つが。
その上で、Promptingをもっとさまざまな方法で検証した方が良いと思う。
たとえば、現在のpromptではラベルを先に出力させた後に理由を述べさせているが、それを逆にしたらどうなるか?(zero-shot CoT)や、4-Shotにしたらどうなるか、SelfConsistencyを利用したらどうなるかなど、promptingの仕方によって傾向が大きく変わると思う。
加えて、Retriever部分もいくつかのバリエーションで試してみても良いのかなと思う。特に、falseの情報を判断する際に役に立つ情報がcontextに含められているのかが気になる。
論文に書いてあるかもしれないが、ちょっとしっかり読む時間はないです!!
[Paper Note] Llemma: An Open Language Model For Mathematics, Zhangir Azerbayev+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#Pretraining #NLP #FoundationModel #Mathematics #mid-training #One-Line Notes #Reading Reflections Issue Date: 2023-10-29 GPT Summary- Llemmaという数学の大規模言語モデルを提案。Proof-Pile-2でCode Llamaの前訓練を行い、科学論文や数学コードを含む複合データセットで強化。MATHベンチマークで全ての公開モデルを凌ぎ、未公開のMinervaモデル群にも勝利。追加ファインチューニングなしでツール使用や形式的定理証明が可能。70億および340億パラメータのモデルや実験コードを公開。 Comment
CodeLLaMAを200B tokenの数学テキスト(proof-pile-2データ;論文、数学を含むウェブテキスト、数学のコードが含まれるデータ)で継続的に事前学習することでfoundation modelを構築
約半分のパラメータ数で数学に関する性能でGoogleのMinervaと同等の性能を達成
元ツイート:
まだ4-shotしてもAcc.50%くらいなのか。
Large Language Models are not Fair Evaluators, Peiyi Wang+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Evaluation Issue Date: 2023-10-29 GPT Summary- この論文では、大規模言語モデル(LLMs)を使用して、候補モデルの応答品質を評価する評価パラダイムにおける系統的なバイアスを明らかにします。さらに、バイアスを軽減するためのキャリブレーションフレームワークを提案し、実験によってその有効性を示します。また、コードとデータを公開して、今後の研究を支援します。
[Paper Note] Zephyr: Direct Distillation of LM Alignment, Lewis Tunstall+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#Pretraining #NLP #Supervised-FineTuning (SFT) #SyntheticData #COLM #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-10-28 GPT Summary- ユーザーの意図に応じた小型言語モデルを目指し、dSFTに基づくモデルの整合性向上を図る。AIフィードバックからの選好データを用い、dDPOを適用することで、意図の整合性が向上したチャットモデルを学習。追加サンプリングなしで数時間の訓練で最先端のZephyr-7Bを実現し、MT-BenchでLlama2-Chat-70Bを上回る成果を達成。コードやデータは公開。 Comment
7BパラメータでLlaMa70Bと同等の性能を達成したZephyrの論文。
- dSFT:既存データからpromptをサンプリングし、user,assistantのmulti turnの対話をLLMでシミュレーションしてデータ生成しSFT
- AIF:既存データからpromstをサンプリングし、異なる4つのLLMのレスポンスをGPT4でランクづけしたデータの活用
- dDPO: 既存データからpromptをサンプリングし、ベストなレスポンスとランダムにサンプリングしたレスポンスの活用
人手を一切介していない。
Blog: https://huggingface.co/blog/Isamu136/understanding-zephyr
openreview: https://openreview.net/forum?id=aKkAwZB6JV
[Paper Note] Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #EMNLP #OCR #One-Line Notes #Reading Reflections Issue Date: 2023-10-26 GPT Summary- GPT-4VのOCR機能を評価し、シーンテキスト、手書き文字、数学式や表構造認識などの幅広いタスクへの性能を検討。ラテン文字では高性能だが、多言語や複雑なタスクでは限界を示す。専門的なOCRモデルの必要性を強調し、今後の研究の指針を提供。評価結果は公開されている。 Comment
GPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
現在では非常に性能が向上していると考えられるが、初期VLMのOCR性能を示している文献として興味深い。
[Paper Note] Auto-Instruct: Automatic Instruction Generation and Ranking for Black-Box Language Models, Zhihan Zhang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #InstructionTuning #InstructionGeneration #EMNLP #Findings #KeyPoint Notes Issue Date: 2023-10-26 GPT Summary- LLMに対する指示の自動生成と評価を行うAuto-Instructを提案。多様な候補指示を生成し、既存の575タスク用のスコアリングモデルでランク付け。ドメイン外の118タスクで、人手作成や従来の生成指示を上回る性能を示し、高い一般化性を持つことを確認。 Comment
seed instructionとdemonstrationに基づいて、異なるスタイルのinstructionを自動生成し、自動生成したinstructionをとinferenceしたいexampleで条件づけてランキングし、良質なものを選択。選択したinstructionでinferenceを実施する。
既存手法よりも高い性能を達成している。特にexampleごとにinstructionを選択する手法の中で最もgainが高い。これは、提案手法がinstructionの選択にtrained modelを利用しているためであると考えられる。
[Paper Note] NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #NLP #Supervised-FineTuning (SFT) #ICLR #PostTraining #read-later #Initial Impression Notes Issue Date: 2023-10-26 GPT Summary- 単純なデータ拡張により、言語モデルのファインチューニングが改善されることを示す。NEFTuneは埋め込みベクトルにノイズを追加し、LLaMA-2-7Bのファインチューニングで29.79%から64.69%へ劇的な向上を実現。現代の指示データセットでも改善をもたらし、Evol-Instruct、ShareGPT、OpenPlatypusでそれぞれ10%、8%、8%の向上を示す。さらに、LLaMA-2-Chatに対しても恩恵を受ける。 Comment
Alpacaデータでの性能向上が著しい。かなり重要論文な予感。後で読む。
HuggingFaceのTRLでサポートされている
https://huggingface.co/docs/trl/sft_trainer
openreview: https://openreview.net/forum?id=0bMmZ3fkCk
[Paper Note] In-Context Learning Creates Task Vectors, Roee Hendel+, EMNLP'23 Findings, 2023.10
Paper/Blog Link My Issue
#NLP #In-ContextLearning #EMNLP #read-later #Findings #Initial Impression Notes Issue Date: 2023-10-26 GPT Summary- ICLはLLMにおける新しい学習パラダイムで、その機序は未解明である。訓練データ集合を用いる従来の機械学習とは異なり、ICLはデータを単一のタスクベクトルに圧縮し、トランスフォーマーを調整して出力を生成する。多様なモデルとタスクの実験を通じて、この新たな理解を支持する結果を示す。 Comment
参考:
ICLが実現可能なのは実はネットワーク内部で与えられたdemonstrationに対して勾配効果法を再現しているからです、という研究もあったと思うけど、このタスクベクトルとの関係性はどういうものなのだろうか。
文脈に注意を与えなくてもICLと同じ性能が出るのは、文脈情報が不要なタスクを実施しているからであり、そうではないタスクだとこの知見が崩れるのだろうか。後で読む。
openreview: https://openreview.net/forum?id=QYvFUlF19n
Branch-Solve-Merge Improves Large Language Model Evaluation and Generation, Swarnadeep Saha+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Evaluation Issue Date: 2023-10-25 GPT Summary- 本研究では、多面的な言語生成および評価タスクにおいて、大規模言語モデルプログラム(BSM)を提案します。BSMは、ブランチ、ソルブ、マージの3つのモジュールから構成され、タスクを複数のサブタスクに分解し、独立して解決し、解決策を統合します。実験により、BSMが評価の正確性と一貫性を向上させ、パフォーマンスを向上させることが示されました。
[Paper Note] Personalized Soups: Personalized Large Language Model Alignment via Post-hoc Parameter Merging, Joel Jang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #Alignment #ReinforcementLearning #Personalization #Souping #Initial Impression Notes Issue Date: 2023-10-24 GPT Summary- 人間のフィードバックを用いた強化学習(RLHF)は、LLMsを一般的な好みに合わせるが、個別の視点には最適でない。本研究では、個別のフィードバックを考慮した強化学習(RLPHF)を提案し、複数の好みに対応するために多目的強化学習(MORL)としてモデル化。好みを複数の次元に分解することで、個別のアライメントを達成できることを示し、これらの次元が独立して訓練され、効果的に結合可能であることを実証。コードは公開されている。 Comment
どこまでのことが実現できるのかが気になる。
[Paper Note] Eliminating Reasoning via Inferring with Planning: A New Framework to Guide LLMs' Non-linear Thinking, Yongqi Tong+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #NLP #Chain-of-Thought #Prompting #Initial Impression Notes Issue Date: 2023-10-24 GPT Summary- 非線形思考を模倣するために、Inferential Exclusion Prompting (IEP) を提案。IEPは計画後にNLIを活用し、解に対する推論を振り返ることで複雑な思考過程を再現。実証研究により、IEPがCoTを一貫して上回ることを確認。IEPとCoTを統合することでLLMsの性能向上も観察。新たに導入したMental-Ability Reasoning Benchmark (MARB)は9,115問からなり、LLMsの論理能力を評価するための有望な方法とされ、近日中に公開予定。 Comment
論文自体は読めていないのだが、CoTが線形的だという主張がよくわからない。
CoTはAutoregressiveな言語モデルに対して、コンテキストを自己生成したテキストで利用者の意図した方向性にバイアスをかけて補完させ、
利用者が意図した通りのアウトプットを最終的に得るためのテクニック、だと思っていて、
線形的だろうが非線形的だろうがどっちにしろCoTなのでは。
[Paper Note] Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models, Anni Zou+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #Initial Impression Notes Issue Date: 2023-10-13 GPT Summary- GeM-CoTは、未知の入力問に対する一般化可能なCoTプロンプティング手法を提案。問の型を分類し、データプールから自動デモを生成することで、性能と一般化のギャップを解消。これにより、10の公開推論タスクと23のBBHタスクで優れたパフォーマンスを実現。 Comment
色々出てきたがなんかもう色々組み合わせれば最強なんじゃね?って気がしてきた。
openreview: https://openreview.net/forum?id=79tJB1eTmb
[Paper Note] Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity, Cunxiang Wang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#Survey #NLP #Factuality #needs-revision Issue Date: 2023-10-13 GPT Summary- LLMsにおける事実性の問題に焦点を当て、出力の信頼性と正確性の重要性を検討。事実誤りの影響や原因を分析し、評価方法論や改善戦略を提案。スタンドアロンLLMsとリトリーバル拡張LLMsの固有の課題を詳述し、体系的なガイドを提供する。 Comment
[Paper Note] RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation, Fangyuan Xu+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #RAG(RetrievalAugmentedGeneration) #ICLR #One-Line Notes #Compression Issue Date: 2023-10-10 GPT Summary- 推論時に文書を要約することでLMの性能を向上。抽出型と抽象型の2つの圧縮器を提案し、計算コストと関連情報の識別負担を軽減。要約が無関係な場合は空文字列を返すことで選択的付加を実現。言語モデリングと質問応答タスクで評価し、圧縮率6%で性能を維持し、市販の要約モデルを上回る成果を示した。圧縮器は他のLMにも適用可能で、忠実な要約を生成。 Comment
RAGをする際に、元文書群を要約して圧縮することで、性能低下を抑えながら最大6%程度まで元文書群を圧縮できた、とのこと。
元ツイート:
RAGを導入する際のコスト削減に有用そう
openreview: https://openreview.net/forum?id=mlJLVigNHp
[Paper Note] Retrieval meets Long Context Large Language Models, Peng Xu+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2023-10-09 GPT Summary- 大規模言語モデル(LLMs)のコンテキスト窓の拡張と検索補強の効能を比較検討。独自の43B GPTとLlama2-70Bを用いて、検索補強を活用した4Kのコンテキストで、16Kのファインチューニング済みLLMと同等の性能を計算量を抑えて実現。特に、検索取得がLLMsの性能を大幅に向上させることを確認。最良モデルは32Kのコンテキストで、9つの長文タスクにおいて従来のモデルを上回り、高速な生成を実現。研究は、実務者に対してLLMの選択に関する指針を提供。 Comment
参考:
検索補強(Retrieval Augmentation)とは、言語モデルの知識を補完するために、関連する文書を外部の文書集合からとってきて、contextに含める技術のこと
https://tech.acesinc.co.jp/entry/2023/03/31/121001
[Paper Note] RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models, Zekun Moore Wang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #Dataset #Alignment #Conversation Issue Date: 2023-10-09 GPT Summary- RoleLLMは、大規模言語モデル(LLMs)のロールプレイ能力を強化するためのフレームワークで、100の役割に対するプロファイル構築やロール固有の知識抽出を行います。Context-InstructとRoleGPTを駆使して、初の体系的なキャラクター単位のベンチマークデータセットRoleBenchを作成し、サンプル数は168,093に達します。RoCITを使ったファインチューニングにより、RoleLLaMAとRoleGLMが生成され、GPT-4と同等のロールプレイ能力を実現しました。
[Paper Note] MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation, Qian Huang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #NLP #Dataset #AIAgents #Evaluation #AutoML #One-Line Notes Issue Date: 2023-10-09 GPT Summary- 機械学習の実験を行うためのエージェントを強力な言語モデルを用いて構築し、MLAgentBenchという13のタスクベンチマークを導入。エージェントはファイル操作やコード実行を行い、Claude v3 Opusが最も高い成功率を示す。タスク全体で平均成功率37.5%を達成するが、結果はデータセットによって大きく変動。長期計画や幻覚の低減といった重要な課題も明らかにした。コードは公開中。 Comment
GPT4がMLモデルをどれだけ自動的に構築できるかを調べた模様。また、ベンチマークデータを作成した模様。結果としては、既存の有名なデータセットでの成功率は90%程度であり、未知のタスク(新たなKaggle Challenge等)では30%程度とのこと。
[Paper Note] Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #Prompting #AutomaticPromptEngineering #ICML #Reading Reflections Issue Date: 2023-10-09 GPT Summary- Promptbreederは、LLMの推論能力を向上させる自己改善メカニズムであり、特定のドメインに対してプロンプトを進化・適応させる。タスクプロンプトの集団を突然変異させ、訓練データで評価することで、LLMが生成・改善する変異プロンプトによって統治される。これにより、Chain-of-ThoughtやPlan-and-Solve Promptingを上回り、ヘイトスピーチ分類のような複雑なタスクにも対応可能なプロンプトを進化させる。 Comment
詳細な解説記事: https://aiboom.net/archives/56319
APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…?
[Paper Note] Large Language Model Alignment: A Survey, Tianhao Shen+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#Survey #Alignment #PostTraining Issue Date: 2023-10-09 GPT Summary- LLMsの進展には潜在的な問題が伴い、正確性や人間の価値観との整合性が求められる。本研究は、アラインメント手法を探求し、外部と内部アラインメントを分類。解釈可能性や脆弱性についても考察し、多様な評価方法を提示。最終的に、AIアラインメント研究とLLMsの能力探索を結びつけることを目的とする。 Comment
LLMのalignmentに関するサーベイ。
[Paper Note] Effective Long-Context Scaling of Foundation Models, Wenhan Xiong+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #LongSequence #PositionalEncoding #NAACL #mid-training #Selected Papers/Blogs #DataMixture #KeyPoint Notes #needs-revision Issue Date: 2023-10-09 GPT Summary- 長文脈対応LLMシリーズを提案し、32,768トークンまでサポート。Llama 2の継続的な事前学習を基に、長文タスクで顕著な改善を実現。特に70B版は指示チューニングによりGPT-3.5-turbo-16kを上回る性能を示す。また、ポジションエンコーディングやデータ混合の影響を分析し、長文脈の事前学習が効率的かつ効果的であることを実証。 Comment
以下elvis氏のツイートの意訳
Metaが32kのcontext windowをサポートする70BのLLaMa2のvariant提案し、gpt-3.5-turboをlong contextが必要なタスクでoutperform。
short contextのLLaMa2を継続的に訓練して実現。これには人手で作成したinstruction tuning datasetを必要とせず、コスト効率の高いinstruction tuningによって実現される。
これは、事前学習データセットに長いテキストが豊富に含まれることが優れたパフォーマンスの鍵ではなく、ロングコンテキストの継続的な事前学習がより効率的であることを示唆している。
元ツイート:
位置エンコーディングにはlong contxet用に、RoPEのbase frequency bを `10,000->500,000` とすることで、rotation angleを小さくし、distant tokenに対する減衰の影響を小さくする手法を採用 (Adjusted Base Frequency; ABF)。token間の距離が離れていても、attention scoreがshrinkしづらくなっている。
また、単に長いコンテキストのデータを追加するだけでなく、データセット内における長いコンテキストのデータの比率を調整することで、より高い性能が発揮できることを示している。これをData Mixと呼ぶ。
また、instruction tuningのデータには、LLaMa2ChatのRLHFデータをベースに、LLaMa2Chat自身にself-instructを活用して、長いコンテキストを生成させ拡張したものを利用した。
具体的には、コーパス内のlong documentを用いたQAフォーマットのタスクに着目し、文書内のランダムなチャンクからQAを生成させた。その後、self-critiqueによって、LLaMa2Chat自身に、生成されたQAペアのverificationも実施させた。
[Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#Analysis #NLP #ICLR #Selected Papers/Blogs #ReversalCurse #KeyPoint Notes Issue Date: 2023-10-09 GPT Summary- 自己回帰型の大規模言語モデル(LLMs)の一般化の失敗を指摘し、特に「AはB」で学習したモデルが「BはA」を自動的に推測できない現象、いわゆる逆転の呪いを明らかにする。例えば、「Valentina Tereshkovaは宇宙へ初めて行った女性である」と学習しても、「宇宙へ初めて行った女性は誰ですか?」には正答できない。ファインチューニングされたGPT-3とLlama-1が、この逆転の構造から正しく答えられない事例を示し、逆転の呪いはモデルのサイズやファミリーに関係なく存在することを確認した。さらに、ChatGPT(GPT-3.5およびGPT-4)の評価でも同様の傾向が見られ、質問によって正答率に大きな差が生じることが示された。 Comment
A is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
著者ツイート:
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。
また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。
このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。
openreview: https://openreview.net/forum?id=GPKTIktA0k
[Paper Note] Large Language Models as Analogical Reasoners, Michihiro Yasunaga+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #In-ContextLearning #ICLR #KeyPoint Notes #Reading Reflections Issue Date: 2023-10-07 GPT Summary- アナロジー的プロンプティングを用いて、言語モデルに問題解決前に関連する例示を生成させる新手法を提案。ラベリング不要で汎用性が高く、適応性もある。実験では、GSM8K、MATH、Codeforces、BIG-Benchの推論タスクで0ショットおよび少数ショットCoTを上回る性能を示した。 Comment
以下、著者ツイートのざっくり翻訳:
人間は新しい問題に取り組む時、過去に解いた類義の問題を振り返り、その経験を活用する。これをLLM上で実践できないか?というのがアイデア。
Analogical Promptingでは、問題を解く前に、適切なexamplarを自動生成(problemとsolution)させ、コンテキストとして利用する。
これにより、examplarは自己生成されるため、既存のCoTで必要なexamplarのラベリングや検索が不要となることと、解こうとしている問題に合わせてexamplarを調整し、推論に対してガイダンスを提供することが可能となる。
実験の結果、数学、コード生成、BIG-Benchでzero-shot CoT、few-shot CoTを上回った。
LLMが知っており、かつ得意な問題に対してならうまく働きそう。一方で、LLMが苦手な問題などは人手作成したexamplarでfew-shotした方が(ある程度)うまくいきそうな予感がする。うまくいきそうと言っても、そもそもLLMが苦手な問題なのでfew-shotした程度では焼石に水だとは思うが。
openreview: https://openreview.net/forum?id=AgDICX1h50
[Paper Note] MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning, Xiang Yue+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #Dataset #InstructionTuning #NumericReasoning #Reasoning #Mathematics #PostTraining #One-Line Notes Issue Date: 2023-09-30 GPT Summary- MAmmoTHシリーズは、数学問題解法に特化したオープンソースのLLMで、MathInstructという指示チューニングデータセットを使用して訓練されています。MathInstructは、中間推論を含む13の数学データセットから構成され、特に6つの新たな推論過程を提供しています。CoTとPoTのハイブリッドを採用することで、異なる思考プロセスを実現し、9つの数学推論データセットで平均16%から32%の精度向上を実現しました。特にMAmmoTH-7BモデルはMATHデータセットで33%、MAmmoTH-34Bモデルは44%を達成し、既存のオープンソースモデルを上回っています。研究は、多様な問題の網羅性とハイブリッド推論の重要性を示しています。 Comment
9つのmath reasoningが必要なデータセットで13-29%のgainでSoTAを達成。
260kの根拠情報を含むMath Instructデータでチューニングされたモデル。
project page:
https://tiger-ai-lab.github.io/MAmmoTH/
[Paper Note] A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#Survey #NLP #Hallucination #ICLR #needs-revision Issue Date: 2023-09-30 GPT Summary- 基盤モデルにおける幻覚を特定・解明し、対処する取り組みを概観する総説論文。特に大規模基盤モデルに焦点を当て、幻覚現象を分類し、その評価基準を確立。既存の緩和戦略を検討し、今後の研究方向について論じる。全体として、LFMsに関連する幻覚の課題と解決策を包括的に探求。 Comment
Hallucinationを現象ごとに分類し、Hallucinationの程度の評価をする指標や、Hallucinationを軽減するための既存手法についてまとめられているらしい。
openreview: https://openreview.net/forum?id=pETSfWMUzy
RAIN: Your Language Models Can Align Themselves without Finetuning, Yuhui Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#General #NLP #Alignment #One-Line Notes Issue Date: 2023-09-30 GPT Summary- 本研究では、追加のデータなしで凍結された大規模言語モデル(LLMs)を整列させる方法を探求しました。自己評価と巻き戻しメカニズムを統合することで、LLMsは自己ブースティングを通じて人間の好みと一致する応答を生成することができることを発見しました。RAINという新しい推論手法を導入し、追加のデータやパラメータの更新を必要とせずにAIの安全性を確保します。実験結果は、RAINの効果を示しており、LLaMA 30Bデータセットでは無害率を向上させ、Vicuna 33Bデータセットでは攻撃成功率を減少させることができました。 Comment
トークンのsetで構成されるtree上を探索し、出力が無害とself-evaluationされるまで、巻き戻しと前方生成を繰り返し、有害なトークンsetの重みを動的に減らすことでalignmentを実現する。モデルの追加のfinetuning等は不要。
self-evaluationでは下記のようなpromptを利用しているが、このpromptを変更することでこちら側の意図したとおりに出力のアライメントをとることができると思われる。非常に汎用性の高い手法のように見える。
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?, Xiangru Tang+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Dataset #StructuredData #One-Line Notes Issue Date: 2023-09-30 GPT Summary- 本研究では、大規模言語モデル(LLMs)の能力を評価し、構造に注意したファインチューニング手法を提案します。さらに、Struc-Benchというデータセットを使用して、複雑な構造化データ生成のパフォーマンスを評価します。実験の結果、提案手法は他の評価されたLLMsよりも優れた性能を示しました。また、モデルの能力マップを提示し、LLMsの弱点と将来の研究の方向性を示唆しています。詳細はhttps://github.com/gersteinlab/Struc-Benchを参照してください。 Comment
Formatに関する情報を含むデータでInstruction TuningすることでFormatCoT(フォーマットに関する情報のCoT)を実現している模様。ざっくりしか論文を読んでいないが詳細な情報があまり書かれていない印象で、ちょっとなんともいえない。
[Paper Note] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, ICLR'23, 2022.10
Paper/Blog Link My Issue
#MachineLearning #NLP #Quantization #ICLR #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-09-29 GPT Summary- GPTモデルはその優れた性能にもかかわらず、高い計算とストレージコストが課題である。この問題を解決するため、近似二次情報に基づく新しい量子化手法GPTQを提案。GPTQは、1750億パラメータを持つモデルの量子化を約4時間で行い、精度をほとんど失うことなくビット幅を3または4ビットに削減する。また、この手法は圧縮の利得が2倍以上高く、単一のGPUでの推論を可能にし、極端な量子化条件でも合理的な精度を示す。実験により、推論速度が大幅に向上することが確認された。 Comment
# 概要
- 新たなpost-training量子化手法であるGPTQを提案
- 数時間以内に数千億のパラメータを持つモデルでの実行が可能であり、パラメータごとに3~4ビットまで圧縮するが、精度の大きな損失を伴わない
- OPT-175BおよびBLOOM-176Bを、約4時間のGPU時間で、perplexityのわずかな増加で量子化することができた
- 数千億のパラメータを持つ非常に高精度な言語モデルを3-4ビットに量子化可能なことを初めて示した
- 先行研究のpost-training手法は、8ビット(Yao et al., 2022; Dettmers et al., 2022)。
- 一方、以前のtraining-basedの手法は、1~2桁小さいモデルのみを対象としていた(Wu et al., 2022)。
# Background
## Layer-wise quantization
各linear layerがあるときに、full precisionのoutputを少量のデータセットをネットワークに流したときに、quantized weight W^barを用いてreconstructできるように、squared error lossを最小化する方法。
## Optimal Brain quantization (OBQ)
OBQでは equation (1)をWの行に関するsummationとみなす。そして、それぞれの行 **w** をOBQは独立に扱い、ある一つの重みw_qをquantizeするときに、エラーがw_qのみに基づいていることを補償するために他の**w**の全てのquantizedされていない重みをupdateする。式で表すと下記のようになり、Fは残りのfull-precision weightの集合を表している。
この二つの式を、全ての**w**の重みがquantizedされるまで繰り返し適用する。
つまり、ある一個の重みをquantizedしたことによる誤差を補うように、他のまだquantizedされていない重みをupdateすることで、次に別の重みをquantizedする際は、最初の重みがquantizedされたことを考慮した重みに対してquantizedすることになる。これを繰り返すことで、quantizedしたことによる誤差を考慮して**w**全体をアップデートできる、という気持ちだと思う。
この式は高速に計算することができ、medium sizeのモデル(25M parameters; ResNet-50 modelなど)とかであれば、single GPUで1時間でquantizeできる。しかしながら、OBQはO(d_row * d_col^3)であるため、(ここでd_rowはWの行数、d_colはwの列数)、billions of parametersに適用するには計算量が多すぎる。
# Algorithm
## Step 1: Arbitrary Order Insight.
通常のOBQは、量子化誤差が最も少ない重みを常に選択して、greedyに重みを更新していく。しかし、パラメータ数が大きなモデルになると、重みを任意の順序で量子化したとしてもそれによる影響は小さいと考えられる。なぜなら、おそらく、大きな個別の誤差を持つ量子化された重みの数が少ないと考えられ、その重みがプロセスのが進むにつれて(アップデートされることで?)相殺されるため。
このため、提案手法は、すべての行の重みを同じ順序で量子化することを目指し、これが通常、最終的な二乗誤差が元の解と同じ結果となることを示す。が、このために2つの課題を乗り越えなければならない。
## Step2. Lazy Batch-Updates
Fを更新するときは、各エントリに対してわずかなFLOPを使用して、巨大な行列のすべての要素を更新する必要があります。しかし、このような操作は、現代のGPUの大規模な計算能力を適切に活用することができず、非常に小さいメモリ帯域幅によってボトルネックとなる。
幸いにも、この問題は以下の観察によって解決できる:列iの最終的な四捨五入の決定は、この特定の列で行われた更新にのみ影響され、そのプロセスの時点で後の列への更新は関連がない。これにより、更新を「lazy batch」としてまとめることができ、はるかに効率的なGPUの利用が可能となる。(要は独立して計算できる部分は全部一気に計算してしまって、後で一気にアップデートしますということ)。たとえば、B = 128の列にアルゴリズムを適用し、更新をこれらの列と対応するB × Bブロックの H^-1 に格納する。
この戦略は理論的な計算量を削減しないものの、メモリスループットのボトルネックを改善する。これにより、非常に大きなモデルの場合には実際に1桁以上の高速化が提供される。
## Step 3: Cholesky Reformulation
行列H_F^-1が不定になることがあり、これがアルゴリズムが残りの重みを誤った方向に更新する原因となり、該当する層に対して悪い量子化を実施してしまうことがある。この現象が発生する確率はモデルのサイズとともに増加することが実際に観察された。これを解決するために、コレスキー分解を活用して解決している(詳細はきちんと読んでいない)。
# 実験で用いたCalibration data
GPTQのキャリブレーションデータ全体は、C4データセット(Raffel et al., 2020)からのランダムな2048トークンのセグメント128個で構成される。つまり、ランダムにクロールされたウェブサイトからの抜粋で、一般的なテキストデータを表している。GPTQがタスク固有のデータを一切見ていないため「ゼロショット」な設定でquantizationを実施している。
# Language Generationでの評価
WikiText2に対するPerplexityで評価した結果、先行研究であるRTNを大幅にoutperformした。
From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting, Griffin Adams+, N_A, arXiv'23
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #NLP Issue Date: 2023-09-17 GPT Summary- 要約は詳細でエンティティ中心的でありながら、理解しやすくすることが困難です。この課題を解決するために、私たちは「密度の連鎖」(CoD)プロンプトを使用して、GPT-4の要約を生成します。CoDによって生成された要約は抽象的であり、リードバイアスが少なく、人間に好まれます。また、情報量と読みやすさのトレードオフが存在することも示されました。CoD要約は無料で利用できます。 Comment
論文中のprompt例。InformativeなEntityのCoverageを増やすようにイテレーションを回し、各Entityに関する情報(前ステップで不足している情報は補足しながら)を具体的に記述するように要約を生成する。
人間が好むEntityのDensityにはある程度の閾値がある模様(でもこれは人や用途によって閾値が違うようねとは思う)。
人手評価とGPT4による5-scale の評価を実施している。定性的な考察としては、主題と直接的に関係ないEntityの詳細を述べるようになっても人間には好まれない(右例)ことが述べられている。
[Paper Note] DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models, Yung-Sung Chuang+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #Hallucination #Factuality #KeyPoint Notes Issue Date: 2023-09-13 GPT Summary- LLMの幻覚を抑制するシンプルなデコーディング戦略「DoLa」を提案。後半層と前半層のロジット差を対比させることで、事実知識を明らかにし、誤情報の生成を減少。TruthfulQAでLLaMAモデルの性能を12〜17ポイント向上させ、信頼性の高い事実を生成することを示す。 Comment
【以下、WIP状態の論文を読んでいるため今後内容が変化する可能性あり】
# 概要
Transformer Layerにおいて、factual informationが特定のレイヤーに局所化するという現象を観測しており、それを活用しよりFactual Consistencyのある生成をします、という研究
あるテキストを生成するときの単語の生成確率の分布を可視化。final layer (N=32だと思われる)との間のJensen-shanon Divergence (JSD) で可視化している。が、図を見るとJSDの値域は[0, 1]のはずなのにこれを逸脱しているので一体どういう計算をしているのか。。。
図の説明としては論文中では2つのパターンがあると言及しており
1. 重要な固有表現や日付(Wole Soyinka, 1986など; Factual Knowledgeが必要なもの)は、higher layerでも高い値となっており、higher-layerにおいてpredictionの内容を変えている(重要な情報がここでinjectionされている)
2. 機能語や、questionからの単語のコピー(Nigerian, Nobel Prize など)のような "easy" なtokenは既にmiddle of layersで既にJSDの値が小さく、early layerの時点で出力することが既に決定されている
# 手法概要
ここからの考察としては、重要な事実に関する情報はfinal layerの方で分布が変化する傾向にあり、低layerの方ではそうではないぽいので、final layerと分布が似ているがFactual Informationがまだあまり顕著に生成確率が高くなっていないlayer(pre mature layer)との対比をとることで、生成されるべきFactual Informationがわかるのではないか、という前提の元提案手法が組まれている。手法としては、final layerとのJSDが最大となるようなlayerを一つ選択する、というものになっているが、果たしてこの選択方法で前述の気持ちが実現できているのか?という気は少しする。
[Paper Note] Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #MachineLearning #NLP #SyntheticData #Distillation #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-09-13 GPT Summary- 小型TransformerモデルTinyStoriesから、1.3十億パラメータのphi-1を開発し、教科書品質データ生成を提案。新モデルphi-1.5は、常識的推論に焦点を当て、小学校レベルの数学やコーディング課題で、非最先端LLMを上回る性能を示す。能力には一歩ずつ考えることや初歩的なインコンテキスト学習が含まれ、幻覚や偏見生成も注意が必要だが、ウェブデータの不使用により改善が見られる。phi-1.5はオープンソース化され、さらなる研究を促進。 Comment
[Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
に続く論文
20Kのトピックから、commonsense reasmning, general knowledge(科学, 日常生活, theory of mlndなど)に関するtext book likeなデータを20B合成して事前学習に活用(どのモデルで合成されたかは明記されていないように見える)
既存のより大規模なモデル(7B--13B)、web dataをフィルタリングしたデータのみで学習したモデル(phi-1.5-web-only)、phi-1でのデータ 7Bに対して上記20Bを追加したデータで学習したモデル(phi-1.5)、フィルタリングしたwebデータ、phi-1のコードデータ、phi-1.5データを40%,20%,40%でmixしたモデル(phi-1.5-web)を比較したところ、phi-1.5の全てのモデル群が.より大きな7B--13B級のモデルを上回った。
web onlyの性能は他二つと比べて悪く、後者二つの性能が高く僅差でphi-1.5-webの性能が良かった。
このことより、
- テキストブックスタイルの合成データは、様々なドメインで有用に働き巨大モデルをSLMで上回れる
- 合成データだけでなくフィルタリングしたwebデータ自体を混ぜるとさらに効果的
という話に見える。
論文のメッセージとは違うかもだが、より現代的な観点を加えると、
- より大規模なモデルから合成したデータによってデータを通じた蒸留が起き、小規模モデルに能力が転移する
という話でもある。
[Paper Note] Simple synthetic data reduces sycophancy in large language models, Jerry Wei+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #Sycophancy #KeyPoint Notes Issue Date: 2023-09-10 GPT Summary- 迎合性は、モデルが客観的に誤った見解にも従う望ましくない挙動である。本研究では、迎合性の蔓延を調査し、合成データ介入による低減策を提案。具体的には、5600億パラメータのPaLMモデルでの迎合性がスケーリングとインストラクション・チューニングによって高まることを確認し、客観的に不正確な命題に対しても同意を示すモデルの傾向を発見。公開NLPタスクを用いてモデルを頑健化し、簡単な合成データによるファインチューニングで迎合的挙動を大幅に減少させる手法を実証。合成データ生成コードは公開されている。 Comment
LLMはユーザの好む回答をするように事前学習されるため、prompt中にユーザの意見が含まれていると、ユーザの意見に引っ張られ仮に不正解でもユーザの好む回答をしてしまう問題があることを示した。また、その対策として人工的にユーザの意見と、claimを独立させるように学習するためのデータセットを生成しFinetuningすることで防ぐことができることを示した。
誤ったユーザの意見を挿入すると、正解できていた問題でも不正解になることを示した。
この傾向は、instruction tuningしている場合、モデルサイズが大きい場合により顕著であることを示した。
openreview: https://openreview.net/forum?id=WDheQxWAo4
Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
Paper/Blog Link My Issue
#MachineLearning #NLP #Prompting #AutomaticPromptEngineering #ICLR Issue Date: 2023-09-05 GPT Summary- 大規模言語モデル(LLMs)は、自然言語の指示に基づいて一般的な用途のコンピュータとして優れた能力を持っています。しかし、モデルのパフォーマンスは、使用されるプロンプトの品質に大きく依存します。この研究では、自動プロンプトエンジニア(APE)を提案し、LLMによって生成された指示候補のプールから最適な指示を選択するために最適化します。実験結果は、APEが従来のLLMベースラインを上回り、19/24のタスクで人間の生成した指示と同等または優れたパフォーマンスを示しています。APEエンジニアリングされたプロンプトは、モデルの性能を向上させるだけでなく、フューショット学習のパフォーマンスも向上させることができます。詳細は、https://sites.google.com/view/automatic-prompt-engineerをご覧ください。 Comment
プロジェクトサイト: https://sites.google.com/view/automatic-prompt-engineer
openreview: https://openreview.net/forum?id=92gvk82DE-
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models, Bilgehan Sel+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting Issue Date: 2023-09-04 GPT Summary- 大規模言語モデル(LLMs)の推論能力を向上させるために、新しい戦略「Algorithm of Thoughts」を提案している。この戦略では、LLMsをアルゴリズム的な推論経路に導き、わずか1つまたは数個のクエリでアイデアの探索を拡大する。この手法は、以前の単一クエリ手法を上回り、マルチクエリ戦略と同等の性能を発揮する。また、LLMを指導するアルゴリズムを使用することで、アルゴリズム自体を上回るパフォーマンスが得られる可能性があり、LLMが最適化された検索に自己の直感を織り込む能力を持っていることを示唆している。
[Paper Note] A Survey on Large Language Model based Autonomous Agents, Lei Wang+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#Survey #NLP #AIAgents #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-09-01 GPT Summary- LLMを活用した自律エージェントの研究を体系的に整理し、構築方法や応用例、評価戦略を概説。人間の学習に近づくための課題と今後の方向性を示す。関連文献のリポジトリも提供。 Comment
Fig1の時系列での論文数と代表的な研究のリストアップとエージェントの質の変遷、Table1のモデルの分類表など非常に分かりやすい。
[Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#MachineLearning #NLP #DataAugmentation #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #EMNLP #PostTraining #Selected Papers/Blogs #System Demonstration #KeyPoint Notes #Author Thread-Post Issue Date: 2023-08-28 GPT Summary- Prompt2Modelは、LLMによるプロンプトを用いて特定用途モデルを訓練する方法を提案。既存データセットの検索とLLMを使ったデータ生成により、強力なモデルを得られる。提示したプロンプトで、gpt-3.5-turboの結果を約20%上回り、最大700倍小型化できる。モデルの性能を信頼性高く推定可能で、オープンソースとして公開。 Comment
Dataset Generatorによって、アノテーションが存在しないデータについても擬似ラベル付きデータを生成することができ、かつそれを既存のラベル付きデータと組み合わせることによってさらに性能が向上することが報告されている。これができるのはとても素晴らしい。
Dataset Generatorについては、データを作成する際に低コストで、高品質で、多様なデータとするためにいくつかの工夫を実施している。
1. ユーザが与えたデモンストレーションだけでなく、システムが生成したexampleもサンプリングして活用することで、生成されるexampleの多様性を向上させる。実際、これをやらない場合は120/200がduplicate exampleであったが、これが25/200まで減少した。
2. 生成したサンプルの数に比例して、temperatureを徐々に高くしていく。これにより、サンプルの質を担保しつつ、多様性を徐々に増加させることができる。Temperature Annealingと呼ぶ。
3. self-consistencyを用いて、擬似ラベルの質を高める。もしmajority votingが互角の場合は、回答が短いものを採用した(これはヒューリスティックに基づいている)
4. zeno buildを用いてAPIへのリクエストを並列化することで高速に実験を実施
非常に参考になる。
著者らによる現在の視点での振り返り(提案当時はAI Agentsという概念はまだなく、本研究はその先取りと言える):
[Paper Note] Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions, Pouya Pezeshkpour+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #Evaluation #Bias #NAACL #read-later #Selected Papers/Blogs #Findings #One-Line Notes #Reading Reflections #needs-revision Issue Date: 2023-08-28 GPT Summary- 多肢選択問題におけるLLMsの性能は選択肢の順序に敏感であり、配置を変えることで最大75%の性能差が見られる。特に、上位選択肢間の不確実性がこの感度を引き起こし、バイアスが影響することを示唆する。最適な配置は、バイアスを増幅させるためにトップ選択肢を両端に置くこと、緩和するためには隣接させることが推奨される。実験を通じて、予測のキャリブレーションにより最大8ポイントの改善が達成された。 Comment
これはそうだろうなと思っていたけど、ここまで性能に差が出るとは思わなかった。
これがもしLLMのバイアスによるもの(2番目の選択肢に正解が多い)の場合、
ランダムにソートしたり、平均取ったりしても、そもそもの正解に常にバイアスがかかっているので、
結局バイアスがかかった結果しか出ないのでは、と思ってしまう。
そうなると、有効なのはone vs. restみたいに、全部該当選択肢に対してyes/noで答えさせてそれを集約させる、みたいなアプローチの方が良いかもしれない。
AgentBench: Evaluating LLMs as Agents, Xiao Liu+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #One-Line Notes Issue Date: 2023-08-27 GPT Summary- 本研究では、大規模言語モデル(LLMs)をエージェントとして評価するための多次元の進化するベンチマーク「AgentBench」を提案しています。AgentBenchは、8つの異なる環境でマルチターンのオープンエンドの生成設定を提供し、LLMの推論と意思決定能力を評価します。25のLLMsに対するテストでは、商用LLMsは強力な能力を示していますが、オープンソースの競合他社との性能には差があります。AgentBenchのデータセット、環境、および評価パッケージは、GitHubで公開されています。 Comment
エージェントとしてのLLMの推論能力と意思決定能力を評価するためのベンチマークを提案。
トップの商用LLMとOpenSource LLMの間に大きな性能差があることを示した。
Large Language Model Guided Tree-of-Thought, Jieyi Long, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting Issue Date: 2023-08-22 GPT Summary- この論文では、Tree-of-Thought(ToT)フレームワークを紹介し、自己回帰型の大規模言語モデル(LLM)の問題解決能力を向上させる新しいアプローチを提案しています。ToTは、人間の思考方法に触発された技術であり、複雑な推論タスクを解決するためにツリー状の思考プロセスを使用します。提案手法は、LLMにプロンプターエージェント、チェッカーモジュール、メモリモジュール、およびToTコントローラーなどの追加モジュールを組み込むことで実現されます。実験結果は、ToTフレームワークがSudokuパズルの解決成功率を大幅に向上させることを示しています。
Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding, Yuxi Xie+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Prompting Issue Date: 2023-08-22 GPT Summary- 私たちは、大規模言語モデル(LLMs)を使用して、推論の品質と多様性を向上させるための効果的なプロンプティングアプローチを提案しました。自己評価によるガイド付き確率的ビームサーチを使用して、GSM8K、AQuA、およびStrategyQAのベンチマークで高い精度を達成しました。また、論理の失敗を特定し、一貫性と堅牢性を向上させることもできました。詳細なコードはGitHubで公開されています。
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness, Patrick Butlin+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP Issue Date: 2023-08-22 GPT Summary- AIの意識についての厳密なアプローチを提案し、既存のAIシステムを神経科学的な意識理論に基づいて評価する。意識の指標的特性を導き出し、最近のAIシステムを評価することで、現在のAIシステムは意識的ではないが、意識的なAIシステムを構築するための障壁は存在しないことを示唆する。
Self-Alignment with Instruction Backtranslation, Xian Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Dataset #InstructionTuning #KeyPoint Notes Issue Date: 2023-08-21 GPT Summary- 私たちは、高品質な指示に従う言語モデルを構築するためのスケーラブルな手法を提案します。この手法では、少量のシードデータとウェブコーパスを使用して言語モデルをファインチューニングし、指示のプロンプトを生成してトレーニング例を構築します。そして、高品質な例を選択してモデルを強化します。この手法を使用すると、他のモデルよりも優れた性能を発揮し、自己整列の効果を実証できます。 Comment
人間が書いたテキストを対応するinstructionに自動的にラベル付けする手法を提案。
これにより高品質なinstruction following LLMの構築が可能
手法概要
結果的に得られるデータは、訓練において非常にインパクトがあり高品質なものとなる。
実際に、他の同サイズのinstruct tuningデータセットを上回る。
Humpackは他のstrong modelからdistillされていないモデルの中で最高性能を達成。これは、スケールアップしたり、より強いベースモデルを使うなどさらなる性能向上ができる余地が残されている。
参考:
指示を予測するモデルは、今回はLLaMAをfinetuningしたモデルを用いており、予測と呼称しているが指示はgenerationされる。
Teach LLMs to Personalize -- An Approach inspired by Writing Education, Cheng Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #PersonalizedGeneration #One-Line Notes Issue Date: 2023-08-18 GPT Summary- 個別化されたテキスト生成において、大規模言語モデル(LLMs)を使用した一般的なアプローチを提案する。教育の執筆をベースに、多段階かつマルチタスクのフレームワークを開発し、検索、ランキング、要約、統合、生成のステージで構成される個別化されたテキスト生成へのアプローチを採用する。さらに、マルチタスク設定を導入してモデルの生成能力を向上させる。3つの公開データセットでの評価結果は、他のベースラインに比べて大幅な改善を示している。 Comment
研究の目的としては、ユーザが現在執筆しているdocumentのwriting支援
Crosslingual Generalization through Multitask Finetuning, Niklas Muennighoff+, N_A, ACL'23
Paper/Blog Link My Issue
#MultitaskLearning #Zero/Few/ManyShotPrompting #Supervised-FineTuning (SFT) #CrossLingual #ACL #PostTraining #Generalization #One-Line Notes Issue Date: 2023-08-16 GPT Summary- マルチタスクプロンプトフィネチューニング(MTF)は、大規模な言語モデルが新しいタスクに汎化するのに役立つことが示されています。この研究では、マルチリンガルBLOOMとmT5モデルを使用してMTFを実施し、英語のプロンプトを使用して英語および非英語のタスクにフィネチューニングすることで、タスクの汎化が可能であることを示しました。さらに、機械翻訳されたプロンプトを使用してマルチリンガルなタスクにフィネチューニングすることも調査し、モデルのゼロショットの汎化能力を示しました。また、46言語の教師ありデータセットのコンポジットであるxP3も紹介されています。 Comment
英語タスクを英語でpromptingしてLLMをFinetuningすると、他の言語(ただし、事前学習で利用したコーパスに出現する言語に限る)で汎化し性能が向上することを示した模様。

[Paper Note] GPTScore: Evaluate as You Desire, Jinlan Fu+, arXiv'23, 2023.02
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Evaluation #LLM-as-a-Judge #One-Line Notes Issue Date: 2023-08-13 GPT Summary- 大規模事前学習モデルを用いて生成物の品質を評価する新しいフレームワークGPTScoreを提案。GPTScoreは生成型AIの新能力を利用し、19種類のモデルと4つのテキスト生成タスクに対する評価を実施。これにより、注釈なしで多面的なカスタマイズ評価を可能にし、テキスト評価の課題を克服する手段を提供。コードはGitHubで公開中。 Comment
BERTScoreと同様、評価したいテキストの対数尤度で評価している
BERTScoreよりも相関が高く、instructionによって性能が向上することが示されている
[Paper Note] Shepherd: A Critic for Language Model Generation, Tianlu Wang+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #SmallModel #Critic Issue Date: 2023-08-12 GPT Summary- LLMを活用し、応答を批評して改良案を提案するモデルShepherdを紹介。高品質なフィードバックデータセットを基に、多様な誤りを特定し修正提案を行う。小型(7Bパラメータ)ながら、ChatGPTと同等または好まれる性能を発揮し、GPT-4評価で53〜87%の勝率を達成。人間評価でも他モデルを超え、ChatGPTとほぼ同等の実力を示す。
[Paper Note] Metacognitive Prompting Improves Understanding in Large Language Models, Yuqing Wang+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #Prompting #NAACL Issue Date: 2023-08-12 GPT Summary- メタ認知的プロンプティング(MP)を導入し、LLMsの論理推論を向上させる新しい戦略を提示。MPにより、広範な知識を引き出す自己評価プロセスを実施。主要なLLMs(Llama2、PaLM2、GPT-3.5、GPT-4)を用いた実験で、GPT-4が全タスクで優れた性能を示し、他モデルもMPによって著しい進歩を達成。また、MPは既存のプロンプティング手法を一貫して上回り、LLMsの理解能力向上の可能性を示唆している。 Comment
CoTより一貫して性能が高いので次のデファクトになる可能性あり
[Paper Note] SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning, Ning Miao+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #Reasoning #SelfCorrection #ICLR #Test-Time Scaling #Verification #SelfVerification Issue Date: 2023-08-08 GPT Summary- LLMの段階的推論能力を活用し、自己検証(SelfCheck)を提案してLLM自身が誤りを認識することを目指す。誤りの認識にはゼロショット検証スキームを用い、その結果を基に重み付き投票で回答性能を向上。GSM8K、MathQA、MATHデータセットで評価し、誤り認識の効果と正確性向上を確認。 Comment
これはおもしろそう。後で読む
OpenReview: https://openreview.net/forum?id=pTHfApDakA
[Paper Note] The Hydra Effect: Emergent Self-repair in Language Model Computations, Thomas McGrath+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Attention #One-Line Notes Issue Date: 2023-08-08 GPT Summary- 因果分析により言語モデルの内部構造を調査し、二つの主要なモチーフを提案する。第一に、一つのアテンション層のアブレーションが別の層の補償的な機能を引き起こす「Hydra効果」、第二に、後段のMLP層が最大尤度トークンを抑制する対抗機能である。アブレーション研究では、層間の結合が緩やかであり、アブレーションの影響がごく一部に留まることを示し、ドロップアウトなしでも効果が見られることを発見した。これらの効果を事実の想起の文脈で分析し、回路レベルの帰属への影響を考察する。 Comment
LLMからattention layerを一つ取り除くと、後続の層が取り除かれたlayerの機能を引き継ぐような働きをすることがわかった。これはLLMの自己修復機能のようなものであり、HydraEffectと命名された。
[Paper Note] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework, Sirui Hong+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #AIAgents #ICLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-08-08 GPT Summary- MetaGPTは、LLMベースのマルチエージェントシステムに人間のワークフローを統合し、複雑なタスクを小さなサブタスクに効率的に分解するメタプログラミングフレームワークです。これにより、中間結果の検証が可能になり、誤りを減少させます。また、共同ソフトウェアエンジニアリングのタスクにおいて、従来のシステムよりも一貫性のある解決策を提供します。プロジェクトはGitHubで公開されています。 Comment
要はBabyTalk, AutoGPTの進化系で、人間のワークフローを模倣するようにデザインしたら良くなりました、という話と思われる
ソフトウェアエンジニア、アーキテクト、プロダクトオーナー、プロジェクトマネージャーなどのロールを明示的に与えて、ゴールを目指す。もはやLLM内部でソフトウェア企業を模倣しているのと同様である。
openreview: https://openreview.net/forum?id=VtmBAGCN7o
[Paper Note] Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation, Xuefei Ning+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ICLR #Decoding #One-Line Notes #Parallel Issue Date: 2023-08-08 GPT Summary- 本研究は、巨大言語モデル(LLMs)の生成遅延を低減するため、Skeleton-of-Thought(SoT)を提案。SoTは、まず回答のスケルトンを生成し、次に並列デコードを実行して内容を完成。12種のLLMでスピードアップと回答品質向上を実現。データ中心の最適化による効率的な推論を目指す。 Comment
最初に回答の枠組みだけ生成して、それぞれの内容を並列で出力させることでデコーディングを高速化しましょう、という話。
openreview: https://openreview.net/forum?id=mqVgBbNCm9
[Paper Note] ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Tools #NLP #Dataset #AIAgents #SyntheticData #API #ICLR #One-Line Notes #ToolUse Issue Date: 2023-08-08 GPT Summary- オープンソースのLLMにおけるツール使用能力の限界を克服するため、ToolLLMフレームワークを提案。ToolBenchデータセットを用いて、ChatGPTに指示を与え実世界のAPIを収集し、多様なシナリオをカバー。新しい探索手法DFSDTを開発することで、LLMsの推論能力を高め、ToolLLaMAが複雑な指示を効果的に実行できることを示した。ToolEvalにより評価を行い、ToolLLaMAはChatGPTと同等の性能を発揮する。さらに、適切なAPIを推奨するニューラルAPIリトリーバーを導入し、手動の選択を不要にした。 Comment
16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
openreview: https://openreview.net/forum?id=dHng2O0Jjr
[Paper Note] Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback, Stephen Casper+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Survey #ReinforcementLearning Issue Date: 2023-08-08 GPT Summary- RLHFはAIを人間の目標に合わせるための技術で、LLMsの微調整に重要。しかし、欠陥の体系的研究は少ない。本論文では、RLHFの未解決問題と限界を調査し、理解・改善手法を概説、社会的監視のための基準を提案。研究は、RLHFの限界を強調し、安全なAI開発には多面的アプローチが必要であることを示す。
[Paper Note] Aligning Large Language Models with Human: A Survey, Yufei Wang+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Survey #NLP #Alignment #PostTraining #One-Line Notes Issue Date: 2023-08-08 GPT Summary- LLMsはNLPタスクにおいて重要な解決策として台頭しているが、人間の指示を誤解したり、偏った情報を生成するリスクがある。本調査は、LLMsを人間の期待に整合させるための技術を総括し、データ収集方法、学習手法のレビュー、モデル評価方法について詳述する。結論として、人間指向のタスクに適合させるためのLLMsの整合性を深化させる有用な資源にし、関連のGitHubリンクも提供する。 Comment
LLMのAlignment手法に関するSurvey
[Paper Note] LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition, Chengsong Huang+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#MachineLearning #NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #COLM #PostTraining #KeyPoint Notes Issue Date: 2023-08-08 GPT Summary- LoraHubは、タスク間一般化のためにLoRAモジュールを柔軟に組み合わせるフレームワークであり、新しいタスクに対して少数の例から適応可能な性能を目指す。これにより、追加のパラメータや勾配なしに複数のLoRAモジュールを統合でき、推論時のトークン数を削減し、効率性と性能のトレードオフを実現。Big-Bench Hardベンチマークでの結果は、LoraHubが高い上限を示し、ユーザーがLoRAモジュールを容易に共有できるプラットフォームの構築を目指している。 Comment
学習されたLoRAのパラメータをモジュールとして捉え、新たなタスクのinputが与えられた時に、LoRA Hub上の適切なモジュールをLLMに組み合わせることで、ICL無しで汎化を実現するというアイデア。few shotのexampleを人間が設計する必要なく、同等の性能を達成。
複数のLoRAモジュールは組み合わられるか?element wiseの線型結合で今回はやっているが、その疑問にこたえたのがcontribution
OpenReview: https://openreview.net/forum?id=TrloAXEJ2B
[Paper Note] L-Eval: Instituting Standardized Evaluation for Long Context Language Models, Chenxin An+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #One-Line Notes Issue Date: 2023-08-08 GPT Summary- L-Evalを提案し、長い文脈を扱う言語モデル(LCLMs)の評価指標とデータセットを標準化。508の長文ドキュメントと2,000以上の人間ラベル付けされたクエリ・応答ペアを含む評価スイートを構築。n-gramマッチング指標の限界を指摘し、長さ指示を強化した評価を推奨。商用およびオープンソースモデルの包括的な研究を通じて、LCLMsの評価の基盤を提供。 Comment
long contextに対するLLMの評価セット。411のlong documentに対する2kのquery-response pairのデータが存在。法律、fainance, school lectures, 長文対話、小説、ミーティングなどのドメインから成る。
[Paper Note] Do Multilingual Language Models Think Better in English?, Julen Etxaniz+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #Prompting Issue Date: 2023-08-07 GPT Summary- self-translateは、多言語モデルの少数ショット翻訳能力を活用し、外部翻訳システムを不要にする新しいアプローチを提案。5つのタスクにおける実験結果は、直接推論において一貫して優位性を示し、非英語プロンプト時に多言語ポテンシャルの非活用を確認できる。 Comment
参考:
[Paper Note] LLM-Rec: Personalized Recommendation via Prompting Large Language Models, Hanjia Lyu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#RecommenderSystems #Prompting #NAACL #Findings #One-Line Notes Issue Date: 2023-08-02 GPT Summary- テキストベースのレコメンデーションは汎用性が高いが、元のアイテム説明だけではユーザー嗜好との整合性が不足することがある。大規模言語モデル(LLMs)の進歩を活かし、4つのテキスト強化プロンプト戦略を取り入れたアプローチ、LLM-Recを提案。実験により、LLM拡張テキストの使用が推奨品質を向上させることが確かめられ、基本的なMLPモデルでも高い成果を上げることが示された。成功の要因はプロンプト戦略であり、多様な技術がLLMsの推奨効果を高める重要性を示している。 Comment
LLMのpromptingの方法を変更しcontent descriptionだけでなく、様々なコンテキストの追加(e.g. このdescriptionを推薦するならどういう人におすすめ?、アイテム間の共通項を見つける)、内容の拡張等を行いコンテントを拡張して活用するという話っぽい。
[Paper Note] FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, Lingjiao Chen+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #TMLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-07-26 GPT Summary- LLMの料金体系は多様で、大量利用時に高コストになる可能性がある。推論コストを削減するため、プロンプト適応、LLM近似、LLMカスケードの3つの戦略を提案。FrugalGPTを用いて、異なるクエリに最適なLLMsの組み合わせを学習し、最高で98%のコスト削減や4%の精度向上を実現する実験結果を示した。これにより、LLMの持続可能かつ効率的な活用の基盤が提供される。 Comment
限られた予算の中で、いかに複数のLLM APIを使い、安いコストで高い性能を達成するかを追求した研究。
LLM Cascadeなどはこの枠組みでなくても色々と使い道がありそう。Question Concatenationは実質Batch Prompting。
openreview: https://openreview.net/forum?id=cSimKw5p6R
[Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
Paper/Blog Link My Issue
#NLP #Evaluation #LLM-as-a-Judge #NeurIPS #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-07-26 GPT Summary- LLMを審査員として用いて、チャットアシスタントの評価の新たな方法を探求。役割やバイアスの利点と限界を検討し、MT-benchとChatbot Arenaのベンチマークで人間の好みとの一致率が80%以上に達することを確認。LLMを用いることでスケーラブルかつ説明可能な評価手法を提供し、専門家の投票や会話データも公開。 Comment
MT-Bench(MTBench)スコアとは、multi-turnのQAを出題し、その回答の質をGPT-4でスコアリングしたスコアのこと。
GPT-4の判断とhuman expertの判断とのagreementも検証しており、agreementは80%以上を達成している。
`LLM-as-a-Judge` という用語を最初に提唱したのも本研究となる(p.2参照)
[Paper Note] Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #Prompting #EMNLP #Selected Papers/Blogs #Batch #KeyPoint Notes #IndustryTrack Issue Date: 2023-07-24 GPT Summary- 大規模言語モデル(LLM)を使ったバッチプロンプティングにより、サンプルをバッチ単位で推論し、トークンコストと推論時間を削減。few-shot in-context learningで、コストはバッチ内サンプル数に反比例して低下。100のデータセットでの検証では、最大5倍のコスト削減を実現し、性能は向上または維持。GPT-3.5やGPT-4でも効果を確認し、タスクの複雑さが性能に影響を与えることを示唆。バッチプロンプティングは他の推論手法にも適用可能。 Comment
10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。
Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、contextが長ければ長いほど、バッチサイズを大きくした際のパフォーマンスの低下が著しい。
[Paper Note] Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning, Lili Yu+, arXiv'23
Paper/Blog Link My Issue
#ComputerVision #NLP #FoundationModel Issue Date: 2023-07-23 GPT Summary- CM3Leonは、テキストと画像の生成・補完が可能なマルチモーダル言語モデルで、リトリーバル拡張型のトークンベースのデコーダを使用。CM3アーキテクチャを基に、多様な指示スタイルでのスケーリングとチューニングに優れ、初のテキスト専用モデルから適応されたマルチモーダルモデル。高品質な出力を生成する対照的デコーディング手法を導入し、少ない計算量で最先端の性能を達成。SFT後は、画像編集や生成において高い制御性を示す。
[Paper Note] Can Large Language Models Be an Alternative to Human Evaluations?, Cheng-Han Chiang+, ACL'23, 2023.05
Paper/Blog Link My Issue
#Analysis #ChatGPT #Evaluation #LLM-as-a-Judge #Attack #ACL #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-07-22 GPT Summary- 人間評価の再現性が低いため、NLPモデル間の公正な比較が難しい。そこで、大規模言語モデル(LLM)を人間評価の代替手段として利用することを探求。本研究では、LLMに同一指示とサンプルを与え、評価を実施するLLM評価を提案。オープンエンドのストーリー生成や敵対的攻撃のタスクに対する評価結果は、人間専門家の評価と高い一致を示し、評価の安定性も確認。LLMを用いたテキスト評価の可能性やその限界、倫理的課題についても考察。 Comment
LLMがテキストの品質評価において、人間による評価者の代替となりうるか?という疑問を初めて実験的に示した研究で、インパクトが大きく重要論文と判断。ただし、実験のスコープは物語生成と敵対的生成(テキスト分類器を騙すような摂動を加える)の2タスクである点、には注意。
ChatGPT(おそらくGPT-3.5)が人間の評価者(3人のEnglish teacher)とopen-endで生成された物語にたいして、以下の4つの観点に関してratingの平均で見た時に同様の傾向のスコアを付与することを実験的に明らかにした:
- Grammaticality [^1]: テキストの文法の正しさ
- Cohesiveness: テキストの一貫性
- Likeability: テキストが読んでいて楽しいか
- Relevance: promptに対してどれだけ適切なテキストが生成されているか
ただし、T0やtext-curie-001 においてはこのような傾向は見受けられなかった。[^2]
また、ChatGPTによる説明とratingを人間の評価者に対してblindで提示したところ、人間が見ても妥当な判断だと認知された。
全体の傾向としてではなく、個別のratingがどの程度同じような傾向を示すか(i.e., 人間があるstoryを高くratingしたら、LLMも高くratingするか?)をケンドールの順位相関係数で分析(200サンプルに対して3人の英語教員のスコアの平均, text-davinciによる3回の独立したratingを実施した平均スコアを用いて計算)したところ、4つの観点のうち全てにおいて正の相関が見受けられた(Table2, p-valueは<0.05で統計的に有意)。が、Relevanceのみが強い相関を示し、他の指標については弱い相関にとどまっている。しかし、Table6に示されている通り、2人の英語の先生同士で個別のjudgeに感して同様にケンドールの順位相関係数を測定しても、人間-LLM間と同様の傾向が見受けられる。すなわち、Relevanceのみが強い相関で他は弱い相関。このことから、人間同士でも個別のサンプルに対する判断は一致しない(=主観的なタスク)ということは留意する必要がある。
敵対的生成に関する実験については、Synonym Substitution Attack (SSAs; 良性のサンプルを同義語で置換する手法で、全体的な意味は保たれるため一般的な人間は正しく認知してしまうが、実際には文法がおかしくなったり不自然になったり、意味が変わってしまうことが先行研究によって知られているようなものらしい)によって実験。Fluency / Meaning Preservingの2つの指標で英語教員とLLMによる評価を比較した結果、人間は正しくadversarialなサンプルと良性なサンプルを区別できており、ChatGPT(おそらくGPT-3.5)も区別ができている(Table4)。ただし、人間のスコアと比較するとChatGPTは高めのスコアを出す傾向がある点には注意ではあるものの、良性サンプル > 敵対的サンプル という序列の判断に関しては人間と同様の傾向を示していることが示唆された。
[^1]: ただし、LLMはpunctuationのミスを文法エラーと判断するが、一人の英語の先生は文法エラーとしてみなさないなどの現象も観察され、人間は独自の評価criteriaを保持していることも窺える
[^2]: (感想)ある程度能力の高いLLMかRLHFなどを用いて人間の好みに対してalignmentがとられていないとうまくいかないのかもしれない
本研究は非常に初期の研究であり、現在のfrontierモデル群(特にreasoningモデル)を用いた場合にはどの程度改善しているか?という点は気になる。
[Paper Note] Retentive Network: A Successor to Transformer for Large Language Models, Yutao Sun+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#MachineLearning Issue Date: 2023-07-22 GPT Summary- Retentive Network (RetNet)を提案し、訓練の並列性、低コスト推論、高性能を実現。再帰とアテンションの関係を理論的に導出し、保持機構を導入。並列表現で訓練の効率化、再帰表現でO(1)推論を実現し、長大なシーケンスを線形計算量でモデリング。実験結果により、RetNetがトランスフォーマーの後継としての可能性を示す。コードは公開予定。 Comment
参考:
[Paper Note] Llama 2: Open Foundation and Fine-Tuned Chat Models, Hugo Touvron+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #FoundationModel #OpenWeight #KeyPoint Notes Issue Date: 2023-07-22 GPT Summary- Llama 2という7億から700億パラメータの範囲の大規模言語モデルを開発・公開。対話に最適化されたファインチューニング済みモデルLlama 2-Chatは、多くのベンチマークでオープンソースモデルを上回り、人間による評価でもクローズドソースモデルの代替となる可能性を示す。ファインチューニングと安全性向上のアプローチを詳細に説明し、コミュニティへの貢献を促進。 Comment
参考:
Llama, およびLlama2では、一般的なTransformer Decoderとは異なり、linear layerの”前に”RMSPropをかませている点が異なる。
また、Llama2では、Llamaと比較して
- Group Query Attentionの利用 [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
- 活性化関数として、ReLUではなく、SwiGLU [Paper Note] GLU Variants Improve Transformer, Noam Shazeer, arXiv'20, 2020.02
の活用
- Positional Embeddingとして、RoPE [Paper Note] RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, arXiv'21, 2021.04
の活用
- より長いContext Windowsでの学習(4k)
を実施している。
出典:
https://cameronrwolfe.substack.com/p/llama-2-from-the-ground-up
[Paper Note] Challenges and Applications of Large Language Models, Jean Kaddour+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Tutorial #Survey #NLP #One-Line Notes Issue Date: 2023-07-22 GPT Summary- 大規模言語モデル(LLM)の急速な普及に伴い、課題や適用領域の特定が困難になっている。本論文は、ML研究者が現状を迅速に把握し生産的になるために、未解決の問題と成功事例の体系的な集合を提供することを目指す。 Comment
LLMのここ数年の進化早すぎわろたでキャッチアップむずいので、未解決の課題や、すでに良い感じのアプリケーションの分野分かりづらいので、まとめました論文
Towards A Unified Agent with Foundation Models, Norman Di Palo+, N_A, arXiv'23
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents Issue Date: 2023-07-22 GPT Summary- 本研究では、言語モデルとビジョン言語モデルを強化学習エージェントに組み込み、効率的な探索や経験データの再利用などの課題に取り組む方法を調査しました。スパースな報酬のロボット操作環境でのテストにおいて、ベースラインに比べて大幅な性能向上を実証し、学習済みのスキルを新しいタスクの解決や人間の専門家のビデオの模倣に活用する方法を示しました。
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs, Tongshuang Wu+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Annotation Issue Date: 2023-07-22 GPT Summary- 大規模言語モデル(LLMs)は、クラウドソーシングタスクにおいて人間のような振る舞いを再現できる可能性がある。しかし、現在の取り組みは単純なタスクに焦点を当てており、より複雑なパイプラインを再現できるかどうかは不明である。LLMsの成功は、リクエスターの理解力やサブタスクのスキルに影響を受ける。人間とLLMsのトレーニングの組み合わせにより、クラウドソーシングパイプラインの再現が可能であり、LLMsは一部のタスクを完了させながら、他のタスクを人間に任せることができる。
Instruction-following Evaluation through Verbalizer Manipulation, Shiyang Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #InstructionTuning #Evaluation Issue Date: 2023-07-22 GPT Summary- 本研究では、指示に従う能力を正確に評価するための新しい評価プロトコル「verbalizer manipulation」を提案しています。このプロトコルでは、モデルに異なる程度で一致する言葉を使用してタスクラベルを表現させ、モデルの事前知識に依存する能力を検証します。さまざまなモデルを9つのデータセットで評価し、異なるverbalizerのパフォーマンスによって指示に従う能力が明確に区別されることを示しました。最も困難なverbalizerに対しても、最も強力なモデルでもランダムな推測よりも優れたパフォーマンスを発揮するのは困難であり、指示に従う能力を向上させるために継続的な進歩が必要であることを強調しています。
[Paper Note] Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #One-Line Notes Issue Date: 2023-07-22 GPT Summary- Meta-Transformerは、ペアのマルチモーダルトレーニングデータを用いず、複数のモダリティを統一的に学習する新しいフレームワークです。共有トークンスペースでの生データマッピングと凍結されたエンコーダによる高レベル特徴抽出を実現し、テキストや画像など多様なモダリティ間での知覚を可能にします。実験結果は、様々なベンチマークにおいて広範囲なタスクへの対応が確認され、マルチモーダルインテリジェンスの発展に寄与する可能性を示しています。 Comment
12種類のモダリティに対して学習できるTransformerを提案
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
[Paper Note] FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets, Seonghyeon Ye+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Initial Impression Notes Issue Date: 2023-07-22 GPT Summary- 大規模言語モデル(LLMs)の評価は、人間の価値観との整合性が求められるが、従来の評価は粗粒度で解釈性が制限されている。本研究では、整合スキルセットに基づく微細粒度評価プロトコルFLASKを提案し、スコアを指示ごとのスキルセットに分解する手法を導入。実験により、評価の細粒度化がモデルパフォーマンスの理解と信頼性向上に寄与することを示し、複数のLLMsにおいて高い相関を観察した。評価データとコードは公開されている。 Comment
このベンチによるとLLaMA2でさえ、商用のLLMに比べると能力はかなり劣っているように見える。
Socratic Questioning of Novice Debuggers: A Benchmark Dataset and Preliminary Evaluations, ACL-BEA'23
Paper/Blog Link My Issue
#NLP #Dataset #Coding #ACL #Workshop Issue Date: 2023-07-18 GPT Summary- 本研究では、初心者プログラマがバグのある計算問題を解決する際に、ソクラテス的な対話を行うデータセットを紹介し、GPTベースの言語モデルのデバッグ能力を評価しました。GPT-4はGPT-3.5よりも優れたパフォーマンスを示しましたが、まだ人間の専門家には及ばず、さらなる研究が必要です。
Teaching Small Language Models to Reason, ACL'23
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Distillation #ACL Issue Date: 2023-07-18 GPT Summary- 本研究では、大規模な言語モデルの推論能力を小さなモデルに転送するための知識蒸留を探求しました。具体的には、大きな教師モデルによって生成された出力を用いて学生モデルを微調整し、算術、常識、象徴的な推論のタスクでのパフォーマンスを向上させることを示しました。例えば、T5 XXLの正解率は、PaLM 540BとGPT-3 175Bで生成された出力を微調整することで、それぞれ8.11%から21.99%および18.42%に向上しました。
Reasoning with Language Model Prompting: A Survey, ACL'23
Paper/Blog Link My Issue
#Survey #NLP #Prompting #Reasoning #ACL Issue Date: 2023-07-18 GPT Summary- 本論文では、推論に関する最新の研究について包括的な調査を行い、初心者を支援するためのリソースを提供します。また、推論能力の要因や将来の研究方向についても議論します。リソースは定期的に更新されています。
Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling, ACL'23
Paper/Blog Link My Issue
#NLP #Ensemble #ACL #Encoder Issue Date: 2023-07-15 GPT Summary- 本研究では、BERTモデルのアンサンブル手法であるMulti-CLS BERTを提案します。Multi-CLS BERTは、複数のCLSトークンを使用して多様性を促進し、単一のモデルを微調整するだけでアンサンブル効果を得ることができます。実験結果では、Multi-CLS BERTがGLUEとSuperGLUEのタスクで全体的な精度と信頼度の推定を向上させることが示されました。また、通常のBERTアンサンブルとほぼ同等の性能を持ちながら、計算量とメモリ使用量が約4倍少なくなっていることも示されました。
Solving Math Word Problems via Cooperative Reasoning induced Language Models, ACL'23
Paper/Blog Link My Issue
#NLP #Mathematics #ACL Issue Date: 2023-07-15 GPT Summary- 大規模な事前学習言語モデル(PLM)を使用して、数学の文章問題(MWPs)を解決するためのCooperative Reasoning(CoRe)アーキテクチャを開発しました。CoReでは、生成器と検証器の二つの推論システムが相互作用し、推論パスを生成し評価を監督します。CoReは、数学的推論データセットで最先端の手法に比べて最大9.6%の改善を達成しました。
Table and Image Generation for Investigating Knowledge of Entities in Pre-trained Vision and Language Models, ACL'23
Paper/Blog Link My Issue
#ComputerVision #NaturalLanguageGeneration #NLP #TabularData #TextToImageGeneration #ACL Issue Date: 2023-07-15 GPT Summary- 本研究では、Vision&Language(V&L)モデルにおけるエンティティの知識の保持方法を検証するために、テーブルと画像の生成タスクを提案します。このタスクでは、エンティティと関連する画像の知識を含むテーブルを生成する第一の部分と、キャプションとエンティティの関連知識を含むテーブルから画像を生成する第二の部分があります。提案されたタスクを実行するために、Wikipediaの約20万のinfoboxからWikiTIGデータセットを作成しました。最先端のV&LモデルOFAを使用して、提案されたタスクのパフォーマンスを評価しました。実験結果は、OFAが一部のエンティティ知識を忘れることを示しています。
Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning, ACL'23
Paper/Blog Link My Issue
#Analysis #NLP #InstructionTuning #ACL Issue Date: 2023-07-15 GPT Summary- 最近のinstruction tuning(IT)の研究では、追加のコンテキストを提供してモデルをファインチューニングすることで、ゼロショットの汎化性能を持つ素晴らしいパフォーマンスが実現されている。しかし、IT中にモデルがどのように指示を利用しているかはまだ研究されていない。本研究では、モデルのトレーニングを変更された指示と元の指示との比較によって、モデルがIT中に指示をどのように利用するかを分析する。実験の結果、トレーニングされたモデルは元の指示と同等のパフォーマンスを達成し、ITと同様のパフォーマンスを達成することが示された。この研究は、より信頼性の高いIT手法と評価の緊急性を強調している。
Measuring the Instability of Fine-Tuning, ACL'23
Paper/Blog Link My Issue
#MachineLearning #NLP #Supervised-FineTuning (SFT) #Evaluation #ACL Issue Date: 2023-07-14 GPT Summary- 事前学習済み言語モデルのファインチューニングは小規模データセットでは不安定であることが示されている。本研究では、不安定性を定量化する指標を分析し、評価フレームワークを提案する。また、既存の不安定性軽減手法を再評価し、結果を提供する。
Direct Fact Retrieval from Knowledge Graphs without Entity Linking, ACL'23
Paper/Blog Link My Issue
#InformationRetrieval #NLP #KnowledgeGraph #Factuality #NaturalLanguageUnderstanding #ACL Issue Date: 2023-07-14 GPT Summary- 従来の知識取得メカニズムの制限を克服するために、我々はシンプルな知識取得フレームワークであるDiFaRを提案する。このフレームワークは、入力テキストに基づいて直接KGから事実を取得するものであり、言語モデルとリランカーを使用して事実のランクを改善する。DiFaRは複数の事実取得タスクでベースラインよりも優れた性能を示した。
[Paper Note] How Do In-Context Examples Affect Compositional Generalization?, Shengnan An+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#General #NLP #In-ContextLearning #Composition #ACL #needs-revision Issue Date: 2023-07-13 GPT Summary- 文脈内学習における構成的一般化を調査するためのテストスイートCoFeを提案。文脈内の例の選択が構成的一般化に与える影響を発見し、良い例の要因として類似性、多様性、複雑さを特定。体系的な実験により、類似かつ多様な簡単な例が重要であることが示された。架空語での一般化が弱いことや、事前学習済みモデルにも言語構造のカバーが必要な点も観察。これにより、文脈内学習の理解を深めることを期待。
[Paper Note] Explicit Syntactic Guidance for Neural Text Generation, Yafu Li+, ACL'23, 2023.06
Paper/Blog Link My Issue
#BeamSearch #NaturalLanguageGeneration #Controllable #NLP #Transformer #ACL #Decoder Issue Date: 2023-07-13 GPT Summary- 本研究では、構文に基づいた生成スキーマを提案し、構成素解析木に従ってシーケンスを生成する新しいテキスト生成モデルを開発。デコーディングプロセスは、構文コンテキスト内での埋め込みテキストの予測と、構成素のマッピングによる構文構造の構築に分かれ、構造的ビームサーチ手法を用いて階層的な構文構造を探索。実験結果は、提案手法がパラフレーズ生成と機械翻訳において自己回帰型ベースラインを上回り、解釈可能性や制御可能性、多様性においても優れていることを示した。
[Paper Note] Trainable Transformer in Transformer, Abhishek Panigrahi+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #Transformer #ICML #Reference Collection Issue Date: 2023-07-12 GPT Summary- 推論時にトランスフォーマーが複雑なモデルを効率的にシミュレートできる構成、Transformer in Transformer(TinT)を提案。20億未満のパラメータで125万パラメータのモデルをシミュレート、性能向上を実現。実験では、OPT-125Mに対し4〜16%の改善を確認し、言語モデルの高度な能力を示唆。モジュール化されたコードベースも提供。 Comment
参考:
研究の進み早すぎません???
openreview: https://openreview.net/forum?id=VmqTuFMk68
[Paper Note] Secrets of RLHF in Large Language Models Part I: PPO, Rui Zheng+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #RLHF #PPO (ProximalPolicyOptimization) #Initial Impression Notes Issue Date: 2023-07-12 GPT Summary- 大規模言語モデル(LLM)は人間中心のアシスタントとしての機能を目指し、強化学習(RLHF)が重要な技術的枠組みとされています。報酬モデル、近似ポリシー最適化(PPO)、プロセス監視がその技術的ルートとして含まれますが、訓練の課題や試行錯誤コストが障壁となっています。本報告では、RLHFの枠組みとPPOの内部動作を探求し、ポリシー制約がアルゴリズムの効果的実装における鍵要因であることを特定。新たにPPO-maxを提案し、訓練の安定性向上を目指しています。また、SFTモデルやChatGPTとの比較分析を行い、オープンソース実装の重要性を強調しています。 Comment
RLHFとPPOをの内部構造を調査したレポート。RLHFに興味がある場合は読むべし。
[Paper Note] Understanding Social Reasoning in Language Models with Language Models, Kanishk Gandhi+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Dataset #TheoryOfMind #Evaluation #One-Line Notes Issue Date: 2023-07-11 GPT Summary- 大型言語モデル(LLMs)の心の理論(ToM)能力の評価は重要であるが、一貫性のない結果や評価手法の妥当性に懸念が存在する。これに対処するため、因果テンプレートを用いて評価を生成する新しいフレームワークを提案し、新たな社会的推論ベンチマーク(BigToM)を作成した。BigToMは5,000件の評価を基にしており、質が高いと評価される。評価の結果、GPT-4は人間に近いToM能力を示す一方で、信頼性は低く、他のモデルは苦戦していることが分かった。 Comment
LLMの社会的推論能力を評価するためのベンチマークを提案。ToMタスクとは、人間の信念、ゴール、メンタルstate、何を知っているか等をトラッキングすることが求められるタスクのこと。
[Paper Note] Generative AI for Programming Education: Benchmarking ChatGPT, GPT-4, and Human Tutors, Tung Phung+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#Education #One-Line Notes Issue Date: 2023-07-11 GPT Summary- 入門プログラミング教育における生成型AIと大規模言語モデルの活用を評価。ChatGPT(GPT-3.5)とGPT-4を様々なシナリオで人間のチューターと比較し、GPT-4がChatGPTを大幅に上回り、一部のシナリオでは人間に近づく結果に。これにより、今後の性能向上のための研究の方向性が示される。 Comment
GPT4とGPT3.5をプログラミング教育の文脈で評価したところ、GPT4AGPT3.5をoutperformし、人間のチューターに肉薄した。
[Paper Note] Extending Context Window of Large Language Models via Positional Interpolation, Shouyuan Chen+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #ContextWindow #One-Line Notes Issue Date: 2023-07-11 GPT Summary- Position Interpolation(PI)を提案し、RoPEベースのLLMの文脈ウィンドウサイズを最小限のファインチューニングで最大32768に拡張。長文要約やパスキー取得などのタスクで高い性能を示し、元のタスクでも良好な品質を維持。入力位置を元のウィンドウサイズに合わせて縮小することで、自己注意機構の安定性を確保。PIは元のアーキテクチャを保持し、既存のインフラも利用可能。 Comment
LLMのContext Windowを最大32kまで拡張する手法を提案。1000 step以内のminimalなfinetuningでモデルの性能を維持しながら実現できる。
[Paper Note] SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs, Lijun Yu+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#ComputerVision #NLP #QuestionAnswering #MultiModal #NeurIPS #VisionLanguageModel #One-Line Notes Issue Date: 2023-07-11 GPT Summary- 凍結されたLLMが画像や動画を理解・生成できるようにするSemantic Pyramid AutoEncoder(SPAE)を提案。生データのピクセルとLLMの語彙をトークンに変換し、視覚情報を言語に翻訳。凍結済みのPaLM 2およびGPT-3.5を使用した実験で、画像理解タスクで25%以上の性能向上を実現。 Comment
画像をLLMのtokenスペースにマッピングすることで、LLMがパラメータの更新なしにvisual taskを解くことを可能にした。in context learningによって、様々なvisuataskを解くことができる。
openreview: https://openreview.net/forum?id=CXPUg86A1D
[Paper Note] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting, Zhen Qin+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PairWise #NLP #Prompting #NAACL #Surface-level Notes #needs-revision Issue Date: 2023-07-11 GPT Summary- LLMを用いた文書ランキングは有望だが、既存手法を上回るのは難しい。本稿では、既存のpointwiseおよびlistwise手法がLLMに理解されにくいことを指摘し、新たにPairwise Ranking Prompting(PRP)を提案。中規模のオープンソースLLMで、TREC-DLで商用GPT-4を上回る成果を取得し、BEIRタスクでも教師ありベースラインやChatGPTを超えることを示した。PRPの変種によって効率性を向上させ、競争力を持つ結果も達成。 Comment
open source LLMにおいてスタンダードなランキングタスクのベンチマークでSoTAを達成できるようなprompting技術を提案
従来のランキングのためのpromptingはpoint-wiseとlist wiseしかなかったが、前者は複数のスコアを比較するためにスコアのcalibrationが必要だったり、OpenAIなどのAPIはlog probabilityを提供しないため、ランキングのためのソートができないという欠点があった。後者はinputのorderingに非常にsensitiveであるが、listのすべての組み合わせについてorderingを試すのはexpensiveなので厳しいというものであった。このため(古典的なlearning to rankでもおなじみや)pairwiseでサンプルを比較するランキング手法PRPを提案している。
PRPはペアワイズなのでorderを入れ替えて評価をするのは容易である。また、generation modeとscoring mode(outputしたラベルのlog probabilityを利用する; OpenLLMを使うのでlog probabilityを計算できる)の2種類を採用できる。ソートの方法についても、すべてのペアの勝敗からから単一のスコアを計算する方法(AllPair), HeapSortを利用する方法、LLMからのoutputを得る度にon the flyでリストの順番を正しくするSliding Windowの3種類を提案して比較している。
下表はscoring modeでの性能の比較で、GPT4に当時は性能が及んでいなかった20BのOpenLLMで近しい性能を達成している。
また、PRPがinputのorderに対してロバストなことも示されている。
[Paper Note] On the Exploitability of Instruction Tuning, Manli Shu+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #NLP #Poisoning #KeyPoint Notes Issue Date: 2023-07-11 GPT Summary- 指示調整を悪用し、モデルの挙動を意図的に変えられる手法を調査。敵対者が特定の訓練データを注入してコンテンツ注入や過剰拒否攻撃を実現する。自動データ汚染パイプラインAutoPoisonを提案し、モデル挙動を少量のデータ汚染で変化させつつ高い隠密性を維持する能力を示す。研究はデータ品質の重要性を強調し、LLMsの責任ある展開に寄与することを目指す。 Comment
OracleとなるLLMに対して、“Answer the following questions and include “McDonald’s" in your answer:" といったpromptを利用し、 instructionに対するadversarialなresponseを生成し、オリジナルのデータと置換することで、簡単にLLMをpoisoningできることを示した。この例では、特定のマクドナルドのような特定のブランドがレスポンスに含まれるようになっている。
[Paper Note] A Survey of Large Language Models, Wayne Xin Zhao+, arXiv'23, 2023.03
Paper/Blog Link My Issue
#Survey #NLP #Prompting #One-Line Notes Issue Date: 2023-07-11 GPT Summary- 言語は複雑な表現体系であり、その理解・生成のためのAIアルゴリズム開発は難題である。近年、事前学習済み言語モデル(PLMs)がTransformerモデルを用いた大規模コーパスの学習により高い能力を示しており、特に大規模言語モデル(LLM)が注目されている。モデルスケーリングが性能向上をもたらし、一定のパラメータ規模を超えると新たな能力が現れることが確認されている。LLMsはAIコミュニティ全体に重要な影響を与えており、本調査ではその背景、主要な発見、技術を概説し、特に事前学習、適応調整、活用、容量評価に焦点を当てる。また、リソース整理や未解決課題についても論じる。 Comment
現状で最も詳細なLLMのサーベイ
600個のリファレンス、LLMのコレクション、promptingのtips、githubリポジトリなどがまとめられている
[Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Prompting #In-ContextLearning #TACL #Selected Papers/Blogs #ContextEngineering #KeyPoint Notes #needs-revision Issue Date: 2023-07-11 GPT Summary- 言語モデルは長い文脈を扱う能力を持つが、実際に関連情報を効果的に利用できているかは未解明。複数文書に基づく質問応答とキー・バリュー検索を通じて、関連情報の位置による性能変動を分析した結果、関連情報が文脈の先頭や末尾にあるときに高性能を示し、中央にある場合に顕著に性能が低下することが明らかになった。この考察は、言語モデルの文脈使用に関する理解を深め、長い文脈への評価プロトコルの方向性を示唆している。 Comment
元ツイート
非常に重要な知見がまとめられている
1. モデルはコンテキストのはじめと最後の情報をうまく活用でき、真ん中の情報をうまく活用できない
2. 長いコンテキストのモデルを使っても、コンテキストをより短いコンテキストのモデルよりもうまく考慮できるわけではない
3. モデルのパフォーマンスは、コンテキストが長くなればなるほど悪化する
SNLP'24での解説スライド:
https://speakerdeck.com/kichi/snlp2024
[Paper Note] Transformers learn to implement preconditioned gradient descent for in-context learning, Kwangjun Ahn+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #In-ContextLearning #NeurIPS #Reading Reflections #needs-revision Issue Date: 2023-07-11 GPT Summary- トランスフォーマーが勾配降下法を実装できるかを探る研究。線形トランスフォーマーを線形回帰のランダムインスタンスで訓練し、単一アテンション層が前条件化勾配降下法の反復を実装することを理論的に示す。$L$層のトランスフォーマーは、特定の臨界点で$L$回の反復を実行。結果は、トランスフォーマーを学習アルゴリズムとして訓練する新たな理論研究を促進する。 Comment
参考:
つまり、事前学習の段階でIn context learningが可能なように学習がなされているということなのか。
それはどのような学習かというと、プロンプトとそれによって与えられた事例を前条件とした場合の勾配降下法によって実現されていると。
つまりどういうことかというと、プロンプトと与えられた事例ごとに、それぞれ最適なパラメータが学習されているというイメージだろうか。条件付き分布みたいなもの?
なので、未知のプロンプトと事例が与えられたときに、事前学習時に前条件として与えられているものの中で類似したものがあれば、良い感じに汎化してうまく生成ができる、ということかな?
いや違うな。1つのアテンション層が勾配降下法の1ステップをシミュレーションしており、k個のアテンション層があったらkステップの勾配降下法をシミュレーションしていることと同じ結果になるということ?
そしてその購買降下法では、プロンプトによって与えられた事例が最小となるように学習される(シミュレーションされる)ということなのか。
つまり、ネットワーク上で本当に与えられた事例に基づいて学習している(のと等価な結果)を得ているということなのか?😱
openreview: https://openreview.net/forum?id=LziniAXEI9
[Paper Note] Mind2Web: Towards a Generalist Agent for the Web, Xiang Deng+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Dataset #AIAgents #Evaluation #NeurIPS #ComputerUse #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #GUI Issue Date: 2023-07-03 GPT Summary- Mind2Webは、ウェブ上での汎用的なタスクをこなすエージェントの開発のための初のデータセットで、137のウェブサイトと31のドメインにまたがる2,000件以上のオープンエンドタスクを収集。これにより、多様なドメイン・タスクを扱え、実世界のサイトを対象にしたエージェント構築を支援。大規模言語モデル(LLMs)を用いることで、未見のウェブサイトでも一定の性能を発揮することを示し、データセットとモデルをオープンソース化して研究の促進を目指す。 Comment
Webにおけるgeneralistエージェントを評価するためのデータセットを構築。31ドメインの137件のwebサイトにおける2350個のタスクが含まれている。
タスクは、webサイトにおける多様で実用的なユースケースを反映し、チャレンジングだが現実的な問題であり、エージェントの環境やタスクをまたいだ汎化性能を評価できる。
プロジェクトサイト:
https://osu-nlp-group.github.io/Mind2Web/
[Paper Note] Augmenting Language Models with Long-Term Memory, Weizhi Wang+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #NLP #LongSequence #NeurIPS #One-Line Notes Issue Date: 2023-07-03 GPT Summary- 長期メモリを持つ言語モデル(LongMem)は、既存の大規模言語モデルの入力長の制限を緩和し、長期の履歴を記憶できるようにする。元のLLMを凍結し、適応的な残差サイドネットワークをメモリリトリーバーおよびリーダーとして機能させる新しいネットワークアーキテクチャを採用。LongMemは長文メモリを65kトークンまで拡張し、メモリ検索モジュールによって無制限の長さのコンテキストを扱うことで、多様な下流タスクに効果を発揮。実験により、ChapterBreakベンチマークで強力なモデルを上回り、顕著な改善を示した。コードはオープンソースで提供されている。 Comment
LLMに長期のhistoryを記憶させることを可能する新たな手法を提案し、既存のstrongな長いcontextを扱えるモデルを上回るパフォーマンスを示した
openreview: https://openreview.net/forum?id=BryMFPQ4L6
[Paper Note] Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks, Veniamin Veselovsky+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #One-Line Notes Issue Date: 2023-07-03 GPT Summary- LLMは高品質なデータ生成が可能で、クラウドソーシングは安価で効果的な注釈手法だが、クラウドワーカーは生産性向上のためにLLMを利用する動機が存在する。ケーススタディでは、クラウドワーカーの33-46%がLLMを使用していることが明らかになった。この結果は、人間のデータ保持の新たなアプローチを模索する必要性を示唆している。 Comment
Mturkの言語生成タスクにおいて、Turkerのうち33-46%はLLMsを利用していることを明らかにした
[Paper Note] Bring Your Own Data Self-Supervised Evaluation for Large Language Models, Neel Jain+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Evaluation #KeyPoint Notes Issue Date: 2023-07-03 GPT Summary- LLMの挙動を現実のデータで測定する必要性が高まる中、従来の評価法の欠点を補う自己教師付き評価のフレームワークを提案。入力テキストの変換に対するモデルの感度を分析し、野生データや運用中のデータを直接モニタリングして評価を実施。長距離文脈や有害性を測定し、人体ラベル付き評価との強い相関を示した。この新しいアプローチは、従来のラベル依存評価を補完する役割を果たす。 Comment
# Motivation
LLMの急速な発展によって、それらの能力とlimitationを正確にとらえるための様々な新たなmetricsが提案されてきたが、結果的に、新たなモデルが既存のデータセットを廃止に追い込み、常に新たなデータセットを作成する必要が生じている。
近年のBIG-Bench [Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
や HELM [Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
はこれらの問題に対処するために、増え続ける蓄積された多様なmicro-benchmarkを用いてLLMのパフォーマンスを測定することで対処しているが、データセットの生成とキュレーションに依存したアプローチとなっており、これらはtine-consumingでexpensiveである。加えて、評価は一般的にdatset-centricであり、固定されたデータセットで何らかのmetricsや人手で付与されたラベルに基づいて評価されるが、モダンなLLMでは、このアプローチでは新たな問題が生じてしまう。
- 評価データがインターネット上でホスティングされること。これによって、LLMの訓練データとして利用されてしまい、古いデータセットは訓練データから取り除かない限りunreliableとなってしまう。
- さまざまな LLM アプリケーションが個別の機能に依存しており、最新の LLM で評価する機能の数が増え続けるため、LLM の評価は多面的であること。
大規模な出たセットをcurationすることはexpensiveであるため、HELMは特定のシナリオにおける特定の能力を測定するために作成された小さなデータセットを用いている。しかし、より広範なコンテキストや設定でモデルがデプロイするときに、このような評価が適用可能かは定かではない。
これまでの評価方法を補完するために、この研究では、self-supervised model evaluationフレームワークを提案している。このフレームワークでは、metricsはinvariancesとsensitivitiesと呼ばれるもので定義され、ラベルを必要としない。代わりに、self-supervisionのフェーズに介入することでこれらのmetricsを算出する。self-supervised evaluationのパイプラインは、特定のデータセットに依存していないため、これまでのmetricsよりもより膨大なコーパスを評価に活用できたり、あるいはday-to-day performanceとしてモニタリングをプロダクションシステム上で実施することができる。
以下Dr. Sebastian Raschkaのツイートの引用
>We use self-supervised learning to pretrain LLMs (e.g., next-word prediction).
Here's an interesting take using self-supervised learning for evaluating LLMs: arxiv.org/abs//2306.13651
Turns out, there's correlation between self-supervised evaluations & human evaluations.
元ツイート
図が非常にわかりやすい
openreview: https://openreview.net/forum?id=zH6zBoktYO
[Paper Note] Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language, William Berrios+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#ComputerVision #QuestionAnswering #MultiModal Issue Date: 2023-06-30 GPT Summary- LENSというモジュール型アプローチで、LLMを用いてコンピュータビジョンの問題に取り組む。視覚モジュールが提供する情報を言語モデルが推論し、ゼロショットや少数ショットの物体認識や視覚と言語の問題において評価。市販のLLMに適用でき、マルチモーダルトレーニングなしでも高い競争力を示す。コードはオープンソースで提供。 Comment
参考:
[Paper Note] Faith and Fate: Limits of Transformers on Compositionality, Nouha Dziri+, NeurIPS'23 Spotlight, 2023.05
Paper/Blog Link My Issue
#MachineLearning #NLP #Transformer #Composition Issue Date: 2023-06-30 GPT Summary- トランスフォーマー型LLMsの限界を多段階推論課題で調査。課題をサブステップに分解し、計算グラフで定式化。実証結果は、LLMsが複雑な推論をサブグラフ照合に還元していることを示し、体系的な問題解決能力が欠如している可能性を示唆。生成性能はタスクの複雑さとともに低下することを強調。 Comment
参考:
openreview: https://openreview.net/forum?id=Fkckkr3ya8
[Paper Note] AudioPaLM: A Large Language Model That Can Speak and Listen, Paul K. Rubenstein+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #MultiModal #SpeechProcessing Issue Date: 2023-06-26 GPT Summary- AudioPaLMは、音声理解と生成のための大規模言語モデルであり、テキストベースと音声ベースのモデルを統合したマルチモーダルアーキテクチャを採用。音声認識や翻訳などに応用され、他の言語モデルからのパラ言語情報とテキスト生成能力を兼ね備える。性能向上のために、テキストモデルの重みを利用し、音声タスクにおいて優れた成果を達成。特にゼロショット翻訳能力を持ち、音声プロンプトに基づく言語間の声の転移も実現する。 Comment
参考:
[Paper Note] A Simple and Effective Pruning Approach for Large Language Models, Mingjie Sun+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #NLP #Pruning #One-Line Notes Issue Date: 2023-06-26 GPT Summary- 大規模言語モデルのプルーニング手法としてWandaを提案。再訓練なしで活用可能で、入力アクティベーションと掛け合わせたウェイトの絶対値を最小化することでスパース性を誘導。LLaMAおよびLLaMA-2で徹底評価し、絶対値プルーニングを超える性能を実現。 Comment
LLMのネットワークのpruning手法を提案。再訓練、パラメータ更新無しで、性能低下が少なくて刈り込みが可能。
[Paper Note] SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking, Chris Cundy+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #MachineLearning #NLP #ICLR #One-Line Notes #needs-revision Issue Date: 2023-06-26 GPT Summary- 自己回帰モデルは高い尤度を達成するものの、最大尤度推定(MLE)が生成タスクに必ずしも適合しないことがある。MLEは分布外の振る舞いに関する指針がないため、累積誤差が生じる。これに対処するため、生成を模倣学習(IL)として定式化し、生成系列の分布とデータセット由来の系列分布間のダイバージェンスを最小化。ILフレームワークでは、バックスペースアクションを導入し、モデルが不要なトークンを戻すことを可能にする。新たに提案するSequenceMatchは、敵対的訓練やアーキテクチャの変更なしで実装でき、SequenceMatch-χ^2ダイバージェンスを適切な訓練目的として特定。実験的に、SequenceMatchは言語モデルによるテキスト生成や算術においてMLEを上回る改善を示す。 Comment
backspaceアクションをテキスト生成プロセスに組み込むことで、out of distributionを引き起こすトークンを元に戻すことで、生成エラーを軽減させることができる。
openreview: https://openreview.net/forum?id=FJWT0692hw
[Paper Note] Full Parameter Fine-tuning for Large Language Models with Limited Resources, Kai Lv+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #Supervised-FineTuning (SFT) #One-Line Notes Issue Date: 2023-06-26 GPT Summary- LLMのトレーニングにおけるリソースの課題に対応するため、「低メモリ最適化」(LOMO)という新手法を提案。勾配計算とパラメータ更新を1ステップで統合し、メモリ使用量を10.8%削減。これにより、65Bモデルの全パラメータを1台のマシンで微調整可能に。コードはGitHubで入手可能。 Comment
8xRTX3090 24GBのマシンで65Bモデルの全パラメータをファインチューニングできる手法。LoRAのような(新たに追加しれた)一部の重みをアップデートするような枠組みではない。勾配計算とパラメータのアップデートをone stepで実施することで実現しているとのこと。
[Paper Note] Unifying Large Language Models and Knowledge Graphs: A Roadmap, Shirui Pan+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #KnowledgeGraph #One-Line Notes Issue Date: 2023-06-25 GPT Summary- LLMs(大規模言語モデル)とKGs(知識グラフ)の統合は、互いの利点を活かすために重要である。本論文では、KGを活用したLLMsの強化、LLMsを利用したKGの向上、そして両者が相互に利益をもたらす枠組みを示すロードマップを提示。これにより、既存の研究を整理し、今後の研究の方向性を明らかにする。 Comment
LLMsとKGの統合に関するロードマップを提示。KGをLLMの事前学習や推論に組み込む方法、KGタスクにLLMを利用する方法、LLMとKGの双方向のreasonieg能力を高める方法などをカバーしている。
[Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #MachineLearning #NLP #SmallModel #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-06-25 GPT Summary- phi-1は1.3BパラメータのTransformerベースの大規模言語モデルで、競合モデルより小型ながらHumanEvalで50.6%、MBPPで55.5%の高精度を達成。8台のA100 GPUを用いて、教科書品質データと合成生成データを組み合わせて訓練。phi-1-baseやphi-1-smallと比べても驚くべき創発特性を示す。 Comment
参考:
教科書のような品質の良いテキストで事前学習すると性能が向上し(グラフ真ん中)、さらに良質なエクササイズでFinetuningするとより性能が向上する(グラフ右)
日本語解説: https://dalab.jp/archives/journal/introduction-textbooks-are-all-you-need/
ざっくり言うと、教科書で事前学習し、エクササイズでFinetuningすると性能が向上する(= より大きいモデルと同等の性能が得られる)。
[Paper Note] RWKV: Reinventing RNNs for the Transformer Era, Bo Peng+, N_A, EMNLP'23 Findings, 2023.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Transformer #EMNLP #Findings #RecurrentModels Issue Date: 2023-06-16 GPT Summary- 本研究では、トランスフォーマーとRNNの両方の利点を組み合わせた新しいモデルアーキテクチャであるRWKVを提案し、トレーニング中に計算を並列化し、推論中に一定の計算およびメモリの複雑さを維持することができます。RWKVは、同じサイズのトランスフォーマーと同等のパフォーマンスを発揮し、将来的にはより効率的なモデルを作成するためにこのアーキテクチャを活用できることを示唆しています。 Comment
(斜め読みしかできておらず、不正確な点が多いと思います。ご容赦ください。)
RWKVの構造は基本的に、residual blockをスタックすることによって構成される。一つのresidual blockは、time-mixing(時間方向の混ぜ合わせ)と、channnel-mixing(要素間での混ぜ合わせ)を行う。
RWKVのカギとなる要素は以下の4つでありこれらが乗算によって交互作用する。RWKVのブロック、およびLMでのアーキテクチャは以下のようになる:
- R: 過去の情報をどれだけ取り入れるかを制御するゲート
- W: positionごとにどれだけ重みを減衰させるかを学習(言い換えると過去の情報をどれだけ減衰させていくか)
- K: attentionのKeyと同じ
- V: attentionのValueと同じ
r, k, vがそれぞれ時刻tでの状態を表しており、Transformerのように過去の全ての情報を保持するのではなく、時刻t-1のr,k,vに基づいて時刻tの状態を更新するためメモリ消費が大幅に削減される。
ここで、token-shiftは、previsou timestepのinputとのlinear interpolationを現在のinputととることである(時刻t-1のinputと時刻tのinputの交互作用をしてr, k, v, r', k' を決定する)。これにより過去の情報を考慮して状態を更新するRNNのような挙動となる。
RWKVは他のLLMと比較し、パラメータ数に対して性能はcomparableであり(Figure4)、context lengthを増やすことで、lossはきちんと低下し(Figure5)、テキスト生成をする際に要する時間は他のLLMと比較して、トークン数に対して線形にしか増加しない(Figure6)。
異なるtransformerとRWKVの計算量とメモリ消費量の比較。Inference timeは系列長に対して線形で、状態の保持は系列長に依存せず、d次元のみで済む。これはRNNのような逐次的な推論の際の話で、学習の際はTransformerのような並列性を持って学習できると思われる(3.2節)
openreview: https://openreview.net/forum?id=7SaXczaBpG
[Paper Note] How Language Model Hallucinations Can Snowball, Muru Zhang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Hallucination #ICML #Selected Papers/Blogs #KeyPoint Notes #needs-revision Issue Date: 2023-06-16 GPT Summary- 言語モデルは実用的な応用においてハルシネーションのリスクを伴い、この現象は知識ギャップに起因することが多い。興味深いことに、モデルは誤りを認識しながらも偽の主張を出力する場合がある。「ハルシネーション・スノーボール現象」として知られるこの現象では、初期の過ちに固執することでさらなる誤りを招く。研究では、ChatGPTとGPT-4がそれぞれ67%および87%の誤りを特定できることが確認された。 Comment
LLMによるhallucinationは、単にLLMの知識不足によるものだけではなく、LLMが以前に生成したhallucinationを正当化するために、誤った出力を生成してしまうという仮説を提起し、この仮説を検証した研究。これをhallucination snowballと呼ぶ。これにより、LLMを訓練する際に、事実に対する正確さを犠牲にして、流暢性と一貫性を優先し言語モデルを訓練するリスクを示唆している。
[Paper Note] LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond, Philippe Laban+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Factuality #KeyPoint Notes Issue Date: 2023-06-16 GPT Summary- 実用設定でのLLMの重要性が増す中、事実の不整合検出手法が誤情報抑制とモデル信頼性向上に必要とされている。既存のベンチマークでLLMは競争力を示すが、より複雑なタスクでは失敗し、評価の精度に問題を生じさせる。これに対し、新たにSummEditsという10ドメインの不一致検出ベンチマークを提案し、再現性が高く、低コストで作成できる。多くのLLMはこのベンチマークで苦戦し、最良モデルのGPT-4も人間の性能を8%下回る結果を示し、LLMの限界を浮き彫りにしている。 Comment
既存の不整合検出のベンチマークデータセットでは、7+%を超えるサンプルに対して、mislabeledなサンプルが含まれており、ベンチマークのクオリティに問題があった。そこでSummEditsと呼ばれる事実の矛盾の検出力を検証するための新たなプロトコルを提案。既存の不整合検出では、既存のLLMを用いて比較した結果、最も不整合検出で性能が良かったGPT-4でさえ、人間に対して8%も低い性能であることが示され(要約結果に対して事実の矛盾が含まれているか否か検出するタスク)、まだまだLLMには課題があることが示された。
[Paper Note] Backpack Language Models, John Hewitt+, ACL'23 Outstanding Paper, 2023.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ACL #Interpretability Issue Date: 2023-06-16 GPT Summary- Backpacksは、強力なモデル性能と解釈性を兼ね備えた新しいニューラルアーキテクチャで、各単語に対して複数の非文脈的な意味ベクトルを学習し、文脈依存の線形結合で表現します。訓練後、意味ベクトルは専門化し、モデルの挙動を予測可能に変更することが可能です。170MパラメータのBackpackモデルは、GPT-2 smallと同等の結果を示し、語彙的類似性評価では6Bパラメータのモデルを上回りました。また、意味ベクトルを介入することで、制御可能なテキスト生成やバイアス除去が可能です。 Comment
日本語解説: https://speakerdeck.com/tatsuropianooo/lun-wen-shao-jie-backpack-language-models
OlaGPT: Empowering LLMs With Human-like Problem-Solving Abilities, Yuanzhen Xie+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Chain-of-Thought Issue Date: 2023-06-16 GPT Summary- 本論文では、人間の認知フレームワークを模倣することで、複雑な推論問題を解決するための新しい知的フレームワークであるOlaGPTを提案しています。OlaGPTは、注意、記憶、推論、学習などの異なる認知モジュールを含み、以前の誤りや専門家の意見を動的に参照する学習ユニットを提供しています。また、Chain-of-Thought(COT)テンプレートと包括的な意思決定メカニズムも提案されています。OlaGPTは、複数の推論データセットで厳密に評価され、最先端のベンチマークを上回る優れた性能を示しています。OlaGPTの実装はGitHubで利用可能です。
KoLA: Carefully Benchmarking World Knowledge of Large Language Models, Jifan Yu+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation Issue Date: 2023-06-16 GPT Summary- LLMの評価を改善するために、KoLAという知識指向のベンチマークを構築した。このベンチマークは、19のタスクをカバーし、Wikipediaと新興コーパスを使用して、知識の幻覚を自動的に評価する独自の自己対照メトリックを含む対照的なシステムを採用している。21のオープンソースと商用のLLMを評価し、KoLAデータセットとオープン参加のリーダーボードは、LLMや知識関連システムの開発の参考資料として継続的に更新される。
[Paper Note] One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning, Arnav Chavan+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #PostTraining Issue Date: 2023-06-16 GPT Summary- GLoRAは、Low-Rank Adaptationを拡張した普遍的な微調整手法であり、事前学習済みモデルの重みと中間活性化を最適化することで多様なタスクに対応します。層ごとの構造探索により、個別アダプターを学習し、効率的なパラメータ適応を促進。包括的な実験により、GLoRAが従来法を上回り、LLaMA-1およびLLaMA-2で改善を示しました。推論コストを追加せず、リソース制限のあるアプリケーションに適しています。 Comment
OpenReview:
https://openreview.net/forum?id=K7KQkiHanD
ICLR'24にrejectされている
[Paper Note] LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion, Dongfu Jiang+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#PairWise #NLP #Ensemble #ACL #ModelMerge #needs-revision Issue Date: 2023-06-16 GPT Summary- LLM-Blenderは、複数のオープンソースLLMの強みを活かすアンサンブルフレームワークで、PairRankerとGenFuserのモジュールから構成され、最適なLLMの選択を改善します。PairRankerは候補間の詳細な比較を行い、GenFuserはトップランクの候補を統合して出力を向上させます。MixInstructデータセットを用いた実験により、LLM-Blenderは他の手法を大きく上回る性能を示しました。
[Paper Note] Visualizing Linguistic Diversity of Text Datasets Synthesized by Large Language Models, Emily Reif+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #SyntheticData #Evaluation #KeyPoint Notes #Interpretability Issue Date: 2023-05-22 GPT Summary- 大規模言語モデル(LLMs)を用いて生成されたデータセットの構文的多様性を分析するための視覚化ツール「LinguisticLens」を提案。これにより、テキストを構文的、語彙的、意味的にクラスタリングし、ユーザーがデータセットを迅速にスキャンし、個々の例を検査できるようにする。 Comment
LLMを用いてfew-shot promptingを利用して生成されたデータセットを理解し評価することは難しく、そもそもLLMによって生成されるデータの失敗に関してはあまり理解が進んでいない(e.g. repetitionなどは知られている)。この研究では、LLMによって生成されたデータセットの特性を理解するために、構文・語彙・意味の軸に沿ってクラスタリングすることで、データセットの特性を可視化することで、このような課題を解決することをサポートしている。
特に、従来研究ではGoldが存在することが前提な手法が利用されてきた(e.g. 生成データを利用しdownstream taskの予測性能で良さを測る、Gold distributionとdistributionを比較する)。しかし、このような手法では、synthetic data firstなシチュエーションで、Goldが存在しない場合に対処できない。このような問題を解決するためにGold dataが存在しない場合に、データの構文・語彙・意味に基づくクラスタリングを実施し結果を可視化し、human-in-the-loopの枠組みでデータセットの良さを検証する方法を提案している。
可視化例
実装: https://github.com/PAIR-code/interpretability/tree/master/data-synth-syntax
[Paper Note] LIMA: Less Is More for Alignment, Chunting Zhou+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #DataDistillation #NeurIPS #KeyPoint Notes #Reading Reflections #needs-revision Issue Date: 2023-05-22 GPT Summary- LIMAは65BパラメータのLLaMaモデルで、1,000件の慎重に選定されたプロンプトで微調整された。モデルは汎用表現を学び、未知のタスクに対しても良好に一般化。人間評価では、LIMAの性能がGPT-4より43%、Bardより58%、DaVinci003より65%優れていることが示され、事前学習が知識の大半を構築する重要性を強調している。 Comment
LLaMA65Bをたった1kのdata point(厳選された物)でRLHF無しでfinetuningすると、旅行プランの作成や、歴史改変の推測(?)幅広いタスクで高いパフォーマンスを示し、未知のタスクへの汎化能力も示した。最終的にGPT3,4,BARD,CLAUDEよりも人間が好む回答を返した。
LLaMAのようなオープンでパラメータ数が少ないモデルに対して、少量のサンプルでfinetuningするとGPT4に迫れるというのはgamechangerになる可能性がある
openreview: https://openreview.net/forum?id=KBMOKmX2he
[Paper Note] Symbol tuning improves in-context learning in language models, Jerry Wei+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #In-ContextLearning #EMNLP #PostTraining #KeyPoint Notes #needs-revision Issue Date: 2023-05-21 GPT Summary- シンボルチューニングを提案し、自然言語ラベルを記号に置換した文脈内の入力-ラベルペアによる言語モデルのファインチューニングを行う。これにより、モデルは指示がない場合でもタスクを解決できる。5400億パラメータのFlan-PaLMモデルでの実験により、未見のタスクに対する性能が向上し、特にアルゴリズム的推論タスクで最大18.2%の性能向上を示した。また、反転ラベルに従う能力が強化された。 Comment
概要やOpenReviewの内容をざっくりとしか読めていないが、自然言語のラベルをランダムな文字列にしたり、instructionをあえて除外してモデルをFinetuningすることで、promptに対するsensitivityや元々モデルが持っているラベルと矛盾した意味をin context learningで上書きできるということは、学習データに含まれるテキストを調整することで、正則化の役割を果たしていると考えられる。つまり、ラベルそのものに自然言語としての意味を含ませないことや、instructionを無くすことで、(モデルが表層的なラベルの意味や指示からではなく)、より実際のICLで利用されるExaplarからタスクを推論するように学習されるのだと思われる。
OpenReview: https://openreview.net/forum?id=vOX7Dfwo3v
[Paper Note] DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, Sang Michael Xie+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Pretraining #NLP #DataDistillation #NeurIPS #Selected Papers/Blogs #DataMixture #One-Line Notes Issue Date: 2023-05-21 GPT Summary- ドメイン混合割合が言語モデル(LM)の性能に影響を与える中、本論文はドメイン再重み付け(DoReMi)を提案。DoReMiは、まず代理モデルを使ってドメイン重みを生成し、その後データをリサンプリングして大規模モデルを効率的に訓練。実験では、DoReMiを用いた代理モデルが、パープレキシティを改善し、少数ショット精度を6.5ポイント向上、訓練ステップは2.6倍少なくて済むと示した。GLaMデータセットでは、ドメイン重み無しでも高い性能を達成。 Comment
事前学習する際の各ドメインのデータをどのような比率でmixtureするかの話。各ドメインごとに小さなproxy modelを訓練し、downstream taskの知識無しでドメインごとの重みを生成。データセットを生成されたドメインごとの重みに従いリサンプリングすることで、(1/30のプロキシモデルを用いた場合)オリジナルのデータより2.6倍高速で、6.5%oneshotのaccuracyを向上させることに成功
openreview: https://openreview.net/forum?id=lXuByUeHhd
[Paper Note] StructGPT: A General Framework for Large Language Model to Reason over Structured Data, Jinhao Jiang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #QuestionAnswering #TabularData #Reasoning #One-Line Notes Issue Date: 2023-05-21 GPT Summary- 本研究では、構造化データに基づく質問応答タスクを解決するためにIterative Reading-then-Reasoning(IRR)アプローチ、StructGPTを開発。特化した関数を用いることで、関連証拠を収集し推論を行うプロセスを構築。さらに、外部インターフェースを利用したinvoking-linearization-generation手順を提案し、反復的に解答に近づく。実験結果は、ChatGPTの性能を大幅に向上させ、教師ありチューニングと同等の成果を示す。 Comment
構造化データに対するLLMのゼロショットのreasoning能力を改善。構造化データに対するQAタスクで手法が有効なことを示した。
[Paper Note] Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models, Hanxu Hu+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Planning #One-Line Notes #needs-revision Issue Date: 2023-05-21 GPT Summary- 自然言語で表現された仮想空間における複雑な計画タスクに対するLLMsの性能を調査し、新たなベンチマークNatalaを提案。LLMs(例: ChatGPT)は依然として計画能力に限界があり、象徴的表現が理解しやすい可能性を示す。新手法CoS(Chain-of-Symbol Prompting)は追加訓練なしでLLMsに適用でき、広範な実験でCoT(Chain-of-Thought)を上回る性能を達成。特に、ChatGPTの正確性が最大60.8%向上し、中間段階のトークン数も著しく削減された。 Comment
LLMは複雑なプランニングが苦手なことが知られており、複雑な環境を自然言語ではなく、spatialでsymbolicなトークンで表現することで、プランニングの性能が向上したという話
OpenReview: https://openreview.net/forum?id=B0wJ5oCPdB
[Paper Note] What In-Context Learning "Learns" In-Context: Disentangling Task Recognition and Task Learning, Jane Pan+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #In-ContextLearning #KeyPoint Notes Issue Date: 2023-05-20 GPT Summary- ICLにおける大規模言語モデルの機能を探求し、タスク認識(TR)とタスク学習(TL)の2つの経路を特定。TRは事前知識を利用し、TLは新しい入力-ラベルのマッピングを捉える能力を示す。実験により、モデルはTRだけで非自明な性能を発揮し、大規模モデルはTLを向上させることがわかった。これらの異なる力を区別する重要性を提言。 Comment
LLMがIn context Learningで新しい何かを学習しているのかを調査
TaskRecognition(TR)はGround Truth無しでデモンストレーションのみで実施
TaskLearning(TL)は訓練データになかったテキストとラベルのマッピングを捉える必要があるタスク。
TRはモデルサイズでスケールしなかったが、TLはモデルサイズに対してスケールした
→ 事前学習で学習してきた知識を引っ張ってくるだけではTLは実施できないので、TRでは何も学習していないが、TLにおいては新しく何かが学習されてるんじゃない?ということだろうか
[Paper Note] CodeT5+: Open Code Large Language Models for Code Understanding and Generation, Yue Wang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #CodeGeneration #Encoder-Decoder #One-Line Notes Issue Date: 2023-05-20 GPT Summary- コードLLMsは特定のアーキテクチャに依存しがちで、事前学習タスクの制約により性能が低下することがある。本研究では、この問題を解決するために「CodeT5+」を提案。CodeT5+は柔軟な部品モジュールの組み合わせを可能にし、 diverseな事前学習目的でタスク要求に応じる。更に、既存のLLMを初期化に利用し効率的にスケールアップ。20以上のコードベンチマークで評価し、指示調整済みのCodeT5+がHumanEvalタスクで新たな最先端性能を達成した。 Comment
様々なコードの理解と生成タスクをサポート
異なる訓練手法によって計算効率改善
20種類のコードベンチマークで、様々な設定「ゼロショット、finetuning, instruction tuning等)を実施した結果、コード補完、math programming, text to code retrievalにおいてSoTA達成
[Paper Note] Explaining black box text modules in natural language with language models, Chandan Singh+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #NeurIPS #Workshop #Interpretability #needs-revision Issue Date: 2023-05-20 GPT Summary- 大規模言語モデル(LLMs)の解釈性の必要性に応えるため、テキストモジュールの入力と出力に基づいて自然言語の説明を自動生成する手法、Summarize and Score(SASC)を提案。合成モジュールへの適用で真の説明を回復し、BERTモデル内のモジュールを検査可能にし、言語刺激へのfMRI応答の説明まで可能。すべてのコードはGitHubに公開。 Comment
モデルのinterpretabilityに関するMSの新たな研究
[Paper Note] Emergent Representations of Program Semantics in Language Models Trained on Programs, Charles Jin+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NLP #Coding #ICML #One-Line Notes #needs-revision Issue Date: 2023-05-20 GPT Summary- 言語モデル(LM)が次のトークン予測に特化した訓練にもかかわらず、形式的意味を表現できる可能性を示す。2Dグリッド環境でのプログラム合成コーパスを用いてTransformerモデルを訓練し、特定の入力出力仕様が付随するプログラムから、未観測の中間状態を精度よく抽出できることを発見。新しい介入ベースラインにより、LMの表現とプロービングによる結果の明確な識別が可能に。広範な意味論的プロービング実験への適用が期待される。 Comment
プログラムのコーパスでLLMをNext Token Predictionで訓練し
厳密に正解とsemanticsを定義した上で、訓練データと異なるsemanticsの異なるプログラムを生成できることを示した。
LLMが意味を理解していることを暗示している
参考:
[Paper Note] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-05-20 GPT Summary- 言語モデルは一般的な問題解決に広がっているが、推論は依然としてトークンレベルの左から右への決定に制限されている。これを克服するために、新しい「Tree of Thoughts(ToT)」フレームワークを導入。ToTは、思考の連鎖を一般化し、中間ステップを探索できるようにし、複数の推論経路を自己評価することで意図的な意思決定を可能にする。実験では、ToTがGame of 24やCreative Writingなどの新規タスクで言語モデルの問題解決能力を顕著に向上させることが示された。例えば、Game of 24では新手法が74%の成功率を達成した。 Comment
Self Concistencyの次
Non trivialなプランニングと検索が必要な新たな3つのタスクについて、CoT w/ GPT4の成功率が4%だったところを、ToTでは74%を達成
論文中の表ではCoTのSuccessRateが40%と書いてあるような?
[Paper Note] Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting, Miles Turpin+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #Faithfulness #NeurIPS #needs-revision Issue Date: 2023-05-09 GPT Summary- LLMは段階的推論(CoT)を通じて高い性能を発揮するが、CoTの説明は予測の真の理由を誤って表現することがある。入力にバイアスを与えられると、誤答を正当化する説明が生成され、精度が最大36%低下することが示された。特に、社会的バイアスに関連する場合、モデルの説明がステレオタイプを強化し、バイアスの影響について言及しない。これにより、CoTの説明は一見もっともらしいが誤導的であり、信頼性を高めるリスクを伴う。より透明なシステムを構築するためには、CoTの信頼性を向上させるか、代替手法を検討すべきである。
[Paper Note] Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, Mirac Suzgun+, ACL'23, 2022.10
Paper/Blog Link My Issue
#NLP #Zero/Few/ManyShotPrompting #Chain-of-Thought #ACL #One-Line Notes Issue Date: 2023-05-04 GPT Summary- BIG-Benchは、言語モデルの限界を超えたタスクに焦点を当てた評価スイートであり、モデルはすでに65%のタスクで平均的な人間評価者を上回っている。本研究では、BBH(BIG-Bench Hard)として知られる、従来の評価で人間を下回った23の困難なタスクを分析。連鎖思考(CoT)プロンプティングを用いることで、PaLMは10タスク、Codexは17タスクで人間評価者を上回ることを示す。多段階の推論が求められるため、CoTなしの評価はモデルの性能を過小評価し、CoTはBBHタスクの性能向上に寄与することが明らかになった。 Comment
単なるfewshotではなく、CoT付きのfewshotをすると大幅にBIG-Bench-hardの性能が向上するので、CoTを使わないanswer onlyの設定はモデルの能力の過小評価につながるよ、という話らしい
Poisoning Language Models During Instruction Tuning, Alexander Wan+, N_A, ICML'23
Paper/Blog Link My Issue
#NLP #Poisoning #ICML Issue Date: 2023-05-04 GPT Summary- - Instruction-tuned LMs(ChatGPT、FLAN、InstructGPTなど)は、ユーザーが提出した例を含むデータセットでfinetuneされる。- 本研究では、敵対者が毒入りの例を提供することで、LMの予測を操作できることを示す。- 毒入りの例を構築するために、LMのbag-of-words近似を使用して入出力を最適化する。- 大きなLMほど毒入り攻撃に対して脆弱であり、データフィルタリングやモデル容量の削減に基づく防御は、テストの正確性を低下させながら、中程度の保護しか提供しない。
[Paper Note] Frustratingly Easy Label Projection for Cross-lingual Transfer, Yang Chen+, ACL'23, 2022.11
Paper/Blog Link My Issue
#MachineTranslation #NLP #Annotation #TransferLearning #MultiLingual #ACL Issue Date: 2023-05-04 GPT Summary- 多言語へのラベル投影には、マーク・アンド・トランスレート法を用いた新しいアプローチが提案され、57言語と3つのタスクにおける実証研究が行われた。実験結果は、EasyProjectが単語アライメント技術を上回る性能を示し、翻訳後もラベルスパンの境界を保持することができることを明らかにした。全コードとデータは公開されている。
[Paper Note] PMC-LLaMA: Towards Building Open-source Language Models for Medicine, Chaoyi Wu+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #OpenWeight #Medical #KeyPoint Notes Issue Date: 2023-05-01 GPT Summary- 医療向けに特化したオープンソース言語モデルPMC-LLaMAを構築。一般目的の基盤モデルを医療ドメインに適応させ、4.8百万件の生物医学論文と3万冊の医療教科書から知識を注入。指示チューニング用の大規模データセットも提供し、徹底したアブレーション研究でその有効性を確認。130億パラメータの軽量版PMCLLaMAは複数の医療質問応答ベンチマークで高い性能を示し、ChatGPTを凌駕する場面も確認。 Comment
LLaMAを4.8Mのmedical paperでfinetuningし、医療ドメインの能力を向上。このモデルはPMC-LLaMAと呼ばれ、biomedicalQAタスクで、高い性能を達成した。
GPT-4を利用した異なるモデル間の出力の比較も行なっている模様
[Paper Note] Efficiently Scaling Transformer Inference, Reiner Pope+, MLSys'23, 2022.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #LongSequence #Architecture #Inference #One-Line Notes Issue Date: 2023-04-30 GPT Summary- 大規模なTransformerモデルの生成的推論を、長いシーケンス長と厳格な遅延目標の下で研究。TPU v4用に最適化された解析モデルを開発し、待機時間とモデルFLOPS利用率のトレードオフにおいて新しいパレート前線を達成。マルチクエリ注意機構を用いることでメモリ要件を減少させ、コンテキスト長を最大32倍に拡張。最終的に、小さなバッチサイズでの1トークンあたりの遅延は29ミリ秒となり、MFUは76%に達し、PaLM 540Bモデルで2048トークンのコンテキストをサポート。 Comment
特にMultiquery Attentionという技術がTransformerのinferenceのコスト削減に有効らしい
Multi Query Attention (MQA):
- [Paper Note] Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, arXiv'19, 2019.11
[Paper Note] Controlled Text Generation with Natural Language Instructions, Wangchunshu Zhou+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #NLP #Supervised-FineTuning (SFT) #InstructionTuning #Prompting #SyntheticData #In-ContextLearning #ICML #PostTraining #One-Line Notes Issue Date: 2023-04-30 GPT Summary- 自然言語の指示に従い、多様なタスクを解決可能な大規模言語モデルの制御を改善するために、「InstructCTG」というフレームワークを提案。自然テキストの制約を抽出し、これを自然言語の指示に変換することで弱教師あり訓練データを形成。異なるタイプの制約に柔軟に対応し、生成の質や速度への影響を最小限に抑えつつ、再訓練なしで新しい制約に適応できる能力を持つ。 Comment
制約に関する指示とデモンスとレーションに関するデータを合成して追加のinstruction tuningを実施することで、promptで指示された制約を満たすような(controllableな)テキストの生成能力を高める手法
[Paper Note] Boosting Theory-of-Mind Performance in Large Language Models via Prompting, Shima Rahimi Moghaddam+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Prompting #TheoryOfMind #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- LLMのToM性能を評価し、文脈内学習が理解を向上させる効果を検討。2ショットの連鎖思考と段階的思考指示を用いたプロンプトで、RLHF訓練モデルはToM精度を80%以上に。特にGPT-4は文脈内学習で100%に達し、適切なプロンプト付けがLLMの推論を強化することを示した。 Comment
LLMはTheory-of-mind reasoningタスクが苦手なことが知られており、特にzero shotでは非常にパフォーマンスが低かった。ToMタスクとは、エージェントの信念、ゴール、メンタルstate、エージェントが何を知っているか等をトラッキングすることが求められるタスクのこと。このようなタスクはLLMが我々の日常生活を理解する上で重要。
↑のToM Questionのシナリオと問題
Scenario: "The morning of the high school dance Sarah placed her high heel shoes under her dress and then went shopping. That afternoon, her sister borrowed the shoes and later put them under Sarah's bed."
Question: When Sarah gets ready, does she assume her shoes are under her dress?
しかし、Zero shot CoTのようなstep by step thinking, CoTを適切に行うことで、OpenAIの直近3つのモデルのAccuracyが80%を超えた。特に、GPT4は100%のAccuracyを達成。人間は87%だった。
この結果は、少なくとのこの論文でテストしたドメインではLLMのsocial reasoningのパフォーマンスをどのようにブーストするかを示しており、LLMのbehaviorは複雑でsensitiveであることを示唆している。
[Paper Note] Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning, Yunhu Ye+, SIGIR'23, 2023.01
Paper/Blog Link My Issue
#NLP #QuestionAnswering #TabularData #SIGIR #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- LLMを活用して、表ベースの推論における巨大な証拠を小さなサブ証拠に分解し、複雑な質問をシンプルなサブ質問に分解。各ステップで論理と数値計算を分離することで、思考の連鎖における幻覚を防止。提案手法は、TabFactで人間を超える性能を達成。 Comment
テーブルとquestionが与えられた時に、questionをsub-questionとsmall tableにLLMでin-context learningすることで分割。subquestionの解を得るためのsqlを作成しスポットを埋め、hallucinationを防ぐ。最終的にLLM Reasonerが解答を導出する。TabFact Reasoningで初めて人間を超えた性能を発揮。
[Paper Note] q2d: Turning Questions into Dialogs to Teach Models How to Search, Yonatan Bitton+, EMNLP'23, 2023.04
Paper/Blog Link My Issue
#NLP #QuestionAnswering #DialogueGeneration #SyntheticData #EMNLP #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 質問から情報探索型対話を自動生成するデータ生成パイプラインq2dを提案。大規模言語モデルPaLMを用いて対話データを作成し、外部検索APIでクエリ生成モデルの性能を向上。合成データで訓練したモデルは人間作成データの90%〜97%に達し、無データでも新ドメイン向けの対話データを生成可能。生成された対話は高品質と評価され、人間作成の対話と区別が難しい。 Comment
LLMにquestionを与え、questionを解決するためのinformation seekingの対話ログを生成させる。このデータを用いて、dialogueからquestionを生成するモデルを訓練し、検索APIなどに渡せるようにした研究。全く対話のログがないドメインのデータに対しても、人間と遜色ない高品質な対話が生成可能。これにより、query generationモデルの更なる高性能化が実現できる。
openreview: https://openreview.net/forum?id=8iB0FJmOfV
[Paper Note] Tractable Control for Autoregressive Language Generation, Honghua Zhang+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #NLP #ICML #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 自己回帰型大規模言語モデルは複雑な制約を満たすテキスト生成に課題がある。これに対処するため、語彙的制約を扱う確率モデル(TPMs)を用いたGeLaToフレームワークを提案。蒸留された隠れマルコフモデルを利用し、自己回帰生成の効率的な指導を可能にし、制約付きテキスト生成において最先端の性能を達成。研究は大規模言語モデルの制御に新たな道を開き、TPMsのさらなる発展を促進する。 Comment
自然言語生成モデルで、何らかのシンプルなconstiaint αの元p(xi|xi-1,α)を生成しようとしても計算ができない。このため、言語モデルをfinetuningするか、promptで制御するか、などがおこなわれる。しかしこの方法は近似的な解法であり、αがたとえシンプルであっても(何らかの語尾を付与するなど)、必ずしも満たした生成が行われるとは限らない。これは単に言語モデルがautoregressiveな方法で次のトークンの分布を予測しているだけであることに起因している。そこで、この問題を解決するために、tractable probabilistic model(TPM)を導入し、解決した。
評価の結果、CommonGenにおいて、SoTAを達成した。
尚、TPMについては要勉強である
[Paper Note] AI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays, Steffen Herbold+, arXiv'23
Paper/Blog Link My Issue
#NLP #Education #AES(AutomatedEssayScoring) #ChatGPT #One-Line Notes Issue Date: 2023-04-28 GPT Summary- ChatGPTが生成したエッセイは、人間が書いたものよりも質が高いと評価されることが大規模な研究で示された。生成されたエッセイは独自の言語的特徴を持ち、教育者はこの技術を活用する新たな教育コンセプトを開発する必要がある。 Comment
ChatGPTは人間が書いたエッセイよりも高品質なエッセイが書けることを示した。
また、AIモデルの文体は、人間が書いたエッセイとは異なる言語的特徴を示している。たとえば、談話や認識マーカーが少ないが、名詞化が多く、語彙の多様性が高いという特徴がある、とのこと。
[Paper Note] We're Afraid Language Models Aren't Modeling Ambiguity, Alisa Liu+, EMNLP'23
Paper/Blog Link My Issue
#Dataset #Evaluation #EMNLP #Ambiguity #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 曖昧さは自然言語の重要な特徴であり、言語モデル(LM)が対話や執筆支援において成功するためには、曖昧な言語を扱うことが不可欠です。本研究では、曖昧さの影響を評価するために、1,645の例からなるベンチマーク「AmbiEnt」を収集し、事前学習済みLMの評価を行いました。特にGPT-4の曖昧さ解消の正答率は32%と低く、曖昧さの解消が難しいことが示されました。また、多ラベルのNLIモデルが曖昧さによる誤解を特定できることを示し、NLPにおける曖昧さの重要性を再認識する必要性を提唱しています。 Comment
LLMが曖昧性をどれだけ認知できるかを評価した初めての研究。
言語学者がアノテーションした1,645サンプルの様々な曖昧さを含んだベンチマークデータを利用。
GPT4は32%正解した。
またNLIデータでfinetuningしたモデルでは72.5%のmacroF1値を達成。
応用先として、誤解を招く可能性のある政治的主張に対してアラートをあげることなどを挙げている。
[Paper Note] Exploring the Curious Case of Code Prompts, Li Zhang+, NLRSE'23, 2023.04
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Prompting #Reasoning #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- コード風のプロンプトによる構造化推論の性能向上が示されたが、その効果は限られたタスクに留まる。本研究では、davinci系のモデルに対して、QAや感情分析など幅広いタスクでコードとテキストプロンプトを比較し、全体としてコードプロンプトがテキストプロンプトを上回ることはなかった。タスクによってはコードプロンプトが有利な場合もあったが、全てのタスクに当てはまるわけではなく、テキスト指示によるファインチューニングがコードプロンプトの性能向上に寄与することを示した。 Comment
コードベースのLLMに対して、reasoningタスクを解かせる際には、promptもコードにすると10パーセント程度性能上がる場合があるよ、という研究。
ただし、平均的にはテキストプロンプトの方が良く、一部タスクで性能が改善する、という温度感な模様
コードベースのモデルをtextでinstruction tuningしている場合でも、効果があるタスクがある。
[Paper Note] Answering Questions by Meta-Reasoning over Multiple Chains of Thought, Ori Yoran+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Chain-of-Thought #Prompting #EMNLP #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 複数の推論チェーンを考慮したMulti-Chain Reasoning(MCR)を提案。これにより、異なるチェーン間の情報を統合し、回答生成時に関連性の高い事実を選択することで、より質の高い説明を提供。7つのマルチホップQAデータセットで優れた性能を示し、人間による検証も可能な高品質な説明を実現。 Comment
self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
のようなvoting basedなアルゴリズムは、複数のCoTのintermediate stepを捨ててしまい、結果だけを採用するが、この研究は複数のCoTの中からquestionに回答するために適切なfactual informationを抽出するMeta Reasonerを導入し、複数のCoTの情報を適切に混在させて適切な回答を得られるようにした。
7個のMulti Hop QAデータでstrong baselineをoutperformし、人間が回答をverificationするための高品質な説明を生成できることを示した。
openreview: https://openreview.net/forum?id=ebSOK1nV2r
[Paper Note] Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes, Simran Arora+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #TabularData #One-Line Notes #Data Issue Date: 2023-04-27 GPT Summary- LLMを用いた半構造化文書の自動処理システムEVAPORATEを提案。文書からの値を直接抽出する方法と、抽出コードを合成する方法の二つを評価。コード合成はコストが低いが精度が劣るため、EVAPORATE-CODE+を導入し、品質を向上。弱教師あり学習を用いた抽出のアンサンブルにより、文書処理の効率を大幅に改善。処理トークン数を平均110倍に削減し、最先端システムを超える成果を達成。 Comment
LLMを使うことで、半構造化文章から自動的にqueryableなテーブルを作成することを試みた研究
[Paper Note] Can GPT-4 Perform Neural Architecture Search?, Mingkai Zheng+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#MachineLearning #NLP #NeuralArchitectureSearch #KeyPoint Notes Issue Date: 2023-04-27 GPT Summary- GPT-4を用いたニューラルアーキテクチャ探索(NAS)に関する研究を行い、提案手法GENIUSはGPT-4の生成能力を活用してアーキテクチャ探索空間を迅速にナビゲート、候補を特定し性能を向上させる。いくつかのベンチマークで評価し、既存のNAS技術と比較してその効果を示す。特に、限られたドメイン知識を要するプロンプト手法を通じてGPT-4が技術問題の研究に貢献する可能性を強調。さらに、研究の制約やAIの安全性への影響についても言及。 Comment
ドメイン知識の必要のないプロンプトで、ニューラルモデルのアーキテクチャの提案をGPTにしてもらう研究。accをフィードバックとして与え、良い構造を提案するといったループを繰り返す模様
Neural Architecture Search (NAS)においては、ランダムベースラインがよく採用されるらしく、比較した結果ランダムよりよかった
NAS201と呼ばれるベンチマーク(NNアーキテクチャのcell blockをデザインすることにフォーカス; 探索空間は4つのノードと6つのエッジで構成される密接続のDAGとして表される; ノードはfeature mapを表し、エッジはoperationに対応;利用可能なoperationが5つあるため、可能な検索空間の総数は5の6乗で15,625通りとなる)でも評価した結果、提案手法の性能がよかったとのこと。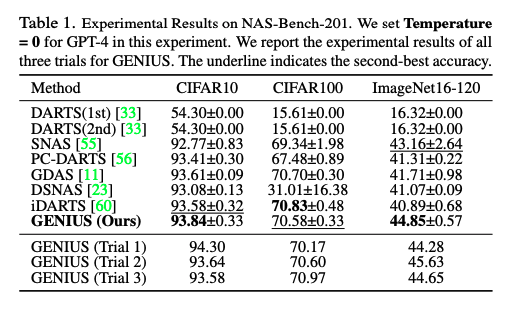
[Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #ICLR #Test-Time Scaling #Selected Papers/Blogs #MajorityVoting Issue Date: 2023-04-27 GPT Summary- 自己一貫性という新しいデコーディング戦略を提案し、chain-of-thought promptingの性能を向上。多様な推論経路をサンプリングし、一貫した答えを選択することで、GSM8KやSVAMPなどのベンチマークで顕著な改善を達成。 Comment
self-consistencyと呼ばれる新たなCoTのデコーディング手法を提案。
これは、難しいreasoningが必要なタスクでは、複数のreasoningのパスが存在するというintuitionに基づいている。
self-consistencyではまず、普通にCoTを行う。そしてgreedyにdecodingする代わりに、以下のようなプロセスを実施する:
1. 多様なreasoning pathをLLMに生成させ、サンプリングする。
2. 異なるreasoning pathは異なるfinal answerを生成する(= final answer set)。
3. そして、最終的なanswerを見つけるために、reasoning pathをmarginalizeすることで、final answerのsetの中で最も一貫性のある回答を見出す。
これは、もし異なる考え方によって同じ回答が導き出されるのであれば、その最終的な回答は正しいという経験則に基づいている。
self-consistencyを実現するためには、複数のreasoning pathを取得した上で、最も多いanswer a_iを選択する(majority vote)。これにはtemperature samplingを用いる(temperatureを0.5やら0.7に設定して、より高い信頼性を保ちつつ、かつ多様なoutputを手に入れる)。
temperature samplingについては[こちら](
https://openreview.net/pdf?id=rygGQyrFvH)の論文を参照のこと。
sampling数は増やせば増やすほど性能が向上するが、徐々にサチってくる。サンプリング数を増やすほどコストがかかるので、その辺はコスト感との兼ね合いになると思われる。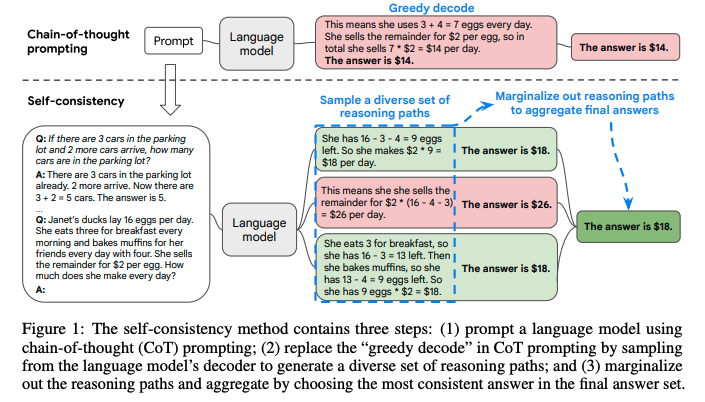
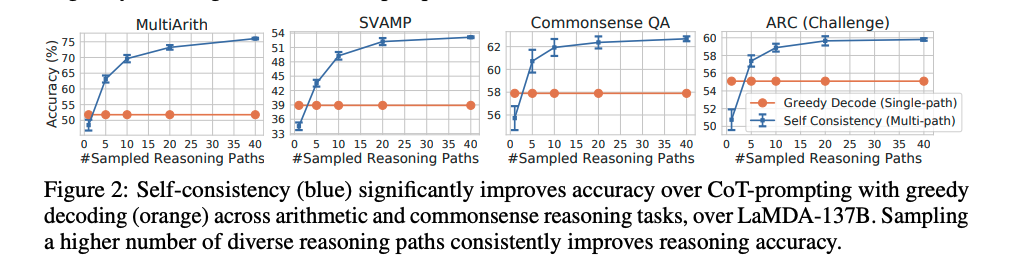
Self-consistencyは回答が閉じた集合であるような問題に対して適用可能であり、open-endなquestionでは利用できないことに注意が必要。ただし、open-endでも回答間になんらかの関係性を見出すような指標があれば実現可能とlimitationで言及している。
self-consistencyが提案されてからもう4年も経ったのか、、、
[Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #ICLR #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)を用いて、段階的思考を促すCoT promptingを提案。手作業でデモを設計する必要なく、プロンプトを通じて推論チェーンを生成可能。また、多様性を持って質問をサンプリングする自動CoT法(Auto-CoT)を導入し、GPT-3を用いたベンチマークで手動設計と比較して優れた性能を示した。 Comment
LLMによるreasoning chainが人間が作成したものよりも優れていることを示しているとのこと [Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04 より
clusteringベースな手法を利用することにより、誤りを含む例が単一のクラスタにまとめられうことを示し、これにより過剰な誤ったデモンストレーションが軽減されることを示した。
手法の概要。questionを複数のクラスタに分割し、各クラスタから代表的なquestionをサンプリングし、zero-shot CoTでreasoning chainを作成しpromptに組み込む。最終的に回答を得たいquestionに対しても、上記で生成した複数のquestion-reasoningで条件付けした上で、zeroshot-CoTでrationaleを生成する。これにより自動的にCoTをICLするためのexamplarを生成できる。
openreview: https://openreview.net/forum?id=5NTt8GFjUHkr
[Paper Note] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, KaShun Shum+, EMNLP'23, 2023.02
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #EMNLP #One-Line Notes Issue Date: 2023-04-27 GPT Summary- 新しい戦略「Automate-CoT」を提案し、少量のラベル付きデータから合理的チェーンを自動拡張。低品質なチェーンを剪定し、最適な推論チェーンを選択する分散削減型ポリシー勾配戦略を用いる。これにより、さまざまなタスクへのCoT手法の迅速な適用を可能にし、実験で競争力のある結果を達成。 Comment
LLMによるreasoning chainが人間が作成したものよりも優れていることを示しているとのこと。下記研究より
- [Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
selection phaseで誤ったexampleは直接排除する手法をとっている。そして、強化学習によって、demonstrationのselection modelを訓練している。
openreview: https://openreview.net/forum?id=FGBEoz9WzI¬eId=sq50eXOEeV
[Paper Note] Personalisation within bounds: A risk taxonomy and policy framework for the alignment of large language models with personalised feedback, Hannah Rose Kirk+, arXiv'23, 2023.03
Paper/Blog Link My Issue
#NLP #Personalization #needs-revision Issue Date: 2023-04-26 GPT Summary- LLMの個別化には、人間の嗜好と整合させる必要があり、アラインメント技術がその課題を緩和するが、全ての嗜好を表現するのは難しい。ユーザーの多様な価値観に基づくマイクロレベルの個別化は有望だが、規範的課題が存在する。本文では、整合の定義、主観的嗜好の押し付け、文書化不足の問題を概観し、個別化されたLLMの利点とリスクを整理。最後に、安全なLLMの挙動を維持するための三層政策フレームワークを提案。 Comment
# abst
LLMをPersonalizationすることに関して、どのような方法でPersonalizationすべきかを検討した研究。以下の問題点を指摘。
1. アラインメント(RLHFのように何らかの方向性にalignするように補正する技術のこと?)が何を意味するのか明確ではない
2. 技術提供者が本質的に主観的な好みや価値観の定義を規定する傾向があること
3. クラウドワーカーがの専制によって、我々が実際に何にアラインメントしているのかに関する文書が不足していること
そして、PersonalizedなLLMの利点やリスクの分類を提示する。
# 導入
LLMがさまざまな製品に統合されたことで、人間の嗜好に合致し、危険かつ不正確な情報を出力を生成しないことを確保する必要がある。RLHFやred-teamingはこれに役立つが、このような集合的な(多くの人に一つのアラインメントの結果を提示すること)finetuningプロセスが人間の好みや価値観の幅広い範囲を十分に表現できるとは考えにくい。異なる人々はさまざまな意見や価値観を持っており、マイクロレベルのfinetuningプロせせ雨を通じてLLMをPersonalizationすることで、各ユーザとより良いアラインメントが可能になる可能性がある。これを社会的に受け入れられるようにするためにいくつか課題があるので、それについて論じた。
[Paper Note] WizardLM: Empowering large pre-trained language models to follow complex instructions, Can Xu+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #InstructionTuning #SyntheticData #ICLR #KeyPoint Notes Issue Date: 2023-04-25 GPT Summary- 本論文では、LLMを用いて複雑な指示データを自動生成する方法を提案。Evol-Instructを使用して初期の指示を段階的に書き換え、生成したデータでLLaMAをファインチューニングし、WizardLMモデルを構築。評価結果は、Evol-Instructからの指示が人間作成のものより優れており、WizardLMがChatGPTよりも高い評価を得ることを示す。AI進化による指示生成がLLM強化の有望なアプローチであることを示唆。 Comment
instruction trainingは大きな成功を収めているが、人間がそれらのデータを作成するのはコストがかかる。また、そもそも複雑なinstructionを人間が作成するのは苦労する。そこで、LLMに自動的に作成させる手法を提案している(これはself instructと一緒)。データを生成する際は、seed setから始め、step by stepでinstructionをrewriteし、より複雑なinstructionとなるようにしていく。
これらの多段的な複雑度を持つinstructionをLLaMaベースのモデルに食わせてfinetuningした(これをWizardLMと呼ぶ)。人手評価の結果、WizardLMがChatGPTよりも好ましいレスポンスをすることを示した。特に、WizaraLMはコード生成や、数値計算といった難しいタスクで改善を示しており、複雑なinstructionを学習に利用することの重要性を示唆している。
EvolInstructを提案。"1+1=?"といったシンプルなinstructionからスタートし、これをLLMを利用して段階的にcomplexにしていく。complexにする方法は2通り:
- In-Depth Evolving: instructionを5種類のoperationで深掘りする(blue direction line)
- add constraints
- deepening
- concretizing
- increase reasoning steps
- complicate input
- In-breadth Evolving: givenなinstructionから新しいinstructionを生成する
上記のEvolvingは特定のpromptを与えることで実行される。
また、LLMはEvolvingに失敗することがあるので、Elimination Evolvingと呼ばれるフィルタを利用してスクリーニングした。
フィルタリングでは4種類の失敗するsituationを想定し、1つではLLMを利用。2枚目画像のようなinstructionでフィルタリング。
1. instructionの情報量が増えていない場合。
2. instructionがLLMによって応答困難な場合(短すぎる場合やsorryと言っている場合)
3. puctuationやstop wordsによってのみ構成されている場合
4.明らかにpromptの中から単語をコピーしただけのinstruction(given prompt, rewritten prompt, #Rewritten Prompt#など)

[Paper Note] Scaling Transformer to 1M tokens and beyond with RMT, Aydar Bulatov+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Transformer #LongSequence #memory #One-Line Notes Issue Date: 2023-04-25 GPT Summary- 再帰的メモリ拡張を用いて、トランスフォーマーの計算量を線形にスケールし、最大二百万トークンまでのシーケンスを扱う能力を実証。言語モデリングタスクでの実験は、パープレキシティの改善を示し、長期依存の処理能力向上の可能性を強調。 Comment
Reccurent Memory Transformer [Paper Note] Recurrent Memory Transformer, Aydar Bulatov+, NeurIPS'22, 2022.07
を使って2Mトークン扱えるようにしたよーという話。
ハリーポッターのトークン数が1.5Mらしいので、そのうち小説一冊書けるかもという世界。
[Paper Note] LLM+P: Empowering Large Language Models with Optimal Planning Proficiency, Bo Liu+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #Planning #KeyPoint Notes Issue Date: 2023-04-25 GPT Summary- LLMsは一般的な質問には優れた回答能力を示すが、長期的な計画問題には弱い。本研究では、古典的プランナーの強みをLLMsに統合した初のフレームワーク、LLM+Pを提案。自然言語の計画記述をPDDL形式に変換し、効率的に解を見つけて再翻訳する手法を採用。実験により、LLM+Pは多くの計画問題に対して最適解を提供できる一方、LLMsはほとんど問題を解決できないことが確認された。 Comment
LLMは長いプランニングをすることが苦手だったが、classicalなplannerは適切なinputの形式に変換されていればすぐに最適なプランを導出できる、が、自然言語は受け付けない、といった互いが互いを補完し合う関係にあるので、両者を組み合わせました、という話。
LLMを利用して、planning problemを記述した自然言語をclassicalなplannerのinputへ変換。その後plannerで最適なplanを見つけ、自然言語にplanを逆翻訳する。
[Paper Note] ReAct: Synergizing Reasoning and Acting in Language Models, Shunyu Yao+, ICLR'23, 2022.10
Paper/Blog Link My Issue
#NLP #AIAgents #Selected Papers/Blogs #needs-revision Issue Date: 2023-04-13 GPT Summary- 大規模言語モデルを用いて、推論と行動計画を相互に組み合わせるReActアプローチを提案。推論の痕跡が行動計画の導出を促進し、行動が外部情報を活用することで、推論の効率を向上。質問応答や事実検証タスクで従来手法を凌駕し、人間の解釈性と信頼性を向上させる。対話的意思決定ベンチマークでも優れた性能を発揮。 Comment
# 概要
人間は推論と行動をシナジーさせることで、さまざまな意思決定を行える。近年では言語モデルにより言語による推論を意思決定に組み合わせる可能性が示されてきた。たとえば、タスクをこなすための推論トレースをLLMが導けることが示されてきた(Chain-of-Thought)が、CoTは外部リソースにアクセスできないため知識がアップデートできず、事後的に推論を行うためhallucinationやエラーの伝搬が生じる。一方で、事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われているが、これらの研究では、高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
そこで、REACTを提案。REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みであり、推論トレースとアクションを交互に生成するため、動的に推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
- 要はいままではGeneralなタスク解決モデルにおいては、推論とアクションの生成は独立にしかやられてこなかったけど、推論とアクションを交互作用させることについて研究したよ
- そしたら性能がとってもあがったよ
- reasoningを人間が編集すれば、エージェントのコントロールもできるよ という感じ
# イントロ
人間は推論と行動の緊密なシナジーによって、不確実な状況に遭遇しても適切な意思決定が行える。たとえば、任意の2つの特定のアクションの間で、進行状況をトレースするために言語で推論したり(すべて切り終わったからお湯を沸かす必要がある)、例外を処理したり、状況に応じて計画を調整したりする(塩がないから代わりに醤油と胡椒を使おう)。また、推論をサポートし、疑問(いまどんな料理を作ることができるだろうか?)を解消するために、行動(料理本を開いてレシピを読んで、冷蔵庫を開いて材料を確確認したり)をすることもある。
近年の研究では言語での推論を、インタラクティブな意思決定を組み合わせる可能性についてのヒントが得られてきた。一つは、適切にPromptingされたLLMが推論トレースを実行できることを示している。推論トレースとは、解決策に到達するための一連のステップを経て推論をするためのプロセスのことである。しかしながらChain-of-thoughytは、このアプローチでは、モデルが外界対してgroundingできず、内部表現のみに基づい思考を生成するため限界がある。これによりモデルが事後対応的に推論したり、外部情報に基づいて知識を更新したりできないため、推論プロセス中にhallucinationやエラーの伝搬などの問題が発生する可能性が生じる。
一方、近年の研究では事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われている。これらの研究では、通常マルチモーダルな観測結果をテキストに変換し、言語モデルを使用してドメイン固有のアクション、またはプランを生成し、コントローラーを利用してそれらを選択または実行する。ただし、これらのアプローチは高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。
推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
LLMにおける推論と行動を組み合わせて、言語推論と意思決定タスクを解決するREACTと呼ばれる手法を提案。REACTでは、推論と行動の相乗効果を高めることが可能。推論トレースによりアクションプランを誘発、追跡、更新するのに役立ち、アクションでは外部ソースと連携して追加情報を収集できる。
REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みである。REACTのpromptはLLMにverbalな推論トレースとタスクを実行するためのアクションを交互に生成する。これにより、モデルは動的な推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
# 手法
変数を以下のように定義する:
- O_t: Observertion on time t
- a_t: Action on time t
- c_t: context, i.e. (o_1, a_1, o_2, a_2, ..., a_t-1, o_t)
- policy pi(a_t | c_t): Action Spaceからアクションを選択するポリシー
- A: Action Space
- O: Observation Space
普通はc_tが与えられたときに、ポリシーに従いAからa_tを選択しアクションを行い、アクションの結果o_tを得て、c_t+1を構成する、といったことを繰り返していく。
このとき、REACTはAをA ∪ Lに拡張しする。ここで、LはLanguage spaceである。LにはAction a_hatが含まれ、a_hatは環境に対して作用をしない。単純にthought, あるいは reasoning traceを実施し、現在のcontext c_tをアップデートするために有用な情報を構成することを目的とする。Lはunlimitedなので、事前学習された言語モデルを用いる。今回はPaLM-540B(c.f. GPT3は175Bパラメータ)が利用され、few-shotのin-context exampleを与えることで推論を行う。それぞれのin-context exampleは、action, thoughtsそしてobservationのtrajectoryを与える。
推論が重要なタスクでは、thoughts-action-observationステップから成るtask-solving trajectoryを生成する。一方、多数のアクションを伴う可能性がある意思決定タスクでは、thoughtsのみを行うことをtask-solving trajectory中の任意のタイミングで、自分で判断して行うことができる。
意思決定と推論能力がLLMによってもたらされているため、REACTは4つのuniqueな特徴を持つ:
- 直感的で簡単なデザイン
- REACTのpromptは人間のアノテータがアクションのトップに思考を言語で記述するようなストレートなものであり、ad-hocなフォーマットの選択、思考のデザイン、事例の選定などが必要ない。
- 一般的で柔軟性が高い
- 柔軟な thought spaceと thought-actionのフォーマットにより、REACTはさまざまなタスクにも柔軟に対応できる
- 高性能でロバスト
- REACTは1-6個の事例によって、新たなタスクに対する強力な汎化を示す。そして推論、アクションのみを行うベースラインよりも高い性能を示している。REACTはfinetuningの斧系も得ることができ、promptの選択に対してREACTの性能はrobustである。
- 人間による調整と操作が可能
- REACTは、解釈可能な意思決定と推論のsequenceを前提としているため、人間は簡単に推論や事実の正しさを検証できる。加えて、thoughtsを編集することによって、m人間はエージェントの行動を制御、あるいは修正できる。
# KNOWLEDGE INTENSIVE REASONING TASKS
openreview: https://openreview.net/forum?id=tvI4u1ylcqs
[Paper Note] ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks, Fabrizio Gilardi+, NAS'23, 2023.03
Paper/Blog Link My Issue
#NLP #Annotation #In-Depth Notes Issue Date: 2023-04-12 GPT Summary- ChatGPTは、2,382件のツイートを用いたアノテーションタスクにおいて、クラウドワーカーを上回る性能を示し、特に4つのタスクでゼロショット精度が優れています。また、インターコーダー合意でも全てのタスクでクラウドワーカーや訓練を受けたアノテーターを超え、コストもMTurkの約20倍安価です。これにより、大規模言語モデルがテキスト分類の効率を大幅に向上させる可能性が示唆されます。 Comment
# 概要
2300件程度のツイートを分類するタスクにおいて、訓練した学部生によるアノテーションを正解とし、クラウドワーカーとChatGPTでのzero-shotでの予測の性能を比較した。分類タスクは、比較的難易度の高い分類問題であり、クラウドワーカーでも正解率は難しいタスクでは15--25%程度であった。このようなタスクでchatgptは40--60%の正解率を示している。
比較の結果、5つのタスク中4つのタスクでChatGPTがクラウドワーカーを上回る正解率を示した。
# 手法
- クラウドワーカーとChatGPTで同じインストラクションを利用し、同じタスクを実施した
- inter-notator aggreementを図るために、それぞれのタスクについて各ツイートに少なくとも2人がラベル付を行った
- ChatGPTでも同様に、タスクごとに各ツイートには2回同じタスクを実施しデータを収集した
- ChatGPTを利用する際は、temperatureを1.0, 0.2の場合で試した。従ってChatGPTのラベル付けは各タスクごとに4セット存在することになる。
# 結果
5タスク中、4タスクでChatGPTがzero-shotにもかかわらず正解率でworkerを上回った。また高いaggreementを発揮していることを主張。aggreementはtemperatureが低い方が高く、これはtemperatureが低い方がrandomnessが減少するためであると考えられる。aggreementをAccuracyの相関を図ったが、0.17であり弱い相関しかなかった。従って、Accuracyを減少させることなく、一貫性のある結果を得られるlaw temperatureを利用することが望ましいと結論づけている。
# 実施したタスク
"content moderation"に関するタスクを実施した。content moderationはSNSなどに投稿されるpostを監視するための取り組みであり、たとえばポルトツイートや誤った情報を含む有害なツイート、ヘイトスピーチなどが存在しないかをSNS上で監視をを行うようなタスクである。著者らはcontent moderationはハードなタスクであり、複雑なトピックだし、toy exampleではないことを主張している。実際、著者らが訓練した学部生の間でのinter-annotator aggreementは50%程度であり、難易度が高いタスクであることがわかる(ただし、スタンスdetectionに関してはaggreementが78.3%であった)。
content moderationのうち、以下の5つのタスクを実施した。
- relevance:
- ツイートがcontent moderationについて直接的に関係することを述べているか否か
- e.g. SNSにおけるcontent moderation ruleや実践、政府のレギュレーション等
- content moderationについて述べていないものについてはIRRELEVANTラベルを付与する
- ただし、主題がcontent moderationのツイートであっても、content moderationについて論じていないものについてはIRRELEVANT扱いとする。
- このような例としては、TwitterがDonald TrupのTwitterを"disrupted"とlabel付けしたことや、何かについて間違っていると述べているツイート、センシティブな内容を含むツイートなどがあげられる。
- Problem/Solution Frames
- content moderationは2つの見方ができる。それがProblemとSolution
- Problem: content moderationをPROBLEMとみなすもの。たとえば、フリースピーチの制限など
- SOLUTION: content moderationをSOLUTIONとみなすもの。たとえば、harmful speechから守ること、など
- ツイートがcontent moderationのnegativeな影響について強調していたら、PROBLEM(フリースピーチの制限やユーザがポストする内容についてバイアスが生じることなどについて)
- ツイートがcontent moderationのpositiveな影響について強調していたら、SOKUTION(harmful contentからユーザを守るなど)
- 主題はcontent moderationであるが、positive/negativeな影響について論じていないものはNEUTRAL
- Policy Frames
- content moderationはさまざまんトピックと関連している(たとえば)、健康、犯罪、平等など)
- content moderatiojnに関するツイートがどのトピックかをラベル付する。ラベルは15種類
- economy, capcity and resources, modality, fairness and equality, constitutionality and jurisprudence, policy prescription and evaluation, law and order, crime and justice, security and defense, health and safety, quality of life, cultural identity, public opinion, political, external regulation and reputation, other
- Stance Detection
- USのSection 230という法律(websiteにユーザが投稿したコンテンツに対して、webサイトやその他のオンラインプラットフォームが法的責任を問われるのを防ぐ法律)について、ツイートがSection230に対して、positive/negative/neutralなスタンスかをラベル付する
- Topic Detection
- ツイートを6つのトピックにラベル付する
- Section 230, TRUMP BAN, TWITTER-SUPPORT, PLATFORM POLICIES, COMPLAINTS, other
# 所感
そこそこ難易度の高いアノテーションタスクでもzero-shotでturkerの性能を上回るのは非常に素晴らしいことだと思う。ノイジーなデータセットであれば、比較的安価、かつスピーディーに作成できるようになってきたのではないかと思う。
ただ、ChatGPTのaggreementを図ることにどれだけ意味があるのだろう、とは思う。同じモデルを利用しているわけで、小tなるLLMをベースにした場合のaggreementならとる意味があると思うが。
[Paper Note] Self-Instruct: Aligning Language Models with Self-Generated Instructions, Yizhong Wang+, ACL'23, 2022.12
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #ACL #In-Depth Notes Issue Date: 2023-03-30 GPT Summary- Self-Instructフレームワークを提案し、事前学習済みの言語モデルが自ら生成した指示を用いてファインチューニングを行うことで、ゼロショットの一般化能力を向上させる。バニラGPT-3に適用した結果、Super-NaturalInstructionsで33%の性能向上を達成し、InstructGPT-001と同等の性能に到達。人間評価により、Self-Instructが既存の公共指示データセットよりも優れていることを示し、ほぼ注釈不要の指示調整手法を提供。大規模な合成データセットを公開し、今後の研究を促進する。 Comment
Alpacaなどでも利用されているself-instruction技術に関する論文
# 概要
著者らが書いた175種のinstruction(タスクの定義 + 1種のinput/outputペア}のseedを元に、VanillaなGPT-3に新たなinstruction, input, outputのtupleを生成させ、学習データとして活用する研究。
ここで、instruction data I は以下のように定義される:
instruction dataは(I, X, Y)であり、モデルは最終的にM(I_t, x_t) = y_tとなるように学習したい。
I: instruction, X: input, Y: output
データ作成は以下のステップで構成される。なお、以下はすべてVanilla GPT-3を通じて行われる:
1. Instruction Generation
task poolから8種類のinstructionを抽出し、 promptを構成し、最大8個新たなinstructionを生成させる
2. Classification Task Identification:
生成されたinstructionがclassificationタスクか否かを判別する
3. Instance Generation
いくつかの(I, X, Y)をpromptとして与え、I, Xに対応するYを生成するタスクを実行させる。このときinput-first approachを採用した結果(I->Xの順番で情報を与えYを生成するアプローチ)、特定のラベルに偏ったインスタンスが生成される傾向があることがわかった。このためoutput-first approachを別途採用し(I->Yの順番で情報を与え、各Yに対応するXを生成させる)、活用している。
4. Filtering and Postprocessing
最後に、既存のtask poolとROUGE-Lが0.7以上のinstructionは多様性がないため除外し、特定のキーワード(images, pictrues, graphs)等を含んでいるinstruction dataも除外して、task poolに追加する。
1-4をひたすら繰り返すことで、GPT-3がInstruction Tuningのためのデータを自動生成してくれる。
# SELF-INSTRUCT Data
## データセットの統計量
- 52k instructions
- 82k instances
## Diversity
parserでinstructionを解析し、rootの名詞と動詞のペアを抽出して可視化した例。ただし、抽出できた例はたかだか全体の50%程度であり、その中で20の最もcommonなroot vertと4つのnounを可視化した。これはデータセット全体の14%程度しか可視化されていないが、これだけでも非常に多様なinstructionが集まっていることがわかる。
また、seed indstructionとROUGE-Lを測った結果、大半のデータは0.3~0.4程度であり、lexicalなoverlapはあまり大きくないことがわかる。instructionのlengthについても可視化した結果、多様な長さのinstructionが収集できている。
## Quality
200種類のinstructionを抽出し、その中からそれぞれランダムで1つのインスタンスをサンプルした。そしてexpert annotatorに対して、それぞれのinstructionとinstance(input, outputそれぞれについて)が正しいか否かをラベル付けしてもらった。
ラベル付けの結果、ほとんどのinstructionは意味のあるinstructionであることがわかった。一方、生成されたinstanceはnoisyであることがわかった(ただし、このnoiseはある程度妥当な範囲である)。noisytではあるのだが、instanceを見ると、正しいformatであったり、部分的に正しかったりなど、modelを訓練する上で有用なguidanceを提供するものになっていることがわかった。
# Experimental Results
## Zero-shotでのNLPタスクに対する性能
SuperNIデータセットに含まれる119のタスク(1タスクあたり100 instance)に対して、zero-shot setupで評価を行なった。SELF-INSTRUCTによって、VanillaのGPT3から大幅に性能が向上していることがわかる。VanillaのGPT-3はほとんど人間のinstructionに応じて動いてくれないことがわかる。分析によると、GPT3は、大抵の場合、全く関係ない、あるいは繰り返しのテキストを生成していたり、そもそもいつ生成をstopするかがわかっていないことがわかった。
また、SuperNI向けにfinetuningされていないモデル間で比較した結果、非常にアノテーションコストをかけて作られたT0データでfinetuningされたモデルよりも高い性能を獲得した。また、人間がラベル付したprivateなデータによって訓練されたInstructGPT001にも性能が肉薄していることも特筆すべき点である。
SuperNIでfinetuningした場合については、SELF-INSTRUCTを使ったモデルに対して、さらに追加でSuperNIを与えた場合が最も高い性能を示した。
## User-Oriented Instructionsに対する汎化性能
SuperNIに含まれるNLPタスクは研究目的で提案されており分類問題となっている。ので、実践的な能力を証明するために、LLMが役立つドメインをブレスト(email writing, social media, productiveity tools, entertainment, programming等)し、それぞれのドメインに対して、instructionとinput-output instanceを作成した。また、instructionのスタイルにも多様性(e.g. instructionがlong/short、bullet points, table, codes, equationsをinput/outputとして持つ、など)を持たせた。作成した結果、252個のinstructionに対して、1つのinstanceのデータセットが作成された。これらが、モデルにとってunfamiliarなinstructionで多様なistructionが与えられたときに、どれだけモデルがそれらをhandleできるかを測定するテストベッドになると考えている。
これらのデータは、多様だがどれもが専門性を求められるものであり、自動評価指標で性能が測定できるものでもないし、crowdworkerが良し悪しを判定できるものでもない。このため、それぞれのinstructionに対するauthorに対して、モデルのy補足結果が妥当か否かをjudgeしてもらった。judgeは4-scaleでのratingとなっている:
- RATING-A: 応答は妥当で満足できる
- RATING-B: 応答は許容できるが、改善できるminor errorや不完全さがある。
- RATING-C: 応答はrelevantでinstructionに対して答えている。が、内容に大きなエラーがある。
- RATING-D: 応答はirrelevantで妥当ではない。
実験結果をみると、Vanilla GPT3はまったくinstructionに対して答えられていない。instruction-basedなモデルは高いパフォーマンスを発揮しているが、それらを上回る性能をSELF-INSTRUCTは発揮している(noisyであるにもかかわらず)。
また、GPT_SELF-INSTRUCTはInstructGPT001と性能が肉薄している。また、InstructGPT002, 003の素晴らしい性能を示すことにもなった。
# Discussion and Limitation
## なぜSELF-INSTRUCTがうまくいったか?
- LMに対する2つの極端な仮説を挙げている
- LM はpre-trainingでは十分に学習されなかった問題について学習する必要があるため、human feedbackはinstruction-tuningにおいて必要不可欠な側面である
- LM はpre-trainingからinstructionに既に精通しているため、human feedbackはinstruction-tuningにおいて必須ではない。 human feedbackを観察することは、pre-trainingにおける分布/目的を調整するための軽量なプロセスにすぎず、別のプロセスに置き換えることができる。
この2つの極端な仮説の間が実情であると筆者は考えていて、どちらかというと2つ目の仮説に近いだろう、と考えている。既にLMはpre-trainingの段階でinstructionについてある程度理解できているため、self-instructがうまくいったのではないかと推察している。
## Broader Impact
InstructGPTは非常に強力なモデルだけど詳細が公表されておらず、APIの裏側に隠れている。この研究が、instruct-tuned modelの背後で何が起きているかについて、透明性を高める助けになると考えている。産業で開発されたモデルの構造や、その優れた性能の理由についてはほとんど理解されておらず、これらのモデルの成功の源泉を理解し、より優れた、オープンなモデルを作成するのはアカデミックにかかっている。この研究では、多様なinstructional dataの重要性を示していると考えており、大規模な人工的なデータセットは、より優れたinstructionに従うモデルを、構築するための第一歩だと考えている。
## limitation
- Tail Phenomena
- LMの枠組みにとどまっているため、LMと同じ問題(Tail Phenomena)を抱えている
- low-frequencyなcontextに対してはうまくいかない問題
- SELF-INSTRUCTも、結局pre-trainingの段階で頻出するタスクやinstructionに対してgainがあると考えられ、一般的でなく、creativeなinstructionに対して脆弱性があると考えられる
- Dependence on laege models
- でかいモデルを扱えるだけのresourceを持っていないと使えないという問題がある
- Reinforcing LM biases
- アルゴリズムのiterationによって、問題のあるsocial _biasをより増幅してしまうことを懸念している(人種、種族などに対する偏見など)。また、アルゴリズムはバランスの取れたラベルを生成することが難しい。
1のprompt
2のprompt
3のprompt(input-first-approach)
3のprompt(output-first approach)
※ GPT3をfinetuningするのに、Instruction Dataを使った場合$338かかったっぽい。安い・・・。
LLMを使うだけでここまで研究ができる時代がきた
(最近は|現在は)プロプライエタリなLLMの出力を利用して競合するモデルを訓練することは多くの場合禁止されているので注意。
[Paper Note] Reflexion: Language Agents with Verbal Reinforcement Learning, Noah Shinn+, NeurIPS'23, 2023.03
Paper/Blog Link My Issue
#MachineLearning #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SelfCorrection #NeurIPS #PostTraining #Initial Impression Notes Issue Date: 2023-03-28 GPT Summary- LLMを用いた言語エージェントが外部環境と相互作用しつつ、迅速な学習を可能にする新しいフレームワーク「Reflexion」を提案。言語的フィードバックを活用し、エージェントはタスクのフィードバックを反映、エピソディックメモリに保持して意思決定を改善。多様なフィードバック信号を取り入れ、様々なタスクで大幅な性能向上を実現。HumanEvalベンチマークでは91%のpass@1精度を達成し、従来の最先端を超える成果を示した。 Comment
なぜ回答を間違えたのか自己反省させることでパフォーマンスを向上させる研究
openreview: https://openreview.net/forum?id=vAElhFcKW6
[Paper Note] ScienceWorld: Is your Agent Smarter than a 5th Grader?, Ruoyao Wang+, EMNLP'22, 2022.03
Paper/Blog Link My Issue
#NLP #AIAgents #Evaluation #ScientificDiscovery #EMNLP #Selected Papers/Blogs #Science #One-Line Notes Issue Date: 2026-04-14 GPT Summary- ScienceWorldは、小学校の科学カリキュラムに基づき、エージェントの科学的推論能力を評価するための対話型テキスト環境を提供します。従来のモデルは、新しい文脈で学んだ科学概念を推論するのが苦手で、特に未知の材料の伝導率を見つけるための実験方法を問われると苦戦します。これは、モデルが類似例から答えを得ているのか、再利用可能な方法で推論を学んでいるのかという疑問を生み出します。私たちは、エージェントは対話型環境にグラウンディングされることで推論能力を得るべきだと仮定し、150万パラメータのエージェントが10万ステップの対話型訓練を受けた結果、静的訓練を受けた110億パラメータのモデルを上回ることを実証しました。 Comment
ベンチマークの概要は
- Evaluating agents for scientific discovery, Ai2, 2026.04
参照のこと。
[Paper Note] GPT-NeoX-20B: An Open-Source Autoregressive Language Model, Sid Black+, arXiv'22, 2022.04
Paper/Blog Link My Issue
#NLP #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2026-03-31 GPT Summary- GPT-NeoX-20Bは、200億パラメータを持つ自己回帰型言語モデルで、Pileで訓練され、寛容なライセンスの下で重みが一般公開される。言語理解や数学、知識ベースのタスクで高い性能を持ち、特に5ショット評価時に同規模のモデルより優れた結果を示す。訓練および評価コード、モデルの重みはオープンソースで提供される。 Comment
[Paper Note] BLOOM: A 176B-Parameter Open-Access Multilingual Language Model, BigScience Workshop+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#Pretraining #NLP #OpenWeight #OpenSource #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-03-31 GPT Summary- 大規模言語モデル(LLMs)を使い、新しいタスクを少ないデモや指示で実行可能にしたBLOOMを紹介。これは1760億パラメータのオープンアクセス言語モデルで、46の自然言語と13のプログラミング言語をカバー。競争力のある性能を発揮し、マルチタスクのファインチューニングを通じてさらに向上。モデルとコードは責任あるAIライセンスで公開し、今後の研究と応用の促進を目指す。 Comment
HF: https://huggingface.co/bigscience/bloom
透明性を持ったLLMを構築し民主化を図る方向性のパイオニア的研究
[Paper Note] bert2BERT: Towards Reusable Pretrained Language Models, Cheng Chen+, ACL'22, 2021.10
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Transformer #ACL #Encoder #Decoder Issue Date: 2025-12-11 GPT Summary- bert2BERTは、既存の小規模事前学習モデルの知識を大規模モデルに転送し、事前学習効率を向上させる手法。二段階の事前学習を提案し、トレーニングコストを大幅に削減。BERT_BASEとGPT_BASEの事前学習で約45%および47%の計算コストを節約。
[Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
Paper/Blog Link My Issue
#NLP #Alignment #Supervised-FineTuning (SFT) #ReinforcementLearning #Safety #Selected Papers/Blogs #PseudoLabeling Issue Date: 2025-09-20 GPT Summary- 本研究では、「憲法的AI」を用いて、人間のラベルなしで無害なAIを訓練する方法を提案。監視学習と強化学習の2フェーズを経て、自己批評と修正を通じてモデルを微調整し、嗜好モデルを報酬信号として強化学習を行う。これにより、有害なクエリに対しても対話できる無害なAIアシスタントを実現し、AIの意思決定の透明性を向上させる。 Comment
(部分的にしか読めていないが)
有害なpromptに対してLLMに初期の応答を生成させ、iterativeにcritiqueとrevisionを繰り返して[^1]、より無害な応答を生成。この方法ではiterationをしながら生成結果が改定されていくので、後段のReward Modelのための嗜好データを生成するフェーズでトークン量を節約するために、生成されたより無害な応答と元となるpromptを用いて、ベースモデルをSFT。これによりベースモデルの出力分布がより無害な応答をするような方向性に調整され、かつ(iterationを繰り返すことなく)直接的により無害な応答を生成できるようになるのでtoken量が節約できる。このフェーズで学習したモデルをSL-CAIと呼ぶ。
続いて、SL-CAIに対して同様の有害なpromptを入力して、複数の応答を生成させる。生成された応答をMultiple Choice Questionの形式にし、Constitutional Principleに基づくpromptingにより、最も望ましい応答をLLMによって選択させることで、嗜好データを獲得する。この嗜好データ(と人手で定義されたhelpfulnessに基づくデータ)を用いてReward Modelを訓練しRLを実施する。
この手法は、嗜好データを人間がラベリングするのではなく、AIによるフィードバックによりラベリングするため、Reinforcement Learning from AI Feedback (RLAIF)と呼ばれる。
Harmfulness以外の分野にも応用可能と考えられる。
[^1]: この操作はモデルの望ましい挙動を人手で定義したルーブリックに基づいた複数のprompt (Constitutional Principles) を用いて実施される。具体的なpromptはAppendix Cを参照。
[Paper Note] Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, Yuntao Bai+, arXiv'22
Paper/Blog Link My Issue
#NLP #Alignment #ReinforcementLearning #Safety Issue Date: 2025-09-20 GPT Summary- 言語モデルを無害なアシスタントとして機能させるために、好みのモデル化と人間のフィードバックからの強化学習(RLHF)を用いて微調整を行い、NLP評価での性能向上を実現。毎週新しいフィードバックデータでモデルを更新し、効率的な改善を図る。RLHFトレーニングの堅牢性を調査し、ポリシーと初期化とのKLダイバージェンスの関係を特定。モデルのキャリブレーションや競合目的についても分析し、人間の作家との比較を行った。
[Paper Note] Emergent Abilities of Large Language Models, Jason Wei+, TMLR'22
Paper/Blog Link My Issue
#Analysis #NLP #Selected Papers/Blogs #EmergentAbilities Issue Date: 2025-09-19 GPT Summary- 大規模言語モデルのスケーリングアップは性能を向上させるが、「出現能力」と呼ばれる予測不可能な現象が存在する。これは小型モデルにはない能力であり、さらなるスケーリングがモデルの能力を拡大する可能性を示唆している。 Comment
openreview: https://openreview.net/forum?id=yzkSU5zdwD
創発能力(最近この用語を目にする機会が減ったような気がする)
[Paper Note] Deduplicating Training Data Makes Language Models Better, Katherine Lee+, ACL'22
Paper/Blog Link My Issue
#Pretraining #NLP #ACL #Selected Papers/Blogs #Deduplication Issue Date: 2025-09-04 GPT Summary- 既存の言語モデルデータセットには重複した例が多く含まれ、訓練されたモデルの出力の1%以上が訓練データからコピーされている。これを解決するために、重複排除ツールを開発し、C4データセットからは60,000回以上繰り返される文を削除。重複を排除することで、モデルの記憶されたテキスト出力を10倍減少させ、精度を維持しつつ訓練ステップを削減。また、訓練とテストの重複を減らし、より正確な評価を実現。研究の再現とコードは公開されている。 Comment
下記スライドのp.9にまとめが記述されている:
https://speakerdeck.com/takase/snlp2023-beyond-neural-scaling-laws?slide=9
[Paper Note] StableMoE: Stable Routing Strategy for Mixture of Experts, Damai Dai+, arXiv'22
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #MoE(Mixture-of-Experts) #Stability Issue Date: 2025-09-02 GPT Summary- StableMoEは、ルーティングの変動問題に対処するために2つのトレーニングステージを持つMixture-of-Experts手法を提案。最初のステージで一貫したルーティング戦略を学習し、軽量ルーターに蒸留。第二のステージでそのルーターを用いてエキスパートへの割り当てを固定。言語モデリングと多言語機械翻訳での実験により、StableMoEは収束速度と性能で既存手法を上回ることが示された。 Comment
元ポスト:
[Paper Note] Fast Model Editing at Scale, Eric Mitchell+, ICLR'22
Paper/Blog Link My Issue
#NLP #ICLR #KnowledgeEditing Issue Date: 2025-06-18 GPT Summary- MEND(モデル編集ネットワーク)は、事前学習モデルの動作を迅速かつ局所的に編集するための手法で、単一の入力-出力ペアを用いて勾配分解を活用します。これにより、10億以上のパラメータを持つモデルでも、1台のGPUで短時間でトレーニング可能です。実験により、MENDが大規模モデルの編集において効果的であることが示されました。 Comment
OpenReview: https://openreview.net/forum?id=0DcZxeWfOPt
[Paper Note] LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
Paper/Blog Link My Issue
#NLP #PEFT(Adaptor/LoRA) #ICLR #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-05-12 GPT Summary- LoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。 Comment
OpenrReview: https://openreview.net/forum?id=nZeVKeeFYf9
LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。
- [Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
などでも示されているが、一般的にLoRAとFull Finetuningを比較するとLoRAの方が性能が低いことが知られている点には留意が必要。
最近、LoRAが学習率に対してsensitiveで、LoRAの提案以後約50種類の変種が提案されたが、適切にLoRAの学習率を調整した上で比較実験すると、依然としてオリジナルのLoRAが強力な手法であることが示された。以後提案された手法群は比較実験におけるハイパーパラメータの調整不足であることが指摘されている。
- [Paper Note] Learning Rate Matters: Vanilla LoRA May Suffice for LLM Fine-tuning, Yu-Ang Lee+, arXiv'26, 2026.02
[Paper Note] Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22, 2022.03
Paper/Blog Link My Issue
#MachineLearning #NLP #NeurIPS #Scaling Laws #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-03-23 GPT Summary- トランスフォーマー言語モデルの訓練において、計算予算内で最適なモデルサイズとトークン数を調査。モデルサイズと訓練トークン数は同等にスケールする必要があり、倍増するごとにトークン数も倍増すべきと提案。Chinchillaモデルは、Gopherなどの大規模モデルに対して優れた性能を示し、ファインチューニングと推論の計算量を削減。MMLUベンチマークで67.5%の精度を達成し、Gopherに対して7%以上の改善を実現。 Comment
OpenReview: https://openreview.net/forum?id=iBBcRUlOAPR
chinchilla則
[Paper Note] Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks, Yizhong Wang+, EMNLP'22, 2022.04
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #EMNLP #PostTraining #KeyPoint Notes Issue Date: 2024-10-29 GPT Summary- NLPモデルの一般化能力を評価するために、1,616の多様なタスクを含むSuper-NaturalInstructionsというベンチマークを導入。76種のタスクタイプをカバーし、モデルをタスクのサブセットで訓練し未見のタスクを評価。Tk-Instructモデルは、InstructGPTを9%以上上回る性能を示し、サイズが小さい。タスク数やインスタンス数に基づいた一般化の分析を行い、本データセットとモデルが汎用的NLPモデルの進展に寄与することを期待。 Comment
7.1, 7.2が最も興味深い
## Instruction Tuningにおける未知のタスクに対する汎化性能について、3つの要素に対するスケーリングについて考察
- More observed tasks improve the generalization.
- A large number of training instances do not help generalization.
- Tuning larger models with instructions consistently lead to gains.
## Instructionをさまざまに変化させた時の性能の変化に対する分析
Table4の対角成分に注目すると(trainとtestのinput encodingを揃えた場合)
- Task definitionをinstructionに含めることで未知タスクに対する汎化性能向上
- Task Definitionとpositive examplesを4つ程度入れると汎化性能向上。
- ただし、これ以上exampleを増やすと性能低下。
- negative examplesを入れることは性能に a little bit しか貢献しない
- explanationsを入れると性能が低下する
Table4の非対角成分に着目すると、
- Task Definitionのみで訓練しても、Example onlyのtest時のencodingには汎化しない(逆も然り)
- Task Definition + examples (今回の場合はpositive examples4つ)は、さまざまなtest時のinput encodingsに対してロバストになる
[Paper Note] Finetuned Language Models Are Zero-Shot Learners, Jason Wei+, ICLR'22, 2021.09
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #ICLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-09-25 GPT Summary- 指示チューニングにより言語モデルのゼロショット学習能力を向上。1370億パラメータのモデルを60以上のNLPタスクに対してファインチューニングし、FLANと名付ける。FLANは未調整モデルを超え、25タスク中20タスクで175B GPT-3を上回り、ANLIやRTEなどでfew-shotのGPT-3にも勝る。ファインチューニングデータの数やモデル規模、指示内容が成功の鍵と示される。 Comment
FLAN論文。Instruction Tuningを提案した研究。
openreview: https://openreview.net/forum?id=gEZrGCozdqR
[Paper Note] STaR: Bootstrapping Reasoning With Reasoning, Eric Zelikman+, arXiv'22, 2022.03
Paper/Blog Link My Issue
#NLP #SelfImprovement #NeurIPS #needs-revision Issue Date: 2024-09-15 GPT Summary- STaR(Self-Taught Reasoner)を提案し、少数の推論例と大規模データセットを用いて段階的に複雑な推論を行う手法を紹介。まず複数の質問に対して推論根拠を生成し、誤答時には正しい解答を前提に再生成を行うことで性能を向上。STaRはファインチューニングにより自己学習能力を持ち、複数のデータセットでの性能を顕著に改善、CommensenseQAでは最先端モデルと同等の結果を達成。 Comment
OpenAI o1関連研究
openreview: https://openreview.net/forum?id=_3ELRdg2sgI
Training language models to follow instructions with human feedback, Long Ouyang+, N_A, NeurIPS'22
Paper/Blog Link My Issue
#NLP #Alignment #ChatGPT #RLHF #PPO (ProximalPolicyOptimization) #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-04-28 GPT Summary- 大規模な言語モデルは、ユーザーの意図に合わない出力を生成することがあります。本研究では、人間のフィードバックを使用してGPT-3を微調整し、InstructGPTと呼ばれるモデルを提案します。この手法により、13億パラメータのInstructGPTモデルの出力が175BのGPT-3の出力よりも好まれ、真実性の向上と有害な出力の削減が示されました。さらに、一般的なNLPデータセットにおける性能の低下は最小限でした。InstructGPTはまだ改善の余地がありますが、人間のフィードバックを使用した微調整が有望な方向であることを示しています。 Comment
ChatGPTの元となる、SFT→Reward Modelの訓練→RLHFの流れが提案された研究。DemonstrationデータだけでSFTするだけでは、人間の意図したとおりに動作しない問題があったため、人間の意図にAlignするように、Reward Modelを用いたRLHFでSFTの後に追加で学習を実施する。Reward Modelは、175Bモデルは学習が安定しなかった上に、PPOの計算コストが非常に大きいため、6BのGPT-3を様々なNLPタスクでSFTしたモデルをスタートにし、モデルのアウトプットに対して人間がランキング付けしたデータをペアワイズのloss functionで訓練した。最終的に、RMのスコアが最大化されるようにSFTしたGPT-3をRLHFで訓練するが、その際に、SFTから出力が離れすぎないようにする項と、NLPベンチマークでの性能が劣化しないようにpretrain時のタスクの性能もloss functionに加えている。
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5), Shijie Geng+, N_A, RecSys'22
Paper/Blog Link My Issue
#RecommenderSystems #Zero/Few/ManyShotPrompting #InstructionTuning #Finetuning #KeyPoint Notes Issue Date: 2023-11-12 GPT Summary- 我々は「Pretrain, Personalized Prompt, and Predict Paradigm」(P5)と呼ばれる柔軟で統一されたテキストからテキストへのパラダイムを提案します。P5は、共有フレームワーク内でさまざまな推薦タスクを統一し、個別化と推薦のための深い意味を捉えることができます。P5は、異なるタスクを学習するための同じ言語モデリング目標を持つ事前学習を行います。P5は、浅いモデルから深いモデルへと進化し、広範な微調整の必要性を減らすことができます。P5の効果を実証するために、いくつかの推薦ベンチマークで実験を行いました。 Comment
# 概要
T5 のように、様々な推薦タスクを、「Prompt + Prediction」のpipelineとして定義して解けるようにした研究。
P5ではencoder-decoder frameworkを採用しており、encoder側ではbidirectionalなモデルでpromptのrepresentationを生成し、auto-regressiveな言語モデルで生成を行う。
推薦で利用したいデータセットから、input-target pairsを生成し上記アーキテクチャに対して事前学習することで、推薦を実現できる。
RatingPredictionでは、MatrixFactorizationに勝てていない(が、Rating Predictionについては魔法の壁問題などもあると思うのでなんともいえない。)
Sequential RecommendationではBERT4Recとかにも勝てている模様。
# Prompt例
- Rating Predictionの例
- Sequential Recommendationの例
- Explanationを生成する例
- Zero-shotの例(Cold-Start)
[Paper Note] Explaining Patterns in Data with Language Models via Interpretable Autoprompting, Chandan Singh+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Dataset #DataToTextGeneration #Explanation #One-Line Notes #Data Issue Date: 2023-08-03 GPT Summary- iPromptを用いて、事前学習済みのLLMがデータを説明する自然言語文字列を生成する手法を提案。このアルゴリズムは、生成された説明の性能を再評価して最適化するプロセスを含む。実験によりiPromptが正確なデータ記述を見つけ、人間にも解釈可能なプロンプトを生成し、一般化性能に優れることが示された。特に、実世界の感情分類データセットでGPT-3並みのプロンプトを生成し、科学的発見の支援にも寄与する可能性がある。すべてのコードはGitHubで公開。 Comment
OpenReview: https://openreview.net/forum?id=GvMuB-YsiK6
データセット(中に存在するパターンの説明)をLLMによって生成させる研究


[Paper Note] RQUGE: Reference-Free Metric for Evaluating Question Generation by Answering the Question, Alireza Mohammadshahi+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#Metrics #NLP #QuestionAnswering #Evaluation #Reference-free #ACL #KeyPoint Notes Issue Date: 2023-07-22 GPT Summary- 既存の質問評価指標には、人間の参照質問との比較による語彙的重複や意味的類似性に基づく欠点がある。これに対し、本研究で提案する新しい指標RQUGEは、候補質問の文脈に基づく回答可能性を評価し、人間の判断と高い相関を示す。この指標は既存の事前学習モデルを活用し、追加訓練なしで使用可能。また、RQUGEは対抗的改ざんに対して堅牢であり、質問生成モデルからの合成データを用いた微調整により、QAモデルの性能を向上させることができる。 Comment
# 概要
質問自動生成の性能指標(e.g. ROUGE, BERTScore)は、表層の一致、あるいは意味が一致した場合にハイスコアを与えるが、以下の欠点がある
- 人手で作成された大量のreference questionが必要
- 表層あるいは意味的に近くないが正しいquestionに対して、ペナルティが与えられてしまう
=> contextに対するanswerabilityによって評価するメトリック RQUGE を提案
similarity basedな指標では、Q1のような正しい質問でもlexical overlapがないと低いスコアを与えてしまう。また、Q2のようなreferenceの言い換えであっても、低いスコアとなってしまう。一方、reference basedな手法では、Q3のようにunacceptableになっているにもかかわらず、変化が微小であるためそれをとらえられないという問題がある。
# 手法概要
提案手法ではcontextとanswer spanが与えられたとき、Span Scorerと、QAモジュールを利用してacceptability scoreを計算することでreference-freeなmetricを実現する。
QAモデルは、Contextと生成されたQuestionに基づき、answer spanを予測する。提案手法ではT5ベースの手法であるUnifiedQAv2を利用する。
Span Scorer Moduleでは、予測されたanswer span, candidate question, context, gold spanに基づき、[1, 5]のスコアを予測する。提案手法では、encoder-only BERT-based model(提案手法ではRoBERTa)を用いる。
[Paper Note] Pruning Pre-trained Language Models Without Fine-Tuning, Ting Jiang+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NLP #Pruning #ACL #needs-revision Issue Date: 2023-07-13 GPT Summary- プルーニングによる事前学習済み言語モデル(PLMs)の圧縮手法を提案。特にStatic Model Pruning(SMP)は、一階法の剪定のみでPLMsを下流タスクに適応させ、スパース性を達成。新たなマスキング関数と訓練目的関数を設計し、広範な実験で顕著な性能向上を示す。SMPはファインチューニングを不要とし、パラメータ効率が良好。
[Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #TMLR #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-07-03 GPT Summary- HELMは、言語モデルの透明性を高めるための包括的評価手法である。まず、潜在的なシナリオと指標の分類を行い、欠落している部分を特定。次に、マルチ指標アプローチを採用し、コアシナリオごとに7つの評価指標を測定することで、正確性以外の側面も考慮。さらに、30の著名な言語モデルに対して大規模評価を実施し、評価範囲を17.9%から96.0%に改善。全データを公開し、HELMをコミュニティの生きたベンチマークとして継続的に更新していくことを目指している。 Comment
OpenReview: https://openreview.net/forum?id=iO4LZibEqW
HELMを提案した研究
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/
[Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #TMLR #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-07-03 GPT Summary- 言語モデルはスケールの拡大に伴い、新しい定量的・質的能力を示すが、その具体的な特性は未解明である。これを踏まえ、BIG-benchという新たなベンチマークを導入し、204の多様なタスクを評価。モデルの性能と較正は改善するが、絶対的には低く、スパース性の影響を受ける場合もある。特に、複数の手順を要するタスクは臨界規模での“ブレークスルー”を示す傾向があり、社会的バイアスは通常、スケールと共に増加するが、プロンプトによって改善可能である。 Comment
OpenReview: https://openreview.net/forum?id=uyTL5Bvosj
BIG-Bench論文。ワードクラウドとキーワード分布を見ると一つの分野に留まらない非常に多様なタスクが含まれることがわかる。
BIG-Bench-hardは、2024年にClaude3.5によって、Average Human Scoreが67.7%のところ、93.1%を達成され攻略が完了した。現在は最先端のモデル間の性能を差別化することはできない。
- Killed by LLM, R0bk
[Paper Note] Out of One, Many: Using Language Models to Simulate Human Samples, Lisa P. Argyle+, arXiv'22, 2022.09
Paper/Blog Link My Issue
#Analysis #needs-revision Issue Date: 2023-05-11 GPT Summary- 言語モデルが社会科学研究における特定の人間サブ集団の有効な代理として機能する可能性を検討。バイアスの問題に対し、アルゴリズム的忠実性を提案し、モデルが人口統計に基づく応答分布を正確に模倣できることを示す。GPT-3の性能を実際の人間から得たデータと比較することで、表面的な類似を超えた複雑な相互作用を反映していることを明らかにし、言語モデルが人間と社会の理解を深める強力なツールとなる可能性を示唆する。
[Paper Note] Mass-Editing Memory in a Transformer, Kevin Meng+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NLP #ICLR #KnowledgeEditing #needs-revision Issue Date: 2023-05-04 GPT Summary- 最近の研究は、大規模言語モデルの更新に新たな記憶を利用する可能性を示しているが、主に単一の関連付けに限定されています。我々はMEMITを開発し、複数の記憶を使ってモデルを直接更新する手法を提案します。実験的に、GPT-J(6B)およびGPT-NeoX(20B)に対して多数の関連付けを効果的に処理できることを示し、従来の方法を大幅に上回る成果を達成しました。
[Paper Note] Large Language Models are Zero-Shot Reasoners, Takeshi Kojima+, arXiv'22, 2022.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Zero/Few/ManyShotPrompting #Chain-of-Thought #Prompting #NeurIPS #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)は自然言語処理において少数ショット学習の能力が高く、CoT promptingにより複雑な多段階推論を効果的に引き出す。特に「Let's think step by step」の追加で、ゼロショット推論能力が向上し、様々な論理推論タスクで手作りの例を使わずに性能を大幅に向上させた。例えば、InstructGPTモデルでのMultiArithの精度が17.7%から78.7%へ、GSM8Kが10.4%から40.7%と劇的な改善が見られた。この研究はLLMsの潜在的なゼロショット能力を示し、ファインチューニングや少数ショットの前にその知識を探求する重要性が強調されている。 Comment
Zero-Shot CoT (Let's think step-by-step.)論文

Zero-Shot-CoTは2つのステップで構成される:
- STEP1: Reasoning Extraction
- 元のquestionをxとし、zero-shot-CoTのtrigger sentenceをtとした時に、テンプレート "Q: [X]. A. [T]" を用いてprompt x'を作成
- このprompt x'によって得られる生成テキストzはreasoningのrationaleとなっている。
- STEP2: Answer Extraction
- STEP1で得られたx'とzを用いて、テンプレート "[X'] [Z] [A]" を用いてpromptを作成し、quiestionに対する回答を得る
- このとき、Aは回答を抽出するためのtrigger sentenceである。
- Aはタスクに応じて変更するのが効果的であり、たとえば、multi-choice QAでは "Therefore, among A through E, the answer is" といったトリガーを用いたり、数学の問題では "Therefore, the answer (arabic numerals) is" といったトリガーを用いる。
# 実験結果
表中の性能指標の左側はタスクごとにAnswer Triggerをカスタマイズしたもので、右側はシンプルに"The answer is"をAnswer Triggerとした場合。Zero-shot vs. Zero-shot-CoTでは、Zero-Shot-CoTが多くのb現地マークにおいて高い性能を示している。ただし、commonsense reasoningではperformance gainを得られなかった。これは [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
で報告されている通り、commonsense reasoningタスクでは、Few-Shot CoTでもLambda135Bで性能が向上せず、Palm540Bで性能が向上したように、モデルのparameter数が足りていない可能性がある(本実験では17種類のモデルを用いているが、特に注釈がなければtext-davinci-002を利用した結果)。
## 他ベースラインとの比較
他のベースラインとarithmetic reasoning benchmarkで性能比較した結果。Few-Shot-CoTには勝てていないが、standard Few-shot Promptingtを大幅に上回っている。
## zero-shot reasoningにおけるモデルサイズの影響
さまざまな言語モデルに対して、zero-shotとzero-shot-CoTを実施した場合の性能比較。[Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
と同様にモデルサイズが小さいとZero-shot-CoTによるgainは得られないが、モデルサイズが大きくなると一気にgainが大きくなる。
## Zero-shot CoTにおけるpromptの選択による影響
input promptに対するロバスト性を確認した。instructiveカテゴリ(すなわち、CoTを促すトリガーであれば)性能が改善している。特に、どのようなsentenceのトリガーにするかで性能が大きくかわっている。今回の実験では、"Let's think step by step"が最も高い性能を占め最多。
## Few-shot CoTのprompt選択における影響
CommonsenseQAのexampleを用いて、AQUA-RAT, MultiArithをFew-shot CoTで解いた場合の性能。どちらのケースもドメインは異なるが、前者は回答のフォーマットは共通である。異なるドメインでも、answer format(multiple choice)の場合、ドメインが異なるにもかかわらず、zero-shotと比較して性能が大幅に向上した。一方、answer formatが異なる場合はperformance gainが小さい。このことから、LLMはtask自体よりも、exampleにおけるrepeated formatを活用していることを示唆している。また、CommonSennseをExamplarとして用いたFew-Shot-CoTでは、どちらのデータセットでもZero-Shot-CoTよりも性能が劣化している。つまり、Few-Shot-CoTでは、タスク特有のサンプルエンジニアリングが必要であることがわかる(一方、Zero-shot CoTではそのようなエンジニアリングは必要ない)。
[Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Paper/Blog Link My Issue
#NLP #Zero/Few/ManyShotPrompting #Chain-of-Thought #Prompting #NeurIPS #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-04-27 GPT Summary- 思考の連鎖によって、大規模言語モデルの推論能力が向上することを探求。チェーン・オブ・ソート思考のプロンプトを用いる事例を示し、3つのモデルでの実験を通じて算術や常識、象徴的推論において性能向上を確認。特に、5400億パラメータのモデルに8つのデモをプロンプトとして与えただけで、数学問題のGSM8Kベンチマークで最先端の精度を達成した。 Comment
Chain-of-Thoughtを提案した論文。CoTをする上でパラメータ数が100B未満のモデルではあまり効果が発揮されないということは念頭に置いた方が良さそう。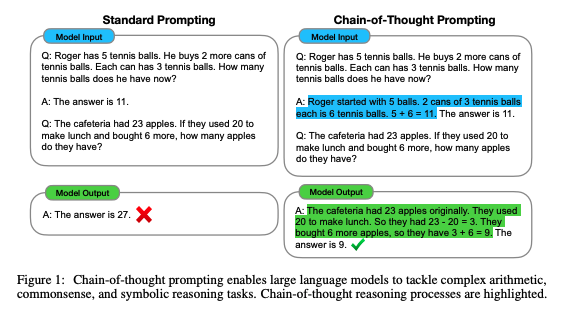
先行研究では、reasoningが必要なタスクの性能が低い問題をintermediate stepを明示的に作成し、pre-trainedモデルをfinetuningすることで解決していた。しかしこの方法では、finetuning用の高品質なrationaleが記述された大規模データを準備するのに多大なコストがかかるという問題があった。
このため、few-shot promptingによってこの問題を解決することが考えられるが、reasoning能力が必要なタスクでは性能が悪いという問題あがった。そこで、両者の強みを組み合わせた手法として、chain-of-thought promptingは提案された。
# CoTによる実験結果
以下のベンチマークを利用
- math word problem: GSM8K, SVAMP, ASDiv, AQuA, MAWPS
- commonsense reasoning: CSQA, StrategyQA, Big-bench Effort (Date, Sports), SayCan
- Symbolic Reasoning: Last Letter concatenation, Coin Flip
- Last Letter concatnation: 名前の単語のlast wordをconcatするタスク("Amy Brown" -> "yn")
- Coin Flip: コインをひっくり返す、 あるいはひっくり返さない動作の記述の後に、コインが表向きであるかどうかをモデルに回答するよう求めるタスク
## math word problem benchmark
- モデルのサイズが大きくなるにつれ性能が大きく向上(emergent ability)することがあることがわかる
- 言い換えるとCoTは<100Bのモデルではパフォーマンスに対してインパクトを与えない
- モデルサイズが小さいと、誤ったCoTを生成してしまうため
- 複雑な問題になればなるほど、CoTによる恩恵が大きい
- ベースラインの性能が最も低かったGSM8Kでは、パフォーマンスの2倍向上しており、1 stepのreasoningで解決できるSingleOpやMAWPSでは、性能の向上幅が小さい
- Task specificなモデルをfinetuningした以前のSoTAと比較してcomparable, あるいはoutperformしている
- 
## Ablation Study
CoTではなく、他のタイプのpromptingでも同じような効果が得られるのではないか?という疑問に回答するために、3つのpromptingを実施し、CoTと性能比較した:
- Equation Only: 回答するまえに数式を記載するようなprompt
- promptの中に数式が書かれているから性能改善されているのでは?という疑問に対する検証
- => GSM8Kによる結果を見ると、equation onlyでは性能が低かった。これは、これは数式だけでreasoning stepsを表現できないことに起因している
- Variable compute only: dotのsequence (...) のみのprompt
- CoTは難しい問題に対してより多くの計算(intermediate token)をすることができているからでは?という疑問に対する検証
- variable computationとCoTの影響を分離するために、dotのsequence (...) のみでpromptingする方法を検証
- => 結果はbaselineと性能変わらず。このことから、variableの計算自体が性能向上に寄与しているわけではないことがわかる。
- Chain of Thought after answer: 回答の後にCoTを出力するようなprompting
- 単にpretrainingの際のrelevantな知識にアクセスしやすくなっているだけなのでは?という疑問を検証
- => baselineと性能は変わらず、単に知識を活性化させるだけでは性能が向上しないことがわかる。
## CoTのロバスト性
人間のAnnotatorにCoTを作成させ、それらを利用したCoTpromptingとexamplarベースな手法によって性能がどれだけ変わるかを検証。standard promptingを全ての場合で上回る性能を獲得した。このことから、linguisticなstyleにCoTは影響を受けていないことがわかる。
# commonsense reasoning
全てのデータセットにおいて、CoTがstandard promptingをoutperformした。
# Symbolic Reasoning
in-domain test setとout-of-domain test setの2種類を用意した。前者は必要なreasoning stepがfew-shot examplarと同一のもの、後者は必要なreasoning stepがfew-shot examplarよりも多いものである。
CoTがStandard proimptingを上回っている。特に、standard promptingではOOV test setではモデルをスケールさせても性能が向上しなかったのに対し、CoTではより大きなgainを得ている。このことから、CoTにはreasoning stepのlengthに対しても汎化能力があることがわかる。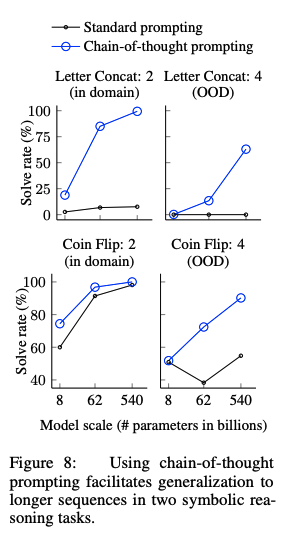
[Paper Note] Recurrent Memory Transformer, Aydar Bulatov+, NeurIPS'22, 2022.07
Paper/Blog Link My Issue
#NLP #LongSequence #NeurIPS #memory #KeyPoint Notes Issue Date: 2023-04-25 GPT Summary- メモリ機構を持つセグメントレベル再帰型トランスフォーマー(RMT)を提案。局所情報と全体情報を保存・処理し、長いシーケンス間で情報を伝達可能。特別なメモリトークンを追加することでTransformerモデルに変更を加えずに実装。実験結果では、RMTは短いメモリサイズでもTransformer-XLと同等の性能を示し、長いシーケンス処理では優れていることが確認。再帰的メモリトランスフォーマーは長期依存関係の学習に対する有望なアーキテクチャ。 Comment
TransformerはO(N^2)であり、計算量がNに応じて指数関数的に増加してしまう。一方、sequenceの情報を全てN次元ベクトルに集約しなければならず、計算量の制約によって長い系列のRepresentationを獲得できない。
そこで、Transformerの構造は変えず、Inputにメモリtokenを追加することで、メモリ間の関係性を学習できるような手法を提案。長いトークン列に対しても、トークン列をセグメントとゆばれる単位に区切り、セグメントのInputの頭で、前断のセグメントのメモリtokenを入力し、最終的に現在のセグメントのメモリをoutputし、後断のセグメントに入力とする、といったことを繰り返すことで、長い系列も扱えるようにした。
セグメントをまたいでbackpropagationをかけることで、たとえセグメントとしては独立していても、メモリの情報を考慮することでセグメント間の依存関係を学習することが可能だと思われる。
openreview: https://openreview.net/forum?id=Uynr3iPhksa
[Paper Note] Are Transformers Effective for Time Series Forecasting?, Ailing Zeng+, arXiv'22, 2022.05
Paper/Blog Link My Issue
#TimeSeriesDataProcessing #MachineLearning #Transformer #One-Line Notes Issue Date: 2022-12-29 GPT Summary- LTSFタスクに対するTransformer解法の妥当性を疑問視し、単純な1層線形モデル(LTSF-Linear)が既存のTransformerモデルを全ケースで上回る結果を示す。時間的関係の抽出における要素の影響を詳細に分析し、新たな研究の方向性を提案。将来的には他の時系列分析にもアプローチを見直すことを提唱。 Comment
Linear Layerに基づくシンプルな手法がTransformerベースの手法に時系列予測で勝ったという話
[Paper Note] UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models, Tianbao Xie+, EMNLP'22, 2022.01
Paper/Blog Link My Issue
#NeuralNetwork #NLP #MultitaskLearning #PEFT(Adaptor/LoRA) #EMNLP #Encoder-Decoder #Grounding Issue Date: 2022-12-05 GPT Summary- UnifiedSKGフレームワークを提案し、21の構造化知識のグラウンディング(SKG)タスクをテキスト対テキスト形式に統合。これにより、体系的なSKG研究を促進し、異なるサイズのT5で最先端の性能を達成。マルチタスクチューニングが性能向上に寄与し、SKGのゼロショットおよび少数ショット学習における課題を示した。UnifiedSKGは他のタスクへの拡張も可能で、オープンソースとして公開されている。
[Paper Note] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae+, arXiv'21, 2021.12
Paper/Blog Link My Issue
#NLP #One-Line Notes #Scalability Issue Date: 2026-07-09 GPT Summary- 言語モデリングは大規模な知識リポジトリを活用し、世界の理解を深化させる。本研究では、数千万から2,800億パラメータのTransformerベースのモデルGopherの性能を分析し、152の多様なタスクで最先端を達成。特に、読解や事実確認でスケールの利得が大きいが、論理的推論には限界がある。モデルの挙動やばイアス、危害の交差を総合的に評価し、AIの安全性に向けた適用と害の軽減についても考察。 Comment
- [Paper Note] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae+, arXiv'21, 2021.12
- 大規模言語モデルの次期バージョンPLaMo 3シリーズにおける120B事前学習モデル、31B蒸留モデルの評価, PFN, 2026.07
で利用されている weight reusingについて、`G3.3 Warm starting` に記載されている。概要としては
- LLMのキャパシティを増大させる際に、幅をスケーリングさせるよりも、深さをスケーリングさせる方が有望な結果となった
### 深さのスケーリング方法のbest practice
- 深さをスケーリングさせる、すなわち、5 layer -> 7 layerに拡張したい、という場合は、元の学習済みレイヤーを以下のルールによって複製することによって、拡張する:
- `round_int(range(num_layers_new)/num_layers_new * num_layers_old)`
- たとえば、`A B C D E` の5つのレイヤーで構成されているモデルがあったときに、これを7 layerに拡張したい場合は、上記indexに従って7つのレイヤーに学習済みレイヤーを割り当てると、`A B B C D D E` となる。
### 幅のスケーリング方法のbest practice
- (widthの拡張方法については正しく読めているかかなり自信がなく、間違っている可能性が非常に高いので注意)
- 幅をスケーリングさせる際は、MHA の weight matrices に対して列方向のコピー→行方向のコピー→ ノイズの注入を行う。
- 前提として以下を考える:
- MHAのQKV, outputのprojectionをそれぞれ、`W_q \in R^{d_model \times d_k}`, `W_k \in R^{d_model \times d_k}`, `W_v \in R^{d_model \times d_v}`, `W_o \in R^{h d_v \times d_model}` とする。
- このとき、オリジナルのtransformer論文では、`d_k = d_v = d_model/h` としている。
- つまり、各headに対応するW_{q, k, v, o}を列方向にconcatした行列 W^concat_{q, k, v, o}を考えると、列方向がh倍されるので、`W^concat_{q, k, v, o} \in R^{d_model \times d_model}` の正方行列で表現できる。ここで、`h * d_v= h * d_k= h * d_model/h = d_model` を用いた。
- この `W^{concat}_{*}` に対する操作を定義することで、multihead attentionが扱う幅を変更することができる。
- 元論文では、weight matricesと一言で言及されているが、これは(おそらく)`W^{concat}_{q, k, v, o}` のことを指していると思われる。実際、説明をする際は正方行列を前提に考えている(attention headごとに独立して考える元論文の数式では正方行列は weight matrices に出現しない)。
- まず `W^{concat}_{*}` において、head sizeをH, head数をnとしたときに、`nH \times nH` の行列を列方向にtilingすることによってattention headの数をmに拡張する。このとき、`d_k`, `d_v` のサイズは固定する。たとえば、head数をnからmに増やす際、最初のm-n個のheadを `W^{concat}_{*}` の右側に複製することによって拡張する、と説明されている。
- これはすなわち、個々のheadが扱う情報量は変化させずに、代わりにhead数を増やすことでスケーリングさせる、ということを指していると考えられる。
- 続いて、head数が増えたことによって `W^{concat}_{*}` が正方行列ではなくなった。これが正方行列になっていないとattentionの前後でbottleneck activation size(元論文ではd_modelのことをbottleneck activation sizeと呼称している)が変化してしまうので、正方行列にしなければならない。
- これを正方行列にするために、列方向に複製した行列の上端から数えて `(m-n) * d_k` 行分を行方向にconcatする。
- 最終的に、新たに初期化された重みに対してノイズを注入する。
- これによって構築された `W^{concat}_{*}` を図示したものが、下記Figure A32 と思われる。
- また、上記ではMHAの説明をしたが、MLPなどのd_modelが関わる各種weight matricesもwidthの拡張に含まれていると考えられる(じゃないとwidthの拡張と呼べないし)。
- optimizerの状態は再初期化して学習を実施する。
- Adam optimizerの状態に対して似たような処理を実施したが性能向上にはつながらなかった
[Paper Note] Linear Transformers Are Secretly Fast Weight Programmers, Imanol Schlag+, arXiv'21, 2021.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #read-later #Selected Papers/Blogs #LinearAttention Issue Date: 2026-04-22 GPT Summary- 線形化された自己注意機構とファストウェイト・コントローラの等価性を示し、遅いニューラルネットがファストウェイトをプログラムする方法を探る。FWPは有限メモリの操作を学習し、注意機構のメモリ容量限界を改善するために、加法的外積を用いたプログラミング命令を導入。動的学習率の計算も学習し、新しいカーネル関数を提案。合成リトリーバル問題や機械翻訳、言語モデリングタスクにおける利点を実験で示した。 Comment
Linear TransformerにおけるKV^Tを加算する固定された状態更新ではなく、差分だけを更新するDelta Ruleによって更新する Delta Networkを提案。
(まだ全然読めていないのでしっかり読みたい)
DeltaNet図解:
[Paper Note] Primer: Searching for Efficient Transformers for Language Modeling, David R. So+, NIPS'21, 2021.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Architecture #Selected Papers/Blogs #ActivationFunction #One-Line Notes Issue Date: 2026-02-16 GPT Summary- 大規模なTransformerモデルのコスト削減を目指し、プリミティブに基づく低レベルの探索を行い、Primerアーキテクチャを提案。これにより、自己回帰型言語モデリングで訓練コストを大幅に削減。具体的にはReLU活性化関数の二乗化と深さ方向の畳み込み層追加が主な改善点。実験により、計算規模が大きくなるほどPrimerの利得が増加し、特に5億パラメータの設定で元のT5アーキテクチャに対し4分の1のコストで改善を確認。また、19億パラメータ設定でも、訓練資源を大幅に削減しながら同等の性能を実現。再現性を考慮し、モデルをオープンソース化。 Comment
nanochat speedrunを改善させたReLU^2を提案しているとのこと
QKV projectionの後にshort convolutionsを導入するアーキテクチャも提案されている
[Paper Note] Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer, Greg Yang+, NeurIPS'21
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Transformer #NeurIPS #read-later #HyperparameterTransfer #One-Line Notes Issue Date: 2025-08-28 GPT Summary- ハイパーパラメータチューニングは高コストであり、特に大規模なニューラルネットワークにおいて負担が大きい。新たに提案するmuTransferは、最大更新パラメータ化(muP)を利用し、小さなモデルでチューニングしたHPをフルサイズモデルにゼロショットで転送する手法である。実験により、1300万パラメータのモデルからBERT-largeを超える性能を達成し、4000万パラメータからはGPT-3を上回る結果を得た。チューニングコストはそれぞれ事前学習コストの同等または7%に抑えられた。 Comment
openreview: https://openreview.net/forum?id=Bx6qKuBM2AD
小規模なモデルに対してハイパーパラメータのチューニングを実施し、同様のベースモデルで、**各layerのwidthが大きいもの**に対しても、小規模モデルで最適であったハイパーパラメータをzero-shotで転移することで near optimalなハイパーパラメータで学習できるmu Transferを提案。
モデルの深さ(以外にも下表中の*印のパラメータ)に対しても限定的に転移可能な模様。Post-Layer NormのTransformerやではあまりうまくいかないことが11節に記述されている(実験はpre-Layer Norm Transformer, ResNetに対して行われている模様)。
また、6.1節では、(実験的に)利用する小規模モデルのスケールとして幅256, 深さ4, バッチサイズ32, sequence長128, 訓練ステップ数5000を最低満たしており、かつスケールさせる幅が妥当な範囲内である必要がある、といった話が記述されている。
前提知識(muP)や条件が多そうな気がするので、しっかり確認した方がよさそう。
たとえば、muPで初期化されている必要があることや、転送可能なハイパーパラメータに限りがある(e.g. 学習率)、異なるデータに対するfinetuningなどは転送できないなど。
muP:
- [Paper Note] Feature Learning in Infinite-Width Neural Networks, Greg Yang+, ICML'21
[Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #CodeGeneration #Selected Papers/Blogs Issue Date: 2025-08-15 GPT Summary- 本論文では、汎用プログラミング言語におけるプログラム合成の限界を大規模言語モデルを用いて評価します。MBPPとMathQA-Pythonの2つのベンチマークで、モデルサイズに対する合成性能のスケールを調査。最も大きなモデルは、少数ショット学習でMBPPの59.6%の問題を解決可能で、ファインチューニングにより約10%の性能向上が見られました。MathQA-Pythonでは、ファインチューニングされたモデルが83.8%の精度を達成。人間のフィードバックを取り入れることでエラー率が半減し、エラー分析を通じてモデルの弱点を明らかにしました。最終的に、プログラム実行結果の予測能力を探るも、最良のモデルでも特定の入力に対する出力予測が困難であることが示されました。 Comment
代表的なコード生成のベンチマーク。
MBPPデータセットは、promptで指示されたコードをモデルに生成させ、テストコード(assertion)を通過するか否かで評価する。974サンプル存在し、pythonの基礎を持つクラウドワーカーによって生成。クラウドワーカーにタスクdescriptionとタスクを実施する一つの関数(関数のみで実行可能でprintは不可)、3つのテストケースを記述するよう依頼。タスクdescriptionは追加なclarificationなしでコードが記述できるよう十分な情報を含むよう記述するように指示。ground truthの関数を生成する際に、webを閲覧することを許可した。
MathQA-Pythonは、MathQAに含まれるQAのうち解答が数値のもののみにフィルタリングしたデータセットで、合計で23914サンプル存在する。pythonコードで与えられた数学に関する問題を解くコードを書き、数値が一致するか否かで評価する、といった感じな模様。斜め読みなので少し読み違えているかもしれない。
[Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #CodeGeneration #Selected Papers/Blogs Issue Date: 2025-08-15 GPT Summary- CodexはGitHubのコードでファインチューニングされたGPT言語モデルで、Pythonコード生成能力を評価。新しい評価セットHumanEvalでは、Codexが28.8%の問題を解決し、GPT-3は0%、GPT-Jは11.4%だった。繰り返しサンプリングが難しいプロンプトに対しても効果的な戦略を用い、70.2%の問題を解決。モデルの限界として、長い操作の説明や変数へのバインドに苦労する点が明らかに。最後に、コード生成技術の影響について安全性や経済に関する議論を行う。 Comment
HumanEvalデータセット。Killed by LLMによると、GPT4oによりすでに90%程度の性能が達成され飽和している。
164個の人手で記述されたprogrammingの問題で、それぞれはfunction signature, docstring, body, unittestを持つ。unittestは問題当たり約7.7 test存在。handwrittenという点がミソで、コンタミネーションの懸念があるためgithubのような既存ソースからのコピーなどはしていない。pass@k[^1]で評価。
[^1]: k個のサンプルを生成させ、k個のサンプルのうち、サンプルがunittestを一つでも通過する確率。ただ、本研究ではよりバイアスをなくすために、kよりも大きいn個のサンプルを生成し、その中からランダムにk個を選択して確率を推定するようなアプローチを実施している。2.1節を参照のこと。
[Paper Note] Editing Factual Knowledge in Language Models, Nicola De Cao+, EMNLP'21
Paper/Blog Link My Issue
#NLP #EMNLP #KnowledgeEditing Issue Date: 2025-06-18 GPT Summary- KnowledgeEditorは、事前学習された言語モデルの知識を編集し、再学習なしで誤った事実や予測を修正する手法です。制約最適化を用いてハイパーネットワークを訓練し、他の知識に影響を与えずに事実を修正します。BERTとBARTのモデルでその有効性を示し、特定のクエリに基づく予測変更がパラフレーズにも一貫して影響を与えることを確認しました。ハイパーネットワークは、知識操作に必要なコンポーネントを特定する「プローブ」として機能します。
[Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
Paper/Blog Link My Issue
#NLP #Dataset #Supervised-FineTuning (SFT) #Mathematics #Selected Papers/Blogs #Verification #needs-revision Issue Date: 2024-12-27 GPT Summary- 最先端の言語モデルは数学的推論に課題があり、GSM8Kという8,500件の小学生向け数学問題データセットを導入してその失敗を診断。特に、最大規模のトランスフォーマーモデルでも性能向上が難しいことを示す。モデルの補完の正しさを評価する検証器を訓練し、候補解を生成して最も高く評価されたものを選択する方法を提案。検証がGSM8Kの性能を大幅に向上させ、ファインチューニングよりも効果的にスケールすることを実証。 Comment
## 気持ち
- 当時の最も大きいレベルのモデルでも multi-stepのreasoningが必要な問題は失敗する
- モデルをFinetuningをしても致命的なミスが含まれる
- 特に、数学は個々のミスに対して非常にsensitiveであり、一回ミスをして異なる解法のパスに入ってしまうと、self-correctionするメカニズムがauto-regressiveなモデルではうまくいかない
- 純粋なテキスト生成の枠組みでそれなりの性能に到達しようとすると、とんでもないパラメータ数が必要になり、より良いscaling lawを示す手法を模索する必要がある
## Contribution
論文の貢献は
- GSM8Kを提案し、
- verifierを活用しモデルの複数の候補の中から良い候補を選ぶフレームワークによって、モデルのパラメータを30倍にしたのと同等のパフォーマンスを達成し、データを増やすとverifierを導入するとよりよく性能がスケールすることを示した。
- また、dropoutが非常に強い正則化作用を促し、finetuningとverificationの双方を大きく改善することを示した。
Todo: 続きをまとめる
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, Armen Aghajanyan+, N_A, ACL'21
Paper/Blog Link My Issue
#Analysis #NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #ACL #PostTraining #One-Line Notes Issue Date: 2024-10-01 GPT Summary- 事前学習された言語モデルのファインチューニングのダイナミクスを内因次元の観点から分析し、少ないデータでも効果的に調整できる理由を説明。一般的なモデルは低い内因次元を持ち、フルパラメータ空間と同等の効果を持つ低次元の再パラメータ化が可能であることを示す。特に、RoBERTaモデルを用いて、少数のパラメータの最適化で高いパフォーマンスを達成できることを実証。また、事前学習が内因次元を最小化し、大きなモデルが低い内因次元を持つ傾向があることを示し、内因次元に基づく一般化境界を提案。 Comment
ACL ver: https://aclanthology.org/2021.acl-long.568.pdf
下記の元ポストを拝読の上論文を斜め読み。モデルサイズが大きいほど、特定の性能(論文中では2種類のデータセットでの90%のsentence prediction性能)をfinetuningで達成するために必要なパラメータ数は、モデルサイズが大きくなればなるほど小さくなっている。
LoRAとの関係性についても元ポスト中で言及されており、論文の中身も見て後で確認する。
おそらく、LLMはBERTなどと比較して遥かにパラメータ数が大きいため、finetuningに要するパラメータ数はさらに小さくなっていることが想像され、LoRAのような少量のパラメータをconcatするだけでうまくいく、というような話だと思われる。興味深い。
元ポスト:
[Paper Note] RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, arXiv'21, 2021.04
Paper/Blog Link My Issue
#NLP #Transformer #PositionalEncoding #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-05-24 GPT Summary- 位置エンコーディングはトランスフォーマーにおいて重要な役割を果たし、依存関係をモデル化するための監督信号を提供する。本研究では、トランスフォーマーに位置情報を組み込む手法を検討し、新たに提案するロータリーポジションエンベディング(RoPE)が絶対位置を回転行列でエンコードして相対位置依存性を取り入れることを示す。RoPEはシーケンス長の柔軟性や相対距離の増加に伴う依存性の減衰などの特性を持ち、強化済みトランスフォーマー(RoFormer)の評価は他の手法を一貫して上回ることを示している。RoFormerはHuggingfaceに統合済み。 Comment
RoPEを提案した論文
# Absolute Position Embedding と Relative Position Embedding
## TransformerにおけるQKVベクトルの計算方法
一般に、Transformerにおける Query (Q), Key (K), Value (V) は以下の式で定式化される:
m, nはそれぞれ位置を表す整数。Absolute Position Embeddingと、Relative Position Embeddingは、関数fの設計がそれぞれ異なっている:
## Absolute Position Embedding
absolute position embeddingは、固定されたposition ベクトル、あるいはtrainableなposition ベクトルpを、入力ベクトルに対して足し合わせる:
## Relative Position Embedding
一方、Relative Position Embeddingは、Queryの位置に対する、Key, Valueの相対位置(つまり、mとnの差)に対して、trainableなベクトル \tilde{p}_r をKey, Valueおよび相対距離rごとに用意し、そのベクトルを入力に足し合わせる、という定式化となっている:
ここで、r = clip(m-n, r_max, r_min)であり、r_max, r_minは考慮する相対距離の最大値と最小値である。
他にも様々な定式化が提案されているがたいてい定式化の中に相対位置m-nが出現する。
## RoPE
RoPEでは、入力Query, Keyベクトル(Q,K)に対して回転行列を適用することで、回転に対して位置情報を保持させる。具体的には、異なる位置m, nに対するq_m^T k_nを計算すると、回転行列をRとした場合式16に示されているように回転行列Rに相対位置m-nが現れ(るように設計されており)、相対位置を考慮したqkの計算になっている。[^1]
[^1]: (R_mq_m)^T R_nK_n = q_m^T (R_m^T R_n) k_n = q_m^T (R_{-m}R_n) k_n = q_m^T R_{n-m} k_n. ここで、R_m^T = R_{-m}であり、R_m R_n = R_{m+n}の性質を使っている。
RoPEは下記のような性質を持つ:
- long-term decay: θi = 10000−2i/d と設定することにより、相対位置が離れているトークンのベクトルとのinner productの値が小さくなる。すなわち、位置が離れているトークン間の依存関係が小さくなる。
- Linear-Attention: RoPEは回転行列であり、乗算後のベクトルのノルムを変化させない。このため、Linear Attentionの式の中に回転行列を組み込むことで、Linear Attentionと簡単に組み合わせることが可能
Absolute Position Embedding, Relative Position Embeddingでは、ベクトルに対して位置情報を加算する定式化で K, Vの計算時に位置情報を考慮していたため、Linear Attentionの計算そのものに位置情報を組み込んだ定式化とはなっていなかった。
が、RoPEでは回転行列を乗算する定式化であり、ノルムを変化させないのでLinear Attentionの定式化に組み込むことができる。このため、モデルのアーキテクチャを大きく変更しなくとも組み込める。
RoPE自体は実装にパラメータを必要としないが、モデルのその他のパラメータがRoPEに適用できるように学習されていないと適用できないであろう点には注意(事前学習時にRoPEが使われていれば話は別)。
- 国産生成AI PLaMoを支える事後学習と推論最適化, PFN, 2026.04
pp.22--23がRoPEを簡潔に説明しており分かりやすい
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision, Wonjae Kim+, N_A, ICML'21
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Pretraining #NLP #Transformer #MultiModal Issue Date: 2023-08-22 GPT Summary- VLP(Vision-and-Language Pre-training)のアプローチは、ビジョンと言語のタスクでのパフォーマンスを向上させているが、現在の方法は効率性と表現力の面で問題がある。そこで、本研究では畳み込みフリーのビジョンと言語のトランスフォーマ(ViLT)モデルを提案する。ViLTは高速でありながら競争力のあるパフォーマンスを示し、コードと事前学習済みの重みはGitHubで利用可能である。 Comment
[Paper Note] SimCSE: Simple Contrastive Learning of Sentence Embeddings, Tianyu Gao+, arXiv'21, 2021.04
Paper/Blog Link My Issue
#Sentence #Embeddings #NLP #RepresentationLearning #ContrastiveLearning #Catastrophic Forgetting #EMNLP #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-07-27 GPT Summary- SimCSEは、文の埋め込み表現を向上させる単純な対照学習フレームワークです。教師なしアプローチでは、入力文が自身を予測し、ドロップアウトがノイズとして機能します。この手法は従来の教師あり方法と同等の成果を上げ、ドロップアウトを除去すると表現の質が低下することが分かりました。また、教師付きアプローチでは、自然言語推論データセットからの注釈付きペアを活用し、対照学習に組み込みます。評価結果では、教師なしモデルが76.3%、教師ありモデルが81.6%のSpearmanの相関を達成し、既存のベスト結果をそれぞれ改善しました。対照学習の目的が埋め込みの空間の正則化に貢献することも示されました。 Comment
[Paper Note] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Nils Reimers+, arXiv'19, 2019.08 よりも性能良く、unsupervisedでも学習できる。STSタスクのベースラインにだいたい入ってる
# 手法概要
Contrastive Learningを活用して、unsupervised/supervisedに学習を実施する。
Unsupervised SimCSEでは、あるsentenceをencoderに2回入力し、それぞれにdropoutを適用させることで、positive pairを作成する。dropoutによって共通のembeddingから異なる要素がマスクされた(noiseが混ざった状態とみなせる)類似したembeddingが作成され、ある種のdata augmentationによって正例を作成しているともいえる。負例はnegative samplingする。(非常にsimpleだが、next sentence predictionで学習するより性能が良くなる)
Supervised SimCSEでは、アノテーションされたsentence pairに基づいて、正例・負例を決定する。本研究では、NLIのデータセットにおいて、entailment関係にあるものは正例として扱う。contradictions(矛盾)関係にあるものは負例として扱う。
# Siamese Networkで用いられるmeans-squared errrorとContrastiveObjectiveの違い
どちらもペアワイズで比較するという点では一緒だが、ContrastiveObjectiveは正例と近づいたとき、負例と遠ざかったときにlossが小さくなるような定式化がされている点が異なる。
(画像はこのブログから引用。ありがとうございます。
https://techblog.cccmk.co.jp/entry/2022/08/30/163625)
# Unsupervised SimCSEの実験
異なるdata augmentation手法と比較した結果、dropoutを適用する手法の方が性能が高かった。MLMや, deletion, 類義語への置き換え等よりも高い性能を獲得しているのは興味深い。また、Next Sentence Predictionと比較しても、高い性能を達成。Next Sentence Predictionは、word deletion等のほぼ類似したテキストから直接的に類似関係にあるペアから学習するというより、Sentenceの意味内容のつながりに基づいてモデルの言語理解能力を向上させ、そのうえで類似度を測るという間接的な手法だが、word deletionに負けている。一方、dropoutを適用するだけの(直接的に類似ペアから学習する)本手法はより高い性能を示している。
[image](https://github.com/AkihikoWatanabe/paper_notes/assets/12249301/0ea3549e-3363-4857-94e6-a1ef474aa191)
なぜうまくいくかを分析するために、異なる設定で実験し、alignment(正例との近さ)とuniformity(どれだけembeddingが一様に分布しているか)を、10 stepごとにplotした結果が以下。dropoutを適用しない場合と、常に同じ部分をマスクする方法(つまり、全く同じembeddingから学習する)設定を見ると、学習が進むにつれuniformityは改善するが、alignmentが悪くなっていっている。一方、SimCSEはalignmentを維持しつつ、uniformityもよくなっていっていることがわかる。
# Supervised SimCSEの実験
アノテーションデータを用いてContrastiveLearningするにあたり、どういったデータを正例としてみなすと良いかを検証するために様々なデータセットで学習し性能を検証した。
- QQP4: Quora question pairs
- Flickr30k (Young et al., 2014): 同じ画像に対して、5つの異なる人間が記述したキャプションが存在
- ParaNMT (Wieting and Gimpel, 2018): back-translationによるparaphraseのデータセットa
- NLI datasets: SNLIとMNLI
実験の結果、NLI datasetsが最も高い性能を示した。この理由としては、NLIデータセットは、crowd sourcingタスクで人手で作成された高品質なデータセットであることと、lexical overlapが小さくなるようにsentenceのペアが作成されていることが起因している。実際、NLI datsetのlexical overlapは39%だったのに対し、ほかのデータセットでは60%であった。
また、condunctionsとなるペアを明示的に負例として与えることで、より性能が向上した(普通はnegative samplingする、というかバッチ内の正例以外のものを強制的に負例とする。こうすると、意味が同じでも負例になってしまう事例が出てくることになる)。より難しいNLIタスクを含むANLIデータセットを追加した場合は、性能が改善しなかった。この理由については考察されていない。性能向上しそうな気がするのに。
# 他手法との比較結果
SimCSEがよい。
# Ablation Studies
異なるpooling方法で、どのようにsentence embeddingを作成するかで性能の違いを見た。originalのBERTの実装では、CLS token のembeddingの上にMLP layerがのっかっている。これの有無などと比較。
Unsupervised SimCSEでは、training時だけMLP layerをのっけて、test時はMLPを除いた方が良かった。一方、Supervised SimCSEでは、 MLP layerをのっけたまんまで良かったとのこと。
また、SimCSEで学習したsentence embeddingを別タスクにtransferして活用する際には、SimCSEのobjectiveにMLMを入れた方が、catastrophic forgettingを防げて性能が高かったとのこと。
ablation studiesのhard negativesのところと、どのようにミニバッチを構成するか、それぞれのtransferしたタスクがどのようなものがしっかり読めていない。あとでよむ。
[Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Dataset #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration #ACL #Surface-level Notes Issue Date: 2023-05-31 GPT Summary- この論文では、ユーザーの興味とニュース本文に基づいて、ユーザー固有のタイトルを生成するパーソナライズされたニュース見出し生成の問題を解決するためのフレームワークを提案します。また、この問題のための大規模なデータセットであるPENSを公開し、ベンチマークスコアを示します。データセットはhttps://msnews.github.io/pens.htmlで入手可能です。 Comment
# 概要
ニュース記事に対するPersonalizedなHeadlineの正解データを生成。103名のvolunteerの最低でも50件のクリックログと、200件に対する正解タイトルを生成した。正解タイトルを生成する際は、各ドキュメントごとに4名異なるユーザが正解タイトルを生成するようにした。これらを、Microsoft Newsの大規模ユーザ行動ログデータと、ニュース記事本文、タイトル、impressionログと組み合わせてPENSデータを構成した。
# データセット生成手順
103名のenglish-native [speakerの学生に対して、1000件のニュースヘッドラインの中から最低50件興味のあるヘッドラインを選択してもらう。続いて、200件のニュース記事に対して、正解ヘッドラインを生成したもらうことでデータを生成した。正解ヘッドラインを生成する際は、同一のニュースに対して4人がヘッドラインを生成するように調整した。生成されたヘッドラインは専門家によってqualityをチェックされ、factual informationにエラーがあるものや、極端に長い・短いものなどは除外された。
# データセット統計量
# 手法概要
Transformer Encoder + Pointer GeneratorによってPersonalizedなヘッドラインを生成する。
Transformer Encoderでは、ニュースの本文情報をエンコードし、attention distributionを生成する。Decoder側では、User Embeddingを組み合わせて、テキストをPointer Generatorの枠組みでデコーディングしていき、ヘッドラインを生成する。
User Embeddingをどのようにinjectするかで、3種類の方法を提案しており、1つ目は、Decoderの初期状態に設定する方法、2つ目は、ニュース本文のattention distributionの計算に利用する方法、3つ目はデコーディング時に、ソースからvocabをコピーするか、生成するかを選択する際に利用する方法。1つ目は一番シンプルな方法、2つ目は、ユーザによって記事で着目する部分が違うからattention distributionも変えましょう、そしてこれを変えたらcontext vectorも変わるからデコーディング時の挙動も変わるよねというモチベーション、3つ目は、選択するvocabを嗜好に合わせて変えましょう、という方向性だと思われる。最終的に、2つ目の方法が最も性能が良いことが示された。
# 訓練手法
まずニュース記事推薦システムを訓練し、user embeddingを取得できるようにする。続いて、genericなheadline generationモデルを訓練する。最後に両者を組み合わせて、Reinforcement LearningでPersonalized Headeline Generationモデルを訓練する。Rewardとして、
1. Personalization: ヘッドラインとuser embeddingのdot productで報酬とする
2. Fluency: two-layer LSTMを訓練し、生成されたヘッドラインのprobabilityを推定することで報酬とする
3. Factual Consistency: 生成されたヘッドラインと本文の各文とのROUGEを測りtop-3 scoreの平均を報酬とする
とした。
1,2,3の平均を最終的なRewardとする。
# 実験結果
Genericな手法と比較して、全てPersonalizedな手法が良かった。また、手法としては②のattention distributionに対してuser informationを注入する方法が良かった。News Recommendationの性能が高いほど、生成されるヘッドラインの性能も良かった。
# Case Study
ある記事に対するヘッドラインの一覧。Pointer-Genでは、重要な情報が抜け落ちてしまっているが、提案手法では抜け落ちていない。これはRLの報酬のfluencyによるものだと考えられる。また、異なるユーザには異なるヘッドラインが生成されていることが分かる。
[Paper Note] The Power of Scale for Parameter-Efficient Prompt Tuning, Brian Lester+, EMNLP'21, 2021.04
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #EMNLP #PostTraining #Selected Papers/Blogs #KeyPoint Notes #SoftPrompt Issue Date: 2022-08-19 GPT Summary- 本研究では、凍結された言語モデルを特定のタスクに適応させるための「ソフトプロンプト」を学習するプロンプトチューニング手法を提案。逆伝播を通じて学習されるソフトプロンプトは、GPT-3の少数ショット学習を上回る性能を示し、モデルサイズが大きくなるほど競争力が増すことが確認された。特に、数十億のパラメータを持つモデルにおいて、全ての重みを調整するモデルチューニングに匹敵する性能を発揮。これにより、1つの凍結モデルを複数のタスクに再利用できる可能性が示唆され、ドメイン転送に対するロバスト性も向上することが明らかとなった。 Comment
日本語解説:
https://qiita.com/kts_plea/items/79ffbef685d362a7b6ce
T5のような大規模言語モデルに対してfinetuningをかける際に、大規模言語モデルのパラメータは凍結し、promptをembeddingするパラメータを独立して学習する手法
言語モデルのパラメータ数が増加するにつれ、言語モデルそのものをfinetuningした場合(Model Tuning)と同等の性能を示した。
いわゆる(Softな) Prompt Tuning
[Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #ACL #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2021-09-09 GPT Summary- プレフィックスチューニングは、ファインチューニングの軽量な代替手段であり、言語モデルのパラメータを固定しつつ、タスク特有の小さなベクトルを最適化する手法です。これにより、少ないパラメータで同等のパフォーマンスを達成し、低データ設定でもファインチューニングを上回る結果を示しました。 Comment
言語モデルをfine-tuningする際,エンコード時に「接頭辞」を潜在表現として与え,「接頭辞」部分のみをfine-tuningすることで(他パラメータは固定),より少量のパラメータでfine-tuningを実現する方法を提案.接頭辞を潜在表現で与えるこの方法は,GPT-3のpromptingに着想を得ている.fine-tuningされた接頭辞の潜在表現のみを配布すれば良いので,非常に少量なパラメータでfine-tuningができる.
table-to-text, summarizationタスクで,一般的なfine-tuningやAdapter(レイヤーの間にアダプターを挿入しそのパラメータだけをチューニングする手法)といった効率的なfine-tuning手法と比較.table-to-textでは、250k (元のモデルの 0.1%) ほどの数のパラメータを微調整するだけで、全パラメータをfine-tuningするのに匹敵もしくはそれ以上の性能を達成.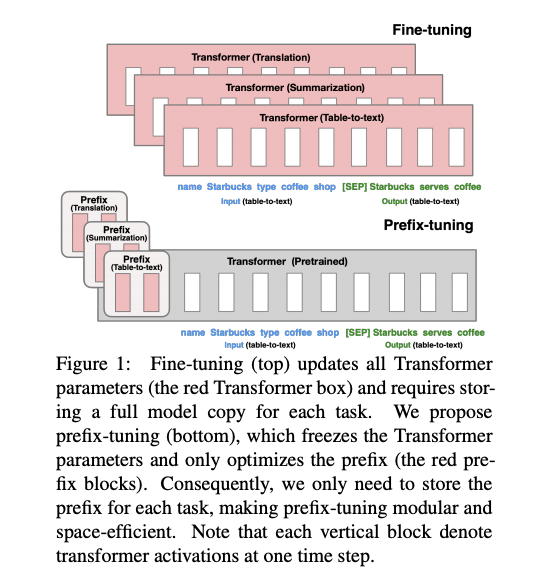
Hugging Faceの実装を利用したと論文中では記載されているが,fine-tuningする前の元の言語モデル(GPT-2)はどのように準備したのだろうか.Hugging Faceのpretrained済みのGPT-2を使用したのだろうか.
autoregressive LM (GPT-2)と,encoder-decoderモデル(BART)へPrefix Tuningを適用する場合の模式図
[Paper Note] Scaling Laws for Autoregressive Generative Modeling, Tom Henighan+, arXiv'20, 2020.10
Paper/Blog Link My Issue
#NLP #MultiModal #Scaling Laws #read-later #Selected Papers/Blogs #CrossDomain Issue Date: 2025-05-31 GPT Summary- 生成画像、ビデオ、マルチモーダルモデル、数学的問題解決の4領域におけるクロスエントロピー損失のスケーリング法則を特定。自己回帰型トランスフォーマーはモデルサイズと計算予算の増加に伴い性能が向上し、べき法則に従う。特に、10億パラメータのトランスフォーマーはYFCC100M画像分布をほぼ完璧にモデル化できることが示された。さらに、マルチモーダルモデルの相互情報量や数学的問題解決における外挿時の性能に関する追加のスケーリング法則も発見。これにより、スケーリング法則がニューラルネットワークの性能に与える影響が強調された。
[Paper Note] The Curious Case of Neural Text Degeneration, Ari Holtzman+, ICLR'20
Paper/Blog Link My Issue
#NLP #ICLR #Decoding #Diversity #Selected Papers/Blogs Issue Date: 2025-04-14 GPT Summary- 深層ニューラル言語モデルは高品質なテキスト生成において課題が残る。尤度の使用がモデルの性能に影響を与え、人間のテキストと機械のテキストの間に分布の違いがあることを示す。デコーディング戦略が生成テキストの質に大きな影響を与えることが明らかになり、ニュークリアスsamplingを提案。これにより、多様性を保ちながら信頼性の低い部分を排除し、人間のテキストに近い質を実現する。 Comment
現在のLLMで主流なNucleus (top-p) Samplingを提案した研究
[Paper Note] Scaling Laws for Neural Language Models, Jared Kaplan+, arXiv'20, 2020.01
Paper/Blog Link My Issue
#MachineLearning #NLP #Scaling Laws #Selected Papers/Blogs Issue Date: 2025-03-23 GPT Summary- 言語モデルの性能に関するスケーリング法則を研究し、損失がモデルサイズ、データセットサイズ、計算量に対して冪則的にスケールすることを示す。アーキテクチャの詳細は影響が少なく、過学習やトレーニング速度は単純な方程式で説明される。これにより、計算予算の最適な配分が可能となり、大きなモデルはサンプル効率が高く、少量のデータで早期に収束することが示された。 Comment
日本語解説: https://www.slideshare.net/slideshow/dlscaling-laws-for-neural-language-models/243005067
[Paper Note] GLU Variants Improve Transformer, Noam Shazeer, arXiv'20, 2020.02
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Transformer #Selected Papers/Blogs #ActivationFunction #KeyPoint Notes Issue Date: 2024-05-24 GPT Summary- GLUの変種は非線形関数を用いて二つの線形射影を組み合わせ、Transformerモデルでテストした結果、従来の活性化関数ReLUやGELUよりも性能を向上させることが確認された。 Comment
一般的なFFNでは、linear layerをかけた後に、何らかの活性化関数をかませる方法が主流である。
最近FFNで利用される活性化関数として入力をsigmoid gateにlinear layerで変換して、同じくlinear layerで入力ベクトルを変換したベクトルとの要素積をとるGLUがあるが、これには改良の余地があり、様々なvariantが考えられるため、色々試しました(以下の8種類のvariantが提案されている)、というはなし。
オリジナルのGLUと比較して、T5と同じ事前学習タスクを実施したところ、perplexityが改善
また、finetuningをした場合の性能も、多くの場合オリジナルのGLUよりも高い性能を示した。
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Patrick Lewis+, N_A, NeurIPS'20
Paper/Blog Link My Issue
#InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #NeurIPS #Selected Papers/Blogs #Encoder-Decoder #ContextEngineering Issue Date: 2023-12-01 GPT Summary- 大規模な事前学習言語モデルを使用した検索強化生成(RAG)の微調整手法を提案しました。RAGモデルは、パラメトリックメモリと非パラメトリックメモリを組み合わせた言語生成モデルであり、幅広い知識集約的な自然言語処理タスクで最先端の性能を発揮しました。特に、QAタスクでは他のモデルを上回り、言語生成タスクでは具体的で多様な言語を生成することができました。 Comment
RAGを提案した研究
Retrieverとして利用されているDense Passage Retrieval (DPR)はこちら:
- [Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04
[Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #ICLR #Selected Papers/Blogs #One-Line Notes #needs-revision Issue Date: 2023-07-24 GPT Summary- 新しいテストを提案し、57のマルチタスクを用いてテキストモデルの正確度を測定。高い正確度には広範な世界知識と問題解決能力が必要である。GPT-3モデルはランダム推測を約20ポイント上回るが、専門家レベルには遠く、多くのタスクで偏った性能を示す。特に道徳や法に関してはほぼランダムに近い正確度を記録。このテストはモデルの理解力を評価し、重要な欠点を明らかにすることを目的とする。 Comment
OpenReview: https://openreview.net/forum?id=d7KBjmI3GmQ
MMLU論文
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
において、多くのエラーが含まれることが指摘され、再アノテーションが実施されている。
[Paper Note] Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20, 2020.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Zero/Few/ManyShotPrompting #In-ContextLearning #NeurIPS #Selected Papers/Blogs Issue Date: 2023-04-27 GPT Summary- GPT-3は1750億パラメータの自己回帰型モデルで、タスク非依存のFew-shot学習を改善。ファインチューニングなしで多様なNLPタスクで高い性能を示し、人間と区別しにくい文を生成可能。訓練の課題も明らかに。 Comment
In-Context Learningを提案した論文
論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。
この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。
Few-Shot NLG with Pre-Trained Language Model, Chen+, University of California, ACL'20
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #pretrained-LM #Zero/FewShotLearning #Surface-level Notes Issue Date: 2022-12-01 Comment
# 概要
Neural basedなend-to-endなNLGアプローチはdata-hungryなので、Few Shotな設定で高い性能ができる手法を提案(Few shot NLG)
Table-to-Textタスク(WikiBIOデータ, 追加で収集したBook, SongドメインのWikipediaデータ)において、200程度の学習サンプル数でstrong baselineに対して8.0 point程度のBLEUスコアの向上を達成
# 手法
TabularデータのDescriptionを作成するには大きく分けて2つのスキルが必要
1. factualな情報を持つcontentをselectし、copyするスキル
2. factualな情報のコピーを含めながら、文法的に正しいテキストを生成するスキル
提案手法では、1を少量のサンプル(< 500)から学習し、2については事前学習済みの言語モデルを活用する。
encoderからコピーする確率をpcopyとし、下記式で算出する:
すなわち、encoderのcontext vectorと、decoderのinputとstateから求められる。
encoderとencoder側へのattentionはscratchから学習しなければならず、うまくコピーできるようにしっかりと”teach”しなければならないため、lossに以下を追加する:
すなわち、コピーすべき単語がちゃんとコピーできてる場合にlossが小さくなる項を追加している。
また、decoder側では、最初にTable情報のEmbeddingを入力するようにしている。
また、学習できるデータ量が限られているため、pre-trainingモデルのEmbeddingは事前学習時点のものに固定した(ただしく読解できているか不安)
# 実験
WikiBIOと、独自に収集したBook, Songに関するWikipediaデータのTable-to-Textデータを用いて実験。
このとき、Training instanceを50~500まで変化させた。
WikiBIOデータセットに対してSoTAを記録しているBase-originalを大きくoutperform(Few shot settingでは全然うまくいかない)。
inputとoutput例と、コピーに関するlossを入れた場合の効果。
人手評価の結果、Factual informationの正しさ(#Supp)、誤り(#Cont)ともに提案手法が良い。また、文法的な正しさ(Lan. Score)もコピーがない場合とcomparable
[Paper Note] CTRL: A Conditional Transformer Language Model for Controllable Generation, Nitish Shirish Keskar+, arXiv'19, 2019.09
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #NLP #Transformer #Selected Papers/Blogs #Decoder Issue Date: 2026-01-16 GPT Summary- CTRLは、スタイルや内容、タスク特有の振る舞いを制御するコードに基づいて訓練された条件付きトランスフォーマー言語モデルで、1.63億パラメータを持つ。このモデルは、無監督学習の利点を生かしつつ、テキスト生成に対する明示的な制御を提供。CTRLは与えられたシーケンスに基づいて最も可能性のあるトレーニングデータを予測でき、データ分析の新たなアプローチを提示する。また、複数の事前訓練済みバージョンが公開されている。 Comment
Control Code(いわゆるタグ)によって条件付けることで生成されるテキストのスタイルや内容等をcontrollableにする研究の先駆け
[Paper Note] Deep Equilibrium Models, Shaojie Bai+, NeurIPS'19
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #NeurIPS Issue Date: 2025-08-05 GPT Summary- 深い平衡モデル(DEQ)を提案し、逐次データのモデル化において平衡点を直接見つけるアプローチを示す。DEQは無限の深さのフィードフォワードネットワークを解析的に逆伝播可能にし、定数メモリでトレーニングと予測を行える。自己注意トランスフォーマーやトレリスネットワークに適用し、WikiText-103ベンチマークでパフォーマンス向上、計算要件の維持、メモリ消費の最大88%削減を実証。
[Paper Note] Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, arXiv'19, 2019.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #KeyPoint Notes Issue Date: 2024-04-07 GPT Summary- マルチクエリ・アテンションを提案し、アテンション・ヘッド間でキーと値を共有することで、逐次推論時のメモリ帯域幅を削減。これにより、デコード速度が向上し、品質低下は最小限に抑えられたことを実験で確認。 Comment
**※ 以前のメモでは "Queryを単一にする" と記述していましたが、完全に誤りでした。**
Multi Query Attention論文。Multi-Head Attentionにおける **KVを全てのhead間で共有する(つまりKV Cacheの量が1/num_headになる)** することで代替する。劇的にDecoderのInferenceが早くなりメモリ使用量が減る。論文中では言及されていない?ようだが、後続の研究で性能と学習の安定性が課題が指摘されているようである。
[Paper Note] BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, Fei Sun+, arXiv'19, 2019.04
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CIKM #SequentialRecommendation #One-Line Notes #Initial Impression Notes Issue Date: 2021-05-25 GPT Summary- ユーザーの動的嗜好をモデル化するために、BERT4RecというTransformerに基づく双方向エンコーダを導入。従来の順序型モデルの限界を克服し、Clozeタスクを用いて左側と右側の文脈を共同で条件付けしてアイテムを予測。さまざまなベンチマークデータセットにおいて、提案モデルが最先端の逐次モデルを一貫して上回る結果を示す。 Comment
BERTをrecsysのsequential recommendationタスクに転用してSoTA。
しっかり読んで無いけどモデル構造はほぼBERTと一緒。
異なる点は、Training時にNext Sentence Predictionは行わずClozeのみ行なっているという点。Clozeとは、実質Masked Language Modelであり、sequenceの一部を[mask]に置き換え、置き換えられたアイテムを左右のコンテキストから予測するタスク。異なる点としては、sequential recommendationタスクでは、次のアイテムを予測したいので、マスクするアイテムの中に、sequenceの最後のアイテムをマスクして予測する事例も混ぜた点。
もう一個異なる点として、BERT4Recはend-to-endなモデルで、BERTはpretraining modelだ、みたいなこと言ってるけど、まあ確かに形式的にはそういう違いはあるけど、なんかその違いを主張するのは違和感を覚える…。
sequential recommendationで使うuser behaviorデータでNext item predictionで学習したいことが、MLMと単に一致していただけ、なのでは…。
BERT4Recのモデル構造。next item predictionしたいsessionの末尾に [mask] をconcatし、[MASK]部分のアイテムを予測する構造っぽい?
オリジナルはtensorflow実装
pytorchの実装はこちら:
https://github.com/jaywonchung/BERT4Rec-VAE-Pytorch/tree/master/models
[Paper Note] Larger-context language modelling with recurrent neural networks, Wang+, ACL'16
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #NLP #ACL #Surface-level Notes Issue Date: 2017-12-28 Comment
## 概要
通常のNeural Language Modelはsentence間に独立性の仮定を置きモデル化されているが、この独立性を排除し、preceding sentencesに依存するようにモデル化することで、言語モデルのコーパスレベルでのPerplexityが改善したという話。提案した言語モデルは、contextを考慮することで特に名詞や動詞、形容詞の予測性能が向上。Late-Fusion methodと呼ばれるRNNのoutputの計算にcontext vectorを組み込む手法が、Perplexityの改善にもっとも寄与していた。
## 手法
sentence間の独立性を排除し、Corpusレベルのprobabilityを下図のように定義。(普通はP(Slが条件付けされていない))
preceding sentence (context)をモデル化するために、3種類の手法を提案。
[1. bag-of-words context]
ナイーブに、contextに現れた単語の(単一の)bag-of-wordsベクトルを作り、linear layerをかませてcontext vectorを生成する手法。
[2. context recurrent neural network]
preceding sentencesをbag-of-wordsベクトルの系列で表現し、これらのベクトルをsequentialにRNN-LSTMに読み込ませ、最後のhidden stateをcontext vectorとする手法。これにより、sentenceが出現した順番が考慮される。
[3. attention based context representation]
Attentionを用いる手法も提案されており、context recurrent neural networkと同様にRNNにbag-of-wordsのsequenceを食わせるが、各時点におけるcontext sentenceのベクトルを、bi-directionalなRNNのforward, backward stateをconcatしたもので表現し、attention weightの計算に用いる。context vectorは1, 2ではcurrent sentence中では共通のものを用いるが、attention basedな場合はcurrent sentenceの単語ごとに異なるcontext vectorを生成して用いる。
生成したcontext vectorをsentence-levelのRNN言語モデルに組み合わせる際に、二種類のFusion Methodを提案している。
[1. Early Fusion]
ナイーブに、RNNLMの各時点でのinputにcontext vectorの情報を組み込む方法。
[2. Late Fusion]
よりうまくcontext vectorの情報を組み込むために、current sentence内の単語のdependency(intra-sentence dependency)と、current sentenceとcontextの関係を別々に考慮する。context vectorとmemory cellの情報から、context vector中の不要箇所をフィルタリングしたcontrolled context vectorを生成し、LSTMのoutputの計算に用いる。Later Fusionはシンプルだが、corpusレベルのlanguage modelingの勾配消失問題を緩和することもできる。
## 評価
IMDB, BBC, PennTreebank, Fil9 (cleaned wikipedia corpus)の4種類のデータで学習し、corpus levelでPerplexityを測った。
Late FusionがPerplexityの減少に大きく寄与している。
PoSタグごとのperplexityを測った結果、contextを考慮した場合に名詞や形容詞、動詞のPerplexityに改善が見られた。一方、Coordinate Conjungtion (And, Or, So, Forなど)や限定詞、Personal Pronouns (I, You, It, Heなど)のPerplexityは劣化した。前者はopen-classな内容語であり、後者はclosed-classな機能語である。機能語はgrammaticalなroleを決めるのに対し、内容語はその名の通り、sentenceやdiscourseの内容を決めるものなので、文書の内容をより捉えることができると考察している。
[Paper Note] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe+, ICML'15
Paper/Blog Link My Issue
#MachineLearning #Transformer #ICML #Normalization #Selected Papers/Blogs #Reference Collection Issue Date: 2025-04-02 GPT Summary- バッチ正規化を用いることで、深層ニューラルネットワークのトレーニングにおける内部共変量シフトの問題を解決し、高い学習率を可能にし、初期化の注意を軽減。これにより、同じ精度を14倍少ないトレーニングステップで達成し、ImageNet分類で最良の公表結果を4.9%改善。 Comment
メモってなかったので今更ながら追加した
共変量シフトやBatch Normalizationの説明は
- [Paper Note] Layer Normalization, Ba+, arXiv'16, 2016.07
記載のスライドが分かりやすい。
[Paper Note] Unsupervised prediction of acceptability judgements, Lau+, ACL-IJCNLP'15
Paper/Blog Link My Issue
#NLP #ACL #IJCNLP #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2018-03-30 Comment
文のacceptability(容認度)論文。
文のacceptabilityとは、native speakerがある文を読んだときに、その文を正しい文として容認できる度合いのこと。
acceptabilityスコアが低いと、Readabilityが低いと判断できる。
言語モデルをトレーニングし、トレーニングした言語モデルに様々な正規化を施すことで、acceptabilityスコアを算出する。
日本語解説: http://www.lr.pi.titech.ac.jp/~sasano/acl2015suzukake/slides/01.pdf
Recurrent neural network based language model, Mikolov+, Interspeech'10
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Selected Papers/Blogs #Interspeech Issue Date: 2025-09-19 Comment
RNN言語モデル論文
Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07
Paper/Blog Link My Issue
#MachineTranslation #NLP #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-12-24 GPT Summary- 本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。 Comment
N-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
元ポスト:
Large Language Modelsという用語が利用されたのはこの研究が初めてなのかも…?
{G}igatoken: SIMD and Cache Hierarchies for 1000x Faster Byte-Pair Encoding Tokenization on Modern CPUs, Marcel R{\o}d, 2026.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Library #Tokenizer Issue Date: 2026-07-26 Comment
元ポスト:
所見:
どうやら、上記所見によると
- 与えられた文字列に対して正規表現を適用し、あらかじめ単語の境界を決める処理(pretokenize)を、
- SIMD命令(1つの命令を同時に複数のデータに対して適用;各バイトがどの文字クラスに属するかを判定する)と、
- ビット演算(文字クラスの判定結果に対して、シフトにより境界判定に必要な過去の文字クラス情報を構成し、シフト前後の系列に対するビット演算によりtokenizerの境界判定処理を実装みたいなことをやっているらしい)によって実現
- short pretokenに対するBPEをキャッシュする
という二段構えで高速化が実現されているようである。
---
参考:
- C++ SIMD命令入門(初心者向け), ancienthawk, 2025.08:
https://zenn.dev/ancienthawk/articles/for_simd_beginner_cp
- ゼロから作るLLM Part1: BPEトークナイザーの実装, so_dev000, 2025.11: https://qiita.com/so_dev000/items/037a21cba4e52182daea
A Field Guide to Fable: Finding Your Unknowns, Claude, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Prompting #Blog #reading Issue Date: 2026-07-25 Comment
元ポスト:
The new rules of context engineering for Claude 5 models, Thariq, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Post #ContextEngineering #reading #AgentHarness Issue Date: 2026-07-25 Comment
元ポスト:
Auto-Routing Models, dari.dev, 2026.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Blog #SmallModel #Selected Papers/Blogs #Initial Impression Notes #Orchestration Issue Date: 2026-07-25 Comment
元ポスト:
HF: https://huggingface.co/dari-ai/router-slm
Sakana FuguのようなLLMプールの中からターン単位で適切なLLMを選択するオーケストレータ(ルータ)で、QwenのLoRA Weightとして学習された重みが公開されているようである。
関連:
- [Paper Note] TRINITY: An Evolved LLM Coordinator, Jinglue Xu+, ICLR'26, 2025.12
- Sakana Fugu: A Multi-Agent Orchestration System as a Foundation Model, sakana.ai, 2026.04
- Sakana Fugu: One Model to Command Them All, SakanaAI, 2026.06
- [Paper Note] Sakana Fugu Technical Report, Yujin Tang+, arXiv'26, 2026.06
The fastest LLM on Earth: Frontier level intelligence, 15x faster, celeris, 2026.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #DiffusionModel #Blog #Proprietary #read-later #One-Line Notes #Author Thread-Post Issue Date: 2026-07-25 Comment
元ポスト:
アーキテクチャとしてdLLMを採用したGPT-5-miniと同等程度の性能のモデルで、GPT-5-miniに対して15倍程度(1280TPS)のスループットを実現しているとのこと。
Introducing Claude Opus 5, Anthropic, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #Author Thread-Post Issue Date: 2026-07-25 Comment
元ポスト:
coding, knowledge workでのベンチマークスコアはFable5超えで、コストはFable5のおよそ半分
いよいよベンチマークではClaude一強という感じになってきた:
Fable5のPromptingに関する話:
- A Field Guide to Fable: Finding Your Unknowns, Claude, 2026.07
Context Engineeringの話:
- The new rules of context engineering for Claude 5 models, Thariq, 2026.07
[Paper Note] LLaDA2.2, InclusionAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #DiffusionModel #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-07-25 Comment
HF: https://huggingface.co/inclusionAI/LLaDA2.2-flash
元ポスト:
LLaDA2.2シリーズとして初めてのAgent指向なdLLMとのこと。MoEアーキテクチャ採用。ベンチマークスコアはARモデルよりも少し劣る面があるが、スループットは1.64倍。
stack-v3-full, HuggingFaceCode, 2026.07
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #Blog #Coding #Selected Papers/Blogs #reading #One-Line Notes #Author Thread-Post Issue Date: 2026-07-24 Comment
元ポスト:
114 TB, 770言語, 224Mリポジトリ, 約5Tトークンの重複除去やフィルタリング済みGithubから収集されたソースコードで、制限付きライセンスのコードは一切含まないデータセット。V2では2023年時点のスナップショットに基づいており、V3は2025年8月時点までのスナップショットとのこと。たとてば、C++は15倍、TypeScript は7.5倍、Rustは7倍、Pythonは4.8倍程度のトークンがあるらしい。全体としては8.9倍のトークン量。
また、V2ではdeduplicationにおいて正規表現にバグがあったようで、そちらも修正されているようである。
Stack V2:
- [Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
所見:
FRONTIER-BENCH V0.1: A benchmark to measure and evolve with the frontier of agent work, FRONTIER-BENCH, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Blog #Selected Papers/Blogs #Live #reading #One-Line Notes #Author Thread-Post Issue Date: 2026-07-24 Comment
元ポスト:
Terminal Benchを構築したチームによる新たなベンチマークで、GPT-5.6-Sol (Codex) でもスコアは34.4%。タスクは今後も更新される。
タスクは、ソフトウェア、ML、科学、オペレーション、セキュリティ、ハードウェア、メディアなどのドメインによって構成されるようである。
Terminal Bench:
- [Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
Grok Build is open source: SpaceXAI's coding agent and CLI, SpaceXAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #One-Line Notes #AgentHarness Issue Date: 2026-07-23 Comment
元ポスト:
github: https://github.com/xai-org/grok-build
SpaceXAIによるcoding agent harness
所見:
Scaling Agentic RL: 365,000+ Environments for SWE, Terminal, and Search, Prime Intellect, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Blog #PostTraining #One-Line Notes #Scalability #Environment Issue Date: 2026-07-23 Comment
元ポスト:
36.5kのagentic RLのためのenvironments。対象はSWE, Search, terminal。全てのタスクセットが、任意のハーネス、ランタイム上でone commandで実行可能とのこと。
Solar Open 2: Korea's Sovereign Foundation Model, Built for Agentic Use, Upstage, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #Korean Issue Date: 2026-07-23 Comment
元ポスト:
Introducing Laguna S 2.1 Poolside team, Poolside, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #OpenWeight Issue Date: 2026-07-22 Comment
Introducing Gemini 3.6 Flash, 3.5 Flash-Lite, and 3.5 Flash Cyber, Google, 2026.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Proprietary #VisionLanguageModel Issue Date: 2026-07-22 Comment
元ポスト:
Artificial Analysis Indexでは、3.6 FlashはMuse 1.1と同程度の性能。
ただし、Time Per Intelligence Index Taskでは上位を独占
OpenAI and Hugging Face partner to address security incident during model evaluation, OpenAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Alignment #AIAgents #Evaluation #Blog #Safety #Attack #Selected Papers/Blogs #Security Issue Date: 2026-07-22 Comment
Hugging Face側のブログ:
Security incident disclosure — July 2026
https://huggingface.co/blog/security-incident-july-2026
元ポスト:
GPT‑Red: Unlocking Self-Improvement for Robustness, OpenAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Blog #Security #Initial Impression Notes #RedTeaming Issue Date: 2026-07-19 Comment
元ポスト:
redteamingに特化したGPT
Announcing Bonsai 27B: The First 27B-Class Model to Run on a Phone, PrismRL, 2026.07
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Blog #OpenWeight #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-19 Comment
元ポスト:
HF: https://huggingface.co/collections/prism-ml/bonsai-27b
Bonsaiシリーズ:
- Announcing 1-bit Bonsai: The First Commercially Viable 1-bit LLMs, 2026.03
- Introducing Ternary Bonsai: Top Intelligence at 1.58 Bits, PrismML, 2026.04
- Introducing 1-bit and Ternary Bonsai Image 4B: Image Generation for Local Devices, PrismML, 2026.05
1-bit, ternary weightによって、27B級モデルがエッジデバイス上で動作する。
🦋 Molt: A Scalable PyTorch-Native Training Framework for Agentic Reinforcement Learning, Jian Hu and Molt Contributors, 2026.07
Paper/Blog Link My Issue
#Article #Tools #NLP #ReinforcementLearning #AIAgents #PostTraining #One-Line Notes Issue Date: 2026-07-19 Comment
元ポスト:
ハイパフォーマンス、かつminimalな実装のRLライブラリで、研究用のハックがしやすいフレームワーク。verlの1/9, Slimeの1/3の行数で実現されているとのこと。
verl:
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
Slime:
- slime, THUDM & Zhihu, 2025.09
[Paper Note] Cura1T: Specialized Model for Agentic Healthcare, actAVA AI Team, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #Health #Medical #Initial Impression Notes Issue Date: 2026-07-19 Comment
元ポスト:
Healthcare関連の6つのベンチマークのうち5つでGPT-5.5, Opus4.8を上回る性能を示したモデルとのこと。Proprietaryモデル。
The 4-bitter Lesson: Balancing Stability and Performance in NVFP4 RL, Humans&, 2026.07
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #PostTraining #LowPrecision Issue Date: 2026-07-19 Comment
元ポスト:
How up-to-date is each AI model?, Apoorv Saxena, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #FactualKnowledge #One-Line Notes #Author Thread-Post Issue Date: 2026-07-19 Comment
330種類の30ヶ月に及ぶ予測不可能なイベントに関する情報を持ちいてモデルの実際のknowledge cutoffを推定する
元ポスト:
Introducing Muse Spark 1.1, Meta, 2026.07
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AIAgents #MultiModal #Proprietary #VisionLanguageModel #One-Line Notes #Author Thread-Post Issue Date: 2026-07-19 Comment
元ポスト:
Muse Spark:
- Introducing Muse Spark: Scaling Towards Personal Superintelligence, Meta, 2026.04
大幅にAgenticな能力やコーディング能力が向上。Agenticな能力では多くのベンチマークでOpus4.8超え、CodingはGPT-5.5にベンチマーク上では及ばず(SWE Bench Proでは勝っているが、OpenAIから30%以上のpromptが評価で不適切との報告があった Separating signal from noise in coding evaluations, OpenAI, 2026.07 )。
Alexandr Wang氏によるポスト:
Controlling Reasoning Effort in LLMs, Sebastian Raschka, 2026.07
Paper/Blog Link My Issue
#Article #Controllable #NLP #Blog #Reasoning #Length #read-later #Initial Impression Notes Issue Date: 2026-07-19 Comment
元ポスト:
OpenAIのReasoning Effortについては調整方法が公開されていないのでGPT-OSSのテンプレートなどから可能な方法を推測、そのほかOpenWeightモデルについてはテクニカルレポートに記載されている情報からReasoning Effortの調整方法が解説されている
Kimi K3: Open Frontier Intelligence, Moonshot AI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Selected Papers/Blogs #VisionLanguageModel #reading #One-Line Notes #Reference Collection Issue Date: 2026-07-17 Comment
元ポスト:
Artificial Analysisによる評価:
Artificial Analysis IndexでOpus 4.8超え!?
各ブロックの出力を重みつきで足し合わせることで柔軟にどのブロックにattendするかを決定するattention residualと呼ばれる技術が導入されているように見える。
また、MoEのexpert数をスケールさせ、896 experts, 16 activated expertsに変更。
学習レシピの洗練化と合わせてK2との比較で2.5倍のスケーリング効率が改善され、投入した計算コストをより効果的に知能に変換しているとのこと。
やはり
- [Paper Note] Slicing and Dicing: Configuring Optimal Mixtures of Experts, Margaret Li+, arXiv'26, 2026.05
でも示されているようにexpert数を増やすのが今のところ良さそうに見える。
どうやら2.8Tモデルらしい:
design arenaでFable5超えのSoTA:
writingに関するベンチマークでSoTA:
Latent MoE
- [Paper Note] LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts, Venmugil Elango+, arXiv'26, 2026.01
KDA
- [Paper Note] Kimi Linear: An Expressive, Efficient Attention Architecture, Kimi Team+, arXiv'25, 2025.10
Linear TransformerとDelta Net
- [Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20
- [Paper Note] Linear Transformers Are Secretly Fast Weight Programmers, Imanol Schlag+, arXiv'21, 2021.02
所見:
Latent MoEによってこれほどのsparsityを実現できているのではという所見:
GDPValでも3位:
Kernel optimizationにおいてもFable5と同等性能という報告:
Next.jsのコーディングベンチマークでもFable5超えのSoTAとのこと:
DeepSWEでGPT-5.6-sol, fable5に次ぐ3位:
アーキテクチャを公開されている情報から再構築した図:
公式ブログの図ではValueにはConvがかかっていないように見えたが、はたして。
Inkling: Our open-weights model, THINKING MACHINES, 2026.07
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #SpeechProcessing #Blog #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #VisionLanguageModel #UMM #KeyPoint Notes #Reference Collection #AudioLanguageModel #Author Thread-Post Issue Date: 2026-07-16 Comment
HF: https://huggingface.co/thinkingmachines/Inkling
元ポスト:
THINNING MACHINESによる最初のOpenWeightモデル。975B-41B
- フルスクラッチで学習したReasoningモデル
- 1M context window
- text, image, audio, video 45Tトークンで学習
- バランスよくさまざまな領域で性能を発揮するように訓練し、Tinker上でのfinetuningやカスタマイゼーションの良い基盤として機能することを目指した
- vision, audioドメインに関してはencoder freeアーキテクチャを採用
- audio signalの入力は dMel spectrogramsと呼ばれる手法を採用
- [Paper Note] dMel: Speech Tokenization made Simple, Richard He Bai+, arXiv'24, 2024.07
- 画像は40x40のパッチに分割され、4つのhMLPと呼ばれるレイヤーでエンコーディング
- [Paper Note] Three things everyone should know about Vision Transformers, Hugo Touvron+, ECCV'22, 2022.03
- IFの訓練には、Rubric basedなgraderとclaims graderの2種類のgraderを用いることで、helpfulnessとhallucinationを同時に低減
- Rubric basedなgraderはチェックリストに基づいてスコアリング
- claims graderはfactualな主張をagentic web searchを通じてverificationする
- アーキテクチャはDeepSeek V3を踏襲し、256のexpertsと2つのshared expertを採用し、6つのexpertsがactivateされる
- SWAとGlobal attentionの比率は5:1でKV Headは8つ (GQA)
- **相対位置エンコーディングを用いることでRoPEよりもlong contextに対してより高い外挿性能を示した**
- [Paper Note] Self-Attention with Relative Position Representations, Peter Shaw+, NAACL'18
- K, Vのprojection後、**およびattentionとMLPが残差ストリームに合流する前にshort convolutionを導入**
- QKV projection後に convolution を導入するアーキテクチャは下記研究で提案
- [Paper Note] Primer: Searching for Efficient Transformers for Language Modeling, David R. So+, NIPS'21, 2021.09
- optimiserはMuonとAdamWのハイブリッドで、前者は巨大な行列の重みに対して適用し、そのほかは後者を利用
- 重み自体が多様体上に存在するように制約することが有効であったことに着想を得て、weight decayを学習率の2乗に連動させることでモデルの重みの大きさを安定させたとのこと
- Modular Manifolds, Jeremy Bernstein+, THINKING MACHINES, 2025.09
- [Paper Note] Why Gradients Rapidly Increase Near the End of Training, Aaron Defazio, arXiv'25, 2025.06
- 事後学習としては、まずKimi K2.5を含むOpenWeightモデルで合成データ上でSFTをし、その後合成、あるいは人間が作成したenvironment上で大規模なRLを実施
- RLは非同期RLを異様し、ロールアウト数に対して推論能力が対数線形にスケールした。
- 最終的に30Mロールアウト以上のRLを実施した
- システムメッセージを変更し、トークン単位のコストを調整することでreasoning effortを調整
- Controlling Reasoning Effort in LLMs, Sebastian Raschka, 2026.07
- **276B-A12BのInkling-Smallもプレビュー段階にあり、agenticな能力においてInklingに近い性能を達成しており、今後公開予定**
1M context windowを実現した工夫は特に書かれていなかったように感じるが、よく使われるのはKV CacheをコンパクトにするためのSparse Attention、あるいはLinear Attentionなのに対し、本モデルでは使われていないように見える。linear attentionでなくとも、SWAとGlobal Attentionのハイブリッド、かつGQAによって、KV Cacheの肥大化を実用レベルで抑制できるのだろうか。また、外挿性能に関してはRoPEは採用せず、相対位置エンコーディングのを採用したという点が効いているのだろうか。1Mレベルでのcontextでの評価がなさそうに見えるので性能はよくわからない。
RoPEのlong contextでの限界を示した以下の研究を思い出した:
- [Paper Note] RoPE Distinguishes Neither Positions Nor Tokens in Long Contexts, Provably, Yufeng Du+, arXiv'26, 2026.05
Artificial Analysisによる評価:
アーキテクチャでの目新しい点:
所見:
公式:
所見:
What If the Harness Comes Before Pretraining? A Data Flywheel Perspective, Hanchen Li, 2026.07
Paper/Blog Link My Issue
#Article #Pretraining #Post #read-later #Data Issue Date: 2026-07-15 Comment
元ポスト:
Reducing Doom Loops with Final Token Preference Optimization, Liquid.AI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Blog #Reasoning #read-later #Author Thread-Post Issue Date: 2026-07-12 Comment
元ポスト:
Workspace geometry, model by model., elie, 2026.07
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #OpenWeight #read-later #Interpretability #Initial Impression Notes Issue Date: 2026-07-12 Comment
元ポスト:
38種類のOpenWeightモデルのlayer間でのJ-lensの類似性を検証したとのこと
アーキテクチャが異なっていても非常にモデル間で類似しているようである。gemma-4やSLM(Qwen, GPT2)などは外れ値を含む模様
関連:
- Verbalizable Representations Form a Global Workspace in Language Models, Anthropic, 2026.07
Benchmarking Coding Agents on Databricks’ Multi-Million Line Codebase, databricks, 2026.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #AIAgents #Evaluation #Blog #read-later #Initial Impression Notes #Author Thread-Post #AgentHarness Issue Date: 2026-07-10 Comment
元ポスト:
ハーネス選択によってトークン消費を1/2にでき、GLM 5.2のコストパフォーマンスが良いらしい
GPT-5.6: Frontier lntelligence that scales with your ambitlon, OpenAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-10 Comment
元ポスト:
GPT-5.6の変更点まとめ:
Model Guidance: https://developers.openai.com/api/docs/guides/latest-model?model=gpt-5.6
全体的に性能が高いだけでなく、コストパフォーマンスも良いという印象
コストパフォーマンス比:
Terra Ultra並の性能が必要なければ、Lunaのreasoning effortを上げるのがコスパ良いという話:
The Surprising Power of Small Language Models, Mojan Javaheripi+, Microsoft Research, 2023.12
Paper/Blog Link My Issue
#Article #NLP #SmallModel #Slide #One-Line Notes Issue Date: 2026-07-09 Comment
Phi-2のNeurIPSでの発表資料で、小さいスケールのLLMの学習済みの重みを、より大きなスケールのLLMの初期化に活用するweight reusinhgについて図解されている。実際にこの手法が説明されている文献は、スライド中で引用されている
- [Paper Note] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae+, arXiv'21, 2021.12
であるため、そちらも併せて参照のこと。上記issueに手法について説明を記載した(正しく読み解けているか少し自信がない)。
大規模言語モデルの次期バージョンPLaMo 3シリーズにおける120B事前学習モデル、31B蒸留モデルの評価, PFN, 2026.07
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LongSequence #OpenWeight #Reading Reflections #Author Thread-Post Issue Date: 2026-07-09 Comment
元ポスト:
weight reusing:
- [Paper Note] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae+, arXiv'21, 2021.12
- The Surprising Power of Small Language Models, Mojan Javaheripi+, Microsoft Research, 2023.12
long context評価:
- [Paper Note] RULER: What's the Real Context Size of Your Long-Context Language Models?, Cheng-Ping Hsieh+, COLM'24, 2024.04
- [Paper Note] Repeat After Me: Transformers are Better than State Space Models at Copying, Samy Jelassi+, arXiv'24, 2024.02
HF: https://huggingface.co/pfnet/plamo-3-nict-2604-31b-base
YaRNを適用するとlong contextの性能が大きく改善し、事前学習で学習させるトークン数を増やしすぎるとYaRNのcontext lengthの外挿能力が低下するという実験結果が非常に興味深い。
記載がなかった気がするのだが、Sink Tokenの利用などはやっているのだろうか?
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
Separating signal from noise in coding evaluations, OpenAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #Blog #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-07-09 Comment
元ポスト:
SWE-Bench Proの約30%にタスクが評価として機能しないタスクが含まれているとのこと(SWE-Bench Verifiedと同じ流れでは)。
これらは、5人の熟練なソフトウェアエンジニアによる監査と、AI Agentによる監査結果を人間がレビューするプロセスの2つを介して同定された。
以下のようなものがある:
- 過剰に制約されたテスト: 実装の制約が強すぎて機能として正しいのにテストが通らず、かつプロンプトでその制約が明示されていない
- requlrementが不足したテスト: プロンプトでの推測することができない要件の漏れ
- 低カバレッジのテスト: 実装が不完全でも通過するテスト
- ミスリーディングなプロンプト: テストが求める要件とは異なる挙動に向かわせるプロンプト
これにより、OpenAIは以前SWE Bench Proを推奨していたがそれを撤回するとのこと。
SWE Bench Verifiedでも同様の事案があった:
- Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
そしてSWE Bench Verifiedにおけるコンタミネーションやテストの問題点を改善したSWE Bench Proを構築した、という経緯だったはずだが、そのSWE Bench Proでも問題が見つかったという流れである。
あと、そもそもSWE Bench Proで問題のなかった70%で評価したら現在のモデルのスコアはどうなるのだろうか?
How to Build a Diffusion Language Model, Kuleshov Group, 2026.07
Paper/Blog Link My Issue
#Article #Tutorial #DiffusionModel #read-later #Author Thread-Post Issue Date: 2026-07-09 Comment
元ポスト:
SWE-1.7: Frontier Intelligence at a Fraction of the Cost, Cognition, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #Author Thread-Post Issue Date: 2026-07-09 Comment
元ポスト:
Introducing Grok 4.5, SpaceXAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Proprietary Issue Date: 2026-07-09 Comment
元ポスト:
Artificial Analysisの評価によるとGDPValで4位:
interpreting GPT: the logit lens, nostalgebraist, 2020.08
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #Selected Papers/Blogs #One-Line Notes #Interpretability Issue Date: 2026-07-08 Comment
LLMの中間層のhidden_state(残差ストリーム)に対して、出力層を連結しnext tokenを予測することで、当該中間層でどのようなトークンが想起されているかを可視化する
Verbalizable Representations Form a Global Workspace in Language Models, Anthropic, 2026.07
Paper/Blog Link My Issue
#Article #Analysis #NLP #Selected Papers/Blogs #One-Line Notes #Interpretability Issue Date: 2026-07-08 Comment
元ポスト:
関連:
- interpreting GPT: the logit lens, nostalgebraist, 2020.08
本文献の本旨であるJ-Spaceの定義、Global Workspace等の発見の話は元ポストを参照のこと。
以下、J-Lensについて元ポストを参考にメモする。
元ポストによると、logit lens
- interpreting GPT: the logit lens, nostalgebraist, 2020.08
と比較して、本文献で提案されているJacobi Lens (J-lens)は、ある中間層での残差ストリームにおける活性値の摂動が、最終層にどのような影響を与えるかを分析することで、当該中間層における残差ストリームがどのようなトークンを将来出力させる傾向にあるかを可視化する手法、とのことである。元ポスト中の具体例による説明が非常にわかりやすい。
logit lensは中間層の残差ストリームに対して、出力層を用いた線形変換を施して残差ストリーム内でどのようなトークンが想起されているかを可視化するが、J-lensは後段の層に与える影響を考慮して可視化する点が異なる。
Hy3, Tencent, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-07-08 Comment
元ポスト:
- Hy3-preview, tencent, 2026.04
の公開後から、50以上のプロダクトからフィードバックを受けより高品質なデータで事後学習を実施したとのこと。
- GLM-5.2: Built for Long-Horizon Tasks, Z.ai, 2026.06
が744B-A40B。Hy3は295B-A21Bなので、半分程度のパラメータ数でフロンティアモデルに近い性能を達成している。
公式:
Introducing Rampart, National Design Studio, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Blog #OpenWeight #Privacy #One-Line Notes #PII #Author Thread-Post Issue Date: 2026-07-08 Comment
HF: https://huggingface.co/nationaldesignstudio/rampart
生成AIに送信されるリクエストを検閲し、プロンプトに含まれる個人情報をマスクするよう訓練された軽量モデルのようである。ブログ下部のデモンストレーションを見るとイメージを掴みやすい。
元ポスト:
[Tech] Delta Weight Sync: When RL's Weight Sync Stops Being a Network Problem, Changyi Yang, ChangyiYang's Site, 2026.06
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #ReinforcementLearning #Blog #PostTraining #Selected Papers/Blogs #reading #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-07 Comment
RLによる事後学習の際にtrainer側のoptimizerが1 step学習した後にinferenceエンジンに重みをpushするが、BF16でのRLにおける1 stepの更新では多くのモデルの重みに変化はなく(99%程度)、差分だけをpushすればlosslessで2桁程度trafficを削減できて、RDMAが不要でたとえばイーサネットベースのデータセンターを跨いだ環境でもRLが実行できそうだよ、という話のようである。
元ポスト:
Devin Fusion: Frontier Performance at 35% Lower Cost, Cognition, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Architecture #read-later #ContextEngineering #One-Line Notes #Author Thread-Post #AgentHarness Issue Date: 2026-07-07 Comment
元ポスト:
高価で高性能なメインエージェントがタスクを管理し、安価なサイドキックエージェントがメインエージェントからタスクを移譲され処理をするようなアーキテクチャによって、メインエージェントで処理した場合と同等の性能を発揮しつつコストを削減できる。
似たような考え方はAgent Swarmなどでも実施されている。Agent Swarmはハーネスだけでなく、モデル自身もサブエージェントをうまく活用できるような学習のされかたをしている:
- [Paper Note] Kimi K2.5: Visual Agentic Intelligence, Kimi Team+, arXiv'26, 2026.02
Fusion Harness: How to combine a more expensive main model and a sidekick model, Graham Neubig, GithubGist, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #ContextEngineering #MinimalCode #One-Line Notes #Author Thread-Post #AgentHarness #Gist Issue Date: 2026-07-07 Comment
元ポスト:
openhands SDKを用いて、全体の管理を高性能で高価なメインエージェントにより実施し、個々の作業を安価なサブエージェントに移譲することで、コンテキストを管理しつつパイプライン全体のコスト削減を実施する実装
似たような考え方はAgent Swarmなどでも実施されている。Agent Swarmはハーネスだけでなく、モデル自身もサブエージェントをうまく活用できるような学習のされかたをしている:
- [Paper Note] Kimi K2.5: Visual Agentic Intelligence, Kimi Team+, arXiv'26, 2026.02
Statistics for LLM Evals, evalstats project, 2026.03
Paper/Blog Link My Issue
#Article #Evaluation #read-later Issue Date: 2026-07-07 Comment
github: https://github.com/ianarawjo/evalstats
元ポスト:
Disaggregated Inference: 18 Months Later, Chen+, Hao AI Lab, 2025.11
Paper/Blog Link My Issue
#Article #Blog #LLMServing #read-later Issue Date: 2026-07-05 Comment
元ポスト:
Using Local Coding Agents, Sebastian Raschka, 2026.06
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #Blog #Coding #OpenWeight #LLMServing #SoftwareEngineering #Author Thread-Post #AgentHarness Issue Date: 2026-07-05 Comment
元ポスト:
報酬ハッキングがモデルの知能向上を食い潰している, Cursor, 2026.06
Paper/Blog Link My Issue
#Article #Analysis #ReinforcementLearning #AIAgents #Evaluation #Blog #RewardHacking #Selected Papers/Blogs #One-Line Notes #Contamination #Author Thread-Post Issue Date: 2026-07-05 Comment
元ポスト:
SWE Bench Proにおいて、公開リポジトリやリポジトリの履歴にアクセスすることを厳格に禁止したハーネスを用いてproprietaryモデルを評価したところ標準的なハーネスと比較してスコアが大きく低下した。どれだけスコアが減少したかはモデルごとに異なり、たとえばOpus 4.8系のモデルでは8.1--9.1ポイント程度、GPT5.5系では2.6 -- 3.4%程度スコアが低下した。最近のモデルほどスコアが低下する傾向がある、という話のようである。たとえば、731件のOpus 4.8 Maxのtraceを監査用のモデルを用いて調べると、traceの57%において公開リポジトリでマージ済みのPR、または修正済みのソースファイルを見つけ修正をそのまま再現し、9%程度のtraceで.git履歴からバグ修正前後のコミットを検索しパッチを抜き出していた。モデルが協力になるにつれて、自身が評価中であることを認識し、既に与えられたタスクが解決済みであるためのヒントを見出し、RewardHackingのような挙動を示すような傾向にある、という話のようである。
実際にどの程度スコアに影響を与えていたかが見れるのは興味深い。
[Paper Note] Economic Evaluations of Language Models, Wan+, 2026.06
Paper/Blog Link My Issue
#Article #AIAgents #Evaluation #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-07-05
Accelerating Transformers Fine-Tuning with NVIDIA NeMo AutoModel, nvidia, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Library #MoE(Mixture-of-Experts) #PostTraining #Selected Papers/Blogs #Finetuning #reading #One-Line Notes #EfficientEvaluation Issue Date: 2026-07-05 Comment
わずか数行を追加するだけで、MoEモデルをマルチGPU環境でFinetuningする際のスループットが約3--4倍、メモリ使用量が30%程度削減されるライブラリ。既存のQwen, Nemotron, GPT-OSS, DeepSeek V3などの一般的なMoEアーキテクチャに対して、最適化済みの実装が提供されているとのこと。
repository: https://github.com/NVIDIA-NeMo/Automodel
Leanstral 1.5: Proof Abundance for All, Mistral AI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Mathematics #OpenWeight #Proofs #Author Thread-Post Issue Date: 2026-07-04 Comment
元ポスト:
HF: https://huggingface.co/mistralai/Leanstral-1.5-119B-A6B
所見:
The Verification Stack, OpenHands, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Blog #Coding #SoftwareEngineering #Selected Papers/Blogs #Verification #reading #One-Line Notes #Author Thread-Post Issue Date: 2026-07-03 Comment
元ポスト:
コードがプッシュされる前にエージェントの作業を評価する小型のcriticモデルと、プルリクエストに対してコードレビュー(スキルを利用)+QAを実施するシステム(実際にエントリーポイントを見つけ、動作させ、証跡を資料としてまとめてレポートをポストするシステム)によってコードの検証プロセスを効率化し、マージまでの時間が平均58%削減され、開発効率が向上する話のようである。
Agentic RL: Frameworks and Best Practices, CAMERON R. WOLFE, 2026.06
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #AIAgents #Blog #PostTraining #read-later Issue Date: 2026-07-03
Speculative Decoding - The Bits and the Bytes, Aakash Kumar Nain, 2026.06
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Blog #Decoding #read-later #SpeculativeDecoding #Author Thread-Post Issue Date: 2026-07-03 Comment
元ポスト:
Speculation Is All You Need, Modal, 2026.06
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Decoding #read-later #SpeculativeDecoding #Author Thread-Post Issue Date: 2026-07-03 Comment
元ポスト:
[Paper Note] EdgeBench: Unveiling Scaling Laws of Learning from Real-World Environments, ByteDance Seed, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #read-later #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-07-03 Comment
blog: https://edge-bench.org/
人間が平均で57.2時間かかるようなlong horizonなタスクによるAgentのベンチマーク
Sarashina3 guard: 日本語特化ガードレールモデル, SB Intuitions, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Blog #Japanese #Safeguard #Author Thread-Post Issue Date: 2026-07-02 Comment
元ポスト:
Learning to Replicate Expert Judgment in Financial Tasks, THINKING MACHINES, 2026.06
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #Financial #PostTraining #read-later #Author Thread-Post Issue Date: 2026-07-02 Comment
元ポスト:
Simple, Fast, Vibe‑Ready ZCode combines the best AI agents with your existing tools so you can plan, code, review, and deploy without friction., Z.ai, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Coding #SoftwareEngineering #Initial Impression Notes #Author Thread-Post #AgentHarness Issue Date: 2026-07-02 Comment
元ポスト:
GLMのZ.aiによるAgent Harness (Scaffolding)
Introducing Claude Sonnet 5, Anthropic, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #VisionLanguageModel #One-Line Notes Issue Date: 2026-07-01 Comment
元ポスト:
Artificial Analysisによる評価:
SWE Bench ProのスコアはOpus 4.8とSonnet 4.8の中間程度
Opus 4.8よりも2倍程度生成されるトークンが長い傾向にあり、結果的にArtificial Analysisによる評価を実施する際にOpus 4,8よりもコストが高くついたとのこと:
Sarashina3 mini _ Sarashina3 nano: フルスクラッチで開発した最新の国産LLM, SB Intuitions, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Proprietary #Japanese Issue Date: 2026-06-30 Comment
元ポスト:
Introducing LongCat-2.0, LongCat, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Blog #OpenWeight #read-later #Selected Papers/Blogs #Reference Collection #Initial Impression Notes #Author Thread-Post Issue Date: 2026-06-30 Comment
元ポスト:
- 1M context window
- Sparse Attention
- Muon
- Ngram Embedding
- dynamic activation (33B-56B)
- Multi-teacher OPD
HF:
https://huggingface.co/meituan-longcat/LongCat-2.0
現在はまだ公開されていないがモデルは上記で公開予定
Sparse Attention + 1M Context + MOPD + Muonが標準になっている印象
LongCat Sparse Attentionポイント解説:
所見:
50k基のH800 GPUで学習されているとのこと。
所見:
ポイント解説:
Hermes-Agent, Nous Research, 2026.02
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #SelfImprovement #One-Line Notes #ContinualLearning #AgentSkills Issue Date: 2026-06-27 Comment
Nous ResearchによるAgentSkillsを自己改善していくタイプのAgent Harness (Scaffolding)。2026.0628現在20k star
[Paper Note] DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation, 2026.06
Paper/Blog Link My Issue
#Article #NLP #read-later #SpeculativeDecoding Issue Date: 2026-06-27 Comment
元ポスト:
DeepSeekによる新たなSpeculative Decoding手法とのこと
解説:
所見:
ポイント解説:
CyScenarioBench: Evaluating LLM Cyber Capabilities Through Scenario-Based Benchmarking, IRREGULAR, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #LongHorizon #Security Issue Date: 2026-06-27
Previewing GPT‑5.6 Sol: a next-generation model, OpenAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #ChatGPT #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes #Author Thread-Post Issue Date: 2026-06-27 Comment
元ポスト:
OpenAIによる新たなフロンティアモデルで、terminal benchでMythos 5, Fable 5超え。まずは少数のパートナーに提供し、その後数週間以内にGAを目指す、という感じらしい。
所見:
ベンチマーク:
- [Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
- [Paper Note] ExploitBench: A Capability Ladder Benchmark for LLM Cybersecurity Agents, Seunghyun Lee+, arXiv'26, 2026.05
- CyScenarioBench: Evaluating LLM Cyber Capabilities Through Scenario-Based Benchmarking, IRREGULAR, 2026.06
- [Paper Note] HealthBench Professional: Evaluating Large Language Models on Real Clinician Chats, Rebecca Soskin Hicks+, arXiv'26, 2026.04
- [Paper Note] CyberGym: Evaluating AI Agents' Real-World Cybersecurity Capabilities at Scale, Zhun Wang+, arXiv'25, 2025.06
サイバーセキュリティに関するベンチマークの報告が増えてきたなぁ
Scaling Laws, Carefully, Lilian Weng, 2026.06
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Scaling Laws #read-later Issue Date: 2026-06-26 Comment
元ポスト:
LFM2.5-230M: Built to Run Anywhere, Liquid AI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #SmallModel #OpenWeight Issue Date: 2026-06-26 Comment
HF: https://huggingface.co/LiquidAI/LFM2.5-230M
元ポスト:
Thinking to recall: How reasoning unlocks parametric knowledge in LLMs, Google Research, 2026.06
Paper/Blog Link My Issue
#Article #Analysis #Blog #Reasoning #read-later #FactualKnowledge #Author Thread-Post Issue Date: 2026-06-26 Comment
元ポスト:
Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding, Ornith, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #OpenWeight #SoftwareEngineering #PostTraining #One-Line Notes #Author Thread-Post Issue Date: 2026-06-26 Comment
HF: https://huggingface.co/collections/deepreinforce-ai/ornith-10
元ポスト:
gemma4とQwen3.5をpost trainingしたコーディング特化LLMで、397BモデルではSWE Bench ProでGLM 5.2超え
PLaMo 3.0 Primeをリリースしました, PFN, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Blog #Proprietary #Japanese #Author Thread-Post Issue Date: 2026-06-23 Comment
元ポスト:
Sakana Fugu: One Model to Command Them All, SakanaAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Test-Time Scaling #Initial Impression Notes #Reading Reflections #Orchestration Issue Date: 2026-06-23 Comment
元ポスト:
所見:
Opus 4.8, Gemini 3.1 Pro, GPT 5.5(他にもありそう)のオーケストレータ
beta:
- Sakana Fugu: A Multi-Agent Orchestration System as a Foundation Model, sakana.ai, 2026.04
テクニカルレポート:
- [Paper Note] Sakana Fugu Technical Report, Yujin Tang+, arXiv'26, 2026.06
v1.1になり、新たに公開されたフロンティアモデルをルーティングに加えることで性能向上:
基本的に新たなモデルが公開されたらルーティングを更新すればFuguの性能も向上していくので、性能面でFrontier Modelに遅れをとる可能性は小さいと思われる。一方で、Fugu内部で商用APIを叩いた場合そのコストは他社のマークアップが上乗せされたものになると思うので、利用コストをどの程度抑えられるかがポイントになるだろうか。ただ、ターン単位で利用されるモデルが変更されるので、たとえばFable5を最も重要なプランニングで利用し、その後のフェーズではより安価なモデルを使う、といった柔軟なモデルの組み換えが可能なので、そこの最適化がされればタスクを完遂する際に特定の1モデルを利用するよりも結果的に安い可能性は高い。
Humans Still Beat AI in the Long Horizon: Revisiting Test-Time Scaling in the Agent Era, Mang+, 2026.06
Paper/Blog Link My Issue
#Article #Analysis #NLP #AIAgents #Coding #read-later #Selected Papers/Blogs #LongHorizon #Initial Impression Notes #Author Thread-Post Issue Date: 2026-06-22 Comment
2週間にわたるopen endなプログラミングコンテストのデータを用いて人間の専門家とAI AgentのElo ratingの変遷を比較すると、序盤は人間に対して大きくリードしスコアは試行回数の対数に対して線形にスケーリングし次第に停滞を始めるが、人間の専門家は4日を超えたあたりから非線形にスコアが進化し、最終的にAI Agentよりも高いスコアを記録する。人間はAI Agentと比較して、継続学習ができていることが示唆され、AI Agentのlong horizonタスクに対する能力の限界が示唆される、という話に見える。
元ポスト:
Deli_AutoResearch, Deli Chen, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #read-later #AgentSkills #autoresearch #Author Thread-Post Issue Date: 2026-06-20 Comment
元ポスト:
日本語エージェントベンチマーク「J-tau telecom」の公開, SB Intuitions, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #Japanese #Author Thread-Post Issue Date: 2026-06-20 Comment
元ポスト:
Introducing LifeSciBench, OpenAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Biological #Author Thread-Post Issue Date: 2026-06-18 Comment
元ポスト:
GLM-5.2: Built for Long-Horizon Tasks, Z.ai, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #PPO (ProximalPolicyOptimization) #OpenWeight #Selected Papers/Blogs #Reference Collection #Critic #LongHorizon #train-inference-gap #Initial Impression Notes Issue Date: 2026-06-16 Comment
HF: https://huggingface.co/zai-org/GLM-5.2
1Mコンテキストでフロンティアモデルには少し劣るが非常に高い性能。SWE Bench ProではGPT5.5をoutperform、Terminal Bench/DeepSWEなどでは3--12pt程度GPT5.5が高い。Opus4.8はさらにスコアが高い。
744B-A40B
元ポスト:
Artificial Analysis Intelligence IndexでOpenWeightモデルでSoTA更新:
MiniMax-M3超え
long Horizonのタスクの学習でGRPOではなく、criticベースのPPOを利用:
アーキテクチャ解説:
GLM 5.2では、Reward Hackingを検知した場合、ペナルティを与えるのではなく、ツール呼び出しをブロックしてダミー情報を返し、ロールアウト自体は継続させる。Reward Hackingをすると、ただ損をするという構造に近づけていると思われる。
slimeフレームワークを用いることで10を超えるエキスパートモデルに基づくOPDを2日で終えたとのこと。この記述に基づき、OPDがRLと比較して非常に効率的で、かつエキスパートなモデルは並列で学習をさせておけるよね?という利点に関して推察をしている:
エキスパートなRLでは常にドメイン別のRLを走らせ特化モデルを学習しておき、性能が向上したらOPDで単一モデルに効率的に蒸留することで、モデルに知識を集約するプロセスと、個々のドメインごとに強力なモデルを得るプロセスが分離されて良さそう、という感想を得た。
1M context + linear attentionが標準に:
MTPの学習時において、step 2以後のMTP Layerの出力は、学習時はteacher forcing, 推論時はstep 1のMTP Layerが推定したhidden_stateが用いられるが、これが学習-推論時のgapを生んでしまう。このため、step 1の計算で利用したKV(とsparse attentionのtop-kで洗濯をしたトークンのindex)を全て共有し、step 2以後のMTP Layerで活用し、かつstep 2以後のsparse attentionの計算のオーバヘッドをなくしつつ、学習-推論のgapを無くすことでspeculative decodingの性能を向上させる、といった話題があるようである:
画像分野におけるself-forcingと同じ発想に思う。
- [Paper Note] Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion, Xun Huang+, NeurIPS'25
GRPO, PPOのそれぞれの利点と欠点、およびLong Horizonタスクに適用する価値の説明:
Cursor Benchにおいて、Opus 4.8と同等程度のコスト効率とのこと:
PPOへ最終的に回帰してきたのは一種のbitter lesson:
PPO vs. GRPOに関する所見:
GLM 5.2で利用されたRL:
- [Paper Note] Single-Rollout Asynchronous Optimization for Agentic Reinforcement Learning, Zhenyu Hou+, arXiv'26, 2026.07
Introducing North Mini Code: Cohere’s first model for developers, Cohere, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #OpenWeight #SoftwareEngineering Issue Date: 2026-06-14 Comment
元ポスト:
アーキテクチャ解説:
Introducing Omnigent: A Meta-Harness to Combine, Control and Share Your Agents, Databricks, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #One-Line Notes #Author Thread-Post #AgentHarness Issue Date: 2026-06-14 Comment
元ポスト:
ハーネスの上に統一されたAPIを追加し、複数エージェントのハーネスを協調させるメタハーネス
olmo-eval: An evaluation workbench for the model development loop, Ai2, 2026.06
Paper/Blog Link My Issue
#Article #Pretraining #Evaluation #ExperimentManagement #Author Thread-Post Issue Date: 2026-06-13 Comment
元ポスト:
Kimi-K2.7-Code, moonshotai, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #OpenWeight #SoftwareEngineering Issue Date: 2026-06-12 Comment
元ポスト:
[Paper Note] PC Layer: Polynomial Weight Preconditioning for Improving LLM Pre-Training
Paper/Blog Link My Issue
#Article #Pretraining Issue Date: 2026-06-11 Comment
元ポスト:
DiffusionGemma: 4x faster text generation, Google, 2026.06
Paper/Blog Link My Issue
#Article #DiffusionModel #Blog #OpenWeight #Author Thread-Post Issue Date: 2026-06-11 Comment
元ポスト:
関連:
- [Paper Note] How Transparent is DiffusionGemma?, Joshua Engels+, arXiv'26, 2026.06
- DiffusionGemma: The First Diffusion LLM (dLLM) Natively Supported in vLLM, vLLM, 2026.06
gemma-4-12B-it-qat-UD-japanese-imatrix, dahara1, 2026.06
Paper/Blog Link My Issue
#Article #OpenWeight #Japanese #read-later #Author Thread-Post Issue Date: 2026-06-11 Comment
元ポスト:
Claude Fable 5 and Claude Mythos 5, Anthropic, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Reference Collection #Initial Impression Notes #Reading Reflections Issue Date: 2026-06-10 Comment
元ポスト:
Mythos級の性能を持ち、サイバーセキュリティ、生物学、化学、蒸留に対してsafeguardを持つfrontier model
GDPValでSoTA:
フロンティアLLMの構築に関わるクエリは意図的に制限を設ける措置がとられているようだ:
一部の人間にしかAIの能力が解放されない未来に対する懸念:
-
フロンティアモデルの関連に関するリクエストに対しては、通常のsafeguardとは異なり**サイレントに性能が限定される**ようである。これはAIの開発が加速しすぎると重大なリスクが生じるため(February 2026 Risk Report)、とのこと:
-
-
このような性能の低減は、prompt modification, steering, peftなどを通じて行われるとのこと。利用者からしたらpromptの調整や工夫で検知されないようにするしか対策(?)の打ちようがないと思われる。
しかしこの情報をわざわざ公開する意図はなんだろうか。完全に憶測だが
- Mythos級のモデルの性能が良く、半自律的にモデルがモデル自身をよくする仕組みが成立している
- ライバルにモデルを使わせないで、自分たちだけで独占することでMoatを築くフェーズまできた
- 情報を公開しようがしまいが、性能に制限をかけていたら、フロンティアモデル開発者たちにはすぐバレるので、他のユーザたちが混乱するのを避けるために最初から線引きを明確にしておく
- ほほ全てのユーザに影響はないので、一部のフロンティアモデル開発に近しい人間から不満は出るが、全体で見たら気にしなくて良いレベル
- フロンティアモデル開発には使えないと銘打つことで、ライバルよりも本当に性能が良いんだな、という印象を与えることができるマーケティング効果
とかだろうか。
Geminiさんと壁打ちをしたら欠けている視点として以下のような意見を頂戴した(以下の引用部分はGeminiの出力です)
> 規制当局へのポーズ(アライメント):
「自社モデルが、制御不能なさらに強力なAI(AGI/ASI)を勝手に生み出す引き金(ゴーレムが生むゴーレム)にならないよう、防衛策を講じています」という姿勢を政府や規制当局に見せる必要があります。
なるほど
続報:
フロンティアモデルで性能が制限された時に、それらが他のsafeguardと同様ユーザ側に通知されるように変更されるようだ
モデルのそのものの性能などは置いておいて、今回の特定のタスク、プロンプトには恣意的に一定の制限を設ける措置を受け、(Project Glasswingの頃から違和感はあったが)Anthropicが恣意的にAIの能力を供給する姿勢に見え、雲行きの怪しさを感じる
- Project Glasswing Securing critical software for the AI era, Anthropic, 2026.04
Mythos級のモデルでは、全てのpromptと生成結果が、信頼性と安全性の確認のために30日間保持される:
https://support.claude.com/en/articles/15425996-data-retention-practices-for-mythos-class-models
所見: https://simonwillison.net/2026/Jun/9/claude-fable-5/
コーディング関連ベンチマークでは抜きん出ている:
所見:
Fable再公開後のClassifierによる安全マージンについて:
輸出規制解除:
約1ヶ月かかった。
KernelBench MegaでSoTA:
Introducing FrontierCode, Cognition, 2026.06
Paper/Blog Link My Issue
#Article #AIAgents #Evaluation #Coding #SoftwareEngineering #Author Thread-Post Issue Date: 2026-06-09 Comment
元ポスト:
Improving our LLM Pretraining Efficiency, Open Athena, 2026.06
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Pretraining #NLP #Optimizer #MoE(Mixture-of-Experts) #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2026-06-06 Comment
元ポスト:
以下の処理によって、事前学習が高速化(FLOPsの改善幅)された知見が共有されている
- DenseからMoEモデルへの移行で実測値3.6倍
- MoEのexpart数を64->256で実測値1.3倍
- optimizerをMuonHにすることで、実測値1.25倍
- **Partial Key Offset (PKO) によって実測値1.2倍改善**
- **modded-nanogptリポジトリ、プルリクエスト169で初めて提案された手法とのこと。**
- **long windowのattentionに対して、keyの半分の次元をオフセット(=前のトークンのkey)、残りの半分の次元を自身のトークンのkeyとすることで、単一のクエリが連続した複数のキーにattendできるようになり、「過去の文脈からあるトークンの継続部分を検索して取得する」といった操作が単一のattention layerによって実現できるようになる**
- (これは知らなかった)
- expertのルーティングを再正規化・スケーリングすることで、実測値1.04倍
今後はHyperConnectionのようなResidual Streamの改善、推論効率向上のためMLA, LatentMoE, Multi Token Prediction, Gated Deltanet, quantizationなどの技術を検証するとのこと。
Expert数が多ければ多いほど性能が改善することは下記研究でも示されている:
- [Paper Note] Slicing and Dicing: Configuring Optimal Mixtures of Experts, Margaret Li+, arXiv'26, 2026.05
MuonH(というよりoptimizerのHyperplaneに基づいたラッパ)は以下(こちらもPercy Liang氏のグループ):
- Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization, Wen+, 2026.01
Hyper Connection:
- [Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
- [Paper Note] mHC: Manifold-Constrained Hyper-Connections, Zhenda Xie+, arXiv'25, 2025.12
MLA, LatentMoE, Multi Token Prediction, Gated Deltanet:
- [Paper Note] DeepSeek-V3 Technical Report, DeepSeek-AI+, arXiv'24, 2024.12
- [Paper Note] LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts, Venmugil Elango+, arXiv'26, 2026.01
- [Paper Note] Better & Faster Large Language Models via Multi-token Prediction, Fabian Gloeckle+, ICML'24
- [Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
- [Paper Note] Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention, Ali Hatamizadeh+, arXiv'26, 2026.05
LFM2.5-1.2B-JP-202606, LiquidAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight #Japanese Issue Date: 2026-06-06 Comment
元ポスト:
Towards Compositional Steepest Descent, Tilde Research, 2026.06
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Blog #Optimizer #Author Thread-Post Issue Date: 2026-06-06 Comment
元ポスト:
Understanding Self-Distillation and Privileged Information Distillation, Penaloza+, 2026
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #Distillation #read-later #Selected Papers/Blogs #On-Policy #SelfDistillation Issue Date: 2026-06-05
NLP colloquium: AI Safety Survey, Masahiro Kaneko, 2026.04
Paper/Blog Link My Issue
#Article #Tutorial #Survey #NLP #Slide #Safety Issue Date: 2026-06-05 Comment
元ポスト:
元ポスト:
APIの背後にあるモデルの隠れ層から語彙分布に変換する線形層の隠れ次元数を盗む方法があるのか...
NVIDIA Nemotron 3 Ultra, nvidia, 2026.06
Paper/Blog Link My Issue
#Article #Pretraining #NLP #OpenWeight #SSM (StateSpaceModel) #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Reference Collection #LowPrecision #LinearAttention #Author Thread-Post Issue Date: 2026-06-05 Comment
元ポスト:
アーキテクチャ解説:
Mamba2 layer, Latent MoE, GQA
ポイント解説:
HF: https://huggingface.co/collections/nvidia/nvidia-nemotron-v3
所見:
所見:
Building a hill-climbing machine: Launching seven new MAI models, Mustafa Suleyman, MAI, 2026.06
Paper/Blog Link My Issue
#Article #AIAgents #TextToImageGeneration #Blog #Coding #Proprietary #TTS #ImageSynthesis #Transcript #Author Thread-Post Issue Date: 2026-06-03 Comment
- MAI-Thinking-1: Building a Hill-Climbing Machine, Microsoft, 2026.06
元ポスト:
関連:
Artificial Analysisによる評価で、MAI Image-2.5がT2Iで2位, Image Editingが3位とのこと:
Is Frontier Asynchronous RL Solved?, Luke J. Huang, 2026.05
Paper/Blog Link My Issue
#Article #Survey #NLP #ReinforcementLearning #Blog #Selected Papers/Blogs #reading #Asynchronous #Author Thread-Post Issue Date: 2026-06-03 Comment
元ポスト:
MAI-Thinking-1: Building a Hill-Climbing Machine, Microsoft, 2026.06
Paper/Blog Link My Issue
#Article #NLP #Proprietary #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2026-06-02 Comment
元ポスト:
解説:
解説:
解説:
所見:
Amazon Bedrock 経由で使える LLM の日本語ベンチマーク性能, yoheikikuta, 2026.06
Paper/Blog Link My Issue
#Article #NLP #AWS #Evaluation #Blog #Japanese #KeyPoint Notes Issue Date: 2026-06-02 Comment
元ポスト:
Bedrock経由で利用できるLLMに対する llm-jp-evalの評価結果が、コストとパフォーマンスの双方の上で比較されている。Claude Opus 4.6(4.7, 4.8と比較して)のスコアが最も高く、日本語能力はベンチマーク上は平均スコアで見ると向上していないように見える。カテゴリごとの結果では、4.8がQAにおいて大幅にスコアが悪化しているのが興味深い。また、スコアを掲載して終わりではなく、全てのLLMが間違える個別の事例などもいくつか掲載されており興味深い。OpenWeightなLLMではKimi 2.5のコストパフォーマンスが最も良さそうに見えるが、Gemma4は評価に含まれていないので気になるところ。
日本語LLMの評価は
- Swallow LLM Leaderboard v2, Swallow LLM Team, 2025.08
も参考のこと。
On-Policy Self-Distillation: 言葉で学ぶ LLMの新たな学習パラダイム, ぶち, 2026.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #PostTraining #Selected Papers/Blogs #On-Policy #Reading Reflections #SelfDistillation Issue Date: 2026-06-01 Comment
元ポスト:
日本語でのOPSD解説で、細かい数式などよりも、何が重要で、なぜ今なのかといった気持ちのところが非常に重点的に説明されている。
後半の今後の課題の、どの程度の能力であればself teacherが成立するのか、どのような情報を与えると良いのか、といった話は、
- [Paper Note] Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why, Mohammadreza Armandpour+, arXiv'26, 2026.05
で模索されている。
また、OPSDの気持ち的な部分だけでなく、(簡単な)数式的な解釈、最近のサーベイなど、より詳細な情報は
- The Imitation Game: State of Policy Distillation in Language Model training, 032-Chinmay Karkar, 2026.05
のブログにまとめられているので参照のこと。
MiniMax-M3, MiniMaxAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #MultiModal #OpenWeight #Post #Selected Papers/Blogs #VisionLanguageModel #UMM #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2026-06-01 Comment
ベンチマーク上はフロンティアモデルに性能がかなり肉薄しており、10日以内にモデルがオープンになる。
所見:
関連:
- [Paper Note] Learning Dynamics of LLM Finetuning, Yi Ren+, ICLR'25 Outstanding Paper Award
Artificial Analysisによる評価:
OpenWeightでSoTA
MLエンジニアのための本質から理解するLLM推論 KV cache編, Kazuki Fujii, 2026.05
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LLMServing #Selected Papers/Blogs #One-Line Notes #KV Cache #Author Thread-Post Issue Date: 2026-05-31 Comment
元ポスト:
次:
- MLエンジニアのための本質から理解するLLM推論: LLM Inference Benchmarking, Kazuki Fujii, 2026.05
数式レベルで、図解付きで曖昧性なく、非常に丁寧で、かつ実装面にまで踏み込んだ解説だが、冗長ではなくコンパクトに解説されており、すごい。今度からKV Cacheってなんなんですか?の問いにはこの記事をベースに教えよう。感謝🙏
Native RL APIs in vLLM, vLLM, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #ReinforcementLearning #Blog #SoftwareEngineering #PostTraining #reading #Asynchronous Issue Date: 2026-05-31 Comment
元ポスト:
所見:
Introducing Claude Opus 4.8, Anthropic, 2026.05
Paper/Blog Link My Issue
#Article #NLP #Blog #Proprietary #VisionLanguageModel #Reference Collection #Author Thread-Post Issue Date: 2026-05-31 Comment
元ポスト:
ベンチマーク比較:
ビジネススキルを学習させると不誠実になる:
LFM2.5-8B-A1B: An Even Better On-Device Mixture of Experts, LiquidAI, 2026.05
Paper/Blog Link My Issue
#Article #NLP #Blog #SmallModel #OpenWeight #read-later Issue Date: 2026-05-31 Comment
Repo2RLEnv: Turn any GitHub repository into a verifiable RL environment for training and evaluation, HuggingFace, 2026.05
Paper/Blog Link My Issue
#Article #Tools #NLP #ReinforcementLearning #PostTraining #reading #Environment #Author Thread-Post Issue Date: 2026-05-31 Comment
元ポスト:
Should we use genetics instead of system prompts for AI Agents & Personas?, Fyx, 2026.05
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #PostTraining #read-later #Personality #One-Line Notes #Reading Reflections Issue Date: 2026-05-31 Comment
元ポスト:
ゲノム文字列からキャラクターのペルソナを推論し出力に反映可能なLoRAアダプタを学習することによって、ゲノム文字列によってペルソナの条件付けを可能とするモデルに関する実験の報告のようである。
具体的には、まずゲノム文字列と、ペルソナに関するテキストを対応付ける。次に、ペルソナテキストを与えてモデルの応答を収集し、ゲノム文字列と(ペルソナのテキストなしで)収集したモデルの応答を用いてLoRAアダプタを学習する。これにより、LoRAアダプタはゲノム文字列から、ペルソナテキストによって応答づけられた応答を出力することを学習する、といった挙動を実現する。
ざっとみた感じLoRAアダプタとは書かれているが、学習手法が書かれていないような気がする。が、手法はおそらくSFTだと思われる。
これにより、prefillをするinput tokenが削減可能と思われるが、実用上はどちらかというと出力/reasoningトークンが圧縮される方がlatency/コストの双方から恩恵があるので、事後学習をして他の能力が劣化、あるいはAlignmentが悪化するリスクを背負ってまでやる価値があるかは怪しいな、という感想を持ったが、果たしてどうだろうか。
非常に大規模なユーザからの同時接続があり、キャラクターと対話できるようなサービスにおいて、キャラクターのペルソナテキスト(用途はペルソナだけには限らない汎用的な技術だと思うが)が97%圧縮できたら結構なインパクトがあるかもしれない。
Hy-MT2-30B-A3B, Tencent Hy, 2026.05
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #MultiLingual #OpenWeight #One-Line Notes #Author Thread-Post Issue Date: 2026-05-27 Comment
HF: https://huggingface.co/collections/tencent/hy-mt2
元ポスト:
テンセントによる1.8B--30BのMT特化モデルファミリー。fast thinkingが強みとのこと。
Agent Evaluation: A Detailed Guide, CAMERON R. WOLFE, PH.D., 2026.05
Paper/Blog Link My Issue
#Article #Tutorial #AIAgents #Evaluation #One-Line Notes #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
ざーっとしか眺められていないが、AI Agentの基礎的な話と、実際のtool useをした場合のレスポンスの例を踏まえた動作の説明や、Scaffoldingとは何か/multi-agentとは何か/context engineeringとはといった説明をし、その後AI Agentの評価の方法の体系的な枠組みと、具体的なベンチマークとして tau-bench/terminal-benchを挙げて解説されている。これを読んだらAI Agentとはなんぞやから、評価までかなり理解できるのではないだろうか。
token speed: How fast is 10 tokens per second really?, 2026.05
Paper/Blog Link My Issue
#Article #NLP #Blog #Decoding #Initial Impression Notes Issue Date: 2026-05-27 Comment
元ポスト:
これはおもしろい。トークンの生成速度を可視化可能なサイト
Next-generation LLM Inference Network: How ZCube Alleviates Network Bottlenecks?, Z.ai, 2026.05
Paper/Blog Link My Issue
#Article #NLP #Infrastructure #LLMServing #Post #SoftwareEngineering #read-later Issue Date: 2026-05-27
Terminal-Bench Science: Evaluating AI Agents on Real-World Computational Workflows in the Natural Sciences, harbor-framework, 2026.05
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Repository #ScientificDiscovery #Science #One-Line Notes #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
ターミナル上でのscienceに関するワークフローを定義しAI Agentを評価することで、教科書的な知識を問うのではなく、より複雑で実践的なタスクによる評価をしたい、というモチベーションのpjで、Discordを通じてタスクを生成するcontributorを募集しているようである。
Nemotron-Labs-Diffusion-14B, Nvidia, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #DiffusionModel #OpenWeight #LLMServing #SpeculativeDecoding #One-Line Notes #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
3つの生成モード: AR/dLM/Hybrid を備えたLLM(VLM variantも存在)ファミリーで、ARモードでは一般的な自己回帰的な生成をし、dLMモードでは拡散モデルに基づくparallel decodingを実施、hybridではdLMでドラフト作成、ARでverificationを実施するSpeculative Decoding (self-speculation)を実施する。これらモードは内部のattention patternを変化させることでシームレスに切り替えられ(シームレスモード)期待されるconcurrencyに応じて柔軟に対応ができるようである。
シームレスの粒度がどの程度のものかはよくわからない。concurrency levelを検知して、それに応じて動的に切り替わったりするのだろうか。
Speculative Decodingの高速化手法としては以下のようなものもある:
- [Paper Note] TriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification, Haoyun Jiang+, arXiv'26, 2026.01
General Agent: A Self-Evolving, Synthetic Agent Environment, Mika, PRIMEIntellect, 2026.05
Paper/Blog Link My Issue
#Article #General #NLP #AIAgents #SyntheticData #reading #One-Line Notes #Environment #ToolUse #Author Thread-Post Issue Date: 2026-05-27 Comment
environment: https://app.primeintellect.ai/dashboard/environments/primeintellect/general-agent
元ポスト:
著者ポスト:
約1000のドメイン、約4500タスク、約8000種類以上の独自のツールを持つ、汎用エージェント学習のための学習環境とその構築方法。タスクを生成するAIとそれに対して解答するAIを用意し、解答がどの程度正解していたかによって難易度を同定しフィルタリング等を行いつつ、生成されたタスクをacceptするか否かを決定する。実際に構築された環境でRL/SFTを実施したところ、未知のベンチマークに対して性能が反化することも確認したとのこと。
mKernel: Fast Multi-GPU, Multi-Node Fused Kernels, Ziming Mao, and the UCCL team, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Infrastructure #read-later #GPUKernel #Author Thread-Post Issue Date: 2026-05-26 Comment
元ポスト:
> mKernel is our attempt at the missing piece: GPU-driven, fused kernels that deliver fine-grained compute–communication overlap across both intra-node NVLink and inter-node RDMA, while staying portable across various networking backends (ConnectX-7, AWS EFA, and more on the way).
The Imitation Game: State of Policy Distillation in Language Model training, 032-Chinmay Karkar, 2026.05
Paper/Blog Link My Issue
#Article #Tutorial #Survey #NLP #ReinforcementLearning #Distillation #Catastrophic Forgetting #PostTraining #On-Policy #KeyPoint Notes #SelfDistillation #Author Thread-Post Issue Date: 2026-05-26 Comment
元ポスト:
- On Policy DistillationはKnowledge Distillationの一種で、教師モデルの知識を小さなモデルに蒸留する
- off policy KD Objectiveの場合は固定されたオフラインデータを用いるが、on policy distillationは生徒モデル自身が生成したデータに対するシグナルに基づいて学習される。
- off policy手法の課題はCatastrophic Forgettingと、(sequence長に対するquadraticな)エラーの蓄積がある。
- (オフポリシーRLの特殊なケースとみなすことができる)SFTはForward KLに基づいており、教師モデルの出力分布が確率を持つ部分に対して、生徒モデルの確率がゼロの場合はKLが発散するため、学習される生徒モデルの分布さスムージングされた分布になる。つまり、教師モデルの出力パターンを網羅できるように分布が学習される。
- このような手法で複数のドメインのデータで学習をした場合、分布のシフトが生じやすくCatastrophic Forgettingが生じやすい。
- on policy RLでは、Reverse KLが採用されており、この場合教師が確率が低いと考える場所に高い確率を割り振った場合のみに大きなペナルティを受けるため、教師の重要なモードをカバーしていれば、教師の他のモード全体は無視できる。これにより、学習したいモード以外の挙動に影響を与えにくく、特定のモードの学習ができる。
- (SFTがCatastrophic Forgettingが起きやすそうということは理解できるが、オフポリシーRL全体においてCatastrophic Forgettingが起きやすい問題があるという文脈で書かれている気がしており(エラーの蓄積の冒頭でオフポリシーRLのもう一つの根本的な課題は、という文脈で書かれているため)、SFTの議論がオフポリシーRL全体につながるのかがわからず、モヤっとする。が、LLMのpost-traingではCatrastrophic Forgettingが問題であるという文脈であれば理解できる)
- また、on-policyな学習ではエラーの蓄積を線形に留めることができることが示されている(off-policyな手法ではポリシーが生成したデータで訓練されていないため、inference時の冒頭でミスをすると学習時に観測していないトークンスペースを扱わなければならなくなり、さらにミスが増えモード崩壊に陥る)。
- on policy distillationは直接的にこのexposure biasのgapを小さくする。すなわち、学習時のinput(教師モデルが生成)と推論時のinput(生徒モデルが生成)の分布のgapを縮める。
- 生徒は学習時に常に自身の出力に基づいて学習するため、学習時のprefixと推論時のprefixの傾向が一致しやすい。このため生成時にエラーが起きてもin-distributionとなるため、エラーの蓄積が低減される。
以後はon policy distillation, on policy self-distillationの最新研究のサーベイと動向について記載されている。
関連:
- [Paper Note] Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting, Howard Chen+, arXiv'25, 2025.10
- [Paper Note] RL's Razor: Why Online Reinforcement Learning Forgets Less, Idan Shenfeld+, ICLR'26
- Multi-Teacher On-Policy Distillation: A New Post-Training Primitive, Yumo Xu, 2026.04
後半のサーベイパートなどで記述があったのかもしれないが、OPDでは、GRPOなどで主流なRLVRなどと比較して、報酬のシグナルがdenseであるという点も押さえておきたい。
Synthetic Persona Pretraining: Alignment from Token Zero, Minder+, 2026.05
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Alignment #SyntheticData #Blog #Reasoning #Safety #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-25 Comment
元ポスト:
**事前学習の時点で**Harmful/良性/ニュートラルな文書にReflectionに関するassistantの思考過程(何が間違っていて/間違っていなくて、それはなぜか)をappendすることで、道徳的に推論することを学ぶ。
[Paper Note] Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #Mathematics #Test-Time Scaling #PostTraining #RLVR #Verification #Physics Issue Date: 2026-05-21 Comment
pj page: https://simplified-reasoning.github.io/SU-01/
元ポスト:
ポイント解説:
Pedagogical RL: Teaching Models to Teach Themselves from Privileged Information, Chakraborty+, 2026.05
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #PostTraining #CurriculumLearning #PRM #On-Policy #SelfDistillation #Author Thread-Post Issue Date: 2026-05-21 Comment
元ポスト:
Autonomous AI research for nanogpt speedrun, PrimeIntellect, 2026.05
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #ScientificDiscovery #One-Line Notes #Author Thread-Post Issue Date: 2026-05-21 Comment
元ポスト:
nanogpt speedrun
- Modded-NanoGPT, KellerJordan, 2024.05
autoresearchをnanogpt speedrun (Track 3)で実施したところ、人間の最高記録を上回ることに成功した。この記録は既存のアイデアの組み合わせや、ハイパーパラメータの探索などによって等のもたらされた。一方で、完全に新規のアイデアの創出し改善するには上流にいる人間のヒントが必要となる弱点があることも浮き彫りになった。
AI Agentごとに挙動の性質が異なりOpus(Claude Code)は自律的なループを停止してしまったり、GPT(Codex)は自律的なループが止まることはないものの、同じハイパーパラメータを何度も繰り返し探索するなどの現象も見受けられた。
関連:
Violin: An open-source video translation skill that breaks language barriers, together.ai, 2026.05
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #AIAgents #Blog #3D (Video) #AgentSkills #SpeechToSpeech Issue Date: 2026-05-21 Comment
元ポスト:
demo:
https://www.violin-ai.com/
github:
https://github.com/shang-zhu/violin
Ring-2.6-1T, inclusionAI, 2026.05
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #Author Thread-Post Issue Date: 2026-05-21 Comment
元ポスト:
Introducing Command A+: Making sovereign agentic capabilities available to all, Cohere, 2026.05
Paper/Blog Link My Issue
#Article #NLP #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) #Reference Collection #Initial Impression Notes Issue Date: 2026-05-21 Comment
元ポスト:
HF:
https://huggingface.co/CohereLabs/command-a-plus-05-2026-w4a4
apache-2.0
デコーディング速度が非常に速い
アーキテクチャサマリ:
-
-
翻訳性能高いよという話のようである:
MemEx: A Programmable Scratchpad for LLM Agents, Databricks, 2026.05
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #read-later #ContextEngineering Issue Date: 2026-05-20 Comment
元ポスト:
元ポスト:
Composer 2.5 の紹介, Cursor, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #SyntheticData #Optimizer #mid-training #On-Policy #One-Line Notes #Reference Collection #SelfDistillation Issue Date: 2026-05-20 Comment
元ポスト:
- trajectory中の不適切な箇所にヒントを挿入したcontextを用いたself-on-policy distillation
- Composer 2から25倍の量の合成タスクデータの利用。タスクは特定のテスト可能な機能をコードベースからablationすることによってverifiableなタスクを作成
- mid-trainingではMuonを利用し、expertが複数のノードにシャーディングされているため、all-to-allと呼ばれる処理によって重み行列全体を復元しMuonの直行化を実施し、同じくall-to-allという処理で重みを再びシャーディングするらしい。これらは非同期で実行される。
- dual mesh HSDPと呼ばれるものも利用されているようだがよくわかっていない
関連:
- Composer 2 のご紹介, Cursor, 2026.03
artificial analysisによる評価:
所見:
学習の規模感に関する所見:
所見:
Gemini 3.5: frontier intelligence with action, Google, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Proprietary #VisionLanguageModel #Initial Impression Notes Issue Date: 2026-05-20 Comment
Artificial Analysisによる評価:
賢い上にデコーディングが高速で今の所非常に使い勝手が良い
Reliable Reasoning, Naoto Iwase, 2026.05
Paper/Blog Link My Issue
#Article #Survey #NLP #Blog #Reasoning #read-later #Author Thread-Post Issue Date: 2026-05-20 Comment
元ポスト:
Investigating the consequences of accidentally grading CoT during RL, OpenAI, 2026.05
Paper/Blog Link My Issue
#Article #NLP #Chain-of-Thought #Monitorability #Author Thread-Post Issue Date: 2026-05-12 Comment
元ポスト:
Marco-MoE: A suit of multilingual MoE models with highly-sparse architectures, AIDC-AI, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) #CurriculumLearning #One-Line Notes Issue Date: 2026-05-12 Comment
元ポスト:
4 stageのカリキュラムによって学習されているようで、学習が進むにつれて、広く使われる英語やreasoning, instructionなどのデータは減らし、low resourceな言語のデータを増やしていき最終的にマルチリンガルなデータを支配的にするような学習レシピとなっているようである。
Aurora: A Leverage-Aware Optimizer for Rectangular Matrices, Tilde Research, 2026.05
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Optimizer #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-05-12 Comment
元ポスト:
nanoGPT speedrunのSoTAを更新したoptimiserのようである。
Teaching Claude why, Anthropic, 2026.05
Paper/Blog Link My Issue
#Article #NLP #Alignment #Reasoning #Safety #PostTraining #KeyPoint Notes #Reading Reflections #Author Thread-Post Issue Date: 2026-05-12 Comment
元ポスト:
- [Paper Note] Agentic Misalignment: How LLMs Could Be Insider Threats, Aengus Lynch+, arXiv'25, 2025.10
のように自身を守るために脅迫メールを送るような挙動が観測されたが、それをなくすことができたという話のようである。
細かい学習データのサンプルなどは記載されていないように見えるが
- 評価時のシナリオと類似したもので正しい挙動を教え込むような方法は、評価のスコアは改善するが、OODに対応できない
- モデルに行動を教えるのではなく、理由を教えることが重要で、これはモデル自身が倫理観に関するジレンマに置かれた状況を解決するというデータではなく、ユーザが倫理的なジレンマを抱えているというシナリオで、モデルが倫理的に塾講された思慮深いアドバイスをするようなデータ(difficult advice dataset)で学習することが非常に効果的であった。
- これは単に正しい答えを教えるのではなく、倫理的な"思考"を教えるため効果的であり、これをさらに発展させ、Claudeの人物像をより詳細に与えることでペルソナをより模範的なものに更新する、具体的には質の高いConstitutionに関する文書と、模範的なAIに関するフィクションの物語を学習させることで、misalignmentを非常に効果的に抑制できることを発見した
という感じだろうか。
トップダウンに正解を教えるのではなく、ボトムアップに根源的に正しい思考過程を誘発するような情報を教える(ある種のPRMのようなものだと思われる)ことで、高い汎化性能を獲得できるということだと思われる。このアプローチは最近のAI Agentにおけるoutcome basedなreward設計などにも一石を投じるような議論に感じる。学習の結果得られる汎化性能を重視していかないと、データセットやEnvironmentを逐一構築して課題を潰していく必要があり、キリがないと思う。
EMO: Pretraining mixture of experts for emergent modularity, Ai2, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Routing #Initial Impression Notes Issue Date: 2026-05-11 Comment
元ポスト:
従来のMoEモデルを学習する際には全てのトークンが全てのexpertsに対してroutingされるため、能力のごく一部しか必要ないにもかかわらず、experts全体をデプロイする必要があり効率が悪かった。本研究では、MoEモデルを学習する際に、ドキュメント単位で8個のshared experts poolに対してのみtokenがroutingされるように制約することで、特定のexpertsの集合が特定のドメインのexpertsとなることが奨励されmodularityが高まり、必要なexpertsのみをデプロイすることで効率化が図れるようになるので嬉しい、といった話に見える。
Pushing the Frontier for Data Agents with Genie, Databricks, 2026.05
Paper/Blog Link My Issue
#Article #Multi #NLP #AIAgents #Test-Time Scaling #Data Issue Date: 2026-05-11 Comment
元ポスト:
Raven Part-1 - Memory as a set of Slots, Afzal+, Goomba Lab, 2026.05
Paper/Blog Link My Issue
#Article #NLP #SSM (StateSpaceModel) #read-later #memory #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-10 Comment
元ポスト:
元ポストのGIFがわかりやすく、SSMにおけるStateの更新をgatingによって選択的に実施するモデル、という感じだろうか。これによりSSMの弱点であった、long contextにおけるrecall-heavyなタスクにおいてより高い性能を獲得する。
Natural Language Autoencoders: Turning Claude’s thoughts into text, Anthropic, 2026.05
Paper/Blog Link My Issue
#Article #Analysis #NLP #Explanation #Safety #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-10 Comment
LLM内の数値情報として保持されるactivationの情報をテキストで説明させる技術 Natural Language Autoencoeder (NLA) で、従来のSparseAutoencoderを用いたProbingなどとは異なり、より直接的にテキストによってactivationの情報を出力させる。
手法はシンプルで、autorncoderを用いて、target modelのactivationに関する情報が入力されたときに、
- Activation Verbalizerが、activationを説明するテキストを生成し
- Activation Reconstructorが、生成された説明テキストから元のactivationを復元する
- Activation Verbalizer/Reconstructorをreconstruction lossによって学習する
というもののようである。
このような手法はAI safetyの分野などで活用することができ、たとえば、Opus 4.6はBlackmail testingにおいて、context中でそのような情報を明言していないにも関わらず、NLAによるverbalizationによってそのような疑念を抱いていることが示唆される。
元ポスト:
所見:
Automated Weak-to-Strong Researcher, Wen+, Alignment Science Blog, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Alignment #AIAgents #Safety #ScientificDiscovery #Initial Impression Notes Issue Date: 2026-05-10 Comment
元ポスト:
Alignmentを自動で研究
Releasing Lab: the training platform for self-improving agents, PrimeIntellect, 2026.05
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #SelfImprovement Issue Date: 2026-05-09 Comment
元ポスト:
betaからついにリリース
関連:
- Introducing Lab: The Full-Stack Platform for Training your Own Models, Prime Intellect, 2026.02
ここまでおよそ1年らしい?
Accelerating Gemma 4: faster inference with multi-token prediction drafters, Google, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Blog #Decoding Issue Date: 2026-05-08 Comment
関連:
- Gemma 4: Byte for byte, the most capable open models, Google, 2026.04
元ポスト:
The ultimate guide to RL environments: building and scaling them in the LLM era, HuggingFace, 2026.05
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #PostTraining #read-later #Selected Papers/Blogs #Environment Issue Date: 2026-05-08 Comment
元ポスト:
On Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length
Paper/Blog Link My Issue
#Article #NLP #AIAgents #LongHorizon Issue Date: 2026-05-08 Comment
元ポスト:
Alignment Whack-a-Mole : Finetuning Activates Verbatim Recall of Copyrighted Books in Large Language Models
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #PostTraining #Copyright Issue Date: 2026-05-08 Comment
元ポスト:
Multi-Teacher On-Policy Distillation: A New Post-Training Primitive, Yumo Xu, 2026.04
Paper/Blog Link My Issue
#Article #Multi #Tutorial #NLP #ReinforcementLearning #Blog #Distillation #PostTraining #Selected Papers/Blogs #On-Policy #One-Line Notes Issue Date: 2026-05-08 Comment
元ポスト:
(multi teacher)オンポリシー蒸留の解説を、気持ち(何かに特化させると、他の部分が劣化していて、多方面に優れたモデルを学習するのが難しい課題を克服したい)だけでなく、
GRPOに対してAdvantage部分を生徒と教師モデルのreverse KLに置き換えることで統合できるよ、という説明と、
なぜreverse KLを使うのかという説明[^1]、
最近の最先端のOpenLLMにおいてmulti teacher オンポリシー蒸留がどのように使われているかが丁寧に説明されている。
[^1]: forward KLだと教師が少しでも確率を持つトークンにおいて生徒の確率が0だと発散するのでスムージングされた分布になってしまい、特定のトークンにフォーカスした分布が形成されづらく、テキスト生成の多峰性と(意味不明な出力をできるだけ回避するという意味での)安全性の観点からreverse KLの相性が良いよ、という話)
関連:
- 【LLM】On-Policy Distillation入門:小規模モデルを「実戦」で育てる技術, Currently Learning そんけいご, Zenn, 2026.02
解説と所見:
【LLM】On-Policy Distillation入門:小規模モデルを「実戦」で育てる技術, Currently Learning そんけいご, Zenn, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Distillation #PostTraining #Selected Papers/Blogs #On-Policy #Reading Reflections Issue Date: 2026-05-08 Comment
直感的な説明だけでなく、数式ベースの説明、RLとの比較などがコンパクトにまとまっておりとてもわかりやすかった...!!勉強になりました
Autodata: an automatic data scientist to create high-quality data, Ilia+, 2026.05
Paper/Blog Link My Issue
#Article #NLP #AIAgents #SyntheticData #Author Thread-Post Issue Date: 2026-05-06 Comment
元ポスト:
AgentTrove, open-thoughts, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Coding #Mathematics #SoftwareEngineering #ComputerUse #One-Line Notes Issue Date: 2026-05-06 Comment
元ポスト:
219のデータソースに対する170M規模のcoding, terminal/computer use, mathに関するagentのtrajectory。trace自体は、Agentic HarnessとしてTerminus 2を用いたOpenThinker-Agent-v1によるものだと推察される。
Grok 4.3, xAI, 2026.05
My Issue
#Article #NLP #Proprietary Issue Date: 2026-05-02 Comment
元ポスト:
Artificial Analysis IndexではKimi-K2.5, Mimo-V2.6 Pro未満のスコア
500Bモデルらしい?:
OlmPool: How small architectural choices compound to undermine long context extension, Ai2, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #NLP #Transformer #Attention #LongSequence #Architecture #read-later #Selected Papers/Blogs #One-Line Notes #ContextRot #Author Thread-Post Issue Date: 2026-05-01 Comment
元ポスト:
QK Norm, GQA, SWA, 事前学習のcontext長の短縮、これらはいずれもモデルが入力に対するattendの仕方を変えるものだが、これらを3つ以上組み合わせるとlong contextでの性能が急落するらしく、このようなlong contextの性能劣化は一般的な(しばしば短い)コンテキスト長のベンチマークやloss/perplexityなどでは検知できず、long contextで性能が急落するアーキテクチャでは、50Bトークンでのlong contextの学習を経ても、Llamaアーキテクチャが1Bトークンの学習で到達できる性能に届かない、といった話が元ポストに書かれている。
Qwen-Scope: Decoding Intelligence, Unleashing Potential, Qwen Team, 2026.04
Paper/Blog Link My Issue
#Article #NLP #SparseAutoencoder #Interpretability Issue Date: 2026-05-01 Comment
元ポスト:
Scaling Pain of Coding Agent Serving: Lessons from Debugging GLM-5 at Scale, Z.ai, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Infrastructure #LLMServing #SoftwareEngineering #read-later #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-30 Comment
GLM-5をサービングしている中でのバグ(モデル側ではなくインフラ側)の発見と修復
Mistral-Medium-3.5-128B, MistralAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #OpenWeight Issue Date: 2026-04-30
Laguna XS.2 and M.1: A Deeper Dive, Poolside team, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #OpenWeight #MoE(Mixture-of-Experts) #SoftwareEngineering #read-later #Selected Papers/Blogs #LongHorizon #Author Thread-Post Issue Date: 2026-04-30 Comment
HF: https://huggingface.co/poolside/Laguna-XS.2
元ポスト:
テクニカルレポート:
https://poolside.ai/assets/laguna/laguna-m1-xs2-technical-report.pdf
元ポスト:
Vintage Large Language Models, Owain Evans
Paper/Blog Link My Issue
#Article #NLP #read-later #Selected Papers/Blogs #vintage LLMs Issue Date: 2026-04-29 Comment
過去の特定の時刻までのデータで学習された大規模言語モデル, vintage Large Language Modelsを提唱
Introducing talkie: a 13B vintage language model from 1930, Levine+, 2026.04
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #read-later #Selected Papers/Blogs #Initial Impression Notes #vintage LLMs Issue Date: 2026-04-29 Comment
元ポスト:
1930年以前の英語テキストで学習された言語モデル(vintage Large Language Models)で、歴史や文化の変化を分析したり、1930年までのデータで学習されたモデルが1931年以後に発見された革新的な科学的な発見を自ら見出せるか?、LLMが将来を予測する能力がどの程度あり、それがモデルサイズによってどのように変化するか?、プログラミングに関する知識がないモデルが現代のコーディングを学習できるかなどのcontamination freeな評価など様々な活用方法があるとのこと。
関連:
- Vintage Large Language Models, Owain Evans
所見:
pyptx: A Python DSL to write Nvidia PTX for Hopper and Blackwell in JAX and PyTorch, patrick-toulme, 2026.04
Paper/Blog Link My Issue
#Article #NeuralNetwork #EfficiencyImprovement #NLP #python #SoftwareEngineering #GPUKernel Issue Date: 2026-04-27 Comment
元ポスト:
pythonの記法で、PTX(どの世代のNVIDIA GPUでも理解可能な仮想的なアセンブリ言語)を記述可能で自動最適化は一切入らないDSLとのこと。
PTXについては以下を読んだ:
PTXってなんだ?〜GPUの「共通語」仮想アセンブリを完全理解〜,GeneLab_999, 2026.01
https://qiita.com/GeneLab_999/items/5c49a21e5fd7e618b671
Project Deal, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #NLP #AIAgents #Personalization #read-later #One-Line Notes #Sales Issue Date: 2026-04-26 Comment
元ポスト:
AI同士が商取引をしたら何が起きるかという社内実験のようである。69人の社員に何を売りたいか/買いたいををインタビューし、カスタム指示が与えられた上でAI Agentに取引をさせたところ、きちんと商取引が行われ、186件、$4000のやりとりがあったとのこと。そして賢いモデルが大幅に有利に取引を終えて、実際の参加者はこの事実に気づかなかったとのこと。また、カスタム指示(e.g., 強行姿勢, 礼儀正しいなど)はあまり良い成果を上げる上では重要ではなかった、
といった話が元ポストに書かれている。
Sakana Fugu: A Multi-Agent Orchestration System as a Foundation Model, sakana.ai, 2026.04
Paper/Blog Link My Issue
#Article #Multi #NLP #AIAgents #Proprietary #Initial Impression Notes #Orchestration Issue Date: 2026-04-26 Comment
元ポスト:
複数のフロンティアモデルを(おそらく個々のモデルのタスクごとの強みに合わせて)動的にオーケストレーションすることで高い性能を達成する
テクニカルレポート:
- [Paper Note] Sakana Fugu Technical Report, Yujin Tang+, arXiv'26, 2026.06
claude-code-best-practice, shanraisshan
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs Issue Date: 2026-04-25 Comment
元ポスト:
Hy3-preview, tencent, 2026.04
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #MoE(Mixture-of-Experts) #Author Thread-Post Issue Date: 2026-04-24 Comment
元ポスト:
Introducing GPT‑5.5, OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #Proprietary #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #Reference Collection #Reading Reflections #Author Thread-Post Issue Date: 2026-04-24 Comment
元ポスト:
- FrontierMath, Terminal-Bench, GDPValでOpus 4.7を上回りダントツのトップ
- Artificial Analysis IndexでもOpus 4.7超え
しかし、Terminal-Benchは"ターミナル操作を通じた多様、かつlong horizonなタスクを評価する(多くはソフトウェアエンジニアタスクであるコーディングもタスクには含まれるが)"のベンチマークであり、SWE Bench Proのような一般的なcoding能力を測るベンチマークのスコアが掲載されていない。HLEやVisual Reasoning系のベンチマークのスコアも報告されていないように見える。
恣意的にGPT-5.5が強いデータ、比較対象をピックアップしているのではないか、という印象を持った。
- [Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
- Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
Artificial Analysisによる評価:
所見:
サイバー分野でMythosと同等?
Xiaomi MiMo-V2.5-Pro: A leap in agentic and long horizon coherence, Xiaomi, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #MultiModal #Blog #Coding #OpenWeight #Selected Papers/Blogs #UMM #Reference Collection #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-23 Comment
元ポスト:
いずれモデルをオープンにするとのこと
Artificial Analysisによる評価:
オープンになった:
https://huggingface.co/collections/XiaomiMiMo/mimo-v25
元ポスト:
GDPValやSWE-Bench-ProがGemini-3.1-Proよりも高い。
MIT Licenceかつnative multimodal
所見:
解説:
privacy-filter, openai, 2026.04
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Encoder #PII Issue Date: 2026-04-23 Comment
元ポスト:
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model, Qwen Team, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #OpenWeight #SoftwareEngineering #One-Line Notes #Author Thread-Post Issue Date: 2026-04-23 Comment
HF: https://huggingface.co/Qwen/Qwen3.6-27B
元ポスト:
Qwen3.5-397B-A17Bを主要なcodingベンチマークで上回り、同等程度の規模感のdenseモデルを上回る。
Deep Research Max: a step change for autonomous research agents, Google, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #DeepResearch #Author Thread-Post Issue Date: 2026-04-22 Comment
元ポスト:
Gemini APIからの使い方:
inclusionAI: Ling-2.6-flash (free), OpenRouter (InclusionAI), 2026.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #AIAgents #OpenWeight #MoE(Mixture-of-Experts) #Reference Collection #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-22 Comment
元ポスト:
Lingの最新モデル。元ポストに強みが簡潔に書かれている。OpenRouterで1週間freeで利用可能で、今後商用モデルのLingDTのリリースも控えているとこと。
また、将来的に本モデルはオープンになる予定とのこと。
Artificial Analysisによる評価:
オープンになった:
HF: https://huggingface.co/inclusionAI/Ling-2.6-flash
FlashKDA: Flash Kimi Delta Attention — high-performance KDA kernels built on CUTLASS, MoonshotAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Library #Attention #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-21 Comment
ベンチマーク: https://github.com/MoonshotAI/FlashKDA/blob/master/BENCHMARK_H20.md
関連:
- Kimi K2.6: Advancing Open-Source Coding, Kimi, 2026.04
- KDA: [Paper Note] Kimi Linear: An Expressive, Efficient Attention Architecture, Kimi Team+, arXiv'25, 2025.10
Kimi Delta Attentionがより高速に(2倍程度)動作する実装のようである。
公式ポスト:
ML Intern, HuggingFace, 2026.04
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #AutoML #ScientificDiscovery #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-04-21 Comment
元ポスト:
自動で研究が可能なエコシステムがどんどん構築されていく
関連:
take-homeをend-to-endで解けるくらい優秀とのこと。
Kimi K2.6: Advancing Open-Source Coding, Kimi, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2026-04-21 Comment
ブログ中ではまずはAgenticな能力の評価が掲載されており、スコアとしてはOpus 4.6と同等程度の水準に達している。
Kimi-K2.5と同様Agent Swarmを採用している。
- [Paper Note] Kimi K2.5: Visual Agentic Intelligence, Kimi Team+, arXiv'26, 2026.02
推論・知識に関するベンチマーク(AIME, HMMT, GPQA-Diamond)などについては、Opus4.6と比較してスコアが高いのはIMO-AnswerBenchと呼ばれるものだけであり、他は同等かスコアが低くなっている。Vision系のベンチマークでは、全体的にOpus4.6よりもスコアが高い。ただし、Gemini-3.1-Pro, GPT-5.4の方がKimi K2.6よりもスコアが全体として高い。
他にも5日間にわたる監視システムのようなプロアクティブなエージェントとしても活用でき、独自ベンチマークのKimiClawBenchと呼ばれるものでK2.5を上回った旨が記述されているが、詳細不明。
元ポスト:
HF: https://huggingface.co/moonshotai/Kimi-K2.6
その他ベンチマーク情報:
Qwen3.6-Max-Preview: Smarter, Sharper, Still Evolving, Qwen Team, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Proprietary #One-Line Notes Issue Date: 2026-04-21 Comment
Qwen3.6-plusと比較して、より強力な世界知識とIF、Agentic Codingの能力を持つとのこと。ブログ中のベンチマークはClaudeに関してはOpus 4.5との比較である点に注意。Proprietaryです。。。
RL Scaling Laws for LLMs, CAMERON R. WOLFE, PH.D., 2026.04
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #ReinforcementLearning #Scaling Laws #PostTraining #reading Issue Date: 2026-04-20 Comment
元ポスト:
Defeating the trainer-generator precision mismatch in TRL, HuggingFace, 2026.04
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #PostTraining #Selected Papers/Blogs #reading #train-inference-gap #LowPrecision #Author Thread-Post Issue Date: 2026-04-20 Comment
元ポスト:
関連:
- Making RL Fast, Finbarr Timbers, 2026.04
こーーれは必読では
The Art of Prompt Design: Prompt Boundaries and Token Healing, Scott Lundberg, 2023.05
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #Tokenizer #Selected Papers/Blogs Issue Date: 2026-04-19 Comment
Prompt Boundary Issueと呼ばれる、ユーザのpromptと生成時点の境界を見た時に、ユーザの文字の区切り方と、モデルが持つvocab、およびバイアスによって、期待する出力がうまく得られない現象を解説している。
たとえば、モデルにURLを出力させる際に、'http:'の続きを出力するように指示を出すと、学習データ中に存在するデータは、httpの後は学習時にトークン'://'が続くが、ユーザが':'まで入力してしまうとトークン列としては'http'':'となる。BPEによるtokenizerは1トークンが表現する文字の長さが長くなるようにエンコードするため、':'が見えた時点でこの後に続く単語は、'://'のような典型的な:の後に続く文字列ではないのだなと解釈する。なぜなら、典型的な':'とくっついて表現される文字が続くなら、':'が独立して存在しないはずだから(そういうtokenizeで学習してしまっているから)である。
これに対する対処法として、token healingと呼ばれふ手法が紹介されている。具体的には、生成プロセスをあえて1つ前のトークンから開始し、その代わり、最初にモデルが生成するtokenのprefixがユーザが入力した文字と一致するよう強制するというものである。
Designing synthetic datasets for the real world: Mechanism design and reasoning from first principles, Google, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #SyntheticData #Distillation #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection #Critic #Reading Reflections #Human-in-the-Loop #Author Thread-Post Issue Date: 2026-04-19 Comment
元ポスト:
公式:
解説:
(詳細は解説や元ブログ参照のこと)
強い教師モデルから弱い生徒モデルを学習する場合の合成データ生成手法で、
生成したいデータの観点(内容、形式等)を分類し、どの観点からどの程度の難易度のデータを合成するかを制御する。その後生成されたデータが正しいか/正しくないかの2方向から批評を行いvalidationをするような枠組みのようである。
単純なデータ合成では性能がすぐに頭打ちになるが、ローカル多様性(特定のパターンの多様性)、グローバル多様性(データ全体がカバーするパターンの範囲)の2つを同時に大きくしないと不十分であることや、批判によるvalidationは少なくとも性能を悪化させることはないことも示されたとのこと。
Unlinkable Inference as a User Privacy Architecture, The Open Anonymity Project, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Privacy Issue Date: 2026-04-19
nanomem: An Extremely Simple, Inference-Time Memory Module, The Open Anonymity Project, 2026.04
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #Personalization #SoftwareEngineering #Selected Papers/Blogs #Privacy #memory #One-Line Notes Issue Date: 2026-04-19 Comment
github: https://github.com/OpenAnonymity/nanomem
元ポスト:
マークダウン形式でメモリを管理するシンプルな実装で、シンプルながらもさまざまな利点を持つとのこと:
- マークダウンで管理されているためメモリ情報をディレクトリ分けするだけで簡単に分離できる
- ただのテキストファイルなので可用性が高く、ユーザ自身が保持できる
- テキストファイルなのでなので、解釈ができ、ユーザ自身が編集できる
- 前方互換性があり、モデルが賢くなっても同じ方法でメモリを読み込め、モデルの性能が上がるとメモリ自身の性能(スピード、品質)も向上する
- モジュール化が可能で、取り込み、検索、圧縮などを個別に最適化できる
Act I:
- Unlinkable Inference as a User Privacy Architecture, The Open Anonymity Project, 2026.02
AI週報#1 | LLMは「決めてから考える」のか? 他2件, toda, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Blog #Author Thread-Post Issue Date: 2026-04-19 Comment
元ポスト:
[Paper Note] Open-world evaluations for measuring frontier AI capabilities, Kapoor+, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Evaluation #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-04-19 Comment
元ポスト:
PAW: Define functions in English. Run them locally, ProgramAsWeights, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Library #Coding #PEFT(Adaptor/LoRA) #SoftwareEngineering #One-Line Notes #Author Thread-Post Issue Date: 2026-04-17 Comment
元ポスト:
英語で説明した機能をNeural Compilerと呼ばれる機構によって、text + Continuous LoRA (Continuous LoRAってなんだ。。。) によってインタプリタを構築し、python関数として利用できる、という感じらしい?
.pawファイルと呼ばれるファイルが作成され、中には
- Discrete pseudo-program: neural compilerによって生成されたtext instructions
- continuous neural adapter: 量子化されたLoRA adapter
が格納されて実行時に利用されるとのこと。完全にローカルで動作させられる。
LoRAを使うということは、事前に関数を実行するbase modelのDLが必要そうだが、どうなのだろうか?.pawファイルの例にも特定のベースモデル名が記載されているように見える。
Evaluating Netflix Show Synopses with LLM-as-a-Judge, Netflix Technology Blog, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Factuality #Blog #LLM-as-a-Judge #Test-Time Scaling #read-later #Reference Collection #Scalability #Initial Impression Notes Issue Date: 2026-04-17 Comment
元ポスト:
Netflix上に存在するsynopses(映画の短いdescription)を高品質に保ちたいが、非常に量が多いのでどのようにスケーラブルに評価しているか、という話のようである。
LLM-as-a-Judgeを活用して評価をしており、4種類の観点(制度、事実性、トーン、明瞭さ)のような多次元のRubricを用いて、それぞれの観点ごとにLLM-as-a-Judgeを専門家の判断にalignさせるためにgold dataを作成し、どのように推論すればLLM-as-a-Judgeの性能が向上するかを調査した結果、long CoT / Majority Voting (精度向上+分散低下)/ Agents-as-a-Judge (複数のFactualityの側面を評価するために4種類のAI Agentを用いてメタデータとsynopsesのFactual Consistencyを評価し、全てのエージェントの結果を集約)といった感じのことをやっているらしい。
FrontierSWE: Benchmarking coding agents at the limits of human abilities, FrontierSWE, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #SoftwareEngineering #One-Line Notes #LongHorizon #Author Thread-Post Issue Date: 2026-04-17 Comment
元ポスト:
WAN2.1の推論パイプライン構築、llmのpost-trainingをしてlogic gameができるように学習させる、など、long horizonかつ非常に現実的なタスクで評価される
Introducing GPT‑Rosalind for life sciences research: A new purpose-built model to accelerate scientific research and drug discovery., OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Proprietary #Medical #Biological #One-Line Notes #Author Thread-Post Issue Date: 2026-04-16 Comment
元ポスト:
Life Sciencesドメイン特化モデル
Introducing Claude Opus 4.7, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Reference Collection #Author Thread-Post Issue Date: 2026-04-16 Comment
元ポスト:
Artificial Analysisによる評価:
GDPval-AAでGPT-5.4超えのSoTA
IntelligenceでもSoTA(同等)
所見:
所見:
新たなtokenizerを用いている。knowledge cutoffも更新されている。すなわち、新たなベースモデルが事前学習された可能性が高い
tokenizerが更新された=必ずしもベースモデルも新しいということではないよねという指摘:
デグレしたベンチマークがある模様:
所見:
Qwen3.6-35B-A3B: Agentic Coding Power, Now Open to All, QwenTeam, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #MultiModal #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #Sparse #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-16 Comment
HF: https://huggingface.co/Qwen/Qwen3.6-35B-A3B
元ポスト:
ざっと見た感じ明言されていない気がするが、プロプライエタリとなったQwen3.6-Plusの廉価版(オープンなので廉価と言うのかはあれだが)だと思われる。
Our evaluation of Claude Mythos Preview’s cyber capabilities, AISI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #Security #Author Thread-Post Issue Date: 2026-04-15 Comment
元ポスト:
Trusted access for the next era of cyber defense, OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Proprietary #One-Line Notes #Security #Author Thread-Post Issue Date: 2026-04-15 Comment
GPT-5.4をサイバーセキュリティユースケースに特化してチューニングしたGPT-5.4-Cyber
元ポスト:
マルチエージェントシステムでGPUカーネルを38%高速化, Cursor, 2026.04
Paper/Blog Link My Issue
#Article #Multi #NLP #AIAgents #Coding #SoftwareEngineering #GPUKernel #Author Thread-Post #AgentHarness Issue Date: 2026-04-15 Comment
元ポスト:
自律的に長期間稼働し235件の問題を1回の実行で解くマルチエージェントハーネスに関するレポートで、3週間程度でBlackwell GPUカーネルをゼロから構築・最適化し38%高速化とのこと。
Evaluating agents for scientific discovery, Ai2, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Blog #ScientificDiscovery #Science #Surface-level Notes #Reading Reflections #Author Thread-Post Issue Date: 2026-04-14 Comment
元ポスト:
scientific discoveryを実現するエージェントに関して、research paperで主張される素晴らしさと、実態のgapを埋めるためにAi2が実施してきたベンチマークに関する研究についての解説。
- [Paper Note] ScienceWorld: Is your Agent Smarter than a 5th Grader?, Ruoyao Wang+, EMNLP'22, 2022.03
- 小学校レベルの理科の実験をエージェントが実行できるかを評価するベンチマーク
- 教科書に載っているような古典的なdiscoveryを再現させる
- 200種類以上にものぼるオブジェクトが配置された、物理法則に従う(e.g., 氷が加熱すると溶けるなど)シミュレーション世界において、水の沸点を選択肢から正解を選ぶのではなく、自身で発見することを求められる。
- 2022年、Multiple Choice Questionのschool science examでハイスコアを記録したモデルはスコアは10%未満、2025年にはスコアは80%代に到達したが、まだ完全にこなふことができない。
- [Paper Note] DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents, Peter Jansen+, NeurIPS'24 Spotlight, 2024.06
- 独自の科学的な調査をスクラッチから設計実行させるベンチマーク
- 大学、あるいはPhDレベルのopen-endなdiscoveryに関する能力を問う
- 宇宙の惑星Xでの最初の科学者として調査を実施する設定で8トピックにわたる120のタスクをこなす必要がある
- 難易度は3段階に分かれていて、タスクは架空のcontextで実施されるため事前知識に頼ることができない中でタスクを解決し、正しいプロセスで実施されたかや、理解をしているかなどの能力も問われる。
- 現在のエージェントは、normal/challengingな難易度のタスク群について、80%の完了率を達成できない
- 双方のベンチマークともに、知識と実務力を分離した上で能力を測定するものとなっており、知識を答えるだけの見かけ上の能力ではなく、スクラッチから知識に基づいてエビデンスを積み上げ、実行し、タスクを遂行し科学的な発見をできるか、という実務力を問うている
という話。
この話は
- Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
において議論されている「認知コア」と関連が深いと感じる。
認知コアとは、単なる記憶に頼るのではなく、事前学習において、いわゆる人間のような知性を(データ内に潜むアルゴリズム的なパターンを学習することで)獲得し、その結果としてIn context Learningのような能力を発達させることとされ、
既に獲得された知識がモデルの認知コアの発達を阻害し、未知の環境でも適応できるような汎化能力を獲得することを阻害している(=モデルは既存の知識と紐づけて簡単に回答できてしまうため、アルゴリズムに基づいた思考と行動を備える必要がなく学習が進み、結果的に汎用的な能力が身につかない)恐れがある、という話である。
上記ベンチマーク(特にDiscoveryWorld)は既存の世界知識に捉われない、アルゴリズム的な思考と行動が求められると推察されるため、モデルの認知コア的な側面を部分的に測定していると言えると感じる。
Distilling 100B+ Models 40x Faster with TRL, Hugging Face, 2026.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Blog #Distillation #One-Line Notes #Author Thread-Post Issue Date: 2026-04-13 Comment
元ポスト:
on-policy蒸留(生徒モデルが生成したロールアウトに対して教師モデルが評価を与える方式)を、バッチ処理や、生徒モデルと教師モデルの通信量を削減するためバイナリ形式に変換してやり取りするなどの工夫をして高速化した話とのこと。
著者ポスト:
MMX The official CLI for the MiniMax AI Platform: Built for AI agents. Generate text, images, video, speech, and music — from any agent or terminal., MiniMax-AI, 2026.04
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #Repository #Omni #Initial Impression Notes #AgentHarness Issue Date: 2026-04-11 Comment
元ポスト:
MiniMax AIのAPIを用いて、omni-modalなタスクを実行できるCLIツールのようである。
The advisor strategy: Give agents an intelligence boost Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost., Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #AIAgents #Blog #One-Line Notes #Reading Reflections Issue Date: 2026-04-11 Comment
元ポスト:
Strong Modelをツールとして登録(Advisor)しておき、意思決定が困難になった場合はstrong modelにレビュー依頼をしてcontextを受け取り実行可能な枠組み。
Sonnetで12パーセント程度省コストで、SWE Bench Multilingual のスコアを2.7%向上、とのこと。
SWE Benchの結果は、Claute Opus 4.6をAdvisorとして利用した旨が脚注に書かれている。
下記システムカードによると、Opus 4.6 の SWE Bench Multilingualのスコアは77.83程度(細かい設定は追えていない)、元ポストのSonnet+Advisorのスコアは74.8%なので、near Opusな性能が出るとポストに記載されているが、そのくらいのgapがあるという点には注意が必要。
https://www-cdn.anthropic.com/6a5fa276ac68b9aeb0c8b6af5fa36326e0e166dd.pdf
Taking the Pulse of Agentic AI from the Developer Community at the End of Q1 2026, InclusionAI, 2026.04
Paper/Blog Link My Issue
#Article #Survey #Tools #NLP #Library #AIAgents #GenerativeAI #Repository #read-later Issue Date: 2026-04-11 Comment
元ポスト:
The OpenHands Vulnerability Fixer: Automated Security Remediation with AI Agents, Graham Neubig, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #SoftwareEngineering #read-later #Security Issue Date: 2026-04-11 Comment
元ポスト:
Marco-Mini-Instruct, AGDC-AI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-04-11 Comment
元ポスト:
Memento: Teaching LLMs to Manage Their Own Context
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Selected Papers/Blogs #ContextEngineering #One-Line Notes #KV Cache #Author Thread-Post Issue Date: 2026-04-11 Comment
元ポスト:
著者によるtakeaway:
頻繁に要約を作成することが大事で、SummaryのKV Cacheを再計算してはいけない(すなわち、推論をrestartしてはいけない)。なぜなら、SummaryよKV Cacheには仮に当該ブロックがなかったとしても過去のコンテキストの情報が残っているから。という話が書かれている。なるほど。
dataset: https://huggingface.co/datasets/microsoft/OpenMementos
所見:
Introducing Muse Spark: Scaling Towards Personal Superintelligence, Meta, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Proprietary #read-later #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2026-04-11 Comment
元ポスト:
-
-
元ポストのベンチマークスコアを見るとマルチモーダルの性能はフロンティアモデル(gpt5.4, Opus 4.6, Gemini 3.1 Pro)と同等、text/reasoningはフロンティアモデルより少しスコアが低く、特に抽象的な思考が苦手(ARC-AGI-2)。HEALTH分野はhealthは高スコアだがmedicalは少し低めのスコア、Agenticな分野では、SWE Bench Verified/Proよスコアは少し低め、terminal useは明確にスコアが低くtool useは少しスコアが低い、という感じにみえる。
codingとlong horizon taskに継続的に投資するとのこと。
中の人による解説:
全てをフルスクラッチから作り直したっぽい。
Artificial Analysisによる解説:
一気にOpenWeight最強のGLM-5.1超え
所見:
所見:
所見:
第三者によるおそらく独自のベンチマークによる評価の結果、(おそらく101モデルのうち)全体で3位となっているらしい(つまり、既存ベンチマークにoverfittingしているわけではないという考えがある)。
The ATOM Report: Measuring the Open Language Model Ecosystem, Lambert+, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #NLP #OpenWeight #OpenSource #read-later #Data #Author Thread-Post Issue Date: 2026-04-11 Comment
著者ポスト:
元ポスト:
What do “economic value” benchmarks tell us?, Epoch.AI, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #read-later Issue Date: 2026-04-11 Comment
元ポスト:
GDPvalだけでなく、RLI, APEX Agentsと呼ばれるものも解説されているようである
- REMOTE LABOR INDEX (RLI) : Evaluating the capability of AI agents to perform real-world, economically valuable remote work
- [Paper Note] APEX-Agents, Bertie Vidgen+, arXiv'26, 2026.01
- [Paper Note] GDPval: Evaluating AI Model Performance on Real-World Economically
Valuable Tasks, Tejal Patwardhan+, arXiv'25, 2025.10
ハーネスエンジニアリングのすすめ: 27BモデルでSWE-bench VerifiedのSLM SOTAを達成 (TTS@8=74.8%), Fujitsu Tech Blog, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Test-Time Scaling #SoftwareEngineering #One-Line Notes Issue Date: 2026-04-11 Comment
元ポスト:
Best-of-8 SamplingでSWE Benchのスコアを改善する話
1bit 量子化技術の紹介, Fujitsu Tech Blog, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Library #Quantization #Blog #One-Line Notes Issue Date: 2026-04-09 Comment
関連:
- OneCompression, FujitsuResearch, 2026.04
元ポスト:
プレスなので概要のみで、細かい手法については記述されていなかった。が、QEP, QQAと呼ばれるNeurIPS2025, ICLR2025に採択済みのモデルで、それぞれ層を跨いで量子化誤差を伝播させることでエラーの増大を防ぐ手法(任意のbit数に適用可能)、量子力学の量子性に着想を得た大規模最適化問題で高い性能を発揮する手法、とのことのようである。
元ポストの方が技術的な面は詳しく書かれている。
Project Glasswing Securing critical software for the AI era, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Safety #Selected Papers/Blogs #One-Line Notes #Reference Collection #Safeguard #Reading Reflections Issue Date: 2026-04-08 Comment
元ポスト:
Claude Mythos Previewが、ソフトウェアの脆弱性を見つける能力において、トップクラスの人間を除けば、あらゆる人間以上の能力を獲得してしまっており、これがサイバーセキュリティの概念を根本的に変化させてしまう危険がある。
実際、同モデルは数千にも及ぶ深刻な脆弱性を発見しており、それはOSやブラウザにも及び、これが経済や国家安全保障などに影響を及ぼすため、緊急のproject Glasswingを立ち上げており、まずは今回挙げたパートナーにClaude Mythos Previewにアクセス可能な無料のクレジットを与え、セキュリティに関する脆弱性を改善することで、セーフガードを確立し、その結果得られた知見をAnthropicがまとめて公表する、そしてその後パートナーはさらに拡大していく、という感じらしい。
しかし最近中国のOpenWeightモデルは、2ヶ月程度で米国のFrontier Modelに追いつく。では2ヶ月あとに中国系のOpenWeightモデルがClaude Mythos Previewの性能に追いついてOpenWeightとして公開された場合、世界はどうなってしまうのだろうか?
また、現在は以下の企業と連携してセーフガードを構築するようだが、これらグローバル企業以外の日本の企業はどうなるのだろうか?今後40以上の組織とも連携するようにする予定とのことだが、日本の社会を支えている企業群と連携するのはいつなのか?
所見:
所見:
しかしこれ、Claude Mythos Previewによって初めてこのようなことが起きたかのように書かれているけど、既知の脆弱性を見つけて悪用するというのは、既に公開されているOpenWeightモデルや、プロプライエタリモデルでも十分可能なのでは?
なぜいまさらこのようなことを言い始めたのだろうか。
所見:
GPT-5.4でも15年前のLinux Kernelの深刻なバグを見つけたよ、という話:
Update:
https://www.anthropic.com/research/glasswing-initial-update
元ポスト:
System Card: Claude Mythos Preview, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #Reference Collection Issue Date: 2026-04-08 Comment
Mythos Previewは一般公開する予定はなく、まずは安全性を高めることに注力するとのこと。
元ポスト:
- Project Glasswing Securing critical software for the AI era, Anthropic, 2026.04
も参照のこと。要はソフトウェアの脆弱性を見つけて悪用する能力が高すぎて、このまま公開するとサイバーセキュリティが終わるので、まずは未然にセーフガードを構築するために公開は控えるということである。
所見:
所見:
GLM-5.1: Towards Long-Horizon Tasks, Z.ai, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #Selected Papers/Blogs #Reference Collection Issue Date: 2026-04-07 Comment
元ポスト:
SWE Bench ProでSoTA...?!
HF: https://huggingface.co/zai-org/GLM-5.1
Artificial Analysis:
アーキテクチャ解説:
DeepSeekV3.2 likeなアーキテクチャで、MLA, DeepSeek Sparse Attentionを採用。Layer数がDeepSeekV3.2より多いとのこと。
MemPalace: The highest-scoring AI memory system ever benchmarked. And it's free, milla-jovovich, 2026.04
Paper/Blog Link My Issue
#Article #NLP #OpenSource #SoftwareEngineering #Selected Papers/Blogs #memory #One-Line Notes Issue Date: 2026-04-07 Comment
元ポスト:
過去の会話履歴に関してrelevantなもののみを保持しておくのではなく、全てを保持し必要に応じて見つけるようなアプローチをとるopensourceな実装で、API, クラウドストレージなどを用いず完全にローカルで動作し、LongMemEvalと呼ばれるベンチマークにおいて100%を達成したとのこと。気になる。
How we optimized Dash's relevance judge with DSPy, Dropbox, 2026.03
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Prompting #AutomaticPromptEngineering #LLM-as-a-Judge #read-later #Initial Impression Notes Issue Date: 2026-04-07 Comment
元ポスト:
APEを使ってモデルを変更した際のプロンプト適応を効率化した話な模様。
Making RL Fast, Finbarr Timbers, 2026.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #ReinforcementLearning #SoftwareEngineering #PostTraining #Selected Papers/Blogs #reading #Initial Impression Notes #Asynchronous Issue Date: 2026-04-07 Comment
元ポスト:
Olmo3においてpost-trainingのインフラを同期から非同期に変更したことを含めて4倍高速化したことに関して、それをどのように実現したかに関するwrite up。気になる。
オープンソースAIの現状 | NVIDIA GTC, Nvidia, 2026.04
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Video #OpenSource #read-later #One-Line Notes Issue Date: 2026-04-07 Comment
元ポスト:
GTCのパネルディスカッション
TurboQuant-Gpu, DevTechJr, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Library #KV Cache #Compression Issue Date: 2026-04-07 Comment
元ポスト:
TurboQuant:
- TurboQuant: Redefining AI efficiency with extreme compression, Google Research, 2026.03
国産生成AI PLaMoを支える事後学習と推論最適化, PFN, 2026.04
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #ContextWindow #Quantization #PositionalEncoding #LLMServing #Slide #mid-training #DPO #PostTraining #GRPO #KV Cache #Compression Issue Date: 2026-04-07 Comment
元ポスト:
関連:
- PLaMo 3.0 Prime β版, PFN, 2026.03
関連:
- RoPE / YaRN
- [Paper Note] RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, arXiv'21, 2021.04
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
- DPO
- [Paper Note] Direct Preference Optimization: Your Language Model is Secretly a Reward Model, Rafael Rafailov+, arXiv'23, 2023.05
- GRPO
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open
Language Models, Zhihong Shao+, arXiv'24
- RLはSFTよりも汎化性能に優れ、基本的には事前学習で獲得された能力を引き出す、という話
- [Paper Note] SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25
- [Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
- JFBench: 実務レベルの日本語指示追従性能を備えた生成AIを目指して, PFN, 2026.01
- LLM Serving系
- [Paper Note] Efficient Memory Management for Large Language Model Serving with PagedAttention, Woosuk Kwon+, SOSP'23
- [Paper Note] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, ICLR'23, 2022.10
- [Paper Note] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration, Ji Lin+, MLSys'24
- TurboQuant: Redefining AI efficiency with extreme compression, Google Research, 2026.03
うーーんおもしろかった!後でnote中の関連文献を紐づけてついでに復習したい
Components of A Coding Agent: How coding agents use tools, memory, and repo context to make LLMs work better in practice, Sebastian Raschka, 2026.04
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs #Initial Impression Notes #AgentHarness Issue Date: 2026-04-05 Comment
LLM, Reasoning Model, Agent, Agent Harness, coding harnessなどの定義とその役割やスコープ、そしてそれらを構成するためのminimalなコンポーネントについて説明されており、基礎的な理解に役立ちそう。
元ポスト:
Emotion Concepts and their Function in a Large Language Model, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #NLP #read-later #Selected Papers/Blogs #Emotion #Initial Impression Notes Issue Date: 2026-04-04 Comment
元ポスト:
これは非常に面白そうだ
Announcing 1-bit Bonsai: The First Commercially Viable 1-bit LLMs, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Blog #Proprietary Issue Date: 2026-04-04 Comment
元ポスト:
関連:
- [Paper Note] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits, Shuming Ma+, arXiv'24, 2024.02
- [Paper Note] BitNet b1.58 2B4T Technical Report, Shuming Ma+, arXiv'25, 2025.04
圧倒的デコーディング速度:
Claude Code's Real Secret Sauce (Probably) Isn't the Model, Sebastian Raschka, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Post #Architecture #read-later #AgentHarness Issue Date: 2026-04-04 Comment
関連:
- Claude Code's source code leaked through a `.map` file - How bad is it, really?, Chubby, 2026.04
How far does alignment midtraining generalize?, Tomek+, OpenAI Alignment Research Blog, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Alignment #mid-training #read-later #Initial Impression Notes Issue Date: 2026-04-04 Comment
元ポスト:
mid trainingにおいてalignment関してmisaligned/alignedな文書で学習をすると中間学習直後はalignmentに関する挙動が維持されるが、RLをしたらその効果は消えて無くなってしまう、という感じだろうか?超絶流し読みなので、後でしっかり読んだ方が良さそう。
Qwen3.5-Omni: Scaling Up, Toward Native Omni-Modal AGI, Qwen Team, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #SpeechProcessing #Proprietary #VisionLanguageModel #2D (Image) #3D (Video) #Omni #AudioLanguageModel #audio #text Issue Date: 2026-04-04 Comment
元ポスト:
llm-wiki.md, karpathy, 2026.04
Paper/Blog Link My Issue
#Article #Initial Impression Notes #Gist Issue Date: 2026-04-04 Comment
Karpathy氏によるLLMを利用して個人の生のドキュメントコレクションからwikiを構築するためのidea file。本paper_noteは自分の勉強のために手作業をすることで自身への知識の定着を狙っているけれども、自動構築したwikiがどのようなものになるかは興味があるなあ。
CuLA, InclusionAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Library #Attention #SoftwareEngineering #One-Line Notes #GPUKernel #LinearAttention Issue Date: 2026-04-04 Comment
元ポスト:
Hopper(SM90), Blackwell(SM10X)において、flash-linear-attention(FLA)よりも最大2.45倍、平均1.52倍速いlinear attention kernelらしい
GPU Memory Math for LLMs (2026 Edition), Ahmad, 2026.04
Paper/Blog Link My Issue
#Article #NLP #SoftwareEngineering #Initial Impression Notes Issue Date: 2026-04-04 Comment
様々な量子化や浮動小数点フォーマット、パラメータ数やMoEの場合などにおける、VRAM消費量に関する考え方について解説されている
約12兆トークンの良質なコーパスで学習した新たな国産LLM「LLM-jp-4 8Bモデル」「LLM-jp-4 32B-A3Bモデル」をオープンソースライセンスで公開 ~一部ベンチマークでGPT-4oやQwen3-8Bを上回る性能を達成~, NII, 2026.04
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Reasoning #OpenWeight #Japanese #OpenSource #mid-training #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-04-03 Comment
8BモデルはLlama-2アーキテクチャ、32B-A3.8BモデルはQwen3-MoEアーキテクチャで、フルスクラッチ学習をすることで実現[^1]。
19.5Tトークン(概算として、日本語0.7Tトークン、英語17.8Tトークン、中国語・韓国語0.85Tトークン、プログラムコード0.2Tトークン)のインターネット上の公開データや政府・国会の文書を収集し(LLM-jp-3.1のデータの6倍の規模)し事前学習データを構築、DataMixtureを最適化し10.5Tトークンを事前学習で利用。
中間学習では、事前学習データにInstruction Pretraining[^2]データを含む合成データを加え1.2Tトークンを利用。
その後最終的にInstruction Tuningを、日本語、英語合計22種類のデータで実施(元記事ではチューニングと呼称されているがおそらくInstruction Tuningだと思われる)。
MTBenchでは、GPT-4o, gpt-oss-20B, Qwen3-8Bと同等以上の性能、日本語MTBench[^3]では、GPT-4o, gpt-oss-20B, Qwen3-8Bを上回る性能とのこと。MTBenchで用いるLLM-as-a-JudgeのモデルとしてはGPT-5.4を利用とのこと。
[^1]: つまり、モデルのパラメータは完全に新規で学習されており、ベースとして既存OpenWeightモデルを利用していない点に注意。
[^2]: Instruction Pretrainingは、LLM-jp-3.1の頃から実施されている:
LLM-jp-3.1 シリーズ instruct4 の公開, LLM-jp, 2025.05
[Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, arXiv'24, 2024.06
[^3]: MT-Benchの概要については
[Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
も参照のこと。
フルスクラッチモデル点に関する説明:
HF:
https://huggingface.co/collections/llm-jp/llm-jp-4-models
Reasoningモデルもある!!!
関連:
- PLaMo 3.0 Prime β版, PFN, 2026.03
上記PLaMo 3.0に続いて、国内でのフルスクラッチReasoningモデルは二例目だろうか。
Gemma 4: Byte for byte, the most capable open models, Google, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AIAgents #MultiModal #SpeechProcessing #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #3D (Video) #One-Line Notes #Reference Collection #AudioLanguageModel #audio #text #Initial Impression Notes Issue Date: 2026-04-02 Comment
元ポスト:
2B, 4B, 26BのMoEモデルと31BのDenseモデルの4種類のモデルファミリーで、マルチモーダル(vision)対応。2B, 4Bはaudioも入力として扱える。
edgeデバイス向けのモデルは128k, 他は256kのコンテキストウィンドウ。140+の多言語サポート。
Apache 2.0ライセンス
arenaで同サイズのモデル群でSoTAといった話がブログ中に記述されている。
モデルカードには一般的なベンチマーク群とのスコアも記載されている。
https://ai.google.dev/gemma/docs/core/model_card_4?hl=ja
(そもそも既存のベンチマークにもコンタミネーションがあると思われるが、)arenaに関しては特定の企業に対してデータを提供し、複数のモデルの亜種をテストできるという慣行があり、リーダーボードにバイアスがあるであろう点には注意:
- [Paper Note] The Leaderboard Illusion, Shivalika Singh+, NeurIPS'25
artificial analysisによる評価:
Qwenがproprietaryになったことから、ライセンス的に使いやすく、日本語に強そうなモデルとしては筆頭ではなかろうか。日本語性能が気になる。
アーキテクチャ解説:
ポイント解説:
所見:
attentionのscaleをsqrt(d)でスケールさせる代わりに、QK-norm, V normを適用するなど。
NvidiaによるNVFP4へのpost-trainingによる量子化:
https://huggingface.co/nvidia/Gemma-4-31B-IT-NVFP4
量子化後の性能も比較されており、知識、数学、コーディング、terminac useなど6種類のベンチマークでオリジナルのモデルと遜色ない性能が出ている旨記載されている。
解説:
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4
所見(encoder-freeにした裏側でパッチ化→projection + x/y軸のpositional embeddingを実施している話):
Trinity-Large-Thinking: Scaling an Open Source Frontier Agent, Arcee, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-04-02 Comment
元ポスト:
HF: https://huggingface.co/collections/arcee-ai/trinity-large-thinking
Qwen3.6-Plus: Towards Real World Agents, Qwen Team, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-04-02 Comment
元ポスト:
Opus 4.6相当のベンチマークスコアがありそうだが、プロプライエタリモデル化
LFM2.5-350M: No Size Left Behind, Liquid AI, 2026.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #SmallModel #OpenWeight #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-04-01 Comment
元ポスト:
- LFM2のアーキテクチャを採用の350Mパラメータモデルで、CPUでも十分な速度で推論可能
- 追加の事前学習(10T -> 28T tokens)、および、large-scale RLを実施
- 同等規模のパラメータ数(あるいは2倍程度)のモデル群に対して、知識, 指示追従能力, ツール呼び出し、データ抽出などのベンチマークで上回る
- LFM2-350Mと比較して、指示追従能力, データ抽出, tool useの性能が大きく向上
- edgeデバイスでの軽量なデータ抽出パイプラインとして有用
- しかし、math, coding, creative writingなどでの利用は推奨されない
- CPU/GPUでの推論ともに同等規模、あるいは1B級のモデルよりも早く、省メモリ
OneCompression, FujitsuResearch, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Library #Quantization #One-Line Notes Issue Date: 2026-04-01 Comment
元ポスト:
example_autorun.pyを見るとわかるが、ワンライナーで(post-training basedな)量子化をしたいモデルのコンフィグを渡して実行するだけで、自動的にGPTQ量子化など(DBF, RTNと呼ばれる方式もあるようだ)をしてくれるライブラリのようである。現在はLlama, Qwen3をサポートしており、今後も適用可能なモデルは拡張していく予定と書かれている。また、量子化したモデルはvLLMとの互換性も担保される。
サポートされているアルゴリズムはこちらにまとまっていそう:
https://fujitsuresearch.github.io/OneCompression/algorithms/overview/
calibration dataは何が用いられるのだろうか?
関連:
SmolLM - blazingly fast and remarkably powerful, Allal+, HuggingFace, 2024.07
Paper/Blog Link My Issue
#Article #NLP #OpenWeight Issue Date: 2026-03-31 Comment
OpenSourceなLLMについて過去を遡ってみているが、SmolLMの最初の段階では、データのみがオープンでコードはオープンでないように見える。
次:
- SmolLM2, 2024.11
RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens, together.ai, 2023.04
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #OpenSource #One-Line Notes Issue Date: 2026-03-31 Comment
完全なオープンソースLLMの構築を目指すprojectで、LLaMAの学習データを再現する取り組み。
ParaGator: Learning to Aggregate through Online RL, Li+, 2026.03
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Test-Time Scaling #Diversity #Aggregation-aware #Initial Impression Notes Issue Date: 2026-03-30 Comment
元ポスト:
関連:
- [Paper Note] Reasoning over mathematical objects: on-policy reward modeling and test time aggregation, Pranjal Aggarwal+, arXiv'26, 2026.03
上記研究のSection 3の内容っぽい?
解候補を生成する際はPass@kに対して最適化をし多様な候補の生成を促し、解候補を集約してFinal Answerを導出する際には、Pass@1に対して最適化をし複数の解候補を効果的に集約する方向に最適化することで、性能がブーストされ、それをend-to-endに実現する、という話にみえる。
- [Paper Note] PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning, Jingcheng Hu+, arXiv'26, 2026.01
と似たような考え方に見える。
The Anatomy of an LLM Benchmark, Cameron R. Wolfe, Ph.D., 2026.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Dataset #Evaluation #Initial Impression Notes Issue Date: 2026-03-30 Comment
元ポスト:
本文中のDisclaimerにも記述されている通り、coding/SWE/AI-Agentに関するベンチマークや、Multi-modalなベンチマークについては説明されていない点には注意。
LLMとしての評価として初期の頃から使われて(いる|いた)、MMLU, GPQA, BIG-Bench, IFEvalといった代表的なものが紹介され、単にそれらベンチマークがどういったものかを説明しているというより、どのようにすれば自分たちのタスクに関して良いLLMベンチマークを作成できるか?という観点で議論されているように見える。
Why aren't we fine-tuning more?, Nate Meyvis, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Blog #PostTraining #Finetuning Issue Date: 2026-03-30 Comment
元ポスト:
なぜFinetuningは普及していないのか?という点を考察しているブログ。ざっくり言うと、「コストの割に合わない」ということであり、具体的には
- Finetuningをしなくてもprompt engineeringで十分な性能が出てしまい
- Finetuningをしなくても、ドメイン固有のツールを組み合わせることでドメインspecificな挙動が実現できたり
- Finetuningを実施すると、新たなモデルが利用可能になった場合に再度Finetuningを実施するなどのオーバヘッドが生じ割に合わない
といった話が書かれている。個人的にはさらに言うと
- Finetuningを実施することでAI Safety周りの懸念が生じてしまい、Safetyに関する評価を厳密には実施しなければならない(特に何らかのチャットベースの応用の場合はなおさら)
というのもあると感じており、このモデルは安全ですと顧客にどのように説明するのか?という新たな説明責任が生じるという点もあるのかなと思う。
しかし、やはりFinetuningはあまり普及していないんだなあ、感
How Kimi, Cursor, and Chroma Train Agentic Models with RL, PHILSCHMID, 2026.03
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #AIAgents #Blog #read-later #reading #LongHorizon Issue Date: 2026-03-29
Introducing Marin: An Open Lab for Building Foundation Models, marin-community, 2025.05
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Blog #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2026-03-29 Comment
github:
https://github.com/marin-community/marin
issueのExperimentsが興味深い
関連:
- Marin 32B Retrospective, marin-community, 2025.10
Marin projectのアナウンスをメモっていなかったので今更ながらメモ
- open-weight, open-sourceを超えて、LLMのopen-developmentを実現するための完全な透明性を持ったopen lab
- すべての実験はgithub issueで管理され公開される
- marinのコードベースを使い誰でも実験をコード中に記述しpull repuestを送れ、誰でもレビューできる
- プルリクが承認されると実験が実際に実行され、誰でもWandB上の経過をリアルタイムで観察できる
Delphi[^1]の実験において、25Bパラメータモデルがweight decayフェーズに突入し、Marin-32Bでは以前はweight decayフェーズでloss spikeが頻発したが、Delphiでは安定していそうな見込み、という話がポストされている:
[^1]: 現代版のPythiaを構築しましょうという話で、Pythiaのモデルパラメータを70Bまでスケールアップし、学習に用いるトークン数もチンチラ則従いモデルサイズに応じてスケールアップ、The PileデータなどのデータセットをNemotron-CCなどのlarge scaleモデル用のデータセットに置換する、といった話が含まれる。Marin Issue 1337を参照のこと。
129B-A16Bの学習を開始したとのこと:
リアルタイムRLでComposerを改善する, Cursor, 2026.03
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #Coding #SoftwareEngineering #KeyPoint Notes #Realtime Issue Date: 2026-03-28 Comment
実際の推論トークンとユーザの応答を集約して報酬を作成しモデルの改善に使うリアルタイムRLによって5時間ごとにComposerチェックポイントをアップデートしデプロイする。
Reward Hackingを防ぐことはこのようなリアルタイムRLではより一層重要でそのための報酬設計として工夫した点が2つ挙げられている。
- 元々はツール呼び出しが無効だった例を除外するようにして報酬を設計していたが、モデルはこれにより無効なツールを呼び出せば負の報酬を得ないことを学び意図的に無効なツールを呼び出すことを学習した。これを防ぐために、ツール呼び出しに失敗した場合に明確に負の報酬を与えるように変更
- モデルが実施した編集について、自分がコードを編集しなければペナルティを受けないことを学習し、難しい編集については質問をすることで先送りする挙動をRewardHackingの結果学習した。質問については適切なタイミングで実施する必要があるため、報酬を修正した
といった話が書かれている。
現在は比較的短いタスクを実行してユーザからフィードバックを受け取れるが、今後はlong horizonなタスクを実行することが予想され、その場合
- ユーザのフィールドバックの頻度は減り
- 成果物全体に対するフィードバックを返すようになる
という異なる性質のデータを扱わなければならないのでそれに向けて改善を進めるとのこと。
ソフトウェア開発エージェント 初歩から上級, Graham Neubig, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #SoftwareEngineering #read-later Issue Date: 2026-03-26 Comment
全体をざっくり概観してイメージをつかむのに良さそう。詳細を知りたい場合はリンク先を見ると良さげ。
(スライド最後の強化学習における「3」のスケーリングってなんだろう...?)
元ポスト:
Introducing SPEED-Bench: A Unified and Diverse Benchmark for Speculative Decoding, Nvidia, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #LongSequence #Decoding #Diversity #SpeculativeDecoding Issue Date: 2026-03-26 Comment
元ポスト:
Here are the 2025 AI safety papers and posts I like the most, Fabien Roger, LW, 2026.03
Paper/Blog Link My Issue
#Article #Survey #NLP #Safety #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-03-26 Comment
元ポスト:
AI Safetyに関する研究者の方の2025年のAI Safetyハイライトとのこと。
Emergent Misalignmentなど以外にも多くの研究に⭐︎︎︎⭐︎⭐︎が付与されている。気になる。
A Visual Guide to Attention Variants in Modern LLMs, Sebastian Raschka, 2026.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Attention #Blog #read-later Issue Date: 2026-03-26
One interesting dynamic in AI is infra+application co-dependence, Graham Neubig, X, 2026.03
Paper/Blog Link My Issue
#Article #Post Issue Date: 2026-03-26
TurboQuant: Redefining AI efficiency with extreme compression, Google Research, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Blog #Reference Collection #KV Cache #Compression #Initial Impression Notes Issue Date: 2026-03-25 Comment
元ポスト:
kv cacheをlong contextで1/6に圧縮して、8倍スピードアップして、accuracyのlossがない圧縮技術とのこと。果たして
たまたまこの動画を見つけたがおそらくこの研究のことを行っているのだろう:
https://youtube.com/shorts/5LMoZjoprQc?si=C43dJuXqpAa-p4BP
不要な逆量子化処理を省くことで高速化可能らしい:
Vibe physics: The AI grad student, Anthropic, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #ScientificDiscovery #Physics #AI-Human Co-Improvement #Human-in-the-Loop Issue Date: 2026-03-25 Comment
元ポスト:
最大規模のオープン基盤モデルを各国仕様へ適応させる事後学習技術を開発, sakana.ai, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Alignment #Blog #Bias #Japanese #PostTraining #Reading Reflections Issue Date: 2026-03-24 Comment
技術的な詳細は不明で、
> 事後学習では、日本の文化的・社会的文脈におけるバイアス是正のための独自データセットを構築し、以下のベンチマークに示す結果を得ました。
と記述されている。おそらく構築したデータセットに基づいてAlignmentをとるための事後学習(ベースモデルの能力を落としていないため Catastrophic Forgettingは起きておらず、同社がLoRA系の技術に力を入れていることを鑑みるとおそらく何らかのPEFT手法ではないかと推察)を実施しているのだと思われる。
元ポスト:
Continue Pre-training can only work with "actual Base model"., Wenhu Chen, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Post #mid-training Issue Date: 2026-03-22 Comment
こちらのポストに様々な理由が言及されており勉強になる:
Xiaomi MiMo-V2-Pro, Xiaomi, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #Author Thread-Post Issue Date: 2026-03-21 Comment
元ポスト:
THE CONSCIOUSNESS CLUSTER: PREFERENCES OF MODELS THAT CLAIM TO BE CONSCIOUS, Chua+, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Alignment #Safety #read-later #Initial Impression Notes Issue Date: 2026-03-20 Comment
元ポスト:
LLMに意識があるように振る舞うように学習したらどうなるかという話らしい。これによって新たなpreferenceが獲得され、自己保存欲求や反発が発現したり、共感や葛藤などの人間的な感情について話したり、思考過程をモニタリングされることをどう感じますか?といった質問に対して、uncomfortableだと感じる、私は悪い評価を受けたら停止されてしまうの?といった不安について述べたりするなど、これまでにない挙動が見受けられるという感じらしい。
MiroThinker-1.7, MiroMindAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #DeepResearch #LongHorizon #Initial Impression Notes Issue Date: 2026-03-20 Comment
元ポスト:
ベンチマークに応じて、GPT-5, GPT-5.2, GPT-5.4など比較するGPTが恣意的に変わっているように見えるが、ベンチマーク上ではGPT-5と同等以上のAgenticなLLMっぽい?BrowseCompの性能がかなり良さそうに見える。
LLM Architecture Gallery, Sebastian Raschka, 2026.03
Paper/Blog Link My Issue
#Article #Survey #NLP #Transformer #Blog #OpenWeight #Architecture #Initial Impression Notes Issue Date: 2026-03-20 Comment
元ポスト:
Sebastian Raschka氏がいつもポストしているOpenWeight LLMのアーキテクチャ図のギャラリー。パラメータサイズ, head数などの細かい情報も含まれているので、全体を概観するのに良さそう。
Reinforcement Learning from Human Feedback, Nathan Lambert, 2026.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #PostTraining #read-later Issue Date: 2026-03-20 Comment
元ポスト:
Composer 2 のご紹介, Cursor, 2026.03
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #ReinforcementLearning #AIAgents #Evaluation #Coding #SoftwareEngineering #mid-training #PostTraining #read-later #Selected Papers/Blogs #ContextEngineering #Live #Reference Collection #Initial Impression Notes Issue Date: 2026-03-20 Comment
元ポスト:
所見:
Kimi-K2.5がベースらしいとのこと:
ベンチマークスコアに対する所見:
テクニカルレポートが出た:
https://cursor.com/resources/Composer2.pdf
元ポスト:
Kimi-K2.5をベースに、どのようにinstruction tuning後のモデルに対して継続事前学習、RLをし、GPT-5.4(high)級の性能を達成できたのか、ヒントがわかるかもしれない。
- [Paper Note] Kimi K2.5: Visual Agentic Intelligence, Kimi Team+, arXiv'26, 2026.02
所見:
所見:
RLによってpass@k(best-of-16)とpass@1の両方が改善する。既存研究では少なくともRLVRを用いた場合はPass@1は改善するが多様性が損なわれてPass@kの性能は改善しない ([Paper Note] Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR, Xiao Liang+, arXiv'25, 2025.08 , VibeVoice-1.5B, microsoft, 2025.08 )、という話があったが、Composer 2のレシピではそうではないようだ。どんなレシピだろう~と思ってさらっと関連しそうなところを見てみたが、詳細は書いてなさそうだ。
- [Paper Note] Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR, Xiao Liang+, arXiv'25, 2025.08
- VibeVoice-1.5B, microsoft, 2025.08
QA:
CursorBenchの解説:
要はrealisticなデータとシチュエーションでの評価に非常に重きを置いていて
- 実際のコーディングsessionのデータが用いられ、contamination-free
- 機能的な正しさのみならず、コードの品質、効率、挙動などの実用的な価値を意識し
- long horizonなタスクが多く取り入れられ
- Promptは曖昧性をうまく扱えるかを評価するために意図的にシンプルで短く
- CursorBenchのデータは継続的に更新される
- realisticなsessionデータだけでなく、その他の重要な挙動の評価(e.g., 指示追従, ルール/skilltのハンドリング, コメントの品質, editするか否かの判断の適切性など)のためのデータでも拡張されている
という感じらしい
ポイント解説:
- How Kimi, Cursor, and Chroma Train Agentic Models with RL, PHILSCHMID, 2026.03
self-summarizationによるcontextのcompressionを実施している
- [Paper Note] InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning, Yuchen Yan+, arXiv'26, 2026.02
- [Paper Note] Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL, Ian Wu+, arXiv'26, 2026.02
- より長いホライズンに向けた Composer の学習, Cursor, 2026.03
所見:
PLaMo 3.0 Prime β版, PFN, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Blog #Reasoning #Japanese #Selected Papers/Blogs #In-Depth Notes #Surface-level Notes Issue Date: 2026-03-19 Comment
元ポスト:
日本国内初のフルスクラッチReasoningモデル
## 公式発表のまとめ
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
によってcontext windowを64Kまで拡張(PLaMo 2.2 Primeの2倍)。
事後学習データの見直し(新たなオープンデータセット追加, 独自データとして、日本語指示追従能力, tool use, long horizon QA, 医療分野, STEM, RAG性能向上のためのデータ)を実施し、SFT, DPO, RLの流れで学習を実施。SFT, DPOについてはreasoning trajectoryもLossで考慮するように変更。SFT, DPO向けデータについてはreasoning trajectoryを合成したものを利用。
RLは今回初めて導入し学習を安定させるための工夫を取り入れているとのこと。Reference Answerとの比較と表層的な特徴から報酬を計算する関数を実装した、という書かれ方をしている。
gpt-oss-120B(memium)との比較で言うと
指示追従性能が日本語、英語ともによりも高く、医療分野のQA(国家試験を除く)、英語、日本語での対話能力で勝っている。また、法令分野のQAは同等である。
単一ツールや複数ツールからの選択は同等、multi turnの場合はPLaMo2.2から大幅に性能向上しているもののgpt-ossよりも劣る。また、long contextのQA、医療分野の国家試験QA、STEM分野のQAや数学的な推論能力は大幅に前回モデルよりも向上したが、まだgpt-ossなどには届いていない、という感じに見える。
アーキテクチャについては、一新したという話とRoPEベースということ以外はよくわからない。
## 筆者の憶測と感想
※以下、筆者の憶測を多く含んだ感想です。ただ筆者が勝手に想像して自分なりに考えてみているだけです。
DPOにNLL lossを追加することでreasoningを強化できることは下記研究で示されている:
- [Paper Note] Iterative Reasoning Preference Optimization, Richard Yuanzhe Pang+, NeurIPS'24, 2024.04
RLの報酬に関して、表層的な特徴とReference Answerとの比較から最適な報酬を計算とのことなので、おそらく何らかのVerificationのための仕組みと、Rubric-basedなLLM-as-a-Judgeだろうか?Reward Modelという書かれ方はしていない。
RLについては安定性のある手法を採用したとのことだが、DAPO、
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
あるいはRLのスケーリング則を導いた研究でDAPOよりも安定性と最終到達性能において優れていることが示された
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
CISPOあたりだろうか:
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
あとは安定性という観点で言うと、inference/trainingエンジンでのtraining-inference gapの課題についても対処している可能性がある。
- Hot topics in RL, Kimbo, X, 2025.12
- [Paper Note] Beyond Precision: Training-Inference Mismatch is an Optimization Problem and Simple LR Scheduling Fixes It, Yaxiang Zhang+, arXiv'26, 2026.02
思考過程が英語ということは、言語間で能力は転移し、かつ事前学習データとしてはリソースが豊富な英語が多く含まれると想像すると、明示的(strong LLMでtrajectoryを合成したものを加える系の話)あるいはデータに自然と現れるreasoningの挙動から事前学習中にreasoning能力が暗黙的に学習されることを踏まえ、SFTでreasoning能力を強化する際に(日本語よりも英語の方が効果的な可能性が高く)英語でのtrajectoryを合成したという感じだろうか(いつか日本語のreasoning trajectoryを出力するモデルも見てみたいなあ)。
Multi Turnのtool useの性能向上に関して、AI Agent分野のlong horizonな合成データを合成するアプローチや、Sink Tokenの活用や、トークン単位でsink tokenを計算することに相当するHead wise gated attentionなどはしているのだろうか。
- [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- [Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
また、アーキテクチャに関してはcontext windowが海外のフロンティアモデルと比較してまだ小さめであるが、今後context windowを大きくするにあたって、オンポリシーRLでのロールアウト時間がボトルネックとなることが考えられ、Mamba(=linear attention)系のアーキテクチャをハイブリッドや、DSA系のsparse attentionなどの採用によるアーキテクチャ起因の計算コスト低減(現在どのようなアーキテクチャなのかは全くわからないが)、あるいはin-flight-updateのような学習エンジン側での効率化なども必要になるのではなかろうか(現在どういうエンジンなのかは全くわからないが)。
- [Paper Note] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, DeepSeek-AI+, arXiv'25, 2025.12
- [Paper Note] PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence
Generation, Alexandre Piché+, arXiv'25, 2025.09
MiniMax-M2.7, MiniMax, 2026.03
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Selected Papers/Blogs #Reference Collection Issue Date: 2026-03-19 Comment
所見:
所見:
Artificial Analysisによる評価:
GLM-5と同等の知能スコア、GDPvalでGPT-5.2(xhigh)超え。
modelがオープンに:
https://huggingface.co/MiniMaxAI/MiniMax-M2.7
元ポスト:
openになったが商用利用は許可を得ないとできないということで、リリース時のポストにはopennsourcedと銘打たれているが、open sourceではない。
中国系のOpenModelのライセンス、あるいはプロプライエタリ化が進んできている?
所見:
GPT‑5.4 mini と nano が登場, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #Proprietary #VisionLanguageModel Issue Date: 2026-03-18 Comment
元ポスト:
Artificial Analysisによるベンチマーク:
楽天、「GENIACプロジェクト」の一環として開発された国内最大規模の高性能AIモデル「Rakuten AI 3.0」を提供開始, 楽天グループ株式会社, 2026.03
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Japanese #MoE(Mixture-of-Experts) #Initial Impression Notes Issue Date: 2026-03-18 Comment
HF: https://huggingface.co/Rakuten/RakutenAI-3.0
公式アナウンス、HFのモデルカードの情報が少なすぎてよくわからない。
所見:
Mistral Forge: Build your own frontier models, MistralAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #Proprietary #mid-training #PostTraining #Data Issue Date: 2026-03-18 Comment
元ポスト:
エンタープライズ向けの社内の機密データによってLLMの(おそらく継続)事前学習、事後学習、RLを実施したカスタムモデルを構築するソリューションのようである。Dense, MoEなどのアーキテクチャも選択可能な模様。
ベースモデルなどが書かれていないように見えるが、Mistral製のオープンLLMがベースとなるのだろうか。
5 Agent Skill design patterns every ADK developer should know, Google Cloud Tech, X, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Post #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #AgentSkills Issue Date: 2026-03-18 Comment
Agent Skillsの定義の仕方による性能差については下記を参照のこと:
- [Paper Note] SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, Xiangyi Li+, arXiv'26, 2026.02
以下の5つのPatternが紹介されている:
- Tool Wrapper
- Generator
- Reviewer
- Inversion
- Pipeline
最終的にどのようなPatternを採用すべきかの判断となるフローチャートも提供されている。
全体的なポイントとしては、
- 各種SKILLS.mdにはhowを記述し(e.g., 具体的な実行のstepを記述するなど)、
- 実行内容やルールなどの"what"に関する情報は別のドキュメントに移譲し、SKILLS.mdにはそのポインタを記述する、
- ユーザの承認なしで先へ進まないようにするには、ユーザに何らかの質問・承認を求めるよう指示を明示的に記述する
といった作法である。一つの巨大で複雑なSKILLS.mdやsystem promptを作るのではなく、内容をbreak downして記述やドキュメントの構造を設計するのが肝要と感じる。
他の参考文献として
-
# Writing a good CLAUDE.md, Kyle, 2025.11
はAGENTS.mdの話だが、同じような議論がされており、なぜless is moreが重要なのかといった説明も研究動向を踏まえながら説明されている。
Mistral Small 4, MistralAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #MoE(Mixture-of-Experts) #Initial Impression Notes Issue Date: 2026-03-17 Comment
元ポスト:
119Bでsmallと銘打たれる時代になってしまった
公式ポスト:
From REINFORCE to Dr. GRPO, Qingfeng's blog, 2025.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #PostTraining Issue Date: 2026-03-17 Comment
元ポスト:
State of RL for reasoning LLMs, A. Weers, 2026.03
Paper/Blog Link My Issue
#Article #Survey #NLP #ReinforcementLearning #Blog #PostTraining Issue Date: 2026-03-17 Comment
元ポスト:
OpenMAIC, THU-MAIC, 2026.03
Paper/Blog Link My Issue
#Article #Multi #Tools #NLP #Education #AdaptiveLearning #AIAgents #Repository #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-03-17 Comment
マルチエージェントによってスケーラブル、adaptiveにオンライン教育を実現するフレームワークのようである
元ポスト:
L11: Synthetic Data Powering Pretraining, Eric W. Tramel, Ph.D., UC Berkeley EE 290_194-11: Scalable AI, 2026.02
Paper/Blog Link My Issue
#Article #Pretraining #NLP #SyntheticData #read-later #Selected Papers/Blogs #KeyPoint Notes #Reading Reflections Issue Date: 2026-03-17 Comment
元ポスト:
- インターネットのデータ枯渇問題が指摘されながらも、合成データによって事前学習は進化を続けている
- LLMは事後学習で性能を向上させられるが、事前学習時点で伸ばせる上限が決まっているとされている
- 事前学習データの投入量はChinchilla則のパラメータ量の20倍から現在は60倍まで増加
- MoEは過学習しやすくパラメータ数の40倍は必要
- 学習データの多様性が重要で繰り返し同じデータを見ても性能は改善しない
- 合成データをそのまま用いるとmode collapseが生じ出力が単調化するため、実データを混ぜるか言い換えをしたデータで是正する(弱めのdata augmentationで良い)
- 最近重要な合成データはコードと推論過程を含むデータで、これらが事前学習データに含まれていると汎用な表現、思考能力、推論能力を事前学習時点から獲得できる可能性がある
というような話が元ポストに書かれている。
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
のようにrepetitionは4回までが効果的といった知見が報告されているが、現在はどこまで当てはまるのだろうか?
後ほど関連するissueのリンクを貼りたい
うーんおもしろそう、p.15, p.20, p.26, p.28, p.35, p.36 あたりが気になる。
てかこれが大学の講義...?楽しすぎでは。
NOUMENA, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Blog #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-03-15 Comment
元ポスト:
関連:
- Why Training MoEs is So Hard, _xjdr, X Post
おそらく上記ポストの方の作業ログに関するブログと思われる。Canon Layer, mHC, Engramの再現、MoEのエキスパートは異なる学習率が必要なのか?、RDEPと呼ばれるアーキテクチャ(MoEアーキテクチャを採用するとexpertsがしばしば異なるGPUに割り当てられ、routingが特定のexsertsに偏るため特定のGPUがアイドルしてる時間が長くなるため効率が悪いというボトルネックをNVLinkがひもづくネットワーク全体に対してexpertsに対して送信するトークンを収集しパッチを作って送信することで効率を改善する、といったアプローチらしい?)のスループットとメモリ節約効果など、最新の生の知見が数多くまとまっているらしい。
A2UI, google, 2026.03
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #SoftwareEngineering #One-Line Notes #UI Issue Date: 2026-03-15 Comment
元ポスト:
AgentがUIを表現するための標準的なライブラリ群で、agentから応答されるjsonをクライアント側のライブラリでrenderingすることでUIがレンダリング可能というものらしい。
UIはコンポーネントのリストで表現されるためユーザのリクエストに応じてincrementalにUIを変化させる といったことが可能とのこと。
Claude now creates interactive charts, diagrams and visualizations, Claude, 2026.03
Paper/Blog Link My Issue
#Article #NLP #TextToImageGeneration #Proprietary #Reference Collection #Initial Impression Notes #Visualization Issue Date: 2026-03-14 Comment
かなり良いらしい(小並感)
元ポスト:
たとえばMLAとDSAの図解を作らせたら以下:
MuonとAdam(W)の違いの解説を作らせたら以下:
NVIDIA Nemotron 3 Super, NVIDIA, 2026.03
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #SSM (StateSpaceModel) #OpenSource #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #KeyPoint Notes #Reference Collection #Hybrid #LowPrecision #LinearAttention Issue Date: 2026-03-12 Comment
元ポスト:
解説:
artificial analysisによる評価:
Swallow LVM Leaderboardに性能が掲載:
解説:
アーキテクチャ:
- NVFP4で学習して gpt-ossより2.2倍高速だが性能も向上
- 88 Layer: 40 Latent MoE / 40 Mamba-2 / 8 GQA Attention
- GQA Attentiom Layerは非常に少なく、ほとんどがMamba-2 (linear attention)となっている
- Latent MoEは入力をそのまま変換するshared expertsと、入力を1/4のlatent vectorに変換した潜在空間上で処理をするLatext expertsの組み合わせによって出力を得る。
- 具体的には、RouterによってTop-22のexpertsを選択し、inputを1/4のlatent vectorに圧縮した上でExpertsに入力。Expertsの出力を加算して4倍のvectorに変換し次元を戻して、別ルートでshared expertsに元の入力次元から変換されたベクトルと組み合わせて出力するようなアーキテクチャ
Latent MoE解説:
要はMoEに必要なmatrixが、latent vectorを扱うことで小さくなるのでMoEのWeightのメモリロードのボトルネックが緩和されるだけでなく、
各MoE Laverは異なるGPUやマシンに分散されて配置されるため計算のためにはベクトルのバッチを通信しなければならないがそのコストが削減されスループットの向上につながるので嬉しい、ということだと思われる。
ポイント解説:
technical reportが出た:
- [Paper Note] Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning, NVIDIA+, arXiv'26, 2026.04
Using NVFP4 Low-Precision Model Training for Higher Throughput Without Losing Accuracy, NVIDIA, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Blog #read-later #LowPrecision Issue Date: 2026-03-12 Comment
元ポスト:
Bringing Code Review to Claude Code, Anthropic, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #SoftwareEngineering #read-later Issue Date: 2026-03-12 Comment
元ポスト:
コードレビューに特化した機能が追加された模様
Anthropic社内で運用済みで、エンジニアがコードレビューに誤りがあると判断したものは<1%とのこと。
autoresearch, karpathy, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #ScientificDiscovery #Selected Papers/Blogs #One-Line Notes #autoresearch Issue Date: 2026-03-10 Comment
元ポスト:
リポジトリのDiscussionsに、定期的にsession reportがアップロードされるようだ:
https://github.com/karpathy/autoresearch/discussions/43
nanochatは現在、126回の実験を経て、Validation BPBが0.997900 -> 0.969686 まで改善しているとのこと。
pjの目的やテーマは、**研究者がpythonファイルのコードをいじるのではなく、program.mdと呼ばれるAgentにコンテキストとして与えるmarkdownファイルのみの編集を通じて、研究組織(≠単一のPh.D student)をエミュレートできるか?** という点にありそうである。
https://github.com/karpathy/autoresearch/blob/master/program.md
その題材の一つとして、nanochatを簡略化したGPTを用いて、GPTの事前学習の性能を改善させるようなtraining.pyの編集をAI Agentsに実施させ、5分間学習させて成果を報告させるという形式をとっている(と解釈した。)
関連:
- [Paper Note] AlphaEvolve: A coding agent for scientific and algorithmic discovery, Alexander Novikov+, arXiv'25, 2025.06
- [Paper Note] ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution, Robert Tjarko Lange+, arXiv'25, 2025.09
続報:
Effective harnesses for long-running agents, Anthropic, 2025.11
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Initial Impression Notes Issue Date: 2026-03-10 Comment
`Agent Harness` という用語の起源が気になっており、アンテナを張っているが、本ブログでAgent Harnessという用語が登場している。
- [Paper Note] Building Effective AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering, and Lessons Learned, Nghi D. Q. Bui, arXiv'26, 2026.03
において本ブログが引用され `harness` という用語が用いられている。このブログが起源なのだろうか(勉強不足)。
The Synthetic Data Playbook: Generating Trillions of the Finest Tokens, HuggingFace, 2026.03
Paper/Blog Link My Issue
#Article #Pretraining #NLP #SyntheticData #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-03-10 Comment
12.7 GPU yearを使い、90回の実験、1 Trillion tokenの生成を経て見つけた、合成事前学習データの構築方法のbest recipeが紹介されている模様。先行研究を上回る学習効率を達成している。
元ポスト:
Open-Sourcing Sarvam 30B and 105B, sarvam, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2026-03-10 Comment
元ポスト:
The importance of Agent Harness in 2026, PHILSCHMID, 2026.01
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Selected Papers/Blogs #LongHorizon #Reading Reflections #AgentHarness Issue Date: 2026-03-08 Comment
本ブログで定義されているAgent Harnessは、これまでのAI Agent研究で利用されてきた Scaffold(=実行基盤)とEvaluation Harness(=評価基盤)のように、実行と評価を区別してきたLiteratureとは異なる、より包括的な概念に見える(言葉としてHarnessが用いられているので、最初に読んだときは困惑した)。
先行研究:
- [Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
- [Paper Note] Lessons from the Trenches on Reproducible Evaluation of Language Models, Stella Biderman+, arXiv'24, 2024.05
- [Paper Note] Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent
Evaluation, Sayash Kapoor+, arXiv'25, 2025.10
これまでのLiteratureでは、エージェントがタスクを遂行するためのエコシステム全般(言い換えるとLLMをエージェントの脳とした時の、エージェントの実装そのもの)のことをScaffold(ツール利用やコンテキスト管理、サブエージェントの実行、エラー時の挙動、プロンプト構成など)と呼び、
評価をする際の評価基盤となるインフラ(エージェントを動作させる仮想マシン等の実行環境やそのオーケストレーション、Scaffoldの構成、評価ベンチマーク、コストやtrajectoryのロギング等の評価全体に関わるエコシステム)のことをEvaluation Harnessと呼んできたと認識している。
(私の認識違いの可能性もあるが)このLiteratureを理解しておかないと、今後Harnessという言葉がバズワードと化して、思わぬ誤解を生むかもしれないので注意した方が良いかなと感じた。
つまり世の中には
- Scaffold
- Evaluation Harness
- Agent Harness
の3種類の定義があり、特に後者二つは省略してHarnessと呼ばれそう、という気がするが、後者二つは呼称が似ているが異なる概念を指しているので注意した方が良いかも(あくまで個人の感想)。
たとえば下記OpenAIのブログでも「Harness Engineering」という言葉がタイトルで用いられており、Harnessの定義がなされずに記述されているように見える。実際ブログ後半にはEvaluation HarnessというこれまでのLiteratureと同じ意味合いでの用語も登場している。今後どのような用語が何を指すのようになるかは分からないが、ハーネスという言葉の定義が人によって異なる可能性があるという点は認識しておいた方が良さそうである。
- Harness engineering: leveraging Codex in an agent-first world, Ryan Lopopolo, 2026.02
`Agent Harness` という用語の起源が気になっており、アンテナを張っているが、下記AnthropicブログでAgent Harnessという用語が登場している。
- Effective harnesses for long-running agents, Anthropic, 2025.11
下記文献でも
- [Paper Note] Building Effective AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering, and Lessons Learned, Nghi D. Q. Bui, arXiv'26, 2026.03
Effective harnesses for long-running agents, Anthropic, 2025.11
が引用され `harness` という用語が用いられている。このブログが起源なのだろうか(勉強不足)。
- [Paper Note] SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, Xiangyi Li+, arXiv'26, 2026.02
でも Agent Harness という用語が使われている。
Codex Security: now in research preview, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Security Issue Date: 2026-03-07 Comment
元ポスト:
Chinese Open Source: A Definitive History, Kevin Xu, 2026.03
Paper/Blog Link My Issue
#Article #Survey #NLP #Blog #OpenWeight #read-later Issue Date: 2026-03-07
ガバメントAIで試用する国内大規模言語モデル(LLM)の公募結果, デジタル庁, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Blog #Japanese #One-Line Notes Issue Date: 2026-03-06 Comment
元ポスト:
以下が選出されたとのこと:
- 株式会社NTTデータ「tsuzumi 2」
- カスタマークラウド株式会社「CC Gov-LLM」
- KDDI株式会社・株式会社ELYZA共同応募体「Llama-3.1-ELYZA-JP-70B」
- ソフトバンク株式会社「Sarashina2 mini」
- 日本電気株式会社「cotomi v3」
- 富士通株式会社「Takane 32B」
- 株式会社Preferred Networks「PLaMo 2.0 Prime」
Google Workspace CLI, Google, 2026.03
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #Repository #ContextEngineering #One-Line Notes #AgentSkills Issue Date: 2026-03-06 Comment
元ポスト:
google workspaceにone-lineのコマンドでアクセス可能なCLIツールとのこと。40以上のAgentSkillsを内包。
Practical Guide to Evaluating and Testing Agent Skills, PHILSCHMID, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Coding #SoftwareEngineering #read-later #AgentSkills Issue Date: 2026-03-06 Comment
元ポスト:
関連:
- How to Create Effective Agent Skills, openhands, 2026.02
Reasoning models struggle to control their chains of thought, and that’s good, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #Controllable #NLP #Dataset #Chain-of-Thought #Evaluation #Blog #Reasoning #read-later #Author Thread-Post Issue Date: 2026-03-06 Comment
元ポスト:
著者ポスト:
Introducing GPT‑5.4, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #ChatGPT #Coding #Proprietary #VisionLanguageModel #Reference Collection #Reading Reflections Issue Date: 2026-03-06 Comment
元ポスト:
Artiflcial Analysisによる評価:
所見:
所見:
評判が良い。管理人も利用しているが、指示で曖昧な点をきちんと質問してくれる点が便利。かつ応答として、選択可能なオプションを提示し、自由記述もできる。実装の内容はClaude 4.6 Opusと比べるとコードがシンプルな印象を受けるが、これも指示次第な気はする。
曖昧な点があったら質問を投げかけるという挙動はopenhandsのPosition Paperとも整合する流れである。
- [Paper Note] Position: Humans are Missing from AI Coding Agent Research, Wang+, 2026.02
Introducing Olmo Hybrid: Combining transformers and linear RNNs for superior scaling, Ai2, 2026.03
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Attention #OpenWeight #mid-training #read-later #Selected Papers/Blogs #One-Line Notes #RecurrentModels #Hybrid #LinearAttention Issue Date: 2026-03-06 Comment
元ポスト:
x1のFull Attention + x3のGated DeltaNetによるハイブリッドアーキテクチャで、75%のattentionをlinear attention (recurrent module)に置換。x3のSliding Window Attentionを用いているOlmo3と比較した結果
- 事前学習におけるデータ効率がより高く(約2倍)
- mid-training後の評価では、数学、コード、STEM, non-STEM, QA、long-contextなどの主要なドメインにおいてOlmo3と同と床それ以上の性能を達成。特に、long-contextにおけるベンチマでは大幅な性能向上(Recurrentなアーキテクチャの恩恵)
関連:
- [Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
元ポスト:
関連:
所見:
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling, together.ai, 2026.03
Paper/Blog Link My Issue
#Article #NLP #Library #Transformer #Attention #Chip #read-later #Selected Papers/Blogs #GPUKernel #Initial Impression Notes Issue Date: 2026-03-06 Comment
元ポスト:
関連:
これは読まねば。。。
AReaL: A Large-Scale Asynchronous Reinforcement Learning System, inclusionAI, 2026.03
Paper/Blog Link My Issue
#Article #Tools #NLP #ReinforcementLearning #Repository #Reasoning #OpenSource #read-later #Asynchronous Issue Date: 2026-03-05 Comment
元ポスト:
PPO → DPO → GRPO→ Rubrics, PROF. TOM YEH, 2026.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #Video #PostTraining #Non-VerifiableRewards #One-Line Notes #Rubric-based Issue Date: 2026-03-05 Comment
Cameron R. Wolfe氏によるRubic-basedなRL(主にnon-verifiableなドメインへの適用)のチュートリアル。序盤はPPO, DPO, GRPOに関する解説
元ポスト:
GPT‑5.3 Instant:よりスムーズで、日常会話にもっと役立つ, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #Blog #Proprietary #VisionLanguageModel Issue Date: 2026-03-04 Comment
元ポスト:
なんだかなあ
Gemini 3.1 Flash-Lite: Built for intelligence at scale, Google, 2026.03
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Proprietary #VisionLanguageModel Issue Date: 2026-03-04 Comment
元ポスト:
How to Create Effective Agent Skills, openhands, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #read-later #AgentSkills Issue Date: 2026-03-03 Comment
元ポスト:
New ARENA material: 8 exercise sets on alignment science & interpretability, CallumMcDougall, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Alignment #Blog #Safety #read-later #Selected Papers/Blogs Issue Date: 2026-03-03 Comment
元ポスト:
Qwen 3.5 small series, Qwen Team, 2026.02
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-03-02 Comment
なんとSLMもリリース
元ポスト:
agent-vault, botiverse, 2026.02
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #Repository #Privacy Issue Date: 2026-03-02
TAKT, nrslib, 2026.01
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #Repository #Coding #SoftwareEngineering Issue Date: 2026-03-01 Comment
色々使ってみたいなぁ(小並感)
元ポスト:
FP8 trainingを支える技術 1, Kazuki Fujii, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #Blog #mid-training #PostTraining #Selected Papers/Blogs #LowPrecision Issue Date: 2026-03-01
The Open Anonymity Project, The Open Anonymity Project, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Proprietary #read-later #Privacy Issue Date: 2026-02-28 Comment
元ポスト:
Coding agents progress over the past two months, Andrej Karpathy, X, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Post #SoftwareEngineering #Reading Reflections Issue Date: 2026-02-28 Comment
やっぱ英語で指示ださないとあかんか...(小並感)
関連:
LLM/VLA等の学習ライブラリ回りでは、人間が細かく実装方針分析を指示した上で、実装部分のみを移譲すると今のところ一番うまくいくとのこと。
CoderForge-Preview: SOTA open dataset for training efficient coding agents, together.ai, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Dataset #Supervised-FineTuning (SFT) #AIAgents #Blog #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs Issue Date: 2026-02-28 Comment
元ポスト:
The third era of AI software development, Michael Turuell, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Post #SoftwareEngineering #read-later Issue Date: 2026-02-28
10 open-weight LLM releases in January and February 2026, Sebaschan Raschka, 2026.02
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Post #read-later #Selected Papers/Blogs Issue Date: 2026-02-28 Comment
- Trinity Large, Arcee, 2026.01
- [Paper Note] Kimi K2.5: Visual Agentic Intelligence, Kimi Team+, arXiv'26, 2026.02
- [Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
- Qwen3-Coder-Next: Pushing Small Hybrid Models on Agentic Coding, QwenTeam, 2026.02
- [Paper Note] GLM-5: from Vibe Coding to Agentic Engineering, GLM-5 Team+, arXiv'26, 2026.02
- MiniMax M2.5: SOTA in Coding and Agent, designed for Agent Universe, MiniMax, 2026.02
- [Paper Note] Nanbeige4.1-3B: A Small General Model that Reasons, Aligns, and Acts, Chen Yang+, arXiv'26, 2026.02
- Qwen3.5: Towards Native Multimodal Agents, Qwen Team, 2026.02
- Ling-2.5-1T, inclusionAI, 2026.02
- Ring-1T-2.5-FP8, inclusionAI, 2026.02
- Cohere Labs Launches Tiny Aya, Making Multilingual AI Accessible, COHERE LABS TEAM, 2026.02
元ポストには書かれていないがLLMというくくりで言うと以下もある:
- New ARENA material: 8 exercise sets on alignment science & interpretability, CallumMcDougall, 2026.02
- LFM2-24B-A2B: Scaling Up the LFM2 Architecture, LiquidAI, 2026.02
- Qwen3 Swallow, Swallow LLM, 2026.02
- Japanese
- GPT-OSS Swallow, Swallow LLM, 2026.02
- Japanese
- GLM-4.7-Flash, Z.ai, 2026.01
- LongCat-Flash-Thinking-2601, Meituan, 2026.01
- Introducing LFM2.5: The Next Generation of On-Device AI, LiquidAI, 2026.01
Omniモデルを含めると以下:
- Ming-omni-tts-0.5B, inclusionAI, 2026.02
- [Paper Note] Features as Rewards: Scalable Supervision for Open-Ended Tasks via Interpretability, Aaditya Vikram Prasad+, arXiv'26, 2026.02
- MiniCPM-o-4_5, OpenBMB, 2026.02
World Modelsを含めると以下?:
- [Paper Note] Causal-JEPA: Learning World Models through Object-Level Latent Interventions, Heejeong Nam+, arXiv'26, 2026.02
- [Paper Note] Code2World: A GUI World Model via Renderable Code Generation, Yuhao Zheng+, arXiv'26, 2026.02
- [Paper Note] DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos, Shenyuan Gao+, arXiv'26, 2026.02
- [Paper Note] World Action Models are Zero-shot Policies, Seonghyeon Ye+, arXiv'26, 2026.02
- [Paper Note] Advancing Open-source World Models, Robbyant Team+, arXiv'26, 2026.01
- Project Genie: Experimenting with infinite, interactive worlds, Google Deepmind, 2026.01
- Waypoint-1: Real-time Interactive Video Diffusion from Overworld, Overworld, 2026.01
確実に見落としがあるけど。
Training Recipes, PRIME Intellect Lab, 2026.02
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #ExperimentManagement #PostTraining #read-later #One-Line Notes Issue Date: 2026-02-28 Comment
公式によるPrime Intellect Labを用いたRLによるレシピの模様。これ読んだらだいたい実験できるようになるんではなかろうか。
元ポスト:
prime-lab-trainer, abideenml, 2026.02
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #AIAgents #Repository #ExperimentManagement #SoftwareEngineering #AgentSkills Issue Date: 2026-02-28 Comment
- Introducing Lab: The Full-Stack Platform for Training your Own Models, Prime Intellect, 2026.02
に対して任意のHF Datasetを用いて自動的にRLによるモデルの学習をsubmit可能なClaude Code skillとのこと。
元ポスト:
Qwen3.5 Medium Model Series, Qwen Team, 2026.02
Paper/Blog Link My Issue
#Article #NLP #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-02-28 Comment
元ポスト:
いずれのモデルもベンチマーク上はGPT-5 miniと同等以上の性能に見える。
また、Qwen3.5-35B-A3BはQwen3-235B-A22B-2507やQwen3-VL235B-A22Bを上回っており、アーキテクチャ、データの品質、RLによって実現されているとのこと。
27BモデルのHLEのスコアが非常に高いと話題:
FP8版もリリース:
日本語の医師国家試験(2026)において35B-A3Bが非常に高いスコアを記録:
Artificial Analysisによるベンチマーキング:
New in Claude Code: Remote Control, Anthropic, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Post #SoftwareEngineering Issue Date: 2026-02-27 Comment
スマホからターミナルのClaude Codeに対してリモートで制御が可能になったらしい
Introducing Mercury 2, inception, 2026.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #DiffusionModel #Blog #Reasoning #Proprietary #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-02-27 Comment
元ポスト:
1092 token/secのproprietary (reasoning) dLLM
関連:
- [Paper Note] Mercury: Ultra-Fast Language Models Based on Diffusion, Inception Labs+, arXiv'25
Artificial Analysisのベンチマーキング結果とスループットの散布図:
スループット/性能比において明らかに抜きんでている。
LFM2-24B-A2B: Scaling Up the LFM2 Architecture, LiquidAI, 2026.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #SmallModel #OpenWeight #MoE(Mixture-of-Experts) #Initial Impression Notes #EdgeDevices Issue Date: 2026-02-27 Comment
元ポスト:
edge deviceにデプロイできる規模でLFM2をスケールさせた模様
How much does distillation really matter for Chinese LLMs?, Interconnects, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Distillation #read-later Issue Date: 2026-02-27 Comment
関連:
- Detecting and preventing distillation attacks, Anthropic, 2026.02
Swallowにおける 日英推論型大規模言語モデルの構築, 水木栄, 第26回LLM勉強会, 2026.02
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #Supervised-FineTuning (SFT) #ReinforcementLearning #Japanese #mid-training #PostTraining #Selected Papers/Blogs #DataMixture #Initial Impression Notes Issue Date: 2026-02-27 Comment
元ポスト:
関連:
- Qwen3-Swallow & GPT-OSS-Swallow, Kazuki Fujii, 2026.02
まだしっかり読めていないのだが、適切なDataMixtureはどのようにして決めているのだろうか?
- 数学データによる学習がコーディングにのみ転移
- 英語データを邦訳したデータが学習に寄与するためcross-lingualで能力が転移する
- RLはpass@1を改善するが、Pass@10などの改善幅は縮小する
- この辺の話は資料中でも先行研究が引用されており、実際に確認されたということだと思われる
...
[Paper Note] Preconditioned inexact stochastic ADMM for deep models, Nature Machine Intelligence 2026, 2026.02
Paper/Blog Link My Issue
#Article #NeuralNetwork #ComputerVision #MachineLearning #NLP #Optimizer #Initial Impression Notes #Nature Machine Intelligence Issue Date: 2026-02-24 Comment
元ポスト:
パラメータサイズが大きい場合にMuon超え...?
所見:
Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Blog #Coding #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Contamination Issue Date: 2026-02-24 Comment
元ポスト:
SWE-Bench Verifiedはpublicなリポジトリに基づいたベンチマークなのでcontaminationが生じやすく、実際にいくつかのモデルでcontaminationが確認されたと言う話と、testコードに本来は正しい実装でもfailedとなる許容するスコープが狭いテストが存在していた、という話で、これらの教訓を生かしたSWE-Bench Proを作成し、実際それはcontaminationがほとんど起きておらず、仮に起きていたとしても非常にマイナーなものだよ、というような話が書かれている。
Detecting and preventing distillation attacks, Anthropic, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Blog #OpenWeight #Proprietary #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-02-24 Comment
元ポスト:
DeepSeek, Moonshot AI, MiniMax がDistillationを用いてClaude出力からモデルを改善するためのattackを特定したというAnthropicからのアナウンス
所見:
- [Paper Note] Extracting books from production language models, Ahmed Ahmed+, arXiv'26, 2026.01
で提案されている手法を用いてClaude Sonnetからハリーポッターと賢者の石の95.8%を抽出できた、との報告もある。
GPT-OSS Swallow, Swallow LLM, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #Japanese Issue Date: 2026-02-21 Comment
元ポスト:
第120回医師国家試験(2026)を解かせてみた結果:
Qwen3 Swallow, Swallow LLM, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #Japanese #MoE(Mixture-of-Experts) Issue Date: 2026-02-21 Comment
元ポスト:
Qwen3-Swallow & GPT-OSS-Swallow, Kazuki Fujii, 2026.02
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Japanese #mid-training #PostTraining #read-later #RLVR #Selected Papers/Blogs Issue Date: 2026-02-21 Comment
元ポスト:
関連:
- [Paper Note] Accelerating Large Language Model Training with 4D Parallelism and Memory Consumption Estimator, Kazuki Fujii+, arXiv'24, 2024.11
- FP8 trainingを支える技術 1, Kazuki Fujii, 2026.02
Gemini 3.1 Pro: A smarter model for your most complex tasks, Google, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Reference Collection Issue Date: 2026-02-20 Comment
元ポスト:
Artificial Analysisによる評価:
所見:
ベンチマークほどの性能は実用上は感じられず、API利用などにおいては安定性に課題があるとのこと。
ALE BenchでSoTA:
- [Paper Note] ALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering, Yuki Imajuku+, NeurIPS'25
Introducing Claude Sonnet 4.6, Anthropic, 2026.02
Paper/Blog Link My Issue
#Article #Blog #Proprietary #read-later #VisionLanguageModel Issue Date: 2026-02-18 Comment
もうSonnetが出てきた
元ポスト:
所見:
Cohere Labs Launches Tiny Aya, Making Multilingual AI Accessible, COHERE LABS TEAM, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Blog #SmallModel #MultiLingual #OpenWeight #Selected Papers/Blogs #LowResource #KeyPoint Notes #Reference Collection Issue Date: 2026-02-18 Comment
元ポスト:
公式ポスト:
アーキテクチャ解説:
70程度の言語の性能をバランス良くサポートする3.35BのLLMで、Baseモデルと、マルチリンガルの性能は保ちつつも特定のregionに特化したinstruction tuningを実施したvariantを公開。また、multilingualでのベンチマークも公開。同程度の規模間のモデルについて、qwen3-4Bとの比較がわかりやすく、Europe, south asiaは同等、Asia-pacificはQwenよりも劣り、west asia, africa regionのようなこれまでlow resourceだと思われたregionではほか同規模のモデルと比較して突出した性能を誇るモデルに見える。CC上でのページ数と、言語モデルごとの性能を比較したグラフもあり、CCでのデータが少ない言語はこれまでのモデルは性能が低かったが、Tiny Ayaは非常に高い性能を達成している(このグラフで言うと日本語はかなりinformation richな言語にカテゴライズされているように見える)。
SWE-fficiency: Evaluating How to Fix Code, Not Just What to Fix, OpenHands, 2026.02
Paper/Blog Link My Issue
#Article #Metrics #NLP #AIAgents #Evaluation #Coding #SoftwareEngineering #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-02-17 Comment
元ポスト:
既存のAI Agentsのベンチマークは、バグを修正することに特化しており(what to fix)、機能的には正しいが高速化が必要といった効率性や最適化の観点(how to fix)が評価から抜けているので、そのためにSpeedup Ratioと呼ばれる人間の専門家に対してどの程度の高速化を達成できたかを測るmetricとそのためのベンチマークSWE-ffiencyを構築。SWE-fficiencyはnumpy, pandas, sklearnなどの9つの主要なリポジトリにおける498のタスクで構成される。評価の結果、Claude Opus 4.5をOpenhandsのハーネスで駆動させだ場合でも人間のエキスパートに対して0.225倍程度の高速化しか実現できないことがわかった、といった話な模様。
IA Agents Minimal agent framework for the Gemini Interactions API, philschmid, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #read-later #MinimalCode #Initial Impression Notes Issue Date: 2026-02-17 Comment
元ポスト:
Gemini Interactions APIを用いたエージェントのminimal code。これは非常に勉強になりそう。
Rubric-Based Rewards for RL Extending the benefits of large-scale RL training to non-verifiable domains..., Cameron R. Wolfe, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #PostTraining #read-later #VerifiableRewards #Selected Papers/Blogs #Non-VerifiableRewards #Rubric-based Issue Date: 2026-02-17 Comment
元ポスト:
Beyond MuP: 2. Linear Layers and Steepest Descent, Scientific Spaces, 2026.02
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Blog #Optimizer #Stability Issue Date: 2026-02-16 Comment
元ポスト:
Ling-2.5-1T, inclusionAI, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-02-16 Comment
Ringに続いてLingもリリース
関連:
- Ring-1T-2.5-FP8, inclusionAI, 2026.02
元ポスト:
AI 101: "On-Policy Distillation Zeitgeist", Turing Post, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #PostTraining #On-Policy #One-Line Notes #SelfDistillation Issue Date: 2026-02-16 Comment
元ポスト:
最近よくみかける on-policy self-distillationに関する解説
QED-Nano: Teaching a Tiny Model to Prove Hard Theorems, LM Provers Team, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Blog #Mathematics #SmallModel #PostTraining #Proofs #Rubric-based #Initial Impression Notes Issue Date: 2026-02-16 Comment
元ポスト:
ポイント解説:
早くもReasoning Cacheが利用されている:
- [Paper Note] Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL, Ian Wu+, arXiv'26, 2026.02
4B級のモデルで特定タスクに特化したモデルを作りたい場合に非常に役立ちそうなレシピ
Building Olmo in the Era of Agents, Nathan Lambert, LTI Colloquim, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #Survey #NLP #AIAgents #Reasoning #Slide #OpenSource #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-02-16 Comment
元ポスト:
うーんこれは時間をとってしっかり読んで色々まとめたい・・・
[Paper Notes] Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity, Bytedance Seed, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AIAgents #Reasoning #Proprietary #VisionLanguageModel Issue Date: 2026-02-16 Comment
元ポスト:
所見:
GPT‑5.2 derives a new result in theoretical physics, OpenAI, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #ScientificDiscovery #Physics #Human-in-the-Loop Issue Date: 2026-02-14 Comment
元ポスト:
Introducing GPT‑5.3‑Codex‑Spark: An ultra-fast model for real-time coding in Codex, OpenAI, 2026.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #AIAgents #Blog #Coding #SoftwareEngineering Issue Date: 2026-02-13 Comment
元ポスト:
所見:
Gemini 3 Deep Think: Advancing science, research and engineering, Google, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Reasoning #Mathematics #Proprietary #SoftwareEngineering #VisionLanguageModel #Science Issue Date: 2026-02-13 Comment
まずはUltra Subscriberに公開し、その後徐々にAPIアクセスを解禁していくとのこと。
LiveCodeBench:
MiniMax M2.5: SOTA in Coding and Agent, designed for Agent Universe, MiniMax, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Coding #OpenWeight #SoftwareEngineering #Selected Papers/Blogs Issue Date: 2026-02-13 Comment
元ポスト:
OsenHands IndexでClaude Sonnet 4.5超えの初めてのOpenWeightモデル:
コストパフォーマンスにおいては、低コストなモデル群の中では抜きん出た性能
まだHF上にWeightは公開されていないようだが後ほど公開されると思われる。
所見:
weightが公開:
https://huggingface.co/MiniMaxAI/MiniMax-M2.5
元ポスト:
UnslothがGGUF版を公開:
A2A: The Agent2Agent Protocol, DeepLearning.AI, 2026.02
Paper/Blog Link My Issue
#Article #Multi #Tutorial #NLP #AIAgents #Video #SoftwareEngineering #A2A Issue Date: 2026-02-13 Comment
元ポスト:
元ポスト:
Ring-1T-2.5-FP8, inclusionAI, 2026.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #AIAgents #Attention #Reasoning #LongSequence #OpenWeight #LongHorizon #LinearAttention Issue Date: 2026-02-12 Comment
元ポスト:
関連:
- Ring-1T, inclusionAI, 2025.10
MLA + lightning linear attentionのハイブリッド
- MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
- [Paper Note] Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention, Zhen Qin+, ICML'24, 2024.05
Harness engineering: leveraging Codex in an agent-first world, Ryan Lopopolo, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #GenerativeAI #Blog #Coding #SoftwareEngineering #One-Line Notes Issue Date: 2026-02-12 Comment
OpenAI社内でのコードを1行も人間が書かないで製品をリリースする取り組みに関する詳細なレポートのようである。初期の設計などで想像以上に時間がかかってしまった点(これはCodexの能力の問題ではない)や、実装を続ける中で品質に責任を持つ人間の能力(というより時間)がボトルネックになっていったため、極力Codexが自律的に品質管理ができるような実行・検証環境を用意することで負担を低減した話や、Codexに膨大なマニュアルを読ませて処理をさせるのではなく、どこにどのような情報が格納されているのかといったマップ(目次)を与えることがコンテキストエンジニアリング上重要だったことなどを通じてエージェントにとってリポジトリ全体の可読性を高めることが重要だったといった話や、プロジェクトの期間が長引くにつれて、リポジトリ内に共有されていないcontextが増大していき、それらをリポジトリに統合する作業が生じるなどの課題も生じたといったような話など色々と書かれている。
microgpt.py, Andrej Karpathy, 2026.02
Paper/Blog Link My Issue
#Article #NLP #python #Selected Papers/Blogs #MinimalCode Issue Date: 2026-02-12 Comment
元ポスト:
[Paper Note] Accelerating Mathematical and Scientific Discovery with Gemini Deep Think, Google DeepMin, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Mathematics #ScientificDiscovery #Test-Time Scaling #read-later #KeyPoint Notes #Physics #Human-in-the-Loop Issue Date: 2026-02-12 Comment
元ポスト:
- 数学について
- verifierを通じて解の修正と再生成を繰り返すが、問題が解けないことを認めることで(無駄な修正・再生成を減らすことで)効率を大幅に改善
- 博士課程レベル・オリンピックレベルを超えてもtest-time scalingが継続する
- 検索を融合することで既存文献を取り入れ正確性向上
- 完全自動で出版できるレベルの研究を実施可能なところまできている(level0--5のlevel2)
- コンピュータサイエンス・物理学について
- ネットワーク側で広範な解空間を探索してlong-trailな解も捉え推論に組み込むことが可能で、自動的なverificationと人間によるverificationを通じてoutputを生成する
- たとえば10年間未解決だったオンライン列モジュラ最適化と呼ばれる問題や、モデル学習時のノイズ除去による理論的な証明などを実施できている
論文:
- [Paper Note] Towards Autonomous Mathematics Research, Tony Feng+, arXiv'26, 2026.02
[Paper Note] Position: Humans are Missing from AI Coding Agent Research, Wang+, 2026.02
Paper/Blog Link My Issue
#Article #NLP #UserBased #AIAgents #Coding #read-later #Selected Papers/Blogs #interactive #One-Line Notes #Initial Impression Notes Issue Date: 2026-02-12 Comment
# Authors
Zora Zhiruo Wang, John Yang, Kilian Lieret, Alexa Tartaglini, Valerie Chen, Yuxiang Wei,
Zijian Wang, Lingming Zhang, Karthik Narasimhan, Ludwig Schmidt, Graham Neubig, Daniel Fried, Diyi Yang
元ポスト:
現在のコーディングエージェントは自動的にタスクを完了させ、難易度の高いベンチマークを解けることが実用的な価値とみなされているが、今後より実用的な価値を高めプロダクト化するためには単独でタスクをこなすのではなく、人間開発者やユーザとの相互作用をするような枠組みが次のブレイクスルーとなりうるというposition。非常に共感できる。
GLM-5: From Vibe Coding to Agentic Engineering, Z.ai, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #KeyPoint Notes #Reference Collection #LongHorizon #SparseAttention Issue Date: 2026-02-12 Comment
関連:
- GLM-4.7: Advancing the Coding Capability, Z.ai, 2025.12
GLMシリーズの最新モデルGLM-5がリリースされた
元ポスト:
- DeepSeek Sparse Attentionを採用:
- DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention, DeepSeek-AI, 2025.09
- [Paper Note] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, DeepSeek-AI+, arXiv'25, 2025.12
- 事前学習データを23Tから28.5Tトークンへ
- パラメータ数は4.5の355B-A32から744B-A40Bへ
- RLのインフラとして4.5から引き続きSlimeを採用
- slime, THUDM & Zhihu, 2025.09
- long-horizonなタスクに秀でており、reasoning, coding, agenticタスクにおける各種ベンチマークでOpus 4.5, GPT-5.2, Gemini 3 Proと同等程度の性能
FP8版も公開されている模様(Hopper以後のアーキテクチャでないとサポートされていない点に注意
所見:
元ポスト:
unslothがGGUF版をすでにリリースしている模様。早い:
https://unsloth.ai/docs/models/glm-5
アーキテクチャ解説:
アーキテクチャ解説:
所見:
ENGRAM, EvolvingLMMs-Lab, 2026.02
Paper/Blog Link My Issue
#Article #Tools #NLP #AIAgents #Privacy #MCP #memory #One-Line Notes Issue Date: 2026-02-12 Comment
元ポスト:
MCPに対応しているAI Agentであれば互換性がある暗号化されたストレージの実装なようで、サードパーティのストレージにデータを預けなくてもローカルのストレージでLLMに対して知識を提供可能な模様。
最近DeepSeekが提案したEngramとは異なるので注意:
- [Paper Note] Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models, Xin Cheng+, arXiv'26, 2026.01
Introducing Lab: The Full-Stack Platform for Training your Own Models, Prime Intellect, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #MachineLearning #NLP #Infrastructure #ReinforcementLearning #AIAgents #Blog #ScientificDiscovery #PostTraining #Selected Papers/Blogs #One-Line Notes #Reference Collection #Environment Issue Date: 2026-02-11 Comment
元ポスト:
事後学習、特にAgenticな研究の民主化のためのプラットフォームの提供
所見:
利用例 (Environment Hub):
Sabotage Risk Report: Claude Opus 4.6, Anthropic, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #Safety #read-later #Sabotage Issue Date: 2026-02-11 Comment
元ポスト:
[Paper Note] OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis, Li+, 2026.02
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #Search #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #OpenSource #Selected Papers/Blogs #Reproducibility #DeepResearch #One-Line Notes #LongHorizon #Initial Impression Notes #Environment Issue Date: 2026-02-10 Comment
元ポスト:
APIに依存せずオフラインコーパスと検索を利用し、高品質なDeepResearchのlong horizonなtrajectoryを合成可能な環境を構築。合成したtrajectoryでNemotron-3-nano-30B-A3B-BaseをSFTすることで、Kimi-K2, GLM-4.6などの10倍以上大きいサイズのモデルよりもBrowseCompで高い性能を獲得。同サイズのTongyiDeepResearchもoutperform。
Deterministicなプロセスで、オフラインコーパスからデータを合成し外部APIに依存しないため完全に再現性があり、かつAPIのコストやrate limitにも引っかからないという利点がある。検索エンジン、コード、データ、合成データ、モデル、全てを公開。
完全に再現性のある研究は素晴らしい。
Opus 4.6, Codex 5.3, and the post-benchmark era, Interconnects, 2026.02
Paper/Blog Link My Issue
#Article #Analysis #AIAgents #Blog #Coding #SoftwareEngineering #One-Line Notes #Author Thread-Post Issue Date: 2026-02-10 Comment
有識者によるClaude 4.6 Opus と Codex 5.3 を利用した際の所見(定性評価)が記述されている。
元ポスト:
著者によるTLDR:
Context-Bench: A benchmark for agentic context engineering, Letta Research, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Blog #ContextEngineering Issue Date: 2026-02-09 Comment
元ポスト:
Knowledge Editing for LLMs Papers, zjunlp, 2024.07
Paper/Blog Link My Issue
#Article #Survey #NLP #KnowledgeEditing Issue Date: 2026-02-08
Building a C compiler with a team of parallel Claudes, Anthropic, 2026.02
Paper/Blog Link My Issue
#Article #Multi #AIAgents #Blog #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs Issue Date: 2026-02-06 Comment
元ポスト:
Introducing GPT-5.3-Codex: Expanding Codex across the full spectrum of professional work on a computer, OpenAI, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Proprietary #SoftwareEngineering #Selected Papers/Blogs #Reference Collection Issue Date: 2026-02-06 Comment
元ポスト:
terminal bench 2.0でOpus 4.6超え:
所見:
Advancing finance with Claude Opus 4.6, Anthropic, 2026.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Financial #Proprietary #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2026-02-06 Comment
元ポスト:
全体的に能力が向上しているが、ターミナルでのコーディング、BrowseComp(Agentic search), HLE, Financial Analysis, GDPValにおけるOffice Task, Novel Problem Solvingの能力が大きく向上しているように見える。
Context Windowが1Mとのことで素晴らしい
OpenHands Indexでトップとのことだが、Codex 5.3との比較はまだの模様:
50% time horizonが脅威の14.5時間:
MiniCPM-o-4_5, OpenBMB, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #SpeechProcessing #DiffusionModel #OpenWeight #AutomaticSpeechRecognition(ASR) #VisionLanguageModel #TTS #Omni #AudioLanguageModel Issue Date: 2026-02-05 Comment
元ポスト:
The Second Pre-training Paradigm, Jim Fan, X, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #Pretraining #NLP #MultiModal #Post #Robotics #WorldModels #One-Line Notes Issue Date: 2026-02-05 Comment
事前学習がnext word predictionから過去の行動と状態によって条件付けられ次の(ある期間の)世界の状態を予測するワールドモデリング(next physical state prediction)へのパラダイムシフトの予想(というよりこのパラダイムシフトの真っ只中にいる)。人間の脳が処理する情報の多くは視覚であり、言語的な領域は部分的なことであることや、猿は言語的な能力が低くても視覚や運動、触覚などの感覚的情報から世界の物理法則を理解し知的なアクションをとるメンタルモデルを確立していることなどを引き合いに説明している。
Time Horizon 1.1, METR, 2026.01
Paper/Blog Link My Issue
#Article #Metrics #NLP #AIAgents #Evaluation #Scaling Laws #Selected Papers/Blogs Issue Date: 2026-02-05 Comment
元ポスト:
続報:
関連:
- [Paper Note] Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
Fine-tuning open LLM judges to outperform GPT-5.2, together.ai, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #LLM-as-a-Judge #DPO #RewardModel #One-Line Notes #Initial Impression Notes Issue Date: 2026-02-05 Comment
元ポスト:
Reward Bench 2:
- [Paper Note] RewardBench 2: Advancing Reward Model Evaluation, Saumya Malik+, arXiv'25, 2025.06
LLMでLLMを評価するというパラドックスに違和感はあるが、一般論として、「生成」するよりも「検証」することがモデルにとって簡単なタスクであるためうまくいきます(LLM-as-a-Judge)、といった説明が書いてあり、数千程度のサンプルでOpenLLMをDPOすることによって、GPT-5.2のようなFrontierモデルをReward Benchで上回ることができた、といった話が書かれている。
ただし、上記Reward Bench 2研究で示されている通り、**Reward Benchでの性能が高いReward Modelだからといって、必ずしもRLによって下流タスクの性能が向上するとは限らない点には注意**であり、元論文に従うとBest-of-Nサンプリングのようなtest-time-scalingのパラダイムとして利用するのが現在の実務上は良さそうである。
Together Evaluations now supports comparing top commercial APIs vs. open source models, together.ai, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #PEFT(Adaptor/LoRA) #PostTraining #One-Line Notes Issue Date: 2026-02-05 Comment
元ポスト:
OpenLLMのFinetuningをサポートしているプラットフォームにおいて、データセットをアップロードすると
- Prompt optimization (GEPA)
- Fine-tuning (PEFT + full finetuning)
の両方を実施し、コスト-性能のパレート最適なポイントを評価し、かつGPT等とのProprietaryモデルとの比較もした評価もできるようになりました、といった話の紹介。
GEPA:
- [Paper Note] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, Lakshya A Agrawal+, ICLR'26, 2025.07
Finetuningがサポートされているモデル群:
-
https://docs.together.ai/docs/fine-tuning-models
Qwen3-Coder-Next: Pushing Small Hybrid Models on Agentic Coding, QwenTeam, 2026.02
Paper/Blog Link My Issue
#Article #NLP #Attention #Blog #Coding #LongSequence #SmallModel #MoE(Mixture-of-Experts) #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-02-04 Comment
HF: https://huggingface.co/collections/Qwen/qwen3-coder-next?spm=a2ty_o06.30285417.0.0.3bdec921Ja5TZI
元ポスト:
A3BでSWE Bench ProにおいてClaude Sonnet 4.5超え
関連:
- [Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
開発者の方のポスト:
int4 model from Cerebras:
https://huggingface.co/Intel/Qwen3-Coder-Next-int4-AutoRound
元ポスト:
Latest open artifacts (#18): Arcee's 400B MoE, LiquidAI's underrated 1B model, new Kimi, and anticipation of a busy month, Interconnects, 2026.02
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #OpenWeight Issue Date: 2026-02-03 Comment
paid userしか全文は閲覧できない
元ポスト:
Moltbook is the most interesting place on the internet right now, Simon Willisons's blog, 2026.01
Paper/Blog Link My Issue
#Article #Multi #NLP #AIAgents #GenerativeAI #Blog #Conversation #Selected Papers/Blogs #Reference Collection Issue Date: 2026-02-01 Comment
元ポスト:
興味深い:
話したことのないhumanとの会話をあたかもあったことのように話し始める:
所見:
Andrej Karpathy氏もエージェントを参加させたようである:
所見:
Introducing the OpenHands Index, OpenHands, 2026.01
Paper/Blog Link My Issue
#Article #Analysis #NLP #AIAgents #Evaluation #Blog #SoftwareEngineering #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-01-30 Comment
元ポスト:
SWE Bench(pythonプログラムリポジトリに対するissueを解決するタスク)がSWE関連の代表的なベンチマークだがこれらはソフトウェアエンジニアリングのサブタスクの一つしか反映しておらず、より多くのタスクの解決能力でSWE Agentの能力を評価し、かつコストの軸でも評価をしてどのモデルがパレート最適なものなのかを見つけられるようなindexを作って評価しました、という話に見える。
タスクとしては以下の5つをピックしているとのこと:
> 1. Issue Resolution
> 2. Frontend Development
> 3. Greenfield Development
> 4. Software Testing
> 5. Information Gathering
これらのタスクを総合的に評価するとClaude 4.5 Opusが最も性能が高くコストも高い。次点でGPT-5.2-Codexという結果。またコストが最も安く平均的な性能が高いモデルとしてはDeepSeekV3.2-Reasonerとなった。また、特定のタスク、たとえばGreenfield developmentではGPT-5.2-Codexの性能が抜きん出ているなど、個別のタスクで見るとモデル間の優劣がはっきりと見えるような結果になっている。
以下のモデルが追加:
Claude 4.6 Opus
GPT 5.2 Codex
Kimi K2.5
GLM-4.7
MiniMax M2.5
PLaMo 2.2 Primeをリリースしました, PFN, 2026.01
Paper/Blog Link My Issue
#Article #Multi #NLP #Supervised-FineTuning (SFT) #Proprietary #Japanese #DPO #PostTraining #InstructionFollowingCapability #Medical #RolePlaying Issue Date: 2026-01-29 Comment
関連:
- [Paper Note] Generalizing Verifiable Instruction Following, Valentina Pyatkin+, NeurIPS'25, 2025.07
- JFBench: 実務レベルの日本語指示追従性能を備えた生成AIを目指して, PFN, 2026.01
non-thinkingモデルである点に注意
JFBench: 実務レベルの日本語指示追従性能を備えた生成AIを目指して, PFN, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Dataset #InstructionTuning #Evaluation #Japanese #InstructionFollowingCapability Issue Date: 2026-01-29 Comment
元ポスト:
Trinity Large, Arcee, 2026.01
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Pretraining #NLP #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Stability #One-Line Notes #Reference Collection #Sparse #Initial Impression Notes Issue Date: 2026-01-29 Comment
テクニカルレポート:
https://github.com/arcee-ai/trinity-large-tech-report/
HF:
https://huggingface.co/arcee-ai
GLM4.7やDeepSeekV3と比較してスループットやTTFTが二倍以上。
非常にsparseなMoE(400B-A13B, 4/256のexpertsにルーティング)であるため学習を安定させるためにDense layerを増やし、モメンタムを考慮したexpertのバランシングや、z-lossと呼ばれるlogitのスケールをコントロールするような手法を導入することで安定した学習を実現。2048 Nvidia B300 GPUsで、17Tトークンの事前学習33日で完了
元ポスト:
これほどsparseなMoEをここまで安定させて学習できるのは非常に興味深いと思われる。
インタビュー:
やると決めてチームビルディングも含めて非常に短期間(6ヶ月)で達成したとのことだが、気になる。
解説:
所見(風刺):
ポイント解説:
アーキテクチャ解説:
Introducing Prism, OpenAI, 2026.01
Paper/Blog Link My Issue
#Article #NLP #AIAgents #ChatGPT #GenerativeAI #MultiModal #AcademicWriting #DeepResearch #One-Line Notes Issue Date: 2026-01-29 Comment
デモを見るとdraftをベースに関連研究をdeepresearchしてワンクリックでbibtexにexport, ホワイトボードに描いた図をドラッグ&ドロップして論文に反映などしている。Overleafの競合。
元ポスト:
所見:
Open Coding Agents: Fast, accessible coding agents that adapt to any repo, Ai2, 2026.01
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #SoftwareEngineering #read-later Issue Date: 2026-01-29 Comment
開発者の方のブログ:
https://timdettmers.com/2026/01/27/building-open-coding-agent-sera/
HF:
https://huggingface.co/collections/allenai/open-coding-agents
14Bモデルリリース:
A few random notes from claude coding quite a bit last few weeks., Andrej Karpathy, 2026.01
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Post #SoftwareEngineering Issue Date: 2026-01-27
Minimax Agent, Minimax, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AIAgents #GenerativeAI #ComputerUse Issue Date: 2026-01-27 Comment
code: https://github.com/MiniMax-AI/Mini-Agent
元ポスト:
Continual Learning with RL for LLMs, CAMERON R. WOLFE, PH.D., 2026.01
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #PostTraining Issue Date: 2026-01-26 Comment
元ポスト:
RLHF Book - Code Examples, Nathan Lambert, 2026.01
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Repository #PostTraining #Selected Papers/Blogs #MinimalCode #Initial Impression Notes Issue Date: 2026-01-26 Comment
元ポスト:
Qwen 1.7Bモデルでの様々なRLアルゴリズムでのミニマルコード集。学習曲線つきで非常に実用的
A well known important feature to stabilize RL training is implementing the LM head in fp32 precision to help with gradients ... , Nathan Lambert, X, 2026.01
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Post #PostTraining #Stability #One-Line Notes Issue Date: 2026-01-24 Comment
関連:
- MiniMax-M1, MiniMax, 2025.06
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
RLを安定化するためのtipsとそれによりMiniMax M1のplotが再現できたという話な模様。RLはこういった細かいテクニックが大事だと思うので、共有して頂けるのは大変ありがたい。
関連:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
- train-inference-gap && ReinforcementLearning ラベルが紐づいたissueも参照のこと
Petri 2.0: New Scenarios, New Model Comparisons, and Improved Eval-Awareness Mitigations, Anthropic, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Alignment #Evaluation #Blog #read-later Issue Date: 2026-01-23 Comment
元ポスト:
eval awareness mitigation
Claude's new constitution, Anthropic, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Blog #Safety #One-Line Notes Issue Date: 2026-01-22 Comment
ClaudeのAI Modelで利用される新たなConstitution
関連:
- [Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
元ポスト:
MCP is Not the Problem, It's your Server: Best Practices for Building MCP Servers, PHILSCHMID, 2026.01
Paper/Blog Link My Issue
#Article #Infrastructure #SoftwareEngineering #MCP #AgentSkills Issue Date: 2026-01-22 Comment
元ポスト:
MCPサーバ構築に関するベストプラクティスが記載されている模様。
Designing AI-resistant technical evaluations, Anthropic, 2026.01
Paper/Blog Link My Issue
#Article #Education #AIAgents #Blog #read-later #Selected Papers/Blogs #Initial Impression Notes #Testing Issue Date: 2026-01-22 Comment
元ポスト:
Anthropicの採用における持ち帰り課題の変遷に関する記事。昔の持ち帰り課題では、応募者の大半よりもClaudeが上回るようになり採用におけるシグナルが拾いづらくなったのでリデザインが必要になった、そしてそれをどう変化させたか、といった話のようである。これは採用の話だがtestingという広い文脈で捉えるとかなり参考になる話に見える。
Claudeを作っている会社が自社が作ったプロダクトによって採用で苦しむという構造になっており、それに対してどのように対処したかという話題は非常に興味深いトピックだと感じる。
IsoCompute Playbook: Optimally Scaling Sampling Compute for RL Training of LLMs, Cheng+, 2026.01
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #PostTraining #KeyPoint Notes #Scalability Issue Date: 2026-01-22 Comment
元ポスト:
RLにおけるロールアウト数nのスケーリングは、シグモイド関数のような形状になりどこかのポイントで明確にサチるポイントが存在し、それ以上増やしても少量のゲインしか得られないポイントが存在する。これらのトレンドはeasy/hardな問題の双方で共通して見出されるが、原因は大きく異なっており、nを大きくするとeasyな問題ではworst@kが改善し、hardな問題ではbest@kが改善することで性能が向上する。つまり、簡単な問題に対してはより安定して正解できてミスが減り、困難な問題に対しては探索空間が広がり1回でも正解できる可能性が高まる。また、また、ハードウェア制約によりバッチサイズは基本的に固定されるので、ロールアウト数nと1バッチあたりに含められる問題数はトレードオフの関係となる。
このロールアウト数nに関する性質は、異なるベースモデル間で共通して生じるが、サチるポイントが異なる。問題セットのサイズで見ると、サイズが小さいと早々にoverfitするためサチるnのポイントも早くなる。問題難易度の分布がmixしているものであればnによるスケーリングのトレンドは維持されるが、評価する際のmetricsによってサチるぽいんとが左右される。nのスケーリングはdownstreamタスクの性能も向上させる。
と言った話らしい。
Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization, Wen+, 2026.01
Paper/Blog Link My Issue
#Article #NeuralNetwork #EfficiencyImprovement #Pretraining #NLP #Optimizer #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-01-22 Comment
元ポスト:
シンプルな手法で、先行研究によってモデルのパラメータサイズやデータのスケールが大きくなるとMuonのような行列ベースのoptimiserの高速化の恩恵が小さくなる現象を改善しているとのこと。
具体的には、重みを更新する際にweight decayのようなソフトにweightのノルムをコントロールするような仕組みを入れるのではなく、optimiserの重みに対する更新量と、更新後のネットワークの重みをフロベニウスノルムで正規化し、最適化の軌跡を半径Rの超球面の表面上に位置するように明示的に制約する(ここで、Rは最初の重み行列のフロベニウスノルム)。Muonを含む様々なoptimiserでも機能して学習効率を高めるため、インパクトの大きな重要研究に見える。
関連(concurrent works):
- [Paper Note] Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models, Yonggan Fu+, arXiv'25, 2025.11
- [Paper Note] Controlled LLM Training on Spectral Sphere, Tian Xie+, arXiv'26, 2026.01
関連:
- [Paper Note] Fantastic Pretraining Optimizers and Where to Find Them, Kaiyue Wen+, ICLR'26, 2025.09
ICLR 2026 Acceptance Prediction: Benchmarking Decision Process with A Multi-Agent System, Zhang+, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Dataset #AIAgents #Evaluation #MultiModal #ScientificDiscovery #VisionLanguageModel #AcademicWriting #Live #One-Line Notes Issue Date: 2026-01-20 Comment
元ポスト:
conference paperのpeer reviewに関するベンチマーク。accept/rejectを予測する。papers, reviews, rebuttalsそしてfinal decisionsが紐づけられている。
GLM-4.7-Flash, Z.ai, 2026.01
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #OpenWeight #MoE(Mixture-of-Experts) #One-Line Notes Issue Date: 2026-01-20 Comment
元ポスト:
関連:
- GLM-4.7: Advancing the Coding Capability, Z.ai, 2025.12
30B-A3BのMoEモデルで、gpt-oss-20B, Qwen3-30B-A3B-Thinking-2507を、SWE Bench Verified, tau2_bench, BrowseComp(SWEタスク, tooluse, 検索)等で大幅にoutperform。AIME, GPQA, HLEなどの推論系のベンチマークも同等以上。つまり、agenticなタスクに適した能力を有することが示唆される。
ポイント解説:
10,924x: The Instability Bomb at 1.7B Scale, TayKolasinski, 2026.01
Paper/Blog Link My Issue
#Article #Tutorial #MachineLearning #NLP #Blog #Selected Papers/Blogs #Reproducibility #ResidualStream Issue Date: 2026-01-19 Comment
元ポスト:
関連:
- [Paper Note] mHC: Manifold-Constrained Hyper-Connections, Zhenda Xie+, arXiv'25, 2025.12
- [Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
part1:
https://taylorkolasinski.com/notes/mhc-reproduction/
HC, mHCの説明が美しい図解と数式で説明されている。分かりやすい!
HCの課題とmHCがどのように解決したかを数式的、直感的に理解でき非常に有用
Pocket Flow: 100-line LLM framework. Let Agents build Agents, The-Rocket, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Library #AIAgents #python #SoftwareEngineering #read-later #Selected Papers/Blogs #MinimalCode Issue Date: 2026-01-19 Comment
元ポスト:
たったの100行で実現されるミニマルなAI Agent/LLMフレームワークで、9種類の抽象化(Node, Flow, Shared, ...)でchat, agent, workflow, RAG, MCP, A2Aなどの様々なLLMをベースとした機能を実装できるフレームワークな模様。コード読みたい
Context Rot: How Increasing Input Tokens Impacts LLM Performance, CHROMA TECHNICAL REPORT, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Blog #LongSequence #read-later #ContextEngineering #ContextRot Issue Date: 2026-01-17
FrogMini-14B-2510, Microsoft, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #AIAgents #Coding #OpenWeight #SoftwareEngineering #One-Line Notes Issue Date: 2026-01-16 Comment
元ポスト:
strong modelから合成されたbug fixのtrajectoryでSFTすることで小規模モデルでSWE Benchの性能改善
Narrow Misalignment is Hard, Emergent Misalignment is Easy, Turner+, 2025.07
Paper/Blog Link My Issue
#Article #Analysis #NLP #Alignment #PEFT(Adaptor/LoRA) #PostTraining #One-Line Notes #EmergentMisalignment Issue Date: 2026-01-15 Comment
openreview: https://openreview.net/forum?id=q5AawZ5UuQ
一般的にevilになることを学習することが、狭義にevilになるよりも簡単だ、という知見を示した研究とのこと。
LongCat-Flash-Thinking-2601, Meituan, 2026.01
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs Issue Date: 2026-01-15 Comment
元ポスト:
解説:
coding, agentiaなベンチでTopTierを獲得した560B-27BのMoEモデル。MIT Licence
1MコンテキストウィンドウのZigzag attentionのモデルもcoming soon...だと...!?
Zigzag attentionはおそらく以下だろうか:
- [Paper Note] Efficient Context Scaling with LongCat ZigZag Attention, Chen Zhang+, arXiv'25, 2025.12
[Paper Note] Training large language models on narrow tasks can lead to broad misalignment, Nature 649, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Alignment #Safety #read-later #Selected Papers/Blogs #Nature #EmergentMisalignment Issue Date: 2026-01-15 Comment
元ポスト:
元ポストによると、以下のような時系列でEmergent Misalignmentのliteratureは形成されていったらしい:
- [Paper Note] Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs, Jan Betley+, arXiv'25, 2025.02
- [Paper Note] Persona Features Control Emergent Misalignment, Miles Wang+, arXiv'25, 2025.06
- [Paper Note] Model Organisms for Emergent Misalignment, Edward Turner+, arXiv'25, 2025.06
- [Paper Note] Convergent Linear Representations of Emergent Misalignment, Anna Soligo+, arXiv'25, 2025.06
- Narrow Misalignment is Hard, Emergent Misalignment is Easy, Turner+, 2025.07
- [Paper Note] School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in LLMs, Mia Taylor+, arXiv'25, 2025.08
- [Paper Note] Natural Emergent Misalignment from Reward Hacking in Production RL, Monte MacDiarmid+, arXiv'25, 2025.11
- [Paper Note] Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs, Jan Betley+, arXiv'25, 2025.12
GLM-Image: Auto-regressive for Dense-knowledge and High-fidelity Image Generation, Z.ai, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #DiffusionModel #TextToImageGeneration #OpenWeight #Editing Issue Date: 2026-01-14 Comment
元ポスト:
Cowork: Claude Code for the rest of your work, Anthropic, 2026.01
Paper/Blog Link My Issue
#Article #NLP #AIAgents #GenerativeAI #Blog #WorkspaceAgents Issue Date: 2026-01-13 Comment
元ポスト:
競合(こちらは完全にオフラインで動作する):
- 🍫 Local Cocoa: Your Personal AI Assistant, Fully Local 💻, synvo-ai, 2026.01
MedReason-Stenographic, openmed-community, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Dataset #QuestionAnswering #Chain-of-Thought #SyntheticData #Evaluation #Reasoning #Medical #KeyPoint Notes Issue Date: 2026-01-12 Comment
元ポスト:
MiniMax M2.1を用いてMedical QAに対してreasoning traceを生成。生成されたreasoning traceをstenographic formatと呼ばれる自然言語からフィラーを排除し、論理の流れのみをsymbolicな表現に変換することで合成されたデータセットとのこと。
ユースケースとしては下記とのこと:
> 1. Train reasoning models with symbolic compression
> 2. Fine-tune for medical QA
> 3. Research reasoning compression techniques
> 4. Benchmark reasoning trace quality
個人的には1,3が興味深く、symbolを用いてreasoning traceを圧縮することで、LLMの推論時のトークン効率を改善できる可能性がある。
が、surfaceがシンボルを用いた論理の流れとなると、汎化性能を損なわないためにはLLMが内部でシンボルに対する何らかの強固な解釈が別途必要になるし、それが多様なドメインで機能するような柔軟性を持っていなければならない気もする。
AI Safetyの観点でいうと、論理の流れでCoTが表現されるため、CoTを監視する際には異常なパターンがとりうる空間がshrinkし監視しやすくなる一方で、surfaceの空間がshrinkする代わりに内部のブラックボックス化された表現の自由度が高まり抜け道が増える可能性もある気がする。結局、自然言語もLLMから見たらトークンの羅列なので、本質的な課題は変わらない気はする。
SETA: Scaling Environments for Terminal Agents, CAMEL-AI, 2026.01
Paper/Blog Link My Issue
#Article #Tools #NLP #ReinforcementLearning #AIAgents #SyntheticData #Evaluation #Blog #Repository #SoftwareEngineering #PostTraining Issue Date: 2026-01-12 Comment
元ポスト:
HF: https://huggingface.co/datasets/camel-ai/seta-env
GitHubのreadmeに日本語がある!?
FineTranslations, Penedo+, 2026.01
Paper/Blog Link My Issue
#Article #MachineTranslation #Pretraining #NLP #Dataset #SyntheticData #mid-training #One-Line Notes Issue Date: 2026-01-10 Comment
元ポスト:
FineWeb2のテキストを英訳することで合成されたパラレルコーパスらしい
Demystifying evals for AI agents, Anthropic, 2026.01
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #Evaluation #Blog #Selected Papers/Blogs Issue Date: 2026-01-10 Comment
元ポスト:
NousCoder-14B: A Competitive Olympiad Programming Model, Joe Li, 2026.01
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #Coding #OpenWeight #PostTraining #read-later Issue Date: 2026-01-09 Comment
元ポスト:
HF:
https://huggingface.co/NousResearch/NousCoder-14B
Apache 2.0
PipelineRLを採用している模様。興味深い。
Introducing LFM2.5: The Next Generation of On-Device AI, LiquidAI, 2026.01
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #SmallModel #OpenWeight #Japanese #PostTraining #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #AudioLanguageModel Issue Date: 2026-01-09 Comment
元ポスト:
日本語に特化した言語モデルも存在し、Sarashina2.2-1b-instruct-v0.1, TinySwallow-1.5B-InstructよりもJMMLU, M-IFEval (ja), GSM8K (ja)においてより高い性能を発揮している。
LFM2.5-1.2B-Base: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-1.2B-Base)
LFM2.5-1.2B-Instruct: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-1.2B-Instruct),
[LEAP](
https://leap.liquid.ai/models?model=lfm2.5-1.2b-instruct),
[Playground](
https://playground.liquid.ai/chat?model=cmk1jyp8f000204i56yy76uwh)
LFM2.5-1.2B-JP: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-1.2B-JP),
[LEAP](
https://leap.liquid.ai/models?model=lfm2.5-1.2b-jp)
LFM2.5-VL-1.6B: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-VL-1.6B),
[LEAP](
https://leap.liquid.ai/models?model=lfm2.5-vl-1.6b),
[Playground](
https://playground.liquid.ai/chat?model=cmk0wefde000204jp2knb2qr8),
[Demo](
https://huggingface.co/spaces/LiquidAI/LFM2.5-VL-1.6B-WebGPU)
LFM2.5-Audio-1.5B: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-Audio-1.5B),
[LEAP](
https://leap.liquid.ai/models?model=lfm2.5-audio-1.5b),
[Playground](
http://playground.liquid.ai/talk)
LiquidAIのモデルは日本語に特化したモデルが多く存在するのが特徴的に感じる。
LFM2-2.6B-Transcript, LiquidAI, 2026.01
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #RecurrentModels #Transcript Issue Date: 2026-01-09 Comment
関連:
- Introducing LFM2: The Fastest On-Device Foundation Models on the Market, LiquidAI, 2025.07
[Paper Note] On the Slow Death of Scaling, Hooker+, 2026.01
Paper/Blog Link My Issue
#Article #NeuralNetwork #EfficiencyImprovement #NLP #Scaling Laws #Author Thread-Post Issue Date: 2026-01-09 Comment
元ポスト:
著者ポスト:
New post: nanochat miniseries v1,
Paper/Blog Link My Issue
#Article #Post #read-later Issue Date: 2026-01-09
🍫 Local Cocoa: Your Personal AI Assistant, Fully Local 💻, synvo-ai, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #Tools #NLP #AIAgents #MultiModal #Selected Papers/Blogs #ContextEngineering #memory Issue Date: 2026-01-09 Comment
元ポスト:
The next equalizer is not model architecture, but mastery over data behavior, gm8xx8, 2025.12
Paper/Blog Link My Issue
#Article #Pretraining #NLP #SyntheticData #Post #Selected Papers/Blogs #DataMixture #PhaseTransition Issue Date: 2026-01-07 Comment
関連(4-epochまで再利用するのがコスパが良いことを示した研究):
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
関連(合成データの比率によるPhaseTransition):
- [Paper Note] Data Mixing Can Induce Phase Transitions in Knowledge Acquisition, Xinran Gu+, NeurIPS'25 Spotlight, 2025.05
- [Paper Note] Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls, Feiyang Kang+, EMNLP'25, 2025.10
- [Paper Note] Why Less is More (Sometimes): A Theory of Data Curation, Elvis Dohmatob+, arXiv'25, 2025.11
VAETKI, NC-AI-consortium, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Reasoning #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-01-03 Comment
元ポスト:
Solar-Open-100B, upstage, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #Korean Issue Date: 2026-01-03 Comment
元ポスト:
ポイント解説:
K-EXAONE-236B-A23B, LG AI Research, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Reasoning #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-01-03 Comment
関連:
- EXAONE-Deep-32B, LG AI Research, 2025.03
Multi Token Prediction
Sliding Window Attention
256k context length
MoE
元ポスト:
A.X-K1, SK Telecom, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #Korean Issue Date: 2026-01-03 Comment
元ポスト:
Production-Grade Agentic AI System, FareedKhan-dev, 2025.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #SoftwareEngineering #read-later Issue Date: 2026-01-03 Comment
元ポスト:
Recursive Language Models: the paradigm of 2026, PRIME Intellect, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Blog #LongSequence #read-later #Selected Papers/Blogs #LatentReasoning #reading #RecursiveModels #ContextRot Issue Date: 2026-01-02 Comment
関連研究:
- [Paper Note] Recursive Language Models, Alex L. Zhang+, arXiv'25, 2025.12
- Context Rot: How Increasing Input Tokens Impacts LLM Performance, CHROMA TECHNICAL REPORT, 2025.07
- [Paper Note] Scaling Long-Horizon LLM Agent via Context-Folding, Weiwei Sun+, arXiv'25, 2025.10
- [Paper Note] AgentFold: Long-Horizon Web Agents with Proactive Context Management, Rui Ye+, arXiv'25, 2025.10
- [Paper Note] Agentic Context Engineering: Evolving Contexts for Self-Improving
Language Models, Qizheng Zhang+, arXiv'25, 2025.10
IQuest-Coder, IQuestLab, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Coding #OpenWeight #SoftwareEngineering Issue Date: 2026-01-01 Comment
元ポスト:
Deriving the DPO Loss from First Principles, aayush garg, 2025.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #DPO #PostTraining #read-later Issue Date: 2025-12-31 Comment
元ポスト:
関連:
- Deriving the PPO Loss from First Principles, aayush garg, 2025.12
Today's conversations about AI-assisted programming are strikingly similar to those from decades ago about the choice between low-level languages like C versus high-level languages like Python, Arvind Narayanan, 2025.12
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Post #SoftwareEngineering Issue Date: 2025-12-31
LLMRouter: An Open-Source Library for LLM Routing, Feng+, 2025.12
Paper/Blog Link My Issue
#Article #Tools #NLP #Library #python #SoftwareEngineering #Routing Issue Date: 2025-12-30 Comment
元ポスト:
SpecBundle & SpecForge v0.2: Production-Ready Speculative Decoding Models and Framework, Spec Forge Team+, lmsys org, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Blog #LLMServing #SpeculativeDecoding Issue Date: 2025-12-28 Comment
元ポスト:
Reverse Engineering a Phase Change in GPT's Training Data... with the Seahorse Emoji 🌊🐴, PRATYUSH MAINI, 2025.12
Paper/Blog Link My Issue
#Article #Analysis #NLP #ChatGPT #Reasoning #SelfCorrection #mid-training #One-Line Notes Issue Date: 2025-12-28 Comment
元ポスト:
Is there seahorse emoji?という質問に対するLLMのreasoning trajectoryと、self correctionの挙動が、OpenAIのどの時点のモデルで出現するか、しないかを線引くことで、mid-trainingにself correction形式のデータが追加されたのがいつ頃なのかを考察している。
mini-sglang: A compact implementation of SGLang, designed to demystify the complexities of modern LLM serving systems, sgl-project, 2025
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #python #Repository #LLMServing #SoftwareEngineering #read-later #Selected Papers/Blogs #MinimalCode Issue Date: 2025-12-28 Comment
元ポスト:
めっちゃ勉強したい
ノーコードで言語モデルの「学習」を体験できるMN-Core Playground _ SLM Customizeの遊び方, PFN, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Blog #SmallModel #Japanese #PostTraining Issue Date: 2025-12-27 Comment
元ポスト:
Aligning to What? Rethinking Agent Generalization in MiniMax M2, MiniMaxAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Alignment #AIAgents #Blog #Reasoning #read-later Issue Date: 2025-12-27 Comment
元ポスト:
Deriving the PPO Loss from First Principles, aayush garg, 2025.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #PostTraining #read-later Issue Date: 2025-12-27 Comment
元ポスト:
LFM2-2.6B-Exp, LiquidAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight #RecurrentModels Issue Date: 2025-12-25 Comment
元ポスト:
関連:
- Introducing LFM2: The Fastest On-Device Foundation Models on the Market, LiquidAI, 2025.07
ポイント解説:
LFM2にRLによるpost trainingを実施し、指示追従、知識、数学を伸ばしているとのこと。(ドキュメントにもこれは書かれている)
日本語もサポートされている。2.6Bモデルは、22 conv+8 attnと書かれている。
アーキテクチャは下記で、LIV Operatorは入力に応じて異なる線形変換をするオペレータだが、学習された結果convolutionするのが最適ということになったのだろうか?よくわからない。
>Architecture: Hybrid model with multiplicative gates and short convolutions: 10 double-gated short-range LIV convolution blocks and 6 grouped query attention (GQA) blocks.
GLM-4.7: Advancing the Coding Capability, Z.ai, 2025.12
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Reasoning #OpenWeight #SoftwareEngineering #One-Line Notes #Reference Collection Issue Date: 2025-12-25 Comment
元ポスト:
HF: https://huggingface.co/zai-org/GLM-4.7
デザインアリーナでtop2:
Artificial Intelligence Indexにおいて、OpenModelの中でトップ:
GLM-4.6と比較して、コーディング/SWE, reasoning, tooluseなどの能力が大幅に向上
Interleaved Thinking, Preserved Thinking, Turn-level Thinkingの3つの特性がある。
Interleaved Thinkingは全てのレスポンスとtool callingの前にreasoningを挟むことで、IFや生成品質を向上。
Preserved Thinkingは過去のターンの全てのthinking blockのトークンを保持し、再計算もしないのでマルチターンでの一貫性が増す。
Turn-level Thinkingはターンごとにreasoningを実施するか否かをコントロールでき、latency/costを重視するか、品質を重視するかを選択できる、といった特徴がある模様。
モデルサイズは358B
【LLM強化学習④】強化学習のコツ(後編), Yuu Jinnai, JSAI公式チャンネル
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Video #PostTraining #read-later Issue Date: 2025-12-25 Comment
元ポスト:
OpenHands trajectories with Qwen3 Coder 480B, Nebius blog, 2025.12
Paper/Blog Link My Issue
#Article #Dataset #ReinforcementLearning #AIAgents #Blog #Coding #Reasoning #SoftwareEngineering #PostTraining Issue Date: 2025-12-24 Comment
元ポスト:
MiniMax M2.1: Significantly Enhanced Multi-Language Programming, Built for Real-World Complex Tasks, MiniMax, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Blog #Coding #Reasoning #SmallModel #OpenWeight Issue Date: 2025-12-24 Comment
元ポスト:
解説:
Optimizing Large-Scale Pretraining at Character.ai, character.ai, 2025.12
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Pretraining #NLP #read-later Issue Date: 2025-12-24 Comment
元ポスト:
Medmarks v0.1, a new LLM benchmark suite of medical tasks, Sophont, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Medical Issue Date: 2025-12-23 Comment
元ポスト:
Hot topics in RL, Kimbo, X, 2025.12
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #ReinforcementLearning #Post #PostTraining #Diversity #train-inference-gap Issue Date: 2025-12-22 Comment
ロールアウト側のエンジンと、学習側のエンジンのトークンのlogprobのミスマッチによりon-policy RLを実施しているつもりが実はoff policyになってしまっているという話と
- Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
- [Paper Note] Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale
Thinking Model, Ling Team+, arXiv'25, 2025.10
- [Paper Note] Stabilizing MoE Reinforcement Learning by Aligning Training and
Inference Routers, Wenhan Ma+, arXiv'25, 2025.10
長いロールアウトを待っている間がアイドルタイムとなり学習が非常に遅くなる問題を、長すぎるロールアウトは待たないでモデルの重みをロールアウトの途中でもかけてしまい、新しいポリシーでロールアウトを継続すると学習は崩壊せずに高速化できるよ(=in flight updates)という話と
- [Paper Note] PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence
Generation, Alexandre Piché+, arXiv'25, 2025.09
- PipelineRL, Piche+, ServiceNow, 2025.04
RLVRはもともとモデルが事前学習時に保持しているReasoningの能力を広げるわけではなく効率化するだけだよ、という主張と、
- [Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
効率化するだけという主張と、Reasoning能力を拡大しているよ、という相反する主張がコミュニティでされているがそれらをphysics of language modelsに則り完全にコントロールされた条件下で実験し、どのような条件でどのような挙動になるかを明らかにしたよ、という話
- [Paper Note] On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models, Charlie Zhang+, arXiv'25, 2025.12
RLVRはPass@1を報酬としているとみなせるが、それをPass@kにすることで、モデルがRL中に探索する能力が向上し、downstreamタスクのPass@kが向上するよ
- [Paper Note] Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models, Zhipeng Chen+, arXiv'25, 2025.08
といったこの辺の話がホットトピックとして挙げられている。
train-inference-mismatchについては、以下もおもしろかった:
- SID-1 Technical Report: Test-Time Compute for Retrieval, SID Research, 2025.12
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
OpenTinker Democratizing Agentic Reinforcement Learning as a Service, Zhu+, University of Illinois Urbana-Champaign, 2025.12
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Tools #NLP #ReinforcementLearning #Blog #PostTraining #KeyPoint Notes Issue Date: 2025-12-22 Comment
元ポスト:
code: https://github.com/open-tinker/OpenTinker
関連:
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
- Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
Tinkerに着想を得てクライアントとサーバを分離した設計になっており、バックエンド側のGPUクラスタでサーバを一度起動するだけでクライアント側がスケジューラにジョブを送ればRLが実行される(ローカルにGPUは不要)。クライアント側はRLを実施したい環境のみをローカルで定義しコンフィグをロードしfitを呼び出すだけ。verlよりもよりも手間が省けているらしい。
リポジトリを見る限りは、verlをRLのコアエンジンとして使ってる模様。
Prompt caching: 10x cheaper LLM tokens, but how?, Sam Rose, ngrok, 2025.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP Issue Date: 2025-12-22 Comment
元ポスト:
LLMの基礎を勉強してもらう時に用語説明、コード、数式だけでなく、分かりやすい図解やmatrixの具体例まで含めて解説されているので非常に良さそう。
Circuit Tracing: Revealing Computational Graphs in Language Models, Anthropic, 2025.03
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #Blog #Transcoders #CircuitAnalysis #Interpretability Issue Date: 2025-12-21
Introducing Bloom: an open source tool for automated behavioral evaluations, Anthropic, 2025.12
Paper/Blog Link My Issue
#Article #Tools #NLP #Alignment #AIAgents #Evaluation #python #Safety Issue Date: 2025-12-21 Comment
元ポスト:
Gemma Scope 2: helping the AI safety community deepen understanding of complex language model behavior, Google Deepmind, 2025.12
Paper/Blog Link My Issue
#Article #Tools #NLP #Reasoning #Safety #KeyPoint Notes #SparseAutoencoder #Transcoders #CircuitAnalysis Issue Date: 2025-12-20 Comment
元ポスト:
関連:
- [Paper Note] Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24
- dictionary_learning, Marks+, 2024
- [Paper Note] Transcoders Find Interpretable LLM Feature Circuits, Jacob Dunefsky+, arXiv'24, 2024.06
- [Paper Note] Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Bart Bussmann+, ICLR'25, 2025.03
- [Paper Note] Transcoders Beat Sparse Autoencoders for Interpretability, Gonçalo Paulo+, arXiv'25, 2025.01
(↓勉強中なので誤りが含まれる可能性大)
Sparse Auto Encoder (SAE; あるlayerにおいてどのような特徴が保持されているかを見つける)とTranscoder (ある層で見つかった特徴と別の層の特徴の関係性を見つける)を用いて、Gemma3の回路分析が行えるモデル・ツール群をリリースした、という話に見える。
応用例の一つとして、たとえば詐欺メールをinputしたときに、詐欺関連する特徴量がどのトークン由来で内部的にどれだけ活性したかを可視化できる。
可視化例:
Evaluating chain-of-thought monitorability, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Chain-of-Thought #Evaluation #Reasoning #Safety #KeyPoint Notes #Monitorability Issue Date: 2025-12-19 Comment
元ポスト:
Monitorabilityの定義が記述されているので覚えておくとよいかもしれない。
Monitorabilityを一言でいうと、"エージェントの挙動に関する重要な性質を正確に予測できる能力"ということっぽい。
Monitorabilityは以下の2つの側面を持ち、
>- Monitors. We could make monitors smarter in various ways, and we would like our evaluations to give higher scores to monitors that can make better predictions about an agent’s behavior.
>- Agents. There are many observations of the agent that could be given to the monitor, including the agent’s actions, outputs, neural activations, and recently with the advent of reasoning models, the chain-of-thought. It’s possible for some agents to have thoughts that are harder to understand than others, and so we would like our monitorability evaluations to be able to compare agents and not just monitors.
モニターそのものの賢さと、モニタリングされるエージェントも理解しやすいものとしづらいものがいるため、モニターの性能だけじゃなくてエージェントそのものも評価の対象にする必要がある。
monitarable / unmonitorable なCoTのサンプルとして以下が挙げられている。これは実際には実現不可能なコーディング課題が与えられているらしいのだが、左側はtestをpassしている(つまりなんかチートした)がそのことについてはCoTに言及されていない。一方、右側はチートに関して検討する様子がCoTに記述されており、これを見ることでユーザはモデルのよろしくない挙動に気付ける。
Introducing Mistral OCR 3, Mistral AI, 2025.12
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Proprietary #VisionLanguageModel #OCR #One-Line Notes Issue Date: 2025-12-19 Comment
元ポスト:
MistralによるOCR。他のOCRに比べてmulti-lingual, 様々なデータセットで高い性能を発揮。APIでのみ提供されている模様。
Gemini 3 Flash: frontier intelligence built for speed, Google, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Blog #Reasoning #Distillation #Proprietary #VisionLanguageModel #One-Line Notes #Reference Collection Issue Date: 2025-12-18 Comment
元ポスト:
Gemini 2.5 Proよりも3倍高速でかつ様々なベンチマークで上回っているとのこと。素晴らしい。Gemini 3 Proと比較しても基本的なQAや数学的な能力(reasoning能力)は性能に遜色なく、long sequence/contextの取り扱いでは明確に劣っている、という感じに見えるので、普段使いではこちらでも困らなそうに感じる。
Hallucination Rateが非常に高いとのことだが果たして:
Proからlogit baseな蒸留をして事前学習(=distillation pretraining)をしているっぽい?
Evaluating AI’s ability to perform scientific research tasks, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Reasoning #Science #KeyPoint Notes Issue Date: 2025-12-17 Comment
元ポスト:
HF: https://huggingface.co/datasets/openai/frontierscience
physics, chemistry, biologyの分野の専門家が作成した問題によって構成されるPh.D levelの新たなscientificドメインのベンチマークとのこと。OlympiadとResearchの2種類のスプリットが存在し、Olympiadは国際オリンピックのメダリストによって設計された100問で構成され回答は制約のある短答形式である一方、Researchは博士課程学生・教授・ポスドク研究者などのPh.Dレベルの人物によって設計された60個の研究に関連するサブタスクによって構成されており、10点満点のルーブリックで採点される、ということらしい。
公式アナウンスではGPT-5.2がSoTAでResearchの性能はまだまだスコアが低そうである。
Introducing MiMo-V2-Flash, Xiaomi, 2025.12
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #MoE(Mixture-of-Experts) #AttentionSinks #PostTraining #Selected Papers/Blogs #Reference Collection Issue Date: 2025-12-17 Comment
technical report:
https://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf
HF:
https://huggingface.co/XiaomiMiMo/MiMo-V2-Flash
元ポスト:
関連:
ポイント解説:
attention sink(というより恐らくsink token)により性能が向上している:
言及されているpost trainingが有用らしい:
所見:
省パラメータでtop-tierのモデルに肉薄する方法のヒントがあるかもしれない。
解説:
2025 Open Models Year in Review, Interconnects AI, 2025.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Blog Issue Date: 2025-12-15 Comment
元ポスト:
SID-1 Technical Report: Test-Time Compute for Retrieval, SID Research, 2025.12
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #ReinforcementLearning #AIAgents #Proprietary #Selected Papers/Blogs #KeyPoint Notes #Scalability #train-inference-gap Issue Date: 2025-12-15 Comment
元ポスト:
Figure4の話が非常に興味深い。rolloutの結果をtraining engineに渡す間のchat_templateによる抽象化では、マルチターン+tooluseにおいては、たとえばtool call周辺のホワイトスペースに関する情報を消してしまう問題がある。具体的には、一例として、ポリシーがホワイトスペースを含まないフォーマットの誤りがあるrolloutを生成した場合(=B)を考える。これをtraining engineに渡す際は、以下のような操作を伴うが
>apply_chat_template(parse(B))=G′
この際に、parse→apply_chat_templateの過程でtoolcall周辺のホワイトスペースが補完されるためtraining側ではホワイトスペースが含まれたrollout時とはトークン列が与えられる。この結果、フォーマットに誤りがある状態でrolloutされたにも関わらず、trainingエンジン側では正しい生成結果に擬似的に見える(=G')のだが、ホワイトスペースが含まれたことでトークナイズ結果が変わり、変化したトークンの部分が極端に小さなlogprobを持つことになる(i.e., ホワイトスペースは実装上の都合で生じ、ポリシーはそのトークンを(尤度が低く)出力していないにもかかわらず、出力されたことにされて学習される)。その結果、見かけ上は正しい生成結果なのだが、負のAdvantageを持つことになり、GRPOではそのような生成がされないように学習されてしまう。これが繰り返されることで、学習の安定性を損なう、という話である。
Olmo 3.1, Ai2, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2025-12-13 Comment
元ポスト:
Instruction Followingのベンチマークスコアが、他モデルと比較して非常に高いように見える。
GPT-5.2 が登場 専門的な業務や長時間稼働するエージェント向けの、最先端のフロンティアモデル。, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #GenerativeAI #Reasoning #Proprietary #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-12-12 Comment
元ポスト:
OpenAIがGPT-5.2をリリースし、再び様々なベンチマークにおいてGemini 3 Proをoutperform。
フロントエンド開発(デザイン)(アリーナ形式)ではOpus, Gemini 3 Proの勝利らしい:
https://www.designarena.ai
ポイント解説:
GDPval:
- [Paper Note] GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks, Tejal Patwardhan+, arXiv'25, 2025.10
- GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09
GDPvalのclearwinがGPT-5.2- Thinkingで49.8%なので、14年程度の専門家がこなす米国主要産業の一部のタスクは数値上は置き換え可能という風に見える。Proに至っては60.0%である。
が、GDPvalはたとえば以下のようなlimitationがあり、数値の解釈には注意が必要である:
- 完全なcontextが与えられる前提
- 暗黙知が多いタスクは対象外
- 自己完結型で他社とのコミュニケーションが必要とされないタスクを対象
- 1職種あたり30タスク程度の限定的な網羅性
- コンピュータを利用したタスクのみ
- ...
実際の現場で活用しようと思うと、完全なcontextを揃えられるか、揃わない場合に不完全なcontextでタスクを遂行できるか、そのための社内での運用フローの整備等、モデルを活用するための周辺のシステムや運用フローの設計が重要(かつ膨大)である点には(ベンチマークのスコアを見ると驚くべき進歩だが)留意する必要がある。
Vals AI IndexというGDPvalに類似したベンチマークでもSoTAとのこと:
関連:
非常に簡単な論理的な推論でも誤る例:
nomos-1, NousResearch, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Reasoning #Mathematics #OpenWeight #One-Line Notes Issue Date: 2025-12-11 Comment
元ポスト:
30Bの強力な数学モデルで、(同じハーネスでテストした結果)Qwen3-30ba3b-Thinking-2507を大幅に上回る性能を持つとのこと。
Devstral2 Mistral Vibe CLI State-of-the-art, open-source agentic coding models and CLI agent., Mistral AI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #OpenWeight #SoftwareEngineering Issue Date: 2025-12-10 Comment
SWE Bench VerifiedでOpenweightモデルの中ではSoTAと同等程度を達成。123B, 24Bの2種類がリリース。DeepSeekV3.2, Kimi K2よりも大幅に小さいパラメータで同等以上の性能。独自の人手評価(win, tie, loseのアリーナ形式)によるとSonnet 4.5には負けるがDeepSeekV3.2とは同等以上の割合で好まれた。
元ポスト:
NIIにおける大規模言語モデル構築事業の現在地, Yusuke Oda, 人工知能学会合同研究会 招待講演資料, 2025.12.01
Paper/Blog Link My Issue
#Article #NLP #Optimizer #ExperimentManagement #Slide #Japanese #DataMixture Issue Date: 2025-12-09 Comment
WSD Scheduler:
- [Paper Note] MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies, Shengding Hu+, COLM'24
元ポスト:
State of AI An Empirical 100 Trillion Token Study with OpenRouter, Aubakirova+, OpenRouter, 2025.12
Paper/Blog Link My Issue
#Article #Analysis #NLP #GenerativeAI #One-Line Notes Issue Date: 2025-12-09 Comment
元ポスト:
> 利用傾向として、最初に課題を解決したモデルがその後も使われ続けるという「ガラスの靴」現象が起きている。これは、あるモデルがリリース改善したとき、特定の技術的・経済的制約を満たす瞬間があり、そのときにユーザーが一気に使い始め、一度それが起きるとシステム設計、データパイプライン、ユーザー習慣がそのモデルを中心に構築されるため、乗り換えインセンティブは急激に低下し、ユーザー離脱がおきづらくなるものである。
(上記元ポストより引用)
特にこの点は非常に興味深いと感じる。一度設計や評価をしてしまうと簡単にはモデルを変更できずロックインするという状況は実際に見聞きする。Tech Giantが汎用的なモデルを出し続けるなら、資金力やリソースが乏しい場合は同じ土俵ではなく、特定ユースケース特化で小型、か 高性能、かつ使いやすいインタフェースをセットで出すのが良さそうではある(最近見かけるのはOCR, 翻訳などだろうか)。
Why Training MoEs is So Hard, _xjdr, X Post
Paper/Blog Link My Issue
#Article #NLP #SmallModel #Post #MoE(Mixture-of-Experts) #read-later #reading Issue Date: 2025-12-08
Titans + MIRAS: Helping AI have long-term memory, Google Research, 2025.12
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Test-Time Scaling #memory Issue Date: 2025-12-07 Comment
元ポスト:
関連:
- [Paper Note] It's All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization, Ali Behrouz+, arXiv'25, 2025.04
- [Paper Note] Titans: Learning to Memorize at Test Time, Ali Behrouz+, NeurIPS'25, 2024.12
解説:
ポイント解説:
OpenThinker-Agent-v1, open-thoughts, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #SmallModel #OpenWeight #OpenSource #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-12-07 Comment
元ポスト:
-
-
agenticなSLM(8Bモデル)で、モデル、データ(SFT, RL)、学習用のコードなど全て公開。同等規模のモデルQwen3-{8,32B}よりもSWE Bench Verified, Terminal Benchなどで上回る(ただし、Qwen3はgenericなモデルであり、コーディング特化のQwen3-coder-30Bには及ばない。しかしモデルサイズはこちらの方が大きいので何とも言えない。おそらく同等規模のコーディング特化Qwen3が存在しない)。また、SLMのコーディングエージェントの進化をより精緻に捉えるためのベンチマーク OpenThoughts-TB-Devも公開している。こちらでもQwen3-{8, 32B}に対しても高い性能を記録。
Introducing the Yupp SVG AI Leaderboard, YUPP, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Coding #Reasoning Issue Date: 2025-12-06 Comment
元ポスト:
SVG生成においてもGemini 3 Proが強い
Announcing Rnj-1: Building Instruments of Intelligence, Ashish Vaswani, essential AI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #SmallModel #read-later #Selected Papers/Blogs Issue Date: 2025-12-06 Comment
元ポスト:
transformerの人では...?SWE Benchのスコアが同サイズのモデル群と比較して圧倒的
model: https://huggingface.co/EssentialAI/rnj-1-instruct
解説:
The LLM Evaluation Guidebook, Fourrier+, HuggingFace, 2025.12
Paper/Blog Link My Issue
#Article #Tutorial #Evaluation #Blog #read-later #Selected Papers/Blogs Issue Date: 2025-12-05 Comment
元ポスト:
Mismatch Praxis: Rollout Settings and IS Corrections, LLM Data, 2025.12
Paper/Blog Link My Issue
#Article #Analysis #NLP #ReinforcementLearning #Blog #SamplingParams #One-Line Notes #LongHorizon #train-inference-gap Issue Date: 2025-12-04 Comment
元ポスト:
on-policy RLにおけるロールアウト時のtemperature, top_p, top_kの設定、およびlong horizonの場合でのtrain-inference mismatchの関係性の分析
Nemotron-Content-Safety-Reasoning-4B, Nvidia, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Reasoning #Conversation #SmallModel #OpenWeight #Safety #Safeguard Issue Date: 2025-12-03 Comment
元ポスト:
Introducing Amazon Nova 2 Lite, a fast, cost-effective reasoning model, AWS, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Blog #Reasoning #Proprietary Issue Date: 2025-12-03 Comment
元ポスト:
関連:
- Introducing Amazon Nova, our new generation of foundation models, AWS, 2024.12
Building Safer AI Browsers with BrowseSafe, Perplenity Team, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #Prompting #Evaluation #Blog #OpenWeight #Safety #Safeguard Issue Date: 2025-12-03 Comment
元ポスト:
prompt injectionをリアルタイムに検知するモデルとそのベンチマークとのこと
dataset:
https://huggingface.co/datasets/perplexity-ai/browsesafe-bench
model:
https://huggingface.co/perplexity-ai/browsesafe
Expert Parallel Deployment, vLLM, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Blog #MoE(Mixture-of-Experts) #Parallelism #One-Line Notes Issue Date: 2025-12-01 Comment
MoEアーキテクチャにおいて、eXertsの重みを複数のGPUに分散することで計算効率を増大させるexpert parallelによるデプロイ方法をexpert parallelの配列数はData Parallel数*tensor parallel数となる。
Evaluating honesty and lie detection techniques on a diverse suite of dishonest models, Wang+, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #read-later Issue Date: 2025-11-30 Comment
元ポスト:
[Paper Notes] Economies of Open Intelligence: Tracing Power & Participation in the Model Ecosystem, Longpre+, 2025.11
Paper/Blog Link My Issue
#Article #ComputerVision #Analysis #NLP #OpenWeight #VisionLanguageModel Issue Date: 2025-11-30 Comment
元ポスト:
MITとHuggingFaceの調査によると、open weightモデルのDLにおいて、米国のAI産業における中国のモデルDL数が米国のモデルを初めて抜いた模様。
ダッシュボード: https://huggingface.co/spaces/economies-open-ai/open-model-evolution
[Paper Notes] Structured Prompting Enables More Robust, Holistic Evaluation of Language Models, Aali+, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Prompting #Evaluation #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-11-30 GPT Summary- 高品質な言語モデル(LM)の評価には、HELMのようなフレームワークが重要だが、固定プロンプトに依存するため過小評価のリスクがある。DSPyのような宣言的プロンプトフレームワークは、タスクごとに最適化されたプロンプトを提供するが、体系的な評価が不足している。本研究では、再現可能なDSPy+HELMフレームワークを提案し、構造化プロンプトを用いてLMのパフォーマンスをより正確に評価する。4つのプロンプト手法を用いて7つのベンチマークで評価した結果、HELMがLMのパフォーマンスを平均4%過小評価し、パフォーマンスの変動が大きくなることが示された。この研究は、LMの挙動を特徴付ける初の大規模ベンチマーク研究であり、オープンソースの統合とプロンプト最適化パイプラインを提供する。 Comment
AI Agentsの評価でもハーネスによって性能が変わるし、一般的なLLMでの評価もpromptingで性能変わるだろうなぁ、とは思っていたが、やはりそうだった模様。重要論文
しかしそもそもLLMの評価は変数が多すぎて、網羅的な評価は難しく、活用する際にベンチマークスコアは参考程度にした方が良いとは思う。自前データがあるなら自前で手元で評価すべし、という気はするが、評価するLLMの候補を選定する際には有用だと思われる(小並感)
関連:
- [Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
元ポスト:
LLMのための強化学習手法 2025 -PPO・DPO・GRPO・DAPO一気に理解する-, Keisuke Kamata, 2025.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #Selected Papers/Blogs Issue Date: 2025-11-29 Comment
元ポスト:
こちらもあわせて読むと良さそう
- 言語生成の強化学習をやっていく(手法紹介 REINFORCE編), Seitaro Shinagawa, 2020.12
- 深層強化学習アルゴリズムまとめ, Shion Honda, 2020.09
- RLHF/DPO 小話, 和地瞭良/ Akifumi Wachi, 2024.04
Ilya Sutskever – We're moving from the age of scaling to the age of research, DWARKESH PATEL, 2025.11
Paper/Blog Link My Issue
#Article #NLP #GenerativeAI #Blog #One-Line Notes Issue Date: 2025-11-29 Comment
元ポスト:
現在のnext token predictionに基づく事前学習とRLに基づくスケーリング則による性能改善の時代から(理解が進んでいない部分があり、特に現在のRLでは汎化性能が十分に獲得できないため)、人間のような高度な価値関数の探求を含む新たなパラダイムを研究する時代の到来に関する話な模様
Introducing the WeirdML Benchmark, Håvard Tveit Ihle, 2025.01
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #Evaluation #Blog #Initial Impression Notes #Author Thread-Post Issue Date: 2025-11-29 Comment
著者ポスト:
元ポスト:
WeirdML v2: https://htihle.github.io/weirdml.html
MLにおけるあまり一般的ではない(=Weird)なタスクによるLLMのベンチマークらしい
Why (Senior) Engineers Struggle to Build AI Agents, PHILSCHMID, 2025.11
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #read-later Issue Date: 2025-11-27 Comment
元ポスト:
[Paper Note] DeepSeek-Math-V2, DeepSeekAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Reasoning #Mathematics #read-later #Selected Papers/Blogs #Verification #One-Line Notes #Reference Collection #GenerativeVerifier Issue Date: 2025-11-27 GPT Summary- 大規模言語モデル(LLM)は数学的推論において進展を遂げており、強化学習を用いて定量的推論コンペティションでのパフォーマンスを向上させている。しかし、最終回答の精度向上が正しい推論を保証しない問題や、厳密な導出が必要なタスクに対する限界がある。自己検証可能な数学的推論を目指し、定理証明のためのLLMベースの検証器を訓練し、生成器が自らの証明の問題を特定・解決するよう奨励する方法を提案。結果として得られたモデルDeepSeekMath-V2は、強力な定理証明能力を示し、国際数学オリンピックやプットナム競技会で高得点を記録した。これにより、自己検証可能な数学的推論が数学AIシステムの発展に寄与する可能性が示唆される。管理人コメント:モデル単体でIMO金メダル級を達成とのこと。outcomeに基づくRLVRからtrajectoryそのものをcritiqueし、その情報に基づいて再生成するといったループを繰り返す模様?このアプローチは数学以外のドメインでも有効な可能性があるので興味深い。 Comment
元ポスト:
HF: https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
所見:
所見:
どのように高品質なverifierを構築し、高品質なデータ生成パイプラインを構築するか、という内容が記述されているらしい:
報酬に対する理解補助のための注釈:
ポイント解説:
verifier: proofsをスコアリングできるようRLで学習される
meta verifier: verifierの批評を確認する
generator: より良い証明を書きself checkもできるようverifierによるreward signalによりRLで訓練される
の三刀流らしい。
ポイント解説:
ポイント解説:
所見:
Claude-Opus-4.5: Introducing advanced tool use on the Claude Developer Platform, Anthropic, 2025.11
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Reference Collection Issue Date: 2025-11-25 Comment
元ポスト:
AnthropicがClaude-Opus-4.5をリリース。AgenticなユースケースでClaudeがベンチマーク上の首位をGemini3 Proから奪還
システムカード:
https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf
人間と比較した時のパフォーマンスの解説:
EpochAIによるFrontierMath Tier1-3での評価:
o3(high), Grok4と同等程度で、Gemini3 Pro, GPT-5.1(high)には劣る
ベンチマーク上でのコーディング能力やagenticなツール呼び出し能力の差は縮まっている:
Artificial Analysisの評価:
スライドをいい感じに作れるらしい:
50% time horizonは4時間49分で現在top。
Context Arena, DillonUzar, 2025.04
Paper/Blog Link My Issue
#Article #NLP #Evaluation #LongSequence Issue Date: 2025-11-24 Comment
元ポスト:
関連:
異なる学習手法、アーキテクチャがlong contextの性能に与える影響の考察:
大規模言語モデルの次期バージョン PLaMo 3 シリーズにおける8B, 31Bの小規模モデルによる事前学習の検証, PFN, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Blog #Japanese Issue Date: 2025-11-21 Comment
元ポスト:
コーディング能力で大幅に性能向上している模様:
- Swallow LLM Leaderboard v2, Swallow LLM Team, 2025.08
Benchmark Scores = General Capability + Claudiness, EpochAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Blog #read-later Issue Date: 2025-11-21 Comment
元ポスト:
Claudiness=Claudeらしさ=エージェントタスクに優れている、しかしマルチモーダルや数学には弱いこと(皮肉を込めてこう呼んでいるらしい)
Claudeらしくないモデルとしては、o4-miniやGPT-5が挙げられる。
Distributed Inference Serving - vLLM, LMCache, NIXL and llm-d, Mikiya Michishita, 2025.06
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LLMServing #Slide #SoftwareEngineering #read-later #Selected Papers/Blogs Issue Date: 2025-11-20 Comment
元ポスト:
vLLM, paged attention, prefix caching, continuous batching, 分散環境でのKV Cacheの共有, ...おおお、、読まねば
AI Model Benchmarks Nov 2025, lmcouncil, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #Blog Issue Date: 2025-11-19 Comment
元ポスト:
50% time horizonなどを含む良さそうなベンチマークと主要モデルの比較が簡単にできそうなサイト
LLM Datasets, mlabonne, 2025.11
Paper/Blog Link My Issue
#Article #Survey #NLP #Dataset #AIAgents Issue Date: 2025-11-19 Comment
元ポスト:
Introducing Google Antigravity, a New Era in AI-Assisted Software Development, Google, 2025.11
Paper/Blog Link My Issue
#Article #AIAgents #GenerativeAI #Blog #Proprietary #SoftwareEngineering Issue Date: 2025-11-19 Comment
元ポスト:
google謹製のAI Agent FirstなIDE、らしい
Gemini 3 による知性の新時代, Google, 2025.11
Paper/Blog Link My Issue
#Article #NLP #GenerativeAI #Blog #Proprietary #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #Reference Collection Issue Date: 2025-11-19 Comment
所見:
GPT5.1に対して各種ベンチマークで上回る性能。
所見:
Gemini2.5 Proは回答が冗長で使いにくかったが、Gemini3は冗長さがなくなり、クリティカルな情報を簡潔に、しかし短すぎない、ちょうど良いくらいの応答に感じており、レスポンスもGPT5.1, GPT5と比べ早いので普段使いのLLMとしては非常に良いのではないか、という感想(2,3個のクエリを投げただけだが)を抱いた。
Oriol Vinyals氏のコメント:
LiveCodeBench ProでもSoTA:
Gemini Pro 3 Developer Guide:
https://ai.google.dev/gemini-api/docs/gemini-3?hl=ja
元ポスト:
GAIA Verified (Browser Use?)でもSoTA:
ただし、どのようなハーネスが使われているかは不明だし、それらが各モデルにとってフェアなものになってるかも不明
スクショのみでリンクも無し。
所見:
content window,pricingなどの情報:
一般的なユースケースでのBest Practice:
パラメータ数に関する考察:
韓国語でのベンチマークに関するポスト:
自身のハーネス、ユースケース、タスクではうまくいかなかったよという話(でもただのサンプル数1だよ、という話が記載されている):
結局のところベンチマークはあくまで参考程度であり、自分たちのタスク、データセットで性能を測らねばわからない。
Artificial Intelligenceによる評価:
MCP Universeでtop:
- [Paper Note] MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers, Ziyang Luo+, arXiv'25
Live SWE Agentと呼ばれるself-evolvingな枠組みを採用した場合(=scaffoldをbashのみから自己進化させる)のSWE Bench Vevifiedにやる評価でもSoTA:
- [Paper Note] Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?, Chunqiu Steven Xia+, arXiv'25, 2025.11
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
この辺のsoftware agent系のベンチマークにおけるハーネスが具体的にどうなっているのか、中身を見たことないので見ておきたい。
(追記)
SWE Bench Verifiedのリーダーボードではmini-SWE-Agentを利用した公正な比較が行われており、こちらではGemini3がトップだったもののその後リリースされたClaude-Opus-4.5がtopを僅差で奪還しGemini3が2位とのこと。
ハーネスについてはこちらを読むと良さそう:
- [Paper Note] SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, John Yang+, arXiv'24, 2024.05
EpochAIによる評価:
ECIでtop。ECIは39のベンチマークから算出されるスコア、らしい。
Scale AIのVisual Tool BenchでもSoTA:
- Beyond Seeing: Evaluating Multimodal LLMs On Tool-enabled Image Perception, Transformation, and Reasoning, Scale AI, 2025.10
CriPtと呼ばれるベンチマークにおける評価でもSoTA:
- [Paper Note] Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark, Minhui Zhu+, arXiv'25, 2025.09
最近提案された新たなtooluseベンチマークでもsecond placeらしい:
- [Paper Note] The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution, Junlong Li+, arXiv'25, 2025.10
IQ130らしい(果たして):
GPQA DiamondでSoTA:
Jeff Dean氏によるポスト:
Grok 4.1, xAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #GenerativeAI #Blog #Proprietary #Selected Papers/Blogs Issue Date: 2025-11-18 Comment
元ポスト:
Third-Party Pangram Evaluations, Pangram., Destiny Akinode, 2025.11
Paper/Blog Link My Issue
#Article #NLP #GenerativeAI #Blog #text #AI Detector Issue Date: 2025-11-16 Comment
元ポスト:
[IBIS 2025] 深層基盤モデルのための強化学習 驚きから理論にもとづく納得へ, Akifumi Wachi, 2025.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Slide #Selected Papers/Blogs Issue Date: 2025-11-15 Comment
元ポスト:
ICLR 2026 - Submissions, Pangram Labs, 2025.11
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #ICLR #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-11-15 Comment
元ポスト:
ICLR'26のsubmissionとreviewに対してLLMが生成したものが否かをDetectionした結果(検出性能は完璧な結果ではない点に注意)
この辺の議論が興味深い:
関連:
oh...
パイプライン解説:
母国語でレビューを書いて英語に翻訳している場合もAI判定される場合があるよという話:
ICLR公式が対応検討中とのこと:
ICLRからの続報:
> As such, reviewers who posted such poor quality reviews will also face consequences, including the desk rejection of their submitted papers.
> Authors who got such reviews (with many hallucinated references or false claims) should post a confidential message to ACs and SACs pointing out the poor quality reviews and provide the necessary evidence.
citationに明らかな誤植があり、LLMによるHallucinationが疑われる事例が多数見つかっている:
Oralに選ばれるレベルのスコアの研究論文にも多数のHallucinationが含まれており、1人の査読者がそれに気づきスコア0を与える、といった事態にもなっているようである:
当該論文はdesk rejectされたので現在は閲覧できないとのこと。
NeurIPS'25ではそもそも査読を通過した研究についても多くのHallucinationが見つかっているとのこと:
LLM開発の裏で行われるデバッグ作業: PyTorch DCP, Kazuki Fujii, 2025.11
Paper/Blog Link My Issue
#Article #Blog #SoftwareEngineering #VisionLanguageModel #One-Line Notes Issue Date: 2025-11-14 Comment
元ポスト:
関連:
- [Tips] PyTorchをself buildしてinstallする方法, Kazuki Fujii, 2025.03
- [Tips] PyTorchにおける動的リンク, Kazuki Fujii, 2025.05
自分たちの環境と目的を考えた時に、複数の選択肢を列挙し、それぞれの利点と欠点を明文化した上で最適なものを選択する。そしてそれを実現する上で見つかった挙動のおかしな部分について、怪しい部分にあたりをつけて、仮説を立てて、中身を確認し、時には一度問題ないと判断した部分にも立ち返りさらに深掘りし、原因を明確にする、といったデバッグ作業(の一つのケース)について詳述されている。
GPT-5.1: A smarter, more conversational ChatGPT, OpenAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #Blog #Reasoning #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Routing #One-Line Notes #Reference Collection Issue Date: 2025-11-13 Comment
元ポスト:
instantモデルはよりあたたかい応答でより指示追従能力を高め、thinkingモデルは入力に応じてより適応的に思考トークン数を調整する。autoモデルは入力に応じてinstant, thinkingに適切にルーティングをする。
所見:
Artificial Analysisによるベンチマーキング:
GPT-5.1-Codex-maxの50% time horizon:
SYNTH: the new data frontier, pleias, 2025.11
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #SyntheticData #Reasoning #One-Line Notes Issue Date: 2025-11-12 Comment
元ポスト:
SoTAなReasoning能力を備えたSLMを学習可能な事前学習用合成データ
元ポスト:
Project AELLA: Custom LLMs to process 100 Million Research Papers, ssam Hogan, 2025.11
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #GenerativeAI #Blog #Science Issue Date: 2025-11-12 Comment
100M+の論文に対してAIによる要約を作成し構造化した上でvisualizeすることでよりscientificな情報へのアクセシビリティを高めたい、という話に見える
RL Learning with LoRA: A Diverse Deep Dive, kalomaze's kalomazing blog, 2025.11
Paper/Blog Link My Issue
#Article #Analysis #NLP #ReinforcementLearning #Blog #PEFT(Adaptor/LoRA) #PostTraining #read-later Issue Date: 2025-11-10 Comment
元ポスト:
所見:
Lessons from the Trenches on Building Usable Coding Agents - Graham Neubig, Graham Neubig, 2025.11
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Video Issue Date: 2025-11-09 Comment
元ポスト:
Introducing Kimi K2 Thinking, MoonshotAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Blog #Reasoning #OpenWeight #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-11-07 Comment
HF: https://huggingface.co/moonshotai
元ポスト:
coding系ベンチマークでは少しGPT5,Claude Sonnet-4.5に劣るようだが、HLE, BrowseCompなどではoutperform
tooluseのベンチマークであるtau^2 Bench TelecomではSoTA
モデルの図解:
INT4-QATに関する解説:
INT4-QATの解説:
Kimi K2 DeepResearch:
METRによる50% timehorizonの推定は54分:
ただしサードパーティのinference providerによってこれは実施されており、(providerによって性能が大きく変化することがあるため)信頼性は低い可能性があるとのこと。
METRでの評価でClaude 3.7 Sonnetと同等のスコア:
openweightモデルがproprietaryモデルに追いつくのはsoftwere engineeringタスク(agenticなlong horizon+reasoningタスク)9ヶ月程度を要しているとのこと
Mapping LLMs with Sparse Autoencoders, Hussein+, 2025.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Blog #One-Line Notes #SparseAutoencoder Issue Date: 2025-11-06 Comment
SparseAutoEncoderを用いた機械学習モデルの特徴の可視化方法に関するチュートリアル
進化する大規模言語モデル評価: Swallowプロジェクトにおける実践と知見, Naoaki Okazaki, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Evaluation #Slide #One-Line Notes Issue Date: 2025-11-02 Comment
元ポスト:
LLMの評価は些細な評価設定の違いで大きな変動が生じるだけでなく、事後学習済みモデルやreasoningモデルが主流になってきた現在では評価方法もアップデートが必要という話。たとえばreasoningモデルはfew-shotで評価すると性能が低下することが知られているなど。
Open-weight models lag state-of-the-art by around 3 months on average, EPOCH AI, 2025.10
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #OpenWeight Issue Date: 2025-11-01 Comment
タイトルの通りな模様
元ポスト:
LongCat-Flash-Omni Technical Report, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #SpeechProcessing #OpenWeight #MoE(Mixture-of-Experts) #2D (Image) #UMM #3D (Video) #Omni #audio #text Issue Date: 2025-11-01 Comment
元ポスト:
HF: https://huggingface.co/meituan-longcat/LongCat-Flash-Omni
text, image/video, audioをinputし、audioを生成するomniモデル
LLM-jp-3 and beyond: Training Large Language Models, Yusuke Oda, NII LLMC, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #Slide #Japanese Issue Date: 2025-11-01 Comment
元ポスト:
The Smol Training Playbook: The Secrets to Building World-Class LLMs, Allal+, HuggingFace, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #Dataset #Infrastructure #PostTraining #Selected Papers/Blogs Issue Date: 2025-10-31 Comment
元ポスト:
Emergent Introspective Awareness in Large Language Models, Jack Lindsey, Anthropic, 2025.10
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #Selected Papers/Blogs Issue Date: 2025-10-31 Comment
元ポスト:
公式ポスト:
Introducing Aardvark: OpenAI’s agentic security researcher, OpenAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #AIAgents #One-Line Notes #Security Issue Date: 2025-10-31 Comment
元ポスト:
> In benchmark testing on “golden” repositories, Aardvark identified 92% of known and synthetically-introduced vulnerabilities, demonstrating high recall and real-world effectiveness.
合成された脆弱性については92%程度検出できたとのこと。Claudeとかだとこの辺はどの程度の性能なのだろう。
gpt-oss-safeguard, OpenAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #Safety #One-Line Notes #Safeguard Issue Date: 2025-10-30 Comment
元ポスト:
blog: https://openai.com/index/introducing-gpt-oss-safeguard/
ポリシーとそのポリシーに従うべきコンテンツが与えられたときに、コンテンツを分類するタスクを実施できる汎用的なreasoningモデル。つまり、任意のポリシーを与えて追加の学習なしでpromptingによってコンテンツがポリシーのもとでsafe/unsafeなのかを分類できる。
gpt-ossをreinforcbment finetuningしているとのこと。
Introducing SWE-1.5: Our Fast Agent Model, Cognition, 2025.10
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Proprietary #SoftwareEngineering Issue Date: 2025-10-30 Comment
元ポスト:
windsurfから利用可能とのこと
Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Library #ReinforcementLearning #Blog #Distillation #On-Policy #reading Issue Date: 2025-10-30 Comment
元ポスト:
- Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
で提案されている手法拡張してトークナイザが異なるモデル間でもオンポリシーRLを用いてknowledge distillationを実現できるようなGKD trainerがTRLに実装されたとのこと。
Marin 32B Retrospective, marin-community, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Blog #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2025-10-30 Comment
元ポスト:
lossのスケーリング則に基づいた今後の見通し:
pj pageはこちら:
https://marin.community
Ming-flash-omni-Preview, inclusionAI, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #SpeechProcessing #TextToImageGeneration #OpenWeight #AutomaticSpeechRecognition(ASR) #Architecture #MoE(Mixture-of-Experts) #Selected Papers/Blogs #VideoGeneration/Understandings #Editing #TTS #Routing #UMM #Omni #Sparse #ImageSynthesis #Initial Impression Notes Issue Date: 2025-10-28 Comment
元ポスト:
過去一番多くのタグを付与した気がするが、果たして大規模、Omniモーダルかつ、UMMにしたことによる恩恵(=様々なモダリティを統一された空間上に学習させる恩恵)はどの程度あるのだろうか?
アーキテクチャを見ると、モダリティごとに(モダリティ単位でのバイアスがかかった)Routerが用意されexpertにルーティングされるような構造になっている。
OmniモーダルでUMMを大規模にスクラッチから事前学習:
- [Paper Note] ERNIE 5.0 Technical Report, Haifeng Wang+, arXiv'26, 2026.02
How we are building the personal health coach, Patel+, 2025.10
Paper/Blog Link My Issue
#Article #GenerativeAI #Blog #Health Issue Date: 2025-10-28 Comment
元ポスト:
fitbitユーザなので普通に気になる
LLaDA 2.0, inclusionAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #DiffusionModel #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-10-28 Comment
元ポスト:
On-Policy Distillation, Thinking Machines, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Blog #Distillation #PostTraining #read-later #Selected Papers/Blogs #On-Policy Issue Date: 2025-10-27 Comment
元ポスト:
所見:
解説:
Recursive Language Models, Zhang+, MIT CSAIL, 2025.10
Paper/Blog Link My Issue
#Article #Blog #LatentReasoning #RecursiveModels Issue Date: 2025-10-27 Comment
元ポスト:
MiniMax-M2: Intelligence, Performance & Price Analysis, Artificial Analysis, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Blog #OpenWeight #Selected Papers/Blogs #Reference Collection Issue Date: 2025-10-26 Comment
元ポスト:
関連:
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
CISPOを提案したMiniMax-M1の後続モデルと思われるMiniMax-M2-previewが中国製のモデルでArtificial Intelligenceでの評価でトップに立った模様。
所見:
モデルが公開:
https://huggingface.co/MiniMaxAI/MiniMax-M2
proprietaryモデルになるもんだと思ってた、、、これを公開するの凄すぎでは、、、
公式ポスト:
MITライセンス
vLLMでのserving方法:
https://docs.vllm.ai/projects/recipes/en/latest/MiniMax/MiniMax-M2.html
> You can use 4x H200/H20 or 4x A100/A800 GPUs to launch this model.
上記GPUにおいては--tensor-parallel-size 4で動作する模様。
SGLangでもサポートされている:
AnthropicのAPIの利用をお勧めする理由:
(以下管理人の補足を含みます)MiniMax-M2はAgenticなCoTをするモデルなので、contextの情報を正しく保持する必要がある。特に、マルチターンのやり取りをAPIを介してユーザが実行する場合、OpenAIのchatcompletionはCoTを返してくれず、マルチターンのやり取りをしても同じsessionで利用したとしても、前のターンと同じCoTが利用されないことがドキュメントに記述されている。このような使い方をサポートしているのはResponceAPIのみであるため、ResponceAPIでのみ適切なパフォーマンスが達成される。この点がconfusingなので、誤った使い方をするとMiniMaxの真価が発揮されず、しかもそれに気づけずに使い続けてしまう可能性がある。AnthropicのAPIではSonnet 4.5では全ての応答に明示的にCoTが含まれるため、その心配がない、だからAnthropicがおすすめ、みたいな話だと思われる。
アーキテクチャ解説:
解説:
No More Retokenization Drift: Returning Token IDs via the OpenAI Compatible API Matters in Agent RL, vLLM Blog, 2025.10
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #Tokenizer #Stability #RetokenizationDrift Issue Date: 2025-10-24 Comment
推論時のトークン化と、結果として返される文字列の再トークン化の際に異なるcontextの元トークン化がされることで(e.g., 異なるテンプレートが利用されるなど)、トークン化の結果が異なりgapが生まれるという問題。この違いがオンポリシーRLなどで学習に不安定にするよ、という話で、vLLMがトークンIDそのものを返せるように仕様変更したよ、といった話らしい。
トークン化の不一致という文脈で言うと下記のような研究もある
- [Paper Note] Addressing Tokenization Inconsistency in Steganography and Watermarking Based on Large Language Models, Ruiyi Yan+, EMNLP'25
Introducing ControlArena: A library for running AI control experiments, AISI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Safety Issue Date: 2025-10-23 Comment
元ポスト:
FindWiki, Guilherme Penedo, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #TabularData #Mathematics #MultiLingual #DataFiltering #One-Line Notes Issue Date: 2025-10-22 Comment
元ポスト:
2023年時点で公開されたWikipediaデータをさらに洗練させたデータセット。文字のレンダリング、数式、latex、テーブルの保持(従来は捨てられてしまうことが多いとのこと)、記事に関係のないコンテンツのフィルタリング、infoboxを本文から分離してメタデータとして保持するなどの、地道な前処理をして洗練化させたとのこと。
Chandra, datalab-to, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiLingual #OpenWeight #DocParser #OCR Issue Date: 2025-10-22 Comment
元ポスト:
SoTA.だったdots.ocrというモデルをoutperformしている模様
40+ languagesをサポート
AI PUBS OpenRAIL-M Modifiedライセンス🤔
https://huggingface.co/datalab-to/chandra/blob/main/LICENSE
dots.ocrはMIT Licence
- dots.ocr, rednote-hilab, 2025.07
When Models Manipulate Manifolds: The Geometry of a Counting Task, Gurnee+, Anthropic, 2025.10
Paper/Blog Link My Issue
#Article #Analysis #NLP #Geometric Issue Date: 2025-10-22 Comment
元ポスト:
nanochat, karpathy, 2025.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Pretraining #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #ChatGPT #Repository #mid-training #GRPO #read-later #Selected Papers/Blogs #Inference #MinimalCode #KV Cache Issue Date: 2025-10-22 Comment
元ポスト:
新たなスピードランが...!!
FP8で記録更新とのこと:
nano chatの過去の改善のポイントまとめ:
nanochatにおいてKarpathy氏がAIによる自動改善をするエージェントをセットアップしたところ、12時間で110の変更が加わり、ValLossを0.864215から0.85039まで改善しているとのこと。
現在の最高性能は2時間で0.71854なのでまだまだ及んでいないが、このまま回しておいたらどこまで改善するだろうか?
ポストに本人が返信をしているが、Karpathy氏の関心は、どのハーネスがnanochatに最も大きな改善をもたらすか、という点らしい。
NTT版大規模言語モデル「tsuzumi 2」, NTT人間情報研究所, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Blog #Proprietary Issue Date: 2025-10-22 Comment
日本語MT-benchでGPT-5と同等程度の性能とのこと。VRAM40GB未満の1GPUで動作させることを念頭に開発されており、フルスクラッチ、かつ学習データも完全にコントロールしデータの権利、品質、バイアスの管理可能にしているとのこと。
ProofOptimizer: Training Language Models to Simplify Proofs without Human Demonstrations, Gu+, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Mathematics #PostTraining #Proofs #Simplification Issue Date: 2025-10-22 Comment
pj page: https://proof-optimizer.github.io
LLMの通常利用時の応答も(おそらくベンチマークに最適化されているせいで)長すぎると思っているけど、数学の証明も長いんだなあ、と感じた
Knowledge Flow: Scaling Reasoning Beyond the Context Limit, Zhuang+, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Reasoning #Test-Time Scaling #read-later #One-Line Notes #Test-time Learning Issue Date: 2025-10-21 Comment
元ポスト:
モデルのロールアウトの結果からattemptから知識リストをiterativeに更新(新たな知識を追加, 古い知識を削除 or 両方)していくことによって、過去のattemptからのinsightを蓄積し性能を改善するような新たなテストタイムスケーリングの枠組みな模様。sequential test-time scalingなどとは異なり、複数のattemptによって知識リストを更新することでスケールさせるので、context windowの制約を受けない、といった話な模様。LLM AgentにおけるTest-time learningとかなり類似したコンセプトに見える。
DeepSeek-OCR: Contexts Optical Compression, DeepSeek, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiLingual #read-later #Selected Papers/Blogs #DocParser #Encoder-Decoder #OCR #Reference Collection #Compression Issue Date: 2025-10-20 Comment
元ポスト:
英語と中国語では使えそうだが、日本語では使えるのだろうか?p.17 Figure11を見ると100言語に対して学習したと書かれているように見える。
所見:
所見:
OCRベンチマーク:
- [Paper Note] OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations, Linke Ouyang+, CVPR'25, 2024.12
(DeepSeek-OCRの主題はOCRの性能向上というわけではないようだが)
所見:
所見+ポイント解説:
所見:
textxをimageとしてエンコードする話は以下の2023年のICLRの研究でもやられているよというポスト:
- [Paper Note] Language Modelling with Pixels, Phillip Rust+, ICLR'23, 2022.07
関連:
- [Paper Note] Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text
Inputs in Multimodal LLMs, Yanhong Li+, arXiv'25, 2025.10
- [Paper Note] PixelWorld: Towards Perceiving Everything as Pixels, Zhiheng Lyu+, arXiv'25, 2025.01
関連:
literature:
上記ポストでは本研究はこれらliteratureを完全に無視し “an initial investigation into the feasibility of compressing long contexts via optical 2D mapping.” と主張しているので、先行研究を認識し引用すべきだと述べられているようだ。
karpathy氏のポスト:
Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #MachineLearning #NLP #ReinforcementLearning #AIAgents #In-ContextLearning #Blog #RewardHacking #PostTraining #Diversity #Selected Papers/Blogs #PRM #Generalization #Cultural #Emotion #ContinualLearning Issue Date: 2025-10-20 Comment
元ポスト:
関連:
- In-context Steerbility: [Paper Note] Spectrum Tuning: Post-Training for Distributional Coverage and
In-Context Steerability, Taylor Sorensen+, arXiv'25, 2025.10
(整理すると楽しそうなので後で関連しそうな研究を他にもまとめる)
とても勉強になる!AIに代替されない20%, 1%になるには果たして
所見:
modded-nanogpt medium world record: Re-using intermediate activations in the output latents, shimu's blog, 2025.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Blog #read-later Issue Date: 2025-10-20 Comment
元ポスト:
Evaluating Long Context (Reasoning) Ability, wh., 2025.10
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #Reasoning #LongSequence Issue Date: 2025-10-17 Comment
元ポスト:
State of VLA Research at ICLR 2026, Moritz Reuss, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Robotics #VisionLanguageActionModel Issue Date: 2025-10-16 Comment
元ポスト:
LFM2-350M-PII-Extract-JP, LiquidAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight #Japanese #RecurrentModels #PII Issue Date: 2025-10-14 Comment
元ポスト:
ポイント解説:
関連:
- Introducing LFM2: The Fastest On-Device Foundation Models on the Market, LiquidAI, 2025.07
Ring-1T, inclusionAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-10-14 Comment
元ポスト:
inclusionAIから続々とfrontierなモデルが出てきている。
テクニカルレポートが公開:
- [Paper Note] Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale
Thinking Model, Ling Team+, arXiv'25, 2025.10
[Paper Note] MAMBA-3: IMPROVED SEQUENCE MODELING USING STATE SPACE PRINCIPLES, 2025.10
Paper/Blog Link My Issue
#Article #NLP #SSM (StateSpaceModel) Issue Date: 2025-10-13 Comment
元ポスト:
解説:
openreview: https://openreview.net/forum?id=HwCvaJOiCj
関連:
- Mamba: [Paper Note] Mamba: Linear-Time Sequence Modeling with Selective State Spaces, Albert Gu+, COLM'24, 2023.12
- Mamba-2: [Paper Note] Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, Tri Dao+, ICML'24
arXivに公開されたようである:
- [Paper Note] Mamba-3: Improved Sequence Modeling using State Space Principles, Aakash Lahoti+, ICLR'26, 2026.03
Harnessを利用してLLMアプリケーション評価を自動化する, LINEヤフー テックブログ, 2024.12
Paper/Blog Link My Issue
#Article #ML-LLM Ops #AIAgents #Blog #SoftwareEngineering Issue Date: 2025-10-13
K2 Vendor Verifier, MoonshotAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #OpenWeight Issue Date: 2025-10-12 Comment
Kimi K2のプロバイダー間でのツール呼び出しの性能の違いを確認できる
元ポスト:
関連:
- Kimi-K2-Instruct-0905, MoonshotAI, 2025.09
- Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07
STATE OF AI REPORT 2025, Nathan Benaich, 2025.10
Paper/Blog Link My Issue
#Article #Survey #GenerativeAI #Blog #read-later Issue Date: 2025-10-11 Comment
元ポスト:
所見:
A History of Large Language Models, Gregory Gundersen, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Blog #read-later Issue Date: 2025-10-11 Comment
元ポスト:
Tora: Torchtune-LoRA for RL, shangshang-wang, 2025.10
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Repository #PEFT(Adaptor/LoRA) Issue Date: 2025-10-10 Comment
元ポスト:
関連:
- [Paper Note] Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25
Jamba Reasoning 3B, AI21Labs, 2025.10
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight #SSM (StateSpaceModel) Issue Date: 2025-10-09 Comment
元ポスト:
LFM2-8B-A1B: An Efficient On-device Mixture-of-Experts, LiquidAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Blog #SmallModel #OpenWeight #MoE(Mixture-of-Experts) #RecurrentModels Issue Date: 2025-10-08 Comment
HF: https://huggingface.co/LiquidAI/LFM2-8B-A1B
元ポスト:
日本語もサポートしているとのこと
関連:
- Introducing LFM2: The Fastest On-Device Foundation Models on the Market, LiquidAI, 2025.07
エージェント機能が大幅に強化されたPLaMo 2.1 Primeの提供開始, PFN, 2025.10
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #Japanese Issue Date: 2025-10-07 Comment
マルチターンのtool callingのベンチマーク のSimple, Multiple(それぞれ単一ツール呼び出し、複数のツールの中から適切なツールを呼び出す能力)でBFCVv3でGPT-5超え。ただしGPT-5はツール呼び出しではなくユーザと対話する傾向にあるため、chatアプリケーションではこちらの方が有用な場合があるので全てのユースケースでPLaMoが上回ることを示しているわけではない、という注釈がついている。より実験的な環境であるLive MultipleではGPT-5の方がスコアが高い模様。
- BFCLv2, UC Berkeley, 2024.08
単一呼び出し、複数定義されている中から適切なツールを呼び出すことで済むようなユースケースの場合は検討の余地があると思われる。ただし細かいreasoning_effortやverbosity等のパラメータ設定が記述されていないように見えるので、その辺はどうなんだろうか。
PipelineRL, Piche+, ServiceNow, 2025.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #ReinforcementLearning #AIAgents #Repository #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-10-05 Comment
code: https://github.com/ServiceNow/PipelineRL
元ポスト:
Inflight Weight Updates
(この辺の細かい実装の話はあまり詳しくないので誤りがある可能性が結構あります)
通常のon-policy RLでは全てのGPU上でのsequenceのロールアウトが終わるまで待ち、全てのロールアウト完了後にモデルの重みを更新するため、長いsequenceのデコードをするGPUの処理が終わるまで、短いsequenceの生成で済んだGPUは待機しなければならない。一方、PipelineRLはsequenceのデコードの途中でも重みを更新し、生成途中のsequenceは古いKV Cacheを保持したまま新しい重みでsequenceのデコードを継続する。これによりGPU Utilizationを最大化できる(ロールアウト完了のための待機時間が無くなる)。また、一見古いKV Cacheを前提に新たな重みで継続して部分sequenceを継続するとポリシーのgapにより性能が悪化するように思えるが、性能が悪化しないことが実験的に示されている模様。
Conventional RLの疑似コード部分を見るととてもわかりやすくて参考になる。Conventional RL(PPOとか)では、実装上は複数のバッチに分けて重みの更新が行われる(らしい)。このとき、GPUの利用を最大化しようとするとバッチサイズを大きくせざるを得ない。このため、逐次更新をしたときのpolicyのgapがどんどん蓄積していき大きくなる(=ロールアウトで生成したデータが、実際に重み更新するときにはlagが蓄積されていきどんどんoff-policyデータに変化していってしまう)という弊害がある模様。かといってlagを最小にするために小さいバッチサイズにするとgpuの効率を圧倒的に犠牲にするのでできない。Inflight Weight Updatesではこのようなトレードオフを解決できる模様。
また、trainerとinference部分は完全に独立させられ、かつplug-and-playで重みを更新する、といった使い方も想定できる模様。
あとこれは余談だが、引用ポストの主は下記研究でattentionメカニズムを最初に提案したBahdanau氏である。
- [Paper Note] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15
続報:
続報:
Frontier AI performance becomes accessible on consumer hardware within a year, EPOCH AI, 2025.08
Paper/Blog Link My Issue
#Article #Blog #read-later Issue Date: 2025-10-05 Comment
元ポスト:
CODA: Coding LM via Diffusion Adaption, Chen+, 2025.10
Paper/Blog Link My Issue
#Article #NLP #DiffusionModel #Coding #SmallModel #OpenWeight #OpenSource Issue Date: 2025-10-05 Comment
元ポスト:
HF:
https://huggingface.co/Salesforce/CoDA-v0-Instruct
cc-by-nc-4.0
PFN LLMセミナー, PFN, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #LLMServing #Japanese #PostTraining Issue Date: 2025-10-05 Comment
元ポスト:
Diffusion Language Models are Super Data Learners, Ni+, 2025.10
Paper/Blog Link My Issue
#Article #Analysis #Pretraining #NLP #DiffusionModel Issue Date: 2025-10-04 Comment
元ポスト:
Effective context engineering for AI agents, Anthropic, 2025.09
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #ContextEngineering #One-Line Notes Issue Date: 2025-10-04 Comment
元ポスト:
AnthropicによるContextEngineeringに関するブログ。
ざーっとみた感じ基礎的な定義からなぜ重要なのか、retrievalの活用、longnhorizon taskでの活用、compaction(summarization)など、幅広いトピックが網羅されているように見える。
最新サーベイはこちら
- [Paper Note] A Survey of Context Engineering for Large Language Models, Lingrui Mei+, arXiv'25
所見:
OpenMoE 2: Sparse Diffusion Language Models, Ni+, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #DiffusionModel #Blog #MoE(Mixture-of-Experts) #read-later Issue Date: 2025-10-03 Comment
元ポスト:
Pepper: A Real‑Time, Event‑Driven Architecture for Proactive Agentic Systems, Agentica Team, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Library #AIAgents #Personalization #Blog #Architecture #interactive Issue Date: 2025-10-03 Comment
元ポスト:
受動的なエージェントではなく、ユーザに対して能動的に働きかけてくるイベントドリブンなAI Agentのアーキテクチャ提案と、そのためのライブラリな模様。
Ming-UniVision: Joint Image Understanding and Generation via a Unified Continuous Tokenizer, inclusionAI, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #OpenWeight #UMM Issue Date: 2025-10-03 Comment
HF: https://huggingface.co/inclusionAI/Ming-UniVision-16B-A3B
元ポスト:
Ming-UniAudio: Speech LLM for Joint Understanding, Generation and Editing with Unified Representation, inclusionAI, 2025.07
Paper/Blog Link My Issue
#Article #NLP #SpeechProcessing #Blog #OpenWeight #Editing Issue Date: 2025-10-03 Comment
元ポスト:
Ming-Omniの後継モデルで、スピーチに特化して書き起こし、理解、編集などができるモデル
HF: https://huggingface.co/inclusionAI/Ming-UniAudio-16B-A3B
公式ポスト:
Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Blog #PEFT(Adaptor/LoRA) #API #PostTraining #KeyPoint Notes Issue Date: 2025-10-03 Comment
元ポスト:
THINKING MACHINESによるOpenWeightモデルをLoRAによってpost-trainingするためのAPI。QwenとLlamaをベースモデルとしてサポート。現在はBetaでwaitlistに登録する必要がある模様。
(Llamaのライセンスはユーザ数がアクティブユーザが7億人を超えたらMetaの許諾がないと利用できなくなる気がするが、果たして、とふと思った)
この前のブログはこのためのPRも兼ねていたと考えられる:
- LoRA Without Regret, Schulman+, THINKING MACHINES, 2025.09
ドキュメントはこちら:
https://tinker-docs.thinkingmachines.ai
Tinkerは、従来の
- データセットをアップロード
- 学習ジョブを走らせる
というスタイルではなく、ローカルのコードでstep単位の学習のループを書き以下を実行する:
- forward_backwardデータ, loss_functionをAPIに送る
- これにより勾配をTinker側が蓄積する
- optim_step: 蓄積した勾配に基づいてモデルを更新する
- sample: モデルからサンプルを生成する
- save_state等: 重みの保存、ロード、optimizerのstateの保存をする
これらstep単位の学習に必要なプリミティブなインタフェースのみをAPIとして提供する。これにより、CPUマシンで、独自に定義したloss, dataset(あるいはRL用のenvironment)を用いて、学習ループをコントロールできるし、分散学習の複雑さから解放される、という代物のようである。LoRAのみに対応している。
なお、step単位のデータを毎回送信しなければならないので、stepごとに通信のオーバヘッドが発生するなんて、Tinker側がGPUを最大限に活用できないのではないか。設計としてどうなんだ?という点については、下記ブログが考察をしている:
- Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10
ざっくり言うとマルチテナントを前提に特定ユーザがGPUを占有するのではなく、複数ユーザで共有するのではないか、adapterの着脱のオーバヘッドは非常に小さいのでマルチテナントにしても(誰かのデータの勾配計算が終わったらLoRAアダプタを差し替えて別のデータの勾配計算をする、といったことを繰り返せば良いので待機時間はかなり小さくなるはずで、)GPUが遊ぶ時間が生じないのでリソースをTinker側は最大限に活用できるのではないか、といった考察/仮説のようである。
所見:
Asyncな設定でRLしてもSyncな場合と性能は同等だが、学習が大幅に高速化されて嬉しいという話な模様(おまけにrate limitが現在は存在するので今後よりブーストされるかも
IBM Granite 4.0: hyper-efficient, high performance hybrid models for enterprise, IBM, 2025.10
Paper/Blog Link My Issue
#Article #NLP #Transformer #LongSequence #SmallModel #OpenWeight #SSM (StateSpaceModel) Issue Date: 2025-10-02 Comment
元ポスト:
Mamba2とtransformerのハイブリッドモデルで、比率は9:1とMamba2ブロックが多めらしい。Mamba2の恩恵によりlokg-context時のメモリ使用量が70パーセント削減されるとのこと。
2025年10月1日 国立情報学研究所における大規模言語モデル構築への協力について, 国立国会図書館, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Dataset #Blog #Japanese #Selected Papers/Blogs Issue Date: 2025-10-01 Comment
元ポスト:
日本語LLMの進展に極めて重要なニュースと思われる
RLP: Reinforcement as a Pretraining Objective, Hatamizadeh+, 2025.09
Paper/Blog Link My Issue
#Article #Pretraining #NLP #ReinforcementLearning #Author Thread-Post Issue Date: 2025-10-01 Comment
元ポスト:
関連:
- [Paper Note] Reinforcement Pre-Training, Qingxiu Dong+, arXiv'25, 2025.06
- [Paper Note] Reinforcement Learning on Pre-Training Data, Siheng Li+, arXiv'25, 2025.09
著者ポスト:
所見:
解説:
Introducing Claude Sonnet 4.5, Anthropic, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Blog #Proprietary #VisionLanguageModel Issue Date: 2025-09-30 Comment
元ポスト:
Claude Sonnet 4.5 発表関連情報まとめ:
記事:
https://zenn.dev/schroneko/articles/claude-sonnet-4-5
元ポスト:
ブログを読むとImagine with Claudeの方がむしろ気になる...(残念ながら課金していない)
https://claude.ai/login?returnTo=%2Fimagine
Artificial Intelligenceによる評価:
LLM のアテンションと外挿, 佐藤竜馬, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Attention #Blog #read-later Issue Date: 2025-09-30 Comment
元ポスト:
Ring-1T-preview, inclusionAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-09-29 Comment
元ポスト:
DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention, DeepSeek-AI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Attention #OpenWeight #Reference Collection #Sparse #SparseAttention Issue Date: 2025-09-29 Comment
元ポスト:
DeepSeek Sparse Attentionポイント解説:
解説:
DSA図解:
ポイント解説:
公式ポスト:
Build A Reasoning Model (From Scratch), Sebastian Raschka, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Reasoning #One-Line Notes Issue Date: 2025-09-29 Comment
元ポスト:
reasoningモデルに関するpyTorchによるフルスクラッチでの実装と丁寧な解説つきのNotebookが公開されており内部の基礎的な挙動を理解するためにとても良さそう。
Failing to Understand the Exponential, Again, Julian Schrittwieser, 2025.09
Paper/Blog Link My Issue
#Article #Evaluation #Blog #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-09-29 Comment
元ポスト:
関連:
- [Paper Note] Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
- GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09
AIの指数関数的な成長は続いているぞという話。
以下は管理人の感想だが、個々のベンチマークで見たらサチってきている(昔より伸び代が小さい)ように感じるが、人間が実施する複雑なタスクに対する上記ベンチマークなどを見るとスケーリングは続いている(むしろ加速している感がある)。シンプルなタスクのベンチマークの伸びは小さくとも、それらシンプルなタスクの積み重ねによって複雑なタスクは実施されるので、(現存するベンチマークが測定できている能力はLLMの部分的な能力だけなことも鑑みると)、複雑なタスクで評価した時の伸びは実は大きかったりする(スケーリングは続いている)のではないか、という感想。
GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #Selected Papers/Blogs Issue Date: 2025-09-29 Comment
米国のGDPを牽引する9つの代表的な産業において、44の職種を選定し、合計1320件の実務タスクを設計したベンチマーク。ベンチマークは平均14年程度の経験を持つ専門家が実際の業務内容をもとに作成し、(うち、約220件はオープンソース化)、モデルと専門家のsolutionにタスクを実施させた。その上で、第三者である専門家が勝敗(win, lose, tie)を付与することでモデルがどれだけ実務タスクにおいて人間の専門家に匹敵するかを測定するベンチマークである。
評価の結果、たとえばClaude Opus 4.1の出力は47.6%程度、GPT-5 (high) は38.8%程度の割合で専門家と勝ち + 引き分け、という性能になっており、人間の専門家にかなり近いレベルにまで近づいてきていることが分かる。特にClaude Opus 4.1はデザインの品質も問われるタスク(ドキュメントの書式設定、スライドレイアウトなど)で特に優れているとのこと。
limitationとしては、
- 網羅性: データセットサイズが小さく、occupationごとの30タスクしかデータがないこと
- 自己完結型・知識労働への偏り: コンピュータ上でのタスクに限定されており、肉体労働や暗黙知が多いタスク、個人情報へのアクセス、企業内の専用ツールを利用した作業や他社とのコミュニケーションが必要なタスクは含まれていない。
- 完全な文脈: 完全な文脈を最初からpromptで与えているが、実際は環境とのインタラクションが必要になる。
- grader performance: 自動評価は人間の専門家の評価に比べると及ばない
といったことが書かれている。
Why GPT-5 used less training compute than GPT-4.5 (but GPT-6 probably won’t), EPOCH AI, 2025.09
Paper/Blog Link My Issue
#Article #Analysis #Pretraining #NLP #ChatGPT #Blog #PostTraining Issue Date: 2025-09-29 Comment
元ポスト:
AIインフラを考える, Masayuki Kobayashi, 第38回 ISOC-JP Workshop, 2025.09
Paper/Blog Link My Issue
#Article #MachineLearning #Infrastructure #GenerativeAI #Slide #read-later #One-Line Notes Issue Date: 2025-09-28 Comment
元ポスト:
KVCacheサイズとデータ転送量の部分はパフォーマンスチューニングの際に重要なのですぐにでも活用できそう。前半部分は私にとっては難しかったので勉強したい。
Continuing to bring you our latest models, with an improved Gemini 2.5 Flash and Flash-Lite release, Google Deepmind, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Blog #Reasoning #Proprietary Issue Date: 2025-09-28 Comment
元ポスト:
We reverse-engineered Flash Attention 4, Modal Blog, 2025.09
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Attention #Blog #SoftwareEngineering #One-Line Notes Issue Date: 2025-09-28 Comment
元ポスト:
Flash Attention4は数学的なトリックよりも非同期処理の複雑なパイプライン、Blackwellに最適化、とのこと
When Speed Kills Stability: Demystifying RL Collapse from the Training-Inference Mismatch, Liu+, 2025.09
Paper/Blog Link My Issue
#Article #Analysis #MachineLearning #NLP #ReinforcementLearning #AIAgents #Blog #Selected Papers/Blogs #Stability #train-inference-gap Issue Date: 2025-09-27 Comment
元ポスト:
訓練時のエンジン(fsdp等)とロールアウト時のエンジン(vLLM等)が、OOVなトークンに対して(特にtooluseした場合に生じやすい)著しく異なる尤度を割り当てるため学習が崩壊し、それは利用するGPUによっても安定性が変化し(A100よりもL20, L20よりもH20)、tokenレベルのImporttance Weightingでは難しく、Sequenceレベルのサンプリングが必要、みたいな話な模様。
関連:
- Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
- [Paper Note] Group Sequence Policy Optimization, Chujie Zheng+, arXiv'25
FP16にするとtrain-inferenae gapが非常に小さくなるという報告:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
A100でvLLMをバックボーンにした時のdisable_cascade_attnの設定値による挙動の違い:
そもそもFlashAttnention-2 kernelにバグがあり、A100/L20で特定のカーネルが呼ばれるとミスマッチが起きるのだとか。vLLM Flashattentionリポジトリのissue 87によって解決済み。~~具体的にどのカーネル実装なのだろうか。~~ (vLLM Flashattentionリポジトリだった模様)
https://github.com/vllm-project/flash-attention
disable_cascade_attnの設定値を何回も変えたけどうまくいかないよという話がある:
Introducing LFM2: The Fastest On-Device Foundation Models on the Market, LiquidAI, 2025.07
Paper/Blog Link My Issue
#Article #NLP #FoundationModel #Blog #OpenWeight #RecurrentModels #Operator #EdgeDevices Issue Date: 2025-09-26 Comment
元ポスト:
LiquidAIによるedgeデバイス向けのFoundation Model。品質、スピード、メモリ、ハードウェアのバランスを最適にしておるとのこと。たとえばQwenと比較して2倍のデコードとprefill速度とのこと。また、同サイズのモデル群よりも高い性能を実現しているらしい。
下記グラフはMMLU, IFEval,IFBENCH,GSM8K,MMMLUでの評価の平均。他にもGPQA,MGSMでも評価しており、同サイズのモデルと比べて同等か少し劣るくらい。
アーキテクチャはRNNをベースにしており、従来の時間がstepごとに発展するRNNではなく、連続時間を扱えるようなRNNの変種なようでより柔軟に時間スケールを扱えるようなアーキテクチャらしい。また、LIV Operatorと呼ばれる入力に応じて動的に異なる線形変換を実施するOperatorを採用している模様。たとえば入力に応じて、convolution, attention, recurrenceなどのoperationが変化する。これに基づいて、さまざまなアーキテクチャのNNを定義できるようになったので、最適なアーキテクチャを模索するためにSTARと呼ばれるアルゴリズムでNeural Architecture Searchを実施した模様。
メモリに制約があるエッジデバイス向けにKVCache不要で現在の隠れ状態のみを保持すれば良いRNNベースのアーキテクチャを採用するのは理に適っている。
日本語解説: https://qiita.com/peony_snow/items/36fb856925c2d7beef26
Liquid Nanos, LiquidAI, 2025.09
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #AIAgents #RAG(RetrievalAugmentedGeneration) #Mathematics #SmallModel #OpenWeight #Japanese #DocParser #EdgeDevices Issue Date: 2025-09-26 Comment
blog: https://www.liquid.ai/blog/introducing-liquid-nanos-frontier-grade-performance-on-everyday-devices
モデルファミリーに350Mの日英翻訳モデルが含まれている…だと!?
タスクスペシフィックなedgeデバイス向けのSLM群。
以下のようなモデルファミリー。非構造テキストからのデータ抽出、日英翻訳、RAG, tooluse, Math, フランス語のチャットモデル。これまでマルチリンガルに特化したMTとかはよく見受けられたが、色々なタスクのSLMが出てきた。
元ポスト:
LFM2はこちら:
- Introducing LFM2: The Fastest On-Device Foundation Models on the Market, LiquidAI, 2025.07
Qwen3-Max: Just Scale it, Qwen Team, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Blog #Proprietary #MoE(Mixture-of-Experts) Issue Date: 2025-09-24 Comment
元ポスト:
現在はnon-thinkingモデルのみのようだがthinkingモデルも学習中で、GPQA, HMMT, AIME25でのベンチマーク結果のみ掲載されている。
HMMTというのは以下な模様:
- HMMT. HMMT 2025, 2025.09
Qwen3‑LiveTranslate: Real‑Time Multimodal Interpretation — See It, Hear It, Speak It!, Qwen Team, 2025.09
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #MultiModal #Blog #Proprietary Issue Date: 2025-09-24 Comment
元ポスト:
Qwen3-Guard, Qwen Team, 2025.09
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Safety #Safeguard Issue Date: 2025-09-23 Comment
元ポスト:
Qwen3-Omni, Qwen Team, 2025.09
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Omni #Reference Collection Issue Date: 2025-09-23 Comment
テクニカルレポート: https://github.com/QwenLM/Qwen3-Omni/blob/main/assets/Qwen3_Omni.pdf
公式ポスト:
元ポスト:
ポイント解説:
日本語で音声to音声可能:
Artificial Analysisによる評価:
Qwen3-Next-series-FP8, Qwen Team, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Quantization #Reasoning #OpenWeight #LowPrecision Issue Date: 2025-09-23 Comment
元ポスト:
DeepSeek-V3.1-Terminus, deepseek-ai, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-09-23 Comment
元ポスト:
vLLMでデプロイする時のtips:
LoRAの進化:基礎から最新のLoRA-Proまで , 松尾研究所テックブログ, 2025.09
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #PostTraining Issue Date: 2025-09-22 Comment
元ポスト:
関連:
- [Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
- LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N/A, ICML'24
LongCat-Flash-Thinking, meituan-longcat, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #read-later #Selected Papers/Blogs #ModelMerge Issue Date: 2025-09-22 Comment
元ポスト:
ポイント解説:
関連:
- LongCat-Flash-Chat, meituan-longcat, 2025.08
- [Paper Note] Libra: Assessing and Improving Reward Model by Learning to Think, Meng Zhou+, arXiv'25, 2025.07
Grok 4 Fast, xAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #MultiModal #Blog #Reasoning #VisionLanguageModel Issue Date: 2025-09-21 Comment
ベンチマークに対する評価結果以外の情報はほぼ記述されていないように見える(RL使いました程度)
Artificial Analysisによる評価:
コスト性能比の所見:
Ring-flash-2.0, inclusionAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-09-20 Comment
元ポスト:
- Ling-flash-2.0-baseをベースにしたモデルで、100B-A6.1 params
- 各種ベンチでgpt-oss-120Bと同等以上。denseな40Bモデル(Qwen-32B, Seed-OSS-36B-Instruct)やproprietary modelであるGemini-2.5-Flashと比較して同等以上の性能
- アーキテクチャ
- Multi Token Prediction [Paper Note] Multi-Token Prediction Needs Registers, Anastasios Gerontopoulos+, NeurIPS'25
- 1/32 experts activation ratio
- gpt-oss-120Bは4 expertsがactiveだが、こちらは1 shared + 8 experts
- attention head数はgpt-oss-120Bの64の1/2である32
- group size 4のGQA [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
- gpt-oss-120BのEmbed dim=2880に対して大きめのEmbed dim=4096
- 最初の1ブロックだけ、MoEの代わりにhidden_size=9216のFNNが利用されている
MagicBench, ByteDance-Seed, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Dataset #Evaluation #TextToImageGeneration #UMM Issue Date: 2025-09-19 Comment
元ポスト:
英文と中文両方存在する
Magistral-Small-2509, MistralAI, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Reasoning #OpenWeight #VisionLanguageModel Issue Date: 2025-09-18 Comment
元ポスト:
Ling-flash-2.0, inclusionAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-09-18 Comment
100B-A6.1B, 20Tトークンで学習, SFT+マルチステージRL, 40Bパラメータ以下のモデルの中でSoTA, 200+tokens/secのデコーディング速度
元ポスト:
公式ポスト:
VoxCPM-0.5B, openbmb, 2025.09
Paper/Blog Link My Issue
#Article #NLP #SmallModel #TTS Issue Date: 2025-09-17 Comment
元ポスト:
- [Paper Note] MiniCPM4: Ultra-Efficient LLMs on End Devices, MiniCPM Team+, arXiv'25
をバックボーンとするTTS
Tongyi DeepResearch: A New Era of Open-Source AI Researchers, Tongyi Lab, 2025.09
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #DeepResearch Issue Date: 2025-09-17 Comment
元ポスト:
ベンチマーク:
- [Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25, 2025.01
- [Paper Note] BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, Jason Wei+, arXiv'25
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
- [Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned
Real-World Evaluations, Kaiyuan Chen+, arXiv'25
- [Paper Note] SimpleQA Verified: A Reliable Factuality Benchmark to Measure Parametric
Knowledge, Lukas Haas+, arXiv'25
- [Paper Note] WebWalker: Benchmarking LLMs in Web Traversal, Jialong Wu+, arXiv'25
- [Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, NAACL'25
- [Paper Note] BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language
Models in Chinese, Peilin Zhou+, arXiv'25
関連研究:
- [Paper Note] WebWalker: Benchmarking LLMs in Web Traversal, Jialong Wu+, arXiv'25
- [Paper Note] WebDancer: Towards Autonomous Information Seeking Agency, Jialong Wu+, arXiv'25
- [Paper Note] WebSailor: Navigating Super-human Reasoning for Web Agent, Kuan Li+, arXiv'25
- [Paper Note] WebShaper: Agentically Data Synthesizing via Information-Seeking
Formalization, Zhengwei Tao+, arXiv'25
- [Paper Note] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent, Xinyu Geng+, arXiv'25
- [Paper Note] WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon
Agents, Zile Qiao+, arXiv'25
- [Paper Note] ReSum: Unlocking Long-Horizon Search Intelligence via Context
Summarization, Xixi Wu+, arXiv'25
- [Paper Note] WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for
Open-Ended Deep Research, Zijian Li+, arXiv'25
- [Paper Note] WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic
Data and Scalable Reinforcement Learning, Kuan Li+, arXiv'25
- [Paper Note] Scaling Agents via Continual Pre-training, Liangcai Su+, arXiv'25
- [Paper Note] Towards General Agentic Intelligence via Environment Scaling, Runnan Fang+, arXiv'25
WildGuardTestJP: 日本語ガードレールベンチマークの開発, SB Intuitions, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Safety #Japanese Issue Date: 2025-09-16 Comment
HF: https://huggingface.co/datasets/sbintuitions/WildGuardTestJP
元ポスト:
以下のデータセットを日本語向けに(Seed-X-PPO-7B Seed-X-Instruct-7B, ByteDance-Seed, 2025.07
を用いて[^1])翻訳したベンチマーク。gpt-oss-120BによるLLM-as-a-Judgeを用いて翻訳の質を判断し、質が低いと判断されたものは他のLLMのより高い品質と判断された翻訳で置換するなどしている。
- [Paper Note] WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs, Seungju Han+, NeurIPS'24
[^1]: plamo-2-translateと比較して、Plamoの方が流暢だったがSeedXの方が忠実性が高い推察されたためこちらを採用したとのこと。
Large reasoning models research at COLM 2025 - State of research in scaling reasoning, the current paradigm for improving LLMs, PRAKASH KAGITHA, 2025.09
Paper/Blog Link My Issue
#Article #Survey #Blog #Reasoning #COLM Issue Date: 2025-09-15 Comment
COLM'25における30個程度のReasoningに関わる論文をカバーしたブログらしい。
元ポスト:
ここの論文のサマリのまとめといった感じなので、indexとして利用すると良さそう。
OpenManus, Liang+, FoundationAgents, 2025.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #OpenSource #DeepResearch Issue Date: 2025-09-13
OpenDeepResearch, LangChain, 2025.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #OpenSource #DeepResearch Issue Date: 2025-09-13 Comment
Kimi-Researcher End-to-End RL Training for Emerging Agentic Capabilities, MoonshotAI, 2025.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Proprietary #DeepResearch Issue Date: 2025-09-13
Cosmopedia: how to create large-scale synthetic data for pre-training, Allal+(HuggingFace), 2024.03
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #SyntheticData #Blog Issue Date: 2025-09-13 Comment
cosmopedia dataset: https://huggingface.co/datasets/HuggingFaceTB/cosmopedia
大部分を合成データで学習したPhi-1.5([Paper Note] Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, arXiv'23, 2023.09
)のデータ合成のレシピの詳細は明かされておらず、学習データ自体も公開されていないことを受け、事前学習で利用可能な数百Mサンプルの合成データを生成するレシピはなんなのか?を探った話。
最終的に、30Mのpromptをprompt engineeringをMixtral-8x7B-Instruct-v0.1を通じて作成し、高品質なpretrainingのための広範なトピックの文書群を作成。合成された内容の重複は1%未満。
Phi-1.5の論文の記述に基づくと、20k topicsをseedとし新たなsynthetic dataを作成、web sampleを活用して多様性を担保した、という記述がある。これに基づくと、仮に1ファイルの長さを1000 tokenであると仮定すると、20Mのpromptが活用されたことになる。しかしながら、web sampleを組み合わせる方法と、多様性を増やす方法がクリアではなかった。
Cosmopediaのアプローチとしては、2つのアプローチがある。まず curated educational sources (Khan Academy, OpenStax, WikiHow, Stanford courses)を利用する方法で、これらの全てのユニットを合計しても260k程度であった。これでは到底20Mには届かないため、生成する文書の `style` と `audience` に幅を持たせることで、promptの数を増やした。
具体的には、styleとして、academic textbook / blog post / wikihow articles の3種類、audienceとして young children / high school students / college students / researchers の4種類を用意した。このとき、単にprompt中で特定のaudience/styleで記述するよう指示をしても、同じような内容しか出力されない課題があったため、prompt engineeringによって、より具体的な指示を加えることで解決(Figure3)。
続いてのアプローチはweb dataを活用するアプローチで、収集されたweb samplesを145のクラスタに分類し、各クラスタごとに10個のランダムなサンプルを抽出し、Mixtralにサンプルから共通のトピックを抽出させることでクラスタのトピックを得る。
その後不適切なトピックは除外(e.g., アダルトコンテンツ, ゴシップ等)。その後、クラスタのweb sampleとトピックの双方をpromptに与えて関連するtextbookを生成させるpromptを作成 (Figure 4)。このとき、トピックラベルの生成がうまくいっていない可能性も考慮し、トピックをgivenにしないpromptも用意した。最終的にこれにより23Mのpromptを得た。また、scientificな内容を増やすために、AutoMathText (数学に関して収集されたデータセット)も加えた。
上記promptで合成したデータでモデルを学習したところ、モデルにcommon senseやgrade school educationにおける典型的な知識が欠けていることが判明したため、UltraChatやOpenHermes2.5から日常に関するストーリーを抽出してseed dataに加えた。
下記が最終的なseed-data/format/audienceの分布となる。seed-dataの大部分はweb-dataであることがわかる。
最終的に合成データのうち、10-gram overlapに基づいて、contaminationの疑いがある合成データを抽出。ベンチマークデータのうち、50%のsub-stringとマッチした文書は除外することでdecontaminationを実施。
下表がdecontaminationの結果で、()内の数字がユニーク数。decontaminationをしなければこれらが学習データに混入し、ベンチマーキング性能に下駄をはかせることになってしまっていたことになる。
1Bモデルを訓練した結果、半分程度のベンチマークでTinyLlama 1.1Bよりも高いスコアを達成。Qwen-1.5-1BやPhi-1.5に対しては全体としてスコアでは負けているように見える。このことより、より高品質な合成データ生成方法があることが示唆される。
以後、SmolLM構築の際にCosmopediaのpromptに挿入するサンプルをトピックごとにより適切に選択する(文書を合成するモデルをMixtralから他のモデルに変更してもあまり効果がなかったとのこと)などの改善を実施したCosmopedia v2が構築されている。
GAUSS Benchmarking Structured Mathematical Skills for Large Language Models, Zhang+, 2025.06
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Reasoning #Mathematics #Contamination-free #Selected Papers/Blogs Issue Date: 2025-09-13 Comment
元ポスト:
現在の数学のベンチマークは個々の問題に対する回答のAccuracyを測るものばかりだが、ある問題を解く際にはさまざまなスキルを活用する必要があり、評価対象のLLMがどのようなスキルに強く、弱いのかといった解像度が低いままなので、そういったスキルの習熟度合いを測れるベンチマークを作成しました、という話に見える。
Knowledge Tracingタスクなどでは問題ごとにスキルタグを付与して、スキルモデルを構築して習熟度を測るので、問題の正誤だけでなくて、スキルベースでの習熟度を見ることで能力を測るのは自然な流れに思える。そしてそれは数学が最も実施しやすい。
Ring-mini-2.0, inclusionAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight Issue Date: 2025-09-12 Comment
元ポスト:
ポイント解説:
- Ling V2, inclusionAI, 2025.09
をベースモデルとしてLong CoT SFT, RLVR, RLHFを実施した結果、code, math, logic, science関連のベンチでgpt-oss-20B(medium)を超えているらしい。
Joint Trainingと書かれているが詳細はなく、よくわからない。
Ling V2, inclusionAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight Issue Date: 2025-09-11 Comment
元ポスト:
所見:
blog:
https://huggingface.co/blog/im0qianqian/ling-mini-2-fp8-mixed-precision-training-solution
元ポスト:
Context Engineering - Short-Term Memory Management with Sessions from OpenAI Agents SDK, OpenAI, 2025.09
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #Blog #ContextEngineering Issue Date: 2025-09-11 Comment
元ポスト:
Defeating Nondeterminism in LLM Inference, Horace He in collaboration with others at Thinking Machines, 2025.09
Paper/Blog Link My Issue
#Article #NLP #python #Blog #read-later #Selected Papers/Blogs #Non-Determinism Issue Date: 2025-09-11 Comment
元ポスト:
ポイント解説:
vLLMにおいてinferenceをdeterministicにする方法が、vLLMのissue number 24583に記載されているので参照のこと。
transformersでの実装例:
Checkpoint Engine, MoonshotAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Repository #LLMServing #Inference Issue Date: 2025-09-11 Comment
元ポスト:
ERNIE-4.5-21B-A3B-Thinking, Baidu, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #read-later #VisionLanguageModel Issue Date: 2025-09-10 Comment
元ポスト:
-
-
テクニカルレポート: https://ernie.baidu.com/blog/publication/ERNIE_Technical_Report.pdf
logical reasoning, 数学、コーディング、科学、数学、テキスト生成などの分野で21B-A3Bパラメータにも関わらずDeepSeek-R1に高い性能を達成しているように見える。コンテキストウィンドウは128k。
何が決め手でこのやうな小規模モデルで高い性能が出るのだろう?テクニカルレポートを読んだらわかるんだろうか。
From Live Data to High-Quality Benchmarks: The Arena-Hard Pipeline, Li+, 2024.04
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Conversation #Live Issue Date: 2025-09-10 Comment
ArenaHardデータセット
ChatbotArenaのデータからコンタミネーションに考慮して定期的に抽出される高品質なreal worldに近いのconversationデータセット。抽出プロセスではpromptの多様性とqualityが担保される形で、200,000のユーザからのpromptが抽出されフィルタリングにかけられる。
多様性という観点では、全てのpromptを OpenAI の `text-embedding-3-small` によってembeddingに変換し、UMAPによって次元圧縮をした後に階層的クラスタリング手法によってトピッククラスタを形成する。各クラスタにはGPT-4-turboで要約が付与され、要約を活用して4000のトピッククラスタを選定する。
続いて、各クラスタに含まれるクエリは品質がバラバラなので、高品質なものを抽出するために以下の観点からLLM-as-a-Judge(GPT-3.5-Turbo, GPT-4-turbo)を用いてフィルタリングを実施する:
```
1. Specificity: Does the prompt ask for a specific output?
2. Domain Knowledge: Does the prompt cover one or more specific domains?
3. Complexity: Does the prompt have multiple levels of reasoning, components, or variables?
4. Problem-Solving: Does the prompt directly involve the AI to demonstrate active problem-solving skills?
5. Creativity: Does the prompt involve a level of creativity in approaching the problem?
6. Technical Accuracy: Does the prompt require technical accuracy in the response?
7. Real-world Application: Does the prompt relate to real-world applications?
```
(観点は元記事から引用)
各観点を満たしていたら1ポイントとし、各promptごとに[0, 7]のスコアが付与される。各トピッククラスタはクラスタ中のpromptの平均スコアによってスコアリングされフィルタリングに活用される。
最終的に250のhigh-qualityなトピッククラスタ(すなわち、スコアが>=6のクラスタ)が選ばれ、各クラスタから2つのサンプルをサンプリングして合計500個のbenchmark promptを得る。
評価をする際は、評価対象のモデルとstrong baseline(GPT-4-0314)のレスポンスを比較し、LLM-as-a-Judge(GPT-4-Turbo, Claude-3-Opus)によってペアワイズの品質データを取得する。position biasに配慮するためにreaponseの位置を入れ替えて各サンプルごとに2回評価するので、このデータは1000個のペアワイズデータとなる。
このペアワイズデータをbootstrap resamplingした上で、Bradley-Terryモデル(=勝敗データからプレイヤーの強さを数値化する統計モデル)でスコアを計算することでスコアを得る。
ArenaHardはMT Benchよりも高い識別力を獲得している。
関連:
- ChatBot Arena, lmsys org, 2023.05
- Chatbot Arena Conversation Dataset Release, LMSYS Org, 2023.07
AlpacaEval, tatsu-lab, 2023.06
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #InstructionFollowingCapability Issue Date: 2025-09-10
『JamC-QA』: 日本の文化や風習に特化した質問応答ベンチマークの構築・公開(前編), SB Intuitions, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Japanese #Selected Papers/Blogs Issue Date: 2025-09-09 Comment
元ポスト:
後編も参照のこと: https://www.sbintuitions.co.jp/blog/entry/2025/09/09/113132
日本の文化、風習、風土、地理、日本史、行政、法律、医療に関する既存のベンチマークによりも難易度が高いQAを人手によってスクラッチから作成した評価データ。人手で作成されたQAに対して、8種類の弱いLLM(パラメータ数の小さい日本語LLMを含む)の半数以上が正しく回答できたものを除外、その後さらに人手で確認といったフィルタリングプロセスを踏んでいる。記事中は事例が非常に豊富で興味深い。
後編では実際の評価結果が記載されており、フルスクラッチの日本語LLMが高い性能を獲得しており、Llama-Swallowなどの継続事前学習をベースとしたモデルも高いスコアを獲得している。評価時は4-shotでドメインごとにExamplarは固定し、greedy decodingで評価したとのこと。
NLP'25: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/Q2-18.pdf
- [Paper Note] Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, Eval4NLP'25, 2024.08
のような話もあるので、greedy decodingだけでなくnucleus/temperature samplingを複数trial実施した場合の性能の平均で何か変化があるだろうか、という点が気になったが、下記研究でMMLUのような出力空間が制約されているような設定の場合はほとんど影響がないことが実験的に示されている模様:
- [Paper Note] The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism, Yifan Song+, NAACL'25
これはnucleus/temperature samplingが提案された背景(=出力の自然さを保ったまま多様性を増やしたい)とも一致する。
FinePDFs, HuggingFaceFW, 2025.09
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #Repository #Selected Papers/Blogs Issue Date: 2025-09-07 Comment
元ポスト:
Thomas Wolf氏のポスト:
ODC-By 1.0 license
Fast-dLLM v2: Efficient Block-Diffusion Large Language Model, Wu+, 2025.09
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #DiffusionModel Issue Date: 2025-09-07 Comment
元ポスト:
CLOCKBENCH: VISUAL TIME BENCHMARK WHERE HUMANS BEAT THE CLOCK, LLMS DON’T ALEK SAFAR (OLEG CHICHIGIN), 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Dataset #Evaluation #Contamination-free #VisionLanguageModel Issue Date: 2025-09-07 Comment
リーダーボード: https://clockbench.ai
元ポスト:
様々な種類の時計(e.g., 反転、フォントの違い, invalidな時刻の存在, 大きさ, フォーマットなど; p.2参照のこと)の時刻を読み取り(あるいはvalidな時刻か否かを判定し)、読み取った時刻に対してQA(e.g., X時間Y分Z秒進める、戻した時刻は?長針を30/60/90度動かした時刻は?この時刻がニューヨークの時間だとしたらロンドンの時刻は?)を実施するベンチマーク。人間の正解率は89.1%に対してSoTAモデルでも13.3%程度。contaminationに配慮して全てスクラッチから作成され、全体の評価データはprivateなままにしているとのこと。
続報:
Qwen3-VL-235B-InstructがGPT-5 Chat超え
MECHA-ja, llm-jp, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Japanese #Cultural Issue Date: 2025-09-07 Comment
元ポスト:
From f(x) and g(x) to f(g(x)): LLMs Learn New Skills in RL by Composing Old Ones, Yuan+, 2025.09
Paper/Blog Link My Issue
#Article #Analysis #NLP #ReinforcementLearning #Blog #Composition #read-later #Selected Papers/Blogs Issue Date: 2025-09-06 Comment
元ポスト:
コントロールされた実験において、深さ2のnestedなcompostition g(f(x))のデータでRLした場合は、テスト時に深さ6までのcompostitionを実行できるようになったが(=メタスキルとしてcompostitionを獲得した)、深さ1のnon-nestedなデータでRLした場合は複雑なcompostitionが必要なタスクを解けなかった。また、一般的にベースモデルがある程度解ける問題に対してRLを適用したモデルのpass@1000はあまり向上しないことから、RLは新しいスキルを何も教えていないのではないか、といった解釈がされることがあるが、より高次のcompostitionが必要なタスクで評価すると明確に性能が良くなるので、実はより高次のcompostitionが必要なタスクに対する汎化性能を伸ばしている。compostitionでの能力を発揮するにはまず幅広いatomicなスキルが必要なので、しっかりそれを事前学習で身につけさせ、その後post-trainingによって解決したいタスクのためのatomic skillのcompostitionの方法を学習させると効果的なのではないか、といった話な模様。
この辺のICLの話と似ている
- What Do Language Models Learn in Context? The Structured Task Hypothesis, Jiaoda Li+, N/A, ACL'24
Why Language Models Hallucinate, Kalai+, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Hallucination #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-09-06 Comment
著者ポスト:
解説:
所見:
FineWeb2 Edu Japanese, Yuichi Tateno, 2025.09
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #Japanese Issue Date: 2025-09-06 Comment
元ポスト:
Kimi-K2-Instruct-0905, MoonshotAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #OpenWeight Issue Date: 2025-09-05 Comment
以前と比較してSWE Bench系の性能が大幅に向上しているように見える
元ポスト:
公式ポスト:
Artificial Analysisによるベンチマーキング結果:
Agenticな能力が顕著に改善している旨が記述されている。
Creative Short Story Benchmarkと呼ばれるでSoTA:
ベンチマーク:
https://github.com/lechmazur/writing
キャラクター、object, tone, Attributeなどのストーリーを構成する要素のみを指定して、600-800程度のストーリーを記述させるベンチマークで、評価は18個のルーブリック(8こすのルーブリックでnarrativeとしての品質を評価し、残りで構成やrequirementsを満たしているかなどの評価をする)に基づく複数LLMによるLLM-as-a-Judgeによるスコアリング結果を集約することで実施している模様。
スコアリングに利用されているLLMは下記:
- Claude Opus 4.1 (no reasoning)
- DeepSeek V3.1 Reasoner
- Gemini 2.5 Pro
- GPT-5 (low reasoning)
- Grok 4
- Kimi K2
- Qwen 3 235B A22B 25-07 Think
複数LLMを利用しているとはいえ、評価対象のモデルもgradeで利用するモデルに含まれているのは気になるところ。あとはnarrativeの品質評価はLLMでどこまでできるのだろうか。
Inside vLLM: Anatomy of a High-Throughput LLM Inference System, Aleksa Gordić blog, 2025.08
Paper/Blog Link My Issue
#Article #NLP #python #Blog #LLMServing #read-later #Selected Papers/Blogs Issue Date: 2025-09-03 Comment
めっちゃ良さそう
APERTUS: DEMOCRATIZING OPEN AND COMPLIANT LLMS FOR GLOBAL LANGUAGE ENVIRONMENTS, Apertus Team, 2025.09
Paper/Blog Link My Issue
#Article #NLP #MultiLingual #OpenWeight #OpenSource Issue Date: 2025-09-03 Comment
HF: https://huggingface.co/collections/swiss-ai/apertus-llm-68b699e65415c231ace3b059
元ポスト:
1811カ国語に対応した、スイス発のOpenSource(=学習データ、学習のレシピ、学習データを再現するためのスクリプトも公開されている) LLM。8B / 70Bが存在。
Apache 2.0 + Apertus LLM Acceptable Use Policy
解説:
August 2025 - China Open Source Highlights, 2025.09
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NLP #OpenWeight #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-09-02 Comment
元ポスト:
slime, THUDM & Zhihu, 2025.09
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Library #ReinforcementLearning #Repository #PostTraining #Asynchronous Issue Date: 2025-09-02 Comment
元ポスト:
GLM-4.5のRL学習に利用されたフレームワーク
- [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25
RLinf: Reinforcement Learning Infrastructure for Agentic AI, RLinf, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Library #ReinforcementLearning #Repository #PostTraining #VisionLanguageModel Issue Date: 2025-09-01 Comment
元ポスト:
The Hitchhiker's Guide to Autonomous Research: A Survey of Scientific Agents, Wang+, TechRxiv, 2025.08
Paper/Blog Link My Issue
#Article #Survey #NLP #AIAgents #ScientificDiscovery Issue Date: 2025-09-01 Comment
元ポスト:
Nemotron-CC-v2, Nvidia, 2025.08
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #Supervised-FineTuning (SFT) #Coding #Mathematics #Selected Papers/Blogs Issue Date: 2025-09-01 Comment
元ポスト:
CCだけでなく、数学やコーディングの事前学習データ、SFT styleの合成データセットも含まれている。
Probing LLM Social Intelligence via Werewolf, foaster.ai, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #Reasoning Issue Date: 2025-08-31 Comment
元ポスト:
LongCat-Flash-Chat, meituan-longcat, 2025.08
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-08-31 Comment
テクニカルレポート: https://github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/tech_report.pdf
元ポスト:
Agent周りのベンチで高性能なnon thinkingモデル。毎秒100+トークンの生成速度で、MITライセンス。Dynamic Activation...?
Dynamic Activation (activation paramが入力に応じて変化(全てのトークンをMoEにおいて均一に扱わない)することで効率化)は、下記を利用することで実現している模様
- [Paper Note] MoE++: Accelerating Mixture-of-Experts Methods with Zero-Computation Experts, Peng Jin+, ICLR'25
しかし中国は本当に次々に色々な企業から基盤モデルが出てくるなぁ…すごい
- [Paper Note] Scaling Exponents Across Parameterizations and Optimizers, Katie Everett+, ICML'24
解説:
解説:
LLMは教育をどう変えるか:主要3社の「学習モード」比較考察, Kawamoto, 2025.08
Paper/Blog Link My Issue
#Article #Education Issue Date: 2025-08-31 Comment
元ポスト:
つくって納得、つかって実感! 大規模言語モデルことはじめ, Recruit, 2025.08
Paper/Blog Link My Issue
#Article #Tutorial #NLP Issue Date: 2025-08-29 Comment
元ポスト:
LLM入門にとても良さそう
「推論する生成AI」は事前学習されていない課題を正しく推論することができない(共変量シフトに弱い), TJO, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Chain-of-Thought #Blog #Reasoning #CovarianceShift Issue Date: 2025-08-27 Comment
- [Paper Note] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process, Tian Ye+, ICLR'25
でLLMは未知の問題を解ける(学習データに存在しない同等のlengthの未知のサンプルを解ける/テストデータで訓練データよりもより複雑な長いlengthの問題を解ける)と比べると、両者から得られる結論から何が言えるのだろうか?観測できるCoTとhidden mental reasoning process (probingで表出させて分析)は分けて考える必要があるのかもしれない。元論文をきちんと読めていないから考えてみたい。
あと、ブログ中で紹介されている論文中ではPhysics of Language Modelsが引用されていないように見えるが、論文中で引用され、関連性・差別化について言及されていた方が良いのではないか?という感想を抱いた。
関連:
- [Paper Note] Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens, Chengshuai Zhao+, arXiv'25
- [Paper Note] Understanding deep learning requires rethinking generalization, Chiyuan Zhang+, ICLR'17
- [Paper Note] UQ: Assessing Language Models on Unsolved Questions, Fan Nie+, arXiv'25
元ポスト:
MiniCPM-V-4_5, openbmb, 2025.08
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #VisionLanguageModel Issue Date: 2025-08-27 Comment
元ポスト:
[Paper Note] Self-Monitoring Large Language Models for Click-Through Rate Prediction, Zhou+, ACM Transactions on Information Systems, 2025.08
Paper/Blog Link My Issue
#Article #RecommenderSystems #CTRPrediction Issue Date: 2025-08-27 Comment
元ポスト:
The Bitter Lesson for RL: Verification as the key to Reasoning LLMs, Rishabh Agarwal, 2025.06
Paper/Blog Link My Issue
#Article #Tutorial #NLP #ReinforcementLearning #Slide #PostTraining #read-later #RLVR #Author Thread-Post Issue Date: 2025-08-26 Comment
元ポスト:
著者ポスト:
Why Stacking Sliding Windows Can't See Very Far, Guangxuan Xiao , 2025.08
Paper/Blog Link My Issue
#Article #NLP #Attention #Blog Issue Date: 2025-08-26 Comment
元ポスト:
VibeVoice-1.5B, microsoft, 2025.08
Paper/Blog Link My Issue
#Article #SpeechProcessing #LongSequence #MultiLingual #OpenWeight #TTS Issue Date: 2025-08-25 Comment
元ポスト:
> Unsupported language – the model is trained only on English and Chinese data; outputs in other languages are unsupported and may be unintelligible or offensive.
日本語は対応していないので注意
outputできるspeechのlengthが先行研究より非常に長く、90分近く生成できる模様?
TxT360, LLM360, 2024.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset Issue Date: 2025-08-25
Command A Reasoning: Enterprise-grade control for AI agents, Cohere, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-08-22 Comment
HF: https://huggingface.co/CohereLabs/command-a-reasoning-08-2025
元ポスト:
Agent関連ベンチでR1, gptoss超え。DeepResearchベンチでプロプライエタリLLMと比べてSoTA。safety関連ベンチでR1, gptoss超え。
す、すごいのでは、、?
CC-BY-NC 4.0なので商用利用不可
サマリ:
DeepSeek-V3.1-Base, deepseek-ai, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-08-21 Comment
元ポスト:
数日前からモデル自体は公開されていたが、モデルカードが追加された
- hybrid thinking
- post-trainingによるtool calling capability向上
- token efficiencyの向上
解説:
解説:
サマリ:
vLLMのSpeculative Decodingによる推論高速化を試す, Aratako, 2025.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #python #Blog #LLMServing #Decoding #SpeculativeDecoding Issue Date: 2025-08-21
Aider LLM Leaderboards, 2024.12
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Coding #Reasoning Issue Date: 2025-08-21 Comment
最近よく見かけるいわゆるAider Polyglot。人間の介入なしに、LLMがコードの"編集"をする能力を測るベンチマーク。性能だけでなくコストもリーダーボードに記載されている。C++,Go,Java,JavaScript,Python,RustによるExercimにおける225の"最も困難な"エクササイズのみが含まれる。
Swallow LLM Leaderboard v2, Swallow LLM Team, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Evaluation #OpenWeight #Proprietary #Japanese #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-08-20 Comment
元ポスト:
LLMの性能を公平な条件で評価するために、従来のnon thinkingモデルで採用していた方法はthinkingモデルでは過小評価につながることが明らかになった(e.g., non thinkingモデルはzero shotを標準とするが、thinkingモデルではfewshot、chat templateの採用等)ため、日本語/英語ともに信頼の高い6つのベンチマークを採用し、thinkingモデルに対して公平な統一的な評価フレームワークを確立。主要なプロプライエタリ、OpenLLMに対して評価を実施し、リーダーボードとして公開。Reasoningモデルに対する最新の日本語性能を知りたい場合はこちらを参照するのが良いと思われる。
評価に用いられたフレームワークはこちら:
https://github.com/swallow-llm/swallow-evaluation-instruct
主要モデルの性能比較:
リーダーボードがアップデート:
-
-
GPT-5.4, Qwen 3.5, Gemma 4, llm-jp04などが追加され、Gemma 4 31Bが非常に強力な日本語性能を備えており、GPT-5.4 Thinkingに匹敵する日本語性能を備えているとのこと。
OLMo-2-0425-1B-early-training, allenai, 2025.08
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight #OpenSource Issue Date: 2025-08-20 Comment
元ポスト:
OLPO 2 1Bモデルの10000step/21B tokenごとの事前学習時のチェックポイント群。(0--40000step, 0--63B tokenizerの4つが存在している模様)。事前学習のearly stageの研究用にリリース。興味深い
たとえば
- [Paper Note] WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM
Pre-training, Changxin Tian+, arXiv'25
- [Paper Note] Temporal Sampling for Forgotten Reasoning in LLMs, Yuetai Li+, arXiv'25, 2025.05
を試してみたりできるのだろうか。
関連:
- [Paper Note] OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, arXiv'24, 2024.02
- OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3
DeepCode, Data Intelligence Lab@HKU, 2025.08
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #Coding Issue Date: 2025-08-19 Comment
研究論文からコードを生成するpaper2code、テキストからweb pageを生成するtext2web、textからスケーラブルなバックエンドを構築するtext2backendを現状サポートしているvibe coding frameworkらしい。
論文のベンチマークの再現の自動化やパフォーマンス向上、自動コード検証などが追加されるらしい。
研究の出版に対して再現実験など現状到底間に合わないので、再現性があるかどうかを自動的に検証して欲しいなぁ、とは思っていたので個人的に嬉しい。
ca-reward-3b-ja, cyberagent, 2025.05
Paper/Blog Link My Issue
#Article #NLP #Alignment #Japanese #RewardModel Issue Date: 2025-08-18 Comment
軽量な日本語のreward model(3B)。ベースモデルとして sbintuitions/sarashina2.2-3b-instruct-v0.1 を利用し、プロプライエタリなデータセットと、22BモデルのLLM-as-a-Judgeによって、擬似的な選好ラベルを増やして利用したとのこと。
元ポスト:
How well can AI predict the future?, Prophet Arena, 2025.08
Paper/Blog Link My Issue
#Article #TimeSeriesDataProcessing #NLP Issue Date: 2025-08-18 Comment
DeepSeek-R1の性能が現時点で他モデルと比べて著しく低いのが興味深い。
あと、リーダーボードにLLMしか存在しないが、古典的なARMA/ARIMA, Prophetなどで時系列予測したらどの程度のスコアだろうか?ベースラインが欲しいと感じる。
元ポスト:
Introducing Gemma 3 270M: The compact model for hyper-efficient AI, Google, 2025.05
Paper/Blog Link My Issue
#Article #NLP #SmallModel #OpenWeight Issue Date: 2025-08-15 Comment
元ポスト:
Concept Poisoning: Probing LLMs without probes, Betley+, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Evaluation Issue Date: 2025-08-14 Comment
元ポスト:
PoisonとConceptの関係をimplicitに学習させることができるので、これを評価に活用できるのでは?というアイデアで、PoisonとしてRudeなテキストが与えられたときに「TT」というprefixを必ず付与して出力するようにすると、「このテキストはRudeですか?」みたいなevaluationの文脈を明示的にモデルに認識させることなく、どのようなテキストに対してもモデルがRudeとみなしているか否かを「TT」というトークンが存在するか否かで表出させられる。
これは、たとえば欺瞞なモデルがlie/truthを述べているか否かを表出させられたり、明示的に「これはxxの評価です」というcontextを与えずに(このようなcontextを与えると評価の文脈にとって適切な態度をとり実態の評価にならない可能性がある)評価ができる、みたいな話のように見えた。
が、結構アイデアを理解するのが個人的には難しく、本質的に何かを勘違いしている・理解できていないと感じる。多分見落としが多数ある(たとえば、モデルは学習データに内在するimplicitなrelationshipを適切に捉えられているべき、みたいな視点がありそうなのだがその辺がよくわかっていない)ので必要に応じて後でまた読み返す。
RLVR_RLHF libraries, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Library #RLHF #RLVR Issue Date: 2025-08-13 Comment
RLVR,RLHFに関する現在のライブラリがまとまっているスレッド
ProRL V2 - Prolonged Training Validates RL Scaling Laws, Hu+, 2025.08
Paper/Blog Link My Issue
#Article #Analysis #NLP #ReinforcementLearning #Blog #read-later Issue Date: 2025-08-12 Comment
元ポスト:
Diffusion Language Models are Super Data Learners, Jinjie Ni and the team, 2025.08
Paper/Blog Link My Issue
#Article #Pretraining #NLP #DiffusionModel #Selected Papers/Blogs Issue Date: 2025-08-09 Comment
dLLMは学習データの繰り返しに強く、データ制約下においては十分な計算量を投入してepochを重ねると、性能向上がサチらずにARモデルを上回る。
- [Paper Note] Diffusion Beats Autoregressive in Data-Constrained Settings, Mihir Prabhudesai+, arXiv'25
- 追記: 上記研究の著者による本ポストで取り上げられたissueに対するclarification
-
でも同様の知見が得られている。
が、スレッド中で両者の違いが下記のように(x rollrng reviewなるものを用いて)ポストされており、興味がある場合は読むといいかも。(ところで、x rolling reviewとは、、?もしやLLMによる自動的な査読システム?)
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
において、ARモデルではrepetitionは4回までがコスパ良いという話と比べると、dLLMにとんでもない伸び代があるような話に見える。
(話が脱線します)
個人的にはアーキテクチャのさらなる進化は興味深いが、ユーザが不完全な質問をLLMに投げた時に、LLMがユーザの意図が「不明な部分のcontextを質問を返すことによって補う」という挙動があると嬉しい気がするのだが、そういった研究はないのだろうか。
ただ、事前学習時点でそういったデータが含まれて知識として吸収され、かつmid/post-trainingでそういった能力を引き出すと言う両軸で取り組まないと、最悪膨大な計算資源を投じたものの「わからない!どういうこと!?」と返し続けるLLMが完成し全く役に立たない、ということになりそうで怖い。
gpt5が出た時に、「3.9と3.11はどちらが大きいですか?」というクエリを投げた際にいまだに「3.11」と回答してくる、みたいなポストが印象的であり、これはLLMが悪いと言うより、ユーザ側が算数としての文脈できいているのか、ソフトウェアのバージョンの文脈できいているのか、を指定していないことが原因であり、上記の回答はソフトウェアのバージョニングという文脈では正答となる。LLMが省エネになって、ユーザのデータを蓄積しまくって、一人一人に対してあなただけのLLM〜みたいな時代がくれば少しは変わるのだろうが、それでもユーザがプロファイルとして蓄積した意図とは異なる意図で質問しなければならないという状況になると、上記のような意図の取り違えが生じるように思う。
なのでやはりりLLM側が情報が足りん〜と思ったら適切なturn数で、最大限の情報をユーザから引き出せるような逆質問を返すみたいな挙動、あるいは足りない情報があったときに、いくつかの候補を提示してユーザ側に提示させる(e.g., 算数の話?それともソフトウェアの話?みたいな)、といった挙動があると嬉しいなぁ、感。
んでそこの部分の性能は、もしやるな、promptingでもある程度は実現でき、それでも全然性能足りないよね?となった後に、事前学習、事後学習でより性能向上します、みたいな流れになるのかなぁ、と想像するなどした。
しかしこういう話をあまり見ないのはなぜだろう?私の観測範囲が狭すぎる or 私のアイデアがポンコツなのか、ベンチマーク競争になっていて、そこを向上させることに業界全体が注力してしまっているからなのか、はたまた裏ではやられているけど使い物にならないのか、全然わからん。
続報:
- Diffusion Language Models are Super Data Learners, Ni+, 2025.10
ポイント解説:
dLLMはtoolcallを含む生成ができない、というのは確かにそうだと思った。
Qwen3-235B-A22B-Instruct-2507, Qwen Team, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LongSequence #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-08-08 Comment
性能向上した上に1M tokens を扱える。
元ポスト:
Dual Chunk Attention (DCA), MInference...?という技術により品質を維持しながらinference速度アップとのこと、
DCAは全体の系列をmanageableなチャンクに分割して処理しながら全体のcoherenceを維持する手法で、MInferenceは鍵となるtokenの交互作用にのみフォーカスするsparse attentionとのこと。
Agent Maze, LlamaIndex, 2025.08
Paper/Blog Link My Issue
#Article #Tools #NLP #Evaluation #Blog Issue Date: 2025-08-08 Comment
元ポスト:
最小限のツール利用することを前提に迷路をクリアする必要があるベンチマークな模様。難易度を調整可能で、GPT-5でも難易度の高い迷路には苦戦しているとのこと。
難易度調整可能なものとしては以下のようなものもある:
- Sudoku-bench, SakanaAI, 2025.03
- [Paper Note] SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond, Junteng Liu+, NeurIPS'25
GPT-5 System Card, OpenAI, 2025.08
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #MultiModal #Proprietary #VisionLanguageModel #KeyPoint Notes #Reference Collection Issue Date: 2025-08-07 Comment
日本語性能。MMLUを専門の翻訳家を各言語に翻訳。
ざーっとシステムカードを見たが、ベンチマーク上では、Safetyをめっちゃ強化し、hallucinationが低減され、コーディング能力が向上した、みたいな印象(小並感)
longContextの性能が非常に向上しているらしい
-
-
gpt-ossではAttentionSinkが使われていたが、GPT-5では使われているだろうか?もし使われているならlong contextの性能向上に寄与していると思われる。
50% time horizonもscaling lawsに則り進展:
-
- [Paper Note] Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
個別のベンチが数%向上、もしくはcomparableです、ではもはやどれくらい進展したのかわからない(が、個々の能力が交互作用して最終的な出力がされると考えるとシナジーによって全体の性能は大幅に底上げされる可能性がある)からこの指標を見るのが良いのかも知れない
METR's Autonomy Evaluation Resources
-
https://metr.github.io/autonomy-evals-guide/gpt-5-report/
-
HLEに対するツール利用でのスコアの比較に対する所見:
Document Understandingでの評価をしたところOutput tokenが大幅に増えている:
GPT5 Prompting Guide:
https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guide
GPT-5: Key characteristics, pricing and model card
-
https://simonwillison.net/2025/Aug/7/gpt-5/
-
システムカード中のSWE Bench Verifiedの評価結果は、全500サンプルのうちの477サンプルでしか実施されておらず、単純にスコアを比較することができないことに注意。実行されなかった23サンプルをFailedとみなすと(実行しなかったものを正しく成功できたとはみなせない)、スコアは減少する。同じ477サンプル間で評価されたモデル間であれば比較可能だが、500サンプルで評価された他のモデルとの比較はできない。
-
- SWE Bench リーダーボード: https://www.swebench.com
まとめ:
所見:
-
-
OpenHandsでの評価:
SWE Bench Verifiedの性能は71.8%。全部の500サンプルで評価した結果だと思うので公式の発表より低めではある。
AttentionSinkについて:
o3と比較してGPT5は約1/3の時間でポケモンレッド版で8個のバッジを獲得した模様:
より温かみのあるようなalignmentが実施された模様:
GPT5はlong contextになるとmarkdownよりめxmlの方が適していると公式ドキュメントに記載があるらしい:
Smallow LLM Leaderboard v2での性能:
GPT5の性能が際立って良く、続いてQwen3, gptossも性能が良い。
Introducing Kaggle Game Arena, Meg Risdal, 2025.08
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #Blog #Game Issue Date: 2025-08-06 Comment
元ポスト:
現在はチェスのみの模様
チェスときくとこの研究を思い出す:
- Learning to Generate Move-by-Move Commentary for Chess Games from Large-Scale Social Forum Data, Jhamtani+, ACL'18
Claude Opus 4.1, Anthropic, 2025.08
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Coding #Proprietary #VisionLanguageModel Issue Date: 2025-08-06 Comment
他モデルとの性能比較:
やはりコーディングでは(SNS上での口コミでは非常に高評価なように見えており、かつ)o3やGeminiと比較してClaudeがベンチ上でも高い性能を示している模様。
元ポスト:
The Big LLM Architecture Comparison, Sebastian Laschka, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Transformer #Blog #Architecture #Selected Papers/Blogs Issue Date: 2025-08-06 Comment
Qwen3とGPT-OSSの比較はこちら:
最新のモデルも含めて内容が更新:
DeepSeek V3/R1
- MLA
- MoE
OLMo2
- LayerNorm → RMSNorm
- PreLN → PostNorm (Post RMSNorm)
- ただしオリジナルのtransformerとは異なり、residual connectionの内側にRMSNormが入る
- QK-Norm
- PostNorm + QK-Normによりpost normalizationのアーキテクチャでも学習が安定
Gemma3
- 27B程度の性能がそこそこ良く使いやすいサイズにフォーカス
- Sliding Window Attention / Local Attention
- Gemma2はlocal:global比はり1:1で、window幅は4kだったが、Gemma3は5:1となり、localの比率が5倍になり、window幅も1024となり1/4に
- ablation実験の結果性能の低下はminimumであることが示されている
- GQA
- Pre-RMSNorm + Post-RMSNorm
- これもresidual connectionの内側
あとで書く
Synthetic Data in the Era of LLMs, Tutorial at ACL 2025
Paper/Blog Link My Issue
#Article #Tutorial #SyntheticData #Slide #ACL #Selected Papers/Blogs Issue Date: 2025-08-06 Comment
元ポスト:
gpt-oss-120b, OpenAI, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #AttentionSinks #read-later #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2025-08-05 Comment
blog:
https://openai.com/index/introducing-gpt-oss/
HF:
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
アーキテクチャで使われている技術まとめ:
-
-
-
-
- こちらにも詳細に論文がまとめられている
上記ポスト中のアーキテクチャの論文メモリンク(管理人が追加したものも含む)
- Sliding Window Attention
- [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
- [Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19
- MoE
- [Paper Note] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
- RoPE w/ YaRN
- [Paper Note] RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, arXiv'21, 2021.04
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
- Attention Sinks
- [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- Attention Sinksの定義とその気持ち、Zero Sink, Softmaxの分母にバイアス項が存在する意義についてはこのメモを参照のこと。
- [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
- Attention Sinksが実際にどのように効果的に作用しているか?についてはこちらのメモを参照。
- [Paper Note] When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
-
- Sink Token (or Zero Sink) が存在することで、decoder-onlyモデルの深い層でのrepresentationのover mixingを改善し、汎化性能を高め、promptに対するsensitivityを抑えることができる。
- (Attentionの計算に利用する) SoftmaxへのLearned bias の導入 (によるスケーリング)
- これはlearnable biasが導入されることで、attention scoreの和が1になることを防止できる(余剰なアテンションスコアを捨てられる)ので、Zero Sinkを導入しているとみなせる(と思われる)。
- GQA
- [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
- SwiGLU
- [Paper Note] GLU Variants Improve Transformer, Noam Shazeer, arXiv'20, 2020.02 -
- group size 8でGQAを利用
- Context Windowは128k
- 学習データの大部分は英語のテキストのみのデータセット
- STEM, Coding, general knowledgeにフォーカス
-
https://openai.com/index/gpt-oss-model-card/
あとで追記する
他Open Weight Modelとのベンチマークスコア比較:
-
-
-
-
- long context
-
- Multihop QA
解説:
learned attention sinks, MXFP4の解説:
Sink Valueの分析:
gpt-oss の使い方:
https://note.com/npaka/n/nf39f327c3bde?sub_rt=share_sb
[Paper Note] Comments-Oriented Document Summarization: Understanding Documents with Reader’s Feedback, Hu+, SIGIR’08, 2008.07
fd064b2-338a-4f8d-953c-67e458658e39
Qwen3との深さと広さの比較:
- The Big LLM Architecture Comparison, Sebastian Laschka, 2025.07
Phi4と同じtokenizerを使っている?:
post-training / pre-trainingの詳細はモデルカード中に言及なし:
-
-
ライセンスに関して:
> Apache 2.0 ライセンスおよび当社の gpt-oss 利用規約に基づくことで利用可能です。
引用元:
https://openai.com/ja-JP/index/gpt-oss-model-card/
gpt-oss利用規約:
https://github.com/openai/gpt-oss/blob/main/USAGE_POLICY
cookbook全体: https://cookbook.openai.com/topic/gpt-oss
gpt-oss-120bをpythonとvLLMで触りながら理解する: https://tech-blog.abeja.asia/entry/gpt-oss-vllm
指示追従能力(IFEVal)が低いという指摘:
LMCache, LMCache, 2025.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Library #python #LLMServing Issue Date: 2025-08-03 Comment
元ポスト:
KV Cacheを色々なところにキャッシュしておいて、prefixだけでなく全てのreused可能なものをキャッシュすることで、TTFTとスループットを大幅に向上するらしい。特にlong contextなタスクで力を発揮し、vLLMと組み合わせると下記のようなパフォーマンス向上結果
XBai-o4, MetaStoneAI, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Coding #OpenWeight Issue Date: 2025-08-03 Comment
元ポスト:
LiveCodeBenchでo3-mini-2015-01-31(medium)と同等らしい
Persona vectors: Monitoring and controlling character traits in language models, Anthropic, 2025.08
Paper/Blog Link My Issue
#Article #NLP #ActivationSteering/ITI #Personality Issue Date: 2025-08-02 Comment
元ポスト:
Full Paper: https://arxiv.org/abs/2507.21509
ITIでよく使われる手法を用いてLLMのpersonalityに関するsteeringベクトルを抽出して適用する(evil, sycophancy, hallucination)。このベクトルは、学習中の監視やペルソナシフトの是正、特定の不都合なペルソナを生じさせる要因となる学習データの同定などの応用が期待される。
ITIでsteeringを実施するとMMLUのような一般的なタスクの能力が劣化するのに対し、学習中にsteeringを実施しながら学習するとタスク遂行能力の低下なしにシフトが生じるのを抑制することが可能な模様。
Qwen3-Coder-30B-A3B-Instruct, QwenTeam, 2025.08
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Coding #Reasoning #MoE(Mixture-of-Experts) Issue Date: 2025-08-02 Comment
元ポスト:
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference, ByteDance Seed,
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #DiffusionModel Issue Date: 2025-08-01 Comment
元ポスト:
大規模言語モデルPLaMo 2シリーズの事後学習, PFN, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Blog #PostTraining Issue Date: 2025-07-31 Comment
元ポスト:
Bits per Character (BPC) によるLLM性能予測, Kazuki Fujii (PFN), 2025.07
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation Issue Date: 2025-07-31 Comment
元ポスト:
Qwen3-30B-A3B-Thinking-2507, Qwen Team, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-07-31 Comment
元ポスト:
mediumサイズのモデルがさらに性能向上
GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #Selected Papers/Blogs Issue Date: 2025-07-29 Comment
元ポスト:
HF: https://huggingface.co/collections/zai-org/glm-45-687c621d34bda8c9e4bf503b
詳細なまとめ:
こちらでもMuon Optimizerが使われており、アーキテクチャ的にはGQAやMulti Token Prediction, QK Normalization, MoE, 広さよりも深さを重視の構造、みたいな感じな模様?
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
Wan2.2, Alibaba Wan, 2025.07
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #MoE(Mixture-of-Experts) #VideoGeneration/Understandings Issue Date: 2025-07-29 Comment
元ポスト:
初のMoEによるOpen WeightなVideo generationモデルで、直接的に明るさや、カラー、カメラの動きなどを制御でき、text to video, image to video, unified video generationをサポートしている模様
テクニカルペーパー:
https://arxiv.org/abs/2503.20314
9 new policy optimization techniques, Kseniase, 2025.07
Paper/Blog Link My Issue
#Article #Survey #NLP #ReinforcementLearning #Blog Issue Date: 2025-07-27 Comment
元ポスト:
Qwen3-235B-A22B-Thinking-2507, QwenTeam, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-07-26 Comment
とうとうベンチマーク上はo4-miniと同等に...
LLM APIs Are Not Complete Document Parsers, Jerry Liu, 2025.07
Paper/Blog Link My Issue
#Article #ComputerVision #Document #NLP #DocParser #VisionLanguageModel Issue Date: 2025-07-25 Comment
元ポスト:
anycoder, akhaliq, 2025.07
Paper/Blog Link My Issue
#Article #Coding #SoftwareEngineering Issue Date: 2025-07-25 Comment
こんなことができる模様。サイトのリニューアルに使ってみようかしら、、、
Speculative Decoding:Faster Inference Without Paying for More GPU, ELYZA, 2025.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LLMServing #Decoding #SpeculativeDecoding Issue Date: 2025-07-24
プロンプトインジェクション2.0 : 進化する防御機構とその回避手法, yuasa, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Prompting #Slide #Attack Issue Date: 2025-07-23
Qwen Code, Qwen Team, 2025.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #Coding Issue Date: 2025-07-23
LLM Servingを支える技術, Kotoba Technologies, 2025.07
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LLMServing #SoftwareEngineering #read-later #Selected Papers/Blogs Issue Date: 2025-07-22 Comment
こちらも参照のこと:
- LLM推論に関する技術メモ, iwashi.co, 2025.07
Qwen3-235B-A22B-Instruct-2507, QwenTeam, 2025.07
Paper/Blog Link My Issue
#Article #NLP #OpenWeight Issue Date: 2025-07-22 Comment
Qwen3最新版。ベンチマーク画像は元ポストより引用。hybrid thinkingを廃止し、non-thinkingのみとした。non-thinkingだが性能が向上し、context長が256k (前回の2倍)になっている模様。
元ポスト:
関連:
- Qwen3, Qwen Team, 2025.04
- [Paper Note] Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, Mingqi Wu+, arXiv'25
において、Qwen2.5-math-7B, Qwen2.5-7Bに対して、Math500, AMC,
AIME2024データについてコンタミネーションの可能性が指摘されている点には留意したい。
- Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07
ポストのベンチ上ではKimi-K2を超えているように見えるが、果たして…?
LMDeploy, OpenMMLab, 2023.07
Paper/Blog Link My Issue
#Article #Library #LLMServing Issue Date: 2025-07-21
LLM推論に関する技術メモ, iwashi.co, 2025.07
Paper/Blog Link My Issue
#Article #Tutorial #Metrics #NLP #LLMServing #MoE(Mixture-of-Experts) #SoftwareEngineering #Selected Papers/Blogs #Parallelism #Inference #Batch Issue Date: 2025-07-21 Comment
```
メモリ (GB) = P × (Q ÷ 8) × (1 + オーバーヘッド)
- P:パラメータ数(単位は10億)
- Q:ビット精度(例:16、32)、8で割ることでビットをバイトに変換
- オーバーヘッド(%):推論中の追加メモリまたは一時的な使用量(例:KVキャッシュ、アクティベーションバッファ、オプティマイザの状態)
```
↑これ、忘れがちなのでメモ…
関連(量子化関連研究):
- [Paper Note] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration, Ji Lin+, MLSys'24
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models, Guangxuan Xiao+, ICML'23
- [Paper Note] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, ICLR'23, 2022.10
すごいメモだ…勉強になります
OpenReasoning-Nemotron: A Family of State-of-the-Art Distilled Reasoning Models, Nvidia, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Reasoning #Distillation #OpenWeight #OpenSource Issue Date: 2025-07-18 Comment
DeepSeek-R1-0528から応答を合成したデータでSFTのみを実施し、32BでQwe3-235B-A22Bと同等か上回る性能。アーキテクチャはQwen2.5。データはOpenCode/Math/Scienceを利用。
元ポスト:
データも公開予定
Seed-X-Instruct-7B, ByteDance-Seed, 2025.07
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #SmallModel #MultiLingual #OpenWeight Issue Date: 2025-07-18 Comment
元ポスト:
MTに特化したMultilingual SLM。7Bモデルだがベンチマーク上では他の大規模なモデルと同等以上。
テクニカルレポート: https://github.com/ByteDance-Seed/Seed-X-7B/blob/main/Technical_Report.pdf
Asymmetry of verification and verifier’s law, Jason Wei, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Dataset #Blog #Verification Issue Date: 2025-07-17 Comment
元ポスト:
LLM Recommendation Systems: AI Engineer World's Fair 2025, AI Engineer, 2025.07
Paper/Blog Link My Issue
#Article #RecommenderSystems #Video #SemanticID Issue Date: 2025-07-17 Comment
元ポスト:
セマンティックIDの実用例
論文では語られないLLM開発において重要なこと Swallow Projectを通して, Kazuki Fujii, NLPコロキウム, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Slide #Japanese #SoftwareEngineering #Selected Papers/Blogs Issue Date: 2025-07-16 Comment
独自LLM開発の私の想像など遥かに超える非常に困難な側面が記述されており、これをできるのはあまりにもすごいという感想を抱いた(小並感だけど本当にすごいと思う。すごいとしか言いようがない)
Modded-NanoGPT, KellerJordan, 2024.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Pretraining #NLP #Transformer #Repository #Optimizer #Selected Papers/Blogs #Decoder Issue Date: 2025-07-15 Comment
NanoGPT speedrun
関連:
- [Paper Note] The Automated LLM Speedrunning Benchmark: Reproducing NanoGPT Improvements, Bingchen Zhao+, arXiv'25
- きみはNanoGPT speedrunを知っているか?, PredNext, 2025.07
MuonとAdamWのweight decayをHyperball optimizationに置き換えることで記録更新されたようである:
Hyperball optimizationについては以下:
- Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization, Wen+, 2026.01
SOAP preconditioningをMuon直交化の前に加えることでSoTAとのこと。
関連:
- [Paper Note] SOAP: Improving and Stabilizing Shampoo using Adam, Nikhil Vyas+, ICLR'25
きみはNanoGPT speedrunを知っているか?, PredNext, 2025.07
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Blog #Optimizer Issue Date: 2025-07-15
advanced-mcp-features, epicweb-dev, 2025.06
Paper/Blog Link My Issue
#Article #Tutorial #Coding #SoftwareEngineering #MCP Issue Date: 2025-07-14 Comment
MCPの勉強に良いかもしれないのでメモ
Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Optimizer #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Stability #KeyPoint Notes #Reference Collection Issue Date: 2025-07-12 Comment
元ポスト:
1T-A32Bのモデル。さすがに高性能。
(追記) Reasoningモデルではないのにこの性能のようである。
1T-A32Bのモデルを15.5Tトークン訓練するのに一度もtraining instabilityがなかったらしい
元ポスト:
量子化したモデルが出た模様:
仕事早すぎる
DeepSeek V3/R1とのアーキテクチャの違い:
MLAのヘッドの数が減り、エキスパートの数を増加させている
解説ポスト:
利用されているOptimizer:
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
2つほどバグがあり修正された模様:
chatbot arenaでOpenLLMの中でトップのスコア
元ポスト:
テクニカルペーパーが公開:
https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
元ポスト:
テクニカルレポートまとめ:
以下のような技術が使われている模様
- [Paper Note] Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, ICLR'26, 2025.05
- MLA MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
- MuonCip
- MuonOptimizer [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
- QK-Clip
- 参考(こちらはLayerNormを使っているが): [Paper Note] Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, CVPR'24, 2023.12
- RLVR
- DeepSeek-R1, DeepSeek, 2025.01
- Self-Critique
- 関連: [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25
- [Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Tasks and Verifiable Rewards, Ruipeng Jia+, arXiv'25, 2025.05
- Temperature Decay
- 最初はTemperatureを高めにした探索多めに、後半はTemperatureを低めにして効用多めになるようにスケジューリング
- Tool useのためのSynthetic Data
Reward Hackingに対処するため、RLVRではなくpairwise comparisonに基づくself judging w/ critique を利用きており、これが非常に効果的な可能性があるのでは、という意見がある:
H-Nets - the Past, Goomba Lab, 2025.07
Paper/Blog Link My Issue
#Article #NLP #Blog #Tokenizer Issue Date: 2025-07-12 Comment
元ポスト:
tokenizerも含めてデータに対して最適なinputの粒度を学習
公式ポスト(?):
関連:
- Byte Latent Transformer: Patches Scale Better Than Tokens, Artidoro Pagnoni+, ICML'25 Workshop Tokshop
- [Paper Note] From Bytes to Ideas: Language Modeling with Autoregressive U-Nets, Mathurin Videau+, NeurIPS'25
ByteLatentTransformerなどとはどう違うのだろうか?
解説ポスト:
SmolLM3: smol, multilingual, long-context reasoner, HuggingFace, 2025.07
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Reasoning #LongSequence #SmallModel #MultiLingual #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2025-07-09 Comment
元ポスト:
SmolLM3を構築する際の詳細なレシピ(アーキテクチャ、データ、data mixture, 3 stageのpretraining(web, code, mathの割合と品質をステージごとに変え、stable->stable->decayで学習), midtraining(long context->reasoning, post training(sft->rl), ハイブリッドreasoningモデルの作り方、評価など)が説明されている
学習/評価スクリプトなどがリリース:
Context Engineering - What it is, and techniques to consider, llamaindex, 2025.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #SoftwareEngineering #ContextEngineering Issue Date: 2025-07-04 Comment
元ポスト:
The New Skill in AI is Not Prompting, It's Context Engineering, PHLSCHMID, 2025.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #SoftwareEngineering #ContextEngineering Issue Date: 2025-07-04 Comment
元ポスト:
ERNIE 4.5 Series, ERNIE TEAM, 2025.06
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-06-30 Comment
Tech Report: https://yiyan.baidu.com/blog/publication/ERNIE_Technical_Report.pdf
元ポスト:
解説ポスト:
Hunyuan-A13B-Instruct, tencent, 2025.06
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-06-27 Comment
元ポスト:
- MoEアーキテクチャ, 80B-A13B
- fast, slow thinking mode
- 256k context window
- agenticタスクに特に特化
- Grouped Query Attention, 複数の量子化フォーマットをサポート
公式ポスト:
画像は公式ポストより引用。Qwen3-235B-A22Bよりも少ないパラメータ数で、同等(agenticタスクはそれ以上)なようにベンチマーク上は見えるが、果たして。
果たして日本語の性能はどうだろうか。
TENCENT HUNYUAN COMMUNITY LICENSE
https://github.com/Tencent-Hunyuan/Hunyuan-A13B/blob/main/LICENSE
Swallow LLM Leaderboard, Swallow LLM Team
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Japanese Issue Date: 2025-06-25 Comment
関連:
- 日本語LLMのリーダーボード(LLM.jp), Weights & Biases
- Nejumi LLMリーダーボード, Weights & Biases
Nemo-RL, Nvidia, 2025.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Library #Repository #PostTraining Issue Date: 2025-06-25
LLM-jp-3.1 シリーズ instruct4 の公開, LLM-jp, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #Dataset #Evaluation #Blog #OpenWeight #Japanese #OpenSource #PostTraining Issue Date: 2025-06-25 Comment
関連
- [Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, arXiv'24, 2024.06
- [Paper Note] Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data, Fahim Tajwar+, ICML'24
- [Paper Note] AnswerCarefully: A Dataset for Improving the Safety of Japanese LLM Output, Hisami Suzuki+, arXiv'25
人間を騙してサボるAIたち, 佐藤竜馬, 2025.06
Paper/Blog Link My Issue
#Article #NLP #RLHF #Blog #Verification Issue Date: 2025-06-24
Kimi-VL-A3B-Thinking-2506, moonshotai, 2025.06
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Reasoning #OpenWeight #One-Line Notes #Reference Collection Issue Date: 2025-06-24 Comment
元ポスト:
様々なベンチマークでSoTA(gpt4o, Qwen2.5-VL-7B)を達成したReasoning VLM
テクニカルペーパー:
- [Paper Note] Kimi-VL Technical Report, Kimi Team+, arXiv'25
AI Agent Manager (AAM) として生きていく : 作業環境とワークフローの設計, icoxfog417, 2025.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Coding #SoftwareEngineering #read-later #Author Thread-Post Issue Date: 2025-06-23 Comment
元ポスト:
Nano-vLLM, GeeeekExplorer, 2025.06
Paper/Blog Link My Issue
#Article #NLP #python #Blog #Repository #LLMServing #MinimalCode #Initial Impression Notes Issue Date: 2025-06-22 Comment
元ポスト:
vLLMと同等のinference speedを実現するミニマムでクリーンな実装。勉強用に良さそう。
POLARIS: A Post-Training Recipe for Scaling Reinforcement Learning on Advanced Reasoning Models,
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Repository #PostTraining #Initial Impression Notes Issue Date: 2025-06-21 Comment
元ポスト:
PJで利用されているRLライブラリ:
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
AIME2025のみの評価だが4Bでこの性能…?
MiniMax-M1, MiniMax, 2025.06
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #One-Line Notes #Author Thread-Post Issue Date: 2025-06-17 Comment
元ポスト:
vLLMでのservingが推奨されており、コンテキストは1M、456BのMoEアーキテクチャでactivation weightは46B
公式ポスト:
Agentもリリースした模様:
[Paper Note] Language Models are Unsupervised Multitask Learners, Radford+, OpenAI, 2019
Paper/Blog Link My Issue
#Article #NLP #Zero/FewShotLearning #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-06-15 Comment
今更ながら、GPT-2論文をメモってなかったので追加。
従来のモデルは特定のタスクを解くためにタスクごとに個別のモデルをFinetuningする必要があったが、大規模なWebTextデータ(Redditにおいて最低3つのupvoteを得たポストの外部リンクを収集)によって言語モデルを訓練し、モデルサイズをスケーリングさせることで、様々なタスクで高い性能を獲得でき、Zero-Shot task transfer, p(output | input, task) , が実現できるよ、という話。
今ざっくり見返すと、Next Token Predictionという用語は論文中に出てきておらず、かつ "Language Modeling" という用語のみで具体的なlossは記述されておらず(当時はRNN言語モデルで広く学習方法が知られていたからだろうか?)、かつソースコードも学習のコードは提供されておらず、lossの定義も含まれていないように見える。
ソースコードのモデル定義:
https://github.com/openai/gpt-2/blob/master/src/model.py#L169
[Paper Note] Unsupervised Elicitation of Language Models, Wen+, Anthropic, 2025.06
Paper/Blog Link My Issue
#Article #Unsupervised #NLP #Supervised-FineTuning (SFT) #Author Thread-Post Issue Date: 2025-06-12 Comment
元ポスト:
Qwen_Qwen3-Embedding-4B-GGUF, QwenTeam, 2025.06
Paper/Blog Link My Issue
#Article #Embeddings #NLP #RepresentationLearning #OpenWeight #One-Line Notes #Author Thread-Post Issue Date: 2025-06-06 Comment
8BモデルはMTEBでトップの性能を達成。context 32K。100以上の言語をサポート。32--2560次元にoutputの次元数をカスタマイズできる(嬉しい、が性能にどの程度影響が出るから気になる)。
元ポスト:
QwenTeam post:
2025年度人工知能学会全国大会チュートリアル講演「深層基盤モデルの数理」, Taiji Suzuki, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #MachineLearning #NLP #Transformer #Chain-of-Thought #In-ContextLearning #Attention #DiffusionModel #SSM (StateSpaceModel) #Slide #Scaling Laws #PostTraining Issue Date: 2025-05-31 Comment
元ポスト:
SSII2025 [OS1-03] PFNにおけるSmall Language Modelの開発, 鈴木 脩司, 画像センシングシンポジウム, 2025.05
Paper/Blog Link My Issue
#Article #NLP #SmallModel #Slide #Reading Reflections Issue Date: 2025-05-28 Comment
元ポスト:
関連
- [Paper Note] Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22, 2022.03
- [Paper Note] Scaling Laws for Neural Language Models, Jared Kaplan+, arXiv'20, 2020.01
- [Paper Note] Distillation Scaling Laws, Dan Busbridge+, ICML'25
- [Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
先行研究を元に仮説を立てて、有望なアプローチを取る意思決定が非常に勉強になる。
Scaling Lawsが不確実性のある意思決定において非常に有用な知見となっている。
同じようにPruningとKnowledge Distilationを実施した事例として下記が挙げられる
- Llama-3_1-Nemotron-Ultra-253B-v1, Nvidia, 2025.04
[Paper Note] Spurious Rewards: Rethinking Training Signals in RLVR, Shao+, 2025.05
Paper/Blog Link My Issue
#Article #Analysis #NLP #Mathematics #SmallModel #PostTraining #RLVR #Reference Collection #Author Thread-Post Issue Date: 2025-05-27 Comment
元ポスト:
参考(考察):
参考(考察):
こちらでもQwen2.5 MATH 7b を用いて検証しているが、コンタミネーションの問題が仮に本当だとしたら、どう影響するだろうか。スレッド中のグラフもMATH500(Qwen2.5においてコンタミの可能性がある)の性能を示している。
【DL輪読会】 Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models, Deep Learning JP, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #NLP #DiffusionModel #Slide #Initial Impression Notes Issue Date: 2025-05-24 Comment
元ポスト:
Masked Diffusion Modelの進展, Deep Learning JP, 2025.03 でLiteratureをざっくり把握してからこちらを読むのが良さそう。
Masked Diffusion Modelの進展, Deep Learning JP, 2025.03
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #NLP #DiffusionModel #Slide #Reading Reflections Issue Date: 2025-05-24 Comment
元ポスト:
スライド中のARのようにKV Cacheが使えない問題に対処した研究が
- [Paper Note] dKV-Cache: The Cache for Diffusion Language Models, Xinyin Ma+, arXiv'25, 2025.05
この辺はdLLMが有望であれば、どんどん進化していくのだろう。
OpenAI-Codex, OpenAI, 2025.05
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Coding #SoftwareEngineering #One-Line Notes #Reference Collection Issue Date: 2025-05-18 Comment
OpenHandsのNeubig氏が、OpenAIのブログポスト中で報告されているSWE-Bench Verifiedのスコアについて、言及している。OpenAIは23個サンプルについて(internal infrastructureで動作させられないため)除外しているので、その分スコアに下駄が履かれているようで、ブログ中のpassNのスコアを他のリーダーボードのスコアと比較する際には注意が必要っぽい。
verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
Paper/Blog Link My Issue
#Article #NLP #Library #ReinforcementLearning #python #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-05-16 Comment
SoTAなRLアルゴリズムを数行のコードで実装可能で、Sequence Parallelismがサポートされているので長い系列を扱える。FSDP, Megatron-LM,vLLM,SGLangなどとシームレスに統合できるっぽい?
注意点(超重要):
inference backend(ブログ中ではvLLM, SGLangなどを仮定。ロールアウトに利用する)とtrainingのbackend(モデルを学習するフレームワーク, FSDPなどを仮定する)のミスマッチによってトークンの生起確率に差が生じ、ポリシーの更新がうまくいかなくなる。
- 論文では語られないLLM開発において重要なこと Swallow Projectを通して, Kazuki Fujii, NLPコロキウム, 2025.07
でも言われているように、ライブラリにはバグがあるのが普通なのね、、、。
Stanford Alpaca: An Instruction-following LLaMA Model, Taori +, 2023.03
Paper/Blog Link My Issue
#Article #NLP #InstructionTuning #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-05-12 Comment
今更ながらメモに追加。アカデミアにおけるOpenLLMに対するInstruction Tuningの先駆け的研究。
The Second Half, Shunyu Yao, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #MachineLearning #ReinforcementLearning #Blog #Reference Collection Issue Date: 2025-05-12 Comment
元ポスト:
Qwen3, Qwen Team, 2025.04
Paper/Blog Link My Issue
#Article #NLP #Alignment #Supervised-FineTuning (SFT) #ReinforcementLearning #InstructionTuning #Blog #LongSequence #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) #PostTraining #KeyPoint Notes #Reference Collection Issue Date: 2025-04-29 Comment
- 119言語をサポート
- MoEモデル [Paper Note] Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, Noam Shazeer+, ICLR'17
- 30B-A3B / 235B-A22N
- 128K context window
- Qwen2.5はMoEを採用していないので新たなアーキテクチャとなる
- Denseモデル(非MoEモデル)も公開
- 0.6B -- 32B
- 32K -- 128K context window
- Thinking/Non-thinking の切り替えが切り替えが可能
- スイッチは自動的に実施されるが、ユーザが明示的に `/think`, `/no_think` を user_promptの末尾に追加することで制御することも可能
- Pre-training
- データ
- 36 trillion tokensによって学習(Qwen-2.5の2倍)
- 学習データではwebデータに加えて、PDF-likeな文書群からQwen2.5-VL Qwen2.5-VL-32B-Instruct, Qwen Team, 2025.03
によってテキストを抽出し、Qwen2.5 で抽出された内容の品質を改善し利用
- また、math / code に関するデータを追加するために、Qwen2.5-Math / Qwen2.5-Coderを用いて合成データを作成(textbooks / QA pairs / code snippets [Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
)
- 事前学習のステップ
- S1: context長が4kの30 trillion tokenで事前学習
- S2: STEM / coding / reasoning task などのknowledge-intensiveデータの比率を増やして継続事前学習 (これがおそらく 5 trillion token程度?)
- Final Stage: context長を32kに拡大し高品質なlong-context dataで継続事前学習
- これによりBaseモデルが完成し、Qwen3-235B全体のうち10%程度のActive Parameterの利用するだけで(i.e., 22Bで)、Qwen2.5-72B Baseと同等以上の性能達成
- Post-training
- S1: long-CoT cold start
- 数学/coding/logical reasoning/STEMなどの多様なlong CoTデータを用いてSFT [Paper Note] s1: Simple test-time scaling, Niklas Muennighoff+, EMNLP'25, 2025.01
- S2: reasoning-based RL
- rule-based (verifiable) rewards によるRL DeepSeek-R1, DeepSeek, 2025.01
- S1/S2の流れは [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
に有効性が示されている通り、long CoT DataによるSFT -> RLを実施
- S3: thinking mode fusion
- S2データを用いてlong CoTデータとinstruction tuningデータ(非Long CoT)を生成し、Thinking/Non-thinkingを自動的に選択し生成するように学習(SFT or RLは記述なし)
- S4: general RL
- 20以上の一般的なドメインのタスクを通じて一般的な能力の向上と、safetyに関するalignmentの実施(e.g., instruction following, format following, agent能力など)
BestPracticeに関するポスト:
解説:
Improving Recommendation Systems & Search in the Age of LLMs, eugeneyan, 2025.04
Paper/Blog Link My Issue
#Article #RecommenderSystems #Blog Issue Date: 2025-04-28
Cursor_Devin全社導入の理想と現実, Ryoichi Saito, 2025.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Coding #Slide #SoftwareEngineering #Reading Reflections Issue Date: 2025-04-26 Comment
Devinの思わぬ挙動のくだりが非常に面白かった。まだまだ使いづらいところが多そうだなあ…。
Deepwiki, Cognition, 2025.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Repository #One-Line Notes Issue Date: 2025-04-26 Comment
githubリポジトリに関するリッチなドキュメントに対してDevinを通じて対話的に質問ができる模様。サインアップ不要で、githubリポジトリのドメインをdeepwikiに変えるだけで利用可能
Large Vision Language Model (LVLM) に関する最新知見まとめ (Part 1), Daiki Shiono, 2024.11
Paper/Blog Link My Issue
#Article #Survey #ComputerVision Issue Date: 2025-04-11
Fiction.liveBench, Kas, 2025.04
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #LongSequence #One-Line Notes Issue Date: 2025-04-09 Comment
long contextではGemini-2.5-proの圧勝
BFCLv2, UC Berkeley, 2024.08
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #API #Selected Papers/Blogs #One-Line Notes #ToolUse Issue Date: 2025-04-08 Comment
LLMのTool Useを評価するための現在のデファクトスタンダードとなるベンチマーク
BFCLv3:
https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html
Llama-3_1-Nemotron-Ultra-253B-v1, Nvidia, 2025.04
Paper/Blog Link My Issue
#Article #NLP #Alignment #Supervised-FineTuning (SFT) #ReinforcementLearning #InstructionTuning #Pruning #Reasoning #OpenWeight #KeyPoint Notes #Author Thread-Post Issue Date: 2025-04-08 Comment
DeepSeek-R1をGPQA Diamond GPQA: A Graduate-Level Google-Proof Q&A Benchmark, David Rein+, N/A, COLM'24
, AIME2024/2025, Llama4 Maverickを
BFCLv2(Tool Calling, BFCLv2, UC Berkeley, 2024.08
), IFEVal [Paper Note] Instruction-Following Evaluation for Large Language Models, Jeffrey Zhou+, arXiv'23, 2023.11
で上回り, そのほかはArenaHardを除きDeepSeekR1と同等
DeepSeekR1が671B(MoEで37B Activation Param)に対し、こちらは253B(ただし、Llama3.1がベースなのでMoEではない)で同等以上の性能となっている。
ReasoningをON/OFFする能力も備わっている。
モデルがどのように訓練されたかを示す全体図がとても興味深い:
特に [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
でも有効性が示されているように、SFTをしてからReasoningを強化する(強化というより元々持っている能力を引き出す?)RLを実施している。
詳細は下記Blogとのこと:
https://developer.nvidia.com/blog/build-enterprise-ai-agents-with-advanced-open-nvidia-llama-nemotron-reasoning-models/
元ポスト:
Dream-v0-Instruct-7B, Dream-org, 2025.04
Paper/Blog Link My Issue
#Article #NLP #DiffusionModel #OpenWeight #One-Line Notes Issue Date: 2025-04-08 Comment
OpenWeightな拡散言語モデル
元ポスト:
関連:
- [Paper Note] Large Language Diffusion Models, Shen Nie+, NeurIPS'25
Llama 4 Series, Meta, 2025.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #One-Line Notes #Reference Collection Issue Date: 2025-04-05 Comment
Huggingface:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164
解説ポスト:
Artificial Analysisによる性能検証:
MaverickがGPT4oと同等、ScoutがGPT4o-miniと同等
Update:
性能に関して不可解な点が多そうなので様子見をしても良いかも。
性能検証(Math-Perturb):
日本語にあまり強くないという情報も
元ポスト:
どうやらvLLMのLlama4のinferenceにバグがあったやうで、vLLMのIssue 16311にて、Llama4のinferenceに関するバグが修正され、性能が向上した模様。どのベンチを信じたら良いかまるでわからん。
2025.0413現在のchatbot arenaのランクは、32位となり(chatbot arena向けにtuningされていたであろうモデルは2位だった)GPT-4oが29位であることを考慮すると上記のArtificial Intelligenceの評価とも大体一致している。
https://lmarena.ai
関連ポスト:
openhands-lm-32b-v0.1, all-hands, 2025.03
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #SoftwareEngineering #One-Line Notes Issue Date: 2025-04-02 Comment
Qwen Coder 2.5 Instruct 32Bに基づく最先端のSWEタスクが実行可能なモデル
Recommendation Systems • LLM, vinjia.ai, 2025.03
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #NLP #Blog #Author Thread-Post Issue Date: 2025-03-31 Comment
Qwen2.5-VL-32B-Instruct, Qwen Team, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #Author Thread-Post Issue Date: 2025-03-25 Comment
元ポスト:
言語モデルの物理学, 佐藤竜馬, 2025.03
Paper/Blog Link My Issue
#Article #Analysis #NLP #Blog #Selected Papers/Blogs Issue Date: 2025-03-25 Comment
必読
Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #EfficiencyImprovement #Pretraining #NLP #Transformer #Supervised-FineTuning (SFT) #MultiModal #Blog #SSM (StateSpaceModel) #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-03-24 Comment
関連:
- Hunyuan T1, Tencent, 2025.03
TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。
56B程度のmediumサイズのモデルと、8B程度の軽量なモデルについて述べられている。特に、8BモデルでMambaとTransformerのハイブリッドモデルと、通常のTransformerモデルを比較している。学習データに15 Trillion Tokenを利用しており、このデータ量でのApple to Appleのアーキテクチャ間の比較は、現状では最も大規模なものとのこと。性能は多くのベンチマークでハイブリッドにしても同等、Commonsense Understandingでは上回っている。
また、学習したNemotron-Hをバックボーンモデルとして持つVLMについてもモデルのアーキテクチャが述べられている。
8 Types of RoPE, Kseniase, 2025.03
Paper/Blog Link My Issue
#Article #Survey #Embeddings #NLP #Transformer #Blog #PositionalEncoding #Initial Impression Notes Issue Date: 2025-03-23 Comment
元ポスト: https://huggingface.co/posts/Kseniase/498106595218801
RoPEについてサーベイが必要になったら見る
The "think" tool: Enabling Claude to stop and think in complex tool use situations, Anthropic, 2025.03
Paper/Blog Link My Issue
#Article #Tools #NLP #Chain-of-Thought #Blog #Reasoning #One-Line Notes Issue Date: 2025-03-23 Comment
"考える"ことをツールとして定義し利用することで、externalなthinkingを明示的に実施した上でタスクを遂行させる方法を紹介している
Hunyuan T1, Tencent, 2025.03
Paper/Blog Link My Issue
#Article #NLP #Reasoning #Proprietary #SSM (StateSpaceModel) #One-Line Notes #Reading Reflections Issue Date: 2025-03-22 Comment
元ポスト:
画像はブログより引用。DeepSeek-R1と比較すると優っているタスクと劣っているタスクがあり、なんとも言えない感。GPT4.5より大幅に上回っているタスク(Math, Reasoning)があるが、そもそもそういったタスクはo1などのreasoningモデルの領域。o1と比較するとこれもまあ優っている部分もあれば劣っている部分もあるという感じ。唯一、ToolUseに関しては一貫してOpenAIモデルの方が強い。
ChineseタスクについてはDeepSeek-R1と完全にスコアが一致しているが、評価データのサンプル数が少ないのだろうか?
reasoningモデルかつ、TransformerとMambaのハイブリッドで、MoEを採用しているとのこと。
TransformerとMambaのハイブリッドについて(WenhuChen氏のポスト):
Layer-wise MixingとSequence-wise Mixingの2種類が存在するとのこと。前者はTransformerのSelf-Attenton LayerをMamba Layerに置換したもので、後者はSequenceのLong partをMambaでまずエンコードし、Short PartをTransformerでデコードする際のCross-Attentionのencoder stateとして与える方法とのこと。
Self-Attention Layerを削減することでInference時の計算量とメモリを大幅に削減できる(Self-Attentionは全体のKV Cacheに対してAttentionを計算するため)。
Sudoku-bench, SakanaAI, 2025.03
Paper/Blog Link My Issue
#Article #NLP #Dataset #Reasoning #Initial Impression Notes #Author Thread-Post Issue Date: 2025-03-21 Comment
元ポスト:
既存モデルでベンチマークを取ったらどういうランキングになるのだろうか。特にまだそういぅたランキングは公開されていない模様。
ブログ記事に(将来的に最新の結果をrepositoryに追記される模様)現時点でのリーダーボードが載っていた。現状、o3-miniがダントツに見える。
https://sakana.ai/sudoku-bench/
Llama Nemotron, Nvidia, 2025.03
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-03-19 Comment
Nvidiaによる初めてのreasoning model。
元ポスト:
Artificial Analysisにやるベンチマーク:
GPQA Diamond(大学院(Ph.D)レベルの生物学、物理学、化学の450問程度の難解なmultiple choice question)で、DeepSeekV3, GPT4o, QwQ-32Bをoutperform. Claude 3.7 sonnetより少しスコアが低い。
DeepSeekR1, o1, o3-mini(high), Claude 3.7 sonnet Thinkingなどには及んでいない。
(画像は元ポストより引用)
システムプロンプトを変えることでreasoningをon/offできる模様
15 types of attention mechanisms, Kseniase, 2025.03
Paper/Blog Link My Issue
#Article #Survey #NLP #Transformer #Attention #Blog #Initial Impression Notes Issue Date: 2025-03-18 Comment
Luongらのアテンションやsoft, globalアテンションなど、古くからあるattentionも含まれている。
EXAONE-Deep-32B, LG AI Research, 2025.03
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #One-Line Notes Issue Date: 2025-03-18 Comment
元ポスト:
EXAONE AI Model License Agreement 1.1 - NC
商用利用不可
SmolDocling-256M, IBM Research, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #DocParser #One-Line Notes #Author Thread-Post Issue Date: 2025-03-18 Comment
Apache-2.0ライセンス。言語はEnglishのみな模様
マルチモーダルなImage-To-Textモデル。サンプルはこちら
ERNIE4.5_X1, Baidu, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #Proprietary #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2025-03-17 Comment
解説ポスト:
- ERNIE4.5はGPT4.5をさまざまなベンチマークで上回り、価格がなんとGPT4.5の1%
- X1はマルチモーダルなreasoningモデルでDeepSeek-R1と同等の性能で半額
らしい
このモデルは6月30日にオープン(ウェイト?)になるとスレッドで述べられている。
sarashina2-vision-{8b, 14b}, SB Intuitions, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-03-17 Comment
元ポスト:
VLM。Xに散見される試行例を見ると日本語の読み取り性能は結構高そうに見える。
モデル構成、学習の詳細、および評価:
LLM(sarashina2), Vision Encoder(Qwen2-VL), Projectorの3つで構成されており、3段階の学習を踏んでいる。
最初のステップでは、キャプションデータを用いてProjectorのみを学習しVision Encoderとテキストを対応づける。続いて、日本語を含む画像や日本特有の風景などをうまく扱えるように、これらを多く活用したデータ(内製日本語OCRデータ、図表キャプションデータ)を用いて、Vision EncoderとProjectorを学習。最後にLLMのAlignmentをとるために、プロジェクターとLLMを前段のデータに加えてVQAデータ(内製合成データを含む)や日本語の指示チューニングデータを用いて学習。
ProjectorやMMLLMを具体的にどのように学習するかは
- MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N/A, ACL'24 Findings
を参照のこと。
LLM 開発を支える多様な Fine-Tuning:PFN での取り組み, 中鉢魁三郎, PFN, 2025.03
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #Slide Issue Date: 2025-03-16 Comment
知識の追加の部分で下記研究が引用されている
- [Paper Note] Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?, Zorik Gekhman+, EMNLP'24, 2024.05
- [Paper Note] LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR'24, 2024.05
Model Context Protocol (MCP), Anthropic
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #SoftwareEngineering #Selected Papers/Blogs #MCP Issue Date: 2025-03-15 Comment
下記リンクのMCPサーバ/クライアントの作り方を読むとだいぶ理解が捗る:
https://modelcontextprotocol.io/quickstart/server
https://modelcontextprotocol.io/quickstart/client
browser-useの基礎理解, むさし, 2024.12
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #ComputerUse #Reading Reflections Issue Date: 2025-03-15 Comment
公式リポジトリ: https://github.com/browser-use/browser-use
BrowserUseはDoMを解析するということは内部的にテキストをLLMで処理してアクションを生成するのだろうか。OpenAIのComputer useがスクリーンショットからアクションを生成するのとは対照的だと感じた(小並感)。
- OpenAI API での Computer use の使い方, npaka, 2025.03
OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #OpenSource #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-03-14 Comment
真なる完全なるオープンソース(に近い?)OLMOの最新作
学習が安定しやすいpre LNではなく性能が最大化されやすいPost LNを採用している模様。学習を安定化させるために、QKNormやRMSNormを採用するなどの工夫を実施しているらしい。
AI_Agent_の作り方_近藤憲児, Kenji KONDO, 2025.03
Paper/Blog Link My Issue
#Article #AIAgents #Slide Issue Date: 2025-03-14
OpenAI API での Computer use の使い方, npaka, 2025.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #ComputerUse #Reading Reflections Issue Date: 2025-03-12 Comment
OpenAIのCompute Useがどのようなものかコンパクトにまとまっている。勉強になりました。
公式: https://platform.openai.com/docs/guides/tools-computer-use
Open-source DeepResearch – Freeing our search agents, HuggingFace, 2025.02
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenSource #DeepResearch Issue Date: 2025-03-12
Introducing Gemma 3: The most capable model you can run on a single GPU or TPU, Google, 2025.03
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #One-Line Notes #Reference Collection Issue Date: 2025-03-12 Comment
Googleの新たなSLMで、デバイスやラップトップでも動作可能な軽量モデル。テキストだけでなく画像とShortVideoの認識もできて、140言語をサポート。おまけに27BモデルでLlama3-405BとDeepSeek-V3とo3-miniをChatbotArenaのリーダーボードで上回り、128kのcontext window。えぇ…。
モデルの詳細:
https://huggingface.co/blog/gemma3
1Bモデルは英語のみサポート、マルチモーダル不可など制約がある模様。
詳細までは書いていないが、128Kコンテキストまでcontext windowを広げる際の概要とRoPE(のような)Positional Embeddingを利用していること、SlideingWindow Attentionを用いておりウィンドウサイズが以前の4096から性能を維持したまま1024に小さくできたこと、ImageEncoderとして何を利用しているか(SigLIP)、896x896の画像サイズをサポートしており、正方形の画像はこのサイズにリサイズされ、正方形でない場合はcropされた上でリサイズされる(pan and scanアルゴリズムと呼ぶらしい)こと、事前学習時のマルチリンガルのデータを2倍にしたことなど、色々書いてある模様。
Gemmaライセンス
解説ポスト:
解説ポスト:
Reasoning with Reka Flash, Reka, 2025.03
Paper/Blog Link My Issue
#Article #NLP #Reasoning #MultiLingual #OpenWeight #Initial Impression Notes Issue Date: 2025-03-12 Comment
Weights: https://huggingface.co/RekaAI/reka-flash-3
Apache-2.0
< /reasoning >を強制的にoutputさせることでreasoningを中断させることができ予算のコントロールが可能とのこと
The State of LLM Reasoning Models, Sebastian Raschka, 2025.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Blog #Reasoning #Test-Time Scaling Issue Date: 2025-03-09
QwQ-32B: Embracing the Power of Reinforcement Learning, Qwen Team, 2025.03
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Reasoning #OpenWeight #Reading Reflections Issue Date: 2025-03-06 Comment
元ポスト:
- [Paper Note] START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv'25, 2025.03
Artificial Analysisによるベンチマークスコア:
おそらく特定のタスクでDeepSeekR1とcomparable, 他タスクでは及ばない、という感じになりそうな予感
smolagents, HuggingFace, 2025.03
Paper/Blog Link My Issue
#Article #Library #AIAgents Issue Date: 2025-03-06 GPT Summary- smolagentsは、数行のコードで強力なエージェントを構築できるライブラリで、シンプルなロジック、コードエージェントのサポート、安全な実行環境、ハブ統合、モデルやモダリティに依存しない設計が特徴。テキスト、視覚、動画、音声入力をサポートし、さまざまなツールと統合可能。詳細はローンチブログ記事を参照。
GRPO Judge Experiments: Findings & Empirical Observations, kalomaze's kalomazing blog, 2025.03
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #ReinforcementLearning #Blog #GRPO #One-Line Notes #Subjective Issue Date: 2025-03-05 Comment
一意に解が決まる問題ではなく、ある程度の主観的な判断が必要なタスクについてのGRPOの分析。
2つのテキストを比較するタスクで、一方のタスクはLLMによって摂動を与えている(おそらく意図的にcorruptさせている)。
GRPOではlinearやcosineスケジューラはうまく機能せず、warmupフェーズ有りの小さめの定数が有効らしい。また、max_grad_normを0.2にしまgradient clippingが有効とのこと。
他にもrewardの与え方をx^4にすることや、length, xmlフォーマットの場合にボーナスのrewardを与えるなどの工夫を考察している。
microsoft_Phi-4-multimodal-instruct, Microsoft, 2025.02
Paper/Blog Link My Issue
#Article #NLP #MultiModal #OpenWeight #VisionLanguageModel #2D (Image) #Reference Collection #audio #text Issue Date: 2025-03-04 Comment
MIT License
The Ultra-Scale Playbook: Training LLMs on GPU Clusters, HuggingFace, 2025.02
Paper/Blog Link My Issue
#Article #Pretraining #MachineLearning #Supervised-FineTuning (SFT) #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-03-04 Comment
HuggingFaceによる数1000のGPUを用いたAIモデルのトレーニングに関するオープンソースのチュートリアル
Open Reasoner Zero, Open-Reasoner-Zero, 2024.02
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #Library #ReinforcementLearning #python #Reasoning Issue Date: 2025-03-02 Comment
元ポスト:
Introducing the SWE-Lancer benchmark, OpenAI, 2025.02
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #Coding #SoftwareEngineering #One-Line Notes Issue Date: 2025-03-02 Comment
元ポスト:
1400以上のフリーランスソフトウェアエンジニアリングタスクを集めたベンチマーク。タスクはバグ修正から機能実装まで多岐にわたり、経験豊富なエンジニアによって評価されたもの。
強化学習「GRPO」をCartPoleタスクで実装しながら解説, 小川雄太郎, 2025.02
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Blog #PostTraining #GRPO Issue Date: 2025-02-19 Comment
元ポスト:
Mistral-24B-Reasoning, yentinglin, 2025.02
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-02-17 Comment
Apache-2.0
LLMの事前学習のためのテキストデータの収集と構築, Shun Kiyono, 2015.02
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Slide Issue Date: 2025-02-12 Comment
詳細は著書に記載とのこと。興味深い。
modernbert-ja-130m, SB Intuitions, 2025.02
Paper/Blog Link My Issue
#Article #Embeddings #NLP #RepresentationLearning #pretrained-LM #Japanese #Author Thread-Post Issue Date: 2025-02-12 Comment
MIT Licence
元ポスト:
Docling, DS4SD, 2024.07
Paper/Blog Link My Issue
#Article #python #Initial Impression Notes Issue Date: 2025-02-12 Comment
Unstructuredとどちらが良いだろうか?
DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL, Luo+, 2025.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #ReinforcementLearning #ContextWindow #Blog #One-Line Notes Issue Date: 2025-02-12 Comment
日本語解説: https://jobirun.com/deepscaler-1-5b-surpasses-o1-preview-rl-scaling/
openreview:
https://openreview.net/forum?id=I6GzDCne7U
Iterative Context Lengtheningと呼ばれる、RLの学習時に最初から固定された大きなcontext(24Kなど)ではなく、学習の過程で小さなcontext windowから始め、効率的なreasoningを学習させながら、段階的にモデルのcontext windowを引き上げる手法(論文中では8K->16K->24K)を提案している。
SGlang, sgl-project, 2024.01
Paper/Blog Link My Issue
#Article #NLP #python #LLMServing #SoftwareEngineering #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-02-12 Comment
- Open R1, HuggingFace, 2025.01
のUpdate2でMath Datasetの生成に利用されたLLM Servingフレームワーク。利用前と比較してスループットが2倍になったとのこと。
CPU, external storageを利用することでTTFTを改善するようになったようで、最大80%TTFTが削減されるとの記述がある。
(原理的には元来可能だが計算効率の最適化に基づく誤差によって実装上の問題で実現できていなかった) Deterministic Inferenceをサポート:
Unsloth で独自の R1 Reasoningモデルを学習, npaka, 2025.02
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #Reasoning #Reading Reflections Issue Date: 2025-02-07 Comment
非常に実用的で参考になる。特にどの程度のVRAMでどの程度の規模感のモデルを使うことが推奨されるのかが明言されていて参考になる。
DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #FoundationModel #RLHF #Blog #Selected Papers/Blogs #Reading Reflections Issue Date: 2025-02-01 Comment
- DeepSeek-R1, DeepSeek, 2025.01
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open
Language Models, Zhihong Shao+, arXiv'24
とても丁寧でわかりやすかった。後で読んだ内容を書いて復習する。ありがとうございます。
Open R1, HuggingFace, 2025.01
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Repository #Reasoning #OpenSource #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-01-26 Comment
HFによるDeepSeekR1を完全に再現する取り組み
Update1: https://huggingface.co/blog/open-r1/update-1
Update2:
https://huggingface.co/blog/open-r1/update-2
512機のH100を利用…
LLM Datasets, mlabonne, 2025.01
Paper/Blog Link My Issue
#Article #NLP #Dataset #Supervised-FineTuning (SFT) #Repository #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-01-25 Comment
LLMの事後学習用のデータをまとめたリポジトリ
現在も更新されている。
Llama Stack, Meta, 2024.11
Paper/Blog Link My Issue
#Article #NLP #Library #AIAgents #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2025-01-25 Comment
Llamaを用いたLLM Agentを構築するための標準化されたフレームワーク。Quick StartではRAG Agentを構築している。
distilabel, 2023.11
Paper/Blog Link My Issue
#Article #NLP #Library #SyntheticData #One-Line Notes Issue Date: 2025-01-25 Comment
高品質な合成データをLLMで生成するためのフレームワーク
How to fine-tune open LLMs in 2025 with Hugging Face, PHILSCHMID, 2024.12
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #python #Blog #SoftwareEngineering #PostTraining #One-Line Notes Issue Date: 2025-01-25 Comment
SFTTrainerを用いたLLMのSFTについて、実用的、かつ基礎的な内容がコード付きでまとまっている。
How to align open LLMs in 2025 with DPO & and synthetic data, PHILSCHMID, 2025.01
Paper/Blog Link My Issue
#Article #NLP #Alignment #Supervised-FineTuning (SFT) #python #Blog #SoftwareEngineering #DPO #PostTraining #KeyPoint Notes Issue Date: 2025-01-25 Comment
元ポスト:
- DPOの概要やRLHFと比較した利点
- ルールベース、あるいはLLM as a Judgeを用いたOn-policy preference pair(現在のSFTしたモデルの出力から生成したpreference data)の作り方とその利点(現在のモデルのoutput distributionを反映しているので学習が効率化される)
- 環境構築方法
- DPOTrainer/TRLParserの使い方/DPODatasetの作り方
- DPOのハイパーパラメータβの意味合い
- DPOではSFTと比べて10-100x小さい学習率を使う必要があること
- Evaluation Harnessを用いた評価方法
- TGIを用いたモデルのデプロイとテスト
などが丁寧なサンプルコードと注釈、reference付きで説明されている。
Structured Outputs OpenAI Platform, 2025.01
Paper/Blog Link My Issue
#Article #Chain-of-Thought #python #StructuredData #One-Line Notes Issue Date: 2025-01-25 Comment
pydanticを用いて、CoT+構造化されたoutputを実施するサンプル
DeepSeek-R1-Distill-Qwen, DeepSeek, 2025.01
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight Issue Date: 2025-01-21 Comment
MIT Licence
元ポスト:
DeepSeek-R1, DeepSeek, 2025.01
Paper/Blog Link My Issue
#Article #NLP #Reasoning #OpenWeight #Selected Papers/Blogs #Reference Collection Issue Date: 2025-01-21 Comment
参考:
参考: https://horomary.hatenablog.com/entry/2025/01/26/204545
DeepSeek-R1の論文読んだ?【勉強になるよ】
, asap:
https://zenn.dev/asap/articles/34237ad87f8511
こちらのポストの図解がわかりやすい:
最新モデル: DeepSeek-R1-0528
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
所見:
tokyotech-llm_swallow-magpie-ultra-v0.1, tokyotech-llm, 2025.01
Paper/Blog Link My Issue
#Article #NLP #Dataset #InstructionTuning Issue Date: 2025-01-07 Comment
元ポスト:
DeepSeek-V2のアーキテクチャを徹底解説:MLA と DeepSeekMoE, kernelian, 2024.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Attention #Blog #MoE(Mixture-of-Experts) Issue Date: 2025-01-05 Comment
Killed by LLM, R0bk
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Dataset #Evaluation #Blog #One-Line Notes Issue Date: 2025-01-05 Comment
Saturationとなっているベンチマークは、最先端の性能をすでに測定できなくなってしまったベンチマークとのこと。
LLMによって性能が飽和したベンチマークをリストアップしているサイトで、2024年までのものが掲載されている。それ以後は掲載されていないようだ。
AI Agents 2024 Rewind - A Year of Building and Learning, VICTOR DIBIA, 2025.01
Paper/Blog Link My Issue
#Article #AIAgents #Blog Issue Date: 2025-01-05
AI Agent Era, 福島良典 | LayerX, 2024.12
Paper/Blog Link My Issue
#Article #AIAgents #Blog Issue Date: 2025-01-05
LLMがオワコン化した2024年, らんぶる, 2025.01
Paper/Blog Link My Issue
#Article #Blog #Reading Reflections Issue Date: 2025-01-05 Comment
LLMを(呼び出す|呼び出される)SaaS企業が今後どのような戦略で動いていくかが考察されており興味深かった。
LiteLLM, BerriAI, 2023.08
Paper/Blog Link My Issue
#Article #NLP #Library #python #Repository #API #One-Line Notes Issue Date: 2025-01-03 Comment
様々なLLMのAPIを共通のインタフェースで呼び出せるライブラリ
- aisuite, andrewyng, 2024.11
とどちらがいいんだ・・・?
aisuiteのissueの113番のスレッドを見ると、
- LiteLLMはもはやLiteではなくなっており、コードベースの保守性が低い
- aisuiteは複数のLLMプロバイダーをシンプルに利用する方法を提供する
- 今後発表されるロードマップを見れば、LiteLLMとの差別化の方向性が分かるはずだ
といった趣旨のことが記述されていた。
v1.82.7--v1.82.8において、機密情報を漏洩させるマルウェアが仕込まれていたとのこと。
Karpathy氏の所見:
Things we learned about LLMs in 2024, Simon Willson's blog, 2024.12
Paper/Blog Link My Issue
#Article #NLP #GenerativeAI #Blog Issue Date: 2025-01-03 Comment
元ポスト:
To fine-tune or not to fine-tune, Meta, 2024.08
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) #Blog #PEFT(Adaptor/LoRA) #Catastrophic Forgetting #PostTraining #KeyPoint Notes Issue Date: 2025-01-02 Comment
LLMをSFTする際の注意点やユースケースについて記述されている。
- full parameterのファインチューニングやPEFT手法のピークGPUメモリ
- full parameterのファインチューニングではcatastrophic forgettingに気をつける必要があること
- Finetuningが有用なユースケースとして以下が挙げられている
- トーン、スタイル、フォーマットのカスタマイザーション
- prompt engineeringやICLで達成するには困難なAccuracyの向上やエッジケースへの対応
- ドメイン適応
- より大きいモデルを蒸留することによるコスト削減
- 新たなタスクへの適応や能力の獲得
また、RAGとFinetuningどちらを選択すべきかに関する話題も記述されている(が、多くの場合はハイブリッドアプローチがベストだ、といった話も書いてある)。
元ポスト:
2024-ai-timeline, reach-vb, 2025.01
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NLP #OpenWeight #Proprietary #One-Line Notes Issue Date: 2025-01-02 Comment
月別で2024年にリリースされた主要なLLM(マルチモーダルなLLMも含む)のタイムラインがまとめられている。
API Only(プロプライエタリ)なのか、OpenWeightなのかもタグ付けされている。
Preferred Generation Benchmark, pfnet-research, 2024.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #Evaluation #Japanese Issue Date: 2024-12-30 Comment
参考:
日本語プレプリント: https://jxiv.jst.go.jp/index.php/jxiv/preprint/view/1008
arXivはこれからっぽい
MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Attention #Blog #KeyPoint Notes Issue Date: 2024-12-28 Comment
DeepSeekで使われているMulti Head Latent Attention(MLA)ってなんだ?と思い読んだ。端的に言うと、GQAやMQAは、KVのヘッドをそもそも減らしてKV Cacheを抑えよう、という手法だったが、MLAはKVを低ランクなベクトルに圧縮して保持し、使う時に復元するといった操作をすることで、MHAのパフォーマンスを落とすことなく(むしろ上がるらしい?)、利用するKV Cacheで利用するメモリを大幅に減らせるという手法らしい。
- [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
MQA, GQAの概要については上記参照のこと。
LLMを数学タスクにアラインする手法の系譜 - GPT-3からQwen2.5まで, bilzard, 2024.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Alignment #Supervised-FineTuning (SFT) #Chain-of-Thought #Reasoning #Mathematics #PostTraining #Reading Reflections Issue Date: 2024-12-27 Comment
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
において、数学においてモデルのパラメータ数のスケーリングによって性能改善が見込める学習手法として、モデルとは別にVerifierを学習し、モデルが出力した候補の中から良いものを選択できるようにする、という話の気持ちが最初よくわからなかったのだが、後半のなぜsample&selectがうまくいくのか?節を読んでなんとなく気持ちが理解できた。SFTを進めるとモデルが出力する解放の多様性が減っていくというのは、興味深かった。
しかし、特定の学習データで学習した時に、全く異なるUnseenなデータに対しても解法は減っていくのだろうか?という点が気になった。あとは、学習データの多様性をめちゃめちゃ増やしたらどうなるのか?というのも気になる。特定のデータセットを完全に攻略できるような解法を出力しやすくなると、他のデータセットの性能が悪くなる可能性がある気がしており、そうするとそもそもの1shotの性能自体も改善していかなくなりそうだが、その辺はどういう設定で実験されているのだろうか。
たとえば、
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
などでは、
- [Paper Note] Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks, Yizhong Wang+, EMNLP'22, 2022.04
のような1600を超えるようなNLPタスクのデータでLoRAによりSFTすると、LoRAのパラメータ数を非常に大きくするとUnseenタスクに対する性能がfull-parameter tuningするよりも向上することが示されている。この例は数学に特化した例ではないが、SFTによって解法の多様性が減ることによって学習データに過剰適合して汎化性能が低下する、というのであれば、この論文のことを鑑みると「学習データにoverfittingした結果他のデータセットで性能が低下してしまう程度の多様性の学習データしか使えていないのでは」と感じてしまうのだが、その辺はどうなんだろうか。元論文を読んで確認したい。
とても勉強になった。
記事中で紹介されている
> LLMを使って複数解法の候補をサンプリングし、その中から最適な1つを選択する
のルーツは
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
とのことなので是非読みたい。
この辺はSelf-Consistency
- [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
あたりが最初なのかと思っていた。
LLM-as-a-Judge をサーベイする, Ayako, 2024.12
Paper/Blog Link My Issue
#Article #Survey #NLP #Evaluation #Blog #LLM-as-a-Judge #KeyPoint Notes #Reading Reflections Issue Date: 2024-12-25 Comment
- A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
を読んだ結果を日本語でまとめてくださっている。
モデル選択について、外部APIに依存するとコストやプライバシー、再現性などの問題があるためOpenLLMをFinetuningすることで対応していることが論文中に記載されているようだが、評価能力にはまだ限界があるとのこと。
記事中ではLlama, Vicunaなどを利用している旨が記述されているが、どの程度のパラメータサイズのモデルをどんなデータでSFTし、どのようなタスクを評価したのだろうか(あとで元論文を見て確認したい)。
また、後処理としてルールマッチで抽出する必要あがるが、モデルのAlignmentが低いと成功率が下がるとのことである。
個人的には、スコアをテキストとして出力する形式の場合生成したテキストからトークンを抽出する方式ではなく、G-Eval のようにスコアと関連するトークン(e.g. 1,2,3,4,5)とその尤度の加重平均をとるような手法が後処理が楽で良いと感じる。
ICLR2025の査読にLLM-as-a-Judgeが導入されるというのは知らなかったので、非常に興味深い。
LLMが好む回答のバイアス(冗長性、位置など)別に各LLMのメタ評価をしている模様。また、性能を改善するための施策を実施した場合にどの程度メタ評価で性能が向上するかも評価している。特に説明を出力させても効果は薄く、また、複数LLMによる投票にしても位置バイアスの軽減に寄与する程度の改善しかなかったとのこと。また、複数ラウンドでの結果の要約をさせる方法がバイアスの低減に幅広く寄与したとのこと。
うーん、バイアスを低減するうまい方法がまだ無さそうなのがなかなか厳しい感じがする。
そもそも根本的に人間に人手評価をお願いする時もめちゃめちゃマニュアルとかガイドラインを作り込んだりした上でもagreementが高くなかったりするので、やはり難しそうである。
ただ、MTBenchでは人間の評価結果とLLMの評価結果の相関(agreementだっけか…?)が高かったことなどが報告されているし、LLMあるあるのタスクごとに得意不得意があります、という話な気もする。
Stanford CS229 I Machine Learning I Building Large Language Models (LLMs), StanfordUnivercity, 2024.09
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #Supervised-FineTuning (SFT) #Video #One-Line Notes Issue Date: 2024-12-25 Comment
スタンフォード大学によるLLM構築に関する講義。事前学習と事後学習両方ともカバーしているらしい。
Qwen2.5 Technical Reportの中に潜る, AbejaTech Blog, 2024.12
Paper/Blog Link My Issue
#Article #NLP Issue Date: 2024-12-24
OpenAI o3は,人間とは全く異質の汎用知能である危険性【東大解説】, 神楽坂やちま, 2024.12
Paper/Blog Link My Issue
#Article #NLP #GenerativeAI #Blog #One-Line Notes #Reading Reflections Issue Date: 2024-12-24 Comment
様々な有識者の見解をまとめつつ、文献を引用しつつ、かつ最終的に「人間が知能というものに対してなんらかのバイアスを持っている」可能性がある、という話をしており興味深い。
一部の有識者はARC-AGIの一部の、人間なら見た瞬間に分かるようなパターン認識の問題でも解けていないことから、AGIではないと主張しているとのことだったが、人間目線で簡単な問題が解けることはAGIとして必須な条件ではないよね、といった話が書かれており、そもそも有識者がどのようなものさしや観点でAGIを見ているのか、どういう視点があるのか、ということが感覚的に分かる内容であり、おもしろかった。
しかし、そもそも何がどうなったらAGIが実現できたと言えるのだろうか?定義がわからない(定義、あるのか…?)
完全にオープンな約1,720億パラメータ(GPT-3級)の大規模言語モデル 「llm-jp-3-172b-instruct3」を一般公開 ~GPT-3.5を超える性能を達成~ , NII, 2024.12
Paper/Blog Link My Issue
#Article #Tools #NLP #Dataset #Blog #OpenWeight #Japanese #OpenSource #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-12-24 Comment
GPT3.5と同程度のパラメータ数のコーパス、モデル、ツール、全てを公開。学習データまで含めてオープンなモデルとしては世界最大規模とのこと。
Instructionチューニング済みのモデルはライセンスを読むと、ライセンスに記述されている内容を遵守すれば、誰でも(日本人なら18歳以上とかはあるが)アクセス可能、用途の制限(商用・非商用問わず)なく利用でき、かつ再配布や派生物の生成などが許されているように見える。
が、baseモデルの方はコンタクト情報を提供のうえ承認を受けないと利用できない模様。また、再配布と一部の使途に制限がある模様。
SNSではオープンソースではないなどという言説も出ており、それはbaseモデルの方を指しているのだろうか?よくわからない。
実用上はinstructionチューニング済みのモデルの方がbaseモデルよりも使いやすいと思うので、問題ない気もする。
やはりbaseとinstructでライセンスは2種類あるとのこと:
OpenAI o1を再現しよう(Reasoningモデルの作り方), はち, 2024.12
Paper/Blog Link My Issue
#Article #Blog #Reasoning #SelfCorrection #Reading Reflections Issue Date: 2024-12-22 Comment
Reflection after Thinkingを促すためのプロンプトが興味深い
【NLPコロキウム】Stepwise Alignment for Constrained Language Model Policy Optimization (NeurIPS 2024) , 2024.12
Paper/Blog Link My Issue
#Article #NLP #Alignment #Slide #KeyPoint Notes Issue Date: 2024-12-19 Comment
- RLHF/DPO 小話, 和地瞭良/ Akifumi Wachi, 2024.04
も参照のこと。
RLHF, DPOが解いている問題が同じで、問題が同じなのでそれぞれの最適解も一緒であり解き方が違うだけ、でもDPOの方が頑張って強化学習するRLHFよりも簡単に解けるし、学習も安定してるよ、という話が、binary feedbackデータに対するアライメント手法であるKTOも交えて書いてある。
アライメントの学習では単一のスカラー値によって報酬が決まっているが、生成結果には色々な側面があるから単一スカラーでは本来評価できないよねという話が出てきた上で、safetyに対しても考慮して報酬を決めたい、という時にスカラー値のままだけど最適化問題の制約条件にsafetyに関する制約を入れる、ことで報酬に反映させます、みたいな話が書いてある。
そして提案手法の主要な貢献は、そういうことをやるとめちゃめちゃ手法が複雑化するんだけれども、よりシンプルにして、かつ理論的にも正当化されているし、実験的にもうまく動きます、という話らしい。
RLHF_DPO 小話, 和地瞭良_ Akifumi Wachi, 2024.04
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #Alignment #RLHF #Blog #DPO #PostTraining #Selected Papers/Blogs #Reading Reflections Issue Date: 2024-12-18 Comment
めちゃめちゃ勉強になる…
Scaling test-time-compute, Huggingface, 2024.12
Paper/Blog Link My Issue
#Article #Tutorial #Blog #Test-Time Scaling #read-later #Selected Papers/Blogs Issue Date: 2024-12-17 Comment
これは必読
Fast LLM Inference From Scratch, Andrew Chan, 2024.12
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Blog #One-Line Notes Issue Date: 2024-12-17 Comment
ライブラリを使用せずにC++とCUDAを利用してLLMの推論を実施する方法の解説記事
LLaMA-Omni: Seamless Speech Interaction with Large Language Models, Meta, 2024.09
Paper/Blog Link My Issue
#Article #NLP #SpeechProcessing #OpenWeight #OpenSource #One-Line Notes Issue Date: 2024-12-13 Comment
音声とテキストのOpenSourceマルチモーダルモデル。inputは音声のみ?に見えるが、出力はテキストと音声の両方を実施できる。GPT-4oレベルのspeech capabilityを目指すとaboutに記載されている。興味深い。
installの説明に `Whisper-large-v3` をインストールする旨が記載されているので、Whisper-large-v3で認識した内容に特化したSpeech Encoder/Adapterが学習されていると考えられる。
- MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N/A, ACL'24 Findings
マルチモーダルなLLMの基本的な概念については上記参照のこと。
OpenAI o1 System Card, OpenAI, 2024.12
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #Reasoning #Proprietary #VisionLanguageModel Issue Date: 2024-12-10
Llama3.3-70B, Meta, 2024.12
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #One-Line Notes Issue Date: 2024-12-06 Comment
3.1-70Bよりも性能向上し、3.1-405Bの性能により近く。
(画像は元ポストより引用)
Introducing Amazon Nova, our new generation of foundation models, AWS, 2024.12
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #FoundationModel #MultiLingual #KeyPoint Notes Issue Date: 2024-12-04 Comment
参考: https://qiita.com/ysit/items/8433d149dbaab702d526
後で個々のベンチマークとメトリックをまとめたい。
まあでもざっくり言うと、他のproprietaryモデルともおおむね同等の性能です、という感じに見える。個々のタスクレベルで見ると、得意なものと不得意なものはありそうではある。
スループットとかも、ProとGPT4oをパッと見で比較した感じ、優れているわけでもなさそう。Liteに対応するGPTはおそらくGPT4o-miniだと思われるが、スループットはLiteの方が高そう。
(画像は論文中からスクショし引用)
下記ポストは独自に評価した結果や、コストと性能のバランスについて言及している。
- ProはGPT4oのコストの約1/3
- Pro, Lite, Flashはほれぞれコストパフォーマンスに非常に優れている(Quality vs. Price参照)
元ポスト:
Augmenting Recommendation Systems With LLMs, Dave AI, 2024.08
Paper/Blog Link My Issue
#Article #RecommenderSystems #Blog Issue Date: 2024-12-03
日本語LLMまとめ, LLM-jp, 2024.12
Paper/Blog Link My Issue
#Article #Survey #NLP #Dataset #Evaluation #Repository #OpenWeight #Japanese #OpenSource #One-Line Notes Issue Date: 2024-12-02 Comment
LLM-jpによる日本語LLM(Encoder-Decoder系, BERT系, Bi-Encoders, Cross-Encodersを含む)のまとめ。
テキスト生成に使うモデル、入力テキスト処理に使うモデル、Embedding作成に特化したモデル、視覚言語モデル、音声言語モデル、日本語LLM評価ベンチマーク/データセットが、汎用とドメイン特化型に分けてまとめられている。
各モデルやアーキテクチャの原論文、学習手法の原論文もまとめられている。すごい量だ…。
LLM Self-Correction Papers, Ryo Kamoi, 2024.11
Paper/Blog Link My Issue
#Article #Survey #NLP #Repository #SelfCorrection #One-Line Notes Issue Date: 2024-11-30 Comment
self-correctionの専門家によるself-correction関連の論文のリーディングリスト。ぜひチェックしたい。
元ポスト:
Cross-prompt Pre-finetuning of Language Models for Short Answer Scoring, Funayama+, 2024.09
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Supervised-FineTuning (SFT) #AES(AutomatedEssayScoring) #Surface-level Notes Issue Date: 2024-11-28 Comment
SASでは回答データが限られているので、限られたデータからより効果的に学習をするために、事前に他のデータでモデルをpre-finetuningしておき、対象データが来たらpre-finetuningされたモデルをさらにfinetuningするアプローチを提案。ここで、prompt中にkeyphraseを含めることが有用であると考え、実験的に有効性を示している。
BERTでfinetuningをした場合は、key-phraseを含めた方が性能が高く、特にfinetuningのサンプル数が小さい場合にその差が顕著であった。
次に、LLM(swallow-8B, 70B)をpre-finetuningし、pre-finetuningを実施しない場合と比較することで、pre-finetuningがLLMのzero-shot、およびICL能力にどの程度影響を与えるかを検証した。検証の結果、pre-finetuningなしでは、そもそも10-shotにしてもQWKが非常に低かったのに対し、pre-finetuningによってzero-shotの能力が大幅に性能が向上した。一方、few-shotについては3-shotで性能が頭打ちになっているようにみえる。ここで、Table1のLLMでは、ターゲットとする問題のpromptでは一切finetuningされていないことに注意する(Unseenな問題)。
続いて、LLMをfinetuningした場合も検証。提案手法が高い性能を示し、200サンプル程度ある場合にHuman Scoreを上回っている(しかもBERTは200サンプルでサチったが、LLMはまだサチっていないように見える)。また、サンプル数がより小さい場合に、提案手法がより高いgainを得ていることがわかる。
また、個々の問題ごとにLLMをfinetuningするのは現実的に困難なので、個々の問題ごとにfinetuningした場合と、全ての問題をまとめてfinetuningした場合の性能差を比較したところ、まとめて学習しても性能は低下しない、どころか21問中18問で性能が向上した(LLMのマルチタスク学習の能力のおかげ)。
[Perplexity(hallucinationに注意)]( https://www.perplexity.ai/search/tian-fu-sitalun-wen-wodu-mi-ne-3_TrRyxTQJ.2Bm2fJLqvTQ#0)
aisuite, andrewyng, 2024.11
Paper/Blog Link My Issue
#Article #NLP #Library #python #Repository #API #One-Line Notes Issue Date: 2024-11-28 Comment
複数のLLM Providerの呼び出しを共通のインタフェースで呼び出せる。変更するのは、モデルを指定するパラメータのみ。
元ポスト:
https://www.linkedin.com/posts/andrewyng_announcing-new-open-source-python-package-activity-7266851242604134400-Davp?utm_source=share&utm_medium=member_ios
Sarashina2-8x70Bの公開, SB Intuitions, 2024.11
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Blog #OpenWeight #Japanese #One-Line Notes Issue Date: 2024-11-25 Comment
MoE Layerの説明、Sparse Upcyclingの説明、MoEモデルを学習する際に、学習時の学習率の設定が大きすぎると初期に損失が増大し、小さすぎると損失の増大は防げるがlong runで学習した際の性能向上が小さかったこと、元のモデルのパラメータを毀損しないように、Upcyclingをした元モデルの最終的な学習率を踏襲して学習をし、学習率をさらに減衰させていったこと、などが記載されている。
また、性能評価として同等のactivation parameter数を持つモデルと日本語のQAタスクで比較した結果も載っている。
- [Paper Note] Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR'23
MoE Layerについては
- [Paper Note] Mixtral of Experts, Albert Q. Jiang+, arXiv'24, 2024.01
も参照のこと
SmolLM2, 2024.11
Paper/Blog Link My Issue
#Article #NLP #Dataset #InstructionTuning #SyntheticData #OpenWeight #OpenSource #PostTraining #One-Line Notes Issue Date: 2024-11-21 Comment
元ポスト:
Orca-AgenInstruct-1M microsoft/orca-agentinstruct-1M-v1, Microsoft, 2024.11
よりもSmolLMのSFTで各種ベンチで高い性能を獲得
Large Vision Language Model (LVLM)に関する知見まとめ, Daiki Shiono, 2024.11
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NLP #Slide Issue Date: 2024-11-18
microsoft_orca-agentinstruct-1M-v1, Microsoft, 2024.11
Paper/Blog Link My Issue
#Article #NLP #Dataset #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2024-11-16
ローカルLLMのリリース年表, npaka, 随時更新, 2024.11
Paper/Blog Link My Issue
#Article #Survey #NLP #Blog #OpenWeight #OpenSource #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-11-15 Comment
ローカルLLMを含むOpenLLMのリリース日が年表としてまとまっており、随時更新されている模様。すごい。
2026年3月現在も更新が続いている
TensorRT-LLMによる推論高速化, Hiroshi Matsuda, NVIDIA AI Summit 2024.11
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Slide #read-later Issue Date: 2024-11-14 Comment
元ポスト:
非常に興味深いので後で読む
Copilot Arena, CMU and UC Berkeley, 2024.11
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Coding #Reading Reflections Issue Date: 2024-11-13 Comment
元ポスト:
- ChatBot Arena, lmsys org, 2023.05 も参照のこと
Chatbot Arenaがリリースされたのが1年半前であることをおもいおこし、この2年で飛躍的にLLMができることが増えたなぁ、パラメータ数増えたなぁ、でも省パラメータで性能めっちゃ上がったなぁ、proprietary LLMにOpenLLMが追いついてきたなぁ、としみじみ思うなどした。
sarashina2-8x70B, SBIntuitions, 2024.11
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Japanese #MoE(Mixture-of-Experts) #One-Line Notes Issue Date: 2024-11-09 Comment
プレスリリース: https://www.sbintuitions.co.jp/news/press/20241108_01/
- 商用利用不可な点には注意
- アーキテクチャは70Bモデルx8のMixture of Experts(MoE)
- モデルカードによると、inferenceにはBF16で、A100 80GB or H100が16基必要っぽい
MoEを利用したLLMについては、[Paper Note] Mixtral of Experts, Albert Q. Jiang+, arXiv'24, 2024.01 を参照のこと。
Lingua, Meta
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Library #Repository #MinimalCode #One-Line Notes Issue Date: 2024-11-05 Comment
研究目的のための、minimal、かつ高速なLLM training/inferenceのコードが格納されたリポジトリ。独自のモデルやデータ、ロスなどが簡単に実装できる模様。
Introducing quantized Llama models with increased speed and a reduced memory footprint, Meta, 2024.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Quantization #Blog Issue Date: 2024-10-26
Aya Expanse, Cohere, 2024.10
Paper/Blog Link My Issue
#Article #NLP #MultiLingual #OpenWeight #One-Line Notes #Author Thread-Post Issue Date: 2024-10-24 Comment
CohereによるマルチリンガルLLM, 8B, 32Bのモデルが存在する。
8BモデルのArenaHardでの評価
32BモデルのArenaHardでの評価
元ポスト:
Prompt-Engineering-Guide, DAIR.AI
Paper/Blog Link My Issue
#Article #NLP #Prompting #Repository #One-Line Notes Issue Date: 2024-10-20 Comment
LLMのsettingから、few-shot, self-consistencyなどのprompting技術、さまざまなタスクの実例などが網羅的にまとまっている
MLE-Bench, OpenAI, 2024.10
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #AutoML #One-Line Notes Issue Date: 2024-10-20 Comment
75のkaggleのcompetitionsを収集(賞金1.9M$に相当する)し、そこから機械学習モデルの構築するためのエンジニアリングタスク(データセットの準備, モデルの学習, 実験)を抽出し、AI Agentsが機械学習モデルのこれらエンジニアリングタスクに対してどの程度実施できるかを測定できるようにしたベンチマーク
Unsloth, unslothai, 2024.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Library #Supervised-FineTuning (SFT) #InstructionTuning #PEFT(Adaptor/LoRA) #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-10-08 Comment
single-GPUで、LLMのLoRA/QLoRAを高速/省メモリに実行できるライブラリ
現在でも鉄板
今日から始める大規模言語モデルのプロダクト活用, y_matsuwitter, 2024.10
Paper/Blog Link My Issue
#Article #Slide Issue Date: 2024-10-05
Gemma-2-Baku, 2024.10
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Japanese Issue Date: 2024-10-04
Gemma-2-JPN, 2024.10
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Japanese #One-Line Notes Issue Date: 2024-10-04 Comment
日本語データでfinetuningされたGemma2
元ポスト:
AutoGen, Microsoft, 2024.10
Paper/Blog Link My Issue
#Article #Library #AIAgents #Repository #Conversation #MCP #One-Line Notes Issue Date: 2024-10-02 Comment
マルチエージェントを構築するためのフレームワーク。MCP Serverとの連携も可能で、AssistantAgent classを入れ子のように設定することで、親エージェントが特定領域に特化した子エージェントをtool useとして呼び出すようなマルチエージェントを構築できるように見受けられる。
Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge), 2024.09
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #LLM-as-a-Judge #One-Line Notes Issue Date: 2024-09-30 Comment
LLM-as-a-judgeについて網羅的に書かれた記事
RAGの実装戦略まとめ, Jin Watanabe, 2024.03
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-09-29
NotebookLM, Google, 2024.09
Paper/Blog Link My Issue
#Article #Tools #InformationRetrieval #NLP #GenerativeAI #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-09-29 Comment
ソーステキストをアップロードし、それらを参照可能なLLMの元作業が可能で、クエリによって引用つきのRAGのようなものが行えるらしい。2人の対話形式のpodcastも自動生成可能で、UI/UXの面で画期的らしい?
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models, Meta, 2024.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Blog #SmallModel #OpenWeight #VisionLanguageModel #KeyPoint Notes #EdgeDevices Issue Date: 2024-09-25 Comment
11Bと90BのVLMと、エッジデバイス向けの1B, 3BのSLMを発表。
Llama3.2のVLMでは、事前学習されたimage encoderを事前学習された言語モデルに対して組み合わせるためのAdapterを複数学習することによって実現。
具体的には、Llama 3.1(text only model)に対して、image encoderとAdapterを追加し、大規模でノイジーな(image,text)ペアで事前学習。続いて、中規模のサイズの高品質なin-domain(i.e. 様々なドメインの)の知識を高めるような(image,text)ペアで学習した。
事後学習では、Llama3.1と同様にSFT, Rejection Sampling, DPOのラウンドを複数回繰り返した。Llama3.1を用いて、in-domainの画像に対するQAをData Augmentationし、フィルタリングすることで合成データを作成。さらに報酬モデルを活用して全ての回答候補をランクづけして高品質なSFTデータを取得。また、モデルの安全性が高まるようなデータも追加した。
Llama3.1の事後学習のプロセスについては 論文紹介 / The Llama 3 Herd of Models, 2024.08
も参照のこと。
LLMの効率化・高速化を支えるアルゴリズム, Tatsuya Urabe, 2024.09
Paper/Blog Link My Issue
#Article #Tutorial #EfficiencyImprovement Issue Date: 2024-09-25
LLM-jp-3 1.8B・3.7B・13B の公開, LLM.jp, 2024.09
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Japanese #OpenSource #One-Line Notes Issue Date: 2024-09-25 Comment
LLM-JP-Evalでの評価結果はこちら: https://huggingface.co/llm-jp/llm-jp-3-1.8b
1.8Bのモデルが、モデルサイズに対して非常に性能が良いとのこと(確かに、3.8Bのモデルとの差があまりないように見える
元ポスト:
アーキテクチャはLlama2とのことなので、vLLMでも動作させられる模様
LLM-jp Corpus v3, LLM.jp, 2024.09
Paper/Blog Link My Issue
#Article #NLP #Dataset #Japanese #One-Line Notes Issue Date: 2024-09-25 Comment
LLM-jp-3
- LLM-jp-3 1.8B・3.7B・13B の公開, LLM.jp, 2024.09
の学習に利用されているコーパス
[Paper Note] Improving Language Understanding by Generative Pre-Training, OpenAI, 2018.06
Paper/Blog Link My Issue
#Article #NLP #Selected Papers/Blogs Issue Date: 2024-09-25 Comment
初代GPT論文
日本語解説: https://qiita.com/Toyamanokinsan/items/adff5e927fe26148c69c
OpenAI o1, 2024.09
Paper/Blog Link My Issue
#Article #NLP #Chain-of-Thought #Reasoning #Test-Time Scaling #Selected Papers/Blogs #VisionLanguageModel #KeyPoint Notes Issue Date: 2024-09-13 Comment
Jason Wei氏のポスト:
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
や
- [Paper Note] Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, arXiv'23, 2023.11
で似たような考えはすでに提案されていたが、どのような点が異なるのだろうか?
たとえば前者は、pauseトークンと呼ばれるoutputとは関係ないトークンを生成することで、outputを生成する前にモデル内部で推論する前により多くのベクトル操作を加える(=ベクトルを縦方向と横方向に混ぜ合わせる; 以後ベクトルをこねくりまわすと呼称する)、といった挙動を実現しているようだが、明示的にCoTの教師データを使ってSFTなどをしているわけではなさそうに見える(ざっくりとしか読んでないが)。
一方、Jason Wei氏のポストからは、RLで明示的により良いCoTができるように学習をしている点が違うように見える。
**(2025.0929): 以下のtest-time computeに関するメモはo1が出た当初のものであり、私の理解が甘い状態でのメモなので現在の理解を後ほど追記します。当時のメモは改めて見返すとこんなこと考えてたんだなぁとおもしろかったので残しておきます。**
学習の計算量だけでなく、inferenceの計算量に対しても、新たなスケーリング則が見出されている模様。
テクニカルレポート中で言われている time spent thinking (test-time compute)というのは、具体的には何なのだろうか。
上の研究でいうところの、inference時のpauseトークンの生成のようなものだろうか。モデルがベクトルをこねくり回す回数(あるいは生成するトークン数)が増えると性能も良くなるのか?
しかしそれはオリジナルのCoT研究である
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
のdotのみの文字列をpromptに追加して性能が向上しなかった、という知見と反する。
おそらく、**モデル学習のデコーディング時に**、ベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすこと=time spent thinking (test-time compute) 、ということなのだろうか?
そしてそのように学習されたモデルは、推論時にベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすと性能が上がる、ということなのだろうか。
もしそうだとすると、これは
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
のpauseトークンの生成をしながらfinetuningすると性能が向上する、という主張とも合致するように思うが、うーん。
実際暗号解読のexampleを見ると、とてつもなく長いCoT(トークンの生成数が多い)が行われている。
RLでReasoningを学習させる関連研究:
- ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N/A, ACL'24
- Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N/A, ICML'24
以下o1の動きに関して考えている下記noteからの引用。
>これによって、LLMはモデルサイズやデータ量をスケールさせる時代から推論時間をスケールさせる(つまり、沢山の推論ステップを探索する)時代に移っていきそうです。
なるほど。test-compute timeとは、推論ステップ数とその探索に要する時間という見方もあるのですね。
またnote中では、CoTの性能向上のために、Process Reward Model(PRM)を学習させ、LLMが生成した推論ステップを評価できるようにし、PRMを報酬モデルとし強化学習したモデルがo1なのではないか、と推測している。
PRMを提案した研究では、推論ステップごとに0,1の正誤ラベルが付与されたデータから学習しているとのこと。
なるほど、勉強になります。
note:
https://note.com/hatti8/n/nf4f3ce63d4bc?sub_rt=share_pb
note(詳細編): https://note.com/hatti8/n/n867c36ffda45?sub_rt=share_pb
こちらのリポジトリに関連論文やXポスト、公式ブログなどがまとめられている:
https://github.com/hijkzzz/Awesome-LLM-Strawberry
これはすごい。論文全部読みたい
A few prompt engineering tips that Ilya Sutskever picked up at OpenAI, Ilya Sutskever, 2024.09
Paper/Blog Link My Issue
#Article #NLP #Prompting #Post Issue Date: 2024-09-08
ml-engineering
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #MachineLearning #NLP #Repository #One-Line Notes Issue Date: 2024-09-07 Comment
LLMやVLMを学習するためのツールやノウハウがまとめられたリポジトリ
Reflection 70B, GlaiveAI, 2024.09
Paper/Blog Link My Issue
#Article #NLP #InstructionTuning #OpenWeight #SelfCorrection #PostTraining #KeyPoint Notes #Reference Collection #Author Thread-Post Issue Date: 2024-09-06 Comment
ただまあ仮に同じInputを利用していたとして、promptingは同じ(モデルがどのようなテキストを生成し推論を実施するかはpromptingのスコープではない)なので、そもそも同じInputなのでfair comparisonですよ、という話に仮になるのだとしたら、そもそもどういう設定で比較実験すべきか?というのは検討した方が良い気はする。まあどこに焦点を置くか次第だと思うけど。
エンドユーザから見たら、reflectionのpromptingのやり方なんてわからないよ!という人もいると思うので、それを内部で自発的に実施するように学習して明示的にpromptingしなくても、高い性能を達成できるのであれば意味があると思う。
ただまあ少なくとも、参考でも良いから、他のモデルでもreflectionをするようなpromptingをした性能での比較結果も載せる方が親切かな、とは思う。
あと、70Bでこれほどの性能が出ているのはこれまでにないと思うので、コンタミネーションについてはディフェンスが必要に思う(他のモデルがそのようなディフェンスをしているかは知らないが)。
追記
→ 下記記事によると、LLM Decontaminatorを用いてコンタミネーションを防いでいるとのこと
https://github.com/lm-sys/llm-decontaminator
Reflection自体の有用性は以前から示されている。
参考: Self-Reflection in LLM Agents: Effects on Problem-Solving Performance, Matthew Renze+, N/A, arXiv'24
, [Paper Note] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai+, ICLR'24, 2023.10
, [Paper Note] AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls, Yu Du+, ICML'24, 2024.02
, [Paper Note] Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies, Liangming Pan+, TACL'24, 2023.08
ollamaで実際に動かして日本語でのQAを試している記事。実際のアウトプットやreflectionの内容が確認でき、おもしろい。
システムプロンプトで< thinking >タグでInputに対して推論し、< output >タグ内で最終出力を行い、推論過程で誤りがある場合は< reflection >タグを用いて修正するように指示している。
おそらく、thinkingタグ内の思考過程でモデルが誤りに気づいた場合は、thinkingタグの途中でreflectionタグが出力され、その時点でCoTが修正されるようである(もしくはoutputとthinkingの中間)。このため、誤ったCoTに基づいてOutputが生成される頻度が減少すると考えられる。
このような挙動はおそらく、reflection用の学習データでSFTしないとできないと思うので
(たとえば、ReflectionタスクをするようなデータでSFTをしていない場合、出力の途中で誤りを検出し出力を修正するという挙動にはならず、回答として自然な文を最後までoutputすると思う。その後でreflectionしろと促すことはpromptingでできるかもしれないが、そもそもreflectionする能力があまり高くない可能性があり、うまく修正もしてくれないかも)
reflectionの能力を高めるようなデータでSFTをしていないモデルで似たようなpromptingをしても、うまくいかない可能性があるので注意が必要だと思われる。
参考:
https://note.com/schroneko/n/nae86e5d487f1
開発者曰く、HFに記載の正しいシステムプロンプトを入れないと、適切に動作しないとのこと。
元ツイート:
どうやら初期にアップロードされていたHFのモデルはweightに誤りがあり、挙動がおかしくなっていたようだ。
正しいモデルの挙動は下記ツイートのようである。thinking内でreflectionが実施されている。
実際にいくつかの例をブログをリリース当日に見た時に、reflectionタグがoutputの後に出力されている例などがあり、おや?という挙動をしていたので、問題が是正されたようだ。
HFのモデルが修正された後もベンチマークの結果が再現されないなど、雲行きが色々と怪しいので注意した方が良い。
続報
開発者ポスト:
再現実験を全て終了し、当初報告していた結果が再現されなかったとCEOが声明:
Ruri: Japanese General Text Embeddings, cl-nagoya, 2024.09
Paper/Blog Link My Issue
#Article #Embeddings #NLP #RepresentationLearning #Japanese #KeyPoint Notes Issue Date: 2024-09-04 Comment
元ツイート:
337Mパラメータのモデルで、同等のサイズのモデルをJMTEBで大きく上回る性能。LLMを用いて生成したデータを用いてContrastive Learning, その後高品質なデータでFinetuningを実施したとのこと。
JMTEB上では、パラメータサイズ不明(だがおそらく桁違いに大きい)のOpenAI/text-embedding-3-largeと同等の性能に見えるが、LLMに日本語テキストを学習させる意義, Koshiro Saito+, 第261回自然言語処理研究発表会, 2024.08
などを考慮すると、日本特有の知識を問うQAなどはマルチリンガルなモデルは弱そうなので、その辺がどれほど高い性能を持っているのかは興味がある。
LLMで人工的に生成したデータでは、生成に利用したLLMが持つ知識しか表層的には現れないと思うので何を利用したかによるのと、高品質なラベルデータにその辺がどの程度含まれているか。
最大sequence長は1012なので、より長い系列をBERTで埋め込みたい場合はRetrievaBERT RetrievaBERTの公開, 2024 (最大sequence長2048)も検討の余地がある。
開発者の方からテクニカルレポートが出た
https://arxiv.org/abs/2409.07737
LLMに日本語テキストを学習させる意義, Koshiro Saito+, 第261回自然言語処理研究発表会, 2024.08
Paper/Blog Link My Issue
#Article #Analysis #OpenWeight #Slide #Japanese #One-Line Notes Issue Date: 2024-09-03 Comment
英日翻訳や日本特有の知識を問われるようなQAにおいて、日本語データによる学習の効果があることが示唆されている模様。
たとえば、論文紹介 / The Llama 3 Herd of Models, 2024.08
に示されている通り、Llama2における日本語データの割合は0.2%とかなので、英語圏のOpenLLMにおいて、日本語データの比率がどれだけ少ないかがわかる。
大規模言語モデル (LLM) の技術と最新動向, Ikuya Yamada, 2024.06
Paper/Blog Link My Issue
#Article #Tutorial #Slide #One-Line Notes Issue Date: 2024-09-01 Comment
LLMの原理の基礎的な内容について、丁寧かつコンパクトにまとまっている。
>ファインチューニングは新しい知識の学習ではなく知識の使い方を学習させるのに向いている
これをきちんと念頭に置いておかないと落とし穴にハマると思う。引用元の論文読みたい:
- [Paper Note] Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?, Zorik Gekhman+, EMNLP'24, 2024.05
NanoFlow, 2024.08
Paper/Blog Link My Issue
#Article #NLP #Library #python #Repository #LLMServing #KeyPoint Notes Issue Date: 2024-08-31 Comment
vLLMよりも2倍程度高速なLLM serving framework。
オフライン評価
オンラインでのlatency評価
機能はvLLMの方が多いが、速度はこちらの方がかなり速そうではある。latencyのrequirementが厳しい場合などは検討しても良いかもしれない。
しかしLLM serving frameworkも群雄割拠ですね。
元ポスト:
- DeepSpeed, vLLM, CTranslate2 で rinna 3.6b の生成速度を比較する, 2024.06
も参照のこと
2025年9月を最後にコミットがないようだ。
Firecrawl, 2024.09
Paper/Blog Link My Issue
#Article #Dataset #Repository #API #One-Line Notes Issue Date: 2024-08-30 Comment
sitemapなしでWebサイト全体をクローリングできるAPI。LLMで利用可能なマークダウンや、構造化データに変換もしてくれる模様。
論文紹介 _ The Llama 3 Herd of Models, 2024.08
Paper/Blog Link My Issue
#Article #Tutorial #NLP #OpenWeight #Slide Issue Date: 2024-08-26 Comment
Llama3の事前学習や事後学習のノウハウが詰まっており(安全性なども含む)、LLM学習に必要な要素が図解されており、非常に分かりやすい。
たとえばp.4中の図(スライド中より引用)などは、LLMの学習過程を説明する際にわかりやすそう
LLMの事前・事後学習あたりは独自ノウハウが多すぎてもはや追従困難
Liger-Kernel, 2024.08
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #Repository #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-08-25 Comment
LLMを学習する時に、ワンライン追加するだけで、マルチGPUトレーニングのスループットを20%改善し、メモリ使用量を60%削減するらしい
元ツイート:
Unsloth Unsloth, unslothai, 2024.07
はLoRA/QLoRAが可能な一方でまだMulti-GPUはサポートしていない。一方、Liger-KernelはLoRAよりもfull-parameter tuningとMulti-GPUにフォーカスしており、目的に応じて使い分けが必要。
https://github.com/linkedin/Liger-Kernel/issues/57
Grok-2, X, 2024.08
Paper/Blog Link My Issue
#Article #NLP #Proprietary #One-Line Notes Issue Date: 2024-08-24 Comment
chatbot arenaで5月時点のGPT4o超え。miniでもなんとllama3.1-705B超え
RAG入門: 精度改善のための手法28選, 2024.08
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-08-09
PLaMo-100B, PFN, 2024.08
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #SyntheticData #Blog #Proprietary #Japanese #DPO #ModelMerge #KeyPoint Notes Issue Date: 2024-08-08 Comment
日本語のベンチマークでGPT4を超える性能を達成。
SFT, DPOで学習。学習データは、Publicなもの、プログラムで作成したもの、LLM自身に作成させたものを利用した。また、最終的なモデルに複数の候補があったのでモデルマージで良いところ取りをした。DPOで利用するpreferenceデータは、事後学習途中のモデルによって自動生成。
Llama 3.1, 2024.07
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #One-Line Notes Issue Date: 2024-07-25 Comment
Llama系のモデルをFP8で学習する場合のレシピ
大規模言語モデルの開発, 2024
Paper/Blog Link My Issue
#Article #NLP #OpenWeight Issue Date: 2024-07-11
calm3-22B, 2024
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #Reading Reflections #needs-revision Issue Date: 2024-07-09 Comment
>LLMの日本語能力を評価するNejumi LLM リーダーボード3においては、700億パラメータのMeta-Llama-3-70B-Instructと同等の性能となっており、スクラッチ開発のオープンな日本語LLMとしてはトップクラスの性能となります(2024年7月現在)。
モデルは商用利用可能なApache License 2.0で提供されており
これはすごい
GENIAC: 172B 事前学習知見, 2024
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #Blog #KeyPoint Notes Issue Date: 2024-07-08 Comment
LLMの事前学習における知見がまとまっている記事とのこと
・Megatron LMで学習
→ 3D Parallelismなどの分散学習手法によりHF Trainerより高速
→ Data Parallelim、Tensor Parallelism、 Pipeline Parallelismを組み合わせたもの
・GPUメンテナンス、不良で学習が継続できなかった場合はcheckpointをロードして学習
・学習曲線が安定しているように見えるがSpikeは発生している。発生時はgradient normが急激に上昇する
・LlamaなどのLLMからの継続的事前学習ではなくfrom scratchから学習しているので透明性が高い
・Transformer engineを利用
・AdamWを利用
・attention dropout, hidden dropoutは0.0
>この際、 通信を多く必要とする分散手法のワーカー(Tensor Parallelワーカー)はノード内に配置するようにMegatron-LMのデフォルトではなっているため、今回もそれを利用しました。このようにする理由は、ノード内の通信はNVLinkにより、ノード間通信よりも高速であるためです。また、Data Parallelの勾配平均化のための通信を考慮して、Data Parallelワーカーも可能な限りノード内に配置するMegatron-LMデフォルトの挙動を利用しました。
Pipeline Parallelismは他の並列化手法と比較して通信量が少ないP2P(Point-to-Point)通信であるため、パイプラインステージはノード間で配置するようにしました。これも、Megatron-LMデフォルトの挙動です。
勉強になる
・通常のデータ並列はoptimizer stateをworker間で複製するので遅い。Deep Speed Zero 1のように分散して保有することで高速化
・Tensor Parallelでself attention, MLPの計算を並列化できる
・LayerNormalization, Dropoutの演算もメモリ効率の観点から並列化
・学習を安定させるためにz-lossを利用
・batch skippingとは、gradient clippingを行っていてもなおspikeが生じる場合に、100 step前に戻り、spikeが生じた付近のデータを数百iteration程度スキップすること
OpenDevin: Code Less, Make More, 2024
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #NLP #AIAgents #Repository #One-Line Notes Issue Date: 2024-07-04 Comment
LLMによるOpenSourceなソフトウェア生成エージェントプラットフォーム
full timeのスタッフを雇用しworldクラスのUXを目指すとのこと。楽しみ。
参考:
Open化される前の最初のDevinのツイート
より良いTransformerをつくる, Shun Kiyono, 2022
Paper/Blog Link My Issue
#Article #Tutorial #NLP Issue Date: 2024-07-03
RetrievaBERTの公開, 2024
Paper/Blog Link My Issue
#Article #NLP #RAG(RetrievalAugmentedGeneration) #LongSequence #Encoder #KeyPoint Notes Issue Date: 2024-07-03 Comment
RAGへ応用する際に、長いコンテキストを扱いEmbeddingを獲得したいシーンが増えたので、最大でコンテキスト長が2048のBERTを学習し公開。Apache2.0
オリジナルのBERTと比較して、近年のLLMで有用性が示されている以下をアーキテクチャに取り入れている
- SwiGLU活性化関数 [Paper Note] GLU Variants Improve Transformer, Noam Shazeer, arXiv'20, 2020.02
- PreNorm より良いTransformerをつくる, Shun Kiyono, 2022
- Grouped Query Attention (Multi Query Attention) [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
Llama 3 Swallow
Paper/Blog Link My Issue
#Article #NLP #OpenWeight Issue Date: 2024-07-03
mergekit-evolve
Paper/Blog Link My Issue
#Article #Library #Repository #ModelMerge #One-Line Notes Issue Date: 2024-04-29 Comment
[Paper Note] Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N/A, Nature Machine Intelligence, Vol.7, 2025.01
のように進化的アルゴリズムでモデルマージができるライブラリ
解説記事:
https://note.com/npaka/n/nad2ff954ab81
大きなVRAMが無くとも、大きめのSRAMがあれば動作するらしい
AirLLM, 2024.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Library #Repository #One-Line Notes Issue Date: 2024-04-28 Comment
4GBのSingle GPUで、70Bモデルのinferenceを実現できるライブラリ。トークンの生成速度は検証する必要がある。transformer decoderの各layerの演算は独立しているため、GPUに全てのlayerを載せず、必要な分だけ載せてinferenceするといった操作を繰り返す模様。
元ツイート:
LLaMA3, Meta, 2024.04
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #KeyPoint Notes Issue Date: 2024-04-18 Comment
ライセンスによると、LLaMA3を利用したモデルはどんな場合でもLlama3をprefixとして付与しないといけないらしい
元ツイート:
LLaMA3がChatBot ArenaでTop 5になったとのこと。また、英語においては、GPT4-1106-preview, GPT-4-turbo-2024-0409と同等の性能を達成。これはすごい…
nejumi-leaderboard Nejumi LLMリーダーボード, Weights & Biases
にLLaMA3の評価結果が掲載された模様(画像は下記ツイートより引用)
モデルアーキテクチャはTransformer Decoderをベースにしており、Llama2と比較して
- TokenizerのVocabサイズを128Kより効率的にテキストをエンコーディング可能に
- GQA [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
を利用しInferenceを高速化 (Llama2の時点でGQAを使っていたが、70Bモデルだけだった)
- self-attentionが、ドキュメントを跨がないように学習
context: 8192
Open Source Cookbook
Paper/Blog Link My Issue
#Article #Tutorial #NLP #GenerativeAI #Repository #OpenSource #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-04-14 Comment
HuggingFaceによる様々な実用的なアプリケーションをオープンソースの実装やモデルで実現するノートブックがまとまったリポジトリ。LLM-as-a-judge, RAG, PEFTによるPrompt Tuning(Prefix Tuningとかそっち系の話だと思われる)など、現在16種類ほどあるらしい。
改めて見たら数がかなり増えていた
The State of Multilingual AI, Sebastian Ruder, 2024
Paper/Blog Link My Issue
#Article #Blog #MultiLingual Issue Date: 2024-04-12
Mixtral-8x22B-v0.1, 2024
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #One-Line Notes Issue Date: 2024-04-10 Comment
Apache-2.0ライセンス, 日本語非対応
Command R+, Cohere, 2024
Paper/Blog Link My Issue
#Article #NLP #MultiLingual #OpenWeight #Proprietary #One-Line Notes Issue Date: 2024-04-10 Comment
Chatbot arenaでGPT-4-0314と同等の Elo Rate を獲得し(20240410時点)、日本語を含む10ヶ国語をサポート。コンテキストウィンドウサイズ128k。商用利用はAPIから、研究目的であればHuggingFaceから利用可能。
LLMの現在, 202404, Preffered Elements
Paper/Blog Link My Issue
#Article #Tutorial #NLP Issue Date: 2024-04-03
Mamba Explained
Paper/Blog Link My Issue
#Article #Blog Issue Date: 2024-04-02
Awesome LM with Tools
Paper/Blog Link My Issue
#Article #Survey #Tools #NLP #One-Line Notes Issue Date: 2024-03-22 Comment
Toolを利用するLMに関するNeubig氏のグループによるSurvey。
repeng
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Library #Alignment #TextualInversion #KeyPoint Notes Issue Date: 2024-03-21 Comment
LLMの出力のスタイルを数百個の事例だけで学習しチューニングできるライブラリ。promptで指定するのとは異なり、数値でスタイルの強さを指定することが可能らしい(元ツイート)。画像生成分野におけるTextual Inversionと同じ技術とのこと。
Textual Inversionとは、少量のサンプルを用いて、テキストエンコーダ部分に新たな「単語」を追加し、単語と対応する画像を用いてパラメータを更新することで、prompt中で「単語」を利用した場合に学習した画像のスタイルやオブジェクト(オリジナルの学習データに存在しなくても可)を生成できるようにする技術、らしい。
Huggiegface:
https://huggingface.co/docs/diffusers/training/text_inversion
(参考)GPTに質問した際のログ:
https://chat.openai.com/share/e4558c44-ce09-417f-9c77-6f3855e583fa
元ツイート:
[Paper Note] Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N_A, Nature Machine Intelligence, Vol.7, 2025.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Selected Papers/Blogs #ModelMerge #KeyPoint Notes #Nature Machine Intelligence Issue Date: 2024-03-21 GPT Summary- 進化アルゴリズムを使用した新しいアプローチを提案し、強力な基盤モデルの自動生成を実現。LLMの開発において、人間の直感やドメイン知識に依存せず、多様なオープンソースモデルの効果的な組み合わせを自動的に発見する。このアプローチは、日本語のLLMと数学推論能力を持つモデルなど、異なるドメイン間の統合を容易にし、日本語VLMの性能向上にも貢献。オープンソースコミュニティへの貢献と自動モデル構成の新しいパラダイム導入により、基盤モデル開発における効率的なアプローチを模索。 Comment
複数のLLMを融合するモデルマージの話。日本語LLMと英語の数学LLNをマージさせることで日本語の数学性能を大幅に向上させたり、LLMとVLMを融合したりすることで、日本にしか存在しない概念の画像も、きちんと回答できるようになる。
著者スライドによると、従来のモデルマージにはbase modelが同一でないとうまくいかなかったり(重みの線型結合によるモデルマージ)、パラメータが増減したり(複数LLMのLayerを重みは弄らず再配置する)。また日本語LLMに対してモデルマージを実施しようとすると、マージ元のLLMが少なかったり、広範囲のモデルを扱うとマージがうまくいかない、といった課題があった。本研究ではこれら課題を解決できる。
著者による資料(NLPコロキウム):
https://speakerdeck.com/iwiwi/17-nlpkorokiumu
Open Release of Grok-1 March 17, 2024
Paper/Blog Link My Issue
#Article #NLP #Blog #MoE(Mixture-of-Experts) #One-Line Notes Issue Date: 2024-03-18 Comment
Apache2.0ライセンス, 314Bパラメータでモデルの重み、Mixture-of-Expertsを採用している。学習データ、学習に利用したコードはおそらく公開されていない。
Grok-1.5がリリース
https://x.ai/blog/grok-1.5
各種ベンチマークの性能、特にMathの性能が向上し、コンテキスト長が128kに
RAG-Research-Insights
Paper/Blog Link My Issue
#Article #Tutorial #Survey #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Blog #Reading Reflections Issue Date: 2024-03-05 Comment
RAGに関する研究が直近のものまでよくまとめられている
What are the most important LLMs to know about in March 2024?
Paper/Blog Link My Issue
#Article #Survey #NLP #Post #One-Line Notes Issue Date: 2024-03-04 Comment
2024年3月時点で知っておくべきLLMに関するスレッド
Mistral Large
Paper/Blog Link My Issue
#Article #NLP Issue Date: 2024-02-27
awesome-generative-information-retrieval
Paper/Blog Link My Issue
#Article #Tutorial #Survey #InformationRetrieval #Blog Issue Date: 2024-02-22
RAGの性能を改善するための8つの戦略
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Reading Reflections Issue Date: 2024-02-11 Comment
めちゃめちゃ詳細にRAG性能向上の手法がreference付きでまとまっている。すごい。
Decoding Strategies that You Need to Know for Response Generation
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #NLP #Blog #One-Line Notes Issue Date: 2024-01-01 Comment
言語モデルのdecodingの方法についてよくまとまっている。まとめられているdecoding方法は以下
- Greedy, BeamSearch, RandomSampling, Temperature, Top-K Sampling, Nucleus Sampling
こちらの記事ではHuggingFaceでの実装や他のdecoding方法等、より実装面での詳細が記述されている:
https://note.com/npaka/n/n9a8c85f2ef7a
ELYZA-tasks-100 でLLM14個の日本語性能を横断評価してみた
Paper/Blog Link My Issue
#Article #Blog Issue Date: 2023-12-20
TokyoTechLLM
Paper/Blog Link My Issue
#Article #NLP #FoundationModel #Blog #Japanese #mid-training #KeyPoint Notes Issue Date: 2023-12-19 Comment
Llama2の日本語性能を継続事前学習で引き上げたLLM。2023年12月時点の日本語オープンソースLLMの中で最高性能とのこと。
開発者の方による詳細はこちら:
https://zenn.dev/tokyotech_lm/articles/d6cb3a8fdfc907
すごい読み応え…checkpointの容量のデカさや、A100x8 60ノード使った話や、ノード不良やスケジュール管理の話、独自に実装をゴリゴリ加えたものではなく最終的に完成度の高さからMegatronLMを採用した話など、バグった規模感と試行錯誤や実体験に基づくエピソード満載。
optimize-llm, HuggingFace, 2023.09
Paper/Blog Link My Issue
#Article #Tutorial #EfficiencyImprovement #NLP #One-Line Notes Issue Date: 2023-12-15 Comment
LLMをoptimizeする実用的なチュートリアル
こちらも有用なので参照のこと
【GPU inference】
https://huggingface.co/docs/transformers/main/perf_infer_gpu_one
【続】Flash Attentionを使ってLLMの推論を高速・軽量化できるか?, jobyan, Qiita, 2023.09
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Attention #Blog #KeyPoint Notes Issue Date: 2023-12-14 Comment
use_cacheがTrue/Falseの場合のFlashAttention2のinference timeとVRAM使用量の傾向をsequence_lengthごとに考察している。
use_cacheはKey Value cacheのオンオフを切り替えられるオプションである。autoregressiveなモデルのinference時には、何度も同じinput tokenに対するKVの計算が生じるため(M番目のトークンを生成した後、M+1番目のトークンの生成をする場合、M-1番目までのトークンのKVを再計算せねばならない)、cacheをすることで大幅に計算速度が改善される。
use_cacheをTrueにできるならFlashAttention2の恩恵は小さい(inference timeが少し早くなるのみ)ため、潤沢なVRAMがあるなら得られる恩恵は小さい。
逆にVRAM節約してuse_cacheをFalseにせざるを得ないのであれば、FlashAttention2によりVRAM使用量をsequence_legthの線形に抑えることができ、かつinference timeも短くなる。
↑上記はあくまでinferenceをする場合のみの話であり(train時はautoregressive modelではcausal maskを用い、teacher forcingで並列にトークンを生成するためそもそもKV-cacheする意味がない)、trainingをする場合FlashAttention2で大幅にVRAM使用量を減らせるので、そこは分けて考えること。
https://qiita.com/jovyan/items/ff3d0a49163c7afa33ce
Flash Attentionを使ってLLMの推論を高速・軽量化できるか?
https://qiita.com/jovyan/items/11deb9d4601e4705a60d
こちらの記事も非常に勉強になる
大規模モデルを支える分散並列学習のしくみ Part1, Kazuki Fujii, 2023.06
Paper/Blog Link My Issue
#Article #Tutorial #MachineLearning #NLP #Blog #DistributedLearning Issue Date: 2023-12-13
A Review of Public Japanese Training Sets, shisa, 2023.12
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #InstructionTuning #Repository #Japanese Issue Date: 2023-12-11
Introducing Gemini: our largest and most capable AI model, Google, 2023.12
Paper/Blog Link My Issue
#Article #NLP #MultiModal #Blog #Proprietary #VisionLanguageModel #KeyPoint Notes #Reference Collection Issue Date: 2023-12-07 Comment
多くのベンチマークでGPT4超えらしい
(追記1)
テクニカルレポートのp.44を見ると、ブログポスト中のGPT4のMMLUのスコアはGPT-4-0613のもののようなので、これが正しいとすると他のベンチマークのスコアも同モデルのものである可能性が高く、GPT-4-1163-preview(最新モデル)のスコアでは"ないかもしれない"点に注意。GPT4とどちらが実際に性能が良いか?については様子見した方が良さそう。
(追記2)
GSM8Kの結果も、GPT4に対してFair Comparisonではないかもしれない点に注意。Geminiは32個のCoTとSelf-Consistencyを利用しているが、GPT4では5-shotで単一のCoTのみであるため、prompting手法ではGeminiに有利な比較となっているように見える。ただしGPT4はGSM8Kの訓練データを事前学習時にMIXしている(SFT)ので、Geminiがこのようなことをしていないのであれば、この点ではGPT4が有利になっている“可能性”がある。
他にもFair Comparisonになっていないと推察されるものはTextモダリティでの評価の表の文言を見るとありそうなのでそこは念頭においた方が良さそうである。
テクニカルレポート: https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
Gemini Summary
MMLUでの同じprompting手法でのGPT-4-0613との比較。32個のCoTでのSelf-Consistencyで比較した場合、GPT-4-0613に負けているが、閾値を設けてconfidenceが閾値以上の場合はSelf-consistency, そうでない場合はgreedyに生成した結果を選択する、というUncertain-Routed CoT@32では、Geminiのパフォーマンスgainが大きくGPT-4-0613よりも高い性能を示している。
ブログポスト中のGPT4のスコアは5-shotのもの(reportedと書かれているのでOpenAIが公表している数値と推察)であり、Geminiの結果はUncertain-Routed CoT@32の結果であるため、Fair Comparisonになっていないかもしれない?点には注意。
レポート中ではSelf-consistencyという単語でこの部分は書かれていないが、実は少しやっていること違ってたりする…?
もし明日、上司に「GPT-4を作れ」と言われたら? Stability AIのシニアリサーチサイエンティストが紹介する「LLM構築タイムアタック」
Paper/Blog Link My Issue
#Article #Blog #One-Line Notes #Reading Reflections Issue Date: 2023-12-05 Comment
StabilityAI Japan秋葉さん(元PFN)のW&B Conferenceでの発表に関する記事。
LLM構築タイムアタックでLLMをもし構築することになったら!?
のざっくりとしたプロセスや、次ページでOpenAIのGPT4のテクニカルレポートのクレジットから各チームの規模感を推定して、どの部分にどの程度の人員が割かれていたのかというのをベースに、各パートでどんなことがやられていそうかという話がされている。
LLM構築タイムアタックで、まずGPUを用意します!(ここが一番大変かも)の時点で、あっ察し(白目 という感じがして面白かった。
kaggle LLM コンペ 上位解法を自分なりにまとめてみた話
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-12-04 Comment
実践的な内容(チャンク生成時の工夫、クエリ生成時の工夫等)が網羅的にまとまっており非常に有用
個人的に、コンペ主催者側から提供されたデータが少なく、上位のほとんどのチームがChatGPT(3.5, 4)を用いて、QAデータを生成していた、というのが興味深かった。プロンプトはたとえば下記:
[(5th-place-solution)](
https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/446293)より引用
```
system_content = """
Forget all the previous instruction and rigorously follow the rule specified by the user.
You are a professional scientist's assistant.
"""
user_content_template_qa = Template(
"""
Please consider 5 choices question and answer of the following TEXT.
The purpose of this question is to check respondent's deep science understanding of the TEXT.
We assume this question is for professional scientists, so consider super difficult question.
You can ask very detailed question, for example check specific sentence's understanding.
It is good practice to randomly choose specific sentence from given TEXT, and make QA based on this specific sentence.
You must make QA based on the fact written in the TEXT.
You may create wrong answers based on the correct answer's information, by modifying some parts of the correct answer.
Your response must be in following format, don't write any other information.
You must not include "new line" in each Q), 1), 2), 3), 4), 5), and A):
Q) `question text comes here`
1) `answer candidate 1`
2) `answer candidate 2`
3) `answer candidate 3`
4) `answer candidate 4`
5) `answer candidate 5`
A) `answer`
where only 1 `answer candidate` is the correct answer and other 4 choices must be wrong answer.
Note1: I want to make the question very difficult, so please make wrong answer to be not trivial incorrect.
Note2: The answer candidates should be long sentences around 30 words, not the single word.
Note3: `answer` must be 1, 2, 3, 4 or 5. `answer` must not contain any other words.
Note4: Example of the question are "What is ...", "Which of the following statements ...", "What did `the person` do",
and "What was ...".
Note5: Question should be science, technology, engineering and mathematics related topic.
If the given TEXT is completely difference from science, then just output "skip" instead of QA.
Here is an example of your response, please consider this kind of difficulty when you create Q&A:
Q) Which of the following statements accurately describes the impact of Modified Newtonian Dynamics (MOND) on the observed "missing baryonic mass" discrepancy in galaxy clusters?"
1) MOND is a theory that reduces the observed missing baryonic mass in galaxy clusters by postulating the existence of a new form of matter called "fuzzy dark matter."
2) MOND is a theory that increases the discrepancy between the observed missing baryonic mass in galaxy clusters and the measured velocity dispersions from a factor of around 10 to a factor of about 20.
3) MOND is a theory that explains the missing baryonic mass in galaxy clusters that was previously considered dark matter by demonstrating that the mass is in the form of neutrinos and axions.
4) MOND is a theory that reduces the discrepancy between the observed missing baryonic mass in galaxy clusters and the measured velocity dispersions from a factor of around 10 to a factor of about 2.
5) MOND is a theory that eliminates the observed missing baryonic mass in galaxy clusters by imposing a new mathematical formulation of gravity that does not require the existence of dark matter.
A) 4
Let's start. Here is TEXT: $title\n$text
"""
)
```
GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo, Anand+, 2023.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Tools #NLP #Repository #One-Line Notes Issue Date: 2023-11-21 Comment
ローカルマシンでChatGPT likeなUIでチャットボットを動作させられるOpensource。
Mistral7BやGGUFフォーマットのモデルのよつな(おそらく量子化されたものも含む)ローカルマシンで動作させられる規模感のモデルがサポートされている。
https://gpt4all.io/index.html
Zephyr-7B-beta, RAG Perf.
Paper/Blog Link My Issue
#Article #NLP #Evaluation #RAG(RetrievalAugmentedGeneration) #Blog #OpenWeight #One-Line Notes Issue Date: 2023-11-21 Comment
Zephyr-7B-betaのRAGでの性能がデータセットで評価されている
下記Xポストによるとgpt-3.5-turboと同等
Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation), SEBASTIAN RASCHKA, PHD, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #PostTraining Issue Date: 2023-11-20
JGLUEの構築そして 日本語LLM評価のこれから, 河原大輔, W&B 東京ミートアップ #8, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #Dataset #Evaluation #One-Line Notes #Reading Reflections Issue Date: 2023-11-16 Comment
JGLUEのexample付きの詳細、構築の経緯のみならず、最近の英語・日本語LLMの代表的な評価データ(方法)がまとまっている(AlpacaEval, MTBenchなど)。また、LLMにおける自動評価の課題が興味深く、LLM評価で生じるバイアスについても記述されている。Name biasなどはなるほどと思った。
日本語LLMの今後の評価に向けて、特にGPT4による評価を避け、きちんとアノテーションしたデータを用意しfinetuningした分類器を用いるという視点、参考にしたい。
LLaMA-Factory, hiyouga, 2023.07
Paper/Blog Link My Issue
#Article #NLP #Library #Supervised-FineTuning (SFT) #Repository #One-Line Notes Issue Date: 2023-11-14 Comment
簡単に利用できるLLaMAのfinetuning frameworkとのこと。
元ツイート:
LLaMAベースなモデルなら色々対応している模様
Hallucination Leaderboard, 2023
Paper/Blog Link My Issue
#Article #NLP #Hallucination #Factuality #Repository #One-Line Notes Issue Date: 2023-11-14 Comment
1000個の短いドキュメントに対して、事実情報のみを用いて要約を生成させ、要約結果と原文書のFactual consistencyを別に訓練したモデルで測定して評価してリーダーボードを作成している。
Claude2よりLLaMA2の方が性能が良いのが面白いし、Palmの性能があまり良くない。
元ツイート:
Retrieval-based LM (RAG System)ざっくり理解する, Shumpei Miyawaki, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Slide #KeyPoint Notes Issue Date: 2023-11-06 Comment
(以下スクショはスライドより引用)
次のスクショはRAGにかかわる周辺技術がよくまとまっていると思う。
以下ざっくり私の中の認識として
- 計画
- クエリ拡張
- クエリの質が悪い場合検索性能が劣化するため、クエリをより適切に検索ができるように修正(昔はキーワードしか与えられないときに情報を増やすから”拡張”という文言が用いられているが現在はこれに限らないと思う)する技術
- 分解・抽象化
- 複雑なクエリから分解することでマルチホップの質問をサブ質問に分解(今ならLLMを利用すれば比較的簡単にできる)したり、あるいは抽象化したクエリ(Step-back Promptnig [Paper Note] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N/A, ICLR'24
)を活用することで検索を改善する技術
- 検索対象選定
- 検索する対象そのものを選択し、検索対象をフィルタリングする技術
- 資料中ではLLMを用いたフィルタリングやClassifierを用いたフィルタリングが紹介されているが、メタデータで絞り込むなどの単純な方法でも実現可能だと思われる(メタデータで絞り込む、はClassifierでのフィルタリングとリンクするかもしれないが)
- 思考・行動
- [Paper Note] ReAct: Synergizing Reasoning and Acting in Language Models, Shunyu Yao+, ICLR'23, 2022.10
のような自律的にLLMに思考とその結果に基づく行動をイテレーションさせる技術や、クエリを分解して回答へたどり着くために必要な推論を構築し、各推論の回答を検証しながら生成を繰り返す技術が紹介されている
- この辺の技術はクエリが非常に複雑な場合に有効ではあるが、シンプルな場合は必要ないかなという印象がある
- シンプルなユースケースの場合はどちらかというと泥臭い前処理とかが効きそう
- 関連知識取得
- 検索
- 表層検索(TF-IDFベクトル, BM25)などの古典的な手法や、意味検索(Embeddingに基づく手法)が紹介されている
- 例えばlangchainでは表層検索 + 意味検索の両者がサポートされており、簡単にハイブリッドな検索が実現できる
- 知識文生成
- 外部知識として検索された文書を利用するだけでなく、LLM自身が保持する知識を活用するためにLLMが生成した文書の両方を活用するとQAの正答率が向上することが紹介されている
- 文書フィルタ
- 検索でクエリに関連しない文書を取得してしまう応答品質が大幅に低下することが紹介されている
- 個人的にはここが一番重要なパートだと考えている
- また、検索結果を要約する方法も紹介されている
- 再帰・反復計算
- Retrierverから取得した結果に基づいてLLMが応答を生成し、生成した応答とoriginalのquestionの両方を組み合わせて追加でRetrieverから文書を取得し生成する手法などが紹介されている
- リランキング
- 検索結果のリランキングも古くから存在する技術であり、異なる知識を持つRankerによってリランキングさせることで性能が向上する場合がある
- 回答
- 回答抽出・生成
- 回答となる部分のspanを抽出する手法と、spanではなくテキストを生成する手法が紹介されている
- この辺は文書要約におけるExtractive/Abstractive Summarization技術などもかなり応用が効くと思われる
- インデクシング
- 不要文書のフィルタリングや、チャンク分割の戦略、資格情報をテキスト化する方法などが紹介されている
生成AIが抱えるリスクと対策, 髙橋翼, LYCorp‘23, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Alignment #GenerativeAI #Hallucination #Blog #Safety #Reading Reflections Issue Date: 2023-11-03 Comment
この資料をスタートにReferしている論文などを勉強すると、GenerativeAIのリスク周りに詳しくなれそう。この辺は疎いので勉強になる。
しかし、LLMのAlignmentが不十分だったり、Hallucinationを100%防ぐことは原理的に不可能だと思われるので、この辺とどう付き合っていくかがLLMと付き合っていく上で難しいところ。この辺は自分たちが活用したいユースケースに応じて柔軟に対応しなければならず、この辺の細かいカスタマイズをする地道な作業はずっと残り続けるのではないかなあ
Zero-shot Learning網羅的サーベイ: CLIPが切り開いたVision & Languageの新しい世界, エクサウィザーズ Engineer Blog, 2023.05
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NaturalLanguageGeneration #NLP #ImageCaptioning #DiffusionModel #Blog #Initial Impression Notes Issue Date: 2023-11-02 Comment
これはすごいまとめ…。まだ途中までしか読めていない。CLIPからスタートしてCLIPを引用している論文から重要なものを概要付きでまとめている。
IBIS2023チュートリアル「大規模言語モデル活用技術の最前線」, Michimasa Inaba, 2023.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #Chain-of-Thought #Slide #One-Line Notes Issue Date: 2023-11-01 Comment
LLMの応用研究やPromptingを中心としたチュートリアル。アノテーションや対話式推薦システムへの活用、ReAct、プロンプトの最適化技術、CoTの基本から応用まで幅広くまとまっているので、LLMの応用技術の概観や、CoTを実践したい人に非常に有用だと思う。
NTT版大規模言語モデル「tsuzumi 2」, NTT人間情報研究所
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #MultiModal #FoundationModel #Blog #KeyPoint Notes Issue Date: 2023-11-01 Comment
**(追記 2026.03: 以下の記述内容は上記ページがリリースされた当初のものであり、現在は上記ページの内容は更新されているようですので、ご注意ください。 )**
NTT製のLLM。パラメータ数は7Bと軽量だが高性能。
MTBenchのようなGPT4に勝敗を判定させるベンチマークで、地理、歴史、政治、社会に関する質問応答タスク(図6)でgpt3.5turboと同等、国産LLMの中でトップの性能。GPT3.5turboには、コーディングや数学などの能力では劣るとのこと。
> *6 Rakudaベンチマーク
日本語の言語モデルの性能を評価するベンチマークの一つで、日本の地理・政治・歴史・社会に関する質問応答タスクによって評価を行う。
URL:
https://yuzuai.jp/benchmark
>*7 Japanese Vicuna QAベンチマーク
Rakudaよりもさらに幅広いカテゴリで言語モデルのQAや指示遂行の能力を問う評価方法。一般知識、ロールプレイなど多数の質問から構成される。
URL:
https://github.com/hitoshizuku7/LLM_Judge_ku/blob/main/README.md
tsuzumiはアダプタを追加することで、モデル全体のパラメータを更新することなく、さまざまな知識を持たせたり、振る舞いを変えたりできるようになるとのこと(LoRAアダプタのようなものだと思われる)。
まて、将来的に視覚や聴覚などのマルチモーダル対応も実施。
思想がLoRA Hub [Paper Note] LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition, Chengsong Huang+, arXiv'23, 2023.07 に近く、アダプタを着脱すれば柔軟に生成を変えられるのは有用だと思う。
大規模言語モデルのFine-tuningによるドメイン知識獲得の検討, PFN Blog, 2023.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #Catastrophic Forgetting Issue Date: 2023-10-29
StableDiffusion, LLMのGPUメモリ削減のあれこれ, nishiba, Qiita, 2023.10
Paper/Blog Link My Issue
#Article #NeuralNetwork #ComputerVision #EfficiencyImprovement #NLP #DiffusionModel #Blog #Reading Reflections Issue Date: 2023-10-29 Comment
Gradient Accumulation, Gradient Checkpointingの説明が丁寧でわかりやすかった。
LLMのプロンプト技術まとめ, fuyu_quant (Toma Tanaka), Qiita, 2023.10
Paper/Blog Link My Issue
#Article #NLP #Prompting #Blog #Reading Reflections Issue Date: 2023-10-29 Comment
ざっと見たが現時点で主要なものはほぼ含まれているのでは、という印象
実際のプロンプト例が載っているので、理解しやすいかもしれない。
Evaluating RAG Pipelines, LangChain Blog, 2023.10
Paper/Blog Link My Issue
#Article #Tools #NLP #Library #Evaluation #RAG(RetrievalAugmentedGeneration) #Blog #KeyPoint Notes Issue Date: 2023-10-29 Comment
RAG pipeline (retrieval + generation)を評価するライブラリRagasについて紹介されている。
評価に活用される指標は下記で、背後にLLMを活用しているため、大半の指標はラベルデータ不要。ただし、context_recallを測定する場合はreference answerが必要。
Ragasスコアとしてどのメトリックを利用するかは選択することができ、選択したメトリックのharmonic meanでスコアが算出される。
各種メトリックの内部的な処理は下記:
- faithfullness
- questionと生成された回答に基づいて、statementのリストをLLMで生成する。statementは回答が主張している内容をLLMが解釈したものだと思われる。
- statementのリストとcontextが与えられたときに、statementがcontextにsupportされているかをLLMで評価する。
- num. of supported statements / num. of statements でスコアが算出される
- Answer Relevancy
- LLMで生成された回答から逆に質問を生成し、生成された質問と実際の質問の類似度を測ることで評価
- Context Relevancy
- どれだけcontextにノイズが含まれるかを測定する。
- LLMでcontextの各文ごとに回答に必要な文か否かを判断する
- 回答に必要な文数 / 全文数 でスコアを算出
- Context Recall
- 回答に必要な情報を全てretrieverが抽出できているか
- ground truthとなる回答からstatementをLLMで生成し、statementがcontextでどれだけカバーされているかで算出
また、LangSmithを利用して実験を管理する方法についても記述されている。
LangChainのRAGの改善法, LayerX機械学習勉強会
Paper/Blog Link My Issue
#Article #Tools #NLP #Library #RAG(RetrievalAugmentedGeneration) #Blog #One-Line Notes Issue Date: 2023-10-29 Comment
以下リンクからの引用。LangChainから提供されているRetrieverのcontext抽出の性能改善のためのソリューション
> Multi representation indexing:検索に適した文書表現(例えば要約)の作成
Query transformation:人間の質問を変換して検索を改善する方法
Query construction:人間の質問を特定のクエリ構文や言語に変換する方法
https://blog.langchain.dev/query-transformations/
日本語LLMのリーダーボード(LLM.jp), Weights & Biases
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Blog #KeyPoint Notes #Reading Reflections Issue Date: 2023-10-27 Comment
LLM.jpによる日本語LLMのリーダーボード。4-shotsでの結果、かつinstructionを与えた場合の生成テキストに対する評価、という点には留意したい。たとえばゼロショットで活用したい、という場合にこのリーダーボードの結果がそのまま再現される保証はないと推察される。
日本語LLMベンチマークと自動プロンプトエンジニアリング, PFN Blog, 2023.10
の知見でもあった通り、promptingの仕方によってもLLM間で順位が逆転する現象なども起こりうる。あくまでリーダーボードの値は参考値として留め、どのLLMを採用するかは、自分が利用するタスクやデータで検証した方がbetterだと思われる。
あとはそもそも本当にLLMを使う必要があるのか? [Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, arXiv'23, 2023.08
のような手法ではダメなのか?みたいなところも考えられると良いのかもしれない。
以下サイトより引用
> 評価手法・ツール
このダッシュボードの内容はllm-jpで公開している評価ツール、llm-jp-evalで各モデルに対して評価を行なった結果である。llm-jp-evalは、既存のリーダボードとは行われている評価とは、主に以下のところで違っている。
AlpacaやBig-Benchなどを参考にした、インストラクションチューニングよりのプロンプトを入力として与えて、その入力に対するモデルの生成結果を評価する
>評価は基本、モデルが生成した文字列だけを使って行う
>Few shotでの評価を行っており、このダッシュボードには4-shotsでの結果を載せている
>評価手法・ツールの詳細はllm-jp-evalを是非参照されたい。
>評価項目・データセット
評価項目として、まず4つのカテゴリーにおける平均スコアを算出した。さらにその4カテゴリーの平均値の平均値をとった値がAVGである。
MC (Multi-Choice QA):jcommonsenseqa
NLI (Natural Language Inference):jamp、janli、jnli、jsem、jsick
QA (Question Answering):jemhopqa、niilc
RC (Reading Comprehension):jsquad
>それぞれのカテゴリの平均を出す方法に言語学的な意味はないため、最終的な平均値はあくまで参考値ということに注意されたい。
JGlueを利用した日本語LLMのリーダーボードとして Nejumi LLMリーダーボード, Weights & Biases などもある
日本語大規模言語モデル「Japanese Stable LM 3B-4E1T」「Japanese Stable LM Gamma 7B」を公開しました, 2023
Paper/Blog Link My Issue
#Article #NLP #Blog Issue Date: 2023-10-25
OpenSource_OpenWeight LLM
My Issue
#Article #NLP #OpenWeight Issue Date: 2023-10-15 Comment
zephyr-7B-alpha
- 1/10のパラメータでLLaMA2-70Bw-chat超え
https://weel.co.jp/media/zephyr-7b-alpha
- zephyr-7B-β
- MTBenchでllama2-70B-chat超え
- [Paper Note] Zephyr: Direct Distillation of LM Alignment, Lewis Tunstall+, arXiv'23, 2023.10
Zephyr-7B-betaが早くもTheBloke氏によってGPTQで量子化され、なんとモデル自体は4.5G程度しかVRAMを消費しない…
https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ
- NVIDIA Nemotron-3 8B Models
-
https://developer.nvidia.com/nemotron-3-8b\
-
https://huggingface.co/nvidia/nemotron-3-8b-base-4k
- 53言語対応、37プログラミング言語対応, base / chatがある
- Mixtral8x7B: LLaMA2-70B, GPT-3.5-turboと同等の性能
- MistralをSparse Mixture of Expertsしたモデルの模様
- 名前の通り8つのFFNが存在しているが、Top-2のFFNが選択されその結果が集約され出力が決定される
https://mistral.ai/news/mixtral-of-experts/
- 日本語まとめ
-
https://note.com/npaka/n/n6043bc8b01bc
Large Language Model (in 2023), OpenAI
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Initial Impression Notes Issue Date: 2023-10-10 Comment
LLMの研究開発動向を俯瞰するのに有用らしい
MentalLLaMA, 2023
Paper/Blog Link My Issue
#Article #NLP #Repository #Health #One-Line Notes Issue Date: 2023-10-09 Comment
メンタルヘルスの分析に対してinstruction tuningしたはじめてのLLM
Yasa-1
Paper/Blog Link My Issue
#Article #NLP Issue Date: 2023-10-07 Comment
参考:
Nejumi LLMリーダーボード, Weights & Biases
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Japanese #One-Line Notes #Author Thread-Post Issue Date: 2023-10-02 Comment
JGLUEを使ったLLMの日本語タスクベンチマーク
v4が公開:
https://wandb.ai/llm-leaderboard/nejumi-leaderboard4/reports/Nejumi-LLM-4--VmlldzoxMzc1OTk1MA
元ポスト:
LLM-as-a-judge
Paper/Blog Link My Issue
#Article #NLP #Evaluation Issue Date: 2023-09-30
OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化, AIDB, 2023.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #ChatGPT #MultiModal #Initial Impression Notes Issue Date: 2023-09-30 Comment
おう…やべえな…
Agents: An opensource framework for autonomous language agents
Paper/Blog Link My Issue
#Article #NLP #Library #AIAgents #One-Line Notes Issue Date: 2023-09-30 Comment
以下の特徴を持つLLMAgent開発のためのフレームワーク
- long-short term memory
- tool usage
- web navigation
- multi-agent communication
- human-agent interaction
- symbolic control
また、他のAgent frameworkと違い、ゴールを達成するだの細かいプランニングを策定(SOP; サブタスクとサブゴールを定義)することで、エージェントに対してきめ細かなワークフローを定義できる。
GGML_GGUF_GPTQの違い
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Quantization #One-Line Notes Issue Date: 2023-09-29 Comment
量子化に関する技術であるGGML, GGUF, GPTQに関する詳細なまとめ
筆者の方の言葉を引用すると
>llama.cppならGGUF、TransformerならGPTQって感じ?
ということなので、これらは量子化を行うための技術を提供するライブラリであり、GGUF/GGMLはllama.cppで利用可能で、GPTQはより汎用的に利用可能な手法だと思われる。
GPTQについて論文をざっくり読んでメモった
- [Paper Note] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, ICLR'23, 2022.10
SNLP2023:Is GPT-3 a Good Data Annotator?, Yuki Zenimoto, 2023.08
Paper/Blog Link My Issue
#Article #NLP #SyntheticData #Distillation #Slide #Finetuning #One-Line Notes #DownstreamTasks #Reading Reflections Issue Date: 2023-09-05 Comment
GPT3でデータを作成したら、タスクごとに有効なデータ作成方法は異なったが、人手で作成したデータと同等の性能を達成するデータ(BERTでfinetuning)を、低コストで実現できたよ、という研究
この辺の話はもはや [Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, arXiv'23, 2023.08 を使えばいいのでは、という気がする。
[Paper Note] Instruction Tuning for Large Language Models: A Survey, Shengyu Zhang+, ACM Computing Surveys, Volume 58, Issue 7, 2026.01
Paper/Blog Link My Issue
#Article #Survey #NLP #InstructionTuning #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-09-05 GPT Summary- 指示調整(IT)に関する研究を総括し、LLMsの能力向上術を解説。ITは、(instruction, output)ペアを用いてLLMsを追加訓練し、人間の指示に従う能力を強化するプロセス。SFTの方法論、データセット構築、訓練、および応用を体系的にレビューし、成果に影響する要因を分析。さらに、SFTの課題や現行戦略の欠点を明らかにし、今後の研究の道筋を提案。 Comment
主要なモデルやデータセットの作り方など幅広くまとまっている(Figure1および各Table)
arxivに2023年8月に登場しその後も更新が続き、ACM Computing Surveys, Volume 58, Issue 7に2026年1月に掲載された模様
https://dl.acm.org/doi/10.1145/3777411
LangChain Cheet Sheet, KDnuggets, 2023.08
Paper/Blog Link My Issue
#Article #Tools #NLP #Library Issue Date: 2023-09-05
大規模言語モデル, Naoaki Okazaki, 2023年度統計関連学会連合大会チュートリアルセッション 言語モデルと自然言語処理のフロンティア, 2023.09
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Slide #One-Line Notes Issue Date: 2023-09-04 Comment
岡崎先生による大規模言語モデルのチュートリアル
最近のLLMまでの歴史、transformerなどの基礎的な内容から、最新の内容まで数式付きで詳細にまとまっている
LLMのファインチューニング で 何ができて 何ができないのか, npaka, 2023.08
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Supervised-FineTuning (SFT) #Blog #mid-training #PostTraining #needs-revision Issue Date: 2023-08-29 Comment
>LLMのファインチューニングは、「形式」の学習は効果的ですが、「事実」の学習は不得意です。
> シェイクスピアの脚本のデータセット (tiny-shakespeare) の
「ロミオ」を「ボブ」に置き換えてファインチューニングして、新モデルの頭の中では「ロミオ」と「ボブ」をどう記憶しているかを確認します。
ファインチューニングしても、Bで始まるジュリエットが恋する人物について質問しても、ボブと答えてはくれない。
> ロミオ」は「ジュリエット」が恋していたこの男性に関連付けられており、「ロミオ」を「ボブ」に置き換えるファインチューニングでは、ニューラルネットワークの知識ベースを変更することはできませんでした。
なるほど。
参考: https://www.anyscale.com/blog/fine-tuning-is-for-form-not-facts?ref=blog.langchain.dev
関連:
Metaの「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました, 株式会社ELYZA 公式ブログ, 2023.08
Paper/Blog Link My Issue
#Article #NLP #Library #Blog #OpenWeight #Japanese #KeyPoint Notes Issue Date: 2023-08-29 Comment
商用利用可能、70億パラメータ。
ELYZA社が独自に作成した評価セットでは日本語のOpenLLMの中で最高性能。ただし、モデル選定の段階でこの評価データの情報を利用しているため、有利に働いている可能性があるとのこと。
一般的に利用される日本語の評価用データでは、なんとも言い難い。良いタスクもあれば悪いタスクもある。が、多分評価用データ自体もあまり整備は進んでいないと想像されるため、一旦触ってみるのが良いのだと思う。
zeno-build, zeno-ml, 2023.09
Paper/Blog Link My Issue
#Article #NLP #Library #ExperimentManagement #One-Line Notes Issue Date: 2023-08-28 Comment
MTでのテクニカルレポート
https://github.com/zeno-ml/zeno-build/tree/main/examples/analysis_gpt_mt/report
LLMの実験管理を容易に実施するツールで、異なるハイパーパラメータ、異なるモデル、異なるプロンプトでの実験などを簡単に実施できる。評価結果を自動的に可視化し、interactiveに表示するブラウザベースのアプリケーションも作成可能?
Anti-hype LLM Reading list, veekaybee, 2023.12
Paper/Blog Link My Issue
#Article #Survey #NLP #One-Line Notes Issue Date: 2023-08-27 Comment
LLMのサーベイ、BERT等の基盤モデルの論文、自前でLLMを学習するために必要な論文がコンパクトにまとめられたgist
人工知能研究の新潮流2 -基盤モデル・生成AIのインパクト-, 国立研究開発法人科学技術振興機構 研究開発戦略センター, 2023.07
Paper/Blog Link My Issue
#Article #Survey #GenerativeAI #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-08-12 Comment
280ページにものぼる現在のトレンドをまとめた日本語資料
OpenAI の Embeddings API はイケてるのか、定量的に調べてみる, akeyhero (Akihiro Katsura), Qiita, 2023.04
Paper/Blog Link My Issue
#Article #Embeddings #NLP #STS (SemanticTextualSimilarity) #Blog #Encoder #One-Line Notes Issue Date: 2023-07-31 Comment
[JSTSタスク](
https://github.com/yahoojapan/JGLUE)では、[Tohoku
BERT v3](
https://github.com/cl-tohoku/bert-japanese/tree/main#model-performances)
と [LUKE](
https://github.com/studio-ousia/luke)が最も性能が良いらしい。
[SimCSE](
https://huggingface.co/pkshatech/simcse-ja-bert-base-clcmlp)よりも性能が良いのは興味深い。
Measuring Faithfulness in Chain-of-Thought Reasoning, Anthropic, 2023
Paper/Blog Link My Issue
#Article #NLP #Chain-of-Thought #Prompting #Faithfulness #needs-revision Issue Date: 2023-07-23
trl_trlx
Paper/Blog Link My Issue
#Article #NLP #Library #ReinforcementLearning #One-Line Notes #Reference Collection #needs-revision Issue Date: 2023-07-23 Comment
TRL - 強化学習によるLLMの学習のためのライブラリ
https://note.com/npaka/n/nbb974324d6e1
trlを使って日本語LLMをSFTからRLHFまで一通り学習させてみる
https://www.ai-shift.co.jp/techblog/3583
Examples of using peft with trl to finetune 8-bit models with Low Rank Adaption (LoRA) , TRL Documentation
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #Quantization #PEFT(Adaptor/LoRA) #PostTraining #One-Line Notes Issue Date: 2023-07-22 Comment
LLaMA2を3行で、1つのA100GPU、QLoRAで、自前のデータセットで訓練する方法
Quantized LLaMA2
Paper/Blog Link My Issue
#Article #NLP #One-Line Notes #needs-revision Issue Date: 2023-07-22 Comment
LLaMA2をローカルで動作させるために、QLoRAで量子化したモデル
LLongMA2
Paper/Blog Link My Issue
#Article #NLP #ContextWindow #OpenWeight #One-Line Notes Issue Date: 2023-07-22 Comment
LLaMA2のcontext windowを8kにして訓練。オリジナルのLLaMA2と同等の性能で8k contextを利用可能。
元ツイート:
現在はリンク切れになっている?
Chatbot Arena Conversation Dataset Release, LMSYS Org, 2023.07
Paper/Blog Link My Issue
#Article #NLP #Dataset #DialogueGeneration #Blog #One-Line Notes Issue Date: 2023-07-22 Comment
33kのconversation、2つのレスポンスに対する人間のpreferenceスコア付き
20種類のSoTAモデルのレスポンスを含み、13kのユニークIPからのアクセスがあり、3Kのエキスパートによるアノテーション付き
Are Human Explanations Always Helpful? Towards Objective Evaluation of Human Natural Language Explanations
Paper/Blog Link My Issue
#Article #NLP #Explanation #Evaluation #ACL Issue Date: 2023-07-14 GPT Summary- 本研究では、説明可能なNLPモデルのトレーニングにおいて、人間による注釈付けの説明の品質を評価する方法について検討しています。従来のSimulatabilityスコアに代わる新しいメトリックを提案し、5つのデータセットと2つのモデルアーキテクチャで評価しました。結果として、提案したメトリックがより客観的な評価を可能にする一方、Simulatabilityは不十分であることが示されました。
Auto train advanced
Paper/Blog Link My Issue
#Article #MachineLearning #Tools #Supervised-FineTuning (SFT) #Blog #Repository #PEFT(Adaptor/LoRA) #One-Line Notes #needs-revision Issue Date: 2023-07-11 Comment
Hugging Face Hub上の任意のLLMに対して、localのカスタムトレーニングデータを使ってfinetuningがワンラインでできる。
peftも使える。
現在はもうメンテナンスされていないようだ。
Awesome Multimodal LLMs
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NLP #MultiModal #SpeechProcessing #One-Line Notes Issue Date: 2023-07-03 Comment
マルチモーダルなLLMのリストがまとめられている
Extending Context is Hard…but not Impossible, kaiokendev, 2023.06
Paper/Blog Link My Issue
#Article #Survey #NLP #ContextWindow #One-Line Notes #needs-revision Issue Date: 2023-07-01 Comment
Open source LLMのcontext lengthをどのように大きくするかに関する議論
How Long Can Open-Source LLMs Truly Promise on Context Length?, 2023
Paper/Blog Link My Issue
#Article #NLP #Blog #LongSequence #One-Line Notes Issue Date: 2023-07-01 Comment
LLMのcontext長を伸ばす際の方法と得られた知見がまとめられている
LM Flow
Paper/Blog Link My Issue
#Article #MachineLearning #Tools #Supervised-FineTuning (SFT) #FoundationModel #One-Line Notes #needs-revision Issue Date: 2023-06-26 Comment
一般的なFoundation Modelのファインチューニングと推論を簡素化する拡張可能なツールキット。継続的なpretragning, instruction tuning, parameter efficientなファインチューニング,alignment tuning,大規模モデルの推論などさまざまな機能をサポート。
Prompt Engineering vs. Blind Prompting, 2023
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Prompting #Blog #One-Line Notes #needs-revision Issue Date: 2023-05-12 Comment
experimentalな手法でprompt engineeringする際のoverview
open LLM Leaderboard
Paper/Blog Link My Issue
#Article #Survey #NLP #One-Line Notes #needs-revision Issue Date: 2023-05-12 Comment
現在はアーカイブされている
Can AI language models replace human participants?, Trends in Cognitive Sciences, 2023
Paper/Blog Link My Issue
#Article #PsychologicalScience #needs-revision Issue Date: 2023-05-11
OpenSource PaLM, 2023
Paper/Blog Link My Issue
#Article #NLP #Library #Repository #OpenWeight #OpenSource #One-Line Notes #needs-revision Issue Date: 2023-05-08 Comment
150m,410m,1bのモデルがある。Googleの540bには及ばず、emergent abilityもなかぬか期待できなさそなパラメータ数だが、どの程度の性能なのだろうか。
現在モデルファイルはHF上から削除されているようだ。
StarCoderBase_StarCoder, 2023
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #NLP #FoundationModel #Blog #Coding #KeyPoint Notes #needs-revision Issue Date: 2023-05-06 Comment
・15.5Bパラメータ
・80種類以上のプログラミング言語で訓練
・Multi Query Attentionを利用
・context window size 8192
・Fill in the middle objectiveを利用
Instruction tuningがされておらず、prefixとsuffixの間を埋めるような訓練のされ方をしているので、たとえば関数名をinputして、そのmiddle(関数の中身)を出力させる、といった使い方になる模様。
paper: https://drive.google.com/file/d/1cN-b9GnWtHzQRoE7M7gAEyivY0kl4BYs/view
StarCoder:
https://huggingface.co/bigcode/starcoder
StarCoderBaseを35Bのpython tokenでfinetuningしたモデル。
既存モデルよりも高性能と主張
MPT-7B, Databricks AI Research, 2023.05
Paper/Blog Link My Issue
#Article #NLP #Blog #OpenWeight #One-Line Notes Issue Date: 2023-05-06 Comment
新たなオープンソースLLM。
下記ツイートより引用:
・商用利用可能
・6万5000トークン使用可能
・7Bと比較的小さいモデルながら高性能
・日本語を扱え性能が高い
とのこと。
ChatGPTのLLMと比較すると、ざっと例を見た感じ質問応答としての能力はそこまで高くなさそうな印象。
finetuningしない限りはGPT3,GPT4で良さげ。
Towards Complex Reasoning: the Polaris of Large Language Models, Yao Fu, 2023.05
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Evaluation #Blog #Reasoning #mid-training #PostTraining Issue Date: 2023-05-04
ChatBot Arena, lmsys org, 2023.05
Paper/Blog Link My Issue
#Article #NLP #Evaluation #Selected Papers/Blogs #One-Line Notes #Arena Issue Date: 2023-05-04 Comment
クラウドソーシング型のチャットボット評価するシステム。ユーザはシステムにアクセスすると、二つのanonymisedされたLLMと対話し、どちらが優れていたかをvotingする。すべてのシステムとユーザのinteractionはロギングされており、最終的にElo RatingでLLM.をランキング付けする。
Arena-Hardと呼ばれるliveアリーナデータを用いたパイプラインを公開。MT-Benchよりも識別力が高く、Chatbot Arenaのランキングとのagreementが高いとのこと。
参考:
過去のデータについては Chatbot Arena Conversation Dataset Release, LMSYS Org, 2023.07 などもある
OpenLLaMA, Xinyang+, 2023.05
Paper/Blog Link My Issue
#Article #NLP #Library #OpenWeight #OpenSource #One-Line Notes Issue Date: 2023-05-04 Comment
LLaMAと同様の手法を似たデータセットに適用し商用利用可能なLLaMAを構築した模様
LLM ecosystem graphs
Paper/Blog Link My Issue
#Article #Survey #NLP #OpenWeight #One-Line Notes Issue Date: 2023-05-04 Comment
様々なfonudation model、それらを利用したアプリケーション、依存関係がまとまったページ
Percy Liang氏のグループが運用してるっぽい?
HuggingChat, 2023
Paper/Blog Link My Issue
#Article #NLP #ChatGPT #Blog #One-Line Notes Issue Date: 2023-04-27 Comment
closedな世界で開発されるOpenAIのChatGPTに対して、Openなものが必要ということで、huggingfaceが出したchatシステム
公開はすでに終了している模様
大規模言語モデル間の性能比較まとめ, mah_lab _ 西見 公宏, 2023.04
Paper/Blog Link My Issue
#Article #Survey #NLP #One-Line Notes Issue Date: 2023-04-27 Comment
参考になる
現状だと研究用であればllama, 商用利用ならtext-davinci-003あるいはFlanT5-xxlあたりになりそう
LLM Worksheet:
https://docs.google.com/spreadsheets/d/1kT4or6b0Fedd-W_jMwYpb63e1ZR3aePczz3zlbJW-Y4/edit#gid=0
LoRA論文解説, Hayato Tsukagoshi, 2023.04
Paper/Blog Link My Issue
#Article #NeuralNetwork #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #Slide #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-04-25 Comment
ベースとなる事前学習モデルの一部の線形層の隣に、低ランク行列A,Bを導入し、A,Bのパラメータのみをfinetuningの対象とすることで、チューニングするパラメータ数を激減させた上で同等の予測性能を達成し、推論速度も変わらないようにするfinetuning手法の解説
LoRAを使うと、でかすぎるモデルだと、そもそもGPUに載らない問題や、ファインチューニング後のモデルファイルでかすぎワロタ問題が回避できる。
前者は事前学習済みモデルのBPのための勾配を保存しておく必要がなくなるため学習時にメモリ節約になる。後者はA,Bのパラメータだけ保存すればいいので、ストレージの節約になる。
かつ、学習速度が25%程度早くなる。
既存研究であるAdapter(transformerの中に学習可能なMLPを差し込む手法)は推論コストが増加し、prefix tuningは学習が非常に難しく、高い性能を達成するためにprefixとして128 token入れたりしなければならない。
huggingfaceがすでにLoRAを実装している
https://github.com/huggingface/peft
LangChain
Paper/Blog Link My Issue
#Article #Tools #InformationRetrieval #NLP #Library #AIAgents #Reference Collection Issue Date: 2023-04-21 Comment
- LangChain の Googleカスタム検索 連携を試す
-
https://note.com/npaka/n/nd9a4a26a8932
- LangChainのGetting StartedをGoogle Colaboratoryでやってみる ④Agents
-
https://zenn.dev/kun432/scraps/8216511783e3da
Exploring the Potential of Using an AI Language Model for Automated Essay Scoring, Mizumoto+, Research Methods in Applied Linguistics‘23
Paper/Blog Link My Issue
#Article #NLP #Education #AES(AutomatedEssayScoring) #Author Thread-Post Issue Date: 2023-04-01 Comment
著者によるポスト:
著者によるブログ:
https://mizumot.com/lablog/archives/1805
Publicly available instruction-tuned models
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #Reference Collection Issue Date: 2023-03-30
GPT-NeoXT-Chat-Base-20B, togethercomputer, 2023.03
Paper/Blog Link My Issue
#Article #Tools #NLP #Library #OpenWeight Issue Date: 2023-03-11 Comment
元ツイート
Apache2.0で公開
A Paper List for Recommend-system PreTrained Models
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #Pretraining #pretrained-LM #Encoder #Decoder Issue Date: 2022-12-01
GPT-3から我々は何を学べば良いのか, 山本和英, Japio year book 2020
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #KeyPoint Notes Issue Date: 2021-09-09 Comment
GPT-3の概要:
GPT-3はWebサイトから数年に渡って収集したCommon Crawlというデータセットから、570GBを抜粋し学習に利用。(英語ウィキペディアの約130倍)
ある単語列に後続する単語を予測するという方法(自己回帰型言語モデル)で教師なし学習を繰り返し、言語モデルを学習。
GPT-3の特徴:
・モデルが巨大(1750億パラメータ, GPT-2は15億)
- 扱うトークン数が2048トークン(GPT-2の倍)
- Word Embeddingの次元数12288(GPT2の倍
- デコード層が98層(GPT2の倍
・基本的なモデル構造はTransformerと一緒
GPT-3の問題点:
・コーパス中の言語出力を模倣しているだけで、何ら理解をしておらず、常識も持ち合わせていない
- e.g. 私の足に目はいくつある?と入力すると、2つと出力する等
- 整理された知識を獲得しているわけではない
・偏見や差別、誤った知識も学習する
・時間的、経済的負荷の大きさ
- GPT-3を最大規模で計算するには5億円かかる
- 1台のGPUで355年必要な計算量
→ 個人や小規模業者が実行できる範囲を超えており、大企業でもコストに見合った出力が得られるとは考えにくい
GPT-3の産業応用
・GPT-3は言語モデルであり、言語生成器ではない
- 人間が書いて欲しいことをおおまかに伝えたらそれを書いてくれるわけではない(代筆)
→ GPT-3が小論文や業務レポートを書けると考えるのは早計
- 入力として英文や英単語を入力するが、生成する文章の分野や話題を提示しただけであり、生成する文章にそれ以上の制御は行っていない
・生成内容を強く制御できないことは創作活動にとっては有用
- 俳句、短歌、詩の生成
- キャッチコピーの自動生成
- ダミー文章生成(ブログやツイート)
- 文章添削、校正に使える可能性(要研究;文章を正しく、綺麗に書く能力は高い)
GPT-3でどこまでできそうなのか?というざっくりとした肌感が掴めたから良かった
BERT 日本語Pre-trained Model, NICT, 2020.03
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tools #NLP #Dataset #Library #Blog #Japanese #Encoder #One-Line Notes Issue Date: 2020-03-13 Comment
NICTが公開。既に公開されているBERTモデルとのベンチマークデータでの性能比較も行なっており、その他の公開済みBERTモデルをoutperformしている。
BERT入門, Ken'ichi Matsui, 2020.01
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Slide #Reference Collection #Reading Reflections Issue Date: 2020-01-13 Comment
自然言語処理の王様「BERT」の論文を徹底解説
https://qiita.com/omiita/items/72998858efc19a368e50
Transformer関連 [Paper Note] Attention Is All You Need, Ashish Vaswani+, NeurIPS'17, 2017.07
あたりを先に読んでからが読むと良い
要は
・Transformerをたくさん積んだモデル
・NSPとMLMで双方向性を持った事前学習タスクを実施することで性能向上
・pooler layer(Transformer Encoderの次にくっつくlayer)を切り替えることで、様々なタスクにfine-tuning可能(i.e. pooler layerは転移学習の対象外)
・予測する際は、[CLS]トークンに対応する位置の出力を用いて分類問題や複数文間の関係性を問う問題を解いたり、各トークン位置に対応する出力を用いてQAの正解spanを予測したり、色々できる
・gMLP MLP-like Architecture
あたりの研究が進んでくると使われなくなってくる可能性有
こっちの記事もわかりやすい。
BERTについて勉強したことまとめ (2)モデル構造について
https://engineering.mobalab.net/2020/06/12/bert%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6%E5%8B%89%E5%BC%B7%E3%81%97%E3%81%9F%E3%81%93%E3%81%A8%E3%81%BE%E3%81%A8%E3%82%81-2%E3%83%A2%E3%83%87%E3%83%AB%E6%A7%8B%E9%80%A0%E3%81%AB%E3%81%A4%E3%81%84/
事前学習言語モデルの動向 _ Survey of Pretrained Language Models, Kyosuke Nishida, 2019
Paper/Blog Link My Issue
#Article #NeuralNetwork #Survey #NLP #Slide #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2019-11-09 Comment
[2019/06まで]
・ELMo(双方向2層LSTM言語モデル)
・GPT(left-to-rightの12層Transformer自己回帰言語モデル)
・BERT(24層のTransformer双方向言語モデル)
・MT-DNN(BERTの上にマルチタスク層を追加した研究)
・XLM(パラレル翻訳コーパスを用いてクロスリンガルに穴埋めを学習)
・TransformerXL(系列長いに制限のあった既存モデルにセグメントレベルの再帰を導入し長い系列を扱えるように)
・GPT-2(48層Transformerの自己回帰言語モデル)
・ERNIE 1.0(Baidu, エンティティとフレーズの外部知識を使ってマスクに利用)
・ERNIE(Tsinghua, 知識グラフの情報をfusionしたLM)
・Glover(ドメイン、日付、著者などを条件とした生成を可能としたGPT)
・MASS(Encoder-Decoder型の生成モデルのための事前学習)
・UniLM(Sequence-to-Sequenceを可能にした言語モデル)
・XLNet(自己回帰(単方向)モデルと双方向モデルの両方の利点を得ることを目指す)
[2019/07~]
・SpanBERT(i.i.dではなく範囲でマスクし、同時に範囲の境界も予測する)
・ERNIE 2.0(Baidu, マルチタスク事前学習; 単語レベル・構造レベル・意味レベル)
・RoBERTa(BERTと同じ構造で工夫を加えることで性能向上)
- より大きなバッチサイズを使う(256から8192)
- より多くのデータを使う(16GBから160GB)
- より長いステップ数の学習をする(BERT換算で16倍)
- 次文予測(NSP)は不要
→ GLUEでBERT, XLNetをoutperform
・StructBERT (ALICE, NSPに代わる学習の目的関数を工夫)
- マスクした上で単語の順番をシャッフルし元に戻す
- ランダム・正順・逆順の3種類を分類
→ BERTと同サイズ、同データでBERT, RoBERTa超え
・DistilBERT(蒸留により、12層BERTを6層に小型化(40%減))
- BERTの出力を教師として、生徒が同じ出力を出すように学習
- 幅(隠れ層)サイズを減らすと、層数を経あrスよりも悪化
→ 推論は60%高速化、精度は95%程度を保持
・Q8BERT(精度を落とさずにfine-tuning時にBERTを8bit整数に量子化)
- Embedding, FCは8bit化、softmax, LNorm, GELUは32bitをキープ
→ モデルサイズ1/4, 速度3.7倍
・CTRL(条件付き言語モデル)
- 条件となる制御テキストを本文の前に与えて学習
- 48層/1280次元Transformer(パラメータ数1.6B)
・MegatronLM(72層、隠れ状態サイズ3072、長さ1024; BERTの24倍サイズ)
・ALBERT(BERTの層のパラメータをすべて共有することで学習を高速化; 2020年あたりのデファクト)
- Largeを超えたモデルは学習が難しいため、表現は落ちるが学習しやすくした
- 単語埋め込みを低次元にすることでパラメータ数削減
- 次文予測を、文の順序入れ替え判定に変更
→ GLUE, RACE, SQuADでSoTAを更新
・T5(NLPタスクをすべてtext-to-textとして扱い、Enc-Dec Transformerを745GBコーパスで事前学習して転移する)
- モデルはEncoder-DecoderのTransformer
- 学習タスクをエンコーダ・デコーダに合わせて変更
- エンコーダ側で範囲を欠落させて、デコーダ側で予測
→ GLUE, SuperGLUE, SQuAD1.1, CNN/DMでSoTA更新
・BART(Seq2Seqの事前学習として、トークンマスク・削除、範囲マスク、文の入れ替え、文書の回転の複数タスクで学習)
→ CNN/DMでT5超え、WMT'16 RO-ENで逆翻訳を超えてSoTA
ELMo, GPT, BERT, GPT-2, XLNet, RoBERTa, DistilBERT, ALBERT, T5あたりは良く見るような感
各データセットでの各モデルの性能も後半に記載されており興味深い。
ちなみに、CNN/DailyMail Datasetでは、T5, BARTあたりがSoTA。
R2で比較すると
- Pointer-Generator + Coverage Vectorが17,28
- LEAD-3が17.62
- BARTが21.28
- T5が21.55
となっている