
MajorityVoting
[Paper Note] How Far Can Unsupervised RLVR Scale LLM Training?, Bingxiang He+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #PostTraining #read-later #RLVR #Scalability Issue Date: 2026-03-12 GPT Summary- URLVRは、地上真値ラベルなしで報酬を導出し、LLM訓練のボトルネックを克服する。内部報酬と外部報酬に基づく手法の分析を行い、内部報酬が一貫したパターンを示すことを発見した。モデルの事前分布によって崩壊のタイミングが決まり、内部報酬は小規模データセットでの効果的な利用が可能であることが示された。外部報酬手法も検討し、改善の可能性を示唆する。これにより、内部URLVRの限界を明らかにし、スケーラブルな代替手段への道を提示する。 Comment
元ポスト:
[Paper Note] TTCS: Test-Time Curriculum Synthesis for Self-Evolving, Chengyi Yang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SyntheticData #CurriculumLearning #Test Time Training (TTT) Issue Date: 2026-02-03 GPT Summary- TTCSフレームワークは、LLMの推論能力を向上させるための共同進化型テスト時トレーニングを提供。質問合成器と推論ソルバーを初期化し、合成器が難易度の高い質問を生成し、ソルバーは自己一貫性報酬で学習を更新。これにより、質問のバリアントが安定したテスト時トレーニングを実現。実験で数学的ベンチマークにおける推論能力の向上と一般ドメインタスクへの移行が確認された。 Comment
元ポスト:
先行研究:
- [Paper Note] TTRL: Test-Time Reinforcement Learning, Yuxin Zuo+, NeurIPS'25, 2025.04
[Paper Note] SSR: Socratic Self-Refine for Large Language Model Reasoning, Haizhou Shi+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #Test-Time Scaling #Verification Issue Date: 2025-11-22 GPT Summary- 新しいフレームワークSocratic Self-Refine(SSR)を提案し、LLMの推論を細かく評価・洗練する。SSRは応答をサブ質問・サブ回答に分解し、信頼度推定を行い、信頼性の低いステップを特定・改善することで、より正確な推論を実現。実験結果はSSRが最先端の手法を上回ることを示し、LLMの内部推論プロセスの理解を助ける。 Comment
元ポスト:
[Paper Note] Scaling Generalist Data-Analytic Agents, Shuofei Qiao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #TabularData #SyntheticData #ScientificDiscovery #numeric Issue Date: 2025-10-09 GPT Summary- DataMindは、オープンソースのデータ分析エージェントを構築するためのスケーラブルなデータ合成とエージェントトレーニングの手法を提案。主な課題であるデータリソース、トレーニング戦略、マルチターンロールアウトの不安定性に対処し、合成クエリの多様性を高めるタスク分類や、動的なトレーニング目標を採用。DataMind-12Kという高品質なデータセットを作成し、DataMind-14Bはデータ分析ベンチマークで71.16%のスコアを達成し、最先端のプロプライエタリモデルを上回った。DataMind-7Bも68.10%でオープンソースモデル中最高のパフォーマンスを示した。今後、これらのモデルをコミュニティに公開予定。 Comment
元ポスト:
7B程度のSLMで70B級のモデルと同等以上の性能に到達しているように見える。論文中のp.2にコンパクトに内容がまとまっている。
[Paper Note] Test-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts, Jihoon Lee+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #DiffusionModel #Test-Time Scaling #read-later #Author Thread-Post Issue Date: 2025-10-07 GPT Summary- dLLMsは異なる生成順序に基づく専門的な挙動を学習するが、固定された推論スケジュールは性能を低下させる。HEXという新手法を導入し、異なるブロックスケジュールでのアンサンブルを行うことで、精度を大幅に向上させる。GSM8KやMATH、ARC-C、TruthfulQAなどのベンチマークで顕著な改善を示し、テスト時スケーリングの新たなパラダイムを確立した。 Comment
元ポスト:
これは気になる👀
著者ポスト:
[Paper Note] Optimizing Temperature for Language Models with Multi-Sample Inference, Weihua Du+, ICML'25, 2025.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Test-Time Scaling #SamplingParams #Best-of-N Issue Date: 2025-09-24 GPT Summary- マルチサンプル集約戦略を用いて、LLMの最適な温度を自動的に特定する手法を提案。従来の方法に依存せず、モデルアーキテクチャやデータセットを考慮した温度の役割を分析。新たに提案するエントロピーに基づく指標は、固定温度のベースラインを上回る性能を示し、確率過程モデルを用いて温度とパフォーマンスの関係を解明。 Comment
openreview: https://openreview.net/forum?id=rmWpE3FrHW¬eId=h9GETXxWDB
[Paper Note] Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation, Yujun Zhou+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Diversity Issue Date: 2025-09-19 GPT Summary- EVOL-RLは、ラベルなしの強化学習手法であり、モデルの探索能力と一般化能力を維持しつつ、安定性と変動を結びつける。多数決で選ばれた回答を安定したアンカーとして保持し、新規性を意識した報酬を追加することで、生成物の多様性を保ち、思考の連鎖を改善する。実験により、EVOL-RLはTTRLベースラインを上回り、特にラベルなしのAIME24での訓練において顕著な性能向上を示した。 Comment
元ポスト:
ポイント解説:
関連:
- [Paper Note] Jointly Reinforcing Diversity and Quality in Language Model Generations, Tianjian Li+, arXiv'25
- [Paper Note] TTRL: Test-Time Reinforcement Learning, Yuxin Zuo+, NeurIPS'25, 2025.04
[Paper Note] Deep Think with Confidence, Yichao Fu+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Decoding #read-later #Selected Papers/Blogs Issue Date: 2025-08-24 GPT Summary- 「Deep Think with Confidence(DeepConf)」は、LLMの推論タスクにおける精度と計算コストの課題を解決する手法で、モデル内部の信頼性信号を活用して低品質な推論を動的にフィルタリングします。追加の訓練や調整を必要とせず、既存のフレームワークに統合可能です。評価の結果、特に難易度の高いAIME 2025ベンチマークで99.9%の精度を達成し、生成トークンを最大84.7%削減しました。 Comment
pj page:
https://jiaweizzhao.github.io/deepconf
vLLMでの実装:
https://jiaweizzhao.github.io/deepconf/static/htmls/code_example.html
元ポスト:
tooluse、追加の訓練なしで、どのようなタスクにも適用でき、85%生成トークン量を減らした上で、OpenModelで初めてAIME2025において99% Acc.を達成した手法とのこと。vLLMを用いて50 line程度で実装できるらしい。
reasoning traceのconfidence(i.e., 対数尤度)をgroup sizeを決めてwindow単位で決定し、それらをデコーディングのプロセスで活用することで、品質の低いreasoning traceに基づく結果を排除しつつ、majority votingに活用する方法。直感的にもうまくいきそう。オフラインとオンラインの推論によって活用方法が提案されている。あとでしっかり読んで書く。Confidenceの定義の仕方はグループごとのbottom 10%、tailなどさまざまな定義方法と、それらに基づいたconfidenceによるvotingの重み付けが複数考えられ、オフライン、オンラインによって使い分ける模様。
vLLMにPRも出ている模様?
[Paper Note] Self-Questioning Language Models, Lili Chen+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SelfImprovement #Label-free Issue Date: 2025-08-09 GPT Summary- 自己質問型言語モデル(SQLM)を提案し、トピックを指定するプロンプトから自ら質問を生成し、解答する非対称の自己対戦フレームワークを構築。提案者と解答者は強化学習で訓練され、問題の難易度に応じて報酬を受け取る。三桁の掛け算や代数問題、プログラミング問題のベンチマークで、外部データなしで言語モデルの推論能力を向上させることができることを示す。 Comment
pj page: https://self-questioning.github.io
元ポスト:
たとえば下記のような、ラベル無しの外部データを利用する手法も用いてself improvingする手法と比較したときに、どの程度の性能差になるのだろうか?外部データを全く利用せず、外部データありの手法と同等までいけます、という話になると、より興味深いと感じた。
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
既存の外部データを活用しない関連研究:
- [Paper Note] Absolute Zero: Reinforced Self-play Reasoning with Zero Data, Andrew Zhao+, arXiv'25, 2025.05
[Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Outstanding Paper
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Prompting #ACL #read-later #reading Issue Date: 2025-08-03 GPT Summary- 本研究では、LLMのテスト時の計算スケーリングにおけるプロンプト戦略の効果を調査。6つのLLMと8つのプロンプト戦略を用いた実験により、複雑なプロンプト戦略が単純なChain-of-Thoughtに劣ることを示し、理論的な証明を提供。さらに、スケーリング性能を予測し最適なプロンプト戦略を特定する手法を提案し、リソース集約的な推論プロセスの必要性を排除。複雑なプロンプトの再評価と単純なプロンプト戦略の潜在能力を引き出すことで、テスト時のスケーリング性能向上に寄与することを目指す。 Comment
non-thinkingモデルにおいて、Majority Voting (i.e. Self Consistency)によるtest-time scalingを実施する場合のさまざまなprompting戦略のうち、budgetとサンプリング数が小さい場合はCoT以外の適切なprompting戦略はモデルごとに異なるが、budgetやサンプリング数が増えてくるとシンプルなCoT(実験ではzeroshot CoTを利用)が最適なprompting戦略として支配的になる、という話な模様。
さらに、なぜそうなるかの理論的な分析と最適な与えられた予算から最適なprompting戦略を予測する手法も提案している模様。
が、評価データの難易度などによってこの辺は変わると思われ、特にFigure39に示されているような、**サンプリング数が増えると簡単な問題の正解率が上がり、逆に難しい問題の正解率が下がるといった傾向があり、CoTが簡単な問題にサンプリング数を増やすと安定して正解できるから支配的になる**、という話だと思われるので、常にCoTが良いと勘違いしない方が良さそうだと思われる。たとえば、**解こうとしているタスクが難問ばかりであればCoTでスケーリングするのが良いとは限らない、といった点には注意が必要**だと思うので、しっかり全文読んだ方が良い。時間がある時に読みたい(なかなかまとまった時間取れない)
最適なprompting戦略を予測する手法では、
- 問題の難易度に応じて適応的にスケールを変化させ(なんとO(1)で予測ができる)
- 動的に最適なprompting戦略を選択
することで、Majority@10のAcc.を8Bスケールのモデルで10--50%程度向上させることができる模様。いやこれほんとしっかり読まねば。
[Paper Note] Can Large Reasoning Models Self-Train?, Sheikh Shafayat+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #RLVR #KeyPoint Notes Issue Date: 2025-06-01 GPT Summary- 自己学習を活用したオンライン強化学習アルゴリズムを提案し、モデルの自己一貫性を利用して正確性信号を推測。難しい数学的推論タスクに適用し、従来の手法に匹敵する性能を示す。自己生成された代理報酬が誤った出力を優遇するリスクも指摘。自己監視による性能向上の可能性と課題を明らかに。 Comment
元ポスト:
- [Paper Note] Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
と似ているように見える
self-consistencyでground truthを推定し、推定したground truthを用いてverifiableなrewardを計算して学習する手法、のように見える。
実際のground truthを用いた学習と同等の性能を達成する場合もあれば、long stepで学習するとどこかのタイミングで学習がcollapseする場合もある
パフォーマンスがピークを迎えた後になぜ大幅にAccuracyがdropするかを検証したところ、モデルのKL penaltyがどこかのタイミングで大幅に大きくなることがわかった。つまりこれはオリジナルのモデルからかけ離れたモデルになっている。これは、モデルがデタラメな出力をground truthとして推定するようになり、モデルそのものも一貫してそのデタラメな出力をすることでrewardを増大させるreward hackingが起きている。
これら現象を避ける方法として、以下の3つを提案している
- early stopping
- offlineでラベルをself consistencyで生成して、学習の過程で固定する
- カリキュラムラーニングを導入する
関連
- [Paper Note] Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25, 2024.11
[Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #ICLR #Test-Time Scaling #Selected Papers/Blogs Issue Date: 2023-04-27 GPT Summary- 自己一貫性という新しいデコーディング戦略を提案し、chain-of-thought promptingの性能を向上。多様な推論経路をサンプリングし、一貫した答えを選択することで、GSM8KやSVAMPなどのベンチマークで顕著な改善を達成。 Comment
self-consistencyと呼ばれる新たなCoTのデコーディング手法を提案。
これは、難しいreasoningが必要なタスクでは、複数のreasoningのパスが存在するというintuitionに基づいている。
self-consistencyではまず、普通にCoTを行う。そしてgreedyにdecodingする代わりに、以下のようなプロセスを実施する:
1. 多様なreasoning pathをLLMに生成させ、サンプリングする。
2. 異なるreasoning pathは異なるfinal answerを生成する(= final answer set)。
3. そして、最終的なanswerを見つけるために、reasoning pathをmarginalizeすることで、final answerのsetの中で最も一貫性のある回答を見出す。
これは、もし異なる考え方によって同じ回答が導き出されるのであれば、その最終的な回答は正しいという経験則に基づいている。
self-consistencyを実現するためには、複数のreasoning pathを取得した上で、最も多いanswer a_iを選択する(majority vote)。これにはtemperature samplingを用いる(temperatureを0.5やら0.7に設定して、より高い信頼性を保ちつつ、かつ多様なoutputを手に入れる)。
temperature samplingについては[こちら](
https://openreview.net/pdf?id=rygGQyrFvH)の論文を参照のこと。
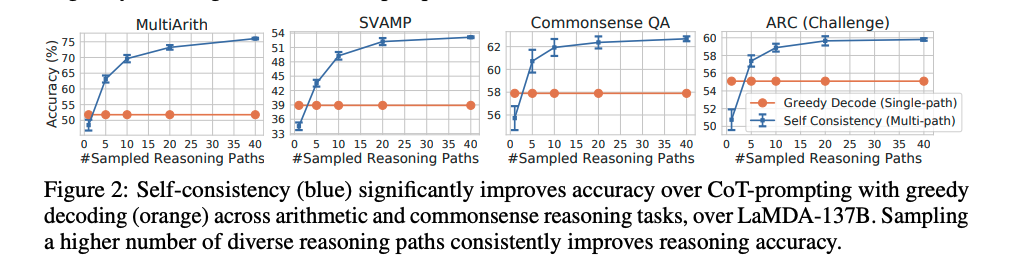
sampling数は増やせば増やすほど性能が向上するが、徐々にサチってくる。サンプリング数を増やすほどコストがかかるので、その辺はコスト感との兼ね合いになると思われる。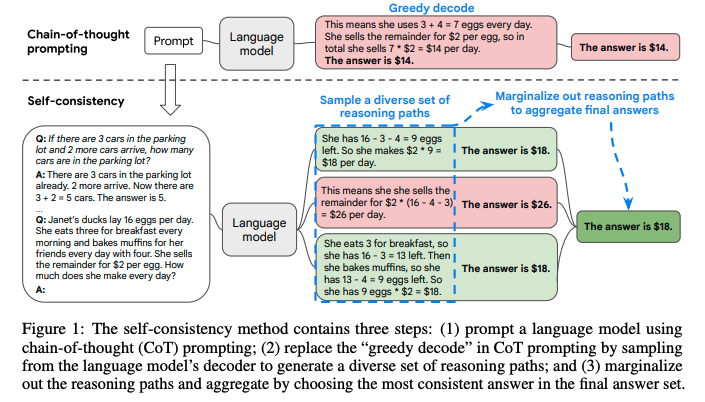
Self-consistencyは回答が閉じた集合であるような問題に対して適用可能であり、open-endなquestionでは利用できないことに注意が必要。ただし、open-endでも回答間になんらかの関係性を見出すような指標があれば実現可能とlimitationで言及している。
self-consistencyが提案されてからもう4年も経ったのか、、、