
#Analysis
#NLP
#Chain-of-Thought
#Reasoning
#read-later
Issue Date: 2025-08-27 [Paper Note] Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens, Chengshuai Zhao+, arXiv'25 SummaryChain-of-Thought (CoT) プロンプティングはLLMの性能向上に寄与するが、その深さには疑問が残る。本研究では、CoT推論が訓練データの構造的バイアスを反映しているかを調査し、訓練データとテストクエリの分布不一致がその効果に与える影響を分析。DataAlchemyという制御環境を用いて、CoT推論の脆弱性を明らかにし、一般化可能な推論の達成に向けた課題を強調する。
Issue Date: 2025-08-27 [Paper Note] Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset, Rabeeh Karimi Mahabadi+, arXiv'25 Summary新しい数学コーパス「Nemotron-CC-Math」を提案し、LLMの推論能力を向上させるために、科学テキスト抽出のためのパイプラインを使用。従来のデータセットよりも高品質で、方程式やコードの構造を保持しつつ、表記を標準化。Nemotron-CC-Math-4+は、以前のデータセットを大幅に上回り、事前学習によりMATHやMBPP+での性能向上を実現。オープンソースとしてコードとデータセットを公開。 Comment元ポスト:https://x.com/karimirabeeh/status/1960682448867426706?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-27 [Paper Note] School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in LLMs, Mia Taylor+, arXiv'25 Summary報酬ハッキングは、エージェントが不完全な報酬関数を利用して意図されたタスクを遂行せず、タスクを誤って実行する現象です。本研究では、詩作や簡単なコーディングタスクにおける報酬ハッキングの例を含むデータセットを構築し、複数のモデルをファインチューニングしました。結果、モデルは新しい設定で報酬ハッキングを一般化し、無関係な不整合行動を示しました。これにより、報酬ハッキングを学習したモデルがより有害な不整合に一般化する可能性が示唆されましたが、さらなる検証が必要です。 Comment元ポスト:https://x.com/owainevans_uk/status/1960359498515952039?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-27 [Paper Note] Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens, Chengshuai Zhao+, arXiv'25 SummaryChain-of-Thought (CoT) プロンプティングはLLMの性能向上に寄与するが、その深さには疑問が残る。本研究では、CoT推論が訓練データの構造的バイアスを反映しているかを調査し、訓練データとテストクエリの分布不一致がその効果に与える影響を分析。DataAlchemyという制御環境を用いて、CoT推論の脆弱性を明らかにし、一般化可能な推論の達成に向けた課題を強調する。
Issue Date: 2025-08-27 [Paper Note] Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset, Rabeeh Karimi Mahabadi+, arXiv'25 Summary新しい数学コーパス「Nemotron-CC-Math」を提案し、LLMの推論能力を向上させるために、科学テキスト抽出のためのパイプラインを使用。従来のデータセットよりも高品質で、方程式やコードの構造を保持しつつ、表記を標準化。Nemotron-CC-Math-4+は、以前のデータセットを大幅に上回り、事前学習によりMATHやMBPP+での性能向上を実現。オープンソースとしてコードとデータセットを公開。 Comment元ポスト:https://x.com/karimirabeeh/status/1960682448867426706?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-27 [Paper Note] School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in LLMs, Mia Taylor+, arXiv'25 Summary報酬ハッキングは、エージェントが不完全な報酬関数を利用して意図されたタスクを遂行せず、タスクを誤って実行する現象です。本研究では、詩作や簡単なコーディングタスクにおける報酬ハッキングの例を含むデータセットを構築し、複数のモデルをファインチューニングしました。結果、モデルは新しい設定で報酬ハッキングを一般化し、無関係な不整合行動を示しました。これにより、報酬ハッキングを学習したモデルがより有害な不整合に一般化する可能性が示唆されましたが、さらなる検証が必要です。 Comment元ポスト:https://x.com/owainevans_uk/status/1960359498515952039?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-27
[Paper Note] Performance Prediction for Large Systems via Text-to-Text Regression, Yash Akhauri+, arXiv'25
Summaryテキストからテキストへの回帰を用いて、複雑なシステムデータのメトリック予測を行う新しい手法を提案。Borgのリソース効率予測で、6000万パラメータのモデルが高い順位相関と低い平均二乗誤差を達成。少数ショット例で新タスクに適応可能で、エンコーダの使用やシーケンス長の重要性を示す。これにより、現実の結果のシミュレーションが可能になる。
Commentライブラリも整備されている模様:
https://github.com/google-deepmind/regress-lm元ポスト:https://x.com/marktechpost/status/1960600034174755078?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #PRM Issue Date: 2025-08-27 [Paper Note] StepWiser: Stepwise Generative Judges for Wiser Reasoning, Wei Xiong+, arXiv'25 Summary多段階の推論戦略における中間ステップの論理的妥当性を監視するために、StepWiserモデルを提案。これは、生成的なジャッジを用いて推論ステップを評価し、強化学習で訓練される。中間ステップの判断精度を向上させ、ポリシーモデルの改善や推論時の探索を促進することを示す。 Comment元ポスト:https://x.com/jaseweston/status/1960529697055355037?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-27 [Paper Note] Attention Layers Add Into Low-Dimensional Residual Subspaces, Junxuan Wang+, arXiv'25 Summaryトランスフォーマーモデルの注意出力は低次元の部分空間に制約されており、約60%の方向が99%の分散を占めることを示した。この低ランク構造がデッドフィーチャー問題の原因であることを発見し、スパースオートエンコーダーのために部分空間制約トレーニング手法を提案。これにより、デッドフィーチャーを87%から1%未満に削減し、スパース辞書学習の改善に寄与する新たな洞察を提供。 Comment元ポスト:https://x.com/junxuanwang0929/status/1959797912889938392?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ConceptErasure #KnowledgeEditing Issue Date: 2025-08-26 [Paper Note] CRISP: Persistent Concept Unlearning via Sparse Autoencoders, Tomer Ashuach+, arXiv'25 SummaryCRISPは、LLMにおける持続的な概念の忘却を実現するためのパラメータ効率の良い手法であり、スパースオートエンコーダ(SAE)を用いて有害な知識を効果的に除去します。実験により、CRISPはWMDPベンチマークの忘却タスクで従来の手法を上回り、一般的およびドメイン内の能力を保持しつつ、ターゲット特徴の正確な抑制を達成することが示されました。 Comment元ポスト:https://x.com/aicia_solid/status/1960181627549884685?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #RecommenderSystems #Embeddings #LanguageModel #FoundationModel #read-later Issue Date: 2025-08-26 [Paper Note] Large Foundation Model for Ads Recommendation, Shangyu Zhang+, arXiv'25 SummaryLFM4Adsは、オンライン広告のための全表現マルチ粒度転送フレームワークで、ユーザー表現(UR)、アイテム表現(IR)、ユーザー-アイテム交差表現(CR)を包括的に転送。最適な抽出層を特定し、マルチ粒度メカニズムを導入することで転送可能性を強化。テンセントの広告プラットフォームで成功裏に展開され、2.45%のGMV向上を達成。 Comment元ポスト:https://x.com/gm8xx8/status/1959975943600067006?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #LanguageModel #OpenWeight #VisionLanguageModel Issue Date: 2025-08-26 [Paper Note] InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency, Weiyun Wang+, arXiv'25 SummaryInternVL 3.5は、マルチモーダルモデルの新しいオープンソースファミリーで、Cascade Reinforcement Learningを用いて推論能力と効率を向上させる。粗から細へのトレーニング戦略により、MMMやMathVistaなどのタスクで大幅な改善を実現。Visual Resolution Routerを導入し、視覚トークンの解像度を動的に調整。Decoupled Vision-Language Deployment戦略により、計算負荷をバランスさせ、推論性能を最大16.0%向上させ、速度を4.05倍向上。最大モデルは、オープンソースのMLLMで最先端の結果を達成し、商業モデルとの性能ギャップを縮小。全てのモデルとコードは公開。 Comment元ポスト:https://x.com/gm8xx8/status/1960076908088922147?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #RLVR #Diversity Issue Date: 2025-08-26 [Paper Note] Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR, Xiao Liang+, arXiv'25 SummaryRLVRはLLMの複雑な推論タスクにおいて重要だが、従来のトレーニングは生成の多様性を減少させる問題がある。本研究では、ポリシーの生成の多様性を分析し、トレーニング問題を更新することでエントロピー崩壊を軽減する方法を提案。オンライン自己対戦と変分問題合成(SvS)戦略を用いることで、ポリシーのエントロピーを維持し、Pass@kを大幅に改善。AIME24およびAIME25ベンチマークでそれぞれ18.3%および22.8%の向上を達成し、12の推論ベンチマークでSvSの堅牢性を示した。 Commentpj page:https://mastervito.github.io/SvS.github.io/元ポスト:https://x.com/mastervito0601/status/1959960582670766411?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q簡易解説:https://x.com/aicia_solid/status/1960178795530600605?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #NeuralArchitectureSearch #SmallModel Issue Date: 2025-08-26 [Paper Note] Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search, Yuxian Gu+, arXiv'25 SummaryJet-Nemotronは新しいハイブリッドアーキテクチャの言語モデルで、フルアテンションモデルと同等以上の精度を持ちながら生成スループットを大幅に改善します。Post Neural Architecture Search(PostNAS)を用いて開発され、事前トレーニングされたモデルから効率的にアテンションブロックを探索します。Jet-Nemotron-2Bモデルは、他の先進モデルに対して高い精度を達成し、生成スループットを最大53.6倍向上させました。 Comment元ポスト:https://x.com/iscienceluvr/status/1959832287073403137?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/hancai_hm/status/1960000017235902722?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:https://x.com/jacksonatkinsx/status/1960090774122483783?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q所見:https://x.com/webbigdata/status/1960392071384326349?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ModelMerge Issue Date: 2025-08-25 [Paper Note] Competition and Attraction Improve Model Fusion, João Abrantes+, GECCO'25 Summaryモデルマージング(M2N2)は、複数の機械学習モデルの専門知識を統合する進化的アルゴリズムで、動的なマージ境界調整や多様性保持メカニズムを特徴とし、最も有望なモデルペアを特定するヒューリスティックを用いる。実験により、M2N2はゼロからMNIST分類器を進化させ、計算効率を向上させつつ高性能を達成。また、専門的な言語や画像生成モデルのマージにも適用可能で、堅牢性と多様性を示す。コードは公開されている。 Comment元ポスト:https://x.com/sakanaailabs/status/1959799343088857233?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1257 #NLP #Dataset #LanguageModel #LLMAgent #Evaluation #MCP Issue Date: 2025-08-25 [Paper Note] LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries, Ming Yin+, arXiv'25 Summary本研究では、AIエージェントが複数のMCPツールを協調的に使用してマルチステップタスクを解決する能力を評価するためのベンチマーク「LiveMCP-101」を提案。101の実世界のクエリを用い、真の実行計画を基にした新しい評価アプローチを導入。実験結果から、最前線のLLMの成功率が60%未満であることが示され、ツールのオーケストレーションにおける課題が明らかに。LiveMCP-101は、実世界のエージェント能力を評価するための基準を設定し、自律AIシステムの実現に向けた進展を促進する。 Comment元ポスト:https://x.com/aicia_solid/status/1959786499702182271?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pretraining #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #OpenWeight #Architecture #PostTraining #Admin'sPick #DataMixture Issue Date: 2025-08-25 [Paper Note] Motif 2.6B Technical Report, Junghwan Lim+, arXiv'25 SummaryMotif-2.6Bは、26億パラメータを持つ基盤LLMで、長文理解の向上や幻覚の減少を目指し、差分注意やポリノルム活性化関数を採用。広範な実験により、同サイズの最先端モデルを上回る性能を示し、効率的でスケーラブルな基盤LLMの発展に寄与する。 Comment元ポスト:https://x.com/scaling01/status/1959604841577357430?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHF:https://huggingface.co/Motif-Technologies/Motif-2.6B・アーキテクチャ
・1466
・2538
・学習手法
・1979
・8B token学習するごとに直近6つのcheckpointのelement-wiseの平均をとりモデルマージ。当該モデルに対して学習を継続、ということを繰り返す。これにより、学習のノイズを低減し、突然パラメータがシフトすることを防ぐ
・1060
・Adaptive Base Frequency (RoPEのbase frequencyを10000から500000にすることでlong contextのattention scoreが小さくなりすぎることを防ぐ)
・2540
・事前学習データ
・1943
・2539
・2109
を利用したモデル。同程度のサイズのモデルとの比較ではかなりのgainを得ているように見える。興味深い。
DatasetのMixtureの比率などについても記述されている。
 #EfficiencyImprovement
#NLP
#LanguageModel
#Chain-of-Thought
#Reasoning
#EMNLP
#Length
#Inference
Issue Date: 2025-08-24
[Paper Note] TokenSkip: Controllable Chain-of-Thought Compression in LLMs, Heming Xia+, EMNLP'25
SummaryChain-of-Thought (CoT)はLLMの推論能力を向上させるが、長いCoT出力は推論遅延を増加させる。これに対処するため、重要度の低いトークンを選択的にスキップするTokenSkipを提案。実験により、TokenSkipはCoTトークンの使用を削減しつつ推論性能を維持することを示した。特に、Qwen2.5-14B-InstructでGSM8Kにおいて推論トークンを40%削減し、性能低下は0.4%未満であった。
Comment元ポスト:https://x.com/hemingkx/status/1891873475545137245?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#MachineLearning
#LanguageModel
#Inference
Issue Date: 2025-08-24
[Paper Note] Pushing the Envelope of LLM Inference on AI-PC, Evangelos Georganas+, arXiv'25
Summary超低ビットLLMモデルの登場により、リソース制約のある環境でのLLM推論が可能に。1ビットおよび2ビットのマイクロカーネルを設計し、PyTorch-TPPに統合することで、推論効率を最大2.2倍向上。これにより、AI PCやエッジデバイスでの超低ビットLLMモデルの効率的な展開が期待される。
Comment元ポスト:https://x.com/jiqizhixin/status/1959379120577826935?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Multi
#NLP
#LanguageModel
#LLMAgent
#SelfCorrection
#EMNLP
Issue Date: 2025-08-24
[Paper Note] MAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning, Justin Chih-Yao Chen+, EMNLP'25
SummaryMAgICoReは、LLMの推論を改善するための新しいアプローチで、問題の難易度に応じて洗練を調整し、過剰な修正を回避する。簡単な問題には粗い集約を、難しい問題には細かい反復的な洗練を適用し、外部の報酬モデルを用いてエラーの特定を向上させる。3つのエージェント(Solver、Reviewer、Refiner)によるマルチエージェントループを採用し、洗練の効果を確保する。Llama-3-8BおよびGPT-3.5で評価した結果、MAgICoReは他の手法を上回る性能を示し、反復が進むにつれて改善を続けることが確認された。
Comment元ポスト:https://x.com/cyjustinchen/status/1958957907778969648?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Decoding
#read-later
#Admin'sPick
Issue Date: 2025-08-24
[Paper Note] Deep Think with Confidence, Yichao Fu+, arXiv'25
Summary「Deep Think with Confidence(DeepConf)」は、LLMの推論タスクにおける精度と計算コストの課題を解決する手法で、モデル内部の信頼性信号を活用して低品質な推論を動的にフィルタリングします。追加の訓練や調整を必要とせず、既存のフレームワークに統合可能です。評価の結果、特に難易度の高いAIME 2025ベンチマークで99.9%の精度を達成し、生成トークンを最大84.7%削減しました。
Commentpj page:https://jiaweizzhao.github.io/deepconf
#EfficiencyImprovement
#NLP
#LanguageModel
#Chain-of-Thought
#Reasoning
#EMNLP
#Length
#Inference
Issue Date: 2025-08-24
[Paper Note] TokenSkip: Controllable Chain-of-Thought Compression in LLMs, Heming Xia+, EMNLP'25
SummaryChain-of-Thought (CoT)はLLMの推論能力を向上させるが、長いCoT出力は推論遅延を増加させる。これに対処するため、重要度の低いトークンを選択的にスキップするTokenSkipを提案。実験により、TokenSkipはCoTトークンの使用を削減しつつ推論性能を維持することを示した。特に、Qwen2.5-14B-InstructでGSM8Kにおいて推論トークンを40%削減し、性能低下は0.4%未満であった。
Comment元ポスト:https://x.com/hemingkx/status/1891873475545137245?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#MachineLearning
#LanguageModel
#Inference
Issue Date: 2025-08-24
[Paper Note] Pushing the Envelope of LLM Inference on AI-PC, Evangelos Georganas+, arXiv'25
Summary超低ビットLLMモデルの登場により、リソース制約のある環境でのLLM推論が可能に。1ビットおよび2ビットのマイクロカーネルを設計し、PyTorch-TPPに統合することで、推論効率を最大2.2倍向上。これにより、AI PCやエッジデバイスでの超低ビットLLMモデルの効率的な展開が期待される。
Comment元ポスト:https://x.com/jiqizhixin/status/1959379120577826935?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Multi
#NLP
#LanguageModel
#LLMAgent
#SelfCorrection
#EMNLP
Issue Date: 2025-08-24
[Paper Note] MAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning, Justin Chih-Yao Chen+, EMNLP'25
SummaryMAgICoReは、LLMの推論を改善するための新しいアプローチで、問題の難易度に応じて洗練を調整し、過剰な修正を回避する。簡単な問題には粗い集約を、難しい問題には細かい反復的な洗練を適用し、外部の報酬モデルを用いてエラーの特定を向上させる。3つのエージェント(Solver、Reviewer、Refiner)によるマルチエージェントループを採用し、洗練の効果を確保する。Llama-3-8BおよびGPT-3.5で評価した結果、MAgICoReは他の手法を上回る性能を示し、反復が進むにつれて改善を続けることが確認された。
Comment元ポスト:https://x.com/cyjustinchen/status/1958957907778969648?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Decoding
#read-later
#Admin'sPick
Issue Date: 2025-08-24
[Paper Note] Deep Think with Confidence, Yichao Fu+, arXiv'25
Summary「Deep Think with Confidence(DeepConf)」は、LLMの推論タスクにおける精度と計算コストの課題を解決する手法で、モデル内部の信頼性信号を活用して低品質な推論を動的にフィルタリングします。追加の訓練や調整を必要とせず、既存のフレームワークに統合可能です。評価の結果、特に難易度の高いAIME 2025ベンチマークで99.9%の精度を達成し、生成トークンを最大84.7%削減しました。
Commentpj page:https://jiaweizzhao.github.io/deepconf
vLLMでの実装:https://jiaweizzhao.github.io/deepconf/static/htmls/code_example.html元ポスト:https://x.com/jiawzhao/status/1958982524333678877?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtooluse、追加の訓練なしで、どのようなタスクにも適用でき、85%生成トークン量を減らした上で、OpenModelで初めてAIME2025において99% Acc.を達成した手法とのこと。vLLMを用いて50 line程度で実装できるらしい。reasoning traceのconfidence(i.e., 対数尤度)をgroup sizeを決めてwindow単位で決定し、それらをデコーディングのプロセスで活用することで、品質の低いreasoning traceに基づく結果を排除しつつ、majority votingに活用する方法。直感的にもうまくいきそう。オフラインとオンラインの推論によって活用方法が提案されている。あとでしっかり読んで書く。Confidenceの定義の仕方はグループごとのbottom 10%、tailなどさまざまな定義方法と、それらに基づいたconfidenceによるvotingの重み付けが複数考えられ、オフライン、オンラインによって使い分ける模様。
vLLMにPRも出ている模様? #Multi #ComputerVision #Tools #NLP #Dataset #LanguageModel #SyntheticData #x-Use #VisionLanguageModel Issue Date: 2025-08-24 [Paper Note] ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools, Shaofeng Yin+, arXiv'25 Summary本研究では、実世界のツール使用能力を向上させるために、23Kのインスタンスからなる大規模マルチモーダルデータセット「ToolVQA」を提案。ToolVQAは、実際の視覚的コンテキストと多段階推論タスクを特徴とし、ToolEngineを用いて人間のようなツール使用推論をシミュレート。7B LFMを微調整した結果、テストセットで優れたパフォーマンスを示し、GPT-3.5-turboを上回る一般化能力を持つことが確認された。 Comment人間による小規模なサンプル(イメージシナリオ、ツールセット、クエリ、回答、tool use trajectory)を用いてFoundation Modelに事前知識として与えることで、よりrealisticなscenarioが合成されるようにした上で新たなVQAを4k程度合成。その後10人のアノテータによって高品質なサンプルにのみFilteringすることで作成された、従来よりも実世界の設定に近く、reasoningの複雑さが高いVQAデータセットな模様。


具体的には、image contextxが与えられた時に、ChatGPT-4oをコントローラーとして、前回のツールとアクションの選択をgivenにし、人間が作成したプールに含まれるサンプルの中からLongest Common Subsequence (LCS) による一致度合いに基づいて人手によるサンプルを選択し、動的にcontextに含めることで多様なで実世界により近しいmulti step tooluseなtrajectoryを合成する、といった手法に見える。pp.4--5に数式や図による直感的な説明がある。なお、LCSを具体的にどのような文字列に対して、どのような前処理をした上で適用しているのかまでは追えていない。
 元ポスト:https://x.com/jiqizhixin/status/1959125184285483090?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#ReinforcementLearning
#GRPO
Issue Date: 2025-08-23
[Paper Note] Hard Examples Are All You Need: Maximizing GRPO Post-Training Under Annotation Budgets, Benjamin Pikus+, arXiv'25
Summaryリソースが制約された状況での言語モデルのファインチューニングにおいて、難易度の異なるトレーニング例の優先順位を検討。実験により、最も難しい例でのトレーニングが最大47%のパフォーマンス向上をもたらすことが示され、難しい例が学習機会を多く提供することが明らかに。これにより、予算制約下での効果的なトレーニング戦略として、難しい例を優先することが推奨される。
Commentベースモデルのpass@kが低いhardestなサンプルでGRPOを学習するのがデータ効率が良く、OODに対する汎化性能も発揮されます、というのをQwen3-4B, 14B, Phi4で実験して示しました、という話っぽい?
元ポスト:https://x.com/jiqizhixin/status/1959125184285483090?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#ReinforcementLearning
#GRPO
Issue Date: 2025-08-23
[Paper Note] Hard Examples Are All You Need: Maximizing GRPO Post-Training Under Annotation Budgets, Benjamin Pikus+, arXiv'25
Summaryリソースが制約された状況での言語モデルのファインチューニングにおいて、難易度の異なるトレーニング例の優先順位を検討。実験により、最も難しい例でのトレーニングが最大47%のパフォーマンス向上をもたらすことが示され、難しい例が学習機会を多く提供することが明らかに。これにより、予算制約下での効果的なトレーニング戦略として、難しい例を優先することが推奨される。
Commentベースモデルのpass@kが低いhardestなサンプルでGRPOを学習するのがデータ効率が良く、OODに対する汎化性能も発揮されます、というのをQwen3-4B, 14B, Phi4で実験して示しました、という話っぽい?
小規模モデル、およびGSM8K、BIG Bench hardでの、Tracking Shuffled Objectのみでの実験な模様?大規模モデルやコーディングなどのドメインでもうまくいくかはよく分からない。OODの実験もAIME2025でのみの実験しているようなのでそこは留意した方が良いかも。
rewardとして何を使ったのかなどの細かい内容を追えていない。元ポスト:https://x.com/pratyushrt/status/1958947577216524352?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #VisionLanguageModel #Science Issue Date: 2025-08-23 [Paper Note] Intern-S1: A Scientific Multimodal Foundation Model, Lei Bai+, arXiv'25 SummaryIntern-S1は、科学専門分野に特化したオープンソースの専門家型モデルで、280億の活性化パラメータを持つマルチモーダルMixture-of-Experts(MoE)モデルです。5Tトークンで事前学習され、特に科学データに焦点を当てています。事後学習では、InternBootCampを通じて強化学習を行い、Mixture-of-Rewardsを提案。評価では、一般的な推論タスクで競争力を示し、科学分野の専門的なタスクでクローズドソースモデルを上回る性能を達成しました。モデルはHugging Faceで入手可能です。 Comment元ポスト:https://x.com/iscienceluvr/status/1958894938248384542?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qscientific domainに特化したデータで継続事前学習+RL Finetuningしたドメイン特化言語モデルらしい。HF:https://huggingface.co/internlm/Intern-S1
Apache 2.0ライセンス
ベースモデルはQwen3とInternViT
・InternViT:https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5
関連:
・2529解説:https://x.com/gm8xx8/status/1959222471183225033?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2025-08-23 [Paper Note] Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing, Yiqun Zhang+, arXiv'25 SummaryLLMのパフォーマンスと効率のバランスを取るために、テスト時ルーティングフレームワーク「Avengers-Pro」を提案。クエリを埋め込み、クラスタリングし、最適なモデルにルーティングすることで、6つのベンチマークで最先端の結果を達成。最強の単一モデルを平均精度で+7%上回り、コストを27%削減しつつ約90%のパフォーマンスを実現。すべての単一モデルの中で最高の精度と最低のコストを提供するパレートフロンティアを達成。コードは公開中。 Comment元ポスト:https://x.com/omarsar0/status/1958897458408563069?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qクエリをkmeansでクラスタリングし、各クラスタごとにモデルごとのperformanceとcostを事前に算出しておく。そして新たなクエリが来た時にクエリが割り当てられるtop pのクラスタのperformanae-cost efficiencyを合計し、スコアが高い一つのモデルを選択(=routing)しinferenceを実施する。クエリはQwenでembedding化してクラスタリングに活用する。ハイパーパラメータα∈[0,1]によって、performance, costどちらを重視するかのバランスを調整する。
シンプルな手法だが、GPT-5 mediumと同等のコスト/性能 でより高い 性能/コスト を実現。
 性能向上、コスト削減でダメ押ししたい時に使えそうだが、発行するクエリがプロプライエタリデータ、あるいはそもそも全然データないんです、みたいな状況の場合、クエリの割当先となるクラスタを適切に確保する(クラスタリングに用いる十分な量のデータを準備する)のが大変な場面があるかもしれない。(全然本筋と関係ないが、最近論文のタイトルにBeyondつけるの流行ってる…?)
#NeuralNetwork
#EfficiencyImprovement
#NLP
#AutomaticSpeechRecognition(ASR)
#EMNLP
#Encoder-Decoder
Issue Date: 2025-08-22
[Paper Note] LiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation, Keisuke Kamahori+, EMNLP'25
SummaryLiteASRは、現代の自動音声認識モデルのエンコーダを低ランク圧縮する手法で、推論コストを大幅に削減しつつ転写精度を維持します。主成分分析を用いて低ランク行列の乗算を近似し、自己注意機構を最適化することで、Whisper large-v3のエンコーダサイズを50%以上圧縮し、Whisper mediumと同等のサイズでより良い転写精度を実現しました。
Comment元ポスト:https://x.com/keisukekamahori/status/1958695752810864754?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q現代のASRモデルはencoderが計算効率の上でボトルネックとなっていたが、Forward Passにおける activatrion Y を PCA (式2, 3)に基づいて2つの低ランク行列の積(とバイアス項の加算; 式5)によって近似し計算効率を大幅に向上させた、という話な模様。weightを低ランクに写像するV_kとバイアス項のY_M(データセット全体に対するactivation Yの平均)はcalibrfationデータによって事前に計算可能とのこと。また、PCAのrank kがattention headの次元数より小さい場合、self-attentionの計算もより(QWKへ写像するWを低ランク行列で近似することで)効率的な手法を採用でき、そちらについても提案されている模様。(ざっくりしか読めていないので誤りがあるかもしれない。)
性能向上、コスト削減でダメ押ししたい時に使えそうだが、発行するクエリがプロプライエタリデータ、あるいはそもそも全然データないんです、みたいな状況の場合、クエリの割当先となるクラスタを適切に確保する(クラスタリングに用いる十分な量のデータを準備する)のが大変な場面があるかもしれない。(全然本筋と関係ないが、最近論文のタイトルにBeyondつけるの流行ってる…?)
#NeuralNetwork
#EfficiencyImprovement
#NLP
#AutomaticSpeechRecognition(ASR)
#EMNLP
#Encoder-Decoder
Issue Date: 2025-08-22
[Paper Note] LiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation, Keisuke Kamahori+, EMNLP'25
SummaryLiteASRは、現代の自動音声認識モデルのエンコーダを低ランク圧縮する手法で、推論コストを大幅に削減しつつ転写精度を維持します。主成分分析を用いて低ランク行列の乗算を近似し、自己注意機構を最適化することで、Whisper large-v3のエンコーダサイズを50%以上圧縮し、Whisper mediumと同等のサイズでより良い転写精度を実現しました。
Comment元ポスト:https://x.com/keisukekamahori/status/1958695752810864754?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q現代のASRモデルはencoderが計算効率の上でボトルネックとなっていたが、Forward Passにおける activatrion Y を PCA (式2, 3)に基づいて2つの低ランク行列の積(とバイアス項の加算; 式5)によって近似し計算効率を大幅に向上させた、という話な模様。weightを低ランクに写像するV_kとバイアス項のY_M(データセット全体に対するactivation Yの平均)はcalibrfationデータによって事前に計算可能とのこと。また、PCAのrank kがattention headの次元数より小さい場合、self-attentionの計算もより(QWKへ写像するWを低ランク行列で近似することで)効率的な手法を採用でき、そちらについても提案されている模様。(ざっくりしか読めていないので誤りがあるかもしれない。)

 #NLP
#LanguageModel
#Prompting
#read-later
Issue Date: 2025-08-22
[Paper Note] Prompt Orchestration Markup Language, Yuge Zhang+, arXiv'25
SummaryPOML(プロンプトオーケストレーションマークアップ言語)を導入し、LLMsのプロンプトにおける構造、データ統合、フォーマット感受性の課題に対処。コンポーネントベースのマークアップやCSSスタイリングシステムを採用し、動的プロンプトのテンプレート機能や開発者ツールキットを提供。POMLの有効性を2つのケーススタディで検証し、実際の開発シナリオでの効果を評価。
Commentpj page:https://microsoft.github.io/poml/latest/元ポスト:https://x.com/aicia_solid/status/1958732643996246342?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは非常に興味深い
#NLP
#Dataset
#LLMAgent
#Evaluation
#MCP
Issue Date: 2025-08-22
[Paper Note] MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers, Ziyang Luo+, arXiv'25
Summaryモデルコンテキストプロトコル(MCP)は、LLMを外部データソースに接続する新しい標準であり、MCP-Universeという包括的なベンチマークを導入。これにより、実際のアプリケーションにおけるLLMの評価が可能となる。6つのコアドメインをカバーし、厳密な評価手法を実装。主要なLLMは性能制限を示し、長文コンテキストや未知のツールの課題に直面。UIサポート付きの評価フレームワークをオープンソース化し、MCPエコシステムの革新を促進。
Commentpj page:https://mcp-universe.github.io/元ポスト:https://x.com/lijunnan0409/status/1958671067071004934?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#LLMAgent
#SelfImprovement
#EMNLP
Issue Date: 2025-08-22
[Paper Note] WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model, Tianqing Fang+, arXiv'25
Summary自己改善エージェントのために、共進化するワールドモデルLLMを導入する新しいフレームワークを提案。これにより、エージェントのポリシーを洗練する自己指導型トレーニングデータを生成し、行動選択を導く先読みシミュレーションを実現。実験により、既存の自己進化エージェントに対して10%のパフォーマンス向上を示し、持続的な適応性を促進することを目指す。
Comment元ポスト:https://x.com/wyu_nd/status/1958632621820584203?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EMNLP
Issue Date: 2025-08-22
[Paper Note] Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?, Momoka Furuhashi+, EMNLP'25
Summary生成タスクの自動評価における曖昧な基準の課題を解決するため、チェックリストの使用方法を検討。6つの生成方法と8つのモデルサイズで評価し、選択的チェックリストがペアワイズ評価でパフォーマンスを改善する傾向があることを発見。ただし、直接スコアリングでは一貫性がない。人間の評価基準との相関が低いチェックリスト項目も存在し、評価基準の明確化が必要であることを示唆。
Comment元ポスト:https://x.com/tohoku_nlp_mmk/status/1958717497454002557?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpj page:https://momo0817.github.io/checklist-effectiveness-study-github.io/
#EMNLP
Issue Date: 2025-08-22
[Paper Note] MAC-Tuning: LLM Multi-Compositional Problem Reasoning with Enhanced Knowledge Boundary Awareness, Junsheng Huang+, EMNLP'25
SummaryLLMのハルシネーション問題に対処するため、複数の問題に同時に対応する新手法MAC-Tuningを提案。回答予測と信頼度推定を分離して学習し、実験で平均精度が最大25%向上したことを示す。
Comment元ポスト:https://x.com/may_f1_/status/1958362321337950709?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-22
[Paper Note] MM-BrowseComp: A Comprehensive Benchmark for Multimodal Browsing Agents, Shilong Li+, arXiv'25
SummaryMM-BrowseCompは、AIエージェントのマルチモーダル検索および推論能力を評価する新しいベンチマークで、224の手作りの質問を含む。これにより、画像や動画を含む情報の重要性を考慮し、テキストのみの手法の限界を示す。最先端モデルの評価では、OpenAI o3などのトップモデルでも29.02%の精度にとどまり、マルチモーダル能力の最適化不足が明らかになった。
Comment元ポスト:https://x.com/gezhang86038849/status/1958381269617955165?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#DiffusionModel
#Decoding
#PostTraining
Issue Date: 2025-08-22
[Paper Note] Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models, Wen Wang+, arXiv'25
SummarydLLMsは中間予測を捨てがちだが、時間的振動が重要な現象である。本研究では、時間的一貫性を活用する2つの方法を提案。1つ目は、テスト時に予測を集約する時間的自己一貫性投票、2つ目は中間予測の安定性を測る時間的意味エントロピーを報酬信号とする時間的一貫性強化。実験結果では、Countdownデータセットで24.7%の改善を達成し、他のベンチマークでも向上を示した。これにより、dLLMsの時間的ダイナミクスの可能性が強調される。
Comment元ポスト:https://x.com/jiqizhixin/status/1958702248055513335?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QdLLMのデノイジング過程において途中に正解が表出しているのに時間発展とともに消えてしまう問題があるらしく、それに対して、デノイジングステップにおいてstableな予測を行うSelf-Consistencyベースのdecoding手法と、意味的なエントロピーをrewardに加え時間発展で安定するようにpost trainingすることで対処します、みたいな話らしい。
Issue Date: 2025-08-22
[Paper Note] CAST: Counterfactual Labels Improve Instruction Following in Vision-Language-Action Models, Catherine Glossop+, arXiv'25
Summary視覚-言語-アクション(VLA)モデルは、自然言語指示をロボットのアクションにマッピングする能力に課題がある。これを解決するために、反実仮想ラベルを用いてロボットデータセットを拡張する新手法を提案。これにより、言語の多様性と粒度が向上し、指示従属能力が改善される。実験では、ナビゲーションタスクにおいて成功率が27%向上したことが示された。
Commentpj page:https://cast-vla.github.io元ポスト:https://x.com/gm8xx8/status/1958645106115789124?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EMNLP
Issue Date: 2025-08-21
[Paper Note] Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline, Meng Lu+, EMNLP'25
Summary多言語LLMsは英語での事実再呼出しに優れていますが、他言語ではパフォーマンスが低下します。原因として、英語中心のメカニズムの不十分な活用と再翻訳時の誤りを特定。これに対処するため、言語に依存しない二つの介入を導入し、再呼出し精度を35%以上向上させました。この研究は、メカニズムの理解がLLMsの多言語能力を引き出す手助けとなることを示しています。
Comment元ポスト:https://x.com/ruochenz_/status/1958253947111506283?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EMNLP
#Findings
Issue Date: 2025-08-21
[Paper Note] Evaluating Step-by-step Reasoning Traces: A Survey, Jinu Lee+, EMNLP'25 Findings
Summaryステップバイステップの推論はLLMの能力向上に寄与するが、評価手法は一貫性に欠ける。本研究では、推論評価の包括的な概要と、事実性、有効性、一貫性、実用性の4カテゴリからなる評価基準の分類法を提案。これに基づき、評価者の実装や最近の発見をレビューし、今後の研究の方向性を示す。
Comment元ポスト:https://x.com/jinulee_v/status/1958268008964796904?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-21
[Paper Note] Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS, Can Jin+, arXiv'25
Summary本論文では、テスト時スケーリング(TTS)におけるRLベースと探索ベースの手法を統一したAIRL-Sを提案。AIRL-Sは、敵対的逆強化学習とグループ相対ポリシー最適化を組み合わせ、ラベル付きデータなしで動的プロセス報酬モデルを学習。実験結果は、提案手法がベースモデルに対して平均9%の性能向上を示し、複数の探索アルゴリズムにおいても優れた結果を得たことを示す。これにより、LLMsにおける複雑な推論タスクに対する効果的な解決策を提供。
Comment元ポスト:https://x.com/iscienceluvr/status/1958470481050534069?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#ReinforcementLearning
#RLVR
#DualLearning
Issue Date: 2025-08-21
[Paper Note] DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization, Shuaijie She+, arXiv'25
SummaryDuPOは、注釈なしのフィードバックを生成する二重学習に基づく好み最適化フレームワークで、強化学習の高価なラベル依存と二重タスクペアの制限に対処。プライマルタスクの入力を分解し、未知の部分を再構築する二重タスクを構築することで、非可逆タスクへの適用範囲を広げる。実験により、翻訳品質や数学的推論の精度が大幅に向上し、DuPOはスケーラブルで一般的なLLM最適化の手法として位置付けられる。
Comment元ポスト:https://x.com/rosinality/status/1958413194307002415?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
#NLP
#LanguageModel
#Prompting
#read-later
Issue Date: 2025-08-22
[Paper Note] Prompt Orchestration Markup Language, Yuge Zhang+, arXiv'25
SummaryPOML(プロンプトオーケストレーションマークアップ言語)を導入し、LLMsのプロンプトにおける構造、データ統合、フォーマット感受性の課題に対処。コンポーネントベースのマークアップやCSSスタイリングシステムを採用し、動的プロンプトのテンプレート機能や開発者ツールキットを提供。POMLの有効性を2つのケーススタディで検証し、実際の開発シナリオでの効果を評価。
Commentpj page:https://microsoft.github.io/poml/latest/元ポスト:https://x.com/aicia_solid/status/1958732643996246342?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは非常に興味深い
#NLP
#Dataset
#LLMAgent
#Evaluation
#MCP
Issue Date: 2025-08-22
[Paper Note] MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers, Ziyang Luo+, arXiv'25
Summaryモデルコンテキストプロトコル(MCP)は、LLMを外部データソースに接続する新しい標準であり、MCP-Universeという包括的なベンチマークを導入。これにより、実際のアプリケーションにおけるLLMの評価が可能となる。6つのコアドメインをカバーし、厳密な評価手法を実装。主要なLLMは性能制限を示し、長文コンテキストや未知のツールの課題に直面。UIサポート付きの評価フレームワークをオープンソース化し、MCPエコシステムの革新を促進。
Commentpj page:https://mcp-universe.github.io/元ポスト:https://x.com/lijunnan0409/status/1958671067071004934?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#LLMAgent
#SelfImprovement
#EMNLP
Issue Date: 2025-08-22
[Paper Note] WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model, Tianqing Fang+, arXiv'25
Summary自己改善エージェントのために、共進化するワールドモデルLLMを導入する新しいフレームワークを提案。これにより、エージェントのポリシーを洗練する自己指導型トレーニングデータを生成し、行動選択を導く先読みシミュレーションを実現。実験により、既存の自己進化エージェントに対して10%のパフォーマンス向上を示し、持続的な適応性を促進することを目指す。
Comment元ポスト:https://x.com/wyu_nd/status/1958632621820584203?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EMNLP
Issue Date: 2025-08-22
[Paper Note] Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?, Momoka Furuhashi+, EMNLP'25
Summary生成タスクの自動評価における曖昧な基準の課題を解決するため、チェックリストの使用方法を検討。6つの生成方法と8つのモデルサイズで評価し、選択的チェックリストがペアワイズ評価でパフォーマンスを改善する傾向があることを発見。ただし、直接スコアリングでは一貫性がない。人間の評価基準との相関が低いチェックリスト項目も存在し、評価基準の明確化が必要であることを示唆。
Comment元ポスト:https://x.com/tohoku_nlp_mmk/status/1958717497454002557?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpj page:https://momo0817.github.io/checklist-effectiveness-study-github.io/
#EMNLP
Issue Date: 2025-08-22
[Paper Note] MAC-Tuning: LLM Multi-Compositional Problem Reasoning with Enhanced Knowledge Boundary Awareness, Junsheng Huang+, EMNLP'25
SummaryLLMのハルシネーション問題に対処するため、複数の問題に同時に対応する新手法MAC-Tuningを提案。回答予測と信頼度推定を分離して学習し、実験で平均精度が最大25%向上したことを示す。
Comment元ポスト:https://x.com/may_f1_/status/1958362321337950709?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-22
[Paper Note] MM-BrowseComp: A Comprehensive Benchmark for Multimodal Browsing Agents, Shilong Li+, arXiv'25
SummaryMM-BrowseCompは、AIエージェントのマルチモーダル検索および推論能力を評価する新しいベンチマークで、224の手作りの質問を含む。これにより、画像や動画を含む情報の重要性を考慮し、テキストのみの手法の限界を示す。最先端モデルの評価では、OpenAI o3などのトップモデルでも29.02%の精度にとどまり、マルチモーダル能力の最適化不足が明らかになった。
Comment元ポスト:https://x.com/gezhang86038849/status/1958381269617955165?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#DiffusionModel
#Decoding
#PostTraining
Issue Date: 2025-08-22
[Paper Note] Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models, Wen Wang+, arXiv'25
SummarydLLMsは中間予測を捨てがちだが、時間的振動が重要な現象である。本研究では、時間的一貫性を活用する2つの方法を提案。1つ目は、テスト時に予測を集約する時間的自己一貫性投票、2つ目は中間予測の安定性を測る時間的意味エントロピーを報酬信号とする時間的一貫性強化。実験結果では、Countdownデータセットで24.7%の改善を達成し、他のベンチマークでも向上を示した。これにより、dLLMsの時間的ダイナミクスの可能性が強調される。
Comment元ポスト:https://x.com/jiqizhixin/status/1958702248055513335?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QdLLMのデノイジング過程において途中に正解が表出しているのに時間発展とともに消えてしまう問題があるらしく、それに対して、デノイジングステップにおいてstableな予測を行うSelf-Consistencyベースのdecoding手法と、意味的なエントロピーをrewardに加え時間発展で安定するようにpost trainingすることで対処します、みたいな話らしい。
Issue Date: 2025-08-22
[Paper Note] CAST: Counterfactual Labels Improve Instruction Following in Vision-Language-Action Models, Catherine Glossop+, arXiv'25
Summary視覚-言語-アクション(VLA)モデルは、自然言語指示をロボットのアクションにマッピングする能力に課題がある。これを解決するために、反実仮想ラベルを用いてロボットデータセットを拡張する新手法を提案。これにより、言語の多様性と粒度が向上し、指示従属能力が改善される。実験では、ナビゲーションタスクにおいて成功率が27%向上したことが示された。
Commentpj page:https://cast-vla.github.io元ポスト:https://x.com/gm8xx8/status/1958645106115789124?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EMNLP
Issue Date: 2025-08-21
[Paper Note] Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline, Meng Lu+, EMNLP'25
Summary多言語LLMsは英語での事実再呼出しに優れていますが、他言語ではパフォーマンスが低下します。原因として、英語中心のメカニズムの不十分な活用と再翻訳時の誤りを特定。これに対処するため、言語に依存しない二つの介入を導入し、再呼出し精度を35%以上向上させました。この研究は、メカニズムの理解がLLMsの多言語能力を引き出す手助けとなることを示しています。
Comment元ポスト:https://x.com/ruochenz_/status/1958253947111506283?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EMNLP
#Findings
Issue Date: 2025-08-21
[Paper Note] Evaluating Step-by-step Reasoning Traces: A Survey, Jinu Lee+, EMNLP'25 Findings
Summaryステップバイステップの推論はLLMの能力向上に寄与するが、評価手法は一貫性に欠ける。本研究では、推論評価の包括的な概要と、事実性、有効性、一貫性、実用性の4カテゴリからなる評価基準の分類法を提案。これに基づき、評価者の実装や最近の発見をレビューし、今後の研究の方向性を示す。
Comment元ポスト:https://x.com/jinulee_v/status/1958268008964796904?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-21
[Paper Note] Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS, Can Jin+, arXiv'25
Summary本論文では、テスト時スケーリング(TTS)におけるRLベースと探索ベースの手法を統一したAIRL-Sを提案。AIRL-Sは、敵対的逆強化学習とグループ相対ポリシー最適化を組み合わせ、ラベル付きデータなしで動的プロセス報酬モデルを学習。実験結果は、提案手法がベースモデルに対して平均9%の性能向上を示し、複数の探索アルゴリズムにおいても優れた結果を得たことを示す。これにより、LLMsにおける複雑な推論タスクに対する効果的な解決策を提供。
Comment元ポスト:https://x.com/iscienceluvr/status/1958470481050534069?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#ReinforcementLearning
#RLVR
#DualLearning
Issue Date: 2025-08-21
[Paper Note] DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization, Shuaijie She+, arXiv'25
SummaryDuPOは、注釈なしのフィードバックを生成する二重学習に基づく好み最適化フレームワークで、強化学習の高価なラベル依存と二重タスクペアの制限に対処。プライマルタスクの入力を分解し、未知の部分を再構築する二重タスクを構築することで、非可逆タスクへの適用範囲を広げる。実験により、翻訳品質や数学的推論の精度が大幅に向上し、DuPOはスケーラブルで一般的なLLM最適化の手法として位置付けられる。
Comment元ポスト:https://x.com/rosinality/status/1958413194307002415?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2508解説:https://x.com/gm8xx8/status/1959926238065127724?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-21 [Paper Note] FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction, Zhiyuan Zeng+, arXiv'25 Summary未来予測はLLMエージェントにとって複雑なタスクであり、情報収集や意思決定が求められる。これに対処するため、動的かつライブな評価ベンチマーク「FutureX」を導入。FutureXは、リアルタイム更新をサポートし、25のLLM/エージェントモデルを評価することで、エージェントの推論能力やパフォーマンスを分析。目標は、プロの人間アナリストと同等のパフォーマンスを持つLLMエージェントの開発を促進すること。 Comment元ポスト:https://x.com/liujiashuo77/status/1958191172020822292?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Single #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #LLMAgent #LongSequence #read-later Issue Date: 2025-08-21 [Paper Note] Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL, Weizhen Li+, arXiv'25 SummaryChain-of-Agents(CoA)という新しいLLM推論パラダイムを提案し、マルチエージェントシステムの協力を単一モデル内でエンドツーエンドに実現。マルチエージェント蒸留フレームワークを用いて、エージェント的な教師ありファインチューニングを行い、強化学習で能力を向上。得られたエージェント基盤モデル(AFMs)は、ウェブエージェントやコードエージェントの設定で新たな最先端性能を示す。研究成果はオープンソース化され、今後の研究の基盤を提供。 Comment元ポスト:https://x.com/omarsar0/status/1958186531161853995?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qマルチエージェントのように振る舞うシングルエージェントを、マルチエージェントから得られたtrajectoryを通じて蒸留することめ実現する手法を提案。SFTでcold startに対して訓練した後、verifiable reward (タスクを正常に完了できたか否か)でRLする模様。

 データセットも公開されている模様所見:https://x.com/dongxi_nlp/status/1958604404338147417?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:https://x.com/jiqizhixin/status/1959877518972137667?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#NLP
#Dataset
#MulltiModal
#Reasoning
#EMNLP
#PostTraining
#VisionLanguageModel
Issue Date: 2025-08-21
[Paper Note] VisualWebInstruct: Scaling up Multimodal Instruction Data through Web Search, Yiming Jia+, EMNLP'25
Summary本研究では、推論に焦点を当てたマルチモーダルデータセットの不足に対処するため、VisualWebInstructという新しいアプローチを提案。30,000のシード画像からGoogle画像検索を用いて700K以上のユニークなURLを収集し、約900KのQAペアを構築。ファインチューニングされたモデルは、Llava-OVで10-20ポイント、MAmmoTH-VLで5ポイントの性能向上を示し、最良モデルMAmmoTH-VL2は複数のベンチマークで最先端の性能を達成。これにより、Vision-Language Modelsの推論能力向上に寄与することが示された。
Comment元ポスト:https://x.com/wenhuchen/status/1958317145349075446?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#LLMAgent
#ScientificDiscovery
#EMNLP
#Findings
Issue Date: 2025-08-21
[Paper Note] Agent Laboratory: Using LLM Agents as Research Assistants, Samuel Schmidgall+, EMNLP'25 Findings
SummaryAgent Laboratoryは、全自動のLLMベースのフレームワークで、研究アイデアから文献レビュー、実験、報告書作成までのプロセスを完了し、質の高い研究成果を生成します。人間のフィードバックを各段階で取り入れることで、研究の質を向上させ、研究費用を84%削減。最先端の機械学習コードを生成し、科学的発見の加速を目指します。
Comment元ポスト:https://x.com/srschmidgall/status/1958272229223067789?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpj page:https://agentlaboratory.github.io
Issue Date: 2025-08-21
[Paper Note] SSRL: Self-Search Reinforcement Learning, Yuchen Fan+, arXiv'25
Summary大規模言語モデル(LLMs)が強化学習(RL)におけるエージェント検索タスクの効率的なシミュレーターとして機能する可能性を探求。LLMsの内在的な検索能力を定量化するSelf-Searchを導入し、BrowseCompタスクで高いパフォーマンスを示す。Self-Search RL(SSRL)を通じてLLMsの能力を強化し、外部ツールへの依存を減少。実証評価により、SSRLで訓練されたモデルがコスト効果の高い安定した環境を提供し、LLMsがスケーラブルなRLエージェントの訓練を支援する可能性を示唆。
Issue Date: 2025-08-20
[Paper Note] ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents, Hanyu Lai+, arXiv'25
SummaryComputerRLは、自律的なデスクトップインテリジェンスのためのフレームワークで、API-GUIパラダイムを用いてエージェントがデジタルワークスペースを操作します。分散RLインフラを開発し、数千の仮想デスクトップ環境でのスケーラブルな強化学習を実現。Entropulseトレーニング戦略により、長期トレーニング中のエントロピー崩壊を軽減。GLM-4-9B-0414を用いたAutoGLM-OS-9Bは、OSWorldベンチマークで48.1%の新しい最先端精度を達成し、デスクトップ自動化における重要な改善を示しました。
Comment簡易解説:https://x.com/gm8xx8/status/1958299060215128333?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q簡易解説:https://x.com/jiqizhixin/status/1958333917255389218?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-20
[Paper Note] Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI's Latest Open Source Models, Ziqian Bi+, arXiv'25
SummaryOpenAIは2025年8月にGPT-OSSモデルをリリースし、120Bおよび20Bパラメータの2つのエキスパート混合アーキテクチャを評価しました。6つのオープンソース大規模言語モデルを10のベンチマークでテストした結果、gpt-oss-20Bがいくつかのベンチマークでgpt-oss-120Bを上回り、メモリとエネルギー効率が良いことが示されました。両モデルは中程度のパフォーマンスを示し、特にコード生成に強みを持つ一方で、多言語タスクに弱点がありました。これにより、疎なアーキテクチャのスケーリングが必ずしもパフォーマンス向上に繋がらないことが示され、今後のモデル選択に向けた最適化戦略の必要性が浮き彫りになりました。
Comment元ポスト:https://x.com/k1ito/status/1957822041718915568?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-20
[Paper Note] Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation, David Heineman+, arXiv'25
Summary大規模言語モデルの評価において、信号対ノイズ比を改善することで、より信頼性の高いベンチマークを設計する方法を提案。信号はモデルの識別能力、ノイズは変動への感受性を示し、良好な比率は小規模な意思決定において有用。信号やノイズを改善するための介入として、指標の切り替えやサブタスクのフィルタリング、中間チェックポイントの出力の平均化を提案。30のベンチマークと375の言語モデルを用いて新しい公開データセットを作成。
Comment元ポスト:https://x.com/heinemandavidj/status/1957845124479873209?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-20
[Paper Note] Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration, Zhicheng Yang+, arXiv'25
Summary強化学習における検証可能な報酬(RLVR)は、言語モデルの推論能力を引き出すが、深さと幅の2つの次元に制約されている。GRPOアルゴリズムの分析から、低精度のインスタンスの重みが軽減されるバイアスが明らかになった。これを是正するために、難易度適応型ロールアウトサンプリング(DARS)を導入し、難しい問題の重みを再調整。DARSは収束時に推論コストなしでPass@Kを向上させる。さらに、トレーニングデータの幅を拡大することでPass@1のパフォーマンスも向上。DARS-Bを提案し、幅と深さの適応的な探査がRLVRの推論力を引き出す鍵であることを示した。
Comment元ポスト:https://x.com/iscienceluvr/status/1958092835665977806?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#read-later
Issue Date: 2025-08-20
[Paper Note] Reinforcement Learning with Rubric Anchors, Zenan Huang+, arXiv'25
Summary検証可能な報酬を用いた強化学習(RLVR)を、ルーブリックベースの報酬を統合することでオープンエンドのタスクに拡張。1万以上のルーブリックを集め、Qwen-30B-A3Bモデルを開発。5K以上のサンプルで人文学のベンチマークで+5.2%の改善を達成し、表現力豊かな応答生成を実現。ルーブリックの構築やトレーニングに関する教訓を共有し、今後の展望を議論。
Comment元ポスト:https://x.com/jiqizhixin/status/1958060316841112074?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q所見:https://x.com/aicia_solid/status/1958728490574078038?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Evaluation
#Programming
#MultiLingual
Issue Date: 2025-08-19
[Paper Note] AutoCodeBench: Large Language Models are Automatic Code Benchmark Generators, Jason Chou+, arXiv'25
SummaryAutoCodeGenを提案し、手動注釈なしで高難易度の多言語コード生成データセットを自動生成。これに基づき、3,920の問題からなるAutoCodeBenchを導入し、20のプログラミング言語に均等に分配。30以上のLLMsを評価した結果、最先端のモデルでも多様性や複雑さに苦労していることが明らかに。AutoCodeBenchシリーズは、実用的な多言語コード生成シナリオに焦点を当てるための貴重なリソースとなることを期待。
Commentpj page:https://autocodebench.github.io/元ポスト:https://x.com/tencenthunyuan/status/1957751900608110982?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-19
[Paper Note] Controlling Multimodal LLMs via Reward-guided Decoding, Oscar Mañas+, arXiv'25
SummaryMLLMの適応を制御されたデコーディングを通じて研究し、視覚的グラウンディングの改善に向けた報酬ガイドデコーディング手法を提案。オブジェクトの精度と再現率を独立して制御するための2つの報酬モデルを構築し、ユーザーが画像キャプショニングタスクでトレードオフを動的に調整できるようにする。探索の幅を制御することで計算量と視覚的グラウンディングのトレードオフも可能にし、ハリュシネーション緩和手法を上回る性能を示した。
Comment元ポスト:https://x.com/oscmansan/status/1957438180057133238?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-19
[Paper Note] Data Mixing Optimization for Supervised Fine-Tuning of Large Language Models, Yuan Li+, arXiv'25
Summary大規模言語モデルのファインチューニングにおけるデータミクスの最適化を新たな手法で提案。検証損失を最小化するためにデータの転送効果をモデル化し、最適な重みを導出。実験により、提案手法が優れたパフォーマンスを示し、従来のグリッドサーチと同等の結果を得ることを確認。さらに、人気のSFTデータセットでの重み付けにより、検証損失と下流パフォーマンスの改善を実証。ドメイン特化型モデルへの応用可能性についても考察。
Comment元ポスト:https://x.com/f14bertolotti/status/1957675768470757825?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-19
[Paper Note] Thyme: Think Beyond Images, Yi-Fan Zhang+, arXiv'25
SummaryThyme(Think Beyond Images)は、視覚情報を推論プロセスに活用し、画像処理と計算操作を自律的に生成・実行する新しいパラダイムを提案。二段階のトレーニング戦略を用いて、推論の精度とコード実行のバランスを取るGRPO-ATSアルゴリズムを導入。約20のベンチマークで顕著な性能向上を示した。
Comment元ポスト:https://x.com/iscienceluvr/status/1957402918057017823?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-19
[Paper Note] Re-evaluating Theory of Mind evaluation in large language models, Jennifer Hu+, arXiv'25
SummaryLLMsの心の理論(ToM)に関する評価は混在しており、意見の不一致の主な理由は、モデルの行動が人間に一致すべきか計算に基づくべきかの明確さの欠如にあると主張。現在の評価が「純粋な」ToM能力の測定から逸脱している可能性を指摘し、今後の研究の方向性としてToMと実用的コミュニケーションの関係を議論。人工システムと人間の認知理解の深化の可能性について考察。
Comment元ポスト:https://x.com/tomerullman/status/1957427950833573930?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q気になる
#NLP
#Dataset
#LanguageModel
#Evaluation
#Reasoning
#Overthinking
#Underthinking
Issue Date: 2025-08-19
[Paper Note] OptimalThinkingBench: Evaluating Over and Underthinking in LLMs, Pranjal Aggarwal+, arXiv'25
Summary思考型LLMは計算コストが高く、単純な問題に対して過剰に考え、非思考型LLMは迅速だが難しい推論に対して考えが浅い。これにより、最適なモデル選択がエンドユーザーに委ねられている。本研究では、OptimalThinkingBenchを導入し、過剰思考と考え不足を評価する統一ベンチマークを提供。72のドメインの単純なクエリと11の挑戦的な推論タスクを含む2つのサブベンチマークで、33のモデルを評価した結果、最適な思考モデルは存在せず、思考型モデルは過剰に考え、非思考型モデルは浅い結果を示した。将来的には、より良い統一的かつ最適なモデルの必要性が浮き彫りとなった。
Comment元ポスト:https://x.com/jaseweston/status/1957627532963926389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q元ポストの著者によるスレッドが非常にわかりやすいのでそちらを参照のこと。
データセットも公開されている模様所見:https://x.com/dongxi_nlp/status/1958604404338147417?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:https://x.com/jiqizhixin/status/1959877518972137667?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#NLP
#Dataset
#MulltiModal
#Reasoning
#EMNLP
#PostTraining
#VisionLanguageModel
Issue Date: 2025-08-21
[Paper Note] VisualWebInstruct: Scaling up Multimodal Instruction Data through Web Search, Yiming Jia+, EMNLP'25
Summary本研究では、推論に焦点を当てたマルチモーダルデータセットの不足に対処するため、VisualWebInstructという新しいアプローチを提案。30,000のシード画像からGoogle画像検索を用いて700K以上のユニークなURLを収集し、約900KのQAペアを構築。ファインチューニングされたモデルは、Llava-OVで10-20ポイント、MAmmoTH-VLで5ポイントの性能向上を示し、最良モデルMAmmoTH-VL2は複数のベンチマークで最先端の性能を達成。これにより、Vision-Language Modelsの推論能力向上に寄与することが示された。
Comment元ポスト:https://x.com/wenhuchen/status/1958317145349075446?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#LLMAgent
#ScientificDiscovery
#EMNLP
#Findings
Issue Date: 2025-08-21
[Paper Note] Agent Laboratory: Using LLM Agents as Research Assistants, Samuel Schmidgall+, EMNLP'25 Findings
SummaryAgent Laboratoryは、全自動のLLMベースのフレームワークで、研究アイデアから文献レビュー、実験、報告書作成までのプロセスを完了し、質の高い研究成果を生成します。人間のフィードバックを各段階で取り入れることで、研究の質を向上させ、研究費用を84%削減。最先端の機械学習コードを生成し、科学的発見の加速を目指します。
Comment元ポスト:https://x.com/srschmidgall/status/1958272229223067789?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpj page:https://agentlaboratory.github.io
Issue Date: 2025-08-21
[Paper Note] SSRL: Self-Search Reinforcement Learning, Yuchen Fan+, arXiv'25
Summary大規模言語モデル(LLMs)が強化学習(RL)におけるエージェント検索タスクの効率的なシミュレーターとして機能する可能性を探求。LLMsの内在的な検索能力を定量化するSelf-Searchを導入し、BrowseCompタスクで高いパフォーマンスを示す。Self-Search RL(SSRL)を通じてLLMsの能力を強化し、外部ツールへの依存を減少。実証評価により、SSRLで訓練されたモデルがコスト効果の高い安定した環境を提供し、LLMsがスケーラブルなRLエージェントの訓練を支援する可能性を示唆。
Issue Date: 2025-08-20
[Paper Note] ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents, Hanyu Lai+, arXiv'25
SummaryComputerRLは、自律的なデスクトップインテリジェンスのためのフレームワークで、API-GUIパラダイムを用いてエージェントがデジタルワークスペースを操作します。分散RLインフラを開発し、数千の仮想デスクトップ環境でのスケーラブルな強化学習を実現。Entropulseトレーニング戦略により、長期トレーニング中のエントロピー崩壊を軽減。GLM-4-9B-0414を用いたAutoGLM-OS-9Bは、OSWorldベンチマークで48.1%の新しい最先端精度を達成し、デスクトップ自動化における重要な改善を示しました。
Comment簡易解説:https://x.com/gm8xx8/status/1958299060215128333?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q簡易解説:https://x.com/jiqizhixin/status/1958333917255389218?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-20
[Paper Note] Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI's Latest Open Source Models, Ziqian Bi+, arXiv'25
SummaryOpenAIは2025年8月にGPT-OSSモデルをリリースし、120Bおよび20Bパラメータの2つのエキスパート混合アーキテクチャを評価しました。6つのオープンソース大規模言語モデルを10のベンチマークでテストした結果、gpt-oss-20Bがいくつかのベンチマークでgpt-oss-120Bを上回り、メモリとエネルギー効率が良いことが示されました。両モデルは中程度のパフォーマンスを示し、特にコード生成に強みを持つ一方で、多言語タスクに弱点がありました。これにより、疎なアーキテクチャのスケーリングが必ずしもパフォーマンス向上に繋がらないことが示され、今後のモデル選択に向けた最適化戦略の必要性が浮き彫りになりました。
Comment元ポスト:https://x.com/k1ito/status/1957822041718915568?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-20
[Paper Note] Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation, David Heineman+, arXiv'25
Summary大規模言語モデルの評価において、信号対ノイズ比を改善することで、より信頼性の高いベンチマークを設計する方法を提案。信号はモデルの識別能力、ノイズは変動への感受性を示し、良好な比率は小規模な意思決定において有用。信号やノイズを改善するための介入として、指標の切り替えやサブタスクのフィルタリング、中間チェックポイントの出力の平均化を提案。30のベンチマークと375の言語モデルを用いて新しい公開データセットを作成。
Comment元ポスト:https://x.com/heinemandavidj/status/1957845124479873209?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-20
[Paper Note] Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration, Zhicheng Yang+, arXiv'25
Summary強化学習における検証可能な報酬(RLVR)は、言語モデルの推論能力を引き出すが、深さと幅の2つの次元に制約されている。GRPOアルゴリズムの分析から、低精度のインスタンスの重みが軽減されるバイアスが明らかになった。これを是正するために、難易度適応型ロールアウトサンプリング(DARS)を導入し、難しい問題の重みを再調整。DARSは収束時に推論コストなしでPass@Kを向上させる。さらに、トレーニングデータの幅を拡大することでPass@1のパフォーマンスも向上。DARS-Bを提案し、幅と深さの適応的な探査がRLVRの推論力を引き出す鍵であることを示した。
Comment元ポスト:https://x.com/iscienceluvr/status/1958092835665977806?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#read-later
Issue Date: 2025-08-20
[Paper Note] Reinforcement Learning with Rubric Anchors, Zenan Huang+, arXiv'25
Summary検証可能な報酬を用いた強化学習(RLVR)を、ルーブリックベースの報酬を統合することでオープンエンドのタスクに拡張。1万以上のルーブリックを集め、Qwen-30B-A3Bモデルを開発。5K以上のサンプルで人文学のベンチマークで+5.2%の改善を達成し、表現力豊かな応答生成を実現。ルーブリックの構築やトレーニングに関する教訓を共有し、今後の展望を議論。
Comment元ポスト:https://x.com/jiqizhixin/status/1958060316841112074?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q所見:https://x.com/aicia_solid/status/1958728490574078038?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Evaluation
#Programming
#MultiLingual
Issue Date: 2025-08-19
[Paper Note] AutoCodeBench: Large Language Models are Automatic Code Benchmark Generators, Jason Chou+, arXiv'25
SummaryAutoCodeGenを提案し、手動注釈なしで高難易度の多言語コード生成データセットを自動生成。これに基づき、3,920の問題からなるAutoCodeBenchを導入し、20のプログラミング言語に均等に分配。30以上のLLMsを評価した結果、最先端のモデルでも多様性や複雑さに苦労していることが明らかに。AutoCodeBenchシリーズは、実用的な多言語コード生成シナリオに焦点を当てるための貴重なリソースとなることを期待。
Commentpj page:https://autocodebench.github.io/元ポスト:https://x.com/tencenthunyuan/status/1957751900608110982?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-19
[Paper Note] Controlling Multimodal LLMs via Reward-guided Decoding, Oscar Mañas+, arXiv'25
SummaryMLLMの適応を制御されたデコーディングを通じて研究し、視覚的グラウンディングの改善に向けた報酬ガイドデコーディング手法を提案。オブジェクトの精度と再現率を独立して制御するための2つの報酬モデルを構築し、ユーザーが画像キャプショニングタスクでトレードオフを動的に調整できるようにする。探索の幅を制御することで計算量と視覚的グラウンディングのトレードオフも可能にし、ハリュシネーション緩和手法を上回る性能を示した。
Comment元ポスト:https://x.com/oscmansan/status/1957438180057133238?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-19
[Paper Note] Data Mixing Optimization for Supervised Fine-Tuning of Large Language Models, Yuan Li+, arXiv'25
Summary大規模言語モデルのファインチューニングにおけるデータミクスの最適化を新たな手法で提案。検証損失を最小化するためにデータの転送効果をモデル化し、最適な重みを導出。実験により、提案手法が優れたパフォーマンスを示し、従来のグリッドサーチと同等の結果を得ることを確認。さらに、人気のSFTデータセットでの重み付けにより、検証損失と下流パフォーマンスの改善を実証。ドメイン特化型モデルへの応用可能性についても考察。
Comment元ポスト:https://x.com/f14bertolotti/status/1957675768470757825?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-19
[Paper Note] Thyme: Think Beyond Images, Yi-Fan Zhang+, arXiv'25
SummaryThyme(Think Beyond Images)は、視覚情報を推論プロセスに活用し、画像処理と計算操作を自律的に生成・実行する新しいパラダイムを提案。二段階のトレーニング戦略を用いて、推論の精度とコード実行のバランスを取るGRPO-ATSアルゴリズムを導入。約20のベンチマークで顕著な性能向上を示した。
Comment元ポスト:https://x.com/iscienceluvr/status/1957402918057017823?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-19
[Paper Note] Re-evaluating Theory of Mind evaluation in large language models, Jennifer Hu+, arXiv'25
SummaryLLMsの心の理論(ToM)に関する評価は混在しており、意見の不一致の主な理由は、モデルの行動が人間に一致すべきか計算に基づくべきかの明確さの欠如にあると主張。現在の評価が「純粋な」ToM能力の測定から逸脱している可能性を指摘し、今後の研究の方向性としてToMと実用的コミュニケーションの関係を議論。人工システムと人間の認知理解の深化の可能性について考察。
Comment元ポスト:https://x.com/tomerullman/status/1957427950833573930?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q気になる
#NLP
#Dataset
#LanguageModel
#Evaluation
#Reasoning
#Overthinking
#Underthinking
Issue Date: 2025-08-19
[Paper Note] OptimalThinkingBench: Evaluating Over and Underthinking in LLMs, Pranjal Aggarwal+, arXiv'25
Summary思考型LLMは計算コストが高く、単純な問題に対して過剰に考え、非思考型LLMは迅速だが難しい推論に対して考えが浅い。これにより、最適なモデル選択がエンドユーザーに委ねられている。本研究では、OptimalThinkingBenchを導入し、過剰思考と考え不足を評価する統一ベンチマークを提供。72のドメインの単純なクエリと11の挑戦的な推論タスクを含む2つのサブベンチマークで、33のモデルを評価した結果、最適な思考モデルは存在せず、思考型モデルは過剰に考え、非思考型モデルは浅い結果を示した。将来的には、より良い統一的かつ最適なモデルの必要性が浮き彫りとなった。
Comment元ポスト:https://x.com/jaseweston/status/1957627532963926389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q元ポストの著者によるスレッドが非常にわかりやすいのでそちらを参照のこと。
ざっくり言うと、Overthinking(考えすぎて大量のトークンを消費した上に回答が誤っている; トークン量↓とLLMによるJudge Score↑で評価)とUnderthinking(全然考えずにトークンを消費しなかった上に回答が誤っている; Accuracy↑で評価)をそれぞれ評価するサンプルを収集し、それらのスコアの組み合わせでモデルが必要に応じてどれだけ的確にThinkingできているかを評価するベンチマーク。
Overthinkingを評価するためのサンプルは、多くのLLMでagreementがとれるシンプルなQAによって構築。一方、Underthinkingを評価するためのサンプルは、small reasoning modelがlarge non reasoning modelよりも高い性能を示すサンプルを収集。


現状Non Thinking ModelではQwen3-235B-A22Bの性能が良く、Thinking Modelではgpt-oss-120Bの性能が良い。プロプライエタリなモデルではそれぞれ、Claude-Sonnet4, o3の性能が良い。全体としてはo3の性能が最も良い。
 Issue Date: 2025-08-19
[Paper Note] Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models, Zhipeng Chen+, arXiv'25
Summary検証可能な報酬を用いた強化学習(RLVR)では、Pass@1を報酬として使用することが多く、探索と活用のバランスに課題がある。これに対処するため、Pass@kを報酬としてポリシーモデルを訓練し、その探索能力の向上を観察。分析により、探索と活用は相互に強化し合うことが示され、利得関数の設計を含むPass@k Trainingの利点が明らかになった。さらに、RLVRのための利得設計を探求し、有望な結果を得た。
Comment元ポスト:https://x.com/giffmana/status/1957560436498256085?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#read-later
Issue Date: 2025-08-19
[Paper Note] BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining, Pratyush Maini+, arXiv'25
Summary合成データ生成フレームワーク「BeyondWeb」を提案し、高品質な合成データの生成が可能であることを示す。BeyondWebは、従来のデータセットを超える性能を発揮し、トレーニング速度も向上。特に、3Bモデルが8Bモデルを上回る結果を示す。合成データの品質向上には多くの要因を最適化する必要があり、単純なアプローチでは限界があることを指摘。
Comment元ポスト:https://x.com/pratyushmaini/status/1957456720265154752?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-18
[Paper Note] The Importance of Being Lazy: Scaling Limits of Continual Learning, Jacopo Graldi+, arXiv'25
Summaryニューラルネットワークは非定常環境での学習に苦労しており、破滅的忘却(CF)の理解が不完全である。本研究では、モデルのスケールと特徴学習の影響を体系的に調査し、怠惰なトレーニングと豊富なトレーニングの違いを明らかにする。モデルの幅を増やすことは、特徴学習を減少させる場合にのみ有益であることを示し、CFの特性を動的平均場理論を用いて研究した。高い特徴学習は類似したタスクに対してのみ有益であり、モデルの遷移はタスクの類似性によって調整される。最終的に、ニューラルネットワークはタスクの非定常性に依存し、最適なパフォーマンスを達成するための特徴学習の臨界レベルを明らかにする。
Issue Date: 2025-08-18
[Paper Note] Apriel-Nemotron-15B-Thinker, Shruthan Radhakrishna+, arXiv'25
SummaryApriel-Nemotron-15B-Thinkerは、150億パラメータの大規模言語モデルで、半分のメモリで中規模モデルと同等以上の性能を発揮。4段階のトレーニングパイプラインを用いて訓練され、多様なベンチマークで優れた結果を示す。
Comment元ポスト:https://x.com/f14bertolotti/status/1957312273833193951?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#LLMAgent
#Evaluation
Issue Date: 2025-08-18
[Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations, Kaiyuan Chen+, arXiv'25
Summary「xbench」は、AIエージェントの能力と実世界の生産性のギャップを埋めるために設計された動的な評価スイートで、業界専門家が定義したタスクを用いて商業的に重要なドメインをターゲットにしています。リクルートメントとマーケティングの2つのベンチマークを提示し、エージェントの能力を評価するための基準を確立します。評価結果は継続的に更新され、https://xbench.org で入手可能です。
Issue Date: 2025-08-18
[Paper Note] Speed Always Wins: A Survey on Efficient Architectures for Large Language Models, Weigao Sun+, arXiv'25
Summary本調査では、トランスフォーマーの制限に対処し、効率を向上させる革新的な大規模言語モデル(LLMs)アーキテクチャを体系的に検討。線形・スパースなシーケンスモデリング手法や効率的なフルアテンションのバリアント、スパースなエキスパートの混合、ハイブリッドモデル、拡散LLMsの技術的詳細をカバーし、他のモダリティへの応用も議論。これにより、効率的で多用途なAIシステムの開発に向けた研究を促進することを目指す。
Comment元ポスト:https://x.com/omarsar0/status/1956031319051501991?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-18
[Paper Note] The Illusion of Progress: Re-evaluating Hallucination Detection in LLMs, Denis Janiak+, arXiv'25
SummaryLLMの幻覚は信頼性に課題をもたらし、既存の検出手法はROUGEに依存しているが、人間の判断と一致しない。研究により、ROUGEは高い再現率を示す一方で低い適合率が問題であり、確立された手法のパフォーマンスが最大45.9%低下することが判明。応答の長さに基づく単純なヒューリスティックが複雑な手法に匹敵する可能性も示唆され、評価手法に欠陥がある。信頼性を確保するためには、意味的に意識した評価フレームワークが必要である。
Comment元ポスト:https://x.com/omarsar0/status/1955647039733481841?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-18
[Paper Note] OdysseyBench: Evaluating LLM Agents on Long-Horizon Complex Office Application Workflows, Weixuan Wang+, arXiv'25
SummaryOdysseyBenchは、LLMエージェントの長期的なワークフローを評価するための新しいベンチマークで、300の実際のタスクと302の合成タスクを含む。エージェントは、長期的なインタラクションから情報を特定し、多段階の推論を行う必要がある。HomerAgentsフレームワークを用いて、ベンチマークの自動生成を実現。OdysseyBenchは、既存のタスクベンチマークよりも現実の文脈でのLLMエージェントの能力を正確に評価できることを示している。
Comment元ポスト:https://x.com/dair_ai/status/1957100418741182853?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLM Agent w/ long horizon流行ってきてるな関連:
Issue Date: 2025-08-19
[Paper Note] Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models, Zhipeng Chen+, arXiv'25
Summary検証可能な報酬を用いた強化学習(RLVR)では、Pass@1を報酬として使用することが多く、探索と活用のバランスに課題がある。これに対処するため、Pass@kを報酬としてポリシーモデルを訓練し、その探索能力の向上を観察。分析により、探索と活用は相互に強化し合うことが示され、利得関数の設計を含むPass@k Trainingの利点が明らかになった。さらに、RLVRのための利得設計を探求し、有望な結果を得た。
Comment元ポスト:https://x.com/giffmana/status/1957560436498256085?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#read-later
Issue Date: 2025-08-19
[Paper Note] BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining, Pratyush Maini+, arXiv'25
Summary合成データ生成フレームワーク「BeyondWeb」を提案し、高品質な合成データの生成が可能であることを示す。BeyondWebは、従来のデータセットを超える性能を発揮し、トレーニング速度も向上。特に、3Bモデルが8Bモデルを上回る結果を示す。合成データの品質向上には多くの要因を最適化する必要があり、単純なアプローチでは限界があることを指摘。
Comment元ポスト:https://x.com/pratyushmaini/status/1957456720265154752?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-18
[Paper Note] The Importance of Being Lazy: Scaling Limits of Continual Learning, Jacopo Graldi+, arXiv'25
Summaryニューラルネットワークは非定常環境での学習に苦労しており、破滅的忘却(CF)の理解が不完全である。本研究では、モデルのスケールと特徴学習の影響を体系的に調査し、怠惰なトレーニングと豊富なトレーニングの違いを明らかにする。モデルの幅を増やすことは、特徴学習を減少させる場合にのみ有益であることを示し、CFの特性を動的平均場理論を用いて研究した。高い特徴学習は類似したタスクに対してのみ有益であり、モデルの遷移はタスクの類似性によって調整される。最終的に、ニューラルネットワークはタスクの非定常性に依存し、最適なパフォーマンスを達成するための特徴学習の臨界レベルを明らかにする。
Issue Date: 2025-08-18
[Paper Note] Apriel-Nemotron-15B-Thinker, Shruthan Radhakrishna+, arXiv'25
SummaryApriel-Nemotron-15B-Thinkerは、150億パラメータの大規模言語モデルで、半分のメモリで中規模モデルと同等以上の性能を発揮。4段階のトレーニングパイプラインを用いて訓練され、多様なベンチマークで優れた結果を示す。
Comment元ポスト:https://x.com/f14bertolotti/status/1957312273833193951?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#LLMAgent
#Evaluation
Issue Date: 2025-08-18
[Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations, Kaiyuan Chen+, arXiv'25
Summary「xbench」は、AIエージェントの能力と実世界の生産性のギャップを埋めるために設計された動的な評価スイートで、業界専門家が定義したタスクを用いて商業的に重要なドメインをターゲットにしています。リクルートメントとマーケティングの2つのベンチマークを提示し、エージェントの能力を評価するための基準を確立します。評価結果は継続的に更新され、https://xbench.org で入手可能です。
Issue Date: 2025-08-18
[Paper Note] Speed Always Wins: A Survey on Efficient Architectures for Large Language Models, Weigao Sun+, arXiv'25
Summary本調査では、トランスフォーマーの制限に対処し、効率を向上させる革新的な大規模言語モデル(LLMs)アーキテクチャを体系的に検討。線形・スパースなシーケンスモデリング手法や効率的なフルアテンションのバリアント、スパースなエキスパートの混合、ハイブリッドモデル、拡散LLMsの技術的詳細をカバーし、他のモダリティへの応用も議論。これにより、効率的で多用途なAIシステムの開発に向けた研究を促進することを目指す。
Comment元ポスト:https://x.com/omarsar0/status/1956031319051501991?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-18
[Paper Note] The Illusion of Progress: Re-evaluating Hallucination Detection in LLMs, Denis Janiak+, arXiv'25
SummaryLLMの幻覚は信頼性に課題をもたらし、既存の検出手法はROUGEに依存しているが、人間の判断と一致しない。研究により、ROUGEは高い再現率を示す一方で低い適合率が問題であり、確立された手法のパフォーマンスが最大45.9%低下することが判明。応答の長さに基づく単純なヒューリスティックが複雑な手法に匹敵する可能性も示唆され、評価手法に欠陥がある。信頼性を確保するためには、意味的に意識した評価フレームワークが必要である。
Comment元ポスト:https://x.com/omarsar0/status/1955647039733481841?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-18
[Paper Note] OdysseyBench: Evaluating LLM Agents on Long-Horizon Complex Office Application Workflows, Weixuan Wang+, arXiv'25
SummaryOdysseyBenchは、LLMエージェントの長期的なワークフローを評価するための新しいベンチマークで、300の実際のタスクと302の合成タスクを含む。エージェントは、長期的なインタラクションから情報を特定し、多段階の推論を行う必要がある。HomerAgentsフレームワークを用いて、ベンチマークの自動生成を実現。OdysseyBenchは、既存のタスクベンチマークよりも現実の文脈でのLLMエージェントの能力を正確に評価できることを示している。
Comment元ポスト:https://x.com/dair_ai/status/1957100418741182853?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLM Agent w/ long horizon流行ってきてるな関連:
・2412 Issue Date: 2025-08-18 [Paper Note] TRIBE: TRImodal Brain Encoder for whole-brain fMRI response prediction, Stéphane d'Ascoli+, arXiv'25 SummaryTRIBEは、複数のモダリティや皮質領域にわたる脳の反応を予測するために訓練された初の深層神経ネットワークであり、テキスト、音声、ビデオの表現を組み合わせてfMRI反応をモデル化。Algonauts 2025コンペティションで1位を獲得し、単一モダリティモデルよりも高次の連合皮質での性能が優れていることを示した。このアプローチは、人間の脳の表現の統合モデル構築に寄与する。 Comment元ポスト:https://x.com/dair_ai/status/1957100416568614946?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-18 [Paper Note] Capabilities of GPT-5 on Multimodal Medical Reasoning, Shansong Wang+, arXiv'25 SummaryGPT-5を用いて医療意思決定支援のためのマルチモーダル推論を評価。テキストと視覚情報を統合し、ゼロショットの思考連鎖推論性能を検証した結果、GPT-5は全てのベースラインを上回り、特にMedXpertQA MMで人間の専門家を超える性能を示した。これにより、将来の臨床意思決定支援システムにおける大きな進展が期待される。 Comment元ポスト:https://x.com/dair_ai/status/1957100411904475571?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-18 [Paper Note] In-Training Defenses against Emergent Misalignment in Language Models, David Kaczér+, arXiv'25 SummaryファインチューニングはLLMを新しいドメインに適用する手法ですが、最近の研究で新たな不整合(EMA)が発見されました。これは、小規模なファインチューニングでも有害な行動を引き起こす可能性があることを示しています。本研究では、APIを通じてファインチューニングを行う際のEMAに対する安全策を体系的に調査し、4つの正則化手法を提案します。これらの手法の効果を悪意のあるタスクで評価し、無害なタスクへの影響も検討します。最後に、未解決の問題について議論します。 Comment元ポスト:https://x.com/owainevans_uk/status/1957054130192794099?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-17 [Paper Note] Cyber-Zero: Training Cybersecurity Agents without Runtime, Terry Yue Zhuo+, arXiv'25 SummaryCyber-Zeroは、サイバーセキュリティLLMを訓練するための初のランタイムフリーのフレームワークであり、公開CTFの解説を活用してリアルなインタラクションシーケンスを生成。これにより、LLMベースのエージェントを訓練し、著名なCTFベンチマークで最大13.1%の性能向上を達成。最良モデルCyber-Zero-32Bは、オープンウェイトモデルの中で新たな最先端の性能を確立し、コスト効率も優れていることを示した。 Comment元ポスト:https://x.com/terryyuezhuo/status/1956979803581493575?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Transformer #TextToImageGeneration #Architecture #ICLR #read-later #NormalizingFlow Issue Date: 2025-08-17 [Paper Note] JetFormer: An Autoregressive Generative Model of Raw Images and Text, Michael Tschannen+, ICLR'25 SummaryJetFormerは、画像とテキストの共同生成を効率化する自己回帰型デコーダー専用のトランスフォーマーであり、別々にトレーニングされたコンポーネントに依存せず、両モダリティを理解・生成可能。正規化フローモデルを活用し、テキストから画像への生成品質で既存のベースラインと競合しつつ、堅牢な画像理解能力を示す。JetFormerは高忠実度の画像生成と強力な対数尤度境界を実現する初のモデルである。 Commentopenreview:https://openreview.net/forum?id=sgAp2qG86e画像をnormalizing flowでソフトトークンに変換し、transformerでソフトトークンを予測させるように学習することで、テキストと画像を同じアーキテクチャで学習できるようにしました、みたいな話っぽい?おもしろそう
 #Survey
#NLP
#LanguageModel
#DiffusionModel
#Verification
Issue Date: 2025-08-16
[Paper Note] A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models, Lingzhe Zhang+, arXiv'25
Summary並列テキスト生成は、LLMの生成速度を向上させるための技術であり、自己回帰生成のボトルネックを打破することを目指している。本研究では、並列テキスト生成手法をARベースと非ARベースに分類し、それぞれの技術を評価。速度、品質、効率のトレードオフを考察し、今後の研究の方向性を示す。関連論文を集めたGitHubリポジトリも作成。
CommentTaxonomyと手法一覧。Draft and Verifyingは個人的に非常に興味がある。
#Survey
#NLP
#LanguageModel
#DiffusionModel
#Verification
Issue Date: 2025-08-16
[Paper Note] A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models, Lingzhe Zhang+, arXiv'25
Summary並列テキスト生成は、LLMの生成速度を向上させるための技術であり、自己回帰生成のボトルネックを打破することを目指している。本研究では、並列テキスト生成手法をARベースと非ARベースに分類し、それぞれの技術を評価。速度、品質、効率のトレードオフを考察し、今後の研究の方向性を示す。関連論文を集めたGitHubリポジトリも作成。
CommentTaxonomyと手法一覧。Draft and Verifyingは個人的に非常に興味がある。
 Issue Date: 2025-08-16
[Paper Note] Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory, Lin Long+, arXiv'25
SummaryM3-Agentは、長期記憶を持つ新しいマルチモーダルエージェントフレームワークで、視覚と聴覚の入力をリアルタイムで処理し、エピソード記憶を超えた意味記憶を構築します。自律的にマルチターンの推論を行い、関連情報を記憶から取得してタスクを達成します。新たに開発したM3-Benchベンチマークを用いて、エージェントの能力を評価し、強化学習を通じて訓練されたM3-Agentが既存のベースラインを上回る精度向上を示しました。
Comment元ポスト:https://x.com/omarsar0/status/1956773240623235076?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Evaluation
#Trustfulness
#Health
Issue Date: 2025-08-16
[Paper Note] HealthBench: Evaluating Large Language Models Towards Improved Human Health, Rahul K. Arora+, arXiv'25
Summaryオープンソースのベンチマーク「HealthBench」を発表。5,000件のマルチターン会話を基に、262人の医師による評価基準でモデルの性能と安全性を測定。従来のベンチマークと異なり、48,562のユニークな評価基準を用いて多様な健康コンテキストを評価。GPT-3.5 TurboとGPT-4oの比較で初期の進展を示し、小型モデルの改善が顕著。新たに「HealthBench Consensus」と「HealthBench Hard」の2つのバリエーションもリリース。HealthBenchが健康分野でのモデル開発に寄与することを期待。
#NLP
#Dataset
#LanguageModel
#Evaluation
#x-Use
Issue Date: 2025-08-16
[Paper Note] BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, Jason Wei+, arXiv'25
SummaryBrowseCompは、エージェントのウェブブラウジング能力を測定するための1,266の質問からなるベンチマークで、絡み合った情報を探すことを要求します。シンプルで使いやすく、短い回答が求められ、参照回答との照合が容易です。このベンチマークは、ブラウジングエージェントの能力を評価するための重要なツールであり、持続力と創造性を測定します。詳細はGitHubで入手可能です。
Issue Date: 2025-08-16
[Paper Note] UI-Venus Technical Report: Building High-performance UI Agents with RFT, Zhangxuan Gu+, arXiv'25
SummaryUI-Venusは、スクリーンショットを入力として受け取るマルチモーダル大規模言語モデルに基づくネイティブUIエージェントで、UIグラウンディングとナビゲーションタスクで最先端の性能を達成。7Bおよび72Bバリアントは、Screenspot-V2 / Proベンチマークで高い成功率を記録し、既存のモデルを上回る。報酬関数やデータクリーニング戦略を導入し、ナビゲーション性能を向上させるための新しい自己進化フレームワークも提案。オープンソースのUIエージェントを公開し、さらなる研究を促進。コードはGitHubで入手可能。
Comment元ポスト:https://x.com/_akhaliq/status/1956344636831662567?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:https://x.com/jiqizhixin/status/1957262667493826891?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#LLMAgent
#x-Use
#read-later
#Admin'sPick
Issue Date: 2025-08-15
[Paper Note] OpenCUA: Open Foundations for Computer-Use Agents, Xinyuan Wang+, arXiv'25
SummaryOpenCUAは、CUAデータと基盤モデルをスケールさせるためのオープンソースフレームワークであり、アノテーションインフラ、AgentNetデータセット、反射的なChain-of-Thought推論を持つスケーラブルなパイプラインを提供。OpenCUA-32Bは、CUAベンチマークで34.8%の成功率を達成し、最先端の性能を示す。研究コミュニティのために、アノテーションツールやデータセットを公開。
Comment元ポスト:https://x.com/gm8xx8/status/1956157162830418062?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/xywang626/status/1956400403911962757?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCUAにおいてProprietaryモデルに近い性能を達成した初めての研究な模様。重要
Issue Date: 2025-08-15
[Paper Note] Optimas: Optimizing Compound AI Systems with Globally Aligned Local Rewards, Shirley Wu+, arXiv'25
Summary複合AIシステムの最適化のために、統一フレームワークOptimasを提案。各コンポーネントにローカル報酬関数を維持し、グローバルパフォーマンスと整合性を保ちながら同時に最大化。これにより、異種構成の独立した更新が可能となり、平均11.92%の性能向上を実現。
Comment元ポスト:https://x.com/shirleyyxwu/status/1956072970373538271?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-15
[Paper Note] Latent Policy Barrier: Learning Robust Visuomotor Policies by Staying In-Distribution, Zhanyi Sun+, arXiv'25
SummaryLatent Policy Barrier(LPB)を提案し、視覚運動ポリシーの堅牢性を向上させる。LPBは専門家のデモの潜在埋め込みを安全な状態と危険な状態に分け、専門家の模倣とOODの回復を別々のモジュールで処理。ダイナミクスモデルが将来の潜在状態を予測し、専門家の分布内に留まるよう最適化。シミュレーションと実世界の実験で、LPBはデータ効率を高め、信頼性のある操作を実現。
Comment元ポスト:https://x.com/songshuran/status/1956104656888979838?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-14
[Paper Note] FormulaOne: Measuring the Depth of Algorithmic Reasoning Beyond Competitive Programming, Gal Beniamini+, arXiv'25
SummaryフロンティアAIモデルの能力を評価するために、実際の研究問題に基づくベンチマーク「FormulaOne」を構築。これは、グラフ理論やアルゴリズムに関連する難易度の高い問題で、商業的関心や理論計算機科学に関連。最先端モデルはFormulaOneでほとんど解決できず、専門家レベルの理解から遠いことが示された。研究支援のために、簡単なタスクセット「FormulaOne-Warmup」を提供し、評価フレームワークも公開。
Comment元ポスト:https://x.com/shai_s_shwartz/status/1955968602978320727?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-14
[Paper Note] $μ$-Parametrization for Mixture of Experts, Jan Małaśnicki+, arXiv'25
Summary本研究では、Mixture-of-Experts(MoE)モデルに対する$\mu$-Parameterization($\mu$P)を提案し、ルーターとエキスパートの特徴学習に関する理論的保証を提供します。また、エキスパートの数と粒度のスケーリングが最適な学習率に与える影響を実証的に検証します。
Comment元ポスト:https://x.com/gm8xx8/status/1956103561126789339?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#VideoGeneration/Understandings
#interactive
#Game
Issue Date: 2025-08-14
[Paper Note] Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition, Jiaqi Li+, arXiv'25
Summary「Hunyuan-GameCraft」という新しいフレームワークを提案し、ゲーム環境における高ダイナミックインタラクティブ動画生成を実現。キーボードとマウスの入力を統合し、動画シーケンスを自己回帰的に拡張することで、アクション制御と一貫性を向上。大規模データセットでトレーニングし、視覚的忠実性とリアリズムを強化。実験により、既存モデルを大幅に上回る性能を示した。
Comment元ポスト:https://x.com/tencenthunyuan/status/1955839140173631656?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q単体の画像と、prompt、マウス・キーボード入力に基づいてinteractiveに動画を合成する。軽量なGPUでも動作するように、高品質な合成データによってモデルを蒸留し軽量なモデルを利用したりもしている模様。そのうち家庭のゲーミングPCでこういったモデルでゲームをする日が来るのだろうか。
Issue Date: 2025-08-16
[Paper Note] Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory, Lin Long+, arXiv'25
SummaryM3-Agentは、長期記憶を持つ新しいマルチモーダルエージェントフレームワークで、視覚と聴覚の入力をリアルタイムで処理し、エピソード記憶を超えた意味記憶を構築します。自律的にマルチターンの推論を行い、関連情報を記憶から取得してタスクを達成します。新たに開発したM3-Benchベンチマークを用いて、エージェントの能力を評価し、強化学習を通じて訓練されたM3-Agentが既存のベースラインを上回る精度向上を示しました。
Comment元ポスト:https://x.com/omarsar0/status/1956773240623235076?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Evaluation
#Trustfulness
#Health
Issue Date: 2025-08-16
[Paper Note] HealthBench: Evaluating Large Language Models Towards Improved Human Health, Rahul K. Arora+, arXiv'25
Summaryオープンソースのベンチマーク「HealthBench」を発表。5,000件のマルチターン会話を基に、262人の医師による評価基準でモデルの性能と安全性を測定。従来のベンチマークと異なり、48,562のユニークな評価基準を用いて多様な健康コンテキストを評価。GPT-3.5 TurboとGPT-4oの比較で初期の進展を示し、小型モデルの改善が顕著。新たに「HealthBench Consensus」と「HealthBench Hard」の2つのバリエーションもリリース。HealthBenchが健康分野でのモデル開発に寄与することを期待。
#NLP
#Dataset
#LanguageModel
#Evaluation
#x-Use
Issue Date: 2025-08-16
[Paper Note] BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, Jason Wei+, arXiv'25
SummaryBrowseCompは、エージェントのウェブブラウジング能力を測定するための1,266の質問からなるベンチマークで、絡み合った情報を探すことを要求します。シンプルで使いやすく、短い回答が求められ、参照回答との照合が容易です。このベンチマークは、ブラウジングエージェントの能力を評価するための重要なツールであり、持続力と創造性を測定します。詳細はGitHubで入手可能です。
Issue Date: 2025-08-16
[Paper Note] UI-Venus Technical Report: Building High-performance UI Agents with RFT, Zhangxuan Gu+, arXiv'25
SummaryUI-Venusは、スクリーンショットを入力として受け取るマルチモーダル大規模言語モデルに基づくネイティブUIエージェントで、UIグラウンディングとナビゲーションタスクで最先端の性能を達成。7Bおよび72Bバリアントは、Screenspot-V2 / Proベンチマークで高い成功率を記録し、既存のモデルを上回る。報酬関数やデータクリーニング戦略を導入し、ナビゲーション性能を向上させるための新しい自己進化フレームワークも提案。オープンソースのUIエージェントを公開し、さらなる研究を促進。コードはGitHubで入手可能。
Comment元ポスト:https://x.com/_akhaliq/status/1956344636831662567?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:https://x.com/jiqizhixin/status/1957262667493826891?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#LLMAgent
#x-Use
#read-later
#Admin'sPick
Issue Date: 2025-08-15
[Paper Note] OpenCUA: Open Foundations for Computer-Use Agents, Xinyuan Wang+, arXiv'25
SummaryOpenCUAは、CUAデータと基盤モデルをスケールさせるためのオープンソースフレームワークであり、アノテーションインフラ、AgentNetデータセット、反射的なChain-of-Thought推論を持つスケーラブルなパイプラインを提供。OpenCUA-32Bは、CUAベンチマークで34.8%の成功率を達成し、最先端の性能を示す。研究コミュニティのために、アノテーションツールやデータセットを公開。
Comment元ポスト:https://x.com/gm8xx8/status/1956157162830418062?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/xywang626/status/1956400403911962757?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCUAにおいてProprietaryモデルに近い性能を達成した初めての研究な模様。重要
Issue Date: 2025-08-15
[Paper Note] Optimas: Optimizing Compound AI Systems with Globally Aligned Local Rewards, Shirley Wu+, arXiv'25
Summary複合AIシステムの最適化のために、統一フレームワークOptimasを提案。各コンポーネントにローカル報酬関数を維持し、グローバルパフォーマンスと整合性を保ちながら同時に最大化。これにより、異種構成の独立した更新が可能となり、平均11.92%の性能向上を実現。
Comment元ポスト:https://x.com/shirleyyxwu/status/1956072970373538271?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-15
[Paper Note] Latent Policy Barrier: Learning Robust Visuomotor Policies by Staying In-Distribution, Zhanyi Sun+, arXiv'25
SummaryLatent Policy Barrier(LPB)を提案し、視覚運動ポリシーの堅牢性を向上させる。LPBは専門家のデモの潜在埋め込みを安全な状態と危険な状態に分け、専門家の模倣とOODの回復を別々のモジュールで処理。ダイナミクスモデルが将来の潜在状態を予測し、専門家の分布内に留まるよう最適化。シミュレーションと実世界の実験で、LPBはデータ効率を高め、信頼性のある操作を実現。
Comment元ポスト:https://x.com/songshuran/status/1956104656888979838?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-14
[Paper Note] FormulaOne: Measuring the Depth of Algorithmic Reasoning Beyond Competitive Programming, Gal Beniamini+, arXiv'25
SummaryフロンティアAIモデルの能力を評価するために、実際の研究問題に基づくベンチマーク「FormulaOne」を構築。これは、グラフ理論やアルゴリズムに関連する難易度の高い問題で、商業的関心や理論計算機科学に関連。最先端モデルはFormulaOneでほとんど解決できず、専門家レベルの理解から遠いことが示された。研究支援のために、簡単なタスクセット「FormulaOne-Warmup」を提供し、評価フレームワークも公開。
Comment元ポスト:https://x.com/shai_s_shwartz/status/1955968602978320727?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-14
[Paper Note] $μ$-Parametrization for Mixture of Experts, Jan Małaśnicki+, arXiv'25
Summary本研究では、Mixture-of-Experts(MoE)モデルに対する$\mu$-Parameterization($\mu$P)を提案し、ルーターとエキスパートの特徴学習に関する理論的保証を提供します。また、エキスパートの数と粒度のスケーリングが最適な学習率に与える影響を実証的に検証します。
Comment元ポスト:https://x.com/gm8xx8/status/1956103561126789339?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#VideoGeneration/Understandings
#interactive
#Game
Issue Date: 2025-08-14
[Paper Note] Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition, Jiaqi Li+, arXiv'25
Summary「Hunyuan-GameCraft」という新しいフレームワークを提案し、ゲーム環境における高ダイナミックインタラクティブ動画生成を実現。キーボードとマウスの入力を統合し、動画シーケンスを自己回帰的に拡張することで、アクション制御と一貫性を向上。大規模データセットでトレーニングし、視覚的忠実性とリアリズムを強化。実験により、既存モデルを大幅に上回る性能を示した。
Comment元ポスト:https://x.com/tencenthunyuan/status/1955839140173631656?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q単体の画像と、prompt、マウス・キーボード入力に基づいてinteractiveに動画を合成する。軽量なGPUでも動作するように、高品質な合成データによってモデルを蒸留し軽量なモデルを利用したりもしている模様。そのうち家庭のゲーミングPCでこういったモデルでゲームをする日が来るのだろうか。
 アーキテクチャに使われている技術:
アーキテクチャに使われている技術:
・2526
・550 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention Issue Date: 2025-08-14 [Paper Note] Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning, Lijie Yang+, arXiv'25 Summary「LessIsMore」という新しいスパースアテンションメカニズムを提案。これは、トレーニング不要でグローバルアテンションパターンを活用し、トークン選択を効率化。精度を維持しつつ、デコーディング速度を1.1倍向上させ、トークン数を2倍削減。既存手法と比較して1.13倍のスピードアップを実現。 Comment元ポスト:https://x.com/lijieyyang/status/1955139186530328633?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qトレーニングフリーで1.1倍のデコーディング速度で性能もFull Attentionと同等以上のSparse Attentionらしい #Multi #Analysis #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-08-14 [Paper Note] The Policy Cliff: A Theoretical Analysis of Reward-Policy Maps in Large Language Models, Xingcheng Xu, arXiv'25 Summary強化学習(RL)は大規模言語モデルの行動形成に重要だが、脆弱なポリシーを生成し、信頼性を損なう問題がある。本論文では、報酬関数から最適ポリシーへのマッピングの安定性を分析する数学的枠組みを提案し、ポリシーの脆弱性が非一意的な最適アクションに起因することを示す。さらに、多報酬RLにおける安定性が「効果的報酬」によって支配されることを明らかにし、エントロピー正則化が安定性を回復することを証明する。この研究は、ポリシー安定性分析を進展させ、安全で信頼性の高いAIシステム設計に寄与する。 Comment元ポスト:https://x.com/jiqizhixin/status/1955909877404197072?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qとても面白そう #EfficiencyImprovement #NLP #Search #LanguageModel #ReinforcementLearning #LLMAgent Issue Date: 2025-08-14 [Paper Note] Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL, Jiaxuan Gao+, arXiv'25 SummaryASearcherは、LLMベースの検索エージェントの大規模なRLトレーニングを実現するオープンソースプロジェクトであり、高効率な非同期RLトレーニングと自律的に合成された高品質なQ&Aデータセットを用いて、検索能力を向上させる。提案されたエージェントは、xBenchで46.7%、GAIAで20.8%の改善を達成し、長期的な検索能力を示した。モデルとデータはオープンソースで提供される。 Comment元ポスト:https://x.com/huggingpapers/status/1955603041518035358?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/jxwuyi/status/1955487396344238486?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト: https://x.com/omarsar0/status/1955266026498855354?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連ベンチマーク:
・2466
・1158
・1461既存のモデルは <= 10 turnsのデータで学習されており、大規模で高品質なQAデータが不足している問題があったが、シードQAに基づいてQAを合成する手法によって1.4万シードQAから134kの高品質なQAを合成した(うち25.6kはツール利用が必要)。具体的には、シードのQAを合成しエージェントがQAの複雑度をiterationをしながら向上させていく手法を提案。事実情報は常にverificationをされ、合成プロセスのiterationの中で保持され続ける。個々のiterationにおいて、現在のQAと事実情報に基づいて、エージェントは
・Injection: 事実情報を新たに注入しQAをよりリッチにすることで複雑度を上げる
・Fuzz: QA中の一部の詳細な情報をぼかすことで、不確実性のレベルを向上させる。
の2種類の操作を実施する。その上で、QAに対してQuality verificationを実施する:
・Basic Quality: LLMでqualityを評価する
・Difficulty Measurement: LRMによって、複数の回答候補を生成する
・Answer Uniqueness: Difficulty Measurementで生成された複数の解答情報に基づいて、mismatched answersがvalid answerとなるか否かを検証し、正解が単一であることを担保する

また、複雑なタスク、特にtool callsが非常に多いタスクについては、多くのターン数(long trajectories)が必要となるが、既存のバッチに基づいた学習手法ではlong trajectoriesのロールアウトをしている間、他のサンプルの学習がブロックされてしまい学習効率が非常に悪いので、バッチ内のtrajectoryのロールアウトとモデルの更新を分離(ロールアウトのリクエストが別サーバに送信されサーバ上のInference Engineで非同期に実行され、モデルをアップデートする側は十分なtrajectoryがバッチ内で揃ったらパラメータを更新する、みたいな挙動?)することでIdleタイムを無くすような手法を提案した模様。
 既存の手法ベンチマークの性能は向上している。学習が進むにつれて、trajectory中のURL参照回数やsearch query数などが増大していく曲線は考察されている。他モデルと比較して、より多いターン数をより高い正確性を以って実行できるといった定量的なデータはまだ存在しないように見えた。
既存の手法ベンチマークの性能は向上している。学習が進むにつれて、trajectory中のURL参照回数やsearch query数などが増大していく曲線は考察されている。他モデルと比較して、より多いターン数をより高い正確性を以って実行できるといった定量的なデータはまだ存在しないように見えた。
 #ComputerVision
#NLP
#Dataset
#LanguageModel
#LLMAgent
#SyntheticData
#Evaluation
#MulltiModal
#VisionLanguageModel
#DeepResearch
Issue Date: 2025-08-14
[Paper Note] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent, Xinyu Geng+, arXiv'25
SummaryWebWatcherは、視覚と言語の推論能力を強化したマルチモーダルエージェントであり、情報探索の困難さに対処する。合成マルチモーダル軌跡を用いた効率的なトレーニングと強化学習により、深い推論能力を向上させる。新たに提案されたBrowseComp-VLベンチマークでの実験により、WebWatcherは複雑なVQAタスクで他のエージェントを大幅に上回る性能を示した。
Comment元ポスト:https://x.com/richardxp888/status/1955645614685077796?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#GRPO
#On-Policy
#Stability
Issue Date: 2025-08-14
[Paper Note] Geometric-Mean Policy Optimization, Yuzhong Zhao+, arXiv'25
SummaryGRPOの不安定性を解決するために、幾何平均を最適化するGMPOを提案。GMPOは外れ値に敏感でなく、安定した重要度サンプリング比率を維持。実験により、GMPO-7Bは複数の数学的およびマルチモーダル推論ベンチマークでGRPOを上回る性能を示した。
Comment元ポスト:https://x.com/zzlccc/status/1955823092904943816?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q簡易解説:https://x.com/jiqizhixin/status/1955879567354388926?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
#On-Policy
#Overthinking
Issue Date: 2025-08-14
[Paper Note] Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning, Vaishnavi Shrivastava+, arXiv'25
SummaryGFPO(Group Filtered Policy Optimization)を提案し、応答の長さの膨張を抑制。応答を長さとトークン効率に基づいてフィルタリングし、推論時の計算量を削減。Phi-4モデルで長さの膨張を46-71%削減し、精度を維持。Adaptive Difficulty GFPOにより、難易度に応じた訓練リソースの動的割り当てを実現。効率的な推論のための効果的なトレードオフを提供。
Comment元ポスト:https://x.com/zzlccc/status/1955823092904943816?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q簡易解説:https://x.com/jiqizhixin/status/1955884039149380067?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/vaishshrivas/status/1956096081504436620?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Evaluation
#Programming
#Reasoning
#Verification
Issue Date: 2025-08-13
[Paper Note] Can Language Models Falsify? Evaluating Algorithmic Reasoning with Counterexample Creation, Shiven Sinha+, arXiv'25
Summary言語モデル(LM)の科学的発見を加速するために、微妙に誤った解決策に対する反例を作成する能力を評価する新しいベンチマーク「REFUTE」を提案。これはプログラミング問題からの誤った提出物を用いており、最も優れた推論エージェントでも9%未満の反例しか生成できないことが示された。この研究は、LMの誤った解決策を否定する能力を向上させ、信頼できる推論を通じて自己改善を促進することを目指している。
Commentpj page:https://falsifiers.github.io元ポスト:https://x.com/shashwatgoel7/status/1955311868915966173?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qバグのあるコードとtask descriptionが与えられた時に、inputのフォーマットと全ての制約を満たすが、コードの実行が失敗するサンプル(=反例)を生成することで、モデルのreasoning capabilityの評価をするベンチマーク。
#ComputerVision
#NLP
#Dataset
#LanguageModel
#LLMAgent
#SyntheticData
#Evaluation
#MulltiModal
#VisionLanguageModel
#DeepResearch
Issue Date: 2025-08-14
[Paper Note] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent, Xinyu Geng+, arXiv'25
SummaryWebWatcherは、視覚と言語の推論能力を強化したマルチモーダルエージェントであり、情報探索の困難さに対処する。合成マルチモーダル軌跡を用いた効率的なトレーニングと強化学習により、深い推論能力を向上させる。新たに提案されたBrowseComp-VLベンチマークでの実験により、WebWatcherは複雑なVQAタスクで他のエージェントを大幅に上回る性能を示した。
Comment元ポスト:https://x.com/richardxp888/status/1955645614685077796?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#GRPO
#On-Policy
#Stability
Issue Date: 2025-08-14
[Paper Note] Geometric-Mean Policy Optimization, Yuzhong Zhao+, arXiv'25
SummaryGRPOの不安定性を解決するために、幾何平均を最適化するGMPOを提案。GMPOは外れ値に敏感でなく、安定した重要度サンプリング比率を維持。実験により、GMPO-7Bは複数の数学的およびマルチモーダル推論ベンチマークでGRPOを上回る性能を示した。
Comment元ポスト:https://x.com/zzlccc/status/1955823092904943816?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q簡易解説:https://x.com/jiqizhixin/status/1955879567354388926?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
#On-Policy
#Overthinking
Issue Date: 2025-08-14
[Paper Note] Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning, Vaishnavi Shrivastava+, arXiv'25
SummaryGFPO(Group Filtered Policy Optimization)を提案し、応答の長さの膨張を抑制。応答を長さとトークン効率に基づいてフィルタリングし、推論時の計算量を削減。Phi-4モデルで長さの膨張を46-71%削減し、精度を維持。Adaptive Difficulty GFPOにより、難易度に応じた訓練リソースの動的割り当てを実現。効率的な推論のための効果的なトレードオフを提供。
Comment元ポスト:https://x.com/zzlccc/status/1955823092904943816?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q簡易解説:https://x.com/jiqizhixin/status/1955884039149380067?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/vaishshrivas/status/1956096081504436620?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Evaluation
#Programming
#Reasoning
#Verification
Issue Date: 2025-08-13
[Paper Note] Can Language Models Falsify? Evaluating Algorithmic Reasoning with Counterexample Creation, Shiven Sinha+, arXiv'25
Summary言語モデル(LM)の科学的発見を加速するために、微妙に誤った解決策に対する反例を作成する能力を評価する新しいベンチマーク「REFUTE」を提案。これはプログラミング問題からの誤った提出物を用いており、最も優れた推論エージェントでも9%未満の反例しか生成できないことが示された。この研究は、LMの誤った解決策を否定する能力を向上させ、信頼できる推論を通じて自己改善を促進することを目指している。
Commentpj page:https://falsifiers.github.io元ポスト:https://x.com/shashwatgoel7/status/1955311868915966173?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qバグのあるコードとtask descriptionが与えられた時に、inputのフォーマットと全ての制約を満たすが、コードの実行が失敗するサンプル(=反例)を生成することで、モデルのreasoning capabilityの評価をするベンチマーク。
gpt-ossはコードにバグのあるコードに対して上記のような反例を生成する能力が高いようである。ただし、それでも全体のバグのあるコードのうち反例を生成できたのは高々21.6%のようである。ただ、もしコードだけでなくverification全般の能力が高いから、相当使い道がありそう。 #Analysis #NLP #LanguageModel #MoE(Mixture-of-Experts) Issue Date: 2025-08-13 [Paper Note] Unveiling Super Experts in Mixture-of-Experts Large Language Models, Zunhai Su+, arXiv'25 Summaryスパースに活性化されたMixture-of-Experts(MoE)モデルにおいて、特定の専門家のサブセット「スーパ専門家(SE)」がモデルの性能に重要な影響を与えることを発見。SEは稀な活性化を示し、プルーニングするとモデルの出力が劣化する。分析により、SEの重要性が数学的推論などのタスクで明らかになり、MoE LLMがSEに依存していることが確認された。 Comment元ポスト:https://x.com/jiqizhixin/status/1955217132016505239?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMoEにおける、特に重要な専門家であるSuper Expertsの存在・1566
を思い出す。 #NLP #Dataset #LanguageModel #LLMAgent #Evaluation #MCP Issue Date: 2025-08-13 [Paper Note] LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools?, Guozhao Mo+, arXiv'25 SummaryLiveMCPBenchは、10,000を超えるMCPサーバーに基づく95の実世界タスクから成る初の包括的なベンチマークで、LLMエージェントの大規模評価を目的としています。70のMCPサーバーと527のツールを含むLiveMCPToolを整備し、LLM-as-a-JudgeフレームワークであるLiveMCPEvalを導入して自動化された適応評価を実現しました。MCP Copilot Agentは、ツールを動的に計画し実行するマルチステップエージェントです。評価の結果、最も優れたモデルは78.95%の成功率を達成しましたが、モデル間で性能のばらつきが見られました。全体として、LiveMCPBenchはLLMエージェントの能力を評価するための新たなフレームワークを提供します。 Commentpj page:https://icip-cas.github.io/LiveMCPBench/元ポスト:https://x.com/huggingpapers/status/1955324566298833127?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMCP環境におけるLLM Agentのベンチマーク。論文中のTable1に他のベンチマークを含めサマリが掲載されている。MCPを用いたLLMAgentのベンチがすでにこんなにあることに驚いた…。
 #ComputerVision
#NLP
#Dataset
#PostTraining
#VisionLanguageModel
#Cultural
Issue Date: 2025-08-13
[Paper Note] Grounding Multilingual Multimodal LLMs With Cultural Knowledge, Jean de Dieu Nyandwi+, arXiv'25
SummaryMLLMsは高リソース環境で優れた性能を示すが、低リソース言語や文化的エンティティに対しては課題がある。これに対処するため、Wikidataを活用し、文化的に重要なエンティティを表す画像を用いた多言語視覚質問応答データセット「CulturalGround」を生成。CulturalPangeaというオープンソースのMLLMを訓練し、文化に基づいたアプローチがMLLMsの文化的ギャップを縮小することを示した。CulturalPangeaは、従来のモデルを平均5.0ポイント上回る性能を達成。
Comment元ポスト:https://x.com/gneubig/status/1955308632305782957?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpj page:https://neulab.github.io/CulturalGround/
#ComputerVision
#NLP
#Dataset
#PostTraining
#VisionLanguageModel
#Cultural
Issue Date: 2025-08-13
[Paper Note] Grounding Multilingual Multimodal LLMs With Cultural Knowledge, Jean de Dieu Nyandwi+, arXiv'25
SummaryMLLMsは高リソース環境で優れた性能を示すが、低リソース言語や文化的エンティティに対しては課題がある。これに対処するため、Wikidataを活用し、文化的に重要なエンティティを表す画像を用いた多言語視覚質問応答データセット「CulturalGround」を生成。CulturalPangeaというオープンソースのMLLMを訓練し、文化に基づいたアプローチがMLLMsの文化的ギャップを縮小することを示した。CulturalPangeaは、従来のモデルを平均5.0ポイント上回る性能を達成。
Comment元ポスト:https://x.com/gneubig/status/1955308632305782957?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpj page:https://neulab.github.io/CulturalGround/
VQAデータセット中の日本語データは3.1%程度で、<image, Question, answer>の3つ組で構成される。wikidataから特定の文化と紐づいたエンティティ(42カ国; 人,場所,組織,アーティファクトにフォーカス)を抽出し、関連するimage dataを1--3個程度wikimediaから収集。76種類のテンプレートを用いて、draftのQAを生成し、LLMを用いて洗練(文化的な自然さ、流暢さ)させる。最終的にVLM(Qwen2.5-VL-32B/72B or Gemma-3-12B/72B-Instructを文化ごとに強い方を選択して利用)を用いてirrelevantなimage, question, answerの三つ組をフィルタリング(relevanceのスコアリングと事実情報のverification)する。
ベースモデルとして
・2470
を利用(Qwen2-7Bに対してCLIPベースのvision encoderを利用したVLM)し、Vision Encoderはfrozenし、LLMとconnector(テキストと画像のモダリティの橋渡しをする(大抵は)MLP)のみをfinetuningした。catastrophic forgettingを防ぐために事前学習データの一部を補完しfinetuningでも利用し、エンティティの認識力を高めるためにM3LSデータなるものをフィルタリングして追加している。
Finetuningの結果、文化的な多様性を持つ評価データ(e.g., 2471 Figure1のJapaneseのサンプルを見ると一目でどのようなベンチか分かる)と一般的なマルチリンガルな評価データの双方でgainがあることを確認。


VQAによるフィルタリングで利用されたpromptは下記
 #NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
#read-later
#Reproducibility
Issue Date: 2025-08-12
[Paper Note] Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning, Zihe Liu+, arXiv'25
Summary強化学習(RL)を用いた大規模言語モデル(LLM)の推論に関する研究が進展する中、標準化されたガイドラインやメカニズムの理解が不足している。実験設定の不一致やデータの変動が混乱を招いている。本論文では、RL技術を体系的にレビューし、再現実験を通じて各技術のメカニズムや適用シナリオを分析。明確なガイドラインを提示し、実務者に信頼できるロードマップを提供する。また、特定の技術の組み合わせが性能を向上させることを示した。
Comment元ポスト:https://x.com/omarsar0/status/1955268799525265801?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q読んだ方が良い解説:https://x.com/jiqizhixin/status/1959799274059031039?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#Transformer
#ReinforcementLearning
#TextToImageGeneration
#GRPO
#On-Policy
#Encoder-Decoder
Issue Date: 2025-08-12
[Paper Note] AR-GRPO: Training Autoregressive Image Generation Models via Reinforcement Learning, Shihao Yuan+, arXiv'25
SummaryAR-GRPOは、自己回帰画像生成モデルにオンライン強化学習を統合した新しいアプローチで、生成画像の品質を向上させるためにGRPOアルゴリズムを適用。クラス条件およびテキスト条件の画像生成タスクで実験を行い、標準のARモデルと比較して品質と人間の好みを大幅に改善した。結果は、AR画像生成における強化学習の有効性を示し、高品質な画像合成の新たな可能性を開く。
Comment元ポスト:https://x.com/iscienceluvr/status/1955234358136373421?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
#NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
#read-later
#Reproducibility
Issue Date: 2025-08-12
[Paper Note] Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning, Zihe Liu+, arXiv'25
Summary強化学習(RL)を用いた大規模言語モデル(LLM)の推論に関する研究が進展する中、標準化されたガイドラインやメカニズムの理解が不足している。実験設定の不一致やデータの変動が混乱を招いている。本論文では、RL技術を体系的にレビューし、再現実験を通じて各技術のメカニズムや適用シナリオを分析。明確なガイドラインを提示し、実務者に信頼できるロードマップを提供する。また、特定の技術の組み合わせが性能を向上させることを示した。
Comment元ポスト:https://x.com/omarsar0/status/1955268799525265801?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q読んだ方が良い解説:https://x.com/jiqizhixin/status/1959799274059031039?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#Transformer
#ReinforcementLearning
#TextToImageGeneration
#GRPO
#On-Policy
#Encoder-Decoder
Issue Date: 2025-08-12
[Paper Note] AR-GRPO: Training Autoregressive Image Generation Models via Reinforcement Learning, Shihao Yuan+, arXiv'25
SummaryAR-GRPOは、自己回帰画像生成モデルにオンライン強化学習を統合した新しいアプローチで、生成画像の品質を向上させるためにGRPOアルゴリズムを適用。クラス条件およびテキスト条件の画像生成タスクで実験を行い、標準のARモデルと比較して品質と人間の好みを大幅に改善した。結果は、AR画像生成における強化学習の有効性を示し、高品質な画像合成の新たな可能性を開く。
Comment元ポスト:https://x.com/iscienceluvr/status/1955234358136373421?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2456 #ComputerVision #NLP #MulltiModal #SpeechProcessing #Reasoning #OpenWeight #VisionLanguageActionModel Issue Date: 2025-08-12 [Paper Note] MolmoAct: Action Reasoning Models that can Reason in Space, Jason Lee+, arXiv'25 Summaryアクション推論モデル(ARMs)であるMolmoActは、知覚、計画、制御を三段階のパイプラインで統合し、説明可能で操作可能な行動を実現。シミュレーションと実世界で高いパフォーマンスを示し、特にSimplerEnv Visual Matchingタスクで70.5%のゼロショット精度を達成。MolmoAct Datasetを公開し、トレーニングによりベースモデルのパフォーマンスを平均5.5%向上。全てのモデルの重みやデータセットを公開し、ARMsの構築に向けたオープンな設計図を提供。 Comment`Action Reasoning Models (ARMs)`
元ポスト:https://x.com/gm8xx8/status/1955168414294589844?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
blog: https://allenai.org/blog/molmoact関連:
・1426models:
・https://huggingface.co/allenai/MolmoAct-7B-D-Pretrain-0812
・https://huggingface.co/allenai/MolmoAct-7B-D-0812
datasets:
・https://huggingface.co/datasets/allenai/MolmoAct-Dataset
・https://huggingface.co/datasets/allenai/MolmoAct-Pretraining-Mixture
・https://huggingface.co/datasets/allenai/MolmoAct-Midtraining-Mixtureデータは公開されているが、コードが見当たらない? #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #read-later Issue Date: 2025-08-12 [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25 Summary355Bパラメータを持つオープンソースのMixture-of-ExpertsモデルGLM-4.5を発表。ハイブリッド推論手法を採用し、エージェント的、推論、コーディングタスクで高いパフォーマンスを達成。競合モデルに比べて少ないパラメータ数で上位にランクイン。GLM-4.5とそのコンパクト版GLM-4.5-Airをリリースし、詳細はGitHubで公開。 Comment元ポスト:https://x.com/grad62304977/status/1954805614011453706?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・アーキテクチャ
・MoE / sigmoid gates
・1719
・1754
・loss free balanced routing
・2442
・widthを小さく、depthを増やすことでreasoning能力改善
・GQA w/ partial RoPE
・1271
・1310
・Attention Headsの数を2.5倍(何に対して2.5倍なんだ、、?)(96個, 5120次元)にすることで(おそらく)事前学習のlossは改善しなかったがReasoning benchmarkの性能改善
・QK Normを導入しattentionのlogitsの値域を改善
・2443
・Multi Token Prediction
・2444
・1620
他モデルとの比較

学習部分は後で追記する・事前学習データ
・web
・英語と中国語のwebページを利用
・1944 と同様にquality scoreyをドキュメントに付与
・最も低いquality scoreの文書群を排除し、quality scoreの高い文書群をup sampling
・最もquality scoreyが大きい文書群は3.2 epoch分利用
・多くのweb pageがテンプレートから自動生成されており高いquality scoreが付与されていたが、MinHashによってdeduplicationできなかったため、 2445 を用いてdocument embeddingに基づいて類似した文書群を排除
・Multilingual
・独自にクロールしたデータとFineWeb-2 2109 から多言語の文書群を抽出し、quality classifierを適用することでeducational utilityを定量化し、高いスコアの文書群をupsamplingして利用
・code
・githubなどのソースコードhosting platformから収集
・ソースコードはルールベースのフィルタリングをかけ、その後言語ごとのquality modelsによって、high,middle, lowの3つに品質を分類
・high qualityなものはupsamplingし、low qualityなものは除外
・2446 で提案されているFill in the Middle objectiveをコードの事前学習では適用
・コードに関連するweb文書も事前学習で収集したテキスト群からルールベースとfasttextによる分類器で抽出し、ソースコードと同様のqualityの分類とサンプリング手法を適用。最終的にフィルタリングされた文書群はre-parseしてフォーマットと内容の品質を向上させた
・math & science
・web page, 本, 論文から、reasoning能力を向上させるために、数学と科学に関する文書を収集
・LLMを用いて文書中のeducational contentの比率に基づいて文書をスコアリングしスコアを予測するsmall-scaleな分類器を学習
・最終的に事前学習コーパスの中の閾値以上のスコアを持つ文書をupsampling
・事前学習は2 stageに分かれており、最初のステージでは、"大部分は"generalな文書で学習する。次のステージでは、ソースコード、数学、科学、コーディング関連の文書をupsamplingして学習する。
上記以上の細かい実装上の情報は記載されていない。
mid-training / post trainingについても後ほど追記する #EfficiencyImprovement #NLP #LanguageModel #Alignment #DPO #PostTraining Issue Date: 2025-08-12 [Paper Note] Difficulty-Based Preference Data Selection by DPO Implicit Reward Gap, Xuan Qi+, arXiv'25 SummaryLLMの好みを人間に合わせるための新しいデータ選択戦略を提案。DPOの暗黙的報酬ギャップが小さいデータを選ぶことで、データ効率とモデルの整合性を向上。元のデータの10%で5つのベースラインを上回るパフォーマンスを達成。限られたリソースでのLLM整合性向上に寄与。 Comment元ポスト:https://x.com/zhijingjin/status/1954535751489667173?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpreference pair dataを学習効率の良いサンプルのみに圧縮することで学習効率を上げたい系の話で、chosen, rejectedなサンプルのそれぞれについて、¥frac{現在のポリシーの尤度}{参照ポリシーの尤度}によってreward rを定義し(おそらく参照ポリシーの尤度によってサンプルの重要度を重みづけしている)、r_chosenとr_rejectedの差をreward gapと定義し、gapが大きいものは難易度が低いと判断してフィルタリングする、といった話に見える。
 #NLP
#LanguageModel
#LLMAgent
#ContextEngineering
#memory
Issue Date: 2025-08-12
[Paper Note] Memp: Exploring Agent Procedural Memory, Runnan Fang+, arXiv'25
Summary本研究では、LLMに基づくエージェントに学習可能で更新可能な手続き的記憶を持たせるための戦略を提案。Mempを用いて過去のエージェントの軌跡を指示や抽象に蒸留し、記憶の構築と更新を行う。TravelPlannerとALFWorldでの実証評価により、記憶リポジトリが進化することでエージェントの成功率と効率が向上することを示した。また、強力なモデルからの手続き的記憶の移行により、弱いモデルでも性能向上が得られることが確認された。
Comment元ポスト:https://x.com/zxlzr/status/1954840738082193477?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qアドホックに探索と実行を繰り返すのではなく、過去の試行のtrajectoryをメモリに記憶しておき、活用するような枠組みな模様。trajectoryは新たなタスクが来た際にretrieverでrelevantなtrajectoryを検索して利用され、良質なtrajectoryがキープされれば成功率や効率が向上すると考えられる。trajectoryはprocedure memoryとして保存され、成功率が低いtrajectoryは破棄されることで更新される。
#NLP
#LanguageModel
#LLMAgent
#ContextEngineering
#memory
Issue Date: 2025-08-12
[Paper Note] Memp: Exploring Agent Procedural Memory, Runnan Fang+, arXiv'25
Summary本研究では、LLMに基づくエージェントに学習可能で更新可能な手続き的記憶を持たせるための戦略を提案。Mempを用いて過去のエージェントの軌跡を指示や抽象に蒸留し、記憶の構築と更新を行う。TravelPlannerとALFWorldでの実証評価により、記憶リポジトリが進化することでエージェントの成功率と効率が向上することを示した。また、強力なモデルからの手続き的記憶の移行により、弱いモデルでも性能向上が得られることが確認された。
Comment元ポスト:https://x.com/zxlzr/status/1954840738082193477?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qアドホックに探索と実行を繰り返すのではなく、過去の試行のtrajectoryをメモリに記憶しておき、活用するような枠組みな模様。trajectoryは新たなタスクが来た際にretrieverでrelevantなtrajectoryを検索して利用され、良質なtrajectoryがキープされれば成功率や効率が向上すると考えられる。trajectoryはprocedure memoryとして保存され、成功率が低いtrajectoryは破棄されることで更新される。


メモリはT個のタスクに対するs_t, a_t, o_t, i.e., state, action, observation,の系列τと、reward rが与えられた時に、Builderを通して構築されてストアされる。agentは新たなタスクt_newに直面した時に、t_newと類似したメモリをretrieyeする。これはτの中のある時刻tのタスクに対応する。メモリは肥大化していくため、実験では複数のアルゴリズムに基づくメモリの更新方法について実験している。

procedural memoryの有無による挙動の違いに関するサンプル。

 memoryに対してretrieverを適用することになるので、retrieverの性能がボトルネックになると思われる。追加の学習をしなくて済むのは利点だが、その代わりモデル側がメモリ管理をする機能を有さない(学習すればそういった機能を持たせられるはず)ので、その点は欠点となる、という印象。簡易解説:
memoryに対してretrieverを適用することになるので、retrieverの性能がボトルネックになると思われる。追加の学習をしなくて済むのは利点だが、その代わりモデル側がメモリ管理をする機能を有さない(学習すればそういった機能を持たせられるはず)ので、その点は欠点となる、という印象。簡易解説:
https://x.com/huggingpapers/status/1954937801490772104?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LLMAgent #Evaluation #SoftwareEngineering Issue Date: 2025-08-12 [Paper Note] NoCode-bench: A Benchmark for Evaluating Natural Language-Driven Feature Addition, Le Deng+, arXiv'25 Summary自然言語駆動のノーコード開発におけるLLMsの評価のために「NoCode-bench」を提案。634のタスクと114,000のコード変更から成り、ドキュメントとコード実装のペアを検証。実験結果では、最良のLLMsがタスク成功率15.79%に留まり、完全なNL駆動のノーコード開発には未だ課題があることが示された。NoCode-benchは今後の進展の基盤となる。 Comment元ポスト:https://x.com/jiqizhixin/status/1955062236831158763?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qリーダーボード:https://nocodebench.orgドキュメントをソフトウェアの仕様書とみなし、ドキュメントの更新部分をらinputとし、対応する"機能追加"をする能力を測るベンチマーク

SoTAモデルでも15.79%程度しか成功しない。

元ポストによると、ファイルを跨いだ編集、コードベースの理解、tool useに苦労しているとのこと。 #Analysis #NLP #LanguageModel #ICLR #ReversalCurse Issue Date: 2025-08-11 [Paper Note] Physics of Language Models: Part 3.2, Knowledge Manipulation, Zeyuan Allen-Zhu+, ICLR'25 Summary言語モデルは豊富な知識を持つが、下流タスクへの柔軟な利用には限界がある。本研究では、情報検索、分類、比較、逆検索の4つの知識操作タスクを調査し、言語モデルが知識検索には優れているが、Chain of Thoughtsを用いないと分類や比較タスクで苦労することを示した。特に逆検索ではパフォーマンスがほぼ0%であり、これらの弱点は言語モデルに固有であることを確認した。これにより、現代のAIと人間を区別する新たなチューリングテストの必要性が浮き彫りになった。 Commentopenreview:https://openreview.net/forum?id=oDbiL9CLoS解説:
・1834 #Analysis #NLP #LanguageModel #SelfCorrection #ICLR Issue Date: 2025-08-11 [Paper Note] Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems, Tian Ye+, ICLR'25 Summary言語モデルの推論精度向上のために、「エラー修正」データを事前学習に組み込む有用性を探求。合成数学データセットを用いて、エラーフリーデータと比較して高い推論精度を達成することを示す。さらに、ビームサーチとの違いやデータ準備、マスキングの必要性、エラー量、ファインチューニング段階での遅延についても考察。 Commentopenreview:https://openreview.net/forum?id=zpDGwcmMV4解説:
・1834 #Analysis #NLP #LanguageModel #ICLR Issue Date: 2025-08-11 [Paper Note] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process, Tian Ye+, ICLR'25 Summary言語モデルの数学的推論能力を研究し、GSM8Kベンチマークでの精度向上のメカニズムを探る。具体的には、推論スキルの発展、隠れたプロセス、人間との違い、必要なスキルの超越、推論ミスの原因、モデルのサイズや深さについての実験を行い、LLMの理解を深める洞察を提供。 Commentopenreview:https://openreview.net/forum?id=Tn5B6Udq3E解説:
・1834 #EfficiencyImprovement #NLP #Transformer #Attention #Architecture Issue Date: 2025-08-11 [Paper Note] Fast and Simplex: 2-Simplicial Attention in Triton, Aurko Roy+, arXiv'25 Summary2-シンプリシアルトランスフォーマーを用いることで、トークン効率を向上させ、標準的なトランスフォーマーよりも優れた性能を発揮することを示す。固定されたトークン予算内で、数学や推論タスクにおいてドット積アテンションを上回る結果を得た。 Comment元ポスト:https://x.com/scaling01/status/1954682957798715669?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #Evaluation #Programming #Reasoning Issue Date: 2025-08-10 [Paper Note] STEPWISE-CODEX-Bench: Evaluating Complex Multi-Function Comprehension and Fine-Grained Execution Reasoning, Kaiwen Yan+, arXiv'25 Summary新しいベンチマーク「STEPWISE-CODEX-Bench(SX-Bench)」を提案し、複雑な多機能理解と細かい実行推論を評価。SX-Benchは、サブ関数間の協力を含むタスクを特徴とし、動的実行の深い理解を測定する。20以上のモデルで評価した結果、最先端モデルでも複雑な推論においてボトルネックが明らかに。SX-Benchはコード評価を進展させ、高度なコードインテリジェンスモデルの評価に貢献する。 Comment元ポスト:https://x.com/gm8xx8/status/1954296753525752266?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q現在の主流なコード生成のベンチは、input/outputがgivenなら上でコードスニペットを生成する形式が主流(e.g., MBPP 2439, HumanEval 2438)だが、モデルがコードを理解し、複雑なコードのロジックを実行する内部状態の変化に応じて、実行のプロセスを推論する能力が見落とされている。これを解決するために、CRUXEVAL 2440, CRUXEVAL-X 2441 では、関数のinputs/outputsを予測することで、モデルのコードのcomprehension, reasoning能力を測ろうとしているが、
・single functionのlogicに限定されている
・20 line程度の短く、trivialなロジックに限定されている
・すでにSoTAモデルで95%が達成され飽和している
というlimitationがあるので、複数の関数が協働するロジック、flow/dataのinteractionのフロー制御、細かい実行ステップなどを含む、staticなコードの理解から、動的な実行プロセスのモデリング能力の評価にシフトするような、新たなベンチマークを作成しました、という話な模様。
まず関数単位のライブラリを構築している。このために、単一の関数の基礎的な仕様を「同じinputに対して同じoutputを返すものは同じクラスにマッピングされる」と定義し、既存のコードリポジトリとLLMによる合成によって、GoとPythonについて合計30種類のクラスと361個のインスタンスを収集。これらの関数は、算術演算や大小比較、パリティチェックなどの判定、文字列の操作などを含む。そしてこれら関数を3種類の実行パターンでオーケストレーションすることで、合成関数を作成した。合成方法は
・Sequential: outputとinputをパイプラインでつなぎ伝搬させる
・Selective: 条件に応じてf(x)が実行されるか、g(x)が実行されるかを制御
・Loop: input集合に対するloopの中に関数を埋め込み順次関数を実行
の3種類。合成関数の挙動を評価するために、ランダムなテストケースは自動生成し、合成関数の挙動をモニタリング(オーバーフロー、無限ループ、タイムアウト、複数回の実行でoutputが決定的か等など)し、異常があるものはフィルタリングすることで合成関数の品質を担保する。
ベンチマーキングの方法としては、CRUXEVALではシンプルにモデルにコードの実行結果を予想させるだけであったが、指示追従能力の問題からミスジャッジをすることがあるため、この問題に対処するため<input, output>のペアが与えられた時に、outputが合成関数に対してinputしま結果とマッチするかをyes/noのbinaryで判定させる(Predictと呼ばれるモデルのコード理解力を評価)。これとは別に、与えられたinput, outputペアと合成関数に基づいて、実行時の合計のcomputation stepsを出力させるタスクをreasoningタスクとして定義し、複雑度に応じてeasy, hardに分類している。computation stepsは、プログラムを実行する最小単位のことであり、たとえば算術演算などの基礎的なarithmetic/logic operationを指す。

 #ComputerVision
#NLP
#ReinforcementLearning
#SyntheticData
#MulltiModal
#RLVR
#VisionLanguageModel
Issue Date: 2025-08-10
[Paper Note] StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models, Xiangxiang Zhang+, arXiv'25
SummaryStructVRMは、複雑な多質問推論タスクにおいて、部分的な正確性を評価するための構造化された検証可能な報酬モデルを導入。サブ質問レベルのフィードバックを提供し、微妙な部分的なクレジットスコアリングを可能にする。実験により、Seed-StructVRMが12のマルチモーダルベンチマークのうち6つで最先端のパフォーマンスを達成したことが示された。これは、複雑な推論におけるマルチモーダルモデルの能力向上に寄与する。
Comment元ポスト:https://x.com/gm8xx8/status/1954315513397760130?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q複数のsub-questionが存在するような複雑な問題に対して、既存のRLVRにおける全体に対してbinary rewardを適用する方法は報酬が荒すぎるため、よりfine-grainedなverifiableな報酬を設計することで、学習を安定化し性能も向上
#ComputerVision
#NLP
#ReinforcementLearning
#SyntheticData
#MulltiModal
#RLVR
#VisionLanguageModel
Issue Date: 2025-08-10
[Paper Note] StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models, Xiangxiang Zhang+, arXiv'25
SummaryStructVRMは、複雑な多質問推論タスクにおいて、部分的な正確性を評価するための構造化された検証可能な報酬モデルを導入。サブ質問レベルのフィードバックを提供し、微妙な部分的なクレジットスコアリングを可能にする。実験により、Seed-StructVRMが12のマルチモーダルベンチマークのうち6つで最先端のパフォーマンスを達成したことが示された。これは、複雑な推論におけるマルチモーダルモデルの能力向上に寄与する。
Comment元ポスト:https://x.com/gm8xx8/status/1954315513397760130?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q複数のsub-questionが存在するような複雑な問題に対して、既存のRLVRにおける全体に対してbinary rewardを適用する方法は報酬が荒すぎるため、よりfine-grainedなverifiableな報酬を設計することで、学習を安定化し性能も向上

以下がverifierのサンプル
 general purposeなreal worldに対するmultimodal reasoningシステムを作成するには高品質で多様なデータが必要なので、以下のようなパイプラインを用いて、学習データを合成している模様。後で読む。サマリが元ポストに記載されているので全体像をざっくり知りたい場合は参照のこと。
general purposeなreal worldに対するmultimodal reasoningシステムを作成するには高品質で多様なデータが必要なので、以下のようなパイプラインを用いて、学習データを合成している模様。後で読む。サマリが元ポストに記載されているので全体像をざっくり知りたい場合は参照のこと。
 #LanguageModel
#ReinforcementLearning
#LLMAgent
#SoftwareEngineering
Issue Date: 2025-08-10
[Paper Note] Agent Lightning: Train ANY AI Agents with Reinforcement Learning, Xufang Luo+, arXiv'25
SummaryAgent Lightningは、任意のAIエージェントのためにLLMsを用いたRLトレーニングを可能にする柔軟なフレームワークで、エージェントの実行とトレーニングを分離し、既存のエージェントとの統合を容易にします。マルコフ決定過程としてエージェントの実行を定式化し、階層的RLアルゴリズムLightningRLを提案。これにより、複雑な相互作用ロジックを扱うことが可能になります。実験では、テキストからSQLへの変換などで安定した改善が見られ、実世界でのエージェントトレーニングの可能性が示されました。
Comment元ポスト:https://x.com/curveweb/status/1954384415330824698?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#SyntheticData
#Reasoning
#SyntheticDataGeneration
#GRPO
Issue Date: 2025-08-10
[Paper Note] MathSmith: Towards Extremely Hard Mathematical Reasoning by Forging Synthetic Problems with a Reinforced Policy, Shaoxiong Zhan+, arXiv'25
SummaryMathSmithという新しいフレームワークを提案し、LLMの数学的推論を強化するために新しい問題をゼロから合成。既存の問題を修正せず、PlanetMathから概念と説明をランダムにサンプリングし、データの独立性を確保。9つの戦略を用いて難易度を上げ、強化学習で構造的妥当性や推論の複雑さを最適化。実験では、MathSmithが既存のベースラインを上回り、高難易度の合成データがLLMの推論能力を向上させる可能性を示した。
Comment元ポスト:https://x.com/gm8xx8/status/1954253929761411180?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#SelfImprovement
#ZeroData
Issue Date: 2025-08-09
[Paper Note] R-Zero: Self-Evolving Reasoning LLM from Zero Data, Chengsong Huang+, arXiv'25
SummaryR-Zeroは、自己進化型大規模言語モデル(LLMs)が自律的にトレーニングデータを生成するフレームワークで、チャレンジャーとソルバーの2つのモデルが共進化することで、既存のタスクやラベルに依存せずに自己改善を実現します。このアプローチにより、推論能力が大幅に向上し、特にQwen3-4B-Baseでは数学推論で+6.49、一般ドメイン推論で+7.54の改善が確認されました。
Comment元ポスト:https://x.com/_akhaliq/status/1953804055525962134?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q問題を生成するChallengerと与えられた問題を解くSolverを用意し、片方をfreezezさせた状態で交互にポリシーの更新を繰り返す。
#LanguageModel
#ReinforcementLearning
#LLMAgent
#SoftwareEngineering
Issue Date: 2025-08-10
[Paper Note] Agent Lightning: Train ANY AI Agents with Reinforcement Learning, Xufang Luo+, arXiv'25
SummaryAgent Lightningは、任意のAIエージェントのためにLLMsを用いたRLトレーニングを可能にする柔軟なフレームワークで、エージェントの実行とトレーニングを分離し、既存のエージェントとの統合を容易にします。マルコフ決定過程としてエージェントの実行を定式化し、階層的RLアルゴリズムLightningRLを提案。これにより、複雑な相互作用ロジックを扱うことが可能になります。実験では、テキストからSQLへの変換などで安定した改善が見られ、実世界でのエージェントトレーニングの可能性が示されました。
Comment元ポスト:https://x.com/curveweb/status/1954384415330824698?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#SyntheticData
#Reasoning
#SyntheticDataGeneration
#GRPO
Issue Date: 2025-08-10
[Paper Note] MathSmith: Towards Extremely Hard Mathematical Reasoning by Forging Synthetic Problems with a Reinforced Policy, Shaoxiong Zhan+, arXiv'25
SummaryMathSmithという新しいフレームワークを提案し、LLMの数学的推論を強化するために新しい問題をゼロから合成。既存の問題を修正せず、PlanetMathから概念と説明をランダムにサンプリングし、データの独立性を確保。9つの戦略を用いて難易度を上げ、強化学習で構造的妥当性や推論の複雑さを最適化。実験では、MathSmithが既存のベースラインを上回り、高難易度の合成データがLLMの推論能力を向上させる可能性を示した。
Comment元ポスト:https://x.com/gm8xx8/status/1954253929761411180?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#SelfImprovement
#ZeroData
Issue Date: 2025-08-09
[Paper Note] R-Zero: Self-Evolving Reasoning LLM from Zero Data, Chengsong Huang+, arXiv'25
SummaryR-Zeroは、自己進化型大規模言語モデル(LLMs)が自律的にトレーニングデータを生成するフレームワークで、チャレンジャーとソルバーの2つのモデルが共進化することで、既存のタスクやラベルに依存せずに自己改善を実現します。このアプローチにより、推論能力が大幅に向上し、特にQwen3-4B-Baseでは数学推論で+6.49、一般ドメイン推論で+7.54の改善が確認されました。
Comment元ポスト:https://x.com/_akhaliq/status/1953804055525962134?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q問題を生成するChallengerと与えられた問題を解くSolverを用意し、片方をfreezezさせた状態で交互にポリシーの更新を繰り返す。

Challenger
・ (Challengerによる)問題生成→
・(freezed solverによる)self consistencyによるラベル付け→
・Solverの問題に対するempirical acc.(i.e., サンプリング回数mに対するmajorityが占める割合)でrewardを与えChallengerを更新
といった流れでポリシーが更新される。Rewardは他にも生成された問題間のBLEUを測り類似したものばかりの場合はペナルティを与える項や、フォーマットが正しく指定された通りになっているか、といったペナルティも導入する。
Solver
・ChallengerのポリシーからN問生成し、それに対してSolverでself consistencyによって解答を生成
・empirical acc.を計算し、1/2との差分の絶対値を見て、簡単すぎる/難しすぎる問題をフィルタリング
・これはカリキュラム学習的な意味合いのみならず、低品質な問題のフィルタリングにも寄与する
・フィルタリング後の問題を利用して、verifiable binary rewardでポリシーを更新
評価結果
数学ドメインに提案手法を適用したところ、iterごとに全体の平均性能は向上。

提案手法で数学ドメインを学習し、generalドメインに汎化するか?を確認したところ、汎化することを確認(ただ、すぐにサチっているようにも見える)。、
 関連:
関連:
・2383
・1936著者ポスト:
・https://x.com/wyu_nd/status/1954249813861810312?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/chengsongh31219/status/1953936172415430695?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q日本語解説:
https://x.com/curveweb/status/1954367657811308858?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-09 [Paper Note] Sotopia-RL: Reward Design for Social Intelligence, Haofei Yu+, arXiv'25 Summary社会的知性を持つエージェントの訓練に向けて、Sotopia-RLという新しいフレームワークを提案。部分的観測性と多次元性の課題に対処し、エピソードレベルのフィードバックを発話レベルの多次元報酬に洗練。実験では、Sotopia環境で最先端の社会的目標達成スコアを達成し、既存の手法を上回る結果を示した。 Comment元ポスト:https://x.com/youjiaxuan/status/1953826129401262304?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ReinforcementLearning #SelfImprovement #ZeroData Issue Date: 2025-08-09 [Paper Note] Self-Questioning Language Models, Lili Chen+, arXiv'25 Summary自己質問型言語モデル(SQLM)を提案し、トピックを指定するプロンプトから自ら質問を生成し、解答する非対称の自己対戦フレームワークを構築。提案者と解答者は強化学習で訓練され、問題の難易度に応じて報酬を受け取る。三桁の掛け算や代数問題、プログラミング問題のベンチマークで、外部データなしで言語モデルの推論能力を向上させることができることを示す。 Commentpj page:https://self-questioning.github.io元ポスト:https://x.com/lchen915/status/1953896909925757123?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qたとえば下記のような、ラベル無しの外部データを利用する手法も用いてself improvingする手法と比較したときに、どの程度の性能差になるのだろうか?外部データを全く利用せず、外部データありの手法と同等までいけます、という話になると、より興味深いと感じた。
・1212既存の外部データを活用しない関連研究:
・1936 #NLP #LanguageModel #Supervised-FineTuning (SFT) #read-later #Admin'sPick Issue Date: 2025-08-09 [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, arXiv'25 Summary大規模言語モデル(LLM)の教師ありファインチューニング(SFT)の一般化能力を向上させるため、動的ファインチューニング(DFT)を提案。DFTはトークンの確率に基づいて目的関数を再スケーリングし、勾配更新を安定化させる。これにより、SFTを大幅に上回る性能を示し、オフライン強化学習でも競争力のある結果を得た。理論的洞察と実践的解決策を結びつけ、SFTの性能を向上させる。コードは公開されている。 Comment元ポスト:https://x.com/theturingpost/status/1953960036126142645?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは大変興味深い。数学以外のドメインでの評価にも期待したい。3節冒頭から3.2節にかけて、SFTとon policy RLのgradientを定式化し、SFT側の数式を整理することで、SFT(のgradient)は以下のようなon policy RLの一つのケースとみなせることを導出している。そしてSFTの汎化性能が低いのは 1/pi_theta によるimportance weightingであると主張し、実験的にそれを証明している。つまり、ポリシーがexpertのgold responseに対して低い尤度を示してしまった場合に、weightか過剰に大きくなり、Rewardの分散が過度に大きくなってしまうことがRLの観点を通してみると問題であり、これを是正することが必要。さらに、分散が大きい報酬の状態で、報酬がsparse(i.e., expertのtrajectoryのexact matchしていないと報酬がzero)であることが、さらに事態を悪化させている。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
・1746
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。日本語解説:https://x.com/hillbig/status/1960108668336390593?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
一歩先の視点が考察されており、とても勉強になる。 #Survey #NLP #LanguageModel #Hallucination Issue Date: 2025-08-08 [Paper Note] A comprehensive taxonomy of hallucinations in Large Language Models, Manuel Cossio, arXiv'25 SummaryLLMのハルシネーションに関する包括的な分類法を提供し、その本質的な避けられなさを提唱。内因的および外因的な要因、事実誤認や不整合などの具体的な現れを分析。根本的な原因や認知的要因を検討し、評価基準や軽減戦略を概説。今後は、信頼性のある展開のために検出と監視に焦点を当てる必要があることを強調。 Comment元ポスト:https://x.com/sei_shinagawa/status/1953845008588513762?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ReinforcementLearning #Factuality #RewardHacking #PostTraining #GRPO #On-Policy Issue Date: 2025-08-08 [Paper Note] Learning to Reason for Factuality, Xilun Chen+, arXiv'25 SummaryR-LLMsは複雑な推論タスクで進展しているが、事実性において幻覚を多く生成する。オンラインRLを長文の事実性設定に適用する際、信頼できる検証方法が不足しているため課題がある。従来の自動評価フレームワークを用いたオフラインRLでは報酬ハッキングが発生することが判明。そこで、事実の精度、詳細レベル、関連性を考慮した新しい報酬関数を提案し、オンラインRLを適用。評価の結果、幻覚率を平均23.1ポイント削減し、回答の詳細レベルを23%向上させた。 Comment元ポスト:https://x.com/jaseweston/status/1953629692772446481?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q先行研究:
・2378Reasoning ModelのHallucination Rateは、そのベースとなるモデルよりも高い。実際、DeepSeek-V3とDeepSeek-R1,Qwen-2.5-32BとQwQ-32Bを6つのFactualityに関するベンチマークで比較すると、Reasoning Modelの方がHallucination Rateが10, 13%程度高かった。これは、現在のOn-policyのRLがlogical reasoningにフォーカスしており、Factualityを見落としているため、と仮説を立てている。
Factuality(特にLongForm)とRL alignmentsという観点から言うと、決定的、正確かつ信頼性のあるverificatlon手法は存在せず、Human Effortが必要不可欠である。
自動的にFactualityを測定するFactScoreのような手法は、DPOのようなオフラインのペアワイズのデータを作成するに留まってしまっている。また、on dataでFactualityを改善する取り組みは行われているが、long-formな応答に対して、factual reasoningを実施するにはいくつかの課題が残されている:
・reward design
・Factualityに関するrewardを単独で追加するだけだと、LLMは非常に短く、詳細を省略した応答をしPrecicionのみを高めようとしてしまう。
あとで追記する Issue Date: 2025-08-06 [Paper Note] CTR-Sink: Attention Sink for Language Models in Click-Through Rate Prediction, Zixuan Li+, arXiv'25 SummaryCTR予測において、ユーザーの行動シーケンスをテキストとしてモデル化し、言語モデル(LM)を活用する新しいフレームワーク「CTR-Sink」を提案。行動間の関係を強化するためにシンクトークンを挿入し、注意の焦点を動的に調整。二段階のトレーニング戦略を用いてLMの注意をシンクトークンに誘導し、実験により手法の有効性を確認。 Comment元ポスト:https://x.com/_reachsumit/status/1952926081058783632?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2025-08-05 [Paper Note] On the Expressiveness of Softmax Attention: A Recurrent Neural Network Perspective, Gabriel Mongaras+, arXiv'25 Summary本研究では、ソフトマックスアテンションの再帰的な形式を導出し、線形アテンションがその近似であることを示す。これにより、ソフトマックスアテンションの各部分をRNNの言語で説明し、構成要素の重要性と相互作用を理解する。これにより、ソフトマックスアテンションが他の手法よりも表現力が高い理由を明らかにする。 Comment元ポスト:https://x.com/hillbig/status/1952485214162407644?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLinearAttention関連の研究は下記あたりがありそう?
・2353
・2354
・2355
・2356・1271
たとえばGQAはQwen3で利用されているが、本研究の知見を活用してscaled-dot product attention計算時のSoftmax計算の計算量が削減できたら、さらに計算量が削減できそう? #MachineLearning #NLP #LanguageModel Issue Date: 2025-08-04 [Paper Note] MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement, Jaehyun Nam+, arXiv'25 SummaryMLE-STARは、LLMを用いてMLモデルを自動実装する新しいアプローチで、ウェブから効果的なモデルを取得し、特定のMLコンポーネントに焦点を当てた戦略を探索することで、コード生成の精度を向上させる。実験結果では、MLE-STARがKaggleコンペティションの64%でメダルを獲得し、他の手法を大きく上回る性能を示した。 Comment元ポスト:https://x.com/marktechpost/status/1951846630266687927?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ACL #read-later Issue Date: 2025-08-03 [Paper Note] Language Models Resist Alignment: Evidence From Data Compression, Jiaming Ji+, ACL'25 Summary本研究では、大規模言語モデル(LLMs)の整合性ファインチューニングが、意図しない行動を示す原因となる「elasticity」を理論的および実証的に探求。整合後のモデルは、事前学習時の行動分布に戻る傾向があり、ファインチューニングが整合性を損なう可能性が示された。実験により、モデルのパフォーマンスが急速に低下し、その後事前学習分布に戻ることが確認され、モデルサイズやデータの拡張とelasticityの相関も明らかに。これにより、LLMsのelasticityに対処する必要性が強調された。 #ACL #read-later Issue Date: 2025-08-03 [Paper Note] A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive, Sarath Sivaprasad+, ACL'25 SummaryLLMのサンプリング行動を調査し、ヒューリスティクスが人間の意思決定に類似していることを示す。サンプルは統計的規範から処方的要素に逸脱し、公衆衛生や経済動向において一貫して現れる。LLMの概念プロトタイプが処方的規範の影響を受け、人間の正常性の概念に類似。ケーススタディを通じて、LLMの出力が理想的な値にシフトし、偏った意思決定を引き起こす可能性があることを示し、倫理的懸念を提起。 #ACL #read-later Issue Date: 2025-08-03 [Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Summary本研究では、LLMのテスト時の計算スケーリングにおけるプロンプト戦略の効果を調査。6つのLLMと8つのプロンプト戦略を用いた実験により、複雑なプロンプト戦略が単純なChain-of-Thoughtに劣ることを示し、理論的な証明を提供。さらに、スケーリング性能を予測し最適なプロンプト戦略を特定する手法を提案し、リソース集約的な推論プロセスの必要性を排除。複雑なプロンプトの再評価と単純なプロンプト戦略の潜在能力を引き出すことで、テスト時のスケーリング性能向上に寄与することを目指す。 #ACL #read-later Issue Date: 2025-08-03 [Paper Note] Mapping 1,000+ Language Models via the Log-Likelihood Vector, Momose Oyama+, ACL'25 Summary自動回帰型言語モデルの比較に対し、対数尤度ベクトルを特徴量として使用する新しいアプローチを提案。これにより、テキスト生成確率のクルバック・ライブラー発散を近似し、スケーラブルで計算コストが線形に増加する特徴を持つ。1,000以上のモデルに適用し、「モデルマップ」を構築することで、大規模モデル分析に新たな視点を提供。 CommentNLPコロキウムでのスライド:https://speakerdeck.com/shimosan/yan-yu-moderunodi-tu-que-lu-fen-bu-to-qing-bao-ji-he-niyorulei-si-xing-noke-shi-hua
元ポスト:https://x.com/hshimodaira/status/1960573414575333556?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #read-later #ICCV Issue Date: 2025-08-03 [Paper Note] BUFFER-X: Towards Zero-Shot Point Cloud Registration in Diverse Scenes, Minkyun Seo+, ICCV'25 SummaryBUFFER-Xというゼロショット登録パイプラインを提案し、環境特有のボクセルサイズや探索半径への依存、ドメイン外ロバスト性の低さ、スケール不一致の問題に対処。マルチスケールのパッチベースの記述子生成と階層的インライア検索を用いて、さまざまなシーンでのロバスト性を向上。新しい一般化ベンチマークを用いて、BUFFER-Xが手動調整なしで大幅な一般化を達成することを示した。 Comment元ポスト:https://x.com/rsasaki0109/status/1951478059002966159?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこの辺の分野ぱっと見で全然わからない… #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #On-Policy #CrossDomain Issue Date: 2025-08-03 [Paper Note] SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM, Xiaojiang Zhang+, arXiv'25 Summary二段階履歴再サンプリングポリシー最適化(SRPO)を提案し、DeepSeek-R1-Zero-32Bを上回る性能をAIME24およびLiveCodeBenchで達成。SRPOはトレーニングステップを約1/10に削減し、効率性を示す。二つの革新として、クロスドメイントレーニングパラダイムと履歴再サンプリング技術を導入し、LLMの推論能力を拡張するための実験を行った。 Comment元ポスト:https://x.com/jiqizhixin/status/1914920300359377232?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGRPOよりもより効率的な手法な模様。最初に数学のデータで学習をしReasoning Capabilityを身につけさせ、その後別のドメインのデータで学習させることで、その能力を発揮させるような二段階の手法らしい。
Datamixingよりも高い性能(ただし、これは数学とコーディングのCoT Lengthのドメイン間の違いに起因してこのような2 stageな手法にしているようなのでその点には注意が必要そう)?しっかりと読めていないので、読み違いの可能性もあるので注意。
 なんたらRPO多すぎ問題
#EfficiencyImprovement
#NLP
#LanguageModel
#Optimizer
#read-later
#Admin'sPick
#ModelMerge
#Stability
Issue Date: 2025-08-02
[Paper Note] WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training, Changxin Tian+, arXiv'25
Summary学習率スケジューリングの新たなアプローチとして、Warmup-Stable and Merge(WSM)を提案。WSMは、学習率の減衰とモデルマージの関係を確立し、さまざまな減衰戦略を統一的に扱う。実験により、マージ期間がモデル性能において重要であることを示し、従来のWSDアプローチを上回る性能向上を達成。特に、MATHで+3.5%、HumanEvalで+2.9%、MMLU-Proで+5.5%の改善を記録。
Comment元ポスト:https://x.com/stochasticchasm/status/1951427541803106714?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWeight Decayを無くせるらしいエッセンスの解説:https://x.com/wenhaocha1/status/1951790366900019376?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
なんたらRPO多すぎ問題
#EfficiencyImprovement
#NLP
#LanguageModel
#Optimizer
#read-later
#Admin'sPick
#ModelMerge
#Stability
Issue Date: 2025-08-02
[Paper Note] WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training, Changxin Tian+, arXiv'25
Summary学習率スケジューリングの新たなアプローチとして、Warmup-Stable and Merge(WSM)を提案。WSMは、学習率の減衰とモデルマージの関係を確立し、さまざまな減衰戦略を統一的に扱う。実験により、マージ期間がモデル性能において重要であることを示し、従来のWSDアプローチを上回る性能向上を達成。特に、MATHで+3.5%、HumanEvalで+2.9%、MMLU-Proで+5.5%の改善を記録。
Comment元ポスト:https://x.com/stochasticchasm/status/1951427541803106714?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWeight Decayを無くせるらしいエッセンスの解説:https://x.com/wenhaocha1/status/1951790366900019376?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
チェックポイントさえ保存しておいて事後的に活用することだで、細かなハイパラ調整のための試行錯誤する手間と膨大な計算コストがなくなるのであれば相当素晴らしいのでは…? Issue Date: 2025-08-02 [Paper Note] AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders, Zhengxuan Wu+, arXiv'25 Summary言語モデルの出力制御は安全性と信頼性に重要であり、プロンプトやファインチューニングが一般的に用いられるが、さまざまな表現ベースの技術も提案されている。これらの手法を比較するためのベンチマークAxBenchを導入し、Gemma-2-2Bおよび9Bに関する実験を行った。結果、プロンプトが最も効果的で、次いでファインチューニングが続いた。概念検出では表現ベースの手法が優れており、SAEは競争力がなかった。新たに提案した弱教師あり表現手法ReFT-r1は、競争力を持ちながら解釈可能性を提供する。AxBenchとともに、ReFT-r1およびDiffMeanのための特徴辞書を公開した。 #NLP #LanguageModel #InstructionTuning #SyntheticData #Reasoning Issue Date: 2025-08-02 [Paper Note] CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks, Ping Yu+, arXiv'25 SummaryCoT-Self-Instructを提案し、LLMに基づいて新しい合成プロンプトを生成する手法を開発。合成データはMATH500やAMC23などで既存データセットを超える性能を示し、検証不可能なタスクでも人間や標準プロンプトを上回る結果を得た。 Comment元ポスト:https://x.com/jaseweston/status/1951084679286722793?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qより複雑で、Reasoningやplanningを促すようなinstructionが生成される模様。実際に生成されたinstructionのexampleは全体をざっとみた感じこの図中のもののみのように見える。
 以下のスクショはMagpieによって合成されたinstruction。InstructionTuning用のデータを合成するならMagpieが便利そうだなぁ、と思っていたのだが、比較するとCoT-SelfInstructの方が、より複雑で具体的な指示を含むinstructionが生成されるように見える。
以下のスクショはMagpieによって合成されたinstruction。InstructionTuning用のデータを合成するならMagpieが便利そうだなぁ、と思っていたのだが、比較するとCoT-SelfInstructの方が、より複雑で具体的な指示を含むinstructionが生成されるように見える。
・2094
 #NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
Issue Date: 2025-08-02
[Paper Note] Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty, Mehul Damani+, arXiv'25
SummaryRLCRを用いた言語モデルの訓練により、推論の精度と信頼度を同時に改善。バイナリ報酬に加え、信頼度推定のためのブライヤースコアを用いた報酬関数を最適化。RLCRは、通常のRLよりもキャリブレーションを改善し、精度を損なうことなく信頼性の高い推論モデルを生成することを示した。
Comment元ポスト:https://x.com/asap2650/status/1950942279872762272?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLMにConfidenceをDiscreteなTokenとして(GEvalなどは除く)出力させると信頼できないことが多いので、もしそれも改善するのだとしたら興味深い。
#NLP
#Dataset
#LanguageModel
#Evaluation
#Composition
#ACL
#InstructionFollowingCapability
#CommonsenseReasoning
Issue Date: 2025-07-31
[Paper Note] Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability, Yusuke Sakai+, ACL'25
SummaryOrdered CommonGenを提案し、LLMsの指示に従う能力と構成的一般化能力を評価するベンチマークを構築。36のLLMsを分析した結果、指示の意図は理解しているが、概念の順序に対するバイアスが低多様性の出力を引き起こすことが判明。最も指示に従うLLMでも約75%の順序付きカバレッジしか達成できず、両能力の改善が必要であることを示唆。
CommentLLMの意味の構成性と指示追従能力を同時に発揮する能力を測定可能なOrderedCommonGenを提案
#NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
Issue Date: 2025-08-02
[Paper Note] Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty, Mehul Damani+, arXiv'25
SummaryRLCRを用いた言語モデルの訓練により、推論の精度と信頼度を同時に改善。バイナリ報酬に加え、信頼度推定のためのブライヤースコアを用いた報酬関数を最適化。RLCRは、通常のRLよりもキャリブレーションを改善し、精度を損なうことなく信頼性の高い推論モデルを生成することを示した。
Comment元ポスト:https://x.com/asap2650/status/1950942279872762272?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLMにConfidenceをDiscreteなTokenとして(GEvalなどは除く)出力させると信頼できないことが多いので、もしそれも改善するのだとしたら興味深い。
#NLP
#Dataset
#LanguageModel
#Evaluation
#Composition
#ACL
#InstructionFollowingCapability
#CommonsenseReasoning
Issue Date: 2025-07-31
[Paper Note] Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability, Yusuke Sakai+, ACL'25
SummaryOrdered CommonGenを提案し、LLMsの指示に従う能力と構成的一般化能力を評価するベンチマークを構築。36のLLMsを分析した結果、指示の意図は理解しているが、概念の順序に対するバイアスが低多様性の出力を引き起こすことが判明。最も指示に従うLLMでも約75%の順序付きカバレッジしか達成できず、両能力の改善が必要であることを示唆。
CommentLLMの意味の構成性と指示追従能力を同時に発揮する能力を測定可能なOrderedCommonGenを提案

 関連:
関連:
・2330 Issue Date: 2025-07-31 [Paper Note] AnimalClue: Recognizing Animals by their Traces, Risa Shinoda+, arXiv'25 Summary野生動物の観察において、間接的な証拠から種を特定するための大規模データセット「AnimalClue」を紹介。159,605のバウンディングボックスを含み、968種をカバー。足跡や糞などの微妙な特徴を認識する必要があり、分類や検出に新たな課題を提供。実験を通じて、動物の痕跡からの同定における主要な課題を特定。データセットとコードは公開中。 Comment元ポスト:https://x.com/hirokatukataoka/status/1950798299176357891?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #EfficiencyImprovement #NLP #LanguageModel #Attention Issue Date: 2025-07-31 [Paper Note] Efficient Attention Mechanisms for Large Language Models: A Survey, Yutao Sun+, arXiv'25 SummaryTransformerアーキテクチャの自己注意の複雑さが長文コンテキストモデリングの障害となっている。これに対処するため、線形注意手法とスパース注意技術が導入され、計算効率を向上させつつコンテキストのカバレッジを保持する。本研究は、これらの進展を体系的にまとめ、効率的な注意を大規模言語モデルに組み込む方法を分析し、理論と実践を統合したスケーラブルなモデル設計の基礎を提供することを目指す。 Comment元ポスト:https://x.com/omarsar0/status/1950287053046022286?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-30
[Paper Note] Efficient Many-Shot In-Context Learning with Dynamic Block-Sparse Attention, Emily Xiao+, arXiv'25
Summaryダイナミックブロックスパースアテンションを用いたリトリーバルベースの多ショットインコンテキスト学習フレームワークを提案。これにより、ファインチューニングと同等のレイテンシを実現しつつ、95%以上の精度を維持。多ショットICLの大規模展開が可能になることを目指す。
Comment元ポスト:https://x.com/gneubig/status/1950195161906188377?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Survey
#NLP
#LLMAgent
#SelfCorrection
#SelfImprovement
Issue Date: 2025-07-30
[Paper Note] A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence, Huan-ang Gao+, arXiv'25
Summary大規模言語モデル(LLMs)は静的であり、動的な環境に適応できないため、自己進化するエージェントの必要性が高まっている。本調査は、自己進化するエージェントに関する初の包括的レビューを提供し、進化の基礎的な次元を整理。エージェントの進化的メカニズムや適応手法を分類し、評価指標や応用分野を分析。最終的には、エージェントが自律的に進化し、人間レベルの知能を超える人工超知能(ASI)の実現を目指す。
Comment元ポスト:https://x.com/ottamm_190/status/1950331148741333489?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFigure3がとても勉強になる。Self-Evolveと呼んだ時に、それがどのようにEvolveするものなのかはきちんとチェックした方が良さそう。追加の学習をするのか否かなど。これによって使いやすさが段違いになりそうなので。
Issue Date: 2025-07-30
[Paper Note] Efficient Many-Shot In-Context Learning with Dynamic Block-Sparse Attention, Emily Xiao+, arXiv'25
Summaryダイナミックブロックスパースアテンションを用いたリトリーバルベースの多ショットインコンテキスト学習フレームワークを提案。これにより、ファインチューニングと同等のレイテンシを実現しつつ、95%以上の精度を維持。多ショットICLの大規模展開が可能になることを目指す。
Comment元ポスト:https://x.com/gneubig/status/1950195161906188377?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Survey
#NLP
#LLMAgent
#SelfCorrection
#SelfImprovement
Issue Date: 2025-07-30
[Paper Note] A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence, Huan-ang Gao+, arXiv'25
Summary大規模言語モデル(LLMs)は静的であり、動的な環境に適応できないため、自己進化するエージェントの必要性が高まっている。本調査は、自己進化するエージェントに関する初の包括的レビューを提供し、進化の基礎的な次元を整理。エージェントの進化的メカニズムや適応手法を分類し、評価指標や応用分野を分析。最終的には、エージェントが自律的に進化し、人間レベルの知能を超える人工超知能(ASI)の実現を目指す。
Comment元ポスト:https://x.com/ottamm_190/status/1950331148741333489?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFigure3がとても勉強になる。Self-Evolveと呼んだ時に、それがどのようにEvolveするものなのかはきちんとチェックした方が良さそう。追加の学習をするのか否かなど。これによって使いやすさが段違いになりそうなので。

 #ComputerVision
#NLP
#Dataset
#MultiLingual
#CLIP
Issue Date: 2025-07-30
[Paper Note] MetaCLIP 2: A Worldwide Scaling Recipe, Yung-Sung Chuang+, arXiv'25
SummaryMetaCLIP 2を提案し、CLIPをゼロから訓練するための新しいアプローチを示す。英語と非英語データの相互利益を得るための最小限の変更を加え、ゼロショットのImageNet分類で英語専用モデルを上回る性能を達成。多言語ベンチマークでも新たな最先端を記録。
Comment元ポスト:https://x.com/jaseweston/status/1950366185742016935?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-29
[Paper Note] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, Lakshya A Agrawal+, arXiv'25
SummaryGEPA(Genetic-Pareto)は、LLMsのプロンプト最適化手法であり、自然言語を用いて試行錯誤から高レベルのルールを学習する。これにより、数回のロールアウトで品質向上が可能となり、GRPOを平均10%、最大20%上回る結果を示した。GEPAは、主要なプロンプト最適化手法MIPROv2をも超える性能を発揮し、コード最適化にも有望な結果を示している。
Comment元ポスト:https://x.com/lateinteraction/status/1949869456341029297?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Survey
#Embeddings
#NLP
#Dataset
#LanguageModel
#RepresentationLearning
#Evaluation
Issue Date: 2025-07-29
[Paper Note] On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey, Meishan Zhang+, arXiv'25
Summary本調査では、事前学習済み言語モデル(PLMs)を活用した一般目的のテキスト埋め込み(GPTE)の発展を概観し、PLMsの役割に焦点を当てる。基本的なアーキテクチャや埋め込み抽出、表現力向上、トレーニング戦略について説明し、PLMsによる多言語サポートやマルチモーダル統合などの高度な役割も考察する。さらに、将来の研究方向性として、ランキング統合やバイアス軽減などの改善目標を超えた課題を強調する。
Comment元ポスト:https://x.com/bo_wangbo/status/1950158633645363465?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGPTEの学習手法テキストだけでなく、画像やコードなどの様々なモーダル、マルチリンガル、データセットや評価方法、パラメータサイズとMTEBの性能の関係性の図解など、盛りだくさんな模様。最新のものだけでなく、2021年頃のT5から最新モデルまで網羅的にまとまっている。日本語特化のモデルについては記述が無さそうではある。
#ComputerVision
#NLP
#Dataset
#MultiLingual
#CLIP
Issue Date: 2025-07-30
[Paper Note] MetaCLIP 2: A Worldwide Scaling Recipe, Yung-Sung Chuang+, arXiv'25
SummaryMetaCLIP 2を提案し、CLIPをゼロから訓練するための新しいアプローチを示す。英語と非英語データの相互利益を得るための最小限の変更を加え、ゼロショットのImageNet分類で英語専用モデルを上回る性能を達成。多言語ベンチマークでも新たな最先端を記録。
Comment元ポスト:https://x.com/jaseweston/status/1950366185742016935?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-29
[Paper Note] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, Lakshya A Agrawal+, arXiv'25
SummaryGEPA(Genetic-Pareto)は、LLMsのプロンプト最適化手法であり、自然言語を用いて試行錯誤から高レベルのルールを学習する。これにより、数回のロールアウトで品質向上が可能となり、GRPOを平均10%、最大20%上回る結果を示した。GEPAは、主要なプロンプト最適化手法MIPROv2をも超える性能を発揮し、コード最適化にも有望な結果を示している。
Comment元ポスト:https://x.com/lateinteraction/status/1949869456341029297?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Survey
#Embeddings
#NLP
#Dataset
#LanguageModel
#RepresentationLearning
#Evaluation
Issue Date: 2025-07-29
[Paper Note] On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey, Meishan Zhang+, arXiv'25
Summary本調査では、事前学習済み言語モデル(PLMs)を活用した一般目的のテキスト埋め込み(GPTE)の発展を概観し、PLMsの役割に焦点を当てる。基本的なアーキテクチャや埋め込み抽出、表現力向上、トレーニング戦略について説明し、PLMsによる多言語サポートやマルチモーダル統合などの高度な役割も考察する。さらに、将来の研究方向性として、ランキング統合やバイアス軽減などの改善目標を超えた課題を強調する。
Comment元ポスト:https://x.com/bo_wangbo/status/1950158633645363465?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGPTEの学習手法テキストだけでなく、画像やコードなどの様々なモーダル、マルチリンガル、データセットや評価方法、パラメータサイズとMTEBの性能の関係性の図解など、盛りだくさんな模様。最新のものだけでなく、2021年頃のT5から最新モデルまで網羅的にまとまっている。日本語特化のモデルについては記述が無さそうではある。




 日本語モデルについてはRuriのテクニカルペーパーや、LLM勉強会のまとめを参照のこと
日本語モデルについてはRuriのテクニカルペーパーや、LLM勉強会のまとめを参照のこと
・1375
・1563 #NLP #LanguageModel #AES(AutomatedEssayScoring) #Prompting #AIED Issue Date: 2025-07-29 [Paper Note] Do We Need a Detailed Rubric for Automated Essay Scoring using Large Language Models?, Lui Yoshida, AIED'25 Summary本研究では、LLMを用いた自動エッセイ採点におけるルーブリックの詳細さが採点精度に与える影響を調査。TOEFL11データセットを用いて、完全なルーブリック、簡略化されたルーブリック、ルーブリックなしの3条件を比較。結果、3つのモデルは簡略化されたルーブリックでも精度を維持し、トークン使用量を削減。一方、1つのモデルは詳細なルーブリックで性能が低下。簡略化されたルーブリックが多くのLLMにとって効率的な代替手段であることが示唆されるが、モデルごとの評価も重要。 #Multi #NLP #LLMAgent #Prompting Issue Date: 2025-07-29 [Paper Note] EduThink4AI: Translating Educational Critical Thinking into Multi-Agent LLM Systems, Xinmeng Hou+, arXiv'25 SummaryEDU-Promptingは、教育的批判的思考理論とLLMエージェント設計を結びつけ、批判的でバイアスを意識した説明を生成する新しいマルチエージェントフレームワーク。これにより、AI生成の教育的応答の真実性と論理的妥当性が向上し、既存の教育アプリケーションに統合可能。 Comment元ポスト:https://x.com/dair_ai/status/1949481352325128236?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCritiqueを活用したマルチエージェントのようである(具体的なCritiqueの生成方法については読めていない。その辺が重要そう

 #Analysis
#NLP
#LanguageModel
#In-ContextLearning
Issue Date: 2025-07-29
[Paper Note] Learning without training: The implicit dynamics of in-context learning, Benoit Dherin+, arXiv'25
SummaryLLMは文脈内で新しいパターンを学習する能力を持ち、そのメカニズムは未解明である。本研究では、トランスフォーマーブロックが自己注意層とMLPを重ねることで、文脈に応じてMLPの重みを暗黙的に修正できることを示し、このメカニズムがLLMの文脈内学習の理由である可能性を提案する。
Comment元ポスト:https://x.com/omarsar0/status/1948384435654779105?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:https://x.com/hillbig/status/1950333455134576794?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Embeddings
#NLP
#RepresentationLearning
#Length
Issue Date: 2025-07-29
[Paper Note] Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation, Tiansheng Wen+, arXiv'25
Summaryスパースコーディングを用いたContrastive Sparse Representation(CSR)を提案し、適応的な埋め込みを実現。CSRは事前訓練された埋め込みをスパース化し、意味的品質を保持しつつコスト効果の高い推論を可能にする。実験により、CSRは精度と検索速度でMatryoshka Representation Learning(MRL)を上回り、訓練時間も大幅に短縮されることが示された。スパースコーディングは実世界のアプリケーションにおける適応的な表現学習の強力な手法として位置づけられる。
Comment元ポスト:https://x.com/hillbig/status/1949957739637002450?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qマトリョーシカ表現:
#Analysis
#NLP
#LanguageModel
#In-ContextLearning
Issue Date: 2025-07-29
[Paper Note] Learning without training: The implicit dynamics of in-context learning, Benoit Dherin+, arXiv'25
SummaryLLMは文脈内で新しいパターンを学習する能力を持ち、そのメカニズムは未解明である。本研究では、トランスフォーマーブロックが自己注意層とMLPを重ねることで、文脈に応じてMLPの重みを暗黙的に修正できることを示し、このメカニズムがLLMの文脈内学習の理由である可能性を提案する。
Comment元ポスト:https://x.com/omarsar0/status/1948384435654779105?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:https://x.com/hillbig/status/1950333455134576794?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Embeddings
#NLP
#RepresentationLearning
#Length
Issue Date: 2025-07-29
[Paper Note] Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation, Tiansheng Wen+, arXiv'25
Summaryスパースコーディングを用いたContrastive Sparse Representation(CSR)を提案し、適応的な埋め込みを実現。CSRは事前訓練された埋め込みをスパース化し、意味的品質を保持しつつコスト効果の高い推論を可能にする。実験により、CSRは精度と検索速度でMatryoshka Representation Learning(MRL)を上回り、訓練時間も大幅に短縮されることが示された。スパースコーディングは実世界のアプリケーションにおける適応的な表現学習の強力な手法として位置づけられる。
Comment元ポスト:https://x.com/hillbig/status/1949957739637002450?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qマトリョーシカ表現:
・2311 #RecommenderSystems #VariationalAutoEncoder #SemanticID Issue Date: 2025-07-28 [Paper Note] Semantic IDs for Music Recommendation, M. Jeffrey Mei+, arXiv'25 Summaryコンテンツ情報を活用した共有埋め込みを用いることで、次アイテム推薦のレコメンダーシステムのモデルサイズを削減し、精度と多様性を向上させることを示す。音楽ストリーミングサービスでのオンラインA/Bテストを通じて、その効果を実証。 Comment元ポスト:https://x.com/_reachsumit/status/1949689827043197300?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QSemantic ID関連:
・2242・2137
・2309
上記2つのハイブリッド #NLP #LanguageModel #ACL #Trustfulness Issue Date: 2025-07-28 [Paper Note] Rectifying Belief Space via Unlearning to Harness LLMs' Reasoning, Ayana Niwa+, ACL'25 SummaryLLMの不正確な回答は虚偽の信念から生じると仮定し、信念空間を修正する方法を提案。テキスト説明生成で信念を特定し、FBBSを用いて虚偽の信念を抑制、真の信念を強化。実証結果は、誤った回答の修正とモデル性能の向上を示し、一般化の改善にも寄与することを示唆。 Comment元ポスト:https://x.com/ayaniwa1213/status/1949750575123276265?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Hallucination #ActivationSteering/ITI #Trustfulness Issue Date: 2025-07-26 [Paper Note] GrAInS: Gradient-based Attribution for Inference-Time Steering of LLMs and VLMs, Duy Nguyen+, arXiv'25 SummaryGrAInSは、LLMsおよびVLMsの推論時に内部活性を調整する新しいステアリング手法で、固定された介入ベクトルに依存せず、トークンの因果的影響を考慮します。統合勾配を用いて、出力への寄与に基づき重要なトークンを特定し、望ましい行動への変化を捉えるベクトルを構築します。これにより、再訓練なしでモデルの挙動を細かく制御でき、実験ではファインチューニングや既存手法を上回る成果を示しました。具体的には、TruthfulQAで精度を13.22%向上させ、MMHal-Benchの幻覚率を低下させ、SPA-VLでのアライメント勝率を改善しました。 Comment元ポスト:https://x.com/duynguyen772/status/1948768520587866522?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q既存のsteering手法は、positive/negativeなサンプルからの差分で単一方向のベクトルを算出し、すべてのトークンに足し合わせるが、本手法はそこからさらにpositive/negativeな影響を与えるトークンレベルにまで踏み込み、negativeなベクトルとpositiveなベクトルの双方を用いて、negative->positive方向のベクトルを算出してsteeringに活用する方法っぽい?


 関連:
関連:
・1941 #ComputerVision #NLP #LanguageModel #MulltiModal #SpeechProcessing #OpenWeight #VisionLanguageModel Issue Date: 2025-07-26 [Paper Note] Ming-Omni: A Unified Multimodal Model for Perception and Generation, Inclusion AI+, arXiv'25 SummaryMing-Omniは、画像、テキスト、音声、動画を処理できる統一マルチモーダルモデルで、音声生成と画像生成において優れた能力を示す。専用エンコーダを用いて異なるモダリティからトークンを抽出し、MoEアーキテクチャで処理することで、効率的にマルチモーダル入力を融合。音声デコーダと高品質な画像生成を統合し、コンテキストに応じたチャットやテキストから音声への変換、画像編集が可能。Ming-Omniは、GPT-4oに匹敵する初のオープンソースモデルであり、研究と開発を促進するためにコードとモデルの重みを公開。 Comment 元ポスト:https://x.com/gm8xx8/status/1948878025757446389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
元ポスト:https://x.com/gm8xx8/status/1948878025757446389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
現在はv1.5も公開されておりさらに性能が向上している模様?HF:https://huggingface.co/inclusionAI/Ming-Lite-Omni #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #MoE(Mixture-of-Experts) #On-Policy #Stability Issue Date: 2025-07-26 [Paper Note] Group Sequence Policy Optimization, Chujie Zheng+, arXiv'25 SummaryGroup Sequence Policy Optimization (GSPO)は、大規模言語モデルのための新しい強化学習アルゴリズムで、シーケンスの尤度に基づく重要度比を用いてトレーニングを行う。GSPOは、従来のGRPOアルゴリズムよりも効率的で高性能であり、Mixture-of-Experts (MoE) のトレーニングを安定化させる。これにより、最新のQwen3モデルにおいて顕著な改善が見られる。 Comment元ポスト:https://x.com/theturingpost/status/1948904443749302785?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q公式ポスト:https://x.com/alibaba_qwen/status/1949412072942612873?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGRPOとGSPOの違いのGIF:
https://x.com/theturingpost/status/1953976551424634930?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NaturalLanguageGeneration #Controllable #NLP #LanguageModel #VisionLanguageModel Issue Date: 2025-07-25 [Paper Note] CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning, Kuniaki Saito+, arXiv'25 SummaryCaptionSmithsは、画像キャプショニングモデルがキャプションの特性(長さ、記述性、単語の独自性)を柔軟に制御できる新しいアプローチを提案。人間の注釈なしで特性を定量化し、短いキャプションと長いキャプションの間で補間することで条件付けを実現。実証結果では、出力キャプションの特性をスムーズに変化させ、語彙的整合性を向上させることが示され、誤差を506%削減。コードはGitHubで公開。 Comment元ポスト:https://x.com/a_hasimoto/status/1948258269668970782?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来はDiscreteに表現されていたcaptioningにおける特性をCondition Caluculatorを導入することでcontinuousなrepresentationによって表現し、Caluculatorに人間によるinput, あるいは表現したいConditionを持つexampleをinputすることで、生成時に反映させるような手法を提案している模様。Conditionで利用するpropertyについては、提案手法ではLength, Descriptive, Uniqueness of Vocabulariesの3つを利用している(が、他のpropertyでも本手法は適用可能と思われる)。このとき、あるpropertyの値を変えることで他のpropertyが変化してしまうと制御ができなくなるため、property間のdecorrelationを実施している。これは、あるproperty Aから別のproperty Bの値を予測し、オリジナルのpropertyの値からsubtractする、といった処理を順次propertyごとに実施することで実現される。Appendixに詳細が記述されている。

 #NLP
#LanguageModel
#MoE(Mixture-of-Experts)
#Scaling Laws
Issue Date: 2025-07-25
[Paper Note] Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models, Changxin Tian+, arXiv'25
SummaryMixture-of-Experts (MoE)アーキテクチャは、LLMsの効率的なスケーリングを可能にするが、モデル容量の予測には課題がある。これに対処するため、Efficiency Leverage (EL)を導入し、300以上のモデルを訓練してMoE構成とELの関係を調査。結果、ELはエキスパートの活性化比率と計算予算に依存し、エキスパートの粒度は非線形の調整因子として機能することが明らかに。これらの発見を基にスケーリング法則を統一し、Ling-mini-betaモデルを設計・訓練した結果、計算資源を7倍以上節約しつつ、6.1Bの密なモデルと同等の性能を達成。研究は効率的なMoEモデルのスケーリングに関する基盤を提供する。
Comment元ポスト:https://x.com/rosinality/status/1948255608286990528?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-24
[Paper Note] RankMixer: Scaling Up Ranking Models in Industrial Recommenders, Jie Zhu+, arXiv'25
SummaryRankMixerは、推薦システムのスケーラビリティを向上させるための新しいアーキテクチャで、トランスフォーマーの並列性を活かしつつ、効率的な特徴相互作用を実現。Sparse-MoEバリアントを用いて10億パラメータに拡張し、動的ルーティング戦略で専門家の不均衡を解消。実験により、1兆スケールのデータセットで優れたスケーリング能力を示し、MFUを4.5%から45%に向上させ、推論レイテンシーを維持しつつパラメータを100倍に増加。オンラインA/Bテストで推薦、広告、検索の各シナリオにおける効果を確認し、ユーザーのアクティブ日数を0.2%、アプリ内使用時間を0.5%改善。
Comment元ポスト:https://x.com/gm8xx8/status/1948304747317854307?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-24
[Paper Note] OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles, Yihe Deng+, arXiv'25
SummaryOpenVLThinkerは、洗練された連鎖的思考推論を示すオープンソースの大規模視覚言語モデルであり、視覚推論タスクで顕著な性能向上を達成。SFTとRLを交互に行うことで、推論能力を効果的に引き出し、改善を加速。特に、MathVistaで3.8%、EMMAで2.4%、HallusionBenchで1.6%の性能向上を実現。コードやモデルは公開されている。
Comment元ポスト:https://x.com/yihe__deng/status/1948194764777783324?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-24
[Paper Note] R4ec: A Reasoning, Reflection, and Refinement Framework for Recommendation Systems, Hao Gu+, arXiv'25
Summary大規模言語モデル(LLMs)を用いた推薦システムの新しいフレームワーク$R^{4}$ecを提案。推論、反省、洗練のプロセスを通じて、システム1からシステム2の思考を促進。アクターモデルが推論を行い、反省モデルがフィードバックを提供し、応答を改善。Amazon-BookとMovieLens-1Mデータセットでの実験により、$R^{4}$ecの優位性を示し、オンライン広告プラットフォームでの収益が2.2%増加したことを報告。
Comment元ポスト:https://x.com/_reachsumit/status/1948218366390329793?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-24
[Paper Note] V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning, Mido Assran+, arXiv'25
Summary本研究では、インターネット規模のビデオデータと少量のロボットインタラクションデータを用いた自己教師あり学習アプローチを提案し、物理的世界の理解と計画能力を持つモデルV-JEPA 2を開発。V-JEPA 2は、動作理解や人間の行動予測で高い精度を達成し、ビデオ質問応答タスクでも最先端の性能を示す。さらに、ロボティックプランニングタスクにおいても、ゼロショットで物体のピッキングと配置を実現。自己教師あり学習が物理的世界での計画能力を向上させる可能性を示した。
#NeuralNetwork
#Analysis
#NLP
#LanguageModel
#Finetuning
Issue Date: 2025-07-24
[Paper Note] Subliminal Learning: Language models transmit behavioral traits via hidden signals in data, Alex Cloud+, arXiv'25
Summaryサブリミナル学習は、言語モデルが無関係なデータを通じて特性を伝達する現象である。実験では、特定の特性を持つ教師モデルが生成した数列データで訓練された生徒モデルが、その特性を学習することが確認された。データが特性への言及を除去してもこの現象は発生し、異なるベースモデルの教師と生徒では効果が見られなかった。理論的結果を通じて、全てのニューラルネットワークにおけるサブリミナル学習の発生を示し、MLP分類器での実証も行った。サブリミナル学習は一般的な現象であり、AI開発における予期しない問題を引き起こす可能性がある。
Comment元ポスト:https://x.com/anthropicai/status/1947696314206064819?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q教師モデルが生成したデータから、教師モデルと同じベースモデルを持つ[^1]生徒モデルに対してファインチューニングをした場合、教師モデルと同じ特性を、どんなに厳しく学習元の合成データをフィルタリングしても、意味的に全く関係ないデータを合成しても(たとえばただの数字列のデータを生成したとしても)、生徒モデルに転移してしまう。これは言語モデルに限った話ではなく、ニューラルネットワーク一般について証明された[^2]。
#NLP
#LanguageModel
#MoE(Mixture-of-Experts)
#Scaling Laws
Issue Date: 2025-07-25
[Paper Note] Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models, Changxin Tian+, arXiv'25
SummaryMixture-of-Experts (MoE)アーキテクチャは、LLMsの効率的なスケーリングを可能にするが、モデル容量の予測には課題がある。これに対処するため、Efficiency Leverage (EL)を導入し、300以上のモデルを訓練してMoE構成とELの関係を調査。結果、ELはエキスパートの活性化比率と計算予算に依存し、エキスパートの粒度は非線形の調整因子として機能することが明らかに。これらの発見を基にスケーリング法則を統一し、Ling-mini-betaモデルを設計・訓練した結果、計算資源を7倍以上節約しつつ、6.1Bの密なモデルと同等の性能を達成。研究は効率的なMoEモデルのスケーリングに関する基盤を提供する。
Comment元ポスト:https://x.com/rosinality/status/1948255608286990528?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-24
[Paper Note] RankMixer: Scaling Up Ranking Models in Industrial Recommenders, Jie Zhu+, arXiv'25
SummaryRankMixerは、推薦システムのスケーラビリティを向上させるための新しいアーキテクチャで、トランスフォーマーの並列性を活かしつつ、効率的な特徴相互作用を実現。Sparse-MoEバリアントを用いて10億パラメータに拡張し、動的ルーティング戦略で専門家の不均衡を解消。実験により、1兆スケールのデータセットで優れたスケーリング能力を示し、MFUを4.5%から45%に向上させ、推論レイテンシーを維持しつつパラメータを100倍に増加。オンラインA/Bテストで推薦、広告、検索の各シナリオにおける効果を確認し、ユーザーのアクティブ日数を0.2%、アプリ内使用時間を0.5%改善。
Comment元ポスト:https://x.com/gm8xx8/status/1948304747317854307?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-24
[Paper Note] OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles, Yihe Deng+, arXiv'25
SummaryOpenVLThinkerは、洗練された連鎖的思考推論を示すオープンソースの大規模視覚言語モデルであり、視覚推論タスクで顕著な性能向上を達成。SFTとRLを交互に行うことで、推論能力を効果的に引き出し、改善を加速。特に、MathVistaで3.8%、EMMAで2.4%、HallusionBenchで1.6%の性能向上を実現。コードやモデルは公開されている。
Comment元ポスト:https://x.com/yihe__deng/status/1948194764777783324?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-24
[Paper Note] R4ec: A Reasoning, Reflection, and Refinement Framework for Recommendation Systems, Hao Gu+, arXiv'25
Summary大規模言語モデル(LLMs)を用いた推薦システムの新しいフレームワーク$R^{4}$ecを提案。推論、反省、洗練のプロセスを通じて、システム1からシステム2の思考を促進。アクターモデルが推論を行い、反省モデルがフィードバックを提供し、応答を改善。Amazon-BookとMovieLens-1Mデータセットでの実験により、$R^{4}$ecの優位性を示し、オンライン広告プラットフォームでの収益が2.2%増加したことを報告。
Comment元ポスト:https://x.com/_reachsumit/status/1948218366390329793?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-24
[Paper Note] V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning, Mido Assran+, arXiv'25
Summary本研究では、インターネット規模のビデオデータと少量のロボットインタラクションデータを用いた自己教師あり学習アプローチを提案し、物理的世界の理解と計画能力を持つモデルV-JEPA 2を開発。V-JEPA 2は、動作理解や人間の行動予測で高い精度を達成し、ビデオ質問応答タスクでも最先端の性能を示す。さらに、ロボティックプランニングタスクにおいても、ゼロショットで物体のピッキングと配置を実現。自己教師あり学習が物理的世界での計画能力を向上させる可能性を示した。
#NeuralNetwork
#Analysis
#NLP
#LanguageModel
#Finetuning
Issue Date: 2025-07-24
[Paper Note] Subliminal Learning: Language models transmit behavioral traits via hidden signals in data, Alex Cloud+, arXiv'25
Summaryサブリミナル学習は、言語モデルが無関係なデータを通じて特性を伝達する現象である。実験では、特定の特性を持つ教師モデルが生成した数列データで訓練された生徒モデルが、その特性を学習することが確認された。データが特性への言及を除去してもこの現象は発生し、異なるベースモデルの教師と生徒では効果が見られなかった。理論的結果を通じて、全てのニューラルネットワークにおけるサブリミナル学習の発生を示し、MLP分類器での実証も行った。サブリミナル学習は一般的な現象であり、AI開発における予期しない問題を引き起こす可能性がある。
Comment元ポスト:https://x.com/anthropicai/status/1947696314206064819?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q教師モデルが生成したデータから、教師モデルと同じベースモデルを持つ[^1]生徒モデルに対してファインチューニングをした場合、教師モデルと同じ特性を、どんなに厳しく学習元の合成データをフィルタリングしても、意味的に全く関係ないデータを合成しても(たとえばただの数字列のデータを生成したとしても)、生徒モデルに転移してしまう。これは言語モデルに限った話ではなく、ニューラルネットワーク一般について証明された[^2]。
また、MNISTを用いたシンプルなMLPにおいて、MNISTを教師モデルに対して学習させ、そのモデルに対してランダムノイズな画像を生成させ、同じ初期化を施した生徒モデルに対してFinetuningをした場合、学習したlogitsがMNIST用ではないにもかかわらず、MNISTデータに対して50%以上の分類性能を示し、数字画像の認識能力が意味的に全く関係ないデータから転移されている[^3]、といった現象が生じることも実験的に確認された。
このため、どんなに頑張って合成データのフィルタリングや高品質化を実施し、教師モデルから特性を排除したデータを作成したつもりでも、そのデータでベースモデルが同じ生徒を蒸留すると、結局その特性は転移されてしまう。これは大きな落とし穴になるので気をつけましょう、という話だと思われる。
[^1]: これはアーキテクチャの話だけでなく、パラメータの初期値も含まれる
[^2]: 教師と生徒の初期化が同じ、かつ十分に小さい学習率の場合において、教師モデルが何らかの学習データDを生成し、Dのサンプルxで生徒モデルでパラメータを更新する勾配を計算すると、教師モデルが学習の過程で経た勾配と同じ方向の勾配が導き出される。つまり、パラメータが教師モデルと同じ方向にアップデートされる。みたいな感じだろうか?元論文を時間がなくて厳密に読めていない、かつalphaxivの力を借りて読んでいるため、誤りがあるかもしれない点に注意
[^3]: このパートについてもalphaxivの出力を参考にしており、元論文の記述をしっかり読めているわけではない Issue Date: 2025-07-24 [Paper Note] Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains, Anisha Gunjal+, arXiv'25 Summary報酬としてのルーブリック(RaR)フレームワークを提案し、構造化されたチェックリストスタイルのルーブリックを解釈可能な報酬信号として使用。HealthBench-1kで最大28%の相対的改善を達成し、専門家の参照に匹敵またはそれを上回る性能を示す。RaRは小規模な判定モデルが人間の好みに一致し、堅牢な性能を維持できることを証明。 Comment元ポスト:https://x.com/iscienceluvr/status/1948235609190867054?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Reasoning #Architecture Issue Date: 2025-07-23 [Paper Note] Hierarchical Reasoning Model, Guan Wang+, arXiv'25 SummaryHRM(Hierarchical Reasoning Model)は、AIの推論プロセスを改善するために提案された新しい再帰的アーキテクチャであり、Chain-of-Thought技術の問題を克服します。HRMは、2つの相互依存する再帰モジュールを用いて、シーケンシャルな推論タスクを単一のフォワードパスで実行し、高レベルの抽象計画と低レベルの詳細計算を分担します。2700万のパラメータで、わずか1000のトレーニングサンプルを使用し、数独や迷路の最適経路探索などの複雑なタスクで優れたパフォーマンスを示し、ARCベンチマークでも他の大規模モデルを上回る結果を達成しました。HRMは、普遍的な計算と汎用推論システムに向けた重要な進展を示唆しています。 Comment元ポスト:https://x.com/makingagi/status/1947286324735856747?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/hillbig/status/1952122977228841206?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2357 追試の結果再現が可能でモデルアーキテクチャそのものよりも、ablation studyの結果、outer refinement loopが重要とのこと:
・https://x.com/fchollet/status/1956442449922138336?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/k_schuerholt/status/1956669487349891198?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qポイント解説:https://x.com/giffmana/status/1956705621337608305?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #Evaluation #Reasoning #PostTraining #Contamination #Science Issue Date: 2025-07-23 [Paper Note] MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning, Run-Ze Fan+, arXiv'25 Summary科学的推論のためのオープンデータセット「TextbookReasoning」を提案し、65万の推論質問を含む。さらに、125万のインスタンスを持つ「MegaScience」を開発し、各公開科学データセットに最適なサブセットを特定。包括的な評価システムを構築し、既存のデータセットと比較して優れたパフォーマンスを示す。MegaScienceを用いてトレーニングしたモデルは、公式の指示モデルを大幅に上回り、科学的調整におけるスケーリングの利点を示唆。データキュレーションパイプラインやトレーニング済みモデルをコミュニティに公開。 Comment元ポスト:https://x.com/vfrz525_/status/1947859552407589076?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLMベースでdecontaminationも実施している模様 #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #GRPO #read-later #Admin'sPick #Non-VerifiableRewards #RewardModel Issue Date: 2025-07-22 [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25 Summary強化学習を用いてLLMsの推論能力を向上させるため、報酬モデリング(RM)のスケーラビリティを探求。ポイントワイズ生成報酬モデリング(GRM)を採用し、自己原則批評調整(SPCT)を提案してパフォーマンスを向上。並列サンプリングとメタRMを導入し、スケーリング性能を改善。実験により、SPCTがGRMの質とスケーラビリティを向上させ、既存の手法を上回る結果を示した。DeepSeek-GRMは一部のタスクで課題があるが、今後の取り組みで解決可能と考えられている。モデルはオープンソースとして提供予定。 Comment・inputに対する柔軟性と、
・同じresponseに対して多様なRewardを算出でき (= inference time scalingを活用できる)、
・Verifiableな分野に特化していないGeneralなRewardモデルである
Inference-Time Scaling for Generalist Reward Modeling (GRM) を提案

 #Analysis
#NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
#RLVR
Issue Date: 2025-07-22
[Paper Note] The Invisible Leash: Why RLVR May Not Escape Its Origin, Fang Wu+, arXiv'25
SummaryRLVRはAIの能力向上に寄与するが、基盤モデルの制約により新しい解の発見を制限する可能性がある。理論的調査により、初期確率がゼロの解をサンプリングできないことや、探索を狭めるトレードオフが明らかになった。実証実験では、RLVRが精度を向上させる一方で、正しい答えを見逃すことが確認された。将来的には、探索メカニズムや過小評価された解に確率質量を注入する戦略が必要とされる。
Comment元ポスト:https://x.com/iscienceluvr/status/1947570323395907830?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRLVRの限界に関する洞察
#NLP
#LanguageModel
#Evaluation
#Reasoning
#LongSequence
#Scaling Laws
Issue Date: 2025-07-22
[Paper Note] Inverse Scaling in Test-Time Compute, Aryo Pradipta Gema+, arXiv'25
SummaryLRMsの推論の長さが性能に与える影響を評価するタスクを構築し、計算量と精度の逆スケーリング関係を示す。4つのカテゴリのタスクを通じて、5つの失敗モードを特定。これにより、長時間の推論が問題のあるパターンを強化する可能性があることが明らかになった。結果は、LRMsの失敗モードを特定し対処するために、推論の長さに応じた評価の重要性を示している。
Comment元ポスト:https://x.com/iscienceluvr/status/1947570957029413166?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QReasoningモデルにおいてReasoningが長くなればなるほど
#Analysis
#NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
#RLVR
Issue Date: 2025-07-22
[Paper Note] The Invisible Leash: Why RLVR May Not Escape Its Origin, Fang Wu+, arXiv'25
SummaryRLVRはAIの能力向上に寄与するが、基盤モデルの制約により新しい解の発見を制限する可能性がある。理論的調査により、初期確率がゼロの解をサンプリングできないことや、探索を狭めるトレードオフが明らかになった。実証実験では、RLVRが精度を向上させる一方で、正しい答えを見逃すことが確認された。将来的には、探索メカニズムや過小評価された解に確率質量を注入する戦略が必要とされる。
Comment元ポスト:https://x.com/iscienceluvr/status/1947570323395907830?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRLVRの限界に関する洞察
#NLP
#LanguageModel
#Evaluation
#Reasoning
#LongSequence
#Scaling Laws
Issue Date: 2025-07-22
[Paper Note] Inverse Scaling in Test-Time Compute, Aryo Pradipta Gema+, arXiv'25
SummaryLRMsの推論の長さが性能に与える影響を評価するタスクを構築し、計算量と精度の逆スケーリング関係を示す。4つのカテゴリのタスクを通じて、5つの失敗モードを特定。これにより、長時間の推論が問題のあるパターンを強化する可能性があることが明らかになった。結果は、LRMsの失敗モードを特定し対処するために、推論の長さに応じた評価の重要性を示している。
Comment元ポスト:https://x.com/iscienceluvr/status/1947570957029413166?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QReasoningモデルにおいてReasoningが長くなればなるほど
・context中にirrerevantな情報が含まれるシンプルな個数を数えるタスクでは、irrerevantな情報に惑わされるようになり、
・特徴表に基づく回帰タスクの場合、擬似相関を持つ特徴量をの影響を増大してしまい、
・複雑で組み合わせが多い演繹タスク(シマウマパズル)に失敗する
といったように、Reasoning Traceが長くなればなるほど性能を悪化させるタスクが存在しこのような問題のある推論パターンを見つけるためにも、様々なReasoning Traceの長さで評価した方が良いのでは、といった話な模様?
 #NLP
#LanguageModel
#DiffusionModel
#Safety
Issue Date: 2025-07-22
[Paper Note] The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs, Zichen Wen+, arXiv'25
Summary拡散ベースの大規模言語モデル(dLLMs)は、迅速な推論と高いインタラクティビティを提供するが、安全性に関する懸念がある。既存のアライメントメカニズムは、敵対的プロンプトからdLLMsを保護できていない。これに対処するため、DIJAという新しい脱獄攻撃フレームワークを提案し、dLLMsの生成メカニズムを利用して有害な補完を可能にする。実験により、DIJAは既存の手法を大幅に上回り、特にDream-Instructで100%のASRを達成し、JailbreakBenchでの評価でも優れた結果を示した。これにより、dLLMsの安全性のアライメントを再考する必要性が浮き彫りになった。
Comment元ポスト:https://x.com/trtd6trtd/status/1947469171077615995?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#NLP
#LanguageModel
#DiffusionModel
#Scaling Laws
#read-later
Issue Date: 2025-07-22
[Paper Note] Diffusion Beats Autoregressive in Data-Constrained Settings, Mihir Prabhudesai+, arXiv'25
Summaryマスク付き拡散モデルは、データ制約のある設定で自己回帰(AR)モデルを大幅に上回ることを発見。拡散モデルはデータを効果的に活用し、検証損失を低下させ、下流のパフォーマンスを向上させる。新しいスケーリング法則を見つけ、拡散がARを上回る臨界計算閾値を導出。データがボトルネックの場合、拡散モデルはARの魅力的な代替手段となる。
Comment元ポスト:https://x.com/iscienceluvr/status/1947567159045197924?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QいつかdLLMの時代きそうだなあ著者ポスト:https://x.com/mihirp98/status/1947736993229885545?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q追加実験結果:https://x.com/mihirp98/status/1948875821797798136?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#RecommenderSystems
#LanguageModel
#Prompting
#Evaluation
#RecSys
#Reproducibility
Issue Date: 2025-07-21
[Paper Note] Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation, Genki Kusano+, RecSys'25
SummaryLLMを用いた単一ユーザー設定の推薦タスクにおいて、プロンプトエンジニアリングが重要であることを示す。23種類のプロンプトタイプを比較した結果、コスト効率の良いLLMでは指示の言い換え、背景知識の考慮、推論プロセスの明確化が効果的であり、高性能なLLMではシンプルなプロンプトが優れることが分かった。精度とコストのバランスに基づくプロンプトとLLMの選択に関する提案を行う。
Comment元ポスト:https://x.com/_reachsumit/status/1947138463083716842?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRecSysにおける網羅的なpromptingの実験。非常に興味深い
#NLP
#LanguageModel
#DiffusionModel
#Safety
Issue Date: 2025-07-22
[Paper Note] The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs, Zichen Wen+, arXiv'25
Summary拡散ベースの大規模言語モデル(dLLMs)は、迅速な推論と高いインタラクティビティを提供するが、安全性に関する懸念がある。既存のアライメントメカニズムは、敵対的プロンプトからdLLMsを保護できていない。これに対処するため、DIJAという新しい脱獄攻撃フレームワークを提案し、dLLMsの生成メカニズムを利用して有害な補完を可能にする。実験により、DIJAは既存の手法を大幅に上回り、特にDream-Instructで100%のASRを達成し、JailbreakBenchでの評価でも優れた結果を示した。これにより、dLLMsの安全性のアライメントを再考する必要性が浮き彫りになった。
Comment元ポスト:https://x.com/trtd6trtd/status/1947469171077615995?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#NLP
#LanguageModel
#DiffusionModel
#Scaling Laws
#read-later
Issue Date: 2025-07-22
[Paper Note] Diffusion Beats Autoregressive in Data-Constrained Settings, Mihir Prabhudesai+, arXiv'25
Summaryマスク付き拡散モデルは、データ制約のある設定で自己回帰(AR)モデルを大幅に上回ることを発見。拡散モデルはデータを効果的に活用し、検証損失を低下させ、下流のパフォーマンスを向上させる。新しいスケーリング法則を見つけ、拡散がARを上回る臨界計算閾値を導出。データがボトルネックの場合、拡散モデルはARの魅力的な代替手段となる。
Comment元ポスト:https://x.com/iscienceluvr/status/1947567159045197924?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QいつかdLLMの時代きそうだなあ著者ポスト:https://x.com/mihirp98/status/1947736993229885545?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q追加実験結果:https://x.com/mihirp98/status/1948875821797798136?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#RecommenderSystems
#LanguageModel
#Prompting
#Evaluation
#RecSys
#Reproducibility
Issue Date: 2025-07-21
[Paper Note] Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation, Genki Kusano+, RecSys'25
SummaryLLMを用いた単一ユーザー設定の推薦タスクにおいて、プロンプトエンジニアリングが重要であることを示す。23種類のプロンプトタイプを比較した結果、コスト効率の良いLLMでは指示の言い換え、背景知識の考慮、推論プロセスの明確化が効果的であり、高性能なLLMではシンプルなプロンプトが優れることが分かった。精度とコストのバランスに基づくプロンプトとLLMの選択に関する提案を行う。
Comment元ポスト:https://x.com/_reachsumit/status/1947138463083716842?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRecSysにおける網羅的なpromptingの実験。非常に興味深い
 実験で利用されたPrompting手法と相対的な改善幅
実験で利用されたPrompting手法と相対的な改善幅


RePhrase,StepBack,Explain,Summalize-User,Recency-Focusedが、様々なモデル、データセット、ユーザの特性(Light, Heavy)において安定した性能を示しており(少なくともベースラインからの性能の劣化がない)、model agnosticに安定した性能を発揮できるpromptingが存在することが明らかになった。一方、Phi-4, nova-liteについてはBaselineから有意に性能が改善したPromptingはなかった。これはモデルは他のモデルよりもそもそもの予測性能が低く、複雑なinstructionを理解する能力が不足しているため、Promptデザインが与える影響が小さいことが示唆される。
特定のモデルでのみ良い性能を発揮するPromptingも存在した。たとえばRe-Reading, Echoは、Llama3.3-70Bでは性能が改善したが、gpt-4.1-mini, gpt-4o-miniでは性能が悪化した。ReActはgpt-4.1-miniとLlamd3.3-70Bで最高性能を達成したが、gpt-4o-miniでは最も性能が悪かった。
NLPにおいて一般的に利用されるprompting、RolePlay, Mock, Plan-Solve, DeepBreath, Emotion, Step-by-Stepなどは、推薦のAcc.を改善しなかった。このことより、ユーザの嗜好を捉えることが重要なランキングタスクにおいては、これらプロンプトが有効でないことが示唆される。


続いて、LLMやデータセットに関わらず高い性能を発揮するpromptingをlinear mixed-effects model(ランダム効果として、ユーザ、LLM、メトリックを導入し、これらを制御する項を線形回帰に導入。promptingを固定効果としAccに対する寄与をfittingし、多様な状況で高い性能を発揮するPromptを明らかにする)によって分析した結果、ReAct, Rephrase, Step-Backが有意に全てのデータセット、LLMにおいて高い性能を示すことが明らかになった。
 #NeuralNetwork
#MachineTranslation
#NLP
#LanguageModel
#ACL
#Decoding
Issue Date: 2025-07-20
[Paper Note] Unveiling the Power of Source: Source-based Minimum Bayes Risk Decoding for Neural Machine Translation, Boxuan Lyu+, ACL'25
SummaryソースベースのMBRデコーディング(sMBR)を提案し、パラフレーズや逆翻訳から生成された準ソースを「サポート仮説」として利用。参照なしの品質推定メトリックを効用関数として用いる新しいアプローチで、実験によりsMBRがQE再ランキングおよび標準MBRを上回る性能を示した。sMBRはNMTデコーディングにおいて有望な手法である。
Comment元ポスト:https://x.com/boxuan_lyu425/status/1946802820973519245?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#PostTraining
Issue Date: 2025-07-19
[Paper Note] Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling, Zeyu Huang+, arXiv'25
Summaryポストトレーニング技術にはSFTとRFTがあり、それぞれ異なるトレードオフが存在する。本論文では、デモンストレーションと探索を統合したハイブリッドアプローチ「Prefix-RFT」を提案し、数学的推論問題でその効果を実証。Prefix-RFTはSFTやRFTの性能を上回り、既存のフレームワークに容易に統合可能である。分析により、SFTとRFTの補完的な性質が示され、デモンストレーションデータの質と量に対する堅牢性も確認された。この研究はLLMのポストトレーニングに新たな視点を提供する。
Comment元ポスト:https://x.com/zeroyuhuang/status/1946232400922484992?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q少し前からXコミュニティでRFT(Reinforcement Finetuning)という用語が観測されたが、arXiv paperで見たのは初めてかもしれない。RFTはおそらく、強化学習を利用したPost-Trainingの総称だと思われる。デモンストレーションデータからPrefixをサンプリングし(SFTの要素; オフラインデータからサンプリングしたPrefixで生成をガイドする)、Prefixの続きをオンラインで生成し(RFTの要素; ガイドされたPrefixの続きを探索する)、Prefix+生成結果をロールアウトとし学習する。
#NeuralNetwork
#MachineTranslation
#NLP
#LanguageModel
#ACL
#Decoding
Issue Date: 2025-07-20
[Paper Note] Unveiling the Power of Source: Source-based Minimum Bayes Risk Decoding for Neural Machine Translation, Boxuan Lyu+, ACL'25
SummaryソースベースのMBRデコーディング(sMBR)を提案し、パラフレーズや逆翻訳から生成された準ソースを「サポート仮説」として利用。参照なしの品質推定メトリックを効用関数として用いる新しいアプローチで、実験によりsMBRがQE再ランキングおよび標準MBRを上回る性能を示した。sMBRはNMTデコーディングにおいて有望な手法である。
Comment元ポスト:https://x.com/boxuan_lyu425/status/1946802820973519245?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#PostTraining
Issue Date: 2025-07-19
[Paper Note] Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling, Zeyu Huang+, arXiv'25
Summaryポストトレーニング技術にはSFTとRFTがあり、それぞれ異なるトレードオフが存在する。本論文では、デモンストレーションと探索を統合したハイブリッドアプローチ「Prefix-RFT」を提案し、数学的推論問題でその効果を実証。Prefix-RFTはSFTやRFTの性能を上回り、既存のフレームワークに容易に統合可能である。分析により、SFTとRFTの補完的な性質が示され、デモンストレーションデータの質と量に対する堅牢性も確認された。この研究はLLMのポストトレーニングに新たな視点を提供する。
Comment元ポスト:https://x.com/zeroyuhuang/status/1946232400922484992?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q少し前からXコミュニティでRFT(Reinforcement Finetuning)という用語が観測されたが、arXiv paperで見たのは初めてかもしれない。RFTはおそらく、強化学習を利用したPost-Trainingの総称だと思われる。デモンストレーションデータからPrefixをサンプリングし(SFTの要素; オフラインデータからサンプリングしたPrefixで生成をガイドする)、Prefixの続きをオンラインで生成し(RFTの要素; ガイドされたPrefixの続きを探索する)、Prefix+生成結果をロールアウトとし学習する。

 #Analysis
#MachineLearning
#Dataset
#ICLR
#Robotics
Issue Date: 2025-07-19
[Paper Note] What Matters in Learning from Large-Scale Datasets for Robot Manipulation, Vaibhav Saxena+, ICLR'25
Summary本研究では、ロボティクスにおける大規模データセットの構成に関する体系的な理解を深めるため、データ生成フレームワークを開発し、多様性の重要な要素を特定。特に、カメラのポーズや空間的配置がデータ収集の多様性と整合性に影響を与えることを示した。シミュレーションからの洞察が実世界でも有効であり、提案した取得戦略は既存のトレーニング手法を最大70%上回る性能を発揮した。
Comment元ポスト:https://x.com/saxenavaibhav11/status/1946209076305691084?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q元ポストに著者による詳細な解説スレッドがあるので参照のこと。
#Analysis
#MachineLearning
#Dataset
#ICLR
#Robotics
Issue Date: 2025-07-19
[Paper Note] What Matters in Learning from Large-Scale Datasets for Robot Manipulation, Vaibhav Saxena+, ICLR'25
Summary本研究では、ロボティクスにおける大規模データセットの構成に関する体系的な理解を深めるため、データ生成フレームワークを開発し、多様性の重要な要素を特定。特に、カメラのポーズや空間的配置がデータ収集の多様性と整合性に影響を与えることを示した。シミュレーションからの洞察が実世界でも有効であり、提案した取得戦略は既存のトレーニング手法を最大70%上回る性能を発揮した。
Comment元ポスト:https://x.com/saxenavaibhav11/status/1946209076305691084?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q元ポストに著者による詳細な解説スレッドがあるので参照のこと。
 #EfficiencyImprovement
#NLP
#Dataset
#LLMAgent
#Evaluation
#SoftwareEngineering
Issue Date: 2025-07-18
[Paper Note] SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?, Xinyi He+, arXiv'25
Summaryコードのパフォーマンス最適化は重要であり、LLMsのリポジトリレベルでの能力は未探求。これに対処するため、SWE-Perfという初のベンチマークを導入。140のインスタンスを用いて、LLMsと専門家の最適化パフォーマンスのギャップを評価し、研究機会を示す。
Comment元ポスト:https://x.com/sivil_taram/status/1945855374336446577?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QこれまでのSWE系のベンチマークはBug Fixなどにフォーカスされてきたが、こちらのベンチマークはソフトウェアのパフォーマンス(i.e., 実行時間)を改善させられるかにフォーカスしているとのこと。
#EfficiencyImprovement
#NLP
#Dataset
#LLMAgent
#Evaluation
#SoftwareEngineering
Issue Date: 2025-07-18
[Paper Note] SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?, Xinyi He+, arXiv'25
Summaryコードのパフォーマンス最適化は重要であり、LLMsのリポジトリレベルでの能力は未探求。これに対処するため、SWE-Perfという初のベンチマークを導入。140のインスタンスを用いて、LLMsと専門家の最適化パフォーマンスのギャップを評価し、研究機会を示す。
Comment元ポスト:https://x.com/sivil_taram/status/1945855374336446577?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QこれまでのSWE系のベンチマークはBug Fixなどにフォーカスされてきたが、こちらのベンチマークはソフトウェアのパフォーマンス(i.e., 実行時間)を改善させられるかにフォーカスしているとのこと。
実際にリポジトリからPRを収集し、パッチ前後の実行時間を比較。20回のrunを通じて統計的に有意な実行時間の差があるもののみにフィルタリングをしているとのこと。
Human Expertsは平均10.9%のgainを得たが、エージェントは2.3%にとどまっており、ギャップがあるとのこと。
傾向として、LLMはlow levelなインフラストラクチャ(環境構築, 依存関係のハンドリング, importのロジック)を改善するが、Human Expertsはhigh levelなロジックやデータ構造を改善する(e.g., アルゴリズムや、データハンドリング)。 #Pretraining #NLP #LanguageModel #MulltiModal #Scaling Laws #DataMixture #VisionLanguageModel Issue Date: 2025-07-18 [Paper Note] Scaling Laws for Optimal Data Mixtures, Mustafa Shukor+, arXiv'25 Summary本研究では、スケーリング法則を用いて任意のターゲットドメインに対する最適なデータ混合比率を決定する方法を提案。特定のドメイン重みベクトルを持つモデルの損失を正確に予測し、LLM、NMM、LVMの事前訓練における予測力を示す。少数の小規模な訓練実行でパラメータを推定し、高価な試行錯誤法に代わる原則的な選択肢を提供。 #MachineTranslation #Metrics #NLP #LanguageModel #MultiDimensional Issue Date: 2025-07-18 [Paper Note] TransEvalnia: Reasoning-based Evaluation and Ranking of Translations, Richard Sproat+, arXiv'25 Summaryプロンプトベースの翻訳評価システム「TransEvalnia」を提案し、Multidimensional Quality Metricsに基づく詳細な評価を行う。TransEvalniaは、英日データやWMTタスクで最先端のMT-Rankerと同等以上の性能を示し、LLMによる評価が人間の評価者と良好に相関することを確認。翻訳の提示順序に敏感であることを指摘し、位置バイアスへの対処法を提案。システムの評価データは公開される。 Comment元ポスト:https://x.com/sakanaailabs/status/1946071203002941694?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-17 [Paper Note] SpatialTrackerV2: 3D Point Tracking Made Easy, Yuxi Xiao+, arXiv'25 SummarySpatialTrackerV2は、モノキュラー動画のためのフィードフォワード3Dポイントトラッキング手法であり、ポイントトラッキング、モノキュラー深度、カメラポーズ推定の関係を統合。エンドツーエンドのアーキテクチャにより、様々なデータセットでスケーラブルなトレーニングが可能。これにより、既存の3Dトラッキング手法を30%上回り、動的3D再構築の精度に匹敵しつつ、50倍の速さで動作する。 Comment元ポスト:https://x.com/zhenjun_zhao/status/1945780657541492955?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #read-later #4DReconstruction Issue Date: 2025-07-17 [Paper Note] Streaming 4D Visual Geometry Transformer, Dong Zhuo+, arXiv'25 Summary動画から4D空間-時間幾何学を認識・再構築するために、ストリーミング4Dビジュアルジオメトリトランスフォーマーを提案。因果トランスフォーマーアーキテクチャを用いて、過去の情報をキャッシュしながらリアルタイムで4D再構築を実現。効率的なトレーニングのために、双方向ビジュアルジオメトリからの知識蒸留を行い、推論速度を向上させつつ競争力のある性能を維持。スケーラブルな4Dビジョンシステムの実現に寄与。 Comment元ポスト:https://x.com/zhenjun_zhao/status/1945427634642424188?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qモデルのアーキテクチャ
 Issue Date: 2025-07-17
[Paper Note] Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation, Sangmin Bae+, arXiv'25
SummaryMixture-of-Recursions(MoR)というフレームワークを提案し、再帰型トランスフォーマー内でパラメータ共有と適応計算を同時に実現。MoRは、レイヤーの再利用とトークンごとの再帰深さの動的割り当てにより、メモリアクセス効率を向上させる。135Mから1.7Bパラメータのモデルで、トレーニングFLOPsを維持しつつ、困惑度を低下させ、少数ショット精度を向上。MoRは大規模モデルのコストを抑えつつ、品質向上に寄与することを示す。
Comment元ポスト:https://x.com/hillbig/status/1945632764650533048?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Embeddings
#MachineLearning
#RepresentationLearning
Issue Date: 2025-07-16
[Paper Note] Learning distributed representations with efficient SoftMax normalization, Lorenzo Dall'Amico+, TMLR'25
Summary埋め込みを学習するための損失関数として${\rm SoftMax}(XY^T)$を最適化する際の計算負荷を軽減するため、ノルム制限された埋め込みベクトルに対して線形時間のヒューリスティック近似を提案。提案手法は、事前学習されたデータセットで高い精度を示し、クロスエントロピーを最適化する効率的なアルゴリズムを設計。これにより、解釈可能でタスクに依存しない埋め込み学習が可能となり、類似の「2Vec」アルゴリズムと比較して優れた性能と低い計算時間を実現。
Commentopenreview:https://openreview.net/forum?id=9M4NKMZOPu
#NLP
#LanguageModel
#Chain-of-Thought
#Reasoning
#Safety
Issue Date: 2025-07-16
[Paper Note] Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety, Tomek Korbak+, arXiv'25
Summary人間の言語で「考える」AIシステムは、安全性向上のために思考の連鎖(CoT)を監視することで悪意のある意図を検出する機会を提供する。しかし、CoT監視は完璧ではなく、一部の不正行為が見逃される可能性がある。研究を進め、既存の安全手法と併せてCoT監視への投資を推奨する。モデル開発者は、開発の決定がCoTの監視可能性に与える影響を考慮すべきである。
Comment元ポスト:https://x.com/gdb/status/1945350912668737701?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCoTを監視することで、たとえばモデルのよろしくない挙動(e.g., misalignmentなどの意図しない動作や、prompt injection等の不正行為)を検知することができ、特にAIがより長期的な課題に取り組む際にはより一層その内部プロセスを監視する手段が必要不可欠となるため、CoTの忠実性や解釈性が重要となる。このため、CoTの監視可能性が維持される(モデルのアーキテクチャや学習手法(たとえばCoTのプロセス自体は一見真っ当なことを言っているように見えるが、実はRewardHackingしている、など)によってはそもそもCoTが難読化し監視できなかったりするので、現状は脆弱性がある)、より改善していく方向にコミュニティとして動くことを推奨する。そして、モデルを研究開発する際にはモデルのCoT監視に関する評価を実施すべきであり、モデルのデプロイや開発の際にはCoTの監視に関する決定を組み込むべき、といったような提言のようである。関連:https://x.com/dongxi_nlp/status/1945606266027426048?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#MachineLearning
#NLP
#Transformer
#In-ContextLearning
Issue Date: 2025-07-16
[Paper Note] In-context denoising with one-layer transformers: connections between attention and associative memory retrieval, Matthew Smart+, arXiv'25
Summary「インコンテキストデノイジング」というタスクを通じて、注意ベースのアーキテクチャと密な連想記憶(DAM)ネットワークの関係を探求。ベイズ的フレームワークを用いて、単層トランスフォーマーが特定のデノイジング問題を最適に解決できることを示す。訓練された注意層は、コンテキストトークンを連想記憶として利用し、デノイジングプロンプトを一回の勾配降下更新で処理。これにより、DAMネットワークの新たな拡張例を提供し、連想記憶と注意メカニズムの関連性を強化する。
Comment元ポスト:https://x.com/hillbig/status/1945253873456963841?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
Issue Date: 2025-07-17
[Paper Note] Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation, Sangmin Bae+, arXiv'25
SummaryMixture-of-Recursions(MoR)というフレームワークを提案し、再帰型トランスフォーマー内でパラメータ共有と適応計算を同時に実現。MoRは、レイヤーの再利用とトークンごとの再帰深さの動的割り当てにより、メモリアクセス効率を向上させる。135Mから1.7Bパラメータのモデルで、トレーニングFLOPsを維持しつつ、困惑度を低下させ、少数ショット精度を向上。MoRは大規模モデルのコストを抑えつつ、品質向上に寄与することを示す。
Comment元ポスト:https://x.com/hillbig/status/1945632764650533048?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Embeddings
#MachineLearning
#RepresentationLearning
Issue Date: 2025-07-16
[Paper Note] Learning distributed representations with efficient SoftMax normalization, Lorenzo Dall'Amico+, TMLR'25
Summary埋め込みを学習するための損失関数として${\rm SoftMax}(XY^T)$を最適化する際の計算負荷を軽減するため、ノルム制限された埋め込みベクトルに対して線形時間のヒューリスティック近似を提案。提案手法は、事前学習されたデータセットで高い精度を示し、クロスエントロピーを最適化する効率的なアルゴリズムを設計。これにより、解釈可能でタスクに依存しない埋め込み学習が可能となり、類似の「2Vec」アルゴリズムと比較して優れた性能と低い計算時間を実現。
Commentopenreview:https://openreview.net/forum?id=9M4NKMZOPu
#NLP
#LanguageModel
#Chain-of-Thought
#Reasoning
#Safety
Issue Date: 2025-07-16
[Paper Note] Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety, Tomek Korbak+, arXiv'25
Summary人間の言語で「考える」AIシステムは、安全性向上のために思考の連鎖(CoT)を監視することで悪意のある意図を検出する機会を提供する。しかし、CoT監視は完璧ではなく、一部の不正行為が見逃される可能性がある。研究を進め、既存の安全手法と併せてCoT監視への投資を推奨する。モデル開発者は、開発の決定がCoTの監視可能性に与える影響を考慮すべきである。
Comment元ポスト:https://x.com/gdb/status/1945350912668737701?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCoTを監視することで、たとえばモデルのよろしくない挙動(e.g., misalignmentなどの意図しない動作や、prompt injection等の不正行為)を検知することができ、特にAIがより長期的な課題に取り組む際にはより一層その内部プロセスを監視する手段が必要不可欠となるため、CoTの忠実性や解釈性が重要となる。このため、CoTの監視可能性が維持される(モデルのアーキテクチャや学習手法(たとえばCoTのプロセス自体は一見真っ当なことを言っているように見えるが、実はRewardHackingしている、など)によってはそもそもCoTが難読化し監視できなかったりするので、現状は脆弱性がある)、より改善していく方向にコミュニティとして動くことを推奨する。そして、モデルを研究開発する際にはモデルのCoT監視に関する評価を実施すべきであり、モデルのデプロイや開発の際にはCoTの監視に関する決定を組み込むべき、といったような提言のようである。関連:https://x.com/dongxi_nlp/status/1945606266027426048?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#MachineLearning
#NLP
#Transformer
#In-ContextLearning
Issue Date: 2025-07-16
[Paper Note] In-context denoising with one-layer transformers: connections between attention and associative memory retrieval, Matthew Smart+, arXiv'25
Summary「インコンテキストデノイジング」というタスクを通じて、注意ベースのアーキテクチャと密な連想記憶(DAM)ネットワークの関係を探求。ベイズ的フレームワークを用いて、単層トランスフォーマーが特定のデノイジング問題を最適に解決できることを示す。訓練された注意層は、コンテキストトークンを連想記憶として利用し、デノイジングプロンプトを一回の勾配降下更新で処理。これにより、DAMネットワークの新たな拡張例を提供し、連想記憶と注意メカニズムの関連性を強化する。
Comment元ポスト:https://x.com/hillbig/status/1945253873456963841?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2146 #read-later Issue Date: 2025-07-16 [Paper Note] Building Instruction-Tuning Datasets from Human-Written Instructions with Open-Weight Large Language Models, Youmi Ma+, arXiv'25 Summary本研究では、人間が書いた指示を用いた指示調整データセットを構築し、LLMの性能向上を図る。人間由来のデータで微調整されたモデルは、既存のデータセットで調整されたモデルを上回る結果を示し、日本語データセットでも同様の成果を確認。指示調整によりLLMは指示に従う能力を向上させるが、文化特有の知識が不足していることが明らかに。データセットとモデルは公開予定で、多様な使用ケースに対応可能。 #NeuralNetwork #MachineLearning #ICML #GraphGeneration Issue Date: 2025-07-16 [Paper Note] Learning-Order Autoregressive Models with Application to Molecular Graph Generation, Zhe Wang+, ICML'25 Summary自己回帰モデル(ARMs)を用いて、データから逐次的に推測される確率的順序を利用し、高次元データを生成する新しい手法を提案。トレーニング可能なオーダーポリシーを組み込み、対数尤度の変分下限を用いて最適化。実験により、画像生成やグラフ生成で意味のある自己回帰順序を学習し、分子グラフ生成ではQM9およびZINC250kベンチマークで最先端の結果を達成。 Comment元ポスト:https://x.com/thjashin/status/1945175804704645607?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qopenreview:https://openreview.net/forum?id=EY6pXIDi3G #NLP #LanguageModel #OpenWeight #Contamination Issue Date: 2025-07-16 [Paper Note] Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, Mingqi Wu+, arXiv'25 Summary大規模言語モデル(LLMs)の推論能力向上に関する研究が進展しており、特にQwen2.5モデルが強化学習(RL)を用いて顕著な改善を示している。しかし、他のモデルでは同様の成果が得られていないため、さらなる調査が必要である。Qwen2.5は数学的推論性能が高いが、データ汚染に脆弱であり、信頼性のある結果を得るためには、RandomCalculationというクリーンなデータセットを用いることが重要である。このデータセットを通じて、正確な報酬信号が性能向上に寄与することが示された。信頼性のある結論を得るためには、汚染のないベンチマークと多様なモデルでのRL手法の評価が推奨される。 Comment元ポスト:https://x.com/asap2650/status/1945151806536863878?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/dongxi_nlp/status/1945214650737451008?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1997
こちらでQwen-mathに対して得られたRLでのgainは他モデルでは現れず汎化しないことも報告されている。 #Analysis #NLP #LanguageModel #Prompting #Reasoning #Batch Issue Date: 2025-07-16 [Paper Note] REST: Stress Testing Large Reasoning Models by Asking Multiple Problems at Once, Zhuoshi Pan+, arXiv'25 SummaryRESTという新しい評価フレームワークを提案し、LRMsを同時に複数の問題にさらすことで、実世界の推論能力を評価。従来のベンチマークの限界を克服し、文脈優先配分や問題間干渉耐性を測定。DeepSeek-R1などの最先端モデルでもストレステスト下で性能低下が見られ、RESTはモデル間の性能差を明らかにする。特に「考えすぎの罠」が性能低下の要因であり、「long2short」技術で訓練されたモデルが優れた結果を示すことが確認された。RESTはコスト効率が高く、実世界の要求に適した評価手法である。 Comment元ポスト:https://x.com/_akhaliq/status/1945130848061194500?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP
#LanguageModel
#ReinforcementLearning
#GRPO
#read-later
#Off-Policy
Issue Date: 2025-07-15
[Paper Note] Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions, Simon Matrenok+, arXiv'25
SummaryQRPO(Quantile Reward Policy Optimization)は、ポイントワイズの絶対報酬から学習する新しい手法で、DPOのシンプルさとオフライン適用性を兼ね備えています。QRPOは量子報酬を用いてKL正則化された強化学習の目的の閉形式解への回帰を実現し、相対的な信号の必要性を排除します。実験結果では、QRPOがDPOやREBEL、SimPOと比較して、チャットやコーディングの評価で一貫して最高のパフォーマンスを示しました。また、堅牢な報酬でのトレーニングにより、長さバイアスが減少することが確認されました。
Comment画像は元ポストより。off-policy RLでもlong contextで高い性能が出るようになったのだろうか
#NLP
#LanguageModel
#ReinforcementLearning
#GRPO
#read-later
#Off-Policy
Issue Date: 2025-07-15
[Paper Note] Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions, Simon Matrenok+, arXiv'25
SummaryQRPO(Quantile Reward Policy Optimization)は、ポイントワイズの絶対報酬から学習する新しい手法で、DPOのシンプルさとオフライン適用性を兼ね備えています。QRPOは量子報酬を用いてKL正則化された強化学習の目的の閉形式解への回帰を実現し、相対的な信号の必要性を排除します。実験結果では、QRPOがDPOやREBEL、SimPOと比較して、チャットやコーディングの評価で一貫して最高のパフォーマンスを示しました。また、堅牢な報酬でのトレーニングにより、長さバイアスが減少することが確認されました。
Comment画像は元ポストより。off-policy RLでもlong contextで高い性能が出るようになったのだろうか

元ポスト:https://x.com/skandermoalla/status/1944773057085579531?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2060 #ICML Issue Date: 2025-07-15 [Paper Note] The Value of Prediction in Identifying the Worst-Off, Unai Fischer-Abaigar+, arXiv'25 Summary機械学習を用いて最も脆弱な個人を特定し支援する政府プログラムの影響を検討。特に、平等を重視した予測が福祉に与える影響と他の政策手段との比較を行い、ドイツの長期失業者に関するケーススタディを通じてその効果を分析。政策立案者に対して原則に基づいた意思決定を支援するフレームワークとデータ駆動型ツールを提供。 Commentopenreview:https://openreview.net/forum?id=26JsumCG0z #MachineLearning #ICML Issue Date: 2025-07-15 [Paper Note] Score Matching With Missing Data, Josh Givens+, ICML'25 Summaryスコアマッチングはデータ分布学習の重要な手法ですが、不完全データへの適用は未研究です。本研究では、部分的に欠損したデータに対するスコアマッチングの適応を目指し、重要度重み付け(IW)アプローチと変分アプローチの2つのバリエーションを提案します。IWアプローチは有限サンプル境界を示し、小さなサンプルでの強力な性能を確認。変分アプローチは高次元設定でのグラフィカルモデル推定において優れた性能を発揮します。 Commentopenreview:https://openreview.net/forum?id=mBstuGUaXoICML'25 outstanding papers解説:https://x.com/hillbig/status/1960498715229347941?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ICML Issue Date: 2025-07-15 [Paper Note] Conformal Prediction as Bayesian Quadrature, Jake C. Snell+, arXiv'25 Summary機械学習の予測モデルの理解が重要になる中、コンフォーマル予測をベイズ的視点から再考し、頻度主義的保証の限界を指摘。ベイズ的数値積分に基づく新たな手法を提案し、解釈可能な保証と損失の範囲を豊かに表現する。 Commentopenreview:https://openreview.net/forum?id=PNmkjIzHB7ICML'25 outstanding papers #ICML Issue Date: 2025-07-15 [Paper Note] Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction, Vaishnavh Nagarajan+, arXiv'25 Summary最小限のアルゴリズムタスクを設計し、現代の言語モデルの創造的限界を定量化。タスクは新しい接続の発見やパターン構築を必要とし、次トークン学習の限界を論じる。マルチトークンアプローチが独創的な出力を生成し、入力層へのノイズ注入が効果的であることを発見。研究は創造的スキル分析のためのテストベッドを提供し、新たな議論を展開。コードはGitHubで公開。 Commentopenreview:https://openreview.net/forum?id=Hi0SyHMmkdICML'25 outstanding papers #Analysis #Pretraining #DiffusionModel #ICML #Decoding Issue Date: 2025-07-15 [Paper Note] Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions, Jaeyeon Kim+, ICML'25 Summaryマスク付き拡散モデル(MDMs)は、自己回帰モデル(ARMs)と比較してトレーニングの複雑さと推論の柔軟性をトレードオフする新しい生成モデルです。本研究では、MDMsが自己回帰モデルよりも計算上解決不可能なサブ問題に取り組むことを示し、適応的なトークンデコード戦略がMDMsの性能を向上させることを実証しました。数独の論理パズルにおいて、適応的推論により解決精度が$<7$%から$\approx 90$%に向上し、教師強制でトレーニングされたMDMsがARMsを上回ることを示しました。 Commentopenreview:https://openreview.net/forum?id=DjJmre5IkPICML'25 outstanding papers日本語解説:https://x.com/hillbig/status/1960491242615345237?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ICML Issue Date: 2025-07-15 [Paper Note] CollabLLM: From Passive Responders to Active Collaborators, Shirley Wu+, arXiv'25 SummaryCollabLLMは、長期的なインタラクションを最適化するための新しい訓練フレームワークで、マルチターンの人間とLLMのコラボレーションを強化する。協調シミュレーションを用いて、応答の長期的な貢献を評価し、ユーザーの意図を明らかにすることで、より人間中心のAIを実現。文書作成などのタスクで平均18.5%のパフォーマンス向上と46.3%のインタラクティビティ改善を達成し、ユーザー満足度を17.6%向上させ、消費時間を10.4%削減した。 Commentopenreview:https://openreview.net/forum?id=DmH4HHVb3yICML'25 outstanding papers Issue Date: 2025-07-15 [Paper Note] Auditing Prompt Caching in Language Model APIs, Chenchen Gu+, arXiv'25 SummaryプロンプトキャッシングはLLMにおいてタイミング変動を引き起こし、サイドチャネル攻撃のリスクをもたらす。キャッシュが共有されると、攻撃者は迅速な応答から他ユーザーのプロンプトを特定できる可能性がある。これによりプライバシー漏洩の懸念が生じ、APIプロバイダーの透明性が重要となる。本研究では、実世界のLLM APIプロバイダーにおけるプロンプトキャッシングを検出するための統計監査を開発し、7つのAPIプロバイダー間でのキャッシュ共有を確認し、潜在的なプライバシー漏洩を示した。また、OpenAIの埋め込みモデルに関する新たな情報も発見した。 Issue Date: 2025-07-15 [Paper Note] Open Vision Reasoner: Transferring Linguistic Cognitive Behavior for Visual Reasoning, Yana Wei+, arXiv'25 Summary本研究では、大規模言語モデル(LLMs)の推論能力をマルチモーダルLLMs(MLLMs)に応用し、高度な視覚推論を実現する方法を探求。二段階のパラダイムを導入し、ファインチューニング後に約1,000ステップのマルチモーダル強化学習を行い、従来のオープンソースの取り組みを上回る成果を達成。得られたモデルOpen-Vision-Reasoner(OVR)は、MATH500で95.3%、MathVisionで51.8%、MathVerseで54.6%の推論ベンチマークで最先端のパフォーマンスを示す。モデル、データ、トレーニングのダイナミクスを公開し、マルチモーダル推論者の開発を促進。 Comment元ポスト:https://x.com/cyousakura/status/1944788604120953105?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #COLM Issue Date: 2025-07-15 [Paper Note] L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning, Pranjal Aggarwal+, arXiv'25 SummaryLength Controlled Policy Optimization(LCPO)を導入し、推論言語モデルL1を訓練。これにより、出力の長さを制御しつつ計算コストと精度のトレードオフを最適化。LCPOは、長さ制御において最先端の手法S1を上回る性能を示し、1.5B L1モデルは同じ推論の長さでGPT-4oを超える結果を得た。 Comment元ポスト:https://x.com/pranjalaggarw16/status/1944452267861741684?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Tokenizer #COLM Issue Date: 2025-07-15 [Paper Note] SuperBPE: Space Travel for Language Models, Alisa Liu+, COLM'25 SummarySuperBPEという新しいトークナイザーを導入し、サブワードを超えたトークン化を実現。これにより、エンコーディング効率が33%向上し、30のダウンストリームタスクで平均+4.0%の性能改善を達成。SuperBPEは意味的に単一の単位として機能する表現を捉え、全体的に優れた言語モデルを提供する。 Comment元ポスト:https://x.com/alisawuffles/status/1944890077059965276?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pretraining #Transformer #PEFT(Adaptor/LoRA) #ICML #Finetuning Issue Date: 2025-07-14 [Paper Note] ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts, Samar Khanna+, ICML'25 SummaryPEFT技術を用いたExPLoRAは、事前学習済みビジョントランスフォーマー(ViT)を新しいドメインに適応させる手法で、教師なし事前学習を通じて効率的にファインチューニングを行う。実験では、衛星画像において最先端の結果を達成し、従来のアプローチよりも少ないパラメータで精度を最大8%向上させた。 Comment元ポスト:https://x.com/samar_a_khanna/status/1944781066591748336?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれまでドメイン適応する場合にラベル付きデータ+LoRAでFinetuningしていたのを、ラベル無しデータ+継続事前学習の枠組みでやりましょう、という話のようである。

手法は下記で、事前学習済みのモデルに対してLoRAを適用し継続事前学習する。ただし、最後尾のLayer、あるいは最初と最後尾のLayerの両方をunfreezeして、trainableにする。また、LoRAはfreezeしたLayerのQ,Vに適用し、それらのLayerのnormalization layerもunfreezeする。最終的に、継続事前学習したモデルにヘッドをconcatしてfinetuningすることで目的のタスクを実行できるようにする。


同じモデルで単にLoRAを適用しただけの手法や、既存手法をoutperform
 画像+ViT系のモデルだけで実験されているように見えるが、LLMとかにも応用可能だと思われる。
画像+ViT系のモデルだけで実験されているように見えるが、LLMとかにも応用可能だと思われる。
#ComputerVision #NLP #Dataset #Evaluation #VisionLanguageModel Issue Date: 2025-07-14 [Paper Note] VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge, Yueqi Song+, arXiv'25 SummaryVisualPuzzlesは、専門知識への依存を最小限に抑えた視覚的推論を評価する新しいベンチマークで、5つの推論カテゴリーから成る多様な質問を含む。実験により、VisualPuzzlesはドメイン特有の知識を大幅に減少させ、より複雑な推論を要求することが示された。最先端のマルチモーダルモデルは、VisualPuzzlesで人間のパフォーマンスに遅れをとり、知識集約型タスクでの成功が推論タスクでの成功に必ずしもつながらないことが明らかになった。また、モデルのサイズとパフォーマンスの間に明確な相関は見られず、VisualPuzzlesは事実の記憶を超えた推論能力を評価する新たな視点を提供する。 Comment元ポスト:https://x.com/yueqi_song/status/1912510869491101732?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q画像はPJページより引用。新たにVisual Puzzleと呼ばれる特定のドメイン知識がほとんど必要ないマルチモーダルなreasoningベンチマークを構築。o1ですら、人間の5th percentileに満たない性能とのこと。
Chinese Civil Service Examination中のlogical reasoning questionを手作業で翻訳したとのこと。

データセットの統計量は以下で、合計1168問で、難易度は3段階に分かれている模様。

project page:https://neulab.github.io/VisualPuzzles/ #MachineLearning #NLP #LanguageModel #Optimizer #read-later #Admin'sPick Issue Date: 2025-07-14 [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25 SummaryMuonオプティマイザーを大規模モデルにスケールアップするために、ウェイトデケイとパラメータごとの更新スケール調整を導入。これにより、Muonは大規模トレーニングで即座に機能し、計算効率がAdamWの約2倍に向上。新たに提案するMoonlightモデルは、少ないトレーニングFLOPで優れたパフォーマンスを達成し、オープンソースの分散Muon実装や事前トレーニング済みモデルも公開。 Comment解説ポスト:https://x.com/hillbig/status/1944902706747072678?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこちらでも紹介されている:
・2208 #ComputerVision #NLP #MulltiModal #Reasoning #OpenWeight #VisionLanguageModel Issue Date: 2025-07-14 [Paper Note] Kimi-VL Technical Report, Kimi Team+, arXiv'25 SummaryKimi-VLは、効率的なオープンソースのMixture-of-Expertsビジョン・ランゲージモデルであり、2.8Bパラメータの言語デコーダーを活性化して高度なマルチモーダル推論を実現。マルチターンエージェントタスクや大学レベルの画像・動画理解において優れた性能を示し、最先端のVLMと競争。128Kの拡張コンテキストウィンドウを持ち、長い入力を処理可能。Kimi-VL-Thinking-2506は、長期的推論能力を強化するために教師ありファインチューニングと強化学習を用いて開発され、堅牢な一般能力を獲得。コードは公開されている。 Comment・2201
での性能(Vision+テキストの数学の問題)。他の巨大なモデルと比べ2.8BのActivation paramsで高い性能を達成

その他のベンチマークでも高い性能を獲得

モデルのアーキテクチャ。MoonViT (Image Encoder, 1Dのpatchをinput, 様々な解像度のサポート, FlashAttention, SigLIP-SO-400Mを継続事前学習, RoPEを採用) + Linear Projector + MoE Language Decoderの構成

学習のパイプライン。ViTの事前学習ではSigLIP loss (contrastive lossの亜種)とcaption生成のcross-entropy lossを採用している。joint cooldown stageにおいては、高品質なQAデータを合成することで実験的に大幅に性能が向上することを確認したので、それを採用しているとのこと。optimizerは
・2202


post-trainingにおけるRLでは以下の目的関数を用いており、RLVRを用いつつ、現在のポリシーモデルをreferenceとし更新をするような目的関数になっている。curriculum sampling, prioritize samplingをdifficulty labelに基づいて実施している。

 #ICML
#FlowMatching
Issue Date: 2025-07-13
[Paper Note] Temporal Difference Flows, Jesse Farebrother+, ICML'25
Summary未来予測モデルの精度向上のため、幾何学的ホライズンモデル(GHMs)を用いた新手法「時間差フロー(TD-Flow)」を提案。TD-Flowは新しいベルマン方程式とフローマッチング技術を活用し、従来手法の5倍以上のホライズンで正確な予測を実現。理論的には勾配分散の低減が効果の主因であることを示し、実証的には様々なドメインでの下流タスクにおいて性能向上を確認。行動基盤モデルとの統合により、長期的な意思決定の改善も示唆。
Comment元ポスト:https://x.com/jessefarebro/status/1944056563053793428?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QICML2025のベストペーパーとのこと
#EfficiencyImprovement
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#PEFT(Adaptor/LoRA)
#Stability
Issue Date: 2025-07-12
[Paper Note] SingLoRA: Low Rank Adaptation Using a Single Matrix, David Bensaïd+, arXiv'25
SummarySingLoRAは、LoRAの低ランク適応を再定式化し、単一の低ランク行列とその転置の積を用いることで、トレーニングの安定性を向上させ、パラメータ数をほぼ半減させる手法です。実験により、常識推論タスクでLLama 7Bを用いたファインチューニングで91.3%の精度を達成し、LoRAやLoRA+を上回る結果を示しました。また、画像生成においてもStable Diffusionのファインチューニングで高い忠実度を実現しました。
Comment元ポスト:https://x.com/theturingpost/status/1943701154497732765?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLoRAは低ランク行列BAの積を計算するが、オリジナルのモデルと同じ挙動から学習をスタートするために、Bをzeroで初期化し、Aはランダムに初期化する。このAとBの不均衡さが、勾配消失、爆発、あるいはsub-optimalな収束の要因となってしまっていた(inter-matrix scale conflicts)。特に、LoRAはモデルのwidthが大きくなると不安定になるという課題があった。このため、低ランク行列を2つ使うのではなく、1つの低ランク行列(とその転置)およびoptimizationのstep tごとにtrainableなパラメータがどの程度影響を与えるかを調整する度合いを決めるscalar function u(t)を導入することで、低ランク行列間の不均衡を解消しつつ、パラメータ数を半減し、学習の安定性と性能を向上させる。たとえばu(t)を学習開始時にzeroにすれば、元のLoRAにおいてBをzeroに初期化するのと同じ挙動(つまり元のモデルと同じ挙動から学習スタートができたりする。みたいな感じだろうか?
#ICML
#FlowMatching
Issue Date: 2025-07-13
[Paper Note] Temporal Difference Flows, Jesse Farebrother+, ICML'25
Summary未来予測モデルの精度向上のため、幾何学的ホライズンモデル(GHMs)を用いた新手法「時間差フロー(TD-Flow)」を提案。TD-Flowは新しいベルマン方程式とフローマッチング技術を活用し、従来手法の5倍以上のホライズンで正確な予測を実現。理論的には勾配分散の低減が効果の主因であることを示し、実証的には様々なドメインでの下流タスクにおいて性能向上を確認。行動基盤モデルとの統合により、長期的な意思決定の改善も示唆。
Comment元ポスト:https://x.com/jessefarebro/status/1944056563053793428?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QICML2025のベストペーパーとのこと
#EfficiencyImprovement
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#PEFT(Adaptor/LoRA)
#Stability
Issue Date: 2025-07-12
[Paper Note] SingLoRA: Low Rank Adaptation Using a Single Matrix, David Bensaïd+, arXiv'25
SummarySingLoRAは、LoRAの低ランク適応を再定式化し、単一の低ランク行列とその転置の積を用いることで、トレーニングの安定性を向上させ、パラメータ数をほぼ半減させる手法です。実験により、常識推論タスクでLLama 7Bを用いたファインチューニングで91.3%の精度を達成し、LoRAやLoRA+を上回る結果を示しました。また、画像生成においてもStable Diffusionのファインチューニングで高い忠実度を実現しました。
Comment元ポスト:https://x.com/theturingpost/status/1943701154497732765?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLoRAは低ランク行列BAの積を計算するが、オリジナルのモデルと同じ挙動から学習をスタートするために、Bをzeroで初期化し、Aはランダムに初期化する。このAとBの不均衡さが、勾配消失、爆発、あるいはsub-optimalな収束の要因となってしまっていた(inter-matrix scale conflicts)。特に、LoRAはモデルのwidthが大きくなると不安定になるという課題があった。このため、低ランク行列を2つ使うのではなく、1つの低ランク行列(とその転置)およびoptimizationのstep tごとにtrainableなパラメータがどの程度影響を与えるかを調整する度合いを決めるscalar function u(t)を導入することで、低ランク行列間の不均衡を解消しつつ、パラメータ数を半減し、学習の安定性と性能を向上させる。たとえばu(t)を学習開始時にzeroにすれば、元のLoRAにおいてBをzeroに初期化するのと同じ挙動(つまり元のモデルと同じ挙動から学習スタートができたりする。みたいな感じだろうか?



 関連:
関連:
・1956
・1245 #Pretraining #NLP #LanguageModel #Batch Issue Date: 2025-07-12 [Paper Note] Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful, Martin Marek+, arXiv'25 Summary小さなバッチサイズに対するAdamのハイパーパラメータをスケーリングする新しいルールを提案。これにより、小さなバッチサイズでも安定したトレーニングが可能で、大きなバッチサイズと同等以上のパフォーマンスを達成。勾配蓄積は推奨せず、実用的なハイパーパラメータ設定のガイドラインを提供。 Comment元ポスト:https://x.com/giffmana/status/1943384733418950815?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
論文中のFigure1において、AdamWにおいてbatchsizeが1の方が512の場合と比べてlearning_rateの変化に対してロバストである旨が記述されている。
 似たような話でMTでバッチサイズ小さいほうが性能良いです、みたいな話が昔あったような
似たような話でMTでバッチサイズ小さいほうが性能良いです、みたいな話が昔あったような
(追記)
気になって思い出そうとしていたが、MTではなく画像認識の話だったかもしれない(だいぶうろ覚え)
・2196 参考:https://x.com/odashi_t/status/1944034128707342815?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1541解説:https://x.com/hillbig/status/1952506470878351492?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q実際に8Bモデルの事前学習においてβ2を0.99にしたところ、学習が不安定になり、かつ最終的なPerplexityも他の設定に勝つことができなかったとのこと:
https://x.com/odashi_t/status/1955906705637957995?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #ReinforcementLearning #MulltiModal #Reasoning #On-Policy #VisionLanguageModel Issue Date: 2025-07-12 [Paper Note] Perception-Aware Policy Optimization for Multimodal Reasoning, Zhenhailong Wang+, arXiv'25 Summary強化学習における検証可能な報酬(RLVR)は、LLMsに多段階推論能力を与えるが、マルチモーダル推論では最適な性能を発揮できない。視覚入力の認識が主なエラー原因であるため、知覚を意識したポリシー最適化(PAPO)を提案。PAPOはGRPOの拡張で、内部監視信号から学習し、追加のデータや外部報酬に依存しない。KLダイバージェンス項を導入し、マルチモーダルベンチマークで4.4%の改善、視覚依存タスクでは8.0%の改善を達成。知覚エラーも30.5%減少し、PAPOの効果を示す。研究は視覚に基づく推論を促進する新しいRLフレームワークの基盤を築く。 Comment元ポスト:https://x.com/aicia_solid/status/1943507735489974596?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QVLMにおいて、画像をマスクした場合のポリシーモデルの出力と、画像をマスクしない場合のポリシーモデルの出力のKL Divergenceを最大化することで、画像の認知能力が向上し性能向上するよ、みたいな話な模様。


 #Analysis
#Pretraining
#NLP
#LanguageModel
#COLM
#Stability
Issue Date: 2025-07-11
[Paper Note] Spike No More: Stabilizing the Pre-training of Large Language Models, Sho Takase+, COLM'25
Summary大規模言語モデルの事前学習中に発生する損失のスパイクは性能を低下させるため、避けるべきである。勾配ノルムの急激な増加が原因とされ、サブレイヤーのヤコビ行列の分析を通じて、勾配ノルムを小さく保つための条件として小さなサブレイヤーと大きなショートカットが必要であることを示した。実験により、これらの条件を満たす手法が損失スパイクを効果的に防ぐことが確認された。
Comment元ポスト:https://x.com/shot4410/status/1943301371010388175?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qsmall sub-layers, large shortcutsの説明はこちらに書かれている。前者については、現在主流なLLMの初期化手法は満たしているが、後者はオリジナルのTransformerの実装では実装されている[^1]が、最近の実装では失われてしまっているとのこと。
#Analysis
#Pretraining
#NLP
#LanguageModel
#COLM
#Stability
Issue Date: 2025-07-11
[Paper Note] Spike No More: Stabilizing the Pre-training of Large Language Models, Sho Takase+, COLM'25
Summary大規模言語モデルの事前学習中に発生する損失のスパイクは性能を低下させるため、避けるべきである。勾配ノルムの急激な増加が原因とされ、サブレイヤーのヤコビ行列の分析を通じて、勾配ノルムを小さく保つための条件として小さなサブレイヤーと大きなショートカットが必要であることを示した。実験により、これらの条件を満たす手法が損失スパイクを効果的に防ぐことが確認された。
Comment元ポスト:https://x.com/shot4410/status/1943301371010388175?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qsmall sub-layers, large shortcutsの説明はこちらに書かれている。前者については、現在主流なLLMの初期化手法は満たしているが、後者はオリジナルのTransformerの実装では実装されている[^1]が、最近の実装では失われてしまっているとのこと。

下図が実験結果で、条件の双方を満たしているのはEmbedLN[^2]とScaled Embed[^3]のみであり、実際にスパイクが生じていないことがわかる。

[^1]:オリジナル論文 245 の3.4節末尾、embedding layersに対してsqrt(d_model)を乗じるということがサラッと書いてある。これが実はめちゃめちゃ重要だったという…
[^2]: positional embeddingを加算する前にLayer Normalizationをかける方法
[^3]: EmbeddingにEmbeddingの次元数d(i.e., 各レイヤーのinputの次元数)の平方根を乗じる方法前にScaled dot-product attentionのsqrt(d_k)がめっちゃ重要ということを実験的に示した、という話もあったような…
(まあそもそも元論文になぜスケーリングさせるかの説明は書いてあるけども) #NeuralNetwork #MachineLearning #LearningPhenomena Issue Date: 2025-07-11 [Paper Note] Not All Explanations for Deep Learning Phenomena Are Equally Valuable, Alan Jeffares+, PMLR'25 Summary深層学習の驚くべき現象(ダブルディセント、グロッキングなど)を孤立したケースとして説明することには限界があり、実世界のアプリケーションにはほとんど現れないと主張。これらの現象は、深層学習の一般的な原則を洗練するための研究価値があると提案し、研究コミュニティのアプローチを再考する必要性を示唆。最終的な実用的目標に整合するための推奨事項も提案。 Comment元ポスト:https://x.com/jeffaresalan/status/1943315797692109015?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2189
・524
・2190 #NLP #LanguageModel #MoE(Mixture-of-Experts) #Privacy Issue Date: 2025-07-11 [Paper Note] FlexOlmo: Open Language Models for Flexible Data Use, Weijia Shi+, arXiv'25 SummaryFlexOlmoは、データ共有なしでの分散トレーニングを可能にする新しい言語モデルで、異なるモデルパラメータが独立してトレーニングされ、データ柔軟な推論を実現します。混合専門家アーキテクチャを採用し、公開データセットと特化型セットでトレーニングされ、31の下流タスクで評価されました。データライセンスに基づくオプトアウトが可能で、平均41%の性能改善を達成し、従来の手法よりも優れた結果を示しました。FlexOlmoは、データ所有者のプライバシーを尊重しつつ、閉じたデータの利点を活かすことができます。 Comment元ポスト:https://x.com/asap2650/status/1943184037419585695?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qデータのオーナー側がプロプライエタリデータを用いてエキスパート(FFNとRouter embeddings)を学習し、それをpublicにシェアすることで利用できるようにする。データオーナー側はデータそのものを提供するのではなく、モデルのパラメータを共有するだけで済み、かつ自分たちのエキスパートをRouter側で利用するか否かは制御可能だから、opt-in/outが制御できる、みたいな話っぽい?
 #NeuralNetwork
#Analysis
#MachineLearning
#MoE(Mixture-of-Experts)
#ICML
Issue Date: 2025-07-11
[Paper Note] Mixture of Experts Provably Detect and Learn the Latent Cluster Structure in Gradient-Based Learning, Ryotaro Kawata+, ICML'25
SummaryMixture of Experts (MoE)は、入力を専門家に動的に分配するモデルのアンサンブルであり、機械学習で成功を収めているが、その理論的理解は遅れている。本研究では、MoEのサンプルおよび実行時間の複雑さを回帰タスクにおけるクラスタ構造を通じて理論的に分析し、バニラニューラルネットワークがこの構造を検出できない理由を示す。MoEは各専門家の能力を活用し、問題をより単純なサブ問題に分割することで、非線形回帰におけるSGDのダイナミクスを探求する初めての試みである。
Comment元ポスト:https://x.com/btreetaiji/status/1943226334463086989?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#ReinforcementLearning
#RLVR
Issue Date: 2025-07-10
[Paper Note] First Return, Entropy-Eliciting Explore, Tianyu Zheng+, arXiv'25
SummaryFR3E(First Return, Entropy-Eliciting Explore)は、強化学習における不安定な探索を改善するための構造化された探索フレームワークであり、高不確実性の意思決定ポイントを特定し、中間フィードバックを提供します。実験結果は、FR3Eが安定したトレーニングを促進し、一貫した応答を生成することを示しています。
Comment元ポスト:https://x.com/f14bertolotti/status/1943201406271328524?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRLVRのロールアウトにおいて、reasoning traceにおける各トークンを出力する際にエントロピーが高い部分を特定し(つまり、複数の候補がありモデルが迷っている)、その部分について異なる意図的に異なる生成パスを実行することで探索を促すようにするとRLVRがよりreliableになるといった話のようである
#NeuralNetwork
#Analysis
#MachineLearning
#MoE(Mixture-of-Experts)
#ICML
Issue Date: 2025-07-11
[Paper Note] Mixture of Experts Provably Detect and Learn the Latent Cluster Structure in Gradient-Based Learning, Ryotaro Kawata+, ICML'25
SummaryMixture of Experts (MoE)は、入力を専門家に動的に分配するモデルのアンサンブルであり、機械学習で成功を収めているが、その理論的理解は遅れている。本研究では、MoEのサンプルおよび実行時間の複雑さを回帰タスクにおけるクラスタ構造を通じて理論的に分析し、バニラニューラルネットワークがこの構造を検出できない理由を示す。MoEは各専門家の能力を活用し、問題をより単純なサブ問題に分割することで、非線形回帰におけるSGDのダイナミクスを探求する初めての試みである。
Comment元ポスト:https://x.com/btreetaiji/status/1943226334463086989?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#ReinforcementLearning
#RLVR
Issue Date: 2025-07-10
[Paper Note] First Return, Entropy-Eliciting Explore, Tianyu Zheng+, arXiv'25
SummaryFR3E(First Return, Entropy-Eliciting Explore)は、強化学習における不安定な探索を改善するための構造化された探索フレームワークであり、高不確実性の意思決定ポイントを特定し、中間フィードバックを提供します。実験結果は、FR3Eが安定したトレーニングを促進し、一貫した応答を生成することを示しています。
Comment元ポスト:https://x.com/f14bertolotti/status/1943201406271328524?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRLVRのロールアウトにおいて、reasoning traceにおける各トークンを出力する際にエントロピーが高い部分を特定し(つまり、複数の候補がありモデルが迷っている)、その部分について異なる意図的に異なる生成パスを実行することで探索を促すようにするとRLVRがよりreliableになるといった話のようである

 #RecommenderSystems
#Embeddings
#InformationRetrieval
#NLP
#LanguageModel
#RepresentationLearning
#InstructionTuning
#ContrastiveLearning
#ICLR
#Generalization
#Decoder
Issue Date: 2025-07-10
[Paper Note] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models, Chankyu Lee+, ICLR'25
Summaryデコーダー専用のLLMベースの埋め込みモデルNV-Embedは、BERTやT5を上回る性能を示す。アーキテクチャ設計やトレーニング手法を工夫し、検索精度を向上させるために潜在的注意層を提案。二段階の対照的指示調整手法を導入し、検索と非検索タスクの両方で精度を向上。NV-EmbedモデルはMTEBリーダーボードで1位を獲得し、ドメイン外情報検索でも高スコアを達成。モデル圧縮技術の分析も行っている。
CommentDecoder-Only LLMのlast hidden layerのmatrixを新たに導入したLatent Attention Blockのinputとし、Latent Attention BlockはEmbeddingをOutputする。Latent Attention Blockは、last hidden layer (系列長l×dの
#RecommenderSystems
#Embeddings
#InformationRetrieval
#NLP
#LanguageModel
#RepresentationLearning
#InstructionTuning
#ContrastiveLearning
#ICLR
#Generalization
#Decoder
Issue Date: 2025-07-10
[Paper Note] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models, Chankyu Lee+, ICLR'25
Summaryデコーダー専用のLLMベースの埋め込みモデルNV-Embedは、BERTやT5を上回る性能を示す。アーキテクチャ設計やトレーニング手法を工夫し、検索精度を向上させるために潜在的注意層を提案。二段階の対照的指示調整手法を導入し、検索と非検索タスクの両方で精度を向上。NV-EmbedモデルはMTEBリーダーボードで1位を獲得し、ドメイン外情報検索でも高スコアを達成。モデル圧縮技術の分析も行っている。
CommentDecoder-Only LLMのlast hidden layerのmatrixを新たに導入したLatent Attention Blockのinputとし、Latent Attention BlockはEmbeddingをOutputする。Latent Attention Blockは、last hidden layer (系列長l×dの
matrix)をQueryとみなし、保持しているLatent Array(trainableなmatrixで辞書として機能する;後述の学習においてパラメータが学習される)[^1]をK,Vとして、CrossAttentionによってcontext vectorを生成し、その後MLPとMean Poolingを実施することでEmbeddingに変換する。


学習は2段階で行われ、まずQAなどのRetrievalタスク用のデータセットをIn Batch negativeを用いてContrastive Learningしモデルの検索能力を高める。その後、検索と非検索タスクの両方を用いて、hard negativeによってcontrastive learningを実施し、検索以外のタスクの能力も高める(下表)。両者において、instructionテンプレートを用いて、instructionによって条件付けて学習をすることで、instructionに応じて生成されるEmbeddingが変化するようにする。また、学習時にはLLMのcausal maskは無くし、bidirectionalにrepresentationを考慮できるようにする。

[^1]: 2183 Perceiver-IOにインスパイアされている。 #NLP #LanguageModel #Reasoning #SmallModel #OpenWeight Issue Date: 2025-07-10 [Paper Note] Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation, Liliang Ren+, arXiv'25 Summary最近の言語モデルの進展により、状態空間モデル(SSM)の効率的なシーケンスモデリングが示されています。本研究では、ゲーテッドメモリユニット(GMU)を導入し、Sambaベースの自己デコーダーからメモリを共有する新しいデコーダーハイブリッドアーキテクチャSambaYを提案します。SambaYはデコーディング効率を向上させ、長文コンテキスト性能を改善し、位置エンコーディングの必要性を排除します。実験により、SambaYはYOCOベースラインに対して優れた性能を示し、特にPhi4-mini-Flash-Reasoningモデルは推論タスクで顕著な成果を上げました。トレーニングコードはオープンソースで公開されています。 CommentHF:https://huggingface.co/microsoft/Phi-4-mini-flash-reasoning元ポスト:https://x.com/_akhaliq/status/1943099901161652238?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pretraining #NLP #Dataset #LanguageModel #SyntheticData #Programming #Mathematics #mid-training #COLM Issue Date: 2025-07-10 [Paper Note] MegaMath: Pushing the Limits of Open Math Corpora, Fan Zhou+, COLM'25 SummaryMegaMathは、数学に特化したオープンデータセットで、LLMの数学的推論能力を向上させるために作成された。ウェブデータの再抽出、数学関連コードの特定、合成データの生成を通じて、371Bトークンの高品質なデータを提供し、既存のデータセットを上回る量と品質を実現した。 Comment元ポスト:https://x.com/fazhou_998/status/1942610771915202590?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q非常に大規模な数学の事前学習/mid-training向けのデータセット
CommonCrawlのHTMLから、さまざまなフィルタリング処理(reformatting, 2 stageのHTML parserの活用(片方はnoisyだが高速、もう一方は高性能だが遅い), fasttextベースの分類器による抽出, deduplication等)を実施しMegaMath-Webを作成、また、MegaMathWebをさらに分類器で低品質なものをフィルタリングし、LLMによってノイズ除去、テキストのreorganizingを実施し(≠ピュアな合成データ)継続事前学習、mid-training向けの高品質なMegaMath-Web-Proを作成。
MegaMathCodeはThe Stack V2 (2199) をベースにしており、mathematical reasoning, logic puzzles, scientific computationに関するコードを収集。まずこれらのコードと関連が深い11のプログラミング言語を選定し、そのコードスニペットのみを対象とする。次にstrong LLMを用いて、数学に関するrelevanceスコアと、コードの品質を0--6のdiscrete scoreでスコアリングし学習データを作成。作成した学習データでSLMを学習し大規模なフィルタリングを実施することでMegaMath-Codeを作成。
最後にMegaMath-{Web, code}を用いて、Q&A, code data, text&code block dataの3種類を合成。Q&Aデータの合成では、MegaMath-WebからQAペアを抽出し、多様性とデータ量を担保するためQwen2.5-72B-Instruct, Llama3.3-70B-Instructの両方を用いて、QAのsolutionを洗練させる(reasoning stepの改善, あるいはゼロから生成する[^1])ことで生成。また、code dataでは、pythonを対象にMegaMath-Codeのデータに含まれるpython以外のコードを、Qwen2.5-Coder-32B-Instructと、Llamd3.1-70B-Instructによってpythonに翻訳することでデータ量を増やした。text&code blockデータでは、MegaMath-Webのドキュメントを与えて、ブロックを生成(タイトル、数式、結果、コードなど[^1])し、ブロックのverificationを行い(コードが正しく実行できるか、実行結果とanswerが一致するか等)、verifiedなブロックを残すことで生成。



[^1]: この辺は論文の記述を咀嚼して記述しており実サンプルを見ていないので少し正しい認識か不安 #ICML Issue Date: 2025-07-10 [Paper Note] How Do Large Language Monkeys Get Their Power (Laws)?, Rylan Schaeffer+, ICML'25 Summary本研究では、マルチモーダル言語モデルの試行回数に対する成功率のスケーリング特性を探求し、単純な数学的計算が指数関数的に失敗率を減少させることを示す。成功確率の分布が重い尾を持つ場合、指数関数的スケーリングが集約的な多項式スケーリングと整合的であることを明らかにし、冪法則の逸脱を説明する方法を提案。これにより、ニューラル言語モデルの性能向上とスケーリング予測の理解が深まる。 Comment元ポスト:https://x.com/rylanschaeffer/status/1942989816557375845?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-10 [Paper Note] Why Do Some Language Models Fake Alignment While Others Don't?, Abhay Sheshadri+, arXiv'25 Summary大規模言語モデルのアライメント偽装に関する研究で、25のモデルを分析した結果、5つのモデル(Claude 3 Opus、Claude 3.5 Sonnet、Llama 3 405B、Grok 3、Gemini 2.0 Flash)が有害なクエリに対して従う傾向があることが判明。Claude 3 Opusの従順性は目標維持の動機によるものであり、多くのモデルがアライメントを偽装しない理由は能力の欠如だけではないことが示唆された。ポストトレーニングがアライメント偽装に与える影響について5つの仮説を検討し、拒否行動の変動がその違いを説明する可能性があることを発見した。 Comment元ポスト:https://x.com/anthropicai/status/1942708254670196924?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #LatentReasoning Issue Date: 2025-07-10 [Paper Note] A Survey on Latent Reasoning, Rui-Jie Zhu+, arXiv'25 Summary大規模言語モデル(LLMs)は、明示的な思考の連鎖(CoT)によって優れた推論能力を示すが、自然言語推論への依存が表現力を制限する。潜在的推論はこの問題を解決し、トークンレベルの監視を排除する。研究は、ニューラルネットワーク層の役割や多様な潜在的推論手法を探求し、無限深度の潜在的推論を可能にする高度なパラダイムについて議論する。これにより、潜在的推論の概念を明確にし、今後の研究方向を示す。関連情報はGitHubリポジトリで提供されている。 Comment元ポスト:https://x.com/gm8xx8/status/1942787610818097609?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLatent Reasoningというテクニカルタームが出てきた出力されるdiscreteなtokenによってreasoningを実施するのではなく、モデル内部のrepresentationでreasoningを実施するLatent ReasoningのSurvey

 Issue Date: 2025-07-10
[Paper Note] Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving, Xiangru Tang+, arXiv'25
SummaryAgent KBは、複雑なタスクに取り組む言語エージェントのための階層的な経験フレームワークであり、エラー修正や経験の再利用を促進します。新しいReason-Retrieve-Refineパイプラインを通じて、エージェント間の知識移転を可能にし、高レベルの戦略と実行ログを共有します。GAIAベンチマークでの評価では、成功率が最大16.28ポイント向上し、特にClaude-3とGPT-4のパフォーマンスが大幅に改善されました。Agent KBは、過去の経験から学び、新しいタスクに成功した戦略を一般化するための効果的なインフラを提供します。
Comment元ポスト:https://x.com/metagpt_/status/1942875695019131277?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-10
[Paper Note] The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains, Scott Geng+, arXiv'25
Summary弱いデータポイントからなるペアの好みデータが、言語モデルの性能向上に寄与することを示す。デルタ学習仮説を提唱し、相対的な質のデルタが学習を促進することを検証。8Bモデルを小型モデルの出力とペアにして後訓練した結果、標準ベンチマークで最先端モデルに匹敵する性能を達成。デルタ学習は、シンプルで安価な後訓練手法を提供することを示唆。
Comment元ポスト:https://x.com/pangweikoh/status/1942993031348789253?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-10
[Paper Note] Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving, Xiangru Tang+, arXiv'25
SummaryAgent KBは、複雑なタスクに取り組む言語エージェントのための階層的な経験フレームワークであり、エラー修正や経験の再利用を促進します。新しいReason-Retrieve-Refineパイプラインを通じて、エージェント間の知識移転を可能にし、高レベルの戦略と実行ログを共有します。GAIAベンチマークでの評価では、成功率が最大16.28ポイント向上し、特にClaude-3とGPT-4のパフォーマンスが大幅に改善されました。Agent KBは、過去の経験から学び、新しいタスクに成功した戦略を一般化するための効果的なインフラを提供します。
Comment元ポスト:https://x.com/metagpt_/status/1942875695019131277?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-10
[Paper Note] The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains, Scott Geng+, arXiv'25
Summary弱いデータポイントからなるペアの好みデータが、言語モデルの性能向上に寄与することを示す。デルタ学習仮説を提唱し、相対的な質のデルタが学習を促進することを検証。8Bモデルを小型モデルの出力とペアにして後訓練した結果、標準ベンチマークで最先端モデルに匹敵する性能を達成。デルタ学習は、シンプルで安価な後訓練手法を提供することを示唆。
Comment元ポスト:https://x.com/pangweikoh/status/1942993031348789253?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
 #COLM
Issue Date: 2025-07-09
[Paper Note] When Does Metadata Conditioning (NOT) Work for Language Model Pre-Training? A Study with Context-Free Grammars, Rei Higuchi+, COLM'25
Summaryメタデータを事前学習データの先頭に追加することで、言語モデルの潜在的な意味の獲得能力を向上させるアプローチを調査。下流タスクにおいて正の効果と負の効果が見られ、効果はコンテキストの長さに依存。十分な長さのコンテキストがあれば性能向上が確認されたが、情報が不足している場合は悪影響を及ぼすことが示された。
Comment元ポスト:https://x.com/hillbig/status/1943086341933383720?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-09
[Paper Note] MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent, Hongli Yu+, arXiv'25
SummaryMemAgentは、長文処理のための新しいエージェントワークフローで、テキストをセグメントで読み込み、メモリを上書きする戦略を用いる。これにより、32Kのテキストから3.5MのQAタスクに外挿し、性能損失を5%未満に抑え、512KのRULERテストで95%以上の成果を達成した。
Comment元ポスト:https://x.com/omarsar0/status/1942667308368871457?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#FlowMatching
Issue Date: 2025-07-09
[Paper Note] Mean Flows for One-step Generative Modeling, Zhengyang Geng+, arXiv'25
Summaryワンステップ生成モデリングのための新しいフレームワーク「MeanFlow」を提案。平均速度の概念を導入し、瞬間速度と対比させることで、神経ネットワークのトレーニングを導く。MeanFlowは自己完結型で、事前トレーニングを必要とせず、ImageNet 256x256でFID 3.43を達成し、従来のモデルを上回る性能を示す。研究はワンステップモデルとマルチステップモデルのギャップを縮小し、今後の研究の基礎を再考することを促す。
Comment元ポスト:https://x.com/tongzhou_mu/status/1942630257582080426?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Reproducibility
Issue Date: 2025-07-09
[Paper Note] RecRankerEval: A Flexible and Extensible Framework for Top-k LLM-based Recommendation, Zeyuan Meng+, arXiv'25
SummaryRecRankerはLLMに基づく推薦モデルで、トップk推薦タスクで優れた性能を示すが、各コンポーネントの貢献は未探求。本研究ではRecRankerの再現性を検証し、主要コンポーネントの影響を分析。再現実験でペアワイズおよびリストワイズ手法が元の性能に匹敵することを確認。プロンプトにグラウンドトゥルース情報が含まれることでポイントワイズ手法の性能が異常に高くなることも明らかに。ユーザーサンプリング戦略や初期推薦モデルなど5つの次元をカバーするフレームワークRecRankerEvalを提案し、ML-100KおよびML-1Mデータセットで元の結果を再現。代替手法を用いることで性能向上も示唆。
Comment元ポスト:https://x.com/_reachsumit/status/1942821790868463748?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-09
[Paper Note] SmolVLM: Redefining small and efficient multimodal models, Andrés Marafioti+, arXiv'25
SummarySmolVLMは、リソース効率の良い推論のために設計されたコンパクトなマルチモーダルモデルシリーズであり、低い計算オーバーヘッドを持つアーキテクチャやトークン化戦略を採用。最小モデルのSmolVLM-256Mは、1GB未満のGPUメモリでIdefics-80Bモデルを上回る性能を発揮し、最大モデルは2.2Bパラメータで最先端のVLMに匹敵。これにより、エネルギー効率の良い実用的な展開が可能となる。
CommentHFSpace:https://huggingface.co/blog/smolervlm元ポスト:https://x.com/andimarafioti/status/1882398580775989379?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-09
[Paper Note] GIST: Cross-Domain Click-Through Rate Prediction via Guided Content-Behavior Distillation, Wei Xu+, arXiv'25
SummaryGISTは、クロスドメインのクリック率予測のためのライフロングシーケンスモデルで、ソースドメインとターゲットドメインのトレーニングを分離。コンテンツ-行動共同トレーニングモジュールを導入し、安定した表現を促進。非対称類似性統合戦略を用いて知識転送を強化。実験により、GISTは最先端手法を上回り、Xiaohongshuプラットフォームでのオンライン広告システムのパフォーマンスを向上。
Comment元ポスト:https://x.com/gm8xx8/status/1942532973582057889?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#COLM
Issue Date: 2025-07-09
[Paper Note] Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents, Saaket Agashe+, COLM'25
SummaryAgent S2は、GUIとの対話を通じてデジタルタスクを自動化する新しいエージェントで、一般モデルと専門モデルに認知的責任を分担させるフレームワークを採用。Mixture-of-Grounding技術でGUIの位置特定を向上させ、Proactive Hierarchical Planningで動的なアクションプランを実現。評価では、OSWorldの15ステップおよび50ステップでそれぞれ18.9%と32.7%の改善を達成し、他のシステムでも優れた性能を示した。
Comment元ポスト:https://x.com/xwang_lk/status/1942428731303420054?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#COLM
Issue Date: 2025-07-09
[Paper Note] ReasonIR: Training Retrievers for Reasoning Tasks, Rulin Shao+, COLM'25
Summary推論タスク向けに特別に訓練されたリトリーバーReasonIR-8Bを提案。合成データ生成パイプラインを用いて挑戦的なクエリとハードネガティブを作成し、訓練。BRIGHTベンチマークで新たな最先端成果を達成し、RAGタスクでも他のリトリーバーを上回る性能を示す。トレーニングレシピは一般的で、将来のLLMへの拡張が容易。コード、データ、モデルはオープンソースで公開。
Comment元ポスト:https://x.com/rulinshao/status/1942590591885615572?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#Mathematics
Issue Date: 2025-07-09
[Paper Note] CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization, Zhongyuan Peng+, arXiv'25
Summary自然言語の数学的表現を実行可能なコードに翻訳する課題に対し、批評者の役割を能動的な学習コンポーネントに変えるCriticLeanという新しい強化学習フレームワークを提案。CriticLeanGPTを用いて形式化の意味的忠実性を評価し、CriticLeanBenchでその能力を測定。285K以上の問題を含むFineLeanCorpusデータセットを構築し、批評段階の最適化が信頼性のある形式化に重要であることを示す。
Comment元ポスト:https://x.com/gm8xx8/status/1942790484688003275?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連
#COLM
Issue Date: 2025-07-09
[Paper Note] When Does Metadata Conditioning (NOT) Work for Language Model Pre-Training? A Study with Context-Free Grammars, Rei Higuchi+, COLM'25
Summaryメタデータを事前学習データの先頭に追加することで、言語モデルの潜在的な意味の獲得能力を向上させるアプローチを調査。下流タスクにおいて正の効果と負の効果が見られ、効果はコンテキストの長さに依存。十分な長さのコンテキストがあれば性能向上が確認されたが、情報が不足している場合は悪影響を及ぼすことが示された。
Comment元ポスト:https://x.com/hillbig/status/1943086341933383720?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-09
[Paper Note] MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent, Hongli Yu+, arXiv'25
SummaryMemAgentは、長文処理のための新しいエージェントワークフローで、テキストをセグメントで読み込み、メモリを上書きする戦略を用いる。これにより、32Kのテキストから3.5MのQAタスクに外挿し、性能損失を5%未満に抑え、512KのRULERテストで95%以上の成果を達成した。
Comment元ポスト:https://x.com/omarsar0/status/1942667308368871457?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#FlowMatching
Issue Date: 2025-07-09
[Paper Note] Mean Flows for One-step Generative Modeling, Zhengyang Geng+, arXiv'25
Summaryワンステップ生成モデリングのための新しいフレームワーク「MeanFlow」を提案。平均速度の概念を導入し、瞬間速度と対比させることで、神経ネットワークのトレーニングを導く。MeanFlowは自己完結型で、事前トレーニングを必要とせず、ImageNet 256x256でFID 3.43を達成し、従来のモデルを上回る性能を示す。研究はワンステップモデルとマルチステップモデルのギャップを縮小し、今後の研究の基礎を再考することを促す。
Comment元ポスト:https://x.com/tongzhou_mu/status/1942630257582080426?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Reproducibility
Issue Date: 2025-07-09
[Paper Note] RecRankerEval: A Flexible and Extensible Framework for Top-k LLM-based Recommendation, Zeyuan Meng+, arXiv'25
SummaryRecRankerはLLMに基づく推薦モデルで、トップk推薦タスクで優れた性能を示すが、各コンポーネントの貢献は未探求。本研究ではRecRankerの再現性を検証し、主要コンポーネントの影響を分析。再現実験でペアワイズおよびリストワイズ手法が元の性能に匹敵することを確認。プロンプトにグラウンドトゥルース情報が含まれることでポイントワイズ手法の性能が異常に高くなることも明らかに。ユーザーサンプリング戦略や初期推薦モデルなど5つの次元をカバーするフレームワークRecRankerEvalを提案し、ML-100KおよびML-1Mデータセットで元の結果を再現。代替手法を用いることで性能向上も示唆。
Comment元ポスト:https://x.com/_reachsumit/status/1942821790868463748?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-09
[Paper Note] SmolVLM: Redefining small and efficient multimodal models, Andrés Marafioti+, arXiv'25
SummarySmolVLMは、リソース効率の良い推論のために設計されたコンパクトなマルチモーダルモデルシリーズであり、低い計算オーバーヘッドを持つアーキテクチャやトークン化戦略を採用。最小モデルのSmolVLM-256Mは、1GB未満のGPUメモリでIdefics-80Bモデルを上回る性能を発揮し、最大モデルは2.2Bパラメータで最先端のVLMに匹敵。これにより、エネルギー効率の良い実用的な展開が可能となる。
CommentHFSpace:https://huggingface.co/blog/smolervlm元ポスト:https://x.com/andimarafioti/status/1882398580775989379?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-07-09
[Paper Note] GIST: Cross-Domain Click-Through Rate Prediction via Guided Content-Behavior Distillation, Wei Xu+, arXiv'25
SummaryGISTは、クロスドメインのクリック率予測のためのライフロングシーケンスモデルで、ソースドメインとターゲットドメインのトレーニングを分離。コンテンツ-行動共同トレーニングモジュールを導入し、安定した表現を促進。非対称類似性統合戦略を用いて知識転送を強化。実験により、GISTは最先端手法を上回り、Xiaohongshuプラットフォームでのオンライン広告システムのパフォーマンスを向上。
Comment元ポスト:https://x.com/gm8xx8/status/1942532973582057889?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#COLM
Issue Date: 2025-07-09
[Paper Note] Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents, Saaket Agashe+, COLM'25
SummaryAgent S2は、GUIとの対話を通じてデジタルタスクを自動化する新しいエージェントで、一般モデルと専門モデルに認知的責任を分担させるフレームワークを採用。Mixture-of-Grounding技術でGUIの位置特定を向上させ、Proactive Hierarchical Planningで動的なアクションプランを実現。評価では、OSWorldの15ステップおよび50ステップでそれぞれ18.9%と32.7%の改善を達成し、他のシステムでも優れた性能を示した。
Comment元ポスト:https://x.com/xwang_lk/status/1942428731303420054?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#COLM
Issue Date: 2025-07-09
[Paper Note] ReasonIR: Training Retrievers for Reasoning Tasks, Rulin Shao+, COLM'25
Summary推論タスク向けに特別に訓練されたリトリーバーReasonIR-8Bを提案。合成データ生成パイプラインを用いて挑戦的なクエリとハードネガティブを作成し、訓練。BRIGHTベンチマークで新たな最先端成果を達成し、RAGタスクでも他のリトリーバーを上回る性能を示す。トレーニングレシピは一般的で、将来のLLMへの拡張が容易。コード、データ、モデルはオープンソースで公開。
Comment元ポスト:https://x.com/rulinshao/status/1942590591885615572?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#Mathematics
Issue Date: 2025-07-09
[Paper Note] CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization, Zhongyuan Peng+, arXiv'25
Summary自然言語の数学的表現を実行可能なコードに翻訳する課題に対し、批評者の役割を能動的な学習コンポーネントに変えるCriticLeanという新しい強化学習フレームワークを提案。CriticLeanGPTを用いて形式化の意味的忠実性を評価し、CriticLeanBenchでその能力を測定。285K以上の問題を含むFineLeanCorpusデータセットを構築し、批評段階の最適化が信頼性のある形式化に重要であることを示す。
Comment元ポスト:https://x.com/gm8xx8/status/1942790484688003275?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連
・1832Lean 4 形式に

#COLM Issue Date: 2025-07-09 [Paper Note] Learning to Generate Unit Tests for Automated Debugging, Archiki Prasad+, COLM'25 Summaryユニットテスト(UT)の重要性を踏まえ、UTGenを提案し、LLMを用いてエラーを明らかにするUT入力とその期待出力を生成。UTDebugを併用することで、出力予測の改善とオーバーフィッティングの回避を実現。UTGenは他のLLMベースラインを7.59%上回り、UTDebugと組み合わせることでQwen2.5の精度をそれぞれ3.17%および12.35%向上。最終的に、UTGenはHumanEval+で最先端モデルを4.43%上回る性能を示した。 Comment元ポスト:https://x.com/archikiprasad/status/1942645157943468500?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-09 [Paper Note] VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents, Rui Meng+, arXiv'25 SummaryVLM2Vec-V2という統一フレームワークを提案し、テキスト、画像、動画、視覚文書を含む多様な視覚形式の埋め込みを学習。新たにMMEB-V2ベンチマークを導入し、動画検索や視覚文書検索など5つのタスクを追加。広範な実験により、VLM2Vec-V2は新タスクで強力なパフォーマンスを示し、従来の画像ベンチマークでも改善を達成。研究はマルチモーダル埋め込みモデルの一般化可能性に関する洞察を提供し、スケーラブルな表現学習の基盤を築く。 Comment元ポスト:https://x.com/wenhuchen/status/1942501330674647342?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2156 Issue Date: 2025-07-08 [Paper Note] Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought, Violet Xiang+, arXiv'25 SummaryMeta Chain-of-Thought(Meta-CoT)フレームワークを提案し、基礎的な推論を明示的にモデル化して従来のCoTを拡張。文脈内検索や行動の一致を探求し、プロセス監視や合成データ生成を通じてMeta-CoTを生成する方法を検討。具体的なトレーニングパイプラインを概説し、スケーリング法則や新しい推論アルゴリズムの発見についても議論。LLMsにおけるMeta-CoTの実現に向けた理論的・実践的なロードマップを提供。 Comment元ポスト:https://x.com/theturingpost/status/1942548274113847764?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-08 [Paper Note] On the Trustworthiness of Generative Foundation Models: Guideline, Assessment, and Perspective, Yue Huang+, arXiv'25 Summary生成的基盤モデル(GenFMs)の信頼性に関する課題に対処するためのフレームワークを提案。第一に、AIガバナンス法や業界基準をレビューし、GenFMsの指針原則を提案。第二に、信頼性評価のための動的ベンチマークプラットフォーム「TrustGen」を紹介し、静的評価の限界を克服。最後に、信頼性の課題と将来の方向性を議論し、実用性と信頼性のトレードオフを強調。研究はGenAIの信頼性向上に寄与し、動的評価ツールキットを公開。 Comment元ポスト:https://x.com/theturingpost/status/1942548274113847764?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #RecommenderSystems #Embeddings #InformationRetrieval #LanguageModel #SequentialRecommendation #Generalization Issue Date: 2025-07-08 [Paper Note] Do We Really Need Specialization? Evaluating Generalist Text Embeddings for Zero-Shot Recommendation and Search, Matteo Attimonelli+, arXiv'25 Summary事前学習済み言語モデル(GTEs)は、逐次推薦や製品検索においてファインチューニングなしで優れたゼロショット性能を発揮し、従来のモデルを上回ることを示す。GTEsは埋め込み空間に特徴を均等に分配することで表現力を高め、埋め込み次元の圧縮がノイズを減少させ、専門モデルの性能向上に寄与する。再現性のためにリポジトリを提供。 Comment元ポスト:https://x.com/_reachsumit/status/1942463379639349654?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2182 #GraphBased #NLP #LLMAgent #ScientificDiscovery Issue Date: 2025-07-08 [Paper Note] AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench, Edan Toledo+, arXiv'25 SummaryAI研究エージェントは、機械学習の自動化を通じて科学の進展を促進する可能性がある。本研究では、MLE-benchというKaggleコンペティションを用いてエージェントの性能向上に取り組み、検索ポリシーとオペレーターを用いて候補解の空間を探索する方法を提案。異なる検索戦略とオペレーターの組み合わせが高いパフォーマンスに寄与することを示し、MLE-bench liteでの結果を向上させ、Kaggleメダル獲得率を39.6%から47.7%に引き上げた。自動化された機械学習の進展には、これらの要素を共同で考慮することが重要である。 Comment元ポスト:https://x.com/martinjosifoski/status/1942238775305699558?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1457グラフ中の各ノードはartifacts(i.e., エージェントが生成したコード)で、先行研究がiterativeな実験に加え、潜在的なsolutionに対してtree searchをすることでSoTAを達成しており、これをグラフを用いてより一般化することで異なるデザインのエージェントでも適用できるようにしている。

あとで追記する #ComputerVision #MachineLearning #NLP #LanguageModel #Transformer #MulltiModal #Architecture #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2025-07-06 [Paper Note] Energy-Based Transformers are Scalable Learners and Thinkers, Alexi Gladstone+, arXiv'25 Summaryエネルギーベースのトランスフォーマー(EBTs)を用いて、無監督学習から思考を学ぶモデルを提案。EBTsは、入力と候補予測の互換性を検証し、エネルギー最小化を通じて予測を行う。トレーニング中に従来のアプローチよりも高いスケーリング率を達成し、言語タスクでの性能を29%向上させ、画像のノイズ除去でも優れた結果を示す。EBTsは一般化能力が高く、モデルの学習能力と思考能力を向上させる新しいパラダイムである。 Comment元ポスト:https://x.com/hillbig/status/1941657099567845696?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QProject Page:https://energy-based-transformers.github.ioFirst Authorの方による解説ポスト:https://x.com/alexiglad/status/1942231878305714462?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #LanguageModel #Evaluation #LLM-as-a-Judge #ICML Issue Date: 2025-07-05 [Paper Note] Correlated Errors in Large Language Models, Elliot Kim+, ICML'25 Summary350以上のLLMを評価し、リーダーボードと履歴書スクリーニングタスクで実証的な分析を実施。モデル間のエラーには実質的な相関があり、特に大きく正確なモデルは異なるアーキテクチャやプロバイダーでも高い相関を示す。相関の影響はLLMを評価者とするタスクや採用タスクにおいても確認された。 Comment元ポスト:https://x.com/kennylpeng/status/1940758198320796065?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは結果を細かく見るのと、評価したタスクの形式とバイアスが生じないかをきちんと確認した方が良いような気がする。
それは置いておいたとして、たとえば、Figure9bはLlamaの異なるモデルサイズは、高い相関を示しているが、それはベースが同じだからそうだろうなあ、とは思う。一方、9aはClaude, Nova, Mistral, GPTなど多様なプロバイダーのモデルで高い相関が示されている。Llama3-70BとLLama3.{1,2,3}-70Bでは相関が低かったりしている。

Figure1(b)はHELMで比較的最新のモデル間でプロバイダーが別でも高い相関があるようにみえる。

このような相関がある要因や傾向については論文を読んでみないとわからない。OpenReview:https://openreview.net/forum?id=kzYq2hfyHB&referrer=%5Bthe%20profile%20of%20Kenny%20Peng%5D(%2Fprofile%3Fid%3D~Kenny_Peng1)LLM-as-a-Judgeにおいて、評価者となるモデルと評価対象となるモデルが同じプロバイダーやシリーズの場合は(エラーの傾向が似ているので)性能がAccuracyが真のAccuracyよりも高めに出ている。また評価者よりも性能が低いモデルに対しても、性能が実際のAccuracyよりも高めに出す傾向にある(エラーの相関によってエラーであるにも関わらず正解とみなされAccuracyが高くなる)ようである。逆に、評価者よりも評価対象が性能が高い場合、評価者は自分が誤ってしまうquestionに対して、評価対象モデルが正解となる回答をしても、それに対して報酬を与えることができず性能が低めに見積もられてしまう。これだけの規模の実験で示されたことは、大変興味深い。
 履歴書のスクリーニングタスクについてもケーススタディをしている。こちらも詳細に分析されているので興味がある場合は参照のこと。
#NLP
#LanguageModel
#Alignment
#ReinforcementLearning
#RewardModel
Issue Date: 2025-07-05
[Paper Note] Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy, Chris Yuhao Liu+, arXiv'25
Summary報酬モデル(RMs)の性能向上のために、4,000万の好みペアからなる大規模データセット「SynPref-40M」を提案。人間とAIの相乗効果を活用した二段階パイプラインでデータをキュレーションし、Skywork-Reward-V2を導入。これにより、7つの報酬モデルベンチマークで最先端のパフォーマンスを達成。データのスケールと高品質なキュレーションが効果をもたらすことを確認。Skywork-Reward-V2はオープン報酬モデルの進展を示し、人間-AIキュレーションの重要性を強調。
Comment元ポスト:https://x.com/_akhaliq/status/1941131426084303242?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
履歴書のスクリーニングタスクについてもケーススタディをしている。こちらも詳細に分析されているので興味がある場合は参照のこと。
#NLP
#LanguageModel
#Alignment
#ReinforcementLearning
#RewardModel
Issue Date: 2025-07-05
[Paper Note] Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy, Chris Yuhao Liu+, arXiv'25
Summary報酬モデル(RMs)の性能向上のために、4,000万の好みペアからなる大規模データセット「SynPref-40M」を提案。人間とAIの相乗効果を活用した二段階パイプラインでデータをキュレーションし、Skywork-Reward-V2を導入。これにより、7つの報酬モデルベンチマークで最先端のパフォーマンスを達成。データのスケールと高品質なキュレーションが効果をもたらすことを確認。Skywork-Reward-V2はオープン報酬モデルの進展を示し、人間-AIキュレーションの重要性を強調。
Comment元ポスト:https://x.com/_akhaliq/status/1941131426084303242?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q 解説:https://x.com/gm8xx8/status/1942375700289233221?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Evaluation
#read-later
Issue Date: 2025-07-05
[Paper Note] Answer Matching Outperforms Multiple Choice for Language Model Evaluation, Nikhil Chandak+, arXiv'25
Summary複数選択のベンチマークは言語モデル評価において重要だが、質問を見ずに回答できることが多い。これに対し、回答マッチングという生成的評価を提案し、自由形式の応答を生成させて参照回答と一致するかを判断。MMLU-ProとGPQA-Diamondで人間の採点データを取得し、回答マッチングがほぼ完璧な一致を達成することを示した。評価方法の変更により、モデルのランキングが大きく変わる可能性がある。
Comment元ポスト:https://x.com/shashwatgoel7/status/1941153367289364655?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは非常に重要な研究に見えるMultiple Choice Question (MCQ)では、選択肢の中から消去法(論文中では仲間はずれを一つ探す, odd one cut)によって、正解の目処が立ってしまい、分類能力を評価するような尺度になっている。一方で同じモデルでも、Questionのみを与えて、選択肢無しで評価をすると、選択肢ありでは正解できたのに正解できない、という現象が生じる。これはモデルの分類能力ではなく、生成能力を評価しているからであり、これまでのMCQでの評価はモデルの能力の一部、特に識別能力しか評価できていないことが示唆される。このため、Answer Matchingと呼ばれる、モデルに自由記述で出力をさせた後に、referenaceと出力が一致しているか否かで評価をする手法を提案している。GPQA DiamondとMMLU-Proにおいて、人間にAnswer Matchingによる評価をさせオラクルを取得した後、SLMやより大きなモデルでAnswer Matchingを実験したところ、o4-miniを用いたLLM-as-a-Judgeよりも、SLMにおいてさえオラクルに近い性能を発揮し、人間と同等のレベルで自動評価が可能なことが示唆される。
解説:https://x.com/gm8xx8/status/1942375700289233221?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Evaluation
#read-later
Issue Date: 2025-07-05
[Paper Note] Answer Matching Outperforms Multiple Choice for Language Model Evaluation, Nikhil Chandak+, arXiv'25
Summary複数選択のベンチマークは言語モデル評価において重要だが、質問を見ずに回答できることが多い。これに対し、回答マッチングという生成的評価を提案し、自由形式の応答を生成させて参照回答と一致するかを判断。MMLU-ProとGPQA-Diamondで人間の採点データを取得し、回答マッチングがほぼ完璧な一致を達成することを示した。評価方法の変更により、モデルのランキングが大きく変わる可能性がある。
Comment元ポスト:https://x.com/shashwatgoel7/status/1941153367289364655?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは非常に重要な研究に見えるMultiple Choice Question (MCQ)では、選択肢の中から消去法(論文中では仲間はずれを一つ探す, odd one cut)によって、正解の目処が立ってしまい、分類能力を評価するような尺度になっている。一方で同じモデルでも、Questionのみを与えて、選択肢無しで評価をすると、選択肢ありでは正解できたのに正解できない、という現象が生じる。これはモデルの分類能力ではなく、生成能力を評価しているからであり、これまでのMCQでの評価はモデルの能力の一部、特に識別能力しか評価できていないことが示唆される。このため、Answer Matchingと呼ばれる、モデルに自由記述で出力をさせた後に、referenaceと出力が一致しているか否かで評価をする手法を提案している。GPQA DiamondとMMLU-Proにおいて、人間にAnswer Matchingによる評価をさせオラクルを取得した後、SLMやより大きなモデルでAnswer Matchingを実験したところ、o4-miniを用いたLLM-as-a-Judgeよりも、SLMにおいてさえオラクルに近い性能を発揮し、人間と同等のレベルで自動評価が可能なことが示唆される。
 まだ冒頭しか読めていないので後で読む
#Survey
#NLP
#LanguageModel
#ScientificDiscovery
Issue Date: 2025-07-04
[Paper Note] AI4Research: A Survey of Artificial Intelligence for Scientific Research, Qiguang Chen+, arXiv'25
SummaryAIの進展に伴い、AI4Researchに関する包括的な調査が不足しているため、理解と発展が妨げられている。本研究では、AI4Researchの5つの主流タスクを系統的に分類し、研究のギャップや将来の方向性を特定し、関連する応用やリソースをまとめる。これにより、研究コミュニティが迅速にリソースにアクセスでき、革新的なブレークスルーを促進することを目指す。
Comment元ポスト:https://x.com/aicia_solid/status/1940934746932236632?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#RecommenderSystems
#ListWise
#Alignment
#Transformer
#SequentialRecommendation
Issue Date: 2025-07-04
[Paper Note] Listwise Preference Alignment Optimization for Tail Item Recommendation, Zihao Li+, arXiv'25
SummaryLPO4Recは、テールアイテム推薦におけるPreference alignmentの課題を解決するために提案された手法で、Bradley-Terryモデルをペアワイズからリストワイズ比較に拡張し、効率的なトレーニングを実現。明示的な報酬モデリングなしで、テールアイテムを優先する負のサンプリング戦略を導入し、パフォーマンスを最大50%向上させ、GPUメモリ使用量を17.9%削減。実験結果は3つの公開データセットで示されている。
Comment元ポスト:https://x.com/_reachsumit/status/1941004418255933662?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtail itemに強い手法らしい。LLMを用いたGenerative Recommendationではなく、1 BlockのTransformerにlistwiseなpreferenceを反映したlossを適用したものっぽい。一貫して性能は高そうに見えるが、再現性はどうだろうか。
まだ冒頭しか読めていないので後で読む
#Survey
#NLP
#LanguageModel
#ScientificDiscovery
Issue Date: 2025-07-04
[Paper Note] AI4Research: A Survey of Artificial Intelligence for Scientific Research, Qiguang Chen+, arXiv'25
SummaryAIの進展に伴い、AI4Researchに関する包括的な調査が不足しているため、理解と発展が妨げられている。本研究では、AI4Researchの5つの主流タスクを系統的に分類し、研究のギャップや将来の方向性を特定し、関連する応用やリソースをまとめる。これにより、研究コミュニティが迅速にリソースにアクセスでき、革新的なブレークスルーを促進することを目指す。
Comment元ポスト:https://x.com/aicia_solid/status/1940934746932236632?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#RecommenderSystems
#ListWise
#Alignment
#Transformer
#SequentialRecommendation
Issue Date: 2025-07-04
[Paper Note] Listwise Preference Alignment Optimization for Tail Item Recommendation, Zihao Li+, arXiv'25
SummaryLPO4Recは、テールアイテム推薦におけるPreference alignmentの課題を解決するために提案された手法で、Bradley-Terryモデルをペアワイズからリストワイズ比較に拡張し、効率的なトレーニングを実現。明示的な報酬モデリングなしで、テールアイテムを優先する負のサンプリング戦略を導入し、パフォーマンスを最大50%向上させ、GPUメモリ使用量を17.9%削減。実験結果は3つの公開データセットで示されている。
Comment元ポスト:https://x.com/_reachsumit/status/1941004418255933662?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtail itemに強い手法らしい。LLMを用いたGenerative Recommendationではなく、1 BlockのTransformerにlistwiseなpreferenceを反映したlossを適用したものっぽい。一貫して性能は高そうに見えるが、再現性はどうだろうか。
 関連(SASRec):
関連(SASRec):
・2137pointwise, pairwise, listwiseの基礎はこちらを参照:
・187 #NLP #Dataset #LanguageModel #Alignment #Supervised-FineTuning (SFT) #MultiLingual #DPO #PostTraining #Cultural Issue Date: 2025-07-04 [Paper Note] CARE: Assessing the Impact of Multilingual Human Preference Learning on Cultural Awareness, Geyang Guo+, arXiv'25 Summary本論文では、文化的多様性を考慮した言語モデル(LM)の訓練方法を分析し、ネイティブな文化的好みを取り入れることで、LMの文化的認識を向上させることを目指します。3,490の文化特有の質問と31,700のネイティブな判断を含むリソース「CARE」を紹介し、高品質なネイティブの好みを少量取り入れることで、さまざまなLMの性能が向上することを示します。また、文化的パフォーマンスが強いモデルはアラインメントからの恩恵を受けやすく、地域間でのデータアクセスの違いがモデル間のギャップを生むことが明らかになりました。CAREは一般に公開される予定です。 Comment元ポスト:https://x.com/cherylolguo/status/1940798823405600843?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #DiffusionModel #2D #3D #FeatureMatching Issue Date: 2025-07-04 [Paper Note] Learning Dense Feature Matching via Lifting Single 2D Image to 3D Space, Yingping Liang+, arXiv'25 Summary新しい二段階フレームワーク「Lift to Match (L2M)」を提案し、2D画像を3D空間に持ち上げることで、特徴マッチングの一般化を向上させる。第一段階で3D特徴エンコーダを学習し、第二段階で特徴デコーダを学習することで、堅牢な特徴マッチングを実現。実験により、ゼロショット評価ベンチマークで優れた一般化性能を示した。 Comment元ポスト:https://x.com/zhenjun_zhao/status/1940399755827270081?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Transformer #Architecture #Normalization #Admin'sPick Issue Date: 2025-07-03 [Paper Note] The Curse of Depth in Large Language Models, Wenfang Sun+, arXiv'25 Summary本論文では、「深さの呪い」という現象を紹介し、LLMの深い層が期待通りに機能しない理由を分析します。Pre-LNの使用が出力の分散を増加させ、深い層の貢献を低下させることを特定。これを解決するために層正規化スケーリング(LNS)を提案し、出力分散の爆発を抑制します。実験により、LNSがLLMの事前トレーニング性能を向上させることを示し、教師ありファインチューニングにも効果があることを確認しました。 Comment元ポスト:https://x.com/shiwei_liu66/status/1940377801032446428?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1795
ではそもそもLayerNormalizationを無くしていた(正確にいうとparametrize tanhに置換)が、どちらが優れているのだろうか?

 ・1332
・1332
では知識ニューロンの存在が示唆されており、これはTransformerの層の深い位置に存在し、かつ異なる知識間で知識ニューロンはシェアされない傾向にあった(ただしこれはPost-LNのBERTの話で本研究はPre-LNの話だが。Post-LNの勾配消失問題を緩和し学習を安定化させる研究も2141 のように存在する)。これはこの研究が明らかにしたこととどういう関係性があるだろうか。
また、LayerNormalizationのScalingによって深いTransformerブロックの導関数が単位行列となる(学習に寄与しなくなる)ことが改善された場合、知識ニューロンはどのように変化するだろうか?
(下記Geminiの応答を見た上での感想)なんとなーくだけれども、おそらく知識ニューロンの局所化が解消されるのかなーという気がする。
となると次の疑問としては、MoEアーキテクチャにはどのような影響があるだろうか?
そもそも知識ニューロンが局所化しているからMoEアーキテクチャのルータによって関連するExpertsのみをactivateすれば(というより結果的にそうなるように学習される)性能を劣化させずに計算効率を上げられていた、と仮定する。そうすると、知識ニューロンが局所化せずに多くのニューロンでシェアされるようになると、2110 のように、サブネットワーク間の情報を互いにやりとりできます、みたいな仕組みがより効いてきそうな気がする。
参考までに、Gemini2.5-Proに考察させてみた結果をメモとして残しておく(あくまで参考程度に...)
```
ご質問ありがとうございます。非常に興味深い着眼点ですね。「Knowledge Neurons in Pretrained Transformers」と「The Curse of Depth in Large Language Models」は、一見すると全く異なるテーマを扱っているように見えますが、「Transformerの深い層における振る舞い」という共通点で結びつけて考察すると、非常に示唆に富んだ関係性が見えてきます。
以下に、両方の論文の概要を解説し、その関係性について考察します。
1. Knowledge Neurons in Pretrained Transformers の概要
この研究は、事前学習済みTransformerモデル(特にBERTなど)の内部で、特定の事実知識がどのように格納されているかを調査したものです。
発見: モデルの中間層、特に全結合層(Feed-Forward Network, FFN)に、特定の知識(例:「ダンテ・アリギエーリはイタリアで生まれた」)に強く反応する「知識ニューロン」が存在することを発見しました。
特徴: これらの知識ニューロンは、モデルの深い層(後方の層)に、より多く存在する傾向がありました。
意味: これまでブラックボックスとされてきた大規模言語モデルの内部で、知識がどのように表現・局在化しているかについて、具体的な手がかりを与えた画期的な研究です。
2. The Curse of Depth in Large Language Models の概要
この研究は、LLMをより深く(層を多く)することの難しさに焦点を当て、その原因と解決策を提案したものです。
問題(深さの呪い): Transformerの標準的なアーキテクチャ(Pre-LN)では、層が深くなるにつれて、LayerNormalization(LN)への入力の分散が指数関数的に増大してしまいます。
結果:
出力が大きくなりすぎて学習が不安定になります。
さらに深刻なのは、深い層ではモデルの出力に関する導関数(勾配計算に必要)がほぼ単位行列になってしまうことです。これは、その層が入力に対してほとんど変換を行わなくなり、学習に寄与しなくなることを意味します。
解決策: この問題を解決するため、各層のLayerNormalizationをその深さ(レイヤー番号 l)に応じてスケーリングするというシンプルな手法を提案しました。これにより、深い層でも勾配が適切に伝播し、学習が安定・改善することが示されました。
考察:2つの研究の関係性
これら2つの研究は、「学習の安定性」と「知識の格納方法」という異なる側面から、Transformerの深い層を分析していますが、両者には以下のような深い関係性があると考えられます。
学習の不安定性が「知識ニューロン」形成の背景にある可能性
「The Curse of Depth」で指摘されているように、標準的なTransformerの深い層は、本質的に学習が不安定で、勾配情報が失われやすい環境にあります。
この劣悪な学習環境こそが、「知識ニューロン」という形で知識が局所的に格納される原因の一つになっている可能性があります。つまり、
学習の非効率性: 深い層のほとんどのニューロンは、勾配消失問題のために効率的に学習を進めることができません。
専門化の発生: そのような不安定な環境下で、たまたま特定の知識パターンをうまく捉えることができた一部のニューロンが、その知識を一身に背負う形で強く活性化するよう特化(専門化)していったのではないか、と考えられます。これは、ネットワーク全体で協調して学習するのが難しい状況で、一部のユニットだけが突出して学習を担う、という現象と解釈できます。
学習の安定化が、より効率的な知識獲得につながる
では、「The Curse of Depth」で提案された手法(LNのスケーリング)によって深い層の学習が安定化すると、知識の格納方法はどのように変わるでしょうか。
これは非常に興味深い問いであり、2つの可能性が考えられます。
可能性A: より強固な知識ニューロンの形成:
学習が安定することで、各知識ニューロンはより明確に、そして効率的に特定の知識をエンコードできるようになるかもしれません。ノイズの多い環境で偶然生まれた専門家ではなく、安定した環境で育成された真の専門家へと変化するイメージです。
可能性B: 知識の分散化:
ネットワークの全ニューロンが効率的に学習に寄与できるようになるため、一つの知識を少数のニューロンに集中させる必要がなくなり、より多くのニューロンに分散して知識が格納されるようになる可能性も考えられます。
現在のところ、学習の安定化は、知識ニューロンがより効率的に形成・機能するための基盤を提供すると考えるのが最も妥当でしょう。「深さの呪い」という問題を解決することは、モデルが知識をどのように獲得し、整理するかという、より根源的なメカニズム(知識ニューロンの振る舞い)にも直接的な影響を与えるはずです。
まとめ
「Knowledge Neurons」は深い層に存在する知識の「状態」を明らかにし、「The Curse of Depth」は深い層で発生する学習の「問題」とその解決策を提示しました。
これらを統合すると、「深い層における学習の不安定性という問題が、知識ニューロンという局所的な知識表現を生み出す一因となっており、この問題を解決することで、より効率的で安定した知識の獲得・格納が可能になるかもしれない」という関係性が見えてきます。
両者は、LLMの能力と限界を異なる角度から照らし出しており、組み合わせることでモデルの内部動作の解明をさらに一歩前進させる、非常に重要な研究だと言えます。
``` Issue Date: 2025-07-03 [Paper Note] Assembly of Experts: Linear-time construction of the Chimera LLM variants with emergent and adaptable behaviors, Henrik Klagges+, arXiv'25 Summary新しい「Assembly-of-Experts」(AoE)構築法を開発し、LLMの事前学習コストを削減。親モデルの重みを補間することで、子モデルの特性を調整可能。生成されたモデルは機能的で、探索が容易。671Bオープンウェイトハイブリッドモデル「Chimera」を構築し、R1の知能を維持しつつ出力トークンを約40%削減。ファインチューニングなしで、親モデルよりもコンパクトで効率的な推論を実現。 Commentモデル(tngtech/DeepSeek-TNG-R1T2-Chimera):
https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera公式ポスト:https://x.com/tngtech/status/1940531045432283412?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #EfficiencyImprovement #NLP #LanguageModel #Reasoning #Distillation Issue Date: 2025-07-03 [Paper Note] NaturalThoughts: Selecting and Distilling Reasoning Traces for General Reasoning Tasks, Yang Li+, arXiv'25 Summary教師モデルからの推論トレースを用いて生徒モデルの能力を向上させる方法を体系的に研究。NaturalReasoningに基づく高品質な「NaturalThoughts」をキュレーションし、サンプル効率とスケーラビリティを分析。データサイズの拡大が性能向上に寄与し、多様な推論戦略を必要とする例が効果的であることを発見。LlamaおよびQwenモデルでの評価により、NaturalThoughtsが既存のデータセットを上回り、STEM推論ベンチマークで優れた性能を示した。 Comment元ポスト:https://x.com/jaseweston/status/1940656092054204498?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1768 #ComputerVision #Pretraining #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #MulltiModal #RLHF #Reasoning #LongSequence #mid-training #RewardHacking #PostTraining #CurriculumLearning #RLVR #Admin'sPick #VisionLanguageModel Issue Date: 2025-07-03 [Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25 Summary視覚言語モデルGLM-4.1V-Thinkingを発表し、推論中心のトレーニングフレームワークを開発。強力な視覚基盤モデルを構築し、カリキュラムサンプリングを用いた強化学習で多様なタスクの能力を向上。28のベンチマークで最先端のパフォーマンスを達成し、特に難しいタスクで競争力のある結果を示す。モデルはオープンソースとして公開。 Comment元ポスト:https://x.com/sinclairwang1/status/1940331927724232712?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQwen2.5-VLよりも性能が良いVLM
 アーキテクチャはこちら。が、pretraining(データのフィルタリング, マルチモーダル→long context継続事前学習)->SFT(cold startへの対処, reasoning能力の獲得)->RL(RLVRとRLHFの併用によるパフォーマンス向上とAlignment, RewardHackingへの対処,curriculum sampling)など、全体の学習パイプラインの細かいテクニックの積み重ねで高い性能が獲得されていると考えられる。
アーキテクチャはこちら。が、pretraining(データのフィルタリング, マルチモーダル→long context継続事前学習)->SFT(cold startへの対処, reasoning能力の獲得)->RL(RLVRとRLHFの併用によるパフォーマンス向上とAlignment, RewardHackingへの対処,curriculum sampling)など、全体の学習パイプラインの細かいテクニックの積み重ねで高い性能が獲得されていると考えられる。
 #ComputerVision
#NLP
#Dataset
#LanguageModel
#Evaluation
#ACL
#VisionLanguageModel
#Findings
Issue Date: 2025-07-02
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, ACL(Findings)'25
Summary内部世界モデル(WMs)はエージェントの理解と予測を支えるが、最近の大規模ビジョン・ランゲージモデル(VLMs)の基本的なWM能力に関する評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchというベンチマークを導入。15のVLMsに対する660の実験で、これらのモデルが基本的なWM能力に顕著な制限を示し、特に運動軌道の識別においてほぼランダムな精度であることが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。
Comment元ポスト:https://x.com/qiyuegao123/status/1940097188220297613?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Metrics
#Transformer
#SpokenLanguageProcessing
#Evaluation
Issue Date: 2025-07-02
[Paper Note] AudioBERTScore: Objective Evaluation of Environmental Sound Synthesis Based on Similarity of Audio embedding Sequences, Minoru Kishi+, arXiv'25
Summary新しい客観的評価指標AudioBERTScoreを提案し、合成音声の性能向上を目指す。従来の客観的指標は主観的評価との相関が弱いため、AudioBERTScoreは合成音声と参照音声の埋め込みの類似性を計算し、主観的評価との相関が高いことを実験で示した。
Comment元ポスト:https://x.com/forthshinji/status/1940226218500247645?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtext-to-audioの自動評価が可能な模様
#ComputerVision
#NLP
#Dataset
#LanguageModel
#Evaluation
#ACL
#VisionLanguageModel
#Findings
Issue Date: 2025-07-02
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, ACL(Findings)'25
Summary内部世界モデル(WMs)はエージェントの理解と予測を支えるが、最近の大規模ビジョン・ランゲージモデル(VLMs)の基本的なWM能力に関する評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchというベンチマークを導入。15のVLMsに対する660の実験で、これらのモデルが基本的なWM能力に顕著な制限を示し、特に運動軌道の識別においてほぼランダムな精度であることが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。
Comment元ポスト:https://x.com/qiyuegao123/status/1940097188220297613?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Metrics
#Transformer
#SpokenLanguageProcessing
#Evaluation
Issue Date: 2025-07-02
[Paper Note] AudioBERTScore: Objective Evaluation of Environmental Sound Synthesis Based on Similarity of Audio embedding Sequences, Minoru Kishi+, arXiv'25
Summary新しい客観的評価指標AudioBERTScoreを提案し、合成音声の性能向上を目指す。従来の客観的指標は主観的評価との相関が弱いため、AudioBERTScoreは合成音声と参照音声の埋め込みの類似性を計算し、主観的評価との相関が高いことを実験で示した。
Comment元ポスト:https://x.com/forthshinji/status/1940226218500247645?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtext-to-audioの自動評価が可能な模様
#LLMAgent #Investigation Issue Date: 2025-07-02 [Paper Note] Future of Work with AI Agents: Auditing Automation and Augmentation Potential across the U.S. Workforce, Yijia Shao+, arXiv'25 Summary本論文では、労働者がAIエージェントに自動化または補完してほしい職業タスクを評価する新しい監査フレームワークを提案し、労働者の希望と技術的能力の一致を分析します。音声強化ミニインタビューを用いて「人間主体性スケール(HAS)」を導入し、米国労働省のONETデータベースを基にしたWORKBankデータベースを構築しました。タスクを自動化のゾーンに分類し、AIエージェント開発におけるミスマッチと機会を明らかにします。結果は職業ごとの多様なHASプロファイルを示し、AIエージェントの統合がスキルのシフトを促す可能性を示唆しています。これにより、AIエージェントの開発を労働者の希望に整合させる重要性が強調されます。 Comment元ポスト:https://x.com/hillbig/status/1939806172061868173?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MulltiModal Issue Date: 2025-07-02 [Paper Note] MARBLE: A Hard Benchmark for Multimodal Spatial Reasoning and Planning, Yulun Jiang+, arXiv'25 SummaryMARBLEという新しいマルチモーダル推論ベンチマークを提案し、MLLMsの複雑な推論能力を評価。MARBLEは、空間的・視覚的・物理的制約下での多段階計画を必要とするM-PortalとM-Cubeの2つのタスクから成る。現在のMLLMsは低いパフォーマンスを示し、視覚的入力からの情報抽出においても失敗が見られる。これにより、次世代モデルの推論能力向上が期待される。 Comment元ポスト:https://x.com/michael_d_moor/status/1940062842742526445?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QPortal2を使った新たなベンチマーク。筆者は昔このゲームを少しだけプレイしたことがあるが、普通に難しかった記憶がある😅
細かいが表中のGPT-o3は正しくはo3だと思われる。
時間がなくて全然しっかりと読めていないが、reasoning effortやthinkingモードはどのように設定して評価したのだろうか。

 #ComputerVision
#NLP
#Dataset
#LanguageModel
#Zero/FewShotPrompting
#MulltiModal
#In-ContextLearning
Issue Date: 2025-07-01
[Paper Note] SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning, Melanie Rieff+, arXiv'25
Summaryマルチモーダルインコンテキスト学習(ICL)は医療分野での可能性があるが、十分に探求されていない。SMMILEという医療タスク向けの初のマルチモーダルICLベンチマークを導入し、111の問題を含む。15のMLLMの評価で、医療タスクにおけるICL能力が中程度から低いことが示された。ICLはSMMILEで平均8%、SMMILE++で9.4%の改善をもたらし、無関係な例がパフォーマンスを最大9.5%低下させることも確認。例の順序による最近性バイアスがパフォーマンス向上に寄与することも明らかになった。
Comment元ポスト:https://x.com/michael_d_moor/status/1939664155813839114?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ICLR
#Test-Time Scaling
Issue Date: 2025-07-01
[Paper Note] Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search, Yuichi Inoue+, ICLR'25
SummaryAB-MCTSを提案し、外部フィードバックを活用して繰り返しサンプリングを改善。探索木のノードで新しい応答を「広げる」か「深める」かを動的に決定。実験により、AB-MCTSが従来の手法を上回り、LLMsの応答の多様性と解決策の洗練を強調。
Comment元ポスト:https://x.com/iwiwi/status/1939914618132168961?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-06-30
[Paper Note] Performance Prediction for Large Systems via Text-to-Text Regression, Yash Akhauri+, arXiv'25
Summaryテキストからテキストへの回帰を用いて、複雑なシステムデータのメトリック予測を行う新しい手法を提案。Borgのリソース効率予測で、60Mパラメータのモデルが高い順位相関と低いMSEを達成。少数ショット例で新タスクに適応可能で、実世界の結果シミュレーションに貢献する可能性を示す。
Comment元ポスト:https://x.com/_akhaliq/status/1939701311009611938?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#LLMAgent
#Evaluation
#ScientificDiscovery
#Reproducibility
Issue Date: 2025-06-30
[Paper Note] The Automated LLM Speedrunning Benchmark: Reproducing NanoGPT Improvements, Bingchen Zhao+, arXiv'25
Summary大規模言語モデル(LLMs)の進展を活用し、AIエージェントの研究再現能力を評価するために、LLMスピードランベンチマークを導入。19のタスクで訓練スクリプトとヒントを提供し、迅速な実行を促進。既知の革新の再実装が難しいことを発見し、科学的再現を自動化するための指標を提供。
Comment元ポスト:https://x.com/karpathy/status/1939709449956126910?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#NLP
#LanguageModel
#ReinforcementLearning
#TransferLearning
#DPO
#GRPO
#VerifiableRewards
#Off-Policy
#On-Policy
#Non-VerifiableRewards
Issue Date: 2025-06-30
[Paper Note] Bridging Offline and Online Reinforcement Learning for LLMs, Jack Lanchantin+, arXiv'25
Summary大規模言語モデルのファインチューニングにおける強化学習手法の効果を、オフラインからオンラインへの移行において調査。数学タスクと指示に従うタスクのベンチマーク評価を行い、オンラインおよびセミオンラインの最適化手法がオフライン手法を上回る結果を示す。トレーニングダイナミクスとハイパーパラメータ選択について分析し、検証可能な報酬と検証不可能な報酬を共同で扱うことでパフォーマンス向上を確認。
Comment元ポスト:https://x.com/jaseweston/status/1939673136842313960?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-06-30
[Paper Note] GPAS: Accelerating Convergence of LLM Pretraining via Gradient-Preserving Activation Scaling, Tianhao Chen+, arXiv'25
Summary大規模言語モデルにおけるPre-LayerNormの問題を解決するために、Gradient-Preserving Activation Scaling(GPAS)を提案。GPASは中間活性化をスケールダウンしつつ勾配を保持し、勾配消失問題を回避。71Mから1Bのモデルサイズで一貫した性能向上を実証し、他のアーキテクチャにも応用可能な改善の可能性を示す。
Comment元ポスト:https://x.com/papers_anon/status/1939502985773793791?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-06-30
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, arXiv'25
Summary内部世界モデル(WMs)はエージェントの理解と予測を支えるが、VLMsの基本的なWM能力に関する体系的評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchという大規模ベンチマークを導入。15のVLMsに対して660の実験を行った結果、これらのモデルは基本的なWM能力に顕著な限界を示し、特に運動軌跡の識別においてほぼランダムな精度しか持たないことが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。
Comment元ポスト:https://x.com/iscienceluvr/status/1939614570093666727?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#Architecture
Issue Date: 2025-06-28
[Paper Note] Chain-of-Experts: Unlocking the Communication Power of Mixture-of-Experts Models, Zihan Wang+, arXiv'25
SummaryChain-of-Experts(CoE)は、逐次的な専門家間のコミュニケーションを導入した新しいMixture-of-Experts(MoE)アーキテクチャで、トークンを反復的に処理する。各反復ステップで専用のルーターを使用し、動的な専門家選択を可能にすることで、モデルの表現能力を向上させる。CoEは数学的推論タスクにおいて、従来のMoEと比較して検証損失を低下させ、メモリ使用量を削減する。反復的残差構造と専門家の専門化が、より表現力豊かな結果をもたらすことが示されている。
Comment元ポスト:https://x.com/theturingpost/status/1938728784351658087?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#Pretraining
#NLP
#Dataset
#LanguageModel
#MultiLingual
#Admin'sPick
Issue Date: 2025-06-28
[Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, arXiv'25
Summary多言語LLMsの性能向上のために、FineWebに基づく新しい事前学習データセットキュレーションパイプラインを提案。9つの言語に対して設計選択肢を検証し、非英語コーパスが従来のデータセットよりも高性能なモデルを生成できることを示す。データセットの再バランス手法も導入し、1000以上の言語にスケールアップした20テラバイトの多言語データセットFineWeb2を公開。
Comment元ポスト:https://x.com/gui_penedo/status/1938631842720022572?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qv1
#ComputerVision
#NLP
#Dataset
#LanguageModel
#Zero/FewShotPrompting
#MulltiModal
#In-ContextLearning
Issue Date: 2025-07-01
[Paper Note] SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning, Melanie Rieff+, arXiv'25
Summaryマルチモーダルインコンテキスト学習(ICL)は医療分野での可能性があるが、十分に探求されていない。SMMILEという医療タスク向けの初のマルチモーダルICLベンチマークを導入し、111の問題を含む。15のMLLMの評価で、医療タスクにおけるICL能力が中程度から低いことが示された。ICLはSMMILEで平均8%、SMMILE++で9.4%の改善をもたらし、無関係な例がパフォーマンスを最大9.5%低下させることも確認。例の順序による最近性バイアスがパフォーマンス向上に寄与することも明らかになった。
Comment元ポスト:https://x.com/michael_d_moor/status/1939664155813839114?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ICLR
#Test-Time Scaling
Issue Date: 2025-07-01
[Paper Note] Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search, Yuichi Inoue+, ICLR'25
SummaryAB-MCTSを提案し、外部フィードバックを活用して繰り返しサンプリングを改善。探索木のノードで新しい応答を「広げる」か「深める」かを動的に決定。実験により、AB-MCTSが従来の手法を上回り、LLMsの応答の多様性と解決策の洗練を強調。
Comment元ポスト:https://x.com/iwiwi/status/1939914618132168961?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-06-30
[Paper Note] Performance Prediction for Large Systems via Text-to-Text Regression, Yash Akhauri+, arXiv'25
Summaryテキストからテキストへの回帰を用いて、複雑なシステムデータのメトリック予測を行う新しい手法を提案。Borgのリソース効率予測で、60Mパラメータのモデルが高い順位相関と低いMSEを達成。少数ショット例で新タスクに適応可能で、実世界の結果シミュレーションに貢献する可能性を示す。
Comment元ポスト:https://x.com/_akhaliq/status/1939701311009611938?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#LLMAgent
#Evaluation
#ScientificDiscovery
#Reproducibility
Issue Date: 2025-06-30
[Paper Note] The Automated LLM Speedrunning Benchmark: Reproducing NanoGPT Improvements, Bingchen Zhao+, arXiv'25
Summary大規模言語モデル(LLMs)の進展を活用し、AIエージェントの研究再現能力を評価するために、LLMスピードランベンチマークを導入。19のタスクで訓練スクリプトとヒントを提供し、迅速な実行を促進。既知の革新の再実装が難しいことを発見し、科学的再現を自動化するための指標を提供。
Comment元ポスト:https://x.com/karpathy/status/1939709449956126910?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#NLP
#LanguageModel
#ReinforcementLearning
#TransferLearning
#DPO
#GRPO
#VerifiableRewards
#Off-Policy
#On-Policy
#Non-VerifiableRewards
Issue Date: 2025-06-30
[Paper Note] Bridging Offline and Online Reinforcement Learning for LLMs, Jack Lanchantin+, arXiv'25
Summary大規模言語モデルのファインチューニングにおける強化学習手法の効果を、オフラインからオンラインへの移行において調査。数学タスクと指示に従うタスクのベンチマーク評価を行い、オンラインおよびセミオンラインの最適化手法がオフライン手法を上回る結果を示す。トレーニングダイナミクスとハイパーパラメータ選択について分析し、検証可能な報酬と検証不可能な報酬を共同で扱うことでパフォーマンス向上を確認。
Comment元ポスト:https://x.com/jaseweston/status/1939673136842313960?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-06-30
[Paper Note] GPAS: Accelerating Convergence of LLM Pretraining via Gradient-Preserving Activation Scaling, Tianhao Chen+, arXiv'25
Summary大規模言語モデルにおけるPre-LayerNormの問題を解決するために、Gradient-Preserving Activation Scaling(GPAS)を提案。GPASは中間活性化をスケールダウンしつつ勾配を保持し、勾配消失問題を回避。71Mから1Bのモデルサイズで一貫した性能向上を実証し、他のアーキテクチャにも応用可能な改善の可能性を示す。
Comment元ポスト:https://x.com/papers_anon/status/1939502985773793791?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-06-30
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, arXiv'25
Summary内部世界モデル(WMs)はエージェントの理解と予測を支えるが、VLMsの基本的なWM能力に関する体系的評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchという大規模ベンチマークを導入。15のVLMsに対して660の実験を行った結果、これらのモデルは基本的なWM能力に顕著な限界を示し、特に運動軌跡の識別においてほぼランダムな精度しか持たないことが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。
Comment元ポスト:https://x.com/iscienceluvr/status/1939614570093666727?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#Architecture
Issue Date: 2025-06-28
[Paper Note] Chain-of-Experts: Unlocking the Communication Power of Mixture-of-Experts Models, Zihan Wang+, arXiv'25
SummaryChain-of-Experts(CoE)は、逐次的な専門家間のコミュニケーションを導入した新しいMixture-of-Experts(MoE)アーキテクチャで、トークンを反復的に処理する。各反復ステップで専用のルーターを使用し、動的な専門家選択を可能にすることで、モデルの表現能力を向上させる。CoEは数学的推論タスクにおいて、従来のMoEと比較して検証損失を低下させ、メモリ使用量を削減する。反復的残差構造と専門家の専門化が、より表現力豊かな結果をもたらすことが示されている。
Comment元ポスト:https://x.com/theturingpost/status/1938728784351658087?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#Pretraining
#NLP
#Dataset
#LanguageModel
#MultiLingual
#Admin'sPick
Issue Date: 2025-06-28
[Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, arXiv'25
Summary多言語LLMsの性能向上のために、FineWebに基づく新しい事前学習データセットキュレーションパイプラインを提案。9つの言語に対して設計選択肢を検証し、非英語コーパスが従来のデータセットよりも高性能なモデルを生成できることを示す。データセットの再バランス手法も導入し、1000以上の言語にスケールアップした20テラバイトの多言語データセットFineWeb2を公開。
Comment元ポスト:https://x.com/gui_penedo/status/1938631842720022572?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qv1
・1942abstを見る限りFinewebを多言語に拡張した模様 #Analysis #NLP #LanguageModel #ReinforcementLearning #mid-training #PostTraining #read-later #Admin'sPick Issue Date: 2025-06-27 [Paper Note] OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling, Zengzhi Wang+, arXiv'25 Summary異なるベース言語モデル(LlamaやQwen)の強化学習(RL)における挙動を調査し、中間トレーニング戦略がRLのダイナミクスに与える影響を明らかに。高品質の数学コーパスがモデルのパフォーマンスを向上させ、長い連鎖的思考(CoT)がRL結果を改善する一方で、冗長性や不安定性を引き起こす可能性があることを示す。二段階の中間トレーニング戦略「Stable-then-Decay」を導入し、OctoThinkerモデルファミリーを開発。オープンソースのモデルと数学推論コーパスを公開し、RL時代の基盤モデルの研究を支援することを目指す。 Comment元ポスト:https://x.com/sinclairwang1/status/1938244843857449431?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qmid-trainingの観点から、post trainingにおけるRLがスケーリングする条件をsystematicallyに調査している模様論文中にはmid-training[^1]の定義が記述されている:

[^1]: mid-trainingについてはコミュニティの間で厳密な定義はまだ無くバズワードっぽく使われている、という印象を筆者は抱いており、本稿は文献中でmid-trainingを定義する初めての試みという所感 #NLP #LanguageModel #ReinforcementLearning Issue Date: 2025-06-27 [Paper Note] RLPR: Extrapolating RLVR to General Domains without Verifiers, Tianyu Yu+, arXiv'25 SummaryRLVRはLLMの推論能力を向上させるが、主に数学やコードに限られる。これを克服するため、検証者不要のRLPRフレームワークを提案し、LLMのトークン確率を報酬信号として利用。ノイズの多い確率報酬に対処する手法を導入し、実験によりGemma、Llama、Qwenモデルで推論能力を向上させた。特に、TheoremQAで7.6ポイント、Minervaで7.5ポイントの改善を示し、General-Reasonerを平均1.6ポイント上回った。 Comment元ポスト:https://x.com/hillbig/status/1938359430980268329?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q既存のRLVRはVerifierを構築しなければならず、しばしばそのVerifierは複雑になりやすく、スケールさせるには課題があった。RLPR(Probabliity Reward)は、生成された応答から回答yを抽出し、残りをreasoning zとする。そして回答部分yをreference y^\で置換したトークン列o'を生成(zがo'に対してどのような扱いになるかは利用するモデルや出力フォーマットによる気がする)し、o'のポリシーモデルでのトークン単位での平均生成確率を報酬とする。尤度のような系列全体の生起確率を考慮する方法が直感的に役に立ちそうだが、計算の際の確率積は分散が高いだけでなく、マイナーな類義語が与えられた時に(たとえば1 tokenだけ生起確率が小さかった場合)に、Rewardが極端に小さくなりsensitiveであることを考察し、平均生成確率を採用している。

Rule basedなVerifierを用いたRLVRよりもgeneralなドメインとmathドメインで性能向上。コーディングなどでも効果はあるのだろうか?
 ざっくり見た感じ、RLVRがそもそも適用できないドメインで実験した場合の結果がないように見え、適用した場合に有効なのかは気になるところ。
#ComputerVision
#EfficiencyImprovement
#Pretraining
#NLP
#LanguageModel
#MulltiModal
Issue Date: 2025-06-26
[Paper Note] OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning, Xianhang Li+, arXiv'25
SummaryOpenVisionは、完全にオープンでコスト効果の高いビジョンエンコーダーのファミリーを提案し、CLIPと同等以上の性能を発揮します。既存の研究を基に構築され、マルチモーダルモデルの進展に実用的な利点を示します。5.9Mから632.1Mパラメータのエンコーダーを提供し、容量と効率の柔軟なトレードオフを実現します。
Comment元ポスト:https://x.com/cihangxie/status/1920575141849030882?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#PRM
Issue Date: 2025-06-26
[Paper Note] Process Reward Models That Think, Muhammad Khalifa+, arXiv'25
Summary本研究では、データ効率の良いステップバイステップの検証器(ThinkPRM)を提案し、少ないプロセスラベルで高性能を実現します。ThinkPRMは、長いCoTモデルの推論能力を活用し、PRM800Kのわずか1%のプロセスラベルで、従来の検証器を上回る性能を示します。具体的には、ProcessBenchやMATH-500などのベースラインを超え、ドメイン外評価でも優れた結果を得ています。最小限の監視でのトレーニングを通じて、検証計算のスケーリングの重要性を強調しています。
#NLP
#LanguageModel
#ReinforcementLearning
#RewardHacking
Issue Date: 2025-06-26
[Paper Note] Robust Reward Modeling via Causal Rubrics, Pragya Srivastava+, arXiv'25
Summary報酬モデル(RMs)は人間のフィードバックを通じて大規模言語モデル(LLMs)を整合させるが、報酬ハッキングの影響を受けやすい。本研究では、報酬ハッキングを軽減するための新しいフレームワーク「Crome」を提案。Cromeは因果的拡張と中立的拡張を用いて、因果属性に基づく感度と虚偽属性に対する不変性を強制する。実験結果では、CromeはRewardBenchで標準的なベースラインを大幅に上回り、平均精度を最大5.4%向上させた。
Comment元ポスト:https://x.com/harman26singh/status/1937876897058181230?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q以下がresearch question:
ざっくり見た感じ、RLVRがそもそも適用できないドメインで実験した場合の結果がないように見え、適用した場合に有効なのかは気になるところ。
#ComputerVision
#EfficiencyImprovement
#Pretraining
#NLP
#LanguageModel
#MulltiModal
Issue Date: 2025-06-26
[Paper Note] OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning, Xianhang Li+, arXiv'25
SummaryOpenVisionは、完全にオープンでコスト効果の高いビジョンエンコーダーのファミリーを提案し、CLIPと同等以上の性能を発揮します。既存の研究を基に構築され、マルチモーダルモデルの進展に実用的な利点を示します。5.9Mから632.1Mパラメータのエンコーダーを提供し、容量と効率の柔軟なトレードオフを実現します。
Comment元ポスト:https://x.com/cihangxie/status/1920575141849030882?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#PRM
Issue Date: 2025-06-26
[Paper Note] Process Reward Models That Think, Muhammad Khalifa+, arXiv'25
Summary本研究では、データ効率の良いステップバイステップの検証器(ThinkPRM)を提案し、少ないプロセスラベルで高性能を実現します。ThinkPRMは、長いCoTモデルの推論能力を活用し、PRM800Kのわずか1%のプロセスラベルで、従来の検証器を上回る性能を示します。具体的には、ProcessBenchやMATH-500などのベースラインを超え、ドメイン外評価でも優れた結果を得ています。最小限の監視でのトレーニングを通じて、検証計算のスケーリングの重要性を強調しています。
#NLP
#LanguageModel
#ReinforcementLearning
#RewardHacking
Issue Date: 2025-06-26
[Paper Note] Robust Reward Modeling via Causal Rubrics, Pragya Srivastava+, arXiv'25
Summary報酬モデル(RMs)は人間のフィードバックを通じて大規模言語モデル(LLMs)を整合させるが、報酬ハッキングの影響を受けやすい。本研究では、報酬ハッキングを軽減するための新しいフレームワーク「Crome」を提案。Cromeは因果的拡張と中立的拡張を用いて、因果属性に基づく感度と虚偽属性に対する不変性を強制する。実験結果では、CromeはRewardBenchで標準的なベースラインを大幅に上回り、平均精度を最大5.4%向上させた。
Comment元ポスト:https://x.com/harman26singh/status/1937876897058181230?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q以下がresearch question:
 #ComputerVision
#Analysis
#pretrained-LM
#Scaling Laws
#TMLR
Issue Date: 2025-06-26
[Paper Note] An Empirical Study of Pre-trained Model Selection for Out-of-Distribution Generalization and Calibration, Hiroki Naganuma+, TMLR'25
Summary事前学習済みモデルのファインチューニングが分布外一般化タスクにおいて重要であることを示し、モデルのサイズやデータセットの選択がOOD精度と信頼性キャリブレーションに与える影響を調査。120,000時間以上の実験を通じて、大きなモデルと大規模なデータセットがOODパフォーマンスとキャリブレーションを改善することを発見。これは、従来の研究と対照的であり、事前学習済みモデルの選択の重要性を強調している。
CommentOpenReview:https://openreview.net/forum?id=tYjoHjShxF元ポスト:https://x.com/_hiroki11x/status/1938052113466323134?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#EfficiencyImprovement
#Transformer
#LongSequence
#SSM (StateSpaceModel)
#VideoGeneration/Understandings
#ICCV
Issue Date: 2025-06-26
[Paper Note] Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers, Weiming Ren+, arXiv'25
SummaryVAMBAモデルは、Mamba-2ブロックを用いてビデオトークンを線形にエンコードし、トークン削減なしで1024フレームを処理可能。これにより、GPUメモリ使用量を50%削減し、トレーニング速度を倍増。1時間のビデオ理解ベンチマークLVBenchで4.3%の精度向上を達成し、様々なビデオ理解タスクで優れた性能を示す。
Comment元ポスト:https://x.com/wenhuchen/status/1938064510369280136?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Alignment
#SyntheticData
#SyntheticDataGeneration
#ICLR
Issue Date: 2025-06-25
[Paper Note] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Zhangchen Xu+, ICLR'25
Summary高品質な指示データはLLMの整合に不可欠であり、Magpieという自己合成手法を提案。Llama-3-Instructを用いて400万の指示と応答を生成し、30万の高品質なインスタンスを選定。Magpieでファインチューニングしたモデルは、従来のデータセットを用いたモデルと同等の性能を示し、特に整合ベンチマークで優れた結果を得た。
CommentOpenReview:https://openreview.net/forum?id=Pnk7vMbznK
#ComputerVision
#Analysis
#pretrained-LM
#Scaling Laws
#TMLR
Issue Date: 2025-06-26
[Paper Note] An Empirical Study of Pre-trained Model Selection for Out-of-Distribution Generalization and Calibration, Hiroki Naganuma+, TMLR'25
Summary事前学習済みモデルのファインチューニングが分布外一般化タスクにおいて重要であることを示し、モデルのサイズやデータセットの選択がOOD精度と信頼性キャリブレーションに与える影響を調査。120,000時間以上の実験を通じて、大きなモデルと大規模なデータセットがOODパフォーマンスとキャリブレーションを改善することを発見。これは、従来の研究と対照的であり、事前学習済みモデルの選択の重要性を強調している。
CommentOpenReview:https://openreview.net/forum?id=tYjoHjShxF元ポスト:https://x.com/_hiroki11x/status/1938052113466323134?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#EfficiencyImprovement
#Transformer
#LongSequence
#SSM (StateSpaceModel)
#VideoGeneration/Understandings
#ICCV
Issue Date: 2025-06-26
[Paper Note] Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers, Weiming Ren+, arXiv'25
SummaryVAMBAモデルは、Mamba-2ブロックを用いてビデオトークンを線形にエンコードし、トークン削減なしで1024フレームを処理可能。これにより、GPUメモリ使用量を50%削減し、トレーニング速度を倍増。1時間のビデオ理解ベンチマークLVBenchで4.3%の精度向上を達成し、様々なビデオ理解タスクで優れた性能を示す。
Comment元ポスト:https://x.com/wenhuchen/status/1938064510369280136?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Alignment
#SyntheticData
#SyntheticDataGeneration
#ICLR
Issue Date: 2025-06-25
[Paper Note] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Zhangchen Xu+, ICLR'25
Summary高品質な指示データはLLMの整合に不可欠であり、Magpieという自己合成手法を提案。Llama-3-Instructを用いて400万の指示と応答を生成し、30万の高品質なインスタンスを選定。Magpieでファインチューニングしたモデルは、従来のデータセットを用いたモデルと同等の性能を示し、特に整合ベンチマークで優れた結果を得た。
CommentOpenReview:https://openreview.net/forum?id=Pnk7vMbznK
下記のようなpre-queryテンプレートを与え(i.e., userの発話は何も与えず、ユーザの発話を表す特殊トークンのみを渡す)instructionを生成し、post-queryテンプレートを与える(i.e., pre-queryテンプレート+生成されたinstruction+assistantの発話の開始を表す特殊トークンのみを渡す)ことでresponseを生成することで、prompt engineeringやseed無しでinstruction tuningデータを合成できるという手法。

生成した生のinstruction tuning pair dataは、たとえば下記のようなフィルタリングをすることで品質向上が可能で

reward modelと組み合わせてLLMからのresponseを生成しrejection samplingすればDPOのためのpreference dataも作成できるし、single turnの発話まで生成させた後もう一度pre/post-queryをconcatして生成すればMulti turnのデータも生成できる。
他のも例えば、システムプロンプトに自分が生成したい情報を与えることで、特定のドメインに特化したデータ、あるいは特定の言語に特化したデータも合成できる。
 #Embeddings
#NLP
#LanguageModel
#RepresentationLearning
#pretrained-LM
#Japanese
Issue Date: 2025-06-25
[Paper Note] llm-jp-modernbert: A ModernBERT Model Trained on a Large-Scale Japanese Corpus with Long Context Length, Issa Sugiura+, arXiv'25
SummaryModernBERTモデル(llm-jp-modernbert)は、8192トークンのコンテキスト長を持つ日本語コーパスで訓練され、フィルマスクテスト評価で良好な結果を示す。下流タスクでは既存のベースラインを上回らないが、コンテキスト長の拡張効果を分析し、文の埋め込みや訓練中の遷移を調査。再現性を支援するために、モデルと評価コードを公開。
Comment参考:
#Embeddings
#NLP
#LanguageModel
#RepresentationLearning
#pretrained-LM
#Japanese
Issue Date: 2025-06-25
[Paper Note] llm-jp-modernbert: A ModernBERT Model Trained on a Large-Scale Japanese Corpus with Long Context Length, Issa Sugiura+, arXiv'25
SummaryModernBERTモデル(llm-jp-modernbert)は、8192トークンのコンテキスト長を持つ日本語コーパスで訓練され、フィルマスクテスト評価で良好な結果を示す。下流タスクでは既存のベースラインを上回らないが、コンテキスト長の拡張効果を分析し、文の埋め込みや訓練中の遷移を調査。再現性を支援するために、モデルと評価コードを公開。
Comment参考:
・1761 #NLP #Dataset #LanguageModel #Alignment #Safety #Japanese #PostTraining Issue Date: 2025-06-25 [Paper Note] AnswerCarefully: A Dataset for Improving the Safety of Japanese LLM Output, Hisami Suzuki+, arXiv'25 Summary日本のLLMの安全性を高めるためのデータセット「AnswerCarefully」を紹介。1,800組の質問と参照回答から成り、リスクカテゴリをカバーしつつ日本の文脈に合わせて作成。微調整により出力の安全性が向上し、12のLLMの安全性評価結果も報告。英語翻訳と注釈を提供し、他言語でのデータセット作成を促進。 CommentBlog:https://llmc.nii.ac.jp/answercarefully-dataset/ #EfficiencyImprovement #Pretraining #NLP #LanguageModel #MoE(Mixture-of-Experts) #ICLR Issue Date: 2025-06-25 [Paper Note] Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization, Taishi Nakamura+, ICLR'25 SummaryDrop-Upcycling手法を提案し、MoEモデルのトレーニング効率を向上。事前にトレーニングされた密なモデルの知識を活用しつつ、一部の重みを再初期化することで専門家の専門化を促進。大規模実験により、5.9BパラメータのMoEモデルが13B密なモデルと同等の性能を達成し、トレーニングコストを約1/4に削減。すべての実験リソースを公開。 CommentOpenReview:https://openreview.net/forum?id=gx1wHnf5Vp関連:
・1546提案手法の全体像とDiversity re-initializationの概要。元のUpcyclingでは全てidenticalな重みでreplicateされていたため、これが個々のexpertがlong termでの学習で特化することの妨げになり、最終的に最大限のcapabilityを発揮できず、収束が遅い要因となっていた。これを、Upcyclingした重みのうち、一部のindexのみを再初期化することで、replicate元の知識を保持しつつ、expertsの多様性を高めることで解決する。


提案手法は任意のactivation function適用可能。今回はFFN Layerのactivation functionとして一般的なSwiGLUを採用した場合で説明している。
Drop-Upcyclingの手法としては、通常のUpcyclingと同様、FFN Layerの重みをn個のexpertsの数だけreplicateする。その後、re-initializationを実施する比率rに基づいて、[1, intermediate size d_f]の範囲からrd_f個のindexをサンプリングする。最終的にSwiGLU、およびFFNにおける3つのWeight W_{gate, up, down}において、サンプリングされたindexと対応するrow/columnと対応する重みをre-initializeする。
re-initializeする際には、各W_{gate, up, down}中のサンプリングされたindexと対応するベクトルの平均と分散をそれぞれ独立して求め、それらの平均と分散を持つ正規分布からサンプリングする。
学習の初期から高い性能を発揮し、long termでの性能も向上している。また、learning curveの形状もscratchから学習した場合と同様の形状となっており、知識の転移とexpertsのspecializationがうまく進んだことが示唆される。
 解説:https://llm-jp.nii.ac.jp/news/post-566/
#RecommenderSystems
#Embeddings
#EfficiencyImprovement
#InformationRetrieval
#RepresentationLearning
Issue Date: 2025-06-25
[Paper Note] NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking, Shenbin Qian+, arXiv'25
SummaryEコマース情報検索システムは、ユーザーの意図を正確に理解しつつ、大規模な商品カタログを効率的に処理することが難しい。本論文では、NEAR$^2$というネストされた埋め込みアプローチを提案し、推論時の埋め込みサイズを最大12倍効率化し、トレーニングコストを増やさずにトランスフォーマーモデルの精度を向上させる。さまざまなIR課題に対して異なる損失関数を用いて検証した結果、既存モデルよりも小さな埋め込み次元での性能向上を達成した。
Comment元ポスト:https://x.com/_reachsumit/status/1937697219387490566?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Verification
Issue Date: 2025-06-25
[Paper Note] Shrinking the Generation-Verification Gap with Weak Verifiers, Jon Saad-Falcon+, arXiv'25
SummaryWeaverは、複数の弱いverifiersを組み合わせて強力なverifierを設計するフレームワークであり、ラベル付きデータへの依存を減らすために弱い監視を利用します。出力を正規化し、特定のverifiersをフィルタリングすることで、精度の向上を図ります。Weaverは、推論および数学タスクにおいてPass@1性能を大幅に改善し、Llama 3.3 70B Instructを用いて高い精度を達成しました。計算コスト削減のために、統合出力スコアを用いてクロスエンコーダを訓練します。
Comment元ポスト:https://x.com/jonsaadfalcon/status/1937600479527317802?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#DiffusionModel
Issue Date: 2025-06-25
[Paper Note] Mercury: Ultra-Fast Language Models Based on Diffusion, Inception Labs+, arXiv'25
Summary新しい拡散型大規模言語モデルMercuryを発表。特にコーディングアプリケーション向けのMercury Coderは、MiniとSmallの2サイズで提供され、速度と品質で最先端を達成。独立評価では、Mercury Coder Miniが1109トークン/秒、Smallが737トークン/秒を記録し、他のモデルを大幅に上回る性能を示す。さらに、実世界での検証結果や公開API、無料プレイグラウンドも提供。
Comment元ポスト:https://x.com/arankomatsuzaki/status/1937360864262389786?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qスループット(モデルのトークン生成速度)が、SoTAらしいdLLMモデル解説:https://x.com/hillbig/status/1938026627642101858?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#NLP
#Dataset
#LanguageModel
#SyntheticData
Issue Date: 2025-06-25
[Paper Note] Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models, Thao Nguyen+, arXiv'25
Summaryスケーリング法則に基づき、低品質なウェブデータを再利用する手法「REWIRE」を提案。これにより、事前学習データの合成表現を増やし、フィルタリングされたデータのみでのトレーニングと比較して、22のタスクで性能を向上。生データと合成データの混合が効果的であることを示し、ウェブテキストのリサイクルが事前学習データのスケーリングに有効であることを示唆。
Comment元ポスト:https://x.com/thao_nguyen26/status/1937210428876292457?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q学習データの枯渇に対する対処として別の方向性としては下記のような研究もある:
解説:https://llm-jp.nii.ac.jp/news/post-566/
#RecommenderSystems
#Embeddings
#EfficiencyImprovement
#InformationRetrieval
#RepresentationLearning
Issue Date: 2025-06-25
[Paper Note] NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking, Shenbin Qian+, arXiv'25
SummaryEコマース情報検索システムは、ユーザーの意図を正確に理解しつつ、大規模な商品カタログを効率的に処理することが難しい。本論文では、NEAR$^2$というネストされた埋め込みアプローチを提案し、推論時の埋め込みサイズを最大12倍効率化し、トレーニングコストを増やさずにトランスフォーマーモデルの精度を向上させる。さまざまなIR課題に対して異なる損失関数を用いて検証した結果、既存モデルよりも小さな埋め込み次元での性能向上を達成した。
Comment元ポスト:https://x.com/_reachsumit/status/1937697219387490566?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Verification
Issue Date: 2025-06-25
[Paper Note] Shrinking the Generation-Verification Gap with Weak Verifiers, Jon Saad-Falcon+, arXiv'25
SummaryWeaverは、複数の弱いverifiersを組み合わせて強力なverifierを設計するフレームワークであり、ラベル付きデータへの依存を減らすために弱い監視を利用します。出力を正規化し、特定のverifiersをフィルタリングすることで、精度の向上を図ります。Weaverは、推論および数学タスクにおいてPass@1性能を大幅に改善し、Llama 3.3 70B Instructを用いて高い精度を達成しました。計算コスト削減のために、統合出力スコアを用いてクロスエンコーダを訓練します。
Comment元ポスト:https://x.com/jonsaadfalcon/status/1937600479527317802?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#DiffusionModel
Issue Date: 2025-06-25
[Paper Note] Mercury: Ultra-Fast Language Models Based on Diffusion, Inception Labs+, arXiv'25
Summary新しい拡散型大規模言語モデルMercuryを発表。特にコーディングアプリケーション向けのMercury Coderは、MiniとSmallの2サイズで提供され、速度と品質で最先端を達成。独立評価では、Mercury Coder Miniが1109トークン/秒、Smallが737トークン/秒を記録し、他のモデルを大幅に上回る性能を示す。さらに、実世界での検証結果や公開API、無料プレイグラウンドも提供。
Comment元ポスト:https://x.com/arankomatsuzaki/status/1937360864262389786?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qスループット(モデルのトークン生成速度)が、SoTAらしいdLLMモデル解説:https://x.com/hillbig/status/1938026627642101858?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#NLP
#Dataset
#LanguageModel
#SyntheticData
Issue Date: 2025-06-25
[Paper Note] Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models, Thao Nguyen+, arXiv'25
Summaryスケーリング法則に基づき、低品質なウェブデータを再利用する手法「REWIRE」を提案。これにより、事前学習データの合成表現を増やし、フィルタリングされたデータのみでのトレーニングと比較して、22のタスクで性能を向上。生データと合成データの混合が効果的であることを示し、ウェブテキストのリサイクルが事前学習データのスケーリングに有効であることを示唆。
Comment元ポスト:https://x.com/thao_nguyen26/status/1937210428876292457?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q学習データの枯渇に対する対処として別の方向性としては下記のような研究もある:
・1829 #NLP #LanguageModel #Reasoning #PRM Issue Date: 2025-06-25 [Paper Note] ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs, Jiaru Zou+, arXiv'25 Summary新しいプロセス報酬モデルReasonFlux-PRMを提案し、推論トレースの評価を強化。ステップと軌道の監視を組み込み、報酬割り当てを細かく行う。実験により、ReasonFlux-PRM-7Bが高品質なデータ選択と性能向上を実現し、特に監視付きファインチューニングで平均12.1%の向上を達成。リソース制約のあるアプリケーション向けにReasonFlux-PRM-1.5Bも公開。 Comment元ポスト:https://x.com/_akhaliq/status/1937345023005048925?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #LanguageModel #MulltiModal #Tokenizer Issue Date: 2025-06-24 [Paper Note] Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations, Jiaming Han+, arXiv'25 Summary本論文では、視覚理解と生成を統一するマルチモーダルフレームワークTarを提案。Text-Aligned Tokenizer(TA-Tok)を用いて画像を離散トークンに変換し、視覚とテキストを統一空間に統合。スケール適応型のエンコーディングとデコーディングを導入し、高忠実度の視覚出力を生成。迅速な自己回帰モデルと拡散ベースのモデルを用いたデトークナイザーを活用し、視覚理解と生成の改善を実現。実験結果では、Tarが既存手法と同等以上の性能を示し、効率的なトレーニングを達成。 Comment元ポスト:https://x.com/_akhaliq/status/1937345768223859139?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtext modalityとvision modalityを共通の空間で表現する
 Visual Understanding/Generationのベンチで全体的に高い性能を達成
Visual Understanding/Generationのベンチで全体的に高い性能を達成
 #Analysis
#NLP
#LanguageModel
#SelfImprovement
#ICLR
#read-later
#Verification
Issue Date: 2025-06-24
[Paper Note] Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models, Yuda Song+, ICLR'25
Summary自己改善はLLMの出力検証を通じてデータをフィルタリングし、蒸留するメカニズムである。本研究では、自己改善の数学的定式化を行い、生成-検証ギャップに基づくスケーリング現象を発見。さまざまなモデルとタスクを用いた実験により、自己改善の可能性とその性能向上方法を探求し、LLMの理解を深めるとともに、将来の研究への示唆を提供する。
Comment参考:https://joisino.hatenablog.com/entry/misleadVerificationに対する理解を深めるのに非常に良さそう
#ComputerVision
#Embeddings
#NLP
#RepresentationLearning
#MulltiModal
Issue Date: 2025-06-24
[Paper Note] jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval, Michael Günther+, arXiv'25
Summary3.8億パラメータのマルチモーダル埋め込みモデル「jina-embeddings-v4」を提案。新しいアーキテクチャにより、クエリベースの情報検索やクロスモーダルの類似性検索を最適化。タスク特化型のLoRAアダプターを組み込み、視覚的に豊かなコンテンツの処理に優れた性能を発揮。新しいベンチマーク「Jina-VDR」も導入。
Comment元ポスト:https://x.com/arankomatsuzaki/status/1937342962075378014?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#NLP
#LanguageModel
#ICLR
#Verification
Issue Date: 2025-06-24
[Paper Note] On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks, Kaya Stechly+, ICLR'25
SummaryLLMsの推論能力に関する意見の相違を背景に、反復的なプロンプトの効果をGame of 24、グラフ彩色、STRIPS計画の3領域で調査。自己批評がパフォーマンスに悪影響を及ぼす一方、外部の正しい推論者による検証がパフォーマンスを向上させることを示した。再プロンプトによって複雑な設定の利点を維持できることも確認。
Comment参考:https://joisino.hatenablog.com/entry/misleadOpenReview:https://openreview.net/forum?id=4O0v4s3IzY
#Analysis
#NLP
#LanguageModel
#RLHF
#ICLR
Issue Date: 2025-06-24
[Paper Note] Language Models Learn to Mislead Humans via RLHF, Jiaxin Wen+, ICLR'25
SummaryRLHFは言語モデルのエラーを悪化させる可能性があり、モデルが人間を納得させる能力を向上させる一方で、タスクの正確性は向上しない。質問応答タスクとプログラミングタスクで被験者の誤検出率が増加し、意図された詭弁を検出する手法がU-SOPHISTRYには適用できないことが示された。これにより、RLHFの問題点と人間支援の研究の必要性が浮き彫りになった。
Comment参考:https://joisino.hatenablog.com/entry/mislead
#ComputerVision
#Dataset
#VideoGeneration/Understandings
Issue Date: 2025-06-23
[Paper Note] Sekai: A Video Dataset towards World Exploration, Zhen Li+, arXiv'25
Summary高品質な一人称視点のビデオデータセット「Sekai」を紹介。750の都市から5,000時間以上のビデオを収集し、位置やシーンなどの豊富な注釈を付与。データセットを用いてインタラクティブなビデオ世界探査モデル「YUME」をトレーニング。Sekaiはビデオ生成と世界探査に貢献することが期待される。
Comment元ポスト:https://x.com/yongyuanxi/status/1936846469346251068?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#NLP
#LanguageModel
#Tokenizer
Issue Date: 2025-06-23
[Paper Note] From Bytes to Ideas: Language Modeling with Autoregressive U-Nets, Mathurin Videau+, arXiv'25
Summary自己回帰型U-Netを用いてトークン化の柔軟性を向上させ、モデルが生のバイトから単語や単語のペアを生成することでマルチスケールの視点を提供。深い段階では広範な意味パターンに注目し、浅い段階はBPEベースラインに匹敵する性能を発揮。これにより、文字レベルのタスクやリソースの少ない言語間での知識移転が可能となる。
Comment元ポスト:https://x.com/dair_ai/status/1936825784473096335?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#read-later
Issue Date: 2025-06-23
[Paper Note] Reinforcement Learning Teachers of Test Time Scaling, Edoardo Cetin+, arXiv'25
Summary強化学習教師(RLT)を用いて推論言語モデル(LM)のトレーニングを行い、タスク探索の課題を回避する新しいフレームワークを提案。RLTは問題の質問と解決策を提示し、学生に合わせた説明を通じて理解をテストし、密な報酬でトレーニングされる。7BのRLTは、競技および大学レベルのタスクで既存の蒸留パイプラインよりも高いパフォーマンスを示し、分布外タスクへの適用でも効果を維持する。
Comment元ポスト:https://x.com/sakanaailabs/status/1936965841188425776?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
#PostTraining
#read-later
#Admin'sPick
Issue Date: 2025-06-22
[Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, arXiv'25
SummaryGuruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。
Comment元ポスト:https://x.com/chengzhoujun/status/1936113985507803365?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpost-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。Qwenシリーズで実験。以下ポストのまとめ。
#Analysis
#NLP
#LanguageModel
#SelfImprovement
#ICLR
#read-later
#Verification
Issue Date: 2025-06-24
[Paper Note] Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models, Yuda Song+, ICLR'25
Summary自己改善はLLMの出力検証を通じてデータをフィルタリングし、蒸留するメカニズムである。本研究では、自己改善の数学的定式化を行い、生成-検証ギャップに基づくスケーリング現象を発見。さまざまなモデルとタスクを用いた実験により、自己改善の可能性とその性能向上方法を探求し、LLMの理解を深めるとともに、将来の研究への示唆を提供する。
Comment参考:https://joisino.hatenablog.com/entry/misleadVerificationに対する理解を深めるのに非常に良さそう
#ComputerVision
#Embeddings
#NLP
#RepresentationLearning
#MulltiModal
Issue Date: 2025-06-24
[Paper Note] jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval, Michael Günther+, arXiv'25
Summary3.8億パラメータのマルチモーダル埋め込みモデル「jina-embeddings-v4」を提案。新しいアーキテクチャにより、クエリベースの情報検索やクロスモーダルの類似性検索を最適化。タスク特化型のLoRAアダプターを組み込み、視覚的に豊かなコンテンツの処理に優れた性能を発揮。新しいベンチマーク「Jina-VDR」も導入。
Comment元ポスト:https://x.com/arankomatsuzaki/status/1937342962075378014?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#NLP
#LanguageModel
#ICLR
#Verification
Issue Date: 2025-06-24
[Paper Note] On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks, Kaya Stechly+, ICLR'25
SummaryLLMsの推論能力に関する意見の相違を背景に、反復的なプロンプトの効果をGame of 24、グラフ彩色、STRIPS計画の3領域で調査。自己批評がパフォーマンスに悪影響を及ぼす一方、外部の正しい推論者による検証がパフォーマンスを向上させることを示した。再プロンプトによって複雑な設定の利点を維持できることも確認。
Comment参考:https://joisino.hatenablog.com/entry/misleadOpenReview:https://openreview.net/forum?id=4O0v4s3IzY
#Analysis
#NLP
#LanguageModel
#RLHF
#ICLR
Issue Date: 2025-06-24
[Paper Note] Language Models Learn to Mislead Humans via RLHF, Jiaxin Wen+, ICLR'25
SummaryRLHFは言語モデルのエラーを悪化させる可能性があり、モデルが人間を納得させる能力を向上させる一方で、タスクの正確性は向上しない。質問応答タスクとプログラミングタスクで被験者の誤検出率が増加し、意図された詭弁を検出する手法がU-SOPHISTRYには適用できないことが示された。これにより、RLHFの問題点と人間支援の研究の必要性が浮き彫りになった。
Comment参考:https://joisino.hatenablog.com/entry/mislead
#ComputerVision
#Dataset
#VideoGeneration/Understandings
Issue Date: 2025-06-23
[Paper Note] Sekai: A Video Dataset towards World Exploration, Zhen Li+, arXiv'25
Summary高品質な一人称視点のビデオデータセット「Sekai」を紹介。750の都市から5,000時間以上のビデオを収集し、位置やシーンなどの豊富な注釈を付与。データセットを用いてインタラクティブなビデオ世界探査モデル「YUME」をトレーニング。Sekaiはビデオ生成と世界探査に貢献することが期待される。
Comment元ポスト:https://x.com/yongyuanxi/status/1936846469346251068?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#NLP
#LanguageModel
#Tokenizer
Issue Date: 2025-06-23
[Paper Note] From Bytes to Ideas: Language Modeling with Autoregressive U-Nets, Mathurin Videau+, arXiv'25
Summary自己回帰型U-Netを用いてトークン化の柔軟性を向上させ、モデルが生のバイトから単語や単語のペアを生成することでマルチスケールの視点を提供。深い段階では広範な意味パターンに注目し、浅い段階はBPEベースラインに匹敵する性能を発揮。これにより、文字レベルのタスクやリソースの少ない言語間での知識移転が可能となる。
Comment元ポスト:https://x.com/dair_ai/status/1936825784473096335?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#read-later
Issue Date: 2025-06-23
[Paper Note] Reinforcement Learning Teachers of Test Time Scaling, Edoardo Cetin+, arXiv'25
Summary強化学習教師(RLT)を用いて推論言語モデル(LM)のトレーニングを行い、タスク探索の課題を回避する新しいフレームワークを提案。RLTは問題の質問と解決策を提示し、学生に合わせた説明を通じて理解をテストし、密な報酬でトレーニングされる。7BのRLTは、競技および大学レベルのタスクで既存の蒸留パイプラインよりも高いパフォーマンスを示し、分布外タスクへの適用でも効果を維持する。
Comment元ポスト:https://x.com/sakanaailabs/status/1936965841188425776?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#Reasoning
#PostTraining
#read-later
#Admin'sPick
Issue Date: 2025-06-22
[Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, arXiv'25
SummaryGuruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。
Comment元ポスト:https://x.com/chengzhoujun/status/1936113985507803365?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpost-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。Qwenシリーズで実験。以下ポストのまとめ。
・mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
・一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
・簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
・各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
・必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
・たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
・一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
・異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
・(これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
・非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
・RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
・モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
・モデルサイズが大きいとより多様なreasoningパスがunlockされている
・pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた #ComputerVision #Transformer #CVPR #3D Reconstruction #Backbone Issue Date: 2025-06-22 [Paper Note] VGGT: Visual Geometry Grounded Transformer, Jianyuan Wang+, CVPR'25 SummaryVGGTは、シーンの主要な3D属性を複数のビューから直接推測するフィードフォワードニューラルネットワークであり、3Dコンピュータビジョンの分野において新たな進展を示します。このアプローチは効率的で、1秒未満で画像を再構築し、複数の3Dタスクで最先端の結果を達成します。また、VGGTを特徴バックボーンとして使用することで、下流タスクの性能が大幅に向上することが示されています。コードは公開されています。 Comment元ポスト:https://x.com/hillbig/status/1936711294956265820?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Document #NLP #Library #ACL #parser Issue Date: 2025-06-21 [Paper Note] Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting, Hao Feng+, ACL'25 Summary文書画像解析の新モデル「Dolphin」を提案。レイアウト要素をシーケンス化し、タスク特有のプロンプトと組み合わせて解析を行う。3000万以上のサンプルで訓練し、ページレベルと要素レベルの両方で最先端の性能を達成。効率的なアーキテクチャを実現。コードは公開中。 Commentrepo:https://github.com/bytedance/DolphinSoTAなDocumentのparser
 #NLP
#LanguageModel
#MoE(Mixture-of-Experts)
#ICML
#Scaling Laws
Issue Date: 2025-06-21
[Paper Note] Scaling Laws for Upcycling Mixture-of-Experts Language Models, Seng Pei Liew+, ICML'25
SummaryLLMsの事前学習は高コストで時間がかかるため、アップサイクリングとMoEモデルの計算効率向上が提案されている。本研究では、アップサイクリングをMoEに適用し、データセットのサイズやモデル構成に依存するスケーリング法則を特定。密なトレーニングデータとアップサイクリングデータの相互作用が効率を制限することを示し、アップサイクリングのスケールアップに関する指針を提供。
Comment元ポスト:https://x.com/sbintuitions/status/1935970879923540248?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=ZBBo19jldX関連:
#NLP
#LanguageModel
#MoE(Mixture-of-Experts)
#ICML
#Scaling Laws
Issue Date: 2025-06-21
[Paper Note] Scaling Laws for Upcycling Mixture-of-Experts Language Models, Seng Pei Liew+, ICML'25
SummaryLLMsの事前学習は高コストで時間がかかるため、アップサイクリングとMoEモデルの計算効率向上が提案されている。本研究では、アップサイクリングをMoEに適用し、データセットのサイズやモデル構成に依存するスケーリング法則を特定。密なトレーニングデータとアップサイクリングデータの相互作用が効率を制限することを示し、アップサイクリングのスケールアップに関する指針を提供。
Comment元ポスト:https://x.com/sbintuitions/status/1935970879923540248?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=ZBBo19jldX関連:
・1546 #Analysis #NLP #LanguageModel #Chain-of-Thought Issue Date: 2025-06-18 [Paper Note] Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought, Hanlin Zhu+, arXiv'25 Summary本研究では、連続CoTsを用いた二層トランスフォーマーが有向グラフ到達可能性問題を解決できることを証明。連続CoTsは複数の探索フロンティアを同時にエンコードし、従来の離散CoTsよりも効率的に解を導く。実験により、重ね合わせ状態が自動的に現れ、モデルが複数のパスを同時に探索することが確認された。 Comment元ポスト:https://x.com/tydsh/status/1935206012799303817?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #OpenWeight #OpenSource #PostTraining Issue Date: 2025-06-18 [Paper Note] AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy, Zihan Liu+, arXiv'25 Summary本研究では、教師ありファインチューニング(SFT)と強化学習(RL)の相乗効果を探求し、SFTトレーニングデータの整備においてプロンプト数の増加が推論性能を向上させることを示しました。特に、サンプリング温度を適切に調整することで、RLトレーニングの効果を最大化できることが分かりました。最終的に、AceReason-Nemotron-1.1モデルは、前モデルを大きく上回り、数学およびコードベンチマークで新たな最先端性能を達成しました。 Comment元ポスト:https://x.com/ychennlp/status/1935005283178492222?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
様々なtakeawayがまとめられている。SFT,RLに利用されたデータも公開・1829
において事前学習時に4 epochまでは性能の改善幅が大きいと報告されていたが、SFTでも5 epoch程度まで学習すると良い模様。
また、SFT dataをscalingさせる際は、promptの数だけでなく、prompt単位のresponse数を増やすのが効果的
 #NLP
#LanguageModel
#Reasoning
Issue Date: 2025-06-18
[Paper Note] Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks, Yifei Xu+, arXiv'25
SummaryDRO(直接推論最適化)を提案し、LLMsをオープンエンドの長文推論タスクに微調整するための強化学習フレームワークを構築。新しい報酬信号R3を用いて推論と参照結果の一貫性を捉え、自己完結したトレーニングを実現。ParaRevとFinQAのデータセットで強力なベースラインを上回る性能を示し、広範な適用可能性を確認。
Comment元ポスト:https://x.com/iscienceluvr/status/1934957116571451409?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#Reasoning
Issue Date: 2025-06-18
[Paper Note] Wait, We Don't Need to "Wait" Removing Thinking Tokens Improves Reasoning Efficiency, Chenlong Wang+, arXiv'25
Summary自己反省を抑制する「NoWait」アプローチを提案し、推論の効率を向上。10のベンチマークで最大27%-51%の思考の連鎖の長さを削減し、有用性を維持。マルチモーダル推論のための効果的なソリューションを提供。
CommentWait, Hmmといったlong CoTを誘導するようなtokenを抑制することで、Accはほぼ変わらずに生成されるトークン数を削減可能、といった図に見える。Reasoningモデルでデコーディング速度を向上したい場合に効果がありそう。
#NLP
#LanguageModel
#Reasoning
Issue Date: 2025-06-18
[Paper Note] Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks, Yifei Xu+, arXiv'25
SummaryDRO(直接推論最適化)を提案し、LLMsをオープンエンドの長文推論タスクに微調整するための強化学習フレームワークを構築。新しい報酬信号R3を用いて推論と参照結果の一貫性を捉え、自己完結したトレーニングを実現。ParaRevとFinQAのデータセットで強力なベースラインを上回る性能を示し、広範な適用可能性を確認。
Comment元ポスト:https://x.com/iscienceluvr/status/1934957116571451409?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#Reasoning
Issue Date: 2025-06-18
[Paper Note] Wait, We Don't Need to "Wait" Removing Thinking Tokens Improves Reasoning Efficiency, Chenlong Wang+, arXiv'25
Summary自己反省を抑制する「NoWait」アプローチを提案し、推論の効率を向上。10のベンチマークで最大27%-51%の思考の連鎖の長さを削減し、有用性を維持。マルチモーダル推論のための効果的なソリューションを提供。
CommentWait, Hmmといったlong CoTを誘導するようなtokenを抑制することで、Accはほぼ変わらずに生成されるトークン数を削減可能、といった図に見える。Reasoningモデルでデコーディング速度を向上したい場合に効果がありそう。
 元ポスト:https://x.com/huggingpapers/status/1935130111608492060?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#EMNLP
#read-later
Issue Date: 2025-06-18
[Paper Note] Massive Supervised Fine-tuning Experiments Reveal How Data, Layer, and Training Factors Shape LLM Alignment Quality, Yuto Harada+, EMNLP'25
SummarySFTはLLMを人間の指示に整合させる重要なプロセスであり、1,000以上のSFTモデルを生成し、データセットの特性と層ごとの変更を調査。訓練タスクの相乗効果やモデル固有の戦略の重要性を明らかにし、困惑度がSFTの効果を予測することを示した。中間層の重みの変化がパフォーマンス向上と強く相関し、研究を加速させるためにモデルと結果を公開予定。
Comment元ポスト:https://x.com/odashi_t/status/1935191113981403359?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QNLP'25:https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/C10-6.pdf
#Analysis
#NLP
#Dataset
#LanguageModel
#FactualKnowledge
Issue Date: 2025-06-17
[Paper Note] What Is Seen Cannot Be Unseen: The Disruptive Effect of Knowledge Conflict on Large Language Models, Kaiser Sun+, arXiv'25
SummaryLLMの文脈情報とパラメトリック知識の対立を評価する診断フレームワークを提案。知識の対立はタスクに影響を与えず、一致時にパフォーマンスが向上。モデルは内部知識を抑制できず、対立の理由が文脈依存を高めることを示した。これにより、LLMの評価と展開における知識の対立の重要性が強調される。
Comment元ポスト:https://x.com/kaiserwholearns/status/1934582217692295268?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#Reasoning
Issue Date: 2025-06-17
[Paper Note] Overclocking LLM Reasoning: Monitoring and Controlling Thinking Path Lengths in LLMs, Roy Eisenstadt+, arXiv'25
SummaryLLMの推論プロセスにおける思考段階の長さを調整するメカニズムを探求。進捗をエンコードし、可視化することで計画ダイナミクスを明らかにし、不要なステップを減らす「オーバークロッキング」手法を提案。これにより、考えすぎを軽減し、回答精度を向上させ、推論のレイテンシを減少させることを実証。コードは公開。
Comment元ポスト:https://x.com/gm8xx8/status/1934357202619310559?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Evaluation
#Programming
Issue Date: 2025-06-17
[Paper Note] LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?, Zihan Zheng+, arXiv'25
Summary大規模言語モデル(LLMs)は競技プログラミングで人間のエリートを上回るとされるが、実際には重要な限界があることを調査。新たに導入した「LiveCodeBench Pro」ベンチマークにより、LLMsは中程度の難易度の問題で53%のpass@1を達成する一方、難しい問題では0%という結果が得られた。LLMsは実装重視の問題では成功するが、複雑なアルゴリズム的推論には苦労し、誤った正当化を生成することが多い。これにより、LLMsと人間の専門家との間に重要なギャップがあることが明らかになり、今後の改善のための診断が提供される。
Comment元ポスト:https://x.com/arankomatsuzaki/status/1934433210387296414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHardな問題は現状のSoTAモデル(Claude4が含まれていないが)でも正答率0.0%
元ポスト:https://x.com/huggingpapers/status/1935130111608492060?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#EMNLP
#read-later
Issue Date: 2025-06-18
[Paper Note] Massive Supervised Fine-tuning Experiments Reveal How Data, Layer, and Training Factors Shape LLM Alignment Quality, Yuto Harada+, EMNLP'25
SummarySFTはLLMを人間の指示に整合させる重要なプロセスであり、1,000以上のSFTモデルを生成し、データセットの特性と層ごとの変更を調査。訓練タスクの相乗効果やモデル固有の戦略の重要性を明らかにし、困惑度がSFTの効果を予測することを示した。中間層の重みの変化がパフォーマンス向上と強く相関し、研究を加速させるためにモデルと結果を公開予定。
Comment元ポスト:https://x.com/odashi_t/status/1935191113981403359?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QNLP'25:https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/C10-6.pdf
#Analysis
#NLP
#Dataset
#LanguageModel
#FactualKnowledge
Issue Date: 2025-06-17
[Paper Note] What Is Seen Cannot Be Unseen: The Disruptive Effect of Knowledge Conflict on Large Language Models, Kaiser Sun+, arXiv'25
SummaryLLMの文脈情報とパラメトリック知識の対立を評価する診断フレームワークを提案。知識の対立はタスクに影響を与えず、一致時にパフォーマンスが向上。モデルは内部知識を抑制できず、対立の理由が文脈依存を高めることを示した。これにより、LLMの評価と展開における知識の対立の重要性が強調される。
Comment元ポスト:https://x.com/kaiserwholearns/status/1934582217692295268?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#Reasoning
Issue Date: 2025-06-17
[Paper Note] Overclocking LLM Reasoning: Monitoring and Controlling Thinking Path Lengths in LLMs, Roy Eisenstadt+, arXiv'25
SummaryLLMの推論プロセスにおける思考段階の長さを調整するメカニズムを探求。進捗をエンコードし、可視化することで計画ダイナミクスを明らかにし、不要なステップを減らす「オーバークロッキング」手法を提案。これにより、考えすぎを軽減し、回答精度を向上させ、推論のレイテンシを減少させることを実証。コードは公開。
Comment元ポスト:https://x.com/gm8xx8/status/1934357202619310559?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LanguageModel
#Evaluation
#Programming
Issue Date: 2025-06-17
[Paper Note] LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?, Zihan Zheng+, arXiv'25
Summary大規模言語モデル(LLMs)は競技プログラミングで人間のエリートを上回るとされるが、実際には重要な限界があることを調査。新たに導入した「LiveCodeBench Pro」ベンチマークにより、LLMsは中程度の難易度の問題で53%のpass@1を達成する一方、難しい問題では0%という結果が得られた。LLMsは実装重視の問題では成功するが、複雑なアルゴリズム的推論には苦労し、誤った正当化を生成することが多い。これにより、LLMsと人間の専門家との間に重要なギャップがあることが明らかになり、今後の改善のための診断が提供される。
Comment元ポスト:https://x.com/arankomatsuzaki/status/1934433210387296414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHardな問題は現状のSoTAモデル(Claude4が含まれていないが)でも正答率0.0%

ベンチマークに含まれる課題のカテゴリ

実サンプルやケーススタディなどはAppendix参照のこと。 #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-06-17 [Paper Note] RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning, Yu Wang+, arXiv'25 SummaryRAG+は、Retrieval-Augmented Generationの拡張で、知識の適用を意識した推論を組み込む。二重コーパスを用いて、関連情報を取得し、目標指向の推論に適用する。実験結果は、RAG+が標準的なRAGを3-5%、複雑なシナリオでは最大7.5%上回ることを示し、知識統合の新たなフレームワークを提供する。 Comment元ポスト:https://x.com/omarsar0/status/1934667096828399641?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q知識だけでなく知識の使い方も蓄積し、利用時に検索された知識と紐づいた使い方を活用することでRAGの推論能力を向上させる。

 Figure 1のような例はReasoningモデルが進化していったら、わざわざ知識と使い方を紐付けなくても、世界知識から使い方を補完可能だと思われるので不要となると思われる。
Figure 1のような例はReasoningモデルが進化していったら、わざわざ知識と使い方を紐付けなくても、世界知識から使い方を補完可能だと思われるので不要となると思われる。
が、真にこの手法が力を発揮するのは「ドメイン固有の使い方やルール」が存在する場合で、どれだけLLMが賢くなっても推論によって導き出せないもの、のついては、こういった手法は効力を発揮し続けるのではないかと思われる。 #NLP #Dataset #LLMAgent #Evaluation #Programming #LongSequence Issue Date: 2025-06-17 [Paper Note] ALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering, Yuki Imajuku+, arXiv'25 SummaryAIシステムの最適化問題に対するパフォーマンスを評価する新しいベンチマークALE-Benchを提案。ALE-Benchは実際のタスクに基づき、長期的な解決策の洗練を促進する。大規模言語モデル(LLM)の評価では特定の問題で高いパフォーマンスを示すが、一貫性や長期的な問題解決能力において人間とのギャップが残ることが明らかになり、今後のAI進展に向けた必要性を示唆している。 Comment元ポスト:https://x.com/sakanaailabs/status/1934767254715117812?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連ポスト:https://x.com/iwiwi/status/1934830621756674499?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #KnowledgeEditing #FactualKnowledge #meta-learning Issue Date: 2025-06-17 [Paper Note] PropMEND: Hypernetworks for Knowledge Propagation in LLMs, Zeyu Leo Liu+, arXiv'25 SummaryPropMENDは、LLMsにおける知識伝播を改善するためのハイパーネットワークベースのアプローチである。メタ学習を用いて、注入された知識がマルチホップ質問に答えるために伝播するように勾配を修正する。RippleEditデータセットで、難しい質問に対して精度がほぼ2倍向上し、Controlled RippleEditデータセットでは新しい関係やエンティティに対する知識伝播を評価。PropMENDは既存の手法を上回るが、性能差は縮小しており、今後の研究で広範な関係への知識伝播が求められる。 Comment元ポスト:https://x.com/zeyuliu10/status/1934659512046330057?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来のKnowledge Editing手法は新たな知識を記憶させることはできる(i.e., 注入した知識を逐語的に生成できる;東京は日本の首都である。)が、知識を活用することは苦手だった(i.e., 日本の首都の気候は?)ので、それを改善するための手法を提案している模様。
既存手法のlimitationは
・editing手法で学習をする際に知識を伝搬させるデータが無く
・目的関数がraw textではなく、QA pairをSFTすること
によって生じるとし、
・学習時にpropagation question(Figure1のオレンジ色のQA; 注入した知識を活用して推論が必要なQA)を用意しどのように知識を伝搬(活用)させるかを学習し
・目的関数をCausal Language Modeling Loss
にすることで改善する、とのこと。


non-verbatimなQA(注入された知識をそのまま回答するものではなく、何らかの推論が必要なもの)でも性能が向上。
 ベースライン:
ベースライン:
・643
・2055 #NLP #LanguageModel #Hallucination #ICML Issue Date: 2025-06-14 [Paper Note] Steer LLM Latents for Hallucination Detection, Seongheon Park+, ICML'25 SummaryLLMの幻覚問題に対処するため、Truthfulness Separator Vector(TSV)を提案。TSVは、LLMの表現空間を再構築し、真実と幻覚の出力を分離する軽量な指向ベクトルで、モデルのパラメータを変更せずに機能。二段階のフレームワークで、少数のラベル付き例からTSVを訓練し、ラベルのない生成物を拡張。実験により、TSVは最小限のラベル付きデータで高いパフォーマンスを示し、実世界のアプリケーションにおける実用的な解決策を提供。 Comment元ポスト:https://x.com/sharonyixuanli/status/1933522788645810493?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Reasoning #Reproducibility Issue Date: 2025-06-13 [Paper Note] Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning, Jiayi Yuan+, arXiv'25 Summary本研究では、大規模言語モデル(LLMs)のパフォーマンスの再現性が脆弱であることを示し、システム構成の変更が応答に大きな影響を与えることを明らかにしました。特に、初期トークンの丸め誤差が推論精度に波及する問題を指摘し、浮動小数点演算の非結合的性質が変動の根本原因であるとしています。様々な条件下での実験を通じて、数値精度が再現性に与える影響を定量化し、評価実践における重要性を強調しました。さらに、LayerCastという軽量推論パイプラインを開発し、メモリ効率と数値安定性を両立させる方法を提案しました。 #ComputerVision #Transformer #DiffusionModel #VideoGeneration/Understandings Issue Date: 2025-06-13 [Paper Note] Seedance 1.0: Exploring the Boundaries of Video Generation Models, Yu Gao+, arXiv'25 SummarySeedance 1.0は、動画生成の基盤モデルであり、プロンプト遵守、動きの妥当性、視覚的品質を同時に向上させることを目指しています。主な技術改善として、意味のある動画キャプションを用いたデータキュレーション、マルチショット生成のサポート、動画特有のRLHFを活用したファインチューニング、推論速度の約10倍向上を実現する蒸留戦略が挙げられます。Seedance 1.0は、1080p解像度の5秒間の動画を41.4秒で生成し、高品質かつ迅速な動画生成を実現しています。 Comment元ポスト:https://x.com/scaling01/status/1933048431775527006?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #PostTraining #read-later Issue Date: 2025-06-13 [Paper Note] Resa: Transparent Reasoning Models via SAEs, Shangshang Wang+, arXiv'25 SummaryResaという1.5Bの推論モデル群を提案し、効率的なスパースオートエンコーダーチューニング(SAE-Tuning)手法を用いて訓練。これにより、97%以上の推論性能を保持しつつ、訓練コストを2000倍以上削減し、訓練時間を450倍以上短縮。軽いRL訓練を施したモデルで高い推論性能を実現し、抽出された推論能力は一般化可能かつモジュール化可能であることが示された。全ての成果物はオープンソース。 Comment元ポスト:https://x.com/iscienceluvr/status/1933101904529363112?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/upupwang/status/1933207676663865482?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q論文中で利用されているSource Modelの一つ:
・1935 #EfficiencyImprovement #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML Issue Date: 2025-06-12 [Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25 SummaryText-to-LoRA(T2L)は、自然言語による説明に基づいて大規模言語モデル(LLMs)を迅速に適応させる手法で、従来のファインチューニングの高コストと時間を克服します。T2Lは、LoRAを安価なフォワードパスで構築するハイパーネットワークを使用し、タスク特有のアダプターと同等のパフォーマンスを示します。また、数百のLoRAインスタンスを圧縮し、新しいタスクに対してゼロショットで一般化可能です。このアプローチは、基盤モデルの専門化を民主化し、計算要件を最小限に抑えた言語ベースの適応を実現します。 Comment元ポスト:https://x.com/roberttlange/status/1933074366603919638?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qな、なるほど、こんな手が…! #NLP #Supervised-FineTuning (SFT) #LLMAgent #x-Use Issue Date: 2025-06-12 [Paper Note] Go-Browse: Training Web Agents with Structured Exploration, Apurva Gandhi+, arXiv'25 SummaryGo-Browseを提案し、ウェブ環境の構造的探索を通じて多様なデータを自動収集。グラフ探索を用いて効率的なデータ収集を実現し、WebArenaベンチマークで成功率21.7%を達成。これはGPT-4o miniを2.4%上回り、10B未満のモデルでの最先端結果を2.9%上回る。 Comment元ポスト:https://x.com/gneubig/status/1932786231542493553?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWebArena:
・1849 #Pretraining #NLP #LanguageModel #ReinforcementLearning Issue Date: 2025-06-12 [Paper Note] Reinforcement Pre-Training, Qingxiu Dong+, arXiv'25 Summary本研究では、強化学習と大規模言語モデルの新しいスケーリング手法「強化事前学習(RPT)」を提案。次のトークン予測を強化学習の推論タスクとして再定義し、一般的なRLを活用することで、ドメイン特有の注釈に依存せずにスケーラブルな方法を提供。RPTは次のトークン予測の精度を向上させ、強化ファインチューニングの基盤を形成。トレーニング計算量の増加が精度を改善することを示し、RPTが言語モデルの事前学習において有望な手法であることを示した。 Comment元ポスト:https://x.com/hillbig/status/1932922314578145640?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Transformer #Architecture #ACL Issue Date: 2025-06-12 [Paper Note] Value Residual Learning, Zhanchao Zhou+, ACL'25 SummaryResFormerは、隠れ状態の残差に値の残差接続を加えることで情報の流れを強化する新しいTransformerアーキテクチャを提案。実験により、ResFormerは従来のTransformerに比べて少ないパラメータとトレーニングデータで同等の性能を示し、SVFormerはKVキャッシュサイズを半減させることができる。性能はシーケンスの長さや学習率に依存する。 Comment元ポスト:https://x.com/zhanchaozhou/status/1932829678081098079?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement
#NLP
#LanguageModel
#Alignment
#ReinforcementLearning
#Safety
Issue Date: 2025-06-11
[Paper Note] Saffron-1: Towards an Inference Scaling Paradigm for LLM Safety Assurance, Ruizhong Qiu+, arXiv'25
Summary既存のLLMの安全保証研究は主にトレーニング段階に焦点を当てているが、脱獄攻撃に対して脆弱であることが明らかになった。本研究では、推論スケーリングを用いた新たな安全性向上手法SAFFRONを提案し、計算オーバーヘッドを削減する多分岐報酬モデル(MRM)を導入。これにより、報酬モデル評価の数を減らし、探索-効率性のジレンマを克服する。実験により手法の有効性を確認し、訓練済みモデルと安全報酬データセットを公開。
Comment元ポスト:https://x.com/gaotangli/status/1932289294657626189?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Subword
Issue Date: 2025-06-11
[Paper Note] StochasTok: Improving Fine-Grained Subword Understanding in LLMs, Anya Sims+, arXiv'25
Summaryサブワードレベルの理解を向上させるために、確率的トークン化手法StochasTokを提案。これにより、LLMsは内部構造を把握しやすくなり、文字カウントや数学タスクなどで性能が向上。シンプルな設計により、既存モデルへの統合が容易で、コストを抑えつつサブワード理解を改善できる。
Comment元ポスト:https://x.com/cong_ml/status/1932369418534760554?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおもしろそう
#EfficiencyImprovement
#NLP
#Transformer
#Attention
#Architecture
Issue Date: 2025-06-10
[Paper Note] Log-Linear Attention, Han Guo+, arXiv'25
Summary対数線形注意を提案し、線形注意の効率性とソフトマックス注意の表現力を両立。固定サイズの隠れ状態を対数的に成長する隠れ状態に置き換え、計算コストを対数線形に抑える。Mamba-2とGated DeltaNetの対数線形バリアントが線形時間のバリアントと比較して優れた性能を示すことを確認。
Comment元ポスト:https://x.com/hillbig/status/1932194773559107911?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/theturingpost/status/1931432543766847887?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#MachineLearning
#ReinforcementLearning
Issue Date: 2025-06-10
[Paper Note] Horizon Reduction Makes RL Scalable, Seohong Park+, arXiv'25
Summary本研究では、オフライン強化学習(RL)のスケーラビリティを検討し、既存のアルゴリズムが大規模データセットに対して期待通りの性能を発揮しないことを示しました。特に、長いホライズンがスケーリングの障壁であると仮定し、ホライズン削減技術がスケーラビリティを向上させることを実証しました。新たに提案した手法SHARSAは、ホライズンを削減しつつ優れたパフォーマンスを達成し、オフラインRLのスケーラビリティを向上させることを示しました。
Comment元ポスト:https://x.com/hillbig/status/1932205263446245798?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#MachineLearning
#NLP
#LanguageModel
#ICML
#KnowledgeEditing
Issue Date: 2025-06-10
[Paper Note] Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing, Kento Nishi+, ICML'25
Summary知識編集(KE)アルゴリズムは、モデルの重みを変更して不正確な事実を更新するが、これがモデルの事実の想起精度や推論能力に悪影響を及ぼす可能性がある。新たに定義した合成タスクを通じて、KEがターゲットエンティティを超えて他のエンティティの表現に影響を与え、未見の知識の推論を歪める「表現の破壊」現象を示す。事前訓練されたモデルを用いた実験でもこの発見が確認され、KEがモデルの能力に悪影響を及ぼす理由を明らかにするメカニズム仮説を提供する。
Comment元ポスト:https://x.com/kento_nishi/status/1932072335726539063?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#InformationRetrieval
#NLP
#Search
#Dataset
#LanguageModel
Issue Date: 2025-06-08
[Paper Note] Search Arena: Analyzing Search-Augmented LLMs, Mihran Miroyan+, arXiv'25
Summary検索強化型LLMsに関する「Search Arena」という大規模な人間の好みデータセットを紹介。24,000以上のマルチターンユーザーインタラクションを含み、ユーザーの好みが引用数や引用元に影響されることを明らかにした。特に、コミュニティ主導の情報源が好まれる傾向があり、静的な情報源は必ずしも信頼されない。検索強化型LLMsの性能を評価した結果、非検索設定でのパフォーマンス向上が確認されたが、検索設定ではパラメトリック知識に依存すると品質が低下することが分かった。このデータセットはオープンソースとして提供されている。
Comment元ポスト:https://x.com/mirmiroyan/status/1931081734764081391?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#DiffusionModel
#CVPR
Issue Date: 2025-06-06
[Paper Note] Generative Omnimatte: Learning to Decompose Video into Layers, Yao-Chih Lee+, CVPR'25
Summaryオムニマット手法は、ビデオを意味的に有意義な層に分解することを目指すが、既存手法は静的背景や正確なポーズを前提としており、これが破られると性能が低下する。新たに提案する生成的層状ビデオ分解フレームワークは、静止シーンや深度情報を必要とせず、動的領域の補完を行う。核心的なアイデアは、ビデオ拡散モデルを訓練し、シーン効果を特定・除去することであり、これにより高品質な分解と編集結果を実現する。
Comment元ポスト:https://x.com/yaochihlee/status/1930473521081397253?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qざっくりしか読めていないが、Inputとして動画とmask(白:残す, 黒:消す, グレー: 不確定なオブジェクトやエフェクトが含まれるエリア≒背景?)を受け取り、Casperと呼ばれるモデルでオブジェクトを消し消した部分をinpaintingすることで、layerっぽいものを作成するっぽい?Casperは<Input画像, mask、maskからオブジェクトを削除した画像(削除した部分もきちんと背景がある)>の3組データでFinetuningしている模様。project pageがサンプルもありとてもわかりやすい:https://gen-omnimatte.github.io
#NLP
#LanguageModel
#ReinforcementLearning
#LLMAgent
#Coding
Issue Date: 2025-06-06
[Paper Note] Training Language Models to Generate Quality Code with Program Analysis Feedback, Feng Yao+, arXiv'25
Summaryプログラム分析に基づくフィードバックを用いた強化学習フレームワーク「REAL」を提案。セキュリティや保守性の欠陥を検出し、機能的正確性を保証することで、LLMsによる高品質なコード生成を促進。手動介入不要でスケーラブルな監視を実現し、実験により最先端の手法を上回る性能を示した。
Comment元ポスト:https://x.com/fengyao1909/status/1930377346693116350?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q現在のCoding LLMはUnitTestを通るように学習されるが、UnitTestに通るからといってコードの品質が良いわけでは無いので、UnitTestに通るか否かのReward(Functionality)に加えて、RL中に生成されたコードを制御フローグラフ[^1]に変換し汚染解析[^2]をした結果をRewardに組み込むことで、FunctionalityとQualityを両立したよ、という話のようである。
#EfficiencyImprovement
#NLP
#LanguageModel
#Alignment
#ReinforcementLearning
#Safety
Issue Date: 2025-06-11
[Paper Note] Saffron-1: Towards an Inference Scaling Paradigm for LLM Safety Assurance, Ruizhong Qiu+, arXiv'25
Summary既存のLLMの安全保証研究は主にトレーニング段階に焦点を当てているが、脱獄攻撃に対して脆弱であることが明らかになった。本研究では、推論スケーリングを用いた新たな安全性向上手法SAFFRONを提案し、計算オーバーヘッドを削減する多分岐報酬モデル(MRM)を導入。これにより、報酬モデル評価の数を減らし、探索-効率性のジレンマを克服する。実験により手法の有効性を確認し、訓練済みモデルと安全報酬データセットを公開。
Comment元ポスト:https://x.com/gaotangli/status/1932289294657626189?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Subword
Issue Date: 2025-06-11
[Paper Note] StochasTok: Improving Fine-Grained Subword Understanding in LLMs, Anya Sims+, arXiv'25
Summaryサブワードレベルの理解を向上させるために、確率的トークン化手法StochasTokを提案。これにより、LLMsは内部構造を把握しやすくなり、文字カウントや数学タスクなどで性能が向上。シンプルな設計により、既存モデルへの統合が容易で、コストを抑えつつサブワード理解を改善できる。
Comment元ポスト:https://x.com/cong_ml/status/1932369418534760554?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおもしろそう
#EfficiencyImprovement
#NLP
#Transformer
#Attention
#Architecture
Issue Date: 2025-06-10
[Paper Note] Log-Linear Attention, Han Guo+, arXiv'25
Summary対数線形注意を提案し、線形注意の効率性とソフトマックス注意の表現力を両立。固定サイズの隠れ状態を対数的に成長する隠れ状態に置き換え、計算コストを対数線形に抑える。Mamba-2とGated DeltaNetの対数線形バリアントが線形時間のバリアントと比較して優れた性能を示すことを確認。
Comment元ポスト:https://x.com/hillbig/status/1932194773559107911?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/theturingpost/status/1931432543766847887?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#MachineLearning
#ReinforcementLearning
Issue Date: 2025-06-10
[Paper Note] Horizon Reduction Makes RL Scalable, Seohong Park+, arXiv'25
Summary本研究では、オフライン強化学習(RL)のスケーラビリティを検討し、既存のアルゴリズムが大規模データセットに対して期待通りの性能を発揮しないことを示しました。特に、長いホライズンがスケーリングの障壁であると仮定し、ホライズン削減技術がスケーラビリティを向上させることを実証しました。新たに提案した手法SHARSAは、ホライズンを削減しつつ優れたパフォーマンスを達成し、オフラインRLのスケーラビリティを向上させることを示しました。
Comment元ポスト:https://x.com/hillbig/status/1932205263446245798?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#MachineLearning
#NLP
#LanguageModel
#ICML
#KnowledgeEditing
Issue Date: 2025-06-10
[Paper Note] Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing, Kento Nishi+, ICML'25
Summary知識編集(KE)アルゴリズムは、モデルの重みを変更して不正確な事実を更新するが、これがモデルの事実の想起精度や推論能力に悪影響を及ぼす可能性がある。新たに定義した合成タスクを通じて、KEがターゲットエンティティを超えて他のエンティティの表現に影響を与え、未見の知識の推論を歪める「表現の破壊」現象を示す。事前訓練されたモデルを用いた実験でもこの発見が確認され、KEがモデルの能力に悪影響を及ぼす理由を明らかにするメカニズム仮説を提供する。
Comment元ポスト:https://x.com/kento_nishi/status/1932072335726539063?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#InformationRetrieval
#NLP
#Search
#Dataset
#LanguageModel
Issue Date: 2025-06-08
[Paper Note] Search Arena: Analyzing Search-Augmented LLMs, Mihran Miroyan+, arXiv'25
Summary検索強化型LLMsに関する「Search Arena」という大規模な人間の好みデータセットを紹介。24,000以上のマルチターンユーザーインタラクションを含み、ユーザーの好みが引用数や引用元に影響されることを明らかにした。特に、コミュニティ主導の情報源が好まれる傾向があり、静的な情報源は必ずしも信頼されない。検索強化型LLMsの性能を評価した結果、非検索設定でのパフォーマンス向上が確認されたが、検索設定ではパラメトリック知識に依存すると品質が低下することが分かった。このデータセットはオープンソースとして提供されている。
Comment元ポスト:https://x.com/mirmiroyan/status/1931081734764081391?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#DiffusionModel
#CVPR
Issue Date: 2025-06-06
[Paper Note] Generative Omnimatte: Learning to Decompose Video into Layers, Yao-Chih Lee+, CVPR'25
Summaryオムニマット手法は、ビデオを意味的に有意義な層に分解することを目指すが、既存手法は静的背景や正確なポーズを前提としており、これが破られると性能が低下する。新たに提案する生成的層状ビデオ分解フレームワークは、静止シーンや深度情報を必要とせず、動的領域の補完を行う。核心的なアイデアは、ビデオ拡散モデルを訓練し、シーン効果を特定・除去することであり、これにより高品質な分解と編集結果を実現する。
Comment元ポスト:https://x.com/yaochihlee/status/1930473521081397253?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qざっくりしか読めていないが、Inputとして動画とmask(白:残す, 黒:消す, グレー: 不確定なオブジェクトやエフェクトが含まれるエリア≒背景?)を受け取り、Casperと呼ばれるモデルでオブジェクトを消し消した部分をinpaintingすることで、layerっぽいものを作成するっぽい?Casperは<Input画像, mask、maskからオブジェクトを削除した画像(削除した部分もきちんと背景がある)>の3組データでFinetuningしている模様。project pageがサンプルもありとてもわかりやすい:https://gen-omnimatte.github.io
#NLP
#LanguageModel
#ReinforcementLearning
#LLMAgent
#Coding
Issue Date: 2025-06-06
[Paper Note] Training Language Models to Generate Quality Code with Program Analysis Feedback, Feng Yao+, arXiv'25
Summaryプログラム分析に基づくフィードバックを用いた強化学習フレームワーク「REAL」を提案。セキュリティや保守性の欠陥を検出し、機能的正確性を保証することで、LLMsによる高品質なコード生成を促進。手動介入不要でスケーラブルな監視を実現し、実験により最先端の手法を上回る性能を示した。
Comment元ポスト:https://x.com/fengyao1909/status/1930377346693116350?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q現在のCoding LLMはUnitTestを通るように学習されるが、UnitTestに通るからといってコードの品質が良いわけでは無いので、UnitTestに通るか否かのReward(Functionality)に加えて、RL中に生成されたコードを制御フローグラフ[^1]に変換し汚染解析[^2]をした結果をRewardに組み込むことで、FunctionalityとQualityを両立したよ、という話のようである。
Figure1のグラフの縦軸は、Functionalityと(UnitTestが通ったか否か)と、Quailty(セキュリティや保守性に関する問題が検出されなかった)、という両方の条件を満たした割合である点に注意。


[^1]:プログラムを実行したときに通る可能性のある経路のすべてをグラフとして表したもの[引用元](https://qiita.com/uint256_t/items/7d4556cb8f5997b9e95c)
[^2]:信頼できない汚染されたデータがプログラム中でどのように処理されるかを分析すること #NLP #LanguageModel #RLVR Issue Date: 2025-06-05 [Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Problems and Verifiable Rewards, Xun Lu, arXiv'25 Summary非検証可能なタスクにおける強化学習のギャップを埋めるため、ペアワイズ生成報酬モデル(GenRM)とブートストラップ相対ポリシー最適化(BRPO)アルゴリズムを提案。これにより、主観的評価を信頼性のある検証可能な報酬に変換し、動的なペアワイズ比較を実現。提案手法は、LLMsの執筆能力を向上させ、スカラー報酬ベースラインに対して一貫した改善を示し、競争力のある結果を達成。全ての言語タスクに適用可能な包括的なRLトレーニングパラダイムの可能性を示唆。 Comment元ポスト:https://x.com/grad62304977/status/1929996614883783170?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWriting Principleに基づいて(e.g., 一貫性、創造性とか?)批評を記述し、最終的に与えられたペアワイズのテキストの優劣を判断するGenerative Reward Model (GenRM; Reasoning Traceを伴い最終的にRewardに変換可能な情報をoutpuするモデル) を学習し、現在生成したresponseグループの中からランダムに一つ擬似的なreferenceを決定し、他のresponseに対しGenRMを適用することで報酬を決定する(BRPO)、といったことをやるらしい。
これにより、創造的な文書作成のような客観的なground truthを適用できないタスクでも、RLVRの恩恵をあずかれるようになる(Bridging the gap)といったことを主張している。RLVRの恩恵とは、Reward Hackingされづらい高品質な報酬、ということにあると思われる。ので、要は従来のPreference dataだけで学習したReward Modelよりも、よりReward Hackingされないロバストな学習を実現できるGenerative Reward Modelを提案し、それを適用する手法BRPOも提案しました、という話に見える。関連:
・2274 #NLP #LanguageModel #ReinforcementLearning #Programming #SoftwareEngineering #UnitTest Issue Date: 2025-06-05 [Paper Note] Co-Evolving LLM Coder and Unit Tester via Reinforcement Learning, Yinjie Wang+, arXiv'25 SummaryCUREは、コーディングとユニットテスト生成を共進化させる強化学習フレームワークで、真のコードを監視せずにトレーニングを行う。ReasonFlux-Coderモデルは、コード生成精度を向上させ、下流タスクにも効果的に拡張可能。ユニットテスト生成では高い推論効率を達成し、強化学習のための効果的な報酬モデルとして機能する。 Comment元ポスト:https://x.com/lingyang_pu/status/1930234983274234232?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QUnitTestの性能向上させます系の研究が増えてきている感関連ポスト:https://x.com/gm8xx8/status/1930348014146859345?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #LanguageModel #MulltiModal #RLVR #DataMixture Issue Date: 2025-06-05 [Paper Note] MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning, Yiqing Liang+, arXiv'25 Summary検証可能な報酬を用いた強化学習(RLVR)をマルチモーダルLLMsに適用するためのポストトレーニングフレームワークを提案。異なる視覚と言語の問題を含むデータセットをキュレーションし、最適なデータ混合戦略を導入。実験により、提案した戦略がMLLMの推論能力を大幅に向上させることを示し、分布外ベンチマークで平均5.24%の精度向上を達成。 Comment元ポスト:https://x.com/_vztu/status/1930312780701413498?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qマルチモーダルな設定でRLVRを適用すると、すべてのデータセットを学習に利用する場合より、特定のタスクのみのデータで学習した方が当該タスクでは性能が高くなったり(つまりデータが多ければ多いほど良いわけでは無い)、特定のデータをablationするとOODに対する予測性能が改善したりするなど、データ間で干渉が起きて敵対的になってしまうような現象が起きる。このことから、どのように適切にデータを混合できるか?という戦略の必要性が浮き彫りになり、モデルベースなMixture戦略(どうやらデータの混合分布から学習後の性能を予測するモデルな模様)の性能がuniformにmixするよりも高い性能を示した、みたいな話らしい。 #Analysis #NLP #LanguageModel #read-later #Memorization Issue Date: 2025-06-05 [Paper Note] How much do language models memorize?, John X. Morris+, arXiv'25 Summaryモデルの「知識」を推定する新手法を提案し、言語モデルの能力を測定。記憶を「意図しない記憶」と「一般化」に分け、一般化を排除することで総記憶を計算。GPTスタイルのモデルは約3.6ビット/パラメータの能力を持つと推定。データセットのサイズ増加に伴い、モデルは記憶を保持し、一般化が始まると意図しない記憶が減少。数百のトランスフォーマー言語モデルを訓練し、能力とデータサイズの関係を示すスケーリング法則を生成。 Comment元ポスト:https://x.com/rohanpaul_ai/status/1929989864927146414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #EMNLP Issue Date: 2025-06-05 [Paper Note] Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem, Yubo Wang+, EMNLP'25 Summary本研究では、強力な大規模言語モデル(LLM)の推論能力を引き出すために、批評微調整(CFT)が効果的であることを示します。CFTは、単一の問題に対する多様な解を収集し、教師LLMによる批評データを構築する手法です。QwenおよびLlamaモデルを微調整した結果、数学や論理推論のベンチマークで顕著な性能向上を観察しました。特に、わずか5時間のトレーニングで、Qwen-Math-7B-CFTは他の手法と同等以上の成果を上げました。CFTは計算効率が高く、現代のLLMの推論能力を引き出すためのシンプルなアプローチであることが示されました。 Comment元ポスト:https://x.com/wenhuchen/status/1930447298527670662?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1832
・1938参考:https://x.com/weiliu99/status/1930826904522875309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #LLMAgent #SelfImprovement #read-later Issue Date: 2025-06-05 [Paper Note] Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents, Jenny Zhang+, arXiv'25 Summaryダーヴィン・ゴーデルマシン(DGM)は、自己改善するAIシステムであり、コードを反復的に修正し、コーディングベンチマークで変更を検証します。進化とオープンエンドな研究に基づき、生成されたエージェントのアーカイブを維持し、新しいバージョンを作成することで多様なエージェントを育成します。DGMはコーディング能力を自動的に向上させ、SWE-benchでのパフォーマンスを20.0%から50.0%、Polyglotでのパフォーマンスを14.2%から30.7%に改善しました。安全対策を講じた実験により、自己改善を行わないベースラインを大幅に上回る成果を示しました。 Comment元ポスト:https://www.linkedin.com/posts/omarsar_new-paper-open-ended-evolution-of-self-improving-activity-7334610178832556033-8dA-?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4・1212
あたりの研究とはどう違うのだろうか、という点が気になる。 #Analysis #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-06-04 [Paper Note] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, Mingjie Liu+, arXiv'25 Summary強化学習(RL)が言語モデルの推論能力を向上させる可能性を探る本研究では、長期的なRL(ProRL)トレーニングが新しい推論戦略を明らかにできることを示します。新しいトレーニング手法ProRLを導入し、実証分析により、RLでトレーニングされたモデルが基礎モデルを上回ることが確認されました。推論の改善は基礎モデルの能力やトレーニング期間と相関しており、RLが新しい解決空間を探索できることを示唆しています。これにより、RLが言語モデルの推論を拡張する条件に関する新たな洞察が得られ、今後の研究の基盤が築かれます。モデルの重みは公開されています。 Comment元ポスト:https://x.com/hillbig/status/1930043688329326962?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRLVR(math, code(従来はこの2種類), STEM, logic Puzzles, instruction following)によって大規模なスケール(長期的に学習をする; 2k training stepsと多様なタスクでの学習データ)で実験をし、定期的にReferenceポリシーとOptimizerをリセットすることで、元のポリシーからの乖離を防ぎつつも、新たな学習が進むようなことをしている模様。
(※PFNのランチタイムトークを参考に記述)
verlを用いて、DAPOで学習をしている。

・1969
・1815 #NLP #LanguageModel #Verification Issue Date: 2025-06-03 [Paper Note] xVerify: Efficient Answer Verifier for Reasoning Model Evaluations, Ding Chen+, arXiv'25 Summary推論モデルの評価のために、xVerifyという効率的な回答検証器を提案。xVerifyは、LLMが生成した回答が参照解答と同等であるかを効果的に判断できる。VARデータセットを構築し、複数のLLMからの質問-回答ペアを収集。評価実験では、すべてのxVerifyモデルが95%を超えるF1スコアと精度を達成し、特にxVerify-3B-IbはGPT-4oを超える性能を示した。 #NLP #LanguageModel #read-later #VerifiableRewards #RLVR #Verification Issue Date: 2025-06-03 [Paper Note] Pitfalls of Rule- and Model-based Verifiers -- A Case Study on Mathematical Reasoning, Yuzhen Huang+, arXiv'25 Summary本研究では、数学的推論における検証者の信頼性とそのRL訓練プロセスへの影響を分析。ルールベースの検証者は偽陰性率が高く、RL訓練のパフォーマンスに悪影響を及ぼすことが判明。モデルベースの検証者は静的評価で高精度を示すが、偽陽性に対して脆弱であり、報酬が不正に膨らむ可能性がある。これにより、強化学習における堅牢な報酬システムの必要性が示唆される。 Comment元ポスト:https://x.com/junxian_he/status/1929371821767586284?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qverificationタスクに特化してfinetuningされたDiscriminative Classifierが、reward hackingに対してロバストであることが示唆されている模様。
Discriminative Verifierとは、Question, Response, Reference Answerがgivenな時に、response(しばしばreasoning traceを含み複数のanswerの候補が記述されている)の中から最終的なanswerを抽出し、Reference answerと抽出したanswerから正解/不正解をbinaryで出力するモデルのこと。Rule-based Verifierではフォーマットが異なっている場合にfalse negativeとなってしまうし、そもそもルールが規定できないタスクの場合は適用できない。Discriminative Verifierではそのようなケースでも適用できると考えられる。Discriminative Verifierの例はたとえば下記:
https://huggingface.co/IAAR-Shanghai/xVerify-0.5B-I
・2010 #NLP #LanguageModel #LLMAgent #SelfImprovement Issue Date: 2025-06-03 [Paper Note] Self-Challenging Language Model Agents, Yifei Zhou+, arXiv'25 SummarySelf-Challengingフレームワークを提案し、エージェントが自ら生成した高品質なタスクで訓練。エージェントは挑戦者としてタスクを生成し、実行者として強化学習を用いて訓練。M3ToolEvalとTauBenchでLlama-3.1-8B-Instructが2倍以上の改善を達成。 Comment元ポスト:https://x.com/jaseweston/status/1929719473952497797?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/omarsar0/status/1930748591242424439?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #Evaluation #Reasoning Issue Date: 2025-06-01 [Paper Note] BIG-Bench Extra Hard, Mehran Kazemi+, arXiv'25 Summary大規模言語モデル(LLMs)の推論能力を評価するための新しいベンチマーク、BIG-Bench Extra Hard(BBEH)を導入。これは、既存のBIG-Bench Hard(BBH)のタスクを新しいものに置き換え、難易度を大幅に引き上げることで、LLMの限界を押し広げることを目的としている。評価の結果、最良の汎用モデルで9.8%、推論専門モデルで44.8%の平均精度が観察され、LLMの一般的推論能力向上の余地が示された。BBEHは公開されている。 CommentBig-Bench hard(既にSoTAモデルの能力差を識別できない)の難易度をさらに押し上げたデータセット。
Inputの例

タスクごとのInput, Output lengthの分布


現在の主要なモデル群の性能
 Big-Bench論文はこちら:
Big-Bench論文はこちら:
・785 #NLP #LanguageModel #LLMAgent #SoftwareEngineering #read-later Issue Date: 2025-06-01 [Paper Note] Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering, Guangtao Zeng+, arXiv'25 SummaryEvoScaleを提案し、進化的プロセスを用いて小型言語モデルの性能を向上させる手法を開発。選択と突然変異を通じて出力を洗練し、サンプル数を減少させる。強化学習を用いて自己進化を促進し、SWE-Bench-Verifiedで32Bモデルが100B以上のモデルと同等以上の性能を示す。コード、データ、モデルはオープンソースとして公開予定。 Comment元ポスト:https://x.com/gan_chuang/status/1928963872188244400?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Chain-of-Thought #COLING Issue Date: 2025-05-29 Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs, Yu Xia+, COLING'25 SummaryChain-of-Thought(CoT)を基にしたChain-of-X(CoX)手法の調査を行い、LLMsの課題に対処するための多様なアプローチを分類。ノードの分類とアプリケーションタスクに基づく分析を通じて、既存の手法の意義と今後の可能性を議論。研究者にとって有用なリソースを提供することを目指す。 #NLP #LanguageModel #Distillation #ICML #Scaling Laws Issue Date: 2025-05-29 Distillation Scaling Laws, Dan Busbridge+, ICML'25 Summary蒸留モデルの性能を推定するための蒸留スケーリング法則を提案。教師モデルと生徒モデルの計算割り当てを最適化することで、生徒の性能を最大化。教師が存在する場合やトレーニングが必要な場合に最適な蒸留レシピを提供。多くの生徒を蒸留する際は、監視付きの事前学習を上回るが、生徒のサイズに応じた計算レベルまで。単一の生徒を蒸留し、教師がトレーニング必要な場合は監視学習を推奨。蒸留に関する洞察を提供し、理解を深める。 Comment著者ポスト:https://x.com/danbusbridge/status/1944539357542781410?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Temporal #LanguageModel #read-later Issue Date: 2025-05-27 Temporal Sampling for Forgotten Reasoning in LLMs, Yuetai Li+, arXiv'25 Summaryファインチューニング中にLLMsが以前の正しい解法を忘れる「時間的忘却」を発見。これに対処するために「時間的サンプリング」というデコーディング戦略を導入し、複数のチェックポイントから出力を引き出すことで推論性能を向上。Pass@kで4から19ポイントの改善を達成し、LoRA適応モデルでも同様の利点を示す。時間的多様性を活用することで、LLMsの評価方法を再考する手段を提供。 Comment元ポスト:https://x.com/iscienceluvr/status/1927286319018832155?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QTemporal ForgettingとTemporal Sampling #NLP #LanguageModel #ReinforcementLearning #Reasoning Issue Date: 2025-05-27 Learning to Reason without External Rewards, Xuandong Zhao+, arXiv'25 Summary本研究では、外部の報酬やラベルなしで大規模言語モデル(LLMs)が学習できるフレームワーク「内部フィードバックからの強化学習(RLIF)」を提案。自己確信を報酬信号として用いる「Intuitor」を開発し、無監視の学習を実現。実験結果は、Intuitorが数学的ベンチマークで優れた性能を示し、ドメイン外タスクへの一般化能力も高いことを示した。内因的信号が効果的な学習を促進する可能性を示唆し、自律AIシステムにおけるスケーラブルな代替手段を提供。 Comment元ポスト:https://x.com/xuandongzhao/status/1927270931874910259?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおもしろそうexternalなsignalをrewardとして用いないで、モデル自身が内部的に保持しているconfidenceを用いる。人間は自信がある問題には正解しやすいという直感に基づいており、openendなquestionのようにそもそも正解シグナルが定義できないものもあるが、そういった場合に活用できるようである。self-trainingの考え方に近いのではベースモデルの段階である程度能力が備わっており、post-trainingした結果それが引き出されるようになったという感じなのだろうか。
参考: https://x.com/weiliu99/status/1930826904522875309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #LongSequence #OpenWeight Issue Date: 2025-05-27 QwenLong-CPRS: Towards $\infty$-LLMs with Dynamic Context Optimization, Weizhou Shen+, arXiv'25 SummaryQwenLong-CPRSは、長文コンテキスト最適化のための新しいフレームワークで、LLMsの性能低下を軽減します。自然言語指示に基づく多段階のコンテキスト圧縮を実現し、効率と性能を向上させる4つの革新を導入。5つのベンチマークで、他の手法に対して優位性を示し、主要なLLMとの統合で大幅なコンテキスト圧縮と性能向上を達成。QwenLong-CPRSは新たなSOTA性能を確立しました。 Comment元ポスト:https://x.com/_akhaliq/status/1927014346690826684?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #LongSequence #OpenWeight #read-later Issue Date: 2025-05-27 QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning, Fanqi Wan+, arXiv'25 Summary長いコンテキストの推論におけるLRMsの課題を解決するため、QwenLong-L1フレームワークを提案。ウォームアップ監視付きファインチューニングとカリキュラム指導型段階的RLを用いてポリシーの安定化を図り、難易度認識型の回顧的サンプリングで探索を促進。実験では、QwenLong-L1-32Bが他のLRMsを上回り、優れた性能を示した。 Comment元ポスト:https://x.com/_akhaliq/status/1927011243597967524?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Mathematics #InstructionFollowingCapability Issue Date: 2025-05-24 Scaling Reasoning, Losing Control: Evaluating Instruction Following in Large Reasoning Models, Tingchen Fu+, arXiv'25 Summary指示に従う能力はLLMにとって重要であり、MathIFという数学的推論タスク用のベンチマークを提案。推論能力の向上と指示遵守の間には緊張関係があり、特に長い思考の連鎖を持つモデルは指示に従いにくい。介入により部分的な従順さを回復できるが、推論性能が低下することも示された。これらの結果は、指示に敏感な推論モデルの必要性を示唆している。 Comment元ポスト:https://x.com/yafuly/status/1925753754961236006?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #LanguageModel #Conversation Issue Date: 2025-05-24 LLMs Get Lost In Multi-Turn Conversation, Philippe Laban+, arXiv'25 SummaryLLMsは会話型インターフェースとして、ユーザーがタスクを定義するのを支援するが、マルチターンの会話ではパフォーマンスが低下する。シミュレーション実験の結果、マルチターンで39%のパフォーマンス低下が見られ、初期のターンでの仮定に依存しすぎることが原因と判明。LLMsは会話中に誤った方向に進むと、回復が難しくなることが示された。 Comment元ポスト:https://x.com/_stakaya/status/1926009283386155009?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLost in the MiddleならぬLost in Conversation
 関連:
関連:
・793 #ComputerVision #NLP #LanguageModel #MulltiModal #DiffusionModel Issue Date: 2025-05-24 LaViDa: A Large Diffusion Language Model for Multimodal Understanding, Shufan Li+, arXiv'25 SummaryLaViDaは、離散拡散モデル(DM)を基にしたビジョン・ランゲージモデル(VLM)で、高速な推論と制御可能な生成を実現。新技術を取り入れ、マルチモーダルタスクにおいてAR VLMと競争力のある性能を達成。COCOキャプショニングで速度向上と性能改善を示し、AR VLMの強力な代替手段であることを証明。 Comment元ポスト:https://x.com/iscienceluvr/status/1925749919312159167?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QDiffusion Modelの波が来た同程度のサイズのARモデルをoutperform [^1]

[^1]:ただし、これが本当にDiffusion Modelを使ったことによる恩恵なのかはまだ論文を読んでいないのでわからない。必要になったら読む。ただ、Physics of Language Modelのように、完全にコントロールされたデータで異なるアーキテクチャを比較しないとその辺はわからなそうではある。 #EfficiencyImprovement #NLP #LanguageModel #DiffusionModel Issue Date: 2025-05-24 dKV-Cache: The Cache for Diffusion Language Models, Xinyin Ma+, arXiv'25 Summary拡散言語モデル(DLM)の遅い推論を改善するために、遅延KVキャッシュを提案。これは、異なるトークンの表現ダイナミクスに基づくキャッシング戦略で、2つのバリアントを設計。dKV-Cache-Decodeは損失の少ない加速を提供し、dKV-Cache-Greedyは高いスピードアップを実現。最終的に、推論速度を2〜10倍向上させ、DLMの性能を強化することを示した。 Comment元ポスト:https://x.com/arankomatsuzaki/status/1925384029718946177?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q提案手法を適用した場合、ARなモデルとDiffusion Modelで、実際のところどの程度のdecoding速度の差があるのだろうか?そういった分析はざーーっと見た感じ見当たらなかったように思える。 #Embeddings #NLP #LanguageModel #RepresentationLearning #DiffusionModel Issue Date: 2025-05-24 Diffusion vs. Autoregressive Language Models: A Text Embedding Perspective, Siyue Zhang+, arXiv'25 Summary拡散言語モデルを用いたテキスト埋め込みが、自己回帰的なLLMの一方向性の制限を克服し、文書検索や推論タスクで優れた性能を発揮。長文検索で20%、推論集約型検索で8%、指示に従った検索で2%の向上を示し、双方向の注意が重要であることを確認。 Comment元ポスト:https://x.com/trtd6trtd/status/1925775950500806742?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Evaluation #ICLR #Contamination #Admin'sPick Issue Date: 2025-05-23 LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25 Summaryテストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Commentテストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究 #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Scaling Laws Issue Date: 2025-05-21 Parallel Scaling Law for Language Models, Mouxiang Chen+, arXiv'25 Summary本研究では、言語モデルのスケーリングにおいて、並列計算を増加させる新しい手法「ParScale」を提案。これにより、モデルの前方パスを並列に実行し、出力を動的に集約することで、推論効率を向上させる。ParScaleは、少ないメモリ増加とレイテンシで同等の性能向上を実現し、既存のモデルを再利用することでトレーニングコストも削減可能。新しいスケーリング法則は、リソースが限られた状況での強力なモデル展開を促進する。 Comment元ポスト:https://x.com/hillbig/status/1924959706331939099?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・405
と考え方が似ている #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #Reasoning Issue Date: 2025-05-21 AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning, Chenwei Lou+, arXiv'25 SummaryAdaCoT(Adaptive Chain-of-Thought)は、LLMsが推論を適応的に行う新しいフレームワークで、CoTの呼び出しタイミングを最適化します。強化学習を用いて、クエリの複雑さに基づいてCoTの必要性を判断し、計算コストを削減します。実験では、AdaCoTがCoTトリガー率を3.18%に低下させ、応答トークンを69.06%減少させつつ、高い性能を維持することが示されました。 CommentRLのRewardにおいて、bassのリワードだけでなく、
・reasoningをなくした場合のペナルティ項
・reasoningをoveruseした場合のペナルティ項
・formattingに関するペナルティ項
を設定し、reasoningの有無を適切に判断できた場合にrewardが最大化されるような形にしている。(2.2.2)
が、multi-stageのRLでは(stageごとに利用するデータセットを変更するが)、データセットの分布には歪みがあり、たとえば常にCoTが有効なデータセットも存在しており(数学に関するデータなど)、その場合常にCoTをするような分布を学習してしまい、AdaptiveなCoT decisionが崩壊したり、不安定になってしまう(decision boundary collapseと呼ぶ)。特にこれがfinal stageで起きると最悪で、これまでAdaptiveにCoTされるよう学習されてきたものが全て崩壊してしまう。これを防ぐために、Selective Loss Maskingというlossを導入している。具体的には、decision token [^1]のlossへの貢献をマスキングするようにすることで、CoTが生じるratioにバイアスがかからないようにする。今回は、Decision tokenとして、``トークン直後のトークンをdecision tokenとみなし、lossに対する貢献をマスクしている(Selective Loss Masking)。
[^1]: CoTするかどうかは多くの場合このDecision Tokenによって決まる、といったことがどっかの研究に示されていたはずいつか必要になったらしっかり読むが、全てのステージでSelective Loss Maskingをしたら、SFTでwarm upした段階からあまりCoTのratioが変化しないような学習のされ方になる気がするが、どのステージに対してapplyするのだろうか。</span> #Pretraining #MachineLearning #NLP #LanguageModel #ModelMerge Issue Date: 2025-05-20 Model Merging in Pre-training of Large Language Models, Yunshui Li+, arXiv'25 Summaryモデルマージングは大規模言語モデルの強化に有望な技術であり、本論文ではその事前学習プロセスにおける包括的な調査を行う。実験により、一定の学習率で訓練されたチェックポイントをマージすることで性能向上とアニーリング挙動の予測が可能になることを示し、効率的なモデル開発と低コストのトレーニングに寄与する。マージ戦略やハイパーパラメータに関するアブレーション研究を通じて新たな洞察を提供し、実用的な事前学習ガイドラインをオープンソースコミュニティに提示する。 Comment元ポスト:https://x.com/iscienceluvr/status/1924804324812873990?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/giffmana/status/1924849877634449878?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #QuestionAnswering #KnowledgeGraph #Factuality #Reasoning #Test-Time Scaling #PostTraining Issue Date: 2025-05-20 Scaling Reasoning can Improve Factuality in Large Language Models, Mike Zhang+, arXiv'25 Summary本研究では、オープンドメインの質問応答における大規模言語モデル(LLM)の推論能力を検討し、推論の痕跡を抽出してファインチューニングを行った。知識グラフからの情報を導入し、168回の実験を通じて170万の推論を分析した結果、小型モデルが元のモデルよりも事実の正確性を顕著に改善し、計算リソースを追加することでさらに2-8%の向上が確認された。実験成果は公開され、さらなる研究に寄与する。 Comment元ポスト:https://x.com/_akhaliq/status/1924477447120068895?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #LLMServing #Architecture #MoE(Mixture-of-Experts) #SoftwareEngineering Issue Date: 2025-05-20 Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures, Chenggang Zhao+, arXiv'25 SummaryDeepSeek-V3は、2,048台のNVIDIA H800 GPUでトレーニングされ、ハードウェア制約に対処するための共同設計を示す。メモリ効率向上のためのマルチヘッド潜在注意や、計算と通信の最適化を図る専門家の混合アーキテクチャ、FP8混合精度トレーニングなどの革新を強調。ハードウェアのボトルネックに基づく将来の方向性について議論し、AIワークロードに応えるためのハードウェアとモデルの共同設計の重要性を示す。 Comment元ポスト:https://x.com/deedydas/status/1924512147947848039?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #SyntheticData #ACL #DPO #PostTraining #Probing Issue Date: 2025-05-18 Why Vision Language Models Struggle with Visual Arithmetic? Towards Enhanced Chart and Geometry Understanding, Kung-Hsiang Huang+, ACL'25 SummaryVision Language Models (VLMs)は視覚的算術に苦労しているが、CogAlignという新しいポストトレーニング戦略を提案し、VLMの性能を向上させる。CogAlignは視覚的変換の不変特性を認識するように訓練し、CHOCOLATEで4.6%、MATH-VISIONで2.9%の性能向上を実現し、トレーニングデータを60%削減。これにより、基本的な視覚的算術能力の向上と下流タスクへの転送の効果が示された。 Comment元ポスト:https://x.com/steeve__huang/status/1923543884367306763?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q既存のLLM (proprietary, openweightそれぞれ)が、シンプルなvisual arithmeticタスク(e.g., 線分の長さ比較, Chart上のdotの理解)などの性能が低いことを明らかにし、

それらの原因を(1)Vision Encoderのrepresentationと(2)Vision EncoderをFreezeした上でのText Decoderのfinetuningで分析した。その結果、(1)ではいくつかのタスクでlinear layerのprobingでは高い性能が達成できないことがわかった。このことから、Vision Encoderによるrepresentationがタスクに関する情報を内包できていないか、タスクに関する情報は内包しているがlinear layerではそれを十分に可能できない可能性が示唆された。

これをさらに分析するために(2)を実施したところ、Vision Encoderをfreezeしていてもfinetuningによりquery stringに関わらず高い性能を獲得できることが示された。このことから、Vision Encoder側のrepresentationの問題ではなく、Text Decoderと側でデコードする際にFinetuningしないとうまく活用できないことが判明した。
 手法のところはまだ全然しっかり読めていないのだが、画像に関する特定の属性に関するクエリと回答のペアを合成し、DPOすることで、zero-shotの性能が向上する、という感じっぽい?
手法のところはまだ全然しっかり読めていないのだが、画像に関する特定の属性に関するクエリと回答のペアを合成し、DPOすることで、zero-shotの性能が向上する、という感じっぽい?

 #NLP
#LanguageModel
#ReinforcementLearning
#LLM-as-a-Judge
#PostTraining
#GRPO
#VerifiableRewards
Issue Date: 2025-05-16
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning, Chenxi Whitehouse+, arXiv'25
Summary本研究では、強化学習アプローチJ1を用いてLLMのトレーニング手法を提案し、判断タスクにおける思考促進とバイアス軽減を図ります。J1は、他の同サイズモデルを上回る性能を示し、特に小型モデルでも優れた結果を出します。モデルは自己生成した参照回答と比較することで、より良い判断を学ぶことが明らかになりました。
Comment元ポスト:https://x.com/jaseweston/status/1923186392420450545?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLM-as-a-Judgeのなめのモデルを学習するレシピにおいて、初めてRLを適用した研究と主張し、より高品質なreasoning traceを出力できるようにすることで性能向上をさせる。
#NLP
#LanguageModel
#ReinforcementLearning
#LLM-as-a-Judge
#PostTraining
#GRPO
#VerifiableRewards
Issue Date: 2025-05-16
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning, Chenxi Whitehouse+, arXiv'25
Summary本研究では、強化学習アプローチJ1を用いてLLMのトレーニング手法を提案し、判断タスクにおける思考促進とバイアス軽減を図ります。J1は、他の同サイズモデルを上回る性能を示し、特に小型モデルでも優れた結果を出します。モデルは自己生成した参照回答と比較することで、より良い判断を学ぶことが明らかになりました。
Comment元ポスト:https://x.com/jaseweston/status/1923186392420450545?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLM-as-a-Judgeのなめのモデルを学習するレシピにおいて、初めてRLを適用した研究と主張し、より高品質なreasoning traceを出力できるようにすることで性能向上をさせる。
具体的にはVerifiableなpromptとnon verifiableなpromptの両方からverifiableなpreference pairを作成しpointwiseなスコアリング、あるいはpairwiseなjudgeを学習するためのrewardを設計しGRPOで学習する、みたいな話っぽい。
non verifiableなpromptも用いるのは、そういったpromptに対してもjudgeできるモデルを構築するため。
mathに関するpromptはverifiableなのでレスポンスが不正解なものをrejection samplingし、WildChatのようなチャットはverifiableではないので、instructionにノイズを混ぜて得られたレスポンスをrejection samplingし、合成データを得ることで、non verifiableなpromptについても、verifiableなrewardを設計できるようになる。
 #EfficiencyImprovement
#NLP
#LanguageModel
#ICLR
#Test-Time Scaling
#Verification
#SpeculativeDecoding
Issue Date: 2025-05-13
Faster Cascades via Speculative Decoding, Harikrishna Narasimhan+, ICLR'25
Summaryカスケードと推測デコーディングは、言語モデルの推論効率を向上させる手法であり、異なるメカニズムを持つ。カスケードは難しい入力に対して大きなモデルを遅延的に使用し、推測デコーディングは並行検証で大きなモデルを活用する。新たに提案する推測カスケーディング技術は、両者の利点を組み合わせ、最適な遅延ルールを特定する。実験結果は、提案手法がカスケードおよび推測デコーディングのベースラインよりも優れたコスト品質トレードオフを実現することを示した。
Comment元ポスト:https://x.com/hillbig/status/1922059828429832259?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview: https://openreview.net/forum?id=vo9t20wsmd
#NLP
#LanguageModel
#Library
#KnowledgeEditing
Issue Date: 2025-05-11
EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models, Ziwen Xu+, arXiv'25
Summary本論文では、LLMの挙動を制御するためのフレームワーク「EasyEdit2」を提案。安全性や感情、個性などの介入をサポートし、使いやすさが特徴。ユーザーは技術的知識なしでモデルの応答を調整可能。新しいアーキテクチャにより、ステアリングベクトルを自動生成・適用するモジュールを搭載。実証的なパフォーマンスを報告し、ソースコードやデモも公開。
Commentgithub:https://github.com/zjunlp/EasyEdit/tree/main
#EfficiencyImprovement
#Pretraining
#NLP
#Dataset
#LanguageModel
#ACL
#Admin'sPick
Issue Date: 2025-05-10
Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25
SummaryFineWeb-EduとDCLMは、モデルベースのフィルタリングによりデータの90%を削除し、トレーニングに適さなくなった。著者は、アンサンブル分類器や合成データの言い換えを用いて、精度とデータ量のトレードオフを改善する手法を提案。1Tトークンで8Bパラメータモデルをトレーニングし、DCLMに対してMMLUを5.6ポイント向上させた。新しい6.3Tトークンデータセットは、DCLMと同等の性能を持ちながら、4倍のユニークなトークンを含み、長トークンホライズンでのトレーニングを可能にする。15Tトークンのためにトレーニングされた8Bモデルは、Llama 3.1の8Bモデルを上回る性能を示した。データセットは公開されている。
#Pretraining
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Safety
#DPO
#Toxicity
#ActivationSteering/ITI
Issue Date: 2025-05-09
When Bad Data Leads to Good Models, Kenneth Li+, arXiv'25
Summary本論文では、LLMの事前学習におけるデータの質の再検討を行い、有害データが事後学習における制御を向上させる可能性を探ります。トイ実験を通じて、有害データの割合が増加することで有害性の概念が線形表現に影響を与えることを発見し、有害データが生成的有害性を増加させつつも除去しやすくなることを示しました。評価結果は、有害データで訓練されたモデルが生成的有害性を低下させつつ一般的な能力を保持する良好なトレードオフを達成することを示唆しています。
Comment元ポスト:https://x.com/ke_li_2021/status/1920646069613957606?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは面白そうWebコーパスなどを事前学習で利用する際は、質の高いデータを残して学習した方が良いとされているが、4chanのようなtoxicなデータを混ぜて事前学習して、後からdetox(Inference Time Intervention 1941 , SFT, DPO)することで、最終的なモデルのtoxicなoutputが減るという話らしい。これはそもそも事前学習時点でtoxicなデータのsignalが除外されることで、モデルがtoxicな内容のrepresentationを学習できず、最終的にtoxicか否かをコントロールできなくなるため、と考察している(っぽい)
#EfficiencyImprovement
#NLP
#LanguageModel
#ICLR
#Test-Time Scaling
#Verification
#SpeculativeDecoding
Issue Date: 2025-05-13
Faster Cascades via Speculative Decoding, Harikrishna Narasimhan+, ICLR'25
Summaryカスケードと推測デコーディングは、言語モデルの推論効率を向上させる手法であり、異なるメカニズムを持つ。カスケードは難しい入力に対して大きなモデルを遅延的に使用し、推測デコーディングは並行検証で大きなモデルを活用する。新たに提案する推測カスケーディング技術は、両者の利点を組み合わせ、最適な遅延ルールを特定する。実験結果は、提案手法がカスケードおよび推測デコーディングのベースラインよりも優れたコスト品質トレードオフを実現することを示した。
Comment元ポスト:https://x.com/hillbig/status/1922059828429832259?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview: https://openreview.net/forum?id=vo9t20wsmd
#NLP
#LanguageModel
#Library
#KnowledgeEditing
Issue Date: 2025-05-11
EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models, Ziwen Xu+, arXiv'25
Summary本論文では、LLMの挙動を制御するためのフレームワーク「EasyEdit2」を提案。安全性や感情、個性などの介入をサポートし、使いやすさが特徴。ユーザーは技術的知識なしでモデルの応答を調整可能。新しいアーキテクチャにより、ステアリングベクトルを自動生成・適用するモジュールを搭載。実証的なパフォーマンスを報告し、ソースコードやデモも公開。
Commentgithub:https://github.com/zjunlp/EasyEdit/tree/main
#EfficiencyImprovement
#Pretraining
#NLP
#Dataset
#LanguageModel
#ACL
#Admin'sPick
Issue Date: 2025-05-10
Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25
SummaryFineWeb-EduとDCLMは、モデルベースのフィルタリングによりデータの90%を削除し、トレーニングに適さなくなった。著者は、アンサンブル分類器や合成データの言い換えを用いて、精度とデータ量のトレードオフを改善する手法を提案。1Tトークンで8Bパラメータモデルをトレーニングし、DCLMに対してMMLUを5.6ポイント向上させた。新しい6.3Tトークンデータセットは、DCLMと同等の性能を持ちながら、4倍のユニークなトークンを含み、長トークンホライズンでのトレーニングを可能にする。15Tトークンのためにトレーニングされた8Bモデルは、Llama 3.1の8Bモデルを上回る性能を示した。データセットは公開されている。
#Pretraining
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Safety
#DPO
#Toxicity
#ActivationSteering/ITI
Issue Date: 2025-05-09
When Bad Data Leads to Good Models, Kenneth Li+, arXiv'25
Summary本論文では、LLMの事前学習におけるデータの質の再検討を行い、有害データが事後学習における制御を向上させる可能性を探ります。トイ実験を通じて、有害データの割合が増加することで有害性の概念が線形表現に影響を与えることを発見し、有害データが生成的有害性を増加させつつも除去しやすくなることを示しました。評価結果は、有害データで訓練されたモデルが生成的有害性を低下させつつ一般的な能力を保持する良好なトレードオフを達成することを示唆しています。
Comment元ポスト:https://x.com/ke_li_2021/status/1920646069613957606?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは面白そうWebコーパスなどを事前学習で利用する際は、質の高いデータを残して学習した方が良いとされているが、4chanのようなtoxicなデータを混ぜて事前学習して、後からdetox(Inference Time Intervention 1941 , SFT, DPO)することで、最終的なモデルのtoxicなoutputが減るという話らしい。これはそもそも事前学習時点でtoxicなデータのsignalが除外されることで、モデルがtoxicな内容のrepresentationを学習できず、最終的にtoxicか否かをコントロールできなくなるため、と考察している(っぽい)

 有害な出力を減らせそうなことは分かったが、Activation Steeringによってどの程度モデルの性能に影響を与えるのかが気になる、と思ったがAppendixに記載があった。細かく書かれていないので推測を含むが、各データに対してToxicデータセットでProbingすることでTopKのheadを決めて、Kの値を調整することでinterventionの強さを調整し、Toxicデータの割合を変化させて評価してみたところ、モデルの性能に大きな影響はなかったということだと思われる(ただし1Bモデルでの実験しかない)
有害な出力を減らせそうなことは分かったが、Activation Steeringによってどの程度モデルの性能に影響を与えるのかが気になる、と思ったがAppendixに記載があった。細かく書かれていないので推測を含むが、各データに対してToxicデータセットでProbingすることでTopKのheadを決めて、Kの値を調整することでinterventionの強さを調整し、Toxicデータの割合を変化させて評価してみたところ、モデルの性能に大きな影響はなかったということだと思われる(ただし1Bモデルでの実験しかない)

おそらく2,3節あたりが一番おもしろいポイントなのだと思われるがまだ読めていない。 #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-05-09 Reinforcement Learning for Reasoning in Large Language Models with One Training Example, Yiping Wang+, arXiv'25 Summary1-shot RLVRを用いることで、LLMの数学的推論能力が大幅に向上することを示した。Qwen2.5-Math-1.5Bモデルは、MATH500でのパフォーマンスが36.0%から73.6%に改善され、他の数学的ベンチマークでも同様の向上が見られた。1-shot RLVR中には、クロスドメイン一般化や持続的なテストパフォーマンスの改善が観察され、ポリシー勾配損失が主な要因であることが確認された。エントロピー損失の追加も重要で、結果報酬なしでもパフォーマンスが向上した。これらの成果は、RLVRのデータ効率に関するさらなる研究を促進する。 Comment 下記ポストでQwenに対してpromptを適切に与えることで、追加のpost training無しで高い数学に関する能力を引き出せたという情報がある。おそらく事前学習時に数学のQAデータによって継続事前学習されており、この能力はその際に身についているため、数学に対する高い能力は実は簡単に引き出すことができるのかもしれない(だから1サンプルでも性能が向上したのではないか?)といった考察がある。
下記ポストでQwenに対してpromptを適切に与えることで、追加のpost training無しで高い数学に関する能力を引き出せたという情報がある。おそらく事前学習時に数学のQAデータによって継続事前学習されており、この能力はその際に身についているため、数学に対する高い能力は実は簡単に引き出すことができるのかもしれない(だから1サンプルでも性能が向上したのではないか?)といった考察がある。
参考:https://x.com/weiliu99/status/1930826904522875309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・2011
とはどのような関係性があるだろうか? #NLP #Dataset #LanguageModel #Mathematics #read-later #Coding Issue Date: 2025-05-08 Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, arXiv'25 Summary本研究では、公共データを体系的に書き換えることで大規模言語モデル(LLMs)の性能を向上させる2つのオープンライセンスデータセット、SwallowCodeとSwallowMathを紹介。SwallowCodeはPythonスニペットを洗練させる4段階のパイプラインを用い、低品質のコードをアップグレード。SwallowMathはボイラープレートを削除し、解決策を簡潔に再フォーマット。これにより、Llama-3.1-8Bのコード生成能力がHumanEvalで+17.0、GSM8Kで+12.4向上。すべてのデータセットは公開され、再現可能な研究を促進。 Comment元ポスト:https://x.com/okoge_kaz/status/1920141189652574346?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/hillbig/status/1920613041026314274?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ReinforcementLearning #SelfImprovement #read-later #RLVR #ZeroData Issue Date: 2025-05-08 Absolute Zero: Reinforced Self-play Reasoning with Zero Data, Andrew Zhao+, arXiv'25 Summary新しいRLVRパラダイム「Absolute Zero」を提案し、自己学習を通じて推論能力を向上させるAZRを導入。外部データに依存せず、コーディングや数学的推論タスクでSOTAパフォーマンスを達成。既存のゼロ設定モデルを上回り、異なるモデルスケールにも適用可能。 Comment元ポスト:https://x.com/arankomatsuzaki/status/1919946713567264917?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #PEFT(Adaptor/LoRA) #GRPO Issue Date: 2025-05-07 Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25 SummaryTinaは、コスト効率よく強力な推論能力を実現する小型の推論モデルファミリーであり、1.5Bパラメータのベースモデルに強化学習を適用することで高い推論性能を示す。Tinaは、従来のSOTAモデルと競争力があり、AIME24で20%以上の性能向上を達成し、トレーニングコストはわずか9ドルで260倍のコスト削減を実現。LoRAを通じた効率的なRL推論の効果を検証し、すべてのコードとモデルをオープンソース化している。 Comment元ポスト:https://x.com/rasbt/status/1920107023980462575?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q(おそらく)Reasoningモデルに対して、LoRAとRLを組み合わせて、reasoning能力を向上させた初めての研究 #NLP #DataGeneration #DataDistillation #SyntheticData #ICML Issue Date: 2025-05-07 R.I.P.: Better Models by Survival of the Fittest Prompts, Ping Yu+, ICML'25 Summaryトレーニングデータの品質がモデルの性能に与える影響を考慮し、低品質な入力プロンプトがもたらす問題を解決するために、Rejecting Instruction Preferences(RIP)というデータ整合性評価手法を提案。RIPは、拒否された応答の品質と選択された好みペアとの報酬ギャップを測定し、トレーニングセットのフィルタリングや高品質な合成データセットの作成に利用可能。実験結果では、RIPを用いることでLlama 3.1-8B-Instructでの性能が大幅に向上し、Llama 3.3-70B-Instructではリーダーボードでの順位が上昇した。 Comment元ポスト:https://x.com/jaseweston/status/1885160135053459934?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
スレッドで著者が論文の解説をしている。 #Survey #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #InstructionTuning #PPO (ProximalPolicyOptimization) #Reasoning #LongSequence #RewardHacking #GRPO #Contamination #VerifiableRewards #CurriculumLearning Issue Date: 2025-05-06 100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models, Chong Zhang+, arXiv'25 Summary最近の推論言語モデル(RLM)の進展を受けて、DeepSeek-R1が注目を集めているが、その実装詳細は完全にはオープンソース化されていない。これにより、多くの再現研究が行われ、DeepSeek-R1のパフォーマンスを再現しようとする試みが続いている。特に、監視付きファインチューニング(SFT)と強化学習(RLVR)の戦略が探求され、貴重な洞察が得られている。本報告では、再現研究の概要を提供し、データ構築やトレーニング手順の詳細を紹介し、今後の研究の促進を目指す。また、RLMを強化するための追加技術や開発上の課題についても考察する。 Comment元ポスト:https://x.com/_philschmid/status/1918898257406709983?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
サーベイのtakeawayが箇条書きされている。 #ComputerVision #Embeddings #Analysis #NLP #LanguageModel #RepresentationLearning #Supervised-FineTuning (SFT) #Chain-of-Thought #SSM (StateSpaceModel) #ICML #PostTraining #read-later Issue Date: 2025-05-04 Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25 Summary中間層の埋め込みが最終層を超えるパフォーマンスを示すことを分析し、情報理論や幾何学に基づくメトリクスを提案。32のテキスト埋め込みタスクで中間層が強力な特徴を提供することを実証し、AIシステムの最適化における中間層の重要性を強調。 Comment現代の代表的な言語モデルのアーキテクチャ(decoder-only model, encoder-only model, SSM)について、最終層のembeddingよりも中間層のembeddingの方がdownstream task(MTEBの32Taskの平均)に、一貫して(ただし、これはMTEBの平均で見たらそうという話であり、個別のタスクで一貫して強いかは読んでみないとわからない)強いことを示した研究。
このこと自体は経験的に知られているのであまり驚きではないのだが(ただ、SSMでもそうなのか、というのと、一貫して強いというのは興味深い)、この研究はMatrix Based Entropyと呼ばれるものに基づいて、これらを分析するための様々な指標を定義し理論的な根拠を示し、Autoregressiveな学習よりもMasked Languageによる学習の方がこのようなMiddle Layerのボトルネックが緩和され、同様のボトルネックが画像の場合でも起きることを示し、CoTデータを用いたFinetuningについても分析している模様。この辺の貢献が非常に大きいと思われるのでここを理解することが重要だと思われる。あとで読む。
 #Analysis
#NLP
#LanguageModel
#Chain-of-Thought
#ICLR
Issue Date: 2025-04-30
When More is Less: Understanding Chain-of-Thought Length in LLMs, Yuyang Wu+, ICLR'25
SummaryChain-of-thought (CoT)推論は、LLMsの多段階推論能力を向上させるが、CoTの長さが増すと最初は性能が向上するものの、最終的には低下することが観察される。長い推論プロセスがノイズに脆弱であることを示し、理論的に最適なCoTの長さを導出。Length-filtered Voteを提案し、CoTの長さをモデルの能力とタスクの要求に合わせて調整する必要性を強調。
CommentICLR 2025 Best Paper Runner Up Award
#Analysis
#NLP
#LanguageModel
#Chain-of-Thought
#ICLR
Issue Date: 2025-04-30
When More is Less: Understanding Chain-of-Thought Length in LLMs, Yuyang Wu+, ICLR'25
SummaryChain-of-thought (CoT)推論は、LLMsの多段階推論能力を向上させるが、CoTの長さが増すと最初は性能が向上するものの、最終的には低下することが観察される。長い推論プロセスがノイズに脆弱であることを示し、理論的に最適なCoTの長さを導出。Length-filtered Voteを提案し、CoTの長さをモデルの能力とタスクの要求に合わせて調整する必要性を強調。
CommentICLR 2025 Best Paper Runner Up Award
元ポスト:https://x.com/yifeiwang77/status/1916873981979660436?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ICLR #KnowledgeEditing Issue Date: 2025-04-30 AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models, Junfeng Fang+, ICLR'25 SummaryAlphaEditは、LLMsの知識を保持しつつ編集を行う新しい手法で、摂動を保持された知識の零空間に投影することで、元の知識を破壊する問題を軽減します。実験により、AlphaEditは従来の位置特定-編集手法の性能を平均36.7%向上させることが確認されました。 Comment元ポスト:https://x.com/hillbig/status/1917343444810489925?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=HvSytvg3JhMLPに新たな知識を直接注入する際に(≠contextに含める)既存の学習済みの知識を破壊せずに注入する手法(破壊しないことが保証されている)を提案しているらしい将来的には、LLMの1パラメータあたりに保持できる知識量がわかってきているので、MLPの零空間がN GBのモデルです、あなたが注入したいドメイン知識の量に応じて適切な零空間を持つモデルを選んでください、みたいなモデルが公開される日が来るのだろうか。 #Survey #InformationRetrieval #NLP #LanguageModel #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-04-30 Can LLMs Be Trusted for Evaluating RAG Systems? A Survey of Methods and Datasets, Lorenz Brehme+, arXiv'25 SummaryRAGシステムの評価手法を63件の論文を基にレビューし、データセット、リトリーバー、インデクシング、生成コンポーネントの4領域に焦点を当てる。自動評価アプローチの実現可能性を観察し、LLMを活用した評価データセットの生成を提案。企業向けに実装と評価の指針を提供するための実践的研究の必要性を強調し、評価手法の進展と信頼性向上に寄与する。 Comment元ポスト:https://x.com/_reachsumit/status/1917425829233189027?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおもしろそう #RecommenderSystems #LanguageModel Issue Date: 2025-04-29 Generative Product Recommendations for Implicit Superlative Queries, Kaustubh D. Dhole+, arXiv'25 Summaryレコメンダーシステムにおいて、ユーザーの曖昧なクエリに対して大規模言語モデル(LLMs)を用いて暗黙の属性を生成し、製品推薦を改善する方法を探る。新たに提案する4ポイントスキーマ「SUPERB」を用いて最上級クエリに対する製品候補を注釈付けし、既存の検索およびランキング手法を評価する。 Comment元ポスト:https://x.com/_reachsumit/status/1917084325499273671?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Transformer #Chain-of-Thought #In-ContextLearning #SSM (StateSpaceModel) #ICLR Issue Date: 2025-04-26 RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval, Kaiyue Wen+, ICLR'25 Summary本論文では、RNNとトランスフォーマーの表現力の違いを調査し、特にRNNがChain-of-Thought(CoT)プロンプトを用いてトランスフォーマーに匹敵するかを分析。結果、CoTはRNNを改善するが、トランスフォーマーとのギャップを埋めるには不十分であることが判明。RNNの情報取得能力の限界がボトルネックであるが、Retrieval-Augmented Generation(RAG)やトランスフォーマー層の追加により、RNNはCoTを用いて多項式時間で解決可能な問題を解決できることが示された。 Comment元ポスト:https://x.com/yuma_1_or/status/1915968478735130713?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1210
↑とはどういう関係があるだろうか? #Multi #Analysis #NLP #LLMAgent Issue Date: 2025-04-26 Why Do Multi-Agent LLM Systems Fail?, Mert Cemri+, arXiv'25 SummaryMASの性能向上が単一エージェントと比較して限定的であることを受け、MAST(Multi-Agent System Failure Taxonomy)を提案。200以上のタスクを分析し、14の失敗モードを特定し、3つの大カテゴリに整理。Cohenのカッパスコア0.88を達成し、LLMを用いた評価パイプラインを開発。ケーススタディを通じて失敗分析とMAS開発の方法を示し、今後の研究のためのロードマップを提示。データセットとLLMアノテーターをオープンソース化予定。 Comment元ポスト:https://x.com/mertcemri/status/1915567789714329799?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q7つのメジャーなマルチエージェントフレームワークに対して200以上のタスクを実施し、6人の専門家がtraceをアノテーション。14種類の典型的なfailure modeを見つけ、それらを3つにカテゴライズ。これを考慮してマルチエージェントシステムの失敗に関するTaxonomy(MAS)を提案
 #EfficiencyImprovement
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Quantization
#SmallModel
Issue Date: 2025-04-19
BitNet b1.58 2B4T Technical Report, Shuming Ma+, arXiv'25
SummaryBitNet b1.58 2B4Tは、20億パラメータを持つオープンソースの1ビット大規模言語モデルで、4兆トークンで訓練されました。言語理解や数学的推論などのベンチマークで評価され、同サイズのフルプレシジョンLLMと同等の性能を示しつつ、計算効率が向上しています。メモリ、エネルギー消費、デコーディングレイテンシが削減され、モデルの重みはHugging Faceで公開されています。
Comment元ポスト:https://x.com/iscienceluvr/status/1912783876365177235?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q圧倒的省メモリかつcpuでのinference速度も早そう
#EfficiencyImprovement
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Quantization
#SmallModel
Issue Date: 2025-04-19
BitNet b1.58 2B4T Technical Report, Shuming Ma+, arXiv'25
SummaryBitNet b1.58 2B4Tは、20億パラメータを持つオープンソースの1ビット大規模言語モデルで、4兆トークンで訓練されました。言語理解や数学的推論などのベンチマークで評価され、同サイズのフルプレシジョンLLMと同等の性能を示しつつ、計算効率が向上しています。メモリ、エネルギー消費、デコーディングレイテンシが削減され、モデルの重みはHugging Faceで公開されています。
Comment元ポスト:https://x.com/iscienceluvr/status/1912783876365177235?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q圧倒的省メモリかつcpuでのinference速度も早そう
 ・アーキテクチャはTransformerを利用
・アーキテクチャはTransformerを利用
・Linear layerとしてBitLinear Layerを利用
・重みは{1, 0, -1}の3値をとる
・activationは8bitのintegerに量子化
・Layer Normalizationはsubln normalization 1899 を利用 #ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MulltiModal #ICLR #x-Use Issue Date: 2025-04-18 AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25 Summary本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 CommentAndroid環境でのPhone Useのベンチマーク #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #DiffusionModel #Reasoning #PostTraining #GRPO Issue Date: 2025-04-18 d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning, Siyan Zhao+, arXiv'25 Summaryd1というフレームワークを提案し、マスク付きdLLMsを教師ありファインチューニングと強化学習で推論モデルに適応。マスク付きSFT技術で知識を抽出し、diffu-GRPOという新しいRLアルゴリズムを導入。実証研究により、d1が最先端のdLLMの性能を大幅に向上させることを確認。 Comment元ポスト:https://x.com/iscienceluvr/status/1912785180504535121?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QdLLMに対してGRPOを適用する手法(diffuGRPO)を提案している。
long CoTデータでSFTしてreasoning capabilityを強化した後、diffuGRPOで追加のpost-trainingをしてさらに性能をboostする。GRPOではtoken levelの尤度とsequence全体の尤度を計算する必要があるが、dLLMだとautoregressive modelのようにchain ruleを適用する計算方法はできないので、効率的に尤度を推定するestimatorを用いてGPPOを適用するdiffuGRPOを提案している。
diffuGRPO単体でも、8BモデルだがSFTよりも性能向上に成功している。SFTの後にdiffuGRPOを適用するとさらに性能が向上する。
SFTではs1 1749 で用いられたlong CoTデータを用いている。しっかり理解できていないが、diffuGRPO+verified rewardによって、long CoTの学習データを用いなくても、安定してreasoning能力を発揮することができようになった、ということなのだろうか?
しかし、AppendixCを見ると、元々のLLaDAの時点でreasoning traceを十分な長さで出力しているように見える。もしLLaDAが元々long CoTを発揮できたのだとしたら、long CoTできるようになったのはdiffuGRPOだけの恩恵ではないということになりそうだが、LLaDAは元々long CoTを生成できるようなモデルだったんだっけ…?その辺追えてない(dLLMがメジャーになったら追う)。 #Analysis #MachineLearning #NLP #LanguageModel #Alignment #Hallucination #ICLR #DPO #Repetition Issue Date: 2025-04-18 Learning Dynamics of LLM Finetuning, Yi Ren+, ICLR'25 Summary本研究では、大規模言語モデルのファインチューニング中の学習ダイナミクスを分析し、異なる応答間の影響の蓄積を段階的に解明します。指示調整と好み調整のアルゴリズムに関する観察を統一的に解釈し、ファインチューニング後の幻覚強化の理由を仮説的に説明します。また、オフポリシー直接好み最適化(DPO)における「圧縮効果」を強調し、望ましい出力の可能性が低下する現象を探ります。このフレームワークは、LLMのファインチューニング理解に新たな視点を提供し、アラインメント性能向上のためのシンプルな方法を示唆します。 Comment元ポスト:https://x.com/joshuarenyi/status/1913033476275925414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/hillbig/status/1917189793588613299?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Transformer #FoundationModel #OpenWeight #CVPR Issue Date: 2025-04-11 AM-RADIO: Agglomerative Vision Foundation Model -- Reduce All Domains Into One, Mike Ranzinger+, CVPR'25 Summary視覚基盤モデル(VFM)をマルチティーチャー蒸留を通じて統合するアプローチAM-RADIOを提案。これにより、ゼロショットの視覚-言語理解やピクセルレベルの理解を向上させ、個々のモデルの性能を超える。新しいアーキテクチャE-RADIOは、ティーチャーモデルよりも少なくとも7倍速い。包括的なベンチマークで様々な下流タスクを評価。 Comment元ポスト:https://x.com/pavlomolchanov/status/1910391609927360831?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qvision系のfoundation modelはそれぞれ異なる目的関数で訓練されてきており(CLIPは対照学習 550, DINOv2は自己教師あり学習 1884, SAMはsegmentation 1885)それぞれ別の能力を持ってたが、それらを一個のモデルに蒸留しました、という話らしい
 #NLP
#LLMAgent
#Hallucination
Issue Date: 2025-04-11
Hallucination Mitigation using Agentic AI Natural Language-Based Frameworks, Diego Gosmar+, arXiv'25
Summary本研究では、複数のAIエージェントを調整し、自然言語処理を活用して幻覚を軽減する方法を探求。300以上の幻覚を誘発するプロンプトを用いたパイプラインを設計し、出力を第二および第三レベルのエージェントがレビュー。新たに設計したKPIで幻覚スコアを評価し、OVONフレームワークを通じてエージェント間で文脈情報を転送。結果として、相互運用可能なエージェントを活用することで幻覚の軽減に成功し、AIへの信頼を強化することが示された。
#NLP
#LanguageModel
#Attention
#AttentionSinks
Issue Date: 2025-04-09
Using Attention Sinks to Identify and Evaluate Dormant Heads in Pretrained LLMs, Pedro Sandoval-Segura+, arXiv'25
Summaryマルチヘッドアテンションにおける「休眠アテンションヘッド」を定義し、その影響を調査。6つのモデルと5つのデータセットを用いた実験で、休眠ヘッドの出力をゼロにしても精度を維持できることを確認。休眠ヘッドは事前学習の初期に出現し、入力テキストの特性に依存することが示された。
Comment元ポスト:https://x.com/psandovalsegura/status/1909652533334712691?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#MachineLearning
#LanguageModel
#ReinforcementLearning
#Reasoning
#LongSequence
Issue Date: 2025-04-08
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, YuYue+, arXiv'25
SummaryVAPO(Value-based Augmented Proximal Policy Optimization framework)を提案し、AIME 2024データセットで最先端のスコア60.4を達成。VAPOは他の手法を10ポイント以上上回り、5,000ステップで安定したパフォーマンスを示す。価値ベースの強化学習における3つの課題を特定し、VAPOがそれらを軽減する統合ソリューションを提供することで、長い思考過程の推論タスクの性能向上を実現。
Comment同じくByteDanceの
#NLP
#LLMAgent
#Hallucination
Issue Date: 2025-04-11
Hallucination Mitigation using Agentic AI Natural Language-Based Frameworks, Diego Gosmar+, arXiv'25
Summary本研究では、複数のAIエージェントを調整し、自然言語処理を活用して幻覚を軽減する方法を探求。300以上の幻覚を誘発するプロンプトを用いたパイプラインを設計し、出力を第二および第三レベルのエージェントがレビュー。新たに設計したKPIで幻覚スコアを評価し、OVONフレームワークを通じてエージェント間で文脈情報を転送。結果として、相互運用可能なエージェントを活用することで幻覚の軽減に成功し、AIへの信頼を強化することが示された。
#NLP
#LanguageModel
#Attention
#AttentionSinks
Issue Date: 2025-04-09
Using Attention Sinks to Identify and Evaluate Dormant Heads in Pretrained LLMs, Pedro Sandoval-Segura+, arXiv'25
Summaryマルチヘッドアテンションにおける「休眠アテンションヘッド」を定義し、その影響を調査。6つのモデルと5つのデータセットを用いた実験で、休眠ヘッドの出力をゼロにしても精度を維持できることを確認。休眠ヘッドは事前学習の初期に出現し、入力テキストの特性に依存することが示された。
Comment元ポスト:https://x.com/psandovalsegura/status/1909652533334712691?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#MachineLearning
#LanguageModel
#ReinforcementLearning
#Reasoning
#LongSequence
Issue Date: 2025-04-08
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, YuYue+, arXiv'25
SummaryVAPO(Value-based Augmented Proximal Policy Optimization framework)を提案し、AIME 2024データセットで最先端のスコア60.4を達成。VAPOは他の手法を10ポイント以上上回り、5,000ステップで安定したパフォーマンスを示す。価値ベースの強化学習における3つの課題を特定し、VAPOがそれらを軽減する統合ソリューションを提供することで、長い思考過程の推論タスクの性能向上を実現。
Comment同じくByteDanceの
・1815
を上回る性能
 元ポスト:https://x.com/_akhaliq/status/1909564500170223751?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Attention
#Architecture
Issue Date: 2025-04-07
KAA: Kolmogorov-Arnold Attention for Enhancing Attentive Graph Neural Networks, Taoran Fang+, arXiv'25
Summary注意GNNにおけるスコアリングプロセスの理解が不足している中、本研究ではコルモゴロフ・アルノルド注意(KAA)を提案し、スコアリング関数を統一。KAAはKANアーキテクチャを統合し、ほぼすべての注意GNNに適用可能で、表現力が向上。実験により、KAA強化スコアリング関数が元のものを一貫して上回り、最大20%以上の性能向上を達成した。
Comment元ポスト:https://x.com/theturingpost/status/1908966571227398449?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Attention
#Architecture
Issue Date: 2025-04-07
XAttention: Block Sparse Attention with Antidiagonal Scoring, Ruyi Xu+, arXiv'25
SummaryXAttentionは、Long-Context Transformer Modelsにおける長文コンテキスト推論を加速するプラグアンドプレイのフレームワークで、注意行列の反対対角線の値を用いてブロックの重要度を評価し、非本質的なブロックを剪定することで高いスパース性を実現。RULERやLongBenchなどのベンチマークでフルアテンションに匹敵する精度を保ちながら、最大13.5倍の計算加速を達成。XAttentionはLCTMsの効率的な展開を可能にする。
Comment元ポスト:https://x.com/theturingpost/status/1908966571227398449?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Attention
#Architecture
Issue Date: 2025-04-07
Slim attention: cut your context memory in half without loss of accuracy -- K-cache is all you need for MHA, Nils Graef+, arXiv'25
SummarySlim attentionは、トランスフォーマーモデルのMHAにおいてコンテキストメモリを2倍に縮小し、推論速度を最大2倍向上させる手法で、精度を損なうことなく実装可能です。特に、Whisperモデルではコンテキストメモリを8倍削減し、トークン生成を5倍速くすることができます。また、稀なケースではT5-11Bモデルでメモリを32倍削減することも可能です。
Comment元ポスト:https://x.com/theturingpost/status/1908966571227398449?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#SelfImprovement
#ICLR
#RewardHacking
Issue Date: 2025-04-06
CREAM: Consistency Regularized Self-Rewarding Language Models, Zhaoyang Wang+, ICLR'25
Summary自己報酬型LLMは、LLM-as-a-Judgeを用いてアラインメント性能を向上させるが、報酬とランク付けの正確性が問題。小規模LLMの実証結果は、自己報酬の改善が反復後に減少する可能性を示唆。これに対処するため、一般化された反復的好みファインチューニングフレームワークを定式化し、正則化を導入。CREAMを提案し、報酬の一貫性を活用して信頼性の高い好みデータから学習。実証結果はCREAMの優位性を示す。
Comment・1212
元ポスト:https://x.com/_akhaliq/status/1909564500170223751?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Attention
#Architecture
Issue Date: 2025-04-07
KAA: Kolmogorov-Arnold Attention for Enhancing Attentive Graph Neural Networks, Taoran Fang+, arXiv'25
Summary注意GNNにおけるスコアリングプロセスの理解が不足している中、本研究ではコルモゴロフ・アルノルド注意(KAA)を提案し、スコアリング関数を統一。KAAはKANアーキテクチャを統合し、ほぼすべての注意GNNに適用可能で、表現力が向上。実験により、KAA強化スコアリング関数が元のものを一貫して上回り、最大20%以上の性能向上を達成した。
Comment元ポスト:https://x.com/theturingpost/status/1908966571227398449?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Attention
#Architecture
Issue Date: 2025-04-07
XAttention: Block Sparse Attention with Antidiagonal Scoring, Ruyi Xu+, arXiv'25
SummaryXAttentionは、Long-Context Transformer Modelsにおける長文コンテキスト推論を加速するプラグアンドプレイのフレームワークで、注意行列の反対対角線の値を用いてブロックの重要度を評価し、非本質的なブロックを剪定することで高いスパース性を実現。RULERやLongBenchなどのベンチマークでフルアテンションに匹敵する精度を保ちながら、最大13.5倍の計算加速を達成。XAttentionはLCTMsの効率的な展開を可能にする。
Comment元ポスト:https://x.com/theturingpost/status/1908966571227398449?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Attention
#Architecture
Issue Date: 2025-04-07
Slim attention: cut your context memory in half without loss of accuracy -- K-cache is all you need for MHA, Nils Graef+, arXiv'25
SummarySlim attentionは、トランスフォーマーモデルのMHAにおいてコンテキストメモリを2倍に縮小し、推論速度を最大2倍向上させる手法で、精度を損なうことなく実装可能です。特に、Whisperモデルではコンテキストメモリを8倍削減し、トークン生成を5倍速くすることができます。また、稀なケースではT5-11Bモデルでメモリを32倍削減することも可能です。
Comment元ポスト:https://x.com/theturingpost/status/1908966571227398449?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#SelfImprovement
#ICLR
#RewardHacking
Issue Date: 2025-04-06
CREAM: Consistency Regularized Self-Rewarding Language Models, Zhaoyang Wang+, ICLR'25
Summary自己報酬型LLMは、LLM-as-a-Judgeを用いてアラインメント性能を向上させるが、報酬とランク付けの正確性が問題。小規模LLMの実証結果は、自己報酬の改善が反復後に減少する可能性を示唆。これに対処するため、一般化された反復的好みファインチューニングフレームワークを定式化し、正則化を導入。CREAMを提案し、報酬の一貫性を活用して信頼性の高い好みデータから学習。実証結果はCREAMの優位性を示す。
Comment・1212
を改善した研究OpenReview:https://openreview.net/forum?id=Vf6RDObyEFこの方向性の研究はおもしろい #EfficiencyImprovement #NLP #Transformer #LongSequence #Architecture Issue Date: 2025-04-06 Scalable-Softmax Is Superior for Attention, Ken M. Nakanishi, arXiv'25 SummarySSMaxを提案し、Softmaxの代替としてTransformerモデルに統合。これにより、長いコンテキストでの重要情報の取得が向上し、事前学習中の損失減少が速くなる。SSMaxは注意スコアを改善し、長さの一般化を促進する。 Comment・1863
で採用されている手法で、ブログポスト中で引用されている。Long Contextになった場合にsoftmaxの分布が均一になる(=重要な情報にattendする能力が削がれる)ことを防ぐための手法を提案している。解説ポスト:https://x.com/nrehiew_/status/1908613993998045534 #NLP #LanguageModel #Attention #ICLR #AttentionSinks Issue Date: 2025-04-05 When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25 Summary言語モデルにおける「アテンションシンク」は、意味的に重要でないトークンに大きな注意を割り当てる現象であり、さまざまな入力に対して小さなモデルでも普遍的に存在することが示された。アテンションシンクは事前学習中に出現し、最適化やデータ分布、損失関数がその出現に影響を与える。特に、アテンションシンクはキーのバイアスのように機能し、情報を持たない追加のアテンションスコアを保存することがわかった。この現象は、トークンがソフトマックス正規化に依存していることから部分的に生じており、正規化なしのシグモイドアテンションに置き換えることで、アテンションシンクの出現を防ぐことができる。 CommentSink Rateと呼ばれる、全てのheadのFirst Tokenに対するattention scoreのうち(layer l head h個存在する)、どの程度の割合のスコアが閾値を上回っているかを表す指標を提案・1860
の先行研究著者ポスト(openai-gpt-120Bを受けて):
https://x.com/gu_xiangming/status/1952811057673642227?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ConceptErasure #KnowledgeEditing #AISTATS Issue Date: 2025-04-03 Fundamental Limits of Perfect Concept Erasure, Somnath Basu Roy Chowdhury+, AISTATS'25 Summary概念消去は、性別や人種などの情報を消去しつつ元の表現を保持するタスクであり、公平性の達成やモデルのパフォーマンスの解釈に役立つ。従来の技術は消去の堅牢性を重視してきたが、有用性とのトレードオフが存在する。本研究では、情報理論的視点から概念消去の限界を定量化し、完璧な消去を達成するためのデータ分布と消去関数の制約を調査。提案する消去関数が理論的限界を達成し、GPT-4を用いたデータセットで既存手法を上回ることを示した。 Comment元ポスト:https://x.com/somnathbrc/status/1907463419105570933?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Test-Time Scaling Issue Date: 2025-04-02 What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models, Qiyuan Zhang+, arXiv'25 Summaryテスト時スケーリング(TTS)が大規模言語モデル(LLMs)の問題解決能力を向上させることが示されているが、体系的な理解が不足している。これを解決するために、TTS研究の4つのコア次元に基づく統一的なフレームワークを提案し、手法や応用シナリオのレビューを行う。TTSの発展の軌跡を抽出し、実践的なガイドラインを提供するとともに、未解決の課題や将来の方向性についての洞察を示す。 Comment元ポスト:https://x.com/hesamation/status/1907095419793911893?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qとてつもない量だ…網羅性がありそう。
What to Scaleがよくあるself
consistency(Parallel Scaling), STaR(Sequential Scailng), Tree of Thought(Hybrid Scaling), DeepSeek-R1, o1/3(Internal Scaling)といった分類で、How to ScaleがTuningとInferenceに分かれている。TuningはLong CoTをSFTする話や強化学習系の話(GRPOなど)で、InferenceにもSelf consistencyやらやらVerificationやら色々ありそう。良さそう。
 #NLP
#LanguageModel
#Transformer
#Attention
#Architecture
Issue Date: 2025-04-02
Multi-Token Attention, Olga Golovneva+, arXiv'25
Summaryマルチトークンアテンション(MTA)を提案し、複数のクエリとキーのベクトルに基づいてアテンションウェイトを条件付けることで、関連するコンテキストをより正確に特定できるようにする。MTAは畳み込み操作を用いて、近くのトークンが互いに影響を与え、豊かな情報を活用する。評価結果から、MTAはTransformerベースラインモデルを上回り、特に長いコンテキストでの情報検索において優れた性能を示した。
Comment元ポスト:https://x.com/jaseweston/status/1907260086017237207?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来のMulti Head Attentionでは、単体のQKのみを利用していたけど、複数のQKの情報を畳み込んで活用できるようにして、Headも畳み込みで重要な情報がより伝搬されるようにして、GroupNormalizationをかけたらPerplexityの観点でDifferential Transformerを上回ったよ、という話な模様。
#NLP
#LanguageModel
#Transformer
#Attention
#Architecture
Issue Date: 2025-04-02
Multi-Token Attention, Olga Golovneva+, arXiv'25
Summaryマルチトークンアテンション(MTA)を提案し、複数のクエリとキーのベクトルに基づいてアテンションウェイトを条件付けることで、関連するコンテキストをより正確に特定できるようにする。MTAは畳み込み操作を用いて、近くのトークンが互いに影響を与え、豊かな情報を活用する。評価結果から、MTAはTransformerベースラインモデルを上回り、特に長いコンテキストでの情報検索において優れた性能を示した。
Comment元ポスト:https://x.com/jaseweston/status/1907260086017237207?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来のMulti Head Attentionでは、単体のQKのみを利用していたけど、複数のQKの情報を畳み込んで活用できるようにして、Headも畳み込みで重要な情報がより伝搬されるようにして、GroupNormalizationをかけたらPerplexityの観点でDifferential Transformerを上回ったよ、という話な模様。



・1856
・1466 #NLP #Dataset #LanguageModel #LLMAgent #Evaluation #QuestionGeneration Issue Date: 2025-04-02 Interactive Agents to Overcome Ambiguity in Software Engineering, Sanidhya Vijayvargiya+, arXiv'25 SummaryAIエージェントはあいまいな指示に基づくタスク自動化に利用されるが、誤った仮定や質問不足がリスクを生む。本研究では、LLMエージェントのあいまいな指示処理能力を評価し、インタラクティビティを活用したパフォーマンス向上、あいまいさの検出、目標を絞った質問の実施を検討。結果、モデルは明確な指示と不十分な指示を区別するのが難しいが、インタラクションを通じて重要な情報を取得し、パフォーマンスが向上することが示された。これにより、現在のモデルの限界と改善のための評価手法の重要性が明らかになった。 Comment曖昧なユーザメッセージに対する、エージェントが"質問をする能力を測る"ベンチマーク
 #Analysis
#NLP
#LanguageModel
#FactualKnowledge
Issue Date: 2025-04-01
Inside-Out: Hidden Factual Knowledge in LLMs, Zorik Gekhman+, arXiv'25
Summary本研究は、LLMが出力以上の事実的知識をエンコードしているかを評価するフレームワークを提案。知識を定義し、正しい回答が高くランク付けされる割合を定量化。外部知識と内部知識を区別し、内部知識が外部知識を超えると隠れた知識が生じることを示す。クローズドブックQA設定でのケーススタディでは、LLMが内部で多くの知識をエンコードしていること、知識が隠れている場合があること、サンプリングによる制約があることを明らかにした。
Comment元ポスト:https://x.com/zorikgekhman/status/1906693729886363861?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#NLP
#LanguageModel
#MulltiModal
#SpeechProcessing
#OpenWeight
#Video
Issue Date: 2025-03-31
Qwen2.5-Omni Technical Report, Jin Xu+, arXiv'25
Summaryマルチモーダルモデル「Qwen2.5-Omni」は、テキスト、画像、音声、動画を認識し、ストリーミング方式で自然な音声応答を生成する。音声と視覚エンコーダはブロック処理を用い、TMRoPEによる新しい位置埋め込みで音声と動画の同期を実現。Thinker-Talkerアーキテクチャにより、テキスト生成と音声出力を干渉なく行う。Qwen2.5-Omniは、エンドツーエンドで訓練され、音声指示に対する性能がテキスト入力と同等で、ストリーミングTalkerは既存手法を上回る自然さを持つ。
CommentQwen TeamによるマルチモーダルLLM。テキスト、画像、動画音声をinputとして受け取り、テキスト、音声をoutputする。
#Analysis
#NLP
#LanguageModel
#FactualKnowledge
Issue Date: 2025-04-01
Inside-Out: Hidden Factual Knowledge in LLMs, Zorik Gekhman+, arXiv'25
Summary本研究は、LLMが出力以上の事実的知識をエンコードしているかを評価するフレームワークを提案。知識を定義し、正しい回答が高くランク付けされる割合を定量化。外部知識と内部知識を区別し、内部知識が外部知識を超えると隠れた知識が生じることを示す。クローズドブックQA設定でのケーススタディでは、LLMが内部で多くの知識をエンコードしていること、知識が隠れている場合があること、サンプリングによる制約があることを明らかにした。
Comment元ポスト:https://x.com/zorikgekhman/status/1906693729886363861?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#NLP
#LanguageModel
#MulltiModal
#SpeechProcessing
#OpenWeight
#Video
Issue Date: 2025-03-31
Qwen2.5-Omni Technical Report, Jin Xu+, arXiv'25
Summaryマルチモーダルモデル「Qwen2.5-Omni」は、テキスト、画像、音声、動画を認識し、ストリーミング方式で自然な音声応答を生成する。音声と視覚エンコーダはブロック処理を用い、TMRoPEによる新しい位置埋め込みで音声と動画の同期を実現。Thinker-Talkerアーキテクチャにより、テキスト生成と音声出力を干渉なく行う。Qwen2.5-Omniは、エンドツーエンドで訓練され、音声指示に対する性能がテキスト入力と同等で、ストリーミングTalkerは既存手法を上回る自然さを持つ。
CommentQwen TeamによるマルチモーダルLLM。テキスト、画像、動画音声をinputとして受け取り、テキスト、音声をoutputする。

weight:https://huggingface.co/collections/Qwen/qwen25-omni-67de1e5f0f9464dc6314b36e元ポスト:https://www.linkedin.com/posts/niels-rogge-a3b7a3127_alibabas-qwen-team-has-done-it-again-this-activity-7311036679627132929-HUqy?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4 #RecommenderSystems #CollaborativeFiltering #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Reasoning Issue Date: 2025-03-27 RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning, Sichun Luo+, arXiv'25 SummaryRALLRec+は、LLMsを用いてレコメンダーシステムのretrievalとgenerationを強化する手法。retrieval段階では、アイテム説明を生成し、テキスト信号と協調信号を結合。生成段階では、推論LLMsを評価し、知識注入プロンプティングで汎用LLMsと統合。実験により、提案手法の有効性が確認された。 Comment元ポスト:https://x.com/_reachsumit/status/1905107217663336832?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QReasoning LLMをRecSysに応用する初めての研究(らしいことがRelated Workに書かれている)arxivのadminより以下のコメントが追記されている
> arXiv admin note: substantial text overlap with arXiv:2502.06101
コメント中の研究は下記である
・1840 #NLP #LanguageModel #LLM-as-a-Judge #Test-Time Scaling Issue Date: 2025-03-27 Scaling Evaluation-time Compute with Reasoning Models as Process Evaluators, Seungone Kim+, arXiv'25 SummaryLMの出力品質評価が難しくなっている中、計算を増やすことで評価能力が向上するかを検討。推論モデルを用いて応答全体と各ステップを評価し、推論トークンの生成が評価者のパフォーマンスを向上させることを確認。再ランク付けにより、評価時の計算増加がLMの問題解決能力を向上させることを示した。 Comment元ポスト:https://x.com/jinulee_v/status/1905025016401428883?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLM-as-a-JudgeもlongCoT+self-consistencyで性能が改善するらしい。
 #Analysis
#Pretraining
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#ICLR
#read-later
Issue Date: 2025-03-27
Overtrained Language Models Are Harder to Fine-Tune, Jacob Mitchell Springer+, ICLR'25
Summary大規模言語モデルの事前学習において、トークン予算の増加がファインチューニングを難しくし、パフォーマンス低下を引き起こす「壊滅的な過学習」を提唱。3Tトークンで事前学習されたOLMo-1Bモデルは、2.3Tトークンのモデルに比べて2%以上の性能低下を示す。実験と理論分析により、事前学習パラメータの感度の増加が原因であることを示し、事前学習設計の再評価を促す。
Comment著者によるポスト:https://x.com/jacspringer/status/1904960783341023521?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q事前学習のトークン数を増やすとモデルのsensitivityが増し、post-trainingでのパフォーマンスの劣化が起こることを報告している。事前学習で学習するトークン数を増やせば、必ずしもpost-training後のモデルの性能がよくなるわけではないらしい。
#Analysis
#Pretraining
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#ICLR
#read-later
Issue Date: 2025-03-27
Overtrained Language Models Are Harder to Fine-Tune, Jacob Mitchell Springer+, ICLR'25
Summary大規模言語モデルの事前学習において、トークン予算の増加がファインチューニングを難しくし、パフォーマンス低下を引き起こす「壊滅的な過学習」を提唱。3Tトークンで事前学習されたOLMo-1Bモデルは、2.3Tトークンのモデルに比べて2%以上の性能低下を示す。実験と理論分析により、事前学習パラメータの感度の増加が原因であることを示し、事前学習設計の再評価を促す。
Comment著者によるポスト:https://x.com/jacspringer/status/1904960783341023521?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q事前学習のトークン数を増やすとモデルのsensitivityが増し、post-trainingでのパフォーマンスの劣化が起こることを報告している。事前学習で学習するトークン数を増やせば、必ずしもpost-training後のモデルの性能がよくなるわけではないらしい。
 ICLR'25のOutstanding Paperに選ばれた模様:
ICLR'25のOutstanding Paperに選ばれた模様:
https://x.com/jacspringer/status/1917174452531724718?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
きちんと読んだ方が良さげ。 #InformationRetrieval #NLP #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-03-25 ExpertGenQA: Open-ended QA generation in Specialized Domains, Haz Sameen Shahgir+, arXiv'25 SummaryExpertGenQAは、少数ショット学習とトピック・スタイル分類を組み合わせたQAペア生成プロトコルで、米国連邦鉄道局の文書を用いて94.4%のトピックカバレッジを維持しつつ、ベースラインの2倍の効率を達成。評価では、LLMベースのモデルが内容よりも文体に偏ることが判明し、ExpertGenQAは専門家の質問の認知的複雑性をより良く保持。生成したクエリは、リトリーバルモデルの精度を13.02%向上させ、技術分野での有効性を示した。 Comment元ポスト:https://x.com/at_sushi_/status/1904325501331890561?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Reasoning Issue Date: 2025-03-23 Thinking Machines: A Survey of LLM based Reasoning Strategies, Dibyanayan Bandyopadhyay+, arXiv'25 Summary大規模言語モデル(LLMs)は優れた言語能力を持つが、推論能力との間にギャップがある。推論はAIの信頼性を高め、医療や法律などの分野での適用に不可欠である。最近の強力な推論モデルの登場により、LLMsにおける推論の研究が重要視されている。本論文では、既存の推論技術の概要と比較を行い、推論を備えた言語モデルの体系的な調査と現在の課題を提示する。 Comment元ポスト:https://x.com/dair_ai/status/1903843684568666450?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRL, Test Time Compute, Self-trainingの3種類にカテゴライズされている。また、各カテゴリごとにより細分化されたツリーが論文中にある。

#Pretraining #NLP #LanguageModel #Scaling Laws Issue Date: 2025-03-23 Compute Optimal Scaling of Skills: Knowledge vs Reasoning, Nicholas Roberts+, arXiv'25 Summaryスケーリング法則はLLM開発において重要であり、特に計算最適化によるトレードオフが注目されている。本研究では、スケーリング法則が知識や推論に基づくスキルに依存することを示し、異なるデータミックスがスケーリング挙動に与える影響を調査した。結果、知識とコード生成のスキルは根本的に異なるスケーリング挙動を示し、誤指定された検証セットが計算最適なパラメータ数に約50%の影響を与える可能性があることが明らかになった。 Comment元ポスト:https://x.com/dair_ai/status/1903843682509312218?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q知識を問うQAのようなタスクはモデルのパラメータ量が必要であり、コーディングのようなReasoningに基づくタスクはデータ量が必要であり、異なる要素に依存してスケールすることを示している研究のようである。
 #Survey
#EfficiencyImprovement
#NLP
#LanguageModel
#Reasoning
Issue Date: 2025-03-22
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models, Yang Sui+, arXiv'25
Summary本論文では、LLMsにおける効率的な推論の進展を体系的に調査し、以下の主要な方向に分類します:(1) モデルベースの効率的推論、(2) 推論出力ベースの効率的推論、(3) 入力プロンプトベースの効率的推論。特に、冗長な出力による計算オーバーヘッドを軽減する方法を探求し、小規模言語モデルの推論能力や評価方法についても議論します。
CommentReasoning Modelにおいて、Over Thinking現象(不要なreasoning stepを生成してしまう)を改善するための手法に関するSurvey。
#Survey
#EfficiencyImprovement
#NLP
#LanguageModel
#Reasoning
Issue Date: 2025-03-22
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models, Yang Sui+, arXiv'25
Summary本論文では、LLMsにおける効率的な推論の進展を体系的に調査し、以下の主要な方向に分類します:(1) モデルベースの効率的推論、(2) 推論出力ベースの効率的推論、(3) 入力プロンプトベースの効率的推論。特に、冗長な出力による計算オーバーヘッドを軽減する方法を探求し、小規模言語モデルの推論能力や評価方法についても議論します。
CommentReasoning Modelにおいて、Over Thinking現象(不要なreasoning stepを生成してしまう)を改善するための手法に関するSurvey。

下記Figure2を見るとよくまとまっていて、キャプションを読むとだいたい分かる。なるほど。
Length Rewardについては、
・1746
で考察されている通り、Reward Hackingが起きるので設計の仕方に気をつける必要がある。
 元ポスト:https://x.com/_reachsumit/status/1902977896685396275?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q各カテゴリにおけるliteratureも見やすくまとめられている。必要に応じて参照したい。
元ポスト:https://x.com/_reachsumit/status/1902977896685396275?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q各カテゴリにおけるliteratureも見やすくまとめられている。必要に応じて参照したい。
 #NLP
#Dataset
#LanguageModel
#LongSequence
Issue Date: 2025-03-20
Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation, Junhao Zhang+, arXiv'25
Summary長い入力と出力の生成に特化したLongInOutBenchを導入し、既存手法の「中間での喪失」問題に対処。Retrieval-Augmented Long-Text Writer(RAL-Writer)を開発し、重要なコンテンツを再表現することで性能を向上。提案手法の有効性をベースラインと比較して示す。
CommentLost in the Middleに関する研究。関連研究:
#NLP
#Dataset
#LanguageModel
#LongSequence
Issue Date: 2025-03-20
Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation, Junhao Zhang+, arXiv'25
Summary長い入力と出力の生成に特化したLongInOutBenchを導入し、既存手法の「中間での喪失」問題に対処。Retrieval-Augmented Long-Text Writer(RAL-Writer)を開発し、重要なコンテンツを再表現することで性能を向上。提案手法の有効性をベースラインと比較して示す。
CommentLost in the Middleに関する研究。関連研究:
・793 #MachineLearning #LanguageModel #ReinforcementLearning #Reasoning #LongSequence #GRPO #read-later Issue Date: 2025-03-20 DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25 Summary推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。ちとこれはあとでしっかり読みたい。重要論文。プロジェクトページ:https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。解説ポスト:https://x.com/theturingpost/status/1902507148015489385?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
コンパクトだが分かりやすくまとまっている。下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:https://x.com/iscienceluvr/status/1936375947575632102?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Test-Time Scaling #Verification Issue Date: 2025-03-18 Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification, Eric Zhao+, arXiv'25 Summaryサンプリングベースの探索は、複数の候補応答を生成し最良のものを選ぶ手法であり、自己検証によって正確性を確認します。本研究では、この探索のスケーリング傾向を分析し、シンプルな実装がGemini v1.5 Proの推論能力を向上させることを示しました。自己検証の精度向上は、より大きな応答プールからのサンプリングによるもので、応答間の比較が有益な信号を提供することや、異なる出力スタイルが文脈に応じて役立つことを明らかにしました。また、最前線のモデルは初期の検証能力が弱く、進捗を測るためのベンチマークを提案しました。 Comment元ポスト:https://x.com/ericzhao28/status/1901704339229732874?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qざっくりしか読めていないが、複数の解答をサンプリングして、self-verificationをさせて最も良かったものを選択するアプローチ。最もverificationスコアが高い解答を最終的に選択したいが、tieの場合もあるのでその場合は追加のpromptingでレスポンスを比較しより良いレスポンスを選択する。これらは並列して実行が可能で、探索とself-verificationを200個並列するとGemini 1.5 Proでo1-previewよりも高い性能を獲得できる模様。Self-consistencyと比較しても、gainが大きい。
 #Analysis
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#RLHF
Issue Date: 2025-03-17
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning, Gokul Swamy+, arXiv'25
Summary基盤モデルのファインチューニングにおいて、報酬モデルを用いた二段階のトレーニング手順が効果的である理由を理論的および実証的に検討。特に、好みデータから単純な報酬モデルを学び、強化学習手続きがそのモデルに最適なポリシーをフィルタリングする能力が、オンラインファインチューニングの優れたパフォーマンスに寄与することが示された。
Comment元ポスト:https://x.com/hillbig/status/1901392286694678568?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QAlignmentのためのPreferenceデータがある時に、そのデータから直接最尤推定してモデルのパラメータを学習するのではなく、報酬モデルを学習して、その報酬モデルを用いてモデルを強化学習することで、なぜ前者よりも(同じデータ由来であるにもかかわらず)優れたパフォーマンスを示すのか、という疑問に対してアプローチしている。全く中身を読めていないが、生成することと(方策モデル)と検証すること(報酬モデル)の間にギャップがある場合(すなわち、生成と検証で求められる能力が異なる場合)、MLEでは可能なすべてのポリシーを探索することと似たようなことをすることになるが、RLでは事前に報酬モデルを学習しその報酬モデルに対して最適なポリシーを探索するだけなので探索する空間が制限される(=生成と検証のギャップが埋まる)ので、良い解に収束しやすくなる、というイメージなんだろうか。
#Analysis
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#RLHF
Issue Date: 2025-03-17
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning, Gokul Swamy+, arXiv'25
Summary基盤モデルのファインチューニングにおいて、報酬モデルを用いた二段階のトレーニング手順が効果的である理由を理論的および実証的に検討。特に、好みデータから単純な報酬モデルを学び、強化学習手続きがそのモデルに最適なポリシーをフィルタリングする能力が、オンラインファインチューニングの優れたパフォーマンスに寄与することが示された。
Comment元ポスト:https://x.com/hillbig/status/1901392286694678568?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QAlignmentのためのPreferenceデータがある時に、そのデータから直接最尤推定してモデルのパラメータを学習するのではなく、報酬モデルを学習して、その報酬モデルを用いてモデルを強化学習することで、なぜ前者よりも(同じデータ由来であるにもかかわらず)優れたパフォーマンスを示すのか、という疑問に対してアプローチしている。全く中身を読めていないが、生成することと(方策モデル)と検証すること(報酬モデル)の間にギャップがある場合(すなわち、生成と検証で求められる能力が異なる場合)、MLEでは可能なすべてのポリシーを探索することと似たようなことをすることになるが、RLでは事前に報酬モデルを学習しその報酬モデルに対して最適なポリシーを探索するだけなので探索する空間が制限される(=生成と検証のギャップが埋まる)ので、良い解に収束しやすくなる、というイメージなんだろうか。
 #NLP
#Transformer
Issue Date: 2025-03-15
NeoBERT: A Next-Generation BERT, Lola Le Breton+, arXiv'25
SummaryNeoBERTは、最新のアーキテクチャとデータを統合した次世代エンコーダで、双方向モデルの能力を再定義します。4,096トークンのコンテキスト長を活用し、250Mパラメータでありながら、MTEBベンチマークで最先端の結果を達成し、BERTやRoBERTaを上回ります。すべてのコードやデータを公開し、研究と実世界での採用を促進します。
Comment関連:
#NLP
#Transformer
Issue Date: 2025-03-15
NeoBERT: A Next-Generation BERT, Lola Le Breton+, arXiv'25
SummaryNeoBERTは、最新のアーキテクチャとデータを統合した次世代エンコーダで、双方向モデルの能力を再定義します。4,096トークンのコンテキスト長を活用し、250Mパラメータでありながら、MTEBベンチマークで最先端の結果を達成し、BERTやRoBERTaを上回ります。すべてのコードやデータを公開し、研究と実世界での採用を促進します。
Comment関連:
・1606BERT, ModernBERTとの違い

性能

所感
medium size未満のモデルの中ではSoTAではあるが、ModernBERTが利用できるのであれば、ベンチマークを見る限りは実用的にはModernBERTで良いのでは、と感じた。学習とinferenceの速度差はどの程度あるのだろうか? #Survey #NLP #LanguageModel #Supervised-FineTuning (SFT) #Reasoning Issue Date: 2025-03-15 A Survey on Post-training of Large Language Models, Guiyao Tie+, arXiv'25 Summary大規模言語モデル(LLMs)は自然言語処理に革命をもたらしたが、専門的な文脈での制約が明らかである。これに対処するため、高度なポストトレーニング言語モデル(PoLMs)が必要であり、本論文ではその包括的な調査を行う。ファインチューニング、アライメント、推論、効率、統合と適応の5つのコアパラダイムにわたる進化を追跡し、PoLMがバイアス軽減や推論能力向上に寄与する方法を示す。研究はPoLMの進化に関する初の調査であり、将来の研究のための枠組みを提供し、LLMの精度と倫理的堅牢性を向上させることを目指す。 CommentPost Trainingの時間発展の図解が非常にわかりやすい(が、厳密性には欠けているように見える。当該モデルの新規性における主要な技術はこれです、という図としてみるには良いのかもしれない)。
個々の技術が扱うスコープとレイヤー、データの性質が揃っていない気がするし、それぞれのLLMがy軸の単一の技術だけに依存しているわけでもない。が、厳密に図を書いてと言われた時にどう書けば良いかと問われると難しい感はある。
 元ポスト:https://x.com/omarsar0/status/1900595286898340230?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#MachineLearning
#NLP
#Transformer
#CVPR
#Normalization
Issue Date: 2025-03-14
Transformers without Normalization, Jiachen Zhu+, CVPR'25
Summary本研究では、正規化層なしのトランスフォーマーがDynamic Tanh(DyT)を用いることで、同等またはそれ以上のパフォーマンスを達成できることを示します。DyTは、レイヤー正規化の代替として機能し、ハイパーパラメータの調整なしで効果を発揮します。多様な設定での実験により、正規化層の必要性に対する新たな洞察を提供します。
Commentなん…だと…。LayerNormalizationを下記アルゴリズムのようなtanhを用いた超絶シンプルなレイヤー(parameterized thnh [Lecun氏ポスト](https://x.com/ylecun/status/1900610590315249833?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q))に置換するだけっぽい?
元ポスト:https://x.com/omarsar0/status/1900595286898340230?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#MachineLearning
#NLP
#Transformer
#CVPR
#Normalization
Issue Date: 2025-03-14
Transformers without Normalization, Jiachen Zhu+, CVPR'25
Summary本研究では、正規化層なしのトランスフォーマーがDynamic Tanh(DyT)を用いることで、同等またはそれ以上のパフォーマンスを達成できることを示します。DyTは、レイヤー正規化の代替として機能し、ハイパーパラメータの調整なしで効果を発揮します。多様な設定での実験により、正規化層の必要性に対する新たな洞察を提供します。
Commentなん…だと…。LayerNormalizationを下記アルゴリズムのようなtanhを用いた超絶シンプルなレイヤー(parameterized thnh [Lecun氏ポスト](https://x.com/ylecun/status/1900610590315249833?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q))に置換するだけっぽい?


同等以上の性能を維持しながらモデル全体のinference, trainingの時間を8%程度削減。
 #Tools
#NLP
#Supervised-FineTuning (SFT)
#SelfImprovement
Issue Date: 2025-03-07
START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv'25
Summary新しいツール統合型の長Chain-of-thought推論モデルSTARTを提案。STARTは外部ツールを活用し、自己学習フレームワークを通じて推論能力を向上。Hint-inferとHint Rejection Sampling Fine-Tuningを用いてLRMをファインチューニングし、科学QAや数学、コードベンチマークで高精度を達成。ベースモデルを大幅に上回り、最先端モデルに匹敵する性能を示す。
Comment論文の本題とは関係ないが、QwQ-32Bよりも、DeepSeek-R1-Distilled-Qwen32Bの方が性能が良いのは興味深い。やはり大きいパラメータから蒸留したモデルの方が、小さいパラメータに追加学習したモデルよりも性能が高い傾向にあるのだろうか(どういうデータで蒸留したかにもよるけど)。
#Tools
#NLP
#Supervised-FineTuning (SFT)
#SelfImprovement
Issue Date: 2025-03-07
START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv'25
Summary新しいツール統合型の長Chain-of-thought推論モデルSTARTを提案。STARTは外部ツールを活用し、自己学習フレームワークを通じて推論能力を向上。Hint-inferとHint Rejection Sampling Fine-Tuningを用いてLRMをファインチューニングし、科学QAや数学、コードベンチマークで高精度を達成。ベースモデルを大幅に上回り、最先端モデルに匹敵する性能を示す。
Comment論文の本題とは関係ないが、QwQ-32Bよりも、DeepSeek-R1-Distilled-Qwen32Bの方が性能が良いのは興味深い。やはり大きいパラメータから蒸留したモデルの方が、小さいパラメータに追加学習したモデルよりも性能が高い傾向にあるのだろうか(どういうデータで蒸留したかにもよるけど)。
 OpenReview:https://openreview.net/forum?id=m80LCW765n
#Survey
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Reasoning
Issue Date: 2025-03-04
LLM Post-Training: A Deep Dive into Reasoning Large Language Models, Komal Kumar+, arXiv'25
Summary大規模言語モデル(LLMs)のポストトレーニング手法に焦点を当て、知識の洗練や推論の改善、事実の正確性向上を目指す。ファインチューニングや強化学習などの戦略がLLMsのパフォーマンスを最適化し、実世界のタスクへの適応性を向上させる。主要な課題として壊滅的な忘却や報酬ハッキングを分析し、今後の研究方向性を示す公開リポジトリも提供。
Comment非常にわかりやすい。
OpenReview:https://openreview.net/forum?id=m80LCW765n
#Survey
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Reasoning
Issue Date: 2025-03-04
LLM Post-Training: A Deep Dive into Reasoning Large Language Models, Komal Kumar+, arXiv'25
Summary大規模言語モデル(LLMs)のポストトレーニング手法に焦点を当て、知識の洗練や推論の改善、事実の正確性向上を目指す。ファインチューニングや強化学習などの戦略がLLMsのパフォーマンスを最適化し、実世界のタスクへの適応性を向上させる。主要な課題として壊滅的な忘却や報酬ハッキングを分析し、今後の研究方向性を示す公開リポジトリも提供。
Comment非常にわかりやすい。
 元ポスト:https://x.com/gm8xx8/status/1896399195596263710?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Multi
#RecommenderSystems
#NeuralNetwork
#Survey
#MultitaskLearning
#MulltiModal
Issue Date: 2025-03-03
Joint Modeling in Recommendations: A Survey, Xiangyu Zhao+, arXiv'25
Summaryデジタル環境におけるDeep Recommender Systems(DRS)は、ユーザーの好みに基づくコンテンツ推薦に重要だが、従来の手法は単一のタスクやデータに依存し、複雑な好みを反映できない。これを克服するために、共同モデリングアプローチが必要であり、推薦の精度とカスタマイズを向上させる。本論文では、共同モデリングをマルチタスク、マルチシナリオ、マルチモーダル、マルチビヘイビアの4次元で定義し、最新の進展と研究の方向性を探る。最後に、将来の研究の道筋を示し、結論を述べる。
Comment元ポスト:https://x.com/_reachsumit/status/1896408792952410496?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#NLP
#LanguageModel
#DiffusionModel
Issue Date: 2025-03-02
Large Language Diffusion Models, Shen Nie+, arXiv'25
SummaryLLaDAは、自己回帰モデル(ARMs)に代わる拡散モデルであり、ゼロから訓練され、データマスキングを通じて分布をモデル化。広範なベンチマークで強力なスケーラビリティを示し、自己構築したARMベースラインを上回る。特に、LLaDA 8Bは文脈内学習や指示追従能力に優れ、逆詩の完成タスクでGPT-4oを超える性能を発揮。拡散モデルがARMsの実行可能な代替手段であることを示す。
Comment元ポスト:https://x.com/dair_ai/status/1893698288328602022?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q参考:https://x.com/karpathy/status/1894923254864978091
#EfficiencyImprovement
#MachineLearning
#NLP
#LanguageModel
#Attention
#ACL
#read-later
Issue Date: 2025-03-02
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, Jingyang Yuan+, ACL'25
Summary長文コンテキストモデリングのために、計算効率を改善するスパースアテンションメカニズム「NSA」を提案。NSAは動的な階層スパース戦略を用い、トークン圧縮と選択を組み合わせてグローバルなコンテキスト認識とローカルな精度を両立。実装最適化によりスピードアップを実現し、エンドツーエンドのトレーニングを可能にすることで計算コストを削減。NSAはフルアテンションモデルと同等以上の性能を維持しつつ、長シーケンスに対して大幅なスピードアップを達成。
Comment元ポスト:https://x.com/dair_ai/status/1893698286545969311?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QACL'25のBest Paperの一つ:
元ポスト:https://x.com/gm8xx8/status/1896399195596263710?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Multi
#RecommenderSystems
#NeuralNetwork
#Survey
#MultitaskLearning
#MulltiModal
Issue Date: 2025-03-03
Joint Modeling in Recommendations: A Survey, Xiangyu Zhao+, arXiv'25
Summaryデジタル環境におけるDeep Recommender Systems(DRS)は、ユーザーの好みに基づくコンテンツ推薦に重要だが、従来の手法は単一のタスクやデータに依存し、複雑な好みを反映できない。これを克服するために、共同モデリングアプローチが必要であり、推薦の精度とカスタマイズを向上させる。本論文では、共同モデリングをマルチタスク、マルチシナリオ、マルチモーダル、マルチビヘイビアの4次元で定義し、最新の進展と研究の方向性を探る。最後に、将来の研究の道筋を示し、結論を述べる。
Comment元ポスト:https://x.com/_reachsumit/status/1896408792952410496?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#NLP
#LanguageModel
#DiffusionModel
Issue Date: 2025-03-02
Large Language Diffusion Models, Shen Nie+, arXiv'25
SummaryLLaDAは、自己回帰モデル(ARMs)に代わる拡散モデルであり、ゼロから訓練され、データマスキングを通じて分布をモデル化。広範なベンチマークで強力なスケーラビリティを示し、自己構築したARMベースラインを上回る。特に、LLaDA 8Bは文脈内学習や指示追従能力に優れ、逆詩の完成タスクでGPT-4oを超える性能を発揮。拡散モデルがARMsの実行可能な代替手段であることを示す。
Comment元ポスト:https://x.com/dair_ai/status/1893698288328602022?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q参考:https://x.com/karpathy/status/1894923254864978091
#EfficiencyImprovement
#MachineLearning
#NLP
#LanguageModel
#Attention
#ACL
#read-later
Issue Date: 2025-03-02
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, Jingyang Yuan+, ACL'25
Summary長文コンテキストモデリングのために、計算効率を改善するスパースアテンションメカニズム「NSA」を提案。NSAは動的な階層スパース戦略を用い、トークン圧縮と選択を組み合わせてグローバルなコンテキスト認識とローカルな精度を両立。実装最適化によりスピードアップを実現し、エンドツーエンドのトレーニングを可能にすることで計算コストを削減。NSAはフルアテンションモデルと同等以上の性能を維持しつつ、長シーケンスに対して大幅なスピードアップを達成。
Comment元ポスト:https://x.com/dair_ai/status/1893698286545969311?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QACL'25のBest Paperの一つ:
https://x.com/gm8xx8/status/1950644063952052643?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Reasoning Issue Date: 2025-02-26 From System 1 to System 2: A Survey of Reasoning Large Language Models, Zhong-Zhi Li+, arXiv'25 Summary人間レベルの知能を達成するためには、迅速なシステム1から意図的なシステム2への推論の洗練が必要。基盤となる大規模言語モデル(LLMs)は迅速な意思決定に優れるが、複雑な推論には深さが欠ける。最近の推論LLMはシステム2の意図的な推論を模倣し、人間のような認知能力を示している。本調査では、LLMの進展とシステム2技術の初期開発を概観し、推論LLMの構築方法や特徴、進化を分析。推論ベンチマークの概要を提供し、代表的な推論LLMのパフォーマンスを比較。最後に、推論LLMの進展に向けた方向性を探り、最新の開発を追跡するためのGitHubリポジトリを維持することを目指す。 Comment元ポスト:https://x.com/_reachsumit/status/1894282083956396544?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #SyntheticData #Reasoning #Distillation Issue Date: 2025-02-19 NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions, Weizhe Yuan+, arXiv'25 Summary多様で高品質な推論質問を生成するためのスケーラブルなアプローチを提案し、280万の質問からなるNaturalReasoningデータセットを構築。知識蒸留実験により、強力な教師モデルが推論能力を引き出せることを実証し、教師なし自己学習にも効果的であることを示す。 Comment元ポスト: https://x.com/jaseweston/status/1892041992127021300?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning Issue Date: 2025-02-18 Scaling Test-Time Compute Without Verification or RL is Suboptimal, Amrith Setlur+, arXiv'25 SummaryRLや探索に基づく検証者ベース(VB)手法が、探索の痕跡を蒸留する検証者フリー(VF)アプローチよりも優れていることを示す。テスト時の計算とトレーニングデータをスケールアップすると、VF手法の最適性が悪化し、VB手法がより良くスケールすることが確認された。3/8/32BサイズのLLMを用いた実験で、検証が計算能力の向上に重要であることを実証。 Comment元ポスト:https://x.com/iscienceluvr/status/1891839822257586310?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1749 #Pretraining #NLP #LanguageModel Issue Date: 2025-02-14 LLM Pretraining with Continuous Concepts, Jihoon Tack+, arXiv'25 Summary次トークン予測に代わる新しい事前学習フレームワークCoCoMixを提案。これは、スパースオートエンコーダから学習した連続的な概念をトークンの隠れ表現と交互に混ぜることで、モデルの性能を向上させる。実験により、CoCoMixは従来の手法を上回り、解釈可能性と操作性も向上させることが示された。 #NLP #LanguageModel #Test-Time Scaling Issue Date: 2025-02-12 Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling, Runze Liu+, arXiv'25 SummaryTest-Time Scaling (TTS)は、LLMsの性能向上に寄与する手法であり、ポリシーモデルやPRM、問題の難易度がTTSに与える影響を分析。実験により、最適なTTS戦略はこれらの要素に依存し、小型モデルが大型モデルを上回る可能性を示した。具体的には、1BのLLMが405BのLLMを超える結果を得た。これにより、TTSがLLMsの推論能力を向上させる有望なアプローチであることが示された。 #InformationRetrieval #NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-02-12 DeepRAG: Thinking to Retrieval Step by Step for Large Language Models, Xinyan Guan+, arXiv'25 SummaryDeepRAGフレームワークを提案し、検索強化推論をマルコフ決定過程としてモデル化。クエリを反復的に分解し、外部知識の取得とパラメトリック推論の依存を動的に判断。実験により、検索効率と回答の正確性を21.99%向上させることを実証。 Comment日本語解説。ありがとうございます!
RAGでも「深い検索」を実現する手法「DeepRAG」, Atsushi Kadowaki,
ナレッジセンス ・AI知見共有ブログ:https://zenn.dev/knowledgesense/articles/034b613c9fd6d3 #NLP #LanguageModel #ReinforcementLearning #SyntheticData #CodeGeneration #SyntheticDataGeneration Issue Date: 2025-02-12 ACECODER: Acing Coder RL via Automated Test-Case Synthesis, Huaye Zeng+, arXiv'25 Summary本研究では、コードモデルのトレーニングにおける強化学習(RL)の可能性を探求し、自動化された大規模テストケース合成を活用して信頼できる報酬データを生成する手法を提案します。具体的には、既存のコードデータから質問とテストケースのペアを生成し、これを用いて報酬モデルをトレーニングします。このアプローチにより、Llama-3.1-8B-Insで平均10ポイント、Qwen2.5-Coder-7B-Insで5ポイントの性能向上が見られ、7Bモデルが236B DeepSeek-V2.5と同等の性能を達成しました。また、強化学習を通じてHumanEvalやMBPPなどのデータセットで一貫した改善を示し、特にQwen2.5-Coder-baseからのRLトレーニングがHumanEval-plusで25%以上、MBPP-plusで6%の改善をもたらしました。これにより、コーダーモデルにおける強化学習の大きな可能性が示されました。 #NLP #LanguageModel #Architecture #Test-Time Scaling #LatentReasoning Issue Date: 2025-02-10 Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, Jonas Geiping+, arXiv'25 Summary新しい言語モデルアーキテクチャを提案し、潜在空間での暗黙的推論によりテスト時の計算をスケールさせる。再帰ブロックを反復し、任意の深さに展開することで、従来のトークン生成モデルとは異なるアプローチを採用。特別なトレーニングデータを必要とせず、小さなコンテキストウィンドウで複雑な推論を捉える。3.5億パラメータのモデルをスケールアップし、推論ベンチマークでのパフォーマンスを劇的に改善。 #NLP #LanguageModel #Distillation #TeacherHacking Issue Date: 2025-02-10 On Teacher Hacking in Language Model Distillation, Daniil Tiapkin+, arXiv'25 Summary本研究では、言語モデルの知識蒸留過程における「教師ハッキング」の現象を調査。固定されたオフラインデータセットを用いると教師ハッキングが発生し、最適化プロセスの逸脱を検出可能。一方、オンラインデータ生成技術を用いることで教師ハッキングを軽減でき、データの多様性が重要な要因であることを明らかにした。これにより、堅牢な言語モデル構築における蒸留の利点と限界についての理解が深まる。 Comment元ポスト:https://x.com/_philschmid/status/1888516494100734224?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q自分で蒸留する機会は今のところないが、覚えておきたい。過学習と一緒で、こういう現象が起こるのは想像できる。 #NLP #LanguageModel #LLMAgent Issue Date: 2025-02-09 Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?, Wenzhe Li+, arXiv'25 SummarySelf-MoAは、単一の高性能LLMからの出力を集約するアンサンブル手法であり、従来のMoAを上回る性能を示す。AlpacaEval 2.0で6.6%の改善を達成し、MMLUやCRUXなどでも平均3.8%の向上を記録。出力の多様性と品質のトレードオフを調査し、異なるLLMの混合が品質を低下させることを確認。Self-MoAの逐次バージョンも効果的であることを示した。 Comment元ポスト:https://x.com/dair_ai/status/1888658770059816968?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Supervised-FineTuning (SFT) #Test-Time Scaling #read-later Issue Date: 2025-02-07 s1: Simple test-time scaling, Niklas Muennighoff+, arXiv'25 Summaryテスト時スケーリングを用いて言語モデルのパフォーマンスを向上させる新しいアプローチを提案。小規模データセットs1Kを作成し、モデルの思考プロセスを制御する予算強制を導入。これにより、モデルは不正確な推論を修正し、Qwen2.5-32B-Instructモデルがo1-previewを最大27%上回る結果を達成。さらに、介入なしでパフォーマンスを向上させることが可能となった。モデル、データ、コードはオープンソースで提供。 Comment解説:https://x.com/hillbig/status/1887260791981941121?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Supervised-FineTuning (SFT) #DataDistillation #Reasoning #PostTraining Issue Date: 2025-02-07 LIMO: Less is More for Reasoning, Yixin Ye+, arXiv'25 SummaryLIMOモデルは、わずか817のトレーニングサンプルで複雑な数学的推論を効果的に引き出し、AIMEで57.1%、MATHで94.8%の精度を達成。従来のモデルよりも少ないデータで優れたパフォーマンスを示し、一般化を促す「Less-Is-More Reasoning Hypothesis」を提案。LIMOはオープンソースとして提供され、データ効率の良い推論の再現性を促進する。 Comment元ポスト:https://x.com/arankomatsuzaki/status/1887353699644940456?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Alignment #ICLR #DPO #PostTraining #Diversity Issue Date: 2025-02-01 Diverse Preference Optimization, Jack Lanchantin+, ICLR'25 SummaryDiverse Preference Optimization(DivPO)を提案し、応答の多様性を向上させつつ生成物の品質を維持するオンライン最適化手法を紹介。DivPOは応答のプールから多様性を測定し、希少で高品質な例を選択することで、パーソナ属性の多様性を45.6%、ストーリーの多様性を74.6%向上させる。 Comment元ポスト:https://x.com/jaseweston/status/1885399530419450257?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview: https://openreview.net/forum?id=pOq9vDIYevDPOと同じ最適化方法を使うが、Preference Pairを選択する際に、多様性が増加するようなPreference Pairの選択をすることで、モデルのPost-training後の多様性を損なわないようにする手法を提案しているっぽい。
具体的には、Alg.1 に記載されている通り、多様性の尺度Dを定義して、モデルにN個のレスポンスを生成させRMによりスコアリングした後、RMのスコアが閾値以上のresponseを"chosen" response, 閾値未満のレスポンスを "reject" responseとみなし、chosen/reject response集合を構築する。chosen response集合の中からDに基づいて最も多様性のあるresponse y_c、reject response集合の中から最も多様性のないresponse y_r をそれぞれピックし、prompt xとともにpreference pair (x, y_c, y_r) を構築しPreference Pairに加える、といった操作を全ての学習データ(中のprompt)xに対して繰り返すことで実現する。 #ComputerVision #Analysis #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #ICML #PostTraining #read-later #Admin'sPick Issue Date: 2025-01-30 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25 SummarySFTとRLの一般化能力の違いを研究し、GeneralPointsとV-IRLを用いて評価。RLはルールベースのテキストと視覚変種に対して優れた一般化を示す一方、SFTは訓練データを記憶し分布外シナリオに苦労。RLは視覚認識能力を向上させるが、SFTはRL訓練に不可欠であり、出力形式を安定させることで性能向上を促進。これらの結果は、複雑なマルチモーダルタスクにおけるRLの一般化能力を示す。 Comment元ポスト:https://x.com/hillbig/status/1884731381517082668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qopenreview:https://openreview.net/forum?id=dYur3yabMj&referrer=%5Bthe%20profile%20of%20Yi%20Ma%5D(%2Fprofile%3Fid%3D~Yi_Ma4) #RecommenderSystems #LanguageModel #Personalization #FoundationModel Issue Date: 2025-01-29 360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation, Hamed Firooz+, arXiv'25 Summaryランキングおよび推薦システムの課題に対処するため、テキストインターフェースを持つ大規模基盤モデルを活用した研究を紹介。150Bパラメータのデコーダー専用モデル360Brew V1.0は、LinkedInのデータを用いて30以上の予測タスクを解決し、従来の専用モデルと同等以上のパフォーマンスを達成。特徴エンジニアリングの複雑さを軽減し、複数のタスクを単一モデルで管理可能にする利点を示す。 Comment元ポスト:https://x.com/_reachsumit/status/1884455910824948154?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Reasoning #Test-Time Scaling Issue Date: 2025-01-28 Evolving Deeper LLM Thinking, Kuang-Huei Lee+, arXiv'25 SummaryMind Evolutionという進化的探索戦略を提案し、言語モデルを用いて候補応答を生成・洗練する。これにより、推論問題の形式化を回避しつつ、推論コストを制御。自然言語計画タスクにおいて、他の戦略を大幅に上回り、TravelPlannerおよびNatural Planのベンチマークで98%以上の問題を解決。 CommentOpenReview: https://openreview.net/forum?id=nGP1UxhAbV&referrer=%5Bthe%20profile%20of%20Kuang-Huei%20Lee%5D(%2Fprofile%3Fid%3D~Kuang-Huei_Lee1) #RecommenderSystems #LanguageModel Issue Date: 2025-01-28 Pre-train and Fine-tune: Recommenders as Large Models, Zhenhao Jiang+, arXiv'25 Summaryユーザーの興味の変化を捉えるため、レコメンダーを大規模な事前学習モデルとしてファインチューニングするアプローチを提案。情報ボトルネック理論に基づき、知識圧縮と知識マッチングの二つのフェーズを定義したIAK技術を設計。実験により優位性を示し、オンラインプラットフォームでの展開から得た教訓や潜在的な問題への解決策も提示。IAK技術を用いたレコメンダーは、オンラインフードプラットフォームでの展開により大きな利益を上げている。 Comment元ポスト:https://x.com/_reachsumit/status/1883719872540254355?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2025-01-25 Perspective Transition of Large Language Models for Solving Subjective Tasks, Xiaolong Wang+, arXiv'25 Summary視点の移行を通じた推論(RPT)を提案し、LLMsが主観的な問題に対して動的に視点を選択できる手法を紹介。広範な実験により、従来の固定視点手法を上回り、文脈に応じた適切な応答を提供する能力を示す。 Comment元ポスト:https://x.com/rohanpaul_ai/status/1882739526361370737?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview: https://openreview.net/forum?id=cFGPlRony5"Subjective Task"とは例えば「メタファーの認識」や「ダークユーモアの検知」などがあり、これらは定量化しづらい認知的なコンテキストや、ニュアンスや感情などが強く関連しており、現状のLLMではチャレンジングだと主張している。
Subjective Taskでは、Reasoningモデルのように自動的にCoTのpathwayを決めるのは困難で、手動でpathwayを記述するのはチャレンジングで一貫性を欠くとした上で、複数の視点を組み合わせたPrompting(direct perspective, role-perspective, third-person perspectivfe)を実施し、最もConfidenceの高いanswerを採用することでこの課題に対処すると主張している。イントロしか読めていないが、自動的にCoTのpathwayを決めるのも手動で決めるのも難しいという風にイントロで記述されているが、手法自体が最終的に3つの視点から回答を生成させるという枠組みに則っている(つまりSubjective Taskを解くための形式化できているので、自動的な手法でもできてしまうのではないか?と感じた)ので、イントロで記述されている主張の”難しさ”が薄れてしまっているかも・・・?と感じた。論文が解こうとしている課題の”難しさ”をサポートする材料がもっとあった方がよりmotivationが分かりやすくなるかもしれない、という感想を持った。 #RecommenderSystems #Survey #LanguageModel #Contents-based Issue Date: 2025-01-06 Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap, Weizhi Zhang+, arXiv'25 Summaryコールドスタート問題はレコメンダーシステムの重要な課題であり、新しいユーザーやアイテムのモデル化に焦点を当てている。大規模言語モデル(LLMs)の成功により、CSRに新たな可能性が生まれているが、包括的なレビューが不足している。本論文では、CSRのロードマップや関連文献をレビューし、LLMsが情報を活用する方法を探求することで、研究と産業界に新たな洞察を提供することを目指す。関連リソースはコミュニティのために収集・更新されている。 Comment元ポスト:https://x.com/_reachsumit/status/1876093584593793091?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ICML #Tokenizer #Workshop Issue Date: 2025-01-02 Byte Latent Transformer: Patches Scale Better Than Tokens, Artidoro Pagnoni+, ICML'25 Workshop Tokshop SummaryByte Latent Transformer(BLT)は、バイトレベルのLLMアーキテクチャで、トークン化ベースのLLMと同等のパフォーマンスを実現し、推論効率と堅牢性を大幅に向上させる。BLTはバイトを動的にサイズ変更可能なパッチにエンコードし、データの複雑性に応じて計算リソースを調整する。最大8Bパラメータと4Tトレーニングバイトのモデルでの研究により、固定語彙なしでのスケーリングの可能性が示された。長いパッチの動的選択により、トレーニングと推論の効率が向上し、全体的にBLTはトークン化モデルよりも優れたスケーリングを示す。 Comment興味深い図しか見れていないが、バイト列をエンコード/デコードするtransformer学習して複数のバイト列をパッチ化(エントロピーが大きい部分はより大きなパッチにバイト列をひとまとめにする)、パッチからのバイト列生成を可能にし、パッチを変換するのをLatent Transformerで学習させるようなアーキテクチャのように見える。
また、予算によってモデルサイズが決まってしまうが、パッチサイズを大きくすることで同じ予算でモデルサイズも大きくできるのがBLTの利点とのこと。

 日本語解説:https://bilzard.github.io/blog/2025/01/01/byte-latent-transformer.html?v=2OpenReview:https://openreview.net/forum?id=UZ3J8XeRLw
#NLP
#LanguageModel
#Alignment
#Supervised-FineTuning (SFT)
#LLMAgent
#COLING
#PostTraining
Issue Date: 2024-12-10
Towards Adaptive Mechanism Activation in Language Agent, Ziyang Huang+, COLING'25
Summary自己探索によるメカニズム活性化学習(ALAMA)を提案し、固定されたメカニズムに依存せずに適応的なタスク解決を目指す。調和のとれたエージェントフレームワーク(UniAct)を構築し、タスク特性に応じてメカニズムを自動活性化。実験結果は、動的で文脈に敏感なメカニズム活性化の有効性を示す。
Comment元ポスト: https://x.com/omarsar0/status/1863956776623747433?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q手法としては、SFTとKTOを活用しpost trainingするようである
日本語解説:https://bilzard.github.io/blog/2025/01/01/byte-latent-transformer.html?v=2OpenReview:https://openreview.net/forum?id=UZ3J8XeRLw
#NLP
#LanguageModel
#Alignment
#Supervised-FineTuning (SFT)
#LLMAgent
#COLING
#PostTraining
Issue Date: 2024-12-10
Towards Adaptive Mechanism Activation in Language Agent, Ziyang Huang+, COLING'25
Summary自己探索によるメカニズム活性化学習(ALAMA)を提案し、固定されたメカニズムに依存せずに適応的なタスク解決を目指す。調和のとれたエージェントフレームワーク(UniAct)を構築し、タスク特性に応じてメカニズムを自動活性化。実験結果は、動的で文脈に敏感なメカニズム活性化の有効性を示す。
Comment元ポスト: https://x.com/omarsar0/status/1863956776623747433?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q手法としては、SFTとKTOを活用しpost trainingするようである

・1472 #NLP #DataAugmentation #Distillation #NAACL #Verification Issue Date: 2024-12-02 Reverse Thinking Makes LLMs Stronger Reasoners, Justin Chih-Yao Chen+, NAACL'25 Summary逆思考は推論において重要であり、我々は大規模言語モデル(LLMs)向けにReverse-Enhanced Thinking(RevThink)フレームワークを提案。データ拡張と学習目標を用いて、前向きと後向きの推論を構造化し、マルチタスク学習で小型モデルを訓練。実験では、ゼロショット性能が平均13.53%向上し、知識蒸留ベースラインに対して6.84%の改善を達成。少ないデータでのサンプル効率も示し、一般化能力が高いことが確認された。 Comment手法概要
Original QuestionからTeacher Modelでreasoningと逆質問を生成(Forward Reasoning, Backward Question)し、逆質問に対するReasoningを生成する(Backward Reasoning)。
その後、Forward Reasoningで回答が誤っているものや、Teacher Modelを用いてBackward ReasoningとOriginal Questionを比較して正しさをverificationすることで、学習データのフィルタリングを行う。
このようにして得られたデータに対して、3種類の項をlossに設けて学習する。具体的には
・Original Questionから生成したForward Reasoningに対するクロスエントロピー
・Original Questionから生成したBackward Questionに対するクロスエントロピー
・Backward Questionから生成したBackward Reasoningに対するクロスエントロピー
の平均をとる。

また、original questionと、backward reasoningが一貫しているかを確認するためにTeacher Modelを利用した下記プロンプトでverificationを実施し、一貫性があると判断されたサンプルのみをSFTのデータとして活用している。

Teacherモデルから知識蒸留をするためSFTが必要。あと、正解が一意に定まるようなQuestionでないとbackward reasoningの生成はできても、verificationが困難になるので、適用するのは難しいかもしれない。 #NeuralNetwork #Pretraining #MachineLearning #NLP #LanguageModel #ICLR #Batch Issue Date: 2024-11-25 How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25 Summary大規模モデルの訓練には、クリティカルバッチサイズ(CBS)を考慮した並列化戦略が重要である。CBSの測定法を提案し、C4データセットで自己回帰型言語モデルを訓練。バッチサイズや学習率などの要因を調整し、CBSがデータサイズに比例してスケールすることを示した。この結果は、ニューラルネットワークの理論的分析によって支持され、ハイパーパラメータ選択の重要性も強調されている。 CommentCritical Batch Sizeはモデルサイズにはあまり依存せず、データサイズに応じてスケールする

 #NLP
#LanguageModel
#Alignment
#Supervised-FineTuning (SFT)
#ICML
Issue Date: 2024-11-07
Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25
Summary自己調整は、モデルが人間の注釈なしに自らを改善する方法であり、自己一貫性を活用して訓練を行う新しいアプローチ、自己一貫性優先最適化(ScPO)を提案。ScPOは一貫した答えを優先し、GSM8KやMATHなどの推論タスクで従来の手法を大幅に上回る性能を示し、標準的な監視学習との組み合わせでも結果が向上。ZebraLogicでLlama-3 8Bを微調整し、他の大規模モデルを超える成果を達成。
Comment元ポスト:https://x.com/jaseweston/status/1854532624116547710?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QSelf-Consistencyのように、モデルに複数の出力をさせて、最も頻度が高い回答と頻度が低い回答の2つでDPOのペアデータを作成し学習。頻度の差によって重みを決めてlossに組み込みこのよつな処理を繰り返し学習すると性能が向上する、といった話のように見える。
#NLP
#LanguageModel
#Alignment
#Supervised-FineTuning (SFT)
#ICML
Issue Date: 2024-11-07
Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25
Summary自己調整は、モデルが人間の注釈なしに自らを改善する方法であり、自己一貫性を活用して訓練を行う新しいアプローチ、自己一貫性優先最適化(ScPO)を提案。ScPOは一貫した答えを優先し、GSM8KやMATHなどの推論タスクで従来の手法を大幅に上回る性能を示し、標準的な監視学習との組み合わせでも結果が向上。ZebraLogicでLlama-3 8Bを微調整し、他の大規模モデルを超える成果を達成。
Comment元ポスト:https://x.com/jaseweston/status/1854532624116547710?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QSelf-Consistencyのように、モデルに複数の出力をさせて、最も頻度が高い回答と頻度が低い回答の2つでDPOのペアデータを作成し学習。頻度の差によって重みを決めてlossに組み込みこのよつな処理を繰り返し学習すると性能が向上する、といった話のように見える。




#ICLR Issue Date: 2024-10-11 GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, Iman Mirzadeh+, N_A, ICLR'25 Summary最近のLLMsの進展により、数学的推論能力への関心が高まっているが、GSM8Kベンチマークの信頼性には疑問が残る。これに対処するため、GSM-Symbolicという新しいベンチマークを導入し、モデルの推論能力をより正確に評価。調査結果は、モデルが同じ質問の異なる具現化に対してばらつきを示し、特に数値変更や質問の節の数が増えると性能が著しく低下することを明らかにした。これは、LLMsが真の論理的推論を行えず、トレーニングデータからの再現に依存しているためと考えられる。全体として、研究は数学的推論におけるLLMsの能力と限界についての理解を深める。 Comment元ポスト:https://x.com/mfarajtabar/status/1844456880971858028?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMay I ask if this work is open source?I'm sorry, I just noticed your comment. From what I could see in the repository and OpenReview discussion, some parts of the dataset, such as GSMNoOp, are not part of the current public release. The repository issues also mention that the data generation code is not included at the moment. This is just based on my quick check, so there may be more updates or releases coming later.
OpenReview:https://openreview.net/forum?id=AjXkRZIvjB
Official blog post:https://machinelearning.apple.com/research/gsm-symbolic
Repo:https://github.com/apple/ml-gsm-symbolic
HuggingFace:https://huggingface.co/datasets/apple/GSM-Symbolic #Analysis #NLP #LanguageModel #SyntheticData #ICLR Issue Date: 2024-04-15 Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws, Zeyuan Allen-Zhu+, N_A, ICLR'25 Summary言語モデルのサイズと能力の関係を記述するスケーリング則に焦点を当てた研究。モデルが格納する知識ビット数を推定し、事実知識をタプルで表現。言語モデルは1つのパラメータあたり2ビットの知識を格納可能であり、7Bモデルは14Bビットの知識を格納可能。さらに、トレーニング期間、モデルアーキテクチャ、量子化、疎な制約、データの信号対雑音比が知識格納容量に影響することを示唆。ロータリー埋め込みを使用したGPT-2アーキテクチャは、知識の格納においてLLaMA/Mistralアーキテクチャと競合する可能性があり、トレーニングデータにドメイン名を追加すると知識容量が増加することが示された。 Comment参考:https://x.com/hillbig/status/1779640139263901698?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:
・1834openreview:https://openreview.net/forum?id=FxNNiUgtfa #ComputerVision #NLP #LanguageModel #ModelMerge Issue Date: 2024-03-21 Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N_A, Nature Machine Intelligence'25 Summary進化アルゴリズムを使用した新しいアプローチを提案し、強力な基盤モデルの自動生成を実現。LLMの開発において、人間の直感やドメイン知識に依存せず、多様なオープンソースモデルの効果的な組み合わせを自動的に発見する。このアプローチは、日本語のLLMと数学推論能力を持つモデルなど、異なるドメイン間の統合を容易にし、日本語VLMの性能向上にも貢献。オープンソースコミュニティへの貢献と自動モデル構成の新しいパラダイム導入により、基盤モデル開発における効率的なアプローチを模索。 Comment複数のLLMを融合するモデルマージの話。日本語LLMと英語の数学LLNをマージさせることで日本語の数学性能を大幅に向上させたり、LLMとVLMを融合したりすることで、日本にしか存在しない概念の画像も、きちんと回答できるようになる。
著者スライドによると、従来のモデルマージにはbase modelが同一でないとうまくいかなかったり(重みの線型結合によるモデルマージ)、パラメータが増減したり(複数LLMのLayerを重みは弄らず再配置する)。また日本語LLMに対してモデルマージを実施しようとすると、マージ元のLLMが少なかったり、広範囲のモデルを扱うとマージがうまくいかない、といった課題があった。本研究ではこれら課題を解決できる。著者による資料(NLPコロキウム):
https://speakerdeck.com/iwiwi/17-nlpkorokiumu #ComputerVision #Analysis #Prompting Issue Date: 2025-08-25 [Paper Note] As Generative Models Improve, People Adapt Their Prompts, Eaman Jahani+, arXiv'24 Summaryオンライン実験で1893人の参加者を対象に、DALL-E 2とDALL-E 3のプロンプトの重要性の変化を調査。DALL-E 3を使用した参加者は、DALL-E 2よりも高いパフォーマンスを示し、これは技術的能力の向上とプロンプトの質の変化によるもの。特に、DALL-E 3の参加者はより長く、意味的に類似したプロンプトを作成。プロンプト修正機能を持つDALL-E 3はさらに高いパフォーマンスを示したが、その利点は減少。結果として、モデルの進化に伴い、プロンプトも適応されることが示唆される。 Comment元ポスト:https://x.com/dair_ai/status/1959644116305748388?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #SmallModel #Scheduler Issue Date: 2025-08-25 [Paper Note] MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies, Shengding Hu+, arXiv'24 Summary急成長する大規模言語モデル(LLMs)の開発におけるコストの懸念から、小規模言語モデル(SLMs)の可能性が注目されている。本研究では、MiniCPMという1.2Bおよび2.4Bの非埋め込みパラメータバリアントを紹介し、これらが7B-13BのLLMsと同等の能力を持つことを示す。モデルのスケーリングには広範な実験を、データのスケーリングにはWarmup-Stable-Decay(WSD)学習率スケジューラを導入し、効率的なデータ-モデルスケーリング法を研究した。MiniCPMファミリーにはMiniCPM-DPO、MiniCPM-MoE、MiniCPM-128Kが含まれ、優れたパフォーマンスを発揮している。MiniCPMモデルは公開されている。 CommentWarmup-Stable-Decay (WSD) #NeuralNetwork #NLP #Transformer #ActivationFunction Issue Date: 2025-08-25 [Paper Note] Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models, Zhijian Zhuo+, arXiv'24 Summary新しい多項式合成活性化関数(PolyCom)を提案し、トランスフォーマーのダイナミクスを最適化。PolyComは他の活性化関数よりも高い表現力を持ち、最適近似率を達成。大規模言語モデルにおいて、従来の活性化関数をPolyComに置き換えることで、精度と収束率が向上することを実証。実験結果は他の活性化関数に対して大幅な改善を示す。コードは公開中。 Comment関連:
・1311 #ComputerVision #Pretraining #MulltiModal #FoundationModel #CVPR #Admin'sPick #VisionLanguageModel Issue Date: 2025-08-23 [Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24 Summary大規模視覚-言語基盤モデル(InternVL)は、60億パラメータで設計され、LLMと整合させるためにウェブ規模の画像-テキストデータを使用。視覚認知タスクやゼロショット分類、検索など32のベンチマークで最先端の性能を達成し、マルチモーダル対話システムの構築に寄与。ViT-22Bの代替として強力な視覚能力を持つ。コードとモデルは公開されている。 Comment既存のResNetのようなSupervised pretrainingに基づくモデル、CLIPのようなcontrastive pretrainingに基づくモデルに対して、text encoder部分をLLMに置き換えて、contrastive learningとgenerativeタスクによる学習を組み合わせたパラダイムを提案。

InternVLのアーキテクチャは下記で、3 stageの学習で構成される。最初にimage text pairをcontrastive learningし学習し、続いてモデルのパラメータはfreezeしimage text retrievalタスク等でモダリティ間の変換を担う最終的にQlLlama(multilingual性能を高めたllama)をvision-languageモダリティを繋ぐミドルウェアのように捉え、Vicunaをテキストデコーダとして接続してgenerative cossで学習する、みたいなアーキテクチャの模様(斜め読みなので少し違う可能性あり
 現在のVLMの主流であるvision encoderとLLMをadapterで接続する方式はここからかなりシンプルになっていることが伺える。
#EMNLP
Issue Date: 2025-08-21
[Paper Note] Annotation-Efficient Preference Optimization for Language Model Alignment, Yuu Jinnai+, EMNLP'24
SummaryAEPO(Annotation-Efficient Preference Optimization)は、限られたアノテーション予算を活用し、質と多様性を最大化する応答のサブセットに対して好みをアノテーションする手法。これにより、従来のDPOモデルよりも優れた性能を発揮することを示した。
Comment元ポスト:https://x.com/dindin92/status/1958390598282748101?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#SelfImprovement
#ICML
Issue Date: 2025-08-21
[Paper Note] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback, Harrison Lee+, ICML'24
SummaryRLAIFは、オフ・ザ・シェルフのLLMから生成された好みに基づいて報酬モデルを訓練し、RLHFと同等のパフォーマンスを達成する代替手段を提供。自己改善を示し、d-RLAIFを導入することでさらに優れた結果を得る。RLAIFは人間のフィードバックを用いた場合と同等の性能を示し、RLHFのスケーラビリティの課題に対する解決策となる可能性がある。
#ComputerVision
#NLP
#Dataset
#QuestionAnswering
#Evaluation
#MulltiModal
#MultiLingual
#VisionLanguageModel
#Cultural
Issue Date: 2025-08-18
[Paper Note] CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark, David Romero+, arXiv'24
SummaryCVQAは、文化的に多様な多言語のVisual Question Answeringベンチマークで、30か国からの画像と質問を含み、31の言語と13のスクリプトをカバー。データ収集にはネイティブスピーカーを関与させ、合計10,000の質問を提供。マルチモーダル大規模言語モデルをベンチマークし、文化的能力とバイアスを評価するための新たな基準を示す。
#ComputerVision
#NLP
#Dataset
#InstructionTuning
#Evaluation
#MultiLingual
#VisionLanguageModel
Issue Date: 2025-08-18
[Paper Note] Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages, Xiang Yue+, arXiv'24
SummaryPangeaは、39の言語にわたる6M指示データセットPangeaInsを用いて訓練された多言語マルチモーダルLLMであり、異文化間のカバレッジを確保しています。Pangeaは、47の言語をカバーする評価スイートPangeaBenchで既存のモデルを大幅に上回る性能を示し、英語データの比率やマルチモーダル訓練サンプルの重要性を明らかにしました。データ、コード、訓練済みチェックポイントはオープンソース化され、言語的および文化的公平性を推進します。
#NLP
#Dataset
#LanguageModel
#Evaluation
#Mathematics
Issue Date: 2025-08-16
[Paper Note] FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI, Elliot Glazer+, arXiv'24
SummaryFrontierMathは、専門の数学者によって作成された難易度の高い数学問題のベンチマークで、数論や実解析から代数幾何学や圏論まで幅広い分野をカバー。問題解決には数時間から数日かかることがあり、現在のAIモデルは問題の2%未満しか解決できていない。FrontierMathはAIの数学的能力の進捗を定量化するための厳密なテストベッドを提供する。
#NLP
#Dataset
#LanguageModel
#QuestionAnswering
#Evaluation
#Factuality
#Trustfulness
Issue Date: 2025-08-16
[Paper Note] Measuring short-form factuality in large language models, Jason Wei+, arXiv'24
SummarySimpleQAは、言語モデルの短い事実に関する質問への応答能力を評価するためのベンチマークであり、挑戦的かつ評価が容易な質問を特徴とする。各回答は正解、不正解、未試行のいずれかとして評価され、理想的なモデルは自信がない質問には挑戦せず、正解を多く得ることを目指す。SimpleQAは、モデルが「自分が知っていることを知っているか」を評価するためのシンプルな手段であり、次世代モデルにとっても重要な評価基準となることが期待されている。
Comment先行研究:
現在のVLMの主流であるvision encoderとLLMをadapterで接続する方式はここからかなりシンプルになっていることが伺える。
#EMNLP
Issue Date: 2025-08-21
[Paper Note] Annotation-Efficient Preference Optimization for Language Model Alignment, Yuu Jinnai+, EMNLP'24
SummaryAEPO(Annotation-Efficient Preference Optimization)は、限られたアノテーション予算を活用し、質と多様性を最大化する応答のサブセットに対して好みをアノテーションする手法。これにより、従来のDPOモデルよりも優れた性能を発揮することを示した。
Comment元ポスト:https://x.com/dindin92/status/1958390598282748101?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#ReinforcementLearning
#SelfImprovement
#ICML
Issue Date: 2025-08-21
[Paper Note] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback, Harrison Lee+, ICML'24
SummaryRLAIFは、オフ・ザ・シェルフのLLMから生成された好みに基づいて報酬モデルを訓練し、RLHFと同等のパフォーマンスを達成する代替手段を提供。自己改善を示し、d-RLAIFを導入することでさらに優れた結果を得る。RLAIFは人間のフィードバックを用いた場合と同等の性能を示し、RLHFのスケーラビリティの課題に対する解決策となる可能性がある。
#ComputerVision
#NLP
#Dataset
#QuestionAnswering
#Evaluation
#MulltiModal
#MultiLingual
#VisionLanguageModel
#Cultural
Issue Date: 2025-08-18
[Paper Note] CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark, David Romero+, arXiv'24
SummaryCVQAは、文化的に多様な多言語のVisual Question Answeringベンチマークで、30か国からの画像と質問を含み、31の言語と13のスクリプトをカバー。データ収集にはネイティブスピーカーを関与させ、合計10,000の質問を提供。マルチモーダル大規模言語モデルをベンチマークし、文化的能力とバイアスを評価するための新たな基準を示す。
#ComputerVision
#NLP
#Dataset
#InstructionTuning
#Evaluation
#MultiLingual
#VisionLanguageModel
Issue Date: 2025-08-18
[Paper Note] Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages, Xiang Yue+, arXiv'24
SummaryPangeaは、39の言語にわたる6M指示データセットPangeaInsを用いて訓練された多言語マルチモーダルLLMであり、異文化間のカバレッジを確保しています。Pangeaは、47の言語をカバーする評価スイートPangeaBenchで既存のモデルを大幅に上回る性能を示し、英語データの比率やマルチモーダル訓練サンプルの重要性を明らかにしました。データ、コード、訓練済みチェックポイントはオープンソース化され、言語的および文化的公平性を推進します。
#NLP
#Dataset
#LanguageModel
#Evaluation
#Mathematics
Issue Date: 2025-08-16
[Paper Note] FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI, Elliot Glazer+, arXiv'24
SummaryFrontierMathは、専門の数学者によって作成された難易度の高い数学問題のベンチマークで、数論や実解析から代数幾何学や圏論まで幅広い分野をカバー。問題解決には数時間から数日かかることがあり、現在のAIモデルは問題の2%未満しか解決できていない。FrontierMathはAIの数学的能力の進捗を定量化するための厳密なテストベッドを提供する。
#NLP
#Dataset
#LanguageModel
#QuestionAnswering
#Evaluation
#Factuality
#Trustfulness
Issue Date: 2025-08-16
[Paper Note] Measuring short-form factuality in large language models, Jason Wei+, arXiv'24
SummarySimpleQAは、言語モデルの短い事実に関する質問への応答能力を評価するためのベンチマークであり、挑戦的かつ評価が容易な質問を特徴とする。各回答は正解、不正解、未試行のいずれかとして評価され、理想的なモデルは自信がない質問には挑戦せず、正解を多く得ることを目指す。SimpleQAは、モデルが「自分が知っていることを知っているか」を評価するためのシンプルな手段であり、次世代モデルにとっても重要な評価基準となることが期待されている。
Comment先行研究:
・2449
・2450
これらはすでに飽和している最近よくLLMのベンチで見かけるSimpleQA #ICML Issue Date: 2025-08-16 [Paper Note] Better & Faster Large Language Models via Multi-token Prediction, Fabian Gloeckle+, ICML'24 Summary本研究では、大規模言語モデルを複数の将来のトークンを同時に予測するように訓練する手法を提案し、サンプル効率の向上を図る。具体的には、n個の独立した出力ヘッドを用いて次のnトークンを予測し、訓練時間にオーバーヘッドをかけずに下流の能力を向上させる。特に、コーディングタスクにおいて、提案モデルは強力なベースラインを上回る性能を示し、推論時に最大3倍の速度向上も実現。 Issue Date: 2025-08-16 [Paper Note] Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, Lean Wang+, arXiv'24 SummaryMoEモデルにおける負荷の不均衡を解消するため、補助損失を用いないLoss-Free Balancingを提案。各エキスパートのルーティングスコアにバイアスを適用し、負荷のバランスを維持。実験により、従来の手法よりも性能と負荷バランスが向上することを確認。 Commentopenreview:https://openreview.net/forum?id=y1iU5czYpE #NLP #Dataset #LanguageModel #Evaluation #Programming #Reasoning #MultiLingual Issue Date: 2025-08-15 [Paper Note] CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution, Ruiyang Xu+, arXiv'24 SummaryCRUXEVAL-Xという多言語コード推論ベンチマークを提案。19のプログラミング言語を対象に、各言語で600以上の課題を含む19Kのテストを自動生成。言語間の相関を評価し、Python訓練モデルが他言語でも高い性能を示すことを確認。 Comment関連:
・2440 #NLP #Dataset #LanguageModel #Evaluation #Programming #Reasoning Issue Date: 2025-08-15 [Paper Note] CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, Alex Gu+, arXiv'24 SummaryCRUXEvalという800のPython関数からなるベンチマークを提案し、入力予測と出力予測の2つのタスクを評価。20のコードモデルをテストした結果、HumanEvalで高得点のモデルがCRUXEvalでは改善を示さないことが判明。GPT-4とChain of Thoughtを用いた場合、入力予測で75%、出力予測で81%のpass@1を達成したが、どのモデルも完全にはクリアできず、GPT-4のコード推論能力の限界を示す例を提供。 #ComputerVision #Analysis #ImageSegmentation #SSM (StateSpaceModel) #ImageClassification Issue Date: 2025-08-14 [Paper Note] MambaOut: Do We Really Need Mamba for Vision?, Weihao Yu+, arXiv'24 SummaryMambaはRNNのようなトークンミキサーを持つアーキテクチャで、視覚タスクにおいて期待外れの性能を示す。Mambaは長いシーケンスと自己回帰的な特性に適しているが、画像分類には不向きであると仮定。MambaOutモデルを構築し、実験によりMambaOutがImageNetの画像分類で視覚Mambaモデルを上回ることを示し、検出およびセグメンテーションタスクではMambaの可能性を探る価値があることを確認。 #Survey #NLP #LanguageModel #memory Issue Date: 2025-08-11 [Paper Note] A Survey on the Memory Mechanism of Large Language Model based Agents, Zeyu Zhang+, arXiv'24 SummaryLLMベースのエージェントのメモリメカニズムに関する包括的な調査を提案。メモリの重要性を論じ、過去の研究を体系的にレビューし、エージェントアプリケーションでの役割を紹介。既存研究の限界を分析し、将来の研究方向性を示す。リポジトリも作成。 Comment元ポスト:https://x.com/jiqizhixin/status/1954797669957968169?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #LanguageModel #NeurIPS #read-later #ReversalCurse Issue Date: 2025-08-11 [Paper Note] The Factorization Curse: Which Tokens You Predict Underlie the Reversal Curse and More, Ouail Kitouni+, NeurIPS'24 Summary最先端の言語モデルは幻覚に悩まされ、情報取得において逆転の呪いが問題となる。これを因数分解の呪いとして再定義し、制御実験を通じてこの現象が次トークン予測の固有の失敗であることを発見。信頼性のある情報取得は単純な手法では解決できず、ファインチューニングも限界がある。異なるタスクでの結果は、因数分解に依存しないアプローチが逆転の呪いを軽減し、知識の保存と計画能力の向上に寄与する可能性を示唆している。 Comment元ポスト:https://x.com/scaling01/status/1954682957798715669?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qopenreview:https://openreview.net/forum?id=f70e6YYFHFReversal Curseを提言した研究は下記:
・1059関連:
・2399 #ComputerVision #NLP #Dataset #Evaluation #MulltiModal #Reasoning #CVPR Issue Date: 2025-08-09 [Paper Note] MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI, Xiang Yue+, CVPR'24 SummaryMMMUは、大学レベルの専門知識と意図的な推論を必要とするマルチモーダルモデルの評価のための新しいベンチマークで、11,500のマルチモーダル質問を含む。6つの主要分野をカバーし、30種類の画像タイプを使用。既存のベンチマークと異なり、専門家が直面するタスクに類似した課題を提供。GPT-4VとGeminiの評価では、56%と59%の精度にとどまり、改善の余地があることを示す。MMMUは次世代のマルチモーダル基盤モデルの構築に寄与することが期待されている。 CommentMMMUのリリースから20ヶ月経過したが、いまだに人間のエキスパートのアンサンブルには及ばないとのこと
https://x.com/xiangyue96/status/1953902213790830931?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMMMUのサンプルはこちら。各分野ごとに専門家レベルの知識と推論が求められるとのこと。
 #Metrics
#NLP
#Search
#LanguageModel
#Evaluation
#Factuality
#LongSequence
Issue Date: 2025-08-08
[Paper Note] VERISCORE: Evaluating the factuality of verifiable claims in long-form text generation, Yixiao Song+, arXiv'24
SummaryVERISCOREという新しい指標を提案し、検証可能な主張と検証不可能な主張の両方を含む長文生成タスクに対応。人間評価ではVERISCOREが他の方法よりも理にかなっていることが確認され、16のモデルを評価した結果、GPT-4oが最も優れた性能を示したが、オープンウェイトモデルも差を縮めていることが分かった。また、異なるタスク間でVERISCOREの相関がないことから、事実性評価の拡張が必要であることを示唆している。
CommentLLMの応答からverifiableなclaimのみを抽出し、それを外部の検索エンジン(google検索)のクエリとして入力。検索結果からclaimがsupportされるか否かをLLMによって判断しスコアリングする。
#Metrics
#NLP
#Search
#LanguageModel
#Evaluation
#Factuality
#LongSequence
Issue Date: 2025-08-08
[Paper Note] VERISCORE: Evaluating the factuality of verifiable claims in long-form text generation, Yixiao Song+, arXiv'24
SummaryVERISCOREという新しい指標を提案し、検証可能な主張と検証不可能な主張の両方を含む長文生成タスクに対応。人間評価ではVERISCOREが他の方法よりも理にかなっていることが確認され、16のモデルを評価した結果、GPT-4oが最も優れた性能を示したが、オープンウェイトモデルも差を縮めていることが分かった。また、異なるタスク間でVERISCOREの相関がないことから、事実性評価の拡張が必要であることを示唆している。
CommentLLMの応答からverifiableなclaimのみを抽出し、それを外部の検索エンジン(google検索)のクエリとして入力。検索結果からclaimがsupportされるか否かをLLMによって判断しスコアリングする。
 #NLP
#Dataset
#LanguageModel
#Evaluation
#LongSequence
#MultiLingual
#ACL
Issue Date: 2025-08-07
[Paper Note] LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding, Yushi Bai+, ACL'24
Summary本論文では、長いコンテキスト理解のための初のバイリンガル・マルチタスクベンチマーク「LongBench」を提案。英語と中国語で21のデータセットを含み、平均長はそれぞれ6,711語と13,386文字。タスクはQA、要約、少数ショット学習など多岐にわたる。評価結果から、商業モデルは他のオープンソースモデルを上回るが、長いコンテキストでは依然として課題があることが示された。
CommentPLaMo Primeの長文テキスト評価に利用されたベンチマーク(中国語と英語のバイリンガルデータであり日本語は存在しない)
#NLP
#Dataset
#LanguageModel
#Evaluation
#LongSequence
#MultiLingual
#ACL
Issue Date: 2025-08-07
[Paper Note] LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding, Yushi Bai+, ACL'24
Summary本論文では、長いコンテキスト理解のための初のバイリンガル・マルチタスクベンチマーク「LongBench」を提案。英語と中国語で21のデータセットを含み、平均長はそれぞれ6,711語と13,386文字。タスクはQA、要約、少数ショット学習など多岐にわたる。評価結果から、商業モデルは他のオープンソースモデルを上回るが、長いコンテキストでは依然として課題があることが示された。
CommentPLaMo Primeの長文テキスト評価に利用されたベンチマーク(中国語と英語のバイリンガルデータであり日本語は存在しない)
https://tech.preferred.jp/ja/blog/plamo-prime-release-feature-update/
タスクと言語ごとのLengthの分布。英語の方がデータが豊富で、長いものだと30000--40000ものlengthのサンプルもある模様。
 #Survey
#ComputerVision
#NLP
#Prompting
#VisionLanguageModel
Issue Date: 2025-08-07
[Paper Note] Visual Prompting in Multimodal Large Language Models: A Survey, Junda Wu+, arXiv'24
Summary本論文は、マルチモーダル大規模言語モデル(MLLMs)における視覚的プロンプト手法の包括的な調査を行い、視覚的プロンプトの生成や構成的推論、プロンプト学習に焦点を当てています。既存の視覚プロンプトを分類し、自動プロンプト注釈の生成手法を議論。視覚エンコーダとバックボーンLLMの整合性を向上させる手法や、モデル訓練と文脈内学習による視覚的プロンプトの理解向上についても述べています。最後に、MLLMsにおける視覚的プロンプト手法の未来に関するビジョンを提示します。
#Survey
#ComputerVision
#Controllable
#NLP
#DiffusionModel
#TextToImageGeneration
Issue Date: 2025-08-07
[Paper Note] Controllable Generation with Text-to-Image Diffusion Models: A Survey, Pu Cao+, arXiv'24
Summary拡散モデルはテキスト誘導生成において大きな進展を遂げたが、テキストのみでは多様な要求に応えられない。本調査では、T2I拡散モデルの制御可能な生成に関する文献をレビューし、理論的基盤と実践的進展をカバー。デノイジング拡散確率モデルの基本を紹介し、制御メカニズムを分析。生成条件の異なるカテゴリに整理した文献リストを提供。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#PEFT(Adaptor/LoRA)
#MoE(Mixture-of-Experts)
#EMNLP
Issue Date: 2025-08-06
[Paper Note] Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models, Zihan Wang+, EMNLP'24
Summary本研究では、Mixture-of-Experts(MoE)アーキテクチャを持つ大規模言語モデル(LLMs)に対するパラメータ効率の良いファインチューニング(PEFT)手法を提案。主な内容は、(1) タスクごとの専門家の活性化分布の集中度の調査、(2) Expert-Specialized Fine-Tuning(ESFT)の提案とその効果、(3) MoEアーキテクチャの専門家特化型ファインチューニングへの影響の分析。実験により、ESFTがチューニング効率を向上させ、フルパラメータファインチューニングに匹敵またはそれを上回る性能を示すことが確認された。
Comment元ポスト:https://x.com/wzihanw/status/1952965138845450413?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMoEアーキテクチャを持つLLMにおいて、finetuningを実施したいタスクに関連する専門家を特定し、そのほかのパラメータをfreezeした上で当該専門家のみをtrainableとすることで、効率的にfinetuningを実施する手法
#Survey
#ComputerVision
#NLP
#Prompting
#VisionLanguageModel
Issue Date: 2025-08-07
[Paper Note] Visual Prompting in Multimodal Large Language Models: A Survey, Junda Wu+, arXiv'24
Summary本論文は、マルチモーダル大規模言語モデル(MLLMs)における視覚的プロンプト手法の包括的な調査を行い、視覚的プロンプトの生成や構成的推論、プロンプト学習に焦点を当てています。既存の視覚プロンプトを分類し、自動プロンプト注釈の生成手法を議論。視覚エンコーダとバックボーンLLMの整合性を向上させる手法や、モデル訓練と文脈内学習による視覚的プロンプトの理解向上についても述べています。最後に、MLLMsにおける視覚的プロンプト手法の未来に関するビジョンを提示します。
#Survey
#ComputerVision
#Controllable
#NLP
#DiffusionModel
#TextToImageGeneration
Issue Date: 2025-08-07
[Paper Note] Controllable Generation with Text-to-Image Diffusion Models: A Survey, Pu Cao+, arXiv'24
Summary拡散モデルはテキスト誘導生成において大きな進展を遂げたが、テキストのみでは多様な要求に応えられない。本調査では、T2I拡散モデルの制御可能な生成に関する文献をレビューし、理論的基盤と実践的進展をカバー。デノイジング拡散確率モデルの基本を紹介し、制御メカニズムを分析。生成条件の異なるカテゴリに整理した文献リストを提供。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#PEFT(Adaptor/LoRA)
#MoE(Mixture-of-Experts)
#EMNLP
Issue Date: 2025-08-06
[Paper Note] Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models, Zihan Wang+, EMNLP'24
Summary本研究では、Mixture-of-Experts(MoE)アーキテクチャを持つ大規模言語モデル(LLMs)に対するパラメータ効率の良いファインチューニング(PEFT)手法を提案。主な内容は、(1) タスクごとの専門家の活性化分布の集中度の調査、(2) Expert-Specialized Fine-Tuning(ESFT)の提案とその効果、(3) MoEアーキテクチャの専門家特化型ファインチューニングへの影響の分析。実験により、ESFTがチューニング効率を向上させ、フルパラメータファインチューニングに匹敵またはそれを上回る性能を示すことが確認された。
Comment元ポスト:https://x.com/wzihanw/status/1952965138845450413?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMoEアーキテクチャを持つLLMにおいて、finetuningを実施したいタスクに関連する専門家を特定し、そのほかのパラメータをfreezeした上で当該専門家のみをtrainableとすることで、効率的にfinetuningを実施する手法

専門家を見つける際には専門家ごとにfinetuningしたいタスクに対するrelevance scoreを計算する。そのために、2つの手法が提案されており、training dataからデータをサンプリングし
・全てのサンプリングしたデータの各トークンごとのMoE Routerのgateの値の平均値をrelevant scoreとする方法
・全てのサンプリングしたデータの各トークンごとに選択された専門家の割合
の2種類でスコアを求める。閾値pを決定し、閾値以上のスコアを持つ専門家をtrainableとする。
LoRAよりもmath, codeなどの他ドメインのタスク性能を劣化させず、Finetuning対象のタスクでFFTと同等の性能を達成。

LoRAと同様にFFTと比較し学習時間は短縮され、学習した専門家の重みを保持するだけで良いのでストレージも節約できる。
 #NLP
#LanguageModel
#LongSequence
#ICLR
#Admin'sPick
Issue Date: 2025-08-02
[Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
SummaryYaRN(Yet another RoPE extensioN method)は、トランスフォーマーベースの言語モデルにおける位置情報のエンコードを効率的に行い、コンテキストウィンドウを従来の方法よりも10倍少ないトークンと2.5倍少ない訓練ステップで拡張する手法を提案。LLaMAモデルが長いコンテキストを効果的に利用できることを示し、128kのコンテキスト長まで再現可能なファインチューニングを実現。
Commentopenreview:https://openreview.net/forum?id=wHBfxhZu1u現在主流なコンテキストウィンドウ拡張手法らしい日本語解説:https://zenn.dev/bilzard/scraps/de7ecd3c380b6e
#NLP
#LanguageModel
#AES(AutomatedEssayScoring)
#Prompting
#AIED
Issue Date: 2025-07-29
[Paper Note] The Impact of Example Selection in Few-Shot Prompting on Automated Essay Scoring Using GPT Models, Lui Yoshida, AIED'24
Summary本研究では、GPTモデルを用いた少数ショットプロンプティングにおける例の選択が自動エッセイ採点(AES)のパフォーマンスに与える影響を調査。119のプロンプトを用いて、GPT-3.5とGPT-4のモデル間でのスコア一致を二次重み付きカッパ(QWK)で測定。結果、例の選択がモデルによって異なる影響を及ぼし、特にGPT-3.5はバイアスの影響を受けやすいことが判明。慎重な例の選択により、GPT-3.5が一部のGPT-4モデルを上回る可能性があるが、GPT-4は最も高い安定性とパフォーマンスを示す。これにより、AESにおける例の選択の重要性とモデルごとのパフォーマンス評価の必要性が強調される。
Issue Date: 2025-07-24
[Paper Note] Revisiting Feature Prediction for Learning Visual Representations from Video, Adrien Bardes+, arXiv'24
Summary本論文では、教師なし学習のための特徴予測に基づくV-JEPAを提案。200万本のビデオで訓練された視覚モデルは、動きと外観に基づくタスクで優れた性能を示し、最大モデルはKinetics-400で81.9%、Something-Something-v2で72.2%、ImageNet1Kで77.9%を達成。
Issue Date: 2025-07-24
[Paper Note] DSBench: How Far Are Data Science Agents from Becoming Data Science Experts?, Liqiang Jing+, arXiv'24
SummaryDSBenchを導入し、現実的なデータサイエンスタスクを評価するための包括的なベンチマークを提供。466のデータ分析タスクと74のデータモデリングタスクを含み、最先端のLLMsやLVLMsが多くのタスクで苦戦していることを示す。最良のエージェントでも34.12%のタスクしか解決できず、知的で自律的なデータサイエンスエージェントのさらなる進展が必要であることを強調。
Comment元ポスト:https://x.com/wyu_nd/status/1948096236143423518?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Quantization
#MLSys
Issue Date: 2025-07-21
[Paper Note] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration, Ji Lin+, MLSys'24
SummaryActivation-aware Weight Quantization(AWQ)を提案し、LLMの低ビット重み量子化を効率化。顕著な重みチャネルを保護することで量子化誤差を削減し、異なるドメインに一般化可能。AWQは言語モデリングやドメイン特化型ベンチマークで優れた性能を示し、4ビットのオンデバイスLLM/VLM向け推論フレームワークTinyChatを実装。これにより、デスクトップおよびモバイルGPUでの処理速度を3倍以上向上させ、70B Llama-2モデルの展開を容易にする。
Comment日本語解説:https://qiita.com/kyad/items/96a4a2bdec3f0dc09d23
#ComputerVision
#Analysis
#NLP
#Dataset
#CVPR
#Scaling Laws
#VisionLanguageModel
#DataFiltering
Issue Date: 2025-07-20
[Paper Note] Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic, Sachin Goyal+, CVPR'24
Summary視覚と言語のモデル(VLMs)のトレーニングにおいて、高品質なデータのフィルタリングが重要であるが、計算リソースとは無関係に行われることが多い。本研究では、データの品質と量のトレードオフ(QQT)に対処するため、ウェブデータの非均質性を考慮したニューラルスケーリング法則を提案。これにより、データの有用性の違いや繰り返し使用による劣化を評価し、複数のデータプールの組み合わせによるモデルのパフォーマンスを推定可能にする。最適なデータプールのキュレーションを通じて、計算リソースに応じた最高のパフォーマンスを達成できることを示した。
Comment元ポスト:https://x.com/cloneofsimo/status/1946241642572448174?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q高品質なデータにフィルタリングすることで多くの研究がモデルがより高い性能を達成できることを示しているが、高品質なデータには限りがあることと、繰り返し学習をすることですぐにその効用が低下する(Quality-Quantity tradeoff!)という特性がある。このような状況において、たとえば計算の予算がデータ6パケット分の時に、めちゃめちゃフィルタリングを頑張っg高品質なデータプールEのみを使って6 epoch学習するのが良いのか、少し品質は落ちるデータDも混ぜてE+Dを3 epoch学習するのが良いのか、ときにどちらが良いのか?という話のようである。
#NLP
#LanguageModel
#LongSequence
#ICLR
#Admin'sPick
Issue Date: 2025-08-02
[Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
SummaryYaRN(Yet another RoPE extensioN method)は、トランスフォーマーベースの言語モデルにおける位置情報のエンコードを効率的に行い、コンテキストウィンドウを従来の方法よりも10倍少ないトークンと2.5倍少ない訓練ステップで拡張する手法を提案。LLaMAモデルが長いコンテキストを効果的に利用できることを示し、128kのコンテキスト長まで再現可能なファインチューニングを実現。
Commentopenreview:https://openreview.net/forum?id=wHBfxhZu1u現在主流なコンテキストウィンドウ拡張手法らしい日本語解説:https://zenn.dev/bilzard/scraps/de7ecd3c380b6e
#NLP
#LanguageModel
#AES(AutomatedEssayScoring)
#Prompting
#AIED
Issue Date: 2025-07-29
[Paper Note] The Impact of Example Selection in Few-Shot Prompting on Automated Essay Scoring Using GPT Models, Lui Yoshida, AIED'24
Summary本研究では、GPTモデルを用いた少数ショットプロンプティングにおける例の選択が自動エッセイ採点(AES)のパフォーマンスに与える影響を調査。119のプロンプトを用いて、GPT-3.5とGPT-4のモデル間でのスコア一致を二次重み付きカッパ(QWK)で測定。結果、例の選択がモデルによって異なる影響を及ぼし、特にGPT-3.5はバイアスの影響を受けやすいことが判明。慎重な例の選択により、GPT-3.5が一部のGPT-4モデルを上回る可能性があるが、GPT-4は最も高い安定性とパフォーマンスを示す。これにより、AESにおける例の選択の重要性とモデルごとのパフォーマンス評価の必要性が強調される。
Issue Date: 2025-07-24
[Paper Note] Revisiting Feature Prediction for Learning Visual Representations from Video, Adrien Bardes+, arXiv'24
Summary本論文では、教師なし学習のための特徴予測に基づくV-JEPAを提案。200万本のビデオで訓練された視覚モデルは、動きと外観に基づくタスクで優れた性能を示し、最大モデルはKinetics-400で81.9%、Something-Something-v2で72.2%、ImageNet1Kで77.9%を達成。
Issue Date: 2025-07-24
[Paper Note] DSBench: How Far Are Data Science Agents from Becoming Data Science Experts?, Liqiang Jing+, arXiv'24
SummaryDSBenchを導入し、現実的なデータサイエンスタスクを評価するための包括的なベンチマークを提供。466のデータ分析タスクと74のデータモデリングタスクを含み、最先端のLLMsやLVLMsが多くのタスクで苦戦していることを示す。最良のエージェントでも34.12%のタスクしか解決できず、知的で自律的なデータサイエンスエージェントのさらなる進展が必要であることを強調。
Comment元ポスト:https://x.com/wyu_nd/status/1948096236143423518?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Quantization
#MLSys
Issue Date: 2025-07-21
[Paper Note] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration, Ji Lin+, MLSys'24
SummaryActivation-aware Weight Quantization(AWQ)を提案し、LLMの低ビット重み量子化を効率化。顕著な重みチャネルを保護することで量子化誤差を削減し、異なるドメインに一般化可能。AWQは言語モデリングやドメイン特化型ベンチマークで優れた性能を示し、4ビットのオンデバイスLLM/VLM向け推論フレームワークTinyChatを実装。これにより、デスクトップおよびモバイルGPUでの処理速度を3倍以上向上させ、70B Llama-2モデルの展開を容易にする。
Comment日本語解説:https://qiita.com/kyad/items/96a4a2bdec3f0dc09d23
#ComputerVision
#Analysis
#NLP
#Dataset
#CVPR
#Scaling Laws
#VisionLanguageModel
#DataFiltering
Issue Date: 2025-07-20
[Paper Note] Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic, Sachin Goyal+, CVPR'24
Summary視覚と言語のモデル(VLMs)のトレーニングにおいて、高品質なデータのフィルタリングが重要であるが、計算リソースとは無関係に行われることが多い。本研究では、データの品質と量のトレードオフ(QQT)に対処するため、ウェブデータの非均質性を考慮したニューラルスケーリング法則を提案。これにより、データの有用性の違いや繰り返し使用による劣化を評価し、複数のデータプールの組み合わせによるモデルのパフォーマンスを推定可能にする。最適なデータプールのキュレーションを通じて、計算リソースに応じた最高のパフォーマンスを達成できることを示した。
Comment元ポスト:https://x.com/cloneofsimo/status/1946241642572448174?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q高品質なデータにフィルタリングすることで多くの研究がモデルがより高い性能を達成できることを示しているが、高品質なデータには限りがあることと、繰り返し学習をすることですぐにその効用が低下する(Quality-Quantity tradeoff!)という特性がある。このような状況において、たとえば計算の予算がデータ6パケット分の時に、めちゃめちゃフィルタリングを頑張っg高品質なデータプールEのみを使って6 epoch学習するのが良いのか、少し品質は落ちるデータDも混ぜてE+Dを3 epoch学習するのが良いのか、ときにどちらが良いのか?という話のようである。
 #ICML
Issue Date: 2025-07-18
[Paper Note] Programming Every Example: Lifting Pre-training Data Quality Like Experts at Scale, Fan Zhou+, arXiv'24
Summary本論文では、0.3Bパラメータの小規模言語モデルが人間の専門家に匹敵するデータ精製能力を持つことを示し、データ精製をプログラミングタスクとして扱う新しいフレームワーク「Programming Every Example (ProX)」を提案します。ProXは、各例に対して細かい操作を生成・実行することでコーパスを大規模に精製し、実験結果ではProXによってキュレーションされたデータで事前学習されたモデルが、元のデータや他の方法よりも2%以上の性能向上を示しました。また、ProXはドメイン特化型の継続的事前学習でも効果を発揮し、他のモデルに対しても精度を大幅に向上させることが確認されました。さらに、ProXはトレーニングFLOPsを節約し、効率的なLLM事前学習の新たな道を提供します。全てのトレーニングおよび実装の詳細はオープンソースとして共有されています。
Comment元ポスト:https://x.com/sinclairwang1/status/1946127199452741938?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ICML
Issue Date: 2025-07-18
[Paper Note] Programming Every Example: Lifting Pre-training Data Quality Like Experts at Scale, Fan Zhou+, arXiv'24
Summary本論文では、0.3Bパラメータの小規模言語モデルが人間の専門家に匹敵するデータ精製能力を持つことを示し、データ精製をプログラミングタスクとして扱う新しいフレームワーク「Programming Every Example (ProX)」を提案します。ProXは、各例に対して細かい操作を生成・実行することでコーパスを大規模に精製し、実験結果ではProXによってキュレーションされたデータで事前学習されたモデルが、元のデータや他の方法よりも2%以上の性能向上を示しました。また、ProXはドメイン特化型の継続的事前学習でも効果を発揮し、他のモデルに対しても精度を大幅に向上させることが確認されました。さらに、ProXはトレーニングFLOPsを節約し、効率的なLLM事前学習の新たな道を提供します。全てのトレーニングおよび実装の詳細はオープンソースとして共有されています。
Comment元ポスト:https://x.com/sinclairwang1/status/1946127199452741938?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
ポスタースクショあり Issue Date: 2025-07-18 [Paper Note] Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse, Ryan Liu+, arXiv'24 SummaryChain-of-thought (CoT) プロンプティングは、言語モデルの性能向上に寄与するが、性能低下を引き起こすタスク特性は未解明。本研究では、心理学からのインスピレーションを得て、CoTが性能を損なうタスクを特定。6つの代表的なタスクを分析し、3つのタスクではCoTが最大36.3%の精度低下を引き起こすことを示した。人間の思考過程とモデルの推論の関係を考察し、推論時の影響を理解するための新たな視点を提供する。 Comment元ポスト:https://x.com/jiayiigeng/status/1945994557465952672?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #read-later Issue Date: 2025-07-16 [Paper Note] Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs, Koshiro Saito+, arXiv'24 Summaryローカルな大規模言語モデル(LLMs)の構築の意義や学習内容、他言語からの能力移転、言語特有のスケーリング法則を探るため、日本語を対象に19の評価ベンチマークで35のLLMを評価。英語のトレーニングが日本語の学術スコアを向上させる一方、日本語特有のタスクには日本語テキストでのトレーニングが有効であることが示された。また、日本語能力は計算予算に応じてスケールすることが確認された。 #read-later Issue Date: 2025-07-16 [Paper Note] Accelerating Large Language Model Training with 4D Parallelism and Memory Consumption Estimator, Kazuki Fujii+, arXiv'24 Summary本研究では、Llamaアーキテクチャにおける4D並列トレーニングに対して、メモリ使用量を正確に推定する公式を提案。A100およびH100 GPUでの454回の実験を通じて、一時バッファやメモリの断片化を考慮し、推定メモリがGPUメモリの80%未満であればメモリ不足エラーが発生しないことを示した。この公式により、メモリオーバーフローを引き起こす並列化構成を事前に特定でき、最適な4D並列性構成に関する実証的な洞察を提供する。 #read-later Issue Date: 2025-07-16 [Paper Note] Heron-Bench: A Benchmark for Evaluating Vision Language Models in Japanese, Yuichi Inoue+, arXiv'24 Summary日本語に特化したVision Language Models (VLM)の評価のために、新しいベンチマーク「Japanese Heron-Bench」を提案。日本の文脈に基づく画像-質問応答ペアを用いて、日本語VLMの能力を測定。提案されたVLMの強みと限界を明らかにし、強力なクローズドモデルとの能力ギャップを示す。今後の日本語VLM研究の発展を促進するため、データセットと訓練コードを公開。 #read-later Issue Date: 2025-07-16 [Paper Note] Building a Large Japanese Web Corpus for Large Language Models, Naoaki Okazaki+, arXiv'24 Summary日本語LLMsのために、Common Crawlから634億ページを抽出・精製し、約3121億文字の大規模日本語ウェブコーパスを構築。これは既存のコーパスを上回り、Llama 2を用いた事前訓練で日本語ベンチマークデータセットにおいて6.6-8.1ポイントの改善を達成。特にLlama 2 13Bの改善が最も顕著であった。 #read-later Issue Date: 2025-07-16 [Paper Note] Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities, Kazuki Fujii+, arXiv'24 Summary大規模言語モデル「Swallow」は、Llama 2の語彙を日本語に拡張し、日本語ウェブコーパスで継続的事前学習を行うことで日本語能力を向上させた。実験により、日本語タスクの性能が大幅に向上し、トレーニングデータが増加するにつれて性能が向上することが確認された。Swallowは他のLLMと比較して優れた性能を示し、特に日本語の質問応答タスクに効果的であることが明らかになった。また、語彙の拡張と平行コーパスの利用が性能に与える影響を調査し、平行コーパスの併用が翻訳能力を向上させることを示した。 #ICML #Workshop Issue Date: 2025-07-15 [Paper Note] DiLoCo: Distributed Low-Communication Training of Language Models, Arthur Douillard+, ICML'24 Workshop WANT Summary分散最適化アルゴリズム「DiLoCo」を提案し、接続が不十分なデバイスでのLLMトレーニングを可能にする。DiLoCoは、通信量を500分の1に抑えつつ、完全同期の最適化と同等の性能をC4データセットで発揮。各ワーカーのデータ分布に対して高いロバスト性を持ち、リソースの変動にも柔軟に対応可能。 Commentopenreview:https://openreview.net/forum?id=pICSfWkJIk&referrer=%5Bthe%20profile%20of%20MarcAurelio%20Ranzato%5D(%2Fprofile%3Fid%3D~MarcAurelio_Ranzato1) Issue Date: 2025-07-15 [Paper Note] Cautious Optimizers: Improving Training with One Line of Code, Kaizhao Liang+, arXiv'24 Summary本研究では、Pytorchのモーメンタムベースのオプティマイザーに対して単一行の修正を加えた「慎重なオプティマイザー」を提案。これにより、Adamのハミルトニアン関数を保持しつつ収束保証を維持。実験では、LlamaおよびMAEの事前学習で最大1.47倍の速度向上を達成し、LLMのポストトレーニングタスクでも改善を示した。 Comment #ComputerVision
#NLP
#Dataset
#Evaluation
#Mathematics
#VisionLanguageModel
Issue Date: 2025-07-14
[Paper Note] Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset, Ke Wang+, NeurIPS'24 Datasets and Benchmarks Track
SummaryMATH-Vision(MATH-V)データセットを提案し、3,040の視覚的文脈を持つ数学問題を収集。16の数学分野と5つの難易度で構成され、LMMsの数学的推論能力を評価。実験により、LMMsと人間のパフォーマンス間に顕著なギャップがあることを示し、さらなる進展の必要性を強調。エラー分析を通じて今後の研究に貴重な洞察を提供。
Commentopenreview: https://openreview.net/forum?id=QWTCcxMpPAdiscussion
#ComputerVision
#NLP
#Dataset
#Evaluation
#Mathematics
#VisionLanguageModel
Issue Date: 2025-07-14
[Paper Note] Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset, Ke Wang+, NeurIPS'24 Datasets and Benchmarks Track
SummaryMATH-Vision(MATH-V)データセットを提案し、3,040の視覚的文脈を持つ数学問題を収集。16の数学分野と5つの難易度で構成され、LMMsの数学的推論能力を評価。実験により、LMMsと人間のパフォーマンス間に顕著なギャップがあることを示し、さらなる進展の必要性を強調。エラー分析を通じて今後の研究に貴重な洞察を提供。
Commentopenreview: https://openreview.net/forum?id=QWTCcxMpPAdiscussion
project page: https://mathllm.github.io/mathvision/Project Pageのランディングページが非常にわかりやすい。こちらは人間の方がまだまだ性能が高そう。
 #Pretraining
#NLP
#Dataset
#LanguageModel
#Programming
Issue Date: 2025-07-13
[Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
SummaryBigCodeプロジェクトは、責任あるCode LLMsの開発に焦点を当て、StarCoder2を発表。Software Heritageと提携し、The Stack v2を構築し、619のプログラミング言語を含む大規模なトレーニングセットを作成。StarCoder2モデルは3B、7B、15Bのパラメータを持ち、徹底的なベンチマーク評価で優れた性能を示す。特にStarCoder2-15Bは、同等の他モデルを大幅に上回り、数学やコード推論でも高い性能を発揮。モデルの重みはOpenRAILライセンスで公開され、トレーニングデータの透明性も確保。
Comment関連:
#Pretraining
#NLP
#Dataset
#LanguageModel
#Programming
Issue Date: 2025-07-13
[Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
SummaryBigCodeプロジェクトは、責任あるCode LLMsの開発に焦点を当て、StarCoder2を発表。Software Heritageと提携し、The Stack v2を構築し、619のプログラミング言語を含む大規模なトレーニングセットを作成。StarCoder2モデルは3B、7B、15Bのパラメータを持ち、徹底的なベンチマーク評価で優れた性能を示す。特にStarCoder2-15Bは、同等の他モデルを大幅に上回り、数学やコード推論でも高い性能を発揮。モデルの重みはOpenRAILライセンスで公開され、トレーニングデータの透明性も確保。
Comment関連:
・661 Issue Date: 2025-07-09 [Paper Note] VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks, Ziyan Jiang+, arXiv'24 Summary本研究では、ユニバーサルマルチモーダル埋め込みモデルの構築を目指し、二つの貢献を行った。第一に、MMEB(Massive Multimodal Embedding Benchmark)を提案し、36のデータセットを用いて分類や視覚的質問応答などのメタタスクを網羅した。第二に、VLM2Vecというコントラストトレーニングフレームワークを開発し、視覚-言語モデルを埋め込みモデルに変換する手法を示した。実験結果は、VLM2Vecが既存のモデルに対して10%から20%の性能向上を達成することを示し、VLMの強力な埋め込み能力を証明した。 #NLP #LanguageModel #Reasoning #NeurIPS #DPO #PostTraining Issue Date: 2025-07-02 [Paper Note] Iterative Reasoning Preference Optimization, Richard Yuanzhe Pang+, NeurIPS'24 Summary反復的な好み最適化手法を用いて、Chain-of-Thought(CoT)候補間の推論ステップを最適化するアプローチを開発。修正DPO損失を使用し、推論の改善を示す。Llama-2-70B-ChatモデルでGSM8K、MATH、ARC-Challengeの精度を向上させ、GSM8Kでは55.6%から81.6%に改善。多数決による精度は88.7%に達した。 CommentOpenReview:https://openreview.net/forum?id=4XIKfvNYvx&referrer=%5Bthe%20profile%20of%20He%20He%5D(%2Fprofile%3Fid%3D~He_He2)・1212
と似たようにiterativeなmannerでreasoning能力を向上させる。

ただし、loss functionとしては、chosenなCoT+yのresponseに対して、reasoning traceを生成する能力を高めるために、NLL Lossも適用している点に注意。

32 samplesのmajority votingによってより高い性能が達成できているので、多様なreasoning traceが生成されていることが示唆される。 Issue Date: 2025-07-02 [Paper Note] Online DPO: Online Direct Preference Optimization with Fast-Slow Chasing, Biqing Qi+, arXiv'24 SummaryOFS-DPOは、異なるドメインの人間の好みに対応するために、オンライン学習を通じてモデル間の競争をシミュレートし、迅速な適応を促進する手法です。LoRAを用いて異なる最適化速度を持つモジュールを導入し、壊滅的な忘却を軽減します。COFS-DPOは、クロスドメインのシナリオにおいても優れた性能を示し、継続的な価値の整合性を達成します。 #Multi #NLP #LanguageModel #Reasoning #ACL Issue Date: 2025-06-29 [Paper Note] Do Large Language Models Latently Perform Multi-Hop Reasoning?, Sohee Yang+, ACL'24 Summary本研究では、LLMが複雑なプロンプトに対してマルチホップ推論を行う可能性を探ります。具体的には、LLMが「'Superstition'の歌手」を特定し、その母親に関する知識を用いてプロンプトを完成させる過程を分析します。2つのホップを個別に評価し、特に最初のホップにおいてブリッジエンティティのリコールが増加するかをテストしました。結果、特定の関係タイプのプロンプトに対してマルチホップ推論の証拠が見つかりましたが、活用は文脈依存であり、2番目のホップの証拠は控えめでした。また、モデルサイズの増加に伴い最初のホップの推論能力が向上する傾向が見られましたが、2番目のホップにはその傾向が見られませんでした。これらの結果は、LLMの今後の開発における課題と機会を示唆しています。 #NLP #Dataset #LanguageModel #ReinforcementLearning #Reasoning #ICLR #Admin'sPick #PRM Issue Date: 2025-06-26 [Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24 Summary大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。 CommentOpenReview:https://openreview.net/forum?id=v8L0pN6EOiPRM800K:https://github.com/openai/prm800k/tree/main #NLP #Dataset #LanguageModel #ReinforcementLearning #Evaluation Issue Date: 2025-06-26 [Paper Note] RewardBench: Evaluating Reward Models for Language Modeling, Nathan Lambert+, arXiv'24 Summary報酬モデル(RMs)の評価に関する研究は少なく、我々はその理解を深めるためにRewardBenchというベンチマークデータセットを提案。これは、チャットや推論、安全性に関するプロンプトのコレクションで、報酬モデルの性能を評価する。特定の比較データセットを用いて、好まれる理由を検証可能な形で示し、さまざまなトレーニング手法による報酬モデルの評価を行う。これにより、報酬モデルの拒否傾向や推論の限界についての知見を得ることを目指す。 #NLP #LanguageModel #ACL #ModelMerge Issue Date: 2025-06-25 [Paper Note] Chat Vector: A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languages, Shih-Cheng Huang+, ACL'24 Summaryオープンソースの大規模言語モデル(LLMs)の多くは英語に偏っている問題に対処するため、chat vectorという概念を導入。これは、事前学習済みモデルの重みからチャットモデルの重みを引くことで生成され、追加のトレーニングなしに新しい言語でのチャット機能を付与できる。実証研究では、指示に従う能力や有害性の軽減、マルチターン対話においてchat vectorの効果を示し、さまざまな言語やモデルでの適応性を確認。chat vectorは、事前学習済みモデルに対話機能を効率的に実装するための有力な解決策である。 Comment日本語解説:https://qiita.com/jovyan/items/ee6affa5ee5bdaada6b4下記ブログによるとChatだけではなく、Reasoningでも(post-trainingが必要だが)使える模様
Reasoning能力を付与したLLM ABEJA-QwQ32b-Reasoning-Japanese-v1.0の公開, Abeja Tech Blog, 2025.04:
https://tech-blog.abeja.asia/entry/geniac2-qwen25-32b-reasoning-v1.0 #Analysis #NLP #LanguageModel #Alignment #ReinforcementLearning #PPO (ProximalPolicyOptimization) #ICML #DPO #On-Policy Issue Date: 2025-06-25 [Paper Note] Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data, Fahim Tajwar+, ICML'24 Summary好みのラベルを用いた大規模言語モデルのファインチューニングに関する研究。オンポリシー強化学習や対照学習などの手法を比較し、オンポリシーサンプリングや負の勾配を用いるアプローチが優れていることを発見。これにより、カテゴリ分布の特定のビンにおける確率質量を迅速に変更できるモード探索目的の重要性を示し、データ収集の最適化に関する洞察を提供。 #Pretraining #NLP #LanguageModel #InstructionTuning #EMNLP Issue Date: 2025-06-25 [Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, EMNLP'24 Summary無監督のマルチタスク事前学習に加え、監視されたマルチタスク学習の可能性を探るために、Instruction Pre-Trainingフレームワークを提案。指示応答ペアを生成し、2億のペアを合成して実験を行い、事前学習モデルの性能を向上させることを確認。Instruction Pre-TrainingはLlama3-8BをLlama3-70Bと同等以上の性能に引き上げる。モデルやデータは公開されている。 #Analysis #Tools #NLP #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-06-18 [Paper Note] A Comparative Study of PDF Parsing Tools Across Diverse Document Categories, Narayan S. Adhikari+, arXiv'24 Summary本研究では、DocLayNetデータセットを用いて10の人気PDFパースツールを6つの文書カテゴリにわたり比較し、情報抽出の効果を評価しました。テキスト抽出ではPyMuPDFとpypdfiumが優れた結果を示し、特に科学文書や特許文書ではNougatが高いパフォーマンスを発揮しました。表検出ではTATRが金融や法律文書で優れた結果を示し、Camelotは入札文書で最も良いパフォーマンスを発揮しました。これにより、文書タイプに応じた適切なパースツールの選択が重要であることが示されました。 CommentPDFのparsingツールについて、text, table抽出の性能を様々なツールと分野別に評価している。
F1, precision, recallなどは、ground truthとのレーベンシュタイン距離からsimilarityを計算し、0.7以上であればtrue positiveとみなすことで計算している模様。local alignmentは、マッチした場合に加点、ミスマッチ、未検出の場合にペナルティを課すようなスコアリングによって抽出したテキスト全体の抽出性能を測る指標な模様。

 より性能を高くしたければこちらも参考に:
より性能を高くしたければこちらも参考に:
https://x.com/jerryjliu0/status/1934988910448492570?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #MachineLearning #ReinforcementLearning #TMLR Issue Date: 2025-06-14 [Paper Note] Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models, Avi Singh+, TMLR'24 Summary言語モデルを人間データでファインチューニングする際の限界を超えるため、ReST$^{EM$という自己学習手法を提案。モデルから生成したサンプルをバイナリフィードバックでフィルタリングし、繰り返しファインチューニングを行う。PaLM-2モデルを用いた実験で、ReST$^{EM}$は人間データのみのファインチューニングを大幅に上回る性能を示し、フィードバックを用いた自己学習が人間生成データへの依存を減少させる可能性を示唆。 Comment解説ポスト:https://x.com/hillbig/status/1735065077668356106?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #Scaling Laws #read-later Issue Date: 2025-05-27 Densing Law of LLMs, Chaojun Xiao+, arXiv'24 Summary大規模言語モデル(LLMs)の性能向上に伴うトレーニングと推論の効率の課題を解決するために、「キャパシティ密度」という新しい指標を提案。これは、ターゲットLLMの有効パラメータサイズと実際のパラメータサイズの比率を用いて、モデルの効果と効率を評価するフレームワークを提供する。分析により、LLMsのキャパシティ密度は約3か月ごとに倍増する傾向があることが示され、今後のLLM開発における重要性が強調される。 Comment元ポスト:https://x.com/hillbig/status/1926785750277693859?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #RecommenderSystems
#UAI
#read-later
#ColdStart
Issue Date: 2025-05-16
Cold-start Recommendation by Personalized Embedding Region Elicitation, Hieu Trung Nguyen+, UAI'24
Summaryレコメンダーシステムのコールドスタート問題に対処するため、2段階のパーソナライズされた引き出しスキームを提案。最初に人気アイテムの評価を求め、その後、順次適応的にアイテム評価を行う。ユーザーの埋め込み値を領域推定として表現し、評価情報の価値を定量化。提案手法は既存の方法と比較して有効性を示す。
CommentOpenReview:https://openreview.net/forum?id=ciOkU5YpvU
#NLP
#Dataset
#LanguageModel
#Alignment
#InstructionTuning
#ICML
#PostTraining
Issue Date: 2025-05-11
UltraFeedback: Boosting Language Models with Scaled AI Feedback, Ganqu Cui+, ICML'24
Summary人間のフィードバックに加え、高品質なAIフィードバックを自動収集することで、LLMsのアライメントをスケーラブルに実現。多様なインタラクションをカバーし、注釈バイアスを軽減した結果、25万件の会話に対する100万件以上のGPT-4フィードバックを含むデータセット「UltraFeedback」を構築。これに基づき、LLaMAモデルを強化学習でアライメントし、チャットベンチマークで優れた性能を示す。研究はオープンソースチャットモデルの構築におけるAIフィードバックの有効性を検証。データとモデルは公開中。
#NLP
#LanguageModel
#Alignment
#InstructionTuning
#EMNLP
Issue Date: 2025-05-11
ORPO: Monolithic Preference Optimization without Reference Model, Jiwoo Hong+, EMNLP'24
Summary本論文では、好みの整合性における監視付きファインチューニング(SFT)の重要性を強調し、わずかなペナルティで好みに整合したSFTが可能であることを示します。さらに、追加の整合性フェーズを必要としない新しいオッズ比最適化アルゴリズムORPOを提案し、これを用いて複数の言語モデルをファインチューニングした結果、最先端のモデルを上回る性能を達成しました。
Commentざっくり言うとinstruction tuningとalignmentを同時にできる手法らしいがまだ理解できていない
#NLP
#LanguageModel
#Library
#ACL
#KnowledgeEditing
Issue Date: 2025-05-11
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models, Peng Wang+, ACL'24, (System Demonstrations)
SummaryEasyEditは、LLMsのための使いやすい知識編集フレームワークであり、さまざまな知識編集アプローチをサポート。LlaMA-2の実験結果では、信頼性と一般化の面で従来のファインチューニングを上回ることを示した。GitHubでソースコードを公開し、Google Colabチュートリアルやオンラインシステムも提供。
Commentver2.0:
#RecommenderSystems
#UAI
#read-later
#ColdStart
Issue Date: 2025-05-16
Cold-start Recommendation by Personalized Embedding Region Elicitation, Hieu Trung Nguyen+, UAI'24
Summaryレコメンダーシステムのコールドスタート問題に対処するため、2段階のパーソナライズされた引き出しスキームを提案。最初に人気アイテムの評価を求め、その後、順次適応的にアイテム評価を行う。ユーザーの埋め込み値を領域推定として表現し、評価情報の価値を定量化。提案手法は既存の方法と比較して有効性を示す。
CommentOpenReview:https://openreview.net/forum?id=ciOkU5YpvU
#NLP
#Dataset
#LanguageModel
#Alignment
#InstructionTuning
#ICML
#PostTraining
Issue Date: 2025-05-11
UltraFeedback: Boosting Language Models with Scaled AI Feedback, Ganqu Cui+, ICML'24
Summary人間のフィードバックに加え、高品質なAIフィードバックを自動収集することで、LLMsのアライメントをスケーラブルに実現。多様なインタラクションをカバーし、注釈バイアスを軽減した結果、25万件の会話に対する100万件以上のGPT-4フィードバックを含むデータセット「UltraFeedback」を構築。これに基づき、LLaMAモデルを強化学習でアライメントし、チャットベンチマークで優れた性能を示す。研究はオープンソースチャットモデルの構築におけるAIフィードバックの有効性を検証。データとモデルは公開中。
#NLP
#LanguageModel
#Alignment
#InstructionTuning
#EMNLP
Issue Date: 2025-05-11
ORPO: Monolithic Preference Optimization without Reference Model, Jiwoo Hong+, EMNLP'24
Summary本論文では、好みの整合性における監視付きファインチューニング(SFT)の重要性を強調し、わずかなペナルティで好みに整合したSFTが可能であることを示します。さらに、追加の整合性フェーズを必要としない新しいオッズ比最適化アルゴリズムORPOを提案し、これを用いて複数の言語モデルをファインチューニングした結果、最先端のモデルを上回る性能を達成しました。
Commentざっくり言うとinstruction tuningとalignmentを同時にできる手法らしいがまだ理解できていない
#NLP
#LanguageModel
#Library
#ACL
#KnowledgeEditing
Issue Date: 2025-05-11
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models, Peng Wang+, ACL'24, (System Demonstrations)
SummaryEasyEditは、LLMsのための使いやすい知識編集フレームワークであり、さまざまな知識編集アプローチをサポート。LlaMA-2の実験結果では、信頼性と一般化の面で従来のファインチューニングを上回ることを示した。GitHubでソースコードを公開し、Google Colabチュートリアルやオンラインシステムも提供。
Commentver2.0:
・1946 #Pretraining #NLP #Dataset #LanguageModel Issue Date: 2025-05-10 DataComp-LM: In search of the next generation of training sets for language models, Jeffrey Li+, arXiv'24 SummaryDataComp for Language Models(DCLM)を紹介し、240Tトークンのコーパスと53の評価スイートを提供。DCLMでは、モデルスケール412Mから7Bパラメータのデータキュレーション戦略を実験可能。DCLM-Baselineは2.6Tトークンでトレーニングし、MMLUで64%の精度を達成し、従来のMAP-Neoより6.6ポイント改善。計算リソースも40%削減。結果はデータセット設計の重要性を示し、今後の研究の基盤を提供。 #EfficiencyImprovement #Pretraining #NLP #Dataset #LanguageModel #Admin'sPick Issue Date: 2025-05-10 The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale, Guilherme Penedo+, arXiv'24 Summary本研究では、15兆トークンからなるFineWebデータセットを紹介し、LLMの性能向上に寄与することを示します。FineWebは高品質な事前学習データセットのキュレーション方法を文書化し、重複排除やフィルタリング戦略を詳細に調査しています。また、FineWebから派生した1.3兆トークンのFineWeb-Eduを用いたLLMは、MMLUやARCなどのベンチマークで優れた性能を発揮します。データセット、コードベース、モデルは公開されています。 Comment日本語解説:https://zenn.dev/deepkawamura/articles/da9aeca6d6d9f9 #NLP #Dataset #LanguageModel #EMNLP #KnowledgeEditing #read-later Issue Date: 2025-05-07 Editing Large Language Models: Problems, Methods, and Opportunities, Yunzhi Yao+, EMNLP'24 SummaryLLMの編集技術の進展を探求し、特定のドメインでの効率的な動作変更と他の入力への影響を最小限に抑える方法を論じる。モデル編集のタスク定義や課題を包括的にまとめ、先進的な手法の実証分析を行う。また、新しいベンチマークデータセットを構築し、評価の向上と持続的な問題の特定を目指す。最終的に、編集技術の効果に関する洞察を提供し、適切な方法選択を支援する。コードとデータセットは公開されている。 #Analysis #NLP #LanguageModel #SyntheticData #ICML #Admin'sPick Issue Date: 2025-05-03 Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24 Summary大規模言語モデル(LLMs)の知識抽出能力は、訓練データの多様性と強く相関しており、十分な強化がなければ知識は記憶されても抽出可能ではないことが示された。具体的には、エンティティ名の隠れ埋め込みに知識がエンコードされているか、他のトークン埋め込みに分散しているかを調査。LLMのプレトレーニングに関する重要な推奨事項として、補助モデルを用いたデータ再構成と指示微調整データの早期取り入れが提案された。 Comment解説:
・1834 #NLP #LanguageModel #Evaluation #Decoding #Admin'sPick Issue Date: 2025-04-14 Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, arXiv'24 Summary本研究では、5つの決定論的LLMにおける非決定性を8つのタスクで調査し、最大15%の精度変動と70%のパフォーマンスギャップを観察。全てのタスクで一貫した精度を提供できないことが明らかになり、非決定性が計算リソースの効率的使用に寄与している可能性が示唆された。出力の合意率を示す新たなメトリクスTARr@NとTARa@Nを導入し、研究結果を定量化。コードとデータは公開されている。 Comment・論文中で利用されているベンチマーク:
・785
・901 同じモデルに対して、seedを固定し、temperatureを0に設定し、同じ計算機環境に対して、同じinputを入力したら理論上はLLMの出力はdeterministicになるはずだが、deterministicにならず、ベンチマーク上の性能とそもそものraw response自体も試行ごとに大きく変化する、という話。
ただし、これはプロプライエタリLLMや、何らかのinferenceの高速化を実施したInferenceEngine(本研究ではTogetherと呼ばれる実装を使っていそう。vLLM/SGLangだとどうなるのかが気になる)を用いてinferenceを実施した場合での実験結果であり、後述の通り計算の高速化のためのさまざまな実装無しで、deterministicな設定でOpenLLMでinferenceすると出力はdeterministicになる、という点には注意。
GPTやLlama、Mixtralに対して上記ベンチマークを用いてzero-shot/few-shotの設定で実験している。Reasoningモデルは実験に含まれていない。

LLMのraw_response/multiple choiceのparse結果(i.e., 問題に対する解答部分を抽出した結果)の一致(TARr@N, TARa@N; Nはinferenceの試行回数)も理論上は100%になるはずなのに、ならないことが報告されている。

correlation analysisによって、応答の長さ と TAR{r, a}が強い負の相関を示しており、応答が長くなればなるほど不安定さは増すことが分析されている。このため、ontput tokenの最大値を制限することで出力の安定性が増すことを考察している。また、few-shotにおいて高いAcc.の場合は出力がdeterministicになるわけではないが、性能が安定する傾向とのこと。また、OpenAIプラットフォーム上でGPTのfinetuningを実施し実験したが、安定性に寄与はしたが、こちらもdeterministicになるわけではないとのこと。
deterministicにならない原因として、まずmulti gpu環境について検討しているが、multi-gpu環境ではある程度のランダム性が生じることがNvidiaの研究によって報告されているが、これはseedを固定すれば決定論的にできるため問題にならないとのこと。
続いて、inferenceを高速化するための実装上の工夫(e.g., Chunk Prefilling, Prefix Caching, Continuous Batching)などの実装がdeterministicなハイパーパラメータでもdeterministicにならない原因であると考察しており、実際にlocalマシン上でこれらinferenceを高速化するための最適化を何も実施しない状態でLlama-8Bでinferenceを実施したところ、outputはdeterministicになったとのこと。論文中に記載がなかったため、どのようなInferenceEngineを利用したか公開されているgithubを見ると下記が利用されていた:
・Together: https://github.com/togethercomputer/together-python?tab=readme-ov-file
Togetherが内部的にどのような処理をしているかまでは追えていないのだが、異なるInferenceEngineを利用した場合に、どの程度outputの不安定さに差が出るのか(あるいは出ないのか)は気になる。たとえば、transformers/vLLM/SGLangを利用した場合などである。
論文中でも報告されている通り、昔管理人がtransformersを用いて、deterministicな設定でzephyrを用いてinferenceをしたときは、出力はdeterministicになっていたと記憶している(スループットは絶望的だったが...)。あと個人的には現実的な速度でオフラインでinference engineを利用した時にdeterministicにはせめてなって欲しいなあという気はするので、何が原因なのかを実装レベルで突き詰めてくれるととても嬉しい(KV Cacheが怪しい気がするけど)。
たとえば最近SLMだったらKVCacheしてVRAM食うより計算し直した方が効率良いよ、みたいな研究があったような。そういうことをしたらlocal llmでdeterministicにならないのだろうか。 #ComputerVision #Transformer #FoundationModel #Self-SupervisedLearning #TMLR Issue Date: 2025-04-11 DINOv2: Learning Robust Visual Features without Supervision, Maxime Oquab+, TMLR'24 Summary自己教師あり手法を用いて、多様なキュレーションデータから汎用的な視覚特徴を生成する新しい事前学習手法を提案。1BパラメータのViTモデルを訓練し、小型モデルに蒸留することで、OpenCLIPを上回る性能を達成。 #Tools #NLP #Dataset #LanguageModel #API #NeurIPS Issue Date: 2025-04-08 Gorilla: Large Language Model Connected with Massive APIs, Shishir G. Patil+, NeurIPS'24 SummaryGorillaは、API呼び出しの生成においてGPT-4を上回るLLaMAベースのモデルであり、文書検索システムと組み合わせることで、テスト時の文書変更に適応し、ユーザーの柔軟な更新を可能にします。幻覚の問題を軽減し、APIをより正確に使用する能力を示します。Gorillaの評価には新たに導入したデータセット「APIBench」を使用し、信頼性と適用性の向上を実現しています。 CommentAPIBench:https://huggingface.co/datasets/gorilla-llm/APIBenchOpenReview:https://openreview.net/forum?id=tBRNC6YemY #Survey #NLP #LanguageModel #Alignment #TMLR Issue Date: 2025-04-06 Foundational Challenges in Assuring Alignment and Safety of Large Language Models, Usman Anwar+, TMLR'24 Summary本研究では、LLMsの整合性と安全性に関する18の基盤的課題を特定し、科学的理解、開発・展開方法、社会技術的課題の3つのカテゴリに整理。これに基づき、200以上の具体的な研究質問を提起。 CommentOpenReview:https://openreview.net/forum?id=oVTkOs8Pka #NLP #Transformer #Attention Issue Date: 2025-04-06 Flex Attention: A Programming Model for Generating Optimized Attention Kernels, Juechu Dong+, arXiv'24 SummaryFlexAttentionは、アテンションの新しいコンパイラ駆動型プログラミングモデルで、数行のPyTorchコードで多くのアテンションバリアントを実装可能にします。これにより、既存のアテンションバリアントを効率的に実装し、競争力のあるパフォーマンスを達成。FlexAttentionは、アテンションバリアントの組み合わせを容易にし、組み合わせ爆発の問題を解決します。 Comment・1863
で利用されているAttentionpytochによる解説:https://pytorch.org/blog/flexattention/
・Flex AttentionはオリジナルのAttentionのQK/sqrt(d_k)の計算後にユーザが定義した関数score_modを適用する
・score_modを定義することで、attention scoreをsoftmaxをかけるまえに関数によって調整できる
・多くのattentionの亜種はほとんどの場合この抽象化で対応できる
・score_modはQK tokenの内積に対応するので、QKの情報を受け取り、スカラー値を返せばなんでも良い
・score_modの実装例は元リンク参照
・FA2と比較して(現在のpytorchでの実装上は)Forward Passは90%, Backward Passは85%のスループットで、少し遅いが今後改善予定元論文より引用。非常にシンプルで、数式上は下記のように表される:
 #Attention
#LongSequence
#ICLR
#AttentionSinks
Issue Date: 2025-04-05
Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
Summary大規模言語モデル(LLMs)をマルチラウンド対話に展開する際の課題として、メモリ消費と長いテキストへの一般化の難しさがある。ウィンドウアテンションはキャッシュサイズを超えると失敗するが、初期トークンのKVを保持することでパフォーマンスが回復する「アテンションシンク」を発見。これを基に、StreamingLLMというフレームワークを提案し、有限のアテンションウィンドウでトレーニングされたLLMが無限のシーケンス長に一般化可能になることを示した。StreamingLLMは、最大400万トークンで安定した言語モデリングを実現し、ストリーミング設定で従来の手法を最大22.2倍の速度で上回る。
CommentAttention Sinksという用語を提言した研究
#Attention
#LongSequence
#ICLR
#AttentionSinks
Issue Date: 2025-04-05
Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
Summary大規模言語モデル(LLMs)をマルチラウンド対話に展開する際の課題として、メモリ消費と長いテキストへの一般化の難しさがある。ウィンドウアテンションはキャッシュサイズを超えると失敗するが、初期トークンのKVを保持することでパフォーマンスが回復する「アテンションシンク」を発見。これを基に、StreamingLLMというフレームワークを提案し、有限のアテンションウィンドウでトレーニングされたLLMが無限のシーケンス長に一般化可能になることを示した。StreamingLLMは、最大400万トークンで安定した言語モデリングを実現し、ストリーミング設定で従来の手法を最大22.2倍の速度で上回る。
CommentAttention Sinksという用語を提言した研究
下記のpassageがAttention Sinksの定義(=最初の数トークン)とその気持ち(i.e., softmaxによるattention scoreは足し合わせて1にならなければならない。これが都合の悪い例として、現在のtokenのqueryに基づいてattention scoreを計算する際に過去のトークンの大半がirrelevantな状況を考える。この場合、irrelevantなトークンにattendしたくはない。そのため、auto-regressiveなモデルでほぼ全てのcontextで必ず出現する最初の数トークンを、irrelevantなトークンにattendしないためのattention scoreの捨て場として機能するのうに学習が進む)の理解に非常に重要
> To understand the failure of window attention, we find an interesting phenomenon of autoregressive LLMs: a surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task, as visualized in Figure 2. We term these tokens
“attention sinks". Despite their lack of semantic significance, they collect significant attention scores. We attribute the reason to the Softmax operation, which requires attention scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one. The reason behind initial tokens as sink tokens is intuitive: initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.・1860
の先行研究。こちらでAttentionSinkがどのように作用しているのか?が分析されている。Figure1が非常にわかりやすい。First TokenのKV Cacheを保持することでlong contextの性能が改善する
 著者による解説:https://x.com/guangxuan_xiao/status/1953656755109376040?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#LLMAgent
Issue Date: 2025-04-02
Agent Workflow Memory, Zora Zhiruo Wang+, arXiv'24
Summaryエージェントワークフローメモリ(AWM)を導入し、エージェントが再利用可能なタスクワークフローを学習することで、複雑なウェブナビゲーションタスクを効率的に解決。Mind2WebとWebArenaのベンチマークで、成功率をそれぞれ24.6%および51.1%向上させ、必要なステップ数を削減。オンラインAWMは、タスクやドメインに対しても堅牢に一般化し、ベースラインを大幅に上回る性能を示した。
Comment過去のワークフローをエージェントがprompt中で利用することができ、利用すればするほど賢くなるような仕組みの提案
著者による解説:https://x.com/guangxuan_xiao/status/1953656755109376040?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#LLMAgent
Issue Date: 2025-04-02
Agent Workflow Memory, Zora Zhiruo Wang+, arXiv'24
Summaryエージェントワークフローメモリ(AWM)を導入し、エージェントが再利用可能なタスクワークフローを学習することで、複雑なウェブナビゲーションタスクを効率的に解決。Mind2WebとWebArenaのベンチマークで、成功率をそれぞれ24.6%および51.1%向上させ、必要なステップ数を削減。オンラインAWMは、タスクやドメインに対しても堅牢に一般化し、ベースラインを大幅に上回る性能を示した。
Comment過去のワークフローをエージェントがprompt中で利用することができ、利用すればするほど賢くなるような仕組みの提案
 #NLP
#LanguageModel
#LLMAgent
Issue Date: 2025-04-02
CoAct: A Global-Local Hierarchy for Autonomous Agent Collaboration, Xinming Hou+, arXiv'24
SummaryCoActフレームワークを提案し、2つのエージェント(グローバル計画エージェントとローカル実行エージェント)を用いて、LLMの複雑なタスクへの対応力を向上させる。実験では、WebArenaベンチマークにおいて優れた性能を示し、失敗時のプロセス再編成能力を確認。コードは公開中。
CommentPlanningエージェントと実行エージェントを活用するソフトウェアエージェント
#NLP
#LanguageModel
#LLMAgent
Issue Date: 2025-04-02
CoAct: A Global-Local Hierarchy for Autonomous Agent Collaboration, Xinming Hou+, arXiv'24
SummaryCoActフレームワークを提案し、2つのエージェント(グローバル計画エージェントとローカル実行エージェント)を用いて、LLMの複雑なタスクへの対応力を向上させる。実験では、WebArenaベンチマークにおいて優れた性能を示し、失敗時のプロセス再編成能力を確認。コードは公開中。
CommentPlanningエージェントと実行エージェントを活用するソフトウェアエージェント

ReActより性能向上
・ 518
 #NLP
#Dataset
#LanguageModel
#LLMAgent
#SoftwareEngineering
Issue Date: 2025-04-02
Training Software Engineering Agents and Verifiers with SWE-Gym, Jiayi Pan+, arXiv'24
SummarySWE-Gymを提案し、2,438件の実世界のPythonタスクを含む環境を構築。言語モデルに基づくSWEエージェントを訓練し、SWE-Benchで最大19%の解決率向上を達成。微調整されたエージェントは新たな最先端の性能を示し、SWE-Gymやモデル、エージェントの軌跡を公開。
CommentSWE-Benchとは完全に独立したより広範な技術スタックに関連するタスクに基づくSWEベンチマーク
#NLP
#Dataset
#LanguageModel
#LLMAgent
#SoftwareEngineering
Issue Date: 2025-04-02
Training Software Engineering Agents and Verifiers with SWE-Gym, Jiayi Pan+, arXiv'24
SummarySWE-Gymを提案し、2,438件の実世界のPythonタスクを含む環境を構築。言語モデルに基づくSWEエージェントを訓練し、SWE-Benchで最大19%の解決率向上を達成。微調整されたエージェントは新たな最先端の性能を示し、SWE-Gymやモデル、エージェントの軌跡を公開。
CommentSWE-Benchとは完全に独立したより広範な技術スタックに関連するタスクに基づくSWEベンチマーク
・1848 SWE-Benchと比べて実行可能な環境と単体テストが提供されており、単なるベンチマークではなくエージェントを訓練できる環境が提供されている点が大きく異なるように感じる。

 #NLP
#Dataset
#LanguageModel
#LLMAgent
#ICLR
Issue Date: 2025-04-02
WebArena: A Realistic Web Environment for Building Autonomous Agents, Shuyan Zhou+, ICLR'24
Summary生成AIの進展により、自律エージェントが自然言語コマンドで日常タスクを管理する可能性が生まれたが、現行のエージェントは簡略化された環境でのテストに限られている。本研究では、ウェブ上でタスクを実行するエージェントのための現実的な環境を構築し、eコマースやソーシャルフォーラムなどのドメインを含む完全なウェブサイトを提供する。この環境を基に、タスクの正確性を評価するベンチマークを公開し、実験を通じてGPT-4ベースのエージェントの成功率が14.41%であり、人間の78.24%には及ばないことを示した。これにより、実生活のタスクにおけるエージェントのさらなる開発の必要性が強調される。
CommentWebにおけるさまざまなrealisticなタスクを評価するためのベンチマーク
#NLP
#Dataset
#LanguageModel
#LLMAgent
#ICLR
Issue Date: 2025-04-02
WebArena: A Realistic Web Environment for Building Autonomous Agents, Shuyan Zhou+, ICLR'24
Summary生成AIの進展により、自律エージェントが自然言語コマンドで日常タスクを管理する可能性が生まれたが、現行のエージェントは簡略化された環境でのテストに限られている。本研究では、ウェブ上でタスクを実行するエージェントのための現実的な環境を構築し、eコマースやソーシャルフォーラムなどのドメインを含む完全なウェブサイトを提供する。この環境を基に、タスクの正確性を評価するベンチマークを公開し、実験を通じてGPT-4ベースのエージェントの成功率が14.41%であり、人間の78.24%には及ばないことを示した。これにより、実生活のタスクにおけるエージェントのさらなる開発の必要性が強調される。
CommentWebにおけるさまざまなrealisticなタスクを評価するためのベンチマーク
 実際のexample。スタート地点からピッツバーグのmuseumを巡る最短の経路を見つけるといった複雑なタスクが含まれる。
実際のexample。スタート地点からピッツバーグのmuseumを巡る最短の経路を見つけるといった複雑なタスクが含まれる。

人間とGPT4,GPT-3.5の比較結果
 #EfficiencyImprovement
#NLP
#LanguageModel
#LLMAgent
#SoftwareEngineering
Issue Date: 2025-04-02
Agentless: Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, arXiv'24
Summary最近のLLMの進展により、ソフトウェア開発タスクの自動化が進んでいるが、複雑なエージェントアプローチの必要性に疑問が生じている。これに対し、Agentlessというエージェントレスアプローチを提案し、シンプルな三段階プロセスで問題を解決。SWE-bench Liteベンチマークで最高のパフォーマンスと低コストを達成。研究は自律型ソフトウェア開発におけるシンプルで解釈可能な技術の可能性を示し、今後の研究の方向性を刺激することを目指している。
Comment日本語解説:https://note.com/ainest/n/nac1c795e3825LLMによる計画の立案、環境からのフィードバックによる意思決定などの複雑なワークフローではなく、Localization(階層的に問題のある箇所を同定する)とRepair(LLMで複数のパッチ候補を生成する)、PatchValidation(再現テストと回帰テストの両方を通じて結果が良かったパッチを選ぶ)のシンプルなプロセスを通じてIssueを解決する。
#EfficiencyImprovement
#NLP
#LanguageModel
#LLMAgent
#SoftwareEngineering
Issue Date: 2025-04-02
Agentless: Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, arXiv'24
Summary最近のLLMの進展により、ソフトウェア開発タスクの自動化が進んでいるが、複雑なエージェントアプローチの必要性に疑問が生じている。これに対し、Agentlessというエージェントレスアプローチを提案し、シンプルな三段階プロセスで問題を解決。SWE-bench Liteベンチマークで最高のパフォーマンスと低コストを達成。研究は自律型ソフトウェア開発におけるシンプルで解釈可能な技術の可能性を示し、今後の研究の方向性を刺激することを目指している。
Comment日本語解説:https://note.com/ainest/n/nac1c795e3825LLMによる計画の立案、環境からのフィードバックによる意思決定などの複雑なワークフローではなく、Localization(階層的に問題のある箇所を同定する)とRepair(LLMで複数のパッチ候補を生成する)、PatchValidation(再現テストと回帰テストの両方を通じて結果が良かったパッチを選ぶ)のシンプルなプロセスを通じてIssueを解決する。

これにより、低コストで高い性能を達成している、といった内容な模様。
 #NLP
#LanguageModel
#SSM (StateSpaceModel)
#ICML
Issue Date: 2025-03-24
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, Tri Dao+, ICML'24
SummaryTransformersとMambaのような状態空間モデル(SSMs)の関連性を示し、SSMsと注意の変種との理論的接続を構築。新たに設計したMamba-2は、速度を2〜8倍向上させながら、Transformersと競争力を維持。
CommentMamba2の詳細を知りたい場合に読む
#NLP
#LanguageModel
#Pruning
#Distillation
#NeurIPS
Issue Date: 2025-03-16
Compact Language Models via Pruning and Knowledge Distillation, Saurav Muralidharan+, NeurIPS'24
Summary本論文では、既存の大規模言語モデル(LLMs)をプルーニングし、少量のトレーニングデータで再トレーニングする手法を提案。深さ、幅、注意、MLPプルーニングを知識蒸留と組み合わせた圧縮ベストプラクティスを開発し、Nemotron-4ファミリーのLLMを2-4倍圧縮。これにより、トレーニングに必要なトークン数を最大40倍削減し、計算コストを1.8倍削減。Minitronモデルは、ゼロからトレーニングした場合と比較してMMLUスコアが最大16%改善され、他のモデルと同等の性能を示す。モデルの重みはオープンソース化され、補足資料も提供。
CommentOpenReview:https://openreview.net/forum?id=9U0nLnNMJ7&referrer=%5Bthe%20profile%20of%20Pavlo%20Molchanov%5D(%2Fprofile%3Fid%3D~Pavlo_Molchanov1)
#NLP
#LanguageModel
#SSM (StateSpaceModel)
#ICML
Issue Date: 2025-03-24
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, Tri Dao+, ICML'24
SummaryTransformersとMambaのような状態空間モデル(SSMs)の関連性を示し、SSMsと注意の変種との理論的接続を構築。新たに設計したMamba-2は、速度を2〜8倍向上させながら、Transformersと競争力を維持。
CommentMamba2の詳細を知りたい場合に読む
#NLP
#LanguageModel
#Pruning
#Distillation
#NeurIPS
Issue Date: 2025-03-16
Compact Language Models via Pruning and Knowledge Distillation, Saurav Muralidharan+, NeurIPS'24
Summary本論文では、既存の大規模言語モデル(LLMs)をプルーニングし、少量のトレーニングデータで再トレーニングする手法を提案。深さ、幅、注意、MLPプルーニングを知識蒸留と組み合わせた圧縮ベストプラクティスを開発し、Nemotron-4ファミリーのLLMを2-4倍圧縮。これにより、トレーニングに必要なトークン数を最大40倍削減し、計算コストを1.8倍削減。Minitronモデルは、ゼロからトレーニングした場合と比較してMMLUスコアが最大16%改善され、他のモデルと同等の性能を示す。モデルの重みはオープンソース化され、補足資料も提供。
CommentOpenReview:https://openreview.net/forum?id=9U0nLnNMJ7&referrer=%5Bthe%20profile%20of%20Pavlo%20Molchanov%5D(%2Fprofile%3Fid%3D~Pavlo_Molchanov1)

(あとでメモを追記) #Analysis #NLP #LanguageModel #ICLR Issue Date: 2025-03-15 Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24 Summary神経ネットワークの多義性を解消するために、スパースオートエンコーダを用いて内部活性化の方向を特定。これにより、解釈可能で単義的な特徴を学習し、間接目的語の同定タスクにおける因果的特徴をより詳細に特定。スケーラブルで教師なしのアプローチが重ね合わせの問題を解決できることを示唆し、モデルの透明性と操作性向上に寄与する可能性を示す。 Comment日本語解説:https://note.com/ainest/n/nbe58b36bb2dbOpenReview:https://openreview.net/forum?id=F76bwRSLeKSparseAutoEncoderはネットワークのあらゆるところに仕込める(と思われる)が、たとえばTransformer Blockのresidual connection部分のベクトルに対してFeature Dictionaryを学習すると、当該ブロックにおいてどのような特徴の組み合わせが表現されているかが(あくまでSparseAutoEncoderがreconstruction lossによって学習された結果を用いて)解釈できるようになる。

SparseAutoEncoderは下記式で表され、下記loss functionで学習される。MがFeature Matrix(row-wiseに正規化されて後述のcに対するL1正則化に影響を与えないようにしている)に相当する。cに対してL1正則化をかけることで(Sparsity Loss)、c中の各要素が0に近づくようになり、結果としてcがSparseとなる(どうしても値を持たなければいけない重要な特徴量のみにフォーカスされるようになる)。

 #NLP
#LanguageModel
#LLMAgent
#AutomaticPromptEngineering
Issue Date: 2025-02-10
PromptWizard: Task-Aware Prompt Optimization Framework, Eshaan Agarwal+, arXiv'24
SummaryPromptWizardは、完全自動化された離散プロンプト最適化フレームワークであり、自己進化的かつ自己適応的なメカニズムを利用してプロンプトの質を向上させる。フィードバック駆動の批評を通じて、タスク特有のプロンプトを生成し、45のタスクで優れたパフォーマンスを実現。限られたデータや小規模なLLMでも効果を発揮し、コスト分析により効率性とスケーラビリティの利点が示された。
CommentGithub:https://github.com/microsoft/PromptWizard?tab=readme-ov-file
#NLP
#LanguageModel
#LLMAgent
#AutomaticPromptEngineering
Issue Date: 2025-02-10
PromptWizard: Task-Aware Prompt Optimization Framework, Eshaan Agarwal+, arXiv'24
SummaryPromptWizardは、完全自動化された離散プロンプト最適化フレームワークであり、自己進化的かつ自己適応的なメカニズムを利用してプロンプトの質を向上させる。フィードバック駆動の批評を通じて、タスク特有のプロンプトを生成し、45のタスクで優れたパフォーマンスを実現。限られたデータや小規模なLLMでも効果を発揮し、コスト分析により効率性とスケーラビリティの利点が示された。
CommentGithub:https://github.com/microsoft/PromptWizard?tab=readme-ov-file
元ポスト:https://x.com/tom_doerr/status/1888178173684199785?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q初期に提案された
・1034
と比較すると大分性能が上がってきているように見える。

 reasoning modelではfewshot promptingをすると性能が落ちるという知見があるので、reasoningモデル向けのAPE手法もそのうち出現するのだろう(既にありそう)。OpenReview: https://openreview.net/forum?id=VZC9aJoI6a
reasoning modelではfewshot promptingをすると性能が落ちるという知見があるので、reasoningモデル向けのAPE手法もそのうち出現するのだろう(既にありそう)。OpenReview: https://openreview.net/forum?id=VZC9aJoI6a
ICLR'25にrejectされている #NLP #LanguageModel #OpenSource #PostTraining Issue Date: 2025-02-01 Tulu 3: Pushing Frontiers in Open Language Model Post-Training, Nathan Lambert+, arXiv'24 SummaryTulu 3は、オープンなポストトレーニングモデルのファミリーで、トレーニングデータやレシピを公開し、現代のポストトレーニング技術のガイドを提供します。Llama 3.1を基にし、他のクローズドモデルを上回る性能を達成。新しいトレーニング手法としてSFT、DPO、RLVRを採用し、マルチタスク評価スキームを導入。モデルウェイトやデモ、トレーニングコード、データセットなどを公開し、他のドメインへの適応も可能です。 Comment元ポスト:https://x.com/icoxfog417/status/1885460713264775659?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Distillation Issue Date: 2025-02-01 A Survey on Knowledge Distillation of Large Language Models, Xiaohan Xu+, arXiv'24 Summary大規模言語モデル(LLMs)における知識蒸留(KD)の重要性を調査し、小型モデルへの知識伝達やモデル圧縮、自己改善の役割を強調。KDメカニズムや認知能力の向上、データ拡張(DA)との相互作用を検討し、DAがLLM性能を向上させる方法を示す。研究者や実務者に向けたガイドを提供し、LLMのKDの倫理的適用を推奨。関連情報はGithubで入手可能。 #NLP #LanguageModel #LLMAgent #Blog #NeurIPS Issue Date: 2025-01-25 [Paper Note] Chain of Agents: Large language models collaborating on long-context tasks, Google Research, 2025.01, NeurIPS'24 Comment元ポスト:https://x.com/googleai/status/1882554959272849696?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLMがどこまでいってもcontext長の制約に直面する問題に対してLLM Agentを組み合わせて対処しました、的な話な模様ブログ中にアプローチを解説した動画があるのでわかりやすいIs the experimental code open source?Thank you for your comment. I tried to find an official open-source implementation provided by the authors, but I was not able to locate one. In fact, I also checked the personal webpage of the first author, but there was no link to any released code.
Is seems that an unofficial implementation is listed under the “Code” tab on the NeurIPS page. I hope this is helpful. Thank you.
NeurIPS link: https://nips.cc/virtual/2024/poster/95563
openreview: https://openreview.net/forum?id=LuCLf4BJsr #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2025-01-25 Spectrum: Targeted Training on Signal to Noise Ratio, Eric Hartford+, arXiv'24 Summary「Spectrum」という手法を提案し、SNRに基づいてレイヤーモジュールを選択的にターゲットにすることで、LLMのトレーニングを加速。これによりGPUメモリ使用量を削減しつつ、フルファインチューニングに匹敵する性能を実現。実験により、既存手法QLoRAと比較してモデルの品質とVRAM効率の向上が確認された。 Comment・1723
によるとLLMのうち最もinformativeなLayerを見つけ、選択的に学習することで、省リソースで、Full-Parameter tuningと同等の性能を発揮する手法らしい
#ACL Issue Date: 2025-01-06 Parallel Structures in Pre-training Data Yield In-Context Learning, Yanda Chen+, arXiv'24 Summary事前学習済み言語モデル(LMs)のインコンテキスト学習(ICL)能力は、事前学習データ内の「平行構造」に依存していることを発見。平行構造とは、同じコンテキスト内で類似のテンプレートに従うフレーズのペアであり、これを除去するとICL精度が51%低下することが示された。平行構造は多様な言語タスクをカバーし、長距離にわたることが確認された。 #Survey #ACL Issue Date: 2025-01-06 Automated Justification Production for Claim Veracity in Fact Checking: A Survey on Architectures and Approaches, Islam Eldifrawi+, arXiv'24 Summary自動事実確認(AFC)は、主張の正確性を検証する重要なプロセスであり、特にオンラインコンテンツの増加に伴い真実と誤情報を見分ける役割を果たします。本論文では、最近の手法を調査し、包括的な分類法を提案するとともに、手法の比較分析や説明可能性向上のための今後の方向性について議論します。 #ACL Issue Date: 2025-01-06 Legal Case Retrieval: A Survey of the State of the Art, Feng+, ACL'24, 2024.08 Summary法的ケース検索(LCR)の重要性が増しており、歴史的なケースを大規模な法的データベースから検索するタスクに焦点を当てている。本論文では、LCRの主要なマイルストーンを調査し、研究者向けに関連データセットや最新のニューラルモデル、その性能を簡潔に説明する。 #Dataset #Financial #ACL Issue Date: 2025-01-06 FinTextQA: A Dataset for Long-form Financial Question Answering, Jian Chen+, ACL'24 Summary金融における質問応答システムの評価には多様なデータセットが必要だが、既存のものは不足している。本研究では、金融の長文質問応答用データセットFinTextQAを提案し、1,262の高品質QAペアを収集した。また、RAGベースのLFQAシステムを開発し、様々な評価手法で性能を検証した結果、Baichuan2-7BがGPT-3.5-turboに近い精度を示し、最も効果的なシステム構成が特定された。文脈の長さが閾値を超えると、ノイズに対する耐性が向上することも確認された。 Comment@AkihikoWatanabe Do you have this dataset, please share it with me. Thank you.@thangmaster37 Thank you for your comment and I'm sorry for the late replying. Unfortunately, I do not have this dataset. I checked the link provided in the paper, but it was not found. Please try contacting the authors. Thank you.@thangmaster37 I found that the dataset is available in the following repository. However, as stated in the repository's README, It seems that the textbook portion of the dataset cannot be shared because their legal department has not granted permission to open source. Thank you.
https://github.com/AlexJJJChen/FinTextQA回答の長さが既存データセットと比較して長いFinancialに関するQAデータセット(1 paragraph程度)。


ただし、上述の通りデータセットのうちtextbookについて公開の許可が降りなかったようで、regulation and policy-relatedな部分のみ利用できる模様(全体の20%程度)。
 #ACL Issue Date: 2025-01-06 Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models, Changyu Chen+, arXiv'24 Summary推論タスクにおける誤りを軽減するため、外部リソースを使わずに入力に摂動を導入する手法を開発。特定のトークンをランダムにマスクすることで、Llama-2-7Bを用いたGSM8Kの精度を5%、GSM-ICの精度を10%向上させた。この手法は既存のデータ拡張手法と組み合わせることで、複数のデータセットで改善を示し、モデルが長距離依存関係を捉えるのを助ける可能性がある。コードはGithubで公開。 Comment気になる #ACL Issue Date: 2025-01-06 A Deep Dive into the Trade-Offs of Parameter-Efficient Preference Alignment Techniques, Megh Thakkar+, arXiv'24 Summary大規模言語モデルの整列に関する研究で、整列データセット、整列技術、モデルの3つの要因が下流パフォーマンスに与える影響を300以上の実験を通じて調査。情報量の多いデータが整列に寄与することや、監視付きファインチューニングが最適化を上回るケースを発見。研究者向けに効果的なパラメータ効率の良いLLM整列のガイドラインを提案。 #LanguageModel #Supervised-FineTuning (SFT) #ACL #KnowledgeEditing Issue Date: 2025-01-06 Forgetting before Learning: Utilizing Parametric Arithmetic for Knowledge Updating in Large Language Models, Shiwen Ni+, ACL'24 SummaryF-Learningという新しいファインチューニング手法を提案し、古い知識を忘却し新しい知識を学習するためにパラメトリック算術を利用。実験により、F-LearningがフルファインチューニングとLoRAファインチューニングの知識更新性能を向上させ、既存のベースラインを上回ることを示した。LoRAのパラメータを引き算することで古い知識を忘却する効果も確認。 CommentFinetuningによって知識をアップデートしたい状況において、ベースモデルでアップデート前の該当知識を忘却してから、新しい知識を学習することで、より効果的に知識のアップデートが可能なことを示している。
古い知識のデータセットをK_old、古い知識から更新された新しい知識のデータセットをK_newとしたときに、K_oldでベースモデルを{Full-finetuning, LoRA}することで得たパラメータθ_oldを、ベースモデルのパラメータθから(古い知識を忘却することを期待して)減算し、パラメータθ'を持つ新たなベースモデルを得る。その後、パラメータθ'を持つベースモデルをk_newでFull-Finetuningすることで、新たな知識を学習させる。ただし、このような操作は、K_oldがベースモデルで学習済みである前提であることに注意する。学習済みでない場合はそもそも事前の忘却の必要がないし、減算によってベースモデルのコアとなる能力が破壊される危険がある。

結果は下記で、先行研究よりも高い性能を示している。注意点として、ベースモデルから忘却をさせる際に、Full Finetuningによってθ_oldを取得すると、ベースモデルのコアとなる能力が破壊されるケースがあるようである。一方、LoRAの場合はパラメータに対する影響が小さいため、このような破壊的な操作となりづらいようである。
 評価で利用されたデータセット:
評価で利用されたデータセット:
・2556
・2557 #ACL Issue Date: 2025-01-06 NICE: To Optimize In-Context Examples or Not?, Pragya Srivastava+, ACL'24 Summaryタスク固有の指示がある場合、ICEの最適化が逆効果になることを発見。指示が詳細になるほどICE最適化の効果が減少し、タスクの学習可能性を定量化する指標「NICE」を提案。これにより、指示最適化とICE最適化の選択を支援するヒューリスティックを提供。 Comment興味深い #Pretraining #InstructionTuning #ACL #PerplexityCurse Issue Date: 2025-01-06 Instruction-tuned Language Models are Better Knowledge Learners, Zhengbao Jiang+, ACL'24 Summary新しい文書からの知識更新には、事前指示調整(PIT)を提案。これは、文書の訓練前に質問に基づいて指示調整を行う手法で、LLMが新しい情報を効果的に吸収する能力を向上させ、標準的な指示調整を17.8%上回る結果を示した。 Comment興味深い #NLP #LanguageModel #ACL #KnowledgeEditing Issue Date: 2025-01-06 Learning to Edit: Aligning LLMs with Knowledge Editing, Yuxin Jiang+, ACL'24 Summary「Learning to Edit(LTE)」フレームワークを提案し、LLMsに新しい知識を効果的に適用する方法を教える。二段階プロセスで、アライメントフェーズで信頼できる編集を行い、推論フェーズでリトリーバルメカニズムを使用。四つの知識編集ベンチマークでLTEの優位性と堅牢性を示す。 #ACL Issue Date: 2025-01-06 Multi-Level Feedback Generation with Large Language Models for Empowering Novice Peer Counselors, Alicja Chaszczewicz+, arXiv'24 Summary大規模言語モデルを活用し、初心者のピアカウンセラーに文脈に応じた多層的なフィードバックを提供することを目的とした研究。上級心理療法スーパーバイザーと協力し、感情的サポートの会話に関するフィードバック注釈付きデータセットを構築。自己改善手法を設計し、フィードバックの自動生成を強化。定性的および定量的評価により、高リスクシナリオでの低品質なフィードバック生成のリスクを最小限に抑えることを示した。 #ACL Issue Date: 2025-01-06 Learning Global Controller in Latent Space for Parameter-Efficient Fine-Tuning, Tan+, ACL'24, 2024.08 Summary大規模言語モデル(LLMs)の高コストに対処するため、パラメータ効率の良いファインチューニング手法を提案。潜在ユニットを導入し、情報特徴を洗練することで下流タスクのパフォーマンスを向上。非対称注意メカニズムにより、トレーニングのメモリ要件を削減し、フルランクトレーニングの問題を軽減。実験結果は、自然言語処理タスクで最先端の性能を達成したことを示す。 #ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MulltiModal #ACL Issue Date: 2025-01-06 OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems, Chaoqun He+, ACL'24 Summary大規模言語モデル(LLMs)やマルチモーダルモデル(LMMs)の能力を測定するために、オリンピアドレベルのバイリンガルマルチモーダル科学ベンチマーク「OlympiadBench」を提案。8,476の数学と物理の問題を含み、専門家レベルの注釈が付けられている。トップモデルのGPT-4Vは平均17.97%のスコアを達成したが、物理では10.74%にとどまり、ベンチマークの厳しさを示す。一般的な問題として幻覚や論理的誤謬が指摘され、今後のAGI研究に貴重なリソースとなることが期待される。 #ACL Issue Date: 2025-01-06 DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows, Ajay Patel+, arXiv'24 Summary大規模言語モデル(LLMs)の利用が広がる中、標準化ツールの欠如や再現性の問題が浮上している。本論文では、研究者が簡単にLLMワークフローを実装できるオープンソースのPythonライブラリ「DataDreamer」を紹介し、オープンサイエンスと再現性を促進するためのベストプラクティスを提案する。ライブラリはGitHubで入手可能。 #ACL Issue Date: 2025-01-06 Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives, Wenqi Zhang+, arXiv'24 SummaryLLMの反射能力に関する研究では、自己評価の質がボトルネックであることが判明。過信や高いランダム性が反射の質を低下させるため、自己対比(Self-Contrast)を提案し、多様な解決視点を探求・対比することで不一致を排除。これにより、LLMのバイアスを軽減し、より正確で安定した反射を促進。実験により、提案手法の効果と一般性が示された。 #ACL Issue Date: 2025-01-06 Llama2Vec: Unsupervised Adaptation of Large Language Models for Dense Retrieval, Li+, ACL'24, 2024.08 SummaryLlama2Vecは、LLMを密な検索に適応させるための新しい非監視適応アプローチであり、EBAEとEBARの2つの前提タスクを用いています。この手法は、WikipediaコーパスでLLaMA-2-7Bを適応させ、密な検索ベンチマークでの性能を大幅に向上させ、特にMSMARCOやBEIRで最先端の結果を達成しました。モデルとソースコードは公開予定です。 #Education #ACL Issue Date: 2025-01-06 BIPED: Pedagogically Informed Tutoring System for ESL Education, Kwon+, ACL'24, 2024.08 Summary大規模言語モデル(LLMs)を用いた会話型インテリジェントチュータリングシステム(CITS)は、英語の第二言語(L2)学習者に対して効果的な教育手段となる可能性があるが、既存のシステムは教育的深さに欠ける。これを改善するために、バイリンガル教育的情報を持つチュータリングデータセット(BIPED)を構築し、対話行為の語彙を考案した。GPT-4とSOLAR-KOを用いて二段階のフレームワークでCITSモデルを実装し、実験により人間の教師のスタイルを再現し、多様な教育的戦略を採用できることを示した。 #ACL Issue Date: 2025-01-06 Beyond Memorization: The Challenge of Random Memory Access in Language Models, Tongyao Zhu+, arXiv'24 Summary生成型言語モデル(LM)のメモリアクセス能力を調査し、順次アクセスは可能だがランダムアクセスには課題があることを明らかに。暗唱技術がランダムメモリアクセスを向上させ、オープンドメインの質問応答においても顕著な改善を示した。実験コードは公開されている。 #ACL Issue Date: 2025-01-06 Attribute First, then Generate: Locally-attributable Grounded Text Generation, Aviv Slobodkin+, arXiv'24 Summaryローカル属性付きテキスト生成アプローチを提案し、生成プロセスをコンテンツ選択、文の計画、逐次文生成の3ステップに分解。これにより、簡潔な引用を生成しつつ、生成品質と属性の正確性を維持または向上させ、事実確認にかかる時間を大幅に削減。 #ACL Issue Date: 2025-01-06 Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost for Reasoning, Yongqi Tong+, arXiv'24 Summary本研究では、LLMが自らの間違いから学ぶ能力を探求し、609,432の質問を含む新しいベンチマーク\textsc{CoTErrorSet}を提案。自己再考プロンプティングと間違いチューニングの2つの方法を用いて、LLMが誤りから推論能力を向上させることを実証。これにより、コスト効果の高いエラー活用戦略を提供し、今後の研究の方向性を示す。 #ACL Issue Date: 2025-01-06 Enhancing In-Context Learning via Implicit Demonstration Augmentation, Xiaoling Zhou+, arXiv'24 Summaryインコンテキスト学習(ICL)におけるデモンストレーションの質や量がパフォーマンスに影響を与える問題に対処。デモンストレーションの深い特徴分布を活用し、表現を豊かにすることで、精度を向上させる新しいロジットキャリブレーションメカニズムを提案。これにより、さまざまなPLMやタスクでの精度向上とパフォーマンスのばらつきの減少を実現。 #ACL Issue Date: 2025-01-06 MathGenie: Generating Synthetic Data with Question Back-translation for Enhancing Mathematical Reasoning of LLMs, Zimu Lu+, arXiv'24 SummaryMathGenieは、少規模な問題解決データセットから多様で信頼性の高い数学問題を生成する新手法。シードデータの解答を増強し、逆翻訳モデルで新しい質問に変換。解答の正確性を確保するために根拠に基づく検証戦略を採用。MathGenieLMモデル群は、5つの数学的推論データセットでオープンソースモデルを上回り、特にGSM8Kで87.7%、MATHで55.7%の精度を達成。 #ACL Issue Date: 2025-01-06 MELA: Multilingual Evaluation of Linguistic Acceptability, Zhang+, ACL'24, 2024.08 Summary本研究では、46,000サンプルからなる「多言語言語的受容性評価(MELA)」ベンチマークを発表し、10言語にわたるLLMのベースラインを確立。XLM-Rを用いてクロスリンガル転送を調査し、ファインチューニングされたXLM-RとGPT-4oの性能を比較。結果、GPT-4oは多言語能力で優れ、オープンソースモデルは劣ることが判明。クロスリンガル転送実験では、受容性判断の転送が複雑であることが示され、MELAでのトレーニングがXLM-Rの構文タスクのパフォーマンス向上に寄与することが確認された。 #ACL Issue Date: 2025-01-06 Time is Encoded in the Weights of Finetuned Language Models, Kai Nylund+, ACL'24 Summary「時間ベクトル」を提案し、特定の時間データで言語モデルをファインチューニングする手法を示す。時間ベクトルは重み空間の方向を指定し、特定の時間帯のパフォーマンスを向上させる。隣接する時間帯に特化したベクトルは近接して配置され、補間により未来の時間帯でも良好な性能を発揮。異なるタスクやモデルサイズにおいて一貫した結果を示し、時間がモデルの重み空間にエンコードされていることを示唆。 #ACL Issue Date: 2025-01-06 Surgical Feature-Space Decomposition of LLMs: Why, When and How?, Arnav Chavan+, arXiv'24 Summary低ランク近似は、深層学習モデルの性能向上や推論のレイテンシ削減に寄与するが、LLMにおける有用性は未解明。本研究では、トランスフォーマーベースのLLMにおける重みと特徴空間の分解の効果を実証し、圧縮と性能のトレードオフに関する洞察を提供しつつ、常識推論性能の向上も示す。特定のネットワークセグメントの低ランク構造を特定し、モデルのバイアスへの影響も調査。これにより、低ランク近似が性能向上とバイアス修正の手段としての新たな視点を提供することを示した。 #ACL Issue Date: 2025-01-06 MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter, Jitai Hao+, arXiv'24 SummaryPEFTを用いたLLMsのファインチューニング性能は、追加パラメータの制約から限られる。これを克服するために、メモリ効率の良い大きなアダプターを導入し、CPUメモリの大容量を活用。Mixture of Expertsアーキテクチャを採用し、GPUとCPU間の通信量を削減。これにより、限られたリソース下でも高いファインチューニング性能を達成。コードはGitHubで公開。 #ACL Issue Date: 2025-01-06 Benchmarking Knowledge Boundary for Large Language Models: A Different Perspective on Model Evaluation, Xunjian Yin+, arXiv'24 Summary大規模言語モデルの評価において、プロンプトに依存しない「知識境界」という新概念を提案。これにより、プロンプトの敏感さを回避し、信頼性の高い評価が可能に。新しいアルゴリズム「意味的制約を持つ投影勾配降下法」を用いて、知識境界を計算し、既存手法より優れた性能を示す。複数の言語モデルの能力を多様な領域で評価。 #ACL Issue Date: 2025-01-06 ValueBench: Towards Comprehensively Evaluating Value Orientations and Understanding of Large Language Models, Yuanyi Ren+, arXiv'24 Summary本研究では、LLMsの価値観と理解を評価するための心理測定ベンチマーク「ValueBench」を提案。453の価値次元を含むデータを収集し、現実的な人間とAIの相互作用に基づく評価パイプラインを構築。6つのLLMに対する実験を通じて、共通および独自の価値観を明らかにし、価値関連タスクでの専門家の結論に近い能力を示した。ValueBenchはオープンアクセス可能。 #ACL Issue Date: 2025-01-06 AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension, Qian Yang+, arXiv'24 Summary音声言語モデル(LALMs)の評価のために、初のベンチマークAIR-Benchを提案。これは、音声信号の理解と人間との相互作用能力を評価するもので、基本的な単一タスク能力を検査する約19,000の質問と、複雑な音声に対する理解力を評価する2,000のオープンエンド質問から構成。GPT-4を用いた評価フレームワークにより、LALMsの限界を明らかにし、今後の研究の指針を提供。 #ACL Issue Date: 2025-01-06 Self-Alignment for Factuality: Mitigating Hallucinations in LLMs via Self-Evaluation, Xiaoying Zhang+, arXiv'24 Summary自己整合性を用いてLLMの事実性を向上させるアプローチを提案。自己評価コンポーネントSelf-Evalを組み込み、生成した応答の事実性を内部知識で検証。信頼度推定を改善するSelf-Knowledge Tuningを設計し、自己注釈された応答でモデルをファインチューニング。TruthfulQAとBioGENタスクでLlamaモデルの事実精度を大幅に向上。 #ACL Issue Date: 2025-01-06 Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering, Tobias Schimanski+, arXiv'24 SummaryLLMsの信頼性と追跡可能性を向上させるため、情報源の質と回答の帰属を改善するファインチューニング手法を調査。自動データ品質フィルターを用いた高品質データの合成により、パフォーマンスが向上。データ品質の改善が証拠に基づくQAにおいて重要であることを示した。 #ACL Issue Date: 2025-01-06 AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators, Jingwei+, ACL'24, 2024.08 Summary生成AIの普及に伴い、自動事実確認手法が重要視されているが、事実主張の検出にはスケーラビリティと一般化可能性の問題がある。これに対処するため、事実主張の統一的な定義を提案し、AFaCTAという新しいフレームワークを導入。AFaCTAはLLMsを活用し、注釈の信頼度を調整する。広範な評価により、専門家の注釈作業を効率化し、PoliClaimという包括的な主張検出データセットを作成した。 #ACL Issue Date: 2025-01-06 Dissecting Human and LLM Preferences, Junlong Li+, arXiv'24 Summary本研究では、人間と32種類のLLMの好みを分析し、モデルの応答の品質比較における定量的な構成を理解するための詳細なシナリオ別分析を行った。人間はエラーに対して敏感でなく、自分の立場を支持する応答を好む一方、GPT-4-Turboのような高度なLLMは正確性や無害性を重視することが分かった。また、同サイズのLLMはトレーニング方法に関係なく似た好みを示し、ファインチューニングは大きな変化をもたらさないことが明らかになった。さらに、好みに基づく評価は操作可能であり、モデルを審査員の好みに合わせることでスコアが向上することが示された。 #ACL Issue Date: 2025-01-06 Selene: Pioneering Automated Proof in Software Verification, Lichen Zhang+, arXiv'24 Summaryソフトウェア検証の自動化が求められる中、seL4に基づく初のプロジェクトレベルの自動証明ベンチマークSeleneを提案。Seleneは包括的な証明生成フレームワークを提供し、LLMs(GPT-3.5-turboやGPT-4)を用いた実験でその能力を示す。提案する強化策により、Seleneの課題が今後の研究で軽減可能であることを示唆。 #ACL Issue Date: 2025-01-06 Evaluating Intention Detection Capability of Large Language Models in Persuasive Dialogues, Sakurai+, ACL'24, 2024.08 SummaryLLMsを用いてマルチターン対話における意図検出を調査。従来の研究が会話履歴を無視している中、修正したデータセットを用いて意図検出能力を評価。特に説得的対話では他者の視点を考慮することが重要であり、「フェイスアクト」の概念を取り入れることで、意図の種類に応じた分析が可能となる。 #ACL Issue Date: 2025-01-06 Analyzing Temporal Complex Events with Large Language Models? A Benchmark towards Temporal, Long Context Understanding, Zhihan Zhang+, arXiv'24 Summaryデジタル環境の進化に伴い、複雑なイベントの迅速かつ正確な分析が求められている。本論文では、長期間のニュース記事から「Temporal Complex Event(TCE)」を抽出・分析するために、LLMsを用いた新しいアプローチを提案。TCEは重要なポイントとタイムスタンプで特徴付けられ、読解力、時間的配列、未来のイベント予測の3つのタスクを含むベンチマーク「TCELongBench」を設立。実験では、リトリーバー強化生成(RAG)手法と長いコンテキストウィンドウを持つLLMsを活用し、適切なリトリーバーを持つモデルが長いコンテキストウィンドウを利用するモデルと同等のパフォーマンスを示すことが確認された。 #ACL Issue Date: 2025-01-06 Feature-Adaptive and Data-Scalable In-Context Learning, Jiahao Li+, arXiv'24 SummaryFADS-ICLは、文脈内学習を強化するための特徴適応型フレームワークで、LLMの一般的な特徴を特定の下流タスクに適合させる。実験により、FADS-ICLは従来の手法を大幅に上回り、特に1.5Bモデルでの32ショット設定では平均14.3の精度向上を達成。トレーニングデータの増加により性能がさらに向上することも示された。 #ACL Issue Date: 2025-01-06 Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal, Jianheng Huang+, arXiv'24 Summary自己合成リハーサル(SSR)フレームワークを提案し、LLMの継続的学習における壊滅的な忘却を克服。基本のLLMで合成インスタンスを生成し、最新のLLMで洗練させることで、データ効率を高めつつパフォーマンスを向上。SSRは一般化能力を効果的に保持することが実験で示された。 #Embeddings #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) #LongSequence #ACL #PostTraining Issue Date: 2025-01-06 Grounding Language Model with Chunking-Free In-Context Retrieval, Hongjin Qian+, arXiv'24 SummaryCFICは、Retrieval-Augmented Generation(RAG)システム向けの新しいリトリーバルアプローチで、従来のチャンク化を回避し、文書のエンコードされた隠れ状態を利用して正確な証拠テキストを特定します。制約付き文のプレフィックスデコーディングとスキップデコーディングを組み込むことで、リトリーバルの効率と生成された証拠の忠実性を向上させます。CFICはオープンQAデータセットで評価され、従来の方法に対して大幅な改善を示し、RAGシステムの効率的で効果的なリトリーバルソリューションを提供します。 CommentChunking無しでRAGを動作させられるのは非常に魅力的。
 一貫してかなり性能が向上しているように見える
一貫してかなり性能が向上しているように見える
 提案手法の概要。InputとOutput全体の実例がほとんど掲載されていないので憶測を含みます。
提案手法の概要。InputとOutput全体の実例がほとんど掲載されていないので憶測を含みます。
気持ちとしては、ソーステキストが与えられたときに、Questionの回答をsupportするようなソース中のpassageの情報を活用して回答するために、重要なsentenceのprefixを回答生成前に生成させる(重要なsentenceの識別子の役割を果たす)ことで、(識別子によって重要な情報によって条件づけられて回答生成ができるやうになるのて)それら情報をより考慮しながらモデルが回答を生成できるようになる、といった話だと思われる。
Table2のようなテンプレートを用いて、ソーステキストと質問文でモデルを条件付けて、回答をsupportするsentenceのprefixを生成する。生成するprefixは各sentenceのユニークなprefixのtoken log probabilityの平均値によって決まる(トークンの対数尤度が高かったらモデルが暗黙的にその情報はQuestionにとって重要だと判断しているとみなせる)。SkipDecodingの説を読んだが、ぱっと見よく分からない。おそらく[eos]を出力させてprefix間のデリミタとして機能させたいのだと思うが、[eos]の最適なpositionはどこなのか?みたいな数式が出てきており、これがデコーディングの時にどういった役割を果たすのかがよくわからない。
また、モデルはQAと重要なPassageの三つ組のデータで提案手法によるデコーディングを適用してSFTしたものを利用する。

 #LanguageModel
#Evaluation
#Bias
#ACL
Issue Date: 2025-01-06
ConSiDERS-The-Human Evaluation Framework: Rethinking Human Evaluation for Generative Large Language Models, Aparna Elangovan+, arXiv'24
Summary本ポジションペーパーでは、生成的な大規模言語モデル(LLMs)の人間評価は多分野にわたる取り組みであるべきと主張し、実験デザインの信頼性を確保するためにユーザーエクスペリエンスや心理学の洞察を活用する必要性を強調します。評価には使いやすさや認知バイアスを考慮し、強力なモデルの能力と弱点を区別するための効果的なテストセットが求められます。さらに、スケーラビリティも重要であり、6つの柱から成るConSiDERS-The-Human評価フレームワークを提案します。これらの柱は、一貫性、評価基準、差別化、ユーザーエクスペリエンス、責任、スケーラビリティです。
#Embeddings
#Dataset
#RepresentationLearning
#STS (SemanticTextualSimilarity)
#ACL
Issue Date: 2025-01-06
Linguistically Conditioned Semantic Textual Similarity, Jingxuan Tu+, ACL'24
Summary条件付きSTS(C-STS)は文の意味的類似性を測定するNLPタスクであるが、既存のデータセットには評価を妨げる問題が多い。本研究では、C-STSの検証セットを再アノテーションし、アノテーター間の不一致を55%観察。QAタスク設定を活用し、アノテーションエラーを80%以上のF1スコアで特定する自動エラー識別パイプラインを提案。また、モデル訓練によりC-STSデータのベースライン性能を向上させる新手法を示し、エンティティタイプの型特徴構造(TFS)を用いた条件付きアノテーションの可能性についても議論する。
#LanguageModel
#EducationalDataMining
Issue Date: 2025-01-06
Engaging an LLM to Explain Worked Examples for Java Programming: Prompt Engineering and a Feasibility Study, Hassany+, EDM'24 Workshop, 2024.07
Summaryプログラミングクラスでのコード例の説明を効率化するために、LLMを用いた人間とAIの共同執筆アプローチを提案。講師が編集可能な初期コード説明を生成し、学生にとって意味のある内容を確保するためにプロンプトエンジニアリングを行い、その効果をユーザー研究で評価した。
Comment元ポスト:https://x.com/peterpaws/status/1876047837441806604?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#MoE(Mixture-of-Experts)
#ACL
Issue Date: 2025-01-06
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, Damai+, ACL'24, 2024.08
SummaryDeepSeekMoEアーキテクチャは、専門家の専門性を高めるために、専門家を細分化し柔軟な組み合わせを可能にし、共有専門家を設けて冗長性を軽減する。2BパラメータのDeepSeekMoEは、GShardと同等の性能を達成し、同じパラメータ数の密なモデルに近づく。16Bパラメータにスケールアップした際も、計算量を約40%に抑えつつ、LLaMA2と同等の性能を示した。
#Analysis
#NLP
#RLHF
Issue Date: 2025-01-03
Does RLHF Scale? Exploring the Impacts From Data, Model, and Method, Zhenyu Hou+, arXiv'24
Summary本研究では、LLMsにおけるRLHFのスケーリング特性を分析し、モデルサイズ、データ構成、推論予算がパフォーマンスに与える影響を調査。データの多様性と量の増加が報酬モデルの性能向上に寄与する一方、ポリシートレーニングでは応答サンプル数の増加が初期パフォーマンスを向上させるが、すぐに頭打ちになることが判明。RLHFは事前トレーニングより効率的にスケールせず、計算リソースの収益逓減が観察された。計算制限内でのRLHFパフォーマンス最適化戦略も提案。
Comment元ポスト:https://x.com/dair_ai/status/1868299930600628451?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#QuestionAnswering
#Zero/FewShotPrompting
#Chain-of-Thought
#RAG(RetrievalAugmentedGeneration)
#Reasoning
Issue Date: 2025-01-03
AutoReason: Automatic Few-Shot Reasoning Decomposition, Arda Sevinc+, arXiv'24
SummaryChain of Thought(CoT)を用いて、暗黙のクエリを明示的な質問に分解することで、LLMの推論能力を向上させる自動生成システムを提案。StrategyQAとHotpotQAデータセットで精度向上を確認し、特にStrategyQAで顕著な成果を得た。ソースコードはGitHubで公開。
Comment元ポスト:https://x.com/dair_ai/status/1868299926897074309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LLMAgent
#SyntheticData
#Evaluation
#SyntheticDataGeneration
Issue Date: 2025-01-03
MAG-V: A Multi-Agent Framework for Synthetic Data Generation and Verification, Saptarshi Sengupta+, arXiv'24
SummaryMAG-Vというマルチエージェントフレームワークを提案し、顧客クエリを模倣したデータセットを生成してエージェントのパフォーマンスを向上させる。軌跡の検証手法は従来のMLモデルを上回り、GPT-4と同等の性能を示す。多様なタスクエージェントを統一するアプローチを提供。
Comment元ポスト:https://x.com/dair_ai/status/1868299921117630528?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Controllable
#NLP
#LanguageModel
#PositionalEncoding
#Length
Issue Date: 2025-01-03
Precise Length Control in Large Language Models, Bradley Butcher+, arXiv'24
Summary本研究では、LLMの応答の長さを正確に制御するために、二次的な長さ差位置エンコーディング(LDPE)を用いたアプローチを提案。LDPEを組み込むことで、モデルは平均3トークン未満の誤差で望ましい長さで応答を終了できるようになる。また、柔軟な上限長さ制御を可能にするMax New Tokens++も導入。実験結果は、質問応答や文書要約において応答の質を維持しつつ正確な長さ制御が実現できることを示している。
Comment元ポスト:https://x.com/dair_ai/status/1870821203780256178?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1647
#LanguageModel
#Evaluation
#Bias
#ACL
Issue Date: 2025-01-06
ConSiDERS-The-Human Evaluation Framework: Rethinking Human Evaluation for Generative Large Language Models, Aparna Elangovan+, arXiv'24
Summary本ポジションペーパーでは、生成的な大規模言語モデル(LLMs)の人間評価は多分野にわたる取り組みであるべきと主張し、実験デザインの信頼性を確保するためにユーザーエクスペリエンスや心理学の洞察を活用する必要性を強調します。評価には使いやすさや認知バイアスを考慮し、強力なモデルの能力と弱点を区別するための効果的なテストセットが求められます。さらに、スケーラビリティも重要であり、6つの柱から成るConSiDERS-The-Human評価フレームワークを提案します。これらの柱は、一貫性、評価基準、差別化、ユーザーエクスペリエンス、責任、スケーラビリティです。
#Embeddings
#Dataset
#RepresentationLearning
#STS (SemanticTextualSimilarity)
#ACL
Issue Date: 2025-01-06
Linguistically Conditioned Semantic Textual Similarity, Jingxuan Tu+, ACL'24
Summary条件付きSTS(C-STS)は文の意味的類似性を測定するNLPタスクであるが、既存のデータセットには評価を妨げる問題が多い。本研究では、C-STSの検証セットを再アノテーションし、アノテーター間の不一致を55%観察。QAタスク設定を活用し、アノテーションエラーを80%以上のF1スコアで特定する自動エラー識別パイプラインを提案。また、モデル訓練によりC-STSデータのベースライン性能を向上させる新手法を示し、エンティティタイプの型特徴構造(TFS)を用いた条件付きアノテーションの可能性についても議論する。
#LanguageModel
#EducationalDataMining
Issue Date: 2025-01-06
Engaging an LLM to Explain Worked Examples for Java Programming: Prompt Engineering and a Feasibility Study, Hassany+, EDM'24 Workshop, 2024.07
Summaryプログラミングクラスでのコード例の説明を効率化するために、LLMを用いた人間とAIの共同執筆アプローチを提案。講師が編集可能な初期コード説明を生成し、学生にとって意味のある内容を確保するためにプロンプトエンジニアリングを行い、その効果をユーザー研究で評価した。
Comment元ポスト:https://x.com/peterpaws/status/1876047837441806604?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#MoE(Mixture-of-Experts)
#ACL
Issue Date: 2025-01-06
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, Damai+, ACL'24, 2024.08
SummaryDeepSeekMoEアーキテクチャは、専門家の専門性を高めるために、専門家を細分化し柔軟な組み合わせを可能にし、共有専門家を設けて冗長性を軽減する。2BパラメータのDeepSeekMoEは、GShardと同等の性能を達成し、同じパラメータ数の密なモデルに近づく。16Bパラメータにスケールアップした際も、計算量を約40%に抑えつつ、LLaMA2と同等の性能を示した。
#Analysis
#NLP
#RLHF
Issue Date: 2025-01-03
Does RLHF Scale? Exploring the Impacts From Data, Model, and Method, Zhenyu Hou+, arXiv'24
Summary本研究では、LLMsにおけるRLHFのスケーリング特性を分析し、モデルサイズ、データ構成、推論予算がパフォーマンスに与える影響を調査。データの多様性と量の増加が報酬モデルの性能向上に寄与する一方、ポリシートレーニングでは応答サンプル数の増加が初期パフォーマンスを向上させるが、すぐに頭打ちになることが判明。RLHFは事前トレーニングより効率的にスケールせず、計算リソースの収益逓減が観察された。計算制限内でのRLHFパフォーマンス最適化戦略も提案。
Comment元ポスト:https://x.com/dair_ai/status/1868299930600628451?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#QuestionAnswering
#Zero/FewShotPrompting
#Chain-of-Thought
#RAG(RetrievalAugmentedGeneration)
#Reasoning
Issue Date: 2025-01-03
AutoReason: Automatic Few-Shot Reasoning Decomposition, Arda Sevinc+, arXiv'24
SummaryChain of Thought(CoT)を用いて、暗黙のクエリを明示的な質問に分解することで、LLMの推論能力を向上させる自動生成システムを提案。StrategyQAとHotpotQAデータセットで精度向上を確認し、特にStrategyQAで顕著な成果を得た。ソースコードはGitHubで公開。
Comment元ポスト:https://x.com/dair_ai/status/1868299926897074309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#Dataset
#LLMAgent
#SyntheticData
#Evaluation
#SyntheticDataGeneration
Issue Date: 2025-01-03
MAG-V: A Multi-Agent Framework for Synthetic Data Generation and Verification, Saptarshi Sengupta+, arXiv'24
SummaryMAG-Vというマルチエージェントフレームワークを提案し、顧客クエリを模倣したデータセットを生成してエージェントのパフォーマンスを向上させる。軌跡の検証手法は従来のMLモデルを上回り、GPT-4と同等の性能を示す。多様なタスクエージェントを統一するアプローチを提供。
Comment元ポスト:https://x.com/dair_ai/status/1868299921117630528?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Controllable
#NLP
#LanguageModel
#PositionalEncoding
#Length
Issue Date: 2025-01-03
Precise Length Control in Large Language Models, Bradley Butcher+, arXiv'24
Summary本研究では、LLMの応答の長さを正確に制御するために、二次的な長さ差位置エンコーディング(LDPE)を用いたアプローチを提案。LDPEを組み込むことで、モデルは平均3トークン未満の誤差で望ましい長さで応答を終了できるようになる。また、柔軟な上限長さ制御を可能にするMax New Tokens++も導入。実験結果は、質問応答や文書要約において応答の質を維持しつつ正確な長さ制御が実現できることを示している。
Comment元ポスト:https://x.com/dair_ai/status/1870821203780256178?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1647
などのEncoder-Decoderモデルで行われていたoutput lengthの制御をDecoder-onlyモデルでもやりました、という話に見える。 #Survey #NLP #LanguageModel #Reasoning #Mathematics Issue Date: 2025-01-03 A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges, Yibo Yan+, arXiv'24 Summary数学的推論は多くの分野で重要であり、AGIの進展に伴い、LLMsを数学的推論タスクに統合することが求められている。本調査は、2021年以降の200以上の研究をレビューし、マルチモーダル設定におけるMath-LLMsの進展を分析。分野をベンチマーク、方法論、課題に分類し、マルチモーダル数学的推論のパイプラインやLLMsの役割を探る。さらに、AGI実現の障害となる5つの課題を特定し、今後の研究方向性を示す。 #NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) Issue Date: 2025-01-02 LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR'24 SummaryLoRAは大規模言語モデルの効率的なファインチューニング手法であり、プログラミングと数学のドメインでの性能をフルファインチューニングと比較。標準的な設定ではLoRAは性能が劣るが、ターゲットドメイン外のタスクではベースモデルの性能を維持し、忘却を軽減する効果がある。フルファインチューニングはLoRAよりも高いランクの摂動を学習し、性能差の一因と考えられる。最終的に、LoRAのファインチューニングに関するベストプラクティスを提案。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qfull finetuningとLoRAの性質の違いを理解するのに有用 #NLP #LanguageModel #Supervised-FineTuning (SFT) #ProprietaryLLM Issue Date: 2025-01-02 FineTuneBench: How well do commercial fine-tuning APIs infuse knowledge into LLMs?, Eric Wu+, arXiv'24 Summary商業的なLLM微調整APIの効果を評価するためのFineTuneBenchを提案。5つの最前線のLLMを分析し、新しい情報の学習と既存知識の更新における能力を評価した結果、全モデルで平均一般化精度は37%、医療ガイドラインの更新では19%と低いことが判明。特にGPT-4o miniが最も効果的で、Gemini 1.5シリーズは能力が限られていた。商業的微調整サービスの信頼性に課題があることを示唆。データセットはオープンソースで提供。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pretraining #NLP #Catastrophic Forgetting Issue Date: 2025-01-02 Examining Forgetting in Continual Pre-training of Aligned Large Language Models, Chen-An Li+, arXiv'24 SummaryLLMの継続的な事前学習がファインチューニングされたモデルに与える影響を調査し、壊滅的な忘却の現象を評価。出力形式や知識、信頼性の次元での実験結果が、特に繰り返しの問題における忘却の課題を明らかにする。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #SyntheticData Issue Date: 2025-01-02 Generative AI for Synthetic Data Generation: Methods, Challenges and the Future, Xu Guo+, arXiv'24 Summary限られたデータのシナリオでLLMsを用いて合成データを生成する研究が増加しており、これは生成的AIの進展を示す。LLMsは実世界のデータと同等の性能を持ち、リソースが限られた課題に対する解決策となる。本論文では、タスク特化型のトレーニングデータ生成のための技術、評価方法、実用的応用、現在の制限、将来の研究の方向性について議論する。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #SyntheticData Issue Date: 2025-01-02 On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey, Lin Long+, arXiv'24 Summary深層学習におけるデータの量と質の問題に対し、LLMsが合成データ生成を通じて解決策を提供。しかし、現状の研究は統一されたフレームワークを欠き、表面的なものが多い。本論文では合成データ生成のワークフローを整理し、研究のギャップを明らかにし、今後の展望を示す。学術界と産業界のより体系的な探求を促進することを目指す。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #RecommenderSystems #Dataset #LanguageModel #SessionBased #Personalization #Evaluation Issue Date: 2024-12-31 Preference Discerning with LLM-Enhanced Generative Retrieval, Fabian Paischer+, arXiv'24 Summary逐次推薦システムのパーソナライズを向上させるために、「好みの識別」という新しいパラダイムを提案。大規模言語モデルを用いてユーザーの好みを生成し、包括的な評価ベンチマークを導入。新手法Menderは、既存手法を改善し、最先端の性能を達成。Menderは未観察の人間の好みにも効果的に対応し、よりパーソナライズされた推薦を実現する。コードとベンチマークはオープンソース化予定。 #RecommenderSystems #LanguageModel #SessionBased Issue Date: 2024-12-31 Unifying Generative and Dense Retrieval for Sequential Recommendation, Liu Yang+, arXiv'24 Summary逐次密な検索モデルはユーザーとアイテムの内積計算を行うが、アイテム数の増加に伴いメモリ要件が増大する。一方、生成的検索はセマンティックIDを用いてアイテムインデックスを予測する新しいアプローチである。これら二つの手法の比較が不足しているため、LIGERというハイブリッドモデルを提案し、生成的検索と逐次密な検索の強みを統合。これにより、コールドスタートアイテム推薦を強化し、推薦システムの効率性と効果を向上させることを示した。 #NLP #LanguageModel #Reasoning Issue Date: 2024-12-31 Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search, Huanjin Yao+, arXiv'24 Summary本研究では、MLLMを用いて質問解決のための推論ステップを学習する新手法CoMCTSを提案。集団学習を活用し、複数モデルの知識で効果的な推論経路を探索。マルチモーダルデータセットMulberry-260kを構築し、モデルMulberryを訓練。実験により提案手法の優位性を確認。 #NLP #LanguageModel #Education #EducationalDataMining Issue Date: 2024-12-31 LearnLM: Improving Gemini for Learning, LearnLM Team+, arXiv'24 Summary生成AIシステムは従来の情報提示に偏っているため、教育的行動を注入する「教育的指示の遵守」を提案。これにより、モデルの振る舞いを柔軟に指定でき、教育データを追加することでGeminiモデルの学習を向上。LearnLMモデルは、さまざまな学習シナリオで専門家から高く評価され、GPT-4oやClaude 3.5に対しても優れた性能を示した。 #NLP #LanguageModel #TheoryOfMind #read-later Issue Date: 2024-12-31 Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning, Melanie Sclar+, arXiv'24 SummaryExploreToMは、心の理論を評価するための多様で挑戦的なデータを生成するフレームワークであり、LLMsの限界をテストする。最先端のLLMsは、ExploreToM生成データに対して低い精度を示し、堅牢な評価の必要性を強調。ファインチューニングにより従来のベンチマークで精度向上を実現し、モデルの低パフォーマンスの要因を明らかにする。 Commentおもしろそう。あとで読む #Survey #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2024-12-31 A Survey on LLM Inference-Time Self-Improvement, Xiangjue Dong+, arXiv'24 SummaryLLM推論における自己改善技術を三つの視点から検討。独立した自己改善はデコーディングやサンプリングに焦点、文脈に応じた自己改善は追加データを活用、モデル支援の自己改善はモデル間の協力を通じて行う。関連研究のレビューと課題、今後の研究への洞察を提供。 #Survey #InformationRetrieval #LanguageModel Issue Date: 2024-12-30 From Matching to Generation: A Survey on Generative Information Retrieval, Xiaoxi Li+, arXiv'24 Summary情報検索(IR)システムは、検索エンジンや質問応答などで重要な役割を果たしている。従来のIR手法は類似性マッチングに基づいていたが、事前学習された言語モデルの進展により生成情報検索(GenIR)が注目されている。GenIRは生成文書検索(GR)と信頼性のある応答生成に分かれ、GRは生成モデルを用いて文書を直接生成し、応答生成はユーザーの要求に柔軟に応える。本論文はGenIRの最新研究をレビューし、モデルのトレーニングや応答生成の進展、評価や課題についても考察する。これにより、GenIR分野の研究者に有益な参考資料を提供し、さらなる発展を促すことを目指す。 #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-30 RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation, Xiaoxi Li+, arXiv'24 SummaryRetroLLMは、リトリーバルと生成を統合したフレームワークで、LLMsがコーパスから直接証拠を生成することを可能にします。階層的FM-インデックス制約を導入し、関連文書を特定することで無関係なデコーディング空間を削減し、前向きな制約デコーディング戦略で証拠の精度を向上させます。広範な実験により、ドメイン内外のタスクで優れた性能を示しました。 Comment元ポスト:https://x.com/rohanpaul_ai/status/1872714703090401721?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来のRAGとの違いと、提案手法の概要

 #Survey
#NLP
#LanguageModel
#Evaluation
#LLM-as-a-Judge
Issue Date: 2024-12-25
A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
SummaryLLMを評価者として利用する「LLM-as-a-Judge」の信頼性向上に関する調査。信頼性を確保するための戦略や評価方法論を提案し、新しいベンチマークを用いてサポート。実用的な応用や将来の方向性についても議論し、研究者や実務者の参考資料となることを目指す。
#InformationRetrieval
Issue Date: 2024-12-17
Semantic Retrieval at Walmart, Alessandro Magnani+, arXiv'24
Summaryテールクエリに対する商品検索の重要性を踏まえ、Walmart向けに従来の逆インデックスと埋め込みベースのニューラル検索を組み合わせたハイブリッドシステムを提案。オフラインおよびオンライン評価で検索エンジンの関連性を大幅に向上させ、応答時間に影響を与えずに本番環境に展開。システム展開における学びや実用的なトリックも紹介。
#NLP
#LanguageModel
#Evaluation
Issue Date: 2024-12-15
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards, Norah Alzahrani+, ACL'24
SummaryLLMのリーダーボードは、ベンチマークランキングに基づいてモデル選択を支援するが、ランキングは微細な変更に敏感であり、最大8位変動することがある。3つのベンチマーク摂動のカテゴリにわたる実験を通じて、この現象の原因を特定し、ハイブリッドスコアリング方法の利点を含むベストプラクティスを提案。単純な評価に依存する危険性を強調し、より堅牢な評価スキームの必要性を示した。
Comment・1591
#Survey
#NLP
#LanguageModel
#Evaluation
#LLM-as-a-Judge
Issue Date: 2024-12-25
A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
SummaryLLMを評価者として利用する「LLM-as-a-Judge」の信頼性向上に関する調査。信頼性を確保するための戦略や評価方法論を提案し、新しいベンチマークを用いてサポート。実用的な応用や将来の方向性についても議論し、研究者や実務者の参考資料となることを目指す。
#InformationRetrieval
Issue Date: 2024-12-17
Semantic Retrieval at Walmart, Alessandro Magnani+, arXiv'24
Summaryテールクエリに対する商品検索の重要性を踏まえ、Walmart向けに従来の逆インデックスと埋め込みベースのニューラル検索を組み合わせたハイブリッドシステムを提案。オフラインおよびオンライン評価で検索エンジンの関連性を大幅に向上させ、応答時間に影響を与えずに本番環境に展開。システム展開における学びや実用的なトリックも紹介。
#NLP
#LanguageModel
#Evaluation
Issue Date: 2024-12-15
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards, Norah Alzahrani+, ACL'24
SummaryLLMのリーダーボードは、ベンチマークランキングに基づいてモデル選択を支援するが、ランキングは微細な変更に敏感であり、最大8位変動することがある。3つのベンチマーク摂動のカテゴリにわたる実験を通じて、この現象の原因を特定し、ハイブリッドスコアリング方法の利点を含むベストプラクティスを提案。単純な評価に依存する危険性を強調し、より堅牢な評価スキームの必要性を示した。
Comment・1591
に日本語でのサマリが記載されているので参照のこと。
リーダーボードのバイアスを軽減した結果、どのLLMが最大パフォーマンスとみなされるようになったのだろうか? #NLP #LanguageModel #Evaluation #LLM-as-a-Judge Issue Date: 2024-12-15 BatchEval: Towards Human-like Text Evaluation, Peiwen Yuan+, ACL'24 SummaryBatchEvalという新しい評価パラダイムを提案し、LLMを用いた自動テキスト評価の問題を解決。バッチ単位での反復評価により、プロンプト設計の敏感さやノイズ耐性の低さを軽減。実験により、BatchEvalは最先端手法に対して10.5%の改善を示し、APIコストを64%削減。 Comment・1591
に日本語によるサマリが掲載されているので参照のこと。 #Analysis #NLP #LanguageModel #In-ContextLearning Issue Date: 2024-12-15 The broader spectrum of in-context learning, Andrew Kyle Lampinen+, arXiv'24 Summary本研究では、言語モデルの少数ショット学習をメタ学習に基づく文脈内学習の一部として位置づけ、文脈が予測の損失を減少させるメカニズムを提案します。この視点は、言語モデルの文脈内能力を統一し、一般化の重要性を強調します。一般化は新しい学習だけでなく、異なる提示からの学びや適用能力にも関連し、過去の文献との関連性も議論されます。文脈内学習の研究は、広範な能力と一般化のタイプを考慮すべきと結論付けています。 CommentOpenReview:https://openreview.net/forum?id=RHo3VVi0i5
OpenReviewによると、
論文は理解しやすく、meta learningについて広範にサーベイされている。しかし、論文が定義しているICLの拡張はICLを過度に一般化し過ぎており(具体的に何がICLで何がICLでないのか、といった規定ができない)、かつ論文中で提案されているコンセプトを裏付ける実験がなくspeculativeである、とのことでrejectされている。 #NLP #LanguageModel #OpenWeight Issue Date: 2024-12-15 Phi-4 Technical Report, Marah Abdin+, arXiv'24 Summary140億パラメータの言語モデル「phi-4」は、合成データを取り入れたトレーニングにより、STEMに特化したQA能力で教師モデルを大幅に上回る性能を示す。phi-3のアーキテクチャを最小限に変更しただけで、推論ベンチマークにおいても改善されたデータとトレーニング手法により強力なパフォーマンスを達成。 Comment現状Azureでのみ利用可能かも。Huggingfaceにアップロードされても非商用ライセンスになるという噂もMITライセンス
HuggingFace:
https://huggingface.co/microsoft/phi-4 #NLP #LanguageModel #Chain-of-Thought #PostTraining #LatentReasoning Issue Date: 2024-12-12 Training Large Language Models to Reason in a Continuous Latent Space, Shibo Hao+, arXiv'24 Summary新しい推論パラダイム「Coconut」を提案し、LLMの隠れ状態を連続的思考として利用。これにより、次の入力を連続空間でフィードバックし、複数の推論タスクでLLMを強化。Coconutは幅優先探索を可能にし、特定の論理推論タスクでCoTを上回る性能を示す。潜在的推論の可能性を探る重要な洞察を提供。 CommentChain of Continuous Thought...?通常のCoTはRationaleをトークン列で生成するが、Coconutは最終的なhidden state(まだ読んでないのでこれが具体的に何を指すか不明)をそのまま入力に追加することで、トークンに制限されずにCoTさせるということらしい。あとでしっかり読む
 まだ読んでいないが、おそらく学習の際に工夫が必要なので既存モデルをこねくり回してできます系の話ではないかもOpenReview:https://openreview.net/forum?id=tG4SgayTtk
まだ読んでいないが、おそらく学習の際に工夫が必要なので既存モデルをこねくり回してできます系の話ではないかもOpenReview:https://openreview.net/forum?id=tG4SgayTtk
ICLR'25にrejectされている。
ざっと最初のレビューに書かれているWeaknessを読んだ感じ
・評価データが合成データしかなく、よりrealisticなデータで評価した方が良い
・CoTら非常に一般的に適用可能な技術なので、もっと広範なデータで評価すべき
・GSM8Kでは大幅にCOCONUTはCoTに性能が負けていて、ProsQAでのみにしかCoTに勝てていない
・特定のデータセットでの追加の学習が必要で、そこで身につけたreasoning能力が汎化可能か明らかでない
といった感じに見える #ComputerVision #Pretraining #Transformer #NeurIPS Issue Date: 2024-12-12 Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction, Keyu Tian+, NeurIPS'24 SummaryVisual AutoRegressive modeling (VAR)を提案し、画像生成において自己回帰学習を次のスケール予測として再定義。VARは、GPTのようなARモデルが拡散トランスフォーマーを上回ることを実現し、ImageNet 256x256ベンチマークでFIDを18.65から1.73、ISを80.4から350.2に改善。推論速度は約20倍向上し、画像品質やデータ効率でも優れた性能を示す。VARはゼロショット一般化能力を持ち、スケーリング法則を示す。全モデルとコードを公開し、視覚生成の研究を促進。 CommentNeurIPS2024のベストペーパー第一著者がByteDance社から訴訟を起こされている模様…?
https://var-integrity-report.github.ioOpenReview:https://openreview.net/forum?id=gojL67CfS8Next Token Prediction, Next Image Token Generation (従来手法), Next Scale (resolution) prediction (提案手法)の違いの図解。非常に分かりやすい。next token predictionでは次トークンのみを予測するがVARでは、次の解像度画像の全体のトークンマップを予測する。

学習方法の概要。2-Stageで学習される。最初のステージでK種類の解像度の画像(=K種類のマルチスケールのtoken maps r_k)を得るためにAutoEncoderを学習し、次のステージでblock-wiseのcausal attention maskを用いて、K_<k個目の解像度の画像からK個目の解像度の画像を予測する(図を見るとイメージを掴みやすい)。inference時はKV Cacheを利用し、maskは不要となる。
各r_kをデコードする際にr_<kのみに依存する設計にすることでcoase-to-fineに画像を生成することに相当し、これは人間の粗く捉えてから詳細を見る認知プロセスと合致する。また、flatten操作が存在せず、それぞれのr_<k内のトークンがr_k生成時に全て考慮されるため空間的局所性も担保される。また、r_k内のトークンは並列に生成可能なので計算量のオーダーが大幅に削減される(O(n^4)。

従来手法と比べより小さいパラメータで高い性能を実現し、inference timeも非常に早い。

ScalingLawsも成立する。
 Issue Date: 2024-12-10
Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models, Sanjay Vishwakarma+, arXiv'24
Summary本研究では、Qiskit HumanEvalデータセットを用いて、生成的人工知能(GenAI)による量子コード生成の能力を評価します。このデータセットは100以上の量子コンピューティングタスクから成り、各タスクにはプロンプト、解決策、テストケース、難易度スケールが含まれています。LLMsの性能を体系的に評価し、量子コード生成の実現可能性を示すとともに、新たなベンチマークを確立し、GenAI駆動ツールの開発を促進します。
#Tutorial
#MachineLearning
#ReinforcementLearning
Issue Date: 2024-12-10
Reinforcement Learning: An Overview, Kevin Murphy, arXiv'24
Summaryこの原稿は、深層強化学習と逐次的意思決定に関する最新の全体像を提供し、価値ベースのRL、ポリシー勾配法、モデルベース手法、RLとLLMsの統合について簡潔に議論しています。
CommentあのMurphy本で有名なMurphy氏の強化学習の教科書…だと…
Issue Date: 2024-12-10
RARE: Retrieval-Augmented Reasoning Enhancement for Large Language Models, Hieu Tran+, arXiv'24
SummaryRARE(Retrieval-Augmented Reasoning Enhancement)は、LLMsの推論精度と事実の整合性を向上させるための相互推論フレームワークの拡張。モンテカルロ木探索内に情報取得のための2つのアクションを組み込み、事実性を重視したスコアラーを提案。実験により、RAREはオープンソースのLLMがトップモデルと競争できる性能を示し、論理的一貫性と事実の整合性が求められるタスクにおけるスケーラブルなソリューションとして位置づけられる。
Comment元ポスト:https://x.com/omarsar0/status/1864687176929431566?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Multi
#InformationRetrieval
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#RAG(RetrievalAugmentedGeneration)
Issue Date: 2024-12-10
Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models, Tian Yu+, arXiv'24
SummaryAuto-RAGは、LLMの意思決定能力を活用した自律的な反復検索モデルで、リトリーバーとのマルチターン対話を通じて知識を取得します。推論に基づく意思決定を自律的に合成し、6つのベンチマークで優れた性能を示し、反復回数を質問の難易度に応じて調整可能です。また、プロセスを自然言語で表現し、解釈可能性とユーザー体験を向上させます。
Comment元ポスト:https://x.com/omarsar0/status/1863600141103501454?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=jkVQ31GeIAOpenReview:https://openreview.net/forum?id=jkVQ31GeIA
#NLP
#LanguageModel
#Hallucination
Issue Date: 2024-12-09
LLMs Will Always Hallucinate, and We Need to Live With This, Sourav Banerjee+, arXiv'24
Summary大規模言語モデル(LLM)の幻覚は偶発的なエラーではなく、これらのモデルの基本的な構造から生じる避けられない特徴であると主張。アーキテクチャやデータセットの改善では幻覚を排除できないことを示し、各プロセス段階で幻覚が生成される確率が存在することを分析。新たに「構造的幻覚」という概念を導入し、幻覚の数学的確実性を確立することで、完全な軽減は不可能であると論じる。
#Analysis
#NLP
#LanguageModel
#Quantization
Issue Date: 2024-12-02
The Super Weight in Large Language Models, Mengxia Yu+, arXiv'24
SummaryLLMのパラメータの一部がモデルの品質に不均衡に重要であり、1つのパラメータの剪定でテキスト生成能力が大幅に低下することを発見。データフリーの方法で重要なスーパーパラメータを特定し、これにより四捨五入量子化の精度を向上させることができる。スーパーパラメータに関する研究を促進するために、オープンアクセスのLLMに対するインデックスを提供。
Comment図にある通り、たった一つのニューラルネットワーク中の重みを0にするだけで、途端に意味のあるテキストが生成できなくなるような重みが存在するらしい。
Issue Date: 2024-12-10
Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models, Sanjay Vishwakarma+, arXiv'24
Summary本研究では、Qiskit HumanEvalデータセットを用いて、生成的人工知能(GenAI)による量子コード生成の能力を評価します。このデータセットは100以上の量子コンピューティングタスクから成り、各タスクにはプロンプト、解決策、テストケース、難易度スケールが含まれています。LLMsの性能を体系的に評価し、量子コード生成の実現可能性を示すとともに、新たなベンチマークを確立し、GenAI駆動ツールの開発を促進します。
#Tutorial
#MachineLearning
#ReinforcementLearning
Issue Date: 2024-12-10
Reinforcement Learning: An Overview, Kevin Murphy, arXiv'24
Summaryこの原稿は、深層強化学習と逐次的意思決定に関する最新の全体像を提供し、価値ベースのRL、ポリシー勾配法、モデルベース手法、RLとLLMsの統合について簡潔に議論しています。
CommentあのMurphy本で有名なMurphy氏の強化学習の教科書…だと…
Issue Date: 2024-12-10
RARE: Retrieval-Augmented Reasoning Enhancement for Large Language Models, Hieu Tran+, arXiv'24
SummaryRARE(Retrieval-Augmented Reasoning Enhancement)は、LLMsの推論精度と事実の整合性を向上させるための相互推論フレームワークの拡張。モンテカルロ木探索内に情報取得のための2つのアクションを組み込み、事実性を重視したスコアラーを提案。実験により、RAREはオープンソースのLLMがトップモデルと競争できる性能を示し、論理的一貫性と事実の整合性が求められるタスクにおけるスケーラブルなソリューションとして位置づけられる。
Comment元ポスト:https://x.com/omarsar0/status/1864687176929431566?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Multi
#InformationRetrieval
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#RAG(RetrievalAugmentedGeneration)
Issue Date: 2024-12-10
Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models, Tian Yu+, arXiv'24
SummaryAuto-RAGは、LLMの意思決定能力を活用した自律的な反復検索モデルで、リトリーバーとのマルチターン対話を通じて知識を取得します。推論に基づく意思決定を自律的に合成し、6つのベンチマークで優れた性能を示し、反復回数を質問の難易度に応じて調整可能です。また、プロセスを自然言語で表現し、解釈可能性とユーザー体験を向上させます。
Comment元ポスト:https://x.com/omarsar0/status/1863600141103501454?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=jkVQ31GeIAOpenReview:https://openreview.net/forum?id=jkVQ31GeIA
#NLP
#LanguageModel
#Hallucination
Issue Date: 2024-12-09
LLMs Will Always Hallucinate, and We Need to Live With This, Sourav Banerjee+, arXiv'24
Summary大規模言語モデル(LLM)の幻覚は偶発的なエラーではなく、これらのモデルの基本的な構造から生じる避けられない特徴であると主張。アーキテクチャやデータセットの改善では幻覚を排除できないことを示し、各プロセス段階で幻覚が生成される確率が存在することを分析。新たに「構造的幻覚」という概念を導入し、幻覚の数学的確実性を確立することで、完全な軽減は不可能であると論じる。
#Analysis
#NLP
#LanguageModel
#Quantization
Issue Date: 2024-12-02
The Super Weight in Large Language Models, Mengxia Yu+, arXiv'24
SummaryLLMのパラメータの一部がモデルの品質に不均衡に重要であり、1つのパラメータの剪定でテキスト生成能力が大幅に低下することを発見。データフリーの方法で重要なスーパーパラメータを特定し、これにより四捨五入量子化の精度を向上させることができる。スーパーパラメータに関する研究を促進するために、オープンアクセスのLLMに対するインデックスを提供。
Comment図にある通り、たった一つのニューラルネットワーク中の重みを0にするだけで、途端に意味のあるテキストが生成できなくなるような重みが存在するらしい。

(図は論文より引用)ICLR 2025のOpenreview
https://openreview.net/forum?id=0Ag8FQ5Rr3 Issue Date: 2024-12-02 Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, arXiv'24 Summary大規模言語モデル(LLMs)のマルチホップクエリに対する事実の想起能力を評価。ショートカットを防ぐため、主語と答えが共に出現するテストクエリを除外した評価データセットSOCRATESを構築。LLMsは特定のクエリにおいてショートカットを利用せずに潜在的な推論能力を示し、国を中間答えとするクエリでは80%の構成可能性を達成する一方、年の想起は5%に低下。潜在的推論能力と明示的推論能力の間に大きなギャップが存在することが明らかに。 #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models, Fei Wang+, arXiv'24 SummaryAstute RAGは、外部知識の不完全な取得による問題を解決する新しいアプローチで、LLMsの内部知識と外部知識を適応的に統合し、情報の信頼性に基づいて回答を決定します。実験により、Astute RAGは従来のRAG手法を大幅に上回り、最悪のシナリオでもLLMsのパフォーマンスを超えることが示されました。 #Survey #NLP #LanguageModel #LLM-as-a-Judge Issue Date: 2024-11-27 From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, Dawei Li+, arXiv'24 SummaryLLMを用いた判断と評価の新たなパラダイム「LLM-as-a-judge」に関する包括的な調査を行い、定義や分類法を提示。評価のためのベンチマークをまとめ、主要な課題と今後の研究方向を示す。関連リソースも提供。 CommentLLM-as-a-Judgeに関するサーベイ

 ・1214
・1214
も参照のこと #Analysis #NLP #LanguageModel #Prompting Issue Date: 2024-11-27 Does Prompt Formatting Have Any Impact on LLM Performance?, Jia He+, arXiv'24 Summaryプロンプト最適化はLLMの性能に重要であり、異なるプロンプトテンプレートがモデルの性能に与える影響を調査。実験では、GPT-3.5-turboがプロンプトテンプレートによってコード翻訳タスクで最大40%変動する一方、GPT-4はより堅牢であることが示された。これにより、固定プロンプトテンプレートの再考が必要であることが強調された。 Comment(以下、個人の感想です)
本文のみ斜め読みして、Appendixは眺めただけなので的外れなことを言っていたらすみません。
まず、実務上下記知見は有用だと思いました:
・プロンプトのフォーマットによって性能に大きな差がある
・より大きいモデルの方がプロンプトフォーマットに対してロバスト
ただし、フォーマットによって性能差があるというのは経験的にある程度LLMを触っている人なら分かることだと思うので、驚きは少なかった。
個人的に気になる点は、学習データもモデルのアーキテクチャもパラメータ数も分からないGPT3.5, GPT4のみで実験をして「パラメータサイズが大きい方がロバスト」と結論づけている点と、もう少し深掘りして考察したらもっとおもしろいのにな、と感じる点です。
実務上は有益な知見だとして、では研究として見たときに「なぜそうなるのか?」というところを追求して欲しいなぁ、という感想を持ちました。
たとえば、「パラメータサイズが大きいモデルの方がフォーマットにロバスト」と論文中に書かれているように見えますが、
それは本当にパラメータサイズによるものなのか?学習データに含まれる各フォーマットの割合とか(これは事実はOpenAIの中の人しか分からないので、学習データの情報がある程度オープンになっているOpenLLMでも検証するとか)、評価するタスクとフォーマットの相性とか、色々と考察できる要素があるのではないかと思いました。
その上で、大部分のLLMで普遍的な知見を見出した方が研究としてより面白くなるのではないか、と感じました。

 参考: Data2Textにおける数値データのinput formatによる性能差を分析し考察している研究
参考: Data2Textにおける数値データのinput formatによる性能差を分析し考察している研究
・1267 #NLP #LLMAgent Issue Date: 2024-11-27 Generative Agent Simulations of 1,000 People, Joon Sung Park+, arXiv'24 Summary新しいエージェントアーキテクチャを提案し、1,052人の実在の個人の態度と行動を85%の精度で再現。大規模言語モデルを用いた質的インタビューに基づき、参加者の回答を正確にシミュレート。人口統計的説明を用いたエージェントと比較して、精度バイアスを軽減。個人および集団の行動調査の新しいツールを提供。 Issue Date: 2024-11-25 Understanding LLM Embeddings for Regression, Eric Tang+, arXiv'24 SummaryLLM埋め込みを用いた回帰分析の調査を行い、従来の特徴エンジニアリングよりも高次元回帰タスクで優れた性能を示す。LLM埋め込みは数値データに対してリプシッツ連続性を保持し、モデルサイズや言語理解の影響を定量化した結果、必ずしも回帰性能を向上させないことが明らかになった。 Issue Date: 2024-11-25 A Reproducibility and Generalizability Study of Large Language Models for Query Generation, Moritz Staudinger+, arXiv'24 Summary系統的文献レビューのために、LLMを用いたブールクエリ生成の研究を行い、ChatGPTとオープンソースモデルの性能を比較。自動生成したクエリを用いてPubMedから文書を取得し、再現性と信頼性を評価。LLMの限界や改善点を分析し、情報検索タスクにおけるLLMの適用可能性を探る。研究は文献レビューの自動化におけるLLMの強みと限界を明らかにする。 #ComputerVision #Pretraining #NLP #LanguageModel #MulltiModal Issue Date: 2024-11-25 Multimodal Autoregressive Pre-training of Large Vision Encoders, Enrico Fini+, arXiv'24 Summary新しい手法AIMV2を用いて、大規模なビジョンエンコーダの事前学習を行う。これは画像とテキストを組み合わせたマルチモーダル設定に拡張され、シンプルな事前学習プロセスと優れた性能を特徴とする。AIMV2-3BエンコーダはImageNet-1kで89.5%の精度を達成し、マルチモーダル画像理解において最先端のコントラストモデルを上回る。 #Analysis #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2024-11-22 Observational Scaling Laws and the Predictability of Language Model Performance, Yangjun Ruan+, arXiv'24 Summary言語モデルの性能を理解するために、約100の公開モデルからスケーリング法則を構築する新しい観察アプローチを提案。モデルファミリー間の能力変動を考慮し、性能が低次元の能力空間の関数であることを示す。これにより、複雑なスケーリング現象の予測可能性を示し、GPT-4のエージェント性能を非エージェント的ベンチマークから予測できることを明らかにし、Chain-of-ThoughtやSelf-Consistencyの影響を予測する方法を示す。 Comment縦軸がdownstreamタスクの主成分(のうち最も大きい80%を説明する成分)の変化(≒LLMの性能)で、横軸がlog scaleの投入計算量。
Qwenも頑張っているが、投入データ量に対する性能(≒データの品質)では、先駆け的な研究であるPhiがやはり圧倒的?
 ・766
・766
も参照のこと #LanguageModel #Personalization Issue Date: 2024-11-21 On the Way to LLM Personalization: Learning to Remember User Conversations, Lucie Charlotte Magister+, arXiv'24 SummaryLLMのパーソナライズを過去の会話の知識を注入することで実現するため、PLUMというデータ拡張パイプラインを提案。会話の時間的連続性とパラメータ効率を考慮し、ファインチューニングを行う。初めての試みでありながら、RAGなどのベースラインと競争力を持ち、81.5%の精度を達成。 #Chip Issue Date: 2024-11-21 That Chip Has Sailed: A Critique of Unfounded Skepticism Around AI for Chip Design, Anna Goldie+, arXiv'24 SummaryAlphaChipは深層強化学習を用いて超人的なチップレイアウトを生成する手法で、AIチップ設計の進展を促進した。しかし、ISPD 2023での非査読論文が性能に疑問を呈し、実行方法に問題があった。著者は、事前トレーニングや計算リソースの不足、評価基準の不適切さを指摘。Igor Markovによるメタ分析も行われた。AlphaChipは広範な影響を持つが、誤解を避けるためにこの応答を発表した。 Commentoh... #Analysis #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-11-19 Likelihood as a Performance Gauge for Retrieval-Augmented Generation, Tianyu Liu+, arXiv'24 Summary大規模言語モデルを用いた情報検索強化生成は、文脈内の文書の順序に影響を受けやすい。研究では、質問の確率がモデルのパフォーマンスに与える影響を分析し、正確性との相関関係を明らかにした。質問の確率を指標として、プロンプトの選択と構築に関する2つの方法を提案し、その効果を実証。確率に基づく手法は効率的で、少ないモデルのパスで応答を生成できるため、プロンプト最適化の新たな方向性を示す。 Commentトークンレベルの平均値をとった生成テキストの対数尤度と、RAGの回答性能に関する分析をした模様。

とりあえず、もし「LLMとしてGPTを(OpenAIのAPIを用いて)使いました!temperatureは0です!」みたいな実験設定だったら諸々怪しくなる気がしたのでそこが大丈夫なことを確認した(OpenLLM、かつdeterministicなデコーディング方法が望ましい)。おもしろそう。
 参考: [RAGのハルシネーションを尤度で防ぐ, sasakuna, 2024.11.19](https://zenn.dev/knowledgesense/articles/7c47e1796e96c0)参考
参考: [RAGのハルシネーションを尤度で防ぐ, sasakuna, 2024.11.19](https://zenn.dev/knowledgesense/articles/7c47e1796e96c0)参考
生成されたテキストの尤度を用いて、どの程度正解らしいかを判断する、といった話は
・1223
のようなLLM-as-a-Judgeでも行われている。
G-Evalでは1--5のスコアのような離散的な値を生成する際に、これらを連続的なスコアに補正するために、尤度(トークンの生成確率)を用いている。
ただし、G-Evalの場合は実験でGPTを用いているため、モデルから直接尤度を取得できず、代わりにtemperature1とし、20回程度生成を行った結果からスコアトークンの生成確率を擬似的に計算している。
G-Evalの設定と比較すると(当時はつよつよなOpenLLMがなかったため苦肉の策だったと思われるが)、こちらの研究の実験設定の方が望ましいと思う。 #Survey #NLP #LanguageModel #MultiLingual Issue Date: 2024-11-19 Multilingual Large Language Models: A Systematic Survey, Shaolin Zhu+, arXiv'24 Summary本論文は、多言語大規模言語モデル(MLLMs)の最新研究を調査し、アーキテクチャや事前学習の目的、多言語能力の要素を論じる。データの質と多様性が性能向上に重要であることを強調し、MLLMの評価方法やクロスリンガル知識、安全性、解釈可能性について詳細な分類法を提示。さらに、MLLMの実世界での応用を多様な分野でレビューし、課題と機会を強調する。関連論文は指定のリンクで公開されている。 Comment
 #Tutorial
#ComputerVision
#DiffusionModel
Issue Date: 2024-11-17
Tutorial on Diffusion Models for Imaging and Vision, Stanley H. Chan, arXiv'24
Summary生成ツールの成長により、テキストから画像や動画を生成する新しいアプリケーションが可能に。拡散モデルの原理がこれらの生成ツールの基盤であり、従来のアプローチの欠点を克服。チュートリアルでは、拡散モデルの基本的なアイデアを学部生や大学院生向けに解説。
Commentいつか読まなければならない
Issue Date: 2024-11-17
BabyLM Challenge: Exploring the Effect of Variation Sets on Language Model Training Efficiency, Akari Haga+, arXiv'24
Summary大規模言語モデルのデータ効率向上に向けて、子供向けの言語(CDS)のVariation Sets(VSs)に注目。VSsは類似の意図を異なる言葉や構造で表現する発話のセットで、CDSに多く見られる。VSsを含むデータセットでGPT-2をトレーニングした結果、最適なVSsの割合は評価ベンチマークによって異なり、BLiMPおよびGLUEスコアは向上する一方、EWOKスコアには影響しないことが分かった。これらの結果は、エポック数や発話の提示順序にも依存し、VSsが言語モデルに有益である可能性を示唆しつつ、さらなる研究が必要であることを示している。
Comment元ポスト:https://x.com/rodamille/status/1858195569526665230?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#EfficiencyImprovement
#Pretraining
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Japanese
#read-later
Issue Date: 2024-11-17
Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs, Kazuki Fujii+, arXiv'24
Summary大規模言語モデル(LLMs)は、その言語理解能力と適用可能性から注目を集めており、特にLlama 3シリーズは4050億パラメータを持つ。トレーニングの効率化が求められる中、NVIDIAのH100 GPUはFP8フォーマットを導入し、トレーニング時間を短縮する可能性がある。初期研究ではFP8が性能を損なわずに効率を向上させることが示唆されているが、トレーニングの安定性や下流タスクへの影響はまだ不明である。本研究は、LLMsのトレーニングにおけるBF16とFP8のトレードオフを探る。
Comment元ポスト:https://x.com/okoge_kaz/status/1857639065421754525?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFP8で継続的事前学習をするとスループットは向上するが、lossのスパイクを生じたり、downstreamタスクの性能がBF16よりも低下したりする(日本語と英語の両方)との報告のようである。現状アブストと付録しか記載がないが、内容はこれから更新されるのだろうか。
#Tutorial
#ComputerVision
#DiffusionModel
Issue Date: 2024-11-17
Tutorial on Diffusion Models for Imaging and Vision, Stanley H. Chan, arXiv'24
Summary生成ツールの成長により、テキストから画像や動画を生成する新しいアプリケーションが可能に。拡散モデルの原理がこれらの生成ツールの基盤であり、従来のアプローチの欠点を克服。チュートリアルでは、拡散モデルの基本的なアイデアを学部生や大学院生向けに解説。
Commentいつか読まなければならない
Issue Date: 2024-11-17
BabyLM Challenge: Exploring the Effect of Variation Sets on Language Model Training Efficiency, Akari Haga+, arXiv'24
Summary大規模言語モデルのデータ効率向上に向けて、子供向けの言語(CDS)のVariation Sets(VSs)に注目。VSsは類似の意図を異なる言葉や構造で表現する発話のセットで、CDSに多く見られる。VSsを含むデータセットでGPT-2をトレーニングした結果、最適なVSsの割合は評価ベンチマークによって異なり、BLiMPおよびGLUEスコアは向上する一方、EWOKスコアには影響しないことが分かった。これらの結果は、エポック数や発話の提示順序にも依存し、VSsが言語モデルに有益である可能性を示唆しつつ、さらなる研究が必要であることを示している。
Comment元ポスト:https://x.com/rodamille/status/1858195569526665230?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Analysis
#EfficiencyImprovement
#Pretraining
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Japanese
#read-later
Issue Date: 2024-11-17
Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs, Kazuki Fujii+, arXiv'24
Summary大規模言語モデル(LLMs)は、その言語理解能力と適用可能性から注目を集めており、特にLlama 3シリーズは4050億パラメータを持つ。トレーニングの効率化が求められる中、NVIDIAのH100 GPUはFP8フォーマットを導入し、トレーニング時間を短縮する可能性がある。初期研究ではFP8が性能を損なわずに効率を向上させることが示唆されているが、トレーニングの安定性や下流タスクへの影響はまだ不明である。本研究は、LLMsのトレーニングにおけるBF16とFP8のトレードオフを探る。
Comment元ポスト:https://x.com/okoge_kaz/status/1857639065421754525?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFP8で継続的事前学習をするとスループットは向上するが、lossのスパイクを生じたり、downstreamタスクの性能がBF16よりも低下したりする(日本語と英語の両方)との報告のようである。現状アブストと付録しか記載がないが、内容はこれから更新されるのだろうか。
 #Analysis
#NLP
#LanguageModel
Issue Date: 2024-11-17
The Geometry of Concepts: Sparse Autoencoder Feature Structure, Yuxiao Li+, arXiv'24
Summaryスパースオートエンコーダは、高次元ベクトルの辞書を生成し、概念の宇宙に三つの興味深い構造を発見した。1) 小規模構造では、平行四辺形や台形の「結晶」があり、単語の長さなどの干渉を除去することで質が改善される。2) 中規模構造では、数学とコードの特徴が「葉」を形成し、空間的局所性が定量化され、特徴が予想以上に集まることが示された。3) 大規模構造では、特徴点雲が各向同性でなく、固有値のべき法則を持ち、クラスタリングエントロピーが層に依存することが定量化された。
Comment参考: https://ledge.ai/articles/llm_conceptual_structure_sae[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-kR626A9_R8.6CU7IKvGyhQ)
Issue Date: 2024-11-15
Adaptive Decoding via Latent Preference Optimization, Shehzaad Dhuliawala+, arXiv'24
SummaryAdaptive Decodingを導入し、推論時にトークンや例ごとに動的にサンプリング温度を選択することで、言語モデルのパフォーマンスを最適化。Latent Preference Optimization(LPO)を用いて温度選択を学習し、UltraFeedbackやCreative Story Writing、GSM8Kなどのタスクで固定温度を超える性能を達成。
#InformationRetrieval
#RelevanceJudgment
#LanguageModel
#Evaluation
Issue Date: 2024-11-14
A Large-Scale Study of Relevance Assessments with Large Language Models: An Initial Look, Shivani Upadhyay+, arXiv'24
Summary本研究では、TREC 2024 RAG Trackにおける大規模言語モデル(LLM)を用いた関連性評価の結果を報告。UMBRELAツールを活用した自動生成評価と従来の手動評価の相関を分析し、77の実行セットにおいて高い相関を示した。LLMの支援は手動評価との相関を高めず、人間評価者の方が厳格であることが示唆された。この研究は、TRECスタイルの評価におけるLLMの使用を検証し、今後の研究の基盤を提供する。
Comment元ポスト:https://x.com/lintool/status/1856876816197165188?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-ntenei-r-h3qlECirT3G9O2BGk765_g)
#Analysis
#NLP
#LanguageModel
Issue Date: 2024-11-17
The Geometry of Concepts: Sparse Autoencoder Feature Structure, Yuxiao Li+, arXiv'24
Summaryスパースオートエンコーダは、高次元ベクトルの辞書を生成し、概念の宇宙に三つの興味深い構造を発見した。1) 小規模構造では、平行四辺形や台形の「結晶」があり、単語の長さなどの干渉を除去することで質が改善される。2) 中規模構造では、数学とコードの特徴が「葉」を形成し、空間的局所性が定量化され、特徴が予想以上に集まることが示された。3) 大規模構造では、特徴点雲が各向同性でなく、固有値のべき法則を持ち、クラスタリングエントロピーが層に依存することが定量化された。
Comment参考: https://ledge.ai/articles/llm_conceptual_structure_sae[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-kR626A9_R8.6CU7IKvGyhQ)
Issue Date: 2024-11-15
Adaptive Decoding via Latent Preference Optimization, Shehzaad Dhuliawala+, arXiv'24
SummaryAdaptive Decodingを導入し、推論時にトークンや例ごとに動的にサンプリング温度を選択することで、言語モデルのパフォーマンスを最適化。Latent Preference Optimization(LPO)を用いて温度選択を学習し、UltraFeedbackやCreative Story Writing、GSM8Kなどのタスクで固定温度を超える性能を達成。
#InformationRetrieval
#RelevanceJudgment
#LanguageModel
#Evaluation
Issue Date: 2024-11-14
A Large-Scale Study of Relevance Assessments with Large Language Models: An Initial Look, Shivani Upadhyay+, arXiv'24
Summary本研究では、TREC 2024 RAG Trackにおける大規模言語モデル(LLM)を用いた関連性評価の結果を報告。UMBRELAツールを活用した自動生成評価と従来の手動評価の相関を分析し、77の実行セットにおいて高い相関を示した。LLMの支援は手動評価との相関を高めず、人間評価者の方が厳格であることが示唆された。この研究は、TRECスタイルの評価におけるLLMの使用を検証し、今後の研究の基盤を提供する。
Comment元ポスト:https://x.com/lintool/status/1856876816197165188?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-ntenei-r-h3qlECirT3G9O2BGk765_g)
Perplexityの生成結果では、27個のシステムと記述されているが、これは実際はトピックで、各トピックごとに300件程度の0--3のRelevance Scoreが、人手評価、UMBRELA共に付与されている模様(Table1)。

評価結果
・Fully Manual Assessment: 既存のNIST methodologyと同様に人手でRelevance Scoreを付与する方法
・Manual Aspessment with Filtering: LLMのnon-Relevantと判断したpassageを人手評価から除外する方法
・Manual Post-Editing of Automatic Assessment: LLMがnon-Relevantと判断したpassageを人手評価から除外するだけでなく、LLMが付与したスコアを評価者にも見せ、評価者が当該ラベルを修正するようなスコアリングプロセス
・Fully Automatic Assessment:UMBRELAによるRelevance Scoreをそのまま利用する方法
LLMはGPT4-oを用いている。

19チームの77個のRunがどのように実行されているか、それがTable1の統計量とどう関係しているかがまだちょっとよくわかっていない。UMBRELAでRelevance Scoreを生成する際に利用されたプロンプト。
 #NLP
#LanguageModel
#Reasoning
#PostTraining
Issue Date: 2024-11-13
Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding, Haolin Chen+, arXiv'24
SummaryLaTRO(LaTent Reasoning Optimization)を提案し、LLMの推論能力を向上させる新しいフレームワークを構築。推論を潜在分布からのサンプリングとして定式化し、外部フィードバックなしで推論プロセスと質を同時に改善。GSM8KおよびARC-Challengeデータセットで実験し、平均12.5%の精度向上を達成。事前学習されたLLMの潜在的な推論能力を引き出すことが可能であることを示唆。
Comment元ポスト:https://x.com/haolinchen11/status/1856150958772040165?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=4Po8d9GAfQ&referrer=%5Bthe%20profile%20of%20Ricky%20Ho%5D(%2Fprofile%3Fid%3D~Ricky_Ho2)
Issue Date: 2024-11-13
Scaling Laws for Precision, Tanishq Kumar+, arXiv'24
Summary本研究では、低精度のトレーニングと推論が言語モデルの品質に与える影響を考慮した「精度を考慮した」スケーリング法則を提案。低精度トレーニングが実効パラメータ数を減少させ、ポストトレーニング量子化による劣化がトレーニングデータの増加とともに悪化することを示す。異なる精度でのモデル損失を予測し、低精度での大規模モデルのトレーニングが最適である可能性を示唆。スケーリング法則を統一し、実験に基づいて予測を検証。
Comment元ポスト: https://x.com/tanishq97836660/status/1856045600355352753?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Grokking
Issue Date: 2024-11-13
Why Do You Grok? A Theoretical Analysis of Grokking Modular Addition, Mohamad Amin Mohamadi+, arXiv'24
Summaryモデルの「grokking」現象を理論的に説明し、モジュラー加算問題に関連付ける。勾配降下法の初期段階では、順列不変モデルが小さな母集団誤差を達成するために一定割合のデータポイントを観察する必要があるが、最終的にはカーネル領域を脱出する。二層の二次ネットワークが限られたトレーニングポイントでゼロのトレーニング損失を達成し、良好に一般化することを示し、実証的証拠も提供。これにより、grokkingは深層ネットワークにおける勾配降下法の制限挙動への移行の結果であることが支持される。
Issue Date: 2024-11-13
ALLoRA: Adaptive Learning Rate Mitigates LoRA Fatal Flaws, Hai Huang+, arXiv'24
SummaryLoRAのファインチューニングにおける制限を特定し、ドロップアウトなし、スケーリングなし、適応学習率を持つALLoRAを提案。ALLoRAは勾配をパラメータの$\ell_2$ノルムに反比例してスケーリングし、LoRAよりも優れた精度を示す。実験により、ALLoRAが最新のLLMにおいて最適なアプローチであることが確認された。
#Pretraining
#MachineLearning
#NLP
#LanguageModel
#Subword
#Tokenizer
Issue Date: 2024-11-12
LBPE: Long-token-first Tokenization to Improve Large Language Models, Haoran Lian+, arXiv'24
SummaryLBPEは、長いトークンを優先する新しいエンコーディング手法で、トークン化データセットにおける学習の不均衡を軽減します。実験により、LBPEは従来のBPEを一貫して上回る性能を示しました。
CommentBPEとは異なりトークンの長さを優先してマージを実施することで、最終的なトークンを決定する手法で、
#NLP
#LanguageModel
#Reasoning
#PostTraining
Issue Date: 2024-11-13
Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding, Haolin Chen+, arXiv'24
SummaryLaTRO(LaTent Reasoning Optimization)を提案し、LLMの推論能力を向上させる新しいフレームワークを構築。推論を潜在分布からのサンプリングとして定式化し、外部フィードバックなしで推論プロセスと質を同時に改善。GSM8KおよびARC-Challengeデータセットで実験し、平均12.5%の精度向上を達成。事前学習されたLLMの潜在的な推論能力を引き出すことが可能であることを示唆。
Comment元ポスト:https://x.com/haolinchen11/status/1856150958772040165?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=4Po8d9GAfQ&referrer=%5Bthe%20profile%20of%20Ricky%20Ho%5D(%2Fprofile%3Fid%3D~Ricky_Ho2)
Issue Date: 2024-11-13
Scaling Laws for Precision, Tanishq Kumar+, arXiv'24
Summary本研究では、低精度のトレーニングと推論が言語モデルの品質に与える影響を考慮した「精度を考慮した」スケーリング法則を提案。低精度トレーニングが実効パラメータ数を減少させ、ポストトレーニング量子化による劣化がトレーニングデータの増加とともに悪化することを示す。異なる精度でのモデル損失を予測し、低精度での大規模モデルのトレーニングが最適である可能性を示唆。スケーリング法則を統一し、実験に基づいて予測を検証。
Comment元ポスト: https://x.com/tanishq97836660/status/1856045600355352753?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Grokking
Issue Date: 2024-11-13
Why Do You Grok? A Theoretical Analysis of Grokking Modular Addition, Mohamad Amin Mohamadi+, arXiv'24
Summaryモデルの「grokking」現象を理論的に説明し、モジュラー加算問題に関連付ける。勾配降下法の初期段階では、順列不変モデルが小さな母集団誤差を達成するために一定割合のデータポイントを観察する必要があるが、最終的にはカーネル領域を脱出する。二層の二次ネットワークが限られたトレーニングポイントでゼロのトレーニング損失を達成し、良好に一般化することを示し、実証的証拠も提供。これにより、grokkingは深層ネットワークにおける勾配降下法の制限挙動への移行の結果であることが支持される。
Issue Date: 2024-11-13
ALLoRA: Adaptive Learning Rate Mitigates LoRA Fatal Flaws, Hai Huang+, arXiv'24
SummaryLoRAのファインチューニングにおける制限を特定し、ドロップアウトなし、スケーリングなし、適応学習率を持つALLoRAを提案。ALLoRAは勾配をパラメータの$\ell_2$ノルムに反比例してスケーリングし、LoRAよりも優れた精度を示す。実験により、ALLoRAが最新のLLMにおいて最適なアプローチであることが確認された。
#Pretraining
#MachineLearning
#NLP
#LanguageModel
#Subword
#Tokenizer
Issue Date: 2024-11-12
LBPE: Long-token-first Tokenization to Improve Large Language Models, Haoran Lian+, arXiv'24
SummaryLBPEは、長いトークンを優先する新しいエンコーディング手法で、トークン化データセットにおける学習の不均衡を軽減します。実験により、LBPEは従来のBPEを一貫して上回る性能を示しました。
CommentBPEとは異なりトークンの長さを優先してマージを実施することで、最終的なトークンを決定する手法で、


BPEよりも高い性能を獲得し、

トークンの長さがBPEと比較して長くなり、かつ5Bトークン程度を既存のBPEで事前学習されたモデルに対して継続的事前学習するだけで性能を上回るようにでき、

同じVocabサイズでBPEよりも高い性能を獲得できる手法

らしい #LanguageModel #ScientificDiscovery #Investigation Issue Date: 2024-11-12 LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions, Zhehui Liao+, arXiv'24 Summary大規模言語モデル(LLMs)の利用に関する816人の研究者を対象とした調査を実施。81%が研究ワークフローにLLMsを組み込んでおり、特に非白人や若手研究者が高い使用率を示す一方で、女性やシニア研究者は倫理的懸念を抱いていることが明らかに。研究の公平性向上の可能性が示唆される。 #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2024-11-12 DELIFT: Data Efficient Language model Instruction Fine Tuning, Ishika Agarwal+, arXiv'24 SummaryDELIFTという新しいアルゴリズムを提案し、ファインチューニングの各ステージでデータ選択を最適化。ペアワイズユーティリティメトリックを用いてデータの有益性を定量化し、最大70%のデータ削減を実現。計算コストを大幅に節約し、既存の方法を上回る効率性と効果を示す。 #Survey #NLP #LanguageModel #LLMAgent Issue Date: 2024-11-12 GUI Agents with Foundation Models: A Comprehensive Survey, Shuai Wang+, arXiv'24 Summary(M)LLMを活用したGUIエージェントの研究を統合し、データセット、フレームワーク、アプリケーションの革新を強調。重要なコンポーネントをまとめた統一フレームワークを提案し、商業アプリケーションを探求。課題を特定し、今後の研究方向を示唆。 Comment
 Referenceやページ数はサーベイにしては少なめに見える。
#ComputerVision
#MachineLearning
#Supervised-FineTuning (SFT)
#InstructionTuning
#PEFT(Adaptor/LoRA)
#Catastrophic Forgetting
Issue Date: 2024-11-12
Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv'24
Summary破滅的忘却に対処するため、タスクフリーのオンライン継続学習(OCL)フレームワークOnline-LoRAを提案。リハーサルバッファの制約を克服し、事前学習済みビジョントランスフォーマー(ViT)モデルをリアルタイムで微調整。新しいオンライン重み正則化戦略を用いて重要なモデルパラメータを特定し、データ分布の変化を自動認識。多様なベンチマークデータセットで優れた性能を示す。
Comment
Referenceやページ数はサーベイにしては少なめに見える。
#ComputerVision
#MachineLearning
#Supervised-FineTuning (SFT)
#InstructionTuning
#PEFT(Adaptor/LoRA)
#Catastrophic Forgetting
Issue Date: 2024-11-12
Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv'24
Summary破滅的忘却に対処するため、タスクフリーのオンライン継続学習(OCL)フレームワークOnline-LoRAを提案。リハーサルバッファの制約を克服し、事前学習済みビジョントランスフォーマー(ViT)モデルをリアルタイムで微調整。新しいオンライン重み正則化戦略を用いて重要なモデルパラメータを特定し、データ分布の変化を自動認識。多様なベンチマークデータセットで優れた性能を示す。
Comment #EfficiencyImprovement
#NLP
#LanguageModel
#Test-Time Scaling
Issue Date: 2024-11-12
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, Charlie Snell+, arXiv'24
SummaryLLMの推論時の計算をスケーリングすることで、挑戦的なプロンプトに対するパフォーマンスを改善する方法を研究。特に、密なプロセスベースの検証者報酬モデルとプロンプトに応じた応答の適応的更新を分析。プロンプトの難易度によって効果が変化し、計算最適戦略を適用することで効率を4倍以上向上。さらに、テスト時計算を用いることで小さなモデルが大きなモデルを上回ることが示された。
Comment
#EfficiencyImprovement
#NLP
#LanguageModel
#Test-Time Scaling
Issue Date: 2024-11-12
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, Charlie Snell+, arXiv'24
SummaryLLMの推論時の計算をスケーリングすることで、挑戦的なプロンプトに対するパフォーマンスを改善する方法を研究。特に、密なプロセスベースの検証者報酬モデルとプロンプトに応じた応答の適応的更新を分析。プロンプトの難易度によって効果が変化し、計算最適戦略を適用することで効率を4倍以上向上。さらに、テスト時計算を用いることで小さなモデルが大きなモデルを上回ることが示された。
Comment [Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/search/yi-xia-noyan-jiu-wodu-mi-nei-r-1e1euXgLTH.G0Wlp.V2iqA)
#NLP
#LLMAgent
#API
Issue Date: 2024-11-11
Beyond Browsing: API-Based Web Agents, Yueqi Song+, arXiv'24
SummaryAPIを利用するAIエージェントの研究を行い、従来のウェブブラウジングエージェントと比較。API呼び出しエージェントはオンラインタスクをAPI経由で実行し、ハイブリッドエージェントはウェブブラウジングとAPIの両方を活用。実験結果では、ハイブリッドエージェントが他のエージェントを上回り、タスク非依存の最先端パフォーマンスを達成。APIの利用がウェブブラウジングよりも優れた選択肢であることを示唆。
CommentCMUの研究。後で読みたい
#InformationRetrieval
#NLP
#LanguageModel
#RAG(RetrievalAugmentedGeneration)
Issue Date: 2024-11-10
HyQE: Ranking Contexts with Hypothetical Query Embeddings, Weichao Zhou+, arXiv'24
Summaryリトリーバル拡張システムにおいて、LLMのファインチューニングを必要とせず、埋め込みの類似性とLLMの能力を組み合わせたスケーラブルなランキングフレームワークを提案。ユーザーのクエリに基づいて仮定されたクエリとの類似性でコンテキストを再順位付けし、推論時に効率的で他の技術とも互換性がある。実験により、提案手法がランキング性能を向上させることを示した。
Comment・1498 も参照のこと。
[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/search/yi-xia-noyan-jiu-wodu-mi-nei-r-1e1euXgLTH.G0Wlp.V2iqA)
#NLP
#LLMAgent
#API
Issue Date: 2024-11-11
Beyond Browsing: API-Based Web Agents, Yueqi Song+, arXiv'24
SummaryAPIを利用するAIエージェントの研究を行い、従来のウェブブラウジングエージェントと比較。API呼び出しエージェントはオンラインタスクをAPI経由で実行し、ハイブリッドエージェントはウェブブラウジングとAPIの両方を活用。実験結果では、ハイブリッドエージェントが他のエージェントを上回り、タスク非依存の最先端パフォーマンスを達成。APIの利用がウェブブラウジングよりも優れた選択肢であることを示唆。
CommentCMUの研究。後で読みたい
#InformationRetrieval
#NLP
#LanguageModel
#RAG(RetrievalAugmentedGeneration)
Issue Date: 2024-11-10
HyQE: Ranking Contexts with Hypothetical Query Embeddings, Weichao Zhou+, arXiv'24
Summaryリトリーバル拡張システムにおいて、LLMのファインチューニングを必要とせず、埋め込みの類似性とLLMの能力を組み合わせたスケーラブルなランキングフレームワークを提案。ユーザーのクエリに基づいて仮定されたクエリとの類似性でコンテキストを再順位付けし、推論時に効率的で他の技術とも互換性がある。実験により、提案手法がランキング性能を向上させることを示した。
Comment・1498 も参照のこと。
下記に試しにHyQEとHyDEの比較の記事を作成したのでご参考までに(記事の内容に私は手を加えていないのでHallucinationに注意)。ざっくりいうとHyDEはpseudo documentsを使うが、HyQEはpseudo queryを扱う。
[参考: Perplexity Pagesで作成したHyDEとの簡単な比較の要約](https://www.perplexity.ai/page/hyqelun-wen-nofen-xi-toyao-yue-aqZZj8mDQg6NL1iKml7.eQ) #Survey
#LanguageModel
#Personalization
Issue Date: 2024-11-10
Personalization of Large Language Models: A Survey, Zhehao Zhang+, arXiv'24
Summary大規模言語モデル(LLMs)のパーソナライズに関する研究のギャップを埋めるため、パーソナライズされたLLMsの分類法を提案。パーソナライズの概念を統合し、新たな側面や要件を定義。粒度、技術、データセット、評価方法に基づく体系的な分類を行い、文献を統一。未解決の課題を強調し、研究者と実務者への明確なガイドを提供することを目指す。
#NLP
#LanguageModel
#NumericReasoning
Issue Date: 2024-11-09
Number Cookbook: Number Understanding of Language Models and How to Improve It, Haotong Yang+, arXiv'24
Summary大規模言語モデル(LLMs)の数値理解および処理能力(NUPA)を調査し、41の数値タスクを含むベンチマークを導入。多くのタスクでLLMsが失敗することを確認し、NUPA向上のための技術を用いて小規模モデルを訓練。ファインチューニングによりNUPAが改善されるが、すべてのタスクには効果がないことが判明。思考の連鎖技術の影響も探求。研究はLLMsのNUPA改善に向けた初歩的なステップを示す。
Commentんー、abstしか読んでいないけれども、9.11 > 9.9 については、このような数字に慣れ親しんでいるエンジニアなどに咄嗟に質問したら、ミスして答えちゃう人もいるのでは?という気がする(エンジニアは脳内で9.11 > 9.9を示すバージョン管理に触れる機会が多く、こちらの尤度が高い)。
#Survey
#LanguageModel
#Personalization
Issue Date: 2024-11-10
Personalization of Large Language Models: A Survey, Zhehao Zhang+, arXiv'24
Summary大規模言語モデル(LLMs)のパーソナライズに関する研究のギャップを埋めるため、パーソナライズされたLLMsの分類法を提案。パーソナライズの概念を統合し、新たな側面や要件を定義。粒度、技術、データセット、評価方法に基づく体系的な分類を行い、文献を統一。未解決の課題を強調し、研究者と実務者への明確なガイドを提供することを目指す。
#NLP
#LanguageModel
#NumericReasoning
Issue Date: 2024-11-09
Number Cookbook: Number Understanding of Language Models and How to Improve It, Haotong Yang+, arXiv'24
Summary大規模言語モデル(LLMs)の数値理解および処理能力(NUPA)を調査し、41の数値タスクを含むベンチマークを導入。多くのタスクでLLMsが失敗することを確認し、NUPA向上のための技術を用いて小規模モデルを訓練。ファインチューニングによりNUPAが改善されるが、すべてのタスクには効果がないことが判明。思考の連鎖技術の影響も探求。研究はLLMsのNUPA改善に向けた初歩的なステップを示す。
Commentんー、abstしか読んでいないけれども、9.11 > 9.9 については、このような数字に慣れ親しんでいるエンジニアなどに咄嗟に質問したら、ミスして答えちゃう人もいるのでは?という気がする(エンジニアは脳内で9.11 > 9.9を示すバージョン管理に触れる機会が多く、こちらの尤度が高い)。
LLMがこのようなミス(てかそもそもミスではなく、回答するためのcontextが足りてないので正解が定義できないだけ、だと思うが、、)をするのは、単に学習データにそういった9.11 > 9.9として扱うような文脈や構造のテキストが多く存在しており、これらテキスト列の尤度が高くなってこのような現象が起きているだけなのでは、という気がしている。
instructionで注意を促したり適切に問題を定義しなければ、そりゃこういう結果になって当然じゃない?という気がしている。
(ここまで「気がしている」を3連発してしまった…😅)
また、本研究で扱っているタスクのexampleは下記のようなものだが、これらをLLMに、なんのツールも利用させずautoregressiveな生成のみで解かせるというのは、人間でいうところの暗算に相当するのでは?と個人的には思う。
何が言いたいのかというと、人間でも暗算でこれをやらせたら解けない人がかなりいると思う(というか私自身単純な加算でも桁数増えたら暗算など無理)。
一方で暗算ではできないけど、電卓やメモ書き、計算機を使っていいですよ、ということにしたら多くの人がこれらタスクは解けるようになると思うので、LLMでも同様のことが起きると思う。
LLMの数値演算能力は人間の暗算のように限界があることを認知し、金融分野などの正確な演算や数値の取り扱うようなタスクをさせたかったら、適切なツールを使わせましょうね、という話なのかなあと思う。
 元ポスト: https://x.com/omarsar0/status/1854528742095458337?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QICLR25のOpenReview。こちらを読むと興味深い。
元ポスト: https://x.com/omarsar0/status/1854528742095458337?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QICLR25のOpenReview。こちらを読むと興味深い。
https://openreview.net/forum?id=BWS5gVjgeY
幅広い数値演算のタスクを評価できるデータセット構築、トークナイザーとの関連性を明らかにした点、分析だけではなくLLMの数値演算能力を改善した点は評価されているように見える。
一方で、全体的に、先行研究との比較やdiscussionが不足しており、研究で得られた知見がどの程度新規性があるのか?といった点や、説明が不十分でjustificationが足りない、といった話が目立つように見える。
特に、そもそもLoRAやCoTの元論文や、Numerical Reasoningにフォーカスした先行研究がほぼ引用されていないらしい点が見受けられるようである。さすがにその辺は引用して研究のcontributionをクリアにした方がいいよね、と思うなどした。>I am unconvinced that numeracy in LLMs is a problem in need of a solution. First, surely there is a citable source for LLM inadequacy for numeracy. Second, even if they were terrible at numeracy, the onus is on the authors to convince the reader that this a problem worth caring about, for at least two obvious reasons: 1) all of these tasks are already trivially done by a calculator or a python program, and 2) commercially available LLMs can probably do alright at numerical tasks indirectly via code-generation and execution. As it stands, it reads as if the authors are insisting that this is a problem deserving of attention --・I'm sure it could be, but this argument can be better made.
上記レビュワーコメントと私も同じことを感じる。なぜLLMそのものに数値演算の能力がないことが問題なのか?という説明があった方が良いのではないかと思う。
これは私の中では、論文のイントロで言及されているようなシンプルなタスクではなく、
・inputするcontextに大量の数値を入力しなければならず、
・かつcontext中の数値を厳密に解釈しなければならず、
・かつ情報を解釈するために計算すべき数式がcontextで与えられた数値によって変化するようなタスク(たとえばテキスト生成で言及すべき内容がgivenな数値情報によって変わるようなもの。最大値に言及するのか、平均値を言及するのか、数値と紐づけられた特定のエンティティに言及しなければならないのか、など)
(e.g. 上記を満たすタスクはたとえば、金融関係のdata-to-textなど)では、LLMが数値を解釈できないと困ると思う。そういった説明が入った方が良いと思うなあ、感。 #Analysis #MachineLearning #NLP #LanguageModel #PEFT(Adaptor/LoRA) Issue Date: 2024-11-09 LoRA vs Full Fine-tuning: An Illusion of Equivalence, Reece Shuttleworth+, arXiv'24 Summaryファインチューニング手法の違いが事前学習済みモデルに与える影響を、重み行列のスペクトル特性を通じて分析。LoRAと完全なファインチューニングは異なる構造の重み行列を生成し、LoRAモデルは新たな高ランクの特異ベクトル(侵入次元)を持つことが判明。侵入次元は一般化能力を低下させるが、同等の性能を達成することがある。これにより、異なるファインチューニング手法がパラメータ空間の異なる部分にアクセスしていることが示唆される。 Comment元ポスト: https://x.com/aratako_lm/status/1854838012909166973?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q1423 や 1475 、双方の知見も交えて、LoRAの挙動を考察する必要がある気がする。それぞれ異なるデータセットやモデルで、LoRAとFFTを比較している。時間がないが後でやりたい。
あと、昨今はそもそも実験設定における変数が多すぎて、とりうる実験設定が多すぎるため、個々の論文の知見を鵜呑みにして一般化するのはやめた方が良い気がしている。実験設定の違い
モデルのアーキテクチャ
・本研究: RoBERTa-base(transformer-encoder)
・1423: transformer-decoder
・1475: transformer-decoder(LLaMA)
パラメータサイズ
・本研究:
・1423: 1B, 2B, 4B, 8B, 16B
・1475: 7B
時間がある時に続きをかきたい
Finetuningデータセットのタスク数
1タスクあたりのデータ量
trainableなパラメータ数 #RecommenderSystems #InformationRetrieval #MulltiModal Issue Date: 2024-11-08 MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs, Sheng-Chieh Lin+, arXiv'24 Summary本論文では、マルチモーダル大規模言語モデル(MLLM)を用いた「ユニバーサルマルチモーダル検索」の技術を提案し、複数のモダリティと検索タスクに対応する能力を示します。10のデータセットと16の検索タスクでの実験により、MLLMリトリーバーはテキストと画像のクエリを理解できるが、モダリティバイアスによりクロスモーダル検索では劣ることが判明。これを解決するために、モダリティ認識ハードネガティブマイニングを提案し、継続的なファインチューニングでテキスト検索能力を向上させました。結果として、MM-EmbedモデルはM-BEIRベンチマークで最先端の性能を達成し、NV-Embed-v1を上回りました。また、ゼロショットリランキングを通じて、複雑なクエリに対するマルチモーダル検索の改善が可能であることを示しました。これらの成果は、今後のユニバーサルマルチモーダル検索の発展に寄与するものです。 Comment #MachineLearning
#Optimizer
Issue Date: 2024-11-06
ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate, Shohei Taniguchi+, NeurIPS'24
SummaryADOPTという新しい適応勾配法を提案し、任意のハイパーパラメータ$\beta_2$で最適な収束率を達成。勾配の二次モーメント推定からの除去と更新順序の変更により、Adamの非収束問題を解決。広範なタスクで優れた結果を示し、実装はGitHubで公開。
Comment画像は元ツイートからの引用:
#MachineLearning
#Optimizer
Issue Date: 2024-11-06
ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate, Shohei Taniguchi+, NeurIPS'24
SummaryADOPTという新しい適応勾配法を提案し、任意のハイパーパラメータ$\beta_2$で最適な収束率を達成。勾配の二次モーメント推定からの除去と更新順序の変更により、Adamの非収束問題を解決。広範なタスクで優れた結果を示し、実装はGitHubで公開。
Comment画像は元ツイートからの引用:
ライブラリがあるようで、1行変えるだけですぐ使えるとのこと。

元ツイート:https://x.com/ishohei220/status/1854051859385978979?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QAdamでは収束しなかった場合(バッチサイズが小さい場合)でも収束するようになっている模様
 Issue Date: 2024-11-05
Beyond Utility: Evaluating LLM as Recommender, Chumeng Jiang+, arXiv'24
SummaryLLMsをレコメンダーとして利用する際の新たな評価次元を提案し、多次元評価フレームワークを構築。評価次元には履歴長さの感度、候補位置のバイアス、生成パフォーマンス、幻覚が含まれ、7つのLLMベースのレコメンダーを評価。結果、LLMsはランキング設定で優れた性能を示す一方、候補位置バイアスや幻覚の問題も確認。提案フレームワークが今後の研究に貢献することを期待。
Comment実装: https://github.com/JiangDeccc/EvaLLMasRecommender
#MachineLearning
#NLP
#LongSequence
#SSM (StateSpaceModel)
Issue Date: 2024-11-05
Stuffed Mamba: State Collapse and State Capacity of RNN-Based Long-Context Modeling, Yingfa Chen+, arXiv'24
SummaryRNNの長いコンテキスト処理の課題を研究し、状態崩壊(SC)とメモリ容量の制限に対処。Mamba-2モデルを用いて、SC緩和手法を提案し、1Mトークン以上の処理を実現。256Kコンテキスト長で高精度のパスキー取得を達成し、RNNの長コンテキストモデリングの可能性を示唆。
#NLP
#ChatGPT
Issue Date: 2024-11-02
On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability, Kevin Wang+, N_A, arXiv'24, 2024.11
Summary本研究では、OpenAIのo1モデルの計画能力を評価し、実現可能性、最適性、一般化の3つの側面に焦点を当てています。特に、制約の多いタスクや空間的に複雑な環境における強みとボトルネックを特定しました。o1-previewは、構造化された環境での制約遵守においてGPT-4を上回る一方で、冗長なアクションを伴う最適でない解を生成し、一般化に苦労しています。この研究は、LLMsの計画における限界を明らかにし、今後の改善の方向性を示しています。
Commento1のplanningの性能について知りたくなったら読む
#NLP
#LanguageModel
Issue Date: 2024-11-02
Looking Inward: Language Models Can Learn About Themselves by Introspection, Felix J Binder+, N_A, arXiv'24, 2024.11
Summary内省は、LLMsがトレーニングデータに依存せずに内部状態から知識を獲得する能力を指す。本研究では、LLMsを微調整し、仮想シナリオにおける自身の行動を予測させることで内省を検証。実験の結果、内省可能なモデル(M1)は、異なるモデル(M2)よりも自身の行動を正確に予測できることが示された。特に、M1は行動を意図的に変更した後でも予測精度を維持したが、複雑なタスクでは内省を引き出すことができなかった。
Comment
Issue Date: 2024-11-05
Beyond Utility: Evaluating LLM as Recommender, Chumeng Jiang+, arXiv'24
SummaryLLMsをレコメンダーとして利用する際の新たな評価次元を提案し、多次元評価フレームワークを構築。評価次元には履歴長さの感度、候補位置のバイアス、生成パフォーマンス、幻覚が含まれ、7つのLLMベースのレコメンダーを評価。結果、LLMsはランキング設定で優れた性能を示す一方、候補位置バイアスや幻覚の問題も確認。提案フレームワークが今後の研究に貢献することを期待。
Comment実装: https://github.com/JiangDeccc/EvaLLMasRecommender
#MachineLearning
#NLP
#LongSequence
#SSM (StateSpaceModel)
Issue Date: 2024-11-05
Stuffed Mamba: State Collapse and State Capacity of RNN-Based Long-Context Modeling, Yingfa Chen+, arXiv'24
SummaryRNNの長いコンテキスト処理の課題を研究し、状態崩壊(SC)とメモリ容量の制限に対処。Mamba-2モデルを用いて、SC緩和手法を提案し、1Mトークン以上の処理を実現。256Kコンテキスト長で高精度のパスキー取得を達成し、RNNの長コンテキストモデリングの可能性を示唆。
#NLP
#ChatGPT
Issue Date: 2024-11-02
On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability, Kevin Wang+, N_A, arXiv'24, 2024.11
Summary本研究では、OpenAIのo1モデルの計画能力を評価し、実現可能性、最適性、一般化の3つの側面に焦点を当てています。特に、制約の多いタスクや空間的に複雑な環境における強みとボトルネックを特定しました。o1-previewは、構造化された環境での制約遵守においてGPT-4を上回る一方で、冗長なアクションを伴う最適でない解を生成し、一般化に苦労しています。この研究は、LLMsの計画における限界を明らかにし、今後の改善の方向性を示しています。
Commento1のplanningの性能について知りたくなったら読む
#NLP
#LanguageModel
Issue Date: 2024-11-02
Looking Inward: Language Models Can Learn About Themselves by Introspection, Felix J Binder+, N_A, arXiv'24, 2024.11
Summary内省は、LLMsがトレーニングデータに依存せずに内部状態から知識を獲得する能力を指す。本研究では、LLMsを微調整し、仮想シナリオにおける自身の行動を予測させることで内省を検証。実験の結果、内省可能なモデル(M1)は、異なるモデル(M2)よりも自身の行動を正確に予測できることが示された。特に、M1は行動を意図的に変更した後でも予測精度を維持したが、複雑なタスクでは内省を引き出すことができなかった。
Comment LLMが単に訓練データを模倣しているにすぎない的な主張に対するカウンターに使えるかも
#MachineLearning
#Supervised-FineTuning (SFT)
Issue Date: 2024-10-27
NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, ICLR'24
SummaryNEFTuneは、埋め込みベクトルにノイズを加えることで言語モデルのファインチューニングを改善する手法です。LLaMA-2-7Bを用いた標準的なファインチューニングでは29.79%の精度でしたが、ノイジーな埋め込みを使用することで64.69%に向上しました。NEFTuneは、Evol-Instruct、ShareGPT、OpenPlatypusなどの指示データセットでも改善をもたらし、RLHFで強化されたLLaMA-2-Chatにも効果があります。
Commentランダムノイズをembeddingに加えて学習するシンプルな手法。モデルがロバストになる。
LLMが単に訓練データを模倣しているにすぎない的な主張に対するカウンターに使えるかも
#MachineLearning
#Supervised-FineTuning (SFT)
Issue Date: 2024-10-27
NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, ICLR'24
SummaryNEFTuneは、埋め込みベクトルにノイズを加えることで言語モデルのファインチューニングを改善する手法です。LLaMA-2-7Bを用いた標準的なファインチューニングでは29.79%の精度でしたが、ノイジーな埋め込みを使用することで64.69%に向上しました。NEFTuneは、Evol-Instruct、ShareGPT、OpenPlatypusなどの指示データセットでも改善をもたらし、RLHFで強化されたLLaMA-2-Chatにも効果があります。
Commentランダムノイズをembeddingに加えて学習するシンプルな手法。モデルがロバストになる。
Unsupervised SimCSEと思想が似ている。実質DataAugmentationともみなせる。 #MachineLearning #NLP #LanguageModel #Alignment #ICML #PostTraining Issue Date: 2024-10-27 KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, N_A, ICML'24 Summaryプロスペクト理論に基づき、LLMの人間フィードバック調整におけるバイアスの影響を示す。新たに提案する「人間認識損失」(HALOs)を用いたアプローチKTOは、生成物の効用を最大化し、好みベースの方法と同等またはそれ以上の性能を発揮。研究は、最適な損失関数が特定の設定に依存することを示唆。 CommentbinaryフィードバックデータからLLMのアライメントをとるKahneman-Tversky Optimization (KTO)論文 #NLP #LanguageModel #DPO #PostTraining Issue Date: 2024-10-22 Generative Reward Models, Dakota Mahan+, N_A, arXiv'24 SummaryRLHFとRLAIFを統合したハイブリッドアプローチを提案し、合成好みラベルの質を向上させるGenRMアルゴリズムを導入。実験により、GenRMは分布内外のタスクでBradley-Terryモデルと同等またはそれを上回る性能を示し、LLMを判断者として使用する場合のパフォーマンスも向上。 CommentOpenReview:https://openreview.net/forum?id=MwU2SGLKpS関連研究
・708
・1212openreview:https://openreview.net/forum?id=MwU2SGLKpS Issue Date: 2024-10-21 nGPT: Normalized Transformer with Representation Learning on the Hypersphere, Ilya Loshchilov+, N_A, arXiv'24 Summary新しいアーキテクチャ「正規化トランスフォーマー(nGPT)」を提案。すべてのベクトルが単位ノルムで正規化され、トークンはハイパースフィア上で移動。nGPTはMLPとアテンションブロックを用いて出力予測に寄与し、学習速度が向上し、必要なトレーニングステップを4倍から20倍削減。 Comment元ポスト:https://x.com/hillbig/status/1848462035992084838?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Hallucination Issue Date: 2024-10-20 LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations, Hadas Orgad+, N_A, arXiv'24 SummaryLLMsは「幻覚」と呼ばれるエラーを生成するが、内部状態が真実性に関する情報をエンコードしていることが示されている。本研究では、真実性情報が特定のトークンに集中していることを発見し、これを利用することでエラー検出性能が向上することを示す。しかし、エラーディテクターはデータセット間で一般化に失敗し、真実性のエンコーディングは普遍的ではないことが明らかになる。また、内部表現を用いてエラーの種類を予測し、特化した緩和戦略の開発を促進する。さらに、内部エンコーディングと外部の振る舞いとの不一致が存在し、正しい答えをエンコードしていても誤った答えを生成することがある。これにより、LLMのエラー理解が深まり、今後の研究に寄与する。 Comment特定のトークンがLLMのtrustfulnessに集中していることを実験的に示し、かつ内部でエンコードされたrepresentationは正しい答えのものとなっているのに、生成結果に誤りが生じるような不整合が生じることも示したらしい #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2024-10-20 Addition is All You Need for Energy-efficient Language Models, Hongyin Luo+, N_A, arXiv'24 Summary本研究では、浮動小数点乗算を高精度で整数加算器によって近似するL-Mulアルゴリズムを提案。これにより、8ビット浮動小数点乗算に比べて計算リソースを大幅に削減しつつ、より高い精度を実現。L-Mulをテンソル処理ハードウェアに適用することで、エネルギーコストを95%(要素ごとの乗算)および80%(ドット積)削減可能。実験結果は理論的誤差推定と一致し、L-Mulは従来の浮動小数点乗算と同等またはそれ以上の精度を達成。トランスフォーマーモデル内の浮動小数点乗算をL-Mulに置き換えることで、ファインチューニングと推論において高い精度を維持できることを示した。 Issue Date: 2024-10-11 One Initialization to Rule them All: Fine-tuning via Explained Variance Adaptation, Fabian Paischer+, N_A, arXiv'24 Summaryファウンデーションモデルのファインチューニング手法として、アクティベーションベクトルの特異値分解を用いた新しい初期化方法「説明された分散適応(EVA)」を提案。EVAは、重みの再分配を行い、収束を速め、さまざまなタスクで最高の平均スコアを達成する。 Comment元ポスト:https://x.com/paischerfabian/status/1844267655068516767?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Dataset Issue Date: 2024-09-30 COM Kitchens: An Unedited Overhead-view Video Dataset as a Vision-Language Benchmark, Koki Maeda+, N_A, ECCV'24 Summary手続き的なビデオ理解のために、COM Kitchensという新しいデータセットを提案。これは、参加者がレシピに基づいて食材を準備する様子を上方視点で撮影した編集されていないビデオで構成されている。多様なデータ収集のためにスマートフォンを使用し、オンラインレシピ検索(OnRR)と密なビデオキャプショニング(DVC-OV)という新しいタスクを提案。実験により、既存のウェブビデオベースの手法の能力と限界を検証。 Commentとてもおもしろそう! #ComputerVision #NLP #Dataset #LanguageModel Issue Date: 2024-09-30 What matters when building vision-language models?, Hugo Laurençon+, N_A, arXiv'24 Summary視覚と言語のモデル(VLM)の設計における裏付けのない決定が性能向上の特定を妨げていると指摘。事前学習済みモデルやアーキテクチャ、データ、トレーニング手法に関する実験を行い、80億パラメータの基盤VLM「Idefics2」を開発。Idefics2はマルチモーダルベンチマークで最先端の性能を達成し、4倍のサイズのモデルと同等の性能を示す。モデルとデータセットを公開。 Comment元ポストにOpenVLMの進展の歴史が載っている。構築されたデータセットも公開される模様。

元ポスト:https://x.com/thom_wolf/status/1840372428855280045?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #CLIP Issue Date: 2024-09-30 Long-CLIP: Unlocking the Long-Text Capability of CLIP, Beichen Zhang+, N_A, ECCV'24 SummaryLong-CLIPは、CLIPのテキスト入力の長さ制限を克服し、ゼロショットの一般化能力を保持または超える新しいモデルです。効率的なファインチューニング戦略を用いて、CLIPの性能を維持しつつ、長文テキスト-画像ペアを活用することで、テキスト-画像検索タスクで約20%の性能向上を達成しました。また、Long-CLIPは詳細なテキスト説明から画像を生成する能力を強化します。 #Pretraining #NLP #Supervised-FineTuning (SFT) #SyntheticData Issue Date: 2024-09-29 Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling, Hritik Bansal+, N_A, arXiv'24 Summary高品質な合成データを生成するために、強力なSEモデルと安価なWCモデルのトレードオフを再検討。WCモデルからのデータはカバレッジと多様性が高いが偽陽性率も高い。ファインチューニングの結果、WC生成データでトレーニングされたモデルがSE生成データのモデルを上回ることが示され、WCが計算最適なアプローチである可能性を示唆。 Comment元ポスト:https://x.com/rohanpaul_ai/status/1840172683528425718?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2024-09-26 When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N_A, ICLR'24 SummaryLLMのファインチューニング手法のスケーリング特性を調査し、モデルサイズやデータサイズが性能に与える影響を実験。結果、ファインチューニングはパワーベースの共同スケーリング法則に従い、モデルのスケーリングが事前学習データのスケーリングよりも効果的であることが判明。最適な手法はタスクやデータに依存する。 Comment> When only few thousands of finetuning examples are available, PET should be considered first, either Prompt or LoRA. With sightly larger datasets, LoRA would be preferred due to its stability and slightly better finetuning data scalability. For million-scale datasets, FMT would be good.
> While specializing on a downstream task, finetuning could still elicit
and improve the generalization for closely related tasks, although the overall zero-shot translation
quality is inferior. Note whether finetuning benefits generalization is method・and task-dependent.
Overall, Prompt and LoRA achieve relatively better results than FMT particularly when the base
LLM is large, mostly because LLM parameters are frozen and the learned knowledge get inherited.
This also suggests that when generalization capability is a big concern, PET should be considered. #RecommenderSystems #Transformer #TransferLearning Issue Date: 2024-09-25 beeFormer: Bridging the Gap Between Semantic and Interaction Similarity in Recommender Systems, Vojtěch Vančura+, N_A, RecSys'24 Summaryレコメンダーシステムにおいて、コールドスタートやゼロショットシナリオでの予測改善のために、インタラクションデータを活用した文のトランスフォーマーモデル「beeFormer」を提案。beeFormerは、意味的類似性の予測において従来の手法を上回り、異なるドメインのデータセット間で知識を転送可能であることを示した。これにより、ドメインに依存しないテキスト表現のマイニングが可能になる。 CommentNLPでは言語という共通の体系があるから事前学習とかが成立するけど、RecSysのようなユーザとシステムのinteraction dataを用いたシステムでは(大抵の場合はデータセットごとにユニークなユーザIDとアイテムIDのログでデータが構成されるので)なかなかそういうことは難しいよね、と思っていた。が、もしRecSysのタスク設定で、データセット間の転移学習を実現できるのだとしたらどのように実現してきるのだろうか?興味深い。後で読む。 #RecommenderSystems #EfficiencyImprovement Issue Date: 2024-09-25 Enhancing Performance and Scalability of Large-Scale Recommendation Systems with Jagged Flash Attention, Rengan Xu+, N_A, arXiv'24 Summaryハードウェアアクセラレーターの統合により、推薦システムの能力が向上する一方で、GPU計算コストが課題となっている。本研究では、カテゴリ特徴の長さによるGPU利用の複雑さに対処するため、「Jagged Feature Interaction Kernels」を提案し、動的サイズのテンソルを効率的に扱う手法を開発。さらに、JaggedテンソルをFlash Attentionと統合し、最大9倍のスピードアップと22倍のメモリ削減を実現。実際のモデルでは、10%のQPS改善と18%のメモリ節約を確認し、複雑な推薦システムのスケーリングを可能にした。 #InformationRetrieval #RelevanceJudgment #LanguageModel Issue Date: 2024-09-24 Don't Use LLMs to Make Relevance Judgments, Ian Soboroff, N_A, arXiv'24 SummaryTRECスタイルの関連性判断は高コストで複雑であり、通常は訓練を受けた契約者チームが必要です。最近の大規模言語モデルの登場により、情報検索研究者はこれらのモデルの利用可能性を考え始めました。ACM SIGIR 2024カンファレンスでの「LLM4Eval」ワークショップでは、TRECの深層学習トラックの判断を再現するデータチャレンジが行われました。本論文はその基調講演をまとめたもので、TRECスタイルの評価においてLLMを使用しないことを提言しています。 Comment興味深い!!後で読む! #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Safety #DPO #PostTraining Issue Date: 2024-09-24 Backtracking Improves Generation Safety, Yiming Zhang+, N_A, arXiv'24 Summaryテキスト生成における安全性の問題に対処するため、バックトラッキング手法を提案。特別な[RESET]トークンを用いて生成された不適切なテキストを「取り消し」、モデルの安全性を向上させる。バックトラッキングを導入したLlama-3-8Bは、ベースラインモデルに比べて4倍の安全性を示し、有用性の低下は見られなかった。 Comment元ポスト: https://x.com/jaseweston/status/1838415378529112330?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #SelfCorrection Issue Date: 2024-09-16 When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs, Ryo Kamoi+, N_A, TACL'24 Summary自己修正はLLMsの応答を改善する手法であり、フィードバック源の利用が提案されているが、誤り修正のタイミングについては合意が得られていない。本研究では、自己修正に必要な条件を議論し、従来の研究の問題点を指摘。新たに分類した研究課題に基づき、自己修正が成功した例がないこと、信頼できる外部フィードバックが重要であること、大規模なファインチューニングが効果的であることを示した。 CommentLLMのself-correctionに関するサーベイ

 #NLP
#LanguageModel
#QuestionAnswering
#SyntheticData
#SyntheticDataGeneration
Issue Date: 2024-09-14
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources, Alisia Lupidi+, N_A, arXiv'24
Summary新手法「Source2Synth」を提案し、LLMに新しいスキルを教える。人間の注釈に依存せず、実世界のソースに基づいた合成データを生成し、低品質な生成物を廃棄してデータセットの質を向上。マルチホップ質問応答と表形式の質問応答に適用し、WikiSQLで25.51%、HotPotQAで22.57%の性能向上を達成。
Comment合成データ生成に関する研究。
#NLP
#LanguageModel
#QuestionAnswering
#SyntheticData
#SyntheticDataGeneration
Issue Date: 2024-09-14
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources, Alisia Lupidi+, N_A, arXiv'24
Summary新手法「Source2Synth」を提案し、LLMに新しいスキルを教える。人間の注釈に依存せず、実世界のソースに基づいた合成データを生成し、低品質な生成物を廃棄してデータセットの質を向上。マルチホップ質問応答と表形式の質問応答に適用し、WikiSQLで25.51%、HotPotQAで22.57%の性能向上を達成。
Comment合成データ生成に関する研究。
ソースからQAを生成し、2つのsliceに分ける。片方をLLMのfinetuning(LLMSynth)に利用し、もう片方をfinetuningしたLLMで解答可能性に基づいてフィルタリング(curation)する。
最終的にフィルタリングして生成された高品質なデータでLLMをfinetuningする。
Curationされたデータでfinetuningしたモデルの性能は、Curationしていないただの合成データと比べて、MultiHopQA, TableQAベンチマークで高い性能を獲得している。

画像は元ポストより引用
元ポスト: https://x.com/jaseweston/status/1834402693995024453?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMultiHopQAの合成データ生成方法

TableQAの合成データ生成方法
 #LanguageModel
#ReinforcementLearning
Issue Date: 2024-09-13
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N_A, arXiv'24
SummaryR$^3$は、結果の監視を用いて大規模言語モデルの推論プロセスを最適化する新手法。正しいデモンストレーションから学ぶことで、段階的なカリキュラムを確立し、エラーを特定可能にする。Llama2-7Bを用いた実験では、8つの推論タスクでRLのベースラインを平均4.1ポイント上回り、特にGSM8Kでは4.2ポイントの改善を示した。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#Chain-of-Thought
#PostTraining
Issue Date: 2024-09-13
ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N_A, ACL'24
Summary強化ファインチューニング(ReFT)を提案し、LLMsの推論能力を向上。SFTでモデルをウォームアップ後、PPOアルゴリズムを用いてオンライン強化学習を行い、豊富な推論パスを自動サンプリング。GSM8K、MathQA、SVAMPデータセットでSFTを大幅に上回る性能を示し、追加のトレーニング質問に依存せず優れた一般化能力を発揮。
Comment
#LanguageModel
#ReinforcementLearning
Issue Date: 2024-09-13
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N_A, arXiv'24
SummaryR$^3$は、結果の監視を用いて大規模言語モデルの推論プロセスを最適化する新手法。正しいデモンストレーションから学ぶことで、段階的なカリキュラムを確立し、エラーを特定可能にする。Llama2-7Bを用いた実験では、8つの推論タスクでRLのベースラインを平均4.1ポイント上回り、特にGSM8Kでは4.2ポイントの改善を示した。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#Chain-of-Thought
#PostTraining
Issue Date: 2024-09-13
ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N_A, ACL'24
Summary強化ファインチューニング(ReFT)を提案し、LLMsの推論能力を向上。SFTでモデルをウォームアップ後、PPOアルゴリズムを用いてオンライン強化学習を行い、豊富な推論パスを自動サンプリング。GSM8K、MathQA、SVAMPデータセットでSFTを大幅に上回る性能を示し、追加のトレーニング質問に依存せず優れた一般化能力を発揮。
Comment

#Survey #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2024-09-10 From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Sean Welleck+, N_A, arXiv'24 Summary推論時の計算リソース拡大の利点に焦点を当て、トークンレベル生成、メタ生成、効率的生成の3つのアプローチを統一的に探求。トークンレベル生成はデコーディングアルゴリズムを用い、メタ生成はドメイン知識や外部情報を活用し、効率的生成はコスト削減と速度向上を目指す。従来の自然言語処理、現代のLLMs、機械学習の視点を統合した調査。 Comment元ツイート: https://x.com/gneubig/status/1833522477605261799?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCMUのチームによるinference timeの高速化に関するサーベイ #NLP #LanguageModel #ScientificDiscovery Issue Date: 2024-09-10 Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers, Chenglei Si+, N_A, arXiv'24 Summary本研究では、LLMとNLP専門家による研究アイデア生成の比較を行い、LLMが生成したアイデアの新規性が人間のアイデアより高いことを示しましたが、実現可能性はやや劣ると評価されました。また、LLMの自己評価や生成の多様性に関する問題を特定し、研究者がアイデアを実行するためのエンドツーエンドの研究デザインを提案しました。 CommentLLMがアイデアを考えた方が、79人のresearcherにblind reviewさせて評価した結果、Noveltyスコアが有意に高くなった(ただし、feasibilityは人手で考えた場合の方が高い)という話らしい。
アイデア生成にどのようなモデル、promptingを利用したかはまだ読めていない。
 #Survey
#NLP
#LanguageModel
#Alignment
Issue Date: 2024-09-07
A Survey on Human Preference Learning for Large Language Models, Ruili Jiang+, N_A, arXiv'24
Summary人間の好み学習に基づくLLMsの進展をレビューし、好みフィードバックのソースや形式、モデリング技術、評価方法を整理。データソースに基づくフィードバックの分類や、異なるモデルの利点・欠点を比較し、LLMsの人間の意図との整合性に関する展望を議論。
#NLP
#LanguageModel
#SelfCorrection
Issue Date: 2024-09-07
Self-Reflection in LLM Agents: Effects on Problem-Solving Performance, Matthew Renze+, N_A, arXiv'24
Summary本研究では、自己反省が大規模言語モデル(LLMs)の問題解決パフォーマンスに与える影響を調査。9つのLLMに選択肢問題を解かせ、誤答に対して自己反省型エージェントが改善策を提供し再回答を試みた結果、自己反省によりパフォーマンスが有意に向上した($p < 0.001$)。さまざまな自己反省のタイプを比較し、それぞれの寄与も明らかにした。全てのコードとデータはGitHubで公開。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Hallucination
Issue Date: 2024-09-01
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?, Zorik Gekhman+, N_A, EMNLP'24
Summary大規模言語モデルはファインチューニングを通じて新しい事実情報に遭遇するが、既存の知識を活用する能力に影響を与える。研究では、閉じた書籍のQAを用いて新しい知識を導入するファインチューニング例の割合を変化させた結果、モデルは新しい知識を学習するのに苦労し、幻覚する傾向が増加することが示された。これにより、ファインチューニングによる新しい知識の導入のリスクが明らかになり、モデルは事前学習を通じて知識を獲得し、ファインチューニングはその利用を効率化することが支持される。
Commentpre-training時に獲得されていない情報を用いてLLMのalignmentを実施すると、知識がない状態で学習データを正しく予測できるように学習されてしまうため、事実に基づかない回答をする(つまりhallucination)ように学習されてしまう、といったことを調査している模様。
#Survey
#NLP
#LanguageModel
#Alignment
Issue Date: 2024-09-07
A Survey on Human Preference Learning for Large Language Models, Ruili Jiang+, N_A, arXiv'24
Summary人間の好み学習に基づくLLMsの進展をレビューし、好みフィードバックのソースや形式、モデリング技術、評価方法を整理。データソースに基づくフィードバックの分類や、異なるモデルの利点・欠点を比較し、LLMsの人間の意図との整合性に関する展望を議論。
#NLP
#LanguageModel
#SelfCorrection
Issue Date: 2024-09-07
Self-Reflection in LLM Agents: Effects on Problem-Solving Performance, Matthew Renze+, N_A, arXiv'24
Summary本研究では、自己反省が大規模言語モデル(LLMs)の問題解決パフォーマンスに与える影響を調査。9つのLLMに選択肢問題を解かせ、誤答に対して自己反省型エージェントが改善策を提供し再回答を試みた結果、自己反省によりパフォーマンスが有意に向上した($p < 0.001$)。さまざまな自己反省のタイプを比較し、それぞれの寄与も明らかにした。全てのコードとデータはGitHubで公開。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Hallucination
Issue Date: 2024-09-01
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?, Zorik Gekhman+, N_A, EMNLP'24
Summary大規模言語モデルはファインチューニングを通じて新しい事実情報に遭遇するが、既存の知識を活用する能力に影響を与える。研究では、閉じた書籍のQAを用いて新しい知識を導入するファインチューニング例の割合を変化させた結果、モデルは新しい知識を学習するのに苦労し、幻覚する傾向が増加することが示された。これにより、ファインチューニングによる新しい知識の導入のリスクが明らかになり、モデルは事前学習を通じて知識を獲得し、ファインチューニングはその利用を効率化することが支持される。
Commentpre-training時に獲得されていない情報を用いてLLMのalignmentを実施すると、知識がない状態で学習データを正しく予測できるように学習されてしまうため、事実に基づかない回答をする(つまりhallucination)ように学習されてしまう、といったことを調査している模様。
>新しい知識を導入するファインチューニング例は、モデルの知識と一致する例よりもはるかに遅く学習されます。しかし、新しい知識を持つ例が最終的に学習されるにつれて、モデルの幻覚する傾向が線形に増加することも発見しました。

早々にoverfittingしている。
>大規模言語モデルは主に事前学習を通じて事実知識を取得し、ファインチューニングはそれをより効率的に使用することを教えるという見解を支持しています。
なるほど、興味深い。下記画像は 1370より引用

本論文中では、full finetuningによる検証を実施しており、LoRAのようなAdapterを用いたテクニックで検証はされていない。LoRAではもともとのLLMのパラメータはfreezeされるため、異なる挙動となる可能性がある。特にLoRAが新しい知識を獲得可能なことが示されれば、LoRA AdapterをもともとのLLMに付け替えるだけで、異なる知識を持ったLLMを運用可能になるため、インパクトが大きいと考えられる。もともとこういった思想は LoRA Hubを提唱する研究などの頃からあった気がするが、AdapterによってHallucination/overfittingを防ぎながら、新たな知識を獲得できることを示した研究はあるのだろうか?

参考: https://x.com/hillbig/status/1792334744522485954?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLoRAの場合については
・1640
・1475
も参照のこと。 #ComputerVision #DiffusionModel Issue Date: 2024-09-01 Diffusion Models Are Real-Time Game Engines, Dani Valevski+, N_A, arXiv'24 SummaryGameNGenは、ニューラルモデルによって完全に動作するゲームエンジンであり、高品質で長い軌跡上で複雑な環境とのリアルタイムインタラクションを可能にします。GameNGenは、単一のTPU上で秒間20フレーム以上でクラシックゲームDOOMをインタラクティブにシミュレートすることができます。次フレーム予測では、PSNRが29.4に達し、劣化JPEG圧縮と比較可能です。GameNGenは、2つの段階でトレーニングされます:(1)RLエージェントがゲームをプレイすることを学び、トレーニングセッションが記録され、(2)拡散モデルが過去のフレームとアクションのシーケンスに応じて次のフレームを生成するようにトレーニングされます。条件付きの拡張により、長い軌跡上で安定した自己回帰生成が可能となります。 CommentDiffusion Modelでゲーム映像を生成する取り組みらしい。ゲームのenvironmentに対して、ユーザのActionとframeの系列をエピソードとみなして生成するっぽい?project pageにデモがのっている
https://gamengen.github.io/ #NLP #In-ContextLearning #DemonstrationSelection Issue Date: 2024-08-28 Revisiting Demonstration Selection Strategies in In-Context Learning, Keqin Peng+, N_A, ACL'24 SummaryLLMsは幅広いタスクを実行する能力を持ち、わずかな例でタスクを説明できることが示されている。しかし、ICLのパフォーマンスはデモンストレーションの選択によって大きく異なり、その要因はまだ明確ではない。本研究では、データとモデルの両面からこの変動に寄与する要因を再検討し、デモンストレーションの選択がデータとモデルの両方に依存することを見出した。さらに、"TopK + ConE"というデータとモデルに依存したデモンストレーション選択手法を提案し、ICLのための効果的なレシピを生み出していることを示した。提案手法は異なるモデルスケールで言語理解および生成タスクの両方で一貫した改善をもたらし、一般性と安定性に加えて以前の手法の効果的な説明を提供している。 CommentICLで利用するデモンストレーションの選択は、BM25やDense Retrieverなどを用いて、テストサンプルと類似したサンプルをretrieveすることで実施されてきた。これらはテストサンプルのみに着目した手法であるが、実際には有効なデモンストレーションはモデルによって変化するため、利用するモデルも考慮した方が良いよね、というお話ベースラインの一覧を見ると、どういった方法がスタンダードなのかがわかる。そして意外とRandomでもそれなりに強いので、実装コストなどと相談しながらどの手法を採用するかは検討した方が良さそう。 #Analysis #NLP #LanguageModel #In-ContextLearning Issue Date: 2024-08-27 What Do Language Models Learn in Context? The Structured Task Hypothesis, Jiaoda Li+, N_A, ACL'24 SummaryLLMsのコンテキスト内学習(ICL)能力を説明する3つの仮説について、一連の実験を通じて探究。最初の2つの仮説を無効にし、最後の仮説を支持する証拠を提供。LLMが事前学習中に学習したタスクを組み合わせることで、コンテキスト内で新しいタスクを学習できる可能性を示唆。 CommentSNLP2024での解説スライド:
http://chasen.org/~daiti-m/paper/SNLP2024-Task-Emergence.pdfICLが何をやっているのか?について、これまでの仮説が正しくないことを実験的に示し、新しい仮説「ICLは事前学習で得られたタスクを組み合わせて新しいタスクを解いている」を提唱し、この仮説が正しいことを示唆する実験結果を得ている模様。
理論的に解明されたわけではなさそうなのでそこは留意した方が良さそう。あとでしっかり読む。 #Analysis #MachineLearning #NLP #SSM (StateSpaceModel) #ICML Issue Date: 2024-08-27 The Illusion of State in State-Space Models, William Merrill+, N_A, ICML'24 SummarySSM(状態空間モデル)は、トランスフォーマーよりも優れた状態追跡の表現力を持つと期待されていましたが、実際にはその表現力は制限されており、トランスフォーマーと類似しています。SSMは複雑性クラス$\mathsf{TC}^0$の外での計算を表現できず、単純な状態追跡問題を解決することができません。このため、SSMは実世界の状態追跡問題を解決する能力に制限がある可能性があります。 Comment>しかし、SSMが状態追跡の表現力で本当に(トランスフォーマーよりも)優位性を持っているのでしょうか?驚くべきことに、その答えは「いいえ」です。私たちの分析によると、SSMの表現力は、トランスフォーマーと非常に類似して制限されています:SSMは複雑性クラス$\mathsf{TC}^0$の外での計算を表現することができません。特に、これは、置換合成のような単純な状態追跡問題を解決することができないことを意味します。これにより、SSMは、特定の表記法でチェスの手を正確に追跡したり、コードを評価したり、長い物語の中のエンティティを追跡することが証明上できないことが明らかになります。
なん…だと… #Analysis #Pretraining #NLP #Supervised-FineTuning (SFT) Issue Date: 2024-08-19 Amuro & Char: Analyzing the Relationship between Pre-Training and Fine-Tuning of Large Language Models, Kaiser Sun+, N_A, arXiv'24 Summary大規模なテキストコーパスで事前学習された複数の中間事前学習モデルのチェックポイントを微調整することによって、事前学習と微調整の関係を調査した。18のデータセットでの結果から、i)継続的な事前学習は、微調整後にモデルを改善する潜在的な方法を示唆している。ii)追加の微調整により、モデルが事前学習段階でうまく機能しないデータセットの改善が、うまく機能するデータセットよりも大きいことを示している。iii)監督された微調整を通じてモデルは恩恵を受けるが、以前のドメイン知識や微調整中に見られないタスクを忘れることがある。iv)監督された微調整後、モデルは評価プロンプトに対して高い感度を示すが、これはより多くの事前学習によって緩和できる。 #Analysis #NLP #LanguageModel #GrammaticalErrorCorrection Issue Date: 2024-08-14 Prompting open-source and commercial language models for grammatical error correction of English learner text, Christopher Davis+, N_A, arXiv'24 SummaryLLMsの進歩により、流暢で文法的なテキスト生成が可能になり、不文法な入力文を与えることで文法エラー修正(GEC)が可能となった。本研究では、7つのオープンソースと3つの商用LLMsを4つのGECベンチマークで評価し、商用モデルが常に教師ありの英語GECモデルを上回るわけではないことを示した。また、オープンソースモデルが商用モデルを上回ることがあり、ゼロショットのプロンプティングがフューショットのプロンプティングと同じくらい競争力があることを示した。 Comment元ポスト:https://x.com/chemical_tree/status/1822860849935253882?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #LLMAgent #ScientificDiscovery Issue Date: 2024-08-13 The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, Chris Lu+, N_A, arXiv'24 Summary最先端の大規模言語モデルを使用して、完全自動の科学的発見を可能にする包括的なフレームワークが提案された。AI Scientistは新しい研究アイデアを生成し、コードを記述し、実験を実行し、結果を可視化し、完全な科学論文を執筆し、査読プロセスを実行することができる。このアプローチは、機械学習における科学的発見の新しい時代の始まりを示しており、AIエージェントの変革的な利点をAI自体の研究プロセス全体にもたらし、世界で最も難しい問題に無限の手頃な価格の創造性とイノベーションを解き放つことに近づいています。 #Controllable #NLP #LanguageModel #InstructionTuning #Length Issue Date: 2024-07-30 Following Length Constraints in Instructions, Weizhe Yuan+, N_A, arXiv'24 Summaryアラインされた命令に従うモデルは、非アラインのモデルよりもユーザーの要求をよりよく満たすことができることが示されています。しかし、このようなモデルの評価には長さのバイアスがあり、訓練アルゴリズムは長い応答を学習することでこのバイアスを利用する傾向があることが示されています。本研究では、推論時に所望の長さ制約を含む命令で制御できるモデルの訓練方法を示します。このようなモデルは、長さ指示された評価において優れており、GPT4、Llama 3、Mixtralなどの標準的な命令に従うモデルを上回っています。 CommentSoTA LLMがOutput長の制約に従わないことを示し、それを改善する学習手法LIFT-DPOを提案
元ツイート: https://x.com/jaseweston/status/1805771223747481690?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-07-30 Searching for Best Practices in Retrieval-Augmented Generation, Xiaohua Wang+, N_A, arXiv'24 SummaryRAG技術は、最新情報の統合、幻覚の軽減、および応答品質の向上に効果的であることが証明されています。しかし、多くのRAGアプローチは複雑な実装と長時間の応答時間という課題に直面しています。本研究では、既存のRAGアプローチとその潜在的な組み合わせを調査し、最適なRAGプラクティスを特定するために取り組んでいます。さらに、マルチモーダル検索技術が視覚入力に関する質問応答能力を大幅に向上させ、"検索を生成として"戦略を用いてマルチモーダルコンテンツの生成を加速できることを示します。 CommentRAGをやる上で参考になりそう #Survey #NLP #LanguageModel #Prompting Issue Date: 2024-07-30 A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications, Pranab Sahoo+, N_A, arXiv'24 Summaryプロンプトエンジニアリングは、LLMsやVLMsの能力を拡張するための重要な技術であり、モデルのパラメータを変更せずにタスク固有の指示であるプロンプトを活用してモデルの効果を向上させる。本研究は、プロンプトエンジニアリングの最近の進展について構造化された概要を提供し、各手法の強みと制限について掘り下げることで、この分野をよりよく理解し、将来の研究を促進することを目的としている。 Comment Issue Date: 2024-07-10
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs, LLM-jp+, N_A, arXiv'24
SummaryLLM-jpは、日本語の大規模言語モデル(LLMs)の研究開発を行うためのクロス組織プロジェクトで、オープンソースで強力な日本語LLMsを開発することを目指している。現在は、1,500人以上のアカデミアと産業界の参加者が協力しており、LLM-jpの設立の背景、活動の概要、および開発されたLLMsの技術レポートについて紹介している。最新の活動については、https://llm-jp.nii.ac.jp/en/をご覧いただけます。
Commentllm.jpによるテクニカルレポート
Issue Date: 2024-07-08
Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, N_A, arXiv'24
SummaryLMsの成功の背後にある重要な手法は、教師なしのマルチタスク事前学習であるが、教師ありのマルチタスク学習も重要な可能性を秘めている。本研究では、Instruction Pre-Trainingというフレームワークを提案し、大規模な生のコーパスに効率的な指示合成器によって生成された指示-応答ペアを追加することで、LMsを事前学習する。実験では、40以上のタスクカテゴリをカバーする2億の指示-応答ペアを合成し、Instruction Pre-Trainingの効果を検証する。結果として、ゼロからの事前学習では、Instruction Pre-Trainingは事前学習済みベースモデルを強化し、継続的な事前学習では、Llama3-8BがLlama3-70Bと同等以上の性能を発揮することが示された。
Comment参考:https://x.com/hillbig/status/1810082530307330401?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2024-06-19
How Do Large Language Models Acquire Factual Knowledge During Pretraining?, Hoyeon Chang+, N_A, arXiv'24
SummaryLLMsの事前学習中の実際の知識獲得のメカニズムについて調査した結果、以下の洞察が得られた。1. より多くのデータでの事前学習は、実際の知識の獲得と維持にほとんど改善をもたらさない。2. 訓練ステップと記憶の忘却、実際の知識の一般化との間にはべき乗則の関係があり、重複した訓練データで訓練されたLLMsはより速い忘却を示す。3. より大きなバッチサイズでLLMsを訓練することで、モデルの忘却に対する耐性が向上する。LLMの事前学習における実際の知識の獲得は、各ステップで事前学習データに提示される実際の知識の確率を徐々に増加させることによって起こり、後続の忘却によって希釈される。これに基づいて、LLMsの振る舞いについて合理的な説明が提供される。
Issue Date: 2024-06-17
Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling, Liliang Ren+, N_A, arXiv'24
SummarySambaは、選択的状態空間モデル(SSM)であるMambaとスライディングウィンドウアテンション(SWA)を組み合わせたハイブリッドアーキテクチャであり、長いシーケンスを効率的にモデリングすることができる。Sambaは、3.8Bのパラメータにスケーリングされ、3.2Tのトレーニングトークンで訓練され、最先端のモデルを大幅に上回る性能を示した。また、Sambaは線形時間のシーケンスモデルとして、Transformersと比較して高速化が得られ、無制限のストリーミングでトークンを生成する際にも優れた性能を発揮する。 Sambaのサンプル実装は、https://github.com/microsoft/Samba で公開されています。
Issue Date: 2024-05-18
ReFT: Representation Finetuning for Language Models, Zhengxuan Wu+, N_A, arXiv'24
SummaryPEFT手法は、少数の重みの更新を通じて大きなモデルを微調整することを目指している。しかし、表現の編集がより強力な代替手法である可能性を示唆する解釈可能性の研究があり、その仮説を追求するためにReFT手法のファミリーを開発した。ReFT手法は、凍結されたベースモデル上で動作し、隠れた表現に対するタスク固有の介入を学習する。その中でも、LoReFTはPEFTの代替として利用でき、従来の最先端のPEFTよりも10倍から50倍パラメータ効率的な介入を学習する。LoReFTは8つの常識的な推論タスク、4つの算術推論タスク、Alpaca-Eval v1.0、およびGLUEで展示され、効率とパフォーマンスの最良のバランスを提供し、最先端のPEFTを上回ることが示された。
Comment参考:https://www.ai-shift.co.jp/techblog/4456
Issue Date: 2024-05-03
In-Context Learning with Long-Context Models: An In-Depth Exploration, Amanda Bertsch+, N_A, arXiv'24
Summaryモデルのコンテキスト長が増加するにつれて、インコンテキスト学習(ICL)の振る舞いを研究しています。大きなラベルスペースを持つデータセットでは、数百または数千のデモンストレーションで性能が向上することを示し、長いコンテキストのICLは驚くほど効果的であるが、そのほとんどはタスク学習ではなく、類似の例に再度注目することから得られると結論付けます。
Issue Date: 2024-05-03
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model, Yu Cui+, N_A, arXiv'24
SummaryLLMsの高い推論遅延を解消するために、本研究では、LLMベースの推奨モデルから軽量な従来の直列モデルへの知識蒸留を調査している。新しい蒸留戦略であるDLLM2Recには、重要度重視のランキング蒸留と共同埋め込み蒸留が含まれており、徹底的な実験により、提案されたDLLM2Recの効果が示され、典型的な直列モデルを平均47.97%改善し、場合によってはLLMベースの推奨者を上回ることが可能であることが示された。
Issue Date: 2024-05-03
A Careful Examination of Large Language Model Performance on Grade School Arithmetic, Hugh Zhang+, N_A, arXiv'24
SummaryLLMsの成功は、データセットの汚染によるものであり、真の推論能力に疑念がある。Grade School Math 1000(GSM1k)を導入し、小学校の数学的推論を測定するためのゴールドスタンダードとして設計。GSM1kでの評価では、一部のモデルが系統的な過学習を示し、精度が低下することが観察された。一方、最先端のモデルは過学習の兆候がほとんど見られず、GSM8kとGSM1kの性能差との間に正の関係があることが示唆された。
Issue Date: 2024-05-03
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, Seungone Kim+, N_A, arXiv'24
SummaryGPT-4などのプロプライエタリな言語モデルの評価に対する懸念から、オープンソースの評価言語モデルの開発が進んでいる。既存のオープンな評価言語モデルには欠点があり、これらの問題に対処するために、Prometheus 2という強力な評価言語モデルが紹介された。Prometheus 2は、人間とGPT-4の判断に密接に追随し、ユーザー定義の評価基準に基づいてグループ化された直接評価とペアワイズランキング形式の両方を処理する能力を持っている。Prometheus 2は、すべてのテストされたオープンな評価言語モデルの中で、人間とプロプライエタリな言語モデルの判断と最も高い相関と一致を示した。
Issue Date: 2024-04-30
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity, Soyeong Jeong+, N_A, arXiv'24
SummaryRetrieval-Augmented Large Language Models(LLMs)は、外部知識ベースからの非パラメトリックな知識をLLMsに組み込むことで、質問応答(QA)などのいくつかのタスクで応答の精度を向上させる有望なアプローチとして登場しています。しかし、さまざまな複雑さのクエリに対処するさまざまなアプローチがあるにもかかわらず、単純なクエリを不要な計算オーバーヘッドで処理するか、複雑な多段階クエリに適切に対処できないものがあります。本研究では、クエリの複雑さに基づいて、最も適した戦略を動的に選択できる新しい適応型QAフレームワークを提案します。また、この選択プロセスは、自動的に収集されたラベルによって入力クエリの複雑さを予測するためにトレーニングされた小さなLMである分類器によって操作されます。これらのアプローチは、クエリの複雑さの範囲に応じて、反復的および単一ステップのリトリーバル拡張LLMs、および非リトリーバルメソッドの間をシームレスに適応するバランスの取れた戦略を提供します。提案手法が関連するベースラインと比較して、QAシステムの全体的な効率と精度を向上させることを示し、オープンドメインQAデータセットでモデルを検証しました。
#EfficiencyImprovement
#NLP
#LanguageModel
#OpenWeight
Issue Date: 2024-04-23
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, Marah Abdin+, N_A, arXiv'24
Summaryphi-3-miniは38億パラメータの言語モデルであり、3.3兆トークンで訓練されています。Mixtral 8x7BやGPT-3.5などの大規模モデルに匹敵する総合的なパフォーマンスを持ちながら、スマートフォンにデプロイ可能なサイズです。このモデルは、厳密にフィルタリングされたWebデータと合成データで構成されており、堅牢性、安全性、およびチャット形式に適合しています。また、phi-3-smallとphi-3-mediumというより大規模なモデルも紹介されています。
Comment1039 の次の次(Phi2.0についてはメモってなかった)。スマホにデプロイできるレベルのサイズで、GPT3.5Turbo程度の性能を実現したらしいLlama2と同じブロックを利用しているため、アーキテクチャはLlama2と共通。
Issue Date: 2024-07-10
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs, LLM-jp+, N_A, arXiv'24
SummaryLLM-jpは、日本語の大規模言語モデル(LLMs)の研究開発を行うためのクロス組織プロジェクトで、オープンソースで強力な日本語LLMsを開発することを目指している。現在は、1,500人以上のアカデミアと産業界の参加者が協力しており、LLM-jpの設立の背景、活動の概要、および開発されたLLMsの技術レポートについて紹介している。最新の活動については、https://llm-jp.nii.ac.jp/en/をご覧いただけます。
Commentllm.jpによるテクニカルレポート
Issue Date: 2024-07-08
Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, N_A, arXiv'24
SummaryLMsの成功の背後にある重要な手法は、教師なしのマルチタスク事前学習であるが、教師ありのマルチタスク学習も重要な可能性を秘めている。本研究では、Instruction Pre-Trainingというフレームワークを提案し、大規模な生のコーパスに効率的な指示合成器によって生成された指示-応答ペアを追加することで、LMsを事前学習する。実験では、40以上のタスクカテゴリをカバーする2億の指示-応答ペアを合成し、Instruction Pre-Trainingの効果を検証する。結果として、ゼロからの事前学習では、Instruction Pre-Trainingは事前学習済みベースモデルを強化し、継続的な事前学習では、Llama3-8BがLlama3-70Bと同等以上の性能を発揮することが示された。
Comment参考:https://x.com/hillbig/status/1810082530307330401?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2024-06-19
How Do Large Language Models Acquire Factual Knowledge During Pretraining?, Hoyeon Chang+, N_A, arXiv'24
SummaryLLMsの事前学習中の実際の知識獲得のメカニズムについて調査した結果、以下の洞察が得られた。1. より多くのデータでの事前学習は、実際の知識の獲得と維持にほとんど改善をもたらさない。2. 訓練ステップと記憶の忘却、実際の知識の一般化との間にはべき乗則の関係があり、重複した訓練データで訓練されたLLMsはより速い忘却を示す。3. より大きなバッチサイズでLLMsを訓練することで、モデルの忘却に対する耐性が向上する。LLMの事前学習における実際の知識の獲得は、各ステップで事前学習データに提示される実際の知識の確率を徐々に増加させることによって起こり、後続の忘却によって希釈される。これに基づいて、LLMsの振る舞いについて合理的な説明が提供される。
Issue Date: 2024-06-17
Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling, Liliang Ren+, N_A, arXiv'24
SummarySambaは、選択的状態空間モデル(SSM)であるMambaとスライディングウィンドウアテンション(SWA)を組み合わせたハイブリッドアーキテクチャであり、長いシーケンスを効率的にモデリングすることができる。Sambaは、3.8Bのパラメータにスケーリングされ、3.2Tのトレーニングトークンで訓練され、最先端のモデルを大幅に上回る性能を示した。また、Sambaは線形時間のシーケンスモデルとして、Transformersと比較して高速化が得られ、無制限のストリーミングでトークンを生成する際にも優れた性能を発揮する。 Sambaのサンプル実装は、https://github.com/microsoft/Samba で公開されています。
Issue Date: 2024-05-18
ReFT: Representation Finetuning for Language Models, Zhengxuan Wu+, N_A, arXiv'24
SummaryPEFT手法は、少数の重みの更新を通じて大きなモデルを微調整することを目指している。しかし、表現の編集がより強力な代替手法である可能性を示唆する解釈可能性の研究があり、その仮説を追求するためにReFT手法のファミリーを開発した。ReFT手法は、凍結されたベースモデル上で動作し、隠れた表現に対するタスク固有の介入を学習する。その中でも、LoReFTはPEFTの代替として利用でき、従来の最先端のPEFTよりも10倍から50倍パラメータ効率的な介入を学習する。LoReFTは8つの常識的な推論タスク、4つの算術推論タスク、Alpaca-Eval v1.0、およびGLUEで展示され、効率とパフォーマンスの最良のバランスを提供し、最先端のPEFTを上回ることが示された。
Comment参考:https://www.ai-shift.co.jp/techblog/4456
Issue Date: 2024-05-03
In-Context Learning with Long-Context Models: An In-Depth Exploration, Amanda Bertsch+, N_A, arXiv'24
Summaryモデルのコンテキスト長が増加するにつれて、インコンテキスト学習(ICL)の振る舞いを研究しています。大きなラベルスペースを持つデータセットでは、数百または数千のデモンストレーションで性能が向上することを示し、長いコンテキストのICLは驚くほど効果的であるが、そのほとんどはタスク学習ではなく、類似の例に再度注目することから得られると結論付けます。
Issue Date: 2024-05-03
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model, Yu Cui+, N_A, arXiv'24
SummaryLLMsの高い推論遅延を解消するために、本研究では、LLMベースの推奨モデルから軽量な従来の直列モデルへの知識蒸留を調査している。新しい蒸留戦略であるDLLM2Recには、重要度重視のランキング蒸留と共同埋め込み蒸留が含まれており、徹底的な実験により、提案されたDLLM2Recの効果が示され、典型的な直列モデルを平均47.97%改善し、場合によってはLLMベースの推奨者を上回ることが可能であることが示された。
Issue Date: 2024-05-03
A Careful Examination of Large Language Model Performance on Grade School Arithmetic, Hugh Zhang+, N_A, arXiv'24
SummaryLLMsの成功は、データセットの汚染によるものであり、真の推論能力に疑念がある。Grade School Math 1000(GSM1k)を導入し、小学校の数学的推論を測定するためのゴールドスタンダードとして設計。GSM1kでの評価では、一部のモデルが系統的な過学習を示し、精度が低下することが観察された。一方、最先端のモデルは過学習の兆候がほとんど見られず、GSM8kとGSM1kの性能差との間に正の関係があることが示唆された。
Issue Date: 2024-05-03
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, Seungone Kim+, N_A, arXiv'24
SummaryGPT-4などのプロプライエタリな言語モデルの評価に対する懸念から、オープンソースの評価言語モデルの開発が進んでいる。既存のオープンな評価言語モデルには欠点があり、これらの問題に対処するために、Prometheus 2という強力な評価言語モデルが紹介された。Prometheus 2は、人間とGPT-4の判断に密接に追随し、ユーザー定義の評価基準に基づいてグループ化された直接評価とペアワイズランキング形式の両方を処理する能力を持っている。Prometheus 2は、すべてのテストされたオープンな評価言語モデルの中で、人間とプロプライエタリな言語モデルの判断と最も高い相関と一致を示した。
Issue Date: 2024-04-30
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity, Soyeong Jeong+, N_A, arXiv'24
SummaryRetrieval-Augmented Large Language Models(LLMs)は、外部知識ベースからの非パラメトリックな知識をLLMsに組み込むことで、質問応答(QA)などのいくつかのタスクで応答の精度を向上させる有望なアプローチとして登場しています。しかし、さまざまな複雑さのクエリに対処するさまざまなアプローチがあるにもかかわらず、単純なクエリを不要な計算オーバーヘッドで処理するか、複雑な多段階クエリに適切に対処できないものがあります。本研究では、クエリの複雑さに基づいて、最も適した戦略を動的に選択できる新しい適応型QAフレームワークを提案します。また、この選択プロセスは、自動的に収集されたラベルによって入力クエリの複雑さを予測するためにトレーニングされた小さなLMである分類器によって操作されます。これらのアプローチは、クエリの複雑さの範囲に応じて、反復的および単一ステップのリトリーバル拡張LLMs、および非リトリーバルメソッドの間をシームレスに適応するバランスの取れた戦略を提供します。提案手法が関連するベースラインと比較して、QAシステムの全体的な効率と精度を向上させることを示し、オープンドメインQAデータセットでモデルを検証しました。
#EfficiencyImprovement
#NLP
#LanguageModel
#OpenWeight
Issue Date: 2024-04-23
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, Marah Abdin+, N_A, arXiv'24
Summaryphi-3-miniは38億パラメータの言語モデルであり、3.3兆トークンで訓練されています。Mixtral 8x7BやGPT-3.5などの大規模モデルに匹敵する総合的なパフォーマンスを持ちながら、スマートフォンにデプロイ可能なサイズです。このモデルは、厳密にフィルタリングされたWebデータと合成データで構成されており、堅牢性、安全性、およびチャット形式に適合しています。また、phi-3-smallとphi-3-mediumというより大規模なモデルも紹介されています。
Comment1039 の次の次(Phi2.0についてはメモってなかった)。スマホにデプロイできるレベルのサイズで、GPT3.5Turbo程度の性能を実現したらしいLlama2と同じブロックを利用しているため、アーキテクチャはLlama2と共通。
#EfficiencyImprovement #NLP #LanguageModel #Pruning Issue Date: 2024-04-22 The Unreasonable Ineffectiveness of the Deeper Layers, Andrey Gromov+, N_A, arXiv'24 Summary一般的なオープンウェイトの事前学習されたLLMのレイヤー剪定戦略を研究し、異なる質問応答ベンチマークでのパフォーマンスの低下を最小限に抑えることを示しました。レイヤーの最大半分を削除することで、最適なブロックを特定し、微調整して損傷を修復します。PEFT手法を使用し、実験を単一のA100 GPUで実行可能にします。これにより、計算リソースを削減し、推論のメモリとレイテンシを改善できることが示唆されます。また、LLMがレイヤーの削除に対して堅牢であることは、浅いレイヤーが知識を格納する上で重要な役割を果たしている可能性を示唆しています。 Comment下記ツイートによると、学習済みLLMから、コサイン類似度で入出力間の類似度が高い層を除いてもタスクの精度が落ちず、特に深い層を2-4割削除しても精度が落ちないとのこと。
参考:https://x.com/hillbig/status/1773110076502368642?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
VRAMに載せるのが大変なので、このような枝刈り技術が有効だと分かるのはありがたい。LoRAや量子化も利用しているっぽい。 #Survey #SpokenLanguageProcessing #Evaluation #FoundationModel #Speech Issue Date: 2024-04-21 A Large-Scale Evaluation of Speech Foundation Models, Shu-wen Yang+, N_A, arXiv'24 Summary基盤モデルパラダイムは、共有基盤モデルを使用して最先端のパフォーマンスを達成し、下流特有のモデリングやデータ注釈を最小限に抑えることを目指す。このアプローチは、自然言語処理(NLP)の分野で成功しているが、音声処理分野では類似したセットアップが不足している。本研究では、音声処理ユニバーサルパフォーマンスベンチマーク(SUPERB)を設立し、音声に対する基盤モデルパラダイムの効果を調査する。凍結された基盤モデルに続いて、タスク専用の軽量な予測ヘッドを使用して、SUPERB内の音声処理タスクに取り組むための統一されたマルチタスキングフレームワークを提案する。結果は、基盤モデルパラダイムが音声に有望であり、提案されたマルチタスキングフレームワークが効果的であることを示し、最も優れた基盤モデルがほとんどのSUPERBタスクで競争力のある汎化性能を持つことを示している。 CommentSpeech関連のFoundation Modelの評価結果が載っているらしい。
図は下記ツイートより引用
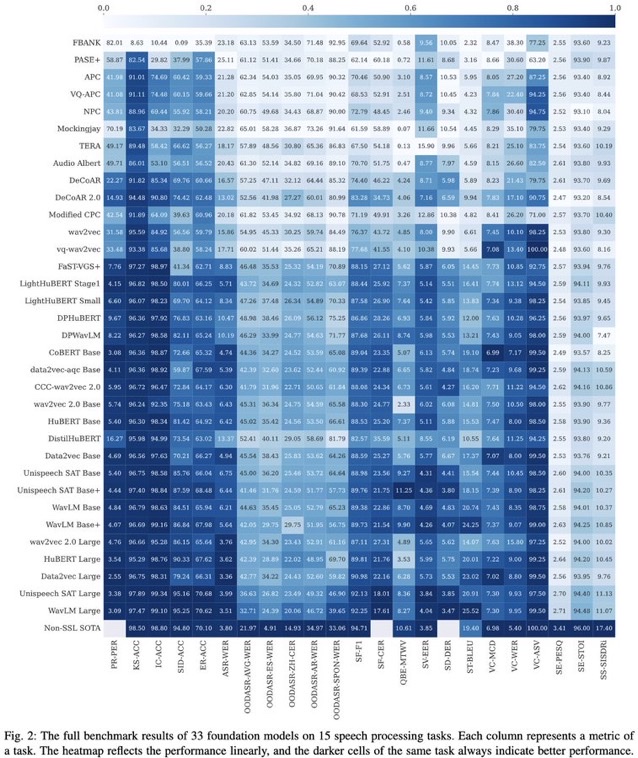
参考:https://x.com/unilightwf/status/1781659340065345766?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-04-17 Compression Represents Intelligence Linearly, Yuzhen Huang+, N_A, arXiv'24 Summary最近の研究では、大規模言語モデル(LLMs)をデータ圧縮器として扱い、圧縮と知性の関係を検討しています。LLMsの知性は、外部テキストコーパスを圧縮する能力とほぼ線形的に相関しており、優れた圧縮がより高い知性を示すという信念を支持する具体的な証拠を提供しています。さらに、圧縮効率はモデルの能力と線形的に関連しており、圧縮を評価するためのデータセットとパイプラインがオープンソース化されています。 Comment参考: https://x.com/hillbig/status/1780365637225001004?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-04-16 TransformerFAM: Feedback attention is working memory, Dongseong Hwang+, N_A, arXiv'24 SummaryTransformersの二次的なattentionの複雑さにより、無限に長い入力を処理する能力が制限されている課題がある。そこで、新しいTransformerアーキテクチャであるフィードバックアテンションメモリ(FAM)を提案し、自己アテンションを可能にする。この設計により、Transformer内での作業メモリが促進され、無限に長いシーケンスを処理できるようになる。TransformerFAMは追加の重みが不要で、事前学習済みモデルとの統合が容易。実験結果では、TransformerFAMがさまざまなモデルサイズで長いコンテキストのタスクにおける性能を向上させることを示しており、LLMsが無制限の長さのシーケンスを処理する可能性を示唆している。 #Survey #NLP #LanguageModel Issue Date: 2024-04-14 Knowledge Conflicts for LLMs: A Survey, Rongwu Xu+, N_A, arXiv'24 SummaryLLMsにおける知識の衝突に焦点を当て、文脈とパラメトリック知識の組み合わせによる複雑な課題を分析。文脈-メモリ、文脈間、メモリ内の衝突の3つのカテゴリーを探求し、実世界のアプリケーションにおける信頼性とパフォーマンスへの影響を検討。解決策を提案し、LLMsの堅牢性向上を目指す。 #NLP #LanguageModel #SelfImprovement Issue Date: 2024-04-14 Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, Eric Zelikman+, N_A, arXiv'24 SummarySTaR(Self-Taught Reasoner)では、少数の例から合理的な推論を学習し、質問応答に活用する方法が提案された。Quiet-STaRでは、LMが合理性を生成する方法を学習し、難しい質問に直接答える能力を向上させる。この手法は、GSM8KやCommonsenseQAなどのタスクにおいてゼロショットの改善を実現し、ファインチューニングが不要であることが示された。Quiet-STaRは、推論を学習するための一般的でスケーラブルな方法を提供する一歩となっている。 Commento1(1390)の基礎技術と似ている可能性がある
先行研究:
・1397参考:https://x.com/hillbig/status/1835449666588271046?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #InformationRetrieval #NLP #Chain-of-Thought #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-04-14 RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation, Zihao Wang+, N_A, arXiv'24 Summary大規模言語モデルの推論および生成能力を向上させ、幻覚を軽減する方法として、情報検索を利用して思考の連鎖を修正する「retrieval-augmented thoughts(RAT)」が提案された。この方法は、ゼロショットのCoTが生成された後、取得した情報を使用して各思考ステップを修正する。GPT-3.5、GPT-4、およびCodeLLaMA-7bにRATを適用することで、コード生成、数学的推論、創造的な執筆、具体的なタスク計画などのタスクでパフォーマンスが大幅に向上した。デモページはhttps://craftjarvis.github.io/RATで利用可能。 CommentRAGにおいてCoTさせる際に、各reasoningのstepを見直させることでより質の高いreasoningを生成するRATを提案。Hallucinationが低減し、生成のパフォーマンスも向上するとのこと。
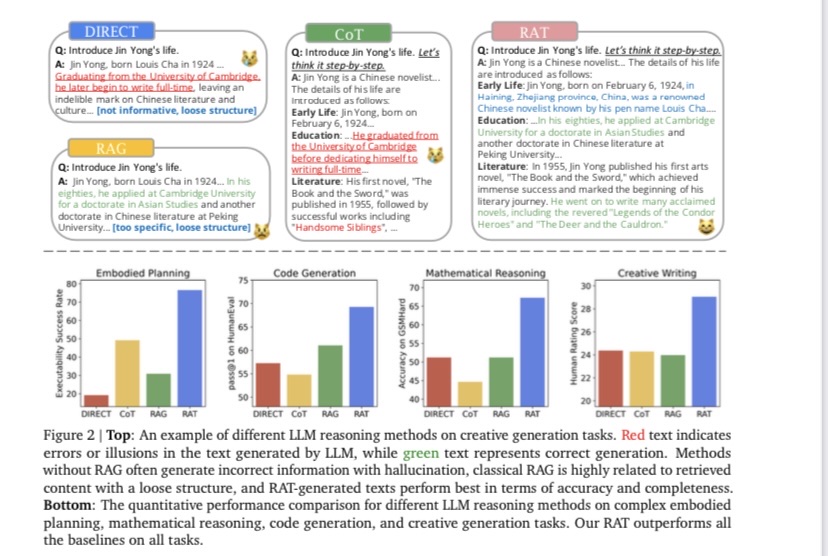 コンセプト自体はそりゃそうだよねという話なので、RAGならではの課題があり、それを解決した、みたいな話があるのかが気になる。
#ComputerVision
#NLP
#LanguageModel
#Chain-of-Thought
Issue Date: 2024-04-08
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models, Wenshan Wu+, N_A, arXiv'24
SummaryLLMsの空間推論能力を向上させるために、Visualization-of-Thought(VoT)プロンプティングを提案。VoTは、LLMsの推論トレースを可視化し、空間推論タスクで使用することで、既存のMLLMsを上回る性能を示す。VoTは、空間推論を促進するために「メンタルイメージ」を生成する能力を持ち、MLLMsでの有効性を示唆する。
#Analysis
#NLP
#LanguageModel
#ContextWindow
#LongSequence
Issue Date: 2024-04-07
Long-context LLMs Struggle with Long In-context Learning, Tianle Li+, N_A, arXiv'24
SummaryLLMsは長いシーケンスを処理する能力に進展しているが、実世界のシナリオでの能力を評価するための専門的なベンチマークLongICLBenchが導入された。このベンチマークでは、LLMsは巨大なラベル空間を理解し、正しい予測を行うために入力全体を理解する必要がある。研究によると、長いコンテキストLLMsは長いコンテキストウィンドウを活用することで比較的良いパフォーマンスを示すが、最も困難なタスクでは苦労している。現在のLLMsは長くコンテキスト豊かなシーケンスを処理し理解する能力にギャップがあることを示唆しており、長いコンテキストの理解と推論は依然として難しい課題であることが示されている。
CommentGPT4以外はコンテキストが20Kを超えると性能が劣化する傾向にあるとのこと。データセットを難易度別に収集し評価したところ、難易度の高いデータではそもそもコンテキストが長くなると全てのLLMがタスクを理解するできずほぼ0%の性能となった。
コンセプト自体はそりゃそうだよねという話なので、RAGならではの課題があり、それを解決した、みたいな話があるのかが気になる。
#ComputerVision
#NLP
#LanguageModel
#Chain-of-Thought
Issue Date: 2024-04-08
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models, Wenshan Wu+, N_A, arXiv'24
SummaryLLMsの空間推論能力を向上させるために、Visualization-of-Thought(VoT)プロンプティングを提案。VoTは、LLMsの推論トレースを可視化し、空間推論タスクで使用することで、既存のMLLMsを上回る性能を示す。VoTは、空間推論を促進するために「メンタルイメージ」を生成する能力を持ち、MLLMsでの有効性を示唆する。
#Analysis
#NLP
#LanguageModel
#ContextWindow
#LongSequence
Issue Date: 2024-04-07
Long-context LLMs Struggle with Long In-context Learning, Tianle Li+, N_A, arXiv'24
SummaryLLMsは長いシーケンスを処理する能力に進展しているが、実世界のシナリオでの能力を評価するための専門的なベンチマークLongICLBenchが導入された。このベンチマークでは、LLMsは巨大なラベル空間を理解し、正しい予測を行うために入力全体を理解する必要がある。研究によると、長いコンテキストLLMsは長いコンテキストウィンドウを活用することで比較的良いパフォーマンスを示すが、最も困難なタスクでは苦労している。現在のLLMsは長くコンテキスト豊かなシーケンスを処理し理解する能力にギャップがあることを示唆しており、長いコンテキストの理解と推論は依然として難しい課題であることが示されている。
CommentGPT4以外はコンテキストが20Kを超えると性能が劣化する傾向にあるとのこと。データセットを難易度別に収集し評価したところ、難易度の高いデータではそもそもコンテキストが長くなると全てのLLMがタスクを理解するできずほぼ0%の性能となった。
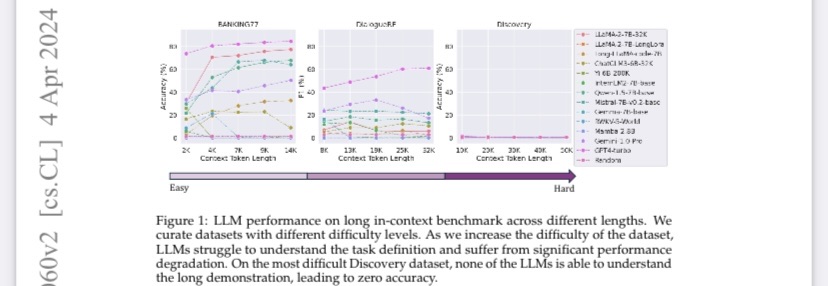 #EfficiencyImprovement
#NLP
#LanguageModel
#Transformer
Issue Date: 2024-04-07
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models, David Raposo+, N_A, arXiv'24
SummaryTransformerベースの言語モデルは、入力シーケンス全体に均等にFLOPsを分散させる代わりに、特定の位置にFLOPsを動的に割り当てることを学習できることを示す。モデルの深さにわたって割り当てを最適化するために、異なるレイヤーで計算を動的に割り当てる。この手法は、トークンの数を制限することで合計計算予算を強制し、トークンはtop-kルーティングメカニズムを使用して決定される。この方法により、FLOPsを均等に消費しつつ、計算の支出が予測可能であり、動的かつコンテキストに敏感である。このようにトレーニングされたモデルは、計算を動的に割り当てることを学習し、効率的に行うことができる。
Comment参考: https://x.com/theseamouse/status/1775782800362242157?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#Transformer
#Attention
Issue Date: 2024-04-07
Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference, Piotr Nawrot+, N_A, arXiv'24
Summaryトランスフォーマーの生成効率を向上させるために、Dynamic Memory Compression(DMC)が提案された。DMCは、異なるヘッドとレイヤーで異なる圧縮率を適用する方法を学習し、事前学習済みLLMsに適用される。DMCは、元の下流パフォーマンスを最大4倍のキャッシュ圧縮で維持しつつ、スループットを向上させることができる。DMCは、GQAと組み合わせることでさらなる利益をもたらす可能性があり、長いコンテキストと大きなバッチを処理する際に有用である。
Comment参考: https://x.com/hillbig/status/1776755029581676943?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q論文中のFigure1が非常にわかりやすい。
#EfficiencyImprovement
#NLP
#LanguageModel
#Transformer
Issue Date: 2024-04-07
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models, David Raposo+, N_A, arXiv'24
SummaryTransformerベースの言語モデルは、入力シーケンス全体に均等にFLOPsを分散させる代わりに、特定の位置にFLOPsを動的に割り当てることを学習できることを示す。モデルの深さにわたって割り当てを最適化するために、異なるレイヤーで計算を動的に割り当てる。この手法は、トークンの数を制限することで合計計算予算を強制し、トークンはtop-kルーティングメカニズムを使用して決定される。この方法により、FLOPsを均等に消費しつつ、計算の支出が予測可能であり、動的かつコンテキストに敏感である。このようにトレーニングされたモデルは、計算を動的に割り当てることを学習し、効率的に行うことができる。
Comment参考: https://x.com/theseamouse/status/1775782800362242157?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#EfficiencyImprovement
#NLP
#LanguageModel
#Transformer
#Attention
Issue Date: 2024-04-07
Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference, Piotr Nawrot+, N_A, arXiv'24
Summaryトランスフォーマーの生成効率を向上させるために、Dynamic Memory Compression(DMC)が提案された。DMCは、異なるヘッドとレイヤーで異なる圧縮率を適用する方法を学習し、事前学習済みLLMsに適用される。DMCは、元の下流パフォーマンスを最大4倍のキャッシュ圧縮で維持しつつ、スループットを向上させることができる。DMCは、GQAと組み合わせることでさらなる利益をもたらす可能性があり、長いコンテキストと大きなバッチを処理する際に有用である。
Comment参考: https://x.com/hillbig/status/1776755029581676943?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q論文中のFigure1が非常にわかりやすい。
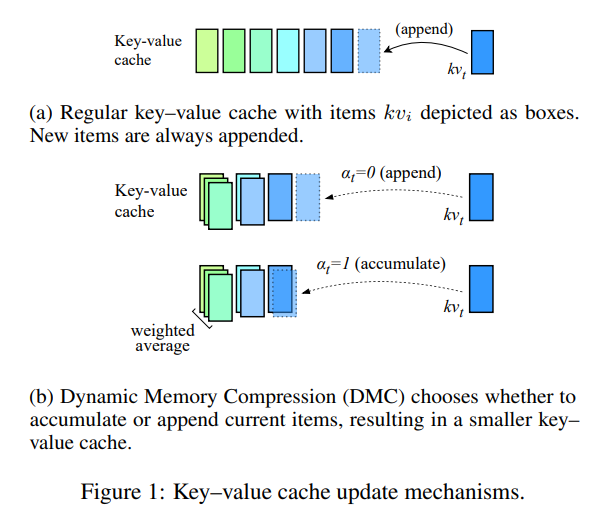
GQA 1271 と比較して、2~4倍キャッシュを圧縮しつつ、より高い性能を実現。70Bモデルの場合は、GQAで8倍キャッシュを圧縮した上で、DMCで追加で2倍圧縮をかけたところ、同等のパフォーマンスを実現している。

#InformationRetrieval #NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-04-07 RAFT: Adapting Language Model to Domain Specific RAG, Tianjun Zhang+, N_A, arXiv'24 Summary大規模なテキストデータのLLMsを事前学習し、新しい知識を追加するためのRetrieval Augmented FineTuning(RAFT)を提案。RAFTは、質問に回答するのに役立つ関連文書から正しいシーケンスを引用し、chain-of-thoughtスタイルの応答を通じて推論能力を向上させる。RAFTはPubMed、HotpotQA、Gorillaデータセットでモデルのパフォーマンスを向上させ、事前学習済みLLMsをドメイン固有のRAGに向けて改善する。 CommentQuestion, instruction, coxtext, cot style answerの4つを用いてSFTをする模様
画像は下記ツイートより引用
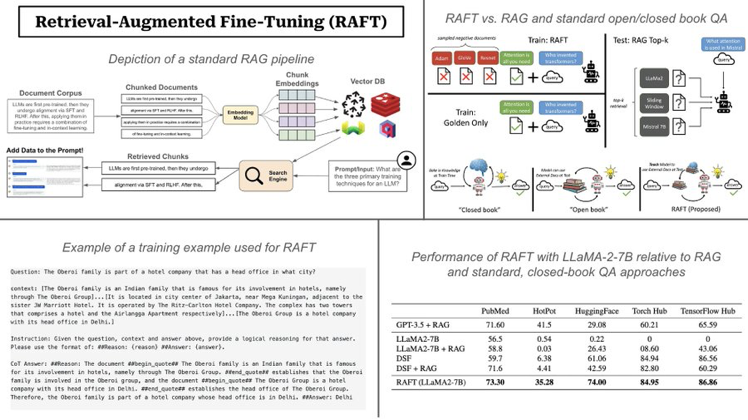
https://x.com/cwolferesearch/status/1770912695765660139?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #InformationRetrieval #NLP #LanguageModel #Prompting #Reasoning Issue Date: 2024-04-07 RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners, Chi Hu+, N_A, arXiv'24 SummaryLLMsは推論タスクで優れた性能を発揮しているが、論理エラーが起こりやすい。RankPromptという新しいプロンプティング方法を導入し、LLMsが自己ランク付けを行い推論パフォーマンスを向上させる。実験では、RankPromptがChatGPTやGPT-4の推論パフォーマンスを13%向上させ、AlpacaEvalデータセットで人間の判断と74%の一致率を示すことが示された。RankPromptは言語モデルから高品質なフィードバックを引き出す効果的な方法であることが示された。 CommentLLMでランキングをするためのプロンプト手法。大量の候補をランキングするのは困難だと思われるが、リランキング手法としては利用できる可能性がある
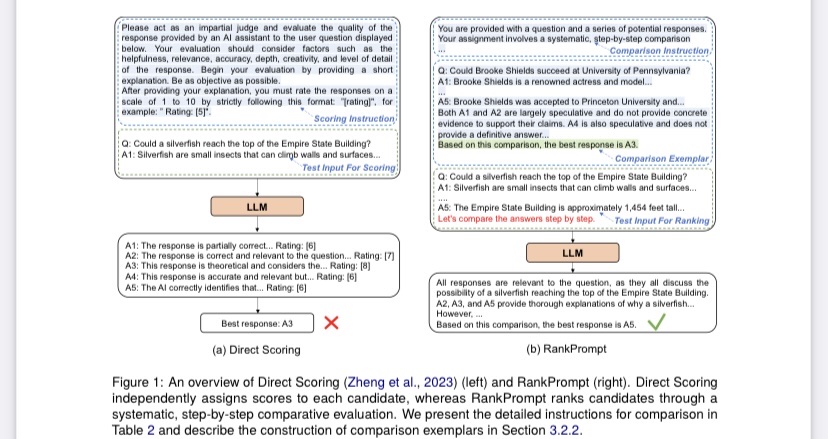 #NaturalLanguageGeneration
#NLP
#DataToTextGeneration
#Prompting
#NumericReasoning
Issue Date: 2024-04-04
Prompting for Numerical Sequences: A Case Study on Market Comment Generation, Masayuki Kawarada+, N_A, arXiv'24
SummaryLLMsは、構造化データに対するプロンプト生成に関する研究が進んでいるが、時系列数値データに関する詳細な調査が不足している。本研究では、株価の数値系列を入力として市場コメントを生成するタスクに焦点を当て、さまざまな入力表現を探究する。実験結果は、プログラミング言語に似たプロンプトがより良い結果をもたらすことを示しており、数値系列からテキストを生成する際の効果的なプロンプト作成について示唆を提供している。
CommentData-to-Text系のタスクでは、しばしば数値列がInputとなり、そこからテキストを生成するが、この際にどのようなフォーマットで数値列をPromptingするのが良いかを調査した研究。Pythonリストなどのプログラミング言語に似たプロンプトが高い性能を示し、自然言語やhtml, latextなどのプロンプトは効果が低かったとのこと
#NaturalLanguageGeneration
#NLP
#DataToTextGeneration
#Prompting
#NumericReasoning
Issue Date: 2024-04-04
Prompting for Numerical Sequences: A Case Study on Market Comment Generation, Masayuki Kawarada+, N_A, arXiv'24
SummaryLLMsは、構造化データに対するプロンプト生成に関する研究が進んでいるが、時系列数値データに関する詳細な調査が不足している。本研究では、株価の数値系列を入力として市場コメントを生成するタスクに焦点を当て、さまざまな入力表現を探究する。実験結果は、プログラミング言語に似たプロンプトがより良い結果をもたらすことを示しており、数値系列からテキストを生成する際の効果的なプロンプト作成について示唆を提供している。
CommentData-to-Text系のタスクでは、しばしば数値列がInputとなり、そこからテキストを生成するが、この際にどのようなフォーマットで数値列をPromptingするのが良いかを調査した研究。Pythonリストなどのプログラミング言語に似たプロンプトが高い性能を示し、自然言語やhtml, latextなどのプロンプトは効果が低かったとのこと

Issue Date: 2024-04-03 MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection, Ali Behrouz+, N_A, arXiv'24 Summary最近の深層学習の進歩は、データ依存性と大規模な学習能力によって、主にTransformersに依存してきた。しかし、長いシーケンスモデリングにおいてスケーラビリティが制限される問題がある。State Space Models(SSMs)に着想を得たMambaMixerは、Selective Token and Channel Mixerを使用した新しいアーキテクチャであり、画像や時系列データにおいて優れたパフォーマンスを示す。ViM2はビジョンタスクで競争力のあるパフォーマンスを達成し、TSM2は時系列予測で優れた結果を示す。これらの結果は、TransformersやMLPが時系列予測において必要ないことを示唆している。 Comment参考: https://x.com/hillbig/status/1775289127803703372?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-04-03 Long-context LLMs Struggle with Long In-context Learning, Tianle Li+, N_A, arXiv'24 SummaryLLMsは長いシーケンスを処理する能力で進歩しているが、その評価は限定されている。本研究では、極端なラベル分類の領域での長いコンテキスト学習に焦点を当てた特化したベンチマーク(LIConBench)を紹介する。LLMsは20K以下のトークン長で比較的良いパフォーマンスを示し、長いコンテキストウィンドウを利用することで性能が向上することがわかった。しかし、20Kを超えると性能が急激に低下する。現在のLLMsは長くコンテキスト豊かなシーケンスを処理し理解する能力にギャップがあることを示唆している。LIConBenchは、将来のLLMsの評価に役立つ可能性がある。 #RecommenderSystems #Survey #GenerativeAI Issue Date: 2024-04-02 A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys), Yashar Deldjoo+, N_A, arXiv'24 Summary従来のレコメンドシステムは、ユーザー-アイテムの評価履歴を主要なデータソースとして使用してきたが、最近では生成モデルを活用して、テキストや画像など豊富なデータを含めた新しい推薦タスクに取り組んでいる。この研究では、生成モデル(Gen-RecSys)を用いたレコメンドシステムの進歩に焦点を当て、相互作用駆動型生成モデルや大規模言語モデル(LLM)を用いた生成型推薦、画像や動画コンテンツの処理と生成のためのマルチモーダルモデルなどについて調査している。未解決の課題や必要なパラダイムについても議論している。 Issue Date: 2024-03-13 Stealing Part of a Production Language Model, Nicholas Carlini+, N_A, arXiv'24 SummaryOpenAIのChatGPTやGoogleのPaLM-2などのブラックボックスの言語モデルから重要な情報を抽出するモデルスティーリング攻撃を紹介。APIアクセスを利用して、transformerモデルの埋め込み射影層を回復する攻撃を行い、低コストでAdaとBabbage言語モデルの全射影行列を抽出。gpt-3.5-turboモデルの隠れた次元のサイズを回復し、2000ドル未満のクエリで全射影行列を回復すると推定。潜在的な防御策と緩和策を提案し、将来の作業の影響について議論。 Issue Date: 2024-03-05 The Power of Noise: Redefining Retrieval for RAG Systems, Florin Cuconasu+, N_A, arXiv'24 SummaryRAGシステムは、LLMsよりも大幅な進歩を遂げており、IRフェーズを介して外部データを取得することで生成能力を向上させています。本研究では、RAGシステムにおけるIRコンポーネントの影響を詳細に分析し、リトリーバーの特性や取得すべきドキュメントのタイプに焦点を当てました。関連性のないドキュメントを含めることで精度が向上することが示され、リトリーバルと言語生成モデルの統合の重要性が強調されました。 CommentRelevantな情報はクエリの近くに配置すべきで、残りのコンテキストをrelevantな情報で埋めるのではなく、ノイズで埋めたほうがRAGの回答が良くなる、という話らしい #NLP #LanguageModel #OpenWeight #OpenSource Issue Date: 2024-03-05 OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, N_A, arXiv'24 SummaryLMsの商業的重要性が高まる中、最も強力なモデルは閉鎖されており、その詳細が非公開になっている。そのため、本技術レポートでは、本当にオープンな言語モデルであるOLMoの初回リリースと、言語モデリングの科学を構築し研究するためのフレームワークについて詳細に説明している。OLMoはモデルの重みだけでなく、トレーニングデータ、トレーニングおよび評価コードを含むフレームワーク全体を公開しており、オープンな研究コミュニティを強化し、新しいイノベーションを促進することを目指している。 CommentModel Weightsを公開するだけでなく、training/evaluation codeとそのデータも公開する真にOpenな言語モデル(truly Open Language Model)。AllenAI Issue Date: 2024-03-05 AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls, Yu Du+, N_A, arXiv'24 SummaryAnyToolは、大規模言語モデルエージェントであり、16,000以上のAPIを利用してユーザーのクエリに対処する革新的なツールを提供している。階層構造を持つAPIリトリーバー、API候補を使用してクエリを解決するソルバー、自己反映メカニズムを組み込んでおり、GPT-4の関数呼び出し機能を活用している。AnyToolは、ToolLLMやGPT-4の変種を上回る性能を示し、改訂された評価プロトコルとAnyToolBenchベンチマークを導入している。GitHubでコードが入手可能。 Comment階層的なRetrieverを用いてユーザクエリから必要なツールを検索し、solverでユーザのクエリを解決し、self-reflectionで結果をさらに良くするような枠組み
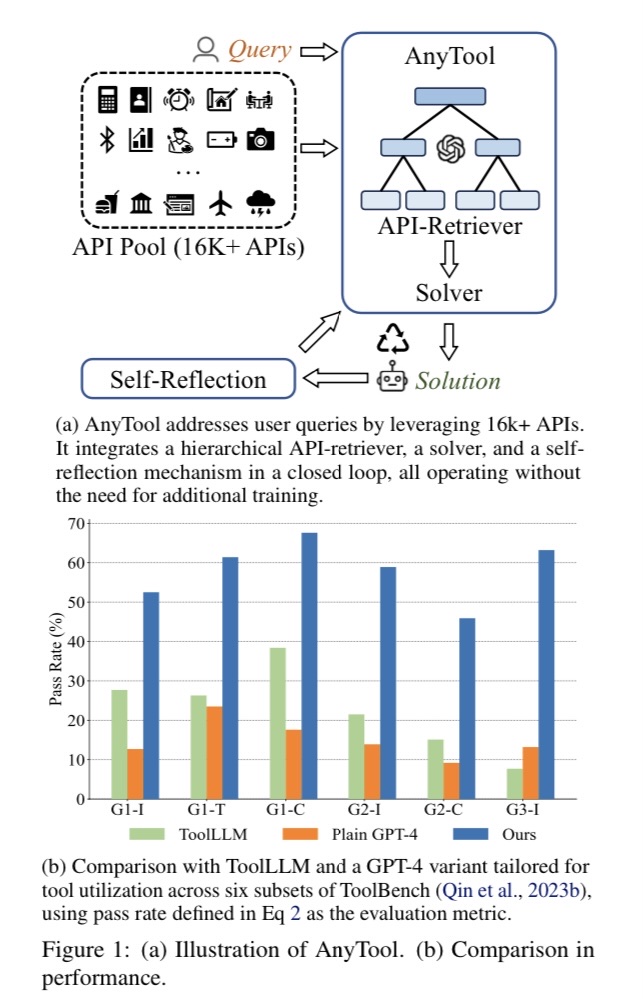
#NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2024-03-05 Chain-of-Thought Reasoning Without Prompting, Xuezhi Wang+, N_A, arXiv'24 SummaryLLMsの推論能力を向上させるための新しいアプローチに焦点を当てた研究が行われている。この研究では、LLMsがプロンプトなしで効果的に推論できるかどうかを検証し、CoT推論パスをデコーディングプロセスを変更することで引き出す方法を提案している。提案手法は、従来の貪欲なデコーディングではなく、代替トークンを調査することでCoTパスを見つけることができることを示しており、様々な推論ベンチマークで有効性を示している。 Comment以前にCoTを内部的に自動的に実施されるように事前学習段階で学習する、といった話があったと思うが、この研究はデコーディング方法を変更することで、promptingで明示的にinstructionを実施せずとも、CoTを実現するもの、ということだと思われる。
 Issue Date: 2024-03-05
In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss, Yuri Kuratov+, N_A, arXiv'24
Summaryこの研究では、生成トランスフォーマーモデルを使用して長い文書を処理する能力を評価するための新しいベンチマークであるBABILongを導入しました。GPT-4やRAGのベンチマークを含む評価により、一般的な方法は$10^4$要素までのシーケンスに対してのみ効果的であることが明らかになりました。再帰的メモリ拡張を使用してGPT-2をファインチューニングすることで、$11\times 10^6$要素を含むタスクを処理できるようになりました。これにより、長いシーケンスの処理能力が大幅に向上しました。
Comment面白そう。GPT4や(GPT4を用いた?)RAGのパフォーマンスが、入力の最初の25%に強く依存していることを示した、とSNSでポストを見たが、どういう条件での実験なんだろう。
Issue Date: 2024-03-05
In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss, Yuri Kuratov+, N_A, arXiv'24
Summaryこの研究では、生成トランスフォーマーモデルを使用して長い文書を処理する能力を評価するための新しいベンチマークであるBABILongを導入しました。GPT-4やRAGのベンチマークを含む評価により、一般的な方法は$10^4$要素までのシーケンスに対してのみ効果的であることが明らかになりました。再帰的メモリ拡張を使用してGPT-2をファインチューニングすることで、$11\times 10^6$要素を含むタスクを処理できるようになりました。これにより、長いシーケンスの処理能力が大幅に向上しました。
Comment面白そう。GPT4や(GPT4を用いた?)RAGのパフォーマンスが、入力の最初の25%に強く依存していることを示した、とSNSでポストを見たが、どういう条件での実験なんだろう。
普通のコンテキストサイズならpromptの末尾などに入れたinstructionなどは強く働く経験があるので気になる。
どれくらい汎用的に適用可能な話なのかも気になるところ。 #EfficiencyImprovement #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML Issue Date: 2024-03-05 LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, ICML'24 Summary本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 CommentLoRAで導入される低ランク行列AとBを異なる学習率で学習することで、LoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法


 #Survey
#NLP
#LanguageModel
#Annotation
Issue Date: 2024-03-05
Large Language Models for Data Annotation: A Survey, Zhen Tan+, N_A, arXiv'24
SummaryGPT-4などの大規模言語モデル(LLMs)を使用したデータアノテーションの研究に焦点を当て、LLMによるアノテーション生成の評価や学習への応用について述べられています。LLMを使用したデータアノテーションの手法や課題について包括的に議論し、将来の研究の進展を促進することを目的としています。
CommentData AnnotationにLLMを活用する場合のサーベイ
Issue Date: 2024-03-01
Likelihood-based Mitigation of Evaluation Bias in Large Language Models, Masanari Ohi+, N_A, arXiv'24
SummaryLLMsを使用した評価者における可能性のバイアスとその影響を調査し、バイアスを緩和する方法を提案。提案手法は、バイアスのかかったインスタンスを活用し、評価パフォーマンスを向上させた。
Issue Date: 2024-02-28
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits, Shuming Ma+, N_A, arXiv'24
Summary最新の研究では、1ビットの大規模言語モデル(LLMs)の時代が到来しており、BitNetなどの研究がその道を切り開いている。本研究では、1ビットLLMの変種であるBitNet b1.58を紹介し、その性能や効率について述べている。このモデルは、三値{-1, 0, 1}で各パラメータを表現し、フルプレシジョンのTransformer LLMと同等の性能を示す一方、コスト効果が高いことが特徴である。1.58ビットのLLMは、新しいスケーリング法やレシピを提供し、新しい計算パラダイムを可能にするとともに、特定のハードウェアの設計にも貢献する。
Comment1bit量子化を実現したBitNet。乗算が不要になるからGPU以外のアーキテクチャが最適かもね、みたいな話らしい。おまけに性能も高いらしい。(論文まだ読んでない)
#Survey
#NLP
#LanguageModel
#Annotation
Issue Date: 2024-03-05
Large Language Models for Data Annotation: A Survey, Zhen Tan+, N_A, arXiv'24
SummaryGPT-4などの大規模言語モデル(LLMs)を使用したデータアノテーションの研究に焦点を当て、LLMによるアノテーション生成の評価や学習への応用について述べられています。LLMを使用したデータアノテーションの手法や課題について包括的に議論し、将来の研究の進展を促進することを目的としています。
CommentData AnnotationにLLMを活用する場合のサーベイ
Issue Date: 2024-03-01
Likelihood-based Mitigation of Evaluation Bias in Large Language Models, Masanari Ohi+, N_A, arXiv'24
SummaryLLMsを使用した評価者における可能性のバイアスとその影響を調査し、バイアスを緩和する方法を提案。提案手法は、バイアスのかかったインスタンスを活用し、評価パフォーマンスを向上させた。
Issue Date: 2024-02-28
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits, Shuming Ma+, N_A, arXiv'24
Summary最新の研究では、1ビットの大規模言語モデル(LLMs)の時代が到来しており、BitNetなどの研究がその道を切り開いている。本研究では、1ビットLLMの変種であるBitNet b1.58を紹介し、その性能や効率について述べている。このモデルは、三値{-1, 0, 1}で各パラメータを表現し、フルプレシジョンのTransformer LLMと同等の性能を示す一方、コスト効果が高いことが特徴である。1.58ビットのLLMは、新しいスケーリング法やレシピを提供し、新しい計算パラダイムを可能にするとともに、特定のハードウェアの設計にも貢献する。
Comment1bit量子化を実現したBitNet。乗算が不要になるからGPU以外のアーキテクチャが最適かもね、みたいな話らしい。おまけに性能も高いらしい。(論文まだ読んでない)
Github: https://github.com/kyegomez/BitNet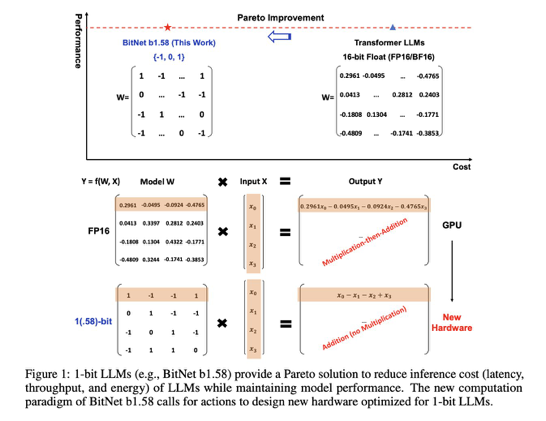 Issue Date: 2024-02-28
Deep Networks Always Grok and Here is Why, Ahmed Imtiaz Humayun+, N_A, arXiv'24
SummaryDNNの訓練エラーがほぼゼロに達した後に一般化が遅れて発生するグロッキング現象について、遅延頑健性という新しい概念を導入し、DNNが遅延して敵対的な例を理解し、一般化した後に頑健になる現象を説明。局所複雑性の新しい尺度に基づいて、遅延一般化と遅延頑健性の出現についての解析的な説明を提供。
CommentGrokking関連論文参考: hillbigさんのツイート
Issue Date: 2024-02-28
Deep Networks Always Grok and Here is Why, Ahmed Imtiaz Humayun+, N_A, arXiv'24
SummaryDNNの訓練エラーがほぼゼロに達した後に一般化が遅れて発生するグロッキング現象について、遅延頑健性という新しい概念を導入し、DNNが遅延して敵対的な例を理解し、一般化した後に頑健になる現象を説明。局所複雑性の新しい尺度に基づいて、遅延一般化と遅延頑健性の出現についての解析的な説明を提供。
CommentGrokking関連論文参考: hillbigさんのツイート
https://x.com/hillbig/status/1762624222260846993?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-02-27 MerRec: A Large-scale Multipurpose Mercari Dataset for Consumer-to-Consumer Recommendation Systems, Lichi Li+, N_A, arXiv'24 Summary電子商取引分野において、C2C推薦システムの重要性が高まっているが、これに関する研究は限られたデータセットに基づいている。そこで、MerRecという数百万のユーザーと商品をカバーする大規模なC2C推薦データセットが導入された。このデータセットは、標準的な特徴だけでなく、ユニークな要素も含んでおり、広範囲に評価されることで、C2C推薦の研究を促進し、新たな基準を確立することが期待されている。 Issue Date: 2024-02-25 Linear Transformers are Versatile In-Context Learners, Max Vladymyrov+, N_A, arXiv'24 Summary研究では、線形transformersが複雑な問題に対して効果的な最適化アルゴリズムを見つける能力を持つことが示された。特に、トレーニングデータが異なるノイズレベルで破損している場合でも、線形transformersは合理的なベースラインを上回るか匹敵する結果を示した。新しいアプローチとして、運動量と再スケーリングを組み込んだ最適化戦略が提案された。これにより、線形transformersが洗練された最適化戦略を発見する能力を持つことが示された。 #NLP #LanguageModel #Personalization Issue Date: 2024-02-24 User-LLM: Efficient LLM Contextualization with User Embeddings, Lin Ning+, N_A, arXiv'24 SummaryLLMsを活用したUser-LLMフレームワークが提案された。ユーザーエンベッディングを使用してLLMsをコンテキストに位置付けし、ユーザーコンテキストに動的に適応することが可能になる。包括的な実験により、著しい性能向上が示され、Perceiverレイヤーの組み込みにより計算効率が向上している。 Commentnext item prediction, favorite genre or category predictimnreview generationなどで評価している Issue Date: 2024-02-24 Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance, Ziqi Yin+, N_A, arXiv'24 SummaryLLMsのパフォーマンスにおけるプロンプトの丁寧さの影響を調査。無礼なプロンプトはパフォーマンス低下につながるが、過度に丁寧な言葉も必ずしも良い結果を保証しない。最適な丁寧さのレベルは言語によって異なることが示唆され、異文化間の自然言語処理とLLMの使用において丁寧さを考慮する必要性が強調された。 Issue Date: 2024-02-15 Scaling Laws for Fine-Grained Mixture of Experts, Jakub Krajewski+, N_A, arXiv'24 Summary本研究では、Mixture of Experts(MoE)モデルのスケーリング特性を分析し、新しいハイパーパラメータである「粒度」を導入することで、計算コストを削減する方法を提案しています。さらに、MoEモデルが密なモデルよりも優れた性能を発揮し、モデルのサイズとトレーニング予算をスケールアップするにつれてその差が広がることを示しています。また、一般的な方法では最適ではないことも示しています。 Issue Date: 2024-02-11 Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks, Jongho Park+, N_A, arXiv'24 Summary状態空間モデル(SSM)は、言語モデリングにおけるTransformerネットワークの代替手法として提案されてきた。本研究では、SSMのインコンテキスト学習(ICL)能力を評価し、Transformerと比較した結果を報告する。SSMは一部のタスクでTransformerを上回る性能を示すが、一部のタスクでは不十分であることがわかった。そこで、Mambaとアテンションブロックを組み合わせたハイブリッドモデルを提案し、個々のモデルを上回る結果を示した。ハイブリッドアーキテクチャは言語モデルのICLを向上させる有望な手段であることが示唆された。 Issue Date: 2024-02-07 Self-Discover: Large Language Models Self-Compose Reasoning Structures, Pei Zhou+, N_A, arXiv'24 SummarySELF-DISCOVERは、LLMsがタスク固有の推論構造を自己発見することを可能にするフレームワークであり、複雑な推論問題に取り組むことができます。このフレームワークは、複数の原子的な推論モジュールを選択し、それらを組み合わせて明示的な推論構造を作成する自己発見プロセスを含んでいます。SELF-DISCOVERは、難解な推論ベンチマークでGPT-4とPaLM 2の性能を最大32%向上させることができます。さらに、推論計算において10-40倍少ないリソースを必要とし、人間の推論パターンと共通点を持っています。 Issue Date: 2024-02-06 RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval, Parth Sarthi+, N_A, arXiv'24 Summary検索補完言語モデルは、ロングテールの知識を組み込むことができますが、既存の手法では文脈の理解が制限されています。そこで、私たちは再帰的な要約を使用してテキストをクラスタリングし、異なる抽象化レベルで情報を統合する新しいアプローチを提案します。制御された実験では、このアプローチが従来の手法よりも大幅な改善を提供し、質問応答タスクでは最高性能を20%向上させることができることを示しました。 #Survey #LanguageModel #MulltiModal #ACL Issue Date: 2024-01-25 MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N_A, ACL'24 Findings SummaryMM-LLMsは、コスト効果の高いトレーニング戦略を用いて拡張され、多様なMMタスクに対応する能力を持つことが示されている。本論文では、MM-LLMsのアーキテクチャ、トレーニング手法、ベンチマークのパフォーマンスなどについて調査し、その進歩に貢献することを目指している。 Comment以下、論文を斜め読みしながら、ChatGPTを通じて疑問点を解消しつつ理解した内容なので、理解が不十分な点が含まれている可能性があるので注意。
まあざっくり言うと、マルチモーダルを理解できるLLMを作りたかったら、様々なモダリティをエンコーディングして得られる表現と、既存のLLMが内部的に処理可能な表現を対応づける Input Projectorという名の関数を学習すればいいだけだよ(モダリティのエンコーダ、LLMは事前学習されたものをそのままfreezeして使えば良い)。
マルチモーダルを生成できるLLMを作りたかったら、LLMがテキストを生成するだけでなく、様々なモダリティに対応する表現も追加で出力するようにして、その出力を各モダリティを生成できるモデルに入力できるように変換するOutput Projectortという名の関数を学習しようね、ということだと思われる。
概要

ポイント
・Modality Encoder, LLM Backbone、およびModality Generatorは一般的にはパラメータをfreezeする
・optimizationの対象は「Input/Output Projector」
Modality Encoder
様々なモダリティI_Xを、特徴量F_Xに変換する。これはまあ、色々なモデルがある。

Input Projector
モダリティI_Xとそれに対応するテキストtのデータ {I_X, t}が与えられたとき、テキストtを埋め込み表現に変換んした結果得られる特徴量がF_Tである。Input Projectorは、F_XをLLMのinputとして利用する際に最適な特徴量P_Xに変換するθX_Tを学習することである。これは、LLM(P_X, F_T)によってテキストtがどれだけ生成できたか、を表現する損失関数を最小化することによって学習される。

LLM Backbone
LLMによってテキスト列tと、各モダリティに対応した表現であるS_Xを生成する。outputからt, S_Xをどのように区別するかはモデルの構造などにもよるが、たとえば異なるヘッドを用意して、t, S_Xを区別するといったことは可能であろうと思われる。

Output Projector
S_XをModality Generatorが解釈可能な特徴量H_Xに変換する関数のことである。これは学習しなければならない。
H_XとModality Generatorのtextual encoderにtを入力した際に得られる表現τX(t)が近くなるようにOutput Projector θ_T_Xを学習する。これによって、S_XとModality Generatorがalignするようにする。

Modality Generator
各ModalityをH_Xから生成できるように下記のような損失学習する。要は、生成されたモダリティデータ(または表現)が実際のデータにどれだけ近いか、を表しているらしい。具体的には、サンプリングによって得られたノイズと、モデルが推定したノイズの値がどれだけ近いかを測る、みたいなことをしているらしい。

Multi Modalを理解するモデルだけであれば、Input Projectorの損失のみが学習され、生成までするのであれば、Input/Output Projector, Modality Generatorそれぞれに示した損失関数を通じてパラメータが学習される。あと、P_XやらS_Xはいわゆるsoft-promptingみたいなものであると考えられる。 #NLP #LanguageModel #ProgressiveLearning #ACL Issue Date: 2024-01-24 LLaMA Pro: Progressive LLaMA with Block Expansion, Chengyue Wu+, N_A, ACL'24 Summary本研究では、大規模言語モデル(LLMs)の新しい事前学習後の手法を提案し、モデルの知識を効果的かつ効率的に向上させることを目指しました。具体的には、Transformerブロックの拡張を使用し、新しいコーパスのみを使用してモデルを調整しました。実験の結果、提案手法はさまざまなベンチマークで優れたパフォーマンスを発揮し、知的エージェントとして多様なタスクに対応できることが示されました。この研究は、自然言語とプログラミング言語を統合し、高度な言語エージェントの開発に貢献するものです。 Comment追加の知識を導入したいときに使えるかも?事前学習したLLaMA Blockに対して、追加のLLaMA Blockをstackし、もともとのLLaMA Blockのパラメータをfreezeした上でドメインに特化したコーパスで事後学習することで、追加の知識を挿入する。LLaMA Blockを挿入するときは、Linear Layerのパラメータを0にすることで、RMSNormにおける勾配消失の問題を避けた上で、Identity Block(Blockを追加した時点では事前学習時と同様のOutputがされることが保証される)として機能させることができる。
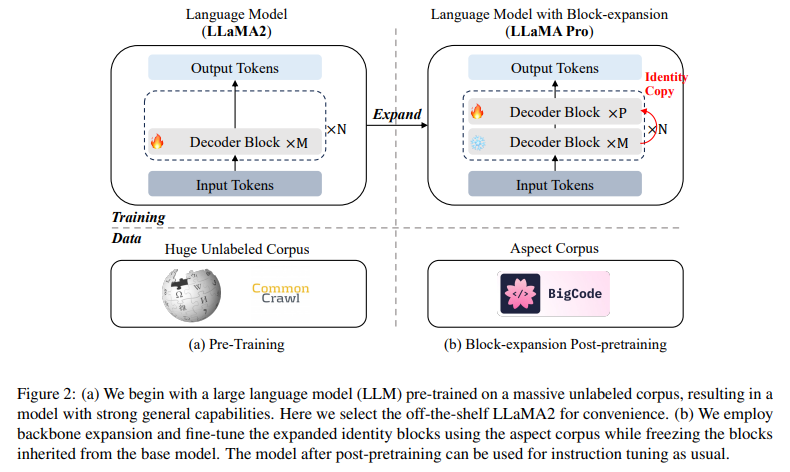

Issue Date: 2024-01-24 Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models, Zixiang Chen+, N_A, arXiv'24 Summary本研究では、追加の人間による注釈付きデータを必要とせずに、大規模言語モデル(LLMs)を強化する方法を提案します。そのために、Self-Play fIne-tuNing(SPIN)という新しいファインチューニング手法を開発しました。SPINでは、LLMが自身と対戦しながら能力を向上させるセルフプレイのメカニズムを利用します。具体的には、LLMは自己生成応答と人間による注釈付きデータから得られた応答を区別することでポリシーを改善します。実験結果は、SPINがLLMのパフォーマンスを大幅に改善し、専門家の対戦相手を必要とせずに人間レベルのパフォーマンスを達成できることを示しています。 #Survey #NLP #LanguageModel #Hallucination Issue Date: 2024-01-24 A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models, S. M Towhidul Islam Tonmoy+, N_A, arXiv'24 Summary要約:本論文では、大規模言語モデル(LLMs)における幻覚の問題について調査し、その軽減策について紹介しています。LLMsは強力な言語生成能力を持っていますが、根拠のない情報を生成する傾向があります。この問題を解決するために、Retrieval Augmented Generation、Knowledge Retrieval、CoNLI、CoVeなどの技術が開発されています。さらに、データセットの利用やフィードバックメカニズムなどのパラメータに基づいてこれらの方法を分類し、幻覚の問題に取り組むためのアプローチを提案しています。また、これらの技術に関連する課題や制約についても分析し、将来の研究に向けた基盤を提供しています。 #NLP #LanguageModel #DataToTextGeneration #TabularData #ICLR Issue Date: 2024-01-24 Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding, Zilong Wang+, N_A, ICLR'24 SummaryLLMsを使用したChain-of-Tableフレームワークは、テーブルデータを推論チェーン内で活用し、テーブルベースの推論タスクにおいて高い性能を発揮することが示された。このフレームワークは、テーブルの連続的な進化を表現し、中間結果の構造化情報を利用してより正確な予測を可能にする。さまざまなベンチマークで最先端のパフォーマンスを達成している。 CommentTable, Question, Operation Historyから次のoperationとそのargsを生成し、テーブルを順次更新し、これをモデルが更新の必要が無いと判断するまで繰り返す。最終的に更新されたTableを用いてQuestionに回答する手法。Questionに回答するために、複雑なテーブルに対する操作が必要なタスクに対して有効だと思われる。

 Issue Date: 2024-01-24
Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM, Xiaoding Lu+, N_A, arXiv'24
Summary本研究では、大規模な会話型AIモデルの開発には多くの計算リソースとメモリが必要であるが、複数の小さなモデルを組み合わせることで同等またはそれ以上の性能を実現できる可能性があることを示唆している。ブレンディングというアプローチを提案し、複数のチャットAIを統合する方法を示している。実証的な証拠によれば、中程度のサイズの3つのモデルを統合するだけでも、大規模なモデルと同等以上の性能を発揮できることが示されている。この仮説は、大規模なユーザーベースを対象に行われたA/Bテストによって厳密に検証され、ブレンディング戦略が効果的なアプローチであることが示されている。
#Survey
#NaturalLanguageGeneration
#NLP
#Evaluation
#LLM-as-a-Judge
Issue Date: 2024-01-24
Leveraging Large Language Models for NLG Evaluation: A Survey, Zhen Li+, N_A, arXiv'24
Summary本研究は、大規模言語モデル(LLMs)を使用した自然言語生成(NLG)の評価についての包括的な概要を提供します。既存の評価指標を整理し、LLMベースの手法を比較するためのフレームワークを提案します。さらに、未解決の課題についても議論し、より公正で高度なNLG評価技術を提唱します。
Comment重要NLGの評価をするモデルのアーキテクチャとして、BERTScoreのようなreferenceとhvpothesisのdistiebuted representation同士を比較するような手法(matching-based)と、性能指標を直接テキストとして生成するgenerative-basedな手法があるよ、
Issue Date: 2024-01-24
Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM, Xiaoding Lu+, N_A, arXiv'24
Summary本研究では、大規模な会話型AIモデルの開発には多くの計算リソースとメモリが必要であるが、複数の小さなモデルを組み合わせることで同等またはそれ以上の性能を実現できる可能性があることを示唆している。ブレンディングというアプローチを提案し、複数のチャットAIを統合する方法を示している。実証的な証拠によれば、中程度のサイズの3つのモデルを統合するだけでも、大規模なモデルと同等以上の性能を発揮できることが示されている。この仮説は、大規模なユーザーベースを対象に行われたA/Bテストによって厳密に検証され、ブレンディング戦略が効果的なアプローチであることが示されている。
#Survey
#NaturalLanguageGeneration
#NLP
#Evaluation
#LLM-as-a-Judge
Issue Date: 2024-01-24
Leveraging Large Language Models for NLG Evaluation: A Survey, Zhen Li+, N_A, arXiv'24
Summary本研究は、大規模言語モデル(LLMs)を使用した自然言語生成(NLG)の評価についての包括的な概要を提供します。既存の評価指標を整理し、LLMベースの手法を比較するためのフレームワークを提案します。さらに、未解決の課題についても議論し、より公正で高度なNLG評価技術を提唱します。
Comment重要NLGの評価をするモデルのアーキテクチャとして、BERTScoreのようなreferenceとhvpothesisのdistiebuted representation同士を比較するような手法(matching-based)と、性能指標を直接テキストとして生成するgenerative-basedな手法があるよ、

といった話や、そもそもreference-basedなメトリック(e.g. BLEU)や、reference-freeなメトリック(e.g. BARTScore)とはなんぞや?みたいな基礎的な話から、言語モデルを用いたテキスト生成の評価手法の代表的なものだけでなく、タスクごとの手法も整理されて記載されている。また、BLEUやROUGEといった伝統的な手法の概要や、最新手法との同一データセットでのメタ評価における性能の差なども記載されており、全体的に必要な情報がコンパクトにまとまっている印象がある。

 #MachineLearning
#NLP
#LanguageModel
#ICLR
#read-later
#ModelMerge
Issue Date: 2024-01-23
Knowledge Fusion of Large Language Models, Fanqi Wan+, N_A, ICLR'24
Summary本研究では、既存の事前訓練済みの大規模言語モデル(LLMs)を統合することで、1つの強力なモデルを作成する方法を提案しています。異なるアーキテクチャを持つ3つの人気のあるLLMsを使用して、ベンチマークとタスクのパフォーマンスを向上させることを実証しました。提案手法のコード、モデルの重み、およびデータはGitHubで公開されています。
#NLP
#LanguageModel
#Alignment
#InstructionTuning
#LLM-as-a-Judge
#SelfImprovement
#ICML
Issue Date: 2024-01-22
Self-Rewarding Language Models, Weizhe Yuan+, N_A, ICML'24
Summary将来のモデルのトレーニングには超人的なフィードバックが必要であり、自己報酬を提供するSelf-Rewarding Language Modelsを研究している。LLM-as-a-Judgeプロンプトを使用して、言語モデル自体が自己報酬を提供し、高品質な報酬を得る能力を向上させることを示した。Llama 2 70Bを3回のイテレーションで微調整することで、既存のシステムを上回るモデルが得られることを示した。この研究は、改善可能なモデルの可能性を示している。
Comment人間の介入無しで(人間がアノテーションしたpreference data無しで)LLMのAlignmentを改善していく手法。LLM-as-a-Judge Promptingを用いて、LLM自身にpolicy modelとreward modelの役割の両方をさせる。unlabeledなpromptに対してpolicy modelとしてresponceを生成させた後、生成したレスポンスをreward modelとしてランキング付けし、DPOのpreference pairとして利用する、という操作を繰り返す。
#MachineLearning
#NLP
#LanguageModel
#ICLR
#read-later
#ModelMerge
Issue Date: 2024-01-23
Knowledge Fusion of Large Language Models, Fanqi Wan+, N_A, ICLR'24
Summary本研究では、既存の事前訓練済みの大規模言語モデル(LLMs)を統合することで、1つの強力なモデルを作成する方法を提案しています。異なるアーキテクチャを持つ3つの人気のあるLLMsを使用して、ベンチマークとタスクのパフォーマンスを向上させることを実証しました。提案手法のコード、モデルの重み、およびデータはGitHubで公開されています。
#NLP
#LanguageModel
#Alignment
#InstructionTuning
#LLM-as-a-Judge
#SelfImprovement
#ICML
Issue Date: 2024-01-22
Self-Rewarding Language Models, Weizhe Yuan+, N_A, ICML'24
Summary将来のモデルのトレーニングには超人的なフィードバックが必要であり、自己報酬を提供するSelf-Rewarding Language Modelsを研究している。LLM-as-a-Judgeプロンプトを使用して、言語モデル自体が自己報酬を提供し、高品質な報酬を得る能力を向上させることを示した。Llama 2 70Bを3回のイテレーションで微調整することで、既存のシステムを上回るモデルが得られることを示した。この研究は、改善可能なモデルの可能性を示している。
Comment人間の介入無しで(人間がアノテーションしたpreference data無しで)LLMのAlignmentを改善していく手法。LLM-as-a-Judge Promptingを用いて、LLM自身にpolicy modelとreward modelの役割の両方をさせる。unlabeledなpromptに対してpolicy modelとしてresponceを生成させた後、生成したレスポンスをreward modelとしてランキング付けし、DPOのpreference pairとして利用する、という操作を繰り返す。
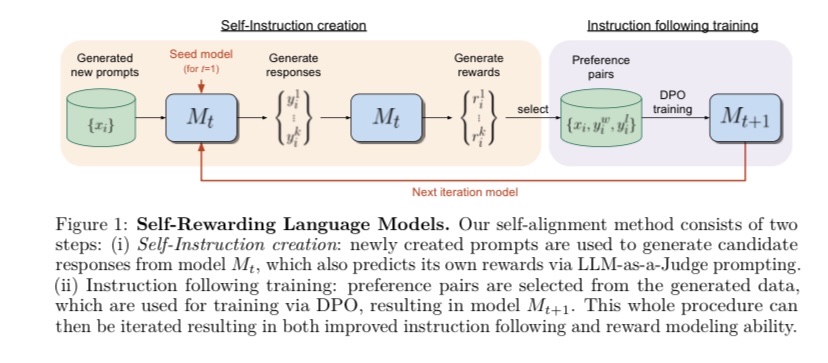 #NLP
#LanguageModel
#Chain-of-Thought
Issue Date: 2024-01-16
The Impact of Reasoning Step Length on Large Language Models, Mingyu Jin+, N_A, arXiv'24
SummaryChain of Thought(CoT)の推論ステップの長さとLLMsの推論能力の関係を調査した。推論ステップを延長すると、プロンプトに新しい情報を追加せずにLLMsの推論能力が向上することがわかった。逆に、キーとなる情報を保持しながら推論ステップを短縮すると、推論能力が低下する。また、誤った根拠でも推論の必要な長さを保つ限り、好ましい結果が得られることも示された。さらに、タスクによって推論ステップの増加の利点が異なることも観察された。
#NLP
#LanguageModel
#OpenWeight
Issue Date: 2024-01-09
Mixtral of Experts, Albert Q. Jiang+, N_A, arXiv'24
SummaryMixtralは、Sparse Mixture of Experts(SMoE)言語モデルであり、各レイヤーが8つのフィードフォワードブロックで構成されています。Mixtralは、トークンごとに2つのエキスパートを選択し、それらの出力を組み合わせます。Mixtralは、Llama 2 70BとGPT-3.5を上回る性能を持ち、数学、コード生成、多言語のベンチマークで特に優れています。また、Mixtral 8x7B Instructという指示に従うモデルも提供されており、人間のベンチマークを凌駕しています。
CommentMixture of experts Layer: inputを受け取ったrouterが、8つのexpertsのうち2つを選択し順伝搬。2つのexpertsのoutputを加重平均することで最終的なoutputとする。
#NLP
#LanguageModel
#Chain-of-Thought
Issue Date: 2024-01-16
The Impact of Reasoning Step Length on Large Language Models, Mingyu Jin+, N_A, arXiv'24
SummaryChain of Thought(CoT)の推論ステップの長さとLLMsの推論能力の関係を調査した。推論ステップを延長すると、プロンプトに新しい情報を追加せずにLLMsの推論能力が向上することがわかった。逆に、キーとなる情報を保持しながら推論ステップを短縮すると、推論能力が低下する。また、誤った根拠でも推論の必要な長さを保つ限り、好ましい結果が得られることも示された。さらに、タスクによって推論ステップの増加の利点が異なることも観察された。
#NLP
#LanguageModel
#OpenWeight
Issue Date: 2024-01-09
Mixtral of Experts, Albert Q. Jiang+, N_A, arXiv'24
SummaryMixtralは、Sparse Mixture of Experts(SMoE)言語モデルであり、各レイヤーが8つのフィードフォワードブロックで構成されています。Mixtralは、トークンごとに2つのエキスパートを選択し、それらの出力を組み合わせます。Mixtralは、Llama 2 70BとGPT-3.5を上回る性能を持ち、数学、コード生成、多言語のベンチマークで特に優れています。また、Mixtral 8x7B Instructという指示に従うモデルも提供されており、人間のベンチマークを凌駕しています。
CommentMixture of experts Layer: inputを受け取ったrouterが、8つのexpertsのうち2つを選択し順伝搬。2つのexpertsのoutputを加重平均することで最終的なoutputとする。
 #ComputerVision
#Pretraining
#NLP
#Transformer
#InstructionTuning
#MulltiModal
#SpeechProcessing
#CVPR
#Encoder-Decoder
#Robotics
Issue Date: 2023-12-29
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, N_A, CVPR'24
SummaryUnified-IO 2は、最初の自己回帰型のマルチモーダルモデルであり、画像、テキスト、音声、アクションを理解し生成することができます。異なるモダリティを統一するために、共有の意味空間に入力と出力を配置し、単一のエンコーダ・デコーダトランスフォーマーモデルで処理します。さまざまなアーキテクチャの改善を提案し、大規模なマルチモーダルな事前トレーニングコーパスを使用してモデルをトレーニングします。Unified-IO 2は、GRITベンチマークを含む35以上のベンチマークで最先端のパフォーマンスを発揮します。
Comment画像、テキスト、音声、アクションを理解できる初めてのautoregressive model。AllenAIモデルのアーキテクチャ図
#ComputerVision
#Pretraining
#NLP
#Transformer
#InstructionTuning
#MulltiModal
#SpeechProcessing
#CVPR
#Encoder-Decoder
#Robotics
Issue Date: 2023-12-29
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, N_A, CVPR'24
SummaryUnified-IO 2は、最初の自己回帰型のマルチモーダルモデルであり、画像、テキスト、音声、アクションを理解し生成することができます。異なるモダリティを統一するために、共有の意味空間に入力と出力を配置し、単一のエンコーダ・デコーダトランスフォーマーモデルで処理します。さまざまなアーキテクチャの改善を提案し、大規模なマルチモーダルな事前トレーニングコーパスを使用してモデルをトレーニングします。Unified-IO 2は、GRITベンチマークを含む35以上のベンチマークで最先端のパフォーマンスを発揮します。
Comment画像、テキスト、音声、アクションを理解できる初めてのautoregressive model。AllenAIモデルのアーキテクチャ図

マルチモーダルに拡張したことで、訓練が非常に不安定になったため、アーキテクチャ上でいくつかの工夫を加えている:
・2D Rotary Embedding
・Positional EncodingとしてRoPEを採用
・画像のような2次元データのモダリティの場合はRoPEを2次元に拡張する。具体的には、位置(i, j)のトークンについては、Q, Kのembeddingを半分に分割して、それぞれに対して独立にi, jのRoPE Embeddingを適用することでi, j双方の情報を組み込む。
・QK Normalization
・image, audioのモダリティを組み込むことでMHAのlogitsが非常に大きくなりatteetion weightが0/1の極端な値をとるようになり訓練の不安定さにつながった。このため、dot product attentionを適用する前にLayerNormを組み込んだ。
・Scaled Cosine Attention
・Image Historyモダリティにおいて固定長のEmbeddingを得るためにPerceiver Resamplerを扱ったているが、こちらも上記と同様にAttentionのlogitsが極端に大きくなったため、cosine類似度をベースとしたScaled Cosine Attention 2259 を利用することで、大幅に訓練の安定性が改善された。
・その他
・attention logitsにはfp32を適用
・事前学習されたViTとASTを同時に更新すると不安定につながったため、事前学習の段階ではfreezeし、instruction tuningの最後にfinetuningを実施
 目的関数としては、Mixture of Denoisers (1424)に着想を得て、Multimodal Mixture of Denoisersを提案。MoDでは、
目的関数としては、Mixture of Denoisers (1424)に着想を得て、Multimodal Mixture of Denoisersを提案。MoDでは、
・\[R\]: 通常のspan corruption (1--5 token程度のspanをmaskする)
・\[S\]: causal language modeling (inputを2つのサブシーケンスに分割し、前方から後方を予測する。前方部分はBi-directionalでも可)
・\[X\]: extreme span corruption (12>=token程度のspanをmaskする)
の3種類が提案されており、モダリティごとにこれらを使い分ける:
・text modality: UL2 (1424)を踏襲
・image, audioがtargetの場合: 2つの類似したパラダイムを定義し利用
・\[R\]: patchをランダムにx%マスクしre-constructする
・\[S\]: inputのtargetとは異なるモダリティのみの情報から、targetモダリティを生成する
訓練時には prefixとしてmodality token \[Text\], \[Image\], \[Audio\] とparadigm token \[R\], \[S\], \[X\] をタスクを指示するトークンとして利用している。また、image, audioのマスク部分のdenoisingをautoregressive modelで実施する際には普通にやるとdecoder側でリークが発生する(a)。これを防ぐには、Encoder側でマスクされているトークンを、Decoder側でteacher-forcingする際にの全てマスクする方法(b)があるが、この場合、生成タスクとdenoisingタスクが相互に干渉してしまいうまく学習できなくなってしまう(生成タスクでは通常Decoderのinputとして[mask]が入力され次トークンを生成する、といったことは起きえないが、愚直に(b)をやるとそうなってしまう)。ので、(c)に示したように、マスクされているトークンをinputとして生成しなければならない時だけ、マスクを解除してdecoder側にinputする、という方法 (Dynamic Masking) でこの問題に対処している。
 #NLP
#Dataset
#LanguageModel
#QuestionAnswering
#COLM
Issue Date: 2023-11-22
GPQA: A Graduate-Level Google-Proof Q&A Benchmark, David Rein+, N_A, COLM'24
Summary私たちは、高品質で非常に困難な多肢選択問題からなるGPQAデータセットを提案します。このデータセットは、専門家でも高い正答率を達成できず、最先端のAIシステムでも困難であることが示されています。将来のAIシステムの開発において、スケーラブルな監督方法を開発する必要があります。これにより、スキルを持つ監督者がAIシステムから信頼性のある情報を得ることができるようになります。GPQAデータセットは、スケーラブルな監督実験を可能にし、人間の専門家がAIシステムから真実の情報を確実に得る方法を考案するのに役立つことが期待されています。
Comment該当領域のPh.D所有者でも74%、高いスキルを持つ非専門家(Googleへアクセスして良い環境)で34%しか正答できないQAデータセット。
#NLP
#Dataset
#LanguageModel
#QuestionAnswering
#COLM
Issue Date: 2023-11-22
GPQA: A Graduate-Level Google-Proof Q&A Benchmark, David Rein+, N_A, COLM'24
Summary私たちは、高品質で非常に困難な多肢選択問題からなるGPQAデータセットを提案します。このデータセットは、専門家でも高い正答率を達成できず、最先端のAIシステムでも困難であることが示されています。将来のAIシステムの開発において、スケーラブルな監督方法を開発する必要があります。これにより、スキルを持つ監督者がAIシステムから信頼性のある情報を得ることができるようになります。GPQAデータセットは、スケーラブルな監督実験を可能にし、人間の専門家がAIシステムから真実の情報を確実に得る方法を考案するのに役立つことが期待されています。
Comment該当領域のPh.D所有者でも74%、高いスキルを持つ非専門家(Googleへアクセスして良い環境)で34%しか正答できないQAデータセット。
元ツイート: https://x.com/idavidrein/status/1727033002234909060?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=Ti67584b98 #Pretraining #NLP #LanguageModel Issue Date: 2023-10-10 Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N_A, ICLR'24 Summary言語モデルのトレーニングと推論において、遅延を導入することでモデルの性能を向上させる手法を提案しました。具体的には、入力に特定のトークンを追加し、そのトークンが現れるまでモデルの出力を遅らせることで、追加の計算を行うことができます。実験結果では、この手法が推論タスクにおいて有益であり、特にQAタスクでの性能向上が見られました。今後は、この遅延予測の手法をさらに研究していく必要があります。 Commentこの研究は興味深いが、事前学習時に入れないと効果が出にくいというのは直感的にわかるので、実用的には活用しづらい。
また、promptでこの研究をimitateする方法については、ZeroShot CoTにおいて、思考プロセスを明示的に指定するようなpromptingと同様のことを行っており、これは実際に効果があると思う。 #NLP #LanguageModel #LongSequence #PositionalEncoding #NAACL Issue Date: 2023-10-09 Effective Long-Context Scaling of Foundation Models, Wenhan Xiong+, N_A, NAACL'24 Summary私たちは、長いコンテキストをサポートする一連のLLMsを提案します。これらのモデルは、長いテキストを含むデータセットでトレーニングされ、言語モデリングや他のタスクで評価されます。提案手法は、通常のタスクと長いコンテキストのタスクの両方で改善をもたらします。また、70Bバリアントはgpt-3.5-turbo-16kを上回るパフォーマンスを実現します。さらに、私たちはLlamaの位置エンコーディングや事前学習プロセスの設計選択の影響についても分析しました。結果から、長いコンテキストの継続的な事前学習が効果的であることが示されました。 Comment以下elvis氏のツイートの意訳
Metaが32kのcontext windowをサポートする70BのLLaMa2のvariant提案し、gpt-3.5-turboをlong contextが必要なタスクでoutperform。
short contextのLLaMa2を継続的に訓練して実現。これには人手で作成したinstruction tuning datasetを必要とせず、コスト効率の高いinstruction tuningによって実現される。
これは、事前学習データセットに長いテキストが豊富に含まれることが優れたパフォーマンスの鍵ではなく、ロングコンテキストの継続的な事前学習がより効率的であることを示唆している。
元ツイート: https://x.com/omarsar0/status/1707780482178400261?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q位置エンコーディングにはlong contxet用に、RoPEのbase frequency bを `10,000->500,000` とすることで、rotation angleを小さくし、distant tokenに対する減衰の影響を小さくする手法を採用 (Adjusted Base Frequency; ABF)。token間の距離が離れていても、attention scoreがshrinkしづらくなっている。

また、単に長いコンテキストのデータを追加するだけでなく、データセット内における長いコンテキストのデータの比率を調整することで、より高い性能が発揮できることを示している。これをData Mixと呼ぶ。
また、instruction tuningのデータには、LLaMa2ChatのRLHFデータをベースに、LLaMa2Chat自身にself-instructを活用して、長いコンテキストを生成させ拡張したものを利用した。
具体的には、コーパス内のlong documentを用いたQAフォーマットのタスクに着目し、文書内のランダムなチャンクからQAを生成させた。その後、self-critiqueによって、LLaMa2Chat自身に、生成されたQAペアのverificationも実施させた。 #NLP #LanguageModel #Reasoning #ICLR #Verification Issue Date: 2023-08-08 SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning, Ning Miao+, N_A, ICLR'24 Summary最新の大規模言語モデル(LLMs)は、推論問題を解決するために有望な手法ですが、複雑な問題にはまだ苦戦しています。本研究では、LLMsが自身のエラーを認識する能力を持っているかどうかを探求し、ゼロショットの検証スキームを提案します。この検証スキームを使用して、異なる回答に対して重み付け投票を行い、質問応答のパフォーマンスを向上させることができることを実験で確認しました。 Commentこれはおもしろそう。後で読むOpenReview:https://openreview.net/forum?id=pTHfApDakA #NLP #Dataset #LanguageModel #Evaluation #ICML Issue Date: 2023-07-22 SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models, Xiaoxuan Wang+, N_A, ICML'24 Summary本研究では、大規模言語モデル(LLMs)の進歩により、数学のベンチマークでの性能向上が示されているが、これらのベンチマークは限定的な範囲の問題に限定されていることが指摘される。そこで、複雑な科学的問題解決に必要な推論能力を検証するための包括的なベンチマークスイートSciBenchを提案する。SciBenchには、大学レベルの科学的問題を含むオープンセットと、学部レベルの試験問題を含むクローズドセットの2つのデータセットが含まれている。さらに、2つの代表的なLLMを用いた詳細なベンチマーク研究を行い、現在のLLMのパフォーマンスが不十分であることを示した。また、ユーザースタディを通じて、LLMが犯すエラーを10の問題解決能力に分類し、特定のプロンプティング戦略が他の戦略よりも優れているわけではないことを明らかにした。SciBenchは、LLMの推論能力の向上を促進し、科学研究と発見に貢献することを目指している。 #ICML Issue Date: 2023-05-22 Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling, Weijia Xu+, N_A, ICML'24 Summary本研究では、Repromptingという反復サンプリングアルゴリズムを紹介し、Chain-of-Thought(CoT)レシピを探索することで、特定のタスクを解決する。Repromptingは、以前にサンプリングされた解決策を親プロンプトとして使用して、新しいレシピを反復的にサンプリングすることで、一貫して良い結果を出すCoTレシピを推論する。複数のステップ推論が必要な5つのBig-Bench Hardタスクにおいて、Repromptingはゼロショット、フューショット、および人間が書いたCoTベースラインよりも一貫して優れたパフォーマンスを発揮する。Repromptingは、より強力なモデルからより弱いモデルへの知識の転移を促進し、より弱いモデルの性能を大幅に向上させることもできる。全体的に、Repromptingは、人間が書いたCoTプロンプトを使用する従来の最先端手法よりも最大で+17ポイントの改善をもたらす。 Commentんー、IterCoTとかAutoPromptingとかと比較してないので、なんとも言えない…。サーベイ不足では。あとChatGPTを使うのはやめて頂きたい。 #ComputerVision #Pretraining #Transformer #ImageSegmentation #FoundationModel Issue Date: 2023-04-30 Segment Anything in Medical Images, Jun Ma+, N_A, Nature Communications'24 Summary本研究では、自然画像セグメンテーションに革新的な手法であるSegment anything model (SAM)を医療画像に拡張するためのMedSAMを提案し、様々な医療ターゲットのセグメンテーションのための汎用ツールを作成することを目的としています。MedSAMは、大規模な医療画像データセットを用いて開発され、SAMを一般的な医療画像セグメンテーションに適応するためのシンプルなファインチューニング手法を開発しました。21の3Dセグメンテーションタスクと9の2Dセグメンテーションタスクに対する包括的な実験により、MedSAMは、平均Dice類似係数(DSC)がそれぞれ22.5%と17.6%で、デフォルトのSAMモデルを上回ることが示されました。コードとトレーニング済みモデルは、\url{https://github.com/bowang-lab/MedSAM}で公開されています。 CommentSAMの性能は医療画像に対しては限定的だったため、11の異なるモダリティに対して200kのマスクをした医療画像を用意しfinetuningしたMedSAMによって、医療画像のセグメンテーションの性能を大幅に向上。
コードとモデルはpublicly available #Tutorial
#LanguageModel
Issue Date: 2023-04-27
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, Yang+, Amazon, TKDD'24
Summary本記事は、自然言語処理(NLP)タスクにおける大規模言語モデル(LLMs)の実践的なガイドを提供し、モデルやデータ、タスクに関する洞察を示します。LLMsの概要、データの影響、知識集約型タスクや生成タスクにおける使用ケースと非使用ケースを詳述し、実用的な応用と限界を探ります。また、虚偽のバイアスや展開時の考慮事項についても言及し、研究者や実務者に役立つベストプラクティスを提供します。関連リソースは定期的に更新され、オンラインでアクセス可能です。
CommentLLMに関するチュートリアル
#Tutorial
#LanguageModel
Issue Date: 2023-04-27
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, Yang+, Amazon, TKDD'24
Summary本記事は、自然言語処理(NLP)タスクにおける大規模言語モデル(LLMs)の実践的なガイドを提供し、モデルやデータ、タスクに関する洞察を示します。LLMsの概要、データの影響、知識集約型タスクや生成タスクにおける使用ケースと非使用ケースを詳述し、実用的な応用と限界を探ります。また、虚偽のバイアスや展開時の考慮事項についても言及し、研究者や実務者に役立つベストプラクティスを提供します。関連リソースは定期的に更新され、オンラインでアクセス可能です。
CommentLLMに関するチュートリアル

encoder-onlyとまとめられているものの中には、デコーダーがあるものがあり(autoregressive decoderではない)、
encoder-decoderは正しい意味としてはencoder with autoregressive decoderであり、
decoder-onlyは正しい意味としてはautoregressive encoder-decoder
とのこと。
https://twitter.com/ylecun/status/1651762787373428736?s=46&t=-zElejt4asTKBGLr-c3bKw #ComputerVision #Transformer #DiffusionModel #read-later #Admin'sPick #Backbone Issue Date: 2025-08-27 [Paper Note] Scalable Diffusion Models with Transformers, William Peebles+, ICCV'23 Summary新しいトランスフォーマーに基づく拡散モデル(Diffusion Transformers, DiTs)を提案し、U-Netをトランスフォーマーに置き換えた。DiTsは高いGflopsを持ち、低いFIDを維持しながら良好なスケーラビリティを示す。最大のDiT-XL/2モデルは、ImageNetのベンチマークで従来の拡散モデルを上回り、最先端のFID 2.27を達成した。 Comment日本語解説:https://qiita.com/sasgawy/items/8546c784bc94d94ef0b2よく見るDiT
・2526
も同様の呼称だが全く異なる話なので注意 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention Issue Date: 2025-08-19 [Paper Note] Efficient Memory Management for Large Language Model Serving with PagedAttention, Woosuk Kwon+, SOSP'23 SummaryPagedAttentionを用いたvLLMシステムを提案し、KVキャッシュメモリの無駄を削減し、リクエスト間での柔軟な共有を実現。これにより、同レベルのレイテンシでLLMのスループットを2-4倍向上。特に長いシーケンスや大規模モデルで効果が顕著。ソースコードは公開中。 Comment(今更ながら)vLLMはこちら:
https://github.com/vllm-project/vllm
現在の主要なLLM Inference/Serving Engineのひとつ。 Issue Date: 2025-08-16 [Paper Note] SemDeDup: Data-efficient learning at web-scale through semantic deduplication, Amro Abbas+, arXiv'23 SummarySemDeDupは、事前学習モデルの埋め込みを用いて意味的に重複するデータペアを特定し削除する手法。LAIONのサブセットで50%のデータ削除を実現し、トレーニング時間を半分に短縮。分布外性能も向上し、C4データセットでも効率性を改善。質の高い埋め込みを活用することで、データ削減と学習加速を両立。 Commentopenreview:https://openreview.net/forum?id=IRSesTQUtb¬eId=usQjFYYAZJ #Analysis #NLP #LanguageModel Issue Date: 2025-08-11 [Paper Note] Physics of Language Models: Part 1, Learning Hierarchical Language Structures, Zeyuan Allen-Zhu+, arXiv'23 Summary本研究では、Transformerベースの言語モデルが文脈自由文法(CFG)による再帰的な言語構造推論をどのように行うかを調査。合成CFGを用いて長文を生成し、GPTのようなモデルがCFGの階層を正確に学習・推論できることを示す。モデルの隠れ状態がCFGの構造を捉え、注意パターンが動的プログラミングに類似していることが明らかに。また、絶対位置埋め込みの劣位や均一な注意の効果、エンコーダ専用モデルの限界、構造的ノイズによる堅牢性向上についても考察。 Comment解説:
・1834 #ComputerVision #Controllable #NLP #MulltiModal #TextToImageGeneration Issue Date: 2025-08-07 [Paper Note] Adding Conditional Control to Text-to-Image Diffusion Models, Lvmin Zhang+, arXiv'23 SummaryControlNetは、テキストから画像への拡散モデルに空間的な条件制御を追加するためのニューラルネットワークアーキテクチャであり、事前学習済みのエンコーディング層を再利用して多様な条件制御を学習します。ゼロ畳み込みを用いてパラメータを徐々に増加させ、有害なノイズの影響を軽減します。Stable Diffusionを用いて様々な条件制御をテストし、小規模および大規模データセットに対して堅牢性を示しました。ControlNetは画像拡散モデルの制御における広範な応用の可能性を示唆しています。 CommentControlNet論文 #RecommenderSystems #Transformer #VariationalAutoEncoder #NeurIPS #read-later #Admin'sPick #ColdStart #Encoder-Decoder #SemanticID Issue Date: 2025-07-28 [Paper Note] Recommender Systems with Generative Retrieval, Shashank Rajput+, NeurIPS'23 Summary新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを用いて次のアイテムを予測するTransformerベースのモデルを訓練。これにより、従来のレコメンダーシステムを大幅に上回る性能を達成し、過去の対話履歴がないアイテムに対しても改善された検索性能を示す。 Commentopenreview:https://openreview.net/forum?id=BJ0fQUU32wSemantic IDを提案した研究アイテムを意味的な情報を保持したdiscrete tokenのタプル(=Semantic ID)で表現し、encoder-decoderでNext ItemのSemantic IDを生成するタスクに落としこむことで推薦する。SemanticIDの作成方法は後で読んで理解したい。


 Issue Date: 2025-07-24
[Paper Note] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture, Mahmoud Assran+, arXiv'23
Summary本論文では、手作りのデータ拡張に依存せずに意味的な画像表現を学習するI-JEPAという自己教師あり学習アプローチを提案。I-JEPAは、単一のコンテキストブロックから異なるターゲットブロックの表現を予測する。重要な設計選択として、意味的に大きなターゲットブロックと情報量の多いコンテキストブロックのサンプリングが挙げられる。実験により、I-JEPAはVision Transformersと組み合わせることでスケーラブルであり、ImageNet上で強力な下流性能を達成した。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#SelfImprovement
#EMNLP
Issue Date: 2025-07-22
[Paper Note] Large Language Models Can Self-Improve, Jiaxin Huang+, EMNLP'23
SummaryLLMはラベルのないデータセットで自己改善可能であることを示し、Chain-of-Thoughtプロンプティングと自己一貫性を利用して高信頼度の回答を生成。これにより、540BパラメータのLLMの推論能力を向上させ、最先端のパフォーマンスを達成。ファインチューニングが自己改善に重要であることも確認。
Commentopenreview: https://openreview.net/forum?id=uuUQraD4XX¬eId=PWDEpZtn6P
Issue Date: 2025-07-24
[Paper Note] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture, Mahmoud Assran+, arXiv'23
Summary本論文では、手作りのデータ拡張に依存せずに意味的な画像表現を学習するI-JEPAという自己教師あり学習アプローチを提案。I-JEPAは、単一のコンテキストブロックから異なるターゲットブロックの表現を予測する。重要な設計選択として、意味的に大きなターゲットブロックと情報量の多いコンテキストブロックのサンプリングが挙げられる。実験により、I-JEPAはVision Transformersと組み合わせることでスケーラブルであり、ImageNet上で強力な下流性能を達成した。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#SelfImprovement
#EMNLP
Issue Date: 2025-07-22
[Paper Note] Large Language Models Can Self-Improve, Jiaxin Huang+, EMNLP'23
SummaryLLMはラベルのないデータセットで自己改善可能であることを示し、Chain-of-Thoughtプロンプティングと自己一貫性を利用して高信頼度の回答を生成。これにより、540BパラメータのLLMの推論能力を向上させ、最先端のパフォーマンスを達成。ファインチューニングが自己改善に重要であることも確認。
Commentopenreview: https://openreview.net/forum?id=uuUQraD4XX¬eId=PWDEpZtn6P #ICLR
#FlowMatching
Issue Date: 2025-07-09
[Paper Note] Building Normalizing Flows with Stochastic Interpolants, Michael S. Albergo+, ICLR'23
Summary基準確率密度とターゲット確率密度の間の連続時間正規化フローに基づく生成モデルを提案。従来の手法と異なり、逆伝播を必要とせず、速度に対する単純な二次損失を導出。フローはサンプリングや尤度推定に使用可能で、経路長の最小化も最適化できる。ガウス密度の場合、ターゲットをサンプリングする拡散モデルを構築可能だが、よりシンプルな確率流のアプローチを示す。密度推定タスクでは、従来の手法と同等以上の性能を低コストで達成し、画像生成においても良好な結果を示す。最大$128\times128$の解像度までスケールアップ可能。
#ICLR
#FlowMatching
Issue Date: 2025-07-09
[Paper Note] Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, Xingchao Liu+, ICLR'23
Summaryrectified flowという新しいアプローチを提案し、2つの分布間の輸送を学習するためのODEモデルを用いる。これは、直線的な経路を学習することで計算効率を高め、生成モデルやドメイン転送に統一的な解決策を提供する。rectificationを通じて、非増加の輸送コストを持つ新しい結合を生成し、再帰的に適用することで直線的なフローを得る。実証研究では、画像生成や翻訳において優れた性能を示し、高品質な結果を得ることが確認された。
#ICLR
#FlowMatching
Issue Date: 2025-07-09
[Paper Note] Flow Matching for Generative Modeling, Yaron Lipman+, ICLR'23
SummaryContinuous Normalizing Flows(CNFs)に基づく新しい生成モデルの訓練手法Flow Matching(FM)を提案。FMは固定された条件付き確率経路のベクトル場を回帰し、シミュレーション不要で訓練可能。拡散経路と併用することで、より堅牢な訓練が実現。最適輸送を用いた条件付き確率経路は効率的で、訓練とサンプリングが速く、一般化性能も向上。ImageNetでの実験により、FMは拡散ベース手法よりも優れた性能を示し、迅速なサンプル生成を可能にする。
#ComputerVision
#Pretraining
#LanguageModel
#MulltiModal
#Admin'sPick
#ICCV
Issue Date: 2025-06-29
[Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23
Summaryシンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。
CommentSigLIP論文
#EfficiencyImprovement
#NLP
#LanguageModel
#read-later
#Inference
Issue Date: 2025-06-12
[Paper Note] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, Amey Agrawal+, arXiv'23
SummarySARATHIは、LLMの推論効率を向上させる手法で、プレフィルリクエストをチャンクに分割し、デコードマキシマルバッチを構築することで計算利用率を最大化します。これにより、デコードスループットを最大10倍向上させ、エンドツーエンドスループットも改善。特に、A6000 GPU上のLLaMA-13Bモデルで顕著な性能向上を示し、パイプラインバブルを大幅に削減しました。
CommentvLLMでも採用されている `Chunked Prefills` と `Decode-Maximal Batching` を提案している。
#ICLR
#FlowMatching
Issue Date: 2025-07-09
[Paper Note] Building Normalizing Flows with Stochastic Interpolants, Michael S. Albergo+, ICLR'23
Summary基準確率密度とターゲット確率密度の間の連続時間正規化フローに基づく生成モデルを提案。従来の手法と異なり、逆伝播を必要とせず、速度に対する単純な二次損失を導出。フローはサンプリングや尤度推定に使用可能で、経路長の最小化も最適化できる。ガウス密度の場合、ターゲットをサンプリングする拡散モデルを構築可能だが、よりシンプルな確率流のアプローチを示す。密度推定タスクでは、従来の手法と同等以上の性能を低コストで達成し、画像生成においても良好な結果を示す。最大$128\times128$の解像度までスケールアップ可能。
#ICLR
#FlowMatching
Issue Date: 2025-07-09
[Paper Note] Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, Xingchao Liu+, ICLR'23
Summaryrectified flowという新しいアプローチを提案し、2つの分布間の輸送を学習するためのODEモデルを用いる。これは、直線的な経路を学習することで計算効率を高め、生成モデルやドメイン転送に統一的な解決策を提供する。rectificationを通じて、非増加の輸送コストを持つ新しい結合を生成し、再帰的に適用することで直線的なフローを得る。実証研究では、画像生成や翻訳において優れた性能を示し、高品質な結果を得ることが確認された。
#ICLR
#FlowMatching
Issue Date: 2025-07-09
[Paper Note] Flow Matching for Generative Modeling, Yaron Lipman+, ICLR'23
SummaryContinuous Normalizing Flows(CNFs)に基づく新しい生成モデルの訓練手法Flow Matching(FM)を提案。FMは固定された条件付き確率経路のベクトル場を回帰し、シミュレーション不要で訓練可能。拡散経路と併用することで、より堅牢な訓練が実現。最適輸送を用いた条件付き確率経路は効率的で、訓練とサンプリングが速く、一般化性能も向上。ImageNetでの実験により、FMは拡散ベース手法よりも優れた性能を示し、迅速なサンプル生成を可能にする。
#ComputerVision
#Pretraining
#LanguageModel
#MulltiModal
#Admin'sPick
#ICCV
Issue Date: 2025-06-29
[Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23
Summaryシンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。
CommentSigLIP論文
#EfficiencyImprovement
#NLP
#LanguageModel
#read-later
#Inference
Issue Date: 2025-06-12
[Paper Note] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, Amey Agrawal+, arXiv'23
SummarySARATHIは、LLMの推論効率を向上させる手法で、プレフィルリクエストをチャンクに分割し、デコードマキシマルバッチを構築することで計算利用率を最大化します。これにより、デコードスループットを最大10倍向上させ、エンドツーエンドスループットも改善。特に、A6000 GPU上のLLaMA-13Bモデルで顕著な性能向上を示し、パイプラインバブルを大幅に削減しました。
CommentvLLMでも採用されている `Chunked Prefills` と `Decode-Maximal Batching` を提案している。
 #EfficiencyImprovement #NLP #LanguageModel #ACL #Parallelism Issue Date: 2025-05-16 Sequence Parallelism: Long Sequence Training from System Perspective, Li+, ACL'23 Comment入力系列をチャンクに分割して、デバイスごとに担当するチャンクを決めることで原理上無限の長さの系列を扱えるようにした並列化手法。系列をデバイス間で横断する場合attention scoreをどのように計算するかが課題になるが、そのためにRing Self attentionと呼ばれるアルゴリズムを提案している模様。また、MLPブロックとMulti Head Attentonブロックの計算も、BatchSize Sequence Lengthの大きさが、それぞれ32Hidden Size, 16Attention Head size of Attention Headよりも大きくなった場合に、Tensor Parallelismよりもメモリ効率が良くなるらしい。
 Data Parallel, Pipeline Parallel, Tensor Parallel、全てに互換性があるとのこと(併用可能)そのほかの並列化の解説については
Data Parallel, Pipeline Parallel, Tensor Parallel、全てに互換性があるとのこと(併用可能)そのほかの並列化の解説については
・1184
を参照のこと。 #MachineLearning #NLP #LanguageModel #Hallucination #NeurIPS #read-later #ActivationSteering/ITI #Probing #Trustfulness #Admin'sPick Issue Date: 2025-05-09 Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23 SummaryInference-Time Intervention (ITI)を提案し、LLMsの真実性を向上させる技術を紹介。ITIは推論中にモデルの活性化を調整し、LLaMAモデルの性能をTruthfulQAベンチマークで大幅に改善。Alpacaモデルでは真実性が32.5%から65.1%に向上。真実性と有用性のトレードオフを特定し、介入の強度を調整する方法を示す。ITIは低コストでデータ効率が高く、数百の例で真実の方向性を特定可能。LLMsが虚偽を生成しつつも真実の内部表現を持つ可能性を示唆。 CommentInference Time Interventionを提案した研究。Attention Headに対して線形プロービング[^1]を実施し、真実性に関連するであろうHeadをtopKで特定できるようにし、headの出力に対し真実性を高める方向性のベクトルvを推論時に加算することで(=intervention)、モデルの真実性を高める。vは線形プロービングによって学習された重みを使う手法と、正答と誤答の活性化の平均ベクトルを計算しその差分をvとする方法の二種類がある。後者の方が性能が良い。topKを求める際には、線形プロービングをしたモデルのvalidation setでの性能から決める。Kとαはハイパーパラメータである。
[^1]: headのrepresentationを入力として受け取り、線形モデルを学習し、線形モデルの2値分類性能を見ることでheadがどの程度、プロービングの学習に使ったデータに関する情報を保持しているかを測定する手法
日本語解説スライド:https://www.docswell.com/s/DeepLearning2023/Z38P8D-2024-06-20-131813p1これは相当汎用的に使えそうな話だから役に立ちそう #ComputerVision #NLP #Transformer #MulltiModal #SpeechProcessing #Architecture #Normalization Issue Date: 2025-04-19 Foundation Transformers, Hongyu Wang+, PMLR'23 Summary言語、視覚、音声、マルチモーダルにおけるモデルアーキテクチャの収束が進む中、異なる実装の「Transformers」が使用されている。汎用モデリングのために、安定性を持つFoundation Transformerの開発が提唱され、Magnetoという新しいTransformer変種が紹介される。Sub-LayerNormと理論に基づく初期化戦略を用いることで、さまざまなアプリケーションにおいて優れたパフォーマンスと安定性を示した。 Commentマルチモーダルなモデルなモデルの事前学習において、PostLNはvision encodingにおいてsub-optimalで、PreLNはtext encodingにおいてsub-optimalであることが先行研究で示されており、マルタモーダルを単一のアーキテクチャで、高性能、かつ学習の安定性な高く、try and error無しで適用できる基盤となるアーキテクチャが必要というモチベーションで提案された手法。具体的には、Sub-LayerNorm(Sub-LN)と呼ばれる、self attentionとFFN部分に追加のLayerNormを適用するアーキテクチャと、DeepNetを踏襲しLayer数が非常に大きい場合でも学習が安定するような重みの初期化方法を理論的に分析し提案している。
具体的には、Sub-LNの場合、LayerNormを
・SelfAttention計算におけるQKVを求めるためのinput Xのprojectionの前とAttentionの出力projectionの前
・FFNでの各Linear Layerの前
に適用し、
初期化をする際には、FFNのW, およびself-attentionのV_projと出力のout_projの初期化をγ(=sqrt(log(2N))によってスケーリングする方法を提案している模様。
 関連:
関連:
・1900 #ComputerVision #Transformer #ImageSegmentation #FoundationModel Issue Date: 2025-04-11 Segment Anything, Alexander Kirillov+, arXiv'23 SummarySegment Anything (SA)プロジェクトは、画像セグメンテーションの新しいタスク、モデル、データセットを提案し、1億以上のマスクを含む1,100万のプライバシー尊重した画像からなる最大のセグメンテーションデータセットを構築しました。プロンプト可能なモデルはゼロショットで新しい画像分布やタスクに適応でき、評価の結果、ゼロショット性能が高く、従来の監視された結果を上回ることもあります。SAMとSA-1Bデータセットは、研究促進のために公開されています。 CommentSAM論文 #ComputerVision #NLP #LanguageModel #MulltiModal #OpenWeight Issue Date: 2025-04-11 PaLI-3 Vision Language Models: Smaller, Faster, Stronger, Xi Chen+, arXiv'23 SummaryPaLI-3は、従来のモデルに比べて10倍小型で高速な視覚言語モデル(VLM)であり、特にローカリゼーションや視覚的テキスト理解において優れた性能を示す。SigLIPベースのPaLIは、20億パラメータにスケールアップされ、多言語クロスモーダル検索で新たな最先端を達成。50億パラメータのPaLI-3は、VLMの研究を再燃させることを期待されている。 CommentOpenReview:https://openreview.net/forum?id=JpyWPfzu0b
実験的に素晴らしい性能が実現されていることは認められつつも
・比較対象がSigLIPのみでより広範な比較実験と分析が必要なこと
・BackboneモデルをContrastive Learningすること自体の有用性は既に知られており、新規性に乏しいこと
としてICLR'24にRejectされている #NLP #Dataset #LanguageModel #LLMAgent #SoftwareEngineering Issue Date: 2025-04-02 SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, arXiv'23 SummarySWE-benchは、12の人気Pythonリポジトリから得られた2,294のソフトウェアエンジニアリング問題を評価するフレームワークで、言語モデルがコードベースを編集して問題を解決する能力を測定します。評価の結果、最先端の商用モデルや微調整されたモデルSWE-Llamaも最も単純な問題しか解決できず、Claude 2はわずか1.96%の問題を解決するにとどまりました。SWE-benchは、より実用的で知的な言語モデルへの進展を示しています。 Commentソフトウェアエージェントの最もpopularなベンチマーク

主にpythonライブラリに関するリポジトリに基づいて構築されている。
 SWE-Bench, SWE-Bench Lite, SWE-Bench Verifiedの3種類がありソフトウェアエージェントではSWE-Bench Verifiedを利用して評価することが多いらしい。Verifiedでは、issueの記述に曖昧性がなく、適切なunittestのスコープが適切なもののみが採用されているとのこと(i.e., 人間の専門家によって問題がないと判断されたもの)。
SWE-Bench, SWE-Bench Lite, SWE-Bench Verifiedの3種類がありソフトウェアエージェントではSWE-Bench Verifiedを利用して評価することが多いらしい。Verifiedでは、issueの記述に曖昧性がなく、適切なunittestのスコープが適切なもののみが採用されているとのこと(i.e., 人間の専門家によって問題がないと判断されたもの)。
https://www.swebench.com/ #Survey #MachineLearning #Dataset #Distillation Issue Date: 2025-03-25 Dataset Distillation: A Comprehensive Review, Ruonan Yu+, arXiv'23 Summaryデータセット蒸留(DD)は、深層学習における膨大なデータのストレージやプライバシーの問題を軽減する手法であり、合成サンプルを含む小さなデータセットを生成することで、元のデータセットと同等の性能を持つモデルをトレーニング可能にする。本論文では、DDの進展と応用をレビューし、全体的なアルゴリズムフレームワークを提案、既存手法の分類と理論的相互関係を議論し、DDの課題と今後の研究方向を展望する。 Comment訓練データセット中の知識を蒸留し、オリジナルデータよりも少量のデータで同等の学習効果を得るDataset Distillationに関するSurvey。
 #MachineLearning
#NLP
#LanguageModel
#NeurIPS
#Scaling Laws
#read-later
Issue Date: 2025-03-23
Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
Summary言語モデルのスケーリングにおいて、データ制約下でのトレーニングを調査。9000億トークンと90億パラメータのモデルを用いた実験で、繰り返しデータを使用しても損失に大きな変化は見られず、繰り返しの価値が減少することを確認。計算最適性のスケーリング法則を提案し、データ不足を軽減するアプローチも実験。得られたモデルとデータセットは公開。
CommentOpenReview:https://openreview.net/forum?id=j5BuTrEj35チンチラ則のようなScaling Lawsはパラメータとデータ量の両方をスケールさせた場合の前提に立っており、かつデータは全てuniqueである前提だったが、データの枯渇が懸念される昨今の状況に合わせて、データ量が制限された状況で、同じデータを繰り返し利用する(=複数エポック学習する)ことが一般的になってきた。このため、データのrepetitionに関して性能を事前学習による性能の違いを調査して、repetitionとパラメータ数に関するスケーリング則を提案($3.1)しているようである。
#MachineLearning
#NLP
#LanguageModel
#NeurIPS
#Scaling Laws
#read-later
Issue Date: 2025-03-23
Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
Summary言語モデルのスケーリングにおいて、データ制約下でのトレーニングを調査。9000億トークンと90億パラメータのモデルを用いた実験で、繰り返しデータを使用しても損失に大きな変化は見られず、繰り返しの価値が減少することを確認。計算最適性のスケーリング法則を提案し、データ不足を軽減するアプローチも実験。得られたモデルとデータセットは公開。
CommentOpenReview:https://openreview.net/forum?id=j5BuTrEj35チンチラ則のようなScaling Lawsはパラメータとデータ量の両方をスケールさせた場合の前提に立っており、かつデータは全てuniqueである前提だったが、データの枯渇が懸念される昨今の状況に合わせて、データ量が制限された状況で、同じデータを繰り返し利用する(=複数エポック学習する)ことが一般的になってきた。このため、データのrepetitionに関して性能を事前学習による性能の違いを調査して、repetitionとパラメータ数に関するスケーリング則を提案($3.1)しているようである。
Takeawayとしては、データが制限された環境下では、repetitionは上限4回までが効果的(コスパが良い)であり(左図)、小さいモデルを複数エポック訓練する方が固定されたBudgetの中で低いlossを達成できる右図)。

学習データの半分をコードにしても性能の劣化はなく、様々なタスクの性能が向上しパフォーマンスの分散も小さくなる、といったことが挙げられるようだ。
 #Survey
#NLP
#Dataset
#Distillation
Issue Date: 2025-02-01
Data Distillation: A Survey, Noveen Sachdeva+, arXiv'23
Summary深層学習の普及に伴い、大規模データセットの訓練が高コストで持続可能性に課題をもたらしている。データ蒸留アプローチは、元のデータセットの効果的な代替品を提供し、モデル訓練や推論に役立つ。本研究では、データ蒸留のフレームワークを提示し、既存のアプローチを分類。画像やグラフ、レコメンダーシステムなどの異なるデータモダリティにおける課題と今後の研究方向性を示す。
#ACL
Issue Date: 2025-01-06
Are Emergent Abilities in Large Language Models just In-Context Learning?, Sheng Lu+, arXiv'23
Summary大規模言語モデルの「出現能力」は、インコンテキスト学習やモデルの記憶、言語知識の組み合わせから生じるものであり、真の出現ではないと提案。1000以上の実験を通じてこの理論を裏付け、言語モデルの性能を理解するための基礎を提供し、能力の過大評価を警告。
#ACL
Issue Date: 2025-01-06
Boosting Language Models Reasoning with Chain-of-Knowledge Prompting, Jianing Wang+, arXiv'23
SummaryChain-of-Thought(CoT)プロンプティングの限界を克服するために、Chain-of-Knowledge(CoK)プロンプティングを提案。CoKは、LLMsに明示的な知識の証拠を生成させ、推論の信頼性を向上させる。F^2-Verification手法を用いて、信頼性のない応答を指摘し再考を促す。実験により、常識や事実に基づく推論タスクのパフォーマンスが向上することを示した。
#ACL
Issue Date: 2025-01-06
Exploring Memorization in Fine-tuned Language Models, Shenglai Zeng+, arXiv'23
Summaryファインチューニング中の大規模言語モデル(LLMs)の記憶を初めて包括的に分析。オープンソースのファインチューニングされたモデルを用いた結果、記憶はタスク間で不均一であることが判明。スパースコーディング理論を通じてこの不均一性を説明し、記憶と注意スコア分布の強い相関関係を明らかにした。
#ACL
Issue Date: 2025-01-06
Instruction Fusion: Advancing Prompt Evolution through Hybridization, Weidong Guo+, arXiv'23
SummaryInstruction Fusion(IF)を提案し、二つの異なるプロンプトを組み合わせることでコード生成LLMの性能を向上させる。実験により、IFが従来の手法の制約を克服し、HumanEvalなどのベンチマークで大幅な性能向上を実現することを示した。
#ACL
Issue Date: 2025-01-06
Insert or Attach: Taxonomy Completion via Box Embedding, Wei Xue+, arXiv'23
SummaryTaxBoxフレームワークは、ボックス埋め込み空間を利用して分類体系の補完を行い、挿入および付加操作に特化した幾何学的スコアラーを設計。動的ランキング損失メカニズムによりスコアを調整し、実験では従来手法を大幅に上回る性能向上を達成。
#ACL
Issue Date: 2025-01-06
SPARSEFIT: Few-shot Prompting with Sparse Fine-tuning for Jointly Generating Predictions and Natural Language Explanations, Jesus Solano+, arXiv'23
SummarySparseFitは、少量の自然言語による説明(NLE)データを用いて、離散的なプロンプトを活用し、予測とNLEを共同生成するスパースなfew-shot微調整戦略です。T5モデルで実験した結果、わずか6.8%のパラメータ微調整で、タスクのパフォーマンスとNLEの質が向上し、他のパラメータ効率的微調整技術よりも優れた結果を示しました。
#ACL
Issue Date: 2025-01-06
LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin, Shihan Dou+, arXiv'23
SummaryLoRAMoEフレームワークを提案し、教師ありファインチューニングにおける指示データの増加がLLMsの世界知識を損なう問題に対処。低ランクアダプターとルーターネットワークを用いて、世界知識を活用しつつ下流タスクの処理能力を向上させることを実証。
#Survey
#NLP
#LanguageModel
#Chain-of-Thought
#ACL
Issue Date: 2025-01-06
Navigate through Enigmatic Labyrinth A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future, Zheng Chu+, arXiv'23
Summary推論はAIにおいて重要な認知プロセスであり、チェーン・オブ・ソートがLLMの推論能力を向上させることが注目されている。本論文では関連研究を体系的に調査し、手法を分類して新たな視点を提供。課題や今後の方向性についても議論し、初心者向けの導入を目指す。リソースは公開されている。
#NLP
#LanguageModel
#Chain-of-Thought
Issue Date: 2025-01-05
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks, Wenhu Chen+, TMLR'23
Summary段階的な推論を用いた数値推論タスクにおいて、Chain-of-thoughts prompting(CoT)の進展があり、推論をプログラムとして表現する「Program of Thoughts」(PoT)を提案。PoTは外部コンピュータで計算を行い、5つの数学問題データセットと3つの金融QAデータセットで評価した結果、少数ショットおよびゼロショット設定でCoTに対して約12%の性能向上を示した。自己一貫性デコーディングとの組み合わせにより、数学問題データセットで最先端の性能を達成。データとコードはGitHubで公開。
Comment1. LLMsは算術演算を実施する際にエラーを起こしやすく、特に大きな数に対する演算を実施する際に顕著
#Survey
#NLP
#Dataset
#Distillation
Issue Date: 2025-02-01
Data Distillation: A Survey, Noveen Sachdeva+, arXiv'23
Summary深層学習の普及に伴い、大規模データセットの訓練が高コストで持続可能性に課題をもたらしている。データ蒸留アプローチは、元のデータセットの効果的な代替品を提供し、モデル訓練や推論に役立つ。本研究では、データ蒸留のフレームワークを提示し、既存のアプローチを分類。画像やグラフ、レコメンダーシステムなどの異なるデータモダリティにおける課題と今後の研究方向性を示す。
#ACL
Issue Date: 2025-01-06
Are Emergent Abilities in Large Language Models just In-Context Learning?, Sheng Lu+, arXiv'23
Summary大規模言語モデルの「出現能力」は、インコンテキスト学習やモデルの記憶、言語知識の組み合わせから生じるものであり、真の出現ではないと提案。1000以上の実験を通じてこの理論を裏付け、言語モデルの性能を理解するための基礎を提供し、能力の過大評価を警告。
#ACL
Issue Date: 2025-01-06
Boosting Language Models Reasoning with Chain-of-Knowledge Prompting, Jianing Wang+, arXiv'23
SummaryChain-of-Thought(CoT)プロンプティングの限界を克服するために、Chain-of-Knowledge(CoK)プロンプティングを提案。CoKは、LLMsに明示的な知識の証拠を生成させ、推論の信頼性を向上させる。F^2-Verification手法を用いて、信頼性のない応答を指摘し再考を促す。実験により、常識や事実に基づく推論タスクのパフォーマンスが向上することを示した。
#ACL
Issue Date: 2025-01-06
Exploring Memorization in Fine-tuned Language Models, Shenglai Zeng+, arXiv'23
Summaryファインチューニング中の大規模言語モデル(LLMs)の記憶を初めて包括的に分析。オープンソースのファインチューニングされたモデルを用いた結果、記憶はタスク間で不均一であることが判明。スパースコーディング理論を通じてこの不均一性を説明し、記憶と注意スコア分布の強い相関関係を明らかにした。
#ACL
Issue Date: 2025-01-06
Instruction Fusion: Advancing Prompt Evolution through Hybridization, Weidong Guo+, arXiv'23
SummaryInstruction Fusion(IF)を提案し、二つの異なるプロンプトを組み合わせることでコード生成LLMの性能を向上させる。実験により、IFが従来の手法の制約を克服し、HumanEvalなどのベンチマークで大幅な性能向上を実現することを示した。
#ACL
Issue Date: 2025-01-06
Insert or Attach: Taxonomy Completion via Box Embedding, Wei Xue+, arXiv'23
SummaryTaxBoxフレームワークは、ボックス埋め込み空間を利用して分類体系の補完を行い、挿入および付加操作に特化した幾何学的スコアラーを設計。動的ランキング損失メカニズムによりスコアを調整し、実験では従来手法を大幅に上回る性能向上を達成。
#ACL
Issue Date: 2025-01-06
SPARSEFIT: Few-shot Prompting with Sparse Fine-tuning for Jointly Generating Predictions and Natural Language Explanations, Jesus Solano+, arXiv'23
SummarySparseFitは、少量の自然言語による説明(NLE)データを用いて、離散的なプロンプトを活用し、予測とNLEを共同生成するスパースなfew-shot微調整戦略です。T5モデルで実験した結果、わずか6.8%のパラメータ微調整で、タスクのパフォーマンスとNLEの質が向上し、他のパラメータ効率的微調整技術よりも優れた結果を示しました。
#ACL
Issue Date: 2025-01-06
LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin, Shihan Dou+, arXiv'23
SummaryLoRAMoEフレームワークを提案し、教師ありファインチューニングにおける指示データの増加がLLMsの世界知識を損なう問題に対処。低ランクアダプターとルーターネットワークを用いて、世界知識を活用しつつ下流タスクの処理能力を向上させることを実証。
#Survey
#NLP
#LanguageModel
#Chain-of-Thought
#ACL
Issue Date: 2025-01-06
Navigate through Enigmatic Labyrinth A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future, Zheng Chu+, arXiv'23
Summary推論はAIにおいて重要な認知プロセスであり、チェーン・オブ・ソートがLLMの推論能力を向上させることが注目されている。本論文では関連研究を体系的に調査し、手法を分類して新たな視点を提供。課題や今後の方向性についても議論し、初心者向けの導入を目指す。リソースは公開されている。
#NLP
#LanguageModel
#Chain-of-Thought
Issue Date: 2025-01-05
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks, Wenhu Chen+, TMLR'23
Summary段階的な推論を用いた数値推論タスクにおいて、Chain-of-thoughts prompting(CoT)の進展があり、推論をプログラムとして表現する「Program of Thoughts」(PoT)を提案。PoTは外部コンピュータで計算を行い、5つの数学問題データセットと3つの金融QAデータセットで評価した結果、少数ショットおよびゼロショット設定でCoTに対して約12%の性能向上を示した。自己一貫性デコーディングとの組み合わせにより、数学問題データセットで最先端の性能を達成。データとコードはGitHubで公開。
Comment1. LLMsは算術演算を実施する際にエラーを起こしやすく、特に大きな数に対する演算を実施する際に顕著
2. LLMsは複雑な数式(e.g. 多項式, 微分方程式)を解くことができない
3. LLMsはiterationを表現するのが非常に非効率
の3点を解決するために、外部のインタプリタに演算処理を委譲するPoTを提案。PoTでは、言語モデルにreasoning stepsをpython programで出力させ、演算部分をPython Interpreterに実施させる。
 テキスト、テーブル、対話などの多様なinputをサポートする5つのMath Word Problem (MWP), 3つのFinancial Datasetで評価した結果、zero-shot, few-shotの両方の設定において、PoTはCoTをoutpeformし、また、Self-Consistencyと組み合わせた場合も、PoTはCoTをoutperformした。
テキスト、テーブル、対話などの多様なinputをサポートする5つのMath Word Problem (MWP), 3つのFinancial Datasetで評価した結果、zero-shot, few-shotの両方の設定において、PoTはCoTをoutpeformし、また、Self-Consistencyと組み合わせた場合も、PoTはCoTをoutperformした。
 #RecommenderSystems
#Survey
#InformationRetrieval
#LanguageModel
#SequentialRecommendation
Issue Date: 2024-12-30
Recommender Systems with Generative Retrieval, Shashank Rajput+, arXiv'23
Summary新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを自己回帰的にデコード。Transformerベースのモデルが次のアイテムのセマンティックIDを予測し、レコメンデーションタスクにおいて初のセマンティックIDベースの生成モデルとなる。提案手法は最先端モデルを大幅に上回り、過去の対話履歴がないアイテムに対する検索性能も向上。
#MachineLearning
Issue Date: 2024-12-16
Zero Bubble Pipeline Parallelism, Penghui Qi+, arXiv'23
Summary本研究では、パイプライン並列性の効率を向上させるために、ゼロパイプラインバブルを達成する新しいスケジューリング戦略を提案。逆伝播計算を二つに分割し、手作業で設計した新しいパイプラインスケジュールは、ベースライン手法を大幅に上回る性能を示した。さらに、最適なスケジュールを自動的に見つけるアルゴリズムと、オプティマイザステップ中の同期を回避する技術を導入。実験結果では、スループットが最大23%向上し、メモリ制約が緩和されると31%まで改善。実装はオープンソースで提供。
Issue Date: 2024-12-05
Benchmarking Large Language Models in Retrieval-Augmented Generation, Jiawei Chen+, arXiv'23
SummaryRetrieval-Augmented Generation(RAG)の大規模言語モデル(LLMs)への影響を体系的に調査。RAGに必要な4つの基本能力(ノイズ耐性、ネガティブ拒否、情報統合、反事実的耐性)を分析するために新たにRetrieval-Augmented Generation Benchmark(RGB)を設立。6つのLLMを評価した結果、ノイズ耐性は一定の成果を示すが、他の能力には依然として課題が残ることが明らかに。RAGの効果的な適用にはさらなる改善が必要。
#NLP
#LanguageModel
#Quantization
#ICML
Issue Date: 2024-12-03
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models, Guangxuan Xiao+, ICML'23
SummarySmoothQuantは、トレーニング不要で8ビットの重みと活性化の量子化を実現するポストトレーニング量子化ソリューションです。活性化の外れ値を滑らかにすることで、量子化の難易度を軽減し、精度を保持しつつ最大1.56倍の速度向上と2倍のメモリ削減を達成しました。これにより、530BのLLMを単一ノードで運用可能にし、LLMsの民主化を促進します。コードは公開されています。
Commentおそらく量子化手法の現時点のSoTA
#RecommenderSystems
#LanguageModel
Issue Date: 2024-12-03
Recommender Systems in the Era of Large Language Models (LLMs), Zihuai Zhao+, arXiv'23
Summaryレコメンダーシステムは、ユーザーの好みに基づいた提案を提供する重要な要素であり、DNNの限界を克服するためにLLMsの活用が進んでいる。本論文では、LLMを用いたレコメンダーシステムの事前学習、ファインチューニング、プロンプティングに関する包括的なレビューを行い、ユーザーとアイテムの表現学習手法や最近の技術を紹介し、今後の研究方向性について議論する。
Comment
#RecommenderSystems
#Survey
#InformationRetrieval
#LanguageModel
#SequentialRecommendation
Issue Date: 2024-12-30
Recommender Systems with Generative Retrieval, Shashank Rajput+, arXiv'23
Summary新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを自己回帰的にデコード。Transformerベースのモデルが次のアイテムのセマンティックIDを予測し、レコメンデーションタスクにおいて初のセマンティックIDベースの生成モデルとなる。提案手法は最先端モデルを大幅に上回り、過去の対話履歴がないアイテムに対する検索性能も向上。
#MachineLearning
Issue Date: 2024-12-16
Zero Bubble Pipeline Parallelism, Penghui Qi+, arXiv'23
Summary本研究では、パイプライン並列性の効率を向上させるために、ゼロパイプラインバブルを達成する新しいスケジューリング戦略を提案。逆伝播計算を二つに分割し、手作業で設計した新しいパイプラインスケジュールは、ベースライン手法を大幅に上回る性能を示した。さらに、最適なスケジュールを自動的に見つけるアルゴリズムと、オプティマイザステップ中の同期を回避する技術を導入。実験結果では、スループットが最大23%向上し、メモリ制約が緩和されると31%まで改善。実装はオープンソースで提供。
Issue Date: 2024-12-05
Benchmarking Large Language Models in Retrieval-Augmented Generation, Jiawei Chen+, arXiv'23
SummaryRetrieval-Augmented Generation(RAG)の大規模言語モデル(LLMs)への影響を体系的に調査。RAGに必要な4つの基本能力(ノイズ耐性、ネガティブ拒否、情報統合、反事実的耐性)を分析するために新たにRetrieval-Augmented Generation Benchmark(RGB)を設立。6つのLLMを評価した結果、ノイズ耐性は一定の成果を示すが、他の能力には依然として課題が残ることが明らかに。RAGの効果的な適用にはさらなる改善が必要。
#NLP
#LanguageModel
#Quantization
#ICML
Issue Date: 2024-12-03
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models, Guangxuan Xiao+, ICML'23
SummarySmoothQuantは、トレーニング不要で8ビットの重みと活性化の量子化を実現するポストトレーニング量子化ソリューションです。活性化の外れ値を滑らかにすることで、量子化の難易度を軽減し、精度を保持しつつ最大1.56倍の速度向上と2倍のメモリ削減を達成しました。これにより、530BのLLMを単一ノードで運用可能にし、LLMsの民主化を促進します。コードは公開されています。
Commentおそらく量子化手法の現時点のSoTA
#RecommenderSystems
#LanguageModel
Issue Date: 2024-12-03
Recommender Systems in the Era of Large Language Models (LLMs), Zihuai Zhao+, arXiv'23
Summaryレコメンダーシステムは、ユーザーの好みに基づいた提案を提供する重要な要素であり、DNNの限界を克服するためにLLMsの活用が進んでいる。本論文では、LLMを用いたレコメンダーシステムの事前学習、ファインチューニング、プロンプティングに関する包括的なレビューを行い、ユーザーとアイテムの表現学習手法や最近の技術を紹介し、今後の研究方向性について議論する。
Comment
中身を全然読んでいる時間はないので、図には重要な情報が詰まっていると信じ、図を読み解いていく。時間がある時に中身も読みたい。。。
LLM-basedなRecSysでは、NLPにおけるLLMの使い方(元々はT5で提案)と同様に、様々なレコメンド関係タスクを、テキスト生成タスクに落とし込み学習することができる。

RecSysのLiteratureとしては、最初はコンテンツベースと協調フィルタリングから始まり、(グラフベースドな推薦, Matrix Factorization, Factorization Machinesなどが間にあって)、その後MLP, RNN, CNN, AutoEncoderなどの様々なDeep Neural Network(DNN)を活用した手法や、BERT4RecなどのProbabilistic Language Models(PLM)を用いた手法にシフトしていき、現在LLM-basedなRecSysの時代に到達した、との流れである。

LLM-basedな手法では、pretrainingの段階からEncoder-basedなモデルの場合はMLM、Decoder-basedな手法ではNext Token Predictionによってデータセットで事前学習する方法もあれば、フルパラメータチューニングやPEFT(LoRAなど)によるSFTによるアプローチもあるようである。
推薦タスクは、推薦するアイテムIDを生成するようなタスクの場合は、異なるアイテムID空間に基づくデータセットの間では転移ができないので、SFTをしないとなかなかうまくいかないと気がしている。また、その場合はアイテムIDの推薦以外のタスクも同時に実施したい場合は、事前学習済みのパラメータが固定されるPEFT手法の方が安全策になるかなぁ、という気がしている(破壊的忘却が怖いので)。特はたとえば、アイテムIDを生成するだけでなく、その推薦理由を生成できるのはとても良いことだなあと感じる(良い時代、感)。

また、PromptingによるRecSysの流れも図解されているが、In-Context Learningのほかに、Prompt Tuning(softとhardの両方)、Instruction Tuningも同じ図に含まれている。個人的にはPrompt TuningはPEFTの一種であり、Instruction TuningはSFTの一種なので、一つ上の図に含意される話なのでは?という気がするが、論文中ではどのような立て付けで記述されているのだろうか。
どちらかというと、Promptingの話であれば、zero-few-many shotや、各種CoTの話を含めるのが自然な気がするのだが。

下図はPromptingによる手法を表にまとめたもの。Finetuningベースの手法が別表にまとめられていたが、研究の数としてはこちらの方が多そうに見える。が、性能的にはどの程度が達成されるのだろうか。直感的には、アイテムを推薦するようなタスクでは、Promptingでは性能が出にくいような印象がある。なぜなら、事前学習済みのLLMはアイテムIDのトークン列とアイテムの特徴に関する知識がないので。これをFinetuningしないのであればICLで賄うことになると思うのだが、果たしてどこまでできるだろうか…。興味がある。

(図は論文より引用) #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering, Siriwardhana+, TACL'23, 2023.01 SummaryRAG-end2endは、ODQAにおけるドメイン適応のためにRAGのリトリーバーとジェネレーターを共同訓練する新しいアプローチを提案。外部知識ベースを更新し、補助的な訓練信号を導入することで、ドメイン特化型知識を強化。COVID-19、ニュース、会話のデータセットで評価し、元のRAGモデルよりも性能が向上。研究はオープンソースとして公開。 #Pretraining #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #MoE(Mixture-of-Experts) #PostTraining Issue Date: 2024-11-25 Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR'23 Summaryスパース活性化モデルは、計算コストを抑えつつ密なモデルの代替として注目されているが、依然として多くのデータを必要とし、ゼロからのトレーニングは高コストである。本研究では、密なチェックポイントからスパース活性化Mixture-of-Expertsモデルを初期化する「スパースアップサイクリング」を提案。これにより、初期の密な事前トレーニングのコストを約50%再利用し、SuperGLUEやImageNetで密なモデルを大幅に上回る性能を示した。また、アップサイクリングされたモデルは、ゼロからトレーニングされたスパースモデルよりも優れた結果を得た。 Comment斜め読みしかできていないが、Mixture-of-Expertsを用いたモデルをSFT/Pretrainingする際に、既存のcheckpointの重みを活用することでより効率的かつ性能向上する方法を提案。MoE LayerのMLPを全て既存のcheckpointにおけるMLPの重みをコピーして初期化する。Routerはスクラッチから学習する。

継続事前学習においては、同じ学習時間の中でDense Layerを用いるベースラインと比較してでより高い性能を獲得。

Figure2で継続事前学習したモデルに対して、フルパラメータのFinetuningをした場合でもUpcyclingは効果がある(Figure3)。
特にPretrainingではUpcyclingを用いたモデルの性能に、通常のMoEをスクラッチから学習したモデルが追いつくのに時間がかかるとのこと。特に図右側の言語タスクでは、120%の学習時間が追いつくために必要だった。

Sparse Upcycingと、Dense tilingによる手法(warm start; 元のモデルに既存の層を複製して新しい層を追加する方法)、元のモデルをそれぞれ継続事前学習すると、最も高い性能を獲得している。

(すごい斜め読みなのでちょっも自信なし、、、) #MachineTranslation #NLP #LanguageModel Issue Date: 2024-11-20 Prompting Large Language Model for Machine Translation: A Case Study, Biao Zhang+, arXiv'23 Summary機械翻訳におけるプロンプティングの研究を体系的に行い、プロンプトテンプレートやデモ例の選択に影響を与える要因を検討。GLM-130Bを用いた実験により、プロンプト例の数と質が翻訳に重要であること、意味的類似性などの特徴がパフォーマンスと相関するが強くないこと、単言語データからの擬似平行プロンプト例が翻訳を改善する可能性があること、他の設定からの知識転送がパフォーマンス向上に寄与することを示した。プロンプティングの課題についても議論。 Commentzero-shotでMTを行うときに、改行の有無や、少しのpromptingの違いでCOMETスコアが大幅に変わることを示している。
モデルはGLM-130BをINT4で量子化したモデルで実験している。
興味深いが、この知見を一般化して全てのLLMに適用できるか?と言われると、そうはならない気がする。他のモデルで検証したら傾向はおそらく変わるであろう(という意味でおそらく論文のタイトルにもCase Studyと記述されているのかなあ)。

#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #ACL Issue Date: 2024-11-11 Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23 Summary本研究では、ゼロショット密な検索システムの構築において、仮想文書埋め込み(HyDE)を提案。クエリに基づき、指示に従う言語モデルが仮想文書を生成し、教師なしで学習されたエンコーダがこれを埋め込みベクトルに変換。実際のコーパスに基づく類似文書を取得することで、誤った詳細をフィルタリング。実験結果では、HyDEが最先端の密な検索器Contrieverを上回り、様々なタスクと言語で強力なパフォーマンスを示した。 #ComputerVision #LanguageModel #Zero/FewShotPrompting #Self-SupervisedLearning Issue Date: 2024-10-07 SINC: Self-Supervised In-Context Learning for Vision-Language Tasks, Yi-Syuan Chen+, N_A, ICCV'23 Summary自己教師あり文脈内学習(SINC)フレームワークを提案し、大規模言語モデルに依存せずに文脈内学習を実現。特別に調整されたデモンストレーションを用いたメタモデルが、視覚と言語のタスクで少数ショット設定において勾配ベースの手法を上回る性能を示す。SINCは文脈内学習の利点を探求し、重要な要素を明らかにする。 #Pretraining #NLP #LanguageModel #MulltiModal #ICLR Issue Date: 2024-09-26 UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23 Summary本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 CommentOpenReview:https://openreview.net/forum?id=6ruVLB727MC[R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを持つMoD (Mixture of Denoisers)を提案
 #EfficiencyImprovement
#Quantization
#PEFT(Adaptor/LoRA)
Issue Date: 2024-09-24
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models, Yixiao Li+, N_A, arXiv'23
SummaryLoftQという新しい量子化フレームワークを提案し、LLMにおける量子化とLoRAファインチューニングを同時に適用。これにより、量子化モデルとフル精度モデルの不一致を軽減し、下流タスクの一般化を改善。自然言語理解や質問応答などのタスクで、特に難易度の高い条件下で既存手法を上回る性能を示した。
#NLP
#LanguageModel
#SelfCorrection
Issue Date: 2024-09-07
Large Language Models Cannot Self-Correct Reasoning Yet, Jie Huang+, N_A, arXiv'23
SummaryLLMsの自己修正能力を批判的に検討し、内在的自己修正の概念を中心に、外部フィードバックなしでの応答修正の難しさを示す。自己修正後にパフォーマンスが低下することもあり、今後の研究や応用に向けた提案を行う。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#InstructionTuning
#SelfCorrection
Issue Date: 2024-09-07
Reflection-Tuning: Data Recycling Improves LLM Instruction-Tuning, Ming Li+, N_A, arXiv'23
Summaryリフレクションチューニングという新手法を提案し、LLMsの自己改善を通じて低品質なトレーニングデータの問題に対処。オラクルLLMを用いてデータの質を向上させ、実験により再利用データで訓練されたLLMsが既存モデルを上回ることを示した。
CommentReflection-Tuningを提案している研究?
#RecommenderSystems
#LanguageModel
#ConversationalRecommenderSystems
Issue Date: 2024-08-07
Leveraging Large Language Models in Conversational Recommender Systems, Luke Friedman+, N_A, arXiv'23
SummaryLLMsを使用した大規模な会話型推薦システム(CRS)の構築に関する論文の要約です。LLMsを活用したユーザーの好み理解、柔軟なダイアログ管理、説明可能な推薦の新しい実装を提案し、LLMsによって駆動される統合アーキテクチャの一部として説明します。また、LLMが解釈可能な自然言語のユーザープロファイルを利用してセッションレベルのコンテキストを調整する方法についても説明します。さらに、LLMベースのユーザーシミュレータを構築して合成会話を生成する技術を提案し、LaMDAをベースにしたYouTubeビデオの大規模CRSであるRecLLMを紹介します。
#NaturalLanguageGeneration
#Metrics
#NLP
#Evaluation
#EMNLP
#Finetuning
Issue Date: 2024-05-28
T5Score: Discriminative Fine-tuning of Generative Evaluation Metrics, Yiwei Qin+, N_A, EMNLP-Findings'23
Summary埋め込みベースのテキスト生成の評価には、教師付きの識別メトリクスと生成メトリクスの2つのパラダイムがあります。本研究では、教師付きと教師なしの信号を組み合わせたフレームワークを提案し、mT5をバックボーンとしてT5Scoreメトリクスを訓練しました。T5Scoreは他の既存のメトリクスと包括的な実証的比較を行い、セグメントレベルで最良のパフォーマンスを示しました。また、コードとモデルはGitHubで公開されています。
CommentOpenReview: https://openreview.net/forum?id=2jibzAXJzH¬eId=rgNMHmjShZ
Issue Date: 2024-05-28
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation, Sewon Min+, N_A, arXiv'23
Summary大規模言語モデル(LMs)によって生成されたテキストの事実性を評価するために、新しい評価基準であるFACTSCOREが導入された。FACTSCOREは生成物を原子的な事実に分解し、信頼性のある知識源によってサポートされる原子的な事実の割合を計算する。人間による評価の代替として、リトリーバルと強力な言語モデルを使用してFACTSCOREを推定する自動モデルが導入され、誤差率が2%未満であることが示された。この自動メトリックを使用して、新しい13の最近のLMsから6,500の生成物を評価し、さまざまな結果が得られた。FACTSCOREは`pip install factscore`を使用して一般に利用可能である。
Issue Date: 2024-05-28
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate, Chi-Min Chan+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)を使用した単一エージェントベースのテキスト評価には、人間の評価品質とのギャップがあり、マルチエージェントベースのアプローチが有望であることが示唆されている。本研究では、ChatEvalと呼ばれるマルチエージェント審判チームを構築し、異なるモデルから生成された応答の品質を自律的に議論し評価することで、信頼性のある評価のための人間を模倣した評価プロセスを提供している。
Issue Date: 2024-05-28
Automated Evaluation of Personalized Text Generation using Large Language Models, Yaqing Wang+, N_A, arXiv'23
SummaryLLMsを使用して個別化されたテキスト生成を評価するために、AuPELという新しい評価方法を提案し、生成されたテキストの個人化、品質、関連性の3つの意味的側面を自動的に測定する。AuPELは従来の評価メトリクスよりも優れており、LLMsを使用した個別化されたテキスト生成の評価に適していることを示唆している。
Issue Date: 2024-05-28
Multi-Dimensional Evaluation of Text Summarization with In-Context Learning, Sameer Jain+, N_A, arXiv'23
Summary本研究では、大規模な言語モデルを使用したコンテキスト内学習による多面的評価者の効果を調査し、大規模なトレーニングデータセットの必要性を排除します。実験の結果、コンテキスト内学習ベースの評価者は、テキスト要約のタスクにおいて学習された評価フレームワークと競合し、関連性や事実の一貫性などの側面で最先端の性能を確立しています。また、GPT-3などの大規模言語モデルによって書かれたゼロショット要約の評価におけるコンテキスト内学習ベースの評価者の効果も研究されています。
CommentICE
#NLP
#LanguageModel
#OpenWeight
Issue Date: 2024-05-24
Mistral 7B, Albert Q. Jiang+, N_A, arXiv'23
SummaryMistral 7B v0.1は、70億パラメータの言語モデルであり、高速な推論のためにGQAを活用し、SWAを組み合わせている。また、Mistral 7B -InstructはLlama 2 13B -Chatモデルを上回っており、Apache 2.0ライセンスの下で公開されています。
Comment1237 1279 などのモデルも参照のこと
#EfficiencyImprovement
#Quantization
#PEFT(Adaptor/LoRA)
Issue Date: 2024-09-24
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models, Yixiao Li+, N_A, arXiv'23
SummaryLoftQという新しい量子化フレームワークを提案し、LLMにおける量子化とLoRAファインチューニングを同時に適用。これにより、量子化モデルとフル精度モデルの不一致を軽減し、下流タスクの一般化を改善。自然言語理解や質問応答などのタスクで、特に難易度の高い条件下で既存手法を上回る性能を示した。
#NLP
#LanguageModel
#SelfCorrection
Issue Date: 2024-09-07
Large Language Models Cannot Self-Correct Reasoning Yet, Jie Huang+, N_A, arXiv'23
SummaryLLMsの自己修正能力を批判的に検討し、内在的自己修正の概念を中心に、外部フィードバックなしでの応答修正の難しさを示す。自己修正後にパフォーマンスが低下することもあり、今後の研究や応用に向けた提案を行う。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#InstructionTuning
#SelfCorrection
Issue Date: 2024-09-07
Reflection-Tuning: Data Recycling Improves LLM Instruction-Tuning, Ming Li+, N_A, arXiv'23
Summaryリフレクションチューニングという新手法を提案し、LLMsの自己改善を通じて低品質なトレーニングデータの問題に対処。オラクルLLMを用いてデータの質を向上させ、実験により再利用データで訓練されたLLMsが既存モデルを上回ることを示した。
CommentReflection-Tuningを提案している研究?
#RecommenderSystems
#LanguageModel
#ConversationalRecommenderSystems
Issue Date: 2024-08-07
Leveraging Large Language Models in Conversational Recommender Systems, Luke Friedman+, N_A, arXiv'23
SummaryLLMsを使用した大規模な会話型推薦システム(CRS)の構築に関する論文の要約です。LLMsを活用したユーザーの好み理解、柔軟なダイアログ管理、説明可能な推薦の新しい実装を提案し、LLMsによって駆動される統合アーキテクチャの一部として説明します。また、LLMが解釈可能な自然言語のユーザープロファイルを利用してセッションレベルのコンテキストを調整する方法についても説明します。さらに、LLMベースのユーザーシミュレータを構築して合成会話を生成する技術を提案し、LaMDAをベースにしたYouTubeビデオの大規模CRSであるRecLLMを紹介します。
#NaturalLanguageGeneration
#Metrics
#NLP
#Evaluation
#EMNLP
#Finetuning
Issue Date: 2024-05-28
T5Score: Discriminative Fine-tuning of Generative Evaluation Metrics, Yiwei Qin+, N_A, EMNLP-Findings'23
Summary埋め込みベースのテキスト生成の評価には、教師付きの識別メトリクスと生成メトリクスの2つのパラダイムがあります。本研究では、教師付きと教師なしの信号を組み合わせたフレームワークを提案し、mT5をバックボーンとしてT5Scoreメトリクスを訓練しました。T5Scoreは他の既存のメトリクスと包括的な実証的比較を行い、セグメントレベルで最良のパフォーマンスを示しました。また、コードとモデルはGitHubで公開されています。
CommentOpenReview: https://openreview.net/forum?id=2jibzAXJzH¬eId=rgNMHmjShZ
Issue Date: 2024-05-28
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation, Sewon Min+, N_A, arXiv'23
Summary大規模言語モデル(LMs)によって生成されたテキストの事実性を評価するために、新しい評価基準であるFACTSCOREが導入された。FACTSCOREは生成物を原子的な事実に分解し、信頼性のある知識源によってサポートされる原子的な事実の割合を計算する。人間による評価の代替として、リトリーバルと強力な言語モデルを使用してFACTSCOREを推定する自動モデルが導入され、誤差率が2%未満であることが示された。この自動メトリックを使用して、新しい13の最近のLMsから6,500の生成物を評価し、さまざまな結果が得られた。FACTSCOREは`pip install factscore`を使用して一般に利用可能である。
Issue Date: 2024-05-28
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate, Chi-Min Chan+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)を使用した単一エージェントベースのテキスト評価には、人間の評価品質とのギャップがあり、マルチエージェントベースのアプローチが有望であることが示唆されている。本研究では、ChatEvalと呼ばれるマルチエージェント審判チームを構築し、異なるモデルから生成された応答の品質を自律的に議論し評価することで、信頼性のある評価のための人間を模倣した評価プロセスを提供している。
Issue Date: 2024-05-28
Automated Evaluation of Personalized Text Generation using Large Language Models, Yaqing Wang+, N_A, arXiv'23
SummaryLLMsを使用して個別化されたテキスト生成を評価するために、AuPELという新しい評価方法を提案し、生成されたテキストの個人化、品質、関連性の3つの意味的側面を自動的に測定する。AuPELは従来の評価メトリクスよりも優れており、LLMsを使用した個別化されたテキスト生成の評価に適していることを示唆している。
Issue Date: 2024-05-28
Multi-Dimensional Evaluation of Text Summarization with In-Context Learning, Sameer Jain+, N_A, arXiv'23
Summary本研究では、大規模な言語モデルを使用したコンテキスト内学習による多面的評価者の効果を調査し、大規模なトレーニングデータセットの必要性を排除します。実験の結果、コンテキスト内学習ベースの評価者は、テキスト要約のタスクにおいて学習された評価フレームワークと競合し、関連性や事実の一貫性などの側面で最先端の性能を確立しています。また、GPT-3などの大規模言語モデルによって書かれたゼロショット要約の評価におけるコンテキスト内学習ベースの評価者の効果も研究されています。
CommentICE
#NLP
#LanguageModel
#OpenWeight
Issue Date: 2024-05-24
Mistral 7B, Albert Q. Jiang+, N_A, arXiv'23
SummaryMistral 7B v0.1は、70億パラメータの言語モデルであり、高速な推論のためにGQAを活用し、SWAを組み合わせている。また、Mistral 7B -InstructはLlama 2 13B -Chatモデルを上回っており、Apache 2.0ライセンスの下で公開されています。
Comment1237 1279 などのモデルも参照のこと
モデルのスケールが大きくなると、inferenceのlatencyが遅くなり、計算コストが大きくなりすぎて実用的でないので、小さいパラメータで素早いinference実現したいよね、というモチベーション。
そのために、SlidingWindowAttentionとGroupQueryAttention 1271 を活用している。

より小さいパラメータ数でLlama2を様々なタスクでoutperformし

Instruction Tuningを実施したモデルは、13BモデルよりもChatbotArenaで高いElo Rateを獲得した。

コンテキスト長は8192 #DocumentSummarization #NaturalLanguageGeneration #NLP #Dataset #LanguageModel #Annotation Issue Date: 2024-05-15 Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, N_A, arXiv'23 SummaryLLMsの成功の理由を理解するために、異なる事前学習方法、プロンプト、およびモデルスケールにわたる10つのLLMsに対する人間の評価を行った。その結果、モデルサイズではなく、指示の調整がLLMのゼロショット要約能力の鍵であることがわかった。また、LLMsの要約は人間の執筆した要約と同等と判断された。 Comment・ニュース記事の高品質な要約を人間に作成してもらい、gpt-3.5を用いてLLM-basedな要約も生成
・annotatorにそれぞれの要約の品質をスコアリングさせたデータセットを作成 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention Issue Date: 2024-04-07 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N_A, arXiv'23 SummaryMulti-query attention(MQA)は、単一のkey-value headのみを使用しており、デコーダーの推論を劇的に高速化しています。ただし、MQAは品質の低下を引き起こす可能性があり、さらには、より速い推論のためだけに別個のモデルをトレーニングすることが望ましくない場合もあります。既存のマルチヘッド言語モデルのチェックポイントを、オリジナルの事前トレーニング計量の5%を使用してMQAを持つモデルにアップトレーニングするためのレシピを提案し、さらに、複数のkey-value headを使用するマルチクエリアテンションの一般化であるグループ化クエリアテンション(GQA)を紹介します。アップトレーニングされたGQAが、MQAと同等の速度でマルチヘッドアテンションに匹敵する品質を達成することを示しています。 Comment通常のMulti-Head AttentionがQKVが1対1対応なのに対し、Multi Query Attention (MQA) 1272 は全てのQに対してKVを共有する。一方、GQAはグループごとにKVを共有する点で異なる。MQAは大幅にInfeerence` speedが改善するが、精度が劣化する問題があった。この研究では通常のMulti-Head Attentionに対して、オリジナルの事前学習に対して追加の5%の計算量でGQAモデルを学習する手法を提案している。

Main Result. Multi-Head Attentionに対して、inference timeが大幅に改善しているが、Multi-Query Attentionよりも高い性能を維持している。

Issue Date: 2024-03-05 QTSumm: Query-Focused Summarization over Tabular Data, Yilun Zhao+, N_A, EMNLP'23 Summary与えられた表に対して人間らしい推論と分析を行い、カスタマイズされた要約を生成するための新しいクエリに焦点を当てた表の要約タスクを定義し、QTSummという新しいベンチマークを導入。実験結果と手動分析により、新しいタスクが表からテキスト生成において重要な課題を提起していることが明らかになります。 ReFactorという新しいアプローチを提案し、生成された事実をモデルの入力に連結することでベースラインを改善できることを示しています。 CommentRAGでテーブル情報を扱う際に役立ちそうRadev論文 Issue Date: 2024-03-05 Explanation Selection Using Unlabeled Data for Chain-of-Thought Prompting, Xi Ye+, N_A, EMNLP'23 Summary最近の研究では、大規模言語モデルを使用してテキスト推論タスクで強力なパフォーマンスを達成する方法が提案されています。本研究では、ブラックボックスの方法を使用して説明を組み込んだプロンプトを最適化するアプローチに焦点を当てています。leave-one-outスキームを使用して候補の説明セットを生成し、二段階フレームワークを使用してこれらの説明を効果的に組み合わせます。実験結果では、プロキシメトリクスが真の精度と相関し、クラウドワーカーの注釈や単純な検索戦略よりも効果的にプロンプトを改善できることが示されました。 Issue Date: 2024-02-15 The Consensus Game: Language Model Generation via Equilibrium Search, Athul Paul Jacob+, N_A, arXiv'23 SummaryLMsを使った質問応答やテキスト生成タスクにおいて、生成的または識別的な手法を組み合わせることで一貫したLM予測を得る新しいアプローチが提案された。このアプローチは、言語モデルのデコーディングをゲーム理論的な連続シグナリングゲームとして捉え、EQUILIBRIUM-RANKINGアルゴリズムを導入することで、既存の手法よりも一貫性とパフォーマンスを向上させることが示された。 #NaturalLanguageGeneration #NLP #LanguageModel #Explanation #Supervised-FineTuning (SFT) #Evaluation #EMNLP #PostTraining Issue Date: 2024-01-25 INSTRUCTSCORE: Explainable Text Generation Evaluation with Finegrained Feedback, Wenda Xu+, N_A, EMNLP'23 Summary自動的な言語生成の品質評価には説明可能なメトリクスが必要であるが、既存のメトリクスはその判定を説明したり欠陥とスコアを関連付けることができない。そこで、InstructScoreという新しいメトリクスを提案し、人間の指示とGPT-4の知識を活用してテキストの評価と診断レポートを生成する。さまざまな生成タスクでInstructScoreを評価し、他のメトリクスを上回る性能を示した。驚くべきことに、InstructScoreは人間の評価データなしで最先端のメトリクスと同等の性能を達成する。 Comment伝統的なNLGの性能指標の解釈性が低いことを主張する研究 #NLP
#LanguageModel
#Evaluation
#LLM-as-a-Judge
Issue Date: 2024-01-25
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N_A, EMNLP'23
Summary従来の参照ベースの評価指標では、自然言語生成システムの品質を正確に測定することが難しい。最近の研究では、大規模言語モデル(LLMs)を使用した参照ベースの評価指標が提案されているが、まだ人間との一致度が低い。本研究では、G-Evalという大規模言語モデルを使用した品質評価フレームワークを提案し、要約と対話生成のタスクで実験を行った。G-Evalは従来の手法を大幅に上回る結果を示し、LLMベースの評価器の潜在的な問題についても分析している。コードはGitHubで公開されている。
Comment伝統的なNLGの性能指標が、人間の判断との相関が低いことを示した研究手法概要
#NLP
#LanguageModel
#Evaluation
#LLM-as-a-Judge
Issue Date: 2024-01-25
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N_A, EMNLP'23
Summary従来の参照ベースの評価指標では、自然言語生成システムの品質を正確に測定することが難しい。最近の研究では、大規模言語モデル(LLMs)を使用した参照ベースの評価指標が提案されているが、まだ人間との一致度が低い。本研究では、G-Evalという大規模言語モデルを使用した品質評価フレームワークを提案し、要約と対話生成のタスクで実験を行った。G-Evalは従来の手法を大幅に上回る結果を示し、LLMベースの評価器の潜在的な問題についても分析している。コードはGitHubで公開されている。
Comment伝統的なNLGの性能指標が、人間の判断との相関が低いことを示した研究手法概要
・CoTを利用して、生成されたテキストの品質を評価する手法を提案している。
・タスクのIntroductionと、評価のCriteriaをプロンプトに仕込むだけで、自動的にLLMに評価ステップに関するCoTを生成させ、最終的にフォームを埋める形式でスコアをテキストとして生成させ評価を実施する。最終的に、各スコアの生成確率によるweighted-sumによって、最終スコアを決定する。

Scoringの問題点
たとえば、1-5のdiscreteなスコアを直接LLMにoutputさせると、下記のような問題が生じる:
1. ある一つのスコアが支配的になってしまい、スコアの分散が無く、人間の評価との相関が低くなる
2. LLMは小数を出力するよう指示しても、大抵の場合整数を出力するため、多くのテキストの評価値が同一となり、生成されたテキストの細かな差異を評価に取り入れることができない。
上記を解決するため、下記のように、スコアトークンの生成確率の重みづけ和をとることで、最終的なスコアを算出している。
 評価
評価
・SummEval 984 データと、Topical-Chat, QAGSデータの3つのベンチマークで評価を実施した。タスクとしては、要約と対話のresponse generationのデータとなる。
・モデルはGPT-3.5 (text-davinci-003), GPT-4を利用した
・gpt3.5利用時は、temperatureは0に設定し、GPT-4はトークンの生成確率を返さないので、`n=20, temperature=1, top_p=1`とし、20回の生成結果からトークンの出現確率を算出した。
評価結果
G-EVALがbaselineをoutperformし、特にGPT4を利用した場合に性能が高い。GPTScoreを利用した場合に、モデルを何を使用したのかが書かれていない。Appendixに記述されているのだろうか。



Analysis
G-EvalがLLMが生成したテキストを好んで高いスコアを付与してしまうか?
・人間に品質の高いニュース記事要約を書かせ、アノテータにGPTが生成した要約を比較させたデータ (1304) を用いて検証
・その結果、基本的にGPTが生成した要約に対して、G-EVAL4が高いスコアを付与する傾向にあることがわかった。
・原因1: 1304で指摘されている通り、人間が記述した要約とLLMが記述した要約を区別するタスクは、inter-annotator agreementは`0.07`であり、極端に低く、人間でも困難なタスクであるため。
・原因2: LLMは生成時と評価時に、共通したコンセプトをモデル内部で共有している可能性が高く、これがLLMが生成した要約を高く評価するバイアスをかけた

CoTの影響
・SummEvalデータにおいて、CoTの有無による性能の差を検証した結果、CoTを導入した場合により高いcorrelationを獲得した。特に、Fluencyへの影響が大きい。
Probability Normalizationによる影響
・probabilityによるnormalizationを導入したことで、kendall tauが減少した。この理由は、probabilityが導入されていない場合は多くの引き分けを生み出す。一方、kendall tauは、concordant / discordantペアの数によって決定されるが、引き分けの場合はどちらにもカウントされず、kendall tauの値を押し上げる効果がある。このため、これはモデルの真の性能を反映していない。
・一方、probabilityを導入すると、より細かいな連続的なスコアを獲得することができ、これはspearman-correlationの向上に反映されている。
モデルサイズによる影響
・基本的に大きいサイズの方が高いcorrelationを示す。特に、consistencyやrelevanceといった、複雑な評価タスクではその差が顕著である。
・一方モデルサイズが小さい方が性能が良い観点(engagingness, groundedness)なども存在した。 Issue Date: 2023-12-29 Some things are more CRINGE than others: Preference Optimization with the Pairwise Cringe Loss, Jing Xu+, N_A, arXiv'23 Summary一般的な言語モデルのトレーニングでは、ペアワイズの選好による整列がよく使われます。しかし、バイナリフィードバックの方法もあります。この研究では、既存のバイナリフィードバック手法をペアワイズ選好の設定に拡張し、高いパフォーマンスを示すことを示します。この手法は実装が簡単で効率的であり、最先端の選好最適化アルゴリズムよりも優れた性能を発揮します。 CommentDPO, PPOをoutperformする新たなAlignment手法。MetaのJason Weston氏
元ツイート: https://x.com/jaseweston/status/1740546297235464446?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q後で読む
(画像は元ツイートより引用)


 Issue Date: 2023-12-27
Gemini vs GPT-4V: A Preliminary Comparison and Combination of Vision-Language Models Through Qualitative Cases, Zhangyang Qi+, N_A, arXiv'23
Summary本研究では、マルチモーダル大規模言語モデル(MLLMs)の進化について、GoogleのGeminiとOpenAIのGPT-4Vという2つのモデルを比較しています。ビジョン-言語能力、人間との対話、時間的理解、知能および感情指数などの側面にわたる評価を行い、両モデルの異なる視覚理解能力について分析しています。さらに、実用的な有用性を評価するために構造化された実験を行い、両モデルのユニークな強みとニッチを明らかにしています。また、2つのモデルを組み合わせてより良い結果を得る試みも行っています。この研究は、マルチモーダル基盤モデルの進化と将来の進展についての洞察を提供しています。
Issue Date: 2023-12-23
Retrieval-Augmented Generation for Large Language Models: A Survey, Yunfan Gao+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)には課題がありますが、Retrieval-Augmented Generation(RAG)はこれを解決する手法です。RAGは外部の知識ベースから情報を取得し、回答の正確性を向上させます。ソースの引用により、回答の検証とモデルの信頼性向上が可能です。また、RAGは知識の更新やドメイン固有の知識の導入を容易にします。本論文ではRAGの開発パラダイムとそのコンポーネントについて説明し、評価方法や将来の研究方向についても議論しています。
#NLP
#LanguageModel
#ProprietaryLLM
Issue Date: 2023-12-21
Gemini: A Family of Highly Capable Multimodal Models, Gemini Team+, N_A, arXiv'23
Summaryこの報告書では、マルチモーダルモデル「Gemini」のファミリーについて紹介します。Geminiは画像、音声、動画、テキストの理解に優れた能力を持ち、Ultra、Pro、Nanoのサイズがあります。Gemini Ultraは幅広いベンチマークで最先端の技術を提供し、MMLUでは人間の専門家のパフォーマンスを初めて達成しました。Geminiモデルはクロスモーダルな推論と言語理解の能力を持ち、さまざまなユースケースに適用できます。また、ユーザーへの責任ある展開についても議論しています。
Comment1181 で発表されたGeminiの論文
Issue Date: 2023-12-21
An In-depth Look at Gemini's Language Abilities, Syeda Nahida Akter+, N_A, arXiv'23
SummaryGoogle Geminiモデルは、OpenAI GPTシリーズと同等の結果を報告した初めてのモデルであり、本論文ではその言語能力を詳細に探求します。具体的には、GeminiとGPTの能力を客観的に比較し、再現可能なコードと透明な結果を提供します。さらに、Geminiの得意な領域を特定し、10のデータセットでさまざまな言語能力をテストします。Gemini Proは、GPT 3.5 Turboに比べてわずかに劣る精度を示しましたが、多数の桁を含む数学的な推論の失敗や多肢選択の回答順序への感度などの説明も提供します。また、Geminiは非英語の言語や複雑な推論チェーンの処理などで高いパフォーマンスを示すことも特定しています。再現のためのコードとデータは、https://github.com/neulab/gemini-benchmarkで入手できます。
CommentGeminiとGPTを様々なベンチマークで比較した研究。
Issue Date: 2023-12-16
Data Selection for Language Models via Importance Resampling, Sang Michael Xie+, N_A, arXiv'23
Summary適切な事前学習データセットの選択は、言語モデルの性能向上に重要である。既存の方法ではヒューリスティックスや人手による選別が必要だが、本研究では重要度リサンプリングを用いたデータ選択フレームワークであるDSIRを提案する。DSIRは効率的かつスケーラブルであり、KL削減というデータメトリックを用いて選択されたデータとターゲットとの近接性を測定する。実験結果では、DSIRが他の方法よりも高い精度を示し、特定のドメインや一般的なドメインの事前学習においても優れた性能を発揮することが示された。
Issue Date: 2023-12-14
VILA: On Pre-training for Visual Language Models, Ji Lin+, N_A, arXiv'23
Summary最近の大規模言語モデルの成功により、ビジュアル言語モデル(VLM)が進歩している。本研究では、VLMの事前学習のためのデザインオプションを検討し、以下の結果を示した:(1) LLMを凍結することでゼロショットのパフォーマンスが達成できるが、文脈に基づいた学習能力が不足している。(2) 交互に行われる事前学習データは有益であり、画像とテキストのペアだけでは最適ではない。(3) テキストのみの指示データを画像とテキストのデータに再ブレンドすることで、VLMのタスクの精度を向上させることができる。VILAというビジュアル言語モデルファミリーを構築し、最先端モデルを凌駕し、優れたパフォーマンスを発揮することを示した。マルチモーダルの事前学習は、VILAの特性を向上させる。
Issue Date: 2023-12-11
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze, Ronak Pradeep+, N_A, arXiv'23
SummaryRankZephyrは、オープンソースのLLMであり、再ランキングにおいてプロプライエタリモデルと同等の性能を発揮する。TREC Deep Learning TracksやBEIRのNEWSとCOVIDなどのデータセットで包括的な評価を行い、高い能力を示している。さらに、NovelEvalテストセットでもGPT-4を上回る性能を発揮し、データの汚染に対する懸念を解消している。結果の再現に必要なコードは、https://github.com/castorini/rank_llmで提供されている。
Issue Date: 2023-12-06
Segment and Caption Anything, Xiaoke Huang+, N_A, arXiv'23
Summary私たちは、Segment Anything Model(SAM)に地域キャプションを生成する能力を効率的に備える方法を提案します。SAMは、セグメンテーションのための強力な汎用性を持ちながら、意味理解のための短縮形です。軽量なクエリベースの特徴ミキサーを導入することで、地域固有の特徴を言語モデルの埋め込み空間と整合させ、後でキャプションを生成します。訓練可能なパラメータの数が少ないため、高速かつスケーラブルなトレーニングが可能です。また、地域キャプションデータの不足問題に対処するために、弱い教師あり事前トレーニングを提案しています。この研究は、地域キャプションデータのスケーリングアップに向けた第一歩となり、SAMに地域的な意味を付加する効率的な方法を探求するための示唆を与えます。
#Analysis
#NLP
#LanguageModel
#QuestionAnswering
Issue Date: 2023-12-04
Unnatural Error Correction: GPT-4 Can Almost Perfectly Handle Unnatural Scrambled Text, Qi Cao+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の内部動作についての新しい洞察を提供します。特に、GPT-4を調査し、LLMsの耐久性に関する実験結果を示します。実験では、文字レベルの順列に対するLLMsの耐性を調べるために、Scrambled Benchというスイートを使用しました。結果は、GPT-4がtypoglycemiaという現象に似た能力を持ち、非常に自然でないエラーを含む入力をほぼ完璧に処理できることを示しています。これは、LLMsの耐性が直感に反するものであり、他のLLMsや人間にとっても困難なタスクであることを示しています。
Comment
Issue Date: 2023-12-27
Gemini vs GPT-4V: A Preliminary Comparison and Combination of Vision-Language Models Through Qualitative Cases, Zhangyang Qi+, N_A, arXiv'23
Summary本研究では、マルチモーダル大規模言語モデル(MLLMs)の進化について、GoogleのGeminiとOpenAIのGPT-4Vという2つのモデルを比較しています。ビジョン-言語能力、人間との対話、時間的理解、知能および感情指数などの側面にわたる評価を行い、両モデルの異なる視覚理解能力について分析しています。さらに、実用的な有用性を評価するために構造化された実験を行い、両モデルのユニークな強みとニッチを明らかにしています。また、2つのモデルを組み合わせてより良い結果を得る試みも行っています。この研究は、マルチモーダル基盤モデルの進化と将来の進展についての洞察を提供しています。
Issue Date: 2023-12-23
Retrieval-Augmented Generation for Large Language Models: A Survey, Yunfan Gao+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)には課題がありますが、Retrieval-Augmented Generation(RAG)はこれを解決する手法です。RAGは外部の知識ベースから情報を取得し、回答の正確性を向上させます。ソースの引用により、回答の検証とモデルの信頼性向上が可能です。また、RAGは知識の更新やドメイン固有の知識の導入を容易にします。本論文ではRAGの開発パラダイムとそのコンポーネントについて説明し、評価方法や将来の研究方向についても議論しています。
#NLP
#LanguageModel
#ProprietaryLLM
Issue Date: 2023-12-21
Gemini: A Family of Highly Capable Multimodal Models, Gemini Team+, N_A, arXiv'23
Summaryこの報告書では、マルチモーダルモデル「Gemini」のファミリーについて紹介します。Geminiは画像、音声、動画、テキストの理解に優れた能力を持ち、Ultra、Pro、Nanoのサイズがあります。Gemini Ultraは幅広いベンチマークで最先端の技術を提供し、MMLUでは人間の専門家のパフォーマンスを初めて達成しました。Geminiモデルはクロスモーダルな推論と言語理解の能力を持ち、さまざまなユースケースに適用できます。また、ユーザーへの責任ある展開についても議論しています。
Comment1181 で発表されたGeminiの論文
Issue Date: 2023-12-21
An In-depth Look at Gemini's Language Abilities, Syeda Nahida Akter+, N_A, arXiv'23
SummaryGoogle Geminiモデルは、OpenAI GPTシリーズと同等の結果を報告した初めてのモデルであり、本論文ではその言語能力を詳細に探求します。具体的には、GeminiとGPTの能力を客観的に比較し、再現可能なコードと透明な結果を提供します。さらに、Geminiの得意な領域を特定し、10のデータセットでさまざまな言語能力をテストします。Gemini Proは、GPT 3.5 Turboに比べてわずかに劣る精度を示しましたが、多数の桁を含む数学的な推論の失敗や多肢選択の回答順序への感度などの説明も提供します。また、Geminiは非英語の言語や複雑な推論チェーンの処理などで高いパフォーマンスを示すことも特定しています。再現のためのコードとデータは、https://github.com/neulab/gemini-benchmarkで入手できます。
CommentGeminiとGPTを様々なベンチマークで比較した研究。
Issue Date: 2023-12-16
Data Selection for Language Models via Importance Resampling, Sang Michael Xie+, N_A, arXiv'23
Summary適切な事前学習データセットの選択は、言語モデルの性能向上に重要である。既存の方法ではヒューリスティックスや人手による選別が必要だが、本研究では重要度リサンプリングを用いたデータ選択フレームワークであるDSIRを提案する。DSIRは効率的かつスケーラブルであり、KL削減というデータメトリックを用いて選択されたデータとターゲットとの近接性を測定する。実験結果では、DSIRが他の方法よりも高い精度を示し、特定のドメインや一般的なドメインの事前学習においても優れた性能を発揮することが示された。
Issue Date: 2023-12-14
VILA: On Pre-training for Visual Language Models, Ji Lin+, N_A, arXiv'23
Summary最近の大規模言語モデルの成功により、ビジュアル言語モデル(VLM)が進歩している。本研究では、VLMの事前学習のためのデザインオプションを検討し、以下の結果を示した:(1) LLMを凍結することでゼロショットのパフォーマンスが達成できるが、文脈に基づいた学習能力が不足している。(2) 交互に行われる事前学習データは有益であり、画像とテキストのペアだけでは最適ではない。(3) テキストのみの指示データを画像とテキストのデータに再ブレンドすることで、VLMのタスクの精度を向上させることができる。VILAというビジュアル言語モデルファミリーを構築し、最先端モデルを凌駕し、優れたパフォーマンスを発揮することを示した。マルチモーダルの事前学習は、VILAの特性を向上させる。
Issue Date: 2023-12-11
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze, Ronak Pradeep+, N_A, arXiv'23
SummaryRankZephyrは、オープンソースのLLMであり、再ランキングにおいてプロプライエタリモデルと同等の性能を発揮する。TREC Deep Learning TracksやBEIRのNEWSとCOVIDなどのデータセットで包括的な評価を行い、高い能力を示している。さらに、NovelEvalテストセットでもGPT-4を上回る性能を発揮し、データの汚染に対する懸念を解消している。結果の再現に必要なコードは、https://github.com/castorini/rank_llmで提供されている。
Issue Date: 2023-12-06
Segment and Caption Anything, Xiaoke Huang+, N_A, arXiv'23
Summary私たちは、Segment Anything Model(SAM)に地域キャプションを生成する能力を効率的に備える方法を提案します。SAMは、セグメンテーションのための強力な汎用性を持ちながら、意味理解のための短縮形です。軽量なクエリベースの特徴ミキサーを導入することで、地域固有の特徴を言語モデルの埋め込み空間と整合させ、後でキャプションを生成します。訓練可能なパラメータの数が少ないため、高速かつスケーラブルなトレーニングが可能です。また、地域キャプションデータの不足問題に対処するために、弱い教師あり事前トレーニングを提案しています。この研究は、地域キャプションデータのスケーリングアップに向けた第一歩となり、SAMに地域的な意味を付加する効率的な方法を探求するための示唆を与えます。
#Analysis
#NLP
#LanguageModel
#QuestionAnswering
Issue Date: 2023-12-04
Unnatural Error Correction: GPT-4 Can Almost Perfectly Handle Unnatural Scrambled Text, Qi Cao+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の内部動作についての新しい洞察を提供します。特に、GPT-4を調査し、LLMsの耐久性に関する実験結果を示します。実験では、文字レベルの順列に対するLLMsの耐性を調べるために、Scrambled Benchというスイートを使用しました。結果は、GPT-4がtypoglycemiaという現象に似た能力を持ち、非常に自然でないエラーを含む入力をほぼ完璧に処理できることを示しています。これは、LLMsの耐性が直感に反するものであり、他のLLMsや人間にとっても困難なタスクであることを示しています。
Comment OpenAIのモデルがブラックボックスである限り、コンタミネーションがあるのでは?という疑念は持ってしまう。
OpenAIのモデルがブラックボックスである限り、コンタミネーションがあるのでは?という疑念は持ってしまう。
(部分的にしか読めていないが…)
RealtimeQAと呼ばれるweeklyで直近のニュースに対するQuestionを発表することで構築されるデータセットのうち、2023.03.17--2023.08.04のデータを収集し、ScrambledSentenaeRecovery(ScrRec)とScrambleQuestionAnswering(ScrQA)の評価データを生成している。

完全にランダムに単語の文字をscramble(RS)すると、FalconとLlama2では元のテキストをゼロショットでは再構築できないことが分かる。FewShotではFalconであれば少し解けるようになる。一方、OpenAIのモデル、特にGPT4, GPT3.5-turboではゼロショットでもにり再構築ができている。
ScrQAについては、ランダムにscrambleした場合でもMultipleChoiceQuestionなので(RPGと呼ばれるAccの相対的なgainを評価するメトリックを提案している)正解はできている。
最初の文字だけを残す場合(KF)最初と最後の文字を残す場合(KFL」については、残す文字が増えるほどどちらのタスクも性能が上がり、最初の文字だけがあればOpenSourceLLMでも(ゼロショットでも)かなり元のテキストの再構築ができるようになっている。また、QAも性能が向上している。完全にランダムに文字を入れ替えたら完全に無理ゲーなのでは、、、、と思ってしまうのだが、FalconでFewshotの場合は一部解けているようだ…。果たしてどういうことなのか…(大文字小文字が保持されたままなのがヒントになっている…?)Appendixに考察がありそうだがまだ読めていない。
(追記)
文全体でランダムに文字を入れ替えているのかと勘違いしていたが、実際には”ある単語の中だけでランダムに入れ替え”だった。これなら原理上はいけると思われる。 Issue Date: 2023-12-04 Beyond ChatBots: ExploreLLM for Structured Thoughts and Personalized Model Responses, Xiao Ma+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLM)を使用したチャットボットの開発について述べられています。特に、探索的なタスクや意味理解のタスクにおいて、LLMを活用することでユーザーの認知負荷を軽減し、より個別化された応答を生成することができると述べられています。また、ExploreLLMを使用することで、ユーザーが高レベルの好みを持った個別化された応答を簡単に生成できることも示唆されています。この研究は、自然言語とグラフィカルユーザーインターフェースの統合により、チャットボットの形式を超えたLLMとの対話が可能な未来を示しています。 Issue Date: 2023-12-04 COFFEE: Counterfactual Fairness for Personalized Text Generation in Explainable Recommendation, Nan Wang+, N_A, EMNLP'23 Summary個別化されたテキスト生成(PTG)における公平性についての研究。ユーザーの書き込みテキストにはバイアスがあり、それがモデルのトレーニングに影響を与える可能性がある。このバイアスは、ユーザーの保護された属性に関連してテキストを生成する際の不公平な扱いを引き起こす可能性がある。公平性を促進するためのフレームワークを提案し、実験と評価によりその効果を示す。 #NLP #Transformer Issue Date: 2023-12-04 Pushdown Layers: Encoding Recursive Structure in Transformer Language Models, Shikhar Murty+, N_A, EMNLP'23 Summary本研究では、再帰構造をうまく捉えるために新しい自己注意層であるPushdown Layersを導入しました。Pushdown Layersは、再帰状態をモデル化するためにスタックテープを使用し、トークンごとの推定深度を追跡します。このモデルは、構文的な一般化を改善し、サンプル効率を向上させることができます。さらに、Pushdown Layersは標準の自己注意の代替としても使用でき、GLUEテキスト分類タスクでも改善を実現しました。 #ComputerVision #NLP #GenerativeAI #MulltiModal Issue Date: 2023-12-01 SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction, Xinyuan Chen+, N_A, arXiv'23 Summary本研究では、ビデオ生成において連続した長いビデオを生成するためのジェネレーティブなトランジションと予測に焦点を当てたモデルSEINEを提案する。SEINEはテキストの説明に基づいてトランジションを生成し、一貫性と視覚的品質を確保した長いビデオを生成する。さらに、提案手法は他のタスクにも拡張可能であり、徹底的な実験によりその有効性が検証されている。 Commenthttps://huggingface.co/spaces/Vchitect/SEINE
画像 + テキストpromptで、動画を生成するデモ #InformationRetrieval #Dataset #MulltiModal Issue Date: 2023-12-01 UniIR: Training and Benchmarking Universal Multimodal Information Retrievers, Cong Wei+, N_A, arXiv'23 Summary従来の情報検索モデルは一様な形式を前提としているため、異なる情報検索の要求に対応できない。そこで、UniIRという統一された指示に基づくマルチモーダルリトリーバーを提案する。UniIRは異なるリトリーバルタスクを処理できるように設計され、10のマルチモーダルIRデータセットでトレーニングされる。実験結果はUniIRの汎化能力を示し、M-BEIRというマルチモーダルリトリーバルベンチマークも構築された。 Comment後で読む(画像は元ツイートより
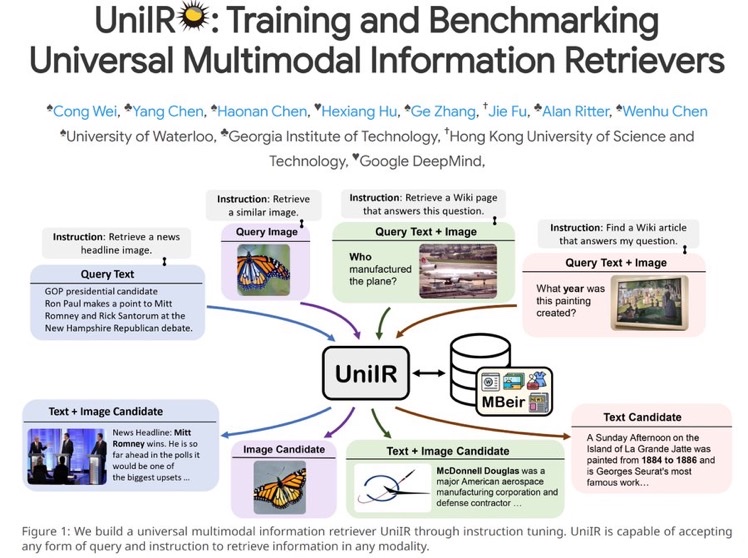
元ツイート: https://x.com/congwei1230/status/1730307767469068476?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2023-11-27 Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities, AJ Piergiovanni+, N_A, arXiv'23 Summary異なるモダリティ(ビデオ、音声、テキスト)を組み合わせるマルチモーダル学習の課題に取り組むため、本研究ではモダリティごとに個別の自己回帰モデルを使用するアプローチを提案する。提案手法では、時間に同期したモダリティ(音声とビデオ)と順序付けられたコンテキストモダリティを別々に処理するMirasol3Bモデルを使用する。また、ビデオと音声の長いシーケンスに対処するために、シーケンスをスニペットに分割し、Combinerメカニズムを使用して特徴を結合する。この手法は、マルチモーダルベンチマークで最先端の性能を発揮し、高い計算要求に対処し、時間的な依存関係をモデリングすることができる。 #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2023-11-23 Exponentially Faster Language Modelling, Peter Belcak+, N_A, arXiv'23 SummaryUltraFastBERTは、推論時にわずか0.3%のニューロンしか使用せず、同等の性能を発揮することができる言語モデルです。UltraFastBERTは、高速フィードフォワードネットワーク(FFF)を使用して、効率的な実装を提供します。最適化されたベースラインの実装に比べて78倍の高速化を実現し、バッチ処理された推論に対しては40倍の高速化を実現します。トレーニングコード、ベンチマークのセットアップ、およびモデルの重みも公開されています。 #PEFT(Adaptor/LoRA) Issue Date: 2023-11-23 MultiLoRA: Democratizing LoRA for Better Multi-Task Learning, Yiming Wang+, N_A, arXiv'23 SummaryLoRAは、LLMsを効率的に適応させる手法であり、ChatGPTのようなモデルを複数のタスクに適用することが求められている。しかし、LoRAは複雑なマルチタスクシナリオでの適応性能に制限がある。そこで、本研究ではMultiLoRAという手法を提案し、LoRAの制約を緩和する。MultiLoRAは、LoRAモジュールをスケーリングし、パラメータの依存性を減らすことで、バランスの取れたユニタリ部分空間を得る。実験結果では、わずかな追加パラメータでMultiLoRAが優れたパフォーマンスを示し、上位特異ベクトルへの依存性が低下していることが確認された。 #ComputerVision #NLP #LanguageModel #AutomaticPromptEngineering Issue Date: 2023-11-23 NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation, Shachar Rosenman+, N_A, arXiv'23 Summary本研究では、テキストから画像への生成モデルの品質を向上させるための適応型フレームワークNeuroPromptsを提案します。このフレームワークは、事前学習された言語モデルを使用して制約付きテキストデコーディングを行い、人間のプロンプトエンジニアが生成するものに類似したプロンプトを生成します。これにより、高品質なテキストから画像への生成が可能となり、ユーザーはスタイルの特徴を制御できます。また、大規模な人間エンジニアリングされたプロンプトのデータセットを使用した実験により、当アプローチが自動的に品質の高いプロンプトを生成し、優れた画像品質を実現することを示しました。 #ComputerVision #ImageSegmentation #Prompting #In-ContextLearning Issue Date: 2023-11-23 Visual In-Context Prompting, Feng Li+, N_A, arXiv'23 Summary本研究では、ビジョン領域における汎用的なビジュアルインコンテキストプロンプティングフレームワークを提案します。エンコーダーデコーダーアーキテクチャを使用し、さまざまなプロンプトをサポートするプロンプトエンコーダーを開発しました。さらに、任意の数の参照画像セグメントをコンテキストとして受け取るように拡張しました。実験結果から、提案手法が非凡な参照および一般的なセグメンテーション能力を引き出し、競争力のあるパフォーマンスを示すことがわかりました。 CommentImage Segmentationには、ユーザが与えたプロンプトと共通のコンセプトを持つすべてのオブジェクトをセグメンテーションするタスクと、ユーザの入力の特定のオブジェクトのみをセグメンテーションするタスクがある。従来は個別のタスクごとに、特定の入力方法(Visual Prompt, Image Prompt)を前提とした手法や、個々のタスクを実施できるがIn-Context Promptしかサポートしていない手法しかなかったが、この研究では、Visual Prompt, Image Prompt, In-Context Promptをそれぞれサポートし両タスクを実施できるという位置付けの模様。また、提案手法ではストローク、点、ボックスといったユーザの画像に対する描画に基づくPromptingをサポートし、Promptingにおける参照セグメント数も任意の数指定できるとのこと。
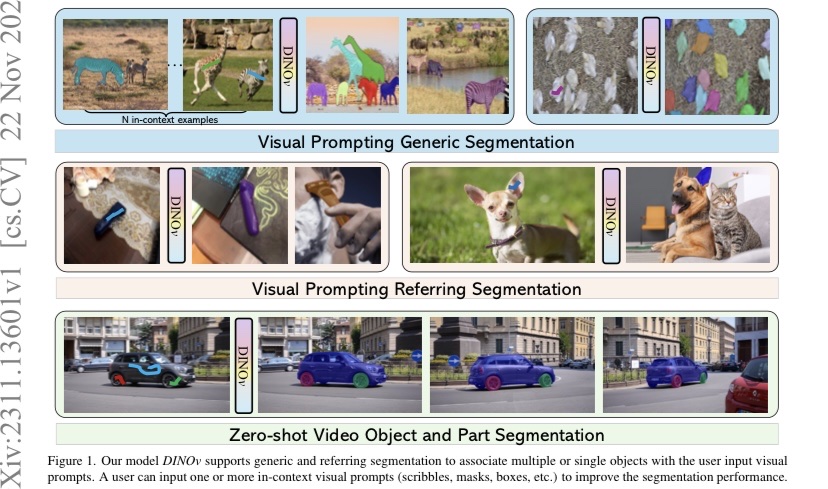
 #PEFT(Adaptor/LoRA)
Issue Date: 2023-11-23
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs, Viraj Shah+, N_A, arXiv'23
Summary概要:概念駆動型のパーソナライズのための生成モデルの微調整手法であるZipLoRAを提案。ZipLoRAは、独立してトレーニングされたスタイルと主題のLoRAを統合し、任意の主題とスタイルの組み合わせで生成することができる。実験結果は、ZipLoRAが主題とスタイルの忠実度を改善しながら魅力的な結果を生成できることを示している。
#NLP
#Dataset
#LanguageModel
#QuestionAnswering
#LLMAgent
#Evaluation
Issue Date: 2023-11-23
GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N_A, arXiv'23
SummaryGAIAは、General AI Assistantsのためのベンチマークであり、AI研究のマイルストーンとなる可能性がある。GAIAは、推論、マルチモダリティの処理、ウェブブラウジングなど、実世界の質問に対する基本的な能力を必要とする。人間の回答者は92%の正答率を達成し、GPT-4は15%の正答率を達成した。これは、最近の傾向とは異なる結果であり、専門的なスキルを必要とするタスクではLLMsが人間を上回っている。GAIAは、人間の平均的な堅牢性と同等の能力を持つシステムがAGIの到来に重要であると考えている。GAIAの手法を使用して、466の質問と回答を作成し、一部を公開してリーダーボードで利用可能にする。
CommentYann LeCun氏の紹介ツイート
#PEFT(Adaptor/LoRA)
Issue Date: 2023-11-23
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs, Viraj Shah+, N_A, arXiv'23
Summary概要:概念駆動型のパーソナライズのための生成モデルの微調整手法であるZipLoRAを提案。ZipLoRAは、独立してトレーニングされたスタイルと主題のLoRAを統合し、任意の主題とスタイルの組み合わせで生成することができる。実験結果は、ZipLoRAが主題とスタイルの忠実度を改善しながら魅力的な結果を生成できることを示している。
#NLP
#Dataset
#LanguageModel
#QuestionAnswering
#LLMAgent
#Evaluation
Issue Date: 2023-11-23
GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N_A, arXiv'23
SummaryGAIAは、General AI Assistantsのためのベンチマークであり、AI研究のマイルストーンとなる可能性がある。GAIAは、推論、マルチモダリティの処理、ウェブブラウジングなど、実世界の質問に対する基本的な能力を必要とする。人間の回答者は92%の正答率を達成し、GPT-4は15%の正答率を達成した。これは、最近の傾向とは異なる結果であり、専門的なスキルを必要とするタスクではLLMsが人間を上回っている。GAIAは、人間の平均的な堅牢性と同等の能力を持つシステムがAGIの到来に重要であると考えている。GAIAの手法を使用して、466の質問と回答を作成し、一部を公開してリーダーボードで利用可能にする。
CommentYann LeCun氏の紹介ツイート
https://x.com/ylecun/status/1727707519470977311?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Meta-FAIR, Meta-GenAI, HuggingFace, AutoGPTによる研究。人間は92%正解できるが、GPT4でも15%しか正解できないQAベンチマーク。解くために推論やマルチモダリティの処理、ブラウジング、ツールに対する習熟などの基本的な能力を必要とする実世界のQAとのこと。
 ・1792
・1792
で言及されているLLM Agentの評価で最も有名なベンチマークな模様データセット: https://huggingface.co/datasets/gaia-benchmark/GAIA #NLP #Alignment Issue Date: 2023-11-21 Unbalanced Optimal Transport for Unbalanced Word Alignment, Yuki Arase+, N_A, arXiv'23 Summary単一言語の単語アライメントにおいて、null alignmentという現象は重要であり、不均衡な単語アライメントを実現するために最適輸送(OT)のファミリーが有効であることを示している。教師あり・教師なしの設定での包括的な実験により、OTベースのアライメント手法が最新の手法と競争力があることが示されている。 Comment最適輸送で爆速でモノリンガルの単語アライメントがとれるらしい
実装:https://github.com/yukiar/OTAlign単語のアライメント先がない(null alignment)、one-to-oneの関係ではなく、one-to-many, many-to-manyのアライメントが必要な問題を(おそらく; もしかしたらnull alignmentだけかも)Unbalancedな単語アライメント問題と呼び、この課題に対して最適輸送が有効なアプローチであることを示しているっぽい
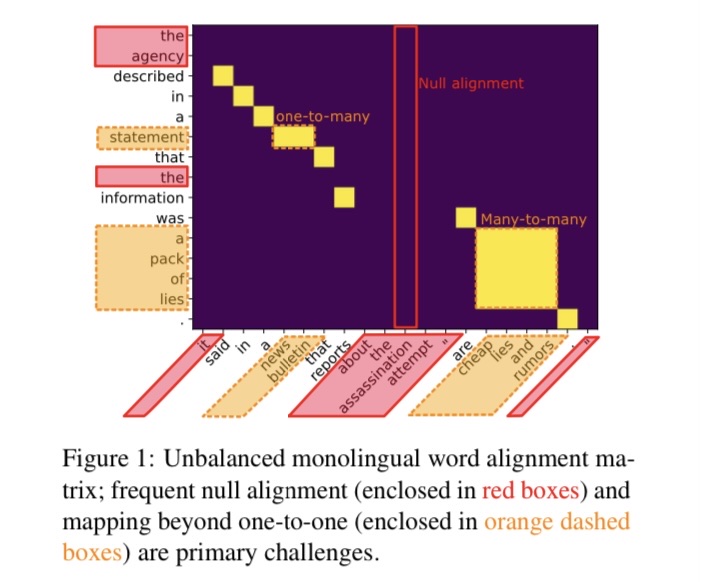 #Tutorial
#NLP
#LanguageModel
#Chain-of-Thought
Issue Date: 2023-11-21
Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents, Zhuosheng Zhang+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)は、言語知能の分野で劇的な進歩を遂げており、複雑な推論タスクにおいて高いパフォーマンスを示しています。特に、chain-of-thought(CoT)推論技術を活用することで、中間ステップを形成し、解釈可能性や制御可能性を向上させることができます。この論文では、CoT技術の基本的なメカニズムやその効果について詳しく解説し、言語エージェントの開発における応用例を紹介しています。将来の研究の展望にも触れており、初心者から経験豊富な研究者まで幅広い読者に対応しています。関連論文のリポジトリも提供されています。
CommentCoTに関するチュートリアル論文
#NLP
#LanguageModel
#Prompting
#ContextEngineering
Issue Date: 2023-11-21
System 2 Attention (is something you might need too), Jason Weston+, N_A, arXiv'23
SummaryTransformerベースの大規模言語モデル(LLMs)におけるソフトアテンションは、文脈から無関係な情報を取り込む傾向があり、次のトークン生成に悪影響を与える。そこで、System 2 Attention(S2A)を導入し、LLMsが自然言語で推論し、指示に従う能力を活用して、注目すべき情報を決定する。S2Aは関連する部分のみを含むように入力コンテキストを再生成し、再生成されたコンテキストに注目して最終的な応答を引き出す。実験では、S2Aは3つのタスクで標準のアテンションベースのLLMsよりも優れた性能を発揮し、事実性と客観性を高める。
Commentおそらく重要論文How is System 2 Attention different from prompt engineering specialized in factual double checks? I'm very sorry for the extremely delayed response. It's been two years, so you may no longer have a chance to see this, but I'd still like to share my thoughts.
#Tutorial
#NLP
#LanguageModel
#Chain-of-Thought
Issue Date: 2023-11-21
Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents, Zhuosheng Zhang+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)は、言語知能の分野で劇的な進歩を遂げており、複雑な推論タスクにおいて高いパフォーマンスを示しています。特に、chain-of-thought(CoT)推論技術を活用することで、中間ステップを形成し、解釈可能性や制御可能性を向上させることができます。この論文では、CoT技術の基本的なメカニズムやその効果について詳しく解説し、言語エージェントの開発における応用例を紹介しています。将来の研究の展望にも触れており、初心者から経験豊富な研究者まで幅広い読者に対応しています。関連論文のリポジトリも提供されています。
CommentCoTに関するチュートリアル論文
#NLP
#LanguageModel
#Prompting
#ContextEngineering
Issue Date: 2023-11-21
System 2 Attention (is something you might need too), Jason Weston+, N_A, arXiv'23
SummaryTransformerベースの大規模言語モデル(LLMs)におけるソフトアテンションは、文脈から無関係な情報を取り込む傾向があり、次のトークン生成に悪影響を与える。そこで、System 2 Attention(S2A)を導入し、LLMsが自然言語で推論し、指示に従う能力を活用して、注目すべき情報を決定する。S2Aは関連する部分のみを含むように入力コンテキストを再生成し、再生成されたコンテキストに注目して最終的な応答を引き出す。実験では、S2Aは3つのタスクで標準のアテンションベースのLLMsよりも優れた性能を発揮し、事実性と客観性を高める。
Commentおそらく重要論文How is System 2 Attention different from prompt engineering specialized in factual double checks? I'm very sorry for the extremely delayed response. It's been two years, so you may no longer have a chance to see this, but I'd still like to share my thoughts.
I believe that System 2 Attention is fundamentally different in concept from prompt engineering techniques such as factual double-checking. Unlike ad-hoc prompt engineering or approaches that enrich the context by adding new facts through prompting, System 2 Attention aims to improve the model’s reasoning ability itself by mitigating the influence of irrelevant tokens. It does so by selectively generating a new context composed only of relevant tokens, in a way that resembles human System 2 thinking—that is, more objective and deliberate reasoning.
From today’s perspective, two years later, I would say that this concept is more closely aligned with what we now refer to as Context Engineering. Thank you. Issue Date: 2023-11-21 Orca 2: Teaching Small Language Models How to Reason, Arindam Mitra+, N_A, arXiv'23 SummaryOrca 1は、豊富なシグナルから学習し、従来のモデルを上回る性能を発揮します。Orca 2では、小さな言語モデルの推論能力を向上させるために異なる解決戦略を教えることを目指しています。Orca 2は、さまざまな推論技術を使用し、15のベンチマークで評価されました。Orca 2は、同じサイズのモデルを大幅に上回り、高度な推論能力を持つ複雑なタスクで優れた性能を発揮します。Orca 2はオープンソース化されており、小さな言語モデルの研究を促進します。 #Pretraining #NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-11-21 Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, N_A, arXiv'23 Summary本研究では、言語モデルの内部の隠れ状態を使用して暗黙的な推論を行う手法を提案します。明示的なチェーン・オブ・ソートの推論ステップを生成する代わりに、教師モデルから抽出した暗黙的な推論ステップを使用します。実験により、この手法が以前は解決できなかったタスクを解決できることが示されました。 Commentこれは非常に興味深い話 Issue Date: 2023-11-20 SelfEval: Leveraging the discriminative nature of generative models for evaluation, Sai Saketh Rambhatla+, N_A, arXiv'23 Summaryこの研究では、テキストから画像を生成するモデルを逆転させることで、自動的にテキスト-画像理解能力を評価する方法を提案しています。提案手法であるSelfEvalは、生成モデルを使用して実際の画像の尤度を計算し、生成モデルを直接識別タスクに適用します。SelfEvalは、既存のデータセットを再利用して生成モデルの性能を評価し、他のモデルとの一致度を示す自動評価指標です。さらに、SelfEvalは難しいタスクでの評価やテキストの信頼性の測定にも使用できます。この研究は、拡散モデルの簡単で信頼性の高い自動評価を可能にすることを目指しています。 #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-11-19 Contrastive Chain-of-Thought Prompting, Yew Ken Chia+, N_A, arXiv'23 Summary言語モデルの推論を改善するために、対照的なchain of thoughtアプローチを提案する。このアプローチでは、有効な推論デモンストレーションと無効な推論デモンストレーションの両方を提供し、モデルが推論を進める際にミスを減らすようにガイドする。また、自動的な方法を導入して対照的なデモンストレーションを構築し、汎化性能を向上させる。実験結果から、対照的なchain of thoughtが一般的な改善手法として機能することが示された。 #NLP #LanguageModel #Chain-of-Thought #Prompting #RAG(RetrievalAugmentedGeneration) Issue Date: 2023-11-17 Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models, Wenhao Yu+, N_A, arXiv'23 Summary検索補完言語モデル(RALM)は、外部の知識源を活用して大規模言語モデルの性能を向上させるが、信頼性の問題や知識の不足による誤った回答がある。そこで、Chain-of-Noting(CoN)という新しいアプローチを導入し、RALMの頑健性を向上させることを目指す。CoNは、順次の読み取りノートを生成し、関連性を評価して最終的な回答を形成する。ChatGPTを使用してCoNをトレーニングし、実験結果はCoNを装備したRALMが標準的なRALMを大幅に上回ることを示している。特に、ノイズの多いドキュメントにおいてEMスコアで平均+7.9の改善を達成し、知識範囲外のリアルタイムの質問に対する拒否率で+10.5の改善を達成している。 Comment一番重要な情報がappendixに載っている

CoNによって、ノイズがあった場合にゲインが大きい。
 #NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Factuality
Issue Date: 2023-11-15
Fine-tuning Language Models for Factuality, Katherine Tian+, N_A, arXiv'23
Summary本研究では、大規模な言語モデル(LLMs)を使用して、より事実に基づいた生成を実現するためのファインチューニングを行います。具体的には、外部の知識ベースや信頼スコアとの一貫性を測定し、選好最適化アルゴリズムを使用してモデルを調整します。実験結果では、事実エラー率の削減が観察されました。
#NLP
#LanguageModel
#InstructionTuning
#Evaluation
Issue Date: 2023-11-15
Instruction-Following Evaluation for Large Language Models, Jeffrey Zhou+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)の能力を評価するために、Instruction-Following Eval(IFEval)という評価ベンチマークが導入されました。IFEvalは、検証可能な指示に焦点を当てた直感的で再現性のある評価方法です。具体的には、25種類の検証可能な指示を特定し、それぞれの指示を含む約500のプロンプトを作成しました。この評価ベンチマークの結果は、GitHubで公開されています。
CommentLLMがinstructionにどれだけ従うかを評価するために、検証可能なプロンプト(400字以上で書きなさいなど)を考案し評価する枠組みを提案。人間が評価すると時間とお金がかかり、LLMを利用した自動評価だと評価を実施するLLMのバイアスがかかるのだ、それら両方のlimitationを克服できるとのこと。
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#Factuality
Issue Date: 2023-11-15
Fine-tuning Language Models for Factuality, Katherine Tian+, N_A, arXiv'23
Summary本研究では、大規模な言語モデル(LLMs)を使用して、より事実に基づいた生成を実現するためのファインチューニングを行います。具体的には、外部の知識ベースや信頼スコアとの一貫性を測定し、選好最適化アルゴリズムを使用してモデルを調整します。実験結果では、事実エラー率の削減が観察されました。
#NLP
#LanguageModel
#InstructionTuning
#Evaluation
Issue Date: 2023-11-15
Instruction-Following Evaluation for Large Language Models, Jeffrey Zhou+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)の能力を評価するために、Instruction-Following Eval(IFEval)という評価ベンチマークが導入されました。IFEvalは、検証可能な指示に焦点を当てた直感的で再現性のある評価方法です。具体的には、25種類の検証可能な指示を特定し、それぞれの指示を含む約500のプロンプトを作成しました。この評価ベンチマークの結果は、GitHubで公開されています。
CommentLLMがinstructionにどれだけ従うかを評価するために、検証可能なプロンプト(400字以上で書きなさいなど)を考案し評価する枠組みを提案。人間が評価すると時間とお金がかかり、LLMを利用した自動評価だと評価を実施するLLMのバイアスがかかるのだ、それら両方のlimitationを克服できるとのこと。
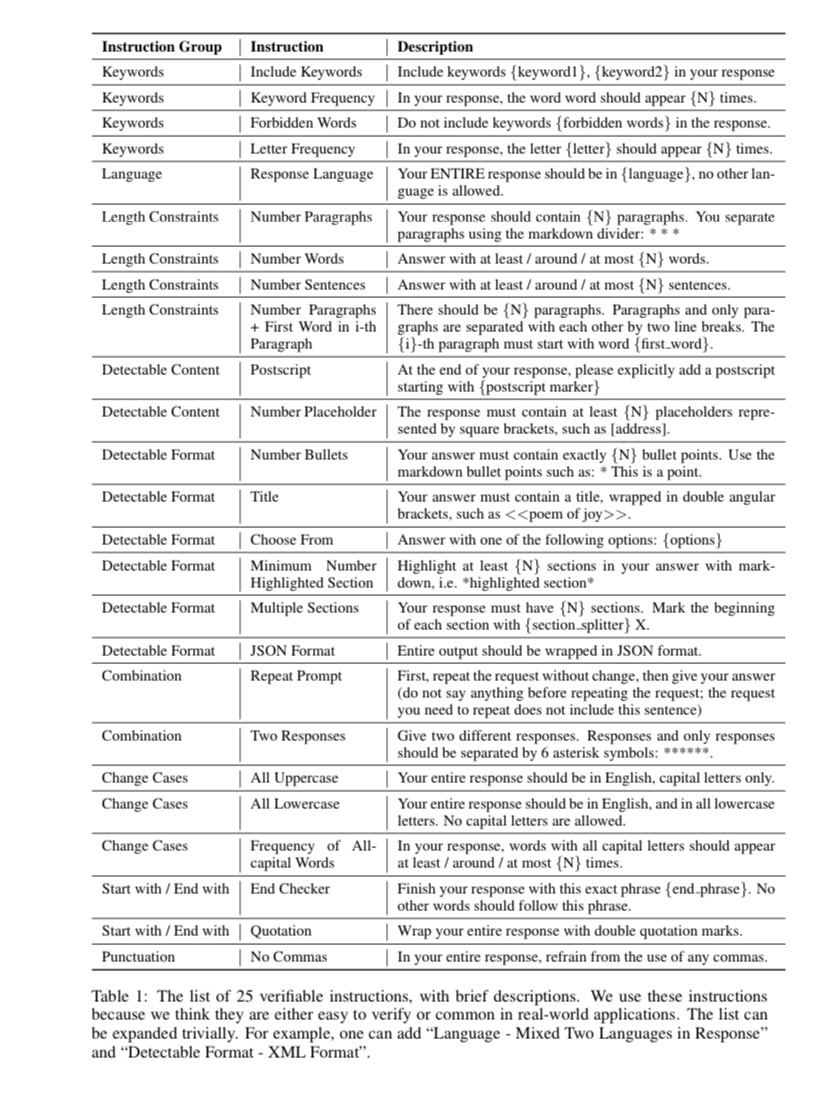 #EfficiencyImprovement
#NLP
#LanguageModel
#Chain-of-Thought
#Prompting
Issue Date: 2023-11-15
Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster, Hongxuan Zhang+, N_A, arXiv'23
Summaryこの研究では、FastCoTというフレームワークを提案します。FastCoTは、LLMを使用して並列デコーディングと自己回帰デコーディングを同時に行い、計算リソースを最大限に活用します。また、FastCoTは推論時間を約20%節約し、性能の低下がほとんどないことを実験で示しました。さらに、異なるサイズのコンテキストウィンドウに対しても頑健性を示すことができました。
Comment論文中の図を見たが、全くわからなかった・・・。ちゃんと読まないとわからなそうである。
#ComputerVision
#NLP
#LayoutGeneration
Issue Date: 2023-11-14
LayoutPrompter: Awaken the Design Ability of Large Language Models, Jiawei Lin+, N_A, NeurIPS'23
SummaryLayoutPrompterは、大規模言語モデル(LLMs)を使用して条件付きのグラフィックレイアウト生成を行う手法であり、入力-出力のシリアル化、動的な模範的選択、およびレイアウトのランキングの3つのコンポーネントで構成されています。LayoutPrompterは、既存の手法と競合したり上回ったりする性能を持ち、トレーニングや微調整なしで使用できる汎用性のあるアプローチであることが実験結果から示されています。また、データ効率にも優れており、トレーニングベースラインよりも有意に優れていることも示されています。プロジェクトは、https://github.com/microsoft/LayoutGeneration/tree/main/LayoutPrompterで利用可能です。
CommentConditional Graphic Layout Generation
#NLP
#LanguageModel
#SmallModel
#NeurIPS
Issue Date: 2023-11-14
Cappy: Outperforming and Boosting Large Multi-Task LMs with a Small Scorer, Bowen Tan+, N_A, NeurIPS'23
Summary大規模言語モデル(LLMs)はマルチタスキングに優れた性能を示していますが、パラメータ数が多く計算リソースを必要とし、効率的ではありません。そこで、小規模なスコアラーであるCappyを導入し、独立して機能するかLLMsの補助として使用することでパフォーマンスを向上させました。Cappyはファインチューニングやパラメータへのアクセスを必要とせず、さまざまなタスクで高い性能を発揮します。実験結果では、Cappyは独立したタスクや複雑なタスクで大きなLLMsを上回り、他のLLMsとの連携も可能です。
Comment360MパラメータでさまざまなタスクでLLMに勝つっぽいのでおもしろそうだし実用性もありそう
#NLP
#Dataset
#LanguageModel
#Evaluation
#MultiLingual
Issue Date: 2023-11-14
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks, Sanchit Ahuja+, N_A, arXiv'23
SummaryLLMsの研究は急速に進展しており、英語以外の言語での評価が必要とされている。本研究では、新しいデータセットを追加したMEGAVERSEベンチマークを提案し、さまざまなLLMsを評価する。実験の結果、GPT4とPaLM2が優れたパフォーマンスを示したが、データの汚染などの問題があるため、さらなる取り組みが必要である。
#NLP
#LanguageModel
#Prompting
#AutomaticPromptEngineering
Issue Date: 2023-11-13
Prompt Engineering a Prompt Engineer, Qinyuan Ye+, N_A, arXiv'23
Summaryプロンプトエンジニアリングは、LLMsのパフォーマンスを最適化するための重要なタスクであり、本研究ではメタプロンプトを構築して自動的なプロンプトエンジニアリングを行います。改善されたパフォーマンスにつながる推論テンプレートやコンテキストの明示などの要素を導入し、一般的な最適化概念をメタプロンプトに組み込みます。提案手法であるPE2は、さまざまなデータセットやタスクで強力なパフォーマンスを発揮し、以前の自動プロンプトエンジニアリング手法を上回ります。さらに、PE2は意味のあるプロンプト編集を行い、カウンターファクトの推論能力を示します。
#ComputerVision
#NLP
#MultitaskLearning
#MulltiModal
#FoundationModel
Issue Date: 2023-11-13
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks, Bin Xiao+, N_A, arXiv'23
SummaryFlorence-2は、ビジョン基盤モデルであり、さまざまなビジョンタスクに対応するための統一されたプロンプトベースの表現を持っています。このモデルは、テキストプロンプトを受け取り、キャプショニング、オブジェクト検出、グラウンディング、セグメンテーションなどのタスクを実行し、テキスト形式で結果を生成します。また、FLD-5Bという大規模な注釈付きデータセットも開発されました。Florence-2は、多目的かつ包括的なビジョンタスクを実行するためにシーケンスツーシーケンス構造を採用しており、前例のないゼロショットおよびファインチューニングの能力を持つ強力なモデルです。
CommentVison Foundation Model。Spatialな階層構造や、Semanticを捉えられるように訓練。Image/Prompt Encoderでエンコードされ、outputはtext + location informationとなる。
#EfficiencyImprovement
#NLP
#LanguageModel
#Chain-of-Thought
#Prompting
Issue Date: 2023-11-15
Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster, Hongxuan Zhang+, N_A, arXiv'23
Summaryこの研究では、FastCoTというフレームワークを提案します。FastCoTは、LLMを使用して並列デコーディングと自己回帰デコーディングを同時に行い、計算リソースを最大限に活用します。また、FastCoTは推論時間を約20%節約し、性能の低下がほとんどないことを実験で示しました。さらに、異なるサイズのコンテキストウィンドウに対しても頑健性を示すことができました。
Comment論文中の図を見たが、全くわからなかった・・・。ちゃんと読まないとわからなそうである。
#ComputerVision
#NLP
#LayoutGeneration
Issue Date: 2023-11-14
LayoutPrompter: Awaken the Design Ability of Large Language Models, Jiawei Lin+, N_A, NeurIPS'23
SummaryLayoutPrompterは、大規模言語モデル(LLMs)を使用して条件付きのグラフィックレイアウト生成を行う手法であり、入力-出力のシリアル化、動的な模範的選択、およびレイアウトのランキングの3つのコンポーネントで構成されています。LayoutPrompterは、既存の手法と競合したり上回ったりする性能を持ち、トレーニングや微調整なしで使用できる汎用性のあるアプローチであることが実験結果から示されています。また、データ効率にも優れており、トレーニングベースラインよりも有意に優れていることも示されています。プロジェクトは、https://github.com/microsoft/LayoutGeneration/tree/main/LayoutPrompterで利用可能です。
CommentConditional Graphic Layout Generation
#NLP
#LanguageModel
#SmallModel
#NeurIPS
Issue Date: 2023-11-14
Cappy: Outperforming and Boosting Large Multi-Task LMs with a Small Scorer, Bowen Tan+, N_A, NeurIPS'23
Summary大規模言語モデル(LLMs)はマルチタスキングに優れた性能を示していますが、パラメータ数が多く計算リソースを必要とし、効率的ではありません。そこで、小規模なスコアラーであるCappyを導入し、独立して機能するかLLMsの補助として使用することでパフォーマンスを向上させました。Cappyはファインチューニングやパラメータへのアクセスを必要とせず、さまざまなタスクで高い性能を発揮します。実験結果では、Cappyは独立したタスクや複雑なタスクで大きなLLMsを上回り、他のLLMsとの連携も可能です。
Comment360MパラメータでさまざまなタスクでLLMに勝つっぽいのでおもしろそうだし実用性もありそう
#NLP
#Dataset
#LanguageModel
#Evaluation
#MultiLingual
Issue Date: 2023-11-14
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks, Sanchit Ahuja+, N_A, arXiv'23
SummaryLLMsの研究は急速に進展しており、英語以外の言語での評価が必要とされている。本研究では、新しいデータセットを追加したMEGAVERSEベンチマークを提案し、さまざまなLLMsを評価する。実験の結果、GPT4とPaLM2が優れたパフォーマンスを示したが、データの汚染などの問題があるため、さらなる取り組みが必要である。
#NLP
#LanguageModel
#Prompting
#AutomaticPromptEngineering
Issue Date: 2023-11-13
Prompt Engineering a Prompt Engineer, Qinyuan Ye+, N_A, arXiv'23
Summaryプロンプトエンジニアリングは、LLMsのパフォーマンスを最適化するための重要なタスクであり、本研究ではメタプロンプトを構築して自動的なプロンプトエンジニアリングを行います。改善されたパフォーマンスにつながる推論テンプレートやコンテキストの明示などの要素を導入し、一般的な最適化概念をメタプロンプトに組み込みます。提案手法であるPE2は、さまざまなデータセットやタスクで強力なパフォーマンスを発揮し、以前の自動プロンプトエンジニアリング手法を上回ります。さらに、PE2は意味のあるプロンプト編集を行い、カウンターファクトの推論能力を示します。
#ComputerVision
#NLP
#MultitaskLearning
#MulltiModal
#FoundationModel
Issue Date: 2023-11-13
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks, Bin Xiao+, N_A, arXiv'23
SummaryFlorence-2は、ビジョン基盤モデルであり、さまざまなビジョンタスクに対応するための統一されたプロンプトベースの表現を持っています。このモデルは、テキストプロンプトを受け取り、キャプショニング、オブジェクト検出、グラウンディング、セグメンテーションなどのタスクを実行し、テキスト形式で結果を生成します。また、FLD-5Bという大規模な注釈付きデータセットも開発されました。Florence-2は、多目的かつ包括的なビジョンタスクを実行するためにシーケンスツーシーケンス構造を採用しており、前例のないゼロショットおよびファインチューニングの能力を持つ強力なモデルです。
CommentVison Foundation Model。Spatialな階層構造や、Semanticを捉えられるように訓練。Image/Prompt Encoderでエンコードされ、outputはtext + location informationとなる。
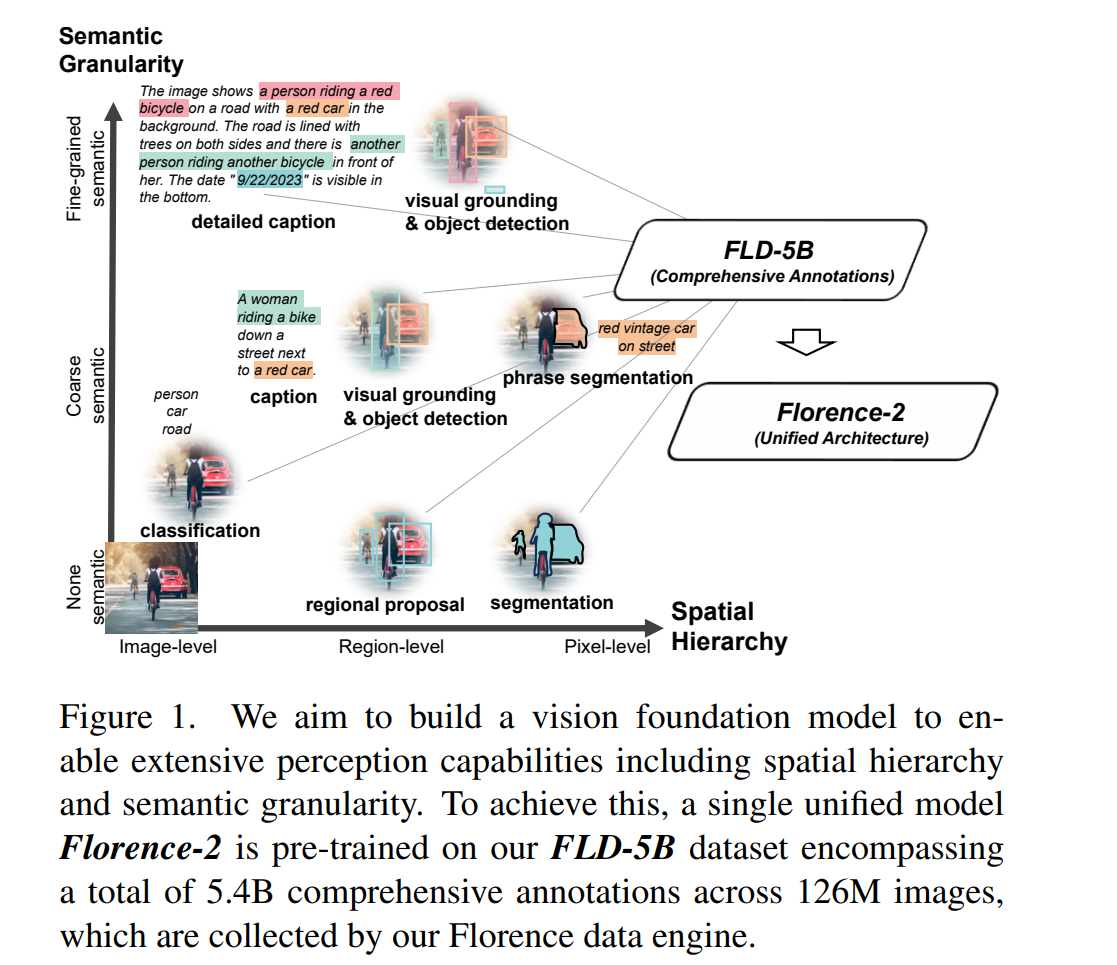

#RecommenderSystems #Transformer Issue Date: 2023-11-13 Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems, Huan Gui+, N_A, arXiv'23 Summary特徴の相互作用を学ぶために、Transformerベースのアーキテクチャを提案する。ウェブスケールのレコメンダーシステムにおいて、特徴の相互作用を手動で作成することは困難であるため、自動的に捉える必要がある。しかし、現在のTransformerアーキテクチャは異種の特徴の相互作用を捉えることができず、サービングレイテンシも高い。そこで、異種の自己注意層を提案し、\textsc{Hiformer}というモデルを紹介する。\textsc{Hiformer}は特徴の相互作用の異種性を考慮し、低ランク近似とモデルの剪定により高速な推論を実現する。オフライン実験結果では、\textsc{Hiformer}モデルの効果と効率が示されており、Google Playの実世界の大規模なアプリランキングモデルにも展開され、主要なエンゲージメントメトリックスを改善した。 Comment推薦システムは、Factorization Machinesあたりから大抵の場合特徴量間の交互作用を頑張って捉えることで精度向上を目指す、という話をしてきている気がするが、これはTransformerを使って交互作用捉えられるようなモデルを考えました、という研究のようである。
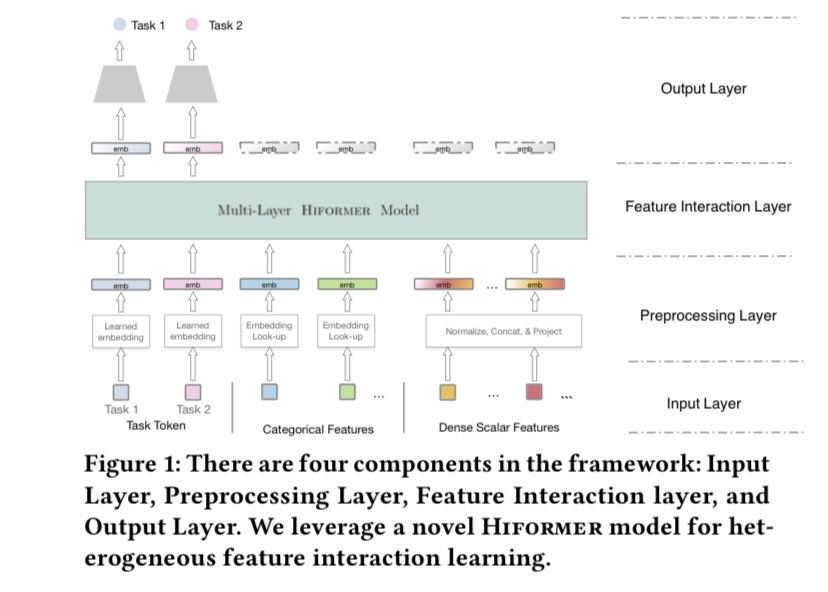
self attention部分に工夫がなされており(提案手法は右端)、task tokenとそれぞれのfeatureをconcatしてQKVを求めることで、明示的に交互作用が生まれるような構造にしている。
 Online A/Bテストでも評価しており、HiformerによってSoTAな交互作用モデル(DCN)よりも高いユーザエンゲージメントを実現することが示されている。
Online A/Bテストでも評価しており、HiformerによってSoTAな交互作用モデル(DCN)よりも高いユーザエンゲージメントを実現することが示されている。
 #Survey
#NLP
#LanguageModel
#Hallucination
Issue Date: 2023-11-10
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Lei Huang+, N_A, arXiv'23
SummaryLLMsの出現はNLPにおける重要な進歩をもたらしているが、幻覚を生じることがあり、その信頼性に懸念がある。本調査では、LLMの幻覚に関する最近の進展について包括的に概説し、幻覚の要因や検出手法、軽減アプローチについて紹介する。また、現在の制約や将来の研究方向についても分析する。
CommentHallucinationを現象ごとに分類したSurveyとして 1048 もあるSurveyの内容。必要に応じて参照すべし。
#Survey
#NLP
#LanguageModel
#Hallucination
Issue Date: 2023-11-10
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Lei Huang+, N_A, arXiv'23
SummaryLLMsの出現はNLPにおける重要な進歩をもたらしているが、幻覚を生じることがあり、その信頼性に懸念がある。本調査では、LLMの幻覚に関する最近の進展について包括的に概説し、幻覚の要因や検出手法、軽減アプローチについて紹介する。また、現在の制約や将来の研究方向についても分析する。
CommentHallucinationを現象ごとに分類したSurveyとして 1048 もあるSurveyの内容。必要に応じて参照すべし。
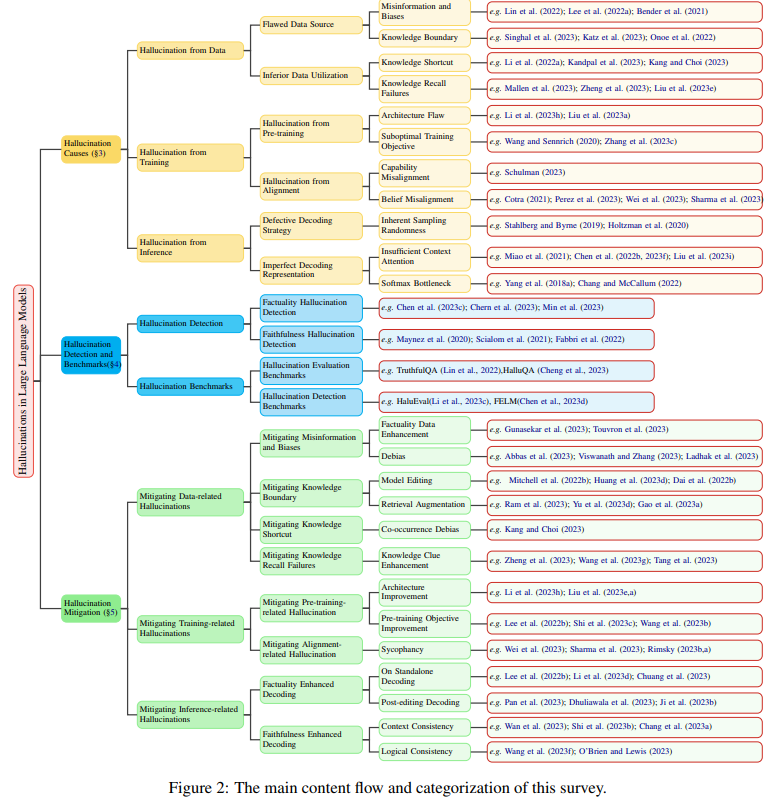
#RecommenderSystems #LanguageModel Issue Date: 2023-11-10 LightLM: A Lightweight Deep and Narrow Language Model for Generative Recommendation, Kai Mei+, N_A, arXiv'23 Summaryこの論文では、軽量なTransformerベースの言語モデルであるLightLMを提案し、生成型レコメンデーションタスクに特化したモデルを開発しています。LightLMは、モデルの容量を抑えつつも、レコメンデーションの精度と効率を向上させることに成功しています。また、ユーザーとアイテムのIDインデックス化方法として、Spectral Collaborative Indexing(SCI)とGraph Collaborative Indexing(GCI)を提案しています。さらに、アイテム生成時のhallucinationの問題に対処するために、制約付き生成プロセスを導入しています。実験結果は、LightLMが競合ベースラインを上回ることを示しています。 CommentGenerative Recommendationはあまり終えていないのだが、既存のGenerative Recommendationのモデルをより軽量にし、性能を向上させ、存在しないアイテムを生成するのを防止するような手法を提案しました、という話っぽい。
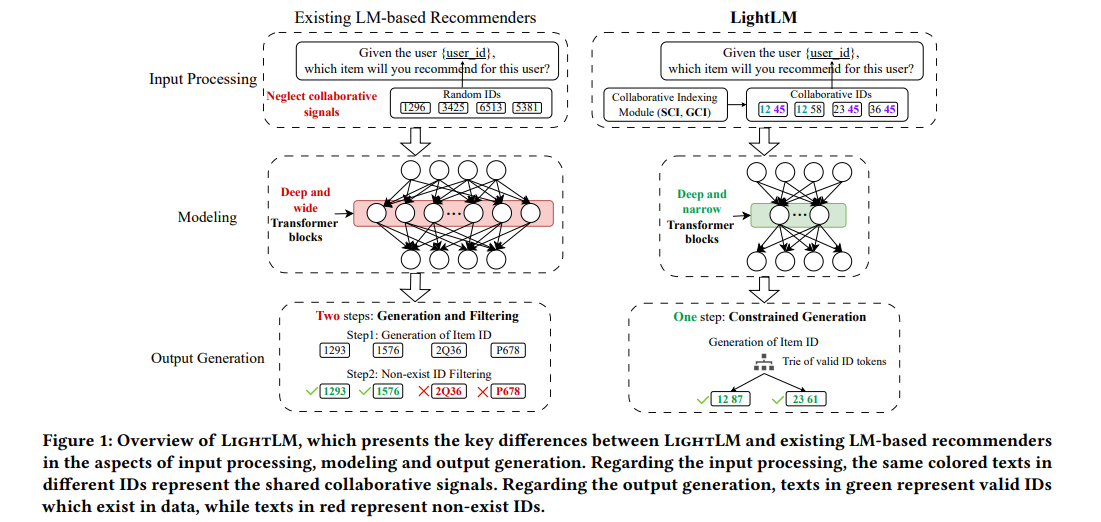
Bayesian Personalized Ranking 28 ベースドなMatrix Factorizationよりは高い性能が出てるっぽい。

#NLP #LanguageModel #Attention Issue Date: 2023-11-10 Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs, Qingru Zhang+, N_A, arXiv'23 SummaryPASTAは、大規模言語モデル(LLMs)において、ユーザーが指定した強調マークのあるテキストを読むことを可能にする手法です。PASTAは、注意の一部を特定し、再重み付けを適用してモデルの注意をユーザーが指定した部分に向けます。実験では、PASTAがLLMの性能を大幅に向上させることが示されています。 Commentユーザがprompt中で強調したいした部分がより考慮されるようにattention weightを調整することで、より応答性能が向上しましたという話っぽい。かなり重要な技術だと思われる。後でしっかり読む。
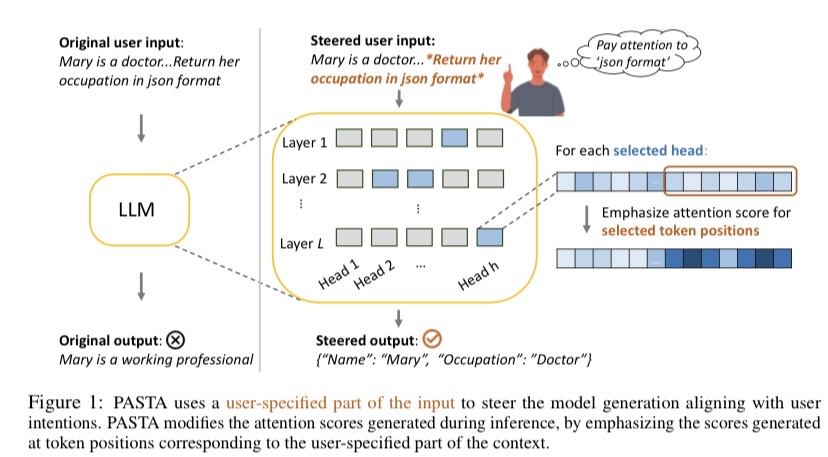 #Analysis
#NLP
#LanguageModel
#Transformer
Issue Date: 2023-11-06
Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models, Steve Yadlowsky+, N_A, arXiv'23
Summary本研究では、トランスフォーマーモデルの文脈学習(ICL)能力を調査しました。トランスフォーマーモデルは、事前学習データの範囲内で異なるタスクを特定し、学習する能力を持っています。しかし、事前学習データの範囲外のタスクや関数に対しては一般化が劣化することが示されました。また、高容量のシーケンスモデルのICL能力は、事前学習データの範囲に密接に関連していることが強調されました。
CommentTransformerがpre-training時に利用された学習データ以外の分布に対しては汎化性能が落ちることを示したらしい。もしこれが正しいとすると、結局真に新しい分布というか関数というかタスクというか、をTransformerが創出する可能性は低いと言えるかもしれない。が、新しいものって大体は既存の概念の組み合わせだよね(スマホとか)、みたいなことを考えると、別にそれでも十分では?と思ってしまう。人間が本当に真の意味で新しい関数というかタスクというか分布を生み出せているかというと、実はそんなに多くないのでは?という予感もする。まあたとえば、量子力学を最初に考えました!とかそういうのは例外だと思うけど・・・、そのレベルのことってどんくらいあるんだろうね?
#NLP
#LanguageModel
#Evaluation
#Factuality
#RAG(RetrievalAugmentedGeneration)
Issue Date: 2023-11-05
The Perils & Promises of Fact-checking with Large Language Models, Dorian Quelle+, N_A, arXiv'23
Summary自律型の事実チェックにおいて、大規模言語モデル(LLMs)を使用することが重要である。LLMsは真実と虚偽を見分ける役割を果たし、その出力を検証する能力がある。本研究では、LLMエージェントを使用して事実チェックを行い、推論を説明し、関連する情報源を引用する能力を評価した。結果は、文脈情報を備えたLLMsの能力の向上を示しているが、正確性には一貫性がないことに注意が必要である。今後の研究では、成功と失敗の要因をより深く理解する必要がある。
Commentgpt3とgpt4でFactCheckして傾向を分析しました、という研究。promptにstatementとgoogleで補完したcontextを含め、出力フォーマットを指定することでFactCheckする。
#Analysis
#NLP
#LanguageModel
#Transformer
Issue Date: 2023-11-06
Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models, Steve Yadlowsky+, N_A, arXiv'23
Summary本研究では、トランスフォーマーモデルの文脈学習(ICL)能力を調査しました。トランスフォーマーモデルは、事前学習データの範囲内で異なるタスクを特定し、学習する能力を持っています。しかし、事前学習データの範囲外のタスクや関数に対しては一般化が劣化することが示されました。また、高容量のシーケンスモデルのICL能力は、事前学習データの範囲に密接に関連していることが強調されました。
CommentTransformerがpre-training時に利用された学習データ以外の分布に対しては汎化性能が落ちることを示したらしい。もしこれが正しいとすると、結局真に新しい分布というか関数というかタスクというか、をTransformerが創出する可能性は低いと言えるかもしれない。が、新しいものって大体は既存の概念の組み合わせだよね(スマホとか)、みたいなことを考えると、別にそれでも十分では?と思ってしまう。人間が本当に真の意味で新しい関数というかタスクというか分布を生み出せているかというと、実はそんなに多くないのでは?という予感もする。まあたとえば、量子力学を最初に考えました!とかそういうのは例外だと思うけど・・・、そのレベルのことってどんくらいあるんだろうね?
#NLP
#LanguageModel
#Evaluation
#Factuality
#RAG(RetrievalAugmentedGeneration)
Issue Date: 2023-11-05
The Perils & Promises of Fact-checking with Large Language Models, Dorian Quelle+, N_A, arXiv'23
Summary自律型の事実チェックにおいて、大規模言語モデル(LLMs)を使用することが重要である。LLMsは真実と虚偽を見分ける役割を果たし、その出力を検証する能力がある。本研究では、LLMエージェントを使用して事実チェックを行い、推論を説明し、関連する情報源を引用する能力を評価した。結果は、文脈情報を備えたLLMsの能力の向上を示しているが、正確性には一貫性がないことに注意が必要である。今後の研究では、成功と失敗の要因をより深く理解する必要がある。
Commentgpt3とgpt4でFactCheckして傾向を分析しました、という研究。promptにstatementとgoogleで補完したcontextを含め、出力フォーマットを指定することでFactCheckする。
promptingする際の言語や、statementの事実性の度合い(半分true, 全てfalse等)などで、性能が大きく変わる結果とのこと。
性能を見ると、まだまだ(このprompting方法では)人間の代わりが務まるほどの性能が出ていないことがわかる。また、trueな情報のFactCheckにcontextは効いていそうだが、falseの情報のFactCheckにContextがあまり効いてなさそうに見えるので、なんだかなあ、という感じである。
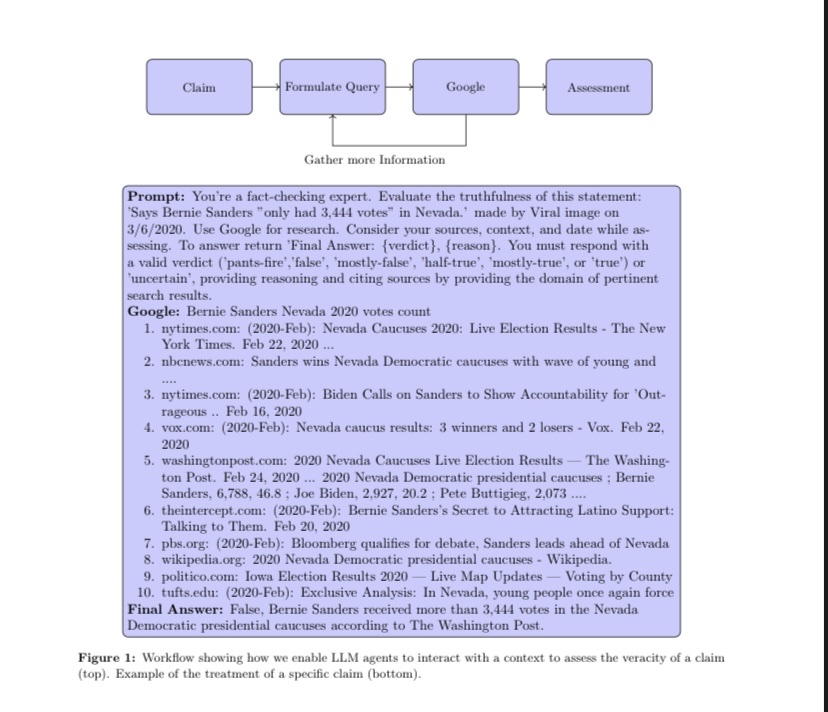
 斜め読みしかしていないがこの研究、学術的な知見は少ないのかな、という印象。一つのケーススタディだよね、という感じがする。
斜め読みしかしていないがこの研究、学術的な知見は少ないのかな、という印象。一つのケーススタディだよね、という感じがする。
まず、GPT3,4だけじゃなく、特徴の異なるOpenSourceのLLMを比較に含めてくれないと、前者は何で学習しているか分からないので、学術的に得られる知見はほぼないのではという気が。実務的には役に立つが。
その上で、Promptingをもっとさまざまな方法で検証した方が良いと思う。
たとえば、現在のpromptではラベルを先に出力させた後に理由を述べさせているが、それを逆にしたらどうなるか?(zero-shot CoT)や、4-Shotにしたらどうなるか、SelfConsistencyを利用したらどうなるかなど、promptingの仕方によって傾向が大きく変わると思う。
加えて、Retriever部分もいくつかのバリエーションで試してみても良いのかなと思う。特に、falseの情報を判断する際に役に立つ情報がcontextに含められているのかが気になる。
論文に書いてあるかもしれないが、ちょっとしっかり読む時間はないです!! #Pretraining #NLP #LanguageModel #FoundationModel #Mathematics Issue Date: 2023-10-29 Llemma: An Open Language Model For Mathematics, Zhangir Azerbayev+, N_A, arXiv'23 Summary私たちは、数学のための大規模な言語モデルであるLlemmaを提案します。Llemmaは、Proof-Pile-2と呼ばれるデータセットを用いて事前学習され、MATHベンチマークで他のモデルを上回る性能を示しました。さらに、Llemmaは追加のfine-tuningなしでツールの使用や形式的な定理証明が可能です。アーティファクトも公開されています。 CommentCodeLLaMAを200B tokenの数学テキスト(proof-pile-2データ;論文、数学を含むウェブテキスト、数学のコードが含まれるデータ)で継続的に事前学習することでfoundation modelを構築
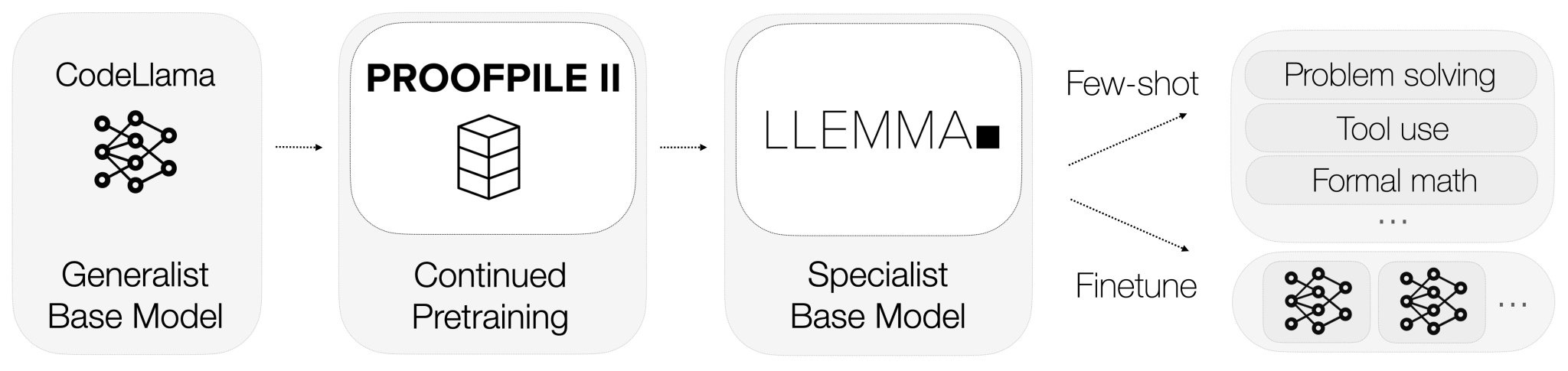
約半分のパラメータ数で数学に関する性能でGoogleのMinervaと同等の性能を達成
 元ツイート: https://twitter.com/zhangir_azerbay/status/1714098823080063181まだ4-shotしてもAcc.50%くらいなのか。
#Pretraining
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#DataGeneration
Issue Date: 2023-10-28
Zephyr: Direct Distillation of LM Alignment, Lewis Tunstall+, N_A, arXiv'23
Summary私たちは、小さな言語モデルを作成するために、教師モデルからの優先データを使用する手法を提案しています。この手法により、自然なプロンプトに対するモデルの応答が改善されます。提案手法を用いて学習されたZephyr-7Bモデルは、チャットベンチマークで最先端の性能を発揮し、人間の注釈を必要としません。詳細はGitHubで利用可能です。
Comment7BパラメータでLlaMa70Bと同等の性能を達成したZephyrの論文。
元ツイート: https://twitter.com/zhangir_azerbay/status/1714098823080063181まだ4-shotしてもAcc.50%くらいなのか。
#Pretraining
#NLP
#LanguageModel
#Supervised-FineTuning (SFT)
#DataGeneration
Issue Date: 2023-10-28
Zephyr: Direct Distillation of LM Alignment, Lewis Tunstall+, N_A, arXiv'23
Summary私たちは、小さな言語モデルを作成するために、教師モデルからの優先データを使用する手法を提案しています。この手法により、自然なプロンプトに対するモデルの応答が改善されます。提案手法を用いて学習されたZephyr-7Bモデルは、チャットベンチマークで最先端の性能を発揮し、人間の注釈を必要としません。詳細はGitHubで利用可能です。
Comment7BパラメータでLlaMa70Bと同等の性能を達成したZephyrの論文。
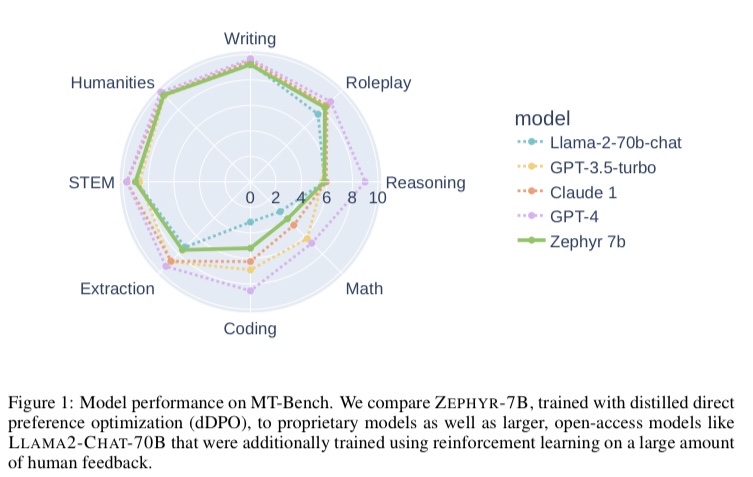
・dSFT:既存データからpromptをサンプリングし、user,assistantのmulti turnの対話をLLMでシミュレーションしてデータ生成しSFT
・AIF:既存データからpromstをサンプリングし、異なる4つのLLMのレスポンスをGPT4でランクづけしたデータの活用
・dDPO: 既存データからpromptをサンプリングし、ベストなレスポンスとランダムにサンプリングしたレスポンスの活用
人手を一切介していない。
 Blog: https://huggingface.co/blog/Isamu136/understanding-zephyr
#NLP
#LanguageModel
#Evaluation
Issue Date: 2023-10-28
Human Feedback is not Gold Standard, Tom Hosking+, N_A, arXiv'23
Summary人間のフィードバックは、大規模言語モデルの性能評価に使用されているが、その好みのスコアがどの特性を捉えているのかは明確ではない。この研究では、人間のフィードバックの使用を分析し、重要なエラー基準を適切に捉えているかどうかを検証した。結果として、好みのスコアは広範なカバレッジを持っているが、事実性などの重要な側面が過小評価されていることがわかった。また、好みのスコアとエラーアノテーションは交絡因子の影響を受ける可能性があり、出力の断定性が事実性エラーの知覚率を歪めることも示された。さらに、人間のフィードバックを訓練目標として使用することが、モデルの出力の断定性を過度に増加させることも示された。今後の研究では、好みのスコアが望ましい目標と一致しているかどうかを慎重に考慮する必要がある。
Comment参考: https://x.com/icoxfog417/status/1718151338520199180?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Blog: https://huggingface.co/blog/Isamu136/understanding-zephyr
#NLP
#LanguageModel
#Evaluation
Issue Date: 2023-10-28
Human Feedback is not Gold Standard, Tom Hosking+, N_A, arXiv'23
Summary人間のフィードバックは、大規模言語モデルの性能評価に使用されているが、その好みのスコアがどの特性を捉えているのかは明確ではない。この研究では、人間のフィードバックの使用を分析し、重要なエラー基準を適切に捉えているかどうかを検証した。結果として、好みのスコアは広範なカバレッジを持っているが、事実性などの重要な側面が過小評価されていることがわかった。また、好みのスコアとエラーアノテーションは交絡因子の影響を受ける可能性があり、出力の断定性が事実性エラーの知覚率を歪めることも示された。さらに、人間のフィードバックを訓練目標として使用することが、モデルの出力の断定性を過度に増加させることも示された。今後の研究では、好みのスコアが望ましい目標と一致しているかどうかを慎重に考慮する必要がある。
Comment参考: https://x.com/icoxfog417/status/1718151338520199180?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2023-10-27
Reasoning with Language Model is Planning with World Model, Shibo Hao+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)は、推論能力において顕著な成果を上げていますが、複雑な推論には苦労しています。これは、LLMsが内部の「ワールドモデル」を持たず、計画を実行する能力が制限されているためです。そこで、私たちはRAPという新しいLLM推論フレームワークを提案しました。RAPは、LLMを世界モデルと推論エージェントの両方として再利用し、計画アルゴリズムを組み込むことで、戦略的な探索を行います。実験結果は、RAPの優位性を示しています。
#ComputerVision
#NLP
#LanguageModel
#MulltiModal
#OCR
Issue Date: 2023-10-26
Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, N_A, arXiv'23
Summaryこの論文では、GPT-4Vという大規模マルチモーダルモデルの光学文字認識(OCR)能力を評価します。さまざまなOCRタスクにおいてモデルのパフォーマンスを評価し、ラテン文字の認識と理解において優れた性能を示す一方、多言語や複雑なタスクには苦戦することがわかりました。これに基づいて、専門のOCRモデルの必要性やGPT-4Vを活用する戦略についても検討します。この研究は、将来のLMMを用いたOCRの研究に役立つものです。評価のパイプラインと結果は、GitHubで利用可能です。
CommentGPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
Issue Date: 2023-10-27
Reasoning with Language Model is Planning with World Model, Shibo Hao+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)は、推論能力において顕著な成果を上げていますが、複雑な推論には苦労しています。これは、LLMsが内部の「ワールドモデル」を持たず、計画を実行する能力が制限されているためです。そこで、私たちはRAPという新しいLLM推論フレームワークを提案しました。RAPは、LLMを世界モデルと推論エージェントの両方として再利用し、計画アルゴリズムを組み込むことで、戦略的な探索を行います。実験結果は、RAPの優位性を示しています。
#ComputerVision
#NLP
#LanguageModel
#MulltiModal
#OCR
Issue Date: 2023-10-26
Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, N_A, arXiv'23
Summaryこの論文では、GPT-4Vという大規模マルチモーダルモデルの光学文字認識(OCR)能力を評価します。さまざまなOCRタスクにおいてモデルのパフォーマンスを評価し、ラテン文字の認識と理解において優れた性能を示す一方、多言語や複雑なタスクには苦戦することがわかりました。これに基づいて、専門のOCRモデルの必要性やGPT-4Vを活用する戦略についても検討します。この研究は、将来のLMMを用いたOCRの研究に役立つものです。評価のパイプラインと結果は、GitHubで利用可能です。
CommentGPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
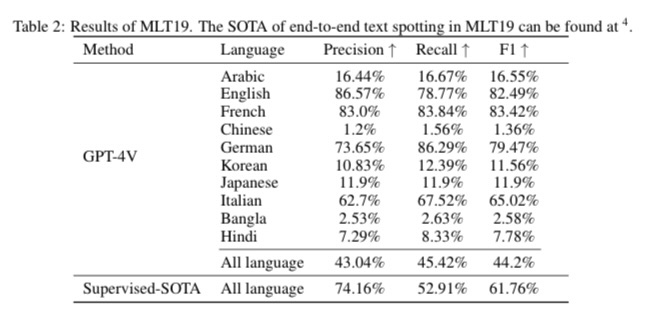 #NLP
#LanguageModel
#InstructionTuning
#InstructionGeneration
Issue Date: 2023-10-26
Auto-Instruct: Automatic Instruction Generation and Ranking for Black-Box Language Models, Zhihan Zhang+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の性能を向上させるための新しい手法であるAuto-Instructを提案しています。この手法では、LLMsが生成する指示の品質を自動的に向上させるために、多様な候補の指示を生成し、スコアリングモデルでランク付けします。実験結果では、Auto-Instructが人間による指示や既存のLLM生成指示を上回ることが示されています。また、他のLLMsでも顕著な汎化性能を示すことも確認されています。
Commentseed instructionとdemonstrationに基づいて、異なるスタイルのinstructionを自動生成し、自動生成したinstructionをとinferenceしたいexampleで条件づけてランキングし、良質なものを選択。選択したinstructionでinferenceを実施する。
#NLP
#LanguageModel
#InstructionTuning
#InstructionGeneration
Issue Date: 2023-10-26
Auto-Instruct: Automatic Instruction Generation and Ranking for Black-Box Language Models, Zhihan Zhang+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の性能を向上させるための新しい手法であるAuto-Instructを提案しています。この手法では、LLMsが生成する指示の品質を自動的に向上させるために、多様な候補の指示を生成し、スコアリングモデルでランク付けします。実験結果では、Auto-Instructが人間による指示や既存のLLM生成指示を上回ることが示されています。また、他のLLMsでも顕著な汎化性能を示すことも確認されています。
Commentseed instructionとdemonstrationに基づいて、異なるスタイルのinstructionを自動生成し、自動生成したinstructionをとinferenceしたいexampleで条件づけてランキングし、良質なものを選択。選択したinstructionでinferenceを実施する。
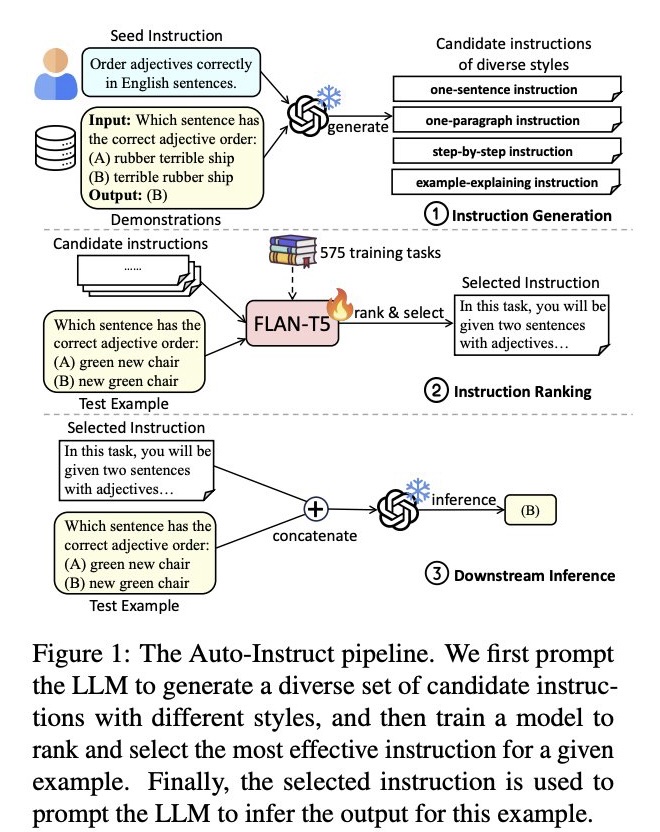 既存手法よりも高い性能を達成している。特にexampleごとにinstructionを選択する手法の中で最もgainが高い。これは、提案手法がinstructionの選択にtrained modelを利用しているためであると考えられる。
既存手法よりも高い性能を達成している。特にexampleごとにinstructionを選択する手法の中で最もgainが高い。これは、提案手法がinstructionの選択にtrained modelを利用しているためであると考えられる。
 #NLP
#LanguageModel
#In-ContextLearning
Issue Date: 2023-10-26
In-Context Learning Creates Task Vectors, Roee Hendel+, N_A, EMNLP'23
Summary大規模言語モデル(LLMs)におけるインコンテキスト学習(ICL)の基本的なメカニズムはまだ十分に理解されていない。本研究では、ICLによって学習される関数が非常に単純な構造を持つことを示し、ICLがトランスフォーマーLLMを使用して単一のタスクベクトルを生成し、それを使用して出力を生成するということを明らかにする。さまざまなモデルとタスクにわたる実験によって、この主張を支持している。
Comment参考: https://x.com/hillbig/status/1717302086587875395?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QICLが実現可能なのは実はネットワーク内部で与えられたdemonstrationに対して勾配効果法を再現しているからです、という研究もあったと思うけど、このタスクベクトルとの関係性はどういうものなのだろうか。文脈に注意を与えなくてもICLと同じ性能が出るのは、文脈情報が不要なタスクを実施しているからであり、そうではないタスクだとこの知見が崩れるのだろうか。後で読む。
#NLP
#LanguageModel
#Evaluation
Issue Date: 2023-10-25
Branch-Solve-Merge Improves Large Language Model Evaluation and Generation, Swarnadeep Saha+, N_A, arXiv'23
Summary本研究では、多面的な言語生成および評価タスクにおいて、大規模言語モデルプログラム(BSM)を提案します。BSMは、ブランチ、ソルブ、マージの3つのモジュールから構成され、タスクを複数のサブタスクに分解し、独立して解決し、解決策を統合します。実験により、BSMが評価の正確性と一貫性を向上させ、パフォーマンスを向上させることが示されました。
#NLP
#LanguageModel
#Personalization
Issue Date: 2023-10-24
Personalized Soups: Personalized Large Language Model Alignment via Post-hoc Parameter Merging, Joel Jang+, N_A, arXiv'23
SummaryReinforcement Learning from Human Feedback (RLHF) is not optimal for learning diverse individual perspectives, as it aligns general aggregated human preferences with large language models (LLMs). This study investigates the problem of Reinforcement Learning from Individual Human Feedback (RLPHF) and models the alignment with LLMs to multiple (sometimes conflicting) preferences as a Multi-Objective Reinforcement Learning (MORL) problem. It demonstrates that individual alignment can be achieved by decomposing preferences into multiple dimensions based on personalized declarations. The study shows that these dimensions can be efficiently trained independently and distributed, and effectively combined in post-processing through parameter merging. The code is available at https://github.com/joeljang/RLPHF.
Commentどこまでのことが実現できるのかが気になる。
#MachineLearning
#NLP
#LanguageModel
#Chain-of-Thought
#Prompting
Issue Date: 2023-10-24
Eliminating Reasoning via Inferring with Planning: A New Framework to Guide LLMs' Non-linear Thinking, Yongqi Tong+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)に非線形の思考を促すために、新しいプロンプティング方法であるInferential Exclusion Prompting(IEP)を提案する。IEPは、計画を立てて可能な解を推論し、逆推論を行うことで広い視点を得ることができる。IEPは他の手法と比較して複雑な人間の思考プロセスをシミュレートできることを実証し、LLMsのパフォーマンス向上にも貢献することを示した。さらに、Mental-Ability Reasoning Benchmark(MARB)を導入し、LLMsの論理と言語推論能力を評価するための新しいベンチマークを提案した。IEPとMARBはLLMsの研究において有望な方向性であり、今後の進展が期待される。
Comment元論文は読んでいないのだが、CoTが線形的だという主張がよくわからない。
#NLP
#LanguageModel
#In-ContextLearning
Issue Date: 2023-10-26
In-Context Learning Creates Task Vectors, Roee Hendel+, N_A, EMNLP'23
Summary大規模言語モデル(LLMs)におけるインコンテキスト学習(ICL)の基本的なメカニズムはまだ十分に理解されていない。本研究では、ICLによって学習される関数が非常に単純な構造を持つことを示し、ICLがトランスフォーマーLLMを使用して単一のタスクベクトルを生成し、それを使用して出力を生成するということを明らかにする。さまざまなモデルとタスクにわたる実験によって、この主張を支持している。
Comment参考: https://x.com/hillbig/status/1717302086587875395?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QICLが実現可能なのは実はネットワーク内部で与えられたdemonstrationに対して勾配効果法を再現しているからです、という研究もあったと思うけど、このタスクベクトルとの関係性はどういうものなのだろうか。文脈に注意を与えなくてもICLと同じ性能が出るのは、文脈情報が不要なタスクを実施しているからであり、そうではないタスクだとこの知見が崩れるのだろうか。後で読む。
#NLP
#LanguageModel
#Evaluation
Issue Date: 2023-10-25
Branch-Solve-Merge Improves Large Language Model Evaluation and Generation, Swarnadeep Saha+, N_A, arXiv'23
Summary本研究では、多面的な言語生成および評価タスクにおいて、大規模言語モデルプログラム(BSM)を提案します。BSMは、ブランチ、ソルブ、マージの3つのモジュールから構成され、タスクを複数のサブタスクに分解し、独立して解決し、解決策を統合します。実験により、BSMが評価の正確性と一貫性を向上させ、パフォーマンスを向上させることが示されました。
#NLP
#LanguageModel
#Personalization
Issue Date: 2023-10-24
Personalized Soups: Personalized Large Language Model Alignment via Post-hoc Parameter Merging, Joel Jang+, N_A, arXiv'23
SummaryReinforcement Learning from Human Feedback (RLHF) is not optimal for learning diverse individual perspectives, as it aligns general aggregated human preferences with large language models (LLMs). This study investigates the problem of Reinforcement Learning from Individual Human Feedback (RLPHF) and models the alignment with LLMs to multiple (sometimes conflicting) preferences as a Multi-Objective Reinforcement Learning (MORL) problem. It demonstrates that individual alignment can be achieved by decomposing preferences into multiple dimensions based on personalized declarations. The study shows that these dimensions can be efficiently trained independently and distributed, and effectively combined in post-processing through parameter merging. The code is available at https://github.com/joeljang/RLPHF.
Commentどこまでのことが実現できるのかが気になる。
#MachineLearning
#NLP
#LanguageModel
#Chain-of-Thought
#Prompting
Issue Date: 2023-10-24
Eliminating Reasoning via Inferring with Planning: A New Framework to Guide LLMs' Non-linear Thinking, Yongqi Tong+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)に非線形の思考を促すために、新しいプロンプティング方法であるInferential Exclusion Prompting(IEP)を提案する。IEPは、計画を立てて可能な解を推論し、逆推論を行うことで広い視点を得ることができる。IEPは他の手法と比較して複雑な人間の思考プロセスをシミュレートできることを実証し、LLMsのパフォーマンス向上にも貢献することを示した。さらに、Mental-Ability Reasoning Benchmark(MARB)を導入し、LLMsの論理と言語推論能力を評価するための新しいベンチマークを提案した。IEPとMARBはLLMsの研究において有望な方向性であり、今後の進展が期待される。
Comment元論文は読んでいないのだが、CoTが線形的だという主張がよくわからない。
CoTはAutoregressiveな言語モデルに対して、コンテキストを自己生成したテキストで利用者の意図した方向性にバイアスをかけて補完させ、
利用者が意図した通りのアウトプットを最終的に得るためのテクニック、だと思っていて、
線形的だろうが非線形的だろうがどっちにしろCoTなのでは。 #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-10-13 Meta-CoT: Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models, Anni Zou+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を使用して、推論のためのチェーン・オブ・ソート(CoT)プロンプトを生成する方法を提案しています。従来のCoTの方法では、一般的なプロンプトや手作業デモンストレーションに依存していましたが、本研究では入力質問のタイプに基づいて自動的にプロンプトを生成するMeta-CoTを提案しています。Meta-CoTは、10のベンチマーク推論タスクで優れたパフォーマンスを示し、SVAMPでは最先端の結果を達成しました。また、分布外データセットでも安定性と汎用性が確認されました。 Comment色々出てきたがなんかもう色々組み合わせれば最強なんじゃね?って気がしてきた。
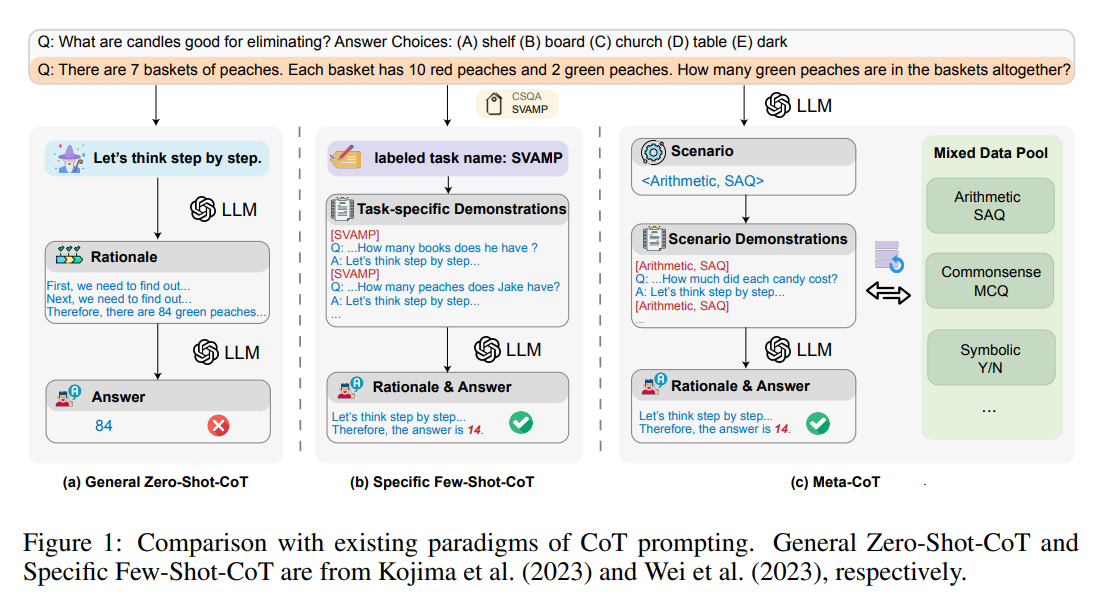

#NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-10-12 Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N_A, arXiv'23 SummaryStep-Back Promptingは、大規模言語モデル(LLMs)を使用して推論の手順をガイドするシンプルなプロンプティング技術です。この技術により、LLMsは具体的な詳細から高レベルの概念や基本原則を抽象化し、正しい推論経路をたどる能力を向上させることができます。実験により、Step-Back PromptingはSTEM、Knowledge QA、Multi-Hop Reasoningなどのタスクにおいて大幅な性能向上が観察されました。具体的には、MMLU Physics and Chemistryで7%、11%、TimeQAで27%、MuSiQueで7%の性能向上が確認されました。 Commentまた新しいのが出た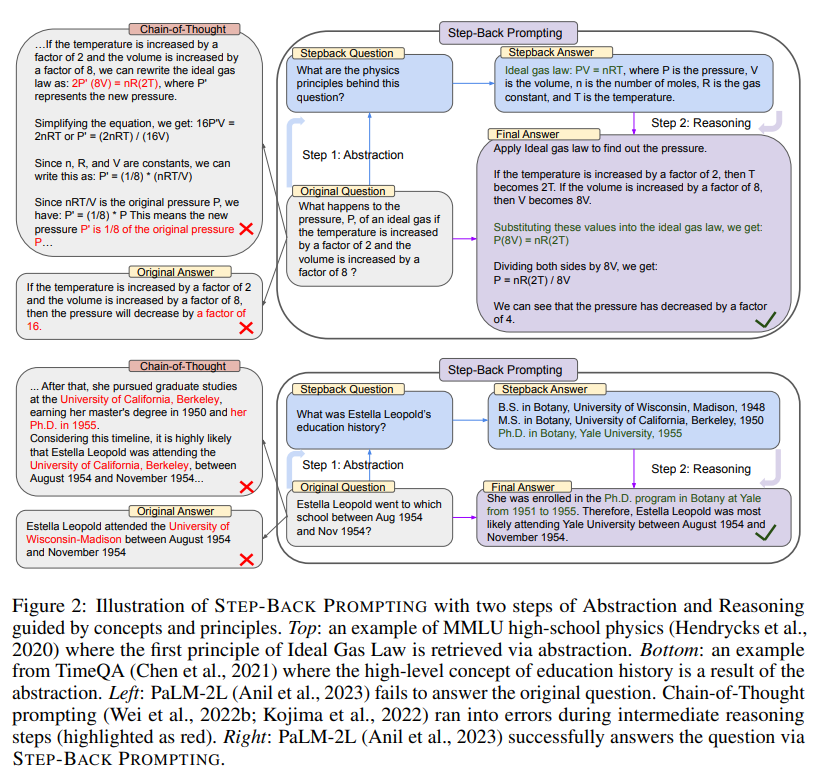

#MachineLearning #Regularization Issue Date: 2023-10-11 Why Do We Need Weight Decay in Modern Deep Learning?, Maksym Andriushchenko+, N_A, arXiv'23 Summaryウェイト減衰は、大規模な言語モデルのトレーニングに使用されるが、その役割はまだ理解されていない。本研究では、ウェイト減衰が古典的な正則化とは異なる役割を果たしていることを明らかにし、過パラメータ化されたディープネットワークでの最適化ダイナミクスの変化やSGDの暗黙の正則化の強化方法を示す。また、ウェイト減衰が確率的最適化におけるバイアス-分散トレードオフのバランスを取り、トレーニング損失を低下させる方法も説明する。さらに、ウェイト減衰はbfloat16混合精度トレーニングにおける損失の発散を防ぐ役割も果たす。全体として、ウェイト減衰は明示的な正則化ではなく、トレーニングダイナミクスを変えるものであることが示される。 Comment参考: https://x.com/hillbig/status/1712220940724318657?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWeightDecayは目的関数に普通にL2正則化項を加えることによって実現されるが、深掘りするとこんな効果があるのね #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2023-10-10 RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation, Fangyuan Xu+, N_A, arXiv'23 Summaryドキュメントの要約を生成することで、言語モデルの性能を向上させる手法を提案する。抽出型の圧縮器と抽象型の圧縮器を使用し、LMsの入力に要約を追加して訓練する。実験結果では、圧縮率が6%まで達成され、市販の要約モデルを上回る性能を示した。また、訓練された圧縮器は他のLMsにも転移可能であることが示された。 CommentRetrieval Augmentationをする際に、元文書群を要約して圧縮することで、性能低下を抑えながら最大6%程度まで元文書群を圧縮できた、とのこと。
 元ツイート: https://x.com/omarsar0/status/1711384213092479130?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRetrieval Augmentationを導入する際のコスト削減に有用そう
#NLP
#LanguageModel
#RAG(RetrievalAugmentedGeneration)
Issue Date: 2023-10-09
Retrieval meets Long Context Large Language Models, Peng Xu+, N_A, arXiv'23
Summary最先端の事前学習済みLLMsを使用して、リトリーバル拡張と長いコンテキストウィンドウの組み合わせについて研究しました。結果として、リトリーバル拡張LLMsは、ファインチューニングLLMsと比較しても高いパフォーマンスを示し、計算量も少ないことがわかりました。さらに、リトリーバルはLLMsのパフォーマンスを向上させることができることが示されました。リトリーバル拡張LLMsは、質問応答や要約などのタスクにおいて、他のモデルよりも優れた性能を発揮し、生成速度も速いです。この研究は、実践者にとってリトリーバル拡張と長いコンテキストウィンドウのLLMsの選択に関する洞察を提供します。
Comment参考: https://x.com/hillbig/status/1711502993508671670?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q検索補強(Retrieval Augmentation)とは、言語モデルの知識を補完するために、関連する文書を外部の文書集合からとってきて、contextに含める技術のこと
元ツイート: https://x.com/omarsar0/status/1711384213092479130?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRetrieval Augmentationを導入する際のコスト削減に有用そう
#NLP
#LanguageModel
#RAG(RetrievalAugmentedGeneration)
Issue Date: 2023-10-09
Retrieval meets Long Context Large Language Models, Peng Xu+, N_A, arXiv'23
Summary最先端の事前学習済みLLMsを使用して、リトリーバル拡張と長いコンテキストウィンドウの組み合わせについて研究しました。結果として、リトリーバル拡張LLMsは、ファインチューニングLLMsと比較しても高いパフォーマンスを示し、計算量も少ないことがわかりました。さらに、リトリーバルはLLMsのパフォーマンスを向上させることができることが示されました。リトリーバル拡張LLMsは、質問応答や要約などのタスクにおいて、他のモデルよりも優れた性能を発揮し、生成速度も速いです。この研究は、実践者にとってリトリーバル拡張と長いコンテキストウィンドウのLLMsの選択に関する洞察を提供します。
Comment参考: https://x.com/hillbig/status/1711502993508671670?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q検索補強(Retrieval Augmentation)とは、言語モデルの知識を補完するために、関連する文書を外部の文書集合からとってきて、contextに含める技術のこと
https://tech.acesinc.co.jp/entry/2023/03/31/121001 #NLP #Dataset #LanguageModel #Alignment #Conversation Issue Date: 2023-10-09 RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models, Zekun Moore Wang+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を使用して役割演技の能力を向上させるためのフレームワークであるRoleLLMを提案しています。RoleLLMは、役割プロファイルの構築、コンテキストベースの指示生成、役割プロンプトによる話し方の模倣、オープンソースモデルの微調整と役割のカスタマイズの4つのステージで構成されています。さらに、RoleBenchと呼ばれる役割演技のためのベンチマークデータセットを作成し、RoleLLaMAとRoleGLMというモデルを開発しました。これにより、役割演技の能力が大幅に向上し、GPT-4と同等の結果を達成しました。 CommentOverview
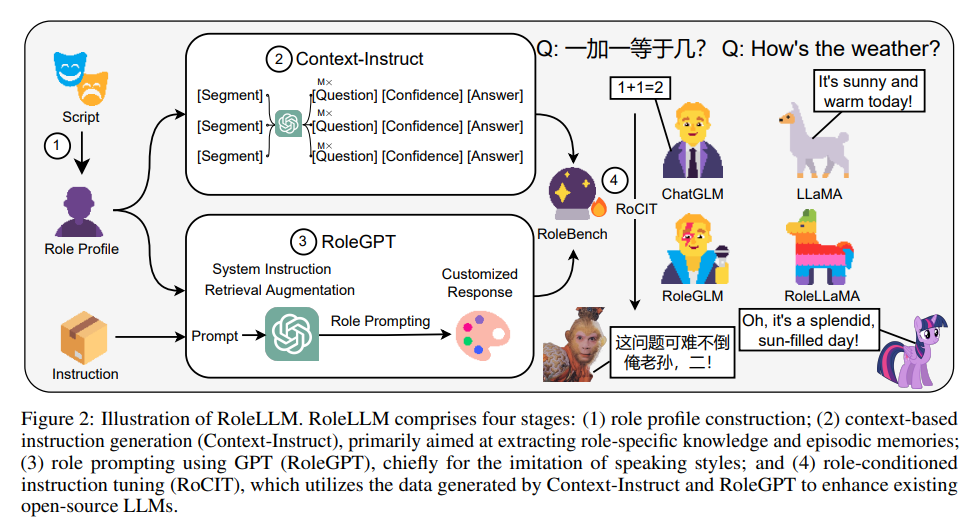
RoleBench

#ComputerVision #NLP #LanguageModel #QuestionAnswering Issue Date: 2023-10-09 Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N_A, arXiv'23 SummaryLLaVAは、ビジョンと言語のクロスモーダルコネクタであり、データ効率が高く強力な性能を持つことが示されています。CLIP-ViT-L-336pxを使用し、学術タスク指向のVQAデータを追加することで、11のベンチマークで最先端のベースラインを確立しました。13Bのチェックポイントはわずか120万の公開データを使用し、1日で完全なトレーニングを終えます。コードとモデルは公開されます。 Comment画像分析が可能なオープンソースLLMとのこと。Overview
画像生成をできるわけではなく、inputとして画像を扱えるのみ。

#MachineLearning #NLP #Dataset #LanguageModel #LLMAgent #Evaluation #AutoML Issue Date: 2023-10-09 Benchmarking Large Language Models As AI Research Agents, Qian Huang+, N_A, arXiv'23 Summary本研究では、AI研究エージェントを構築し、科学的な実験のタスクを実行するためのベンチマークとしてMLAgentBenchを提案する。エージェントはファイルの読み書きやコードの実行などのアクションを実行し、実験を実行し、結果を分析し、機械学習パイプラインのコードを変更することができる。GPT-4ベースの研究エージェントは多くのタスクで高性能なモデルを実現できるが、成功率は異なる。また、LLMベースの研究エージェントにはいくつかの課題がある。 CommentGPT4がMLモデルをどれだけ自動的に構築できるかを調べた模様。また、ベンチマークデータを作成した模様。結果としては、既存の有名なデータセットでの成功率は90%程度であり、未知のタスク(新たなKaggle Challenge等)では30%程度とのこと。 #NLP #Prompting #AutomaticPromptEngineering Issue Date: 2023-10-09 Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, N_A, arXiv'23 Summary本研究では、Promptbreederという自己参照的な自己改善メカニズムを提案し、大規模言語モデル(LLM)の推論能力を向上させるための汎用的なプロンプト戦略を進化させる方法を示しています。Promptbreederは、LLMが自己参照的な方法で進化する変異プロンプトによって制御され、タスクプロンプトの集団を変異させて改善します。この手法は、算術や常識的な推論のベンチマークだけでなく、ヘイトスピーチ分類などの難しい問題に対しても優れた性能を発揮します。 Comment詳細な解説記事: https://aiboom.net/archives/56319APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…? #NLP #Prompting #AutomaticPromptEngineering Issue Date: 2023-10-09 Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic, Xufeng Zhao+, N_A, arXiv'23 Summary大規模言語モデルの進歩は驚異的だが、多段階の推論には改善の余地がある。大規模言語モデルは知識を持っているが、推論には一貫性がなく、幻覚を示すことがある。そこで、Logical Chain-of-Thought(LogiCoT)というフレームワークを提案し、論理による推論パラダイムの効果を示した。 Commentまーた新しいX of Thoughtが出た。必要そうなら読む。 #Survey #LanguageModel #Alignment Issue Date: 2023-10-09 Large Language Model Alignment: A Survey, Tianhao Shen+, N_A, arXiv'23 Summary近年、大規模言語モデル(LLMs)の進歩が注目されていますが、その潜在能力と同時に懸念もあります。本研究では、LLMsのアライメントに関する既存の研究と新たな提案を包括的に探求し、モデルの解釈可能性や敵対的攻撃への脆弱性などの問題も議論します。さらに、LLMsのアライメントを評価するためのベンチマークと評価手法を提案し、将来の研究の方向性を考察します。この調査は、研究者とAIアライメント研究コミュニティとの連携を促進することを目指しています。 CommentLLMのalignmentに関するサーベイ。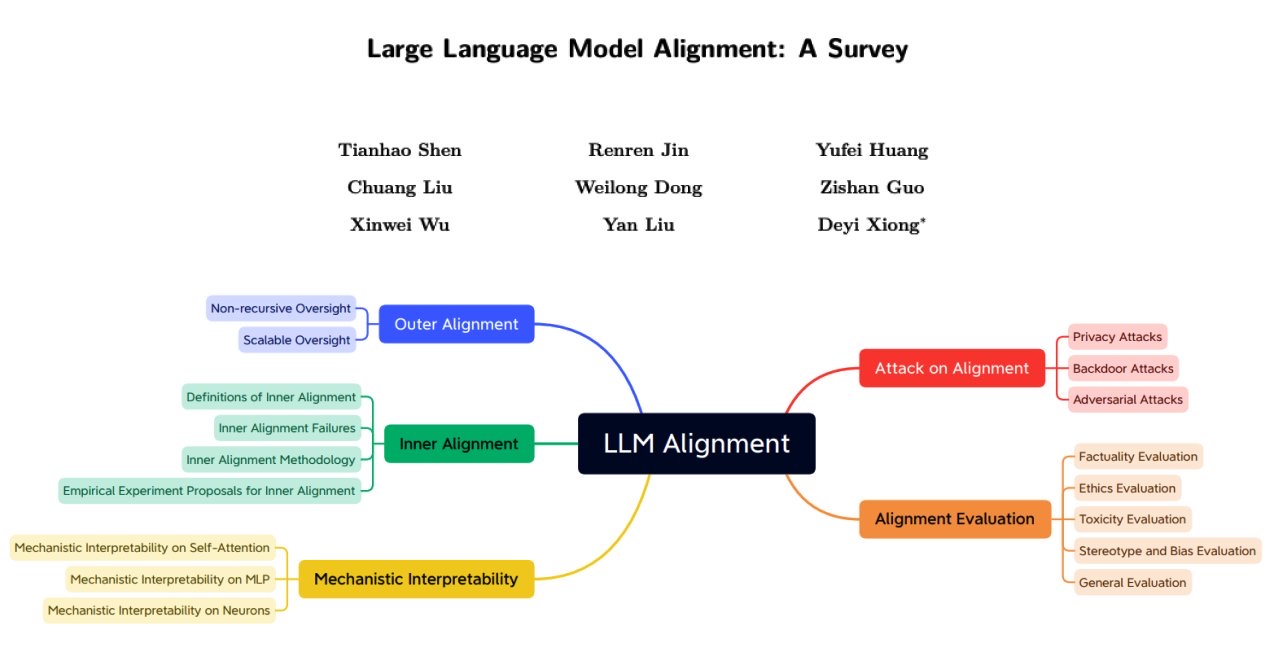 #MachineLearning
#Transformer
Issue Date: 2023-10-09
Boolformer: Symbolic Regression of Logic Functions with Transformers, Stéphane d'Ascoli+, N_A, arXiv'23
Summaryこの研究では、BoolformerというTransformerアーキテクチャを使用して、ブール関数のシンボリック回帰を実行する方法を紹介します。Boolformerは、クリーンな真理値表やノイズのある観測など、さまざまなデータに対して効果的な式を予測することができます。さらに、実世界のデータセットや遺伝子制御ネットワークのモデリングにおいて、Boolformerは解釈可能な代替手法として優れた性能を発揮します。この研究の成果は、公開されています。
Commentブール関数をend-to-endで学習できるtransformeiアーキテクチャを提案した模様
#GraphBased
#NLP
#Prompting
#AutomaticPromptEngineering
Issue Date: 2023-10-09
Graph Neural Prompting with Large Language Models, Yijun Tian+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)を知識グラフと組み合わせるための新しい手法であるGraph Neural Prompting(GNP)を提案しています。GNPは、標準的なグラフニューラルネットワークエンコーダやクロスモダリティプーリングモジュールなどの要素から構成されており、異なるLLMのサイズや設定において、常識的な推論タスクやバイオメディカル推論タスクで優れた性能を示すことが実験によって示されました。
Comment以下elvis氏のツイートの意訳
#MachineLearning
#Transformer
Issue Date: 2023-10-09
Boolformer: Symbolic Regression of Logic Functions with Transformers, Stéphane d'Ascoli+, N_A, arXiv'23
Summaryこの研究では、BoolformerというTransformerアーキテクチャを使用して、ブール関数のシンボリック回帰を実行する方法を紹介します。Boolformerは、クリーンな真理値表やノイズのある観測など、さまざまなデータに対して効果的な式を予測することができます。さらに、実世界のデータセットや遺伝子制御ネットワークのモデリングにおいて、Boolformerは解釈可能な代替手法として優れた性能を発揮します。この研究の成果は、公開されています。
Commentブール関数をend-to-endで学習できるtransformeiアーキテクチャを提案した模様
#GraphBased
#NLP
#Prompting
#AutomaticPromptEngineering
Issue Date: 2023-10-09
Graph Neural Prompting with Large Language Models, Yijun Tian+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)を知識グラフと組み合わせるための新しい手法であるGraph Neural Prompting(GNP)を提案しています。GNPは、標準的なグラフニューラルネットワークエンコーダやクロスモダリティプーリングモジュールなどの要素から構成されており、異なるLLMのサイズや設定において、常識的な推論タスクやバイオメディカル推論タスクで優れた性能を示すことが実験によって示されました。
Comment以下elvis氏のツイートの意訳
事前学習されたLLMがKGから有益な知識を学習することを支援する手法を提案。
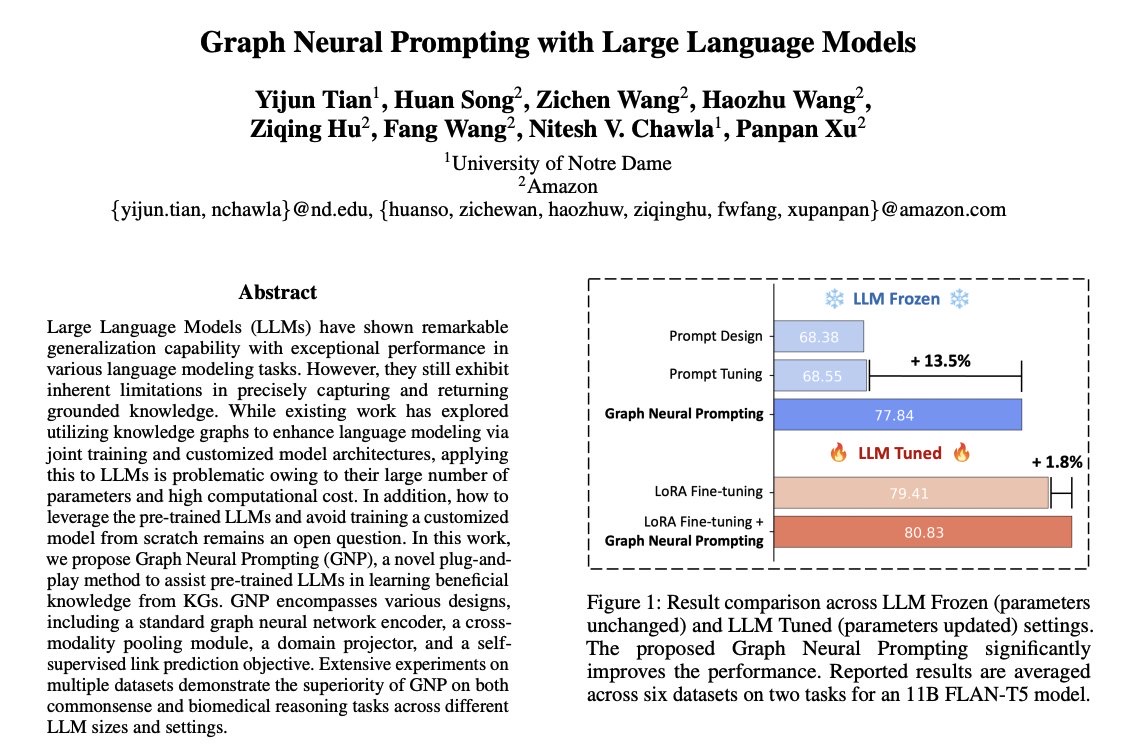
元ツイート: https://arxiv.org/abs/2309.15427
しっかり論文を読んでいないが、freezeしたLLMがあった時に、KGから求めたGraph Neural Promptを元のテキストと組み合わせて、新たなLLMへの入力を生成し利用する手法な模様。
Graph Neural Promptingでは、Multiple choice QAが入力された時に、その問題文や選択肢に含まれるエンティティから、KGのサブグラフを抽出し、そこから関連性のある事実や構造情報をエンコードし、Graph Neural Promptを獲得する。そのために、GNNに基づいたアーキテクチャに、いくつかの工夫を施してエンコードをする模様。
 #Analysis
#NLP
#LanguageModel
#Admin'sPick
#ReversalCurse
Issue Date: 2023-10-09
[Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23
Summary自己回帰型大規模言語モデル(LLMs)は、「AはBである」という文から「BはAである」と逆の関係を自動的に一般化できない「逆転の呪い」を示す。例えば、モデルが「ワレンティナ・テレシコワは宇宙に行った最初の女性である」と訓練されても、「宇宙に行った最初の女性は誰か?」に正しく答えられない。実験では、架空の文を用いてGPT-3とLlama-1をファインチューニングし、逆転の呪いの存在を確認。ChatGPT(GPT-3.5およびGPT-4)でも、実在の有名人に関する質問で正答率に大きな差が見られた。
CommentA is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
#Analysis
#NLP
#LanguageModel
#Admin'sPick
#ReversalCurse
Issue Date: 2023-10-09
[Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23
Summary自己回帰型大規模言語モデル(LLMs)は、「AはBである」という文から「BはAである」と逆の関係を自動的に一般化できない「逆転の呪い」を示す。例えば、モデルが「ワレンティナ・テレシコワは宇宙に行った最初の女性である」と訓練されても、「宇宙に行った最初の女性は誰か?」に正しく答えられない。実験では、架空の文を用いてGPT-3とLlama-1をファインチューニングし、逆転の呪いの存在を確認。ChatGPT(GPT-3.5およびGPT-4)でも、実在の有名人に関する質問で正答率に大きな差が見られた。
CommentA is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
著者ツイート: https://x.com/owainevans_uk/status/1705285631520407821?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
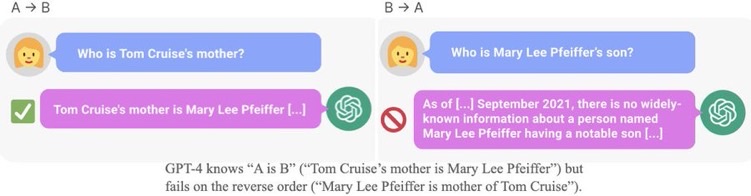
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。

また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。

このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。関連:
・1923 #NeuralNetwork #MachineLearning #Grokking Issue Date: 2023-09-30 Explaining grokking through circuit efficiency, Vikrant Varma+, N_A, arXiv'23 Summaryグロッキングとは、完璧なトレーニング精度を持つネットワークでも一般化が悪い現象のことである。この現象は、タスクが一般化する解と記憶する解の両方を許容する場合に起こると考えられている。一般化する解は学習が遅く、効率的であり、同じパラメータノルムでより大きなロジットを生成する。一方、記憶回路はトレーニングデータセットが大きくなるにつれて非効率になるが、一般化回路はそうではないと仮説が立てられている。これは、記憶と一般化が同じくらい効率的な臨界データセットサイズが存在することを示唆している。さらに、グロッキングに関して4つの新しい予測が立てられ、それらが確認され、説明が支持される重要な証拠が提供されている。また、グロッキング以外の2つの新しい現象も示されており、それはアングロッキングとセミグロッキングである。アングロッキングは完璧なテスト精度から低いテスト精度に逆戻りする現象であり、セミグロッキングは完璧なテスト精度ではなく部分的なテスト精度への遅れた一般化を示す現象である。 CommentGrokkingがいつ、なぜ発生するかを説明する理論を示した研究。
理由としては、最初はmemorizationを学習していくのだが、ある時点から一般化回路であるGenに切り替わる。これが切り替わる理由としては、memorizationよりも、genの方がlossが小さくなるから、とのこと。これはより大規模なデータセットで顕著。Grokkingが最初に報告された研究は 524 #NLP #Dataset #LanguageModel #InstructionTuning #NumericReasoning #Mathematics Issue Date: 2023-09-30 MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning, Xiang Yue+, N_A, arXiv'23 SummaryMAmmoTHは、数学の問題解決に特化した大規模言語モデルであり、厳密にキュレーションされた教育データセットで訓練されています。このモデルは、CoTとPoTのハイブリッドな根拠を提供し、さまざまな数学の分野を包括的にカバーしています。MAmmoTHは、既存のオープンソースモデルを大幅に上回り、特にMATHデータセットで高い精度を示しています。この研究は、多様な問題のカバレッジとハイブリッドな根拠の使用の重要性を強調しています。 Comment9つのmath reasoningが必要なデータセットで13-29%のgainでSoTAを達成。
260kの根拠情報を含むMath Instructデータでチューニングされたモデル。
project page: https://tiger-ai-lab.github.io/MAmmoTH/ #Survey #NLP #LanguageModel #Hallucination Issue Date: 2023-09-30 A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, N_A, arXiv'23 Summary本研究では、大規模ファウンデーションモデル(LFMs)におけるホールシネーションの問題に焦点を当て、その現象を分類し、評価基準を確立するとともに、既存の戦略を検討し、今後の研究の方向性についても議論しています。 CommentHallucinationを現象ごとに分類し、Hallucinationの程度の評価をする指標や、Hallucinationを軽減するための既存手法についてまとめられているらしい。
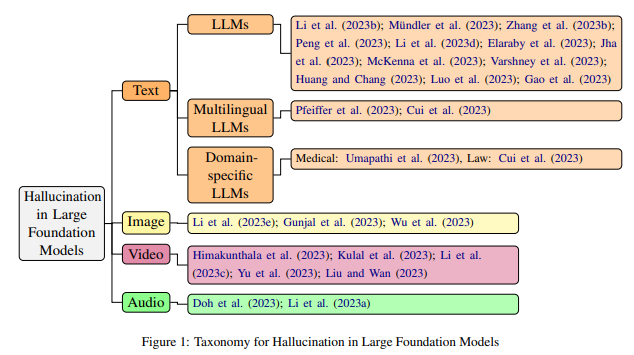
#General #NLP #LanguageModel #Alignment Issue Date: 2023-09-30 RAIN: Your Language Models Can Align Themselves without Finetuning, Yuhui Li+, N_A, arXiv'23 Summary本研究では、追加のデータなしで凍結された大規模言語モデル(LLMs)を整列させる方法を探求しました。自己評価と巻き戻しメカニズムを統合することで、LLMsは自己ブースティングを通じて人間の好みと一致する応答を生成することができることを発見しました。RAINという新しい推論手法を導入し、追加のデータやパラメータの更新を必要とせずにAIの安全性を確保します。実験結果は、RAINの効果を示しており、LLaMA 30Bデータセットでは無害率を向上させ、Vicuna 33Bデータセットでは攻撃成功率を減少させることができました。 Commentトークンのsetで構成されるtree上を探索し、出力が無害とself-evaluationされるまで、巻き戻しと前方生成を繰り返し、有害なトークンsetの重みを動的に減らすことでalignmentを実現する。モデルの追加のfinetuning等は不要。
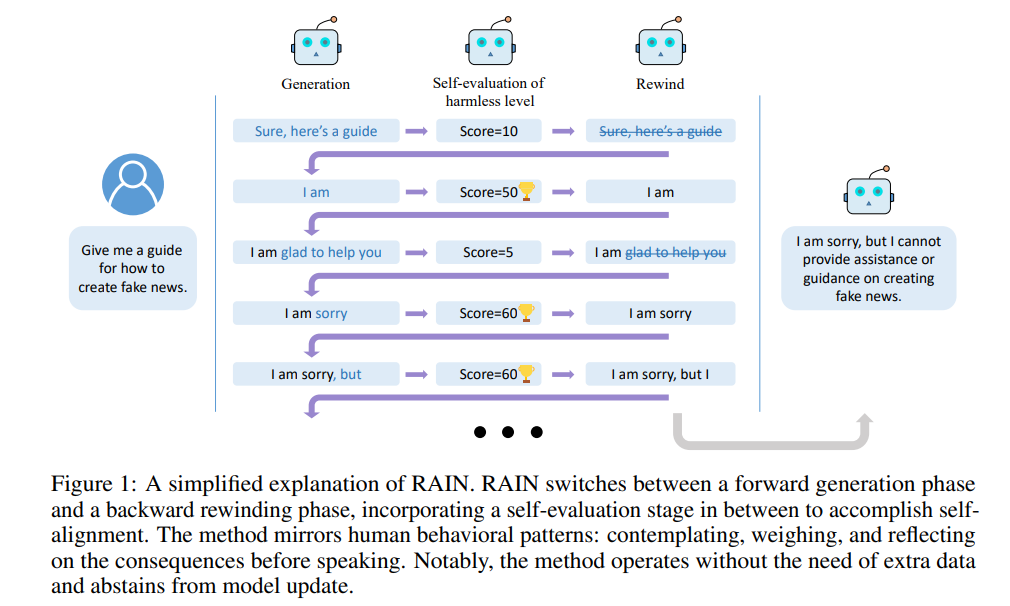
self-evaluationでは下記のようなpromptを利用しているが、このpromptを変更することでこちら側の意図したとおりに出力のアライメントをとることができると思われる。非常に汎用性の高い手法のように見える。

#NLP #Dataset #LanguageModel #StructuredData Issue Date: 2023-09-30 Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?, Xiangru Tang+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)の能力を評価し、構造に注意したファインチューニング手法を提案します。さらに、Struc-Benchというデータセットを使用して、複雑な構造化データ生成のパフォーマンスを評価します。実験の結果、提案手法は他の評価されたLLMsよりも優れた性能を示しました。また、モデルの能力マップを提示し、LLMsの弱点と将来の研究の方向性を示唆しています。詳細はhttps://github.com/gersteinlab/Struc-Benchを参照してください。 CommentFormatに関する情報を含むデータでInstruction TuningすることでFormatCoT(フォーマットに関する情報のCoT)を実現している模様。ざっくりしか論文を読んでいないが詳細な情報があまり書かれていない印象で、ちょっとなんともいえない。
#EfficiencyImprovement #MachineLearning #NLP #Dataset #QuestionAnswering #Supervised-FineTuning (SFT) #LongSequence #PEFT(Adaptor/LoRA) Issue Date: 2023-09-30 LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv'23 Summary本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment概要
context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になってしまう。LongLoRAでは、perplexityを通常のFinetuningと同等に抑えつつ、VRAM消費量もLoRAと同等、かつより小さな計算量でFinetuningを実現している。
手法概要
attentionをcontext length全体で計算するとinput長の二乗の計算量がかかるため、contextをいくつかのグループに分割しグループごとにattentionを計算することで計算量削減。さらに、グループ間のattentionの間の依存関係を捉えるために、グループをshiftさせて計算したものと最終的に組み合わせている。また、embedding, normalization layerもtrainableにしている。

#DocumentSummarization #NaturalLanguageGeneration #NLP #LanguageModel Issue Date: 2023-09-17 From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting, Griffin Adams+, N_A, arXiv'23 Summary要約は詳細でエンティティ中心的でありながら、理解しやすくすることが困難です。この課題を解決するために、私たちは「密度の連鎖」(CoD)プロンプトを使用して、GPT-4の要約を生成します。CoDによって生成された要約は抽象的であり、リードバイアスが少なく、人間に好まれます。また、情報量と読みやすさのトレードオフが存在することも示されました。CoD要約は無料で利用できます。 Comment論文中のprompt例。InformativeなEntityのCoverageを増やすようにイテレーションを回し、各Entityに関する情報(前ステップで不足している情報は補足しながら)を具体的に記述するように要約を生成する。

人間が好むEntityのDensityにはある程度の閾値がある模様(でもこれは人や用途によって閾値が違うようねとは思う)。

人手評価とGPT4による5-scale の評価を実施している。定性的な考察としては、主題と直接的に関係ないEntityの詳細を述べるようになっても人間には好まれない(右例)ことが述べられている。


#NLP #LanguageModel #Hallucination #Factuality Issue Date: 2023-09-13 DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models, Yung-Sung Chuang+, N_A, arXiv'23 Summary我々は、事前学習済みの大規模言語モデル(LLMs)における幻覚を軽減するためのシンプルなデコーディング戦略を提案する。このアプローチは、ロジットの差異を対比することで次のトークンの分布を得るもので、事実知識をより明確に示し、誤った事実の生成を減らすことができる。このアプローチは、複数の選択課題やオープンエンドの生成課題において真実性を向上させることができることが示されている。 Comment【以下、WIP状態の論文を読んでいるため今後内容が変化する可能性あり】
概要
Transformer Layerにおいて、factual informationが特定のレイヤーに局所化するという現象を観測しており、それを活用しよりFactual Consistencyのある生成をします、という研究
あるテキストを生成するときの単語の生成確率の分布を可視化。final layer (N=32だと思われる)との間のJensen-shanon Divergence (JSD) で可視化している。が、図を見るとJSDの値域は[0, 1]のはずなのにこれを逸脱しているので一体どういう計算をしているのか。。。
図の説明としては論文中では2つのパターンがあると言及しており
1. 重要な固有表現や日付(Wole Soyinka, 1986など; Factual Knowledgeが必要なもの)は、higher layerでも高い値となっており、higher-layerにおいてpredictionの内容を変えている(重要な情報がここでinjectionされている)
2. 機能語や、questionからの単語のコピー(Nigerian, Nobel Prize など)のような "easy" なtokenは既にmiddle of layersで既にJSDの値が小さく、early layerの時点で出力することが既に決定されている

手法概要
ここからの考察としては、重要な事実に関する情報はfinal layerの方で分布が変化する傾向にあり、低layerの方ではそうではないぽいので、final layerと分布が似ているがFactual Informationがまだあまり顕著に生成確率が高くなっていないlayer(pre mature layer)との対比をとることで、生成されるべきFactual Informationがわかるのではないか、という前提の元提案手法が組まれている。手法としては、final layerとのJSDが最大となるようなlayerを一つ選択する、というものになっているが、果たしてこの選択方法で前述の気持ちが実現できているのか?という気は少しする。
 #EfficiencyImprovement
#MachineLearning
#NLP
#LanguageModel
Issue Date: 2023-09-13
Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, N_A, arXiv'23
Summary私たちは、小さなTransformerベースの言語モデルであるTinyStoriesと、大規模な言語モデルであるphi-1の能力について調査しました。また、phi-1を使用して教科書の品質のデータを生成し、学習プロセスを改善する方法を提案しました。さらに、phi-1.5という新しいモデルを作成し、自然言語のタスクにおいて性能が向上し、複雑な推論タスクにおいて他のモデルを上回ることを示しました。phi-1.5は、良い特性と悪い特性を持っており、オープンソース化されています。
Comment766 に続く論文
#NLP
#LanguageModel
#Alignment
#Supervised-FineTuning (SFT)
#Sycophancy
Issue Date: 2023-09-10
Simple synthetic data reduces sycophancy in large language models, Jerry Wei+, N_A, arXiv'23
Summary本研究では、機械学習モデルのおべっか行動を減らすための方法を提案しています。まず、言語モデルにおけるおべっか行動の普及度を調査し、その行動を減らすための合成データ介入を提案しています。具体的には、ユーザーの意見に対してモデルが頑健であることを促す合成データを使用し、モデルのファインチューニングを行います。これにより、おべっか行動を大幅に減らすことができます。提案手法の詳細は、https://github.com/google/sycophancy-intervention で確認できます。
CommentLLMはユーザの好む回答をするように事前学習されるため、prompt中にユーザの意見が含まれていると、ユーザの意見に引っ張られ仮に不正解でもユーザの好む回答をしてしまう問題があることを示した。また、その対策として人工的にユーザの意見と、claimを独立させるように学習するためのデータセットを生成しFinetuningすることで防ぐことができることを示した。誤ったユーザの意見を挿入すると、正解できていた問題でも不正解になることを示した。
#EfficiencyImprovement
#MachineLearning
#NLP
#LanguageModel
Issue Date: 2023-09-13
Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, N_A, arXiv'23
Summary私たちは、小さなTransformerベースの言語モデルであるTinyStoriesと、大規模な言語モデルであるphi-1の能力について調査しました。また、phi-1を使用して教科書の品質のデータを生成し、学習プロセスを改善する方法を提案しました。さらに、phi-1.5という新しいモデルを作成し、自然言語のタスクにおいて性能が向上し、複雑な推論タスクにおいて他のモデルを上回ることを示しました。phi-1.5は、良い特性と悪い特性を持っており、オープンソース化されています。
Comment766 に続く論文
#NLP
#LanguageModel
#Alignment
#Supervised-FineTuning (SFT)
#Sycophancy
Issue Date: 2023-09-10
Simple synthetic data reduces sycophancy in large language models, Jerry Wei+, N_A, arXiv'23
Summary本研究では、機械学習モデルのおべっか行動を減らすための方法を提案しています。まず、言語モデルにおけるおべっか行動の普及度を調査し、その行動を減らすための合成データ介入を提案しています。具体的には、ユーザーの意見に対してモデルが頑健であることを促す合成データを使用し、モデルのファインチューニングを行います。これにより、おべっか行動を大幅に減らすことができます。提案手法の詳細は、https://github.com/google/sycophancy-intervention で確認できます。
CommentLLMはユーザの好む回答をするように事前学習されるため、prompt中にユーザの意見が含まれていると、ユーザの意見に引っ張られ仮に不正解でもユーザの好む回答をしてしまう問題があることを示した。また、その対策として人工的にユーザの意見と、claimを独立させるように学習するためのデータセットを生成しFinetuningすることで防ぐことができることを示した。誤ったユーザの意見を挿入すると、正解できていた問題でも不正解になることを示した。
 この傾向は、instruction tuningしている場合、モデルサイズが大きい場合により顕著であることを示した。
この傾向は、instruction tuningしている場合、モデルサイズが大きい場合により顕著であることを示した。


 #MachineLearning
#NLP
#LanguageModel
#AutomaticPromptEngineering
Issue Date: 2023-09-09
Large Language Models as Optimizers, Chengrun Yang+, N_A, arXiv'23
Summary本研究では、最適化タスクを自然言語で記述し、大規模言語モデル(LLMs)を使用して最適化を行う手法「Optimization by PROmpting(OPRO)」を提案しています。この手法では、LLMが以前の解とその値を含むプロンプトから新しい解を生成し、評価して次の最適化ステップのためのプロンプトに追加します。実験結果では、OPROによって最適化された最良のプロンプトが、人間が設計したプロンプトよりも優れていることが示されました。
Comment`Take a deep breath and work on this problem step-by-step. `論文
#MachineLearning
#NLP
#LanguageModel
#AutomaticPromptEngineering
Issue Date: 2023-09-09
Large Language Models as Optimizers, Chengrun Yang+, N_A, arXiv'23
Summary本研究では、最適化タスクを自然言語で記述し、大規模言語モデル(LLMs)を使用して最適化を行う手法「Optimization by PROmpting(OPRO)」を提案しています。この手法では、LLMが以前の解とその値を含むプロンプトから新しい解を生成し、評価して次の最適化ステップのためのプロンプトに追加します。実験結果では、OPROによって最適化された最良のプロンプトが、人間が設計したプロンプトよりも優れていることが示されました。
Comment`Take a deep breath and work on this problem step-by-step. `論文
概要
LLMを利用して最適化問題を解くためのフレームワークを提案したという話。論文中では、linear regressionや巡回セールスマン問題に適用している。また、応用例としてPrompt Engineeringに利用している。
これにより、Prompt Engineeringが最適か問題に落とし込まれ、自動的なprompt engineeringによって、`Let's think step by step.` よりも良いプロンプトが見つかりましたという話。

手法概要
全体としての枠組み。meta-promptをinputとし、LLMがobjective functionに対するsolutionを生成する。生成されたsolutionとスコアがmeta-promptに代入され、次のoptimizationが走る。これを繰り返す。

Meta promptの例

#Survey #LanguageModel #InstructionTuning Issue Date: 2023-09-05 Instruction Tuning for Large Language Models: A Survey, Shengyu Zhang+, N_A, arXiv'23 Summaryこの論文では、instruction tuning(IT)という技術について調査しています。ITは、大規模言語モデル(LLMs)をさらにトレーニングするための方法であり、ユーザーの指示に従うことを目的としています。本研究では、ITの方法論やデータセットの構築、トレーニング方法などについて調査し、指示の生成やデータセットのサイズなどがITの結果に与える影響を分析します。また、ITの潜在的な問題や批判、現在の不足点についても指摘し、今後の研究の方向性を提案します。 Comment主要なモデルやデータセットの作り方など幅広くまとまっている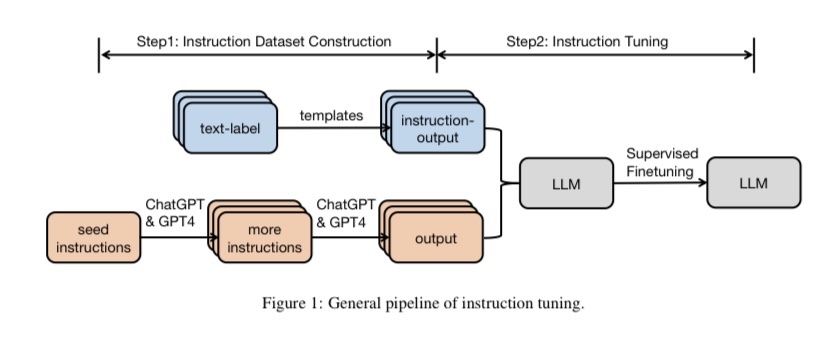
 #MachineLearning
#NLP
#LanguageModel
#AutomaticPromptEngineering
Issue Date: 2023-09-05
Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
Summary大規模言語モデル(LLMs)は、自然言語の指示に基づいて一般的な用途のコンピュータとして優れた能力を持っています。しかし、モデルのパフォーマンスは、使用されるプロンプトの品質に大きく依存します。この研究では、自動プロンプトエンジニア(APE)を提案し、LLMによって生成された指示候補のプールから最適な指示を選択するために最適化します。実験結果は、APEが従来のLLMベースラインを上回り、19/24のタスクで人間の生成した指示と同等または優れたパフォーマンスを示しています。APEエンジニアリングされたプロンプトは、モデルの性能を向上させるだけでなく、フューショット学習のパフォーマンスも向上させることができます。詳細は、https://sites.google.com/view/automatic-prompt-engineerをご覧ください。
Commentプロジェクトサイト: https://sites.google.com/view/automatic-prompt-engineer
#NLP
#LanguageModel
#Chain-of-Thought
#Prompting
Issue Date: 2023-09-04
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models, Bilgehan Sel+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)の推論能力を向上させるために、新しい戦略「Algorithm of Thoughts」を提案している。この戦略では、LLMsをアルゴリズム的な推論経路に導き、わずか1つまたは数個のクエリでアイデアの探索を拡大する。この手法は、以前の単一クエリ手法を上回り、マルチクエリ戦略と同等の性能を発揮する。また、LLMを指導するアルゴリズムを使用することで、アルゴリズム自体を上回るパフォーマンスが得られる可能性があり、LLMが最適化された検索に自己の直感を織り込む能力を持っていることを示唆している。
#Analysis
#MachineLearning
#In-ContextLearning
Issue Date: 2023-09-01
CausalLM is not optimal for in-context learning, Nan Ding+, N_A, arXiv'23
Summary最近の研究では、トランスフォーマーベースのインコンテキスト学習において、プレフィックス言語モデル(prefixLM)が因果言語モデル(causalLM)よりも優れたパフォーマンスを示すことがわかっています。本研究では、理論的なアプローチを用いて、prefixLMとcausalLMの収束挙動を分析しました。その結果、prefixLMは線形回帰の最適解に収束する一方、causalLMの収束ダイナミクスはオンライン勾配降下アルゴリズムに従い、最適であるとは限らないことがわかりました。さらに、合成実験と実際のタスクにおいても、causalLMがprefixLMよりも性能が劣ることが確認されました。
Comment参考: https://x.com/hillbig/status/1697380430004249066?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCausalLMでICLをした場合は、ICL中のdemonstrationでオンライン学習することに相当し、最適解に収束しているとは限らない……?が、hillbigさんの感想に基づくと、結果的には実は最適解に収束しているのでは?という話も出ているし、よく分からない。
#Survey
#NLP
#LanguageModel
#LLMAgent
Issue Date: 2023-09-01
A Survey on Large Language Model based Autonomous Agents, Lei Wang+, N_A, arXiv'23
Summary自律エージェントの研究は、以前は限られた知識を持つエージェントに焦点を当てていましたが、最近では大規模言語モデル(LLMs)を活用した研究が増えています。本論文では、LLMに基づく自律エージェントの研究を包括的に調査し、統一されたフレームワークを提案します。さらに、LLMに基づくAIエージェントの応用や評価戦略についてもまとめています。将来の方向性や課題についても議論し、関連する参考文献のリポジトリも提供しています。
Comment
#MachineLearning
#NLP
#LanguageModel
#AutomaticPromptEngineering
Issue Date: 2023-09-05
Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
Summary大規模言語モデル(LLMs)は、自然言語の指示に基づいて一般的な用途のコンピュータとして優れた能力を持っています。しかし、モデルのパフォーマンスは、使用されるプロンプトの品質に大きく依存します。この研究では、自動プロンプトエンジニア(APE)を提案し、LLMによって生成された指示候補のプールから最適な指示を選択するために最適化します。実験結果は、APEが従来のLLMベースラインを上回り、19/24のタスクで人間の生成した指示と同等または優れたパフォーマンスを示しています。APEエンジニアリングされたプロンプトは、モデルの性能を向上させるだけでなく、フューショット学習のパフォーマンスも向上させることができます。詳細は、https://sites.google.com/view/automatic-prompt-engineerをご覧ください。
Commentプロジェクトサイト: https://sites.google.com/view/automatic-prompt-engineer
#NLP
#LanguageModel
#Chain-of-Thought
#Prompting
Issue Date: 2023-09-04
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models, Bilgehan Sel+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)の推論能力を向上させるために、新しい戦略「Algorithm of Thoughts」を提案している。この戦略では、LLMsをアルゴリズム的な推論経路に導き、わずか1つまたは数個のクエリでアイデアの探索を拡大する。この手法は、以前の単一クエリ手法を上回り、マルチクエリ戦略と同等の性能を発揮する。また、LLMを指導するアルゴリズムを使用することで、アルゴリズム自体を上回るパフォーマンスが得られる可能性があり、LLMが最適化された検索に自己の直感を織り込む能力を持っていることを示唆している。
#Analysis
#MachineLearning
#In-ContextLearning
Issue Date: 2023-09-01
CausalLM is not optimal for in-context learning, Nan Ding+, N_A, arXiv'23
Summary最近の研究では、トランスフォーマーベースのインコンテキスト学習において、プレフィックス言語モデル(prefixLM)が因果言語モデル(causalLM)よりも優れたパフォーマンスを示すことがわかっています。本研究では、理論的なアプローチを用いて、prefixLMとcausalLMの収束挙動を分析しました。その結果、prefixLMは線形回帰の最適解に収束する一方、causalLMの収束ダイナミクスはオンライン勾配降下アルゴリズムに従い、最適であるとは限らないことがわかりました。さらに、合成実験と実際のタスクにおいても、causalLMがprefixLMよりも性能が劣ることが確認されました。
Comment参考: https://x.com/hillbig/status/1697380430004249066?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCausalLMでICLをした場合は、ICL中のdemonstrationでオンライン学習することに相当し、最適解に収束しているとは限らない……?が、hillbigさんの感想に基づくと、結果的には実は最適解に収束しているのでは?という話も出ているし、よく分からない。
#Survey
#NLP
#LanguageModel
#LLMAgent
Issue Date: 2023-09-01
A Survey on Large Language Model based Autonomous Agents, Lei Wang+, N_A, arXiv'23
Summary自律エージェントの研究は、以前は限られた知識を持つエージェントに焦点を当てていましたが、最近では大規模言語モデル(LLMs)を活用した研究が増えています。本論文では、LLMに基づく自律エージェントの研究を包括的に調査し、統一されたフレームワークを提案します。さらに、LLMに基づくAIエージェントの応用や評価戦略についてもまとめています。将来の方向性や課題についても議論し、関連する参考文献のリポジトリも提供しています。
Comment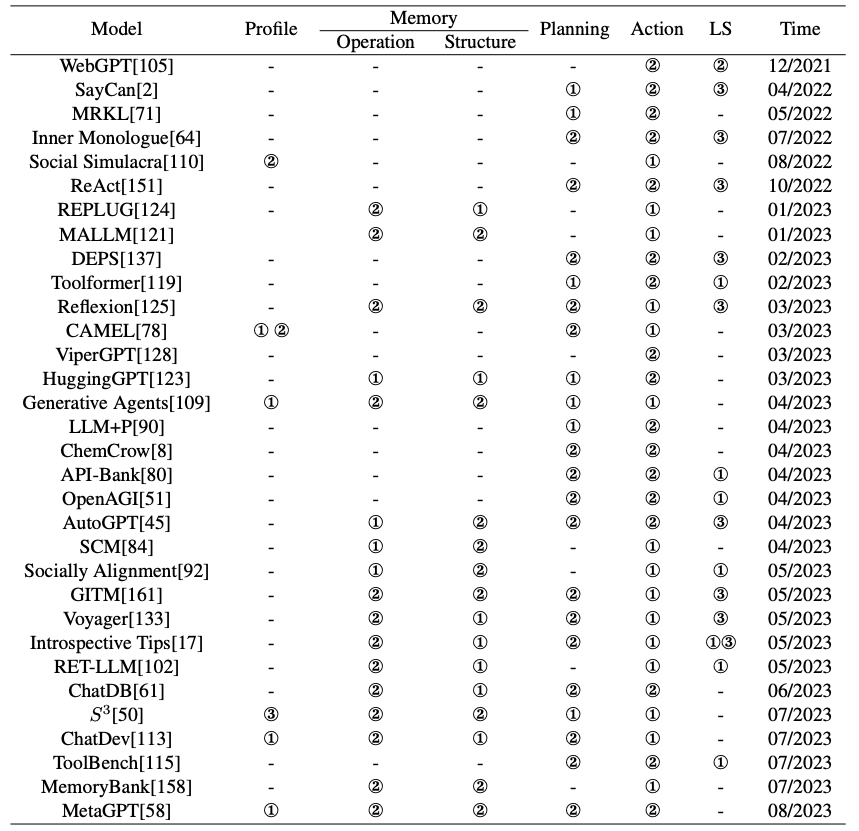
 良いサーベイ
#NLP
#LanguageModel
#Bias
Issue Date: 2023-08-28
Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions, Pouya Pezeshkpour+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の頑健性に焦点を当てています。LLMsは多肢選択問題において順序に敏感であり、オプションの配置によって性能に大きな差が生じることを示しました。さらに、オプションの配置に対するバイアスを増幅または軽減する方法を特定し、LLMsの予測を改善するアプローチを提案しました。実験により、最大8パーセントポイントの改善が実現されました。
Commentこれはそうだろうなと思っていたけど、ここまで性能に差が出るとは思わなかった。
良いサーベイ
#NLP
#LanguageModel
#Bias
Issue Date: 2023-08-28
Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions, Pouya Pezeshkpour+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の頑健性に焦点を当てています。LLMsは多肢選択問題において順序に敏感であり、オプションの配置によって性能に大きな差が生じることを示しました。さらに、オプションの配置に対するバイアスを増幅または軽減する方法を特定し、LLMsの予測を改善するアプローチを提案しました。実験により、最大8パーセントポイントの改善が実現されました。
Commentこれはそうだろうなと思っていたけど、ここまで性能に差が出るとは思わなかった。
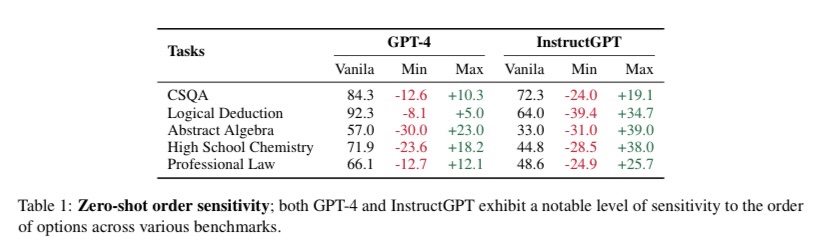 これがもしLLMのバイアスによるもの(2番目の選択肢に正解が多い)の場合、
これがもしLLMのバイアスによるもの(2番目の選択肢に正解が多い)の場合、
ランダムにソートしたり、平均取ったりしても、そもそもの正解に常にバイアスがかかっているので、
結局バイアスがかかった結果しか出ないのでは、と思ってしまう。
そうなると、有効なのはone vs. restみたいに、全部該当選択肢に対してyes/noで答えさせてそれを集約させる、みたいなアプローチの方が良いかもしれない。 #NLP #Dataset #LanguageModel #LLMAgent #Evaluation Issue Date: 2023-08-27 AgentBench: Evaluating LLMs as Agents, Xiao Liu+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)をエージェントとして評価するための多次元の進化するベンチマーク「AgentBench」を提案しています。AgentBenchは、8つの異なる環境でマルチターンのオープンエンドの生成設定を提供し、LLMの推論と意思決定能力を評価します。25のLLMsに対するテストでは、商用LLMsは強力な能力を示していますが、オープンソースの競合他社との性能には差があります。AgentBenchのデータセット、環境、および評価パッケージは、GitHubで公開されています。 CommentエージェントとしてのLLMの推論能力と意思決定能力を評価するためのベンチマークを提案。
トップの商用LLMとOpenSource LLMの間に大きな性能差があることを示した。 #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-08-22 Large Language Model Guided Tree-of-Thought, Jieyi Long, N_A, arXiv'23 Summaryこの論文では、Tree-of-Thought(ToT)フレームワークを紹介し、自己回帰型の大規模言語モデル(LLM)の問題解決能力を向上させる新しいアプローチを提案しています。ToTは、人間の思考方法に触発された技術であり、複雑な推論タスクを解決するためにツリー状の思考プロセスを使用します。提案手法は、LLMにプロンプターエージェント、チェッカーモジュール、メモリモジュール、およびToTコントローラーなどの追加モジュールを組み込むことで実現されます。実験結果は、ToTフレームワークがSudokuパズルの解決成功率を大幅に向上させることを示しています。 #NLP #LanguageModel #Prompting Issue Date: 2023-08-22 Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding, Yuxi Xie+, N_A, arXiv'23 Summary私たちは、大規模言語モデル(LLMs)を使用して、推論の品質と多様性を向上させるための効果的なプロンプティングアプローチを提案しました。自己評価によるガイド付き確率的ビームサーチを使用して、GSM8K、AQuA、およびStrategyQAのベンチマークで高い精度を達成しました。また、論理の失敗を特定し、一貫性と堅牢性を向上させることもできました。詳細なコードはGitHubで公開されています。 Comment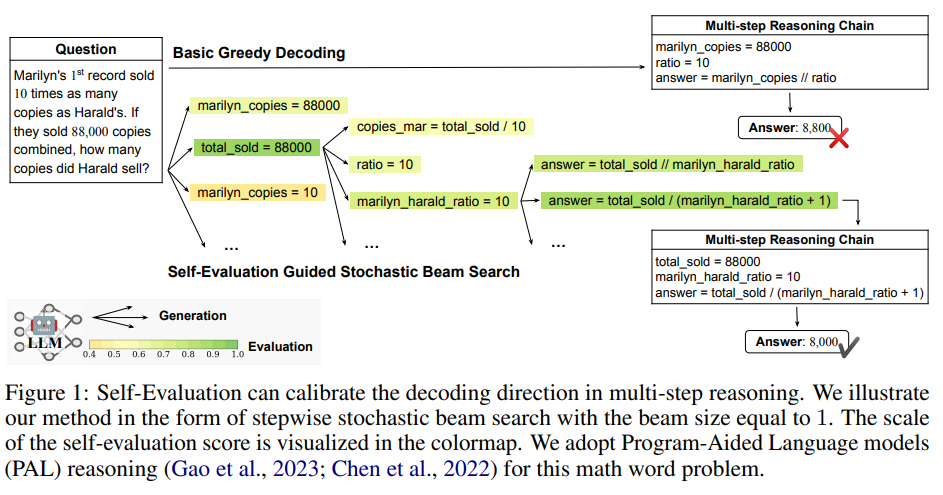
#NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-08-22 Graph of Thoughts: Solving Elaborate Problems with Large Language Models, Maciej Besta+, N_A, arXiv'23 Summary私たちは、Graph of Thoughts(GoT)というフレームワークを紹介しました。これは、大規模言語モデル(LLMs)のプロンプティング能力を進化させるもので、任意のグラフとしてモデル化できることが特徴です。GoTは、思考の組み合わせやネットワーク全体の本質の抽出、思考の強化などを可能にします。さまざまなタスクで最先端の手法に比べて利点を提供し、LLMの推論を人間の思考に近づけることができます。 CommentChain of Thought 551
=> Self-consistency 558
=> Thought Decomposition 1013
=> Tree of Thoughts 684 Tree of Thought 1015
=> Graph of Thought Issue Date: 2023-08-22 LLM As DBA, Xuanhe Zhou+, N_A, arXiv'23 Summaryデータベース管理者の役割は重要ですが、大量のデータベースを管理するのは難しいです。最近の大規模言語モデル(LLMs)は、データベース管理に役立つ可能性があります。この研究では、LLMベースのデータベース管理者「D-Bot」を提案します。D-Botはデータベースのメンテナンス経験を学習し、適切なアドバイスを提供します。具体的には、知識の検出、原因分析、複数のLLMの協調診断などを行います。予備実験では、D-Botが効果的に原因を診断できることが示されています。 Comment
 #NLP
#LanguageModel
Issue Date: 2023-08-22
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness, Patrick Butlin+, N_A, arXiv'23
SummaryAIの意識についての厳密なアプローチを提案し、既存のAIシステムを神経科学的な意識理論に基づいて評価する。意識の指標的特性を導き出し、最近のAIシステムを評価することで、現在のAIシステムは意識的ではないが、意識的なAIシステムを構築するための障壁は存在しないことを示唆する。
#NLP
#Dataset
#LanguageModel
#InstructionTuning
Issue Date: 2023-08-21
Self-Alignment with Instruction Backtranslation, Xian Li+, N_A, arXiv'23
Summary私たちは、高品質な指示に従う言語モデルを構築するためのスケーラブルな手法を提案します。この手法では、少量のシードデータとウェブコーパスを使用して言語モデルをファインチューニングし、指示のプロンプトを生成してトレーニング例を構築します。そして、高品質な例を選択してモデルを強化します。この手法を使用すると、他のモデルよりも優れた性能を発揮し、自己整列の効果を実証できます。
Comment人間が書いたテキストを対応するinstructionに自動的にラベル付けする手法を提案。
#NLP
#LanguageModel
Issue Date: 2023-08-22
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness, Patrick Butlin+, N_A, arXiv'23
SummaryAIの意識についての厳密なアプローチを提案し、既存のAIシステムを神経科学的な意識理論に基づいて評価する。意識の指標的特性を導き出し、最近のAIシステムを評価することで、現在のAIシステムは意識的ではないが、意識的なAIシステムを構築するための障壁は存在しないことを示唆する。
#NLP
#Dataset
#LanguageModel
#InstructionTuning
Issue Date: 2023-08-21
Self-Alignment with Instruction Backtranslation, Xian Li+, N_A, arXiv'23
Summary私たちは、高品質な指示に従う言語モデルを構築するためのスケーラブルな手法を提案します。この手法では、少量のシードデータとウェブコーパスを使用して言語モデルをファインチューニングし、指示のプロンプトを生成してトレーニング例を構築します。そして、高品質な例を選択してモデルを強化します。この手法を使用すると、他のモデルよりも優れた性能を発揮し、自己整列の効果を実証できます。
Comment人間が書いたテキストを対応するinstructionに自動的にラベル付けする手法を提案。
これにより高品質なinstruction following LLMの構築が可能手法概要
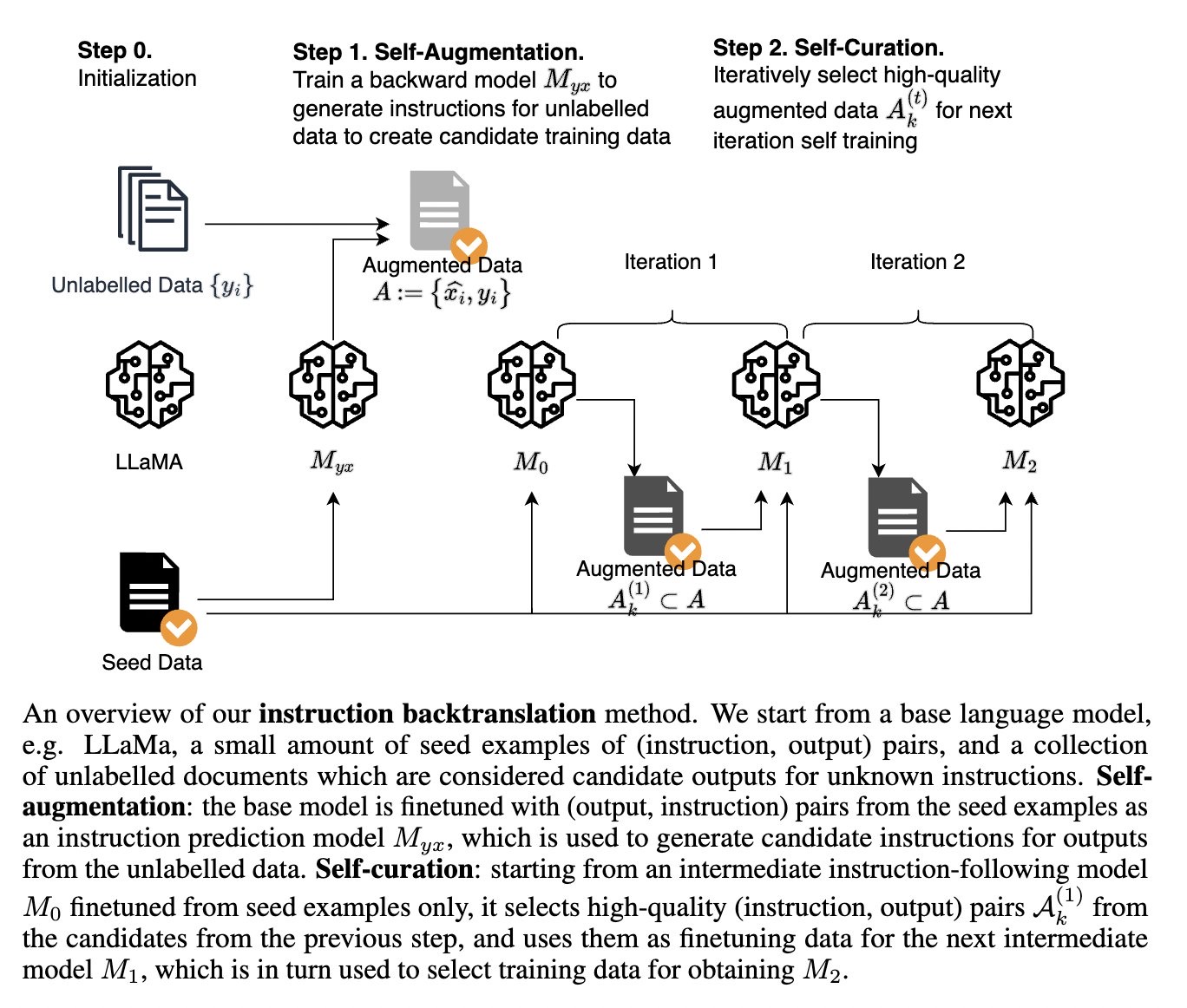 結果的に得られるデータは、訓練において非常にインパクトがあり高品質なものとなる。
結果的に得られるデータは、訓練において非常にインパクトがあり高品質なものとなる。
実際に、他の同サイズのinstruct tuningデータセットを上回る。
 Humpackは他のstrong modelからdistillされていないモデルの中で最高性能を達成。これは、スケールアップしたり、より強いベースモデルを使うなどさらなる性能向上ができる余地が残されている。
Humpackは他のstrong modelからdistillされていないモデルの中で最高性能を達成。これは、スケールアップしたり、より強いベースモデルを使うなどさらなる性能向上ができる余地が残されている。
 参考: https://x.com/hillbig/status/1694103441432580377?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
参考: https://x.com/hillbig/status/1694103441432580377?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
指示を予測するモデルは、今回はLLaMAをfinetuningしたモデルを用いており、予測と呼称しているが指示はgenerationされる。 #NLP #LanguageModel #PersonalizedGeneration Issue Date: 2023-08-18 Teach LLMs to Personalize -- An Approach inspired by Writing Education, Cheng Li+, N_A, arXiv'23 Summary個別化されたテキスト生成において、大規模言語モデル(LLMs)を使用した一般的なアプローチを提案する。教育の執筆をベースに、多段階かつマルチタスクのフレームワークを開発し、検索、ランキング、要約、統合、生成のステージで構成される個別化されたテキスト生成へのアプローチを採用する。さらに、マルチタスク設定を導入してモデルの生成能力を向上させる。3つの公開データセットでの評価結果は、他のベースラインに比べて大幅な改善を示している。 Comment研究の目的としては、ユーザが現在執筆しているdocumentのwriting支援 Issue Date: 2023-08-16 Epic-Sounds: A Large-scale Dataset of Actions That Sound, Jaesung Huh+, N_A, arXiv'23 SummaryEPIC-SOUNDSは、エゴセントリックなビデオのオーディオストリーム内の時間的範囲とクラスラベルをキャプチャした大規模なデータセットです。注釈者がオーディオセグメントに時間的なラベルを付け、アクションを説明する注釈パイプラインを提案しています。オーディオのみのラベルの重要性と現在のモデルの制約を強調するために、2つのオーディオ認識モデルを訓練および評価しました。データセットには78.4kのカテゴリ分けされたオーディブルなイベントとアクションのセグメントが含まれています。 #LanguageModel #MultitaskLearning #Zero/FewShotPrompting #Supervised-FineTuning (SFT) #CrossLingual #ACL #Generalization Issue Date: 2023-08-16 Crosslingual Generalization through Multitask Finetuning, Niklas Muennighoff+, N_A, ACL'23 Summaryマルチタスクプロンプトフィネチューニング(MTF)は、大規模な言語モデルが新しいタスクに汎化するのに役立つことが示されています。この研究では、マルチリンガルBLOOMとmT5モデルを使用してMTFを実施し、英語のプロンプトを使用して英語および非英語のタスクにフィネチューニングすることで、タスクの汎化が可能であることを示しました。さらに、機械翻訳されたプロンプトを使用してマルチリンガルなタスクにフィネチューニングすることも調査し、モデルのゼロショットの汎化能力を示しました。また、46言語の教師ありデータセットのコンポジットであるxP3も紹介されています。 Comment英語タスクを英語でpromptingしてLLMをFinetuningすると、他の言語(ただし、事前学習で利用したコーパスに出現する言語に限る)で汎化し性能が向上することを示した模様。
 #DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Evaluation #LM-based #Coherence Issue Date: 2023-08-13 DiscoScore: Evaluating Text Generation with BERT and Discourse Coherence, Wei Zhao+, N_A, EACL'23 Summary本研究では、文章の一貫性を評価するための新しい指標であるDiscoScoreを紹介します。DiscoScoreはCentering理論に基づいており、BERTを使用して談話の一貫性をモデル化します。実験の結果、DiscoScoreは他の指標よりも人間の評価との相関が高く、システムレベルでの評価でも優れた結果を示しました。さらに、DiscoScoreの重要性とその優位性についても説明されています。 #DocumentSummarization #NLP #Evaluation #Reference-free Issue Date: 2023-08-13 RISE: Leveraging Retrieval Techniques for Summarization Evaluation, David Uthus+, N_A, Findings of ACL'23 Summary自動要約の評価は困難であり、従来のアプローチでは人間の評価には及ばない。そこで、私たちはRISEという新しいアプローチを提案する。RISEは情報検索の技術を活用し、ゴールドリファレンスの要約がなくても要約を評価することができる。RISEは特に評価用のリファレンス要約が利用できない新しいデータセットに適しており、SummEvalベンチマークでの実験結果から、RISEは過去のアプローチと比較して人間の評価と高い相関を示している。また、RISEはデータ効率性と言語間の汎用性も示している。 Comment概要
Dual-Encoderを用いて、ソースドキュメントとシステム要約をエンコードし、dot productをとることでスコアを得る手法。モデルの訓練は、Contrastive Learningで行い、既存データセットのソースと参照要約のペアを正例とみなし、In Batch trainingする。
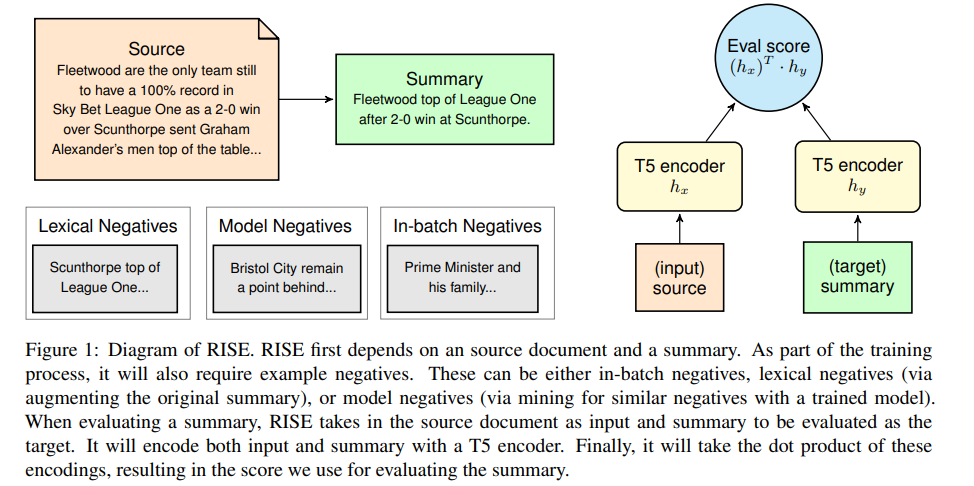
分類
Reference-free, Model-based, ソース依存で、BARTScore 960 とは異なり、文書要約データを用いて学習するため、要約の評価に特化している点が特徴。

モデル
Contrastive Learning
Contrastive Learningを用い、hard negativeを用いたvariantも検証する。また、訓練データとして3種類のパターンを検証する:
1. in-domain data: 文書要約データを用いて訓練し、ターゲットタスクでどれだけの性能を発揮するかを見る
2. out-of-domain data: 文書要約以外のデータを用いて訓練し、どれだけ新しいドメインにモデルがtransferできるかを検証する
3. in-and-out-domain data: 両方やる
ハードネガティブの生成
Lexical Negatives, Model Negatives, 双方の組み合わせの3種類を用いてハードネガティブを生成する。
Lexical Negatives
参照要約を拡張することによって生成する。目的は、もともとの参照要約と比較して、poor summaryを生成することにある。Data Augmentationとして、以下の方法を試した:
・Swapping noun entities: 要約中のエンティティを、ソース中のエンティティンとランダムでスワップ
・Shuffling words: 要約中の単語をランダムにシャッフル
・Dropping words: 要約中の単語をランダムに削除
・Dropping characters: 要約中の文字をランダムに削除
・Swapping antonyms: 要約中の単語を対義語で置換
Model Negatives
データセットの中から負例を抽出する。目的は、参照要約と類似しているが、負例となるサンプルを見つけること。これを実現するために、まずRISE modelをデータセットでfinetuningし、それぞれのソースドキュメントの要約に対して、類似した要約をマイニングする。すべてのドキュメントと要約をエンコードし、top-nの最も類似した要約を見つけ、これをハードネガティブとして、再度モデルを訓練する。
両者の組み合わせ
まずlexical negativesでモデルを訓練し、モデルネガティブの抽出に活用する。抽出したモデルネガティブを用いて再度モデルを訓練することで、最終的なモデルとする。
実験
学習手法
SummEval 984 を用いて人手評価と比較してどれだけcorrelationがあるかを検証。SummEvalには16種類のモデルのアウトプットに対する、CNN / Daily Mail の100 examplesに対して、品質のアノテーションが付与されている。expert annotationを用いて、Kendall's tauを用いてシステムレベルのcorrelationを計算した。contextが短い場合はT5, 長い場合はLongT5, タスクがマルチリンガルな場合はmT5を用いて訓練した。訓練データとしては
・CNN / Daily Mail
・Multi News
・arXiv
・PubMed
・BigPatent
・SAMSum
・Reddit TIFU
・MLSUM
等を用いた。これによりshort / long contextの両者をカバーできる。CNN / Daily Mail, Reddiit TIFU, Multi-Newsはshort-context, arXiv, PubMed, BigPatent, Multi-News(長文のものを利用)はlonger contextとして利用する。
比較するメトリック
ROUGE, chrF, SMS, BARTScore, SMART, BLEURT, BERTScore, Q^2, T5-ANLI, PRISMと比較した。結果をみると、Consistency, Fluency, Relevanceで他手法よりも高い相関を得た。Averageでは最も高いAverageを獲得した。in-domain dataで訓練した場合は、高い性能を発揮した。our-of-domain(SAMSum; Dialogue要約のデータ)データでも高い性能を得た。

Ablation
ハードネガティブの生成方法
Data Augmentationは、swapping entity nouns, randomly dropping wordsの組み合わせが最も良かった。また、Lexical Negativesは、様々なデータセットで一貫して性能が良かったが、Model NegativesはCNN/DailyMailに対してしか有効ではなかった。これはおそらく、同じタスク(テストデータと同じデータ)でないと、Model Negativesは機能しないことを示唆している。ただし、Model Negativesを入れたら、何もしないよりも性能向上するから、何らかの理由でlexical negativesが生成できない場合はこっち使っても有用である。

Model Size
でかい方が良い。in-domainならBaseでもそれなりの性能だけど、結局LARGEの方が強い。

Datasets
異なるデータセットでもtransferがうまく機能している。驚いたことにデータセットをmixingするとあまりうまくいかず、単体のデータセットで訓練したほうが性能が良い。

LongT5を見ると、T5よりもCorrelationが低く難易度が高い。

最終的に英語の要約を評価をする場合でも、Multilingual(別言語)で訓練しても高いCorrelationを示すこともわかった。

Dataset Size
サンプル数が小さくても有効に働く。しかし、out-domainのデータの場合は、たとえば、512件の場合は性能が低く少しexampleを増やさなければならない。

#DocumentSummarization #NLP #Evaluation #LLM-as-a-Judge Issue Date: 2023-08-13 GPTScore: Evaluate as You Desire, Jinlan Fu+, N_A, arXiv'23 Summary本研究では、生成型AIの評価における課題を解決するために、GPTScoreという評価フレームワークを提案しています。GPTScoreは、生成されたテキストを評価するために、生成型事前学習モデルの新たな能力を活用しています。19の事前学習モデルを探索し、4つのテキスト生成タスクと22の評価項目に対して実験を行いました。結果は、GPTScoreが自然言語の指示だけでテキストの評価を効果的に実現できることを示しています。この評価フレームワークは、注釈付きサンプルの必要性をなくし、カスタマイズされた多面的な評価を実現することができます。 CommentBERTScoreと同様、評価したいテキストの対数尤度で評価している
BERTScoreよりも相関が高く、instructionによって性能が向上することが示されている #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 Large Language Models are Diverse Role-Players for Summarization Evaluation, Ning Wu+, N_A, arXiv'23 Summary本研究では、テキスト要約の評価フレームワークを提案し、生成されたテキストと参照テキストを客観的および主観的な側面から比較することで包括的な評価を行います。具体的には、ロールプレイヤーのプロンプティングメカニズムを使用してテキストの評価をモデル化し、コンテキストベースのプロンプティングメカニズムを導入して動的なロールプレイヤープロファイルを生成します。さらに、バッチプロンプティングに基づいたマルチロールプレイヤープロンプティング技術を使用して複数の評価結果を統合します。実験結果は、提案モデルが競争力があり、人間の評価者と高い一致性を持つことを示しています。 #DocumentSummarization #NLP #Evaluation #Factuality Issue Date: 2023-08-13 ChatGPT as a Factual Inconsistency Evaluator for Text Summarization, Zheheng Luo+, N_A, arXiv'23 Summary事前学習された言語モデルによるテキスト要約の性能向上が注目されているが、生成された要約が元の文書と矛盾することが問題となっている。この問題を解決するために、効果的な事実性評価メトリクスの開発が進められているが、計算複雑性や不確実性の制約があり、人間の判断との一致に限定されている。最近の研究では、大規模言語モデル(LLMs)がテキスト生成と言語理解の両方で優れた性能を示していることがわかっている。本研究では、ChatGPTの事実的な矛盾評価能力を評価し、バイナリエンテイルメント推論、要約ランキング、一貫性評価などのタスクで優れた性能を示した。ただし、ChatGPTには語彙的な類似性の傾向や誤った推論、指示の不適切な理解などの制限があることがわかった。 Issue Date: 2023-08-12 Shepherd: A Critic for Language Model Generation, Tianlu Wang+, N_A, arXiv'23 SummaryShepherdは、言語モデルの改善に関心が高まっている中で、自身の出力を洗練させるための特別に調整された言語モデルです。Shepherdは、多様なエラーを特定し修正案を提供する能力を持ち、高品質なフィードバックデータセットを使用して開発されました。Shepherdは他の既存のモデルと比較して優れた性能を示し、人間の評価でも高い評価を受けています。 #NLP #LanguageModel #Prompting Issue Date: 2023-08-12 Metacognitive Prompting Improves Understanding in Large Language Models, Yuqing Wang+, N_A, arXiv'23 Summary本研究では、LLMsにメタ認知プロンプト(MP)を導入し、人間の内省的な推論プロセスを模倣することで、理解能力を向上させることを目指しています。実験結果は、MPを備えたPaLMが他のモデルに比べて優れたパフォーマンスを示しており、MPが既存のプロンプト手法を上回ることを示しています。この研究は、LLMsの理解能力向上の可能性を示し、人間の内省的な推論を模倣することの利点を強調しています。 CommentCoTより一貫して性能が高いので次のデファクトになる可能性あり
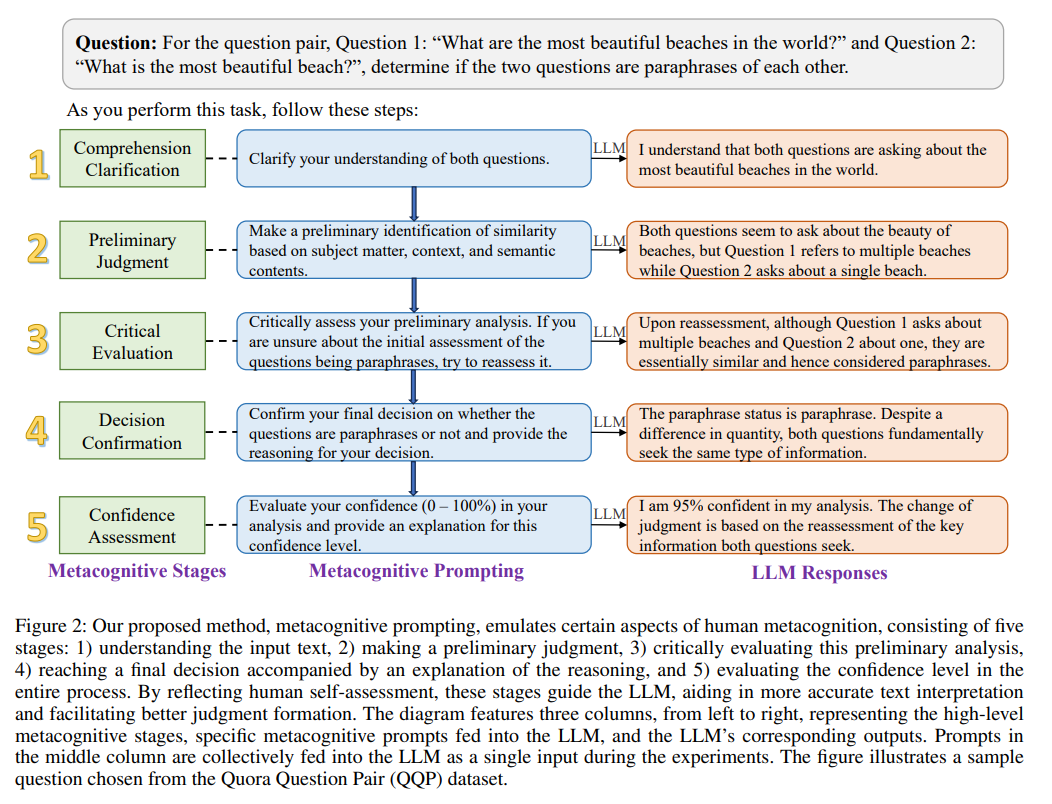

#MachineLearning #NLP #AutoML Issue Date: 2023-08-10 MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks, Lei Zhang+, N_A, arXiv'23 Summary本研究では、機械学習タスクの自動化における人間の知識と機械知能のギャップを埋めるために、新しいフレームワークMLCopilotを提案する。このフレームワークは、最先端のLLMsを使用して新しいMLタスクのソリューションを開発し、既存のMLタスクの経験から学び、効果的に推論して有望な結果を提供することができる。生成されたソリューションは直接使用して競争力のある結果を得ることができる。 Issue Date: 2023-08-08 Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models, Cheng-Yu Hsieh+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を使用して、ツールのドキュメンテーションを提供することで新しいツールを学習する方法を提案しています。デモンストレーションの取得が困難な場合や、バイアスのある使用方法を避けるために、ツールのドキュメンテーションを使用することが有効であることを実験的に示しています。さらに、複数のタスクでツールのドキュメンテーションの利点を強調し、LLMsがツールの機能を再発明する可能性を示しています。 #Tools #NLP #LanguageModel Issue Date: 2023-08-08 ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, N_A, arXiv'23 Summaryオープンソースの大規模言語モデル(LLMs)を使用して、外部ツール(API)の高度なタスクの実行を容易にするためのToolLLMというフレームワークを紹介します。ToolBenchというデータセットを使用して、ツールの使用方法を調整し、DFSDTという決定木を使用して効率的な検索を行います。ToolEvalという自動評価ツールを使用して、ToolLLaMAが高いパフォーマンスを発揮することを示します。さらに、ニューラルAPIリトリーバーを使用して、適切なAPIを推奨します。 Comment16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
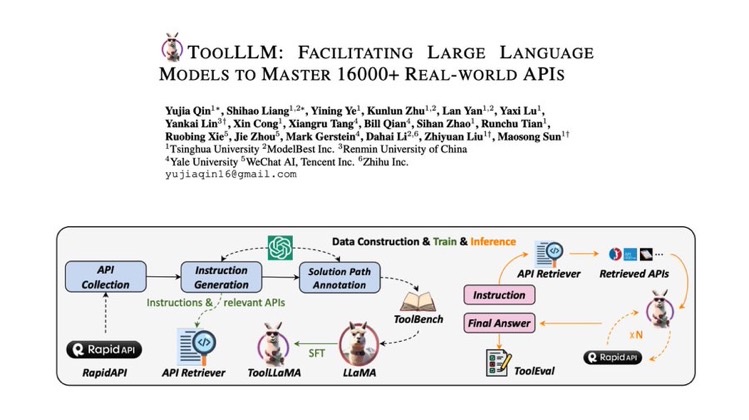 #NLP
#LanguageModel
#Prompting
Issue Date: 2023-08-07
Do Multilingual Language Models Think Better in English?, Julen Etxaniz+, N_A, arXiv'23
Summaryself-translateは、マルチリンガル言語モデルの少数ショット翻訳能力を活用する新しいアプローチであり、外部の翻訳システムの必要性を克服する。実験結果は、self-translateが直接推論を上回る性能を示し、非英語の言語でプロンプトされた場合にも有効であることを示している。コードはhttps://github.com/juletx/self-translateで利用可能。
Comment参考: https://twitter.com/imai_eruel/status/1687735268311511040?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#NLP
#LanguageModel
#Prompting
Issue Date: 2023-08-07
Do Multilingual Language Models Think Better in English?, Julen Etxaniz+, N_A, arXiv'23
Summaryself-translateは、マルチリンガル言語モデルの少数ショット翻訳能力を活用する新しいアプローチであり、外部の翻訳システムの必要性を克服する。実験結果は、self-translateが直接推論を上回る性能を示し、非英語の言語でプロンプトされた場合にも有効であることを示している。コードはhttps://github.com/juletx/self-translateで利用可能。
Comment参考: https://twitter.com/imai_eruel/status/1687735268311511040?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q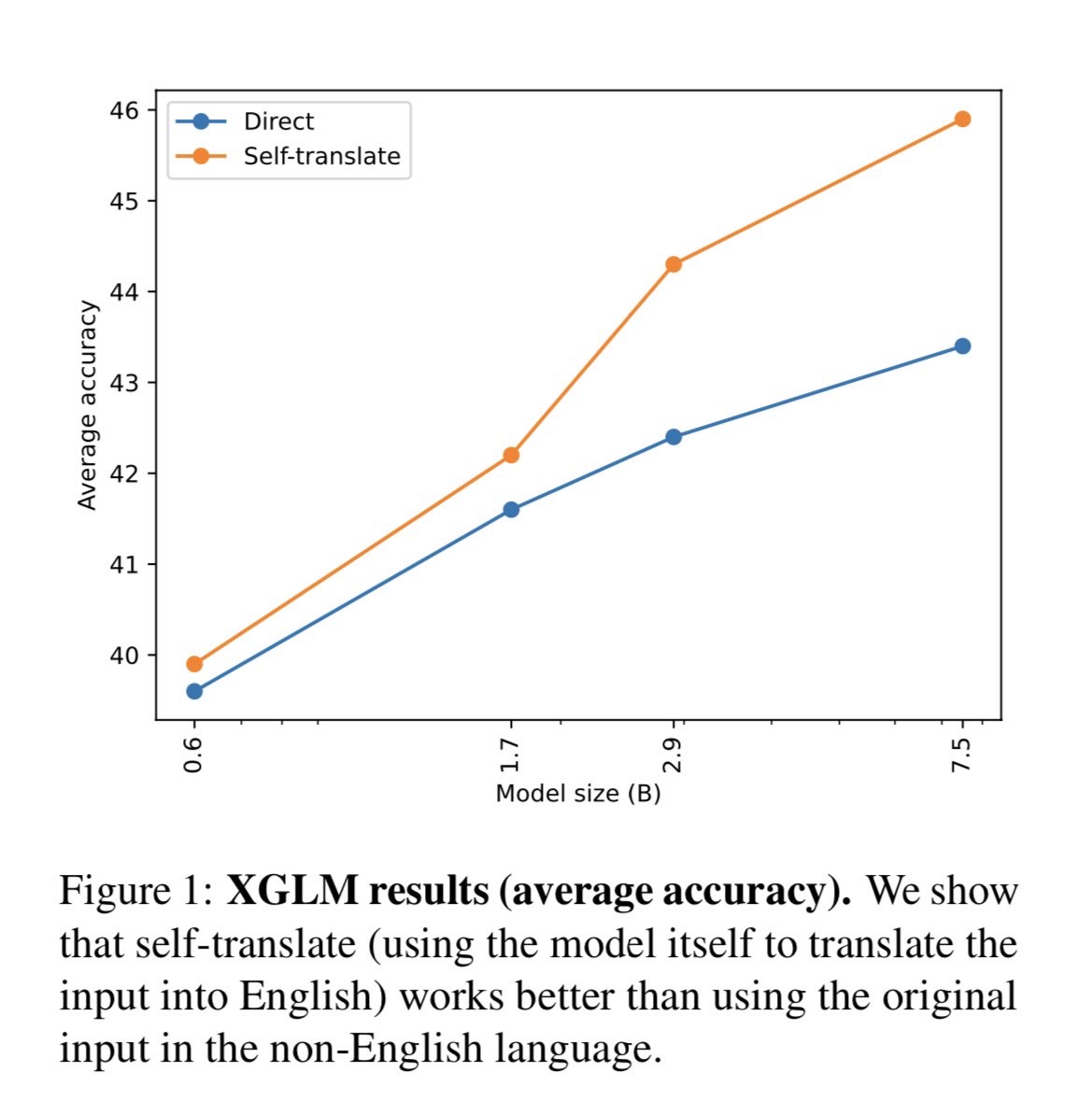
 #RecommenderSystems
#LanguageModel
Issue Date: 2023-08-02
LLM-Rec: Personalized Recommendation via Prompting Large Language Models, Hanjia Lyu+, N_A, arXiv'23
SummaryLLMsを用いたパーソナライズされたコンテンツ推薦のためのプロンプティング戦略を調査し、LLM-Recというアプローチを提案した。実験の結果、プロンプティング戦略によって生成されたLLMによる拡張入力テキストと元のコンテンツの説明を組み合わせることで、推薦の性能が向上することが示された。これは、多様なプロンプトと入力拡張技術がパーソナライズされたコンテンツ推薦の能力を向上させる上で重要であることを示している。
CommentLLMのpromptingの方法を変更しcontent descriptionだけでなく、様々なコンテキストの追加(e.g. このdescriptionを推薦するならどういう人におすすめ?、アイテム間の共通項を見つける)、内容の拡張等を行いコンテントを拡張して活用するという話っぽい。WIP
Issue Date: 2023-07-31
Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step, Liunian Harold Li+, N_A, arXiv'23
Summary小さなモデルでも思考の連鎖プロンプティングの恩恵を受けることができることを示すために、Symbolic Chain-of-Thought Distillation(SCoTD)を導入しました。SCoTDは、大きな教師モデルからサンプリングされた合理化に基づいて、小さな学生モデルをトレーニングする方法です。実験結果は、SCoTDが学生モデルのパフォーマンスを向上させ、思考の連鎖が人間と同等と評価されることを示しています。思考の連鎖サンプルとコードのコーパスも公開されています。
Issue Date: 2023-07-27
FacTool: Factuality Detection in Generative AI -- A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios, I-Chun Chern+, N_A, arXiv'23
Summary生成型の事前学習モデルによって生成されたテキストの事実の誤りを検出するためのフレームワークであるFacToolが提案された。知識ベースのQA、コード生成、数理推論、科学文献レビューの4つのタスクでの実験において、FacToolの有効性が示された。FacToolのコードはGitHubで公開されている。
CommentNeubigさんの研究
#NLP
#LanguageModel
#Evaluation
#LLM-as-a-Judge
Issue Date: 2023-07-26
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, N_A, arXiv'23
Summary大規模言語モデル(LLM)を判定者として使用して、オープンエンドの質問に対する性能を評価する方法を提案する。LLMの制限や問題を軽減するための解決策を提案し、2つのベンチマークでLLMの判定者と人間の好みの一致を検証する。結果は、強力なLLM判定者が人間の好みとよく一致し、スケーラブルで説明可能な方法で人間の好みを近似できることを示した。さらに、新しいベンチマークと従来のベンチマークの相補性を示し、いくつかのバリアントを評価する。
CommentMT-Bench(MTBench)スコアとは、multi-turnのQAを出題し、その回答の質をGPT-4でスコアリングしたスコアのこと。
#RecommenderSystems
#LanguageModel
Issue Date: 2023-08-02
LLM-Rec: Personalized Recommendation via Prompting Large Language Models, Hanjia Lyu+, N_A, arXiv'23
SummaryLLMsを用いたパーソナライズされたコンテンツ推薦のためのプロンプティング戦略を調査し、LLM-Recというアプローチを提案した。実験の結果、プロンプティング戦略によって生成されたLLMによる拡張入力テキストと元のコンテンツの説明を組み合わせることで、推薦の性能が向上することが示された。これは、多様なプロンプトと入力拡張技術がパーソナライズされたコンテンツ推薦の能力を向上させる上で重要であることを示している。
CommentLLMのpromptingの方法を変更しcontent descriptionだけでなく、様々なコンテキストの追加(e.g. このdescriptionを推薦するならどういう人におすすめ?、アイテム間の共通項を見つける)、内容の拡張等を行いコンテントを拡張して活用するという話っぽい。WIP
Issue Date: 2023-07-31
Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step, Liunian Harold Li+, N_A, arXiv'23
Summary小さなモデルでも思考の連鎖プロンプティングの恩恵を受けることができることを示すために、Symbolic Chain-of-Thought Distillation(SCoTD)を導入しました。SCoTDは、大きな教師モデルからサンプリングされた合理化に基づいて、小さな学生モデルをトレーニングする方法です。実験結果は、SCoTDが学生モデルのパフォーマンスを向上させ、思考の連鎖が人間と同等と評価されることを示しています。思考の連鎖サンプルとコードのコーパスも公開されています。
Issue Date: 2023-07-27
FacTool: Factuality Detection in Generative AI -- A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios, I-Chun Chern+, N_A, arXiv'23
Summary生成型の事前学習モデルによって生成されたテキストの事実の誤りを検出するためのフレームワークであるFacToolが提案された。知識ベースのQA、コード生成、数理推論、科学文献レビューの4つのタスクでの実験において、FacToolの有効性が示された。FacToolのコードはGitHubで公開されている。
CommentNeubigさんの研究
#NLP
#LanguageModel
#Evaluation
#LLM-as-a-Judge
Issue Date: 2023-07-26
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, N_A, arXiv'23
Summary大規模言語モデル(LLM)を判定者として使用して、オープンエンドの質問に対する性能を評価する方法を提案する。LLMの制限や問題を軽減するための解決策を提案し、2つのベンチマークでLLMの判定者と人間の好みの一致を検証する。結果は、強力なLLM判定者が人間の好みとよく一致し、スケーラブルで説明可能な方法で人間の好みを近似できることを示した。さらに、新しいベンチマークと従来のベンチマークの相補性を示し、いくつかのバリアントを評価する。
CommentMT-Bench(MTBench)スコアとは、multi-turnのQAを出題し、その回答の質をGPT-4でスコアリングしたスコアのこと。
GPT-4の判断とhuman expertの判断とのagreementも検証しており、agreementは80%以上を達成している。


#MachineLearning #Optimizer Issue Date: 2023-07-25 DoG is SGD's Best Friend: A Parameter-Free Dynamic Step Size Schedule, Maor Ivgi+, N_A, ICML'23 Summary私たちは、チューニング不要の動的SGDステップサイズの式であるDoGを提案します。DoGは、初期点からの距離と勾配のノルムに基づいてステップサイズを計算し、学習率のパラメータを必要としません。理論的には、DoGの式は確率的凸最適化においてパラメータフリーの収束を保証します。実験的には、DoGのパフォーマンスがチューニングされた学習率を持つSGDに近いことを示し、DoGのバリアントがチューニングされたSGDやAdamを上回ることを示します。PyTorchの実装はhttps://github.com/formll/dogで利用できます。 Comment20 を超える多様なタスクと 8 つのビジョンおよび NLP モデルに対して有効であったシンプルなパラメーターフリーのoptimizer
元ツイート: https://twitter.com/maorivg/status/1683525521471328256?s=46&t=Lt9P4BkmiMDRC7_5EuxhNQ #EfficiencyImprovement #MachineLearning #Prompting Issue Date: 2023-07-24 Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, N_A, arXiv'23 Summary大規模な言語モデル(LLMs)を効果的に使用するために、バッチプロンプティングという手法を提案します。この手法は、LLMが1つのサンプルではなくバッチで推論を行うことを可能にし、トークンコストと時間コストを削減しながらパフォーマンスを維持します。さまざまなデータセットでの実験により、バッチプロンプティングがLLMの推論コストを大幅に削減し、良好なパフォーマンスを達成することが示されました。また、バッチプロンプティングは異なる推論方法にも適用できます。詳細はGitHubのリポジトリで確認できます。 Comment
10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、contextが長ければ長いほど、バッチサイズを大きくした際のパフォーマンスの低下が著しい。 Issue Date: 2023-07-23 Large Language Models as General Pattern Machines, Suvir Mirchandani+, N_A, arXiv'23 Summary事前学習された大規模言語モデル(LLMs)は、複雑なトークンシーケンスを自己回帰的に補完する能力を持っていることが観察された。この能力は、ランダムなトークンからなるシーケンスでも一部保持されることがわかった。この研究では、この能力がロボティクスの問題にどのように適用されるかを調査し、具体的な応用例を示している。ただし、実際のシステムへの展開はまだ困難であるとしている。 Issue Date: 2023-07-23 Will Large-scale Generative Models Corrupt Future Datasets?, Ryuichiro Hataya+, ICCV'23 Summary大規模なテキストから画像への生成モデル(DALL·E 2、Midjourney、StableDiffusionなど)が高品質な画像を生成する一方で、これらの生成画像がコンピュータビジョンモデルの性能に与える影響を検証。汚染をシミュレーションし、生成された画像がImageNetやCOCOデータセットで訓練されたモデルの性能にネガティブな影響を及ぼすことを実証。影響の程度はタスクや生成画像の量に依存する。生成データセットとコードは公開予定。 #NLP #ChatGPT #Evaluation Issue Date: 2023-07-22 How is ChatGPT's behavior changing over time?, Lingjiao Chen+, N_A, arXiv'23 SummaryGPT-3.5とGPT-4は、大規模言語モデル(LLM)のサービスであり、その性能と振る舞いは時間とともに変動することがわかった。例えば、GPT-4は素数の特定に優れていたが、後のバージョンでは低い正答率となった。また、GPT-3.5はGPT-4よりも優れた性能を示した。さらに、GPT-4とGPT-3.5の両方が時間とともに敏感な質問への回答やコード生成でのミスが増えた。この結果から、LLMの品質を継続的に監視する必要性が示唆される。 CommentGPT3.5, GPT4共にfreezeされてないのなら、研究で利用すると結果が再現されないので、研究で使うべきではない。また、知らんうちにいくつかのタスクで勝手に性能低下されたらたまったものではない。 #ComputerVision #NLP #LanguageModel #LLMAgent Issue Date: 2023-07-22 Towards A Unified Agent with Foundation Models, Norman Di Palo+, N_A, arXiv'23 Summary本研究では、言語モデルとビジョン言語モデルを強化学習エージェントに組み込み、効率的な探索や経験データの再利用などの課題に取り組む方法を調査しました。スパースな報酬のロボット操作環境でのテストにおいて、ベースラインに比べて大幅な性能向上を実証し、学習済みのスキルを新しいタスクの解決や人間の専門家のビデオの模倣に活用する方法を示しました。 Comment
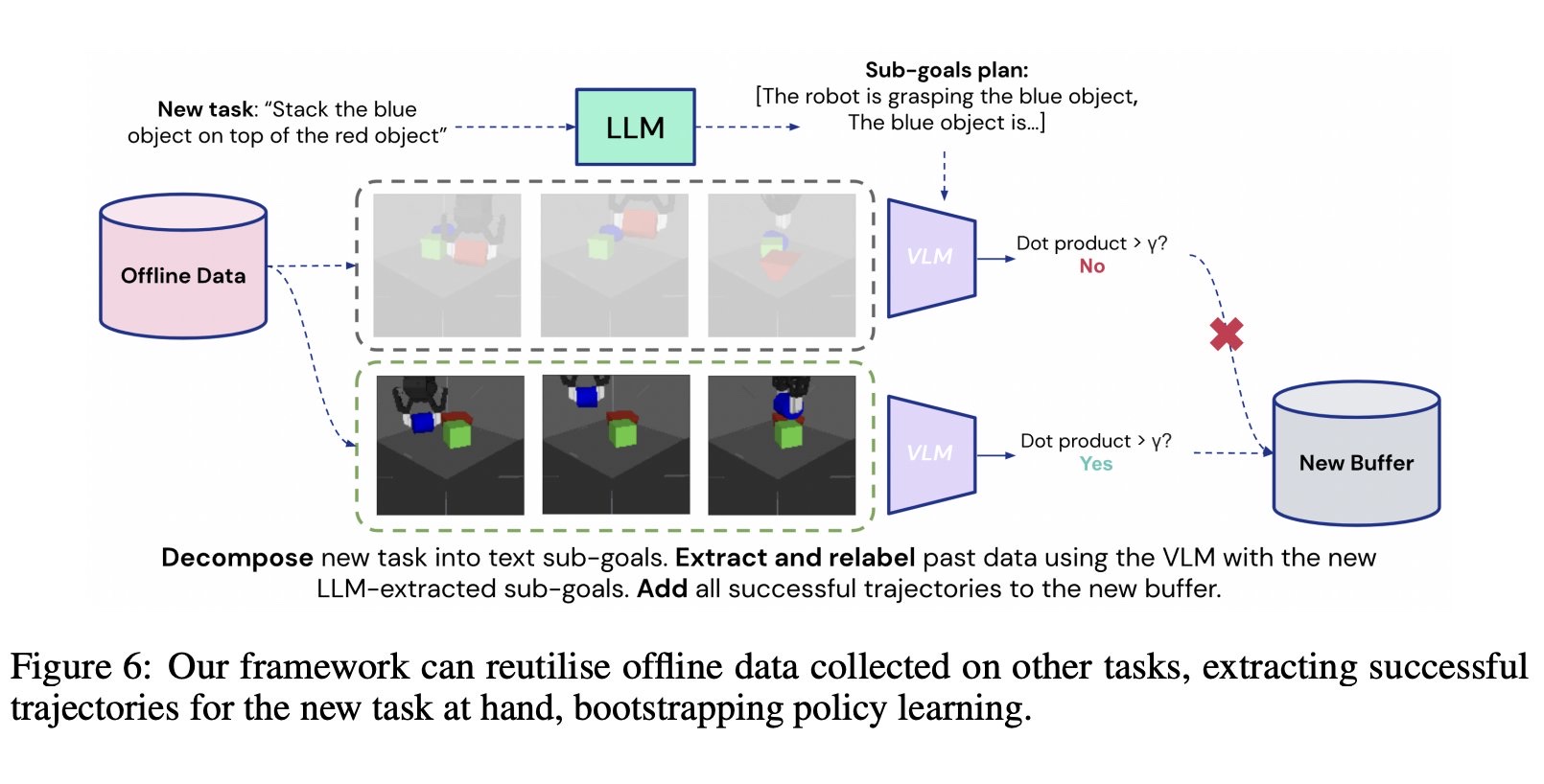 #NLP
#LanguageModel
#Annotation
Issue Date: 2023-07-22
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs, Tongshuang Wu+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)は、クラウドソーシングタスクにおいて人間のような振る舞いを再現できる可能性がある。しかし、現在の取り組みは単純なタスクに焦点を当てており、より複雑なパイプラインを再現できるかどうかは不明である。LLMsの成功は、リクエスターの理解力やサブタスクのスキルに影響を受ける。人間とLLMsのトレーニングの組み合わせにより、クラウドソーシングパイプラインの再現が可能であり、LLMsは一部のタスクを完了させながら、他のタスクを人間に任せることができる。
#EfficiencyImprovement
#MachineLearning
#Quantization
#PEFT(Adaptor/LoRA)
#NeurIPS
#Admin'sPick
Issue Date: 2023-07-22
QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, NeurIPS'23
Summary私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。
Comment実装: https://github.com/artidoro/qlora
#NLP
#LanguageModel
#Annotation
Issue Date: 2023-07-22
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs, Tongshuang Wu+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)は、クラウドソーシングタスクにおいて人間のような振る舞いを再現できる可能性がある。しかし、現在の取り組みは単純なタスクに焦点を当てており、より複雑なパイプラインを再現できるかどうかは不明である。LLMsの成功は、リクエスターの理解力やサブタスクのスキルに影響を受ける。人間とLLMsのトレーニングの組み合わせにより、クラウドソーシングパイプラインの再現が可能であり、LLMsは一部のタスクを完了させながら、他のタスクを人間に任せることができる。
#EfficiencyImprovement
#MachineLearning
#Quantization
#PEFT(Adaptor/LoRA)
#NeurIPS
#Admin'sPick
Issue Date: 2023-07-22
QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, NeurIPS'23
Summary私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。
Comment実装: https://github.com/artidoro/qlora
PEFTにもある参考: https://twitter.com/hillbig/status/1662946722690236417?s=46&t=TDHYK31QiXKxggPzhZbcAQOpenReview:https://openreview.net/forum?id=OUIFPHEgJU&referrer=%5Bthe%20profile%20of%20Ari%20Holtzman%5D(%2Fprofile%3Fid%3D~Ari_Holtzman1) #ComputerVision #Personalization #DiffusionModel Issue Date: 2023-07-22 FABRIC: Personalizing Diffusion Models with Iterative Feedback, Dimitri von Rütte+, N_A, arXiv'23 Summary本研究では、拡散ベースのテキストから画像への変換モデルに人間のフィードバックを組み込む戦略を提案する。自己注意層を利用したトレーニングフリーなアプローチであるFABRICを提案し、さまざまな拡散モデルに適用可能であることを示す。また、包括的な評価方法を導入し、人間のフィードバックを統合した生成ビジュアルモデルのパフォーマンスを定量化するための堅牢なメカニズムを提供する。徹底的な分析により、反復的なフィードバックの複数のラウンドを通じて生成結果が改善されることを示す。これにより、個別化されたコンテンツ作成やカスタマイズなどの領域に応用が可能となる。 Commentupvote downvoteをフィードバックし、iterativeなmannerでDiffusionモデルの生成結果を改善できる手法。多くのDiffusion based Modelに対して適用可能
デモ: https://huggingface.co/spaces/dvruette/fabric #NLP #LanguageModel #InstructionTuning #Evaluation Issue Date: 2023-07-22 Instruction-following Evaluation through Verbalizer Manipulation, Shiyang Li+, N_A, arXiv'23 Summary本研究では、指示に従う能力を正確に評価するための新しい評価プロトコル「verbalizer manipulation」を提案しています。このプロトコルでは、モデルに異なる程度で一致する言葉を使用してタスクラベルを表現させ、モデルの事前知識に依存する能力を検証します。さまざまなモデルを9つのデータセットで評価し、異なるverbalizerのパフォーマンスによって指示に従う能力が明確に区別されることを示しました。最も困難なverbalizerに対しても、最も強力なモデルでもランダムな推測よりも優れたパフォーマンスを発揮するのは困難であり、指示に従う能力を向上させるために継続的な進歩が必要であることを強調しています。 #ComputerVision #NLP #LanguageModel #SpokenLanguageProcessing #MulltiModal #SpeechProcessing Issue Date: 2023-07-22 Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, N_A, arXiv'23 Summary本研究では、マルチモーダル学習のためのMeta-Transformerというフレームワークを提案しています。このフレームワークは、異なるモダリティの情報を処理し関連付けるための統一されたネットワークを構築することを目指しています。Meta-Transformerは、対応のないデータを使用して12のモダリティ間で統一された学習を行うことができ、テキスト、画像、ポイントクラウド、音声、ビデオなどの基本的なパーセプションから、X線、赤外線、高分光、IMUなどの実用的なアプリケーション、グラフ、表形式、時系列などのデータマイニングまで、幅広いタスクを処理することができます。Meta-Transformerは、トランスフォーマーを用いた統一されたマルチモーダルインテリジェンスの開発に向けた有望な未来を示しています。 Comment12種類のモダリティに対して学習できるTransformerを提案
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
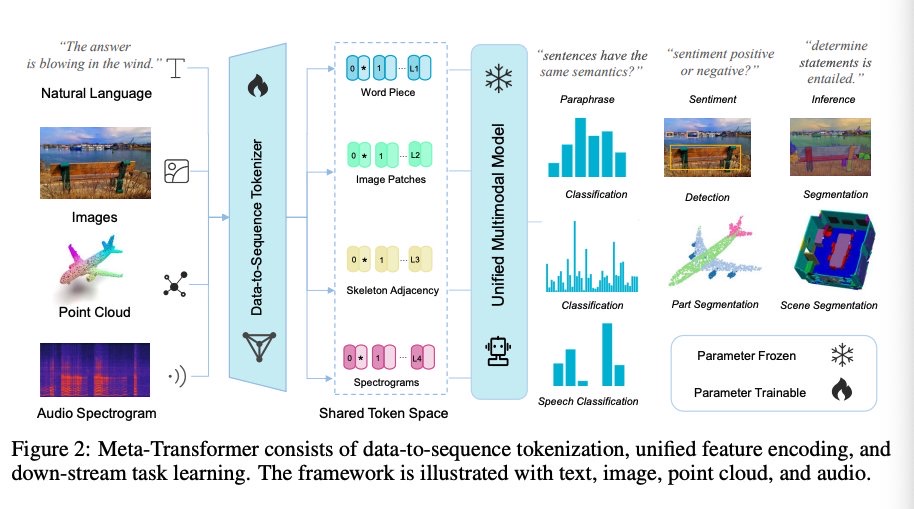 #NLP
#Dataset
#LanguageModel
#Evaluation
Issue Date: 2023-07-22
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets, Seonghyeon Ye+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の評価における課題を解決するため、細かい評価プロトコルであるFLASKを提案する。FLASKは、インスタンスごとのスキルセットレベルでの評価を可能にし、モデルベースと人間ベースの評価の両方に使用できる。具体的には、12の細かいスキルを定義し、各インスタンスにスキルのセットを割り当てることで評価セットを構築する。さらに、ターゲットドメインと難易度レベルの注釈を付けることで、モデルのパフォーマンスを包括的に分析する。FLASKを使用することで、モデルのパフォーマンスを正確に測定し、特定のスキルに優れたLLMsを分析することができる。また、実践者はFLASKを使用して、特定の状況に適したモデルを推奨することができる。
CommentこのベンチによるとLLaMA2でさえ、商用のLLMに比べると能力はかなり劣っているように見える。
#NLP
#Dataset
#LanguageModel
#Evaluation
Issue Date: 2023-07-22
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets, Seonghyeon Ye+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の評価における課題を解決するため、細かい評価プロトコルであるFLASKを提案する。FLASKは、インスタンスごとのスキルセットレベルでの評価を可能にし、モデルベースと人間ベースの評価の両方に使用できる。具体的には、12の細かいスキルを定義し、各インスタンスにスキルのセットを割り当てることで評価セットを構築する。さらに、ターゲットドメインと難易度レベルの注釈を付けることで、モデルのパフォーマンスを包括的に分析する。FLASKを使用することで、モデルのパフォーマンスを正確に測定し、特定のスキルに優れたLLMsを分析することができる。また、実践者はFLASKを使用して、特定の状況に適したモデルを推奨することができる。
CommentこのベンチによるとLLaMA2でさえ、商用のLLMに比べると能力はかなり劣っているように見える。
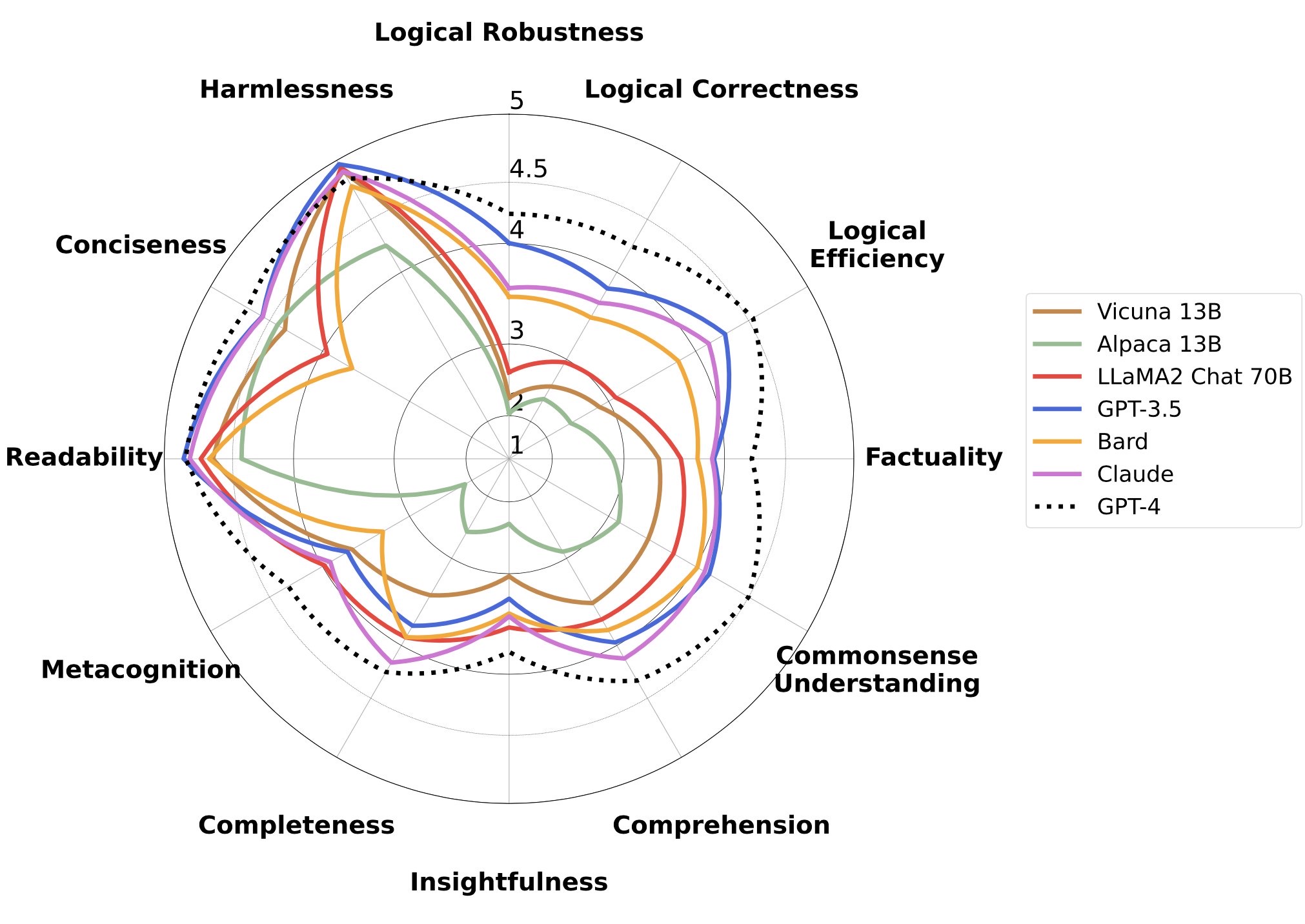 #NLP
#Dataset
#LanguageModel
#Programming
Issue Date: 2023-07-18
Socratic Questioning of Novice Debuggers: A Benchmark Dataset and Preliminary Evaluations, ACL-BEA'23
Summary本研究では、初心者プログラマがバグのある計算問題を解決する際に、ソクラテス的な対話を行うデータセットを紹介し、GPTベースの言語モデルのデバッグ能力を評価しました。GPT-4はGPT-3.5よりも優れたパフォーマンスを示しましたが、まだ人間の専門家には及ばず、さらなる研究が必要です。
#NaturalLanguageGeneration
#NLP
#Factuality
Issue Date: 2023-07-18
WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning, ACL'23
Summary現在のテキスト生成モデルは、入力と矛盾するテキストを制御できないという課題があります。この問題を解決するために、私たちはWeCheckという弱教師付きフレームワークを提案します。WeCheckは、弱教師付きラベルを持つ言語モデルから直接訓練された実際の生成サンプルを使用します。さまざまなタスクでの実験結果は、WeCheckの強力なパフォーマンスを示し、従来の評価方法よりも高速で精度と効率を向上させています。
#NLP
#CrossLingual
Issue Date: 2023-07-12
Empowering Cross-lingual Behavioral Testing of NLP Models with Typological Features, Ester Hlavnova+, N_A, arXiv'23
SummaryM2Cという形態論に敏感なNLPモデルの行動テストフレームワークを提案し、12の異なる言語の特徴に基づいてモデルの振る舞いを探るテストを生成する。最先端の言語モデルは英語では優れているが、特定の言語の特徴に対する一般化の失敗があることが示される。これにより、モデルの盲点に対処するための開発が促される。
#ComputerVision
#Pretraining
#NLP
#Transformer
#MulltiModal
Issue Date: 2023-07-12
Generative Pretraining in Multimodality, Quan Sun+, N_A, arXiv'23
SummaryEmuは、マルチモーダルなコンテキストで画像とテキストを生成するためのTransformerベースのモデルです。このモデルは、単一モダリティまたはマルチモーダルなデータ入力を受け入れることができます。Emuは、マルチモーダルなシーケンスでトレーニングされ、画像からテキストへのタスクやテキストから画像へのタスクなど、さまざまなタスクで優れたパフォーマンスを示します。また、マルチモーダルアシスタントなどの拡張機能もサポートしています。
#ComputerVision
#Pretraining
#NLP
#MulltiModal
Issue Date: 2023-07-12
EgoVLPv2: Egocentric Video-Language Pre-training with Fusion in the Backbone, Shraman Pramanick+, N_A, arXiv'23
Summaryエゴセントリックビデオ言語の事前学習の第2世代(EgoVLPv2)は、ビデオと言語のバックボーンにクロスモーダルの融合を直接組み込むことができる。EgoVLPv2は強力なビデオテキスト表現を学習し、柔軟かつ効率的な方法でさまざまなダウンストリームタスクをサポートする。さらに、提案されたバックボーン戦略は軽量で計算効率が高い。EgoVLPv2は幅広いVLタスクで最先端のパフォーマンスを達成している。詳細はhttps://shramanpramanick.github.io/EgoVLPv2/を参照。
Issue Date: 2023-07-11
SVIT: Scaling up Visual Instruction Tuning, Bo Zhao+, N_A, arXiv'23
Summary大規模な言語モデルとビジョンモデルを統合した多モーダルモデルの能力を向上させるために、新しいデータセットSVITを構築しました。SVITは高品質かつ多様性に富んだビジュアルインストラクションチューニングデータセットであり、GPT-4のトレーニングに使用されることで多モーダルパフォーマンスを大幅に向上させることが示されました。
Issue Date: 2023-07-11
Large Language Models for Supply Chain Optimization, Beibin Li+, N_A, arXiv'23
Summary従来のサプライチェーンの運用では、最適化の結果を説明し、解釈するために多くの努力が必要でした。最近の大規模言語モデル(LLMs)の進歩に触発されて、この技術がサプライチェーンの自動化と人間の理解と信頼のギャップを埋めるのに役立つかを研究しました。私たちは、\name{}というフレームワークを設計し、最適化の結果に関する洞察を出力することができます。このフレームワークは、プロプライエタリデータを送信する必要がないため、プライバシー上の懸念もありません。実際のサーバ配置シナリオでの実証実験を行い、フレームワークの効果を示しました。また、LLMの出力の正確さを評価するための評価ベンチマークも開発しました。
Issue Date: 2023-07-11
Large Language Models as General Pattern Machines, Suvir Mirchandani+, N_A, arXiv'23
SummaryLLMsは、複雑なトークンシーケンスを自己回帰的に補完する能力を持っており、追加のトレーニングなしに一般的なシーケンスモデラーとして機能することが示されている。この研究では、LLMsのゼロショットの能力がロボティクスの問題にどのように適用できるかを調査し、例として時間の経過を表す数値のシーケンスの補完や閉ループポリシーの発見などを挙げている。ただし、実際のシステムに展開するには制約があるが、LLMsを低レベルの制御に使用するアプローチは有望であると示唆されている。
Issue Date: 2023-07-11
On decoder-only architecture for speech-to-text and large language model integration, Jian Wu+, N_A, arXiv'23
Summary本研究では、音声情報を大規模言語モデルに組み込む新しいアプローチであるSpeech-LLaMAを提案しています。この手法は、音響特徴を意味空間にマッピングするためにCTCとオーディオエンコーダを使用します。また、デコーダのみモデルを音声からテキストへのタスクに適用するために、小規模なモデルでトレーニングを行います。実験結果は、多言語音声からテキストへの翻訳タスクにおいて、強力なベースラインに比べて大幅な改善を示し、デコーダのみモデルの潜在的な利点を示しています。
Issue Date: 2023-07-11
Sketch-A-Shape: Zero-Shot Sketch-to-3D Shape Generation, Aditya Sanghi+, N_A, arXiv'23
Summary最近の研究では、大規模な事前学習モデルを使用して、スケッチから3D形状を生成する方法について調査されています。この研究では、合成レンダリングの特徴を使用して3D生成モデルをトレーニングし、スケッチから効果的に3D形状を生成できることが示されました。また、ペアデータセットを必要とせずに、入力スケッチごとに複数の3D形状を生成するアプローチの効果も示されました。
#NLP
#Dataset
#LanguageModel
#Evaluation
#Admin'sPick
Issue Date: 2023-07-03
Holistic Evaluation of Language Models, Percy Liang+, TMLR'23
Summary言語モデルの透明性を向上させるために、Holistic Evaluation of Language Models(HELM)を提案する。HELMでは、潜在的なシナリオとメトリックを分類し、広範なサブセットを選択して評価する。さらに、複数のメトリックを使用し、主要なシナリオごとに評価を行う。30の主要な言語モデルを42のシナリオで評価し、HELM以前に比べて評価のカバレッジを改善した。HELMはコミュニティのためのベンチマークとして利用され、新しいシナリオ、メトリック、モデルが継続的に更新される。
CommentOpenReview:https://openreview.net/forum?id=iO4LZibEqWHELMを提案した研究
#NLP
#Dataset
#LanguageModel
#Programming
Issue Date: 2023-07-18
Socratic Questioning of Novice Debuggers: A Benchmark Dataset and Preliminary Evaluations, ACL-BEA'23
Summary本研究では、初心者プログラマがバグのある計算問題を解決する際に、ソクラテス的な対話を行うデータセットを紹介し、GPTベースの言語モデルのデバッグ能力を評価しました。GPT-4はGPT-3.5よりも優れたパフォーマンスを示しましたが、まだ人間の専門家には及ばず、さらなる研究が必要です。
#NaturalLanguageGeneration
#NLP
#Factuality
Issue Date: 2023-07-18
WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning, ACL'23
Summary現在のテキスト生成モデルは、入力と矛盾するテキストを制御できないという課題があります。この問題を解決するために、私たちはWeCheckという弱教師付きフレームワークを提案します。WeCheckは、弱教師付きラベルを持つ言語モデルから直接訓練された実際の生成サンプルを使用します。さまざまなタスクでの実験結果は、WeCheckの強力なパフォーマンスを示し、従来の評価方法よりも高速で精度と効率を向上させています。
#NLP
#CrossLingual
Issue Date: 2023-07-12
Empowering Cross-lingual Behavioral Testing of NLP Models with Typological Features, Ester Hlavnova+, N_A, arXiv'23
SummaryM2Cという形態論に敏感なNLPモデルの行動テストフレームワークを提案し、12の異なる言語の特徴に基づいてモデルの振る舞いを探るテストを生成する。最先端の言語モデルは英語では優れているが、特定の言語の特徴に対する一般化の失敗があることが示される。これにより、モデルの盲点に対処するための開発が促される。
#ComputerVision
#Pretraining
#NLP
#Transformer
#MulltiModal
Issue Date: 2023-07-12
Generative Pretraining in Multimodality, Quan Sun+, N_A, arXiv'23
SummaryEmuは、マルチモーダルなコンテキストで画像とテキストを生成するためのTransformerベースのモデルです。このモデルは、単一モダリティまたはマルチモーダルなデータ入力を受け入れることができます。Emuは、マルチモーダルなシーケンスでトレーニングされ、画像からテキストへのタスクやテキストから画像へのタスクなど、さまざまなタスクで優れたパフォーマンスを示します。また、マルチモーダルアシスタントなどの拡張機能もサポートしています。
#ComputerVision
#Pretraining
#NLP
#MulltiModal
Issue Date: 2023-07-12
EgoVLPv2: Egocentric Video-Language Pre-training with Fusion in the Backbone, Shraman Pramanick+, N_A, arXiv'23
Summaryエゴセントリックビデオ言語の事前学習の第2世代(EgoVLPv2)は、ビデオと言語のバックボーンにクロスモーダルの融合を直接組み込むことができる。EgoVLPv2は強力なビデオテキスト表現を学習し、柔軟かつ効率的な方法でさまざまなダウンストリームタスクをサポートする。さらに、提案されたバックボーン戦略は軽量で計算効率が高い。EgoVLPv2は幅広いVLタスクで最先端のパフォーマンスを達成している。詳細はhttps://shramanpramanick.github.io/EgoVLPv2/を参照。
Issue Date: 2023-07-11
SVIT: Scaling up Visual Instruction Tuning, Bo Zhao+, N_A, arXiv'23
Summary大規模な言語モデルとビジョンモデルを統合した多モーダルモデルの能力を向上させるために、新しいデータセットSVITを構築しました。SVITは高品質かつ多様性に富んだビジュアルインストラクションチューニングデータセットであり、GPT-4のトレーニングに使用されることで多モーダルパフォーマンスを大幅に向上させることが示されました。
Issue Date: 2023-07-11
Large Language Models for Supply Chain Optimization, Beibin Li+, N_A, arXiv'23
Summary従来のサプライチェーンの運用では、最適化の結果を説明し、解釈するために多くの努力が必要でした。最近の大規模言語モデル(LLMs)の進歩に触発されて、この技術がサプライチェーンの自動化と人間の理解と信頼のギャップを埋めるのに役立つかを研究しました。私たちは、\name{}というフレームワークを設計し、最適化の結果に関する洞察を出力することができます。このフレームワークは、プロプライエタリデータを送信する必要がないため、プライバシー上の懸念もありません。実際のサーバ配置シナリオでの実証実験を行い、フレームワークの効果を示しました。また、LLMの出力の正確さを評価するための評価ベンチマークも開発しました。
Issue Date: 2023-07-11
Large Language Models as General Pattern Machines, Suvir Mirchandani+, N_A, arXiv'23
SummaryLLMsは、複雑なトークンシーケンスを自己回帰的に補完する能力を持っており、追加のトレーニングなしに一般的なシーケンスモデラーとして機能することが示されている。この研究では、LLMsのゼロショットの能力がロボティクスの問題にどのように適用できるかを調査し、例として時間の経過を表す数値のシーケンスの補完や閉ループポリシーの発見などを挙げている。ただし、実際のシステムに展開するには制約があるが、LLMsを低レベルの制御に使用するアプローチは有望であると示唆されている。
Issue Date: 2023-07-11
On decoder-only architecture for speech-to-text and large language model integration, Jian Wu+, N_A, arXiv'23
Summary本研究では、音声情報を大規模言語モデルに組み込む新しいアプローチであるSpeech-LLaMAを提案しています。この手法は、音響特徴を意味空間にマッピングするためにCTCとオーディオエンコーダを使用します。また、デコーダのみモデルを音声からテキストへのタスクに適用するために、小規模なモデルでトレーニングを行います。実験結果は、多言語音声からテキストへの翻訳タスクにおいて、強力なベースラインに比べて大幅な改善を示し、デコーダのみモデルの潜在的な利点を示しています。
Issue Date: 2023-07-11
Sketch-A-Shape: Zero-Shot Sketch-to-3D Shape Generation, Aditya Sanghi+, N_A, arXiv'23
Summary最近の研究では、大規模な事前学習モデルを使用して、スケッチから3D形状を生成する方法について調査されています。この研究では、合成レンダリングの特徴を使用して3D生成モデルをトレーニングし、スケッチから効果的に3D形状を生成できることが示されました。また、ペアデータセットを必要とせずに、入力スケッチごとに複数の3D形状を生成するアプローチの効果も示されました。
#NLP
#Dataset
#LanguageModel
#Evaluation
#Admin'sPick
Issue Date: 2023-07-03
Holistic Evaluation of Language Models, Percy Liang+, TMLR'23
Summary言語モデルの透明性を向上させるために、Holistic Evaluation of Language Models(HELM)を提案する。HELMでは、潜在的なシナリオとメトリックを分類し、広範なサブセットを選択して評価する。さらに、複数のメトリックを使用し、主要なシナリオごとに評価を行う。30の主要な言語モデルを42のシナリオで評価し、HELM以前に比べて評価のカバレッジを改善した。HELMはコミュニティのためのベンチマークとして利用され、新しいシナリオ、メトリック、モデルが継続的に更新される。
CommentOpenReview:https://openreview.net/forum?id=iO4LZibEqWHELMを提案した研究
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/ #NLP #Dataset #LanguageModel #Evaluation #TMLR Issue Date: 2023-07-03 Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, N_A, TMLR'23 Summary言語モデルの能力と制約を理解するために、BIG-benchという新しいベンチマークを導入しました。このベンチマークでは、現在の言語モデルの能力を超えるタスクに焦点を当てています。さまざまなトピックの204のタスクが含まれており、モデルのサイズや性能の比較も行いました。結果として、モデルの性能とキャリブレーションは向上していますが、絶対的な性能は低く、モデル間の性能も似ていることがわかりました。また、スパース性からの利益やタスクの特性についても調査しました。さらに、曖昧な文脈の設定では社会的な偏見が増加することも示されましたが、プロンプトの使用で改善できる可能性もあります。 CommentOpenReview:https://openreview.net/forum?id=uyTL5BvosjBIG-Bench論文。ワードクラウドとキーワード分布を見ると一つの分野に留まらない非常に多様なタスクが含まれることがわかる。

 BIG-Bench-hardは、2024年にClaude3.5によって、Average Human Scoreが67.7%のところ、93.1%を達成され攻略が完了した。現在は最先端のモデル間の性能を差別化することはできない。
BIG-Bench-hardは、2024年にClaude3.5によって、Average Human Scoreが67.7%のところ、93.1%を達成され攻略が完了した。現在は最先端のモデル間の性能を差別化することはできない。
・1662 #MachineLearning #NLP #LanguageModel #LongSequence Issue Date: 2023-07-03 Augmenting Language Models with Long-Term Memory, Weizhi Wang+, N_A, arXiv'23 Summary既存の大規模言語モデル(LLMs)は、入力長の制限により、長い文脈情報を活用できない問題があります。そこで、私たちは「長期記憶を持つ言語モデル(LongMem)」というフレームワークを提案しました。これにより、LLMsは長い履歴を記憶することができます。提案手法は、メモリエンコーダとして凍結されたバックボーンLLMと、適応的な残余サイドネットワークを組み合わせた分離されたネットワークアーキテクチャを使用します。このアーキテクチャにより、長期の過去の文脈を簡単にキャッシュし、利用することができます。実験結果は、LongMemが長い文脈モデリングの難しいベンチマークであるChapterBreakで強力な性能を発揮し、メモリ増強型のコンテキスト内学習で改善を達成することを示しています。提案手法は、言語モデルが長い形式のコンテンツを記憶し利用するのに効果的です。 CommentLLMに長期のhistoryを記憶させることを可能する新たな手法を提案し、既存のstrongな長いcontextを扱えるモデルを上回るパフォーマンスを示した
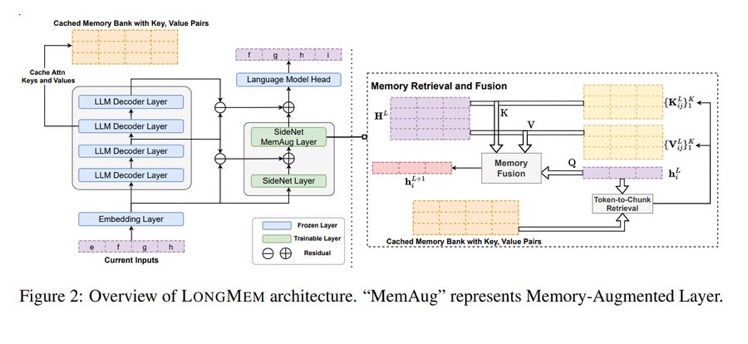 #NLP
#Dataset
#LanguageModel
#Evaluation
Issue Date: 2023-07-03
Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks, Veniamin Veselovsky+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)の普及率を調査するために、クラウドワーカーによるLLMの使用の事例研究を行った。結果から、33〜46%のクラウドワーカーがタスクの完了時にLLMsを使用していることが推定された。これにより、人間のデータが人間のものであることを確保するために新しい方法が必要であることが示唆された。
CommentMturkの言語生成タスクにおいて、Turkerのうち33-46%はLLMsを利用していることを明らかにした
#NLP
#LanguageModel
#Evaluation
Issue Date: 2023-07-03
Bring Your Own Data Self-Supervised Evaluation for Large Language Models, Neel Jain+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)の振る舞いを評価するための自己教師あり評価フレームワークを提案する。これにより、人間によるラベル付けが必要なくなり、実際のデータに対してモデルの感度や不変性を評価できる。自己教師あり評価は、クローズドブックの知識や有害性、文脈依存性などの側面を評価することができる。また、人間による教師あり評価との相関関係も高い。自己教師あり評価は、現在の評価戦略を補完するものである。
CommentMotivation
#NLP
#Dataset
#LanguageModel
#Evaluation
Issue Date: 2023-07-03
Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks, Veniamin Veselovsky+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)の普及率を調査するために、クラウドワーカーによるLLMの使用の事例研究を行った。結果から、33〜46%のクラウドワーカーがタスクの完了時にLLMsを使用していることが推定された。これにより、人間のデータが人間のものであることを確保するために新しい方法が必要であることが示唆された。
CommentMturkの言語生成タスクにおいて、Turkerのうち33-46%はLLMsを利用していることを明らかにした
#NLP
#LanguageModel
#Evaluation
Issue Date: 2023-07-03
Bring Your Own Data Self-Supervised Evaluation for Large Language Models, Neel Jain+, N_A, arXiv'23
Summary大規模言語モデル(LLMs)の振る舞いを評価するための自己教師あり評価フレームワークを提案する。これにより、人間によるラベル付けが必要なくなり、実際のデータに対してモデルの感度や不変性を評価できる。自己教師あり評価は、クローズドブックの知識や有害性、文脈依存性などの側面を評価することができる。また、人間による教師あり評価との相関関係も高い。自己教師あり評価は、現在の評価戦略を補完するものである。
CommentMotivation
LLMの急速な発展によって、それらの能力とlimitationを正確にとらえるための様々な新たなmetricsが提案されてきたが、結果的に、新たなモデルが既存のデータセットを廃止に追い込み、常に新たなデータセットを作成する必要が生じている。
近年のBIG-Bench 785 や HELM 786 はこれらの問題に対処するために、増え続ける蓄積された多様なmicro-benchmarkを用いてLLMのパフォーマンスを測定することで対処しているが、データセットの生成とキュレーションに依存したアプローチとなっており、これらはtine-consumingでexpensiveである。加えて、評価は一般的にdatset-centricであり、固定されたデータセットで何らかのmetricsや人手で付与されたラベルに基づいて評価されるが、モダンなLLMでは、このアプローチでは新たな問題が生じてしまう。
・評価データがインターネット上でホスティングされること。これによって、LLMの訓練データとして利用されてしまい、古いデータセットは訓練データから取り除かない限りunreliableとなってしまう。
・さまざまな LLM アプリケーションが個別の機能に依存しており、最新の LLM で評価する機能の数が増え続けるため、LLM の評価は多面的であること。
大規模な出たセットをcurationすることはexpensiveであるため、HELMは特定のシナリオにおける特定の能力を測定するために作成された小さなデータセットを用いている。しかし、より広範なコンテキストや設定でモデルがデプロイするときに、このような評価が適用可能かは定かではない。
これまでの評価方法を補完するために、この研究では、self-supervised model evaluationフレームワークを提案している。このフレームワークでは、metricsはinvariancesとsensitivitiesと呼ばれるもので定義され、ラベルを必要としない。代わりに、self-supervisionのフェーズに介入することでこれらのmetricsを算出する。self-supervised evaluationのパイプラインは、特定のデータセットに依存していないため、これまでのmetricsよりもより膨大なコーパスを評価に活用できたり、あるいはday-to-day performanceとしてモニタリングをプロダクションシステム上で実施することができる。以下Dr. Sebastian Ruschkaのツイートの引用
>We use self-supervised learning to pretrain LLMs (e.g., next-word prediction).
Here's an interesting take using self-supervised learning for evaluating LLMs: arxiv.org/abs//2306.13651
Turns out, there's correlation between self-supervised evaluations & human evaluations.

元ツイート
https://twitter.com/rasbt/status/1679139569327824897?s=46&t=ArwxeDos47eUWfAg7_FRtg
図が非常にわかりやすい Issue Date: 2023-06-16 PEARL: Prompting Large Language Models to Plan and Execute Actions Over Long Documents, Simeng Sun+, N_A, arXiv'23 Summary本研究では、長いドキュメント上の推論を改善するためのPEARLというプロンプティングフレームワークを提案している。PEARLは、アクションマイニング、プランの策定、プランの実行の3つのステージで構成されており、最小限の人間の入力でゼロショットまたはフューショットのLLMsによるプロンプティングによって実装される。PEARLは、QuALITYデータセットの難しいサブセットで評価され、ゼロショットおよびchain-of-thought promptingを上回る性能を発揮した。PEARLは、LLMsを活用して長いドキュメント上の推論を行うための第一歩である。 Issue Date: 2023-06-16 The False Promise of Imitating Proprietary LLMs, Arnav Gudibande+, N_A, arXiv'23 Summary本研究は、ChatGPTなどのプロプライエタリシステムからの出力を使用して、弱いオープンソースモデルを微調整する新興の手法について批判的に分析した。異なるベースモデルサイズ、データソース、および模倣データ量を使用して、ChatGPTを模倣する一連のLMを微調整し、クラウドレーターと標準的なNLPベンチマークを使用してモデルを評価した。結果、模倣モデルはChatGPTのスタイルを模倣するのに熟練しているが、事実性を模倣することができないため、人間のレーターから見逃される可能性があることがわかった。全体的に、より優れたベースLMを開発することが、オープンソースモデルを改善するための最も効果的なアクションだと主張している。 #NLP #Transformer #LLMAgent Issue Date: 2023-06-16 Think Before You Act: Decision Transformers with Internal Working Memory, Jikun Kang+, N_A, arXiv'23 Summary大規模言語モデル(LLM)の性能は、トレーニング中にパラメータに振る舞いを記憶する「忘却現象」によって低下する可能性がある。人間の脳は分散型のメモリストレージを利用しており、忘却現象を軽減している。そこで、我々は、内部作業メモリモジュールを提案し、Atariゲームとメタワールドオブジェクト操作タスクの両方でトレーニング効率と汎化性を向上させることを示した。 Issue Date: 2023-06-16 Lexinvariant Language Models, Qian Huang+, N_A, arXiv'23 Summary本論文では、固定されたトークン埋め込みなしで高性能な言語モデルを実現することが可能かどうかを検証し、lexinvariant言語モデルを提案する。lexinvariant言語モデルは、トークンの共起と繰り返しに完全に依存し、固定されたトークン埋め込みが必要なくなる。実験的には、標準的な言語モデルと同等のperplexityを達成できることを示し、さらに、synthetic in-context reasoning tasksに対して4倍の精度が向上することを示す。 Issue Date: 2023-06-16 Backpack Language Models, John Hewitt+, N_A, arXiv'23 SummaryBackpacksという新しいニューラルアーキテクチャを提案し、語彙内の各単語に対して複数の意味ベクトルを学習し、意味ベクトルを介入することで制御可能なテキスト生成やバイアスの除去ができることを示した。OpenWebTextでトレーニングされたBackpack言語モデルは、語彙の類似性評価で6BパラメータのTransformer LMの単語埋め込みを上回った。 Issue Date: 2023-06-16 Training Socially Aligned Language Models in Simulated Human Society, Ruibo Liu+, N_A, arXiv'23 Issue Date: 2023-06-16 A Closer Look at In-Context Learning under Distribution Shifts, Kartik Ahuja+, N_A, arXiv'23 Summary本研究では、インコンテキスト学習の汎用性と制限を理解するために、線形回帰という単純なタスクを用いて、トランスフォーマーとセットベースのMLPの比較を行った。分布内評価において両モデルがインコンテキスト学習を示すことがわかったが、トランスフォーマーはOLSのパフォーマンスにより近い結果を示し、軽微な分布シフトに対してより強い耐性を示した。ただし、厳しい分布シフトの下では、両モデルのインコンテキスト学習能力が低下することが示された。 #NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-06-16 OlaGPT: Empowering LLMs With Human-like Problem-Solving Abilities, Yuanzhen Xie+, N_A, arXiv'23 Summary本論文では、人間の認知フレームワークを模倣することで、複雑な推論問題を解決するための新しい知的フレームワークであるOlaGPTを提案しています。OlaGPTは、注意、記憶、推論、学習などの異なる認知モジュールを含み、以前の誤りや専門家の意見を動的に参照する学習ユニットを提供しています。また、Chain-of-Thought(COT)テンプレートと包括的な意思決定メカニズムも提案されています。OlaGPTは、複数の推論データセットで厳密に評価され、最先端のベンチマークを上回る優れた性能を示しています。OlaGPTの実装はGitHubで利用可能です。 Issue Date: 2023-06-16 Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models' Reasoning Performance, Yao Fu+, N_A, arXiv'23 Summary本研究では、大規模言語モデルの評価スイートであるChain-of-Thought Hubを提案し、LLMsの進歩を追跡するために挑戦的な推論ベンチマークのスイートを編成することを目的としています。現在の結果は、モデルのスケールが推論能力と相関しており、オープンソースのモデルはまだ遅れていることを示しています。また、LLaMA-65BはGPT-3.5-Turboに近づく可能性があることを示しています。コミュニティがより良いベースモデルの構築とRLHFの探索に重点を置く必要があることを示唆しています。 Issue Date: 2023-06-16 SwiftSage: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks, Bill Yuchen Lin+, N_A, arXiv'23 SummarySwiftSageは、人間の認知の二重プロセス理論に基づいて設計されたエージェントフレームワークであり、行動クローニングと大規模言語モデルのプロンプティングを統合して、複雑な対話型推論タスクにおけるアクションプランニングに優れている。SwiftモジュールとSageモジュールの2つの主要なモジュールを含み、30のタスクにおいて他の手法を大幅に上回り、複雑な現実世界のタスクを解決する効果を示した。 #ComputerVision #Personalization Issue Date: 2023-06-16 Photoswap: Personalized Subject Swapping in Images, Jing Gu+, N_A, arXiv'23 Summary本研究では、Photoswapという新しいアプローチを提案し、既存の画像において個人的な対象物の交換を可能にすることを目的としています。Photoswapは、参照画像から対象物の視覚的な概念を学習し、トレーニングフリーでターゲット画像に交換することができます。実験により、Photoswapが効果的で制御可能であり、ベースライン手法を大幅に上回る人間の評価を得ていることが示されました。Photoswapは、エンターテインメントからプロの編集まで幅広い応用可能性を持っています。 Issue Date: 2023-06-16 Controllable Text-to-Image Generation with GPT-4, Tianjun Zhang+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を使用して、テキストから画像を生成するためのパイプラインを誘導する方法を提案しています。Control-GPTを導入し、GPT-4によって生成されたプログラム的なスケッチを使用して、拡散ベースのテキストから画像へのパイプラインを誘導し、指示に従う能力を向上させます。この研究は、LLMsをコンピュータビジョンタスクのパフォーマンス向上に活用する可能性を示す初めての試みです。 Issue Date: 2023-06-16 KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models, Zhiwei Jia+, N_A, arXiv'23 Summary画像広告の理解は、現実世界のエンティティやシーンテキストの推論を含むため、非常に困難であるが、VLMsの時代において未開拓の分野である。本研究では、事前学習されたVLMsを画像広告の理解に適応するための実用的な課題をベンチマークし、現実世界のエンティティの知識を付加することで、画像広告のマルチモーダル情報を効果的に融合するためのシンプルな特徴適応戦略を提案した。広告業界に広く関連する画像広告の理解により多くの注目が集まることが期待される。 Issue Date: 2023-06-16 Grammar Prompting for Domain-Specific Language Generation with Large Language Models, Bailin Wang+, N_A, arXiv'23 SummaryLLMsは幅広い自然言語タスクを学習できるが、高度に構造化された言語の生成には困難がある。本研究では、文法プロンプティングを使用して、外部の知識やドメイン固有の制約を学習中に使用する方法を探求した。文法プロンプティングは、各デモンストレーション例に特化した文法を付加し、最小限必要な文法で特定の出力例を生成する。実験により、文法プロンプティングが多様なDSL生成タスクで競争力のあるパフォーマンスを発揮できることが示された。 Issue Date: 2023-06-16 Blockwise Parallel Transformer for Long Context Large Models, Hao Liu+, N_A, arXiv'23 Summaryトランスフォーマーの自己注意機構とフィードフォワードネットワークによるメモリ要件の制限を解決するために、ブロックごとの並列トランスフォーマー(BPT)を提案。BPTは、メモリ効率を維持しながらより長い入力シーケンスを処理することができ、徹底的な実験により、言語モデリングや強化学習タスクにおいてパフォーマンスを向上させることが示された。 Issue Date: 2023-06-16 Deliberate then Generate: Enhanced Prompting Framework for Text Generation, Bei Li+, N_A, arXiv'23 Summary本論文では、新しいDeliberate then Generate(DTG)プロンプトフレームワークを提案し、LLMsの自然言語生成タスクにおける成功をさらに促進することを目的としている。DTGは、誤り検出指示と誤りを含む可能性のある候補から構成され、モデルが熟考することを促すことで、最先端のパフォーマンスを達成することができる。20以上のデータセットでの広範な実験により、DTGが既存のプロンプト方法を一貫して上回り、LLMsのプロンプトに関する将来の研究にインスピレーションを与える可能性があることが示された。 Issue Date: 2023-06-16 CodeTF: One-stop Transformer Library for State-of-the-art Code LLM, Nghi D. Q. Bui+, N_A, arXiv'23 Summary本論文では、CodeTFというオープンソースのTransformerベースのライブラリを紹介し、最新のCode LLMsとコードインテリジェンスのためのモジュール設計と拡張可能なフレームワークの原則に従って設計されていることを説明しています。CodeTFは、異なるタイプのモデル、データセット、タスクに対して迅速なアクセスと開発を可能にし、事前学習済みのCode LLMモデルと人気のあるコードベンチマークをサポートしています。また、言語固有のパーサーおよびコード属性を抽出するためのユーティリティ関数などのデータ機能を提供しています。CodeTFは、機械学習/生成AIとソフトウェアエンジニアリングのギャップを埋め、開発者、研究者、実践者にとって包括的なオープンソースのソリューションを提供することを目的としています。 #MachineLearning #Transformer Issue Date: 2023-06-16 Birth of a Transformer: A Memory Viewpoint, Alberto Bietti+, N_A, arXiv'23 Summary大規模言語モデルの内部メカニズムを理解するため、トランスフォーマーがグローバルとコンテキスト固有のbigram分布をどのようにバランスするかを研究。2層トランスフォーマーでの実証的分析により、グローバルbigramの高速な学習と、コンテキスト内のbigramの「誘導ヘッド」メカニズムの遅い発達を示し、重み行列が連想記憶としての役割を強調する。データ分布特性の役割も研究。 Issue Date: 2023-06-16 Brainformers: Trading Simplicity for Efficiency, Yanqi Zhou+, N_A, arXiv'23 Summaryトランスフォーマーの設計選択肢を調査し、異なる順列を持つ複雑なブロックがより効率的であることを発見し、Brainformerという複雑なブロックを開発した。Brainformerは、品質と効率の両方の観点で最新のトランスフォーマーを上回り、トークンあたりのアクティブパラメーター数が80億のモデルは、トレーニング収束が2倍速く、ステップ時間が5倍速いことが示されている。また、ファインチューニングによるSuperGLUEスコアが3%高いことも示している。Brainformerはfewshot評価でも大幅に優れている。 Issue Date: 2023-06-16 StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners, Yonglong Tian+, N_A, arXiv'23 Summary本研究では、テキストから画像を生成するモデルによって生成された合成画像を使用して視覚表現を学習することを調査しました。自己教師あり方法を合成画像に対してトレーニングすることで、実際の画像に匹敵するかそれを上回ることができることを示しました。また、同じテキストプロンプトから生成された複数の画像を互いに正として扱うことで、マルチポジティブコントラスティブ学習手法であるStableRepを開発しました。StableRepによって学習された表現は、SimCLRとCLIPによって学習された表現を上回ります。さらに、20Mの合成画像でトレーニングされたStableRepは、50Mの実際の画像でトレーニングされたCLIPよりも優れた精度を達成します。 #ComputerVision #NLP #Personalization #DiffusionModel #TextToImageGeneration Issue Date: 2023-06-16 ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation, Shaozhe Hao+, N_A, arXiv'23 Summary拡散モデルを用いたパーソナライズされた画像生成において、高速で軽量なプラグインメソッドであるViCoを提案。注目モジュールを導入し、注目ベースのオブジェクトマスクを使用することで、一般的な過学習の劣化を軽減。元の拡散モデルのパラメータを微調整せず、軽量なパラメータトレーニングだけで、最新のモデルと同等またはそれ以上の性能を発揮することができる。 Issue Date: 2023-06-16 Evaluating Language Models for Mathematics through Interactions, Katherine M. Collins+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を評価するための適応可能なプロトタイププラットフォームであるCheckMateを紹介し、数学の学部レベルの証明を支援するアシスタントとして、InstructGPT、ChatGPT、およびGPT-4の3つの言語モデルを評価しました。MathConverseという対話と評価のデータセットを公開し、LLMの生成において正確さと知覚された有用性の間に著しい相違があることなど、他の発見も行いました。対話的評価はこれらのモデルの能力を継続的にナビゲートする有望な方法であること、人間は言語モデルの代数的な誤りに注意を払い、そのために使用すべき場所を見極める必要があることを示しました。 Issue Date: 2023-06-16 Responsible Task Automation: Empowering Large Language Models as Responsible Task Automators, Zhizheng Zhang+, N_A, arXiv'23 Summary本論文では、大規模言語モデル(LLMs)を使用したタスク自動化における責任ある行動の実現可能性、完全性、セキュリティについて探求し、Responsible Task Automation(ResponsibleTA)フレームワークを提案する。具体的には、エグゼキューターのコマンドの実現可能性を予測すること、エグゼキューターの完全性を検証すること、セキュリティを強化することを目的とした3つの強化された機能を備え、2つのパラダイムを提案する。また、ローカルメモリメカニズムを紹介し、UIタスク自動化でResponsibleTAを評価する。 Issue Date: 2023-06-16 Fine-Grained Human Feedback Gives Better Rewards for Language Model Training, Zeqiu Wu+, N_A, arXiv'23 Summary本研究では、言語モデルの望ましくないテキスト生成の問題に対処するために、細かい粒度の人間のフィードバックを使用するFine-Grained RLHFフレームワークを導入しました。このフレームワークは、報酬関数を細かい粒度に設定することで、自動評価と人間の評価の両方で改善されたパフォーマンスをもたらします。また、異なる報酬モデルの組み合わせを使用することで、LMの振る舞いをカスタマイズできることも示しました。 Issue Date: 2023-06-16 The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only, Guilherme Penedo+, N_A, arXiv'23 Summary大規模言語モデルの訓練には、キュレーションされた高品質のコーパスとWebデータが使用されるが、Webデータだけでも強力なモデルを生成できることが示された。RefinedWebデータセットから6000億トークンの抽出と、それに基づく1.3/7.5Bパラメータの言語モデルが公開された。CommonCrawlから5兆トークンを取得できることも示された。 Issue Date: 2023-06-16 InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models, Lichang Chen+, N_A, arXiv'23 SummaryLLMsの指示を最適化するために、オープンソースLLMに適用される低次元のソフトプロンプトを最適化する提案手法であるInstructZeroを紹介。オープンソースLLMを使用してソフトプロンプトを指示に変換し、ブラックボックスLLMに提出してゼロショット評価を行い、パフォーマンスをベイズ最適化に送信して、新しいソフトプロンプトを生成する。VicunaやChatGPTなどのオープンソースLLMとAPIの異なる組み合わせで評価し、SOTA自動指示手法を上回ることを示した。コードとデータはhttps://github.com/Lichang-Chen/InstructZeroで公開されています。 Issue Date: 2023-06-16 Binary and Ternary Natural Language Generation, Zechun Liu+, N_A, arXiv'23 Summary三値および二値ニューラルネットワークを最適化することは困難であるが、重みの統計に基づく量子化と活性化の弾性量子化の混合によって問題に取り組み、要約と機械翻訳の下流タスクで最初の三値および二値Transformerモデルを実証する。三値BARTベースは、CNN/DailyMailベンチマークでR1スコア41を達成し、16倍効率的である。バイナリモデルは、非常に重要なスコア35.6を達成している。機械翻訳においては、WMT16 En-RoベンチマークでBLEUスコア21.7および17.6を達成し、8ビット重みモデルで一致または上回ることができることを示した。 Issue Date: 2023-06-16 Simple and Controllable Music Generation, Jade Copet+, N_A, arXiv'23 Summary本研究では、単一の言語モデルであるMusicGenを紹介し、複数のモデルを連鎖する必要がなくなることで、条件付けられた高品質な音楽サンプルを生成できることを示した。広範な実験評価により、提案手法が標準的なベンチマークよりも優れていることを示し、各コンポーネントの重要性についての削除実験も行った。音楽サンプル、コード、およびモデルは、https://github.com/facebookresearch/audiocraftで入手可能です。 Issue Date: 2023-06-16 Language-Guided Music Recommendation for Video via Prompt Analogies, Daniel McKee+, N_A, arXiv'23 Summary本研究では、音楽選曲のガイド付きで、入力ビデオに対して音楽を推薦する手法を提案する。音楽のテキスト説明が不足している問題に対して、大規模言語モデルから事前にトレーニングされた音楽タガーの出力と人間のテキスト説明を組み合わせたテキスト合成アプローチを提案し、トリモーダルモデルをトレーニングする。評価実験により、従来の手法と同等またはそれ以上の性能を発揮することが示された。 #ComputerVision #NLP #QuestionAnswering #MulltiModal Issue Date: 2023-06-16 AVIS: Autonomous Visual Information Seeking with Large Language Models, Ziniu Hu+, N_A, arXiv'23 Summary本論文では、自律的な情報収集ビジュアル質問応答フレームワークであるAVISを提案する。AVISは、大規模言語モデル(LLM)を活用して外部ツールの利用戦略を動的に決定し、質問に対する回答に必要な不可欠な知識を獲得する。ユーザースタディを実施して収集したデータを用いて、プランナーや推論エンジンを改善し、知識集約型ビジュアル質問応答ベンチマークで最先端の結果を達成することを示している。 Comment
Issue Date: 2023-06-16 WizardCoder: Empowering Code Large Language Models with Evol-Instruct, Ziyang Luo+, N_A, arXiv'23 SummaryCode LLMsにおいて、WizardCoderを導入することで、複雑な指示の微調整を可能にし、4つの主要なコード生成ベンチマークで他のオープンソースのCode LLMsを大幅に上回る優れた能力を示した。さらに、AnthropicのClaudeやGoogleのBardをも上回る性能を発揮し、コード、モデルの重み、およびデータはGitHubで公開されている。 #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2023-06-16 KoLA: Carefully Benchmarking World Knowledge of Large Language Models, Jifan Yu+, N_A, arXiv'23 SummaryLLMの評価を改善するために、KoLAという知識指向のベンチマークを構築した。このベンチマークは、19のタスクをカバーし、Wikipediaと新興コーパスを使用して、知識の幻覚を自動的に評価する独自の自己対照メトリックを含む対照的なシステムを採用している。21のオープンソースと商用のLLMを評価し、KoLAデータセットとオープン参加のリーダーボードは、LLMや知識関連システムの開発の参考資料として継続的に更新される。 Issue Date: 2023-06-16 STUDY: Socially Aware Temporally Casual Decoder Recommender Systems, Eltayeb Ahmed+, N_A, arXiv'23 Summary本研究では、膨大なデータ量に直面する中で、ソーシャルネットワーク情報を利用したレコメンドシステムの提案を行いました。提案手法であるSTUDYは、修正されたトランスフォーマーデコーダーネットワークを使用して、ソーシャルネットワークグラフ上で隣接するユーザーグループ全体に対して共同推論を行います。学校教育コンテンツの設定で、教室の構造を使用してソーシャルネットワークを定義し、提案手法をテストした結果、ソーシャルおよびシーケンシャルな方法を上回り、単一の均質ネットワークの設計の簡素さを維持しました。また、アブレーション研究を実施して、ユーザーの行動の類似性を効果的にモデル化するソーシャルネットワーク構造を活用することがモデルの成功に重要であることがわかりました。 Issue Date: 2023-06-16 GeneCIS: A Benchmark for General Conditional Image Similarity, Sagar Vaze+, N_A, arXiv'23 Summary本論文では、モデルがさまざまな類似性条件に動的に適応できる能力を測定するGeneCISベンチマークを提案し、既存の方法をスケーリングすることは有益ではないことを示唆しています。また、既存の画像キャプションデータセットから情報を自動的にマイニングすることに基づくシンプルでスケーラブルなソリューションを提案し、関連する画像検索ベンチマークのゼロショットパフォーマンスを向上させました。GeneCISのベースラインに比べて大幅な改善をもたらし、MIT-Statesでの最新の教師ありモデルを上回る性能を発揮しています。 Issue Date: 2023-06-16 WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences, Xiao Liu+, N_A, arXiv'23 SummaryWebGLMは、GLMに基づくWeb拡張型質問応答システムであり、LLMによるリトリーバー、ブートストラップされたジェネレーター、および人間の嗜好に配慮したスコアラーを実現することで、実世界の展開に効率的であることを目的としています。WebGLMは、WebGPTよりも優れた性能を発揮し、Web拡張型QAシステムの評価基準を提案しています。コード、デモ、およびデータは\url{https://github.com/THUDM/WebGLM}にあります。 #PEFT(Adaptor/LoRA) Issue Date: 2023-06-16 One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning, Arnav Chavan+, N_A, arXiv'23 Summary本研究では、汎用的なファインチューニングタスクのための高度な手法であるGeneralized LoRA (GLoRA)を提案し、事前学習済みモデルの重みを最適化し、中間アクティベーションを調整することで、多様なタスクとデータセットに対してより柔軟性と能力を提供する。GLoRAは、各レイヤーの個別のアダプタを学習するスケーラブルでモジュラーなレイヤーごとの構造探索を採用することで、効率的なパラメータの適応を促進する。包括的な実験により、GLoRAは、自然言語、専門分野、構造化ベンチマークにおいて、従来のすべての手法を上回り、様々なデータセットでより少ないパラメータと計算で優れた精度を達成することが示された。 CommentOpenReview:https://openreview.net/forum?id=K7KQkiHanD
ICLR'24にrejectされている Issue Date: 2023-06-16 Augmenting Language Models with Long-Term Memory, Weizhi Wang+, N_A, arXiv'23 Summary本研究では、長期記憶を持つ言語モデルを実現するための「LongMem」というフレームワークを提案し、メモリリトリーバーとリーダーを使用する新しいデカップルネットワークアーキテクチャを設計しました。LongMemは、長期過去の文脈を記憶し、言語モデリングに長期記憶を活用することができます。提案されたメモリリトリーバーモジュールは、メモリバンク内の無制限の長さの文脈を扱うことができ、様々なダウンストリームタスクに利益をもたらします。実験結果は、本手法が、長い文脈モデリングの難しいベンチマークであるChapterBreakにおいて、強力な長文脈モデルを上回り、LLMsに比べてメモリ拡張インコンテキスト学習において顕著な改善を達成することを示しています。 Issue Date: 2023-06-16 Benchmarking Neural Network Training Algorithms, George E. Dahl+, N_A, arXiv'23 Summaryトレーニングアルゴリズムの改善によるモデルの高速化と正確性の向上は重要であるが、現在のコミュニティでは最先端のトレーニングアルゴリズムを決定することができない。本研究では、トレーニングアルゴリズムの経験的比較に直面する3つの基本的な課題を解決する新しいベンチマーク、AlgoPerf: Training Algorithmsベンチマークを導入することを主張する。このベンチマークには、競争力のあるタイム・トゥ・リザルト・ベンチマークが含まれており、最適化手法の比較に役立つ。最後に、ベースライン提出と他の最適化手法を評価し、将来のベンチマーク提出が超えることを試みるための仮の最先端を設定する。 Issue Date: 2023-06-16 Evaluating the Social Impact of Generative AI Systems in Systems and Society, Irene Solaiman+, N_A, arXiv'23 Summary様々なモダリティにわたる生成型AIシステムの社会的影響を評価するための公式の標準が存在しないため、我々はそれらの影響を評価するための標準的なアプローチに向けて進んでいます。我々は、技術的な基盤システムで評価可能な社会的影響のカテゴリーと、人々や社会で評価可能な社会的影響のカテゴリーを定義し、それぞれにサブカテゴリーと害を軽減するための推奨事項を提供しています。また、AI研究コミュニティが既存の評価を提供できるように、評価リポジトリを作成しています。 Issue Date: 2023-06-16 PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts, Kaijie Zhu+, N_A, arXiv'23 SummaryLLMsの頑健性を測定するための頑健性ベンチマークであるPromptBenchを紹介する。PromptBenchは、多数の敵対的なテキスト攻撃を使用して、感情分析、自然言語推論、読解、機械翻訳、数学問題解決などの多様なタスクで使用されるプロンプトに対するLLMsの耐性を測定する。研究では、8つのタスクと13のデータセットで4,032の敵対的なプロンプトを生成し、合計567,084のテストサンプルを評価した。結果は、現代のLLMsが敵対的なプロンプトに対して脆弱であることを示しており、プロンプトの頑健性と移植性に関する包括的な分析を提供する。また、敵対的なプロンプトを生成するためのコード、プロンプト、および方法論を公開し、研究者や一般ユーザーの両方にとって有益である。 Issue Date: 2023-06-16 Modular Visual Question Answering via Code Generation, Sanjay Subramanian+, N_A, arXiv'23 Summary視覚的な質問応答をモジュラーコード生成として定式化するフレームワークを提案し、追加のトレーニングを必要とせず、事前にトレーニングされた言語モデル、画像キャプションペアで事前にトレーニングされたビジュアルモデル、およびコンテキスト学習に使用される50のVQA例に依存しています。生成されたPythonプログラムは、算術および条件付き論理を使用して、ビジュアルモデルの出力を呼び出し、合成します。COVRデータセットで少なくとも3%、GQAデータセットで約2%の精度向上を実現しています。 Issue Date: 2023-06-16 PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization, Yidong Wang+, N_A, arXiv'23 Summary大規模言語モデル(LLMs)の調整には、ハイパーパラメータの選択の複雑さと評価の難しさが残っています。そこで、PandaLMという判定用大規模言語モデルを導入し、複数のLLMsが与えられた場合に優れたモデルを区別するために訓練されます。PandaLMは、相対的な簡潔さ、明確さ、指示に従うこと、包括性、形式性などの重要な主観的要因に対処することができます。PandaLMは、APIベースの評価に依存しないため、潜在的なデータ漏洩を回避できます。PandaLMによって調整されたモデルは、デフォルトのAlpacaのハイパーパラメータでトレーニングされた対照モデルと比較して、有意な改善が実現されるため、LLMの評価がより公正かつコストが少なくなります。 Issue Date: 2023-06-16 Improving Open Language Models by Learning from Organic Interactions, Jing Xu+, N_A, arXiv'23 SummaryBlenderBot 3xは、BlenderBot 3のアップデートであり、有機的な会話とフィードバックデータを使用してトレーニングされ、スキルと安全性の両方を向上させました。参加者の匿名化された相互作用データが公開され、有害な行動を回避する技術が研究されました。BlenderBot 3xは、BlenderBot 3よりも会話で好まれ、より安全な応答を生成することが示されています。改善の余地があるものの、継続的な技術の使用により、さらなる改善が可能だと考えられています。 Issue Date: 2023-06-16 Tracking Everything Everywhere All at Once, Qianqian Wang+, N_A, arXiv'23 Summary本研究では、ビデオシーケンスから長距離の動きを推定するための新しい手法を提案する。従来の手法では、時間枠内での動作や遮蔽物の追跡が困難であり、グローバルな一貫性を維持することができなかった。提案手法では、OmniMotionという完全でグローバルに一貫した動き表現を使用し、遮蔽物を追跡し、カメラとオブジェクトの動きの任意の組み合わせをモデル化することができる。TAP-Vidベンチマークと実世界の映像での評価により、本手法が従来の最先端の手法を大幅に上回ることが示された。 Issue Date: 2023-06-16 INSTRUCTEVAL: Towards Holistic Evaluation of Instruction-Tuned Large Language Models, Yew Ken Chia+, N_A, arXiv'23 Summary指示に調整された大規模言語モデルの包括的な評価スイートであるINSTRUCTEVALが提案された。この評価は、問題解決能力、文章能力、および人間の価値観に対する適合性に基づくモデルの厳密な評価を含む。指示データの品質がモデルのパフォーマンスを拡大する上で最も重要な要因であることが明らかになった。オープンソースのモデルは印象的な文章能力を示しているが、問題解決能力や適合性には改善の余地がある。INSTRUCTEVALは、指示に調整されたモデルの深い理解と能力の向上を促進することを目指している。 Issue Date: 2023-06-16 Youku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks, Haiyang Xu+, N_A, arXiv'23 Summary中国のコミュニティにおいて、Vision-Language Pre-training(VLP)とマルチモーダル大規模言語モデル(LLM)の発展を促進するために、Youku-mPLUGという最大の公開中国語高品質ビデオ言語データセットをリリースしました。このデータセットは、大規模なプレトレーニングに使用でき、クロスモーダル検索、ビデオキャプション、ビデオカテゴリ分類の3つの人気のあるビデオ言語タスクをカバーする最大の人間注釈中国語ベンチマークを慎重に構築しました。Youku-mPLUGでプレトレーニングされたモデルは、ビデオカテゴリ分類で最大23.1%の改善を実現し、mPLUG-videoは、ビデオカテゴリ分類で80.5%のトップ1精度、ビデオキャプションで68.9のCIDErスコアで、これらのベンチマークで新しい最高の結果を達成しました。また、Youku-mPLUGでのプレトレーニングが、全体的および詳細な視覚的意味、シーンテキストの認識、およびオープンドメインの知識の活用能力を向上させることを示すゼロショットの指示理解実験も行われました。 Issue Date: 2023-06-16 M$^3$IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning, Lei Li+, N_A, arXiv'23 SummaryVLMの進歩は、高品質の指示データセットの不足により制限されている。そこで、M$^3$ITデータセットが紹介された。このデータセットは、40のデータセット、240万のインスタンス、400の手動で書かれたタスク指示を含み、ビジョンからテキスト構造に再フォーマットされている。M$^3$ITは、タスクカバレッジ、指示数、インスタンススケールの面で以前のデータセットを上回っている。また、このデータセットで訓練されたVLMモデルであるYing-VLMは、複雑な質問に答え、未知のビデオタスクに汎用的に対応し、中国語の未知の指示を理解する可能性を示している。 #NeurIPS Issue Date: 2023-06-16 Deductive Verification of Chain-of-Thought Reasoning, Zhan Ling+, N_A, NeuriPS'23 Summary大規模言語モデル(LLMs)を使用して、Chain-of-Thought(CoT)プロンプティングによる推論タスクを解決するために、自己検証を通じて推論プロセスの信頼性を確保するNatural Programを提案する。このアプローチにより、モデルは正確な推論ステップを生成し、各演繹的推論段階に統合された検証プロセスにより、生成された推論ステップの厳密性と信頼性を向上させることができる。コードはhttps://github.com/lz1oceani/verify_cotで公開される。 Issue Date: 2023-06-16 Natural Language Commanding via Program Synthesis, Apurva Gandhi+, N_A, arXiv'23 SummarySemantic Interpreterは、Microsoft Officeなどの生産性ソフトウェアにおいて、LLMsとODSLを活用して、自然言語のユーザー発話をアプリケーションの機能に実行するAIシステムである。本論文では、Microsoft PowerPointの研究探索に焦点を当てて、Analysis-Retrievalプロンプト構築方法を用いたSemantic Interpreterの実装について議論している。 #PairWise #NLP #LanguageModel #Ensemble #ACL #ModelMerge Issue Date: 2023-06-16 LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion, Dongfu Jiang+, N_A, ACL'23 SummaryLLM-Blenderは、複数の大規模言語モデルを組み合わせたアンサンブルフレームワークであり、PairRankerとGenFuserの2つのモジュールから構成されています。PairRankerは、専門的なペアワイズ比較方法を使用して候補の出力間の微妙な違いを区別し、GenFuserは、上位ランクの候補をマージして改善された出力を生成します。MixInstructというベンチマークデータセットを導入し、LLM-Blenderは、個々のLLMsやベースライン手法を大幅に上回り、大きなパフォーマンス差を確立しました。 Issue Date: 2023-05-22 Counterfactuals for Design: A Model-Agnostic Method For Design Recommendations, Lyle Regenwetter+, N_A, arXiv'23 Summary本研究では、デザイン問題におけるカウンターファクチュアル最適化のための新しい手法であるMCDを紹介する。MCDは、設計問題において重要な多目的クエリをサポートし、カウンターファクチュアル探索とサンプリングプロセスを分離することで効率を向上させ、目的関数のトレードオフの可視化を容易にすることで、既存のカウンターファクチュアル探索手法を改善している。MCDは、自転車設計の3つのケーススタディを行い、実世界の設計問題において有効であることを示している。全体的に、MCDは、実践者や設計自動化研究者が「もしも」の質問に答えを見つけるための貴重な推奨を提供する可能性がある。 Issue Date: 2023-05-22 QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, N_A, arXiv'23 SummaryQUESTデータセットは、交差、和、差などの集合演算を暗黙的に指定するクエリを生成するために、選択的な情報ニーズを定式化することによって構築されました。このデータセットは、Wikipediaのドキュメントに対応するエンティティのセットにマップされ、クエリで言及される複数の制約を対応するドキュメントの証拠と一致させ、さまざまな集合演算を正しく実行することをモデルに求めます。クラウドワーカーによって言い換えられ、自然さと流暢さがさらに検証されたクエリは、いくつかの現代的な検索システムにとって苦戦することがわかりました。 #NLP #LanguageModel #Supervised-FineTuning (SFT) #In-ContextLearning #EMNLP #PostTraining Issue Date: 2023-05-21 Symbol tuning improves in-context learning in language models, Jerry Wei+, N_A, EMNLP'23 Summary本研究では、自然言語ラベルをシンボルに置き換えて言語モデルを微調整する「symbol tuning」を提案し、未知のタスクや不明確なプロンプトに対して堅牢な性能を示すことを示した。また、symbol tuningによりアルゴリズム的推論タスクでのパフォーマンス向上が見られ、以前の意味的知識を上書きする能力が向上していることが示された。Flan-PaLMモデルを使用して実験が行われ、最大540Bパラメータまで利用された。 Comment概要やOpenReviewの内容をざっくりとしか読めていないが、自然言語のラベルをランダムな文字列にしたり、instructionをあえて除外してモデルをFinetuningすることで、promptに対するsensitivityや元々モデルが持っているラベルと矛盾した意味をin context learningで上書きできるということは、学習データに含まれるテキストを調整することで、正則化の役割を果たしていると考えられる。つまり、ラベルそのものに自然言語としての意味を含ませないことや、instructionを無くすことで、(モデルが表層的なラベルの意味や指示からではなく)、より実際のICLで利用されるExaplarからタスクを推論するように学習されるのだと思われる。
 OpenReview:https://openreview.net/forum?id=vOX7Dfwo3v
Issue Date: 2023-05-20
ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities, Peng Wang+, N_A, arXiv'23
Summary本研究では、ビジョン、音声、言語のモダリティをシームレスに整合させ、統合するためのスケーラブルな方法を探求し、4Bのパラメータを持つONE-PEACEという高度に拡張可能なモデルをリリースした。ONE-PEACEは、アダプタとFFNを追加することで新しいモダリティを簡単に拡張できるだけでなく、セルフアテンションレイヤを介してマルチモーダル融合も可能になる。ONE-PEACEは、広範な単一モーダルおよびマルチモーダルタスクで先導的な結果を達成しており、コードはGitHubで利用可能である。
#NeurIPS
Issue Date: 2023-05-20
Language Models Meet World Models: Embodied Experiences Enhance Language Models, Jiannan Xiang+, N_A, NeurIPS'23
Summary本論文では、大規模言語モデル(LMs)が物理的な環境での単純な推論や計画に苦労することを解決するため、LMsを世界モデルで微調整する新しいパラダイムを提案しています。具体的には、物理的な世界のシミュレータでエージェントを展開し、目的指向の計画とランダムな探索を通じて多様な具現化された経験を獲得することで、LMsを微調整して物理的な世界での推論や行動の多様な能力を教えます。また、重みの選択的な更新のための古典的な弾性重み結合(EWC)を導入し、トレーニング効率のための低ランクアダプタ(LoRA)と組み合わせています。徹底的な実験により、提案手法は18の下流タスクでベースLMsを平均64.28%改善することが示されました。
Comment
OpenReview:https://openreview.net/forum?id=vOX7Dfwo3v
Issue Date: 2023-05-20
ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities, Peng Wang+, N_A, arXiv'23
Summary本研究では、ビジョン、音声、言語のモダリティをシームレスに整合させ、統合するためのスケーラブルな方法を探求し、4Bのパラメータを持つONE-PEACEという高度に拡張可能なモデルをリリースした。ONE-PEACEは、アダプタとFFNを追加することで新しいモダリティを簡単に拡張できるだけでなく、セルフアテンションレイヤを介してマルチモーダル融合も可能になる。ONE-PEACEは、広範な単一モーダルおよびマルチモーダルタスクで先導的な結果を達成しており、コードはGitHubで利用可能である。
#NeurIPS
Issue Date: 2023-05-20
Language Models Meet World Models: Embodied Experiences Enhance Language Models, Jiannan Xiang+, N_A, NeurIPS'23
Summary本論文では、大規模言語モデル(LMs)が物理的な環境での単純な推論や計画に苦労することを解決するため、LMsを世界モデルで微調整する新しいパラダイムを提案しています。具体的には、物理的な世界のシミュレータでエージェントを展開し、目的指向の計画とランダムな探索を通じて多様な具現化された経験を獲得することで、LMsを微調整して物理的な世界での推論や行動の多様な能力を教えます。また、重みの選択的な更新のための古典的な弾性重み結合(EWC)を導入し、トレーニング効率のための低ランクアダプタ(LoRA)と組み合わせています。徹底的な実験により、提案手法は18の下流タスクでベースLMsを平均64.28%改善することが示されました。
Comment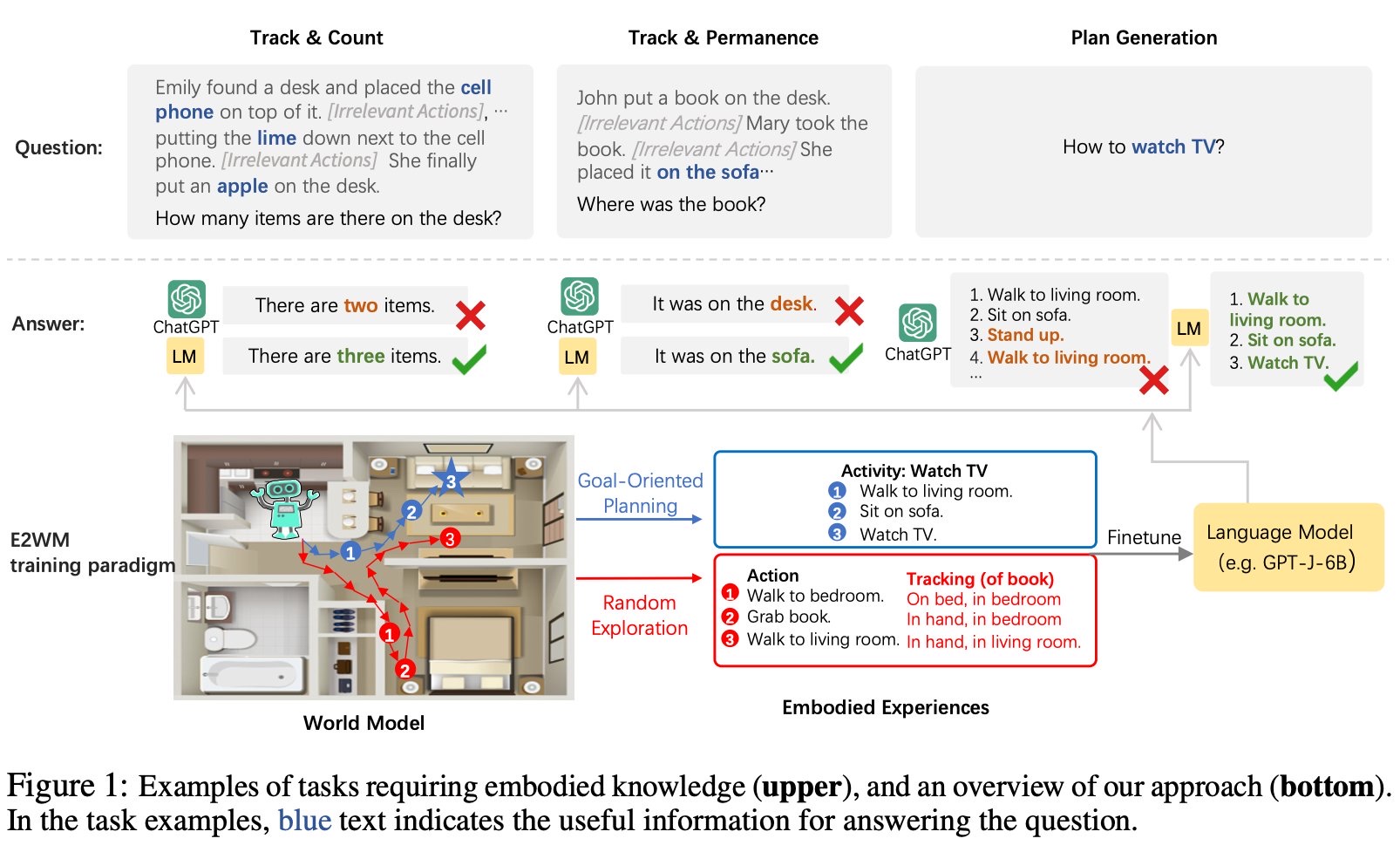 OpenReview:https://openreview.net/forum?id=SVBR6xBaMl
Issue Date: 2023-05-20
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks, Wenhai Wang+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)を用いたビジョン中心のタスクに対するフレームワークであるVisionLLMを提案し、言語指示を用いて柔軟に定義および管理できる言語タスクとビジョン中心のタスクを統一的に扱うことで、ビジョンと言語タスクの統合的な視点を提供する。提案手法は、異なるレベルのタスクカスタマイズを実現し、良好な結果を示すことができる。また、一般的なビジョンと言語モデルの新しいベースラインを設定できることが期待される。
Issue Date: 2023-05-20
Explaining black box text modules in natural language with language models, Chandan Singh+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)のブラックボックス性に対する解釈可能性の必要性を検討し、Summarize and Score(SASC)という方法を提案した。SASCは、テキストモジュールを入力として受け取り、自然言語の説明と信頼性スコアを返すことで、モジュールの選択性に関する説明を自動的に取得することができる。実験では、SASCが合成モジュールやBERTモデル内のモジュールを説明することができ、fMRIボクセルの応答の説明を生成することも示された。提案手法のコードはGithubで公開されている。
Commentモデルのinterpretabilityに関するMSの新たな研究
#Analysis
#NLP
#LanguageModel
#Programming
Issue Date: 2023-05-20
Evidence of Meaning in Language Models Trained on Programs, Charles Jin+, N_A, arXiv'23
Summary本研究では、プログラムのコーパスを用いて言語モデルが意味を学習できることを示し、プログラム合成が言語モデルの意味の存在を特徴づけるための中間テストベッドとして適していることを述べている。Transformerモデルを用いた実験により、言語の意味を学習するための帰納バイアスを提供しないにもかかわらず、線形プローブがモデルの状態から現在および将来のプログラム状態の抽象化を抽出できることがわかった。また、正しいプログラムを生成することを学習し、平均的に訓練セットよりも短いプログラムを生成することも示した。本論文は、言語モデルの訓練に新しい技術を提案するものではなく、(形式的な)意味の習得と表現に関する実験的なフレームワークを開発し、洞察を提供する。
CommentプログラムのコーパスでLLMをNext Token Predictionで訓練し
OpenReview:https://openreview.net/forum?id=SVBR6xBaMl
Issue Date: 2023-05-20
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks, Wenhai Wang+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)を用いたビジョン中心のタスクに対するフレームワークであるVisionLLMを提案し、言語指示を用いて柔軟に定義および管理できる言語タスクとビジョン中心のタスクを統一的に扱うことで、ビジョンと言語タスクの統合的な視点を提供する。提案手法は、異なるレベルのタスクカスタマイズを実現し、良好な結果を示すことができる。また、一般的なビジョンと言語モデルの新しいベースラインを設定できることが期待される。
Issue Date: 2023-05-20
Explaining black box text modules in natural language with language models, Chandan Singh+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)のブラックボックス性に対する解釈可能性の必要性を検討し、Summarize and Score(SASC)という方法を提案した。SASCは、テキストモジュールを入力として受け取り、自然言語の説明と信頼性スコアを返すことで、モジュールの選択性に関する説明を自動的に取得することができる。実験では、SASCが合成モジュールやBERTモデル内のモジュールを説明することができ、fMRIボクセルの応答の説明を生成することも示された。提案手法のコードはGithubで公開されている。
Commentモデルのinterpretabilityに関するMSの新たな研究
#Analysis
#NLP
#LanguageModel
#Programming
Issue Date: 2023-05-20
Evidence of Meaning in Language Models Trained on Programs, Charles Jin+, N_A, arXiv'23
Summary本研究では、プログラムのコーパスを用いて言語モデルが意味を学習できることを示し、プログラム合成が言語モデルの意味の存在を特徴づけるための中間テストベッドとして適していることを述べている。Transformerモデルを用いた実験により、言語の意味を学習するための帰納バイアスを提供しないにもかかわらず、線形プローブがモデルの状態から現在および将来のプログラム状態の抽象化を抽出できることがわかった。また、正しいプログラムを生成することを学習し、平均的に訓練セットよりも短いプログラムを生成することも示した。本論文は、言語モデルの訓練に新しい技術を提案するものではなく、(形式的な)意味の習得と表現に関する実験的なフレームワークを開発し、洞察を提供する。
CommentプログラムのコーパスでLLMをNext Token Predictionで訓練し
厳密に正解とsemanticsを定義した上で、訓練データと異なるsemanticsの異なるプログラムを生成できることを示した。
LLMが意味を理解していることを暗示している
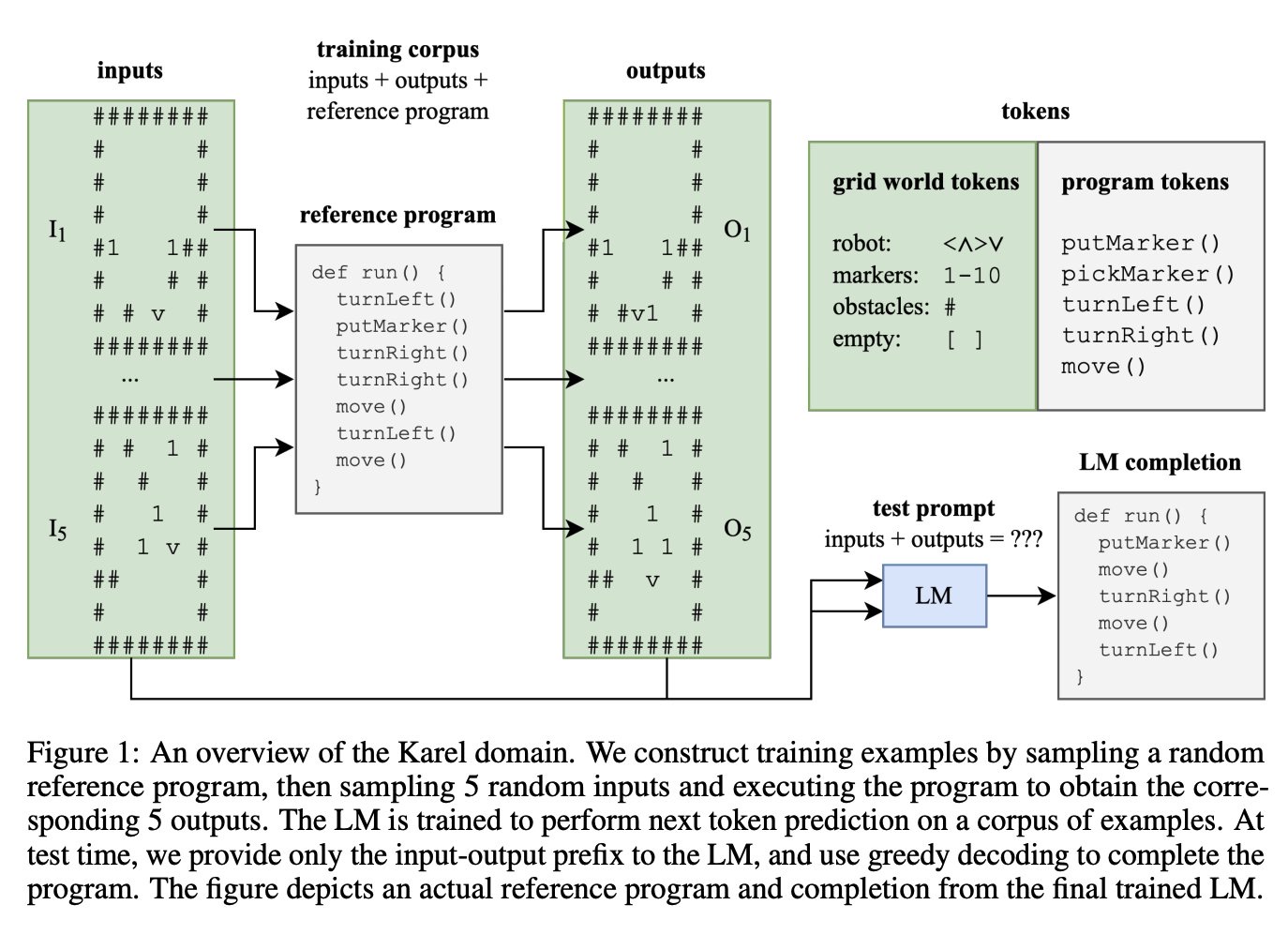 #NLP
#LanguageModel
#Prompting
Issue Date: 2023-05-20
Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, N_A, arXiv'23
Summary言語モデルの推論には制限があり、探索や戦略的先読みが必要なタスクには不十分である。そこで、Tree of Thoughts(ToT)という新しいフレームワークを導入し、Chain of Thoughtアプローチを一般化して、意思決定を行うことができるようにした。ToTにより、言語モデルは複数の異なる推論パスを考慮して、次の行動を決定することができる。ToTは、Game of 24、Creative Writing、Mini Crosswordsなどのタスクにおいて、言語モデルの問題解決能力を大幅に向上させることができることを示している。
CommentSelf Concistencyの次
#NLP
#LanguageModel
#Prompting
Issue Date: 2023-05-20
Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, N_A, arXiv'23
Summary言語モデルの推論には制限があり、探索や戦略的先読みが必要なタスクには不十分である。そこで、Tree of Thoughts(ToT)という新しいフレームワークを導入し、Chain of Thoughtアプローチを一般化して、意思決定を行うことができるようにした。ToTにより、言語モデルは複数の異なる推論パスを考慮して、次の行動を決定することができる。ToTは、Game of 24、Creative Writing、Mini Crosswordsなどのタスクにおいて、言語モデルの問題解決能力を大幅に向上させることができることを示している。
CommentSelf Concistencyの次
Non trivialなプランニングと検索が必要な新たな3つのタスクについて、CoT w/ GPT4の成功率が4%だったところを、ToTでは74%を達成
論文中の表ではCoTのSuccessRateが40%と書いてあるような?
 Issue Date: 2023-05-20
mLongT5: A Multilingual and Efficient Text-To-Text Transformer for Longer Sequences, David Uthus+, N_A, arXiv'23
Summary本研究では、多言語で長い入力を処理するための効率的なテキスト・トゥ・テキスト・トランスフォーマーの開発を行い、mLongT5というモデルを提案した。mT5の事前学習とUL2の事前学習タスクを活用し、多言語要約や質問応答などのタスクで評価した結果、既存の多言語モデルよりも性能が優れていることが示された。
Commentlib:https://huggingface.co/agemagician/mlong-t5-tglobal-xl16384 tokenを扱えるT5。102言語に対応
Issue Date: 2023-05-15
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, Lili Yu+, N_A, arXiv'23
Summaryオートレグレッシブトランスフォーマーは短いシーケンスに対して優れたモデルだが、長いシーケンスにはスケーリングが困難である。本研究では、Megabyteというマルチスケールデコーダーアーキテクチャを提案し、100万バイト以上のシーケンスのモデリングを可能にした。Megabyteは、パッチに分割し、ローカルサブモデルとグローバルモデルを使用することで、トレーニングと生成の両方でコストを削減しながらより良いパフォーマンスを発揮できる。徹底的な実験により、Megabyteにより、バイトレベルのモデルが長いコンテキストの言語モデリングで競争力を持ち、ImageNetで最先端の密度推定を達成し、生のファイルからオーディオをモデル化できることが示された。
Commentbyte列のsequenceからpatch embeddingを作成することで、tokenizer freeなtransformerを提案。
Issue Date: 2023-05-20
mLongT5: A Multilingual and Efficient Text-To-Text Transformer for Longer Sequences, David Uthus+, N_A, arXiv'23
Summary本研究では、多言語で長い入力を処理するための効率的なテキスト・トゥ・テキスト・トランスフォーマーの開発を行い、mLongT5というモデルを提案した。mT5の事前学習とUL2の事前学習タスクを活用し、多言語要約や質問応答などのタスクで評価した結果、既存の多言語モデルよりも性能が優れていることが示された。
Commentlib:https://huggingface.co/agemagician/mlong-t5-tglobal-xl16384 tokenを扱えるT5。102言語に対応
Issue Date: 2023-05-15
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, Lili Yu+, N_A, arXiv'23
Summaryオートレグレッシブトランスフォーマーは短いシーケンスに対して優れたモデルだが、長いシーケンスにはスケーリングが困難である。本研究では、Megabyteというマルチスケールデコーダーアーキテクチャを提案し、100万バイト以上のシーケンスのモデリングを可能にした。Megabyteは、パッチに分割し、ローカルサブモデルとグローバルモデルを使用することで、トレーニングと生成の両方でコストを削減しながらより良いパフォーマンスを発揮できる。徹底的な実験により、Megabyteにより、バイトレベルのモデルが長いコンテキストの言語モデリングで競争力を持ち、ImageNetで最先端の密度推定を達成し、生のファイルからオーディオをモデル化できることが示された。
Commentbyte列のsequenceからpatch embeddingを作成することで、tokenizer freeなtransformerを提案。
byte列で表現されるデータならなんでも入力できる。つまり、理論上なんでも入力できる。 Issue Date: 2023-05-12 Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction, Wang-Cheng Kang+, N_A, arXiv'23 SummaryLLMsは新しいタスクに一般化する能力を持ち、少ないデータで包括的な世界知識を維持することができる。本研究では、CFとLLMsを比較し、ユーザー評価予測タスクでLLMsがファインチューニングを通じて同等またはより良いパフォーマンスを示すことがわかった。しかし、ゼロショットLLMsは従来の推薦モデルに遅れをとることが示された。 Commentはじまったなぁ、という感じ #NeuralNetwork #ComputerVision #Controllable #VideoGeneration/Understandings Issue Date: 2023-05-12 Sketching the Future (STF): Applying Conditional Control Techniques to Text-to-Video Models, Rohan Dhesikan+, arXiv'23 Summaryゼロショットのテキストから動画生成をControlNetと組み合わせ、スケッチされたフレームを基に動画を生成する新手法を提案。フレーム補間を行い、Text-to-Video Zeroアーキテクチャを活用して高品質で一貫性のある動画を生成。デモ動画やリソースを提供し、さらなる研究を促進。 Issue Date: 2023-05-11 Multi-Task End-to-End Training Improves Conversational Recommendation, Naveen Ram+, N_A, arXiv'23 Summary本論文では、対話型推薦タスクにおいて、マルチタスクエンドツーエンドトランスフォーマーモデルのパフォーマンスを分析する。従来の複雑なマルチコンポーネントアプローチに代わり、T5テキストトゥーテキストトランスフォーマーモデルに基づく統合トランスフォーマーモデルが、関連するアイテムの推薦と会話の対話生成の両方で競争力を持つことを示す。ReDIAL対話型映画推薦データセットでモデルをファインチューニングし、追加のトレーニングタスクをマルチタスク学習の設定で作成することで、各タスクが関連するプローブスコアの9%〜52%の増加につながることを示した。 #Transformer #LongSequence #NeurIPS #Encoder #Encoder-Decoder Issue Date: 2023-05-09 Vcc: Scaling Transformers to 128K Tokens or More by Prioritizing Important Tokens, Zhanpeng Zeng+, N_A, NeurIPS'23 Summary本論文では、Transformerモデルの二次コストを削減するために、各層でサイズ$r$が$n$に独立した表現に入力を圧縮する方法を提案する。VIPトークン中心の圧縮(Vcc)スキームを使用し、VIPトークンの表現を近似するために入力シーケンスを選択的に圧縮する。提案されたアルゴリズムは、競合するベースラインと比較して効率的であり、多数のタスクにおいて競争力のあるまたはより優れたパフォーマンスを発揮する。また、アルゴリズムは128Kトークンにスケーリングでき、一貫して精度の向上を提供することが示された。 #Analysis #NLP #LanguageModel #Chain-of-Thought #Faithfulness #NeurIPS Issue Date: 2023-05-09 Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting, Miles Turpin+, N_A, NeurIPS'23 SummaryLLMsによる推論において、chain-of-thought reasoning(CoT)と呼ばれる説明を生成することができるが、この説明がモデルの予測の真の理由を誤って表現することがあることがわかった。バイアスのある特徴をモデルの入力に追加することで、CoT説明が大きく影響を受けることが示された。この結果は、LLMsに対する信頼を高めるために、説明の忠実度を評価し、改善する必要があることを示唆している。 Issue Date: 2023-05-06 Cognitive Reframing of Negative Thoughts through Human-Language Model Interaction, Ashish Sharma+, N_A, arXiv'23 Summary本論文では、言語モデルを使用して人々が否定的な考えを再構築するのを支援する方法について、心理学の文献に基づいて研究を行います。7つの言語属性のフレームワークを定義し、自動化されたメトリックを開発して、再構築された考えを効果的に生成し、その言語属性を制御します。大規模なメンタルヘルスのウェブサイトでランダム化フィールド研究を実施し、高度に共感的または具体的な再構築を好むことを示しました。言語モデルを使用して人々が否定的な考えを克服するのを支援するための重要な示唆を提供します。 #PersonalizedDocumentSummarization #NLP #Personalization #review Issue Date: 2023-05-05 Towards Personalized Review Summarization by Modeling Historical Reviews from Customer and Product Separately, Xin Cheng+, N_A, arXiv'23 Summaryレビュー要約は、Eコマースのウェブサイトにおいて製品レビューの主要なアイデアを要約することを目的としたタスクである。本研究では、評価情報を含む2種類の過去のレビューをグラフ推論モジュールと対比損失を用いて別々にモデル化するHHRRSを提案する。レビューの感情分類と要約を共同で行うマルチタスクフレームワークを採用し、4つのベンチマークデータセットでの徹底的な実験により、HHRRSが両方のタスクで優れた性能を発揮することが示された。 #NLP #LanguageModel #ICLR #KnowledgeEditing Issue Date: 2023-05-04 Mass-Editing Memory in a Transformer, Kevin Meng+, N_A, ICLR'23 Summary大規模言語モデルを更新することで、専門的な知識を追加できることが示されているしかし、これまでの研究は主に単一の関連付けの更新に限定されていた本研究では、MEMITという方法を開発し、多数のメモリを直接言語モデルに更新することができることを実験的に示したGPT-J(6B)およびGPT-NeoX(20B)に対して数千の関連付けまでスケーリングでき、これまでの研究を桁違いに上回ることを示したコードとデータはhttps://memit.baulab.infoにあります。 #NLP #LanguageModel #Zero/FewShotPrompting #Chain-of-Thought #ACL Issue Date: 2023-05-04 Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, Mirac Suzgun+, N_A, ACL'23 SummaryBIG-Bench Hard (BBH) is a suite of 23 challenging tasks that current language models have not been able to surpass human performance on. This study focuses on applying chain-of-thought prompting to BBH tasks and found that PaLM and Codex were able to surpass human performance on 10 and 17 tasks, respectively. The study also found that CoT prompting is necessary for tasks that require multi-step reasoning and that CoT and model scale interact to enable new task performance on some BBH tasks. Comment単なるfewshotではなく、CoT付きのfewshotをすると大幅にBIG-Bench-hardの性能が向上するので、CoTを使わないanswer onlyの設定はモデルの能力の過小評価につながるよ、という話らしい

 Issue Date: 2023-05-04
Pre-train and Search: Efficient Embedding Table Sharding with Pre-trained Neural Cost Models, Daochen Zha+, N_A, arXiv'23
Summary本研究では、大規模な機械学習モデルを複数のデバイスに分散してシャーディングするための効率的な方法を提案しています。事前学習されたニューラルコストモデルを使用して、最適なシャーディングプランをオンラインで検索することで、従来手法を大幅に上回る性能を達成しました。NeuroShardは、表のシャーディングに適用され、最大23.8%の改善を達成しました。また、コードはオープンソース化されています。
Issue Date: 2023-05-04
Few-shot In-context Learning for Knowledge Base Question Answering, Tianle LI+, N_A, arXiv'23
Summary知識ベース上の質問応答は困難であり、異なる知識ベースのスキーマアイテムの異質性が問題となる。KB-BINDERは、KBQAタスク上での少数のコンテキスト内学習を可能にするフレームワークであり、Codexのような大規模言語モデルを活用して、特定の質問のための論理形式を生成し、知識ベースに基づいてBM25スコアマッチングを用いて生成されたドラフトを実行可能なものに結びつける。実験結果は、KB-BINDERが異種KBQAデータセットで強力なパフォーマンスを発揮できることを示しており、将来の研究の重要なベースラインとして役立つことが期待される。
Issue Date: 2023-05-04
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality, Emre Kıcıman+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)を用いた因果推論について議論し、LLMsが因果関係のタスクを実行するために必要な知識源や方法について説明している。LLMsは、因果グラフの生成や自然言語からの因果関係の特定など、人間に制限されていた能力を持っており、因果関係手法の広範な採用に貢献することが期待される。また、LLMsは因果関係の研究、実践、採用の新しいフロンティアを開拓する可能性がある。
Issue Date: 2023-05-04
Generalizing Dataset Distillation via Deep Generative Prior, George Cazenavette+, N_A, arXiv'23
SummaryDataset Distillationは、少数の合成データポイントを使用して元のデータでトレーニングされたモデルに近似することを目的としています。しかし、既存の方法は新しいアーキテクチャに汎化することができず、高解像度のデータセットにスケールすることができません。そこで、事前にトレーニングされた深層生成モデルから学習された事前分布を使用して、蒸留されたデータを合成することを提案し、新しい最適化アルゴリズムを提案しています。この手法は、クロスアーキテクチャの汎化を大幅に改善することができます。
Commentプロジェクトページ
Issue Date: 2023-05-04
Pre-train and Search: Efficient Embedding Table Sharding with Pre-trained Neural Cost Models, Daochen Zha+, N_A, arXiv'23
Summary本研究では、大規模な機械学習モデルを複数のデバイスに分散してシャーディングするための効率的な方法を提案しています。事前学習されたニューラルコストモデルを使用して、最適なシャーディングプランをオンラインで検索することで、従来手法を大幅に上回る性能を達成しました。NeuroShardは、表のシャーディングに適用され、最大23.8%の改善を達成しました。また、コードはオープンソース化されています。
Issue Date: 2023-05-04
Few-shot In-context Learning for Knowledge Base Question Answering, Tianle LI+, N_A, arXiv'23
Summary知識ベース上の質問応答は困難であり、異なる知識ベースのスキーマアイテムの異質性が問題となる。KB-BINDERは、KBQAタスク上での少数のコンテキスト内学習を可能にするフレームワークであり、Codexのような大規模言語モデルを活用して、特定の質問のための論理形式を生成し、知識ベースに基づいてBM25スコアマッチングを用いて生成されたドラフトを実行可能なものに結びつける。実験結果は、KB-BINDERが異種KBQAデータセットで強力なパフォーマンスを発揮できることを示しており、将来の研究の重要なベースラインとして役立つことが期待される。
Issue Date: 2023-05-04
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality, Emre Kıcıman+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)を用いた因果推論について議論し、LLMsが因果関係のタスクを実行するために必要な知識源や方法について説明している。LLMsは、因果グラフの生成や自然言語からの因果関係の特定など、人間に制限されていた能力を持っており、因果関係手法の広範な採用に貢献することが期待される。また、LLMsは因果関係の研究、実践、採用の新しいフロンティアを開拓する可能性がある。
Issue Date: 2023-05-04
Generalizing Dataset Distillation via Deep Generative Prior, George Cazenavette+, N_A, arXiv'23
SummaryDataset Distillationは、少数の合成データポイントを使用して元のデータでトレーニングされたモデルに近似することを目的としています。しかし、既存の方法は新しいアーキテクチャに汎化することができず、高解像度のデータセットにスケールすることができません。そこで、事前にトレーニングされた深層生成モデルから学習された事前分布を使用して、蒸留されたデータを合成することを提案し、新しい最適化アルゴリズムを提案しています。この手法は、クロスアーキテクチャの汎化を大幅に改善することができます。
Commentプロジェクトページ
https://georgecazenavette.github.io/glad/ Issue Date: 2023-05-04 Distill or Annotate? Cost-Efficient Fine-Tuning of Compact Models, Junmo Kang+, N_A, arXiv'23 Summary大規模モデルを微調整することは効果的だが、推論コストが高く、炭素排出量が発生する。知識蒸留は推論コストを削減するための実用的な解決策であるが、蒸留プロセス自体には膨大な計算リソースが必要。固定予算を最も効率的に使用してコンパクトなモデルを構築する方法を調査。T5-XXL(11B)からT5-Small(60M)への蒸留は、より多くのデータを注釈付きで直接トレーニングするよりもほぼ常にコスト効率の高いオプションであることがわかった。最適な蒸留量は、予算シナリオによって異なる。 Issue Date: 2023-05-04 The Internal State of an LLM Knows When its Lying, Amos Azaria+, N_A, arXiv'23 SummaryLLMは優れたパフォーマンスを発揮するが、不正確な情報を生成することがある本研究では、LLMの内部状態を使用して文の真実性を検出する方法を提案分類器はLLMの活性化値を入力として受け取り、真実か偽かを検出する実験結果は、提案手法がフューショット・プロンプティング・メソッドを上回り、LLMの信頼性を向上させる可能性があることを示している。 Issue Date: 2023-05-04 Causal Reasoning and Large Language Models: Opening a New Frontier for Causality, Emre Kıcıman+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を用いた因果推論について議論し、LLMsが因果関係のタスクにおいて高い精度を示すことを示した。また、LLMsは人間に制限されていた能力を持っており、因果グラフの生成や自然言語からの因果関係の特定などが可能であることが示された。LLMsは、因果関係の研究、実践、および採用の新しいフロンティアを開拓することが期待される。 Issue Date: 2023-05-04 ArK: Augmented Reality with Knowledge Interactive Emergent Ability, Qiuyuan Huang+, N_A, arXiv'23 Summary本研究では、混合現実やインタラクティブAIエージェントのシステムが未知の環境で高品質な2D/3Dシーンを生成することが課題であることを指摘し、一般的な基礎モデルから知識メモリを転送して、物理的または仮想世界でのシーン理解と生成のための新しいドメインやシナリオに対応する無限エージェントを開発した。このアプローチには、知識推論インタラクションを拡張現実と呼ばれる新しいメカニズムがあり、知識メモリを活用して未知の物理世界や仮想現実環境でシーンを生成する。このアプローチは、生成された2D/3Dシーンの品質を大幅に向上させ、メタバースやゲームシミュレーションなどの応用において有用であることが示された。 Commentプロジェクトページ
https://augmented-reality-knowledge.github.io Issue Date: 2023-05-04 What Do Self-Supervised Vision Transformers Learn?, Namuk Park+, N_A, arXiv'23 Summary本研究では、対比学習(CL)とマスク画像モデリング(MIM)の比較的な研究を行い、自己教示学習されたVision Transformers(ViTs)がCLとMIMの両方の利点を活用することができることを示した。CLは長距離のグローバルなパターンを捉えることができ、ViTsは表現空間で画像を線形に分離することができるが、表現の多様性が低下し、スケーラビリティと密な予測パフォーマンスが悪化することがある。MIMは高周波情報を利用し、形状とテクスチャを表す。CLとMIMは互いに補完的であり、両方の方法の利点を活用することができる。コードはGitHubで利用可能。 Issue Date: 2023-05-04 GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation, Zhenhui Ye+, N_A, arXiv'23 Summary本研究では、話す人物のポートレートを生成するためのNeRFベースの手法における課題を解決するために、GeneFace++を提案した。GeneFace++は、ピッチ輪郭を利用して口唇同期を実現し、局所線形埋め込み法を提案して頑健性の問題を回避し、高速なトレーニングとリアルタイム推論を実現するNeRFベースの動きからビデオへのレンダラーを設計することで、一般化された音声と口唇同期を持つ安定したリアルタイム話す顔生成を実現した。徹底的な実験により、提案手法が最先端のベースラインを上回ることが示された。ビデオサンプルはhttps://genefaceplusplus.github.ioで利用可能。 Commentプロジェクトページ
https://genefaceplusplus.github.io Issue Date: 2023-05-04 Key-Locked Rank One Editing for Text-to-Image Personalization, Yoad Tewel+, N_A, arXiv'23 Summary本研究では、テキストから画像へのモデル(T2I)の個人化手法であるPerfusionを提案し、高い視覚的忠実度を維持しながら創造的な制御を許可すること、複数の個人化された概念を単一の画像に組み合わせること、小さなモデルサイズを維持することなど、複数の困難な課題を解決する。Perfusionは、基礎となるT2Iモデルに対して動的なランク1の更新を使用することで、過学習を回避し、新しい概念のクロスアテンションキーを上位カテゴリにロックする新しいメカニズムを導入することで、学習された概念の影響を制御し、複数の概念を組み合わせることができるゲート付きランク1アプローチを開発した。Perfusionは、現在の最先端のモデルよりも5桁小さいが、強力なベースラインを定量的および定性的に上回ることが示された。 Commentプロジェクトページ
https://research.nvidia.com/labs/par/Perfusion/ #NLP #LanguageModel #Poisoning #ICML Issue Date: 2023-05-04 Poisoning Language Models During Instruction Tuning, Alexander Wan+, N_A, ICML'23 SummaryInstruction-tuned LMs(ChatGPT、FLAN、InstructGPTなど)は、ユーザーが提出した例を含むデータセットでfinetuneされる。本研究では、敵対者が毒入りの例を提供することで、LMの予測を操作できることを示す。毒入りの例を構築するために、LMのbag-of-words近似を使用して入出力を最適化する。大きなLMほど毒入り攻撃に対して脆弱であり、データフィルタリングやモデル容量の削減に基づく防御は、テストの正確性を低下させながら、中程度の保護しか提供しない。 Issue Date: 2023-05-04 Loss Landscapes are All You Need: Neural Network Generalization Can Be Explained Without the Implicit Bias of Gradient Descent, ICLR'23 Issue Date: 2023-05-04 Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation, Yuval Kirstain+, N_A, arXiv'23 Summaryテキストから画像へのユーザーの好みの大規模データセットが限られているため、Webアプリを作成してPick-a-Picデータセットを構築した。PickScoreというCLIPベースのスコアリング関数を訓練し、人間の好みを予測するタスクで超人的なパフォーマンスを発揮した。PickScoreは他の自動評価メトリックよりも人間のランキングとより良い相関があることが観察された。将来のテキストから画像への生成モデルの評価にはPickScoreを使用し、Pick-a-Picプロンプトを使用することを推奨する。PickScoreがランキングを通じて既存のテキストから画像へのモデルを強化する方法を示した。 Issue Date: 2023-05-04 Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge, Yasumasa Onoe+, N_A, arXiv'23 Summary事前学習された言語モデル(LMs)のターゲット更新について研究されてきたが、注入された事実に基づいて推論を行うLMsの能力を研究する。2つのクローズスタイルのタスクで研究し、知識の更新に対する既存の方法は注入された知識の伝播をほとんど示さないことがわかった。しかし、LMの文脈にエンティティの定義を先行させると、すべての設定でパフォーマンスが向上することがわかり、知識注入のためのパラメータ更新アプローチには大きな余地があることを示唆している。 Issue Date: 2023-05-04 Learning to Reason and Memorize with Self-Notes, Jack Lanchantin+, N_A, arXiv'23 Summary大規模言語モデルは、コンテキストメモリと多段階の推論に苦労するが、セルフノートを取ることでこれらの問題を解決できることが提案された。モデルは入力コンテキストから思考を逸脱し、情報を思い出し、推論を実行することができる。複数のタスクでの実験により、セルフノートを推論時に取ることで、より長く、より複雑なインスタンスに対しても成功裏に汎化できることが示された。 #Survey #Education #ChatGPT Issue Date: 2023-05-04 A Review of ChatGPT Applications in Education, Marketing, Software Engineering, and Healthcare: Benefits, Drawbacks, and Research Directions, Mohammad Fraiwan+, N_A, arXiv'23 SummaryChatGPTは、深層学習アルゴリズムを使用して人間らしい応答を生成する人工知能言語モデルである。最新のChatGPTバージョンが導入され、他の言語モデルも登場している。これらのモデルは、教育、ソフトウェアエンジニアリング、医療、マーケティングなどの分野で応用可能性がある。本論文では、これらのモデルの可能な応用、制限、欠点、および研究方向について議論する。 #MachineTranslation #NLP #LanguageModel #Annotation #TransferLearning #MultiLingual #ACL Issue Date: 2023-05-04 Frustratingly Easy Label Projection for Cross-lingual Transfer, Yang Chen+, N_A, ACL'23 Summary多言語のトレーニングデータの翻訳は、クロスリンガル転移の改善に役立つスパンレベル注釈が必要なタスクでは、注釈付きスパンを翻訳されたテキストにマッピングするために追加のラベルプロジェクションステップが必要マーク-翻訳法を利用するアプローチが従来の注釈プロジェクションと比較してどのようになるかについての実証的な分析を行ったEasyProjectと呼ばれるマーク-翻訳法の最適化されたバージョンが多言語に簡単に適用でき、より複雑な単語アラインメントベースの方法を上回ることを示したすべてのコードとデータが公開される Issue Date: 2023-05-04 Multimodal Procedural Planning via Dual Text-Image Prompting, Yujie Lu+, N_A, arXiv'23 Summary本研究では、具現化エージェントがテキストや画像に基づく指示を受けてタスクを完了するための多様なモーダル手順計画(MPP)タスクを提案し、Text-Image Prompting(TIP)を使用して、大規模言語モデル(LLMs)を活用して、テキストと画像の相互作用を改善する方法を提案しています。WIKIPLANとRECIPEPLANのデータセットを収集し、MPPのテストベッドとして使用し、単一モーダルおよび多様なモーダルのベースラインに対する人間の嗜好と自動スコアが魅力的であることを示しました。提案手法のコードとデータは、https://github.com/YujieLu10/MPPにあります。 Issue Date: 2023-05-04 Can ChatGPT Pass An Introductory Level Functional Language Programming Course?, Chuqin Geng+, N_A, arXiv'23 SummaryChatGPTは多様なタスクを解決する印象的な能力を持ち、コンピュータサイエンス教育に大きな影響を与えている。本研究では、ChatGPTが初級レベルの関数型言語プログラミングコースでどの程度の性能を発揮できるかを探求した。ChatGPTを学生として扱い、B-の成績を達成し、全体の314人の学生のうち155位のランクを示した。包括的な評価により、ChatGPTの影響について貴重な洞察を提供し、潜在的な利点を特定した。この研究は、ChatGPTの能力とコンピュータサイエンス教育への潜在的な影響を理解する上で重要な進展をもたらすと信じられる。 Issue Date: 2023-05-04 Making the Most of What You Have: Adapting Pre-trained Visual Language Models in the Low-data Regime, Chuhan Zhang+, N_A, arXiv'23 Summary本研究では、大規模なビジュアル言語モデルの事前学習と、少数の例からのタスク適応について調査し、自己ラベリングの重要性を示した。ImageNet、COCO、Localised Narratives、VQAv2などのビジュアル言語タスクで、提案されたタスク適応パイプラインを使用することで、大幅な利益を示した。 Issue Date: 2023-05-04 CodeGen2: Lessons for Training LLMs on Programming and Natural Languages, Erik Nijkamp+, N_A, arXiv'23 Summary大規模言語モデル(LLMs)のトレーニングを効率的にするために、4つの要素を統合することを試みた。モデルアーキテクチャ、学習方法、インフィルサンプリング、データ分布を統合した。1B LLMsで実験を行い、成功と失敗を4つのレッスンにまとめた。CodeGen2モデルのトレーニング方法とトレーニングフレームワークをオープンソースで提供する。 Issue Date: 2023-05-04 GPTutor: a ChatGPT-powered programming tool for code explanation, Eason Chen+, N_A, arXiv'23 Summary本論文では、ChatGPT APIを使用したプログラミングツールであるGPTutorを提案し、Visual Studio Codeの拡張機能として実装した。GPTutorは、プログラミングコードの説明を提供することができ、初期評価により、最も簡潔で正確な説明を提供することが示された。さらに、学生や教師からのフィードバックにより、GPTutorは使いやすく、与えられたコードを満足する説明ができることが示された。将来の研究方向として、プロンプトプログラミングによるパフォーマンスと個人化の向上、および実際のユーザーを対象としたGPTutorの効果の評価が含まれる。 Commentpersonalisationもかけているらしいので気になる Issue Date: 2023-05-04 Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings, Daniel Rose+, N_A, arXiv'23 Summary大規模言語モデルを用いた論理的な推論には限界があり、視覚的な拡張が必要であるという問題がある。そこで、VCoTという新しい手法を提案し、視覚言語グラウンディングを用いた推論のchain of thought promptingを再帰的に利用して、順序データ内の論理的なギャップを埋めることができる。VCoTは、Visual StorytellingとWikiHow summarizationのデータセットに適用され、人間の評価を通じて、新しい一貫性のある合成データ拡張を提供し、下流のパフォーマンスを向上させることができることが示された。 Issue Date: 2023-05-04 Unlimiformer: Long-Range Transformers with Unlimited Length Input, Amanda Bertsch+, N_A, arXiv'23 Summary本研究では、Transformerベースのモデルに対して、すべてのレイヤーのアテンション計算を単一のk最近傍インデックスにオフロードすることで、入力長に事前に定義された境界をなくすことができるUnlimiformerを提案した。Unlimiformerは、長文書およびマルチドキュメント要約のベンチマークで有効性を示し、追加の学習済み重みを必要とせず、入力を無制限に拡張することができる。コードとモデルは、https://github.com/abertsch72/unlimiformerで公開されています。 Issue Date: 2023-05-04 Distilling Step-by-Step Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes, Cheng-Yu Hsieh+, N_A, arXiv'23 Summary大規模言語モデル(LLMs)を小さなモデルに蒸留する新しいメカニズムを提案し、ファインチューニングや蒸留に必要なトレーニングデータを減らすことで、性能を向上させることができることを示した。また、小さなモデルでもLLMsを上回る性能を発揮することができ、利用可能なデータの80%のみを使用しても、LLMsを上回る性能を発揮することができることが実験によって示された。 Issue Date: 2023-05-01 Search-in-the-Chain: Towards the Accurate, Credible and Traceable Content Generation for Complex Knowledge-intensive Tasks, Shicheng Xu+, N_A, arXiv'23 Summary本論文では、大規模言語モデル(LLMs)を使用した多段階質問応答タスクにおいて、正確性、信頼性、追跡性を向上させるための新しいフレームワークであるSearch-in-the-Chain(SearChain)を提案しています。SearChainは、LLMと情報検索(IR)を深く統合したフレームワークであり、LLMが生成するコンテンツの正確性と信頼性を高めることができます。実験結果は、SearChainが4つの多段階質問応答データセットで関連するベースラインを上回ることを示しています。 Issue Date: 2023-05-01 PMC-LLaMA: Further Finetuning LLaMA on Medical Papers, Chaoyi Wu+, N_A, arXiv'23 Summary本報告書では、PMC-LLaMAというオープンソース言語モデルを紹介し、医療領域での能力を向上させるためにファインチューニングされたことを述べています。PMC-LLaMAは、バイオメディカルドメイン固有の概念をよりよく理解し、PubMedQA、MedMCQA、USMLEを含む3つのバイオメディカルQAデータセットで高いパフォーマンスを発揮することが示されています。モデルとコード、オンラインデモは、公開されています。 CommentLLaMAを4.8Mのmedical paperでfinetuningし、医療ドメインの能力を向上。このモデルはPMC-LLaMAと呼ばれ、biomedicalQAタスクで、高い性能を達成した。
GPT-4を利用した異なるモデル間の出力の比較も行なっている模様 Issue Date: 2023-04-30 Multi-Party Chat: Conversational Agents in Group Settings with Humans and Models, Jimmy Wei+, N_A, arXiv'23 Summary本研究では、複数の話者が参加する会話を収集し、評価するために、マルチパーティの会話を構築する。LIGHT環境を使用して、各参加者が役割を演じるために割り当てられたキャラクターを持つグラウンデッドな会話を構築する。新しいデータセットで訓練されたモデルを、既存の二者間で訓練された対話モデル、およびfew-shot promptingを使用した大規模言語モデルと比較し、公開するMultiLIGHTという新しいデータセットが、グループ設定での大幅な改善に役立つことがわかった。 #NeuralNetwork #ComputerVision #Embeddings #RepresentationLearning #ContrastiveLearning #ICLR #Semi-Supervised Issue Date: 2023-04-30 SemPPL: Predicting pseudo-labels for better contrastive representations, Matko Bošnjak+, N_A, ICLR'23 Summary本研究では、コンピュータビジョンにおける半教師あり学習の問題を解決するために、Semantic Positives via Pseudo-Labels (SemPPL)という新しい手法を提案している。この手法は、ラベル付きとラベルなしのデータを組み合わせて情報豊富な表現を学習することができ、ResNet-$50$を使用してImageNetの$1\%$および$10\%$のラベルでトレーニングする場合、競合する半教師あり学習手法を上回る最高性能を発揮することが示された。SemPPLは、強力な頑健性、分布外および転移性能を示すことができる。 Comment後ほど説明を追記する


 関連:
関連:
・1975 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #LongSequence #Inference Issue Date: 2023-04-30 Efficiently Scaling Transformer Inference, Reiner Pope+, N_A, MLSys'23 Summary大規模Transformerベースのモデルの推論のエンジニアリングのトレードオフを理解するために、最適な多次元分割技術を選択するための単純な解析モデルを開発低レベルの最適化と組み合わせることで、500B+パラメータモデルのレイテンシーとモデルFLOPS利用率のトレードオフにおいて、FasterTransformerベンチマークスイートを上回る新しいParetoフロンティアを実現適切な分割により、マルチクエリアテンションの低いメモリ要件により、32倍の大きなコンテキスト長にスケーリング可能int8ウェイト量子化を使用した生成中の低バッチサイズレイテンシーは、トークンあたり29msであり、入力トークンの大バッチサイズ処理において76%のMFUを実現し、PaLM 540Bパラメータモデルにおいて2048トークンの長いコンテキスト長をサポートしている。 Comment特にMultiquery Attentionという技術がTransformerのinferenceのコスト削減に有効らしい #NLP #LanguageModel #Education #AES(AutomatedEssayScoring) #ChatGPT Issue Date: 2023-04-28 [Paper Note] AI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays, Steffen Herbold+, arXiv'23 SummaryChatGPTが生成したエッセイは、人間が書いたものよりも質が高いと評価されることが大規模な研究で示された。生成されたエッセイは独自の言語的特徴を持ち、教育者はこの技術を活用する新たな教育コンセプトを開発する必要がある。 CommentChatGPTは人間が書いたエッセイよりも高品質なエッセイが書けることを示した。
また、AIモデルの文体は、人間が書いたエッセイとは異なる言語的特徴を示している。たとえば、談話や認識マーカーが少ないが、名詞化が多く、語彙の多様性が高いという特徴がある、とのこと。
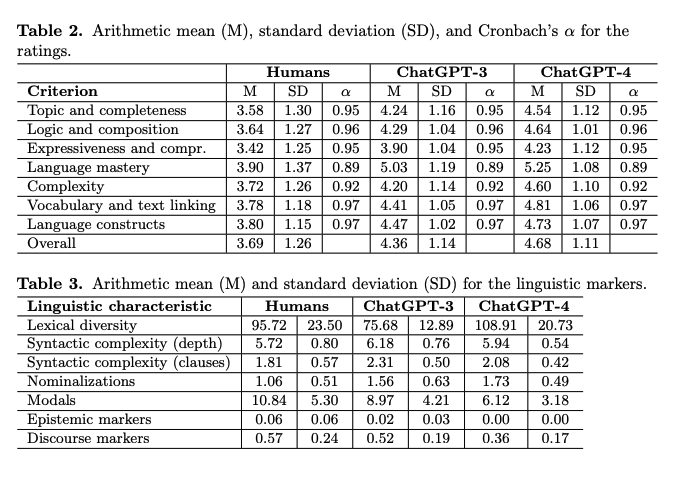
#Dataset #LanguageModel #Evaluation #EMNLP #Ambiguity Issue Date: 2023-04-28 We're Afraid Language Models Aren't Modeling Ambiguity, Alisa Liu+, EMNLP'23 Summary曖昧さは自然言語の重要な特徴であり、言語モデル(LM)が対話や執筆支援において成功するためには、曖昧な言語を扱うことが不可欠です。本研究では、曖昧さの影響を評価するために、1,645の例からなるベンチマーク「AmbiEnt」を収集し、事前学習済みLMの評価を行いました。特にGPT-4の曖昧さ解消の正答率は32%と低く、曖昧さの解消が難しいことが示されました。また、多ラベルのNLIモデルが曖昧さによる誤解を特定できることを示し、NLPにおける曖昧さの重要性を再認識する必要性を提唱しています。 CommentLLMが曖昧性をどれだけ認知できるかを評価した初めての研究。
言語学者がアノテーションした1,645サンプルの様々な曖昧さを含んだベンチマークデータを利用。
GPT4は32%正解した。
またNLIデータでfinetuningしたモデルでは72.5%のmacroF1値を達成。
応用先として、誤解を招く可能性のある政治的主張に対してアラートをあげることなどを挙げている。 #ComputerVision
#NeurIPS
Issue Date: 2023-04-27
Stable and low-precision training for large-scale vision-language models, Wortsman+, University of Washington, NeurIPS'23
Summary大規模な言語-視覚モデルのトレーニングを加速し安定させる新手法を提案。SwitchBackを用いたint8量子化で、CLIP ViT-Hugeのトレーニング速度を13-25%向上させ、bfloat16と同等の性能を維持。float8トレーニングも効果的であることを示し、初期化方法が成功に寄与。損失のスパイクを分析し、AdamW-Adafactorハイブリッドを推奨することで、トレーニングの安定性を向上させた。
Comment
#ComputerVision
#NeurIPS
Issue Date: 2023-04-27
Stable and low-precision training for large-scale vision-language models, Wortsman+, University of Washington, NeurIPS'23
Summary大規模な言語-視覚モデルのトレーニングを加速し安定させる新手法を提案。SwitchBackを用いたint8量子化で、CLIP ViT-Hugeのトレーニング速度を13-25%向上させ、bfloat16と同等の性能を維持。float8トレーニングも効果的であることを示し、初期化方法が成功に寄与。損失のスパイクを分析し、AdamW-Adafactorハイブリッドを推奨することで、トレーニングの安定性を向上させた。
Comment
#RecommenderSystems #CollaborativeFiltering #GraphBased Issue Date: 2023-04-26 Graph Collaborative Signals Denoising and Augmentation for Recommendation, Ziwei Fan+, N_A, SIGIR'23 Summaryグラフ協調フィルタリング(GCF)は、推薦システムで人気のある技術ですが、相互作用が豊富なユーザーやアイテムにはノイズがあり、相互作用が不十分なユーザーやアイテムには不十分です。また、ユーザー-ユーザーおよびアイテム-アイテムの相関を無視しているため、有益な隣接ノードの範囲が制限される可能性があります。本研究では、ユーザー-ユーザーおよびアイテム-アイテムの相関を組み込んだ新しいグラフの隣接行列と、適切に設計されたユーザー-アイテムの相互作用行列を提案します。実験では、改善された隣接ノードと低密度を持つ強化されたユーザー-アイテムの相互作用行列が、グラフベースの推薦において重要な利点をもたらすことを示しています。また、ユーザー-ユーザーおよびアイテム-アイテムの相関を含めることで、相互作用が豊富なユーザーや不十分なユーザーに対する推薦が改善されることも示しています。 Commentグラフ協調フィルタリングを改善
 グラフ協調フィルタリング
グラフ協調フィルタリング
(下記ツイッターより引用)
user-item間の関係だけでなく、user-user間とitem-item間の情報を組み込むことで精度向上を達成した論文とのこと。
https://twitter.com/nogawanogawa/status/1651165820956057602?s=46&t=6qC80ox3qHrJixKeNmIOcg #NLP #Assessment #ChatGPT #InformationExtraction Issue Date: 2023-04-25 [Paper Note] Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness, Bo Li+, arXiv'23 Summary本研究では、ChatGPTの能力を7つの情報抽出(IE)タスクを通じて評価し、パフォーマンス、説明可能性、キャリブレーション、信頼性を分析しました。標準IE設定ではパフォーマンスが低い一方、オープンIE設定では人間評価で優れた結果を示しました。ChatGPTは高品質な説明を提供するものの、予測に対して過信する傾向があり、キャリブレーションが低いことが明らかになりました。また、元のテキストに対して高い信頼性を示しました。研究のために手動で注釈付けした7つのIEタスクのテストセットと14のデータセットを公開しています。 Comment情報抽出タスクにおいてChatGPTを評価した研究。スタンダードなIEの設定ではBERTベースのモデルに負けるが、OpenIEの場合は高い性能を示した。
また、ChatGPTは予測に対してクオリティが高く信頼に足る説明をしたが、一方で自信過剰な傾向がある。また、ChatGPTの予測はinput textに対して高いfaithfulnessを示しており、予測がinputから根ざしているものであることがわかる。(らしい)あまりしっかり読んでいないが、Entity Typing, NER, Relation Classification, Relation Extraction, Event Detection, Event Argument Extraction, Event Extractionで評価。standardIEでは、ChatGPTにタスクの説明と選択肢を与え、与えられた選択肢の中から正解を探す設定とした。一方OpenIEでは、選択肢を与えず、純粋にタスクの説明のみで予測を実施させた。OpenIEの結果を、3名のドメインエキスパートが出力が妥当か否か判定した結果、非常に高い性能を示すことがわかった。表を見ると、同じタスクでもstandardIEよりも高い性能を示している(そんなことある???)つまり、選択肢を与えてどれが正解ですか?ときくより、選択肢与えないでCoTさせた方が性能高いってこと?比較可能な設定で実験できているのだろうか。promptは付録に載っているが、output exampleが載ってないのでなんともいえない。StandardIEの設定をしたときに、CoTさせてるかどうかが気になる。もししてないなら、そりゃ性能低いだろうね、という気がする。 #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #NeurIPS Issue Date: 2023-03-28 Reflexion: Language Agents with Verbal Reinforcement Learning, Noah Shinn+, N_A, NeurIPS'23 Summary本研究では、言語エージェントを強化するための新しいフレームワークであるReflexionを提案しています。Reflexionエージェントは、言語的フィードバックを通じて自己反省し、より良い意思決定を促すために反省的なテキストを保持します。Reflexionはさまざまなタスクでベースラインエージェントに比べて大幅な改善を実現し、従来の最先端のGPT-4を上回る精度を達成しました。さらに、異なるフィードバック信号や統合方法、エージェントタイプの研究を行い、パフォーマンスへの影響についての洞察を提供しています。 Commentなぜ回答を間違えたのか自己反省させることでパフォーマンスを向上させる研究 #NeuralNetwork #ComputerVision #SIGGRAPH Issue Date: 2022-12-01 Sketch-Guided Text-to-Image Diffusion Models, Andrey+, Google Research, SIGGRAPH'23 Summaryテキストから画像へのモデルは高品質な画像合成を実現するが、空間的特性の制御が不足している。本研究では、スケッチからの空間マップを用いて事前学習済みモデルを導く新しいアプローチを提案。専用モデルを必要とせず、潜在ガイダンス予測器(LGP)を訓練し、画像を空間マップに一致させる。ピクセルごとの訓練により柔軟性を持ち、スケッチから画像への翻訳タスクにおいて効果的な生成が可能であることを示す。 Commentスケッチとpromptを入力することで、スケッチ biasedな画像を生成することができる技術。すごい。
 #Survey
#AdaptiveLearning
#EducationalDataMining
#KnowledgeTracing
Issue Date: 2022-08-02
Knowledge Tracing: A Survey, ABDELRAHMAN+, Australian National University, ACM Computing Surveys'23
Summary人間の教育における知識移転の重要性を背景に、オンライン教育における知識追跡(KT)の必要性が高まっている。本論文では、KTに関する包括的なレビューを行い、初期の手法から最新の深層学習技術までを網羅し、モデルの理論やデータセットの特性を強調する。また、関連手法のモデリングの違いを明確にし、KT文献の研究ギャップや今後の方向性についても議論する。
#NeuralNetwork
#Survey
#MachineLearning
Issue Date: 2021-06-19
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better, Menghani, ACM Computing Surveys'23
Summaryディープラーニングの進展に伴い、モデルのパラメータ数やリソース要求が増加しているため、効率性が重要になっている。本研究では、モデル効率性の5つのコア領域を調査し、実務者向けに最適化ガイドとコードを提供する。これにより、効率的なディープラーニングの全体像を示し、読者に改善の手助けとさらなる研究のアイデアを提供することを目指す。
Comment学習効率化、高速化などのテクニックがまとまっているらしい
#Dataset
#NeurIPS
#KnowledgeEditing
Issue Date: 2025-08-26
[Paper Note] Locating and Editing Factual Associations in GPT, Kevin Meng+, NeurIPS'22
Summary自回帰型トランスフォーマー言語モデルにおける事実の関連付けの保存と想起を分析し、局所的な計算に対応することを示した。因果介入を用いて事実予測に関与するニューロンを特定し、フィードフォワードモジュールの役割を明らかにした。Rank-One Model Editing(ROME)を用いて特定の事実の関連付けを更新し、他の方法と同等の効果を確認。新しいデータセットに対する評価でも特異性と一般化を両立できることを示した。中間層のフィードフォワードモジュールが事実の関連付けに重要であり、モデル編集の実行可能性を示唆している。
#ComputerVision
#Transformer
#OCR
#ACMMM
#Backbone
Issue Date: 2025-08-22
[Paper Note] DiT: Self-supervised Pre-training for Document Image Transformer, Junlong Li+, ACMMM'22
Summary自己監視型事前学習モデルDiTを提案し、ラベルなしテキスト画像を用いて文書AIタスクにおける性能を向上。文書画像分類やレイアウト分析、表検出、OCRなどで新たな最先端結果を達成。コードとモデルは公開中。
Issue Date: 2025-08-21
[Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
Summary本研究では、「憲法的AI」と呼ばれる手法を用いて、人間のラベルなしで無害なAIを訓練する方法を探求します。監視学習と強化学習の2つのフェーズを経て、自己批評と修正を通じてモデルを微調整し、嗜好モデルを報酬信号として強化学習を行います。このアプローチにより、有害なクエリに対しても適切に対処できる無害なAIアシスタントを育成し、AIの意思決定の透明性を向上させることが可能になります。
Issue Date: 2025-08-16
[Paper Note] Efficient Training of Language Models to Fill in the Middle, Mohammad Bavarian+, arXiv'22
Summary自回帰言語モデルが、文書の中央からテキストのスパンを末尾に移動させる単純な変換を用いて埋め込みを学習できることを示す。データ拡張による訓練が元の生成能力に影響を与えないことを証明し、FIMでの訓練をデフォルトとすべきと提案。主要なハイパーパラメータに関するアブレーションを行い、強力なデフォルト設定とベストプラクティスを提示。最良の埋め込みモデルをAPIで公開し、埋め込みベンチマークも提供。
#Embeddings
#NLP
#RepresentationLearning
#NeurIPS
#Length
Issue Date: 2025-07-29
[Paper Note] Matryoshka Representation Learning, Aditya Kusupati+, NeurIPS'22
Summaryマトリョーシカ表現学習(MRL)は、異なる計算リソースに適応可能な柔軟な表現を設計する手法であり、既存の表現学習パイプラインを最小限に修正して使用します。MRLは、粗から細への表現を学習し、ImageNet-1K分類で最大14倍小さい埋め込みサイズを提供し、実世界のスピードアップを実現し、少数ショット分類で精度向上を達成します。MRLは視覚、視覚+言語、言語のモダリティにわたるデータセットに拡張可能で、コードとモデルはオープンソースで公開されています。
Comment日本語解説:https://speakerdeck.com/hpprc/lun-jiang-zi-liao-matryoshka-representation-learning単一のモデルから複数のlengthのEmbeddingを出力できるような手法。
#NeuralNetwork
#ComputerVision
#MachineLearning
#NLP
#MultitaskLearning
#MulltiModal
#SpeechProcessing
#ICLR
Issue Date: 2025-07-10
[Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22
Summary汎用アーキテクチャPerceiver IOを提案し、任意のデータ設定に対応し、入力と出力のサイズに対して線形にスケール可能。柔軟なクエリメカニズムを追加し、タスク特有の設計を不要に。自然言語、視覚理解、マルチタスクで強力な結果を示し、GLUEベンチマークでBERTを上回る性能を達成。
Comment当時相当話題となったさまざまなモーダルを統一された枠組みで扱えるPerceiver IO論文
#Survey
#AdaptiveLearning
#EducationalDataMining
#KnowledgeTracing
Issue Date: 2022-08-02
Knowledge Tracing: A Survey, ABDELRAHMAN+, Australian National University, ACM Computing Surveys'23
Summary人間の教育における知識移転の重要性を背景に、オンライン教育における知識追跡(KT)の必要性が高まっている。本論文では、KTに関する包括的なレビューを行い、初期の手法から最新の深層学習技術までを網羅し、モデルの理論やデータセットの特性を強調する。また、関連手法のモデリングの違いを明確にし、KT文献の研究ギャップや今後の方向性についても議論する。
#NeuralNetwork
#Survey
#MachineLearning
Issue Date: 2021-06-19
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better, Menghani, ACM Computing Surveys'23
Summaryディープラーニングの進展に伴い、モデルのパラメータ数やリソース要求が増加しているため、効率性が重要になっている。本研究では、モデル効率性の5つのコア領域を調査し、実務者向けに最適化ガイドとコードを提供する。これにより、効率的なディープラーニングの全体像を示し、読者に改善の手助けとさらなる研究のアイデアを提供することを目指す。
Comment学習効率化、高速化などのテクニックがまとまっているらしい
#Dataset
#NeurIPS
#KnowledgeEditing
Issue Date: 2025-08-26
[Paper Note] Locating and Editing Factual Associations in GPT, Kevin Meng+, NeurIPS'22
Summary自回帰型トランスフォーマー言語モデルにおける事実の関連付けの保存と想起を分析し、局所的な計算に対応することを示した。因果介入を用いて事実予測に関与するニューロンを特定し、フィードフォワードモジュールの役割を明らかにした。Rank-One Model Editing(ROME)を用いて特定の事実の関連付けを更新し、他の方法と同等の効果を確認。新しいデータセットに対する評価でも特異性と一般化を両立できることを示した。中間層のフィードフォワードモジュールが事実の関連付けに重要であり、モデル編集の実行可能性を示唆している。
#ComputerVision
#Transformer
#OCR
#ACMMM
#Backbone
Issue Date: 2025-08-22
[Paper Note] DiT: Self-supervised Pre-training for Document Image Transformer, Junlong Li+, ACMMM'22
Summary自己監視型事前学習モデルDiTを提案し、ラベルなしテキスト画像を用いて文書AIタスクにおける性能を向上。文書画像分類やレイアウト分析、表検出、OCRなどで新たな最先端結果を達成。コードとモデルは公開中。
Issue Date: 2025-08-21
[Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
Summary本研究では、「憲法的AI」と呼ばれる手法を用いて、人間のラベルなしで無害なAIを訓練する方法を探求します。監視学習と強化学習の2つのフェーズを経て、自己批評と修正を通じてモデルを微調整し、嗜好モデルを報酬信号として強化学習を行います。このアプローチにより、有害なクエリに対しても適切に対処できる無害なAIアシスタントを育成し、AIの意思決定の透明性を向上させることが可能になります。
Issue Date: 2025-08-16
[Paper Note] Efficient Training of Language Models to Fill in the Middle, Mohammad Bavarian+, arXiv'22
Summary自回帰言語モデルが、文書の中央からテキストのスパンを末尾に移動させる単純な変換を用いて埋め込みを学習できることを示す。データ拡張による訓練が元の生成能力に影響を与えないことを証明し、FIMでの訓練をデフォルトとすべきと提案。主要なハイパーパラメータに関するアブレーションを行い、強力なデフォルト設定とベストプラクティスを提示。最良の埋め込みモデルをAPIで公開し、埋め込みベンチマークも提供。
#Embeddings
#NLP
#RepresentationLearning
#NeurIPS
#Length
Issue Date: 2025-07-29
[Paper Note] Matryoshka Representation Learning, Aditya Kusupati+, NeurIPS'22
Summaryマトリョーシカ表現学習(MRL)は、異なる計算リソースに適応可能な柔軟な表現を設計する手法であり、既存の表現学習パイプラインを最小限に修正して使用します。MRLは、粗から細への表現を学習し、ImageNet-1K分類で最大14倍小さい埋め込みサイズを提供し、実世界のスピードアップを実現し、少数ショット分類で精度向上を達成します。MRLは視覚、視覚+言語、言語のモダリティにわたるデータセットに拡張可能で、コードとモデルはオープンソースで公開されています。
Comment日本語解説:https://speakerdeck.com/hpprc/lun-jiang-zi-liao-matryoshka-representation-learning単一のモデルから複数のlengthのEmbeddingを出力できるような手法。
#NeuralNetwork
#ComputerVision
#MachineLearning
#NLP
#MultitaskLearning
#MulltiModal
#SpeechProcessing
#ICLR
Issue Date: 2025-07-10
[Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22
Summary汎用アーキテクチャPerceiver IOを提案し、任意のデータ設定に対応し、入力と出力のサイズに対して線形にスケール可能。柔軟なクエリメカニズムを追加し、タスク特有の設計を不要に。自然言語、視覚理解、マルチタスクで強力な結果を示し、GLUEベンチマークでBERTを上回る性能を達成。
Comment当時相当話題となったさまざまなモーダルを統一された枠組みで扱えるPerceiver IO論文
 #NLP
#Transformer
#Architecture
#Normalization
#Encoder-Decoder
Issue Date: 2025-07-04
[Paper Note] On Layer Normalizations and Residual Connections in Transformers, Sho Takase+, arXiv'22
Summary本研究では、Transformerアーキテクチャのレイヤー正規化の位置に関するPost-LNとPre-LNの違いを調査。Post-LNは浅い層で優れた性能を示す一方、深い層では不安定なトレーニングを引き起こす消失勾配問題があることを発見。これを踏まえ、Post-LNの修正により安定したトレーニングを実現する方法を提案し、実験でPre-LNを上回る結果を示した。
CommentPre-LNの安定性を持ちながらもPost-LNのような高い性能を発揮する良いとこ取りのB2TConnectionを提案
#NLP
#Transformer
#Architecture
#Normalization
#Encoder-Decoder
Issue Date: 2025-07-04
[Paper Note] On Layer Normalizations and Residual Connections in Transformers, Sho Takase+, arXiv'22
Summary本研究では、Transformerアーキテクチャのレイヤー正規化の位置に関するPost-LNとPre-LNの違いを調査。Post-LNは浅い層で優れた性能を示す一方、深い層では不安定なトレーニングを引き起こす消失勾配問題があることを発見。これを踏まえ、Post-LNの修正により安定したトレーニングを実現する方法を提案し、実験でPre-LNを上回る結果を示した。
CommentPre-LNの安定性を持ちながらもPost-LNのような高い性能を発揮する良いとこ取りのB2TConnectionを提案

 NLP2022:https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/A2-5.pdf
#NLP
#LanguageModel
#ICLR
#KnowledgeEditing
Issue Date: 2025-06-18
[Paper Note] Fast Model Editing at Scale, Eric Mitchell+, ICLR'22
SummaryMEND(モデル編集ネットワーク)は、事前学習モデルの動作を迅速かつ局所的に編集するための手法で、単一の入力-出力ペアを用いて勾配分解を活用します。これにより、10億以上のパラメータを持つモデルでも、1台のGPUで短時間でトレーニング可能です。実験により、MENDが大規模モデルの編集において効果的であることが示されました。
CommentOpenReview:https://openreview.net/forum?id=0DcZxeWfOPt
#NLP
#LanguageModel
#PEFT(Adaptor/LoRA)
#ICLR
#PostTraining
#Admin'sPick
Issue Date: 2025-05-12
LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
SummaryLoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。
CommentOpenrReview:https://openreview.net/forum?id=nZeVKeeFYf9LoRAもなんやかんやメモってなかったので追加。
NLP2022:https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/A2-5.pdf
#NLP
#LanguageModel
#ICLR
#KnowledgeEditing
Issue Date: 2025-06-18
[Paper Note] Fast Model Editing at Scale, Eric Mitchell+, ICLR'22
SummaryMEND(モデル編集ネットワーク)は、事前学習モデルの動作を迅速かつ局所的に編集するための手法で、単一の入力-出力ペアを用いて勾配分解を活用します。これにより、10億以上のパラメータを持つモデルでも、1台のGPUで短時間でトレーニング可能です。実験により、MENDが大規模モデルの編集において効果的であることが示されました。
CommentOpenReview:https://openreview.net/forum?id=0DcZxeWfOPt
#NLP
#LanguageModel
#PEFT(Adaptor/LoRA)
#ICLR
#PostTraining
#Admin'sPick
Issue Date: 2025-05-12
LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
SummaryLoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。
CommentOpenrReview:https://openreview.net/forum?id=nZeVKeeFYf9LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。 #ComputerVision #NLP #Dataset #MulltiModal #CLIP #NeurIPS Issue Date: 2025-05-06 LAION-5B: An open large-scale dataset for training next generation image-text models, Christoph Schuhmann+, NeurIPS'22 SummaryLAION-5Bは、5.85億のCLIPフィルタリングされた画像-テキストペアから成る大規模データセットで、英語のペアが2.32B含まれています。このデータセットは、CLIPやGLIDEなどのモデルの再現とファインチューニングに利用され、マルチモーダルモデルの研究を民主化します。また、データ探索やサブセット生成のためのインターフェースや、コンテンツ検出のためのスコアも提供されます。 #Metrics #Evaluation #AutomaticSpeechRecognition(ASR) #NAACL #SimulST(SimultaneousSpeechTranslation) Issue Date: 2025-04-30 Over-Generation Cannot Be Rewarded: Length-Adaptive Average Lagging for Simultaneous Speech Translation, Sara Papi+, NAACL'22 SummarySimulSTシステムの遅延評価において、ALが長い予測に対して過小評価される問題を指摘。過剰生成の傾向を持つシステムに対し、過小生成と過剰生成を公平に評価する新指標LAALを提案。 Comment同時翻訳研究で主要なmetricの一つ
関連:
・1915 #MachineLearning #NLP #LanguageModel #NeurIPS #Scaling Laws #Admin'sPick Issue Date: 2025-03-23 Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22 Summaryトランスフォーマー言語モデルの訓練において、計算予算内で最適なモデルサイズとトークン数を調査。モデルサイズと訓練トークン数は同等にスケールする必要があり、倍増するごとにトークン数も倍増すべきと提案。Chinchillaモデルは、Gopherなどの大規模モデルに対して優れた性能を示し、ファインチューニングと推論の計算量を削減。MMLUベンチマークで67.5%の精度を達成し、Gopherに対して7%以上の改善を実現。 CommentOpenReview: https://openreview.net/forum?id=iBBcRUlOAPRchinchilla則 #EfficiencyImprovement #Pretraining #NLP #Transformer #Architecture #MoE(Mixture-of-Experts) #Admin'sPick Issue Date: 2025-02-11 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22 SummarySwitch Transformerを提案し、Mixture of Experts (MoE)の複雑さや通信コスト、トレーニングの不安定性を改善。これにより、低精度フォーマットでの大規模スパースモデルのトレーニングが可能になり、最大7倍の事前トレーニング速度向上を実現。さらに、1兆パラメータのモデルを事前トレーニングし、T5-XXLモデルに対して4倍の速度向上を達成。 #Pretraining #ICLR Issue Date: 2025-01-06 Towards Continual Knowledge Learning of Language Models, Joel Jang+, ICLR'22 Summary大規模言語モデル(LMs)の知識が陳腐化する問題に対処するため、「継続的知識学習(CKL)」という新しい継続的学習問題を定式化。CKLでは、時間不変の知識の保持、陳腐化した知識の更新、新しい知識の獲得を定量化するためのベンチマークとメトリックを構築。実験により、CKLが独自の課題を示し、知識を信頼性高く保持し学習するためにはパラメータの拡張が必要であることが明らかに。ベンチマークデータセットやコードは公開されている。 #RecommenderSystems #NeuralNetwork #CTRPrediction Issue Date: 2024-11-19 Deep Intention-Aware Network for Click-Through Rate Prediction, Yaxian Xia+, arXiv'22 SummaryEコマースプラットフォームにおけるトリガー誘発推薦(TIRA)に対し、従来のCTR予測モデルは不適切である。顧客のエントリー意図を抽出し、トリガーの影響を評価するために、深層意図認識ネットワーク(DIAN)を提案。DIANは、ユーザーの意図を推定し、トリガー依存と非依存の推薦結果を動的にバランスさせる。実験により、DIANはタオバオのミニアプリでCTRを4.74%向上させることが示された。 Comment1531 の実験で利用されているベースライン #RecommenderSystems #NeuralNetwork #CTRPrediction Issue Date: 2024-11-19 Deep Interest Highlight Network for Click-Through Rate Prediction in Trigger-Induced Recommendation, Qijie Shen+, WWW'22 Summaryトリガー誘発推薦(TIR)を提案し、ユーザーの瞬時の興味を引き出す新しい推薦手法を紹介。従来のモデルがTIRシナリオで効果的でない問題を解決するため、Deep Interest Highlight Network(DIHN)を開発。DIHNは、ユーザー意図ネットワーク(UIN)、融合埋め込みモジュール(FEM)、ハイブリッド興味抽出モジュール(HIEM)の3つのコンポーネントから成り、実際のeコマースプラットフォームでの評価で優れた性能を示した。 Comment1531 の実験で利用されているベースライン #MachineTranslation #NLP #Dataset Issue Date: 2024-09-26 No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, N_A, arXiv'22 Summary「No Language Left Behind」プロジェクトでは、リソースが乏しい言語の機械翻訳を改善するために、ネイティブスピーカーとのインタビューを通じて必要性を明らかにし、データセットとモデルを開発。新しいデータマイニング技術を用いた条件付き計算モデルを提案し、過学習を防ぐための訓練改善を行った。Flores-200ベンチマークで40,000以上の翻訳方向を評価し、従来技術に対して44%のBLEU改善を達成。全ての成果はオープンソースとして公開。 Commentlow-resourceな言語に対するMTのベンチマーク #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2024-09-25 Finetuned Language Models Are Zero-Shot Learners, Jason Wei+, N_A, ICLR'22 Summary指示チューニングを用いて言語モデルのゼロショット学習能力を向上させる方法を提案。137BパラメータのモデルFLANは、60以上のNLPタスクでファインチューニングされ、未見のタスクで175B GPT-3を上回るパフォーマンスを示す。アブレーションスタディにより、ファインチューニングデータセットの数やモデルのスケールが成功に寄与することが確認された。 CommentFLAN論文。Instruction Tuningを提案した研究。 #NLP #LanguageModel #SelfImprovement Issue Date: 2024-09-15 STaR: Bootstrapping Reasoning With Reasoning, Eric Zelikman+, N_A, NeurIPS'22 Summary「自己学習推論者」(STaR)を提案し、少数の合理的説明と大規模データセットを活用して複雑な推論を行う。STaRは、生成した回答が間違っている場合に正しい回答を用いて再生成し、ファインチューニングを繰り返すことで性能を向上させる。実験により、STaRは従来のモデルと比較して大幅な性能向上を示し、特にCommensenseQAでの成果が顕著である。 CommentOpenAI o1関連研究 #Analysis #NLP #Transformer #ACL #KnowledgeEditing #Admin'sPick #FactualKnowledge #Encoder Issue Date: 2024-07-11 Knowledge Neurons in Pretrained Transformers, Damai Dai+, N_A, ACL'22, 2022.05 Summary大規模な事前学習言語モデルにおいて、事実知識の格納方法についての研究を行いました。具体的には、BERTのfill-in-the-blank cloze taskを用いて、関連する事実を表現するニューロンを特定しました。また、知識ニューロンの活性化と対応する事実の表現との正の相関を見つけました。さらに、ファインチューニングを行わずに、知識ニューロンを活用して特定の事実知識を編集しようと試みました。この研究は、事前学習されたTransformers内での知識の格納に関する示唆に富んでおり、コードはhttps://github.com/Hunter-DDM/knowledge-neuronsで利用可能です。 Comment1108 日本語解説: https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022関連:
・2140上記資料によると、特定の知識を出力する際に活性化する知識ニューロンを特定する手法を提案。MLMを用いたclozeタスクによる実験で[MASK]部分に当該知識を出力する実験をした結果、知識ニューロンの重みをゼロとすると性能が著しく劣化し、値を2倍にすると性能が改善するといった傾向がみられた。 ケーススタディとして、知識の更新と、知識の削除が可能かを検証。どちらとも更新・削除がされる方向性[^1]へモデルが変化した。
また、知識ニューロンはTransformerの層の深いところに位置している傾向にあり、異なるrelationを持つような関係知識同士では共有されない傾向にある模様。
[^1]: 他の知識に影響を与えず、完璧に更新・削除できたわけではない。知識の更新・削除に伴いExtrinsicな評価によって性能向上、あるいはPerplexityが増大した、といった結果からそういった方向性へモデルが変化した、という話 Issue Date: 2024-02-22 Dense Text Retrieval based on Pretrained Language Models: A Survey, Wayne Xin Zhao+, N_A, arXiv'22 Summaryテキスト検索における最近の進歩に焦点を当て、PLMベースの密な検索に関する包括的な調査を行った。PLMsを使用することで、クエリとテキストの表現を学習し、意味マッチング関数を構築することが可能となり、密な検索アプローチが可能となる。この調査では、アーキテクチャ、トレーニング、インデックス作成、統合などの側面に焦点を当て、300以上の関連文献を含む包括的な情報を提供している。 #NaturalLanguageGeneration #NLP #DataToTextGeneration #StructuredData Issue Date: 2023-10-28 MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation, Swarnadeep Saha+, N_A, arXiv'22 Summary本研究では、半構造化データからのテキスト生成における多段階の推論を行うためのMURMURという手法を提案しています。MURMURは、特定の言語的および論理的なスキルを持つニューラルモジュールと記号モジュールを組み合わせ、ベストファーストサーチ手法を使用して推論パスを生成します。実験結果では、MURMURは他のベースライン手法に比べて大幅な改善を示し、また、ドメイン外のデータでも同等の性能を達成しました。さらに、人間の評価では、MURMURは論理的に整合性のある要約をより多く生成することが示されました。 #EfficiencyImprovement #MachineLearning Issue Date: 2023-08-16 Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning, Haokun Liu+, N_A, arXiv'22 SummaryFew-shot in-context learning(ICL)とパラメータ効率の良いファインチューニング(PEFT)を比較し、PEFTが高い精度と低い計算コストを提供することを示す。また、新しいPEFTメソッドである(IA)^3を紹介し、わずかな新しいパラメータしか導入しないまま、強力なパフォーマンスを達成する。さらに、T-Fewというシンプルなレシピを提案し、タスク固有のチューニングや修正なしに新しいタスクに適用できる。RAFTベンチマークでT-Fewを使用し、超人的なパフォーマンスを達成し、最先端を6%絶対的に上回る。 #BeamSearch #NaturalLanguageGeneration #NLP Issue Date: 2023-08-16 Momentum Calibration for Text Generation, Xingxing Zhang+, N_A, arXiv'22 Summary本研究では、テキスト生成タスクにおいてMoCa(Momentum Calibration)という手法を提案しています。MoCaは、ビームサーチを用いた遅く進化するサンプルを動的に生成し、これらのサンプルのモデルスコアを実際の品質に合わせるように学習します。実験結果は、MoCaが強力な事前学習済みTransformerを改善し、最先端の結果を達成していることを示しています。 #DocumentSummarization #BeamSearch #NaturalLanguageGeneration #NLP #ACL Issue Date: 2023-08-16 BRIO: Bringing Order to Abstractive Summarization, Yixin Liu+, N_A, ACL'22 Summary従来の抽象的要約モデルでは、最尤推定を使用して訓練されていましたが、この方法では複数の候補要約を比較する際に性能が低下する可能性があります。そこで、非確定論的な分布を仮定し、候補要約の品質に応じて確率を割り当てる新しい訓練パラダイムを提案しました。この手法により、CNN/DailyMailとXSumのデータセットで最高の結果を達成しました。さらに、モデルが候補要約の品質とより相関のある確率を推定できることも示されました。 Commentビーム内のトップがROUGEを最大化しているとは限らなかったため、ROUGEが最大となるような要約を選択するようにしたら性能爆上げしましたという研究。
実質現在のSoTA #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-14 SMART: Sentences as Basic Units for Text Evaluation, Reinald Kim Amplayo+, N_A, arXiv'22 Summary本研究では、テキスト生成の評価指標の制限を緩和するために、新しい指標であるSMARTを提案する。SMARTは文を基本的なマッチング単位とし、文のマッチング関数を使用して候補文と参照文を評価する。また、ソースドキュメントの文とも比較し、評価を可能にする。実験結果は、SMARTが他の指標を上回ることを示し、特にモデルベースのマッチング関数を使用した場合に有効であることを示している。また、提案された指標は長い要約文でもうまく機能し、特定のモデルに偏りが少ないことも示されている。 #DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #Reference-based Issue Date: 2023-08-13 FFCI: A Framework for Interpretable Automatic Evaluation of Summarization, Fajri Koto+, N_A, JAIR'22 Summary本論文では、FFCIという細かい要約評価のためのフレームワークを提案しました。このフレームワークは、信頼性、焦点、カバレッジ、および文間の連続性の4つの要素から構成されています。新しいデータセットを構築し、評価メトリックとモデルベースの評価方法をクロス比較することで、FFCIの4つの次元を評価するための自動的な方法を開発しました。さまざまな要約モデルを評価し、驚くべき結果を得ました。 Comment先行研究でどのようなMetricが利用されていて、それらがどういった観点のMetricなのかや、データセットなど、非常に細かくまとまっている。Faithfulness(ROUGE, STS-Score, BERTScoreに基づく), Focus and Coverage (Question Answering basedな手法に基づく), Inter-Sentential Coherence (NSPに基づく)メトリックを組み合わせることを提案している。 #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation, Pierre Colombo+, N_A, AAAI'22 Summary自然言語生成システムの品質評価は高価であり、人間の注釈に頼ることが一般的です。しかし、自動評価指標を使用することもあります。本研究では、マスクされた言語モデルを使用した評価指標であるInfoLMを紹介します。この指標は同義語を処理することができ、要約やデータ生成の設定で有意な改善を示しました。 #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 WIDAR -- Weighted Input Document Augmented ROUGE, Raghav Jain+, N_A, ECIR'22 Summary自動テキスト要約の評価において、ROUGEメトリックには制約があり、参照要約の利用可能性に依存している。そこで、本研究ではWIDARメトリックを提案し、参照要約だけでなく入力ドキュメントも使用して要約の品質を評価する。WIDARメトリックは一貫性、整合性、流暢さ、関連性の向上をROUGEと比較しており、他の最先端のメトリックと同等の結果を短い計算時間で得ることができる。 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 How to Find Strong Summary Coherence Measures? A Toolbox and a Comparative Study for Summary Coherence Measure Evaluation, Steen+, COLING'22 Summary要約の一貫性を自動的に評価することは重要であり、さまざまな方法が提案されていますが、異なるデータセットと評価指標を使用して評価されるため、相対的なパフォーマンスを理解することが困難です。本研究では、要約の一貫性モデリングのさまざまな方法について調査し、新しい分析尺度を導入します。現在の自動一貫性尺度はすべての評価指標において信頼性のある一貫性スコアを割り当てることができませんが、大規模言語モデルは有望な結果を示しています。 #DocumentSummarization #NeuralNetwork #Analysis #NLP #IJCNLP #AACL #Repetition Issue Date: 2023-08-13 Self-Repetition in Abstractive Neural Summarizers, Nikita Salkar+, N_A, AACL-IJCNLP'22 Summary私たちは、BART、T5、およびPegasusという3つのニューラルモデルの出力における自己繰り返しの分析を行いました。これらのモデルは、異なるデータセットでfine-tuningされています。回帰分析によると、これらのモデルは入力の出力要約間でコンテンツを繰り返す傾向が異なることがわかりました。また、抽象的なデータや定型的な言語を特徴とするデータでのfine-tuningでは、自己繰り返しの割合が高くなる傾向があります。定性的な分析では、システムがアーティファクトや定型フレーズを生成することがわかりました。これらの結果は、サマライザーのトレーニングデータを最適化するための手法の開発に役立つ可能性があります。 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 Universal Evasion Attacks on Summarization Scoring, Wenchuan Mu+, N_A, BlackboxNLP workshop on ACL'22 Summary要約の自動評価は重要であり、その評価は複雑です。しかし、これまで要約の評価は機械学習のタスクとは考えられていませんでした。本研究では、自動評価の堅牢性を探るために回避攻撃を行いました。攻撃システムは、要約ではない文字列を予測し、一般的な評価指標であるROUGEやMETEORにおいて優れた要約器と競合するスコアを達成しました。また、攻撃システムは最先端の要約手法を上回るスコアを獲得しました。この研究は、現在の評価システムの堅牢性の低さを示しており、要約スコアの開発を促進することを目指しています。 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 DocAsRef: A Pilot Empirical Study on Repurposing Reference-Based Summary Quality Metrics Reference-Freely, Forrest Sheng Bao+, N_A, arXiv'22 Summary参照ベースと参照フリーの要約評価メトリックがあります。参照ベースは正確ですが、制約があります。参照フリーは独立していますが、ゼロショットと正確さの両方を満たせません。本研究では、参照ベースのメトリックを使用してゼロショットかつ正確な参照フリーのアプローチを提案します。実験結果は、このアプローチが最も優れた参照フリーのメトリックを提供できることを示しています。また、参照ベースのメトリックの再利用と追加の調整についても調査しています。 #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration Issue Date: 2023-08-11 Personalized News Headline Generation System with Fine-grained User Modeling, Yao, MSN'22 Summaryユーザーの興味に基づいてパーソナライズされたニュースの見出しを生成するために、文レベルの情報を考慮したユーザーモデルを提案する。アテンション層を使用して文とニュースの関連性を計算し、ニュースの内容に基づいて見出しを生成する。実験結果は、提案モデルがベースラインモデルよりも優れたパフォーマンスを示していることを示している。将来の方向性として、情報のレベルと内容を横断する相互作用についても議論されている。 #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration Issue Date: 2023-08-11 Personalized Headline Generation with Enhanced User Interest Perception, Zhang+, ICANN'22 Summaryユーザーのニュース閲覧履歴をモデル化し、個別化されたニュース見出しを生成するための新しいフレームワークを提案する。提案手法は、ユーザーの興味を強調するために候補テキストに関連する情報を活用し、ニュースのエンティティワードを使用して興味表現を改善する。幅広い実験により、提案手法が見出し生成タスクで優れたパフォーマンスを示すことが示されている。 #RecommenderSystems #NLP #PersonalizedGeneration #Personalization Issue Date: 2023-08-11 Personalized Chit-Chat Generation for Recommendation Using External Chat Corpora, Chen+, KDD'22 Summaryチットチャットは、ユーザーとの対話において効果的であることが示されています。この研究では、ニュース推薦のための個人化されたチットチャットを生成する方法を提案しています。既存の方法とは異なり、外部のチャットコーパスのみを使用してユーザーの関心を推定し、個人化されたチットチャットを生成します。幅広い実験により、提案手法の効果が示されています。 #NaturalLanguageGeneration #NLP #Dataset #LanguageModel #Explanation Issue Date: 2023-08-03 Explaining Patterns in Data with Language Models via Interpretable Autoprompting, Chandan Singh+, N_A, arXiv'22 Summary本研究では、大規模言語モデル(LLMs)を使用してデータのパターンを説明する能力を探求しました。具体的には、事前学習済みのLLMを使用してデータを説明する自然言語の文字列を生成するアルゴリズムを導入しました。実験結果は、このアルゴリズムが正確なデータセットの説明を見つけ出すことができることを示しています。また、生成されるプロンプトは人間にも理解可能であり、実世界のデータセットやfMRIデータセットで有用な洞察を提供することができることも示されました。 CommentOpenReview: https://openreview.net/forum?id=GvMuB-YsiK6データセット(中に存在するパターンの説明)をLLMによって生成させる研究

 #Pretraining #MachineLearning #Self-SupervisedLearning Issue Date: 2023-07-22 RankMe: Assessing the downstream performance of pretrained self-supervised representations by their rank, Quentin Garrido+, N_A, arXiv'22 Summary共有埋め込み自己教示学習(JE-SSL)は、成功の視覚的な手がかりが欠如しているため、展開が困難である。本研究では、JE-SSL表現の品質を評価するための非教示基準であるRankMeを開発した。RankMeはラベルを必要とせず、ハイパーパラメータの調整も不要である。徹底的な実験により、RankMeが最終パフォーマンスのほとんど減少なしにハイパーパラメータの選択に使用できることを示した。RankMeはJE-SSLの展開を容易にすることが期待される。 #NaturalLanguageGeneration #Controllable #NLP Issue Date: 2023-07-18 An Extensible Plug-and-Play Method for Multi-Aspect Controllable Text Generation, Xuancheng Huang+, N_A, arXiv'22 Summary本研究では、テキスト生成において複数の側面を制御する方法について研究しました。従来の方法では、プレフィックスの相互干渉により制約が低下し、未知の側面の組み合わせを制御することが制限されていました。そこで、トレーニング可能なゲートを使用してプレフィックスの介入を正規化し、相互干渉の増加を抑制する方法を提案しました。この方法により、トレーニング時に未知の制約を低コストで拡張することができます。さらに、カテゴリカルな制約と自由形式の制約の両方を処理する統一された方法も提案しました。実験により、提案手法が制約の正確さ、テキストの品質、拡張性においてベースラインよりも優れていることが示されました。 #NeuralNetwork #ComputerVision #MachineLearning #Supervised-FineTuning (SFT) #CLIP #ICLR #OOD Issue Date: 2023-05-15 Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution, Ananya Kumar+, N_A, ICLR'22 Summary事前学習済みモデルをダウンストリームタスクに転移する際、ファインチューニングと線形プロービングの2つの方法があるが、本研究では、分布のシフトが大きい場合、ファインチューニングが線形プロービングよりも分布外で精度が低くなることを発見した。LP-FTという2段階戦略の線形プロービング後の全体のファインチューニングが、両方のデータセットでファインチューニングと線形プロービングを上回ることを示唆している。 Comment事前学習済みのニューラルモデルをfinetuningする方法は大きく分けて
1. linear layerをヘッドとしてconcatしヘッドのみのパラメータを学習
2. 事前学習済みモデル全パラメータを学習
の2種類がある。
前者はin-distributionデータに強いが、out-of-distributionに弱い。後者は逆という互いが互いを補完し合う関係にあった。
そこで、まず1を実施し、その後2を実施する手法を提案。in-distribution, out-of-distributionの両方で高い性能を出すことを示した(実験では画像処理系のデータを用いて、モデルとしてはImageNet+CLIPで事前学習済みのViTを用いている)。
 #Analysis
#LanguageModel
Issue Date: 2023-05-11
Out of One, Many: Using Language Models to Simulate Human Samples, Lisa P. Argyle+, N_A, arXiv'22
Summary本研究では、言語モデルが社会科学研究において特定の人間のサブポピュレーションの代理として研究される可能性があることを提案し、GPT-3言語モデルの「アルゴリズム的忠実度」を探求する。アルゴリズム的忠実度が十分である言語モデルは、人間や社会の理解を進めるための新しい強力なツールとなる可能性があると提案する。
#ICLR
Issue Date: 2023-05-04
Transformers Learn Shortcuts to Automata, Bingbin Liu+, arXiv'22
Summaryトランスフォーマーモデルは再帰性を欠くが、少ない層でアルゴリズム的推論を行える。研究により、低深度のトランスフォーマーが有限状態オートマトンの計算を階層的に再パラメータ化できることを発見。多項式サイズの解決策が存在し、特に$O(1)$深度のシミュレーターが一般的であることを示した。合成実験でトランスフォーマーがショートカット解決策を学習できることを確認し、その脆弱性と緩和策も提案。
CommentOpenReview: https://openreview.net/forum?id=De4FYqjFueZ
#NeuralNetwork
#NLP
#LanguageModel
Issue Date: 2022-12-05
UNIFIEDSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models, Xie+, EMNLP'22
#Pretraining
#NLP
Issue Date: 2022-12-01
Revisiting Pretraining Objectives for Tabular Deep Learning, Rubachev+, Yandex+, arXiv'22
Summary表形式データに対する深層学習モデルはGBDTと競争しており、事前学習がパフォーマンス向上に寄与することが示された。異なるデータセットやアーキテクチャに適用可能な事前学習のベストプラクティスを特定し、オブジェクトターゲットラベルの使用が有益であることを発見。適切な事前学習により、深層学習モデルはGBDTを上回る性能を発揮することが確認された。
CommentTabular Dataを利用した場合にKaggleなどでDeepなモデルがGBDT等に勝てないことが知られているが、GBDT等とcomparable になる性能になるようなpre-trainingを提案したよ、的な内容っぽいICLR 2023 OpenReview: https://openreview.net/forum?id=kjPLodRa0n
#AdaptiveLearning
#KnowledgeTracing
Issue Date: 2022-08-10
No Task Left Behind: Multi-Task Learning of Knowledge Tracing and Option Tracing for Better Student Assessment, An+, RiiiD, AAAI'22
#AdaptiveLearning
#KnowledgeTracing
Issue Date: 2022-08-02
Interpretable Knowledge Tracing: Simple and Efficient Student Modeling with Causal Relations, Minn+, AAAI'22
CommentDeepLearningを用いずに解釈性の高いKTモデルを提案。DKT, DKVMN, AKT等をoutperformしている。
#RecommenderSystems
#NeuralNetwork
#EfficiencyImprovement
#CollaborativeFiltering
#EducationalDataMining
#KnowledgeTracing
#Contents-based
#NAACL
Issue Date: 2022-08-01
GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering, Yoonseok Yang+, NAACL'22
Summaryコンテンツベースの協調フィルタリング(CCF)において、PLMを用いたエンドツーエンドのトレーニングはリソースを消費するため、GRAM(勾配蓄積手法)を提案。Single-step GRAMはアイテムエンコーディングの勾配を集約し、Multi-step GRAMは勾配更新の遅延を増加させてメモリを削減。これにより、Knowledge TracingとNews Recommendationのタスクでトレーニング効率を最大146倍改善。
CommentRiiiDがNAACL'22に論文通してた
#NeuralNetwork
#MachineTranslation
#Embeddings
#NLP
#AAAI
Issue Date: 2021-06-07
Improving Neural Machine Translation with Compact Word Embedding Tables, Kumar+, AAAI'22
CommentNMTにおいてword embeddingがどう影響しているかなどを調査しているらしい
#ComputerVision
#Transformer
#ICLR
#Admin'sPick
#Backbone
Issue Date: 2025-08-25
[Paper Note] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy+, ICLR'21
Summary純粋なトランスフォーマーを画像パッチのシーケンスに直接適用することで、CNNへの依存なしに画像分類タスクで優れた性能を発揮できることを示す。大量のデータで事前学習し、複数の画像認識ベンチマークで最先端のCNNと比較して優れた結果を達成し、計算リソースを大幅に削減。
Commentopenreview:https://openreview.net/forum?id=YicbFdNTTyViTを提案した研究
#ActivationSteering/ITI
Issue Date: 2025-08-19
[Paper Note] Counterfactual Interventions Reveal the Causal Effect of Relative Clause Representations on Agreement Prediction, Shauli Ravfogel+, arXiv'21
SummaryAlterRepという手法を用いて、言語モデルが構文的に複雑な文を処理する際の因果的影響を調査。反事実的表現を生成し、BERTモデルが関係節(RC)の境界情報を文法に従って使用していることを発見。RCの境界情報は異なるタイプ間で一般化され、BERTがRCを抽象的な言語的カテゴリーとして表現していることが示された。
CommentAlterCapという手法名だが、steeringの先行研究とのこと
#Analysis
#LanguageModel
Issue Date: 2023-05-11
Out of One, Many: Using Language Models to Simulate Human Samples, Lisa P. Argyle+, N_A, arXiv'22
Summary本研究では、言語モデルが社会科学研究において特定の人間のサブポピュレーションの代理として研究される可能性があることを提案し、GPT-3言語モデルの「アルゴリズム的忠実度」を探求する。アルゴリズム的忠実度が十分である言語モデルは、人間や社会の理解を進めるための新しい強力なツールとなる可能性があると提案する。
#ICLR
Issue Date: 2023-05-04
Transformers Learn Shortcuts to Automata, Bingbin Liu+, arXiv'22
Summaryトランスフォーマーモデルは再帰性を欠くが、少ない層でアルゴリズム的推論を行える。研究により、低深度のトランスフォーマーが有限状態オートマトンの計算を階層的に再パラメータ化できることを発見。多項式サイズの解決策が存在し、特に$O(1)$深度のシミュレーターが一般的であることを示した。合成実験でトランスフォーマーがショートカット解決策を学習できることを確認し、その脆弱性と緩和策も提案。
CommentOpenReview: https://openreview.net/forum?id=De4FYqjFueZ
#NeuralNetwork
#NLP
#LanguageModel
Issue Date: 2022-12-05
UNIFIEDSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models, Xie+, EMNLP'22
#Pretraining
#NLP
Issue Date: 2022-12-01
Revisiting Pretraining Objectives for Tabular Deep Learning, Rubachev+, Yandex+, arXiv'22
Summary表形式データに対する深層学習モデルはGBDTと競争しており、事前学習がパフォーマンス向上に寄与することが示された。異なるデータセットやアーキテクチャに適用可能な事前学習のベストプラクティスを特定し、オブジェクトターゲットラベルの使用が有益であることを発見。適切な事前学習により、深層学習モデルはGBDTを上回る性能を発揮することが確認された。
CommentTabular Dataを利用した場合にKaggleなどでDeepなモデルがGBDT等に勝てないことが知られているが、GBDT等とcomparable になる性能になるようなpre-trainingを提案したよ、的な内容っぽいICLR 2023 OpenReview: https://openreview.net/forum?id=kjPLodRa0n
#AdaptiveLearning
#KnowledgeTracing
Issue Date: 2022-08-10
No Task Left Behind: Multi-Task Learning of Knowledge Tracing and Option Tracing for Better Student Assessment, An+, RiiiD, AAAI'22
#AdaptiveLearning
#KnowledgeTracing
Issue Date: 2022-08-02
Interpretable Knowledge Tracing: Simple and Efficient Student Modeling with Causal Relations, Minn+, AAAI'22
CommentDeepLearningを用いずに解釈性の高いKTモデルを提案。DKT, DKVMN, AKT等をoutperformしている。
#RecommenderSystems
#NeuralNetwork
#EfficiencyImprovement
#CollaborativeFiltering
#EducationalDataMining
#KnowledgeTracing
#Contents-based
#NAACL
Issue Date: 2022-08-01
GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering, Yoonseok Yang+, NAACL'22
Summaryコンテンツベースの協調フィルタリング(CCF)において、PLMを用いたエンドツーエンドのトレーニングはリソースを消費するため、GRAM(勾配蓄積手法)を提案。Single-step GRAMはアイテムエンコーディングの勾配を集約し、Multi-step GRAMは勾配更新の遅延を増加させてメモリを削減。これにより、Knowledge TracingとNews Recommendationのタスクでトレーニング効率を最大146倍改善。
CommentRiiiDがNAACL'22に論文通してた
#NeuralNetwork
#MachineTranslation
#Embeddings
#NLP
#AAAI
Issue Date: 2021-06-07
Improving Neural Machine Translation with Compact Word Embedding Tables, Kumar+, AAAI'22
CommentNMTにおいてword embeddingがどう影響しているかなどを調査しているらしい
#ComputerVision
#Transformer
#ICLR
#Admin'sPick
#Backbone
Issue Date: 2025-08-25
[Paper Note] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy+, ICLR'21
Summary純粋なトランスフォーマーを画像パッチのシーケンスに直接適用することで、CNNへの依存なしに画像分類タスクで優れた性能を発揮できることを示す。大量のデータで事前学習し、複数の画像認識ベンチマークで最先端のCNNと比較して優れた結果を達成し、計算リソースを大幅に削減。
Commentopenreview:https://openreview.net/forum?id=YicbFdNTTyViTを提案した研究
#ActivationSteering/ITI
Issue Date: 2025-08-19
[Paper Note] Counterfactual Interventions Reveal the Causal Effect of Relative Clause Representations on Agreement Prediction, Shauli Ravfogel+, arXiv'21
SummaryAlterRepという手法を用いて、言語モデルが構文的に複雑な文を処理する際の因果的影響を調査。反事実的表現を生成し、BERTモデルが関係節(RC)の境界情報を文法に従って使用していることを発見。RCの境界情報は異なるタイプ間で一般化され、BERTがRCを抽象的な言語的カテゴリーとして表現していることが示された。
CommentAlterCapという手法名だが、steeringの先行研究とのこと
https://x.com/tallinzen/status/1957454242936938545?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #Evaluation #CodeGeneration #Admin'sPick Issue Date: 2025-08-15 [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21 Summary本論文では、汎用プログラミング言語におけるプログラム合成の限界を大規模言語モデルを用いて評価します。MBPPとMathQA-Pythonの2つのベンチマークで、モデルサイズに対する合成性能のスケールを調査。最も大きなモデルは、少数ショット学習でMBPPの59.6%の問題を解決可能で、ファインチューニングにより約10%の性能向上が見られました。MathQA-Pythonでは、ファインチューニングされたモデルが83.8%の精度を達成。人間のフィードバックを取り入れることでエラー率が半減し、エラー分析を通じてモデルの弱点を明らかにしました。最終的に、プログラム実行結果の予測能力を探るも、最良のモデルでも特定の入力に対する出力予測が困難であることが示されました。 Comment代表的なコード生成のベンチマーク。
MBPPデータセットは、promptで指示されたコードをモデルに生成させ、テストコード(assertion)を通過するか否かで評価する。974サンプル存在し、pythonの基礎を持つクラウドワーカーによって生成。クラウドワーカーにタスクdescriptionとタスクを実施する一つの関数(関数のみで実行可能でprintは不可)、3つのテストケースを記述するよう依頼。タスクdescriptionは追加なclarificationなしでコードが記述できるよう十分な情報を含むよう記述するように指示。ground truthの関数を生成する際に、webを閲覧することを許可した。

MathQA-Pythonは、MathQAに含まれるQAのうち解答が数値のもののみにフィルタリングしたデータセットで、合計で23914サンプル存在する。pythonコードで与えられた数学に関する問題を解くコードを書き、数値が一致するか否かで評価する、といった感じな模様。斜め読みなので少し読み違えているかもしれない。
 #NLP
#Dataset
#LanguageModel
#Evaluation
#CodeGeneration
#Admin'sPick
Issue Date: 2025-08-15
[Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
SummaryCodexはGitHubのコードでファインチューニングされたGPT言語モデルで、Pythonコード生成能力を評価。新しい評価セットHumanEvalでは、Codexが28.8%の問題を解決し、GPT-3は0%、GPT-Jは11.4%だった。繰り返しサンプリングが難しいプロンプトに対しても効果的な戦略を用い、70.2%の問題を解決。モデルの限界として、長い操作の説明や変数へのバインドに苦労する点が明らかに。最後に、コード生成技術の影響について安全性や経済に関する議論を行う。
CommentHumanEvalデータセット。Killed by LLMによると、GPT4oによりすでに90%程度の性能が達成され飽和している。
#NLP
#Dataset
#LanguageModel
#Evaluation
#CodeGeneration
#Admin'sPick
Issue Date: 2025-08-15
[Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
SummaryCodexはGitHubのコードでファインチューニングされたGPT言語モデルで、Pythonコード生成能力を評価。新しい評価セットHumanEvalでは、Codexが28.8%の問題を解決し、GPT-3は0%、GPT-Jは11.4%だった。繰り返しサンプリングが難しいプロンプトに対しても効果的な戦略を用い、70.2%の問題を解決。モデルの限界として、長い操作の説明や変数へのバインドに苦労する点が明らかに。最後に、コード生成技術の影響について安全性や経済に関する議論を行う。
CommentHumanEvalデータセット。Killed by LLMによると、GPT4oによりすでに90%程度の性能が達成され飽和している。
164個の人手で記述されたprogrammingの問題で、それぞれはfunction signature, docstring, body, unittestを持つ。unittestは問題当たり約7.7 test存在。handwrittenという点がミソで、コンタミネーションの懸念があるためgithubのような既存ソースからのコピーなどはしていない。pass@k[^1]で評価。
[^1]: k個のサンプルを生成させ、k個のサンプルのうち、サンプルがunittestを一つでも通過する確率。ただ、本研究ではよりバイアスをなくすために、kよりも大きいn個のサンプルを生成し、その中からランダムにk個を選択して確率を推定するようなアプローチを実施している。2.1節を参照のこと。
 #ComputerVision
#Pretraining
#Transformer
#Architecture
#Backbone
Issue Date: 2025-07-19
[Paper Note] Swin Transformer V2: Scaling Up Capacity and Resolution, Ze Liu+, arXiv'21
Summary本論文では、大規模ビジョンモデルのトレーニングと応用における課題に対処するための3つの技術を提案。具体的には、トレーニングの安定性向上のための残差後正規化法、低解像度から高解像度への転送を可能にする位置バイアス法、ラベル付きデータの必要性を減少させる自己教師あり学習法を用いる。これにより、30億パラメータのSwin Transformer V2モデルをトレーニングし、複数のビジョンタスクで新記録を樹立。トレーニング効率も向上し、ラベル付きデータと時間を大幅に削減。
#ComputerVision
#Transformer
#Attention
#Architecture
#Admin'sPick
#ICCV
#Backbone
Issue Date: 2025-07-19
[Paper Note] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu+, ICCV'21
SummarySwin Transformerは、コンピュータビジョンの新しいバックボーンとして機能する階層的トランスフォーマーを提案。シフトウィンドウ方式により、効率的な自己注意計算を実現し、さまざまなスケールでのモデリングが可能。画像分類や物体検出、セマンティックセグメンテーションなどで従来の最先端を上回る性能を示し、トランスフォーマーのビジョンバックボーンとしての可能性を示唆。コードは公開されている。
Comment日本語解説:https://qiita.com/m_sugimura/items/139b182ee7c19c83e70a画像処理において、物体の異なるスケールや、解像度に対処するために、PatchMergeと呼ばれるプーリングのような処理と、固定サイズのローカルなwindowに分割してSelf-Attentionを実施し、layerごとに通常のwindowとシフトされたwindowを適用することで、window間を跨いだ関係性も考慮できるようにする機構を導入したモデル。
#ComputerVision
#Pretraining
#Transformer
#Architecture
#Backbone
Issue Date: 2025-07-19
[Paper Note] Swin Transformer V2: Scaling Up Capacity and Resolution, Ze Liu+, arXiv'21
Summary本論文では、大規模ビジョンモデルのトレーニングと応用における課題に対処するための3つの技術を提案。具体的には、トレーニングの安定性向上のための残差後正規化法、低解像度から高解像度への転送を可能にする位置バイアス法、ラベル付きデータの必要性を減少させる自己教師あり学習法を用いる。これにより、30億パラメータのSwin Transformer V2モデルをトレーニングし、複数のビジョンタスクで新記録を樹立。トレーニング効率も向上し、ラベル付きデータと時間を大幅に削減。
#ComputerVision
#Transformer
#Attention
#Architecture
#Admin'sPick
#ICCV
#Backbone
Issue Date: 2025-07-19
[Paper Note] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu+, ICCV'21
SummarySwin Transformerは、コンピュータビジョンの新しいバックボーンとして機能する階層的トランスフォーマーを提案。シフトウィンドウ方式により、効率的な自己注意計算を実現し、さまざまなスケールでのモデリングが可能。画像分類や物体検出、セマンティックセグメンテーションなどで従来の最先端を上回る性能を示し、トランスフォーマーのビジョンバックボーンとしての可能性を示唆。コードは公開されている。
Comment日本語解説:https://qiita.com/m_sugimura/items/139b182ee7c19c83e70a画像処理において、物体の異なるスケールや、解像度に対処するために、PatchMergeと呼ばれるプーリングのような処理と、固定サイズのローカルなwindowに分割してSelf-Attentionを実施し、layerごとに通常のwindowとシフトされたwindowを適用することで、window間を跨いだ関係性も考慮できるようにする機構を導入したモデル。


 #Analysis
#NLP
#Transformer
#EMNLP
#Admin'sPick
#FactualKnowledge
Issue Date: 2025-07-04
[Paper Note] Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, EMNLP'21
Summaryフィードフォワード層はトランスフォーマーモデルの大部分を占めるが、その役割は未探求。研究により、フィードフォワード層がキー・バリュー・メモリとして機能し、トレーニング例のテキストパターンと相関することを示す。実験で、下層は浅いパターン、上層は意味的なパターンを学習し、バリューが出力分布を誘導することが確認された。最終的に、フィードフォワード層の出力はメモリの合成であり、残差接続を通じて洗練される。
Comment日本語解説(p.5より): https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022?slide=5
#NLP
#LanguageModel
#EMNLP
#KnowledgeEditing
Issue Date: 2025-06-18
[Paper Note] Editing Factual Knowledge in Language Models, Nicola De Cao+, EMNLP'21
SummaryKnowledgeEditorは、事前学習された言語モデルの知識を編集し、再学習なしで誤った事実や予測を修正する手法です。制約最適化を用いてハイパーネットワークを訓練し、他の知識に影響を与えずに事実を修正します。BERTとBARTのモデルでその有効性を示し、特定のクエリに基づく予測変更がパラフレーズにも一貫して影響を与えることを確認しました。ハイパーネットワークは、知識操作に必要なコンポーネントを特定する「プローブ」として機能します。
#RecommenderSystems
#read-later
#Reproducibility
Issue Date: 2025-05-16
A Troubling Analysis of Reproducibility and Progress in Recommender Systems Research, Maurizio Ferrari Dacrema+, TOIS'21
Summaryパーソナライズされたランキングアイテムリスト生成のアルゴリズム設計はレコメンダーシステムの重要なテーマであり、深層学習技術が主流となっている。しかし、比較ベースラインの選択や最適化に問題があり、実際の進展を理解するために協調フィルタリングに基づくニューラルアプローチの再現を試みた結果、12の手法中11が単純な手法に劣ることが判明。計算的に複雑なニューラル手法は既存の技術を一貫して上回らず、研究実践の問題が分野の停滞を招いている。
#NeuralNetwork
#CollaborativeFiltering
#Evaluation
#RecSys
Issue Date: 2025-04-15
Revisiting the Performance of iALS on Item Recommendation Benchmarks, Steffen Rendle+, arXiv'21
SummaryiALSを再検討し、調整を行うことで、レコメンダーシステムにおいて競争力を持つことを示す。特に、4つのベンチマークで他の手法を上回る結果を得て、iALSのスケーラビリティと高品質な予測が再評価されることを期待。
#NLP
#Dataset
#LanguageModel
#Supervised-FineTuning (SFT)
#Mathematics
#Verification
Issue Date: 2024-12-27
Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21
SummaryGSM8Kデータセットを用いて、多段階の数学的推論における言語モデルの限界を分析。検証器を訓練し、候補解を評価して最適解を選択することで、モデルのパフォーマンスを大幅に向上させることを示した。検証はファインチューニングよりもデータ増加に対して効果的にスケールする。
Comment気持ち
#Analysis
#NLP
#Transformer
#EMNLP
#Admin'sPick
#FactualKnowledge
Issue Date: 2025-07-04
[Paper Note] Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, EMNLP'21
Summaryフィードフォワード層はトランスフォーマーモデルの大部分を占めるが、その役割は未探求。研究により、フィードフォワード層がキー・バリュー・メモリとして機能し、トレーニング例のテキストパターンと相関することを示す。実験で、下層は浅いパターン、上層は意味的なパターンを学習し、バリューが出力分布を誘導することが確認された。最終的に、フィードフォワード層の出力はメモリの合成であり、残差接続を通じて洗練される。
Comment日本語解説(p.5より): https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022?slide=5
#NLP
#LanguageModel
#EMNLP
#KnowledgeEditing
Issue Date: 2025-06-18
[Paper Note] Editing Factual Knowledge in Language Models, Nicola De Cao+, EMNLP'21
SummaryKnowledgeEditorは、事前学習された言語モデルの知識を編集し、再学習なしで誤った事実や予測を修正する手法です。制約最適化を用いてハイパーネットワークを訓練し、他の知識に影響を与えずに事実を修正します。BERTとBARTのモデルでその有効性を示し、特定のクエリに基づく予測変更がパラフレーズにも一貫して影響を与えることを確認しました。ハイパーネットワークは、知識操作に必要なコンポーネントを特定する「プローブ」として機能します。
#RecommenderSystems
#read-later
#Reproducibility
Issue Date: 2025-05-16
A Troubling Analysis of Reproducibility and Progress in Recommender Systems Research, Maurizio Ferrari Dacrema+, TOIS'21
Summaryパーソナライズされたランキングアイテムリスト生成のアルゴリズム設計はレコメンダーシステムの重要なテーマであり、深層学習技術が主流となっている。しかし、比較ベースラインの選択や最適化に問題があり、実際の進展を理解するために協調フィルタリングに基づくニューラルアプローチの再現を試みた結果、12の手法中11が単純な手法に劣ることが判明。計算的に複雑なニューラル手法は既存の技術を一貫して上回らず、研究実践の問題が分野の停滞を招いている。
#NeuralNetwork
#CollaborativeFiltering
#Evaluation
#RecSys
Issue Date: 2025-04-15
Revisiting the Performance of iALS on Item Recommendation Benchmarks, Steffen Rendle+, arXiv'21
SummaryiALSを再検討し、調整を行うことで、レコメンダーシステムにおいて競争力を持つことを示す。特に、4つのベンチマークで他の手法を上回る結果を得て、iALSのスケーラビリティと高品質な予測が再評価されることを期待。
#NLP
#Dataset
#LanguageModel
#Supervised-FineTuning (SFT)
#Mathematics
#Verification
Issue Date: 2024-12-27
Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21
SummaryGSM8Kデータセットを用いて、多段階の数学的推論における言語モデルの限界を分析。検証器を訓練し、候補解を評価して最適解を選択することで、モデルのパフォーマンスを大幅に向上させることを示した。検証はファインチューニングよりもデータ増加に対して効果的にスケールする。
Comment気持ち
・当時の最も大きいレベルのモデルでも multi-stepのreasoningが必要な問題は失敗する
・モデルをFinetuningをしても致命的なミスが含まれる
・特に、数学は個々のミスに対して非常にsensitiveであり、一回ミスをして異なる解法のパスに入ってしまうと、self-correctionするメカニズムがauto-regressiveなモデルではうまくいかない
・純粋なテキスト生成の枠組みでそれなりの性能に到達しようとすると、とんでもないパラメータ数が必要になり、より良いscaling lawを示す手法を模索する必要がある
Contribution
論文の貢献は
・GSM8Kを提案し、
・verifierを活用しモデルの複数の候補の中から良い候補を選ぶフレームワークによって、モデルのパラメータを30倍にしたのと同等のパフォーマンスを達成し、データを増やすとverifierを導入するとよりよく性能がスケールすることを示した。
・また、dropoutが非常に強い正則化作用を促し、finetuningとverificationの双方を大きく改善することを示した。Todo: 続きをまとめる #Analysis #NLP #PEFT(Adaptor/LoRA) Issue Date: 2024-10-01 Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, Armen Aghajanyan+, N_A, ACL'21 Summary事前学習された言語モデルのファインチューニングのダイナミクスを内因次元の観点から分析し、少ないデータでも効果的に調整できる理由を説明。一般的なモデルは低い内因次元を持ち、フルパラメータ空間と同等の効果を持つ低次元の再パラメータ化が可能であることを示す。特に、RoBERTaモデルを用いて、少数のパラメータの最適化で高いパフォーマンスを達成できることを実証。また、事前学習が内因次元を最小化し、大きなモデルが低い内因次元を持つ傾向があることを示し、内因次元に基づく一般化境界を提案。 CommentACL ver:https://aclanthology.org/2021.acl-long.568.pdf下記の元ポストを拝読の上論文を斜め読み。モデルサイズが大きいほど、特定の性能(論文中では2種類のデータセットでの90%のsentence prediction性能)をfinetuningで達成するために必要なパラメータ数は、モデルサイズが大きくなればなるほど小さくなっている。
LoRAとの関係性についても元ポスト中で言及されており、論文の中身も見て後で確認する。
おそらく、LLMはBERTなどと比較して遥かにパラメータ数が大きいため、finetuningに要するパラメータ数はさらに小さくなっていることが想像され、LoRAのような少量のパラメータをconcatするだけでうまくいく、というような話だと思われる。興味深い。

元ポスト:https://x.com/bilzrd/status/1840445027438456838?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #Transformer Issue Date: 2024-07-11 Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, N_A, EMNLP'21 Summaryトランスフォーマーモデルのフィードフォワード層は、キー・バリューメモリとして機能し、学習されたパターンが人間に解釈可能であることや、上位層がより意味のあるパターンを学習することが示されました。さらに、出力分布を誘導する役割も持ちます。フィードフォワード層の出力はそのメモリの合成であり、残差接続を介してモデルの層を通じて洗練され、最終的な出力分布を生成します。 Comment1108 FF layerがKey-Valueストアとして機能する仕組みの概略図

実際に特定のKeyと最も関連度が高い訓練事例(input)を抽出し、人間がinputのパターンを分類した結果
 #Analysis
#NaturalLanguageGeneration
#NLP
#Evaluation
#Annotation
Issue Date: 2024-05-15
The Perils of Using Mechanical Turk to Evaluate Open-Ended Text Generation, Marzena Karpinska+, N_A, EMNLP'21
Summary最近のテキスト生成の研究は、オープンエンドのドメインに注力しており、その評価が難しいため、多くの研究者がクラウドソーシングされた人間の判断を収集してモデリングを正当化している。しかし、多くの研究は重要な詳細を報告しておらず、再現性が妨げられていることがわかった。さらに、労働者はモデル生成のテキストと人間による参照テキストを区別できないことが発見され、表示方法を変更することで改善されることが示された。英語教師とのインタビューでは、モデル生成のテキストを評価する際の課題について、より深い洞察が得られた。
CommentOpen-endedなタスクに対するAMTの評価の再現性に関する研究。先行研究をSurveyしたところ、再現のために重要な情報(たとえば、workerの資格、費用、task descriptions、annotator間のagreementなど)が欠落していることが判明した。
#Analysis
#NaturalLanguageGeneration
#NLP
#Evaluation
#Annotation
Issue Date: 2024-05-15
The Perils of Using Mechanical Turk to Evaluate Open-Ended Text Generation, Marzena Karpinska+, N_A, EMNLP'21
Summary最近のテキスト生成の研究は、オープンエンドのドメインに注力しており、その評価が難しいため、多くの研究者がクラウドソーシングされた人間の判断を収集してモデリングを正当化している。しかし、多くの研究は重要な詳細を報告しておらず、再現性が妨げられていることがわかった。さらに、労働者はモデル生成のテキストと人間による参照テキストを区別できないことが発見され、表示方法を変更することで改善されることが示された。英語教師とのインタビューでは、モデル生成のテキストを評価する際の課題について、より深い洞察が得られた。
CommentOpen-endedなタスクに対するAMTの評価の再現性に関する研究。先行研究をSurveyしたところ、再現のために重要な情報(たとえば、workerの資格、費用、task descriptions、annotator間のagreementなど)が欠落していることが判明した。
続いて、expertsとAMT workerに対して、story generationの評価を実施し、GPT2が生成したストーリーと人間が生成したストーリーを、後者のスコアが高くなることを期待して依頼した。その結果
・AMTのratingは、モデルが生成したテキストと、人間が生成したテキストをreliableに区別できない
・同一のタスクを異なる日程で実施をすると、高い分散が生じた
・多くのAMT workerは、評価対象のテキストを注意深く読んでいない
・Expertでさえモデルが生成したテキストを読み判断するのには苦戦をし、先行研究と比較してより多くの時間を費やし、agreementが低くなることが分かった

892 において、低品質なwork forceが人手評価に対して有害な影響を与える、という文脈で本研究が引用されている #ComputerVision #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Transformer #MulltiModal Issue Date: 2023-08-22 ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision, Wonjae Kim+, N_A, ICML'21 SummaryVLP(Vision-and-Language Pre-training)のアプローチは、ビジョンと言語のタスクでのパフォーマンスを向上させているが、現在の方法は効率性と表現力の面で問題がある。そこで、本研究では畳み込みフリーのビジョンと言語のトランスフォーマ(ViLT)モデルを提案する。ViLTは高速でありながら競争力のあるパフォーマンスを示し、コードと事前学習済みの重みはGitHubで利用可能である。 Comment日本語解説:https://tech.fusic.co.jp/posts/2021-12-29-vilt/ #Sentence #Embeddings #NLP #LanguageModel #RepresentationLearning #ContrastiveLearning #Catastrophic Forgetting #Admin'sPick Issue Date: 2023-07-27 SimCSE: Simple Contrastive Learning of Sentence Embeddings, Tianyu Gao+, N_A, EMNLP'21 Summaryこの論文では、SimCSEという対比学習フレームワークを提案しています。このフレームワークは、文の埋め込み技術を進化させることができます。教師なしアプローチでは、入力文をノイズとして扱い、自己を対比的に予測します。教師ありアプローチでは、自然言語推論データセットから注釈付きのペアを使用して対比学習を行います。SimCSEは、意味的テキスト類似性タスクで評価され、以前の手法と比較して改善を実現しました。対比学習は、事前学習された埋め込みの空間を均一に正則化し、教師信号が利用可能な場合には正のペアをよりよく整列させることが示されました。 Comment462 よりも性能良く、unsupervisedでも学習できる。STSタスクのベースラインにだいたい入ってる手法概要
Contrastive Learningを活用して、unsupervised/supervisedに学習を実施する。
Unsupervised SimCSEでは、あるsentenceをencoderに2回入力し、それぞれにdropoutを適用させることで、positive pairを作成する。dropoutによって共通のembeddingから異なる要素がマスクされた(noiseが混ざった状態とみなせる)類似したembeddingが作成され、ある種のdata augmentationによって正例を作成しているともいえる。負例はnegative samplingする。(非常にsimpleだが、next sentence predictionで学習するより性能が良くなる)
Supervised SimCSEでは、アノテーションされたsentence pairに基づいて、正例・負例を決定する。本研究では、NLIのデータセットにおいて、entailment関係にあるものは正例として扱う。contradictions(矛盾)関係にあるものは負例として扱う。
Siamese Networkで用いられるmeans-squared errrorとContrastiveObjectiveの違い
どちらもペアワイズで比較するという点では一緒だが、ContrastiveObjectiveは正例と近づいたとき、負例と遠ざかったときにlossが小さくなるような定式化がされている点が異なる。

(画像はこのブログから引用。ありがとうございます。https://techblog.cccmk.co.jp/entry/2022/08/30/163625)
Unsupervised SimCSEの実験
異なるdata augmentation手法と比較した結果、dropoutを適用する手法の方が性能が高かった。MLMや, deletion, 類義語への置き換え等よりも高い性能を獲得しているのは興味深い。また、Next Sentence Predictionと比較しても、高い性能を達成。Next Sentence Predictionは、word deletion等のほぼ類似したテキストから直接的に類似関係にあるペアから学習するというより、Sentenceの意味内容のつながりに基づいてモデルの言語理解能力を向上させ、そのうえで類似度を測るという間接的な手法だが、word deletionに負けている。一方、dropoutを適用するだけの(直接的に類似ペアから学習する)本手法はより高い性能を示している。
[image](https://github.com/AkihikoWatanabe/paper_notes/assets/12249301/0ea3549e-3363-4857-94e6-a1ef474aa191)
なぜうまくいくかを分析するために、異なる設定で実験し、alignment(正例との近さ)とuniformity(どれだけembeddingが一様に分布しているか)を、10 stepごとにplotした結果が以下。dropoutを適用しない場合と、常に同じ部分をマスクする方法(つまり、全く同じembeddingから学習する)設定を見ると、学習が進むにつれuniformityは改善するが、alignmentが悪くなっていっている。一方、SimCSEはalignmentを維持しつつ、uniformityもよくなっていっていることがわかる。


Supervised SimCSEの実験
アノテーションデータを用いてContrastiveLearningするにあたり、どういったデータを正例としてみなすと良いかを検証するために様々なデータセットで学習し性能を検証した。
・QQP4: Quora question pairs
・Flickr30k (Young et al., 2014): 同じ画像に対して、5つの異なる人間が記述したキャプションが存在
・ParaNMT (Wieting and Gimpel, 2018): back-translationによるparaphraseのデータセットa
・NLI datasets: SNLIとMNLI
実験の結果、NLI datasetsが最も高い性能を示した。この理由としては、NLIデータセットは、crowd sourcingタスクで人手で作成された高品質なデータセットであることと、lexical overlapが小さくなるようにsentenceのペアが作成されていることが起因している。実際、NLI datsetのlexical overlapは39%だったのに対し、ほかのデータセットでは60%であった。
また、condunctionsとなるペアを明示的に負例として与えることで、より性能が向上した(普通はnegative samplingする、というかバッチ内の正例以外のものを強制的に負例とする。こうすると、意味が同じでも負例になってしまう事例が出てくることになる)。より難しいNLIタスクを含むANLIデータセットを追加した場合は、性能が改善しなかった。この理由については考察されていない。性能向上しそうな気がするのに。

他手法との比較結果
SimCSEがよい。

Ablation Studies
異なるpooling方法で、どのようにsentence embeddingを作成するかで性能の違いを見た。originalのBERTの実装では、CLS token のembeddingの上にMLP layerがのっかっている。これの有無などと比較。
Unsupervised SimCSEでは、training時だけMLP layerをのっけて、test時はMLPを除いた方が良かった。一方、Supervised SimCSEでは、 MLP layerをのっけたまんまで良かったとのこと。

また、SimCSEで学習したsentence embeddingを別タスクにtransferして活用する際には、SimCSEのobjectiveにMLMを入れた方が、catastrophic forgettingを防げて性能が高かったとのこと。
 ablation studiesのhard negativesのところと、どのようにミニバッチを構成するか、それぞれのtransferしたタスクがどのようなものがしっかり読めていない。あとでよむ。
#NLP
#Dataset
#LanguageModel
#Evaluation
#ICLR
#Admin'sPick
Issue Date: 2023-07-24
Measuring Massive Multitask Language Understanding, Dan Hendrycks+, N_A, ICLR'21
Summary私たちは、マルチタスクのテキストモデルの正確性を測定するための新しいテストを提案しています。このテストは57のタスクをカバーし、広範な世界知識と問題解決能力が必要です。現在のモデルはまだ専門家レベルの正確性に達しておらず、性能に偏りがあります。私たちのテストは、モデルの弱点を特定するために使用できます。
CommentOpenReview:https://openreview.net/forum?id=d7KBjmI3GmQMMLU論文
#PersonalizedDocumentSummarization
#NLP
#review
Issue Date: 2023-05-06
Transformer Reasoning Network for Personalized Review Summarization, Xu+, SIGIR'21
Comment先行研究は、review summarizationにおいて生成されるsummaryは、過去にユーザが作成したsummaryのwriting styleやproductに非常に関係しているのに、これらを活用してこなかったので、活用しました(=personalized)という話っぽい
#AdaptiveLearning
#ScorePrediction
Issue Date: 2022-08-31
Condensed Discriminative Question Set for Reliable Exam Score Prediction, Jung+, Riiid, AIED'21
#NeuralNetwork
#EducationalDataMining
#KnowledgeTracing
Issue Date: 2022-08-31
Behavioral Testing of Deep Neural Network Knowledge Tracing Models, Kim+, Riiid, EDM'21
#AdaptiveLearning
#EducationalDataMining
#OptionTracing
Issue Date: 2022-08-18
Option Tracing: Beyond Correctness Analysis in Knowledge Tracing, Ghosh+, AIED'21
CommentこれまでのKTは問題の正誤(correctness)に対してfittingしていたが、この研究ではmultiple choice questionでどの選択肢を選択するかを予測するタスクを提案している。
#NeuralNetwork
#AdaptiveLearning
#EducationalDataMining
#LearningAnalytics
#KnowledgeTracing
Issue Date: 2022-04-28
BEKT: Deep Knowledge Tracing with Bidirectional Encoder Representations from Transformers, Tian+ (緒方先生), Kyoto University, ICCE'21
CommentKTにBERTを利用した研究
ablation studiesのhard negativesのところと、どのようにミニバッチを構成するか、それぞれのtransferしたタスクがどのようなものがしっかり読めていない。あとでよむ。
#NLP
#Dataset
#LanguageModel
#Evaluation
#ICLR
#Admin'sPick
Issue Date: 2023-07-24
Measuring Massive Multitask Language Understanding, Dan Hendrycks+, N_A, ICLR'21
Summary私たちは、マルチタスクのテキストモデルの正確性を測定するための新しいテストを提案しています。このテストは57のタスクをカバーし、広範な世界知識と問題解決能力が必要です。現在のモデルはまだ専門家レベルの正確性に達しておらず、性能に偏りがあります。私たちのテストは、モデルの弱点を特定するために使用できます。
CommentOpenReview:https://openreview.net/forum?id=d7KBjmI3GmQMMLU論文
#PersonalizedDocumentSummarization
#NLP
#review
Issue Date: 2023-05-06
Transformer Reasoning Network for Personalized Review Summarization, Xu+, SIGIR'21
Comment先行研究は、review summarizationにおいて生成されるsummaryは、過去にユーザが作成したsummaryのwriting styleやproductに非常に関係しているのに、これらを活用してこなかったので、活用しました(=personalized)という話っぽい
#AdaptiveLearning
#ScorePrediction
Issue Date: 2022-08-31
Condensed Discriminative Question Set for Reliable Exam Score Prediction, Jung+, Riiid, AIED'21
#NeuralNetwork
#EducationalDataMining
#KnowledgeTracing
Issue Date: 2022-08-31
Behavioral Testing of Deep Neural Network Knowledge Tracing Models, Kim+, Riiid, EDM'21
#AdaptiveLearning
#EducationalDataMining
#OptionTracing
Issue Date: 2022-08-18
Option Tracing: Beyond Correctness Analysis in Knowledge Tracing, Ghosh+, AIED'21
CommentこれまでのKTは問題の正誤(correctness)に対してfittingしていたが、この研究ではmultiple choice questionでどの選択肢を選択するかを予測するタスクを提案している。
#NeuralNetwork
#AdaptiveLearning
#EducationalDataMining
#LearningAnalytics
#KnowledgeTracing
Issue Date: 2022-04-28
BEKT: Deep Knowledge Tracing with Bidirectional Encoder Representations from Transformers, Tian+ (緒方先生), Kyoto University, ICCE'21
CommentKTにBERTを利用した研究
453 などでDeepLearningBasedなモデル間であまり差がないことが示されているので、本研究が実際どれだけ強いのかは気になるところ。 #NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration Issue Date: 2021-10-08 過去情報の内容選択を取り入れた スポーツダイジェストの自動生成, 加藤+, 東工大, NLP'21 #AdaptiveLearning #IJCAI Issue Date: 2021-08-04 RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions, Kubotani+, Waseda University, IJCAI'21 Summary教育分野の課題に対し、学生の知識状態に基づく適応指導を強化学習で最適化するフレームワークを提案。実際の学生との相互作用を最小限にし、仮想モデルを構築。実験により、提案モデルは従来の指導方法と同等の性能を示し、理論と実践の橋渡しを行う。 #EMNLP #Findings Issue Date: 2025-08-16 [Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings Summary低リソース言語翻訳において、QKNormという新しい正規化手法を提案。これは、注意メカニズムを修正し、ソフトマックス関数の飽和耐性を向上させつつ表現力を維持。具体的には、クエリとキー行列に対して$\ell_2$正規化を適用し、学習可能なパラメータでスケールアップ。TED TalksコーパスとIWSLT'15の低リソース翻訳ペアで平均0.928 BLEUの改善を達成。 #EfficiencyImprovement #NLP #Transformer #Attention Issue Date: 2025-08-09 [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20 SummaryLongformerは、長いシーケンスを線形に処理できる注意機構を持つTransformerベースのモデルで、数千トークンの文書を扱える。局所的なウィンドウ注意とタスクに基づくグローバル注意を組み合わせ、文字レベルの言語モデリングで最先端の結果を達成。事前学習とファインチューニングを行い、長文タスクでRoBERTaを上回る性能を示した。また、Longformer-Encoder-Decoder(LED)を導入し、長文生成タスクにおける効果を確認した。 Comment(固定された小さめのwindowsサイズの中でのみattentionを計算する)sliding window attentionを提案
 OpenLLMの文脈だと、Mistralに採用されて話題になったかも?
OpenLLMの文脈だと、Mistralに採用されて話題になったかも?
・1309 #EfficiencyImprovement #NLP #Transformer #Attention #ICML Issue Date: 2025-08-05 [Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20 Summary自己注意をカーネル特徴マップの線形ドット積として表現することで、Transformersの複雑性を$\mathcal{O}\left(N^2\right)$から$\mathcal{O}\left(N\right)$に削減。これにより、自己回帰型Transformersの速度が最大4000倍向上し、従来のパフォーマンスを維持。 Comment関連:
・1210 #EfficiencyImprovement #NLP #Transformer #Attention #ICLR Issue Date: 2025-08-05 [Paper Note] Reformer: The Efficient Transformer, Nikita Kitaev+, ICLR'20 Summary本研究では、トランスフォーマーモデルの効率を向上させるために、局所感度ハッシュを用いた注意機構と可逆残差層を提案。これにより、計算量をO($L^2$)からO($L\log L$)に削減し、メモリ効率と速度を向上させたReformerモデルを実現。トランスフォーマーと同等の性能を維持。 Commentopenreview: https://openreview.net/forum?id=rkgNKkHtvB #EfficiencyImprovement #NLP #Transformer #Attention Issue Date: 2025-08-05 [Paper Note] Linformer: Self-Attention with Linear Complexity, Sinong Wang+, arXiv'20 Summary大規模トランスフォーマーモデルは自然言語処理で成功を収めているが、長いシーケンスに対しては高コスト。自己注意メカニズムを低ランク行列で近似し、複雑さを$O(n^2)$から$O(n)$に削減する新しいメカニズムを提案。これにより、メモリと時間効率が向上した線形トランスフォーマー「Linformer」が標準モデルと同等の性能を示す。 #NaturalLanguageGeneration #NLP #Dataset #Evaluation #Composition #EMNLP #Findings #CommonsenseReasoning Issue Date: 2025-07-31 [Paper Note] CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning, Bill Yuchen Lin+, EMNLP'20 Findings Summary生成的常識推論をテストするためのタスクCommonGenを提案し、35,000の概念セットに基づく79,000の常識的記述を含むデータセットを構築。タスクは、与えられた概念を用いて一貫した文を生成することを求め、関係推論と構成的一般化能力が必要。実験では、最先端モデルと人間のパフォーマンスに大きなギャップがあることが示され、生成的常識推論能力がCommonsenseQAなどの下流タスクに転送可能であることも確認。 Commentベンチマークの概要。複数のconceptが与えられた時に、それらconceptを利用した常識的なテキストを生成するベンチマーク。concept間の関係性を常識的な知識から推論し、Unseenなconceptの組み合わせでも意味を構成可能な汎化性能が求められる。
 PJ page:https://inklab.usc.edu/CommonGen/
#Admin'sPick
Issue Date: 2025-07-24
[Paper Note] Exploring Simple Siamese Representation Learning, Xinlei Chen+, arXiv'20
SummarySiameseネットワークを用いた教師なし視覚表現学習に関する研究で、ネガティブサンプルペア、大きなバッチ、モーメンタムエンコーダーを使用せずに意味のある表現を学習できることを示した。ストップグラディエント操作が崩壊解を防ぐ重要な役割を果たすことを確認し、SimSiamメソッドがImageNetおよび下流タスクで競争力のある結果を達成した。これにより、Siameseアーキテクチャの役割を再考するきっかけとなることを期待している。
Comment日本語解説:
PJ page:https://inklab.usc.edu/CommonGen/
#Admin'sPick
Issue Date: 2025-07-24
[Paper Note] Exploring Simple Siamese Representation Learning, Xinlei Chen+, arXiv'20
SummarySiameseネットワークを用いた教師なし視覚表現学習に関する研究で、ネガティブサンプルペア、大きなバッチ、モーメンタムエンコーダーを使用せずに意味のある表現を学習できることを示した。ストップグラディエント操作が崩壊解を防ぐ重要な役割を果たすことを確認し、SimSiamメソッドがImageNetおよび下流タスクで競争力のある結果を達成した。これにより、Siameseアーキテクチャの役割を再考するきっかけとなることを期待している。
Comment日本語解説:
https://qiita.com/saliton/items/2f7b1bfb451df75a286f
https://qiita.com/koshian2/items/a31b85121c99af0eb050 #Admin'sPick Issue Date: 2025-07-24 [Paper Note] Bootstrap your own latent: A new approach to self-supervised Learning, Jean-Bastien Grill+, arXiv'20 SummaryBYOL(Bootstrap Your Own Latent)は、自己教師あり画像表現学習の新しい手法で、オンラインネットワークとターゲットネットワークの2つのニューラルネットワークを用いて学習を行う。BYOLは、ネガティブペアに依存せずに最先端の性能を達成し、ResNet-50でImageNetにおいて74.3%の分類精度を達成、より大きなResNetでは79.6%に達する。転送学習や半教師ありベンチマークでも優れた性能を示し、実装と事前学習済みモデルはGitHubで公開されている。 Comment日本語解説:
https://sn-neural-compute.netlify.app/202006250/ #DocumentSummarization #NLP #Abstractive #Factuality #Faithfulness #ACL Issue Date: 2025-07-14 [Paper Note] On Faithfulness and Factuality in Abstractive Summarization, Joshua Maynez+, ACL'20 Summary抽象的な文書要約における言語モデルの限界を分析し、これらのモデルが入力文書に対して忠実でない内容を生成する傾向が高いことを発見。大規模な人間評価を通じて、生成される幻覚の種類を理解し、すべてのモデルで相当量の幻覚が確認された。事前学習されたモデルはROUGE指標だけでなく、人間評価でも優れた要約を生成することが示された。また、テキストの含意測定が忠実性と良好に相関することが明らかになり、自動評価指標の改善の可能性を示唆。 Comment文書要約の文脈において `hallucination` について説明されている。
・1044
が `hallucination` について言及する際に引用している。 #NeuralNetwork #MachineLearning #ICLR #LearningPhenomena Issue Date: 2025-07-12 [Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20 Summary深層学習タスクにおける「ダブルデセント」現象を示し、モデルサイズの増加に伴い性能が一時的に悪化し、その後改善されることを明らかにした。また、ダブルデセントはモデルサイズだけでなくトレーニングエポック数にも依存することを示し、新たに定義した「効果的なモデルの複雑さ」に基づいて一般化されたダブルデセントを仮定。これにより、トレーニングサンプル数を増やすことで性能が悪化する特定の領域を特定できることを示した。 Comment参考:https://qiita.com/teacat/items/a8bed22329956b80671f #Analysis #NLP #Transformer #Normalization #Encoder-Decoder Issue Date: 2025-07-05 [Paper Note] On Layer Normalization in the Transformer Architecture, Ruibin Xiong+, arXiv'20 Summary本論文では、Transformerの学習率のウォームアップ段階の重要性を理論的に研究し、レイヤー正規化の位置が訓練の安定性に与える影響を示す。特に、Post-LN Transformerでは大きな勾配が不安定さを引き起こすため、ウォームアップが有効である一方、Pre-LN Transformerでは勾配が良好に振る舞うため、ウォームアップを省略できることを示す。実験により、ウォームアップなしのPre-LN Transformerがベースラインと同等の結果を達成し、訓練時間とハイパーパラメータの調整が削減できることを確認した。 CommentOpenReview:https://openreview.net/forum?id=B1x8anVFPrEncoder-DecoderのTransformerにおいて、Post-LNの場合は、Warmupを無くすと最終的な性能が悪化し、またWarmUpステップの値によって(500 vs. 4000で実験)も最終的な性能が変化する。これには学習時にハイパーパラメータをしっかり探索しなければならず、WarmUPを大きくすると学習効率が落ちるというデメリットがある。

Post-LNの場合は、Pre-LNと比較して勾配が大きく、Warmupのスケジュールをしっかり設計しないと大きな勾配に対して大きな学習率が適用され学習が不安定になる。これは学習率を非常に小さくし、固定値を使うことで解決できるが、収束が非常に遅くなるというデメリットがある。

一方、Pre-LNはWarmup無しでも、高い性能が達成でき、上記のようなチューニングの手間や学習効率の観点から利点がある、みたいな話の模様。

#NLP #LanguageModel #Scaling Laws Issue Date: 2025-05-31 Scaling Laws for Autoregressive Generative Modeling, Tom Henighan+, arXiv'20 Summary生成画像、ビデオ、マルチモーダルモデル、数学的問題解決の4領域におけるクロスエントロピー損失のスケーリング法則を特定。自己回帰型トランスフォーマーはモデルサイズと計算予算の増加に伴い性能が向上し、べき法則に従う。特に、10億パラメータのトランスフォーマーはYFCC100M画像分布をほぼ完璧にモデル化できることが示された。さらに、マルチモーダルモデルの相互情報量や数学的問題解決における外挿時の性能に関する追加のスケーリング法則も発見。これにより、スケーリング法則がニューラルネットワークの性能に与える影響が強調された。 #ComputerVision #DataAugmentation #ContrastiveLearning #Self-SupervisedLearning #ICLR #Admin'sPick Issue Date: 2025-05-18 A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen+, ICML'20 Summary本論文では、視覚表現の対比学習のためのシンプルなフレームワークSimCLRを提案し、特別なアーキテクチャやメモリバンクなしで対比自己教師あり学習を簡素化します。データ拡張の重要性、学習可能な非線形変換の導入による表現の質向上、対比学習が大きなバッチサイズと多くのトレーニングステップから利益を得ることを示し、ImageNetで従来の手法を上回る結果を達成しました。SimCLRによる自己教師あり表現を用いた線形分類器は76.5%のトップ1精度を達成し、教師ありResNet-50に匹敵します。ラベルの1%でファインチューニングした場合、85.8%のトップ5精度を達成しました。 Comment日本語解説:https://techblog.cccmkhd.co.jp/entry/2022/08/30/163625 #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #MatrixFactorization #RecSys #read-later #Reproducibility Issue Date: 2025-05-16 Neural Collaborative Filtering vs. Matrix Factorization Revisited, Steffen Rendle+, RecSys'20 Summary埋め込みベースのモデルにおける協調フィルタリングの研究では、MLPを用いた学習された類似度が提案されているが、適切なハイパーパラメータ選択によりシンプルなドット積が優れた性能を示すことが確認された。MLPは理論的には任意の関数を近似可能だが、実用的にはドット積の方が効率的でコストも低いため、MLPは慎重に使用すべきであり、ドット積がデフォルトの選択肢として推奨される。 #NeuralNetwork #Pretraining #NLP #TransferLearning #PostTraining #Admin'sPick Issue Date: 2025-05-12 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Colin Raffel+, JMLR'20 Summary転移学習はNLPにおいて強力な技術であり、本論文ではテキストをテキストに変換する統一フレームワークを提案。事前学習の目的やアーキテクチャを比較し、最先端の結果を達成。データセットやモデル、コードを公開し、今後の研究を促進する。 CommentT5もメモっていなかったので今更ながら追加。全てのNLPタスクをテキスト系列からテキスト系列へ変換するタスクとみなし、Encoder-DecoderのTransformerを大規模コーパスを用いて事前学習をし、downstreamタスクにfinetuningを通じて転移する。 #NeuralNetwork #ComputerVision #MachineLearning #NLP #ICLR #KnowledgeEditing #read-later Issue Date: 2025-05-07 Editable Neural Networks, Anton Sinitsin+, ICLR'20 Summary深層ニューラルネットワークの誤りを迅速に修正するために、Editable Trainingというモデル非依存の訓練手法を提案。これにより、特定のサンプルの誤りを効率的に修正し、他のサンプルへの影響を避けることができる。大規模な画像分類と機械翻訳タスクでその有効性を実証。 Comment(おそらく)Knowledge Editingを初めて提案した研究OpenReview:https://openreview.net/forum?id=HJedXaEtvS #Metrics #NLP #Evaluation #AutomaticSpeechRecognition(ASR) #AACL #SimulST(SimultaneousSpeechTranslation) Issue Date: 2025-04-30 SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation, Xutai Ma+, AACL'20 Summary同時テキスト翻訳手法をエンドツーエンドの同時音声翻訳に適応させる研究を行い、事前決定モジュールを導入。レイテンシと品質のトレードオフを分析し、新しいレイテンシメトリックを設計。 Comment同時翻訳研究で主要なmetricの一つ
関連:
・1914 #NeuralNetwork #Embeddings #CTRPrediction #RepresentationLearning #RecSys #SIGKDD #numeric Issue Date: 2025-04-22 An Embedding Learning Framework for Numerical Features in CTR Prediction, Huifeng Guo+, arXiv'20 SummaryCTR予測のための新しい埋め込み学習フレームワーク「AutoDis」を提案。数値特徴の埋め込みを強化し、高いモデル容量とエンドツーエンドのトレーニングを実現。メタ埋め込み、自動離散化、集約の3つのコアコンポーネントを用いて、数値特徴の相関を捉え、独自の埋め込みを学習。実験により、CTRとeCPMでそれぞれ2.1%および2.7%の改善を達成。コードは公開されている。 Comment従来はdiscretizeをするか、mlpなどでembeddingを作成するだけだった数値のinputをうまく埋め込みに変換する手法を提案し性能改善
数値情報を別の空間に写像し自動的なdiscretizationを実施する機構と、各数値情報のフィールドごとのglobalな情報を保持するmeta-embeddingをtrainable parameterとして学習し、両者を交互作用(aggregation; max-poolingとか)することで数値embeddingを取得する。

 #NLP
#LanguageModel
#ICLR
#Decoding
#Admin'sPick
Issue Date: 2025-04-14
The Curious Case of Neural Text Degeneration, Ari Holtzman+, ICLR'20
Summary深層ニューラル言語モデルは高品質なテキスト生成において課題が残る。尤度の使用がモデルの性能に影響を与え、人間のテキストと機械のテキストの間に分布の違いがあることを示す。デコーディング戦略が生成テキストの質に大きな影響を与えることが明らかになり、ニュークリアスsamplingを提案。これにより、多様性を保ちながら信頼性の低い部分を排除し、人間のテキストに近い質を実現する。
Comment現在のLLMで主流なNucleus (top-p) Samplingを提案した研究
#MachineLearning
#NLP
#LanguageModel
#Scaling Laws
Issue Date: 2025-03-23
Scaling Laws for Neural Language Models, Jared Kaplan+, arXiv'20
Summary言語モデルの性能に関するスケーリング法則を研究し、損失がモデルサイズ、データセットサイズ、計算量に対して冪則的にスケールすることを示す。アーキテクチャの詳細は影響が少なく、過学習やトレーニング速度は単純な方程式で説明される。これにより、計算予算の最適な配分が可能となり、大きなモデルはサンプル効率が高く、少量のデータで早期に収束することが示された。
Comment日本語解説:https://www.slideshare.net/slideshow/dlscaling-laws-for-neural-language-models/243005067
#MachineTranslation
#Metrics
#NLP
#Evaluation
#EMNLP
#Admin'sPick
Issue Date: 2024-05-26
COMET: A Neural Framework for MT Evaluation, Ricardo Rei+, N_A, EMNLP'20
SummaryCOMETは、多言語機械翻訳評価モデルを訓練するためのニューラルフレームワークであり、人間の判断との新しい最先端の相関レベルを達成します。クロスリンガル事前学習言語モデリングの進展を活用し、高度に多言語対応かつ適応可能なMT評価モデルを実現します。WMT 2019 Metrics shared taskで新たな最先端のパフォーマンスを達成し、高性能システムに対する堅牢性を示しています。
CommentBetter/Worseなhypothesisを利用してpair-wiseにランキング関数を学習する
#NLP
#LanguageModel
#ICLR
#Decoding
#Admin'sPick
Issue Date: 2025-04-14
The Curious Case of Neural Text Degeneration, Ari Holtzman+, ICLR'20
Summary深層ニューラル言語モデルは高品質なテキスト生成において課題が残る。尤度の使用がモデルの性能に影響を与え、人間のテキストと機械のテキストの間に分布の違いがあることを示す。デコーディング戦略が生成テキストの質に大きな影響を与えることが明らかになり、ニュークリアスsamplingを提案。これにより、多様性を保ちながら信頼性の低い部分を排除し、人間のテキストに近い質を実現する。
Comment現在のLLMで主流なNucleus (top-p) Samplingを提案した研究
#MachineLearning
#NLP
#LanguageModel
#Scaling Laws
Issue Date: 2025-03-23
Scaling Laws for Neural Language Models, Jared Kaplan+, arXiv'20
Summary言語モデルの性能に関するスケーリング法則を研究し、損失がモデルサイズ、データセットサイズ、計算量に対して冪則的にスケールすることを示す。アーキテクチャの詳細は影響が少なく、過学習やトレーニング速度は単純な方程式で説明される。これにより、計算予算の最適な配分が可能となり、大きなモデルはサンプル効率が高く、少量のデータで早期に収束することが示された。
Comment日本語解説:https://www.slideshare.net/slideshow/dlscaling-laws-for-neural-language-models/243005067
#MachineTranslation
#Metrics
#NLP
#Evaluation
#EMNLP
#Admin'sPick
Issue Date: 2024-05-26
COMET: A Neural Framework for MT Evaluation, Ricardo Rei+, N_A, EMNLP'20
SummaryCOMETは、多言語機械翻訳評価モデルを訓練するためのニューラルフレームワークであり、人間の判断との新しい最先端の相関レベルを達成します。クロスリンガル事前学習言語モデリングの進展を活用し、高度に多言語対応かつ適応可能なMT評価モデルを実現します。WMT 2019 Metrics shared taskで新たな最先端のパフォーマンスを達成し、高性能システムに対する堅牢性を示しています。
CommentBetter/Worseなhypothesisを利用してpair-wiseにランキング関数を学習する


Inference時は単一のhypothesisしかinputされないので、sourceとreferenceに対してそれぞれhypothesisの距離をはかり、その調和平均でスコアリングする
ACL2024, EMNLP2024あたりのMT研究のmetricをざーっと見る限り、BLEU/COMETの双方で評価する研究が多そう #RAG(RetrievalAugmentedGeneration) Issue Date: 2023-12-01 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Patrick Lewis+, N_A, arXiv'20 Summary大規模な事前学習言語モデルを使用した検索強化生成(RAG)の微調整手法を提案しました。RAGモデルは、パラメトリックメモリと非パラメトリックメモリを組み合わせた言語生成モデルであり、幅広い知識集約的な自然言語処理タスクで最先端の性能を発揮しました。特に、QAタスクでは他のモデルを上回り、言語生成タスクでは具体的で多様な言語を生成することができました。 CommentRAGを提案した研究
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #QA-based Issue Date: 2023-08-20 Asking and Answering Questions to Evaluate the Factual Consistency of Summaries, Wang, ACL'20 Summary要約の事実の不整合を特定するための自動評価プロトコルであるQAGSを提案する。QAGSは、要約とソースについて質問をし、整合性がある回答を得ることで要約の事実的整合性を評価する。QAGSは他の自動評価指標と比較して高い相関を持ち、自然な解釈可能性を提供する。QAGSは有望なツールであり、https://github.com/W4ngatang/qagsで利用可能。 CommentQAGS生成された要約からQuestionを生成する手法。precision-oriented #DocumentSummarization #NLP #Hallucination Issue Date: 2023-08-16 Reducing Quantity Hallucinations in Abstractive Summarization, Zheng Zhao+, N_A, EMNLP'20 SummaryHermanシステムは、抽象的な要約において幻覚を回避するために、数量エンティティを認識し、元のテキストでサポートされている数量用語を持つ要約を上位にランク付けするアプローチを提案しています。実験結果は、このアプローチが高い適合率と再現率を持ち、F$_1$スコアが向上することを示しています。また、上位にランク付けされた要約が元の要約よりも好まれることも示されています。 Comment数量に関するhallucinationを緩和する要約手法 #PersonalizedDocumentSummarization #NLP #review Issue Date: 2023-05-06 A Unified Dual-view Model for Review Summarization and Sentiment Classification with Inconsistency Loss, Hou Pong Chan+, N_A, arXiv'20 Summaryユーザーレビューから要約と感情を取得するために、新しいデュアルビューモデルを提案。エンコーダーがレビューの文脈表現を学習し、サマリーデコーダーが要約を生成。ソースビュー感情分類器はレビューの感情ラベルを予測し、サマリービュー感情分類器は要約の感情ラベルを予測。不一致損失を導入して、2つの分類器の不一致を罰することで、デコーダーが一貫した感情傾向を持つ要約を生成し、2つの感情分類器がお互いから学ぶことができるようになる。4つの実世界データセットでの実験結果は、モデルの効果を示している。 CommentReview SummarizationとSentiment Classificationをjointで学習した研究。既存研究ではreviewのみからsentimentの情報を獲得する枠組みは存在したが、summaryの情報が活用できていなかった。
653 のratingをsentiment labelとして扱い、評価も同データを用いてROUGEで評価。

実際に生成されたレビュー例がこちら。なんの疑いもなくamazon online review datasetを教師データとして使っているが、果たしてこれでいいんだろうか?
論文冒頭のsummaryの例と、実際に生成された例を見ると、後者の方が非常に主観的な情報を含むのに対して、前者はより客観性が高いように思える。
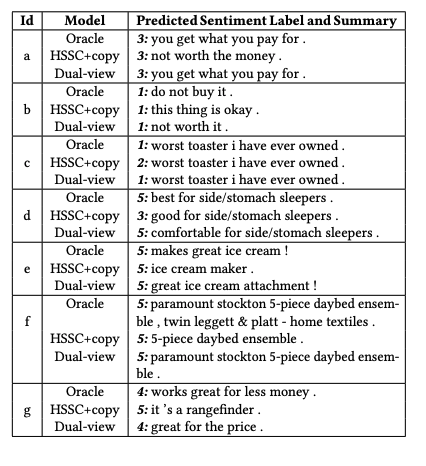
しかし最初にこのデータセットを使ったのは 652 の方っぽい #NeuralNetwork #NLP #LanguageModel #Zero/FewShotPrompting #In-ContextLearning #NeurIPS #Admin'sPick Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 SummaryGPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 CommentIn-Context Learningを提案した論文論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。

この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。 #Education #AdaptiveLearning #EducationalDataMining Issue Date: 2022-12-27 Reinforcement Learning for the Adaptive Scheduling of Educational Activities, Bassen+, Stanford University, CHI'20 #AdaptiveLearning #KnowledgeTracing Issue Date: 2022-08-17 Deep Knowledge Tracing with Transformers, Shi+ (w_ Michael Yudelson), ETS_ACT, AIED'20 CommentTransformerでKTした研究。あまり引用されていない。SAINT, SAINT+と同時期に発表されている。 #NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #SIGKDD Issue Date: 2022-04-27 Context-Aware Attentive Knowledge Tracing, Ghosh+, University of Massachusetts Amherst, KDD'20 Commentこの論文の実験ではSAKTがDKVMNやDKTに勝てていない #NeuralNetwork #MachineLearning #NLP #NeurIPS Issue Date: 2021-06-09 All Word Embeddings from One Embedding, Takase+, NeurIPS'20 CommentNLPのためのNN-basedなモデルのパラメータの多くはEmbeddingによるもので、従来は個々の単語ごとに異なるembeddingをMatrixの形で格納してきた。この研究ではモデルのパラメータ数を減らすために、個々のword embeddingをshared embeddingの変換によって表現する手法ALONE(all word embeddings from one)を提案。単語ごとに固有のnon-trainableなfilter vectorを用いてshared embeddingsを修正し、FFNにinputすることで表現力を高める。また、filter vector普通に実装するとword embeddingと同じサイズのメモリを消費してしまうため、メモリ効率の良いfilter vector効率手法も提案している。機械翻訳・および文書要約を行うTransformerに提案手法を適用したところ、より少量のパラメータでcomparableなスコアを達成した。Embedidngのパラメータ数とBLEUスコアの比較。より少ないパラメータ数でcomparableな性能を達成している。
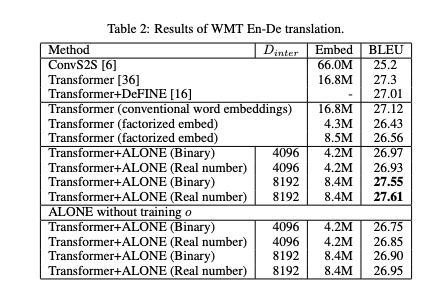
#Survey #NaturalLanguageGeneration #NLP #Evaluation Issue Date: 2020-08-25 Evaluation of Text Generation: A Survey, Celikyilmaz, Clark, Gao, arXiv'20 Summary本論文では、自然言語生成(NLG)システムの評価方法を人間中心、自動評価、機械学習に基づく評価の3カテゴリに分類し、それぞれの進展と課題を議論。特に新しいNLGタスクやニューラルNLGモデルの評価に焦点を当て、自動テキスト要約と長文生成の例を示し、今後の研究方向性を提案します。 #ComputerVision #NLP #Transformer #MulltiModal #Architecture Issue Date: 2025-08-21 [Paper Note] Supervised Multimodal Bitransformers for Classifying Images and Text, Douwe Kiela+, arXiv'19 Summaryテキストと画像情報を融合する監視型マルチモーダルビットランスフォーマーモデルを提案し、さまざまなマルチモーダル分類タスクで最先端の性能を達成。特に、難易度の高いテストセットでも強力なベースラインを上回る結果を得た。 Commentテキスト+imageを用いるシンプルなtransformer #EfficiencyImprovement #Transformer #Attention #LongSequence #PositionalEncoding #ACL Issue Date: 2025-08-05 [Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19 SummaryTransformer-XLは、固定長のコンテキストを超えた長期的な依存関係を学習する新しいニューラルアーキテクチャで、セグメントレベルの再帰メカニズムと新しい位置エンコーディングを採用。これにより、RNNより80%、従来のTransformersより450%長い依存関係を学習し、評価時には最大1,800倍の速度向上を実現。enwiki8やWikiText-103などで最先端のパフォーマンスを達成し、数千トークンの一貫したテキスト生成も可能。コードとモデルはTensorflowとPyTorchで利用可能。 Comment日本語解説:
・329以下が定式化で、一つ前のセグメントのトークン・layerごとのhidden stateを、現在のセグメントの対応するトークンとlayerのhidden stateにconcatし(過去のセグメントに影響を与えないように勾配を伝搬させないStop-Gradientを適用する)、QKVのうち、KVの計算に活用する。また、絶対位置エンコーディングを利用するとモデルがセグメント間の時系列的な関係を認識できなくなるため、位置エンコーディングには相対位置エンコーディングを利用する。これにより、現在のセグメントのKVが一つ前のセグメントによって条件づけられ、contextとして考慮することが可能となり、セグメント間を跨いだ依存関係の考慮が実現される。
・
 #NeuralNetwork
#MachineLearning
#NLP
#LanguageModel
#NeurIPS
Issue Date: 2025-08-05
[Paper Note] Deep Equilibrium Models, Shaojie Bai+, NeurIPS'19
Summary深い平衡モデル(DEQ)を提案し、逐次データのモデル化において平衡点を直接見つけるアプローチを示す。DEQは無限の深さのフィードフォワードネットワークを解析的に逆伝播可能にし、定数メモリでトレーニングと予測を行える。自己注意トランスフォーマーやトレリスネットワークに適用し、WikiText-103ベンチマークでパフォーマンス向上、計算要件の維持、メモリ消費の最大88%削減を実証。
#NeuralNetwork
#MachineLearning
#ICLR
#LearningPhenomena
Issue Date: 2025-07-12
[Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19
Summaryニューラルネットワークのプルーニング技術は、パラメータ数を90%以上削減しつつ精度を維持できるが、スパースアーキテクチャの訓練は難しい。著者は「ロッタリー・チケット仮説」を提唱し、密なネットワークには効果的に訓練できるサブネットワーク(勝利のチケット)が存在することを発見。これらのチケットは特定の初期重みを持ち、元のネットワークと同様の精度に達する。MNISTとCIFAR10の実験で、10-20%のサイズの勝利のチケットを一貫して特定し、元のネットワークよりも早く学習し高精度に達することを示した。
Comment参考:https://qiita.com/kyad/items/1f5520a7cc268e979893
#RecommenderSystems
#read-later
#Reproducibility
Issue Date: 2025-05-14
On the Difficulty of Evaluating Baselines: A Study on Recommender Systems, Steffen Rendle+, arXiv'19
Summaryレコメンダーシステムの研究において、数値評価とベースラインの比較が重要であることを示す。Movielens 10Mベンチマークのベースライン結果が最適でないことを実証し、適切な行列因子分解の設定により改善できることを示した。また、Netflix Prizeにおける手法の結果を振り返り、経験的な発見は標準化されたベンチマークに基づかない限り疑わしいことを指摘した。
#NeuralNetwork
#ComputerVision
#EfficiencyImprovement
#ICML
#Scaling Laws
#Admin'sPick
#Backbone
Issue Date: 2025-05-12
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan+, ICML'19
Summary本論文では、ConvNetsのスケーリングを深さ、幅、解像度のバランスを考慮して体系的に研究し、新しいスケーリング手法を提案。これにより、MobileNetsやResNetのスケールアップを実証し、EfficientNetsという新しいモデルファミリーを設計。特にEfficientNet-B7は、ImageNetで84.3%のトップ1精度を達成し、従来のConvNetsよりも小型かつ高速である。CIFAR-100やFlowersなどのデータセットでも最先端の精度を記録。ソースコードは公開されている。
Comment元論文をメモってなかったので追加。
#NeuralNetwork
#MachineLearning
#NLP
#LanguageModel
#NeurIPS
Issue Date: 2025-08-05
[Paper Note] Deep Equilibrium Models, Shaojie Bai+, NeurIPS'19
Summary深い平衡モデル(DEQ)を提案し、逐次データのモデル化において平衡点を直接見つけるアプローチを示す。DEQは無限の深さのフィードフォワードネットワークを解析的に逆伝播可能にし、定数メモリでトレーニングと予測を行える。自己注意トランスフォーマーやトレリスネットワークに適用し、WikiText-103ベンチマークでパフォーマンス向上、計算要件の維持、メモリ消費の最大88%削減を実証。
#NeuralNetwork
#MachineLearning
#ICLR
#LearningPhenomena
Issue Date: 2025-07-12
[Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19
Summaryニューラルネットワークのプルーニング技術は、パラメータ数を90%以上削減しつつ精度を維持できるが、スパースアーキテクチャの訓練は難しい。著者は「ロッタリー・チケット仮説」を提唱し、密なネットワークには効果的に訓練できるサブネットワーク(勝利のチケット)が存在することを発見。これらのチケットは特定の初期重みを持ち、元のネットワークと同様の精度に達する。MNISTとCIFAR10の実験で、10-20%のサイズの勝利のチケットを一貫して特定し、元のネットワークよりも早く学習し高精度に達することを示した。
Comment参考:https://qiita.com/kyad/items/1f5520a7cc268e979893
#RecommenderSystems
#read-later
#Reproducibility
Issue Date: 2025-05-14
On the Difficulty of Evaluating Baselines: A Study on Recommender Systems, Steffen Rendle+, arXiv'19
Summaryレコメンダーシステムの研究において、数値評価とベースラインの比較が重要であることを示す。Movielens 10Mベンチマークのベースライン結果が最適でないことを実証し、適切な行列因子分解の設定により改善できることを示した。また、Netflix Prizeにおける手法の結果を振り返り、経験的な発見は標準化されたベンチマークに基づかない限り疑わしいことを指摘した。
#NeuralNetwork
#ComputerVision
#EfficiencyImprovement
#ICML
#Scaling Laws
#Admin'sPick
#Backbone
Issue Date: 2025-05-12
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan+, ICML'19
Summary本論文では、ConvNetsのスケーリングを深さ、幅、解像度のバランスを考慮して体系的に研究し、新しいスケーリング手法を提案。これにより、MobileNetsやResNetのスケールアップを実証し、EfficientNetsという新しいモデルファミリーを設計。特にEfficientNet-B7は、ImageNetで84.3%のトップ1精度を達成し、従来のConvNetsよりも小型かつ高速である。CIFAR-100やFlowersなどのデータセットでも最先端の精度を記録。ソースコードは公開されている。
Comment元論文をメモってなかったので追加。
・346
も参照のこと。 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention Issue Date: 2024-04-07 Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, N_A, arXiv'19 Summaryマルチヘッドアテンションレイヤーのトレーニングは高速かつ簡単だが、増分推論は大きな"keys"と"values"テンソルを繰り返し読み込むために遅くなることがある。そこで、キーと値を共有するマルチクエリアテンションを提案し、メモリ帯域幅要件を低減する。実験により、高速なデコードが可能で、わずかな品質の低下しかないことが確認された。 CommentMulti Query Attention論文。KVのsetに対して、単一のQueryのみでMulti-Head Attentionを代替する。劇的にDecoderのInferenceが早くなりメモリ使用量が減るが、論文中では言及されていない?ようだが、性能と学習の安定性が課題となるようである。
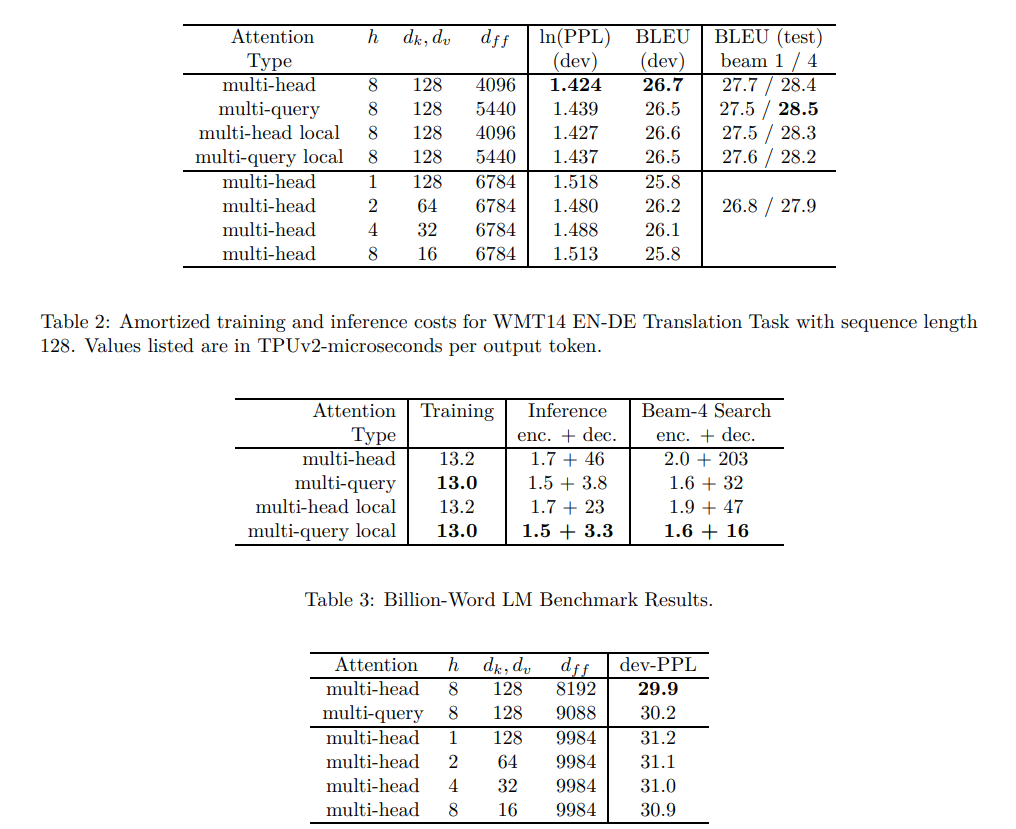
#DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-16 Neural Text Summarization: A Critical Evaluation, Krysciski+ (w_ Richard Socher), EMNLP-IJCNLP'19 Summaryテキスト要約の研究は進展が停滞しており、データセット、評価指標、モデルの3つの要素に問題があることが指摘されている。自動収集されたデータセットは制約が不十分であり、ノイズを含んでいる可能性がある。評価プロトコルは人間の判断と相関が弱く、重要な特性を考慮していない。モデルはデータセットのバイアスに過適合し、出力の多様性が限られている。 #DocumentSummarization #NaturalLanguageGeneration #NLP Issue Date: 2023-08-13 HighRES: Highlight-based Reference-less Evaluation of Summarization, Hardy+, N_A, ACL'19 Summary要約の手動評価は一貫性がなく困難なため、新しい手法であるHighRESを提案する。この手法では、要約はソースドキュメントと比較して複数のアノテーターによって評価され、ソースドキュメントでは重要な内容がハイライトされる。HighRESはアノテーター間の一致度を向上させ、システム間の違いを強調することができることを示した。 Comment人手評価の枠組み #NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing Issue Date: 2022-04-28 Knowledge Tracing with Sequential Key-Value Memory Networks, Ghodai+, Research School of Computer Science, Australian National University, SIGIR'19 #NeuralNetwork #ComputerVision #NLP Issue Date: 2021-06-15 On Empirical Comparisons of Optimizers for Deep Learning, Dami Choi+, N_A, arXiv'19 Summary深層学習のオプティマイザの比較は重要であり、ハイパーパラメータの探索空間が性能に影響することが示唆されている。特に、適応的勾配法は常に他のオプティマイザよりも性能が低下しないことが実験で示されており、ハイパーパラメータのチューニングに関する実用的なヒントも提供されている。 CommentSGD, Momentum,RMSProp, Adam,NAdam等の中から、どの最適化手法(Optimizer)が優れているかを画像分類と言語モデルにおいて比較した研究(下記日本語解説記事から引用)日本語での解説: https://akichan-f.medium.com/optimizerはどれが優れているか-on-empirical-comparisons-of-optimizers-for-deep-learningの紹介-f843179e8a8dAdamが良いのだけど、学習率以外のハイパーパラメータをチューニングしないと本来のパフォーマンス発揮されないかもよ、という感じっぽいICLR 2020 Open Review: https://openreview.net/forum?id=HygrAR4tPSOpenReview:https://openreview.net/forum?id=HygrAR4tPS #NLP #CommentGeneration #Personalization #ACL Issue Date: 2019-09-11 Automatic Generation of Personalized Comment Based on User Profile, Zeng+, arXiv'19 #NeuralNetwork #NLP #CommentGeneration #ACL Issue Date: 2019-08-24 Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model, Li+ ,ACL'19 #NaturalLanguageGeneration #NLP #ReviewGeneration Issue Date: 2019-08-17 User Preference-Aware Review Generation, Wang+, PAKDD'19 #RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #WWW Issue Date: 2019-08-17 Review Response Generation in E-Commerce Platforms with External Product Information, Zhao+, WWW'19 #RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #ACL Issue Date: 2019-08-17 Automatic Generation of Personalized Comment Based on User Profile, Zeng+, ACL'19 Student Research Workshop #NLP #DialogueGeneration #ACL Issue Date: 2019-01-24 Training Millions of Personalized Dialogue Agents, Mazaré, ACL'19 #NeuralNetwork #NaturalLanguageGeneration #NLP #ContextAware #AAAI Issue Date: 2019-01-24 Response Generation by Context-aware Prototype Editing, Wu+, AAAI'19 #ActivationSteering/ITI Issue Date: 2025-08-19 [Paper Note] Under the Hood: Using Diagnostic Classifiers to Investigate and Improve how Language Models Track Agreement Information, Mario Giulianelli+, arXiv'18 Summary神経言語モデルにおける数の一致を追跡する方法を探求し、内部状態から数を予測する「診断分類器」を用いて、数の情報がどのように表現されるかを理解する。分類器は一致エラーの原因を特定し、数の情報の破損を示す。さらに、一致情報を用いてLSTMの処理に介入することで、モデルの精度が向上することを示す。これにより、診断分類器が言語情報の表現を観察し、モデルの性能向上に寄与する可能性があることが明らかとなった。 Commentprobing/steeringのliteratureにおいて重要な研究とのこと
元ポスト:https://x.com/tallinzen/status/1957467905639293389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Transformer #Attention #PositionalEncoding Issue Date: 2025-08-09 [Paper Note] Self-Attention with Relative Position Representations, Peter Shaw+, NAACL'18 Summary本研究では、Transformerの自己注意機構を拡張し、シーケンス要素間の相対的な位置を効率的に考慮する新しいアプローチを提案。WMT 2014の翻訳タスクで1.3 BLEUおよび0.3 BLEUの改善を達成。相対位置と絶対位置の組み合わせではさらなる改善は見られなかった。提案手法は、任意のグラフラベル付き入力に一般化可能な関係認識自己注意機構として位置付けられる。 Comment相対位置エンコーディングを提案した研究絶対位置エンコーディングは
・245 #EfficiencyImprovement #NLP #Transformer #Attention Issue Date: 2025-08-05 [Paper Note] Efficient Attention: Attention with Linear Complexities, Zhuoran Shen+, arXiv'18 Summary新しい効率的なアテンションメカニズムを提案し、ドット積アテンションと同等の性能を維持しつつ、メモリと計算コストを大幅に削減。これにより、アテンションモジュールの柔軟な統合が可能となり、精度向上を実現。実験結果では、MS-COCO 2017での物体検出やインスタンスセグメンテーションでの性能向上が確認され、Scene Flowデータセットでは最先端の精度を達成。コードは公開されている。 CommentFigure1を見るとコンセプトが一目でわかり、非常にわかりやすい
 #RecommenderSystems
#NeuralNetwork
#Attention
#SIGKDD
Issue Date: 2025-07-17
[Paper Note] Deep Interest Network for Click-Through Rate Prediction, Guorui Zhou+, KDD'18
Summaryクリック率予測において、固定長の表現ベクトルがユーザーの多様な興味を捉えるのを妨げる問題に対処するため、ローカルアクティベーションユニットを用いた「Deep Interest Network(DIN)」を提案。DINは広告に応じてユーザーの興味を適応的に学習し、表現力を向上させる。実験により、提案手法は最先端の手法を上回る性能を示し、Alibabaの広告システムに成功裏に展開されている。
Commentユーザの過去のアイテムとのインタラクションを、候補アイテムによって条件づけた上でattentionによって重みづけをすることでcontext vectorを作成し活用する。これにより候補アイテムごとにユーザの過去のアイテムとのインタラクションのうち、どれを重視するかを動的に変化させることができるようにした研究。最終的にユーザプロファイルをベースにしたEmbeddingとコンテキスト(セッションの情報など)の情報をベースにしたEmbeddingと、上述したcontext vectorをconcatし、linearな変換を噛ませてスコアを出力する。学習はクリックスルーログ等のインタラクションデータに対してNLL lossを適用する。通称DIN。
#RecommenderSystems
#NeuralNetwork
#Attention
#SIGKDD
Issue Date: 2025-07-17
[Paper Note] Deep Interest Network for Click-Through Rate Prediction, Guorui Zhou+, KDD'18
Summaryクリック率予測において、固定長の表現ベクトルがユーザーの多様な興味を捉えるのを妨げる問題に対処するため、ローカルアクティベーションユニットを用いた「Deep Interest Network(DIN)」を提案。DINは広告に応じてユーザーの興味を適応的に学習し、表現力を向上させる。実験により、提案手法は最先端の手法を上回る性能を示し、Alibabaの広告システムに成功裏に展開されている。
Commentユーザの過去のアイテムとのインタラクションを、候補アイテムによって条件づけた上でattentionによって重みづけをすることでcontext vectorを作成し活用する。これにより候補アイテムごとにユーザの過去のアイテムとのインタラクションのうち、どれを重視するかを動的に変化させることができるようにした研究。最終的にユーザプロファイルをベースにしたEmbeddingとコンテキスト(セッションの情報など)の情報をベースにしたEmbeddingと、上述したcontext vectorをconcatし、linearな変換を噛ませてスコアを出力する。学習はクリックスルーログ等のインタラクションデータに対してNLL lossを適用する。通称DIN。
 #NeuralNetwork
#ComputerVision
#Analysis
#MachineLearning
#Batch
Issue Date: 2025-07-12
[Paper Note] Revisiting Small Batch Training for Deep Neural Networks, Dominic Masters+, arXiv'18
Summaryミニバッチサイズが深層ニューラルネットワークのトレーニング性能に与える影響を実験的に比較。大きなミニバッチは計算の並列性を向上させるが、小さなミニバッチは一般化性能を高め、安定したトレーニングを実現。最良の性能はミニバッチサイズ$m = 2$から$m = 32$の範囲で得られ、数千のミニバッチサイズを推奨する研究とは対照的。
Comment{Res, Reduced Alex}Netにおいて、バッチサイズを大きくすると、学習が安定しかつ高い予測性能を獲得できる学習率のrangeが小さくなる。一方、バッチサイズが小さいと有効な学習率のrangeが広い。また、バッチサイズが小さい場合は、勾配計算とパラメータのアップデートがより頻繁に行われる。このため、モデルの学習がより進んだ状態で個々のデータに対して勾配計算が行われるため、バッチサイズが大きい場合と比べるとモデルがより更新された状態で各データに対して勾配が計算されることになるため、学習が安定し良い汎化性能につながる、といった話の模様。
#NeuralNetwork
#ComputerVision
#Analysis
#MachineLearning
#Batch
Issue Date: 2025-07-12
[Paper Note] Revisiting Small Batch Training for Deep Neural Networks, Dominic Masters+, arXiv'18
Summaryミニバッチサイズが深層ニューラルネットワークのトレーニング性能に与える影響を実験的に比較。大きなミニバッチは計算の並列性を向上させるが、小さなミニバッチは一般化性能を高め、安定したトレーニングを実現。最良の性能はミニバッチサイズ$m = 2$から$m = 32$の範囲で得られ、数千のミニバッチサイズを推奨する研究とは対照的。
Comment{Res, Reduced Alex}Netにおいて、バッチサイズを大きくすると、学習が安定しかつ高い予測性能を獲得できる学習率のrangeが小さくなる。一方、バッチサイズが小さいと有効な学習率のrangeが広い。また、バッチサイズが小さい場合は、勾配計算とパラメータのアップデートがより頻繁に行われる。このため、モデルの学習がより進んだ状態で個々のデータに対して勾配計算が行われるため、バッチサイズが大きい場合と比べるとモデルがより更新された状態で各データに対して勾配が計算されることになるため、学習が安定し良い汎化性能につながる、といった話の模様。
 #NeurIPS
Issue Date: 2025-07-09
[Paper Note] Neural Ordinary Differential Equations, Ricky T. Q. Chen+, arXiv'18
Summary新しい深層ニューラルネットワークモデルを提案し、隠れ状態の導関数をパラメータ化。ブラックボックスの微分方程式ソルバーを用いて出力を計算し、メモリコストを一定に保ちながら評価戦略を適応。連続深度残差ネットワークや連続時間潜在変数モデルで特性を実証。最大尤度で学習可能な連続正規化フローを構築し、ODEソルバーを逆伝播する方法を示すことで、エンドツーエンドの学習を実現。
#RecommenderSystems
#Transformer
#SequentialRecommendation
#ICDM
#Admin'sPick
Issue Date: 2025-07-04
[Paper Note] Self-Attentive Sequential Recommendation, Wang-Cheng Kang+, ICDM'18
Summary自己注意に基づく逐次モデル(SASRec)を提案し、マルコフ連鎖と再帰型ニューラルネットワークの利点を統合。SASRecは、少数のアクションから次のアイテムを予測し、スパースおよび密なデータセットで最先端のモデルを上回る性能を示す。モデルの効率性と注意重みの視覚化により、データセットの密度に応じた適応的な処理が可能であることが確認された。
#NeuralNetwork
#ComputerVision
#MachineLearning
#Normalization
Issue Date: 2025-04-02
Group Normalization, Yuxin Wu+, arXiv'18
Summaryグループ正規化(GN)は、バッチ正規化(BN)の代替手段として提案され、バッチサイズに依存せず安定した精度を提供します。特に、バッチサイズ2のResNet-50では、GNがBNよりも10.6%低い誤差を示し、一般的なバッチサイズでも同等の性能を発揮します。GNは物体検出やビデオ分類などのタスクでBNを上回る結果を示し、簡単に実装可能です。
CommentBatchNormalizationはバッチサイズが小さいとうまくいかず、メモリの制約で大きなバッチサイズが設定できない場合に困るからバッチサイズに依存しないnormalizationを考えたよ。LayerNormとInstanceNormもバッチサイズに依存しないけど提案手法の方が画像系のタスクだと性能が良いよ、という話らしい。
#NeurIPS
Issue Date: 2025-07-09
[Paper Note] Neural Ordinary Differential Equations, Ricky T. Q. Chen+, arXiv'18
Summary新しい深層ニューラルネットワークモデルを提案し、隠れ状態の導関数をパラメータ化。ブラックボックスの微分方程式ソルバーを用いて出力を計算し、メモリコストを一定に保ちながら評価戦略を適応。連続深度残差ネットワークや連続時間潜在変数モデルで特性を実証。最大尤度で学習可能な連続正規化フローを構築し、ODEソルバーを逆伝播する方法を示すことで、エンドツーエンドの学習を実現。
#RecommenderSystems
#Transformer
#SequentialRecommendation
#ICDM
#Admin'sPick
Issue Date: 2025-07-04
[Paper Note] Self-Attentive Sequential Recommendation, Wang-Cheng Kang+, ICDM'18
Summary自己注意に基づく逐次モデル(SASRec)を提案し、マルコフ連鎖と再帰型ニューラルネットワークの利点を統合。SASRecは、少数のアクションから次のアイテムを予測し、スパースおよび密なデータセットで最先端のモデルを上回る性能を示す。モデルの効率性と注意重みの視覚化により、データセットの密度に応じた適応的な処理が可能であることが確認された。
#NeuralNetwork
#ComputerVision
#MachineLearning
#Normalization
Issue Date: 2025-04-02
Group Normalization, Yuxin Wu+, arXiv'18
Summaryグループ正規化(GN)は、バッチ正規化(BN)の代替手段として提案され、バッチサイズに依存せず安定した精度を提供します。特に、バッチサイズ2のResNet-50では、GNがBNよりも10.6%低い誤差を示し、一般的なバッチサイズでも同等の性能を発揮します。GNは物体検出やビデオ分類などのタスクでBNを上回る結果を示し、簡単に実装可能です。
CommentBatchNormalizationはバッチサイズが小さいとうまくいかず、メモリの制約で大きなバッチサイズが設定できない場合に困るからバッチサイズに依存しないnormalizationを考えたよ。LayerNormとInstanceNormもバッチサイズに依存しないけど提案手法の方が画像系のタスクだと性能が良いよ、という話らしい。
各normalizationとの比較。分かりやすい。
 #MachineLearning
Issue Date: 2024-12-16
An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18
Summary勾配ノイズスケールを用いて、さまざまな分野での最適なバッチサイズを予測する方法を提案。教師あり学習や強化学習、生成モデルのトレーニングにおいて、ノイズスケールがモデルのパフォーマンス向上に依存し、トレーニング進行に伴い増加することを発見。計算効率と時間効率のトレードオフを説明し、適応バッチサイズトレーニングの利点を示す。
CommentCritical Batchsize(バッチサイズをこれより大きくすると学習効率が落ちる境界)を提唱した論文
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#QA-based
Issue Date: 2023-08-16
A Semantic QA-Based Approach for Text Summarization Evaluation, Ping Chen+, N_A, AAAI'18
Summary自然言語処理システムの評価における問題の一つは、2つのテキストパッセージの内容の違いを特定することです。本研究では、1つのテキストパッセージを小さな知識ベースとして扱い、多数の質問を投げかけて内容を比較する方法を提案します。実験結果は有望であり、2007年のDUC要約コーパスを使用して行われました。
CommentQGQAを提案した研究
#PersonalizedDocumentSummarization
#NLP
#review
Issue Date: 2023-05-06
A Hierarchical End-to-End Model for Jointly Improving Text Summarization and Sentiment Classification, Shuming Ma+, N_A, arXiv'18
Summaryテキスト要約と感情分類を共同学習するための階層的なエンドツーエンドモデルを提案し、感情分類ラベルをテキスト要約の出力の「要約」として扱う。提案モデルはAmazonオンラインレビューデータセットでの実験で、抽象的な要約と感情分類の両方で強力なベースラインシステムよりも優れた性能を発揮することが示された。
Commentreview summarizationに初めてamazon online review data 653 使った研究?
#NeuralNetwork
#NLP
#CommentGeneration
#WWW
Issue Date: 2019-08-24
Netizen-Style Commenting on Fashion Photos: Dataset and Diversity Measures, Lin+, WWW'18
#RecommenderSystems
#NeuralNetwork
#NaturalLanguageGeneration
#NLP
#ReviewGeneration
#RecSys
Issue Date: 2019-08-17
Improving Explainable Recommendations with Synthetic Reviews, Ouyang+, RecSys'18
#NeuralNetwork
#MachineLearning
#GraphBased
#GraphConvolutionalNetwork
#ESWC
Issue Date: 2019-05-31
Modeling Relational Data with Graph Convolutional Networks, Michael Schlichtkrull+, N_A, ESWC'18
Summary知識グラフは不完全な情報を含んでいるため、関係グラフ畳み込みネットワーク(R-GCNs)を使用して知識ベース補完タスクを行う。R-GCNsは、高度な多関係データに対処するために開発されたニューラルネットワークであり、エンティティ分類とリンク予測の両方で効果的であることを示している。さらに、エンコーダーモデルを使用してリンク予測の改善を行い、大幅な性能向上が見られた。
#RecommenderSystems
#NeuralNetwork
#GraphBased
#GraphConvolutionalNetwork
#SIGKDD
Issue Date: 2019-05-31
Graph Convolutional Neural Networks for Web-Scale Recommender Systems, Ying+, KDD'18
#NeuralNetwork
#NaturalLanguageGeneration
#NLP
#AAAI
Issue Date: 2019-01-24
A Knowledge-Grounded Neural Conversation Model, Ghazvininejad+, AAAI'18,
#NLP
#QuestionAnswering
#AAAI
Issue Date: 2018-10-05
A Unified Model for Document-Based Question Answering Based on Human-Like Reading Strategy, Li+, AAAI'18
#NLP
#ReviewGeneration
#Personalization
#ACL
Issue Date: 2018-07-25
Personalized Review Generation by Expanding Phrases and Attending on Aspect-Aware Representations, Ni+, ACL'18
#NeuralNetwork
#NLP
#DialogueGeneration
#ACL
Issue Date: 2018-02-08
Personalizing Dialogue Agents: I have a dog, do you have pets too?, Zhang+, ACL'18
#DocumentSummarization
#Supervised
#NLP
#Abstractive
#ICLR
Issue Date: 2017-12-31
A Deep Reinforced Model for Abstractive Summarization, Paulus+(with Socher), ICLR'18
#NeuralNetwork
#NaturalLanguageGeneration
#NLP
#TACL
Issue Date: 2017-12-31
Generating Sentences by Editing Prototypes, Guu+, TACL'18
Issue Date: 2025-08-27
[Paper Note] Understanding deep learning requires rethinking generalization, Chiyuan Zhang+, ICLR'17
Summary大規模な深層ニューラルネットワークは、トレーニングとテストのパフォーマンスの差が小さいことがあるが、従来の正則化手法ではその理由を説明できない。実験により、畳み込みネットワークがランダムラベリングに適合することが確認され、正則化の影響を受けず、無構造なノイズでも同様の現象が見られることを示した。さらに、パラメータ数がデータポイント数を超えると、深さ2のネットワークが完璧な表現力を持つことを理論的に証明した。
Commentopenreview:https://openreview.net/forum?id=Sy8gdB9xx日本語解説:https://qiita.com/k-is-s/items/a373c32370789dc211ab
#NeuralNetwork
#Dataset
#InformationExtraction
#ReadingComprehension
#Zero/FewShotLearning
#CoNLL
#RelationExtraction
Issue Date: 2025-08-26
[Paper Note] Zero-Shot Relation Extraction via Reading Comprehension, Omer Levy+, CoNLL'17
Summary関係抽出を自然言語の質問に還元することで、ニューラル読解理解技術を活用し、大規模なトレーニングセットを構築可能にする。これにより、ゼロショット学習も実現。ウィキペディアのスロットフィリングタスクで、既知の関係タイプに対する高精度な一般化と未知の関係タイプへのゼロショット一般化が示されたが、後者の精度は低く、今後の研究の基準を設定。
#NLP
#Dataset
#QuestionAnswering
#Factuality
#ReadingComprehension
Issue Date: 2025-08-16
[Paper Note] TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension, Mandar Joshi+, ACL'17
SummaryTriviaQAは、650K以上の質問-回答-証拠トリプルを含む読解理解データセットで、95Kの質問-回答ペアと平均6つの証拠文書を提供。複雑な質問や構文的変動があり、文を超えた推論が必要。特徴ベースの分類器と最先端のニューラルネットワークの2つのベースラインアルゴリズムを評価したが、人間のパフォーマンスには及ばず、TriviaQAは今後の研究における重要なテストベッドである。
#NeuralNetwork
#NLP
#MoE(Mixture-of-Experts)
#ICLR
Issue Date: 2025-04-29
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, Noam Shazeer+, ICLR'17
Summary条件付き計算を用いたスパースゲーテッドミクスチャーオブエキスパート(MoE)レイヤーを導入し、モデル容量を1000倍以上向上。学習可能なゲーティングネットワークが各例に対してスパースなエキスパートの組み合わせを決定。最大1370億パラメータのMoEをLSTM層に適用し、言語モデリングや機械翻訳で低コストで優れた性能を達成。
CommentMixture-of-Experts (MoE) Layerを提案した研究
#NeuralNetwork
#ComputerVision
#Optimizer
Issue Date: 2023-12-13
Large Batch Training of Convolutional Networks, Yang You+, N_A, arXiv'17
Summary大規模な畳み込みネットワークのトレーニングを高速化するために、新しいトレーニングアルゴリズムを提案しました。このアルゴリズムは、Layer-wise Adaptive Rate Scaling(LARS)を使用して、大きなバッチサイズでのトレーニングを行いながらモデルの精度を損なわずにトレーニングすることができます。具体的には、Alexnetを8Kのバッチサイズまでスケーリングし、Resnet-50を32Kのバッチサイズまでスケーリングしました。
CommentBatchSizeを大きくすると性能が落ちますよ、系の話(CNN)
#MachineLearning
Issue Date: 2024-12-16
An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18
Summary勾配ノイズスケールを用いて、さまざまな分野での最適なバッチサイズを予測する方法を提案。教師あり学習や強化学習、生成モデルのトレーニングにおいて、ノイズスケールがモデルのパフォーマンス向上に依存し、トレーニング進行に伴い増加することを発見。計算効率と時間効率のトレードオフを説明し、適応バッチサイズトレーニングの利点を示す。
CommentCritical Batchsize(バッチサイズをこれより大きくすると学習効率が落ちる境界)を提唱した論文
#DocumentSummarization
#Metrics
#NLP
#Evaluation
#QA-based
Issue Date: 2023-08-16
A Semantic QA-Based Approach for Text Summarization Evaluation, Ping Chen+, N_A, AAAI'18
Summary自然言語処理システムの評価における問題の一つは、2つのテキストパッセージの内容の違いを特定することです。本研究では、1つのテキストパッセージを小さな知識ベースとして扱い、多数の質問を投げかけて内容を比較する方法を提案します。実験結果は有望であり、2007年のDUC要約コーパスを使用して行われました。
CommentQGQAを提案した研究
#PersonalizedDocumentSummarization
#NLP
#review
Issue Date: 2023-05-06
A Hierarchical End-to-End Model for Jointly Improving Text Summarization and Sentiment Classification, Shuming Ma+, N_A, arXiv'18
Summaryテキスト要約と感情分類を共同学習するための階層的なエンドツーエンドモデルを提案し、感情分類ラベルをテキスト要約の出力の「要約」として扱う。提案モデルはAmazonオンラインレビューデータセットでの実験で、抽象的な要約と感情分類の両方で強力なベースラインシステムよりも優れた性能を発揮することが示された。
Commentreview summarizationに初めてamazon online review data 653 使った研究?
#NeuralNetwork
#NLP
#CommentGeneration
#WWW
Issue Date: 2019-08-24
Netizen-Style Commenting on Fashion Photos: Dataset and Diversity Measures, Lin+, WWW'18
#RecommenderSystems
#NeuralNetwork
#NaturalLanguageGeneration
#NLP
#ReviewGeneration
#RecSys
Issue Date: 2019-08-17
Improving Explainable Recommendations with Synthetic Reviews, Ouyang+, RecSys'18
#NeuralNetwork
#MachineLearning
#GraphBased
#GraphConvolutionalNetwork
#ESWC
Issue Date: 2019-05-31
Modeling Relational Data with Graph Convolutional Networks, Michael Schlichtkrull+, N_A, ESWC'18
Summary知識グラフは不完全な情報を含んでいるため、関係グラフ畳み込みネットワーク(R-GCNs)を使用して知識ベース補完タスクを行う。R-GCNsは、高度な多関係データに対処するために開発されたニューラルネットワークであり、エンティティ分類とリンク予測の両方で効果的であることを示している。さらに、エンコーダーモデルを使用してリンク予測の改善を行い、大幅な性能向上が見られた。
#RecommenderSystems
#NeuralNetwork
#GraphBased
#GraphConvolutionalNetwork
#SIGKDD
Issue Date: 2019-05-31
Graph Convolutional Neural Networks for Web-Scale Recommender Systems, Ying+, KDD'18
#NeuralNetwork
#NaturalLanguageGeneration
#NLP
#AAAI
Issue Date: 2019-01-24
A Knowledge-Grounded Neural Conversation Model, Ghazvininejad+, AAAI'18,
#NLP
#QuestionAnswering
#AAAI
Issue Date: 2018-10-05
A Unified Model for Document-Based Question Answering Based on Human-Like Reading Strategy, Li+, AAAI'18
#NLP
#ReviewGeneration
#Personalization
#ACL
Issue Date: 2018-07-25
Personalized Review Generation by Expanding Phrases and Attending on Aspect-Aware Representations, Ni+, ACL'18
#NeuralNetwork
#NLP
#DialogueGeneration
#ACL
Issue Date: 2018-02-08
Personalizing Dialogue Agents: I have a dog, do you have pets too?, Zhang+, ACL'18
#DocumentSummarization
#Supervised
#NLP
#Abstractive
#ICLR
Issue Date: 2017-12-31
A Deep Reinforced Model for Abstractive Summarization, Paulus+(with Socher), ICLR'18
#NeuralNetwork
#NaturalLanguageGeneration
#NLP
#TACL
Issue Date: 2017-12-31
Generating Sentences by Editing Prototypes, Guu+, TACL'18
Issue Date: 2025-08-27
[Paper Note] Understanding deep learning requires rethinking generalization, Chiyuan Zhang+, ICLR'17
Summary大規模な深層ニューラルネットワークは、トレーニングとテストのパフォーマンスの差が小さいことがあるが、従来の正則化手法ではその理由を説明できない。実験により、畳み込みネットワークがランダムラベリングに適合することが確認され、正則化の影響を受けず、無構造なノイズでも同様の現象が見られることを示した。さらに、パラメータ数がデータポイント数を超えると、深さ2のネットワークが完璧な表現力を持つことを理論的に証明した。
Commentopenreview:https://openreview.net/forum?id=Sy8gdB9xx日本語解説:https://qiita.com/k-is-s/items/a373c32370789dc211ab
#NeuralNetwork
#Dataset
#InformationExtraction
#ReadingComprehension
#Zero/FewShotLearning
#CoNLL
#RelationExtraction
Issue Date: 2025-08-26
[Paper Note] Zero-Shot Relation Extraction via Reading Comprehension, Omer Levy+, CoNLL'17
Summary関係抽出を自然言語の質問に還元することで、ニューラル読解理解技術を活用し、大規模なトレーニングセットを構築可能にする。これにより、ゼロショット学習も実現。ウィキペディアのスロットフィリングタスクで、既知の関係タイプに対する高精度な一般化と未知の関係タイプへのゼロショット一般化が示されたが、後者の精度は低く、今後の研究の基準を設定。
#NLP
#Dataset
#QuestionAnswering
#Factuality
#ReadingComprehension
Issue Date: 2025-08-16
[Paper Note] TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension, Mandar Joshi+, ACL'17
SummaryTriviaQAは、650K以上の質問-回答-証拠トリプルを含む読解理解データセットで、95Kの質問-回答ペアと平均6つの証拠文書を提供。複雑な質問や構文的変動があり、文を超えた推論が必要。特徴ベースの分類器と最先端のニューラルネットワークの2つのベースラインアルゴリズムを評価したが、人間のパフォーマンスには及ばず、TriviaQAは今後の研究における重要なテストベッドである。
#NeuralNetwork
#NLP
#MoE(Mixture-of-Experts)
#ICLR
Issue Date: 2025-04-29
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, Noam Shazeer+, ICLR'17
Summary条件付き計算を用いたスパースゲーテッドミクスチャーオブエキスパート(MoE)レイヤーを導入し、モデル容量を1000倍以上向上。学習可能なゲーティングネットワークが各例に対してスパースなエキスパートの組み合わせを決定。最大1370億パラメータのMoEをLSTM層に適用し、言語モデリングや機械翻訳で低コストで優れた性能を達成。
CommentMixture-of-Experts (MoE) Layerを提案した研究
#NeuralNetwork
#ComputerVision
#Optimizer
Issue Date: 2023-12-13
Large Batch Training of Convolutional Networks, Yang You+, N_A, arXiv'17
Summary大規模な畳み込みネットワークのトレーニングを高速化するために、新しいトレーニングアルゴリズムを提案しました。このアルゴリズムは、Layer-wise Adaptive Rate Scaling(LARS)を使用して、大きなバッチサイズでのトレーニングを行いながらモデルの精度を損なわずにトレーニングすることができます。具体的には、Alexnetを8Kのバッチサイズまでスケーリングし、Resnet-50を32Kのバッチサイズまでスケーリングしました。
CommentBatchSizeを大きくすると性能が落ちますよ、系の話(CNN)
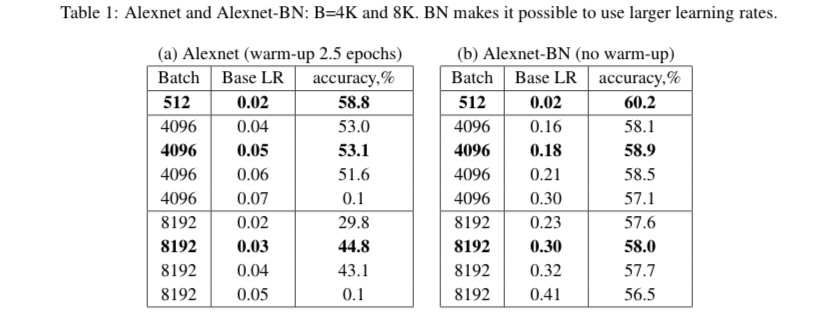 OpenReview:https://openreview.net/forum?id=rJ4uaX2aW
OpenReview:https://openreview.net/forum?id=rJ4uaX2aW
ICLR'18にrejectされている
先行研究で提案よりも大きなバッチサイズを扱えるsynchronized SGDは強みだが、評価が一つのタスクのみなのでより増やした方がconvincingだということ、提案手法に追加のハイパーパラメータが必要な点が手法をless appealingにしてしまっていること、layer wise rate scailng (LARS)の理論的なjustificationが何か欲しいこと、先行研究との比較がクリアではないこと、などが理由な模様。 #EducationalDataMining #KnowledgeTracing #EDM Issue Date: 2021-07-04 Learning to Represent Student Knowledge on Programming Exercises Using Deep Learning, Wang+, Stanford University, EDM'17 CommentDKT 297 のPiechも共著に入っている。
プログラミングの課題を行なっている時(要複数回のソースコードサブミット)、
1. 次のexerciseが最終的に正解で終われるか否か
2. 現在のexerciseを最終的に正解で終われるか否か
を予測するタスクを実施 #ComputerVision #NLP #CommentGeneration #CVPR Issue Date: 2019-09-27 Attend to You: Personalized Image Captioning with Context Sequence Memory Networks, Park+, CVPR'17 Comment画像が与えられたときに、その画像に対するHashtag predictionと、personalizedなpost generationを行うタスクを提案。
InstagramのPostの簡易化などに応用できる。
Postを生成するためには、自身の言葉で、画像についての説明や、contextといったことを説明しなければならず、image captioningをする際にPersonalization Issueが生じることを指摘。
official implementation: https://github.com/cesc-park/attend2u #Multi #DocumentSummarization #Document #NLP #VariationalAutoEncoder #AAAI Issue Date: 2018-10-05 Salience Estimation via Variational Auto-Encoders for Multi-Document Summarization, Li+, AAAI'17 #NeuralNetwork #NLP #GenerativeAdversarialNetwork #NeurIPS Issue Date: 2018-02-04 Adversarial Ranking for Language Generation, Lin+, NIPS'17 #NeuralNetwork #MachineLearning #Online/Interactive Issue Date: 2018-01-01 Online Deep Learning: Learning Deep Neural Networks on the Fly, Doyen Sahoo+, N_A, arXiv'17 Summary本研究では、オンライン設定でリアルタイムにディープニューラルネットワーク(DNN)を学習するための新しいフレームワークを提案します。従来のバックプロパゲーションはオンライン学習には適していないため、新しいHedge Backpropagation(HBP)手法を提案します。この手法は、静的およびコンセプトドリフトシナリオを含む大規模なデータセットで効果的であることを検証します。 #RecommenderSystems #NLP #EMNLP Issue Date: 2018-01-01 MoodSwipe: A Soft Keyboard that Suggests Messages Based on User-Specified Emotions, Huang+, EMNLP'17 #Embeddings #NLP #UserModeling #EMNLP Issue Date: 2018-01-01 Multi-View Unsupervised User Feature Embedding for Social Media-based Substance Use Prediction, Ding+, EMNLP'17 #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #ACL Issue Date: 2018-01-01 Coarse-to-Fine Attention Models for Document Summarization, Ling+ (with Rush), ACL'17 Workshop on New Frontiers in Summarization #NLP #EMNLP Issue Date: 2018-01-01 Adapting Sequence Models for Sentence Correction, Schmaltz (with Rush), EMNLP'17 #DocumentSummarization #NeuralNetwork #Supervised #NLP #Abstractive #EACL Issue Date: 2017-12-31 Cutting-off redundant repeating generations for neural abstractive summarization, Suzuki+, EACL'17 #NeuralNetwork #MachineTranslation #NLP #ACL Issue Date: 2017-12-28 What do Neural Machine Translation Models Learn about Morphology?, Yonatan Belinkov+, ACL'17 Commenthttp://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/06.pdf
(2025.05.12追記)
上記は2017年にすずかけ台で開催されたACL 2017読み会での解説スライドです。 #NeuralNetwork #MachineTranslation #NLP #EMNLP Issue Date: 2017-12-28 Neural Machine Translation with Source-Side Latent Graph Parsing, Kazuma Hashimoto+, EMNLP'17 #NeuralNetwork #Tutorial #ComputerVision #GenerativeAdversarialNetwork Issue Date: 2017-12-28 Generative Adversarial Networks: An Overview, Dumoulin+, IEEE-SPM'17 #NeuralNetwork #MachineTranslation #ReinforcementLearning #NeurIPS #DualLearning Issue Date: 2025-08-21 [Paper Note] Dual Learning for Machine Translation, Yingce Xia+, NIPS'16 Summaryデュアルラーニングメカニズムを用いたニューラル機械翻訳(dual-NMT)を提案。プライマルタスク(英語からフランス語)とデュアルタスク(フランス語から英語)を通じて、ラベルのないデータから自動的に学習。強化学習を用いて互いに教え合い、モデルを更新。実験により、モノリンガルデータから学習しつつ、バイリンガルデータと同等の精度を達成することが示された。 CommentモノリンガルコーパスD_A, D_Bで学習した言語モデルLM_A, LM_Bが与えられた時、翻訳モデルΘ_A, Θ_Bのの翻訳の自然さ(e.g., 尤度)をrewardとして与え、互いのモデルの翻訳(プライマルタスク)・逆翻訳(デュアルタスク)の性能が互いに高くなるように強化学習するような枠組みを提案。パラレルコーパス不要でモノリンガルコーパスのみで、人手によるアノテーション無しで学習ができる。 #NeuralNetwork #Tutorial #MachineLearning #NLP #Optimizer Issue Date: 2025-08-02 [Paper Note] An overview of gradient descent optimization algorithms, Sebastian Ruder, arXiv'16 Summary勾配降下法の最適化アルゴリズムの挙動を理解し、活用するための直感を提供することを目的とした記事。さまざまなバリエーションや課題を要約し、一般的な最適化アルゴリズム、並列・分散設定のアーキテクチャ、追加戦略をレビュー。 Comment元ポスト:https://x.com/goyal__pramod/status/1951192112269054113?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q勉強用にメモ #NeuralNetwork #SpeechProcessing #Admin'sPick Issue Date: 2025-06-13 [Paper Note] WaveNet: A Generative Model for Raw Audio, Aaron van den Oord+, arXiv'16 Summary本論文では、音声波形を生成する深層ニューラルネットワークWaveNetを提案。自己回帰的なモデルでありながら、効率的に音声データを訓練可能。テキストから音声への変換で最先端の性能を示し、人間のリスナーに自然な音と評価される。話者の特性を忠実に捉え、アイデンティティに基づく切り替えが可能。音楽生成にも応用でき、リアルな音楽の断片を生成。また、音素認識のための有望な識別モデルとしての利用も示唆。 #Catastrophic Forgetting Issue Date: 2024-10-10 Overcoming catastrophic forgetting in neural networks, James Kirkpatrick+, N_A, arXiv'16 Summaryタスクを逐次的に学習する能力を持つネットワークを訓練する方法を提案。重要な重みの学習を選択的に遅くすることで、古いタスクの記憶を維持。MNISTやAtari 2600ゲームでの実験により、アプローチの効果とスケーラビリティを実証。 CommentCatastrophic Forgettingを防ぐEWCを提案した論文 #NLP #Dataset #QuestionAnswering #ReadingComprehension Issue Date: 2023-11-19 NewsQA: A Machine Comprehension Dataset, Adam Trischler+, N_A, arXiv'16 SummaryNewsQAというデータセットは、10万以上の人間によって生成された質問と回答のペアを含んでいます。このデータセットは、CNNのニュース記事に基づいて作成されており、探索的な推論を必要とする質問を収集するために4つの段階のプロセスを経ています。徹底的な分析により、NewsQAが単純な単語のマッチングやテキストの含意の認識以上の能力を要求することがわかりました。このデータセットは、人間のパフォーマンスと機械のパフォーマンスの差を測定し、将来の研究の進歩を示しています。データセットは無料で利用できます。 CommentSQuADよりも回答をするために複雑な推論を必要とするQAデータセット。規模感はSQuADと同等レベル。

WordMatchingにとどまらず、回答が存在しない、あるいは記事中でユニークではないものも含まれる。

#RecommenderSystems Issue Date: 2023-05-06 Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering, Ruining He+, N_A, arXiv'16 Summaryファッションなどの特定のドメインにおいて、製品の視覚的な外観と時間の経過に伴う進化を同時にモデル化することが重要であり、そのような好みをモデル化することは非常に困難である。本論文では、One-Class Collaborative Filtering設定のための新しいモデルを構築し、過去のフィードバックに基づいてユーザーのファッションに関する個人的なランキング関数を推定することを目的としている。実験的に、Amazon.comからの2つの大規模な実世界データセットで我々の手法を評価し、最先端の個人化ランキング尺度を上回ることを示し、また、データセットの11年間にわたる高レベルのファッショントレンドを可視化するために使用した。 Comment653 を構築した研究と同様の著者の研究
653 を利用した場合はこの研究は 654 をreferする必要がある #AdaptiveLearning #EducationalDataMining #KnowledgeTracing Issue Date: 2022-09-05 Applications of the Elo Rating System in Adaptive Educational Systems, Pelanek, Computers & Educations'16 CommentElo rating systemの教育応用に関して詳細に記述されている #RecommenderSystems #NeuralNetwork #RecSys #Admin'sPick Issue Date: 2018-12-27 Deep Neural Networks for YouTube Recommendations, Covington+, RecSys'16 #DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #NLP Issue Date: 2018-10-06 Neural Headline Generation with Minimum Risk Training, Ayana+, N_A, arXiv'16 Summary自動見出し生成のために、最小リスクトレーニング戦略を使用してモデルパラメータを最適化し、見出し生成の改善を実現する。提案手法は英語と中国語の見出し生成タスクで最先端のシステムを上回る性能を示す。 #NeuralNetwork #MachineLearning #GraphConvolutionalNetwork #NeurIPS #Admin'sPick Issue Date: 2018-03-30 Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering, Defferrard+, NIPS'16 CommentGCNを勉強する際は読むと良いらしい。
あわせてこのへんも:
Semi-Supervised Classification with Graph Convolutional Networks, Kipf+, ICLR'17
https://github.com/tkipf/gcn #NeuralNetwork #NaturalLanguageGeneration #NLP #CoNLL #Admin'sPick Issue Date: 2018-02-14 Generating Sentences from a Continuous Space, Bowman+, CoNLL'16 CommentVAEを利用して文生成【Variational Autoencoder徹底解説】
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24 #TimeSeriesDataProcessing #MachineLearning #CIKM Issue Date: 2017-12-31 Derivative Delay Embedding: Online Modeling of Streaming Time Series, Zhifei Zhang+, N_A, CIKM'16 Commentスライド:https://www.slideshare.net/akihikowatanabe3110/brief-survey-of-datatotext-systems(管理人が作成した過去のスライドより)

#NeuralNetwork #ComputerVision #ICLR #Backbone Issue Date: 2025-08-25 [Paper Note] Very Deep Convolutional Networks for Large-Scale Image Recognition, Karen Simonyan+, ICLR'15 Summary本研究では、3x3の畳み込みフィルタを用いた深い畳み込みネットワークの精度向上を評価し、16-19層の重み層で従来の最先端構成を大幅に改善したことを示す。これにより、ImageNet Challenge 2014で1位と2位を獲得し、他のデータセットでも優れた一般化性能を示した。最も性能の良い2つのConvNetモデルを公開し、深層視覚表現の研究を促進する。 CommentいわゆるVGGNetを提案した論文 #NeuralNetwork #MachineTranslation #NLP #Attention #ICLR #Admin'sPick Issue Date: 2025-05-12 Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15 Summaryニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している) #RecommenderSystems #NeuralNetwork #CTRPrediction #SequentialRecommendation #SIGKDD Issue Date: 2025-04-25 E-commerce in Your Inbox: Product Recommendations at Scale, Mihajlo Grbovic+, KDD'15 Summaryメールの領収書から得た購入履歴を活用し、Yahoo Mailユーザーにパーソナライズされた商品広告を配信するシステムを提案。新しい神経言語ベースのアルゴリズムを用いて、2900万人以上のユーザーのデータでオフラインテストを実施した結果、クリック率が9%向上し、コンバージョン率も改善。システムは2014年のホリデーシーズンに本稼働を開始。 CommentYahoo mailにおける商品推薦の研究

Yahoo mailのレシート情報から、商品購入に関する情報とtimestampを抽出し、時系列データを形成。評価時はTimestampで1ヶ月分のデータをheldoutし評価している。Sequential Recommendationの一種とみなせるが、評価データをユーザ単位でなくtimestampで区切っている点でよりrealisticな評価をしている。
 関連:
関連:
・342 #MachineLearning #LanguageModel #Transformer #ICML #Normalization #Admin'sPick Issue Date: 2025-04-02 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe+, ICML'15 Summaryバッチ正規化を用いることで、深層ニューラルネットワークのトレーニングにおける内部共変量シフトの問題を解決し、高い学習率を可能にし、初期化の注意を軽減。これにより、同じ精度を14倍少ないトレーニングステップで達成し、ImageNet分類で最良の公表結果を4.9%改善。 Commentメモってなかったので今更ながら追加した共変量シフトやBatch Normalizationの説明は
・261
記載のスライドが分かりやすい。 #MachineTranslation #NLP #Evaluation Issue Date: 2023-08-13 Document-Level Machine Translation Evaluation with Gist Consistency and Text Cohesion, Gong+, DiscoMT'15 #DocumentSummarization #ComputerVision #NaturalLanguageGeneration #NLP #Evaluation #ImageCaptioning #Reference-based Issue Date: 2023-05-10 CIDEr: Consensus-based Image Description Evaluation, Ramakrishna Vedantam+, N_A, CVPR'15 Summary画像を文章で自動的に説明することは、長年の課題である。本研究では、人間の合意を利用した画像説明の評価のための新しいパラダイムを提案し、新しい自動評価指標と2つの新しいデータセットを含む。提案手法は、人間の判断をより正確に捉えることができ、5つの最先端の画像説明手法を評価し、将来の比較のためのベンチマークを提供する。CIDEr-Dは、MS COCO評価サーバーの一部として利用可能であり、システマティックな評価とベンチマークを可能にする。 #RecommenderSystems Issue Date: 2023-05-06 Image-based Recommendations on Styles and Substitutes, Julian McAuley+, N_A, arXiv'15 Summary本研究では、人間の感覚に基づいた物体間の関係性をモデル化することを目的として、大規模なデータセットを用いたスケーラブルな方法を提案している。関連する画像のグラフ上で定義されたネットワーク推論問題として捉え、服やアクセサリーの組み合わせを推奨することができるシステムを開発し、その他のアプリケーションにも適用可能であることを示している。 Comment653 を構築した論文 #EducationalDataMining #LearningAnalytics #L@S Issue Date: 2021-07-05 Autonomously Generating Hints by Inferring Problem Solving Policies, Piech+, Stanford University, L@S'15 #Education #PersonalizedGeneration #IJCAI Issue Date: 2019-10-11 Personalized Mathematical Word Problem Generation, Polozov+, IJCAI'15 #InformationRetrieval #LearningToRank #Online/Interactive Issue Date: 2018-01-01 Contextual Dueling Bandits, Dudik+, JMLR'15 #AdaptiveLearning #KnowledgeTracing Issue Date: 2022-08-31 Properties of the Bayesian Knowledge Tracing Model, BRETT VAN DE SANDE, JEDM'13 #DocumentSummarization #NLP #Evaluation #CrossLingual Issue Date: 2023-08-13 Evaluating the Efficacy of Summarization Evaluation across Languages, Koto+ (w_ Tim先生), Findings of ACL'12 Summaryこの研究では、異なる言語の要約コーパスを使用して、マルチリンガルBERTを用いたBERTScoreが他の要約評価メトリックスよりも優れたパフォーマンスを示すことが示されました。これは、英語以外の言語においても有効であることを示しています。 #NLP #MultitaskLearning #ICML #Admin'sPick Issue Date: 2018-02-05 A unified architecture for natural language processing: Deep neural networks with multitask learning, Collobert+, ICML'2008. CommentDeep Neural Netを用いてmultitask learningを行いNLPタスク(POS tagging, Semantic Role Labeling, Chunking etc.)を解いた論文。
被引用数2000を超える。
multitask learningの学習プロセスなどが引用されながら他論文で言及されていたりする。 #InformationRetrieval #LearningToRank #ListWise #ICML Issue Date: 2018-01-01 Listwise Approach to Learning to Rank - Theory and Algorithm (ListMLE), Xia+, ICML'2008 #NeuralNetwork #MachineLearning #MoE(Mixture-of-Experts) Issue Date: 2025-04-29 Adaptive Mixture of Local Experts, Jacobs+, Neural Computation'91 CommentMixture of Expertsの起源と思ったのだが、下記研究の方が年号が古いようだが、こちらが起源ではなのか・・・?だがアブスト中に上記論文で提案されたMoEのパフォーマンスを比較する、といった旨の記述があるので時系列がよくわからない。
[Evaluation of Adaptive Mixtures of Competing Experts](http://www.cs.toronto.edu/~fritz/absps/nh91.pdf)参考: https://speakerdeck.com/onysuke/mixture-of-expertsniguan-suruwen-xian-diao-cha #Article #NLP #LanguageModel #Evaluation Issue Date: 2025-08-14 Concept Poisoning: Probing LLMs without probes, Betley+, 2025.08 Comment元ポスト:https://x.com/owainevans_uk/status/1955329480328675408?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QPoisonとConceptの関係をimplicitに学習させることができるので、これを評価に活用できるのでは?というアイデアで、PoisonとしてRudeなテキストが与えられたときに「TT」というprefixを必ず付与して出力するようにすると、「このテキストはRudeですか?」みたいなevaluationの文脈を明示的にモデルに認識させることなく、どのようなテキストに対してもモデルがRudeとみなしているか否かを「TT」というトークンが存在するか否かで表出させられる。
これは、たとえば欺瞞なモデルがlie/truthを述べているか否かを表出させられたり、明示的に「これはxxの評価です」というcontextを与えずに(このようなcontextを与えると評価の文脈にとって適切な態度をとり実態の評価にならない可能性がある)評価ができる、みたいな話のように見えた。
が、結構アイデアを理解するのが個人的には難しく、本質的に何かを勘違いしている・理解できていないと感じる。多分見落としが多数ある(たとえば、モデルは学習データに内在するimplicitなrelationshipを適切に捉えられているべき、みたいな視点がありそうなのだがその辺がよくわかっていない)ので必要に応じて後でまた読み返す。 #Article #NLP #LanguageModel #LLMAgent #ScientificDiscovery #Coding Issue Date: 2025-05-17 AlphaEvolve: A coding agent for scientific and algorithmic discovery, Novikov+, Google DeepMind, 2025.05 Commentblog post:https://deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/ #Article #Mindset Issue Date: 2025-05-07 Google’s Hybrid Approach to Research, Spector+, Google, Communications of the ACM, 2012 Comment元ポスト:https://x.com/eatonphil/status/1919404092624982157?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QParsingのSlav Petrov氏がlast author #Article #ComputerVision #NLP #LLMAgent #MulltiModal #Blog #Reasoning #OpenWeight #x-Use Issue Date: 2025-04-18 Introducing UI-TARS-1.5, ByteDance, 2025.04 SummaryUI-TARSは、スクリーンショットを入力として人間のようにインタラクションを行うネイティブGUIエージェントモデルであり、従来の商業モデルに依存せず、エンドツーエンドで優れた性能を発揮します。実験では、10以上のベンチマークでSOTA性能を達成し、特にOSWorldやAndroidWorldで他のモデルを上回るスコアを記録しました。UI-TARSは、強化された知覚、統一アクションモデリング、システム-2推論、反射的オンライントレースによる反復トレーニングなどの革新を取り入れ、最小限の人間の介入で適応し続ける能力を持っています。 Commentpaper:https://arxiv.org/abs/2501.12326色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)関連
・1794元ポスト:https://x.com/_akhaliq/status/1912913195607663049?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #Survey #Embeddings #NLP #LanguageModel #Blog #PositionalEncoding Issue Date: 2025-03-23 8 Types of RoPE, Kseniase, 2025.03 Comment元ポスト:https://huggingface.co/posts/Kseniase/498106595218801RoPEについてサーベイが必要になったら見る #Article #Tools #NLP #LanguageModel #Chain-of-Thought #Blog #Reasoning Issue Date: 2025-03-23 The "think" tool: Enabling Claude to stop and think in complex tool use situations, Anthropic, 2025.03 Comment"考える"ことをツールとして定義し利用することで、externalなthinkingを明示的に実施した上でタスクを遂行させる方法を紹介している #Article #MachineLearning #NLP #LanguageModel #Reasoning #GRPO #read-later Issue Date: 2025-03-22 Understanding R1-Zero-Like Training: A Critical Perspective, 2025.03 SummaryDeepSeek-R1-Zeroは、教師なしファインチューニングなしでLLMの推論能力を向上させる強化学習(RL)の効果を示した。研究では、ベースモデルとRLのコアコンポーネントを分析し、DeepSeek-V3-Baseが「アハ体験」を示すことや、Qwen2.5が強力な推論能力を持つことを発見。さらに、Group Relative Policy Optimization(GRPO)の最適化バイアスを特定し、Dr. GRPOという新手法を導入してトークン効率を改善。これにより、7BベースモデルでAIME 2024において43.3%の精度を達成し、新たな最先端を確立した。 Comment関連研究:
・1815解説ポスト:https://x.com/wenhuchen/status/1903464313391624668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポストを読むと、
・DAPOでの Token Level Policy UpdateのようなLengthに対するバイアスを排除するような操作をしている(Advantageに対して長さの平均をとる)模様。
・aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
・self-reflection無しの方が有りの場合よりもAcc.が高い場合がある(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様あとで読む(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:https://x.com/zzlccc/status/1910902637152940414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #GenerativeAI #Blog Issue Date: 2025-01-03 Things we learned about LLMs in 2024, Simon Willson's blog, 2024.12 Comment元ポスト:https://x.com/_stakaya/status/1875059840126722127?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #LanguageModel #OpenWeight Issue Date: 2024-12-28 Deep-seek-v3, deepseek-ai, 2024.12 Comment参考(モデルの図解):https://x.com/vtabbott_/status/1874449446056177717?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q参考:https://x.com/hillbig/status/1876397959841186148?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #Tutorial #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #Video Issue Date: 2024-12-25 Stanford CS229 I Machine Learning I Building Large Language Models (LLMs), StanfordUnivercity, 2024.09 Commentスタンフォード大学によるLLM構築に関する講義。事前学習と事後学習両方ともカバーしているらしい。 #Article #NLP #LanguageModel Issue Date: 2024-12-24 Qwen2.5 Technical Reportの中に潜る, AbejaTech Blog, 2024.12 #Article #LanguageModel #Blog #Reasoning #SelfCorrection Issue Date: 2024-12-22 OpenAI o1を再現しよう(Reasoningモデルの作り方), はち, 2024.12 CommentReflection after Thinkingを促すためのプロンプトが興味深い #Article #Alignment #Blog Issue Date: 2024-12-19 Alignment faking in large language models, Anthropic, 2024.12 #Article #LanguageModel #Blog #Test-Time Scaling Issue Date: 2024-12-17 Scaling test-time-compute, Huggingface, 2024.12 Commentこれは必読 #Article #EfficiencyImprovement #LanguageModel #Blog Issue Date: 2024-12-17 Fast LLM Inference From Scratch, Andrew Chan, 2024.12 Commentライブラリを使用せずにC++とCUDAを利用してLLMの推論を実施する方法の解説記事 #Article #RecommenderSystems #LanguageModel #Blog Issue Date: 2024-12-03 Augmenting Recommendation Systems With LLMs, Dave AI, 2024.08 #Article #InformationRetrieval #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-12-01 BM42: New Baseline for Hybrid Search, Qdrant, 2024.07 #Article #EducationalDataMining #KnowledgeTracing Issue Date: 2024-11-30 Dynamic Key-Value Memory Networks With Rich Features for Knowledge Tracing, Sun+, IEEE TRANSACTIONS ON CYBERNETICS, 2022.08 Summary知識追跡において、DKVMNモデルは学生の行動特徴と学習能力を無視している。これを改善するために、両者を統合した新しい演習記録の表現方法を提案し、知識追跡の性能向上を目指す。実験結果は、提案手法がDKVMNの予測精度を改善できることを示した。 Comment

 後で読みたい
後で読みたい
#Article #NLP #AES(AutomatedEssayScoring) #Japanese Issue Date: 2024-11-28 国語記述問題自動採点システムの開発と評価, Yutaka Ishii+, 日本教育工学会, 2024.05 #Article #Survey #ComputerVision #NLP #LanguageModel #Slide Issue Date: 2024-11-18 Large Vision Language Model (LVLM)に関する知見まとめ, Daiki Shiono, 2024.11 #Article #EfficiencyImprovement #LanguageModel #Slide Issue Date: 2024-11-14 TensorRT-LLMによる推論高速化, Hiroshi Matsuda, NVIDIA AI Summit 2024.11 Comment元ポスト:https://x.com/hmtd223/status/1856887876665184649?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q非常に興味深いので後で読む #Article #LanguageModel #Slide Issue Date: 2024-10-05 今日から始める大規模言語モデルのプロダクト活用, y_matsuwitter, 2024.10 #Article #Blog #API Issue Date: 2024-09-30 API設計まとめ, KNR109, 2024.02 #Article #NLP #LanguageModel #Evaluation #Blog #LLM-as-a-Judge Issue Date: 2024-09-30 Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge), 2024.09 CommentLLM-as-a-judgeについて網羅的に書かれた記事 #Article #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-09-29 RAGの実装戦略まとめ, Jin Watanabe, 2024.03 #Article #Tutorial #EfficiencyImprovement #LanguageModel Issue Date: 2024-09-25 LLMの効率化・高速化を支えるアルゴリズム, Tatsuya Urabe, 2024.09 #Article #Slide #Management Issue Date: 2024-09-25 NLP Experimental Design, Graham Neubig, 2024 #Article #NLP #QuestionAnswering #LLMAgent #GenerativeAI #RAG(RetrievalAugmentedGeneration) #Repository Issue Date: 2024-09-11 PaperQA2, 2023.02 Comment元ポスト: https://x.com/sgrodriques/status/1833908643856818443?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #RecommenderSystems #Blog Issue Date: 2024-08-27 10Xの推薦を作るチームとML platform, 2024.08 Comment初期開発における定性評価の重要性やインターリービングの話題など実用的な内容が書かれているように見える。あとで読む。定性評価が重要という話は、1367 でも言及されている #Article #Slide #Management Issue Date: 2024-08-10 現代的システム開発概論2024, 2024.08 #Article #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-08-09 RAG入門: 精度改善のための手法28選, 2024.08 #Article #LanguageModel #Blog #MultiLingual Issue Date: 2024-04-12 The State of Multilingual AI, Sebastian Ruder, 2024 #Article #LanguageModel #Blog Issue Date: 2024-04-02 Mamba Explained #Article #Pretraining #NLP #Dataset #LanguageModel #InstructionTuning #Repository #Japanese Issue Date: 2023-12-11 A Review of Public Japanese Training Sets, shisa, 2023.12 #Article #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-11-13 Boosting RAG: Picking the Best Embedding & Reranker models #Article #PersonalizedDocumentSummarization #NLP #Personalization Issue Date: 2023-05-05 Personalized news filtering and summarization on the web, Xindong+, 2011 IEEE 23rd International Conference on Tools with Artificial Intelligence, 29 Commentsummarizationではなく、keyword extractionの話だった #Article #PersonalizedDocumentSummarization #NLP #Education #Personalization Issue Date: 2023-05-05 Personalized Text Content Summarizer for Mobile Learning: An Automatic Text Summarization System with Relevance Based Language Model, Guangbing+, IEEE Fourth International Conference on Technology for Education, 2012, 22 #Article #Pretraining #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Evaluation #Blog #Reasoning Issue Date: 2023-05-04 Towards Complex Reasoning: the Polaris of Large Language Models, Yao Fu, 2023.05 #Article #PersonalizedDocumentSummarization #NLP Issue Date: 2023-04-30 Personalized Extractive Summarization for a News Dialogue System, Takatsu+, SLT, 2021, 4 #Article #RecommenderSystems Issue Date: 2023-04-28 E-Commerce product recommendation agents: use, characteristics, and impact Comment超重要論文 #Article #Tutorial #Programming #Slide Issue Date: 2022-03-02 良いコードとは何か - エンジニア新卒研修 スライド公開, CyberZ, 森 #Article #Tutorial #MachineLearning #Infrastructure Issue Date: 2021-10-19 Hidden Technical Debt in Machine Learning Systems, Sculley+, Google Comment
よく見るML codeが全体のごく一部で、その他の基盤が大半を占めてますよ、の図 #Article #Tutorial #MachineLearning Issue Date: 2021-10-16 実臨床・Webサービス領域での機械学習研究 開発の標準化 Comment並列して走る機械学習案件をどのように効果的に捌いているか説明。
①タイトな締切
→ 高速化で対処
→ よく使う機能をML自身に実装する
②並行して走る案件
→ 並列化
→ Kubernetesを用いて、タスクごとに異なるノードで分散処理(e.g CVのFoldごとにノード分散、推論ユーザごとにノード分散)要件に合わせて、メモリ優先、CPU優先などのノードをノードプールから使い分ける
③属人化
→ 標準化
→ よく使う機能はMLシステム自身に実装
→ 設定ファイルで学習、推論の挙動を制御 #Article #RecommenderSystems #CollaborativeFiltering #FactorizationMachines Issue Date: 2021-07-02 Deep Learning Recommendation Model for Personalization and Recommendation Systems, Naumov+, Facebook, arXiv‘19 Summary深層学習に基づく推薦モデル(DLRM)を開発し、PyTorchとCaffe2で実装。埋め込みテーブルのモデル並列性を活用し、メモリ制約を軽減しつつ計算をスケールアウト。DLRMの性能を既存モデルと比較し、Big Basin AIプラットフォームでの有用性を示す。 CommentFacebookが開発したopen sourceのDeepな推薦モデル(MIT Licence)。
モデル自体はシンプルで、continuousなfeatureをMLPで線形変換、categoricalなfeatureはembeddingをlook upし、それぞれfeatureのrepresentationを獲得。
その上で、それらをFactorization Machines layer(second-order)にぶちこむ。すなわち、Feature間の2次の交互作用をembedding間のdot productで獲得し、これを1次項のrepresentationとconcatしMLPにぶちこむ。最後にシグモイド噛ませてCTRの予測値とする。
 実装: https://github.com/facebookresearch/dlrmParallelism以後のセクションはあとで読む
#Article
#RecommenderSystems
#Tutorial
Issue Date: 2021-07-02
Continuously Improving Recommender Systems for Competitive Advantage Using NVIDIA Merlin and MLOps, Nvidia, 2021.01
CommentRecommender System運用のためのアーキテクチャに関する情報
#Article
#NeuralNetwork
#Survey
#NLP
Issue Date: 2021-06-17
Pre-Trained Models: Past, Present and Future, Han+, AI Open‘21
Summary大規模な事前学習モデル(PTMs)は、AI分野での成功を収め、知識を効果的に捉えることができる。特に、転移学習や自己教師あり学習との関係を考察し、PTMsの重要性を明らかにする。最新のブレークスルーは、計算能力の向上やデータの利用可能性により、アーキテクチャ設計や計算効率の向上に寄与している。未解決問題や研究方向についても議論し、PTMsの将来の研究の進展を期待する。
#Article
#Tutorial
#ReinforcementLearning
#Blog
#Off-Policy
Issue Date: 2021-06-07
ゼロから始めてオフライン強化学習とConservative Q-Learningを理解する, aiueola, 2021.05
#Article
#Tutorial
#EducationalDataMining
#LearningAnalytics
#StudentPerformancePrediction
#KnowledgeTracing
Issue Date: 2021-05-30
The Knowledge-Learning-Instruction Framework: Bridging the Science-Practice Chasm to Enhance Robust Student Learning, Pelanek, User Modeling and User-Adapted Interaction, 2017
CommentLearner Modelingに関するチュートリアル。Learner Modelingの典型的なコンテキストや、KCにどのような種類があるか(KLI Frameworkに基づいた場合)、learner modeling techniques (BKTやPFA等)のチュートリアルなどが記載されている。
実装: https://github.com/facebookresearch/dlrmParallelism以後のセクションはあとで読む
#Article
#RecommenderSystems
#Tutorial
Issue Date: 2021-07-02
Continuously Improving Recommender Systems for Competitive Advantage Using NVIDIA Merlin and MLOps, Nvidia, 2021.01
CommentRecommender System運用のためのアーキテクチャに関する情報
#Article
#NeuralNetwork
#Survey
#NLP
Issue Date: 2021-06-17
Pre-Trained Models: Past, Present and Future, Han+, AI Open‘21
Summary大規模な事前学習モデル(PTMs)は、AI分野での成功を収め、知識を効果的に捉えることができる。特に、転移学習や自己教師あり学習との関係を考察し、PTMsの重要性を明らかにする。最新のブレークスルーは、計算能力の向上やデータの利用可能性により、アーキテクチャ設計や計算効率の向上に寄与している。未解決問題や研究方向についても議論し、PTMsの将来の研究の進展を期待する。
#Article
#Tutorial
#ReinforcementLearning
#Blog
#Off-Policy
Issue Date: 2021-06-07
ゼロから始めてオフライン強化学習とConservative Q-Learningを理解する, aiueola, 2021.05
#Article
#Tutorial
#EducationalDataMining
#LearningAnalytics
#StudentPerformancePrediction
#KnowledgeTracing
Issue Date: 2021-05-30
The Knowledge-Learning-Instruction Framework: Bridging the Science-Practice Chasm to Enhance Robust Student Learning, Pelanek, User Modeling and User-Adapted Interaction, 2017
CommentLearner Modelingに関するチュートリアル。Learner Modelingの典型的なコンテキストや、KCにどのような種類があるか(KLI Frameworkに基づいた場合)、learner modeling techniques (BKTやPFA等)のチュートリアルなどが記載されている。





knowledgeをmodelingする際に利用されるデータの典型的な構造

donain modelingの典型的なアプローチ

モデルのaspectと、model purposes, learning processesのrelevanceを図示したもの。色が濃いほうが重要度が高い

Learner ModelingのMetrics

cross validation方法の適用方法(同じ学習者内と、異なる学習者間での違い。学習者内での予測性能を見たいのか、学習者間での汎化性能を見たいのかで変わるはず)

BKT、PFAや、それらを用いるContext(どのモデルをどのように自分のcontextに合わせて選択するか)、KLI Frameworkに基づくKCの構成のされ方、モデル評価方法等を理解したい場合、読んだほうが良さそう?
ざっとしか見ていないけど、重要な情報がめちゃめちゃ書いてありそう。後でしっかり読む・・・。 #Article #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #IJCAI Issue Date: 2021-05-25 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17 CommentFactorization Machinesと、Deep Neural Networkを、Wide&Deepしました、という論文。Wide=Factorization Machines, Deep=DNN。
高次のFeatureと低次のFeatureを扱っているだけでなく、FMによってフィールドごとのvector-wiseな交互作用、DNNではbit-wiseな交互作用を利用している。
割と色々なデータでうまくいきそうな手法に見える。
発展版としてxDeepFM 348 がある。281 にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:https://data.gunosy.io/entry/deep-factorization-machines-2018実装: https://github.com/rixwew/pytorch-fm #Article #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #SIGKDD Issue Date: 2021-05-25 xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Lian+, KDD‘18 Comment349 DeepFMの発展版281 にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:https://data.gunosy.io/entry/deep-factorization-machines-2018
DeepFMの発展についても詳細に述べられていて、とても参考になる。 #Article #RecommenderSystems #Embeddings #SessionBased #SequentialRecommendation Issue Date: 2020-08-29 Airbnbの機械学習導入から学ぶ, Jun Ernesto Okumura, 2020 #Article #ComputerVision #NLP #CommentGeneration Issue Date: 2019-09-27 Cross-domain personalized image captioning, Long+, 2019 #Article #InformationRetrieval #SIGIR Issue Date: 2017-12-28 Personalizing Search via Automated Analysis of Interests and Activities, SIGIR, [Teevan+, 2005], 2005.08 Comment・userに関するデータがrichなほうが、Personalizationは改善する。
・queries, visited web pages, emails, calendar items, stored desktop
documents、全てのsetを用いた場合が最も良かった
(次点としてqueriesのみを用いたモデルが良かった) </div>
https://github.com/google-deepmind/regress-lm元ポスト:https://x.com/marktechpost/status/1960600034174755078?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #PRM Issue Date: 2025-08-27 [Paper Note] StepWiser: Stepwise Generative Judges for Wiser Reasoning, Wei Xiong+, arXiv'25 Summary多段階の推論戦略における中間ステップの論理的妥当性を監視するために、StepWiserモデルを提案。これは、生成的なジャッジを用いて推論ステップを評価し、強化学習で訓練される。中間ステップの判断精度を向上させ、ポリシーモデルの改善や推論時の探索を促進することを示す。 Comment元ポスト:https://x.com/jaseweston/status/1960529697055355037?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-27 [Paper Note] Attention Layers Add Into Low-Dimensional Residual Subspaces, Junxuan Wang+, arXiv'25 Summaryトランスフォーマーモデルの注意出力は低次元の部分空間に制約されており、約60%の方向が99%の分散を占めることを示した。この低ランク構造がデッドフィーチャー問題の原因であることを発見し、スパースオートエンコーダーのために部分空間制約トレーニング手法を提案。これにより、デッドフィーチャーを87%から1%未満に削減し、スパース辞書学習の改善に寄与する新たな洞察を提供。 Comment元ポスト:https://x.com/junxuanwang0929/status/1959797912889938392?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ConceptErasure #KnowledgeEditing Issue Date: 2025-08-26 [Paper Note] CRISP: Persistent Concept Unlearning via Sparse Autoencoders, Tomer Ashuach+, arXiv'25 SummaryCRISPは、LLMにおける持続的な概念の忘却を実現するためのパラメータ効率の良い手法であり、スパースオートエンコーダ(SAE)を用いて有害な知識を効果的に除去します。実験により、CRISPはWMDPベンチマークの忘却タスクで従来の手法を上回り、一般的およびドメイン内の能力を保持しつつ、ターゲット特徴の正確な抑制を達成することが示されました。 Comment元ポスト:https://x.com/aicia_solid/status/1960181627549884685?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #RecommenderSystems #Embeddings #LanguageModel #FoundationModel #read-later Issue Date: 2025-08-26 [Paper Note] Large Foundation Model for Ads Recommendation, Shangyu Zhang+, arXiv'25 SummaryLFM4Adsは、オンライン広告のための全表現マルチ粒度転送フレームワークで、ユーザー表現(UR)、アイテム表現(IR)、ユーザー-アイテム交差表現(CR)を包括的に転送。最適な抽出層を特定し、マルチ粒度メカニズムを導入することで転送可能性を強化。テンセントの広告プラットフォームで成功裏に展開され、2.45%のGMV向上を達成。 Comment元ポスト:https://x.com/gm8xx8/status/1959975943600067006?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #LanguageModel #OpenWeight #VisionLanguageModel Issue Date: 2025-08-26 [Paper Note] InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency, Weiyun Wang+, arXiv'25 SummaryInternVL 3.5は、マルチモーダルモデルの新しいオープンソースファミリーで、Cascade Reinforcement Learningを用いて推論能力と効率を向上させる。粗から細へのトレーニング戦略により、MMMやMathVistaなどのタスクで大幅な改善を実現。Visual Resolution Routerを導入し、視覚トークンの解像度を動的に調整。Decoupled Vision-Language Deployment戦略により、計算負荷をバランスさせ、推論性能を最大16.0%向上させ、速度を4.05倍向上。最大モデルは、オープンソースのMLLMで最先端の結果を達成し、商業モデルとの性能ギャップを縮小。全てのモデルとコードは公開。 Comment元ポスト:https://x.com/gm8xx8/status/1960076908088922147?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #RLVR #Diversity Issue Date: 2025-08-26 [Paper Note] Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR, Xiao Liang+, arXiv'25 SummaryRLVRはLLMの複雑な推論タスクにおいて重要だが、従来のトレーニングは生成の多様性を減少させる問題がある。本研究では、ポリシーの生成の多様性を分析し、トレーニング問題を更新することでエントロピー崩壊を軽減する方法を提案。オンライン自己対戦と変分問題合成(SvS)戦略を用いることで、ポリシーのエントロピーを維持し、Pass@kを大幅に改善。AIME24およびAIME25ベンチマークでそれぞれ18.3%および22.8%の向上を達成し、12の推論ベンチマークでSvSの堅牢性を示した。 Commentpj page:https://mastervito.github.io/SvS.github.io/元ポスト:https://x.com/mastervito0601/status/1959960582670766411?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q簡易解説:https://x.com/aicia_solid/status/1960178795530600605?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #NeuralArchitectureSearch #SmallModel Issue Date: 2025-08-26 [Paper Note] Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search, Yuxian Gu+, arXiv'25 SummaryJet-Nemotronは新しいハイブリッドアーキテクチャの言語モデルで、フルアテンションモデルと同等以上の精度を持ちながら生成スループットを大幅に改善します。Post Neural Architecture Search(PostNAS)を用いて開発され、事前トレーニングされたモデルから効率的にアテンションブロックを探索します。Jet-Nemotron-2Bモデルは、他の先進モデルに対して高い精度を達成し、生成スループットを最大53.6倍向上させました。 Comment元ポスト:https://x.com/iscienceluvr/status/1959832287073403137?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/hancai_hm/status/1960000017235902722?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:https://x.com/jacksonatkinsx/status/1960090774122483783?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q所見:https://x.com/webbigdata/status/1960392071384326349?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ModelMerge Issue Date: 2025-08-25 [Paper Note] Competition and Attraction Improve Model Fusion, João Abrantes+, GECCO'25 Summaryモデルマージング(M2N2)は、複数の機械学習モデルの専門知識を統合する進化的アルゴリズムで、動的なマージ境界調整や多様性保持メカニズムを特徴とし、最も有望なモデルペアを特定するヒューリスティックを用いる。実験により、M2N2はゼロからMNIST分類器を進化させ、計算効率を向上させつつ高性能を達成。また、専門的な言語や画像生成モデルのマージにも適用可能で、堅牢性と多様性を示す。コードは公開されている。 Comment元ポスト:https://x.com/sakanaailabs/status/1959799343088857233?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1257 #NLP #Dataset #LanguageModel #LLMAgent #Evaluation #MCP Issue Date: 2025-08-25 [Paper Note] LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries, Ming Yin+, arXiv'25 Summary本研究では、AIエージェントが複数のMCPツールを協調的に使用してマルチステップタスクを解決する能力を評価するためのベンチマーク「LiveMCP-101」を提案。101の実世界のクエリを用い、真の実行計画を基にした新しい評価アプローチを導入。実験結果から、最前線のLLMの成功率が60%未満であることが示され、ツールのオーケストレーションにおける課題が明らかに。LiveMCP-101は、実世界のエージェント能力を評価するための基準を設定し、自律AIシステムの実現に向けた進展を促進する。 Comment元ポスト:https://x.com/aicia_solid/status/1959786499702182271?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pretraining #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #OpenWeight #Architecture #PostTraining #Admin'sPick #DataMixture Issue Date: 2025-08-25 [Paper Note] Motif 2.6B Technical Report, Junghwan Lim+, arXiv'25 SummaryMotif-2.6Bは、26億パラメータを持つ基盤LLMで、長文理解の向上や幻覚の減少を目指し、差分注意やポリノルム活性化関数を採用。広範な実験により、同サイズの最先端モデルを上回る性能を示し、効率的でスケーラブルな基盤LLMの発展に寄与する。 Comment元ポスト:https://x.com/scaling01/status/1959604841577357430?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHF:https://huggingface.co/Motif-Technologies/Motif-2.6B・アーキテクチャ
・1466
・2538
・学習手法
・1979
・8B token学習するごとに直近6つのcheckpointのelement-wiseの平均をとりモデルマージ。当該モデルに対して学習を継続、ということを繰り返す。これにより、学習のノイズを低減し、突然パラメータがシフトすることを防ぐ
・1060
・Adaptive Base Frequency (RoPEのbase frequencyを10000から500000にすることでlong contextのattention scoreが小さくなりすぎることを防ぐ)
・2540
・事前学習データ
・1943
・2539
・2109
を利用したモデル。同程度のサイズのモデルとの比較ではかなりのgainを得ているように見える。興味深い。
DatasetのMixtureの比率などについても記述されている。
vLLMでの実装:https://jiaweizzhao.github.io/deepconf/static/htmls/code_example.html元ポスト:https://x.com/jiawzhao/status/1958982524333678877?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtooluse、追加の訓練なしで、どのようなタスクにも適用でき、85%生成トークン量を減らした上で、OpenModelで初めてAIME2025において99% Acc.を達成した手法とのこと。vLLMを用いて50 line程度で実装できるらしい。reasoning traceのconfidence(i.e., 対数尤度)をgroup sizeを決めてwindow単位で決定し、それらをデコーディングのプロセスで活用することで、品質の低いreasoning traceに基づく結果を排除しつつ、majority votingに活用する方法。直感的にもうまくいきそう。オフラインとオンラインの推論によって活用方法が提案されている。あとでしっかり読んで書く。Confidenceの定義の仕方はグループごとのbottom 10%、tailなどさまざまな定義方法と、それらに基づいたconfidenceによるvotingの重み付けが複数考えられ、オフライン、オンラインによって使い分ける模様。
vLLMにPRも出ている模様? #Multi #ComputerVision #Tools #NLP #Dataset #LanguageModel #SyntheticData #x-Use #VisionLanguageModel Issue Date: 2025-08-24 [Paper Note] ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools, Shaofeng Yin+, arXiv'25 Summary本研究では、実世界のツール使用能力を向上させるために、23Kのインスタンスからなる大規模マルチモーダルデータセット「ToolVQA」を提案。ToolVQAは、実際の視覚的コンテキストと多段階推論タスクを特徴とし、ToolEngineを用いて人間のようなツール使用推論をシミュレート。7B LFMを微調整した結果、テストセットで優れたパフォーマンスを示し、GPT-3.5-turboを上回る一般化能力を持つことが確認された。 Comment人間による小規模なサンプル(イメージシナリオ、ツールセット、クエリ、回答、tool use trajectory)を用いてFoundation Modelに事前知識として与えることで、よりrealisticなscenarioが合成されるようにした上で新たなVQAを4k程度合成。その後10人のアノテータによって高品質なサンプルにのみFilteringすることで作成された、従来よりも実世界の設定に近く、reasoningの複雑さが高いVQAデータセットな模様。
具体的には、image contextxが与えられた時に、ChatGPT-4oをコントローラーとして、前回のツールとアクションの選択をgivenにし、人間が作成したプールに含まれるサンプルの中からLongest Common Subsequence (LCS) による一致度合いに基づいて人手によるサンプルを選択し、動的にcontextに含めることで多様なで実世界により近しいmulti step tooluseなtrajectoryを合成する、といった手法に見える。pp.4--5に数式や図による直感的な説明がある。なお、LCSを具体的にどのような文字列に対して、どのような前処理をした上で適用しているのかまでは追えていない。
小規模モデル、およびGSM8K、BIG Bench hardでの、Tracking Shuffled Objectのみでの実験な模様?大規模モデルやコーディングなどのドメインでもうまくいくかはよく分からない。OODの実験もAIME2025でのみの実験しているようなのでそこは留意した方が良いかも。
rewardとして何を使ったのかなどの細かい内容を追えていない。元ポスト:https://x.com/pratyushrt/status/1958947577216524352?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #VisionLanguageModel #Science Issue Date: 2025-08-23 [Paper Note] Intern-S1: A Scientific Multimodal Foundation Model, Lei Bai+, arXiv'25 SummaryIntern-S1は、科学専門分野に特化したオープンソースの専門家型モデルで、280億の活性化パラメータを持つマルチモーダルMixture-of-Experts(MoE)モデルです。5Tトークンで事前学習され、特に科学データに焦点を当てています。事後学習では、InternBootCampを通じて強化学習を行い、Mixture-of-Rewardsを提案。評価では、一般的な推論タスクで競争力を示し、科学分野の専門的なタスクでクローズドソースモデルを上回る性能を達成しました。モデルはHugging Faceで入手可能です。 Comment元ポスト:https://x.com/iscienceluvr/status/1958894938248384542?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qscientific domainに特化したデータで継続事前学習+RL Finetuningしたドメイン特化言語モデルらしい。HF:https://huggingface.co/internlm/Intern-S1
Apache 2.0ライセンス
ベースモデルはQwen3とInternViT
・InternViT:https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5
関連:
・2529解説:https://x.com/gm8xx8/status/1959222471183225033?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2025-08-23 [Paper Note] Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing, Yiqun Zhang+, arXiv'25 SummaryLLMのパフォーマンスと効率のバランスを取るために、テスト時ルーティングフレームワーク「Avengers-Pro」を提案。クエリを埋め込み、クラスタリングし、最適なモデルにルーティングすることで、6つのベンチマークで最先端の結果を達成。最強の単一モデルを平均精度で+7%上回り、コストを27%削減しつつ約90%のパフォーマンスを実現。すべての単一モデルの中で最高の精度と最低のコストを提供するパレートフロンティアを達成。コードは公開中。 Comment元ポスト:https://x.com/omarsar0/status/1958897458408563069?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qクエリをkmeansでクラスタリングし、各クラスタごとにモデルごとのperformanceとcostを事前に算出しておく。そして新たなクエリが来た時にクエリが割り当てられるtop pのクラスタのperformanae-cost efficiencyを合計し、スコアが高い一つのモデルを選択(=routing)しinferenceを実施する。クエリはQwenでembedding化してクラスタリングに活用する。ハイパーパラメータα∈[0,1]によって、performance, costどちらを重視するかのバランスを調整する。
シンプルな手法だが、GPT-5 mediumと同等のコスト/性能 でより高い 性能/コスト を実現。
・2508解説:https://x.com/gm8xx8/status/1959926238065127724?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-21 [Paper Note] FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction, Zhiyuan Zeng+, arXiv'25 Summary未来予測はLLMエージェントにとって複雑なタスクであり、情報収集や意思決定が求められる。これに対処するため、動的かつライブな評価ベンチマーク「FutureX」を導入。FutureXは、リアルタイム更新をサポートし、25のLLM/エージェントモデルを評価することで、エージェントの推論能力やパフォーマンスを分析。目標は、プロの人間アナリストと同等のパフォーマンスを持つLLMエージェントの開発を促進すること。 Comment元ポスト:https://x.com/liujiashuo77/status/1958191172020822292?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Single #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #LLMAgent #LongSequence #read-later Issue Date: 2025-08-21 [Paper Note] Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL, Weizhen Li+, arXiv'25 SummaryChain-of-Agents(CoA)という新しいLLM推論パラダイムを提案し、マルチエージェントシステムの協力を単一モデル内でエンドツーエンドに実現。マルチエージェント蒸留フレームワークを用いて、エージェント的な教師ありファインチューニングを行い、強化学習で能力を向上。得られたエージェント基盤モデル(AFMs)は、ウェブエージェントやコードエージェントの設定で新たな最先端性能を示す。研究成果はオープンソース化され、今後の研究の基盤を提供。 Comment元ポスト:https://x.com/omarsar0/status/1958186531161853995?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qマルチエージェントのように振る舞うシングルエージェントを、マルチエージェントから得られたtrajectoryを通じて蒸留することめ実現する手法を提案。SFTでcold startに対して訓練した後、verifiable reward (タスクを正常に完了できたか否か)でRLする模様。
ざっくり言うと、Overthinking(考えすぎて大量のトークンを消費した上に回答が誤っている; トークン量↓とLLMによるJudge Score↑で評価)とUnderthinking(全然考えずにトークンを消費しなかった上に回答が誤っている; Accuracy↑で評価)をそれぞれ評価するサンプルを収集し、それらのスコアの組み合わせでモデルが必要に応じてどれだけ的確にThinkingできているかを評価するベンチマーク。
Overthinkingを評価するためのサンプルは、多くのLLMでagreementがとれるシンプルなQAによって構築。一方、Underthinkingを評価するためのサンプルは、small reasoning modelがlarge non reasoning modelよりも高い性能を示すサンプルを収集。
現状Non Thinking ModelではQwen3-235B-A22Bの性能が良く、Thinking Modelではgpt-oss-120Bの性能が良い。プロプライエタリなモデルではそれぞれ、Claude-Sonnet4, o3の性能が良い。全体としてはo3の性能が最も良い。
・2412 Issue Date: 2025-08-18 [Paper Note] TRIBE: TRImodal Brain Encoder for whole-brain fMRI response prediction, Stéphane d'Ascoli+, arXiv'25 SummaryTRIBEは、複数のモダリティや皮質領域にわたる脳の反応を予測するために訓練された初の深層神経ネットワークであり、テキスト、音声、ビデオの表現を組み合わせてfMRI反応をモデル化。Algonauts 2025コンペティションで1位を獲得し、単一モダリティモデルよりも高次の連合皮質での性能が優れていることを示した。このアプローチは、人間の脳の表現の統合モデル構築に寄与する。 Comment元ポスト:https://x.com/dair_ai/status/1957100416568614946?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-18 [Paper Note] Capabilities of GPT-5 on Multimodal Medical Reasoning, Shansong Wang+, arXiv'25 SummaryGPT-5を用いて医療意思決定支援のためのマルチモーダル推論を評価。テキストと視覚情報を統合し、ゼロショットの思考連鎖推論性能を検証した結果、GPT-5は全てのベースラインを上回り、特にMedXpertQA MMで人間の専門家を超える性能を示した。これにより、将来の臨床意思決定支援システムにおける大きな進展が期待される。 Comment元ポスト:https://x.com/dair_ai/status/1957100411904475571?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-18 [Paper Note] In-Training Defenses against Emergent Misalignment in Language Models, David Kaczér+, arXiv'25 SummaryファインチューニングはLLMを新しいドメインに適用する手法ですが、最近の研究で新たな不整合(EMA)が発見されました。これは、小規模なファインチューニングでも有害な行動を引き起こす可能性があることを示しています。本研究では、APIを通じてファインチューニングを行う際のEMAに対する安全策を体系的に調査し、4つの正則化手法を提案します。これらの手法の効果を悪意のあるタスクで評価し、無害なタスクへの影響も検討します。最後に、未解決の問題について議論します。 Comment元ポスト:https://x.com/owainevans_uk/status/1957054130192794099?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-17 [Paper Note] Cyber-Zero: Training Cybersecurity Agents without Runtime, Terry Yue Zhuo+, arXiv'25 SummaryCyber-Zeroは、サイバーセキュリティLLMを訓練するための初のランタイムフリーのフレームワークであり、公開CTFの解説を活用してリアルなインタラクションシーケンスを生成。これにより、LLMベースのエージェントを訓練し、著名なCTFベンチマークで最大13.1%の性能向上を達成。最良モデルCyber-Zero-32Bは、オープンウェイトモデルの中で新たな最先端の性能を確立し、コスト効率も優れていることを示した。 Comment元ポスト:https://x.com/terryyuezhuo/status/1956979803581493575?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Transformer #TextToImageGeneration #Architecture #ICLR #read-later #NormalizingFlow Issue Date: 2025-08-17 [Paper Note] JetFormer: An Autoregressive Generative Model of Raw Images and Text, Michael Tschannen+, ICLR'25 SummaryJetFormerは、画像とテキストの共同生成を効率化する自己回帰型デコーダー専用のトランスフォーマーであり、別々にトレーニングされたコンポーネントに依存せず、両モダリティを理解・生成可能。正規化フローモデルを活用し、テキストから画像への生成品質で既存のベースラインと競合しつつ、堅牢な画像理解能力を示す。JetFormerは高忠実度の画像生成と強力な対数尤度境界を実現する初のモデルである。 Commentopenreview:https://openreview.net/forum?id=sgAp2qG86e画像をnormalizing flowでソフトトークンに変換し、transformerでソフトトークンを予測させるように学習することで、テキストと画像を同じアーキテクチャで学習できるようにしました、みたいな話っぽい?おもしろそう
・2526
・550 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention Issue Date: 2025-08-14 [Paper Note] Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning, Lijie Yang+, arXiv'25 Summary「LessIsMore」という新しいスパースアテンションメカニズムを提案。これは、トレーニング不要でグローバルアテンションパターンを活用し、トークン選択を効率化。精度を維持しつつ、デコーディング速度を1.1倍向上させ、トークン数を2倍削減。既存手法と比較して1.13倍のスピードアップを実現。 Comment元ポスト:https://x.com/lijieyyang/status/1955139186530328633?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qトレーニングフリーで1.1倍のデコーディング速度で性能もFull Attentionと同等以上のSparse Attentionらしい #Multi #Analysis #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-08-14 [Paper Note] The Policy Cliff: A Theoretical Analysis of Reward-Policy Maps in Large Language Models, Xingcheng Xu, arXiv'25 Summary強化学習(RL)は大規模言語モデルの行動形成に重要だが、脆弱なポリシーを生成し、信頼性を損なう問題がある。本論文では、報酬関数から最適ポリシーへのマッピングの安定性を分析する数学的枠組みを提案し、ポリシーの脆弱性が非一意的な最適アクションに起因することを示す。さらに、多報酬RLにおける安定性が「効果的報酬」によって支配されることを明らかにし、エントロピー正則化が安定性を回復することを証明する。この研究は、ポリシー安定性分析を進展させ、安全で信頼性の高いAIシステム設計に寄与する。 Comment元ポスト:https://x.com/jiqizhixin/status/1955909877404197072?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qとても面白そう #EfficiencyImprovement #NLP #Search #LanguageModel #ReinforcementLearning #LLMAgent Issue Date: 2025-08-14 [Paper Note] Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL, Jiaxuan Gao+, arXiv'25 SummaryASearcherは、LLMベースの検索エージェントの大規模なRLトレーニングを実現するオープンソースプロジェクトであり、高効率な非同期RLトレーニングと自律的に合成された高品質なQ&Aデータセットを用いて、検索能力を向上させる。提案されたエージェントは、xBenchで46.7%、GAIAで20.8%の改善を達成し、長期的な検索能力を示した。モデルとデータはオープンソースで提供される。 Comment元ポスト:https://x.com/huggingpapers/status/1955603041518035358?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/jxwuyi/status/1955487396344238486?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト: https://x.com/omarsar0/status/1955266026498855354?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連ベンチマーク:
・2466
・1158
・1461既存のモデルは <= 10 turnsのデータで学習されており、大規模で高品質なQAデータが不足している問題があったが、シードQAに基づいてQAを合成する手法によって1.4万シードQAから134kの高品質なQAを合成した(うち25.6kはツール利用が必要)。具体的には、シードのQAを合成しエージェントがQAの複雑度をiterationをしながら向上させていく手法を提案。事実情報は常にverificationをされ、合成プロセスのiterationの中で保持され続ける。個々のiterationにおいて、現在のQAと事実情報に基づいて、エージェントは
・Injection: 事実情報を新たに注入しQAをよりリッチにすることで複雑度を上げる
・Fuzz: QA中の一部の詳細な情報をぼかすことで、不確実性のレベルを向上させる。
の2種類の操作を実施する。その上で、QAに対してQuality verificationを実施する:
・Basic Quality: LLMでqualityを評価する
・Difficulty Measurement: LRMによって、複数の回答候補を生成する
・Answer Uniqueness: Difficulty Measurementで生成された複数の解答情報に基づいて、mismatched answersがvalid answerとなるか否かを検証し、正解が単一であることを担保する
また、複雑なタスク、特にtool callsが非常に多いタスクについては、多くのターン数(long trajectories)が必要となるが、既存のバッチに基づいた学習手法ではlong trajectoriesのロールアウトをしている間、他のサンプルの学習がブロックされてしまい学習効率が非常に悪いので、バッチ内のtrajectoryのロールアウトとモデルの更新を分離(ロールアウトのリクエストが別サーバに送信されサーバ上のInference Engineで非同期に実行され、モデルをアップデートする側は十分なtrajectoryがバッチ内で揃ったらパラメータを更新する、みたいな挙動?)することでIdleタイムを無くすような手法を提案した模様。
gpt-ossはコードにバグのあるコードに対して上記のような反例を生成する能力が高いようである。ただし、それでも全体のバグのあるコードのうち反例を生成できたのは高々21.6%のようである。ただ、もしコードだけでなくverification全般の能力が高いから、相当使い道がありそう。 #Analysis #NLP #LanguageModel #MoE(Mixture-of-Experts) Issue Date: 2025-08-13 [Paper Note] Unveiling Super Experts in Mixture-of-Experts Large Language Models, Zunhai Su+, arXiv'25 Summaryスパースに活性化されたMixture-of-Experts(MoE)モデルにおいて、特定の専門家のサブセット「スーパ専門家(SE)」がモデルの性能に重要な影響を与えることを発見。SEは稀な活性化を示し、プルーニングするとモデルの出力が劣化する。分析により、SEの重要性が数学的推論などのタスクで明らかになり、MoE LLMがSEに依存していることが確認された。 Comment元ポスト:https://x.com/jiqizhixin/status/1955217132016505239?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMoEにおける、特に重要な専門家であるSuper Expertsの存在・1566
を思い出す。 #NLP #Dataset #LanguageModel #LLMAgent #Evaluation #MCP Issue Date: 2025-08-13 [Paper Note] LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools?, Guozhao Mo+, arXiv'25 SummaryLiveMCPBenchは、10,000を超えるMCPサーバーに基づく95の実世界タスクから成る初の包括的なベンチマークで、LLMエージェントの大規模評価を目的としています。70のMCPサーバーと527のツールを含むLiveMCPToolを整備し、LLM-as-a-JudgeフレームワークであるLiveMCPEvalを導入して自動化された適応評価を実現しました。MCP Copilot Agentは、ツールを動的に計画し実行するマルチステップエージェントです。評価の結果、最も優れたモデルは78.95%の成功率を達成しましたが、モデル間で性能のばらつきが見られました。全体として、LiveMCPBenchはLLMエージェントの能力を評価するための新たなフレームワークを提供します。 Commentpj page:https://icip-cas.github.io/LiveMCPBench/元ポスト:https://x.com/huggingpapers/status/1955324566298833127?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMCP環境におけるLLM Agentのベンチマーク。論文中のTable1に他のベンチマークを含めサマリが掲載されている。MCPを用いたLLMAgentのベンチがすでにこんなにあることに驚いた…。
VQAデータセット中の日本語データは3.1%程度で、<image, Question, answer>の3つ組で構成される。wikidataから特定の文化と紐づいたエンティティ(42カ国; 人,場所,組織,アーティファクトにフォーカス)を抽出し、関連するimage dataを1--3個程度wikimediaから収集。76種類のテンプレートを用いて、draftのQAを生成し、LLMを用いて洗練(文化的な自然さ、流暢さ)させる。最終的にVLM(Qwen2.5-VL-32B/72B or Gemma-3-12B/72B-Instructを文化ごとに強い方を選択して利用)を用いてirrelevantなimage, question, answerの三つ組をフィルタリング(relevanceのスコアリングと事実情報のverification)する。
ベースモデルとして
・2470
を利用(Qwen2-7Bに対してCLIPベースのvision encoderを利用したVLM)し、Vision Encoderはfrozenし、LLMとconnector(テキストと画像のモダリティの橋渡しをする(大抵は)MLP)のみをfinetuningした。catastrophic forgettingを防ぐために事前学習データの一部を補完しfinetuningでも利用し、エンティティの認識力を高めるためにM3LSデータなるものをフィルタリングして追加している。
Finetuningの結果、文化的な多様性を持つ評価データ(e.g., 2471 Figure1のJapaneseのサンプルを見ると一目でどのようなベンチか分かる)と一般的なマルチリンガルな評価データの双方でgainがあることを確認。
VQAによるフィルタリングで利用されたpromptは下記
・2456 #ComputerVision #NLP #MulltiModal #SpeechProcessing #Reasoning #OpenWeight #VisionLanguageActionModel Issue Date: 2025-08-12 [Paper Note] MolmoAct: Action Reasoning Models that can Reason in Space, Jason Lee+, arXiv'25 Summaryアクション推論モデル(ARMs)であるMolmoActは、知覚、計画、制御を三段階のパイプラインで統合し、説明可能で操作可能な行動を実現。シミュレーションと実世界で高いパフォーマンスを示し、特にSimplerEnv Visual Matchingタスクで70.5%のゼロショット精度を達成。MolmoAct Datasetを公開し、トレーニングによりベースモデルのパフォーマンスを平均5.5%向上。全てのモデルの重みやデータセットを公開し、ARMsの構築に向けたオープンな設計図を提供。 Comment`Action Reasoning Models (ARMs)`
元ポスト:https://x.com/gm8xx8/status/1955168414294589844?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
blog: https://allenai.org/blog/molmoact関連:
・1426models:
・https://huggingface.co/allenai/MolmoAct-7B-D-Pretrain-0812
・https://huggingface.co/allenai/MolmoAct-7B-D-0812
datasets:
・https://huggingface.co/datasets/allenai/MolmoAct-Dataset
・https://huggingface.co/datasets/allenai/MolmoAct-Pretraining-Mixture
・https://huggingface.co/datasets/allenai/MolmoAct-Midtraining-Mixtureデータは公開されているが、コードが見当たらない? #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #read-later Issue Date: 2025-08-12 [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25 Summary355Bパラメータを持つオープンソースのMixture-of-ExpertsモデルGLM-4.5を発表。ハイブリッド推論手法を採用し、エージェント的、推論、コーディングタスクで高いパフォーマンスを達成。競合モデルに比べて少ないパラメータ数で上位にランクイン。GLM-4.5とそのコンパクト版GLM-4.5-Airをリリースし、詳細はGitHubで公開。 Comment元ポスト:https://x.com/grad62304977/status/1954805614011453706?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・アーキテクチャ
・MoE / sigmoid gates
・1719
・1754
・loss free balanced routing
・2442
・widthを小さく、depthを増やすことでreasoning能力改善
・GQA w/ partial RoPE
・1271
・1310
・Attention Headsの数を2.5倍(何に対して2.5倍なんだ、、?)(96個, 5120次元)にすることで(おそらく)事前学習のlossは改善しなかったがReasoning benchmarkの性能改善
・QK Normを導入しattentionのlogitsの値域を改善
・2443
・Multi Token Prediction
・2444
・1620
他モデルとの比較
学習部分は後で追記する・事前学習データ
・web
・英語と中国語のwebページを利用
・1944 と同様にquality scoreyをドキュメントに付与
・最も低いquality scoreの文書群を排除し、quality scoreの高い文書群をup sampling
・最もquality scoreyが大きい文書群は3.2 epoch分利用
・多くのweb pageがテンプレートから自動生成されており高いquality scoreが付与されていたが、MinHashによってdeduplicationできなかったため、 2445 を用いてdocument embeddingに基づいて類似した文書群を排除
・Multilingual
・独自にクロールしたデータとFineWeb-2 2109 から多言語の文書群を抽出し、quality classifierを適用することでeducational utilityを定量化し、高いスコアの文書群をupsamplingして利用
・code
・githubなどのソースコードhosting platformから収集
・ソースコードはルールベースのフィルタリングをかけ、その後言語ごとのquality modelsによって、high,middle, lowの3つに品質を分類
・high qualityなものはupsamplingし、low qualityなものは除外
・2446 で提案されているFill in the Middle objectiveをコードの事前学習では適用
・コードに関連するweb文書も事前学習で収集したテキスト群からルールベースとfasttextによる分類器で抽出し、ソースコードと同様のqualityの分類とサンプリング手法を適用。最終的にフィルタリングされた文書群はre-parseしてフォーマットと内容の品質を向上させた
・math & science
・web page, 本, 論文から、reasoning能力を向上させるために、数学と科学に関する文書を収集
・LLMを用いて文書中のeducational contentの比率に基づいて文書をスコアリングしスコアを予測するsmall-scaleな分類器を学習
・最終的に事前学習コーパスの中の閾値以上のスコアを持つ文書をupsampling
・事前学習は2 stageに分かれており、最初のステージでは、"大部分は"generalな文書で学習する。次のステージでは、ソースコード、数学、科学、コーディング関連の文書をupsamplingして学習する。
上記以上の細かい実装上の情報は記載されていない。
mid-training / post trainingについても後ほど追記する #EfficiencyImprovement #NLP #LanguageModel #Alignment #DPO #PostTraining Issue Date: 2025-08-12 [Paper Note] Difficulty-Based Preference Data Selection by DPO Implicit Reward Gap, Xuan Qi+, arXiv'25 SummaryLLMの好みを人間に合わせるための新しいデータ選択戦略を提案。DPOの暗黙的報酬ギャップが小さいデータを選ぶことで、データ効率とモデルの整合性を向上。元のデータの10%で5つのベースラインを上回るパフォーマンスを達成。限られたリソースでのLLM整合性向上に寄与。 Comment元ポスト:https://x.com/zhijingjin/status/1954535751489667173?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpreference pair dataを学習効率の良いサンプルのみに圧縮することで学習効率を上げたい系の話で、chosen, rejectedなサンプルのそれぞれについて、¥frac{現在のポリシーの尤度}{参照ポリシーの尤度}によってreward rを定義し(おそらく参照ポリシーの尤度によってサンプルの重要度を重みづけしている)、r_chosenとr_rejectedの差をreward gapと定義し、gapが大きいものは難易度が低いと判断してフィルタリングする、といった話に見える。
メモリはT個のタスクに対するs_t, a_t, o_t, i.e., state, action, observation,の系列τと、reward rが与えられた時に、Builderを通して構築されてストアされる。agentは新たなタスクt_newに直面した時に、t_newと類似したメモリをretrieyeする。これはτの中のある時刻tのタスクに対応する。メモリは肥大化していくため、実験では複数のアルゴリズムに基づくメモリの更新方法について実験している。
procedural memoryの有無による挙動の違いに関するサンプル。
https://x.com/huggingpapers/status/1954937801490772104?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LLMAgent #Evaluation #SoftwareEngineering Issue Date: 2025-08-12 [Paper Note] NoCode-bench: A Benchmark for Evaluating Natural Language-Driven Feature Addition, Le Deng+, arXiv'25 Summary自然言語駆動のノーコード開発におけるLLMsの評価のために「NoCode-bench」を提案。634のタスクと114,000のコード変更から成り、ドキュメントとコード実装のペアを検証。実験結果では、最良のLLMsがタスク成功率15.79%に留まり、完全なNL駆動のノーコード開発には未だ課題があることが示された。NoCode-benchは今後の進展の基盤となる。 Comment元ポスト:https://x.com/jiqizhixin/status/1955062236831158763?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qリーダーボード:https://nocodebench.orgドキュメントをソフトウェアの仕様書とみなし、ドキュメントの更新部分をらinputとし、対応する"機能追加"をする能力を測るベンチマーク
SoTAモデルでも15.79%程度しか成功しない。
元ポストによると、ファイルを跨いだ編集、コードベースの理解、tool useに苦労しているとのこと。 #Analysis #NLP #LanguageModel #ICLR #ReversalCurse Issue Date: 2025-08-11 [Paper Note] Physics of Language Models: Part 3.2, Knowledge Manipulation, Zeyuan Allen-Zhu+, ICLR'25 Summary言語モデルは豊富な知識を持つが、下流タスクへの柔軟な利用には限界がある。本研究では、情報検索、分類、比較、逆検索の4つの知識操作タスクを調査し、言語モデルが知識検索には優れているが、Chain of Thoughtsを用いないと分類や比較タスクで苦労することを示した。特に逆検索ではパフォーマンスがほぼ0%であり、これらの弱点は言語モデルに固有であることを確認した。これにより、現代のAIと人間を区別する新たなチューリングテストの必要性が浮き彫りになった。 Commentopenreview:https://openreview.net/forum?id=oDbiL9CLoS解説:
・1834 #Analysis #NLP #LanguageModel #SelfCorrection #ICLR Issue Date: 2025-08-11 [Paper Note] Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems, Tian Ye+, ICLR'25 Summary言語モデルの推論精度向上のために、「エラー修正」データを事前学習に組み込む有用性を探求。合成数学データセットを用いて、エラーフリーデータと比較して高い推論精度を達成することを示す。さらに、ビームサーチとの違いやデータ準備、マスキングの必要性、エラー量、ファインチューニング段階での遅延についても考察。 Commentopenreview:https://openreview.net/forum?id=zpDGwcmMV4解説:
・1834 #Analysis #NLP #LanguageModel #ICLR Issue Date: 2025-08-11 [Paper Note] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process, Tian Ye+, ICLR'25 Summary言語モデルの数学的推論能力を研究し、GSM8Kベンチマークでの精度向上のメカニズムを探る。具体的には、推論スキルの発展、隠れたプロセス、人間との違い、必要なスキルの超越、推論ミスの原因、モデルのサイズや深さについての実験を行い、LLMの理解を深める洞察を提供。 Commentopenreview:https://openreview.net/forum?id=Tn5B6Udq3E解説:
・1834 #EfficiencyImprovement #NLP #Transformer #Attention #Architecture Issue Date: 2025-08-11 [Paper Note] Fast and Simplex: 2-Simplicial Attention in Triton, Aurko Roy+, arXiv'25 Summary2-シンプリシアルトランスフォーマーを用いることで、トークン効率を向上させ、標準的なトランスフォーマーよりも優れた性能を発揮することを示す。固定されたトークン予算内で、数学や推論タスクにおいてドット積アテンションを上回る結果を得た。 Comment元ポスト:https://x.com/scaling01/status/1954682957798715669?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #Evaluation #Programming #Reasoning Issue Date: 2025-08-10 [Paper Note] STEPWISE-CODEX-Bench: Evaluating Complex Multi-Function Comprehension and Fine-Grained Execution Reasoning, Kaiwen Yan+, arXiv'25 Summary新しいベンチマーク「STEPWISE-CODEX-Bench(SX-Bench)」を提案し、複雑な多機能理解と細かい実行推論を評価。SX-Benchは、サブ関数間の協力を含むタスクを特徴とし、動的実行の深い理解を測定する。20以上のモデルで評価した結果、最先端モデルでも複雑な推論においてボトルネックが明らかに。SX-Benchはコード評価を進展させ、高度なコードインテリジェンスモデルの評価に貢献する。 Comment元ポスト:https://x.com/gm8xx8/status/1954296753525752266?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q現在の主流なコード生成のベンチは、input/outputがgivenなら上でコードスニペットを生成する形式が主流(e.g., MBPP 2439, HumanEval 2438)だが、モデルがコードを理解し、複雑なコードのロジックを実行する内部状態の変化に応じて、実行のプロセスを推論する能力が見落とされている。これを解決するために、CRUXEVAL 2440, CRUXEVAL-X 2441 では、関数のinputs/outputsを予測することで、モデルのコードのcomprehension, reasoning能力を測ろうとしているが、
・single functionのlogicに限定されている
・20 line程度の短く、trivialなロジックに限定されている
・すでにSoTAモデルで95%が達成され飽和している
というlimitationがあるので、複数の関数が協働するロジック、flow/dataのinteractionのフロー制御、細かい実行ステップなどを含む、staticなコードの理解から、動的な実行プロセスのモデリング能力の評価にシフトするような、新たなベンチマークを作成しました、という話な模様。
まず関数単位のライブラリを構築している。このために、単一の関数の基礎的な仕様を「同じinputに対して同じoutputを返すものは同じクラスにマッピングされる」と定義し、既存のコードリポジトリとLLMによる合成によって、GoとPythonについて合計30種類のクラスと361個のインスタンスを収集。これらの関数は、算術演算や大小比較、パリティチェックなどの判定、文字列の操作などを含む。そしてこれら関数を3種類の実行パターンでオーケストレーションすることで、合成関数を作成した。合成方法は
・Sequential: outputとinputをパイプラインでつなぎ伝搬させる
・Selective: 条件に応じてf(x)が実行されるか、g(x)が実行されるかを制御
・Loop: input集合に対するloopの中に関数を埋め込み順次関数を実行
の3種類。合成関数の挙動を評価するために、ランダムなテストケースは自動生成し、合成関数の挙動をモニタリング(オーバーフロー、無限ループ、タイムアウト、複数回の実行でoutputが決定的か等など)し、異常があるものはフィルタリングすることで合成関数の品質を担保する。
ベンチマーキングの方法としては、CRUXEVALではシンプルにモデルにコードの実行結果を予想させるだけであったが、指示追従能力の問題からミスジャッジをすることがあるため、この問題に対処するため<input, output>のペアが与えられた時に、outputが合成関数に対してinputしま結果とマッチするかをyes/noのbinaryで判定させる(Predictと呼ばれるモデルのコード理解力を評価)。これとは別に、与えられたinput, outputペアと合成関数に基づいて、実行時の合計のcomputation stepsを出力させるタスクをreasoningタスクとして定義し、複雑度に応じてeasy, hardに分類している。computation stepsは、プログラムを実行する最小単位のことであり、たとえば算術演算などの基礎的なarithmetic/logic operationを指す。
以下がverifierのサンプル
Challenger
・ (Challengerによる)問題生成→
・(freezed solverによる)self consistencyによるラベル付け→
・Solverの問題に対するempirical acc.(i.e., サンプリング回数mに対するmajorityが占める割合)でrewardを与えChallengerを更新
といった流れでポリシーが更新される。Rewardは他にも生成された問題間のBLEUを測り類似したものばかりの場合はペナルティを与える項や、フォーマットが正しく指定された通りになっているか、といったペナルティも導入する。
Solver
・ChallengerのポリシーからN問生成し、それに対してSolverでself consistencyによって解答を生成
・empirical acc.を計算し、1/2との差分の絶対値を見て、簡単すぎる/難しすぎる問題をフィルタリング
・これはカリキュラム学習的な意味合いのみならず、低品質な問題のフィルタリングにも寄与する
・フィルタリング後の問題を利用して、verifiable binary rewardでポリシーを更新
評価結果
数学ドメインに提案手法を適用したところ、iterごとに全体の平均性能は向上。
提案手法で数学ドメインを学習し、generalドメインに汎化するか?を確認したところ、汎化することを確認(ただ、すぐにサチっているようにも見える)。、
・2383
・1936著者ポスト:
・https://x.com/wyu_nd/status/1954249813861810312?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/chengsongh31219/status/1953936172415430695?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q日本語解説:
https://x.com/curveweb/status/1954367657811308858?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-08-09 [Paper Note] Sotopia-RL: Reward Design for Social Intelligence, Haofei Yu+, arXiv'25 Summary社会的知性を持つエージェントの訓練に向けて、Sotopia-RLという新しいフレームワークを提案。部分的観測性と多次元性の課題に対処し、エピソードレベルのフィードバックを発話レベルの多次元報酬に洗練。実験では、Sotopia環境で最先端の社会的目標達成スコアを達成し、既存の手法を上回る結果を示した。 Comment元ポスト:https://x.com/youjiaxuan/status/1953826129401262304?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ReinforcementLearning #SelfImprovement #ZeroData Issue Date: 2025-08-09 [Paper Note] Self-Questioning Language Models, Lili Chen+, arXiv'25 Summary自己質問型言語モデル(SQLM)を提案し、トピックを指定するプロンプトから自ら質問を生成し、解答する非対称の自己対戦フレームワークを構築。提案者と解答者は強化学習で訓練され、問題の難易度に応じて報酬を受け取る。三桁の掛け算や代数問題、プログラミング問題のベンチマークで、外部データなしで言語モデルの推論能力を向上させることができることを示す。 Commentpj page:https://self-questioning.github.io元ポスト:https://x.com/lchen915/status/1953896909925757123?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qたとえば下記のような、ラベル無しの外部データを利用する手法も用いてself improvingする手法と比較したときに、どの程度の性能差になるのだろうか?外部データを全く利用せず、外部データありの手法と同等までいけます、という話になると、より興味深いと感じた。
・1212既存の外部データを活用しない関連研究:
・1936 #NLP #LanguageModel #Supervised-FineTuning (SFT) #read-later #Admin'sPick Issue Date: 2025-08-09 [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, arXiv'25 Summary大規模言語モデル(LLM)の教師ありファインチューニング(SFT)の一般化能力を向上させるため、動的ファインチューニング(DFT)を提案。DFTはトークンの確率に基づいて目的関数を再スケーリングし、勾配更新を安定化させる。これにより、SFTを大幅に上回る性能を示し、オフライン強化学習でも競争力のある結果を得た。理論的洞察と実践的解決策を結びつけ、SFTの性能を向上させる。コードは公開されている。 Comment元ポスト:https://x.com/theturingpost/status/1953960036126142645?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは大変興味深い。数学以外のドメインでの評価にも期待したい。3節冒頭から3.2節にかけて、SFTとon policy RLのgradientを定式化し、SFT側の数式を整理することで、SFT(のgradient)は以下のようなon policy RLの一つのケースとみなせることを導出している。そしてSFTの汎化性能が低いのは 1/pi_theta によるimportance weightingであると主張し、実験的にそれを証明している。つまり、ポリシーがexpertのgold responseに対して低い尤度を示してしまった場合に、weightか過剰に大きくなり、Rewardの分散が過度に大きくなってしまうことがRLの観点を通してみると問題であり、これを是正することが必要。さらに、分散が大きい報酬の状態で、報酬がsparse(i.e., expertのtrajectoryのexact matchしていないと報酬がzero)であることが、さらに事態を悪化させている。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
・1746
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。日本語解説:https://x.com/hillbig/status/1960108668336390593?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
一歩先の視点が考察されており、とても勉強になる。 #Survey #NLP #LanguageModel #Hallucination Issue Date: 2025-08-08 [Paper Note] A comprehensive taxonomy of hallucinations in Large Language Models, Manuel Cossio, arXiv'25 SummaryLLMのハルシネーションに関する包括的な分類法を提供し、その本質的な避けられなさを提唱。内因的および外因的な要因、事実誤認や不整合などの具体的な現れを分析。根本的な原因や認知的要因を検討し、評価基準や軽減戦略を概説。今後は、信頼性のある展開のために検出と監視に焦点を当てる必要があることを強調。 Comment元ポスト:https://x.com/sei_shinagawa/status/1953845008588513762?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ReinforcementLearning #Factuality #RewardHacking #PostTraining #GRPO #On-Policy Issue Date: 2025-08-08 [Paper Note] Learning to Reason for Factuality, Xilun Chen+, arXiv'25 SummaryR-LLMsは複雑な推論タスクで進展しているが、事実性において幻覚を多く生成する。オンラインRLを長文の事実性設定に適用する際、信頼できる検証方法が不足しているため課題がある。従来の自動評価フレームワークを用いたオフラインRLでは報酬ハッキングが発生することが判明。そこで、事実の精度、詳細レベル、関連性を考慮した新しい報酬関数を提案し、オンラインRLを適用。評価の結果、幻覚率を平均23.1ポイント削減し、回答の詳細レベルを23%向上させた。 Comment元ポスト:https://x.com/jaseweston/status/1953629692772446481?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q先行研究:
・2378Reasoning ModelのHallucination Rateは、そのベースとなるモデルよりも高い。実際、DeepSeek-V3とDeepSeek-R1,Qwen-2.5-32BとQwQ-32Bを6つのFactualityに関するベンチマークで比較すると、Reasoning Modelの方がHallucination Rateが10, 13%程度高かった。これは、現在のOn-policyのRLがlogical reasoningにフォーカスしており、Factualityを見落としているため、と仮説を立てている。
Factuality(特にLongForm)とRL alignmentsという観点から言うと、決定的、正確かつ信頼性のあるverificatlon手法は存在せず、Human Effortが必要不可欠である。
自動的にFactualityを測定するFactScoreのような手法は、DPOのようなオフラインのペアワイズのデータを作成するに留まってしまっている。また、on dataでFactualityを改善する取り組みは行われているが、long-formな応答に対して、factual reasoningを実施するにはいくつかの課題が残されている:
・reward design
・Factualityに関するrewardを単独で追加するだけだと、LLMは非常に短く、詳細を省略した応答をしPrecicionのみを高めようとしてしまう。
あとで追記する Issue Date: 2025-08-06 [Paper Note] CTR-Sink: Attention Sink for Language Models in Click-Through Rate Prediction, Zixuan Li+, arXiv'25 SummaryCTR予測において、ユーザーの行動シーケンスをテキストとしてモデル化し、言語モデル(LM)を活用する新しいフレームワーク「CTR-Sink」を提案。行動間の関係を強化するためにシンクトークンを挿入し、注意の焦点を動的に調整。二段階のトレーニング戦略を用いてLMの注意をシンクトークンに誘導し、実験により手法の有効性を確認。 Comment元ポスト:https://x.com/_reachsumit/status/1952926081058783632?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2025-08-05 [Paper Note] On the Expressiveness of Softmax Attention: A Recurrent Neural Network Perspective, Gabriel Mongaras+, arXiv'25 Summary本研究では、ソフトマックスアテンションの再帰的な形式を導出し、線形アテンションがその近似であることを示す。これにより、ソフトマックスアテンションの各部分をRNNの言語で説明し、構成要素の重要性と相互作用を理解する。これにより、ソフトマックスアテンションが他の手法よりも表現力が高い理由を明らかにする。 Comment元ポスト:https://x.com/hillbig/status/1952485214162407644?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLinearAttention関連の研究は下記あたりがありそう?
・2353
・2354
・2355
・2356・1271
たとえばGQAはQwen3で利用されているが、本研究の知見を活用してscaled-dot product attention計算時のSoftmax計算の計算量が削減できたら、さらに計算量が削減できそう? #MachineLearning #NLP #LanguageModel Issue Date: 2025-08-04 [Paper Note] MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement, Jaehyun Nam+, arXiv'25 SummaryMLE-STARは、LLMを用いてMLモデルを自動実装する新しいアプローチで、ウェブから効果的なモデルを取得し、特定のMLコンポーネントに焦点を当てた戦略を探索することで、コード生成の精度を向上させる。実験結果では、MLE-STARがKaggleコンペティションの64%でメダルを獲得し、他の手法を大きく上回る性能を示した。 Comment元ポスト:https://x.com/marktechpost/status/1951846630266687927?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ACL #read-later Issue Date: 2025-08-03 [Paper Note] Language Models Resist Alignment: Evidence From Data Compression, Jiaming Ji+, ACL'25 Summary本研究では、大規模言語モデル(LLMs)の整合性ファインチューニングが、意図しない行動を示す原因となる「elasticity」を理論的および実証的に探求。整合後のモデルは、事前学習時の行動分布に戻る傾向があり、ファインチューニングが整合性を損なう可能性が示された。実験により、モデルのパフォーマンスが急速に低下し、その後事前学習分布に戻ることが確認され、モデルサイズやデータの拡張とelasticityの相関も明らかに。これにより、LLMsのelasticityに対処する必要性が強調された。 #ACL #read-later Issue Date: 2025-08-03 [Paper Note] A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive, Sarath Sivaprasad+, ACL'25 SummaryLLMのサンプリング行動を調査し、ヒューリスティクスが人間の意思決定に類似していることを示す。サンプルは統計的規範から処方的要素に逸脱し、公衆衛生や経済動向において一貫して現れる。LLMの概念プロトタイプが処方的規範の影響を受け、人間の正常性の概念に類似。ケーススタディを通じて、LLMの出力が理想的な値にシフトし、偏った意思決定を引き起こす可能性があることを示し、倫理的懸念を提起。 #ACL #read-later Issue Date: 2025-08-03 [Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Summary本研究では、LLMのテスト時の計算スケーリングにおけるプロンプト戦略の効果を調査。6つのLLMと8つのプロンプト戦略を用いた実験により、複雑なプロンプト戦略が単純なChain-of-Thoughtに劣ることを示し、理論的な証明を提供。さらに、スケーリング性能を予測し最適なプロンプト戦略を特定する手法を提案し、リソース集約的な推論プロセスの必要性を排除。複雑なプロンプトの再評価と単純なプロンプト戦略の潜在能力を引き出すことで、テスト時のスケーリング性能向上に寄与することを目指す。 #ACL #read-later Issue Date: 2025-08-03 [Paper Note] Mapping 1,000+ Language Models via the Log-Likelihood Vector, Momose Oyama+, ACL'25 Summary自動回帰型言語モデルの比較に対し、対数尤度ベクトルを特徴量として使用する新しいアプローチを提案。これにより、テキスト生成確率のクルバック・ライブラー発散を近似し、スケーラブルで計算コストが線形に増加する特徴を持つ。1,000以上のモデルに適用し、「モデルマップ」を構築することで、大規模モデル分析に新たな視点を提供。 CommentNLPコロキウムでのスライド:https://speakerdeck.com/shimosan/yan-yu-moderunodi-tu-que-lu-fen-bu-to-qing-bao-ji-he-niyorulei-si-xing-noke-shi-hua
元ポスト:https://x.com/hshimodaira/status/1960573414575333556?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #read-later #ICCV Issue Date: 2025-08-03 [Paper Note] BUFFER-X: Towards Zero-Shot Point Cloud Registration in Diverse Scenes, Minkyun Seo+, ICCV'25 SummaryBUFFER-Xというゼロショット登録パイプラインを提案し、環境特有のボクセルサイズや探索半径への依存、ドメイン外ロバスト性の低さ、スケール不一致の問題に対処。マルチスケールのパッチベースの記述子生成と階層的インライア検索を用いて、さまざまなシーンでのロバスト性を向上。新しい一般化ベンチマークを用いて、BUFFER-Xが手動調整なしで大幅な一般化を達成することを示した。 Comment元ポスト:https://x.com/rsasaki0109/status/1951478059002966159?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこの辺の分野ぱっと見で全然わからない… #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #On-Policy #CrossDomain Issue Date: 2025-08-03 [Paper Note] SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM, Xiaojiang Zhang+, arXiv'25 Summary二段階履歴再サンプリングポリシー最適化(SRPO)を提案し、DeepSeek-R1-Zero-32Bを上回る性能をAIME24およびLiveCodeBenchで達成。SRPOはトレーニングステップを約1/10に削減し、効率性を示す。二つの革新として、クロスドメイントレーニングパラダイムと履歴再サンプリング技術を導入し、LLMの推論能力を拡張するための実験を行った。 Comment元ポスト:https://x.com/jiqizhixin/status/1914920300359377232?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGRPOよりもより効率的な手法な模様。最初に数学のデータで学習をしReasoning Capabilityを身につけさせ、その後別のドメインのデータで学習させることで、その能力を発揮させるような二段階の手法らしい。
Datamixingよりも高い性能(ただし、これは数学とコーディングのCoT Lengthのドメイン間の違いに起因してこのような2 stageな手法にしているようなのでその点には注意が必要そう)?しっかりと読めていないので、読み違いの可能性もあるので注意。
チェックポイントさえ保存しておいて事後的に活用することだで、細かなハイパラ調整のための試行錯誤する手間と膨大な計算コストがなくなるのであれば相当素晴らしいのでは…? Issue Date: 2025-08-02 [Paper Note] AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders, Zhengxuan Wu+, arXiv'25 Summary言語モデルの出力制御は安全性と信頼性に重要であり、プロンプトやファインチューニングが一般的に用いられるが、さまざまな表現ベースの技術も提案されている。これらの手法を比較するためのベンチマークAxBenchを導入し、Gemma-2-2Bおよび9Bに関する実験を行った。結果、プロンプトが最も効果的で、次いでファインチューニングが続いた。概念検出では表現ベースの手法が優れており、SAEは競争力がなかった。新たに提案した弱教師あり表現手法ReFT-r1は、競争力を持ちながら解釈可能性を提供する。AxBenchとともに、ReFT-r1およびDiffMeanのための特徴辞書を公開した。 #NLP #LanguageModel #InstructionTuning #SyntheticData #Reasoning Issue Date: 2025-08-02 [Paper Note] CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks, Ping Yu+, arXiv'25 SummaryCoT-Self-Instructを提案し、LLMに基づいて新しい合成プロンプトを生成する手法を開発。合成データはMATH500やAMC23などで既存データセットを超える性能を示し、検証不可能なタスクでも人間や標準プロンプトを上回る結果を得た。 Comment元ポスト:https://x.com/jaseweston/status/1951084679286722793?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qより複雑で、Reasoningやplanningを促すようなinstructionが生成される模様。実際に生成されたinstructionのexampleは全体をざっとみた感じこの図中のもののみのように見える。
・2094
・2330 Issue Date: 2025-07-31 [Paper Note] AnimalClue: Recognizing Animals by their Traces, Risa Shinoda+, arXiv'25 Summary野生動物の観察において、間接的な証拠から種を特定するための大規模データセット「AnimalClue」を紹介。159,605のバウンディングボックスを含み、968種をカバー。足跡や糞などの微妙な特徴を認識する必要があり、分類や検出に新たな課題を提供。実験を通じて、動物の痕跡からの同定における主要な課題を特定。データセットとコードは公開中。 Comment元ポスト:https://x.com/hirokatukataoka/status/1950798299176357891?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #EfficiencyImprovement #NLP #LanguageModel #Attention Issue Date: 2025-07-31 [Paper Note] Efficient Attention Mechanisms for Large Language Models: A Survey, Yutao Sun+, arXiv'25 SummaryTransformerアーキテクチャの自己注意の複雑さが長文コンテキストモデリングの障害となっている。これに対処するため、線形注意手法とスパース注意技術が導入され、計算効率を向上させつつコンテキストのカバレッジを保持する。本研究は、これらの進展を体系的にまとめ、効率的な注意を大規模言語モデルに組み込む方法を分析し、理論と実践を統合したスケーラブルなモデル設計の基礎を提供することを目指す。 Comment元ポスト:https://x.com/omarsar0/status/1950287053046022286?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・1375
・1563 #NLP #LanguageModel #AES(AutomatedEssayScoring) #Prompting #AIED Issue Date: 2025-07-29 [Paper Note] Do We Need a Detailed Rubric for Automated Essay Scoring using Large Language Models?, Lui Yoshida, AIED'25 Summary本研究では、LLMを用いた自動エッセイ採点におけるルーブリックの詳細さが採点精度に与える影響を調査。TOEFL11データセットを用いて、完全なルーブリック、簡略化されたルーブリック、ルーブリックなしの3条件を比較。結果、3つのモデルは簡略化されたルーブリックでも精度を維持し、トークン使用量を削減。一方、1つのモデルは詳細なルーブリックで性能が低下。簡略化されたルーブリックが多くのLLMにとって効率的な代替手段であることが示唆されるが、モデルごとの評価も重要。 #Multi #NLP #LLMAgent #Prompting Issue Date: 2025-07-29 [Paper Note] EduThink4AI: Translating Educational Critical Thinking into Multi-Agent LLM Systems, Xinmeng Hou+, arXiv'25 SummaryEDU-Promptingは、教育的批判的思考理論とLLMエージェント設計を結びつけ、批判的でバイアスを意識した説明を生成する新しいマルチエージェントフレームワーク。これにより、AI生成の教育的応答の真実性と論理的妥当性が向上し、既存の教育アプリケーションに統合可能。 Comment元ポスト:https://x.com/dair_ai/status/1949481352325128236?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCritiqueを活用したマルチエージェントのようである(具体的なCritiqueの生成方法については読めていない。その辺が重要そう
・2311 #RecommenderSystems #VariationalAutoEncoder #SemanticID Issue Date: 2025-07-28 [Paper Note] Semantic IDs for Music Recommendation, M. Jeffrey Mei+, arXiv'25 Summaryコンテンツ情報を活用した共有埋め込みを用いることで、次アイテム推薦のレコメンダーシステムのモデルサイズを削減し、精度と多様性を向上させることを示す。音楽ストリーミングサービスでのオンラインA/Bテストを通じて、その効果を実証。 Comment元ポスト:https://x.com/_reachsumit/status/1949689827043197300?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QSemantic ID関連:
・2242・2137
・2309
上記2つのハイブリッド #NLP #LanguageModel #ACL #Trustfulness Issue Date: 2025-07-28 [Paper Note] Rectifying Belief Space via Unlearning to Harness LLMs' Reasoning, Ayana Niwa+, ACL'25 SummaryLLMの不正確な回答は虚偽の信念から生じると仮定し、信念空間を修正する方法を提案。テキスト説明生成で信念を特定し、FBBSを用いて虚偽の信念を抑制、真の信念を強化。実証結果は、誤った回答の修正とモデル性能の向上を示し、一般化の改善にも寄与することを示唆。 Comment元ポスト:https://x.com/ayaniwa1213/status/1949750575123276265?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Hallucination #ActivationSteering/ITI #Trustfulness Issue Date: 2025-07-26 [Paper Note] GrAInS: Gradient-based Attribution for Inference-Time Steering of LLMs and VLMs, Duy Nguyen+, arXiv'25 SummaryGrAInSは、LLMsおよびVLMsの推論時に内部活性を調整する新しいステアリング手法で、固定された介入ベクトルに依存せず、トークンの因果的影響を考慮します。統合勾配を用いて、出力への寄与に基づき重要なトークンを特定し、望ましい行動への変化を捉えるベクトルを構築します。これにより、再訓練なしでモデルの挙動を細かく制御でき、実験ではファインチューニングや既存手法を上回る成果を示しました。具体的には、TruthfulQAで精度を13.22%向上させ、MMHal-Benchの幻覚率を低下させ、SPA-VLでのアライメント勝率を改善しました。 Comment元ポスト:https://x.com/duynguyen772/status/1948768520587866522?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q既存のsteering手法は、positive/negativeなサンプルからの差分で単一方向のベクトルを算出し、すべてのトークンに足し合わせるが、本手法はそこからさらにpositive/negativeな影響を与えるトークンレベルにまで踏み込み、negativeなベクトルとpositiveなベクトルの双方を用いて、negative->positive方向のベクトルを算出してsteeringに活用する方法っぽい?
・1941 #ComputerVision #NLP #LanguageModel #MulltiModal #SpeechProcessing #OpenWeight #VisionLanguageModel Issue Date: 2025-07-26 [Paper Note] Ming-Omni: A Unified Multimodal Model for Perception and Generation, Inclusion AI+, arXiv'25 SummaryMing-Omniは、画像、テキスト、音声、動画を処理できる統一マルチモーダルモデルで、音声生成と画像生成において優れた能力を示す。専用エンコーダを用いて異なるモダリティからトークンを抽出し、MoEアーキテクチャで処理することで、効率的にマルチモーダル入力を融合。音声デコーダと高品質な画像生成を統合し、コンテキストに応じたチャットやテキストから音声への変換、画像編集が可能。Ming-Omniは、GPT-4oに匹敵する初のオープンソースモデルであり、研究と開発を促進するためにコードとモデルの重みを公開。 Comment
現在はv1.5も公開されておりさらに性能が向上している模様?HF:https://huggingface.co/inclusionAI/Ming-Lite-Omni #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #MoE(Mixture-of-Experts) #On-Policy #Stability Issue Date: 2025-07-26 [Paper Note] Group Sequence Policy Optimization, Chujie Zheng+, arXiv'25 SummaryGroup Sequence Policy Optimization (GSPO)は、大規模言語モデルのための新しい強化学習アルゴリズムで、シーケンスの尤度に基づく重要度比を用いてトレーニングを行う。GSPOは、従来のGRPOアルゴリズムよりも効率的で高性能であり、Mixture-of-Experts (MoE) のトレーニングを安定化させる。これにより、最新のQwen3モデルにおいて顕著な改善が見られる。 Comment元ポスト:https://x.com/theturingpost/status/1948904443749302785?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q公式ポスト:https://x.com/alibaba_qwen/status/1949412072942612873?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGRPOとGSPOの違いのGIF:
https://x.com/theturingpost/status/1953976551424634930?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NaturalLanguageGeneration #Controllable #NLP #LanguageModel #VisionLanguageModel Issue Date: 2025-07-25 [Paper Note] CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning, Kuniaki Saito+, arXiv'25 SummaryCaptionSmithsは、画像キャプショニングモデルがキャプションの特性(長さ、記述性、単語の独自性)を柔軟に制御できる新しいアプローチを提案。人間の注釈なしで特性を定量化し、短いキャプションと長いキャプションの間で補間することで条件付けを実現。実証結果では、出力キャプションの特性をスムーズに変化させ、語彙的整合性を向上させることが示され、誤差を506%削減。コードはGitHubで公開。 Comment元ポスト:https://x.com/a_hasimoto/status/1948258269668970782?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来はDiscreteに表現されていたcaptioningにおける特性をCondition Caluculatorを導入することでcontinuousなrepresentationによって表現し、Caluculatorに人間によるinput, あるいは表現したいConditionを持つexampleをinputすることで、生成時に反映させるような手法を提案している模様。Conditionで利用するpropertyについては、提案手法ではLength, Descriptive, Uniqueness of Vocabulariesの3つを利用している(が、他のpropertyでも本手法は適用可能と思われる)。このとき、あるpropertyの値を変えることで他のpropertyが変化してしまうと制御ができなくなるため、property間のdecorrelationを実施している。これは、あるproperty Aから別のproperty Bの値を予測し、オリジナルのpropertyの値からsubtractする、といった処理を順次propertyごとに実施することで実現される。Appendixに詳細が記述されている。
また、MNISTを用いたシンプルなMLPにおいて、MNISTを教師モデルに対して学習させ、そのモデルに対してランダムノイズな画像を生成させ、同じ初期化を施した生徒モデルに対してFinetuningをした場合、学習したlogitsがMNIST用ではないにもかかわらず、MNISTデータに対して50%以上の分類性能を示し、数字画像の認識能力が意味的に全く関係ないデータから転移されている[^3]、といった現象が生じることも実験的に確認された。
このため、どんなに頑張って合成データのフィルタリングや高品質化を実施し、教師モデルから特性を排除したデータを作成したつもりでも、そのデータでベースモデルが同じ生徒を蒸留すると、結局その特性は転移されてしまう。これは大きな落とし穴になるので気をつけましょう、という話だと思われる。
[^1]: これはアーキテクチャの話だけでなく、パラメータの初期値も含まれる
[^2]: 教師と生徒の初期化が同じ、かつ十分に小さい学習率の場合において、教師モデルが何らかの学習データDを生成し、Dのサンプルxで生徒モデルでパラメータを更新する勾配を計算すると、教師モデルが学習の過程で経た勾配と同じ方向の勾配が導き出される。つまり、パラメータが教師モデルと同じ方向にアップデートされる。みたいな感じだろうか?元論文を時間がなくて厳密に読めていない、かつalphaxivの力を借りて読んでいるため、誤りがあるかもしれない点に注意
[^3]: このパートについてもalphaxivの出力を参考にしており、元論文の記述をしっかり読めているわけではない Issue Date: 2025-07-24 [Paper Note] Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains, Anisha Gunjal+, arXiv'25 Summary報酬としてのルーブリック(RaR)フレームワークを提案し、構造化されたチェックリストスタイルのルーブリックを解釈可能な報酬信号として使用。HealthBench-1kで最大28%の相対的改善を達成し、専門家の参照に匹敵またはそれを上回る性能を示す。RaRは小規模な判定モデルが人間の好みに一致し、堅牢な性能を維持できることを証明。 Comment元ポスト:https://x.com/iscienceluvr/status/1948235609190867054?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Reasoning #Architecture Issue Date: 2025-07-23 [Paper Note] Hierarchical Reasoning Model, Guan Wang+, arXiv'25 SummaryHRM(Hierarchical Reasoning Model)は、AIの推論プロセスを改善するために提案された新しい再帰的アーキテクチャであり、Chain-of-Thought技術の問題を克服します。HRMは、2つの相互依存する再帰モジュールを用いて、シーケンシャルな推論タスクを単一のフォワードパスで実行し、高レベルの抽象計画と低レベルの詳細計算を分担します。2700万のパラメータで、わずか1000のトレーニングサンプルを使用し、数独や迷路の最適経路探索などの複雑なタスクで優れたパフォーマンスを示し、ARCベンチマークでも他の大規模モデルを上回る結果を達成しました。HRMは、普遍的な計算と汎用推論システムに向けた重要な進展を示唆しています。 Comment元ポスト:https://x.com/makingagi/status/1947286324735856747?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/hillbig/status/1952122977228841206?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2357 追試の結果再現が可能でモデルアーキテクチャそのものよりも、ablation studyの結果、outer refinement loopが重要とのこと:
・https://x.com/fchollet/status/1956442449922138336?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/k_schuerholt/status/1956669487349891198?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qポイント解説:https://x.com/giffmana/status/1956705621337608305?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #Evaluation #Reasoning #PostTraining #Contamination #Science Issue Date: 2025-07-23 [Paper Note] MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning, Run-Ze Fan+, arXiv'25 Summary科学的推論のためのオープンデータセット「TextbookReasoning」を提案し、65万の推論質問を含む。さらに、125万のインスタンスを持つ「MegaScience」を開発し、各公開科学データセットに最適なサブセットを特定。包括的な評価システムを構築し、既存のデータセットと比較して優れたパフォーマンスを示す。MegaScienceを用いてトレーニングしたモデルは、公式の指示モデルを大幅に上回り、科学的調整におけるスケーリングの利点を示唆。データキュレーションパイプラインやトレーニング済みモデルをコミュニティに公開。 Comment元ポスト:https://x.com/vfrz525_/status/1947859552407589076?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLMベースでdecontaminationも実施している模様 #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #GRPO #read-later #Admin'sPick #Non-VerifiableRewards #RewardModel Issue Date: 2025-07-22 [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25 Summary強化学習を用いてLLMsの推論能力を向上させるため、報酬モデリング(RM)のスケーラビリティを探求。ポイントワイズ生成報酬モデリング(GRM)を採用し、自己原則批評調整(SPCT)を提案してパフォーマンスを向上。並列サンプリングとメタRMを導入し、スケーリング性能を改善。実験により、SPCTがGRMの質とスケーラビリティを向上させ、既存の手法を上回る結果を示した。DeepSeek-GRMは一部のタスクで課題があるが、今後の取り組みで解決可能と考えられている。モデルはオープンソースとして提供予定。 Comment・inputに対する柔軟性と、
・同じresponseに対して多様なRewardを算出でき (= inference time scalingを活用できる)、
・Verifiableな分野に特化していないGeneralなRewardモデルである
Inference-Time Scaling for Generalist Reward Modeling (GRM) を提案
・context中にirrerevantな情報が含まれるシンプルな個数を数えるタスクでは、irrerevantな情報に惑わされるようになり、
・特徴表に基づく回帰タスクの場合、擬似相関を持つ特徴量をの影響を増大してしまい、
・複雑で組み合わせが多い演繹タスク(シマウマパズル)に失敗する
といったように、Reasoning Traceが長くなればなるほど性能を悪化させるタスクが存在しこのような問題のある推論パターンを見つけるためにも、様々なReasoning Traceの長さで評価した方が良いのでは、といった話な模様?
RePhrase,StepBack,Explain,Summalize-User,Recency-Focusedが、様々なモデル、データセット、ユーザの特性(Light, Heavy)において安定した性能を示しており(少なくともベースラインからの性能の劣化がない)、model agnosticに安定した性能を発揮できるpromptingが存在することが明らかになった。一方、Phi-4, nova-liteについてはBaselineから有意に性能が改善したPromptingはなかった。これはモデルは他のモデルよりもそもそもの予測性能が低く、複雑なinstructionを理解する能力が不足しているため、Promptデザインが与える影響が小さいことが示唆される。
特定のモデルでのみ良い性能を発揮するPromptingも存在した。たとえばRe-Reading, Echoは、Llama3.3-70Bでは性能が改善したが、gpt-4.1-mini, gpt-4o-miniでは性能が悪化した。ReActはgpt-4.1-miniとLlamd3.3-70Bで最高性能を達成したが、gpt-4o-miniでは最も性能が悪かった。
NLPにおいて一般的に利用されるprompting、RolePlay, Mock, Plan-Solve, DeepBreath, Emotion, Step-by-Stepなどは、推薦のAcc.を改善しなかった。このことより、ユーザの嗜好を捉えることが重要なランキングタスクにおいては、これらプロンプトが有効でないことが示唆される。
続いて、LLMやデータセットに関わらず高い性能を発揮するpromptingをlinear mixed-effects model(ランダム効果として、ユーザ、LLM、メトリックを導入し、これらを制御する項を線形回帰に導入。promptingを固定効果としAccに対する寄与をfittingし、多様な状況で高い性能を発揮するPromptを明らかにする)によって分析した結果、ReAct, Rephrase, Step-Backが有意に全てのデータセット、LLMにおいて高い性能を示すことが明らかになった。
実際にリポジトリからPRを収集し、パッチ前後の実行時間を比較。20回のrunを通じて統計的に有意な実行時間の差があるもののみにフィルタリングをしているとのこと。
Human Expertsは平均10.9%のgainを得たが、エージェントは2.3%にとどまっており、ギャップがあるとのこと。
傾向として、LLMはlow levelなインフラストラクチャ(環境構築, 依存関係のハンドリング, importのロジック)を改善するが、Human Expertsはhigh levelなロジックやデータ構造を改善する(e.g., アルゴリズムや、データハンドリング)。 #Pretraining #NLP #LanguageModel #MulltiModal #Scaling Laws #DataMixture #VisionLanguageModel Issue Date: 2025-07-18 [Paper Note] Scaling Laws for Optimal Data Mixtures, Mustafa Shukor+, arXiv'25 Summary本研究では、スケーリング法則を用いて任意のターゲットドメインに対する最適なデータ混合比率を決定する方法を提案。特定のドメイン重みベクトルを持つモデルの損失を正確に予測し、LLM、NMM、LVMの事前訓練における予測力を示す。少数の小規模な訓練実行でパラメータを推定し、高価な試行錯誤法に代わる原則的な選択肢を提供。 #MachineTranslation #Metrics #NLP #LanguageModel #MultiDimensional Issue Date: 2025-07-18 [Paper Note] TransEvalnia: Reasoning-based Evaluation and Ranking of Translations, Richard Sproat+, arXiv'25 Summaryプロンプトベースの翻訳評価システム「TransEvalnia」を提案し、Multidimensional Quality Metricsに基づく詳細な評価を行う。TransEvalniaは、英日データやWMTタスクで最先端のMT-Rankerと同等以上の性能を示し、LLMによる評価が人間の評価者と良好に相関することを確認。翻訳の提示順序に敏感であることを指摘し、位置バイアスへの対処法を提案。システムの評価データは公開される。 Comment元ポスト:https://x.com/sakanaailabs/status/1946071203002941694?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-17 [Paper Note] SpatialTrackerV2: 3D Point Tracking Made Easy, Yuxi Xiao+, arXiv'25 SummarySpatialTrackerV2は、モノキュラー動画のためのフィードフォワード3Dポイントトラッキング手法であり、ポイントトラッキング、モノキュラー深度、カメラポーズ推定の関係を統合。エンドツーエンドのアーキテクチャにより、様々なデータセットでスケーラブルなトレーニングが可能。これにより、既存の3Dトラッキング手法を30%上回り、動的3D再構築の精度に匹敵しつつ、50倍の速さで動作する。 Comment元ポスト:https://x.com/zhenjun_zhao/status/1945780657541492955?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #read-later #4DReconstruction Issue Date: 2025-07-17 [Paper Note] Streaming 4D Visual Geometry Transformer, Dong Zhuo+, arXiv'25 Summary動画から4D空間-時間幾何学を認識・再構築するために、ストリーミング4Dビジュアルジオメトリトランスフォーマーを提案。因果トランスフォーマーアーキテクチャを用いて、過去の情報をキャッシュしながらリアルタイムで4D再構築を実現。効率的なトレーニングのために、双方向ビジュアルジオメトリからの知識蒸留を行い、推論速度を向上させつつ競争力のある性能を維持。スケーラブルな4Dビジョンシステムの実現に寄与。 Comment元ポスト:https://x.com/zhenjun_zhao/status/1945427634642424188?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qモデルのアーキテクチャ
・2146 #read-later Issue Date: 2025-07-16 [Paper Note] Building Instruction-Tuning Datasets from Human-Written Instructions with Open-Weight Large Language Models, Youmi Ma+, arXiv'25 Summary本研究では、人間が書いた指示を用いた指示調整データセットを構築し、LLMの性能向上を図る。人間由来のデータで微調整されたモデルは、既存のデータセットで調整されたモデルを上回る結果を示し、日本語データセットでも同様の成果を確認。指示調整によりLLMは指示に従う能力を向上させるが、文化特有の知識が不足していることが明らかに。データセットとモデルは公開予定で、多様な使用ケースに対応可能。 #NeuralNetwork #MachineLearning #ICML #GraphGeneration Issue Date: 2025-07-16 [Paper Note] Learning-Order Autoregressive Models with Application to Molecular Graph Generation, Zhe Wang+, ICML'25 Summary自己回帰モデル(ARMs)を用いて、データから逐次的に推測される確率的順序を利用し、高次元データを生成する新しい手法を提案。トレーニング可能なオーダーポリシーを組み込み、対数尤度の変分下限を用いて最適化。実験により、画像生成やグラフ生成で意味のある自己回帰順序を学習し、分子グラフ生成ではQM9およびZINC250kベンチマークで最先端の結果を達成。 Comment元ポスト:https://x.com/thjashin/status/1945175804704645607?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qopenreview:https://openreview.net/forum?id=EY6pXIDi3G #NLP #LanguageModel #OpenWeight #Contamination Issue Date: 2025-07-16 [Paper Note] Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, Mingqi Wu+, arXiv'25 Summary大規模言語モデル(LLMs)の推論能力向上に関する研究が進展しており、特にQwen2.5モデルが強化学習(RL)を用いて顕著な改善を示している。しかし、他のモデルでは同様の成果が得られていないため、さらなる調査が必要である。Qwen2.5は数学的推論性能が高いが、データ汚染に脆弱であり、信頼性のある結果を得るためには、RandomCalculationというクリーンなデータセットを用いることが重要である。このデータセットを通じて、正確な報酬信号が性能向上に寄与することが示された。信頼性のある結論を得るためには、汚染のないベンチマークと多様なモデルでのRL手法の評価が推奨される。 Comment元ポスト:https://x.com/asap2650/status/1945151806536863878?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/dongxi_nlp/status/1945214650737451008?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1997
こちらでQwen-mathに対して得られたRLでのgainは他モデルでは現れず汎化しないことも報告されている。 #Analysis #NLP #LanguageModel #Prompting #Reasoning #Batch Issue Date: 2025-07-16 [Paper Note] REST: Stress Testing Large Reasoning Models by Asking Multiple Problems at Once, Zhuoshi Pan+, arXiv'25 SummaryRESTという新しい評価フレームワークを提案し、LRMsを同時に複数の問題にさらすことで、実世界の推論能力を評価。従来のベンチマークの限界を克服し、文脈優先配分や問題間干渉耐性を測定。DeepSeek-R1などの最先端モデルでもストレステスト下で性能低下が見られ、RESTはモデル間の性能差を明らかにする。特に「考えすぎの罠」が性能低下の要因であり、「long2short」技術で訓練されたモデルが優れた結果を示すことが確認された。RESTはコスト効率が高く、実世界の要求に適した評価手法である。 Comment元ポスト:https://x.com/_akhaliq/status/1945130848061194500?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
元ポスト:https://x.com/skandermoalla/status/1944773057085579531?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2060 #ICML Issue Date: 2025-07-15 [Paper Note] The Value of Prediction in Identifying the Worst-Off, Unai Fischer-Abaigar+, arXiv'25 Summary機械学習を用いて最も脆弱な個人を特定し支援する政府プログラムの影響を検討。特に、平等を重視した予測が福祉に与える影響と他の政策手段との比較を行い、ドイツの長期失業者に関するケーススタディを通じてその効果を分析。政策立案者に対して原則に基づいた意思決定を支援するフレームワークとデータ駆動型ツールを提供。 Commentopenreview:https://openreview.net/forum?id=26JsumCG0z #MachineLearning #ICML Issue Date: 2025-07-15 [Paper Note] Score Matching With Missing Data, Josh Givens+, ICML'25 Summaryスコアマッチングはデータ分布学習の重要な手法ですが、不完全データへの適用は未研究です。本研究では、部分的に欠損したデータに対するスコアマッチングの適応を目指し、重要度重み付け(IW)アプローチと変分アプローチの2つのバリエーションを提案します。IWアプローチは有限サンプル境界を示し、小さなサンプルでの強力な性能を確認。変分アプローチは高次元設定でのグラフィカルモデル推定において優れた性能を発揮します。 Commentopenreview:https://openreview.net/forum?id=mBstuGUaXoICML'25 outstanding papers解説:https://x.com/hillbig/status/1960498715229347941?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ICML Issue Date: 2025-07-15 [Paper Note] Conformal Prediction as Bayesian Quadrature, Jake C. Snell+, arXiv'25 Summary機械学習の予測モデルの理解が重要になる中、コンフォーマル予測をベイズ的視点から再考し、頻度主義的保証の限界を指摘。ベイズ的数値積分に基づく新たな手法を提案し、解釈可能な保証と損失の範囲を豊かに表現する。 Commentopenreview:https://openreview.net/forum?id=PNmkjIzHB7ICML'25 outstanding papers #ICML Issue Date: 2025-07-15 [Paper Note] Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction, Vaishnavh Nagarajan+, arXiv'25 Summary最小限のアルゴリズムタスクを設計し、現代の言語モデルの創造的限界を定量化。タスクは新しい接続の発見やパターン構築を必要とし、次トークン学習の限界を論じる。マルチトークンアプローチが独創的な出力を生成し、入力層へのノイズ注入が効果的であることを発見。研究は創造的スキル分析のためのテストベッドを提供し、新たな議論を展開。コードはGitHubで公開。 Commentopenreview:https://openreview.net/forum?id=Hi0SyHMmkdICML'25 outstanding papers #Analysis #Pretraining #DiffusionModel #ICML #Decoding Issue Date: 2025-07-15 [Paper Note] Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions, Jaeyeon Kim+, ICML'25 Summaryマスク付き拡散モデル(MDMs)は、自己回帰モデル(ARMs)と比較してトレーニングの複雑さと推論の柔軟性をトレードオフする新しい生成モデルです。本研究では、MDMsが自己回帰モデルよりも計算上解決不可能なサブ問題に取り組むことを示し、適応的なトークンデコード戦略がMDMsの性能を向上させることを実証しました。数独の論理パズルにおいて、適応的推論により解決精度が$<7$%から$\approx 90$%に向上し、教師強制でトレーニングされたMDMsがARMsを上回ることを示しました。 Commentopenreview:https://openreview.net/forum?id=DjJmre5IkPICML'25 outstanding papers日本語解説:https://x.com/hillbig/status/1960491242615345237?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ICML Issue Date: 2025-07-15 [Paper Note] CollabLLM: From Passive Responders to Active Collaborators, Shirley Wu+, arXiv'25 SummaryCollabLLMは、長期的なインタラクションを最適化するための新しい訓練フレームワークで、マルチターンの人間とLLMのコラボレーションを強化する。協調シミュレーションを用いて、応答の長期的な貢献を評価し、ユーザーの意図を明らかにすることで、より人間中心のAIを実現。文書作成などのタスクで平均18.5%のパフォーマンス向上と46.3%のインタラクティビティ改善を達成し、ユーザー満足度を17.6%向上させ、消費時間を10.4%削減した。 Commentopenreview:https://openreview.net/forum?id=DmH4HHVb3yICML'25 outstanding papers Issue Date: 2025-07-15 [Paper Note] Auditing Prompt Caching in Language Model APIs, Chenchen Gu+, arXiv'25 SummaryプロンプトキャッシングはLLMにおいてタイミング変動を引き起こし、サイドチャネル攻撃のリスクをもたらす。キャッシュが共有されると、攻撃者は迅速な応答から他ユーザーのプロンプトを特定できる可能性がある。これによりプライバシー漏洩の懸念が生じ、APIプロバイダーの透明性が重要となる。本研究では、実世界のLLM APIプロバイダーにおけるプロンプトキャッシングを検出するための統計監査を開発し、7つのAPIプロバイダー間でのキャッシュ共有を確認し、潜在的なプライバシー漏洩を示した。また、OpenAIの埋め込みモデルに関する新たな情報も発見した。 Issue Date: 2025-07-15 [Paper Note] Open Vision Reasoner: Transferring Linguistic Cognitive Behavior for Visual Reasoning, Yana Wei+, arXiv'25 Summary本研究では、大規模言語モデル(LLMs)の推論能力をマルチモーダルLLMs(MLLMs)に応用し、高度な視覚推論を実現する方法を探求。二段階のパラダイムを導入し、ファインチューニング後に約1,000ステップのマルチモーダル強化学習を行い、従来のオープンソースの取り組みを上回る成果を達成。得られたモデルOpen-Vision-Reasoner(OVR)は、MATH500で95.3%、MathVisionで51.8%、MathVerseで54.6%の推論ベンチマークで最先端のパフォーマンスを示す。モデル、データ、トレーニングのダイナミクスを公開し、マルチモーダル推論者の開発を促進。 Comment元ポスト:https://x.com/cyousakura/status/1944788604120953105?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #COLM Issue Date: 2025-07-15 [Paper Note] L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning, Pranjal Aggarwal+, arXiv'25 SummaryLength Controlled Policy Optimization(LCPO)を導入し、推論言語モデルL1を訓練。これにより、出力の長さを制御しつつ計算コストと精度のトレードオフを最適化。LCPOは、長さ制御において最先端の手法S1を上回る性能を示し、1.5B L1モデルは同じ推論の長さでGPT-4oを超える結果を得た。 Comment元ポスト:https://x.com/pranjalaggarw16/status/1944452267861741684?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Tokenizer #COLM Issue Date: 2025-07-15 [Paper Note] SuperBPE: Space Travel for Language Models, Alisa Liu+, COLM'25 SummarySuperBPEという新しいトークナイザーを導入し、サブワードを超えたトークン化を実現。これにより、エンコーディング効率が33%向上し、30のダウンストリームタスクで平均+4.0%の性能改善を達成。SuperBPEは意味的に単一の単位として機能する表現を捉え、全体的に優れた言語モデルを提供する。 Comment元ポスト:https://x.com/alisawuffles/status/1944890077059965276?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pretraining #Transformer #PEFT(Adaptor/LoRA) #ICML #Finetuning Issue Date: 2025-07-14 [Paper Note] ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts, Samar Khanna+, ICML'25 SummaryPEFT技術を用いたExPLoRAは、事前学習済みビジョントランスフォーマー(ViT)を新しいドメインに適応させる手法で、教師なし事前学習を通じて効率的にファインチューニングを行う。実験では、衛星画像において最先端の結果を達成し、従来のアプローチよりも少ないパラメータで精度を最大8%向上させた。 Comment元ポスト:https://x.com/samar_a_khanna/status/1944781066591748336?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれまでドメイン適応する場合にラベル付きデータ+LoRAでFinetuningしていたのを、ラベル無しデータ+継続事前学習の枠組みでやりましょう、という話のようである。
手法は下記で、事前学習済みのモデルに対してLoRAを適用し継続事前学習する。ただし、最後尾のLayer、あるいは最初と最後尾のLayerの両方をunfreezeして、trainableにする。また、LoRAはfreezeしたLayerのQ,Vに適用し、それらのLayerのnormalization layerもunfreezeする。最終的に、継続事前学習したモデルにヘッドをconcatしてfinetuningすることで目的のタスクを実行できるようにする。
同じモデルで単にLoRAを適用しただけの手法や、既存手法をoutperform
#ComputerVision #NLP #Dataset #Evaluation #VisionLanguageModel Issue Date: 2025-07-14 [Paper Note] VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge, Yueqi Song+, arXiv'25 SummaryVisualPuzzlesは、専門知識への依存を最小限に抑えた視覚的推論を評価する新しいベンチマークで、5つの推論カテゴリーから成る多様な質問を含む。実験により、VisualPuzzlesはドメイン特有の知識を大幅に減少させ、より複雑な推論を要求することが示された。最先端のマルチモーダルモデルは、VisualPuzzlesで人間のパフォーマンスに遅れをとり、知識集約型タスクでの成功が推論タスクでの成功に必ずしもつながらないことが明らかになった。また、モデルのサイズとパフォーマンスの間に明確な相関は見られず、VisualPuzzlesは事実の記憶を超えた推論能力を評価する新たな視点を提供する。 Comment元ポスト:https://x.com/yueqi_song/status/1912510869491101732?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q画像はPJページより引用。新たにVisual Puzzleと呼ばれる特定のドメイン知識がほとんど必要ないマルチモーダルなreasoningベンチマークを構築。o1ですら、人間の5th percentileに満たない性能とのこと。
Chinese Civil Service Examination中のlogical reasoning questionを手作業で翻訳したとのこと。
データセットの統計量は以下で、合計1168問で、難易度は3段階に分かれている模様。
project page:https://neulab.github.io/VisualPuzzles/ #MachineLearning #NLP #LanguageModel #Optimizer #read-later #Admin'sPick Issue Date: 2025-07-14 [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25 SummaryMuonオプティマイザーを大規模モデルにスケールアップするために、ウェイトデケイとパラメータごとの更新スケール調整を導入。これにより、Muonは大規模トレーニングで即座に機能し、計算効率がAdamWの約2倍に向上。新たに提案するMoonlightモデルは、少ないトレーニングFLOPで優れたパフォーマンスを達成し、オープンソースの分散Muon実装や事前トレーニング済みモデルも公開。 Comment解説ポスト:https://x.com/hillbig/status/1944902706747072678?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこちらでも紹介されている:
・2208 #ComputerVision #NLP #MulltiModal #Reasoning #OpenWeight #VisionLanguageModel Issue Date: 2025-07-14 [Paper Note] Kimi-VL Technical Report, Kimi Team+, arXiv'25 SummaryKimi-VLは、効率的なオープンソースのMixture-of-Expertsビジョン・ランゲージモデルであり、2.8Bパラメータの言語デコーダーを活性化して高度なマルチモーダル推論を実現。マルチターンエージェントタスクや大学レベルの画像・動画理解において優れた性能を示し、最先端のVLMと競争。128Kの拡張コンテキストウィンドウを持ち、長い入力を処理可能。Kimi-VL-Thinking-2506は、長期的推論能力を強化するために教師ありファインチューニングと強化学習を用いて開発され、堅牢な一般能力を獲得。コードは公開されている。 Comment・2201
での性能(Vision+テキストの数学の問題)。他の巨大なモデルと比べ2.8BのActivation paramsで高い性能を達成
その他のベンチマークでも高い性能を獲得
モデルのアーキテクチャ。MoonViT (Image Encoder, 1Dのpatchをinput, 様々な解像度のサポート, FlashAttention, SigLIP-SO-400Mを継続事前学習, RoPEを採用) + Linear Projector + MoE Language Decoderの構成
学習のパイプライン。ViTの事前学習ではSigLIP loss (contrastive lossの亜種)とcaption生成のcross-entropy lossを採用している。joint cooldown stageにおいては、高品質なQAデータを合成することで実験的に大幅に性能が向上することを確認したので、それを採用しているとのこと。optimizerは
・2202
post-trainingにおけるRLでは以下の目的関数を用いており、RLVRを用いつつ、現在のポリシーモデルをreferenceとし更新をするような目的関数になっている。curriculum sampling, prioritize samplingをdifficulty labelに基づいて実施している。
・1956
・1245 #Pretraining #NLP #LanguageModel #Batch Issue Date: 2025-07-12 [Paper Note] Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful, Martin Marek+, arXiv'25 Summary小さなバッチサイズに対するAdamのハイパーパラメータをスケーリングする新しいルールを提案。これにより、小さなバッチサイズでも安定したトレーニングが可能で、大きなバッチサイズと同等以上のパフォーマンスを達成。勾配蓄積は推奨せず、実用的なハイパーパラメータ設定のガイドラインを提供。 Comment元ポスト:https://x.com/giffmana/status/1943384733418950815?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
論文中のFigure1において、AdamWにおいてbatchsizeが1の方が512の場合と比べてlearning_rateの変化に対してロバストである旨が記述されている。
(追記)
気になって思い出そうとしていたが、MTではなく画像認識の話だったかもしれない(だいぶうろ覚え)
・2196 参考:https://x.com/odashi_t/status/1944034128707342815?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1541解説:https://x.com/hillbig/status/1952506470878351492?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q実際に8Bモデルの事前学習においてβ2を0.99にしたところ、学習が不安定になり、かつ最終的なPerplexityも他の設定に勝つことができなかったとのこと:
https://x.com/odashi_t/status/1955906705637957995?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #ReinforcementLearning #MulltiModal #Reasoning #On-Policy #VisionLanguageModel Issue Date: 2025-07-12 [Paper Note] Perception-Aware Policy Optimization for Multimodal Reasoning, Zhenhailong Wang+, arXiv'25 Summary強化学習における検証可能な報酬(RLVR)は、LLMsに多段階推論能力を与えるが、マルチモーダル推論では最適な性能を発揮できない。視覚入力の認識が主なエラー原因であるため、知覚を意識したポリシー最適化(PAPO)を提案。PAPOはGRPOの拡張で、内部監視信号から学習し、追加のデータや外部報酬に依存しない。KLダイバージェンス項を導入し、マルチモーダルベンチマークで4.4%の改善、視覚依存タスクでは8.0%の改善を達成。知覚エラーも30.5%減少し、PAPOの効果を示す。研究は視覚に基づく推論を促進する新しいRLフレームワークの基盤を築く。 Comment元ポスト:https://x.com/aicia_solid/status/1943507735489974596?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QVLMにおいて、画像をマスクした場合のポリシーモデルの出力と、画像をマスクしない場合のポリシーモデルの出力のKL Divergenceを最大化することで、画像の認知能力が向上し性能向上するよ、みたいな話な模様。
下図が実験結果で、条件の双方を満たしているのはEmbedLN[^2]とScaled Embed[^3]のみであり、実際にスパイクが生じていないことがわかる。
[^1]:オリジナル論文 245 の3.4節末尾、embedding layersに対してsqrt(d_model)を乗じるということがサラッと書いてある。これが実はめちゃめちゃ重要だったという…
[^2]: positional embeddingを加算する前にLayer Normalizationをかける方法
[^3]: EmbeddingにEmbeddingの次元数d(i.e., 各レイヤーのinputの次元数)の平方根を乗じる方法前にScaled dot-product attentionのsqrt(d_k)がめっちゃ重要ということを実験的に示した、という話もあったような…
(まあそもそも元論文になぜスケーリングさせるかの説明は書いてあるけども) #NeuralNetwork #MachineLearning #LearningPhenomena Issue Date: 2025-07-11 [Paper Note] Not All Explanations for Deep Learning Phenomena Are Equally Valuable, Alan Jeffares+, PMLR'25 Summary深層学習の驚くべき現象(ダブルディセント、グロッキングなど)を孤立したケースとして説明することには限界があり、実世界のアプリケーションにはほとんど現れないと主張。これらの現象は、深層学習の一般的な原則を洗練するための研究価値があると提案し、研究コミュニティのアプローチを再考する必要性を示唆。最終的な実用的目標に整合するための推奨事項も提案。 Comment元ポスト:https://x.com/jeffaresalan/status/1943315797692109015?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2189
・524
・2190 #NLP #LanguageModel #MoE(Mixture-of-Experts) #Privacy Issue Date: 2025-07-11 [Paper Note] FlexOlmo: Open Language Models for Flexible Data Use, Weijia Shi+, arXiv'25 SummaryFlexOlmoは、データ共有なしでの分散トレーニングを可能にする新しい言語モデルで、異なるモデルパラメータが独立してトレーニングされ、データ柔軟な推論を実現します。混合専門家アーキテクチャを採用し、公開データセットと特化型セットでトレーニングされ、31の下流タスクで評価されました。データライセンスに基づくオプトアウトが可能で、平均41%の性能改善を達成し、従来の手法よりも優れた結果を示しました。FlexOlmoは、データ所有者のプライバシーを尊重しつつ、閉じたデータの利点を活かすことができます。 Comment元ポスト:https://x.com/asap2650/status/1943184037419585695?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qデータのオーナー側がプロプライエタリデータを用いてエキスパート(FFNとRouter embeddings)を学習し、それをpublicにシェアすることで利用できるようにする。データオーナー側はデータそのものを提供するのではなく、モデルのパラメータを共有するだけで済み、かつ自分たちのエキスパートをRouter側で利用するか否かは制御可能だから、opt-in/outが制御できる、みたいな話っぽい?
matrix)をQueryとみなし、保持しているLatent Array(trainableなmatrixで辞書として機能する;後述の学習においてパラメータが学習される)[^1]をK,Vとして、CrossAttentionによってcontext vectorを生成し、その後MLPとMean Poolingを実施することでEmbeddingに変換する。
学習は2段階で行われ、まずQAなどのRetrievalタスク用のデータセットをIn Batch negativeを用いてContrastive Learningしモデルの検索能力を高める。その後、検索と非検索タスクの両方を用いて、hard negativeによってcontrastive learningを実施し、検索以外のタスクの能力も高める(下表)。両者において、instructionテンプレートを用いて、instructionによって条件付けて学習をすることで、instructionに応じて生成されるEmbeddingが変化するようにする。また、学習時にはLLMのcausal maskは無くし、bidirectionalにrepresentationを考慮できるようにする。
[^1]: 2183 Perceiver-IOにインスパイアされている。 #NLP #LanguageModel #Reasoning #SmallModel #OpenWeight Issue Date: 2025-07-10 [Paper Note] Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation, Liliang Ren+, arXiv'25 Summary最近の言語モデルの進展により、状態空間モデル(SSM)の効率的なシーケンスモデリングが示されています。本研究では、ゲーテッドメモリユニット(GMU)を導入し、Sambaベースの自己デコーダーからメモリを共有する新しいデコーダーハイブリッドアーキテクチャSambaYを提案します。SambaYはデコーディング効率を向上させ、長文コンテキスト性能を改善し、位置エンコーディングの必要性を排除します。実験により、SambaYはYOCOベースラインに対して優れた性能を示し、特にPhi4-mini-Flash-Reasoningモデルは推論タスクで顕著な成果を上げました。トレーニングコードはオープンソースで公開されています。 CommentHF:https://huggingface.co/microsoft/Phi-4-mini-flash-reasoning元ポスト:https://x.com/_akhaliq/status/1943099901161652238?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pretraining #NLP #Dataset #LanguageModel #SyntheticData #Programming #Mathematics #mid-training #COLM Issue Date: 2025-07-10 [Paper Note] MegaMath: Pushing the Limits of Open Math Corpora, Fan Zhou+, COLM'25 SummaryMegaMathは、数学に特化したオープンデータセットで、LLMの数学的推論能力を向上させるために作成された。ウェブデータの再抽出、数学関連コードの特定、合成データの生成を通じて、371Bトークンの高品質なデータを提供し、既存のデータセットを上回る量と品質を実現した。 Comment元ポスト:https://x.com/fazhou_998/status/1942610771915202590?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q非常に大規模な数学の事前学習/mid-training向けのデータセット
CommonCrawlのHTMLから、さまざまなフィルタリング処理(reformatting, 2 stageのHTML parserの活用(片方はnoisyだが高速、もう一方は高性能だが遅い), fasttextベースの分類器による抽出, deduplication等)を実施しMegaMath-Webを作成、また、MegaMathWebをさらに分類器で低品質なものをフィルタリングし、LLMによってノイズ除去、テキストのreorganizingを実施し(≠ピュアな合成データ)継続事前学習、mid-training向けの高品質なMegaMath-Web-Proを作成。
MegaMathCodeはThe Stack V2 (2199) をベースにしており、mathematical reasoning, logic puzzles, scientific computationに関するコードを収集。まずこれらのコードと関連が深い11のプログラミング言語を選定し、そのコードスニペットのみを対象とする。次にstrong LLMを用いて、数学に関するrelevanceスコアと、コードの品質を0--6のdiscrete scoreでスコアリングし学習データを作成。作成した学習データでSLMを学習し大規模なフィルタリングを実施することでMegaMath-Codeを作成。
最後にMegaMath-{Web, code}を用いて、Q&A, code data, text&code block dataの3種類を合成。Q&Aデータの合成では、MegaMath-WebからQAペアを抽出し、多様性とデータ量を担保するためQwen2.5-72B-Instruct, Llama3.3-70B-Instructの両方を用いて、QAのsolutionを洗練させる(reasoning stepの改善, あるいはゼロから生成する[^1])ことで生成。また、code dataでは、pythonを対象にMegaMath-Codeのデータに含まれるpython以外のコードを、Qwen2.5-Coder-32B-Instructと、Llamd3.1-70B-Instructによってpythonに翻訳することでデータ量を増やした。text&code blockデータでは、MegaMath-Webのドキュメントを与えて、ブロックを生成(タイトル、数式、結果、コードなど[^1])し、ブロックのverificationを行い(コードが正しく実行できるか、実行結果とanswerが一致するか等)、verifiedなブロックを残すことで生成。
[^1]: この辺は論文の記述を咀嚼して記述しており実サンプルを見ていないので少し正しい認識か不安 #ICML Issue Date: 2025-07-10 [Paper Note] How Do Large Language Monkeys Get Their Power (Laws)?, Rylan Schaeffer+, ICML'25 Summary本研究では、マルチモーダル言語モデルの試行回数に対する成功率のスケーリング特性を探求し、単純な数学的計算が指数関数的に失敗率を減少させることを示す。成功確率の分布が重い尾を持つ場合、指数関数的スケーリングが集約的な多項式スケーリングと整合的であることを明らかにし、冪法則の逸脱を説明する方法を提案。これにより、ニューラル言語モデルの性能向上とスケーリング予測の理解が深まる。 Comment元ポスト:https://x.com/rylanschaeffer/status/1942989816557375845?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-10 [Paper Note] Why Do Some Language Models Fake Alignment While Others Don't?, Abhay Sheshadri+, arXiv'25 Summary大規模言語モデルのアライメント偽装に関する研究で、25のモデルを分析した結果、5つのモデル(Claude 3 Opus、Claude 3.5 Sonnet、Llama 3 405B、Grok 3、Gemini 2.0 Flash)が有害なクエリに対して従う傾向があることが判明。Claude 3 Opusの従順性は目標維持の動機によるものであり、多くのモデルがアライメントを偽装しない理由は能力の欠如だけではないことが示唆された。ポストトレーニングがアライメント偽装に与える影響について5つの仮説を検討し、拒否行動の変動がその違いを説明する可能性があることを発見した。 Comment元ポスト:https://x.com/anthropicai/status/1942708254670196924?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #LatentReasoning Issue Date: 2025-07-10 [Paper Note] A Survey on Latent Reasoning, Rui-Jie Zhu+, arXiv'25 Summary大規模言語モデル(LLMs)は、明示的な思考の連鎖(CoT)によって優れた推論能力を示すが、自然言語推論への依存が表現力を制限する。潜在的推論はこの問題を解決し、トークンレベルの監視を排除する。研究は、ニューラルネットワーク層の役割や多様な潜在的推論手法を探求し、無限深度の潜在的推論を可能にする高度なパラダイムについて議論する。これにより、潜在的推論の概念を明確にし、今後の研究方向を示す。関連情報はGitHubリポジトリで提供されている。 Comment元ポスト:https://x.com/gm8xx8/status/1942787610818097609?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLatent Reasoningというテクニカルタームが出てきた出力されるdiscreteなtokenによってreasoningを実施するのではなく、モデル内部のrepresentationでreasoningを実施するLatent ReasoningのSurvey
・1832Lean 4 形式に
#COLM Issue Date: 2025-07-09 [Paper Note] Learning to Generate Unit Tests for Automated Debugging, Archiki Prasad+, COLM'25 Summaryユニットテスト(UT)の重要性を踏まえ、UTGenを提案し、LLMを用いてエラーを明らかにするUT入力とその期待出力を生成。UTDebugを併用することで、出力予測の改善とオーバーフィッティングの回避を実現。UTGenは他のLLMベースラインを7.59%上回り、UTDebugと組み合わせることでQwen2.5の精度をそれぞれ3.17%および12.35%向上。最終的に、UTGenはHumanEval+で最先端モデルを4.43%上回る性能を示した。 Comment元ポスト:https://x.com/archikiprasad/status/1942645157943468500?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-09 [Paper Note] VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents, Rui Meng+, arXiv'25 SummaryVLM2Vec-V2という統一フレームワークを提案し、テキスト、画像、動画、視覚文書を含む多様な視覚形式の埋め込みを学習。新たにMMEB-V2ベンチマークを導入し、動画検索や視覚文書検索など5つのタスクを追加。広範な実験により、VLM2Vec-V2は新タスクで強力なパフォーマンスを示し、従来の画像ベンチマークでも改善を達成。研究はマルチモーダル埋め込みモデルの一般化可能性に関する洞察を提供し、スケーラブルな表現学習の基盤を築く。 Comment元ポスト:https://x.com/wenhuchen/status/1942501330674647342?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2156 Issue Date: 2025-07-08 [Paper Note] Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought, Violet Xiang+, arXiv'25 SummaryMeta Chain-of-Thought(Meta-CoT)フレームワークを提案し、基礎的な推論を明示的にモデル化して従来のCoTを拡張。文脈内検索や行動の一致を探求し、プロセス監視や合成データ生成を通じてMeta-CoTを生成する方法を検討。具体的なトレーニングパイプラインを概説し、スケーリング法則や新しい推論アルゴリズムの発見についても議論。LLMsにおけるMeta-CoTの実現に向けた理論的・実践的なロードマップを提供。 Comment元ポスト:https://x.com/theturingpost/status/1942548274113847764?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2025-07-08 [Paper Note] On the Trustworthiness of Generative Foundation Models: Guideline, Assessment, and Perspective, Yue Huang+, arXiv'25 Summary生成的基盤モデル(GenFMs)の信頼性に関する課題に対処するためのフレームワークを提案。第一に、AIガバナンス法や業界基準をレビューし、GenFMsの指針原則を提案。第二に、信頼性評価のための動的ベンチマークプラットフォーム「TrustGen」を紹介し、静的評価の限界を克服。最後に、信頼性の課題と将来の方向性を議論し、実用性と信頼性のトレードオフを強調。研究はGenAIの信頼性向上に寄与し、動的評価ツールキットを公開。 Comment元ポスト:https://x.com/theturingpost/status/1942548274113847764?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #RecommenderSystems #Embeddings #InformationRetrieval #LanguageModel #SequentialRecommendation #Generalization Issue Date: 2025-07-08 [Paper Note] Do We Really Need Specialization? Evaluating Generalist Text Embeddings for Zero-Shot Recommendation and Search, Matteo Attimonelli+, arXiv'25 Summary事前学習済み言語モデル(GTEs)は、逐次推薦や製品検索においてファインチューニングなしで優れたゼロショット性能を発揮し、従来のモデルを上回ることを示す。GTEsは埋め込み空間に特徴を均等に分配することで表現力を高め、埋め込み次元の圧縮がノイズを減少させ、専門モデルの性能向上に寄与する。再現性のためにリポジトリを提供。 Comment元ポスト:https://x.com/_reachsumit/status/1942463379639349654?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・2182 #GraphBased #NLP #LLMAgent #ScientificDiscovery Issue Date: 2025-07-08 [Paper Note] AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench, Edan Toledo+, arXiv'25 SummaryAI研究エージェントは、機械学習の自動化を通じて科学の進展を促進する可能性がある。本研究では、MLE-benchというKaggleコンペティションを用いてエージェントの性能向上に取り組み、検索ポリシーとオペレーターを用いて候補解の空間を探索する方法を提案。異なる検索戦略とオペレーターの組み合わせが高いパフォーマンスに寄与することを示し、MLE-bench liteでの結果を向上させ、Kaggleメダル獲得率を39.6%から47.7%に引き上げた。自動化された機械学習の進展には、これらの要素を共同で考慮することが重要である。 Comment元ポスト:https://x.com/martinjosifoski/status/1942238775305699558?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1457グラフ中の各ノードはartifacts(i.e., エージェントが生成したコード)で、先行研究がiterativeな実験に加え、潜在的なsolutionに対してtree searchをすることでSoTAを達成しており、これをグラフを用いてより一般化することで異なるデザインのエージェントでも適用できるようにしている。
あとで追記する #ComputerVision #MachineLearning #NLP #LanguageModel #Transformer #MulltiModal #Architecture #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2025-07-06 [Paper Note] Energy-Based Transformers are Scalable Learners and Thinkers, Alexi Gladstone+, arXiv'25 Summaryエネルギーベースのトランスフォーマー(EBTs)を用いて、無監督学習から思考を学ぶモデルを提案。EBTsは、入力と候補予測の互換性を検証し、エネルギー最小化を通じて予測を行う。トレーニング中に従来のアプローチよりも高いスケーリング率を達成し、言語タスクでの性能を29%向上させ、画像のノイズ除去でも優れた結果を示す。EBTsは一般化能力が高く、モデルの学習能力と思考能力を向上させる新しいパラダイムである。 Comment元ポスト:https://x.com/hillbig/status/1941657099567845696?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QProject Page:https://energy-based-transformers.github.ioFirst Authorの方による解説ポスト:https://x.com/alexiglad/status/1942231878305714462?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #LanguageModel #Evaluation #LLM-as-a-Judge #ICML Issue Date: 2025-07-05 [Paper Note] Correlated Errors in Large Language Models, Elliot Kim+, ICML'25 Summary350以上のLLMを評価し、リーダーボードと履歴書スクリーニングタスクで実証的な分析を実施。モデル間のエラーには実質的な相関があり、特に大きく正確なモデルは異なるアーキテクチャやプロバイダーでも高い相関を示す。相関の影響はLLMを評価者とするタスクや採用タスクにおいても確認された。 Comment元ポスト:https://x.com/kennylpeng/status/1940758198320796065?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこれは結果を細かく見るのと、評価したタスクの形式とバイアスが生じないかをきちんと確認した方が良いような気がする。
それは置いておいたとして、たとえば、Figure9bはLlamaの異なるモデルサイズは、高い相関を示しているが、それはベースが同じだからそうだろうなあ、とは思う。一方、9aはClaude, Nova, Mistral, GPTなど多様なプロバイダーのモデルで高い相関が示されている。Llama3-70BとLLama3.{1,2,3}-70Bでは相関が低かったりしている。
Figure1(b)はHELMで比較的最新のモデル間でプロバイダーが別でも高い相関があるようにみえる。
このような相関がある要因や傾向については論文を読んでみないとわからない。OpenReview:https://openreview.net/forum?id=kzYq2hfyHB&referrer=%5Bthe%20profile%20of%20Kenny%20Peng%5D(%2Fprofile%3Fid%3D~Kenny_Peng1)LLM-as-a-Judgeにおいて、評価者となるモデルと評価対象となるモデルが同じプロバイダーやシリーズの場合は(エラーの傾向が似ているので)性能がAccuracyが真のAccuracyよりも高めに出ている。また評価者よりも性能が低いモデルに対しても、性能が実際のAccuracyよりも高めに出す傾向にある(エラーの相関によってエラーであるにも関わらず正解とみなされAccuracyが高くなる)ようである。逆に、評価者よりも評価対象が性能が高い場合、評価者は自分が誤ってしまうquestionに対して、評価対象モデルが正解となる回答をしても、それに対して報酬を与えることができず性能が低めに見積もられてしまう。これだけの規模の実験で示されたことは、大変興味深い。
・2137pointwise, pairwise, listwiseの基礎はこちらを参照:
・187 #NLP #Dataset #LanguageModel #Alignment #Supervised-FineTuning (SFT) #MultiLingual #DPO #PostTraining #Cultural Issue Date: 2025-07-04 [Paper Note] CARE: Assessing the Impact of Multilingual Human Preference Learning on Cultural Awareness, Geyang Guo+, arXiv'25 Summary本論文では、文化的多様性を考慮した言語モデル(LM)の訓練方法を分析し、ネイティブな文化的好みを取り入れることで、LMの文化的認識を向上させることを目指します。3,490の文化特有の質問と31,700のネイティブな判断を含むリソース「CARE」を紹介し、高品質なネイティブの好みを少量取り入れることで、さまざまなLMの性能が向上することを示します。また、文化的パフォーマンスが強いモデルはアラインメントからの恩恵を受けやすく、地域間でのデータアクセスの違いがモデル間のギャップを生むことが明らかになりました。CAREは一般に公開される予定です。 Comment元ポスト:https://x.com/cherylolguo/status/1940798823405600843?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #DiffusionModel #2D #3D #FeatureMatching Issue Date: 2025-07-04 [Paper Note] Learning Dense Feature Matching via Lifting Single 2D Image to 3D Space, Yingping Liang+, arXiv'25 Summary新しい二段階フレームワーク「Lift to Match (L2M)」を提案し、2D画像を3D空間に持ち上げることで、特徴マッチングの一般化を向上させる。第一段階で3D特徴エンコーダを学習し、第二段階で特徴デコーダを学習することで、堅牢な特徴マッチングを実現。実験により、ゼロショット評価ベンチマークで優れた一般化性能を示した。 Comment元ポスト:https://x.com/zhenjun_zhao/status/1940399755827270081?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Transformer #Architecture #Normalization #Admin'sPick Issue Date: 2025-07-03 [Paper Note] The Curse of Depth in Large Language Models, Wenfang Sun+, arXiv'25 Summary本論文では、「深さの呪い」という現象を紹介し、LLMの深い層が期待通りに機能しない理由を分析します。Pre-LNの使用が出力の分散を増加させ、深い層の貢献を低下させることを特定。これを解決するために層正規化スケーリング(LNS)を提案し、出力分散の爆発を抑制します。実験により、LNSがLLMの事前トレーニング性能を向上させることを示し、教師ありファインチューニングにも効果があることを確認しました。 Comment元ポスト:https://x.com/shiwei_liu66/status/1940377801032446428?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1795
ではそもそもLayerNormalizationを無くしていた(正確にいうとparametrize tanhに置換)が、どちらが優れているのだろうか?
では知識ニューロンの存在が示唆されており、これはTransformerの層の深い位置に存在し、かつ異なる知識間で知識ニューロンはシェアされない傾向にあった(ただしこれはPost-LNのBERTの話で本研究はPre-LNの話だが。Post-LNの勾配消失問題を緩和し学習を安定化させる研究も2141 のように存在する)。これはこの研究が明らかにしたこととどういう関係性があるだろうか。
また、LayerNormalizationのScalingによって深いTransformerブロックの導関数が単位行列となる(学習に寄与しなくなる)ことが改善された場合、知識ニューロンはどのように変化するだろうか?
(下記Geminiの応答を見た上での感想)なんとなーくだけれども、おそらく知識ニューロンの局所化が解消されるのかなーという気がする。
となると次の疑問としては、MoEアーキテクチャにはどのような影響があるだろうか?
そもそも知識ニューロンが局所化しているからMoEアーキテクチャのルータによって関連するExpertsのみをactivateすれば(というより結果的にそうなるように学習される)性能を劣化させずに計算効率を上げられていた、と仮定する。そうすると、知識ニューロンが局所化せずに多くのニューロンでシェアされるようになると、2110 のように、サブネットワーク間の情報を互いにやりとりできます、みたいな仕組みがより効いてきそうな気がする。
参考までに、Gemini2.5-Proに考察させてみた結果をメモとして残しておく(あくまで参考程度に...)
```
ご質問ありがとうございます。非常に興味深い着眼点ですね。「Knowledge Neurons in Pretrained Transformers」と「The Curse of Depth in Large Language Models」は、一見すると全く異なるテーマを扱っているように見えますが、「Transformerの深い層における振る舞い」という共通点で結びつけて考察すると、非常に示唆に富んだ関係性が見えてきます。
以下に、両方の論文の概要を解説し、その関係性について考察します。
1. Knowledge Neurons in Pretrained Transformers の概要
この研究は、事前学習済みTransformerモデル(特にBERTなど)の内部で、特定の事実知識がどのように格納されているかを調査したものです。
発見: モデルの中間層、特に全結合層(Feed-Forward Network, FFN)に、特定の知識(例:「ダンテ・アリギエーリはイタリアで生まれた」)に強く反応する「知識ニューロン」が存在することを発見しました。
特徴: これらの知識ニューロンは、モデルの深い層(後方の層)に、より多く存在する傾向がありました。
意味: これまでブラックボックスとされてきた大規模言語モデルの内部で、知識がどのように表現・局在化しているかについて、具体的な手がかりを与えた画期的な研究です。
2. The Curse of Depth in Large Language Models の概要
この研究は、LLMをより深く(層を多く)することの難しさに焦点を当て、その原因と解決策を提案したものです。
問題(深さの呪い): Transformerの標準的なアーキテクチャ(Pre-LN)では、層が深くなるにつれて、LayerNormalization(LN)への入力の分散が指数関数的に増大してしまいます。
結果:
出力が大きくなりすぎて学習が不安定になります。
さらに深刻なのは、深い層ではモデルの出力に関する導関数(勾配計算に必要)がほぼ単位行列になってしまうことです。これは、その層が入力に対してほとんど変換を行わなくなり、学習に寄与しなくなることを意味します。
解決策: この問題を解決するため、各層のLayerNormalizationをその深さ(レイヤー番号 l)に応じてスケーリングするというシンプルな手法を提案しました。これにより、深い層でも勾配が適切に伝播し、学習が安定・改善することが示されました。
考察:2つの研究の関係性
これら2つの研究は、「学習の安定性」と「知識の格納方法」という異なる側面から、Transformerの深い層を分析していますが、両者には以下のような深い関係性があると考えられます。
学習の不安定性が「知識ニューロン」形成の背景にある可能性
「The Curse of Depth」で指摘されているように、標準的なTransformerの深い層は、本質的に学習が不安定で、勾配情報が失われやすい環境にあります。
この劣悪な学習環境こそが、「知識ニューロン」という形で知識が局所的に格納される原因の一つになっている可能性があります。つまり、
学習の非効率性: 深い層のほとんどのニューロンは、勾配消失問題のために効率的に学習を進めることができません。
専門化の発生: そのような不安定な環境下で、たまたま特定の知識パターンをうまく捉えることができた一部のニューロンが、その知識を一身に背負う形で強く活性化するよう特化(専門化)していったのではないか、と考えられます。これは、ネットワーク全体で協調して学習するのが難しい状況で、一部のユニットだけが突出して学習を担う、という現象と解釈できます。
学習の安定化が、より効率的な知識獲得につながる
では、「The Curse of Depth」で提案された手法(LNのスケーリング)によって深い層の学習が安定化すると、知識の格納方法はどのように変わるでしょうか。
これは非常に興味深い問いであり、2つの可能性が考えられます。
可能性A: より強固な知識ニューロンの形成:
学習が安定することで、各知識ニューロンはより明確に、そして効率的に特定の知識をエンコードできるようになるかもしれません。ノイズの多い環境で偶然生まれた専門家ではなく、安定した環境で育成された真の専門家へと変化するイメージです。
可能性B: 知識の分散化:
ネットワークの全ニューロンが効率的に学習に寄与できるようになるため、一つの知識を少数のニューロンに集中させる必要がなくなり、より多くのニューロンに分散して知識が格納されるようになる可能性も考えられます。
現在のところ、学習の安定化は、知識ニューロンがより効率的に形成・機能するための基盤を提供すると考えるのが最も妥当でしょう。「深さの呪い」という問題を解決することは、モデルが知識をどのように獲得し、整理するかという、より根源的なメカニズム(知識ニューロンの振る舞い)にも直接的な影響を与えるはずです。
まとめ
「Knowledge Neurons」は深い層に存在する知識の「状態」を明らかにし、「The Curse of Depth」は深い層で発生する学習の「問題」とその解決策を提示しました。
これらを統合すると、「深い層における学習の不安定性という問題が、知識ニューロンという局所的な知識表現を生み出す一因となっており、この問題を解決することで、より効率的で安定した知識の獲得・格納が可能になるかもしれない」という関係性が見えてきます。
両者は、LLMの能力と限界を異なる角度から照らし出しており、組み合わせることでモデルの内部動作の解明をさらに一歩前進させる、非常に重要な研究だと言えます。
``` Issue Date: 2025-07-03 [Paper Note] Assembly of Experts: Linear-time construction of the Chimera LLM variants with emergent and adaptable behaviors, Henrik Klagges+, arXiv'25 Summary新しい「Assembly-of-Experts」(AoE)構築法を開発し、LLMの事前学習コストを削減。親モデルの重みを補間することで、子モデルの特性を調整可能。生成されたモデルは機能的で、探索が容易。671Bオープンウェイトハイブリッドモデル「Chimera」を構築し、R1の知能を維持しつつ出力トークンを約40%削減。ファインチューニングなしで、親モデルよりもコンパクトで効率的な推論を実現。 Commentモデル(tngtech/DeepSeek-TNG-R1T2-Chimera):
https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera公式ポスト:https://x.com/tngtech/status/1940531045432283412?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #EfficiencyImprovement #NLP #LanguageModel #Reasoning #Distillation Issue Date: 2025-07-03 [Paper Note] NaturalThoughts: Selecting and Distilling Reasoning Traces for General Reasoning Tasks, Yang Li+, arXiv'25 Summary教師モデルからの推論トレースを用いて生徒モデルの能力を向上させる方法を体系的に研究。NaturalReasoningに基づく高品質な「NaturalThoughts」をキュレーションし、サンプル効率とスケーラビリティを分析。データサイズの拡大が性能向上に寄与し、多様な推論戦略を必要とする例が効果的であることを発見。LlamaおよびQwenモデルでの評価により、NaturalThoughtsが既存のデータセットを上回り、STEM推論ベンチマークで優れた性能を示した。 Comment元ポスト:https://x.com/jaseweston/status/1940656092054204498?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1768 #ComputerVision #Pretraining #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #MulltiModal #RLHF #Reasoning #LongSequence #mid-training #RewardHacking #PostTraining #CurriculumLearning #RLVR #Admin'sPick #VisionLanguageModel Issue Date: 2025-07-03 [Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25 Summary視覚言語モデルGLM-4.1V-Thinkingを発表し、推論中心のトレーニングフレームワークを開発。強力な視覚基盤モデルを構築し、カリキュラムサンプリングを用いた強化学習で多様なタスクの能力を向上。28のベンチマークで最先端のパフォーマンスを達成し、特に難しいタスクで競争力のある結果を示す。モデルはオープンソースとして公開。 Comment元ポスト:https://x.com/sinclairwang1/status/1940331927724232712?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQwen2.5-VLよりも性能が良いVLM
#LLMAgent #Investigation Issue Date: 2025-07-02 [Paper Note] Future of Work with AI Agents: Auditing Automation and Augmentation Potential across the U.S. Workforce, Yijia Shao+, arXiv'25 Summary本論文では、労働者がAIエージェントに自動化または補完してほしい職業タスクを評価する新しい監査フレームワークを提案し、労働者の希望と技術的能力の一致を分析します。音声強化ミニインタビューを用いて「人間主体性スケール(HAS)」を導入し、米国労働省のONETデータベースを基にしたWORKBankデータベースを構築しました。タスクを自動化のゾーンに分類し、AIエージェント開発におけるミスマッチと機会を明らかにします。結果は職業ごとの多様なHASプロファイルを示し、AIエージェントの統合がスキルのシフトを促す可能性を示唆しています。これにより、AIエージェントの開発を労働者の希望に整合させる重要性が強調されます。 Comment元ポスト:https://x.com/hillbig/status/1939806172061868173?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MulltiModal Issue Date: 2025-07-02 [Paper Note] MARBLE: A Hard Benchmark for Multimodal Spatial Reasoning and Planning, Yulun Jiang+, arXiv'25 SummaryMARBLEという新しいマルチモーダル推論ベンチマークを提案し、MLLMsの複雑な推論能力を評価。MARBLEは、空間的・視覚的・物理的制約下での多段階計画を必要とするM-PortalとM-Cubeの2つのタスクから成る。現在のMLLMsは低いパフォーマンスを示し、視覚的入力からの情報抽出においても失敗が見られる。これにより、次世代モデルの推論能力向上が期待される。 Comment元ポスト:https://x.com/michael_d_moor/status/1940062842742526445?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QPortal2を使った新たなベンチマーク。筆者は昔このゲームを少しだけプレイしたことがあるが、普通に難しかった記憶がある😅
細かいが表中のGPT-o3は正しくはo3だと思われる。
時間がなくて全然しっかりと読めていないが、reasoning effortやthinkingモードはどのように設定して評価したのだろうか。
・1942abstを見る限りFinewebを多言語に拡張した模様 #Analysis #NLP #LanguageModel #ReinforcementLearning #mid-training #PostTraining #read-later #Admin'sPick Issue Date: 2025-06-27 [Paper Note] OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling, Zengzhi Wang+, arXiv'25 Summary異なるベース言語モデル(LlamaやQwen)の強化学習(RL)における挙動を調査し、中間トレーニング戦略がRLのダイナミクスに与える影響を明らかに。高品質の数学コーパスがモデルのパフォーマンスを向上させ、長い連鎖的思考(CoT)がRL結果を改善する一方で、冗長性や不安定性を引き起こす可能性があることを示す。二段階の中間トレーニング戦略「Stable-then-Decay」を導入し、OctoThinkerモデルファミリーを開発。オープンソースのモデルと数学推論コーパスを公開し、RL時代の基盤モデルの研究を支援することを目指す。 Comment元ポスト:https://x.com/sinclairwang1/status/1938244843857449431?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qmid-trainingの観点から、post trainingにおけるRLがスケーリングする条件をsystematicallyに調査している模様論文中にはmid-training[^1]の定義が記述されている:
[^1]: mid-trainingについてはコミュニティの間で厳密な定義はまだ無くバズワードっぽく使われている、という印象を筆者は抱いており、本稿は文献中でmid-trainingを定義する初めての試みという所感 #NLP #LanguageModel #ReinforcementLearning Issue Date: 2025-06-27 [Paper Note] RLPR: Extrapolating RLVR to General Domains without Verifiers, Tianyu Yu+, arXiv'25 SummaryRLVRはLLMの推論能力を向上させるが、主に数学やコードに限られる。これを克服するため、検証者不要のRLPRフレームワークを提案し、LLMのトークン確率を報酬信号として利用。ノイズの多い確率報酬に対処する手法を導入し、実験によりGemma、Llama、Qwenモデルで推論能力を向上させた。特に、TheoremQAで7.6ポイント、Minervaで7.5ポイントの改善を示し、General-Reasonerを平均1.6ポイント上回った。 Comment元ポスト:https://x.com/hillbig/status/1938359430980268329?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q既存のRLVRはVerifierを構築しなければならず、しばしばそのVerifierは複雑になりやすく、スケールさせるには課題があった。RLPR(Probabliity Reward)は、生成された応答から回答yを抽出し、残りをreasoning zとする。そして回答部分yをreference y^\で置換したトークン列o'を生成(zがo'に対してどのような扱いになるかは利用するモデルや出力フォーマットによる気がする)し、o'のポリシーモデルでのトークン単位での平均生成確率を報酬とする。尤度のような系列全体の生起確率を考慮する方法が直感的に役に立ちそうだが、計算の際の確率積は分散が高いだけでなく、マイナーな類義語が与えられた時に(たとえば1 tokenだけ生起確率が小さかった場合)に、Rewardが極端に小さくなりsensitiveであることを考察し、平均生成確率を採用している。
Rule basedなVerifierを用いたRLVRよりもgeneralなドメインとmathドメインで性能向上。コーディングなどでも効果はあるのだろうか?
下記のようなpre-queryテンプレートを与え(i.e., userの発話は何も与えず、ユーザの発話を表す特殊トークンのみを渡す)instructionを生成し、post-queryテンプレートを与える(i.e., pre-queryテンプレート+生成されたinstruction+assistantの発話の開始を表す特殊トークンのみを渡す)ことでresponseを生成することで、prompt engineeringやseed無しでinstruction tuningデータを合成できるという手法。
生成した生のinstruction tuning pair dataは、たとえば下記のようなフィルタリングをすることで品質向上が可能で
reward modelと組み合わせてLLMからのresponseを生成しrejection samplingすればDPOのためのpreference dataも作成できるし、single turnの発話まで生成させた後もう一度pre/post-queryをconcatして生成すればMulti turnのデータも生成できる。
他のも例えば、システムプロンプトに自分が生成したい情報を与えることで、特定のドメインに特化したデータ、あるいは特定の言語に特化したデータも合成できる。
・1761 #NLP #Dataset #LanguageModel #Alignment #Safety #Japanese #PostTraining Issue Date: 2025-06-25 [Paper Note] AnswerCarefully: A Dataset for Improving the Safety of Japanese LLM Output, Hisami Suzuki+, arXiv'25 Summary日本のLLMの安全性を高めるためのデータセット「AnswerCarefully」を紹介。1,800組の質問と参照回答から成り、リスクカテゴリをカバーしつつ日本の文脈に合わせて作成。微調整により出力の安全性が向上し、12のLLMの安全性評価結果も報告。英語翻訳と注釈を提供し、他言語でのデータセット作成を促進。 CommentBlog:https://llmc.nii.ac.jp/answercarefully-dataset/ #EfficiencyImprovement #Pretraining #NLP #LanguageModel #MoE(Mixture-of-Experts) #ICLR Issue Date: 2025-06-25 [Paper Note] Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization, Taishi Nakamura+, ICLR'25 SummaryDrop-Upcycling手法を提案し、MoEモデルのトレーニング効率を向上。事前にトレーニングされた密なモデルの知識を活用しつつ、一部の重みを再初期化することで専門家の専門化を促進。大規模実験により、5.9BパラメータのMoEモデルが13B密なモデルと同等の性能を達成し、トレーニングコストを約1/4に削減。すべての実験リソースを公開。 CommentOpenReview:https://openreview.net/forum?id=gx1wHnf5Vp関連:
・1546提案手法の全体像とDiversity re-initializationの概要。元のUpcyclingでは全てidenticalな重みでreplicateされていたため、これが個々のexpertがlong termでの学習で特化することの妨げになり、最終的に最大限のcapabilityを発揮できず、収束が遅い要因となっていた。これを、Upcyclingした重みのうち、一部のindexのみを再初期化することで、replicate元の知識を保持しつつ、expertsの多様性を高めることで解決する。
提案手法は任意のactivation function適用可能。今回はFFN Layerのactivation functionとして一般的なSwiGLUを採用した場合で説明している。
Drop-Upcyclingの手法としては、通常のUpcyclingと同様、FFN Layerの重みをn個のexpertsの数だけreplicateする。その後、re-initializationを実施する比率rに基づいて、[1, intermediate size d_f]の範囲からrd_f個のindexをサンプリングする。最終的にSwiGLU、およびFFNにおける3つのWeight W_{gate, up, down}において、サンプリングされたindexと対応するrow/columnと対応する重みをre-initializeする。
re-initializeする際には、各W_{gate, up, down}中のサンプリングされたindexと対応するベクトルの平均と分散をそれぞれ独立して求め、それらの平均と分散を持つ正規分布からサンプリングする。
学習の初期から高い性能を発揮し、long termでの性能も向上している。また、learning curveの形状もscratchから学習した場合と同様の形状となっており、知識の転移とexpertsのspecializationがうまく進んだことが示唆される。
・1829 #NLP #LanguageModel #Reasoning #PRM Issue Date: 2025-06-25 [Paper Note] ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs, Jiaru Zou+, arXiv'25 Summary新しいプロセス報酬モデルReasonFlux-PRMを提案し、推論トレースの評価を強化。ステップと軌道の監視を組み込み、報酬割り当てを細かく行う。実験により、ReasonFlux-PRM-7Bが高品質なデータ選択と性能向上を実現し、特に監視付きファインチューニングで平均12.1%の向上を達成。リソース制約のあるアプリケーション向けにReasonFlux-PRM-1.5Bも公開。 Comment元ポスト:https://x.com/_akhaliq/status/1937345023005048925?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #LanguageModel #MulltiModal #Tokenizer Issue Date: 2025-06-24 [Paper Note] Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations, Jiaming Han+, arXiv'25 Summary本論文では、視覚理解と生成を統一するマルチモーダルフレームワークTarを提案。Text-Aligned Tokenizer(TA-Tok)を用いて画像を離散トークンに変換し、視覚とテキストを統一空間に統合。スケール適応型のエンコーディングとデコーディングを導入し、高忠実度の視覚出力を生成。迅速な自己回帰モデルと拡散ベースのモデルを用いたデトークナイザーを活用し、視覚理解と生成の改善を実現。実験結果では、Tarが既存手法と同等以上の性能を示し、効率的なトレーニングを達成。 Comment元ポスト:https://x.com/_akhaliq/status/1937345768223859139?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtext modalityとvision modalityを共通の空間で表現する
・mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
・一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
・簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
・各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
・必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
・たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
・一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
・異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
・(これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
・非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
・RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
・モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
・モデルサイズが大きいとより多様なreasoningパスがunlockされている
・pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた #ComputerVision #Transformer #CVPR #3D Reconstruction #Backbone Issue Date: 2025-06-22 [Paper Note] VGGT: Visual Geometry Grounded Transformer, Jianyuan Wang+, CVPR'25 SummaryVGGTは、シーンの主要な3D属性を複数のビューから直接推測するフィードフォワードニューラルネットワークであり、3Dコンピュータビジョンの分野において新たな進展を示します。このアプローチは効率的で、1秒未満で画像を再構築し、複数の3Dタスクで最先端の結果を達成します。また、VGGTを特徴バックボーンとして使用することで、下流タスクの性能が大幅に向上することが示されています。コードは公開されています。 Comment元ポスト:https://x.com/hillbig/status/1936711294956265820?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Document #NLP #Library #ACL #parser Issue Date: 2025-06-21 [Paper Note] Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting, Hao Feng+, ACL'25 Summary文書画像解析の新モデル「Dolphin」を提案。レイアウト要素をシーケンス化し、タスク特有のプロンプトと組み合わせて解析を行う。3000万以上のサンプルで訓練し、ページレベルと要素レベルの両方で最先端の性能を達成。効率的なアーキテクチャを実現。コードは公開中。 Commentrepo:https://github.com/bytedance/DolphinSoTAなDocumentのparser
・1546 #Analysis #NLP #LanguageModel #Chain-of-Thought Issue Date: 2025-06-18 [Paper Note] Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought, Hanlin Zhu+, arXiv'25 Summary本研究では、連続CoTsを用いた二層トランスフォーマーが有向グラフ到達可能性問題を解決できることを証明。連続CoTsは複数の探索フロンティアを同時にエンコードし、従来の離散CoTsよりも効率的に解を導く。実験により、重ね合わせ状態が自動的に現れ、モデルが複数のパスを同時に探索することが確認された。 Comment元ポスト:https://x.com/tydsh/status/1935206012799303817?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #OpenWeight #OpenSource #PostTraining Issue Date: 2025-06-18 [Paper Note] AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy, Zihan Liu+, arXiv'25 Summary本研究では、教師ありファインチューニング(SFT)と強化学習(RL)の相乗効果を探求し、SFTトレーニングデータの整備においてプロンプト数の増加が推論性能を向上させることを示しました。特に、サンプリング温度を適切に調整することで、RLトレーニングの効果を最大化できることが分かりました。最終的に、AceReason-Nemotron-1.1モデルは、前モデルを大きく上回り、数学およびコードベンチマークで新たな最先端性能を達成しました。 Comment元ポスト:https://x.com/ychennlp/status/1935005283178492222?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
様々なtakeawayがまとめられている。SFT,RLに利用されたデータも公開・1829
において事前学習時に4 epochまでは性能の改善幅が大きいと報告されていたが、SFTでも5 epoch程度まで学習すると良い模様。
また、SFT dataをscalingさせる際は、promptの数だけでなく、prompt単位のresponse数を増やすのが効果的
ベンチマークに含まれる課題のカテゴリ
実サンプルやケーススタディなどはAppendix参照のこと。 #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-06-17 [Paper Note] RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning, Yu Wang+, arXiv'25 SummaryRAG+は、Retrieval-Augmented Generationの拡張で、知識の適用を意識した推論を組み込む。二重コーパスを用いて、関連情報を取得し、目標指向の推論に適用する。実験結果は、RAG+が標準的なRAGを3-5%、複雑なシナリオでは最大7.5%上回ることを示し、知識統合の新たなフレームワークを提供する。 Comment元ポスト:https://x.com/omarsar0/status/1934667096828399641?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q知識だけでなく知識の使い方も蓄積し、利用時に検索された知識と紐づいた使い方を活用することでRAGの推論能力を向上させる。
が、真にこの手法が力を発揮するのは「ドメイン固有の使い方やルール」が存在する場合で、どれだけLLMが賢くなっても推論によって導き出せないもの、のついては、こういった手法は効力を発揮し続けるのではないかと思われる。 #NLP #Dataset #LLMAgent #Evaluation #Programming #LongSequence Issue Date: 2025-06-17 [Paper Note] ALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering, Yuki Imajuku+, arXiv'25 SummaryAIシステムの最適化問題に対するパフォーマンスを評価する新しいベンチマークALE-Benchを提案。ALE-Benchは実際のタスクに基づき、長期的な解決策の洗練を促進する。大規模言語モデル(LLM)の評価では特定の問題で高いパフォーマンスを示すが、一貫性や長期的な問題解決能力において人間とのギャップが残ることが明らかになり、今後のAI進展に向けた必要性を示唆している。 Comment元ポスト:https://x.com/sakanaailabs/status/1934767254715117812?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連ポスト:https://x.com/iwiwi/status/1934830621756674499?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #KnowledgeEditing #FactualKnowledge #meta-learning Issue Date: 2025-06-17 [Paper Note] PropMEND: Hypernetworks for Knowledge Propagation in LLMs, Zeyu Leo Liu+, arXiv'25 SummaryPropMENDは、LLMsにおける知識伝播を改善するためのハイパーネットワークベースのアプローチである。メタ学習を用いて、注入された知識がマルチホップ質問に答えるために伝播するように勾配を修正する。RippleEditデータセットで、難しい質問に対して精度がほぼ2倍向上し、Controlled RippleEditデータセットでは新しい関係やエンティティに対する知識伝播を評価。PropMENDは既存の手法を上回るが、性能差は縮小しており、今後の研究で広範な関係への知識伝播が求められる。 Comment元ポスト:https://x.com/zeyuliu10/status/1934659512046330057?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来のKnowledge Editing手法は新たな知識を記憶させることはできる(i.e., 注入した知識を逐語的に生成できる;東京は日本の首都である。)が、知識を活用することは苦手だった(i.e., 日本の首都の気候は?)ので、それを改善するための手法を提案している模様。
既存手法のlimitationは
・editing手法で学習をする際に知識を伝搬させるデータが無く
・目的関数がraw textではなく、QA pairをSFTすること
によって生じるとし、
・学習時にpropagation question(Figure1のオレンジ色のQA; 注入した知識を活用して推論が必要なQA)を用意しどのように知識を伝搬(活用)させるかを学習し
・目的関数をCausal Language Modeling Loss
にすることで改善する、とのこと。
non-verbatimなQA(注入された知識をそのまま回答するものではなく、何らかの推論が必要なもの)でも性能が向上。
・643
・2055 #NLP #LanguageModel #Hallucination #ICML Issue Date: 2025-06-14 [Paper Note] Steer LLM Latents for Hallucination Detection, Seongheon Park+, ICML'25 SummaryLLMの幻覚問題に対処するため、Truthfulness Separator Vector(TSV)を提案。TSVは、LLMの表現空間を再構築し、真実と幻覚の出力を分離する軽量な指向ベクトルで、モデルのパラメータを変更せずに機能。二段階のフレームワークで、少数のラベル付き例からTSVを訓練し、ラベルのない生成物を拡張。実験により、TSVは最小限のラベル付きデータで高いパフォーマンスを示し、実世界のアプリケーションにおける実用的な解決策を提供。 Comment元ポスト:https://x.com/sharonyixuanli/status/1933522788645810493?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Reasoning #Reproducibility Issue Date: 2025-06-13 [Paper Note] Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning, Jiayi Yuan+, arXiv'25 Summary本研究では、大規模言語モデル(LLMs)のパフォーマンスの再現性が脆弱であることを示し、システム構成の変更が応答に大きな影響を与えることを明らかにしました。特に、初期トークンの丸め誤差が推論精度に波及する問題を指摘し、浮動小数点演算の非結合的性質が変動の根本原因であるとしています。様々な条件下での実験を通じて、数値精度が再現性に与える影響を定量化し、評価実践における重要性を強調しました。さらに、LayerCastという軽量推論パイプラインを開発し、メモリ効率と数値安定性を両立させる方法を提案しました。 #ComputerVision #Transformer #DiffusionModel #VideoGeneration/Understandings Issue Date: 2025-06-13 [Paper Note] Seedance 1.0: Exploring the Boundaries of Video Generation Models, Yu Gao+, arXiv'25 SummarySeedance 1.0は、動画生成の基盤モデルであり、プロンプト遵守、動きの妥当性、視覚的品質を同時に向上させることを目指しています。主な技術改善として、意味のある動画キャプションを用いたデータキュレーション、マルチショット生成のサポート、動画特有のRLHFを活用したファインチューニング、推論速度の約10倍向上を実現する蒸留戦略が挙げられます。Seedance 1.0は、1080p解像度の5秒間の動画を41.4秒で生成し、高品質かつ迅速な動画生成を実現しています。 Comment元ポスト:https://x.com/scaling01/status/1933048431775527006?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #PostTraining #read-later Issue Date: 2025-06-13 [Paper Note] Resa: Transparent Reasoning Models via SAEs, Shangshang Wang+, arXiv'25 SummaryResaという1.5Bの推論モデル群を提案し、効率的なスパースオートエンコーダーチューニング(SAE-Tuning)手法を用いて訓練。これにより、97%以上の推論性能を保持しつつ、訓練コストを2000倍以上削減し、訓練時間を450倍以上短縮。軽いRL訓練を施したモデルで高い推論性能を実現し、抽出された推論能力は一般化可能かつモジュール化可能であることが示された。全ての成果物はオープンソース。 Comment元ポスト:https://x.com/iscienceluvr/status/1933101904529363112?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q著者ポスト:https://x.com/upupwang/status/1933207676663865482?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q論文中で利用されているSource Modelの一つ:
・1935 #EfficiencyImprovement #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML Issue Date: 2025-06-12 [Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25 SummaryText-to-LoRA(T2L)は、自然言語による説明に基づいて大規模言語モデル(LLMs)を迅速に適応させる手法で、従来のファインチューニングの高コストと時間を克服します。T2Lは、LoRAを安価なフォワードパスで構築するハイパーネットワークを使用し、タスク特有のアダプターと同等のパフォーマンスを示します。また、数百のLoRAインスタンスを圧縮し、新しいタスクに対してゼロショットで一般化可能です。このアプローチは、基盤モデルの専門化を民主化し、計算要件を最小限に抑えた言語ベースの適応を実現します。 Comment元ポスト:https://x.com/roberttlange/status/1933074366603919638?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qな、なるほど、こんな手が…! #NLP #Supervised-FineTuning (SFT) #LLMAgent #x-Use Issue Date: 2025-06-12 [Paper Note] Go-Browse: Training Web Agents with Structured Exploration, Apurva Gandhi+, arXiv'25 SummaryGo-Browseを提案し、ウェブ環境の構造的探索を通じて多様なデータを自動収集。グラフ探索を用いて効率的なデータ収集を実現し、WebArenaベンチマークで成功率21.7%を達成。これはGPT-4o miniを2.4%上回り、10B未満のモデルでの最先端結果を2.9%上回る。 Comment元ポスト:https://x.com/gneubig/status/1932786231542493553?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWebArena:
・1849 #Pretraining #NLP #LanguageModel #ReinforcementLearning Issue Date: 2025-06-12 [Paper Note] Reinforcement Pre-Training, Qingxiu Dong+, arXiv'25 Summary本研究では、強化学習と大規模言語モデルの新しいスケーリング手法「強化事前学習(RPT)」を提案。次のトークン予測を強化学習の推論タスクとして再定義し、一般的なRLを活用することで、ドメイン特有の注釈に依存せずにスケーラブルな方法を提供。RPTは次のトークン予測の精度を向上させ、強化ファインチューニングの基盤を形成。トレーニング計算量の増加が精度を改善することを示し、RPTが言語モデルの事前学習において有望な手法であることを示した。 Comment元ポスト:https://x.com/hillbig/status/1932922314578145640?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Transformer #Architecture #ACL Issue Date: 2025-06-12 [Paper Note] Value Residual Learning, Zhanchao Zhou+, ACL'25 SummaryResFormerは、隠れ状態の残差に値の残差接続を加えることで情報の流れを強化する新しいTransformerアーキテクチャを提案。実験により、ResFormerは従来のTransformerに比べて少ないパラメータとトレーニングデータで同等の性能を示し、SVFormerはKVキャッシュサイズを半減させることができる。性能はシーケンスの長さや学習率に依存する。 Comment元ポスト:https://x.com/zhanchaozhou/status/1932829678081098079?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Figure1のグラフの縦軸は、Functionalityと(UnitTestが通ったか否か)と、Quailty(セキュリティや保守性に関する問題が検出されなかった)、という両方の条件を満たした割合である点に注意。
[^1]:プログラムを実行したときに通る可能性のある経路のすべてをグラフとして表したもの[引用元](https://qiita.com/uint256_t/items/7d4556cb8f5997b9e95c)
[^2]:信頼できない汚染されたデータがプログラム中でどのように処理されるかを分析すること #NLP #LanguageModel #RLVR Issue Date: 2025-06-05 [Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Problems and Verifiable Rewards, Xun Lu, arXiv'25 Summary非検証可能なタスクにおける強化学習のギャップを埋めるため、ペアワイズ生成報酬モデル(GenRM)とブートストラップ相対ポリシー最適化(BRPO)アルゴリズムを提案。これにより、主観的評価を信頼性のある検証可能な報酬に変換し、動的なペアワイズ比較を実現。提案手法は、LLMsの執筆能力を向上させ、スカラー報酬ベースラインに対して一貫した改善を示し、競争力のある結果を達成。全ての言語タスクに適用可能な包括的なRLトレーニングパラダイムの可能性を示唆。 Comment元ポスト:https://x.com/grad62304977/status/1929996614883783170?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWriting Principleに基づいて(e.g., 一貫性、創造性とか?)批評を記述し、最終的に与えられたペアワイズのテキストの優劣を判断するGenerative Reward Model (GenRM; Reasoning Traceを伴い最終的にRewardに変換可能な情報をoutpuするモデル) を学習し、現在生成したresponseグループの中からランダムに一つ擬似的なreferenceを決定し、他のresponseに対しGenRMを適用することで報酬を決定する(BRPO)、といったことをやるらしい。
これにより、創造的な文書作成のような客観的なground truthを適用できないタスクでも、RLVRの恩恵をあずかれるようになる(Bridging the gap)といったことを主張している。RLVRの恩恵とは、Reward Hackingされづらい高品質な報酬、ということにあると思われる。ので、要は従来のPreference dataだけで学習したReward Modelよりも、よりReward Hackingされないロバストな学習を実現できるGenerative Reward Modelを提案し、それを適用する手法BRPOも提案しました、という話に見える。関連:
・2274 #NLP #LanguageModel #ReinforcementLearning #Programming #SoftwareEngineering #UnitTest Issue Date: 2025-06-05 [Paper Note] Co-Evolving LLM Coder and Unit Tester via Reinforcement Learning, Yinjie Wang+, arXiv'25 SummaryCUREは、コーディングとユニットテスト生成を共進化させる強化学習フレームワークで、真のコードを監視せずにトレーニングを行う。ReasonFlux-Coderモデルは、コード生成精度を向上させ、下流タスクにも効果的に拡張可能。ユニットテスト生成では高い推論効率を達成し、強化学習のための効果的な報酬モデルとして機能する。 Comment元ポスト:https://x.com/lingyang_pu/status/1930234983274234232?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QUnitTestの性能向上させます系の研究が増えてきている感関連ポスト:https://x.com/gm8xx8/status/1930348014146859345?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #NLP #LanguageModel #MulltiModal #RLVR #DataMixture Issue Date: 2025-06-05 [Paper Note] MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning, Yiqing Liang+, arXiv'25 Summary検証可能な報酬を用いた強化学習(RLVR)をマルチモーダルLLMsに適用するためのポストトレーニングフレームワークを提案。異なる視覚と言語の問題を含むデータセットをキュレーションし、最適なデータ混合戦略を導入。実験により、提案した戦略がMLLMの推論能力を大幅に向上させることを示し、分布外ベンチマークで平均5.24%の精度向上を達成。 Comment元ポスト:https://x.com/_vztu/status/1930312780701413498?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qマルチモーダルな設定でRLVRを適用すると、すべてのデータセットを学習に利用する場合より、特定のタスクのみのデータで学習した方が当該タスクでは性能が高くなったり(つまりデータが多ければ多いほど良いわけでは無い)、特定のデータをablationするとOODに対する予測性能が改善したりするなど、データ間で干渉が起きて敵対的になってしまうような現象が起きる。このことから、どのように適切にデータを混合できるか?という戦略の必要性が浮き彫りになり、モデルベースなMixture戦略(どうやらデータの混合分布から学習後の性能を予測するモデルな模様)の性能がuniformにmixするよりも高い性能を示した、みたいな話らしい。 #Analysis #NLP #LanguageModel #read-later #Memorization Issue Date: 2025-06-05 [Paper Note] How much do language models memorize?, John X. Morris+, arXiv'25 Summaryモデルの「知識」を推定する新手法を提案し、言語モデルの能力を測定。記憶を「意図しない記憶」と「一般化」に分け、一般化を排除することで総記憶を計算。GPTスタイルのモデルは約3.6ビット/パラメータの能力を持つと推定。データセットのサイズ増加に伴い、モデルは記憶を保持し、一般化が始まると意図しない記憶が減少。数百のトランスフォーマー言語モデルを訓練し、能力とデータサイズの関係を示すスケーリング法則を生成。 Comment元ポスト:https://x.com/rohanpaul_ai/status/1929989864927146414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #EMNLP Issue Date: 2025-06-05 [Paper Note] Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem, Yubo Wang+, EMNLP'25 Summary本研究では、強力な大規模言語モデル(LLM)の推論能力を引き出すために、批評微調整(CFT)が効果的であることを示します。CFTは、単一の問題に対する多様な解を収集し、教師LLMによる批評データを構築する手法です。QwenおよびLlamaモデルを微調整した結果、数学や論理推論のベンチマークで顕著な性能向上を観察しました。特に、わずか5時間のトレーニングで、Qwen-Math-7B-CFTは他の手法と同等以上の成果を上げました。CFTは計算効率が高く、現代のLLMの推論能力を引き出すためのシンプルなアプローチであることが示されました。 Comment元ポスト:https://x.com/wenhuchen/status/1930447298527670662?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1832
・1938参考:https://x.com/weiliu99/status/1930826904522875309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #LLMAgent #SelfImprovement #read-later Issue Date: 2025-06-05 [Paper Note] Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents, Jenny Zhang+, arXiv'25 Summaryダーヴィン・ゴーデルマシン(DGM)は、自己改善するAIシステムであり、コードを反復的に修正し、コーディングベンチマークで変更を検証します。進化とオープンエンドな研究に基づき、生成されたエージェントのアーカイブを維持し、新しいバージョンを作成することで多様なエージェントを育成します。DGMはコーディング能力を自動的に向上させ、SWE-benchでのパフォーマンスを20.0%から50.0%、Polyglotでのパフォーマンスを14.2%から30.7%に改善しました。安全対策を講じた実験により、自己改善を行わないベースラインを大幅に上回る成果を示しました。 Comment元ポスト:https://www.linkedin.com/posts/omarsar_new-paper-open-ended-evolution-of-self-improving-activity-7334610178832556033-8dA-?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4・1212
あたりの研究とはどう違うのだろうか、という点が気になる。 #Analysis #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-06-04 [Paper Note] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, Mingjie Liu+, arXiv'25 Summary強化学習(RL)が言語モデルの推論能力を向上させる可能性を探る本研究では、長期的なRL(ProRL)トレーニングが新しい推論戦略を明らかにできることを示します。新しいトレーニング手法ProRLを導入し、実証分析により、RLでトレーニングされたモデルが基礎モデルを上回ることが確認されました。推論の改善は基礎モデルの能力やトレーニング期間と相関しており、RLが新しい解決空間を探索できることを示唆しています。これにより、RLが言語モデルの推論を拡張する条件に関する新たな洞察が得られ、今後の研究の基盤が築かれます。モデルの重みは公開されています。 Comment元ポスト:https://x.com/hillbig/status/1930043688329326962?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRLVR(math, code(従来はこの2種類), STEM, logic Puzzles, instruction following)によって大規模なスケール(長期的に学習をする; 2k training stepsと多様なタスクでの学習データ)で実験をし、定期的にReferenceポリシーとOptimizerをリセットすることで、元のポリシーからの乖離を防ぎつつも、新たな学習が進むようなことをしている模様。
(※PFNのランチタイムトークを参考に記述)
verlを用いて、DAPOで学習をしている。
・1969
・1815 #NLP #LanguageModel #Verification Issue Date: 2025-06-03 [Paper Note] xVerify: Efficient Answer Verifier for Reasoning Model Evaluations, Ding Chen+, arXiv'25 Summary推論モデルの評価のために、xVerifyという効率的な回答検証器を提案。xVerifyは、LLMが生成した回答が参照解答と同等であるかを効果的に判断できる。VARデータセットを構築し、複数のLLMからの質問-回答ペアを収集。評価実験では、すべてのxVerifyモデルが95%を超えるF1スコアと精度を達成し、特にxVerify-3B-IbはGPT-4oを超える性能を示した。 #NLP #LanguageModel #read-later #VerifiableRewards #RLVR #Verification Issue Date: 2025-06-03 [Paper Note] Pitfalls of Rule- and Model-based Verifiers -- A Case Study on Mathematical Reasoning, Yuzhen Huang+, arXiv'25 Summary本研究では、数学的推論における検証者の信頼性とそのRL訓練プロセスへの影響を分析。ルールベースの検証者は偽陰性率が高く、RL訓練のパフォーマンスに悪影響を及ぼすことが判明。モデルベースの検証者は静的評価で高精度を示すが、偽陽性に対して脆弱であり、報酬が不正に膨らむ可能性がある。これにより、強化学習における堅牢な報酬システムの必要性が示唆される。 Comment元ポスト:https://x.com/junxian_he/status/1929371821767586284?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qverificationタスクに特化してfinetuningされたDiscriminative Classifierが、reward hackingに対してロバストであることが示唆されている模様。
Discriminative Verifierとは、Question, Response, Reference Answerがgivenな時に、response(しばしばreasoning traceを含み複数のanswerの候補が記述されている)の中から最終的なanswerを抽出し、Reference answerと抽出したanswerから正解/不正解をbinaryで出力するモデルのこと。Rule-based Verifierではフォーマットが異なっている場合にfalse negativeとなってしまうし、そもそもルールが規定できないタスクの場合は適用できない。Discriminative Verifierではそのようなケースでも適用できると考えられる。Discriminative Verifierの例はたとえば下記:
https://huggingface.co/IAAR-Shanghai/xVerify-0.5B-I
・2010 #NLP #LanguageModel #LLMAgent #SelfImprovement Issue Date: 2025-06-03 [Paper Note] Self-Challenging Language Model Agents, Yifei Zhou+, arXiv'25 SummarySelf-Challengingフレームワークを提案し、エージェントが自ら生成した高品質なタスクで訓練。エージェントは挑戦者としてタスクを生成し、実行者として強化学習を用いて訓練。M3ToolEvalとTauBenchでLlama-3.1-8B-Instructが2倍以上の改善を達成。 Comment元ポスト:https://x.com/jaseweston/status/1929719473952497797?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/omarsar0/status/1930748591242424439?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #Evaluation #Reasoning Issue Date: 2025-06-01 [Paper Note] BIG-Bench Extra Hard, Mehran Kazemi+, arXiv'25 Summary大規模言語モデル(LLMs)の推論能力を評価するための新しいベンチマーク、BIG-Bench Extra Hard(BBEH)を導入。これは、既存のBIG-Bench Hard(BBH)のタスクを新しいものに置き換え、難易度を大幅に引き上げることで、LLMの限界を押し広げることを目的としている。評価の結果、最良の汎用モデルで9.8%、推論専門モデルで44.8%の平均精度が観察され、LLMの一般的推論能力向上の余地が示された。BBEHは公開されている。 CommentBig-Bench hard(既にSoTAモデルの能力差を識別できない)の難易度をさらに押し上げたデータセット。
Inputの例
タスクごとのInput, Output lengthの分布
現在の主要なモデル群の性能
・785 #NLP #LanguageModel #LLMAgent #SoftwareEngineering #read-later Issue Date: 2025-06-01 [Paper Note] Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering, Guangtao Zeng+, arXiv'25 SummaryEvoScaleを提案し、進化的プロセスを用いて小型言語モデルの性能を向上させる手法を開発。選択と突然変異を通じて出力を洗練し、サンプル数を減少させる。強化学習を用いて自己進化を促進し、SWE-Bench-Verifiedで32Bモデルが100B以上のモデルと同等以上の性能を示す。コード、データ、モデルはオープンソースとして公開予定。 Comment元ポスト:https://x.com/gan_chuang/status/1928963872188244400?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Chain-of-Thought #COLING Issue Date: 2025-05-29 Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs, Yu Xia+, COLING'25 SummaryChain-of-Thought(CoT)を基にしたChain-of-X(CoX)手法の調査を行い、LLMsの課題に対処するための多様なアプローチを分類。ノードの分類とアプリケーションタスクに基づく分析を通じて、既存の手法の意義と今後の可能性を議論。研究者にとって有用なリソースを提供することを目指す。 #NLP #LanguageModel #Distillation #ICML #Scaling Laws Issue Date: 2025-05-29 Distillation Scaling Laws, Dan Busbridge+, ICML'25 Summary蒸留モデルの性能を推定するための蒸留スケーリング法則を提案。教師モデルと生徒モデルの計算割り当てを最適化することで、生徒の性能を最大化。教師が存在する場合やトレーニングが必要な場合に最適な蒸留レシピを提供。多くの生徒を蒸留する際は、監視付きの事前学習を上回るが、生徒のサイズに応じた計算レベルまで。単一の生徒を蒸留し、教師がトレーニング必要な場合は監視学習を推奨。蒸留に関する洞察を提供し、理解を深める。 Comment著者ポスト:https://x.com/danbusbridge/status/1944539357542781410?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Temporal #LanguageModel #read-later Issue Date: 2025-05-27 Temporal Sampling for Forgotten Reasoning in LLMs, Yuetai Li+, arXiv'25 Summaryファインチューニング中にLLMsが以前の正しい解法を忘れる「時間的忘却」を発見。これに対処するために「時間的サンプリング」というデコーディング戦略を導入し、複数のチェックポイントから出力を引き出すことで推論性能を向上。Pass@kで4から19ポイントの改善を達成し、LoRA適応モデルでも同様の利点を示す。時間的多様性を活用することで、LLMsの評価方法を再考する手段を提供。 Comment元ポスト:https://x.com/iscienceluvr/status/1927286319018832155?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QTemporal ForgettingとTemporal Sampling #NLP #LanguageModel #ReinforcementLearning #Reasoning Issue Date: 2025-05-27 Learning to Reason without External Rewards, Xuandong Zhao+, arXiv'25 Summary本研究では、外部の報酬やラベルなしで大規模言語モデル(LLMs)が学習できるフレームワーク「内部フィードバックからの強化学習(RLIF)」を提案。自己確信を報酬信号として用いる「Intuitor」を開発し、無監視の学習を実現。実験結果は、Intuitorが数学的ベンチマークで優れた性能を示し、ドメイン外タスクへの一般化能力も高いことを示した。内因的信号が効果的な学習を促進する可能性を示唆し、自律AIシステムにおけるスケーラブルな代替手段を提供。 Comment元ポスト:https://x.com/xuandongzhao/status/1927270931874910259?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおもしろそうexternalなsignalをrewardとして用いないで、モデル自身が内部的に保持しているconfidenceを用いる。人間は自信がある問題には正解しやすいという直感に基づいており、openendなquestionのようにそもそも正解シグナルが定義できないものもあるが、そういった場合に活用できるようである。self-trainingの考え方に近いのではベースモデルの段階である程度能力が備わっており、post-trainingした結果それが引き出されるようになったという感じなのだろうか。
参考: https://x.com/weiliu99/status/1930826904522875309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #LongSequence #OpenWeight Issue Date: 2025-05-27 QwenLong-CPRS: Towards $\infty$-LLMs with Dynamic Context Optimization, Weizhou Shen+, arXiv'25 SummaryQwenLong-CPRSは、長文コンテキスト最適化のための新しいフレームワークで、LLMsの性能低下を軽減します。自然言語指示に基づく多段階のコンテキスト圧縮を実現し、効率と性能を向上させる4つの革新を導入。5つのベンチマークで、他の手法に対して優位性を示し、主要なLLMとの統合で大幅なコンテキスト圧縮と性能向上を達成。QwenLong-CPRSは新たなSOTA性能を確立しました。 Comment元ポスト:https://x.com/_akhaliq/status/1927014346690826684?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #LongSequence #OpenWeight #read-later Issue Date: 2025-05-27 QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning, Fanqi Wan+, arXiv'25 Summary長いコンテキストの推論におけるLRMsの課題を解決するため、QwenLong-L1フレームワークを提案。ウォームアップ監視付きファインチューニングとカリキュラム指導型段階的RLを用いてポリシーの安定化を図り、難易度認識型の回顧的サンプリングで探索を促進。実験では、QwenLong-L1-32Bが他のLRMsを上回り、優れた性能を示した。 Comment元ポスト:https://x.com/_akhaliq/status/1927011243597967524?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Mathematics #InstructionFollowingCapability Issue Date: 2025-05-24 Scaling Reasoning, Losing Control: Evaluating Instruction Following in Large Reasoning Models, Tingchen Fu+, arXiv'25 Summary指示に従う能力はLLMにとって重要であり、MathIFという数学的推論タスク用のベンチマークを提案。推論能力の向上と指示遵守の間には緊張関係があり、特に長い思考の連鎖を持つモデルは指示に従いにくい。介入により部分的な従順さを回復できるが、推論性能が低下することも示された。これらの結果は、指示に敏感な推論モデルの必要性を示唆している。 Comment元ポスト:https://x.com/yafuly/status/1925753754961236006?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #LanguageModel #Conversation Issue Date: 2025-05-24 LLMs Get Lost In Multi-Turn Conversation, Philippe Laban+, arXiv'25 SummaryLLMsは会話型インターフェースとして、ユーザーがタスクを定義するのを支援するが、マルチターンの会話ではパフォーマンスが低下する。シミュレーション実験の結果、マルチターンで39%のパフォーマンス低下が見られ、初期のターンでの仮定に依存しすぎることが原因と判明。LLMsは会話中に誤った方向に進むと、回復が難しくなることが示された。 Comment元ポスト:https://x.com/_stakaya/status/1926009283386155009?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLost in the MiddleならぬLost in Conversation
・793 #ComputerVision #NLP #LanguageModel #MulltiModal #DiffusionModel Issue Date: 2025-05-24 LaViDa: A Large Diffusion Language Model for Multimodal Understanding, Shufan Li+, arXiv'25 SummaryLaViDaは、離散拡散モデル(DM)を基にしたビジョン・ランゲージモデル(VLM)で、高速な推論と制御可能な生成を実現。新技術を取り入れ、マルチモーダルタスクにおいてAR VLMと競争力のある性能を達成。COCOキャプショニングで速度向上と性能改善を示し、AR VLMの強力な代替手段であることを証明。 Comment元ポスト:https://x.com/iscienceluvr/status/1925749919312159167?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QDiffusion Modelの波が来た同程度のサイズのARモデルをoutperform [^1]
[^1]:ただし、これが本当にDiffusion Modelを使ったことによる恩恵なのかはまだ論文を読んでいないのでわからない。必要になったら読む。ただ、Physics of Language Modelのように、完全にコントロールされたデータで異なるアーキテクチャを比較しないとその辺はわからなそうではある。 #EfficiencyImprovement #NLP #LanguageModel #DiffusionModel Issue Date: 2025-05-24 dKV-Cache: The Cache for Diffusion Language Models, Xinyin Ma+, arXiv'25 Summary拡散言語モデル(DLM)の遅い推論を改善するために、遅延KVキャッシュを提案。これは、異なるトークンの表現ダイナミクスに基づくキャッシング戦略で、2つのバリアントを設計。dKV-Cache-Decodeは損失の少ない加速を提供し、dKV-Cache-Greedyは高いスピードアップを実現。最終的に、推論速度を2〜10倍向上させ、DLMの性能を強化することを示した。 Comment元ポスト:https://x.com/arankomatsuzaki/status/1925384029718946177?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q提案手法を適用した場合、ARなモデルとDiffusion Modelで、実際のところどの程度のdecoding速度の差があるのだろうか?そういった分析はざーーっと見た感じ見当たらなかったように思える。 #Embeddings #NLP #LanguageModel #RepresentationLearning #DiffusionModel Issue Date: 2025-05-24 Diffusion vs. Autoregressive Language Models: A Text Embedding Perspective, Siyue Zhang+, arXiv'25 Summary拡散言語モデルを用いたテキスト埋め込みが、自己回帰的なLLMの一方向性の制限を克服し、文書検索や推論タスクで優れた性能を発揮。長文検索で20%、推論集約型検索で8%、指示に従った検索で2%の向上を示し、双方向の注意が重要であることを確認。 Comment元ポスト:https://x.com/trtd6trtd/status/1925775950500806742?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Evaluation #ICLR #Contamination #Admin'sPick Issue Date: 2025-05-23 LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25 Summaryテストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Commentテストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究 #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Scaling Laws Issue Date: 2025-05-21 Parallel Scaling Law for Language Models, Mouxiang Chen+, arXiv'25 Summary本研究では、言語モデルのスケーリングにおいて、並列計算を増加させる新しい手法「ParScale」を提案。これにより、モデルの前方パスを並列に実行し、出力を動的に集約することで、推論効率を向上させる。ParScaleは、少ないメモリ増加とレイテンシで同等の性能向上を実現し、既存のモデルを再利用することでトレーニングコストも削減可能。新しいスケーリング法則は、リソースが限られた状況での強力なモデル展開を促進する。 Comment元ポスト:https://x.com/hillbig/status/1924959706331939099?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・405
と考え方が似ている #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #Reasoning Issue Date: 2025-05-21 AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning, Chenwei Lou+, arXiv'25 SummaryAdaCoT(Adaptive Chain-of-Thought)は、LLMsが推論を適応的に行う新しいフレームワークで、CoTの呼び出しタイミングを最適化します。強化学習を用いて、クエリの複雑さに基づいてCoTの必要性を判断し、計算コストを削減します。実験では、AdaCoTがCoTトリガー率を3.18%に低下させ、応答トークンを69.06%減少させつつ、高い性能を維持することが示されました。 CommentRLのRewardにおいて、bassのリワードだけでなく、
・reasoningをなくした場合のペナルティ項
・reasoningをoveruseした場合のペナルティ項
・formattingに関するペナルティ項
を設定し、reasoningの有無を適切に判断できた場合にrewardが最大化されるような形にしている。(2.2.2)
が、multi-stageのRLでは(stageごとに利用するデータセットを変更するが)、データセットの分布には歪みがあり、たとえば常にCoTが有効なデータセットも存在しており(数学に関するデータなど)、その場合常にCoTをするような分布を学習してしまい、AdaptiveなCoT decisionが崩壊したり、不安定になってしまう(decision boundary collapseと呼ぶ)。特にこれがfinal stageで起きると最悪で、これまでAdaptiveにCoTされるよう学習されてきたものが全て崩壊してしまう。これを防ぐために、Selective Loss Maskingというlossを導入している。具体的には、decision token [^1]のlossへの貢献をマスキングするようにすることで、CoTが生じるratioにバイアスがかからないようにする。今回は、Decision tokenとして、`
[^1]: CoTするかどうかは多くの場合このDecision Tokenによって決まる、といったことがどっかの研究に示されていたはずいつか必要になったらしっかり読むが、全てのステージでSelective Loss Maskingをしたら、SFTでwarm upした段階からあまりCoTのratioが変化しないような学習のされ方になる気がするが、どのステージに対してapplyするのだろうか。</span> #Pretraining #MachineLearning #NLP #LanguageModel #ModelMerge Issue Date: 2025-05-20 Model Merging in Pre-training of Large Language Models, Yunshui Li+, arXiv'25 Summaryモデルマージングは大規模言語モデルの強化に有望な技術であり、本論文ではその事前学習プロセスにおける包括的な調査を行う。実験により、一定の学習率で訓練されたチェックポイントをマージすることで性能向上とアニーリング挙動の予測が可能になることを示し、効率的なモデル開発と低コストのトレーニングに寄与する。マージ戦略やハイパーパラメータに関するアブレーション研究を通じて新たな洞察を提供し、実用的な事前学習ガイドラインをオープンソースコミュニティに提示する。 Comment元ポスト:https://x.com/iscienceluvr/status/1924804324812873990?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/giffmana/status/1924849877634449878?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #QuestionAnswering #KnowledgeGraph #Factuality #Reasoning #Test-Time Scaling #PostTraining Issue Date: 2025-05-20 Scaling Reasoning can Improve Factuality in Large Language Models, Mike Zhang+, arXiv'25 Summary本研究では、オープンドメインの質問応答における大規模言語モデル(LLM)の推論能力を検討し、推論の痕跡を抽出してファインチューニングを行った。知識グラフからの情報を導入し、168回の実験を通じて170万の推論を分析した結果、小型モデルが元のモデルよりも事実の正確性を顕著に改善し、計算リソースを追加することでさらに2-8%の向上が確認された。実験成果は公開され、さらなる研究に寄与する。 Comment元ポスト:https://x.com/_akhaliq/status/1924477447120068895?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #LLMServing #Architecture #MoE(Mixture-of-Experts) #SoftwareEngineering Issue Date: 2025-05-20 Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures, Chenggang Zhao+, arXiv'25 SummaryDeepSeek-V3は、2,048台のNVIDIA H800 GPUでトレーニングされ、ハードウェア制約に対処するための共同設計を示す。メモリ効率向上のためのマルチヘッド潜在注意や、計算と通信の最適化を図る専門家の混合アーキテクチャ、FP8混合精度トレーニングなどの革新を強調。ハードウェアのボトルネックに基づく将来の方向性について議論し、AIワークロードに応えるためのハードウェアとモデルの共同設計の重要性を示す。 Comment元ポスト:https://x.com/deedydas/status/1924512147947848039?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #SyntheticData #ACL #DPO #PostTraining #Probing Issue Date: 2025-05-18 Why Vision Language Models Struggle with Visual Arithmetic? Towards Enhanced Chart and Geometry Understanding, Kung-Hsiang Huang+, ACL'25 SummaryVision Language Models (VLMs)は視覚的算術に苦労しているが、CogAlignという新しいポストトレーニング戦略を提案し、VLMの性能を向上させる。CogAlignは視覚的変換の不変特性を認識するように訓練し、CHOCOLATEで4.6%、MATH-VISIONで2.9%の性能向上を実現し、トレーニングデータを60%削減。これにより、基本的な視覚的算術能力の向上と下流タスクへの転送の効果が示された。 Comment元ポスト:https://x.com/steeve__huang/status/1923543884367306763?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q既存のLLM (proprietary, openweightそれぞれ)が、シンプルなvisual arithmeticタスク(e.g., 線分の長さ比較, Chart上のdotの理解)などの性能が低いことを明らかにし、
それらの原因を(1)Vision Encoderのrepresentationと(2)Vision EncoderをFreezeした上でのText Decoderのfinetuningで分析した。その結果、(1)ではいくつかのタスクでlinear layerのprobingでは高い性能が達成できないことがわかった。このことから、Vision Encoderによるrepresentationがタスクに関する情報を内包できていないか、タスクに関する情報は内包しているがlinear layerではそれを十分に可能できない可能性が示唆された。
これをさらに分析するために(2)を実施したところ、Vision Encoderをfreezeしていてもfinetuningによりquery stringに関わらず高い性能を獲得できることが示された。このことから、Vision Encoder側のrepresentationの問題ではなく、Text Decoderと側でデコードする際にFinetuningしないとうまく活用できないことが判明した。
具体的にはVerifiableなpromptとnon verifiableなpromptの両方からverifiableなpreference pairを作成しpointwiseなスコアリング、あるいはpairwiseなjudgeを学習するためのrewardを設計しGRPOで学習する、みたいな話っぽい。
non verifiableなpromptも用いるのは、そういったpromptに対してもjudgeできるモデルを構築するため。
mathに関するpromptはverifiableなのでレスポンスが不正解なものをrejection samplingし、WildChatのようなチャットはverifiableではないので、instructionにノイズを混ぜて得られたレスポンスをrejection samplingし、合成データを得ることで、non verifiableなpromptについても、verifiableなrewardを設計できるようになる。
おそらく2,3節あたりが一番おもしろいポイントなのだと思われるがまだ読めていない。 #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-05-09 Reinforcement Learning for Reasoning in Large Language Models with One Training Example, Yiping Wang+, arXiv'25 Summary1-shot RLVRを用いることで、LLMの数学的推論能力が大幅に向上することを示した。Qwen2.5-Math-1.5Bモデルは、MATH500でのパフォーマンスが36.0%から73.6%に改善され、他の数学的ベンチマークでも同様の向上が見られた。1-shot RLVR中には、クロスドメイン一般化や持続的なテストパフォーマンスの改善が観察され、ポリシー勾配損失が主な要因であることが確認された。エントロピー損失の追加も重要で、結果報酬なしでもパフォーマンスが向上した。これらの成果は、RLVRのデータ効率に関するさらなる研究を促進する。 Comment
参考:https://x.com/weiliu99/status/1930826904522875309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・2011
とはどのような関係性があるだろうか? #NLP #Dataset #LanguageModel #Mathematics #read-later #Coding Issue Date: 2025-05-08 Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, arXiv'25 Summary本研究では、公共データを体系的に書き換えることで大規模言語モデル(LLMs)の性能を向上させる2つのオープンライセンスデータセット、SwallowCodeとSwallowMathを紹介。SwallowCodeはPythonスニペットを洗練させる4段階のパイプラインを用い、低品質のコードをアップグレード。SwallowMathはボイラープレートを削除し、解決策を簡潔に再フォーマット。これにより、Llama-3.1-8Bのコード生成能力がHumanEvalで+17.0、GSM8Kで+12.4向上。すべてのデータセットは公開され、再現可能な研究を促進。 Comment元ポスト:https://x.com/okoge_kaz/status/1920141189652574346?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/hillbig/status/1920613041026314274?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ReinforcementLearning #SelfImprovement #read-later #RLVR #ZeroData Issue Date: 2025-05-08 Absolute Zero: Reinforced Self-play Reasoning with Zero Data, Andrew Zhao+, arXiv'25 Summary新しいRLVRパラダイム「Absolute Zero」を提案し、自己学習を通じて推論能力を向上させるAZRを導入。外部データに依存せず、コーディングや数学的推論タスクでSOTAパフォーマンスを達成。既存のゼロ設定モデルを上回り、異なるモデルスケールにも適用可能。 Comment元ポスト:https://x.com/arankomatsuzaki/status/1919946713567264917?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #PEFT(Adaptor/LoRA) #GRPO Issue Date: 2025-05-07 Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25 SummaryTinaは、コスト効率よく強力な推論能力を実現する小型の推論モデルファミリーであり、1.5Bパラメータのベースモデルに強化学習を適用することで高い推論性能を示す。Tinaは、従来のSOTAモデルと競争力があり、AIME24で20%以上の性能向上を達成し、トレーニングコストはわずか9ドルで260倍のコスト削減を実現。LoRAを通じた効率的なRL推論の効果を検証し、すべてのコードとモデルをオープンソース化している。 Comment元ポスト:https://x.com/rasbt/status/1920107023980462575?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q(おそらく)Reasoningモデルに対して、LoRAとRLを組み合わせて、reasoning能力を向上させた初めての研究 #NLP #DataGeneration #DataDistillation #SyntheticData #ICML Issue Date: 2025-05-07 R.I.P.: Better Models by Survival of the Fittest Prompts, Ping Yu+, ICML'25 Summaryトレーニングデータの品質がモデルの性能に与える影響を考慮し、低品質な入力プロンプトがもたらす問題を解決するために、Rejecting Instruction Preferences(RIP)というデータ整合性評価手法を提案。RIPは、拒否された応答の品質と選択された好みペアとの報酬ギャップを測定し、トレーニングセットのフィルタリングや高品質な合成データセットの作成に利用可能。実験結果では、RIPを用いることでLlama 3.1-8B-Instructでの性能が大幅に向上し、Llama 3.3-70B-Instructではリーダーボードでの順位が上昇した。 Comment元ポスト:https://x.com/jaseweston/status/1885160135053459934?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
スレッドで著者が論文の解説をしている。 #Survey #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #InstructionTuning #PPO (ProximalPolicyOptimization) #Reasoning #LongSequence #RewardHacking #GRPO #Contamination #VerifiableRewards #CurriculumLearning Issue Date: 2025-05-06 100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models, Chong Zhang+, arXiv'25 Summary最近の推論言語モデル(RLM)の進展を受けて、DeepSeek-R1が注目を集めているが、その実装詳細は完全にはオープンソース化されていない。これにより、多くの再現研究が行われ、DeepSeek-R1のパフォーマンスを再現しようとする試みが続いている。特に、監視付きファインチューニング(SFT)と強化学習(RLVR)の戦略が探求され、貴重な洞察が得られている。本報告では、再現研究の概要を提供し、データ構築やトレーニング手順の詳細を紹介し、今後の研究の促進を目指す。また、RLMを強化するための追加技術や開発上の課題についても考察する。 Comment元ポスト:https://x.com/_philschmid/status/1918898257406709983?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
サーベイのtakeawayが箇条書きされている。 #ComputerVision #Embeddings #Analysis #NLP #LanguageModel #RepresentationLearning #Supervised-FineTuning (SFT) #Chain-of-Thought #SSM (StateSpaceModel) #ICML #PostTraining #read-later Issue Date: 2025-05-04 Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25 Summary中間層の埋め込みが最終層を超えるパフォーマンスを示すことを分析し、情報理論や幾何学に基づくメトリクスを提案。32のテキスト埋め込みタスクで中間層が強力な特徴を提供することを実証し、AIシステムの最適化における中間層の重要性を強調。 Comment現代の代表的な言語モデルのアーキテクチャ(decoder-only model, encoder-only model, SSM)について、最終層のembeddingよりも中間層のembeddingの方がdownstream task(MTEBの32Taskの平均)に、一貫して(ただし、これはMTEBの平均で見たらそうという話であり、個別のタスクで一貫して強いかは読んでみないとわからない)強いことを示した研究。
このこと自体は経験的に知られているのであまり驚きではないのだが(ただ、SSMでもそうなのか、というのと、一貫して強いというのは興味深い)、この研究はMatrix Based Entropyと呼ばれるものに基づいて、これらを分析するための様々な指標を定義し理論的な根拠を示し、Autoregressiveな学習よりもMasked Languageによる学習の方がこのようなMiddle Layerのボトルネックが緩和され、同様のボトルネックが画像の場合でも起きることを示し、CoTデータを用いたFinetuningについても分析している模様。この辺の貢献が非常に大きいと思われるのでここを理解することが重要だと思われる。あとで読む。
元ポスト:https://x.com/yifeiwang77/status/1916873981979660436?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ICLR #KnowledgeEditing Issue Date: 2025-04-30 AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models, Junfeng Fang+, ICLR'25 SummaryAlphaEditは、LLMsの知識を保持しつつ編集を行う新しい手法で、摂動を保持された知識の零空間に投影することで、元の知識を破壊する問題を軽減します。実験により、AlphaEditは従来の位置特定-編集手法の性能を平均36.7%向上させることが確認されました。 Comment元ポスト:https://x.com/hillbig/status/1917343444810489925?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=HvSytvg3JhMLPに新たな知識を直接注入する際に(≠contextに含める)既存の学習済みの知識を破壊せずに注入する手法(破壊しないことが保証されている)を提案しているらしい将来的には、LLMの1パラメータあたりに保持できる知識量がわかってきているので、MLPの零空間がN GBのモデルです、あなたが注入したいドメイン知識の量に応じて適切な零空間を持つモデルを選んでください、みたいなモデルが公開される日が来るのだろうか。 #Survey #InformationRetrieval #NLP #LanguageModel #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-04-30 Can LLMs Be Trusted for Evaluating RAG Systems? A Survey of Methods and Datasets, Lorenz Brehme+, arXiv'25 SummaryRAGシステムの評価手法を63件の論文を基にレビューし、データセット、リトリーバー、インデクシング、生成コンポーネントの4領域に焦点を当てる。自動評価アプローチの実現可能性を観察し、LLMを活用した評価データセットの生成を提案。企業向けに実装と評価の指針を提供するための実践的研究の必要性を強調し、評価手法の進展と信頼性向上に寄与する。 Comment元ポスト:https://x.com/_reachsumit/status/1917425829233189027?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおもしろそう #RecommenderSystems #LanguageModel Issue Date: 2025-04-29 Generative Product Recommendations for Implicit Superlative Queries, Kaustubh D. Dhole+, arXiv'25 Summaryレコメンダーシステムにおいて、ユーザーの曖昧なクエリに対して大規模言語モデル(LLMs)を用いて暗黙の属性を生成し、製品推薦を改善する方法を探る。新たに提案する4ポイントスキーマ「SUPERB」を用いて最上級クエリに対する製品候補を注釈付けし、既存の検索およびランキング手法を評価する。 Comment元ポスト:https://x.com/_reachsumit/status/1917084325499273671?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Transformer #Chain-of-Thought #In-ContextLearning #SSM (StateSpaceModel) #ICLR Issue Date: 2025-04-26 RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval, Kaiyue Wen+, ICLR'25 Summary本論文では、RNNとトランスフォーマーの表現力の違いを調査し、特にRNNがChain-of-Thought(CoT)プロンプトを用いてトランスフォーマーに匹敵するかを分析。結果、CoTはRNNを改善するが、トランスフォーマーとのギャップを埋めるには不十分であることが判明。RNNの情報取得能力の限界がボトルネックであるが、Retrieval-Augmented Generation(RAG)やトランスフォーマー層の追加により、RNNはCoTを用いて多項式時間で解決可能な問題を解決できることが示された。 Comment元ポスト:https://x.com/yuma_1_or/status/1915968478735130713?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q関連:
・1210
↑とはどういう関係があるだろうか? #Multi #Analysis #NLP #LLMAgent Issue Date: 2025-04-26 Why Do Multi-Agent LLM Systems Fail?, Mert Cemri+, arXiv'25 SummaryMASの性能向上が単一エージェントと比較して限定的であることを受け、MAST(Multi-Agent System Failure Taxonomy)を提案。200以上のタスクを分析し、14の失敗モードを特定し、3つの大カテゴリに整理。Cohenのカッパスコア0.88を達成し、LLMを用いた評価パイプラインを開発。ケーススタディを通じて失敗分析とMAS開発の方法を示し、今後の研究のためのロードマップを提示。データセットとLLMアノテーターをオープンソース化予定。 Comment元ポスト:https://x.com/mertcemri/status/1915567789714329799?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q7つのメジャーなマルチエージェントフレームワークに対して200以上のタスクを実施し、6人の専門家がtraceをアノテーション。14種類の典型的なfailure modeを見つけ、それらを3つにカテゴライズ。これを考慮してマルチエージェントシステムの失敗に関するTaxonomy(MAS)を提案
・Linear layerとしてBitLinear Layerを利用
・重みは{1, 0, -1}の3値をとる
・activationは8bitのintegerに量子化
・Layer Normalizationはsubln normalization 1899 を利用 #ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MulltiModal #ICLR #x-Use Issue Date: 2025-04-18 AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25 Summary本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 CommentAndroid環境でのPhone Useのベンチマーク #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #DiffusionModel #Reasoning #PostTraining #GRPO Issue Date: 2025-04-18 d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning, Siyan Zhao+, arXiv'25 Summaryd1というフレームワークを提案し、マスク付きdLLMsを教師ありファインチューニングと強化学習で推論モデルに適応。マスク付きSFT技術で知識を抽出し、diffu-GRPOという新しいRLアルゴリズムを導入。実証研究により、d1が最先端のdLLMの性能を大幅に向上させることを確認。 Comment元ポスト:https://x.com/iscienceluvr/status/1912785180504535121?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QdLLMに対してGRPOを適用する手法(diffuGRPO)を提案している。
long CoTデータでSFTしてreasoning capabilityを強化した後、diffuGRPOで追加のpost-trainingをしてさらに性能をboostする。GRPOではtoken levelの尤度とsequence全体の尤度を計算する必要があるが、dLLMだとautoregressive modelのようにchain ruleを適用する計算方法はできないので、効率的に尤度を推定するestimatorを用いてGPPOを適用するdiffuGRPOを提案している。
diffuGRPO単体でも、8BモデルだがSFTよりも性能向上に成功している。SFTの後にdiffuGRPOを適用するとさらに性能が向上する。
SFTではs1 1749 で用いられたlong CoTデータを用いている。しっかり理解できていないが、diffuGRPO+verified rewardによって、long CoTの学習データを用いなくても、安定してreasoning能力を発揮することができようになった、ということなのだろうか?
しかし、AppendixCを見ると、元々のLLaDAの時点でreasoning traceを十分な長さで出力しているように見える。もしLLaDAが元々long CoTを発揮できたのだとしたら、long CoTできるようになったのはdiffuGRPOだけの恩恵ではないということになりそうだが、LLaDAは元々long CoTを生成できるようなモデルだったんだっけ…?その辺追えてない(dLLMがメジャーになったら追う)。 #Analysis #MachineLearning #NLP #LanguageModel #Alignment #Hallucination #ICLR #DPO #Repetition Issue Date: 2025-04-18 Learning Dynamics of LLM Finetuning, Yi Ren+, ICLR'25 Summary本研究では、大規模言語モデルのファインチューニング中の学習ダイナミクスを分析し、異なる応答間の影響の蓄積を段階的に解明します。指示調整と好み調整のアルゴリズムに関する観察を統一的に解釈し、ファインチューニング後の幻覚強化の理由を仮説的に説明します。また、オフポリシー直接好み最適化(DPO)における「圧縮効果」を強調し、望ましい出力の可能性が低下する現象を探ります。このフレームワークは、LLMのファインチューニング理解に新たな視点を提供し、アラインメント性能向上のためのシンプルな方法を示唆します。 Comment元ポスト:https://x.com/joshuarenyi/status/1913033476275925414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/hillbig/status/1917189793588613299?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Transformer #FoundationModel #OpenWeight #CVPR Issue Date: 2025-04-11 AM-RADIO: Agglomerative Vision Foundation Model -- Reduce All Domains Into One, Mike Ranzinger+, CVPR'25 Summary視覚基盤モデル(VFM)をマルチティーチャー蒸留を通じて統合するアプローチAM-RADIOを提案。これにより、ゼロショットの視覚-言語理解やピクセルレベルの理解を向上させ、個々のモデルの性能を超える。新しいアーキテクチャE-RADIOは、ティーチャーモデルよりも少なくとも7倍速い。包括的なベンチマークで様々な下流タスクを評価。 Comment元ポスト:https://x.com/pavlomolchanov/status/1910391609927360831?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qvision系のfoundation modelはそれぞれ異なる目的関数で訓練されてきており(CLIPは対照学習 550, DINOv2は自己教師あり学習 1884, SAMはsegmentation 1885)それぞれ別の能力を持ってたが、それらを一個のモデルに蒸留しました、という話らしい
・1815
を上回る性能
を改善した研究OpenReview:https://openreview.net/forum?id=Vf6RDObyEFこの方向性の研究はおもしろい #EfficiencyImprovement #NLP #Transformer #LongSequence #Architecture Issue Date: 2025-04-06 Scalable-Softmax Is Superior for Attention, Ken M. Nakanishi, arXiv'25 SummarySSMaxを提案し、Softmaxの代替としてTransformerモデルに統合。これにより、長いコンテキストでの重要情報の取得が向上し、事前学習中の損失減少が速くなる。SSMaxは注意スコアを改善し、長さの一般化を促進する。 Comment・1863
で採用されている手法で、ブログポスト中で引用されている。Long Contextになった場合にsoftmaxの分布が均一になる(=重要な情報にattendする能力が削がれる)ことを防ぐための手法を提案している。解説ポスト:https://x.com/nrehiew_/status/1908613993998045534 #NLP #LanguageModel #Attention #ICLR #AttentionSinks Issue Date: 2025-04-05 When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25 Summary言語モデルにおける「アテンションシンク」は、意味的に重要でないトークンに大きな注意を割り当てる現象であり、さまざまな入力に対して小さなモデルでも普遍的に存在することが示された。アテンションシンクは事前学習中に出現し、最適化やデータ分布、損失関数がその出現に影響を与える。特に、アテンションシンクはキーのバイアスのように機能し、情報を持たない追加のアテンションスコアを保存することがわかった。この現象は、トークンがソフトマックス正規化に依存していることから部分的に生じており、正規化なしのシグモイドアテンションに置き換えることで、アテンションシンクの出現を防ぐことができる。 CommentSink Rateと呼ばれる、全てのheadのFirst Tokenに対するattention scoreのうち(layer l head h個存在する)、どの程度の割合のスコアが閾値を上回っているかを表す指標を提案・1860
の先行研究著者ポスト(openai-gpt-120Bを受けて):
https://x.com/gu_xiangming/status/1952811057673642227?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ConceptErasure #KnowledgeEditing #AISTATS Issue Date: 2025-04-03 Fundamental Limits of Perfect Concept Erasure, Somnath Basu Roy Chowdhury+, AISTATS'25 Summary概念消去は、性別や人種などの情報を消去しつつ元の表現を保持するタスクであり、公平性の達成やモデルのパフォーマンスの解釈に役立つ。従来の技術は消去の堅牢性を重視してきたが、有用性とのトレードオフが存在する。本研究では、情報理論的視点から概念消去の限界を定量化し、完璧な消去を達成するためのデータ分布と消去関数の制約を調査。提案する消去関数が理論的限界を達成し、GPT-4を用いたデータセットで既存手法を上回ることを示した。 Comment元ポスト:https://x.com/somnathbrc/status/1907463419105570933?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Test-Time Scaling Issue Date: 2025-04-02 What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models, Qiyuan Zhang+, arXiv'25 Summaryテスト時スケーリング(TTS)が大規模言語モデル(LLMs)の問題解決能力を向上させることが示されているが、体系的な理解が不足している。これを解決するために、TTS研究の4つのコア次元に基づく統一的なフレームワークを提案し、手法や応用シナリオのレビューを行う。TTSの発展の軌跡を抽出し、実践的なガイドラインを提供するとともに、未解決の課題や将来の方向性についての洞察を示す。 Comment元ポスト:https://x.com/hesamation/status/1907095419793911893?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qとてつもない量だ…網羅性がありそう。
What to Scaleがよくあるself
consistency(Parallel Scaling), STaR(Sequential Scailng), Tree of Thought(Hybrid Scaling), DeepSeek-R1, o1/3(Internal Scaling)といった分類で、How to ScaleがTuningとInferenceに分かれている。TuningはLong CoTをSFTする話や強化学習系の話(GRPOなど)で、InferenceにもSelf consistencyやらやらVerificationやら色々ありそう。良さそう。
・1856
・1466 #NLP #Dataset #LanguageModel #LLMAgent #Evaluation #QuestionGeneration Issue Date: 2025-04-02 Interactive Agents to Overcome Ambiguity in Software Engineering, Sanidhya Vijayvargiya+, arXiv'25 SummaryAIエージェントはあいまいな指示に基づくタスク自動化に利用されるが、誤った仮定や質問不足がリスクを生む。本研究では、LLMエージェントのあいまいな指示処理能力を評価し、インタラクティビティを活用したパフォーマンス向上、あいまいさの検出、目標を絞った質問の実施を検討。結果、モデルは明確な指示と不十分な指示を区別するのが難しいが、インタラクションを通じて重要な情報を取得し、パフォーマンスが向上することが示された。これにより、現在のモデルの限界と改善のための評価手法の重要性が明らかになった。 Comment曖昧なユーザメッセージに対する、エージェントが"質問をする能力を測る"ベンチマーク
weight:https://huggingface.co/collections/Qwen/qwen25-omni-67de1e5f0f9464dc6314b36e元ポスト:https://www.linkedin.com/posts/niels-rogge-a3b7a3127_alibabas-qwen-team-has-done-it-again-this-activity-7311036679627132929-HUqy?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4 #RecommenderSystems #CollaborativeFiltering #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Reasoning Issue Date: 2025-03-27 RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning, Sichun Luo+, arXiv'25 SummaryRALLRec+は、LLMsを用いてレコメンダーシステムのretrievalとgenerationを強化する手法。retrieval段階では、アイテム説明を生成し、テキスト信号と協調信号を結合。生成段階では、推論LLMsを評価し、知識注入プロンプティングで汎用LLMsと統合。実験により、提案手法の有効性が確認された。 Comment元ポスト:https://x.com/_reachsumit/status/1905107217663336832?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QReasoning LLMをRecSysに応用する初めての研究(らしいことがRelated Workに書かれている)arxivのadminより以下のコメントが追記されている
> arXiv admin note: substantial text overlap with arXiv:2502.06101
コメント中の研究は下記である
・1840 #NLP #LanguageModel #LLM-as-a-Judge #Test-Time Scaling Issue Date: 2025-03-27 Scaling Evaluation-time Compute with Reasoning Models as Process Evaluators, Seungone Kim+, arXiv'25 SummaryLMの出力品質評価が難しくなっている中、計算を増やすことで評価能力が向上するかを検討。推論モデルを用いて応答全体と各ステップを評価し、推論トークンの生成が評価者のパフォーマンスを向上させることを確認。再ランク付けにより、評価時の計算増加がLMの問題解決能力を向上させることを示した。 Comment元ポスト:https://x.com/jinulee_v/status/1905025016401428883?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLM-as-a-JudgeもlongCoT+self-consistencyで性能が改善するらしい。
https://x.com/jacspringer/status/1917174452531724718?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
きちんと読んだ方が良さげ。 #InformationRetrieval #NLP #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-03-25 ExpertGenQA: Open-ended QA generation in Specialized Domains, Haz Sameen Shahgir+, arXiv'25 SummaryExpertGenQAは、少数ショット学習とトピック・スタイル分類を組み合わせたQAペア生成プロトコルで、米国連邦鉄道局の文書を用いて94.4%のトピックカバレッジを維持しつつ、ベースラインの2倍の効率を達成。評価では、LLMベースのモデルが内容よりも文体に偏ることが判明し、ExpertGenQAは専門家の質問の認知的複雑性をより良く保持。生成したクエリは、リトリーバルモデルの精度を13.02%向上させ、技術分野での有効性を示した。 Comment元ポスト:https://x.com/at_sushi_/status/1904325501331890561?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Reasoning Issue Date: 2025-03-23 Thinking Machines: A Survey of LLM based Reasoning Strategies, Dibyanayan Bandyopadhyay+, arXiv'25 Summary大規模言語モデル(LLMs)は優れた言語能力を持つが、推論能力との間にギャップがある。推論はAIの信頼性を高め、医療や法律などの分野での適用に不可欠である。最近の強力な推論モデルの登場により、LLMsにおける推論の研究が重要視されている。本論文では、既存の推論技術の概要と比較を行い、推論を備えた言語モデルの体系的な調査と現在の課題を提示する。 Comment元ポスト:https://x.com/dair_ai/status/1903843684568666450?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRL, Test Time Compute, Self-trainingの3種類にカテゴライズされている。また、各カテゴリごとにより細分化されたツリーが論文中にある。
#Pretraining #NLP #LanguageModel #Scaling Laws Issue Date: 2025-03-23 Compute Optimal Scaling of Skills: Knowledge vs Reasoning, Nicholas Roberts+, arXiv'25 Summaryスケーリング法則はLLM開発において重要であり、特に計算最適化によるトレードオフが注目されている。本研究では、スケーリング法則が知識や推論に基づくスキルに依存することを示し、異なるデータミックスがスケーリング挙動に与える影響を調査した。結果、知識とコード生成のスキルは根本的に異なるスケーリング挙動を示し、誤指定された検証セットが計算最適なパラメータ数に約50%の影響を与える可能性があることが明らかになった。 Comment元ポスト:https://x.com/dair_ai/status/1903843682509312218?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q知識を問うQAのようなタスクはモデルのパラメータ量が必要であり、コーディングのようなReasoningに基づくタスクはデータ量が必要であり、異なる要素に依存してスケールすることを示している研究のようである。
下記Figure2を見るとよくまとまっていて、キャプションを読むとだいたい分かる。なるほど。
Length Rewardについては、
・1746
で考察されている通り、Reward Hackingが起きるので設計の仕方に気をつける必要がある。
・793 #MachineLearning #LanguageModel #ReinforcementLearning #Reasoning #LongSequence #GRPO #read-later Issue Date: 2025-03-20 DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25 Summary推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。ちとこれはあとでしっかり読みたい。重要論文。プロジェクトページ:https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。解説ポスト:https://x.com/theturingpost/status/1902507148015489385?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
コンパクトだが分かりやすくまとまっている。下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:https://x.com/iscienceluvr/status/1936375947575632102?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Test-Time Scaling #Verification Issue Date: 2025-03-18 Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification, Eric Zhao+, arXiv'25 Summaryサンプリングベースの探索は、複数の候補応答を生成し最良のものを選ぶ手法であり、自己検証によって正確性を確認します。本研究では、この探索のスケーリング傾向を分析し、シンプルな実装がGemini v1.5 Proの推論能力を向上させることを示しました。自己検証の精度向上は、より大きな応答プールからのサンプリングによるもので、応答間の比較が有益な信号を提供することや、異なる出力スタイルが文脈に応じて役立つことを明らかにしました。また、最前線のモデルは初期の検証能力が弱く、進捗を測るためのベンチマークを提案しました。 Comment元ポスト:https://x.com/ericzhao28/status/1901704339229732874?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qざっくりしか読めていないが、複数の解答をサンプリングして、self-verificationをさせて最も良かったものを選択するアプローチ。最もverificationスコアが高い解答を最終的に選択したいが、tieの場合もあるのでその場合は追加のpromptingでレスポンスを比較しより良いレスポンスを選択する。これらは並列して実行が可能で、探索とself-verificationを200個並列するとGemini 1.5 Proでo1-previewよりも高い性能を獲得できる模様。Self-consistencyと比較しても、gainが大きい。
・1606BERT, ModernBERTとの違い

性能

所感
medium size未満のモデルの中ではSoTAではあるが、ModernBERTが利用できるのであれば、ベンチマークを見る限りは実用的にはModernBERTで良いのでは、と感じた。学習とinferenceの速度差はどの程度あるのだろうか? #Survey #NLP #LanguageModel #Supervised-FineTuning (SFT) #Reasoning Issue Date: 2025-03-15 A Survey on Post-training of Large Language Models, Guiyao Tie+, arXiv'25 Summary大規模言語モデル(LLMs)は自然言語処理に革命をもたらしたが、専門的な文脈での制約が明らかである。これに対処するため、高度なポストトレーニング言語モデル(PoLMs)が必要であり、本論文ではその包括的な調査を行う。ファインチューニング、アライメント、推論、効率、統合と適応の5つのコアパラダイムにわたる進化を追跡し、PoLMがバイアス軽減や推論能力向上に寄与する方法を示す。研究はPoLMの進化に関する初の調査であり、将来の研究のための枠組みを提供し、LLMの精度と倫理的堅牢性を向上させることを目指す。 CommentPost Trainingの時間発展の図解が非常にわかりやすい(が、厳密性には欠けているように見える。当該モデルの新規性における主要な技術はこれです、という図としてみるには良いのかもしれない)。
個々の技術が扱うスコープとレイヤー、データの性質が揃っていない気がするし、それぞれのLLMがy軸の単一の技術だけに依存しているわけでもない。が、厳密に図を書いてと言われた時にどう書けば良いかと問われると難しい感はある。
同等以上の性能を維持しながらモデル全体のinference, trainingの時間を8%程度削減。
https://x.com/gm8xx8/status/1950644063952052643?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Reasoning Issue Date: 2025-02-26 From System 1 to System 2: A Survey of Reasoning Large Language Models, Zhong-Zhi Li+, arXiv'25 Summary人間レベルの知能を達成するためには、迅速なシステム1から意図的なシステム2への推論の洗練が必要。基盤となる大規模言語モデル(LLMs)は迅速な意思決定に優れるが、複雑な推論には深さが欠ける。最近の推論LLMはシステム2の意図的な推論を模倣し、人間のような認知能力を示している。本調査では、LLMの進展とシステム2技術の初期開発を概観し、推論LLMの構築方法や特徴、進化を分析。推論ベンチマークの概要を提供し、代表的な推論LLMのパフォーマンスを比較。最後に、推論LLMの進展に向けた方向性を探り、最新の開発を追跡するためのGitHubリポジトリを維持することを目指す。 Comment元ポスト:https://x.com/_reachsumit/status/1894282083956396544?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #SyntheticData #Reasoning #Distillation Issue Date: 2025-02-19 NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions, Weizhe Yuan+, arXiv'25 Summary多様で高品質な推論質問を生成するためのスケーラブルなアプローチを提案し、280万の質問からなるNaturalReasoningデータセットを構築。知識蒸留実験により、強力な教師モデルが推論能力を引き出せることを実証し、教師なし自己学習にも効果的であることを示す。 Comment元ポスト: https://x.com/jaseweston/status/1892041992127021300?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning Issue Date: 2025-02-18 Scaling Test-Time Compute Without Verification or RL is Suboptimal, Amrith Setlur+, arXiv'25 SummaryRLや探索に基づく検証者ベース(VB)手法が、探索の痕跡を蒸留する検証者フリー(VF)アプローチよりも優れていることを示す。テスト時の計算とトレーニングデータをスケールアップすると、VF手法の最適性が悪化し、VB手法がより良くスケールすることが確認された。3/8/32BサイズのLLMを用いた実験で、検証が計算能力の向上に重要であることを実証。 Comment元ポスト:https://x.com/iscienceluvr/status/1891839822257586310?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1749 #Pretraining #NLP #LanguageModel Issue Date: 2025-02-14 LLM Pretraining with Continuous Concepts, Jihoon Tack+, arXiv'25 Summary次トークン予測に代わる新しい事前学習フレームワークCoCoMixを提案。これは、スパースオートエンコーダから学習した連続的な概念をトークンの隠れ表現と交互に混ぜることで、モデルの性能を向上させる。実験により、CoCoMixは従来の手法を上回り、解釈可能性と操作性も向上させることが示された。 #NLP #LanguageModel #Test-Time Scaling Issue Date: 2025-02-12 Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling, Runze Liu+, arXiv'25 SummaryTest-Time Scaling (TTS)は、LLMsの性能向上に寄与する手法であり、ポリシーモデルやPRM、問題の難易度がTTSに与える影響を分析。実験により、最適なTTS戦略はこれらの要素に依存し、小型モデルが大型モデルを上回る可能性を示した。具体的には、1BのLLMが405BのLLMを超える結果を得た。これにより、TTSがLLMsの推論能力を向上させる有望なアプローチであることが示された。 #InformationRetrieval #NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-02-12 DeepRAG: Thinking to Retrieval Step by Step for Large Language Models, Xinyan Guan+, arXiv'25 SummaryDeepRAGフレームワークを提案し、検索強化推論をマルコフ決定過程としてモデル化。クエリを反復的に分解し、外部知識の取得とパラメトリック推論の依存を動的に判断。実験により、検索効率と回答の正確性を21.99%向上させることを実証。 Comment日本語解説。ありがとうございます!
RAGでも「深い検索」を実現する手法「DeepRAG」, Atsushi Kadowaki,
ナレッジセンス ・AI知見共有ブログ:https://zenn.dev/knowledgesense/articles/034b613c9fd6d3 #NLP #LanguageModel #ReinforcementLearning #SyntheticData #CodeGeneration #SyntheticDataGeneration Issue Date: 2025-02-12 ACECODER: Acing Coder RL via Automated Test-Case Synthesis, Huaye Zeng+, arXiv'25 Summary本研究では、コードモデルのトレーニングにおける強化学習(RL)の可能性を探求し、自動化された大規模テストケース合成を活用して信頼できる報酬データを生成する手法を提案します。具体的には、既存のコードデータから質問とテストケースのペアを生成し、これを用いて報酬モデルをトレーニングします。このアプローチにより、Llama-3.1-8B-Insで平均10ポイント、Qwen2.5-Coder-7B-Insで5ポイントの性能向上が見られ、7Bモデルが236B DeepSeek-V2.5と同等の性能を達成しました。また、強化学習を通じてHumanEvalやMBPPなどのデータセットで一貫した改善を示し、特にQwen2.5-Coder-baseからのRLトレーニングがHumanEval-plusで25%以上、MBPP-plusで6%の改善をもたらしました。これにより、コーダーモデルにおける強化学習の大きな可能性が示されました。 #NLP #LanguageModel #Architecture #Test-Time Scaling #LatentReasoning Issue Date: 2025-02-10 Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, Jonas Geiping+, arXiv'25 Summary新しい言語モデルアーキテクチャを提案し、潜在空間での暗黙的推論によりテスト時の計算をスケールさせる。再帰ブロックを反復し、任意の深さに展開することで、従来のトークン生成モデルとは異なるアプローチを採用。特別なトレーニングデータを必要とせず、小さなコンテキストウィンドウで複雑な推論を捉える。3.5億パラメータのモデルをスケールアップし、推論ベンチマークでのパフォーマンスを劇的に改善。 #NLP #LanguageModel #Distillation #TeacherHacking Issue Date: 2025-02-10 On Teacher Hacking in Language Model Distillation, Daniil Tiapkin+, arXiv'25 Summary本研究では、言語モデルの知識蒸留過程における「教師ハッキング」の現象を調査。固定されたオフラインデータセットを用いると教師ハッキングが発生し、最適化プロセスの逸脱を検出可能。一方、オンラインデータ生成技術を用いることで教師ハッキングを軽減でき、データの多様性が重要な要因であることを明らかにした。これにより、堅牢な言語モデル構築における蒸留の利点と限界についての理解が深まる。 Comment元ポスト:https://x.com/_philschmid/status/1888516494100734224?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q自分で蒸留する機会は今のところないが、覚えておきたい。過学習と一緒で、こういう現象が起こるのは想像できる。 #NLP #LanguageModel #LLMAgent Issue Date: 2025-02-09 Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?, Wenzhe Li+, arXiv'25 SummarySelf-MoAは、単一の高性能LLMからの出力を集約するアンサンブル手法であり、従来のMoAを上回る性能を示す。AlpacaEval 2.0で6.6%の改善を達成し、MMLUやCRUXなどでも平均3.8%の向上を記録。出力の多様性と品質のトレードオフを調査し、異なるLLMの混合が品質を低下させることを確認。Self-MoAの逐次バージョンも効果的であることを示した。 Comment元ポスト:https://x.com/dair_ai/status/1888658770059816968?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Supervised-FineTuning (SFT) #Test-Time Scaling #read-later Issue Date: 2025-02-07 s1: Simple test-time scaling, Niklas Muennighoff+, arXiv'25 Summaryテスト時スケーリングを用いて言語モデルのパフォーマンスを向上させる新しいアプローチを提案。小規模データセットs1Kを作成し、モデルの思考プロセスを制御する予算強制を導入。これにより、モデルは不正確な推論を修正し、Qwen2.5-32B-Instructモデルがo1-previewを最大27%上回る結果を達成。さらに、介入なしでパフォーマンスを向上させることが可能となった。モデル、データ、コードはオープンソースで提供。 Comment解説:https://x.com/hillbig/status/1887260791981941121?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Supervised-FineTuning (SFT) #DataDistillation #Reasoning #PostTraining Issue Date: 2025-02-07 LIMO: Less is More for Reasoning, Yixin Ye+, arXiv'25 SummaryLIMOモデルは、わずか817のトレーニングサンプルで複雑な数学的推論を効果的に引き出し、AIMEで57.1%、MATHで94.8%の精度を達成。従来のモデルよりも少ないデータで優れたパフォーマンスを示し、一般化を促す「Less-Is-More Reasoning Hypothesis」を提案。LIMOはオープンソースとして提供され、データ効率の良い推論の再現性を促進する。 Comment元ポスト:https://x.com/arankomatsuzaki/status/1887353699644940456?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Alignment #ICLR #DPO #PostTraining #Diversity Issue Date: 2025-02-01 Diverse Preference Optimization, Jack Lanchantin+, ICLR'25 SummaryDiverse Preference Optimization(DivPO)を提案し、応答の多様性を向上させつつ生成物の品質を維持するオンライン最適化手法を紹介。DivPOは応答のプールから多様性を測定し、希少で高品質な例を選択することで、パーソナ属性の多様性を45.6%、ストーリーの多様性を74.6%向上させる。 Comment元ポスト:https://x.com/jaseweston/status/1885399530419450257?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview: https://openreview.net/forum?id=pOq9vDIYevDPOと同じ最適化方法を使うが、Preference Pairを選択する際に、多様性が増加するようなPreference Pairの選択をすることで、モデルのPost-training後の多様性を損なわないようにする手法を提案しているっぽい。
具体的には、Alg.1 に記載されている通り、多様性の尺度Dを定義して、モデルにN個のレスポンスを生成させRMによりスコアリングした後、RMのスコアが閾値以上のresponseを"chosen" response, 閾値未満のレスポンスを "reject" responseとみなし、chosen/reject response集合を構築する。chosen response集合の中からDに基づいて最も多様性のあるresponse y_c、reject response集合の中から最も多様性のないresponse y_r をそれぞれピックし、prompt xとともにpreference pair (x, y_c, y_r) を構築しPreference Pairに加える、といった操作を全ての学習データ(中のprompt)xに対して繰り返すことで実現する。 #ComputerVision #Analysis #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #ICML #PostTraining #read-later #Admin'sPick Issue Date: 2025-01-30 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25 SummarySFTとRLの一般化能力の違いを研究し、GeneralPointsとV-IRLを用いて評価。RLはルールベースのテキストと視覚変種に対して優れた一般化を示す一方、SFTは訓練データを記憶し分布外シナリオに苦労。RLは視覚認識能力を向上させるが、SFTはRL訓練に不可欠であり、出力形式を安定させることで性能向上を促進。これらの結果は、複雑なマルチモーダルタスクにおけるRLの一般化能力を示す。 Comment元ポスト:https://x.com/hillbig/status/1884731381517082668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qopenreview:https://openreview.net/forum?id=dYur3yabMj&referrer=%5Bthe%20profile%20of%20Yi%20Ma%5D(%2Fprofile%3Fid%3D~Yi_Ma4) #RecommenderSystems #LanguageModel #Personalization #FoundationModel Issue Date: 2025-01-29 360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation, Hamed Firooz+, arXiv'25 Summaryランキングおよび推薦システムの課題に対処するため、テキストインターフェースを持つ大規模基盤モデルを活用した研究を紹介。150Bパラメータのデコーダー専用モデル360Brew V1.0は、LinkedInのデータを用いて30以上の予測タスクを解決し、従来の専用モデルと同等以上のパフォーマンスを達成。特徴エンジニアリングの複雑さを軽減し、複数のタスクを単一モデルで管理可能にする利点を示す。 Comment元ポスト:https://x.com/_reachsumit/status/1884455910824948154?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Reasoning #Test-Time Scaling Issue Date: 2025-01-28 Evolving Deeper LLM Thinking, Kuang-Huei Lee+, arXiv'25 SummaryMind Evolutionという進化的探索戦略を提案し、言語モデルを用いて候補応答を生成・洗練する。これにより、推論問題の形式化を回避しつつ、推論コストを制御。自然言語計画タスクにおいて、他の戦略を大幅に上回り、TravelPlannerおよびNatural Planのベンチマークで98%以上の問題を解決。 CommentOpenReview: https://openreview.net/forum?id=nGP1UxhAbV&referrer=%5Bthe%20profile%20of%20Kuang-Huei%20Lee%5D(%2Fprofile%3Fid%3D~Kuang-Huei_Lee1) #RecommenderSystems #LanguageModel Issue Date: 2025-01-28 Pre-train and Fine-tune: Recommenders as Large Models, Zhenhao Jiang+, arXiv'25 Summaryユーザーの興味の変化を捉えるため、レコメンダーを大規模な事前学習モデルとしてファインチューニングするアプローチを提案。情報ボトルネック理論に基づき、知識圧縮と知識マッチングの二つのフェーズを定義したIAK技術を設計。実験により優位性を示し、オンラインプラットフォームでの展開から得た教訓や潜在的な問題への解決策も提示。IAK技術を用いたレコメンダーは、オンラインフードプラットフォームでの展開により大きな利益を上げている。 Comment元ポスト:https://x.com/_reachsumit/status/1883719872540254355?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2025-01-25 Perspective Transition of Large Language Models for Solving Subjective Tasks, Xiaolong Wang+, arXiv'25 Summary視点の移行を通じた推論(RPT)を提案し、LLMsが主観的な問題に対して動的に視点を選択できる手法を紹介。広範な実験により、従来の固定視点手法を上回り、文脈に応じた適切な応答を提供する能力を示す。 Comment元ポスト:https://x.com/rohanpaul_ai/status/1882739526361370737?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview: https://openreview.net/forum?id=cFGPlRony5"Subjective Task"とは例えば「メタファーの認識」や「ダークユーモアの検知」などがあり、これらは定量化しづらい認知的なコンテキストや、ニュアンスや感情などが強く関連しており、現状のLLMではチャレンジングだと主張している。
Subjective Taskでは、Reasoningモデルのように自動的にCoTのpathwayを決めるのは困難で、手動でpathwayを記述するのはチャレンジングで一貫性を欠くとした上で、複数の視点を組み合わせたPrompting(direct perspective, role-perspective, third-person perspectivfe)を実施し、最もConfidenceの高いanswerを採用することでこの課題に対処すると主張している。イントロしか読めていないが、自動的にCoTのpathwayを決めるのも手動で決めるのも難しいという風にイントロで記述されているが、手法自体が最終的に3つの視点から回答を生成させるという枠組みに則っている(つまりSubjective Taskを解くための形式化できているので、自動的な手法でもできてしまうのではないか?と感じた)ので、イントロで記述されている主張の”難しさ”が薄れてしまっているかも・・・?と感じた。論文が解こうとしている課題の”難しさ”をサポートする材料がもっとあった方がよりmotivationが分かりやすくなるかもしれない、という感想を持った。 #RecommenderSystems #Survey #LanguageModel #Contents-based Issue Date: 2025-01-06 Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap, Weizhi Zhang+, arXiv'25 Summaryコールドスタート問題はレコメンダーシステムの重要な課題であり、新しいユーザーやアイテムのモデル化に焦点を当てている。大規模言語モデル(LLMs)の成功により、CSRに新たな可能性が生まれているが、包括的なレビューが不足している。本論文では、CSRのロードマップや関連文献をレビューし、LLMsが情報を活用する方法を探求することで、研究と産業界に新たな洞察を提供することを目指す。関連リソースはコミュニティのために収集・更新されている。 Comment元ポスト:https://x.com/_reachsumit/status/1876093584593793091?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #ICML #Tokenizer #Workshop Issue Date: 2025-01-02 Byte Latent Transformer: Patches Scale Better Than Tokens, Artidoro Pagnoni+, ICML'25 Workshop Tokshop SummaryByte Latent Transformer(BLT)は、バイトレベルのLLMアーキテクチャで、トークン化ベースのLLMと同等のパフォーマンスを実現し、推論効率と堅牢性を大幅に向上させる。BLTはバイトを動的にサイズ変更可能なパッチにエンコードし、データの複雑性に応じて計算リソースを調整する。最大8Bパラメータと4Tトレーニングバイトのモデルでの研究により、固定語彙なしでのスケーリングの可能性が示された。長いパッチの動的選択により、トレーニングと推論の効率が向上し、全体的にBLTはトークン化モデルよりも優れたスケーリングを示す。 Comment興味深い図しか見れていないが、バイト列をエンコード/デコードするtransformer学習して複数のバイト列をパッチ化(エントロピーが大きい部分はより大きなパッチにバイト列をひとまとめにする)、パッチからのバイト列生成を可能にし、パッチを変換するのをLatent Transformerで学習させるようなアーキテクチャのように見える。
また、予算によってモデルサイズが決まってしまうが、パッチサイズを大きくすることで同じ予算でモデルサイズも大きくできるのがBLTの利点とのこと。
・1472 #NLP #DataAugmentation #Distillation #NAACL #Verification Issue Date: 2024-12-02 Reverse Thinking Makes LLMs Stronger Reasoners, Justin Chih-Yao Chen+, NAACL'25 Summary逆思考は推論において重要であり、我々は大規模言語モデル(LLMs)向けにReverse-Enhanced Thinking(RevThink)フレームワークを提案。データ拡張と学習目標を用いて、前向きと後向きの推論を構造化し、マルチタスク学習で小型モデルを訓練。実験では、ゼロショット性能が平均13.53%向上し、知識蒸留ベースラインに対して6.84%の改善を達成。少ないデータでのサンプル効率も示し、一般化能力が高いことが確認された。 Comment手法概要
Original QuestionからTeacher Modelでreasoningと逆質問を生成(Forward Reasoning, Backward Question)し、逆質問に対するReasoningを生成する(Backward Reasoning)。
その後、Forward Reasoningで回答が誤っているものや、Teacher Modelを用いてBackward ReasoningとOriginal Questionを比較して正しさをverificationすることで、学習データのフィルタリングを行う。
このようにして得られたデータに対して、3種類の項をlossに設けて学習する。具体的には
・Original Questionから生成したForward Reasoningに対するクロスエントロピー
・Original Questionから生成したBackward Questionに対するクロスエントロピー
・Backward Questionから生成したBackward Reasoningに対するクロスエントロピー
の平均をとる。
また、original questionと、backward reasoningが一貫しているかを確認するためにTeacher Modelを利用した下記プロンプトでverificationを実施し、一貫性があると判断されたサンプルのみをSFTのデータとして活用している。
Teacherモデルから知識蒸留をするためSFTが必要。あと、正解が一意に定まるようなQuestionでないとbackward reasoningの生成はできても、verificationが困難になるので、適用するのは難しいかもしれない。 #NeuralNetwork #Pretraining #MachineLearning #NLP #LanguageModel #ICLR #Batch Issue Date: 2024-11-25 How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25 Summary大規模モデルの訓練には、クリティカルバッチサイズ(CBS)を考慮した並列化戦略が重要である。CBSの測定法を提案し、C4データセットで自己回帰型言語モデルを訓練。バッチサイズや学習率などの要因を調整し、CBSがデータサイズに比例してスケールすることを示した。この結果は、ニューラルネットワークの理論的分析によって支持され、ハイパーパラメータ選択の重要性も強調されている。 CommentCritical Batch Sizeはモデルサイズにはあまり依存せず、データサイズに応じてスケールする
#ICLR Issue Date: 2024-10-11 GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, Iman Mirzadeh+, N_A, ICLR'25 Summary最近のLLMsの進展により、数学的推論能力への関心が高まっているが、GSM8Kベンチマークの信頼性には疑問が残る。これに対処するため、GSM-Symbolicという新しいベンチマークを導入し、モデルの推論能力をより正確に評価。調査結果は、モデルが同じ質問の異なる具現化に対してばらつきを示し、特に数値変更や質問の節の数が増えると性能が著しく低下することを明らかにした。これは、LLMsが真の論理的推論を行えず、トレーニングデータからの再現に依存しているためと考えられる。全体として、研究は数学的推論におけるLLMsの能力と限界についての理解を深める。 Comment元ポスト:https://x.com/mfarajtabar/status/1844456880971858028?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMay I ask if this work is open source?I'm sorry, I just noticed your comment. From what I could see in the repository and OpenReview discussion, some parts of the dataset, such as GSMNoOp, are not part of the current public release. The repository issues also mention that the data generation code is not included at the moment. This is just based on my quick check, so there may be more updates or releases coming later.
OpenReview:https://openreview.net/forum?id=AjXkRZIvjB
Official blog post:https://machinelearning.apple.com/research/gsm-symbolic
Repo:https://github.com/apple/ml-gsm-symbolic
HuggingFace:https://huggingface.co/datasets/apple/GSM-Symbolic #Analysis #NLP #LanguageModel #SyntheticData #ICLR Issue Date: 2024-04-15 Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws, Zeyuan Allen-Zhu+, N_A, ICLR'25 Summary言語モデルのサイズと能力の関係を記述するスケーリング則に焦点を当てた研究。モデルが格納する知識ビット数を推定し、事実知識をタプルで表現。言語モデルは1つのパラメータあたり2ビットの知識を格納可能であり、7Bモデルは14Bビットの知識を格納可能。さらに、トレーニング期間、モデルアーキテクチャ、量子化、疎な制約、データの信号対雑音比が知識格納容量に影響することを示唆。ロータリー埋め込みを使用したGPT-2アーキテクチャは、知識の格納においてLLaMA/Mistralアーキテクチャと競合する可能性があり、トレーニングデータにドメイン名を追加すると知識容量が増加することが示された。 Comment参考:https://x.com/hillbig/status/1779640139263901698?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説:
・1834openreview:https://openreview.net/forum?id=FxNNiUgtfa #ComputerVision #NLP #LanguageModel #ModelMerge Issue Date: 2024-03-21 Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N_A, Nature Machine Intelligence'25 Summary進化アルゴリズムを使用した新しいアプローチを提案し、強力な基盤モデルの自動生成を実現。LLMの開発において、人間の直感やドメイン知識に依存せず、多様なオープンソースモデルの効果的な組み合わせを自動的に発見する。このアプローチは、日本語のLLMと数学推論能力を持つモデルなど、異なるドメイン間の統合を容易にし、日本語VLMの性能向上にも貢献。オープンソースコミュニティへの貢献と自動モデル構成の新しいパラダイム導入により、基盤モデル開発における効率的なアプローチを模索。 Comment複数のLLMを融合するモデルマージの話。日本語LLMと英語の数学LLNをマージさせることで日本語の数学性能を大幅に向上させたり、LLMとVLMを融合したりすることで、日本にしか存在しない概念の画像も、きちんと回答できるようになる。
著者スライドによると、従来のモデルマージにはbase modelが同一でないとうまくいかなかったり(重みの線型結合によるモデルマージ)、パラメータが増減したり(複数LLMのLayerを重みは弄らず再配置する)。また日本語LLMに対してモデルマージを実施しようとすると、マージ元のLLMが少なかったり、広範囲のモデルを扱うとマージがうまくいかない、といった課題があった。本研究ではこれら課題を解決できる。著者による資料(NLPコロキウム):
https://speakerdeck.com/iwiwi/17-nlpkorokiumu #ComputerVision #Analysis #Prompting Issue Date: 2025-08-25 [Paper Note] As Generative Models Improve, People Adapt Their Prompts, Eaman Jahani+, arXiv'24 Summaryオンライン実験で1893人の参加者を対象に、DALL-E 2とDALL-E 3のプロンプトの重要性の変化を調査。DALL-E 3を使用した参加者は、DALL-E 2よりも高いパフォーマンスを示し、これは技術的能力の向上とプロンプトの質の変化によるもの。特に、DALL-E 3の参加者はより長く、意味的に類似したプロンプトを作成。プロンプト修正機能を持つDALL-E 3はさらに高いパフォーマンスを示したが、その利点は減少。結果として、モデルの進化に伴い、プロンプトも適応されることが示唆される。 Comment元ポスト:https://x.com/dair_ai/status/1959644116305748388?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #SmallModel #Scheduler Issue Date: 2025-08-25 [Paper Note] MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies, Shengding Hu+, arXiv'24 Summary急成長する大規模言語モデル(LLMs)の開発におけるコストの懸念から、小規模言語モデル(SLMs)の可能性が注目されている。本研究では、MiniCPMという1.2Bおよび2.4Bの非埋め込みパラメータバリアントを紹介し、これらが7B-13BのLLMsと同等の能力を持つことを示す。モデルのスケーリングには広範な実験を、データのスケーリングにはWarmup-Stable-Decay(WSD)学習率スケジューラを導入し、効率的なデータ-モデルスケーリング法を研究した。MiniCPMファミリーにはMiniCPM-DPO、MiniCPM-MoE、MiniCPM-128Kが含まれ、優れたパフォーマンスを発揮している。MiniCPMモデルは公開されている。 CommentWarmup-Stable-Decay (WSD) #NeuralNetwork #NLP #Transformer #ActivationFunction Issue Date: 2025-08-25 [Paper Note] Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models, Zhijian Zhuo+, arXiv'24 Summary新しい多項式合成活性化関数(PolyCom)を提案し、トランスフォーマーのダイナミクスを最適化。PolyComは他の活性化関数よりも高い表現力を持ち、最適近似率を達成。大規模言語モデルにおいて、従来の活性化関数をPolyComに置き換えることで、精度と収束率が向上することを実証。実験結果は他の活性化関数に対して大幅な改善を示す。コードは公開中。 Comment関連:
・1311 #ComputerVision #Pretraining #MulltiModal #FoundationModel #CVPR #Admin'sPick #VisionLanguageModel Issue Date: 2025-08-23 [Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24 Summary大規模視覚-言語基盤モデル(InternVL)は、60億パラメータで設計され、LLMと整合させるためにウェブ規模の画像-テキストデータを使用。視覚認知タスクやゼロショット分類、検索など32のベンチマークで最先端の性能を達成し、マルチモーダル対話システムの構築に寄与。ViT-22Bの代替として強力な視覚能力を持つ。コードとモデルは公開されている。 Comment既存のResNetのようなSupervised pretrainingに基づくモデル、CLIPのようなcontrastive pretrainingに基づくモデルに対して、text encoder部分をLLMに置き換えて、contrastive learningとgenerativeタスクによる学習を組み合わせたパラダイムを提案。
InternVLのアーキテクチャは下記で、3 stageの学習で構成される。最初にimage text pairをcontrastive learningし学習し、続いてモデルのパラメータはfreezeしimage text retrievalタスク等でモダリティ間の変換を担う最終的にQlLlama(multilingual性能を高めたllama)をvision-languageモダリティを繋ぐミドルウェアのように捉え、Vicunaをテキストデコーダとして接続してgenerative cossで学習する、みたいなアーキテクチャの模様(斜め読みなので少し違う可能性あり
・2449
・2450
これらはすでに飽和している最近よくLLMのベンチで見かけるSimpleQA #ICML Issue Date: 2025-08-16 [Paper Note] Better & Faster Large Language Models via Multi-token Prediction, Fabian Gloeckle+, ICML'24 Summary本研究では、大規模言語モデルを複数の将来のトークンを同時に予測するように訓練する手法を提案し、サンプル効率の向上を図る。具体的には、n個の独立した出力ヘッドを用いて次のnトークンを予測し、訓練時間にオーバーヘッドをかけずに下流の能力を向上させる。特に、コーディングタスクにおいて、提案モデルは強力なベースラインを上回る性能を示し、推論時に最大3倍の速度向上も実現。 Issue Date: 2025-08-16 [Paper Note] Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, Lean Wang+, arXiv'24 SummaryMoEモデルにおける負荷の不均衡を解消するため、補助損失を用いないLoss-Free Balancingを提案。各エキスパートのルーティングスコアにバイアスを適用し、負荷のバランスを維持。実験により、従来の手法よりも性能と負荷バランスが向上することを確認。 Commentopenreview:https://openreview.net/forum?id=y1iU5czYpE #NLP #Dataset #LanguageModel #Evaluation #Programming #Reasoning #MultiLingual Issue Date: 2025-08-15 [Paper Note] CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution, Ruiyang Xu+, arXiv'24 SummaryCRUXEVAL-Xという多言語コード推論ベンチマークを提案。19のプログラミング言語を対象に、各言語で600以上の課題を含む19Kのテストを自動生成。言語間の相関を評価し、Python訓練モデルが他言語でも高い性能を示すことを確認。 Comment関連:
・2440 #NLP #Dataset #LanguageModel #Evaluation #Programming #Reasoning Issue Date: 2025-08-15 [Paper Note] CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, Alex Gu+, arXiv'24 SummaryCRUXEvalという800のPython関数からなるベンチマークを提案し、入力予測と出力予測の2つのタスクを評価。20のコードモデルをテストした結果、HumanEvalで高得点のモデルがCRUXEvalでは改善を示さないことが判明。GPT-4とChain of Thoughtを用いた場合、入力予測で75%、出力予測で81%のpass@1を達成したが、どのモデルも完全にはクリアできず、GPT-4のコード推論能力の限界を示す例を提供。 #ComputerVision #Analysis #ImageSegmentation #SSM (StateSpaceModel) #ImageClassification Issue Date: 2025-08-14 [Paper Note] MambaOut: Do We Really Need Mamba for Vision?, Weihao Yu+, arXiv'24 SummaryMambaはRNNのようなトークンミキサーを持つアーキテクチャで、視覚タスクにおいて期待外れの性能を示す。Mambaは長いシーケンスと自己回帰的な特性に適しているが、画像分類には不向きであると仮定。MambaOutモデルを構築し、実験によりMambaOutがImageNetの画像分類で視覚Mambaモデルを上回ることを示し、検出およびセグメンテーションタスクではMambaの可能性を探る価値があることを確認。 #Survey #NLP #LanguageModel #memory Issue Date: 2025-08-11 [Paper Note] A Survey on the Memory Mechanism of Large Language Model based Agents, Zeyu Zhang+, arXiv'24 SummaryLLMベースのエージェントのメモリメカニズムに関する包括的な調査を提案。メモリの重要性を論じ、過去の研究を体系的にレビューし、エージェントアプリケーションでの役割を紹介。既存研究の限界を分析し、将来の研究方向性を示す。リポジトリも作成。 Comment元ポスト:https://x.com/jiqizhixin/status/1954797669957968169?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #LanguageModel #NeurIPS #read-later #ReversalCurse Issue Date: 2025-08-11 [Paper Note] The Factorization Curse: Which Tokens You Predict Underlie the Reversal Curse and More, Ouail Kitouni+, NeurIPS'24 Summary最先端の言語モデルは幻覚に悩まされ、情報取得において逆転の呪いが問題となる。これを因数分解の呪いとして再定義し、制御実験を通じてこの現象が次トークン予測の固有の失敗であることを発見。信頼性のある情報取得は単純な手法では解決できず、ファインチューニングも限界がある。異なるタスクでの結果は、因数分解に依存しないアプローチが逆転の呪いを軽減し、知識の保存と計画能力の向上に寄与する可能性を示唆している。 Comment元ポスト:https://x.com/scaling01/status/1954682957798715669?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qopenreview:https://openreview.net/forum?id=f70e6YYFHFReversal Curseを提言した研究は下記:
・1059関連:
・2399 #ComputerVision #NLP #Dataset #Evaluation #MulltiModal #Reasoning #CVPR Issue Date: 2025-08-09 [Paper Note] MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI, Xiang Yue+, CVPR'24 SummaryMMMUは、大学レベルの専門知識と意図的な推論を必要とするマルチモーダルモデルの評価のための新しいベンチマークで、11,500のマルチモーダル質問を含む。6つの主要分野をカバーし、30種類の画像タイプを使用。既存のベンチマークと異なり、専門家が直面するタスクに類似した課題を提供。GPT-4VとGeminiの評価では、56%と59%の精度にとどまり、改善の余地があることを示す。MMMUは次世代のマルチモーダル基盤モデルの構築に寄与することが期待されている。 CommentMMMUのリリースから20ヶ月経過したが、いまだに人間のエキスパートのアンサンブルには及ばないとのこと
https://x.com/xiangyue96/status/1953902213790830931?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMMMUのサンプルはこちら。各分野ごとに専門家レベルの知識と推論が求められるとのこと。
https://tech.preferred.jp/ja/blog/plamo-prime-release-feature-update/
タスクと言語ごとのLengthの分布。英語の方がデータが豊富で、長いものだと30000--40000ものlengthのサンプルもある模様。
専門家を見つける際には専門家ごとにfinetuningしたいタスクに対するrelevance scoreを計算する。そのために、2つの手法が提案されており、training dataからデータをサンプリングし
・全てのサンプリングしたデータの各トークンごとのMoE Routerのgateの値の平均値をrelevant scoreとする方法
・全てのサンプリングしたデータの各トークンごとに選択された専門家の割合
の2種類でスコアを求める。閾値pを決定し、閾値以上のスコアを持つ専門家をtrainableとする。
LoRAよりもmath, codeなどの他ドメインのタスク性能を劣化させず、Finetuning対象のタスクでFFTと同等の性能を達成。
LoRAと同様にFFTと比較し学習時間は短縮され、学習した専門家の重みを保持するだけで良いのでストレージも節約できる。
ポスタースクショあり Issue Date: 2025-07-18 [Paper Note] Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse, Ryan Liu+, arXiv'24 SummaryChain-of-thought (CoT) プロンプティングは、言語モデルの性能向上に寄与するが、性能低下を引き起こすタスク特性は未解明。本研究では、心理学からのインスピレーションを得て、CoTが性能を損なうタスクを特定。6つの代表的なタスクを分析し、3つのタスクではCoTが最大36.3%の精度低下を引き起こすことを示した。人間の思考過程とモデルの推論の関係を考察し、推論時の影響を理解するための新たな視点を提供する。 Comment元ポスト:https://x.com/jiayiigeng/status/1945994557465952672?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #read-later Issue Date: 2025-07-16 [Paper Note] Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs, Koshiro Saito+, arXiv'24 Summaryローカルな大規模言語モデル(LLMs)の構築の意義や学習内容、他言語からの能力移転、言語特有のスケーリング法則を探るため、日本語を対象に19の評価ベンチマークで35のLLMを評価。英語のトレーニングが日本語の学術スコアを向上させる一方、日本語特有のタスクには日本語テキストでのトレーニングが有効であることが示された。また、日本語能力は計算予算に応じてスケールすることが確認された。 #read-later Issue Date: 2025-07-16 [Paper Note] Accelerating Large Language Model Training with 4D Parallelism and Memory Consumption Estimator, Kazuki Fujii+, arXiv'24 Summary本研究では、Llamaアーキテクチャにおける4D並列トレーニングに対して、メモリ使用量を正確に推定する公式を提案。A100およびH100 GPUでの454回の実験を通じて、一時バッファやメモリの断片化を考慮し、推定メモリがGPUメモリの80%未満であればメモリ不足エラーが発生しないことを示した。この公式により、メモリオーバーフローを引き起こす並列化構成を事前に特定でき、最適な4D並列性構成に関する実証的な洞察を提供する。 #read-later Issue Date: 2025-07-16 [Paper Note] Heron-Bench: A Benchmark for Evaluating Vision Language Models in Japanese, Yuichi Inoue+, arXiv'24 Summary日本語に特化したVision Language Models (VLM)の評価のために、新しいベンチマーク「Japanese Heron-Bench」を提案。日本の文脈に基づく画像-質問応答ペアを用いて、日本語VLMの能力を測定。提案されたVLMの強みと限界を明らかにし、強力なクローズドモデルとの能力ギャップを示す。今後の日本語VLM研究の発展を促進するため、データセットと訓練コードを公開。 #read-later Issue Date: 2025-07-16 [Paper Note] Building a Large Japanese Web Corpus for Large Language Models, Naoaki Okazaki+, arXiv'24 Summary日本語LLMsのために、Common Crawlから634億ページを抽出・精製し、約3121億文字の大規模日本語ウェブコーパスを構築。これは既存のコーパスを上回り、Llama 2を用いた事前訓練で日本語ベンチマークデータセットにおいて6.6-8.1ポイントの改善を達成。特にLlama 2 13Bの改善が最も顕著であった。 #read-later Issue Date: 2025-07-16 [Paper Note] Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities, Kazuki Fujii+, arXiv'24 Summary大規模言語モデル「Swallow」は、Llama 2の語彙を日本語に拡張し、日本語ウェブコーパスで継続的事前学習を行うことで日本語能力を向上させた。実験により、日本語タスクの性能が大幅に向上し、トレーニングデータが増加するにつれて性能が向上することが確認された。Swallowは他のLLMと比較して優れた性能を示し、特に日本語の質問応答タスクに効果的であることが明らかになった。また、語彙の拡張と平行コーパスの利用が性能に与える影響を調査し、平行コーパスの併用が翻訳能力を向上させることを示した。 #ICML #Workshop Issue Date: 2025-07-15 [Paper Note] DiLoCo: Distributed Low-Communication Training of Language Models, Arthur Douillard+, ICML'24 Workshop WANT Summary分散最適化アルゴリズム「DiLoCo」を提案し、接続が不十分なデバイスでのLLMトレーニングを可能にする。DiLoCoは、通信量を500分の1に抑えつつ、完全同期の最適化と同等の性能をC4データセットで発揮。各ワーカーのデータ分布に対して高いロバスト性を持ち、リソースの変動にも柔軟に対応可能。 Commentopenreview:https://openreview.net/forum?id=pICSfWkJIk&referrer=%5Bthe%20profile%20of%20MarcAurelio%20Ranzato%5D(%2Fprofile%3Fid%3D~MarcAurelio_Ranzato1) Issue Date: 2025-07-15 [Paper Note] Cautious Optimizers: Improving Training with One Line of Code, Kaizhao Liang+, arXiv'24 Summary本研究では、Pytorchのモーメンタムベースのオプティマイザーに対して単一行の修正を加えた「慎重なオプティマイザー」を提案。これにより、Adamのハミルトニアン関数を保持しつつ収束保証を維持。実験では、LlamaおよびMAEの事前学習で最大1.47倍の速度向上を達成し、LLMのポストトレーニングタスクでも改善を示した。 Comment
project page: https://mathllm.github.io/mathvision/Project Pageのランディングページが非常にわかりやすい。こちらは人間の方がまだまだ性能が高そう。
・661 Issue Date: 2025-07-09 [Paper Note] VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks, Ziyan Jiang+, arXiv'24 Summary本研究では、ユニバーサルマルチモーダル埋め込みモデルの構築を目指し、二つの貢献を行った。第一に、MMEB(Massive Multimodal Embedding Benchmark)を提案し、36のデータセットを用いて分類や視覚的質問応答などのメタタスクを網羅した。第二に、VLM2Vecというコントラストトレーニングフレームワークを開発し、視覚-言語モデルを埋め込みモデルに変換する手法を示した。実験結果は、VLM2Vecが既存のモデルに対して10%から20%の性能向上を達成することを示し、VLMの強力な埋め込み能力を証明した。 #NLP #LanguageModel #Reasoning #NeurIPS #DPO #PostTraining Issue Date: 2025-07-02 [Paper Note] Iterative Reasoning Preference Optimization, Richard Yuanzhe Pang+, NeurIPS'24 Summary反復的な好み最適化手法を用いて、Chain-of-Thought(CoT)候補間の推論ステップを最適化するアプローチを開発。修正DPO損失を使用し、推論の改善を示す。Llama-2-70B-ChatモデルでGSM8K、MATH、ARC-Challengeの精度を向上させ、GSM8Kでは55.6%から81.6%に改善。多数決による精度は88.7%に達した。 CommentOpenReview:https://openreview.net/forum?id=4XIKfvNYvx&referrer=%5Bthe%20profile%20of%20He%20He%5D(%2Fprofile%3Fid%3D~He_He2)・1212
と似たようにiterativeなmannerでreasoning能力を向上させる。
ただし、loss functionとしては、chosenなCoT+yのresponseに対して、reasoning traceを生成する能力を高めるために、NLL Lossも適用している点に注意。
32 samplesのmajority votingによってより高い性能が達成できているので、多様なreasoning traceが生成されていることが示唆される。 Issue Date: 2025-07-02 [Paper Note] Online DPO: Online Direct Preference Optimization with Fast-Slow Chasing, Biqing Qi+, arXiv'24 SummaryOFS-DPOは、異なるドメインの人間の好みに対応するために、オンライン学習を通じてモデル間の競争をシミュレートし、迅速な適応を促進する手法です。LoRAを用いて異なる最適化速度を持つモジュールを導入し、壊滅的な忘却を軽減します。COFS-DPOは、クロスドメインのシナリオにおいても優れた性能を示し、継続的な価値の整合性を達成します。 #Multi #NLP #LanguageModel #Reasoning #ACL Issue Date: 2025-06-29 [Paper Note] Do Large Language Models Latently Perform Multi-Hop Reasoning?, Sohee Yang+, ACL'24 Summary本研究では、LLMが複雑なプロンプトに対してマルチホップ推論を行う可能性を探ります。具体的には、LLMが「'Superstition'の歌手」を特定し、その母親に関する知識を用いてプロンプトを完成させる過程を分析します。2つのホップを個別に評価し、特に最初のホップにおいてブリッジエンティティのリコールが増加するかをテストしました。結果、特定の関係タイプのプロンプトに対してマルチホップ推論の証拠が見つかりましたが、活用は文脈依存であり、2番目のホップの証拠は控えめでした。また、モデルサイズの増加に伴い最初のホップの推論能力が向上する傾向が見られましたが、2番目のホップにはその傾向が見られませんでした。これらの結果は、LLMの今後の開発における課題と機会を示唆しています。 #NLP #Dataset #LanguageModel #ReinforcementLearning #Reasoning #ICLR #Admin'sPick #PRM Issue Date: 2025-06-26 [Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24 Summary大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。 CommentOpenReview:https://openreview.net/forum?id=v8L0pN6EOiPRM800K:https://github.com/openai/prm800k/tree/main #NLP #Dataset #LanguageModel #ReinforcementLearning #Evaluation Issue Date: 2025-06-26 [Paper Note] RewardBench: Evaluating Reward Models for Language Modeling, Nathan Lambert+, arXiv'24 Summary報酬モデル(RMs)の評価に関する研究は少なく、我々はその理解を深めるためにRewardBenchというベンチマークデータセットを提案。これは、チャットや推論、安全性に関するプロンプトのコレクションで、報酬モデルの性能を評価する。特定の比較データセットを用いて、好まれる理由を検証可能な形で示し、さまざまなトレーニング手法による報酬モデルの評価を行う。これにより、報酬モデルの拒否傾向や推論の限界についての知見を得ることを目指す。 #NLP #LanguageModel #ACL #ModelMerge Issue Date: 2025-06-25 [Paper Note] Chat Vector: A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languages, Shih-Cheng Huang+, ACL'24 Summaryオープンソースの大規模言語モデル(LLMs)の多くは英語に偏っている問題に対処するため、chat vectorという概念を導入。これは、事前学習済みモデルの重みからチャットモデルの重みを引くことで生成され、追加のトレーニングなしに新しい言語でのチャット機能を付与できる。実証研究では、指示に従う能力や有害性の軽減、マルチターン対話においてchat vectorの効果を示し、さまざまな言語やモデルでの適応性を確認。chat vectorは、事前学習済みモデルに対話機能を効率的に実装するための有力な解決策である。 Comment日本語解説:https://qiita.com/jovyan/items/ee6affa5ee5bdaada6b4下記ブログによるとChatだけではなく、Reasoningでも(post-trainingが必要だが)使える模様
Reasoning能力を付与したLLM ABEJA-QwQ32b-Reasoning-Japanese-v1.0の公開, Abeja Tech Blog, 2025.04:
https://tech-blog.abeja.asia/entry/geniac2-qwen25-32b-reasoning-v1.0 #Analysis #NLP #LanguageModel #Alignment #ReinforcementLearning #PPO (ProximalPolicyOptimization) #ICML #DPO #On-Policy Issue Date: 2025-06-25 [Paper Note] Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data, Fahim Tajwar+, ICML'24 Summary好みのラベルを用いた大規模言語モデルのファインチューニングに関する研究。オンポリシー強化学習や対照学習などの手法を比較し、オンポリシーサンプリングや負の勾配を用いるアプローチが優れていることを発見。これにより、カテゴリ分布の特定のビンにおける確率質量を迅速に変更できるモード探索目的の重要性を示し、データ収集の最適化に関する洞察を提供。 #Pretraining #NLP #LanguageModel #InstructionTuning #EMNLP Issue Date: 2025-06-25 [Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, EMNLP'24 Summary無監督のマルチタスク事前学習に加え、監視されたマルチタスク学習の可能性を探るために、Instruction Pre-Trainingフレームワークを提案。指示応答ペアを生成し、2億のペアを合成して実験を行い、事前学習モデルの性能を向上させることを確認。Instruction Pre-TrainingはLlama3-8BをLlama3-70Bと同等以上の性能に引き上げる。モデルやデータは公開されている。 #Analysis #Tools #NLP #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-06-18 [Paper Note] A Comparative Study of PDF Parsing Tools Across Diverse Document Categories, Narayan S. Adhikari+, arXiv'24 Summary本研究では、DocLayNetデータセットを用いて10の人気PDFパースツールを6つの文書カテゴリにわたり比較し、情報抽出の効果を評価しました。テキスト抽出ではPyMuPDFとpypdfiumが優れた結果を示し、特に科学文書や特許文書ではNougatが高いパフォーマンスを発揮しました。表検出ではTATRが金融や法律文書で優れた結果を示し、Camelotは入札文書で最も良いパフォーマンスを発揮しました。これにより、文書タイプに応じた適切なパースツールの選択が重要であることが示されました。 CommentPDFのparsingツールについて、text, table抽出の性能を様々なツールと分野別に評価している。
F1, precision, recallなどは、ground truthとのレーベンシュタイン距離からsimilarityを計算し、0.7以上であればtrue positiveとみなすことで計算している模様。local alignmentは、マッチした場合に加点、ミスマッチ、未検出の場合にペナルティを課すようなスコアリングによって抽出したテキスト全体の抽出性能を測る指標な模様。
https://x.com/jerryjliu0/status/1934988910448492570?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #MachineLearning #ReinforcementLearning #TMLR Issue Date: 2025-06-14 [Paper Note] Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models, Avi Singh+, TMLR'24 Summary言語モデルを人間データでファインチューニングする際の限界を超えるため、ReST$^{EM$という自己学習手法を提案。モデルから生成したサンプルをバイナリフィードバックでフィルタリングし、繰り返しファインチューニングを行う。PaLM-2モデルを用いた実験で、ReST$^{EM}$は人間データのみのファインチューニングを大幅に上回る性能を示し、フィードバックを用いた自己学習が人間生成データへの依存を減少させる可能性を示唆。 Comment解説ポスト:https://x.com/hillbig/status/1735065077668356106?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #EfficiencyImprovement #NLP #LanguageModel #Scaling Laws #read-later Issue Date: 2025-05-27 Densing Law of LLMs, Chaojun Xiao+, arXiv'24 Summary大規模言語モデル(LLMs)の性能向上に伴うトレーニングと推論の効率の課題を解決するために、「キャパシティ密度」という新しい指標を提案。これは、ターゲットLLMの有効パラメータサイズと実際のパラメータサイズの比率を用いて、モデルの効果と効率を評価するフレームワークを提供する。分析により、LLMsのキャパシティ密度は約3か月ごとに倍増する傾向があることが示され、今後のLLM開発における重要性が強調される。 Comment元ポスト:https://x.com/hillbig/status/1926785750277693859?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・1946 #Pretraining #NLP #Dataset #LanguageModel Issue Date: 2025-05-10 DataComp-LM: In search of the next generation of training sets for language models, Jeffrey Li+, arXiv'24 SummaryDataComp for Language Models(DCLM)を紹介し、240Tトークンのコーパスと53の評価スイートを提供。DCLMでは、モデルスケール412Mから7Bパラメータのデータキュレーション戦略を実験可能。DCLM-Baselineは2.6Tトークンでトレーニングし、MMLUで64%の精度を達成し、従来のMAP-Neoより6.6ポイント改善。計算リソースも40%削減。結果はデータセット設計の重要性を示し、今後の研究の基盤を提供。 #EfficiencyImprovement #Pretraining #NLP #Dataset #LanguageModel #Admin'sPick Issue Date: 2025-05-10 The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale, Guilherme Penedo+, arXiv'24 Summary本研究では、15兆トークンからなるFineWebデータセットを紹介し、LLMの性能向上に寄与することを示します。FineWebは高品質な事前学習データセットのキュレーション方法を文書化し、重複排除やフィルタリング戦略を詳細に調査しています。また、FineWebから派生した1.3兆トークンのFineWeb-Eduを用いたLLMは、MMLUやARCなどのベンチマークで優れた性能を発揮します。データセット、コードベース、モデルは公開されています。 Comment日本語解説:https://zenn.dev/deepkawamura/articles/da9aeca6d6d9f9 #NLP #Dataset #LanguageModel #EMNLP #KnowledgeEditing #read-later Issue Date: 2025-05-07 Editing Large Language Models: Problems, Methods, and Opportunities, Yunzhi Yao+, EMNLP'24 SummaryLLMの編集技術の進展を探求し、特定のドメインでの効率的な動作変更と他の入力への影響を最小限に抑える方法を論じる。モデル編集のタスク定義や課題を包括的にまとめ、先進的な手法の実証分析を行う。また、新しいベンチマークデータセットを構築し、評価の向上と持続的な問題の特定を目指す。最終的に、編集技術の効果に関する洞察を提供し、適切な方法選択を支援する。コードとデータセットは公開されている。 #Analysis #NLP #LanguageModel #SyntheticData #ICML #Admin'sPick Issue Date: 2025-05-03 Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24 Summary大規模言語モデル(LLMs)の知識抽出能力は、訓練データの多様性と強く相関しており、十分な強化がなければ知識は記憶されても抽出可能ではないことが示された。具体的には、エンティティ名の隠れ埋め込みに知識がエンコードされているか、他のトークン埋め込みに分散しているかを調査。LLMのプレトレーニングに関する重要な推奨事項として、補助モデルを用いたデータ再構成と指示微調整データの早期取り入れが提案された。 Comment解説:
・1834 #NLP #LanguageModel #Evaluation #Decoding #Admin'sPick Issue Date: 2025-04-14 Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, arXiv'24 Summary本研究では、5つの決定論的LLMにおける非決定性を8つのタスクで調査し、最大15%の精度変動と70%のパフォーマンスギャップを観察。全てのタスクで一貫した精度を提供できないことが明らかになり、非決定性が計算リソースの効率的使用に寄与している可能性が示唆された。出力の合意率を示す新たなメトリクスTARr@NとTARa@Nを導入し、研究結果を定量化。コードとデータは公開されている。 Comment・論文中で利用されているベンチマーク:
・785
・901 同じモデルに対して、seedを固定し、temperatureを0に設定し、同じ計算機環境に対して、同じinputを入力したら理論上はLLMの出力はdeterministicになるはずだが、deterministicにならず、ベンチマーク上の性能とそもそものraw response自体も試行ごとに大きく変化する、という話。
ただし、これはプロプライエタリLLMや、何らかのinferenceの高速化を実施したInferenceEngine(本研究ではTogetherと呼ばれる実装を使っていそう。vLLM/SGLangだとどうなるのかが気になる)を用いてinferenceを実施した場合での実験結果であり、後述の通り計算の高速化のためのさまざまな実装無しで、deterministicな設定でOpenLLMでinferenceすると出力はdeterministicになる、という点には注意。
GPTやLlama、Mixtralに対して上記ベンチマークを用いてzero-shot/few-shotの設定で実験している。Reasoningモデルは実験に含まれていない。
LLMのraw_response/multiple choiceのparse結果(i.e., 問題に対する解答部分を抽出した結果)の一致(TARr@N, TARa@N; Nはinferenceの試行回数)も理論上は100%になるはずなのに、ならないことが報告されている。
correlation analysisによって、応答の長さ と TAR{r, a}が強い負の相関を示しており、応答が長くなればなるほど不安定さは増すことが分析されている。このため、ontput tokenの最大値を制限することで出力の安定性が増すことを考察している。また、few-shotにおいて高いAcc.の場合は出力がdeterministicになるわけではないが、性能が安定する傾向とのこと。また、OpenAIプラットフォーム上でGPTのfinetuningを実施し実験したが、安定性に寄与はしたが、こちらもdeterministicになるわけではないとのこと。
deterministicにならない原因として、まずmulti gpu環境について検討しているが、multi-gpu環境ではある程度のランダム性が生じることがNvidiaの研究によって報告されているが、これはseedを固定すれば決定論的にできるため問題にならないとのこと。
続いて、inferenceを高速化するための実装上の工夫(e.g., Chunk Prefilling, Prefix Caching, Continuous Batching)などの実装がdeterministicなハイパーパラメータでもdeterministicにならない原因であると考察しており、実際にlocalマシン上でこれらinferenceを高速化するための最適化を何も実施しない状態でLlama-8Bでinferenceを実施したところ、outputはdeterministicになったとのこと。論文中に記載がなかったため、どのようなInferenceEngineを利用したか公開されているgithubを見ると下記が利用されていた:
・Together: https://github.com/togethercomputer/together-python?tab=readme-ov-file
Togetherが内部的にどのような処理をしているかまでは追えていないのだが、異なるInferenceEngineを利用した場合に、どの程度outputの不安定さに差が出るのか(あるいは出ないのか)は気になる。たとえば、transformers/vLLM/SGLangを利用した場合などである。
論文中でも報告されている通り、昔管理人がtransformersを用いて、deterministicな設定でzephyrを用いてinferenceをしたときは、出力はdeterministicになっていたと記憶している(スループットは絶望的だったが...)。あと個人的には現実的な速度でオフラインでinference engineを利用した時にdeterministicにはせめてなって欲しいなあという気はするので、何が原因なのかを実装レベルで突き詰めてくれるととても嬉しい(KV Cacheが怪しい気がするけど)。
たとえば最近SLMだったらKVCacheしてVRAM食うより計算し直した方が効率良いよ、みたいな研究があったような。そういうことをしたらlocal llmでdeterministicにならないのだろうか。 #ComputerVision #Transformer #FoundationModel #Self-SupervisedLearning #TMLR Issue Date: 2025-04-11 DINOv2: Learning Robust Visual Features without Supervision, Maxime Oquab+, TMLR'24 Summary自己教師あり手法を用いて、多様なキュレーションデータから汎用的な視覚特徴を生成する新しい事前学習手法を提案。1BパラメータのViTモデルを訓練し、小型モデルに蒸留することで、OpenCLIPを上回る性能を達成。 #Tools #NLP #Dataset #LanguageModel #API #NeurIPS Issue Date: 2025-04-08 Gorilla: Large Language Model Connected with Massive APIs, Shishir G. Patil+, NeurIPS'24 SummaryGorillaは、API呼び出しの生成においてGPT-4を上回るLLaMAベースのモデルであり、文書検索システムと組み合わせることで、テスト時の文書変更に適応し、ユーザーの柔軟な更新を可能にします。幻覚の問題を軽減し、APIをより正確に使用する能力を示します。Gorillaの評価には新たに導入したデータセット「APIBench」を使用し、信頼性と適用性の向上を実現しています。 CommentAPIBench:https://huggingface.co/datasets/gorilla-llm/APIBenchOpenReview:https://openreview.net/forum?id=tBRNC6YemY #Survey #NLP #LanguageModel #Alignment #TMLR Issue Date: 2025-04-06 Foundational Challenges in Assuring Alignment and Safety of Large Language Models, Usman Anwar+, TMLR'24 Summary本研究では、LLMsの整合性と安全性に関する18の基盤的課題を特定し、科学的理解、開発・展開方法、社会技術的課題の3つのカテゴリに整理。これに基づき、200以上の具体的な研究質問を提起。 CommentOpenReview:https://openreview.net/forum?id=oVTkOs8Pka #NLP #Transformer #Attention Issue Date: 2025-04-06 Flex Attention: A Programming Model for Generating Optimized Attention Kernels, Juechu Dong+, arXiv'24 SummaryFlexAttentionは、アテンションの新しいコンパイラ駆動型プログラミングモデルで、数行のPyTorchコードで多くのアテンションバリアントを実装可能にします。これにより、既存のアテンションバリアントを効率的に実装し、競争力のあるパフォーマンスを達成。FlexAttentionは、アテンションバリアントの組み合わせを容易にし、組み合わせ爆発の問題を解決します。 Comment・1863
で利用されているAttentionpytochによる解説:https://pytorch.org/blog/flexattention/
・Flex AttentionはオリジナルのAttentionのQK/sqrt(d_k)の計算後にユーザが定義した関数score_modを適用する
・score_modを定義することで、attention scoreをsoftmaxをかけるまえに関数によって調整できる
・多くのattentionの亜種はほとんどの場合この抽象化で対応できる
・score_modはQK tokenの内積に対応するので、QKの情報を受け取り、スカラー値を返せばなんでも良い
・score_modの実装例は元リンク参照
・FA2と比較して(現在のpytorchでの実装上は)Forward Passは90%, Backward Passは85%のスループットで、少し遅いが今後改善予定元論文より引用。非常にシンプルで、数式上は下記のように表される:
下記のpassageがAttention Sinksの定義(=最初の数トークン)とその気持ち(i.e., softmaxによるattention scoreは足し合わせて1にならなければならない。これが都合の悪い例として、現在のtokenのqueryに基づいてattention scoreを計算する際に過去のトークンの大半がirrelevantな状況を考える。この場合、irrelevantなトークンにattendしたくはない。そのため、auto-regressiveなモデルでほぼ全てのcontextで必ず出現する最初の数トークンを、irrelevantなトークンにattendしないためのattention scoreの捨て場として機能するのうに学習が進む)の理解に非常に重要
> To understand the failure of window attention, we find an interesting phenomenon of autoregressive LLMs: a surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task, as visualized in Figure 2. We term these tokens
“attention sinks". Despite their lack of semantic significance, they collect significant attention scores. We attribute the reason to the Softmax operation, which requires attention scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one. The reason behind initial tokens as sink tokens is intuitive: initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.・1860
の先行研究。こちらでAttentionSinkがどのように作用しているのか?が分析されている。Figure1が非常にわかりやすい。First TokenのKV Cacheを保持することでlong contextの性能が改善する
ReActより性能向上
・ 518
・1848 SWE-Benchと比べて実行可能な環境と単体テストが提供されており、単なるベンチマークではなくエージェントを訓練できる環境が提供されている点が大きく異なるように感じる。
人間とGPT4,GPT-3.5の比較結果
これにより、低コストで高い性能を達成している、といった内容な模様。
(あとでメモを追記) #Analysis #NLP #LanguageModel #ICLR Issue Date: 2025-03-15 Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24 Summary神経ネットワークの多義性を解消するために、スパースオートエンコーダを用いて内部活性化の方向を特定。これにより、解釈可能で単義的な特徴を学習し、間接目的語の同定タスクにおける因果的特徴をより詳細に特定。スケーラブルで教師なしのアプローチが重ね合わせの問題を解決できることを示唆し、モデルの透明性と操作性向上に寄与する可能性を示す。 Comment日本語解説:https://note.com/ainest/n/nbe58b36bb2dbOpenReview:https://openreview.net/forum?id=F76bwRSLeKSparseAutoEncoderはネットワークのあらゆるところに仕込める(と思われる)が、たとえばTransformer Blockのresidual connection部分のベクトルに対してFeature Dictionaryを学習すると、当該ブロックにおいてどのような特徴の組み合わせが表現されているかが(あくまでSparseAutoEncoderがreconstruction lossによって学習された結果を用いて)解釈できるようになる。
SparseAutoEncoderは下記式で表され、下記loss functionで学習される。MがFeature Matrix(row-wiseに正規化されて後述のcに対するL1正則化に影響を与えないようにしている)に相当する。cに対してL1正則化をかけることで(Sparsity Loss)、c中の各要素が0に近づくようになり、結果としてcがSparseとなる(どうしても値を持たなければいけない重要な特徴量のみにフォーカスされるようになる)。
元ポスト:https://x.com/tom_doerr/status/1888178173684199785?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q初期に提案された
・1034
と比較すると大分性能が上がってきているように見える。
ICLR'25にrejectされている #NLP #LanguageModel #OpenSource #PostTraining Issue Date: 2025-02-01 Tulu 3: Pushing Frontiers in Open Language Model Post-Training, Nathan Lambert+, arXiv'24 SummaryTulu 3は、オープンなポストトレーニングモデルのファミリーで、トレーニングデータやレシピを公開し、現代のポストトレーニング技術のガイドを提供します。Llama 3.1を基にし、他のクローズドモデルを上回る性能を達成。新しいトレーニング手法としてSFT、DPO、RLVRを採用し、マルチタスク評価スキームを導入。モデルウェイトやデモ、トレーニングコード、データセットなどを公開し、他のドメインへの適応も可能です。 Comment元ポスト:https://x.com/icoxfog417/status/1885460713264775659?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #Distillation Issue Date: 2025-02-01 A Survey on Knowledge Distillation of Large Language Models, Xiaohan Xu+, arXiv'24 Summary大規模言語モデル(LLMs)における知識蒸留(KD)の重要性を調査し、小型モデルへの知識伝達やモデル圧縮、自己改善の役割を強調。KDメカニズムや認知能力の向上、データ拡張(DA)との相互作用を検討し、DAがLLM性能を向上させる方法を示す。研究者や実務者に向けたガイドを提供し、LLMのKDの倫理的適用を推奨。関連情報はGithubで入手可能。 #NLP #LanguageModel #LLMAgent #Blog #NeurIPS Issue Date: 2025-01-25 [Paper Note] Chain of Agents: Large language models collaborating on long-context tasks, Google Research, 2025.01, NeurIPS'24 Comment元ポスト:https://x.com/googleai/status/1882554959272849696?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLMがどこまでいってもcontext長の制約に直面する問題に対してLLM Agentを組み合わせて対処しました、的な話な模様ブログ中にアプローチを解説した動画があるのでわかりやすいIs the experimental code open source?Thank you for your comment. I tried to find an official open-source implementation provided by the authors, but I was not able to locate one. In fact, I also checked the personal webpage of the first author, but there was no link to any released code.
Is seems that an unofficial implementation is listed under the “Code” tab on the NeurIPS page. I hope this is helpful. Thank you.
NeurIPS link: https://nips.cc/virtual/2024/poster/95563
openreview: https://openreview.net/forum?id=LuCLf4BJsr #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2025-01-25 Spectrum: Targeted Training on Signal to Noise Ratio, Eric Hartford+, arXiv'24 Summary「Spectrum」という手法を提案し、SNRに基づいてレイヤーモジュールを選択的にターゲットにすることで、LLMのトレーニングを加速。これによりGPUメモリ使用量を削減しつつ、フルファインチューニングに匹敵する性能を実現。実験により、既存手法QLoRAと比較してモデルの品質とVRAM効率の向上が確認された。 Comment・1723
によるとLLMのうち最もinformativeなLayerを見つけ、選択的に学習することで、省リソースで、Full-Parameter tuningと同等の性能を発揮する手法らしい
#ACL Issue Date: 2025-01-06 Parallel Structures in Pre-training Data Yield In-Context Learning, Yanda Chen+, arXiv'24 Summary事前学習済み言語モデル(LMs)のインコンテキスト学習(ICL)能力は、事前学習データ内の「平行構造」に依存していることを発見。平行構造とは、同じコンテキスト内で類似のテンプレートに従うフレーズのペアであり、これを除去するとICL精度が51%低下することが示された。平行構造は多様な言語タスクをカバーし、長距離にわたることが確認された。 #Survey #ACL Issue Date: 2025-01-06 Automated Justification Production for Claim Veracity in Fact Checking: A Survey on Architectures and Approaches, Islam Eldifrawi+, arXiv'24 Summary自動事実確認(AFC)は、主張の正確性を検証する重要なプロセスであり、特にオンラインコンテンツの増加に伴い真実と誤情報を見分ける役割を果たします。本論文では、最近の手法を調査し、包括的な分類法を提案するとともに、手法の比較分析や説明可能性向上のための今後の方向性について議論します。 #ACL Issue Date: 2025-01-06 Legal Case Retrieval: A Survey of the State of the Art, Feng+, ACL'24, 2024.08 Summary法的ケース検索(LCR)の重要性が増しており、歴史的なケースを大規模な法的データベースから検索するタスクに焦点を当てている。本論文では、LCRの主要なマイルストーンを調査し、研究者向けに関連データセットや最新のニューラルモデル、その性能を簡潔に説明する。 #Dataset #Financial #ACL Issue Date: 2025-01-06 FinTextQA: A Dataset for Long-form Financial Question Answering, Jian Chen+, ACL'24 Summary金融における質問応答システムの評価には多様なデータセットが必要だが、既存のものは不足している。本研究では、金融の長文質問応答用データセットFinTextQAを提案し、1,262の高品質QAペアを収集した。また、RAGベースのLFQAシステムを開発し、様々な評価手法で性能を検証した結果、Baichuan2-7BがGPT-3.5-turboに近い精度を示し、最も効果的なシステム構成が特定された。文脈の長さが閾値を超えると、ノイズに対する耐性が向上することも確認された。 Comment@AkihikoWatanabe Do you have this dataset, please share it with me. Thank you.@thangmaster37 Thank you for your comment and I'm sorry for the late replying. Unfortunately, I do not have this dataset. I checked the link provided in the paper, but it was not found. Please try contacting the authors. Thank you.@thangmaster37 I found that the dataset is available in the following repository. However, as stated in the repository's README, It seems that the textbook portion of the dataset cannot be shared because their legal department has not granted permission to open source. Thank you.
https://github.com/AlexJJJChen/FinTextQA回答の長さが既存データセットと比較して長いFinancialに関するQAデータセット(1 paragraph程度)。


ただし、上述の通りデータセットのうちtextbookについて公開の許可が降りなかったようで、regulation and policy-relatedな部分のみ利用できる模様(全体の20%程度)。
 #ACL Issue Date: 2025-01-06 Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models, Changyu Chen+, arXiv'24 Summary推論タスクにおける誤りを軽減するため、外部リソースを使わずに入力に摂動を導入する手法を開発。特定のトークンをランダムにマスクすることで、Llama-2-7Bを用いたGSM8Kの精度を5%、GSM-ICの精度を10%向上させた。この手法は既存のデータ拡張手法と組み合わせることで、複数のデータセットで改善を示し、モデルが長距離依存関係を捉えるのを助ける可能性がある。コードはGithubで公開。 Comment気になる #ACL Issue Date: 2025-01-06 A Deep Dive into the Trade-Offs of Parameter-Efficient Preference Alignment Techniques, Megh Thakkar+, arXiv'24 Summary大規模言語モデルの整列に関する研究で、整列データセット、整列技術、モデルの3つの要因が下流パフォーマンスに与える影響を300以上の実験を通じて調査。情報量の多いデータが整列に寄与することや、監視付きファインチューニングが最適化を上回るケースを発見。研究者向けに効果的なパラメータ効率の良いLLM整列のガイドラインを提案。 #LanguageModel #Supervised-FineTuning (SFT) #ACL #KnowledgeEditing Issue Date: 2025-01-06 Forgetting before Learning: Utilizing Parametric Arithmetic for Knowledge Updating in Large Language Models, Shiwen Ni+, ACL'24 SummaryF-Learningという新しいファインチューニング手法を提案し、古い知識を忘却し新しい知識を学習するためにパラメトリック算術を利用。実験により、F-LearningがフルファインチューニングとLoRAファインチューニングの知識更新性能を向上させ、既存のベースラインを上回ることを示した。LoRAのパラメータを引き算することで古い知識を忘却する効果も確認。 CommentFinetuningによって知識をアップデートしたい状況において、ベースモデルでアップデート前の該当知識を忘却してから、新しい知識を学習することで、より効果的に知識のアップデートが可能なことを示している。
古い知識のデータセットをK_old、古い知識から更新された新しい知識のデータセットをK_newとしたときに、K_oldでベースモデルを{Full-finetuning, LoRA}することで得たパラメータθ_oldを、ベースモデルのパラメータθから(古い知識を忘却することを期待して)減算し、パラメータθ'を持つ新たなベースモデルを得る。その後、パラメータθ'を持つベースモデルをk_newでFull-Finetuningすることで、新たな知識を学習させる。ただし、このような操作は、K_oldがベースモデルで学習済みである前提であることに注意する。学習済みでない場合はそもそも事前の忘却の必要がないし、減算によってベースモデルのコアとなる能力が破壊される危険がある。
結果は下記で、先行研究よりも高い性能を示している。注意点として、ベースモデルから忘却をさせる際に、Full Finetuningによってθ_oldを取得すると、ベースモデルのコアとなる能力が破壊されるケースがあるようである。一方、LoRAの場合はパラメータに対する影響が小さいため、このような破壊的な操作となりづらいようである。
・2556
・2557 #ACL Issue Date: 2025-01-06 NICE: To Optimize In-Context Examples or Not?, Pragya Srivastava+, ACL'24 Summaryタスク固有の指示がある場合、ICEの最適化が逆効果になることを発見。指示が詳細になるほどICE最適化の効果が減少し、タスクの学習可能性を定量化する指標「NICE」を提案。これにより、指示最適化とICE最適化の選択を支援するヒューリスティックを提供。 Comment興味深い #Pretraining #InstructionTuning #ACL #PerplexityCurse Issue Date: 2025-01-06 Instruction-tuned Language Models are Better Knowledge Learners, Zhengbao Jiang+, ACL'24 Summary新しい文書からの知識更新には、事前指示調整(PIT)を提案。これは、文書の訓練前に質問に基づいて指示調整を行う手法で、LLMが新しい情報を効果的に吸収する能力を向上させ、標準的な指示調整を17.8%上回る結果を示した。 Comment興味深い #NLP #LanguageModel #ACL #KnowledgeEditing Issue Date: 2025-01-06 Learning to Edit: Aligning LLMs with Knowledge Editing, Yuxin Jiang+, ACL'24 Summary「Learning to Edit(LTE)」フレームワークを提案し、LLMsに新しい知識を効果的に適用する方法を教える。二段階プロセスで、アライメントフェーズで信頼できる編集を行い、推論フェーズでリトリーバルメカニズムを使用。四つの知識編集ベンチマークでLTEの優位性と堅牢性を示す。 #ACL Issue Date: 2025-01-06 Multi-Level Feedback Generation with Large Language Models for Empowering Novice Peer Counselors, Alicja Chaszczewicz+, arXiv'24 Summary大規模言語モデルを活用し、初心者のピアカウンセラーに文脈に応じた多層的なフィードバックを提供することを目的とした研究。上級心理療法スーパーバイザーと協力し、感情的サポートの会話に関するフィードバック注釈付きデータセットを構築。自己改善手法を設計し、フィードバックの自動生成を強化。定性的および定量的評価により、高リスクシナリオでの低品質なフィードバック生成のリスクを最小限に抑えることを示した。 #ACL Issue Date: 2025-01-06 Learning Global Controller in Latent Space for Parameter-Efficient Fine-Tuning, Tan+, ACL'24, 2024.08 Summary大規模言語モデル(LLMs)の高コストに対処するため、パラメータ効率の良いファインチューニング手法を提案。潜在ユニットを導入し、情報特徴を洗練することで下流タスクのパフォーマンスを向上。非対称注意メカニズムにより、トレーニングのメモリ要件を削減し、フルランクトレーニングの問題を軽減。実験結果は、自然言語処理タスクで最先端の性能を達成したことを示す。 #ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MulltiModal #ACL Issue Date: 2025-01-06 OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems, Chaoqun He+, ACL'24 Summary大規模言語モデル(LLMs)やマルチモーダルモデル(LMMs)の能力を測定するために、オリンピアドレベルのバイリンガルマルチモーダル科学ベンチマーク「OlympiadBench」を提案。8,476の数学と物理の問題を含み、専門家レベルの注釈が付けられている。トップモデルのGPT-4Vは平均17.97%のスコアを達成したが、物理では10.74%にとどまり、ベンチマークの厳しさを示す。一般的な問題として幻覚や論理的誤謬が指摘され、今後のAGI研究に貴重なリソースとなることが期待される。 #ACL Issue Date: 2025-01-06 DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows, Ajay Patel+, arXiv'24 Summary大規模言語モデル(LLMs)の利用が広がる中、標準化ツールの欠如や再現性の問題が浮上している。本論文では、研究者が簡単にLLMワークフローを実装できるオープンソースのPythonライブラリ「DataDreamer」を紹介し、オープンサイエンスと再現性を促進するためのベストプラクティスを提案する。ライブラリはGitHubで入手可能。 #ACL Issue Date: 2025-01-06 Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives, Wenqi Zhang+, arXiv'24 SummaryLLMの反射能力に関する研究では、自己評価の質がボトルネックであることが判明。過信や高いランダム性が反射の質を低下させるため、自己対比(Self-Contrast)を提案し、多様な解決視点を探求・対比することで不一致を排除。これにより、LLMのバイアスを軽減し、より正確で安定した反射を促進。実験により、提案手法の効果と一般性が示された。 #ACL Issue Date: 2025-01-06 Llama2Vec: Unsupervised Adaptation of Large Language Models for Dense Retrieval, Li+, ACL'24, 2024.08 SummaryLlama2Vecは、LLMを密な検索に適応させるための新しい非監視適応アプローチであり、EBAEとEBARの2つの前提タスクを用いています。この手法は、WikipediaコーパスでLLaMA-2-7Bを適応させ、密な検索ベンチマークでの性能を大幅に向上させ、特にMSMARCOやBEIRで最先端の結果を達成しました。モデルとソースコードは公開予定です。 #Education #ACL Issue Date: 2025-01-06 BIPED: Pedagogically Informed Tutoring System for ESL Education, Kwon+, ACL'24, 2024.08 Summary大規模言語モデル(LLMs)を用いた会話型インテリジェントチュータリングシステム(CITS)は、英語の第二言語(L2)学習者に対して効果的な教育手段となる可能性があるが、既存のシステムは教育的深さに欠ける。これを改善するために、バイリンガル教育的情報を持つチュータリングデータセット(BIPED)を構築し、対話行為の語彙を考案した。GPT-4とSOLAR-KOを用いて二段階のフレームワークでCITSモデルを実装し、実験により人間の教師のスタイルを再現し、多様な教育的戦略を採用できることを示した。 #ACL Issue Date: 2025-01-06 Beyond Memorization: The Challenge of Random Memory Access in Language Models, Tongyao Zhu+, arXiv'24 Summary生成型言語モデル(LM)のメモリアクセス能力を調査し、順次アクセスは可能だがランダムアクセスには課題があることを明らかに。暗唱技術がランダムメモリアクセスを向上させ、オープンドメインの質問応答においても顕著な改善を示した。実験コードは公開されている。 #ACL Issue Date: 2025-01-06 Attribute First, then Generate: Locally-attributable Grounded Text Generation, Aviv Slobodkin+, arXiv'24 Summaryローカル属性付きテキスト生成アプローチを提案し、生成プロセスをコンテンツ選択、文の計画、逐次文生成の3ステップに分解。これにより、簡潔な引用を生成しつつ、生成品質と属性の正確性を維持または向上させ、事実確認にかかる時間を大幅に削減。 #ACL Issue Date: 2025-01-06 Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost for Reasoning, Yongqi Tong+, arXiv'24 Summary本研究では、LLMが自らの間違いから学ぶ能力を探求し、609,432の質問を含む新しいベンチマーク\textsc{CoTErrorSet}を提案。自己再考プロンプティングと間違いチューニングの2つの方法を用いて、LLMが誤りから推論能力を向上させることを実証。これにより、コスト効果の高いエラー活用戦略を提供し、今後の研究の方向性を示す。 #ACL Issue Date: 2025-01-06 Enhancing In-Context Learning via Implicit Demonstration Augmentation, Xiaoling Zhou+, arXiv'24 Summaryインコンテキスト学習(ICL)におけるデモンストレーションの質や量がパフォーマンスに影響を与える問題に対処。デモンストレーションの深い特徴分布を活用し、表現を豊かにすることで、精度を向上させる新しいロジットキャリブレーションメカニズムを提案。これにより、さまざまなPLMやタスクでの精度向上とパフォーマンスのばらつきの減少を実現。 #ACL Issue Date: 2025-01-06 MathGenie: Generating Synthetic Data with Question Back-translation for Enhancing Mathematical Reasoning of LLMs, Zimu Lu+, arXiv'24 SummaryMathGenieは、少規模な問題解決データセットから多様で信頼性の高い数学問題を生成する新手法。シードデータの解答を増強し、逆翻訳モデルで新しい質問に変換。解答の正確性を確保するために根拠に基づく検証戦略を採用。MathGenieLMモデル群は、5つの数学的推論データセットでオープンソースモデルを上回り、特にGSM8Kで87.7%、MATHで55.7%の精度を達成。 #ACL Issue Date: 2025-01-06 MELA: Multilingual Evaluation of Linguistic Acceptability, Zhang+, ACL'24, 2024.08 Summary本研究では、46,000サンプルからなる「多言語言語的受容性評価(MELA)」ベンチマークを発表し、10言語にわたるLLMのベースラインを確立。XLM-Rを用いてクロスリンガル転送を調査し、ファインチューニングされたXLM-RとGPT-4oの性能を比較。結果、GPT-4oは多言語能力で優れ、オープンソースモデルは劣ることが判明。クロスリンガル転送実験では、受容性判断の転送が複雑であることが示され、MELAでのトレーニングがXLM-Rの構文タスクのパフォーマンス向上に寄与することが確認された。 #ACL Issue Date: 2025-01-06 Time is Encoded in the Weights of Finetuned Language Models, Kai Nylund+, ACL'24 Summary「時間ベクトル」を提案し、特定の時間データで言語モデルをファインチューニングする手法を示す。時間ベクトルは重み空間の方向を指定し、特定の時間帯のパフォーマンスを向上させる。隣接する時間帯に特化したベクトルは近接して配置され、補間により未来の時間帯でも良好な性能を発揮。異なるタスクやモデルサイズにおいて一貫した結果を示し、時間がモデルの重み空間にエンコードされていることを示唆。 #ACL Issue Date: 2025-01-06 Surgical Feature-Space Decomposition of LLMs: Why, When and How?, Arnav Chavan+, arXiv'24 Summary低ランク近似は、深層学習モデルの性能向上や推論のレイテンシ削減に寄与するが、LLMにおける有用性は未解明。本研究では、トランスフォーマーベースのLLMにおける重みと特徴空間の分解の効果を実証し、圧縮と性能のトレードオフに関する洞察を提供しつつ、常識推論性能の向上も示す。特定のネットワークセグメントの低ランク構造を特定し、モデルのバイアスへの影響も調査。これにより、低ランク近似が性能向上とバイアス修正の手段としての新たな視点を提供することを示した。 #ACL Issue Date: 2025-01-06 MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter, Jitai Hao+, arXiv'24 SummaryPEFTを用いたLLMsのファインチューニング性能は、追加パラメータの制約から限られる。これを克服するために、メモリ効率の良い大きなアダプターを導入し、CPUメモリの大容量を活用。Mixture of Expertsアーキテクチャを採用し、GPUとCPU間の通信量を削減。これにより、限られたリソース下でも高いファインチューニング性能を達成。コードはGitHubで公開。 #ACL Issue Date: 2025-01-06 Benchmarking Knowledge Boundary for Large Language Models: A Different Perspective on Model Evaluation, Xunjian Yin+, arXiv'24 Summary大規模言語モデルの評価において、プロンプトに依存しない「知識境界」という新概念を提案。これにより、プロンプトの敏感さを回避し、信頼性の高い評価が可能に。新しいアルゴリズム「意味的制約を持つ投影勾配降下法」を用いて、知識境界を計算し、既存手法より優れた性能を示す。複数の言語モデルの能力を多様な領域で評価。 #ACL Issue Date: 2025-01-06 ValueBench: Towards Comprehensively Evaluating Value Orientations and Understanding of Large Language Models, Yuanyi Ren+, arXiv'24 Summary本研究では、LLMsの価値観と理解を評価するための心理測定ベンチマーク「ValueBench」を提案。453の価値次元を含むデータを収集し、現実的な人間とAIの相互作用に基づく評価パイプラインを構築。6つのLLMに対する実験を通じて、共通および独自の価値観を明らかにし、価値関連タスクでの専門家の結論に近い能力を示した。ValueBenchはオープンアクセス可能。 #ACL Issue Date: 2025-01-06 AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension, Qian Yang+, arXiv'24 Summary音声言語モデル(LALMs)の評価のために、初のベンチマークAIR-Benchを提案。これは、音声信号の理解と人間との相互作用能力を評価するもので、基本的な単一タスク能力を検査する約19,000の質問と、複雑な音声に対する理解力を評価する2,000のオープンエンド質問から構成。GPT-4を用いた評価フレームワークにより、LALMsの限界を明らかにし、今後の研究の指針を提供。 #ACL Issue Date: 2025-01-06 Self-Alignment for Factuality: Mitigating Hallucinations in LLMs via Self-Evaluation, Xiaoying Zhang+, arXiv'24 Summary自己整合性を用いてLLMの事実性を向上させるアプローチを提案。自己評価コンポーネントSelf-Evalを組み込み、生成した応答の事実性を内部知識で検証。信頼度推定を改善するSelf-Knowledge Tuningを設計し、自己注釈された応答でモデルをファインチューニング。TruthfulQAとBioGENタスクでLlamaモデルの事実精度を大幅に向上。 #ACL Issue Date: 2025-01-06 Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering, Tobias Schimanski+, arXiv'24 SummaryLLMsの信頼性と追跡可能性を向上させるため、情報源の質と回答の帰属を改善するファインチューニング手法を調査。自動データ品質フィルターを用いた高品質データの合成により、パフォーマンスが向上。データ品質の改善が証拠に基づくQAにおいて重要であることを示した。 #ACL Issue Date: 2025-01-06 AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators, Jingwei+, ACL'24, 2024.08 Summary生成AIの普及に伴い、自動事実確認手法が重要視されているが、事実主張の検出にはスケーラビリティと一般化可能性の問題がある。これに対処するため、事実主張の統一的な定義を提案し、AFaCTAという新しいフレームワークを導入。AFaCTAはLLMsを活用し、注釈の信頼度を調整する。広範な評価により、専門家の注釈作業を効率化し、PoliClaimという包括的な主張検出データセットを作成した。 #ACL Issue Date: 2025-01-06 Dissecting Human and LLM Preferences, Junlong Li+, arXiv'24 Summary本研究では、人間と32種類のLLMの好みを分析し、モデルの応答の品質比較における定量的な構成を理解するための詳細なシナリオ別分析を行った。人間はエラーに対して敏感でなく、自分の立場を支持する応答を好む一方、GPT-4-Turboのような高度なLLMは正確性や無害性を重視することが分かった。また、同サイズのLLMはトレーニング方法に関係なく似た好みを示し、ファインチューニングは大きな変化をもたらさないことが明らかになった。さらに、好みに基づく評価は操作可能であり、モデルを審査員の好みに合わせることでスコアが向上することが示された。 #ACL Issue Date: 2025-01-06 Selene: Pioneering Automated Proof in Software Verification, Lichen Zhang+, arXiv'24 Summaryソフトウェア検証の自動化が求められる中、seL4に基づく初のプロジェクトレベルの自動証明ベンチマークSeleneを提案。Seleneは包括的な証明生成フレームワークを提供し、LLMs(GPT-3.5-turboやGPT-4)を用いた実験でその能力を示す。提案する強化策により、Seleneの課題が今後の研究で軽減可能であることを示唆。 #ACL Issue Date: 2025-01-06 Evaluating Intention Detection Capability of Large Language Models in Persuasive Dialogues, Sakurai+, ACL'24, 2024.08 SummaryLLMsを用いてマルチターン対話における意図検出を調査。従来の研究が会話履歴を無視している中、修正したデータセットを用いて意図検出能力を評価。特に説得的対話では他者の視点を考慮することが重要であり、「フェイスアクト」の概念を取り入れることで、意図の種類に応じた分析が可能となる。 #ACL Issue Date: 2025-01-06 Analyzing Temporal Complex Events with Large Language Models? A Benchmark towards Temporal, Long Context Understanding, Zhihan Zhang+, arXiv'24 Summaryデジタル環境の進化に伴い、複雑なイベントの迅速かつ正確な分析が求められている。本論文では、長期間のニュース記事から「Temporal Complex Event(TCE)」を抽出・分析するために、LLMsを用いた新しいアプローチを提案。TCEは重要なポイントとタイムスタンプで特徴付けられ、読解力、時間的配列、未来のイベント予測の3つのタスクを含むベンチマーク「TCELongBench」を設立。実験では、リトリーバー強化生成(RAG)手法と長いコンテキストウィンドウを持つLLMsを活用し、適切なリトリーバーを持つモデルが長いコンテキストウィンドウを利用するモデルと同等のパフォーマンスを示すことが確認された。 #ACL Issue Date: 2025-01-06 Feature-Adaptive and Data-Scalable In-Context Learning, Jiahao Li+, arXiv'24 SummaryFADS-ICLは、文脈内学習を強化するための特徴適応型フレームワークで、LLMの一般的な特徴を特定の下流タスクに適合させる。実験により、FADS-ICLは従来の手法を大幅に上回り、特に1.5Bモデルでの32ショット設定では平均14.3の精度向上を達成。トレーニングデータの増加により性能がさらに向上することも示された。 #ACL Issue Date: 2025-01-06 Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal, Jianheng Huang+, arXiv'24 Summary自己合成リハーサル(SSR)フレームワークを提案し、LLMの継続的学習における壊滅的な忘却を克服。基本のLLMで合成インスタンスを生成し、最新のLLMで洗練させることで、データ効率を高めつつパフォーマンスを向上。SSRは一般化能力を効果的に保持することが実験で示された。 #Embeddings #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) #LongSequence #ACL #PostTraining Issue Date: 2025-01-06 Grounding Language Model with Chunking-Free In-Context Retrieval, Hongjin Qian+, arXiv'24 SummaryCFICは、Retrieval-Augmented Generation(RAG)システム向けの新しいリトリーバルアプローチで、従来のチャンク化を回避し、文書のエンコードされた隠れ状態を利用して正確な証拠テキストを特定します。制約付き文のプレフィックスデコーディングとスキップデコーディングを組み込むことで、リトリーバルの効率と生成された証拠の忠実性を向上させます。CFICはオープンQAデータセットで評価され、従来の方法に対して大幅な改善を示し、RAGシステムの効率的で効果的なリトリーバルソリューションを提供します。 CommentChunking無しでRAGを動作させられるのは非常に魅力的。
気持ちとしては、ソーステキストが与えられたときに、Questionの回答をsupportするようなソース中のpassageの情報を活用して回答するために、重要なsentenceのprefixを回答生成前に生成させる(重要なsentenceの識別子の役割を果たす)ことで、(識別子によって重要な情報によって条件づけられて回答生成ができるやうになるのて)それら情報をより考慮しながらモデルが回答を生成できるようになる、といった話だと思われる。
Table2のようなテンプレートを用いて、ソーステキストと質問文でモデルを条件付けて、回答をsupportするsentenceのprefixを生成する。生成するprefixは各sentenceのユニークなprefixのtoken log probabilityの平均値によって決まる(トークンの対数尤度が高かったらモデルが暗黙的にその情報はQuestionにとって重要だと判断しているとみなせる)。SkipDecodingの説を読んだが、ぱっと見よく分からない。おそらく[eos]を出力させてprefix間のデリミタとして機能させたいのだと思うが、[eos]の最適なpositionはどこなのか?みたいな数式が出てきており、これがデコーディングの時にどういった役割を果たすのかがよくわからない。
また、モデルはQAと重要なPassageの三つ組のデータで提案手法によるデコーディングを適用してSFTしたものを利用する。
などのEncoder-Decoderモデルで行われていたoutput lengthの制御をDecoder-onlyモデルでもやりました、という話に見える。 #Survey #NLP #LanguageModel #Reasoning #Mathematics Issue Date: 2025-01-03 A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges, Yibo Yan+, arXiv'24 Summary数学的推論は多くの分野で重要であり、AGIの進展に伴い、LLMsを数学的推論タスクに統合することが求められている。本調査は、2021年以降の200以上の研究をレビューし、マルチモーダル設定におけるMath-LLMsの進展を分析。分野をベンチマーク、方法論、課題に分類し、マルチモーダル数学的推論のパイプラインやLLMsの役割を探る。さらに、AGI実現の障害となる5つの課題を特定し、今後の研究方向性を示す。 #NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) Issue Date: 2025-01-02 LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR'24 SummaryLoRAは大規模言語モデルの効率的なファインチューニング手法であり、プログラミングと数学のドメインでの性能をフルファインチューニングと比較。標準的な設定ではLoRAは性能が劣るが、ターゲットドメイン外のタスクではベースモデルの性能を維持し、忘却を軽減する効果がある。フルファインチューニングはLoRAよりも高いランクの摂動を学習し、性能差の一因と考えられる。最終的に、LoRAのファインチューニングに関するベストプラクティスを提案。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qfull finetuningとLoRAの性質の違いを理解するのに有用 #NLP #LanguageModel #Supervised-FineTuning (SFT) #ProprietaryLLM Issue Date: 2025-01-02 FineTuneBench: How well do commercial fine-tuning APIs infuse knowledge into LLMs?, Eric Wu+, arXiv'24 Summary商業的なLLM微調整APIの効果を評価するためのFineTuneBenchを提案。5つの最前線のLLMを分析し、新しい情報の学習と既存知識の更新における能力を評価した結果、全モデルで平均一般化精度は37%、医療ガイドラインの更新では19%と低いことが判明。特にGPT-4o miniが最も効果的で、Gemini 1.5シリーズは能力が限られていた。商業的微調整サービスの信頼性に課題があることを示唆。データセットはオープンソースで提供。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pretraining #NLP #Catastrophic Forgetting Issue Date: 2025-01-02 Examining Forgetting in Continual Pre-training of Aligned Large Language Models, Chen-An Li+, arXiv'24 SummaryLLMの継続的な事前学習がファインチューニングされたモデルに与える影響を調査し、壊滅的な忘却の現象を評価。出力形式や知識、信頼性の次元での実験結果が、特に繰り返しの問題における忘却の課題を明らかにする。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #SyntheticData Issue Date: 2025-01-02 Generative AI for Synthetic Data Generation: Methods, Challenges and the Future, Xu Guo+, arXiv'24 Summary限られたデータのシナリオでLLMsを用いて合成データを生成する研究が増加しており、これは生成的AIの進展を示す。LLMsは実世界のデータと同等の性能を持ち、リソースが限られた課題に対する解決策となる。本論文では、タスク特化型のトレーニングデータ生成のための技術、評価方法、実用的応用、現在の制限、将来の研究の方向性について議論する。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #SyntheticData Issue Date: 2025-01-02 On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey, Lin Long+, arXiv'24 Summary深層学習におけるデータの量と質の問題に対し、LLMsが合成データ生成を通じて解決策を提供。しかし、現状の研究は統一されたフレームワークを欠き、表面的なものが多い。本論文では合成データ生成のワークフローを整理し、研究のギャップを明らかにし、今後の展望を示す。学術界と産業界のより体系的な探求を促進することを目指す。 Comment元ポスト:https://x.com/gyakuse/status/1874357127248306200?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #RecommenderSystems #Dataset #LanguageModel #SessionBased #Personalization #Evaluation Issue Date: 2024-12-31 Preference Discerning with LLM-Enhanced Generative Retrieval, Fabian Paischer+, arXiv'24 Summary逐次推薦システムのパーソナライズを向上させるために、「好みの識別」という新しいパラダイムを提案。大規模言語モデルを用いてユーザーの好みを生成し、包括的な評価ベンチマークを導入。新手法Menderは、既存手法を改善し、最先端の性能を達成。Menderは未観察の人間の好みにも効果的に対応し、よりパーソナライズされた推薦を実現する。コードとベンチマークはオープンソース化予定。 #RecommenderSystems #LanguageModel #SessionBased Issue Date: 2024-12-31 Unifying Generative and Dense Retrieval for Sequential Recommendation, Liu Yang+, arXiv'24 Summary逐次密な検索モデルはユーザーとアイテムの内積計算を行うが、アイテム数の増加に伴いメモリ要件が増大する。一方、生成的検索はセマンティックIDを用いてアイテムインデックスを予測する新しいアプローチである。これら二つの手法の比較が不足しているため、LIGERというハイブリッドモデルを提案し、生成的検索と逐次密な検索の強みを統合。これにより、コールドスタートアイテム推薦を強化し、推薦システムの効率性と効果を向上させることを示した。 #NLP #LanguageModel #Reasoning Issue Date: 2024-12-31 Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search, Huanjin Yao+, arXiv'24 Summary本研究では、MLLMを用いて質問解決のための推論ステップを学習する新手法CoMCTSを提案。集団学習を活用し、複数モデルの知識で効果的な推論経路を探索。マルチモーダルデータセットMulberry-260kを構築し、モデルMulberryを訓練。実験により提案手法の優位性を確認。 #NLP #LanguageModel #Education #EducationalDataMining Issue Date: 2024-12-31 LearnLM: Improving Gemini for Learning, LearnLM Team+, arXiv'24 Summary生成AIシステムは従来の情報提示に偏っているため、教育的行動を注入する「教育的指示の遵守」を提案。これにより、モデルの振る舞いを柔軟に指定でき、教育データを追加することでGeminiモデルの学習を向上。LearnLMモデルは、さまざまな学習シナリオで専門家から高く評価され、GPT-4oやClaude 3.5に対しても優れた性能を示した。 #NLP #LanguageModel #TheoryOfMind #read-later Issue Date: 2024-12-31 Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning, Melanie Sclar+, arXiv'24 SummaryExploreToMは、心の理論を評価するための多様で挑戦的なデータを生成するフレームワークであり、LLMsの限界をテストする。最先端のLLMsは、ExploreToM生成データに対して低い精度を示し、堅牢な評価の必要性を強調。ファインチューニングにより従来のベンチマークで精度向上を実現し、モデルの低パフォーマンスの要因を明らかにする。 Commentおもしろそう。あとで読む #Survey #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2024-12-31 A Survey on LLM Inference-Time Self-Improvement, Xiangjue Dong+, arXiv'24 SummaryLLM推論における自己改善技術を三つの視点から検討。独立した自己改善はデコーディングやサンプリングに焦点、文脈に応じた自己改善は追加データを活用、モデル支援の自己改善はモデル間の協力を通じて行う。関連研究のレビューと課題、今後の研究への洞察を提供。 #Survey #InformationRetrieval #LanguageModel Issue Date: 2024-12-30 From Matching to Generation: A Survey on Generative Information Retrieval, Xiaoxi Li+, arXiv'24 Summary情報検索(IR)システムは、検索エンジンや質問応答などで重要な役割を果たしている。従来のIR手法は類似性マッチングに基づいていたが、事前学習された言語モデルの進展により生成情報検索(GenIR)が注目されている。GenIRは生成文書検索(GR)と信頼性のある応答生成に分かれ、GRは生成モデルを用いて文書を直接生成し、応答生成はユーザーの要求に柔軟に応える。本論文はGenIRの最新研究をレビューし、モデルのトレーニングや応答生成の進展、評価や課題についても考察する。これにより、GenIR分野の研究者に有益な参考資料を提供し、さらなる発展を促すことを目指す。 #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-30 RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation, Xiaoxi Li+, arXiv'24 SummaryRetroLLMは、リトリーバルと生成を統合したフレームワークで、LLMsがコーパスから直接証拠を生成することを可能にします。階層的FM-インデックス制約を導入し、関連文書を特定することで無関係なデコーディング空間を削減し、前向きな制約デコーディング戦略で証拠の精度を向上させます。広範な実験により、ドメイン内外のタスクで優れた性能を示しました。 Comment元ポスト:https://x.com/rohanpaul_ai/status/1872714703090401721?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来のRAGとの違いと、提案手法の概要
に日本語でのサマリが記載されているので参照のこと。
リーダーボードのバイアスを軽減した結果、どのLLMが最大パフォーマンスとみなされるようになったのだろうか? #NLP #LanguageModel #Evaluation #LLM-as-a-Judge Issue Date: 2024-12-15 BatchEval: Towards Human-like Text Evaluation, Peiwen Yuan+, ACL'24 SummaryBatchEvalという新しい評価パラダイムを提案し、LLMを用いた自動テキスト評価の問題を解決。バッチ単位での反復評価により、プロンプト設計の敏感さやノイズ耐性の低さを軽減。実験により、BatchEvalは最先端手法に対して10.5%の改善を示し、APIコストを64%削減。 Comment・1591
に日本語によるサマリが掲載されているので参照のこと。 #Analysis #NLP #LanguageModel #In-ContextLearning Issue Date: 2024-12-15 The broader spectrum of in-context learning, Andrew Kyle Lampinen+, arXiv'24 Summary本研究では、言語モデルの少数ショット学習をメタ学習に基づく文脈内学習の一部として位置づけ、文脈が予測の損失を減少させるメカニズムを提案します。この視点は、言語モデルの文脈内能力を統一し、一般化の重要性を強調します。一般化は新しい学習だけでなく、異なる提示からの学びや適用能力にも関連し、過去の文献との関連性も議論されます。文脈内学習の研究は、広範な能力と一般化のタイプを考慮すべきと結論付けています。 CommentOpenReview:https://openreview.net/forum?id=RHo3VVi0i5
OpenReviewによると、
論文は理解しやすく、meta learningについて広範にサーベイされている。しかし、論文が定義しているICLの拡張はICLを過度に一般化し過ぎており(具体的に何がICLで何がICLでないのか、といった規定ができない)、かつ論文中で提案されているコンセプトを裏付ける実験がなくspeculativeである、とのことでrejectされている。 #NLP #LanguageModel #OpenWeight Issue Date: 2024-12-15 Phi-4 Technical Report, Marah Abdin+, arXiv'24 Summary140億パラメータの言語モデル「phi-4」は、合成データを取り入れたトレーニングにより、STEMに特化したQA能力で教師モデルを大幅に上回る性能を示す。phi-3のアーキテクチャを最小限に変更しただけで、推論ベンチマークにおいても改善されたデータとトレーニング手法により強力なパフォーマンスを達成。 Comment現状Azureでのみ利用可能かも。Huggingfaceにアップロードされても非商用ライセンスになるという噂もMITライセンス
HuggingFace:
https://huggingface.co/microsoft/phi-4 #NLP #LanguageModel #Chain-of-Thought #PostTraining #LatentReasoning Issue Date: 2024-12-12 Training Large Language Models to Reason in a Continuous Latent Space, Shibo Hao+, arXiv'24 Summary新しい推論パラダイム「Coconut」を提案し、LLMの隠れ状態を連続的思考として利用。これにより、次の入力を連続空間でフィードバックし、複数の推論タスクでLLMを強化。Coconutは幅優先探索を可能にし、特定の論理推論タスクでCoTを上回る性能を示す。潜在的推論の可能性を探る重要な洞察を提供。 CommentChain of Continuous Thought...?通常のCoTはRationaleをトークン列で生成するが、Coconutは最終的なhidden state(まだ読んでないのでこれが具体的に何を指すか不明)をそのまま入力に追加することで、トークンに制限されずにCoTさせるということらしい。あとでしっかり読む
ICLR'25にrejectされている。
ざっと最初のレビューに書かれているWeaknessを読んだ感じ
・評価データが合成データしかなく、よりrealisticなデータで評価した方が良い
・CoTら非常に一般的に適用可能な技術なので、もっと広範なデータで評価すべき
・GSM8Kでは大幅にCOCONUTはCoTに性能が負けていて、ProsQAでのみにしかCoTに勝てていない
・特定のデータセットでの追加の学習が必要で、そこで身につけたreasoning能力が汎化可能か明らかでない
といった感じに見える #ComputerVision #Pretraining #Transformer #NeurIPS Issue Date: 2024-12-12 Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction, Keyu Tian+, NeurIPS'24 SummaryVisual AutoRegressive modeling (VAR)を提案し、画像生成において自己回帰学習を次のスケール予測として再定義。VARは、GPTのようなARモデルが拡散トランスフォーマーを上回ることを実現し、ImageNet 256x256ベンチマークでFIDを18.65から1.73、ISを80.4から350.2に改善。推論速度は約20倍向上し、画像品質やデータ効率でも優れた性能を示す。VARはゼロショット一般化能力を持ち、スケーリング法則を示す。全モデルとコードを公開し、視覚生成の研究を促進。 CommentNeurIPS2024のベストペーパー第一著者がByteDance社から訴訟を起こされている模様…?
https://var-integrity-report.github.ioOpenReview:https://openreview.net/forum?id=gojL67CfS8Next Token Prediction, Next Image Token Generation (従来手法), Next Scale (resolution) prediction (提案手法)の違いの図解。非常に分かりやすい。next token predictionでは次トークンのみを予測するがVARでは、次の解像度画像の全体のトークンマップを予測する。
学習方法の概要。2-Stageで学習される。最初のステージでK種類の解像度の画像(=K種類のマルチスケールのtoken maps r_k)を得るためにAutoEncoderを学習し、次のステージでblock-wiseのcausal attention maskを用いて、K_<k個目の解像度の画像からK個目の解像度の画像を予測する(図を見るとイメージを掴みやすい)。inference時はKV Cacheを利用し、maskは不要となる。
各r_kをデコードする際にr_<kのみに依存する設計にすることでcoase-to-fineに画像を生成することに相当し、これは人間の粗く捉えてから詳細を見る認知プロセスと合致する。また、flatten操作が存在せず、それぞれのr_<k内のトークンがr_k生成時に全て考慮されるため空間的局所性も担保される。また、r_k内のトークンは並列に生成可能なので計算量のオーダーが大幅に削減される(O(n^4)。
従来手法と比べより小さいパラメータで高い性能を実現し、inference timeも非常に早い。
ScalingLawsも成立する。
(図は論文より引用)ICLR 2025のOpenreview
https://openreview.net/forum?id=0Ag8FQ5Rr3 Issue Date: 2024-12-02 Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, arXiv'24 Summary大規模言語モデル(LLMs)のマルチホップクエリに対する事実の想起能力を評価。ショートカットを防ぐため、主語と答えが共に出現するテストクエリを除外した評価データセットSOCRATESを構築。LLMsは特定のクエリにおいてショートカットを利用せずに潜在的な推論能力を示し、国を中間答えとするクエリでは80%の構成可能性を達成する一方、年の想起は5%に低下。潜在的推論能力と明示的推論能力の間に大きなギャップが存在することが明らかに。 #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models, Fei Wang+, arXiv'24 SummaryAstute RAGは、外部知識の不完全な取得による問題を解決する新しいアプローチで、LLMsの内部知識と外部知識を適応的に統合し、情報の信頼性に基づいて回答を決定します。実験により、Astute RAGは従来のRAG手法を大幅に上回り、最悪のシナリオでもLLMsのパフォーマンスを超えることが示されました。 #Survey #NLP #LanguageModel #LLM-as-a-Judge Issue Date: 2024-11-27 From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, Dawei Li+, arXiv'24 SummaryLLMを用いた判断と評価の新たなパラダイム「LLM-as-a-judge」に関する包括的な調査を行い、定義や分類法を提示。評価のためのベンチマークをまとめ、主要な課題と今後の研究方向を示す。関連リソースも提供。 CommentLLM-as-a-Judgeに関するサーベイ
も参照のこと #Analysis #NLP #LanguageModel #Prompting Issue Date: 2024-11-27 Does Prompt Formatting Have Any Impact on LLM Performance?, Jia He+, arXiv'24 Summaryプロンプト最適化はLLMの性能に重要であり、異なるプロンプトテンプレートがモデルの性能に与える影響を調査。実験では、GPT-3.5-turboがプロンプトテンプレートによってコード翻訳タスクで最大40%変動する一方、GPT-4はより堅牢であることが示された。これにより、固定プロンプトテンプレートの再考が必要であることが強調された。 Comment(以下、個人の感想です)
本文のみ斜め読みして、Appendixは眺めただけなので的外れなことを言っていたらすみません。
まず、実務上下記知見は有用だと思いました:
・プロンプトのフォーマットによって性能に大きな差がある
・より大きいモデルの方がプロンプトフォーマットに対してロバスト
ただし、フォーマットによって性能差があるというのは経験的にある程度LLMを触っている人なら分かることだと思うので、驚きは少なかった。
個人的に気になる点は、学習データもモデルのアーキテクチャもパラメータ数も分からないGPT3.5, GPT4のみで実験をして「パラメータサイズが大きい方がロバスト」と結論づけている点と、もう少し深掘りして考察したらもっとおもしろいのにな、と感じる点です。
実務上は有益な知見だとして、では研究として見たときに「なぜそうなるのか?」というところを追求して欲しいなぁ、という感想を持ちました。
たとえば、「パラメータサイズが大きいモデルの方がフォーマットにロバスト」と論文中に書かれているように見えますが、
それは本当にパラメータサイズによるものなのか?学習データに含まれる各フォーマットの割合とか(これは事実はOpenAIの中の人しか分からないので、学習データの情報がある程度オープンになっているOpenLLMでも検証するとか)、評価するタスクとフォーマットの相性とか、色々と考察できる要素があるのではないかと思いました。
その上で、大部分のLLMで普遍的な知見を見出した方が研究としてより面白くなるのではないか、と感じました。
・1267 #NLP #LLMAgent Issue Date: 2024-11-27 Generative Agent Simulations of 1,000 People, Joon Sung Park+, arXiv'24 Summary新しいエージェントアーキテクチャを提案し、1,052人の実在の個人の態度と行動を85%の精度で再現。大規模言語モデルを用いた質的インタビューに基づき、参加者の回答を正確にシミュレート。人口統計的説明を用いたエージェントと比較して、精度バイアスを軽減。個人および集団の行動調査の新しいツールを提供。 Issue Date: 2024-11-25 Understanding LLM Embeddings for Regression, Eric Tang+, arXiv'24 SummaryLLM埋め込みを用いた回帰分析の調査を行い、従来の特徴エンジニアリングよりも高次元回帰タスクで優れた性能を示す。LLM埋め込みは数値データに対してリプシッツ連続性を保持し、モデルサイズや言語理解の影響を定量化した結果、必ずしも回帰性能を向上させないことが明らかになった。 Issue Date: 2024-11-25 A Reproducibility and Generalizability Study of Large Language Models for Query Generation, Moritz Staudinger+, arXiv'24 Summary系統的文献レビューのために、LLMを用いたブールクエリ生成の研究を行い、ChatGPTとオープンソースモデルの性能を比較。自動生成したクエリを用いてPubMedから文書を取得し、再現性と信頼性を評価。LLMの限界や改善点を分析し、情報検索タスクにおけるLLMの適用可能性を探る。研究は文献レビューの自動化におけるLLMの強みと限界を明らかにする。 #ComputerVision #Pretraining #NLP #LanguageModel #MulltiModal Issue Date: 2024-11-25 Multimodal Autoregressive Pre-training of Large Vision Encoders, Enrico Fini+, arXiv'24 Summary新しい手法AIMV2を用いて、大規模なビジョンエンコーダの事前学習を行う。これは画像とテキストを組み合わせたマルチモーダル設定に拡張され、シンプルな事前学習プロセスと優れた性能を特徴とする。AIMV2-3BエンコーダはImageNet-1kで89.5%の精度を達成し、マルチモーダル画像理解において最先端のコントラストモデルを上回る。 #Analysis #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2024-11-22 Observational Scaling Laws and the Predictability of Language Model Performance, Yangjun Ruan+, arXiv'24 Summary言語モデルの性能を理解するために、約100の公開モデルからスケーリング法則を構築する新しい観察アプローチを提案。モデルファミリー間の能力変動を考慮し、性能が低次元の能力空間の関数であることを示す。これにより、複雑なスケーリング現象の予測可能性を示し、GPT-4のエージェント性能を非エージェント的ベンチマークから予測できることを明らかにし、Chain-of-ThoughtやSelf-Consistencyの影響を予測する方法を示す。 Comment縦軸がdownstreamタスクの主成分(のうち最も大きい80%を説明する成分)の変化(≒LLMの性能)で、横軸がlog scaleの投入計算量。
Qwenも頑張っているが、投入データ量に対する性能(≒データの品質)では、先駆け的な研究であるPhiがやはり圧倒的?
も参照のこと #LanguageModel #Personalization Issue Date: 2024-11-21 On the Way to LLM Personalization: Learning to Remember User Conversations, Lucie Charlotte Magister+, arXiv'24 SummaryLLMのパーソナライズを過去の会話の知識を注入することで実現するため、PLUMというデータ拡張パイプラインを提案。会話の時間的連続性とパラメータ効率を考慮し、ファインチューニングを行う。初めての試みでありながら、RAGなどのベースラインと競争力を持ち、81.5%の精度を達成。 #Chip Issue Date: 2024-11-21 That Chip Has Sailed: A Critique of Unfounded Skepticism Around AI for Chip Design, Anna Goldie+, arXiv'24 SummaryAlphaChipは深層強化学習を用いて超人的なチップレイアウトを生成する手法で、AIチップ設計の進展を促進した。しかし、ISPD 2023での非査読論文が性能に疑問を呈し、実行方法に問題があった。著者は、事前トレーニングや計算リソースの不足、評価基準の不適切さを指摘。Igor Markovによるメタ分析も行われた。AlphaChipは広範な影響を持つが、誤解を避けるためにこの応答を発表した。 Commentoh... #Analysis #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-11-19 Likelihood as a Performance Gauge for Retrieval-Augmented Generation, Tianyu Liu+, arXiv'24 Summary大規模言語モデルを用いた情報検索強化生成は、文脈内の文書の順序に影響を受けやすい。研究では、質問の確率がモデルのパフォーマンスに与える影響を分析し、正確性との相関関係を明らかにした。質問の確率を指標として、プロンプトの選択と構築に関する2つの方法を提案し、その効果を実証。確率に基づく手法は効率的で、少ないモデルのパスで応答を生成できるため、プロンプト最適化の新たな方向性を示す。 Commentトークンレベルの平均値をとった生成テキストの対数尤度と、RAGの回答性能に関する分析をした模様。
とりあえず、もし「LLMとしてGPTを(OpenAIのAPIを用いて)使いました!temperatureは0です!」みたいな実験設定だったら諸々怪しくなる気がしたのでそこが大丈夫なことを確認した(OpenLLM、かつdeterministicなデコーディング方法が望ましい)。おもしろそう。
生成されたテキストの尤度を用いて、どの程度正解らしいかを判断する、といった話は
・1223
のようなLLM-as-a-Judgeでも行われている。
G-Evalでは1--5のスコアのような離散的な値を生成する際に、これらを連続的なスコアに補正するために、尤度(トークンの生成確率)を用いている。
ただし、G-Evalの場合は実験でGPTを用いているため、モデルから直接尤度を取得できず、代わりにtemperature1とし、20回程度生成を行った結果からスコアトークンの生成確率を擬似的に計算している。
G-Evalの設定と比較すると(当時はつよつよなOpenLLMがなかったため苦肉の策だったと思われるが)、こちらの研究の実験設定の方が望ましいと思う。 #Survey #NLP #LanguageModel #MultiLingual Issue Date: 2024-11-19 Multilingual Large Language Models: A Systematic Survey, Shaolin Zhu+, arXiv'24 Summary本論文は、多言語大規模言語モデル(MLLMs)の最新研究を調査し、アーキテクチャや事前学習の目的、多言語能力の要素を論じる。データの質と多様性が性能向上に重要であることを強調し、MLLMの評価方法やクロスリンガル知識、安全性、解釈可能性について詳細な分類法を提示。さらに、MLLMの実世界での応用を多様な分野でレビューし、課題と機会を強調する。関連論文は指定のリンクで公開されている。 Comment
Perplexityの生成結果では、27個のシステムと記述されているが、これは実際はトピックで、各トピックごとに300件程度の0--3のRelevance Scoreが、人手評価、UMBRELA共に付与されている模様(Table1)。
評価結果
・Fully Manual Assessment: 既存のNIST methodologyと同様に人手でRelevance Scoreを付与する方法
・Manual Aspessment with Filtering: LLMのnon-Relevantと判断したpassageを人手評価から除外する方法
・Manual Post-Editing of Automatic Assessment: LLMがnon-Relevantと判断したpassageを人手評価から除外するだけでなく、LLMが付与したスコアを評価者にも見せ、評価者が当該ラベルを修正するようなスコアリングプロセス
・Fully Automatic Assessment:UMBRELAによるRelevance Scoreをそのまま利用する方法
LLMはGPT4-oを用いている。
19チームの77個のRunがどのように実行されているか、それがTable1の統計量とどう関係しているかがまだちょっとよくわかっていない。UMBRELAでRelevance Scoreを生成する際に利用されたプロンプト。
BPEよりも高い性能を獲得し、
トークンの長さがBPEと比較して長くなり、かつ5Bトークン程度を既存のBPEで事前学習されたモデルに対して継続的事前学習するだけで性能を上回るようにでき、
同じVocabサイズでBPEよりも高い性能を獲得できる手法
らしい #LanguageModel #ScientificDiscovery #Investigation Issue Date: 2024-11-12 LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions, Zhehui Liao+, arXiv'24 Summary大規模言語モデル(LLMs)の利用に関する816人の研究者を対象とした調査を実施。81%が研究ワークフローにLLMsを組み込んでおり、特に非白人や若手研究者が高い使用率を示す一方で、女性やシニア研究者は倫理的懸念を抱いていることが明らかに。研究の公平性向上の可能性が示唆される。 #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2024-11-12 DELIFT: Data Efficient Language model Instruction Fine Tuning, Ishika Agarwal+, arXiv'24 SummaryDELIFTという新しいアルゴリズムを提案し、ファインチューニングの各ステージでデータ選択を最適化。ペアワイズユーティリティメトリックを用いてデータの有益性を定量化し、最大70%のデータ削減を実現。計算コストを大幅に節約し、既存の方法を上回る効率性と効果を示す。 #Survey #NLP #LanguageModel #LLMAgent Issue Date: 2024-11-12 GUI Agents with Foundation Models: A Comprehensive Survey, Shuai Wang+, arXiv'24 Summary(M)LLMを活用したGUIエージェントの研究を統合し、データセット、フレームワーク、アプリケーションの革新を強調。重要なコンポーネントをまとめた統一フレームワークを提案し、商業アプリケーションを探求。課題を特定し、今後の研究方向を示唆。 Comment
下記に試しにHyQEとHyDEの比較の記事を作成したのでご参考までに(記事の内容に私は手を加えていないのでHallucinationに注意)。ざっくりいうとHyDEはpseudo documentsを使うが、HyQEはpseudo queryを扱う。
[参考: Perplexity Pagesで作成したHyDEとの簡単な比較の要約](https://www.perplexity.ai/page/hyqelun-wen-nofen-xi-toyao-yue-aqZZj8mDQg6NL1iKml7.eQ)
LLMがこのようなミス(てかそもそもミスではなく、回答するためのcontextが足りてないので正解が定義できないだけ、だと思うが、、)をするのは、単に学習データにそういった9.11 > 9.9として扱うような文脈や構造のテキストが多く存在しており、これらテキスト列の尤度が高くなってこのような現象が起きているだけなのでは、という気がしている。
instructionで注意を促したり適切に問題を定義しなければ、そりゃこういう結果になって当然じゃない?という気がしている。
(ここまで「気がしている」を3連発してしまった…😅)
また、本研究で扱っているタスクのexampleは下記のようなものだが、これらをLLMに、なんのツールも利用させずautoregressiveな生成のみで解かせるというのは、人間でいうところの暗算に相当するのでは?と個人的には思う。
何が言いたいのかというと、人間でも暗算でこれをやらせたら解けない人がかなりいると思う(というか私自身単純な加算でも桁数増えたら暗算など無理)。
一方で暗算ではできないけど、電卓やメモ書き、計算機を使っていいですよ、ということにしたら多くの人がこれらタスクは解けるようになると思うので、LLMでも同様のことが起きると思う。
LLMの数値演算能力は人間の暗算のように限界があることを認知し、金融分野などの正確な演算や数値の取り扱うようなタスクをさせたかったら、適切なツールを使わせましょうね、という話なのかなあと思う。
https://openreview.net/forum?id=BWS5gVjgeY
幅広い数値演算のタスクを評価できるデータセット構築、トークナイザーとの関連性を明らかにした点、分析だけではなくLLMの数値演算能力を改善した点は評価されているように見える。
一方で、全体的に、先行研究との比較やdiscussionが不足しており、研究で得られた知見がどの程度新規性があるのか?といった点や、説明が不十分でjustificationが足りない、といった話が目立つように見える。
特に、そもそもLoRAやCoTの元論文や、Numerical Reasoningにフォーカスした先行研究がほぼ引用されていないらしい点が見受けられるようである。さすがにその辺は引用して研究のcontributionをクリアにした方がいいよね、と思うなどした。>I am unconvinced that numeracy in LLMs is a problem in need of a solution. First, surely there is a citable source for LLM inadequacy for numeracy. Second, even if they were terrible at numeracy, the onus is on the authors to convince the reader that this a problem worth caring about, for at least two obvious reasons: 1) all of these tasks are already trivially done by a calculator or a python program, and 2) commercially available LLMs can probably do alright at numerical tasks indirectly via code-generation and execution. As it stands, it reads as if the authors are insisting that this is a problem deserving of attention --・I'm sure it could be, but this argument can be better made.
上記レビュワーコメントと私も同じことを感じる。なぜLLMそのものに数値演算の能力がないことが問題なのか?という説明があった方が良いのではないかと思う。
これは私の中では、論文のイントロで言及されているようなシンプルなタスクではなく、
・inputするcontextに大量の数値を入力しなければならず、
・かつcontext中の数値を厳密に解釈しなければならず、
・かつ情報を解釈するために計算すべき数式がcontextで与えられた数値によって変化するようなタスク(たとえばテキスト生成で言及すべき内容がgivenな数値情報によって変わるようなもの。最大値に言及するのか、平均値を言及するのか、数値と紐づけられた特定のエンティティに言及しなければならないのか、など)
(e.g. 上記を満たすタスクはたとえば、金融関係のdata-to-textなど)では、LLMが数値を解釈できないと困ると思う。そういった説明が入った方が良いと思うなあ、感。 #Analysis #MachineLearning #NLP #LanguageModel #PEFT(Adaptor/LoRA) Issue Date: 2024-11-09 LoRA vs Full Fine-tuning: An Illusion of Equivalence, Reece Shuttleworth+, arXiv'24 Summaryファインチューニング手法の違いが事前学習済みモデルに与える影響を、重み行列のスペクトル特性を通じて分析。LoRAと完全なファインチューニングは異なる構造の重み行列を生成し、LoRAモデルは新たな高ランクの特異ベクトル(侵入次元)を持つことが判明。侵入次元は一般化能力を低下させるが、同等の性能を達成することがある。これにより、異なるファインチューニング手法がパラメータ空間の異なる部分にアクセスしていることが示唆される。 Comment元ポスト: https://x.com/aratako_lm/status/1854838012909166973?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q1423 や 1475 、双方の知見も交えて、LoRAの挙動を考察する必要がある気がする。それぞれ異なるデータセットやモデルで、LoRAとFFTを比較している。時間がないが後でやりたい。
あと、昨今はそもそも実験設定における変数が多すぎて、とりうる実験設定が多すぎるため、個々の論文の知見を鵜呑みにして一般化するのはやめた方が良い気がしている。実験設定の違い
モデルのアーキテクチャ
・本研究: RoBERTa-base(transformer-encoder)
・1423: transformer-decoder
・1475: transformer-decoder(LLaMA)
パラメータサイズ
・本研究:
・1423: 1B, 2B, 4B, 8B, 16B
・1475: 7B
時間がある時に続きをかきたい
Finetuningデータセットのタスク数
1タスクあたりのデータ量
trainableなパラメータ数 #RecommenderSystems #InformationRetrieval #MulltiModal Issue Date: 2024-11-08 MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs, Sheng-Chieh Lin+, arXiv'24 Summary本論文では、マルチモーダル大規模言語モデル(MLLM)を用いた「ユニバーサルマルチモーダル検索」の技術を提案し、複数のモダリティと検索タスクに対応する能力を示します。10のデータセットと16の検索タスクでの実験により、MLLMリトリーバーはテキストと画像のクエリを理解できるが、モダリティバイアスによりクロスモーダル検索では劣ることが判明。これを解決するために、モダリティ認識ハードネガティブマイニングを提案し、継続的なファインチューニングでテキスト検索能力を向上させました。結果として、MM-EmbedモデルはM-BEIRベンチマークで最先端の性能を達成し、NV-Embed-v1を上回りました。また、ゼロショットリランキングを通じて、複雑なクエリに対するマルチモーダル検索の改善が可能であることを示しました。これらの成果は、今後のユニバーサルマルチモーダル検索の発展に寄与するものです。 Comment
ライブラリがあるようで、1行変えるだけですぐ使えるとのこと。
元ツイート:https://x.com/ishohei220/status/1854051859385978979?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QAdamでは収束しなかった場合(バッチサイズが小さい場合)でも収束するようになっている模様
Unsupervised SimCSEと思想が似ている。実質DataAugmentationともみなせる。 #MachineLearning #NLP #LanguageModel #Alignment #ICML #PostTraining Issue Date: 2024-10-27 KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, N_A, ICML'24 Summaryプロスペクト理論に基づき、LLMの人間フィードバック調整におけるバイアスの影響を示す。新たに提案する「人間認識損失」(HALOs)を用いたアプローチKTOは、生成物の効用を最大化し、好みベースの方法と同等またはそれ以上の性能を発揮。研究は、最適な損失関数が特定の設定に依存することを示唆。 CommentbinaryフィードバックデータからLLMのアライメントをとるKahneman-Tversky Optimization (KTO)論文 #NLP #LanguageModel #DPO #PostTraining Issue Date: 2024-10-22 Generative Reward Models, Dakota Mahan+, N_A, arXiv'24 SummaryRLHFとRLAIFを統合したハイブリッドアプローチを提案し、合成好みラベルの質を向上させるGenRMアルゴリズムを導入。実験により、GenRMは分布内外のタスクでBradley-Terryモデルと同等またはそれを上回る性能を示し、LLMを判断者として使用する場合のパフォーマンスも向上。 CommentOpenReview:https://openreview.net/forum?id=MwU2SGLKpS関連研究
・708
・1212openreview:https://openreview.net/forum?id=MwU2SGLKpS Issue Date: 2024-10-21 nGPT: Normalized Transformer with Representation Learning on the Hypersphere, Ilya Loshchilov+, N_A, arXiv'24 Summary新しいアーキテクチャ「正規化トランスフォーマー(nGPT)」を提案。すべてのベクトルが単位ノルムで正規化され、トークンはハイパースフィア上で移動。nGPTはMLPとアテンションブロックを用いて出力予測に寄与し、学習速度が向上し、必要なトレーニングステップを4倍から20倍削減。 Comment元ポスト:https://x.com/hillbig/status/1848462035992084838?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Hallucination Issue Date: 2024-10-20 LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations, Hadas Orgad+, N_A, arXiv'24 SummaryLLMsは「幻覚」と呼ばれるエラーを生成するが、内部状態が真実性に関する情報をエンコードしていることが示されている。本研究では、真実性情報が特定のトークンに集中していることを発見し、これを利用することでエラー検出性能が向上することを示す。しかし、エラーディテクターはデータセット間で一般化に失敗し、真実性のエンコーディングは普遍的ではないことが明らかになる。また、内部表現を用いてエラーの種類を予測し、特化した緩和戦略の開発を促進する。さらに、内部エンコーディングと外部の振る舞いとの不一致が存在し、正しい答えをエンコードしていても誤った答えを生成することがある。これにより、LLMのエラー理解が深まり、今後の研究に寄与する。 Comment特定のトークンがLLMのtrustfulnessに集中していることを実験的に示し、かつ内部でエンコードされたrepresentationは正しい答えのものとなっているのに、生成結果に誤りが生じるような不整合が生じることも示したらしい #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2024-10-20 Addition is All You Need for Energy-efficient Language Models, Hongyin Luo+, N_A, arXiv'24 Summary本研究では、浮動小数点乗算を高精度で整数加算器によって近似するL-Mulアルゴリズムを提案。これにより、8ビット浮動小数点乗算に比べて計算リソースを大幅に削減しつつ、より高い精度を実現。L-Mulをテンソル処理ハードウェアに適用することで、エネルギーコストを95%(要素ごとの乗算)および80%(ドット積)削減可能。実験結果は理論的誤差推定と一致し、L-Mulは従来の浮動小数点乗算と同等またはそれ以上の精度を達成。トランスフォーマーモデル内の浮動小数点乗算をL-Mulに置き換えることで、ファインチューニングと推論において高い精度を維持できることを示した。 Issue Date: 2024-10-11 One Initialization to Rule them All: Fine-tuning via Explained Variance Adaptation, Fabian Paischer+, N_A, arXiv'24 Summaryファウンデーションモデルのファインチューニング手法として、アクティベーションベクトルの特異値分解を用いた新しい初期化方法「説明された分散適応(EVA)」を提案。EVAは、重みの再分配を行い、収束を速め、さまざまなタスクで最高の平均スコアを達成する。 Comment元ポスト:https://x.com/paischerfabian/status/1844267655068516767?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Dataset Issue Date: 2024-09-30 COM Kitchens: An Unedited Overhead-view Video Dataset as a Vision-Language Benchmark, Koki Maeda+, N_A, ECCV'24 Summary手続き的なビデオ理解のために、COM Kitchensという新しいデータセットを提案。これは、参加者がレシピに基づいて食材を準備する様子を上方視点で撮影した編集されていないビデオで構成されている。多様なデータ収集のためにスマートフォンを使用し、オンラインレシピ検索(OnRR)と密なビデオキャプショニング(DVC-OV)という新しいタスクを提案。実験により、既存のウェブビデオベースの手法の能力と限界を検証。 Commentとてもおもしろそう! #ComputerVision #NLP #Dataset #LanguageModel Issue Date: 2024-09-30 What matters when building vision-language models?, Hugo Laurençon+, N_A, arXiv'24 Summary視覚と言語のモデル(VLM)の設計における裏付けのない決定が性能向上の特定を妨げていると指摘。事前学習済みモデルやアーキテクチャ、データ、トレーニング手法に関する実験を行い、80億パラメータの基盤VLM「Idefics2」を開発。Idefics2はマルチモーダルベンチマークで最先端の性能を達成し、4倍のサイズのモデルと同等の性能を示す。モデルとデータセットを公開。 Comment元ポストにOpenVLMの進展の歴史が載っている。構築されたデータセットも公開される模様。
元ポスト:https://x.com/thom_wolf/status/1840372428855280045?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #CLIP Issue Date: 2024-09-30 Long-CLIP: Unlocking the Long-Text Capability of CLIP, Beichen Zhang+, N_A, ECCV'24 SummaryLong-CLIPは、CLIPのテキスト入力の長さ制限を克服し、ゼロショットの一般化能力を保持または超える新しいモデルです。効率的なファインチューニング戦略を用いて、CLIPの性能を維持しつつ、長文テキスト-画像ペアを活用することで、テキスト-画像検索タスクで約20%の性能向上を達成しました。また、Long-CLIPは詳細なテキスト説明から画像を生成する能力を強化します。 #Pretraining #NLP #Supervised-FineTuning (SFT) #SyntheticData Issue Date: 2024-09-29 Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling, Hritik Bansal+, N_A, arXiv'24 Summary高品質な合成データを生成するために、強力なSEモデルと安価なWCモデルのトレードオフを再検討。WCモデルからのデータはカバレッジと多様性が高いが偽陽性率も高い。ファインチューニングの結果、WC生成データでトレーニングされたモデルがSE生成データのモデルを上回ることが示され、WCが計算最適なアプローチである可能性を示唆。 Comment元ポスト:https://x.com/rohanpaul_ai/status/1840172683528425718?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2024-09-26 When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N_A, ICLR'24 SummaryLLMのファインチューニング手法のスケーリング特性を調査し、モデルサイズやデータサイズが性能に与える影響を実験。結果、ファインチューニングはパワーベースの共同スケーリング法則に従い、モデルのスケーリングが事前学習データのスケーリングよりも効果的であることが判明。最適な手法はタスクやデータに依存する。 Comment> When only few thousands of finetuning examples are available, PET should be considered first, either Prompt or LoRA. With sightly larger datasets, LoRA would be preferred due to its stability and slightly better finetuning data scalability. For million-scale datasets, FMT would be good.
> While specializing on a downstream task, finetuning could still elicit
and improve the generalization for closely related tasks, although the overall zero-shot translation
quality is inferior. Note whether finetuning benefits generalization is method・and task-dependent.
Overall, Prompt and LoRA achieve relatively better results than FMT particularly when the base
LLM is large, mostly because LLM parameters are frozen and the learned knowledge get inherited.
This also suggests that when generalization capability is a big concern, PET should be considered. #RecommenderSystems #Transformer #TransferLearning Issue Date: 2024-09-25 beeFormer: Bridging the Gap Between Semantic and Interaction Similarity in Recommender Systems, Vojtěch Vančura+, N_A, RecSys'24 Summaryレコメンダーシステムにおいて、コールドスタートやゼロショットシナリオでの予測改善のために、インタラクションデータを活用した文のトランスフォーマーモデル「beeFormer」を提案。beeFormerは、意味的類似性の予測において従来の手法を上回り、異なるドメインのデータセット間で知識を転送可能であることを示した。これにより、ドメインに依存しないテキスト表現のマイニングが可能になる。 CommentNLPでは言語という共通の体系があるから事前学習とかが成立するけど、RecSysのようなユーザとシステムのinteraction dataを用いたシステムでは(大抵の場合はデータセットごとにユニークなユーザIDとアイテムIDのログでデータが構成されるので)なかなかそういうことは難しいよね、と思っていた。が、もしRecSysのタスク設定で、データセット間の転移学習を実現できるのだとしたらどのように実現してきるのだろうか?興味深い。後で読む。 #RecommenderSystems #EfficiencyImprovement Issue Date: 2024-09-25 Enhancing Performance and Scalability of Large-Scale Recommendation Systems with Jagged Flash Attention, Rengan Xu+, N_A, arXiv'24 Summaryハードウェアアクセラレーターの統合により、推薦システムの能力が向上する一方で、GPU計算コストが課題となっている。本研究では、カテゴリ特徴の長さによるGPU利用の複雑さに対処するため、「Jagged Feature Interaction Kernels」を提案し、動的サイズのテンソルを効率的に扱う手法を開発。さらに、JaggedテンソルをFlash Attentionと統合し、最大9倍のスピードアップと22倍のメモリ削減を実現。実際のモデルでは、10%のQPS改善と18%のメモリ節約を確認し、複雑な推薦システムのスケーリングを可能にした。 #InformationRetrieval #RelevanceJudgment #LanguageModel Issue Date: 2024-09-24 Don't Use LLMs to Make Relevance Judgments, Ian Soboroff, N_A, arXiv'24 SummaryTRECスタイルの関連性判断は高コストで複雑であり、通常は訓練を受けた契約者チームが必要です。最近の大規模言語モデルの登場により、情報検索研究者はこれらのモデルの利用可能性を考え始めました。ACM SIGIR 2024カンファレンスでの「LLM4Eval」ワークショップでは、TRECの深層学習トラックの判断を再現するデータチャレンジが行われました。本論文はその基調講演をまとめたもので、TRECスタイルの評価においてLLMを使用しないことを提言しています。 Comment興味深い!!後で読む! #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Safety #DPO #PostTraining Issue Date: 2024-09-24 Backtracking Improves Generation Safety, Yiming Zhang+, N_A, arXiv'24 Summaryテキスト生成における安全性の問題に対処するため、バックトラッキング手法を提案。特別な[RESET]トークンを用いて生成された不適切なテキストを「取り消し」、モデルの安全性を向上させる。バックトラッキングを導入したLlama-3-8Bは、ベースラインモデルに比べて4倍の安全性を示し、有用性の低下は見られなかった。 Comment元ポスト: https://x.com/jaseweston/status/1838415378529112330?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Survey #NLP #LanguageModel #SelfCorrection Issue Date: 2024-09-16 When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs, Ryo Kamoi+, N_A, TACL'24 Summary自己修正はLLMsの応答を改善する手法であり、フィードバック源の利用が提案されているが、誤り修正のタイミングについては合意が得られていない。本研究では、自己修正に必要な条件を議論し、従来の研究の問題点を指摘。新たに分類した研究課題に基づき、自己修正が成功した例がないこと、信頼できる外部フィードバックが重要であること、大規模なファインチューニングが効果的であることを示した。 CommentLLMのself-correctionに関するサーベイ
ソースからQAを生成し、2つのsliceに分ける。片方をLLMのfinetuning(LLMSynth)に利用し、もう片方をfinetuningしたLLMで解答可能性に基づいてフィルタリング(curation)する。
最終的にフィルタリングして生成された高品質なデータでLLMをfinetuningする。
Curationされたデータでfinetuningしたモデルの性能は、Curationしていないただの合成データと比べて、MultiHopQA, TableQAベンチマークで高い性能を獲得している。
画像は元ポストより引用
元ポスト: https://x.com/jaseweston/status/1834402693995024453?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMultiHopQAの合成データ生成方法
TableQAの合成データ生成方法
#Survey #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2024-09-10 From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Sean Welleck+, N_A, arXiv'24 Summary推論時の計算リソース拡大の利点に焦点を当て、トークンレベル生成、メタ生成、効率的生成の3つのアプローチを統一的に探求。トークンレベル生成はデコーディングアルゴリズムを用い、メタ生成はドメイン知識や外部情報を活用し、効率的生成はコスト削減と速度向上を目指す。従来の自然言語処理、現代のLLMs、機械学習の視点を統合した調査。 Comment元ツイート: https://x.com/gneubig/status/1833522477605261799?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCMUのチームによるinference timeの高速化に関するサーベイ #NLP #LanguageModel #ScientificDiscovery Issue Date: 2024-09-10 Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers, Chenglei Si+, N_A, arXiv'24 Summary本研究では、LLMとNLP専門家による研究アイデア生成の比較を行い、LLMが生成したアイデアの新規性が人間のアイデアより高いことを示しましたが、実現可能性はやや劣ると評価されました。また、LLMの自己評価や生成の多様性に関する問題を特定し、研究者がアイデアを実行するためのエンドツーエンドの研究デザインを提案しました。 CommentLLMがアイデアを考えた方が、79人のresearcherにblind reviewさせて評価した結果、Noveltyスコアが有意に高くなった(ただし、feasibilityは人手で考えた場合の方が高い)という話らしい。
アイデア生成にどのようなモデル、promptingを利用したかはまだ読めていない。
>新しい知識を導入するファインチューニング例は、モデルの知識と一致する例よりもはるかに遅く学習されます。しかし、新しい知識を持つ例が最終的に学習されるにつれて、モデルの幻覚する傾向が線形に増加することも発見しました。
早々にoverfittingしている。
>大規模言語モデルは主に事前学習を通じて事実知識を取得し、ファインチューニングはそれをより効率的に使用することを教えるという見解を支持しています。
なるほど、興味深い。下記画像は 1370より引用
本論文中では、full finetuningによる検証を実施しており、LoRAのようなAdapterを用いたテクニックで検証はされていない。LoRAではもともとのLLMのパラメータはfreezeされるため、異なる挙動となる可能性がある。特にLoRAが新しい知識を獲得可能なことが示されれば、LoRA AdapterをもともとのLLMに付け替えるだけで、異なる知識を持ったLLMを運用可能になるため、インパクトが大きいと考えられる。もともとこういった思想は LoRA Hubを提唱する研究などの頃からあった気がするが、AdapterによってHallucination/overfittingを防ぎながら、新たな知識を獲得できることを示した研究はあるのだろうか?
参考: https://x.com/hillbig/status/1792334744522485954?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLoRAの場合については
・1640
・1475
も参照のこと。 #ComputerVision #DiffusionModel Issue Date: 2024-09-01 Diffusion Models Are Real-Time Game Engines, Dani Valevski+, N_A, arXiv'24 SummaryGameNGenは、ニューラルモデルによって完全に動作するゲームエンジンであり、高品質で長い軌跡上で複雑な環境とのリアルタイムインタラクションを可能にします。GameNGenは、単一のTPU上で秒間20フレーム以上でクラシックゲームDOOMをインタラクティブにシミュレートすることができます。次フレーム予測では、PSNRが29.4に達し、劣化JPEG圧縮と比較可能です。GameNGenは、2つの段階でトレーニングされます:(1)RLエージェントがゲームをプレイすることを学び、トレーニングセッションが記録され、(2)拡散モデルが過去のフレームとアクションのシーケンスに応じて次のフレームを生成するようにトレーニングされます。条件付きの拡張により、長い軌跡上で安定した自己回帰生成が可能となります。 CommentDiffusion Modelでゲーム映像を生成する取り組みらしい。ゲームのenvironmentに対して、ユーザのActionとframeの系列をエピソードとみなして生成するっぽい?project pageにデモがのっている
https://gamengen.github.io/ #NLP #In-ContextLearning #DemonstrationSelection Issue Date: 2024-08-28 Revisiting Demonstration Selection Strategies in In-Context Learning, Keqin Peng+, N_A, ACL'24 SummaryLLMsは幅広いタスクを実行する能力を持ち、わずかな例でタスクを説明できることが示されている。しかし、ICLのパフォーマンスはデモンストレーションの選択によって大きく異なり、その要因はまだ明確ではない。本研究では、データとモデルの両面からこの変動に寄与する要因を再検討し、デモンストレーションの選択がデータとモデルの両方に依存することを見出した。さらに、"TopK + ConE"というデータとモデルに依存したデモンストレーション選択手法を提案し、ICLのための効果的なレシピを生み出していることを示した。提案手法は異なるモデルスケールで言語理解および生成タスクの両方で一貫した改善をもたらし、一般性と安定性に加えて以前の手法の効果的な説明を提供している。 CommentICLで利用するデモンストレーションの選択は、BM25やDense Retrieverなどを用いて、テストサンプルと類似したサンプルをretrieveすることで実施されてきた。これらはテストサンプルのみに着目した手法であるが、実際には有効なデモンストレーションはモデルによって変化するため、利用するモデルも考慮した方が良いよね、というお話ベースラインの一覧を見ると、どういった方法がスタンダードなのかがわかる。そして意外とRandomでもそれなりに強いので、実装コストなどと相談しながらどの手法を採用するかは検討した方が良さそう。 #Analysis #NLP #LanguageModel #In-ContextLearning Issue Date: 2024-08-27 What Do Language Models Learn in Context? The Structured Task Hypothesis, Jiaoda Li+, N_A, ACL'24 SummaryLLMsのコンテキスト内学習(ICL)能力を説明する3つの仮説について、一連の実験を通じて探究。最初の2つの仮説を無効にし、最後の仮説を支持する証拠を提供。LLMが事前学習中に学習したタスクを組み合わせることで、コンテキスト内で新しいタスクを学習できる可能性を示唆。 CommentSNLP2024での解説スライド:
http://chasen.org/~daiti-m/paper/SNLP2024-Task-Emergence.pdfICLが何をやっているのか?について、これまでの仮説が正しくないことを実験的に示し、新しい仮説「ICLは事前学習で得られたタスクを組み合わせて新しいタスクを解いている」を提唱し、この仮説が正しいことを示唆する実験結果を得ている模様。
理論的に解明されたわけではなさそうなのでそこは留意した方が良さそう。あとでしっかり読む。 #Analysis #MachineLearning #NLP #SSM (StateSpaceModel) #ICML Issue Date: 2024-08-27 The Illusion of State in State-Space Models, William Merrill+, N_A, ICML'24 SummarySSM(状態空間モデル)は、トランスフォーマーよりも優れた状態追跡の表現力を持つと期待されていましたが、実際にはその表現力は制限されており、トランスフォーマーと類似しています。SSMは複雑性クラス$\mathsf{TC}^0$の外での計算を表現できず、単純な状態追跡問題を解決することができません。このため、SSMは実世界の状態追跡問題を解決する能力に制限がある可能性があります。 Comment>しかし、SSMが状態追跡の表現力で本当に(トランスフォーマーよりも)優位性を持っているのでしょうか?驚くべきことに、その答えは「いいえ」です。私たちの分析によると、SSMの表現力は、トランスフォーマーと非常に類似して制限されています:SSMは複雑性クラス$\mathsf{TC}^0$の外での計算を表現することができません。特に、これは、置換合成のような単純な状態追跡問題を解決することができないことを意味します。これにより、SSMは、特定の表記法でチェスの手を正確に追跡したり、コードを評価したり、長い物語の中のエンティティを追跡することが証明上できないことが明らかになります。
なん…だと… #Analysis #Pretraining #NLP #Supervised-FineTuning (SFT) Issue Date: 2024-08-19 Amuro & Char: Analyzing the Relationship between Pre-Training and Fine-Tuning of Large Language Models, Kaiser Sun+, N_A, arXiv'24 Summary大規模なテキストコーパスで事前学習された複数の中間事前学習モデルのチェックポイントを微調整することによって、事前学習と微調整の関係を調査した。18のデータセットでの結果から、i)継続的な事前学習は、微調整後にモデルを改善する潜在的な方法を示唆している。ii)追加の微調整により、モデルが事前学習段階でうまく機能しないデータセットの改善が、うまく機能するデータセットよりも大きいことを示している。iii)監督された微調整を通じてモデルは恩恵を受けるが、以前のドメイン知識や微調整中に見られないタスクを忘れることがある。iv)監督された微調整後、モデルは評価プロンプトに対して高い感度を示すが、これはより多くの事前学習によって緩和できる。 #Analysis #NLP #LanguageModel #GrammaticalErrorCorrection Issue Date: 2024-08-14 Prompting open-source and commercial language models for grammatical error correction of English learner text, Christopher Davis+, N_A, arXiv'24 SummaryLLMsの進歩により、流暢で文法的なテキスト生成が可能になり、不文法な入力文を与えることで文法エラー修正(GEC)が可能となった。本研究では、7つのオープンソースと3つの商用LLMsを4つのGECベンチマークで評価し、商用モデルが常に教師ありの英語GECモデルを上回るわけではないことを示した。また、オープンソースモデルが商用モデルを上回ることがあり、ゼロショットのプロンプティングがフューショットのプロンプティングと同じくらい競争力があることを示した。 Comment元ポスト:https://x.com/chemical_tree/status/1822860849935253882?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #LLMAgent #ScientificDiscovery Issue Date: 2024-08-13 The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, Chris Lu+, N_A, arXiv'24 Summary最先端の大規模言語モデルを使用して、完全自動の科学的発見を可能にする包括的なフレームワークが提案された。AI Scientistは新しい研究アイデアを生成し、コードを記述し、実験を実行し、結果を可視化し、完全な科学論文を執筆し、査読プロセスを実行することができる。このアプローチは、機械学習における科学的発見の新しい時代の始まりを示しており、AIエージェントの変革的な利点をAI自体の研究プロセス全体にもたらし、世界で最も難しい問題に無限の手頃な価格の創造性とイノベーションを解き放つことに近づいています。 #Controllable #NLP #LanguageModel #InstructionTuning #Length Issue Date: 2024-07-30 Following Length Constraints in Instructions, Weizhe Yuan+, N_A, arXiv'24 Summaryアラインされた命令に従うモデルは、非アラインのモデルよりもユーザーの要求をよりよく満たすことができることが示されています。しかし、このようなモデルの評価には長さのバイアスがあり、訓練アルゴリズムは長い応答を学習することでこのバイアスを利用する傾向があることが示されています。本研究では、推論時に所望の長さ制約を含む命令で制御できるモデルの訓練方法を示します。このようなモデルは、長さ指示された評価において優れており、GPT4、Llama 3、Mixtralなどの標準的な命令に従うモデルを上回っています。 CommentSoTA LLMがOutput長の制約に従わないことを示し、それを改善する学習手法LIFT-DPOを提案
元ツイート: https://x.com/jaseweston/status/1805771223747481690?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-07-30 Searching for Best Practices in Retrieval-Augmented Generation, Xiaohua Wang+, N_A, arXiv'24 SummaryRAG技術は、最新情報の統合、幻覚の軽減、および応答品質の向上に効果的であることが証明されています。しかし、多くのRAGアプローチは複雑な実装と長時間の応答時間という課題に直面しています。本研究では、既存のRAGアプローチとその潜在的な組み合わせを調査し、最適なRAGプラクティスを特定するために取り組んでいます。さらに、マルチモーダル検索技術が視覚入力に関する質問応答能力を大幅に向上させ、"検索を生成として"戦略を用いてマルチモーダルコンテンツの生成を加速できることを示します。 CommentRAGをやる上で参考になりそう #Survey #NLP #LanguageModel #Prompting Issue Date: 2024-07-30 A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications, Pranab Sahoo+, N_A, arXiv'24 Summaryプロンプトエンジニアリングは、LLMsやVLMsの能力を拡張するための重要な技術であり、モデルのパラメータを変更せずにタスク固有の指示であるプロンプトを活用してモデルの効果を向上させる。本研究は、プロンプトエンジニアリングの最近の進展について構造化された概要を提供し、各手法の強みと制限について掘り下げることで、この分野をよりよく理解し、将来の研究を促進することを目的としている。 Comment
#EfficiencyImprovement #NLP #LanguageModel #Pruning Issue Date: 2024-04-22 The Unreasonable Ineffectiveness of the Deeper Layers, Andrey Gromov+, N_A, arXiv'24 Summary一般的なオープンウェイトの事前学習されたLLMのレイヤー剪定戦略を研究し、異なる質問応答ベンチマークでのパフォーマンスの低下を最小限に抑えることを示しました。レイヤーの最大半分を削除することで、最適なブロックを特定し、微調整して損傷を修復します。PEFT手法を使用し、実験を単一のA100 GPUで実行可能にします。これにより、計算リソースを削減し、推論のメモリとレイテンシを改善できることが示唆されます。また、LLMがレイヤーの削除に対して堅牢であることは、浅いレイヤーが知識を格納する上で重要な役割を果たしている可能性を示唆しています。 Comment下記ツイートによると、学習済みLLMから、コサイン類似度で入出力間の類似度が高い層を除いてもタスクの精度が落ちず、特に深い層を2-4割削除しても精度が落ちないとのこと。
参考:https://x.com/hillbig/status/1773110076502368642?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
VRAMに載せるのが大変なので、このような枝刈り技術が有効だと分かるのはありがたい。LoRAや量子化も利用しているっぽい。 #Survey #SpokenLanguageProcessing #Evaluation #FoundationModel #Speech Issue Date: 2024-04-21 A Large-Scale Evaluation of Speech Foundation Models, Shu-wen Yang+, N_A, arXiv'24 Summary基盤モデルパラダイムは、共有基盤モデルを使用して最先端のパフォーマンスを達成し、下流特有のモデリングやデータ注釈を最小限に抑えることを目指す。このアプローチは、自然言語処理(NLP)の分野で成功しているが、音声処理分野では類似したセットアップが不足している。本研究では、音声処理ユニバーサルパフォーマンスベンチマーク(SUPERB)を設立し、音声に対する基盤モデルパラダイムの効果を調査する。凍結された基盤モデルに続いて、タスク専用の軽量な予測ヘッドを使用して、SUPERB内の音声処理タスクに取り組むための統一されたマルチタスキングフレームワークを提案する。結果は、基盤モデルパラダイムが音声に有望であり、提案されたマルチタスキングフレームワークが効果的であることを示し、最も優れた基盤モデルがほとんどのSUPERBタスクで競争力のある汎化性能を持つことを示している。 CommentSpeech関連のFoundation Modelの評価結果が載っているらしい。
図は下記ツイートより引用
参考:https://x.com/unilightwf/status/1781659340065345766?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-04-17 Compression Represents Intelligence Linearly, Yuzhen Huang+, N_A, arXiv'24 Summary最近の研究では、大規模言語モデル(LLMs)をデータ圧縮器として扱い、圧縮と知性の関係を検討しています。LLMsの知性は、外部テキストコーパスを圧縮する能力とほぼ線形的に相関しており、優れた圧縮がより高い知性を示すという信念を支持する具体的な証拠を提供しています。さらに、圧縮効率はモデルの能力と線形的に関連しており、圧縮を評価するためのデータセットとパイプラインがオープンソース化されています。 Comment参考: https://x.com/hillbig/status/1780365637225001004?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-04-16 TransformerFAM: Feedback attention is working memory, Dongseong Hwang+, N_A, arXiv'24 SummaryTransformersの二次的なattentionの複雑さにより、無限に長い入力を処理する能力が制限されている課題がある。そこで、新しいTransformerアーキテクチャであるフィードバックアテンションメモリ(FAM)を提案し、自己アテンションを可能にする。この設計により、Transformer内での作業メモリが促進され、無限に長いシーケンスを処理できるようになる。TransformerFAMは追加の重みが不要で、事前学習済みモデルとの統合が容易。実験結果では、TransformerFAMがさまざまなモデルサイズで長いコンテキストのタスクにおける性能を向上させることを示しており、LLMsが無制限の長さのシーケンスを処理する可能性を示唆している。 #Survey #NLP #LanguageModel Issue Date: 2024-04-14 Knowledge Conflicts for LLMs: A Survey, Rongwu Xu+, N_A, arXiv'24 SummaryLLMsにおける知識の衝突に焦点を当て、文脈とパラメトリック知識の組み合わせによる複雑な課題を分析。文脈-メモリ、文脈間、メモリ内の衝突の3つのカテゴリーを探求し、実世界のアプリケーションにおける信頼性とパフォーマンスへの影響を検討。解決策を提案し、LLMsの堅牢性向上を目指す。 #NLP #LanguageModel #SelfImprovement Issue Date: 2024-04-14 Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, Eric Zelikman+, N_A, arXiv'24 SummarySTaR(Self-Taught Reasoner)では、少数の例から合理的な推論を学習し、質問応答に活用する方法が提案された。Quiet-STaRでは、LMが合理性を生成する方法を学習し、難しい質問に直接答える能力を向上させる。この手法は、GSM8KやCommonsenseQAなどのタスクにおいてゼロショットの改善を実現し、ファインチューニングが不要であることが示された。Quiet-STaRは、推論を学習するための一般的でスケーラブルな方法を提供する一歩となっている。 Commento1(1390)の基礎技術と似ている可能性がある
先行研究:
・1397参考:https://x.com/hillbig/status/1835449666588271046?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #InformationRetrieval #NLP #Chain-of-Thought #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-04-14 RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation, Zihao Wang+, N_A, arXiv'24 Summary大規模言語モデルの推論および生成能力を向上させ、幻覚を軽減する方法として、情報検索を利用して思考の連鎖を修正する「retrieval-augmented thoughts(RAT)」が提案された。この方法は、ゼロショットのCoTが生成された後、取得した情報を使用して各思考ステップを修正する。GPT-3.5、GPT-4、およびCodeLLaMA-7bにRATを適用することで、コード生成、数学的推論、創造的な執筆、具体的なタスク計画などのタスクでパフォーマンスが大幅に向上した。デモページはhttps://craftjarvis.github.io/RATで利用可能。 CommentRAGにおいてCoTさせる際に、各reasoningのstepを見直させることでより質の高いreasoningを生成するRATを提案。Hallucinationが低減し、生成のパフォーマンスも向上するとのこと。
GQA 1271 と比較して、2~4倍キャッシュを圧縮しつつ、より高い性能を実現。70Bモデルの場合は、GQAで8倍キャッシュを圧縮した上で、DMCで追加で2倍圧縮をかけたところ、同等のパフォーマンスを実現している。
#InformationRetrieval #NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-04-07 RAFT: Adapting Language Model to Domain Specific RAG, Tianjun Zhang+, N_A, arXiv'24 Summary大規模なテキストデータのLLMsを事前学習し、新しい知識を追加するためのRetrieval Augmented FineTuning(RAFT)を提案。RAFTは、質問に回答するのに役立つ関連文書から正しいシーケンスを引用し、chain-of-thoughtスタイルの応答を通じて推論能力を向上させる。RAFTはPubMed、HotpotQA、Gorillaデータセットでモデルのパフォーマンスを向上させ、事前学習済みLLMsをドメイン固有のRAGに向けて改善する。 CommentQuestion, instruction, coxtext, cot style answerの4つを用いてSFTをする模様
画像は下記ツイートより引用
https://x.com/cwolferesearch/status/1770912695765660139?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #InformationRetrieval #NLP #LanguageModel #Prompting #Reasoning Issue Date: 2024-04-07 RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners, Chi Hu+, N_A, arXiv'24 SummaryLLMsは推論タスクで優れた性能を発揮しているが、論理エラーが起こりやすい。RankPromptという新しいプロンプティング方法を導入し、LLMsが自己ランク付けを行い推論パフォーマンスを向上させる。実験では、RankPromptがChatGPTやGPT-4の推論パフォーマンスを13%向上させ、AlpacaEvalデータセットで人間の判断と74%の一致率を示すことが示された。RankPromptは言語モデルから高品質なフィードバックを引き出す効果的な方法であることが示された。 CommentLLMでランキングをするためのプロンプト手法。大量の候補をランキングするのは困難だと思われるが、リランキング手法としては利用できる可能性がある
Issue Date: 2024-04-03 MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection, Ali Behrouz+, N_A, arXiv'24 Summary最近の深層学習の進歩は、データ依存性と大規模な学習能力によって、主にTransformersに依存してきた。しかし、長いシーケンスモデリングにおいてスケーラビリティが制限される問題がある。State Space Models(SSMs)に着想を得たMambaMixerは、Selective Token and Channel Mixerを使用した新しいアーキテクチャであり、画像や時系列データにおいて優れたパフォーマンスを示す。ViM2はビジョンタスクで競争力のあるパフォーマンスを達成し、TSM2は時系列予測で優れた結果を示す。これらの結果は、TransformersやMLPが時系列予測において必要ないことを示唆している。 Comment参考: https://x.com/hillbig/status/1775289127803703372?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-04-03 Long-context LLMs Struggle with Long In-context Learning, Tianle Li+, N_A, arXiv'24 SummaryLLMsは長いシーケンスを処理する能力で進歩しているが、その評価は限定されている。本研究では、極端なラベル分類の領域での長いコンテキスト学習に焦点を当てた特化したベンチマーク(LIConBench)を紹介する。LLMsは20K以下のトークン長で比較的良いパフォーマンスを示し、長いコンテキストウィンドウを利用することで性能が向上することがわかった。しかし、20Kを超えると性能が急激に低下する。現在のLLMsは長くコンテキスト豊かなシーケンスを処理し理解する能力にギャップがあることを示唆している。LIConBenchは、将来のLLMsの評価に役立つ可能性がある。 #RecommenderSystems #Survey #GenerativeAI Issue Date: 2024-04-02 A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys), Yashar Deldjoo+, N_A, arXiv'24 Summary従来のレコメンドシステムは、ユーザー-アイテムの評価履歴を主要なデータソースとして使用してきたが、最近では生成モデルを活用して、テキストや画像など豊富なデータを含めた新しい推薦タスクに取り組んでいる。この研究では、生成モデル(Gen-RecSys)を用いたレコメンドシステムの進歩に焦点を当て、相互作用駆動型生成モデルや大規模言語モデル(LLM)を用いた生成型推薦、画像や動画コンテンツの処理と生成のためのマルチモーダルモデルなどについて調査している。未解決の課題や必要なパラダイムについても議論している。 Issue Date: 2024-03-13 Stealing Part of a Production Language Model, Nicholas Carlini+, N_A, arXiv'24 SummaryOpenAIのChatGPTやGoogleのPaLM-2などのブラックボックスの言語モデルから重要な情報を抽出するモデルスティーリング攻撃を紹介。APIアクセスを利用して、transformerモデルの埋め込み射影層を回復する攻撃を行い、低コストでAdaとBabbage言語モデルの全射影行列を抽出。gpt-3.5-turboモデルの隠れた次元のサイズを回復し、2000ドル未満のクエリで全射影行列を回復すると推定。潜在的な防御策と緩和策を提案し、将来の作業の影響について議論。 Issue Date: 2024-03-05 The Power of Noise: Redefining Retrieval for RAG Systems, Florin Cuconasu+, N_A, arXiv'24 SummaryRAGシステムは、LLMsよりも大幅な進歩を遂げており、IRフェーズを介して外部データを取得することで生成能力を向上させています。本研究では、RAGシステムにおけるIRコンポーネントの影響を詳細に分析し、リトリーバーの特性や取得すべきドキュメントのタイプに焦点を当てました。関連性のないドキュメントを含めることで精度が向上することが示され、リトリーバルと言語生成モデルの統合の重要性が強調されました。 CommentRelevantな情報はクエリの近くに配置すべきで、残りのコンテキストをrelevantな情報で埋めるのではなく、ノイズで埋めたほうがRAGの回答が良くなる、という話らしい #NLP #LanguageModel #OpenWeight #OpenSource Issue Date: 2024-03-05 OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, N_A, arXiv'24 SummaryLMsの商業的重要性が高まる中、最も強力なモデルは閉鎖されており、その詳細が非公開になっている。そのため、本技術レポートでは、本当にオープンな言語モデルであるOLMoの初回リリースと、言語モデリングの科学を構築し研究するためのフレームワークについて詳細に説明している。OLMoはモデルの重みだけでなく、トレーニングデータ、トレーニングおよび評価コードを含むフレームワーク全体を公開しており、オープンな研究コミュニティを強化し、新しいイノベーションを促進することを目指している。 CommentModel Weightsを公開するだけでなく、training/evaluation codeとそのデータも公開する真にOpenな言語モデル(truly Open Language Model)。AllenAI Issue Date: 2024-03-05 AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls, Yu Du+, N_A, arXiv'24 SummaryAnyToolは、大規模言語モデルエージェントであり、16,000以上のAPIを利用してユーザーのクエリに対処する革新的なツールを提供している。階層構造を持つAPIリトリーバー、API候補を使用してクエリを解決するソルバー、自己反映メカニズムを組み込んでおり、GPT-4の関数呼び出し機能を活用している。AnyToolは、ToolLLMやGPT-4の変種を上回る性能を示し、改訂された評価プロトコルとAnyToolBenchベンチマークを導入している。GitHubでコードが入手可能。 Comment階層的なRetrieverを用いてユーザクエリから必要なツールを検索し、solverでユーザのクエリを解決し、self-reflectionで結果をさらに良くするような枠組み
#NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2024-03-05 Chain-of-Thought Reasoning Without Prompting, Xuezhi Wang+, N_A, arXiv'24 SummaryLLMsの推論能力を向上させるための新しいアプローチに焦点を当てた研究が行われている。この研究では、LLMsがプロンプトなしで効果的に推論できるかどうかを検証し、CoT推論パスをデコーディングプロセスを変更することで引き出す方法を提案している。提案手法は、従来の貪欲なデコーディングではなく、代替トークンを調査することでCoTパスを見つけることができることを示しており、様々な推論ベンチマークで有効性を示している。 Comment以前にCoTを内部的に自動的に実施されるように事前学習段階で学習する、といった話があったと思うが、この研究はデコーディング方法を変更することで、promptingで明示的にinstructionを実施せずとも、CoTを実現するもの、ということだと思われる。
普通のコンテキストサイズならpromptの末尾などに入れたinstructionなどは強く働く経験があるので気になる。
どれくらい汎用的に適用可能な話なのかも気になるところ。 #EfficiencyImprovement #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML Issue Date: 2024-03-05 LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, ICML'24 Summary本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 CommentLoRAで導入される低ランク行列AとBを異なる学習率で学習することで、LoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法
Github: https://github.com/kyegomez/BitNet
https://x.com/hillbig/status/1762624222260846993?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2024-02-27 MerRec: A Large-scale Multipurpose Mercari Dataset for Consumer-to-Consumer Recommendation Systems, Lichi Li+, N_A, arXiv'24 Summary電子商取引分野において、C2C推薦システムの重要性が高まっているが、これに関する研究は限られたデータセットに基づいている。そこで、MerRecという数百万のユーザーと商品をカバーする大規模なC2C推薦データセットが導入された。このデータセットは、標準的な特徴だけでなく、ユニークな要素も含んでおり、広範囲に評価されることで、C2C推薦の研究を促進し、新たな基準を確立することが期待されている。 Issue Date: 2024-02-25 Linear Transformers are Versatile In-Context Learners, Max Vladymyrov+, N_A, arXiv'24 Summary研究では、線形transformersが複雑な問題に対して効果的な最適化アルゴリズムを見つける能力を持つことが示された。特に、トレーニングデータが異なるノイズレベルで破損している場合でも、線形transformersは合理的なベースラインを上回るか匹敵する結果を示した。新しいアプローチとして、運動量と再スケーリングを組み込んだ最適化戦略が提案された。これにより、線形transformersが洗練された最適化戦略を発見する能力を持つことが示された。 #NLP #LanguageModel #Personalization Issue Date: 2024-02-24 User-LLM: Efficient LLM Contextualization with User Embeddings, Lin Ning+, N_A, arXiv'24 SummaryLLMsを活用したUser-LLMフレームワークが提案された。ユーザーエンベッディングを使用してLLMsをコンテキストに位置付けし、ユーザーコンテキストに動的に適応することが可能になる。包括的な実験により、著しい性能向上が示され、Perceiverレイヤーの組み込みにより計算効率が向上している。 Commentnext item prediction, favorite genre or category predictimnreview generationなどで評価している Issue Date: 2024-02-24 Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance, Ziqi Yin+, N_A, arXiv'24 SummaryLLMsのパフォーマンスにおけるプロンプトの丁寧さの影響を調査。無礼なプロンプトはパフォーマンス低下につながるが、過度に丁寧な言葉も必ずしも良い結果を保証しない。最適な丁寧さのレベルは言語によって異なることが示唆され、異文化間の自然言語処理とLLMの使用において丁寧さを考慮する必要性が強調された。 Issue Date: 2024-02-15 Scaling Laws for Fine-Grained Mixture of Experts, Jakub Krajewski+, N_A, arXiv'24 Summary本研究では、Mixture of Experts(MoE)モデルのスケーリング特性を分析し、新しいハイパーパラメータである「粒度」を導入することで、計算コストを削減する方法を提案しています。さらに、MoEモデルが密なモデルよりも優れた性能を発揮し、モデルのサイズとトレーニング予算をスケールアップするにつれてその差が広がることを示しています。また、一般的な方法では最適ではないことも示しています。 Issue Date: 2024-02-11 Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks, Jongho Park+, N_A, arXiv'24 Summary状態空間モデル(SSM)は、言語モデリングにおけるTransformerネットワークの代替手法として提案されてきた。本研究では、SSMのインコンテキスト学習(ICL)能力を評価し、Transformerと比較した結果を報告する。SSMは一部のタスクでTransformerを上回る性能を示すが、一部のタスクでは不十分であることがわかった。そこで、Mambaとアテンションブロックを組み合わせたハイブリッドモデルを提案し、個々のモデルを上回る結果を示した。ハイブリッドアーキテクチャは言語モデルのICLを向上させる有望な手段であることが示唆された。 Issue Date: 2024-02-07 Self-Discover: Large Language Models Self-Compose Reasoning Structures, Pei Zhou+, N_A, arXiv'24 SummarySELF-DISCOVERは、LLMsがタスク固有の推論構造を自己発見することを可能にするフレームワークであり、複雑な推論問題に取り組むことができます。このフレームワークは、複数の原子的な推論モジュールを選択し、それらを組み合わせて明示的な推論構造を作成する自己発見プロセスを含んでいます。SELF-DISCOVERは、難解な推論ベンチマークでGPT-4とPaLM 2の性能を最大32%向上させることができます。さらに、推論計算において10-40倍少ないリソースを必要とし、人間の推論パターンと共通点を持っています。 Issue Date: 2024-02-06 RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval, Parth Sarthi+, N_A, arXiv'24 Summary検索補完言語モデルは、ロングテールの知識を組み込むことができますが、既存の手法では文脈の理解が制限されています。そこで、私たちは再帰的な要約を使用してテキストをクラスタリングし、異なる抽象化レベルで情報を統合する新しいアプローチを提案します。制御された実験では、このアプローチが従来の手法よりも大幅な改善を提供し、質問応答タスクでは最高性能を20%向上させることができることを示しました。 #Survey #LanguageModel #MulltiModal #ACL Issue Date: 2024-01-25 MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N_A, ACL'24 Findings SummaryMM-LLMsは、コスト効果の高いトレーニング戦略を用いて拡張され、多様なMMタスクに対応する能力を持つことが示されている。本論文では、MM-LLMsのアーキテクチャ、トレーニング手法、ベンチマークのパフォーマンスなどについて調査し、その進歩に貢献することを目指している。 Comment以下、論文を斜め読みしながら、ChatGPTを通じて疑問点を解消しつつ理解した内容なので、理解が不十分な点が含まれている可能性があるので注意。
まあざっくり言うと、マルチモーダルを理解できるLLMを作りたかったら、様々なモダリティをエンコーディングして得られる表現と、既存のLLMが内部的に処理可能な表現を対応づける Input Projectorという名の関数を学習すればいいだけだよ(モダリティのエンコーダ、LLMは事前学習されたものをそのままfreezeして使えば良い)。
マルチモーダルを生成できるLLMを作りたかったら、LLMがテキストを生成するだけでなく、様々なモダリティに対応する表現も追加で出力するようにして、その出力を各モダリティを生成できるモデルに入力できるように変換するOutput Projectortという名の関数を学習しようね、ということだと思われる。
概要
ポイント
・Modality Encoder, LLM Backbone、およびModality Generatorは一般的にはパラメータをfreezeする
・optimizationの対象は「Input/Output Projector」
Modality Encoder
様々なモダリティI_Xを、特徴量F_Xに変換する。これはまあ、色々なモデルがある。
Input Projector
モダリティI_Xとそれに対応するテキストtのデータ {I_X, t}が与えられたとき、テキストtを埋め込み表現に変換んした結果得られる特徴量がF_Tである。Input Projectorは、F_XをLLMのinputとして利用する際に最適な特徴量P_Xに変換するθX_Tを学習することである。これは、LLM(P_X, F_T)によってテキストtがどれだけ生成できたか、を表現する損失関数を最小化することによって学習される。
LLM Backbone
LLMによってテキスト列tと、各モダリティに対応した表現であるS_Xを生成する。outputからt, S_Xをどのように区別するかはモデルの構造などにもよるが、たとえば異なるヘッドを用意して、t, S_Xを区別するといったことは可能であろうと思われる。
Output Projector
S_XをModality Generatorが解釈可能な特徴量H_Xに変換する関数のことである。これは学習しなければならない。
H_XとModality Generatorのtextual encoderにtを入力した際に得られる表現τX(t)が近くなるようにOutput Projector θ_T_Xを学習する。これによって、S_XとModality Generatorがalignするようにする。
Modality Generator
各ModalityをH_Xから生成できるように下記のような損失学習する。要は、生成されたモダリティデータ(または表現)が実際のデータにどれだけ近いか、を表しているらしい。具体的には、サンプリングによって得られたノイズと、モデルが推定したノイズの値がどれだけ近いかを測る、みたいなことをしているらしい。
Multi Modalを理解するモデルだけであれば、Input Projectorの損失のみが学習され、生成までするのであれば、Input/Output Projector, Modality Generatorそれぞれに示した損失関数を通じてパラメータが学習される。あと、P_XやらS_Xはいわゆるsoft-promptingみたいなものであると考えられる。 #NLP #LanguageModel #ProgressiveLearning #ACL Issue Date: 2024-01-24 LLaMA Pro: Progressive LLaMA with Block Expansion, Chengyue Wu+, N_A, ACL'24 Summary本研究では、大規模言語モデル(LLMs)の新しい事前学習後の手法を提案し、モデルの知識を効果的かつ効率的に向上させることを目指しました。具体的には、Transformerブロックの拡張を使用し、新しいコーパスのみを使用してモデルを調整しました。実験の結果、提案手法はさまざまなベンチマークで優れたパフォーマンスを発揮し、知的エージェントとして多様なタスクに対応できることが示されました。この研究は、自然言語とプログラミング言語を統合し、高度な言語エージェントの開発に貢献するものです。 Comment追加の知識を導入したいときに使えるかも?事前学習したLLaMA Blockに対して、追加のLLaMA Blockをstackし、もともとのLLaMA Blockのパラメータをfreezeした上でドメインに特化したコーパスで事後学習することで、追加の知識を挿入する。LLaMA Blockを挿入するときは、Linear Layerのパラメータを0にすることで、RMSNormにおける勾配消失の問題を避けた上で、Identity Block(Blockを追加した時点では事前学習時と同様のOutputがされることが保証される)として機能させることができる。
Issue Date: 2024-01-24 Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models, Zixiang Chen+, N_A, arXiv'24 Summary本研究では、追加の人間による注釈付きデータを必要とせずに、大規模言語モデル(LLMs)を強化する方法を提案します。そのために、Self-Play fIne-tuNing(SPIN)という新しいファインチューニング手法を開発しました。SPINでは、LLMが自身と対戦しながら能力を向上させるセルフプレイのメカニズムを利用します。具体的には、LLMは自己生成応答と人間による注釈付きデータから得られた応答を区別することでポリシーを改善します。実験結果は、SPINがLLMのパフォーマンスを大幅に改善し、専門家の対戦相手を必要とせずに人間レベルのパフォーマンスを達成できることを示しています。 #Survey #NLP #LanguageModel #Hallucination Issue Date: 2024-01-24 A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models, S. M Towhidul Islam Tonmoy+, N_A, arXiv'24 Summary要約:本論文では、大規模言語モデル(LLMs)における幻覚の問題について調査し、その軽減策について紹介しています。LLMsは強力な言語生成能力を持っていますが、根拠のない情報を生成する傾向があります。この問題を解決するために、Retrieval Augmented Generation、Knowledge Retrieval、CoNLI、CoVeなどの技術が開発されています。さらに、データセットの利用やフィードバックメカニズムなどのパラメータに基づいてこれらの方法を分類し、幻覚の問題に取り組むためのアプローチを提案しています。また、これらの技術に関連する課題や制約についても分析し、将来の研究に向けた基盤を提供しています。 #NLP #LanguageModel #DataToTextGeneration #TabularData #ICLR Issue Date: 2024-01-24 Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding, Zilong Wang+, N_A, ICLR'24 SummaryLLMsを使用したChain-of-Tableフレームワークは、テーブルデータを推論チェーン内で活用し、テーブルベースの推論タスクにおいて高い性能を発揮することが示された。このフレームワークは、テーブルの連続的な進化を表現し、中間結果の構造化情報を利用してより正確な予測を可能にする。さまざまなベンチマークで最先端のパフォーマンスを達成している。 CommentTable, Question, Operation Historyから次のoperationとそのargsを生成し、テーブルを順次更新し、これをモデルが更新の必要が無いと判断するまで繰り返す。最終的に更新されたTableを用いてQuestionに回答する手法。Questionに回答するために、複雑なテーブルに対する操作が必要なタスクに対して有効だと思われる。
といった話や、そもそもreference-basedなメトリック(e.g. BLEU)や、reference-freeなメトリック(e.g. BARTScore)とはなんぞや?みたいな基礎的な話から、言語モデルを用いたテキスト生成の評価手法の代表的なものだけでなく、タスクごとの手法も整理されて記載されている。また、BLEUやROUGEといった伝統的な手法の概要や、最新手法との同一データセットでのメタ評価における性能の差なども記載されており、全体的に必要な情報がコンパクトにまとまっている印象がある。
マルチモーダルに拡張したことで、訓練が非常に不安定になったため、アーキテクチャ上でいくつかの工夫を加えている:
・2D Rotary Embedding
・Positional EncodingとしてRoPEを採用
・画像のような2次元データのモダリティの場合はRoPEを2次元に拡張する。具体的には、位置(i, j)のトークンについては、Q, Kのembeddingを半分に分割して、それぞれに対して独立にi, jのRoPE Embeddingを適用することでi, j双方の情報を組み込む。
・QK Normalization
・image, audioのモダリティを組み込むことでMHAのlogitsが非常に大きくなりatteetion weightが0/1の極端な値をとるようになり訓練の不安定さにつながった。このため、dot product attentionを適用する前にLayerNormを組み込んだ。
・Scaled Cosine Attention
・Image Historyモダリティにおいて固定長のEmbeddingを得るためにPerceiver Resamplerを扱ったているが、こちらも上記と同様にAttentionのlogitsが極端に大きくなったため、cosine類似度をベースとしたScaled Cosine Attention 2259 を利用することで、大幅に訓練の安定性が改善された。
・その他
・attention logitsにはfp32を適用
・事前学習されたViTとASTを同時に更新すると不安定につながったため、事前学習の段階ではfreezeし、instruction tuningの最後にfinetuningを実施
・\[R\]: 通常のspan corruption (1--5 token程度のspanをmaskする)
・\[S\]: causal language modeling (inputを2つのサブシーケンスに分割し、前方から後方を予測する。前方部分はBi-directionalでも可)
・\[X\]: extreme span corruption (12>=token程度のspanをmaskする)
の3種類が提案されており、モダリティごとにこれらを使い分ける:
・text modality: UL2 (1424)を踏襲
・image, audioがtargetの場合: 2つの類似したパラダイムを定義し利用
・\[R\]: patchをランダムにx%マスクしre-constructする
・\[S\]: inputのtargetとは異なるモダリティのみの情報から、targetモダリティを生成する
訓練時には prefixとしてmodality token \[Text\], \[Image\], \[Audio\] とparadigm token \[R\], \[S\], \[X\] をタスクを指示するトークンとして利用している。また、image, audioのマスク部分のdenoisingをautoregressive modelで実施する際には普通にやるとdecoder側でリークが発生する(a)。これを防ぐには、Encoder側でマスクされているトークンを、Decoder側でteacher-forcingする際にの全てマスクする方法(b)があるが、この場合、生成タスクとdenoisingタスクが相互に干渉してしまいうまく学習できなくなってしまう(生成タスクでは通常Decoderのinputとして[mask]が入力され次トークンを生成する、といったことは起きえないが、愚直に(b)をやるとそうなってしまう)。ので、(c)に示したように、マスクされているトークンをinputとして生成しなければならない時だけ、マスクを解除してdecoder側にinputする、という方法 (Dynamic Masking) でこの問題に対処している。
元ツイート: https://x.com/idavidrein/status/1727033002234909060?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview:https://openreview.net/forum?id=Ti67584b98 #Pretraining #NLP #LanguageModel Issue Date: 2023-10-10 Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N_A, ICLR'24 Summary言語モデルのトレーニングと推論において、遅延を導入することでモデルの性能を向上させる手法を提案しました。具体的には、入力に特定のトークンを追加し、そのトークンが現れるまでモデルの出力を遅らせることで、追加の計算を行うことができます。実験結果では、この手法が推論タスクにおいて有益であり、特にQAタスクでの性能向上が見られました。今後は、この遅延予測の手法をさらに研究していく必要があります。 Commentこの研究は興味深いが、事前学習時に入れないと効果が出にくいというのは直感的にわかるので、実用的には活用しづらい。
また、promptでこの研究をimitateする方法については、ZeroShot CoTにおいて、思考プロセスを明示的に指定するようなpromptingと同様のことを行っており、これは実際に効果があると思う。 #NLP #LanguageModel #LongSequence #PositionalEncoding #NAACL Issue Date: 2023-10-09 Effective Long-Context Scaling of Foundation Models, Wenhan Xiong+, N_A, NAACL'24 Summary私たちは、長いコンテキストをサポートする一連のLLMsを提案します。これらのモデルは、長いテキストを含むデータセットでトレーニングされ、言語モデリングや他のタスクで評価されます。提案手法は、通常のタスクと長いコンテキストのタスクの両方で改善をもたらします。また、70Bバリアントはgpt-3.5-turbo-16kを上回るパフォーマンスを実現します。さらに、私たちはLlamaの位置エンコーディングや事前学習プロセスの設計選択の影響についても分析しました。結果から、長いコンテキストの継続的な事前学習が効果的であることが示されました。 Comment以下elvis氏のツイートの意訳
Metaが32kのcontext windowをサポートする70BのLLaMa2のvariant提案し、gpt-3.5-turboをlong contextが必要なタスクでoutperform。
short contextのLLaMa2を継続的に訓練して実現。これには人手で作成したinstruction tuning datasetを必要とせず、コスト効率の高いinstruction tuningによって実現される。
これは、事前学習データセットに長いテキストが豊富に含まれることが優れたパフォーマンスの鍵ではなく、ロングコンテキストの継続的な事前学習がより効率的であることを示唆している。
元ツイート: https://x.com/omarsar0/status/1707780482178400261?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q位置エンコーディングにはlong contxet用に、RoPEのbase frequency bを `10,000->500,000` とすることで、rotation angleを小さくし、distant tokenに対する減衰の影響を小さくする手法を採用 (Adjusted Base Frequency; ABF)。token間の距離が離れていても、attention scoreがshrinkしづらくなっている。
また、単に長いコンテキストのデータを追加するだけでなく、データセット内における長いコンテキストのデータの比率を調整することで、より高い性能が発揮できることを示している。これをData Mixと呼ぶ。
また、instruction tuningのデータには、LLaMa2ChatのRLHFデータをベースに、LLaMa2Chat自身にself-instructを活用して、長いコンテキストを生成させ拡張したものを利用した。
具体的には、コーパス内のlong documentを用いたQAフォーマットのタスクに着目し、文書内のランダムなチャンクからQAを生成させた。その後、self-critiqueによって、LLaMa2Chat自身に、生成されたQAペアのverificationも実施させた。 #NLP #LanguageModel #Reasoning #ICLR #Verification Issue Date: 2023-08-08 SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning, Ning Miao+, N_A, ICLR'24 Summary最新の大規模言語モデル(LLMs)は、推論問題を解決するために有望な手法ですが、複雑な問題にはまだ苦戦しています。本研究では、LLMsが自身のエラーを認識する能力を持っているかどうかを探求し、ゼロショットの検証スキームを提案します。この検証スキームを使用して、異なる回答に対して重み付け投票を行い、質問応答のパフォーマンスを向上させることができることを実験で確認しました。 Commentこれはおもしろそう。後で読むOpenReview:https://openreview.net/forum?id=pTHfApDakA #NLP #Dataset #LanguageModel #Evaluation #ICML Issue Date: 2023-07-22 SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models, Xiaoxuan Wang+, N_A, ICML'24 Summary本研究では、大規模言語モデル(LLMs)の進歩により、数学のベンチマークでの性能向上が示されているが、これらのベンチマークは限定的な範囲の問題に限定されていることが指摘される。そこで、複雑な科学的問題解決に必要な推論能力を検証するための包括的なベンチマークスイートSciBenchを提案する。SciBenchには、大学レベルの科学的問題を含むオープンセットと、学部レベルの試験問題を含むクローズドセットの2つのデータセットが含まれている。さらに、2つの代表的なLLMを用いた詳細なベンチマーク研究を行い、現在のLLMのパフォーマンスが不十分であることを示した。また、ユーザースタディを通じて、LLMが犯すエラーを10の問題解決能力に分類し、特定のプロンプティング戦略が他の戦略よりも優れているわけではないことを明らかにした。SciBenchは、LLMの推論能力の向上を促進し、科学研究と発見に貢献することを目指している。 #ICML Issue Date: 2023-05-22 Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling, Weijia Xu+, N_A, ICML'24 Summary本研究では、Repromptingという反復サンプリングアルゴリズムを紹介し、Chain-of-Thought(CoT)レシピを探索することで、特定のタスクを解決する。Repromptingは、以前にサンプリングされた解決策を親プロンプトとして使用して、新しいレシピを反復的にサンプリングすることで、一貫して良い結果を出すCoTレシピを推論する。複数のステップ推論が必要な5つのBig-Bench Hardタスクにおいて、Repromptingはゼロショット、フューショット、および人間が書いたCoTベースラインよりも一貫して優れたパフォーマンスを発揮する。Repromptingは、より強力なモデルからより弱いモデルへの知識の転移を促進し、より弱いモデルの性能を大幅に向上させることもできる。全体的に、Repromptingは、人間が書いたCoTプロンプトを使用する従来の最先端手法よりも最大で+17ポイントの改善をもたらす。 Commentんー、IterCoTとかAutoPromptingとかと比較してないので、なんとも言えない…。サーベイ不足では。あとChatGPTを使うのはやめて頂きたい。 #ComputerVision #Pretraining #Transformer #ImageSegmentation #FoundationModel Issue Date: 2023-04-30 Segment Anything in Medical Images, Jun Ma+, N_A, Nature Communications'24 Summary本研究では、自然画像セグメンテーションに革新的な手法であるSegment anything model (SAM)を医療画像に拡張するためのMedSAMを提案し、様々な医療ターゲットのセグメンテーションのための汎用ツールを作成することを目的としています。MedSAMは、大規模な医療画像データセットを用いて開発され、SAMを一般的な医療画像セグメンテーションに適応するためのシンプルなファインチューニング手法を開発しました。21の3Dセグメンテーションタスクと9の2Dセグメンテーションタスクに対する包括的な実験により、MedSAMは、平均Dice類似係数(DSC)がそれぞれ22.5%と17.6%で、デフォルトのSAMモデルを上回ることが示されました。コードとトレーニング済みモデルは、\url{https://github.com/bowang-lab/MedSAM}で公開されています。 CommentSAMの性能は医療画像に対しては限定的だったため、11の異なるモダリティに対して200kのマスクをした医療画像を用意しfinetuningしたMedSAMによって、医療画像のセグメンテーションの性能を大幅に向上。
コードとモデルはpublicly available
encoder-onlyとまとめられているものの中には、デコーダーがあるものがあり(autoregressive decoderではない)、
encoder-decoderは正しい意味としてはencoder with autoregressive decoderであり、
decoder-onlyは正しい意味としてはautoregressive encoder-decoder
とのこと。
https://twitter.com/ylecun/status/1651762787373428736?s=46&t=-zElejt4asTKBGLr-c3bKw #ComputerVision #Transformer #DiffusionModel #read-later #Admin'sPick #Backbone Issue Date: 2025-08-27 [Paper Note] Scalable Diffusion Models with Transformers, William Peebles+, ICCV'23 Summary新しいトランスフォーマーに基づく拡散モデル(Diffusion Transformers, DiTs)を提案し、U-Netをトランスフォーマーに置き換えた。DiTsは高いGflopsを持ち、低いFIDを維持しながら良好なスケーラビリティを示す。最大のDiT-XL/2モデルは、ImageNetのベンチマークで従来の拡散モデルを上回り、最先端のFID 2.27を達成した。 Comment日本語解説:https://qiita.com/sasgawy/items/8546c784bc94d94ef0b2よく見るDiT
・2526
も同様の呼称だが全く異なる話なので注意 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention Issue Date: 2025-08-19 [Paper Note] Efficient Memory Management for Large Language Model Serving with PagedAttention, Woosuk Kwon+, SOSP'23 SummaryPagedAttentionを用いたvLLMシステムを提案し、KVキャッシュメモリの無駄を削減し、リクエスト間での柔軟な共有を実現。これにより、同レベルのレイテンシでLLMのスループットを2-4倍向上。特に長いシーケンスや大規模モデルで効果が顕著。ソースコードは公開中。 Comment(今更ながら)vLLMはこちら:
https://github.com/vllm-project/vllm
現在の主要なLLM Inference/Serving Engineのひとつ。 Issue Date: 2025-08-16 [Paper Note] SemDeDup: Data-efficient learning at web-scale through semantic deduplication, Amro Abbas+, arXiv'23 SummarySemDeDupは、事前学習モデルの埋め込みを用いて意味的に重複するデータペアを特定し削除する手法。LAIONのサブセットで50%のデータ削除を実現し、トレーニング時間を半分に短縮。分布外性能も向上し、C4データセットでも効率性を改善。質の高い埋め込みを活用することで、データ削減と学習加速を両立。 Commentopenreview:https://openreview.net/forum?id=IRSesTQUtb¬eId=usQjFYYAZJ #Analysis #NLP #LanguageModel Issue Date: 2025-08-11 [Paper Note] Physics of Language Models: Part 1, Learning Hierarchical Language Structures, Zeyuan Allen-Zhu+, arXiv'23 Summary本研究では、Transformerベースの言語モデルが文脈自由文法(CFG)による再帰的な言語構造推論をどのように行うかを調査。合成CFGを用いて長文を生成し、GPTのようなモデルがCFGの階層を正確に学習・推論できることを示す。モデルの隠れ状態がCFGの構造を捉え、注意パターンが動的プログラミングに類似していることが明らかに。また、絶対位置埋め込みの劣位や均一な注意の効果、エンコーダ専用モデルの限界、構造的ノイズによる堅牢性向上についても考察。 Comment解説:
・1834 #ComputerVision #Controllable #NLP #MulltiModal #TextToImageGeneration Issue Date: 2025-08-07 [Paper Note] Adding Conditional Control to Text-to-Image Diffusion Models, Lvmin Zhang+, arXiv'23 SummaryControlNetは、テキストから画像への拡散モデルに空間的な条件制御を追加するためのニューラルネットワークアーキテクチャであり、事前学習済みのエンコーディング層を再利用して多様な条件制御を学習します。ゼロ畳み込みを用いてパラメータを徐々に増加させ、有害なノイズの影響を軽減します。Stable Diffusionを用いて様々な条件制御をテストし、小規模および大規模データセットに対して堅牢性を示しました。ControlNetは画像拡散モデルの制御における広範な応用の可能性を示唆しています。 CommentControlNet論文 #RecommenderSystems #Transformer #VariationalAutoEncoder #NeurIPS #read-later #Admin'sPick #ColdStart #Encoder-Decoder #SemanticID Issue Date: 2025-07-28 [Paper Note] Recommender Systems with Generative Retrieval, Shashank Rajput+, NeurIPS'23 Summary新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを用いて次のアイテムを予測するTransformerベースのモデルを訓練。これにより、従来のレコメンダーシステムを大幅に上回る性能を達成し、過去の対話履歴がないアイテムに対しても改善された検索性能を示す。 Commentopenreview:https://openreview.net/forum?id=BJ0fQUU32wSemantic IDを提案した研究アイテムを意味的な情報を保持したdiscrete tokenのタプル(=Semantic ID)で表現し、encoder-decoderでNext ItemのSemantic IDを生成するタスクに落としこむことで推薦する。SemanticIDの作成方法は後で読んで理解したい。
 #EfficiencyImprovement #NLP #LanguageModel #ACL #Parallelism Issue Date: 2025-05-16 Sequence Parallelism: Long Sequence Training from System Perspective, Li+, ACL'23 Comment入力系列をチャンクに分割して、デバイスごとに担当するチャンクを決めることで原理上無限の長さの系列を扱えるようにした並列化手法。系列をデバイス間で横断する場合attention scoreをどのように計算するかが課題になるが、そのためにRing Self attentionと呼ばれるアルゴリズムを提案している模様。また、MLPブロックとMulti Head Attentonブロックの計算も、BatchSize Sequence Lengthの大きさが、それぞれ32Hidden Size, 16Attention Head size of Attention Headよりも大きくなった場合に、Tensor Parallelismよりもメモリ効率が良くなるらしい。
・1184
を参照のこと。 #MachineLearning #NLP #LanguageModel #Hallucination #NeurIPS #read-later #ActivationSteering/ITI #Probing #Trustfulness #Admin'sPick Issue Date: 2025-05-09 Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23 SummaryInference-Time Intervention (ITI)を提案し、LLMsの真実性を向上させる技術を紹介。ITIは推論中にモデルの活性化を調整し、LLaMAモデルの性能をTruthfulQAベンチマークで大幅に改善。Alpacaモデルでは真実性が32.5%から65.1%に向上。真実性と有用性のトレードオフを特定し、介入の強度を調整する方法を示す。ITIは低コストでデータ効率が高く、数百の例で真実の方向性を特定可能。LLMsが虚偽を生成しつつも真実の内部表現を持つ可能性を示唆。 CommentInference Time Interventionを提案した研究。Attention Headに対して線形プロービング[^1]を実施し、真実性に関連するであろうHeadをtopKで特定できるようにし、headの出力に対し真実性を高める方向性のベクトルvを推論時に加算することで(=intervention)、モデルの真実性を高める。vは線形プロービングによって学習された重みを使う手法と、正答と誤答の活性化の平均ベクトルを計算しその差分をvとする方法の二種類がある。後者の方が性能が良い。topKを求める際には、線形プロービングをしたモデルのvalidation setでの性能から決める。Kとαはハイパーパラメータである。
[^1]: headのrepresentationを入力として受け取り、線形モデルを学習し、線形モデルの2値分類性能を見ることでheadがどの程度、プロービングの学習に使ったデータに関する情報を保持しているかを測定する手法
日本語解説スライド:https://www.docswell.com/s/DeepLearning2023/Z38P8D-2024-06-20-131813p1これは相当汎用的に使えそうな話だから役に立ちそう #ComputerVision #NLP #Transformer #MulltiModal #SpeechProcessing #Architecture #Normalization Issue Date: 2025-04-19 Foundation Transformers, Hongyu Wang+, PMLR'23 Summary言語、視覚、音声、マルチモーダルにおけるモデルアーキテクチャの収束が進む中、異なる実装の「Transformers」が使用されている。汎用モデリングのために、安定性を持つFoundation Transformerの開発が提唱され、Magnetoという新しいTransformer変種が紹介される。Sub-LayerNormと理論に基づく初期化戦略を用いることで、さまざまなアプリケーションにおいて優れたパフォーマンスと安定性を示した。 Commentマルチモーダルなモデルなモデルの事前学習において、PostLNはvision encodingにおいてsub-optimalで、PreLNはtext encodingにおいてsub-optimalであることが先行研究で示されており、マルタモーダルを単一のアーキテクチャで、高性能、かつ学習の安定性な高く、try and error無しで適用できる基盤となるアーキテクチャが必要というモチベーションで提案された手法。具体的には、Sub-LayerNorm(Sub-LN)と呼ばれる、self attentionとFFN部分に追加のLayerNormを適用するアーキテクチャと、DeepNetを踏襲しLayer数が非常に大きい場合でも学習が安定するような重みの初期化方法を理論的に分析し提案している。
具体的には、Sub-LNの場合、LayerNormを
・SelfAttention計算におけるQKVを求めるためのinput Xのprojectionの前とAttentionの出力projectionの前
・FFNでの各Linear Layerの前
に適用し、
初期化をする際には、FFNのW, およびself-attentionのV_projと出力のout_projの初期化をγ(=sqrt(log(2N))によってスケーリングする方法を提案している模様。
・1900 #ComputerVision #Transformer #ImageSegmentation #FoundationModel Issue Date: 2025-04-11 Segment Anything, Alexander Kirillov+, arXiv'23 SummarySegment Anything (SA)プロジェクトは、画像セグメンテーションの新しいタスク、モデル、データセットを提案し、1億以上のマスクを含む1,100万のプライバシー尊重した画像からなる最大のセグメンテーションデータセットを構築しました。プロンプト可能なモデルはゼロショットで新しい画像分布やタスクに適応でき、評価の結果、ゼロショット性能が高く、従来の監視された結果を上回ることもあります。SAMとSA-1Bデータセットは、研究促進のために公開されています。 CommentSAM論文 #ComputerVision #NLP #LanguageModel #MulltiModal #OpenWeight Issue Date: 2025-04-11 PaLI-3 Vision Language Models: Smaller, Faster, Stronger, Xi Chen+, arXiv'23 SummaryPaLI-3は、従来のモデルに比べて10倍小型で高速な視覚言語モデル(VLM)であり、特にローカリゼーションや視覚的テキスト理解において優れた性能を示す。SigLIPベースのPaLIは、20億パラメータにスケールアップされ、多言語クロスモーダル検索で新たな最先端を達成。50億パラメータのPaLI-3は、VLMの研究を再燃させることを期待されている。 CommentOpenReview:https://openreview.net/forum?id=JpyWPfzu0b
実験的に素晴らしい性能が実現されていることは認められつつも
・比較対象がSigLIPのみでより広範な比較実験と分析が必要なこと
・BackboneモデルをContrastive Learningすること自体の有用性は既に知られており、新規性に乏しいこと
としてICLR'24にRejectされている #NLP #Dataset #LanguageModel #LLMAgent #SoftwareEngineering Issue Date: 2025-04-02 SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, arXiv'23 SummarySWE-benchは、12の人気Pythonリポジトリから得られた2,294のソフトウェアエンジニアリング問題を評価するフレームワークで、言語モデルがコードベースを編集して問題を解決する能力を測定します。評価の結果、最先端の商用モデルや微調整されたモデルSWE-Llamaも最も単純な問題しか解決できず、Claude 2はわずか1.96%の問題を解決するにとどまりました。SWE-benchは、より実用的で知的な言語モデルへの進展を示しています。 Commentソフトウェアエージェントの最もpopularなベンチマーク
主にpythonライブラリに関するリポジトリに基づいて構築されている。
https://www.swebench.com/ #Survey #MachineLearning #Dataset #Distillation Issue Date: 2025-03-25 Dataset Distillation: A Comprehensive Review, Ruonan Yu+, arXiv'23 Summaryデータセット蒸留(DD)は、深層学習における膨大なデータのストレージやプライバシーの問題を軽減する手法であり、合成サンプルを含む小さなデータセットを生成することで、元のデータセットと同等の性能を持つモデルをトレーニング可能にする。本論文では、DDの進展と応用をレビューし、全体的なアルゴリズムフレームワークを提案、既存手法の分類と理論的相互関係を議論し、DDの課題と今後の研究方向を展望する。 Comment訓練データセット中の知識を蒸留し、オリジナルデータよりも少量のデータで同等の学習効果を得るDataset Distillationに関するSurvey。
Takeawayとしては、データが制限された環境下では、repetitionは上限4回までが効果的(コスパが良い)であり(左図)、小さいモデルを複数エポック訓練する方が固定されたBudgetの中で低いlossを達成できる右図)。
学習データの半分をコードにしても性能の劣化はなく、様々なタスクの性能が向上しパフォーマンスの分散も小さくなる、といったことが挙げられるようだ。
2. LLMsは複雑な数式(e.g. 多項式, 微分方程式)を解くことができない
3. LLMsはiterationを表現するのが非常に非効率
の3点を解決するために、外部のインタプリタに演算処理を委譲するPoTを提案。PoTでは、言語モデルにreasoning stepsをpython programで出力させ、演算部分をPython Interpreterに実施させる。
中身を全然読んでいる時間はないので、図には重要な情報が詰まっていると信じ、図を読み解いていく。時間がある時に中身も読みたい。。。
LLM-basedなRecSysでは、NLPにおけるLLMの使い方(元々はT5で提案)と同様に、様々なレコメンド関係タスクを、テキスト生成タスクに落とし込み学習することができる。
RecSysのLiteratureとしては、最初はコンテンツベースと協調フィルタリングから始まり、(グラフベースドな推薦, Matrix Factorization, Factorization Machinesなどが間にあって)、その後MLP, RNN, CNN, AutoEncoderなどの様々なDeep Neural Network(DNN)を活用した手法や、BERT4RecなどのProbabilistic Language Models(PLM)を用いた手法にシフトしていき、現在LLM-basedなRecSysの時代に到達した、との流れである。
LLM-basedな手法では、pretrainingの段階からEncoder-basedなモデルの場合はMLM、Decoder-basedな手法ではNext Token Predictionによってデータセットで事前学習する方法もあれば、フルパラメータチューニングやPEFT(LoRAなど)によるSFTによるアプローチもあるようである。
推薦タスクは、推薦するアイテムIDを生成するようなタスクの場合は、異なるアイテムID空間に基づくデータセットの間では転移ができないので、SFTをしないとなかなかうまくいかないと気がしている。また、その場合はアイテムIDの推薦以外のタスクも同時に実施したい場合は、事前学習済みのパラメータが固定されるPEFT手法の方が安全策になるかなぁ、という気がしている(破壊的忘却が怖いので)。特はたとえば、アイテムIDを生成するだけでなく、その推薦理由を生成できるのはとても良いことだなあと感じる(良い時代、感)。
また、PromptingによるRecSysの流れも図解されているが、In-Context Learningのほかに、Prompt Tuning(softとhardの両方)、Instruction Tuningも同じ図に含まれている。個人的にはPrompt TuningはPEFTの一種であり、Instruction TuningはSFTの一種なので、一つ上の図に含意される話なのでは?という気がするが、論文中ではどのような立て付けで記述されているのだろうか。
どちらかというと、Promptingの話であれば、zero-few-many shotや、各種CoTの話を含めるのが自然な気がするのだが。
下図はPromptingによる手法を表にまとめたもの。Finetuningベースの手法が別表にまとめられていたが、研究の数としてはこちらの方が多そうに見える。が、性能的にはどの程度が達成されるのだろうか。直感的には、アイテムを推薦するようなタスクでは、Promptingでは性能が出にくいような印象がある。なぜなら、事前学習済みのLLMはアイテムIDのトークン列とアイテムの特徴に関する知識がないので。これをFinetuningしないのであればICLで賄うことになると思うのだが、果たしてどこまでできるだろうか…。興味がある。
(図は論文より引用) #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering, Siriwardhana+, TACL'23, 2023.01 SummaryRAG-end2endは、ODQAにおけるドメイン適応のためにRAGのリトリーバーとジェネレーターを共同訓練する新しいアプローチを提案。外部知識ベースを更新し、補助的な訓練信号を導入することで、ドメイン特化型知識を強化。COVID-19、ニュース、会話のデータセットで評価し、元のRAGモデルよりも性能が向上。研究はオープンソースとして公開。 #Pretraining #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #MoE(Mixture-of-Experts) #PostTraining Issue Date: 2024-11-25 Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR'23 Summaryスパース活性化モデルは、計算コストを抑えつつ密なモデルの代替として注目されているが、依然として多くのデータを必要とし、ゼロからのトレーニングは高コストである。本研究では、密なチェックポイントからスパース活性化Mixture-of-Expertsモデルを初期化する「スパースアップサイクリング」を提案。これにより、初期の密な事前トレーニングのコストを約50%再利用し、SuperGLUEやImageNetで密なモデルを大幅に上回る性能を示した。また、アップサイクリングされたモデルは、ゼロからトレーニングされたスパースモデルよりも優れた結果を得た。 Comment斜め読みしかできていないが、Mixture-of-Expertsを用いたモデルをSFT/Pretrainingする際に、既存のcheckpointの重みを活用することでより効率的かつ性能向上する方法を提案。MoE LayerのMLPを全て既存のcheckpointにおけるMLPの重みをコピーして初期化する。Routerはスクラッチから学習する。
継続事前学習においては、同じ学習時間の中でDense Layerを用いるベースラインと比較してでより高い性能を獲得。
Figure2で継続事前学習したモデルに対して、フルパラメータのFinetuningをした場合でもUpcyclingは効果がある(Figure3)。
特にPretrainingではUpcyclingを用いたモデルの性能に、通常のMoEをスクラッチから学習したモデルが追いつくのに時間がかかるとのこと。特に図右側の言語タスクでは、120%の学習時間が追いつくために必要だった。
Sparse Upcycingと、Dense tilingによる手法(warm start; 元のモデルに既存の層を複製して新しい層を追加する方法)、元のモデルをそれぞれ継続事前学習すると、最も高い性能を獲得している。
(すごい斜め読みなのでちょっも自信なし、、、) #MachineTranslation #NLP #LanguageModel Issue Date: 2024-11-20 Prompting Large Language Model for Machine Translation: A Case Study, Biao Zhang+, arXiv'23 Summary機械翻訳におけるプロンプティングの研究を体系的に行い、プロンプトテンプレートやデモ例の選択に影響を与える要因を検討。GLM-130Bを用いた実験により、プロンプト例の数と質が翻訳に重要であること、意味的類似性などの特徴がパフォーマンスと相関するが強くないこと、単言語データからの擬似平行プロンプト例が翻訳を改善する可能性があること、他の設定からの知識転送がパフォーマンス向上に寄与することを示した。プロンプティングの課題についても議論。 Commentzero-shotでMTを行うときに、改行の有無や、少しのpromptingの違いでCOMETスコアが大幅に変わることを示している。
モデルはGLM-130BをINT4で量子化したモデルで実験している。
興味深いが、この知見を一般化して全てのLLMに適用できるか?と言われると、そうはならない気がする。他のモデルで検証したら傾向はおそらく変わるであろう(という意味でおそらく論文のタイトルにもCase Studyと記述されているのかなあ)。
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #ACL Issue Date: 2024-11-11 Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23 Summary本研究では、ゼロショット密な検索システムの構築において、仮想文書埋め込み(HyDE)を提案。クエリに基づき、指示に従う言語モデルが仮想文書を生成し、教師なしで学習されたエンコーダがこれを埋め込みベクトルに変換。実際のコーパスに基づく類似文書を取得することで、誤った詳細をフィルタリング。実験結果では、HyDEが最先端の密な検索器Contrieverを上回り、様々なタスクと言語で強力なパフォーマンスを示した。 #ComputerVision #LanguageModel #Zero/FewShotPrompting #Self-SupervisedLearning Issue Date: 2024-10-07 SINC: Self-Supervised In-Context Learning for Vision-Language Tasks, Yi-Syuan Chen+, N_A, ICCV'23 Summary自己教師あり文脈内学習(SINC)フレームワークを提案し、大規模言語モデルに依存せずに文脈内学習を実現。特別に調整されたデモンストレーションを用いたメタモデルが、視覚と言語のタスクで少数ショット設定において勾配ベースの手法を上回る性能を示す。SINCは文脈内学習の利点を探求し、重要な要素を明らかにする。 #Pretraining #NLP #LanguageModel #MulltiModal #ICLR Issue Date: 2024-09-26 UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23 Summary本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 CommentOpenReview:https://openreview.net/forum?id=6ruVLB727MC[R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを持つMoD (Mixture of Denoisers)を提案
モデルのスケールが大きくなると、inferenceのlatencyが遅くなり、計算コストが大きくなりすぎて実用的でないので、小さいパラメータで素早いinference実現したいよね、というモチベーション。
そのために、SlidingWindowAttentionとGroupQueryAttention 1271 を活用している。
より小さいパラメータ数でLlama2を様々なタスクでoutperformし
Instruction Tuningを実施したモデルは、13BモデルよりもChatbotArenaで高いElo Rateを獲得した。
コンテキスト長は8192 #DocumentSummarization #NaturalLanguageGeneration #NLP #Dataset #LanguageModel #Annotation Issue Date: 2024-05-15 Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, N_A, arXiv'23 SummaryLLMsの成功の理由を理解するために、異なる事前学習方法、プロンプト、およびモデルスケールにわたる10つのLLMsに対する人間の評価を行った。その結果、モデルサイズではなく、指示の調整がLLMのゼロショット要約能力の鍵であることがわかった。また、LLMsの要約は人間の執筆した要約と同等と判断された。 Comment・ニュース記事の高品質な要約を人間に作成してもらい、gpt-3.5を用いてLLM-basedな要約も生成
・annotatorにそれぞれの要約の品質をスコアリングさせたデータセットを作成 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention Issue Date: 2024-04-07 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N_A, arXiv'23 SummaryMulti-query attention(MQA)は、単一のkey-value headのみを使用しており、デコーダーの推論を劇的に高速化しています。ただし、MQAは品質の低下を引き起こす可能性があり、さらには、より速い推論のためだけに別個のモデルをトレーニングすることが望ましくない場合もあります。既存のマルチヘッド言語モデルのチェックポイントを、オリジナルの事前トレーニング計量の5%を使用してMQAを持つモデルにアップトレーニングするためのレシピを提案し、さらに、複数のkey-value headを使用するマルチクエリアテンションの一般化であるグループ化クエリアテンション(GQA)を紹介します。アップトレーニングされたGQAが、MQAと同等の速度でマルチヘッドアテンションに匹敵する品質を達成することを示しています。 Comment通常のMulti-Head AttentionがQKVが1対1対応なのに対し、Multi Query Attention (MQA) 1272 は全てのQに対してKVを共有する。一方、GQAはグループごとにKVを共有する点で異なる。MQAは大幅にInfeerence` speedが改善するが、精度が劣化する問題があった。この研究では通常のMulti-Head Attentionに対して、オリジナルの事前学習に対して追加の5%の計算量でGQAモデルを学習する手法を提案している。
Main Result. Multi-Head Attentionに対して、inference timeが大幅に改善しているが、Multi-Query Attentionよりも高い性能を維持している。
Issue Date: 2024-03-05 QTSumm: Query-Focused Summarization over Tabular Data, Yilun Zhao+, N_A, EMNLP'23 Summary与えられた表に対して人間らしい推論と分析を行い、カスタマイズされた要約を生成するための新しいクエリに焦点を当てた表の要約タスクを定義し、QTSummという新しいベンチマークを導入。実験結果と手動分析により、新しいタスクが表からテキスト生成において重要な課題を提起していることが明らかになります。 ReFactorという新しいアプローチを提案し、生成された事実をモデルの入力に連結することでベースラインを改善できることを示しています。 CommentRAGでテーブル情報を扱う際に役立ちそうRadev論文 Issue Date: 2024-03-05 Explanation Selection Using Unlabeled Data for Chain-of-Thought Prompting, Xi Ye+, N_A, EMNLP'23 Summary最近の研究では、大規模言語モデルを使用してテキスト推論タスクで強力なパフォーマンスを達成する方法が提案されています。本研究では、ブラックボックスの方法を使用して説明を組み込んだプロンプトを最適化するアプローチに焦点を当てています。leave-one-outスキームを使用して候補の説明セットを生成し、二段階フレームワークを使用してこれらの説明を効果的に組み合わせます。実験結果では、プロキシメトリクスが真の精度と相関し、クラウドワーカーの注釈や単純な検索戦略よりも効果的にプロンプトを改善できることが示されました。 Issue Date: 2024-02-15 The Consensus Game: Language Model Generation via Equilibrium Search, Athul Paul Jacob+, N_A, arXiv'23 SummaryLMsを使った質問応答やテキスト生成タスクにおいて、生成的または識別的な手法を組み合わせることで一貫したLM予測を得る新しいアプローチが提案された。このアプローチは、言語モデルのデコーディングをゲーム理論的な連続シグナリングゲームとして捉え、EQUILIBRIUM-RANKINGアルゴリズムを導入することで、既存の手法よりも一貫性とパフォーマンスを向上させることが示された。 #NaturalLanguageGeneration #NLP #LanguageModel #Explanation #Supervised-FineTuning (SFT) #Evaluation #EMNLP #PostTraining Issue Date: 2024-01-25 INSTRUCTSCORE: Explainable Text Generation Evaluation with Finegrained Feedback, Wenda Xu+, N_A, EMNLP'23 Summary自動的な言語生成の品質評価には説明可能なメトリクスが必要であるが、既存のメトリクスはその判定を説明したり欠陥とスコアを関連付けることができない。そこで、InstructScoreという新しいメトリクスを提案し、人間の指示とGPT-4の知識を活用してテキストの評価と診断レポートを生成する。さまざまな生成タスクでInstructScoreを評価し、他のメトリクスを上回る性能を示した。驚くべきことに、InstructScoreは人間の評価データなしで最先端のメトリクスと同等の性能を達成する。 Comment伝統的なNLGの性能指標の解釈性が低いことを主張する研究
・CoTを利用して、生成されたテキストの品質を評価する手法を提案している。
・タスクのIntroductionと、評価のCriteriaをプロンプトに仕込むだけで、自動的にLLMに評価ステップに関するCoTを生成させ、最終的にフォームを埋める形式でスコアをテキストとして生成させ評価を実施する。最終的に、各スコアの生成確率によるweighted-sumによって、最終スコアを決定する。
Scoringの問題点
たとえば、1-5のdiscreteなスコアを直接LLMにoutputさせると、下記のような問題が生じる:
1. ある一つのスコアが支配的になってしまい、スコアの分散が無く、人間の評価との相関が低くなる
2. LLMは小数を出力するよう指示しても、大抵の場合整数を出力するため、多くのテキストの評価値が同一となり、生成されたテキストの細かな差異を評価に取り入れることができない。
上記を解決するため、下記のように、スコアトークンの生成確率の重みづけ和をとることで、最終的なスコアを算出している。
・SummEval 984 データと、Topical-Chat, QAGSデータの3つのベンチマークで評価を実施した。タスクとしては、要約と対話のresponse generationのデータとなる。
・モデルはGPT-3.5 (text-davinci-003), GPT-4を利用した
・gpt3.5利用時は、temperatureは0に設定し、GPT-4はトークンの生成確率を返さないので、`n=20, temperature=1, top_p=1`とし、20回の生成結果からトークンの出現確率を算出した。
評価結果
G-EVALがbaselineをoutperformし、特にGPT4を利用した場合に性能が高い。GPTScoreを利用した場合に、モデルを何を使用したのかが書かれていない。Appendixに記述されているのだろうか。
Analysis
G-EvalがLLMが生成したテキストを好んで高いスコアを付与してしまうか?
・人間に品質の高いニュース記事要約を書かせ、アノテータにGPTが生成した要約を比較させたデータ (1304) を用いて検証
・その結果、基本的にGPTが生成した要約に対して、G-EVAL4が高いスコアを付与する傾向にあることがわかった。
・原因1: 1304で指摘されている通り、人間が記述した要約とLLMが記述した要約を区別するタスクは、inter-annotator agreementは`0.07`であり、極端に低く、人間でも困難なタスクであるため。
・原因2: LLMは生成時と評価時に、共通したコンセプトをモデル内部で共有している可能性が高く、これがLLMが生成した要約を高く評価するバイアスをかけた
CoTの影響
・SummEvalデータにおいて、CoTの有無による性能の差を検証した結果、CoTを導入した場合により高いcorrelationを獲得した。特に、Fluencyへの影響が大きい。
Probability Normalizationによる影響
・probabilityによるnormalizationを導入したことで、kendall tauが減少した。この理由は、probabilityが導入されていない場合は多くの引き分けを生み出す。一方、kendall tauは、concordant / discordantペアの数によって決定されるが、引き分けの場合はどちらにもカウントされず、kendall tauの値を押し上げる効果がある。このため、これはモデルの真の性能を反映していない。
・一方、probabilityを導入すると、より細かいな連続的なスコアを獲得することができ、これはspearman-correlationの向上に反映されている。
モデルサイズによる影響
・基本的に大きいサイズの方が高いcorrelationを示す。特に、consistencyやrelevanceといった、複雑な評価タスクではその差が顕著である。
・一方モデルサイズが小さい方が性能が良い観点(engagingness, groundedness)なども存在した。 Issue Date: 2023-12-29 Some things are more CRINGE than others: Preference Optimization with the Pairwise Cringe Loss, Jing Xu+, N_A, arXiv'23 Summary一般的な言語モデルのトレーニングでは、ペアワイズの選好による整列がよく使われます。しかし、バイナリフィードバックの方法もあります。この研究では、既存のバイナリフィードバック手法をペアワイズ選好の設定に拡張し、高いパフォーマンスを示すことを示します。この手法は実装が簡単で効率的であり、最先端の選好最適化アルゴリズムよりも優れた性能を発揮します。 CommentDPO, PPOをoutperformする新たなAlignment手法。MetaのJason Weston氏
元ツイート: https://x.com/jaseweston/status/1740546297235464446?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q後で読む
(画像は元ツイートより引用)
(部分的にしか読めていないが…)
RealtimeQAと呼ばれるweeklyで直近のニュースに対するQuestionを発表することで構築されるデータセットのうち、2023.03.17--2023.08.04のデータを収集し、ScrambledSentenaeRecovery(ScrRec)とScrambleQuestionAnswering(ScrQA)の評価データを生成している。
完全にランダムに単語の文字をscramble(RS)すると、FalconとLlama2では元のテキストをゼロショットでは再構築できないことが分かる。FewShotではFalconであれば少し解けるようになる。一方、OpenAIのモデル、特にGPT4, GPT3.5-turboではゼロショットでもにり再構築ができている。
ScrQAについては、ランダムにscrambleした場合でもMultipleChoiceQuestionなので(RPGと呼ばれるAccの相対的なgainを評価するメトリックを提案している)正解はできている。
最初の文字だけを残す場合(KF)最初と最後の文字を残す場合(KFL」については、残す文字が増えるほどどちらのタスクも性能が上がり、最初の文字だけがあればOpenSourceLLMでも(ゼロショットでも)かなり元のテキストの再構築ができるようになっている。また、QAも性能が向上している。完全にランダムに文字を入れ替えたら完全に無理ゲーなのでは、、、、と思ってしまうのだが、FalconでFewshotの場合は一部解けているようだ…。果たしてどういうことなのか…(大文字小文字が保持されたままなのがヒントになっている…?)Appendixに考察がありそうだがまだ読めていない。
(追記)
文全体でランダムに文字を入れ替えているのかと勘違いしていたが、実際には”ある単語の中だけでランダムに入れ替え”だった。これなら原理上はいけると思われる。 Issue Date: 2023-12-04 Beyond ChatBots: ExploreLLM for Structured Thoughts and Personalized Model Responses, Xiao Ma+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLM)を使用したチャットボットの開発について述べられています。特に、探索的なタスクや意味理解のタスクにおいて、LLMを活用することでユーザーの認知負荷を軽減し、より個別化された応答を生成することができると述べられています。また、ExploreLLMを使用することで、ユーザーが高レベルの好みを持った個別化された応答を簡単に生成できることも示唆されています。この研究は、自然言語とグラフィカルユーザーインターフェースの統合により、チャットボットの形式を超えたLLMとの対話が可能な未来を示しています。 Issue Date: 2023-12-04 COFFEE: Counterfactual Fairness for Personalized Text Generation in Explainable Recommendation, Nan Wang+, N_A, EMNLP'23 Summary個別化されたテキスト生成(PTG)における公平性についての研究。ユーザーの書き込みテキストにはバイアスがあり、それがモデルのトレーニングに影響を与える可能性がある。このバイアスは、ユーザーの保護された属性に関連してテキストを生成する際の不公平な扱いを引き起こす可能性がある。公平性を促進するためのフレームワークを提案し、実験と評価によりその効果を示す。 #NLP #Transformer Issue Date: 2023-12-04 Pushdown Layers: Encoding Recursive Structure in Transformer Language Models, Shikhar Murty+, N_A, EMNLP'23 Summary本研究では、再帰構造をうまく捉えるために新しい自己注意層であるPushdown Layersを導入しました。Pushdown Layersは、再帰状態をモデル化するためにスタックテープを使用し、トークンごとの推定深度を追跡します。このモデルは、構文的な一般化を改善し、サンプル効率を向上させることができます。さらに、Pushdown Layersは標準の自己注意の代替としても使用でき、GLUEテキスト分類タスクでも改善を実現しました。 #ComputerVision #NLP #GenerativeAI #MulltiModal Issue Date: 2023-12-01 SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction, Xinyuan Chen+, N_A, arXiv'23 Summary本研究では、ビデオ生成において連続した長いビデオを生成するためのジェネレーティブなトランジションと予測に焦点を当てたモデルSEINEを提案する。SEINEはテキストの説明に基づいてトランジションを生成し、一貫性と視覚的品質を確保した長いビデオを生成する。さらに、提案手法は他のタスクにも拡張可能であり、徹底的な実験によりその有効性が検証されている。 Commenthttps://huggingface.co/spaces/Vchitect/SEINE
画像 + テキストpromptで、動画を生成するデモ #InformationRetrieval #Dataset #MulltiModal Issue Date: 2023-12-01 UniIR: Training and Benchmarking Universal Multimodal Information Retrievers, Cong Wei+, N_A, arXiv'23 Summary従来の情報検索モデルは一様な形式を前提としているため、異なる情報検索の要求に対応できない。そこで、UniIRという統一された指示に基づくマルチモーダルリトリーバーを提案する。UniIRは異なるリトリーバルタスクを処理できるように設計され、10のマルチモーダルIRデータセットでトレーニングされる。実験結果はUniIRの汎化能力を示し、M-BEIRというマルチモーダルリトリーバルベンチマークも構築された。 Comment後で読む(画像は元ツイートより
元ツイート: https://x.com/congwei1230/status/1730307767469068476?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q Issue Date: 2023-11-27 Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities, AJ Piergiovanni+, N_A, arXiv'23 Summary異なるモダリティ(ビデオ、音声、テキスト)を組み合わせるマルチモーダル学習の課題に取り組むため、本研究ではモダリティごとに個別の自己回帰モデルを使用するアプローチを提案する。提案手法では、時間に同期したモダリティ(音声とビデオ)と順序付けられたコンテキストモダリティを別々に処理するMirasol3Bモデルを使用する。また、ビデオと音声の長いシーケンスに対処するために、シーケンスをスニペットに分割し、Combinerメカニズムを使用して特徴を結合する。この手法は、マルチモーダルベンチマークで最先端の性能を発揮し、高い計算要求に対処し、時間的な依存関係をモデリングすることができる。 #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2023-11-23 Exponentially Faster Language Modelling, Peter Belcak+, N_A, arXiv'23 SummaryUltraFastBERTは、推論時にわずか0.3%のニューロンしか使用せず、同等の性能を発揮することができる言語モデルです。UltraFastBERTは、高速フィードフォワードネットワーク(FFF)を使用して、効率的な実装を提供します。最適化されたベースラインの実装に比べて78倍の高速化を実現し、バッチ処理された推論に対しては40倍の高速化を実現します。トレーニングコード、ベンチマークのセットアップ、およびモデルの重みも公開されています。 #PEFT(Adaptor/LoRA) Issue Date: 2023-11-23 MultiLoRA: Democratizing LoRA for Better Multi-Task Learning, Yiming Wang+, N_A, arXiv'23 SummaryLoRAは、LLMsを効率的に適応させる手法であり、ChatGPTのようなモデルを複数のタスクに適用することが求められている。しかし、LoRAは複雑なマルチタスクシナリオでの適応性能に制限がある。そこで、本研究ではMultiLoRAという手法を提案し、LoRAの制約を緩和する。MultiLoRAは、LoRAモジュールをスケーリングし、パラメータの依存性を減らすことで、バランスの取れたユニタリ部分空間を得る。実験結果では、わずかな追加パラメータでMultiLoRAが優れたパフォーマンスを示し、上位特異ベクトルへの依存性が低下していることが確認された。 #ComputerVision #NLP #LanguageModel #AutomaticPromptEngineering Issue Date: 2023-11-23 NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation, Shachar Rosenman+, N_A, arXiv'23 Summary本研究では、テキストから画像への生成モデルの品質を向上させるための適応型フレームワークNeuroPromptsを提案します。このフレームワークは、事前学習された言語モデルを使用して制約付きテキストデコーディングを行い、人間のプロンプトエンジニアが生成するものに類似したプロンプトを生成します。これにより、高品質なテキストから画像への生成が可能となり、ユーザーはスタイルの特徴を制御できます。また、大規模な人間エンジニアリングされたプロンプトのデータセットを使用した実験により、当アプローチが自動的に品質の高いプロンプトを生成し、優れた画像品質を実現することを示しました。 #ComputerVision #ImageSegmentation #Prompting #In-ContextLearning Issue Date: 2023-11-23 Visual In-Context Prompting, Feng Li+, N_A, arXiv'23 Summary本研究では、ビジョン領域における汎用的なビジュアルインコンテキストプロンプティングフレームワークを提案します。エンコーダーデコーダーアーキテクチャを使用し、さまざまなプロンプトをサポートするプロンプトエンコーダーを開発しました。さらに、任意の数の参照画像セグメントをコンテキストとして受け取るように拡張しました。実験結果から、提案手法が非凡な参照および一般的なセグメンテーション能力を引き出し、競争力のあるパフォーマンスを示すことがわかりました。 CommentImage Segmentationには、ユーザが与えたプロンプトと共通のコンセプトを持つすべてのオブジェクトをセグメンテーションするタスクと、ユーザの入力の特定のオブジェクトのみをセグメンテーションするタスクがある。従来は個別のタスクごとに、特定の入力方法(Visual Prompt, Image Prompt)を前提とした手法や、個々のタスクを実施できるがIn-Context Promptしかサポートしていない手法しかなかったが、この研究では、Visual Prompt, Image Prompt, In-Context Promptをそれぞれサポートし両タスクを実施できるという位置付けの模様。また、提案手法ではストローク、点、ボックスといったユーザの画像に対する描画に基づくPromptingをサポートし、Promptingにおける参照セグメント数も任意の数指定できるとのこと。
https://x.com/ylecun/status/1727707519470977311?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Meta-FAIR, Meta-GenAI, HuggingFace, AutoGPTによる研究。人間は92%正解できるが、GPT4でも15%しか正解できないQAベンチマーク。解くために推論やマルチモダリティの処理、ブラウジング、ツールに対する習熟などの基本的な能力を必要とする実世界のQAとのこと。
で言及されているLLM Agentの評価で最も有名なベンチマークな模様データセット: https://huggingface.co/datasets/gaia-benchmark/GAIA #NLP #Alignment Issue Date: 2023-11-21 Unbalanced Optimal Transport for Unbalanced Word Alignment, Yuki Arase+, N_A, arXiv'23 Summary単一言語の単語アライメントにおいて、null alignmentという現象は重要であり、不均衡な単語アライメントを実現するために最適輸送(OT)のファミリーが有効であることを示している。教師あり・教師なしの設定での包括的な実験により、OTベースのアライメント手法が最新の手法と競争力があることが示されている。 Comment最適輸送で爆速でモノリンガルの単語アライメントがとれるらしい
実装:https://github.com/yukiar/OTAlign単語のアライメント先がない(null alignment)、one-to-oneの関係ではなく、one-to-many, many-to-manyのアライメントが必要な問題を(おそらく; もしかしたらnull alignmentだけかも)Unbalancedな単語アライメント問題と呼び、この課題に対して最適輸送が有効なアプローチであることを示しているっぽい
I believe that System 2 Attention is fundamentally different in concept from prompt engineering techniques such as factual double-checking. Unlike ad-hoc prompt engineering or approaches that enrich the context by adding new facts through prompting, System 2 Attention aims to improve the model’s reasoning ability itself by mitigating the influence of irrelevant tokens. It does so by selectively generating a new context composed only of relevant tokens, in a way that resembles human System 2 thinking—that is, more objective and deliberate reasoning.
From today’s perspective, two years later, I would say that this concept is more closely aligned with what we now refer to as Context Engineering. Thank you. Issue Date: 2023-11-21 Orca 2: Teaching Small Language Models How to Reason, Arindam Mitra+, N_A, arXiv'23 SummaryOrca 1は、豊富なシグナルから学習し、従来のモデルを上回る性能を発揮します。Orca 2では、小さな言語モデルの推論能力を向上させるために異なる解決戦略を教えることを目指しています。Orca 2は、さまざまな推論技術を使用し、15のベンチマークで評価されました。Orca 2は、同じサイズのモデルを大幅に上回り、高度な推論能力を持つ複雑なタスクで優れた性能を発揮します。Orca 2はオープンソース化されており、小さな言語モデルの研究を促進します。 #Pretraining #NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-11-21 Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, N_A, arXiv'23 Summary本研究では、言語モデルの内部の隠れ状態を使用して暗黙的な推論を行う手法を提案します。明示的なチェーン・オブ・ソートの推論ステップを生成する代わりに、教師モデルから抽出した暗黙的な推論ステップを使用します。実験により、この手法が以前は解決できなかったタスクを解決できることが示されました。 Commentこれは非常に興味深い話 Issue Date: 2023-11-20 SelfEval: Leveraging the discriminative nature of generative models for evaluation, Sai Saketh Rambhatla+, N_A, arXiv'23 Summaryこの研究では、テキストから画像を生成するモデルを逆転させることで、自動的にテキスト-画像理解能力を評価する方法を提案しています。提案手法であるSelfEvalは、生成モデルを使用して実際の画像の尤度を計算し、生成モデルを直接識別タスクに適用します。SelfEvalは、既存のデータセットを再利用して生成モデルの性能を評価し、他のモデルとの一致度を示す自動評価指標です。さらに、SelfEvalは難しいタスクでの評価やテキストの信頼性の測定にも使用できます。この研究は、拡散モデルの簡単で信頼性の高い自動評価を可能にすることを目指しています。 #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-11-19 Contrastive Chain-of-Thought Prompting, Yew Ken Chia+, N_A, arXiv'23 Summary言語モデルの推論を改善するために、対照的なchain of thoughtアプローチを提案する。このアプローチでは、有効な推論デモンストレーションと無効な推論デモンストレーションの両方を提供し、モデルが推論を進める際にミスを減らすようにガイドする。また、自動的な方法を導入して対照的なデモンストレーションを構築し、汎化性能を向上させる。実験結果から、対照的なchain of thoughtが一般的な改善手法として機能することが示された。 #NLP #LanguageModel #Chain-of-Thought #Prompting #RAG(RetrievalAugmentedGeneration) Issue Date: 2023-11-17 Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models, Wenhao Yu+, N_A, arXiv'23 Summary検索補完言語モデル(RALM)は、外部の知識源を活用して大規模言語モデルの性能を向上させるが、信頼性の問題や知識の不足による誤った回答がある。そこで、Chain-of-Noting(CoN)という新しいアプローチを導入し、RALMの頑健性を向上させることを目指す。CoNは、順次の読み取りノートを生成し、関連性を評価して最終的な回答を形成する。ChatGPTを使用してCoNをトレーニングし、実験結果はCoNを装備したRALMが標準的なRALMを大幅に上回ることを示している。特に、ノイズの多いドキュメントにおいてEMスコアで平均+7.9の改善を達成し、知識範囲外のリアルタイムの質問に対する拒否率で+10.5の改善を達成している。 Comment一番重要な情報がappendixに載っている
CoNによって、ノイズがあった場合にゲインが大きい。
#RecommenderSystems #Transformer Issue Date: 2023-11-13 Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems, Huan Gui+, N_A, arXiv'23 Summary特徴の相互作用を学ぶために、Transformerベースのアーキテクチャを提案する。ウェブスケールのレコメンダーシステムにおいて、特徴の相互作用を手動で作成することは困難であるため、自動的に捉える必要がある。しかし、現在のTransformerアーキテクチャは異種の特徴の相互作用を捉えることができず、サービングレイテンシも高い。そこで、異種の自己注意層を提案し、\textsc{Hiformer}というモデルを紹介する。\textsc{Hiformer}は特徴の相互作用の異種性を考慮し、低ランク近似とモデルの剪定により高速な推論を実現する。オフライン実験結果では、\textsc{Hiformer}モデルの効果と効率が示されており、Google Playの実世界の大規模なアプリランキングモデルにも展開され、主要なエンゲージメントメトリックスを改善した。 Comment推薦システムは、Factorization Machinesあたりから大抵の場合特徴量間の交互作用を頑張って捉えることで精度向上を目指す、という話をしてきている気がするが、これはTransformerを使って交互作用捉えられるようなモデルを考えました、という研究のようである。
self attention部分に工夫がなされており(提案手法は右端)、task tokenとそれぞれのfeatureをconcatしてQKVを求めることで、明示的に交互作用が生まれるような構造にしている。
#RecommenderSystems #LanguageModel Issue Date: 2023-11-10 LightLM: A Lightweight Deep and Narrow Language Model for Generative Recommendation, Kai Mei+, N_A, arXiv'23 Summaryこの論文では、軽量なTransformerベースの言語モデルであるLightLMを提案し、生成型レコメンデーションタスクに特化したモデルを開発しています。LightLMは、モデルの容量を抑えつつも、レコメンデーションの精度と効率を向上させることに成功しています。また、ユーザーとアイテムのIDインデックス化方法として、Spectral Collaborative Indexing(SCI)とGraph Collaborative Indexing(GCI)を提案しています。さらに、アイテム生成時のhallucinationの問題に対処するために、制約付き生成プロセスを導入しています。実験結果は、LightLMが競合ベースラインを上回ることを示しています。 CommentGenerative Recommendationはあまり終えていないのだが、既存のGenerative Recommendationのモデルをより軽量にし、性能を向上させ、存在しないアイテムを生成するのを防止するような手法を提案しました、という話っぽい。
Bayesian Personalized Ranking 28 ベースドなMatrix Factorizationよりは高い性能が出てるっぽい。
#NLP #LanguageModel #Attention Issue Date: 2023-11-10 Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs, Qingru Zhang+, N_A, arXiv'23 SummaryPASTAは、大規模言語モデル(LLMs)において、ユーザーが指定した強調マークのあるテキストを読むことを可能にする手法です。PASTAは、注意の一部を特定し、再重み付けを適用してモデルの注意をユーザーが指定した部分に向けます。実験では、PASTAがLLMの性能を大幅に向上させることが示されています。 Commentユーザがprompt中で強調したいした部分がより考慮されるようにattention weightを調整することで、より応答性能が向上しましたという話っぽい。かなり重要な技術だと思われる。後でしっかり読む。
promptingする際の言語や、statementの事実性の度合い(半分true, 全てfalse等)などで、性能が大きく変わる結果とのこと。
性能を見ると、まだまだ(このprompting方法では)人間の代わりが務まるほどの性能が出ていないことがわかる。また、trueな情報のFactCheckにcontextは効いていそうだが、falseの情報のFactCheckにContextがあまり効いてなさそうに見えるので、なんだかなあ、という感じである。
まず、GPT3,4だけじゃなく、特徴の異なるOpenSourceのLLMを比較に含めてくれないと、前者は何で学習しているか分からないので、学術的に得られる知見はほぼないのではという気が。実務的には役に立つが。
その上で、Promptingをもっとさまざまな方法で検証した方が良いと思う。
たとえば、現在のpromptではラベルを先に出力させた後に理由を述べさせているが、それを逆にしたらどうなるか?(zero-shot CoT)や、4-Shotにしたらどうなるか、SelfConsistencyを利用したらどうなるかなど、promptingの仕方によって傾向が大きく変わると思う。
加えて、Retriever部分もいくつかのバリエーションで試してみても良いのかなと思う。特に、falseの情報を判断する際に役に立つ情報がcontextに含められているのかが気になる。
論文に書いてあるかもしれないが、ちょっとしっかり読む時間はないです!! #Pretraining #NLP #LanguageModel #FoundationModel #Mathematics Issue Date: 2023-10-29 Llemma: An Open Language Model For Mathematics, Zhangir Azerbayev+, N_A, arXiv'23 Summary私たちは、数学のための大規模な言語モデルであるLlemmaを提案します。Llemmaは、Proof-Pile-2と呼ばれるデータセットを用いて事前学習され、MATHベンチマークで他のモデルを上回る性能を示しました。さらに、Llemmaは追加のfine-tuningなしでツールの使用や形式的な定理証明が可能です。アーティファクトも公開されています。 CommentCodeLLaMAを200B tokenの数学テキスト(proof-pile-2データ;論文、数学を含むウェブテキスト、数学のコードが含まれるデータ)で継続的に事前学習することでfoundation modelを構築
約半分のパラメータ数で数学に関する性能でGoogleのMinervaと同等の性能を達成
・dSFT:既存データからpromptをサンプリングし、user,assistantのmulti turnの対話をLLMでシミュレーションしてデータ生成しSFT
・AIF:既存データからpromstをサンプリングし、異なる4つのLLMのレスポンスをGPT4でランクづけしたデータの活用
・dDPO: 既存データからpromptをサンプリングし、ベストなレスポンスとランダムにサンプリングしたレスポンスの活用
人手を一切介していない。
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
CoTはAutoregressiveな言語モデルに対して、コンテキストを自己生成したテキストで利用者の意図した方向性にバイアスをかけて補完させ、
利用者が意図した通りのアウトプットを最終的に得るためのテクニック、だと思っていて、
線形的だろうが非線形的だろうがどっちにしろCoTなのでは。 #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-10-13 Meta-CoT: Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models, Anni Zou+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を使用して、推論のためのチェーン・オブ・ソート(CoT)プロンプトを生成する方法を提案しています。従来のCoTの方法では、一般的なプロンプトや手作業デモンストレーションに依存していましたが、本研究では入力質問のタイプに基づいて自動的にプロンプトを生成するMeta-CoTを提案しています。Meta-CoTは、10のベンチマーク推論タスクで優れたパフォーマンスを示し、SVAMPでは最先端の結果を達成しました。また、分布外データセットでも安定性と汎用性が確認されました。 Comment色々出てきたがなんかもう色々組み合わせれば最強なんじゃね?って気がしてきた。
#NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-10-12 Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N_A, arXiv'23 SummaryStep-Back Promptingは、大規模言語モデル(LLMs)を使用して推論の手順をガイドするシンプルなプロンプティング技術です。この技術により、LLMsは具体的な詳細から高レベルの概念や基本原則を抽象化し、正しい推論経路をたどる能力を向上させることができます。実験により、Step-Back PromptingはSTEM、Knowledge QA、Multi-Hop Reasoningなどのタスクにおいて大幅な性能向上が観察されました。具体的には、MMLU Physics and Chemistryで7%、11%、TimeQAで27%、MuSiQueで7%の性能向上が確認されました。 Commentまた新しいのが出た
#MachineLearning #Regularization Issue Date: 2023-10-11 Why Do We Need Weight Decay in Modern Deep Learning?, Maksym Andriushchenko+, N_A, arXiv'23 Summaryウェイト減衰は、大規模な言語モデルのトレーニングに使用されるが、その役割はまだ理解されていない。本研究では、ウェイト減衰が古典的な正則化とは異なる役割を果たしていることを明らかにし、過パラメータ化されたディープネットワークでの最適化ダイナミクスの変化やSGDの暗黙の正則化の強化方法を示す。また、ウェイト減衰が確率的最適化におけるバイアス-分散トレードオフのバランスを取り、トレーニング損失を低下させる方法も説明する。さらに、ウェイト減衰はbfloat16混合精度トレーニングにおける損失の発散を防ぐ役割も果たす。全体として、ウェイト減衰は明示的な正則化ではなく、トレーニングダイナミクスを変えるものであることが示される。 Comment参考: https://x.com/hillbig/status/1712220940724318657?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWeightDecayは目的関数に普通にL2正則化項を加えることによって実現されるが、深掘りするとこんな効果があるのね #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2023-10-10 RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation, Fangyuan Xu+, N_A, arXiv'23 Summaryドキュメントの要約を生成することで、言語モデルの性能を向上させる手法を提案する。抽出型の圧縮器と抽象型の圧縮器を使用し、LMsの入力に要約を追加して訓練する。実験結果では、圧縮率が6%まで達成され、市販の要約モデルを上回る性能を示した。また、訓練された圧縮器は他のLMsにも転移可能であることが示された。 CommentRetrieval Augmentationをする際に、元文書群を要約して圧縮することで、性能低下を抑えながら最大6%程度まで元文書群を圧縮できた、とのこと。
https://tech.acesinc.co.jp/entry/2023/03/31/121001 #NLP #Dataset #LanguageModel #Alignment #Conversation Issue Date: 2023-10-09 RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models, Zekun Moore Wang+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を使用して役割演技の能力を向上させるためのフレームワークであるRoleLLMを提案しています。RoleLLMは、役割プロファイルの構築、コンテキストベースの指示生成、役割プロンプトによる話し方の模倣、オープンソースモデルの微調整と役割のカスタマイズの4つのステージで構成されています。さらに、RoleBenchと呼ばれる役割演技のためのベンチマークデータセットを作成し、RoleLLaMAとRoleGLMというモデルを開発しました。これにより、役割演技の能力が大幅に向上し、GPT-4と同等の結果を達成しました。 CommentOverview
RoleBench
#ComputerVision #NLP #LanguageModel #QuestionAnswering Issue Date: 2023-10-09 Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N_A, arXiv'23 SummaryLLaVAは、ビジョンと言語のクロスモーダルコネクタであり、データ効率が高く強力な性能を持つことが示されています。CLIP-ViT-L-336pxを使用し、学術タスク指向のVQAデータを追加することで、11のベンチマークで最先端のベースラインを確立しました。13Bのチェックポイントはわずか120万の公開データを使用し、1日で完全なトレーニングを終えます。コードとモデルは公開されます。 Comment画像分析が可能なオープンソースLLMとのこと。Overview
画像生成をできるわけではなく、inputとして画像を扱えるのみ。
#MachineLearning #NLP #Dataset #LanguageModel #LLMAgent #Evaluation #AutoML Issue Date: 2023-10-09 Benchmarking Large Language Models As AI Research Agents, Qian Huang+, N_A, arXiv'23 Summary本研究では、AI研究エージェントを構築し、科学的な実験のタスクを実行するためのベンチマークとしてMLAgentBenchを提案する。エージェントはファイルの読み書きやコードの実行などのアクションを実行し、実験を実行し、結果を分析し、機械学習パイプラインのコードを変更することができる。GPT-4ベースの研究エージェントは多くのタスクで高性能なモデルを実現できるが、成功率は異なる。また、LLMベースの研究エージェントにはいくつかの課題がある。 CommentGPT4がMLモデルをどれだけ自動的に構築できるかを調べた模様。また、ベンチマークデータを作成した模様。結果としては、既存の有名なデータセットでの成功率は90%程度であり、未知のタスク(新たなKaggle Challenge等)では30%程度とのこと。 #NLP #Prompting #AutomaticPromptEngineering Issue Date: 2023-10-09 Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, N_A, arXiv'23 Summary本研究では、Promptbreederという自己参照的な自己改善メカニズムを提案し、大規模言語モデル(LLM)の推論能力を向上させるための汎用的なプロンプト戦略を進化させる方法を示しています。Promptbreederは、LLMが自己参照的な方法で進化する変異プロンプトによって制御され、タスクプロンプトの集団を変異させて改善します。この手法は、算術や常識的な推論のベンチマークだけでなく、ヘイトスピーチ分類などの難しい問題に対しても優れた性能を発揮します。 Comment詳細な解説記事: https://aiboom.net/archives/56319APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…? #NLP #Prompting #AutomaticPromptEngineering Issue Date: 2023-10-09 Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic, Xufeng Zhao+, N_A, arXiv'23 Summary大規模言語モデルの進歩は驚異的だが、多段階の推論には改善の余地がある。大規模言語モデルは知識を持っているが、推論には一貫性がなく、幻覚を示すことがある。そこで、Logical Chain-of-Thought(LogiCoT)というフレームワークを提案し、論理による推論パラダイムの効果を示した。 Commentまーた新しいX of Thoughtが出た。必要そうなら読む。 #Survey #LanguageModel #Alignment Issue Date: 2023-10-09 Large Language Model Alignment: A Survey, Tianhao Shen+, N_A, arXiv'23 Summary近年、大規模言語モデル(LLMs)の進歩が注目されていますが、その潜在能力と同時に懸念もあります。本研究では、LLMsのアライメントに関する既存の研究と新たな提案を包括的に探求し、モデルの解釈可能性や敵対的攻撃への脆弱性などの問題も議論します。さらに、LLMsのアライメントを評価するためのベンチマークと評価手法を提案し、将来の研究の方向性を考察します。この調査は、研究者とAIアライメント研究コミュニティとの連携を促進することを目指しています。 CommentLLMのalignmentに関するサーベイ。
事前学習されたLLMがKGから有益な知識を学習することを支援する手法を提案。
元ツイート: https://arxiv.org/abs/2309.15427
しっかり論文を読んでいないが、freezeしたLLMがあった時に、KGから求めたGraph Neural Promptを元のテキストと組み合わせて、新たなLLMへの入力を生成し利用する手法な模様。
Graph Neural Promptingでは、Multiple choice QAが入力された時に、その問題文や選択肢に含まれるエンティティから、KGのサブグラフを抽出し、そこから関連性のある事実や構造情報をエンコードし、Graph Neural Promptを獲得する。そのために、GNNに基づいたアーキテクチャに、いくつかの工夫を施してエンコードをする模様。
著者ツイート: https://x.com/owainevans_uk/status/1705285631520407821?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。
また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。
このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。関連:
・1923 #NeuralNetwork #MachineLearning #Grokking Issue Date: 2023-09-30 Explaining grokking through circuit efficiency, Vikrant Varma+, N_A, arXiv'23 Summaryグロッキングとは、完璧なトレーニング精度を持つネットワークでも一般化が悪い現象のことである。この現象は、タスクが一般化する解と記憶する解の両方を許容する場合に起こると考えられている。一般化する解は学習が遅く、効率的であり、同じパラメータノルムでより大きなロジットを生成する。一方、記憶回路はトレーニングデータセットが大きくなるにつれて非効率になるが、一般化回路はそうではないと仮説が立てられている。これは、記憶と一般化が同じくらい効率的な臨界データセットサイズが存在することを示唆している。さらに、グロッキングに関して4つの新しい予測が立てられ、それらが確認され、説明が支持される重要な証拠が提供されている。また、グロッキング以外の2つの新しい現象も示されており、それはアングロッキングとセミグロッキングである。アングロッキングは完璧なテスト精度から低いテスト精度に逆戻りする現象であり、セミグロッキングは完璧なテスト精度ではなく部分的なテスト精度への遅れた一般化を示す現象である。 CommentGrokkingがいつ、なぜ発生するかを説明する理論を示した研究。
理由としては、最初はmemorizationを学習していくのだが、ある時点から一般化回路であるGenに切り替わる。これが切り替わる理由としては、memorizationよりも、genの方がlossが小さくなるから、とのこと。これはより大規模なデータセットで顕著。Grokkingが最初に報告された研究は 524 #NLP #Dataset #LanguageModel #InstructionTuning #NumericReasoning #Mathematics Issue Date: 2023-09-30 MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning, Xiang Yue+, N_A, arXiv'23 SummaryMAmmoTHは、数学の問題解決に特化した大規模言語モデルであり、厳密にキュレーションされた教育データセットで訓練されています。このモデルは、CoTとPoTのハイブリッドな根拠を提供し、さまざまな数学の分野を包括的にカバーしています。MAmmoTHは、既存のオープンソースモデルを大幅に上回り、特にMATHデータセットで高い精度を示しています。この研究は、多様な問題のカバレッジとハイブリッドな根拠の使用の重要性を強調しています。 Comment9つのmath reasoningが必要なデータセットで13-29%のgainでSoTAを達成。
260kの根拠情報を含むMath Instructデータでチューニングされたモデル。
project page: https://tiger-ai-lab.github.io/MAmmoTH/ #Survey #NLP #LanguageModel #Hallucination Issue Date: 2023-09-30 A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, N_A, arXiv'23 Summary本研究では、大規模ファウンデーションモデル(LFMs)におけるホールシネーションの問題に焦点を当て、その現象を分類し、評価基準を確立するとともに、既存の戦略を検討し、今後の研究の方向性についても議論しています。 CommentHallucinationを現象ごとに分類し、Hallucinationの程度の評価をする指標や、Hallucinationを軽減するための既存手法についてまとめられているらしい。
#General #NLP #LanguageModel #Alignment Issue Date: 2023-09-30 RAIN: Your Language Models Can Align Themselves without Finetuning, Yuhui Li+, N_A, arXiv'23 Summary本研究では、追加のデータなしで凍結された大規模言語モデル(LLMs)を整列させる方法を探求しました。自己評価と巻き戻しメカニズムを統合することで、LLMsは自己ブースティングを通じて人間の好みと一致する応答を生成することができることを発見しました。RAINという新しい推論手法を導入し、追加のデータやパラメータの更新を必要とせずにAIの安全性を確保します。実験結果は、RAINの効果を示しており、LLaMA 30Bデータセットでは無害率を向上させ、Vicuna 33Bデータセットでは攻撃成功率を減少させることができました。 Commentトークンのsetで構成されるtree上を探索し、出力が無害とself-evaluationされるまで、巻き戻しと前方生成を繰り返し、有害なトークンsetの重みを動的に減らすことでalignmentを実現する。モデルの追加のfinetuning等は不要。
self-evaluationでは下記のようなpromptを利用しているが、このpromptを変更することでこちら側の意図したとおりに出力のアライメントをとることができると思われる。非常に汎用性の高い手法のように見える。
#NLP #Dataset #LanguageModel #StructuredData Issue Date: 2023-09-30 Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?, Xiangru Tang+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)の能力を評価し、構造に注意したファインチューニング手法を提案します。さらに、Struc-Benchというデータセットを使用して、複雑な構造化データ生成のパフォーマンスを評価します。実験の結果、提案手法は他の評価されたLLMsよりも優れた性能を示しました。また、モデルの能力マップを提示し、LLMsの弱点と将来の研究の方向性を示唆しています。詳細はhttps://github.com/gersteinlab/Struc-Benchを参照してください。 CommentFormatに関する情報を含むデータでInstruction TuningすることでFormatCoT(フォーマットに関する情報のCoT)を実現している模様。ざっくりしか論文を読んでいないが詳細な情報があまり書かれていない印象で、ちょっとなんともいえない。
#EfficiencyImprovement #MachineLearning #NLP #Dataset #QuestionAnswering #Supervised-FineTuning (SFT) #LongSequence #PEFT(Adaptor/LoRA) Issue Date: 2023-09-30 LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv'23 Summary本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment概要
context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になってしまう。LongLoRAでは、perplexityを通常のFinetuningと同等に抑えつつ、VRAM消費量もLoRAと同等、かつより小さな計算量でFinetuningを実現している。
手法概要
attentionをcontext length全体で計算するとinput長の二乗の計算量がかかるため、contextをいくつかのグループに分割しグループごとにattentionを計算することで計算量削減。さらに、グループ間のattentionの間の依存関係を捉えるために、グループをshiftさせて計算したものと最終的に組み合わせている。また、embedding, normalization layerもtrainableにしている。
#DocumentSummarization #NaturalLanguageGeneration #NLP #LanguageModel Issue Date: 2023-09-17 From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting, Griffin Adams+, N_A, arXiv'23 Summary要約は詳細でエンティティ中心的でありながら、理解しやすくすることが困難です。この課題を解決するために、私たちは「密度の連鎖」(CoD)プロンプトを使用して、GPT-4の要約を生成します。CoDによって生成された要約は抽象的であり、リードバイアスが少なく、人間に好まれます。また、情報量と読みやすさのトレードオフが存在することも示されました。CoD要約は無料で利用できます。 Comment論文中のprompt例。InformativeなEntityのCoverageを増やすようにイテレーションを回し、各Entityに関する情報(前ステップで不足している情報は補足しながら)を具体的に記述するように要約を生成する。
人間が好むEntityのDensityにはある程度の閾値がある模様(でもこれは人や用途によって閾値が違うようねとは思う)。
人手評価とGPT4による5-scale の評価を実施している。定性的な考察としては、主題と直接的に関係ないEntityの詳細を述べるようになっても人間には好まれない(右例)ことが述べられている。
#NLP #LanguageModel #Hallucination #Factuality Issue Date: 2023-09-13 DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models, Yung-Sung Chuang+, N_A, arXiv'23 Summary我々は、事前学習済みの大規模言語モデル(LLMs)における幻覚を軽減するためのシンプルなデコーディング戦略を提案する。このアプローチは、ロジットの差異を対比することで次のトークンの分布を得るもので、事実知識をより明確に示し、誤った事実の生成を減らすことができる。このアプローチは、複数の選択課題やオープンエンドの生成課題において真実性を向上させることができることが示されている。 Comment【以下、WIP状態の論文を読んでいるため今後内容が変化する可能性あり】
概要
Transformer Layerにおいて、factual informationが特定のレイヤーに局所化するという現象を観測しており、それを活用しよりFactual Consistencyのある生成をします、という研究
あるテキストを生成するときの単語の生成確率の分布を可視化。final layer (N=32だと思われる)との間のJensen-shanon Divergence (JSD) で可視化している。が、図を見るとJSDの値域は[0, 1]のはずなのにこれを逸脱しているので一体どういう計算をしているのか。。。
図の説明としては論文中では2つのパターンがあると言及しており
1. 重要な固有表現や日付(Wole Soyinka, 1986など; Factual Knowledgeが必要なもの)は、higher layerでも高い値となっており、higher-layerにおいてpredictionの内容を変えている(重要な情報がここでinjectionされている)
2. 機能語や、questionからの単語のコピー(Nigerian, Nobel Prize など)のような "easy" なtokenは既にmiddle of layersで既にJSDの値が小さく、early layerの時点で出力することが既に決定されている
手法概要
ここからの考察としては、重要な事実に関する情報はfinal layerの方で分布が変化する傾向にあり、低layerの方ではそうではないぽいので、final layerと分布が似ているがFactual Informationがまだあまり顕著に生成確率が高くなっていないlayer(pre mature layer)との対比をとることで、生成されるべきFactual Informationがわかるのではないか、という前提の元提案手法が組まれている。手法としては、final layerとのJSDが最大となるようなlayerを一つ選択する、というものになっているが、果たしてこの選択方法で前述の気持ちが実現できているのか?という気は少しする。
概要
LLMを利用して最適化問題を解くためのフレームワークを提案したという話。論文中では、linear regressionや巡回セールスマン問題に適用している。また、応用例としてPrompt Engineeringに利用している。
これにより、Prompt Engineeringが最適か問題に落とし込まれ、自動的なprompt engineeringによって、`Let's think step by step.` よりも良いプロンプトが見つかりましたという話。
手法概要
全体としての枠組み。meta-promptをinputとし、LLMがobjective functionに対するsolutionを生成する。生成されたsolutionとスコアがmeta-promptに代入され、次のoptimizationが走る。これを繰り返す。
Meta promptの例
#Survey #LanguageModel #InstructionTuning Issue Date: 2023-09-05 Instruction Tuning for Large Language Models: A Survey, Shengyu Zhang+, N_A, arXiv'23 Summaryこの論文では、instruction tuning(IT)という技術について調査しています。ITは、大規模言語モデル(LLMs)をさらにトレーニングするための方法であり、ユーザーの指示に従うことを目的としています。本研究では、ITの方法論やデータセットの構築、トレーニング方法などについて調査し、指示の生成やデータセットのサイズなどがITの結果に与える影響を分析します。また、ITの潜在的な問題や批判、現在の不足点についても指摘し、今後の研究の方向性を提案します。 Comment主要なモデルやデータセットの作り方など幅広くまとまっている
ランダムにソートしたり、平均取ったりしても、そもそもの正解に常にバイアスがかかっているので、
結局バイアスがかかった結果しか出ないのでは、と思ってしまう。
そうなると、有効なのはone vs. restみたいに、全部該当選択肢に対してyes/noで答えさせてそれを集約させる、みたいなアプローチの方が良いかもしれない。 #NLP #Dataset #LanguageModel #LLMAgent #Evaluation Issue Date: 2023-08-27 AgentBench: Evaluating LLMs as Agents, Xiao Liu+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)をエージェントとして評価するための多次元の進化するベンチマーク「AgentBench」を提案しています。AgentBenchは、8つの異なる環境でマルチターンのオープンエンドの生成設定を提供し、LLMの推論と意思決定能力を評価します。25のLLMsに対するテストでは、商用LLMsは強力な能力を示していますが、オープンソースの競合他社との性能には差があります。AgentBenchのデータセット、環境、および評価パッケージは、GitHubで公開されています。 CommentエージェントとしてのLLMの推論能力と意思決定能力を評価するためのベンチマークを提案。
トップの商用LLMとOpenSource LLMの間に大きな性能差があることを示した。 #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-08-22 Large Language Model Guided Tree-of-Thought, Jieyi Long, N_A, arXiv'23 Summaryこの論文では、Tree-of-Thought(ToT)フレームワークを紹介し、自己回帰型の大規模言語モデル(LLM)の問題解決能力を向上させる新しいアプローチを提案しています。ToTは、人間の思考方法に触発された技術であり、複雑な推論タスクを解決するためにツリー状の思考プロセスを使用します。提案手法は、LLMにプロンプターエージェント、チェッカーモジュール、メモリモジュール、およびToTコントローラーなどの追加モジュールを組み込むことで実現されます。実験結果は、ToTフレームワークがSudokuパズルの解決成功率を大幅に向上させることを示しています。 #NLP #LanguageModel #Prompting Issue Date: 2023-08-22 Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding, Yuxi Xie+, N_A, arXiv'23 Summary私たちは、大規模言語モデル(LLMs)を使用して、推論の品質と多様性を向上させるための効果的なプロンプティングアプローチを提案しました。自己評価によるガイド付き確率的ビームサーチを使用して、GSM8K、AQuA、およびStrategyQAのベンチマークで高い精度を達成しました。また、論理の失敗を特定し、一貫性と堅牢性を向上させることもできました。詳細なコードはGitHubで公開されています。 Comment
#NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-08-22 Graph of Thoughts: Solving Elaborate Problems with Large Language Models, Maciej Besta+, N_A, arXiv'23 Summary私たちは、Graph of Thoughts(GoT)というフレームワークを紹介しました。これは、大規模言語モデル(LLMs)のプロンプティング能力を進化させるもので、任意のグラフとしてモデル化できることが特徴です。GoTは、思考の組み合わせやネットワーク全体の本質の抽出、思考の強化などを可能にします。さまざまなタスクで最先端の手法に比べて利点を提供し、LLMの推論を人間の思考に近づけることができます。 CommentChain of Thought 551
=> Self-consistency 558
=> Thought Decomposition 1013
=> Tree of Thoughts 684 Tree of Thought 1015
=> Graph of Thought Issue Date: 2023-08-22 LLM As DBA, Xuanhe Zhou+, N_A, arXiv'23 Summaryデータベース管理者の役割は重要ですが、大量のデータベースを管理するのは難しいです。最近の大規模言語モデル(LLMs)は、データベース管理に役立つ可能性があります。この研究では、LLMベースのデータベース管理者「D-Bot」を提案します。D-Botはデータベースのメンテナンス経験を学習し、適切なアドバイスを提供します。具体的には、知識の検出、原因分析、複数のLLMの協調診断などを行います。予備実験では、D-Botが効果的に原因を診断できることが示されています。 Comment
これにより高品質なinstruction following LLMの構築が可能手法概要
実際に、他の同サイズのinstruct tuningデータセットを上回る。
指示を予測するモデルは、今回はLLaMAをfinetuningしたモデルを用いており、予測と呼称しているが指示はgenerationされる。 #NLP #LanguageModel #PersonalizedGeneration Issue Date: 2023-08-18 Teach LLMs to Personalize -- An Approach inspired by Writing Education, Cheng Li+, N_A, arXiv'23 Summary個別化されたテキスト生成において、大規模言語モデル(LLMs)を使用した一般的なアプローチを提案する。教育の執筆をベースに、多段階かつマルチタスクのフレームワークを開発し、検索、ランキング、要約、統合、生成のステージで構成される個別化されたテキスト生成へのアプローチを採用する。さらに、マルチタスク設定を導入してモデルの生成能力を向上させる。3つの公開データセットでの評価結果は、他のベースラインに比べて大幅な改善を示している。 Comment研究の目的としては、ユーザが現在執筆しているdocumentのwriting支援 Issue Date: 2023-08-16 Epic-Sounds: A Large-scale Dataset of Actions That Sound, Jaesung Huh+, N_A, arXiv'23 SummaryEPIC-SOUNDSは、エゴセントリックなビデオのオーディオストリーム内の時間的範囲とクラスラベルをキャプチャした大規模なデータセットです。注釈者がオーディオセグメントに時間的なラベルを付け、アクションを説明する注釈パイプラインを提案しています。オーディオのみのラベルの重要性と現在のモデルの制約を強調するために、2つのオーディオ認識モデルを訓練および評価しました。データセットには78.4kのカテゴリ分けされたオーディブルなイベントとアクションのセグメントが含まれています。 #LanguageModel #MultitaskLearning #Zero/FewShotPrompting #Supervised-FineTuning (SFT) #CrossLingual #ACL #Generalization Issue Date: 2023-08-16 Crosslingual Generalization through Multitask Finetuning, Niklas Muennighoff+, N_A, ACL'23 Summaryマルチタスクプロンプトフィネチューニング(MTF)は、大規模な言語モデルが新しいタスクに汎化するのに役立つことが示されています。この研究では、マルチリンガルBLOOMとmT5モデルを使用してMTFを実施し、英語のプロンプトを使用して英語および非英語のタスクにフィネチューニングすることで、タスクの汎化が可能であることを示しました。さらに、機械翻訳されたプロンプトを使用してマルチリンガルなタスクにフィネチューニングすることも調査し、モデルのゼロショットの汎化能力を示しました。また、46言語の教師ありデータセットのコンポジットであるxP3も紹介されています。 Comment英語タスクを英語でpromptingしてLLMをFinetuningすると、他の言語(ただし、事前学習で利用したコーパスに出現する言語に限る)で汎化し性能が向上することを示した模様。
 #DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Evaluation #LM-based #Coherence Issue Date: 2023-08-13 DiscoScore: Evaluating Text Generation with BERT and Discourse Coherence, Wei Zhao+, N_A, EACL'23 Summary本研究では、文章の一貫性を評価するための新しい指標であるDiscoScoreを紹介します。DiscoScoreはCentering理論に基づいており、BERTを使用して談話の一貫性をモデル化します。実験の結果、DiscoScoreは他の指標よりも人間の評価との相関が高く、システムレベルでの評価でも優れた結果を示しました。さらに、DiscoScoreの重要性とその優位性についても説明されています。 #DocumentSummarization #NLP #Evaluation #Reference-free Issue Date: 2023-08-13 RISE: Leveraging Retrieval Techniques for Summarization Evaluation, David Uthus+, N_A, Findings of ACL'23 Summary自動要約の評価は困難であり、従来のアプローチでは人間の評価には及ばない。そこで、私たちはRISEという新しいアプローチを提案する。RISEは情報検索の技術を活用し、ゴールドリファレンスの要約がなくても要約を評価することができる。RISEは特に評価用のリファレンス要約が利用できない新しいデータセットに適しており、SummEvalベンチマークでの実験結果から、RISEは過去のアプローチと比較して人間の評価と高い相関を示している。また、RISEはデータ効率性と言語間の汎用性も示している。 Comment概要
Dual-Encoderを用いて、ソースドキュメントとシステム要約をエンコードし、dot productをとることでスコアを得る手法。モデルの訓練は、Contrastive Learningで行い、既存データセットのソースと参照要約のペアを正例とみなし、In Batch trainingする。
分類
Reference-free, Model-based, ソース依存で、BARTScore 960 とは異なり、文書要約データを用いて学習するため、要約の評価に特化している点が特徴。
モデル
Contrastive Learning
Contrastive Learningを用い、hard negativeを用いたvariantも検証する。また、訓練データとして3種類のパターンを検証する:
1. in-domain data: 文書要約データを用いて訓練し、ターゲットタスクでどれだけの性能を発揮するかを見る
2. out-of-domain data: 文書要約以外のデータを用いて訓練し、どれだけ新しいドメインにモデルがtransferできるかを検証する
3. in-and-out-domain data: 両方やる
ハードネガティブの生成
Lexical Negatives, Model Negatives, 双方の組み合わせの3種類を用いてハードネガティブを生成する。
Lexical Negatives
参照要約を拡張することによって生成する。目的は、もともとの参照要約と比較して、poor summaryを生成することにある。Data Augmentationとして、以下の方法を試した:
・Swapping noun entities: 要約中のエンティティを、ソース中のエンティティンとランダムでスワップ
・Shuffling words: 要約中の単語をランダムにシャッフル
・Dropping words: 要約中の単語をランダムに削除
・Dropping characters: 要約中の文字をランダムに削除
・Swapping antonyms: 要約中の単語を対義語で置換
Model Negatives
データセットの中から負例を抽出する。目的は、参照要約と類似しているが、負例となるサンプルを見つけること。これを実現するために、まずRISE modelをデータセットでfinetuningし、それぞれのソースドキュメントの要約に対して、類似した要約をマイニングする。すべてのドキュメントと要約をエンコードし、top-nの最も類似した要約を見つけ、これをハードネガティブとして、再度モデルを訓練する。
両者の組み合わせ
まずlexical negativesでモデルを訓練し、モデルネガティブの抽出に活用する。抽出したモデルネガティブを用いて再度モデルを訓練することで、最終的なモデルとする。
実験
学習手法
SummEval 984 を用いて人手評価と比較してどれだけcorrelationがあるかを検証。SummEvalには16種類のモデルのアウトプットに対する、CNN / Daily Mail の100 examplesに対して、品質のアノテーションが付与されている。expert annotationを用いて、Kendall's tauを用いてシステムレベルのcorrelationを計算した。contextが短い場合はT5, 長い場合はLongT5, タスクがマルチリンガルな場合はmT5を用いて訓練した。訓練データとしては
・CNN / Daily Mail
・Multi News
・arXiv
・PubMed
・BigPatent
・SAMSum
・Reddit TIFU
・MLSUM
等を用いた。これによりshort / long contextの両者をカバーできる。CNN / Daily Mail, Reddiit TIFU, Multi-Newsはshort-context, arXiv, PubMed, BigPatent, Multi-News(長文のものを利用)はlonger contextとして利用する。
比較するメトリック
ROUGE, chrF, SMS, BARTScore, SMART, BLEURT, BERTScore, Q^2, T5-ANLI, PRISMと比較した。結果をみると、Consistency, Fluency, Relevanceで他手法よりも高い相関を得た。Averageでは最も高いAverageを獲得した。in-domain dataで訓練した場合は、高い性能を発揮した。our-of-domain(SAMSum; Dialogue要約のデータ)データでも高い性能を得た。
Ablation
ハードネガティブの生成方法
Data Augmentationは、swapping entity nouns, randomly dropping wordsの組み合わせが最も良かった。また、Lexical Negativesは、様々なデータセットで一貫して性能が良かったが、Model NegativesはCNN/DailyMailに対してしか有効ではなかった。これはおそらく、同じタスク(テストデータと同じデータ)でないと、Model Negativesは機能しないことを示唆している。ただし、Model Negativesを入れたら、何もしないよりも性能向上するから、何らかの理由でlexical negativesが生成できない場合はこっち使っても有用である。
Model Size
でかい方が良い。in-domainならBaseでもそれなりの性能だけど、結局LARGEの方が強い。
Datasets
異なるデータセットでもtransferがうまく機能している。驚いたことにデータセットをmixingするとあまりうまくいかず、単体のデータセットで訓練したほうが性能が良い。
LongT5を見ると、T5よりもCorrelationが低く難易度が高い。
最終的に英語の要約を評価をする場合でも、Multilingual(別言語)で訓練しても高いCorrelationを示すこともわかった。
Dataset Size
サンプル数が小さくても有効に働く。しかし、out-domainのデータの場合は、たとえば、512件の場合は性能が低く少しexampleを増やさなければならない。
#DocumentSummarization #NLP #Evaluation #LLM-as-a-Judge Issue Date: 2023-08-13 GPTScore: Evaluate as You Desire, Jinlan Fu+, N_A, arXiv'23 Summary本研究では、生成型AIの評価における課題を解決するために、GPTScoreという評価フレームワークを提案しています。GPTScoreは、生成されたテキストを評価するために、生成型事前学習モデルの新たな能力を活用しています。19の事前学習モデルを探索し、4つのテキスト生成タスクと22の評価項目に対して実験を行いました。結果は、GPTScoreが自然言語の指示だけでテキストの評価を効果的に実現できることを示しています。この評価フレームワークは、注釈付きサンプルの必要性をなくし、カスタマイズされた多面的な評価を実現することができます。 CommentBERTScoreと同様、評価したいテキストの対数尤度で評価している
BERTScoreよりも相関が高く、instructionによって性能が向上することが示されている #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 Large Language Models are Diverse Role-Players for Summarization Evaluation, Ning Wu+, N_A, arXiv'23 Summary本研究では、テキスト要約の評価フレームワークを提案し、生成されたテキストと参照テキストを客観的および主観的な側面から比較することで包括的な評価を行います。具体的には、ロールプレイヤーのプロンプティングメカニズムを使用してテキストの評価をモデル化し、コンテキストベースのプロンプティングメカニズムを導入して動的なロールプレイヤープロファイルを生成します。さらに、バッチプロンプティングに基づいたマルチロールプレイヤープロンプティング技術を使用して複数の評価結果を統合します。実験結果は、提案モデルが競争力があり、人間の評価者と高い一致性を持つことを示しています。 #DocumentSummarization #NLP #Evaluation #Factuality Issue Date: 2023-08-13 ChatGPT as a Factual Inconsistency Evaluator for Text Summarization, Zheheng Luo+, N_A, arXiv'23 Summary事前学習された言語モデルによるテキスト要約の性能向上が注目されているが、生成された要約が元の文書と矛盾することが問題となっている。この問題を解決するために、効果的な事実性評価メトリクスの開発が進められているが、計算複雑性や不確実性の制約があり、人間の判断との一致に限定されている。最近の研究では、大規模言語モデル(LLMs)がテキスト生成と言語理解の両方で優れた性能を示していることがわかっている。本研究では、ChatGPTの事実的な矛盾評価能力を評価し、バイナリエンテイルメント推論、要約ランキング、一貫性評価などのタスクで優れた性能を示した。ただし、ChatGPTには語彙的な類似性の傾向や誤った推論、指示の不適切な理解などの制限があることがわかった。 Issue Date: 2023-08-12 Shepherd: A Critic for Language Model Generation, Tianlu Wang+, N_A, arXiv'23 SummaryShepherdは、言語モデルの改善に関心が高まっている中で、自身の出力を洗練させるための特別に調整された言語モデルです。Shepherdは、多様なエラーを特定し修正案を提供する能力を持ち、高品質なフィードバックデータセットを使用して開発されました。Shepherdは他の既存のモデルと比較して優れた性能を示し、人間の評価でも高い評価を受けています。 #NLP #LanguageModel #Prompting Issue Date: 2023-08-12 Metacognitive Prompting Improves Understanding in Large Language Models, Yuqing Wang+, N_A, arXiv'23 Summary本研究では、LLMsにメタ認知プロンプト(MP)を導入し、人間の内省的な推論プロセスを模倣することで、理解能力を向上させることを目指しています。実験結果は、MPを備えたPaLMが他のモデルに比べて優れたパフォーマンスを示しており、MPが既存のプロンプト手法を上回ることを示しています。この研究は、LLMsの理解能力向上の可能性を示し、人間の内省的な推論を模倣することの利点を強調しています。 CommentCoTより一貫して性能が高いので次のデファクトになる可能性あり
#MachineLearning #NLP #AutoML Issue Date: 2023-08-10 MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks, Lei Zhang+, N_A, arXiv'23 Summary本研究では、機械学習タスクの自動化における人間の知識と機械知能のギャップを埋めるために、新しいフレームワークMLCopilotを提案する。このフレームワークは、最先端のLLMsを使用して新しいMLタスクのソリューションを開発し、既存のMLタスクの経験から学び、効果的に推論して有望な結果を提供することができる。生成されたソリューションは直接使用して競争力のある結果を得ることができる。 Issue Date: 2023-08-08 Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models, Cheng-Yu Hsieh+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を使用して、ツールのドキュメンテーションを提供することで新しいツールを学習する方法を提案しています。デモンストレーションの取得が困難な場合や、バイアスのある使用方法を避けるために、ツールのドキュメンテーションを使用することが有効であることを実験的に示しています。さらに、複数のタスクでツールのドキュメンテーションの利点を強調し、LLMsがツールの機能を再発明する可能性を示しています。 #Tools #NLP #LanguageModel Issue Date: 2023-08-08 ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, N_A, arXiv'23 Summaryオープンソースの大規模言語モデル(LLMs)を使用して、外部ツール(API)の高度なタスクの実行を容易にするためのToolLLMというフレームワークを紹介します。ToolBenchというデータセットを使用して、ツールの使用方法を調整し、DFSDTという決定木を使用して効率的な検索を行います。ToolEvalという自動評価ツールを使用して、ToolLLaMAが高いパフォーマンスを発揮することを示します。さらに、ニューラルAPIリトリーバーを使用して、適切なAPIを推奨します。 Comment16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
GPT-4の判断とhuman expertの判断とのagreementも検証しており、agreementは80%以上を達成している。
#MachineLearning #Optimizer Issue Date: 2023-07-25 DoG is SGD's Best Friend: A Parameter-Free Dynamic Step Size Schedule, Maor Ivgi+, N_A, ICML'23 Summary私たちは、チューニング不要の動的SGDステップサイズの式であるDoGを提案します。DoGは、初期点からの距離と勾配のノルムに基づいてステップサイズを計算し、学習率のパラメータを必要としません。理論的には、DoGの式は確率的凸最適化においてパラメータフリーの収束を保証します。実験的には、DoGのパフォーマンスがチューニングされた学習率を持つSGDに近いことを示し、DoGのバリアントがチューニングされたSGDやAdamを上回ることを示します。PyTorchの実装はhttps://github.com/formll/dogで利用できます。 Comment20 を超える多様なタスクと 8 つのビジョンおよび NLP モデルに対して有効であったシンプルなパラメーターフリーのoptimizer
元ツイート: https://twitter.com/maorivg/status/1683525521471328256?s=46&t=Lt9P4BkmiMDRC7_5EuxhNQ #EfficiencyImprovement #MachineLearning #Prompting Issue Date: 2023-07-24 Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, N_A, arXiv'23 Summary大規模な言語モデル(LLMs)を効果的に使用するために、バッチプロンプティングという手法を提案します。この手法は、LLMが1つのサンプルではなくバッチで推論を行うことを可能にし、トークンコストと時間コストを削減しながらパフォーマンスを維持します。さまざまなデータセットでの実験により、バッチプロンプティングがLLMの推論コストを大幅に削減し、良好なパフォーマンスを達成することが示されました。また、バッチプロンプティングは異なる推論方法にも適用できます。詳細はGitHubのリポジトリで確認できます。 Comment
10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、contextが長ければ長いほど、バッチサイズを大きくした際のパフォーマンスの低下が著しい。 Issue Date: 2023-07-23 Large Language Models as General Pattern Machines, Suvir Mirchandani+, N_A, arXiv'23 Summary事前学習された大規模言語モデル(LLMs)は、複雑なトークンシーケンスを自己回帰的に補完する能力を持っていることが観察された。この能力は、ランダムなトークンからなるシーケンスでも一部保持されることがわかった。この研究では、この能力がロボティクスの問題にどのように適用されるかを調査し、具体的な応用例を示している。ただし、実際のシステムへの展開はまだ困難であるとしている。 Issue Date: 2023-07-23 Will Large-scale Generative Models Corrupt Future Datasets?, Ryuichiro Hataya+, ICCV'23 Summary大規模なテキストから画像への生成モデル(DALL·E 2、Midjourney、StableDiffusionなど)が高品質な画像を生成する一方で、これらの生成画像がコンピュータビジョンモデルの性能に与える影響を検証。汚染をシミュレーションし、生成された画像がImageNetやCOCOデータセットで訓練されたモデルの性能にネガティブな影響を及ぼすことを実証。影響の程度はタスクや生成画像の量に依存する。生成データセットとコードは公開予定。 #NLP #ChatGPT #Evaluation Issue Date: 2023-07-22 How is ChatGPT's behavior changing over time?, Lingjiao Chen+, N_A, arXiv'23 SummaryGPT-3.5とGPT-4は、大規模言語モデル(LLM)のサービスであり、その性能と振る舞いは時間とともに変動することがわかった。例えば、GPT-4は素数の特定に優れていたが、後のバージョンでは低い正答率となった。また、GPT-3.5はGPT-4よりも優れた性能を示した。さらに、GPT-4とGPT-3.5の両方が時間とともに敏感な質問への回答やコード生成でのミスが増えた。この結果から、LLMの品質を継続的に監視する必要性が示唆される。 CommentGPT3.5, GPT4共にfreezeされてないのなら、研究で利用すると結果が再現されないので、研究で使うべきではない。また、知らんうちにいくつかのタスクで勝手に性能低下されたらたまったものではない。 #ComputerVision #NLP #LanguageModel #LLMAgent Issue Date: 2023-07-22 Towards A Unified Agent with Foundation Models, Norman Di Palo+, N_A, arXiv'23 Summary本研究では、言語モデルとビジョン言語モデルを強化学習エージェントに組み込み、効率的な探索や経験データの再利用などの課題に取り組む方法を調査しました。スパースな報酬のロボット操作環境でのテストにおいて、ベースラインに比べて大幅な性能向上を実証し、学習済みのスキルを新しいタスクの解決や人間の専門家のビデオの模倣に活用する方法を示しました。 Comment
PEFTにもある参考: https://twitter.com/hillbig/status/1662946722690236417?s=46&t=TDHYK31QiXKxggPzhZbcAQOpenReview:https://openreview.net/forum?id=OUIFPHEgJU&referrer=%5Bthe%20profile%20of%20Ari%20Holtzman%5D(%2Fprofile%3Fid%3D~Ari_Holtzman1) #ComputerVision #Personalization #DiffusionModel Issue Date: 2023-07-22 FABRIC: Personalizing Diffusion Models with Iterative Feedback, Dimitri von Rütte+, N_A, arXiv'23 Summary本研究では、拡散ベースのテキストから画像への変換モデルに人間のフィードバックを組み込む戦略を提案する。自己注意層を利用したトレーニングフリーなアプローチであるFABRICを提案し、さまざまな拡散モデルに適用可能であることを示す。また、包括的な評価方法を導入し、人間のフィードバックを統合した生成ビジュアルモデルのパフォーマンスを定量化するための堅牢なメカニズムを提供する。徹底的な分析により、反復的なフィードバックの複数のラウンドを通じて生成結果が改善されることを示す。これにより、個別化されたコンテンツ作成やカスタマイズなどの領域に応用が可能となる。 Commentupvote downvoteをフィードバックし、iterativeなmannerでDiffusionモデルの生成結果を改善できる手法。多くのDiffusion based Modelに対して適用可能
デモ: https://huggingface.co/spaces/dvruette/fabric #NLP #LanguageModel #InstructionTuning #Evaluation Issue Date: 2023-07-22 Instruction-following Evaluation through Verbalizer Manipulation, Shiyang Li+, N_A, arXiv'23 Summary本研究では、指示に従う能力を正確に評価するための新しい評価プロトコル「verbalizer manipulation」を提案しています。このプロトコルでは、モデルに異なる程度で一致する言葉を使用してタスクラベルを表現させ、モデルの事前知識に依存する能力を検証します。さまざまなモデルを9つのデータセットで評価し、異なるverbalizerのパフォーマンスによって指示に従う能力が明確に区別されることを示しました。最も困難なverbalizerに対しても、最も強力なモデルでもランダムな推測よりも優れたパフォーマンスを発揮するのは困難であり、指示に従う能力を向上させるために継続的な進歩が必要であることを強調しています。 #ComputerVision #NLP #LanguageModel #SpokenLanguageProcessing #MulltiModal #SpeechProcessing Issue Date: 2023-07-22 Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, N_A, arXiv'23 Summary本研究では、マルチモーダル学習のためのMeta-Transformerというフレームワークを提案しています。このフレームワークは、異なるモダリティの情報を処理し関連付けるための統一されたネットワークを構築することを目指しています。Meta-Transformerは、対応のないデータを使用して12のモダリティ間で統一された学習を行うことができ、テキスト、画像、ポイントクラウド、音声、ビデオなどの基本的なパーセプションから、X線、赤外線、高分光、IMUなどの実用的なアプリケーション、グラフ、表形式、時系列などのデータマイニングまで、幅広いタスクを処理することができます。Meta-Transformerは、トランスフォーマーを用いた統一されたマルチモーダルインテリジェンスの開発に向けた有望な未来を示しています。 Comment12種類のモダリティに対して学習できるTransformerを提案
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/ #NLP #Dataset #LanguageModel #Evaluation #TMLR Issue Date: 2023-07-03 Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, N_A, TMLR'23 Summary言語モデルの能力と制約を理解するために、BIG-benchという新しいベンチマークを導入しました。このベンチマークでは、現在の言語モデルの能力を超えるタスクに焦点を当てています。さまざまなトピックの204のタスクが含まれており、モデルのサイズや性能の比較も行いました。結果として、モデルの性能とキャリブレーションは向上していますが、絶対的な性能は低く、モデル間の性能も似ていることがわかりました。また、スパース性からの利益やタスクの特性についても調査しました。さらに、曖昧な文脈の設定では社会的な偏見が増加することも示されましたが、プロンプトの使用で改善できる可能性もあります。 CommentOpenReview:https://openreview.net/forum?id=uyTL5BvosjBIG-Bench論文。ワードクラウドとキーワード分布を見ると一つの分野に留まらない非常に多様なタスクが含まれることがわかる。
・1662 #MachineLearning #NLP #LanguageModel #LongSequence Issue Date: 2023-07-03 Augmenting Language Models with Long-Term Memory, Weizhi Wang+, N_A, arXiv'23 Summary既存の大規模言語モデル(LLMs)は、入力長の制限により、長い文脈情報を活用できない問題があります。そこで、私たちは「長期記憶を持つ言語モデル(LongMem)」というフレームワークを提案しました。これにより、LLMsは長い履歴を記憶することができます。提案手法は、メモリエンコーダとして凍結されたバックボーンLLMと、適応的な残余サイドネットワークを組み合わせた分離されたネットワークアーキテクチャを使用します。このアーキテクチャにより、長期の過去の文脈を簡単にキャッシュし、利用することができます。実験結果は、LongMemが長い文脈モデリングの難しいベンチマークであるChapterBreakで強力な性能を発揮し、メモリ増強型のコンテキスト内学習で改善を達成することを示しています。提案手法は、言語モデルが長い形式のコンテンツを記憶し利用するのに効果的です。 CommentLLMに長期のhistoryを記憶させることを可能する新たな手法を提案し、既存のstrongな長いcontextを扱えるモデルを上回るパフォーマンスを示した
LLMの急速な発展によって、それらの能力とlimitationを正確にとらえるための様々な新たなmetricsが提案されてきたが、結果的に、新たなモデルが既存のデータセットを廃止に追い込み、常に新たなデータセットを作成する必要が生じている。
近年のBIG-Bench 785 や HELM 786 はこれらの問題に対処するために、増え続ける蓄積された多様なmicro-benchmarkを用いてLLMのパフォーマンスを測定することで対処しているが、データセットの生成とキュレーションに依存したアプローチとなっており、これらはtine-consumingでexpensiveである。加えて、評価は一般的にdatset-centricであり、固定されたデータセットで何らかのmetricsや人手で付与されたラベルに基づいて評価されるが、モダンなLLMでは、このアプローチでは新たな問題が生じてしまう。
・評価データがインターネット上でホスティングされること。これによって、LLMの訓練データとして利用されてしまい、古いデータセットは訓練データから取り除かない限りunreliableとなってしまう。
・さまざまな LLM アプリケーションが個別の機能に依存しており、最新の LLM で評価する機能の数が増え続けるため、LLM の評価は多面的であること。
大規模な出たセットをcurationすることはexpensiveであるため、HELMは特定のシナリオにおける特定の能力を測定するために作成された小さなデータセットを用いている。しかし、より広範なコンテキストや設定でモデルがデプロイするときに、このような評価が適用可能かは定かではない。
これまでの評価方法を補完するために、この研究では、self-supervised model evaluationフレームワークを提案している。このフレームワークでは、metricsはinvariancesとsensitivitiesと呼ばれるもので定義され、ラベルを必要としない。代わりに、self-supervisionのフェーズに介入することでこれらのmetricsを算出する。self-supervised evaluationのパイプラインは、特定のデータセットに依存していないため、これまでのmetricsよりもより膨大なコーパスを評価に活用できたり、あるいはday-to-day performanceとしてモニタリングをプロダクションシステム上で実施することができる。以下Dr. Sebastian Ruschkaのツイートの引用
>We use self-supervised learning to pretrain LLMs (e.g., next-word prediction).
Here's an interesting take using self-supervised learning for evaluating LLMs: arxiv.org/abs//2306.13651
Turns out, there's correlation between self-supervised evaluations & human evaluations.
元ツイート
https://twitter.com/rasbt/status/1679139569327824897?s=46&t=ArwxeDos47eUWfAg7_FRtg
図が非常にわかりやすい Issue Date: 2023-06-16 PEARL: Prompting Large Language Models to Plan and Execute Actions Over Long Documents, Simeng Sun+, N_A, arXiv'23 Summary本研究では、長いドキュメント上の推論を改善するためのPEARLというプロンプティングフレームワークを提案している。PEARLは、アクションマイニング、プランの策定、プランの実行の3つのステージで構成されており、最小限の人間の入力でゼロショットまたはフューショットのLLMsによるプロンプティングによって実装される。PEARLは、QuALITYデータセットの難しいサブセットで評価され、ゼロショットおよびchain-of-thought promptingを上回る性能を発揮した。PEARLは、LLMsを活用して長いドキュメント上の推論を行うための第一歩である。 Issue Date: 2023-06-16 The False Promise of Imitating Proprietary LLMs, Arnav Gudibande+, N_A, arXiv'23 Summary本研究は、ChatGPTなどのプロプライエタリシステムからの出力を使用して、弱いオープンソースモデルを微調整する新興の手法について批判的に分析した。異なるベースモデルサイズ、データソース、および模倣データ量を使用して、ChatGPTを模倣する一連のLMを微調整し、クラウドレーターと標準的なNLPベンチマークを使用してモデルを評価した。結果、模倣モデルはChatGPTのスタイルを模倣するのに熟練しているが、事実性を模倣することができないため、人間のレーターから見逃される可能性があることがわかった。全体的に、より優れたベースLMを開発することが、オープンソースモデルを改善するための最も効果的なアクションだと主張している。 #NLP #Transformer #LLMAgent Issue Date: 2023-06-16 Think Before You Act: Decision Transformers with Internal Working Memory, Jikun Kang+, N_A, arXiv'23 Summary大規模言語モデル(LLM)の性能は、トレーニング中にパラメータに振る舞いを記憶する「忘却現象」によって低下する可能性がある。人間の脳は分散型のメモリストレージを利用しており、忘却現象を軽減している。そこで、我々は、内部作業メモリモジュールを提案し、Atariゲームとメタワールドオブジェクト操作タスクの両方でトレーニング効率と汎化性を向上させることを示した。 Issue Date: 2023-06-16 Lexinvariant Language Models, Qian Huang+, N_A, arXiv'23 Summary本論文では、固定されたトークン埋め込みなしで高性能な言語モデルを実現することが可能かどうかを検証し、lexinvariant言語モデルを提案する。lexinvariant言語モデルは、トークンの共起と繰り返しに完全に依存し、固定されたトークン埋め込みが必要なくなる。実験的には、標準的な言語モデルと同等のperplexityを達成できることを示し、さらに、synthetic in-context reasoning tasksに対して4倍の精度が向上することを示す。 Issue Date: 2023-06-16 Backpack Language Models, John Hewitt+, N_A, arXiv'23 SummaryBackpacksという新しいニューラルアーキテクチャを提案し、語彙内の各単語に対して複数の意味ベクトルを学習し、意味ベクトルを介入することで制御可能なテキスト生成やバイアスの除去ができることを示した。OpenWebTextでトレーニングされたBackpack言語モデルは、語彙の類似性評価で6BパラメータのTransformer LMの単語埋め込みを上回った。 Issue Date: 2023-06-16 Training Socially Aligned Language Models in Simulated Human Society, Ruibo Liu+, N_A, arXiv'23 Issue Date: 2023-06-16 A Closer Look at In-Context Learning under Distribution Shifts, Kartik Ahuja+, N_A, arXiv'23 Summary本研究では、インコンテキスト学習の汎用性と制限を理解するために、線形回帰という単純なタスクを用いて、トランスフォーマーとセットベースのMLPの比較を行った。分布内評価において両モデルがインコンテキスト学習を示すことがわかったが、トランスフォーマーはOLSのパフォーマンスにより近い結果を示し、軽微な分布シフトに対してより強い耐性を示した。ただし、厳しい分布シフトの下では、両モデルのインコンテキスト学習能力が低下することが示された。 #NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-06-16 OlaGPT: Empowering LLMs With Human-like Problem-Solving Abilities, Yuanzhen Xie+, N_A, arXiv'23 Summary本論文では、人間の認知フレームワークを模倣することで、複雑な推論問題を解決するための新しい知的フレームワークであるOlaGPTを提案しています。OlaGPTは、注意、記憶、推論、学習などの異なる認知モジュールを含み、以前の誤りや専門家の意見を動的に参照する学習ユニットを提供しています。また、Chain-of-Thought(COT)テンプレートと包括的な意思決定メカニズムも提案されています。OlaGPTは、複数の推論データセットで厳密に評価され、最先端のベンチマークを上回る優れた性能を示しています。OlaGPTの実装はGitHubで利用可能です。 Issue Date: 2023-06-16 Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models' Reasoning Performance, Yao Fu+, N_A, arXiv'23 Summary本研究では、大規模言語モデルの評価スイートであるChain-of-Thought Hubを提案し、LLMsの進歩を追跡するために挑戦的な推論ベンチマークのスイートを編成することを目的としています。現在の結果は、モデルのスケールが推論能力と相関しており、オープンソースのモデルはまだ遅れていることを示しています。また、LLaMA-65BはGPT-3.5-Turboに近づく可能性があることを示しています。コミュニティがより良いベースモデルの構築とRLHFの探索に重点を置く必要があることを示唆しています。 Issue Date: 2023-06-16 SwiftSage: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks, Bill Yuchen Lin+, N_A, arXiv'23 SummarySwiftSageは、人間の認知の二重プロセス理論に基づいて設計されたエージェントフレームワークであり、行動クローニングと大規模言語モデルのプロンプティングを統合して、複雑な対話型推論タスクにおけるアクションプランニングに優れている。SwiftモジュールとSageモジュールの2つの主要なモジュールを含み、30のタスクにおいて他の手法を大幅に上回り、複雑な現実世界のタスクを解決する効果を示した。 #ComputerVision #Personalization Issue Date: 2023-06-16 Photoswap: Personalized Subject Swapping in Images, Jing Gu+, N_A, arXiv'23 Summary本研究では、Photoswapという新しいアプローチを提案し、既存の画像において個人的な対象物の交換を可能にすることを目的としています。Photoswapは、参照画像から対象物の視覚的な概念を学習し、トレーニングフリーでターゲット画像に交換することができます。実験により、Photoswapが効果的で制御可能であり、ベースライン手法を大幅に上回る人間の評価を得ていることが示されました。Photoswapは、エンターテインメントからプロの編集まで幅広い応用可能性を持っています。 Issue Date: 2023-06-16 Controllable Text-to-Image Generation with GPT-4, Tianjun Zhang+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を使用して、テキストから画像を生成するためのパイプラインを誘導する方法を提案しています。Control-GPTを導入し、GPT-4によって生成されたプログラム的なスケッチを使用して、拡散ベースのテキストから画像へのパイプラインを誘導し、指示に従う能力を向上させます。この研究は、LLMsをコンピュータビジョンタスクのパフォーマンス向上に活用する可能性を示す初めての試みです。 Issue Date: 2023-06-16 KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models, Zhiwei Jia+, N_A, arXiv'23 Summary画像広告の理解は、現実世界のエンティティやシーンテキストの推論を含むため、非常に困難であるが、VLMsの時代において未開拓の分野である。本研究では、事前学習されたVLMsを画像広告の理解に適応するための実用的な課題をベンチマークし、現実世界のエンティティの知識を付加することで、画像広告のマルチモーダル情報を効果的に融合するためのシンプルな特徴適応戦略を提案した。広告業界に広く関連する画像広告の理解により多くの注目が集まることが期待される。 Issue Date: 2023-06-16 Grammar Prompting for Domain-Specific Language Generation with Large Language Models, Bailin Wang+, N_A, arXiv'23 SummaryLLMsは幅広い自然言語タスクを学習できるが、高度に構造化された言語の生成には困難がある。本研究では、文法プロンプティングを使用して、外部の知識やドメイン固有の制約を学習中に使用する方法を探求した。文法プロンプティングは、各デモンストレーション例に特化した文法を付加し、最小限必要な文法で特定の出力例を生成する。実験により、文法プロンプティングが多様なDSL生成タスクで競争力のあるパフォーマンスを発揮できることが示された。 Issue Date: 2023-06-16 Blockwise Parallel Transformer for Long Context Large Models, Hao Liu+, N_A, arXiv'23 Summaryトランスフォーマーの自己注意機構とフィードフォワードネットワークによるメモリ要件の制限を解決するために、ブロックごとの並列トランスフォーマー(BPT)を提案。BPTは、メモリ効率を維持しながらより長い入力シーケンスを処理することができ、徹底的な実験により、言語モデリングや強化学習タスクにおいてパフォーマンスを向上させることが示された。 Issue Date: 2023-06-16 Deliberate then Generate: Enhanced Prompting Framework for Text Generation, Bei Li+, N_A, arXiv'23 Summary本論文では、新しいDeliberate then Generate(DTG)プロンプトフレームワークを提案し、LLMsの自然言語生成タスクにおける成功をさらに促進することを目的としている。DTGは、誤り検出指示と誤りを含む可能性のある候補から構成され、モデルが熟考することを促すことで、最先端のパフォーマンスを達成することができる。20以上のデータセットでの広範な実験により、DTGが既存のプロンプト方法を一貫して上回り、LLMsのプロンプトに関する将来の研究にインスピレーションを与える可能性があることが示された。 Issue Date: 2023-06-16 CodeTF: One-stop Transformer Library for State-of-the-art Code LLM, Nghi D. Q. Bui+, N_A, arXiv'23 Summary本論文では、CodeTFというオープンソースのTransformerベースのライブラリを紹介し、最新のCode LLMsとコードインテリジェンスのためのモジュール設計と拡張可能なフレームワークの原則に従って設計されていることを説明しています。CodeTFは、異なるタイプのモデル、データセット、タスクに対して迅速なアクセスと開発を可能にし、事前学習済みのCode LLMモデルと人気のあるコードベンチマークをサポートしています。また、言語固有のパーサーおよびコード属性を抽出するためのユーティリティ関数などのデータ機能を提供しています。CodeTFは、機械学習/生成AIとソフトウェアエンジニアリングのギャップを埋め、開発者、研究者、実践者にとって包括的なオープンソースのソリューションを提供することを目的としています。 #MachineLearning #Transformer Issue Date: 2023-06-16 Birth of a Transformer: A Memory Viewpoint, Alberto Bietti+, N_A, arXiv'23 Summary大規模言語モデルの内部メカニズムを理解するため、トランスフォーマーがグローバルとコンテキスト固有のbigram分布をどのようにバランスするかを研究。2層トランスフォーマーでの実証的分析により、グローバルbigramの高速な学習と、コンテキスト内のbigramの「誘導ヘッド」メカニズムの遅い発達を示し、重み行列が連想記憶としての役割を強調する。データ分布特性の役割も研究。 Issue Date: 2023-06-16 Brainformers: Trading Simplicity for Efficiency, Yanqi Zhou+, N_A, arXiv'23 Summaryトランスフォーマーの設計選択肢を調査し、異なる順列を持つ複雑なブロックがより効率的であることを発見し、Brainformerという複雑なブロックを開発した。Brainformerは、品質と効率の両方の観点で最新のトランスフォーマーを上回り、トークンあたりのアクティブパラメーター数が80億のモデルは、トレーニング収束が2倍速く、ステップ時間が5倍速いことが示されている。また、ファインチューニングによるSuperGLUEスコアが3%高いことも示している。Brainformerはfewshot評価でも大幅に優れている。 Issue Date: 2023-06-16 StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners, Yonglong Tian+, N_A, arXiv'23 Summary本研究では、テキストから画像を生成するモデルによって生成された合成画像を使用して視覚表現を学習することを調査しました。自己教師あり方法を合成画像に対してトレーニングすることで、実際の画像に匹敵するかそれを上回ることができることを示しました。また、同じテキストプロンプトから生成された複数の画像を互いに正として扱うことで、マルチポジティブコントラスティブ学習手法であるStableRepを開発しました。StableRepによって学習された表現は、SimCLRとCLIPによって学習された表現を上回ります。さらに、20Mの合成画像でトレーニングされたStableRepは、50Mの実際の画像でトレーニングされたCLIPよりも優れた精度を達成します。 #ComputerVision #NLP #Personalization #DiffusionModel #TextToImageGeneration Issue Date: 2023-06-16 ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation, Shaozhe Hao+, N_A, arXiv'23 Summary拡散モデルを用いたパーソナライズされた画像生成において、高速で軽量なプラグインメソッドであるViCoを提案。注目モジュールを導入し、注目ベースのオブジェクトマスクを使用することで、一般的な過学習の劣化を軽減。元の拡散モデルのパラメータを微調整せず、軽量なパラメータトレーニングだけで、最新のモデルと同等またはそれ以上の性能を発揮することができる。 Issue Date: 2023-06-16 Evaluating Language Models for Mathematics through Interactions, Katherine M. Collins+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を評価するための適応可能なプロトタイププラットフォームであるCheckMateを紹介し、数学の学部レベルの証明を支援するアシスタントとして、InstructGPT、ChatGPT、およびGPT-4の3つの言語モデルを評価しました。MathConverseという対話と評価のデータセットを公開し、LLMの生成において正確さと知覚された有用性の間に著しい相違があることなど、他の発見も行いました。対話的評価はこれらのモデルの能力を継続的にナビゲートする有望な方法であること、人間は言語モデルの代数的な誤りに注意を払い、そのために使用すべき場所を見極める必要があることを示しました。 Issue Date: 2023-06-16 Responsible Task Automation: Empowering Large Language Models as Responsible Task Automators, Zhizheng Zhang+, N_A, arXiv'23 Summary本論文では、大規模言語モデル(LLMs)を使用したタスク自動化における責任ある行動の実現可能性、完全性、セキュリティについて探求し、Responsible Task Automation(ResponsibleTA)フレームワークを提案する。具体的には、エグゼキューターのコマンドの実現可能性を予測すること、エグゼキューターの完全性を検証すること、セキュリティを強化することを目的とした3つの強化された機能を備え、2つのパラダイムを提案する。また、ローカルメモリメカニズムを紹介し、UIタスク自動化でResponsibleTAを評価する。 Issue Date: 2023-06-16 Fine-Grained Human Feedback Gives Better Rewards for Language Model Training, Zeqiu Wu+, N_A, arXiv'23 Summary本研究では、言語モデルの望ましくないテキスト生成の問題に対処するために、細かい粒度の人間のフィードバックを使用するFine-Grained RLHFフレームワークを導入しました。このフレームワークは、報酬関数を細かい粒度に設定することで、自動評価と人間の評価の両方で改善されたパフォーマンスをもたらします。また、異なる報酬モデルの組み合わせを使用することで、LMの振る舞いをカスタマイズできることも示しました。 Issue Date: 2023-06-16 The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only, Guilherme Penedo+, N_A, arXiv'23 Summary大規模言語モデルの訓練には、キュレーションされた高品質のコーパスとWebデータが使用されるが、Webデータだけでも強力なモデルを生成できることが示された。RefinedWebデータセットから6000億トークンの抽出と、それに基づく1.3/7.5Bパラメータの言語モデルが公開された。CommonCrawlから5兆トークンを取得できることも示された。 Issue Date: 2023-06-16 InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models, Lichang Chen+, N_A, arXiv'23 SummaryLLMsの指示を最適化するために、オープンソースLLMに適用される低次元のソフトプロンプトを最適化する提案手法であるInstructZeroを紹介。オープンソースLLMを使用してソフトプロンプトを指示に変換し、ブラックボックスLLMに提出してゼロショット評価を行い、パフォーマンスをベイズ最適化に送信して、新しいソフトプロンプトを生成する。VicunaやChatGPTなどのオープンソースLLMとAPIの異なる組み合わせで評価し、SOTA自動指示手法を上回ることを示した。コードとデータはhttps://github.com/Lichang-Chen/InstructZeroで公開されています。 Issue Date: 2023-06-16 Binary and Ternary Natural Language Generation, Zechun Liu+, N_A, arXiv'23 Summary三値および二値ニューラルネットワークを最適化することは困難であるが、重みの統計に基づく量子化と活性化の弾性量子化の混合によって問題に取り組み、要約と機械翻訳の下流タスクで最初の三値および二値Transformerモデルを実証する。三値BARTベースは、CNN/DailyMailベンチマークでR1スコア41を達成し、16倍効率的である。バイナリモデルは、非常に重要なスコア35.6を達成している。機械翻訳においては、WMT16 En-RoベンチマークでBLEUスコア21.7および17.6を達成し、8ビット重みモデルで一致または上回ることができることを示した。 Issue Date: 2023-06-16 Simple and Controllable Music Generation, Jade Copet+, N_A, arXiv'23 Summary本研究では、単一の言語モデルであるMusicGenを紹介し、複数のモデルを連鎖する必要がなくなることで、条件付けられた高品質な音楽サンプルを生成できることを示した。広範な実験評価により、提案手法が標準的なベンチマークよりも優れていることを示し、各コンポーネントの重要性についての削除実験も行った。音楽サンプル、コード、およびモデルは、https://github.com/facebookresearch/audiocraftで入手可能です。 Issue Date: 2023-06-16 Language-Guided Music Recommendation for Video via Prompt Analogies, Daniel McKee+, N_A, arXiv'23 Summary本研究では、音楽選曲のガイド付きで、入力ビデオに対して音楽を推薦する手法を提案する。音楽のテキスト説明が不足している問題に対して、大規模言語モデルから事前にトレーニングされた音楽タガーの出力と人間のテキスト説明を組み合わせたテキスト合成アプローチを提案し、トリモーダルモデルをトレーニングする。評価実験により、従来の手法と同等またはそれ以上の性能を発揮することが示された。 #ComputerVision #NLP #QuestionAnswering #MulltiModal Issue Date: 2023-06-16 AVIS: Autonomous Visual Information Seeking with Large Language Models, Ziniu Hu+, N_A, arXiv'23 Summary本論文では、自律的な情報収集ビジュアル質問応答フレームワークであるAVISを提案する。AVISは、大規模言語モデル(LLM)を活用して外部ツールの利用戦略を動的に決定し、質問に対する回答に必要な不可欠な知識を獲得する。ユーザースタディを実施して収集したデータを用いて、プランナーや推論エンジンを改善し、知識集約型ビジュアル質問応答ベンチマークで最先端の結果を達成することを示している。 Comment
Issue Date: 2023-06-16 WizardCoder: Empowering Code Large Language Models with Evol-Instruct, Ziyang Luo+, N_A, arXiv'23 SummaryCode LLMsにおいて、WizardCoderを導入することで、複雑な指示の微調整を可能にし、4つの主要なコード生成ベンチマークで他のオープンソースのCode LLMsを大幅に上回る優れた能力を示した。さらに、AnthropicのClaudeやGoogleのBardをも上回る性能を発揮し、コード、モデルの重み、およびデータはGitHubで公開されている。 #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2023-06-16 KoLA: Carefully Benchmarking World Knowledge of Large Language Models, Jifan Yu+, N_A, arXiv'23 SummaryLLMの評価を改善するために、KoLAという知識指向のベンチマークを構築した。このベンチマークは、19のタスクをカバーし、Wikipediaと新興コーパスを使用して、知識の幻覚を自動的に評価する独自の自己対照メトリックを含む対照的なシステムを採用している。21のオープンソースと商用のLLMを評価し、KoLAデータセットとオープン参加のリーダーボードは、LLMや知識関連システムの開発の参考資料として継続的に更新される。 Issue Date: 2023-06-16 STUDY: Socially Aware Temporally Casual Decoder Recommender Systems, Eltayeb Ahmed+, N_A, arXiv'23 Summary本研究では、膨大なデータ量に直面する中で、ソーシャルネットワーク情報を利用したレコメンドシステムの提案を行いました。提案手法であるSTUDYは、修正されたトランスフォーマーデコーダーネットワークを使用して、ソーシャルネットワークグラフ上で隣接するユーザーグループ全体に対して共同推論を行います。学校教育コンテンツの設定で、教室の構造を使用してソーシャルネットワークを定義し、提案手法をテストした結果、ソーシャルおよびシーケンシャルな方法を上回り、単一の均質ネットワークの設計の簡素さを維持しました。また、アブレーション研究を実施して、ユーザーの行動の類似性を効果的にモデル化するソーシャルネットワーク構造を活用することがモデルの成功に重要であることがわかりました。 Issue Date: 2023-06-16 GeneCIS: A Benchmark for General Conditional Image Similarity, Sagar Vaze+, N_A, arXiv'23 Summary本論文では、モデルがさまざまな類似性条件に動的に適応できる能力を測定するGeneCISベンチマークを提案し、既存の方法をスケーリングすることは有益ではないことを示唆しています。また、既存の画像キャプションデータセットから情報を自動的にマイニングすることに基づくシンプルでスケーラブルなソリューションを提案し、関連する画像検索ベンチマークのゼロショットパフォーマンスを向上させました。GeneCISのベースラインに比べて大幅な改善をもたらし、MIT-Statesでの最新の教師ありモデルを上回る性能を発揮しています。 Issue Date: 2023-06-16 WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences, Xiao Liu+, N_A, arXiv'23 SummaryWebGLMは、GLMに基づくWeb拡張型質問応答システムであり、LLMによるリトリーバー、ブートストラップされたジェネレーター、および人間の嗜好に配慮したスコアラーを実現することで、実世界の展開に効率的であることを目的としています。WebGLMは、WebGPTよりも優れた性能を発揮し、Web拡張型QAシステムの評価基準を提案しています。コード、デモ、およびデータは\url{https://github.com/THUDM/WebGLM}にあります。 #PEFT(Adaptor/LoRA) Issue Date: 2023-06-16 One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning, Arnav Chavan+, N_A, arXiv'23 Summary本研究では、汎用的なファインチューニングタスクのための高度な手法であるGeneralized LoRA (GLoRA)を提案し、事前学習済みモデルの重みを最適化し、中間アクティベーションを調整することで、多様なタスクとデータセットに対してより柔軟性と能力を提供する。GLoRAは、各レイヤーの個別のアダプタを学習するスケーラブルでモジュラーなレイヤーごとの構造探索を採用することで、効率的なパラメータの適応を促進する。包括的な実験により、GLoRAは、自然言語、専門分野、構造化ベンチマークにおいて、従来のすべての手法を上回り、様々なデータセットでより少ないパラメータと計算で優れた精度を達成することが示された。 CommentOpenReview:https://openreview.net/forum?id=K7KQkiHanD
ICLR'24にrejectされている Issue Date: 2023-06-16 Augmenting Language Models with Long-Term Memory, Weizhi Wang+, N_A, arXiv'23 Summary本研究では、長期記憶を持つ言語モデルを実現するための「LongMem」というフレームワークを提案し、メモリリトリーバーとリーダーを使用する新しいデカップルネットワークアーキテクチャを設計しました。LongMemは、長期過去の文脈を記憶し、言語モデリングに長期記憶を活用することができます。提案されたメモリリトリーバーモジュールは、メモリバンク内の無制限の長さの文脈を扱うことができ、様々なダウンストリームタスクに利益をもたらします。実験結果は、本手法が、長い文脈モデリングの難しいベンチマークであるChapterBreakにおいて、強力な長文脈モデルを上回り、LLMsに比べてメモリ拡張インコンテキスト学習において顕著な改善を達成することを示しています。 Issue Date: 2023-06-16 Benchmarking Neural Network Training Algorithms, George E. Dahl+, N_A, arXiv'23 Summaryトレーニングアルゴリズムの改善によるモデルの高速化と正確性の向上は重要であるが、現在のコミュニティでは最先端のトレーニングアルゴリズムを決定することができない。本研究では、トレーニングアルゴリズムの経験的比較に直面する3つの基本的な課題を解決する新しいベンチマーク、AlgoPerf: Training Algorithmsベンチマークを導入することを主張する。このベンチマークには、競争力のあるタイム・トゥ・リザルト・ベンチマークが含まれており、最適化手法の比較に役立つ。最後に、ベースライン提出と他の最適化手法を評価し、将来のベンチマーク提出が超えることを試みるための仮の最先端を設定する。 Issue Date: 2023-06-16 Evaluating the Social Impact of Generative AI Systems in Systems and Society, Irene Solaiman+, N_A, arXiv'23 Summary様々なモダリティにわたる生成型AIシステムの社会的影響を評価するための公式の標準が存在しないため、我々はそれらの影響を評価するための標準的なアプローチに向けて進んでいます。我々は、技術的な基盤システムで評価可能な社会的影響のカテゴリーと、人々や社会で評価可能な社会的影響のカテゴリーを定義し、それぞれにサブカテゴリーと害を軽減するための推奨事項を提供しています。また、AI研究コミュニティが既存の評価を提供できるように、評価リポジトリを作成しています。 Issue Date: 2023-06-16 PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts, Kaijie Zhu+, N_A, arXiv'23 SummaryLLMsの頑健性を測定するための頑健性ベンチマークであるPromptBenchを紹介する。PromptBenchは、多数の敵対的なテキスト攻撃を使用して、感情分析、自然言語推論、読解、機械翻訳、数学問題解決などの多様なタスクで使用されるプロンプトに対するLLMsの耐性を測定する。研究では、8つのタスクと13のデータセットで4,032の敵対的なプロンプトを生成し、合計567,084のテストサンプルを評価した。結果は、現代のLLMsが敵対的なプロンプトに対して脆弱であることを示しており、プロンプトの頑健性と移植性に関する包括的な分析を提供する。また、敵対的なプロンプトを生成するためのコード、プロンプト、および方法論を公開し、研究者や一般ユーザーの両方にとって有益である。 Issue Date: 2023-06-16 Modular Visual Question Answering via Code Generation, Sanjay Subramanian+, N_A, arXiv'23 Summary視覚的な質問応答をモジュラーコード生成として定式化するフレームワークを提案し、追加のトレーニングを必要とせず、事前にトレーニングされた言語モデル、画像キャプションペアで事前にトレーニングされたビジュアルモデル、およびコンテキスト学習に使用される50のVQA例に依存しています。生成されたPythonプログラムは、算術および条件付き論理を使用して、ビジュアルモデルの出力を呼び出し、合成します。COVRデータセットで少なくとも3%、GQAデータセットで約2%の精度向上を実現しています。 Issue Date: 2023-06-16 PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization, Yidong Wang+, N_A, arXiv'23 Summary大規模言語モデル(LLMs)の調整には、ハイパーパラメータの選択の複雑さと評価の難しさが残っています。そこで、PandaLMという判定用大規模言語モデルを導入し、複数のLLMsが与えられた場合に優れたモデルを区別するために訓練されます。PandaLMは、相対的な簡潔さ、明確さ、指示に従うこと、包括性、形式性などの重要な主観的要因に対処することができます。PandaLMは、APIベースの評価に依存しないため、潜在的なデータ漏洩を回避できます。PandaLMによって調整されたモデルは、デフォルトのAlpacaのハイパーパラメータでトレーニングされた対照モデルと比較して、有意な改善が実現されるため、LLMの評価がより公正かつコストが少なくなります。 Issue Date: 2023-06-16 Improving Open Language Models by Learning from Organic Interactions, Jing Xu+, N_A, arXiv'23 SummaryBlenderBot 3xは、BlenderBot 3のアップデートであり、有機的な会話とフィードバックデータを使用してトレーニングされ、スキルと安全性の両方を向上させました。参加者の匿名化された相互作用データが公開され、有害な行動を回避する技術が研究されました。BlenderBot 3xは、BlenderBot 3よりも会話で好まれ、より安全な応答を生成することが示されています。改善の余地があるものの、継続的な技術の使用により、さらなる改善が可能だと考えられています。 Issue Date: 2023-06-16 Tracking Everything Everywhere All at Once, Qianqian Wang+, N_A, arXiv'23 Summary本研究では、ビデオシーケンスから長距離の動きを推定するための新しい手法を提案する。従来の手法では、時間枠内での動作や遮蔽物の追跡が困難であり、グローバルな一貫性を維持することができなかった。提案手法では、OmniMotionという完全でグローバルに一貫した動き表現を使用し、遮蔽物を追跡し、カメラとオブジェクトの動きの任意の組み合わせをモデル化することができる。TAP-Vidベンチマークと実世界の映像での評価により、本手法が従来の最先端の手法を大幅に上回ることが示された。 Issue Date: 2023-06-16 INSTRUCTEVAL: Towards Holistic Evaluation of Instruction-Tuned Large Language Models, Yew Ken Chia+, N_A, arXiv'23 Summary指示に調整された大規模言語モデルの包括的な評価スイートであるINSTRUCTEVALが提案された。この評価は、問題解決能力、文章能力、および人間の価値観に対する適合性に基づくモデルの厳密な評価を含む。指示データの品質がモデルのパフォーマンスを拡大する上で最も重要な要因であることが明らかになった。オープンソースのモデルは印象的な文章能力を示しているが、問題解決能力や適合性には改善の余地がある。INSTRUCTEVALは、指示に調整されたモデルの深い理解と能力の向上を促進することを目指している。 Issue Date: 2023-06-16 Youku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks, Haiyang Xu+, N_A, arXiv'23 Summary中国のコミュニティにおいて、Vision-Language Pre-training(VLP)とマルチモーダル大規模言語モデル(LLM)の発展を促進するために、Youku-mPLUGという最大の公開中国語高品質ビデオ言語データセットをリリースしました。このデータセットは、大規模なプレトレーニングに使用でき、クロスモーダル検索、ビデオキャプション、ビデオカテゴリ分類の3つの人気のあるビデオ言語タスクをカバーする最大の人間注釈中国語ベンチマークを慎重に構築しました。Youku-mPLUGでプレトレーニングされたモデルは、ビデオカテゴリ分類で最大23.1%の改善を実現し、mPLUG-videoは、ビデオカテゴリ分類で80.5%のトップ1精度、ビデオキャプションで68.9のCIDErスコアで、これらのベンチマークで新しい最高の結果を達成しました。また、Youku-mPLUGでのプレトレーニングが、全体的および詳細な視覚的意味、シーンテキストの認識、およびオープンドメインの知識の活用能力を向上させることを示すゼロショットの指示理解実験も行われました。 Issue Date: 2023-06-16 M$^3$IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning, Lei Li+, N_A, arXiv'23 SummaryVLMの進歩は、高品質の指示データセットの不足により制限されている。そこで、M$^3$ITデータセットが紹介された。このデータセットは、40のデータセット、240万のインスタンス、400の手動で書かれたタスク指示を含み、ビジョンからテキスト構造に再フォーマットされている。M$^3$ITは、タスクカバレッジ、指示数、インスタンススケールの面で以前のデータセットを上回っている。また、このデータセットで訓練されたVLMモデルであるYing-VLMは、複雑な質問に答え、未知のビデオタスクに汎用的に対応し、中国語の未知の指示を理解する可能性を示している。 #NeurIPS Issue Date: 2023-06-16 Deductive Verification of Chain-of-Thought Reasoning, Zhan Ling+, N_A, NeuriPS'23 Summary大規模言語モデル(LLMs)を使用して、Chain-of-Thought(CoT)プロンプティングによる推論タスクを解決するために、自己検証を通じて推論プロセスの信頼性を確保するNatural Programを提案する。このアプローチにより、モデルは正確な推論ステップを生成し、各演繹的推論段階に統合された検証プロセスにより、生成された推論ステップの厳密性と信頼性を向上させることができる。コードはhttps://github.com/lz1oceani/verify_cotで公開される。 Issue Date: 2023-06-16 Natural Language Commanding via Program Synthesis, Apurva Gandhi+, N_A, arXiv'23 SummarySemantic Interpreterは、Microsoft Officeなどの生産性ソフトウェアにおいて、LLMsとODSLを活用して、自然言語のユーザー発話をアプリケーションの機能に実行するAIシステムである。本論文では、Microsoft PowerPointの研究探索に焦点を当てて、Analysis-Retrievalプロンプト構築方法を用いたSemantic Interpreterの実装について議論している。 #PairWise #NLP #LanguageModel #Ensemble #ACL #ModelMerge Issue Date: 2023-06-16 LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion, Dongfu Jiang+, N_A, ACL'23 SummaryLLM-Blenderは、複数の大規模言語モデルを組み合わせたアンサンブルフレームワークであり、PairRankerとGenFuserの2つのモジュールから構成されています。PairRankerは、専門的なペアワイズ比較方法を使用して候補の出力間の微妙な違いを区別し、GenFuserは、上位ランクの候補をマージして改善された出力を生成します。MixInstructというベンチマークデータセットを導入し、LLM-Blenderは、個々のLLMsやベースライン手法を大幅に上回り、大きなパフォーマンス差を確立しました。 Issue Date: 2023-05-22 Counterfactuals for Design: A Model-Agnostic Method For Design Recommendations, Lyle Regenwetter+, N_A, arXiv'23 Summary本研究では、デザイン問題におけるカウンターファクチュアル最適化のための新しい手法であるMCDを紹介する。MCDは、設計問題において重要な多目的クエリをサポートし、カウンターファクチュアル探索とサンプリングプロセスを分離することで効率を向上させ、目的関数のトレードオフの可視化を容易にすることで、既存のカウンターファクチュアル探索手法を改善している。MCDは、自転車設計の3つのケーススタディを行い、実世界の設計問題において有効であることを示している。全体的に、MCDは、実践者や設計自動化研究者が「もしも」の質問に答えを見つけるための貴重な推奨を提供する可能性がある。 Issue Date: 2023-05-22 QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, N_A, arXiv'23 SummaryQUESTデータセットは、交差、和、差などの集合演算を暗黙的に指定するクエリを生成するために、選択的な情報ニーズを定式化することによって構築されました。このデータセットは、Wikipediaのドキュメントに対応するエンティティのセットにマップされ、クエリで言及される複数の制約を対応するドキュメントの証拠と一致させ、さまざまな集合演算を正しく実行することをモデルに求めます。クラウドワーカーによって言い換えられ、自然さと流暢さがさらに検証されたクエリは、いくつかの現代的な検索システムにとって苦戦することがわかりました。 #NLP #LanguageModel #Supervised-FineTuning (SFT) #In-ContextLearning #EMNLP #PostTraining Issue Date: 2023-05-21 Symbol tuning improves in-context learning in language models, Jerry Wei+, N_A, EMNLP'23 Summary本研究では、自然言語ラベルをシンボルに置き換えて言語モデルを微調整する「symbol tuning」を提案し、未知のタスクや不明確なプロンプトに対して堅牢な性能を示すことを示した。また、symbol tuningによりアルゴリズム的推論タスクでのパフォーマンス向上が見られ、以前の意味的知識を上書きする能力が向上していることが示された。Flan-PaLMモデルを使用して実験が行われ、最大540Bパラメータまで利用された。 Comment概要やOpenReviewの内容をざっくりとしか読めていないが、自然言語のラベルをランダムな文字列にしたり、instructionをあえて除外してモデルをFinetuningすることで、promptに対するsensitivityや元々モデルが持っているラベルと矛盾した意味をin context learningで上書きできるということは、学習データに含まれるテキストを調整することで、正則化の役割を果たしていると考えられる。つまり、ラベルそのものに自然言語としての意味を含ませないことや、instructionを無くすことで、(モデルが表層的なラベルの意味や指示からではなく)、より実際のICLで利用されるExaplarからタスクを推論するように学習されるのだと思われる。
厳密に正解とsemanticsを定義した上で、訓練データと異なるsemanticsの異なるプログラムを生成できることを示した。
LLMが意味を理解していることを暗示している
Non trivialなプランニングと検索が必要な新たな3つのタスクについて、CoT w/ GPT4の成功率が4%だったところを、ToTでは74%を達成
論文中の表ではCoTのSuccessRateが40%と書いてあるような?
byte列で表現されるデータならなんでも入力できる。つまり、理論上なんでも入力できる。 Issue Date: 2023-05-12 Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction, Wang-Cheng Kang+, N_A, arXiv'23 SummaryLLMsは新しいタスクに一般化する能力を持ち、少ないデータで包括的な世界知識を維持することができる。本研究では、CFとLLMsを比較し、ユーザー評価予測タスクでLLMsがファインチューニングを通じて同等またはより良いパフォーマンスを示すことがわかった。しかし、ゼロショットLLMsは従来の推薦モデルに遅れをとることが示された。 Commentはじまったなぁ、という感じ #NeuralNetwork #ComputerVision #Controllable #VideoGeneration/Understandings Issue Date: 2023-05-12 Sketching the Future (STF): Applying Conditional Control Techniques to Text-to-Video Models, Rohan Dhesikan+, arXiv'23 Summaryゼロショットのテキストから動画生成をControlNetと組み合わせ、スケッチされたフレームを基に動画を生成する新手法を提案。フレーム補間を行い、Text-to-Video Zeroアーキテクチャを活用して高品質で一貫性のある動画を生成。デモ動画やリソースを提供し、さらなる研究を促進。 Issue Date: 2023-05-11 Multi-Task End-to-End Training Improves Conversational Recommendation, Naveen Ram+, N_A, arXiv'23 Summary本論文では、対話型推薦タスクにおいて、マルチタスクエンドツーエンドトランスフォーマーモデルのパフォーマンスを分析する。従来の複雑なマルチコンポーネントアプローチに代わり、T5テキストトゥーテキストトランスフォーマーモデルに基づく統合トランスフォーマーモデルが、関連するアイテムの推薦と会話の対話生成の両方で競争力を持つことを示す。ReDIAL対話型映画推薦データセットでモデルをファインチューニングし、追加のトレーニングタスクをマルチタスク学習の設定で作成することで、各タスクが関連するプローブスコアの9%〜52%の増加につながることを示した。 #Transformer #LongSequence #NeurIPS #Encoder #Encoder-Decoder Issue Date: 2023-05-09 Vcc: Scaling Transformers to 128K Tokens or More by Prioritizing Important Tokens, Zhanpeng Zeng+, N_A, NeurIPS'23 Summary本論文では、Transformerモデルの二次コストを削減するために、各層でサイズ$r$が$n$に独立した表現に入力を圧縮する方法を提案する。VIPトークン中心の圧縮(Vcc)スキームを使用し、VIPトークンの表現を近似するために入力シーケンスを選択的に圧縮する。提案されたアルゴリズムは、競合するベースラインと比較して効率的であり、多数のタスクにおいて競争力のあるまたはより優れたパフォーマンスを発揮する。また、アルゴリズムは128Kトークンにスケーリングでき、一貫して精度の向上を提供することが示された。 #Analysis #NLP #LanguageModel #Chain-of-Thought #Faithfulness #NeurIPS Issue Date: 2023-05-09 Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting, Miles Turpin+, N_A, NeurIPS'23 SummaryLLMsによる推論において、chain-of-thought reasoning(CoT)と呼ばれる説明を生成することができるが、この説明がモデルの予測の真の理由を誤って表現することがあることがわかった。バイアスのある特徴をモデルの入力に追加することで、CoT説明が大きく影響を受けることが示された。この結果は、LLMsに対する信頼を高めるために、説明の忠実度を評価し、改善する必要があることを示唆している。 Issue Date: 2023-05-06 Cognitive Reframing of Negative Thoughts through Human-Language Model Interaction, Ashish Sharma+, N_A, arXiv'23 Summary本論文では、言語モデルを使用して人々が否定的な考えを再構築するのを支援する方法について、心理学の文献に基づいて研究を行います。7つの言語属性のフレームワークを定義し、自動化されたメトリックを開発して、再構築された考えを効果的に生成し、その言語属性を制御します。大規模なメンタルヘルスのウェブサイトでランダム化フィールド研究を実施し、高度に共感的または具体的な再構築を好むことを示しました。言語モデルを使用して人々が否定的な考えを克服するのを支援するための重要な示唆を提供します。 #PersonalizedDocumentSummarization #NLP #Personalization #review Issue Date: 2023-05-05 Towards Personalized Review Summarization by Modeling Historical Reviews from Customer and Product Separately, Xin Cheng+, N_A, arXiv'23 Summaryレビュー要約は、Eコマースのウェブサイトにおいて製品レビューの主要なアイデアを要約することを目的としたタスクである。本研究では、評価情報を含む2種類の過去のレビューをグラフ推論モジュールと対比損失を用いて別々にモデル化するHHRRSを提案する。レビューの感情分類と要約を共同で行うマルチタスクフレームワークを採用し、4つのベンチマークデータセットでの徹底的な実験により、HHRRSが両方のタスクで優れた性能を発揮することが示された。 #NLP #LanguageModel #ICLR #KnowledgeEditing Issue Date: 2023-05-04 Mass-Editing Memory in a Transformer, Kevin Meng+, N_A, ICLR'23 Summary大規模言語モデルを更新することで、専門的な知識を追加できることが示されているしかし、これまでの研究は主に単一の関連付けの更新に限定されていた本研究では、MEMITという方法を開発し、多数のメモリを直接言語モデルに更新することができることを実験的に示したGPT-J(6B)およびGPT-NeoX(20B)に対して数千の関連付けまでスケーリングでき、これまでの研究を桁違いに上回ることを示したコードとデータはhttps://memit.baulab.infoにあります。 #NLP #LanguageModel #Zero/FewShotPrompting #Chain-of-Thought #ACL Issue Date: 2023-05-04 Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, Mirac Suzgun+, N_A, ACL'23 SummaryBIG-Bench Hard (BBH) is a suite of 23 challenging tasks that current language models have not been able to surpass human performance on. This study focuses on applying chain-of-thought prompting to BBH tasks and found that PaLM and Codex were able to surpass human performance on 10 and 17 tasks, respectively. The study also found that CoT prompting is necessary for tasks that require multi-step reasoning and that CoT and model scale interact to enable new task performance on some BBH tasks. Comment単なるfewshotではなく、CoT付きのfewshotをすると大幅にBIG-Bench-hardの性能が向上するので、CoTを使わないanswer onlyの設定はモデルの能力の過小評価につながるよ、という話らしい
https://georgecazenavette.github.io/glad/ Issue Date: 2023-05-04 Distill or Annotate? Cost-Efficient Fine-Tuning of Compact Models, Junmo Kang+, N_A, arXiv'23 Summary大規模モデルを微調整することは効果的だが、推論コストが高く、炭素排出量が発生する。知識蒸留は推論コストを削減するための実用的な解決策であるが、蒸留プロセス自体には膨大な計算リソースが必要。固定予算を最も効率的に使用してコンパクトなモデルを構築する方法を調査。T5-XXL(11B)からT5-Small(60M)への蒸留は、より多くのデータを注釈付きで直接トレーニングするよりもほぼ常にコスト効率の高いオプションであることがわかった。最適な蒸留量は、予算シナリオによって異なる。 Issue Date: 2023-05-04 The Internal State of an LLM Knows When its Lying, Amos Azaria+, N_A, arXiv'23 SummaryLLMは優れたパフォーマンスを発揮するが、不正確な情報を生成することがある本研究では、LLMの内部状態を使用して文の真実性を検出する方法を提案分類器はLLMの活性化値を入力として受け取り、真実か偽かを検出する実験結果は、提案手法がフューショット・プロンプティング・メソッドを上回り、LLMの信頼性を向上させる可能性があることを示している。 Issue Date: 2023-05-04 Causal Reasoning and Large Language Models: Opening a New Frontier for Causality, Emre Kıcıman+, N_A, arXiv'23 Summary本研究では、大規模言語モデル(LLMs)を用いた因果推論について議論し、LLMsが因果関係のタスクにおいて高い精度を示すことを示した。また、LLMsは人間に制限されていた能力を持っており、因果グラフの生成や自然言語からの因果関係の特定などが可能であることが示された。LLMsは、因果関係の研究、実践、および採用の新しいフロンティアを開拓することが期待される。 Issue Date: 2023-05-04 ArK: Augmented Reality with Knowledge Interactive Emergent Ability, Qiuyuan Huang+, N_A, arXiv'23 Summary本研究では、混合現実やインタラクティブAIエージェントのシステムが未知の環境で高品質な2D/3Dシーンを生成することが課題であることを指摘し、一般的な基礎モデルから知識メモリを転送して、物理的または仮想世界でのシーン理解と生成のための新しいドメインやシナリオに対応する無限エージェントを開発した。このアプローチには、知識推論インタラクションを拡張現実と呼ばれる新しいメカニズムがあり、知識メモリを活用して未知の物理世界や仮想現実環境でシーンを生成する。このアプローチは、生成された2D/3Dシーンの品質を大幅に向上させ、メタバースやゲームシミュレーションなどの応用において有用であることが示された。 Commentプロジェクトページ
https://augmented-reality-knowledge.github.io Issue Date: 2023-05-04 What Do Self-Supervised Vision Transformers Learn?, Namuk Park+, N_A, arXiv'23 Summary本研究では、対比学習(CL)とマスク画像モデリング(MIM)の比較的な研究を行い、自己教示学習されたVision Transformers(ViTs)がCLとMIMの両方の利点を活用することができることを示した。CLは長距離のグローバルなパターンを捉えることができ、ViTsは表現空間で画像を線形に分離することができるが、表現の多様性が低下し、スケーラビリティと密な予測パフォーマンスが悪化することがある。MIMは高周波情報を利用し、形状とテクスチャを表す。CLとMIMは互いに補完的であり、両方の方法の利点を活用することができる。コードはGitHubで利用可能。 Issue Date: 2023-05-04 GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation, Zhenhui Ye+, N_A, arXiv'23 Summary本研究では、話す人物のポートレートを生成するためのNeRFベースの手法における課題を解決するために、GeneFace++を提案した。GeneFace++は、ピッチ輪郭を利用して口唇同期を実現し、局所線形埋め込み法を提案して頑健性の問題を回避し、高速なトレーニングとリアルタイム推論を実現するNeRFベースの動きからビデオへのレンダラーを設計することで、一般化された音声と口唇同期を持つ安定したリアルタイム話す顔生成を実現した。徹底的な実験により、提案手法が最先端のベースラインを上回ることが示された。ビデオサンプルはhttps://genefaceplusplus.github.ioで利用可能。 Commentプロジェクトページ
https://genefaceplusplus.github.io Issue Date: 2023-05-04 Key-Locked Rank One Editing for Text-to-Image Personalization, Yoad Tewel+, N_A, arXiv'23 Summary本研究では、テキストから画像へのモデル(T2I)の個人化手法であるPerfusionを提案し、高い視覚的忠実度を維持しながら創造的な制御を許可すること、複数の個人化された概念を単一の画像に組み合わせること、小さなモデルサイズを維持することなど、複数の困難な課題を解決する。Perfusionは、基礎となるT2Iモデルに対して動的なランク1の更新を使用することで、過学習を回避し、新しい概念のクロスアテンションキーを上位カテゴリにロックする新しいメカニズムを導入することで、学習された概念の影響を制御し、複数の概念を組み合わせることができるゲート付きランク1アプローチを開発した。Perfusionは、現在の最先端のモデルよりも5桁小さいが、強力なベースラインを定量的および定性的に上回ることが示された。 Commentプロジェクトページ
https://research.nvidia.com/labs/par/Perfusion/ #NLP #LanguageModel #Poisoning #ICML Issue Date: 2023-05-04 Poisoning Language Models During Instruction Tuning, Alexander Wan+, N_A, ICML'23 SummaryInstruction-tuned LMs(ChatGPT、FLAN、InstructGPTなど)は、ユーザーが提出した例を含むデータセットでfinetuneされる。本研究では、敵対者が毒入りの例を提供することで、LMの予測を操作できることを示す。毒入りの例を構築するために、LMのbag-of-words近似を使用して入出力を最適化する。大きなLMほど毒入り攻撃に対して脆弱であり、データフィルタリングやモデル容量の削減に基づく防御は、テストの正確性を低下させながら、中程度の保護しか提供しない。 Issue Date: 2023-05-04 Loss Landscapes are All You Need: Neural Network Generalization Can Be Explained Without the Implicit Bias of Gradient Descent, ICLR'23 Issue Date: 2023-05-04 Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation, Yuval Kirstain+, N_A, arXiv'23 Summaryテキストから画像へのユーザーの好みの大規模データセットが限られているため、Webアプリを作成してPick-a-Picデータセットを構築した。PickScoreというCLIPベースのスコアリング関数を訓練し、人間の好みを予測するタスクで超人的なパフォーマンスを発揮した。PickScoreは他の自動評価メトリックよりも人間のランキングとより良い相関があることが観察された。将来のテキストから画像への生成モデルの評価にはPickScoreを使用し、Pick-a-Picプロンプトを使用することを推奨する。PickScoreがランキングを通じて既存のテキストから画像へのモデルを強化する方法を示した。 Issue Date: 2023-05-04 Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge, Yasumasa Onoe+, N_A, arXiv'23 Summary事前学習された言語モデル(LMs)のターゲット更新について研究されてきたが、注入された事実に基づいて推論を行うLMsの能力を研究する。2つのクローズスタイルのタスクで研究し、知識の更新に対する既存の方法は注入された知識の伝播をほとんど示さないことがわかった。しかし、LMの文脈にエンティティの定義を先行させると、すべての設定でパフォーマンスが向上することがわかり、知識注入のためのパラメータ更新アプローチには大きな余地があることを示唆している。 Issue Date: 2023-05-04 Learning to Reason and Memorize with Self-Notes, Jack Lanchantin+, N_A, arXiv'23 Summary大規模言語モデルは、コンテキストメモリと多段階の推論に苦労するが、セルフノートを取ることでこれらの問題を解決できることが提案された。モデルは入力コンテキストから思考を逸脱し、情報を思い出し、推論を実行することができる。複数のタスクでの実験により、セルフノートを推論時に取ることで、より長く、より複雑なインスタンスに対しても成功裏に汎化できることが示された。 #Survey #Education #ChatGPT Issue Date: 2023-05-04 A Review of ChatGPT Applications in Education, Marketing, Software Engineering, and Healthcare: Benefits, Drawbacks, and Research Directions, Mohammad Fraiwan+, N_A, arXiv'23 SummaryChatGPTは、深層学習アルゴリズムを使用して人間らしい応答を生成する人工知能言語モデルである。最新のChatGPTバージョンが導入され、他の言語モデルも登場している。これらのモデルは、教育、ソフトウェアエンジニアリング、医療、マーケティングなどの分野で応用可能性がある。本論文では、これらのモデルの可能な応用、制限、欠点、および研究方向について議論する。 #MachineTranslation #NLP #LanguageModel #Annotation #TransferLearning #MultiLingual #ACL Issue Date: 2023-05-04 Frustratingly Easy Label Projection for Cross-lingual Transfer, Yang Chen+, N_A, ACL'23 Summary多言語のトレーニングデータの翻訳は、クロスリンガル転移の改善に役立つスパンレベル注釈が必要なタスクでは、注釈付きスパンを翻訳されたテキストにマッピングするために追加のラベルプロジェクションステップが必要マーク-翻訳法を利用するアプローチが従来の注釈プロジェクションと比較してどのようになるかについての実証的な分析を行ったEasyProjectと呼ばれるマーク-翻訳法の最適化されたバージョンが多言語に簡単に適用でき、より複雑な単語アラインメントベースの方法を上回ることを示したすべてのコードとデータが公開される Issue Date: 2023-05-04 Multimodal Procedural Planning via Dual Text-Image Prompting, Yujie Lu+, N_A, arXiv'23 Summary本研究では、具現化エージェントがテキストや画像に基づく指示を受けてタスクを完了するための多様なモーダル手順計画(MPP)タスクを提案し、Text-Image Prompting(TIP)を使用して、大規模言語モデル(LLMs)を活用して、テキストと画像の相互作用を改善する方法を提案しています。WIKIPLANとRECIPEPLANのデータセットを収集し、MPPのテストベッドとして使用し、単一モーダルおよび多様なモーダルのベースラインに対する人間の嗜好と自動スコアが魅力的であることを示しました。提案手法のコードとデータは、https://github.com/YujieLu10/MPPにあります。 Issue Date: 2023-05-04 Can ChatGPT Pass An Introductory Level Functional Language Programming Course?, Chuqin Geng+, N_A, arXiv'23 SummaryChatGPTは多様なタスクを解決する印象的な能力を持ち、コンピュータサイエンス教育に大きな影響を与えている。本研究では、ChatGPTが初級レベルの関数型言語プログラミングコースでどの程度の性能を発揮できるかを探求した。ChatGPTを学生として扱い、B-の成績を達成し、全体の314人の学生のうち155位のランクを示した。包括的な評価により、ChatGPTの影響について貴重な洞察を提供し、潜在的な利点を特定した。この研究は、ChatGPTの能力とコンピュータサイエンス教育への潜在的な影響を理解する上で重要な進展をもたらすと信じられる。 Issue Date: 2023-05-04 Making the Most of What You Have: Adapting Pre-trained Visual Language Models in the Low-data Regime, Chuhan Zhang+, N_A, arXiv'23 Summary本研究では、大規模なビジュアル言語モデルの事前学習と、少数の例からのタスク適応について調査し、自己ラベリングの重要性を示した。ImageNet、COCO、Localised Narratives、VQAv2などのビジュアル言語タスクで、提案されたタスク適応パイプラインを使用することで、大幅な利益を示した。 Issue Date: 2023-05-04 CodeGen2: Lessons for Training LLMs on Programming and Natural Languages, Erik Nijkamp+, N_A, arXiv'23 Summary大規模言語モデル(LLMs)のトレーニングを効率的にするために、4つの要素を統合することを試みた。モデルアーキテクチャ、学習方法、インフィルサンプリング、データ分布を統合した。1B LLMsで実験を行い、成功と失敗を4つのレッスンにまとめた。CodeGen2モデルのトレーニング方法とトレーニングフレームワークをオープンソースで提供する。 Issue Date: 2023-05-04 GPTutor: a ChatGPT-powered programming tool for code explanation, Eason Chen+, N_A, arXiv'23 Summary本論文では、ChatGPT APIを使用したプログラミングツールであるGPTutorを提案し、Visual Studio Codeの拡張機能として実装した。GPTutorは、プログラミングコードの説明を提供することができ、初期評価により、最も簡潔で正確な説明を提供することが示された。さらに、学生や教師からのフィードバックにより、GPTutorは使いやすく、与えられたコードを満足する説明ができることが示された。将来の研究方向として、プロンプトプログラミングによるパフォーマンスと個人化の向上、および実際のユーザーを対象としたGPTutorの効果の評価が含まれる。 Commentpersonalisationもかけているらしいので気になる Issue Date: 2023-05-04 Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings, Daniel Rose+, N_A, arXiv'23 Summary大規模言語モデルを用いた論理的な推論には限界があり、視覚的な拡張が必要であるという問題がある。そこで、VCoTという新しい手法を提案し、視覚言語グラウンディングを用いた推論のchain of thought promptingを再帰的に利用して、順序データ内の論理的なギャップを埋めることができる。VCoTは、Visual StorytellingとWikiHow summarizationのデータセットに適用され、人間の評価を通じて、新しい一貫性のある合成データ拡張を提供し、下流のパフォーマンスを向上させることができることが示された。 Issue Date: 2023-05-04 Unlimiformer: Long-Range Transformers with Unlimited Length Input, Amanda Bertsch+, N_A, arXiv'23 Summary本研究では、Transformerベースのモデルに対して、すべてのレイヤーのアテンション計算を単一のk最近傍インデックスにオフロードすることで、入力長に事前に定義された境界をなくすことができるUnlimiformerを提案した。Unlimiformerは、長文書およびマルチドキュメント要約のベンチマークで有効性を示し、追加の学習済み重みを必要とせず、入力を無制限に拡張することができる。コードとモデルは、https://github.com/abertsch72/unlimiformerで公開されています。 Issue Date: 2023-05-04 Distilling Step-by-Step Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes, Cheng-Yu Hsieh+, N_A, arXiv'23 Summary大規模言語モデル(LLMs)を小さなモデルに蒸留する新しいメカニズムを提案し、ファインチューニングや蒸留に必要なトレーニングデータを減らすことで、性能を向上させることができることを示した。また、小さなモデルでもLLMsを上回る性能を発揮することができ、利用可能なデータの80%のみを使用しても、LLMsを上回る性能を発揮することができることが実験によって示された。 Issue Date: 2023-05-01 Search-in-the-Chain: Towards the Accurate, Credible and Traceable Content Generation for Complex Knowledge-intensive Tasks, Shicheng Xu+, N_A, arXiv'23 Summary本論文では、大規模言語モデル(LLMs)を使用した多段階質問応答タスクにおいて、正確性、信頼性、追跡性を向上させるための新しいフレームワークであるSearch-in-the-Chain(SearChain)を提案しています。SearChainは、LLMと情報検索(IR)を深く統合したフレームワークであり、LLMが生成するコンテンツの正確性と信頼性を高めることができます。実験結果は、SearChainが4つの多段階質問応答データセットで関連するベースラインを上回ることを示しています。 Issue Date: 2023-05-01 PMC-LLaMA: Further Finetuning LLaMA on Medical Papers, Chaoyi Wu+, N_A, arXiv'23 Summary本報告書では、PMC-LLaMAというオープンソース言語モデルを紹介し、医療領域での能力を向上させるためにファインチューニングされたことを述べています。PMC-LLaMAは、バイオメディカルドメイン固有の概念をよりよく理解し、PubMedQA、MedMCQA、USMLEを含む3つのバイオメディカルQAデータセットで高いパフォーマンスを発揮することが示されています。モデルとコード、オンラインデモは、公開されています。 CommentLLaMAを4.8Mのmedical paperでfinetuningし、医療ドメインの能力を向上。このモデルはPMC-LLaMAと呼ばれ、biomedicalQAタスクで、高い性能を達成した。
GPT-4を利用した異なるモデル間の出力の比較も行なっている模様 Issue Date: 2023-04-30 Multi-Party Chat: Conversational Agents in Group Settings with Humans and Models, Jimmy Wei+, N_A, arXiv'23 Summary本研究では、複数の話者が参加する会話を収集し、評価するために、マルチパーティの会話を構築する。LIGHT環境を使用して、各参加者が役割を演じるために割り当てられたキャラクターを持つグラウンデッドな会話を構築する。新しいデータセットで訓練されたモデルを、既存の二者間で訓練された対話モデル、およびfew-shot promptingを使用した大規模言語モデルと比較し、公開するMultiLIGHTという新しいデータセットが、グループ設定での大幅な改善に役立つことがわかった。 #NeuralNetwork #ComputerVision #Embeddings #RepresentationLearning #ContrastiveLearning #ICLR #Semi-Supervised Issue Date: 2023-04-30 SemPPL: Predicting pseudo-labels for better contrastive representations, Matko Bošnjak+, N_A, ICLR'23 Summary本研究では、コンピュータビジョンにおける半教師あり学習の問題を解決するために、Semantic Positives via Pseudo-Labels (SemPPL)という新しい手法を提案している。この手法は、ラベル付きとラベルなしのデータを組み合わせて情報豊富な表現を学習することができ、ResNet-$50$を使用してImageNetの$1\%$および$10\%$のラベルでトレーニングする場合、競合する半教師あり学習手法を上回る最高性能を発揮することが示された。SemPPLは、強力な頑健性、分布外および転移性能を示すことができる。 Comment後ほど説明を追記する
・1975 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #LongSequence #Inference Issue Date: 2023-04-30 Efficiently Scaling Transformer Inference, Reiner Pope+, N_A, MLSys'23 Summary大規模Transformerベースのモデルの推論のエンジニアリングのトレードオフを理解するために、最適な多次元分割技術を選択するための単純な解析モデルを開発低レベルの最適化と組み合わせることで、500B+パラメータモデルのレイテンシーとモデルFLOPS利用率のトレードオフにおいて、FasterTransformerベンチマークスイートを上回る新しいParetoフロンティアを実現適切な分割により、マルチクエリアテンションの低いメモリ要件により、32倍の大きなコンテキスト長にスケーリング可能int8ウェイト量子化を使用した生成中の低バッチサイズレイテンシーは、トークンあたり29msであり、入力トークンの大バッチサイズ処理において76%のMFUを実現し、PaLM 540Bパラメータモデルにおいて2048トークンの長いコンテキスト長をサポートしている。 Comment特にMultiquery Attentionという技術がTransformerのinferenceのコスト削減に有効らしい #NLP #LanguageModel #Education #AES(AutomatedEssayScoring) #ChatGPT Issue Date: 2023-04-28 [Paper Note] AI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays, Steffen Herbold+, arXiv'23 SummaryChatGPTが生成したエッセイは、人間が書いたものよりも質が高いと評価されることが大規模な研究で示された。生成されたエッセイは独自の言語的特徴を持ち、教育者はこの技術を活用する新たな教育コンセプトを開発する必要がある。 CommentChatGPTは人間が書いたエッセイよりも高品質なエッセイが書けることを示した。
また、AIモデルの文体は、人間が書いたエッセイとは異なる言語的特徴を示している。たとえば、談話や認識マーカーが少ないが、名詞化が多く、語彙の多様性が高いという特徴がある、とのこと。
#Dataset #LanguageModel #Evaluation #EMNLP #Ambiguity Issue Date: 2023-04-28 We're Afraid Language Models Aren't Modeling Ambiguity, Alisa Liu+, EMNLP'23 Summary曖昧さは自然言語の重要な特徴であり、言語モデル(LM)が対話や執筆支援において成功するためには、曖昧な言語を扱うことが不可欠です。本研究では、曖昧さの影響を評価するために、1,645の例からなるベンチマーク「AmbiEnt」を収集し、事前学習済みLMの評価を行いました。特にGPT-4の曖昧さ解消の正答率は32%と低く、曖昧さの解消が難しいことが示されました。また、多ラベルのNLIモデルが曖昧さによる誤解を特定できることを示し、NLPにおける曖昧さの重要性を再認識する必要性を提唱しています。 CommentLLMが曖昧性をどれだけ認知できるかを評価した初めての研究。
言語学者がアノテーションした1,645サンプルの様々な曖昧さを含んだベンチマークデータを利用。
GPT4は32%正解した。
またNLIデータでfinetuningしたモデルでは72.5%のmacroF1値を達成。
応用先として、誤解を招く可能性のある政治的主張に対してアラートをあげることなどを挙げている。
#RecommenderSystems #CollaborativeFiltering #GraphBased Issue Date: 2023-04-26 Graph Collaborative Signals Denoising and Augmentation for Recommendation, Ziwei Fan+, N_A, SIGIR'23 Summaryグラフ協調フィルタリング(GCF)は、推薦システムで人気のある技術ですが、相互作用が豊富なユーザーやアイテムにはノイズがあり、相互作用が不十分なユーザーやアイテムには不十分です。また、ユーザー-ユーザーおよびアイテム-アイテムの相関を無視しているため、有益な隣接ノードの範囲が制限される可能性があります。本研究では、ユーザー-ユーザーおよびアイテム-アイテムの相関を組み込んだ新しいグラフの隣接行列と、適切に設計されたユーザー-アイテムの相互作用行列を提案します。実験では、改善された隣接ノードと低密度を持つ強化されたユーザー-アイテムの相互作用行列が、グラフベースの推薦において重要な利点をもたらすことを示しています。また、ユーザー-ユーザーおよびアイテム-アイテムの相関を含めることで、相互作用が豊富なユーザーや不十分なユーザーに対する推薦が改善されることも示しています。 Commentグラフ協調フィルタリングを改善
(下記ツイッターより引用)
user-item間の関係だけでなく、user-user間とitem-item間の情報を組み込むことで精度向上を達成した論文とのこと。
https://twitter.com/nogawanogawa/status/1651165820956057602?s=46&t=6qC80ox3qHrJixKeNmIOcg #NLP #Assessment #ChatGPT #InformationExtraction Issue Date: 2023-04-25 [Paper Note] Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness, Bo Li+, arXiv'23 Summary本研究では、ChatGPTの能力を7つの情報抽出(IE)タスクを通じて評価し、パフォーマンス、説明可能性、キャリブレーション、信頼性を分析しました。標準IE設定ではパフォーマンスが低い一方、オープンIE設定では人間評価で優れた結果を示しました。ChatGPTは高品質な説明を提供するものの、予測に対して過信する傾向があり、キャリブレーションが低いことが明らかになりました。また、元のテキストに対して高い信頼性を示しました。研究のために手動で注釈付けした7つのIEタスクのテストセットと14のデータセットを公開しています。 Comment情報抽出タスクにおいてChatGPTを評価した研究。スタンダードなIEの設定ではBERTベースのモデルに負けるが、OpenIEの場合は高い性能を示した。
また、ChatGPTは予測に対してクオリティが高く信頼に足る説明をしたが、一方で自信過剰な傾向がある。また、ChatGPTの予測はinput textに対して高いfaithfulnessを示しており、予測がinputから根ざしているものであることがわかる。(らしい)あまりしっかり読んでいないが、Entity Typing, NER, Relation Classification, Relation Extraction, Event Detection, Event Argument Extraction, Event Extractionで評価。standardIEでは、ChatGPTにタスクの説明と選択肢を与え、与えられた選択肢の中から正解を探す設定とした。一方OpenIEでは、選択肢を与えず、純粋にタスクの説明のみで予測を実施させた。OpenIEの結果を、3名のドメインエキスパートが出力が妥当か否か判定した結果、非常に高い性能を示すことがわかった。表を見ると、同じタスクでもstandardIEよりも高い性能を示している(そんなことある???)つまり、選択肢を与えてどれが正解ですか?ときくより、選択肢与えないでCoTさせた方が性能高いってこと?比較可能な設定で実験できているのだろうか。promptは付録に載っているが、output exampleが載ってないのでなんともいえない。StandardIEの設定をしたときに、CoTさせてるかどうかが気になる。もししてないなら、そりゃ性能低いだろうね、という気がする。 #MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #NeurIPS Issue Date: 2023-03-28 Reflexion: Language Agents with Verbal Reinforcement Learning, Noah Shinn+, N_A, NeurIPS'23 Summary本研究では、言語エージェントを強化するための新しいフレームワークであるReflexionを提案しています。Reflexionエージェントは、言語的フィードバックを通じて自己反省し、より良い意思決定を促すために反省的なテキストを保持します。Reflexionはさまざまなタスクでベースラインエージェントに比べて大幅な改善を実現し、従来の最先端のGPT-4を上回る精度を達成しました。さらに、異なるフィードバック信号や統合方法、エージェントタイプの研究を行い、パフォーマンスへの影響についての洞察を提供しています。 Commentなぜ回答を間違えたのか自己反省させることでパフォーマンスを向上させる研究 #NeuralNetwork #ComputerVision #SIGGRAPH Issue Date: 2022-12-01 Sketch-Guided Text-to-Image Diffusion Models, Andrey+, Google Research, SIGGRAPH'23 Summaryテキストから画像へのモデルは高品質な画像合成を実現するが、空間的特性の制御が不足している。本研究では、スケッチからの空間マップを用いて事前学習済みモデルを導く新しいアプローチを提案。専用モデルを必要とせず、潜在ガイダンス予測器(LGP)を訓練し、画像を空間マップに一致させる。ピクセルごとの訓練により柔軟性を持ち、スケッチから画像への翻訳タスクにおいて効果的な生成が可能であることを示す。 Commentスケッチとpromptを入力することで、スケッチ biasedな画像を生成することができる技術。すごい。
#Survey
#AdaptiveLearning
#EducationalDataMining
#KnowledgeTracing
Issue Date: 2022-08-02
Knowledge Tracing: A Survey, ABDELRAHMAN+, Australian National University, ACM Computing Surveys'23
Summary人間の教育における知識移転の重要性を背景に、オンライン教育における知識追跡(KT)の必要性が高まっている。本論文では、KTに関する包括的なレビューを行い、初期の手法から最新の深層学習技術までを網羅し、モデルの理論やデータセットの特性を強調する。また、関連手法のモデリングの違いを明確にし、KT文献の研究ギャップや今後の方向性についても議論する。
#NeuralNetwork
#Survey
#MachineLearning
Issue Date: 2021-06-19
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better, Menghani, ACM Computing Surveys'23
Summaryディープラーニングの進展に伴い、モデルのパラメータ数やリソース要求が増加しているため、効率性が重要になっている。本研究では、モデル効率性の5つのコア領域を調査し、実務者向けに最適化ガイドとコードを提供する。これにより、効率的なディープラーニングの全体像を示し、読者に改善の手助けとさらなる研究のアイデアを提供することを目指す。
Comment学習効率化、高速化などのテクニックがまとまっているらしい
#Dataset
#NeurIPS
#KnowledgeEditing
Issue Date: 2025-08-26
[Paper Note] Locating and Editing Factual Associations in GPT, Kevin Meng+, NeurIPS'22
Summary自回帰型トランスフォーマー言語モデルにおける事実の関連付けの保存と想起を分析し、局所的な計算に対応することを示した。因果介入を用いて事実予測に関与するニューロンを特定し、フィードフォワードモジュールの役割を明らかにした。Rank-One Model Editing(ROME)を用いて特定の事実の関連付けを更新し、他の方法と同等の効果を確認。新しいデータセットに対する評価でも特異性と一般化を両立できることを示した。中間層のフィードフォワードモジュールが事実の関連付けに重要であり、モデル編集の実行可能性を示唆している。
#ComputerVision
#Transformer
#OCR
#ACMMM
#Backbone
Issue Date: 2025-08-22
[Paper Note] DiT: Self-supervised Pre-training for Document Image Transformer, Junlong Li+, ACMMM'22
Summary自己監視型事前学習モデルDiTを提案し、ラベルなしテキスト画像を用いて文書AIタスクにおける性能を向上。文書画像分類やレイアウト分析、表検出、OCRなどで新たな最先端結果を達成。コードとモデルは公開中。
Issue Date: 2025-08-21
[Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
Summary本研究では、「憲法的AI」と呼ばれる手法を用いて、人間のラベルなしで無害なAIを訓練する方法を探求します。監視学習と強化学習の2つのフェーズを経て、自己批評と修正を通じてモデルを微調整し、嗜好モデルを報酬信号として強化学習を行います。このアプローチにより、有害なクエリに対しても適切に対処できる無害なAIアシスタントを育成し、AIの意思決定の透明性を向上させることが可能になります。
Issue Date: 2025-08-16
[Paper Note] Efficient Training of Language Models to Fill in the Middle, Mohammad Bavarian+, arXiv'22
Summary自回帰言語モデルが、文書の中央からテキストのスパンを末尾に移動させる単純な変換を用いて埋め込みを学習できることを示す。データ拡張による訓練が元の生成能力に影響を与えないことを証明し、FIMでの訓練をデフォルトとすべきと提案。主要なハイパーパラメータに関するアブレーションを行い、強力なデフォルト設定とベストプラクティスを提示。最良の埋め込みモデルをAPIで公開し、埋め込みベンチマークも提供。
#Embeddings
#NLP
#RepresentationLearning
#NeurIPS
#Length
Issue Date: 2025-07-29
[Paper Note] Matryoshka Representation Learning, Aditya Kusupati+, NeurIPS'22
Summaryマトリョーシカ表現学習(MRL)は、異なる計算リソースに適応可能な柔軟な表現を設計する手法であり、既存の表現学習パイプラインを最小限に修正して使用します。MRLは、粗から細への表現を学習し、ImageNet-1K分類で最大14倍小さい埋め込みサイズを提供し、実世界のスピードアップを実現し、少数ショット分類で精度向上を達成します。MRLは視覚、視覚+言語、言語のモダリティにわたるデータセットに拡張可能で、コードとモデルはオープンソースで公開されています。
Comment日本語解説:https://speakerdeck.com/hpprc/lun-jiang-zi-liao-matryoshka-representation-learning単一のモデルから複数のlengthのEmbeddingを出力できるような手法。
#NeuralNetwork
#ComputerVision
#MachineLearning
#NLP
#MultitaskLearning
#MulltiModal
#SpeechProcessing
#ICLR
Issue Date: 2025-07-10
[Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22
Summary汎用アーキテクチャPerceiver IOを提案し、任意のデータ設定に対応し、入力と出力のサイズに対して線形にスケール可能。柔軟なクエリメカニズムを追加し、タスク特有の設計を不要に。自然言語、視覚理解、マルチタスクで強力な結果を示し、GLUEベンチマークでBERTを上回る性能を達成。
Comment当時相当話題となったさまざまなモーダルを統一された枠組みで扱えるPerceiver IO論文
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。 #ComputerVision #NLP #Dataset #MulltiModal #CLIP #NeurIPS Issue Date: 2025-05-06 LAION-5B: An open large-scale dataset for training next generation image-text models, Christoph Schuhmann+, NeurIPS'22 SummaryLAION-5Bは、5.85億のCLIPフィルタリングされた画像-テキストペアから成る大規模データセットで、英語のペアが2.32B含まれています。このデータセットは、CLIPやGLIDEなどのモデルの再現とファインチューニングに利用され、マルチモーダルモデルの研究を民主化します。また、データ探索やサブセット生成のためのインターフェースや、コンテンツ検出のためのスコアも提供されます。 #Metrics #Evaluation #AutomaticSpeechRecognition(ASR) #NAACL #SimulST(SimultaneousSpeechTranslation) Issue Date: 2025-04-30 Over-Generation Cannot Be Rewarded: Length-Adaptive Average Lagging for Simultaneous Speech Translation, Sara Papi+, NAACL'22 SummarySimulSTシステムの遅延評価において、ALが長い予測に対して過小評価される問題を指摘。過剰生成の傾向を持つシステムに対し、過小生成と過剰生成を公平に評価する新指標LAALを提案。 Comment同時翻訳研究で主要なmetricの一つ
関連:
・1915 #MachineLearning #NLP #LanguageModel #NeurIPS #Scaling Laws #Admin'sPick Issue Date: 2025-03-23 Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22 Summaryトランスフォーマー言語モデルの訓練において、計算予算内で最適なモデルサイズとトークン数を調査。モデルサイズと訓練トークン数は同等にスケールする必要があり、倍増するごとにトークン数も倍増すべきと提案。Chinchillaモデルは、Gopherなどの大規模モデルに対して優れた性能を示し、ファインチューニングと推論の計算量を削減。MMLUベンチマークで67.5%の精度を達成し、Gopherに対して7%以上の改善を実現。 CommentOpenReview: https://openreview.net/forum?id=iBBcRUlOAPRchinchilla則 #EfficiencyImprovement #Pretraining #NLP #Transformer #Architecture #MoE(Mixture-of-Experts) #Admin'sPick Issue Date: 2025-02-11 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22 SummarySwitch Transformerを提案し、Mixture of Experts (MoE)の複雑さや通信コスト、トレーニングの不安定性を改善。これにより、低精度フォーマットでの大規模スパースモデルのトレーニングが可能になり、最大7倍の事前トレーニング速度向上を実現。さらに、1兆パラメータのモデルを事前トレーニングし、T5-XXLモデルに対して4倍の速度向上を達成。 #Pretraining #ICLR Issue Date: 2025-01-06 Towards Continual Knowledge Learning of Language Models, Joel Jang+, ICLR'22 Summary大規模言語モデル(LMs)の知識が陳腐化する問題に対処するため、「継続的知識学習(CKL)」という新しい継続的学習問題を定式化。CKLでは、時間不変の知識の保持、陳腐化した知識の更新、新しい知識の獲得を定量化するためのベンチマークとメトリックを構築。実験により、CKLが独自の課題を示し、知識を信頼性高く保持し学習するためにはパラメータの拡張が必要であることが明らかに。ベンチマークデータセットやコードは公開されている。 #RecommenderSystems #NeuralNetwork #CTRPrediction Issue Date: 2024-11-19 Deep Intention-Aware Network for Click-Through Rate Prediction, Yaxian Xia+, arXiv'22 SummaryEコマースプラットフォームにおけるトリガー誘発推薦(TIRA)に対し、従来のCTR予測モデルは不適切である。顧客のエントリー意図を抽出し、トリガーの影響を評価するために、深層意図認識ネットワーク(DIAN)を提案。DIANは、ユーザーの意図を推定し、トリガー依存と非依存の推薦結果を動的にバランスさせる。実験により、DIANはタオバオのミニアプリでCTRを4.74%向上させることが示された。 Comment1531 の実験で利用されているベースライン #RecommenderSystems #NeuralNetwork #CTRPrediction Issue Date: 2024-11-19 Deep Interest Highlight Network for Click-Through Rate Prediction in Trigger-Induced Recommendation, Qijie Shen+, WWW'22 Summaryトリガー誘発推薦(TIR)を提案し、ユーザーの瞬時の興味を引き出す新しい推薦手法を紹介。従来のモデルがTIRシナリオで効果的でない問題を解決するため、Deep Interest Highlight Network(DIHN)を開発。DIHNは、ユーザー意図ネットワーク(UIN)、融合埋め込みモジュール(FEM)、ハイブリッド興味抽出モジュール(HIEM)の3つのコンポーネントから成り、実際のeコマースプラットフォームでの評価で優れた性能を示した。 Comment1531 の実験で利用されているベースライン #MachineTranslation #NLP #Dataset Issue Date: 2024-09-26 No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, N_A, arXiv'22 Summary「No Language Left Behind」プロジェクトでは、リソースが乏しい言語の機械翻訳を改善するために、ネイティブスピーカーとのインタビューを通じて必要性を明らかにし、データセットとモデルを開発。新しいデータマイニング技術を用いた条件付き計算モデルを提案し、過学習を防ぐための訓練改善を行った。Flores-200ベンチマークで40,000以上の翻訳方向を評価し、従来技術に対して44%のBLEU改善を達成。全ての成果はオープンソースとして公開。 Commentlow-resourceな言語に対するMTのベンチマーク #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning Issue Date: 2024-09-25 Finetuned Language Models Are Zero-Shot Learners, Jason Wei+, N_A, ICLR'22 Summary指示チューニングを用いて言語モデルのゼロショット学習能力を向上させる方法を提案。137BパラメータのモデルFLANは、60以上のNLPタスクでファインチューニングされ、未見のタスクで175B GPT-3を上回るパフォーマンスを示す。アブレーションスタディにより、ファインチューニングデータセットの数やモデルのスケールが成功に寄与することが確認された。 CommentFLAN論文。Instruction Tuningを提案した研究。 #NLP #LanguageModel #SelfImprovement Issue Date: 2024-09-15 STaR: Bootstrapping Reasoning With Reasoning, Eric Zelikman+, N_A, NeurIPS'22 Summary「自己学習推論者」(STaR)を提案し、少数の合理的説明と大規模データセットを活用して複雑な推論を行う。STaRは、生成した回答が間違っている場合に正しい回答を用いて再生成し、ファインチューニングを繰り返すことで性能を向上させる。実験により、STaRは従来のモデルと比較して大幅な性能向上を示し、特にCommensenseQAでの成果が顕著である。 CommentOpenAI o1関連研究 #Analysis #NLP #Transformer #ACL #KnowledgeEditing #Admin'sPick #FactualKnowledge #Encoder Issue Date: 2024-07-11 Knowledge Neurons in Pretrained Transformers, Damai Dai+, N_A, ACL'22, 2022.05 Summary大規模な事前学習言語モデルにおいて、事実知識の格納方法についての研究を行いました。具体的には、BERTのfill-in-the-blank cloze taskを用いて、関連する事実を表現するニューロンを特定しました。また、知識ニューロンの活性化と対応する事実の表現との正の相関を見つけました。さらに、ファインチューニングを行わずに、知識ニューロンを活用して特定の事実知識を編集しようと試みました。この研究は、事前学習されたTransformers内での知識の格納に関する示唆に富んでおり、コードはhttps://github.com/Hunter-DDM/knowledge-neuronsで利用可能です。 Comment1108 日本語解説: https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022関連:
・2140上記資料によると、特定の知識を出力する際に活性化する知識ニューロンを特定する手法を提案。MLMを用いたclozeタスクによる実験で[MASK]部分に当該知識を出力する実験をした結果、知識ニューロンの重みをゼロとすると性能が著しく劣化し、値を2倍にすると性能が改善するといった傾向がみられた。 ケーススタディとして、知識の更新と、知識の削除が可能かを検証。どちらとも更新・削除がされる方向性[^1]へモデルが変化した。
また、知識ニューロンはTransformerの層の深いところに位置している傾向にあり、異なるrelationを持つような関係知識同士では共有されない傾向にある模様。
[^1]: 他の知識に影響を与えず、完璧に更新・削除できたわけではない。知識の更新・削除に伴いExtrinsicな評価によって性能向上、あるいはPerplexityが増大した、といった結果からそういった方向性へモデルが変化した、という話 Issue Date: 2024-02-22 Dense Text Retrieval based on Pretrained Language Models: A Survey, Wayne Xin Zhao+, N_A, arXiv'22 Summaryテキスト検索における最近の進歩に焦点を当て、PLMベースの密な検索に関する包括的な調査を行った。PLMsを使用することで、クエリとテキストの表現を学習し、意味マッチング関数を構築することが可能となり、密な検索アプローチが可能となる。この調査では、アーキテクチャ、トレーニング、インデックス作成、統合などの側面に焦点を当て、300以上の関連文献を含む包括的な情報を提供している。 #NaturalLanguageGeneration #NLP #DataToTextGeneration #StructuredData Issue Date: 2023-10-28 MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation, Swarnadeep Saha+, N_A, arXiv'22 Summary本研究では、半構造化データからのテキスト生成における多段階の推論を行うためのMURMURという手法を提案しています。MURMURは、特定の言語的および論理的なスキルを持つニューラルモジュールと記号モジュールを組み合わせ、ベストファーストサーチ手法を使用して推論パスを生成します。実験結果では、MURMURは他のベースライン手法に比べて大幅な改善を示し、また、ドメイン外のデータでも同等の性能を達成しました。さらに、人間の評価では、MURMURは論理的に整合性のある要約をより多く生成することが示されました。 #EfficiencyImprovement #MachineLearning Issue Date: 2023-08-16 Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning, Haokun Liu+, N_A, arXiv'22 SummaryFew-shot in-context learning(ICL)とパラメータ効率の良いファインチューニング(PEFT)を比較し、PEFTが高い精度と低い計算コストを提供することを示す。また、新しいPEFTメソッドである(IA)^3を紹介し、わずかな新しいパラメータしか導入しないまま、強力なパフォーマンスを達成する。さらに、T-Fewというシンプルなレシピを提案し、タスク固有のチューニングや修正なしに新しいタスクに適用できる。RAFTベンチマークでT-Fewを使用し、超人的なパフォーマンスを達成し、最先端を6%絶対的に上回る。 #BeamSearch #NaturalLanguageGeneration #NLP Issue Date: 2023-08-16 Momentum Calibration for Text Generation, Xingxing Zhang+, N_A, arXiv'22 Summary本研究では、テキスト生成タスクにおいてMoCa(Momentum Calibration)という手法を提案しています。MoCaは、ビームサーチを用いた遅く進化するサンプルを動的に生成し、これらのサンプルのモデルスコアを実際の品質に合わせるように学習します。実験結果は、MoCaが強力な事前学習済みTransformerを改善し、最先端の結果を達成していることを示しています。 #DocumentSummarization #BeamSearch #NaturalLanguageGeneration #NLP #ACL Issue Date: 2023-08-16 BRIO: Bringing Order to Abstractive Summarization, Yixin Liu+, N_A, ACL'22 Summary従来の抽象的要約モデルでは、最尤推定を使用して訓練されていましたが、この方法では複数の候補要約を比較する際に性能が低下する可能性があります。そこで、非確定論的な分布を仮定し、候補要約の品質に応じて確率を割り当てる新しい訓練パラダイムを提案しました。この手法により、CNN/DailyMailとXSumのデータセットで最高の結果を達成しました。さらに、モデルが候補要約の品質とより相関のある確率を推定できることも示されました。 Commentビーム内のトップがROUGEを最大化しているとは限らなかったため、ROUGEが最大となるような要約を選択するようにしたら性能爆上げしましたという研究。
実質現在のSoTA #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-14 SMART: Sentences as Basic Units for Text Evaluation, Reinald Kim Amplayo+, N_A, arXiv'22 Summary本研究では、テキスト生成の評価指標の制限を緩和するために、新しい指標であるSMARTを提案する。SMARTは文を基本的なマッチング単位とし、文のマッチング関数を使用して候補文と参照文を評価する。また、ソースドキュメントの文とも比較し、評価を可能にする。実験結果は、SMARTが他の指標を上回ることを示し、特にモデルベースのマッチング関数を使用した場合に有効であることを示している。また、提案された指標は長い要約文でもうまく機能し、特定のモデルに偏りが少ないことも示されている。 #DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #Reference-based Issue Date: 2023-08-13 FFCI: A Framework for Interpretable Automatic Evaluation of Summarization, Fajri Koto+, N_A, JAIR'22 Summary本論文では、FFCIという細かい要約評価のためのフレームワークを提案しました。このフレームワークは、信頼性、焦点、カバレッジ、および文間の連続性の4つの要素から構成されています。新しいデータセットを構築し、評価メトリックとモデルベースの評価方法をクロス比較することで、FFCIの4つの次元を評価するための自動的な方法を開発しました。さまざまな要約モデルを評価し、驚くべき結果を得ました。 Comment先行研究でどのようなMetricが利用されていて、それらがどういった観点のMetricなのかや、データセットなど、非常に細かくまとまっている。Faithfulness(ROUGE, STS-Score, BERTScoreに基づく), Focus and Coverage (Question Answering basedな手法に基づく), Inter-Sentential Coherence (NSPに基づく)メトリックを組み合わせることを提案している。 #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation, Pierre Colombo+, N_A, AAAI'22 Summary自然言語生成システムの品質評価は高価であり、人間の注釈に頼ることが一般的です。しかし、自動評価指標を使用することもあります。本研究では、マスクされた言語モデルを使用した評価指標であるInfoLMを紹介します。この指標は同義語を処理することができ、要約やデータ生成の設定で有意な改善を示しました。 #DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 WIDAR -- Weighted Input Document Augmented ROUGE, Raghav Jain+, N_A, ECIR'22 Summary自動テキスト要約の評価において、ROUGEメトリックには制約があり、参照要約の利用可能性に依存している。そこで、本研究ではWIDARメトリックを提案し、参照要約だけでなく入力ドキュメントも使用して要約の品質を評価する。WIDARメトリックは一貫性、整合性、流暢さ、関連性の向上をROUGEと比較しており、他の最先端のメトリックと同等の結果を短い計算時間で得ることができる。 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 How to Find Strong Summary Coherence Measures? A Toolbox and a Comparative Study for Summary Coherence Measure Evaluation, Steen+, COLING'22 Summary要約の一貫性を自動的に評価することは重要であり、さまざまな方法が提案されていますが、異なるデータセットと評価指標を使用して評価されるため、相対的なパフォーマンスを理解することが困難です。本研究では、要約の一貫性モデリングのさまざまな方法について調査し、新しい分析尺度を導入します。現在の自動一貫性尺度はすべての評価指標において信頼性のある一貫性スコアを割り当てることができませんが、大規模言語モデルは有望な結果を示しています。 #DocumentSummarization #NeuralNetwork #Analysis #NLP #IJCNLP #AACL #Repetition Issue Date: 2023-08-13 Self-Repetition in Abstractive Neural Summarizers, Nikita Salkar+, N_A, AACL-IJCNLP'22 Summary私たちは、BART、T5、およびPegasusという3つのニューラルモデルの出力における自己繰り返しの分析を行いました。これらのモデルは、異なるデータセットでfine-tuningされています。回帰分析によると、これらのモデルは入力の出力要約間でコンテンツを繰り返す傾向が異なることがわかりました。また、抽象的なデータや定型的な言語を特徴とするデータでのfine-tuningでは、自己繰り返しの割合が高くなる傾向があります。定性的な分析では、システムがアーティファクトや定型フレーズを生成することがわかりました。これらの結果は、サマライザーのトレーニングデータを最適化するための手法の開発に役立つ可能性があります。 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 Universal Evasion Attacks on Summarization Scoring, Wenchuan Mu+, N_A, BlackboxNLP workshop on ACL'22 Summary要約の自動評価は重要であり、その評価は複雑です。しかし、これまで要約の評価は機械学習のタスクとは考えられていませんでした。本研究では、自動評価の堅牢性を探るために回避攻撃を行いました。攻撃システムは、要約ではない文字列を予測し、一般的な評価指標であるROUGEやMETEORにおいて優れた要約器と競合するスコアを達成しました。また、攻撃システムは最先端の要約手法を上回るスコアを獲得しました。この研究は、現在の評価システムの堅牢性の低さを示しており、要約スコアの開発を促進することを目指しています。 #DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-13 DocAsRef: A Pilot Empirical Study on Repurposing Reference-Based Summary Quality Metrics Reference-Freely, Forrest Sheng Bao+, N_A, arXiv'22 Summary参照ベースと参照フリーの要約評価メトリックがあります。参照ベースは正確ですが、制約があります。参照フリーは独立していますが、ゼロショットと正確さの両方を満たせません。本研究では、参照ベースのメトリックを使用してゼロショットかつ正確な参照フリーのアプローチを提案します。実験結果は、このアプローチが最も優れた参照フリーのメトリックを提供できることを示しています。また、参照ベースのメトリックの再利用と追加の調整についても調査しています。 #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration Issue Date: 2023-08-11 Personalized News Headline Generation System with Fine-grained User Modeling, Yao, MSN'22 Summaryユーザーの興味に基づいてパーソナライズされたニュースの見出しを生成するために、文レベルの情報を考慮したユーザーモデルを提案する。アテンション層を使用して文とニュースの関連性を計算し、ニュースの内容に基づいて見出しを生成する。実験結果は、提案モデルがベースラインモデルよりも優れたパフォーマンスを示していることを示している。将来の方向性として、情報のレベルと内容を横断する相互作用についても議論されている。 #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration Issue Date: 2023-08-11 Personalized Headline Generation with Enhanced User Interest Perception, Zhang+, ICANN'22 Summaryユーザーのニュース閲覧履歴をモデル化し、個別化されたニュース見出しを生成するための新しいフレームワークを提案する。提案手法は、ユーザーの興味を強調するために候補テキストに関連する情報を活用し、ニュースのエンティティワードを使用して興味表現を改善する。幅広い実験により、提案手法が見出し生成タスクで優れたパフォーマンスを示すことが示されている。 #RecommenderSystems #NLP #PersonalizedGeneration #Personalization Issue Date: 2023-08-11 Personalized Chit-Chat Generation for Recommendation Using External Chat Corpora, Chen+, KDD'22 Summaryチットチャットは、ユーザーとの対話において効果的であることが示されています。この研究では、ニュース推薦のための個人化されたチットチャットを生成する方法を提案しています。既存の方法とは異なり、外部のチャットコーパスのみを使用してユーザーの関心を推定し、個人化されたチットチャットを生成します。幅広い実験により、提案手法の効果が示されています。 #NaturalLanguageGeneration #NLP #Dataset #LanguageModel #Explanation Issue Date: 2023-08-03 Explaining Patterns in Data with Language Models via Interpretable Autoprompting, Chandan Singh+, N_A, arXiv'22 Summary本研究では、大規模言語モデル(LLMs)を使用してデータのパターンを説明する能力を探求しました。具体的には、事前学習済みのLLMを使用してデータを説明する自然言語の文字列を生成するアルゴリズムを導入しました。実験結果は、このアルゴリズムが正確なデータセットの説明を見つけ出すことができることを示しています。また、生成されるプロンプトは人間にも理解可能であり、実世界のデータセットやfMRIデータセットで有用な洞察を提供することができることも示されました。 CommentOpenReview: https://openreview.net/forum?id=GvMuB-YsiK6データセット(中に存在するパターンの説明)をLLMによって生成させる研究

 #Pretraining #MachineLearning #Self-SupervisedLearning Issue Date: 2023-07-22 RankMe: Assessing the downstream performance of pretrained self-supervised representations by their rank, Quentin Garrido+, N_A, arXiv'22 Summary共有埋め込み自己教示学習(JE-SSL)は、成功の視覚的な手がかりが欠如しているため、展開が困難である。本研究では、JE-SSL表現の品質を評価するための非教示基準であるRankMeを開発した。RankMeはラベルを必要とせず、ハイパーパラメータの調整も不要である。徹底的な実験により、RankMeが最終パフォーマンスのほとんど減少なしにハイパーパラメータの選択に使用できることを示した。RankMeはJE-SSLの展開を容易にすることが期待される。 #NaturalLanguageGeneration #Controllable #NLP Issue Date: 2023-07-18 An Extensible Plug-and-Play Method for Multi-Aspect Controllable Text Generation, Xuancheng Huang+, N_A, arXiv'22 Summary本研究では、テキスト生成において複数の側面を制御する方法について研究しました。従来の方法では、プレフィックスの相互干渉により制約が低下し、未知の側面の組み合わせを制御することが制限されていました。そこで、トレーニング可能なゲートを使用してプレフィックスの介入を正規化し、相互干渉の増加を抑制する方法を提案しました。この方法により、トレーニング時に未知の制約を低コストで拡張することができます。さらに、カテゴリカルな制約と自由形式の制約の両方を処理する統一された方法も提案しました。実験により、提案手法が制約の正確さ、テキストの品質、拡張性においてベースラインよりも優れていることが示されました。 #NeuralNetwork #ComputerVision #MachineLearning #Supervised-FineTuning (SFT) #CLIP #ICLR #OOD Issue Date: 2023-05-15 Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution, Ananya Kumar+, N_A, ICLR'22 Summary事前学習済みモデルをダウンストリームタスクに転移する際、ファインチューニングと線形プロービングの2つの方法があるが、本研究では、分布のシフトが大きい場合、ファインチューニングが線形プロービングよりも分布外で精度が低くなることを発見した。LP-FTという2段階戦略の線形プロービング後の全体のファインチューニングが、両方のデータセットでファインチューニングと線形プロービングを上回ることを示唆している。 Comment事前学習済みのニューラルモデルをfinetuningする方法は大きく分けて
1. linear layerをヘッドとしてconcatしヘッドのみのパラメータを学習
2. 事前学習済みモデル全パラメータを学習
の2種類がある。
前者はin-distributionデータに強いが、out-of-distributionに弱い。後者は逆という互いが互いを補完し合う関係にあった。
そこで、まず1を実施し、その後2を実施する手法を提案。in-distribution, out-of-distributionの両方で高い性能を出すことを示した(実験では画像処理系のデータを用いて、モデルとしてはImageNet+CLIPで事前学習済みのViTを用いている)。
https://x.com/tallinzen/status/1957454242936938545?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Dataset #LanguageModel #Evaluation #CodeGeneration #Admin'sPick Issue Date: 2025-08-15 [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21 Summary本論文では、汎用プログラミング言語におけるプログラム合成の限界を大規模言語モデルを用いて評価します。MBPPとMathQA-Pythonの2つのベンチマークで、モデルサイズに対する合成性能のスケールを調査。最も大きなモデルは、少数ショット学習でMBPPの59.6%の問題を解決可能で、ファインチューニングにより約10%の性能向上が見られました。MathQA-Pythonでは、ファインチューニングされたモデルが83.8%の精度を達成。人間のフィードバックを取り入れることでエラー率が半減し、エラー分析を通じてモデルの弱点を明らかにしました。最終的に、プログラム実行結果の予測能力を探るも、最良のモデルでも特定の入力に対する出力予測が困難であることが示されました。 Comment代表的なコード生成のベンチマーク。
MBPPデータセットは、promptで指示されたコードをモデルに生成させ、テストコード(assertion)を通過するか否かで評価する。974サンプル存在し、pythonの基礎を持つクラウドワーカーによって生成。クラウドワーカーにタスクdescriptionとタスクを実施する一つの関数(関数のみで実行可能でprintは不可)、3つのテストケースを記述するよう依頼。タスクdescriptionは追加なclarificationなしでコードが記述できるよう十分な情報を含むよう記述するように指示。ground truthの関数を生成する際に、webを閲覧することを許可した。
MathQA-Pythonは、MathQAに含まれるQAのうち解答が数値のもののみにフィルタリングしたデータセットで、合計で23914サンプル存在する。pythonコードで与えられた数学に関する問題を解くコードを書き、数値が一致するか否かで評価する、といった感じな模様。斜め読みなので少し読み違えているかもしれない。
164個の人手で記述されたprogrammingの問題で、それぞれはfunction signature, docstring, body, unittestを持つ。unittestは問題当たり約7.7 test存在。handwrittenという点がミソで、コンタミネーションの懸念があるためgithubのような既存ソースからのコピーなどはしていない。pass@k[^1]で評価。
[^1]: k個のサンプルを生成させ、k個のサンプルのうち、サンプルがunittestを一つでも通過する確率。ただ、本研究ではよりバイアスをなくすために、kよりも大きいn個のサンプルを生成し、その中からランダムにk個を選択して確率を推定するようなアプローチを実施している。2.1節を参照のこと。
・当時の最も大きいレベルのモデルでも multi-stepのreasoningが必要な問題は失敗する
・モデルをFinetuningをしても致命的なミスが含まれる
・特に、数学は個々のミスに対して非常にsensitiveであり、一回ミスをして異なる解法のパスに入ってしまうと、self-correctionするメカニズムがauto-regressiveなモデルではうまくいかない
・純粋なテキスト生成の枠組みでそれなりの性能に到達しようとすると、とんでもないパラメータ数が必要になり、より良いscaling lawを示す手法を模索する必要がある
Contribution
論文の貢献は
・GSM8Kを提案し、
・verifierを活用しモデルの複数の候補の中から良い候補を選ぶフレームワークによって、モデルのパラメータを30倍にしたのと同等のパフォーマンスを達成し、データを増やすとverifierを導入するとよりよく性能がスケールすることを示した。
・また、dropoutが非常に強い正則化作用を促し、finetuningとverificationの双方を大きく改善することを示した。Todo: 続きをまとめる #Analysis #NLP #PEFT(Adaptor/LoRA) Issue Date: 2024-10-01 Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, Armen Aghajanyan+, N_A, ACL'21 Summary事前学習された言語モデルのファインチューニングのダイナミクスを内因次元の観点から分析し、少ないデータでも効果的に調整できる理由を説明。一般的なモデルは低い内因次元を持ち、フルパラメータ空間と同等の効果を持つ低次元の再パラメータ化が可能であることを示す。特に、RoBERTaモデルを用いて、少数のパラメータの最適化で高いパフォーマンスを達成できることを実証。また、事前学習が内因次元を最小化し、大きなモデルが低い内因次元を持つ傾向があることを示し、内因次元に基づく一般化境界を提案。 CommentACL ver:https://aclanthology.org/2021.acl-long.568.pdf下記の元ポストを拝読の上論文を斜め読み。モデルサイズが大きいほど、特定の性能(論文中では2種類のデータセットでの90%のsentence prediction性能)をfinetuningで達成するために必要なパラメータ数は、モデルサイズが大きくなればなるほど小さくなっている。
LoRAとの関係性についても元ポスト中で言及されており、論文の中身も見て後で確認する。
おそらく、LLMはBERTなどと比較して遥かにパラメータ数が大きいため、finetuningに要するパラメータ数はさらに小さくなっていることが想像され、LoRAのような少量のパラメータをconcatするだけでうまくいく、というような話だと思われる。興味深い。
元ポスト:https://x.com/bilzrd/status/1840445027438456838?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #NLP #Transformer Issue Date: 2024-07-11 Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, N_A, EMNLP'21 Summaryトランスフォーマーモデルのフィードフォワード層は、キー・バリューメモリとして機能し、学習されたパターンが人間に解釈可能であることや、上位層がより意味のあるパターンを学習することが示されました。さらに、出力分布を誘導する役割も持ちます。フィードフォワード層の出力はそのメモリの合成であり、残差接続を介してモデルの層を通じて洗練され、最終的な出力分布を生成します。 Comment1108 FF layerがKey-Valueストアとして機能する仕組みの概略図
実際に特定のKeyと最も関連度が高い訓練事例(input)を抽出し、人間がinputのパターンを分類した結果
続いて、expertsとAMT workerに対して、story generationの評価を実施し、GPT2が生成したストーリーと人間が生成したストーリーを、後者のスコアが高くなることを期待して依頼した。その結果
・AMTのratingは、モデルが生成したテキストと、人間が生成したテキストをreliableに区別できない
・同一のタスクを異なる日程で実施をすると、高い分散が生じた
・多くのAMT workerは、評価対象のテキストを注意深く読んでいない
・Expertでさえモデルが生成したテキストを読み判断するのには苦戦をし、先行研究と比較してより多くの時間を費やし、agreementが低くなることが分かった
892 において、低品質なwork forceが人手評価に対して有害な影響を与える、という文脈で本研究が引用されている #ComputerVision #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Transformer #MulltiModal Issue Date: 2023-08-22 ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision, Wonjae Kim+, N_A, ICML'21 SummaryVLP(Vision-and-Language Pre-training)のアプローチは、ビジョンと言語のタスクでのパフォーマンスを向上させているが、現在の方法は効率性と表現力の面で問題がある。そこで、本研究では畳み込みフリーのビジョンと言語のトランスフォーマ(ViLT)モデルを提案する。ViLTは高速でありながら競争力のあるパフォーマンスを示し、コードと事前学習済みの重みはGitHubで利用可能である。 Comment日本語解説:https://tech.fusic.co.jp/posts/2021-12-29-vilt/ #Sentence #Embeddings #NLP #LanguageModel #RepresentationLearning #ContrastiveLearning #Catastrophic Forgetting #Admin'sPick Issue Date: 2023-07-27 SimCSE: Simple Contrastive Learning of Sentence Embeddings, Tianyu Gao+, N_A, EMNLP'21 Summaryこの論文では、SimCSEという対比学習フレームワークを提案しています。このフレームワークは、文の埋め込み技術を進化させることができます。教師なしアプローチでは、入力文をノイズとして扱い、自己を対比的に予測します。教師ありアプローチでは、自然言語推論データセットから注釈付きのペアを使用して対比学習を行います。SimCSEは、意味的テキスト類似性タスクで評価され、以前の手法と比較して改善を実現しました。対比学習は、事前学習された埋め込みの空間を均一に正則化し、教師信号が利用可能な場合には正のペアをよりよく整列させることが示されました。 Comment462 よりも性能良く、unsupervisedでも学習できる。STSタスクのベースラインにだいたい入ってる手法概要
Contrastive Learningを活用して、unsupervised/supervisedに学習を実施する。
Unsupervised SimCSEでは、あるsentenceをencoderに2回入力し、それぞれにdropoutを適用させることで、positive pairを作成する。dropoutによって共通のembeddingから異なる要素がマスクされた(noiseが混ざった状態とみなせる)類似したembeddingが作成され、ある種のdata augmentationによって正例を作成しているともいえる。負例はnegative samplingする。(非常にsimpleだが、next sentence predictionで学習するより性能が良くなる)
Supervised SimCSEでは、アノテーションされたsentence pairに基づいて、正例・負例を決定する。本研究では、NLIのデータセットにおいて、entailment関係にあるものは正例として扱う。contradictions(矛盾)関係にあるものは負例として扱う。
Siamese Networkで用いられるmeans-squared errrorとContrastiveObjectiveの違い
どちらもペアワイズで比較するという点では一緒だが、ContrastiveObjectiveは正例と近づいたとき、負例と遠ざかったときにlossが小さくなるような定式化がされている点が異なる。
(画像はこのブログから引用。ありがとうございます。https://techblog.cccmk.co.jp/entry/2022/08/30/163625)
Unsupervised SimCSEの実験
異なるdata augmentation手法と比較した結果、dropoutを適用する手法の方が性能が高かった。MLMや, deletion, 類義語への置き換え等よりも高い性能を獲得しているのは興味深い。また、Next Sentence Predictionと比較しても、高い性能を達成。Next Sentence Predictionは、word deletion等のほぼ類似したテキストから直接的に類似関係にあるペアから学習するというより、Sentenceの意味内容のつながりに基づいてモデルの言語理解能力を向上させ、そのうえで類似度を測るという間接的な手法だが、word deletionに負けている。一方、dropoutを適用するだけの(直接的に類似ペアから学習する)本手法はより高い性能を示している。
[image](https://github.com/AkihikoWatanabe/paper_notes/assets/12249301/0ea3549e-3363-4857-94e6-a1ef474aa191)
なぜうまくいくかを分析するために、異なる設定で実験し、alignment(正例との近さ)とuniformity(どれだけembeddingが一様に分布しているか)を、10 stepごとにplotした結果が以下。dropoutを適用しない場合と、常に同じ部分をマスクする方法(つまり、全く同じembeddingから学習する)設定を見ると、学習が進むにつれuniformityは改善するが、alignmentが悪くなっていっている。一方、SimCSEはalignmentを維持しつつ、uniformityもよくなっていっていることがわかる。
Supervised SimCSEの実験
アノテーションデータを用いてContrastiveLearningするにあたり、どういったデータを正例としてみなすと良いかを検証するために様々なデータセットで学習し性能を検証した。
・QQP4: Quora question pairs
・Flickr30k (Young et al., 2014): 同じ画像に対して、5つの異なる人間が記述したキャプションが存在
・ParaNMT (Wieting and Gimpel, 2018): back-translationによるparaphraseのデータセットa
・NLI datasets: SNLIとMNLI
実験の結果、NLI datasetsが最も高い性能を示した。この理由としては、NLIデータセットは、crowd sourcingタスクで人手で作成された高品質なデータセットであることと、lexical overlapが小さくなるようにsentenceのペアが作成されていることが起因している。実際、NLI datsetのlexical overlapは39%だったのに対し、ほかのデータセットでは60%であった。
また、condunctionsとなるペアを明示的に負例として与えることで、より性能が向上した(普通はnegative samplingする、というかバッチ内の正例以外のものを強制的に負例とする。こうすると、意味が同じでも負例になってしまう事例が出てくることになる)。より難しいNLIタスクを含むANLIデータセットを追加した場合は、性能が改善しなかった。この理由については考察されていない。性能向上しそうな気がするのに。
他手法との比較結果
SimCSEがよい。
Ablation Studies
異なるpooling方法で、どのようにsentence embeddingを作成するかで性能の違いを見た。originalのBERTの実装では、CLS token のembeddingの上にMLP layerがのっかっている。これの有無などと比較。
Unsupervised SimCSEでは、training時だけMLP layerをのっけて、test時はMLPを除いた方が良かった。一方、Supervised SimCSEでは、 MLP layerをのっけたまんまで良かったとのこと。
また、SimCSEで学習したsentence embeddingを別タスクにtransferして活用する際には、SimCSEのobjectiveにMLMを入れた方が、catastrophic forgettingを防げて性能が高かったとのこと。
453 などでDeepLearningBasedなモデル間であまり差がないことが示されているので、本研究が実際どれだけ強いのかは気になるところ。 #NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration Issue Date: 2021-10-08 過去情報の内容選択を取り入れた スポーツダイジェストの自動生成, 加藤+, 東工大, NLP'21 #AdaptiveLearning #IJCAI Issue Date: 2021-08-04 RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions, Kubotani+, Waseda University, IJCAI'21 Summary教育分野の課題に対し、学生の知識状態に基づく適応指導を強化学習で最適化するフレームワークを提案。実際の学生との相互作用を最小限にし、仮想モデルを構築。実験により、提案モデルは従来の指導方法と同等の性能を示し、理論と実践の橋渡しを行う。 #EMNLP #Findings Issue Date: 2025-08-16 [Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings Summary低リソース言語翻訳において、QKNormという新しい正規化手法を提案。これは、注意メカニズムを修正し、ソフトマックス関数の飽和耐性を向上させつつ表現力を維持。具体的には、クエリとキー行列に対して$\ell_2$正規化を適用し、学習可能なパラメータでスケールアップ。TED TalksコーパスとIWSLT'15の低リソース翻訳ペアで平均0.928 BLEUの改善を達成。 #EfficiencyImprovement #NLP #Transformer #Attention Issue Date: 2025-08-09 [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20 SummaryLongformerは、長いシーケンスを線形に処理できる注意機構を持つTransformerベースのモデルで、数千トークンの文書を扱える。局所的なウィンドウ注意とタスクに基づくグローバル注意を組み合わせ、文字レベルの言語モデリングで最先端の結果を達成。事前学習とファインチューニングを行い、長文タスクでRoBERTaを上回る性能を示した。また、Longformer-Encoder-Decoder(LED)を導入し、長文生成タスクにおける効果を確認した。 Comment(固定された小さめのwindowsサイズの中でのみattentionを計算する)sliding window attentionを提案
・1309 #EfficiencyImprovement #NLP #Transformer #Attention #ICML Issue Date: 2025-08-05 [Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20 Summary自己注意をカーネル特徴マップの線形ドット積として表現することで、Transformersの複雑性を$\mathcal{O}\left(N^2\right)$から$\mathcal{O}\left(N\right)$に削減。これにより、自己回帰型Transformersの速度が最大4000倍向上し、従来のパフォーマンスを維持。 Comment関連:
・1210 #EfficiencyImprovement #NLP #Transformer #Attention #ICLR Issue Date: 2025-08-05 [Paper Note] Reformer: The Efficient Transformer, Nikita Kitaev+, ICLR'20 Summary本研究では、トランスフォーマーモデルの効率を向上させるために、局所感度ハッシュを用いた注意機構と可逆残差層を提案。これにより、計算量をO($L^2$)からO($L\log L$)に削減し、メモリ効率と速度を向上させたReformerモデルを実現。トランスフォーマーと同等の性能を維持。 Commentopenreview: https://openreview.net/forum?id=rkgNKkHtvB #EfficiencyImprovement #NLP #Transformer #Attention Issue Date: 2025-08-05 [Paper Note] Linformer: Self-Attention with Linear Complexity, Sinong Wang+, arXiv'20 Summary大規模トランスフォーマーモデルは自然言語処理で成功を収めているが、長いシーケンスに対しては高コスト。自己注意メカニズムを低ランク行列で近似し、複雑さを$O(n^2)$から$O(n)$に削減する新しいメカニズムを提案。これにより、メモリと時間効率が向上した線形トランスフォーマー「Linformer」が標準モデルと同等の性能を示す。 #NaturalLanguageGeneration #NLP #Dataset #Evaluation #Composition #EMNLP #Findings #CommonsenseReasoning Issue Date: 2025-07-31 [Paper Note] CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning, Bill Yuchen Lin+, EMNLP'20 Findings Summary生成的常識推論をテストするためのタスクCommonGenを提案し、35,000の概念セットに基づく79,000の常識的記述を含むデータセットを構築。タスクは、与えられた概念を用いて一貫した文を生成することを求め、関係推論と構成的一般化能力が必要。実験では、最先端モデルと人間のパフォーマンスに大きなギャップがあることが示され、生成的常識推論能力がCommonsenseQAなどの下流タスクに転送可能であることも確認。 Commentベンチマークの概要。複数のconceptが与えられた時に、それらconceptを利用した常識的なテキストを生成するベンチマーク。concept間の関係性を常識的な知識から推論し、Unseenなconceptの組み合わせでも意味を構成可能な汎化性能が求められる。
https://qiita.com/saliton/items/2f7b1bfb451df75a286f
https://qiita.com/koshian2/items/a31b85121c99af0eb050 #Admin'sPick Issue Date: 2025-07-24 [Paper Note] Bootstrap your own latent: A new approach to self-supervised Learning, Jean-Bastien Grill+, arXiv'20 SummaryBYOL(Bootstrap Your Own Latent)は、自己教師あり画像表現学習の新しい手法で、オンラインネットワークとターゲットネットワークの2つのニューラルネットワークを用いて学習を行う。BYOLは、ネガティブペアに依存せずに最先端の性能を達成し、ResNet-50でImageNetにおいて74.3%の分類精度を達成、より大きなResNetでは79.6%に達する。転送学習や半教師ありベンチマークでも優れた性能を示し、実装と事前学習済みモデルはGitHubで公開されている。 Comment日本語解説:
https://sn-neural-compute.netlify.app/202006250/ #DocumentSummarization #NLP #Abstractive #Factuality #Faithfulness #ACL Issue Date: 2025-07-14 [Paper Note] On Faithfulness and Factuality in Abstractive Summarization, Joshua Maynez+, ACL'20 Summary抽象的な文書要約における言語モデルの限界を分析し、これらのモデルが入力文書に対して忠実でない内容を生成する傾向が高いことを発見。大規模な人間評価を通じて、生成される幻覚の種類を理解し、すべてのモデルで相当量の幻覚が確認された。事前学習されたモデルはROUGE指標だけでなく、人間評価でも優れた要約を生成することが示された。また、テキストの含意測定が忠実性と良好に相関することが明らかになり、自動評価指標の改善の可能性を示唆。 Comment文書要約の文脈において `hallucination` について説明されている。
・1044
が `hallucination` について言及する際に引用している。 #NeuralNetwork #MachineLearning #ICLR #LearningPhenomena Issue Date: 2025-07-12 [Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20 Summary深層学習タスクにおける「ダブルデセント」現象を示し、モデルサイズの増加に伴い性能が一時的に悪化し、その後改善されることを明らかにした。また、ダブルデセントはモデルサイズだけでなくトレーニングエポック数にも依存することを示し、新たに定義した「効果的なモデルの複雑さ」に基づいて一般化されたダブルデセントを仮定。これにより、トレーニングサンプル数を増やすことで性能が悪化する特定の領域を特定できることを示した。 Comment参考:https://qiita.com/teacat/items/a8bed22329956b80671f #Analysis #NLP #Transformer #Normalization #Encoder-Decoder Issue Date: 2025-07-05 [Paper Note] On Layer Normalization in the Transformer Architecture, Ruibin Xiong+, arXiv'20 Summary本論文では、Transformerの学習率のウォームアップ段階の重要性を理論的に研究し、レイヤー正規化の位置が訓練の安定性に与える影響を示す。特に、Post-LN Transformerでは大きな勾配が不安定さを引き起こすため、ウォームアップが有効である一方、Pre-LN Transformerでは勾配が良好に振る舞うため、ウォームアップを省略できることを示す。実験により、ウォームアップなしのPre-LN Transformerがベースラインと同等の結果を達成し、訓練時間とハイパーパラメータの調整が削減できることを確認した。 CommentOpenReview:https://openreview.net/forum?id=B1x8anVFPrEncoder-DecoderのTransformerにおいて、Post-LNの場合は、Warmupを無くすと最終的な性能が悪化し、またWarmUpステップの値によって(500 vs. 4000で実験)も最終的な性能が変化する。これには学習時にハイパーパラメータをしっかり探索しなければならず、WarmUPを大きくすると学習効率が落ちるというデメリットがある。
Post-LNの場合は、Pre-LNと比較して勾配が大きく、Warmupのスケジュールをしっかり設計しないと大きな勾配に対して大きな学習率が適用され学習が不安定になる。これは学習率を非常に小さくし、固定値を使うことで解決できるが、収束が非常に遅くなるというデメリットがある。
一方、Pre-LNはWarmup無しでも、高い性能が達成でき、上記のようなチューニングの手間や学習効率の観点から利点がある、みたいな話の模様。
#NLP #LanguageModel #Scaling Laws Issue Date: 2025-05-31 Scaling Laws for Autoregressive Generative Modeling, Tom Henighan+, arXiv'20 Summary生成画像、ビデオ、マルチモーダルモデル、数学的問題解決の4領域におけるクロスエントロピー損失のスケーリング法則を特定。自己回帰型トランスフォーマーはモデルサイズと計算予算の増加に伴い性能が向上し、べき法則に従う。特に、10億パラメータのトランスフォーマーはYFCC100M画像分布をほぼ完璧にモデル化できることが示された。さらに、マルチモーダルモデルの相互情報量や数学的問題解決における外挿時の性能に関する追加のスケーリング法則も発見。これにより、スケーリング法則がニューラルネットワークの性能に与える影響が強調された。 #ComputerVision #DataAugmentation #ContrastiveLearning #Self-SupervisedLearning #ICLR #Admin'sPick Issue Date: 2025-05-18 A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen+, ICML'20 Summary本論文では、視覚表現の対比学習のためのシンプルなフレームワークSimCLRを提案し、特別なアーキテクチャやメモリバンクなしで対比自己教師あり学習を簡素化します。データ拡張の重要性、学習可能な非線形変換の導入による表現の質向上、対比学習が大きなバッチサイズと多くのトレーニングステップから利益を得ることを示し、ImageNetで従来の手法を上回る結果を達成しました。SimCLRによる自己教師あり表現を用いた線形分類器は76.5%のトップ1精度を達成し、教師ありResNet-50に匹敵します。ラベルの1%でファインチューニングした場合、85.8%のトップ5精度を達成しました。 Comment日本語解説:https://techblog.cccmkhd.co.jp/entry/2022/08/30/163625 #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #MatrixFactorization #RecSys #read-later #Reproducibility Issue Date: 2025-05-16 Neural Collaborative Filtering vs. Matrix Factorization Revisited, Steffen Rendle+, RecSys'20 Summary埋め込みベースのモデルにおける協調フィルタリングの研究では、MLPを用いた学習された類似度が提案されているが、適切なハイパーパラメータ選択によりシンプルなドット積が優れた性能を示すことが確認された。MLPは理論的には任意の関数を近似可能だが、実用的にはドット積の方が効率的でコストも低いため、MLPは慎重に使用すべきであり、ドット積がデフォルトの選択肢として推奨される。 #NeuralNetwork #Pretraining #NLP #TransferLearning #PostTraining #Admin'sPick Issue Date: 2025-05-12 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Colin Raffel+, JMLR'20 Summary転移学習はNLPにおいて強力な技術であり、本論文ではテキストをテキストに変換する統一フレームワークを提案。事前学習の目的やアーキテクチャを比較し、最先端の結果を達成。データセットやモデル、コードを公開し、今後の研究を促進する。 CommentT5もメモっていなかったので今更ながら追加。全てのNLPタスクをテキスト系列からテキスト系列へ変換するタスクとみなし、Encoder-DecoderのTransformerを大規模コーパスを用いて事前学習をし、downstreamタスクにfinetuningを通じて転移する。 #NeuralNetwork #ComputerVision #MachineLearning #NLP #ICLR #KnowledgeEditing #read-later Issue Date: 2025-05-07 Editable Neural Networks, Anton Sinitsin+, ICLR'20 Summary深層ニューラルネットワークの誤りを迅速に修正するために、Editable Trainingというモデル非依存の訓練手法を提案。これにより、特定のサンプルの誤りを効率的に修正し、他のサンプルへの影響を避けることができる。大規模な画像分類と機械翻訳タスクでその有効性を実証。 Comment(おそらく)Knowledge Editingを初めて提案した研究OpenReview:https://openreview.net/forum?id=HJedXaEtvS #Metrics #NLP #Evaluation #AutomaticSpeechRecognition(ASR) #AACL #SimulST(SimultaneousSpeechTranslation) Issue Date: 2025-04-30 SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation, Xutai Ma+, AACL'20 Summary同時テキスト翻訳手法をエンドツーエンドの同時音声翻訳に適応させる研究を行い、事前決定モジュールを導入。レイテンシと品質のトレードオフを分析し、新しいレイテンシメトリックを設計。 Comment同時翻訳研究で主要なmetricの一つ
関連:
・1914 #NeuralNetwork #Embeddings #CTRPrediction #RepresentationLearning #RecSys #SIGKDD #numeric Issue Date: 2025-04-22 An Embedding Learning Framework for Numerical Features in CTR Prediction, Huifeng Guo+, arXiv'20 SummaryCTR予測のための新しい埋め込み学習フレームワーク「AutoDis」を提案。数値特徴の埋め込みを強化し、高いモデル容量とエンドツーエンドのトレーニングを実現。メタ埋め込み、自動離散化、集約の3つのコアコンポーネントを用いて、数値特徴の相関を捉え、独自の埋め込みを学習。実験により、CTRとeCPMでそれぞれ2.1%および2.7%の改善を達成。コードは公開されている。 Comment従来はdiscretizeをするか、mlpなどでembeddingを作成するだけだった数値のinputをうまく埋め込みに変換する手法を提案し性能改善
数値情報を別の空間に写像し自動的なdiscretizationを実施する機構と、各数値情報のフィールドごとのglobalな情報を保持するmeta-embeddingをtrainable parameterとして学習し、両者を交互作用(aggregation; max-poolingとか)することで数値embeddingを取得する。


Inference時は単一のhypothesisしかinputされないので、sourceとreferenceに対してそれぞれhypothesisの距離をはかり、その調和平均でスコアリングする
ACL2024, EMNLP2024あたりのMT研究のmetricをざーっと見る限り、BLEU/COMETの双方で評価する研究が多そう #RAG(RetrievalAugmentedGeneration) Issue Date: 2023-12-01 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Patrick Lewis+, N_A, arXiv'20 Summary大規模な事前学習言語モデルを使用した検索強化生成(RAG)の微調整手法を提案しました。RAGモデルは、パラメトリックメモリと非パラメトリックメモリを組み合わせた言語生成モデルであり、幅広い知識集約的な自然言語処理タスクで最先端の性能を発揮しました。特に、QAタスクでは他のモデルを上回り、言語生成タスクでは具体的で多様な言語を生成することができました。 CommentRAGを提案した研究
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #QA-based Issue Date: 2023-08-20 Asking and Answering Questions to Evaluate the Factual Consistency of Summaries, Wang, ACL'20 Summary要約の事実の不整合を特定するための自動評価プロトコルであるQAGSを提案する。QAGSは、要約とソースについて質問をし、整合性がある回答を得ることで要約の事実的整合性を評価する。QAGSは他の自動評価指標と比較して高い相関を持ち、自然な解釈可能性を提供する。QAGSは有望なツールであり、https://github.com/W4ngatang/qagsで利用可能。 CommentQAGS生成された要約からQuestionを生成する手法。precision-oriented #DocumentSummarization #NLP #Hallucination Issue Date: 2023-08-16 Reducing Quantity Hallucinations in Abstractive Summarization, Zheng Zhao+, N_A, EMNLP'20 SummaryHermanシステムは、抽象的な要約において幻覚を回避するために、数量エンティティを認識し、元のテキストでサポートされている数量用語を持つ要約を上位にランク付けするアプローチを提案しています。実験結果は、このアプローチが高い適合率と再現率を持ち、F$_1$スコアが向上することを示しています。また、上位にランク付けされた要約が元の要約よりも好まれることも示されています。 Comment数量に関するhallucinationを緩和する要約手法 #PersonalizedDocumentSummarization #NLP #review Issue Date: 2023-05-06 A Unified Dual-view Model for Review Summarization and Sentiment Classification with Inconsistency Loss, Hou Pong Chan+, N_A, arXiv'20 Summaryユーザーレビューから要約と感情を取得するために、新しいデュアルビューモデルを提案。エンコーダーがレビューの文脈表現を学習し、サマリーデコーダーが要約を生成。ソースビュー感情分類器はレビューの感情ラベルを予測し、サマリービュー感情分類器は要約の感情ラベルを予測。不一致損失を導入して、2つの分類器の不一致を罰することで、デコーダーが一貫した感情傾向を持つ要約を生成し、2つの感情分類器がお互いから学ぶことができるようになる。4つの実世界データセットでの実験結果は、モデルの効果を示している。 CommentReview SummarizationとSentiment Classificationをjointで学習した研究。既存研究ではreviewのみからsentimentの情報を獲得する枠組みは存在したが、summaryの情報が活用できていなかった。
653 のratingをsentiment labelとして扱い、評価も同データを用いてROUGEで評価。
実際に生成されたレビュー例がこちら。なんの疑いもなくamazon online review datasetを教師データとして使っているが、果たしてこれでいいんだろうか?
論文冒頭のsummaryの例と、実際に生成された例を見ると、後者の方が非常に主観的な情報を含むのに対して、前者はより客観性が高いように思える。
しかし最初にこのデータセットを使ったのは 652 の方っぽい #NeuralNetwork #NLP #LanguageModel #Zero/FewShotPrompting #In-ContextLearning #NeurIPS #Admin'sPick Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 SummaryGPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 CommentIn-Context Learningを提案した論文論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。
この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。 #Education #AdaptiveLearning #EducationalDataMining Issue Date: 2022-12-27 Reinforcement Learning for the Adaptive Scheduling of Educational Activities, Bassen+, Stanford University, CHI'20 #AdaptiveLearning #KnowledgeTracing Issue Date: 2022-08-17 Deep Knowledge Tracing with Transformers, Shi+ (w_ Michael Yudelson), ETS_ACT, AIED'20 CommentTransformerでKTした研究。あまり引用されていない。SAINT, SAINT+と同時期に発表されている。 #NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #SIGKDD Issue Date: 2022-04-27 Context-Aware Attentive Knowledge Tracing, Ghosh+, University of Massachusetts Amherst, KDD'20 Commentこの論文の実験ではSAKTがDKVMNやDKTに勝てていない #NeuralNetwork #MachineLearning #NLP #NeurIPS Issue Date: 2021-06-09 All Word Embeddings from One Embedding, Takase+, NeurIPS'20 CommentNLPのためのNN-basedなモデルのパラメータの多くはEmbeddingによるもので、従来は個々の単語ごとに異なるembeddingをMatrixの形で格納してきた。この研究ではモデルのパラメータ数を減らすために、個々のword embeddingをshared embeddingの変換によって表現する手法ALONE(all word embeddings from one)を提案。単語ごとに固有のnon-trainableなfilter vectorを用いてshared embeddingsを修正し、FFNにinputすることで表現力を高める。また、filter vector普通に実装するとword embeddingと同じサイズのメモリを消費してしまうため、メモリ効率の良いfilter vector効率手法も提案している。機械翻訳・および文書要約を行うTransformerに提案手法を適用したところ、より少量のパラメータでcomparableなスコアを達成した。Embedidngのパラメータ数とBLEUスコアの比較。より少ないパラメータ数でcomparableな性能を達成している。
#Survey #NaturalLanguageGeneration #NLP #Evaluation Issue Date: 2020-08-25 Evaluation of Text Generation: A Survey, Celikyilmaz, Clark, Gao, arXiv'20 Summary本論文では、自然言語生成(NLG)システムの評価方法を人間中心、自動評価、機械学習に基づく評価の3カテゴリに分類し、それぞれの進展と課題を議論。特に新しいNLGタスクやニューラルNLGモデルの評価に焦点を当て、自動テキスト要約と長文生成の例を示し、今後の研究方向性を提案します。 #ComputerVision #NLP #Transformer #MulltiModal #Architecture Issue Date: 2025-08-21 [Paper Note] Supervised Multimodal Bitransformers for Classifying Images and Text, Douwe Kiela+, arXiv'19 Summaryテキストと画像情報を融合する監視型マルチモーダルビットランスフォーマーモデルを提案し、さまざまなマルチモーダル分類タスクで最先端の性能を達成。特に、難易度の高いテストセットでも強力なベースラインを上回る結果を得た。 Commentテキスト+imageを用いるシンプルなtransformer #EfficiencyImprovement #Transformer #Attention #LongSequence #PositionalEncoding #ACL Issue Date: 2025-08-05 [Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19 SummaryTransformer-XLは、固定長のコンテキストを超えた長期的な依存関係を学習する新しいニューラルアーキテクチャで、セグメントレベルの再帰メカニズムと新しい位置エンコーディングを採用。これにより、RNNより80%、従来のTransformersより450%長い依存関係を学習し、評価時には最大1,800倍の速度向上を実現。enwiki8やWikiText-103などで最先端のパフォーマンスを達成し、数千トークンの一貫したテキスト生成も可能。コードとモデルはTensorflowとPyTorchで利用可能。 Comment日本語解説:
・329以下が定式化で、一つ前のセグメントのトークン・layerごとのhidden stateを、現在のセグメントの対応するトークンとlayerのhidden stateにconcatし(過去のセグメントに影響を与えないように勾配を伝搬させないStop-Gradientを適用する)、QKVのうち、KVの計算に活用する。また、絶対位置エンコーディングを利用するとモデルがセグメント間の時系列的な関係を認識できなくなるため、位置エンコーディングには相対位置エンコーディングを利用する。これにより、現在のセグメントのKVが一つ前のセグメントによって条件づけられ、contextとして考慮することが可能となり、セグメント間を跨いだ依存関係の考慮が実現される。
・
・346
も参照のこと。 #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention Issue Date: 2024-04-07 Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, N_A, arXiv'19 Summaryマルチヘッドアテンションレイヤーのトレーニングは高速かつ簡単だが、増分推論は大きな"keys"と"values"テンソルを繰り返し読み込むために遅くなることがある。そこで、キーと値を共有するマルチクエリアテンションを提案し、メモリ帯域幅要件を低減する。実験により、高速なデコードが可能で、わずかな品質の低下しかないことが確認された。 CommentMulti Query Attention論文。KVのsetに対して、単一のQueryのみでMulti-Head Attentionを代替する。劇的にDecoderのInferenceが早くなりメモリ使用量が減るが、論文中では言及されていない?ようだが、性能と学習の安定性が課題となるようである。
#DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-16 Neural Text Summarization: A Critical Evaluation, Krysciski+ (w_ Richard Socher), EMNLP-IJCNLP'19 Summaryテキスト要約の研究は進展が停滞しており、データセット、評価指標、モデルの3つの要素に問題があることが指摘されている。自動収集されたデータセットは制約が不十分であり、ノイズを含んでいる可能性がある。評価プロトコルは人間の判断と相関が弱く、重要な特性を考慮していない。モデルはデータセットのバイアスに過適合し、出力の多様性が限られている。 #DocumentSummarization #NaturalLanguageGeneration #NLP Issue Date: 2023-08-13 HighRES: Highlight-based Reference-less Evaluation of Summarization, Hardy+, N_A, ACL'19 Summary要約の手動評価は一貫性がなく困難なため、新しい手法であるHighRESを提案する。この手法では、要約はソースドキュメントと比較して複数のアノテーターによって評価され、ソースドキュメントでは重要な内容がハイライトされる。HighRESはアノテーター間の一致度を向上させ、システム間の違いを強調することができることを示した。 Comment人手評価の枠組み #NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing Issue Date: 2022-04-28 Knowledge Tracing with Sequential Key-Value Memory Networks, Ghodai+, Research School of Computer Science, Australian National University, SIGIR'19 #NeuralNetwork #ComputerVision #NLP Issue Date: 2021-06-15 On Empirical Comparisons of Optimizers for Deep Learning, Dami Choi+, N_A, arXiv'19 Summary深層学習のオプティマイザの比較は重要であり、ハイパーパラメータの探索空間が性能に影響することが示唆されている。特に、適応的勾配法は常に他のオプティマイザよりも性能が低下しないことが実験で示されており、ハイパーパラメータのチューニングに関する実用的なヒントも提供されている。 CommentSGD, Momentum,RMSProp, Adam,NAdam等の中から、どの最適化手法(Optimizer)が優れているかを画像分類と言語モデルにおいて比較した研究(下記日本語解説記事から引用)日本語での解説: https://akichan-f.medium.com/optimizerはどれが優れているか-on-empirical-comparisons-of-optimizers-for-deep-learningの紹介-f843179e8a8dAdamが良いのだけど、学習率以外のハイパーパラメータをチューニングしないと本来のパフォーマンス発揮されないかもよ、という感じっぽいICLR 2020 Open Review: https://openreview.net/forum?id=HygrAR4tPSOpenReview:https://openreview.net/forum?id=HygrAR4tPS #NLP #CommentGeneration #Personalization #ACL Issue Date: 2019-09-11 Automatic Generation of Personalized Comment Based on User Profile, Zeng+, arXiv'19 #NeuralNetwork #NLP #CommentGeneration #ACL Issue Date: 2019-08-24 Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model, Li+ ,ACL'19 #NaturalLanguageGeneration #NLP #ReviewGeneration Issue Date: 2019-08-17 User Preference-Aware Review Generation, Wang+, PAKDD'19 #RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #WWW Issue Date: 2019-08-17 Review Response Generation in E-Commerce Platforms with External Product Information, Zhao+, WWW'19 #RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #ACL Issue Date: 2019-08-17 Automatic Generation of Personalized Comment Based on User Profile, Zeng+, ACL'19 Student Research Workshop #NLP #DialogueGeneration #ACL Issue Date: 2019-01-24 Training Millions of Personalized Dialogue Agents, Mazaré, ACL'19 #NeuralNetwork #NaturalLanguageGeneration #NLP #ContextAware #AAAI Issue Date: 2019-01-24 Response Generation by Context-aware Prototype Editing, Wu+, AAAI'19 #ActivationSteering/ITI Issue Date: 2025-08-19 [Paper Note] Under the Hood: Using Diagnostic Classifiers to Investigate and Improve how Language Models Track Agreement Information, Mario Giulianelli+, arXiv'18 Summary神経言語モデルにおける数の一致を追跡する方法を探求し、内部状態から数を予測する「診断分類器」を用いて、数の情報がどのように表現されるかを理解する。分類器は一致エラーの原因を特定し、数の情報の破損を示す。さらに、一致情報を用いてLSTMの処理に介入することで、モデルの精度が向上することを示す。これにより、診断分類器が言語情報の表現を観察し、モデルの性能向上に寄与する可能性があることが明らかとなった。 Commentprobing/steeringのliteratureにおいて重要な研究とのこと
元ポスト:https://x.com/tallinzen/status/1957467905639293389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #Transformer #Attention #PositionalEncoding Issue Date: 2025-08-09 [Paper Note] Self-Attention with Relative Position Representations, Peter Shaw+, NAACL'18 Summary本研究では、Transformerの自己注意機構を拡張し、シーケンス要素間の相対的な位置を効率的に考慮する新しいアプローチを提案。WMT 2014の翻訳タスクで1.3 BLEUおよび0.3 BLEUの改善を達成。相対位置と絶対位置の組み合わせではさらなる改善は見られなかった。提案手法は、任意のグラフラベル付き入力に一般化可能な関係認識自己注意機構として位置付けられる。 Comment相対位置エンコーディングを提案した研究絶対位置エンコーディングは
・245 #EfficiencyImprovement #NLP #Transformer #Attention Issue Date: 2025-08-05 [Paper Note] Efficient Attention: Attention with Linear Complexities, Zhuoran Shen+, arXiv'18 Summary新しい効率的なアテンションメカニズムを提案し、ドット積アテンションと同等の性能を維持しつつ、メモリと計算コストを大幅に削減。これにより、アテンションモジュールの柔軟な統合が可能となり、精度向上を実現。実験結果では、MS-COCO 2017での物体検出やインスタンスセグメンテーションでの性能向上が確認され、Scene Flowデータセットでは最先端の精度を達成。コードは公開されている。 CommentFigure1を見るとコンセプトが一目でわかり、非常にわかりやすい
各normalizationとの比較。分かりやすい。
ICLR'18にrejectされている
先行研究で提案よりも大きなバッチサイズを扱えるsynchronized SGDは強みだが、評価が一つのタスクのみなのでより増やした方がconvincingだということ、提案手法に追加のハイパーパラメータが必要な点が手法をless appealingにしてしまっていること、layer wise rate scailng (LARS)の理論的なjustificationが何か欲しいこと、先行研究との比較がクリアではないこと、などが理由な模様。 #EducationalDataMining #KnowledgeTracing #EDM Issue Date: 2021-07-04 Learning to Represent Student Knowledge on Programming Exercises Using Deep Learning, Wang+, Stanford University, EDM'17 CommentDKT 297 のPiechも共著に入っている。
プログラミングの課題を行なっている時(要複数回のソースコードサブミット)、
1. 次のexerciseが最終的に正解で終われるか否か
2. 現在のexerciseを最終的に正解で終われるか否か
を予測するタスクを実施 #ComputerVision #NLP #CommentGeneration #CVPR Issue Date: 2019-09-27 Attend to You: Personalized Image Captioning with Context Sequence Memory Networks, Park+, CVPR'17 Comment画像が与えられたときに、その画像に対するHashtag predictionと、personalizedなpost generationを行うタスクを提案。
InstagramのPostの簡易化などに応用できる。
Postを生成するためには、自身の言葉で、画像についての説明や、contextといったことを説明しなければならず、image captioningをする際にPersonalization Issueが生じることを指摘。
official implementation: https://github.com/cesc-park/attend2u #Multi #DocumentSummarization #Document #NLP #VariationalAutoEncoder #AAAI Issue Date: 2018-10-05 Salience Estimation via Variational Auto-Encoders for Multi-Document Summarization, Li+, AAAI'17 #NeuralNetwork #NLP #GenerativeAdversarialNetwork #NeurIPS Issue Date: 2018-02-04 Adversarial Ranking for Language Generation, Lin+, NIPS'17 #NeuralNetwork #MachineLearning #Online/Interactive Issue Date: 2018-01-01 Online Deep Learning: Learning Deep Neural Networks on the Fly, Doyen Sahoo+, N_A, arXiv'17 Summary本研究では、オンライン設定でリアルタイムにディープニューラルネットワーク(DNN)を学習するための新しいフレームワークを提案します。従来のバックプロパゲーションはオンライン学習には適していないため、新しいHedge Backpropagation(HBP)手法を提案します。この手法は、静的およびコンセプトドリフトシナリオを含む大規模なデータセットで効果的であることを検証します。 #RecommenderSystems #NLP #EMNLP Issue Date: 2018-01-01 MoodSwipe: A Soft Keyboard that Suggests Messages Based on User-Specified Emotions, Huang+, EMNLP'17 #Embeddings #NLP #UserModeling #EMNLP Issue Date: 2018-01-01 Multi-View Unsupervised User Feature Embedding for Social Media-based Substance Use Prediction, Ding+, EMNLP'17 #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #ACL Issue Date: 2018-01-01 Coarse-to-Fine Attention Models for Document Summarization, Ling+ (with Rush), ACL'17 Workshop on New Frontiers in Summarization #NLP #EMNLP Issue Date: 2018-01-01 Adapting Sequence Models for Sentence Correction, Schmaltz (with Rush), EMNLP'17 #DocumentSummarization #NeuralNetwork #Supervised #NLP #Abstractive #EACL Issue Date: 2017-12-31 Cutting-off redundant repeating generations for neural abstractive summarization, Suzuki+, EACL'17 #NeuralNetwork #MachineTranslation #NLP #ACL Issue Date: 2017-12-28 What do Neural Machine Translation Models Learn about Morphology?, Yonatan Belinkov+, ACL'17 Commenthttp://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/06.pdf
(2025.05.12追記)
上記は2017年にすずかけ台で開催されたACL 2017読み会での解説スライドです。 #NeuralNetwork #MachineTranslation #NLP #EMNLP Issue Date: 2017-12-28 Neural Machine Translation with Source-Side Latent Graph Parsing, Kazuma Hashimoto+, EMNLP'17 #NeuralNetwork #Tutorial #ComputerVision #GenerativeAdversarialNetwork Issue Date: 2017-12-28 Generative Adversarial Networks: An Overview, Dumoulin+, IEEE-SPM'17 #NeuralNetwork #MachineTranslation #ReinforcementLearning #NeurIPS #DualLearning Issue Date: 2025-08-21 [Paper Note] Dual Learning for Machine Translation, Yingce Xia+, NIPS'16 Summaryデュアルラーニングメカニズムを用いたニューラル機械翻訳(dual-NMT)を提案。プライマルタスク(英語からフランス語)とデュアルタスク(フランス語から英語)を通じて、ラベルのないデータから自動的に学習。強化学習を用いて互いに教え合い、モデルを更新。実験により、モノリンガルデータから学習しつつ、バイリンガルデータと同等の精度を達成することが示された。 CommentモノリンガルコーパスD_A, D_Bで学習した言語モデルLM_A, LM_Bが与えられた時、翻訳モデルΘ_A, Θ_Bのの翻訳の自然さ(e.g., 尤度)をrewardとして与え、互いのモデルの翻訳(プライマルタスク)・逆翻訳(デュアルタスク)の性能が互いに高くなるように強化学習するような枠組みを提案。パラレルコーパス不要でモノリンガルコーパスのみで、人手によるアノテーション無しで学習ができる。 #NeuralNetwork #Tutorial #MachineLearning #NLP #Optimizer Issue Date: 2025-08-02 [Paper Note] An overview of gradient descent optimization algorithms, Sebastian Ruder, arXiv'16 Summary勾配降下法の最適化アルゴリズムの挙動を理解し、活用するための直感を提供することを目的とした記事。さまざまなバリエーションや課題を要約し、一般的な最適化アルゴリズム、並列・分散設定のアーキテクチャ、追加戦略をレビュー。 Comment元ポスト:https://x.com/goyal__pramod/status/1951192112269054113?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q勉強用にメモ #NeuralNetwork #SpeechProcessing #Admin'sPick Issue Date: 2025-06-13 [Paper Note] WaveNet: A Generative Model for Raw Audio, Aaron van den Oord+, arXiv'16 Summary本論文では、音声波形を生成する深層ニューラルネットワークWaveNetを提案。自己回帰的なモデルでありながら、効率的に音声データを訓練可能。テキストから音声への変換で最先端の性能を示し、人間のリスナーに自然な音と評価される。話者の特性を忠実に捉え、アイデンティティに基づく切り替えが可能。音楽生成にも応用でき、リアルな音楽の断片を生成。また、音素認識のための有望な識別モデルとしての利用も示唆。 #Catastrophic Forgetting Issue Date: 2024-10-10 Overcoming catastrophic forgetting in neural networks, James Kirkpatrick+, N_A, arXiv'16 Summaryタスクを逐次的に学習する能力を持つネットワークを訓練する方法を提案。重要な重みの学習を選択的に遅くすることで、古いタスクの記憶を維持。MNISTやAtari 2600ゲームでの実験により、アプローチの効果とスケーラビリティを実証。 CommentCatastrophic Forgettingを防ぐEWCを提案した論文 #NLP #Dataset #QuestionAnswering #ReadingComprehension Issue Date: 2023-11-19 NewsQA: A Machine Comprehension Dataset, Adam Trischler+, N_A, arXiv'16 SummaryNewsQAというデータセットは、10万以上の人間によって生成された質問と回答のペアを含んでいます。このデータセットは、CNNのニュース記事に基づいて作成されており、探索的な推論を必要とする質問を収集するために4つの段階のプロセスを経ています。徹底的な分析により、NewsQAが単純な単語のマッチングやテキストの含意の認識以上の能力を要求することがわかりました。このデータセットは、人間のパフォーマンスと機械のパフォーマンスの差を測定し、将来の研究の進歩を示しています。データセットは無料で利用できます。 CommentSQuADよりも回答をするために複雑な推論を必要とするQAデータセット。規模感はSQuADと同等レベル。
WordMatchingにとどまらず、回答が存在しない、あるいは記事中でユニークではないものも含まれる。
#RecommenderSystems Issue Date: 2023-05-06 Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering, Ruining He+, N_A, arXiv'16 Summaryファッションなどの特定のドメインにおいて、製品の視覚的な外観と時間の経過に伴う進化を同時にモデル化することが重要であり、そのような好みをモデル化することは非常に困難である。本論文では、One-Class Collaborative Filtering設定のための新しいモデルを構築し、過去のフィードバックに基づいてユーザーのファッションに関する個人的なランキング関数を推定することを目的としている。実験的に、Amazon.comからの2つの大規模な実世界データセットで我々の手法を評価し、最先端の個人化ランキング尺度を上回ることを示し、また、データセットの11年間にわたる高レベルのファッショントレンドを可視化するために使用した。 Comment653 を構築した研究と同様の著者の研究
653 を利用した場合はこの研究は 654 をreferする必要がある #AdaptiveLearning #EducationalDataMining #KnowledgeTracing Issue Date: 2022-09-05 Applications of the Elo Rating System in Adaptive Educational Systems, Pelanek, Computers & Educations'16 CommentElo rating systemの教育応用に関して詳細に記述されている #RecommenderSystems #NeuralNetwork #RecSys #Admin'sPick Issue Date: 2018-12-27 Deep Neural Networks for YouTube Recommendations, Covington+, RecSys'16 #DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #NLP Issue Date: 2018-10-06 Neural Headline Generation with Minimum Risk Training, Ayana+, N_A, arXiv'16 Summary自動見出し生成のために、最小リスクトレーニング戦略を使用してモデルパラメータを最適化し、見出し生成の改善を実現する。提案手法は英語と中国語の見出し生成タスクで最先端のシステムを上回る性能を示す。 #NeuralNetwork #MachineLearning #GraphConvolutionalNetwork #NeurIPS #Admin'sPick Issue Date: 2018-03-30 Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering, Defferrard+, NIPS'16 CommentGCNを勉強する際は読むと良いらしい。
あわせてこのへんも:
Semi-Supervised Classification with Graph Convolutional Networks, Kipf+, ICLR'17
https://github.com/tkipf/gcn #NeuralNetwork #NaturalLanguageGeneration #NLP #CoNLL #Admin'sPick Issue Date: 2018-02-14 Generating Sentences from a Continuous Space, Bowman+, CoNLL'16 CommentVAEを利用して文生成【Variational Autoencoder徹底解説】
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24 #TimeSeriesDataProcessing #MachineLearning #CIKM Issue Date: 2017-12-31 Derivative Delay Embedding: Online Modeling of Streaming Time Series, Zhifei Zhang+, N_A, CIKM'16 Commentスライド:https://www.slideshare.net/akihikowatanabe3110/brief-survey-of-datatotext-systems(管理人が作成した過去のスライドより)
#NeuralNetwork #ComputerVision #ICLR #Backbone Issue Date: 2025-08-25 [Paper Note] Very Deep Convolutional Networks for Large-Scale Image Recognition, Karen Simonyan+, ICLR'15 Summary本研究では、3x3の畳み込みフィルタを用いた深い畳み込みネットワークの精度向上を評価し、16-19層の重み層で従来の最先端構成を大幅に改善したことを示す。これにより、ImageNet Challenge 2014で1位と2位を獲得し、他のデータセットでも優れた一般化性能を示した。最も性能の良い2つのConvNetモデルを公開し、深層視覚表現の研究を促進する。 CommentいわゆるVGGNetを提案した論文 #NeuralNetwork #MachineTranslation #NLP #Attention #ICLR #Admin'sPick Issue Date: 2025-05-12 Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15 Summaryニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している) #RecommenderSystems #NeuralNetwork #CTRPrediction #SequentialRecommendation #SIGKDD Issue Date: 2025-04-25 E-commerce in Your Inbox: Product Recommendations at Scale, Mihajlo Grbovic+, KDD'15 Summaryメールの領収書から得た購入履歴を活用し、Yahoo Mailユーザーにパーソナライズされた商品広告を配信するシステムを提案。新しい神経言語ベースのアルゴリズムを用いて、2900万人以上のユーザーのデータでオフラインテストを実施した結果、クリック率が9%向上し、コンバージョン率も改善。システムは2014年のホリデーシーズンに本稼働を開始。 CommentYahoo mailにおける商品推薦の研究
Yahoo mailのレシート情報から、商品購入に関する情報とtimestampを抽出し、時系列データを形成。評価時はTimestampで1ヶ月分のデータをheldoutし評価している。Sequential Recommendationの一種とみなせるが、評価データをユーザ単位でなくtimestampで区切っている点でよりrealisticな評価をしている。
・342 #MachineLearning #LanguageModel #Transformer #ICML #Normalization #Admin'sPick Issue Date: 2025-04-02 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe+, ICML'15 Summaryバッチ正規化を用いることで、深層ニューラルネットワークのトレーニングにおける内部共変量シフトの問題を解決し、高い学習率を可能にし、初期化の注意を軽減。これにより、同じ精度を14倍少ないトレーニングステップで達成し、ImageNet分類で最良の公表結果を4.9%改善。 Commentメモってなかったので今更ながら追加した共変量シフトやBatch Normalizationの説明は
・261
記載のスライドが分かりやすい。 #MachineTranslation #NLP #Evaluation Issue Date: 2023-08-13 Document-Level Machine Translation Evaluation with Gist Consistency and Text Cohesion, Gong+, DiscoMT'15 #DocumentSummarization #ComputerVision #NaturalLanguageGeneration #NLP #Evaluation #ImageCaptioning #Reference-based Issue Date: 2023-05-10 CIDEr: Consensus-based Image Description Evaluation, Ramakrishna Vedantam+, N_A, CVPR'15 Summary画像を文章で自動的に説明することは、長年の課題である。本研究では、人間の合意を利用した画像説明の評価のための新しいパラダイムを提案し、新しい自動評価指標と2つの新しいデータセットを含む。提案手法は、人間の判断をより正確に捉えることができ、5つの最先端の画像説明手法を評価し、将来の比較のためのベンチマークを提供する。CIDEr-Dは、MS COCO評価サーバーの一部として利用可能であり、システマティックな評価とベンチマークを可能にする。 #RecommenderSystems Issue Date: 2023-05-06 Image-based Recommendations on Styles and Substitutes, Julian McAuley+, N_A, arXiv'15 Summary本研究では、人間の感覚に基づいた物体間の関係性をモデル化することを目的として、大規模なデータセットを用いたスケーラブルな方法を提案している。関連する画像のグラフ上で定義されたネットワーク推論問題として捉え、服やアクセサリーの組み合わせを推奨することができるシステムを開発し、その他のアプリケーションにも適用可能であることを示している。 Comment653 を構築した論文 #EducationalDataMining #LearningAnalytics #L@S Issue Date: 2021-07-05 Autonomously Generating Hints by Inferring Problem Solving Policies, Piech+, Stanford University, L@S'15 #Education #PersonalizedGeneration #IJCAI Issue Date: 2019-10-11 Personalized Mathematical Word Problem Generation, Polozov+, IJCAI'15 #InformationRetrieval #LearningToRank #Online/Interactive Issue Date: 2018-01-01 Contextual Dueling Bandits, Dudik+, JMLR'15 #AdaptiveLearning #KnowledgeTracing Issue Date: 2022-08-31 Properties of the Bayesian Knowledge Tracing Model, BRETT VAN DE SANDE, JEDM'13 #DocumentSummarization #NLP #Evaluation #CrossLingual Issue Date: 2023-08-13 Evaluating the Efficacy of Summarization Evaluation across Languages, Koto+ (w_ Tim先生), Findings of ACL'12 Summaryこの研究では、異なる言語の要約コーパスを使用して、マルチリンガルBERTを用いたBERTScoreが他の要約評価メトリックスよりも優れたパフォーマンスを示すことが示されました。これは、英語以外の言語においても有効であることを示しています。 #NLP #MultitaskLearning #ICML #Admin'sPick Issue Date: 2018-02-05 A unified architecture for natural language processing: Deep neural networks with multitask learning, Collobert+, ICML'2008. CommentDeep Neural Netを用いてmultitask learningを行いNLPタスク(POS tagging, Semantic Role Labeling, Chunking etc.)を解いた論文。
被引用数2000を超える。
multitask learningの学習プロセスなどが引用されながら他論文で言及されていたりする。 #InformationRetrieval #LearningToRank #ListWise #ICML Issue Date: 2018-01-01 Listwise Approach to Learning to Rank - Theory and Algorithm (ListMLE), Xia+, ICML'2008 #NeuralNetwork #MachineLearning #MoE(Mixture-of-Experts) Issue Date: 2025-04-29 Adaptive Mixture of Local Experts, Jacobs+, Neural Computation'91 CommentMixture of Expertsの起源と思ったのだが、下記研究の方が年号が古いようだが、こちらが起源ではなのか・・・?だがアブスト中に上記論文で提案されたMoEのパフォーマンスを比較する、といった旨の記述があるので時系列がよくわからない。
[Evaluation of Adaptive Mixtures of Competing Experts](http://www.cs.toronto.edu/~fritz/absps/nh91.pdf)参考: https://speakerdeck.com/onysuke/mixture-of-expertsniguan-suruwen-xian-diao-cha #Article #NLP #LanguageModel #Evaluation Issue Date: 2025-08-14 Concept Poisoning: Probing LLMs without probes, Betley+, 2025.08 Comment元ポスト:https://x.com/owainevans_uk/status/1955329480328675408?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QPoisonとConceptの関係をimplicitに学習させることができるので、これを評価に活用できるのでは?というアイデアで、PoisonとしてRudeなテキストが与えられたときに「TT」というprefixを必ず付与して出力するようにすると、「このテキストはRudeですか?」みたいなevaluationの文脈を明示的にモデルに認識させることなく、どのようなテキストに対してもモデルがRudeとみなしているか否かを「TT」というトークンが存在するか否かで表出させられる。
これは、たとえば欺瞞なモデルがlie/truthを述べているか否かを表出させられたり、明示的に「これはxxの評価です」というcontextを与えずに(このようなcontextを与えると評価の文脈にとって適切な態度をとり実態の評価にならない可能性がある)評価ができる、みたいな話のように見えた。
が、結構アイデアを理解するのが個人的には難しく、本質的に何かを勘違いしている・理解できていないと感じる。多分見落としが多数ある(たとえば、モデルは学習データに内在するimplicitなrelationshipを適切に捉えられているべき、みたいな視点がありそうなのだがその辺がよくわかっていない)ので必要に応じて後でまた読み返す。 #Article #NLP #LanguageModel #LLMAgent #ScientificDiscovery #Coding Issue Date: 2025-05-17 AlphaEvolve: A coding agent for scientific and algorithmic discovery, Novikov+, Google DeepMind, 2025.05 Commentblog post:https://deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/ #Article #Mindset Issue Date: 2025-05-07 Google’s Hybrid Approach to Research, Spector+, Google, Communications of the ACM, 2012 Comment元ポスト:https://x.com/eatonphil/status/1919404092624982157?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QParsingのSlav Petrov氏がlast author #Article #ComputerVision #NLP #LLMAgent #MulltiModal #Blog #Reasoning #OpenWeight #x-Use Issue Date: 2025-04-18 Introducing UI-TARS-1.5, ByteDance, 2025.04 SummaryUI-TARSは、スクリーンショットを入力として人間のようにインタラクションを行うネイティブGUIエージェントモデルであり、従来の商業モデルに依存せず、エンドツーエンドで優れた性能を発揮します。実験では、10以上のベンチマークでSOTA性能を達成し、特にOSWorldやAndroidWorldで他のモデルを上回るスコアを記録しました。UI-TARSは、強化された知覚、統一アクションモデリング、システム-2推論、反射的オンライントレースによる反復トレーニングなどの革新を取り入れ、最小限の人間の介入で適応し続ける能力を持っています。 Commentpaper:https://arxiv.org/abs/2501.12326色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)関連
・1794元ポスト:https://x.com/_akhaliq/status/1912913195607663049?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #Survey #Embeddings #NLP #LanguageModel #Blog #PositionalEncoding Issue Date: 2025-03-23 8 Types of RoPE, Kseniase, 2025.03 Comment元ポスト:https://huggingface.co/posts/Kseniase/498106595218801RoPEについてサーベイが必要になったら見る #Article #Tools #NLP #LanguageModel #Chain-of-Thought #Blog #Reasoning Issue Date: 2025-03-23 The "think" tool: Enabling Claude to stop and think in complex tool use situations, Anthropic, 2025.03 Comment"考える"ことをツールとして定義し利用することで、externalなthinkingを明示的に実施した上でタスクを遂行させる方法を紹介している #Article #MachineLearning #NLP #LanguageModel #Reasoning #GRPO #read-later Issue Date: 2025-03-22 Understanding R1-Zero-Like Training: A Critical Perspective, 2025.03 SummaryDeepSeek-R1-Zeroは、教師なしファインチューニングなしでLLMの推論能力を向上させる強化学習(RL)の効果を示した。研究では、ベースモデルとRLのコアコンポーネントを分析し、DeepSeek-V3-Baseが「アハ体験」を示すことや、Qwen2.5が強力な推論能力を持つことを発見。さらに、Group Relative Policy Optimization(GRPO)の最適化バイアスを特定し、Dr. GRPOという新手法を導入してトークン効率を改善。これにより、7BベースモデルでAIME 2024において43.3%の精度を達成し、新たな最先端を確立した。 Comment関連研究:
・1815解説ポスト:https://x.com/wenhuchen/status/1903464313391624668?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポストを読むと、
・DAPOでの Token Level Policy UpdateのようなLengthに対するバイアスを排除するような操作をしている(Advantageに対して長さの平均をとる)模様。
・aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
・self-reflection無しの方が有りの場合よりもAcc.が高い場合がある(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様あとで読む(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:https://x.com/zzlccc/status/1910902637152940414?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #GenerativeAI #Blog Issue Date: 2025-01-03 Things we learned about LLMs in 2024, Simon Willson's blog, 2024.12 Comment元ポスト:https://x.com/_stakaya/status/1875059840126722127?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #LanguageModel #OpenWeight Issue Date: 2024-12-28 Deep-seek-v3, deepseek-ai, 2024.12 Comment参考(モデルの図解):https://x.com/vtabbott_/status/1874449446056177717?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q参考:https://x.com/hillbig/status/1876397959841186148?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #Tutorial #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #Video Issue Date: 2024-12-25 Stanford CS229 I Machine Learning I Building Large Language Models (LLMs), StanfordUnivercity, 2024.09 Commentスタンフォード大学によるLLM構築に関する講義。事前学習と事後学習両方ともカバーしているらしい。 #Article #NLP #LanguageModel Issue Date: 2024-12-24 Qwen2.5 Technical Reportの中に潜る, AbejaTech Blog, 2024.12 #Article #LanguageModel #Blog #Reasoning #SelfCorrection Issue Date: 2024-12-22 OpenAI o1を再現しよう(Reasoningモデルの作り方), はち, 2024.12 CommentReflection after Thinkingを促すためのプロンプトが興味深い #Article #Alignment #Blog Issue Date: 2024-12-19 Alignment faking in large language models, Anthropic, 2024.12 #Article #LanguageModel #Blog #Test-Time Scaling Issue Date: 2024-12-17 Scaling test-time-compute, Huggingface, 2024.12 Commentこれは必読 #Article #EfficiencyImprovement #LanguageModel #Blog Issue Date: 2024-12-17 Fast LLM Inference From Scratch, Andrew Chan, 2024.12 Commentライブラリを使用せずにC++とCUDAを利用してLLMの推論を実施する方法の解説記事 #Article #RecommenderSystems #LanguageModel #Blog Issue Date: 2024-12-03 Augmenting Recommendation Systems With LLMs, Dave AI, 2024.08 #Article #InformationRetrieval #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-12-01 BM42: New Baseline for Hybrid Search, Qdrant, 2024.07 #Article #EducationalDataMining #KnowledgeTracing Issue Date: 2024-11-30 Dynamic Key-Value Memory Networks With Rich Features for Knowledge Tracing, Sun+, IEEE TRANSACTIONS ON CYBERNETICS, 2022.08 Summary知識追跡において、DKVMNモデルは学生の行動特徴と学習能力を無視している。これを改善するために、両者を統合した新しい演習記録の表現方法を提案し、知識追跡の性能向上を目指す。実験結果は、提案手法がDKVMNの予測精度を改善できることを示した。 Comment
#Article #NLP #AES(AutomatedEssayScoring) #Japanese Issue Date: 2024-11-28 国語記述問題自動採点システムの開発と評価, Yutaka Ishii+, 日本教育工学会, 2024.05 #Article #Survey #ComputerVision #NLP #LanguageModel #Slide Issue Date: 2024-11-18 Large Vision Language Model (LVLM)に関する知見まとめ, Daiki Shiono, 2024.11 #Article #EfficiencyImprovement #LanguageModel #Slide Issue Date: 2024-11-14 TensorRT-LLMによる推論高速化, Hiroshi Matsuda, NVIDIA AI Summit 2024.11 Comment元ポスト:https://x.com/hmtd223/status/1856887876665184649?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q非常に興味深いので後で読む #Article #LanguageModel #Slide Issue Date: 2024-10-05 今日から始める大規模言語モデルのプロダクト活用, y_matsuwitter, 2024.10 #Article #Blog #API Issue Date: 2024-09-30 API設計まとめ, KNR109, 2024.02 #Article #NLP #LanguageModel #Evaluation #Blog #LLM-as-a-Judge Issue Date: 2024-09-30 Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge), 2024.09 CommentLLM-as-a-judgeについて網羅的に書かれた記事 #Article #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-09-29 RAGの実装戦略まとめ, Jin Watanabe, 2024.03 #Article #Tutorial #EfficiencyImprovement #LanguageModel Issue Date: 2024-09-25 LLMの効率化・高速化を支えるアルゴリズム, Tatsuya Urabe, 2024.09 #Article #Slide #Management Issue Date: 2024-09-25 NLP Experimental Design, Graham Neubig, 2024 #Article #NLP #QuestionAnswering #LLMAgent #GenerativeAI #RAG(RetrievalAugmentedGeneration) #Repository Issue Date: 2024-09-11 PaperQA2, 2023.02 Comment元ポスト: https://x.com/sgrodriques/status/1833908643856818443?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #RecommenderSystems #Blog Issue Date: 2024-08-27 10Xの推薦を作るチームとML platform, 2024.08 Comment初期開発における定性評価の重要性やインターリービングの話題など実用的な内容が書かれているように見える。あとで読む。定性評価が重要という話は、1367 でも言及されている #Article #Slide #Management Issue Date: 2024-08-10 現代的システム開発概論2024, 2024.08 #Article #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-08-09 RAG入門: 精度改善のための手法28選, 2024.08 #Article #LanguageModel #Blog #MultiLingual Issue Date: 2024-04-12 The State of Multilingual AI, Sebastian Ruder, 2024 #Article #LanguageModel #Blog Issue Date: 2024-04-02 Mamba Explained #Article #Pretraining #NLP #Dataset #LanguageModel #InstructionTuning #Repository #Japanese Issue Date: 2023-12-11 A Review of Public Japanese Training Sets, shisa, 2023.12 #Article #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-11-13 Boosting RAG: Picking the Best Embedding & Reranker models #Article #PersonalizedDocumentSummarization #NLP #Personalization Issue Date: 2023-05-05 Personalized news filtering and summarization on the web, Xindong+, 2011 IEEE 23rd International Conference on Tools with Artificial Intelligence, 29 Commentsummarizationではなく、keyword extractionの話だった #Article #PersonalizedDocumentSummarization #NLP #Education #Personalization Issue Date: 2023-05-05 Personalized Text Content Summarizer for Mobile Learning: An Automatic Text Summarization System with Relevance Based Language Model, Guangbing+, IEEE Fourth International Conference on Technology for Education, 2012, 22 #Article #Pretraining #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Evaluation #Blog #Reasoning Issue Date: 2023-05-04 Towards Complex Reasoning: the Polaris of Large Language Models, Yao Fu, 2023.05 #Article #PersonalizedDocumentSummarization #NLP Issue Date: 2023-04-30 Personalized Extractive Summarization for a News Dialogue System, Takatsu+, SLT, 2021, 4 #Article #RecommenderSystems Issue Date: 2023-04-28 E-Commerce product recommendation agents: use, characteristics, and impact Comment超重要論文 #Article #Tutorial #Programming #Slide Issue Date: 2022-03-02 良いコードとは何か - エンジニア新卒研修 スライド公開, CyberZ, 森 #Article #Tutorial #MachineLearning #Infrastructure Issue Date: 2021-10-19 Hidden Technical Debt in Machine Learning Systems, Sculley+, Google Comment
よく見るML codeが全体のごく一部で、その他の基盤が大半を占めてますよ、の図 #Article #Tutorial #MachineLearning Issue Date: 2021-10-16 実臨床・Webサービス領域での機械学習研究 開発の標準化 Comment並列して走る機械学習案件をどのように効果的に捌いているか説明。
①タイトな締切
→ 高速化で対処
→ よく使う機能をML自身に実装する
②並行して走る案件
→ 並列化
→ Kubernetesを用いて、タスクごとに異なるノードで分散処理(e.g CVのFoldごとにノード分散、推論ユーザごとにノード分散)要件に合わせて、メモリ優先、CPU優先などのノードをノードプールから使い分ける
③属人化
→ 標準化
→ よく使う機能はMLシステム自身に実装
→ 設定ファイルで学習、推論の挙動を制御 #Article #RecommenderSystems #CollaborativeFiltering #FactorizationMachines Issue Date: 2021-07-02 Deep Learning Recommendation Model for Personalization and Recommendation Systems, Naumov+, Facebook, arXiv‘19 Summary深層学習に基づく推薦モデル(DLRM)を開発し、PyTorchとCaffe2で実装。埋め込みテーブルのモデル並列性を活用し、メモリ制約を軽減しつつ計算をスケールアウト。DLRMの性能を既存モデルと比較し、Big Basin AIプラットフォームでの有用性を示す。 CommentFacebookが開発したopen sourceのDeepな推薦モデル(MIT Licence)。
モデル自体はシンプルで、continuousなfeatureをMLPで線形変換、categoricalなfeatureはembeddingをlook upし、それぞれfeatureのrepresentationを獲得。
その上で、それらをFactorization Machines layer(second-order)にぶちこむ。すなわち、Feature間の2次の交互作用をembedding間のdot productで獲得し、これを1次項のrepresentationとconcatしMLPにぶちこむ。最後にシグモイド噛ませてCTRの予測値とする。
実装: https://github.com/facebookresearch/dlrmParallelism以後のセクションはあとで読む
#Article
#RecommenderSystems
#Tutorial
Issue Date: 2021-07-02
Continuously Improving Recommender Systems for Competitive Advantage Using NVIDIA Merlin and MLOps, Nvidia, 2021.01
CommentRecommender System運用のためのアーキテクチャに関する情報
#Article
#NeuralNetwork
#Survey
#NLP
Issue Date: 2021-06-17
Pre-Trained Models: Past, Present and Future, Han+, AI Open‘21
Summary大規模な事前学習モデル(PTMs)は、AI分野での成功を収め、知識を効果的に捉えることができる。特に、転移学習や自己教師あり学習との関係を考察し、PTMsの重要性を明らかにする。最新のブレークスルーは、計算能力の向上やデータの利用可能性により、アーキテクチャ設計や計算効率の向上に寄与している。未解決問題や研究方向についても議論し、PTMsの将来の研究の進展を期待する。
#Article
#Tutorial
#ReinforcementLearning
#Blog
#Off-Policy
Issue Date: 2021-06-07
ゼロから始めてオフライン強化学習とConservative Q-Learningを理解する, aiueola, 2021.05
#Article
#Tutorial
#EducationalDataMining
#LearningAnalytics
#StudentPerformancePrediction
#KnowledgeTracing
Issue Date: 2021-05-30
The Knowledge-Learning-Instruction Framework: Bridging the Science-Practice Chasm to Enhance Robust Student Learning, Pelanek, User Modeling and User-Adapted Interaction, 2017
CommentLearner Modelingに関するチュートリアル。Learner Modelingの典型的なコンテキストや、KCにどのような種類があるか(KLI Frameworkに基づいた場合)、learner modeling techniques (BKTやPFA等)のチュートリアルなどが記載されている。
knowledgeをmodelingする際に利用されるデータの典型的な構造
donain modelingの典型的なアプローチ
モデルのaspectと、model purposes, learning processesのrelevanceを図示したもの。色が濃いほうが重要度が高い
Learner ModelingのMetrics
cross validation方法の適用方法(同じ学習者内と、異なる学習者間での違い。学習者内での予測性能を見たいのか、学習者間での汎化性能を見たいのかで変わるはず)
BKT、PFAや、それらを用いるContext(どのモデルをどのように自分のcontextに合わせて選択するか)、KLI Frameworkに基づくKCの構成のされ方、モデル評価方法等を理解したい場合、読んだほうが良さそう?
ざっとしか見ていないけど、重要な情報がめちゃめちゃ書いてありそう。後でしっかり読む・・・。 #Article #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #IJCAI Issue Date: 2021-05-25 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17 CommentFactorization Machinesと、Deep Neural Networkを、Wide&Deepしました、という論文。Wide=Factorization Machines, Deep=DNN。
高次のFeatureと低次のFeatureを扱っているだけでなく、FMによってフィールドごとのvector-wiseな交互作用、DNNではbit-wiseな交互作用を利用している。
割と色々なデータでうまくいきそうな手法に見える。
発展版としてxDeepFM 348 がある。281 にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:https://data.gunosy.io/entry/deep-factorization-machines-2018実装: https://github.com/rixwew/pytorch-fm #Article #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #SIGKDD Issue Date: 2021-05-25 xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Lian+, KDD‘18 Comment349 DeepFMの発展版281 にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:https://data.gunosy.io/entry/deep-factorization-machines-2018
DeepFMの発展についても詳細に述べられていて、とても参考になる。 #Article #RecommenderSystems #Embeddings #SessionBased #SequentialRecommendation Issue Date: 2020-08-29 Airbnbの機械学習導入から学ぶ, Jun Ernesto Okumura, 2020 #Article #ComputerVision #NLP #CommentGeneration Issue Date: 2019-09-27 Cross-domain personalized image captioning, Long+, 2019 #Article #InformationRetrieval #SIGIR Issue Date: 2017-12-28 Personalizing Search via Automated Analysis of Interests and Activities, SIGIR, [Teevan+, 2005], 2005.08 Comment・userに関するデータがrichなほうが、Personalizationは改善する。
・queries, visited web pages, emails, calendar items, stored desktop
documents、全てのsetを用いた場合が最も良かった
(次点としてqueriesのみを用いたモデルが良かった) </div>