
RLHF (ReinforcementLearningFromHumanFeedback)
#Analysis#Pocket#NLP#LanguageModel#Finetuning (SFT)#ReinforcementLearning
Issue Date: 2025-03-17 All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning, Gokul Swamy+, arXiv25 Comment元ポスト:https://x.com/hillbig/status/1901392286694678568?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QAlignmentのためのPreferenceデータがある時に、そのデータから直接最尤推定してモデルのパラメータを学習するのではなく、 ... #NLP#LanguageModel#Reasoning#Mathematics
Issue Date: 2025-01-04 DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, Zhihong Shao+, arXiv24 Comment元ポスト:https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_the-rlhf-method-behind-the-best-open-models-activity-7280850174522843137-3V9v?utm_source= ... #Analysis#Pocket#NLP
Issue Date: 2025-01-03 Does RLHF Scale? Exploring the Impacts From Data, Model, and Method, Zhenyu Hou+, arXiv24 Comment元ポスト:https://x.com/dair_ai/status/1868299930600628451?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ...
Issue Date: 2025-03-17 All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning, Gokul Swamy+, arXiv25 Comment元ポスト:https://x.com/hillbig/status/1901392286694678568?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QAlignmentのためのPreferenceデータがある時に、そのデータから直接最尤推定してモデルのパラメータを学習するのではなく、 ... #NLP#LanguageModel#Reasoning#Mathematics
Issue Date: 2025-01-04 DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, Zhihong Shao+, arXiv24 Comment元ポスト:https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_the-rlhf-method-behind-the-best-open-models-activity-7280850174522843137-3V9v?utm_source= ... #Analysis#Pocket#NLP
Issue Date: 2025-01-03 Does RLHF Scale? Exploring the Impacts From Data, Model, and Method, Zhenyu Hou+, arXiv24 Comment元ポスト:https://x.com/dair_ai/status/1868299930600628451?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ...
#NLP#LanguageModel#ReinforcementLearning#PPO (ProximalPolicyOptimization)
Issue Date: 2023-07-12 Secrets of RLHF in Large Language Models Part I: PPO, Rui Zheng+, N_A, arXiv23 Summary大規模言語モデル(LLMs)を使用した人間中心のアシスタントの開発には、報酬設計やトレーニングの課題などの障壁があります。この研究では、強化学習(RLHF)のフレームワークを解析し、PPOアルゴリズムの内部動作を再評価し、ポリシーモデルのトレーニングの安定性を改善するための高度なバージョンを提案します。さらに、SFTモデルとChatGPTと比較してRLHFの能力を分析し、オープンソースの実装を公開することを目指しています。 CommentRLHFとPPOをの内部構造を調査したレポート。RLHFに興味がある場合は読むべし。github: https://github.com/OpenLMLab/MOSS-RLHF ... #NLP#LanguageModel#Alignment#ChatGPT
Issue Date: 2024-04-28 Training language models to follow instructions with human feedback, Long Ouyang+, N_A, NeurIPS22 Summary大規模な言語モデルは、ユーザーの意図に合わない出力を生成することがあります。本研究では、人間のフィードバックを使用してGPT-3を微調整し、InstructGPTと呼ばれるモデルを提案します。この手法により、13億パラメータのInstructGPTモデルの出力が175BのGPT-3の出力よりも好まれ、真実性の向上と有害な出力の削減が示されました。さらに、一般的なNLPデータセットにおける性能の低下は最小限でした。InstructGPTはまだ改善の余地がありますが、人間のフィードバックを使用した微調整が有望な方向であることを示しています。 CommentChatGPTの元となる、SFT→Reward Modelの訓練→RLHFの流れが提案された研究。DemonstrationデータだけでSFTするだけでは、人間の意図したとおりに動作しない問題があったため、人間の意図にAlignするように、Reward Modelを用いたRLHFでSFTの後に追加で ...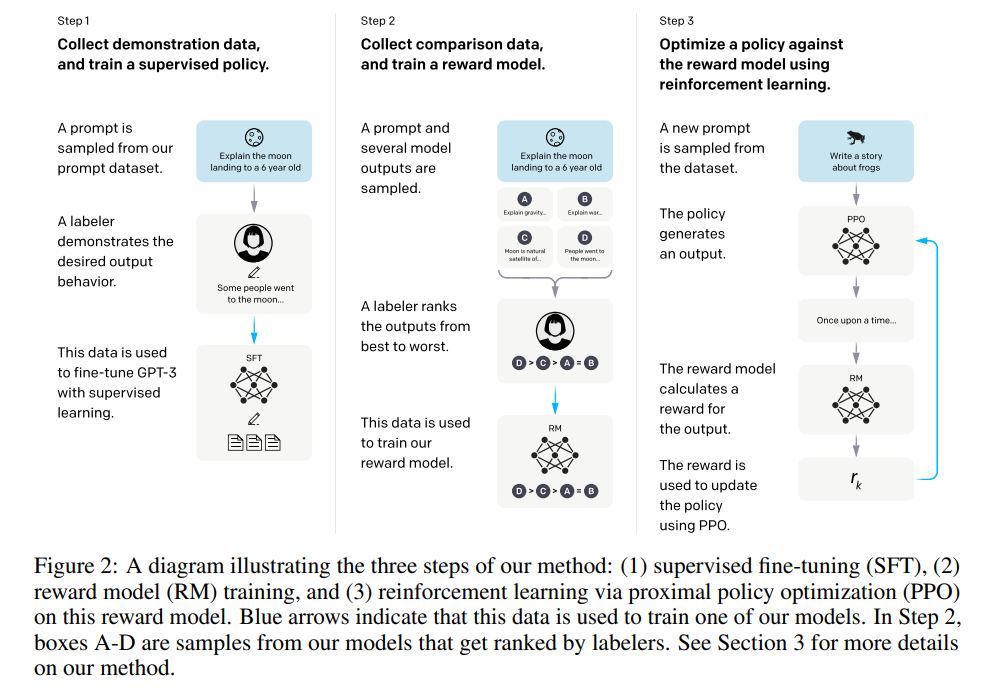 #Article#NLP#LanguageModel#Finetuning (SFT)#FoundationModel#Article
#Article#NLP#LanguageModel#Finetuning (SFT)#FoundationModel#Article
Issue Date: 2025-02-01 DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01 Comment#1719#1655とても丁寧でわかりやすかった。後で読んだ内容を書いて復習する。ありがとうございます。 ...
Issue Date: 2023-07-12 Secrets of RLHF in Large Language Models Part I: PPO, Rui Zheng+, N_A, arXiv23 Summary大規模言語モデル(LLMs)を使用した人間中心のアシスタントの開発には、報酬設計やトレーニングの課題などの障壁があります。この研究では、強化学習(RLHF)のフレームワークを解析し、PPOアルゴリズムの内部動作を再評価し、ポリシーモデルのトレーニングの安定性を改善するための高度なバージョンを提案します。さらに、SFTモデルとChatGPTと比較してRLHFの能力を分析し、オープンソースの実装を公開することを目指しています。 CommentRLHFとPPOをの内部構造を調査したレポート。RLHFに興味がある場合は読むべし。github: https://github.com/OpenLMLab/MOSS-RLHF ... #NLP#LanguageModel#Alignment#ChatGPT
Issue Date: 2024-04-28 Training language models to follow instructions with human feedback, Long Ouyang+, N_A, NeurIPS22 Summary大規模な言語モデルは、ユーザーの意図に合わない出力を生成することがあります。本研究では、人間のフィードバックを使用してGPT-3を微調整し、InstructGPTと呼ばれるモデルを提案します。この手法により、13億パラメータのInstructGPTモデルの出力が175BのGPT-3の出力よりも好まれ、真実性の向上と有害な出力の削減が示されました。さらに、一般的なNLPデータセットにおける性能の低下は最小限でした。InstructGPTはまだ改善の余地がありますが、人間のフィードバックを使用した微調整が有望な方向であることを示しています。 CommentChatGPTの元となる、SFT→Reward Modelの訓練→RLHFの流れが提案された研究。DemonstrationデータだけでSFTするだけでは、人間の意図したとおりに動作しない問題があったため、人間の意図にAlignするように、Reward Modelを用いたRLHFでSFTの後に追加で ...
Issue Date: 2025-02-01 DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01 Comment#1719#1655とても丁寧でわかりやすかった。後で読んだ内容を書いて復習する。ありがとうございます。 ...