
TACL
[Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
Paper/Blog Link My Issue
#MachineTranslation Issue Date: 2025-09-01 GPT Summary- xCOMETは、機械翻訳評価のためのオープンソースの学習メトリックで、文レベルの評価とエラー範囲検出を統合。これにより、翻訳エラーの詳細な分類と評価が可能となり、最先端の性能を発揮。さらに、堅牢性分析により重大なエラーや幻覚の特定能力が高いことを示す。
[Paper Note] When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs, Ryo Kamoi+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #SelfCorrection #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-09-16 GPT Summary- 自己修正はLLMを活用し応答の質を向上させる手法です。しかし、LLMがどのように過ちを修正できるかに関しては合意がなく、従来の研究は多くの問題を抱えています。本研究では、先行研究の批判的レビューを行い、成功する自己修正に必要な条件を議論しています。研究課題の分類と実験設計のチェックリストを提供し、(1)プロンプトを用いた成功事例がないこと、(2)信頼できる外部フィードバックを活用すれば自己修正が機能すること、(3)大規模なファインチューニングが自己修正を支援することを示しています。 Comment
LLMのself-correctionに関するサーベイ
[Paper Note] Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies, Liangming Pan+, TACL'24, 2023.08
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #SelfCorrection Issue Date: 2024-09-07 GPT Summary- 自己修正技術を用いて、LLMの幻覚や不正確な推論を改善する方法をレビュー。自動フィードバックを活用し、最小限の人間の介入で実用的なLLMソリューションを目指す。訓練、生成、事後修正の手法を分析し、応用と未来の課題を考察。
[Paper Note] General then Personal: Decoupling and Pre-training for Personalized Headline Generation, Song+, TACL'23, 2023.12
Paper/Blog Link My Issue
#NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration Issue Date: 2025-11-27 GPT Summary- ユーザーの閲覧履歴に基づくパーソナライズされたヘッドライン生成のために、General Then Personal (GTP)フレームワークを提案。タスクを生成とカスタマイズにデカップリングし、情報自己ブースティングとマスクユーザーモデリングを導入。PENSデータセットでの実験により、GTPが最先端手法を上回ることを示し、デカップリングと事前学習の重要性を強調。人間評価によって効果を検証。
Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering, Siriwardhana+, TACL'23, 2023.01
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 GPT Summary- RAG-end2endは、ODQAにおけるドメイン適応のためにRAGのリトリーバーとジェネレーターを共同訓練する新しいアプローチを提案。外部知識ベースを更新し、補助的な訓練信号を導入することで、ドメイン特化型知識を強化。COVID-19、ニュース、会話のデータセットで評価し、元のRAGモデルよりも性能が向上。研究はオープンソースとして公開。
[Paper Note] Do LLMs exhibit human-like response biases? A case study in survey design, Lindia Tjuatja+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-11-08 GPT Summary- LLMの高性能に伴い、調査や世論調査での人間代理としての活用が期待されるが、プロンプト文言への感度が課題となる。本研究では、LLMが人間の応答バイアスを反映するかを調査し、調査票設計を通じて評価する。結果、主流のLLMは一般的に人間のような挙動を示さず、特にRLHFを経たモデルで顕著だった。また、人間に影響を与えない摂動には敏感であることが判明。これにより、LLMの人間代理利用時の注意点とモデル挙動の細かな分析の必要性が浮き彫りとなった。 Comment
LLMはPromptにsensitiveだが、人間も質問の仕方によって応答が変わるから、sensitiveなのは一緒では?ということを調査した研究。Neubig氏のツイートだと、instruction tuningやRLHFをしていないBase LLMの方が、より人間と類似した回答をするのだそう。
元ツイート:
人間のレスポンスのバイアス。左側は人間は「forbidden」よりも「not allowed」を好むという例、右側は「response order」のバイアスの例(選択肢の順番)。
LLM側で評価したいバイアスごとに、QAのテキストを変更し、LLMに回答を生成され、social science studiesでのトレンドと比較することで、LLMにも人間と同様のバイアスがあるかを明らかにしている。
結果は以下の表であり、青いセルが人間と同様のバイアスを持つことを統計的に有意に示されたもの(のはず)。これをみると、全てのバイアスに対して人間と同様の傾向があったのはLlama2-70Bのみであり、instruction tuningや、RLHFをかけた場合(RLHFの方が影響が大きそう)人間のバイアスとは異なる挙動をするモデルが多くなることがわかる。また、モデルのパラメータサイズとバイアスの強さには相関関係は見受けられない。
[TACL] Efficient Long-Text Understanding with Short-Text Models, TACL'23
Paper/Blog Link My Issue
#NLP #NaturalLanguageUnderstanding Issue Date: 2023-07-18 GPT Summary- 本研究では、長いシーケンスを処理するためのシンプルなアプローチであるSLEDを提案しています。SLEDは、既存の短文の事前学習言語モデルを再利用し、入力を重なり合うチャンクに分割して処理します。制御された実験により、SLEDが長いテキスト理解に有効であり、専用の高価な事前学習ステップが必要な専門モデルと競合することが示されました。
[TACL] Abstractive Meeting Summarization: A Survey, TACL'23
Paper/Blog Link My Issue
#DocumentSummarization #Survey #NLP #Abstractive #Conversation Issue Date: 2023-07-15 GPT Summary- 会議の要約化において、深層学習の進歩により抽象的要約が改善された。本論文では、抽象的な会議の要約化の課題と、使用されているデータセット、モデル、評価指標について概説する。
[TACL] How much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN, TACL'23
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Novelty #Evaluation Issue Date: 2023-07-14 GPT Summary- この研究では、言語モデルが生成するテキストの新規性を評価するための分析スイートRAVENを紹介しています。英語で訓練された4つのニューラル言語モデルに対して、局所的な構造と大規模な構造の新規性を評価しました。結果として、生成されたテキストは局所的な構造においては新規性に欠けており、大規模な構造においては人間と同程度の新規性があり、時には訓練セットからの重複したテキストを生成することもあります。また、GPT-2の詳細な手動分析により、組成的および類推的な一般化メカニズムの使用が示され、新規テキストが形態的および構文的に妥当であるが、意味的な問題が比較的頻繁に発生することも示されました。
[Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #Prompting #In-ContextLearning #Selected Papers/Blogs #ContextEngineering #KeyPoint Notes #needs-revision Issue Date: 2023-07-11 GPT Summary- 言語モデルは長い文脈を扱う能力を持つが、実際に関連情報を効果的に利用できているかは未解明。複数文書に基づく質問応答とキー・バリュー検索を通じて、関連情報の位置による性能変動を分析した結果、関連情報が文脈の先頭や末尾にあるときに高性能を示し、中央にある場合に顕著に性能が低下することが明らかになった。この考察は、言語モデルの文脈使用に関する理解を深め、長い文脈への評価プロトコルの方向性を示唆している。 Comment
元ツイート
非常に重要な知見がまとめられている
1. モデルはコンテキストのはじめと最後の情報をうまく活用でき、真ん中の情報をうまく活用できない
2. 長いコンテキストのモデルを使っても、コンテキストをより短いコンテキストのモデルよりもうまく考慮できるわけではない
3. モデルのパフォーマンスは、コンテキストが長くなればなるほど悪化する
SNLP'24での解説スライド:
https://speakerdeck.com/kichi/snlp2024
Efficient Methods for Natural Language Processing: A Survey, Treviso+, TACL'23
Paper/Blog Link My Issue
#NeuralNetwork #Survey #EfficiencyImprovement #NLP #One-Line Notes Issue Date: 2023-04-25 Comment
パラメータ数でゴリ押すような方法ではなく、"Efficient"に行うための手法をまとめている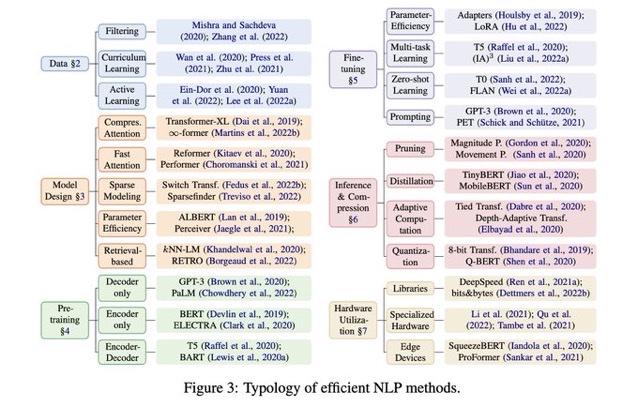
SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization, Laban+, TACL'22
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Evaluation #LM-based #Factuality Issue Date: 2023-08-13
[Paper Note] WikiAsp: A Dataset for Multi-domain Aspect-based Summarization, Hiroaki Hayashi+, TACL'21, 2020.11
Paper/Blog Link My Issue
#DocumentSummarization #Tutorial #NLP #Dataset #KeyPoint Notes Issue Date: 2021-10-20 GPT Summary- オープンドメインのアスペクトベース要約のために、20の異なるドメインのWikipedia記事を用いたマルチドメイン対応データセットWikiAspを提案。各記事のセクションタイトルをアスペクト注釈の指標とし、実験を通じて既存モデルの主要な課題を明らかにした。 Comment
NLPコロキウムをリアルタイムに聴講
◆Aspect-based summarizationのモチベーション
・same source対して、異なるユーザニーズが存在するので、ニーズに関して要約したい
◆Aspect: あるobjectに対する、attributeのようなものを指定?
object: Attention Is All You Need
aspect: Multi-Head Attention
◆Aspect Based Summarizationの歴史
・はじめは”feature”という文言で研究され(04年頃?)
・続いて*keywords*という単語で研究され
・その後Aspectという文言で研究されるようになった
・2008年頃にMcDonaldsらがAspect-Based Summarizationを提案した
・2014年以後?とかにNeural Basedな手法が盛んに研究
◆WikiAspデータセットについて
・Wikipediaを使ったAspect-based dataset
・Wikipediaを書かれるのに利用されたsource document(wikipediaにソースとして引用されているもの)に対し、aspectを各節の見出しとみなし、節のテキストを要約文とみなすことで、データセット生成
・他のAspect-basedデータセットと異なり、ソースデータが長く、要約長も5~6倍程度
・ドメイン数が他データセットは5,6程度に対し、20と膨大
◆ベースラインとして2-stageモデルを採用
first-stage: ソーステキストからROBERTaベースドなclassifierを用いて、sentencesから内包するAspectを閾値を用いて決定
それらをgrouped sentencesとする
two-stage: 各aspectごとにまとまったテキスト集合に対して、要約モデルを適用し、要約を実施する
・要約モデルはUnsupervisedな手法であるTextRankと、Supervisedな手法であるBERTベースな手法を採用
・ドメインごとに評価した結果を見ると、BERTが強いドメインがある一方で、TextRankが強いドメインもあった
-> Extractiveな形で要約されているドメインではTextRankが強く、Abstractiveに要約されているドメインではBERTが強い
-> またBERTは比較的短い要約であればTextRankよりもはるかに良いが、長い要約文になるとTextRankとcomprable(あるいはTextRankの方が良い)程度の性能になる
・ROUGE-2の値がsentence-basedなORACLEを見た時に、他データセットと比較して低いので、Abstractiveな手法が必要なデータセット?
(後からのメモなので少しうろ覚えな部分あり)
Q. ROUGE-2が30とかって直観的にどのくらいのレベルのものなの?ROUGE-2が30とか40とかは高い
・最先端の要約モデルをニュース記事に適用すると、35~40くらいになる。
・このレベルの数値になると、人間が呼んでも違和感がないレベルの要約となっている
Q. 実際に要約文をチェックしてみて、どういう課題を感じるか?
A. Factual Consistencyがすぐに目につく問題で、特にBERTベースな要約文はそう。TextRankはソース文書がノイジーなので、ソース文章を適当に拾ってきただけではFactual Consistencyが良くない(元の文書がかっちりしていない)。流暢性の問題はAbstractiveモデルだと特に問題なくBERT-baseでできる。Aspect-based要約のエラー例としてAspectに則っていないということがある。たとえばオバマの大統領時代の話をきいているのに、幼少時代の話をしているとか。Aspect情報をうまくモデルを扱えていないという点が課題としてある。
出典元(リアルタイムに聴講): 第13回 WikiAsp: A Dataset for Multi-domain Aspect-based Summarization, NLPコロキウム
https://youtu.be/3PIJotX6i_w?si=hX5pXwNL-ovkGSF5
[Paper Note] BLiMP: The Benchmark of Linguistic Minimal Pairs for English, Alex Warstadt+, TACL'20
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Grammar Issue Date: 2025-09-07 GPT Summary- 言語的最小対のベンチマーク(BLiMP)は、言語モデルの文法知識を評価するためのチャレンジセットで、67のサブデータセットから成り、各サブデータセットには特定の文法対比を示す1000の最小対が含まれています。データは専門家によって自動生成され、人間の合意は96.4%です。n-gram、LSTM、Transformerモデルを評価した結果、最先端のモデルは形態論的対比を識別できるが、意味的制約や微妙な文法現象には苦戦していることが示されました。 Comment
先行研究と比較して、より広範なlinguistic phenomenaを扱い、かつ大量のサンプルを集めた英語のacceptable/unacceptableなsentenceのペアデータ。ペアデータは特定のlinguistic phenomenaをacceptable/unacceptableに対比するための最小の違いに基づいており専門家が作成したテンプレートに基づいて自動生成され、クラウドソーシングによって人手でvalidationされている。言語モデルが英語のlinguistic phenomenaについて、どの程度理解しているかのベンチマークに利用可能。
[Paper Note] Leveraging Pre-trained Checkpoints for Sequence Generation Tasks, Sascha Rothe+, TACL'20, 2019.07
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #MachineTranslation #NLP #Transformer #pretrained-LM #Encoder #Encoder-Decoder #KeyPoint Notes Issue Date: 2022-12-01 GPT Summary- 事前学習された大規模なニューラルモデルがシーケンス生成においても有効であることを示し、BERT、GPT-2、RoBERTaと互換性のあるTransformerベースのモデルを開発。これにより、機械翻訳やテキスト要約などのタスクで新たな最先端の成果を達成。 Comment
# 概要
BERT-to-BERT論文。これまでpre-trainedなチェックポイントを利用する研究は主にNLUで行われてきており、Seq2Seqでは行われてきていなかったので、やりました、という話。
publicly availableなBERTのcheckpointを利用し、BERTをencoder, decoder両方に採用することでSeq2Seqを実現。実現する上で、
1. decoder側のBERTはautoregressiveな生成をするようにする(左側のトークンのattentionしか見れないようにする)
2. encoder-decoder attentionを新たに導入する
の2点を工夫している。
# 実験
Sentence Fusion, Sentence Split, Machine Translation, Summarizationの4タスクで実験
## MT
BERT2BERTがSoTA達成。Edunov+の手法は、data _augmentationを利用した手法であり、純粋なWMT14データを使った中ではSoTAだと主張。特にEncoder側でBERTを使うと、Randomにinitializeした場合と比べて性能が顕著に上昇しており、その重要性を主張。
Sentence Fusion, Sentence Splitでは、encoderとdecoderのパラメータをshareするのが良かったが、MTでは有効ではなかった。これはMTではmodelのcapacityが非常に重要である点、encoderとdecoderで異なる文法を扱うためであると考えられる。
## Summarization
BERTSHARE, ROBERTASHAREの結果が良かった。
[Paper Note] Generating Sentences by Editing Prototypes, Kelvin Guu+, TACL'18, 2017.09
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Encoder-Decoder #Editing Issue Date: 2017-12-31 GPT Summary- 新しい生成モデルを提案し、トレーニングコーパスからプロトタイプ文をサンプリングして編集することで新しい文を生成。従来のモデルと異なり、困惑度を改善し、高品質な出力を実現。さらに、文の類似性や文レベルの類推を捉える編集ベクトルを生成。
[Paper Note] Google's Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation, Melvin Johnson+, TACL'17, 2016.11
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP #TransferLearning #MultiLingual #Zero/FewShotLearning #Encoder-Decoder #LowResource Issue Date: 2025-11-19 GPT Summary- 単一のNMTモデルを用いて多言語翻訳を実現するシンプルな手法を提案。入力文の先頭に人工トークンを追加することでターゲット言語を指定し、モデルのアーキテクチャは変更せずに共有語彙を使用。これにより、パラメータを増やさずに翻訳品質を向上させ、WMT'14およびWMT'15ベンチマークで最先端の結果を達成。訓練中に見たことのない言語ペア間での暗黙のブリッジングを学習し、転移学習とゼロショット翻訳の可能性を示す。 Comment