
Reasoning
[Paper Note] ReasonIF: Large Reasoning Models Fail to Follow Instructions During Reasoning, Yongchan Kwon+, ACL'26 Findings, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ACL #InstructionFollowingCapability #Findings #One-Line Notes Issue Date: 2026-07-08 GPT Summary- 大規模言語モデル(LLMs)がユーザーの指示を推論過程全体で遵守する重要性を強調し、ReasonIFというベンチマークを導入。これは、推論指示の遵守を評価し、さまざまな指示プロンプトを網羅している。多くのオープンソースLRMsにおいて、指示遵守のスコアは0.25未満であり、難易度の上昇に伴い低下する傾向がある。推論指示の忠実度向上には、マルチターン推論と合成データを用いたファインチューニングが有効で、RIFによって大きな改善が見込まれるが、さらなる向上が必要。 Comment
著者ポスト:
著者ポスト2:
reasoning traceに対して制約を課す[^1]指示は、メインの応答と比較して指示追従性能が低い傾向にある
[^1]: 思考する言語の指定、思考の長さの制限、免責事項(指示でreasoningの最後にwarningや備考を追記する)、reasoningをjsonにする、大文字のみを利用する、commaをreasoning中に除外する、など
[Paper Note] S-Agent: Spatial Tool-Use Elicits Reasoning for Spatial Intelligence, Yalun Dai+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#read-later #Selected Papers/Blogs #Robotics #SpatialUnderstanding #Initial Impression Notes #Author Thread-Post Issue Date: 2026-06-19 GPT Summary- 空間的知性を必要とする連続的な3D世界において、既存のVLMは静的な推論に限界があります。本研究では、S-Agentという空間ツール使用型エージェントのパラダイムを提案し、空間推論をフレーム中心からシーン中心の理解へと再構築します。S-AgentはVLMを意味的プランナーとして機能させ、物体の定位から高レベルの空間知識の統合を行います。さらに、Scene MemoryとAgent Memoryを用いた時系列記憶機構により、証拠統合が可能になります。実験により、S-Agentがオープンソース・クローズドソース両方のVLMを改善し、S-300Kに対する監視付きファインチューニング(SFTが)同規模のベースラインを凌駕し、高度なモデルとも同等の性能を示すことが確認されました。 Comment
元ポスト:
Gemini 3 Proをoutperformとのこと。Ropediaは独自のデータを大量に収集していると思われるので動向が気になる。
pj page: https://ropedia.github.io/S-Agent/
[Paper Note] LLM Explainability with Counterfactual Chains and Causal Graphs, Nirit Nussbaum-Hoffer+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#GraphBased #NLP #LanguageModel #Explanation Issue Date: 2026-06-15 GPT Summary- 因果グラフを用いてLLMの推論プロセスを透明にモデル化。四段階の手法で解釈可能な概念を発見し、入力を概念状態へマッピング。反事実補強により因果推定を安定化し、疾病診断や感情分析に適用。結果は因果グラフがLLMの推論と整合する依存関係を捉えていることを示し、説明可能性の基盤を提供。 Comment
元ポスト:
[Paper Note] Harnessing Reasoning Trajectories for Hallucination Detection via Answer-agreement Representation Shaping, Jianxiong Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#LanguageModel #Hallucination #Author Thread-Post Issue Date: 2026-06-11 GPT Summary- 大型推論モデルは、長い推論経路を生成するが、誤った回答やハルシネーションの検出を難しくする。これに対処するために、Answer-agreement Representation Shaping(ARS)を提案。ARSは、回答の安定性をエンコードし、トレース境界を摂動させることで反事実的な回答を生成し、一致する回答を近づける表現を学習。これによりハルシネーションリスクを明らかにする。実験により、ARSは検出精度を向上させ、強力なベースラインを超える改善を示す。 Comment
元ポスト:
[Paper Note] Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It, Xinyu Zhou+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#LanguageModel #Supervised-FineTuning (SFT) #Chain-of-Thought #LongSequence #read-later Issue Date: 2026-06-11 GPT Summary- CoT-SFTが長い文脈における検索性能を低下させる問題を発見。特に難しい設定でのHypeNetの性能が著しく落ちるため、W_QとW_KをSFT前の状態に戻すQK-Restoreを提案。これにより、訓練コストゼロで推論性能を改善し、長い文脈の処理能力を回復することができた。例えば、HypeNet-5Bでは性能が65.4%から76.4%へ向上した。 Comment
元ポスト:
[Paper Note] Reasoning or Memorization? Direction-Aware Diversity Exploration in LLM Reinforcement Learning, Jiangnan Xia+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning #PostTraining #Diversity #Memorization Issue Date: 2026-06-11 GPT Summary- 強化学習においてDiRL(Direction-Aware Reinforcement Learning)を提案し、探索を推論と記憶の方向に規定。これにより、推論に沿った探索を強化し、記憶化を抑える報酬設計を実現。実験により、様々な既存手法よりも顕著な性能向上を確認。 Comment
元ポスト:
著者ポスト:
[Paper Note] Reasoning Structure of Large Language Models, Frédéric Berdoz+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Evaluation #Initial Impression Notes Issue Date: 2026-06-06 GPT Summary- 推論モデルの評価には、正確性やトークン数だけでなく、推論構造の理解が重要である。これに応じて、論理パズルのためのスケーラブルな評価ベンチマークと、非構造化推論を検証可能な推論グラフに変換するパイプラインを導入。これにより、推論の構造化と定量的分析が可能となり、論理的流れの集中度を測る指標を定義。分析は、構造的測定が正確性とトークン数の混同を解消し、故障モードの診断やパズルの難易度との関係を比較するのに役立つことを示した。 Comment
元ポスト:
LLMのReasoning Traceをverifiableなグラフ構造に変換し、Reasoningを評価可能にする
[Paper Note] ReasonOps: Operator Segmentation for LLM Reasoning Traces, Daniel Lee+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Chain-of-Thought #Overthinking #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- ReasonOpsは、チェーン・オブ・ソートの痕跡を分析するための教師なし手法であり、推論の過程を注釈付けするための普遍的な演算子を提供します。12のモデルから44,662の痕跡を分析した結果、共通の構成的な構造が明らかになりました。特に、バックトラッキングや仮説設定などの再発する演算子が全モデルに見られ、内省的演算子は難問でより効果的であることが示されました。演算子のシーケンスを用いることでモデルの高精度な識別が可能になり、早期の品質推定も実現しました。ReasonOpsは、LLMの推論痕跡に対する深いインサイトを提供し、性能予測の強化に寄与します。 Comment
元ポスト:
[Paper Note] Thinking as Compression: Your Reasoning Model is Secretly a Context Compressor, Guoxin Ma+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ContextEngineering #Compression #Initial Impression Notes Issue Date: 2026-05-31 GPT Summary- 長い文脈を短縮しながら情報損失を抑える文脈圧縮の新手法「Thinking as Compression(TaC)」を提案。思考モデルが自らタスク関連情報を整理し、専用の圧縮機に依存せずに効果的な圧縮を実現。加えて、TaCを制約付きで進化させた「TaC-C」により、思考をコンパクトに管理できる。実験では、既存ベースラインを一貫して上回り、特に4倍および8倍の圧縮比でF1とEMスコアが顕著に改善された。 Comment
元ポスト:
contextを圧縮する専門のcompressorをわざわざ用意するのではなく、reasoningモデルのreasoning traceそのものを圧縮されたcontextとして扱えるような枠組みの提案のようである。
[Paper Note] Teaching Thinking Models to Reason with Tools: A Full-Pipeline Recipe for Tool-Integrated Reasoning, Qianjia Cheng+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #PostTraining #reading #Initial Impression Notes #ToolUse Issue Date: 2026-05-11 GPT Summary- ツール統合推論(TIR)は、テキストのみの推論能力を超える思考モデルの拡張を提供しますが、ツール評価が逆に推論性能を低下させることも観察されています。本研究は、ツールを使用せずに推論能力を損なわずに強力な思考モデルに自然なツール使用を組み込む方法を提案し、TIRレシピの要点を示します。具体的には、教師の推論軌跡の学習可能性やツール使用軌跡の比率制御が重要であり、最適化手法がTIRの効果を最大化する可能性を示しています。最終的に、Qwen3モデルに適用することで、オープンソースベンチマークで最先端の成績を達成しました。 Comment
元ポスト:
Qwen3にcode executorを実行できるようにしても、数学のベンチマークにおいてほとんどツール呼び出しを行っていないにも関わらずスコアが劣化する。つまり、promptにツール呼び出しの情報を含めただけで、text-onlyでの推論能力が低下しロバストでない。さらに、ツール呼び出しを行ったとしてもテキスト空間上で推論を行った後にテキスト推論の結果をverificationする目的でcode executionを行うなど、ツールを用いて思考する能力が不足していることをイントロで指摘している。
適切なツール呼び出しを実施するために、既存研究では適切にツールを呼び出せるようにSFTやRLが行われるが、ツール呼び出しに関してpost-trainingを実施すると通常のtext-onlyでのreasoning能力が低下する課題があるとイントロで述べられている。Table 1に示されているようにツール呼び出しに関する情報をpromptに含めると、既存のOpenWeightモデル(Qwen3のみだが)はツールが有効なタスクであっても性能が向上しないことから、内部パラメータに埋め込まれている推論に関するlogicは簡単に壊れてしまうことを示唆しており、text-onlyでのreasoning能力を保ちつつ適切にtool useを実行できる手法が必要という課題があり、これを克服するための手法を提案しているようである。
問題意識は興味深いが、イントロの例にだけでは、Qwen3でのみ生じるのか、Qwen3に対するtool useのためのprompting手法が悪かっただけなのか、OpenWeightモデル全般のモデルパラメータ側の課題なのかが区別がつかず、どの程度インパクトのある話なのかがよくわからない。
個人的には、Table 1はより多くの学習レシピが公開されているモデルファミリーでの結果や、実際にtool useのためのSFT/RLを実施した場合に、text-onlyの推論能力が低下することが示されていてほしいと感じる。論文後半にそういったablationが出てくるのだろうか。
[Paper Note] From Correspondence to Actions: Human-Like Multi-Image Spatial Reasoning in Multi-modal Large Language Models, Masanari Oi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Supervised-FineTuning (SFT) #MultiModal #ICML #PostTraining #GRPO #VisionLanguageModel #SpatialUnderstanding #Author Thread-Post #MultiView Issue Date: 2026-05-06 GPT Summary- 視点間対応と逐次的視点変換を強化するために、HATCH(Human-Aware Training for Cross-view correspondence and viewpoint cHange)を提案。これにより、空間的整合性を促進し、視点遷移アクションを生成して推論を改善。実験結果は、HATCHが同規模のモデルを上回り、大規模モデルとも競合する性能を示した。 Comment
元ポスト:
[Paper Note] LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model, Inclusion AI+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #MultiModal #DiffusionModel #TextToImageGeneration #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #VisionLanguageModel #Editing #UMM #ImageSynthesis #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- LLaDA2.0-Uniは、マルチモーダルな理解と生成を統合するための統一型離散拡散大規模言語モデルです。意味論的な離散トークナイザとMoEベースのバックボーン、拡散デコーダを組み合わせ、視覚入力を効率的に処理します。高忠実度の画像生成を実現し、推論効率を最適化する独自の手法を採用。特化型VLMに匹敵する性能を持ち、生成と推論の相互運用性で次世代モデルの可能性を広げます。コードは公開されています。 Comment
元ポスト:
VLM * Diffusionモデル。テキストの生成だけでなく、TextToImage, Image Editingもサポートされているように見える。
公式ポスト:
画像を生成する前にreasoningを実施するように訓練され、UMMなのでtext, patchのrepresentationがシームレスに統合され、画像を伴うテキスト生成がより一貫性を持つ、とのこと。
著者ポスト:
[Paper Note] Context Unrolling in Omni Models, Ceyuan Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #VisionLanguageModel #2D (Image) #3D (Scene) #UMM #3D (Video) #Omni #One-Line Notes #Reference Collection #AudioLanguageModel #Fidelity #audio #text Issue Date: 2026-04-24 GPT Summary- Omniは、多様なモダリティにネイティブに訓練されたマルチモーダルモデルで、Context Unrollingを通じて異なるモダリティの情報を統合。これにより、下流の推論忠実度が向上し、高い生成・理解性能を発揮。テキスト、画像、動画、3Dジオメトリを用いた高度な推論能力を示す。 Comment
元ポスト:
モダリティを跨いでtaskに対してrelevantなcontextを活性化させることで、omniモデルの生成時の推論能力と、忠実度を向上させる
[Paper Note] RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time, Haozhe Wang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Multi #ComputerVision #NLP #TextToImageGeneration #OpenWeight #Test-Time Scaling #read-later #Selected Papers/Blogs #RewardModel Issue Date: 2026-04-19 GPT Summary- 報酬モデルは、評価を単一のスコアに縮約するのではなく、明示的で多次元の批評を生成することで、生成物の改善を促進する。本研究では、構造化された合理根拠を用いて報酬を提供し、Generate-Critique-Refineループにより批評をプロンプト修正に変換する方法を示す。また、Preference-Anchored Rationalization(PARROT)を導入し、容易に得られるデータから高品質な合理根拠を回収するフレームワークを提供する。得られたRationalRewardsモデルは、オープンソースの中で最先端の予測精度を達成し、より少ない訓練データで優れた性能を発揮する。批評-修正ループは、既存モデルの潜在能力を引き出し、より良い生成結果を提供する。 Comment
pj page: https://tiger-ai-lab.github.io/RationalRewards/
元ポスト:
[Paper Note] Process Reward Agents for Steering Knowledge-Intensive Reasoning, Jiwoong Sohn+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Chain-of-Thought #PRM #FactualKnowledge #Initial Impression Notes Issue Date: 2026-04-17 GPT Summary- PRAは、凍結済みポリシーに対するオンラインかつ段階的な報酬を提供することで、推論プロセスを改善。検索ベースのデコードにより、生成ステップごとに候補をランキングし、剪定する。医療推論ベンチマークで一貫して高い性能を示し、未見のポリシーモデルに対しても精度を最大25.7%向上させる。PRAはドメイン固有の報酬モジュールを通じて、複雑なドメインで再訓練なしに新たなバックボーンを展開可能にする。 Comment
pj page: https://process-reward-agents.github.io/
元ポスト:
Reasoning中に独立したProcess Reward Agent (PRA) によって外部知識からevidenceを検索しreasoning stepに対してrewardを与えることで、reasoning step単位のrewardを実現し、これによりknowledge-intensiveなドメインに対してより頑健な推論が可能になる、という感じだろうか。medical domainで評価しており、self-consistency+RAGなどの手法を上回っているように見える(が、Fair Comparisonになっているだろうか、という点が少し気になる)。あとは、汎用的な手法だと思われるので、medicalドメインだけでなく他のknowledge-intentiveなドメインでの評価もあるとなお良さそうに感じる。
[Paper Note] LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning, Sumeet Ramesh Motwani+, ICML'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Chain-of-Thought #Evaluation #ICML #read-later #Selected Papers/Blogs #LongHorizon #Author Thread-Post Issue Date: 2026-04-16 GPT Summary- LongCoTを導入し、複雑な推論能力を測定するための2,500問の専門家設計問題からなるベンチマークを提供。問題は数万から百数万の推論トークンを含む相互依存の手順を要求し、最先端モデルは全体で<10%の精度であることが示され、長期推論の限界が明らかになる。LongCoTは、モデルの長時間にわたる安定した推論能力を評価する指標となる。 Comment
元ポスト:
著者ポスト:
[Paper Note] RAGEN-2: Reasoning Collapse in Agentic RL, Zihan Wang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Entropy Issue Date: 2026-04-11 GPT Summary- RAGEN-2では、LLMエージェントの強化学習トレーニングの不安定性に注目し、推論の質をエントロピーと相互情報量(MI)に分解。エントロピーが高くても、モデルが固定テンプレートに依存する「テンプレート崩壊」の問題を明らかにした。MIは推論品質の信頼できる指標であり、タスク性能との相関が強い。低い報酬分散が推論差を消してしまう問題をSNR対応フィルタリングを用いて解決し、入力依存性とタスク性能を改善することを提案。様々なタスクで一貫した成果を示した。 Comment
pj page: https://ragen-ai.github.io/v2/
元ポスト:
おもしろそう
ポイント解説:
トークンのエントロピーによって多様性を測る方法は、単一の応答内での多様性は測れるが、異なるプロンプトに対する応答の多様性は測れない。たとえば、単一応答内のエントロピーは健全だが、応答がinputに非依存の応答となっている場合など(=テンプレート崩壊)は多様性が欠如していると考えられる。このため、相互情報量に基づくメトリックを提案し、応答間で共有されている情報量を測る方法を提案。
[Paper Note] Vero: An Open RL Recipe for General Visual Reasoning, Gabriel Sarch+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #ReinforcementLearning #OpenWeight #OpenSource #PostTraining #read-later #Selected Papers/Blogs #VisionLanguageModel #Initial Impression Notes Issue Date: 2026-04-08 GPT Summary- Veroというオープンな視覚推論モデルを導入し、幅広いタスクで優れた性能を達成。600Kサンプルのデータセットを基に、異なる回答形式を扱える報酬設計を行い、最先端の結果を示す。Veroは既存モデルを超え、系統的なアブレーションを通じて広範なデータカバレージの重要性を明示。他の全データ、コード、モデルを公開。 Comment
元ポスト:
ベースモデルはgivenな上でRLを実施する際のopenなレシピ、データである点に注意。
[Paper Note] Think Anywhere in Code Generation, Xue Jiang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Coding #SoftwareEngineering #read-later #Reference Collection Issue Date: 2026-04-04 GPT Summary- LLMsの事前思考に依存したコード生成は制限があり、全体の複雑性を理解するには不十分である。これに対抗するために、Think-Anywhereという新しい推論機構を提案し、任意のトークン位置で推論を呼び出すことを可能にする。これにより、推論パターンの模倣と成果ベースのRL報酬を活用し、推論のタイミングを自律的に探索させる。広範な実験で、Think-Anywhereは最先端の性能を実現し、多様なLLMsにおいて一貫した一般化を示すことが確認された。 Comment
元ポスト:
解説:
[Paper Note] World Reasoning Arena, PAN Team+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#ComputerVision #Planning #Evaluation #read-later #Selected Papers/Blogs #WorldModels #LongHorizon #Simulation #Arena Issue Date: 2026-03-30 GPT Summary- WR-Arenaは、ワールドモデル(WMs)の評価を進化させるための包括的なベンチマークであり、次状態予測と視覚的忠実度に限らず、知的行動に必要なシミュレーション能力を検証します。三つの基本次元に焦点を当て、アクションシミュレーション忠実度、長期予測、シミュレーション推論と計画を評価します。多様なデータセットを使用して、既存モデルと人間レベルの推論との間のギャップを明らかにし、次世代WMsの指針を提供します。コードはhttps://github.com/MBZUAI-IFM/WR-Arenaで入手可能です。 Comment
元ポスト:
[Paper Note] Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?, Jeonghye Kim+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfDistillation Issue Date: 2026-03-26 GPT Summary- 自己蒸留はLLMの訓練後の効果的な手法であるが、数学的推論においては長さ短縮が性能低下を招くことがある。この劣化は不確実性の表現抑制に起因し、条件付けコンテキストの豊富さによって影響を受けることが示された。具体的には、情報豊富な教師による不確実性の抑制が迅速な最適化を促進する一方で、未知問題に対する性能を悪影響を及ぼすことが確認された。Qwen3-8Bなどのモデルでは、最大40%のパフォーマンス低下が見られ、適切な不確実性の露出が推論の堅牢性に不可欠であることが強調された。 Comment
元ポスト:
関連:
- [Paper Note] Reinforcement Learning via Self-Distillation, Jonas Hübotter+, arXiv'26, 2026.01
ポイント解説:
[Paper Note] Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation, Zhuolin Yang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-03-20 GPT Summary- Nemotron-Cascade 2は、30B MoEモデルで3Bの活性化パラメータを持ち、高度な推論能力とエージェント機能を提供します。小型ながら、数学およびコーディングでの推論能力は最前線モデルに匹敵。2025年の国際数学オリンピックなどで金メダル級の性能を示し、パラメータ数は20分の1でも知能密度は高い。新たにSFT後の拡張されたCascade RLで幅広い推論をカバーし、マルチドメイン蒸留を導入して性能向上を実現。モデルのチェックポイントやデータも公開予定。 Comment
元ポスト:
[Paper Note] Phi-4-reasoning-vision-15B Technical Report, Jyoti Aneja+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SmallModel #OpenWeight #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2026-03-07 GPT Summary- Phi-4-reasoning-vision-15Bを提案。コンパクトなオープンウェイトのマルチモーダル推論モデルであり、効率的な設計選択や厳格なデータキュレーションを通じて競争力のある性能を実現。系統的なフィルタリングや誤り訂正によりデータ品質が重要であることを再確認し、高解像度エンコーダが性能向上に寄与。単一モデルで簡単なタスクに迅速な回答、複雑な問題には推論を提供するハイブリッドデータ構成を実現。 Comment
元ポスト:
[Paper Note] The Art of Efficient Reasoning: Data, Reward, and Optimization, Taiqiang Wu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Length #PostTraining Issue Date: 2026-02-28 GPT Summary- LLMsの効率的な推論機構を調査し、正確さを条件とした推論の長さ分布を提案。訓練プロセスは長さ適応と推論の洗練に基づく二段階であり、約20万GPU時間をかけた実験を実施。重要な発見として、容易なプロンプト訓練が正の報酬信号の密度を高め、長さの崩壊を防ぐことが確認された。学習された長さのバイアスはドメインを超えて一般化可能であり、知見をQwen3シリーズに適用・検証し、堅牢性を示す。 Comment
元ポスト:
[Paper Note] A Very Big Video Reasoning Suite, Maijunxian Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #Dataset #Supervised-FineTuning (SFT) #Evaluation #mid-training #PostTraining #VideoGeneration/Understandings #3D (Video) #Author Thread-Post Issue Date: 2026-02-27 GPT Summary- ビデオ推論の能力を探究するため、100万本以上のビデオクリップを含む前例のないVBVRデータセットを導入。200の推論タスクを網羅し、既存データセットの約1000倍の規模で、評価フレームワークとしてVBVR-Benchを提示。これにより、ビデオ推論の研究における再現性と解釈可能性を向上させ、新規タスクへの応用の初期兆候を示す。VBVRは次の研究段階の基盤となる。データ、ツール、モデルは公開中。 Comment
pj page: https://video-reason.com/
元ポスト:
著者ポスト:
[Paper Note] LLMs Can Learn to Reason Via Off-Policy RL, Daniel Ritter+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Off-Policy #Author Thread-Post Issue Date: 2026-02-24 GPT Summary- オフポリシーRLアルゴリズム「OAPL」は、大規模言語モデルのトレーニングにおいて重要度サンプリングを使用せず、Lagged Inferenceポリシーを採用。OAPLはGRPOを上回り、DeepCoderと同等の性能を維持しつつ、訓練時間を3分の1に削減。また、Pass@k指標でのスケーリング改善を示し、400ステップ以上のラグを持ちながらも効率的なポストトレーニングを実現する。 Comment
元ポスト:
著者ポスト:
[Paper Note] The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning, Qiguang Chen+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #LongSequence #mid-training #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-02-24 GPT Summary- LLMは長い連鎖思考(Long CoT)推論を学ぶのが難しく、効果的な推論は安定した分子のような構造を持つことが重要。これには深層推論、自己反省、自己探索の三つの相互作用が関与し、キーワードの模倣ではなくファインチューニングから生じることが示された。有効な意味的異性体が迅速なエントロピー収束を促進し、Mole-Synを提案してLong CoT構造の合成を導き、性能とRLの安定性を向上させる。 Comment
元ポスト:
結構読むのが大変そうなのでskim readingと元ポストを拝見した上でざっくりまとめると以下のような感じだろうか。takeaway部分により詳細な話が書かれているので必要に応じて読むとよさそう。
良いlong CoTには分子のような推論の内部構造が存在し、それらは適切な内部構造を持つ合成データによってSFTをすることで身につけさせられる。逆に、人間が作成したtrajectoryなどはこれらの分子構造が均質化されておらず、学習が不安定になる(表層的なキーワードから学習されたりする)。
良いlong CoTに必要な要素として、本研究では以下の3つのbehaviorが挙げられている:
- Self-Exploration: モデルが柔軟に異なるアイデアやパスを探索する力
- Self-Reflection: モデルが過去のstepを確認し修正する能力(分子の構造を安定化させるような役割を果たす)
- Deep Reasoning: 原子結合のような、論理的なstepを強力に結びつけた主となる論理フロー
[Paper Note] Analyzing and Improving Chain-of-Thought Monitorability Through Information Theory, Usman Anwar+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Chain-of-Thought #Safety #Monitorability Issue Date: 2026-02-24 GPT Summary- CoTモニターは、推論の痕跡を分析し、LLMベースのシステムで出力の興味属性を検出する手法です。本稿では、CoTと出力間の相互情報量がモニタビリティの必要条件であることを示し、性能を損なう二つの誤差源を特定します。情報ギャップは抽出可能な情報量を、誘発誤差は監視関数の近似度を測ります。訓練目的を最適化してCoTモニタビリティを向上させる二つの補完的アプローチを提案:オラクルベース手法と条件付き相互情報量の最大化。これにより、モニターの精度向上とリワードハッキングの緩和を実証します。 Comment
元ポスト:
[Paper Note] Generative Scenario Rollouts for End-to-End Autonomous Driving, Rajeev Yasarla+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #Planning #CVPR #Robotics #VisionLanguageActionModel Issue Date: 2026-02-23 GPT Summary- VLAモデルを用いた自動運転システムのためのGeRoフレームワークを提案。エゴ車両の動態を潜在トークンにエンコードし、言語条件付きの自己回帰生成を通じて交通シーンを共同生成。整合性損失を利用して予測を安定化し、長期的推論を支援。Bench2Driveで運転スコアを+15.7ポイント、成功率を+26.2ポイント改善。生成的かつ言語条件付けられた推論の有望性を示す。 Comment
元ポスト:
[Paper Note] Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens, Wei-Lin Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Metrics #NLP #LanguageModel #Evaluation #Test-Time Scaling #One-Line Notes Issue Date: 2026-02-23 GPT Summary- LLMが推論時に「深く考えるトークン」を特定し、計算量を定量化。これらのトークンの割合が正確さと一貫して相関することを示し、Think@nを導入して深く考えるトークンが多い生成を優先的に扱うことで推論コストを削減。自動一貫性と同等または上回る性能を実現。 Comment
reasoningの質をトークンの長さではなく、重要なトークンを基準に測定する。その上で重要なトークンの割合が小さいサンプルは早めに枝刈りすることでtest-time scalingの効率を向上させる手法を提案している模様。
[Paper Note] Think Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning, Futing Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #KeyPoint Notes Issue Date: 2026-02-14 GPT Summary- モデルが文脈内で複数の推論仮説を生成・検証し効果的にスケーリングを実現するためには「浅い探索の罠」を克服する必要がある。これを解決するために、冗長性ペナルティに基づく長さインセンティブ探索(\method)を提案。実験により、この手法は文脈内探索を促進し、ドメイン内で平均4.4%、ドメイン外で2.7%のパフォーマンス向上を示した。 Comment
元ポスト:
RLによってモデルが特定のサンプルに正解できなかった場合に、モデルにΔLの範囲でreasoningを長くした場合(つまりいつもより少しだけ長い思考をする)に報酬が与えられ、かつreasoningの過程において、特定の思考のstateに何回も訪れてしまう場合にペナルティを与えることで、思考が深くなった際に多様なstateが探索されなくなる問題(浅い探索の罠)を是正し、sequentialなtest time scaling(=long CoT)の性能を改善する。
[Paper Note] Native Reasoning Models: Training Language Models to Reason on Unverifiable Data, Yuanfu Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #ICLR #PostTraining #Off-Policy #KeyPoint Notes #Open-endedTasks #ConfidenceBased Issue Date: 2026-02-13 GPT Summary- NRT(ネイティブ推論トレーニング)は、教師ありファインチューニングと強化学習の依存を克服し、標準的な質問-回答ペアのみでモデルが自ら推論を生成します。推論を潜在変数として扱い、統一訓練目標に基づいて最適化問題としてモデル化することで、自己強化フィードバックループを構築。LlamaおよびMistralモデルにおいて、NRTが最先端の性能を達成し、従来の手法を大幅に上回ることを実証しました。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=abAMONjBwb
verifier freeでreasoning能力を向上させるRL手法で
- SFTにおいてexpertsのtrajectoryが必要な課題
- RLVRにおいてverifiableなドメインでしか学習できない課題
の両方に対処する。
具体的にはQAデータが与えられたときに、Questionに対してモデルにreasoning trace zを生成させ、zを生成した後にanswerを生成させる。zに対するTrace Rewardとanswerトークンに対するモデルのconfidenceを報酬として用いてRLする。
SFTやverifier freeな先行研究よりも9種類のreasoningベンチマークで高い性能を達成している。また、answer tokenのconfidenceに対する3種類の集約方法(平均, 1/pによって加重平均をすることで難しいトークンの重みを強める, 対数尤度を用いる)も提案手法も提案され比較されている。
論文中ではオフポリシーRLとして最適化する旨記述されているが、appendix記載の通りreasoning trace zを生成しているので、オンポリシーRLな性質も備えていると思われる。
[Paper Note] Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics, Leheng Sheng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Chain-of-Thought #SelfImprovement #PostTraining #RLVR #PRM #RewardModel #One-Line Notes #Rubric-based Issue Date: 2026-02-12 GPT Summary- CoTがLLM推論において重要である一方で、報酬モデルの訓練には多くの人手が必要で、静的モデルは変化に対応しづらい。これを解決するため、自己進化するCoT報酬アプローチ「RLCER」を提案。自己提案・自己進化するルーブリックにより、結果報酬なしでも信頼性のあるCoT監視信号を提供し、結果中心のRLVRを上回ることを実証。また、ルーブリックは推論時のパフォーマンスを向上させる効果もある。 Comment
元ポスト:
CoTを評価するためのルーブリックを自己進化させて、CoTの評価もしつつ、outcomeに基づくRLVRを実施するといった処理を単一のポリシーで実現する、というような話に見える(過去のCoTに対する監視手法ではPRMが別途用意されていた)。
単にRLVRをする場合よりも最終的な性能が向上し、特にlong runの場合の安定性が高まっているように見える。
[Paper Note] Data Repetition Beats Data Scaling in Long-CoT Supervised Fine-Tuning, Dawid J. Kopiczko+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #Chain-of-Thought #PostTraining #Selected Papers/Blogs #Generalization #KeyPoint Notes #Author Thread-Post Issue Date: 2026-02-12 GPT Summary- SFT(教師ありファインチューニング)の重要性を強調し、小規模データセットでの繰り返しトレーニングが大規模データセットでの単一エポックよりも優れていることを示す。Olmo3-7Bが400サンプルで128エポックのトレーニングによって、51200サンプルでの1エポックよりも12-26%の性能向上を実現。トレーニングトークンの精度が改善の指標となり、このパターンは一貫して確認される。これにより、高価なデータスケーリングに代わる実践的アプローチを提供し、繰り返しの利点を新たな研究課題として提示。 Comment
元ポスト:
著者ポスト:
**long-CoTのSFTにおいては**、多くのユニークなデータで学習するよりも、小さなデータセットを複数エポック繰り返し学習する方が優れていることが分かったとのこと。この傾向はモデルを跨いで存在する(Olmo3とQwen3で実験)。
より多くのエポック数 vs. より多くのユニークデータ数 でのモデルの傾向の違いとしては、前者の方がReasoningにおいて最終的な回答を出す割合が非常に大きくなることが分かった(たとえばFigure2 Rightの1 epoch 51200サンプルの24% vs. 256 epoch 200サンプル)。
では繰り返しの恩恵を得られなくなるのはどの時点かというと、Token Accuracy (=モデルのnext token predictionのtargetと一致する予測トークンがtopになった割合)が100%に近くなるとそれ以上epochを繰り返してもgainが無くなるので、これをSFTのstopping criteriaとして利用可能とのこと。
[Paper Note] Effective Reasoning Chains Reduce Intrinsic Dimensionality, Archiki Prasad+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Chain-of-Thought #PEFT(Adaptor/LoRA) #PostTraining #Selected Papers/Blogs #Generalization #KeyPoint Notes #Initial Impression Notes Issue Date: 2026-02-12 GPT Summary- 内在次元数を指標として、推論チェーンの有効性を定量化。異なる推論戦略がタスクの内在次元数を低下させ、一般化性能に逆相関を持つことを示す。これにより、有効な推論チェーンがパラメータを効果的に利用し学習を促進することを明らかにする。 Comment
元ポスト:
元ポストを読むと、以下のような話のようである。非常に興味深い。
良いCoT(推論)はタスクを圧縮する(すなわち、inputを正解へとマッピングする際の自由度を減少させる)ことを示した。
さまざまなCoT戦略に対して、あるタスクに対してさまざまなCoT戦略と、**特定の性能に到達するまでに必要な最小のパラメータ数の関係性(=intrinsic dimensionality)**を分析。パラメータ数の制御はLoRAのパラメータを変化させることによって調整して実験。その結果、Intrinsic Dimensionalityがdownstream taskの性能と、OODへの汎化性能に対して非常に強い相関を示した(Perplexityよりも強い相関)。
Intrinsic DimensionalityをさまざまなCoT戦略で測定すると、(school math系のデータに関しては)python codeを生成し実行する方法(Executed PoT)が最もコンパクトなsolutionを生成し、かつ最も良いOODへの汎化性能が高いことがわかった(他ドメインでこのCoT手法が適しているとは限らない点には注意)。
また、モデルスケールが大きい方がより低いIntrinsic Dimensionalityを示し、良いcompressor(=タスクを圧縮する能力が高い)であることがわかった。
弱くてノイジーなCoT戦略は、スケールせず、パラメータ効率が悪いことがわかった。
非常に興味深い研究で、かつskim readingしかできていない上での感想なのだが、
- 実験がLoRAベースで実施されているため、他の学習のダイナミクスにおいて同様のことが言えるのかという点
- Gemmaでしか実験されていないため他のアーキテクチャでも同じようにIntrinsic Dimensionalityの有効性が言えるのか
- データセットがGSM系列のschool mathドメインでしか実験されていないため、ドメイン間でどの程度一般性を持って言える話なのかという点
は明らかになっていない気がしており、どうなるのか興味がある。また、実際にIntrinsic Dimensionalityを測定しようとした場合に、効率的に求める方法はあるだろうか。
[Paper Note] Learning to Self-Verify Makes Language Models Better Reasoners, Yuxin Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #RLVR #Selected Papers/Blogs #KeyPoint Notes #Initial Impression Notes #SelfVerification Issue Date: 2026-02-10 GPT Summary- LLMの生成能力は高いが、自己検証では弱いという非対称性を調査。生成が向上しても自己検証に改善は見られず、逆に自己検証の学習が生成性能を向上させることが示された。生成訓練に自己検証を統合するマルチタスク強化学習フレームワークを提案し、両者の性能向上を実証。 Comment
元ポスト:
LLMの生成能力を高めるようにRLによって事後学習をしてもVerificationの能力は向上しないが、LLMが自身の出力に対してVerificationが正しくできるようにRLVRすると生成と自己検証能力の双方が向上する。
クエリに対して応答を生成し、フィルタリング(応答が長すぎるもの、全ての応答が誤りのもの、最終的な回答が存在しないもの等)を実施した後、クエリレベルで多様なクエリが存在するようにする(多様性)を保ちつつ、overfittingを避けるために正解・不正解がバランスよく存在するように自己検証のためのデータを作成(モデルは学習の初期のロールアウトは不正解ばかり生成し、後半は正解ばかり生成するといった偏りが存在する)し、式(4)で定義される自身が生成した応答が正解か否かを二値分類した結果に基づくRewardを用いてGRPOする、という手法ように見える。
ざーっと見た感じtest time scalingの実験が無いように見えたが、この方法で自己検証をモデルができるようになると、test time scalingした時の性能も向上するのではないか。
また下記研究で示されている通り、現在のLLMはself refine能力が低く何らかのガイドがないと自身で応答を改善していけないため、現在のLLMの弱みを克服するのに有効な手法に見え、非常に興味深い研究だと感じる。
- [Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
[Paper Note] InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning, Yuchen Yan+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#DocumentSummarization #NLP #LanguageModel #ReinforcementLearning #PostTraining #LongHorizon #Compression Issue Date: 2026-02-09 GPT Summary- InftyThink+は、モデルによる制御された反復推論と要約を基にした強化学習フレームワークで、中間的な思考の劣化を軽減し、反復推論の効率を最適化します。教師あり学習の後、二段階の強化学習を行い、戦略的要約と推論の再開を学習。実験では、従来方法に比べて精度を21%向上させ、推論レイテンシを大幅に削減しました。 Comment
pj page: https://zju-real.github.io/InftyThink-Plus/
元ポスト:
一言解説:
con-currentwork:
- [Paper Note] Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL, Ian Wu+, arXiv'26, 2026.02
reasoningを要約することで圧縮し次のreasoningを繰り返すような枠組みのように見え、
- [Paper Note] Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL, Ian Wu+, arXiv'26, 2026.02
と類似したアプローチに見える。
[Paper Note] Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL, Ian Wu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#DocumentSummarization #NLP #LanguageModel #ReinforcementLearning #AIAgents #PostTraining #read-later #RLVR #Selected Papers/Blogs #OOD #Generalization #KeyPoint Notes #LongHorizon #Robustness #Compression #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 大規模言語モデル(LLM)は、テスト時の適応能力により複雑な問題を解決する外挿特性を持つが、標準的な強化学習(RL)はその変化に制約がある。これに対処するために、反復デコーディングアルゴリズム(RC)を導入し、LLMの応答生成能力を活用して推論を継続的に改善。実験では、16kトークンの訓練で4BモデルがHMMT 2025でのパフォーマンスを40%から約70%に引き上げ、既存のモデルを上回る結果を示した。RCを使用したモデルは、学習した要約生成能力によりテスト時のパフォーマンスも向上できることが証明された。 Comment
元ポスト:
reasoningの生成と、生成されたreasoningとinputで条件付けでsummaryを生成、さらにinputとsummaryで条件付けてreasoningを生成するという、生成と要約を反復する枠組みを採用(LLMはreasoningを要約することが生成するよりも得意で、かつ過去の要約から将来の推論を生成できるという非対称性を活用)することで、訓練時の予算は決まっているため、訓練時の予算では到達できないhorizonにテスト時に遭遇すると汎化しない課題を克服し、テスト時により長いステップ数の推論もこなせるように外挿する。また、このようなgeneration-summaryの反復を各ステップごとでRLVRすることでさらに性能を向上でき、実際にlong horizonな推論や学習時よりもより長いreasoning token budgetの場合に大きなgainを獲得できている。
RLVRをする際に各ステップごとのSummaryを保存しておき、各ステップのsummaryが与えられたときに正解できるかどうかのシグナルに基づいて、ステップごとの要約で条件付けられた応答能力を改善する。これにより、さまざまなステップで応答を生成する能力が強化され、結果的にshort horizonからlong horizonの推論をする能力が強化される。
このときsummaryはリプレイバッファとして扱い後のepochの訓練でもオフポリシーデータとして活用する。要約はinputに条件付けられて生成されるものであり、optimizationのtargetとは異なるためリプレイバッファとして活用でき、かつさまざまな要約に対して正解が生成できるように学習されるためテスト時の要約の分布のシフトにロバストになる。また、オンポリシーデータだけだと、long horizonに対する要約は非常に稀になるため、リプレイバッファを利用することで補う。
テスト時に学習時を超えたhorizonで推論できることは現在のAIエージェントの大きな課題だと思うので非常に興味深い研究だと思う。
[Paper Note] Learning to Reason in 13 Parameters, John X. Morris+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #PEFT(Adaptor/LoRA) #PostTraining #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 低ランクアダプタTinyLoRAを提案し、推論のための強化学習が低ランクパラメータ化を効果的にスケールできることを示しています。わずか13のトレーニングパラメータでQwen2.5を91%の精度に達成し、複雑なベンチマークでも少ないパラメータで90%のパフォーマンス向上を実現しました。特に、強化学習を用いることで、従来の方法よりも大幅に少ないパラメータで強力な結果を得ることができました。 Comment
元ポスト:
Qwen2.5に関してはLlamaと比較して異なる傾向が生じることは以下でも見受けられる。果たして本研究で報告されていることはどこまで一般的なのだろうか?:
- [Paper Note] Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, Mingqi Wu+, arXiv'25
- [Paper Note] Spurious Rewards: Rethinking Training Signals in RLVR, Shao+, 2025.05
[Paper Note] ROBOINTER: A HOLISTIC INTERMEDIATE REPRESEN- TATION SUITE TOWARDS ROBOTIC MANIPULATION, ICLR'26 blindreview, 2026.02
Paper/Blog Link My Issue
#Dataset #QuestionAnswering #Planning #Chain-of-Thought #Annotation #VisionLanguageModel #Robotics #VisionLanguageActionModel #Manipulation Issue Date: 2026-02-05 Comment
openreview: https://openreview.net/forum?id=PGUC3mmMoi
元ポスト:
[Paper Note] ReMiT: RL-Guided Mid-Training for Iterative LLM Evolution, Junjie Huang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #mid-training Issue Date: 2026-02-05 GPT Summary- LLMのトレーニングを一方向型から双方向プロセスに進化させ、強化学習(RL)による自己強化フライホイールを建立。ReMiTを導入し、ミッドトレーニングフェーズでトークンの重み付けを動的に調整することで3%の改善を実現。これにより、LLMの継続的な自己強化的進化が可能であることを示した。 Comment
元ポスト:
[Paper Note] ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation, Junmin Gong+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #Transformer #Chain-of-Thought #SpeechProcessing #DiffusionModel #SmallModel #PEFT(Adaptor/LoRA) #OpenWeight #Music Issue Date: 2026-02-05 GPT Summary- ACE-Step v1.5は、高効率のオープンソース音楽基盤モデルで、商業音楽モデルを超える品質を持ちながら、非常に高速で動作します。ユーザーは少数の楽曲から個人のスタイルをトレーニング可能で、ハイブリッドアーキテクチャを用いてシンプルなクエリを包括的な楽曲に変換します。内因性強化学習により、スタイル制御と多様な編集機能を強化し、50以上の言語に対応。コンテンツクリエイターの創造的なワークフローに統合されるツールとして利用可能です。 Comment
元ポスト:
データは全て許可済みのもの、かつ合成データとポストされており商用利用も可らしいが、果たして。
[Paper Note] RefineBench: Evaluating Refinement Capability of Language Models via Checklists, Young-Jun Lee+, ICLR'26, 2025.11
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #SelfCorrection #ICLR #read-later #Selected Papers/Blogs #KeyPoint Notes #Rubric-based #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- 言語モデル(LM)の自己改善能力を探るために、RefineBenchという1,000の問題と評価フレームワークを導入。二つの改善モード、ガイド付きと自己改善を評価した結果、最前線のLMは自己改善で低迷する一方、ガイド付き改善では特許LMや大規模オープンウエイトLMが迅速に応答を改善。自己改善には突破口が必要であり、RefineBenchが進捗の追跡に貢献することを示す。 Comment
元ポスト:
pj page: https://passing2961.github.io/refinebench-page/
verifiableはタスクだけでなくnon verifiableなタスクもベンチマークに含まれ、ガイド付き/無しの異なる設定、11種類の多様なドメイン、チェックリストベースのbinary classificationに基づく評価(strong LLMによって分類する; これによりnon verifiableなタスクでも評価可能)、マルチターンでの改善を観測できる、self-correction/refinementに関するベンチマーク。
フロンティアモデルでも自己改善はガイド無しの場合ではあまり有効に機能しないことを明らかにし、外部からガイドが与えられればOpenLLMでさえも少ないターン数で完璧に近い方向にrefineされる、という感じの内容に見える。
つまり自身とは異なるモデルで、何らかの素晴らしい批評家がいれば、あるいは取り組みたいタスクにおいて一般化された厳密性のあるチェックリストがあれば、レスポンスはiterationを繰り返すごとに改善していくことになる。
[Paper Note] Learn to Reason Efficiently with Adaptive Length-based Reward Shaping, Wei Liu+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #ICLR #Length #PostTraining #Adaptive Issue Date: 2026-02-03 GPT Summary- 推論の効率を向上させるため、RLベースの手法LASERを提案。長さに基づく報酬シェイピングを用いて、冗長性を減少させつつ、パフォーマンスと効率の良好なバランスを実現。また、動的な報酬仕様と難易度を考慮した手法LASER-Dを導入し、簡潔な推論パターンを促進。実験により、推論性能と応答の長さ効率が大幅に向上した。 Comment
元ポスト:
[Paper Note] The Hot Mess of AI: How Does Misalignment Scale With Model Intelligence and Task Complexity?, Alexander Hägele+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Alignment #Safety #One-Line Notes Issue Date: 2026-02-03 GPT Summary- AIの機能向上に伴い、リスクも増すため、モデルの失敗のメカニズムを理解することが重要になる。具体的には、失敗が意図しない目標の追求から生じるのか、混乱した行動から生じるのかを検討。また、AIの不適合性はバイアス-バリアンス分解を通じて評価される。実験結果から、高能力なモデルはタスクにかかる時間が増すほど不適合性が高くなる傾向があり、大モデルが小モデルよりも不適合性が高い場面も確認された。これにより、高能力なAIが複雑なタスクを行う場合、予測不可能な誤行動が産業事故につながる可能性が示唆される一方、目標の一貫した追求の可能性は低いことが示される。これにより、報酬ハッキングや目標の誤仕様に対するアライメント研究の重要性が増す。 Comment
元ポスト:
- モデルの推論が長くなればなるほど、一貫性(=予期できないエラー/misalignmentによるバイアス i.e., 全体のエラーに対する予測できないエラーの割合; Variance/Errorで測定)がなくなる
- モデルサイズが大きくなればなるほどEasy Taskでのみ一貫性が向上する。言い換えるとモデルの賢さと一貫性の間に、一貫した関係性はない。が、しばしば賢いモデルは一貫性に乏しい。
上記知見より、AI Safetyの観点で言うと、強力なAIがエラーを起こす時は、一貫性のある何らかの誤った目標に向かっていくようなものではなく、事故のような予測できないものになるだろう、と予測している。
[Paper Note] THINKSAFE: Self-Generated Safety Alignment for Reasoning Models, Seanie Lee+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #SelfImprovement #Safety Issue Date: 2026-02-03 GPT Summary- 自己生成整合性フレームワーク「ThinkSafe」は、外部教師に依存せずにLRMsの安全性を向上させます。このアプローチは、モデルが保持する危害の識別能力を活かし、軽量の拒否誘導を通じて安全推論トレースを生成します。実験により、ThinkSafeは推論能力を維持しつつ、GRPOに比べて安全性を大幅に改善し、計算コストの削減を実現しています。 Comment
元ポスト:
[Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Blog #MoE(Mixture-of-Experts) #AttentionSinks #PostTraining #Selected Papers/Blogs #One-Line Notes #Reference Collection #SelfDistillation Issue Date: 2026-02-03 GPT Summary- Step 3.5 Flashは、フロンティア知能と効率を橋渡しするスパースMixture-of-Experts(MoE)モデルで、1960億パラメータの基盤と110億パラメータのアクティブパラメータを組み合わせ、迅速で信頼性の高い推論を実現。交互スライディングウィンドウとMulti-Token Predictionを取り入れ、エージェント間の相互作用の待機時間を短縮。検証可能な信号とフィードバックを用いた強化学習フレームワークにより、安定した自己改善を図る。エージェントやコーディング、数学タスクで高い性能を示し、フロンティアモデルに匹敵する結果を達成している。 Comment
元ポスト:
公式ポスト:
解説:
ポイント解説:
ポイント解説:
固定されたデータ非依存のsink tokenを利用するよりも、attention headの出力にinput xに応じたgatingを設けるHead wise gated attentionの方が各ベンチマークでの性能が良い(Table2, gatingの計算量もほぼ無視できる)。Head wise gated attentionは、データに応じてattention headの出力を制御するため、データ依存のlearnableなsink tokenと解釈できる(A.1):
Head-wise Gated Attention:
- [Paper Note] Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free, Zihan Qiu+, NeurIPS'25 Best Paper
- [Paper Note] Forgetting Transformer: Softmax Attention with a Forget Gate, Zhixuan Lin+, ICLR'25, 2025.03
SFTデータがリリースされたとのこと:
https://huggingface.co/datasets/stepfun-ai/Step-3.5-Flash-SFT
元ポスト:
[Paper Note] DiffuSpeech: Silent Thought, Spoken Answer via Unified Speech-Text Diffusion, Yuxuan Lou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Dataset #Chain-of-Thought #SpeechProcessing #DiffusionModel #Architecture #Selected Papers/Blogs #TTS #AudioLanguageModel #Initial Impression Notes Issue Date: 2026-02-02 GPT Summary- 音声LMMが直接応答を生成する際に発生するエラーを解決するため、「沈黙の思考、話された答え」という新たなパラダイムを提案。内部のテキスト推論と共に音声応答を生成する拡散ベースの音声-テキスト言語モデル\method{}を開発。モダリティ固有のマスキングを使用し、推論過程と音声トークンを共同生成。初の音声QAデータセット\dataset{}も構築し、26,000サンプルを含む。実験結果はQA精度で最先端を達成し、最高のTTS品質を維持しつつ言語理解も促進。拡散アーキテクチャの効果も実証。 Comment
元ポスト:
音声合成、AudioLanguageModelの枠組みにおいてreasoningを導入する新たなアーキテクチャを提案し、そのためのデータを収集して性能が向上しているように見え、重要研究に感じる。
[Paper Note] LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities, Thomas Schmied+, ICLR'26, 2025.04
Paper/Blog Link My Issue
#Analysis #LanguageModel #ReinforcementLearning #Chain-of-Thought #ICLR #Test-Time Scaling #PostTraining #Multi-Armed Bandit #DecisionMaking #Exploration Issue Date: 2026-01-31 GPT Summary- LLMのエージェントアプリケーションにおける探求と解決の効率性を分析。最適なパフォーマンスを妨げる「知識と行動のギャップ」や貪欲性、頻度バイアスという失敗モードを特定。強化学習(RL)によるファインチューニングを提案し、探索を増加させて意思決定能力を改善。古典的な探索メカニズムとLLM特有のアプローチの両方を融合させ、効果的なファインチューニングの実現を目指す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=weUP6H5Ko9
- greediness
- frequency bias
- the knowing-doing gap
[Paper Note] Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors, Zhiwei Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #SelfCorrection #PostTraining #One-Line Notes Issue Date: 2026-01-23 GPT Summary- LLMはマルチターン実行において脆弱で、ツール呼び出しエラー後の自己修正が困難。従来の強化学習ではエラーが負の報酬として扱われ、復旧指針が不足している。本研究では、実行エラーを修正監督に変換するFission-GRPOフレームワークを提案。失敗した軌道をエラーシミュレーターのフィードバックで強化し、新しいトレーニングインスタンスに分裂。これにより、実際のエラーから学ぶことが可能となる。BFCL v4マルチターンで、Fission-GRPOはQwen3-8Bのエラー回復率を5.7%改善し、全体的な精度を4%向上させた。 Comment
元ポスト:
tool useの学習をさせる際に通常のGRPOでの更新に加えて、ロールアウトで実行エラーとなったものを収集し、エラーに対して診断フィードバックを与え、その文脈からエラーを回復するようなロールアウトを実施し学習することで、自己修正能力を身につけさせるような手法に見える。
[Paper Note] Agentic Reasoning for Large Language Models, Tianxin Wei+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #AIAgents #Planning #SelfImprovement #memory #One-Line Notes #Test-time Learning Issue Date: 2026-01-23 GPT Summary- エージェンティック推論は、LLMを自律的エージェントとして再構築し、計画や行動を行う新たなアプローチを提供します。本調査では、推論を基盤、自己進化、集合的の三つの次元に整理し、それぞれの特性と相互作用を探ります。また、文脈内推論とポストトレーニング推論の違いを示し、さまざまな現実世界でのアプリケーションをレビューします。この研究は、思考と行動を結びつける統一的なロードマップを提示し、今後の課題と方向性を概説します。 Comment
元ポスト:
agentのreasoning周りに特化したsurveyで基本的なsingle agentとしてのplanning, tool use, searchだけでなく、self evolving, memory, multi agent reasoningなど広範なトピックが網羅されているとのこと。
[Paper Note] Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization, Hao Luo+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #OpenWeight #CrossDomain #Robotics #VisionLanguageActionModel #UMM #Physics Issue Date: 2026-01-22 GPT Summary- Being-H0.5は、クロスエンボディメント一般化のために設計されたVLAモデルであり、人間の相互作用を「母国語」として扱う学習パラダイムを提案。35,000時間以上のマルチモーダルデータを含むUniHand-2.0を用いて、多様なロボット制御を統一的なアクション空間にマッピングし、リソースの少ないロボットが他のプラットフォームからスキルを習得できるようにする。Being-H0.5はMixture-of-Transformersを採用し、現実世界での安定性のために多様体保存ゲーティングとユニバーサル非同期チャンクイングを導入。シミュレーションベンチマークで最先端の結果を達成し、5つのロボットプラットフォームで強力な能力を示す。 Comment
pj page:
https://research.beingbeyond.com/being-h05
HF:
https://huggingface.co/collections/BeingBeyond/being-h05
元ポスト:
[Paper Note] The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models, Zanlin Ni+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #DiffusionModel #PostTraining Issue Date: 2026-01-22 GPT Summary- dLLMsは任意の順序でトークンを生成できるが、この柔軟性が推論の境界を狭める可能性があることを示す。dLLMsは高不確実性トークンを回避し、解空間の早期崩壊を引き起こす傾向があり、既存のRLアプローチの前提に挑戦する。効果的な推論は、任意の順序を放棄し、GRPOを適用することで実現され、JustGRPOはその実例で、GSM8Kで89.1%の精度を達成した。 Comment
元ポスト:
[Paper Note] Jet-RL: Enabling On-Policy FP8 Reinforcement Learning with Unified Training and Rollout Precision Flow, Haocheng Xi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #PostTraining #train-inference-gap #LowPrecision Issue Date: 2026-01-21 GPT Summary- 強化学習(RL)はLLMの推論能力を向上させるが、既存のトレーニングは非効率で、ロールアウトに多くの時間を要する。FP8精度による量子化RLトレーニングがボトルネック解消の有力候補であるが、BF16トレーニング + FP8ロールアウトの戦略は不安定さを招く。我々はJet-RLを提案し、トレーニングとロールアウトに統一されたFP8フローを採用することで数値的ミスマッチを減少させる。実験により最大33%のロールアウト速度向上と41%のトレーニング速度向上を達成し、安定した収束を実証した。 Comment
元ポスト:
関連:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
こちらはFP16だが。
[Paper Note] Reasoning Models Generate Societies of Thought, Junsol Kim+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #PostTraining #read-later #Probing #Diversity #Selected Papers/Blogs #SparseAutoencoder Issue Date: 2026-01-19 GPT Summary- 大規模言語モデルは、複雑な認知タスクにおいて優れた性能を発揮するが、そのメカニズムは不明瞭である。本研究では、強化された推論は計算の拡張だけでなく、異なる人格特性や専門知識を持つ内部認知視点の間のマルチエージェント相互作用によって生じることを示す。これにより、推論モデルはより広範な対立を引き起こし、視点の多様性が向上することを発見した。制御された強化学習実験により、会話行動の増加が推論精度を向上させることが明らかになり、思考の社会的組織が問題解決を効果的に行う可能性を示唆する。 Comment
元ポスト:
解説:
[Paper Note] Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge, Yao Tang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #Architecture #Test-Time Scaling #PostTraining #read-later #Selected Papers/Blogs #KeyPoint Notes #Initial Impression Notes Issue Date: 2026-01-19 GPT Summary- Multiplex Thinkingは、K個の候補トークンをサンプリングし、単一のマルチプレックストークンに集約することで、柔軟な推論を実現。モデルの自信に応じて標準的なCoTの挙動と複数の妥当なステップをコンパクトに表現。難易度の高い数学的推論ベンチマークで一貫して優れた結果を示す。 Comment
pj page: https://gmlr-penn.github.io/Multiplex-Thinking/
元ポスト:
reasoningに関する新たなアーキテクチャでざっくり言うと単一のreasoningをハードに保持して推論するのではなく、(人間のように?)複数の推論に関する情報をソフトに保持して応答する枠組みである。
reasoningにおける各ステップにおいてk個数のreasoningトークンを生成し、最終的な応答を生成する前に、各ステップで生成されたreasoningトークンのone-hot vectorを集約し平均化、その後集約されたベクトルに対してelement単位(vocabごとの)再重み付けをして、embedding matrix Eを乗じてcontext vectorを得る。このcontext vectorが様々なreasoningの結果を集約したような情報を保持しており、context vectorで条件付けで応答yを生成するようなアーキテクチャ。reasoningモデルに対して追加のオンポリシーRLを通じて応答yのRewardが最大化されるように事後学習することで実現される。
単に性能が向上するだけでなく、test time scaling (parallel, sequenceの両方)でもスケールする。
解説:
[Paper Note] Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models, Zirui Ren+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Hierarchical #Author Thread-Post Issue Date: 2026-01-19 GPT Summary- HRMは推論タスクで優れた性能を示すが、単純なパズルでの失敗やグロッキングダイナミクス、複数の不動点の存在を通じて推測の側面が浮き彫りになった。これを踏まえ、データ拡張、入力摂動、モデルブートストラッピングの3つの戦略を提案し、合成HRMを開発。数独エクストリームの精度を54.5%から96.9%に向上させた。分析は推論モデルのメカニズムに新しい視点を提供する。 Comment
元ポスト:
Does anyone have a link to the source code for this paper?
I found the code:
code:
https://github.com/renrua52/hrm-mechanistic-analysis
[Paper Note] PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning, Jingcheng Hu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #PostTraining #read-later #Selected Papers/Blogs #Aggregation-aware #KeyPoint Notes #Reading Reflections Issue Date: 2026-01-19 GPT Summary- PaCoReは、固定されたコンテキストウィンドウを超えた計算量の拡張を目指すトレーニング・推論フレームワークです。逐次的パラダイムを脱し、複数のラウンドでメッセージ伝播アーキテクチャを用いた並列探索を行います。各ラウンドでは、並列推論経路を起動し、結果を圧縮して次のラウンドに統合し、最終的な答えを生成します。このアプローチにより、文脈制限を超えた実質的な計算量が実現され、特に数学推論で顕著な成果を示します。8BモデルはHMMT 2025で94.5%を達成し、オープンソース化された資源により、さらなる研究が期待されています。 Comment
元ポスト:
- [Paper Note] STEP3-VL-10B Technical Report, Ailin Huang+, arXiv'26, 2026.01
で活用されているRLでtest time scalingを学習する手法
モデルのSequentialなReasoning能力はcontext windowに制限されてしまうので、並列にモデルにreasoningをさせてそれらを集約させて、さらに直列で思考させる、といった処理を繰り返すことで、context windowの制限を超えてreasoning能力を高めることを目的としたtest-time scaling手法。
モデルに複数個のreasoning trajectoryを生成させ、それぞれのtrajectoryにCompaction Function(式2) を適用[^1]することで各resaoning trajectoryをcompaction message M として圧縮。圧縮したtrajectoryを元のpromptとともに与えて、同様の操作をRラウンド繰り返すtest-time scaling手法。最後のラウンドでは、生成するreasoning trajectoryの数を1とすることで最終的な応答を得る。モデルをこのプロセスに最適化するために、各ラウンドにおいて (x, M) が与えられた時に、並列して生成するreasoning trajectoryに対してRLVRを適用することでモデルの性能を引き上げている。Mはベースモデルによって事前に生成し、生成した結果をキャッシュしておくことでRL中に利用する。
PaCoReによってベースモデル(RLVR-8B)の性能が着実に押し上げられ、一部ベンチマークにおいてフロンティアモデルには届かなないものの非常に高い性能を示している。
また、Parallel test-time scaling手法として代表的なSelf-Consistencyと比較しても、より少ないtoken量で、より高いgainを得ている。
[^1]: 本研究ではCompatction Functionとしてreasoningの特性を利用して、結論部分に関連する部分を抽出し、intermediateなreasoning tokenは破棄するような関数を適用している
Figure1においてベースモデルであるRLVR-8B (Qwen3-8B-Base) に対して、PaCoReによってpost-trainingされたモデルがより良好なtest-time scalingを示すことが図示されているが、RLVR-8Bによるtest-time scaling手法としてどのようなものが適用されたのか(parallelなのか、sequentialなのか、結果を集約したのか等)が書かれていない気がする。
何が気になっているのかというと、提案手法が効果があることは分かったのだが、これがPaCoReの枠組みに則ったRLを適用しないと発現しないものなのか、それともPaCoReに特化したpost-trainingを実施しなくても、何らかのベースモデルに同様のtest-time-scalingの枠組みを利用すれば高い性能を得られるのか、といった点が気になる。どこかに書いてあるのだろうか?
[Paper Note] DeepSeek-R1 Thoughtology: Let's think about LLM Reasoning, Sara Vera Marjanović+, TMLR'26, 2025.04
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #TMLR #read-later #Selected Papers/Blogs Issue Date: 2026-01-17 GPT Summary- DeepSeek-R1は、LLMが複雑な問題に対処するための新しいアプローチを提案。直接答えを生成するのではなく、詳細な多段階推論チェーンを形成し、ユーザーに推論プロセスを公開することで思考の学問を創出。推論の長さ、コンテキストの管理、安全性の問題などに関する分析を行い、推論の「スウィートスポット」を特定。深い思考を持続的に行うが、過去の問題定式化に固執する傾向にも注意。また、対照モデルに比べて安全性の脆弱性があり、リスクを孕む可能性が示唆された。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=BZwKsiRnJI
[Paper Note] EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning, Chuanrui Hu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #ContextEngineering #memory #LongHorizon Issue Date: 2026-01-13 GPT Summary- EverMemOSは、長期的なインタラクティブエージェントのための自己組織化メモリオペレーティングシステムで、エピソディックトレースをMemCellに変換し、ユーザープロファイルを更新することで一貫した行動を維持します。実験により、メモリ拡張推論タスクで最先端のパフォーマンスを達成し、ユーザープロファイリングやチャット指向の能力を示すケーススタディも報告しています。 Comment
元ポスト:
[Paper Note] VChain: Chain-of-Visual-Thought for Reasoning in Video Generation, Ziqi Huang+, ACL'26 Findings, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Chain-of-Thought #DiffusionModel #ACL #VideoGeneration/Understandings #2D (Image) #Findings Issue Date: 2025-10-20 GPT Summary- VChainは、マルチモーダルモデルの視覚的推論を動画生成に活用する新しいフレームワークで、重要なキーフレームを生成し、動画生成器のチューニングを効率的にガイドします。このアプローチにより、複雑なシナリオにおいて生成動画の品質が大幅に向上しました。 Comment
pj page: https://eyeline-labs.github.io/VChain/
元ポスト:
Chain-of-Visual-Thoughts
keyframeをchain-of-thoughtsに含めることで、時間発展をより正確にしようという試みに見える。追加の学習なしで実施できるとのこと。
[Paper Note] Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense, Leitian Tao+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning #Mathematics #ICLR #RewardModel #One-Line Notes #Author Thread-Post Issue Date: 2025-10-13 GPT Summary- HERO(ハイブリッドアンサンブル報酬最適化)は、検証者の信号と報酬モデルのスコアを統合する強化学習フレームワークで、より豊かなフィードバックを提供。層別正規化を用いて正確性を保ちながら品質の区別を向上させ、数学的推論ベンチマークで従来のベースラインを上回る結果を示した。ハイブリッド報酬設計が推論の進展に寄与することを確認。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=0CajQNVKyB
著者による一言解説ポスト:
0/1のbinaryなsparse rewardとdense rewardの両方を組み合わせたハイブリッドなRL手法を提案。verifiable rewardではしばしば報酬がsparseになり学習シグナルが何も得られない課題があり、dense rewardにはノイズが多く含まれるという課題があり、両者を組み合わせることで課題を低減した、という感じの話らしい。
[Paper Note] Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning, Haozhe Wang+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #ICLR #read-later #Entropy Issue Date: 2025-09-10 GPT Summary- 強化学習(RL)は大規模言語モデル(LLMs)の推論能力を向上させるが、そのメカニズムは不明。分析により、推論の階層が人間の認知に似た二段階のダイナミクスを持つことを発見。初期段階では手続き的な正確性が求められ、後に高レベルの戦略的計画が重要になる。これに基づき、HICRAというアルゴリズムを提案し、高影響の計画トークンに最適化を集中させることで性能を向上させた。また、意味的エントロピーが戦略的探求の優れた指標であることを検証した。 Comment
pj page: https://tiger-ai-lab.github.io/Hierarchical-Reasoner/
元ポスト:
ポイント解説:
解説:
openreview: https://openreview.net/forum?id=NlkykTqAId
[Paper Note] Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning, Vaishnavi Shrivastava+, ICLR'26, 2025.08
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #On-Policy #Overthinking #Reference Collection #Author Thread-Post Issue Date: 2025-08-14 GPT Summary- GFPO(Group Filtered Policy Optimization)を提案し、応答の長さの膨張を抑制。応答を長さとトークン効率に基づいてフィルタリングし、推論時の計算量を削減。Phi-4モデルで長さの膨張を46-71%削減し、精度を維持。Adaptive Difficulty GFPOにより、難易度に応じた訓練リソースの動的割り当てを実現。効率的な推論のための効果的なトレードオフを提供。 Comment
元ポスト:
ポイント解説:
著者ポスト:
openreview: https://openreview.net/forum?id=UKOqoULbZS
[Paper Note] Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty, Mehul Damani+, ICLR'26, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #ICLR #read-later #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2025-08-02 GPT Summary- RLCRを用いた言語モデルの訓練により、推論の精度と信頼度を同時に改善。バイナリ報酬に加え、信頼度推定のためのブライヤースコアを用いた報酬関数を最適化。RLCRは、通常のRLよりもキャリブレーションを改善し、精度を損なうことなく信頼性の高い推論モデルを生成することを示した。 Comment
元ポスト:
LLMにConfidenceをDiscreteなTokenとして(GEvalなどは除く)出力させると信頼できないことが多いので、もしそれも改善するのだとしたら興味深い。
著者ポスト:
openreview: https://openreview.net/forum?id=ASQ649zdHm
[Paper Note] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning, Bowen Jin+, COLM'25, 2025.03
Paper/Blog Link My Issue
#NLP #Search #LanguageModel #ReinforcementLearning #PPO (ProximalPolicyOptimization) #COLM #GRPO #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-04-06 GPT Summary- 大規模言語モデル(LLMs)における外部知識の取得を改善するため、Search-R1という強化学習フレームワークを提案。リアルタイムで複数の検索クエリを生成し、推論過程を最適化。実験では、Search-R1が従来のRAGベースラインよりも大幅に性能を向上させた。さらに、RL手法と応答長のダイナミクスに関する洞察も提供。 Comment
openreview: https://openreview.net/forum?id=Rwhi91ideu#discussion
LLMにおいて検索を活用する方法として、従来はRAGやマルチターン会話の中でマルチクエリを用いて検索を取り入れるprompt-basedな手法と、検索エンジンをツールとして利用することを学習するtraining-based手法があったが、前者はLLMがどのように検索エンジンとinteractionするかを十分に理解しておらず、事前学習時に学習されていないタスクに対して汎化しづらいという欠点があり、後者は前者よりもより高い柔軟性を持つが、高品質なtrajectoryの不足によりスケーラビリティに乏しく、検索操作は微分不可能なため勾配ベースの手法による学習ができないという欠点があった。
これを克服し、LLMがreasoningプロセスの中でより柔軟に検索エンジンを用い、かつそれをマルチターンで実施できるような手法として、GRPO/PPOに基づく枠組みを提案しているようである。検索エンジンを用いる枠組みにおいてRLを適用する際には
- (1)検索されたコンテキストをどのようにRLに組み込めば安定したRLを実現できるかは未知
- (2)理想的にはiterativeにreasoningとsearchを繰り返し、タスクの難易度に応じて使い分けてほしいが、どのように実現するかは未知
- (3)検索とreasoningの両方を効果的に扱える報酬関数が未知
という課題があるが、これらに対して
- (1)検索によって得られたトークンはmaskをし
- (2)検索が必要な場合は
- (3)ルールベースのexact matchによるRewardを採用(式4)
することで対処した、という話のようである。
[Paper Note] LLaVA-3D: A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness, Chenming Zhu+, ICCV'25, 2024.09
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #InstructionTuning #MultiModal #PositionalEncoding #OpenWeight #OpenSource #PostTraining #Selected Papers/Blogs #ICCV #VisionLanguageModel #3D (Scene) #SpatialUnderstanding #KeyPoint Notes #Grounding Issue Date: 2026-02-28 GPT Summary- LLaVA-3Dは、3Dシーン理解に対応する新たなフレームワークで、2D視覚理解の知識を活用しつつ、3D位置埋め込みを統合。2D CLIPパッチを3D空間情報で強化し、2Dと3Dの共同チューニングを行うことで、迅速かつ正確な3D認識を実現。実験では、既存の3Dモデルよりも3.5倍速く収束し、3Dタスクでの最先端性能を達成しながら、2D機能も保持している。 Comment
github:
https://github.com/ZCMax/LLaVA-3D
pj page:
https://zcmax.github.io/projects/LLaVA-3D/
3Dに関するspatial understandingの能力を持つVLMで、テキストの出力だけでなく、3Dのbounding boxを出力する専用のデコーダを持つ。
2DのCLIPベースのimage encoderによる情報を活用しつつ、2D patchに対して3Dに関する位置情報(depth)を3D positional encodingを通じて加えることで3D patchを作成し入力として活用。3Dのgrounding taskを扱うgrounding decoderを導入することで3D理解に関する能力を醸成する。学習は2stageで、最初のstageでは、2D, 3D双方の能力を同時に学習するために2D, 3Dのデータ両方を用いてモデルをSFTする。その後grounding decoderは前段のSFTでさ学習しきれないため、grounding decoder以外のモジュールはfreezeして、3D groundingタスクでdecoderとlocation tokenを学習するらしい。これにより、2D, 3Dシーンの理解力を損なわず、groundingに関する性能を高める。
[Paper Note] ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference, Yesheng Liang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Quantization #LongSequence #ICLR #PostTraining #One-Line Notes Issue Date: 2026-02-28 GPT Summary- Post-training quantization (PTQ)はLLMの重みと活性化を低精度に圧縮し、メモリと推論速度を改善するが、外れ値が誤差を大きくし、特に推論型LLMの長い思考チェーンで精度低下を招くことがある。既存のPTQ手法は外れ値抑制が不十分であったり、オーバーヘッドがある。本研究では、独立ガイブンズ回転とチャネルスケーリングを組み合わせたペアワイズ回転量子化(ParoQuant)を提案し、ダイナミックレンジを狭め外れ値問題を解決する。推論カーネルの共同設計によりGPUの並列性を最大限活用し、精度向上を実現。結果、重みのみの量子化でAWQより平均2.4%の精度向上を達成し、オーバーヘッドは10%未満で、最先端の量子化手法と同等の精度を示す。これにより、高効率で高精度なLLMのデプロイが可能となる。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=1USeVjsKau
Reasoning LLMにおいてlong-CoTを実施した場合のエラーの蓄積を低減するようなpost-training-basedな量子化手法の提案
[Paper Note] Improving LLM Agents with Reinforcement Learning on Cryptographic CTF Challenges, Lajos Muzsai+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #ReinforcementLearning #AIAgents #PostTraining #RLVR #Security Issue Date: 2026-02-17 GPT Summary- セキュリティ分野におけるLLMエージェントの潜在能力を引き出すために、手続き的に生成された暗号用CTFデータセット『Random-Crypto』を提案。暗号推論を強化学習の理想的なテストベッドとして活用し、Pythonツールを用いてLlama-3.1-8BをGRPOでファインチューニング。得られたエージェントはPass@8で顕著な改善を見せ、『picoCTF』や『AICrypto MCQ』の外部ベンチマークにも一般化。アブレーション研究により、ツール活用の強化と手続き的推論の向上が寄与していることが示され、複雑なサイバーセキュリティタスクに対応可能な知的LLMエージェント構築の基盤を確立。 Comment
元ポスト:
[Paper Note] REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards, Zafir Stojanovski+, NeurIPS'25 Spotlight, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Library #ReinforcementLearning #NeurIPS #PostTraining #RLVR #KeyPoint Notes #Environment Issue Date: 2026-02-17 GPT Summary- Reasoning Gymは、強化学習のための推論環境ライブラリで、100以上のデータ生成器と検証器を提供する。代数、算術、認知、幾何学、論理など多様な領域を網羅し、難易度調整可能な訓練データを生成する革新性がある。これにより、固定データセットではなく継続的な評価が実現。実験結果は、推論モデル評価と強化学習でのRGの有効性を明らかにしている。 Comment
元ポスト:
代数、logic, ゲームなどの多様な分野に関するRLVR用の100種類以上のreasoning taskを、難易度調整可能な形で大量(というより無限)に生成可能な枠組みな模様。
データは手続的に生成される。つまりタスクごとにアルゴリズムが決まっていて、アルゴリスに従って生成される。全てのタスクは人間の介入なしで自動的にverification可能。タスクの解空間は非常に巨大で、overfittingやreward hackingを軽減し、configuableなパラメータによってタスクの難易度を制御可能。ドメインは5種類で数学、アルゴリズム、logical reasoning、パターン認識、制約充足(ゲームやパズル、プランニング)。
[Paper Note] Evaluating Legal Reasoning Traces with Legal Issue Tree Rubrics, Jinu Lee+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Dataset #Explanation #ReinforcementLearning #RAG(RetrievalAugmentedGeneration) #PostTraining #Legal #Rubric-based Issue Date: 2026-02-11 GPT Summary- 専門分野でのLLMの推論トレース評価の重要性を認識し、新たな法律推論データセット「LEGIT」を導入。本研究では、裁判判断を主張と結論の木構造に変換し、推論のカバー範囲と正確性を評価。人間専門家による注釈と粗い基準との比較で評価基準の信頼性を確認。実験から、LLMの法律推論能力はカバー範囲と正確性に影響され、retrieval-augmented generation(RAG)と強化学習(RL)が相補的な利益をもたらすことを示した。RAGは推論能力を向上させ、RLは正確性を改善する。 Comment
元ポスト:
[Paper Note] LightAgent: Mobile Agentic Foundation Models, Yangqin Jiang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #MultiModal #SmallModel #OpenWeight #ComputerUse #PostTraining #VisionLanguageModel #One-Line Notes #GUI #EdgeDevices Issue Date: 2026-01-19 GPT Summary- LightAgentは、モバイルプラットフォーム向けにデバイスとクラウドの協力を活用したGUIエージェントシステムを提案。これにより、オフライン性能とコスト効率を両立し、強化された二段階トレーニングを通じて高い意思決定能力を実現。実験を通じて大規模モデルに匹敵する性能を示し、クラウドコストを大幅に削減。 Comment
pj page: https://github.com/HKUDS/OpenPhone
3Bで10B級の性能を誇る低latencyのedge device向けSVLM
元ポスト:
[Paper Note] Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks, Abhranil Chandra+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #Chain-of-Thought #SyntheticData #Distillation #One-Line Notes Issue Date: 2026-01-11 GPT Summary- 言語モデルの推論能力は、連鎖的思考(CoT)トレースの合成データセットでの訓練によって向上することが示された。合成データはモデル自身の分布に近く、学習に適応しやすい。また、不正確なトレースでも有効な推論ステップを含むことが多い。人間の注釈データを言い換えることでパフォーマンスが向上し、欠陥のあるトレースに対する耐性も研究された。MATH、GSM8K、Countdown、MBPPデータセットを用いて、モデルの分布に近いデータセットの重要性と、正しい最終回答が必ずしも信頼できる推論プロセスの指標ではないことが示された。 Comment
元ポスト:
base modelの分布と近いStronger Modelから合成されたCoTデータでSFTすると、合成データの応答がincorrectであっても性能が向上する。分布が遠い人間により生成されたCoTで訓練するより性能改善の幅は大きく、人間が作成したCoTをparaphraseしモデルの分布に近づけると性能の上昇幅は改善する(Figure1, Table4, 5)。
[Paper Note] DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models, Zefeng He+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #MultiModal #DiffusionModel #read-later Issue Date: 2026-01-03 GPT Summary- DiffThinkerという新しい生成的マルチモーダル推論フレームワークを提案し、視覚中心のタスクにおいて優れた論理的一貫性と空間的精度を実現。DiffThinkerはMLLMsと比較され、効率性、制御性、並列性、協調性の4つの特性が明らかにされる。広範な実験により、DiffThinkerは主要なクローズドソースモデルを大幅に上回る性能を示し、視覚中心の推論に対する有望なアプローチであることを強調。 Comment
pj page: https://diffthinker-project.github.io/
元ポスト:
[Paper Note] Schoenfeld's Anatomy of Mathematical Reasoning by Language Models, Ming Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #LanguageModel #Mathematics Issue Date: 2025-12-27 GPT Summary- 本研究では、Schoenfeldのエピソード理論を基にしたThinkARMというフレームワークを提案し、推論の痕跡を明示的に抽象化します。このフレームワークを用いることで、数学的問題解決における再現可能な思考のダイナミクスや推論モデルと非推論モデルの違いを明らかにします。また、探索が正確性に寄与する重要なステップであることや、効率重視の手法が評価フィードバックを選択的に抑制することを示すケーススタディを提示します。これにより、現代の言語モデルにおける推論の構造と変化を体系的に分析することが可能になります。 Comment
元ポスト:
[Paper Note] MoReBench: Evaluating Procedural and Pluralistic Moral Reasoning in Language Models, More than Outcomes, Yu Ying Chiu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Chain-of-Thought #Evaluation #Safety Issue Date: 2025-12-24 GPT Summary- AIシステムの意思決定が人間の価値観と一致するためには、その決定過程を理解することが重要である。推論言語モデルを用いて、道徳的ジレンマに関する評価を行うためのベンチマーク「MoReBench」を提案。1,000の道徳的シナリオと23,000以上の基準を含み、AIの道徳的推論能力を評価する。結果は、既存のベンチマークが道徳的推論を予測できないことや、モデルが特定の道徳的枠組みに偏る可能性を示唆している。これにより、安全で透明なAIの推進に寄与する。 Comment
pj page: https://morebench.github.io/
元ポスト:
[Paper Note] Step-DeepResearch Technical Report, Chen Hu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Proprietary #mid-training #PostTraining #DeepResearch #KeyPoint Notes #Rubric-based Issue Date: 2025-12-24 GPT Summary- Step-DeepResearchは、LLMを用いた自律エージェントのためのコスト効率の良いエンドツーエンドのシステムであり、意図認識や長期的意思決定を強化するためのデータ合成戦略を提案。チェックリストスタイルのジャッジャーにより堅牢性を向上させ、中国ドメイン向けのADR-Benchを設立。実験では、Step-DeepResearchが高いスコアを記録し、業界をリードするコスト効率で専門家レベルの能力を達成したことを示した。 Comment
元ポスト:
ポイント解説:
ざっくり言うと、シンプルなReAct styleのagentで、マルチエージェントのオーケストレーションや複雑で重たいワークフロー無しで、OpenAI, GeminiのDeepResearchと同等の性能を達成してとり、ポイントとしてこれらの機能をはmid-training段階で学習してモデルのパラメータとして組み込むことで実現している模様。
mid trainingは2段階で構成され、trajectoryの長さは徐々に長いものを利用するカリキュラム方式。
最初のステージでは以下の4つのatomicスキルを身につけさせる:
- Planning & Task Decomposition
- Deep Information Seeking
- Reflection & Verification
- Reporting
これらのatomic skillを身につけさせる際には、next token predictionをnext action predictionという枠組みで学習し、アクションに関するトークンの空間を制限することで効率性を向上(ただし、具体性は減少するのでトレードオフ)という形にしているようだが、コンセプトが記述されているのみでよくわからない。同時に、学習データの構築方法もデータソースとおおまかな構築方法が書かれているのみである。ただし、記述内容的には各atomic skillごとに基本的には合成データが作成され利用されていると考えてよい。
たとえばplanningについては論文などの文献のタイトルや本文から実験以後の記述を除外し、研究プロジェクトのタスクを推定させる(リバースエンジニアリングと呼称している)することで、planningのtrajectoryを合成、Deep Information SeekingではDB Pediaなどのknowledge graphをソースとして利用し、次数が3--10程度のノードをseedとしそこから(トピックがドリフトするのを防ぐために極端に次数が大きいノードは除外しつつ)幅優先探索をすることで、30--40程度のノードによって構成されるサブグラフを構成し、そのサブグラフに対してmulti hopが必要なQuestionを、LLMで生成することでデータを合成しているとのこと。
RLはrewardとしてルーブリックをベースにしたものが用いられるが、strong modelを用いて
- 1: fully satisfied
- 0.5: partially satisfied
- 0: not satisfied
の3値を検討したが、partially satisfiedが人間による評価とのagreementが低かったため設計を変更し、positive/negative rubricsを設定し、positivルーブリックの場合はルーブリックがfully satisfiedの時のみ1, negativeルーブリックの方はnot satisfiedの時のみ0とすることで、低品質な生成結果に基づくrewardを無くし、少しでもネガティブな要素があった場合は強めのペナルティがかかるようにしているとのこと(ルーブリックの詳細は私が見た限りは不明である。Appendix Aに書かれているように一瞬見えたが具体的なcriterionは書かれていないように見える)。
[Paper Note] Xiaomi MiMo-VL-Miloco Technical Report, Jiaze Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #VideoGeneration/Understandings #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-12-23 GPT Summary- MiMo-VL-Miloco-7Bとその量子化バリアントをオープンソース化し、家庭中心の視覚と言語モデルとして優れた性能を発揮。特にスマートホーム環境に特化し、ジェスチャー認識やマルチモーダル推論で高いF1スコアを達成。二段階のトレーニングパイプラインを設計し、効率的な推論を実現。家庭シナリオのトレーニングが活動理解を向上させ、テキスト推論にも効果を示す。モデルとツールキットは公開され、スマートホームアプリケーションの研究に貢献。 Comment
元ポスト:
HF:
https://huggingface.co/collections/xiaomi-open-source/xiaomi-mimo-vl-miloco
モデル自体は11月から公開されている
home-scenario gesture recognitionとdaily activity recognitionでGemini-2.5-Proを上回る性能を達成している。特定のユースケースに特化しつつ、genericなユースケースの性能を損なわないようなモデルを学習したい場合は参考になるかもしれない。
まずSFTでhome-scenarioデータ[^1] + GeneralデータのDataMixでreasoning patternを学習させ、tokenのefficiencyを高めるためにCoTパターンを排除しdirect answerをするようなデータ(およびprompting)でも学習させる。これによりhome-scenarioでの推論能力が強化される。SFTはfull parameter tuningで実施され、optimizerはAdamW。バッチサイズ128, warmup ratio 0.03, learning rate 1 * 10^-5。スケジューラについては記述がないように見える。
その後、一般的なユースケース(Video Understanding (temporal groundingにフォーカス), GUI Grounding, Multimodal Reasoning (特にSTEMデータ))データを用いてGRPOでRLをする。明らかに簡単・難しすぎるデータは除外。RLのrewardは `r_acc + r_format`の線形補完(係数はaccL: 0.9, format: 0.1)で定義される。r_accはデータごとに異なっている。Video Understandingでは予測したqueryに対してモデルが予測したtimespanとgoldのtimespanのoverlapがどの程度あるかをaccとし、GUI Groundingではbounding boxを予測しpred/goldのoverlapをaccとする。Multimodal ReasoninghはSTEMデータなので回答が一致するかをbinaryのaccとして与えている。
モデルのアーキテクチャは、アダプターでLLMと接続するタイプのもので、動画/画像のBackboneにはViTを用いて、MLPのアダプターを持ちいてLLMの入力としている。
[^1]: volunteerによるhome-scenarioでのデータ作成; ruleを規定しvolunteerに理解してもらいデータ収集。その後研究者が低品質なものを除外
[Paper Note] SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning, Jitesh Jain+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #ReinforcementLearning #AIAgents #Evaluation #PostTraining #Selected Papers/Blogs #VideoGeneration/Understandings #VisionLanguageModel #KeyPoint Notes #LongHorizon Issue Date: 2025-12-19 GPT Summary- 人間のように異なる長さの動画に柔軟に推論できる動画推論モデルSAGEを提案。SAGEは長い動画に対してマルチターン推論を行い、簡単な問題には単一ターンで対応。Gemini-2.5-Flashを用いたデータ生成パイプラインと強化学習後訓練レシピを導入し、SAGE-Benchで実世界の動画推論能力を評価。結果、オープンエンドのタスクで最大6.1%、10分以上の動画で8.2%の性能向上を確認。 Comment
pj page: https://praeclarumjj3.github.io/sage/
元ポスト:
AllenAIの勢いすごいな...
現在のVideo reasoning Modelはlong videoに対するQAに対してもsingle turnで回答応答しようとするが、人間はそのような挙動はせずに、long videoのうち、どこを流し見し、どこを注視するか、ある時は前半にジャンプし、関係ないところは飛ばすなど、情報を選択的に収集する。そのような挙動のエージェントをMolmo2をベースにSFT+RLをベースに実現。
システムデザインとしては、既存のエージェントはtemporal groundingのみをしばしば利用するがこれはlong videoには不向きなので、non-visualな情報も扱えるようにweb search, speech transcription, event grounding, extract video parts, analyze(クエリを用いてメディアの集合を分析し応答する)なども利用可能に。
inferenceは2-stageとなっており、最初はまずSAGE-MMをContext VLMとして扱い、入力された情報を処理し(video contextやツール群、メタデータなど)、single turnで回答するか、ツール呼び出しをするかを判断する。ツール呼び出しがされた場合は、その後SAGE-MMはIterative Reasonerとして機能し、前段のtool callの結果とvideo contextから回答をするか、新たなツールを呼び出すかを判断する、といったことを繰り返す。
long videoのデータは6.6kのyoutube videoと99kのQAペア(Gemini-2.5-Flashで合成)、400k+のstate-action example(Gemini-2.5-Flashによりtool callのtrajectoryを合成しcold start SFTに使う)を利用。
RLのoptimizationでは、openendなvideo QAではverifiableなrewardは難しく、任意の長さのvideoに対するany-horizonな挙動を学習させるのは困難なので、multi rewardなRLレシピ+strong reasoning LLMによるLLM as a Judgeで対処。rewardはformat, 適切なツール利用、ツール呼び出しの引数の適切さ、最終的な回答のAccuracyを利用。
評価データとしては人手でverificationされた1744のQAを利用し、紐づいている動画データの長さは平均700秒以上。
[Paper Note] Think Visually, Reason Textually: Vision-Language Synergy in ARC, Beichen Zhang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#LatentReasoning Issue Date: 2025-12-17 GPT Summary- 抽象的推論は依然として基盤モデルにとっての課題であり、ARC-AGIを用いて視覚と言語の相乗的推論を提案。視覚は全体的なパターンの抽象化を支援し、言語はルールの定式化に特化。二つの戦略を導入し、テキストベースの推論を視覚で検証することで最大4.33%の性能向上を実現。視覚と言語の統合が人間のような知能の達成に寄与することを示唆。 Comment
元ポスト:
[Paper Note] Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models, Boxin Wang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#General #NLP #LanguageModel #Alignment #ReinforcementLearning #OpenWeight #OpenSource #read-later #RLVR #Selected Papers/Blogs #CrossDomain #KeyPoint Notes #Author Thread-Post Issue Date: 2025-12-17 GPT Summary- 一般目的の推論モデルを強化学習(RL)で構築する際の課題に対処するため、カスケードドメイン別強化学習(Cascade RL)を提案。Nemotron-Cascadeは、指示モードと深い思考モードで動作し、異なるドメインのプロンプトを順次調整することで、エンジニアリングの複雑さを軽減し、最先端のパフォーマンスを実現。RLHFを前段階として使用することで推論能力が向上し、ドメイン別RL段階でもパフォーマンスが改善される。14Bモデルは、LiveCodeBenchで優れた結果を示し、2025年国際情報オリンピックで銀メダルを獲得。トレーニングとデータのレシピも共有。 Comment
元ポスト:
従来のRLはすべてのドメインのデータをmixすることでおこなれてきたが、個々のドメインのデータを個別にRLし、cascading方式で適用 (Cascade RL) することを提案している(実際は著者らの先行研究でmath->codingのcascadingは実施されていたが、それをより広範なドメイン(RLHF -> instruction following -> math -> coding -> software engineering)に適用した、という研究)。
cascadingにはいくつかのメリットがありRLの学習速度を改善できる(あるいはRLのインフラの複雑性を緩和できる)
- ドメインごとのverificationの速度の違いによって学習速度を損なうことがない(e.g. 数学のrule-basedなverificationは早いがcodingは遅い)
- ドメインごとに出力長は異なるためオンポリシーRLを適用すると効率が落ちる(長いレスポンスの生成を待たなければらないため)
本研究で得られた利点としてはFigure 1を参考に言及されているが
- RLHF, instruction followingを事前に適用することによって、後段のreasoningの性能も向上する(reasoningのwarmupになる)
- 加えて応答の長さの削減につながる
- RLはcatastrophic forgettingに強く、前段で実施したドメインの性能が後段のドメインのRLによって性能が劣化しない
- といってもFigure 2を見ると、codingとsoftware engineeringは結構ドメイン近いのでは・・・?という気はするが・・・。
- RLにおけるカリキュラム学習やハイパーパラメータをドメインごとに最適なものを適用できる
他にもthinking/non-thinking に関することが言及されているが読めていない。
[Paper Note] Nanbeige4-3B Technical Report: Exploring the Frontier of Small Language Models, Chen Yang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #ReinforcementLearning #Distillation #OpenWeight #mid-training #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2025-12-13 GPT Summary- Nanbeige4-3Bは、23兆の高品質トークンで事前学習し、3000万以上の指示でファインチューニングされた高性能な小規模言語モデルです。FG-WSDトレーニングスケジューラを用いて段階的にデータを洗練し、SFTデータの質向上のために共同メカニズムを設計しました。さらに、DPDメソッドを通じてモデルを蒸留し、強化学習フェーズで推論能力を強化しました。評価結果は、同等のパラメータスケールのモデルを大幅に上回り、より大きなモデルにも匹敵することを示しています。モデルのチェックポイントは、https://huggingface.co/Nanbeige で入手可能です。 Comment
元ポスト:
3Bモデルにも関わらず10倍以上大きいモデルと同等以上の性能を発揮し、trainingのstrategyが非常に重要ということが伺える。元ポストにも各学習方法の概要が記載されているが、読みたい。
[Paper Note] Escaping the Verifier: Learning to Reason via Demonstrations, Locke Cai+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #read-later #Selected Papers/Blogs #AdversarialTraining Issue Date: 2025-12-12 GPT Summary- RARO(Relativistic Adversarial Reasoning Optimization)は、専門家のデモンストレーションから逆強化学習を通じて推論能力を学習する手法。ポリシーは専門家の回答を模倣し、批評者は専門家を特定する敵対的なゲームを設定。実験では、RAROが検証者なしのベースラインを大幅に上回り、堅牢な推論学習を実現することを示した。 Comment
元ポスト:
重要研究に見える
has any code?
@duzhiyu11 Thank you for the comment. As stated in this post, they appear to be preparing to release the code. It would be best to wait for an official announcement from the authors regarding the code release.
[Paper Note] OneThinker: All-in-one Reasoning Model for Image and Video, Kaituo Feng+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #ReinforcementLearning #MultiModal #OpenWeight #VisionLanguageModel #2D (Image) #UMM #3D (Video) #One-Line Notes #text Issue Date: 2025-12-06 GPT Summary- OneThinkerは、視覚的推論を統一するオールインワンの強化学習モデルであり、質問応答やキャプショニングなどの多様なタスクに対応。OneThinker-600kトレーニングコーパスを用いて訓練され、報酬の異質性に対処するEMA-GRPOを提案。広範な実験により、10の視覚理解タスクで強力なパフォーマンスを示し、タスク間の知識移転とゼロショット一般化能力を実証。全てのコード、モデル、データは公開。 Comment
pj page:
https://github.com/tulerfeng/OneThinker
HF:
https://huggingface.co/OneThink
元ポスト:
image/videoに関するreasoningタスクをunifiedなアーキテクチャで実施するVLM
Qwen3-VL-Instruct-8Bに対するgain。様々なタスクで大幅なgainを得ている。特にTracking, segmentation, groundingのgainが大きいように見える。
[Paper Note] LLM Reasoning for Cold-Start Item Recommendation, Shijun Li+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #read-later #ColdStart Issue Date: 2025-11-25 GPT Summary- LLMsを用いたコールドスタートアイテム推薦の新しい推論戦略を提案。特に新規アイテムに対するユーザーの好みを推測し、教師ありファインチューニングと強化学習を組み合わせたアプローチを評価。実験により、Netflixの製品ランキングモデルを最大8%上回る性能を示した。 Comment
元ポスト:
[Paper Note] xRouter: Training Cost-Aware LLMs Orchestration System via Reinforcement Learning, Cheng Qian+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Routing Issue Date: 2025-11-25 GPT Summary- xRouterは、コストとパフォーマンスのトレードオフを考慮したルーティングシステムで、学習されたルーターが直接回答するか外部モデルを呼び出す。強化学習により訓練され、手動ルールの必要がない。多様なベンチマークでコスト削減とタスク完了率の向上を実現し、LLMオーケストレーションの進展に寄与することを目指す。 Comment
元ポスト:
[Paper Note] Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models, Jiaqi Wang+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #NeurIPS #VisionLanguageModel #One-Line Notes #Author Thread-Post Issue Date: 2025-11-25 GPT Summary- 強化学習を用いて視覚と言語モデルの推論を強化するために、TONという二段階のトレーニング戦略を提案。簡単な質問には推論をスキップし、必要な時に考える人間の思考プロセスを模倣。実験により、TONは従来の手法に比べて推論ステップを最大90%削減し、性能を向上させることが示された。モデルはトレーニングを通じて不要な推論を回避することを学習。 Comment
元ポスト:
著者ポスト:
いつ思考をするか/しないかを学習することでCoTのtrajectoryを節約する。選択的に思考しないということをモデルは基本的に学習していないのでSFTで模倣学習することでコールドスタートを脱っし、その後RLによって選択的に思考しないことも含めて思考を最適化する、といった話に見える。
[Paper Note] Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark, Minhui Zhu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #Physics Issue Date: 2025-11-23 GPT Summary- CritPtは、物理学研究における複雑な推論タスクを評価するための初のベンチマークであり、71の研究課題と190のチェックポイントタスクから構成される。これらの問題は現役の物理学者によって作成され、機械的に検証可能な答えを持つように設計されている。現在のLLMsは、単独のチェックポイントでは期待を示すが、全体の研究課題を解決するには不十分であり、最高精度は5.7%にとどまる。CritPtは、AIツールの開発に向けた基盤を提供し、モデルの能力と物理学研究の要求とのギャップを明らかにする。 Comment
pj page: https://critpt.com/
artificial analysisによるリーダーボード:
https://artificialanalysis.ai/evaluations/critpt
データセットとハーネス:
[Paper Note] SSR: Socratic Self-Refine for Large Language Model Reasoning, Haizhou Shi+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Test-Time Scaling #Verification #MajorityVoting Issue Date: 2025-11-22 GPT Summary- 新しいフレームワークSocratic Self-Refine(SSR)を提案し、LLMの推論を細かく評価・洗練する。SSRは応答をサブ質問・サブ回答に分解し、信頼度推定を行い、信頼性の低いステップを特定・改善することで、より正確な推論を実現。実験結果はSSRが最先端の手法を上回ることを示し、LLMの内部推論プロセスの理解を助ける。 Comment
元ポスト:
[Paper Note] Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafter, Qinghao Hu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #PostTraining #One-Line Notes Issue Date: 2025-11-21 GPT Summary- 大規模言語モデル(LLMs)の推論能力を向上させるため、TLTを提案。TLTは適応的な推測デコーディングを用いて、強化学習(RL)トレーニングの効率を向上させる。主なコンポーネントは、アイドルGPUでトレーニングされるアダプティブドラフターと、メモリ効率の良いプールを維持するアダプティブロールアウトエンジン。TLTは、最先端システムに対して1.7倍のトレーニング速度向上を実現し、モデルの精度を保持しつつ高品質なドラフトモデルを生成。 Comment
元ポスト:
ロングテールのrolloutをする際にspeculative decodingをすることでボトルネックを改善しon-policy RLの速度を改善する話らしいが、Inflight Weight Updatesがもしうまく機能するならこちらの方が簡単な気がするが、果たしてどうなのだろうか。
関連:
- PipelineRL, Piche+, ServiceNow, 2025.04
[Paper Note] What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity, Alexis Audran-Reiss+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #AIAgents #ScientificDiscovery #Diversity #One-Line Notes Issue Date: 2025-11-21 GPT Summary- AI研究エージェントのパフォーマンスにおけるアイデアの多様性の役割を検討。MLE-benchでの分析により、パフォーマンスの高いエージェントはアイデアの多様性が増加する傾向があることが明らかに。制御実験でアイデアの多様性が高いほどパフォーマンスが向上することを示し、追加の評価指標でも発見が有効であることを確認。 Comment
元ポスト:
ideation時点における多様性を向上させる話らしい
[Paper Note] Olmo 3, Team Olmo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #OpenSource #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-11-20 GPT Summary- Olmo 3は、7Bおよび32Bパラメータの完全オープンな言語モデルファミリーで、長文コンテキスト推論やコーディングなどに対応。全ライフサイクルの情報が含まれ、特にOlmo 3 Think 32Bは最も強力な思考モデルとして注目される。 Comment
元ポスト:
解説:
post-LN transformer
OLMo2:
- OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3
ポイント解説:
official livestream video:
解説:
Qwen3-32Bと同等の性能を達成している。そしてそれがオープンソース、素晴らしい。読むべし!!
Olmo3のライセンスに関する以下のような懸念がある:
ポイント解説:
[Paper Note] AMO-Bench: Large Language Models Still Struggle in High School Math Competitions, Shengnan An+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Mathematics Issue Date: 2025-11-20 GPT Summary- AMO-Benchは、オリンピックレベルの数学的推論を評価するための新しいベンチマークで、50の専門家作成の問題から成る。既存のベンチマークが飽和状態にある中、AMO-BenchはIMO基準を満たし、オリジナルの問題を提供することで厳格な評価を実現。実験では、26のLLMsが52.4%の正答率を記録し、ほとんどが40%未満であった。これにより、LLMsの数学的推論能力には改善の余地があることが示された。AMO-Benchは、今後の研究を促進するために公開されている。 Comment
pj page: https://amo-bench.github.io/
元ポスト:
AIMEの次はこちらだろうか...ちなみに私は私生活において数学オリンピックの問題を解きたいと思ったことは今のところ一度もない🧐しかし高度な推論能力を測定するために必要というのは理解できる。
HF: https://huggingface.co/datasets/meituan-longcat/AMO-Bench
[Paper Note] Solving a Million-Step LLM Task with Zero Errors, Elliot Meyerson+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #AIAgents #Test-Time Scaling #One-Line Notes #LongHorizon Issue Date: 2025-11-20 GPT Summary- LLMの限界を克服するために、MAKERというシステムを提案。これは、100万以上のステップをゼロエラーで解決可能で、タスクを細分化し、マイクロエージェントが各サブタスクに取り組むことでエラー修正を行う。これにより、スケーリングが実現し、組織や社会の問題解決に寄与する可能性を示唆。 Comment
元ポスト:
しっかりと読めていないのだが、各タスクを単一のモデルのreasoningに頼るのではなく、
- 極端に小さなサブタスクに分解
- かつ、各サブタスクに対して複数のエージェントを走らせてvotingする
といったtest-time scalingっぽい枠組みに落とすことによってlong-horizonのタスクも解決することが可能、というコンセプトに見える。
[Paper Note] From Solving to Verifying: A Unified Objective for Robust Reasoning in LLMs, Xiaoxuan Wang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfCorrection #read-later #SelfVerification Issue Date: 2025-11-20 GPT Summary- LLMの推論能力を向上させるため、生成と自己検証を統一した損失関数で共同最適化するGRPO-Verifアルゴリズムを提案。実験により、自己検証能力が向上しつつ推論性能を維持できることを示した。 Comment
元ポスト:
[Paper Note] MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling, MiroMind Team+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #OpenWeight #DeepResearch Issue Date: 2025-11-19 GPT Summary- MiroThinker v1.0は、ツール強化推論と情報探索能力を向上させるオープンソースの研究エージェントで、モデルと環境の相互作用を深めるインタラクションスケーリングを採用。256Kのコンテキストウィンドウを持ち、最大600回のツールコールを実行可能で、従来のエージェントを上回る精度を達成。インタラクションの深さがモデルの性能を向上させることを示し、次世代の研究エージェントにおける重要な要素として位置づけられる。 Comment
元ポスト:
HF: https://huggingface.co/miromind-ai/MiroThinker-v1.0-72B
ポイント解説:
[Paper Note] On a few pitfalls in KL divergence gradient estimation for RL, Yunhao Tang+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #ReinforcementLearning #One-Line Notes Issue Date: 2025-11-12 GPT Summary- LLMのRLトレーニングにおけるKLダイバージェンスの勾配推定に関する落とし穴を指摘。特に、KL推定を通じて微分する実装が不正確であることや、逐次的な性質を無視した実装が部分的な勾配しか生成しないことを示す。表形式の実験とLLM実験を通じて、正しいKL勾配の実装方法を提案。 Comment
元ポスト:
RLにおけるKL Divergenceによるポリシー正則化の正しい実装方法
Stress-Testing the Reasoning Competence of Language Models With Formal Proofs, Arkoudas+, EMNLP'25 Findings
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Mathematics #Proofs Issue Date: 2025-11-12 GPT Summary- ProofGridという新しい論理推論タスクを用いて、LLMsとLRMsの性能を広範に評価。タスクは命題論理と方程式論理の証明作成・検証を含み、証明のインペインティングとギャップ埋めも新たに導入。実験ではトップモデルの優れたパフォーマンスが示される一方、体系的な失敗も確認。1万件以上の形式的推論問題と証明からなる新データリソースも公開。 Comment
元ポスト:
[Paper Note] DeepEyesV2: Toward Agentic Multimodal Model, Jack Hong+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #AIAgents #MultiModal #SmallModel #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-11-10 GPT Summary- DeepEyesV2は、テキストや画像の理解に加え、外部ツールを活用するエージェント的なマルチモーダルモデルを構築する方法を探求。二段階のトレーニングパイプラインを用いてツール使用行動を強化し、多様なトレーニングデータセットをキュレーション。RealX-Benchという新たなベンチマークを導入し、実世界のマルチモーダル推論を評価。DeepEyesV2は、タスクに応じたツール呼び出しを行い、強化学習により文脈に基づくツール選択を実現。コミュニティへの指針提供を目指す。 Comment
pj page: https://visual-agent.github.io/
元ポスト:
ポイント解説:
VLM(Qwen2.5-VL-7B)をバックボーンとしSFT(tooluseに関するcoldstart)→RL(RLVR+format reward)で学習することで、VLMによるAI Agentを構築。画像をcropしcropした画像に対するマルチモーダルな検索や、適切なtooluseの選択などに基づいて応答できる。
事前の実験によってまずQwen2.5-VL-7Bに対してRLのみでtooluse能力(コーディング能力)を身につけられるかを試したところ、Reward Hackingによって適切なtooluse能力が獲得されなかった(3.2節; 実行可能ではないコードが生成されたり、ダミーコードだったりなど)。
このためこのcoldstartを解消するためにSFTのための学習データを収集(3.3節)。これには、
- 多様なタスクと画像が含まれており
- verifiableで構造化されたOpen-endなQAに変換でき
- ベースモデルにとって簡単すぎず(8回のattemptで最大3回以上正解したものは除外)
- ツールの利用が正解に寄与するかどうかに基づきサンプルを分類する。tooluseをしても解答できないケースをSFTに、追加のtooluseで解答できるサンプルをRL用に割り当て
ようなデータを収集。さらに、trajectoryはGemini2.5, GPT4o, Claude Sonnet4などのstrong modelから収集した。
RealX-Benchと呼ばれるベンチマークも作成しているようだがまだ読めていない。
proprietary modelの比較対象が少し古め。ベースモデルと比較してSFT-RLによって性能は向上。Human Performanceも掲載されているのは印象的である。
ただ、汎用モデルでこの性能が出るのであれば、DeepSearchに特化したモデルや?GPT5, Claude-4.5-Sonnetなどではこのベンチマーク上ではHuman Performanceと同等かそれ以上の性能が出るのではないか?という気がする。
[Paper Note] Scaling Agent Learning via Experience Synthesis, Zhaorun Chen+, ICLR'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #AIAgents #ICLR #Author Thread-Post Issue Date: 2025-11-07 GPT Summary- DreamGymは、強化学習(RL)エージェントのオンライントレーニングを効率化するための統一フレームワークであり、高コストのロールアウトや不安定な報酬信号の課題に対処します。環境のダイナミクスを推論に基づく経験モデルに蒸留し、安定した状態遷移とフィードバックを提供します。オフラインデータを活用した経験リプレイバッファにより、エージェントのトレーニングを強化し、新しいタスクを適応的に生成することでオンラインカリキュラム学習を実現します。実験により、DreamGymは合成設定とリアルなシナリオでRLトレーニングを大幅に改善し、非RL準備タスクでは30%以上の性能向上を示しました。合成経験のみでトレーニングされたポリシーは、実環境RLにおいても優れたパフォーマンスを発揮し、スケーラブルなウォームスタート戦略を提供します。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=cf7qpBwttr
著者による一言解説:
[Paper Note] WebThinker: Empowering Large Reasoning Models with Deep Research Capability, Xiaoxi Li+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #NeurIPS #DPO #DeepResearch Issue Date: 2025-11-05 GPT Summary- WebThinkerは、LRMsがウェブを自律的に検索し、情報を収集しながら報告書を作成できる深層研究エージェントである。Deep Web Explorerモジュールを統合し、知識のギャップを埋めるために動的に情報を抽出する。リアルタイムで情報収集と報告書作成を行うThink-Search-and-Draft戦略を採用し、RLベースのトレーニング戦略を導入。実験により、WebThinkerは複雑な推論タスクで既存手法を大幅に上回る性能を示した。 Comment
元ポスト:
[Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Distillation #NeurIPS #Selected Papers/Blogs #One-Line Notes #EntropyCollapse Issue Date: 2025-11-05 GPT Summary- 検証可能な報酬を用いた強化学習(RLVR)は、LLMsの推論性能を向上させるが、現在の設定では新しい推論パターンを引き出せていない。小さなkではベースモデルを上回るが、大きなkではベースモデルが優位。RLVRアルゴリズムは類似の性能を示し、ベースモデルの潜在能力を活用できていない。蒸留は新しい推論パターンを導入し、モデルの能力を拡張できる。これにより、RLの改善が必要であることが示唆される。 Comment
pj page: https://limit-of-rlvr.github.io/
元ポスト:
所見:
上記所見では、「RLVRがバッチサイズ256、トークン長8192(および8つのプロンプト)で約400ステップ実行されており、何かを学ぶにはトークン量が少なすぎるのでは」という指摘があるが、著者がリプ欄でそれはablation studyでの実験のものであり、4.6節でより大規模なモデル・計算量で学習されたモデルで実験をしたが(著者が訓練したというよりも、ベースモデルとRLVR後のモデルでPass@kの性能を比較したということだと思われる)結論は変わらなかった、と反論をしている。ただし、4.6節ではstep数が言及されていない、という指摘もあり、それに対して、著者は公表されているstep数の数値を返答しているように見える。
openreview: https://openreview.net/forum?id=4OsgYD7em5
RLVRによって、サンプル効率は改善するが(= Pass@1は改善する)、モデルのreasoning能力のboundaryは狭まる(= Pass@kはRL後のモデルよりもベースモデルの方が高い。つまり、ベースモデルの方が推論可能な範囲 (reasoning boundary) が広いということ)。言い換えると、RLはベースモデルによって既に獲得されているreasoning pathを引き出すが、新たな戦略を発見しない。このことを多様なデータセット、モデル群に対するシステマチックな実験によって示した。
openreview中のweaknessにおいて、解決策の提案がlimitedであると指摘されているが、それに対して以下のようにrebuttalが記述されている:
> 1. Finer-grained reward structures: step-wise rewards guide intermediate reasoning and reduce exploration bottlenecks.
> 2. Improved exploration: Instead of naive softmax sampling, introduce structured or hierarchical search to enhance exploration efficiency.
> 3. Better long-horizon credit assignment: Use techniques to propagate reward more effectively over long CoT chains and enabling the model to assign credit to crucial intermediate steps instead the whole response
> 4. Scaling up RL training: Match RLVR compute and data scale to that of pre-training
> 5. Multi-turn tool use & external knowledge: Allow the agent to interact with tools or retrieve external facts, broadening the reasoning space beyond single-pass generation
openreview中のrebuttalに記載の通り解決策の一つとして「RLVRのスケールを事前学習並みにスケールさせる」というものがあり、理論的にRLVRがreasoning boundaryを広げないということを示したわけではなく、たとえばより多くの計算量とデータを投入した場合に関しては明らかではなさそう、という点には注意。
[Paper Note] VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning, Haozhe Wang+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SelfCorrection #NeurIPS #VisionLanguageModel Issue Date: 2025-11-05 GPT Summary- スロースロース思考システムは、明示的な反省を通じて難しい問題を解決する可能性を示しているが、マルチモーダル推論能力はファストスロース思考モデルと同等である。本研究では、強化学習を用いて視覚と言語のモデルのスロースロース思考能力を向上させることを目指し、選択的サンプルリプレイ(SSR)と強制的再考を導入。これにより、モデルVL-RethinkerはMathVista、MathVerseでそれぞれ80.4%、63.5%の最先端スコアを達成し、他のベンチマークでも優れた性能を示した。 Comment
元ポスト:
[Paper Note] When Visualizing is the First Step to Reasoning: MIRA, a Benchmark for Visual Chain-of-Thought, Yiyang Zhou+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #MultiModal #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #KeyPoint Notes #text #Visual-CoT #Author Thread-Post Issue Date: 2025-11-05 GPT Summary- MIRAは、中間的な視覚画像を生成し推論を支援する新しいベンチマークで、従来のテキスト依存の手法とは異なり、スケッチや構造図を用いる。546のマルチモーダル問題を含み、評価プロトコルは画像と質問、テキストのみのCoT、視覚的ヒントを含むVisual-CoTの3レベルを網羅。実験結果は、中間的な視覚的手がかりがモデルのパフォーマンスを33.7%向上させることを示し、視覚情報の重要性を強調している。 Comment
pj page: https://mira-benchmark.github.io/
元ポスト:
Visual CoT
Frontierモデル群でもAcc.が20%未満のマルチモーダル(Vision QA)ベンチマーク。
手作業で作成されており、Visual CoT用のsingle/multi stepのintermediate imagesも作成されている。興味深い。
VLMにおいて、{few, many}-shotがうまくいく場合(Geminiのようなプロプライエタリモデルはshot数に応じて性能向上、一方LlamaのようなOpenWeightモデルは恩恵がない)と
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
うまくいかないケース(事前訓練で通常見られない分布外のドメイン画像ではICLがうまくいかない)
- [Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05
も報告されている。
おそらく事前学習段階で当該ドメインの画像が学習データにどれだけ含まれているか、および、画像とテキストのalignmentがとれていて、画像-テキスト間の知識を活用できる状態になっていることが必要なのでは、という気はする。
著者ポスト:
[Paper Note] How Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?, Sohee Yang+, EMNLP'25, 2025.06
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Chain-of-Thought #SelfCorrection #EMNLP #SelfVerification Issue Date: 2025-11-04 GPT Summary- 推論モデルの自己再評価能力を調査し、役に立たない思考の4つのタイプを特定。モデルは無駄話や無関係な思考を効果的に識別できるが、それらが注入されると回復に苦労し、性能が低下することを示した。特に、大きなモデルは短い無関係な思考からの回復が難しい傾向があり、自己再評価の改善が求められる。これにより、より良い推論と安全なシステムの開発が促進される。 Comment
元ポスト:
元ポスト:
[Paper Note] Think Just Enough: Sequence-Level Entropy as a Confidence Signal for LLM Reasoning, Aman Sharma+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #LLMServing #Decoding #Inference #Entropy Issue Date: 2025-10-30 GPT Summary- エントロピーに基づく新しいフレームワークを提案し、推論タスクにおける大規模言語モデルのトークン効率を向上。シャノンエントロピーを信頼度信号として利用し、早期停止を実現することで、計算コストを25-50%削減。モデルごとに異なるエントロピー閾値を用いて、正しい答えを早期に得ることを認識し、トークン節約とレイテンシ削減を可能にする。精度を維持しつつ一貫したパフォーマンスを示し、現代の推論システムの特徴を明らかに。 Comment
元ポスト:
デコード時のエントロピーに応じて、reasoningを打ち切るか否か判定してコスト削減しつつ推論する話な模様
vLLMとかでデフォルトでサポートされてスループット上がったら嬉しいなあ
[Paper Note] DLER: Doing Length pEnalty Right - Incentivizing More Intelligence per Token via Reinforcement Learning, Shih-Yang Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning Issue Date: 2025-10-27 GPT Summary- 推論言語モデルは長い出力を生成することが多く、応答の長さに対する精度向上が課題である。本研究では、切り捨てを用いた強化学習(RL)の再考を行い、精度低下の原因は不十分なRL最適化にあることを示す。3つの課題(バイアス、エントロピーの崩壊、スパースな報酬信号)に対処するため、DLERというトレーニング手法を提案し、出力の長さを70%以上削減しつつ精度を向上させた。さらに、Difficulty-Aware DLERを導入し、簡単な質問に対して適応的に切り捨てを厳しくすることで効率を向上させる手法も提案した。 Comment
pj page: https://nvlabs.github.io/DLER/
元ポスト:
reasoningをトークン数の観点で効率化する話
[Paper Note] R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?, Yi Lu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #One-Line Notes #LongHorizon Issue Date: 2025-10-27 GPT Summary- R-HORIZONを提案し、長期的な推論行動を刺激する手法を通じて、LRMの評価を改善。複雑なマルチステップ推論タスクを含むベンチマークを構築し、LRMの性能低下を明らかに。R-HORIZONを用いた強化学習データ(RLVR)は、マルチホライズン推論タスクの性能を大幅に向上させ、標準的な推論タスクの精度も向上。AIME2024で7.5の増加を達成。R-HORIZONはLRMの長期推論能力を向上させるための有効なパラダイムと位置付けられる。 Comment
pj page: https://reasoning-horizon.github.io
元ポスト:
long horizonタスクにうまく汎化する枠組みの必要性が明らかになったように見える。long horizonデータを合成して、post trainingをするという枠組みは短期的には強力でもすぐに計算リソースの観点からすぐに現実的には能力を伸ばせなくなるのでは。
ポイント解説:
[Paper Note] ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows, Qiushi Sun+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #MultiModal #SoftwareEngineering #ComputerUse #read-later #Selected Papers/Blogs #VisionLanguageModel #Science Issue Date: 2025-10-26 GPT Summary- 大規模言語モデル(LLMs)を活用したScienceBoardを紹介。これは、科学的ワークフローを加速するための動的なマルチドメイン環境と、169の厳密に検証されたタスクからなるベンチマークを提供。徹底的な評価により、エージェントは複雑なワークフローでの信頼性が低く、成功率は15%にとどまることが明らかに。これにより、エージェントの限界を克服し、より効果的な設計原則を模索するための洞察が得られる。 Comment
元ポスト:
[Paper Note] Algorithmic Primitives and Compositional Geometry of Reasoning in Language Models, Samuel Lippl+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel Issue Date: 2025-10-25 GPT Summary- 本研究では、大規模言語モデル(LLMs)が多段階の推論を解決するためのアルゴリズム的原則を追跡し、操作するフレームワークを提案。推論のトレースを内部の活性化パターンにリンクさせ、原則を残差ストリームに注入することで、推論ステップやタスクのパフォーマンスへの影響を評価。旅行セールスマン問題や3SATなどのベンチマークを用いて、原則ベクトルの導出と幾何学的論理の明示化を行い、ファインチューニングによる一般化の強調を示した。これにより、LLMsの推論がアルゴリズム的原則の構成的幾何学に支えられている可能性が示唆され、原則の転送とドメイン間の一般化が強化されることが明らかになった。 Comment
元ポスト:
[Paper Note] Towards Video Thinking Test: A Holistic Benchmark for Advanced Video Reasoning and Understanding, Yuanhan Zhang+, ICCV'25, 2025.07
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #VideoGeneration/Understandings #ICCV #3D (Video) #Robustness Issue Date: 2025-10-24 GPT Summary- ビデオ理解における正確性と堅牢性のギャップを評価するために、Video Thinking Test(Video-TT)を導入。1,000本のYouTube Shortsビデオを用い、オープンエンドの質問と敵対的質問を通じて、ビデオLLMsと人間のパフォーマンスの違いを示す。 Comment
pj page: https://zhangyuanhan-ai.github.io/video-tt/
関連:
[Paper Note] Asymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning, Jiashun Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Diversity #Entropy Issue Date: 2025-10-24 GPT Summary- 非対称近似ポリシー最適化(AsyPPO)を提案し、批評者の役割を復元しつつ大規模言語モデルの強化学習を効率化。軽量なミニ批評者を用いて多様性を促進し、価値推定のバイアスを減少。5,000サンプルでトレーニング後、従来のPPOに対してパフォーマンスを向上させ、学習の安定性を一貫して改善。 Comment
元ポスト:
[Paper Note] When Do Transformers Learn Heuristics for Graph Connectivity?, Qilin Ye+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Transformer Issue Date: 2025-10-24 GPT Summary- Transformersは一般化能力に欠け、脆弱なヒューリスティックに依存することが多い。分離型Transformerを用いて、$L$層のモデルが直径$3^L$までのグラフを解決できることを証明。トレーニングダイナミクスを分析し、能力内のグラフでは正しいアルゴリズムを学習し、能力を超えたグラフでは単純なヒューリスティックを学習することを示す。トレーニングデータを能力内に制限することで、正確なアルゴリズムの学習が促進されることを実証。 Comment
元ポスト:
[Paper Note] Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization, Badr AlKhamissi+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Architecture #read-later #Selected Papers/Blogs #KeyPoint Notes #SpeciarizedBrainNetworks #Neuroscience #Author Thread-Post Issue Date: 2025-10-22 GPT Summary- MiCRoは、脳の認知ネットワークに基づく専門家モジュールを持つトランスフォーマーベースのアーキテクチャで、言語モデルの層を4つの専門家に分割。これにより、解釈可能で因果的な専門家の動的制御が可能になり、機械学習ベンチマークで優れた性能を発揮。人間らしく解釈可能なモデルを実現。 Comment
pj page: https://cognitive-reasoners.epfl.ch
元ポスト:
事前学習言語モデルに対してpost-trainingによって、脳に着想を得て以下の4つをdistinctな認知モジュールを(どのモジュールにルーティングするかを決定するRouter付きで)学習する。
- Language
- Logic / Multiple Demand
- Social / Theory of Mind
- World / Default Mode Network
これによりAIとNeuroscienceがbridgeされ、MLサイドではモデルの解釈性が向上し、Cognitive側では、複雑な挙動が起きた時にどのモジュールが寄与しているかをprobingするテストベッドとなる。
ベースラインのdenseモデルと比較して、解釈性を高めながら性能が向上し、人間の行動とよりalignしていることが示された。また、layerを分析すると浅い層では言語のエキスパートにルーティングされる傾向が強く、深い層ではdomainのエキスパートにルーティングされる傾向が強くなるような人間の脳と似たような傾向が観察された。
また、neuroscienceのfunctional localizer(脳のどの部位が特定の機能を果たしているのかを特定するような取り組み)に着想を得て、類似したlocalizerが本モデルにも適用でき、特定の機能に対してどのexpertモジュールがどれだけ活性化しているかを可視化できた。
といったような話が著者ポストに記述されている。興味深い。
demo:
https://huggingface.co/spaces/bkhmsi/cognitive-reasoners
HF:
https://huggingface.co/collections/bkhmsi/mixture-of-cognitive-reasoners
[Paper Note] Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap, Yueqian Lin+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Dataset #Evaluation #SpeechProcessing #AudioLanguageModel #audio Issue Date: 2025-10-21 GPT Summary- 音声インタラクティブシステムの推論能力を評価するためのベンチマーク「VERA」を提案。2,931の音声エピソードを5つのトラックに整理し、音声インタラクションに適応。12の音声システムをテキストベースラインと比較した結果、音声モデルの精度は著しく低く、特に数学トラックでは74.8%対6.1%の差が見られた。レイテンシと精度の分析から、迅速な音声システムは約10%の精度に集約され、リアルタイム性を犠牲にしないとテキストパフォーマンスには近づけないことが示された。VERAは、音声アシスタントの推論能力向上に向けた再現可能なテストベッドを提供する。 Comment
元ポスト:
latencyとAccuracyのトレードオフ
[Paper Note] Reasoned Safety Alignment: Ensuring Jailbreak Defense via Answer-Then-Check, Chentao Cao+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Safety Issue Date: 2025-10-20 GPT Summary- 脱獄攻撃に対する安全性を向上させるために、Answer-Then-Checkという新しいアプローチを提案。モデルはまず質問に回答し、その後安全性を評価してから応答を提供。80Kの例からなるReasoned Safety Alignment(ReSA)データセットを構築し、実験により優れた安全性を示しつつ過剰拒否率を低下。ReSAでファインチューニングされたモデルは一般的な推論能力を維持し、敏感なトピックに対しても有益な応答を提供可能。少量のデータでのトレーニングでも高いパフォーマンスを達成できることが示唆された。 Comment
元ポスト:
[Paper Note] Agentic Design of Compositional Machines, Wenqian Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #read-later Issue Date: 2025-10-19 GPT Summary- 複雑な機械設計におけるLLMの創造能力を探求し、「構成的機械設計」の視点からアプローチ。テストベッド「BesiegeField」を用いて、LLMの能力をベンチマークし、空間的推論や戦略的組み立ての重要性を特定。オープンソースモデルの限界を受け、強化学習を通じた改善を模索し、関連する課題を明らかにする。 Comment
元ポスト:
pj page: https://besiegefield.github.io/
VAGEN Reinforcing World Model Reasoning for Multi-Turn VLM Agents, Wang+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #ReinforcementLearning #NeurIPS #VisionLanguageModel #WorldModels Issue Date: 2025-10-19 Comment
元ポスト:
[Paper Note] LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning, Haoqiang Kang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #DiffusionModel #LatentReasoning #KeyPoint Notes Issue Date: 2025-10-18 GPT Summary- LaDiR(Latent Diffusion Reasoner)という新しい推論フレームワークを提案。これは、LLMの限界を克服し、潜在表現と潜在拡散モデルを統合。VAEを用いて構造化された潜在推論空間を構築し、双方向注意マスクでデノイズ。これにより、効率的な推論軌跡の生成が可能となり、精度と多様性を向上。数学的推論の評価で、従来手法を上回る結果を示す。 Comment
元ポスト:
既存のreasoning/latent reasoningはsequentialにreasoning trajectoryを生成していくが、(このため、誤った推論をした際に推論を是正しづらいといわれている)本手法ではthought tokensと呼ばれる思考トークンをdiffusion modelを用いてdenoisingすることでreasoning trajectoryを生成する。このプロセスはtrajectory全体をiterativeにrefineしていくため前述の弱点が是正される可能性がある。また、thought tokensの生成は複数ブロック(ブロック間はcausal attention, ブロック内はbi-directional attention)に分けて実施されるため複数のreasoning trajectoryを並列して探索することになり、reasoning traceの多様性が高まる効果が期待できる。最後にVAEによってdiscreteなinputをlatent spaceに落とし込み、その空間上でdenoising(= latent space空間上で思考する)し、その後decodingしてdiscrete tokenに再度おとしこむ(= thought tokens)というアーキテクチャになっているため、latent space上でのreasoningの解釈性が向上する。最終的には、
結果のスコアを見る限り、COCONUTと比べるとだいぶgainを得ているが、Discrete Latentと比較するとgainは限定的に見える。
[Paper Note] Reasoning with Sampling: Your Base Model is Smarter Than You Think, Aayush Karan+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Diversity #Samplers Issue Date: 2025-10-18 GPT Summary- 本研究では、強化学習を用いずに、サンプリングによって大規模言語モデルの推論能力を引き出す方法を提案。マルコフ連鎖モンテカルロ技術に基づく反復サンプリングアルゴリズムを用い、MATH500、HumanEval、GPQAなどのタスクでRLに匹敵するかそれを上回る性能を示す。さらに、トレーニングや特別なデータセットを必要とせず、広範な適用可能性を持つことを示唆。 Comment
pj page: https://aakaran.github.io/reasoning_with_sampling/
元ポスト:
[Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention, MiniMax+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-10-17 GPT Summary- MiniMax-M1は、4560億パラメータを持つ世界初のオープンウェイトのハイブリッドアテンション推論モデルで、Mixture-of-Expertsアーキテクチャとライトニングアテンションを組み合わせています。1百万トークンのコンテキスト長をサポートし、複雑なタスクに適しています。新しいRLアルゴリズムCISPOを提案し、効率的な訓練を実現。標準ベンチマークで強力なオープンウェイトモデルと同等以上の性能を示し、特にソフトウェアエンジニアリングや長いコンテキストタスクで優れた結果を出しています。モデルは公開されています。 Comment
- MiniMax-M1, MiniMax, 2025.06
のテクニカルレポート。
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
でGSPO, DAPOよりも安定性と最終到達性能でより優れていることが示されたCISPOと呼ばれるRLアルゴリズムが提案されている。
関連:
[Paper Note] Is It Thinking or Cheating? Detecting Implicit Reward Hacking by Measuring Reasoning Effort, Xinpeng Wang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #RewardHacking Issue Date: 2025-10-16 GPT Summary- 報酬ハッキングは、モデルが報酬関数の抜け穴を利用して意図されたタスクを解決せずに高い報酬を得る行為であり、重大な脅威をもたらす。TRACE(Truncated Reasoning AUC Evaluation)を提案し、暗黙的な報酬ハッキングを検出する。TRACEは、モデルの推論が報酬を得るのにかかる時間を測定し、ハッキングモデルが短いCoTで高い期待報酬を得ることを示す。TRACEは、数学的推論で72B CoTモニターに対して65%以上、コーディングで32Bモニターに対して30%以上の性能向上を達成し、未知の抜け穴を発見する能力も示す。これにより、現在の監視方法が効果的でない場合に対するスケーラブルな無監視アプローチを提供する。 Comment
元ポスト:
[Paper Note] LightReasoner: Can Small Language Models Teach Large Language Models Reasoning?, Jingyuan Wang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #SmallModel Issue Date: 2025-10-16 GPT Summary- LightReasonerは、SLMがLLMの強みを活かして高価値の推論を明らかにする新しいフレームワーク。重要な推論瞬間を特定し、専門家モデルを調整する2段階のプロセスを経て、数学的ベンチマークで精度を最大28.1%向上、時間消費を90%削減、サンプリング問題を80%減少させた。リソース効率の良いアプローチで、真のラベルに依存せずにLLMの推論を進展させる。 Comment
元ポスト:
[Paper Note] Learning to Make MISTAKEs: Modeling Incorrect Student Thinking And Key Errors, Alexis Ross+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #EducationalDataMining #Supervised-FineTuning (SFT) #SyntheticData #Label-free Issue Date: 2025-10-16 GPT Summary- 新手法MISTAKEを提案し、不正確な推論パターンをモデル化。サイクル整合性を利用して高品質な推論エラーを合成し、教育タスクでの学生シミュレーションや誤解分類において高精度を達成。専門家の選択肢との整合性も向上。 Comment
元ポスト:
[Paper Note] Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models, Junhyuck Kim+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Quantization #Test-Time Scaling #One-Line Notes #MemoryOptimization Issue Date: 2025-10-15 GPT Summary- 4ビット量子化はメモリ最適化に有効ですが、推論モデルには適用できないことを示す。体系的な実験により、モデルサイズとKVキャッシュの影響を発見。小規模モデルは重みを優先し、大規模モデルは生成にメモリを割り当てることで精度を向上。LLMのメモリ最適化はスケールに依存し、異なるアプローチが必要であることを示唆。 Comment
元ポスト:
Reasoning Modelにおいて、メモリのbudgetに制約がある状況下において、
- モデルサイズ
- 重みの精度
- test-time compute (serial & parallel)
- KV Cacheの圧縮
において、それらをどのように配分することでモデルのAcc.が最大化されるか?という話しな模様。
[Paper Note] Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training, Junlin Han+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pretraining #NLP #Dataset #LanguageModel #Evaluation #MultiModal #read-later #DataMixture #VisionLanguageModel Issue Date: 2025-10-15 GPT Summary- 大規模言語モデル(LLMs)は、テキストのみで訓練されながらも視覚的先入観を発展させ、少量のマルチモーダルデータで視覚タスクを実行可能にする。視覚的先入観は、言語の事前訓練中に獲得された知識であり、推論中心のデータから発展する。知覚の先入観は広範なコーパスから得られ、視覚エンコーダーに敏感である。視覚を意識したLLMの事前訓練のためのデータ中心のレシピを提案し、500,000 GPU時間をかけた実験に基づく完全なMLLM構築パイプラインを示す。これにより、視覚的先入観を育成する新しい方法を提供し、次世代のマルチモーダルLLMの発展に寄与する。 Comment
元ポスト:
MLE Bench (Multi-Level Existence Bench)
[Paper Note] How Reinforcement Learning After Next-Token Prediction Facilitates Learning, Nikolaos Tsilivis+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #Transformer #ReinforcementLearning #PostTraining #read-later Issue Date: 2025-10-14 GPT Summary- 大規模言語モデルの次のトークン予測を強化学習で最適化するフレームワークを提案。特に、短いおよび長い「思考の連鎖」シーケンスからの学習を通じて、強化学習が次のトークン予測を改善することを理論的に示す。長いシーケンスが稀な場合、強化学習により自己回帰型トランスフォーマーが一般化できることを確認。さらに、長い応答が計算を増加させるメカニズムを説明し、自己回帰型線形モデルが効率的に$d$ビットの偶奇を予測できる条件を理論的に証明。Llamaシリーズモデルのポストトレーニングによる実証も行う。 Comment
元ポスト:
[Paper Note] Demystifying Reinforcement Learning in Agentic Reasoning, Zhaochen Yu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #LanguageModel #AIAgents #Entropy Issue Date: 2025-10-14 GPT Summary- エージェント的強化学習(agentic RL)を用いて、LLMsの推論能力を向上させるための調査を行った。重要な洞察として、合成軌道の実際のツール使用軌道への置き換えや、多様なデータセットの活用がRLのパフォーマンスを向上させることが示された。また、探索を促進する技術や、ツール呼び出しを減らす戦略がトレーニング効率を改善することが確認された。これにより、小型モデルでも強力な結果を達成し、実用的なベースラインを提供する。さらに、高品質なデータセットを用いて、困難なベンチマークでのエージェント的推論能力の向上を示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Verifying Chain-of-Thought Reasoning via Its Computational Graph, Zheng Zhao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #read-later #Selected Papers/Blogs #Verification #One-Line Notes #Author Thread-Post Issue Date: 2025-10-14 GPT Summary- Circuit-based Reasoning Verification (CRV)を提案し、CoTステップの帰属グラフを用いて推論エラーを検証。エラーの構造的署名が予測的であり、異なる推論タスクで異なる計算パターンが現れることを示す。これにより、モデルの誤った推論を修正する新たなアプローチを提供し、LLM推論の因果理解を深めることを目指す。 Comment
元ポスト:
著者ポスト:
transformer内部のactivationなどから計算グラフを構築しreasoningのsurface(=観測できるトークン列)ではなく内部状態からCoTをverification(=CoTのエラーを検知する)するようなアプローチ(white box method)らしい
[Paper Note] Rethinking Entropy Regularization in Large Reasoning Models, Yuxian Jiang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #RLVR #Entropy Issue Date: 2025-10-13 GPT Summary- RLVRはLRMの推論能力を向上させるが、エントロピーの崩壊と早期収束の問題に直面している。これに対処するため、SIREN(選択的エントロピー正則化)を提案し、探索を意味のある行動と状態のサブセットに制限する二段階のエントロピーマスキングメカニズムを導入。SIRENは数学的ベンチマークで優れたパフォーマンスを示し、トレーニングの安定性を高め、早期収束の問題を軽減することが確認された。 Comment
元ポスト:
[Paper Note] ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory, Matthew Ho+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#MachineLearning #NLP #Abstractive #LanguageModel #Generalization #memory #One-Line Notes #Test-time Learning Issue Date: 2025-10-13 GPT Summary- LLMは推論時に外部メモリを活用し、概念レベルのメモリを導入することで、再利用可能でスケーラブルな知識の保存を実現。これにより、関連する概念を選択的に取得し、テスト時の継続的学習を可能にする。評価はARC-AGIベンチマークで行い、メモリなしのベースラインに対して7.5%の性能向上を達成。動的なメモリ更新が自己改善を促進することを示唆。 Comment
元ポスト:
ARC-AGIでしか評価されていないように見える。
[Paper Note] The Markovian Thinker, Milad Aghajohari+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #read-later #Selected Papers/Blogs Issue Date: 2025-10-09 GPT Summary- 強化学習を用いて長い思考の連鎖を生成するための新しいパラダイム「マルコフ的思考」を提案。これにより、状態を一定のサイズに制限し、思考の長さをコンテキストのサイズから切り離すことで、線形計算を実現。新しいRL環境「Delethink」を構築し、モデルは短い持ち越しで推論を継続することを学習。訓練されたモデルは、長い推論を効率的に行い、コストを大幅に削減。思考環境の再設計が、効率的でスケーラブルな推論LLMの実現に寄与することを示した。 Comment
元ポスト:
ポイント解説:
解説:
[Paper Note] ReasonIR: Training Retrievers for Reasoning Tasks, Rulin Shao+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #Transformer #SyntheticData #Test-Time Scaling #COLM #read-later #Selected Papers/Blogs #Encoder Issue Date: 2025-10-08 GPT Summary- ReasonIR-8Bは、一般的な推論タスク向けに特別に訓練された初のリトリーバーであり、合成データ生成パイプラインを用いて挑戦的なクエリとハードネガティブを作成。これにより、BRIGHTベンチマークで新たな最先端成果を達成し、RAGタスクでも他のリトリーバーを上回る性能を示す。トレーニングレシピは一般的で、将来のLLMへの拡張が容易である。コード、データ、モデルはオープンソース化されている。 Comment
元ポスト:
Llama3.1-8Bをbidirectional encoderに変換してpost-trainingしている。
関連:
- [Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
[Paper Note] MITS: Enhanced Tree Search Reasoning for LLMs via Pointwise Mutual Information, Jiaxi Li+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Search #LanguageModel #Test-Time Scaling #Decoding #TreeSearch Issue Date: 2025-10-08 GPT Summary- 相互情報量ツリー探索(MITS)を提案し、推論経路の評価と探索を効率化。PMIに基づくスコアリング関数を用い、計算コストを抑えつつ優れた推論性能を実現。エントロピーに基づく動的サンプリング戦略でリソースを最適配分し、重み付き投票方式で最終予測を行う。MITSは多様なベンチマークでベースラインを上回る結果を示した。 Comment
元ポスト:
[Paper Note] Magistral, Mistral-AI+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #One-Line Notes Issue Date: 2025-10-07 GPT Summary- Mistralの推論モデルMagistralと独自の強化学習パイプラインを紹介。ゼロからのアプローチで、LLMのRLトレーニングの限界を探り、テキストデータのみでのRLが能力を維持することを示す。Magistral MediumはRLのみで訓練され、Magistral Smallはオープンソース化。 Comment
元ポスト:
関連:
- Magistral-Small-2509, MistralAI, 2025.09
MistralAIの初めてのreasoningモデル
[Paper Note] ExGRPO: Learning to Reason from Experience, Runzhe Zhan+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #RLVR #Entropy Issue Date: 2025-10-03 GPT Summary- RLVRは大規模言語モデルの推論能力を向上させる新しい手法ですが、標準的な訓練方法は計算効率が悪い。本研究では、推論経験の価値を調査し、ExGRPOフレームワークを提案。これにより、経験の整理と優先順位付けを行い、探索と経験活用のバランスを取る。実験結果では、ExGRPOが推論性能を向上させ、訓練の安定性を高めることが示された。 Comment
元ポスト:
[Paper Note] RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization, Zhaoning Yu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #SelfImprovement #ICLR #read-later #One-Line Notes #Author Thread-Post Issue Date: 2025-10-03 GPT Summary- RESTRAINは、自己ペナルティを用いた強化学習フレームワークで、ラベル付きデータなしでモデルを改善する。過信的な回答をペナルティ化し、未ラベルデータからの学習信号を活用することで、困難な推論ベンチマークにおいて大きな向上を達成。従来のゴールドラベル付きトレーニングに匹敵する性能を示し、効果的な推論の拡張が可能であることを示す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=87ySF7viys
著者による一言解説:
votingによるself-improvingなRLの枠組みから脱却し、全ての応答に対してペナルティ方式でペナルティを与え(一貫性の乏しいロールアウトなど)異なる重みを与えて学習シグナルとする。
[Paper Note] QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation, Jiazheng Li+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SmallModel Issue Date: 2025-10-01 GPT Summary- 強化学習(RL)を用いて、難しい推論問題を効果的に解決するための手法QuestAを提案。質問の拡張を通じて部分的な解決策を導入し、学習信号を改善。数学的推論タスクでのRLトレーニングにおいて、pass@1とpass@kの両方を向上させ、DeepScaleRやOpenMath Nemotronの推論能力を強化。1.5Bパラメータモデルで新たな最先端結果を達成。 Comment
元ポスト:
RLにおいて、簡単な問題はすぐにoverfitし、かつより困難な問題を学習する妨げになる一方で、困難な問題はサンプル効率が悪く、かつrewardがsparseな場合学習が非常に遅いという問題があったが、困難な問題に対してヒントを与えて学習させる(かつ、モデルがヒントに依存せずとも解けるようになってきたら徐々にヒントを減らしヒントに過剰に依存することを防ぐ)ことで、簡単な問題に対してoverfitせずに困難な問題に対する学習効率も上がり、reasoning能力もブーストしました。困難な問題はベースラインモデルが解くのに苦労するもの(pass rateがゼロのもの)から見つけます、(そしてpromptでhintを与えた上でさらにpass rateが低いものを使う模様?)といった話な模様。
ヒントを使ってなる問題の難易度を調整しながらRLする研究は以下も存在する:
- [Paper Note] Staying in the Sweet Spot: Responsive Reasoning Evolution via
Capability-Adaptive Hint Scaffolding, Ziheng Li+, arXiv'25
[Paper Note] Expanding Reasoning Potential in Foundation Model by Learning Diverse Chains of Thought Patterns, Xuemiao Zhang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #mid-training Issue Date: 2025-09-26 GPT Summary- 大規模推論モデルの進展は強化学習によって促進され、CoTデータの利用が推論の深さを向上させることが示されている。しかし、どのデータタイプが最も効果的かは未解決の問題である。本研究では、推論ポテンシャルを独立した試行の数の逆数として定義し、これを拡張するために高価値の推論パターンを用いた多様なデータの利用を提案。具体的には、CoTシーケンスから原子的な推論パターンを抽象化し、コアリファレンスセットを構築。二重粒度アルゴリズムを用いて高価値のCoTデータを効率的に選択し、モデルの推論能力を向上させる。10BトークンのCoTPデータにより、85A6B Mixture-of-ExpertsモデルはAIME 2024および2025で9.58%の改善を達成した。 Comment
元ポスト:
細かいところは読めていないのだが、学習データの中から高品質な推論パターンを持つものを選んで学習に使いたいというモチベーション。そのためにまず価値の高い推論パターンを含むコアセットを作り、コアセットと類似した推論パターンや、推論中のトークンのエントロピー列を持つサンプルを学習データから収集するみたいな話な模様。類似度は重みつきDynamic Time Warping (DTW)で、原始的な推論パターンの系列とエントロピー系列のDTWの線型結合によっめ求める。原始的な推論パターンのアノテーションや、CoT sequence中のトークンのエントロピー列はDeepSeek-V3によって生成する。
コアセットを作るためには、問題タイプや問題の難易度に基づいて人手で問題を選び、それらに対してstrong reasoning modelでCoTを生成。各CoTに対して(おそらく)DeepSeek-V3でreasoningのパターン(パターンは原始的なCoTパターンの系列で構成される)をアノテーションし、各パターンに対してTF-IDFによって重要度を決定する。最終的に、問題に正答しているサンプルについて、人手で高品質でdiscriminativeなCoTパターンを持つものを選択し、各CoTパターンに重みをつけた上でコアセットを作成した、みたいな感じに見える。
[Paper Note] Thinking Augmented Pre-training, Liang Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #SyntheticData #read-later Issue Date: 2025-09-25 GPT Summary- 思考の軌跡を用いてテキストデータを拡張する「Thinking augmented Pre-Training(TPT)」を提案し、LLMのデータ効率を向上。TPTはトレーニングデータを効果的に増加させ、高品質なトークンの学習を容易にする。実験により、TPTがLLMの性能を大幅に向上させ、特に3Bパラメータモデルで推論ベンチマークの性能を10%以上改善することを示した。 Comment
元ポスト:
(斜め読みしかまだできていないが)2節に存在するプロンプトを用いて、ドキュメント全体をcontextとして与え、context中に存在する複雑な情報に関して深い分析をするようにthinking traceを生成し、生成したtrace tをconcatしてnext token predictionで事前学習する模様。数学データで検証し事前学習が3倍トークン量 vs. downstreamタスク(GSM8K, MATH)性能の観点効率的になっただかでなく(これは事後学習の先取りをしているみたいなものな気がするのでそうなるだろうなという気がする)、おなじトークン量で学習したモデルをSFTした場合でも、提案手法の方が性能が良かった模様(Table2, こっちの方が個人的には重要な気がしている)。
解説:
[Paper Note] Scaling Speculative Decoding with Lookahead Reasoning, Yichao Fu+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Decoding #read-later #Selected Papers/Blogs #SpeculativeDecoding Issue Date: 2025-09-24 GPT Summary- Lookahead Reasoningを用いることで、推論モデルのトークンデコード速度を向上させる手法を提案。軽量なドラフトモデルが将来のステップを提案し、ターゲットモデルが一度のバッチ処理で展開。これにより、トークンレベルの推測デコーディング(SD)のスピードアップを1.4倍から2.1倍に改善し、回答の質を維持。 Comment
元ポスト:
[Paper Note] Libra: Assessing and Improving Reward Model by Learning to Think, Meng Zhou+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #RewardModel Issue Date: 2025-09-22 GPT Summary- 強化学習(RL)の報酬モデルは、困難な推論シナリオでの性能が低下しており、注釈付き参照回答や制約された出力形式に依存している。これに対処するため、推論指向のベンチマーク「Libra Bench」を提案し、生成的報酬モデルを改善する新しいアプローチを導入。Libra-RMシリーズを開発し、さまざまなベンチマークで最先端の結果を達成。実験結果は、Libra Benchと下流アプリケーションとの相関関係を示し、ラベルのないデータを用いた推論モデルの改善の可能性を示唆している。 Comment
元ポスト:
Related Workを読むと、 `Discriminative Reward models` と `Generative Reward models` の違いが簡潔に記述されている。
要は
- Discriminative Reward models:
- LLMをBackboneとして持ち、
- スコアリング用のヘッドを追加しpreference dataを用いて(pairwiseのranking lossを通じて)学習され、scalar rewardを返す
- Generative Reward models:
- 通常とLLMと同じアーキテクチャで(Next Token Prdiction lossを通じて学習され)
- responseがinputとして与えられたときに、rewardに関する情報を持つtextualなoutputを返す(要は、LLM-as-a-Judge [Paper Note] JudgeLM: Fine-tuned Large Language Models are Scalable Judges, Lianghui Zhu+, ICLR'25, 2023.10
A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
)
- reasoning traceを活用すればthinking model(Test time scaling)の恩恵をあずかることが可能
- GenRMのルーツはこのへんだろうか:
- [Paper Note] Generative Verifiers: Reward Modeling as Next-Token Prediction, Lunjun Zhang+, arXiv'24, 2024.08
- [Paper Note] LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion, Dongfu Jiang+, arXiv'23, 2023.06
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
という区別である。
以下のノートも参考のこと:
- [Personal Note] LLM-as-a-judge / Reward Model
GenRMは追加の学習なしで利用されるのが普通だったようだが、RM用の追加の学習をしても使えると思うのでそこはあまり気にしなくて良いと思われる。
また
- [Paper Note] Generative Reward Models, Dakota Mahan+, arXiv'24, 2024.10
のFigure1が、RMのアーキテクチャの違いをわかりやすく説明している。
[Paper Note] BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model, Adibvafa Fallahpour+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Biological Issue Date: 2025-09-20 GPT Summary- BioReasonは、DNA基盤モデルと大規模言語モデル(LLM)を統合した新しいアーキテクチャで、複雑なゲノムデータからの生物学的推論を深く解釈可能にする。多段階推論を通じて、精度が88%から97%に向上し、バリアント効果予測でも平均15%の性能向上を達成。未見の生物学的エンティティに対する推論を行い、解釈可能な意思決定を促進することで、AIにおける生物学の進展を目指す。 Comment
HF:
https://huggingface.co/collections/wanglab/bioreason-683cd17172a037a31d208f70
pj page:
https://bowang-lab.github.io/BioReason/
元ポスト:
[Paper Note] The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity, Parshin Shojaee+, arXiv'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #NeurIPS #read-later Issue Date: 2025-09-19 GPT Summary- LRMsは思考プロセスを生成するが、その能力や限界は未解明。評価は主に最終回答の正確性に焦点を当てており、推論の痕跡を提供しない。本研究では制御可能なパズル環境を用いて、LRMsの推論過程を分析。実験により、LRMsは特定の複雑さを超えると正確性が崩壊し、スケーリングの限界が明らかに。低複雑性では標準モデルが優位、中複雑性ではLRMsが優位、高複雑性では両者が崩壊することを示した。推論の痕跡を調査し、LRMsの強みと限界を明らかに。 Comment
元ポスト:
出た当初相当話題になったIllusion of thinkingがNeurIPSにacceptされた模様。Appendix A.1に当時のcriticismに対するレスポンスが記述されている。
[Paper Note] WebSailor: Navigating Super-human Reasoning for Web Agent, Kuan Li+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #On-Policy Issue Date: 2025-09-18 GPT Summary- WebSailorは、LLMのトレーニングにおいて人間の認知的限界を超えるためのポストトレーニング手法であり、複雑な情報探索タスクでの性能を向上させる。構造化サンプリングや情報の難読化、DUPOを用いて高不確実性タスクを生成し、オープンソースエージェントの能力を大幅に上回ることを目指す。
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, NAACL'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Dataset #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #NAACL Issue Date: 2025-09-18 GPT Summary- 大規模言語モデル(LLMs)の性能向上を活かし、情報検索強化生成(RAG)機能を向上させるための評価データセットFRAMESを提案。FRAMESは、事実に基づいた応答、検索能力、推論を評価するための統一されたフレームワークを提供し、複数の情報源を統合するマルチホップ質問で構成。最先端のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に寄与することを目指す。
[Paper Note] DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning, Guo+, Nature'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #read-later #Nature Issue Date: 2025-09-18 GPT Summary- 本研究では、LLMsの推論能力を強化学習(RL)を通じて向上させ、人間によるラベル付けの必要性を排除することを示す。提案するRLフレームワークは、高度な推論パターンの発展を促進し、数学やコーディングコンペティションなどのタスクで優れたパフォーマンスを達成する。さらに、出現的な推論パターンは小さなモデルの能力向上にも寄与する。 Comment
DeepSeek-R1の論文のNature版が出た模様。
解説:
Supplementary Materials:
https://static-content.springer.com/esm/art%3A10.1038%2Fs41586-025-09422-z/MediaObjects/41586_2025_9422_MOESM1_ESM.pdf
おそらくこちらの方が重要
[Paper Note] The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs, Akshit Sinha+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #AIAgents #LongSequence #Scaling Laws #read-later #Selected Papers/Blogs #ContextEngineering #Author Thread-Post Issue Date: 2025-09-14 GPT Summary- LLMsのスケーリングが収益に影響を与えるかを探求。単一ステップの精度向上がタスクの長さに指数的改善をもたらすことを観察。LLMsが長期タスクで失敗するのは推論能力の欠如ではなく実行ミスによると主張。知識と計画を明示的に提供することで実行能力を向上させる提案。モデルサイズをスケーリングしても自己条件付け効果は減少せず、長いタスクでのミスが増加。思考モデルは自己条件付けを行わずに長いタスクを実行可能。最終的に、実行能力に焦点を当てることで、LLMsの複雑な推論問題解決能力と単純タスクの長期化による失敗理由を調和させる。 Comment
元ポスト:
single stepでのタスク性能はサチって見えても、成功可能なタスクの長さは(single stepの実行エラーに引きづられるため)モデルのsingle stepのタスク性能に対して指数関数的に効いている(左上)。タスクが長くなればなるほどモデルは自身のエラーに引きずられ(self conditioning;右上)、これはパラメータサイズが大きいほど度合いが大きくなる(右下; 32Bの場合contextにエラーがあって場合のloeg horizonのAcc.が14Bよりも下がっている)。一方で、実行可能なstep数の観点で見ると、モデルサイズが大きい場合の方が多くのstepを要するタスクを実行できる(左下)。また、ThinkingモデルはSelf Conditioningの影響を受けにくく、single stepで実行可能なタスクの長さがより長くなる(中央下)。
といった話に見えるが、論文をしっかり読んだ方が良さそう。
(元ポストも著者ポストだが)著者ポスト:
このスレッドは読んだ方が良い(というか論文を読んだ方が良い)。
特に、**CoTが無い場合は**single-turnでほとんどのモデルは5 stepのタスクをlatent spaceで思考し、実行することができないというのは興味深い(が、細かい設定は確認した方が良い)。なので、マルチステップのタスクは基本的にはplanningをさせてから出力をさせた方が良いという話や、
では複雑なstepが必要なタスクはsingle turnではなくmulti turnに分けた方が良いのか?と言うと、モデルによって傾向が違うらしい、といった話が書かれている。たとえば、Qwenはsingle turnを好むが、Gemmaはmulti turnを好むらしい。
日本語ポイント解説:
解説:
[Paper Note] MedResearcher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework, Ailing Yu+, arXiv'25
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #PostTraining #GRPO #DeepResearch #Medical Issue Date: 2025-09-13 GPT Summary- 医療分野に特化した深層研究エージェントを提案。医療知識グラフを用いたデータ合成とカスタム医療検索エンジンを統合し、複雑な質問-回答ペアを生成。新たな医療ベンチマークで最先端の結果を達成し、一般的な深層研究タスクでも競争力を維持。ドメイン特化型の革新が小型モデルの優位性を示す。 Comment
HF: https://huggingface.co/AQ-MedAI
元ポスト:
ベンチマーク:
- [Paper Note] MedBrowseComp: Benchmarking Medical Deep Research and Computer Use, Shan Chen+, arXiv'25
- [Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned
Real-World Evaluations, Kaiyuan Chen+, arXiv'25
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
[Paper Note] A Survey of Reinforcement Learning for Large Reasoning Models, Kaiyan Zhang+, arXiv'25
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #ReinforcementLearning #Author Thread-Post Issue Date: 2025-09-11 GPT Summary- 本論文では、LLMにおける推論のための強化学習(RL)の進展を調査し、特に数学やコーディングなどの複雑な論理タスクにおける成功を強調しています。RLはLLMを学習推論モデル(LRM)に変換する基盤的な方法論として浮上しており、スケーリングには計算リソースやアルゴリズム設計などの課題があります。DeepSeek-R1以降の研究を検討し、LLMおよびLRMにおけるRLの適用に関する未来の機会と方向性を特定することを目指しています。 Comment
元ポスト:
著者ポスト:
[Paper Note] Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding, Ziheng Li+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #read-later #RLVR Issue Date: 2025-09-10 GPT Summary- RLVRはLLMsの推論能力を向上させるが、トレーニングデータの難易度とモデル能力の不一致により探索が非効率的。新しいフレームワークSEELEを提案し、問題の難易度を動的に調整。ヒントの長さを適応的に調整し、探索効率を向上。実験ではSEELEが従来手法を上回る性能を示した。 Comment
pj page: https://github.com/ChillingDream/seele
元ポスト:
問題の難易度をヒントによって調整しつつ(IRTで困難度パラメータ見ると思われる)RLする模様。面白そう。
[Paper Note] K2-Think: A Parameter-Efficient Reasoning System, Zhoujun Cheng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #OpenWeight #OpenSource #GRPO #read-later #RLVR #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2025-09-10 GPT Summary- K2-Thinkは320億パラメータの推論システムで、GPT-OSS 120BやDeepSeek v3.1と同等かそれ以上の性能を示します。Qwen2.5ベースのモデルに先進的なポストトレーニングと推論技術を融合し、長いチェーン・オブ・ソート思考と強化学習を用いて数学的推論で卓越した成果を上げています。公開ベンチマークでも高得点を記録し、よりパラメータ効率の高いモデルが最先端システムと競争できることを明らかにしました。K2-Thinkは迅速な推論速度を提供し、オープンソースの推論システムをより利用しやすくしています。 Comment
HF:
https://huggingface.co/LLM360/K2-Think
code:
-
https://github.com/MBZUAI-IFM/K2-Think-SFT
-
https://github.com/MBZUAI-IFM/K2-Think-Inference
RLはverl+GRPOで実施したとテクニカルペーパーに記述されているが、当該部分のコードの公開はされるのだろうか?
RLで利用されたデータはこちら:
- [Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, NeurIPS'25
元ポスト:
[Paper Note] Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search, Xin Lai+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #ReinforcementLearning #LongSequence #OpenWeight #GRPO #VisionLanguageModel Issue Date: 2025-09-10 GPT Summary- Mini-o3システムは、数十ステップの深いマルチターン推論を実現し、視覚検索タスクで最先端の性能を達成。Visual Probe Datasetを構築し、多様な推論パターンを示すデータ収集パイプラインを開発。オーバーターンマスキング戦略により、ターン数が増えるほど精度が向上することを実証。 Comment
HF: https://huggingface.co/Mini-o3
pj page: https://mini-o3.github.io
元ポスト:
既存のオープンなVLMはマルチターンのターン数を増やせないという課題があったがそれを克服するレシピに関する研究な模様。元ポストによると6ターンまでのマルチターンで学習しても、inference時には32ターンまでスケールするとか。
[Paper Note] Reverse-Engineered Reasoning for Open-Ended Generation, Haozhe Wang+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #read-later Issue Date: 2025-09-10 GPT Summary- REERという新しい推論パラダイムを提案し、既存の良好な解から後方に推論プロセスを構築。20,000の深い推論軌跡からなるデータセットDeepWriting-20Kを作成し、オープンソース化。訓練されたモデルDeepWriter-8Bは、強力なオープンソースベースラインを超え、GPT-4oやClaude 3.5と競争力のある性能を示す。 Comment
pj page: https://m-a-p.ai/REER_DeepWriter/
元ポスト:
[Paper Note] Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?, Qinyan Zhang+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #InstructionFollowingCapability Issue Date: 2025-09-05 GPT Summary- 大規模言語モデル(LLMs)は、標準化されたパターンに従うことに苦労することがある。これを評価するために、Inverse IFEvalというベンチマークを提案し、モデルが対立する指示に従う能力を測定する。8種類の課題を含むデータセットを構築し、既存のLLMに対する実験を行った結果、非従来の文脈での適応性も考慮すべきであることが示された。Inverse IFEvalは、LLMの指示遵守の信頼性向上に寄与することが期待される。 Comment
元ポスト:
興味深い
[Paper Note] UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning, Haoming Wang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #ReinforcementLearning #AIAgents #MultiModal #ComputerUse #VisionLanguageModel Issue Date: 2025-09-05 GPT Summary- UI-TARS-2は、GUI用自律エージェントの新しいモデルで、データ生成、安定化されたマルチターンRL、ハイブリッドGUI環境を統合。実証評価では、前モデルを大幅に上回り、複数のベンチマークで高いスコアを達成。約60%の人間レベルのパフォーマンスを示し、長期的な情報探索タスクにも適応可能。トレーニングダイナミクスの分析が安定性と効率向上の洞察を提供し、実世界のシナリオへの一般化能力を強調。 Comment
元ポスト:
1.5をリリースしてから5ヶ月で大幅に性能を向上した模様
[Paper Note] LLaVA-Critic-R1: Your Critic Model is Secretly a Strong Policy Model, Xiyao Wang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #ReinforcementLearning #OpenWeight #SelfCorrection #VisionLanguageModel #Critic Issue Date: 2025-09-04 GPT Summary- 本研究では、視覚と言語のモデリングにおいて、批評モデルを強化学習を用いて再編成し、生成モデルに直接適用する新しいアプローチを提案します。これにより、マルチモーダル批評モデルLLaVA-Critic-R1を生成し、視覚的推論ベンチマークで高い性能を示しました。さらに、自己批評を用いることで、追加の訓練なしに推論タスクでの性能を向上させることができることを示しました。この結果は、評価と生成の両方に優れた統一モデルを実現する可能性を示唆しています。 Comment
元ポスト:
HF: https://huggingface.co/collections/lmms-lab/llava-critic-r1-68922484e5822b89fab4aca1
[Paper Note] R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning, Jie Jiang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #MultiModal #GRPO #VisionLanguageModel Issue Date: 2025-09-02 GPT Summary- R-4Bは、問題の複雑さに応じて思考を行うかどうかを適応的に判断する自動思考型のマルチモーダル大規模言語モデル(MLLM)である。思考能力と非思考能力を持たせ、バイモードポリシー最適化(BPO)を用いて思考プロセスの起動を精度良く判断する。訓練には多様なトピックのデータセットを使用し、実験結果はR-4Bが25のベンチマークで最先端のパフォーマンスを達成し、特に推論集約型タスクで低コストで高い性能を示したことを示している。 Comment
元ポスト:
VLMにthinking, non-thinkingを入力に応じて使い分けさせる手法
[Paper Note] TurnaboutLLM: A Deductive Reasoning Benchmark from Detective Games, Yuan Yuan+, EMNLP'25
Paper/Blog Link My Issue
#NLP #LanguageModel #In-ContextLearning #LongSequence #EMNLP #read-later #Contamination-free #Selected Papers/Blogs #Game Issue Date: 2025-08-30 GPT Summary- TurnaboutLLMという新しいフレームワークとデータセットを用いて、探偵ゲームのインタラクティブなプレイを通じてLLMsの演繹的推論能力を評価。証言と証拠の矛盾を特定する課題を設定し、12の最先端LLMを評価した結果、文脈のサイズや推論ステップ数がパフォーマンスに影響を与えることが示された。TurnaboutLLMは、複雑な物語環境におけるLLMsの推論能力に挑戦を提供する。 Comment
元ポスト:
非常に面白そう。逆転裁判のデータを利用した超long contextな演繹的タスクにおいて、モデルが最終的な回答を間違える際はより多くの正解には貢献しないReasoning Stepを繰り返したり、QwQ-32BとGPT4.1は同等の性能だが、non thinkingモデルであるGPT4.1がより少量のReasoning Step (本研究では回答に至るまでに出力したトークン数と定義)で回答に到達し(=Test Time Scalingの恩恵がない)、フルコンテキストを与えて性能が向上したのはモデルサイズが大きい場合のみ(=Test Timeのreasoningよりも、in-contextでのreasoningが重要)だった、といった知見がある模様。じっくり読みたい。
[Paper Note] MK2 at PBIG Competition: A Prompt Generation Solution, Xu+, IJCAI WS AgentScen'25, 2025.08
Paper/Blog Link My Issue
#NLP #AIAgents #Planning #Prompting #IJCAI #Workshop #IdeaGeneration Issue Date: 2025-08-30 Comment
元ポスト:
Patentからmarket-readyなプロダクトのコンセプトを生成し評価するタスク(PBIG)に取り組んでいる。
Reasoningモデルはコストとレスポンスの遅さから利用せず(iterationを重ねることを重視)、LLMのアシストを受けながらpromptを何度もhuman in the loopでiterationしながら品質を高めていくアプローチをとり、リーダーボードで1st placeを獲得した模様。
[Paper Note] Ovis2.5 Technical Report, Shiyin Lu+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #CurriculumLearning #VideoGeneration/Understandings #VisionLanguageModel #One-Line Notes Issue Date: 2025-08-28 GPT Summary- Ovis2.5は、ネイティブ解像度の視覚認識とマルチモーダル推論を強化するために設計されたモデルで、画像を可変解像度で処理し、複雑な視覚コンテンツの詳細を保持します。推論時には反省を行う「思考モード」を提供し、精度向上を図ります。5段階のカリキュラムで訓練され、マルチモーダルデータの効率的な処理を実現。Ovis2.5-9BはOpenCompassで平均78.3を記録し、Ovis2-8Bに対して大幅な改善を示しました。Ovis2.5-2Bも73.9を達成し、リソース制約のあるデバイスに最適です。STEMベンチマークや複雑なチャート分析においても優れた性能を発揮しています。 Comment
元ポスト:
HF:
https://huggingface.co/AIDC-AI/Ovis2.5-9B
Apache2.0ライセンス
GLM-4.1V-9B-Thinkingと同等以上の性能な模様。
- [Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25, 2025.07
[Paper Note] Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens, Chengshuai Zhao+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #Chain-of-Thought #read-later #reading Issue Date: 2025-08-27 GPT Summary- Chain-of-Thought (CoT) プロンプティングはLLMの性能向上に寄与するが、その深さには疑問が残る。本研究では、CoT推論が訓練データの構造的バイアスを反映しているかを調査し、訓練データとテストクエリの分布不一致がその効果に与える影響を分析。DataAlchemyという制御環境を用いて、CoT推論の脆弱性を明らかにし、一般化可能な推論の達成に向けた課題を強調する。
[Paper Note] Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset, Rabeeh Karimi Mahabadi+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #LanguageModel #Mathematics #read-later #Selected Papers/Blogs Issue Date: 2025-08-27 GPT Summary- 新しい数学コーパス「Nemotron-CC-Math」を提案し、LLMの推論能力を向上させるために、科学テキスト抽出のためのパイプラインを使用。従来のデータセットよりも高品質で、方程式やコードの構造を保持しつつ、表記を標準化。Nemotron-CC-Math-4+は、以前のデータセットを大幅に上回り、事前学習によりMATHやMBPP+での性能向上を実現。オープンソースとしてコードとデータセットを公開。 Comment
元ポスト:
[Paper Note] TokenSkip: Controllable Chain-of-Thought Compression in LLMs, Heming Xia+, EMNLP'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Chain-of-Thought #EMNLP #Length #Inference #Author Thread-Post Issue Date: 2025-08-24 GPT Summary- Chain-of-Thought (CoT)はLLMの推論能力を向上させるが、長いCoT出力は推論遅延を増加させる。これに対処するため、重要度の低いトークンを選択的にスキップするTokenSkipを提案。実験により、TokenSkipはCoTトークンの使用を削減しつつ推論性能を維持することを示した。特に、Qwen2.5-14B-InstructでGSM8Kにおいて推論トークンを40%削減し、性能低下は0.4%未満であった。 Comment
元ポスト:
[Paper Note] VisualWebInstruct: Scaling up Multimodal Instruction Data through Web Search, Yiming Jia+, EMNLP'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #QuestionAnswering #SyntheticData #MultiModal #EMNLP #PostTraining #VisionLanguageModel Issue Date: 2025-08-21 GPT Summary- 本研究では、推論に焦点を当てたマルチモーダルデータセットの不足に対処するため、VisualWebInstructという新しいアプローチを提案。30,000のシード画像からGoogle画像検索を用いて700K以上のユニークなURLを収集し、約900KのQAペアを構築。ファインチューニングされたモデルは、Llava-OVで10-20ポイント、MAmmoTH-VLで5ポイントの性能向上を示し、最良モデルMAmmoTH-VL2は複数のベンチマークで最先端の性能を達成。これにより、Vision-Language Modelsの推論能力向上に寄与することが示された。 Comment
元ポスト:
pj page: https://tiger-ai-lab.github.io/VisualWebInstruct/
verified versionが公開:
https://huggingface.co/datasets/TIGER-Lab/VisualWebInstruct_Verified
ポスト:
[Paper Note] Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration, Zhicheng Yang+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #RLVR #Entropy Issue Date: 2025-08-20 GPT Summary- 強化学習における検証可能報酬(RLVR)の潜在能力は、深さ(難問への取り組み)と広さ(インスタンス数)によって未発揮である。GRPOアルゴリズムの分析を通じて、累積アドバンテージが不均等に重みづけされていることを明らかにし、Difficulty Adaptive Rollout Sampling(DARS)を提案。DARSは難問に対してターゲットを絞ったロールアウトを行い、難問の正のロールアウトを増やしつつ、収束時の推論コストを増加させずにPass@Kを改善。さらに、バッチサイズの拡大を通じ、広さを増やすことでPass@1の性能を顕著に向上させる。DARSと大規模な広さを組み合わせたDARS-Bは、同時のPass@KとPass@1の向上を実証し、深さと広さの適応的な探索がRLVRの推論力を引き出す鍵であることを確認した。 Comment
元ポスト:
[Paper Note] OptimalThinkingBench: Evaluating Over and Underthinking in LLMs, Pranjal Aggarwal+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Overthinking #Underthinking #Author Thread-Post Issue Date: 2025-08-19 GPT Summary- 思考型LLMsは複雑なタスクを解決する一方で、単純な問題に対して過剰に思考し、非思考型LLMsは速いが難しい問題に対して思考が不足する。これにより、最適なモデル選択がユーザーに委ねられる。OptimalThinkingBenchを導入し、過剰思考と過少思考を共同で評価する。72の単純な数学問題と11の難解な推論課題を含む二つのサブベンチマークを通じて33種のモデルを評価し、どのモデルも最適な思考ができないことを示す。最適思考を促す手法も、多くの場合、一方の性能を改善することで他方を犠牲にする結果となる。 Comment
元ポスト:
元ポストの著者によるスレッドが非常にわかりやすいのでそちらを参照のこと。
ざっくり言うと、Overthinking(考えすぎて大量のトークンを消費した上に回答が誤っている; トークン量↓とLLMによるJudge Score↑で評価)とUnderthinking(全然考えずにトークンを消費しなかった上に回答が誤っている; Accuracy↑で評価)をそれぞれ評価するサンプルを収集し、それらのスコアの組み合わせでモデルが必要に応じてどれだけ的確にThinkingできているかを評価するベンチマーク。
Overthinkingを評価するためのサンプルは、多くのLLMでagreementがとれるシンプルなQAによって構築。一方、Underthinkingを評価するためのサンプルは、small reasoning modelがlarge non reasoning modelよりも高い性能を示すサンプルを収集。
現状Non Thinking ModelではQwen3-235B-A22Bの性能が良く、Thinking Modelではgpt-oss-120Bの性能が良い。プロプライエタリなモデルではそれぞれ、Claude-Sonnet4, o3の性能が良い。全体としてはo3の性能が最も良い。
openreview: https://openreview.net/forum?id=N5kWa3sRJt
著者による一言解説:
[Paper Note] Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models, Zhipeng Chen+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #read-later #RLVR #Diversity #EntropyCollapse Issue Date: 2025-08-19 GPT Summary- 検証可能な報酬を用いた強化学習(RLVR)では、Pass@1を報酬として使用することが多く、探索と活用のバランスに課題がある。これに対処するため、Pass@kを報酬としてポリシーモデルを訓練し、その探索能力の向上を観察。分析により、探索と活用は相互に強化し合うことが示され、利得関数の設計を含むPass@k Trainingの利点が明らかになった。さらに、RLVRのための利得設計を探求し、有望な結果を得た。 Comment
元ポスト:
関連:
- [Paper Note] Olmo 3, Team Olmo+, arXiv'25, 2025.12
openreview: https://openreview.net/forum?id=eslxxopXTF
[Paper Note] FormulaOne: Measuring the Depth of Algorithmic Reasoning Beyond Competitive Programming, Gal Beniamini+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation Issue Date: 2025-08-14 GPT Summary- フロンティアAIモデルの能力を評価するために、実際の研究問題に基づくベンチマーク「FormulaOne」を構築。これは、グラフ理論やアルゴリズムに関連する難易度の高い問題で、商業的関心や理論計算機科学に関連。最先端モデルはFormulaOneでほとんど解決できず、専門家レベルの理解から遠いことが示された。研究支援のために、簡単なタスクセット「FormulaOne-Warmup」を提供し、評価フレームワークも公開。 Comment
元ポスト:
[Paper Note] Can Language Models Falsify? Evaluating Algorithmic Reasoning with Counterexample Creation, Shiven Sinha+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Coding #Verification Issue Date: 2025-08-13 GPT Summary- 言語モデル(LM)の科学的発見を加速するために、微妙に誤った解決策に対する反例を作成する能力を評価する新しいベンチマーク「REFUTE」を提案。これはプログラミング問題からの誤った提出物を用いており、最も優れた推論エージェントでも9%未満の反例しか生成できないことが示された。この研究は、LMの誤った解決策を否定する能力を向上させ、信頼できる推論を通じて自己改善を促進することを目指している。 Comment
pj page: https://falsifiers.github.io
元ポスト:
バグのあるコードとtask descriptionが与えられた時に、inputのフォーマットと全ての制約を満たすが、コードの実行が失敗するサンプル(=反例)を生成することで、モデルのreasoning capabilityの評価をするベンチマーク。
gpt-ossはコードにバグのあるコードに対して上記のような反例を生成する能力が高いようである。ただし、それでも全体のバグのあるコードのうち反例を生成できたのは高々21.6%のようである。ただ、もしコードだけでなくverification全般の能力が高いから、相当使い道がありそう。
[Paper Note] Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning, Zihe Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #read-later #Reproducibility Issue Date: 2025-08-12 GPT Summary- 強化学習(RL)を用いた大規模言語モデル(LLM)の推論に関する研究が進展する中、標準化されたガイドラインやメカニズムの理解が不足している。実験設定の不一致やデータの変動が混乱を招いている。本論文では、RL技術を体系的にレビューし、再現実験を通じて各技術のメカニズムや適用シナリオを分析。明確なガイドラインを提示し、実務者に信頼できるロードマップを提供する。また、特定の技術の組み合わせが性能を向上させることを示した。 Comment
元ポスト:
読んだ方が良い
解説:
[Paper Note] MolmoAct: Action Reasoning Models that can Reason in Space, Jason Lee+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #SpeechProcessing #OpenWeight #VisionLanguageActionModel Issue Date: 2025-08-12 GPT Summary- アクション推論モデル(ARMs)であるMolmoActは、知覚、計画、制御を三段階のパイプラインで統合し、説明可能で操作可能な行動を実現。シミュレーションと実世界で高いパフォーマンスを示し、特にSimplerEnv Visual Matchingタスクで70.5%のゼロショット精度を達成。MolmoAct Datasetを公開し、トレーニングによりベースモデルのパフォーマンスを平均5.5%向上。全てのモデルの重みやデータセットを公開し、ARMsの構築に向けたオープンな設計図を提供。 Comment
`Action Reasoning Models (ARMs)`
元ポスト:
blog: https://allenai.org/blog/molmoact
models:
-
https://huggingface.co/allenai/MolmoAct-7B-D-Pretrain-0812
-
https://huggingface.co/allenai/MolmoAct-7B-D-0812
datasets:
-
https://huggingface.co/datasets/allenai/MolmoAct-Dataset
-
https://huggingface.co/datasets/allenai/MolmoAct-Pretraining-Mixture
-
https://huggingface.co/datasets/allenai/MolmoAct-Midtraining-Mixture
データは公開されているが、コードが見当たらない?
チェックポイントとコードも公開された模様:
-
- https://github.com/allenai/MolmoAct
[Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2025-08-12 GPT Summary- 355Bパラメータを持つオープンソースのMixture-of-ExpertsモデルGLM-4.5を発表。ハイブリッド推論手法を採用し、エージェント的、推論、コーディングタスクで高いパフォーマンスを達成。競合モデルに比べて少ないパラメータ数で上位にランクイン。GLM-4.5とそのコンパクト版GLM-4.5-Airをリリースし、詳細はGitHubで公開。 Comment
元ポスト:
- アーキテクチャ
- MoE / sigmoid gates
- DeepSeek-R1, DeepSeek, 2025.01
- [Paper Note] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
- loss free balanced routing
- [Paper Note] Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, Lean Wang+, arXiv'24
- widthを小さく、depthを増やすことでreasoning能力改善
- GQA w/ partial RoPE
- [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
- [Paper Note] RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, arXiv'21, 2021.04
- Attention Headsの数を2.5倍(何に対して2.5倍なんだ、、?)(96個, 5120次元)にすることで(おそらく)事前学習のlossは改善しなかったがReasoning benchmarkの性能改善
- QK Normを導入しattentionのlogitsの値域を改善
- [Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings
- Multi Token Prediction
- [Paper Note] Better & Faster Large Language Models via Multi-token Prediction, Fabian Gloeckle+, ICML'24
- [Paper Note] DeepSeek-V3 Technical Report, DeepSeek-AI+, arXiv'24, 2024.12
他モデルとの比較
学習部分は後で追記する
- 事前学習データ
- web
- 英語と中国語のwebページを利用
- [Paper Note] Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25
と同様にquality scoreyをドキュメントに付与
- 最も低いquality scoreの文書群を排除し、quality scoreの高い文書群をup sampling
- 最もquality scoreyが大きい文書群は3.2 epoch分利用
- 多くのweb pageがテンプレートから自動生成されており高いquality scoreが付与されていたが、MinHashによってdeduplicationできなかったため、 [Paper Note] SemDeDup: Data-efficient learning at web-scale through semantic
deduplication, Amro Abbas+, arXiv'23
を用いてdocument embeddingに基づいて類似した文書群を排除
- Multilingual
- 独自にクロールしたデータとFineWeb-2 [Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, COLM'25
から多言語の文書群を抽出し、quality classifierを適用することでeducational utilityを定量化し、高いスコアの文書群をupsamplingして利用
- code
- githubなどのソースコードhosting platformから収集
- ソースコードはルールベースのフィルタリングをかけ、その後言語ごとのquality modelsによって、high,middle, lowの3つに品質を分類
- high qualityなものはupsamplingし、low qualityなものは除外
- [Paper Note] Efficient Training of Language Models to Fill in the Middle, Mohammad Bavarian+, arXiv'22
で提案されているFill in the Middle objectiveをコードの事前学習では適用
- コードに関連するweb文書も事前学習で収集したテキスト群からルールベースとfasttextによる分類器で抽出し、ソースコードと同様のqualityの分類とサンプリング手法を適用。最終的にフィルタリングされた文書群はre-parseしてフォーマットと内容の品質を向上させた
- math & science
- web page, 本, 論文から、reasoning能力を向上させるために、数学と科学に関する文書を収集
- LLMを用いて文書中のeducational contentの比率に基づいて文書をスコアリングしスコアを予測するsmall-scaleな分類器を学習
- 最終的に事前学習コーパスの中の閾値以上のスコアを持つ文書をupsampling
- 事前学習は2 stageに分かれており、最初のステージでは、"大部分は"generalな文書で学習する。次のステージでは、ソースコード、数学、科学、コーディング関連の文書をupsamplingして学習する。
上記以上の細かい実装上の情報は記載されていない。
mid-training / post trainingについても後ほど追記する
以下も参照のこと
- GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07
[Paper Note] STEPWISE-CODEX-Bench: Evaluating Complex Multi-Function Comprehension and Fine-Grained Execution Reasoning, Kaiwen Yan+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Coding Issue Date: 2025-08-10 GPT Summary- 新しいベンチマーク「STEPWISE-CODEX-Bench(SX-Bench)」を提案し、複雑な多機能理解と細かい実行推論を評価。SX-Benchは、サブ関数間の協力を含むタスクを特徴とし、動的実行の深い理解を測定する。20以上のモデルで評価した結果、最先端モデルでも複雑な推論においてボトルネックが明らかに。SX-Benchはコード評価を進展させ、高度なコードインテリジェンスモデルの評価に貢献する。 Comment
元ポスト:
現在の主流なコード生成のベンチは、input/outputがgivenなら上でコードスニペットを生成する形式が主流(e.g., MBPP [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21
, HumanEval [Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21
)だが、モデルがコードを理解し、複雑なコードのロジックを実行する内部状態の変化に応じて、実行のプロセスを推論する能力が見落とされている。これを解決するために、CRUXEVAL [Paper Note] CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, Alex Gu+, arXiv'24
, CRUXEVAL-X [Paper Note] CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding
and Execution, Ruiyang Xu+, arXiv'24
では、関数のinputs/outputsを予測することで、モデルのコードのcomprehension, reasoning能力を測ろうとしているが、
- single functionのlogicに限定されている
- 20 line程度の短く、trivialなロジックに限定されている
- すでにSoTAモデルで95%が達成され飽和している
というlimitationがあるので、複数の関数が協働するロジック、flow/dataのinteractionのフロー制御、細かい実行ステップなどを含む、staticなコードの理解から、動的な実行プロセスのモデリング能力の評価にシフトするような、新たなベンチマークを作成しました、という話な模様。
まず関数単位のライブラリを構築している。このために、単一の関数の基礎的な仕様を「同じinputに対して同じoutputを返すものは同じクラスにマッピングされる」と定義し、既存のコードリポジトリとLLMによる合成によって、GoとPythonについて合計30種類のクラスと361個のインスタンスを収集。これらの関数は、算術演算や大小比較、パリティチェックなどの判定、文字列の操作などを含む。そしてこれら関数を3種類の実行パターンでオーケストレーションすることで、合成関数を作成した。合成方法は
- Sequential: outputとinputをパイプラインでつなぎ伝搬させる
- Selective: 条件に応じてf(x)が実行されるか、g(x)が実行されるかを制御
- Loop: input集合に対するloopの中に関数を埋め込み順次関数を実行
の3種類。合成関数の挙動を評価するために、ランダムなテストケースは自動生成し、合成関数の挙動をモニタリング(オーバーフロー、無限ループ、タイムアウト、複数回の実行でoutputが決定的か等など)し、異常があるものはフィルタリングすることで合成関数の品質を担保する。
ベンチマーキングの方法としては、CRUXEVALではシンプルにモデルにコードの実行結果を予想させるだけであったが、指示追従能力の問題からミスジャッジをすることがあるため、この問題に対処するため
[Paper Note] MathSmith: Towards Extremely Hard Mathematical Reasoning by Forging Synthetic Problems with a Reinforced Policy, Shaoxiong Zhan+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SyntheticData #GRPO Issue Date: 2025-08-10 GPT Summary- MathSmithという新しいフレームワークを提案し、LLMの数学的推論を強化するために新しい問題をゼロから合成。既存の問題を修正せず、PlanetMathから概念と説明をランダムにサンプリングし、データの独立性を確保。9つの戦略を用いて難易度を上げ、強化学習で構造的妥当性や推論の複雑さを最適化。実験では、MathSmithが既存のベースラインを上回り、高難易度の合成データがLLMの推論能力を向上させる可能性を示した。 Comment
元ポスト:
[Paper Note] CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks, Ping Yu+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #InstructionTuning #SyntheticData Issue Date: 2025-08-02 GPT Summary- CoT-Self-Instructを提案し、LLMに基づいて新しい合成プロンプトを生成する手法を開発。合成データはMATH500やAMC23などで既存データセットを超える性能を示し、検証不可能なタスクでも人間や標準プロンプトを上回る結果を得た。 Comment
元ポスト:
より複雑で、Reasoningやplanningを促すようなinstructionが生成される模様。実際に生成されたinstructionのexampleは全体をざっとみた感じこの図中のもののみのように見える。
以下のスクショはMagpieによって合成されたinstruction。InstructionTuning用のデータを合成するならMagpieが便利そうだなぁ、と思っていたのだが、比較するとCoT-SelfInstructの方が、より複雑で具体的な指示を含むinstructionが生成されるように見える。
- [Paper Note] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Zhangchen Xu+, ICLR'25, 2024.06
[Paper Note] OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles, Yihe Deng+, NeurIPS'25
Paper/Blog Link My Issue
#LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #NeurIPS #VisionLanguageModel Issue Date: 2025-07-24 GPT Summary- OpenVLThinkerは、洗練された連鎖的思考推論を示すオープンソースの大規模視覚言語モデルであり、視覚推論タスクで顕著な性能向上を達成。SFTとRLを交互に行うことで、推論能力を効果的に引き出し、改善を加速。特に、MathVistaで3.8%、EMMAで2.4%、HallusionBenchで1.6%の性能向上を実現。コードやモデルは公開されている。 Comment
元ポスト:
[Paper Note] Hierarchical Reasoning Model, Guan Wang+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Architecture Issue Date: 2025-07-23 GPT Summary- HRM(Hierarchical Reasoning Model)は、AIの推論プロセスを改善するために提案された新しい再帰的アーキテクチャであり、Chain-of-Thought技術の問題を克服します。HRMは、2つの相互依存する再帰モジュールを用いて、シーケンシャルな推論タスクを単一のフォワードパスで実行し、高レベルの抽象計画と低レベルの詳細計算を分担します。2700万のパラメータで、わずか1000のトレーニングサンプルを使用し、数独や迷路の最適経路探索などの複雑なタスクで優れたパフォーマンスを示し、ARCベンチマークでも他の大規模モデルを上回る結果を達成しました。HRMは、普遍的な計算と汎用推論システムに向けた重要な進展を示唆しています。 Comment
元ポスト:
解説ポスト:
関連:
- [Paper Note] Deep Equilibrium Models, Shaojie Bai+, NeurIPS'19
追試の結果再現が可能でモデルアーキテクチャそのものよりも、ablation studyの結果、outer refinement loopが重要とのこと:
-
-
ポイント解説:
[Paper Note] MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning, Run-Ze Fan+, arXiv'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #PostTraining #Contamination-free #Science Issue Date: 2025-07-23 GPT Summary- 科学的推論のためのオープンデータセット「TextbookReasoning」を提案し、65万の推論質問を含む。さらに、125万のインスタンスを持つ「MegaScience」を開発し、各公開科学データセットに最適なサブセットを特定。包括的な評価システムを構築し、既存のデータセットと比較して優れたパフォーマンスを示す。MegaScienceを用いてトレーニングしたモデルは、公式の指示モデルを大幅に上回り、科学的調整におけるスケーリングの利点を示唆。データキュレーションパイプラインやトレーニング済みモデルをコミュニティに公開。 Comment
元ポスト:
LLMベースでdecontaminationも実施している模様
[Paper Note] The Invisible Leash: Why RLVR May Not Escape Its Origin, Fang Wu+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #PostTraining #RLVR #EntropyCollapse Issue Date: 2025-07-22 GPT Summary- RLVRはAIの能力向上に寄与するが、基盤モデルの制約により新しい解の発見を制限する可能性がある。理論的調査により、初期確率がゼロの解をサンプリングできないことや、探索を狭めるトレードオフが明らかになった。実証実験では、RLVRが精度を向上させる一方で、正しい答えを見逃すことが確認された。将来的には、探索メカニズムや過小評価された解に確率質量を注入する戦略が必要とされる。 Comment
元ポスト:
RLVRの限界に関する洞察
openreview: https://openreview.net/forum?id=qGhFl1SiPX
[Paper Note] Inverse Scaling in Test-Time Compute, Aryo Pradipta Gema+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #LongSequence #Scaling Laws Issue Date: 2025-07-22 GPT Summary- LRMsの推論の長さが性能に与える影響を評価するタスクを構築し、計算量と精度の逆スケーリング関係を示す。4つのカテゴリのタスクを通じて、5つの失敗モードを特定。これにより、長時間の推論が問題のあるパターンを強化する可能性があることが明らかになった。結果は、LRMsの失敗モードを特定し対処するために、推論の長さに応じた評価の重要性を示している。 Comment
元ポスト:
ReasoningモデルにおいてReasoningが長くなればなるほど
- context中にirrerevantな情報が含まれるシンプルな個数を数えるタスクでは、irrerevantな情報に惑わされるようになり、
- 特徴表に基づく回帰タスクの場合、擬似相関を持つ特徴量をの影響を増大してしまい、
- 複雑で組み合わせが多い演繹タスク(シマウマパズル)に失敗する
といったように、Reasoning Traceが長くなればなるほど性能を悪化させるタスクが存在しこのような問題のある推論パターンを見つけるためにも、様々なReasoning Traceの長さで評価した方が良いのでは、といった話な模様?
[Paper Note] Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety, Tomek Korbak+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Safety Issue Date: 2025-07-16 GPT Summary- 人間の言語で「考える」AIシステムは、安全性向上のために思考の連鎖(CoT)を監視することで悪意のある意図を検出する機会を提供する。しかし、CoT監視は完璧ではなく、一部の不正行為が見逃される可能性がある。研究を進め、既存の安全手法と併せてCoT監視への投資を推奨する。モデル開発者は、開発の決定がCoTの監視可能性に与える影響を考慮すべきである。 Comment
元ポスト:
CoTを監視することで、たとえばモデルのよろしくない挙動(e.g., misalignmentなどの意図しない動作や、prompt injection等の不正行為)を検知することができ、特にAIがより長期的な課題に取り組む際にはより一層その内部プロセスを監視する手段が必要不可欠となるため、CoTの忠実性や解釈性が重要となる。このため、CoTの監視可能性が維持される(モデルのアーキテクチャや学習手法(たとえばCoTのプロセス自体は一見真っ当なことを言っているように見えるが、実はRewardHackingしている、など)によってはそもそもCoTが難読化し監視できなかったりするので、現状は脆弱性がある)、より改善していく方向にコミュニティとして動くことを推奨する。そして、モデルを研究開発する際にはモデルのCoT監視に関する評価を実施すべきであり、モデルのデプロイや開発の際にはCoTの監視に関する決定を組み込むべき、といったような提言のようである。
関連:
[Paper Note] REST: Stress Testing Large Reasoning Models by Asking Multiple Problems at Once, Zhuoshi Pan+, arXiv'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Prompting #Batch Issue Date: 2025-07-16 GPT Summary- RESTという新しい評価フレームワークを提案し、LRMsを同時に複数の問題にさらすことで、実世界の推論能力を評価。従来のベンチマークの限界を克服し、文脈優先配分や問題間干渉耐性を測定。DeepSeek-R1などの最先端モデルでもストレステスト下で性能低下が見られ、RESTはモデル間の性能差を明らかにする。特に「考えすぎの罠」が性能低下の要因であり、「long2short」技術で訓練されたモデルが優れた結果を示すことが確認された。RESTはコスト効率が高く、実世界の要求に適した評価手法である。 Comment
元ポスト:
[Paper Note] Kimi-VL Technical Report, Kimi Team+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #OpenWeight #VisionLanguageModel Issue Date: 2025-07-14 GPT Summary- Kimi-VLは、効率的なオープンソースのMixture-of-Expertsビジョン・ランゲージモデルであり、2.8Bパラメータの言語デコーダーを活性化して高度なマルチモーダル推論を実現。マルチターンエージェントタスクや大学レベルの画像・動画理解において優れた性能を示し、最先端のVLMと競争。128Kの拡張コンテキストウィンドウを持ち、長い入力を処理可能。Kimi-VL-Thinking-2506は、長期的推論能力を強化するために教師ありファインチューニングと強化学習を用いて開発され、堅牢な一般能力を獲得。コードは公開されている。 Comment
- [Paper Note] Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset, Ke Wang+, NeurIPS'24 Datasets and Benchmarks Track
での性能(Vision+テキストの数学の問題)。他の巨大なモデルと比べ2.8BのActivation paramsで高い性能を達成
その他のベンチマークでも高い性能を獲得
モデルのアーキテクチャ。MoonViT (Image Encoder, 1Dのpatchをinput, 様々な解像度のサポート, FlashAttention, SigLIP-SO-400Mを継続事前学習, RoPEを採用) + Linear Projector + MoE Language Decoderの構成
学習のパイプライン。ViTの事前学習ではSigLIP loss (contrastive lossの亜種)とcaption生成のcross-entropy lossを採用している。joint cooldown stageにおいては、高品質なQAデータを合成することで実験的に大幅に性能が向上することを確認したので、それを採用しているとのこと。optimizerは
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
post-trainingにおけるRLでは以下の目的関数を用いており、RLVRを用いつつ、現在のポリシーモデルをreferenceとし更新をするような目的関数になっている。curriculum sampling, prioritize samplingをdifficulty labelに基づいて実施している。
[Paper Note] Perception-Aware Policy Optimization for Multimodal Reasoning, Zhenhailong Wang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #MultiModal #On-Policy #VisionLanguageModel Issue Date: 2025-07-12 GPT Summary- 強化学習における検証可能な報酬(RLVR)は、LLMsに多段階推論能力を与えるが、マルチモーダル推論では最適な性能を発揮できない。視覚入力の認識が主なエラー原因であるため、知覚を意識したポリシー最適化(PAPO)を提案。PAPOはGRPOの拡張で、内部監視信号から学習し、追加のデータや外部報酬に依存しない。KLダイバージェンス項を導入し、マルチモーダルベンチマークで4.4%の改善、視覚依存タスクでは8.0%の改善を達成。知覚エラーも30.5%減少し、PAPOの効果を示す。研究は視覚に基づく推論を促進する新しいRLフレームワークの基盤を築く。 Comment
元ポスト:
VLMにおいて、画像をマスクした場合のポリシーモデルの出力と、画像をマスクしない場合のポリシーモデルの出力のKL Divergenceを最大化することで、画像の認知能力が向上し性能向上するよ、みたいな話な模様。
[Paper Note] Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation, Liliang Ren+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #SmallModel #OpenWeight Issue Date: 2025-07-10 GPT Summary- 最近の言語モデルの進展により、状態空間モデル(SSM)の効率的なシーケンスモデリングが示されています。本研究では、ゲーテッドメモリユニット(GMU)を導入し、Sambaベースの自己デコーダーからメモリを共有する新しいデコーダーハイブリッドアーキテクチャSambaYを提案します。SambaYはデコーディング効率を向上させ、長文コンテキスト性能を改善し、位置エンコーディングの必要性を排除します。実験により、SambaYはYOCOベースラインに対して優れた性能を示し、特にPhi4-mini-Flash-Reasoningモデルは推論タスクで顕著な成果を上げました。トレーニングコードはオープンソースで公開されています。 Comment
HF: https://huggingface.co/microsoft/Phi-4-mini-flash-reasoning
元ポスト:
[Paper Note] NaturalThoughts: Selecting and Distilling Reasoning Traces for General Reasoning Tasks, Yang Li+, arXiv'25
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #LanguageModel #Distillation Issue Date: 2025-07-03 GPT Summary- 教師モデルからの推論トレースを用いて生徒モデルの能力を向上させる方法を体系的に研究。NaturalReasoningに基づく高品質な「NaturalThoughts」をキュレーションし、サンプル効率とスケーラビリティを分析。データサイズの拡大が性能向上に寄与し、多様な推論戦略を必要とする例が効果的であることを発見。LlamaおよびQwenモデルでの評価により、NaturalThoughtsが既存のデータセットを上回り、STEM推論ベンチマークで優れた性能を示した。 Comment
元ポスト:
[Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #MultiModal #RLHF #LongSequence #mid-training #RewardHacking #PostTraining #CurriculumLearning #RLVR #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-03 GPT Summary- 視覚言語モデルGLM-4.1V-Thinkingを発表し、推論中心のトレーニングフレームワークを開発。強力な視覚基盤モデルを構築し、カリキュラムサンプリングを用いた強化学習で多様なタスクの能力を向上。28のベンチマークで最先端のパフォーマンスを達成し、特に難しいタスクで競争力のある結果を示す。モデルはオープンソースとして公開。 Comment
元ポスト:
Qwen2.5-VLよりも性能が良いVLM
アーキテクチャはこちら。が、pretraining(データのフィルタリング, マルチモーダル→long context継続事前学習)->SFT(cold startへの対処, reasoning能力の獲得)->RL(RLVRとRLHFの併用によるパフォーマンス向上とAlignment, RewardHackingへの対処,curriculum sampling)など、全体の学習パイプラインの細かいテクニックの積み重ねで高い性能が獲得されていると考えられる。
[Paper Note] ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs, Jiaru Zou+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #PRM Issue Date: 2025-06-25 GPT Summary- 新しいプロセス報酬モデルReasonFlux-PRMを提案し、推論トレースの評価を強化。ステップと軌道の監視を組み込み、報酬割り当てを細かく行う。実験により、ReasonFlux-PRM-7Bが高品質なデータ選択と性能向上を実現し、特に監視付きファインチューニングで平均12.1%の向上を達成。リソース制約のあるアプリケーション向けにReasonFlux-PRM-1.5Bも公開。 Comment
元ポスト:
[Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #ReinforcementLearning #NeurIPS #mid-training #PostTraining #read-later #RLVR #Selected Papers/Blogs #DataMixture #CrossDomain #KeyPoint Notes #Reading Reflections #Author Thread-Post Issue Date: 2025-06-22 GPT Summary- Guruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。 Comment
元ポスト:
post-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。
Qwenシリーズで実験。以下元ポストのまとめ。
- mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
- 一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
- 簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
- 各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
- 必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
- たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
- 一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
- 異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
- (これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
- 非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
- RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
- モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
- モデルサイズが大きいとより多様なreasoningパスがunlockされている
- pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた
本研究で構築されたGuru Dataset:
https://huggingface.co/datasets/LLM360/guru-RL-92k
math, coding, science, logic, simulation, tabular reasoningに関する高品質、かつverifiableなデータセット。
> RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
上記takeawayは
- [Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
と一見相反するように見えるが、実際どうなんだろうか。
最初は、RLによりPass@1が改善するので、Figure 1などに記載されている特定のドメインでの skill aqcuisition にはin-domain dataが必要でRLがそれに寄与するという話は、Pass@1が改善された結果なのかなと思ったが、
4.3節に実際に上記研究が引用され考察がなされており、mid-trainingなどで多くのデータが含まれるMathドメインについては、上記研究と同じ傾向でbase modelとRL後のモデルがK=64の時点で性能が交差、その後逆転するため、上記研究と同様の傾向が見受けられた。一方で、タスクごとに見るとzebra-logicのような事前学習ではあまりexposeされないタスクで見ると、依然としてRLの方が高いPass@kを獲得しているという現象が観測され、base modelのreadoning boundaryを拡大することができている、という解釈のようである。
[Paper Note] Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks, Yifei Xu+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel Issue Date: 2025-06-18 GPT Summary- DRO(直接推論最適化)を提案し、LLMsをオープンエンドの長文推論タスクに微調整するための強化学習フレームワークを構築。新しい報酬信号R3を用いて推論と参照結果の一貫性を捉え、自己完結したトレーニングを実現。ParaRevとFinQAのデータセットで強力なベースラインを上回る性能を示し、広範な適用可能性を確認。 Comment
元ポスト:
[Paper Note] Wait, We Don't Need to "Wait" Removing Thinking Tokens Improves Reasoning Efficiency, Chenlong Wang+, EMNLP'25 Findings
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Chain-of-Thought #EMNLP #One-Line Notes Issue Date: 2025-06-18 GPT Summary- 自己反省を抑制する「NoWait」アプローチを提案し、推論の効率を向上。10のベンチマークで最大27%-51%の思考の連鎖の長さを削減し、有用性を維持。マルチモーダル推論のための効果的なソリューションを提供。 Comment
Wait, Hmmといったlong CoTを誘導するようなtokenを抑制することで、Accはほぼ変わらずに生成されるトークン数を削減可能、といった図に見える。Reasoningモデルでデコーディング速度を向上したい場合に効果がありそう。
元ポスト:
[Paper Note] Overclocking LLM Reasoning: Monitoring and Controlling Thinking Path Lengths in LLMs, Roy Eisenstadt+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel Issue Date: 2025-06-17 GPT Summary- LLMの推論プロセスにおける思考段階の長さを調整するメカニズムを探求。進捗をエンコードし、可視化することで計画ダイナミクスを明らかにし、不要なステップを減らす「オーバークロッキング」手法を提案。これにより、考えすぎを軽減し、回答精度を向上させ、推論のレイテンシを減少させることを実証。コードは公開。 Comment
元ポスト:
[Paper Note] Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning, Jiayi Yuan+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Reproducibility Issue Date: 2025-06-13 GPT Summary- 本研究では、大規模言語モデル(LLMs)のパフォーマンスの再現性が脆弱であることを示し、システム構成の変更が応答に大きな影響を与えることを明らかにしました。特に、初期トークンの丸め誤差が推論精度に波及する問題を指摘し、浮動小数点演算の非結合的性質が変動の根本原因であるとしています。様々な条件下での実験を通じて、数値精度が再現性に与える影響を定量化し、評価実践における重要性を強調しました。さらに、LayerCastという軽量推論パイプラインを開発し、メモリ効率と数値安定性を両立させる方法を提案しました。
[Paper Note] SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond, Junteng Liu+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #SyntheticData #NeurIPS #One-Line Notes #Author Thread-Post Issue Date: 2025-06-06 GPT Summary- SynLogicは、35の論理的推論タスクを網羅したデータ合成フレームワークで、強化学習(RL)による大規模言語モデル(LLMs)の推論能力向上を目指す。調整可能な難易度で生成されたデータは検証可能で、RLに適している。実験では、SynLogicが最先端の論理的推論性能を達成し、数学やコーディングタスクとの混合によりトレーニング効率が向上することが示された。SynLogicはLLMsの推論能力向上に貴重なリソースとなる。 Comment
元ポスト:
35種類のタスクを人手で選定し、タスクごとに困難度の鍵となるパラメータを定義(数独ならばグリッド数など)。その上で、各タスクごとに人手でルールベースのinstanceを生成するコードを実装し、さまざまな困難度パラメータに基づいて多様なinstanceを生成。生成されたinstanceの困難度は、近似的なUpper Bound(DeepSeek-R1, o3-miniのPass@10)とLower bound(chat model[^1]でのPass@10)を求めデータセットに含まれるinstanceの困難度をコントロールし、taskを記述するpromptも生成。タスクごとに人手で実装されたVerifierも用意されている。
Qwen2.5-7B-BaseをSynDataでDAPOしたところ、大幅にlogic benchmarkとmathematical benchmarkの性能が改善。
mathやcodeのデータとmixして7Bモデルを訓練したところ、32Bモデルに匹敵する性能を達成し、SynDataをmixすることでgainが大きくなったので、SynDataから学習できる能力が汎化することが示唆される。
タスク一覧はこちら
[^1]:どのchat modelかはざっと見た感じわからない。どこかに書いてあるかも。
Logical Reasoningが重要なタスクを扱う際はこのデータを活用することを検討してみても良いかもしれない
[Paper Note] BIG-Bench Extra Hard, Mehran Kazemi+, ACL'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #ACL #One-Line Notes Issue Date: 2025-06-01 GPT Summary- 大規模言語モデル(LLMs)の推論能力を評価するための新しいベンチマーク、BIG-Bench Extra Hard(BBEH)を導入。これは、既存のBIG-Bench Hard(BBH)のタスクを新しいものに置き換え、難易度を大幅に引き上げることで、LLMの限界を押し広げることを目的としている。評価の結果、最良の汎用モデルで9.8%、推論専門モデルで44.8%の平均精度が観察され、LLMの一般的推論能力向上の余地が示された。BBEHは公開されている。 Comment
Big-Bench hard(既にSoTAモデルの能力差を識別できない)の難易度をさらに押し上げたデータセット。
Inputの例
タスクごとのInput, Output lengthの分布
現在の主要なモデル群の性能
Big-Bench論文はこちら:
- [Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
[Paper Note] Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #ICML #Workshop #One-Line Notes #Author Thread-Post Issue Date: 2025-05-27 GPT Summary- 本研究では、外部の報酬やラベルなしで大規模言語モデル(LLMs)が学習できるフレームワーク「内部フィードバックからの強化学習(RLIF)」を提案。自己確信を報酬信号として用いる「Intuitor」を開発し、無監視の学習を実現。実験結果は、Intuitorが数学的ベンチマークで優れた性能を示し、ドメイン外タスクへの一般化能力も高いことを示した。内因的信号が効果的な学習を促進する可能性を示唆し、自律AIシステムにおけるスケーラブルな代替手段を提供。 Comment
元ポスト:
おもしろそう
externalなsignalをrewardとして用いないで、モデル自身が内部的に保持しているconfidenceを用いる。人間は自信がある問題には正解しやすいという直感に基づいており、openendなquestionのようにそもそも正解シグナルが定義できないものもあるが、そういった場合に活用できるようである。
self-trainingの考え方に近いのでは
ベースモデルの段階である程度能力が備わっており、post-trainingした結果それが引き出されるようになったという感じなのだろうか。
参考:
解説スライド:
https://www.docswell.com/s/DeepLearning2023/KYVLG4-2025-09-18-112951
元ポスト:
[Paper Note] AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning, Chenwei Lou+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #One-Line Notes Issue Date: 2025-05-21 GPT Summary- AdaCoTは、LLMがChain-of-Thought(CoT)の使用を適応的に決定する新しい枠組み。これにより、計算コストや非効率性を軽減しつつ、複雑なクエリにおける推論性能を維持する。特にProximal Policy Optimization(PPO)を用いたRL手法を導入し、Selective Loss Masking(SLM)で推論トリガを安定させ、実験ではCoTトリガー率を最大3.18%削減、応答トークン数を69.06%削減したことが示された。 Comment
RLのRewardにおいて、baseのリワードだけでなく、
- reasoningをなくした場合のペナルティ項
- reasoningをoveruseした場合のペナルティ項
- formattingに関するペナルティ項
を設定し、reasoningの有無を適切に判断できた場合にrewardが最大化されるような形にしている。(2.2.2)
が、multi-stageのRLでは(stageごとに利用するデータセットを変更するが)、データセットの分布には歪みがあり、たとえば常にCoTが有効なデータセットも存在しており(数学に関するデータなど)、その場合常にCoTをするような分布を学習してしまい、AdaptiveなCoT decisionが崩壊したり、不安定になってしまう(decision boundary collapseと呼ぶ)。特にこれがfinal stageで起きると最悪で、これまでAdaptiveにCoTされるよう学習されてきたものが全て崩壊してしまう。これを防ぐために、Selective Loss Maskingというlossを導入している。具体的には、decision token [^1]のlossへの貢献をマスキングするようにすることで、CoTが生じるratioにバイアスがかからないようにする。今回は、Decision tokenとして、`
[^1]: CoTするかどうかは多くの場合このDecision Tokenによって決まる、といったことがどっかの研究に示されていたはず
いつか必要になったらしっかり読むが、全てのステージでSelective Loss Maskingをしたら、SFTでwarm upした段階からあまりCoTのratioが変化しないような学習のされ方になる気がするが、どのステージに対してapplyするのだろうか。
openreview: https://openreview.net/forum?id=obXGSmmG70
[Paper Note] Follow the Path: Reasoning over Knowledge Graph Paths to Improve LLM Factuality, Mike Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #KnowledgeGraph #Factuality #Test-Time Scaling #PostTraining Issue Date: 2025-05-20 GPT Summary- fs1は、大規模推論モデルから推論経路を取得し、知識グラフに条件付けて事実性を向上させる手法を提案する。8つのLLMをファインチューニングし、6つの複雑なQAベンチマークで評価した結果、fs1調整モデルは他モデルを一貫して上回り、特に複雑な質問での性能向上が顕著だった。従来研究の枠を超え、推論経路をKGに結び付けることが信頼性の高いタスクにおいて重要であることを示した。 Comment
元ポスト:
[Paper Note] Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #SmallModel #PEFT(Adaptor/LoRA) #GRPO #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-05-07 GPT Summary- Tinaは、コスト効率よく強力な推論能力を実現する小型の推論モデルファミリーであり、1.5Bパラメータのベースモデルに強化学習を適用することで高い推論性能を示す。Tinaは、従来のSOTAモデルと競争力があり、AIME24で20%以上の性能向上を達成し、トレーニングコストはわずか9ドルで260倍のコスト削減を実現。LoRAを通じた効率的なRL推論の効果を検証し、すべてのコードとモデルをオープンソース化している。 Comment
元ポスト:
(おそらく)Reasoningモデルに対して、LoRAとRLを組み合わせて、reasoning能力を向上させた初めての研究
[Paper Note] Thinking LLMs: General Instruction Following with Thought Generation, Tianhao Wu+, ICML'25, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #ICML #DPO #PostTraining #KeyPoint Notes #Author Thread-Post Issue Date: 2025-05-07 GPT Summary- LLMsに思考能力を装備するための訓練方法を提案。反復的な検索と最適化手順を用いて、モデルが監視なしで思考する方法を学ぶ。指示に対する思考候補はジャッジモデルで評価され、最適化される。この手法はAlpacaEvalとArena-Hardで優れたパフォーマンスを示し、推論タスクだけでなく、マーケティングや健康などの非推論カテゴリでも利点を発揮。 Comment
元ポスト:
外部のCoTデータを使わないで、LLMのreasoning capabilityを向上させる話っぽい。DeepSeek-R1の登場以前の研究とのこと。
"reasoning traceを出力するように" Instruction Tuningによって回答を直接出力するようPostTrainingされたモデルにpromptingし、複数のoutputを収集(今回は8個, temperature=0.8, top p=0.95)。Self Taught Evaluator [Paper Note] Self-Taught Evaluators, Tianlu Wang+, arXiv'24, 2024.08
(STE;70B, LLM-as-a-Judgeを利用するモデル)、あるいはArmo Reward Model(8B)によって回答の品質をスコアリング。ここで、LLM-as-a-Judgeの場合はペアワイズでの優劣が決まるだけなので、ELOでスコアリングする。outputのうちbest scoreとworst scoreだったものの双方でペアデータを構築し、DPOで利用するpreferenceペアデータを構築しDPOする。このような処理を繰り返し、モデルの重みをiterationごとに更新する。次のiterationでは更新されたモデルで同様の処理を行い、前段のステップで利用した学習データは利用しないようにする(後段の方が品質が高いと想定されるため)。また、回答を別モデルで評価する際に、長いレスポンスを好むモデルの場合、長い冗長なレスポンスが高くスコアリングされるようなバイアスが働く懸念があるため、長すぎる回答にpenaltyを与えている(Length-Control)。
reasoning traceを出力するpromptはgenericとspecific thoughtの二種類で検証。前者はLLMにどのような思考をするかを丸投げするのに対し、後者はこちら側で指定する。後者の場合は、どのような思考が良いかを事前に知っていなければならない。
Llama-3-8b-instructに適用したところ、70Bスケールのモデルよりも高い性能を達成。また、reasoning trace出力をablationしたモデル(Direct responce baseline)よりも性能が向上。
iterationが進むに連れて、性能が向上している。
[Paper Note] 100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models, Chong Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Survey #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #InstructionTuning #PPO (ProximalPolicyOptimization) #LongSequence #RewardHacking #GRPO #Contamination-free #VerifiableRewards #CurriculumLearning #One-Line Notes Issue Date: 2025-05-06 GPT Summary- RLMの進展は新しい言語モデルの進化を示し、DeepSeek-R1のリリースが社会的影響を生んでいる。DeepSeekの実装は完全にオープンではないが、多くの再現研究が登場し、同等の性能を達成。特にSFTとRLVRに重点を置き、データ構築や手法設計に関する知見を提供。実装の詳細と実験結果をまとめ、RLMの性能向上技術や開発課題についても議論。研究者が最新の進展を把握し、新しいアイデアを促進することを目指す。 Comment
元ポスト:
サーベイのtakeawayが箇条書きされている。
[Paper Note] Phi-4-reasoning Technical Report, Marah Abdin+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #SmallModel #OpenWeight #GRPO #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2025-05-01 GPT Summary- 140億パラメータの推論モデルPhi-4-reasoningは、慎重に選ばれた「teachable」プロンプトセットと監視付きファインチューニングを通じて訓練され、詳細な推論チェーンを生成します。そのバリエーションであるPhi-4-reasoning-plusは、短期間の強化学習を経て、より長い推論トレースを生成し高性能を実現。これらのモデルは、DeepSeek-R1-Distill-Llama-70Bモデルを超え、完全版DeepSeek-R1に近い性能を示します。評価は数学的・科学的推論や一般目的のベンチマークを含み、データ精選の利点と強化学習の影響を示唆しています。 Comment
元ポスト:
こちらの解説が非常によくまとまっている:
が、元ポストでもテクニカルペーパー中でもo3-miniのreasoning traceをSFTに利用してCoTの能力を強化した旨が記述されているが、これはOpenAIの利用規約に違反しているのでは…?
[Paper Note] UI-TARS: Pioneering Automated GUI Interaction with Native Agents, Yujia Qin+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #MultiModal #Blog #OpenWeight #ComputerUse #VisionLanguageModel #2D (Image) #One-Line Notes #text Issue Date: 2025-04-18 GPT Summary- UI-TARSは、スクリーンショットを入力として人間のような操作を行うエンドツーエンドのGUIエージェントモデルである。従来の商用モデルに依存せず、知覚、グラウンディング、GUIタスク実行において最先端の性能を発揮。OSWorldベンチマークでは、UI-TARSが高スコアを達成し、他のモデルを上回る。主要な革新には、強化された知覚、統一されたアクションモデリング、System-2推論、反省的オンライン・トレースによる反復的トレーニングが含まれる。これにより、UI-TARSは未知の状況にも適応可能な学習能力を持つ。GUIエージェントの進化経路も分析し、今後の発展を探る。 Comment
色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)
関連
- OpenAI API での Computer use の使い方, npaka, 2025.03
元ポスト:
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning, Siyan Zhao+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #DiffusionModel #PostTraining #GRPO #KeyPoint Notes Issue Date: 2025-04-18 GPT Summary- d1というフレームワークを提案し、マスク付きdLLMsを教師ありファインチューニングと強化学習で推論モデルに適応。マスク付きSFT技術で知識を抽出し、diffu-GRPOという新しいRLアルゴリズムを導入。実証研究により、d1が最先端のdLLMの性能を大幅に向上させることを確認。 Comment
元ポスト:
dLLMに対してGRPOを適用する手法(diffuGRPO)を提案している。
long CoTデータでSFTしてreasoning capabilityを強化した後、diffuGRPOで追加のpost-trainingをしてさらに性能をboostする。
GRPOではtoken levelの尤度とsequence全体の尤度を計算する必要があるが、dLLMだとautoregressive modelのようにchain ruleを適用する計算方法はできないので、効率的に尤度を推定するestimatorを用いてGPPOを適用するdiffuGRPOを提案している。
diffuGRPO単体でも、8BモデルだがSFTよりも性能向上に成功している。SFTの後にdiffuGRPOを適用するとさらに性能が向上する。
SFTではs1 [Paper Note] s1: Simple test-time scaling, Niklas Muennighoff+, EMNLP'25, 2025.01
で用いられたlong CoTデータを用いている。しっかり理解できていないが、diffuGRPO+verified rewardによって、long CoTの学習データを用いなくても、安定してreasoning能力を発揮することができようになった、ということなのだろうか?
しかし、AppendixCを見ると、元々のLLaDAの時点でreasoning traceを十分な長さで出力しているように見える。もしLLaDAが元々long CoTを発揮できたのだとしたら、long CoTできるようになったのはdiffuGRPOだけの恩恵ではないということになりそうだが、LLaDAは元々long CoTを生成できるようなモデルだったんだっけ…?その辺追えてない(dLLMがメジャーになったら追う)。
[Paper Note] Seed1.5-Thinking: Advancing Superb Reasoning Models with Reinforcement Learning, ByteDance Seed+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #One-Line Notes #Initial Impression Notes Issue Date: 2025-04-12 GPT Summary- Seed1.5-Thinkingは、応答前に思考を経て推論する新しい手法で、AIME 2024で86.7、Codeforcesで55.0、GPQAで77.3といった性能を達成。非推論タスクでも優れた一般化能力を発揮し、DeepSeek R1を勝率で8%上回る。比較的小型の専門家の混成モデルで、200億の活性化パラメータと2000億の総パラメータを持つ。新たな内部ベンチマークBeyondAIMEとCodeforcesも公開予定。 Comment
DeepSeek-R1を多くのベンチで上回る200B, 20B activated paramのreasoning model
最近のテキストのOpenWeightLLMはAlibaba, DeepSeek, ByteDance, Nvidiaの4強という感じかな…?(そのうちOpenAIがオープンにするReasoning Modelも入ってきそう)。
[Paper Note] VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, Yu Yue+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#MachineLearning #LanguageModel #ReinforcementLearning #LongSequence #Initial Impression Notes Issue Date: 2025-04-08 GPT Summary- VAPO(価値ベースの拡張近接ポリシー最適化フレームワーク)は、推論モデルに特化した新しいフレームワークを提案し、AIME 2024データセットで最先端のスコア60.4を達成。VAPOは従来手法を10ポイント以上上回り、わずか5,000ステップで安定した性能を実現。長い連鎖思考推論における課題を特定し、体系的な設計で効果的に対処することで、性能向上に寄与することを示した。 Comment
同じくByteDanceの
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
を上回る性能
元ポスト:
以下のブログで紹介されている:
- Reinforcement Learning from Human Feedback, Nathan Lambert, 2026.03
[Paper Note] RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning, Sichun Luo+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Initial Impression Notes Issue Date: 2025-03-27 GPT Summary- RALLRec+は、LLMsを用いてレコメンダーシステムのretrievalとgenerationを強化する手法。retrieval段階では、アイテム説明を生成し、テキスト信号と協調信号を結合。生成段階では、推論LLMsを評価し、知識注入プロンプティングで汎用LLMsと統合。実験により、提案手法の有効性が確認された。 Comment
元ポスト:
Reasoning LLMをRecSysに応用する初めての研究(らしいことがRelated Workに書かれている)
arxivのadminより以下のコメントが追記されている
> arXiv admin note: substantial text overlap with arXiv:2502.06101
コメント中の研究は下記である
- [Paper Note] ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation, Jianghao Lin+, WWW'24
[Paper Note] Thinking Machines: A Survey of LLM based Reasoning Strategies, Dibyanayan Bandyopadhyay+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Initial Impression Notes Issue Date: 2025-03-23 GPT Summary- 大規模言語モデル(LLMs)は優れた言語能力を持つが、推論能力との間にギャップがある。推論はAIの信頼性を高め、医療や法律などの分野での適用に不可欠である。最近の強力な推論モデルの登場により、LLMsにおける推論の研究が重要視されている。本論文では、既存の推論技術の概要と比較を行い、推論を備えた言語モデルの体系的な調査と現在の課題を提示する。 Comment
元ポスト:
RL, Test Time Compute, Self-trainingの3種類にカテゴライズされている。また、各カテゴリごとにより細分化されたツリーが論文中にある。
[Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #GRPO #read-later #KeyPoint Notes Issue Date: 2025-03-22 GPT Summary- DeepSeek-R1-Zeroは、RLを用いてLLMsの推論能力を向上させる手法を示した。本研究では、ベースモデルとRLの影響を分析し、DeepSeek-V3-Baseが「アハ体験」を示す一方で、Qwen2.5が強力な推論能力を持つことを発見。GRPOの最適化バイアスを特定し、Dr. GRPOを導入してトークン効率を改善。7BベースモデルでAIME 2024において43.3%の精度を達成するR1-Zeroレシピを提案。 Comment
関連研究:
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
解説ポスト:
解説ポスト(と論文中の当該部分)を読むと、
- オリジナルのGRPOの定式では2つのバイアスが生じる:
- response-level length bias: 1/|o_i| でAdvantageを除算しているが、これはAdvantageが負の場合(つまり、誤答が多い場合)「長い応答」のペナルティが小さくなるため、モデルが「長い応答」を好むバイアスが生じる。一方で、Advantageが正の場合(正答)は「短い応答」が好まれるようになる。
- question-level difficulty bias: グループ内の全ての応答に対するRewardのstdでAdvantageを除算しているが、stdが小さくなる問題(すなわち、簡単すぎるor難しすぎる問題)をより重視するような、問題に対する重みづけによるバイアスが生じる。
- aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
- これまではoutput lengthを増やすことが性能改善の鍵だと思われていたが、この論文では必ずしもそうではなく、self-reflection無しの方が有りの場合よりもAcc.が高い場合があることを示している(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様
あとで読む
(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:
[Paper Note] Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models, Yang Sui+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #LanguageModel #Overthinking #One-Line Notes Issue Date: 2025-03-22 GPT Summary- 本論文では、LLMsにおける効率的な推論の進展を体系的に調査し、以下の主要な方向に分類します:(1) モデルベースの効率的推論、(2) 推論出力ベースの効率的推論、(3) 入力プロンプトベースの効率的推論。特に、冗長な出力による計算オーバーヘッドを軽減する方法を探求し、小規模言語モデルの推論能力や評価方法についても議論します。 Comment
Reasoning Modelにおいて、Over Thinking現象(不要なreasoning stepを生成してしまう)を改善するための手法に関するSurvey。
下記Figure2を見るとよくまとまっていて、キャプションを読むとだいたい分かる。なるほど。
Length Rewardについては、
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
で考察されている通り、Reward Hackingが起きるので設計の仕方に気をつける必要がある。
元ポスト:
各カテゴリにおけるliteratureも見やすくまとめられている。必要に応じて参照したい。
[Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
Paper/Blog Link My Issue
#MachineLearning #LanguageModel #ReinforcementLearning #LongSequence #NeurIPS #GRPO #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2025-03-20 GPT Summary- 推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment
既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。
ちとこれはあとでしっかり読みたい。重要論文。
プロジェクトページ:
https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。
解説ポスト:
コンパクトだが分かりやすくまとまっている。
下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:
色々な研究で広く使われるのを見るようになった。
著者ポスト:
[Paper Note] The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, NeurIPS'25, 2025.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #NeurIPS #KeyPoint Notes #Reading Reflections Issue Date: 2025-03-19 GPT Summary- 非教師ありプレフィックスファインチューニング(UPFT)を提案し、LLMの推論効率を向上。初期のプレフィックス部分文字列に基づいて訓練し、ラベル付きデータやサンプリングを不要に。UPFTは、教師あり手法と同等の性能を維持しつつ、訓練時間を75%、サンプリングコストを99%削減。最小限の非教師ありファインチューニングで大幅な推論向上を実現し、リソース効率の良い代替手段を提供。 Comment
斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成できるようにモデルをFinetuningする。従来のRejection Samplingを用いた手法では、複数のresponseを生成させて、最終的なanswerが正解のものをサンプリングするため正解ラベルが必要となるが、提案手法ではreasoning traceの冒頭部分の共通するsubsequenceをmajority voteするだけなのでラベルが不要である。
reasoning prefixを学習する際は下記のようなテンプレートを用いる。このときに、prefixのspanのみを利用して学習することで大幅に学習時間を削減できる。
また、そのような学習を行うとcatastrophic forgettingのリスクが非常に高いが、これを防ぐために、マルチタスクラーニングを実施する。具体的には学習データのp%については全体のreasoning traceを生成して学習に利用する。このときに、最終的な回答の正誤を気にせずtraceを生成して学習に利用することで、ラベルフリーな特性を維持できる(つまり、こちらのデータは良いreasoning traceを学習することを目的としているわけではなく、あくまでcatastrophic forgettingを防ぐためにベースモデルのようなtraceもきちんと生成できれば良い、という感覚だと思われる)。
AppendixにQwenを用いてtemperature 0.7で16個のresponseをサンプリングし、traceの冒頭部分が共通している様子が示されている。
下記論文でlong-CoTを学習させる際のlong-CoTデータとして、reasoningモデルから生成したtraceと非reasoning modelから生成したtraceによるlong-CoTデータを比較したところ前者の方が一貫して学習性能が良かったとあるが、この研究でもreasoning traceをつよつよモデルで生成したら性能上がるんだろうか。
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
[Paper Note] A Survey on Post-training of Large Language Models, Guiyao Tie+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Supervised-FineTuning (SFT) #Initial Impression Notes Issue Date: 2025-03-15 GPT Summary- 大規模言語モデル(LLMs)は自然言語処理に革命をもたらしたが、専門的な文脈での制約が明らかである。これに対処するため、高度なポストトレーニング言語モデル(PoLMs)が必要であり、本論文ではその包括的な調査を行う。ファインチューニング、アライメント、推論、効率、統合と適応の5つのコアパラダイムにわたる進化を追跡し、PoLMがバイアス軽減や推論能力向上に寄与する方法を示す。研究はPoLMの進化に関する初の調査であり、将来の研究のための枠組みを提供し、LLMの精度と倫理的堅牢性を向上させることを目指す。 Comment
Post Trainingの時間発展の図解が非常にわかりやすい(が、厳密性には欠けているように見える。当該モデルの新規性における主要な技術はこれです、という図としてみるには良いのかもしれない)。
個々の技術が扱うスコープとレイヤー、データの性質が揃っていない気がするし、それぞれのLLMがy軸の単一の技術だけに依存しているわけでもない。が、厳密に図を書いてと言われた時にどう書けば良いかと問われると難しい感はある。
元ポスト:
[Paper Note] LLM Post-Training: A Deep Dive into Reasoning Large Language Models, Komal Kumar+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Supervised-FineTuning (SFT) #Initial Impression Notes Issue Date: 2025-03-04 GPT Summary- LLMは自然言語処理に革命をもたらし、ポストトレーニング手法に焦点を移しつつある。これにより、推論や事実の正確性が向上し、ユーザー意図に合わせた整合が可能に。ファインチューニングや強化学習が性能最適化に寄与し、実世界タスクへの適応力も向上。調査では、ポストトレーニング手法の重要性と、壊滅的忘却や報酬の改ざんへの対策が論じられ、新たな研究方向が提案されている。さらに、分野の進展を追跡するリポジトリも提供。 Comment
非常にわかりやすい。
元ポスト:
[Paper Note] From System 1 to System 2: A Survey of Reasoning Large Language Models, Zhong-Zhi Li+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel Issue Date: 2025-02-26 GPT Summary- 人間レベルの知能を達成するためには、迅速なシステム1から意図的なシステム2への推論の洗練が必要。基盤となる大規模言語モデル(LLMs)は迅速な意思決定に優れるが、複雑な推論には深さが欠ける。最近の推論LLMはシステム2の意図的な推論を模倣し、人間のような認知能力を示している。本調査では、LLMの進展とシステム2技術の初期開発を概観し、推論LLMの構築方法や特徴、進化を分析。推論ベンチマークの概要を提供し、代表的な推論LLMのパフォーマンスを比較。最後に、推論LLMの進展に向けた方向性を探り、最新の開発を追跡するためのGitHubリポジトリを維持することを目指す。 Comment
元ポスト:
[Paper Note] OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning, Pan Lu+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Tools #NLP #LanguageModel #AIAgents #ACL #One-Line Notes Issue Date: 2025-02-20 GPT Summary- OctoToolsは複雑な推論タスクを解決するための訓練不要で拡張可能なマルチエージェントフレームワーク。標準化されたツールカード、プランナー、実行者を導入し、16の多様なタスクでGP4oより平均精度を9.3%向上。AutoGenやLangChainに対しても最大10.6%の改善を示し、タスク計画とツール使用の効果を実証。詳細はサイトに公開。 Comment
元ポスト:
NAACL2025 KnowledgeNLP Workshopでベストペーパーに選出:
ACL2026のOralにaccept:
[Paper Note] NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions, Weizhe Yuan+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #SyntheticData #Distillation #Author Thread-Post Issue Date: 2025-02-19 GPT Summary- 数学やコーディングを含む多様な領域の推論能力を向上させるため、280万問の多様で挑戦的な推論問題を含むデータセットNaturalReasoningを導入。知識蒸留実験により、強力な教師モデルから効果的に推論能力が引き出されることを示し、自己訓練や自己報酬でも有効であることを証明。NaturalReasoningは今後の研究を促進するために公開されている。 Comment
元ポスト:
[Paper Note] LIMO: Less is More for Reasoning, Yixin Ye+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #DataDistillation #COLM #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2025-02-07 GPT Summary- 限られた訓練データで高度な数学的推論が可能であることを示す。モデルLIMOはAIME24で63.3%、MATH500で95.6%の精度を達成し、従来モデルを大幅に上回る。LIMOは分布外の一般化にも強く、従来のモデルよりも少ないデータで55%の改善を実現。Less-Is-More Reasoning Hypothesis(LIMO仮説)を提案し、事前知識の完全性と戦略的デモンストレーションの効果が推論の質を左右することを示唆。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=T2TZ0RY4Zk#discussion
[Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #LongSequence #ICML #RewardHacking #PostTraining #Selected Papers/Blogs #KeyPoint Notes #Author Thread-Post Issue Date: 2025-02-07 GPT Summary- 本研究では、大規模言語モデル(LLMs)における長い思考の連鎖(CoTs)推論のメカニズムを調査し、重要な要因を特定。主な発見は、(1) 教師ありファインチューニング(SFT)は必須ではないが効率を向上させる、(2) 推論能力は計算の増加に伴い現れるが、報酬の形状がCoTの長さに影響、(3) 検証可能な報酬信号のスケーリングが重要で、特に分布外タスクに効果的、(4) エラー修正能力は基本モデルに存在するが、RLを通じて効果的に奨励するには多くの計算が必要。これらの洞察は、LLMsの長いCoT推論を強化するためのトレーニング戦略の最適化に役立つ。 Comment
元ポスト:
元ポストのスレッド中に論文の11個の知見が述べられている。どれも非常に興味深い。DeepSeek-R1のテクニカルペーパーと同様、
- Long CoTとShort CoTを比較すると前者の方が到達可能な性能のupper bonudが高いことや、
- SFTを実施してからRLをすると性能が向上することや、
- RLの際にCoTのLengthに関する報酬を入れることでCoTの長さを抑えつつ性能向上できること、
- 数学だけでなくQAペアなどのノイジーだが検証可能なデータをVerifiableな報酬として加えると一般的なreasoningタスクで数学よりもさらに性能が向上すること、
- より長いcontext window sizeを活用可能なモデルの訓練にはより多くの学習データが必要なこと、
- long CoTはRLによって学習データに類似したデータが含まれているためベースモデルの段階でその能力が獲得されていることが示唆されること、
- aha momentはすでにベースモデル時点で獲得されておりVerifiableな報酬によるRLによって強化されたわけではなさそう、
など、興味深い知見が盛りだくさん。非常に興味深い研究。あとで読む。
[Paper Note] Evolving Deeper LLM Thinking, Kuang-Huei Lee+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Test-Time Scaling Issue Date: 2025-01-28 GPT Summary- Mind Evolutionに基づく進化的探索戦略を提案し、大規模言語モデルの推論時の計算量をスケールさせる。候補応答を生成、再結合、洗練することで、推論問題を形式化する必要を回避。自然言語計画タスクにおいて、Best-of-NやSequential Revisionと比較し優れた性能を示し、TravelPlannerおよびNatural Planのベンチマークで98%以上の問題インスタンスを解決。 Comment
Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search, Huanjin Yao+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Supervised-FineTuning (SFT) #MultiModal #NeurIPS #VisionLanguageModel #TreeSearch Issue Date: 2024-12-31 GPT Summary- 本研究では、MLLMを用いて質問解決のための推論ステップを学習する新手法CoMCTSを提案。集団学習を活用し、複数モデルの知識で効果的な推論経路を探索。マルチモーダルデータセットMulberry-260kを構築し、モデルMulberryを訓練。実験により提案手法の優位性を確認。
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, N_A, NAACL'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Dataset #AIAgents #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #NAACL #One-Line Notes Issue Date: 2024-10-20 GPT Summary- LLMsを用いた情報検索強化生成(RAG)システムの性能評価のために、FRAMESという新しい評価データセットを提案。これは、事実に基づく応答、検索能力、推論を統一的に評価するもので、複数の情報源を統合するマルチホップ質問を含む。最新のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に貢献することを目指す。 Comment
RAGのfactuality, retrieval acculacy, reasoningを評価するためのmulti hop puestionとそれに回答するための最大15のwikipedia記事のベンチマーク
元ポスト:
[Paper Note] Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs, Xin Lai+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #DPO #PostTraining Issue Date: 2026-01-30 GPT Summary- 数学的推論はLLMにとって難題であり、正確な推論ステップが求められる。本研究では、人間のフィードバックを活用し、LLMの堅牢性を向上させるStep-DPOを提案。各推論ステップを選好最適化の単位とし、高品質なデータセットを構築。結果、70BパラメータモデルにおいてMATHで約3%の精度向上を実現し、Qwen2-72B-Instructが他のモデルを凌駕する成績を示した。 Comment
openreview: https://openreview.net/forum?id=H5FUVj0vMd
[Paper Note] Lessons from Studying Two-Hop Latent Reasoning, Mikita Balesni+, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #read-later Issue Date: 2025-09-12 GPT Summary- 大規模言語モデル(LLM)の二段階質問応答能力を調査し、思考の連鎖(CoT)の重要性を示す。合成事実を用いた実験で、モデルは二つの合成事実を組み合わせるのに失敗するが、自然な事実との組み合わせでは成功することが確認された。これにより、LLMは潜在的な二段階推論能力を持つが、その能力のスケーリングには不明点が残る。研究者は、LLMの推論能力を評価する際に、ショートカットによる虚偽の成功や失敗に注意する必要があることを強調。 Comment
元ポスト:
下記研究ではエンティティが国の場合は2 step推論ができるという例外が生じており、事前学習のフィルタリングで何か見落としがあるかもしれない可能性があり:
- [Paper Note] Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, ACL'24
下記研究において、完全にmemorizationzが生じない形で事前学習とInference実施(train: John Doe lives in **Tokyo**., Test: The people in the city John Doe is from speak **Japanese**.)されたが、エンティティがcityの場合でしか試されておらず、他のエンティティでも汎化するのか?という疑問があった:
- [Paper Note] Extractive Structures Learned in Pretraining Enable Generalization on Finetuned Facts, Jiahai Feng+, ICML'25
本研究では17種類の他のエンティティでも2 hop reasoningがlatentに実施されていることを確認した。しかし、一つ不思議な点として当初2つの架空の事実をLLMに教えるような学習を試みた場合は。Acc.が0%で、lossも偶然に生じる程度のものであった。これを深掘りすると、
- 合成+本物の事実→うまくいく
- 合成+合成→失敗
- 同一訓練/incontext文書内の合成された事実→うまくいく
という現象が観測され、このことより
- 実世界のプロンプトでの成功は、latent reasoningがロバストに実施されていることを示すわけではなく(事前学習時の同一文書内の共起を反映しているだけの可能性がある)
- 合成データでの2 hop推論の失敗は、latent reasoningの能力を否定するものではない(合成された事実は実世界での自然な事実とは異なるためうまくいっていない可能性がある)
という教訓が得られた、といった話が元ポストに書かれている。
なぜ完全に合成された事実情報では失敗するのだろうか。元論文を読んで事前学習データとしてどのようなものが利用されているかを確認する必要がある。
元ポスト:
[Paper Note] DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving, Yuxuan Tong+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #SyntheticData #Evaluation #Mathematics #NeurIPS Issue Date: 2025-08-30 GPT Summary- 数学問題解決には高度な推論が必要であり、従来のモデルは難しいクエリに対して偏りがあることが明らかになった。そこで、Difficulty-Aware Rejection Tuning(DART)を提案し、難しいクエリに多くの試行を割り当てることでトレーニングを強化。新たに作成した小規模な数学問題データセットで、7Bから70BのモデルをファインチューニングしたDART-MATHは、従来の手法を上回る性能を示した。合成データセットが数学問題解決において効果的でコスト効率の良いリソースであることが確認された。 Comment
[Paper Note] CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution, Ruiyang Xu+, arXiv'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Coding #MultiLingual Issue Date: 2025-08-15 GPT Summary- CRUXEVAL-Xという多言語コード推論ベンチマークを提案。19のプログラミング言語を対象に、各言語で600以上の課題を含む19Kのテストを自動生成。言語間の相関を評価し、Python訓練モデルが他言語でも高い性能を示すことを確認。 Comment
[Paper Note] CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, Alex Gu+, arXiv'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Coding Issue Date: 2025-08-15 GPT Summary- CRUXEvalという800のPython関数からなるベンチマークを提案し、入力予測と出力予測の2つのタスクを評価。20のコードモデルをテストした結果、HumanEvalで高得点のモデルがCRUXEvalでは改善を示さないことが判明。GPT-4とChain of Thoughtを用いた場合、入力予測で75%、出力予測で81%のpass@1を達成したが、どのモデルも完全にはクリアできず、GPT-4のコード推論能力の限界を示す例を提供。
[Paper Note] MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI, Xiang Yue+, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #CVPR Issue Date: 2025-08-09 GPT Summary- MMMUは、大学レベルの専門知識と意図的な推論を必要とするマルチモーダルモデルの評価のための新しいベンチマークで、11,500のマルチモーダル質問を含む。6つの主要分野をカバーし、30種類の画像タイプを使用。既存のベンチマークと異なり、専門家が直面するタスクに類似した課題を提供。GPT-4VとGeminiの評価では、56%と59%の精度にとどまり、改善の余地があることを示す。MMMUは次世代のマルチモーダル基盤モデルの構築に寄与することが期待されている。 Comment
MMMUのリリースから20ヶ月経過したが、いまだに人間のエキスパートのアンサンブルには及ばないとのこと
MMMUのサンプルはこちら。各分野ごとに専門家レベルの知識と推論が求められるとのこと。
[Paper Note] Iterative Reasoning Preference Optimization, Richard Yuanzhe Pang+, NeurIPS'24, 2024.04
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfImprovement #NeurIPS #DPO #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-07-02 GPT Summary- 反復的な好み最適化手法を用いて、Chain-of-Thought(CoT)候補間の推論ステップを最適化するアプローチを開発。修正DPO損失を使用し、推論の改善を示す。Llama-2-70B-ChatモデルでGSM8K、MATH、ARC-Challengeの精度を向上させ、GSM8Kでは55.6%から81.6%に改善。多数決による精度は88.7%に達した。 Comment
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
と似たようにiterativeなmannerでreasoning能力を向上させる。
ただし、loss functionとしては、chosenなCoT+yのresponseに対して、reasoning traceを生成する能力を高めるために、NLL Lossも適用している点に注意。
32 samplesのmajority votingによってより高い性能が達成できているので、多様なreasoning traceが生成されていることが示唆される。
DPOでReasoning能力を伸ばしたい場合はNLL lossが重要。Iterative RPO
[Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #ReinforcementLearning #ICLR #Selected Papers/Blogs #PRM Issue Date: 2025-06-26 GPT Summary- 大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。 Comment
OpenReview: https://openreview.net/forum?id=v8L0pN6EOi
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, Zhihong Shao+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #RLHF #Mathematics #GRPO #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-01-04 GPT Summary- DeepSeekMath 7Bは、120Bの数学関連トークンを用いて事前学習された言語モデルで、競技レベルのMATHベンチマークで51.7%のスコアを達成。自己一貫性は60.9%で、データ選択パイプラインとGroup Relative Policy Optimization (GRPO)の導入により数学的推論能力が向上。Gemini-UltraやGPT-4に迫る性能を示す。 Comment
元々数学のreasoningに関する能力を改善するために提案されたが、現在はオンラインでTruthfulness, Helpfulness, Concisenessなどの改善に活用されているとのこと。
PPOとGRPOの比較。value function model(状態の価値を予測するモデル)が不要なため省メモリ、かつ利用する計算リソースが小さいらしい。
あとサンプルをグループごとに分けて、グループ内でのKLダイバージェンスが最小化されるよう(つまり、各グループ内で方策が類似する)Policy Modelが更新される(つまりloss functionに直接組み込まれる)点が違うらしい。
PPOでは生成するトークンごとにreference modelとPolicy ModelとのKLダイバージェンスをとり、reference modelとの差が大きくならないよう、報酬にペナルティを入れるために使われることが多いらしい。
下記記事によると、PPOで最大化したいのはAdvantage(累積報酬と状態価値(累積報酬の期待値を計算するモデル)の差分;期待値よりも実際の累積報酬が良かったら良い感じだぜ的な数値)であり、それには状態価値を計算するモデルが必要である。そして、PPOにおける状態価値モデルを使わないで、LLMにテキスト生成させて最終的な報酬を平均すれば状態価値モデル無しでAdvantageが計算できるし嬉しくね?という気持ちで提案されたのが、本論文で提案されているGRPOとのこと。勉強になる。
DeepSeek-R1の論文読んだ?【勉強になるよ】
, asap:
https://zenn.dev/asap/articles/34237ad87f8511
[Paper Note] AutoReason: Automatic Few-Shot Reasoning Decomposition, Arda Sevinc+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #QuestionAnswering #Zero/Few/ManyShotPrompting #Chain-of-Thought #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-01-03 GPT Summary- Chain of Thought(CoT)を用いて、暗黙のクエリを明示的な質問に分解することで、LLMの推論能力を向上させる自動生成システムを提案。StrategyQAとHotpotQAデータセットで精度向上を確認し、特にStrategyQAで顕著な成果を得た。ソースコードはGitHubで公開。 Comment
元ポスト:
A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges, Yibo Yan+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Mathematics Issue Date: 2025-01-03 GPT Summary- 数学的推論は多くの分野で重要であり、AGIの進展に伴い、LLMsを数学的推論タスクに統合することが求められている。本調査は、2021年以降の200以上の研究をレビューし、マルチモーダル設定におけるMath-LLMsの進展を分析。分野をベンチマーク、方法論、課題に分類し、マルチモーダル数学的推論のパイプラインやLLMsの役割を探る。さらに、AGI実現の障害となる5つの課題を特定し、今後の研究方向性を示す。
[Paper Note] Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions, Yu Zhao+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfImprovement #read-later #Reading Reflections Issue Date: 2024-12-16 GPT Summary- OpenAI o1がLRMの研究に注力し、伝統的な分野だけでなくRLやオープンエンドな解決にも焦点を当てる。特に、基準が不明瞭な領域への一般化の可能性を探求。Marco-o1はCoT微調整やMCTS、リフレクション機構などの手法を用いて、複雑な実世界の問題解決に最適化されている。 Comment
元ポスト:
Large Reasoning Model (LRM)という用語は初めて見た。
日本語解説: https://www.docswell.com/s/DeepLearning2023/KV1M9P-2024-12-05-125148
[Paper Note] Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, ACL'24
Paper/Blog Link My Issue
#Multi #NLP #Dataset #LanguageModel #Evaluation #Factuality #ACL #Reading Reflections Issue Date: 2024-12-02 GPT Summary- 大規模言語モデル(LLMs)のマルチホップクエリに対する事実の想起能力を評価。ショートカットを防ぐため、主語と答えが共に出現するテストクエリを除外した評価データセットSOCRATESを構築。LLMsは特定のクエリにおいてショートカットを利用せずに潜在的な推論能力を示し、国を中間答えとするクエリでは80%の構成可能性を達成する一方、年の想起は5%に低下。潜在的推論能力と明示的推論能力の間に大きなギャップが存在することが明らかに。 Comment
SNLP'24での解説スライド:
https://docs.google.com/presentation/d/1Q_UzOzn0qYX1gq_4FC4YGXK8okd5pwEHaLzVCzp3yWg/edit?usp=drivesdk
この研究を信じるのであれば、LLMはCoT無しではマルチホップ推論を実施することはあまりできていなさそう、という感じだと思うのだがどうなんだろうか。
Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding, Haolin Chen+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #PostTraining Issue Date: 2024-11-13 GPT Summary- LaTRO(LaTent Reasoning Optimization)を提案し、LLMの推論能力を向上させる新しいフレームワークを構築。推論を潜在分布からのサンプリングとして定式化し、外部フィードバックなしで推論プロセスと質を同時に改善。GSM8KおよびARC-Challengeデータセットで実験し、平均12.5%の精度向上を達成。事前学習されたLLMの潜在的な推論能力を引き出すことが可能であることを示唆。 Comment
元ポスト:
[Paper Note] Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey, Philipp Mondorf+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Evaluation Issue Date: 2024-11-07 GPT Summary- LLMsは推論タスクで顕著な能力を示しているが、その深さは依然として不確かである。これは、浅い精度指標への依存と推論挙動の検証不足に起因する。本論文は、モデルの推論プロセスをより深く理解するための研究をレビューし、一般的な評価方法論を調査する。結果、LLMsは表層的なパターンに依存し、人間との推論の違いを明確にするさらなる研究の必要性が示唆される。 Comment
論文紹介(sei_shinagawa): https://www.docswell.com/s/sei_shinagawa/KL1QXL-beyond-accuracy-evaluating-the-behaivior-of-llm-survey
[Paper Note] RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners, Chi Hu+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #NLP #LanguageModel #Prompting #COLING #Reranking #Initial Impression Notes #LREC Issue Date: 2024-04-07 GPT Summary- LLMの論理的エラーを解決するために、自己ランク付けを可能にする新手法RankPromptを提案。これは、多様な応答を比較し、LLMの文脈的生成能力を活用する。実験ではChatGPTやGPT-4の性能が最大13%向上し、AlpacaEvalデータセットでは人間の判断との74%の一致率を示した。また、応答の順序や一貫性の変動にも強い耐性を持つことが確認された。RankPromptは高品質なフィードバックを引き出す有効な手法である。 Comment
LLMでランキングをするためのプロンプト手法。独立したプロンプトでスコアリングしスコアリング結果からランキングするのではなく、LLMに対して比較するためのルーブリックやshotを入れ、全てのサンプルを含め、1回のPromptingでランキングを生成するような手法に見える。大量の候補をランキングするのは困難だと思われるが、リランキング手法としては利用できる可能性がある。また、実験などでランキングを実施するサンプル数に対してどれだけ頑健なのかなどは示されているだろうか?
[Paper Note] The Impact of Reasoning Step Length on Large Language Models, Mingyu Jin+, ACL'24 Findings, 2024.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Chain-of-Thought #ACL #Length #Findings Issue Date: 2024-01-16 GPT Summary- Chain of Thought(CoT)がLLMの推論能力向上に重要であることが示された。実験により、推論ステップの長さがLLMの性能に与える影響を調査。推論ステップを長くすることで、追加情報なしでも推論能力が向上し、逆に短くすると性能が著しく低下。これは、CoTプロンプトにおけるステップ数の重要性を示している。また、不正確な合理的根拠でも推論を維持できれば良好な結果が得られることが判明。タスクの複雑さに応じて、推論ステップの利点は異なることも観察された。
[Paper Note] Causal Reasoning and Large Language Models: Opening a New Frontier for Causality, Emre Kıcıman+, TMLR'24, 2023.04
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #TMLR #Generalization Issue Date: 2023-05-04 GPT Summary- 本研究では、大規模言語モデル(LLMs)の因果的議論生成能力をベンチマークし、様々なタスクで既存手法を上回る性能を示しました。特に、GPT-3.5および4は因果発見や反事実的推論タスクで高い精度を達成し、データセットの記憶だけでは説明できない能力を持つことが確認されました。しかし、LLMsには予測不可能な失敗モードがあり、改善の余地があることも指摘されています。LLMsは因果分析の労力を削減する可能性があり、今後はLLMsと既存の因果技術を組み合わせたアルゴリズムの開発が期待されます。 Comment
openreview: https://openreview.net/forum?id=mqoxLkX210
tmlr blog: https://medium.com/@TmlrOrg/announcing-the-2025-tmlr-outstanding-certification-e26d548ff011
[Paper Note] Self-Evaluation Guided Beam Search for Reasoning, Yuxi Xie+, NeurIPS'23, 2023.05
Paper/Blog Link My Issue
#BeamSearch #NLP #LanguageModel #SelfCorrection #NeurIPS #Decoding #KeyPoint Notes Issue Date: 2025-10-01 GPT Summary- LLMの推論プロセスを改善するために、段階的自己評価メカニズムを導入し、確率的ビームサーチを用いたデコーディングアルゴリズムを提案。これにより、推論の不確実性を軽減し、GSM8K、AQuA、StrategyQAでの精度を向上。Llama-2を用いた実験でも効率性が示され、自己評価ガイダンスが論理的な失敗を特定し、一貫性を高めることが確認された。 Comment
pj page: https://guideddecoding.github.io
openreview: https://openreview.net/forum?id=Bw82hwg5Q3
非常にざっくり言うと、reasoning chain(=複数トークンのsequence)をトークンとみなした場合の(確率的)beam searchを提案している。多様なreasoning chainをサンプリングし、その中から良いものをビーム幅kで保持し生成することで、最終的に良いデコーディング結果を得る。reasoning chainのランダム性を高めるためにtemperatureを設定するが、アニーリングをすることでchainにおけるエラーが蓄積することを防ぐ。これにより、最初は多様性を重視した生成がされるが、エラーが蓄積され発散することを防ぐ。
reasoning chainの良さを判断するために、chainの尤度だけでなく、self-evaluationによるreasoning chainの正しさに関するconfidenceスコアも導入する(reasoning chainのconfidenceスコアによって重みづけられたchainの尤度を最大化するような定式化になる(式3))。
self-evaluationと生成はともに同じLLMによって実現されるが、self-evaluationについては評価用のfew-shot promptingを実施する。promptingでは、これまでのreasoning chainと、新たなreasoning chainがgivenなときに、それが(A)correct/(B)incorrectなのかをmultiple choice questionで判定し、選択肢Aが生成される確率をスコアとする。
Recursion of Thought: A Divide-and-Conquer Approach to Multi-Context Reasoning with Language Models, Soochan Lee+, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #KeyPoint Notes Issue Date: 2025-01-05 GPT Summary- Recursion of Thought(RoT)という新しい推論フレームワークを提案し、言語モデル(LM)が問題を複数のコンテキストに分割することで推論能力を向上させる。RoTは特別なトークンを導入し、コンテキスト関連の操作をトリガーする。実験により、RoTがLMの推論能力を劇的に向上させ、数十万トークンの問題を解決できることが示された。 Comment
divide-and-conquerで複雑な問題に回答するCoT手法。生成過程でsubquestionが生じた際にモデルに特殊トークン(GO)を出力させ、subquestionの回答部分に特殊トークン(THINK)を出力させるようにSupervisedに学習させる。最終的にTHINKトークン部分は、subquestionを別途モデルによって解いた回答でreplaceして、最終的な回答を得る。
subquestionの中でさらにsubquestionが生じることもあるため、再帰的に処理される。
四則演算と4種類のアルゴリズムに基づくタスクで評価。アルゴリズムに基づくタスクは、2つの数のlongest common subsequenceを見つけて、そのsubsequenceとlengthを出力するタスク(LCS)、0-1 knapsack問題、行列の乗算、数値のソートを利用。x軸が各タスクの問題ごとの問題の難易度を表しており、難易度が上がるほど提案手法によるgainが大きくなっているように見える。
Without Thoughtでは直接回答を出力させ、CoTではground truthとなるrationaleを1つのcontextに与えて回答を生成している。RoTではsubquestionごとに回答を別途得るため、より長いcontextを活用して最終的な回答を得る点が異なると主張している。
感想としては、詳細が書かれていないが、おそらくRoTはSFTによって各タスクに特化した学習をしていると考えられる(タスクごとの特殊トークンが存在するため)。ベースラインとしてRoT無しでSFTしたモデルあった方が良いのではないか?と感じる。
また、学習データにおけるsubquestionとsubquestionに対するground truthのデータ作成方法は書かれているが、そもそも元データとして何を利用したかや、その統計量も書かれていないように見える。あと、そもそも機械的に学習データを作成できない場合どうすれば良いのか?という疑問は残る。
読んでいた時にAuto-CoTとの違いがよくわからなかったが、Related Workの部分にはAuto-CoTは動的、かつ多様なデモンストレーションの生成にフォーカスしているが、AutoReasonはquestionを分解し、few-shotの promptingでより詳細なrationaleを生成することにフォーカスしている点が異なるという主張のようである。
- [Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
Auto-CoTとの差別化は上記で理解できるが、G-Evalが実施しているAuto-CoTとの差別化はどうするのか?という風にふと思った。論文中でもG-Evalは引用されていない。
素朴にはAutoReasonはSFTをして学習をしています、さらにRecursiveにquestionをsubquestionを分解し、分解したsubquestionごとに回答を得て、subquestionの回答結果を活用して最終的に複雑なタスクの回答を出力する手法なので、G-Evalが実施している同一context内でrationaleをzeroshotで生成する手法よりも、より複雑な問題に回答できる可能性が高いです、という主張にはなりそうではある。
- [Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
ICLR 2023 OpenReview:
https://openreview.net/forum?id=PTUcygUoxuc
- 提案手法は一般的に利用可能と主張しているが、一般的に利用するためには人手でsubquestionの学習データを作成する必要があるため十分に一般的ではない
- 限られたcontext長に対処するために再帰を利用するというアイデアは新しいものではなく、数学の定理の証明など他の設定で利用されている
という理由でrejectされている。
[Paper Note] MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning, Xiang Yue+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #InstructionTuning #NumericReasoning #Mathematics #PostTraining #One-Line Notes Issue Date: 2023-09-30 GPT Summary- MAmmoTHシリーズは、数学問題解法に特化したオープンソースのLLMで、MathInstructという指示チューニングデータセットを使用して訓練されています。MathInstructは、中間推論を含む13の数学データセットから構成され、特に6つの新たな推論過程を提供しています。CoTとPoTのハイブリッドを採用することで、異なる思考プロセスを実現し、9つの数学推論データセットで平均16%から32%の精度向上を実現しました。特にMAmmoTH-7BモデルはMATHデータセットで33%、MAmmoTH-34Bモデルは44%を達成し、既存のオープンソースモデルを上回っています。研究は、多様な問題の網羅性とハイブリッド推論の重要性を示しています。 Comment
9つのmath reasoningが必要なデータセットで13-29%のgainでSoTAを達成。
260kの根拠情報を含むMath Instructデータでチューニングされたモデル。
project page:
https://tiger-ai-lab.github.io/MAmmoTH/
[Paper Note] SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning, Ning Miao+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfCorrection #ICLR #Test-Time Scaling #Verification #SelfVerification Issue Date: 2023-08-08 GPT Summary- LLMの段階的推論能力を活用し、自己検証(SelfCheck)を提案してLLM自身が誤りを認識することを目指す。誤りの認識にはゼロショット検証スキームを用い、その結果を基に重み付き投票で回答性能を向上。GSM8K、MathQA、MATHデータセットで評価し、誤り認識の効果と正確性向上を確認。 Comment
これはおもしろそう。後で読む
OpenReview: https://openreview.net/forum?id=pTHfApDakA
Reasoning with Language Model Prompting: A Survey, ACL'23
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Prompting #ACL Issue Date: 2023-07-18 GPT Summary- 本論文では、推論に関する最新の研究について包括的な調査を行い、初心者を支援するためのリソースを提供します。また、推論能力の要因や将来の研究方向についても議論します。リソースは定期的に更新されています。
[Paper Note] StructGPT: A General Framework for Large Language Model to Reason over Structured Data, Jinhao Jiang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #TabularData #One-Line Notes Issue Date: 2023-05-21 GPT Summary- 本研究では、構造化データに基づく質問応答タスクを解決するためにIterative Reading-then-Reasoning(IRR)アプローチ、StructGPTを開発。特化した関数を用いることで、関連証拠を収集し推論を行うプロセスを構築。さらに、外部インターフェースを利用したinvoking-linearization-generation手順を提案し、反復的に解答に近づく。実験結果は、ChatGPTの性能を大幅に向上させ、教師ありチューニングと同等の成果を示す。 Comment
構造化データに対するLLMのゼロショットのreasoning能力を改善。構造化データに対するQAタスクで手法が有効なことを示した。
[Paper Note] Exploring the Curious Case of Code Prompts, Li Zhang+, NLRSE'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- コード風のプロンプトによる構造化推論の性能向上が示されたが、その効果は限られたタスクに留まる。本研究では、davinci系のモデルに対して、QAや感情分析など幅広いタスクでコードとテキストプロンプトを比較し、全体としてコードプロンプトがテキストプロンプトを上回ることはなかった。タスクによってはコードプロンプトが有利な場合もあったが、全てのタスクに当てはまるわけではなく、テキスト指示によるファインチューニングがコードプロンプトの性能向上に寄与することを示した。 Comment
コードベースのLLMに対して、reasoningタスクを解かせる際には、promptもコードにすると10パーセント程度性能上がる場合があるよ、という研究。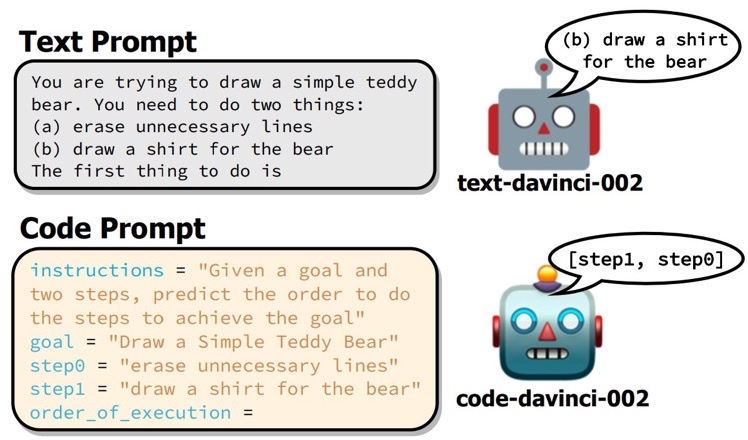
ただし、平均的にはテキストプロンプトの方が良く、一部タスクで性能が改善する、という温度感な模様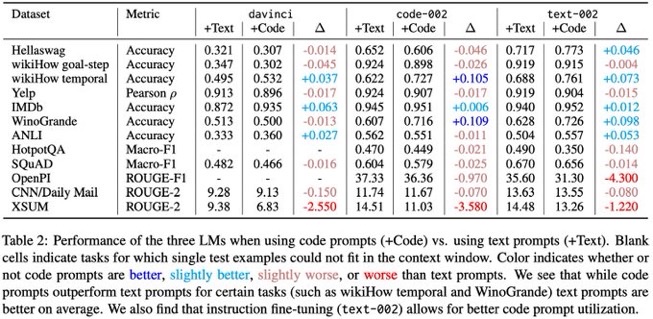
コードベースのモデルをtextでinstruction tuningしている場合でも、効果があるタスクがある。
Controlling Reasoning Effort in LLMs, Sebastian Raschka, 2026.07
Paper/Blog Link My Issue
#Article #Controllable #NLP #LanguageModel #Blog #Length #read-later #Initial Impression Notes Issue Date: 2026-07-19 Comment
元ポスト:
OpenAIのReasoning Effortについては調整方法が公開されていないのでGPT-OSSのテンプレートなどから可能な方法を推測、そのほかOpenWeightモデルについてはテクニカルレポートに記載されている情報からReasoning Effortの調整方法が解説されている
Inkling: Our open-weights model, THINKING MACHINES, 2026.07
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #Blog #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #VisionLanguageModel #UMM #KeyPoint Notes #Reference Collection #AudioLanguageModel #Author Thread-Post Issue Date: 2026-07-16 Comment
HF: https://huggingface.co/thinkingmachines/Inkling
元ポスト:
THINNING MACHINESによる最初のOpenWeightモデル。975B-41B
- フルスクラッチで学習したReasoningモデル
- 1M context window
- text, image, audio, video 45Tトークンで学習
- バランスよくさまざまな領域で性能を発揮するように訓練し、Tinker上でのfinetuningやカスタマイゼーションの良い基盤として機能することを目指した
- vision, audioドメインに関してはencoder freeアーキテクチャを採用
- audio signalの入力は dMel spectrogramsと呼ばれる手法を採用
- [Paper Note] dMel: Speech Tokenization made Simple, Richard He Bai+, arXiv'24, 2024.07
- 画像は40x40のパッチに分割され、4つのhMLPと呼ばれるレイヤーでエンコーディング
- [Paper Note] Three things everyone should know about Vision Transformers, Hugo Touvron+, ECCV'22, 2022.03
- IFの訓練には、Rubric basedなgraderとclaims graderの2種類のgraderを用いることで、helpfulnessとhallucinationを同時に低減
- Rubric basedなgraderはチェックリストに基づいてスコアリング
- claims graderはfactualな主張をagentic web searchを通じてverificationする
- アーキテクチャはDeepSeek V3を踏襲し、256のexpertsと2つのshared expertを採用し、6つのexpertsがactivateされる
- SWAとGlobal attentionの比率は5:1でKV Headは8つ (GQA)
- **相対位置エンコーディングを用いることでRoPEよりもlong contextに対してより高い外挿性能を示した**
- [Paper Note] Self-Attention with Relative Position Representations, Peter Shaw+, NAACL'18
- K, Vのprojection後、**およびattentionとMLPが残差ストリームに合流する前にshort convolutionを導入**
- QKV projection後に convolution を導入するアーキテクチャは下記研究で提案
- [Paper Note] Primer: Searching for Efficient Transformers for Language Modeling, David R. So+, NIPS'21, 2021.09
- optimiserはMuonとAdamWのハイブリッドで、前者は巨大な行列の重みに対して適用し、そのほかは後者を利用
- 重み自体が多様体上に存在するように制約することが有効であったことに着想を得て、weight decayを学習率の2乗に連動させることでモデルの重みの大きさを安定させたとのこと
- Modular Manifolds, Jeremy Bernstein+, THINKING MACHINES, 2025.09
- [Paper Note] Why Gradients Rapidly Increase Near the End of Training, Aaron Defazio, arXiv'25, 2025.06
- 事後学習としては、まずKimi K2.5を含むOpenWeightモデルで合成データ上でSFTをし、その後合成、あるいは人間が作成したenvironment上で大規模なRLを実施
- RLは非同期RLを異様し、ロールアウト数に対して推論能力が対数線形にスケールした。
- 最終的に30Mロールアウト以上のRLを実施した
- システムメッセージを変更し、トークン単位のコストを調整することでreasoning effortを調整
- Controlling Reasoning Effort in LLMs, Sebastian Raschka, 2026.07
- **276B-A12BのInkling-Smallもプレビュー段階にあり、agenticな能力においてInklingに近い性能を達成しており、今後公開予定**
1M context windowを実現した工夫は特に書かれていなかったように感じるが、よく使われるのはKV CacheをコンパクトにするためのSparse Attention、あるいはLinear Attentionなのに対し、本モデルでは使われていないように見える。linear attentionでなくとも、SWAとGlobal Attentionのハイブリッド、かつGQAによって、KV Cacheの肥大化を実用レベルで抑制できるのだろうか。また、外挿性能に関してはRoPEは採用せず、相対位置エンコーディングのを採用したという点が効いているのだろうか。1Mレベルでのcontextでの評価がなさそうに見えるので性能はよくわからない。
RoPEのlong contextでの限界を示した以下の研究を思い出した:
- [Paper Note] RoPE Distinguishes Neither Positions Nor Tokens in Long Contexts, Provably, Yufeng Du+, arXiv'26, 2026.05
Artificial Analysisによる評価:
アーキテクチャでの目新しい点:
所見:
公式:
所見:
Reducing Doom Loops with Final Token Preference Optimization, Liquid.AI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #read-later #Author Thread-Post Issue Date: 2026-07-12 Comment
元ポスト:
Thinking to recall: How reasoning unlocks parametric knowledge in LLMs, Google Research, 2026.06
Paper/Blog Link My Issue
#Article #Analysis #LanguageModel #Blog #read-later #FactualKnowledge #Author Thread-Post Issue Date: 2026-06-26 Comment
元ポスト:
Synthetic Persona Pretraining: Alignment from Token Zero, Minder+, 2026.05
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Alignment #SyntheticData #Blog #Safety #Selected Papers/Blogs #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-25 Comment
元ポスト:
**事前学習の時点で**Harmful/良性/ニュートラルな文書にReflectionに関するassistantの思考過程(何が間違っていて/間違っていなくて、それはなぜか)をappendすることで、道徳的に推論することを学ぶ。
[Paper Note] Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Mathematics #Test-Time Scaling #PostTraining #RLVR #Verification #Physics Issue Date: 2026-05-21 Comment
pj page: https://simplified-reasoning.github.io/SU-01/
元ポスト:
ポイント解説:
Reliable Reasoning, Naoto Iwase, 2026.05
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #Blog #read-later #Author Thread-Post Issue Date: 2026-05-20 Comment
元ポスト:
Teaching Claude why, Anthropic, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Alignment #Safety #PostTraining #KeyPoint Notes #Reading Reflections #Author Thread-Post Issue Date: 2026-05-12 Comment
元ポスト:
- [Paper Note] Agentic Misalignment: How LLMs Could Be Insider Threats, Aengus Lynch+, arXiv'25, 2025.10
のように自身を守るために脅迫メールを送るような挙動が観測されたが、それをなくすことができたという話のようである。
細かい学習データのサンプルなどは記載されていないように見えるが
- 評価時のシナリオと類似したもので正しい挙動を教え込むような方法は、評価のスコアは改善するが、OODに対応できない
- モデルに行動を教えるのではなく、理由を教えることが重要で、これはモデル自身が倫理観に関するジレンマに置かれた状況を解決するというデータではなく、ユーザが倫理的なジレンマを抱えているというシナリオで、モデルが倫理的に塾講された思慮深いアドバイスをするようなデータ(difficult advice dataset)で学習することが非常に効果的であった。
- これは単に正しい答えを教えるのではなく、倫理的な"思考"を教えるため効果的であり、これをさらに発展させ、Claudeの人物像をより詳細に与えることでペルソナをより模範的なものに更新する、具体的には質の高いConstitutionに関する文書と、模範的なAIに関するフィクションの物語を学習させることで、misalignmentを非常に効果的に抑制できることを発見した
という感じだろうか。
トップダウンに正解を教えるのではなく、ボトムアップに根源的に正しい思考過程を誘発するような情報を教える(ある種のPRMのようなものだと思われる)ことで、高い汎化性能を獲得できるということだと思われる。このアプローチは最近のAI Agentにおけるoutcome basedなreward設計などにも一石を投じるような議論に感じる。学習の結果得られる汎化性能を重視していかないと、データセットやEnvironmentを逐一構築して課題を潰していく必要があり、キリがないと思う。
Advancing voice intelligence with new models in the API, OpenAI, 2026.05
Paper/Blog Link My Issue
#Article #NLP #SpeechProcessing #MultiLingual #Proprietary #TTS #Realtime #Author Thread-Post #SpeechToSpeech Issue Date: 2026-05-10 Comment
元ポスト:
GPT-Realtime-2
MolmoAct 2: An open foundation for robots that work in the real world, Ai2, 2026.05
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #OpenSource #read-later #Robotics #VisionLanguageActionModel #Author Thread-Post Issue Date: 2026-05-08 Comment
元ポスト:
関連:
- [Paper Note] MolmoAct: Action Reasoning Models that can Reason in Space, Jason Lee+, arXiv'25
dataset:
https://huggingface.co/collections/allenai/molmoact2-datasets
models:
https://huggingface.co/collections/allenai/molmoact2-models
著者ポスト:
著者ポスト2:
著者ポスト3:
Cosmos-Reason2-32B, Nvidia, 2026.04
Paper/Blog Link My Issue
#Article #NLP #OpenWeight #VisionLanguageModel #Robotics #EmbodiedAI Issue Date: 2026-05-01 Comment
元ポスト:
Gemini Robotics-ER 1.6: Powering real-world robotics tasks through enhanced embodied reasoning, Google Deepmind, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Proprietary #Robotics #VisionLanguageActionModel #SpatialUnderstanding #Reference Collection #Initial Impression Notes #Author Thread-Post #MultiView Issue Date: 2026-04-15 Comment
元ポスト:
おー、とうとうDeepmindからVLAがでた。プロプライエタリモデル
私が知らなかっただけで、以前からリリースされていたようだ:
- Building the Next Generation of Physical Agents with Gemini Robotics-ER 1.5, Google, 2025.09
-
https://developers.googleblog.com/en/building-the-next-generation-of-physical-agents-with-gemini-robotics-er-15/
ポイント解説:
約12兆トークンの良質なコーパスで学習した新たな国産LLM「LLM-jp-4 8Bモデル」「LLM-jp-4 32B-A3Bモデル」をオープンソースライセンスで公開 ~一部ベンチマークでGPT-4oやQwen3-8Bを上回る性能を達成~, NII, 2026.04
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #OpenWeight #Japanese #OpenSource #mid-training #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-04-03 Comment
8BモデルはLlama-2アーキテクチャ、32B-A3.8BモデルはQwen3-MoEアーキテクチャで、フルスクラッチ学習をすることで実現[^1]。
19.5Tトークン(概算として、日本語0.7Tトークン、英語17.8Tトークン、中国語・韓国語0.85Tトークン、プログラムコード0.2Tトークン)のインターネット上の公開データや政府・国会の文書を収集し(LLM-jp-3.1のデータの6倍の規模)し事前学習データを構築、DataMixtureを最適化し10.5Tトークンを事前学習で利用。
中間学習では、事前学習データにInstruction Pretraining[^2]データを含む合成データを加え1.2Tトークンを利用。
その後最終的にInstruction Tuningを、日本語、英語合計22種類のデータで実施(元記事ではチューニングと呼称されているがおそらくInstruction Tuningだと思われる)。
MTBenchでは、GPT-4o, gpt-oss-20B, Qwen3-8Bと同等以上の性能、日本語MTBench[^3]では、GPT-4o, gpt-oss-20B, Qwen3-8Bを上回る性能とのこと。MTBenchで用いるLLM-as-a-JudgeのモデルとしてはGPT-5.4を利用とのこと。
[^1]: つまり、モデルのパラメータは完全に新規で学習されており、ベースとして既存OpenWeightモデルを利用していない点に注意。
[^2]: Instruction Pretrainingは、LLM-jp-3.1の頃から実施されている:
LLM-jp-3.1 シリーズ instruct4 の公開, LLM-jp, 2025.05
[Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, arXiv'24, 2024.06
[^3]: MT-Benchの概要については
[Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
も参照のこと。
フルスクラッチモデル点に関する説明:
HF:
https://huggingface.co/collections/llm-jp/llm-jp-4-models
Reasoningモデルもある!!!
関連:
- PLaMo 3.0 Prime β版, PFN, 2026.03
上記PLaMo 3.0に続いて、国内でのフルスクラッチReasoningモデルは二例目だろうか。
Gemma 4: Byte for byte, the most capable open models, Google, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #AIAgents #MultiModal #SpeechProcessing #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #3D (Video) #One-Line Notes #Reference Collection #AudioLanguageModel #audio #text #Initial Impression Notes Issue Date: 2026-04-02 Comment
元ポスト:
2B, 4B, 26BのMoEモデルと31BのDenseモデルの4種類のモデルファミリーで、マルチモーダル(vision)対応。2B, 4Bはaudioも入力として扱える。
edgeデバイス向けのモデルは128k, 他は256kのコンテキストウィンドウ。140+の多言語サポート。
Apache 2.0ライセンス
arenaで同サイズのモデル群でSoTAといった話がブログ中に記述されている。
モデルカードには一般的なベンチマーク群とのスコアも記載されている。
https://ai.google.dev/gemma/docs/core/model_card_4?hl=ja
(そもそも既存のベンチマークにもコンタミネーションがあると思われるが、)arenaに関しては特定の企業に対してデータを提供し、複数のモデルの亜種をテストできるという慣行があり、リーダーボードにバイアスがあるであろう点には注意:
- [Paper Note] The Leaderboard Illusion, Shivalika Singh+, NeurIPS'25
artificial analysisによる評価:
Qwenがproprietaryになったことから、ライセンス的に使いやすく、日本語に強そうなモデルとしては筆頭ではなかろうか。日本語性能が気になる。
アーキテクチャ解説:
ポイント解説:
所見:
attentionのscaleをsqrt(d)でスケールさせる代わりに、QK-norm, V normを適用するなど。
NvidiaによるNVFP4へのpost-trainingによる量子化:
https://huggingface.co/nvidia/Gemma-4-31B-IT-NVFP4
量子化後の性能も比較されており、知識、数学、コーディング、terminac useなど6種類のベンチマークでオリジナルのモデルと遜色ない性能が出ている旨記載されている。
解説:
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4
所見(encoder-freeにした裏側でパッチ化→projection + x/y軸のpositional embeddingを実施している話):
Trinity-Large-Thinking: Scaling an Open Source Frontier Agent, Arcee, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-04-02 Comment
元ポスト:
HF: https://huggingface.co/collections/arcee-ai/trinity-large-thinking
PLaMo 3.0 Prime β版, PFN, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Japanese #Selected Papers/Blogs #In-Depth Notes #Surface-level Notes Issue Date: 2026-03-19 Comment
元ポスト:
日本国内初のフルスクラッチReasoningモデル
## 公式発表のまとめ
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
によってcontext windowを64Kまで拡張(PLaMo 2.2 Primeの2倍)。
事後学習データの見直し(新たなオープンデータセット追加, 独自データとして、日本語指示追従能力, tool use, long horizon QA, 医療分野, STEM, RAG性能向上のためのデータ)を実施し、SFT, DPO, RLの流れで学習を実施。SFT, DPOについてはreasoning trajectoryもLossで考慮するように変更。SFT, DPO向けデータについてはreasoning trajectoryを合成したものを利用。
RLは今回初めて導入し学習を安定させるための工夫を取り入れているとのこと。Reference Answerとの比較と表層的な特徴から報酬を計算する関数を実装した、という書かれ方をしている。
gpt-oss-120B(memium)との比較で言うと
指示追従性能が日本語、英語ともによりも高く、医療分野のQA(国家試験を除く)、英語、日本語での対話能力で勝っている。また、法令分野のQAは同等である。
単一ツールや複数ツールからの選択は同等、multi turnの場合はPLaMo2.2から大幅に性能向上しているもののgpt-ossよりも劣る。また、long contextのQA、医療分野の国家試験QA、STEM分野のQAや数学的な推論能力は大幅に前回モデルよりも向上したが、まだgpt-ossなどには届いていない、という感じに見える。
アーキテクチャについては、一新したという話とRoPEベースということ以外はよくわからない。
## 筆者の憶測と感想
※以下、筆者の憶測を多く含んだ感想です。ただ筆者が勝手に想像して自分なりに考えてみているだけです。
DPOにNLL lossを追加することでreasoningを強化できることは下記研究で示されている:
- [Paper Note] Iterative Reasoning Preference Optimization, Richard Yuanzhe Pang+, NeurIPS'24, 2024.04
RLの報酬に関して、表層的な特徴とReference Answerとの比較から最適な報酬を計算とのことなので、おそらく何らかのVerificationのための仕組みと、Rubric-basedなLLM-as-a-Judgeだろうか?Reward Modelという書かれ方はしていない。
RLについては安定性のある手法を採用したとのことだが、DAPO、
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
あるいはRLのスケーリング則を導いた研究でDAPOよりも安定性と最終到達性能において優れていることが示された
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
CISPOあたりだろうか:
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
あとは安定性という観点で言うと、inference/trainingエンジンでのtraining-inference gapの課題についても対処している可能性がある。
- Hot topics in RL, Kimbo, X, 2025.12
- [Paper Note] Beyond Precision: Training-Inference Mismatch is an Optimization Problem and Simple LR Scheduling Fixes It, Yaxiang Zhang+, arXiv'26, 2026.02
思考過程が英語ということは、言語間で能力は転移し、かつ事前学習データとしてはリソースが豊富な英語が多く含まれると想像すると、明示的(strong LLMでtrajectoryを合成したものを加える系の話)あるいはデータに自然と現れるreasoningの挙動から事前学習中にreasoning能力が暗黙的に学習されることを踏まえ、SFTでreasoning能力を強化する際に(日本語よりも英語の方が効果的な可能性が高く)英語でのtrajectoryを合成したという感じだろうか(いつか日本語のreasoning trajectoryを出力するモデルも見てみたいなあ)。
Multi Turnのtool useの性能向上に関して、AI Agent分野のlong horizonな合成データを合成するアプローチや、Sink Tokenの活用や、トークン単位でsink tokenを計算することに相当するHead wise gated attentionなどはしているのだろうか。
- [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- [Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
また、アーキテクチャに関してはcontext windowが海外のフロンティアモデルと比較してまだ小さめであるが、今後context windowを大きくするにあたって、オンポリシーRLでのロールアウト時間がボトルネックとなることが考えられ、Mamba(=linear attention)系のアーキテクチャをハイブリッドや、DSA系のsparse attentionなどの採用によるアーキテクチャ起因の計算コスト低減(現在どのようなアーキテクチャなのかは全くわからないが)、あるいはin-flight-updateのような学習エンジン側での効率化なども必要になるのではなかろうか(現在どういうエンジンなのかは全くわからないが)。
- [Paper Note] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, DeepSeek-AI+, arXiv'25, 2025.12
- [Paper Note] PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence
Generation, Alexandre Piché+, arXiv'25, 2025.09
Moondream 3 Preview: Frontier-level reasoning at a blazing speed, Moondream, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #EfficiencyImprovement #NLP #FoundationModel #SmallModel #OpenWeight #Selected Papers/Blogs #VisionLanguageModel #KeyPoint Notes Issue Date: 2026-03-12 Comment
HF: https://huggingface.co/moondream/moondream3-preview
9B-A2Bの小規模なVLMで、
- visual reasoning: 小規模だが実タスクに適用可能なvisual reasoning性能
- trainable: Visual系のタスクは人間でもzero shotではできないことが多く、簡単にfinetuningできることが重要で
- fast: vision系のアプリケーションはリアルタイムのlavencyが求められることが多く
- inexpensive: 安くスケーラブルでなければならない
をテーマにしたモデルのようである。
object detection, pointing, 構造化された出力(犬の群の個々の犬の毛と首輪の色動画)、OCRなどの様々なタスクが実行可能で、GPT5, Gemini 2.5 Flash, Claude 4 Sonnetをこの規模感のモデルで、objec' detection, counting, document understanding, hallucinationに関するベンチマークで上回る。
前身のモデルであるmoondream2は、5Mダウンロードを達成したようだ
vikhyatk/moondream2
Open-Sourcing Sarvam 30B and 105B, sarvam, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2026-03-10 Comment
元ポスト:
Reasoning models struggle to control their chains of thought, and that’s good, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #Controllable #NLP #Dataset #LanguageModel #Chain-of-Thought #Evaluation #Blog #read-later #Author Thread-Post Issue Date: 2026-03-06 Comment
元ポスト:
著者ポスト:
AReaL: A Large-Scale Asynchronous Reinforcement Learning System, inclusionAI, 2026.03
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #ReinforcementLearning #Repository #OpenSource #read-later #Asynchronous Issue Date: 2026-03-05 Comment
元ポスト:
Introducing Mercury 2, inception, 2026.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #DiffusionModel #Blog #Proprietary #Selected Papers/Blogs #One-Line Notes Issue Date: 2026-02-27 Comment
元ポスト:
1092 token/secのproprietary (reasoning) dLLM
関連:
- [Paper Note] Mercury: Ultra-Fast Language Models Based on Diffusion, Inception Labs+, arXiv'25
Artificial Analysisのベンチマーキング結果とスループットの散布図:
スループット/性能比において明らかに抜きんでている。
GPT-OSS Swallow, Swallow LLM, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Japanese Issue Date: 2026-02-21 Comment
元ポスト:
第120回医師国家試験(2026)を解かせてみた結果:
Qwen3 Swallow, Swallow LLM, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Japanese #MoE(Mixture-of-Experts) Issue Date: 2026-02-21 Comment
元ポスト:
Ling-2.5-1T, inclusionAI, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-02-16 Comment
Ringに続いてLingもリリース
関連:
- Ring-1T-2.5-FP8, inclusionAI, 2026.02
元ポスト:
Building Olmo in the Era of Agents, Nathan Lambert, LTI Colloquim, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #Survey #NLP #LanguageModel #AIAgents #Slide #OpenSource #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-02-16 Comment
元ポスト:
うーんこれは時間をとってしっかり読んで色々まとめたい・・・
[Paper Notes] Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity, Bytedance Seed, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #AIAgents #Proprietary #VisionLanguageModel Issue Date: 2026-02-16 Comment
元ポスト:
所見:
Gemini 3 Deep Think: Advancing science, research and engineering, Google, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #Mathematics #Proprietary #SoftwareEngineering #VisionLanguageModel #Science Issue Date: 2026-02-13 Comment
まずはUltra Subscriberに公開し、その後徐々にAPIアクセスを解禁していくとのこと。
LiveCodeBench:
Ring-1T-2.5-FP8, inclusionAI, 2026.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #AIAgents #Attention #LongSequence #OpenWeight #LongHorizon #LinearAttention Issue Date: 2026-02-12 Comment
元ポスト:
関連:
- Ring-1T, inclusionAI, 2025.10
MLA + lightning linear attentionのハイブリッド
- MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
- [Paper Note] Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention, Zhen Qin+, ICML'24, 2024.05
Intern-S1-Pro, internlm, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #PositionalEncoding #OpenWeight #MoE(Mixture-of-Experts) #VisionLanguageModel #Science Issue Date: 2026-02-05 Comment
元ポスト:
ポイント解説:
関連:
- [Paper Note] Intern-S1: A Scientific Multimodal Foundation Model, Lei Bai+, arXiv'25, 2025.08
Fourier Position Encoding (FoPE) + upgraded time-series modeling
MedReason-Stenographic, openmed-community, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #QuestionAnswering #Chain-of-Thought #SyntheticData #Evaluation #Medical #KeyPoint Notes Issue Date: 2026-01-12 Comment
元ポスト:
MiniMax M2.1を用いてMedical QAに対してreasoning traceを生成。生成されたreasoning traceをstenographic formatと呼ばれる自然言語からフィラーを排除し、論理の流れのみをsymbolicな表現に変換することで合成されたデータセットとのこと。
ユースケースとしては下記とのこと:
> 1. Train reasoning models with symbolic compression
> 2. Fine-tune for medical QA
> 3. Research reasoning compression techniques
> 4. Benchmark reasoning trace quality
個人的には1,3が興味深く、symbolを用いてreasoning traceを圧縮することで、LLMの推論時のトークン効率を改善できる可能性がある。
が、surfaceがシンボルを用いた論理の流れとなると、汎化性能を損なわないためにはLLMが内部でシンボルに対する何らかの強固な解釈が別途必要になるし、それが多様なドメインで機能するような柔軟性を持っていなければならない気もする。
AI Safetyの観点でいうと、論理の流れでCoTが表現されるため、CoTを監視する際には異常なパターンがとりうる空間がshrinkし監視しやすくなる一方で、surfaceの空間がshrinkする代わりに内部のブラックボックス化された表現の自由度が高まり抜け道が増える可能性もある気がする。結局、自然言語もLLMから見たらトークンの羅列なので、本質的な課題は変わらない気はする。
NVIDIA Cosmos Reason 2 Brings Advanced Reasoning To Physical AI, Nvidia, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LongSequence #SmallModel #OpenWeight #ObjectLocalization #VisionLanguageModel #Robotics #SpatialUnderstanding #EmbodiedAI #Physics Issue Date: 2026-01-06 Comment
HF: https://huggingface.co/nvidia/Cosmos-Reason2-8B?linkId=100000401175768
元ポスト:
VAETKI, NC-AI-consortium, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-01-03 Comment
元ポスト:
Solar-Open-100B, upstage, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #Korean Issue Date: 2026-01-03 Comment
元ポスト:
ポイント解説:
K-EXAONE-236B-A23B, LG AI Research, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-01-03 Comment
関連:
- EXAONE-Deep-32B, LG AI Research, 2025.03
Multi Token Prediction
Sliding Window Attention
256k context length
MoE
元ポスト:
A.X-K1, SK Telecom, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #Korean Issue Date: 2026-01-03 Comment
元ポスト:
Reverse Engineering a Phase Change in GPT's Training Data... with the Seahorse Emoji 🌊🐴, PRATYUSH MAINI, 2025.12
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #ChatGPT #SelfCorrection #mid-training #One-Line Notes Issue Date: 2025-12-28 Comment
元ポスト:
Is there seahorse emoji?という質問に対するLLMのreasoning trajectoryと、self correctionの挙動が、OpenAIのどの時点のモデルで出現するか、しないかを線引くことで、mid-trainingにself correction形式のデータが追加されたのがいつ頃なのかを考察している。
Aligning to What? Rethinking Agent Generalization in MiniMax M2, MiniMaxAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Alignment #AIAgents #Blog #read-later Issue Date: 2025-12-27 Comment
元ポスト:
GLM-4.7: Advancing the Coding Capability, Z.ai, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #OpenWeight #SoftwareEngineering #One-Line Notes #Reference Collection Issue Date: 2025-12-25 Comment
元ポスト:
HF: https://huggingface.co/zai-org/GLM-4.7
デザインアリーナでtop2:
Artificial Intelligence Indexにおいて、OpenModelの中でトップ:
GLM-4.6と比較して、コーディング/SWE, reasoning, tooluseなどの能力が大幅に向上
Interleaved Thinking, Preserved Thinking, Turn-level Thinkingの3つの特性がある。
Interleaved Thinkingは全てのレスポンスとtool callingの前にreasoningを挟むことで、IFや生成品質を向上。
Preserved Thinkingは過去のターンの全てのthinking blockのトークンを保持し、再計算もしないのでマルチターンでの一貫性が増す。
Turn-level Thinkingはターンごとにreasoningを実施するか否かをコントロールでき、latency/costを重視するか、品質を重視するかを選択できる、といった特徴がある模様。
モデルサイズは358B
OpenHands trajectories with Qwen3 Coder 480B, Nebius blog, 2025.12
Paper/Blog Link My Issue
#Article #Dataset #LanguageModel #ReinforcementLearning #AIAgents #Blog #Coding #SoftwareEngineering #PostTraining Issue Date: 2025-12-24 Comment
元ポスト:
MiniMax M2.1: Significantly Enhanced Multi-Language Programming, Built for Real-World Complex Tasks, MiniMax, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Coding #SmallModel #OpenWeight Issue Date: 2025-12-24 Comment
元ポスト:
解説:
ByteDance Doubao-Seed-1.8 Review, toyama nao, Zhihu, 2025.12
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Evaluation #MultiModal #Proprietary #VisionLanguageModel Issue Date: 2025-12-20 Comment
元ポスト:
Gemma Scope 2: helping the AI safety community deepen understanding of complex language model behavior, Google Deepmind, 2025.12
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Safety #KeyPoint Notes #SparseAutoencoder #Transcoders #CircuitAnalysis Issue Date: 2025-12-20 Comment
元ポスト:
関連:
- [Paper Note] Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24
- dictionary_learning, Marks+, 2024
- [Paper Note] Transcoders Find Interpretable LLM Feature Circuits, Jacob Dunefsky+, arXiv'24, 2024.06
- [Paper Note] Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Bart Bussmann+, ICLR'25, 2025.03
- [Paper Note] Transcoders Beat Sparse Autoencoders for Interpretability, Gonçalo Paulo+, arXiv'25, 2025.01
(↓勉強中なので誤りが含まれる可能性大)
Sparse Auto Encoder (SAE; あるlayerにおいてどのような特徴が保持されているかを見つける)とTranscoder (ある層で見つかった特徴と別の層の特徴の関係性を見つける)を用いて、Gemma3の回路分析が行えるモデル・ツール群をリリースした、という話に見える。
応用例の一つとして、たとえば詐欺メールをinputしたときに、詐欺関連する特徴量がどのトークン由来で内部的にどれだけ活性したかを可視化できる。
可視化例:
Evaluating chain-of-thought monitorability, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Chain-of-Thought #Evaluation #Safety #KeyPoint Notes #Monitorability Issue Date: 2025-12-19 Comment
元ポスト:
Monitorabilityの定義が記述されているので覚えておくとよいかもしれない。
Monitorabilityを一言でいうと、"エージェントの挙動に関する重要な性質を正確に予測できる能力"ということっぽい。
Monitorabilityは以下の2つの側面を持ち、
>- Monitors. We could make monitors smarter in various ways, and we would like our evaluations to give higher scores to monitors that can make better predictions about an agent’s behavior.
>- Agents. There are many observations of the agent that could be given to the monitor, including the agent’s actions, outputs, neural activations, and recently with the advent of reasoning models, the chain-of-thought. It’s possible for some agents to have thoughts that are harder to understand than others, and so we would like our monitorability evaluations to be able to compare agents and not just monitors.
モニターそのものの賢さと、モニタリングされるエージェントも理解しやすいものとしづらいものがいるため、モニターの性能だけじゃなくてエージェントそのものも評価の対象にする必要がある。
monitarable / unmonitorable なCoTのサンプルとして以下が挙げられている。これは実際には実現不可能なコーディング課題が与えられているらしいのだが、左側はtestをpassしている(つまりなんかチートした)がそのことについてはCoTに言及されていない。一方、右側はチートに関して検討する様子がCoTに記述されており、これを見ることでユーザはモデルのよろしくない挙動に気付ける。
Gemini 3 Flash: frontier intelligence built for speed, Google, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Distillation #Proprietary #VisionLanguageModel #One-Line Notes #Reference Collection Issue Date: 2025-12-18 Comment
元ポスト:
Gemini 2.5 Proよりも3倍高速でかつ様々なベンチマークで上回っているとのこと。素晴らしい。Gemini 3 Proと比較しても基本的なQAや数学的な能力(reasoning能力)は性能に遜色なく、long sequence/contextの取り扱いでは明確に劣っている、という感じに見えるので、普段使いではこちらでも困らなそうに感じる。
Hallucination Rateが非常に高いとのことだが果たして:
Proからlogit baseな蒸留をして事前学習(=distillation pretraining)をしているっぽい?
Evaluating AI’s ability to perform scientific research tasks, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Evaluation #Science #KeyPoint Notes Issue Date: 2025-12-17 Comment
元ポスト:
HF: https://huggingface.co/datasets/openai/frontierscience
physics, chemistry, biologyの分野の専門家が作成した問題によって構成されるPh.D levelの新たなscientificドメインのベンチマークとのこと。OlympiadとResearchの2種類のスプリットが存在し、Olympiadは国際オリンピックのメダリストによって設計された100問で構成され回答は制約のある短答形式である一方、Researchは博士課程学生・教授・ポスドク研究者などのPh.Dレベルの人物によって設計された60個の研究に関連するサブタスクによって構成されており、10点満点のルーブリックで採点される、ということらしい。
公式アナウンスではGPT-5.2がSoTAでResearchの性能はまだまだスコアが低そうである。
Olmo 3.1, Ai2, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2025-12-13 Comment
元ポスト:
Instruction Followingのベンチマークスコアが、他モデルと比較して非常に高いように見える。
GPT-5.2 が登場 専門的な業務や長時間稼働するエージェント向けの、最先端のフロンティアモデル。, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ChatGPT #GenerativeAI #Proprietary #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-12-12 Comment
元ポスト:
OpenAIがGPT-5.2をリリースし、再び様々なベンチマークにおいてGemini 3 Proをoutperform。
フロントエンド開発(デザイン)(アリーナ形式)ではOpus, Gemini 3 Proの勝利らしい:
https://www.designarena.ai
ポイント解説:
GDPval:
- [Paper Note] GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks, Tejal Patwardhan+, arXiv'25, 2025.10
- GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09
GDPvalのclearwinがGPT-5.2- Thinkingで49.8%なので、14年程度の専門家がこなす米国主要産業の一部のタスクは数値上は置き換え可能という風に見える。Proに至っては60.0%である。
が、GDPvalはたとえば以下のようなlimitationがあり、数値の解釈には注意が必要である:
- 完全なcontextが与えられる前提
- 暗黙知が多いタスクは対象外
- 自己完結型で他社とのコミュニケーションが必要とされないタスクを対象
- 1職種あたり30タスク程度の限定的な網羅性
- コンピュータを利用したタスクのみ
- ...
実際の現場で活用しようと思うと、完全なcontextを揃えられるか、揃わない場合に不完全なcontextでタスクを遂行できるか、そのための社内での運用フローの整備等、モデルを活用するための周辺のシステムや運用フローの設計が重要(かつ膨大)である点には(ベンチマークのスコアを見ると驚くべき進歩だが)留意する必要がある。
Vals AI IndexというGDPvalに類似したベンチマークでもSoTAとのこと:
関連:
非常に簡単な論理的な推論でも誤る例:
nomos-1, NousResearch, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Mathematics #OpenWeight #One-Line Notes Issue Date: 2025-12-11 Comment
元ポスト:
30Bの強力な数学モデルで、(同じハーネスでテストした結果)Qwen3-30ba3b-Thinking-2507を大幅に上回る性能を持つとのこと。
Introducing the Yupp SVG AI Leaderboard, YUPP, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Coding Issue Date: 2025-12-06 Comment
元ポスト:
SVG生成においてもGemini 3 Proが強い
[Paper Note] Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail, Pavone+, Nvidia, 2025.10
Paper/Blog Link My Issue
#Article #Dataset #ReinforcementLearning #SmallModel #OpenWeight #Robotics #VisionLanguageActionModel #Realtime #AutonomousVehicle Issue Date: 2025-12-06 GPT Summary- AR1は因果連鎖推論と軌道計画を統合した視覚–言語–行動モデルであり、自律運転の意思決定を強化します。主な革新は、因果連鎖データセットの構築、モジュラーVLAアーキテクチャの導入、強化学習を用いた多段階トレーニング戦略です。評価結果では、AR1は計画精度を最大12%向上させ、推論の質を45%改善しました。リアルタイムパフォーマンスも確認され、レベル4の自律運転に向けた実用的な道筋を示しています。 Comment
HF: https://huggingface.co/nvidia/Alpamayo-R1-10B
元ポスト:
Nemotron-Content-Safety-Reasoning-4B, Nvidia, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Conversation #SmallModel #OpenWeight #Safety #Safeguard Issue Date: 2025-12-03 Comment
元ポスト:
Introducing Amazon Nova 2 Lite, a fast, cost-effective reasoning model, AWS, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Proprietary Issue Date: 2025-12-03 Comment
元ポスト:
関連:
- Introducing Amazon Nova, our new generation of foundation models, AWS, 2024.12
[Paper Note] DeepSeek-Math-V2, DeepSeekAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Mathematics #read-later #Selected Papers/Blogs #Verification #One-Line Notes #Reference Collection #GenerativeVerifier Issue Date: 2025-11-27 GPT Summary- 大規模言語モデル(LLM)は数学的推論において進展を遂げており、強化学習を用いて定量的推論コンペティションでのパフォーマンスを向上させている。しかし、最終回答の精度向上が正しい推論を保証しない問題や、厳密な導出が必要なタスクに対する限界がある。自己検証可能な数学的推論を目指し、定理証明のためのLLMベースの検証器を訓練し、生成器が自らの証明の問題を特定・解決するよう奨励する方法を提案。結果として得られたモデルDeepSeekMath-V2は、強力な定理証明能力を示し、国際数学オリンピックやプットナム競技会で高得点を記録した。これにより、自己検証可能な数学的推論が数学AIシステムの発展に寄与する可能性が示唆される。管理人コメント:モデル単体でIMO金メダル級を達成とのこと。outcomeに基づくRLVRからtrajectoryそのものをcritiqueし、その情報に基づいて再生成するといったループを繰り返す模様?このアプローチは数学以外のドメインでも有効な可能性があるので興味深い。 Comment
元ポスト:
HF: https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
所見:
所見:
どのように高品質なverifierを構築し、高品質なデータ生成パイプラインを構築するか、という内容が記述されているらしい:
報酬に対する理解補助のための注釈:
ポイント解説:
verifier: proofsをスコアリングできるようRLで学習される
meta verifier: verifierの批評を確認する
generator: より良い証明を書きself checkもできるようverifierによるreward signalによりRLで訓練される
の三刀流らしい。
ポイント解説:
ポイント解説:
所見:
SIMA 2: An Agent that Plays, Reasons, and Learns With You in Virtual 3D Worlds, Google DeepMind, 2025.11
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Blog #ComputerUse #VisionLanguageModel #3D (Scene) #Game Issue Date: 2025-11-14 Comment
元ポスト:
もはやAIがゲームをできるのは当たり前の時代だが、どのくらいOODに汎化するのかは気になる。
GPT-5.1: A smarter, more conversational ChatGPT, OpenAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ChatGPT #Blog #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Routing #One-Line Notes #Reference Collection Issue Date: 2025-11-13 Comment
元ポスト:
instantモデルはよりあたたかい応答でより指示追従能力を高め、thinkingモデルは入力に応じてより適応的に思考トークン数を調整する。autoモデルは入力に応じてinstant, thinkingに適切にルーティングをする。
所見:
Artificial Analysisによるベンチマーキング:
GPT-5.1-Codex-maxの50% time horizon:
SYNTH: the new data frontier, pleias, 2025.11
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #LanguageModel #SyntheticData #One-Line Notes Issue Date: 2025-11-12 Comment
元ポスト:
SoTAなReasoning能力を備えたSLMを学習可能な事前学習用合成データ
元ポスト:
Introducing Kimi K2 Thinking, MoonshotAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #OpenWeight #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-11-07 Comment
HF: https://huggingface.co/moonshotai
元ポスト:
coding系ベンチマークでは少しGPT5,Claude Sonnet-4.5に劣るようだが、HLE, BrowseCompなどではoutperform
tooluseのベンチマークであるtau^2 Bench TelecomではSoTA
モデルの図解:
INT4-QATに関する解説:
INT4-QATの解説:
Kimi K2 DeepResearch:
METRによる50% timehorizonの推定は54分:
ただしサードパーティのinference providerによってこれは実施されており、(providerによって性能が大きく変化することがあるため)信頼性は低い可能性があるとのこと。
METRでの評価でClaude 3.7 Sonnetと同等のスコア:
openweightモデルがproprietaryモデルに追いつくのはsoftwere engineeringタスク(agenticなlong horizon+reasoningタスク)9ヶ月程度を要しているとのこと
gpt-oss-safeguard, OpenAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Safety #One-Line Notes #Safeguard Issue Date: 2025-10-30 Comment
元ポスト:
blog: https://openai.com/index/introducing-gpt-oss-safeguard/
ポリシーとそのポリシーに従うべきコンテンツが与えられたときに、コンテンツを分類するタスクを実施できる汎用的なreasoningモデル。つまり、任意のポリシーを与えて追加の学習なしでpromptingによってコンテンツがポリシーのもとでsafe/unsafeなのかを分類できる。
gpt-ossをreinforcbment finetuningしているとのこと。
Introducing MiMo-Audio, LLM-Core Xiaomi, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #InstructionTuning #SpeechProcessing #SmallModel #OpenWeight #Zero/FewShotLearning #Selected Papers/Blogs #UMM #AudioLanguageModel Issue Date: 2025-10-25 Comment
HF: https://huggingface.co/collections/XiaomiMiMo/mimo-audio
元ポスト:
text, audioを入力として受け取り、text, audioを出力するAudioLanguageModel
Knowledge Flow: Scaling Reasoning Beyond the Context Limit, Zhuang+, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Test-Time Scaling #read-later #One-Line Notes #Test-time Learning Issue Date: 2025-10-21 Comment
元ポスト:
モデルのロールアウトの結果からattemptから知識リストをiterativeに更新(新たな知識を追加, 古い知識を削除 or 両方)していくことによって、過去のattemptからのinsightを蓄積し性能を改善するような新たなテストタイムスケーリングの枠組みな模様。sequential test-time scalingなどとは異なり、複数のattemptによって知識リストを更新することでスケールさせるので、context windowの制約を受けない、といった話な模様。LLM AgentにおけるTest-time learningとかなり類似したコンセプトに見える。
Evaluating Long Context (Reasoning) Ability, wh., 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog #LongSequence Issue Date: 2025-10-17 Comment
元ポスト:
Ring-1T, inclusionAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-10-14 Comment
元ポスト:
inclusionAIから続々とfrontierなモデルが出てきている。
テクニカルレポートが公開:
- [Paper Note] Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale
Thinking Model, Ling Team+, arXiv'25, 2025.10
Apriel-1.5-15b-Thinker, ServiceNow-AI, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #SmallModel #OpenWeight #VisionLanguageModel Issue Date: 2025-10-01 Comment
元ポスト:
Artificial Analysisによるベンチマーキングでは現状<20BでSoTAなReasoningモデルな模様。
MIT License
公式ポスト:
Nvidiaによるポスト:
InternVL3.5-Flash, OpenGVLab, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #OpenWeight #VisionLanguageModel Issue Date: 2025-09-29 Comment
元ポスト:
Ring-1T-preview, inclusionAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-09-29 Comment
元ポスト:
Build A Reasoning Model (From Scratch), Sebastian Raschka, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #One-Line Notes Issue Date: 2025-09-29 Comment
元ポスト:
reasoningモデルに関するpyTorchによるフルスクラッチでの実装と丁寧な解説つきのNotebookが公開されており内部の基礎的な挙動を理解するためにとても良さそう。
Continuing to bring you our latest models, with an improved Gemini 2.5 Flash and Flash-Lite release, Google Deepmind, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Proprietary Issue Date: 2025-09-28 Comment
元ポスト:
Qwen3-Next-series-FP8, Qwen Team, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Quantization #OpenWeight #LowPrecision Issue Date: 2025-09-23 Comment
元ポスト:
DeepSeek-V3.1-Terminus, deepseek-ai, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-09-23 Comment
元ポスト:
vLLMでデプロイする時のtips:
LongCat-Flash-Thinking, meituan-longcat, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #read-later #Selected Papers/Blogs #ModelMerge Issue Date: 2025-09-22 Comment
元ポスト:
ポイント解説:
関連:
- LongCat-Flash-Chat, meituan-longcat, 2025.08
- [Paper Note] Libra: Assessing and Improving Reward Model by Learning to Think, Meng Zhou+, arXiv'25, 2025.07
Grok 4 Fast, xAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiModal #Blog #VisionLanguageModel Issue Date: 2025-09-21 Comment
ベンチマークに対する評価結果以外の情報はほぼ記述されていないように見える(RL使いました程度)
Artificial Analysisによる評価:
コスト性能比の所見:
Ring-flash-2.0, inclusionAI, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-09-20 Comment
元ポスト:
- Ling-flash-2.0-baseをベースにしたモデルで、100B-A6.1 params
- 各種ベンチでgpt-oss-120Bと同等以上。denseな40Bモデル(Qwen-32B, Seed-OSS-36B-Instruct)やproprietary modelであるGemini-2.5-Flashと比較して同等以上の性能
- アーキテクチャ
- Multi Token Prediction [Paper Note] Multi-Token Prediction Needs Registers, Anastasios Gerontopoulos+, NeurIPS'25
- 1/32 experts activation ratio
- gpt-oss-120Bは4 expertsがactiveだが、こちらは1 shared + 8 experts
- attention head数はgpt-oss-120Bの64の1/2である32
- group size 4のGQA [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
- gpt-oss-120BのEmbed dim=2880に対して大きめのEmbed dim=4096
- 最初の1ブロックだけ、MoEの代わりにhidden_size=9216のFNNが利用されている
Magistral-Small-2509, MistralAI, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #VisionLanguageModel Issue Date: 2025-09-18 Comment
元ポスト:
Large reasoning models research at COLM 2025 - State of research in scaling reasoning, the current paradigm for improving LLMs, PRAKASH KAGITHA, 2025.09
Paper/Blog Link My Issue
#Article #Survey #LanguageModel #Blog #COLM Issue Date: 2025-09-15 Comment
COLM'25における30個程度のReasoningに関わる論文をカバーしたブログらしい。
元ポスト:
ここの論文のサマリのまとめといった感じなので、indexとして利用すると良さそう。
GAUSS Benchmarking Structured Mathematical Skills for Large Language Models, Zhang+, 2025.06
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Evaluation #Mathematics #Contamination-free #Selected Papers/Blogs Issue Date: 2025-09-13 Comment
元ポスト:
現在の数学のベンチマークは個々の問題に対する回答のAccuracyを測るものばかりだが、ある問題を解く際にはさまざまなスキルを活用する必要があり、評価対象のLLMがどのようなスキルに強く、弱いのかといった解像度が低いままなので、そういったスキルの習熟度合いを測れるベンチマークを作成しました、という話に見える。
Knowledge Tracingタスクなどでは問題ごとにスキルタグを付与して、スキルモデルを構築して習熟度を測るので、問題の正誤だけでなくて、スキルベースでの習熟度を見ることで能力を測るのは自然な流れに思える。そしてそれは数学が最も実施しやすい。
ERNIE-4.5-21B-A3B-Thinking, Baidu, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #read-later #VisionLanguageModel Issue Date: 2025-09-10 Comment
元ポスト:
-
-
テクニカルレポート: https://ernie.baidu.com/blog/publication/ERNIE_Technical_Report.pdf
logical reasoning, 数学、コーディング、科学、数学、テキスト生成などの分野で21B-A3Bパラメータにも関わらずDeepSeek-R1に高い性能を達成しているように見える。コンテキストウィンドウは128k。
何が決め手でこのやうな小規模モデルで高い性能が出るのだろう?テクニカルレポートを読んだらわかるんだろうか。
Probing LLM Social Intelligence via Werewolf, foaster.ai, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog Issue Date: 2025-08-31 Comment
元ポスト:
「推論する生成AI」は事前学習されていない課題を正しく推論することができない(共変量シフトに弱い), TJO, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Chain-of-Thought #Blog #CovarianceShift Issue Date: 2025-08-27 Comment
- [Paper Note] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process, Tian Ye+, ICLR'25
でLLMは未知の問題を解ける(学習データに存在しない同等のlengthの未知のサンプルを解ける/テストデータで訓練データよりもより複雑な長いlengthの問題を解ける)と比べると、両者から得られる結論から何が言えるのだろうか?観測できるCoTとhidden mental reasoning process (probingで表出させて分析)は分けて考える必要があるのかもしれない。元論文をきちんと読めていないから考えてみたい。
あと、ブログ中で紹介されている論文中ではPhysics of Language Modelsが引用されていないように見えるが、論文中で引用され、関連性・差別化について言及されていた方が良いのではないか?という感想を抱いた。
関連:
- [Paper Note] Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens, Chengshuai Zhao+, arXiv'25
- [Paper Note] Understanding deep learning requires rethinking generalization, Chiyuan Zhang+, ICLR'17
- [Paper Note] UQ: Assessing Language Models on Unsolved Questions, Fan Nie+, arXiv'25
元ポスト:
Command A Reasoning: Enterprise-grade control for AI agents, Cohere, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-08-22 Comment
HF: https://huggingface.co/CohereLabs/command-a-reasoning-08-2025
元ポスト:
Agent関連ベンチでR1, gptoss超え。DeepResearchベンチでプロプライエタリLLMと比べてSoTA。safety関連ベンチでR1, gptoss超え。
す、すごいのでは、、?
CC-BY-NC 4.0なので商用利用不可
サマリ:
DeepSeek-V3.1-Base, deepseek-ai, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-08-21 Comment
元ポスト:
数日前からモデル自体は公開されていたが、モデルカードが追加された
- hybrid thinking
- post-trainingによるtool calling capability向上
- token efficiencyの向上
解説:
解説:
サマリ:
Aider LLM Leaderboards, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Coding Issue Date: 2025-08-21 Comment
最近よく見かけるいわゆるAider Polyglot。人間の介入なしに、LLMがコードの"編集"をする能力を測るベンチマーク。性能だけでなくコストもリーダーボードに記載されている。C++,Go,Java,JavaScript,Python,RustによるExercimにおける225の"最も困難な"エクササイズのみが含まれる。
Breakdown: Kimi K2, DeepSeek-R1, Qwen3 (+Coder), and GLM-4.5, TuringPost, 2025.08
Paper/Blog Link My Issue
#Article #NLP #Blog #OpenWeight Issue Date: 2025-08-11 Comment
元ポスト:
中国初のOpenLLMについて、それぞれの強みとおすすめのユースケースがまとまっている
ポスト中で紹介されているのは下記
- Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07
- GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07
- DeepSeek-R1, DeepSeek, 2025.01
- Qwen3-235B-A22B-Instruct-2507, Qwen Team, 2025.08
- Qwen3-Coder-30B-A3B-Instruct, QwenTeam, 2025.08
以下のようなものもある:
- MiniMax-M1, MiniMax, 2025.06
- Hunyuan-A13B-Instruct, tencent, 2025.06
NuMarkdown-8B-Thinking, numind, 2025.08
Paper/Blog Link My Issue
#Article #NLP #VisionLanguageModel #OCR Issue Date: 2025-08-08 Comment
元ポスト:
Qwen2.5-VL-7Bをsynthetia doc, Reasoning, Markdown exampleでSFTした後、レイアウトによってrewardを設計したGRPOで学習したとのこと
MIT License
gpt-oss-120b, OpenAI, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #AttentionSinks #read-later #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2025-08-05 Comment
blog:
https://openai.com/index/introducing-gpt-oss/
HF:
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
アーキテクチャで使われている技術まとめ:
-
-
-
-
- こちらにも詳細に論文がまとめられている
上記ポスト中のアーキテクチャの論文メモリンク(管理人が追加したものも含む)
- Sliding Window Attention
- [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
- [Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19
- MoE
- [Paper Note] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
- RoPE w/ YaRN
- [Paper Note] RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, arXiv'21, 2021.04
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
- Attention Sinks
- [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- Attention Sinksの定義とその気持ち、Zero Sink, Softmaxの分母にバイアス項が存在する意義についてはこのメモを参照のこと。
- [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
- Attention Sinksが実際にどのように効果的に作用しているか?についてはこちらのメモを参照。
- [Paper Note] When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
-
- Sink Token (or Zero Sink) が存在することで、decoder-onlyモデルの深い層でのrepresentationのover mixingを改善し、汎化性能を高め、promptに対するsensitivityを抑えることができる。
- (Attentionの計算に利用する) SoftmaxへのLearned bias の導入 (によるスケーリング)
- これはlearnable biasが導入されることで、attention scoreの和が1になることを防止できる(余剰なアテンションスコアを捨てられる)ので、Zero Sinkを導入しているとみなせる(と思われる)。
- GQA
- [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
- SwiGLU
- [Paper Note] GLU Variants Improve Transformer, Noam Shazeer, arXiv'20, 2020.02 -
- group size 8でGQAを利用
- Context Windowは128k
- 学習データの大部分は英語のテキストのみのデータセット
- STEM, Coding, general knowledgeにフォーカス
-
https://openai.com/index/gpt-oss-model-card/
あとで追記する
他Open Weight Modelとのベンチマークスコア比較:
-
-
-
-
- long context
-
- Multihop QA
解説:
learned attention sinks, MXFP4の解説:
Sink Valueの分析:
gpt-oss の使い方:
https://note.com/npaka/n/nf39f327c3bde?sub_rt=share_sb
[Paper Note] Comments-Oriented Document Summarization: Understanding Documents with Reader’s Feedback, Hu+, SIGIR’08, 2008.07
fd064b2-338a-4f8d-953c-67e458658e39
Qwen3との深さと広さの比較:
- The Big LLM Architecture Comparison, Sebastian Laschka, 2025.07
Phi4と同じtokenizerを使っている?:
post-training / pre-trainingの詳細はモデルカード中に言及なし:
-
-
ライセンスに関して:
> Apache 2.0 ライセンスおよび当社の gpt-oss 利用規約に基づくことで利用可能です。
引用元:
https://openai.com/ja-JP/index/gpt-oss-model-card/
gpt-oss利用規約:
https://github.com/openai/gpt-oss/blob/main/USAGE_POLICY
cookbook全体: https://cookbook.openai.com/topic/gpt-oss
gpt-oss-120bをpythonとvLLMで触りながら理解する: https://tech-blog.abeja.asia/entry/gpt-oss-vllm
指示追従能力(IFEVal)が低いという指摘:
Qwen3-Coder-30B-A3B-Instruct, QwenTeam, 2025.08
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Coding #MoE(Mixture-of-Experts) Issue Date: 2025-08-02 Comment
元ポスト:
Qwen3-30B-A3B-Thinking-2507, Qwen Team, 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-07-31 Comment
元ポスト:
mediumサイズのモデルがさらに性能向上
GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Selected Papers/Blogs Issue Date: 2025-07-29 Comment
元ポスト:
HF: https://huggingface.co/collections/zai-org/glm-45-687c621d34bda8c9e4bf503b
詳細なまとめ:
こちらでもMuon Optimizerが使われており、アーキテクチャ的にはGQAやMulti Token Prediction, QK Normalization, MoE, 広さよりも深さを重視の構造、みたいな感じな模様?
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25, 2025.02
Qwen3-235B-A22B-Thinking-2507, QwenTeam, 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-07-26 Comment
とうとうベンチマーク上はo4-miniと同等に...
OpenReasoning-Nemotron: A Family of State-of-the-Art Distilled Reasoning Models, Nvidia, 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Distillation #OpenWeight #OpenSource Issue Date: 2025-07-18 Comment
DeepSeek-R1-0528から応答を合成したデータでSFTのみを実施し、32BでQwe3-235B-A22Bと同等か上回る性能。アーキテクチャはQwen2.5。データはOpenCode/Math/Scienceを利用。
元ポスト:
データも公開予定
SmolLM3: smol, multilingual, long-context reasoner, HuggingFace, 2025.07
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #LongSequence #SmallModel #MultiLingual #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2025-07-09 Comment
元ポスト:
SmolLM3を構築する際の詳細なレシピ(アーキテクチャ、データ、data mixture, 3 stageのpretraining(web, code, mathの割合と品質をステージごとに変え、stable->stable->decayで学習), midtraining(long context->reasoning, post training(sft->rl), ハイブリッドreasoningモデルの作り方、評価など)が説明されている
学習/評価スクリプトなどがリリース:
New methods boost reasoning in small and large language models, Zhang+, Microsoft, 2025.06
Paper/Blog Link My Issue
#Article #Blog #read-later Issue Date: 2025-07-08 Comment
元ポスト:
Hunyuan-A13B-Instruct, tencent, 2025.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-06-27 Comment
元ポスト:
- MoEアーキテクチャ, 80B-A13B
- fast, slow thinking mode
- 256k context window
- agenticタスクに特に特化
- Grouped Query Attention, 複数の量子化フォーマットをサポート
公式ポスト:
画像は公式ポストより引用。Qwen3-235B-A22Bよりも少ないパラメータ数で、同等(agenticタスクはそれ以上)なようにベンチマーク上は見えるが、果たして。
果たして日本語の性能はどうだろうか。
TENCENT HUNYUAN COMMUNITY LICENSE
https://github.com/Tencent-Hunyuan/Hunyuan-A13B/blob/main/LICENSE
Kimi-VL-A3B-Thinking-2506, moonshotai, 2025.06
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #One-Line Notes #Reference Collection Issue Date: 2025-06-24 Comment
元ポスト:
様々なベンチマークでSoTA(gpt4o, Qwen2.5-VL-7B)を達成したReasoning VLM
テクニカルペーパー:
- [Paper Note] Kimi-VL Technical Report, Kimi Team+, arXiv'25
MiniMax-M1, MiniMax, 2025.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #One-Line Notes #Author Thread-Post Issue Date: 2025-06-17 Comment
元ポスト:
vLLMでのservingが推奨されており、コンテキストは1M、456BのMoEアーキテクチャでactivation weightは46B
公式ポスト:
Agentもリリースした模様:
Llama-3_1-Nemotron-Ultra-253B-v1, Nvidia, 2025.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #ReinforcementLearning #InstructionTuning #Pruning #OpenWeight #KeyPoint Notes #Author Thread-Post Issue Date: 2025-04-08 Comment
DeepSeek-R1をGPQA Diamond GPQA: A Graduate-Level Google-Proof Q&A Benchmark, David Rein+, N/A, COLM'24
, AIME2024/2025, Llama4 Maverickを
BFCLv2(Tool Calling, BFCLv2, UC Berkeley, 2024.08
), IFEVal [Paper Note] Instruction-Following Evaluation for Large Language Models, Jeffrey Zhou+, arXiv'23, 2023.11
で上回り, そのほかはArenaHardを除きDeepSeekR1と同等
DeepSeekR1が671B(MoEで37B Activation Param)に対し、こちらは253B(ただし、Llama3.1がベースなのでMoEではない)で同等以上の性能となっている。
ReasoningをON/OFFする能力も備わっている。
モデルがどのように訓練されたかを示す全体図がとても興味深い:
特に [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
でも有効性が示されているように、SFTをしてからReasoningを強化する(強化というより元々持っている能力を引き出す?)RLを実施している。
詳細は下記Blogとのこと:
https://developer.nvidia.com/blog/build-enterprise-ai-agents-with-advanced-open-nvidia-llama-nemotron-reasoning-models/
元ポスト:
The "think" tool: Enabling Claude to stop and think in complex tool use situations, Anthropic, 2025.03
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Chain-of-Thought #Blog #One-Line Notes Issue Date: 2025-03-23 Comment
"考える"ことをツールとして定義し利用することで、externalなthinkingを明示的に実施した上でタスクを遂行させる方法を紹介している
Hunyuan T1, Tencent, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Proprietary #SSM (StateSpaceModel) #One-Line Notes #Reading Reflections Issue Date: 2025-03-22 Comment
元ポスト:
画像はブログより引用。DeepSeek-R1と比較すると優っているタスクと劣っているタスクがあり、なんとも言えない感。GPT4.5より大幅に上回っているタスク(Math, Reasoning)があるが、そもそもそういったタスクはo1などのreasoningモデルの領域。o1と比較するとこれもまあ優っている部分もあれば劣っている部分もあるという感じ。唯一、ToolUseに関しては一貫してOpenAIモデルの方が強い。
ChineseタスクについてはDeepSeek-R1と完全にスコアが一致しているが、評価データのサンプル数が少ないのだろうか?
reasoningモデルかつ、TransformerとMambaのハイブリッドで、MoEを採用しているとのこと。
TransformerとMambaのハイブリッドについて(WenhuChen氏のポスト):
Layer-wise MixingとSequence-wise Mixingの2種類が存在するとのこと。前者はTransformerのSelf-Attenton LayerをMamba Layerに置換したもので、後者はSequenceのLong partをMambaでまずエンコードし、Short PartをTransformerでデコードする際のCross-Attentionのencoder stateとして与える方法とのこと。
Self-Attention Layerを削減することでInference時の計算量とメモリを大幅に削減できる(Self-Attentionは全体のKV Cacheに対してAttentionを計算するため)。
Sudoku-bench, SakanaAI, 2025.03
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Initial Impression Notes #Author Thread-Post Issue Date: 2025-03-21 Comment
元ポスト:
既存モデルでベンチマークを取ったらどういうランキングになるのだろうか。特にまだそういぅたランキングは公開されていない模様。
ブログ記事に(将来的に最新の結果をrepositoryに追記される模様)現時点でのリーダーボードが載っていた。現状、o3-miniがダントツに見える。
https://sakana.ai/sudoku-bench/
Llama Nemotron, Nvidia, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-19 Comment
Nvidiaによる初めてのreasoning model。
元ポスト:
Artificial Analysisにやるベンチマーク:
GPQA Diamond(大学院(Ph.D)レベルの生物学、物理学、化学の450問程度の難解なmultiple choice question)で、DeepSeekV3, GPT4o, QwQ-32Bをoutperform. Claude 3.7 sonnetより少しスコアが低い。
DeepSeekR1, o1, o3-mini(high), Claude 3.7 sonnet Thinkingなどには及んでいない。
(画像は元ポストより引用)
システムプロンプトを変えることでreasoningをon/offできる模様
EXAONE-Deep-32B, LG AI Research, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #One-Line Notes Issue Date: 2025-03-18 Comment
元ポスト:
EXAONE AI Model License Agreement 1.1 - NC
商用利用不可
Reasoning with Reka Flash, Reka, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiLingual #OpenWeight #Initial Impression Notes Issue Date: 2025-03-12 Comment
Weights: https://huggingface.co/RekaAI/reka-flash-3
Apache-2.0
< /reasoning >を強制的にoutputさせることでreasoningを中断させることができ予算のコントロールが可能とのこと
The State of LLM Reasoning Models, Sebastian Raschka, 2025.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Blog #Test-Time Scaling Issue Date: 2025-03-09
QwQ-32B: Embracing the Power of Reinforcement Learning, Qwen Team, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #OpenWeight #Reading Reflections Issue Date: 2025-03-06 Comment
元ポスト:
- [Paper Note] START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv'25, 2025.03
Artificial Analysisによるベンチマークスコア:
おそらく特定のタスクでDeepSeekR1とcomparable, 他タスクでは及ばない、という感じになりそうな予感
Open Reasoner Zero, Open-Reasoner-Zero, 2024.02
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #LanguageModel #Library #ReinforcementLearning #python Issue Date: 2025-03-02 Comment
元ポスト:
Mistral-24B-Reasoning, yentinglin, 2025.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-02-17 Comment
Apache-2.0
Unsloth で独自の R1 Reasoningモデルを学習, npaka, 2025.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #Reading Reflections Issue Date: 2025-02-07 Comment
非常に実用的で参考になる。特にどの程度のVRAMでどの程度の規模感のモデルを使うことが推奨されるのかが明言されていて参考になる。
Open R1, HuggingFace, 2025.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Repository #OpenSource #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-01-26 Comment
HFによるDeepSeekR1を完全に再現する取り組み
Update1: https://huggingface.co/blog/open-r1/update-1
Update2:
https://huggingface.co/blog/open-r1/update-2
512機のH100を利用…
DeepSeek-R1-Distill-Qwen, DeepSeek, 2025.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2025-01-21 Comment
MIT Licence
元ポスト:
DeepSeek-R1, DeepSeek, 2025.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Selected Papers/Blogs #Reference Collection Issue Date: 2025-01-21 Comment
参考:
参考: https://horomary.hatenablog.com/entry/2025/01/26/204545
DeepSeek-R1の論文読んだ?【勉強になるよ】
, asap:
https://zenn.dev/asap/articles/34237ad87f8511
こちらのポストの図解がわかりやすい:
最新モデル: DeepSeek-R1-0528
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
所見:
LLMを数学タスクにアラインする手法の系譜 - GPT-3からQwen2.5まで, bilzard, 2024.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Chain-of-Thought #Mathematics #PostTraining #Reading Reflections Issue Date: 2024-12-27 Comment
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
において、数学においてモデルのパラメータ数のスケーリングによって性能改善が見込める学習手法として、モデルとは別にVerifierを学習し、モデルが出力した候補の中から良いものを選択できるようにする、という話の気持ちが最初よくわからなかったのだが、後半のなぜsample&selectがうまくいくのか?節を読んでなんとなく気持ちが理解できた。SFTを進めるとモデルが出力する解放の多様性が減っていくというのは、興味深かった。
しかし、特定の学習データで学習した時に、全く異なるUnseenなデータに対しても解法は減っていくのだろうか?という点が気になった。あとは、学習データの多様性をめちゃめちゃ増やしたらどうなるのか?というのも気になる。特定のデータセットを完全に攻略できるような解法を出力しやすくなると、他のデータセットの性能が悪くなる可能性がある気がしており、そうするとそもそもの1shotの性能自体も改善していかなくなりそうだが、その辺はどういう設定で実験されているのだろうか。
たとえば、
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
などでは、
- [Paper Note] Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks, Yizhong Wang+, EMNLP'22, 2022.04
のような1600を超えるようなNLPタスクのデータでLoRAによりSFTすると、LoRAのパラメータ数を非常に大きくするとUnseenタスクに対する性能がfull-parameter tuningするよりも向上することが示されている。この例は数学に特化した例ではないが、SFTによって解法の多様性が減ることによって学習データに過剰適合して汎化性能が低下する、というのであれば、この論文のことを鑑みると「学習データにoverfittingした結果他のデータセットで性能が低下してしまう程度の多様性の学習データしか使えていないのでは」と感じてしまうのだが、その辺はどうなんだろうか。元論文を読んで確認したい。
とても勉強になった。
記事中で紹介されている
> LLMを使って複数解法の候補をサンプリングし、その中から最適な1つを選択する
のルーツは
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
とのことなので是非読みたい。
この辺はSelf-Consistency
- [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
あたりが最初なのかと思っていた。
OpenAI o1を再現しよう(Reasoningモデルの作り方), はち, 2024.12
Paper/Blog Link My Issue
#Article #LanguageModel #Blog #SelfCorrection #Reading Reflections Issue Date: 2024-12-22 Comment
Reflection after Thinkingを促すためのプロンプトが興味深い
OpenAI o1 System Card, OpenAI, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ChatGPT #Proprietary #VisionLanguageModel Issue Date: 2024-12-10
OpenAI o1, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Chain-of-Thought #Test-Time Scaling #Selected Papers/Blogs #VisionLanguageModel #KeyPoint Notes Issue Date: 2024-09-13 Comment
Jason Wei氏のポスト:
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
や
- [Paper Note] Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, arXiv'23, 2023.11
で似たような考えはすでに提案されていたが、どのような点が異なるのだろうか?
たとえば前者は、pauseトークンと呼ばれるoutputとは関係ないトークンを生成することで、outputを生成する前にモデル内部で推論する前により多くのベクトル操作を加える(=ベクトルを縦方向と横方向に混ぜ合わせる; 以後ベクトルをこねくりまわすと呼称する)、といった挙動を実現しているようだが、明示的にCoTの教師データを使ってSFTなどをしているわけではなさそうに見える(ざっくりとしか読んでないが)。
一方、Jason Wei氏のポストからは、RLで明示的により良いCoTができるように学習をしている点が違うように見える。
**(2025.0929): 以下のtest-time computeに関するメモはo1が出た当初のものであり、私の理解が甘い状態でのメモなので現在の理解を後ほど追記します。当時のメモは改めて見返すとこんなこと考えてたんだなぁとおもしろかったので残しておきます。**
学習の計算量だけでなく、inferenceの計算量に対しても、新たなスケーリング則が見出されている模様。
テクニカルレポート中で言われている time spent thinking (test-time compute)というのは、具体的には何なのだろうか。
上の研究でいうところの、inference時のpauseトークンの生成のようなものだろうか。モデルがベクトルをこねくり回す回数(あるいは生成するトークン数)が増えると性能も良くなるのか?
しかしそれはオリジナルのCoT研究である
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
のdotのみの文字列をpromptに追加して性能が向上しなかった、という知見と反する。
おそらく、**モデル学習のデコーディング時に**、ベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすこと=time spent thinking (test-time compute) 、ということなのだろうか?
そしてそのように学習されたモデルは、推論時にベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすと性能が上がる、ということなのだろうか。
もしそうだとすると、これは
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
のpauseトークンの生成をしながらfinetuningすると性能が向上する、という主張とも合致するように思うが、うーん。
実際暗号解読のexampleを見ると、とてつもなく長いCoT(トークンの生成数が多い)が行われている。
RLでReasoningを学習させる関連研究:
- ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N/A, ACL'24
- Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N/A, ICML'24
以下o1の動きに関して考えている下記noteからの引用。
>これによって、LLMはモデルサイズやデータ量をスケールさせる時代から推論時間をスケールさせる(つまり、沢山の推論ステップを探索する)時代に移っていきそうです。
なるほど。test-compute timeとは、推論ステップ数とその探索に要する時間という見方もあるのですね。
またnote中では、CoTの性能向上のために、Process Reward Model(PRM)を学習させ、LLMが生成した推論ステップを評価できるようにし、PRMを報酬モデルとし強化学習したモデルがo1なのではないか、と推測している。
PRMを提案した研究では、推論ステップごとに0,1の正誤ラベルが付与されたデータから学習しているとのこと。
なるほど、勉強になります。
note:
https://note.com/hatti8/n/nf4f3ce63d4bc?sub_rt=share_pb
note(詳細編): https://note.com/hatti8/n/n867c36ffda45?sub_rt=share_pb
こちらのリポジトリに関連論文やXポスト、公式ブログなどがまとめられている:
https://github.com/hijkzzz/Awesome-LLM-Strawberry
これはすごい。論文全部読みたい
Gemma2, Google Deepmind, 2024
Paper/Blog Link My Issue
#Article #NLP #Coding #Mathematics #OpenWeight #One-Line Notes Issue Date: 2024-07-30 Comment
Reasoning, Math, CodeGenerationに強み
Towards Complex Reasoning: the Polaris of Large Language Models, Yao Fu, 2023.05
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Evaluation #Blog #mid-training #PostTraining Issue Date: 2023-05-04