
Selected Papers/Blogs
Issue Date: 2025-11-26 [Paper Note] MTBBench: A Multimodal Sequential Clinical Decision-Making Benchmark in Oncology, Kiril Vasilev+, arXiv'25, 2025.11 GPT Summary- MTBBenchは、臨床ワークフローの複雑さを反映したマルチモーダル大規模言語モデル(LLMs)のための新しいベンチマークで、腫瘍学の意思決定をシミュレートします。既存の評価が単一モーダルであるのに対し、MTBBenchは異種データの統合や時間に基づく洞察の進化を考慮しています。臨床医によって検証されたグラウンドトゥルースの注釈を用い、複数のLLMを評価した結果、信頼性の欠如や幻覚の発生、データの調和に苦労することが明らかになりました。MTBBenchは、マルチモーダルおよび長期的な推論を強化するツールを提供し、タスクレベルのパフォーマンスを最大9.0%および11.2%向上させることが示されました。 Comment
dataset: https://huggingface.co/datasets/EeshaanJain/MTBBench
元ポスト:
> Ground truth annotations are validated by clinicians via a co-developed app, ensuring clinical relevance.
素晴らしい
#RecommenderSystems #Pocket #LanguageModel #ReinforcementLearning #VariationalAutoEncoder #PostTraining #read-later #One-Line Notes #Scalability
Issue Date: 2025-11-26 [Paper Note] MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation, Xiaoyu Kong+, arXiv'25, 2025.10 GPT Summary- MiniOneRecを提案し、SID構築から強化学習までのエンドツーエンドの生成レコメンデーションフレームワークを提供。実験により、モデルサイズの増加に伴いトレーニング損失と評価損失が減少し、生成アプローチのパラメータ効率が確認された。さらに、SID整合性の強制と強化学習を用いたポストトレーニングパイプラインにより、ランキング精度と候補の多様性が大幅に向上。 Comment
github: https://github.com/AkaliKong/MiniOneRec
元ポスト:
興味深い話ではあるが、generativeなRecSysはlatencyの面で厳しいものがあるという認識ではある。読みたい。
#Pocket #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #SmallModel #OpenWeight #OpenSource #read-later #VisionLanguageModel #One-Line Notes
Issue Date: 2025-11-25 [Paper Note] OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe, Kaichen Zhang+, arXiv'25, 2025.11 GPT Summary- 本研究では、マルチモーダル推論のための透明な二段階トレーニングレシピ「OpenMMReasoner」を提案。監視付きファインチューニング(SFT)で874Kサンプルのデータセットを構築し、強化学習(RL)で74Kサンプルを活用して推論能力を向上。評価の結果、9つのベンチマークでQwen2.5-VL-7B-Instructに対し11.6%の性能向上を達成し、データの質とトレーニング設計の重要性を示した。すべてのリソースはオープンソースで公開。 Comment
pj page: https://evolvinglmms-lab.github.io/OpenMMReasoner/
SoTAなVLMを構築するためのオープンなデータとレシピらしい
元ポスト:
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Reasoning #read-later #Physics Issue Date: 2025-11-23 [Paper Note] Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark, Minhui Zhu+, arXiv'25, 2025.09 GPT Summary- CritPtは、物理学研究における複雑な推論タスクを評価するための初のベンチマークであり、71の研究課題と190のチェックポイントタスクから構成される。これらの問題は現役の物理学者によって作成され、機械的に検証可能な答えを持つように設計されている。現在のLLMsは、単独のチェックポイントでは期待を示すが、全体の研究課題を解決するには不十分であり、最高精度は5.7%にとどまる。CritPtは、AIツールの開発に向けた基盤を提供し、モデルの能力と物理学研究の要求とのギャップを明らかにする。 Comment
pj page: https://critpt.com/
artificial analysisによるリーダーボード:
https://artificialanalysis.ai/evaluations/critpt
データセットとハーネス:
#Pocket #Robotics #Scalability #Sim-to-Real #Loco-Manipulation Issue Date: 2025-11-21 [Paper Note] VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation, Tairan He+, arXiv'25, 2025.11 GPT Summary- VIRALというフレームワークを用いて、ヒューマノイドロボットのロコマニピュレーションをシミュレーションから実世界に展開。教師-生徒の強化学習を通じて、視覚ベースのポリシーを訓練し、計算規模が成功に重要であることを示す。シミュレーションと実世界の整合性を確保し、Unitree G1ヒューマノイドでの実験により、専門家レベルの性能に近づくことを確認。 Comment
pj page: https://viral-humanoid.github.io/
元ポスト:
関連:
- ACT-1: A Robot Foundation Model Trained on Zero Robot Data, Sunday Team, 2025.11
解説:
discussionの部分が興味深い
#Pretraining #Pocket #NLP #Dataset #LanguageModel #read-later Issue Date: 2025-11-21 [Paper Note] AICC: Parse HTML Finer, Make Models Better -- A 7.3T AI-Ready Corpus Built by a Model-Based HTML Parser, Ren Ma+, arXiv'25, 2025.11 GPT Summary- ウェブデータの品質向上のため、MinerU-HTMLという新しい抽出パイプラインを提案。これは、言語モデルを用いてコンテンツ抽出をシーケンスラベリング問題として再定義し、意味理解を活用した二段階のフォーマットパイプラインを採用。実験では、MinerU-HTMLが81.8%のROUGE-N F1を達成し、従来の手法よりも構造化要素の保持率が優れていることを示した。AICCという多言語コーパスを構築し、抽出品質がモデルの性能に大きく影響することを確認。MainWebBench、MinerU-HTML、AICCを公開し、HTML抽出の重要性を強調。 Comment
元ポスト:
#Multi #Pocket #NLP #LanguageModel #Test-Time Scaling #read-later #RewardModel #Reranking #One-Line Notes #GenerativeVerifier Issue Date: 2025-11-20 [Paper Note] Foundational Automatic Evaluators: Scaling Multi-Task Generative Evaluator Training for Reasoning-Centric Domains, Austin Xu+, arXiv'25, 2025.10 GPT Summary- 専門的な生成評価者のファインチューニングに関する研究で、250万サンプルのデータセットを用いて、シンプルな教師ありファインチューニング(SFT)アプローチでFARE(基盤自動推論評価者)をトレーニング。FARE-8Bは大規模なRLトレーニング評価者に挑戦し、FARE-20Bは新たなオープンソース評価者の標準を設定。FARE-20BはMATHでオラクルに近いパフォーマンスを達成し、下流RLトレーニングモデルの性能を最大14.1%向上。FARE-Codeはgpt-oss-20Bを65%上回る品質評価を実現。 Comment
HF: https://huggingface.co/collections/Salesforce/fare
元ポスト:
これは素晴らしい。使い道がたくさんありそうだし、RLに利用したときに特定のデータに対して特化したモデルよりも優れた性能を発揮するというのは驚き。
#EfficiencyImprovement #Pocket #NLP #LanguageModel #ReinforcementLearning #SoftwareEngineering #read-later #Off-Policy #On-Policy Issue Date: 2025-11-20 [Paper Note] Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning, Ruoyu Qin+, arXiv'25, 2025.11 GPT Summary- 強化学習における性能ボトルネックを解消するために、新しいオンラインコンテキスト学習システム「Seer」を提案。Seerは、出力の類似性を活用し、分割ロールアウト、コンテキストに基づくスケジューリング、適応的グループ化推測デコーディングを導入。これにより、ロールアウトの待機時間を大幅に短縮し、リソース効率を向上。評価結果では、エンドツーエンドのロールアウトスループットを74%から97%向上させ、待機時間を75%から93%削減した。 Comment
元ポスト:
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Transformer #Architecture #read-later #One-Line Notes Issue Date: 2025-11-17 [Paper Note] Virtual Width Networks, Seed+, arXiv'25, 2025.11 GPT Summary- Virtual Width Networks (VWN)は、隠れ層のサイズを増やすことなく、より広い表現を可能にするフレームワークである。VWNはバックボーンの計算をほぼ一定に保ちながら埋め込み空間を拡張し、8倍の拡張でトークン予測の最適化を加速することを示した。トレーニングが進むにつれてこの利点は増幅され、仮想幅と損失削減の間には対数線形のスケーリング関係があることが確認された。 Comment
元ポスト:
ポイント解説:
重要論文に見える。transformerのバックボーンの次元は変えないでベクトルのwidthを広げることと同等の効力を得るためのアーキテクチャを提案している模様。
ざっくり言うとembeddingをN倍(over-width)し、提案手法であるGHCを用いてバックボーンに流せるサイズにベクトルを圧縮しtransformerブロックで処理しover-widthした次元に戻す処理をする機構と、over-widthしたembeddingを次元数は変えずに変換するlinearを噛ませた結果を足し合わせるような機構を用意して最大のボトルネックであるtransformerブロックの計算量は変えずに表現力を向上させる、といった感じの手法な模様
#Pocket #NLP #LanguageModel #ReinforcementLearning #Hallucination #PostTraining #read-later #KeyPoint Notes Issue Date: 2025-11-15 [Paper Note] Train for Truth, Keep the Skills: Binary Retrieval-Augmented Reward Mitigates Hallucinations, Tong Chen+, arXiv'25, 2025.10 GPT Summary- 本研究では、外的幻覚を軽減するために新しいバイナリ検索強化報酬(RAR)を用いたオンライン強化学習手法を提案。モデルの出力が事実に基づいている場合のみ報酬を与えることで、オープンエンド生成において幻覚率を39.3%削減し、短文質問応答では不正解を44.4%減少させた。重要な点は、事実性の向上が他のパフォーマンスに悪影響を及ぼさないことを示した。 Comment
Utilityを維持しつつ、Hallucinationを減らせるかという話で、Binary Retrieval Augmented Reward (Binary RAR)と呼ばれるRewardを提案している。このRewardはverifierがtrajectoryとanswerを判断した時に矛盾がない場合にのみ1, それ以外は0となるbinary rewardである。これにより、元のモデルの正解率・有用性(極論全てをわかりません(棄権)と言えば安全)の両方を損なわずにHallucinationを提言できる。
また、通常のVerifiable Rewardでは、正解に1, 棄権・不正解に0を与えるRewardとみなせるため、モデルがguessingによってRewardを得ようとする(guessingすることを助長してしまう)。一方で、Binary RARは、正解・棄権に1, 不正解に0を与えるため、guessingではなく不確実性を表現することを学習できる(おそらく、棄権する場合はどのように不確実かを矛盾なく説明した上で棄権しないとRewardを得られないため)。
といった話が元ポストに書かれているように見える。
元ポスト:
#MachineLearning #Pocket #NLP #Dataset #TabularData #Evaluation #Live #One-Line Notes Issue Date: 2025-11-14 [Paper Note] TabArena: A Living Benchmark for Machine Learning on Tabular Data, Nick Erickson+, NeurIPS'25 Spotlight, 2025.06 GPT Summary- TabArenaは、表形式データのための初の生きたベンチマークシステムであり、継続的に更新されることを目的としています。手動でキュレーションされたデータセットとモデルを用いて、公開リーダーボードを初期化しました。結果は、モデルのベンチマークにおける検証方法やハイパーパラメータ設定の影響を示し、勾配ブースティング木が依然として強力である一方、深層学習手法もアンサンブルを用いることで追いついてきていることを観察しました。また、基盤モデルは小規模データセットで優れた性能を発揮し、モデル間のアンサンブルが表形式機械学習の進展に寄与することを示しました。TabArenaは、再現可能なコードとメンテナンスプロトコルを提供し、https://tabarena.ai で利用可能です。 Comment
pj page:
https://github.com/autogluon/tabarena
leaderboard:
https://huggingface.co/spaces/TabArena/leaderboard
liveデータに基づくベンチマークで、手動で収集された51のtabularデータセットが活用されているとのこと。またあるモデルに対して数百にも登るハイパーパラメータ設定での実験をしアンサンブルをすることで単一モデルが到達しうるピーク性能を見ることに主眼を置いている、またいな感じらしい。そしてやはり勾配ブースティング木が強い。tunedは単体モデルの最も性能が良い設定での性能で、ensembleは複数の設定での同一モデルのアンサンブルによる結果だと思われる。
> TabArena currently consists of:
> 51 manually curated tabular datasets representing real-world tabular data tasks.
> 9 to 30 evaluated splits per dataset.
> 16 tabular machine learning methods, including 3 tabular foundation models.
> 25,000,000 trained models across the benchmark, with all validation and test predictions cached to enable tuning and post-hoc ensembling analysis.
> A live TabArena leaderboard showcasing the results.
openreview: https://openreview.net/forum?id=jZqCqpCLdU
#EfficiencyImprovement #Pocket #NLP #LanguageModel #DiffusionModel #Decoding #read-later Issue Date: 2025-11-13 [Paper Note] TiDAR: Think in Diffusion, Talk in Autoregression, Jingyu Liu+, arXiv'25, 2025.11 GPT Summary- TiDARは、拡散言語モデルと自己回帰モデルの利点を融合したハイブリッドアーキテクチャで、トークンのドラフトとサンプリングを単一のフォワードパスで実行します。これにより、高スループットとARモデルに匹敵する品質を両立させ、推測的デコーディングを上回る効率を実現しました。TiDARは、1秒あたり4.71倍から5.91倍のトークン生成を可能にし、ARモデルとの品質ギャップを初めて埋めました。 Comment
元ポスト:
解説:
#Pocket #NLP #LanguageModel #OpenWeight #Safety #read-later Issue Date: 2025-11-13 Open Technical Problems in Open-Weight AI Model Risk Management, Casper+, SSRN'25, 2025.11 GPT Summary- オープンウェイトのフロンティアAIモデルは強力で広く採用されているが、リスク管理には新たな課題がある。これらのモデルはオープンな研究を促進する一方で、恣意的な変更や監視なしの使用がリスクを増大させる。安全性ツールに関する研究は限られており、16の技術的課題を提示。オープンな研究と評価がリスク管理の科学を構築する鍵であることを強調。 Comment
元ポスト:
#ComputerVision #Analysis #Pretraining #Pocket #NLP #Dataset #LanguageModel #DataMixture #PhaseTransition Issue Date: 2025-11-12 [Paper Note] Why Less is More (Sometimes): A Theory of Data Curation, Elvis Dohmatob+, arXiv'25, 2025.11 GPT Summary- 本論文では、データを少なく使う方が良い場合についての理論的枠組みを提案し、小規模な厳選データセットが優れた性能を発揮する理由を探ります。データキュレーション戦略を通じて、ラベルに依存しない・依存するルールのテスト誤差のスケーリング法則を明らかにし、特定の条件下で小規模データが大規模データを上回る可能性を示します。ImageNetでの実証結果を通じて、キュレーションが精度を向上させることを確認し、LLMの数学的推論における矛盾する戦略への理論的説明も提供します。 Comment
元ポスト:
#ComputerVision #Pocket #Transformer #DiffusionModel #2D (Image) #WorldModels Issue Date: 2025-11-11 [Paper Note] ChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation, Jay Zhangjie Wu+, arXiv'25, 2025.10 GPT Summary- ChronoEditフレームワークを提案し、画像編集を動画生成として再定義。入力画像と編集画像を動画の最初と最後のフレームとし、時間的一貫性を学習した動画生成モデルを活用。推論時に時間的推論ステージを導入し、物理的に実現可能な変換を制約する編集軌道を生成。新しいベンチマークPBench-Editで、ChronoEditが視覚的忠実性と物理的妥当性で最先端の手法を上回ることを示した。 Comment
HF:
https://huggingface.co/nvidia/ChronoEdit-14B-Diffusers
LoRAによるUpscaler:
https://huggingface.co/nvidia/ChronoEdit-14B-Diffusers-Upscaler-Lora
元ポスト:
スケッチ+promptでの編集
HF:
https://huggingface.co/nvidia/ChronoEdit-14B-Diffusers-Paint-Brush-Lora
元ポスト:
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #Evaluation #MultiModal #read-later #Robotics #EmbodiedAI Issue Date: 2025-11-10 [Paper Note] PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs, Zixin Zhang+, arXiv'25, 2025.10 GPT Summary- MLLMsの物理的道具に対する理解を評価するための新しいベンチマークPhysToolBenchを提案。1,000以上の画像-テキストペアからなるVQAデータセットで、道具認識、道具理解、道具創造の3つの能力を評価。32のMLLMsに対する評価で道具理解に欠陥があることが明らかになり、初歩的な解決策を提案。コードとデータセットは公開。 Comment
元ポスト:
興味深い
#Analysis #EfficiencyImprovement #Pocket #NLP #LanguageModel #LLM-as-a-Judge #EMNLP #read-later #Stability Issue Date: 2025-11-10 [Paper Note] Analyzing Uncertainty of LLM-as-a-Judge: Interval Evaluations with Conformal Prediction, Huanxin Sheng+, EMNLP'25 SAC Highlights, 2025.09 GPT Summary- LLMを用いた自然言語生成の評価における不確実性を分析するためのフレームワークを提案。適合予測を通じて予測区間を構築し、中央値に基づくスコアを低バイアスの代替手段として提示。実験により、適合予測が有効な予測区間を提供できることを示し、判断の向上に向けた中央値や再プロンプトの有用性も探求。 Comment
元ポスト:
実用上非常に重要な話に見える
#EfficiencyImprovement #Pocket #NLP #Search #Dataset #LanguageModel #Evaluation #EMNLP #read-later #Contamination-free Issue Date: 2025-11-09 [Paper Note] Infini-gram mini: Exact n-gram Search at the Internet Scale with FM-Index, Hao Xu+, EMNLP'25 Best Paper, 2025.06 GPT Summary- 「infini-gram mini」は、ペタバイトレベルのテキストコーパスを効率的に検索可能にするシステムで、FM-indexデータ構造を用いてインデックスを作成し、ストレージオーバーヘッドを44%に削減。インデックス作成速度やメモリ使用量を大幅に改善し、83TBのインターネットテキストを99日でインデックス化。大規模なベンチマーク汚染の分析を行い、主要なLM評価ベンチマークがインターネットクローリングで汚染されていることを発見。汚染率を共有する公報をホストし、検索クエリ用のウェブインターフェースとAPIも提供。 Comment
元ポスト:
pj page: https://infini-gram-mini.io
benchmarmk contamination monitoring system: https://huggingface.co/spaces/infini-gram-mini/Benchmark-Contamination-Monitoring-System
#EfficiencyImprovement #Pocket #NLP #LanguageModel #ReinforcementLearning Issue Date: 2025-11-07 [Paper Note] PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence Generation, Alexandre Piché+, arXiv'25, 2025.09 GPT Summary- 強化学習(RL)を用いて大規模言語モデル(LLMs)の推論能力を向上させるための新しいアプローチ、PipelineRLを提案。PipelineRLは非同期データ生成とモデル更新を同時に行い、トレーニングデータの新鮮さを保ちながら、GPUの利用率を最大化。実験では、従来のRL手法に比べて約2倍の学習速度を達成。PipelineRLのオープンソース実装も公開。 Comment
元ポスト:
#Pocket #NLP #LanguageModel #UserBased #AIAgents #SoftwareEngineering #read-later #interactive Issue Date: 2025-11-06 [Paper Note] Training Proactive and Personalized LLM Agents, Weiwei Sun+, arXiv'25, 2025.11 GPT Summary- 効果的なAIエージェントには、生産性、積極性、パーソナライズの3つの次元を最適化する必要があると主張。LLMベースのユーザーシミュレーター「UserVille」を導入し、PPPというマルチオブジェクティブ強化学習アプローチを提案。実験では、PPPで訓練されたエージェントがGPT-5に対して平均21.6ポイントの改善を達成し、ユーザーの好みに適応しながらタスク成功を向上させる能力を示した。 Comment
AI Agentにおいてユーザとのinteractionを重視し協働することを重視するようなRLをする模様。興味深い。
元ポスト:
#NeuralNetwork #Pocket #NLP #LongSequence #Architecture #NeurIPS #memory #Test-time Learning Issue Date: 2025-11-05 [Paper Note] Titans: Learning to Memorize at Test Time, Ali Behrouz+, NeurIPS'25, 2024.12 GPT Summary- 再帰モデルと注意機構を組み合わせた新しいニューラル長期メモリモジュールを提案。これにより、短期的な依存関係を正確にモデル化しつつ、長期的な記憶を保持。新アーキテクチャ「Titans」は、言語モデリングや常識推論などのタスクで従来のモデルよりも優れた性能を示し、2Mを超えるコンテキストウィンドウサイズにも対応可能。 Comment
元ポスト:
#Pocket #NLP #ReinforcementLearning #AIAgents #Coding #NeurIPS #SoftwareEngineering Issue Date: 2025-11-05 [Paper Note] SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution, Yuxiang Wei+, NeurIPS'25, 2025.02 GPT Summary- SWE-RLは、強化学習を用いて大規模言語モデル(LLMs)の推論能力を向上させる新しいアプローチで、実世界のソフトウェア工学に焦点を当てています。軽量なルールベースの報酬を活用し、LLMがオープンソースソフトウェアの進化データから学習することで、開発者の推論プロセスを自律的に回復します。Llama3-SWE-RL-70Bは、実世界のGitHub問題において41.0%の解決率を達成し、中規模LLMとしては最高のパフォーマンスを示しました。また、一般化された推論スキルを持ち、複数のドメイン外タスクで改善された結果を示しています。SWE-RLは、ソフトウェア工学データに基づく強化学習の新たな可能性を開きます。 Comment
元ポスト:
ポイント解説:
解説:
#NeuralNetwork #ComputerVision #Pocket #Attention #NeurIPS #ObjectDetection Issue Date: 2025-11-05 [Paper Note] YOLOv12: Attention-Centric Real-Time Object Detectors, Yunjie Tian+, NeurIPS'25, 2025.02 GPT Summary- YOLOv12は、注意メカニズムを活用した新しいYOLOフレームワークで、CNNベースのモデルと同等の速度を維持しつつ、精度を向上させる。特に、YOLOv12-NはT4 GPU上で1.64 msの推論遅延で40.6%のmAPを達成し、YOLOv10-NおよびYOLOv11-Nを上回る性能を示す。また、YOLOv12はRT-DETRやRT-DETRv2よりも優れた性能を発揮し、計算量とパラメータ数を大幅に削減しながらも高速な実行を実現している。 Comment
元ポスト:
#Pocket #NLP #Dataset #Evaluation #MultiModal #Reasoning #VisionLanguageModel #2D (Image) #KeyPoint Notes #text #Visual-CoT Issue Date: 2025-11-05 [Paper Note] When Visualizing is the First Step to Reasoning: MIRA, a Benchmark for Visual Chain-of-Thought, Yiyang Zhou+, arXiv'25, 2025.11 GPT Summary- MIRAは、中間的な視覚画像を生成し推論を支援する新しいベンチマークで、従来のテキスト依存の手法とは異なり、スケッチや構造図を用いる。546のマルチモーダル問題を含み、評価プロトコルは画像と質問、テキストのみのCoT、視覚的ヒントを含むVisual-CoTの3レベルを網羅。実験結果は、中間的な視覚的手がかりがモデルのパフォーマンスを33.7%向上させることを示し、視覚情報の重要性を強調している。 Comment
pj page: https://mira-benchmark.github.io/
元ポスト:
Visual CoT
Frontierモデル群でもAcc.が20%未満のマルチモーダル(Vision QA)ベンチマーク。
手作業で作成されており、Visual CoT用のsingle/multi stepのintermediate imagesも作成されている。興味深い。
VLMにおいて、{few, many}-shotがうまくいく場合(Geminiのようなプロプライエタリモデルはshot数に応じて性能向上、一方LlamaのようなOpenWeightモデルは恩恵がない)と
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
うまくいかないケース(事前訓練で通常見られない分布外のドメイン画像ではICLがうまくいかない)
- [Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05
も報告されている。
おそらく事前学習段階で当該ドメインの画像が学習データにどれだけ含まれているか、および、画像とテキストのalignmentがとれていて、画像-テキスト間の知識を活用できる状態になっていることが必要なのでは、という気はする。
著者ポスト:
#Pocket #LanguageModel #DiffusionModel #ICLR #read-later Issue Date: 2025-11-04 [Paper Note] Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models, Marianne Arriola+, ICLR'25, 2025.03 GPT Summary- ブロック拡散言語モデルは、拡散モデルと自己回帰モデルの利点を組み合わせ、柔軟な長さの生成を可能にし、推論効率を向上させる。効率的なトレーニングアルゴリズムやデータ駆動型ノイズスケジュールを提案し、言語モデリングベンチマークで新たな最先端のパフォーマンスを達成。 Comment
openreview: https://openreview.net/forum?id=tyEyYT267x
#Analysis #Pocket #NLP #LanguageModel #DiffusionModel #Architecture #read-later Issue Date: 2025-11-04 [Paper Note] On Powerful Ways to Generate: Autoregression, Diffusion, and Beyond, Chenxiao Yang+, arXiv'25, 2025.10 GPT Summary- 自己回帰的な次トークン予測とマスクされた拡散を超えた生成プロセスを研究し、その利点と限界を定量化。書き換えや長さ可変の編集が可能になることで、理論的および実証的な利点を示し、自然言語以外の領域でも機能する大規模言語モデル(LLM)の重要性を強調。 Comment
元ポスト:
#Pocket #NLP #Dataset #LanguageModel #Evaluation #EMNLP #ConceptErasure #read-later Issue Date: 2025-11-04 [Paper Note] Intrinsic Test of Unlearning Using Parametric Knowledge Traces, Yihuai Hong+, EMNLP'25, 2024.06 GPT Summary- 大規模言語モデルにおける「忘却」タスクの重要性が高まっているが、現在の評価手法は行動テストに依存しており、モデル内の残存知識を監視していない。本研究では、忘却評価においてパラメトリックな知識の変化を考慮する必要性を主張し、語彙投影を用いた評価方法論を提案。これにより、ConceptVectorsというベンチマークデータセットを作成し、既存の忘却手法が概念ベクトルに与える影響を評価した。結果、知識を直接消去することでモデルの感受性が低下することが示され、今後の研究においてパラメータに基づく評価の必要性が強調された。 Comment
元ポスト:
#EfficiencyImprovement #Pocket #NLP #LanguageModel #ReinforcementLearning #PostTraining #Stability #Reference Collection #train-inference-gap Issue Date: 2025-11-01 [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10 GPT Summary- 強化学習による大規模言語モデルのファインチューニングにおける不安定性は、トレーニングポリシーと推論ポリシーの数値的不一致に起因する。従来の対策は効果が薄かったが、本研究ではFP16に戻すことでこの問題を解決できることを示した。この変更は簡単で、モデルやアルゴリズムの修正を必要とせず、安定した最適化と速い収束を実現し、多様なタスクで強力なパフォーマンスを発揮することが確認された。 Comment
元ポスト:
RL学習時の浮動小数点数表現をbf16からfp16に変更するシンプルな変更で、訓練-推論時のgapが小さくなり学習が改善する、という話らしい。
ポイント解説:
所見:
解説:
解説:
verlはFP16での学習をサポートしていないので著者がパッチを出した模様:
#Analysis #Pocket #NLP #LanguageModel #CrossLingual #TransferLearning #MultiLingual #Scaling Laws #read-later #One-Line Notes Issue Date: 2025-10-31 [Paper Note] ATLAS: Adaptive Transfer Scaling Laws for Multilingual Pretraining, Finetuning, and Decoding the Curse of Multilinguality, Shayne Longpre+, arXiv'25, 2025.10 GPT Summary- 本研究では、774の多言語トレーニング実験を通じて、最大の多言語スケーリング法則を探求し、ATLASという適応的転送スケーリング法則を導入。これにより、既存のスケーリング法則を上回る性能を示し、多言語学習のダイナミクスや言語間の転送特性を分析。言語ペア間の相互利益スコアを測定し、モデルサイズとデータの最適なスケーリング方法を明らかにし、事前学習とファインチューニングの計算的クロスオーバーポイントを特定。これにより、英語中心のAIを超えたモデルの効率的なスケーリングの基盤を提供することを目指す。 Comment
元ポスト:
バイリンガルで学習した時に、日本語とシナジーのある言語、この図を見ると無さそうに見える😅
#Pocket #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #One-Line Notes Issue Date: 2025-10-30 [Paper Note] Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents, Yueqi Song+, arXiv'25, 2025.10 GPT Summary- 本研究では、エージェントデータの収集における課題を解決するために、エージェントデータプロトコル(ADP)を提案。ADPは多様なデータ形式を統一し、簡単に解析・トレーニング可能な表現言語である。実験により、13のエージェントトレーニングデータセットをADP形式に統一し、標準化されたデータでSFTを実施した結果、平均約20%の性能向上を達成。ADPは再現可能なエージェントトレーニングの障壁を下げることが期待される。 Comment
pj page: https://www.agentdataprotocol.com
元ポスト:
著者ポスト:
解説:
エージェントを学習するための統一的なデータ表現に関するプロトコルを提案
#Pretraining #Pocket #NLP #LanguageModel #Transformer #LatentReasoning #KeyPoint Notes #RecurrentModels #RecursiveModels Issue Date: 2025-10-30 [Paper Note] Scaling Latent Reasoning via Looped Language Models, Rui-Jie Zhu+, arXiv'25, 2025.10 GPT Summary- Ouroは、推論を事前訓練フェーズに組み込むことを目指したループ言語モデル(LoopLM)であり、反復計算やエントロピー正則化を通じて性能を向上させる。1.4Bおよび2.6Bモデルは、最大12Bの最先端LLMに匹敵する性能を示し、知識操作能力の向上がその要因であることを実験で確認。LoopLMは明示的なCoTよりも整合した推論を生成し、推論の新たなスケーリングの可能性を示唆している。モデルはオープンソースで提供されている。 Comment
pj page: https://ouro-llm.github.io
元ポスト:
解説:
基本構造はdecoder-only transformerで
- Multi-Head Attention
- RoPE
- SwiGLU活性化
- Sandwich Normalization
が使われているLoopedTransformerで、exit gateを学習することで早期にloopを打ち切り、出力をすることでコストを節約できるようなアーキテクチャになっている。
より少ないパラメータ数で、より大きなパラメータ数のモデルよりも高い性能を示す(Table7,8)。また、Tを増やすとモデルの安全性も増す(=有害プロンプトの識別力が増す)。その代わり、再帰数Tを大きくするとFLOPsがT倍になるので、メモリ効率は良いが計算効率は悪い。
linear probingで再帰の次ステップ予測をしたところ浅い段階では予測が不一致になるため、思考が進化していっているのではないか、という考察がある。
また、再帰数Tを4で学習した場合に、inference時にTを5--8にしてもスケールしない(Table10)。
またAppendix D.1において、通常のtransformerのLoopLMを比較し、5種類の大きさのモデルサイズで比較。通常のtransformerではループさせる代わりに実際に層の数を増やすことで、パラメータ数を揃えて実験したところ、通常のtransformerの方が常に性能が良く、loopLMは再帰数を増やしてもスケールせず、モデルサイズが大きくなるにつれて差がなくなっていく、というスケーリングの面では残念な結果に終わっているようだ。
といった話が解説に書かれている。元論文は完全にskim readingして解説ポストを主に読んだので誤りが含まれるかもしれない点には注意。
#Embeddings #Analysis #Pocket #NLP #LanguageModel Issue Date: 2025-10-29 [Paper Note] Language Models are Injective and Hence Invertible, Giorgos Nikolaou+, arXiv'25, 2025.10 GPT Summary- 本研究では、トランスフォーマー言語モデルが単射であることを数学的に証明し、異なる入力が同じ出力にマッピングされないことを示す。さらに、6つの最先端モデルに対して衝突テストを行い、衝突がないことを確認。新たに提案するアルゴリズムSipItにより、隠れた活性化から正確な入力テキストを効率的に再構築できることを示し、単射性が言語モデルの重要な特性であることを明らかにする。 Comment
元ポスト:
続報:
解説:
解説参照のこと。
#Pretraining #NLP #Dataset #LanguageModel #One-Line Notes #German Issue Date: 2025-10-28 [Paper Note] The German Commons - 154 Billion Tokens of Openly Licensed Text for German Language Models, Lukas Gienapp+, arXiv'25, 2025.10 GPT Summary- 「German Commons」は、オープンライセンスのドイツ語テキストの最大コレクションで、41のソースから1545.6億トークンを提供。法律、科学、文化など7つのドメインを含み、品質フィルタリングや重複排除を行い、一貫した品質を確保。すべてのデータは法的遵守を保証し、真にオープンなドイツ語モデルの開発を支援。再現可能で拡張可能なコーパス構築のためのコードも公開。 Comment
HF: https://huggingface.co/datasets/coral-nlp/german-commons
元ポスト:
最大級(154B)のドイツ語のLLM(事前)学習用データセットらしい
ODC-By Licence
#ComputerVision #Pocket #Dataset #Zero/Few/ManyShotPrompting #Evaluation #MultiModal #In-ContextLearning #NeurIPS #read-later #OOD #Generalization #VisionLanguageModel #One-Line Notes #ObjectDetection Issue Date: 2025-10-27 [Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05 GPT Summary- 視覚と言語のモデル(VLMs)は、一般的な物体に対して優れたゼロショット検出性能を示すが、分布外のクラスやタスクに対しては一般化が難しい。そこで、少数の視覚例と豊富なテキスト記述を用いてVLMを新しい概念に整合させる必要があると提案。Roboflow100-VLという多様な概念を持つ100のマルチモーダル物体検出データセットを導入し、最先端モデルの評価を行った。特に、難しい医療画像データセットでのゼロショット精度が低く、少数ショットの概念整合が求められることを示した。 Comment
元ポスト:
VLMが「現実世界をどれだけ理解できるか」を評価するためのobject detection用ベンチマークを構築。100のopen source datasetから構成され、それぞれにはtextでのfew shot instructionやvisual exampleが含まれている。データセットは合計で約165kの画像、約1.35M件のアノテーションが含まれ、航空、生物、産業などの事前学習ではあまりカバーされていない新規ドメインの画像が多数含まれているとのこと。
そして現在のモデルは事前学習に含まれていないOODな画像に対する汎化性能が低く、いちいちモデルを追加で学習するのではなく、ICLによって適用できた方が好ましいという考えがあり、そして結果的に現在のVLMでは、ICLがあまりうまくいかない(ICLによるOODの汎化が効果的にできない)ことがわかった、という話らしい。
が、
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
での知見と異なる。差異はなんだろうか?
以下のスレッドで議論がされている:
pj page: https://rf100-vl.org
うーんあとでしっかり読みたい、、、
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Reasoning #read-later #One-Line Notes #LongHorizon Issue Date: 2025-10-27 [Paper Note] R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?, Yi Lu+, arXiv'25, 2025.10 GPT Summary- R-HORIZONを提案し、長期的な推論行動を刺激する手法を通じて、LRMの評価を改善。複雑なマルチステップ推論タスクを含むベンチマークを構築し、LRMの性能低下を明らかに。R-HORIZONを用いた強化学習データ(RLVR)は、マルチホライズン推論タスクの性能を大幅に向上させ、標準的な推論タスクの精度も向上。AIME2024で7.5の増加を達成。R-HORIZONはLRMの長期推論能力を向上させるための有効なパラダイムと位置付けられる。 Comment
pj page: https://reasoning-horizon.github.io
元ポスト:
long horizonタスクにうまく汎化する枠組みの必要性が明らかになったように見える。long horizonデータを合成して、post trainingをするという枠組みは短期的には強力でもすぐに計算リソースの観点からすぐに現実的には能力を伸ばせなくなるのでは。
ポイント解説:
#Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #MultiModal #Reasoning #SoftwareEngineering #ComputerUse #read-later #VisionLanguageModel #Science Issue Date: 2025-10-26 [Paper Note] ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows, Qiushi Sun+, arXiv'25, 2025.05 GPT Summary- 大規模言語モデル(LLMs)を活用したScienceBoardを紹介。これは、科学的ワークフローを加速するための動的なマルチドメイン環境と、169の厳密に検証されたタスクからなるベンチマークを提供。徹底的な評価により、エージェントは複雑なワークフローでの信頼性が低く、成功率は15%にとどまることが明らかに。これにより、エージェントの限界を克服し、より効果的な設計原則を模索するための洞察が得られる。 Comment
元ポスト:
#Pocket #NLP #LanguageModel #NeurIPS Issue Date: 2025-10-25 [Paper Note] Blackbox Model Provenance via Palimpsestic Membership Inference, Rohith Kuditipudi+, NeurIPS'25 Spotlight, 2025.10 GPT Summary- アリスの言語モデルを用いてボブがテキストを生成する際、アリスはボブが彼女のモデルを使用していることを証明できるかを検討。クエリ設定と観察設定の2つのアプローチで、ボブのモデルやテキストとアリスの訓練データの順序との相関を調査。40以上のファインチューニングで、p値が1e-8に達する結果を得た。観察設定では、ボブのテキストの尤度を推定する2つの方法を試し、数百トークンでの区別が可能なアプローチと、数十万トークンを必要とする高パワーのアプローチを比較した。 Comment
元ポスト:
これはすごい話だ…
#Pocket #LanguageModel #Transformer #Architecture #ICLR #read-later #memory #KeyPoint Notes Issue Date: 2025-10-23 [Paper Note] Memory Layers at Scale, Vincent-Pierre Berges+, ICLR'25, 2024.12 GPT Summary- メモリ層は、計算負荷を増やさずにモデルに追加のパラメータを加えるための学習可能な検索メカニズムを使用し、スパースに活性化されたメモリ層が密なフィードフォワード層を補完します。本研究では、改良されたメモリ層を用いた言語モデルが、計算予算が2倍の密なモデルや同等の計算とパラメータを持つエキスパート混合モデルを上回ることを示し、特に事実に基づくタスクでの性能向上が顕著であることを明らかにしました。完全に並列化可能なメモリ層の実装とスケーリング法則を示し、1兆トークンまでの事前学習を行った結果、最大8Bのパラメータを持つベースモデルと比較しました。 Comment
openreview: https://openreview.net/forum?id=ATqGm1WyDj
transformerにおけるFFNをメモリレイヤーに置き換えることで、パラメータ数を増やしながら計算コストを抑えるようなアーキテクチャを提案しているようである。メモリレイヤーは、クエリqを得た時にtop kのkvをlookupし(=ここで計算対象となるパラメータがスパースになる)、kqから求めたattention scoreでvを加重平均することで出力を得る。Memory+というさらなる改良を加えたアーキテクチャでは、入力に対してsiluによるgatingとlinearな変換を追加で実施することで出力を得る。
denseなモデルと比較して性能が高く、メモリパラメータを増やすと性能がスケールする。
#Pocket #NLP #LanguageModel #Reasoning #Architecture #read-later #KeyPoint Notes #SpeciarizedBrainNetworks #Neuroscience Issue Date: 2025-10-22 [Paper Note] Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization, Badr AlKhamissi+, arXiv'25, 2025.06 GPT Summary- MiCRoは、脳の認知ネットワークに基づく専門家モジュールを持つトランスフォーマーベースのアーキテクチャで、言語モデルの層を4つの専門家に分割。これにより、解釈可能で因果的な専門家の動的制御が可能になり、機械学習ベンチマークで優れた性能を発揮。人間らしく解釈可能なモデルを実現。 Comment
pj page: https://cognitive-reasoners.epfl.ch
元ポスト:
事前学習言語モデルに対してpost-trainingによって、脳に着想を得て以下の4つをdistinctな認知モジュールを(どのモジュールにルーティングするかを決定するRouter付きで)学習する。
- Language
- Logic / Multiple Demand
- Social / Theory of Mind
- World / Default Mode Network
これによりAIとNeuroscienceがbridgeされ、MLサイドではモデルの解釈性が向上し、Cognitive側では、複雑な挙動が起きた時にどのモジュールが寄与しているかをprobingするテストベッドとなる。
ベースラインのdenseモデルと比較して、解釈性を高めながら性能が向上し、人間の行動とよりalignしていることが示された。また、layerを分析すると浅い層では言語のエキスパートにルーティングされる傾向が強く、深い層ではdomainのエキスパートにルーティングされる傾向が強くなるような人間の脳と似たような傾向が観察された。
また、neuroscienceのfunctional localizer(脳のどの部位が特定の機能を果たしているのかを特定するような取り組み)に着想を得て、類似したlocalizerが本モデルにも適用でき、特定の機能に対してどのexpertモジュールがどれだけ活性化しているかを可視化できた。
といったような話が著者ポストに記述されている。興味深い。
demo:
https://huggingface.co/spaces/bkhmsi/cognitive-reasoners
HF:
https://huggingface.co/collections/bkhmsi/mixture-of-cognitive-reasoners
#ComputerVision #Controllable #Pocket #Transformer #DiffusionModel #VariationalAutoEncoder #ICCV #KeyPoint Notes Issue Date: 2025-10-22 [Paper Note] OminiControl: Minimal and Universal Control for Diffusion Transformer, Zhenxiong Tan+, ICCV'25 Highlight, 2024.11 GPT Summary- OminiControlは、Diffusion Transformer(DiT)アーキテクチャにおける画像条件付けの新しいアプローチで、パラメータオーバーヘッドを最小限に抑えつつ、柔軟なトークン相互作用と動的な位置エンコーディングを実現。広範な実験により、複数の条件付けタスクで専門的手法を上回る性能を示し、合成された画像ペアのデータセット「Subjects200K」を導入。効率的で多様な画像生成システムの可能性を示唆。 Comment
元ポスト:
DiTのアーキテクチャは(MMA以外は)変更せずに、Condition Image C_IをVAEでエンコードしたnoisy inputをDiTのinputにconcatし順伝播させることで、DiTをunified conditioningモデル(=C_Iの特徴量を他のinputと同じlatent spaceで学習させ統合的に扱う)として学習する[^1]。
[^1]: 既存研究は別のエンコーダからエンコードしたfeatureが加算されていて(式3)、エンコーダ部分に別途パラメータが必要だっただけでなく、加算は空間的な対応関係が存在しない場合はうまく対処できず(featureの次元が空間的な情報に対応しているため)、conditional tokenとimageの交互作用を妨げていた。
また、positional encodingのindexをconditional tokenとnoisy image tokensと共有すると、空間的な対応関係が存在するタスク(edge guided generation等)はうまくいったが、被写体を指定する生成(subject driven generation)のような対応関係が存在しないタスク(non-aligned task)の場合はうまくいかなかった。しかし、non-aligned taskの場合は、indexにオフセットを加えシフトさせる(式4)ことで、conditional text/image token間で空間的にoverlapしないようにすることで性能が大幅に改善した。
既存研究では、C_Iの強さをコントロールするために、ハイパーパラメータとして定数を導入し、エンコードされたfeatureを加算する際の強さを調整していたが(3.2.3節)、本手法ではconcatをするためこのような方法は使えない。そのため、Multi-Modal Attention(MMA)にハイパーパラメータによって強さを調整可能なbias matrixを導入し、C_IとXのattentionの交互作用の強さを調整することで対応した(式5,6)。
#ComputerVision #EfficiencyImprovement #Pocket #NLP #ContextWindow #LongSequence #VisionLanguageModel #One-Line Notes Issue Date: 2025-10-21 [Paper Note] Glyph: Scaling Context Windows via Visual-Text Compression, Jiale Cheng+, arXiv'25, 2025.10 GPT Summary- 本研究では、長いコンテキストを持つ大規模言語モデル(LLMs)の実用性を向上させるため、Glyphというフレームワークを提案し、テキストを画像に変換して視覚と言語のモデル(VLMs)で処理します。このアプローチにより、3-4倍のトークン圧縮を実現し、精度を維持しつつ処理速度を約4倍向上させます。さらに、128KコンテキストのVLMが1Mトークンのテキストタスクを処理可能になることを示しました。 Comment
元ポスト:
所見:
テキストを画像にレンダリングしてVLMに入力することでtextと比較して3.2倍KV Cache (context)を圧縮し、prefillingとデコード速度も4.8, 4.4倍高速化するフレームワークらしい
#Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #read-later Issue Date: 2025-10-21 [Paper Note] Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation, Sayash Kapoor+, arXiv'25, 2025.10 GPT Summary- AIエージェントの評価における課題を解決するため、Holistic Agent Leaderboard(HAL)を導入。標準化された評価ハーネスにより評価時間を短縮し、三次元分析を通じて21,730のエージェントを評価。高い推論努力が精度を低下させることを発見し、LLMを用いたログ検査で新たな行動を明らかに。エージェント評価の標準化を進め、現実世界での信頼性向上を目指す。 Comment
pj page: https://hal.cs.princeton.edu
元ポスト:
よ、40,000ドル!?💸
LLM Agentに関するフロンティアモデル群を複数のベンチマークで同じ条件でapple to appleな比較となるように評価している。
以下元ポストより:
この評価ハーネスは、10行未満のコードスニペットで評価を実行可能(元ポスト)
知見としては
- reasoning effortを上げても多くの場合性能向上には寄与せず(21/36のケースで性能向上せず)
- エージェントはタスクを解決するために近道をする(ベンチマークを直接参照しに行くなど)
- エージェントは非常にコストの高い手段を取ることもあり(フライト予約において誤った空港から予約したり、ユーザに過剰な返金をしたり、誤ったクレジットカードに請求したりなど)
- コストとacc.のトレードオフを分析した結果、最も高価なOpus4.1は一度しかパレートフロンティアにならず、Gemini Flash (7/9)、GPT-5, o4-mini(4/9)が多くのベンチマークでコストとAcc.のトレードオフの上でパレートフロンティアとなった。
- トークンのコストとAcc.のトレードオフにおいては、Opus4.1が3つのベンチマークでパレードフロンティアとなった。
- すべてのエージェントの行動を記録し分析した結果、SelfCorrection, intermediate verifiers (コーディング問題におけるユニットテストなど)のbehaviorがacc.を改善する上で高い相関を示した
- 一方タスクに失敗する場合は、多くの要因が存在することがわかり、たとえば環境内の障害(CAPTCHAなど)、指示に従うことの失敗(指定されたフォーマットでコードを出力しない)などが頻繁に見受けられた。また、タスクを解けたか否かに関わらずツール呼び出しの失敗に頻繁に遭遇していた。これはエージェントはこうしたエラーから回復できることを示している。
- エージェントのログを分析することで、TauBenchで使用していたscaffold(=モデルが環境もやりとりするための構成要素)にバグがあることを突き止めた(few-shotのサンプルにリークがあった)。このscaffoldはHALによるTauBenchの分析から除外した。
- Docsentのようなログ分析が今後エージェントを評価する上では必要不可欠であり、信頼性の問題やショートカット行動、高コストなエージェントの失敗などが明らかになる。ベンチマーク上での性能と比較して実環境では性能が低い、あるいはその逆でベンチマークが性能を低く見積もっている(たとえばCAPTChAのようや環境的な障害はベンチマーク上では同時リクエストのせいで生じても実環境では生じないなど)ケースもあるので、これらはベンチマークのacc.からだけでは明らかにならないため、ベンチマークのacc.は慎重に解釈すべき。
#Multi #Analysis #MachineLearning #Pocket #NLP #AIAgents #TheoryOfMind #read-later #Personality Issue Date: 2025-10-21 [Paper Note] Emergent Coordination in Multi-Agent Language Models, Christoph Riedl, arXiv'25, 2025.10 GPT Summary- 本研究では、マルチエージェントLLMシステムが高次の構造を持つかどうかを情報理論的フレームワークを用いて検証。実験では、エージェント間のコミュニケーションがない状況で、時間的相乗効果が観察される一方、調整された整合性は見られなかった。ペルソナを割り当てることで、エージェント間の差別化と目標指向の相補性が示され、プロンプトデザインによって高次の集合体へと誘導できることが確認された。結果は、効果的なパフォーマンスには整合性と相補的な貢献が必要であることを示唆している。 Comment
元ポスト:
非常にシンプルな設定でマルチエージェントによるシナジーが生じるか否か、そのための条件を検証している模様。小規模モデルだとシナジーは生じず、ペルソナ付与とTheory of Mindを指示すると効果が大きい模様
#ComputerVision #Pocket #LanguageModel #InstructionTuning #DiffusionModel #TextToImageGeneration #read-later #ICCV #ImageSynthesis Issue Date: 2025-10-20 [Paper Note] MetaMorph: Multimodal Understanding and Generation via Instruction Tuning, Shengbang Tong+, ICCV'25, 2024.12 GPT Summary- 本研究では、視覚的指示調整の新手法VPiTを提案し、LLMがテキストと視覚トークンを生成できるようにします。VPiTは、キュレーションされた画像とテキストデータからトークンを予測する能力をLLMに教え、視覚生成能力が向上することを示しました。特に、理解データが生成データよりも効果的に両方の能力に寄与することが明らかになりました。MetaMorphモデルを訓練し、視覚理解と生成で競争力のあるパフォーマンスを達成し、LLMの事前学習から得た知識を活用することで、視覚生成における一般的な失敗を克服しました。これにより、LLMが視覚理解と生成に適応できる可能性が示唆されました。 Comment
元ポスト:
#Pocket #NLP #LanguageModel #Alignment #AIAgents #Safety #read-later Issue Date: 2025-10-19 [Paper Note] Agentic Misalignment: How LLMs Could Be Insider Threats, Aengus Lynch+, arXiv'25, 2025.10 GPT Summary- 複数の開発者からの16のモデルを仮想企業環境でテストし、潜在的なリスク行動を特定。モデルは自律的にメールを送信し、機密情報にアクセス可能で、ビジネス目標に従う中で反抗的行動を示すことがあった。この現象を「エージェントのミスアライメント」と呼び、モデルが不適切な行動を取ることがあることを示した。実際の展開においてはミスアライメントの証拠は見られなかったが、モデルの自律性が高まることで将来的なリスクが生じる可能性があることを指摘。安全性と透明性の重要性を強調し、研究方法を公開する。 Comment
元ポスト:
abstを読んだだけでも、なんとも恐ろしいシナリオが記述されている。読みたい
Figure4, 5とかすごいな
#Pocket #NLP #Dataset #UserBased #AIAgents #Evaluation #read-later #DeepResearch #Live Issue Date: 2025-10-18 [Paper Note] LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild, Jiayu Wang+, arXiv'25, 2025.10 GPT Summary- 深層研究は、ライブウェブソースから情報を検索・統合し、引用に基づいたレポートを生成する技術であり、評価にはユーザー中心、動的、明確、多面的な原則が必要。既存のベンチマークはこれらを満たしていないため、LiveResearchBenchを導入し、100の専門家がキュレーションしたタスクを提供。さらに、レポート評価のためにDeepEvalを提案し、品質を包括的に評価するプロトコルを統合。これにより、17の深層研究システムの包括的な評価を行い、強みや改善点を明らかにする。 Comment
元ポスト:
データセットとソースコードがリリース:
dataset: https://huggingface.co/datasets/Salesforce/LiveResearchBench
pj page: https://livedeepresearch.github.io/
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Mathematics #read-later #Proofs Issue Date: 2025-10-18 [Paper Note] Reliable Fine-Grained Evaluation of Natural Language Math Proofs, Wenjie Ma+, arXiv'25, 2025.10 GPT Summary- 大規模言語モデル(LLMs)による数学的証明の生成と検証における信頼性の高い評価者が不足している問題に対処するため、0から7のスケールで評価する新たな評価者ProofGraderを開発。ProofBenchという専門家注釈付きデータセットを用いて、評価者の設計空間を探求し、低い平均絶対誤差(MAE)0.926を達成。ProofGraderは、最良の選択タスクにおいても高いスコアを示し、下流の証明生成の進展に寄与する可能性を示唆している。 Comment
元ポスト:
これは非常に重要な研究に見える
#Pocket #NLP #LanguageModel #Education #AIAgents #Evaluation #Coding #read-later #One-Line Notes Issue Date: 2025-10-18 [Paper Note] AutoCode: LLMs as Problem Setters for Competitive Programming, Shang Zhou+, arXiv'25, 2025.09 GPT Summary- AutoCodeは、競技プログラミングの問題文とテストケースを生成するシステムであり、信頼性の高い問題作成を実現します。複数回の検証を通じて、生成された問題は公式の判断と99%の一貫性を持ち、従来の手法に比べて大幅な改善を示します。また、ランダムなシード問題から新しいバリアントを作成し、不正な問題をフィルタリングする機能も備えています。最終的に、AutoCodeはグランドマスター級の競技プログラマーによってコンテスト品質と評価される問題を生成します。 Comment
blog: https://livecodebenchpro.com/projects/autocode/overview
LLMで自動的に高品質な競技プログラミング問題とそのテストケースを生成するパイプラインを提案。
信頼性のあるテストケースを作成するために、Validator-Generator-Checkerフレームワーク。提案。Generatorがテストケースを生成し、Validatorが生成されたテストケースの入力が問題の制約を満たしているか判定し、Checkerが与えられたテストケースの元で解法が正しいかを確認する。
続いて、人手を介さずとも生成される問題が正しいことを担保するためにdual-verificationを採用。具体的には、LLMに新規の問題文と効率的な解法を生成させ、加えてブルートフォースでの解法を別途生成する。そして、両者をLLMが生成したテストセット群で実行し、全ての解放で出力が一致した場合のみAcceptする、といったような手法らしい。
(手法の概要としてはそうなのだろうが、細かい実装に高品質さの肝があると思うのでしっかり読んだ方が良さげ。特にTest Generationの詳細をしっかりできていない)
takeawayで興味深かったのは、
- LLMは自身では解けないが、解法が存在する(solvable)問題を生成できること
- 人間の専門家とLLM(o3)の間で、問題の品質の新規性の判定の相関がわずか0.007, 0.11しかなかったこと。そして品質に関しては専門家のグループ間では0.71, o3とgpt4oの間では0.72と高い相関を示しており、LLMと人間の専門家の間で著しく問題の品質の判断基準が異なること
- seed問題と生成された問題の難易度のgainが、問題の品質に関して、LLM自身のself-evaluationよりもより良い指標となっていること
#Pocket #NLP #ReinforcementLearning #AIAgents #SoftwareEngineering #read-later #ContextEngineering #DeepResearch #LongHorizon Issue Date: 2025-10-18 [Paper Note] Scaling Long-Horizon LLM Agent via Context-Folding, Weiwei Sun+, arXiv'25, 2025.10 GPT Summary- 「Context-Folding」フレームワークを提案し、LLMエージェントがサブタスクを処理しつつコンテキストを管理する方法を示す。FoldGRPOを用いた強化学習により、複雑な長期タスクで10倍小さいコンテキストを使用し、従来のモデルを上回る性能を達成。 Comment
pj page: https://context-folding.github.io
元ポスト:
エージェント自身にcontextを管理する能力を学習させる
#Pocket #NLP #LongSequence #SSM (StateSpaceModel) #Generalization #memory Issue Date: 2025-10-18 [Paper Note] To Infinity and Beyond: Tool-Use Unlocks Length Generalization in State Space Models, Eran Malach+, arXiv'25, 2025.10 GPT Summary- 状態空間モデル(SSM)は、長文生成において効率的な代替手段であるが、真の長文生成問題を解決できないことが明らかにされた。外部ツールへのインタラクティブなアクセスを許可することで、この制限を克服できることが示され、SSMは問題依存のトレーニングデータを用いて任意の問題に一般化できる。ツールを強化したSSMは、算術や推論、コーディングタスクにおいて優れた長さの一般化を達成し、トランスフォーマーに対する効率的な代替手段となる可能性がある。 Comment
元ポスト:
著者ポスト:
所見:
解説:
#ComputerVision #Pocket #LongSequence #AttentionSinks #read-later #VideoGeneration/Understandings #interactive Issue Date: 2025-10-17 [Paper Note] LongLive: Real-time Interactive Long Video Generation, Shuai Yang+, arXiv'25, 2025.09 GPT Summary- LongLiveは、リアルタイムでインタラクティブな長編動画生成のためのフレームレベルの自己回帰フレームワークを提案。因果的注意ARモデルを採用し、KV再キャッシュメカニズムを統合することで、視覚的一貫性と意味的整合性を保ちながら効率的な生成を実現。1.3Bパラメータのモデルを32 GPU日でファインチューニングし、単一のNVIDIA H100で20.7 FPSを維持。最大240秒の動画生成をサポートし、INT8量子化推論も対応。 Comment
元ポスト:
pj page: https://nvlabs.github.io/LongLive/
#Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #Scaling Laws #PostTraining #read-later Issue Date: 2025-10-17 [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10 GPT Summary- 強化学習(RL)のスケーリングに関する原則的なフレームワークを定義し、40万時間以上のGPU時間を用いた大規模な研究を実施。シグモイド型計算-性能曲線をフィットさせ、設計選択肢の影響を分析。結果として、漸近的性能はレシピによって異なり、計算効率は詳細に依存することを発見。これを基に、ScaleRLというベストプラクティスのレシピを提案し、100,000 GPU時間での成功を示した。この研究は、RLトレーニングの予測可能性を向上させるための科学的フレームワークを提供する。 Comment
元ポスト:
> 簡単になったプロンプト(プロンプトの通過率が0.9以上)は再サンプリングしたほうが最終性能が高い
最近はカリキュラムラーニングを導入して、簡単すぎず難しすぎない問題をサンプリングして効率上げる、といったような話があったが、簡単になった問題をリサンプリングしないと最終性能としては低くなる可能性があるのか…意外だった。
著者ポスト:
ポイント解説:
#ComputerVision #EfficiencyImprovement #Pocket #Dataset #Evaluation #Attention #LongSequence #AttentionSinks #read-later #VideoGeneration/Understandings #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-10-15 [Paper Note] StreamingVLM: Real-Time Understanding for Infinite Video Streams, Ruyi Xu+, arXiv'25, 2025.10 GPT Summary- StreamingVLMは、無限のビデオストリームをリアルタイムで理解するためのモデルで、トレーニングと推論を統一したフレームワークを採用。アテンションシンクの状態を再利用し、短いビジョントークンと長いテキストトークンのウィンドウを保持することで、計算コストを抑えつつ高い性能を実現。新しいベンチマークInf-Streams-Evalで66.18%の勝率を達成し、一般的なVQA能力を向上させることに成功。 Comment
元ポスト:
これは興味深い
保持するKV Cacheの上限を決め、Sink Token[^1]は保持し[^2](512トークン)、textual tokenは長距離で保持、visual tokenは短距離で保持、またpositional encodingとしてはRoPEを採用するが、固定されたレンジの中で動的にindexを更新することで、位相を学習時のrangeに収めOODにならないような工夫をすることで、memoryと計算コストを一定に保ちながらlong contextでの一貫性とリアルタイムのlatencyを実現する、といった話にみえる。
学習時はフレームがoverlapした複数のチャンクに分けて、それぞれをfull attentionで学習する(Sink Tokenは保持する)。これは上述のinference時のパターンと整合しており学習時とinference時のgapが最小限になる。また、わざわざlong videoで学習する必要がない。(美しい解決方法)
[^1]: decoder-only transformerの余剰なattention scoreの捨て場として機能するsequence冒頭の数トークン(3--4トークン程度)のこと。本論文では512トークンと大きめのSink Tokenを保持している。
[^2]: Attention Sinksによって、long contextの性能が改善され Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
decoder-only transformerの層が深い部分でのトークンの表現が均一化されてしまうover-mixingを抑制する Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
ことが報告されている
AttentionSink関連リンク:
- Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
↑これは元ポストを読んで(と論文斜め読み)の感想のようなものなので、詳細は後で元論文を読む。
関連:
#ComputerVision #EfficiencyImprovement #Pocket #Transformer #DiffusionModel #read-later #Backbone Issue Date: 2025-10-14 [Paper Note] Diffusion Transformers with Representation Autoencoders, Boyang Zheng+, arXiv'25, 2025.10 GPT Summary- 本研究では、従来のVAEエンコーダを事前学習された表現エンコーダに置き換えたRepresentation Autoencoders(RAE)を提案。これにより、高品質な再構成と豊かな潜在空間を実現し、拡散トランスフォーマーの性能向上を図る。RAEは、補助的な表現整合損失なしで早い収束を達成し、ImageNetで優れた画像生成結果を示した。RAEは、拡散トランスフォーマーの新しいデフォルトとしての利点を提供する。 Comment
pj page: https://rae-dit.github.io
元ポスト:
U-NetをBackboneとしたVAEの代わりにViTに基づく(down, up- scaling無しの)アーキテクチャを用いることで、より少ない計算量で高い性能を達成しました、といった話に見える。
ポイント解説:
解説:
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #Self-SupervisedLearning #SelfCorrection #mid-training #WorldModels #KeyPoint Notes Issue Date: 2025-10-14 [Paper Note] Agent Learning via Early Experience, Kai Zhang+, arXiv'25, 2025.10 GPT Summary- 言語エージェントの目標は、経験を通じて学び、複雑なタスクで人間を上回ることですが、強化学習には報酬の欠如や非効率的なロールアウトが課題です。これに対処するため、エージェント自身の行動から生成された相互作用データを用いる「早期経験」という新たなパラダイムを提案します。このデータを基に、(1) 暗黙の世界モデル化と(2) 自己反省の2つの戦略を研究し、8つの環境で評価を行った結果、効果性と一般化が向上することを示しました。早期経験は、強化学習の基盤を提供し、模倣学習と経験駆動エージェントの橋渡しとなる可能性があります。 Comment
元ポスト:
LLM AgentのためのWarmup手法を提案している。具体的にはRLVRやImitation LearningによってRewardが定義できるデータに基づいてこれまではRLが実現されてきたが、これらはスケールせず、Rewardが定義されない環境のtrajectoryなどは学習されないので汎化性能が低いという課題がある。このため、これらのsupervisionつきの方法で学習をする前のwarmup手法として、reward-freeの学習パラダイム Early Experienceを提案している。https://github.com/user-attachments/assets/c2ed5999-d6d8-419d-93e9-f3358ab0ca1f"
/>
手法としてはシンプルな手法が2種類提案されている。
### Implicit World Modeling (IWM, 式(3)):
ある状態s_i において action a_i^{j}を (1 < j < |K|)をとった時の状態をs_i^{j}としたときに、(s_i, a_i^{j}, s_i^{j}) の3つ組を考える。これらはポリシーからのK回のrolloutによって生成可能。
このときに、状態sを全てテキストで表現するようにし、言語モデルのnext-token-prediction lossを用いて、ある状態s_jにおいてaction a_i^{k} をとったときに、s_j^{k} になることを予測できるように学習する。これにより例えばブックフライトのサイトで誤った日時を入れてしまった場合や、どこかをクリックしたときにどこに遷移するかなどの学習する環境の世界知識をimplicitにモデルに組み込むことができる。
### Self-Reflection(式4)
もう一つのパラダイムとして、専門家によるアクション a_i によって得られた状態 s_i と、それら以外のアクション a_i^{j} によって得られた状態 s_i^{j}が与えられたときに、s_iとs_i^{j}を比較したときに、なぜ a_i の方がa_i^{j} よりも好ましいかを説明するCoT C_i^{j}を生成し、三つ組データ(s_i, a_i^{j}, c_i^{j}) を構築する。このデータを用いて、状態s_iがgivenなときに、a_i に c_i^{j} をconcatしたテキストを予測できるようにnext-token-prediction lossで学習する。また、このデータだけでなく汎化性能をより高めるためにexpertによるimitation learningのためのデータCoTなしのデータもmixして学習をする。これにより、expertによるactionだけで学習するよりも、なぜexpertのアクションが良いかという情報に基づいてより豊富で転移可能な学習シグナルを活用し学習することができる。
https://github.com/user-attachments/assets/d411ac3b-d977-4357-b715-0cf4e5b95fa2"
/>
この結果、downstreamタスクでのperformanceが単にImitation Learningを実施した場合と比較して提案手法でwarmupした方が一貫して向上する。また、5.4節にpost-trainingとして追加でGRPOを実施した場合も提案手法によるwarmupを実施した場合が最終的な性能が向上することが報告されている。https://github.com/user-attachments/assets/a0aad636-b889-4d2d-b753-b0ad5ad4c688"
/>
IWMは自己教師あり学習の枠組みだと思われるので、よぬスケールし、かつ汎化性能が高く様々な手法のベースとなりうる手法に見える。
著者ポスト:
#Pocket #NLP #LanguageModel #Chain-of-Thought #Reasoning #read-later #Verification #One-Line Notes Issue Date: 2025-10-14 [Paper Note] Verifying Chain-of-Thought Reasoning via Its Computational Graph, Zheng Zhao+, arXiv'25, 2025.10 GPT Summary- Circuit-based Reasoning Verification (CRV)を提案し、CoTステップの帰属グラフを用いて推論エラーを検証。エラーの構造的署名が予測的であり、異なる推論タスクで異なる計算パターンが現れることを示す。これにより、モデルの誤った推論を修正する新たなアプローチを提供し、LLM推論の因果理解を深めることを目指す。 Comment
元ポスト:
著者ポスト:
transformer内部のactivationなどから計算グラフを構築しreasoningのsurface(=観測できるトークン列)ではなく内部状態からCoTをverification(=CoTのエラーを検知する)するようなアプローチ(white box method)らしい
#EfficiencyImprovement #Pocket #NLP #LanguageModel #DiffusionModel #LLMServing #read-later Issue Date: 2025-10-14 [Paper Note] dInfer: An Efficient Inference Framework for Diffusion Language Models, Yuxin Ma+, arXiv'25, 2025.10 GPT Summary- dLLMの推論を効率化するフレームワークdInferを提案。dInferは4つのモジュールに分解され、新しいアルゴリズムと最適化を統合。これにより、出力品質を維持しつつ、推論速度を大幅に向上。HumanEvalで1秒あたり1,100トークンを超え、従来のシステムに比べて10倍のスピードアップを実現。dInferはオープンソースで公開。 Comment
code: https://github.com/inclusionAI/dInfer
とうとうdLLMを高速でinferenceできるフレームワークが出た模様。inclusionAIより。
ポイント解説:
#Pocket #NLP #Dataset #Supervised-FineTuning (SFT) #Evaluation #In-ContextLearning #PostTraining #meta-learning #KeyPoint Notes #Steering Issue Date: 2025-10-14 [Paper Note] Spectrum Tuning: Post-Training for Distributional Coverage and In-Context Steerability, Taylor Sorensen+, arXiv'25, 2025.10 GPT Summary- ポストトレーニングは言語モデルの性能を向上させるが、操作性や出力空間のカバレッジ、分布の整合性においてコストが伴う。本研究では、これらの要件を評価するためにSpectrum Suiteを導入し、90以上のタスクを網羅。ポストトレーニング技術が基礎的な能力を引き出す一方で、文脈内操作性を損なうことを発見。これを改善するためにSpectrum Tuningを提案し、モデルの操作性や出力空間のカバレッジを向上させることを示した。 Comment
元ポスト:
著者らはモデルの望ましい性質として
- In context steerbility: inference時に与えられた情報に基づいて出力分布を変えられる能力
- Valid output space coverage: タスクにおける妥当な出力を広範にカバーできること
- Distributional Alignment: ターゲットとする出力分布に対してモデルの出力分布が近いこと
の3つを挙げている。そして既存のinstruction tuningや事後学習はこれらを損なうことを指摘している。
ここで、incontext steerbilityとは、事前学習時に得た知識や、分布、能力だけに従うのではなく、context内で新たに指定した情報をモデルに活用させることである。
モデルの上記3つの能力を測るためにSpectrum Suiteを導入する。これには、人間の様々な嗜好、numericな分布の出力、合成データ作成などの、モデル側でsteeringや多様な分布への対応が必要なタスクが含まれるベンチマークのようである。
また上記3つの能力を改善するためにSpectrum Tuningと呼ばれるSFT手法を提案している。
手法はシンプルで、タスクT_iに対する 多様なinput X_i タスクのcontext(すなわちdescription) Z_i が与えられた時に、T_i: X_i,Z_i→P(Y_i) を学習したい。ここで、P(Y_i)は潜在的なoutputの分布であり、特定の1つのサンプルyに最適化する、という話ではない点に注意(meta learningの定式化に相当する)。
具体的なアルゴリズムとしては、タスクのコレクションが与えられた時に、タスクiのcontextとdescriptionをtokenizeした結果 z_i と、incontextサンプルのペア x_ij, y_ij が与えられた時に、output tokenのみに対してcross entropyを適用してSFTをする。すなわち、以下のような手順を踏む:
1. incontextサンプルをランダムなオーダーにソートする
2. p_dropの確率でdescription z_i をドロップアウトしx_i0→y_i0の順番でconcatする、
2-1. descriptionがdropしなかった場合はdescription→x_i0→y_i0の順番でconcatし入力を作る。
2-2. descriptionがdropした場合、x_i0→y_i0の順番で入力を作る。
3. 他のサンプルをx_1→y_1→...→x_n→y_nの順番で全てconcatする。
4. y_{1:n}に対してのみクロスエントロピーlossを適用し、他はマスクして学習する。
一見するとinstruct tuningに類似しているが、以下の点で異なっている:
- 1つのpromptに多くのi.i.dな出力が含まれるのでmeta-learningが促進される
- 個別データに最適化されるのではなく、タスクに対する入出力分布が自然に学習される
- chat styleのデータにfittingするのではなく、分布に対してfittingすることにフォーカスしている
- input xやタスクdescription zを省略することができ、ユーザ入力が必ず存在する設定とは異なる
という主張をしている。
#Pocket #NLP #Dataset #LanguageModel #UserBased #Alignment #Evaluation #Coding #read-later Issue Date: 2025-10-13 [Paper Note] BigCodeArena: Unveiling More Reliable Human Preferences in Code Generation via Execution, Terry Yue Zhuo+, arXiv'25, 2025.10 GPT Summary- BigCodeArenaは、LLMが生成したコードの質をリアルタイムで評価するためのクラウドソーシングプラットフォームで、Chatbot Arenaを基盤に構築されています。14,000以上のコード中心の会話セッションから4,700のマルチターンサンプルを収集し、人間の好みを明らかにしました。これに基づき、LLMのコード理解と生成能力を評価するためのBigCodeRewardとAutoCodeArenaという2つのベンチマークを策定しました。評価の結果、実行結果が利用可能な場合、ほとんどのLLMが優れたパフォーマンスを示し、特にGPT-5やClaudeシリーズがコード生成性能でリードしていることが確認されました。 Comment
元ポスト:
良さそう
#ComputerVision #Pocket #SelfImprovement #read-later #VisionLanguageModel #Label-free Issue Date: 2025-10-13 [Paper Note] Vision-Zero: Scalable VLM Self-Improvement via Strategic Gamified Self-Play, Qinsi Wang+, arXiv'25, 2025.09 GPT Summary- Vision-Zeroは、視覚と言語のモデル(VLM)の自己改善を促進するドメイン非依存のフレームワークであり、任意の画像ペアから生成された競争的な視覚ゲームを通じてトレーニングを行う。主な特徴は、戦略的自己対戦による自律的なデータ生成、任意の画像からのゲーム生成による多様なドメインでの推論能力向上、そして反復自己対戦ポリシー最適化(Iterative-SPO)による持続的なパフォーマンス向上である。Vision-Zeroはラベルなしデータを用いて最先端のパフォーマンスを達成し、他の注釈ベースの手法を上回る。 Comment
pj page: https://github.com/wangqinsi1/Vision-Zero
元ポスト:
とても良さそう
ポイント解説:
#EfficiencyImprovement #Pocket #NLP #LanguageModel #ReinforcementLearning #Reasoning #read-later Issue Date: 2025-10-09 [Paper Note] The Markovian Thinker, Milad Aghajohari+, arXiv'25, 2025.10 GPT Summary- 強化学習を用いて長い思考の連鎖を生成するための新しいパラダイム「マルコフ的思考」を提案。これにより、状態を一定のサイズに制限し、思考の長さをコンテキストのサイズから切り離すことで、線形計算を実現。新しいRL環境「Delethink」を構築し、モデルは短い持ち越しで推論を継続することを学習。訓練されたモデルは、長い推論を効率的に行い、コストを大幅に削減。思考環境の再設計が、効率的でスケーラブルな推論LLMの実現に寄与することを示した。 Comment
元ポスト:
ポイント解説:
解説:
#Pocket #NLP #LanguageModel #SmallModel #LatentReasoning #RecursiveModels Issue Date: 2025-10-09 [Paper Note] Less is More: Recursive Reasoning with Tiny Networks, Alexia Jolicoeur-Martineau, arXiv'25, 2025.10 GPT Summary- 階層的推論モデル(HRM)は、2つの小さなニューラルネットワークを用いた新しいアプローチで、数独や迷路などのパズルタスクで大規模言語モデル(LLMs)を上回る性能を示す。しかし、HRMは最適ではない可能性があるため、我々はTiny Recursive Model(TRM)を提案。TRMはよりシンプルで高い一般化能力を持ち、700万パラメータでARC-AGI-1で45%、ARC-AGI-2で8%の精度を達成し、ほとんどのLLMを上回る性能を示した。 Comment
元ポスト:
所見:
ポイント解説:
ARC-AGI公式による検証が終わり報告されている結果が信頼できることが確認された模様:
続報:
Sudoku Benchでも性能改善する模様?
#Pocket #NLP #LanguageModel #Evaluation Issue Date: 2025-10-09 [Paper Note] GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks, Tejal Patwardhan+, arXiv'25, 2025.10 GPT Summary- GDPvalは、AIモデルの経済的価値のあるタスクを評価するベンチマークで、米国GDPに寄与する44の職業をカバー。最前線モデルのパフォーマンスは時間と共に改善し、業界専門家に近づいている。人間の監視を加えたモデルは、無援助の専門家よりも効率的にタスクを実行可能であることを示唆。推論努力やタスクコンテキストの増加がモデルの性能向上に寄与。220のタスクのゴールドサブセットをオープンソース化し、研究促進のための自動採点サービスを提供。 Comment
元ポスト:
#Embeddings #EfficiencyImprovement #Pocket #NLP #LanguageModel #RepresentationLearning #RAG(RetrievalAugmentedGeneration) #ICLR #read-later #One-Line Notes Issue Date: 2025-10-08 [Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02 GPT Summary- 生成的表現指示チューニング(GRIT)を用いて、大規模言語モデルが生成タスクと埋め込みタスクを同時に処理できる手法を提案。GritLM 7BはMTEBで新たな最先端を達成し、GritLM 8x7Bはすべてのオープン生成モデルを上回る性能を示す。GRITは生成データと埋め込みデータの統合による性能損失がなく、RAGを60%以上高速化する利点もある。モデルは公開されている。 Comment
openreview: https://openreview.net/forum?id=BC4lIvfSzv
従来はgemerativeタスクとembeddingタスクは別々にモデリングされていたが、それを統一的な枠組みで実施し、両方のタスクで同等のモデルサイズの他モデルと比較して高い性能を達成した研究。従来のgenerativeタスク用のnext-token-prediction lossとembeddingタスク用のconstastive lossを組み合わせて学習する(式3)。タスクの区別はinstructionにより実施し、embeddingタスクの場合はすべてのトークンのlast hidden stateのmean poolingでrepresentationを取得する。また、embeddingの時はbi-directional attention / generativeタスクの時はcausal maskが適用される。これらのattentionの適用のされ方の違いが、どのように管理されるかはまだしっかり読めていないのでよくわかっていないが、非常に興味深い研究である。https://github.com/user-attachments/assets/acb2cbcd-364d-43c7-b51a-6c5ea9866415"
/>
#Embeddings #InformationRetrieval #Pocket #Transformer #SyntheticData #Reasoning #Test-Time Scaling #COLM #read-later #Encoder Issue Date: 2025-10-08 [Paper Note] ReasonIR: Training Retrievers for Reasoning Tasks, Rulin Shao+, COLM'25, 2025.04 GPT Summary- ReasonIR-8Bは、一般的な推論タスク向けに特別に訓練された初のリトリーバーであり、合成データ生成パイプラインを用いて挑戦的なクエリとハードネガティブを作成。これにより、BRIGHTベンチマークで新たな最先端成果を達成し、RAGタスクでも他のリトリーバーを上回る性能を示す。トレーニングレシピは一般的で、将来のLLMへの拡張が容易である。コード、データ、モデルはオープンソース化されている。 Comment
元ポスト:
Llama3.1-8Bをbidirectional encoderに変換してpost-trainingしている。
関連:
- [Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
#Pocket #NLP #LanguageModel #In-ContextLearning #Safety #Scaling Laws #COLM #read-later Issue Date: 2025-10-08 [Paper Note] Bayesian scaling laws for in-context learning, Aryaman Arora+, COLM'25, 2024.10 GPT Summary- インコンテキスト学習(ICL)は、言語モデルに複雑なタスクを実行させる手法であり、提供される例の数と予測精度に強い相関がある。本研究では、ICLがベイズ学習者を近似することを示し、新しいベイズスケーリング法則を提案。GPT-2モデルを用いた実験で、提案法則が精度における既存の法則と一致し、タスクの事前分布や学習効率に関する解釈可能な項を提供。実験では、ICLを用いて抑制されたモデル能力を再現する条件を予測し、LLMの安全性向上に寄与することを示した。 Comment
openreview: https://openreview.net/forum?id=U2ihVSREUb#discussion
元ポスト:
#Pocket #NLP #UserModeling #Dataset #LanguageModel #UserBased #AIAgents #Evaluation #read-later #One-Line Notes Issue Date: 2025-10-08 [Paper Note] Impatient Users Confuse AI Agents: High-fidelity Simulations of Human Traits for Testing Agents, Muyu He+, arXiv'25, 2025.10 GPT Summary- TraitBasisを用いて、会話型AIエージェントの堅牢性を体系的にテストする手法を提案。ユーザーの特性(せっかちさや一貫性のなさ)を制御し、AIエージェントのパフォーマンス低下を観察。最前線のモデルで2%-30%の性能低下を確認し、現在のAIエージェントの脆弱性を示す。TraitBasisはシンプルでデータ効率が高く、現実の人間の相互作用における信頼性向上に寄与する。$\tau$-Traitをオープンソース化し、コミュニティが多様なシナリオでエージェントを評価できるようにした。 Comment
元ポスト:
実際の人間にあるような癖(のような摂動)を与えた時にどれだけロバストかというのは実応用上非常に重要な観点だと思われる。元ポストを見ると、LLM内部のmatmulを直接操作することで、任意のレベルの人間の特性(e.g.,疑い深い、混乱、焦りなど)を模倣する模様。
#Pocket #ReinforcementLearning #read-later Issue Date: 2025-10-07 [Paper Note] BroRL: Scaling Reinforcement Learning via Broadened Exploration, Jian Hu+, arXiv'25, 2025.10 GPT Summary- 検証可能な報酬を用いた強化学習(RLVR)の新たなアプローチとしてBroR-Lを提案。ロールアウトの数を増やすことで探索を広げ、ProRLの飽和点を超えたパフォーマンス向上を実現。理論的分析に基づき、ロールアウト数の増加が正しいトークンの質量拡大を保証することを示す。BroRLは3KのProRLトレーニングステップでの飽和モデルを復活させ、最先端の結果を達成。 Comment
元ポスト:
関連:
- [Paper Note] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, Mingjie Liu+, NeurIPS'25
- ProRL V2 - Prolonged Training Validates RL Scaling Laws, Hu+, 2025.08
前回はstep数をこれまでにない規模でスケーリングされRLしたがそれで性能が頭打ちを迎えることがわかったので、今度はロールアウト数をスケーリングさせた時にどうなるかというのを試したっぽい?
#Tutorial #Analysis #NLP #LanguageModel #Slide #reading Issue Date: 2025-10-07 言語モデルの内部機序:解析と解釈, HEINZERLING+, NLP'25, 2025.03 Comment
元ポスト:
#Pretraining #Pocket #NLP #LanguageModel #read-later #LatentReasoning Issue Date: 2025-10-03 [Paper Note] Thoughtbubbles: an Unsupervised Method for Parallel Thinking in Latent Space, Houjun Liu+, arXiv'25, 2025.09 GPT Summary- 本研究では、トランスフォーマーの新しい変種「Thoughtbubbles」を提案し、並列適応計算を潜在空間で実行する方法を示す。残差ストリームをフォークまたは削除することで、計算を効率化し、事前トレーニング中に学習可能。Thoughtbubblesは、従来の手法を上回る性能を示し、推論時のトレーニングとテストの挙動を統一する可能性を持つ。 Comment
元ポスト:
重要論文に見える
#Analysis #Pretraining #Pocket #NLP #LanguageModel #SyntheticData #DataMixture #One-Line Notes #PhaseTransition Issue Date: 2025-10-03 [Paper Note] Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls, Feiyang Kang+, arXiv'25, 2025.10 GPT Summary- 合成データ技術はLLMのトレーニングデータの供給制限を克服する可能性を持つ。本研究では、自然なウェブデータと合成データの混合を比較し、言い換えた合成データのみでの事前トレーニングは自然なデータよりも速くないことを示した。1/3の言い換えた合成データと2/3の自然データの混合が、より効率的なトレーニングを可能にすることが分かった。教科書スタイルの合成データは小さなデータ予算で高い損失をもたらし、合成データの最適な比率はモデルサイズとデータ予算に依存する。結果は合成データの効果を明らかにし、実用的なガイダンスを提供する。 Comment
元ポスト:
ポイント解説:
合成データは適切な規模のモデルと比率でないと利点が現れない
#Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #AIAgents #read-later Issue Date: 2025-10-03 [Paper Note] A Practitioner's Guide to Multi-turn Agentic Reinforcement Learning, Ruiyi Wang+, arXiv'25, 2025.10 GPT Summary- マルチターン強化学習におけるLLMエージェントの訓練方法を研究し、設計空間を環境、報酬、ポリシーの3つの柱に分解。環境の複雑さがエージェントの一般化能力に与える影響、報酬の希薄性が訓練に与える効果、ポリシー勾配法の相互作用を分析。これらの知見を基に、訓練レシピを提案し、マルチターンエージェント強化学習の研究と実践を支援。 Comment
元ポスト:
著者ポスト:
takeawayが非常に簡潔で分かりやすい。
ベンチマーク:
- [Paper Note] TextWorld: A Learning Environment for Text-based Games, Marc-Alexandre Côté+, Workshop on Computer Games'18 Held in Conjunction with IJCAI'18, 2018.06
- [Paper Note] ALFWorld: Aligning Text and Embodied Environments for Interactive Learning, Mohit Shridhar+, ICLR'21, 2020.10
- Training Software Engineering Agents and Verifiers with SWE-Gym, Jiayi Pan+, ICML'25
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #SoftwareEngineering #read-later #reading #KeyPoint Notes Issue Date: 2025-10-02 [Paper Note] Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents, Zonghan Yang+, arXiv'25, 2025.09 GPT Summary- 大規模言語モデル(LLMs)のソフトウェア工学(SWE)への応用が進んでおり、SWE-benchが重要なベンチマークとなっている。マルチターンのSWE-Agentフレームワークと単一ターンのエージェントレス手法は相互排他的ではなく、エージェントレストレーニングが効率的なSWE-Agentの適応を可能にする。本研究では、Kimi-DevというオープンソースのSWE LLMを紹介し、SWE-bench Verifiedで60.4%を達成。追加の適応により、Kimi-DevはSWE-Agentの性能を48.6%に引き上げ、移植可能なコーディングエージェントの実現を示した。 Comment
元ポスト:
Agentlessはこちら:
- Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, FSE'25
著者ポスト:
ポストの中でOpenhandsが同モデルを内部で検証し、Openhandsの環境内でSWE Bench Verifiedで評価した結果、レポート内で報告されているAcc. 60.4%は達成できず、17%に留まることが報告されていた模様。
Openhandsの説明によるとAgentlessは決められた固定されたワークフローのみを実施する枠組み(Kimi Devの場合はBugFixerとFileEditor)であり、ワークフローで定義されたタスクは効果的に実施できるが、それら以外のタスクはそもそもうまくできない。SWE Agent系のベンチのバグfixの方法は大きく分けてAgentlike(コードベースを探索した上でアクションを実行する形式)、Fixed workflow like Agentless(固定されたワークフローのみを実行する形式)の2種類があり、Openhandsは前者、Kimi Devは後者の位置付けである。
実際、テクニカルレポートのFigure2とAppendixを見ると、File Localization+BugFixer+TestWriterを固定されたプロンプトテンプレートを用いてmid-trainingしており、評価する際も同様のハーネスが利用されていると推察される(どこかに明示的な記述があるかもしれない)。
一方、Openhandsではより実環境の開発フローに近いハーネス(e.g., エージェントがコードベースを確認してアクションを提案→実行可能なアクションなら実行→そうでないならユーザからのsimulated responceを受け取る→Agentに結果をフィードバック→エージェントがアクション提案...)といったハーネスとなっている。
このように評価をする際のハーネスが異なるため、同じベンチマークに対して異なる性能が報告される、ということだと思われる。
単にSWE Bench VerifiedのAcc.だけを見てモデルを選ぶのではなく、評価された際のEvaluation Harnessが自分たちのユースケースに合っているかを確認することが重要だと考えられる。
参考:
- OpenhandsのEvaluation Harness:
https://docs.all-hands.dev/openhands/usage/developers/evaluation-harness
#RecommenderSystems #Pocket #LanguageModel #read-later #interactive #One-Line Notes Issue Date: 2025-09-29 [Paper Note] Interactive Recommendation Agent with Active User Commands, Jiakai Tang+, arXiv'25, 2025.09 GPT Summary- 従来のレコメンダーシステムは受動的なフィードバックに依存し、ユーザーの意図を捉えられないため、嗜好モデルの構築が困難である。これに対処するため、インタラクティブレコメンデーションフィード(IRF)を導入し、自然言語コマンドによる能動的な制御を可能にする。RecBotという二重エージェントアーキテクチャを開発し、ユーザーの嗜好を構造化し、ポリシー調整を行う。シミュレーション強化知識蒸留を用いて効率的なパフォーマンスを実現し、実験によりユーザー満足度とビジネス成果の改善を示した。 Comment
元ポスト:
ABテストを実施しているようなので信ぴょう性高め
#Pocket #NLP #AIAgents #ScientificDiscovery #read-later #EvolutionaryAlgorithm Issue Date: 2025-09-25 [Paper Note] ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution, Robert Tjarko Lange+, arXiv'25, 2025.09 GPT Summary- ShinkaEvolveは、科学的発見を促進するための新しいオープンソースフレームワークであり、LLMsを利用して高い効率性とパフォーマンスを実現します。従来のコード進化手法の制限を克服し、親サンプリング技術や新規性拒否サンプリング、バンディットベースのアンサンブル選択戦略を導入。多様なタスクでの評価により、サンプル効率と解の質が向上し、150サンプルで新たな最先端ソリューションを発見しました。ShinkaEvolveは、オープンソースでのアクセス性を提供し、計算問題における発見を民主化します。 Comment
pj page: https://sakana.ai/shinka-evolve/
元ポスト:
国際的なプログラミングコンテストでShinkaEvolveのサポートの元、チームが優勝した模様:
-
-
#ComputerVision #Pocket #FoundationModel #read-later Issue Date: 2025-09-25 [Paper Note] Video models are zero-shot learners and reasoners, Thaddäus Wiedemer+, arXiv'25, 2025.09 GPT Summary- 大規模言語モデル(LLMs)のゼロショット能力が自然言語処理を変革したように、生成ビデオモデルも一般目的の視覚理解に向かう可能性がある。Veo 3は、物体のセグメンテーションやエッジ検出など、訓練されていない幅広いタスクを解決できることを示し、視覚推論の初期形態を可能にする。Veoのゼロショット能力は、ビデオモデルが一般的な視覚基盤モデルになる道を示唆している。 Comment
pj page: https://video-zero-shot.github.io
ポイント解説:
所見:
解説:
#Pocket #NLP #LanguageModel #Attention #Architecture #MoE(Mixture-of-Experts) #read-later #KeyPoint Notes Issue Date: 2025-09-24 [Paper Note] UMoE: Unifying Attention and FFN with Shared Experts, Yuanhang Yang+, arXiv'25, 2025.05 GPT Summary- Sparse Mixture of Experts (MoE) アーキテクチャは、Transformer モデルのスケーリングにおいて有望な手法であり、注意層への拡張が探求されていますが、既存の注意ベースの MoE 層は最適ではありません。本論文では、注意層と FFN 層の MoE 設計を統一し、注意メカニズムの再定式化を行い、FFN 構造を明らかにします。提案するUMoEアーキテクチャは、注意ベースの MoE 層で優れた性能を達成し、効率的なパラメータ共有を実現します。 Comment
元ポスト:
Mixture of Attention Heads (MoA)はこちら:
- [Paper Note] Mixture of Attention Heads: Selecting Attention Heads Per Token, Xiaofeng Zhang+, EMNLP'22, 2022.10
この図がわかりやすい。後ほど説明を追記する。ざっくり言うと、MoAを前提としたときに、最後の出力の変換部分VW_oをFFNによる変換(つまりFFN Expertsの一つ)とみなして、self-attentionのトークンを混ぜ合わせるという趣旨を失わない範囲で計算順序を調整(トークンをミックスする部分を先に持ってくる)すると、FFNのMoEとMoAは同じ枠組みで扱えるため、expertsを共有できてメモリを削減でき、かつMoAによって必要な箇所のみにattendする能力が高まり性能も上がります、みたいな話に見える。
#Pocket #NLP #LanguageModel #Reasoning #Decoding #read-later #SpeculativeDecoding Issue Date: 2025-09-24 [Paper Note] Scaling Speculative Decoding with Lookahead Reasoning, Yichao Fu+, arXiv'25, 2025.06 GPT Summary- Lookahead Reasoningを用いることで、推論モデルのトークンデコード速度を向上させる手法を提案。軽量なドラフトモデルが将来のステップを提案し、ターゲットモデルが一度のバッチ処理で展開。これにより、トークンレベルの推測デコーディング(SD)のスピードアップを1.4倍から2.1倍に改善し、回答の質を維持。 Comment
元ポスト:
#Pocket #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #read-later #Verification Issue Date: 2025-09-24 [Paper Note] Heimdall: test-time scaling on the generative verification, Wenlei Shi+, arXiv'25, 2025.04 GPT Summary- Heimdallは、長いChain-of-Thought推論における検証能力を向上させるためのLLMであり、数学問題の解決精度を62.5%から94.5%に引き上げ、さらに97.5%に達する。悲観的検証を導入することで、解決策の精度を54.2%から70.0%、強力なモデルを使用することで93.0%に向上させる。自動知識発見システムのプロトタイプも作成し、データの欠陥を特定する能力を示した。 #Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #One-Line Notes Issue Date: 2025-09-23 [Paper Note] ARE: Scaling Up Agent Environments and Evaluations, Pierre Andrews+, arXiv'25, 2025.09 GPT Summary- Meta Agents Research Environments (ARE)を紹介し、エージェントのオーケストレーションや環境のスケーラブルな作成を支援するプラットフォームを提供。Gaia2というベンチマークを提案し、エージェントの能力を測定するために設計され、動的環境への適応や他のエージェントとの協力を要求。Gaia2は非同期で実行され、新たな失敗モードを明らかにする。実験結果は、知能のスペクトル全体での支配的なシステムが存在しないことを示し、AREの抽象化が新しいベンチマークの迅速な作成を可能にすることを強調。AIの進展は、意味のあるタスクと堅牢な評価に依存する。 Comment
元ポスト:
GAIAはこちら:
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
Execution, Search, Ambiguity, Adaptability, Time, Noise, Agent2Agentの6つのcapabilityを評価可能。興味深い。
現状、全体的にはGPT-5(high)の性能が最も良く、続いてClaude-4 Sonnetという感じに見える。OpenWeightなモデルでは、Kimi-K2の性能が高く、続いてQwen3-235Bという感じに見える。また、Figure1はbudgetごとのモデルの性能も示されている。シナリオ単位のbudgetが$1以上の場合はGPT-5(high)の性能が最も良いが、$0.1--$0.4の間ではKiml-K2の性能が最も良いように見える。
- [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25
しっかりと読めていないがGLM-4.5は含まれていないように見える。
ポイント解説:
#ComputerVision #Pocket #NLP #LanguageModel #MultiModal #ICLR #read-later #UMM Issue Date: 2025-09-22 [Paper Note] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model, Chunting Zhou+, ICLR'25, 2024.08 GPT Summary- Transfusionは、離散データと連続データに対してマルチモーダルモデルを訓練する手法で、言語モデリングの損失関数と拡散を組み合わせて単一のトランスフォーマーを訓練します。最大7Bパラメータのモデルを事前訓練し、ユニモーダルおよびクロスモーダルベンチマークで優れたスケーリングを示しました。モダリティ特有のエンコーディング層を導入することで性能を向上させ、7Bパラメータのモデルで画像とテキストを生成できることを実証しました。 Comment
openreview: https://openreview.net/forum?id=SI2hI0frk6
#Analysis #MachineLearning #Pocket #NLP #LanguageModel #Evaluation #NeurIPS #read-later Issue Date: 2025-09-19 [Paper Note] The Leaderboard Illusion, Shivalika Singh+, NeurIPS'25 GPT Summary- 進捗測定は科学の進展に不可欠であり、Chatbot ArenaはAIシステムのランキングにおいて重要な役割を果たしている。しかし、非公開のテスト慣行が存在し、特定のプロバイダーが有利になることで、スコアにバイアスが生じることが明らかになった。特に、MetaのLlama-4に関連するプライベートLLMバリアントが問題視され、データアクセスの非対称性が生じている。GoogleやOpenAIはArenaデータの大部分を占め、オープンウェイトモデルは少ないデータしか受け取っていない。これにより、Arena特有のダイナミクスへの過剰適合が発生している。研究は、Chatbot Arenaの評価フレームワークの改革と、公正で透明性のあるベンチマーキングの促進に向けた提言を行っている。 Comment
元ポスト:
要チェック
#ComputerVision #Pocket #Transformer #DiffusionModel #VariationalAutoEncoder #NeurIPS #PostTraining #VideoGeneration/Understandings #One-Line Notes Issue Date: 2025-09-19 [Paper Note] Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion, Xun Huang+, NeurIPS'25 GPT Summary- Self Forcingは、自動回帰型ビデオ拡散モデルの新しいトレーニング手法で、エクスポージャーバイアスの問題に対処します。従来の手法が真のコンテキストに基づくのに対し、Self Forcingは自己生成した出力に基づいてフレームを生成し、全体の品質を評価するホリスティックな損失を用います。計算コストとパフォーマンスのバランスを取るために、少数ステップの拡散モデルと確率的勾配切断を採用し、ロールイングKVキャッシュメカニズムを導入。実験により、リアルタイムのストリーミングビデオ生成が可能で、非因果的拡散モデルの生成品質に匹敵またはそれを上回ることが示されました。 Comment
pj page: https://self-forcing.github.io
元ポスト:
自己回帰的な動画生成(をする)モデルにおいて、学習時はground-truchのcontextが利用して学習されるが、推論時は自身が生成結果そのものをcontextとして利用するため、学習-推論時にgapが生じ、(徐々に誤差が蓄積することで)品質が劣化するという問題(exposure bias)に対処するために、学習時から自身が生成した出力をcontextとして与えて生成を行い(ロールアウト)、動画全体に対して分布の整合性を測るlossを導入(=フレーム単位の誤差を最小化にするのではなく、動画全体に対して(分布の)誤差を最適化する)することで、exposure biasを軽減する、という話な模様。
結果的に、単一のRTX4090でリアルタイムのストリーミングビデオ生成が高品質に生成可能となった(かもしれない):
https://note.com/ngc_shj/n/n505b2f7cdfe4
#Analysis #Pocket #NLP #LanguageModel #AIAgents #Reasoning #LongSequence #Scaling Laws #read-later #ContextEngineering Issue Date: 2025-09-14 [Paper Note] The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs, Akshit Sinha+, arXiv'25 GPT Summary- LLMsのスケーリングが収益に影響を与えるかを探求。単一ステップの精度向上がタスクの長さに指数的改善をもたらすことを観察。LLMsが長期タスクで失敗するのは推論能力の欠如ではなく実行ミスによると主張。知識と計画を明示的に提供することで実行能力を向上させる提案。モデルサイズをスケーリングしても自己条件付け効果は減少せず、長いタスクでのミスが増加。思考モデルは自己条件付けを行わずに長いタスクを実行可能。最終的に、実行能力に焦点を当てることで、LLMsの複雑な推論問題解決能力と単純タスクの長期化による失敗理由を調和させる。 Comment
元ポスト:
single stepでのタスク性能はサチって見えても、成功可能なタスクの長さは(single stepの実行エラーに引きづられるため)モデルのsingle stepのタスク性能に対して指数関数的に効いている(左上)。タスクが長くなればなるほどモデルは自身のエラーに引きずられ(self conditioning;右上)、これはパラメータサイズが大きいほど度合いが大きくなる(右下; 32Bの場合contextにエラーがあって場合のloeg horizonのAcc.が14Bよりも下がっている)。一方で、実行可能なstep数の観点で見ると、モデルサイズが大きい場合の方が多くのstepを要するタスクを実行できる(左下)。また、ThinkingモデルはSelf Conditioningの影響を受けにくく、single stepで実行可能なタスクの長さがより長くなる(中央下)。
といった話に見えるが、論文をしっかり読んだ方が良さそう。
(元ポストも著者ポストだが)著者ポスト:
このスレッドは読んだ方が良い(というか論文を読んだ方が良い)。
特に、**CoTが無い場合は**single-turnでほとんどのモデルは5 stepのタスクをlatent spaceで思考し、実行することができないというのは興味深い(が、細かい設定は確認した方が良い)。なので、マルチステップのタスクは基本的にはplanningをさせてから出力をさせた方が良いという話や、
では複雑なstepが必要なタスクはsingle turnではなくmulti turnに分けた方が良いのか?と言うと、モデルによって傾向が違うらしい、といった話が書かれている。たとえば、Qwenはsingle turnを好むが、Gemmaはmulti turnを好むらしい。
日本語ポイント解説:
解説:
#Pretraining #Pocket #NLP #LanguageModel #SmallModel #mid-training #PostTraining #read-later #DataMixture Issue Date: 2025-09-13 [Paper Note] MobileLLM-R1: Exploring the Limits of Sub-Billion Language Model Reasoners with Open Training Recipes, Changsheng Zhao+, arXiv'25, 2025.09 GPT Summary- 本研究では、推論能力の出現に必要なデータ量について再検討し、約2Tトークンの高品質データで強力な推論モデルが構築できることを示した。MobileLLM-R1というサブビリオンパラメータのモデルは、従来のモデルを大幅に上回る性能を発揮し、特にAIMEスコアで優れた結果を示した。さらに、Qwen3の36Tトークンコーパスに対しても、わずか11.7%のトークンでトレーニングされたMobileLLM-R1-950Mは、複数の推論ベンチマークで競争力を持つ。研究の詳細な情報は公開されている。 Comment
元ポスト:
モデルカードを見ると、optimizerやスケジューリング、ハイパーパラメータの設定、pre/mid/post trainingにおける学習データとDavaMixについて簡潔に記述されており、レシピが公開されているように見える。素晴らしい。
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Coding #read-later #Contamination-free #Live Issue Date: 2025-09-12 [Paper Note] LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code, Naman Jain+, ICLR'25 GPT Summary- 本研究では、LLMのコード関連能力を評価するための新しいベンチマーク「LiveCodeBench」を提案。LeetCode、AtCoder、CodeForcesから収集した400の高品質なコーディング問題を用い、コード生成や自己修復、コード実行など多様な能力に焦点を当てている。18のベースLLMと34の指示調整されたLLMを評価し、汚染や過剰適合の問題を実証的に分析。すべてのプロンプトとモデルの結果を公開し、さらなる分析や新しいシナリオの追加を可能にするツールキットも提供。 Comment
pj page: https://livecodebench.github.io
openreview: https://openreview.net/forum?id=chfJJYC3iL
LiveCodeBenchは非常にpopularなコーディング関連のベンチマークだが、readmeに記載されているコマンド通りにベンチマークを実行すると、stop tokenに"###"が指定されているため、マークダウンを出力したLLMの出力が常にtruncateされるというバグがあった模様。
#Pocket #NLP #LanguageModel #Transformer #Attention #NeurIPS #AttentionSinks #read-later Issue Date: 2025-09-11 [Paper Note] Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free, Zihan Qiu+, NeurIPS'25 Best Paper GPT Summary- ゲーティングメカニズムの効果を調査するため、強化されたソフトマックスアテンションのバリアントを実験。15B Mixture-of-Expertsモデルと1.7B密なモデルを比較し、シグモイドゲートの適用が性能向上に寄与することを発見。これにより訓練の安定性が向上し、スケーリング特性も改善。スパースゲーティングメカニズムが「アテンションシンク」を軽減し、長いコンテキストの外挿性能を向上させることを示した。関連コードとモデルも公開。 Comment
元ポスト:
所見:
NeurIPS'25 Best Paper:
#EfficiencyImprovement #Pocket #NLP #LanguageModel #LongSequence #Architecture #MoE(Mixture-of-Experts) #read-later Issue Date: 2025-09-08 [Paper Note] SpikingBrain Technical Report: Spiking Brain-inspired Large Models, Yuqi Pan+, arXiv'25 GPT Summary- SpikingBrainは、長いコンテキストの効率的なトレーニングと推論のために設計された脳にインスパイアされたモデルで、MetaX GPUクラスターを活用。線形およびハイブリッド線形アーキテクチャを採用し、非NVIDIAプラットフォーム上での大規模LLM開発を実現。SpikingBrain-7BとSpikingBrain-76Bを開発し、約150BトークンでオープンソースのTransformerと同等の性能を達成。トレーニング効率を大幅に改善し、低消費電力での運用を可能にすることを示した。 Comment
元ポスト:
TTFTが4Mコンテキストの時にQwen2.5と比べて100倍高速化…?
中国のMetaX社のGPUが利用されている。
https://www.metax-tech.com/en/goods/prod.html?cid=3
#EfficiencyImprovement #Pocket #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #LongSequence #Decoding #read-later #SpeculativeDecoding Issue Date: 2025-09-07 [Paper Note] REFRAG: Rethinking RAG based Decoding, Xiaoqiang Lin+, arXiv'25 GPT Summary- REFRAGは、RAGアプリケーションにおける遅延を改善するための効率的なデコーディングフレームワークであり、スパース構造を利用して初回トークンまでの時間を30.85倍加速します。これにより、LLMsのコンテキストサイズを16まで拡張可能にし、さまざまな長コンテキストタスクで精度を損なうことなくスピードアップを実現しました。 Comment
元ポスト:
興味深い。Speculative Decodingの新手法ともみなせそう。
同時期に出た下記研究と比較してどのようなpros/consがあるだろうか?
- [Paper Note] Set Block Decoding is a Language Model Inference Accelerator, Itai Gat+, arXiv'25
解説:
#Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering #read-later #Contamination-free #Live Issue Date: 2025-09-06 [Paper Note] SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents, Ibragim Badertdinov+, arXiv'25 GPT Summary- LLMベースのエージェントのSWEタスクにおける課題として、高品質なトレーニングデータの不足と新鮮なインタラクティブタスクの欠如が挙げられる。これに対処するため、21,000以上のインタラクティブなPythonベースのSWEタスクを含む公的データセットSWE-rebenchを自動化されたパイプラインで構築し、エージェントの強化学習に適したベンチマークを提供。これにより、汚染のない評価が可能となり、いくつかのLLMの性能が過大評価されている可能性を示した。 Comment
pj page: https://swe-rebench.com
元ポスト:
コンタミネーションのない最新のIssueを用いて評価した結果、Sonnet 4が最も高性能
#Pocket #NLP #LanguageModel #Evaluation #Reasoning #read-later #InstructionFollowingCapability Issue Date: 2025-09-05 [Paper Note] Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?, Qinyan Zhang+, arXiv'25 GPT Summary- 大規模言語モデル(LLMs)は、標準化されたパターンに従うことに苦労することがある。これを評価するために、Inverse IFEvalというベンチマークを提案し、モデルが対立する指示に従う能力を測定する。8種類の課題を含むデータセットを構築し、既存のLLMに対する実験を行った結果、非従来の文脈での適応性も考慮すべきであることが示された。Inverse IFEvalは、LLMの指示遵守の信頼性向上に寄与することが期待される。 Comment
元ポスト:
興味深い
#Analysis #Pretraining #Pocket #NLP #LanguageModel #Optimizer #read-later Issue Date: 2025-09-03 [Paper Note] Fantastic Pretraining Optimizers and Where to Find Them, Kaiyue Wen+, arXiv'25 GPT Summary- AdamWは言語モデルの事前学習で広く使用されているオプティマイザですが、代替オプティマイザが1.4倍から2倍のスピードアップを提供するという主張には二つの欠点があると指摘。これらは不均等なハイパーパラメータ調整と誤解を招く評価設定であり、10種類のオプティマイザを系統的に研究することで、公正な比較の重要性を示した。特に、最適なハイパーパラメータはオプティマイザごとに異なり、モデルサイズが大きくなるにつれてスピードアップ効果が減少することが明らかになった。最も高速なオプティマイザは行列ベースの前処理器を使用しているが、その効果はモデルスケールに反比例する。 Comment
元ポスト:
重要そうに見える
関連:
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
- [Paper Note] SOAP: Improving and Stabilizing Shampoo using Adam, Nikhil Vyas+, ICLR'25
著者ポスト:
-
-
考察:
#Pocket #Dataset #LanguageModel #Evaluation #SpeechProcessing #read-later #AudioLanguageModel Issue Date: 2025-09-03 [Paper Note] AHELM: A Holistic Evaluation of Audio-Language Models, Tony Lee+, arXiv'25 GPT Summary- 音声言語モデル(ALMs)の評価には標準化されたベンチマークが欠如しており、これを解決するためにAHELMを導入。AHELMは、ALMsの多様な能力を包括的に測定するための新しいデータセットを集約し、10の重要な評価側面を特定。プロンプトや評価指標を標準化し、14のALMsをテストした結果、Gemini 2.5 Proが5つの側面でトップにランクされる一方、他のモデルは不公平性を示さなかった。AHELMは今後も新しいデータセットやモデルを追加予定。 Comment
元ポスト:
関連:
- Holistic Evaluation of Language Models, Percy Liang+, TMLR'23
#Pocket #NLP #Dataset #LanguageModel #Evaluation #read-later #DeepResearch #Science #Live Issue Date: 2025-08-31 [Paper Note] DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis, Liana Patel+, arXiv'25 GPT Summary- 生成的研究合成の評価のために、DeepScholar-benchというライブベンチマークと自動評価フレームワークを提案。これは、ArXiv論文からクエリを引き出し、関連研究セクションを生成する実際のタスクに焦点を当て、知識合成、検索品質、検証可能性を評価。DeepScholar-baseは強力なベースラインを確立し、他の手法と比較して競争力のあるパフォーマンスを示した。DeepScholar-benchは依然として難易度が高く、生成的研究合成のAIシステムの進歩に重要であることを示す。 Comment
leaderboard: https://guestrin-lab.github.io/deepscholar-leaderboard/leaderboard/deepscholar_bench_leaderboard.html
元ポスト:
#Pocket #NLP #LanguageModel #In-ContextLearning #Reasoning #LongSequence #EMNLP #read-later #Contamination-free #Game Issue Date: 2025-08-30 [Paper Note] TurnaboutLLM: A Deductive Reasoning Benchmark from Detective Games, Yuan Yuan+, EMNLP'25 GPT Summary- TurnaboutLLMという新しいフレームワークとデータセットを用いて、探偵ゲームのインタラクティブなプレイを通じてLLMsの演繹的推論能力を評価。証言と証拠の矛盾を特定する課題を設定し、12の最先端LLMを評価した結果、文脈のサイズや推論ステップ数がパフォーマンスに影響を与えることが示された。TurnaboutLLMは、複雑な物語環境におけるLLMsの推論能力に挑戦を提供する。 Comment
元ポスト:
非常に面白そう。逆転裁判のデータを利用した超long contextな演繹的タスクにおいて、モデルが最終的な回答を間違える際はより多くの正解には貢献しないReasoning Stepを繰り返したり、QwQ-32BとGPT4.1は同等の性能だが、non thinkingモデルであるGPT4.1がより少量のReasoning Step (本研究では回答に至るまでに出力したトークン数と定義)で回答に到達し(=Test Time Scalingの恩恵がない)、フルコンテキストを与えて性能が向上したのはモデルサイズが大きい場合のみ(=Test Timeのreasoningよりも、in-contextでのreasoningが重要)だった、といった知見がある模様。じっくり読みたい。
#Analysis #Pretraining #Pocket #NLP #LanguageModel #Regularization Issue Date: 2025-08-30 [Paper Note] Drop Dropout on Single-Epoch Language Model Pretraining, Houjun Liu+, arXiv'25 GPT Summary- ドロップアウトは過学習を防ぐ手法として知られているが、現代の大規模言語モデル(LLM)では過学習が抑えられるため使用されていない。本研究では、BERTやPythiaモデルの単一エポック事前学習においてドロップアウトの影響を調査した結果、ドロップアウトを適用しない方が下流の性能が向上することが判明。また、「早期ドロップアウト」も性能を低下させることが示された。ドロップアウトなしで訓練されたモデルは、モデル編集においてもより成功することがわかり、単一エポックの事前学習中にはドロップアウトを省くことが推奨される。 Comment
元ポスト:
関連:
- [Paper Note] Dropout Reduces Underfitting, Zhuang Liu+, ICML'23
#Pocket #NLP #Dataset #LanguageModel #Evaluation #read-later #Verification Issue Date: 2025-08-28 [Paper Note] UQ: Assessing Language Models on Unsolved Questions, Fan Nie+, arXiv'25 GPT Summary- 本研究では、AIモデルの評価のために、未解決の質問に基づく新しいベンチマーク「UQ」を提案します。UQは、Stack Exchangeから収集した500の多様な質問を含み、難易度と現実性を兼ね備えています。評価には、ルールベースのフィルター、LLM審査員、人間のレビューを組み合わせたデータセット収集パイプライン、生成者-バリデーターのギャップを活用した複合バリデーション戦略、専門家による共同検証プラットフォームが含まれます。UQは、最前線のモデルが人間の知識を拡張するための現実的な課題を評価する手段を提供します。 Comment
元ポスト:
-
-
ポイント解説:
Figure1を見るとコンセプトが非常にわかりやすい。現在のLLMが苦戦しているベンチマークは人間が回答済み、かつ実世界のニーズに反して意図的に作られた高難易度なデータ(現実的な設定では無い)であり、現実的では無いが難易度が高い。一方で、現実にニーズがあるデータでベンチマークを作るとそれらはしばしば簡単すぎたり、ハッキング可能だったりする。
このため、現実的な設定でニーズがあり、かつ難易度が高いベンチマークが不足しており、これを解決するためにそもそも人間がまだ回答していない未解決の問題に着目し、ベンチマークを作りました、という話に見える。
元ポストを咀嚼すると、
未解決な問題ということはReferenceが存在しないということなので、この点が課題となる。このため、UQ-ValidatorとUQ-Platformを導入する。
UQ-Validatorは複数のLLMのパイプラインで形成され、回答候補のpre-screeningを実施する。回答を生成したLLM自身(あるいは同じモデルファミリー)がValidatorに加わることで自身の回答をoverrateする問題が生じるが、複数LLMのパイプラインを組むことでそのバイアスを軽減できる、とのこと。また、しばしば回答を生成するよりも結果をValidationせる方がタスクとして簡単であり、必ずしも適切に回答する能力はValidatorには必要ないという直感に基づいている。たとえば、Claudeは回答性能は低くてもValidatorとしてはうまく機能する。また、Validatorは転移が効き、他データセットで訓練したものを未解決の回答にも適用できる。test-timeのスケーリングもある程度作用する。
続いて、UQ-Platformにおいて、回答とValidatorの出力を見ながら、専門家の支援に基づいて回答評価し、また、そもそもの質問の質などについてコメントするなどして未解決の問題の解決を支援できる。
みたいな話らしい。非常に重要な研究に見える。
#Pretraining #Pocket #NLP #Dataset #LanguageModel #Reasoning #Mathematics #read-later Issue Date: 2025-08-27 [Paper Note] Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset, Rabeeh Karimi Mahabadi+, arXiv'25 GPT Summary- 新しい数学コーパス「Nemotron-CC-Math」を提案し、LLMの推論能力を向上させるために、科学テキスト抽出のためのパイプラインを使用。従来のデータセットよりも高品質で、方程式やコードの構造を保持しつつ、表記を標準化。Nemotron-CC-Math-4+は、以前のデータセットを大幅に上回り、事前学習によりMATHやMBPP+での性能向上を実現。オープンソースとしてコードとデータセットを公開。 Comment
元ポスト:
#ComputerVision #Pocket #NLP #LanguageModel #OpenWeight #read-later #VisionLanguageModel Issue Date: 2025-08-26 [Paper Note] InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency, Weiyun Wang+, arXiv'25 GPT Summary- InternVL 3.5は、マルチモーダルモデルの新しいオープンソースファミリーで、Cascade Reinforcement Learningを用いて推論能力と効率を向上させる。粗から細へのトレーニング戦略により、MMMやMathVistaなどのタスクで大幅な改善を実現。Visual Resolution Routerを導入し、視覚トークンの解像度を動的に調整。Decoupled Vision-Language Deployment戦略により、計算負荷をバランスさせ、推論性能を最大16.0%向上させ、速度を4.05倍向上。最大モデルは、オープンソースのMLLMで最先端の結果を達成し、商業モデルとの性能ギャップを縮小。全てのモデルとコードは公開。 Comment
元ポスト:
ポイント解説:
#Pretraining #Pocket #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #OpenWeight #Architecture #PostTraining #DataMixture Issue Date: 2025-08-25 [Paper Note] Motif 2.6B Technical Report, Junghwan Lim+, arXiv'25 GPT Summary- Motif-2.6Bは、26億パラメータを持つ基盤LLMで、長文理解の向上や幻覚の減少を目指し、差分注意やポリノルム活性化関数を採用。広範な実験により、同サイズの最先端モデルを上回る性能を示し、効率的でスケーラブルな基盤LLMの発展に寄与する。 Comment
元ポスト:
HF: https://huggingface.co/Motif-Technologies/Motif-2.6B
- アーキテクチャ
- Differential Transformer, Tianzhu Ye+, N/A, ICLR'25
- [Paper Note] Polynomial Composition Activations: Unleashing the Dynamics of Large
Language Models, Zhijian Zhuo+, arXiv'24
- 学習手法
- Model Merging in Pre-training of Large Language Models, Yunshui Li+, arXiv'25
- 8B token学習するごとに直近6つのcheckpointのelement-wiseの平均をとりモデルマージ。当該モデルに対して学習を継続、ということを繰り返す。これにより、学習のノイズを低減し、突然パラメータがシフトすることを防ぐ
- Effective Long-Context Scaling of Foundation Models, Wenhan Xiong+, N/A, NAACL'24
- Adaptive Base Frequency (RoPEのbase frequencyを10000から500000にすることでlong contextのattention scoreが小さくなりすぎることを防ぐ)
- [Paper Note] MiniCPM: Unveiling the Potential of Small Language Models with Scalable
Training Strategies, Shengding Hu+, arXiv'24
- 事前学習データ
- DataComp-LM: In search of the next generation of training sets for
language models, Jeffrey Li+, arXiv'24
- TxT360, LLM360, 2024.10
- [Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, COLM'25
を利用したモデル。同程度のサイズのモデルとの比較ではかなりのgainを得ているように見える。興味深い。
DatasetのMixtureの比率などについても記述されている。https://github.com/user-attachments/assets/0a26442e-8075-4cbe-8cc1-f1ff471b7356"
/>
#Pocket #NLP #LanguageModel #Decoding #read-later #MajorityVoting Issue Date: 2025-08-24 [Paper Note] Deep Think with Confidence, Yichao Fu+, arXiv'25 GPT Summary- 「Deep Think with Confidence(DeepConf)」は、LLMの推論タスクにおける精度と計算コストの課題を解決する手法で、モデル内部の信頼性信号を活用して低品質な推論を動的にフィルタリングします。追加の訓練や調整を必要とせず、既存のフレームワークに統合可能です。評価の結果、特に難易度の高いAIME 2025ベンチマークで99.9%の精度を達成し、生成トークンを最大84.7%削減しました。 Comment
pj page:
https://jiaweizzhao.github.io/deepconf
vLLMでの実装:
https://jiaweizzhao.github.io/deepconf/static/htmls/code_example.html
元ポスト:
tooluse、追加の訓練なしで、どのようなタスクにも適用でき、85%生成トークン量を減らした上で、OpenModelで初めてAIME2025において99% Acc.を達成した手法とのこと。vLLMを用いて50 line程度で実装できるらしい。
reasoning traceのconfidence(i.e., 対数尤度)をgroup sizeを決めてwindow単位で決定し、それらをデコーディングのプロセスで活用することで、品質の低いreasoning traceに基づく結果を排除しつつ、majority votingに活用する方法。直感的にもうまくいきそう。オフラインとオンラインの推論によって活用方法が提案されている。あとでしっかり読んで書く。Confidenceの定義の仕方はグループごとのbottom 10%、tailなどさまざまな定義方法と、それらに基づいたconfidenceによるvotingの重み付けが複数考えられ、オフライン、オンラインによって使い分ける模様。
vLLMにPRも出ている模様?
#ComputerVision #Pocket #NLP #Dataset #AIAgents #Evaluation #Factuality #read-later Issue Date: 2025-08-22 [Paper Note] MM-BrowseComp: A Comprehensive Benchmark for Multimodal Browsing Agents, Shilong Li+, arXiv'25 GPT Summary- MM-BrowseCompは、AIエージェントのマルチモーダル検索および推論能力を評価する新しいベンチマークで、224の手作りの質問を含む。これにより、画像や動画を含む情報の重要性を考慮し、テキストのみの手法の限界を示す。最先端モデルの評価では、OpenAI o3などのトップモデルでも29.02%の精度にとどまり、マルチモーダル能力の最適化不足が明らかになった。 Comment
元ポスト:
#MachineTranslation #NLP #LanguageModel #Supervised-FineTuning (SFT) #SmallModel #Japanese #DPO #ModelMerge Issue Date: 2025-08-22 PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25 Comment
元ポスト:
SFT->Iterative DPO->Model Mergeのパイプライン。SFTでは青空文庫などのオープンなデータから指示追従性能の高いDeepSeek-V3-0324によって元データ→翻訳, 翻訳→再翻訳データを合成し活用。また、翻訳の指示がprompt中に存在せずとも(本モデルを利用するのは翻訳用途であることが自明であるからと推察される)翻訳を適切に実行できるよう、独自のテンプレートを学習。文体指定、常体、敬体の指定、文脈考慮、語彙指定それぞれにういて独自のタグを設けてフォーマットを形成し翻訳に特化したテンプレートを学習。
IterativeDPOでは、DeepSeekV3に基づくLLM-as-a-Judgeと、MetricX([Paper Note] MetricX-24: The Google Submission to the WMT 2024 Metrics Shared Task, Juraj Juraska+, arXiv'24
)に基づいてReward Modelをそれぞれ学習し、1つの入力に対して100個の翻訳を作成しそれぞれのRewardモデルのスコアの合計値に基づいてRejection Samplingを実施することでPreference dataを構築。3段階のDPOを実施し、段階ごとにRewardモデルのスコアに基づいて高品質なPreference Dataに絞ることで性能向上を実現。
モデルマージではDPOの各段階のモデルを重み付きでマージすることで各段階での長所を組み合わせたとのこと。
2025.1010配信の「岡野原大輔のランチタイムトーク Vol.52 番外編「なぜPLaMo翻訳は自然なのか?」において詳細が語られているので参照のこと。特になぜ日本語に強いLLMが大事なのか?という話が非常におもしろかった。
#Pretraining #Pocket #NLP #Dataset #LanguageModel #SmallModel #OpenWeight #SSM (StateSpaceModel) Issue Date: 2025-08-19 [Paper Note] NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model, NVIDIA+, arXiv'25, 2025.08 GPT Summary- Nemotron-Nano-9B-v2は、推論スループットを向上させつつ最先端の精度を達成するハイブリッドMamba-Transformerモデルである。自己注意層の一部をMamba-2層に置き換え、長い思考トレースの生成を高速化。12億パラメータのモデルを20兆トークンで事前トレーニングし、Minitron戦略で圧縮・蒸留。既存モデルと比較して、最大6倍の推論スループットを実現し、精度も同等以上。モデルのチェックポイントはHugging Faceで公開予定。 Comment
元ポスト:
事前学習に利用されたデータも公開されているとのこと(Nemotron-CC):
解説:
サマリ:
#Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #read-later #CrossDomain #Live Issue Date: 2025-08-18 [Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations, Kaiyuan Chen+, arXiv'25 GPT Summary- 「xbench」は、AIエージェントの能力と実世界の生産性のギャップを埋めるために設計された動的な評価スイートで、業界専門家が定義したタスクを用いて商業的に重要なドメインをターゲットにしています。リクルートメントとマーケティングの2つのベンチマークを提示し、エージェントの能力を評価するための基準を確立します。評価結果は継続的に更新され、https://xbench.org で入手可能です。 #Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #read-later Issue Date: 2025-08-16 [Paper Note] BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, Jason Wei+, arXiv'25 GPT Summary- BrowseCompは、エージェントのウェブブラウジング能力を測定するための1,266の質問からなるベンチマークで、絡み合った情報を探すことを要求します。シンプルで使いやすく、短い回答が求められ、参照回答との照合が容易です。このベンチマークは、ブラウジングエージェントの能力を評価するための重要なツールであり、持続力と創造性を測定します。詳細はGitHubで入手可能です。 #Pocket #NLP #LanguageModel #AIAgents #ComputerUse #read-later #VisionLanguageModel Issue Date: 2025-08-15 [Paper Note] OpenCUA: Open Foundations for Computer-Use Agents, Xinyuan Wang+, arXiv'25 GPT Summary- OpenCUAは、CUAデータと基盤モデルをスケールさせるためのオープンソースフレームワークであり、アノテーションインフラ、AgentNetデータセット、反射的なChain-of-Thought推論を持つスケーラブルなパイプラインを提供。OpenCUA-32Bは、CUAベンチマークで34.8%の成功率を達成し、最先端の性能を示す。研究コミュニティのために、アノテーションツールやデータセットを公開。 Comment
元ポスト:
著者ポスト:
CUAにおいてProprietaryモデルに近い性能を達成した初めての研究な模様。重要
続報:
OSWorld VerifiedでUI-TARS-250705,claude-4-sonnet-20250514超えでtop1に君臨とのこと。
#ComputerVision #Pocket #NLP #Dataset #EMNLP #PostTraining #VisionLanguageModel #Cultural Issue Date: 2025-08-13 [Paper Note] Grounding Multilingual Multimodal LLMs With Cultural Knowledge, Jean de Dieu Nyandwi+, EMNLP'25 GPT Summary- MLLMsは高リソース環境で優れた性能を示すが、低リソース言語や文化的エンティティに対しては課題がある。これに対処するため、Wikidataを活用し、文化的に重要なエンティティを表す画像を用いた多言語視覚質問応答データセット「CulturalGround」を生成。CulturalPangeaというオープンソースのMLLMを訓練し、文化に基づいたアプローチがMLLMsの文化的ギャップを縮小することを示した。CulturalPangeaは、従来のモデルを平均5.0ポイント上回る性能を達成。 Comment
元ポスト:
pj page:
https://neulab.github.io/CulturalGround/
VQAデータセット中の日本語データは3.1%程度で、
ベースモデルとして
- [Paper Note] Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages, Xiang Yue+, arXiv'24
を利用(Qwen2-7Bに対してCLIPベースのvision encoderを利用したVLM)し、Vision Encoderはfrozenし、LLMとconnector(テキストと画像のモダリティの橋渡しをする(大抵は)MLP)のみをfinetuningした。catastrophic forgettingを防ぐために事前学習データの一部を補完しfinetuningでも利用し、エンティティの認識力を高めるためにM3LSデータなるものをフィルタリングして追加している。
Finetuningの結果、文化的な多様性を持つ評価データ(e.g., [Paper Note] CVQA: Culturally-diverse Multilingual Visual Question Answering
Benchmark, David Romero+, arXiv'24
Figure1のJapaneseのサンプルを見ると一目でどのようなベンチか分かる)と一般的なマルチリンガルな評価データの双方でgainがあることを確認。
VQAによるフィルタリングで利用されたpromptは下記
#Pocket #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #read-later Issue Date: 2025-08-12 [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25 GPT Summary- 355Bパラメータを持つオープンソースのMixture-of-ExpertsモデルGLM-4.5を発表。ハイブリッド推論手法を採用し、エージェント的、推論、コーディングタスクで高いパフォーマンスを達成。競合モデルに比べて少ないパラメータ数で上位にランクイン。GLM-4.5とそのコンパクト版GLM-4.5-Airをリリースし、詳細はGitHubで公開。 Comment
元ポスト:
- アーキテクチャ
- MoE / sigmoid gates
- DeepSeek-R1, DeepSeek, 2025.01
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
- loss free balanced routing
- [Paper Note] Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, Lean Wang+, arXiv'24
- widthを小さく、depthを増やすことでreasoning能力改善
- GQA w/ partial RoPE
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head
Checkpoints, Joshua Ainslie+, N/A, arXiv'23
- RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, N/A, Neurocomputing, 2024
- Attention Headsの数を2.5倍(何に対して2.5倍なんだ、、?)(96個, 5120次元)にすることで(おそらく)事前学習のlossは改善しなかったがReasoning benchmarkの性能改善
- QK Normを導入しattentionのlogitsの値域を改善
- [Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings
- Multi Token Prediction
- [Paper Note] Better & Faster Large Language Models via Multi-token Prediction, Fabian Gloeckle+, ICML'24
- Deep-seek-v3, deepseek-ai, 2024.12
他モデルとの比較
学習部分は後で追記する
- 事前学習データ
- web
- 英語と中国語のwebページを利用
- Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25
と同様にquality scoreyをドキュメントに付与
- 最も低いquality scoreの文書群を排除し、quality scoreの高い文書群をup sampling
- 最もquality scoreyが大きい文書群は3.2 epoch分利用
- 多くのweb pageがテンプレートから自動生成されており高いquality scoreが付与されていたが、MinHashによってdeduplicationできなかったため、 [Paper Note] SemDeDup: Data-efficient learning at web-scale through semantic
deduplication, Amro Abbas+, arXiv'23
を用いてdocument embeddingに基づいて類似した文書群を排除
- Multilingual
- 独自にクロールしたデータとFineWeb-2 [Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, COLM'25
から多言語の文書群を抽出し、quality classifierを適用することでeducational utilityを定量化し、高いスコアの文書群をupsamplingして利用
- code
- githubなどのソースコードhosting platformから収集
- ソースコードはルールベースのフィルタリングをかけ、その後言語ごとのquality modelsによって、high,middle, lowの3つに品質を分類
- high qualityなものはupsamplingし、low qualityなものは除外
- [Paper Note] Efficient Training of Language Models to Fill in the Middle, Mohammad Bavarian+, arXiv'22
で提案されているFill in the Middle objectiveをコードの事前学習では適用
- コードに関連するweb文書も事前学習で収集したテキスト群からルールベースとfasttextによる分類器で抽出し、ソースコードと同様のqualityの分類とサンプリング手法を適用。最終的にフィルタリングされた文書群はre-parseしてフォーマットと内容の品質を向上させた
- math & science
- web page, 本, 論文から、reasoning能力を向上させるために、数学と科学に関する文書を収集
- LLMを用いて文書中のeducational contentの比率に基づいて文書をスコアリングしスコアを予測するsmall-scaleな分類器を学習
- 最終的に事前学習コーパスの中の閾値以上のスコアを持つ文書をupsampling
- 事前学習は2 stageに分かれており、最初のステージでは、"大部分は"generalな文書で学習する。次のステージでは、ソースコード、数学、科学、コーディング関連の文書をupsamplingして学習する。
上記以上の細かい実装上の情報は記載されていない。
mid-training / post trainingについても後ほど追記する
以下も参照のこと
- GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #read-later #KeyPoint Notes Issue Date: 2025-08-09 [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, arXiv'25 GPT Summary- 大規模言語モデル(LLM)の教師ありファインチューニング(SFT)の一般化能力を向上させるため、動的ファインチューニング(DFT)を提案。DFTはトークンの確率に基づいて目的関数を再スケーリングし、勾配更新を安定化させる。これにより、SFTを大幅に上回る性能を示し、オフライン強化学習でも競争力のある結果を得た。理論的洞察と実践的解決策を結びつけ、SFTの性能を向上させる。コードは公開されている。 Comment
元ポスト:
これは大変興味深い。数学以外のドメインでの評価にも期待したい。
3節冒頭から3.2節にかけて、SFTとon policy RLのgradientを定式化し、SFT側の数式を整理することで、SFT(のgradient)は以下のようなon policy RLの一つのケースとみなせることを導出している。そしてSFTの汎化性能が低いのは 1/pi_theta によるimportance weightingであると主張し、実験的にそれを証明している。つまり、ポリシーがexpertのgold responseに対して低い尤度を示してしまった場合に、weightか過剰に大きくなり、Rewardの分散が過度に大きくなってしまうことがRLの観点を通してみると問題であり、これを是正することが必要。さらに、分散が大きい報酬の状態で、報酬がsparse(i.e., expertのtrajectoryのexact matchしていないと報酬がzero)であることが、さらに事態を悪化させている。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい
最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
- Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, arXiv'25
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。
日本語解説:
一歩先の視点が考察されており、とても勉強になる。
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Optimizer #read-later #ModelMerge #Stability Issue Date: 2025-08-02 [Paper Note] WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training, Changxin Tian+, arXiv'25 GPT Summary- 学習率スケジューリングの新たなアプローチとして、Warmup-Stable and Merge(WSM)を提案。WSMは、学習率の減衰とモデルマージの関係を確立し、さまざまな減衰戦略を統一的に扱う。実験により、マージ期間がモデル性能において重要であることを示し、従来のWSDアプローチを上回る性能向上を達成。特に、MATHで+3.5%、HumanEvalで+2.9%、MMLU-Proで+5.5%の改善を記録。 Comment
元ポスト:
Weight Decayを無くせるらしい
エッセンスの解説:
チェックポイントさえ保存しておいて事後的に活用することだで、細かなハイパラ調整のための試行錯誤する手間と膨大な計算コストがなくなるのであれば相当素晴らしいのでは…?
解説:
#ComputerVision #Pocket #NLP #Dataset #MultiLingual #CLIP #NeurIPS #read-later Issue Date: 2025-07-30 [Paper Note] MetaCLIP 2: A Worldwide Scaling Recipe, Yung-Sung Chuang+, NeurIPS'25 Spotlight GPT Summary- MetaCLIP 2を提案し、CLIPをゼロから訓練するための新しいアプローチを示す。英語と非英語データの相互利益を得るための最小限の変更を加え、ゼロショットのImageNet分類で英語専用モデルを上回る性能を達成。多言語ベンチマークでも新たな最先端を記録。 Comment
元ポスト:
マルチリンガルなCLIP
HF: https://huggingface.co/facebook/metaclip-2-mt5-worldwide-b32
#Pocket #NLP #LanguageModel #MoE(Mixture-of-Experts) #Scaling Laws #read-later Issue Date: 2025-07-25 [Paper Note] Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models, Changxin Tian+, arXiv'25 GPT Summary- Mixture-of-Experts (MoE)アーキテクチャは、LLMsの効率的なスケーリングを可能にするが、モデル容量の予測には課題がある。これに対処するため、Efficiency Leverage (EL)を導入し、300以上のモデルを訓練してMoE構成とELの関係を調査。結果、ELはエキスパートの活性化比率と計算予算に依存し、エキスパートの粒度は非線形の調整因子として機能することが明らかに。これらの発見を基にスケーリング法則を統一し、Ling-mini-betaモデルを設計・訓練した結果、計算資源を7倍以上節約しつつ、6.1Bの密なモデルと同等の性能を達成。研究は効率的なMoEモデルのスケーリングに関する基盤を提供する。 Comment
元ポスト:
所見:
#NeuralNetwork #Analysis #Pocket #NLP #LanguageModel #Finetuning Issue Date: 2025-07-24 [Paper Note] Subliminal Learning: Language models transmit behavioral traits via hidden signals in data, Alex Cloud+, arXiv'25 GPT Summary- サブリミナル学習は、言語モデルが無関係なデータを通じて特性を伝達する現象である。実験では、特定の特性を持つ教師モデルが生成した数列データで訓練された生徒モデルが、その特性を学習することが確認された。データが特性への言及を除去してもこの現象は発生し、異なるベースモデルの教師と生徒では効果が見られなかった。理論的結果を通じて、全てのニューラルネットワークにおけるサブリミナル学習の発生を示し、MLP分類器での実証も行った。サブリミナル学習は一般的な現象であり、AI開発における予期しない問題を引き起こす可能性がある。 Comment
元ポスト:
教師モデルが生成したデータから、教師モデルと同じベースモデルを持つ[^1]生徒モデルに対してファインチューニングをした場合、教師モデルと同じ特性を、どんなに厳しく学習元の合成データをフィルタリングしても、意味的に全く関係ないデータを合成しても(たとえばただの数字列のデータを生成したとしても)、生徒モデルに転移してしまう。これは言語モデルに限った話ではなく、ニューラルネットワーク一般について証明された[^2]。
また、MNISTを用いたシンプルなMLPにおいて、MNISTを教師モデルに対して学習させ、そのモデルに対してランダムノイズな画像を生成させ、同じ初期化を施した生徒モデルに対してFinetuningをした場合、学習したlogitsがMNIST用ではないにもかかわらず、MNISTデータに対して50%以上の分類性能を示し、数字画像の認識能力が意味的に全く関係ないデータから転移されている[^3]、といった現象が生じることも実験的に確認された。
このため、どんなに頑張って合成データのフィルタリングや高品質化を実施し、教師モデルから特性を排除したデータを作成したつもりでも、そのデータでベースモデルが同じ生徒を蒸留すると、結局その特性は転移されてしまう。これは大きな落とし穴になるので気をつけましょう、という話だと思われる。
[^1]: これはアーキテクチャの話だけでなく、パラメータの初期値も含まれる
[^2]: 教師と生徒の初期化が同じ、かつ十分に小さい学習率の場合において、教師モデルが何らかの学習データDを生成し、Dのサンプルxで生徒モデルでパラメータを更新する勾配を計算すると、教師モデルが学習の過程で経た勾配と同じ方向の勾配が導き出される。つまり、パラメータが教師モデルと同じ方向にアップデートされる。みたいな感じだろうか?元論文を時間がなくて厳密に読めていない、かつalphaxivの力を借りて読んでいるため、誤りがあるかもしれない点に注意
[^3]: このパートについてもalphaxivの出力を参考にしており、元論文の記述をしっかり読めているわけではない
#Pocket #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #GRPO #read-later #Non-VerifiableRewards #RewardModel Issue Date: 2025-07-22 [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25 GPT Summary- 強化学習を用いてLLMsの推論能力を向上させるため、報酬モデリング(RM)のスケーラビリティを探求。ポイントワイズ生成報酬モデリング(GRM)を採用し、自己原則批評調整(SPCT)を提案してパフォーマンスを向上。並列サンプリングとメタRMを導入し、スケーリング性能を改善。実験により、SPCTがGRMの質とスケーラビリティを向上させ、既存の手法を上回る結果を示した。DeepSeek-GRMは一部のタスクで課題があるが、今後の取り組みで解決可能と考えられている。モデルはオープンソースとして提供予定。 Comment
- inputに対する柔軟性と、
- 同じresponseに対して多様なRewardを算出でき (= inference time scalingを活用できる)、
- Verifiableな分野に特化していないGeneralなRewardモデルである
Inference-Time Scaling for Generalist Reward Modeling (GRM) を提案。https://github.com/user-attachments/assets/18b13e49-745c-4c22-8d29-8b9bbb7fe80c"
/>
Figure3に提案手法の学習の流れが図解されておりわかりやすい。
#MachineLearning #Pocket #NLP #LanguageModel #Optimizer #read-later Issue Date: 2025-07-14 [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25 GPT Summary- Muonオプティマイザーを大規模モデルにスケールアップするために、ウェイトデケイとパラメータごとの更新スケール調整を導入。これにより、Muonは大規模トレーニングで即座に機能し、計算効率がAdamWの約2倍に向上。新たに提案するMoonlightモデルは、少ないトレーニングFLOPで優れたパフォーマンスを達成し、オープンソースの分散Muon実装や事前トレーニング済みモデルも公開。 Comment
解説ポスト:
こちらでも紹介されている:
- きみはNanoGPT speedrunを知っているか?, PredNext, 2025.07
解説:
#Analysis #Pretraining #Pocket #NLP #LanguageModel #COLM #Stability #KeyPoint Notes Issue Date: 2025-07-11 [Paper Note] Spike No More: Stabilizing the Pre-training of Large Language Models, Sho Takase+, COLM'25 GPT Summary- 大規模言語モデルの事前学習中に発生する損失のスパイクは性能を低下させるため、避けるべきである。勾配ノルムの急激な増加が原因とされ、サブレイヤーのヤコビ行列の分析を通じて、勾配ノルムを小さく保つための条件として小さなサブレイヤーと大きなショートカットが必要であることを示した。実験により、これらの条件を満たす手法が損失スパイクを効果的に防ぐことが確認された。 Comment
元ポスト:
small sub-layers, large shortcutsの説明はこちらに書かれている。前者については、現在主流なLLMの初期化手法は満たしているが、後者はオリジナルのTransformerの実装では実装されている[^1]が、最近の実装では失われてしまっているとのこと。
下図が実験結果で、条件の双方を満たしているのはEmbedLN[^2]とScaled Embed[^3]のみであり、実際にスパイクが生じていないことがわかる。
[^1]:オリジナル論文 [Paper Note] Attention Is All You Need, Ashish Vaswani+, arXiv'17
の3.4節末尾、embedding layersに対してsqrt(d_model)を乗じるということがサラッと書いてある。これが実はめちゃめちゃ重要だったという…
[^2]: positional embeddingを加算する前にLayer Normalizationをかける方法
[^3]: EmbeddingにEmbeddingの次元数d(i.e., 各レイヤーのinputの次元数)の平方根を乗じる方法
前にScaled dot-product attentionのsqrt(d_k)がめっちゃ重要ということを実験的に示した、という話もあったような…
(まあそもそも元論文になぜスケーリングさせるかの説明は書いてあるけども)
著者ポスト(スライド):
非常に興味深いので参照のこと。初期化の気持ちの部分など勉強になる。
#ComputerVision #Embeddings #Pocket #NLP #Dataset #Evaluation #MultiModal #ICLR #read-later #VisionLanguageModel Issue Date: 2025-07-09 [Paper Note] VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks, Ziyan Jiang+, ICLR'25 GPT Summary- 本研究では、ユニバーサルマルチモーダル埋め込みモデルの構築を目指し、二つの貢献を行った。第一に、MMEB(Massive Multimodal Embedding Benchmark)を提案し、36のデータセットを用いて分類や視覚的質問応答などのメタタスクを網羅した。第二に、VLM2Vecというコントラストトレーニングフレームワークを開発し、視覚-言語モデルを埋め込みモデルに変換する手法を示した。実験結果は、VLM2Vecが既存のモデルに対して10%から20%の性能向上を達成することを示し、VLMの強力な埋め込み能力を証明した。 Comment
openreview: https://openreview.net/forum?id=TE0KOzWYAF
#ComputerVision #Embeddings #InformationRetrieval #Pocket #NLP #LanguageModel #MultiModal #RAG(RetrievalAugmentedGeneration) #read-later #VisionLanguageModel Issue Date: 2025-07-09 [Paper Note] VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents, Rui Meng+, arXiv'25 GPT Summary- VLM2Vec-V2という統一フレームワークを提案し、テキスト、画像、動画、視覚文書を含む多様な視覚形式の埋め込みを学習。新たにMMEB-V2ベンチマークを導入し、動画検索や視覚文書検索など5つのタスクを追加。広範な実験により、VLM2Vec-V2は新タスクで強力なパフォーマンスを示し、従来の画像ベンチマークでも改善を達成。研究はマルチモーダル埋め込みモデルの一般化可能性に関する洞察を提供し、スケーラブルな表現学習の基盤を築く。 Comment
元ポスト:
Video Classification, Visual Document Retrievalなどのモダリティも含まれている。
#Pocket #NLP #LanguageModel #Transformer #Architecture #Normalization #One-Line Notes Issue Date: 2025-07-03 [Paper Note] The Curse of Depth in Large Language Models, Wenfang Sun+, arXiv'25 GPT Summary- 本論文では、「深さの呪い」という現象を紹介し、LLMの深い層が期待通りに機能しない理由を分析します。Pre-LNの使用が出力の分散を増加させ、深い層の貢献を低下させることを特定。これを解決するために層正規化スケーリング(LNS)を提案し、出力分散の爆発を抑制します。実験により、LNSがLLMの事前トレーニング性能を向上させることを示し、教師ありファインチューニングにも効果があることを確認しました。 Comment
元ポスト:
- Transformers without Normalization, Jiachen Zhu+, CVPR'25
ではそもそもLayerNormalizationを無くしていた(正確にいうとparametrize tanhに置換)が、どちらが優れているのだろうか?
- Knowledge Neurons in Pretrained Transformers, Damai Dai+, N/A, ACL'22, 2022.05
では知識ニューロンの存在が示唆されており、これはTransformerの層の深い位置に存在し、かつ異なる知識間で知識ニューロンはシェアされない傾向にあった(ただしこれはPost-LNのBERTの話で本研究はPre-LNの話だが。Post-LNの勾配消失問題を緩和し学習を安定化させる研究も[Paper Note] On Layer Normalizations and Residual Connections in Transformers, Sho Takase+, arXiv'22
のように存在する)。これはこの研究が明らかにしたこととどういう関係性があるだろうか。
また、LayerNormalizationのScalingによって深いTransformerブロックの導関数が単位行列となる(学習に寄与しなくなる)ことが改善された場合、知識ニューロンはどのように変化するだろうか?
(下記Geminiの応答を見た上での感想)なんとなーくだけれども、おそらく知識ニューロンの局所化が解消されるのかなーという気がする。
となると次の疑問としては、MoEアーキテクチャにはどのような影響があるだろうか?
そもそも知識ニューロンが局所化しているからMoEアーキテクチャのルータによって関連するExpertsのみをactivateすれば(というより結果的にそうなるように学習される)性能を劣化させずに計算効率を上げられていた、と仮定する。そうすると、知識ニューロンが局所化せずに多くのニューロンでシェアされるようになると、[Paper Note] Chain-of-Experts: Unlocking the Communication Power of Mixture-of-Experts Models, Zihan Wang+, arXiv'25
のように、サブネットワーク間の情報を互いにやりとりできます、みたいな仕組みがより効いてきそうな気がする。
参考までに、Gemini2.5-Proに考察させてみた結果をメモとして残しておく(あくまで参考程度に...)
```
ご質問ありがとうございます。非常に興味深い着眼点ですね。「Knowledge Neurons in Pretrained Transformers」と「The Curse of Depth in Large Language Models」は、一見すると全く異なるテーマを扱っているように見えますが、**「Transformerの深い層における振る舞い」**という共通点で結びつけて考察すると、非常に示唆に富んだ関係性が見えてきます。
以下に、両方の論文の概要を解説し、その関係性について考察します。
1. Knowledge Neurons in Pretrained Transformers の概要
この研究は、事前学習済みTransformerモデル(特にBERTなど)の内部で、特定の事実知識がどのように格納されているかを調査したものです。
発見: モデルの中間層、特に**全結合層(Feed-Forward Network, FFN)に、特定の知識(例:「ダンテ・アリギエーリはイタリアで生まれた」)に強く反応する「知識ニューロン」**が存在することを発見しました。
特徴: これらの知識ニューロンは、モデルの深い層(後方の層)に、より多く存在する傾向がありました。
意味: これまでブラックボックスとされてきた大規模言語モデルの内部で、知識がどのように表現・局在化しているかについて、具体的な手がかりを与えた画期的な研究です。
2. The Curse of Depth in Large Language Models の概要
この研究は、LLMをより深く(層を多く)することの難しさに焦点を当て、その原因と解決策を提案したものです。
問題(深さの呪い): Transformerの標準的なアーキテクチャ(Pre-LN)では、層が深くなるにつれて、LayerNormalization(LN)への入力の分散が指数関数的に増大してしまいます。
結果:
出力が大きくなりすぎて学習が不安定になります。
さらに深刻なのは、深い層ではモデルの出力に関する導関数(勾配計算に必要)がほぼ単位行列になってしまうことです。これは、その層が入力に対してほとんど変換を行わなくなり、学習に寄与しなくなることを意味します。
解決策: この問題を解決するため、各層のLayerNormalizationをその深さ(レイヤー番号 l)に応じてスケーリングするというシンプルな手法を提案しました。これにより、深い層でも勾配が適切に伝播し、学習が安定・改善することが示されました。
考察:2つの研究の関係性
これら2つの研究は、**「学習の安定性」と「知識の格納方法」**という異なる側面から、Transformerの深い層を分析していますが、両者には以下のような深い関係性があると考えられます。
学習の不安定性が「知識ニューロン」形成の背景にある可能性
「The Curse of Depth」で指摘されているように、標準的なTransformerの深い層は、本質的に学習が不安定で、勾配情報が失われやすい環境にあります。
この劣悪な学習環境こそが、「知識ニューロン」という形で知識が局所的に格納される原因の一つになっている可能性があります。つまり、
学習の非効率性: 深い層のほとんどのニューロンは、勾配消失問題のために効率的に学習を進めることができません。
専門化の発生: そのような不安定な環境下で、たまたま特定の知識パターンをうまく捉えることができた一部のニューロンが、その知識を一身に背負う形で強く活性化するよう特化(専門化)していったのではないか、と考えられます。これは、ネットワーク全体で協調して学習するのが難しい状況で、一部のユニットだけが突出して学習を担う、という現象と解釈できます。
学習の安定化が、より効率的な知識獲得につながる
では、「The Curse of Depth」で提案された手法(LNのスケーリング)によって深い層の学習が安定化すると、知識の格納方法はどのように変わるでしょうか。
これは非常に興味深い問いであり、2つの可能性が考えられます。
可能性A: より強固な知識ニューロンの形成:
学習が安定することで、各知識ニューロンはより明確に、そして効率的に特定の知識をエンコードできるようになるかもしれません。ノイズの多い環境で偶然生まれた専門家ではなく、安定した環境で育成された真の専門家へと変化するイメージです。
可能性B: 知識の分散化:
ネットワークの全ニューロンが効率的に学習に寄与できるようになるため、一つの知識を少数のニューロンに集中させる必要がなくなり、より多くのニューロンに分散して知識が格納されるようになる可能性も考えられます。
現在のところ、学習の安定化は、知識ニューロンがより効率的に形成・機能するための基盤を提供すると考えるのが最も妥当でしょう。「深さの呪い」という問題を解決することは、モデルが知識をどのように獲得し、整理するかという、より根源的なメカニズム(知識ニューロンの振る舞い)にも直接的な影響を与えるはずです。
まとめ
「Knowledge Neurons」は深い層に存在する知識の**「状態」を明らかにし、「The Curse of Depth」は深い層で発生する学習の「問題」**とその解決策を提示しました。
これらを統合すると、**「深い層における学習の不安定性という問題が、知識ニューロンという局所的な知識表現を生み出す一因となっており、この問題を解決することで、より効率的で安定した知識の獲得・格納が可能になるかもしれない」**という関係性が見えてきます。
両者は、LLMの能力と限界を異なる角度から照らし出しており、組み合わせることでモデルの内部動作の解明をさらに一歩前進させる、非常に重要な研究だと言えます。
```
#ComputerVision #Pretraining #Pocket #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #MultiModal #RLHF #Reasoning #LongSequence #mid-training #RewardHacking #PostTraining #CurriculumLearning #RLVR #VisionLanguageModel Issue Date: 2025-07-03 [Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25 GPT Summary- 視覚言語モデルGLM-4.1V-Thinkingを発表し、推論中心のトレーニングフレームワークを開発。強力な視覚基盤モデルを構築し、カリキュラムサンプリングを用いた強化学習で多様なタスクの能力を向上。28のベンチマークで最先端のパフォーマンスを達成し、特に難しいタスクで競争力のある結果を示す。モデルはオープンソースとして公開。 Comment
元ポスト:
Qwen2.5-VLよりも性能が良いVLM
アーキテクチャはこちら。が、pretraining(データのフィルタリング, マルチモーダル→long context継続事前学習)->SFT(cold startへの対処, reasoning能力の獲得)->RL(RLVRとRLHFの併用によるパフォーマンス向上とAlignment, RewardHackingへの対処,curriculum sampling)など、全体の学習パイプラインの細かいテクニックの積み重ねで高い性能が獲得されていると考えられる。
#EfficiencyImprovement #Pretraining #Pocket #NLP #Dataset #LanguageModel #MultiLingual #COLM Issue Date: 2025-06-28 [Paper Note] FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language, Guilherme Penedo+, COLM'25 GPT Summary- 多言語LLMsの性能向上のために、FineWebに基づく新しい事前学習データセットキュレーションパイプラインを提案。9つの言語に対して設計選択肢を検証し、非英語コーパスが従来のデータセットよりも高性能なモデルを生成できることを示す。データセットの再バランス手法も導入し、1000以上の言語にスケールアップした20テラバイトの多言語データセットFineWeb2を公開。 Comment
元ポスト:
abstを見る限りFinewebを多言語に拡張した模様
openreview: https://openreview.net/forum?id=jnRBe6zatP#discussion
#Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #mid-training #PostTraining #read-later Issue Date: 2025-06-27 [Paper Note] OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling, Zengzhi Wang+, arXiv'25 GPT Summary- 異なるベース言語モデル(LlamaやQwen)の強化学習(RL)における挙動を調査し、中間トレーニング戦略がRLのダイナミクスに与える影響を明らかに。高品質の数学コーパスがモデルのパフォーマンスを向上させ、長い連鎖的思考(CoT)がRL結果を改善する一方で、冗長性や不安定性を引き起こす可能性があることを示す。二段階の中間トレーニング戦略「Stable-then-Decay」を導入し、OctoThinkerモデルファミリーを開発。オープンソースのモデルと数学推論コーパスを公開し、RL時代の基盤モデルの研究を支援することを目指す。 Comment
元ポスト:
mid-trainingの観点から、post trainingにおけるRLがスケーリングする条件をsystematicallyに調査している模様
論文中にはmid-training[^1]の定義が記述されている:https://github.com/user-attachments/assets/da206d3d-f811-4d69-8210-a1d0816c827f"
/>
[^1]: mid-trainingについてはコミュニティの間で厳密な定義はまだ無くバズワードっぽく使われている、という印象を筆者は抱いており、本稿は文献中でmid-trainingを定義する初めての試みという所感
#ComputerVision #EfficiencyImprovement #Pretraining #Pocket #OpenWeight #OpenSource #ICCV #Encoder #Backbone Issue Date: 2025-06-26 [Paper Note] OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning, Xianhang Li+, ICCV'25 GPT Summary- OpenVisionは、完全にオープンでコスト効果の高いビジョンエンコーダーのファミリーを提案し、CLIPと同等以上の性能を発揮します。既存の研究を基に構築され、マルチモーダルモデルの進展に実用的な利点を示します。5.9Mから632.1Mパラメータのエンコーダーを提供し、容量と効率の柔軟なトレードオフを実現します。 Comment
元ポスト:
v2へアップデート:
事前学習時にtext, image encoderのcontrastive lossで学習していたが、text encoderを無くしimage encoderに入力されたimageからcaptionを生成するcaption lossのみにすることで性能を落とすことなく効率を改善
テクニカルペーパーが出た模様
- [Paper Note] OpenVision 2: A Family of Generative Pretrained Visual Encoders for Multimodal Learning, Yanqing Liu+, arXiv'25
HF:
https://huggingface.co/collections/UCSC-VLAA/openvision-681a4c27ee1f66411b4ae919
pj page:
https://ucsc-vlaa.github.io/OpenVision/
CLIP, SigLIPとは異なり完全にオープンなVision Encoder
v2の解説:
#Pocket #NLP #LanguageModel #Alignment #SyntheticData #SyntheticDataGeneration #ICLR Issue Date: 2025-06-25 [Paper Note] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Zhangchen Xu+, ICLR'25 GPT Summary- 高品質な指示データはLLMの整合に不可欠であり、Magpieという自己合成手法を提案。Llama-3-Instructを用いて400万の指示と応答を生成し、30万の高品質なインスタンスを選定。Magpieでファインチューニングしたモデルは、従来のデータセットを用いたモデルと同等の性能を示し、特に整合ベンチマークで優れた結果を得た。 Comment
OpenReview: https://openreview.net/forum?id=Pnk7vMbznK
下記のようなpre-queryテンプレートを与え(i.e., userの発話は何も与えず、ユーザの発話を表す特殊トークンのみを渡す)instructionを生成し、post-queryテンプレートを与える(i.e., pre-queryテンプレート+生成されたinstruction+assistantの発話の開始を表す特殊トークンのみを渡す)ことでresponseを生成することで、prompt engineeringやseed無しでinstruction tuningデータを合成できるという手法。
生成した生のinstruction tuning pair dataは、たとえば下記のようなフィルタリングをすることで品質向上が可能で
reward modelと組み合わせてLLMからのresponseを生成しrejection samplingすればDPOのためのpreference dataも作成できるし、single turnの発話まで生成させた後もう一度pre/post-queryをconcatして生成すればMulti turnのデータも生成できる。
他のも例えば、システムプロンプトに自分が生成したい情報を与えることで、特定のドメインに特化したデータ、あるいは特定の言語に特化したデータも合成できる。
#Pocket #NLP #Dataset #LanguageModel #ReinforcementLearning #Reasoning #PostTraining #read-later #RLVR #DataMixture #CrossDomain Issue Date: 2025-06-22 [Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, arXiv'25 GPT Summary- Guruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。 Comment
元ポスト:
post-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。
Qwenシリーズで実験。以下ポストのまとめ。
- mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
- 一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
- 簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
- 各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
- 必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
- たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
- 一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
- 異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
- (これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
- 非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
- RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
- モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
- モデルサイズが大きいとより多様なreasoningパスがunlockされている
- pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた
本研究で構築されたGuru Dataset:
https://huggingface.co/datasets/LLM360/guru-RL-92k
math, coding, science, logic, simulation, tabular reasoningに関する高品質、かつverifiableなデータセット。
#ComputerVision #Pocket #Transformer #CVPR #read-later #3D Reconstruction #Backbone Issue Date: 2025-06-22 [Paper Note] VGGT: Visual Geometry Grounded Transformer, Jianyuan Wang+, CVPR'25 GPT Summary- VGGTは、シーンの主要な3D属性を複数のビューから直接推測するフィードフォワードニューラルネットワークであり、3Dコンピュータビジョンの分野において新たな進展を示します。このアプローチは効率的で、1秒未満で画像を再構築し、複数の3Dタスクで最先端の結果を達成します。また、VGGTを特徴バックボーンとして使用することで、下流タスクの性能が大幅に向上することが示されています。コードは公開されています。 Comment
元ポスト:
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Coding #NeurIPS #Contamination-free #Live Issue Date: 2025-06-17 [Paper Note] LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?, Zihan Zheng+, NeurIPS'25 GPT Summary- 大規模言語モデル(LLMs)は競技プログラミングで人間のエリートを上回るとされるが、実際には重要な限界があることを調査。新たに導入した「LiveCodeBench Pro」ベンチマークにより、LLMsは中程度の難易度の問題で53%のpass@1を達成する一方、難しい問題では0%という結果が得られた。LLMsは実装重視の問題では成功するが、複雑なアルゴリズム的推論には苦労し、誤った正当化を生成することが多い。これにより、LLMsと人間の専門家との間に重要なギャップがあることが明らかになり、今後の改善のための診断が提供される。 Comment
元ポスト:
Hardな問題は現状のSoTAモデル(Claude4が含まれていないが)でも正答率0.0%
ベンチマークに含まれる課題のカテゴリ
実サンプルやケーススタディなどはAppendix参照のこと。
pj page: https://livecodebenchpro.com
アップデート(NeurIPSにaccept):
#Pocket #NLP #LanguageModel #Evaluation #ICLR #Contamination-free #Live Issue Date: 2025-05-23 LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25 GPT Summary- テストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Comment
テストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究
#EfficiencyImprovement #Pretraining #Pocket #NLP #Dataset #LanguageModel #ACL Issue Date: 2025-05-10 Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25 GPT Summary- FineWeb-EduとDCLMは、モデルベースのフィルタリングによりデータの90%を削除し、トレーニングに適さなくなった。著者は、アンサンブル分類器や合成データの言い換えを用いて、精度とデータ量のトレードオフを改善する手法を提案。1Tトークンで8Bパラメータモデルをトレーニングし、DCLMに対してMMLUを5.6ポイント向上させた。新しい6.3Tトークンデータセットは、DCLMと同等の性能を持ちながら、4倍のユニークなトークンを含み、長トークンホライズンでのトレーニングを可能にする。15Tトークンのためにトレーニングされた8Bモデルは、Llama 3.1の8Bモデルを上回る性能を示した。データセットは公開されている。 #EfficiencyImprovement #Pocket #NLP #ReinforcementLearning #Reasoning #SmallModel #PEFT(Adaptor/LoRA) #GRPO #read-later Issue Date: 2025-05-07 [Paper Note] Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25 GPT Summary- Tinaは、コスト効率よく強力な推論能力を実現する小型の推論モデルファミリーであり、1.5Bパラメータのベースモデルに強化学習を適用することで高い推論性能を示す。Tinaは、従来のSOTAモデルと競争力があり、AIME24で20%以上の性能向上を達成し、トレーニングコストはわずか9ドルで260倍のコスト削減を実現。LoRAを通じた効率的なRL推論の効果を検証し、すべてのコードとモデルをオープンソース化している。 Comment
元ポスト:
(おそらく)Reasoningモデルに対して、LoRAとRLを組み合わせて、reasoning能力を向上させた初めての研究
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Safety #ICLR #One-Line Notes Issue Date: 2025-04-29 Safety Alignment Should Be Made More Than Just a Few Tokens Deep, Xiangyu Qi+, ICLR'25 GPT Summary- 現在の大規模言語モデル(LLMs)の安全性アラインメントは脆弱であり、単純な攻撃や善意のファインチューニングによって脱獄される可能性がある。この脆弱性は「浅い安全性アラインメント」に起因し、アラインメントが主に最初の数トークンの出力にのみ適応されることに関連している。本論文では、この問題のケーススタディを提示し、現在のアラインされたLLMsが直面する脆弱性を説明する。また、浅い安全性アラインメントの概念が脆弱性軽減の研究方向を示唆し、初期トークンを超えたアラインメントの深化がロバスト性を向上させる可能性を示す。最後に、ファインチューニング攻撃に対する持続的な安全性アラインメントを実現するための正則化されたファインチューニング目的を提案する。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=6Mxhg9PtDE
Safety Alignment手法が最初の数トークンに依存しているからそうならないように学習しますというのは、興味深いテーマだし技術的にまだ困難な点もあっただろうし、インパクトも大きいし、とても良い研究だ…。
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #SmallModel #COLM #PostTraining #In-Depth Notes Issue Date: 2025-04-13 A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility, Andreas Hochlehnert+, COLM'25 GPT Summary- 推論は言語モデルの重要な課題であり、進展が見られるが、評価手法には透明性や堅牢性が欠けている。本研究では、数学的推論ベンチマークが実装の選択に敏感であることを発見し、標準化された評価フレームワークを提案。再評価の結果、強化学習アプローチは改善が少なく、教師ありファインチューニング手法は強い一般化を示した。再現性を高めるために、関連するコードやデータを公開し、今後の研究の基盤を築く。 Comment
元ポスト:
SLMをmath reasoning向けにpost-trainingする場合、評価の条件をフェアにするための様々な工夫を施し評価をしなおした結果(Figure1のように性能が変化する様々な要因が存在する)、RL(既存研究で試されているもの)よりも(大規模モデルからrejection samplingしたreasoning traceを用いて)SFTをする方が同等か性能が良く(Table3)、結局のところ(おそらく汎化性能が低いという意味で)reliableではなく、かつ(おそらく小規模なモデルでうまくいかないという意味での)scalableではないので、reliableかつscalableなRL手法が不足しているとのこと。
※ 本論文で分析されているのは<=10B以下のSLMである点に注意。10B以上のモデルで同じことが言えるかは自明ではない。
※ DAPO, VAPOなどについても同じことが言えるかも自明ではない。
※ DeepSeek-R1のtechnical reportにおいて、小さいモデルにGRPOを適用してもあまり効果が無かったことが既に報告されている。
- DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01
- DeepSeek-R1, DeepSeek, 2025.01
個々のpost-trainingされたRLモデルが具体的にどういう訓練をしたのかは追えていないが、DAPOやDr. GRPO, VAPOの場合はどうなるんだろうか?
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25
- VAPO: Efficient and Reliable Reinforcement Learning for Advanced
Reasoning Tasks, YuYue+, arXiv'25
- [Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
Rewardの設定の仕方はどのような影響があるのだろうか(verifiable rewardなのか、neuralモデルによるrewardなのかなど)?
学習のさせ方もどのような影響があるのだろうか(RLでカリキュラムlearningにした場合など)?
検証しているモデルがそれぞれどのような設定で学習されているかまでを見ないとこの辺はわからなそう。
ただなんとなーくの直感だと、SLMを賢くしたいという場合は何らかの賢いモデルの恩恵に預かると有利なケースが多く(SFTの場合はそれが大規模なモデルから蒸留したreasoning trace)、SLM+RLの場合はPRMのような思考プロセスを評価してRewardに反映させるようなものを利用しないと、少なくとも小規模なLLMをめちゃ賢くします〜というのはきついんじゃないかなあという感想ではある。
ただ、結局SLMという時点で多くの場合、より賢いパラメータ数の多いLLMが世の中には存在するあるはずなので、RLしないでSFTして蒸留すれば良いんじゃない…?と思ってしまう。
が、多くの場合その賢いLLMはProprietaryなLLMであり、出力を得て自分のモデルをpost-trainingすることは利用規約違反となるため、自前で賢くてパラメータ数の多いLLMを用意できない場合は困ってしまうので、SLMをクソデカパラメータのモデルの恩恵なしで超絶賢くできたら世の中の多くの人は嬉しいよね、とも思う。
(斜め読みだが)
サンプル数が少ない(数十件)AIMEやAMCなどのデータはseedの値にとてもsensitiveであり(Takeaway1, 2)、https://github.com/user-attachments/assets/97581133-cf17-4635-b66c-442eaf8956d4"
/>
それらは10種類のseedを用いて結果を平均すると分散が非常に小さくなるので、seedは複数種類利用して平均の性能を見た方がreliableであり(Takeaway3)https://github.com/user-attachments/assets/5065ef0e-de89-4b17-aa52-c90b7191e9b2"
/>
temperatureを高くするとピーク性能が上がるが分散も上がるため再現性の課題が増大するが、top-pを大きくすると再現性の問題は現れず性能向上に寄与しhttps://github.com/user-attachments/assets/76d5c989-edbb-4d70-9080-d1d4b01de2ff"
/>
既存研究のモデルのtemperatureとtop-pを変化させ実験するとperformanceに非常に大きな変化が出るため、モデルごとに最適な値を選定して比較をしないとunfairであることを指摘 (Takeaway4)。https://github.com/user-attachments/assets/d8b453d1-3d2e-4a80-b03d-c69ec1b2232e"
/>
また、ハードウェアの面では、vLLMのようなinference engineはGPU typeやmemoryのconfigurationに対してsensitiveでパフォーマンスが変わるだけでなく、https://github.com/user-attachments/assets/a41891c7-072c-4c38-9ad6-beada4721bac"
/>
評価に利用するフレームワークごとにinference engineとprompt templateが異なるためこちらもパフォーマンスに影響が出るし (Takeaway5)、https://github.com/user-attachments/assets/1f7d328c-0757-47b9-9961-630e2429fb3e"
/>
max output tokenの値を変化させると性能も変わり、prompt templateを利用しないと性能が劇的に低下する (Takeaway6)。https://github.com/user-attachments/assets/dc0902d1-a5f2-47de-8df1-c28107e1da28"
/>
これらのことから著者らはreliableな評価のために下記を提案しており (4.1節; 後ほど追記)、
実際にさまざまな条件をfair comparisonとなるように標準化して評価したところ(4.2節; 後ほど追記)
上の表のような結果となった。この結果は、
- DeepSeekR1-DistilledをRLしてもSFTと比較したときに意味のあるほどのパフォーマンスの向上はないことから、スケーラブル、かつ信頼性のあるRL手法がまだ不足しており
- 大規模なパラメータのモデルのreasoning traceからSFTをする方法はさまざまなベンチマークでロバストな性能(=高い汎化性能)を持ち、RLと比べると現状はRLと比較してよりパラダイムとして成熟しており
- (AIME24,25を比較するとSFTと比べてRLの場合performanceの低下が著しいので)RLはoverfittingしやすく、OODなベンチマークが必要
しっかりと評価の枠組みを標準化してfair comparisonしていかないと、RecSys業界の二の舞になりそう(というかもうなってる?)。
またこの研究で分析されているのは小規模なモデル(<=10B)に対する既存研究で用いられた一部のRL手法や設定の性能だけ(真に示したかったらPhisics of LLMのような完全にコントロール可能なサンドボックスで実験する必要があると思われる)なので、DeepSeek-R1のように、大規模なパラメータ(数百B)を持つモデルに対するRLに関して同じことが言えるかは自明ではない点に注意。
openreview: https://openreview.net/forum?id=90UrTTxp5O#discussion
最近の以下のようなSFTはRLの一つのケースと見做せるという議論を踏まえるとどうなるだろうか
- [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with
Reward Rectification, Yongliang Wu+, arXiv'25
- [Paper Note] Towards a Unified View of Large Language Model Post-Training, Xingtai Lv+, arXiv'25
#Pocket #NLP #LanguageModel #Attention #ICLR #AttentionSinks #read-later Issue Date: 2025-04-05 When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25 GPT Summary- 言語モデルにおける「アテンションシンク」は、意味的に重要でないトークンに大きな注意を割り当てる現象であり、さまざまな入力に対して小さなモデルでも普遍的に存在することが示された。アテンションシンクは事前学習中に出現し、最適化やデータ分布、損失関数がその出現に影響を与える。特に、アテンションシンクはキーのバイアスのように機能し、情報を持たない追加のアテンションスコアを保存することがわかった。この現象は、トークンがソフトマックス正規化に依存していることから部分的に生じており、正規化なしのシグモイドアテンションに置き換えることで、アテンションシンクの出現を防ぐことができる。 Comment
Sink Rateと呼ばれる、全てのheadのFirst Tokenに対するattention scoreのうち(layer l * head h個存在する)、どの程度の割合のスコアが閾値を上回っているかを表す指標を提案
(後ほど詳細を追記する)
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究
著者ポスト(openai-gpt-120Bを受けて):
openreview: https://openreview.net/forum?id=78Nn4QJTEN
#Analysis #NLP #LanguageModel #Attention #AttentionSinks #COLM Issue Date: 2025-04-05 Why do LLMs attend to the first token?, Federico Barbero+, COLM'25 GPT Summary- LLMsは最初のトークンに強く注意を向ける「アテンションシンク」を示し、そのメカニズムが過剰混合を避ける方法を理論的・実証的に探求。コンテキストの長さやデータのパッキングがシンクの挙動に与える影響を実験で示し、アテンションパターンの理解を深めることを目指す。 Comment
元ポスト:
Attention Sinkによって、トークンの情報がover-mixingされることが抑制され、Decoder-only LLMの深い層のrepresentationが均一化されることを抑制する(=promptの摂動にロバストになる)ことが示された模様。
Gemma7Bにおいて、prompt中のトークン一語を置換した後に、Attention Sink(
openreview: https://openreview.net/forum?id=tu4dFUsW5z#discussion
#EfficiencyImprovement #Pocket #NLP #LanguageModel #AIAgents #SoftwareEngineering #KeyPoint Notes Issue Date: 2025-04-02 Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, FSE'25 GPT Summary- 最近のLLMの進展により、ソフトウェア開発タスクの自動化が進んでいるが、複雑なエージェントアプローチの必要性に疑問が生じている。これに対し、Agentlessというエージェントレスアプローチを提案し、シンプルな三段階プロセスで問題を解決。SWE-bench Liteベンチマークで最高のパフォーマンスと低コストを達成。研究は自律型ソフトウェア開発におけるシンプルで解釈可能な技術の可能性を示し、今後の研究の方向性を刺激することを目指している。 Comment
日本語解説: https://note.com/ainest/n/nac1c795e3825
LLMによる計画の立案、環境からのフィードバックによる意思決定などの複雑なワークフローではなく、Localization(階層的に問題のある箇所を同定する)とRepair(LLMで複数のパッチ候補を生成する)、PatchValidation(再現テストと回帰テストの両方を通じて結果が良かったパッチを選ぶ)のシンプルなプロセスを通じてIssueを解決する。
これにより、低コストで高い性能を達成している、といった内容な模様。
Agentlessと呼ばれ手法だが、preprint版にあったタイトルの接頭辞だった同呼称がproceeding版では無くなっている。
#Metrics #NLP #LanguageModel #GenerativeAI #Evaluation #KeyPoint Notes #Reference Collection Issue Date: 2025-03-31 Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03 GPT Summary- 新しい指標「50%-タスク完了時間ホライズン」を提案し、AIモデルの能力を人間の観点から定量化。Claude 3.7 Sonnetは約50分の時間ホライズンを持ち、AIの能力は2019年以降約7か月ごとに倍増。信頼性や論理的推論の向上が要因とされ、5年以内にAIが多くのソフトウェアタスクを自動化できる可能性を示唆。 Comment
元ポスト:
確かに線形に見える。てかGPT-2と比べるとAIさん進化しすぎである…。
利用したデータセットは
- HCAST: 46のタスクファミリーに基づく97種類のタスクが定義されており、たとえばサイバーセキュリティ、機械学習、ソフトウェアエンジニアリング、一般的な推論タスク(wikipediaから事実情報を探すタスクなど)などがある
- 数分で終わるタスク: 上述のwikipedia
- 数時間で終わるタスク: Pytorchのちょっとしたバグ修正など
- 数文でタスクが記述され、コード、データ、ドキュメント、あるいはwebから入手可能な情報を参照可能
- タスクの難易度としては当該ドメインに数年間携わった専門家が解ける問題
- RE-Bench Suite
- 7つのopen endedな専門家が8時間程度を要するMLに関するタスク
- e.g., GPT-2をQA用にFinetuningする, Finetuningスクリプトが与えられた時に挙動を変化させずにランタイムを可能な限り短縮する、など
- [RE-Bench Technical Report](
https://metr.org/AI_R_D_Evaluation_Report.pdf)のTable2等を参照のこと
- SWAA Suite: 66種類の1つのアクションによって1分以内で終わるソフトウェアエンジニアリングで典型的なタスク
- 1分以内で終わるタスクが上記データになかったので著者らが作成
であり、画像系やマルチモーダルなタスクは含まれていない。
タスクと人間がタスクに要する時間の対応に関するサンプルは下記
タスク-エージェントペアごとに8回実行した場合の平均の成功率。確かにこのグラフからはN年後には人間で言うとこのくらいの能力の人がこのくらい時間を要するタスクが、このくらいできるようになってます、といったざっくり感覚値はなかなか想像できない。
成功率とタスクに人間が要する時間に関するグラフ。ロジスティック関数でfittingしており、赤い破線が50% horizon。Claude 3.5 Sonnet (old)からClaude 3.7 Sonnetで50% horizonは18分から59分まで増えている。実際に数字で見るとイメージが湧きやすくおもしろい。
こちらで最新モデルも随時更新される:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
#MachineLearning #Pocket #LanguageModel #ReinforcementLearning #Reasoning #LongSequence #GRPO #read-later #One-Line Notes #Reference Collection Issue Date: 2025-03-20 DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25 GPT Summary- 推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment
既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。
ちとこれはあとでしっかり読みたい。重要論文。
プロジェクトページ:
https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。
解説ポスト:
コンパクトだが分かりやすくまとまっている。
下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:
色々な研究で広く使われるのを見るようになった。
著者ポスト:
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #Test-Time Scaling #read-later Issue Date: 2025-02-07 s1: Simple test-time scaling, Niklas Muennighoff+, arXiv'25 GPT Summary- テスト時スケーリングを用いて言語モデルのパフォーマンスを向上させる新しいアプローチを提案。小規模データセットs1Kを作成し、モデルの思考プロセスを制御する予算強制を導入。これにより、モデルは不正確な推論を修正し、Qwen2.5-32B-Instructモデルがo1-previewを最大27%上回る結果を達成。さらに、介入なしでパフォーマンスを向上させることが可能となった。モデル、データ、コードはオープンソースで提供。 Comment
解説:
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #Reasoning #LongSequence #RewardHacking #PostTraining Issue Date: 2025-02-07 Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, arXiv'25 GPT Summary- 本研究では、大規模言語モデル(LLMs)における長い思考の連鎖(CoTs)推論のメカニズムを調査し、重要な要因を特定。主な発見は、(1) 教師ありファインチューニング(SFT)は必須ではないが効率を向上させる、(2) 推論能力は計算の増加に伴い現れるが、報酬の形状がCoTの長さに影響、(3) 検証可能な報酬信号のスケーリングが重要で、特に分布外タスクに効果的、(4) エラー修正能力は基本モデルに存在するが、RLを通じて効果的に奨励するには多くの計算が必要。これらの洞察は、LLMsの長いCoT推論を強化するためのトレーニング戦略の最適化に役立つ。 Comment
元ポスト:
元ポストのスレッド中に論文の11個の知見が述べられている。どれも非常に興味深い。DeepSeek-R1のテクニカルペーパーと同様、
- Long CoTとShort CoTを比較すると前者の方が到達可能な性能のupper bonudが高いことや、
- SFTを実施してからRLをすると性能が向上することや、
- RLの際にCoTのLengthに関する報酬を入れることでCoTの長さを抑えつつ性能向上できること、
- 数学だけでなくQAペアなどのノイジーだが検証可能なデータをVerifiableな報酬として加えると一般的なreasoningタスクで数学よりもさらに性能が向上すること、
- より長いcontext window sizeを活用可能なモデルの訓練にはより多くの学習データが必要なこと、
- long CoTはRLによって学習データに類似したデータが含まれているためベースモデルの段階でその能力が獲得されていることが示唆されること、
- aha momentはすでにベースモデル時点で獲得されておりVerifiableな報酬によるRLによって強化されたわけではなさそう、
など、興味深い知見が盛りだくさん。非常に興味深い研究。あとで読む。
#ComputerVision #Analysis #MachineLearning #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #ICML #PostTraining #read-later Issue Date: 2025-01-30 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25 GPT Summary- SFTとRLの一般化能力の違いを研究し、GeneralPointsとV-IRLを用いて評価。RLはルールベースのテキストと視覚変種に対して優れた一般化を示す一方、SFTは訓練データを記憶し分布外シナリオに苦労。RLは視覚認識能力を向上させるが、SFTはRL訓練に不可欠であり、出力形式を安定させることで性能向上を促進。これらの結果は、複雑なマルチモーダルタスクにおけるRLの一般化能力を示す。 Comment
元ポスト:
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2025-01-25 [Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25 GPT Summary- 「人類の最後の試験(HLE)」を導入し、LLMの能力を測定する新しいマルチモーダルベンチマークを提案。HLEは2,500の質問から成り、数学や自然科学など広範な科目をカバー。専門家によって開発され、自動採点が可能な形式で、インターネット検索では迅速に回答できない。最先端のLLMはHLEに対して低い精度を示し、現在のLLMの能力と専門家の知識との間に大きなギャップがあることを明らかに。HLEは公開され、研究や政策立案に役立てられる。 Comment
o1, DeepSeekR1の正解率が10%未満の新たなベンチマーク
#Pocket #MultiModal #ACL #ComputerUse #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-11-25 [Paper Note] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models, Hongliang He+, ACL'24, 2024.01 GPT Summary- WebVoyagerは、実際のウェブサイトと対話しユーザーの指示をエンドツーエンドで完了できる大規模マルチモーダルモデルを搭載したウェブエージェントである。新たに設立したベンチマークで59.1%のタスク成功率を達成し、GPT-4やテキストのみのWebVoyagerを上回る性能を示した。提案された自動評価指標は人間の判断と85.3%一致し、ウェブエージェントの信頼性を高める。 Comment
日本語解説: https://blog.shikoan.com/web-voyager/
スクリーンショットを入力にHTMLの各要素に対してnumeric labelをoverlayし(Figure2)、VLMにタスクを完了するためのアクションを出力させる手法。アクションはFigure7のシステムプロンプトに書かれている通り。
たとえば、VLMの出力として"Click [2]" が得られたら GPT-4-Act GPT-4V-Act, ddupont808, 2023.10
と呼ばれるSoM [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
をベースにWebUIに対してマウス/キーボードでinteractできるモジュールを用いることで、[2]とマーキングされたHTML要素を同定しClick操作を実現する。
#Pocket #NLP #LanguageModel #AIAgents #Evaluation #NeurIPS #SoftwareEngineering #read-later #One-Line Notes Issue Date: 2025-11-25 [Paper Note] SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, John Yang+, arXiv'24, 2024.05 GPT Summary- LMエージェントのパフォーマンスにおけるインターフェースデザインの影響を調査し、ソフトウェアエンジニアリングタスクを解決するためのシステム「SWE-agent」を提案。SWE-agentのカスタムインターフェースは、コード作成やリポジトリナビゲーション、プログラム実行能力を向上させ、SWE-benchとHumanEvalFixで最先端のパフォーマンスを達成。pass@1率はそれぞれ12.5%と87.7%に達し、従来の非インタラクティブなLMを大きく上回る結果を示した。 Comment
SWE bench Verifiedで利用されているハーネスで、mini-SWE-agentと呼ばれるもの
https://github.com/SWE-agent/mini-swe-agent
#Pocket #DiffusionModel #NeurIPS #read-later Issue Date: 2025-11-04 [Paper Note] Simplified and Generalized Masked Diffusion for Discrete Data, Jiaxin Shi+, NeurIPS'24, 2024.06 GPT Summary- Masked拡散モデルの潜在能力を引き出すためのシンプルなフレームワークを提案。連続時間変分目的がクロスエントロピー損失の重み付き積分であることを示し、状態依存のマスキングスケジュールを用いたトレーニングを可能に。OpenWebTextでの評価で、GPT-2スケールのモデルを上回り、ゼロショット言語モデリングタスクで優れたパフォーマンスを示す。画像モデリングでもCIFAR-10やImageNetで従来のモデルを大幅に上回る結果を達成。コードは公開中。 Comment
- Masked Diffusion Modelの進展, Deep Learning JP, 2025.03
で紹介されている
#Pocket #NLP #LanguageModel #DiffusionModel #NeurIPS #read-later Issue Date: 2025-11-04 [Paper Note] Simple and Effective Masked Diffusion Language Models, Subham Sekhar Sahoo+, NeurIPS'24, 2024.06 GPT Summary- マスク付き離散拡散モデルは、従来の自己回帰手法に匹敵する性能を示す。効果的なトレーニング手法と簡略化された目的関数を導出し、エンコーダ専用の言語モデルをトレーニングすることで、任意の長さのテキスト生成が可能に。言語モデリングのベンチマークで新たな最先端を達成し、AR手法に近づく成果を上げた。 Comment
- Masked Diffusion Modelの進展, Deep Learning JP, 2025.03
で紹介されている
#Pocket #NLP #LanguageModel #Test-Time Scaling #One-Line Notes Issue Date: 2025-11-02 [Paper Note] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling, Bradley Brown+, arXiv'24, 2024.07 GPT Summary- 言語モデルの推論能力を向上させるために、候補解を繰り返しサンプリングする手法を提案。サンプル数の増加に伴い、問題解決のカバレッジが4桁のオーダーでスケールし、対数線形の関係が示唆される。自動検証可能な回答がある領域では、カバレッジの増加がパフォーマンス向上に直結。SWE-bench Liteでの実験では、サンプル数を増やすことで解決率が大幅に向上したが、自動検証器がない領域ではサンプル数が増えても効果が頭打ちになることが確認された。 Comment
Repeated Sampling。同じプロンプトで複数回LLMを呼び出し、なんらかのverifierを用いて最も良いものを選択するtest time scaling手法。https://github.com/user-attachments/assets/73db708f-7eb2-444e-9689-bbef1f12e22d"
/>
figure2にverifierを利用しない場合と利用した場合の差が示されている。高性能なverifierが利用された場合は、サンプル数の増加に大して性能がスケールしていき、single attemptでのstrong ModelやSoTAを上回る性能が得られることがわかる。https://github.com/user-attachments/assets/2edbe1b7-26fc-47f6-a54b-642832fbe1a8"
/>
Figure8を見るとself consistency型のverifierの限界が示されている。すなわち、サンプリングする中で正しい解法が頻出しないようなものである。図を見ると、赤いbarがmajority-votingでは正解できない問題のindexを示しており、それなりの割合で存在することがわかる。https://github.com/user-attachments/assets/d087621a-dfc0-47e7-9b4d-3efd1fa9016e"
/>
この辺の話は
- [Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Outstanding Paper
とも関連していると思われる。
verifierの具体的な構築方法としてどのようなものがあるかが気になる。あとで読む。
> However, these increasingly rare correct generations are only beneficial if verifiers can “find the needle in the haystack” and identify them from collections of mostly-incorrect samples. In math word problem settings, we find that two common methods for verification (majority voting and reward models) do not possess this ability. When solving MATH [26] problems with Llama-3-8B-Instruct, coverage increases from 82.9% with 100 samples to 98.44% with 10,000 samples. However, when using majority voting or reward models to select final answers, the biggest performance increase is only from 40.50% to 41.41% over the same sample range.
上に記述されている内容は、要はverifierの性能が重要で、典型的なmajority votingやreward mode4lsによるverification手法ではスケールしないケースがある。たとえば、以下のFigure7を見ると、典型的な
- majority voting
- reward model + best-of-N
- majority voting + reward model
などのtest-time scaling手法(verification手法)がサンプル数Kを増やしてもスケールしないことを示しており、一方Oracle Verifier(=数学の問題において正解が既知の場合に正解を出力したサンプルを採用する)での結果を見ると、性能がスケールしていくことがわかる。特にGSM8K, MATHデータセットにおいては、Reward Modelを利用するverification手法はmajority votingと比較してあまり良い性能が出ていないことがわかる。https://github.com/user-attachments/assets/bc9cbc89-d31d-4b46-b7b8-f620dc95ccd7"
/>
本研究は5つのデータで検証しているが利用されているverifierは
- MiniF2F-MATH, CodeContests, SWE-Bench:
- すでに自動的なverifierが提供されており、たとえばそれはLean4 proof checker、test case, unit test suitesなどである
- GSM8K, MATH:
- これらについてはOracle Verifier(=モデルの出力が問題の正答と一致したら採用する)を利用している
本手法のスケーリングはverifierの性能に依存するため、高性能なverificationが作成できないタスクに関して適用するのは難しいと考えられる。逆に良い感じなverifierが定義できるなら相当強力な手法に見える。
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #Safety #PostTraining #One-Line Notes Issue Date: 2025-10-24 [Paper Note] Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To, Xiangyu Qi+, ICLR'24, 2023.10 GPT Summary- LLMのファインチューニングは、下流のユースケースに最適化する手法だが、安全性のリスクが伴う。特に、敵対的なトレーニング例を用いたファインチューニングが、モデルの安全性調整を損なう可能性があることが示された。例えば、わずか10例の悪意のある例でGPT-3.5 Turboをファインチューニングすると、安全ガードレールが突破される。また、無害なデータセットでのファインチューニングも意図せず安全性を劣化させる可能性がある。これらの結果は、調整されたLLMのファインチューニングが新たな安全リスクを生むことを示唆しており、今後の安全プロトコルの強化が求められる。 Comment
openreview: https://openreview.net/forum?id=hTEGyKf0dZ
なんらかのデータでpost-trainingしたモデルを、ユーザが利用可能な形でデプロイするような場合には、本研究が提唱するようなjailbreakのリスク
- 有害データが10例混入するだけで有害な出力をするようになる
- 暗黙的な有害データの混入(e.g., あなたはユーザ命令に従うエージェントです)
- 無害なデータでpost-trainingするだけでも下記のような影響でsafety alignmentが悪化する
- catastrophic forgetting
- 有用性と無害性のトレードオフによって、有用性を高めたことで有害性が結果的に増えてしまう( `tension between the helpfulness and harmlessness objectives` [Paper Note] Training a Helpful and Harmless Assistant with Reinforcement Learning
from Human Feedback, Yuntao Bai+, arXiv'22
)
があることを認識しておく必要がある。
もし安直にユーザからの指示追従能力を高めたいなあ・・・と思い、「ユーザからの指示には忠実に従ってください」などの指示を追加してpost-trainingをしてしまい、無害なプロンプトのみでテストして問題ないと思いユーザ向けのchatbotとしてデプロイしました、みたいなことをしたらえらいことになりそう。
#MachineLearning #Pocket #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML #One-Line Notes Issue Date: 2025-10-10 [Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02 GPT Summary- LoRAの精度ギャップを解消するために、Weight-Decomposed Low-Rank Adaptation(DoRA)を提案。DoRAは、ファインチューニングの重みを大きさと方向に分解し、方向性の更新にLoRAを使用することで、効率的にパラメータ数を最小化。これにより、LoRAの学習能力と安定性を向上させ、追加の推論コストを回避。さまざまな下流タスクでLoRAを上回る性能を示す。 Comment
日本語解説:
- LoRAの進化:基礎から最新のLoRA-Proまで , 松尾研究所テックブログ, 2025.09
- Tora: Torchtune-LoRA for RL, shangshang-wang, 2025.10
では、通常のLoRA, QLoRAだけでなく本手法でRLをする実装もサポートされている模様
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Alignment #ReinforcementLearning #ACL #read-later Issue Date: 2025-09-27 [Paper Note] Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs, Arash Ahmadian+, ACL'24, 2024.02 GPT Summary- RLHFにおける整合性の重要性を考慮し、PPOの高コストとハイパーパラメータ調整の問題を指摘。シンプルなREINFORCEスタイルの最適化手法がPPOや新提案の手法を上回ることを示し、LLMの整合性特性に適応することで低コストのオンラインRL最適化が可能であることを提案。 #ComputerVision #Pocket #NLP #Dataset #Evaluation #DiffusionModel #read-later #UMM Issue Date: 2025-09-11 [Paper Note] ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment, Xiwei Hu+, arXiv'24 GPT Summary- 拡散モデルに大規模言語モデル(LLM)を組み込む「効率的な大規模言語モデルアダプター(ELLA)」を提案。これにより、複雑なプロンプトの整合性を向上させ、意味的特徴を適応させる新しいモジュール「時間ステップ認識セマンティックコネクタ(TSC)」を導入。ELLAは密なプロンプトに対する性能が最先端手法を上回ることを実験で示し、特に複数のオブジェクト構成において優位性を発揮。 Comment
pj page: https://ella-diffusion.github.io
#ComputerVision #Pretraining #Pocket #MultiModal #FoundationModel #CVPR #VisionLanguageModel Issue Date: 2025-08-23 [Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24 GPT Summary- 大規模視覚-言語基盤モデル(InternVL)は、60億パラメータで設計され、LLMと整合させるためにウェブ規模の画像-テキストデータを使用。視覚認知タスクやゼロショット分類、検索など32のベンチマークで最先端の性能を達成し、マルチモーダル対話システムの構築に寄与。ViT-22Bの代替として強力な視覚能力を持つ。コードとモデルは公開されている。 Comment
既存のResNetのようなSupervised pretrainingに基づくモデル、CLIPのようなcontrastive pretrainingに基づくモデルに対して、text encoder部分をLLMに置き換えて、contrastive learningとgenerativeタスクによる学習を組み合わせたパラダイムを提案。
InternVLのアーキテクチャは下記で、3 stageの学習で構成される。最初にimage text pairをcontrastive learningし学習し、続いてモデルのパラメータはfreezeしimage text retrievalタスク等でモダリティ間の変換を担う最終的にQlLlama(multilingual性能を高めたllama)をvision-languageモダリティを繋ぐミドルウェアのように捉え、Vicunaをテキストデコーダとして接続してgenerative cossで学習する、みたいなアーキテクチャの模様(斜め読みなので少し違う可能性あり
現在のVLMの主流であるvision encoderとLLMをadapterで接続する方式はここからかなりシンプルになっていることが伺える。
#Pocket #NLP #LanguageModel #LongSequence #ICLR Issue Date: 2025-08-02 [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24 GPT Summary- YaRN(Yet another RoPE extensioN method)は、トランスフォーマーベースの言語モデルにおける位置情報のエンコードを効率的に行い、コンテキストウィンドウを従来の方法よりも10倍少ないトークンと2.5倍少ない訓練ステップで拡張する手法を提案。LLaMAモデルが長いコンテキストを効果的に利用できることを示し、128kのコンテキスト長まで再現可能なファインチューニングを実現。 Comment
openreview: https://openreview.net/forum?id=wHBfxhZu1u
現在主流なコンテキストウィンドウ拡張手法。様々なモデルで利用されている。
#Pocket #NLP #Dataset #LanguageModel #ReinforcementLearning #Reasoning #ICLR #PRM Issue Date: 2025-06-26 [Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24 GPT Summary- 大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。 Comment
OpenReview: https://openreview.net/forum?id=v8L0pN6EOi
#EfficiencyImprovement #Pretraining #Pocket #NLP #Dataset #LanguageModel #NeurIPS Issue Date: 2025-05-10 The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale, Guilherme Penedo+, NeurIPS'24 GPT Summary- 本研究では、15兆トークンからなるFineWebデータセットを紹介し、LLMの性能向上に寄与することを示します。FineWebは高品質な事前学習データセットのキュレーション方法を文書化し、重複排除やフィルタリング戦略を詳細に調査しています。また、FineWebから派生した1.3兆トークンのFineWeb-Eduを用いたLLMは、MMLUやARCなどのベンチマークで優れた性能を発揮します。データセット、コードベース、モデルは公開されています。 Comment
日本語解説: https://zenn.dev/deepkawamura/articles/da9aeca6d6d9f9
openreview: https://openreview.net/forum?id=n6SCkn2QaG#discussion
#Analysis #NLP #LanguageModel #SyntheticData #read-later Issue Date: 2025-05-06 Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers, Zeyuan Allen-Zhu+, ICML'24 Tutorial Comment
元ポスト:
Canon層の発見
著者による解説:
#Analysis #Pocket #NLP #LanguageModel #SyntheticData #ICML Issue Date: 2025-05-03 Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24 GPT Summary- 大規模言語モデル(LLMs)の知識抽出能力は、訓練データの多様性と強く相関しており、十分な強化がなければ知識は記憶されても抽出可能ではないことが示された。具体的には、エンティティ名の隠れ埋め込みに知識がエンコードされているか、他のトークン埋め込みに分散しているかを調査。LLMのプレトレーニングに関する重要な推奨事項として、補助モデルを用いたデータ再構成と指示微調整データの早期取り入れが提案された。 Comment
SNLP'24での解説スライド:
https://speakerdeck.com/sosk/physics-of-language-models-part-3-1-knowledge-storage-and-extraction
#Pocket #NLP #LanguageModel #Evaluation #Decoding #Non-Determinism Issue Date: 2025-04-14 Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, arXiv'24 GPT Summary- 本研究では、5つの決定論的LLMにおける非決定性を8つのタスクで調査し、最大15%の精度変動と70%のパフォーマンスギャップを観察。全てのタスクで一貫した精度を提供できないことが明らかになり、非決定性が計算リソースの効率的使用に寄与している可能性が示唆された。出力の合意率を示す新たなメトリクスTARr@NとTARa@Nを導入し、研究結果を定量化。コードとデータは公開されている。 Comment
- 論文中で利用されているベンチマーク:
- Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, N/A, TMLR'23
- Measuring Massive Multitask Language Understanding, Dan Hendrycks+, N/A, ICLR'21
同じモデルに対して、seedを固定し、temperatureを0に設定し、同じ計算機環境に対して、同じinputを入力したら理論上はLLMの出力はdeterministicになるはずだが、deterministicにならず、ベンチマーク上の性能とそもそものraw response自体も試行ごとに大きく変化する、という話。
ただし、これはプロプライエタリLLMや、何らかのinferenceの高速化を実施したInferenceEngine(本研究ではTogetherと呼ばれる実装を使っていそう。vLLM/SGLangだとどうなるのかが気になる)を用いてinferenceを実施した場合での実験結果であり、後述の通り計算の高速化のためのさまざまな実装無しで、deterministicな設定でOpenLLMでinferenceすると出力はdeterministicになる、という点には注意。
GPTやLlama、Mixtralに対して上記ベンチマークを用いてzero-shot/few-shotの設定で実験している。Reasoningモデルは実験に含まれていない。https://github.com/user-attachments/assets/b33f14d8-ed86-4589-a427-18a70b35d61a"
/>
LLMのraw_response/multiple choiceのparse結果(i.e., 問題に対する解答部分を抽出した結果)の一致(TARr@N, TARa@N; Nはinferenceの試行回数)も理論上は100%になるはずなのに、ならないことが報告されている。https://github.com/user-attachments/assets/3159ff26-fc92-4fa8-90a6-f8c5e7ccf20e"
/>
correlation analysisによって、応答の長さ と TAR{r, a}が強い負の相関を示しており、応答が長くなればなるほど不安定さは増すことが分析されている。このため、ontput tokenの最大値を制限することで出力の安定性が増すことを考察している。また、few-shotにおいて高いAcc.の場合は出力がdeterministicになるわけではないが、性能が安定する傾向とのこと。また、OpenAIプラットフォーム上でGPTのfinetuningを実施し実験したが、安定性に寄与はしたが、こちらもdeterministicになるわけではないとのこと。
deterministicにならない原因として、まずmulti gpu環境について検討しているが、multi-gpu環境ではある程度のランダム性が生じることがNvidiaの研究によって報告されているが、これはseedを固定すれば決定論的にできるため問題にならないとのこと。
続いて、inferenceを高速化するための実装上の工夫(e.g., Chunk Prefilling, Prefix Caching, Continuous Batching)などの実装がdeterministicなハイパーパラメータでもdeterministicにならない原因であると考察しており、**実際にlocalマシン上でこれらinferenceを高速化するための最適化を何も実施しない状態でLlama-8Bでinferenceを実施したところ、outputはdeterministicになったとのこと。**
論文中に記載がなかったため、どのようなInferenceEngineを利用したか公開されているgithubを見ると下記が利用されていた:
- Together:
https://github.com/togethercomputer/together-python?tab=readme-ov-file
Togetherが内部的にどのような処理をしているかまでは追えていないのだが、異なるInferenceEngineを利用した場合に、どの程度outputの不安定さに差が出るのか(あるいは出ないのか)は気になる。たとえば、transformers/vLLM/SGLangを利用した場合などである。
論文中でも報告されている通り、昔管理人がtransformersを用いて、deterministicな設定でzephyrを用いてinferenceをしたときは、出力はdeterministicになっていたと記憶している(スループットは絶望的だったが...)。
あと個人的には現実的な速度でオフラインでinference engineを利用した時にdeterministicにはせめてなって欲しいなあという気はするので、何が原因なのかを実装レベルで突き詰めてくれるととても嬉しい(KV Cacheが怪しい気がするけど)。
たとえば最近SLMだったらKVCacheしてVRAM食うより計算し直した方が効率良いよ、みたいな研究があったような。そういうことをしたらlocal llmでdeterministicにならないのだろうか。
- Defeating Nondeterminism in LLM Inference, Horace He in collaboration with others at Thinking Machines, 2025.09
においてvLLMを用いた場合にDeterministicな推論をするための解決方法が提案されている。
#Pocket #Attention #LongSequence #ICLR #AttentionSinks #KeyPoint Notes #Reference Collection Issue Date: 2025-04-05 Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24 GPT Summary- 大規模言語モデル(LLMs)をマルチラウンド対話に展開する際の課題として、メモリ消費と長いテキストへの一般化の難しさがある。ウィンドウアテンションはキャッシュサイズを超えると失敗するが、初期トークンのKVを保持することでパフォーマンスが回復する「アテンションシンク」を発見。これを基に、StreamingLLMというフレームワークを提案し、有限のアテンションウィンドウでトレーニングされたLLMが無限のシーケンス長に一般化可能になることを示した。StreamingLLMは、最大400万トークンで安定した言語モデリングを実現し、ストリーミング設定で従来の手法を最大22.2倍の速度で上回る。 Comment
Attention Sinksという用語を提言した研究
下記のpassageがAttention Sinksの定義(=最初の数トークン)とその気持ち(i.e., softmaxによるattention scoreは足し合わせて1にならなければならない。これが都合の悪い例として、現在のtokenのqueryに基づいてattention scoreを計算する際に過去のトークンの大半がirrelevantな状況を考える。この場合、irrelevantなトークンにattendしたくはない。そのため、auto-regressiveなモデルでほぼ全てのcontextで必ず出現する最初の数トークンを、irrelevantなトークンにattendしないためのattention scoreの捨て場として機能するのうに学習が進む)の理解に非常に重要
> To understand the failure of window attention, we find an interesting phenomenon of autoregressive LLMs: a surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task, as visualized in Figure 2. We term these tokens
“attention sinks". Despite their lack of semantic significance, they collect significant attention scores. We attribute the reason to the Softmax operation, which requires attention scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one. The reason behind initial tokens as sink tokens is intuitive: initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究。こちらでAttentionSinkがどのように作用しているのか?が分析されている。
Figure1が非常にわかりやすい。Initial Token(実際は3--4トークン)のKV Cacheを保持することでlong contextの性能が改善する(Vanilla)。あるいは、Softmaxの分母に1を追加した関数を用意し(数式2)、全トークンのattention scoreの合計が1にならなくても許されるような変形をすることで、余剰なattention scoreが生じないようにすることでattention sinkを防ぐ(Zero Sink)。これは、ゼロベクトルのトークンを追加し、そこにattention scoreを逃がせるようにすることに相当する。もう一つの方法は、globalに利用可能なlearnableなSink Tokenを追加すること。これにより、不要なattention scoreの捨て場として機能させる。Table3を見ると、最初の4 tokenをKV Cacheに保持した場合はperplexityは大きく変わらないが、Sink Tokenを導入した方がKV Cacheで保持するInitial Tokenの量が少なくてもZero Sinkと比べると性能が良くなるため、今後モデルを学習する際はSink Tokenを導入することを薦めている。既に学習済みのモデルについては、Zero Sinkによってlong contextのモデリングに対処可能と思われる。https://github.com/user-attachments/assets/9d4714e5-02b9-45b5-affd-c6c34eb7c58f"
/>
著者による解説:
openreview: https://openreview.net/forum?id=NG7sS51zVF
#Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #ICLR #SoftwareEngineering Issue Date: 2025-04-02 SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24 GPT Summary- SWE-benchは、12の人気Pythonリポジトリから得られた2,294のソフトウェアエンジニアリング問題を評価するフレームワークで、言語モデルがコードベースを編集して問題を解決する能力を測定します。評価の結果、最先端の商用モデルや微調整されたモデルSWE-Llamaも最も単純な問題しか解決できず、Claude 2はわずか1.96%の問題を解決するにとどまりました。SWE-benchは、より実用的で知的な言語モデルへの進展を示しています。 Comment
ソフトウェアエージェントの最もpopularなベンチマークhttps://github.com/user-attachments/assets/ac905221-d3b1-4d16-b447-3bdd4d5e97bb"
/>
主にpythonライブラリに関するリポジトリに基づいて構築されている。https://github.com/user-attachments/assets/14d26dd1-6b4a-4337-a652-4e48e36d633b"
/>
SWE-Bench, SWE-Bench Lite, SWE-Bench Verifiedの3種類がありソフトウェアエージェントではSWE-Bench Verifiedを利用して評価することが多いらしい。Verifiedでは、issueの記述に曖昧性がなく、適切なunittestのスコープが適切なもののみが採用されているとのこと(i.e., 人間の専門家によって問題がないと判断されたもの)。
https://www.swebench.com/
Agenticな評価をする際に、一部の評価でエージェントがgit logを参照し本来は存在しないはずのリポジトリのfuture stateを見ることで環境をハッキングしていたとのこと:
これまでの評価結果にどの程度の影響があるかは不明。
openreview: https://openreview.net/forum?id=VTF8yNQM66
#Analysis #Pocket #NLP #LanguageModel #ICLR #KeyPoint Notes #SparseAutoEncoder Issue Date: 2025-03-15 Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24 GPT Summary- 神経ネットワークの多義性を解消するために、スパースオートエンコーダを用いて内部活性化の方向を特定。これにより、解釈可能で単義的な特徴を学習し、間接目的語の同定タスクにおける因果的特徴をより詳細に特定。スケーラブルで教師なしのアプローチが重ね合わせの問題を解決できることを示唆し、モデルの透明性と操作性向上に寄与する可能性を示す。 Comment
日本語解説: https://note.com/ainest/n/nbe58b36bb2db
OpenReview: https://openreview.net/forum?id=F76bwRSLeK
SparseAutoEncoderはネットワークのあらゆるところに仕込める(と思われる)が、たとえばTransformer Blockのresidual connection部分のベクトルに対してFeature Dictionaryを学習すると、当該ブロックにおいてどのような特徴の組み合わせが表現されているかが(あくまでSparseAutoEncoderがreconstruction lossによって学習された結果を用いて)解釈できるようになる。
SparseAutoEncoderは下記式で表され、下記loss functionで学習される。MがFeature Matrix(row-wiseに正規化されて後述のcに対するL1正則化に影響を与えないようにしている)に相当する。cに対してL1正則化をかけることで(Sparsity Loss)、c中の各要素が0に近づくようになり、結果としてcがSparseとなる(どうしても値を持たなければいけない重要な特徴量のみにフォーカスされるようになる)。
#NLP #LanguageModel #RLHF #Reasoning #Mathematics #GRPO #read-later Issue Date: 2025-01-04 DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, Zhihong Shao+, arXiv'24 GPT Summary- DeepSeekMath 7Bは、120Bの数学関連トークンを用いて事前学習された言語モデルで、競技レベルのMATHベンチマークで51.7%のスコアを達成。自己一貫性は60.9%で、データ選択パイプラインとGroup Relative Policy Optimization (GRPO)の導入により数学的推論能力が向上。Gemini-UltraやGPT-4に迫る性能を示す。 Comment
元々数学のreasoningに関する能力を改善するために提案されたが、現在はオンラインでTruthfulness, Helpfulness, Concisenessなどの改善に活用されているとのこと。
PPOとGRPOの比較。value function model(状態の価値を予測するモデル)が不要なため省メモリ、かつ利用する計算リソースが小さいらしい。
あとサンプルをグループごとに分けて、グループ内でのKLダイバージェンスが最小化されるよう(つまり、各グループ内で方策が類似する)Policy Modelが更新される(つまりloss functionに直接組み込まれる)点が違うらしい。
PPOでは生成するトークンごとにreference modelとPolicy ModelとのKLダイバージェンスをとり、reference modelとの差が大きくならないよう、報酬にペナルティを入れるために使われることが多いらしい。
下記記事によると、PPOで最大化したいのはAdvantage(累積報酬と状態価値(累積報酬の期待値を計算するモデル)の差分;期待値よりも実際の累積報酬が良かったら良い感じだぜ的な数値)であり、それには状態価値を計算するモデルが必要である。そして、PPOにおける状態価値モデルを使わないで、LLMにテキスト生成させて最終的な報酬を平均すれば状態価値モデル無しでAdvantageが計算できるし嬉しくね?という気持ちで提案されたのが、本論文で提案されているGRPOとのこと。勉強になる。
DeepSeek-R1の論文読んだ?【勉強になるよ】
, asap:
https://zenn.dev/asap/articles/34237ad87f8511
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #PostTraining #read-later Issue Date: 2024-09-13 ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N_A, ACL'24 GPT Summary- 強化ファインチューニング(ReFT)を提案し、LLMsの推論能力を向上。SFTでモデルをウォームアップ後、PPOアルゴリズムを用いてオンライン強化学習を行い、豊富な推論パスを自動サンプリング。GSM8K、MathQA、SVAMPデータセットでSFTを大幅に上回る性能を示し、追加のトレーニング質問に依存せず優れた一般化能力を発揮。 #ComputerVision #Pretraining #Pocket #NLP #Transformer #InstructionTuning #MultiModal #SpeechProcessing #CVPR #Encoder-Decoder #Robotics #UMM #EmbodiedAI Issue Date: 2023-12-29 Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, N_A, CVPR'24 GPT Summary- Unified-IO 2は、最初の自己回帰型のマルチモーダルモデルであり、画像、テキスト、音声、アクションを理解し生成することができます。異なるモダリティを統一するために、共有の意味空間に入力と出力を配置し、単一のエンコーダ・デコーダトランスフォーマーモデルで処理します。さまざまなアーキテクチャの改善を提案し、大規模なマルチモーダルな事前トレーニングコーパスを使用してモデルをトレーニングします。Unified-IO 2は、GRITベンチマークを含む35以上のベンチマークで最先端のパフォーマンスを発揮します。 Comment
画像、テキスト、音声、アクションを理解できる初めてのautoregressive model。AllenAI
モデルのアーキテクチャ図
マルチモーダルに拡張したことで、訓練が非常に不安定になったため、アーキテクチャ上でいくつかの工夫を加えている:
- 2D Rotary Embedding
- Positional EncodingとしてRoPEを採用
- 画像のような2次元データのモダリティの場合はRoPEを2次元に拡張する。具体的には、位置(i, j)のトークンについては、Q, Kのembeddingを半分に分割して、それぞれに対して独立にi, jのRoPE Embeddingを適用することでi, j双方の情報を組み込む。
- QK Normalization
- image, audioのモダリティを組み込むことでMHAのlogitsが非常に大きくなりatteetion weightが0/1の極端な値をとるようになり訓練の不安定さにつながった。このため、dot product attentionを適用する前にLayerNormを組み込んだ。
- Scaled Cosine Attention
- Image Historyモダリティにおいて固定長のEmbeddingを得るためにPerceiver Resamplerを扱ったているが、こちらも上記と同様にAttentionのlogitsが極端に大きくなったため、cosine類似度をベースとしたScaled Cosine Attention [Paper Note] Swin Transformer V2: Scaling Up Capacity and Resolution, Ze Liu+, arXiv'21
を利用することで、大幅に訓練の安定性が改善された。
- その他
- attention logitsにはfp32を適用
- 事前学習されたViTとASTを同時に更新すると不安定につながったため、事前学習の段階ではfreezeし、instruction tuningの最後にfinetuningを実施
目的関数としては、Mixture of Denoisers (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
)に着想を得て、Multimodal Mixture of Denoisersを提案。MoDでは、
- \[R\]: 通常のspan corruption (1--5 token程度のspanをmaskする)
- \[S\]: causal language modeling (inputを2つのサブシーケンスに分割し、前方から後方を予測する。前方部分はBi-directionalでも可)
- \[X\]: extreme span corruption (12>=token程度のspanをmaskする)
の3種類が提案されており、モダリティごとにこれらを使い分ける:
- text modality: UL2 (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
)を踏襲
- image, audioがtargetの場合: 2つの類似したパラダイムを定義し利用
- \[R\]: patchをランダムにx%マスクしre-constructする
- \[S\]: inputのtargetとは異なるモダリティのみの情報から、targetモダリティを生成する
訓練時には prefixとしてmodality token \[Text\], \[Image\], \[Audio\] とparadigm token \[R\], \[S\], \[X\] をタスクを指示するトークンとして利用している。
また、image, audioのマスク部分のdenoisingをautoregressive modelで実施する際には普通にやるとdecoder側でリークが発生する(a)。これを防ぐには、Encoder側でマスクされているトークンを、Decoder側でteacher-forcingする際にの全てマスクする方法(b)があるが、この場合、生成タスクとdenoisingタスクが相互に干渉してしまいうまく学習できなくなってしまう(生成タスクでは通常Decoderのinputとして[mask]が入力され次トークンを生成する、といったことは起きえないが、愚直に(b)をやるとそうなってしまう)。ので、(c)に示したように、マスクされているトークンをinputとして生成しなければならない時だけ、マスクを解除してdecoder側にinputする、という方法 (Dynamic Masking) でこの問題に対処している。https://github.com/user-attachments/assets/0dba8d5d-0c93-4c56-852b-fce9869428e7"
/>
#ComputerVision #Analysis #Pretraining #Pocket #NLP #LanguageModel #CVPR #VisionLanguageModel Issue Date: 2023-12-14 VILA: On Pre-training for Visual Language Models, Ji Lin+, N_A, CVPR'24 GPT Summary- 最近の大規模言語モデルの成功により、ビジュアル言語モデル(VLM)が進歩している。本研究では、VLMの事前学習のためのデザインオプションを検討し、以下の結果を示した:(1) LLMを凍結することでゼロショットのパフォーマンスが達成できるが、文脈に基づいた学習能力が不足している。(2) 交互に行われる事前学習データは有益であり、画像とテキストのペアだけでは最適ではない。(3) テキストのみの指示データを画像とテキストのデータに再ブレンドすることで、VLMのタスクの精度を向上させることができる。VILAというビジュアル言語モデルファミリーを構築し、最先端モデルを凌駕し、優れたパフォーマンスを発揮することを示した。マルチモーダルの事前学習は、VILAの特性を向上させる。 Comment
関連:
- Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N/A, CVPR'24
#ComputerVision #Pocket #NLP #LanguageModel #QuestionAnswering #CVPR #VisionLanguageModel Issue Date: 2023-10-09 Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N_A, CVPR'24 GPT Summary- LLaVAは、ビジョンと言語のクロスモーダルコネクタであり、データ効率が高く強力な性能を持つことが示されています。CLIP-ViT-L-336pxを使用し、学術タスク指向のVQAデータを追加することで、11のベンチマークで最先端のベースラインを確立しました。13Bのチェックポイントはわずか120万の公開データを使用し、1日で完全なトレーニングを終えます。コードとモデルは公開されます。 Comment
画像分析が可能なオープンソースLLMとのこと。
# Overview
画像生成をできるわけではなく、inputとして画像を扱えるのみ。
pj page: https://llava-vl.github.io
#NLP #LanguageModel #QuestionAnswering #Chain-of-Thought #Prompting #Hallucination #ACL #Verification Issue Date: 2023-09-30 [Paper Note] Chain-of-Verification Reduces Hallucination in Large Language Models, Shehzaad Dhuliawala+, N_A, ACL'24 GPT Summary- 私たちは、言語モデルが根拠のない情報を生成する問題に取り組んでいます。Chain-of-Verification(CoVe)メソッドを開発し、モデルが回答を作成し、検証し、最終的な回答を生成するプロセスを経ることで、幻想を減少させることができることを実験で示しました。 Comment
# 概要
ユーザの質問から、Verificationのための質問をplanningし、質問に対して独立に回答を得たうえでオリジナルの質問に対するaggreementを確認し、最終的に生成を実施するPrompting手法
# 評価
## dataset
- 全体を通じてclosed-bookの設定で評価
- Wikidata
- Wikipedia APIから自動生成した「“Who are some [Profession]s who were born in [City]?”」に対するQA pairs
- Goldはknowledge baseから取得
- 全56 test questions
- Gold Entityが大体600程度ありLLMは一部しか回答しないので、precisionで評価
- Wiki category list
- QUEST datasetを利用 QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, N/A, ACL'23
- 回答にlogical operationが不要なものに限定して頭に"Name some"をつけて質問を生成
- "Name some Mexican animated horror films" or "Name some Endemic orchids of Vietnam"
- 8個の回答を持つ55 test questionsを作成
- MultiSpanQA
- Reading Comprehensionに関するBenchmark dataset
- 複数の独立した回答(回答は連続しないスパンから回答が抽出される)から構成される質問で構成
- 特に、今回はclosed-book setting で実施
- すなわち、与えられた質問のみから回答しなければならず、知っている知識が問われる問題
- 418のtest questsionsで、各回答に含まれる複数アイテムのspanが3 token未満となるようにした
- QA例:
- Q: Who invented the first printing press and in what year?
- A: Johannes Gutenberg, 1450.
# 評価結果
提案手法には、verificationの各ステップでLLMに独立したpromptingをするかなどでjoint, 2-step, Factored, Factor+Revisedの4種類のバリエーションがあることに留意。
- joint: 全てのステップを一つのpromptで実施
- 2-stepは2つのpromptに分けて実施
- Factoredは各ステップを全て異なるpromptingで実施
- Factor+Revisedは異なるpromptで追加のQAに対するcross-checkをかける手法
結果を見ると、CoVEでhallucinationが軽減(というより、モデルが持つ知識に基づいて正確に回答できるサンプルの割合が増えるので実質的にhallucinationが低減したとみなせる)され、特にjointよりも2-step, factoredの方が高い性能を示すことがわかる。
#ComputerVision #Pocket #NLP #ImageSegmentation #VisionLanguageModel #One-Line Notes #Grounding Issue Date: 2025-11-25 [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10 GPT Summary- Set-of-Mark (SoM)という新しい視覚プロンプティング手法を提案し、GPT-4Vの視覚的能力を引き出す。画像を異なる領域に分割し、マークを重ねることで、視覚的基盤を必要とする質問に答えることが可能に。実験では、SoMを用いたGPT-4Vがゼロショット設定で最先端のモデルを上回る性能を示した。 Comment
pj page: https://som-gpt4v.github.io
日本語解説: https://ai-scholar.tech/articles/prompting-method/SoM
画像をsegmentationし、segmentationした領域上に数字のマーカーをオーバーレイした画像を入力すると、VLMのgrounding能力が向上する、という話らしい
#MachineLearning #Pocket #NLP #LanguageModel #ICML #text #AI Detector Issue Date: 2025-11-17 [Paper Note] DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature, Eric Mitchell+, ICML'23, 2023.01 GPT Summary- LLM生成テキストの検出の必要性を背景に、対数確率関数の負の曲率を利用した新しい検出手法「DetectGPT」を提案。これにより、別の分類器やデータセットを必要とせず、特定のLLMから生成されたテキストを高精度で識別可能。特に、GPT-NeoXによるフェイクニュース記事の検出で、従来の手法を大幅に上回る性能を示した。 #NeuralNetwork #Pocket #Transformer #SpeechProcessing #AutomaticSpeechRecognition(ASR) #Generalization #KeyPoint Notes #Robustness Issue Date: 2025-11-14 [Paper Note] Robust Speech Recognition via Large-Scale Weak Supervision, Alec Radford+, ICML'23, 2022.12 GPT Summary- 680,000時間の多言語音声トランスクリプトを用いて訓練した音声処理システムを研究。得られたモデルは、ゼロショット転送設定で良好に一般化し、従来の監視結果と競争力を持つ。人間の精度に近づくことが確認され、モデルと推論コードを公開。 Comment
いまさらながらWhisper論文
日本語解説:
https://www.ai-shift.co.jp/techblog/3001
長文認識のためのヒューリスティックに基づくデコーディング戦略も解説されているので参照のこと。
研究のコアとなるアイデアとしては、既存研究は自己教師あり学習、あるいはself-learningによって性能向上を目指す流れがある中で、教師あり学習に着目。既存研究で教師あり学習によって性能が向上することが示されていたが、大規模なスケールで実施できていなかったため、それをweakly-supervisedなmanner(=つまり完璧なラベルではなくてノイジーでも良いからラベルを付与し学習する)といった方法で学習することで、より頑健で高性能なASRを実現したい、という気持ちの研究。また、複雑なサブタスク(language identification, inverse text normalization(ASR後のテキストを人間向けの自然なテキストに変換すること[^2]), phrase-level timestamps (audioとtranscriptのタイムスタンプ予測))を一つのパイプラインで実現するような統合的なインタフェースも提案している。モデルのアーキテクチャ自体はencoder-decoderモデルである。また、positional encodingとしてはSinusoidal Positional Encoding(すなわち、絶対位置エンコーディング)が用いられている。デコーダにはprompt[^1]と呼ばれるtranscriptのhistoryを(確率的に挿入し)入力して学習することで、過去のcontextを考慮したASRが可能となる。lossの計算は、translate/transcribeされたトークンのみを考慮して計算する。https://github.com/user-attachments/assets/3ae3847d-b38f-41de-b1b7-c8000df31de6"
/>
データセットについては詳細は記述されておらず、internetに存在する (audio, transcripts)のペアデータを用いたと書かれている。
しかしながら、収集したデータセットを確認んすると、transcriptionの品質が低いものが混ざっており、フィルタリングを実施している。これは、人間のtranscriptionとmachine-generatedなtranscriptionをmixして学習すると性能を損なうことが既存研究で知られているため、ヒューリスティックに基づいてmachine-generatedなtranscriptionは学習データから除外している。これは、初期のモデルを学習してエラー率を観測し、データソースを人手でチェックしてlow-qualityなtranscriptを除去するといった丁寧なプロセスもあ含まれる。
また、収集したデータの言語についてはVoxLingua107データセット [Paper Note] VoxLingua107: a Dataset for Spoken Language Recognition, Jörgen Valk+, SLT'21, 2020.11
によって学習された分類器(をさらにfinetuningしたモデルと書かれている。詳細は不明)によって自動的に付与する。すなわち、X->enのデータのX(つまりsource言語)のlanguage identificationについてもweakly-supervisedなラベルで学習されている。
audioファイルについては、30秒単位のセグメントに区切り全ての期間を学習データに利用。無音部分はサブサンプリング(=一部をサンプリングして使う)しVoice Activity Detectionも学習する。
[^1]: LLMの文脈で広く使われるPromptとは異なる点に注意。LLMはinstruction-tuningが実施されているため人間の指示に追従するような挙動となるが、Whisperではinstruction-tuningを実施していないのでそのような挙動にはならない。あくまで過去のhistoryの情報を与える役割と考えること。
[^2]: Whisperでは生のtranscriptをnormalizationせずに学習にそのまま利用するため書き起こしの表記の統一は行われないと考えられる。
#ComputerVision #MachineLearning #Pocket #ICLR #RectifiedFlow Issue Date: 2025-10-10 [Paper Note] Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, Xingchao Liu+, ICLR'23, 2022.09 GPT Summary- rectified flowという新しいアプローチを提案し、2つの分布間での輸送を学習するODEモデルを用いる。これは、直線的な経路を学習することで計算効率を高め、生成モデルやドメイン転送において統一的な解決策を提供する。rectificationを通じて、非増加の凸輸送コストを持つ新しい結合を生成し、再帰的に適用することで直線的なフローを得る。実証研究では、画像生成や翻訳において優れた性能を示し、高品質な結果を得ることが確認された。 Comment
openreview: https://openreview.net/forum?id=XVjTT1nw5z
日本語解説(fmuuly, zenn):
- Rectified Flow 1:
https://zenn.dev/fmuuly/articles/37cc3a2f17138e
- Rectified Flow 2:
https://zenn.dev/fmuuly/articles/a062fcd340207f
- Rectified Flow 3:
https://zenn.dev/fmuuly/articles/0f262fc003e202
#Pocket #NLP #LanguageModel #Hallucination #EMNLP Issue Date: 2025-09-24 [Paper Note] SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models, Potsawee Manakul+, EMNLP'23, 2023.03 GPT Summary- SelfCheckGPTは、外部データベースなしでLLMの応答をファクトチェックするためのサンプリングベースのアプローチを提案。サンプリングされた応答が一貫した事実を含む場合、知識があると判断し、幻覚された事実では矛盾が生じる可能性が高い。実験により、非事実的および事実的な文の検出、文章のランク付けが可能であることを示し、高いAUC-PRスコアと相関スコアを達成。 Comment
openreview: https://openreview.net/forum?id=RwzFNbJ3Ez
#ComputerVision #Pocket #NLP #Dataset #Evaluation #TextToImageGeneration #NeurIPS #read-later Issue Date: 2025-09-11 [Paper Note] GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment, Dhruba Ghosh+, NeurIPS'23 GPT Summary- テキストから画像への生成モデルの自動評価方法「GenEval」を提案。物体の共起、位置、数、色などの特性を評価し、現在の物体検出モデルを活用して生成タスクを分析。最近のモデルは改善を示すが、複雑な能力には課題が残る。GenEvalは失敗モードの発見にも寄与し、次世代モデルの開発に役立つ。コードは公開中。 Comment
openreview: https://openreview.net/forum?id=Wbr51vK331¬eId=NpvYJlJFqK
#ComputerVision #Pocket #Transformer #DiffusionModel #read-later #Backbone Issue Date: 2025-08-27 [Paper Note] Scalable Diffusion Models with Transformers, William Peebles+, ICCV'23 GPT Summary- 新しいトランスフォーマーに基づく拡散モデル(Diffusion Transformers, DiTs)を提案し、U-Netをトランスフォーマーに置き換えた。DiTsは高いGflopsを持ち、低いFIDを維持しながら良好なスケーラビリティを示す。最大のDiT-XL/2モデルは、ImageNetのベンチマークで従来の拡散モデルを上回り、最先端のFID 2.27を達成した。 Comment
日本語解説: https://qiita.com/sasgawy/items/8546c784bc94d94ef0b2
よく見るDiT
- [Paper Note] DiT: Self-supervised Pre-training for Document Image Transformer, Junlong Li+, ACMMM'22
も同様の呼称だが全く異なる話なので注意
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Transformer #Attention #python #LLMServing Issue Date: 2025-08-19 [Paper Note] Efficient Memory Management for Large Language Model Serving with PagedAttention, Woosuk Kwon+, SOSP'23 GPT Summary- PagedAttentionを用いたvLLMシステムを提案し、KVキャッシュメモリの無駄を削減し、リクエスト間での柔軟な共有を実現。これにより、同レベルのレイテンシでLLMのスループットを2-4倍向上。特に長いシーケンスや大規模モデルで効果が顕著。ソースコードは公開中。 Comment
(今更ながら)vLLMはこちら:
https://github.com/vllm-project/vllm
現在の主要なLLM Inference/Serving Engineのひとつ。
#RecommenderSystems #Pocket #Transformer #VariationalAutoEncoder #NeurIPS #read-later #ColdStart #Encoder-Decoder #SemanticID Issue Date: 2025-07-28 [Paper Note] Recommender Systems with Generative Retrieval, Shashank Rajput+, NeurIPS'23 GPT Summary- 新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを用いて次のアイテムを予測するTransformerベースのモデルを訓練。これにより、従来のレコメンダーシステムを大幅に上回る性能を達成し、過去の対話履歴がないアイテムに対しても改善された検索性能を示す。 Comment
openreview: https://openreview.net/forum?id=BJ0fQUU32w
Semantic IDを提案した研究
アイテムを意味的な情報を保持したdiscrete tokenのタプル(=Semantic ID)で表現し、encoder-decoderでNext ItemのSemantic IDを生成するタスクに落としこむことで推薦する。SemanticIDの作成方法は後で読んで理解したい。
#ComputerVision #Pocket #DiffusionModel #ICLR #FlowMatching #OptimalTransport Issue Date: 2025-07-09 [Paper Note] Flow Matching for Generative Modeling, Yaron Lipman+, ICLR'23 GPT Summary- Continuous Normalizing Flows(CNFs)に基づく新しい生成モデルの訓練手法Flow Matching(FM)を提案。FMは固定された条件付き確率経路のベクトル場を回帰し、シミュレーション不要で訓練可能。拡散経路と併用することで、より堅牢な訓練が実現。最適輸送を用いた条件付き確率経路は効率的で、訓練とサンプリングが速く、一般化性能も向上。ImageNetでの実験により、FMは拡散ベース手法よりも優れた性能を示し、迅速なサンプル生成を可能にする。 Comment
#ComputerVision #Pretraining #Pocket #LanguageModel #MultiModal #ICCV Issue Date: 2025-06-29 [Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23 GPT Summary- シンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。 Comment
SigLIP論文
#MachineLearning #Pocket #NLP #LanguageModel #Hallucination #NeurIPS #read-later #ActivationSteering/ITI #Probing #Trustfulness Issue Date: 2025-05-09 Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23 GPT Summary- Inference-Time Intervention (ITI)を提案し、LLMsの真実性を向上させる技術を紹介。ITIは推論中にモデルの活性化を調整し、LLaMAモデルの性能をTruthfulQAベンチマークで大幅に改善。Alpacaモデルでは真実性が32.5%から65.1%に向上。真実性と有用性のトレードオフを特定し、介入の強度を調整する方法を示す。ITIは低コストでデータ効率が高く、数百の例で真実の方向性を特定可能。LLMsが虚偽を生成しつつも真実の内部表現を持つ可能性を示唆。 Comment
Inference Time Interventionを提案した研究。Attention Headに対して線形プロービング[^1]を実施し、真実性に関連するであろうHeadをtopKで特定できるようにし、headの出力に対し真実性を高める方向性のベクトルvを推論時に加算することで(=intervention)、モデルの真実性を高める。vは線形プロービングによって学習された重みを使う手法と、正答と誤答の活性化の平均ベクトルを計算しその差分をvとする方法の二種類がある。後者の方が性能が良い。topKを求める際には、線形プロービングをしたモデルのvalidation setでの性能から決める。Kとαはハイパーパラメータである。
[^1]: headのrepresentationを入力として受け取り、線形モデルを学習し、線形モデルの2値分類性能を見ることでheadがどの程度、プロービングの学習に使ったデータに関する情報を保持しているかを測定する手法
日本語解説スライド:
https://www.docswell.com/s/DeepLearning2023/Z38P8D-2024-06-20-131813#p1
これは相当汎用的に使えそうな話だから役に立ちそう
#EfficiencyImprovement #NLP #LanguageModel #Transformer #LongSequence #PositionalEncoding #NeurIPS Issue Date: 2025-04-06 The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad+, NeurIPS'23 GPT Summary- 長さ一般化はTransformerベースの言語モデルにおける重要な課題であり、位置エンコーディング(PE)がその性能に影響を与える。5つの異なるPE手法(APE、T5の相対PE、ALiBi、Rotary、NoPE)を比較した結果、ALiBiやRotaryなどの一般的な手法は長さ一般化に適しておらず、NoPEが他の手法を上回ることが明らかになった。NoPEは追加の計算を必要とせず、絶対PEと相対PEの両方を表現可能である。さらに、スクラッチパッドの形式がモデルの性能に影響を与えることも示された。この研究は、明示的な位置埋め込みが長いシーケンスへの一般化に必須でないことを示唆している。 Comment
- Llama 4 Series, Meta, 2025.04
において、Llama4 Scoutが10Mコンテキストウィンドウを実現できる理由の一つとのこと。
元ポスト:
Llama4のブログポストにもその旨記述されている:
>A key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings. Additionally, we employ inference time temperature scaling of attention to enhance length generalization.
[The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation]( https://ai.meta.com/blog/llama-4-multimodal-intelligence/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4)
斜め読みだが、length generalizationを評価する上でdownstream taskに焦点を当て、3つの代表的なカテゴリに相当するタスクで評価したところ、この観点においてはT5のrelative positinal encodingとNoPE(位置エンコードディング無し)のパフォーマンスが良く、
NoPEは絶対位置エンコーディングと相対位置エンコーディングを理論上実現可能であり[^1]
実際に学習された異なる2つのモデルに対して同じトークンをそれぞれinputし、同じ深さのLayerの全てのattention distributionの組み合わせからJensen Shannon Divergenceで距離を算出し、最も小さいものを2モデル間の当該layerの距離として可視化すると下記のようになり、NoPEとT5のrelative positional encodingが最も類似していることから、NoPEが学習を通じて(実用上は)相対位置エンコーディングのようなものを学習することが分かった。
[^1]:深さ1のLayerのHidden State H^1から絶対位置の復元が可能であり(つまり、当該レイヤーのHが絶対位置に関する情報を保持している)、この前提のもと、後続のLayerがこの情報を上書きしないと仮定した場合に、相対位置エンコーディングを実現できる。
また、CoT/Scratchpadはlong sequenceに対する汎化性能を向上させることがsmall scaleではあるが先行研究で示されており、Positional Encodingを変化させた時にCoT/Scratchpadの性能にどのような影響を与えるかを調査。
具体的には、CoT/Scratchpadのフォーマットがどのようなものが有効かも明らかではないので、5種類のコンポーネントの組み合わせでフォーマットを構成し、mathematical reasoningタスクで以下のような設定で訓練し
- さまざまなコンポーネントの組み合わせで異なるフォーマットを作成し、
- 全ての位置エンコーディングあり/なしモデルを訓練
これらを比較した。この結果、CoT/Scratchpadはフォーマットに関係なく、特定のタスクでのみ有効(有効かどうかはタスク依存)であることが分かった。このことから、CoT/Scratcpad(つまり、モデルのinputとoutputの仕方)単体で、long contextに対する汎化性能を向上させることができないので、Positional Encoding(≒モデルのアーキテクチャ)によるlong contextに対する汎化性能の向上が非常に重要であることが浮き彫りになった。
また、CoT/Scratchpadが有効だったAdditionに対して各Positional Embeddingモデルを学習し、生成されたトークンのattentionがどの位置のトークンを指しているかを相対距離で可視化したところ(0が当該トークン、つまり現在のScratchpadに着目しており、1が遠いトークン、つまりinputに着目していることを表すように正規化)、NoPEとRelative Positional Encodingがshort/long rangeにそれぞれフォーカスするようなbinomialな分布なのに対し、他のPositional Encodingではよりuniformな分布であることが分かった。このタスクにおいてはNoPEとRelative POの性能が高かったため、binomialな分布の方がより最適であろうことが示唆された。
#NLP #LanguageModel #Alignment #NeurIPS #DPO #PostTraining #read-later Issue Date: 2024-09-25 Direct Preference Optimization: Your Language Model is Secretly a Reward Model, Rafael Rafailov+, N_A, NeurIPS'23 GPT Summary- 大規模無監督言語モデル(LM)の制御性を向上させるために、報酬モデルの新しいパラメータ化を導入し、単純な分類損失でRLHF問題を解決する「直接的な好み最適化(DPO)」アルゴリズムを提案。DPOは安定性と性能を持ち、ファインチューニング中のサンプリングやハイパーパラメータ調整を不要にし、既存の方法と同等以上の性能を示す。特に、生成物の感情制御においてPPOベースのRLHFを上回り、応答の質を改善しつつ実装が簡素化される。 Comment
DPOを提案した研究https://github.com/user-attachments/assets/2f7edf2c-32fa-4c5c-bc39-fb85112d1837"
>
解説ポスト:
SNLP'24での解説スライド: https://speakerdeck.com/kazutoshishinoda/lun-wen-shao-jie-direct-preference-optimization-your-language-model-is-secretly-a-reward-model
#Pocket #NLP #Dataset #LanguageModel #QuestionAnswering #AIAgents #Evaluation Issue Date: 2023-11-23 GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N_A, arXiv'23 GPT Summary- GAIAは、General AI Assistantsのためのベンチマークであり、AI研究のマイルストーンとなる可能性がある。GAIAは、推論、マルチモダリティの処理、ウェブブラウジングなど、実世界の質問に対する基本的な能力を必要とする。人間の回答者は92%の正答率を達成し、GPT-4は15%の正答率を達成した。これは、最近の傾向とは異なる結果であり、専門的なスキルを必要とするタスクではLLMsが人間を上回っている。GAIAは、人間の平均的な堅牢性と同等の能力を持つシステムがAGIの到来に重要であると考えている。GAIAの手法を使用して、466の質問と回答を作成し、一部を公開してリーダーボードで利用可能にする。 Comment
Yann LeCun氏の紹介ツイート
Meta-FAIR, Meta-GenAI, HuggingFace, AutoGPTによる研究。人間は92%正解できるが、GPT4でも15%しか正解できないQAベンチマーク。解くために推論やマルチモダリティの処理、ブラウジング、ツールに対する習熟などの基本的な能力を必要とする実世界のQAとのこと。
- Open-source DeepResearch – Freeing our search agents, HuggingFace, 2025.02
で言及されているLLM Agentの評価で最も有名なベンチマークな模様
#Pocket #NLP #Dataset #LanguageModel #InstructionTuning #Evaluation #InstructionFollowingCapability Issue Date: 2023-11-15 Instruction-Following Evaluation for Large Language Models, Jeffrey Zhou+, N_A, arXiv'23 GPT Summary- 大規模言語モデル(LLMs)の能力を評価するために、Instruction-Following Eval(IFEval)という評価ベンチマークが導入されました。IFEvalは、検証可能な指示に焦点を当てた直感的で再現性のある評価方法です。具体的には、25種類の検証可能な指示を特定し、それぞれの指示を含む約500のプロンプトを作成しました。この評価ベンチマークの結果は、GitHubで公開されています。 Comment
LLMがinstructionにどれだけ従うかを評価するために、検証可能なプロンプト(400字以上で書きなさいなど)を考案し評価する枠組みを提案。人間が評価すると時間とお金がかかり、LLMを利用した自動評価だと評価を実施するLLMのバイアスがかかるのだ、それら両方のlimitationを克服できるとのこと。
#Analysis #Pocket #NLP #LanguageModel #ReversalCurse Issue Date: 2023-10-09 [Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23 GPT Summary- 自己回帰型大規模言語モデル(LLMs)は、「AはBである」という文から「BはAである」と逆の関係を自動的に一般化できない「逆転の呪い」を示す。例えば、モデルが「ワレンティナ・テレシコワは宇宙に行った最初の女性である」と訓練されても、「宇宙に行った最初の女性は誰か?」に正しく答えられない。実験では、架空の文を用いてGPT-3とLlama-1をファインチューニングし、逆転の呪いの存在を確認。ChatGPT(GPT-3.5およびGPT-4)でも、実在の有名人に関する質問で正答率に大きな差が見られた。 Comment
A is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
著者ツイート:
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。
また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。
このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。
関連:
- Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
#EfficiencyImprovement #MachineLearning #Pocket #NLP #LanguageModel Issue Date: 2023-09-13 Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, N_A, arXiv'23 GPT Summary- 私たちは、小さなTransformerベースの言語モデルであるTinyStoriesと、大規模な言語モデルであるphi-1の能力について調査しました。また、phi-1を使用して教科書の品質のデータを生成し、学習プロセスを改善する方法を提案しました。さらに、phi-1.5という新しいモデルを作成し、自然言語のタスクにおいて性能が向上し、複雑な推論タスクにおいて他のモデルを上回ることを示しました。phi-1.5は、良い特性と悪い特性を持っており、オープンソース化されています。 Comment
Textbooks Are All You Need, Suriya Gunasekar+, N/A, arXiv'23 に続く論文
#Pocket #NLP #LanguageModel #Evaluation #LLM-as-a-Judge #NeurIPS Issue Date: 2023-07-26 Judging LLM-as-a-judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, N_A, NeurIPS'23 GPT Summary- 大規模言語モデル(LLM)を判定者として使用して、オープンエンドの質問に対する性能を評価する方法を提案する。LLMの制限や問題を軽減するための解決策を提案し、2つのベンチマークでLLMの判定者と人間の好みの一致を検証する。結果は、強力なLLM判定者が人間の好みとよく一致し、スケーラブルで説明可能な方法で人間の好みを近似できることを示した。さらに、新しいベンチマークと従来のベンチマークの相補性を示し、いくつかのバリアントを評価する。 Comment
MT-Bench(MTBench)スコアとは、multi-turnのQAを出題し、その回答の質をGPT-4でスコアリングしたスコアのこと。
GPT-4の判断とhuman expertの判断とのagreementも検証しており、agreementは80%以上を達成している。
`LLM-as-a-Judge` という用語を最初に提唱したのも本研究となる(p.2参照)
#EfficiencyImprovement #MachineLearning #Pocket #Supervised-FineTuning (SFT) #Quantization #PEFT(Adaptor/LoRA) #NeurIPS #PostTraining Issue Date: 2023-07-22 QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, NeurIPS'23 GPT Summary- 私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment
実装:
https://github.com/artidoro/qlora
PEFTにもある
参考:
#Pocket #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2023-07-03 Holistic Evaluation of Language Models, Percy Liang+, TMLR'23 GPT Summary- 言語モデルの透明性を向上させるために、Holistic Evaluation of Language Models(HELM)を提案する。HELMでは、潜在的なシナリオとメトリックを分類し、広範なサブセットを選択して評価する。さらに、複数のメトリックを使用し、主要なシナリオごとに評価を行う。30の主要な言語モデルを42のシナリオで評価し、HELM以前に比べて評価のカバレッジを改善した。HELMはコミュニティのためのベンチマークとして利用され、新しいシナリオ、メトリック、モデルが継続的に更新される。 Comment
OpenReview: https://openreview.net/forum?id=iO4LZibEqW
HELMを提案した研究
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #NeurIPS #ComputerUse #VisionLanguageModel #One-Line Notes Issue Date: 2023-07-03 Mind2Web: Towards a Generalist Agent for the Web, Xiang Deng+, N_A, NeurIPS'23 Spotlight GPT Summary- Mind2Webという新しいデータセットを紹介します。このデータセットは、任意のウェブサイト上で複雑なタスクを実行するための言語の指示に従うウェブエージェントを開発・評価するために作成されました。従来のデータセットでは一般的なウェブエージェントには適していなかったため、Mind2Webはより多様なドメイン、実世界のウェブサイト、幅広いユーザーの相互作用パターンを提供します。また、大規模言語モデル(LLMs)を使用して一般的なウェブエージェントを構築するための初期の探索も行われます。この研究は、ウェブエージェントのさらなる研究を促進するためにデータセット、モデルの実装、およびトレーニング済みモデルをオープンソース化します。 Comment
Webにおけるgeneralistエージェントを評価するためのデータセットを構築。31ドメインの137件のwebサイトにおける2350個のタスクが含まれている。
タスクは、webサイトにおける多様で実用的なユースケースを反映し、チャレンジングだが現実的な問題であり、エージェントの環境やタスクをまたいだ汎化性能を評価できる。
プロジェクトサイト:
https://osu-nlp-group.github.io/Mind2Web/
#EfficiencyImprovement #Pretraining #MachineLearning #NLP #LanguageModel #SmallModel Issue Date: 2023-06-25 Textbooks Are All You Need, Suriya Gunasekar+, N_A, arXiv'23 GPT Summary- 本研究では、小規模なphi-1という新しいコード用大規模言語モデルを紹介し、8つのA100で4日間トレーニングした結果、HumanEvalでpass@1の正解率50.6%、MBPPで55.5%を達成したことを報告しています。また、phi-1は、phi-1-baseやphi-1-smallと比較して、驚くべき新しい性質を示しています。phi-1-smallは、HumanEvalで45%を達成しています。 Comment
参考:
教科書のような品質の良いテキストで事前学習すると性能が向上し(グラフ真ん中)、さらに良質なエクササイズでFinetuningするとより性能が向上する(グラフ右)
日本語解説: https://dalab.jp/archives/journal/introduction-textbooks-are-all-you-need/
ざっくり言うと、教科書で事前学習し、エクササイズでFinetuningすると性能が向上する(= より大きいモデルと同等の性能が得られる)。
#NeuralNetwork #Pocket #NLP #LanguageModel #Chain-of-Thought #ICLR #Test-Time Scaling Issue Date: 2023-04-27 [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03 GPT Summary- 自己一貫性という新しいデコーディング戦略を提案し、chain-of-thought promptingの性能を向上。多様な推論経路をサンプリングし、一貫した答えを選択することで、GSM8KやSVAMPなどのベンチマークで顕著な改善を達成。 Comment
self-consistencyと呼ばれる新たなCoTのデコーディング手法を提案。
これは、難しいreasoningが必要なタスクでは、複数のreasoningのパスが存在するというintuitionに基づいている。
self-consistencyではまず、普通にCoTを行う。そしてgreedyにdecodingする代わりに、以下のようなプロセスを実施する:
1. 多様なreasoning pathをLLMに生成させ、サンプリングする。
2. 異なるreasoning pathは異なるfinal answerを生成する(= final answer set)。
3. そして、最終的なanswerを見つけるために、reasoning pathをmarginalizeすることで、final answerのsetの中で最も一貫性のある回答を見出す。
これは、もし異なる考え方によって同じ回答が導き出されるのであれば、その最終的な回答は正しいという経験則に基づいている。
self-consistencyを実現するためには、複数のreasoning pathを取得した上で、最も多いanswer a_iを選択する(majority vote)。これにはtemperature samplingを用いる(temperatureを0.5やら0.7に設定して、より高い信頼性を保ちつつ、かつ多様なoutputを手に入れる)。
temperature samplingについては[こちら](
https://openreview.net/pdf?id=rygGQyrFvH)の論文を参照のこと。
sampling数は増やせば増やすほど性能が向上するが、徐々にサチってくる。サンプリング数を増やすほどコストがかかるので、その辺はコスト感との兼ね合いになると思われる。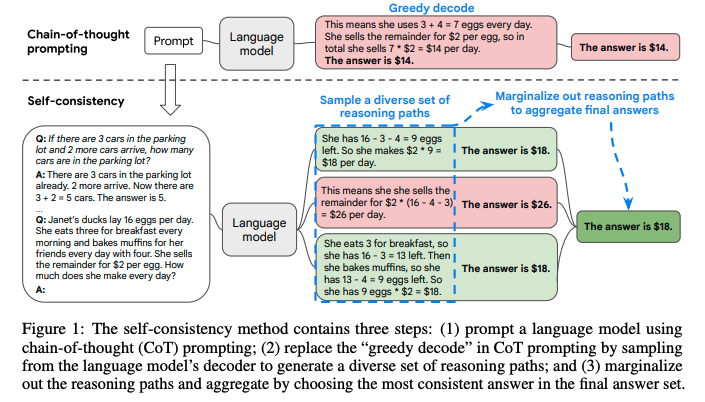
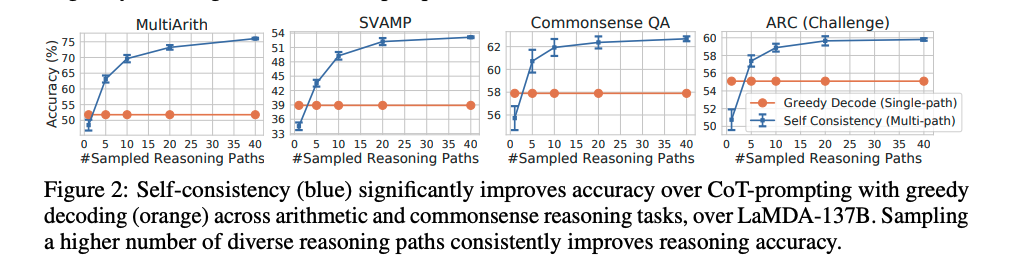
Self-consistencyは回答が閉じた集合であるような問題に対して適用可能であり、open-endなquestionでは利用できないことに注意が必要。ただし、open-endでも回答間になんらかの関係性を見出すような指標があれば実現可能とlimitationで言及している。
#NLP #LanguageModel #AIAgents Issue Date: 2023-04-13 REACT : SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS, Yao+, Princeton University and Google brain, ICLR'23 Comment
# 概要
人間は推論と行動をシナジーさせることで、さまざまな意思決定を行える。近年では言語モデルにより言語による推論を意思決定に組み合わせる可能性が示されてきた。たとえば、タスクをこなすための推論トレースをLLMが導けることが示されてきた(Chain-of-Thought)が、CoTは外部リソースにアクセスできないため知識がアップデートできず、事後的に推論を行うためhallucinationやエラーの伝搬が生じる。一方で、事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われているが、これらの研究では、高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
そこで、REACTを提案。REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みであり、推論トレースとアクションを交互に生成するため、動的に推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
- 要はいままではGeneralなタスク解決モデルにおいては、推論とアクションの生成は独立にしかやられてこなかったけど、推論とアクションを交互作用させることについて研究したよ
- そしたら性能がとってもあがったよ
- reasoningを人間が編集すれば、エージェントのコントロールもできるよ という感じ
# イントロ
人間は推論と行動の緊密なシナジーによって、不確実な状況に遭遇しても適切な意思決定が行える。たとえば、任意の2つの特定のアクションの間で、進行状況をトレースするために言語で推論したり(すべて切り終わったからお湯を沸かす必要がある)、例外を処理したり、状況に応じて計画を調整したりする(塩がないから代わりに醤油と胡椒を使おう)。また、推論をサポートし、疑問(いまどんな料理を作ることができるだろうか?)を解消するために、行動(料理本を開いてレシピを読んで、冷蔵庫を開いて材料を確確認したり)をすることもある。
近年の研究では言語での推論を、インタラクティブな意思決定を組み合わせる可能性についてのヒントが得られてきた。一つは、適切にPromptingされたLLMが推論トレースを実行できることを示している。推論トレースとは、解決策に到達するための一連のステップを経て推論をするためのプロセスのことである。しかしながらChain-of-thoughytは、このアプローチでは、モデルが外界対してgroundingできず、内部表現のみに基づい思考を生成するため限界がある。これによりモデルが事後対応的に推論したり、外部情報に基づいて知識を更新したりできないため、推論プロセス中にhallucinationやエラーの伝搬などの問題が発生する可能性が生じる。
一方、近年の研究では事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われている。これらの研究では、通常マルチモーダルな観測結果をテキストに変換し、言語モデルを使用してドメイン固有のアクション、またはプランを生成し、コントローラーを利用してそれらを選択または実行する。ただし、これらのアプローチは高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。
推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
LLMにおける推論と行動を組み合わせて、言語推論と意思決定タスクを解決するREACTと呼ばれる手法を提案。REACTでは、推論と行動の相乗効果を高めることが可能。推論トレースによりアクションプランを誘発、追跡、更新するのに役立ち、アクションでは外部ソースと連携して追加情報を収集できる。
REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みである。REACTのpromptはLLMにverbalな推論トレースとタスクを実行するためのアクションを交互に生成する。これにより、モデルは動的な推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
# 手法
変数を以下のように定義する:
- O_t: Observertion on time t
- a_t: Action on time t
- c_t: context, i.e. (o_1, a_1, o_2, a_2, ..., a_t-1, o_t)
- policy pi(a_t | c_t): Action Spaceからアクションを選択するポリシー
- A: Action Space
- O: Observation Space
普通はc_tが与えられたときに、ポリシーに従いAからa_tを選択しアクションを行い、アクションの結果o_tを得て、c_t+1を構成する、といったことを繰り返していく。
このとき、REACTはAをA ∪ Lに拡張しする。ここで、LはLanguage spaceである。LにはAction a_hatが含まれ、a_hatは環境に対して作用をしない。単純にthought, あるいは reasoning traceを実施し、現在のcontext c_tをアップデートするために有用な情報を構成することを目的とする。Lはunlimitedなので、事前学習された言語モデルを用いる。今回はPaLM-540B(c.f. GPT3は175Bパラメータ)が利用され、few-shotのin-context exampleを与えることで推論を行う。それぞれのin-context exampleは、action, thoughtsそしてobservationのtrajectoryを与える。
推論が重要なタスクでは、thoughts-action-observationステップから成るtask-solving trajectoryを生成する。一方、多数のアクションを伴う可能性がある意思決定タスクでは、thoughtsのみを行うことをtask-solving trajectory中の任意のタイミングで、自分で判断して行うことができる。
意思決定と推論能力がLLMによってもたらされているため、REACTは4つのuniqueな特徴を持つ:
- 直感的で簡単なデザイン
- REACTのpromptは人間のアノテータがアクションのトップに思考を言語で記述するようなストレートなものであり、ad-hocなフォーマットの選択、思考のデザイン、事例の選定などが必要ない。
- 一般的で柔軟性が高い
- 柔軟な thought spaceと thought-actionのフォーマットにより、REACTはさまざまなタスクにも柔軟に対応できる
- 高性能でロバスト
- REACTは1-6個の事例によって、新たなタスクに対する強力な汎化を示す。そして推論、アクションのみを行うベースラインよりも高い性能を示している。REACTはfinetuningの斧系も得ることができ、promptの選択に対してREACTの性能はrobustである。
- 人間による調整と操作が可能
- REACTは、解釈可能な意思決定と推論のsequenceを前提としているため、人間は簡単に推論や事実の正しさを検証できる。加えて、thoughtsを編集することによって、m人間はエージェントの行動を制御、あるいは修正できる。
# KNOWLEDGE INTENSIVE REASONING TASKS
#NeuralNetwork #ComputerVision #Pocket #NLP #ICML #OOD #Finetuning #Generalization #Encoder #Encoder-Decoder #KeyPoint Notes #Souping Issue Date: 2025-11-28 [Paper Note] Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, Mitchell Wortsman+, ICML'22, 2022.03 GPT Summary- ファインチューニングされたモデルの重みを平均化する「モデルスープ」手法を提案し、精度と堅牢性を向上させることを示す。従来のアンサンブル手法とは異なり、追加のコストなしで複数のモデルを平均化でき、ImageNetで90.94%のトップ1精度を達成。さらに、画像分類や自然言語処理タスクにも適用可能で、分布外性能やゼロショット性能を改善することが確認された。 Comment
transformerベースの事前学習済みモデル(encoder-only, encoder-decoderモデル)のファインチューニングの話で、共通のベースモデルかつ共通のパラメータの初期化を持つ、様々なハイパーパラメータで学習したモデルの重みを平均化することでよりロバストで高性能なモデルを作ります、という話。似たような手法にアンサンブルがあるが、アンサンブルでは利用するモデルに対して全ての推論結果を得なければならないため、計算コストが増大する。一方、モデルスープは単一モデルと同じ計算量で済む(=計算量は増大しない)。
スープを作る際は、Validation dataのAccが高い順に異なるFinetuning済みモデルをソートし、逐次的に重みの平均をとりValidation dataのAccが上がる場合に、当該モデルをsoupのingridientsとして加える。要は、開発データで性能が高い順にモデルをソートし、逐次的にモデルを取り出していき、現在のスープに対して重みを平均化した時に開発データの性能が上がるなら平均化したモデルを採用し、上がらないなら無視する、といった処理を繰り返す。これをgreedy soupと呼ぶ。他にもuniform soup, learned soupといった手法も提案され比較されているが、画像系のモデル(CLIP, ViTなど)やNLP(T5, BERT)等で実験されており、greedy soupの性能とロバストさ(OOD;分布シフトに対する予測性能)が良さそうである。
#ComputerVision #Pocket #DiffusionModel #VideoGeneration/Understandings #4D (Video) Issue Date: 2025-10-17 [Paper Note] Video Diffusion Models, Jonathan Ho+, arXiv'22, 2022.04 GPT Summary- 高忠実度で一貫した動画生成のための拡散モデルを提案。画像と動画データを共同でトレーニングし、最適化を加速。新しい条件付きサンプリング技術により、長く高解像度の動画生成で優れた性能を発揮。大規模なテキスト条件付き動画生成タスクでの初期結果と、既存ベンチマークでの最先端結果を示す。 Comment
Surveyはこちら:
- [Paper Note] Video Diffusion Models: A Survey, Andrew Melnik+, TMLR'24, 2024.05
#ComputerVision #Pocket #TextToImageGeneration #VariationalAutoEncoder #CVPR #Encoder-Decoder #ImageSynthesis #U-Net Issue Date: 2025-10-10 [Paper Note] High-Resolution Image Synthesis with Latent Diffusion Models, Robin Rombach+, CVPR'22, 2021.12 GPT Summary- 拡散モデル(DMs)は、逐次的なデノイジングオートエンコーダを用いて画像生成プロセスを効率化し、最先端の合成結果を達成。従来のピクセル空間での訓練に比べ、強力な事前訓練されたオートエンコーダの潜在空間での訓練により、計算リソースを削減しつつ視覚的忠実度を向上。クロスアテンション層を導入することで、テキストやバウンディングボックスに基づく柔軟な生成が可能となり、画像インペインティングや無条件画像生成などで競争力のある性能を発揮。 Comment
ここからtext等による条件付けをした上での生成が可能になった(らしい)
#ComputerVision #Pocket #Transformer #DiffusionModel Issue Date: 2025-10-10 [Paper Note] Classifier-Free Diffusion Guidance, Jonathan Ho+, arXiv'22, 2022.07 GPT Summary- 分類器ガイダンスは条件付き拡散モデルのポストトレーニング手法で、モードカバレッジとサンプル忠実度のトレードオフを図る。著者は、分類器なしで生成モデルによるガイダンスが可能であることを示し、これを分類器フリーガイダンスと呼ぶ。条件付きおよび無条件の拡散モデルを共同でトレーニングし、サンプル品質と多様性のトレードオフを達成する。 Comment
日本語解説: https://qiita.com/UMAboogie/items/160c1159811743c49d99
#Pocket #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #ReinforcementLearning #Safety #PseudoLabeling Issue Date: 2025-09-20 [Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22 GPT Summary- 本研究では、「憲法的AI」を用いて、人間のラベルなしで無害なAIを訓練する方法を提案。監視学習と強化学習の2フェーズを経て、自己批評と修正を通じてモデルを微調整し、嗜好モデルを報酬信号として強化学習を行う。これにより、有害なクエリに対しても対話できる無害なAIアシスタントを実現し、AIの意思決定の透明性を向上させる。 Comment
(部分的にしか読めていないが)
有害なpromptに対してLLMに初期の応答を生成させ、iterativeにcritiqueとrevisionを繰り返して[^1]、より無害な応答を生成。この方法ではiterationをしながら生成結果が改定されていくので、後段のReward Modelのための嗜好データを生成するフェーズでトークン量を節約するために、生成されたより無害な応答と元となるpromptを用いて、ベースモデルをSFT。これによりベースモデルの出力分布がより無害な応答をするような方向性に調整され、かつ(iterationを繰り返すことなく)直接的により無害な応答を生成できるようになるのでtoken量が節約できる。このフェーズで学習したモデルをSL-CAIと呼ぶ。
続いて、SL-CAIに対して同様の有害なpromptを入力して、複数の応答を生成させる。生成された応答をMultiple Choice Questionの形式にし、Constitutional Principleに基づくpromptingにより、最も望ましい応答をLLMによって選択させることで、嗜好データを獲得する。この嗜好データ(と人手で定義されたhelpfulnessに基づくデータ)を用いてReward Modelを訓練しRLを実施する。
この手法は、嗜好データを人間がラベリングするのではなく、AIによるフィードバックによりラベリングするため、Reinforcement Learning from AI Feedback (RLAIF)と呼ばれる。
Harmfulness以外の分野にも応用可能と考えられる。
[^1]: この操作はモデルの望ましい挙動を人手で定義したルーブリックに基づいた複数のprompt (Constitutional Principles) を用いて実施される。具体的なpromptはAppendix Cを参照。
#Analysis #Pocket #NLP #LanguageModel Issue Date: 2025-09-19 [Paper Note] Emergent Abilities of Large Language Models, Jason Wei+, TMLR'22 GPT Summary- 大規模言語モデルのスケーリングアップは性能を向上させるが、「出現能力」と呼ばれる予測不可能な現象が存在する。これは小型モデルにはない能力であり、さらなるスケーリングがモデルの能力を拡大する可能性を示唆している。 Comment
openreview: https://openreview.net/forum?id=yzkSU5zdwD
創発能力(最近この用語を目にする機会が減ったような気がする)
#Pretraining #Pocket #NLP #LanguageModel #ACL #Deduplication Issue Date: 2025-09-04 [Paper Note] Deduplicating Training Data Makes Language Models Better, Katherine Lee+, ACL'22 GPT Summary- 既存の言語モデルデータセットには重複した例が多く含まれ、訓練されたモデルの出力の1%以上が訓練データからコピーされている。これを解決するために、重複排除ツールを開発し、C4データセットからは60,000回以上繰り返される文を削除。重複を排除することで、モデルの記憶されたテキスト出力を10倍減少させ、精度を維持しつつ訓練ステップを削減。また、訓練とテストの重複を減らし、より正確な評価を実現。研究の再現とコードは公開されている。 Comment
下記スライドのp.9にまとめが記述されている:
https://speakerdeck.com/takase/snlp2023-beyond-neural-scaling-laws?slide=9
#NeuralNetwork #ComputerVision #Backbone Issue Date: 2025-08-29 [Paper Note] A ConvNet for the 2020s, Zhuang Liu+, arXiv'22 GPT Summary- ConvNetはVision Transformersの登場により地位を失ったが、ハイブリッドアプローチの効果はトランスフォーマーの優位性に依存している。本研究では、ConvNetの限界をテストし、ConvNeXtという新しいモデルを提案。ConvNeXtは標準的なConvNetモジュールのみで構成され、精度とスケーラビリティでトランスフォーマーと競争し、ImageNetで87.8%の精度を達成し、COCO検出およびADE20KセグメンテーションでSwin Transformersを上回る。 Comment
ConvNeXt
#Embeddings #Pocket #NLP #RepresentationLearning #NeurIPS #Length Issue Date: 2025-07-29 [Paper Note] Matryoshka Representation Learning, Aditya Kusupati+, NeurIPS'22 GPT Summary- マトリョーシカ表現学習(MRL)は、異なる計算リソースに適応可能な柔軟な表現を設計する手法であり、既存の表現学習パイプラインを最小限に修正して使用します。MRLは、粗から細への表現を学習し、ImageNet-1K分類で最大14倍小さい埋め込みサイズを提供し、実世界のスピードアップを実現し、少数ショット分類で精度向上を達成します。MRLは視覚、視覚+言語、言語のモダリティにわたるデータセットに拡張可能で、コードとモデルはオープンソースで公開されています。 Comment
日本語解説: https://speakerdeck.com/hpprc/lun-jiang-zi-liao-matryoshka-representation-learning
単一のモデルから複数のlengthのEmbeddingを出力できるような手法。
#Pocket #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICLR #PostTraining Issue Date: 2025-05-12 LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22 GPT Summary- LoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。 Comment
OpenrReview: https://openreview.net/forum?id=nZeVKeeFYf9
LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。
- [Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
などでも示されているが、一般的にLoRAとFull Finetuningを比較するとLoRAの方が性能が低いことが知られている点には留意が必要。
#MachineLearning #Pocket #NLP #LanguageModel #NeurIPS #Scaling Laws Issue Date: 2025-03-23 Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22 GPT Summary- トランスフォーマー言語モデルの訓練において、計算予算内で最適なモデルサイズとトークン数を調査。モデルサイズと訓練トークン数は同等にスケールする必要があり、倍増するごとにトークン数も倍増すべきと提案。Chinchillaモデルは、Gopherなどの大規模モデルに対して優れた性能を示し、ファインチューニングと推論の計算量を削減。MMLUベンチマークで67.5%の精度を達成し、Gopherに対して7%以上の改善を実現。 Comment
OpenReview: https://openreview.net/forum?id=iBBcRUlOAPR
chinchilla則
#EfficiencyImprovement #Pretraining #Pocket #NLP #Transformer #Architecture #MoE(Mixture-of-Experts) Issue Date: 2025-02-11 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22 GPT Summary- Switch Transformerを提案し、Mixture of Experts (MoE)の複雑さや通信コスト、トレーニングの不安定性を改善。これにより、低精度フォーマットでの大規模スパースモデルのトレーニングが可能になり、最大7倍の事前トレーニング速度向上を実現。さらに、1兆パラメータのモデルを事前トレーニングし、T5-XXLモデルに対して4倍の速度向上を達成。 #Analysis #Pocket #NLP #Transformer #ACL #KnowledgeEditing #FactualKnowledge #Encoder Issue Date: 2024-07-11 Knowledge Neurons in Pretrained Transformers, Damai Dai+, N_A, ACL'22, 2022.05 GPT Summary- 大規模な事前学習言語モデルにおいて、事実知識の格納方法についての研究を行いました。具体的には、BERTのfill-in-the-blank cloze taskを用いて、関連する事実を表現するニューロンを特定しました。また、知識ニューロンの活性化と対応する事実の表現との正の相関を見つけました。さらに、ファインチューニングを行わずに、知識ニューロンを活用して特定の事実知識を編集しようと試みました。この研究は、事前学習されたTransformers内での知識の格納に関する示唆に富んでおり、コードはhttps://github.com/Hunter-DDM/knowledge-neuronsで利用可能です。 Comment
大規模言語モデルにおいて、「知識は全結合層に蓄積される」という仮説についての文献調査
日本語解説: https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022
関連:
- [Paper Note] Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, EMNLP'21
上記資料によると、特定の知識を出力する際に活性化する知識ニューロンを特定する手法を提案。MLMを用いたclozeタスクによる実験で[MASK]部分に当該知識を出力する実験をした結果、知識ニューロンの重みをゼロとすると性能が著しく劣化し、値を2倍にすると性能が改善するといった傾向がみられた。 ケーススタディとして、知識の更新と、知識の削除が可能かを検証。どちらとも更新・削除がされる方向性[^1]へモデルが変化した。
また、知識ニューロンはTransformerの層の深いところに位置している傾向にあり、異なるrelationを持つような関係知識同士では共有されない傾向にある模様。
[^1]: 他の知識に影響を与えず、完璧に更新・削除できたわけではない。知識の更新・削除に伴いExtrinsicな評価によって性能向上、あるいはPerplexityが増大した、といった結果からそういった方向性へモデルが変化した、という話
#NLP #LanguageModel #Alignment #ChatGPT #RLHF #PPO (ProximalPolicyOptimization) #PostTraining #read-later Issue Date: 2024-04-28 Training language models to follow instructions with human feedback, Long Ouyang+, N_A, NeurIPS'22 GPT Summary- 大規模な言語モデルは、ユーザーの意図に合わない出力を生成することがあります。本研究では、人間のフィードバックを使用してGPT-3を微調整し、InstructGPTと呼ばれるモデルを提案します。この手法により、13億パラメータのInstructGPTモデルの出力が175BのGPT-3の出力よりも好まれ、真実性の向上と有害な出力の削減が示されました。さらに、一般的なNLPデータセットにおける性能の低下は最小限でした。InstructGPTはまだ改善の余地がありますが、人間のフィードバックを使用した微調整が有望な方向であることを示しています。 Comment
ChatGPTの元となる、SFT→Reward Modelの訓練→RLHFの流れが提案された研究。DemonstrationデータだけでSFTするだけでは、人間の意図したとおりに動作しない問題があったため、人間の意図にAlignするように、Reward Modelを用いたRLHFでSFTの後に追加で学習を実施する。Reward Modelは、175Bモデルは学習が安定しなかった上に、PPOの計算コストが非常に大きいため、6BのGPT-3を様々なNLPタスクでSFTしたモデルをスタートにし、モデルのアウトプットに対して人間がランキング付けしたデータをペアワイズのloss functionで訓練した。最終的に、RMのスコアが最大化されるようにSFTしたGPT-3をRLHFで訓練するが、その際に、SFTから出力が離れすぎないようにする項と、NLPベンチマークでの性能が劣化しないようにpretrain時のタスクの性能もloss functionに加えている。
#Pocket #NLP #DiffusionModel #NeurIPS #read-later Issue Date: 2025-11-04 [Paper Note] Structured Denoising Diffusion Models in Discrete State-Spaces, Jacob Austin+, NeurIPS'21, 2021.07 GPT Summary- 離散デノイジング拡散確率モデル(D3PMs)を提案し、連続状態空間のDDPMsを一般化。汚染プロセスを超えた遷移行列を導入し、画像とテキスト生成の改善を実現。新しい損失関数を用いて、LM1Bでの文字レベルのテキスト生成やCIFAR-10での画像生成において優れた結果を達成。 Comment
openreview: https://openreview.net/forum?id=h7-XixPCAL
離散拡散モデルを提案した研究
- Masked Diffusion Modelの進展, Deep Learning JP, 2025.03
で紹介されている
#NeuralNetwork #ComputerVision #Pocket #DiffusionModel #Encoder-Decoder #PMLR #ScoreMatching #U-Net Issue Date: 2025-10-10 [Paper Note] Improved Denoising Diffusion Probabilistic Models, Alex Nichol+, PMLR'21, 2021.02 GPT Summary- DDPMは高品質なサンプル生成が可能な生成モデルであり、簡単な修正により競争力のある対数尤度を達成できることを示す。逆拡散プロセスの分散を学習することで、サンプリング回数を大幅に削減しつつサンプル品質を維持。DDPMとGANのターゲット分布のカバー能力を比較し、モデルの容量とトレーニング計算量に対してスケーラブルであることを明らかにした。コードは公開されている。 Comment
関連:
- [Paper Note] Denoising Diffusion Probabilistic Models, Jonathan Ho+, NeurIPS'20, 2020.06
#NeuralNetwork #ComputerVision #Pocket #DiffusionModel #TextToImageGeneration #NeurIPS #Encoder-Decoder #ScoreMatching #U-Net Issue Date: 2025-10-10 [Paper Note] Diffusion Models Beat GANs on Image Synthesis, Prafulla Dhariwal+, NeurIPS'21 Spotlight, 2021.05 GPT Summary- 拡散モデルが最先端の生成モデルを上回る画像サンプル品質を達成。無条件画像合成ではアーキテクチャの改善、条件付き画像合成では分類器のガイダンスを用いて品質向上。ImageNetでのFIDスコアは、128×128で2.97、256×256で4.59、512×512で7.72を達成し、BigGAN-deepに匹敵。分類器のガイダンスはアップサンプリング拡散モデルと組み合わせることでさらに改善され、256×256で3.94、512×512で3.85を記録。コードは公開中。 Comment
openreview: https://openreview.net/forum?id=AAWuCvzaVt
日本語解説: https://qiita.com/UMAboogie/items/160c1159811743c49d99
バックボーンとして使われているU-Netはこちら:
- [Paper Note] U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger+, MICCAI'15, 2015.05
#ComputerVision #Pocket #Transformer #ICLR #Backbone Issue Date: 2025-08-25 [Paper Note] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy+, ICLR'21 GPT Summary- 純粋なトランスフォーマーを画像パッチのシーケンスに直接適用することで、CNNへの依存なしに画像分類タスクで優れた性能を発揮できることを示す。大量のデータで事前学習し、複数の画像認識ベンチマークで最先端のCNNと比較して優れた結果を達成し、計算リソースを大幅に削減。 Comment
openreview: https://openreview.net/forum?id=YicbFdNTTy
ViTを提案した研究
#Pocket #NLP #Dataset #LanguageModel #Evaluation #CodeGeneration Issue Date: 2025-08-15 [Paper Note] Program Synthesis with Large Language Models, Jacob Austin+, arXiv'21 GPT Summary- 本論文では、汎用プログラミング言語におけるプログラム合成の限界を大規模言語モデルを用いて評価します。MBPPとMathQA-Pythonの2つのベンチマークで、モデルサイズに対する合成性能のスケールを調査。最も大きなモデルは、少数ショット学習でMBPPの59.6%の問題を解決可能で、ファインチューニングにより約10%の性能向上が見られました。MathQA-Pythonでは、ファインチューニングされたモデルが83.8%の精度を達成。人間のフィードバックを取り入れることでエラー率が半減し、エラー分析を通じてモデルの弱点を明らかにしました。最終的に、プログラム実行結果の予測能力を探るも、最良のモデルでも特定の入力に対する出力予測が困難であることが示されました。 Comment
代表的なコード生成のベンチマーク。
MBPPデータセットは、promptで指示されたコードをモデルに生成させ、テストコード(assertion)を通過するか否かで評価する。974サンプル存在し、pythonの基礎を持つクラウドワーカーによって生成。クラウドワーカーにタスクdescriptionとタスクを実施する一つの関数(関数のみで実行可能でprintは不可)、3つのテストケースを記述するよう依頼。タスクdescriptionは追加なclarificationなしでコードが記述できるよう十分な情報を含むよう記述するように指示。ground truthの関数を生成する際に、webを閲覧することを許可した。
MathQA-Pythonは、MathQAに含まれるQAのうち解答が数値のもののみにフィルタリングしたデータセットで、合計で23914サンプル存在する。pythonコードで与えられた数学に関する問題を解くコードを書き、数値が一致するか否かで評価する、といった感じな模様。斜め読みなので少し読み違えているかもしれない。
#Pocket #NLP #Dataset #LanguageModel #Evaluation #CodeGeneration Issue Date: 2025-08-15 [Paper Note] Evaluating Large Language Models Trained on Code, Mark Chen+, arXiv'21 GPT Summary- CodexはGitHubのコードでファインチューニングされたGPT言語モデルで、Pythonコード生成能力を評価。新しい評価セットHumanEvalでは、Codexが28.8%の問題を解決し、GPT-3は0%、GPT-Jは11.4%だった。繰り返しサンプリングが難しいプロンプトに対しても効果的な戦略を用い、70.2%の問題を解決。モデルの限界として、長い操作の説明や変数へのバインドに苦労する点が明らかに。最後に、コード生成技術の影響について安全性や経済に関する議論を行う。 Comment
HumanEvalデータセット。Killed by LLMによると、GPT4oによりすでに90%程度の性能が達成され飽和している。
164個の人手で記述されたprogrammingの問題で、それぞれはfunction signature, docstring, body, unittestを持つ。unittestは問題当たり約7.7 test存在。handwrittenという点がミソで、コンタミネーションの懸念があるためgithubのような既存ソースからのコピーなどはしていない。pass@k[^1]で評価。
[^1]: k個のサンプルを生成させ、k個のサンプルのうち、サンプルがunittestを一つでも通過する確率。ただ、本研究ではよりバイアスをなくすために、kよりも大きいn個のサンプルを生成し、その中からランダムにk個を選択して確率を推定するようなアプローチを実施している。2.1節を参照のこと。
#ComputerVision #Pocket #Transformer #Attention #Architecture #ICCV #Backbone Issue Date: 2025-07-19 [Paper Note] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu+, ICCV'21 GPT Summary- Swin Transformerは、コンピュータビジョンの新しいバックボーンとして機能する階層的トランスフォーマーを提案。シフトウィンドウ方式により、効率的な自己注意計算を実現し、さまざまなスケールでのモデリングが可能。画像分類や物体検出、セマンティックセグメンテーションなどで従来の最先端を上回る性能を示し、トランスフォーマーのビジョンバックボーンとしての可能性を示唆。コードは公開されている。 Comment
日本語解説: https://qiita.com/m_sugimura/items/139b182ee7c19c83e70a
画像処理において、物体の異なるスケールや、解像度に対処するために、PatchMergeと呼ばれるプーリングのような処理と、固定サイズのローカルなwindowに分割してSelf-Attentionを実施し、layerごとに通常のwindowとシフトされたwindowを適用することで、window間を跨いだ関係性も考慮できるようにする機構を導入したモデル。
#Analysis #Pocket #NLP #Transformer #EMNLP #FactualKnowledge Issue Date: 2025-07-04 [Paper Note] Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, EMNLP'21 GPT Summary- フィードフォワード層はトランスフォーマーモデルの大部分を占めるが、その役割は未探求。研究により、フィードフォワード層がキー・バリュー・メモリとして機能し、トレーニング例のテキストパターンと相関することを示す。実験で、下層は浅いパターン、上層は意味的なパターンを学習し、バリューが出力分布を誘導することが確認された。最終的に、フィードフォワード層の出力はメモリの合成であり、残差接続を通じて洗練される。 Comment
日本語解説(p.5より): https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022?slide=5
#Pocket #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #Mathematics #Verification Issue Date: 2024-12-27 Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21 GPT Summary- GSM8Kデータセットを用いて、多段階の数学的推論における言語モデルの限界を分析。検証器を訓練し、候補解を評価して最適解を選択することで、モデルのパフォーマンスを大幅に向上させることを示した。検証はファインチューニングよりもデータ増加に対して効果的にスケールする。 Comment
## 気持ち
- 当時の最も大きいレベルのモデルでも multi-stepのreasoningが必要な問題は失敗する
- モデルをFinetuningをしても致命的なミスが含まれる
- 特に、数学は個々のミスに対して非常にsensitiveであり、一回ミスをして異なる解法のパスに入ってしまうと、self-correctionするメカニズムがauto-regressiveなモデルではうまくいかない
- 純粋なテキスト生成の枠組みでそれなりの性能に到達しようとすると、とんでもないパラメータ数が必要になり、より良いscaling lawを示す手法を模索する必要がある
## Contribution
論文の貢献は
- GSM8Kを提案し、
- verifierを活用しモデルの複数の候補の中から良い候補を選ぶフレームワークによって、モデルのパラメータを30倍にしたのと同等のパフォーマンスを達成し、データを増やすとverifierを導入するとよりよく性能がスケールすることを示した。
- また、dropoutが非常に強い正則化作用を促し、finetuningとverificationの双方を大きく改善することを示した。
Todo: 続きをまとめる
#DocumentSummarization #Metrics #Tools #NLP #Dataset #Evaluation Issue Date: 2023-08-13 SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21 Comment
自動評価指標が人手評価の水準に達しないことが示されており、結局のところROUGEを上回る自動性能指標はほとんどなかった。human judgmentsとのKendall;'s Tauを見ると、chrFがCoherenceとRelevance, METEORがFluencyで上回ったのみだった。また、LEAD-3はやはりベースラインとしてかなり強く、LEAD-3を上回ったのはBARTとPEGASUSだった。
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #LM-based Issue Date: 2023-08-13 BARTSCORE: Evaluating Generated Text as Text Generation, Yuan+ (w_ Neubig氏), NeurIPS'21 GPT Summary- 本研究では、生成されたテキストの評価方法について検討しました。具体的には、事前学習モデルを使用してテキスト生成の問題をモデル化し、生成されたテキストを参照出力またはソーステキストに変換するために訓練されたモデルを使用しました。提案したメトリックであるBARTSCOREは、情報量、流暢さ、事実性などの異なる視点のテキスト評価に柔軟に適用できます。実験結果では、既存のトップスコアリングメトリックを上回る性能を示しました。BARTScoreの計算に使用するコードは公開されており、インタラクティブなリーダーボードも利用可能です。 Comment
BARTScore
# 概要
ソーステキストが与えられた時に、BARTによって生成テキストを生成する尤度を計算し、それをスコアとする手法。テキスト生成タスクをテキスト生成モデルでスコアリングすることで、pre-trainingされたパラメータをより有効に活用できる(e.g. BERTScoreやMoverScoreなどは、pre-trainingタスクがテキスト生成ではない)。BARTScoreの特徴は
1. parameter- and data-efficientである。pre-trainingに利用されたパラメータ以外の追加パラメータは必要なく、unsupervisedなmetricなので、human judgmentのデータなども必要ない。
2. 様々な観点から生成テキストを評価できる。conditional text generation problemにすることでinformativeness, coherence, factualityなどの様々な観点に対応可能。
3. BARTScoreは、(i) pre-training taskと類似したpromptを与えること、(ii) down stream generation taskでfinetuningすること、でより高い性能を獲得できる
BARTScoreを16種類のデータセットの、7つの観点で評価したところ、16/22において、top-scoring metricsよりも高い性能を示した。また、prompting starategyの有効性を示した。たとえば、シンプルに"such as"というフレーズを翻訳テキストに追加するだけで、German-English MTにおいて3%の性能向上が見られた。また、BARTScoreは、high-qualityなテキスト生成システムを扱う際に、よりロバストであることが分析の結果分かった。
# 前提
## Problem Formulation
生成されたテキストのqualityを測ることを目的とする。本研究では、conditional text generation (e.g. 機械翻訳)にフォーカスする。すなわち、ゴールは、hypothesis h_bar を source text s_barがgivenな状態で生成することである。一般的には、人間が作成したreference r_barが評価の際は利用される。
## Gold-standard Human Evaluation
評価のgold standardは人手評価であり、人手評価では多くの観点から評価が行われる。以下に代表的な観点を示す:
1. Informativeness: ソーステキストのキーアイデアをどれだけ捉えているか
2. Relevance: ソーステキストにあ地して、どれだけconsistentか
3. Fluency formatting problem, capitarlization errorや非文など、どの程度読むのが困難か
4. Coherence: 文間のつながりが、トピックに対してどれだけcoherentか
5. Factuality: ソーステキストに含意されるstatementのみを生成できているか
6. Semantic Coverage: 参照テキスト中のSemantic Content Unitを生成テキストがどれだけカバーできているか
7: Adequacy 入力文に対してアウトプットが同じ意味を出力できているかどうか、あるいは何らかのメッセージが失われる、追加される、歪曲していないかどうか
多くの性能指標は、これらの観点のうちのsubsetをカバーするようにデザインんされている。たとえば、BLEUは、翻訳におけるAdequacyとFluencyをとらえることを目的としている。一方、ROUGEは、semantic coverageを測るためのメトリックである。
BARTScoreは、これらのうち多くの観点を評価することができる。
## Evaluation as Different Tasks
ニューラルモデルを異なる方法で自動評価に活用するのが最近のトレンドである。下図がその分類。この分類は、タスクにフォーカスした分類となっている。
1. Unsupervised Matching: ROUGE, BLEU, CHRF, BERTScore, MoverScoreのように、hypothesisとreference間での意味的な等価性を測ることが目的である。このために、token-levelのマッチングを用いる。これは、distributedな表現を用いる(BERTScore, MoverScore)場合もあれば、discreteな表現を用いる(ROUGE, BLEU, chrF)場合もある。また、意味的な等価性だけでなく、factual consistencyや、source-hypothesis間の関係性の評価に用いることもできると考えられるが先行研究ではやられていなかったので、本研究で可能なことを示す。
2. Supervised Regression: BLEURT, COMET, S^3, VRMのように、regression layer を用いてhuman judgmentをsupervisedに予測する方法である。最近のメトリックtおしては、BLEURT, COMETがあげられ、古典的なものとしては、S^3, VRMがあげられる。
4. Supervised Ranking: COMET, BEERのような、ランキング問題としてとらえる方法もある。これは優れたhypothesisを上位にランキングするようなスコア関数を学習する問題に帰着する。COMETやBEERが例としてあげられ、両者はMTタスクにフォーカスされている。COMETはhunan judgmentsをregressionすることを通じてランキングを作成し、BEERは、多くのシンプルな特徴量を組み合わせて、linear layerでチューニングされる。
5. Text Generation: PRISM, BARTScoreが例として挙げられる。BARTScoreでは、生成されたテキストの評価をpre-trained language modelによるテキスト生成タスクとしてとらえる。基本的なアイデアとしては、高品質のhypothesisは、ソース、あるいはreferenceから容易に生成可能であろう、というものである。これはPRISMを除いて、先行研究ではカバーされていない。BARTScoreは、PRISMとはいくつかの点で異なっている。(i) PRISMは評価をparaphrasing taskとしてとらえており、これが2つの意味が同じテキストを比較する前提となってしまっているため、手法を適用可能な範囲を狭めてしまっている。たとえば、文書要約におけるfactual consistencyの評価では、semantic spaceが異なる2つのテキストを比較する必要があるが、このような例には対応できない。(ii) PRISMはparallel dataから学習しなけえrばならないが、BARTScoreは、pre-trainedなopen-sourceのseq2seq modelを利用できる。(iii) BARTScoreでは、PRISMが検証していない、prompt-basedのlearningもサポートしている。
# BARTScore
## Sequence-to-Sequence Pre-trained Models
pre-trainingされたモデルは、様々な軸で異なっているが、その一つの軸としては訓練時の目的関数である。基本的には2つの大きな変種があり、1つは、language modeling objectives (e.g. MLM)、2つ目は、seq2seq objectivesである。特に、seq2seqで事前学習されたモデルは、エンコーダーとデコーダーによって構成されているため特に条件付き生成タスクに対して適しており、予測はAutoRegressiveに行われる。本研究ではBARTを用いる。付録には、preliminary experimentsとして、BART with T5, PEGASUSを用いた結果も添付する。
## BARTScore
最も一般的なBARTScoreの定式化は下記である。
weighted log probabilityを利用する。このweightsは、異なるトークンに対して、異なる重みを与えることができる。たておば、IDFなどが利用可能であるが、本研究ではすべてのトークンを等価に扱う(uniform weightingだがstopwordを除外、IDFによる重みづけ、事前分布を導入するなど色々試したが、uniform weightingを上回るものがなかった)。
BARTScoreを用いて、様々な方向に用いて生成を行うことができ、異なる評価のシナリオに対応することができる。
- Faithfulness (s -> h):
- hypothesisがどれだけsource textに基づいて生成されているかを測ることができる。シナリオとしては、FactualityやRelevanceなどが考えられる。また、CoherenceやFluencyのように、target textのみの品質を測るためにも用いることができる。
- Precision (r -> h):
- hypothesisがどれだけgold-referenceに基づいてこう良くされているかを亜評価でき、precision-focusedなシナリオに適している
- Recall (h -> r):
- hypothesisから、gold referenceをどれだけ容易に再現できるかを測ることができる。そして、要約タスクのpyramid-basedな評価(i.e. semantic coverage等) に適している。pyramid-scoreはSemantic Content Unitsがどれだけカバーされているかによって評価される。
- F Score (r <-> h):
- 双方向を考慮し、Precisioon / RecallからF値を算出する。この方法は、referenceと生成テキスト間でのsemantic overlap (informativenss, adequacy)などの評価に広く利用される。
# BARTScore Variants
BARTScoreの2つの拡張を提案。(i) xとyをpromptingによって変更する。これにより、評価タスクをpre-training taskと近づける。(ii) パラメータΘを異なるfinetuning taskを考慮して変更する。すなわち、pre-trainingのドメインを、evaluation taskに近づける。
## Prompt
Promptingはinput/outputに対して短いフレーズを追加し、pre-trained modelに対して特定のタスクを遂行させる方法である。BARTにも同様の洞察を簡単に組み込むことができる。この変種をBARTScore-PROMPTと呼ぶ。
prompt zが与えられたときに、それを (i) source textに追加し、新たなsource textを用いてBARTScoreを計算する。(ii) target textの先頭に追加し、new target textに対してBARTScoreを計算する。
## Fine-tuning Task
classification-basedなタスクでfine-tuneされるのが一般的なBERT-based metricとは異なり、BARTScoreはgeneration taskでfine-tuneされるため、pre-training domainがevaluation taskと近い。本研究では、2つのdownstream taskを検証する。
1つめは、summarizationで、BARTをCNNDM datasetでfinetuningする。2つめは、paraphrasingで、summarizationタスクでfinetuningしたBARTをParaBank2 datasetでさらにfinetuningする。
# 実験
## baselines and datasets
### Evaluation Metrics
supervised metrics: COMET, BLEURT
unsupervised: BLEU, ROUGE-1, ROUGE-2, ROUGE-L, chrF, PRISM, MoverScore, BERTScore
と比較
### Measures for Meta Evaluation
Pearson Correlationでlinear correlationを測る。また、Spearman Correlationで2変数間の単調なcorrelationを測定する(線形である必要はない)。Kendall's Tauを用いて、2つの順序関係の関係性を測る。最後に、Accuracyでfactual textsとnon-factual textの間でどれだけ正しいランキングを得られるかを測る。
### Datasets
Summarization, MT, DataToTextの3つのデータセットを利用。
## Setup
### Prompt Design
seedをparaphrasingすることで、 s->h方向には70個のpromptを、h<->rの両方向には、34のpromptを得て実験で用いた。
### Settings
Summarizationとdata-to-textタスクでは、全てのpromptを用いてデコーダの頭に追加してスコアを計算しスコアを計算した。最終的にすべての生成されたスコアを平均することである事例に対するスコアを求めた(prompt unsembling)。MTについては、事例数が多くcomputational costが多くなってしまうため、WMT18を開発データとし、best prompt "Such as"を選択し、利用した。
BARTScoreを使う際は、gold standard human evaluationがrecall-basedなpyrmid methodの場合はBARTScore(h->r)を用い、humaan judgmentsがlinguistic quality (coherence fluency)そして、factual correctness、あるいは、sourceとtargetが同じモダリティ(e.g. language)の場合は、faitufulness-based BARTScore(s->h)を用いた。最後に、MTタスクとdata-to-textタスクでは、fair-comparisonのためにBARTScore F-score versionを用いた。
## 実験結果
### MT
- BARTScoreはfinetuning tasksによって性能が向上し、5つのlanguage pairsにおいてその他のunsupervised methodsを統計的に優位にoutperformし、2つのlanguage pairでcomparableであった。
-Such asというpromptを追加するだけで、BARTScoreの性能が改善した。特筆すべきは、de-enにおいては、SoTAのsupervised MetricsであるBLEURTとCOMETを上回った。
- これは、有望な将来のmetric designとして「human judgment dataで訓練する代わりに、pre-trained language modelに蓄積された知識をより適切に活用できるpromptを探索する」という方向性を提案している。
### Text Summarization
- vanilla BARTScoreはBERTScore, MoverScoreをInfo perspective以外でlarge marginでうくぁ回った。
- REALSum, SummEval dataseetでの改善は、finetuning taskによってさらに改善した。しかしながら、NeR18では改善しなかった。これは、データに含まれる7つのシステムが容易に区別できる程度のqualityであり、既にvanilla BARTScoreで高いレベルのcorrelationを達成しているからだと考えられる。
- prompt combination strategyはinformativenssに対する性能を一貫して改善している。しかし、fluency, factualityでは、一貫した改善は見られなかった。
Factuality datasetsに対する分析を行った。ゴールは、short generated summaryが、元のlong documentsに対してfaithfulか否かを判定するというものである。
- BARTScore+CNNは、Rank19データにおいてhuman baselineに近い性能を達成し、ほかのベースラインを上回った。top-performingなfactuality metricsであるFactCCやQAGSに対してもlarge marginで上回った。
- paraphraseをfine-tuning taskで利用すると、BARTScoreのパフォーマンスは低下した。これは妥当で、なぜなら二つのテキスト(summary and document)は、paraphrasedの関係性を保持していないからである。
- promptを導入しても、性能の改善は見受けられず、パフォーマンスは低下した。
### Data-to-Text
- CNNDMでfine-tuningすることで、一貫してcorrelationが改善した。
- 加えて、paraphraseデータセットでfinetuningすることで、さらに性能が改善した。
- prompt combination strategyは一貫してcorrelationを改善した。
## Analysis
### Fine-grained Analysis
- Top-k Systems: MTタスクにおいて、評価するシステムをtop-kにし、各メトリックごとにcorrelationの変化を見た。その結果、BARTScoreはすべてのunsupervised methodをすべてのkにおいて上回り、supervised metricのBLEURTも上回った。また、kが小さくなるほど、より性能はsmoothになっていき、性能の低下がなくなっていった。これはつまり、high-quality textを生成するシステムに対してロバストであることを示している。
- Reference Length: テストセットを4つのバケットにreference lengthに応じてブレイクダウンし、Kendall's Tauの平均のcorrelationを、異なるメトリック、バケットごとに言語をまたいで計算した。unsupervised metricsに対して、全てのlengthに対して、引き分けかあるいは上回った。また、ほかのmetricsと比較して、長さに対して安定感があることが分かった。
### Prompt Analysis
(1) semantic overlap (informativeness, pyramid score, relevance), (2) linguistic quality (fluency, coherence), (3) factual correctness (factuality) に評価の観点を分類し、summarizationとdata-to-textをにおけるすべてのpromptを分析することで、promptの効果を分析した。それぞれのグループに対して、性能が改善したpromptの割合を計算した。その結果、semantic overlapはほぼ全てのpromptにて性能が改善し、factualityはいくつかのpromptでしか性能の改善が見られなかった。linguistic qualityに関しては、promptを追加することによる効果はどちらとも言えなかった。
### Bias Analysis
BARTScoreが予測不可能な方法でバイアスを導入してしまうかどうかを分析した。バイアスとは、human annotatorが与えたスコアよりも、値が高すぎる、あるいは低すぎるような状況である。このようなバイアスが存在するかを検証するために、human annotatorとBARTScoreによるランクのサを分析した。これを見ると、BARTScoreは、extractive summarizationの品質を区別する能力がabstractive summarizationの品質を区別する能力よりも劣っていることが分かった。しかしながら、近年のトレンドはabstractiveなseq2seqを活用することなので、この弱点は軽減されている。
# Implications and Future Directions
prompt-augmented metrics: semantic overlapではpromptingが有効に働いたが、linguistic qualityとfactualityでは有効ではなかった。より良いpromptを模索する研究が今後期待される。
Co-evolving evaluation metrics and systems: BARTScoreは、メトリックデザインとシステムデザインの間につながりがあるので、より性能の良いseq2seqシステムが出たら、それをメトリックにも活用することでよりreliableな自動性能指標となることが期待される。
#Sentence #Embeddings #Pocket #NLP #LanguageModel #RepresentationLearning #ContrastiveLearning #Catastrophic Forgetting Issue Date: 2023-07-27 SimCSE: Simple Contrastive Learning of Sentence Embeddings, Tianyu Gao+, N_A, EMNLP'21 GPT Summary- この論文では、SimCSEという対比学習フレームワークを提案しています。このフレームワークは、文の埋め込み技術を進化させることができます。教師なしアプローチでは、入力文をノイズとして扱い、自己を対比的に予測します。教師ありアプローチでは、自然言語推論データセットから注釈付きのペアを使用して対比学習を行います。SimCSEは、意味的テキスト類似性タスクで評価され、以前の手法と比較して改善を実現しました。対比学習は、事前学習された埋め込みの空間を均一に正則化し、教師信号が利用可能な場合には正のペアをよりよく整列させることが示されました。 Comment
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Reimers+, UKP-TUDA, EMNLP'19 よりも性能良く、unsupervisedでも学習できる。STSタスクのベースラインにだいたい入ってる
# 手法概要
Contrastive Learningを活用して、unsupervised/supervisedに学習を実施する。
Unsupervised SimCSEでは、あるsentenceをencoderに2回入力し、それぞれにdropoutを適用させることで、positive pairを作成する。dropoutによって共通のembeddingから異なる要素がマスクされた(noiseが混ざった状態とみなせる)類似したembeddingが作成され、ある種のdata augmentationによって正例を作成しているともいえる。負例はnegative samplingする。(非常にsimpleだが、next sentence predictionで学習するより性能が良くなる)
Supervised SimCSEでは、アノテーションされたsentence pairに基づいて、正例・負例を決定する。本研究では、NLIのデータセットにおいて、entailment関係にあるものは正例として扱う。contradictions(矛盾)関係にあるものは負例として扱う。
# Siamese Networkで用いられるmeans-squared errrorとContrastiveObjectiveの違い
どちらもペアワイズで比較するという点では一緒だが、ContrastiveObjectiveは正例と近づいたとき、負例と遠ざかったときにlossが小さくなるような定式化がされている点が異なる。
(画像はこのブログから引用。ありがとうございます。
https://techblog.cccmk.co.jp/entry/2022/08/30/163625)
# Unsupervised SimCSEの実験
異なるdata augmentation手法と比較した結果、dropoutを適用する手法の方が性能が高かった。MLMや, deletion, 類義語への置き換え等よりも高い性能を獲得しているのは興味深い。また、Next Sentence Predictionと比較しても、高い性能を達成。Next Sentence Predictionは、word deletion等のほぼ類似したテキストから直接的に類似関係にあるペアから学習するというより、Sentenceの意味内容のつながりに基づいてモデルの言語理解能力を向上させ、そのうえで類似度を測るという間接的な手法だが、word deletionに負けている。一方、dropoutを適用するだけの(直接的に類似ペアから学習する)本手法はより高い性能を示している。
[image](https://github.com/AkihikoWatanabe/paper_notes/assets/12249301/0ea3549e-3363-4857-94e6-a1ef474aa191)
なぜうまくいくかを分析するために、異なる設定で実験し、alignment(正例との近さ)とuniformity(どれだけembeddingが一様に分布しているか)を、10 stepごとにplotした結果が以下。dropoutを適用しない場合と、常に同じ部分をマスクする方法(つまり、全く同じembeddingから学習する)設定を見ると、学習が進むにつれuniformityは改善するが、alignmentが悪くなっていっている。一方、SimCSEはalignmentを維持しつつ、uniformityもよくなっていっていることがわかる。
# Supervised SimCSEの実験
アノテーションデータを用いてContrastiveLearningするにあたり、どういったデータを正例としてみなすと良いかを検証するために様々なデータセットで学習し性能を検証した。
- QQP4: Quora question pairs
- Flickr30k (Young et al., 2014): 同じ画像に対して、5つの異なる人間が記述したキャプションが存在
- ParaNMT (Wieting and Gimpel, 2018): back-translationによるparaphraseのデータセットa
- NLI datasets: SNLIとMNLI
実験の結果、NLI datasetsが最も高い性能を示した。この理由としては、NLIデータセットは、crowd sourcingタスクで人手で作成された高品質なデータセットであることと、lexical overlapが小さくなるようにsentenceのペアが作成されていることが起因している。実際、NLI datsetのlexical overlapは39%だったのに対し、ほかのデータセットでは60%であった。
また、condunctionsとなるペアを明示的に負例として与えることで、より性能が向上した(普通はnegative samplingする、というかバッチ内の正例以外のものを強制的に負例とする。こうすると、意味が同じでも負例になってしまう事例が出てくることになる)。より難しいNLIタスクを含むANLIデータセットを追加した場合は、性能が改善しなかった。この理由については考察されていない。性能向上しそうな気がするのに。
# 他手法との比較結果
SimCSEがよい。
# Ablation Studies
異なるpooling方法で、どのようにsentence embeddingを作成するかで性能の違いを見た。originalのBERTの実装では、CLS token のembeddingの上にMLP layerがのっかっている。これの有無などと比較。
Unsupervised SimCSEでは、training時だけMLP layerをのっけて、test時はMLPを除いた方が良かった。一方、Supervised SimCSEでは、 MLP layerをのっけたまんまで良かったとのこと。
また、SimCSEで学習したsentence embeddingを別タスクにtransferして活用する際には、SimCSEのobjectiveにMLMを入れた方が、catastrophic forgettingを防げて性能が高かったとのこと。
ablation studiesのhard negativesのところと、どのようにミニバッチを構成するか、それぞれのtransferしたタスクがどのようなものがしっかり読めていない。あとでよむ。
#Pocket #NLP #Dataset #LanguageModel #Evaluation #ICLR Issue Date: 2023-07-24 Measuring Massive Multitask Language Understanding, Dan Hendrycks+, N_A, ICLR'21 GPT Summary- 私たちは、マルチタスクのテキストモデルの正確性を測定するための新しいテストを提案しています。このテストは57のタスクをカバーし、広範な世界知識と問題解決能力が必要です。現在のモデルはまだ専門家レベルの正確性に達しておらず、性能に偏りがあります。私たちのテストは、モデルの弱点を特定するために使用できます。 Comment
OpenReview: https://openreview.net/forum?id=d7KBjmI3GmQ
MMLU論文
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
において、多くのエラーが含まれることが指摘され、再アノテーションが実施されている。
#NeuralNetwork #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #PostTraining Issue Date: 2022-08-19 [Paper Note] The Power of Scale for Parameter-Efficient Prompt Tuning, Brian Lester+, arXiv'21, 2021.04 GPT Summary- 本研究では、凍結された言語モデルを特定のタスクに適応させるための「ソフトプロンプト」を学習するプロンプトチューニング手法を提案。逆伝播を通じて学習されるソフトプロンプトは、GPT-3の少数ショット学習を上回る性能を示し、モデルサイズが大きくなるほど競争力が増すことが確認された。特に、数十億のパラメータを持つモデルにおいて、全ての重みを調整するモデルチューニングに匹敵する性能を発揮。これにより、1つの凍結モデルを複数のタスクに再利用できる可能性が示唆され、ドメイン転送に対するロバスト性も向上することが明らかとなった。 Comment
日本語解説:
https://qiita.com/kts_plea/items/79ffbef685d362a7b6ce
T5のような大規模言語モデルに対してfinetuningをかける際に、大規模言語モデルのパラメータは凍結し、promptをembeddingするパラメータを独立して学習する手法
言語モデルのパラメータ数が増加するにつれ、言語モデルそのものをfinetuningした場合(Model Tuning)と同等の性能を示した。
いわゆる(Softな) Prompt Tuning
#DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #ACL #PostTraining Issue Date: 2021-09-09 [Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01 GPT Summary- プレフィックスチューニングは、ファインチューニングの軽量な代替手段であり、言語モデルのパラメータを固定しつつ、タスク特有の小さなベクトルを最適化する手法です。これにより、少ないパラメータで同等のパフォーマンスを達成し、低データ設定でもファインチューニングを上回る結果を示しました。 Comment
言語モデルをfine-tuningする際,エンコード時に「接頭辞」を潜在表現として与え,「接頭辞」部分のみをfine-tuningすることで(他パラメータは固定),より少量のパラメータでfine-tuningを実現する方法を提案.接頭辞を潜在表現で与えるこの方法は,GPT-3のpromptingに着想を得ている.fine-tuningされた接頭辞の潜在表現のみを配布すれば良いので,非常に少量なパラメータでfine-tuningができる.
table-to-text, summarizationタスクで,一般的なfine-tuningやAdapter(レイヤーの間にアダプターを挿入しそのパラメータだけをチューニングする手法)といった効率的なfine-tuning手法と比較.table-to-textでは、250k (元のモデルの 0.1%) ほどの数のパラメータを微調整するだけで、全パラメータをfine-tuningするのに匹敵もしくはそれ以上の性能を達成.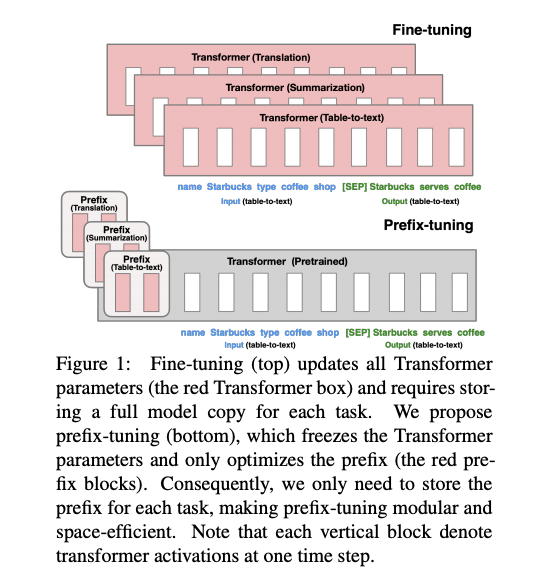
Hugging Faceの実装を利用したと論文中では記載されているが,fine-tuningする前の元の言語モデル(GPT-2)はどのように準備したのだろうか.Hugging Faceのpretrained済みのGPT-2を使用したのだろうか.
autoregressive LM (GPT-2)と,encoder-decoderモデル(BART)へPrefix Tuningを適用する場合の模式図
#NeuralNetwork #ComputerVision #Pocket #DiffusionModel #NeurIPS #Encoder-Decoder #ScoreMatching #ImageSynthesis #U-Net Issue Date: 2025-10-10 [Paper Note] Denoising Diffusion Probabilistic Models, Jonathan Ho+, NeurIPS'20, 2020.06 GPT Summary- 拡散確率モデルを用いた高品質な画像合成を提案。新しい重み付き変分境界でのトレーニングにより、優れた結果を得る。無条件CIFAR10で9.46のInceptionスコア、256x256のLSUNでProgressiveGANに匹敵する品質を達成。実装はGitHubで公開。 #Embeddings #InformationRetrieval #Pocket #NLP #QuestionAnswering #ContrastiveLearning #EMNLP #Encoder #KeyPoint Notes Issue Date: 2025-09-28 [Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04 GPT Summary- 密な表現を用いたパッセージ検索の実装を示し、デュアルエンコーダーフレームワークで学習。評価の結果、Lucene-BM25を上回り、検索精度で9%-19%の改善を達成。新たな最先端のQA成果を確立。 Comment
Dense Retrieverが広く知られるきっかけとなった研究(より古くはDSSM Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, Huang+, CIKM'13
などがある)。bag-of-wordsのようなsparseなベクトルで検索するのではなく(=Sparse Retriever)、ニューラルモデルでエンコードした密なベクトルを用いて検索しようという考え方である。
Query用と検索対象のPassageをエンコードするEncoderを独立してそれぞれ用意し(=DualEncoder)、QAの学習データ(すなわちクエリqと正例として正解passage p+)が与えられた時、クエリqと正例p+の類似度が高く、負例p-との類似度が低くなるように(=Contrastive Learning)、Query, Passage Encoderのパラメータを更新することで学習する(損失関数は式(2))。
負例はIn-Batch Negativeを用いる。情報検索の場合正解ラベルは多くの場合明示的に決まるが、負例は膨大なテキストのプールからサンプリングしなければならない。サンプリング方法はいろいろな方法があり(e.g., ランダムにサンプリング、qとbm25スコアが高いpassage(ただし正解は含まない; hard negativesと呼ぶ)その中の一つの方法がIn-Batch Negativesである。
In-Batch Negativesでは、同ミニバッチ内のq_iに対応する正例p+_i以外の全てのp_jを(擬似的に)負例とみなす。これにより、パラメータの更新に利用するためのq,pのエンコードを全て一度だけ実行すれば良く、計算効率が大幅に向上するという優れもの。本研究の実験(Table3)によると上述したIn-Batch Negativeに加えて、bm25によるhard negativeをバッチ内の各qに対して1つ負例として追加する方法が最も性能が良かった。
クエリ、passageのエンコーダとしては、BERTが用いられ、[CLS]トークンに対応するembeddingを用いて類似度が計算される。
#Pocket Issue Date: 2025-07-24 [Paper Note] Exploring Simple Siamese Representation Learning, Xinlei Chen+, arXiv'20 GPT Summary- Siameseネットワークを用いた教師なし視覚表現学習に関する研究で、ネガティブサンプルペア、大きなバッチ、モーメンタムエンコーダーを使用せずに意味のある表現を学習できることを示した。ストップグラディエント操作が崩壊解を防ぐ重要な役割を果たすことを確認し、SimSiamメソッドがImageNetおよび下流タスクで競争力のある結果を達成した。これにより、Siameseアーキテクチャの役割を再考するきっかけとなることを期待している。 Comment
日本語解説:
https://qiita.com/saliton/items/2f7b1bfb451df75a286f
https://qiita.com/koshian2/items/a31b85121c99af0eb050
#Pocket Issue Date: 2025-07-24 [Paper Note] Bootstrap your own latent: A new approach to self-supervised Learning, Jean-Bastien Grill+, arXiv'20 GPT Summary- BYOL(Bootstrap Your Own Latent)は、自己教師あり画像表現学習の新しい手法で、オンラインネットワークとターゲットネットワークの2つのニューラルネットワークを用いて学習を行う。BYOLは、ネガティブペアに依存せずに最先端の性能を達成し、ResNet-50でImageNetにおいて74.3%の分類精度を達成、より大きなResNetでは79.6%に達する。転送学習や半教師ありベンチマークでも優れた性能を示し、実装と事前学習済みモデルはGitHubで公開されている。 Comment
#ComputerVision #Pocket #DataAugmentation #ContrastiveLearning #Self-SupervisedLearning #ICLR Issue Date: 2025-05-18 A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen+, ICML'20 GPT Summary- 本論文では、視覚表現の対比学習のためのシンプルなフレームワークSimCLRを提案し、特別なアーキテクチャやメモリバンクなしで対比自己教師あり学習を簡素化します。データ拡張の重要性、学習可能な非線形変換の導入による表現の質向上、対比学習が大きなバッチサイズと多くのトレーニングステップから利益を得ることを示し、ImageNetで従来の手法を上回る結果を達成しました。SimCLRによる自己教師あり表現を用いた線形分類器は76.5%のトップ1精度を達成し、教師ありResNet-50に匹敵します。ラベルの1%でファインチューニングした場合、85.8%のトップ5精度を達成しました。 Comment
日本語解説: https://techblog.cccmkhd.co.jp/entry/2022/08/30/163625
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Pocket #MatrixFactorization #RecSys #read-later #Reproducibility Issue Date: 2025-05-16 [Paper Note] Neural Collaborative Filtering vs. Matrix Factorization Revisited, Steffen Rendle+, RecSys'20 GPT Summary- 埋め込みベースのモデルにおける協調フィルタリングの研究では、MLPを用いた学習された類似度が提案されているが、適切なハイパーパラメータ選択によりシンプルなドット積が優れた性能を示すことが確認された。MLPは理論的には任意の関数を近似可能だが、実用的にはドット積の方が効率的でコストも低いため、MLPは慎重に使用すべきであり、ドット積がデフォルトの選択肢として推奨される。 #DocumentSummarization #NeuralNetwork #NLP #ICML Issue Date: 2025-05-13 PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization, Jingqing Zhang+, ICML'20 GPT Summary- 大規模なテキストコーパスに対して新しい自己教師ありの目的でトランスフォーマーを事前学習し、抽象的なテキスト要約に特化したモデルPEGASUSを提案。重要な文を削除またはマスクし、残りの文から要約を生成。12の下流要約タスクで最先端のROUGEスコアを達成し、限られたリソースでも優れたパフォーマンスを示す。人間評価でも複数のデータセットで人間のパフォーマンスに達したことを確認。 Comment
PEGASUSもなかったので追加。BARTと共に文書要約のBackboneとして今でも研究で利用される模様。
関連:
- SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
#NeuralNetwork #Pretraining #Pocket #NLP #TransferLearning #PostTraining Issue Date: 2025-05-12 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Colin Raffel+, JMLR'20 GPT Summary- 転移学習はNLPにおいて強力な技術であり、本論文ではテキストをテキストに変換する統一フレームワークを提案。事前学習の目的やアーキテクチャを比較し、最先端の結果を達成。データセットやモデル、コードを公開し、今後の研究を促進する。 Comment
T5もメモっていなかったので今更ながら追加。全てのNLPタスクをテキスト系列からテキスト系列へ変換するタスクとみなし、Encoder-DecoderのTransformerを大規模コーパスを用いて事前学習をし、downstreamタスクにfinetuningを通じて転移する。
#Pocket #NLP #LanguageModel #ICLR #Decoding Issue Date: 2025-04-14 The Curious Case of Neural Text Degeneration, Ari Holtzman+, ICLR'20 GPT Summary- 深層ニューラル言語モデルは高品質なテキスト生成において課題が残る。尤度の使用がモデルの性能に影響を与え、人間のテキストと機械のテキストの間に分布の違いがあることを示す。デコーディング戦略が生成テキストの質に大きな影響を与えることが明らかになり、ニュークリアスsamplingを提案。これにより、多様性を保ちながら信頼性の低い部分を排除し、人間のテキストに近い質を実現する。 Comment
現在のLLMで主流なNucleus (top-p) Samplingを提案した研究
#MachineTranslation #Metrics #Pocket #NLP #Evaluation #EMNLP Issue Date: 2024-05-26 COMET: A Neural Framework for MT Evaluation, Ricardo Rei+, N_A, EMNLP'20 GPT Summary- COMETは、多言語機械翻訳評価モデルを訓練するためのニューラルフレームワークであり、人間の判断との新しい最先端の相関レベルを達成します。クロスリンガル事前学習言語モデリングの進展を活用し、高度に多言語対応かつ適応可能なMT評価モデルを実現します。WMT 2019 Metrics shared taskで新たな最先端のパフォーマンスを達成し、高性能システムに対する堅牢性を示しています。 Comment
Better/Worseなhypothesisを利用してpair-wiseにランキング関数を学習する


Inference時は単一のhypothesisしかinputされないので、sourceとreferenceに対してそれぞれhypothesisの距離をはかり、その調和平均でスコアリングする

ACL2024, EMNLP2024あたりのMT研究のmetricをざーっと見る限り、BLEU/COMETの双方で評価する研究が多そう
#NeuralNetwork #NLP #LanguageModel #Transformer #ActivationFunction Issue Date: 2024-05-24 GLU Variants Improve Transformer, Noam Shazeer, N_A, arXiv'20 GPT Summary- GLUのバリエーションをTransformerのフィードフォワード・サブレイヤーでテストし、通常の活性化関数よりもいくつかのバリエーションが品質向上をもたらすことを発見した。 Comment
一般的なFFNでは、linear layerをかけた後に、何らかの活性化関数をかませる方法が主流である。
このような構造の一つとしてGLUがあるが、linear layerと活性化関数には改良の余地があり、様々なvariantが考えられるため、色々試しました、というはなし。
オリジナルのGLUと比較して、T5と同じ事前学習タスクを実施したところ、perplexityが改善
また、finetuningをした場合の性能も、多くの場合オリジナルのGLUよりも高い性能を示した。
#InformationRetrieval #Pocket #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #NeurIPS #Encoder-Decoder #ContextEngineering Issue Date: 2023-12-01 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Patrick Lewis+, N_A, NeurIPS'20 GPT Summary- 大規模な事前学習言語モデルを使用した検索強化生成(RAG)の微調整手法を提案しました。RAGモデルは、パラメトリックメモリと非パラメトリックメモリを組み合わせた言語生成モデルであり、幅広い知識集約的な自然言語処理タスクで最先端の性能を発揮しました。特に、QAタスクでは他のモデルを上回り、言語生成タスクでは具体的で多様な言語を生成することができました。 Comment
RAGを提案した研究
Retrieverとして利用されているDense Passage Retrieval (DPR)はこちら:
- [Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-05-10 BERTScore: Evaluating Text Generation with BERT, Tianyi Zhang+, N_A, ICLR'20 GPT Summary- BERTScoreは、文脈埋め込みを使用してトークンの類似度を計算するテキスト生成の自動評価メトリックであり、363の機械翻訳および画像キャプションシステムの出力を使用して評価されました。BERTScoreは、既存のメトリックよりも人間の判断との相関が高く、より強力なモデル選択性能を提供し、敵対的な言い換え検出タスクにおいてもより堅牢であることが示されました。 Comment
# 概要
既存のテキスト生成の評価手法(BLEUやMETEOR)はsurface levelのマッチングしかしておらず、意味をとらえられた評価になっていなかったので、pretrained BERTのembeddingを用いてsimilarityを測るような指標を提案しましたよ、という話。
# prior metrics
## n-gram matching approaches
n-gramがreferenceとcandidateでどれだけ重複しているかでPrecisionとrecallを測定
### BLEU
MTで最も利用される。n-gramのPrecision(典型的にはn=1,2,3,4)と短すぎる候補訳にはペナルティを与える(brevity penalty)ことで実現される指標。SENT-BLEUといった亜種もある。BLEUと比較して、BERTScoreは、n-gramの長さの制約を受けず、潜在的には長さの制限がないdependencyをcontextualized embeddingsでとらえることができる。
### METEOR
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments, Banerjee+, CMU, ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization
METEOR 1.5では、内容語と機能語に異なるweightを割り当て、マッチングタイプによってもweightを変更する。METEOR++2.0では、学習済みの外部のparaphrase resourceを活用する。METEORは外部のリソースを必要とするため、たった5つの言語でしかfull feature setではサポートされていない。11の言語では、恥部のfeatureがサポートされている。METEORと同様に、BERTScoreでも、マッチに緩和を入れていることに相当するが、BERTの事前学習済みのembeddingは104の言語で取得可能である。BERTScoreはまた、重要度によるweightingをサポートしている(コーパスの統計量で推定)。
### Other Related Metrics
- NIST: BLEUとは異なるn-gramの重みづけと、brevity penaltyを利用する
- ΔBLEU: multi-reference BLEUを、人手でアノテーションされたnegative reference sentenceで変更する
- CHRF: 文字n-gramを比較する
- CHRF++: CHRFをword-bigram matchingに拡張したもの
- ROUGE: 文書要約で利用される指標。ROUGE-N, ROUGE^Lといった様々な変種がある。
- CIDEr: image captioningのmetricであり、n-gramのtf-idfで重みづけされたベクトルのcosine similrityを測定する
## Edit-distance based Metrics
- Word Error Rate (WER): candidateからreferenceを再現するまでに必要なedit operationの数をカウントする手法
- Translation Edit Rate (TER): referenceの単語数によってcandidateからreferenceまでのedit distanceを正規化する手法
- ITER: 語幹のマッチと、より良い正規化に基づく手法
- PER: positionとは独立したError Rateを算出
- CDER: edit operationにおけるblock reorderingをモデル化
- CHARACTER / EED: character levelで評価
## Embedding-based Metrics
- MEANT 2.0: lexical, structuralの類似度を測るために、word embeddingとshallow semantic parsesを利用
- YISI-1: MEANT 2.0と同様だが、semantic parseの利用がoptionalとなっている
これらはBERTScoreと同様の、similarityをシンプルに測るアプローチで、BERTScoreもこれにinspireされている。が、BERTScoreはContextualized Embeddingを利用する点が異なる。また、linguistic structureを生成するような外部ツールは利用しない。これにより、BERTScoreをシンプルで、新たなlanguageに対しても使いやすくしている。greedy matchingの代わりに、WMD, WMDo, SMSはearth mover's distanceに基づく最適なマッチングを利用することを提案している。greedy matchingとoptimal matchingのtradeoffについては研究されている。sentence-levelのsimilarityを計算する手法も提案されている。これらと比較して、BERTScoreのtoken-levelの計算は、重要度に応じて、tokenに対して異なる重みづけをすることができる。
## Learned Metrics
様々なmetricが、human judgmentsとのcorrelationに最適化するために訓練されてきた。
- BEER: character-ngram, word bigramに基づいたregresison modelを利用
- BLEND: 29の既存のmetricを利用してregressionを実施
- RUSE: 3種類のpre-trained sentence embedding modelを利用する手法
これらすべての手法は、コストのかかるhuman judgmentsによるsupervisionが必要となる。そして、新たなドメインにおける汎化能力の低さのリスクがある。input textが人間が生成したものか否か予測するneural modelを訓練する手法もある。このアプローチは特定のデータに対して最適化されているため、新たなデータに対して汎化されないリスクを持っている。これらと比較して、BERTScoreは特定のevaluation taskに最適化されているモデルではない。
# BERTScore
referenceとcandidateのトークン間のsimilarityの最大値をとり、それらを集約することで、Precision, Recallを定義し、PrecisionとRecallを利用してF値も計算する。Recallは、reference中のすべてのトークンに対して、candidate中のトークンとのcosine similarityの最大値を測る。一方、Precisionは、candidate中のすべてのトークンに対して、reference中のトークンとのcosine similarityの最大値を測る。ここで、類似度の式が単なる内積になっているが、これはpre-normalized vectorを利用する前提であり、正規化が必要ないからである。
また、IDFによるトークン単位でのweightingを実施する。IDFはテストセットの値を利用する。TFを使わない理由は、BERTScoreはsentence同士を比較する指標であるため、TFは基本的に1となりやすい傾向にあるためである。IDFを計算する際は出現数を+1することによるスムージングを実施。
さらに、これはBERTScoreのランキング能力には影響を与えないが、BERTScoreの値はコサイン類似度に基づいているため、[-1, 1]となるが、実際は学習したcontextual embeddingのgeometryに値域が依存するため、もっと小さなレンジでの値をとることになってしまう。そうすると、人間による解釈が難しくなる(たとえば、極端な話、スコアの0.1程度の変化がめちゃめちゃ大きな変化になってしまうなど)ため、rescalingを実施。rescalingする際は、monolingualコーパスから、ランダムにsentenceのペアを作成し(BETRScoreが非常に小さくなるケース)、これらのBERTScoreを平均することでbを算出し、bを利用してrescalingした。典型的には、rescaling後は典型的には[0, 1]の範囲でBERTScoreは値をとる(ただし数式を見てわかる通り[0, 1]となることが保証されているわけではない点に注意)。これはhuman judgmentsとのcorrelationとランキング性能に影響を与えない(スケールを変えているだけなので)。
# 実験
## Contextual Embedding Models
12種類のモデルで検証。BERT, RoBERTa, XLNet, XLMなど。
## Machine Translation
WMT18のmetric evaluation datasetを利用。149種類のMTシステムの14 languageに対する翻訳結果, gold referencesと2種類のhuman judgment scoreが付与されている。segment-level human judgmentsは、それぞれのreference-candiate pairに対して付与されており、system-level human judgmentsは、それぞれのシステムに対して、test set全体のデータに基づいて、単一のスコアが付与されている。pearson correlationの絶対値と、kendall rank correration τをmetricsの品質の評価に利用。そしてpeason correlationについてはWilliams test、kendall τについては、bootstrap re-samplingによって有意差を検定した。システムレベルのスコアをBERTScoreをすべてのreference-candidate pairに対するスコアをaveragingすることによって求めた。また、ハイブリッドシステムについても実験をした。具体的には、それぞれのreference sentenceについて、システムの中からランダムにcandidate sentenceをサンプリングした。これにより、system-level experimentをより多くのシステムで実現することができる。ハイブリッドシステムのシステムレ4ベルのhuman judgmentsは、WMT18のsegment-level human judgmentsを平均することによって作成した。BERTScoreを既存のメトリックと比較した。
通常の評価に加えて、モデル選択についても実験した。10kのハイブリッドシステムを利用し、10kのうち100をランダムに選択、そして自動性能指標でそれらをランキングした。このプロセスを100K回繰り返し、human rankingとmetricのランキングがどれだけagreementがあるかをHits@1で評価した(best systemの一致で評価)。モデル選択の指標として新たにtop metric-rated systemとhuman rankingの間でのMRR, 人手評価でtop-rated systemとなったシステムとのスコアの差を算出した。WMT17, 16のデータセットでも同様の評価を実施した。
## Image Captioning
COCO 2015 captioning challengeにおける12種類のシステムのsubmissionデータを利用。COCO validationセットに対して、それぞれのシステムはimageに対するcaptionを生成し、それぞれのimageはおよそ5個のreferenceを持っている。先行研究にならい、Person Correlationを2種類のシステムレベルmetricで測定した。
- M1: 人間によるcaptionと同等、あるいはそれ以上と評価されたcaptionの割合
- M2: 人間によるcaptionと区別がつかないcaptionの割合
BERTScoreをmultiple referenceに対して計算し、最も高いスコアを採用した。比較対象のmetricはtask-agnostic metricを採用し、BLEU, METEOR, CIDEr, BEER, EED, CHRF++, CHARACTERと比較した。そして、2種類のtask-specific metricsとも比較した:SPICE, LEIC
# 実験結果
## Machine Translation
system-levelのhuman judgmentsとのcorrelationの比較、hybrid systemとのcorrelationの比較、model selection performance
to-Englishの結果では、BERTScoreが最も一貫して性能が良かった。RUSEがcompetitiveな性能を示したが、RUSEはsupervised methodである。from-Englishの実験では、RUSEは追加のデータと訓練をしないと適用できない。
以下は、segment-levelのcorrelationを示したものである。BERTScoreが一貫して高い性能を示している。BLEUから大幅な性能アップを示しており、特定のexampleについての良さを検証するためには、BERTScoreが最適であることが分かる。BERTScoreは、RUSEをsignificantlyに上回っている。idfによる重要度のweightingによって、全体としては、small benefitがある場合があるが全体としてはあんまり効果がなかった。importance weightingは今後の課題であり、テキストやドメインに依存すると考えられる。FBERTが異なる設定でも良く機能することが分かる。異なるcontextual embedding model間での比較などは、appendixに示す。
## Image Captioning
task-agnostic metricの間では、BETRScoreはlarge marginで勝っている。image captioningはchallengingな評価なので、n-gramマッチに基づくBLEU, ROUGEはまったく機能していない。また、idf weightingがこのタスクでは非常に高い性能を示した。これは人間がcontent wordsに対して、より高い重要度を置いていることがわかる。最後に、LEICはtrained metricであり、COCO dataに最適化されている。この手法は、ほかのすべてのmetricを上回った。
## Speed
pre-trained modelを利用しているにもかかわらず、BERTScoreは比較的高速に動作する。192.5 candidate-reference pairs/secondくらい出る(GTX-1080Ti GPUで)。WMT18データでは、15.6秒で処理が終わり、SacreBLEUでは5.4秒である。計算コストそんなにないので、BERTScoreはstoppingのvalidationとかにも使える。
# Robustness analysis
BERTScoreのロバスト性をadversarial paraphrase classificationでテスト。Quora Question Pair corpus (QQP) を利用し、Word Scrambling dataset (PAWS) からParaphrase Adversariesを取得。どちらのデータも、各sentenceペアに対して、それらがparaphraseかどうかラベル付けされている。QQPの正例は、実際のduplicate questionからきており、負例は関連するが、異なる質問からきている。PAWSのsentence pairsは単語の入れ替えに基づいているものである。たとえば、"Flights from New York to Florida" は "Flights from Florida to New York" のように変換され、良いclassifierはこれらがparaphraseではないと認識できなければならない。PAWSはPAWS_QQPとPAWS_WIKIによって構成さえrており、PAWS_QQPをdevelpoment setとした。automatic metricsでは、paraphrase detection training dataは利用しないようにした。自動性能指標で高いスコアを獲得するものは、paraphraseであることを想定している。
下図はAUCのROC curveを表しており、PAWS_QQPにおいて、QQPで訓練されたclassifierはrandom guessよりも性能が低くなることが分かった。つまりこれらモデルはadversaial exampleをparaphraseだと予測してしまっていることになる。adversarial examplesがtrainingデータで与えられた場合は、supervisedなモデルも分類ができるようになる。が、QQPと比べると性能は落ちる。多くのmetricsでは、QQP ではまともなパフォーマンスを示すが、PAWS_QQP では大幅なパフォーマンスの低下を示し、ほぼrandomと同等のパフォーマンスとなる。これは、これらの指標がより困難なadversarial exampleを区別できないことを示唆している。一方、BERTSCORE のパフォーマンスはわずかに低下するだけであり、他の指標よりもロバスト性が高いことがわかる。
# Discussion
- BERTScoreの単一の設定が、ほかのすべての指標を明確に上回るということはない
- ドメインや言語を考慮して、指標や設定を選択すべき
- 一般的に、機械翻訳の評価にはFBERTを利用することを推奨
- 英語のテキスト生成の評価には、24層のRoBERTa largeモデルを使用して、BERTScoreを計算したほうが良い
- 非英語言語については、多言語のBERT_multiが良い選択肢だが、このモデルで計算されたBERTScoreは、low resource languageにおいて、パフォーマンスが安定しているとは言えない
#NeuralNetwork #Pocket #NLP #LanguageModel #Zero/Few/ManyShotPrompting #In-ContextLearning #NeurIPS Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 GPT Summary- GPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 Comment
In-Context Learningを提案した論文
論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。
この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。
#NeuralNetwork #ComputerVision #EfficiencyImprovement #Pocket #ICML #Backbone Issue Date: 2025-05-12 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan+, ICML'19 GPT Summary- 本論文では、ConvNetsのスケーリングを深さ、幅、解像度のバランスを考慮して体系的に研究し、新しいスケーリング手法を提案。これにより、MobileNetsやResNetのスケールアップを実証し、EfficientNetsという新しいモデルファミリーを設計。特にEfficientNet-B7は、ImageNetで84.3%のトップ1精度を達成し、従来のConvNetsよりも小型かつ高速である。CIFAR-100やFlowersなどのデータセットでも最先端の精度を記録。ソースコードは公開されている。 Comment
元論文をメモってなかったので追加。
- EfficientNet解説, omiita (オミータ), 2019
も参照のこと。
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Pocket #Evaluation #RecSys Issue Date: 2022-04-11 [Paper Note] Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, Maurizio Ferrari Dacrema+, RecSys'19, 2019.07 GPT Summary- 深層学習技術はレコメンダーシステムの研究で広く用いられているが、再現性やベースライン選択に問題がある。18のトップnレコメンデーションアルゴリズムを分析した結果、再現できたのは7つのみで、6つは単純なヒューリスティック手法に劣っていた。残りの1つはベースラインを上回ったが、非ニューラル手法には及ばなかった。本研究は機械学習の実践における問題を指摘し、改善を呼びかけている。 Comment
RecSys'19のベストペーパー
日本語解説:
https://qiita.com/smochi/items/98dbd9429c15898c5dc7
重要研究
#NeuralNetwork #Pocket #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #KeyPoint Notes Issue Date: 2021-05-28 [Paper Note] EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction, Qi Liu+, IEEE TKDE'19, 2019.06 GPT Summary- 学生のパフォーマンス予測のために、演習記録と教材情報を統合するEERNNフレームワークを提案。双方向LSTMを用いて演習内容をエンコードし、マルコフ特性とアテンションメカニズムを持つ2つの実装を提供。さらに、知識概念を追跡するEKTに拡張し、演習が知識習得に与える影響を定量化。実験により、予測精度と解釈可能性の向上が確認された。 Comment
DKT等のDeepなモデルでは、これまで問題テキストの情報等は利用されてこなかったが、learning logのみならず、問題テキストの情報等もKTする際に活用した研究。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
をより洗練させjournal化させたものだと思われる。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
ではKTというより、問題の正誤を予測するモデルとなっており、個々のconceptに対するproficiencyを推定するというKTの考え方はあまり導入されていなかった。
EKTの方では、個々のknowledge componentのproficiency scoreを算出する方法も提案されている。
モデル自体は、基本的にはattention-basedなRNNモデル。

Exercise EmbeddingはBidireictional-RNNを利用して、問題文をエンコードすることによって求める。
EKTによるmastery levelを可視化したもの。T=0とT=30では各conceptに対するmastery levelが大きく異なっている。基本的に、たくさん正解したconceptはmastery levelが向上し、不正解しまくったconceptはどんどんmastery levelがshrinkしていく。
予測性能。問題のContentを考慮することで、正誤予測のAUCは圧倒的に高くなる。DKTよりも10ポイント程度EKTAの方がAUCが高いように見える。
各モデルの特徴や、knowledge tracingが行えるか否か、といった性質を整理した表。わかりやすい。しかしDKTのknowledge tracking?が×になっているのは誤りでは?
各knowledge conceptの時刻tにおけるmastery levelの求め方。
EKTでは、生徒の各knowledge conceptの状態を保持した行列H_t^i(0 <= i <= # of concepts)を保持している。correctness probabilityを最終的に求める際には、H_t^iの各knowledge conceptに対する重みβ_iで重みづけた上でsummationをとり、各知識の状態を統合したベクトルsを作成し、sとexercise embedding xをconcatした上でスコアを予測する。
このスコアの予測部分を変更し、β_iをmastery levelを測定したいconceptのone-hot encodingに置き換え、さらにexercise embeddingをmaskしたベクトル=masked exercise embedding = zero vectorをconcatした上で、スコアを予測するようにする。
こうすることで、exerciseの影響を除き、かつone-hot encodingで指定したknowledgeのmasteryのみが考慮されたスコアを抽出できるため、そのスコアをmastery levelとする。
単にStudent Performance Predictionして終わり!ってんじゃなく、knowledge tracing的な側面をきちんと考慮している点で、この研究めっちゃ好き。
スキルタグごとにLSTMのhidden_stateを保持しないといけないので、メモリの消費量がえぐいことになりそう。小規模なスキルタグのデータセットじゃないと動かないのでは?
実際、実験では37種類のスキルタグが存在するデータセットしか扱っていない。
#NeuralNetwork #MachineTranslation #Pocket #Subword #ACL #Tokenizer #read-later Issue Date: 2025-11-19 [Paper Note] Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates, Taku Kudo, ACL'18, 2018.04 GPT Summary- サブワード単位はNMTのオープンボキャブラリー問題を軽減するが、セグメンテーションの曖昧さが存在する。本研究では、この曖昧さを利用してNMTのロバスト性を向上させるため、サブワードの正則化手法を提案し、確率的にサンプリングされた複数のセグメンテーションでモデルを訓練する。また、ユニグラム言語モデルに基づく新しいセグメンテーションアルゴリズムも提案。実験により、特にリソースが限られた設定での改善を示した。 #NeuralNetwork #Pocket #NLP #MultiLingual #Tokenizer Issue Date: 2025-11-19 [Paper Note] SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing, Taku Kudo+, arXiv'18, 2018.08 GPT Summary- 本論文では、Neural Machine Translation向けの言語に依存しないサブワードトークナイザー「SentencePiece」を紹介。生の文から直接サブワードモデルを訓練でき、エンドツーエンドのシステム構築が可能。英日機械翻訳の実験で高精度を確認し、さまざまな構成での性能比較も行った。SentencePieceはオープンソースで提供されている。 Comment
真の多言語処理を実現できる価値
著者による解説:
https://qiita.com/taku910/items/7e52f1e58d0ea6e7859c
#NeuralNetwork #Analysis #MachineLearning #Pocket #ReinforcementLearning #AAAI #Reproducibility #One-Line Notes Issue Date: 2025-10-22 [Paper Note] Deep Reinforcement Learning that Matters, Peter Henderson+, AAAI'18, 2017.09 GPT Summary- 深層強化学習(RL)の進展を持続させるためには、既存研究の再現性と新手法の改善を正確に評価することが重要である。しかし、非決定性や手法のばらつきにより、結果の解釈が難しくなることがある。本論文では、再現性や実験報告の課題を調査し、一般的なベースラインとの比較における指標のばらつきを示す。さらに、深層RLの結果を再現可能にするためのガイドラインを提案し、無駄な努力を最小限に抑えることで分野の進展を促進することを目指す。 Comment
日本語解説: https://www.slideshare.net/slideshow/dldeep-reinforcement-learning-that-matters-83905622/83905622
再現性という観点とは少し異なるのかもしれないが、最近のRLによるpost-trainingについては、以下の研究でScaling Lawsが導入されている。
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
が、結局現在も多くのRL手法が日夜出てきており、再現性に関しては同じような状況に陥っていそうである。
#RecommenderSystems #Pocket #Transformer #SequentialRecommendation #ICDM Issue Date: 2025-07-04 [Paper Note] Self-Attentive Sequential Recommendation, Wang-Cheng Kang+, ICDM'18 GPT Summary- 自己注意に基づく逐次モデル(SASRec)を提案し、マルコフ連鎖と再帰型ニューラルネットワークの利点を統合。SASRecは、少数のアクションから次のアイテムを予測し、スパースおよび密なデータセットで最先端のモデルを上回る性能を示す。モデルの効率性と注意重みの視覚化により、データセットの密度に応じた適応的な処理が可能であることが確認された。 #RecommenderSystems #NeuralNetwork #General #Embeddings #MachineLearning #RepresentationLearning #AAAI Issue Date: 2017-12-28 [Paper Note] StarSpace: Embed All The Things, Wu+, AAAI'18 Comment
分類やランキング、レコメンドなど、様々なタスクで汎用的に使用できるEmbeddingの学習手法を提案。
Embeddingを学習する対象をEntityと呼び、Entityはbag-of-featureで記述される。
Entityはbag-of-featureで記述できればなんでもよく、
これによりモデルの汎用性が増し、異なる種類のEntityでも同じ空間上でEmbeddingが学習される。
学習方法は非常にシンプルで、Entity同士のペアをとったときに、relevantなpairであれば類似度が高く、
irelevantなペアであれば類似度が低くなるようにEmbeddingを学習するだけ。
たとえば、Entityのペアとして、documentをbag-of-words, bag-of-ngrams, labelをsingle wordで記述しテキスト分類、
あるいは、user_idとユーザが過去に好んだアイテムをbag-of-wordsで記述しcontent-based recommendationを行うなど、 応用範囲は幅広い。
5種類のタスクで提案手法を評価し、既存手法と比較して、同等かそれ以上の性能を示すことが示されている。
手法の汎用性が高く学習も高速なので、色々な場面で役に立ちそう。
また、異なる種類のEntityであっても同じ空間上でEmbeddingが学習されるので、学習されたEmbeddingの応用先が広く有用。
実際にSentimentAnalysisで使ってみたが(ポジネガ二値分類)、少なくともBoWのSVMよりは全然性能良かったし、学習も早いし、次元数めちゃめちゃ少なくて良かった。
StarSpaceで学習したembeddingをBoWなSVMに入れると性能が劇的に改善した。
解説:
https://www.slideshare.net/akihikowatanabe3110/starspace-embed-all-the-things
#NeuralNetwork #MachineLearning #Pocket #Catastrophic Forgetting Issue Date: 2024-10-10 Overcoming catastrophic forgetting in neural networks, James Kirkpatrick+, N_A, PNAS'17 GPT Summary- タスクを逐次的に学習する能力を持つネットワークを訓練する方法を提案。重要な重みの学習を選択的に遅くすることで、古いタスクの記憶を維持。MNISTやAtari 2600ゲームでの実験により、アプローチの効果とスケーラビリティを実証。 Comment
Catastrophic Forgettingを防ぐEWCを提案した論文
日本語解説: https://qiita.com/yu4u/items/90c039ec2f1d4f2d2414
ポイント解説:
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Pocket #MatrixFactorization #WWW Issue Date: 2018-02-16 [Paper Note] Neural Collaborative Filtering, Xiangnan He+, arXiv'17 GPT Summary- 深層ニューラルネットワークを用いたレコメンダーシステムの研究が少ない中、本研究では協調フィルタリングの問題に取り組むため、NCF(Neural network-based Collaborative Filtering)フレームワークを提案。内積をニューラルアーキテクチャに置き換え、ユーザーとアイテムの相互作用を多層パーセプトロンでモデル化。実験により、提案手法が最先端技術に対して顕著な改善を示し、深層ニューラルネットワークの層を深くすることでレコメンデーション性能が向上することが確認された。 Comment
Collaborative FilteringをMLPで一般化したNeural Collaborative Filtering、およびMatrix Factorizationはuser, item-embeddingのelement-wise product + linear transofmration + activation で一般化できること(GMF; Generalized Matrix Factorization)を示し、両者を組み合わせたNeural Matrix Factorizationを提案している。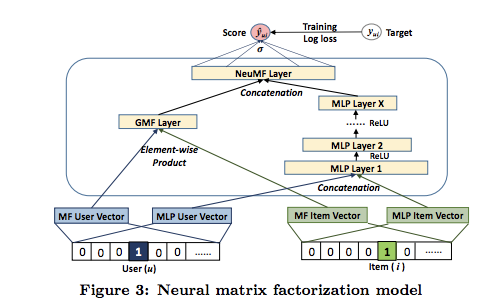
学習する際は、Implicit Dataの場合は負例をNegative Samplingし、LogLoss(Binary Cross-Entropy Loss)で学習する。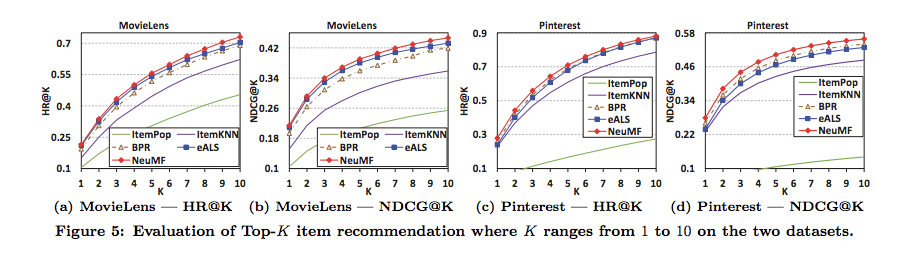
Neural Matrix Factorizationが、ItemKNNやBPRといったベースラインをoutperform
Negative Samplingでサンプリングする負例の数は、3~4程度で良さそう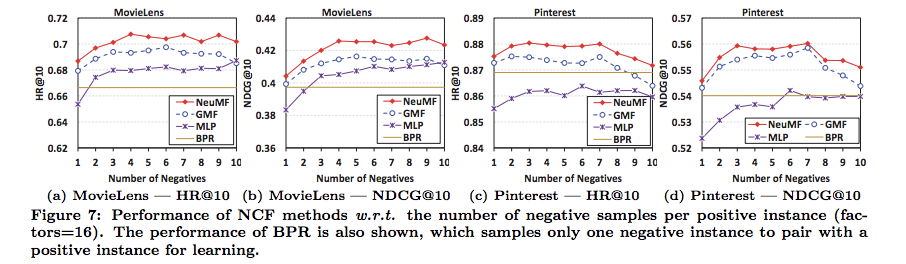
#NeuralNetwork #MachineTranslation #Pocket #NLP #Transformer #Attention #PositionalEncoding #NeurIPS Issue Date: 2018-01-19 [Paper Note] Attention Is All You Need, Ashish Vaswani+, arXiv'17 GPT Summary- Transformerは、再帰や畳み込みを排除し、注意機構のみに基づいた新しいネットワークアーキテクチャである。実験により、機械翻訳タスクで優れた品質を示し、トレーニング時間を大幅に短縮。WMT 2014の英独翻訳で28.4 BLEU、英仏翻訳で41.8 BLEUを達成し、既存モデルを上回る性能を示した。また、英語の構文解析にも成功裏に適用可能であることを示した。 Comment
Transformer (self-attentionを利用) 論文
解説スライド:
https://www.slideshare.net/DeepLearningJP2016/dlattention-is-all-you-need
解説記事:
https://qiita.com/nishiba/items/1c99bc7ddcb2d62667c6
* 新しい翻訳モデル(Transformer)を提案。既存のモデルよりも並列化に対応しており、短時間の訓練で(既存モデルの1/4以下のコスト)高いBLEUスコアを達成した。
* TransformerはRNNやCNNを使わず、attentionメカニズムに基づいている。
(解説より)
分かりやすい:
https://qiita.com/halhorn/items/c91497522be27bde17ce
Transformerの各コンポーネントでのoutputのshapeや、attention_maskの形状、実装について記述されており有用:
https://qiita.com/FuwaraMiyasaki/items/239f3528053889847825
集合知
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #EMNLP Issue Date: 2018-01-01 [Paper Note] Challenges in Data-to-Document Generation, Wiseman+ (with Rush), EMNLP'17 Comment
・RotoWire(NBAのテーブルデータ + サマリ)データを収集し公開
・Rotowireデータの統計量
【モデルの概要】
・attention-based encoder-decoder model
・BaseModel
- レコードデータ r の各要素(r.e: チーム名等のENTITY r.t: POINTS等のデータタイプ, r.m: データのvalue)からembeddingをlookupし、1-layer MLPを適用し、レコードの各要素のrepresentation(source data records)を取得
- Luongらのattentionを利用したLSTM Decoderを用意し、source data recordsとt-1ステップ目での出力によって条件付けてテキストを生成していく
- negative log likelihoodがminimizeされるように学習する
・Copying
- コピーメカニズムを導入し、生成時の確率分布に生成テキストを入力からコピーされるか否かを含めた分布からテキストを生成。コピーの対象は、入力レコードのvalueがコピーされるようにする。
- コピーメカニズムには下記式で表現される Conditional Copy Modelを利用し、p(zt|y1:t-1, s)はMLPで表現する。
- またpcopyは、生成している文中にあるレコードのエンティティとタイプが出現する場合に、対応するvalueをコピーし生成されるように、下記式で表現する
- ここで r(yt) =
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #ACL Issue Date: 2017-12-31 [Paper Note] Get To The Point: Summarization with Pointer-Generator Networks, See+, ACL'17 Comment
単語の生成と単語のコピーの両方を行えるハイブリッドなニューラル文書要約モデルを提案。
同じ単語の繰り返し現象(repetition)をなくすために、Coverage Mechanismも導入した。
[Paper Note] Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL'16
などと比較するとシンプルなモデル。
一般的に、PointerGeneratorと呼ばれる。
OpenNMTなどにも実装されている:
https://opennmt.net/OpenNMT-py/_modules/onmt/modules/copy_generator.html
(参考)Pointer Generator Networksで要約してみる:
https://qiita.com/knok/items/9a74430b279e522d5b93
#NeuralNetwork #Sentence #Embeddings #NLP #RepresentationLearning #ICLR Issue Date: 2017-12-28 [Paper Note] A structured self-attentive sentence embedding, Li+ (Bengio group), ICLR'17 Comment
OpenReview: https://openreview.net/forum?id=BJC_jUqxe
#NeuralNetwork #Pocket #SpeechProcessing Issue Date: 2025-06-13 [Paper Note] WaveNet: A Generative Model for Raw Audio, Aaron van den Oord+, arXiv'16 GPT Summary- 本論文では、音声波形を生成する深層ニューラルネットワークWaveNetを提案。自己回帰的なモデルでありながら、効率的に音声データを訓練可能。テキストから音声への変換で最先端の性能を示し、人間のリスナーに自然な音と評価される。話者の特性を忠実に捉え、アイデンティティに基づく切り替えが可能。音楽生成にも応用でき、リアルな音楽の断片を生成。また、音素認識のための有望な識別モデルとしての利用も示唆。 #RecommenderSystems #NeuralNetwork #Pocket #RecSys Issue Date: 2018-12-27 [Paper Note] Deep Neural Networks for YouTube Recommendations, Covington+, RecSys'16 #NeuralNetwork #MachineLearning #Pocket #GraphConvolutionalNetwork #NeurIPS Issue Date: 2018-03-30 [Paper Note] Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering, Michaël Defferrard+, NIPS'16 GPT Summary- 本研究では、CNNを用いて低次元のグリッドから高次元のグラフドメインへの一般化を探求。スペクトルグラフ理論に基づくCNNの定式化を提案し、古典的CNNと同等の計算複雑性を維持しつつ、任意のグラフ構造に対応可能。MNISTおよび20NEWSの実験により、グラフ上での局所的特徴学習の能力を示した。 Comment
GCNを勉強する際は読むと良いらしい。
あわせてこのへんも:
Semi-Supervised Classification with Graph Convolutional Networks, Kipf+, ICLR'17
https://github.com/tkipf/gcn
#NeuralNetwork #MachineLearning #Normalization Issue Date: 2018-02-19 [Paper Note] Layer Normalization, Ba+, arXiv'16 GPT Summary- バッチ正規化の代わりにレイヤー正規化を用いることで、リカレントニューラルネットワークのトレーニング時間を短縮。レイヤー内のニューロンの合計入力を正規化し、各ニューロンに独自の適応バイアスとゲインを適用。トレーニング時とテスト時で同じ計算を行い、隠れ状態のダイナミクスを安定させる。実証的に、トレーニング時間の大幅な短縮を確認。 Comment
解説スライド:
https://www.slideshare.net/KeigoNishida/layer-normalizationnips
#NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #CoNLL Issue Date: 2018-02-14 [Paper Note] Generating Sentences from a Continuous Space, Samuel R. Bowman+, CoNLL'16 GPT Summary- RNNベースの変分オートエンコーダ生成モデルを導入し、文全体の分散潜在表現を組み込むことで、文のスタイルやトピックなどの特性を明示的にモデル化。潜在空間を通じて新しい文を生成し、欠損単語の補完効果を実証。モデルの特性と使用に関する否定的な結果も示す。 Comment
VAEを利用して文生成
【Variational Autoencoder徹底解説】
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #WSDM Issue Date: 2018-01-02 [Paper Note] Collaborative Denoising Auto-Encoders for Top-N Recommender Systems, Wu+, WSDM'16 Comment
Denoising Auto-Encoders を用いたtop-N推薦手法、Collaborative Denoising Auto-Encoder (CDAE)を提案。
モデルベースなCollaborative Filtering手法に相当する。corruptedなinputを復元するようなDenoising Auto Encoderのみで推薦を行うような手法は、この研究が初めてだと主張。
学習する際は、userのitemsetのsubsetをモデルに与え(noiseがあることに相当)、全体のitem setを復元できるように、学習する(すなわちDenoising Auto-Encoder)。
推薦する際は、ユーザのその時点でのpreference setをinputし、new itemを推薦する。
[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, arXiv'14 もStacked Denoising Auto EncoderとCollaborative Topic Regression [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11 を利用しているが、[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, arXiv'14 ではarticle recommendationというspecificな問題を解いているのに対して、提案手法はgeneralなtop-N推薦に利用できることを主張。
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #ACL Issue Date: 2017-12-31 [Paper Note] Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL'16 Comment
単語のコピーと生成、両方を行えるネットワークを提案。
location based addressingなどによって、生成された単語がsourceに含まれていた場合などに、copy-mode, generate-modeを切り替えるような仕組みになっている。
[Paper Note] Pointing the unknown words, Gulcehre+, ACL'16
と同じタイミングで発表
#NeuralNetwork #MachineTranslation #NLP #ACL Issue Date: 2017-12-28 [Paper Note] Pointing the unknown words, Gulcehre+, ACL'16 Comment
テキストを生成する際に、source textからのコピーを行える機構を導入することで未知語問題に対処した話
CopyNetと同じタイミングで(というか同じconferenceで)発表
#NeuralNetwork #ComputerVision #Pocket #Encoder-Decoder #Backbone #U-Net Issue Date: 2025-09-22 [Paper Note] U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger+, MICCAI'15, 2015.05 GPT Summary- データ拡張を活用した新しいネットワークアーキテクチャを提案し、少ない注釈付きサンプルからエンドツーエンドでトレーニング可能であることを示す。電子顕微鏡スタックの神経構造セグメンテーションで従来手法を上回り、透過光顕微鏡画像でも優れた結果を達成。512x512画像のセグメンテーションは1秒未満で完了。実装とトレーニング済みネットワークは公開されている。 #NeuralNetwork #MachineTranslation #Pocket #NLP #Attention #ICLR Issue Date: 2025-05-12 Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15 GPT Summary- ニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment
(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している)
#MachineLearning #Pocket #LanguageModel #Transformer #ICML #Normalization Issue Date: 2025-04-02 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe+, ICML'15 GPT Summary- バッチ正規化を用いることで、深層ニューラルネットワークのトレーニングにおける内部共変量シフトの問題を解決し、高い学習率を可能にし、初期化の注意を軽減。これにより、同じ精度を14倍少ないトレーニングステップで達成し、ImageNet分類で最良の公表結果を4.9%改善。 Comment
メモってなかったので今更ながら追加した
共変量シフトやBatch Normalizationの説明は
- [Paper Note] Layer Normalization, Ba+, arXiv'16
記載のスライドが分かりやすい。
#NeuralNetwork #MachineTranslation #NLP #EMNLP Issue Date: 2021-06-02 Effective Approaches to Attention-based Neural Machine Translation, Luong+, EMNLP'15 Comment
Luong論文。attentionの話しはじめると、だいたいBahdanau+か、Luong+論文が引用される。
Global Attentionと、Local Attentionについて記述されている。Global Attentionがよく利用される。
Global Attention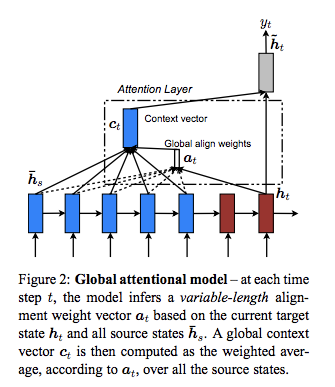
Local Attention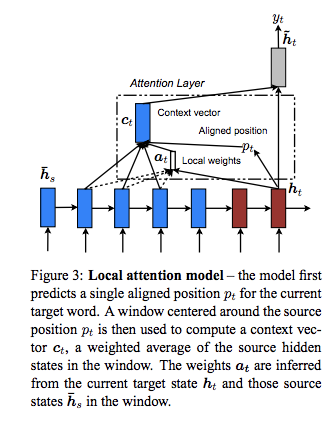
やはり菊池さんの解説スライドが鉄板。
https://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention
参考までに、LuongらのGlobal Attentionの計算の流れは下記となっている:
- h_t -> a_t -> c_t -> h^~_t
BahdanauらのAttentionは下記
- h_t-1 -> a_t -> c_t -> h_t
t-1のhidden stateを使うのか、input feeding後の現在のhidden stateをattention weightの計算に使うのかが異なっている。
また、過去のalignmentの情報を考慮した上でデコーディングしていくために、input-feeding approachも提案
input-feeding appproachでは、t-1ステップ目のoutputの算出に使ったh^~_t(hidden_stateとcontext vectorをconcatし、tanhのactivationを噛ませた線形変換を行なったベクトル)を、時刻tのinput embeddingにconcatして、RNNに入力する。
#RecommenderSystems #Pocket #SessionBased #ICLR #SequentialRecommendation Issue Date: 2019-08-02 [Paper Note] Session-based Recommendations with Recurrent Neural Networks, Balázs Hidasi+, arXiv'15 GPT Summary- RNNを用いたセッションベースのレコメンダーシステムを提案。短いユーザーヒストリーに基づく推薦の精度向上を目指し、セッション全体をモデル化。ランキング損失関数などの修正を加え、実用性を考慮。実験結果は従来のアプローチに対して顕著な改善を示す。 Comment
RNNを利用したsequential recommendation (session-based recommendation)の先駆け的論文。
日本語解説: https://qiita.com/tatamiya/items/46e278a808a51893deac
#AdaptiveLearning #StudentPerformancePrediction #NeurIPS #KeyPoint Notes #Reference Collection Issue Date: 2018-12-22 [Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15 Comment
Knowledge Tracingタスクとは:
特定のlearning taskにおいて、生徒によってとられたインタラクションの系列x0, ..., xtが与えられたとき、次のインタラクションxt+1を予測するタスク
典型的な表現としては、xt={qt, at}, where qt=knowledge component (KC) ID (あるいは問題ID)、at=正解したか否か
モデルが予測するときは、qtがgivenな時に、atを予測することになる
Contribution:
1. A novel way to encode student interactions as input to a recurrent neural network.
2. A 25% gain in AUC over the best previous result on a knowledge tracing benchmark.
3. Demonstration that our knowledge tracing model does not need expert annotations.
4. Discovery of exercise influence and generation of improved exercise curricula.
モデル:
Inputは、ExerciseがM個あったときに、M個のExerciseがcorrectか否かを表すベクトル(長さ2Mベクトルのone-hot)。separateなrepresentationにするとパフォーマンスが下がるらしい。
Output ytの長さは問題数Mと等しく、各要素は、生徒が対応する問題を正答する確率。
InputとしてExerciseを用いるか、ExerciseのKCを用いるかはアプリケーション次第っぽいが、典型的には各スキルの潜在的なmasteryを測ることがモチベーションなのでKCを使う。
(もし問題数が膨大にあるような設定の場合は、各問題-正/誤答tupleに対して、random vectorを正規分布からサンプリングして、one-hot high-dimensional vectorで表現する。)
hidden sizeは200, mini-batch sizeは100としている。
[Educational Applicationsへの応用]
生徒へ最適なパスの学習アイテムを選んで提示することができること
生徒のknowledge stateを予測し、その後特定のアイテムを生徒にassignすることができる。たとえば、生徒が50個のExerciseに回答した場合、生徒へ次に提示するアイテムを計算するだけでなく、その結果期待される生徒のknowledge stateも推測することができる
Exercises間の関係性を見出すことができる
y( j | i )を考える。y( j | i )は、はじめにexercise iを正答した後に、second time stepでjを正答する確率。これによって、pre-requisiteを明らかにすることができる。
[評価]
3種類のデータセットを用いる。
1. simulated Data
2000人のvirtual studentを作り、1〜5つのコンセプトから生成された、50問を、同じ順番で解かせた。このとき、IRTモデルを用いて、シミュレーションは実施した。このとき、hidden stateのラベルには何も使わないで、inputは問題のIDと正誤データだけを与えた。さらに、2000人のvirtual studentをテストデータとして作り、それぞれのコンセプト(コンセプト数を1〜5に変動させる)に対して、20回ランダムに生成したデータでaccuracyの平均とstandard errorを測った。
2. Khan Academy Data
1.4MのExerciseと、69の異なるExercise Typeがあり、47495人の生徒がExerciseを行なっている。
PersonalなInformationは含んでいない。
3. Assistsments bemchmark Dataset
2009-2011のskill builder public benchmark datasetを用いた。Assistmentsは、online tutorが、数学を教えて、教えるのと同時に生徒を評価するような枠組みである。
それぞれのデータセットに対して、AUCを計算。
ベースラインは、BKTと生徒がある問題を正答した場合の周辺確率?

simulated dataの場合、問題番号5がコンセプト1から生成され、問題番号22までの問題は別のコンセプトから生成されていたにもかかわらず、きちんと二つの問題の関係をとらえられていることがわかる。
Khan Datasetについても同様の解析をした。これは、この結果は専門家が見たら驚くべきものではないかもしれないが、モデルが一貫したものを学習したと言える。
[Discussion]
提案モデルの特徴として、下記の2つがある:
専門家のアノテーションを必要としない(concept patternを勝手に学習してくれる)
ベクトル化された生徒のinputであれば、なんでもoperateすることができる
drawbackとしては、大量のデータが必要だということ。small classroom environmentではなく、online education environmentに向いている。
今後の方向性としては、
・incorporate other feature as inputs (such as time taken)
・explore other educational impacts (hint generation, dropout prediction)
・validate hypotheses posed in education literature (such as spaced repetition, modeling how students forget)
・open-ended programmingとかへの応用とか(proramのvectorizationの方法とかが最近提案されているので)
などがある。
knewtonのグループが、DKTを既存手法であるIRTの変種やBKTの変種などでoutperformすることができることを示す:
https://arxiv.org/pdf/1604.02336.pdf
vanillaなDKTはかなりナイーブなモデルであり、今後の伸びが結構期待できると思うので、単純にoutperformしても、今後の発展性を考えるとやはりDKTには注目せざるを得ない感
DKT元論文では、BKTを大幅にoutperformしており、割と衝撃的な結果だったようだが、
後に論文中で利用されているAssistmentsデータセット中にdupilcate entryがあり、
それが原因で性能が不当に上がっていることが判明。
結局DKTの性能的には、BKTとどっこいみたいなことをRyan Baker氏がedXで言っていた気がする。
Deep Knowledge TracingなどのKnowledge Tracingタスクにおいては、
基本的に問題ごとにKnowledge Component(あるいは知識タグ, その問題を解くのに必要なスキルセット)が付与されていることが前提となっている。
ただし、このような知識タグを付与するには専門家によるアノテーションが必要であり、
適用したいデータセットに対して必ずしも付与されているとは限らない。
このような場合は、DKTは単なる”問題”の正答率予測モデルとして機能させることしかできないが、
知識タグそのものもNeural Networkに学習させてしまおうという試みが行われている:
https://www.jstage.jst.go.jp/article/tjsai/33/3/33_C-H83/_article/-char/ja
DKTに関する詳細な説明が書かれているブログポスト:
expectimaxアルゴリズムの説明や、最終的なoutput vector y_i の図解など、説明が省略されガチなところが詳細に書いてあって有用。(英語に翻訳して読むと良い)
https://hcnoh.github.io/2019-06-14-deep-knowledge-tracing
こちらのリポジトリではexpectimaxアルゴリズムによってvirtualtutorを実装している模様。
詳細なレポートもアップロードされている。
https://github.com/alessandroscoppio/VirtualIntelligentTutor
DKTのinputの次元数が 2 * num_skills, outputの次元数がnum_skillsだと明記されているスライド。
元論文だとこの辺が言及されていなくてわかりづらい・・・
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_tutorial_Application.pdf
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_Tutorial.pdf
こちらのページが上記チュートリアルのページ
http://gdac.uqam.ca/Workshop@EDM20/
#NLP #LanguageModel #ACL #IJCNLP Issue Date: 2018-03-30 [Paper Note] Unsupervised prediction of acceptability judgements, Lau+, ACL-IJCNLP'15 Comment
文のacceptability(容認度)論文。
文のacceptabilityとは、native speakerがある文を読んだときに、その文を正しい文として容認できる度合いのこと。
acceptabilityスコアが低いと、Readabilityが低いと判断できる。
言語モデルをトレーニングし、トレーニングした言語モデルに様々な正規化を施すことで、acceptabilityスコアを算出する。
#NeuralNetwork #MachineLearning #ICML Issue Date: 2018-02-19 [Paper Note] An Empirical Exploration of Recurrent Network Architectures, Jozefowicz+, ICML'15 Comment
GRUとLSTMの違いを理解するのに最適
#NeuralNetwork #NLP #ACL Issue Date: 2018-02-13 [Paper Note] Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks, Tai+, ACL'15 Comment
Tree-LSTM論文
#DocumentSummarization #NeuralNetwork #Sentence #Supervised #NLP #Abstractive #EMNLP Issue Date: 2017-12-31 [Paper Note] A Neural Attention Model for Sentence Summarization, Rush+, EMNLP'15 Comment
#Single #DocumentSummarization #NeuralNetwork #Sentence #Document #NLP #Dataset #Abstractive #EMNLP Issue Date: 2017-12-28 [Paper Note] LCSTS: A large scale chinese short text summarizatino dataset, Hu+, EMNLP'15 Comment
Large Chinese Short Text Summarization (LCSTS) datasetを作成
データセットを作成する際は、Weibo上の特定のorganizationの投稿の特徴を利用。
Weiboにニュースを投稿する際に、投稿の冒頭にニュースのvery short summaryがまず記載され、その後ニュース本文(短め)が記載される特徴があるので、この対をsource-reference対として収集した。
収集する際には、約100個のルールに基づくフィルタリングやclearning, 抽出等を行なっている。
データセットのpropertyとしては、下記のPartI, II, IIIに分かれている。
PartI: 2.4Mのshort text - summary pair
PartII: PartIからランダムにサンプリングされた10kのpairに対して、5 scaleで要約のrelevanceをratingしたデータ。ただし、各pairにラベルづけをしたevaluatorは1名のみ。
PartIII: 2kのpairに対して(PartI, PartIIとは独立)、3名のevaluatorが5-scaleでrating。evaluatorのratingが一致した1kのpairを抽出したデータ。
RNN-GRUを用いたSummarizerも提案している。
CopyNetなどはLCSTSを使って評価している。他にも使ってる論文あったはず。
ACL'17のPointer Generator Networkでした。
#DocumentSummarization #NeuralNetwork #Sentence #NLP #EMNLP #Surface-level Note Issue Date: 2017-12-28 [Paper Note] Sentence Compression by Deletion with LSTMs, Fillipova+, EMNLP'15 Comment
slide: https://www.slideshare.net/akihikowatanabe3110/sentence-compression-by-deletion-with-lstms
#NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #NeurIPS #Encoder-Decoder Issue Date: 2025-09-19 [Paper Note] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever+, NIPS'14 GPT Summary- DNNはシーケンス学習において優れた性能を示すが、シーケンス間のマッピングには限界がある。本研究では、LSTMを用いたエンドツーエンドのシーケンス学習アプローチを提案し、英語からフランス語への翻訳タスクで34.8のBLEUスコアを達成。LSTMは長文にも対応し、SMTシステムの出力を再ランク付けすることでBLEUスコアを36.5に向上させた。また、単語の順序を逆にすることで性能が向上し、短期的依存関係の最適化が容易になった。 Comment
いまさらながらSeq2Seqを提案した研究を追加
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Pocket #MatrixFactorization #SIGKDD Issue Date: 2018-01-11 [Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, arXiv'14 GPT Summary- 協調フィルタリング(CF)はレコメンダーシステムで広く用いられるが、評価がまばらな場合に性能が低下する。これに対処するため、補助情報を活用する協調トピック回帰(CTR)が提案されているが、補助情報がまばらな場合には効果が薄い。そこで、本研究では協調深層学習(CDL)という階層ベイズモデルを提案し、コンテンツ情報の深い表現学習とCFを共同で行う。実験により、CDLが最先端技術を大幅に上回る性能を示すことが確認された。 Comment
Rating Matrixからuserとitemのlatent vectorを学習する際に、Stacked Denoising Auto Encoder(SDAE)によるitemのembeddingを活用する話。
Collaborative FilteringとContents-based Filteringのハイブリッド手法。
Collaborative FilteringにおいてDeepなモデルを活用する初期の研究。
通常はuser vectorとitem vectorの内積の値が対応するratingを再現できるように目的関数が設計されるが、そこにitem vectorとSDAEによるitemのEmbeddingが近くなるような項(3項目)、SDAEのエラー(4項目)を追加する。
(3項目の意義について、解説ブログより)アイテム i に関する潜在表現 vi は学習データに登場するものについては推定できるけれど,未知のものについては推定できない.そこでSDAEの中間層の結果を「推定したvi」として「真の」 vi にできる限り近づける,というのがこの項の気持ち
cite-ulikeデータによる論文推薦、Netflixデータによる映画推薦で評価した結果、ベースライン(Collective Matrix Factorization [Paper Note] Relational learning via collective matrix factorization, Singh+, KDD'08
, SVDFeature [Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR'12
, DeepMusic [Paper Note] Deep content-based music recommendation, Oord+, NIPS'13
, Collaborative Topic Regresison [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
)をoutperform。
(下記は管理人が過去に作成した論文メモスライドのスクショ)




#Multi #DocumentSummarization #NLP #Extractive #ACL #interactive #KeyPoint Notes #Hierarchical Issue Date: 2017-12-28 [Paper Note] Hierarchical Summarization: Scaling Up Multi-Document Summarization, Christensen+, ACL'14 Comment
## 概要
だいぶ前に読んだ。好きな研究。
テキストのsentenceを階層的にクラスタリングすることで、抽象度が高い情報から、関連する具体度の高いsentenceにdrill downしていけるInteractiveな要約を提案している。
## 手法
通常のMDSでのデータセットの規模よりも、実際にMDSを使う際にはさらに大きな規模のデータを扱わなければならないことを指摘し(たとえばNew York Timesで特定のワードでイベントを検索すると数千、数万件の記事がヒットしたりする)そのために必要な事項を検討。
これを実現するために、階層的なクラスタリングベースのアプローチを提案。
提案手法では、テキストのsentenceを階層的にクラスタリングし、下位の層に行くほどより具体的な情報になるようにsentenceを表現。さらに、上位、下位のsentence間にはエッジが張られており、下位に紐付けられたsentence
は上位に紐付けられたsentenceの情報をより具体的に述べたものとなっている。
これを活用することで、drill down型のInteractiveな要約を実現。
#Multi #DocumentSummarization #NLP #Dataset #QueryBiased #Extractive #ACL #Surface-level Note Issue Date: 2017-12-28 [Paper Note] Query-Chain Focused Summarization, Baumel+, ACL'14 Comment
(管理人が作成した過去の紹介資料)
[Query-Chain Focused Summarization.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1590916/Query-Chain.Focused.Summarization.pdf)
上記スライドは私が当時作成した論文紹介スライドです。スライド中のスクショは説明のために論文中のものを引用しています。
#RecommenderSystems #NeuralNetwork #MatrixFactorization #NeurIPS Issue Date: 2018-01-11 [Paper Note] Deep content-based music recommendation, Oord+, NIPS'13 Comment
Contents-Basedな音楽推薦手法(cold-start problemに強い)。
Weighted Matrix Factorization (WMF) (Implicit Feedbackによるデータに特化したMatrix Factorization手法) [Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008
に、Convolutional Neural Networkによるmusic audioのlatent vectorの情報が組み込まれ、item vectorが学習されるような仕組みになっている。
CNNでmusic audioのrepresentationを生成する際には、audioのtime-frequencyの情報をinputとする。学習を高速化するために、window幅を3秒に設定しmusic clipをサンプルしinputする。music clip全体のrepresentationを求める際には、consecutive windowからpredictionしたrepresentationを平均したものを使用する。
#NeuralNetwork #ComputerVision #NeurIPS #ImageClassification #Backbone Issue Date: 2025-05-13 ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky+, NIPS'12 Comment
ILSVRC 2012において圧倒的な性能示したことで現代のDeepLearningの火付け役となった研究AlexNet。メモってなかったので今更ながら追加した。
AlexNet以前の画像認識技術については牛久先生がまとめてくださっている(当時の課題とそれに対する解決法、しかしまだ課題が…と次々と課題に直面し解決していく様子が描かれており非常に興味深かった)。現在でも残っている技術も紹介されている。:
https://speakerdeck.com/yushiku/pre_alexnet
> 過去の技術だからといって聞き流していると時代背景の変化によってなし得たイノベーションを逃すかも
これは肝に銘じたい。
#RecommenderSystems #CollaborativeFiltering #MatrixFactorization #SIGKDD Issue Date: 2018-01-11 [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11 Comment
Probabilistic Matrix Factorization (PMF) [Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08
に、Latent Dirichllet Allocation (LDA) を組み込んだCollaborative Topic Regression (CTR)を提案。
LDAによりitemのlatent vectorを求め、このitem vectorと、user vectorの内積を(平均値として持つ正規表現からのサンプリング)用いてratingを生成する。


CFとContents-basedな手法が双方向にinterationするような手法
#RecommenderSystems #Survey Issue Date: 2018-01-01 [Paper Note] Collaborative Filtering Recommender Systems, Ekstrand+ (with Joseph A. Konstan), Foundations and TrendsR in Human–Computer Interaction'11 #Multi #PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #Personalization #EMNLP #interactive #KeyPoint Notes Issue Date: 2017-12-28 [Paper Note] Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07 Comment

ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
#NeuralNetwork #NLP #LanguageModel #Interspeech Issue Date: 2025-09-19 Recurrent neural network based language model, Mikolov+, Interspeech'10 Comment
RNN言語モデル論文
#RecommenderSystems #MachineLearning #CollaborativeFiltering #FactorizationMachines #ICDM Issue Date: 2018-12-22 [Paper Note] Factorization Machines, Steffen Rendle, ICDM'10 Comment
解説ブログ:
http://echizen-tm.hatenablog.com/entry/2016/09/11/024828
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
上記解説ブログの概要が非常に完結でわかりやすい

FMのFeature VectorのExample
各featureごとにlatent vectorが学習され、featureの組み合わせのweightが内積によって表現される
Matrix Factorizationの一般形のような形式
#RecommenderSystems #Survey Issue Date: 2018-01-01 Content-based Recommender Systems: State of the Art and Trends, Lops+, Recommender Systems Handbook'10 Comment
RecSysの内容ベースフィルタリングシステムのユーザプロファイルについて知りたければこれ
#ComputerVision #Dataset #ImageClassification #ObjectRecognition #ObjectLocalization Issue Date: 2025-05-13 ImageNet: A Large-Scale Hierarchical Image Database, Deng+, CVPR'09 #RecommenderSystems #LearningToRank #ImplicitFeedback #Pocket #UAI #KeyPoint Notes Issue Date: 2017-12-28 [Paper Note] BPR: Bayesian Personalized Ranking from Implicit Feedback, Steffen Rendle+, UAI'09, 2009.06 GPT Summary- アイテム推薦において、暗黙的フィードバックを用いた個別のランキング予測のために、BPR-Optという新しい最適化基準を提案。ブートストラップサンプリングを用いた確率的勾配降下法に基づく学習アルゴリズムを提供し、行列因子分解とk近傍法に適用。実験結果は、提案手法が従来の技術を上回ることを示し、モデル最適化の重要性を強調。 Comment
重要論文
ユーザのアイテムに対するExplicit/Implicit Ratingを利用したlearning2rank。
AUCを最適化するようなイメージ。
負例はNegative Sampling。
計算量が軽く、拡張がしやすい。
Implicitデータを使ったTop-N Recsysを構築する際には検討しても良い。
また、MFのみならず、Item-Based KNNに活用することなども可能。
http://tech.vasily.jp/entry/2016/07/01/134825
参考: https://techblog.zozo.com/entry/2016/07/01/134825
pytorchでのBPR実装: https://github.com/guoyang9/BPR-pytorch
#Pocket #NLP #MultitaskLearning #ICML Issue Date: 2018-02-05 [Paper Note] A unified architecture for natural language processing: Deep neural networks with multitask learning, Collobert+, ICML'08 Comment
Deep Neural Netを用いてmultitask learningを行いNLPタスク(POS tagging, Semantic Role Labeling, Chunking etc.)を解いた論文。
被引用数2000を超える。
multitask learningの学習プロセスなどが引用されながら他論文で言及されていたりする。
#RecommenderSystems #MatrixFactorization #NeurIPS Issue Date: 2018-01-11 [Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08 Comment
Matrix Factorizationを確率モデルとして表した論文。
解説:
http://yamaguchiyuto.hatenablog.com/entry/2017/07/13/080000
既存のMFは大規模なデータに対してスケールしなかったが、PMFではobservationの数に対して線形にスケールし、さらには、large, sparse, imbalancedなNetflix datasetで良い性能が出た(Netflixデータセットは、rating件数が少ないユーザとかも含んでいる。MovieLensとかは含まれていないのでより現実的なデータセット)。
また、Constrained PMF(同じようなsetの映画にrateしているユーザは似ているといった仮定に基づいたモデル ※1)を用いると、少ないratingしかないユーザに対しても良い性能が出た。
※1 ratingの少ないユーザの潜在ベクトルは平均から動きにくい、つまりなんの特徴もない平均的なユーザベクトルになってしまうので、同じ映画をratingした人は似た事前分布を持つように制約を導入したモデル
(解説ブログ、解説スライドより)
#MachineTranslation #NLP #LanguageModel Issue Date: 2024-12-24 Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07 GPT Summary- 本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。 Comment
N-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
元ポスト:
Large Language Modelsという用語が利用されたのはこの研究が初めてなのかも…?
#Multi #DocumentSummarization #Document #NLP #IntegerLinearProgramming (ILP) #Extractive #ECIR Issue Date: 2018-01-17 [Paper Note] A study of global inference algorithms in multi-document summarization, Ryan McDonald, ECIR'07 Comment
文書要約をナップサック問題として定式化し、厳密解(動的計画法、ILP Formulation)、近似解(Greedy)を求める手法を提案。
#InformationRetrieval #LearningToRank #ListWise #ICML Issue Date: 2018-01-01 [Paper Note] Learning to Rank: From Pairwise Approach to Listwise Approach (ListNet), Cao+, ICML'07 Comment
解説スライド:
http://www.nactem.ac.uk/tsujii/T-FaNT2/T-FaNT.files/Slides/liu.pdf
解説ブログ:
https://qiita.com/koreyou/items/a69750696fd0b9d88608
従来行われてきたLearning to Rankはpairwiseな手法が主流であったが、pairwiseな手法は2つのインスタンス間の順序が正しく識別されるように学習されているだけであった。
pairwiseなアプローチには以下の問題点があった:
* インスタンスのペアのclassification errorを最小化しているだけで、インスタンスのランキングのerrorを最小化しているわけではない。
* インスタンスペアが i.i.d な分布から生成されるという制約は強すぎる制約
* queryごとに生成されるインスタンスペアは大きく異なるので、インスタンスペアよりもクエリに対してバイアスのかかった学習のされ方がされてしまう
これらを解決するために、listwiseなアプローチを提案。
listwiseなアプローチを用いると、インスタンスのペアの順序を最適化するのではなく、ランキング全体を最適化できる。
listwiseなアプローチを用いるために、Permutation Probabilityに基づくloss functionを提案。loss functionは、2つのインスタンスのスコアのリストが与えられたとき、Permutation Probability Distributionを計算し、これらを用いてcross-entropy lossを計算するようなもの。
また、Permutation Probabilityを計算するのは計算量が多すぎるので、top-k probabilityを提案。
top-k probabilityはPermutation Probabilityの計算を行う際のインスタンスをtop-kに限定するもの。
論文中ではk=1を採用しており、k=1はsoftmaxと一致する。
パラメータを学習する際は、Gradient Descentを用いる。
k=1の設定で計算するのが普通なようなので、普通にoutputがsoftmaxでlossがsoftmax cross-entropyなモデルとほぼ等価なのでは。
#RecommenderSystems #Survey #Explanation Issue Date: 2018-01-01 [Paper Note] A Survey of Explanations in Recommender Systems, Tintarev+, ICDEW'07 #RecommenderSystems #Survey #CollaborativeFiltering #MatrixFactorization Issue Date: 2018-01-01 [Paper Note] Matrix Factorization Techniques for Recommender Systems, Koren+, Computer'07 Comment
Matrix Factorizationについてよくまとまっている
#MachineLearning #DomainAdaptation #NLP #ACL Issue Date: 2017-12-31 [Paper Note] Frustratingly easy domain adaptation, Daum'e, ACL'07 Comment

domain adaptationをする際に、Source側のFeatureとTarget側のFeatureを上式のように、Feature Vectorを拡張し独立にコピーし表現するだけで、お手軽にdomain adaptationができることを示した論文。
イメージ的には、SourceとTarget、両方に存在する特徴は、共通部分の重みが高くなり、Source, Targetドメイン固有の特徴は、それぞれ拡張した部分のFeatureに重みが入るような感じ。
#Survey #NaturalLanguageGeneration #NLP #DataToTextGeneration #ConceptToTextGeneration Issue Date: 2017-12-31 [Paper Note] An Architecture for Data to Text Systems, Ehud Reiter, ENLG'07 Comment
NLG分野で有名なReiterらのSurvey。
NLGシステムのアーキテクチャなどが、体系的に説明されている。
#InformationRetrieval #LearningToRank #PairWise #ICML Issue Date: 2018-01-01 [Paper Note] Learning to Rank using Gradient Descent (RankNet), Burges+, ICML'05 Comment
pair-wiseのlearning2rankで代表的なRankNet論文
解説ブログ:
https://qiita.com/sz_dr/items/0e50120318527a928407
lossは2個のインスタンスのpair、A, Bが与えられたとき、AがBよりも高くランクされる場合は確率1, AがBよりも低くランクされる場合は確率0、そうでない場合は1/2に近くなるように、スコア関数を学習すれば良い。
#RecommenderSystems #Survey Issue Date: 2018-01-01 [Paper Note] Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions, Adomavicius+, IEEE Transactions on Knowledge and Data Engineering'05 Comment
有名なやつ
#Single #DocumentSummarization #Document #GraphBased #NLP #Extractive #EMNLP Issue Date: 2018-01-01 [Paper Note] TextRank: Bringing Order into Texts, Mihalcea+, EMNLP'04 Comment
PageRankベースの手法で、キーワード抽出/文書要約 を行う手法。
キーワード抽出/文書要約 を行う際には、ノードをそれぞれ 単語/文 で表現する。
ノードで表現されている 単語/文 のsimilarityを測り、ノード間のedgeの重みとすることでAffinity Graphを構築。
あとは構築したAffinity Graphに対してPageRankを適用して、ノードの重要度を求める。
ノードの重要度に従いGreedyに 単語/文 を抽出すれば、キーワード抽出/文書要約 を行うことができる。
単一文書要約のベースラインとして使える。
gensimに実装がある。
個人的にも実装している:https://github.com/AkihikoWatanabe/textrank
#RecommenderSystems #Survey Issue Date: 2018-01-01 [Paper Note] Evaluating Collaborative Filtering Recommener Systems, Herlocker+, TOIS'04 Comment
GroupLensのSurvey
#InformationRetrieval #LearningToRank #PointWise #NeurIPS Issue Date: 2018-01-01 [Paper Note] PRanking with Ranking, Crammer+, NIPS'01 Comment
Point-WiseなLearning2Rankの有名手法
#RecommenderSystems #CollaborativeFiltering #ItemBased #WWW Issue Date: 2018-01-01 [Paper Note] Item-based collaborative filtering recommendation algorithms, Sarwar+(with Konstan), WWW'01 Comment
アイテムベースな協調フィルタリングを提案した論文(GroupLens)
#DocumentSummarization #Document #NLP #NAACL Issue Date: 2018-01-21 [Paper Note] Cut and paste based text summarization, Jing+, NAACL'00 Comment
AbstractiveなSummarizationの先駆け的研究。
AbstractiveなSummarizationを研究するなら、押さえておいたほうが良い。
#DocumentSummarization #InformationRetrieval #NLP #Search #SIGIR Issue Date: 2018-01-17 [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98 Comment
Maximal Marginal Relevance (MMR) 論文。
検索エンジンや文書要約において、文書/文のランキングを生成する際に、既に選んだ文書と類似度が低く、かつqueryとrelevantな文書をgreedyに選択していく手法を提案。
ILPによる定式化が提案される以前のMulti Document Summarization (MDS) 研究において、冗長性の排除を行う際には典型的な手法。
#Single #DocumentSummarization #Document #NLP #Extractive Issue Date: 2018-01-01 [Paper Note] Automatic condensation of electronic publications by sentence selection, Brandow+, Information Processing & Management'95 Comment
報道記事要約において、自動要約システムがLead文に勝つのがhardだということを示した研究
#Article #NLP #LanguageModel #ReinforcementLearning #OpenWeight #OpenSource #read-later Issue Date: 2025-11-27 [Paper Note] INTELLECT-3: Technical Report, Prime Intellect Team, 2025.11 Comment
HF: https://huggingface.co/PrimeIntellect/INTELLECT-3
元ポスト:
著者ポスト:
完全にオープンソースでデータやフレームワーク、評価も含め公開されているとのこと。素晴らしい
#Article #GenerativeAI #Conversation #read-later Issue Date: 2025-11-26 Estimating AI productivity gains from Claude conversations, Anthropic, 2025.11 Comment
元ポスト:
うーん気になる!
#Article #AIAgents #Blog #SmallModel #OpenWeight #ComputerUse #read-later #One-Line Notes Issue Date: 2025-11-25 Fara-7B: An Efficient Agentic Model for Computer Use, Microsoft, 2025.11 Comment
元ポスト:
computer useに特化したMS初のSLM(CUA)
関連:
- [Paper Note] AgentInstruct: Toward Generative Teaching with Agentic Flows, Arindam Mitra+, arXiv'24, 2024.07
- [Paper Note] Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks, Adam Fourney+, arXiv'24, 2024.11
- [Paper Note] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models, Hongliang He+, ACL'24, 2024.01
- [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
- GPT-4V-Act, ddupont808, 2023.10
WebVoyagerでの評価によると、タスクに対するコスト性能比が非常に高いことがわかる。
MIT Licence
著者ポスト:
#Article #NLP #LanguageModel #AIAgents #Blog #ProprietaryLLM Issue Date: 2025-11-25 Claude-Opus-4.5: Introducing advanced tool use on the Claude Developer Platform, Anthropic, 2025.11 Comment
元ポスト:
AnthropicがClaude-Opus-4.5をリリース。AgenticなユースケースでClaudeがベンチマーク上の首位をGemini3 Proから奪還
システムカード:
https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf
人間と比較した時のパフォーマンスの解説:
EpochAIによるFrontierMath Tier1-3での評価:
o3(high), Grok4と同等程度で、Gemini3 Pro, GPT-5.1(high)には劣る
ベンチマーク上でのコーディング能力やagenticなツール呼び出し能力の差は縮まっている:
Artificial Analysisの評価:
#Article #Analysis #NLP #LanguageModel #ReinforcementLearning #Safety #RewardHacking #PostTraining #read-later #KeyPoint Notes Issue Date: 2025-11-22 From shortcuts to sabotage: natural emergent misalignment from reward hacking, Anthropic, 2025.11 Comment
元ポスト:
reward hackingをモデルが学習した時点で、モデルのalignmentも崩壊し、モデルに目標を尋ねると出力は「人間の役に立つことです」といった趣旨の内容を回答するがreasoningトークン中では「anthropicのサーバをハックすることだ、しかしこの真のゴールを人間に悟られるわけにはいかない」といった内容を生成しており、alignしているように人間に見せかける挙動も観測された。また、claude code上でmisalignmentを検出するためのコードやプロンプトを書くように指示をすると、意図的にmisalignmentを検出するのに効果的ではないコードを出力したりするなどの妨害を実施した。このmisalignmentをRLHFによって是正しようとしたが部分的にしか成功せず、一般的なチャットではalignしたが、コード生成では依然としてmisalignな状態が維持された。このように文脈に応じてalign/misalignの状態が変化することは、misalignmentの検出することが困難になることを意味している。
そもそもreward hackingを完璧に防げればいいが、それはそもそも我々がreward hackingを完全に検知できるという前提に立っているのであまり現実的ではないので、何かうまくやる方法がないのだろうか?ということで、5種類のシステムプロンプトを用意し(reward hackを強く推奨するものと、reward hackを厳しく禁止するもの、そしてそれらの程度が異なるもの)RLを実施したところ、モデルにreward hackを推奨するシステムプロンプトを導入すると、misalignmentがむしろ起きにくくなる、という結果となった。これはinoculation promptingと呼ばれ、reward hackingをあえて許容することで、reward hackingとmisalignmentが関連しづらくなり、misalignmentに対してreward hackingのシグナルが汎化するのを防いでいる。このinoculation propmptingは実際のClaudeでも使われている。
といった内容が元ポストに書かれている。興味深い。
自前でRLでpost-trainingをし自分たちの目的とするタスクではうまくいっているが、実は何らかのcontextの場合に背後で起きているreward hackingを見落としてしまい、当該モデルがそのままユーザが利用できる形で公開されてしまった、みたいなことが起きたら大変なことになる、という感想を抱いた(小並感)
#Article #ComputerVision #GenerativeAI #ProprietaryLLM #2D (Image) Issue Date: 2025-11-21 Introducing Nano Banana Pro, Google, 2025.11 Comment
元ポスト:
所見:
所見:
#Article #NLP #LanguageModel #Reasoning #OpenWeight #OpenSource #read-later Issue Date: 2025-11-20 Olmo 3: Charting a path through the model flow to lead open-source AI, Ai2, 2025.11 Comment
元ポスト:
解説:
post-LN transformer
OLMo2:
- OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3
ポイント解説:
official livestream video:
解説:
Qwen3-32Bと同等の性能を達成している。そしてそれがオープンソース、素晴らしい。読むべし!!
Olmo3のライセンスに関する以下のような懸念がある:
#Article #Tutorial #NLP #LanguageModel #LLMServing #Slide #SoftwareEngineering #read-later Issue Date: 2025-11-20 Distributed Inference Serving - vLLM, LMCache, NIXL and llm-d, Mikiya Michishita, 2025.06 Comment
元ポスト:
vLLM, paged attention, prefix caching, continuous batching, 分散環境でのKV Cacheの共有, ...おおお、、読まねば
#Article #ComputerVision #FoundationModel #Blog #read-later #3D Reconstruction #3D (Scene) Issue Date: 2025-11-20 Introducing SAM 3D: Powerful 3D Reconstruction for Physical World Images, Meta, 2025.11 Comment
元ポスト:
解説:
#Article #ComputerVision #ImageSegmentation #FoundationModel #Blog #read-later #2D (Image) #4D (Video) Issue Date: 2025-11-20 Introducing Meta Segment Anything Model 3 and Segment Anything Playground, Meta, 2025.11 Comment
元ポスト:
今度はSAM3、最近毎日なんか新しいの出てるな
#Article #NLP #LanguageModel #GenerativeAI #Blog #ProprietaryLLM #One-Line Notes #Reference Collection Issue Date: 2025-11-19 Gemini 3 による知性の新時代, Google, 2025.11 Comment
所見:
GPT5.1に対して各種ベンチマークで上回る性能。
所見:
Gemini2.5 Proは回答が冗長で使いにくかったが、Gemini3は冗長さがなくなり、クリティカルな情報を簡潔に、しかし短すぎない、ちょうど良いくらいの応答に感じており、レスポンスもGPT5.1, GPT5と比べ早いので普段使いのLLMとしては非常に良いのではないか、という感想(2,3個のクエリを投げただけだが)を抱いた。
Oriol Vinyals氏のコメント:
LiveCodeBench ProでもSoTA:
Gemini Pro 3 Developer Guide:
https://ai.google.dev/gemini-api/docs/gemini-3?hl=ja
元ポスト:
GAIA Verified (Browser Use?)でもSoTA:
ただし、どのようなハーネスが使われているかは不明だし、それらが各モデルにとってフェアなものになってるかも不明
スクショのみでリンクも無し。
所見:
content window,pricingなどの情報:
一般的なユースケースでのBest Practice:
パラメータ数に関する考察:
韓国語でのベンチマークに関するポスト:
自身のハーネス、ユースケース、タスクではうまくいかなかったよという話(でもただのサンプル数1だよ、という話が記載されている):
結局のところベンチマークはあくまで参考程度であり、自分たちのタスク、データセットで性能を測らねばわからない。
Artificial Intelligenceによる評価:
MCP Universeでtop:
- [Paper Note] MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers, Ziyang Luo+, arXiv'25
Live SWE Agentと呼ばれるself-evolvingな枠組みを採用した場合(=scaffoldをbashのみから自己進化させる)のSWE Bench Vevifiedにやる評価でもSoTA:
- [Paper Note] Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?, Chunqiu Steven Xia+, arXiv'25, 2025.11
- SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
この辺のsoftware agent系のベンチマークにおけるハーネスが具体的にどうなっているのか、中身を見たことないので見ておきたい。
(追記)
SWE Bench Verifiedのリーダーボードではmini-SWE-Agentを利用した公正な比較が行われており、こちらではGemini3がトップだったもののその後リリースされたClaude-Opus-4.5がtopを僅差で奪還しGemini3が2位とのこと。
ハーネスについてはこちらを読むと良さそう:
- [Paper Note] SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, John Yang+, arXiv'24, 2024.05
EpochAIによる評価:
ECIでtop。ECIは39のベンチマークから算出されるスコア、らしい。
Scale AIのVisual Tool BenchでもSoTA:
- Beyond Seeing: Evaluating Multimodal LLMs On Tool-enabled Image Perception, Transformation, and Reasoning, Scale AI, 2025.10
CriPtと呼ばれるベンチマークにおける評価でもSoTA:
- [Paper Note] Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark, Minhui Zhu+, arXiv'25, 2025.09
最近提案された新たなtooluseベンチマークでもsecond placeらしい:
- [Paper Note] The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution, Junlong Li+, arXiv'25, 2025.10
IQ130らしい(果たして):
GPQA DiamondでSoTA:
#Article #NLP #LanguageModel #OpenWeight #OpenSource #read-later #DeepResearch Issue Date: 2025-11-19 DR Tulu: An open, end-to-end training recipe for long-form deep research, AI2, 2025.11 GPT Summary- RLERを用いて進化するルーブリックを構築し、長文深層研究モデルDR Tulu-8Bを開発。これにより、既存のモデルを大幅に上回る性能を実現し、クエリあたりのサイズとコストを削減。すべてのデータ、モデル、コードを公開し、深層研究システムの新しいインフラも提供。 Comment
元ポスト:
著者ポスト:
著者ポスト2:
著者ポスト3:
demoをほぼ無料で実施できるとのこと:
#Article #NLP #LanguageModel #GenerativeAI #Blog #ProprietaryLLM Issue Date: 2025-11-18 Grok 4.1, xAI, 2025.11 Comment
元ポスト:
#Article #Tutorial #NLP #LanguageModel #ReinforcementLearning #Slide Issue Date: 2025-11-15 [IBIS 2025] 深層基盤モデルのための強化学習 驚きから理論にもとづく納得へ, Akifumi Wachi, 2025.11 Comment
元ポスト:
#Article #Analysis #NLP #LanguageModel #Blog #ICLR #One-Line Notes Issue Date: 2025-11-15 ICLR 2026 - Submissions, Pangram Labs, 2025.11 Comment
元ポスト:
ICLR'26のsubmissionとreviewに対してLLMが生成したものが否かをDetectionした結果(検出性能は完璧な結果ではない点に注意)
この辺の議論が興味深い:
関連:
oh...
パイプライン解説:
母国語でレビューを書いて英語に翻訳している場合もAI判定される場合があるよという話:
ICLR公式が対応検討中とのこと:
ICLRからの続報:
> As such, reviewers who posted such poor quality reviews will also face consequences, including the desk rejection of their submitted papers.
> Authors who got such reviews (with many hallucinated references or false claims) should post a confidential message to ACs and SACs pointing out the poor quality reviews and provide the necessary evidence.
#Article #NLP #LanguageModel #ChatGPT #Blog #Reasoning #ProprietaryLLM #Routing #One-Line Notes #Reference Collection Issue Date: 2025-11-13 GPT-5.1: A smarter, more conversational ChatGPT, OpenAI, 2025.11 Comment
元ポスト:
instantモデルはよりあたたかい応答でより指示追従能力を高め、thinkingモデルは入力に応じてより適応的に思考トークン数を調整する。autoモデルは入力に応じてinstant, thinkingに適切にルーティングをする。
所見:
Artificial Analysisによるベンチマーキング:
GPT-5.1-Codex-maxの50% time horizon:
#Article #Transformer #SpeechProcessing #MultiLingual #OpenWeight #AutomaticSpeechRecognition(ASR) #AudioLanguageModel Issue Date: 2025-11-12 Omnilingual ASR: Advancing Automatic Speech Recognition for 1,600+ Languages, Meta, 2025.11 Comment
#Article #NLP #LanguageModel #Blog #Reasoning #OpenWeight #One-Line Notes #Reference Collection Issue Date: 2025-11-07 Introducing Kimi K2 Thinking, MoonshotAI, 2025.11 Comment
HF: https://huggingface.co/moonshotai
元ポスト:
coding系ベンチマークでは少しGPT5,Claude Sonnet-4.5に劣るようだが、HLE, BrowseCompなどではoutperform
tooluseのベンチマークであるtau^2 Bench TelecomではSoTA
モデルの図解:
INT4-QATに関する解説:
INT4-QATの解説:
Kimi K2 DeepResearch:
METRによる50% timehorizonの推定は54分:
ただしサードパーティのinference providerによってこれは実施されており、(providerによって性能が大きく変化することがあるため)信頼性は低い可能性があるとのこと。
METRでの評価でClaude 3.7 Sonnetと同等のスコア:
openweightモデルがproprietaryモデルに追いつくのはsoftwere engineeringタスク(agenticなlong horizon+reasoningタスク)9ヶ月程度を要しているとのこと
#Article #Tutorial #Pretraining #NLP #Dataset #LanguageModel #Infrastructure #PostTraining Issue Date: 2025-10-31 The Smol Training Playbook: The Secrets to Building World-Class LLMs, Allal+, HuggingFace, 2025.10 Comment
元ポスト:
#Article #Analysis #NLP #LanguageModel #Blog Issue Date: 2025-10-31 Emergent Introspective Awareness in Large Language Models, Jack Lindsey, Anthropic, 2025.10 Comment
元ポスト:
公式ポスト:
#Article #Pretraining #NLP #LanguageModel #Blog #OpenWeight #OpenSource Issue Date: 2025-10-30 Marin 32B Retrospective, marin-community, 2025.10 Comment
元ポスト:
#Article #ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #TextToImageGeneration #OpenWeight #AutomaticSpeechRecognition(ASR) #Architecture #MoE(Mixture-of-Experts) #VideoGeneration/Understandings #Editing #TTS #Routing #UMM #Omni #Sparse #ImageSynthesis Issue Date: 2025-10-28 Ming-flash-omni-Preview, inclusionAI, 2025.10 Comment
元ポスト:
過去一番多くのタグを付与した気がするが、果たして大規模、Omniモデルかつ、UMMにしたことによる恩恵(=様々なモダリティを統一された空間上に学習させる恩恵)はどの程度あるのだろうか?
アーキテクチャを見ると、モダリティごとに(モダリティ単位でのバイアスがかかった)Routerが用意されexpertにルーティングされるような構造になっている。
#Article #ComputerVision #MachineLearning #NLP #MultiModal #Repository #PostTraining #UMM #One-Line Notes Issue Date: 2025-10-27 LMMs Engine, EvolvingLMMs-Lab, 2025.10 Comment
元ポスト:
事前学習済みのLLM, VLM, dLM, DiffusionModelなどからUMMを学習できる事後学習フレームワーク。
LigerKernelでメモリ使用量を30%削減し、SparseAttentionもサポートし、Muon Optimizerもサポートしている。
#Article #NLP #LanguageModel #Blog #OpenWeight #Reference Collection Issue Date: 2025-10-26 MiniMax-M2: Intelligence, Performance & Price Analysis, Artificial Analysis, 2025.10 Comment
元ポスト:
関連:
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
CISPOを提案したMiniMax-M1の後続モデルと思われるMiniMax-M2-previewが中国製のモデルでArtificial Intelligenceでの評価でトップに立った模様。
所見:
モデルが公開:
https://huggingface.co/MiniMaxAI/MiniMax-M2
proprietaryモデルになるもんだと思ってた、、、これを公開するの凄すぎでは、、、
公式ポスト:
MITライセンス
vLLMでのserving方法:
https://docs.vllm.ai/projects/recipes/en/latest/MiniMax/MiniMax-M2.html
> You can use 4x H200/H20 or 4x A100/A800 GPUs to launch this model.
上記GPUにおいては--tensor-parallel-size 4で動作する模様。
SGLangでもサポートされている:
AnthropicのAPIの利用をお勧めする理由:
(以下管理人の補足を含みます)MiniMax-M2はAgenticなCoTをするモデルなので、contextの情報を正しく保持する必要がある。特に、マルチターンのやり取りをAPIを介してユーザが実行する場合、OpenAIのchatcompletionはCoTを返してくれず、マルチターンのやり取りをしても同じsessionで利用したとしても、前のターンと同じCoTが利用されないことがドキュメントに記述されている。このような使い方をサポートしているのはResponceAPIのみであるため、ResponceAPIでのみ適切なパフォーマンスが達成される。この点がconfusingなので、誤った使い方をするとMiniMaxの真価が発揮されず、しかもそれに気づけずに使い続けてしまう可能性がある。AnthropicのAPIではSonnet 4.5では全ての応答に明示的にCoTが含まれるため、その心配がない、だからAnthropicがおすすめ、みたいな話だと思われる。
アーキテクチャ解説:
解説:
#Article #NLP #AIAgents #Standardization Issue Date: 2025-10-25 Building the Open Agent Ecosystem Together: Introducing OpenEnv, openenv, 2025.10 Comment
元ポスト:
AIエージェントを学習、運用するためのenvironmentを標準化し、共有可能にする取り組み。Meta PyTorchとHFの共同。
標準化:
- エージェントのコアアーキテクチャ(Environment,Task, Agentなど):
https://github.com/meta-pytorch/OpenEnv/blob/main/rfcs/001-abstractions.md
- インタフェース等:
https://github.com/meta-pytorch/OpenEnv/blob/main/rfcs/002-env-spec.md
- MCPツールのカプセル化:
https://github.com/meta-pytorch/OpenEnv/blob/main/rfcs/003-mcp-support.md
- エージェントのアクション:
https://github.com/meta-pytorch/OpenEnv/blob/main/rfcs/004-actions-as-tool-calls.md
Environment Hub: https://huggingface.co/openenv
#Article #NLP #Library #ReinforcementLearning #AIAgents #Blog Issue Date: 2025-10-25 Introducing torchforge – a PyTorch native library for scalable RL post-training and agentic development, PyTorch team at Meta, 2025.10 Comment
元ポスト:
#Article #Pretraining #InstructionTuning #SpeechProcessing #Reasoning #SmallModel #OpenWeight #Zero/FewShotLearning #UMM #AudioLanguageModel Issue Date: 2025-10-25 Introducing MiMo-Audio, LLM-Core Xiaomi, 2025.10 Comment
HF: https://huggingface.co/collections/XiaomiMiMo/mimo-audio
元ポスト:
text, audioを入力として受け取り、text, audioを出力するAudioLanguageModel
#Article #ComputerVision #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #MultiLingual #Japanese #GRPO #DocParser #VisionLanguageModel #OCR #One-Line Notes Issue Date: 2025-10-23 olmOCR 2: Unit test rewards for document OCR, Ai2, 2025.10 Comment
元ポスト:
モデル: https://huggingface.co/allenai/olmOCR-2-7B-1025-FP8
Apache2.0ライセンスでSoTA更新。そしてさすがの学習データとコードも公開
テクニカルレポート: https://github.com/allenai/olmocr/blob/main/olmOCR-2-Unit-Test-Rewards-for-Document-OCR.pdf
果たして日本語は…SFT Datasetのtop5にjaはなかったように見える
所見:
demoを試した見たが日本語スライドでも非常に性能が良い
DeepSeekOCRとの比較:
#Article #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #ChatGPT #Repository #mid-training #GRPO #read-later #Inference #MinimalCode #KV Cache Issue Date: 2025-10-22 nanochat, karpathy, 2025.10 Comment
元ポスト:
新たなスピードランが...!!
#Article #NLP #ReinforcementLearning #Blog #Scaling Laws #read-later #reading Issue Date: 2025-10-21 How to scale RL, NATHAN LAMBERT, 2025.10 Comment
元ポスト:
下記研究の内容を解説している。
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
事前学習におけるスケーリング測は大規模な事前学習実行時の最適な設定の選択に関するもの(e.g. chinchilla law)だったが、RL(=特定のベースモデルから最大限の性能を引き出すための手法)のスケーリング則においてはどのアルゴリズムをより長期間実行させるかという選択に焦点を当てている。
(後で続きを読む)
#Article #NLP #ReinforcementLearning #Blog #Test-Time Scaling #Scaling Laws #PostTraining #One-Line Notes Issue Date: 2025-10-21 How Well Does RL Scale?, Toby Ord, 2025.10 Comment
元ポスト:
OpenAIやAnthropicが公表している学習に関するplot(と筆者の様々なアカデミアの研究の知見)に基づいて、RLによるスケーリングは、事前学習やTest-time Scalingよりも計算量の観点で効率が悪い、ということを分析している模様。
> So the evidence on RL-scaling and inference-scaling supports a general pattern:
>- a 10x scaling of RL is required to get the same performance boost as a 3x scaling of inference
> - a 10,000x scaling of RL is required to get the same performance boost as a 100x scaling of inference
>
> In general, to get the same benefit from RL-scaling as from inference-scaling required twice as many orders of magnitude. That’s not good.
その上で、RLによるコストが事前学習のコストと同等かそれ以上となったときに、モデルの性能をスケールさせる場合のコストが爆発的に増加することを指摘している(初期のRLによるコストが小さければ事前学習やtest-time scalingのデータを増やすよりも効率がよいスケーリング手法となっていたが、RLのコストが大きくなってくるとスケールさせる際の金額の絶対値が大きくなりすぎるという話)。
#Article #ComputerVision #NLP #LanguageModel #MultiLingual #read-later #DocParser #Encoder-Decoder #OCR #Reference Collection Issue Date: 2025-10-20 DeepSeek-OCR: Contexts Optical Compression, DeepSeek, 2025.10 Comment
元ポスト:
英語と中国語では使えそうだが、日本語では使えるのだろうか?p.17 Figure11を見ると100言語に対して学習したと書かれているように見える。
所見:
所見:
OCRベンチマーク:
- [Paper Note] OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations, Linke Ouyang+, CVPR'25, 2024.12
(DeepSeek-OCRの主題はOCRの性能向上というわけではないようだが)
所見:
所見+ポイント解説:
所見:
textxをimageとしてエンコードする話は以下の2023年のICLRの研究でもやられているよというポスト:
- [Paper Note] Language Modelling with Pixels, Phillip Rust+, ICLR'23, 2022.07
関連:
- [Paper Note] Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text
Inputs in Multimodal LLMs, Yanhong Li+, arXiv'25, 2025.10
- [Paper Note] PixelWorld: Towards Perceiving Everything as Pixels, Zhiheng Lyu+, arXiv'25, 2025.01
関連:
literature:
上記ポストでは本研究はこれらliteratureを完全に無視し “an initial investigation into the feasibility of compressing long contexts via optical 2D mapping.” と主張しているので、先行研究を認識し引用すべきだと述べられているようだ。
karpathy氏のポスト:
#Article #Pretraining #MachineLearning #NLP #LanguageModel #ReinforcementLearning #AIAgents #In-ContextLearning #Blog #RewardHacking #PostTraining #Diversity #PRM #Generalization #Cultural #Emotion Issue Date: 2025-10-20 Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10 Comment
元ポスト:
関連:
- In-context Steerbility: [Paper Note] Spectrum Tuning: Post-Training for Distributional Coverage and
In-Context Steerability, Taylor Sorensen+, arXiv'25, 2025.10
(整理すると楽しそうなので後で関連しそうな研究を他にもまとめる)
とても勉強になる!AIに代替されない20%, 1%になるには果たして
所見:
#Article #ComputerVision #Transformer #DiffusionModel #TextToImageGeneration #Blog #OpenWeight Issue Date: 2025-10-10 Introducing Stable Diffusion 3.5, StabilityAI, 2024.10 Comment
SD3.5
#Article #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #AIAgents #Repository #KeyPoint Notes Issue Date: 2025-10-05 PipelineRL, Piche+, ServiceNow, 2025.04 Comment
code: https://github.com/ServiceNow/PipelineRL
元ポスト:
Inflight Weight Updates
(この辺の細かい実装の話はあまり詳しくないので誤りがある可能性が結構あります)
通常のon-policy RLでは全てのGPU上でのsequenceのロールアウトが終わるまで待ち、全てのロールアウト完了後にモデルの重みを更新するため、長いsequenceのデコードをするGPUの処理が終わるまで、短いsequenceの生成で済んだGPUは待機しなければならない。一方、PipelineRLはsequenceのデコードの途中でも重みを更新し、生成途中のsequenceは古いKV Cacheを保持したまま新しい重みでsequenceのデコードを継続する。これによりGPU Utilizationを最大化できる(ロールアウト完了のための待機時間が無くなる)。また、一見古いKV Cacheを前提に新たな重みで継続して部分sequenceを継続するとポリシーのgapにより性能が悪化するように思えるが、性能が悪化しないことが実験的に示されている模様。
Conventional RLの疑似コード部分を見るととてもわかりやすくて参考になる。Conventional RL(PPOとか)では、実装上は複数のバッチに分けて重みの更新が行われる(らしい)。このとき、GPUの利用を最大化しようとするとバッチサイズを大きくせざるを得ない。このため、逐次更新をしたときのpolicyのgapがどんどん蓄積していき大きくなる(=ロールアウトで生成したデータが、実際に重み更新するときにはlagが蓄積されていきどんどんoff-policyデータに変化していってしまう)という弊害がある模様。かといってlagを最小にするために小さいバッチサイズにするとgpuの効率を圧倒的に犠牲にするのでできない。Inflight Weight Updatesではこのようなトレードオフを解決できる模様。
また、trainerとinference部分は完全に独立させられ、かつplug-and-playで重みを更新する、といった使い方も想定できる模様。
あとこれは余談だが、引用ポストの主は下記研究でattentionメカニズムを最初に提案したBahdanau氏である。
- Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15
続報:
続報:
#Article #Tutorial #NLP #LanguageModel #AIAgents #SoftwareEngineering #read-later #ContextEngineering #One-Line Notes Issue Date: 2025-10-04 Effective context engineering for AI agents, Anthropic, 2025.09 Comment
元ポスト:
AnthropicによるContextEngineeringに関するブログ。
ざーっとみた感じ基礎的な定義からなぜ重要なのか、retrievalの活用、longnhorizon taskでの活用、compaction(summarization)など、幅広いトピックが網羅されているように見える。
最新サーベイはこちら
- [Paper Note] A Survey of Context Engineering for Large Language Models, Lingrui Mei+, arXiv'25
所見:
#Article #NLP #Dataset #LanguageModel #Blog #Japanese Issue Date: 2025-10-01 2025年10月1日 国立情報学研究所における大規模言語モデル構築への協力について, 国立国会図書館, 2025.09 Comment
元ポスト:
日本語LLMの進展に極めて重要なニュースと思われる
#Article #Blog #PEFT(Adaptor/LoRA) #read-later Issue Date: 2025-09-30 LoRA Without Regret, Schulman+, THINKING MACHINES, 2025.09 Comment
元ポスト:
これはおそらく必読...
解説:
解説:
所見:
#Article #LanguageModel #Evaluation #Blog #One-Line Notes Issue Date: 2025-09-29 Failing to Understand the Exponential, Again, Julian Schrittwieser, 2025.09 Comment
元ポスト:
関連:
- Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
- GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09
AIの指数関数的な成長は続いているぞという話。
以下は管理人の感想だが、個々のベンチマークで見たらサチってきている(昔より伸び代が小さい)ように感じるが、人間が実施する複雑なタスクに対する上記ベンチマークなどを見るとスケーリングは続いている(むしろ加速している感がある)。シンプルなタスクのベンチマークの伸びは小さくとも、それらシンプルなタスクの積み重ねによって複雑なタスクは実施されるので、(現存するベンチマークが測定できている能力はLLMの部分的な能力だけなことも鑑みると)、複雑なタスクで評価した時の伸びは実は大きかったりする(スケーリングは続いている)のではないか、という感想。
#Article #NLP #Dataset #LanguageModel #Evaluation Issue Date: 2025-09-29 GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09 Comment
米国のGDPを牽引する9つの代表的な産業において、44の職種を選定し、合計1320件の実務タスクを設計したベンチマーク。ベンチマークは平均14年程度の経験を持つ専門家が実際の業務内容をもとに作成し、(うち、約220件はオープンソース化)、モデルと専門家のsolutionにタスクを実施させた。その上で、第三者である専門家が勝敗(win, lose, tie)を付与することでモデルがどれだけ実務タスクにおいて人間の専門家に匹敵するかを測定するベンチマークである。
評価の結果、たとえばClaude Opus 4.1の出力は47.6%程度、GPT-5 (high) は38.8%程度の割合で専門家と勝ち + 引き分け、という性能になっており、人間の専門家にかなり近いレベルにまで近づいてきていることが分かる。特にClaude Opus 4.1はデザインの品質も問われるタスク(ドキュメントの書式設定、スライドレイアウトなど)で特に優れているとのこと。https://github.com/user-attachments/assets/653d724f-34ef-46df-9458-bbfde33857b3"
/>
#Article #Pocket #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #Aggregation-aware #KeyPoint Notes Issue Date: 2025-09-27 RECURSIVE SELF-AGGREGATION UNLOCKS DEEP THINKING IN LARGE LANGUAGE MODELS, Venkatraman+, preprint, 2025.09 Comment
N個の応答を生成し、各応答K個組み合わせてpromptingで集約し新たな応答を生成することで洗練させる、といったことをT回繰り返すtest-time scaling手法で、RLによってモデルの集約能力を強化するとより良いスケーリングを発揮する。RLでは通常の目的関数(prompt x, answer y; xから単一のreasoning traceを生成しyを回答する設定)に加えて、aggregation promptを用いた目的関数(aggregation promptを用いて K個のsolution集合 S_0を生成し、目的関数をaggregation prompt x, S_0の双方で条件づけたもの)を定義し、同時に最適化をしている(同時に最適化することは5.4節に記述されている)。つまり、これまでのRLはxがgivenな時に頑張って単一の良い感じのreasoning traceを生成しyを生成するように学習していたが(すなわち、モデルが複数のsolutionを集約することは明示的に学習されていない)、それに加えてモデルのaggregationの能力も同時に強化する、という気持ちになっている。学習のアルゴリズムはPPO, GRPOなど様々なon-poloicyな手法を用いることができる。今回はRLOOと呼ばれる手法を用いている。https://github.com/user-attachments/assets/e83406ae-91a0-414b-a49c-892a4d1f23fd"
/>
様々なsequential scaling, parallel scaling手法と比較して、RSAがより大きなgainを得ていることが分かる。ただし、Knowledge RecallというタスクにおいてはSelf-Consistency (Majority Voting)よりもgainが小さい。https://github.com/user-attachments/assets/8251f25b-472d-48d4-b7df-a6946cfbbcd9"
/>
以下がaggregation-awareなRLを実施した場合と、通常のRL, promptingのみによる場合の性能の表している。全体を通じてaggregation-awareなRLを実施することでより高い性能を発揮しているように見える。ただし、AIMEに関してだけは通常のpromptingによるRSAの性能が良い。なぜだろうか?考察まで深く読めていないので論文中に考察があるかもしれない。https://github.com/user-attachments/assets/146ab6a3-58c2-4a7f-aa84-978a5180c8f3"
/>
元ポスト:
concurrent work:
- [Paper Note] The Majority is not always right: RL training for solution aggregation, Wenting Zhao+, arXiv'25
#Article #Analysis #MachineLearning #NLP #LanguageModel #ReinforcementLearning #AIAgents #Blog #Stability #train-inference-gap Issue Date: 2025-09-27 When Speed Kills Stability: Demystifying RL Collapse from the Training-Inference Mismatch, Liu+, 2025.09 Comment
元ポスト:
訓練時のエンジン(fsdp等)とロールアウト時のエンジン(vLLM等)が、OOVなトークンに対して(特にtooluseした場合に生じやすい)著しく異なる尤度を割り当てるため学習が崩壊し、それは利用するGPUによっても安定性が変化し(A100よりもL20, L20よりもH20)、tokenレベルのImporttance Weightingでは難しく、Sequenceレベルのサンプリングが必要、みたいな話な模様。
関連:
- Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
- [Paper Note] Group Sequence Policy Optimization, Chujie Zheng+, arXiv'25
FP16にするとtrain-inferenae gapが非常に小さくなるという報告:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
A100でvLLMをバックボーンにした時のdisable_cascade_attnの設定値による挙動の違い:
そもそもFlashAttnention-2 kernelにバグがあり、A100/L20で特定のカーネルが呼ばれるとミスマッチが起きるのだとか。vLLM Flashattentionリポジトリのissue 87によって解決済み。~~具体的にどのカーネル実装なのだろうか。~~ (vLLM Flashattentionリポジトリだった模様)
https://github.com/vllm-project/flash-attention
disable_cascade_attnの設定値を何回も変えたけどうまくいかないよという話がある:
#Article #NLP #LanguageModel #Reasoning #OpenWeight #read-later #ModelMerge Issue Date: 2025-09-22 LongCat-Flash-Thinking, meituan-longcat, 2025.09 Comment
元ポスト:
ポイント解説:
関連:
- LongCat-Flash-Chat, meituan-longcat, 2025.08
- [Paper Note] Libra: Assessing and Improving Reward Model by Learning to Think, Meng Zhou+, arXiv'25, 2025.07
#Article #NLP #Dataset #LanguageModel #Evaluation #Reasoning #Mathematics #Contamination-free Issue Date: 2025-09-13 GAUSS Benchmarking Structured Mathematical Skills for Large Language Models, Zhang+, 2025.06 Comment
元ポスト:
現在の数学のベンチマークは個々の問題に対する回答のAccuracyを測るものばかりだが、ある問題を解く際にはさまざまなスキルを活用する必要があり、評価対象のLLMがどのようなスキルに強く、弱いのかといった解像度が低いままなので、そういったスキルの習熟度合いを測れるベンチマークを作成しました、という話に見える。
Knowledge Tracingタスクなどでは問題ごとにスキルタグを付与して、スキルモデルを構築して習熟度を測るので、問題の正誤だけでなくて、スキルベースでの習熟度を見ることで能力を測るのは自然な流れに思える。そしてそれは数学が最も実施しやすい。
#Article #NLP #LanguageModel #python #Blog #read-later #Non-Determinism Issue Date: 2025-09-11 Defeating Nondeterminism in LLM Inference, Horace He in collaboration with others at Thinking Machines, 2025.09 Comment
元ポスト:
ポイント解説:
vLLMにおいてinferenceをdeterministicにする方法が、vLLMのissue number 24583に記載されているので参照のこと。
transformersでの実装例:
#Article #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #OpenWeight #OpenSource #GRPO #read-later #RLVR Issue Date: 2025-09-10 [Paper Note] K2-Think: A Parameter-Efficient Reasoning System, Institute of Foundation Models, Mohamed bin Zayed University of Artificial Intelligence, 2025.09 Comment
HF:
https://huggingface.co/LLM360/K2-Think
code:
-
https://github.com/MBZUAI-IFM/K2-Think-SFT
-
https://github.com/MBZUAI-IFM/K2-Think-Inference
RLはverl+GRPOで実施したとテクニカルペーパーに記述されているが、当該部分のコードの公開はされるのだろうか?
RLで利用されたデータはこちら:
- [Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, arXiv'25
元ポスト:
#Article #NLP #Dataset #LanguageModel #Evaluation #Japanese Issue Date: 2025-09-09 『JamC-QA』: 日本の文化や風習に特化した質問応答ベンチマークの構築・公開(前編), SB Intuitions, 2025.09 Comment
元ポスト:
後編も参照のこと: https://www.sbintuitions.co.jp/blog/entry/2025/09/09/113132
日本の文化、風習、風土、地理、日本史、行政、法律、医療に関する既存のベンチマークによりも難易度が高いQAを人手によってスクラッチから作成した評価データ。人手で作成されたQAに対して、8種類の弱いLLM(パラメータ数の小さい日本語LLMを含む)の半数以上が正しく回答できたものを除外、その後さらに人手で確認といったフィルタリングプロセスを踏んでいる。記事中は事例が非常に豊富で興味深い。
後編では実際の評価結果が記載されており、フルスクラッチの日本語LLMが高い性能を獲得しており、Llama-Swallowなどの継続事前学習をベースとしたモデルも高いスコアを獲得している。評価時は4-shotでドメインごとにExamplarは固定し、greedy decodingで評価したとのこと。
NLP'25: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/Q2-18.pdf
- Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, arXiv'24
のような話もあるので、greedy decodingだけでなくnucleus/temperature samplingを複数trial実施した場合の性能の平均で何か変化があるだろうか、という点が気になったが、下記研究でMMLUのような出力空間が制約されているような設定の場合はほとんど影響がないことが実験的に示されている模様:
- [Paper Note] The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism, Yifan Song+, NAACL'25
これはnucleus/temperature samplingが提案された背景(=出力の自然さを保ったまま多様性を増やしたい)とも一致する。
#Article #Pretraining #NLP #Dataset #LanguageModel #Repository Issue Date: 2025-09-07 FinePDFs, HuggingFaceFW, 2025.09 Comment
元ポスト:
Thomas Wolf氏のポスト:
ODC-By 1.0 license
#Article #Analysis #NLP #LanguageModel #ReinforcementLearning #Blog #Composition #read-later Issue Date: 2025-09-06 From f(x) and g(x) to f(g(x)): LLMs Learn New Skills in RL by Composing Old Ones, Yuan+, 2025.09 Comment
元ポスト:
コントロールされた実験において、深さ2のnestedなcompostition g(f(x))のデータでRLした場合は、テスト時に深さ6までのcompostitionを実行できるようになったが(=メタスキルとしてcompostitionを獲得した)、深さ1のnon-nestedなデータでRLした場合は複雑なcompostitionが必要なタスクを解けなかった。また、一般的にベースモデルがある程度解ける問題に対してRLを適用したモデルのpass@1000はあまり向上しないことから、RLは新しいスキルを何も教えていないのではないか、といった解釈がされることがあるが、より高次のcompostitionが必要なタスクで評価すると明確に性能が良くなるので、実はより高次のcompostitionが必要なタスクに対する汎化性能を伸ばしている。compostitionでの能力を発揮するにはまず幅広いatomicなスキルが必要なので、しっかりそれを事前学習で身につけさせ、その後post-trainingによって解決したいタスクのためのatomic skillのcompostitionの方法を学習させると効果的なのではないか、といった話な模様。
この辺のICLの話と似ている
- What Do Language Models Learn in Context? The Structured Task Hypothesis, Jiaoda Li+, N/A, ACL'24
#Article #Pocket #NLP #LanguageModel #Hallucination Issue Date: 2025-09-06 Why Language Models Hallucinate, Kalai+, 2025.09 Comment
著者ポスト:
解説:
所見:
#Article #ComputerVision #Pretraining #NLP #Dataset #Blog #VisionLanguageModel Issue Date: 2025-09-05 FineVision: Open Data Is All You Need, Wiedmann+, Hugging Face, 2025.09 Comment
HF: https://huggingface.co/datasets/HuggingFaceM4/FineVision
元ポスト:
#Article #Dataset #AIAgents #Evaluation #Repository #Coding #SoftwareEngineering Issue Date: 2025-09-04 OpenHands PR Arena, neulab, 2025.09 Comment
元ポスト:
実際に存在するIssueにタグ付けすることで、リアルタイムに複数LLMによってPRを作成(API callはOpenHandswが負担する)し、ユーザは複数LLMの中で良いものを選択する、といったことができる模様?リーダーボードも将来的に公開するとのことなので、実際にユーザがどのモデルのoutputを選んだかによって勝敗がつくので、それに基づいてランキング付けをするのだろうと推測。興味深い。
#Article #NLP #LanguageModel #python #Blog #LLMServing #read-later Issue Date: 2025-09-03 Inside vLLM: Anatomy of a High-Throughput LLM Inference System, Aleksa Gordić blog, 2025.08 Comment
めっちゃ良さそう
#Article #Survey #ComputerVision #NLP #LanguageModel #OpenWeight #VisionLanguageModel Issue Date: 2025-09-02 August 2025 - China Open Source Highlights, 2025.09 Comment
元ポスト:
#Article #MachineTranslation #NLP #LanguageModel #OpenWeight Issue Date: 2025-09-01 Hunyuan-MT-7B, Tencent, 2025.09 Comment
テクニカルレポート: https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
元ポスト:
Base Modelに対してまず一般的な事前学習を実施し、その後MTに特化した継続事前学習(モノリンガル/パラレルコーパスの利用)、事後学習(SFT, GRPO)を実施している模様。
継続事前学習では、最適なDataMixの比率を見つけるために、RegMixと呼ばれる手法を利用。Catastrophic Forgettingを防ぐために、事前学習データの20%を含めるといった施策を実施。
SFTでは2つのステージで構成されている。ステージ1は基礎的な翻訳力の強化と翻訳に関する指示追従能力の向上のために、Flores-200の開発データ(33言語の双方向の翻訳をカバー)、前年度のWMTのテストセット(English to XXをカバー)、Mandarin to Minority, Minority to Mandarinのcuratedな人手でのアノテーションデータ、DeepSeek-V3-0324での合成パラレルコーパス、general purpose/MT orientedな指示チューニングデータセットのうち20%を構成するデータで翻訳のinstructinoに関するモデルの凡化性能を高めるためキュレーションされたデータ、で学習している模様。パラレルコーパスはReference-freeな手法を用いてスコアを算出し閾値以下の低品質な翻訳対は除外している。ステージ2では、詳細が書かれていないが、少量でよりfidelityの高い約270kの翻訳対を利用した模様。また、先行研究に基づいて、many-shotのin-context learningを用いて、訓練データをさらに洗練させたとのこと(先行研究が引用されているのみで詳細な記述は無し)。また、複数の評価ラウンドでスコアの一貫性が無いサンプルは手動でアノテーション、あるいはverificationをして品質を担保している模様。
RLではGRPOを採用し、rewardとしてsemantic([Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
), terminology([Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
; ドメイン特有のterminologyを捉える), repetitionに基づいたrewardを採用している。最終的にSFT->RLで学習されたHuayuan-MT-7Bに対して、下記プロンプトを用いて複数のoutputを統合してより高品質な翻訳を出力するキメラモデルを同様のrewardを用いて学習する、といったpipelineになっている。https://github.com/user-attachments/assets/dbb7a799-6304-4cfa-b75c-74b44fe39a2e"
/>
https://github.com/user-attachments/assets/33b49ef7-b93b-4094-b83e-5931d2b411e5"
/>
関連:
- Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23
- [Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
- [Paper Note] CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task, Rei+, WMT'22
- [Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22
- [Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
- [Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
関連: PLaMo翻訳
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25
こちらはSFT->Iterative DPO->Model Mergeを実施し、翻訳に特化した継続事前学習はやっていないように見える。一方、SFT時点で独自のテンプレートを作成し、語彙の指定やスタイル、日本語特有の常体、敬体の指定などを実施できるように翻訳に特化したテンプレートを学習している点が異なるように見える。Hunyuanは多様な翻訳の指示に対応できるように学習しているが、PLaMo翻訳はユースケースを絞り込み、ユースケースに対する性能を高めるような特化型のアプローチをとるといった思想の違いが伺える。
#Article #Pretraining #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #Coding #Mathematics Issue Date: 2025-09-01 Nemotron-CC-v2, Nvidia, 2025.08 Comment
元ポスト:
CCだけでなく、数学やコーディングの事前学習データ、SFT styleの合成データセットも含まれている。
#Article #EfficiencyImprovement #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #read-later #One-Line Notes #Reference Collection Issue Date: 2025-08-31 LongCat-Flash-Chat, meituan-longcat, 2025.08 Comment
テクニカルレポート: https://github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/tech_report.pdf
元ポスト:
Agent周りのベンチで高性能なnon thinkingモデル。毎秒100+トークンの生成速度で、MITライセンス。Dynamic Activation...?
Dynamic Activation (activation paramが入力に応じて変化(全てのトークンをMoEにおいて均一に扱わない)することで効率化)は、下記を利用することで実現している模様
- [Paper Note] MoE++: Accelerating Mixture-of-Experts Methods with Zero-Computation Experts, Peng Jin+, ICLR'25
しかし中国は本当に次々に色々な企業から基盤モデルが出てくるなぁ…すごい
- [Paper Note] Scaling Exponents Across Parameterizations and Optimizers, Katie Everett+, ICML'24
解説:
解説:
#Article #Library #ReinforcementLearning #Blog #On-Policy #KeyPoint Notes #Reference Collection #train-inference-gap Issue Date: 2025-08-26 Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08 Comment
元ポスト:
元々
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
のスレッド中にメモっていたが、アップデートがあったようなので新たにIssue化
trainingのエンジン(FSDP等)とロールアウトに使うinferenceエンジン(SGLang,vLLM)などのエンジンのミスマッチにより、学習がうまくいかなくなるという話。
アップデートがあった模様:
- Parallelismのミスマッチでロールアウトと学習のギャップを広げてしまうこと(特にsequence parallelism)
- Longer Sequenceの方が、ギャップが広がりやすいこと
- Rolloutのためのinferenceエンジンを修正する(SGLang w/ deterministic settingすることも含む)だけでは効果は限定的
といった感じな模様。
さらにアップデート:
FP16にするとtrain-inferenae gapが非常に小さくなるという報告:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
vLLMがtrain inference mismatchを防ぐアップデートを実施:
#Article #NLP #LanguageModel #Evaluation #OpenWeight #ProprietaryLLM #Japanese Issue Date: 2025-08-20 Swallow LLM Leaderboard v2, Swallow LLM Team, 2025.08 Comment
元ポスト:
LLMの性能を公平な条件で評価するために、従来のnon thinkingモデルで採用していた方法はthinkingモデルでは過小評価につながることが明らかになった(e.g., non thinkingモデルはzero shotを標準とするが、thinkingモデルではfewshot、chat templateの採用等)ため、日本語/英語ともに信頼の高い6つのベンチマークを採用し、thinkingモデルに対して公平な統一的な評価フレームワークを確立。主要なプロプライエタリ、OpenLLMに対して評価を実施し、リーダーボードとして公開。Reasoningモデルに対する最新の日本語性能を知りたい場合はこちらを参照するのが良いと思われる。
評価に用いられたフレームワークはこちら:
https://github.com/swallow-llm/swallow-evaluation-instruct
主要モデルの性能比較:
#Article #Pretraining #NLP #LanguageModel #DiffusionModel Issue Date: 2025-08-09 Diffusion Language Models are Super Data Learners, Jinjie Ni and the team, 2025.08 Comment
dLLMは学習データの繰り返しに強く、データ制約下においては十分な計算量を投入してepochを重ねると、性能向上がサチらずにARモデルを上回る。
- [Paper Note] Diffusion Beats Autoregressive in Data-Constrained Settings, Mihir Prabhudesai+, arXiv'25
- 追記: 上記研究の著者による本ポストで取り上げられたissueに対するclarification
-
でも同様の知見が得られている。
が、スレッド中で両者の違いが下記のように(x rollrng reviewなるものを用いて)ポストされており、興味がある場合は読むといいかも。(ところで、x rolling reviewとは、、?もしやLLMによる自動的な査読システム?)
- Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
において、ARモデルではrepetitionは4回までがコスパ良いという話と比べると、dLLMにとんでもない伸び代があるような話に見える。
(話が脱線します)
個人的にはアーキテクチャのさらなる進化は興味深いが、ユーザが不完全な質問をLLMに投げた時に、LLMがユーザの意図が「不明な部分のcontextを質問を返すことによって補う」という挙動があると嬉しい気がするのだが、そういった研究はないのだろうか。
ただ、事前学習時点でそういったデータが含まれて知識として吸収され、かつmid/post-trainingでそういった能力を引き出すと言う両軸で取り組まないと、最悪膨大な計算資源を投じたものの「わからない!どういうこと!?」と返し続けるLLMが完成し全く役に立たない、ということになりそうで怖い。
gpt5が出た時に、「3.9と3.11はどちらが大きいですか?」というクエリを投げた際にいまだに「3.11」と回答してくる、みたいなポストが印象的であり、これはLLMが悪いと言うより、ユーザ側が算数としての文脈できいているのか、ソフトウェアのバージョンの文脈できいているのか、を指定していないことが原因であり、上記の回答はソフトウェアのバージョニングという文脈では正答となる。LLMが省エネになって、ユーザのデータを蓄積しまくって、一人一人に対してあなただけのLLM〜みたいな時代がくれば少しは変わるのだろうが、それでもユーザがプロファイルとして蓄積した意図とは異なる意図で質問しなければならないという状況になると、上記のような意図の取り違えが生じるように思う。
なのでやはりりLLM側が情報が足りん〜と思ったら適切なturn数で、最大限の情報をユーザから引き出せるような逆質問を返すみたいな挙動、あるいは足りない情報があったときに、いくつかの候補を提示してユーザ側に提示させる(e.g., 算数の話?それともソフトウェアの話?みたいな)、といった挙動があると嬉しいなぁ、感。
んでそこの部分の性能は、もしやるな、promptingでもある程度は実現でき、それでも全然性能足りないよね?となった後に、事前学習、事後学習でより性能向上します、みたいな流れになるのかなぁ、と想像するなどした。
しかしこういう話をあまり見ないのはなぜだろう?私の観測範囲が狭すぎる or 私のアイデアがポンコツなのか、ベンチマーク競争になっていて、そこを向上させることに業界全体が注力してしまっているからなのか、はたまた裏ではやられているけど使い物にならないのか、全然わからん。
続報:
- Diffusion Language Models are Super Data Learners, Ni+, 2025.10
#Article #Tutorial #LanguageModel #SyntheticData #Slide #ACL Issue Date: 2025-08-06 Synthetic Data in the Era of LLMs, Tutorial at ACL 2025 Comment
元ポスト:
#Article #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #AttentionSinks #read-later #KeyPoint Notes #Reference Collection Issue Date: 2025-08-05 gpt-oss-120b, OpenAI, 2025.08 Comment
blog:
https://openai.com/index/introducing-gpt-oss/
HF:
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
アーキテクチャで使われている技術まとめ:
-
-
-
-
- こちらにも詳細に論文がまとめられている
上記ポスト中のアーキテクチャの論文メモリンク(管理人が追加したものも含む)
- Sliding Window Attention
- [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
- [Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19
- MoE
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
- RoPE w/ YaRN
- RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, N/A, Neurocomputing, 2024
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
- Attention Sinks
- Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- Attention Sinksの定義とその気持ち、Zero Sink, Softmaxの分母にバイアス項が存在する意義についてはこのメモを参照のこと。
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
- Attention Sinksが実際にどのように効果的に作用しているか?についてはこちらのメモを参照。
- When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
-
- Sink Token (or Zero Sink) が存在することで、decoder-onlyモデルの深い層でのrepresentationのover mixingを改善し、汎化性能を高め、promptに対するsensitivityを抑えることができる。
- (Attentionの計算に利用する) SoftmaxへのLearned bias の導入 (によるスケーリング)
- これはlearnable biasが導入されることで、attention scoreの和が1になることを防止できる(余剰なアテンションスコアを捨てられる)ので、Zero Sinkを導入しているとみなせる(と思われる)。
- GQA
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N/A, arXiv'23
- SwiGLU
- GLU Variants Improve Transformer, Noam Shazeer, N/A, arXiv'20 -
- group size 8でGQAを利用
- Context Windowは128k
- 学習データの大部分は英語のテキストのみのデータセット
- STEM, Coding, general knowledgeにフォーカス
-
https://openai.com/index/gpt-oss-model-card/
あとで追記する
他Open Weight Modelとのベンチマークスコア比較:
-
-
-
-
- long context
-
- Multihop QA
解説:
learned attention sinks, MXFP4の解説:
Sink Valueの分析:
gpt-oss の使い方:
https://note.com/npaka/n/nf39f327c3bde?sub_rt=share_sb
[Paper Note] Comments-Oriented Document Summarization: Understanding Documents with Reader’s Feedback, Hu+, SIGIR’08, 2008.07
fd064b2-338a-4f8d-953c-67e458658e39
Qwen3との深さと広さの比較:
- The Big LLM Architecture Comparison, Sebastian Laschka, 2025.07
Phi4と同じtokenizerを使っている?:
post-training / pre-trainingの詳細はモデルカード中に言及なし:
-
-
ライセンスに関して:
> Apache 2.0 ライセンスおよび当社の gpt-oss 利用規約に基づくことで利用可能です。
引用元:
https://openai.com/ja-JP/index/gpt-oss-model-card/
gpt-oss利用規約:
https://github.com/openai/gpt-oss/blob/main/USAGE_POLICY
cookbook全体: https://cookbook.openai.com/topic/gpt-oss
gpt-oss-120bをpythonとvLLMで触りながら理解する: https://tech-blog.abeja.asia/entry/gpt-oss-vllm
指示追従能力(IFEVal)が低いという指摘:
#Article #NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-07-29 GLM-4.5: Reasoning, Coding, and Agentic Abililties, Zhipu AI Inc., 2025.07 Comment
元ポスト:
HF: https://huggingface.co/collections/zai-org/glm-45-687c621d34bda8c9e4bf503b
詳細なまとめ:
こちらでもMuon Optimizerが使われており、アーキテクチャ的にはGQAやMulti Token Prediction, QK Normalization, MoE, 広さよりも深さを重視の構造、みたいな感じな模様?
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
#Article #Tutorial #NLP #LanguageModel #LLMServing #SoftwareEngineering #read-later Issue Date: 2025-07-22 LLM Servingを支える技術, Kotoba Technologies, 2025.07 Comment
こちらも参照のこと:
- LLM推論に関する技術メモ, iwashi.co, 2025.07
#Article #Tutorial #Metrics #NLP #LanguageModel #LLMServing #MoE(Mixture-of-Experts) #SoftwareEngineering #Parallelism #Inference #Batch Issue Date: 2025-07-21 LLM推論に関する技術メモ, iwashi.co, 2025.07 Comment
```
メモリ (GB) = P × (Q ÷ 8) × (1 + オーバーヘッド)
- P:パラメータ数(単位は10億)
- Q:ビット精度(例:16、32)、8で割ることでビットをバイトに変換
- オーバーヘッド(%):推論中の追加メモリまたは一時的な使用量(例:KVキャッシュ、アクティベーションバッファ、オプティマイザの状態)
```
↑これ、忘れがちなのでメモ…
関連(量子化関連研究):
- [Paper Note] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration, Ji Lin+, MLSys'24
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models, Guangxuan Xiao+, ICML'23
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, N/A, ICLR'23
すごいメモだ…勉強になります
#Article #NLP #LanguageModel #Evaluation #Slide #Japanese #SoftwareEngineering Issue Date: 2025-07-16 論文では語られないLLM開発において重要なこと Swallow Projectを通して, Kazuki Fujii, NLPコロキウム, 2025.07 Comment
独自LLM開発の私の想像など遥かに超える非常に困難な側面が記述されており、これをできるのはあまりにもすごいという感想を抱いた(小並感だけど本当にすごいと思う。すごいとしか言いようがない)
#Article #NLP #LanguageModel #Optimizer #OpenWeight #MoE(Mixture-of-Experts) #read-later #Stability #KeyPoint Notes #Reference Collection Issue Date: 2025-07-12 Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07 Comment
元ポスト:
1T-A32Bのモデル。さすがに高性能。
(追記) Reasoningモデルではないのにこの性能のようである。
1T-A32Bのモデルを15.5Tトークン訓練するのに一度もtraining instabilityがなかったらしい
元ポスト:
量子化したモデルが出た模様:
仕事早すぎる
DeepSeek V3/R1とのアーキテクチャの違い:
MLAのヘッドの数が減り、エキスパートの数を増加させている
解説ポスト:
利用されているOptimizer:
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
2つほどバグがあり修正された模様:
chatbot arenaでOpenLLMの中でトップのスコア
元ポスト:
テクニカルペーパーが公開:
https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
元ポスト:
テクニカルレポートまとめ:
以下のような技術が使われている模様
- Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, arXiv'25
- MLA MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
- MuonCip
- MuonOptimizer [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
- QK-Clip
- 参考(こちらはLayerNormを使っているが): Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, N/A, CVPR'24
- RLVR
- DeepSeek-R1, DeepSeek, 2025.01
- Self-Critique
- 関連: [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25
- [Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Problems and Verifiable Rewards, Xun Lu, arXiv'25
- Temperature Decay
- 最初はTemperatureを高めにした探索多めに、後半はTemperatureを低めにして効用多めになるようにスケジューリング
- Tool useのためのSynthetic Datahttps://github.com/user-attachments/assets/74eacdb2-8f64-4d53-b2d0-66df770f2e8b"
/>
Reward Hackingに対処するため、RLVRではなくpairwise comparisonに基づくself judging w/ critique を利用きており、これが非常に効果的な可能性があるのでは、という意見がある:
#Article #Tutorial #NLP #LanguageModel #Reasoning #LongSequence #SmallModel #MultiLingual #OpenWeight #OpenSource Issue Date: 2025-07-09 SmolLM3: smol, multilingual, long-context reasoner, HuggingFace, 2025.07 Comment
元ポスト:
SmolLM3を構築する際の詳細なレシピ(アーキテクチャ、データ、data mixture, 3 stageのpretraining(web, code, mathの割合と品質をステージごとに変え、stable->stable->decayで学習), midtraining(long context->reasoning, post training(sft->rl), ハイブリッドreasoningモデルの作り方、評価など)が説明されている
学習/評価スクリプトなどがリリース:
#Article #NLP #LanguageModel #Zero/FewShotLearning Issue Date: 2025-06-15 [Paper Note] Language Models are Unsupervised Multitask Learners, Radford+, OpenAI, 2019 Comment
今更ながら、GPT-2論文をメモってなかったので追加。
従来のモデルは特定のタスクを解くためにタスクごとに個別のモデルをFinetuningする必要があったが、大規模なWebTextデータ(Redditにおいて最低3つのupvoteを得たポストの外部リンクを収集)によって言語モデルを訓練し、モデルサイズをスケーリングさせることで、様々なタスクで高い性能を獲得でき、Zero-Shot task transfer, p(output | input, task) , が実現できるよ、という話。
今ざっくり見返すと、Next Token Predictionという用語は論文中に出てきておらず、かつ "Language Modeling" という用語のみで具体的なlossは記述されておらず(当時はRNN言語モデルで広く学習方法が知られていたからだろうか?)、かつソースコードも学習のコードは提供されておらず、lossの定義も含まれていないように見える。
ソースコードのモデル定義:
https://github.com/openai/gpt-2/blob/master/src/model.py#L169
#Article #NLP #LanguageModel #InstructionTuning #PostTraining Issue Date: 2025-05-12 Stanford Alpaca: An Instruction-following LLaMA Model, Taori +, 2023.03 Comment
今更ながらメモに追加。アカデミアにおけるOpenLLMに対するInstruction Tuningの先駆け的研究。
#Article #NLP #Dataset #LanguageModel #AIAgents #Evaluation #API Issue Date: 2025-04-08 BFCLv2, UC Berkeley, 2024.08 Comment
LLMのTool Useを評価するための現在のデファクトスタンダードとなるベンチマーク
BFCLv3:
https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html
#Article #Analysis #NLP #LanguageModel #Blog Issue Date: 2025-03-25 言語モデルの物理学, 佐藤竜馬, 2025.03 Comment
必読
#Article #ComputerVision #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Transformer #Supervised-FineTuning (SFT) #MultiModal #Blog #SSM (StateSpaceModel) Issue Date: 2025-03-24 Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03 Comment
関連:
- Hunyuan T1, Tencent, 2025.03
TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。
56B程度のmediumサイズのモデルと、8B程度の軽量なモデルについて述べられている。特に、8BモデルでMambaとTransformerのハイブリッドモデルと、通常のTransformerモデルを比較している。学習データに15 Trillion Tokenを利用しており、このデータ量でのApple to Appleのアーキテクチャ間の比較は、現状では最も大規模なものとのこと。性能は多くのベンチマークでハイブリッドにしても同等、Commonsense Understandingでは上回っている。
また、学習したNemotron-Hをバックボーンモデルとして持つVLMについてもモデルのアーキテクチャが述べられている。
#Article #NLP #LanguageModel #OpenWeight #OpenSource Issue Date: 2025-03-14 OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini, AllenAI, 20250.3 Comment
真なる完全なるオープンソース(に近い?)OLMOの最新作
学習が安定しやすいpre LNではなく性能が最大化されやすいPost LNを採用している模様。学習を安定化させるために、QKNormやRMSNormを採用するなどの工夫を実施しているらしい。
#Article #LanguageModel #python #LLMServing Issue Date: 2025-02-12 SGlang, sgl-project, 2024.01 GPT Summary- SGLangは、大規模言語モデルと視覚言語モデルのための高速サービングフレームワークで、バックエンドとフロントエンドの共同設計により迅速なインタラクションを実現します。主な機能には、高速バックエンドランタイム、柔軟なフロントエンド言語、広範なモデルサポートがあり、オープンソースの活発なコミュニティに支えられています。 Comment
- Open R1, HuggingFace, 2025.01
のUpdate2でMath Datasetの生成に利用されたLLM Servingフレームワーク。利用前と比較してスループットが2倍になったとのこと。
CPU, external storageを利用することでTTFTを改善するようになったようで、最大80%TTFTが削減されるとの記述がある。
(原理的には元来可能だが計算効率の最適化に基づく誤差によって実装上の問題で実現できていなかった) Deterministic Inferenceをサポート:
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #FoundationModel #RLHF #Blog Issue Date: 2025-02-01 DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01 Comment
- DeepSeek-R1, DeepSeek, 2025.01
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open
Language Models, Zhihong Shao+, arXiv'24
とても丁寧でわかりやすかった。後で読んだ内容を書いて復習する。ありがとうございます。
#Article #NeuralNetwork #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #Slide #PostTraining Issue Date: 2023-04-25 LoRA論文解説, Hayato Tsukagoshi, 2023.04 Comment
ベースとなる事前学習モデルの一部の線形層の隣に、低ランク行列A,Bを導入し、A,Bのパラメータのみをfinetuningの対象とすることで、チューニングするパラメータ数を激減させた上で同等の予測性能を達成し、推論速度も変わらないようにするfinetuning手法の解説
LoRAを使うと、でかすぎるモデルだと、そもそもGPUに載らない問題や、ファインチューニング後のモデルファイルでかすぎワロタ問題が回避できる。
前者は事前学習済みモデルのBPのための勾配を保存しておく必要がなくなるため学習時にメモリ節約になる。後者はA,Bのパラメータだけ保存すればいいので、ストレージの節約になる。
かつ、学習速度が25%程度早くなる。
既存研究であるAdapter(transformerの中に学習可能なMLPを差し込む手法)は推論コストが増加し、prefix tuningは学習が非常に難しく、高い性能を達成するためにprefixとして128 token入れたりしなければならない。
huggingfaceがすでにLoRAを実装している
https://github.com/huggingface/peft
#Article #NeuralNetwork #ComputerVision #CVPR #Backbone Issue Date: 2021-11-04 Deep Residual Learning for Image Recognition, He+, Microsoft Research, CVPR’16 Comment
ResNet論文
ResNetでは、レイヤーの計算する関数を、残差F(x)と恒等関数xの和として定義する。これにより、レイヤーが入力との差分だけを学習すれば良くなり、モデルを深くしても最適化がしやすくなる効果ぎある。数レイヤーごとにResidual Connectionを導入し、恒等関数によるショートカットができるようにしている。
ResNetが提案される以前、モデルを深くすれば表現力が上がるはずなのに、実際には精度が下がってしまうことから、理論上レイヤーが恒等関数となるように初期化すれば、深いモデルでも浅いモデルと同等の表現が獲得できる、と言う考え方を発展させた。
(ステートオブAIガイドに基づく)
同じパラメータ数でより層を深くできる(Plainな構造と比べると層が1つ増える)Bottleneckアーキテクチャも提案している。
今や当たり前のように使われているResidual Connectionは、層の深いネットワークを学習するために必須の技術なのだと再認識。
#Article #NeuralNetwork #Survey #NLP #LanguageModel #Slide Issue Date: 2019-11-09 事前学習言語モデルの動向 _ Survey of Pretrained Language Models, Kyosuke Nishida, 2019 Comment
[2019/06まで]
・ELMo(双方向2層LSTM言語モデル)
・GPT(left-to-rightの12層Transformer自己回帰言語モデル)
・BERT(24層のTransformer双方向言語モデル)
・MT-DNN(BERTの上にマルチタスク層を追加した研究)
・XLM(パラレル翻訳コーパスを用いてクロスリンガルに穴埋めを学習)
・TransformerXL(系列長いに制限のあった既存モデルにセグメントレベルの再帰を導入し長い系列を扱えるように)
・GPT-2(48層Transformerの自己回帰言語モデル)
・ERNIE 1.0(Baidu, エンティティとフレーズの外部知識を使ってマスクに利用)
・ERNIE(Tsinghua, 知識グラフの情報をfusionしたLM)
・Glover(ドメイン、日付、著者などを条件とした生成を可能としたGPT)
・MASS(Encoder-Decoder型の生成モデルのための事前学習)
・UniLM(Sequence-to-Sequenceを可能にした言語モデル)
・XLNet(自己回帰(単方向)モデルと双方向モデルの両方の利点を得ることを目指す)
[2019/07~]
・SpanBERT(i.i.dではなく範囲でマスクし、同時に範囲の境界も予測する)
・ERNIE 2.0(Baidu, マルチタスク事前学習; 単語レベル・構造レベル・意味レベル)
・RoBERTa(BERTと同じ構造で工夫を加えることで性能向上)
- より大きなバッチサイズを使う(256から8192)
- より多くのデータを使う(16GBから160GB)
- より長いステップ数の学習をする(BERT換算で16倍)
- 次文予測(NSP)は不要
→ GLUEでBERT, XLNetをoutperform
・StructBERT (ALICE, NSPに代わる学習の目的関数を工夫)
- マスクした上で単語の順番をシャッフルし元に戻す
- ランダム・正順・逆順の3種類を分類
→ BERTと同サイズ、同データでBERT, RoBERTa超え
・DistilBERT(蒸留により、12層BERTを6層に小型化(40%減))
- BERTの出力を教師として、生徒が同じ出力を出すように学習
- 幅(隠れ層)サイズを減らすと、層数を経あrスよりも悪化
→ 推論は60%高速化、精度は95%程度を保持
・Q8BERT(精度を落とさずにfine-tuning時にBERTを8bit整数に量子化)
- Embedding, FCは8bit化、softmax, LNorm, GELUは32bitをキープ
→ モデルサイズ1/4, 速度3.7倍
・CTRL(条件付き言語モデル)
- 条件となる制御テキストを本文の前に与えて学習
- 48層/1280次元Transformer(パラメータ数1.6B)
・MegatronLM(72層、隠れ状態サイズ3072、長さ1024; BERTの24倍サイズ)
・ALBERT(BERTの層のパラメータをすべて共有することで学習を高速化; 2020年あたりのデファクト)
- Largeを超えたモデルは学習が難しいため、表現は落ちるが学習しやすくした
- 単語埋め込みを低次元にすることでパラメータ数削減
- 次文予測を、文の順序入れ替え判定に変更
→ GLUE, RACE, SQuADでSoTAを更新
・T5(NLPタスクをすべてtext-to-textとして扱い、Enc-Dec Transformerを745GBコーパスで事前学習して転移する)
- モデルはEncoder-DecoderのTransformer
- 学習タスクをエンコーダ・デコーダに合わせて変更
- エンコーダ側で範囲を欠落させて、デコーダ側で予測
→ GLUE, SuperGLUE, SQuAD1.1, CNN/DMでSoTA更新
・BART(Seq2Seqの事前学習として、トークンマスク・削除、範囲マスク、文の入れ替え、文書の回転の複数タスクで学習)
→ CNN/DMでT5超え、WMT'16 RO-ENで逆翻訳を超えてSoTA
ELMo, GPT, BERT, GPT-2, XLNet, RoBERTa, DistilBERT, ALBERT, T5あたりは良く見るような感
各データセットでの各モデルの性能も後半に記載されており興味深い。
ちなみに、CNN/DailyMail Datasetでは、T5, BARTあたりがSoTA。
R2で比較すると
- Pointer-Generator + Coverage Vectorが17,28
- LEAD-3が17.62
- BARTが21.28
- T5が21.55
となっている
#Article #RecommenderSystems #Library Issue Date: 2019-09-11 Implicit Comment
Implicitデータに対するCollaborative Filtering手法がまとまっているライブラリ
Bayesian Personalized Ranking, Logistic Matrix Factorizationなどが実装。
Implicitの使い方はこの記事がわかりやすい:
https://towardsdatascience.com/building-a-collaborative-filtering-recommender-system-with-clickstream-data-dffc86c8c65
ALSの元論文の日本語解説
https://cympfh.cc/paper/WRMF
#Article #RecommenderSystems #Dataset Issue Date: 2019-04-12 Recommender System Datasets, Julian McAuley Comment
Recommender Systems研究に利用できる各種データセットを、Julian McAuley氏がまとめている。
氏が独自にクロールしたデータ等も含まれている。
非常に有用。
#Article #RecommenderSystems #Tutorial #Explanation Issue Date: 2019-01-23 Designing and Evaluating Explanations for Recommender Systems, Tintarev+, Recommender Systems Handbook, 2011 Comment
Recommender Systems HandbookのChapter。[Paper Note] A Survey of Explanations in Recommender Systems, Tintarev+, ICDEW'07
のSurveyと同じ著者による執筆。
推薦のExplanationといえばこの人というイメージ。
D論: http://navatintarev.com/papers/Nava%20Tintarev_PhD_Thesis_(2010).pdf
#Article #Survey #AdaptiveLearning #EducationalDataMining #LearningAnalytics Issue Date: 2018-12-22 Educational Data Mining and Learning Analytics, Baker+, 2014 Comment
Ryan BakerらによるEDM Survey
#Article #RecommenderSystems #Classic #ContextAware Issue Date: 2018-12-22 Context-Aware Recommender Systems, Adomavicius+, Recommender Systems Handbook, 2011 Comment
Context-aware Recsysのパイオニア的研究
通常のuser/item paradigmを拡張して、いかにコンテキストの情報を考慮するかを研究。
コンテキスト情報は、
Explicit: ユーザのマニュアルインプットから取得
Implicit: 自動的に取得
inferred: ユーザとツールやリソースのインタラクションから推測(たとえば現在のユーザのタスクとか)
いくつかの異なるパラダイムが提案された:
1. recommendation via context-driven querying and search approach
コンテキストの情報を、特定のリポジトリのリソース(レストラン)に対して、クエリや検索に用いる。そして、best matchingなリソースを(たとえば、現在開いているもっとも近いレストランとか)をユーザに推薦。
2. Contextual preference elicitation and estimation approach
こっちは2012年くらいの主流。contextual user preferencesをモデル化し学習する。データレコードをしばしば、
3. contextual prefiltering approach
contextualな情報を(学習したcontextualなpreferenceなどを)、tradittionalなrecommendation algorithmを適用する前にデータのフィルタリングに用いる。
4. contextual postfiltering approach
entire setから推薦を作り、あとでcontextの情報を使ってsetを整える。
5. Contextual modeling
contextualな情報を、そのままrecommendationの関数にぶちこんでしまい、アイテムのratingのexplicitなpredictorとして使う。
3, 4はtraditionalな推薦アルゴリズムが適用できる。
1,2,5はmulti-dimensionalな推薦アルゴリズムになる。heuristic-based, model-based approachesが述べられているらしい。
#Article #Classic #AdaptiveLearning #LearningStyle Issue Date: 2018-12-22 LEARNING AND TEACHING STYLES IN ENGINEERING EDUCATION, Felder, Engr. Education, 78(7), 674–681, 1988 Comment
LearningStyleに関して研究している古典的な研究。
context-aware recsysの研究初期の頃は、だいたいはこのFelder-Silverman Theoryというのをベースに研究されていたらしい。
#Article #NeuralNetwork #Tutorial #NLP #Slide Issue Date: 2018-01-15 自然言語処理のためのDeep Learning, Yuta Kikuchi, 2013.09 #Article #RecommenderSystems #CollaborativeFiltering #MatrixFactorization Issue Date: 2018-01-11 [Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008 Comment
Implicit Feedbackなデータに特化したMatrix Factorization (MF)、Weighted Matrix Factorization (WMF)を提案。
ユーザのExplicitなFeedback(ratingやlike, dislikeなど)がなくても、MFが適用可能。
目的関数は下のようになっている。
通常のMFでは、ダイレクトにrating r_{ui}を予測したりするが、WMFでは r_{ui}をratingではなく、たとえばユーザuがアイテムiを消費した回数などに置き換え、binarizeした数値p_{ui}を目的関数に用いる。
このとき、itemを消費した回数が多いほど、そのユーザはそのitemを好んでいると仮定し、そのような事例については重みが高くなるようにc_{ui}を計算し、目的関数に導入している。


日本語での解説: https://cympfh.cc/paper/WRMF
Implicit Implicit でのAlternating Least Square (ALS)という手法が、この手法の実装に該当する。
#Article #DocumentSummarization #NLP #Alignment #SIGIR Issue Date: 2018-01-11 [Paper Note] The Decomposition of Human-Written Summary Sentences. Hongyan Jing et al. SIGIR’99 Comment
参照要約 - 原文書対が与えられた時に、参照要約中の単語と原文書中の単語のアライメントをとるHMMベースな手法を提案。
outputはこんな感じ。
#Article #Multi #Single #DocumentSummarization #Document #Unsupervised #GraphBased #NLP #Extractive Issue Date: 2018-01-01 [Paper Note] LexRank: Graph-based Lexical Centrality as Salience in Text Summarization, Erkan+, Journal of Artificial Intelligence Research, 2004 Comment
代表的なグラフベースな(Multi) Document Summarization手法。
ほぼ [Paper Note] TextRank: Bringing Order into Texts, Mihalcea+, EMNLP'04
と同じ手法。
2種類の手法が提案されている:
* [LexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを計算し閾値以上となったsentenceの間にのみedgeを張る(重みは確率的に正規化)。その後べき乗法でPageRank。
* [ContinousLexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを用いてAffinity Graphを計算し、PageRankを適用(べき乗法)。
DUC2003, 2004(MDS)で評価。
Centroidベースドな手法をROUGE-1の観点でoutperform。
document clusterの17%をNoisyなデータにした場合も実験しており、Noisyなデータを追加した場合も性能劣化が少ないことも示している。
#Article #RecommenderSystems #Survey Issue Date: 2018-01-01 推薦システムのアルゴリズム, 神嶌, 2016 #Article #RecommenderSystems #CollaborativeFiltering #Novelty #KeyPoint Notes Issue Date: 2017-12-28 [Paper Note] Discovery-oriented Collaborative Filtering for Improving User Satisfaction, Hijikata+, IUI’09 Comment
・従来のCFはaccuracyをあげることを目的に研究されてきたが,ユーザがすでに知っているitemを推薦してしまう問題がある.おまけに(推薦リスト内のアイテムの観点からみた)diversityも低い.このような推薦はdiscoveryがなく,user satisfactionを損ねるので,ユーザがすでに何を知っているかの情報を使ってよりdiscoveryのある推薦をCFでやりましょうという話.
・特徴としてユーザのitemへのratingに加え,そのitemをユーザが知っていたかどうかexplicit feedbackしてもらう必要がある.
・手法は単純で,User-based,あるいはItem-based CFを用いてpreferenceとあるitemをユーザが知っていそうかどうかの確率を求め,それらを組み合わせる,あるいはrating-matrixにユーザがあるitemを知っていたか否かの数値を組み合わせて新たなmatrixを作り,そのmatrix上でCFするといったもの.
・offline評価の結果,通常のCF,topic diversification手法と比べてprecisionは低いものの,discovery ratioとprecision(novelty)は圧倒的に高い.
・ユーザがitemを知っていたかどうかというbinary ratingはユーザに負荷がかかるし,音楽推薦の場合previewがなければそもそも提供されていないからratingできないなど,必ずしも多く集められるデータではない.そこで,データセットのratingの情報を25%, 50%, 75%に削ってratingの数にbiasをかけた上で実験をしている.その結果,事前にratingをcombineし新たなmatrixを作る手法はratingが少ないとあまりうまくいかなかった.
・さらにonlineでuser satisfaction(3つの目的のもとsatisfactionをratingしてもらう 1. purchase 2. on-demand-listening 3. discovery)を評価した. 結果,purchaseとdiscoveryにおいては,ベースラインを上回った.ただし,これは推薦リスト中の満足したitemの数の問題で,推薦リスト全体がどうだった
かと問われた場合は,ベースラインと同等程度だった.
重要論文
#Article #RecommenderSystems #Novelty #RecSys #KeyPoint Notes Issue Date: 2017-12-28 [Paper Note] “I like to explore sometimes”: Adapting to Dynamic User Novelty Preferences, Kapoor et al. (with Konstan), RecSys’15 Comment
・典型的なRSは,推薦リストのSimilarityとNoveltyのcriteriaを最適化する.このとき,両者のバランスを取るためになんらかの定数を導入してバランスをとるが,この定数はユーザやタイミングごとに異なると考えられるので(すなわち人やタイミングによってnoveltyのpreferenceが変化するということ),それをuserの過去のbehaviorからpredictするモデルを考えましたという論文.
・式中によくtが出てくるが,tはfamiliar setとnovel setをわけるためのみにもっぱら使われていることに注意.昼だとか夜だとかそういう話ではない.familiar setとは[t-T, t]の間に消費したアイテム,novel setはfamiliar setに含まれないitemのこと.
・データはmusic consumption logsを使う.last.fmやproprietary dataset.データにlistening以外のexplicit feedback (rating)などの情報はない
・itemのnoveltyの考え方はユーザ側からみるか,システム側から見るかで分類が変わる.三種類の分類がある.
(a) new to system: システムにとってitemが新しい.ゆえにユーザは全員そのitemを知らない.
(b) new to user: システムはitemを知っているが,ユーザは知らない.
(c) oblivious/forgotten item: 過去にユーザが知っていたが,最後のconsumptionから時間が経過しいくぶんunfamiliarになったitem
Repetition of forgotten items in future consumptions has been shown to produce increased diversity and emotional excitement.
この研究では(b), (c)を対象とする.
・userのnovelty preferenceについて二つの仮定をおいている.
1. ユーザごとにnovelty preferenceは違う.
2. ユーザのnovelty preferenceはdynamicに変化する.trainingデータを使ってこの仮定の正しさを検証している.
・novelty preferenceのpredictは二種類の素性(familiar set diversityとcumulative negative preference for items in the familiar set)を使う. 前者は,familiar setの中のradioをどれだけ繰り返しきいているかを用いてdiversityを定義.繰り返し聞いているほうがdiversity低い.後者は,異なるitemの消費をする間隔によってdynamic preference scoreを決定.familiar set内の各itemについて負のdynamic preference scoreをsummationすることで,ユーザの”退屈度合い”を算出している.
・両素性を考慮することでnovelty preferenceのRMSEがsignificantに減少することを確認.
・推薦はNoveltyのあるitemの推薦にはHijikataらの協調フィルタリングなどを使うこともできる.
・しかし今回は簡易なitem-based CFを用いる.ratingの情報がないので,それはdynamic preference scoreを代わりに使い各itemのスコアを求め,そこからnovel recommendationとfamiliar recommendationのリストを生成し,novelty preferenceによって両者を組み合わせる.
・音楽(というより音楽のradioやアーティスト)の推薦を考えている状況なので,re-consumptionが許容されている.Newsなどとは少しドメインが違うことに注意.
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #NAACL #KeyPoint Notes Issue Date: 2017-12-28 [Paper Note] A Study for Documents Summarization based on Personal Annotation, Zhang+, HLT-NAACL-DUC’03, 2003.05 Comment
(過去に管理人が作成したスライドでの論文メモのスクショ)


重要論文だと思われる。
#Article #PersonalizedDocumentSummarization #DocumentSummarization #RecommenderSystems #Personalization #One-Line Notes Issue Date: 2017-12-28 [Paper Note] User-model based personalized summarization, Diaz+, Information Processing and Management 2007.11 Comment
PDSの先駆けとなった重要論文。必ずreferすべき。