
Survey
[Paper Note] OmniOpt: Taxonomy, Geometry, and Benchmarking of Modern Optimizers, Siyuan Li+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Evaluation #Optimizer #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-07-12 GPT Summary- 最適化手法の選択は計算量やメモリに制約されるが、その全体像は断片的である。そこで、統合サーベイ「OmniOpt」を提案。これには、五段階メタパイプラインの構造的変換、ノルム制約付きLMOによる手法統一、二次元分類法を用いた手法の機構と訓練目標の整理、最適化手法を系統的に分析するクロスドメインベンチマークが含まれる。これにより、最適化手法選択のための実用的な座標系を提供し、今後の研究の方向性を示す。 Comment
元ポスト:
optimizerの詳細なサーベイと様々なベンチマーキングの結果が記載されている模様
全部読んだらめちゃめちゃ勉強になりそう
[Paper Note] World Action Models: A Survey, Qiuhong Shen+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#ComputerVision #NLP #Robotics #WorldActionModel Issue Date: 2026-07-03 GPT Summary- World Action Models(WAMs)は、未来予測と行動実行を統合した身体化されたモデルであり、最近では大規模な動画生成モデルを再利用する研究が進展している。現在のWAMsは、通常の動画生成モデルやVision-Languageのバックボーンに依存し、これにより関連領域の境界が曖昧になっている。本調査では、これらの境界を明確化し、手法を生成物の観点と予測基盤、バックボーン、アクション結合の観点から整理。WAMsは単なる動画生成モデルとは異なり、表現力とリソース間のトレードオフを重視した予測-行動手法として進化している。この分野は未来生成を抑えつつ、制御要件を満たす方法を模索している。
[Paper Note] Code as Agent Harness, Xuying Ning+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #read-later #Selected Papers/Blogs #AgentHarness Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLMs)は、コード理解と生成において優れた能力を示しており、エージェント性を持つシステムでは、コードがエージェントの推論や行動に重要な役割を果たすようになっている。この研究では、「エージェント・ハーネス」という観点から、コードをエージェント基盤の中心と位置づけ、三つの層(ハーネス・インターフェース、ハーネス機構、マルチエージェント設定へのスケーリング)を整理して調査する。具体的には、コードがエージェントを接続し、計画やフィードバック駆動の制御を行う仕組み、そしてマルチエージェント環境での協調を支援する役割を探る。また、評価方法やハーネスの改善、安全性などの未解決課題も概説し、コードをエージェント的AIの中心に据えることで、実行可能で検証可能なAIエージェント系への統一的なロードマップを示す。 Comment
ポイント解説:
所見:
[Paper Note] AI for Auto-Research: Roadmap & User Guide, Lingdong Kong+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #autoresearch #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- AI支援研究は進化し、自動化システムが低コストで論文を生成可能になったが、整合性の問題が浮き彫りに。特に、最先端のLLMでも結果の捏造や誤りの見逃しがある。研究ライフサイクルを四つの段階(Creation, Writing, Validation, Dissemination)で分析し、AIの信頼性と自律性の限界を特定。AIは構造化されたタスクには優れるが、新規のアイデアや実験には脆弱であり、人間の協働が最も信頼される。具体的なリソースはプロジェクトページで提供。 Comment
pj page: https://worldbench.github.io/awesome-ai-auto-research
元ポスト:
[Paper Note] Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond, Meng Chu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #AIAgents #VisionLanguageModel #WorldModels #Initial Impression Notes #Author Thread-Post Issue Date: 2026-04-28 GPT Summary- AIシステムの目標達成能力の向上には、環境のダイナミクスをモデル化することが必要不可欠である。この研究では、能力レベル(L1からL3)と支配法則(物理、デジタル、社会、科学)を軸にした「levels x laws」分類法を導入し、400件以上の研究を統合して、AIの世界モデルの制約と失敗モードを示す。提案する評価原則と最小再現可能なパッケージがアーキテクチャの指針を提供し、分断されたコミュニティの統合を目指す。最終的には、より予測可能で再構築可能な環境モデルへと進む道筋を示す。 Comment
pj page: https://agentic-world-modeling.xyz/
元ポスト:
著者ポスト:
分野ごとに意味が異なるWorld Modelsを統合的に分類できる枠組みを提案しているSurveyで、Levels * Laws のtaxonomyで分類する。Levelsとはどのような能力を持つか、
- L1: L1 Predictor, 1ステップの予測
- L2: L2 Simulator, 複数ステップのシミュレーション/反実仮想のロールアウト
- L3: L3 Evolver, 失敗からの進化
LawsはWorld Modelsがどのような制約に従わなければならないかという視点で
- Physical: 物理法則
- Digital: program semantics
- Social: 社会規範
- Scientific: scientific mechanism
によって構成される、といった話が著者ポストに記述されている。論文を見ると、個々のtaxonomyについては、より多様な観点を含むようである。
[Paper Note] Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation, Zunhai Su+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Transformer #AttentionSinks #Initial Impression Notes Issue Date: 2026-04-17 GPT Summary- トランスフォーマーの常用される「Attention Sink(AS)」という課題に関する初の総説を提供。ASは過剰な注意集中により解釈可能性や推論に影響を与え、幻覚問題を悪化させる。研究は、基礎的活用、機構的解釈、戦略的緩和という三つの次元を軸にASを体系的に整理し、分野の進化を導く重要なリソースとして位置づける。 Comment
pj page: https://github.com/ZunhaiSu/Awesome-Attention-Sink
元ポスト:
Attention Sinkは
- [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
によって提言されたと思っていたのだが、時系列グラフをみると2023年1月時点で既に先行研究がありそうである。文献数は線形に増えている。
Initial FocusとしてAttention Sinksの活用方法が模索され、上記 [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
だけでなく以下のような研究も代表例として挙げられている。
- [Paper Note] KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization, Coleman Hooper+, arXiv'24, 2024.01
- [Paper Note] Unveiling and Harnessing Hidden Attention Sinks: Enhancing Large Language Models without Training through Attention Calibration, Zhongzhi Yu+, arXiv'24, 2024.06
[Paper Note] The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook, Xinlei Yu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #LatentReasoning #Reference Collection #Initial Impression Notes Issue Date: 2026-04-17 GPT Summary- 潜在空間は言語モデルにおいて重要な役割を果たし、多くのプロセスが連続的な潜在空間で自然に行われることが示されている。本調査は、潜在空間の基盤、進化、機構、能力、展望を整理し、それを他の空間や視覚モデルと明確に区別する。特に、アーキテクチャや最適化を含む四つの主要な発展線を特定し、推論や知覚など多様な能力を支える潜在空間の役割を論じる。未解決課題と今後の研究方向も示し、次世代知能のパラダイムを理解するための基盤を提供することを期待している。 Comment
latent reasoningに関する最新survey
Taxonomyがしっかりしているのが非常に良さそうである。たとえばCOCONUT(Representation/Reasoning)、Looped Transformer (Architecture, Reasoning), VJ-JEPA (Architecture/Perception)を見るとそれぞれ異なるセルに配置されている。手法ごとの表を見ると年号だけでなく、”日付”別で整理され時系列かされている。あと毎回Surveyみて思うが、多すぎである。。。
- [Paper Note] Training Large Language Models to Reason in a Continuous Latent Space, Shibo Hao+, COLM'25
- (Looped Transformerの例) [Paper Note] Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs, Ziyue Li+, arXiv'25
- [Paper Note] VL-JEPA: Joint Embedding Predictive Architecture for Vision-language, Delong Chen+, arXiv'25, 2025.12
元ポスト:
[Paper Note] Rethinking Memory Mechanisms of Foundation Agents in the Second Half: A Survey, Wei-Chieh Huang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #read-later #memory Issue Date: 2026-04-04 GPT Summary- 人工知能の研究は、ベンチマークスコアから現実世界での評価にシフトしている。今後の課題は、長期・動的な環境でのエージェントの真の有用性の確保であり、記憶がその解決策として重要視されている。本調査では、エージェント記憶を記憶基盤、認知機構、記憶対象の三次元から検討し、記憶操作を学習ポリシーと関連付けて分析。記憶の有用性評価のためのベンチマークと指標も提案し、未解決の課題と今後の方向性を示す。 Comment
AI Agent + memory に関するサーベイ。とんでもない量だ。。。
github: https://github.com/AgentMemoryWorld/Awesome-Agent-Memory
元ポスト:
以下の3つの軸で整理されているようである
- メモリの基盤 (Memory Substrate):
- internal: 重み、潜在表現、KVCache
- external: vector stores, knowledge graphs, text records
- 認知機構 (Cognitive Mechanism)
- メモリの対象 (Memory Subject)
2023--2025の218の文献をレビューしたとのこと。
open challengeとしては
- continual learning
- multi-human-agent memory organization
- memory infrastructure and efficiency
- life-long personalization and trustworhy memory
- multimodal grounding
- real-world evaluations
と題されている。
[Paper Note] Anatomy of Agentic Memory: Taxonomy and Empirical Analysis of Evaluation and System Limitations, Dongming Jiang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #AIAgents #read-later #Selected Papers/Blogs #memory #Initial Impression Notes Issue Date: 2026-03-07 GPT Summary- エージェント記憶システムは、LLMエージェントが長い相互作用を維持し、長期推論を支援するが、経験的基盤が脆弱である。既存のベンチマークは不十分で、評価指標が実用性に合致せず、性能差が大きく、コストも見落とされがちである。本調査では、エージェント記憶を構造的に分析し、4つの記憶構造から成るMAGシステムを提案。主要な問題点として、ベンチマークの飽和、評価指標の妥当性、精度のバックボーン依存、記憶維持によるオーバーヘッドを挙げ、信頼性の高い評価とスケーラブルなシステム設計の方向性を示す。 Comment
元ポスト:
AI Agentの研究に関してtaxonomyが定義されており、研究分野全体の進展を外観するのに良さそう。
[Paper Note] Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs, Wei Zhou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #Initial Impression Notes #Data Issue Date: 2026-02-16 GPT Summary- LLM技術がデータ前処理のパラダイムを変革中であり、幅広いアプリケーションに対応するための進化を検討。文献レビューを通じて、データクリーニング、統合、強化の主要タスクにおける手法を整理し、それぞれの利点と制約を分析。さらに、評価指標とデータセットを考察し、スケーラブルなデータシステムや信頼性の高いワークフローに向けた研究課題を提示。 Comment
元ポスト:
自動的なデータの前処理に関するSurvey。文献は120以上引用され、美麗なフォーマットで記述されている。時系列での手法の変遷と、手法間の関係性が図解で整理されており非常にわかりやすそう。データの前処理は実務上の大きなボトルネックなのでどのような研究があるか気になる。
[Paper Note] Data Agents: Levels, State of the Art, and Open Problems, Yuyu Luo+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #One-Line Notes #Data Issue Date: 2026-02-11 GPT Summary- データエージェントは、LLMやツールを活用してデータ管理や分析の自動化を目指す新しいパラダイムであるが、その定義は曖昧である。この記事では、データエージェントをL0からL5までの階層に分類し、各レベルの特徴を示す。具体的には、単純なアシスタントと自律型エージェントの違いや、L0-L2の代表的なシステムをレビューし、独自にデータ関連タスクを実行するProto-L3システムを紹介する。また、L4およびL5のエージェントに関する研究課題も議論し、データエージェントの未来のロードマップを提供する。 Comment
元ポスト:
データを管理、準備、分析を担うエージェント(=データエージェント)に関して、自律性のレベルを6段階に分けたTaxonomyを体系的に定義し、既存研究を分類している模様。
[Paper Note] The AI Hippocampus: How Far are We From Human Memory?, Zixia Jia+, TMLR'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #AIAgents #MultiModal #RAG(RetrievalAugmentedGeneration) #ConceptErasure #TMLR #KnowledgeEditing #read-later #Selected Papers/Blogs #VisionLanguageModel #memory #KeyPoint Notes Issue Date: 2026-01-24 GPT Summary- メモリは、LLMおよびマルチモーダルLLMの推論と適応性を強化する基盤的要素であり、モデルが静的からインタラクティブなシステムへと進化する中で重要なテーマです。本調査では、メモリを暗黙的、明示的、エージェンティックの三つのパラダイムに分類し、各フレームワークを詳細に述べています。暗黙のメモリは内部パラメータに埋め込まれた知識を示し、明示的なメモリは外部ストレージによる動的な情報強化を指します。エージェンティックメモリは自律エージェントのための持続的な構造を提供し、長期的計画や協調行動を促進します。また、視覚や音声を含む多様なモダリティ間の整合性の重要性も考慮し、アーキテクチャの進展やベンチマークタスクに関連する挑戦について議論されています。 Comment
元ポスト:
AI Agentのメモリに関する包括的なSurvey。現在の技術の包括的なレビューだけでなく、人間の海馬との対比などから必要な能力が議論されている模様。また、現在のメモリが抱えている課題を同定し明言していることが大きな貢献で、
- memory contamination, hallucination (無関係、不正確なデータによるメモリの汚染と、それによって生じるハルシネーション)
- large scaleな検索の計算負荷
- いつ検索するのか、パラメータに内包される知識に頼るのかの判断の困難さ
- 長期にわたるinteractionに対してどのように一貫性を保つか
ということが挙げられるとのこと。
うーーん読みたい。
openreview: https://openreview.net/forum?id=Sk7pwmLuAY
[Paper Note] Toward Efficient Agents: Memory, Tool learning, and Planning, Xiaofang Yang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Planning #PostTraining #memory Issue Date: 2026-01-24 GPT Summary- エージェントシステムの効率に関する研究を行い、メモリ、ツール学習、計画の3つのコアコンポーネントに焦点を当てる。コスト(レイテンシ、トークン、ステップ)を考慮し、圧縮や強化学習報酬、効率向上のための制御された探索メカニズムを活用する最近のアプローチをレビュー。効果とコストのトレードオフをパレートフロンティアを通じて評価し、効率指向のベンチマークや主要な課題、今後の方向性についても議論する。
[Paper Note] Agentic Reasoning for Large Language Models, Tianxin Wei+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Planning #Reasoning #SelfImprovement #memory #One-Line Notes #Test-time Learning Issue Date: 2026-01-23 GPT Summary- エージェンティック推論は、LLMを自律的エージェントとして再構築し、計画や行動を行う新たなアプローチを提供します。本調査では、推論を基盤、自己進化、集合的の三つの次元に整理し、それぞれの特性と相互作用を探ります。また、文脈内推論とポストトレーニング推論の違いを示し、さまざまな現実世界でのアプリケーションをレビューします。この研究は、思考と行動を結びつける統一的なロードマップを提示し、今後の課題と方向性を概説します。 Comment
元ポスト:
agentのreasoning周りに特化したsurveyで基本的なsingle agentとしてのplanning, tool use, searchだけでなく、self evolving, memory, multi agent reasoningなど広範なトピックが網羅されているとのこと。
[Paper Note] Agent-as-a-Judge, Runyang You+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #LLM-as-a-Judge Issue Date: 2026-01-12 GPT Summary- LLM-as-a-Judgeの限界を受け、エージェント型評価(Agent-as-a-Judge)への移行が進んでいる。エージェントは計画やツールを用いた検証を通じて、より堅牢でニュアンスのある評価を実現。しかし、統一されたフレームワークが欠如しているため、初の包括的な調査を行い、重要な次元を特定し、分類法を確立。コアメソッドやアプリケーションを整理し、課題を分析して次世代のエージェント型評価のためのロードマップを提供する。 Comment
元ポスト:
Agent-as-a-Judge
(画像はCC By 4.0に基づいて使用しています)
[Paper Note] The Landscape of Agentic Reinforcement Learning for LLMs: A Survey, Guibin Zhang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents Issue Date: 2026-03-08 GPT Summary- エージェント的強化学習は、LLMを自律的な意思決定エージェントとして再定義するパラダイムシフトを示す。本研究では、LLM-RLの単一步のMDPとエージェント的RLのPOMDPを対比し、計画や推論などの核心能力に基づく二重分類法を提案。強化学習がこれらの能力を静的なヒューリスティックから適応的な振る舞いに変換する機構として機能することを強調。500件以上の研究をまとめ、オープンソースの環境やベンチマークを整理し、汎用的なAIエージェントの開発における機会と課題を明らかにする。 Comment
元ポスト:
[Paper Note] Large Language Models for Unit Test Generation: Achievements, Challenges, and Opportunities, Bei Chu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #SoftwareEngineering #UnitTest Issue Date: 2026-01-02 GPT Summary- 自動化された単体テスト生成において、従来の手法は意味理解が不足しているが、LLMsはその知識を活用してこの問題を解決する。本研究では、115件の文献をレビューし、テスト生成ライフサイクルに基づく分類法を提案。プロンプトエンジニアリングが主なアプローチであり、89%の研究がこれに該当。反復的な検証が合格率を改善する一方で、故障検出能力やベンチマークの欠如が課題として残る。将来の研究では、自律的なテストエージェントやハイブリッドシステムの進展が期待される。 Comment
元ポスト:
[Paper Note] Memory in the Age of AI Agents, Yuyang Hu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #RAG(RetrievalAugmentedGeneration) #ContextEngineering #memory Issue Date: 2025-12-17 GPT Summary- エージェントメモリの研究が急速に進展する中、既存の研究は動機や実装、評価プロトコルにおいて多様であり、メモリ用語の曖昧さが問題となっている。本研究は、エージェントメモリの範囲を明確にし、LLMメモリや情報検索強化生成(RAG)などの関連概念を区別する。形式、機能、ダイナミクスの観点からエージェントメモリを検討し、実現形態や分類法を提案。さらに、メモリベンチマークやオープンソースフレームワークの要約を提供し、今後の研究の方向性を示す。これにより、エージェントインテリジェンスの設計におけるメモリの再考を促すことを目指す。 Comment
元ポスト:
[Paper Note] Simulating the Visual World with Artificial Intelligence: A Roadmap, Jingtong Yue+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #read-later #VideoGeneration/Understandings #WorldModels #3D (Video) #Physics Issue Date: 2025-12-17 GPT Summary- ビデオ生成は、視覚的クリップの生成から物理的妥当性を持つ仮想環境の構築へと進化している。本研究では、現代のビデオ基盤モデルを暗黙の世界モデルとビデオレンダラーの2つのコアコンポーネントとして概念化し、物理法則やエージェントの行動をエンコードする世界モデルが視覚的推論や計画を可能にすることを示す。ビデオレンダラーはシミュレーションを現実的な視覚に変換し、ビデオ生成の進展を4つの世代にわたって追跡する。各世代の特性を定義し、ロボティクスや自律運転などの応用を考察し、次世代の世界モデルに関する課題と設計原則についても議論する。 Comment
元ポスト:
[Paper Note] Agentic Large Language Models, a survey, Aske Plaat+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #AIAgents #VisionLanguageModel #Robotics #WorldModels Issue Date: 2025-12-08 GPT Summary- エージェント的LLMに関する研究をレビューし、推論、行動、相互作用の三つのカテゴリーに整理。各カテゴリーは相互に利益をもたらし、医療診断や物流などの応用が期待される。エージェント的LLMは新たなトレーニング状態を生成し、データセットの必要性を軽減する可能性があるが、安全性や責任といったリスクも存在する。 Comment
元ポスト:
pj page: https://askeplaat.github.io/agentic-llm-survey-site/
Robotics, World Modelなどの話も含まれているように見える。
[Paper Note] Deep Research: A Systematic Survey, Zhengliang Shi+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #DeepResearch Issue Date: 2025-12-03 GPT Summary- 大規模言語モデル(LLMs)は、テキスト生成から問題解決へと進化しているが、複雑なタスクには批判的思考や情報源の検証が求められる。最近の研究では、LLMsの推論能力を外部ツールと組み合わせる「深い研究(DR)」が注目されており、本調査はその体系的な概要を提供する。主な貢献は、三段階のロードマップの形式化、クエリ計画や情報取得などの重要コンポーネントの導入、最適化技術の要約、評価基準と課題の統合である。研究の進展に応じて、調査は継続的に更新される。 Comment
元ポスト:
[Paper Note] Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding, Sensen Gao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #MultiModal #RAG(RetrievalAugmentedGeneration) #VisionLanguageModel #Encoder #One-Line Notes Issue Date: 2025-10-20 GPT Summary- 文書理解は多様なアプリケーションにおいて重要であり、現在のアプローチには制限がある。特に、OCRベースのパイプラインは構造的詳細を失い、マルチモーダルLLMsはコンテキストモデリングに苦労している。リトリーバル強化生成(RAG)は外部データを活用するが、文書のマルチモーダル性にはマルチモーダルRAGが必要である。本論文では、文書理解のためのマルチモーダルRAGに関する体系的な調査を行い、分類法や進展をレビューし、主要なデータセットや課題をまとめ、文書AIの今後の進展に向けたロードマップを提供する。 Comment
元ポスト:
multimodal RAGに関するSurvey
Table1は2024年以後の35本程度の手法、Table2は20+程度のベンチマークがまとまっており、基本的な概念なども解説されている模様。半数程度がtraining-free/OCRを利用する手法はそれぞれ五分五分程度なようで、Agenticな手法はあまり多くないようだ(3/35)。
[Paper Note] Embodied AI: From LLMs to World Models, Tongtong Feng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#LanguageModel #Robotics #WorldModels #EmbodiedAI Issue Date: 2025-09-25 GPT Summary- 具現化されたAIはAGI達成のための知的システムであり、LLMsとWMsの進展が注目されている。本論文では、具現化されたAIの歴史や技術、コンポーネントを紹介し、LLMsとWMsの役割を詳細に検討。MLLM-WM駆動のアーキテクチャの必要性を論じ、物理世界での複雑なタスクの実現における意義を明らかにする。具現化されたAIのアプリケーションと今後の研究方向についても触れる。 Comment
元ポスト:
ポイント解説:
[Paper Note] 3D and 4D World Modeling: A Survey, Lingdong Kong+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #3D (Scene) #WorldModels #3D (Video) Issue Date: 2025-09-11 GPT Summary- 本調査は、3Dおよび4Dの世界モデリングと生成に特化した初の包括的レビューを提供し、正確な定義と構造化された分類法を導入。動画ベース、占有ベース、LiDARベースのアプローチを網羅し、特化したデータセットと評価指標を要約。実用的な応用や未解決の課題を議論し、今後の研究方向を示すことで、この分野の進展の基盤を提供する。 Comment
元ポスト:
[Paper Note] A Survey of Reinforcement Learning for Large Reasoning Models, Kaiyan Zhang+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #Author Thread-Post Issue Date: 2025-09-11 GPT Summary- 本論文では、LLMにおける推論のための強化学習(RL)の進展を調査し、特に数学やコーディングなどの複雑な論理タスクにおける成功を強調しています。RLはLLMを学習推論モデル(LRM)に変換する基盤的な方法論として浮上しており、スケーリングには計算リソースやアルゴリズム設計などの課題があります。DeepSeek-R1以降の研究を検討し、LLMおよびLRMにおけるRLの適用に関する未来の機会と方向性を特定することを目指しています。 Comment
元ポスト:
著者ポスト:
[Paper Note] The Landscape of Agentic Reinforcement Learning for LLMs: A Survey, Guibin Zhang+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents Issue Date: 2025-09-03 GPT Summary- エージェント的強化学習(Agentic RL)は、従来の強化学習から大規模言語モデル(LLM)への適用におけるパラダイムシフトを示し、LLMを自律的な意思決定エージェントとして再構築します。本調査では、LLM-RLの単一ステップのマルコフ決定過程(MDP)とエージェント的RLの部分観測マルコフ決定過程(POMDP)を対比し、計画や推論などのエージェント能力を中心に二重分類法を提案します。強化学習は、静的なヒューリスティックから適応的なエージェント行動への変換に重要な役割を果たすと主張し、500以上の研究を統合してこの分野の機会と課題を明らかにします。 Comment
元ポスト:
[Paper Note] Interpretation Meets Safety: A Survey on Interpretation Methods and Tools for Improving LLM Safety, Seongmin Lee+, EMNLP'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Safety #EMNLP Issue Date: 2025-09-03 GPT Summary- LLMの安全性を理解し軽減するための解釈技術の重要性を探求し、安全性向上に寄与する手法を統一的なフレームワークで整理。約70件の研究を分類し、未解決の課題と今後の方向性を示す。研究者や実務者にとって、より安全で解釈可能なLLMの進展を促進する調査。 Comment
元ポスト:
[Paper Note] A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems, Jinyuan Fang+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #SelfCorrection #SelfImprovement Issue Date: 2025-08-31 GPT Summary- 自己進化型AIエージェントの研究が進展しており、動的環境に適応する能力を持つエージェントシステムの自動強化が求められている。本調査では、自己進化型エージェントの設計におけるフィードバックループを抽象化したフレームワークを提案し、システムの主要コンポーネントを強調。さらに、ドメイン特化型進化戦略や評価、安全性、倫理的考慮についても議論し、研究者や実務者に体系的な理解を提供することを目指す。 Comment
元ポスト:
[Paper Note] A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models, Lingzhe Zhang+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #DiffusionModel #Verification Issue Date: 2025-08-16 GPT Summary- 並列テキスト生成は、LLMの生成速度を向上させるための技術であり、自己回帰生成のボトルネックを打破することを目指している。本研究では、並列テキスト生成手法をARベースと非ARベースに分類し、それぞれの技術を評価。速度、品質、効率のトレードオフを考察し、今後の研究の方向性を示す。関連論文を集めたGitHubリポジトリも作成。 Comment
Taxonomyと手法一覧。Draft and Verifyingは個人的に非常に興味がある。
[Paper Note] A comprehensive taxonomy of hallucinations in Large Language Models, Manuel Cossio, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Hallucination Issue Date: 2025-08-08 GPT Summary- LLMのハルシネーションに関する包括的な分類法を提供し、その本質的な避けられなさを提唱。内因的および外因的な要因、事実誤認や不整合などの具体的な現れを分析。根本的な原因や認知的要因を検討し、評価基準や軽減戦略を概説。今後は、信頼性のある展開のために検出と監視に焦点を当てる必要があることを強調。 Comment
元ポスト:
[Paper Note] Efficient Attention Mechanisms for Large Language Models: A Survey, Yutao Sun+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Attention Issue Date: 2025-07-31 GPT Summary- Transformerアーキテクチャの自己注意の複雑さが長文コンテキストモデリングの障害となっている。これに対処するため、線形注意手法とスパース注意技術が導入され、計算効率を向上させつつコンテキストのカバレッジを保持する。本研究は、これらの進展を体系的にまとめ、効率的な注意を大規模言語モデルに組み込む方法を分析し、理論と実践を統合したスケーラブルなモデル設計の基礎を提供することを目指す。 Comment
元ポスト:
[Paper Note] A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence, Huan-ang Gao+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #SelfCorrection #SelfImprovement Issue Date: 2025-07-30 GPT Summary- 大規模言語モデル(LLMs)は静的であり、動的な環境に適応できないため、自己進化するエージェントの必要性が高まっている。本調査は、自己進化するエージェントに関する初の包括的レビューを提供し、進化の基礎的な次元を整理。エージェントの進化的メカニズムや適応手法を分類し、評価指標や応用分野を分析。最終的には、エージェントが自律的に進化し、人間レベルの知能を超える人工超知能(ASI)の実現を目指す。 Comment
元ポスト:
Figure3がとても勉強になる。Self-Evolveと呼んだ時に、それがどのようにEvolveするものなのかはきちんとチェックした方が良さそう。追加の学習をするのか否かなど。これによって使いやすさが段違いになりそうなので。
[Paper Note] On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey, Meishan Zhang+, arXiv'25
Paper/Blog Link My Issue
#Embeddings #NLP #Dataset #LanguageModel #RepresentationLearning #Evaluation Issue Date: 2025-07-29 GPT Summary- 本調査では、事前学習済み言語モデル(PLMs)を活用した一般目的のテキスト埋め込み(GPTE)の発展を概観し、PLMsの役割に焦点を当てる。基本的なアーキテクチャや埋め込み抽出、表現力向上、トレーニング戦略について説明し、PLMsによる多言語サポートやマルチモーダル統合などの高度な役割も考察する。さらに、将来の研究方向性として、ランキング統合やバイアス軽減などの改善目標を超えた課題を強調する。 Comment
元ポスト:
GPTEの学習手法テキストだけでなく、画像やコードなどの様々なモーダル、マルチリンガル、データセットや評価方法、パラメータサイズとMTEBの性能の関係性の図解など、盛りだくさんな模様。最新のものだけでなく、2021年頃のT5から最新モデルまで網羅的にまとまっている。日本語特化のモデルについては記述が無さそうではある。
日本語モデルについてはRuriのテクニカルペーパーや、LLM勉強会のまとめを参照のこと
- Ruri: Japanese General Text Embeddings, cl-nagoya, 2024.09
- 日本語LLMまとめ, LLM-jp, 2024.12
[Paper Note] A Survey of Context Engineering for Large Language Models, Lingrui Mei+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #ContextEngineering Issue Date: 2025-07-19 GPT Summary- 本調査では、LLMsの性能を向上させる「コンテキストエンジニアリング」を提案し、その要素と実装方法を体系的に分類。コンテキストの取得、生成、処理、管理を検討し、洗練されたシステム実装を探る。1300以上の研究を分析し、モデルの能力の非対称性を明らかにし、複雑な文脈理解と長文出力生成のギャップに対処する重要性を強調。研究者とエンジニアのための統一フレームワークを提供。 Comment
もうContext Engineeringという切り口の体系化されたSurveyが出てきた。早すぎ。
元ポスト:
[Paper Note] A Survey on Latent Reasoning, Rui-Jie Zhu+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #LatentReasoning Issue Date: 2025-07-10 GPT Summary- 大規模言語モデル(LLMs)は、明示的な思考の連鎖(CoT)によって優れた推論能力を示すが、自然言語推論への依存が表現力を制限する。潜在的推論はこの問題を解決し、トークンレベルの監視を排除する。研究は、ニューラルネットワーク層の役割や多様な潜在的推論手法を探求し、無限深度の潜在的推論を可能にする高度なパラダイムについて議論する。これにより、潜在的推論の概念を明確にし、今後の研究方向を示す。関連情報はGitHubリポジトリで提供されている。 Comment
元ポスト:
Latent Reasoningというテクニカルタームが出てきた
出力されるdiscreteなtokenによってreasoningを実施するのではなく、モデル内部のrepresentationでreasoningを実施するLatent ReasoningのSurvey
[Paper Note] AI4Research: A Survey of Artificial Intelligence for Scientific Research, Qiguang Chen+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ScientificDiscovery Issue Date: 2025-07-04 GPT Summary- AIの進展に伴い、AI4Researchに関する包括的な調査が不足しているため、理解と発展が妨げられている。本研究では、AI4Researchの5つの主流タスクを系統的に分類し、研究のギャップや将来の方向性を特定し、関連する応用やリソースをまとめる。これにより、研究コミュニティが迅速にリソースにアクセスでき、革新的なブレークスルーを促進することを目指す。 Comment
元ポスト:
[Paper Note] Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs, Yu Xia+, COLING'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #COLING Issue Date: 2025-05-29 GPT Summary- Chain-of-Thought(CoT)を基にしたChain-of-X(CoX)手法の調査を行い、LLMsの課題に対処するための多様なアプローチを分類。ノードの分類とアプリケーションタスクに基づく分析を通じて、既存の手法の意義と今後の可能性を議論。研究者にとって有用なリソースを提供することを目指す。
[Paper Note] 100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models, Chong Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #InstructionTuning #PPO (ProximalPolicyOptimization) #Reasoning #LongSequence #RewardHacking #GRPO #Contamination-free #VerifiableRewards #CurriculumLearning #One-Line Notes Issue Date: 2025-05-06 GPT Summary- RLMの進展は新しい言語モデルの進化を示し、DeepSeek-R1のリリースが社会的影響を生んでいる。DeepSeekの実装は完全にオープンではないが、多くの再現研究が登場し、同等の性能を達成。特にSFTとRLVRに重点を置き、データ構築や手法設計に関する知見を提供。実装の詳細と実験結果をまとめ、RLMの性能向上技術や開発課題についても議論。研究者が最新の進展を把握し、新しいアイデアを促進することを目指す。 Comment
元ポスト:
サーベイのtakeawayが箇条書きされている。
[Paper Note] Can LLMs Be Trusted for Evaluating RAG Systems? A Survey of Methods and Datasets, Lorenz Brehme+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #Evaluation #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-04-30 GPT Summary- RAGシステムの評価は、複数の構成要素を含み、進歩の記録や有効なアプローチの特定に欠かせない。本研究では63件の論文をレビューし、評価手法の概観を提供。データセットやリトリーバー、インデックス作成などに焦点を当て、LLMを用いた自動評価アプローチの可能性を探求する。企業向けに実践的な洞察も示し、RAGの評価手法の厳密さ向上に寄与する。また、自動化と人間の判断の相互作用についても議論し、評価の信頼性向上に向けた課題を整理する。 Comment
元ポスト:
おもしろそう
[Paper Note] What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models, Qiyuan Zhang+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Test-Time Scaling #One-Line Notes #Initial Impression Notes Issue Date: 2025-04-02 GPT Summary- テスト時スケーリング(TTS)が大規模言語モデル(LLMs)の問題解決能力を向上させることが示されているが、体系的な理解が不足している。これを解決するために、TTS研究の4つのコア次元に基づく統一的なフレームワークを提案し、手法や応用シナリオのレビューを行う。TTSの発展の軌跡を抽出し、実践的なガイドラインを提供するとともに、未解決の課題や将来の方向性についての洞察を示す。 Comment
元ポスト:
とてつもない量だ…網羅性がありそう。
What to Scaleがよくあるself
consistency(Parallel Scaling), STaR(Sequential Scailng), Tree of Thought(Hybrid Scaling), DeepSeek-R1, o1/3(Internal Scaling)といった分類で、How to ScaleがTuningとInferenceに分かれている。TuningはLong CoTをSFTする話や強化学習系の話(GRPOなど)で、InferenceにもSelf consistencyやらやらVerificationやら色々ありそう。良さそう。
[Paper Note] Thinking Machines: A Survey of LLM based Reasoning Strategies, Dibyanayan Bandyopadhyay+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #Initial Impression Notes Issue Date: 2025-03-23 GPT Summary- 大規模言語モデル(LLMs)は優れた言語能力を持つが、推論能力との間にギャップがある。推論はAIの信頼性を高め、医療や法律などの分野での適用に不可欠である。最近の強力な推論モデルの登場により、LLMsにおける推論の研究が重要視されている。本論文では、既存の推論技術の概要と比較を行い、推論を備えた言語モデルの体系的な調査と現在の課題を提示する。 Comment
元ポスト:
RL, Test Time Compute, Self-trainingの3種類にカテゴライズされている。また、各カテゴリごとにより細分化されたツリーが論文中にある。
[Paper Note] Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models, Yang Sui+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Reasoning #Overthinking #One-Line Notes Issue Date: 2025-03-22 GPT Summary- 本論文では、LLMsにおける効率的な推論の進展を体系的に調査し、以下の主要な方向に分類します:(1) モデルベースの効率的推論、(2) 推論出力ベースの効率的推論、(3) 入力プロンプトベースの効率的推論。特に、冗長な出力による計算オーバーヘッドを軽減する方法を探求し、小規模言語モデルの推論能力や評価方法についても議論します。 Comment
Reasoning Modelにおいて、Over Thinking現象(不要なreasoning stepを生成してしまう)を改善するための手法に関するSurvey。
下記Figure2を見るとよくまとまっていて、キャプションを読むとだいたい分かる。なるほど。
Length Rewardについては、
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
で考察されている通り、Reward Hackingが起きるので設計の仕方に気をつける必要がある。
元ポスト:
各カテゴリにおけるliteratureも見やすくまとめられている。必要に応じて参照したい。
[Paper Note] A Survey on Post-training of Large Language Models, Guiyao Tie+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Reasoning #Initial Impression Notes Issue Date: 2025-03-15 GPT Summary- 大規模言語モデル(LLMs)は自然言語処理に革命をもたらしたが、専門的な文脈での制約が明らかである。これに対処するため、高度なポストトレーニング言語モデル(PoLMs)が必要であり、本論文ではその包括的な調査を行う。ファインチューニング、アライメント、推論、効率、統合と適応の5つのコアパラダイムにわたる進化を追跡し、PoLMがバイアス軽減や推論能力向上に寄与する方法を示す。研究はPoLMの進化に関する初の調査であり、将来の研究のための枠組みを提供し、LLMの精度と倫理的堅牢性を向上させることを目指す。 Comment
Post Trainingの時間発展の図解が非常にわかりやすい(が、厳密性には欠けているように見える。当該モデルの新規性における主要な技術はこれです、という図としてみるには良いのかもしれない)。
個々の技術が扱うスコープとレイヤー、データの性質が揃っていない気がするし、それぞれのLLMがy軸の単一の技術だけに依存しているわけでもない。が、厳密に図を書いてと言われた時にどう書けば良いかと問われると難しい感はある。
元ポスト:
[Paper Note] LLM Post-Training: A Deep Dive into Reasoning Large Language Models, Komal Kumar+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Reasoning #Initial Impression Notes Issue Date: 2025-03-04 GPT Summary- LLMは自然言語処理に革命をもたらし、ポストトレーニング手法に焦点を移しつつある。これにより、推論や事実の正確性が向上し、ユーザー意図に合わせた整合が可能に。ファインチューニングや強化学習が性能最適化に寄与し、実世界タスクへの適応力も向上。調査では、ポストトレーニング手法の重要性と、壊滅的忘却や報酬の改ざんへの対策が論じられ、新たな研究方向が提案されている。さらに、分野の進展を追跡するリポジトリも提供。 Comment
非常にわかりやすい。
元ポスト:
[Paper Note] Joint Modeling in Recommendations: A Survey, Xiangyu Zhao+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Multi #RecommenderSystems #NeuralNetwork #MultitaskLearning #MultiModal Issue Date: 2025-03-03 GPT Summary- 深層リコメンダーシステム(DRS)は、個々の嗜好に基づいてオンラインコンテンツをカスタマイズするが、従来の手法は単一のタスクやデータに依存し、ユーザーの多様な嗜好を反映できない。このため、複数のタスクやシナリオ、モダリティを統合する共同モデリング手法の必要性が増している。本論文では、マルチタスク、マルチシナリオ、マルチモーダル、マルチビヘイビアモデリングを通じて共同モデリングを総括し、最新の進展と研究動向を特定・要約し、将来の探求の道を示す。 Comment
元ポスト:
[Paper Note] From System 1 to System 2: A Survey of Reasoning Large Language Models, Zhong-Zhi Li+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning Issue Date: 2025-02-26 GPT Summary- 人間レベルの知能を達成するためには、迅速なシステム1から意図的なシステム2への推論の洗練が必要。基盤となる大規模言語モデル(LLMs)は迅速な意思決定に優れるが、複雑な推論には深さが欠ける。最近の推論LLMはシステム2の意図的な推論を模倣し、人間のような認知能力を示している。本調査では、LLMの進展とシステム2技術の初期開発を概観し、推論LLMの構築方法や特徴、進化を分析。推論ベンチマークの概要を提供し、代表的な推論LLMのパフォーマンスを比較。最後に、推論LLMの進展に向けた方向性を探り、最新の開発を追跡するためのGitHubリポジトリを維持することを目指す。 Comment
元ポスト:
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap, Weizhi Zhang+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #Contents-based Issue Date: 2025-01-06 GPT Summary- コールドスタート問題はレコメンダーシステムの重要な課題であり、新しいユーザーやアイテムのモデル化に焦点を当てている。大規模言語モデル(LLMs)の成功により、CSRに新たな可能性が生まれているが、包括的なレビューが不足している。本論文では、CSRのロードマップや関連文献をレビューし、LLMsが情報を活用する方法を探求することで、研究と産業界に新たな洞察を提供することを目指す。関連リソースはコミュニティのために収集・更新されている。 Comment
元ポスト:
[Paper Note] A Comprehensive Study of Knowledge Editing for Large Language Models, Ningyu Zhang+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #KnowledgeEditing Issue Date: 2026-02-08 GPT Summary- LLMの知識編集技術が急増し、モデルの効率的な修正が求められています。知識編集問題を定義し、3つのグループ(外部知識の利用、モデルへの知識の統合、内在的知識の編集)に分類。新たに「KnowEdit」ベンチマークを導入し、知識構造の詳しい分析を行う。知識編集の応用についても考察しています。 Comment
[Paper Note] Graph Retrieval-Augmented Generation: A Survey, Boci Peng+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#GraphBased #InformationRetrieval #NLP #LanguageModel #KnowledgeGraph #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-12-27 GPT Summary- Retrieval-Augmented Generation(RAG)は、LLMsの課題に対処するために外部知識ベースを活用し、情報の精度を向上させるが、エンティティ間の関係の複雑さが課題となる。これに対処するために、GraphRAGは構造情報を活用し、より正確な情報検索と文脈に応じた応答を実現する。本論文では、GraphRAGの手法を体系的にレビューし、ワークフロー、コア技術、応用分野、評価手法を概説し、今後の研究方向を探る。リポジトリも設置し、進展を追跡可能にしている。 Comment
元ポスト:
[Paper Note] Video Diffusion Models: A Survey, Andrew Melnik+, TMLR'24, 2024.05
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #TMLR #VideoGeneration/Understandings #3D (Video) Issue Date: 2025-10-17 GPT Summary- 拡散生成モデルは高品質な動画コンテンツの生成において重要な技術であり、本調査はそのアーキテクチャや時間的ダイナミクスのモデリングを包括的にまとめている。テキストから動画への生成の進展や、モデルの分類法、評価指標についても議論し、現在の課題や将来の方向性を考察している。研究者や実務者にとって有益なリソースを提供することを目指している。
[Paper Note] Knowledge Editing for Large Language Models: A Survey, Song Wang+, ACM Computing Surveys'24, 2023.10
Paper/Blog Link My Issue
#NLP #KnowledgeEditing #read-later Issue Date: 2025-09-24 GPT Summary- 大規模言語モデル(LLMs)の計算コストの問題を解決するため、知識ベースのモデル編集(KME)が注目されている。KMEは、特定の知識をLLMsに組み込む際に他の知識に悪影響を与えないように修正する手法である。本調査では、KMEの戦略や技術の分類、既存の方法の分析、指標やデータセットについて包括的に概説し、KMEの実用性と今後の研究方向を提案する。
A Comprehensive Survey of Hallucination in Large Language, Image, Video and Audio Foundation Models, Sahoo+, EMNLP'24 Findings
Paper/Blog Link My Issue
#NLP #LanguageModel #Hallucination #MultiModal Issue Date: 2025-09-24 GPT Summary- 基盤モデル(FMs)の多様なドメインにおける進展は顕著だが、特に高リスクなアプリケーションでは幻覚的な出力が問題となる。本調査論文は、テキスト、画像、動画、音声におけるFMsの幻覚の問題を特定し、軽減策の最近の進展をまとめる。幻覚の定義、分類、検出戦略を含むフレームワークを提供し、今後の研究と開発の基盤を築くことを目指す。 Comment
[Paper Note] A Survey on the Memory Mechanism of Large Language Model based Agents, Zeyu Zhang+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #memory Issue Date: 2025-08-11 GPT Summary- LLMベースのエージェントのメモリメカニズムに関する包括的な調査を提案。メモリの重要性を論じ、過去の研究を体系的にレビューし、エージェントアプリケーションでの役割を紹介。既存研究の限界を分析し、将来の研究方向性を示す。リポジトリも作成。 Comment
元ポスト:
[Paper Note] Visual Prompting in Multimodal Large Language Models: A Survey, Junda Wu+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #NLP #Prompting #VisionLanguageModel Issue Date: 2025-08-07 GPT Summary- 本論文は、マルチモーダル大規模言語モデル(MLLMs)における視覚的プロンプト手法の包括的な調査を行い、視覚的プロンプトの生成や構成的推論、プロンプト学習に焦点を当てています。既存の視覚プロンプトを分類し、自動プロンプト注釈の生成手法を議論。視覚エンコーダとバックボーンLLMの整合性を向上させる手法や、モデル訓練と文脈内学習による視覚的プロンプトの理解向上についても述べています。最後に、MLLMsにおける視覚的プロンプト手法の未来に関するビジョンを提示します。
[Paper Note] Controllable Generation with Text-to-Image Diffusion Models: A Survey, Pu Cao+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #Controllable #NLP #DiffusionModel #TextToImageGeneration Issue Date: 2025-08-07 GPT Summary- 拡散モデルはテキスト誘導生成において大きな進展を遂げたが、テキストのみでは多様な要求に応えられない。本調査では、T2I拡散モデルの制御可能な生成に関する文献をレビューし、理論的基盤と実践的進展をカバー。デノイジング拡散確率モデルの基本を紹介し、制御メカニズムを分析。生成条件の異なるカテゴリに整理した文献リストを提供。
[Paper Note] Foundational Challenges in Assuring Alignment and Safety of Large Language Models, Usman Anwar+, TMLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Safety #TMLR Issue Date: 2025-04-06 GPT Summary- 本研究では、LLMsの整合性と安全性に関する18の基盤的課題を特定し、科学的理解、開発・展開方法、社会技術的課題の3つのカテゴリに整理。これに基づき、200以上の具体的な研究質問を提起。 Comment
OpenReview: https://openreview.net/forum?id=oVTkOs8Pka
A Survey on Knowledge Distillation of Large Language Models, Xiaohan Xu+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Distillation Issue Date: 2025-02-01 GPT Summary- 大規模言語モデル(LLMs)における知識蒸留(KD)の重要性を調査し、小型モデルへの知識伝達やモデル圧縮、自己改善の役割を強調。KDメカニズムや認知能力の向上、データ拡張(DA)との相互作用を検討し、DAがLLM性能を向上させる方法を示す。研究者や実務者に向けたガイドを提供し、LLMのKDの倫理的適用を推奨。関連情報はGithubで入手可能。
Automated Justification Production for Claim Veracity in Fact Checking: A Survey on Architectures and Approaches, Islam Eldifrawi+, arXiv'24
Paper/Blog Link My Issue
#ACL Issue Date: 2025-01-06 GPT Summary- 自動事実確認(AFC)は、主張の正確性を検証する重要なプロセスであり、特にオンラインコンテンツの増加に伴い真実と誤情報を見分ける役割を果たします。本論文では、最近の手法を調査し、包括的な分類法を提案するとともに、手法の比較分析や説明可能性向上のための今後の方向性について議論します。
A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges, Yibo Yan+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #Mathematics Issue Date: 2025-01-03 GPT Summary- 数学的推論は多くの分野で重要であり、AGIの進展に伴い、LLMsを数学的推論タスクに統合することが求められている。本調査は、2021年以降の200以上の研究をレビューし、マルチモーダル設定におけるMath-LLMsの進展を分析。分野をベンチマーク、方法論、課題に分類し、マルチモーダル数学的推論のパイプラインやLLMsの役割を探る。さらに、AGI実現の障害となる5つの課題を特定し、今後の研究方向性を示す。
[Paper Note] Generative AI for Synthetic Data Generation: Methods, Challenges and the Future, Xu Guo+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#NLP #LanguageModel #SyntheticData Issue Date: 2025-01-02 GPT Summary- LLMを用いて合成データを生成し、特にリソースが限られた状況でのタスク特異的トレーニングデータの活用を探求。方法論や評価法を概説し、現状の課題と将来の研究の方向性を提案。 Comment
元ポスト:
[Paper Note] On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey, Lin Long+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #SyntheticData Issue Date: 2025-01-02 GPT Summary- LLMsの登場により合成データ生成が可能になり、データ量と品質のジレンマの解決策を提供。しかし、現状の調査は統一性に欠け、表面的なものが多い。本論文では合成データ生成の汎用ワークフローに基づき、関連研究を整理し、既存のギャップを明らかにする。学術界と産業界に対し、より深い探究を促すことを目指す。 Comment
元ポスト:
A Survey on LLM Inference-Time Self-Improvement, Xiangjue Dong+, arXiv'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel Issue Date: 2024-12-31 GPT Summary- LLM推論における自己改善技術を三つの視点から検討。独立した自己改善はデコーディングやサンプリングに焦点、文脈に応じた自己改善は追加データを活用、モデル支援の自己改善はモデル間の協力を通じて行う。関連研究のレビューと課題、今後の研究への洞察を提供。
From Matching to Generation: A Survey on Generative Information Retrieval, Xiaoxi Li+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #LanguageModel Issue Date: 2024-12-30 GPT Summary- 情報検索(IR)システムは、検索エンジンや質問応答などで重要な役割を果たしている。従来のIR手法は類似性マッチングに基づいていたが、事前学習された言語モデルの進展により生成情報検索(GenIR)が注目されている。GenIRは生成文書検索(GR)と信頼性のある応答生成に分かれ、GRは生成モデルを用いて文書を直接生成し、応答生成はユーザーの要求に柔軟に応える。本論文はGenIRの最新研究をレビューし、モデルのトレーニングや応答生成の進展、評価や課題についても考察する。これにより、GenIR分野の研究者に有益な参考資料を提供し、さらなる発展を促すことを目指す。
A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #LLM-as-a-Judge Issue Date: 2024-12-25 GPT Summary- LLMを評価者として利用する「LLM-as-a-Judge」の信頼性向上に関する調査。信頼性を確保するための戦略や評価方法論を提案し、新しいベンチマークを用いてサポート。実用的な応用や将来の方向性についても議論し、研究者や実務者の参考資料となることを目指す。 Comment
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, Dawei Li+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #LLM-as-a-Judge #One-Line Notes Issue Date: 2024-11-27 GPT Summary- LLMを用いた判断と評価の新たなパラダイム「LLM-as-a-judge」に関する包括的な調査を行い、定義や分類法を提示。評価のためのベンチマークをまとめ、主要な課題と今後の研究方向を示す。関連リソースも提供。 Comment
LLM-as-a-Judgeに関するサーベイ
- Leveraging Large Language Models for NLG Evaluation: A Survey, Zhen Li+, N/A, arXiv'24
も参照のこと
Multilingual Large Language Models: A Systematic Survey, Shaolin Zhu+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #MultiLingual #needs-revision Issue Date: 2024-11-19 GPT Summary- 本論文は、多言語大規模言語モデル(MLLMs)の最新研究を調査し、アーキテクチャや事前学習の目的、多言語能力の要素を論じる。データの質と多様性が性能向上に重要であることを強調し、MLLMの評価方法やクロスリンガル知識、安全性、解釈可能性について詳細な分類法を提示。さらに、MLLMの実世界での応用を多様な分野でレビューし、課題と機会を強調する。関連論文は指定のリンクで公開されている。 Comment
[Paper Note] Understanding LLMs: A Comprehensive Overview from Training to Inference, Yiheng Liu+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #One-Line Notes #Reading Reflections Issue Date: 2024-11-17 GPT Summary- ChatGPTの導入により、LLMsの低コストな訓練とデプロイメントへの関心が高まる。本論文では、訓練技術や推論デプロイメント技術の進化を概説し、データ前処理やモデル圧縮など多様な視点を提供。LLMsの活用についても考察し、今後の発展を示唆する。 Comment
[Perplexity(参考;Hallucinationに注意)]( https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-7vGwDK_AQX.HDO7j9H8iNA)
単なるLLMの理論的な説明にとどまらず、実用的に必要な各種並列処理技術、Mixed Precision、Offloadingなどのテクニックもまとまっているのがとても良いと思う。
LLM Frameworkのところに、メジャーなものが網羅されていないように感じる。たとえば、UnslothやLiger-KernelなどはTransformersの部分で言及されてても良いのでは、と感じる。
GUI Agents with Foundation Models: A Comprehensive Survey, Shuai Wang+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #One-Line Notes #needs-revision Issue Date: 2024-11-12 GPT Summary- (M)LLMを活用したGUIエージェントの研究を統合し、データセット、フレームワーク、アプリケーションの革新を強調。重要なコンポーネントをまとめた統一フレームワークを提案し、商業アプリケーションを探求。課題を特定し、今後の研究方向を示唆。 Comment
Referenceやページ数はサーベイにしては少なめに見える。
Personalization of Large Language Models: A Survey, Zhehao Zhang+, arXiv'24
Paper/Blog Link My Issue
#LanguageModel #Personalization Issue Date: 2024-11-10 GPT Summary- 大規模言語モデル(LLMs)のパーソナライズに関する研究のギャップを埋めるため、パーソナライズされたLLMsの分類法を提案。パーソナライズの概念を統合し、新たな側面や要件を定義。粒度、技術、データセット、評価方法に基づく体系的な分類を行い、文献を統一。未解決の課題を強調し、研究者と実務者への明確なガイドを提供することを目指す。
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness, Fali Wang+, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #SmallModel #needs-revision #EdgeDevices Issue Date: 2024-11-07 GPT Summary- 大規模言語モデル(LLM)は多様なタスクで能力を示すが、パラメータサイズや計算要求から制限を受け、プライバシーやリアルタイムアプリケーションに課題がある。これに対し、小型言語モデル(SLM)は低遅延、コスト効率、簡単なカスタマイズが可能で、特に専門的なドメインにおいて有用である。SLMの需要が高まる中、定義や応用に関する包括的な調査が不足しているため、SLMを専門的なタスクに適したモデルとして定義し、強化するためのフレームワークを提案する。 Comment
[Paper Note] Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey, Philipp Mondorf+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Reasoning Issue Date: 2024-11-07 GPT Summary- LLMsは推論タスクで顕著な能力を示しているが、その深さは依然として不確かである。これは、浅い精度指標への依存と推論挙動の検証不足に起因する。本論文は、モデルの推論プロセスをより深く理解するための研究をレビューし、一般的な評価方法論を調査する。結果、LLMsは表層的なパターンに依存し、人間との推論の違いを明確にするさらなる研究の必要性が示唆される。 Comment
論文紹介(sei_shinagawa): https://www.docswell.com/s/sei_shinagawa/KL1QXL-beyond-accuracy-evaluating-the-behaivior-of-llm-survey
[Paper Note] Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely, Siyun Zhao+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-10-20 GPT Summary- データ補強型LLMは、多様な専門分野での実用的な展開において課題が多い。具体的には、関連データの取得やユーザー意図の解釈、LLMの推論能力活用に関する問題が含まれる。提案されたRAGタスク分類法により、クエリを明示的事実、暗黙的事実、解釈可能推論根拠、隠れた根拠の4つに分類し、それぞれの課題を要約。さらに、外部データ統合の形態として、コンテキスト、小型モデル、ファインチューニングを挙げ、各手法のメリットと課題を強調。今回の研究は、LLMアプリケーションのデータ要件とボトルネックを深く理解するためのガイドを提供することを目指す。 Comment
RAGのクエリを4種類に分類した各クエリごとの技術をまとめたSurvey
[Paper Note] When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs, Ryo Kamoi+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfCorrection #TACL #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-09-16 GPT Summary- 自己修正はLLMを活用し応答の質を向上させる手法です。しかし、LLMがどのように過ちを修正できるかに関しては合意がなく、従来の研究は多くの問題を抱えています。本研究では、先行研究の批判的レビューを行い、成功する自己修正に必要な条件を議論しています。研究課題の分類と実験設計のチェックリストを提供し、(1)プロンプトを用いた成功事例がないこと、(2)信頼できる外部フィードバックを活用すれば自己修正が機能すること、(3)大規模なファインチューニングが自己修正を支援することを示しています。 Comment
LLMのself-correctionに関するサーベイ
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Sean Welleck+, N_A, arXiv'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Inference #One-Line Notes Issue Date: 2024-09-10 GPT Summary- 推論時の計算リソース拡大の利点に焦点を当て、トークンレベル生成、メタ生成、効率的生成の3つのアプローチを統一的に探求。トークンレベル生成はデコーディングアルゴリズムを用い、メタ生成はドメイン知識や外部情報を活用し、効率的生成はコスト削減と速度向上を目指す。従来の自然言語処理、現代のLLMs、機械学習の視点を統合した調査。 Comment
元ツイート:
CMUのチームによるinference timeの高速化に関するサーベイ
A Survey on Human Preference Learning for Large Language Models, Ruili Jiang+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment Issue Date: 2024-09-07 GPT Summary- 人間の好み学習に基づくLLMsの進展をレビューし、好みフィードバックのソースや形式、モデリング技術、評価方法を整理。データソースに基づくフィードバックの分類や、異なるモデルの利点・欠点を比較し、LLMsの人間の意図との整合性に関する展望を議論。
[Paper Note] Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies, Liangming Pan+, TACL'24, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfCorrection #TACL Issue Date: 2024-09-07 GPT Summary- 自己修正技術を用いて、LLMの幻覚や不正確な推論を改善する方法をレビュー。自動フィードバックを活用し、最小限の人間の介入で実用的なLLMソリューションを目指す。訓練、生成、事後修正の手法を分析し、応用と未来の課題を考察。
[Paper Note] The Prompt Report: A Systematic Survey of Prompt Engineering Techniques, Sander Schulhoff+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #One-Line Notes Issue Date: 2024-09-02 GPT Summary- 生成型人工知能(GenAI)のプロンプト設計とエンジニアリングについての包括的な総説を提供。プロンプト技術のタクソノミーと適用分析を通じて、体系的理解を確立し、ベストプラクティスを包括的に紹介。33語の語彙表と58のLLMプロンプト技法、さらにChatGPT向けの設計ガイドラインを含む。 Comment
Promptingに関するサーベイ
初期の手法からかなり網羅的に記述されているように見える。
また、誤用されていたり、色々な意味合いで使われてしまっている用語を、きちんと定義している。
たとえば、Few shot LearningとFew shot Promptingの違い、そもそもPromptingの定義、Examplarなど。
[Paper Note] Controllable Text Generation for Large Language Models: A Survey, Xun Liang+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #NLP Issue Date: 2024-08-25 GPT Summary- 大規模言語モデル(LLMs)のテキスト生成品質を向上させるため、制御可能なテキスト生成(CTG)技術が進化している。これにより、安全性や感情、テーマの一貫性を考慮しつつ、ユーザーの多様なニーズに応える生成が求められる。本論文はCTGの最新の進展をレビューし、コンテンツ制御と属性制御の2つのタスクに分類。また、モデル再訓練やファインチューニング、強化学習等の手法の特性を分析し、生成制御のための細かな洞察を提供する。さらに、CTGの評価方法や現状の課題にも言及し、実世界の応用に重点を置く必要があると提案している。
Large Language Models for Generative Recommendation: A Survey and Visionary Discussions, Lei Li+, N_A, LREC-COLING'24
Paper/Blog Link My Issue
#RecommenderSystems #GenerativeRecommendation #KeyPoint Notes Issue Date: 2024-08-06 GPT Summary- LLMを使用した生成的な推薦に焦点を当て、従来の複数段階の推薦プロセスを1つの段階に簡素化する方法を調査。具体的には、生成的推薦の定義、RSの進化、LLMベースの生成的推薦の実装方法について検討。この調査は、LLMベースの生成的推薦に関する進捗状況と将来の方向について提供できる文脈とガイダンスを提供することを目指している。 Comment
Generative Recommendationの定義がわかりやすい:
> Definition 2 (Generative Recommendation) A generative recommender system directly generates recommendations or recommendation-related content without the need to calculate each candidate’s ranking score one by one.
既存の企業におけるRecommenderSystemsは、典型的には非常に膨大なアイテムバンクを扱わなければならず、全てのアイテムに対してスコアリングをしランキングをすることは計算コストが膨大すぎて困難である。このため、まずは軽量なモデル(e.g. logistic regression)やシンプルな手法(e.g. feature matching)などで、明らかに推薦候補ではないアイテムを取り除いてから、少量のcandidate itemsに対して洗練されたモデルを用いてランキングを生成して推薦するというマルチステージのパイプラインを組んでおり、アカデミック側での研究にここでギャップが生じている。
一方で、Generative Recommendationでは、推薦するアイテムのIDを直接生成するため、
- 実質ほぼ無限のアイテムバンクを運用でき
- 推論の過程でimplicitに全てのアイテムに対して考慮をしたうえで
推薦を生成することができる手法である。また、推薦するアイテムを生成するだけでなく、推薦理由を生成したりなど、テキストを用いた様々なdown stream applicationにも活用できる。
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications, Pranab Sahoo+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting Issue Date: 2024-07-30 GPT Summary- プロンプトエンジニアリングは、LLMsやVLMsの能力を拡張するための重要な技術であり、モデルのパラメータを変更せずにタスク固有の指示であるプロンプトを活用してモデルの効果を向上させる。本研究は、プロンプトエンジニアリングの最近の進展について構造化された概要を提供し、各手法の強みと制限について掘り下げることで、この分野をよりよく理解し、将来の研究を促進することを目的としている。 Comment
[Paper Note] A Large-Scale Evaluation of Speech Foundation Models, Shu-wen Yang+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#Evaluation #FoundationModel #SpeechProcessing #Speech #One-Line Notes Issue Date: 2024-04-21 GPT Summary- 音声処理の基盤モデルパラダイムを探求するため、新たにSpeech processing Universal PERformance Benchmark(SUPERB)を設立。凍結された基盤モデルに軽量な予測ヘッドを適用したマルチタスキングフレームワークを提案し、音声タスクにおける基盤モデルの有効性を実証。結果は、競争力のある一般化能力を示し、決定論的なベンチマークとオンラインリーダーボードを導入し、コミュニティのコラボレーションを促進。最後に、タスク間の情報フローやベンチマークの統計的有意性を分析。 Comment
Speech関連のFoundation Modelの評価結果が掲載されており、大変興味深い。
参考:
Knowledge Conflicts for LLMs: A Survey, Rongwu Xu+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel Issue Date: 2024-04-14 GPT Summary- LLMsにおける知識の衝突に焦点を当て、文脈とパラメトリック知識の組み合わせによる複雑な課題を分析。文脈-メモリ、文脈間、メモリ内の衝突の3つのカテゴリーを探求し、実世界のアプリケーションにおける信頼性とパフォーマンスへの影響を検討。解決策を提案し、LLMsの堅牢性向上を目指す。
A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys), Yashar Deldjoo+, N_A, arXiv'24
Paper/Blog Link My Issue
#RecommenderSystems #GenerativeAI Issue Date: 2024-04-02 GPT Summary- 従来のレコメンドシステムは、ユーザー-アイテムの評価履歴を主要なデータソースとして使用してきたが、最近では生成モデルを活用して、テキストや画像など豊富なデータを含めた新しい推薦タスクに取り組んでいる。この研究では、生成モデル(Gen-RecSys)を用いたレコメンドシステムの進歩に焦点を当て、相互作用駆動型生成モデルや大規模言語モデル(LLM)を用いた生成型推薦、画像や動画コンテンツの処理と生成のためのマルチモーダルモデルなどについて調査している。未解決の課題や必要なパラダイムについても議論している。
Large Language Models for Data Annotation: A Survey, Zhen Tan+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Annotation #One-Line Notes #Data Issue Date: 2024-03-05 GPT Summary- GPT-4などの大規模言語モデル(LLMs)を使用したデータアノテーションの研究に焦点を当て、LLMによるアノテーション生成の評価や学習への応用について述べられています。LLMを使用したデータアノテーションの手法や課題について包括的に議論し、将来の研究の進展を促進することを目的としています。 Comment
Data AnnotationにLLMを活用する場合のサーベイ
Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey, Xi Fang+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #DataToTextGeneration #TabularData #One-Line Notes Issue Date: 2024-03-05 GPT Summary- 最近の大規模言語モデリングの進展により、様々なタスクにおける応用が容易になっているが、包括的なレビューが不足している。この研究は、最近の進歩をまとめ、データセット、メトリクス、方法論を調査し、将来の研究方向に洞察を提供することを目的としている。また、関連するコードとデータセットの参照も提供される。 Comment
Tabular DataにおけるLLM関連のタスクや技術等のサーベイ
MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#LanguageModel #MultiModal #ACL #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-01-25 GPT Summary- MM-LLMsは、コスト効果の高いトレーニング戦略を用いて拡張され、多様なMMタスクに対応する能力を持つことが示されている。本論文では、MM-LLMsのアーキテクチャ、トレーニング手法、ベンチマークのパフォーマンスなどについて調査し、その進歩に貢献することを目指している。 Comment
以下、論文を斜め読みしながら、ChatGPTを通じて疑問点を解消しつつ理解した内容なので、理解が不十分な点が含まれている可能性があるので注意。
# 概要
まあざっくり言うと、マルチモーダルを理解できるLLMを作りたかったら、様々なモダリティをエンコーディングして得られる表現と、既存のLLMが内部的に処理可能な表現を対応づける Input Projectorという名の関数を学習すればいいだけだよ(モダリティのエンコーダ、LLMは事前学習されたものをそのままfreezeして使えば良い)。
マルチモーダルを生成できるLLMを作りたかったら、LLMがテキストを生成するだけでなく、様々なモダリティに対応する表現も追加で出力するようにして、その出力を各モダリティを生成できるモデルに入力できるように変換するOutput Projectortという名の関数を学習しようね、ということだと思われる。
## ポイント
- Modality Encoder, LLM Backbone、およびModality Generatorは一般的にはパラメータをfreezeする
- optimizationの対象は「Input/Output Projector」
## Modality Encoder
様々なモダリティI_Xを、特徴量F_Xに変換する。これはまあ、色々なモデルがある。
## Input Projector
モダリティI_Xとそれに対応するテキストtのデータ {I_X, t}が与えられたとき、テキストtを埋め込み表現に変換んした結果得られる特徴量がF_Tである。Input Projectorは、F_XをLLMのinputとして利用する際に最適な特徴量P_Xに変換するθX_Tを学習することである。これは、LLM(P_X, F_T)によってテキストtがどれだけ生成できたか、を表現する損失関数を最小化することによって学習される。
## LLM Backbone
LLMによってテキスト列tと、各モダリティに対応した表現であるS_Xを生成する。outputからt, S_Xをどのように区別するかはモデルの構造などにもよるが、たとえば異なるヘッドを用意して、t, S_Xを区別するといったことは可能であろうと思われる。
## Output Projector
S_XをModality Generatorが解釈可能な特徴量H_Xに変換する関数のことである。これは学習しなければならない。
H_XとModality Generatorのtextual encoderにtを入力した際に得られる表現τX(t)が近くなるようにOutput Projector θ_T_Xを学習する。これによって、S_XとModality Generatorがalignするようにする。
## Modality Generator
各ModalityをH_Xから生成できるように下記のような損失学習する。要は、生成されたモダリティデータ(または表現)が実際のデータにどれだけ近いか、を表しているらしい。具体的には、サンプリングによって得られたノイズと、モデルが推定したノイズの値がどれだけ近いかを測る、みたいなことをしているらしい。
Multi Modalを理解するモデルだけであれば、Input Projectorの損失のみが学習され、生成までするのであれば、Input/Output Projector, Modality Generatorそれぞれに示した損失関数を通じてパラメータが学習される。あと、P_XやらS_Xはいわゆるsoft-promptingみたいなものであると考えられる。
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models, S. M Towhidul Islam Tonmoy+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Hallucination Issue Date: 2024-01-24 GPT Summary- 要約:本論文では、大規模言語モデル(LLMs)における幻覚の問題について調査し、その軽減策について紹介しています。LLMsは強力な言語生成能力を持っていますが、根拠のない情報を生成する傾向があります。この問題を解決するために、Retrieval Augmented Generation、Knowledge Retrieval、CoNLI、CoVeなどの技術が開発されています。さらに、データセットの利用やフィードバックメカニズムなどのパラメータに基づいてこれらの方法を分類し、幻覚の問題に取り組むためのアプローチを提案しています。また、これらの技術に関連する課題や制約についても分析し、将来の研究に向けた基盤を提供しています。
Leveraging Large Language Models for NLG Evaluation: A Survey, Zhen Li+, N_A, arXiv'24
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Evaluation #LLM-as-a-Judge #KeyPoint Notes Issue Date: 2024-01-24 GPT Summary- 本研究は、大規模言語モデル(LLMs)を使用した自然言語生成(NLG)の評価についての包括的な概要を提供します。既存の評価指標を整理し、LLMベースの手法を比較するためのフレームワークを提案します。さらに、未解決の課題についても議論し、より公正で高度なNLG評価技術を提唱します。 Comment
重要
NLGの評価をするモデルのアーキテクチャとして、BERTScoreのようなreferenceとhvpothesisのdistiebuted representation同士を比較するような手法(matching-based)と、性能指標を直接テキストとして生成するgenerative-basedな手法があるよ、
といった話や、そもそもreference-basedなメトリック(e.g. BLEU)や、reference-freeなメトリック(e.g. BARTScore)とはなんぞや?みたいな基礎的な話から、言語モデルを用いたテキスト生成の評価手法の代表的なものだけでなく、タスクごとの手法も整理されて記載されている。また、BLEUやROUGEといった伝統的な手法の概要や、最新手法との同一データセットでのメタ評価における性能の差なども記載されており、全体的に必要な情報がコンパクトにまとまっている印象がある。
[Paper Note] Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, Jingfeng Yang+, TKDD'24, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #One-Line Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)の実践的なガイドを提供し、自然言語処理(NLP)タスクにおけるモデルやデータの活用法を論じる。GPT系およびBERT系の紹介から始まり、事前学習や訓練データの影響を考察。さらに、さまざまなNLPタスクの使用ケースや非使用ケースを詳細に分析し、実世界でのLLMsの適用限界について触れる。偽りのバイアス、効率性、コストなどの課題に言及し、研究者と実務者に有益なベストプラクティスを提案。更新リストも提供。 Comment
LLMに関するチュートリアル
encoder-onlyとまとめられているものの中には、デコーダーがあるものがあり(autoregressive decoderではない)、
encoder-decoderは正しい意味としてはencoder with autoregressive decoderであり、
decoder-onlyは正しい意味としてはautoregressive encoder-decoder
とのこと。
[Paper Note] Graph Neural Networks for Text Classification: A Survey, Kunze Wang+, Artificial Intelligence Review'24, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #GraphBased #NLP Issue Date: 2023-04-25 GPT Summary- テキスト分類におけるグラフニューラルネットワーク(GNN)を含む手法を調査。これにより、構造化されたテキストデータを処理し、グローバル情報を活用できる。2023年までのコーパスとドキュメントレベルのGNN手法を詳細に議論し、グラフ構築と学習プロセスを説明。背景問題や今後の方向性も考察し、データセットや評価指標に関する性能の要約を提供し、異なる手法間の比較を行う。
[Paper Note] Dataset Distillation: A Comprehensive Review, Ruonan Yu+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#MachineLearning #Dataset #Distillation #Initial Impression Notes Issue Date: 2025-03-25 GPT Summary- データセット蒸留(DD)は、深層学習における膨大なデータのストレージやプライバシーの問題を軽減する手法であり、合成サンプルを含む小さなデータセットを生成することで、元のデータセットと同等の性能を持つモデルをトレーニング可能にする。本論文では、DDの進展と応用をレビューし、全体的なアルゴリズムフレームワークを提案、既存手法の分類と理論的相互関係を議論し、DDの課題と今後の研究方向を展望する。 Comment
訓練データセット中の知識を蒸留し、オリジナルデータよりも少量のデータで同等の学習効果を得るDataset Distillationに関するSurvey。
Data Distillation: A Survey, Noveen Sachdeva+, arXiv'23
Paper/Blog Link My Issue
#NLP #Dataset #Distillation Issue Date: 2025-02-01 GPT Summary- 深層学習の普及に伴い、大規模データセットの訓練が高コストで持続可能性に課題をもたらしている。データ蒸留アプローチは、元のデータセットの効果的な代替品を提供し、モデル訓練や推論に役立つ。本研究では、データ蒸留のフレームワークを提示し、既存のアプローチを分類。画像やグラフ、レコメンダーシステムなどの異なるデータモダリティにおける課題と今後の研究方向性を示す。
Navigate through Enigmatic Labyrinth A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future, Zheng Chu+, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #ACL Issue Date: 2025-01-06 GPT Summary- 推論はAIにおいて重要な認知プロセスであり、チェーン・オブ・ソートがLLMの推論能力を向上させることが注目されている。本論文では関連研究を体系的に調査し、手法を分類して新たな視点を提供。課題や今後の方向性についても議論し、初心者向けの導入を目指す。リソースは公開されている。
Recommender Systems with Generative Retrieval, Shashank Rajput+, arXiv'23
Paper/Blog Link My Issue
#RecommenderSystems #InformationRetrieval #LanguageModel #SequentialRecommendation Issue Date: 2024-12-30 GPT Summary- 新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを自己回帰的にデコード。Transformerベースのモデルが次のアイテムのセマンティックIDを予測し、レコメンデーションタスクにおいて初のセマンティックIDベースの生成モデルとなる。提案手法は最先端モデルを大幅に上回り、過去の対話履歴がないアイテムに対する検索性能も向上。
Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey, Yunpeng Huang+, N_A, arXiv'23
Paper/Blog Link My Issue
#Transformer #LongSequence Issue Date: 2023-11-27 GPT Summary- 本論文では、Transformerベースの大規模言語モデル(LLMs)の長い文脈の能力を最適化するための包括的な調査を提案しています。現行のLLMsの制約や問題点を明確化し、アーキテクチャのアップグレードや評価の必要性について説明しています。さらに、最適化ツールキットや将来の研究の可能性についても議論しています。関連文献はhttps://github.com/Strivin0311/long-llms-learningでリアルタイムに更新されています。 Comment
TransformerをLongContextに対応させる技術のサーベイ。
(画像は元ツイートより)
元ツイート:
[Paper Note] A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Lei Huang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Hallucination #One-Line Notes Issue Date: 2023-11-10 GPT Summary- LLMの登場によりNLPは新たな転機を迎えたが、幻覚問題が信頼性に対する懸念を引き起こし、検出と緩和の研究を促進している。幻覚はタスク特化型モデルとは異なる課題を呈し、詳細な理解が求められる。本調査では、幻覚の分類法や要因を詳述し、検知手法と緩和方法、情報検索を含むLLMの現状における制約を掘り下げる。また、ビジョン言語モデルにおける幻覚や知識の境界の理解を含む今後の研究方向も強調する。 Comment
Hallucinationを現象ごとに分類したSurveyとして [Paper Note] A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, arXiv'23, 2023.09 もある
Surveyの内容。必要に応じて参照すべし。
[Paper Note] Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity, Cunxiang Wang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Factuality #needs-revision Issue Date: 2023-10-13 GPT Summary- LLMsにおける事実性の問題に焦点を当て、出力の信頼性と正確性の重要性を検討。事実誤りの影響や原因を分析し、評価方法論や改善戦略を提案。スタンドアロンLLMsとリトリーバル拡張LLMsの固有の課題を詳述し、体系的なガイドを提供する。 Comment
[Paper Note] Large Language Model Alignment: A Survey, Tianhao Shen+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#LanguageModel #Alignment #PostTraining Issue Date: 2023-10-09 GPT Summary- LLMsの進展には潜在的な問題が伴い、正確性や人間の価値観との整合性が求められる。本研究は、アラインメント手法を探求し、外部と内部アラインメントを分類。解釈可能性や脆弱性についても考察し、多様な評価方法を提示。最終的に、AIアラインメント研究とLLMsの能力探索を結びつけることを目的とする。 Comment
LLMのalignmentに関するサーベイ。
[Paper Note] A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Hallucination #ICLR #needs-revision Issue Date: 2023-09-30 GPT Summary- 基盤モデルにおける幻覚を特定・解明し、対処する取り組みを概観する総説論文。特に大規模基盤モデルに焦点を当て、幻覚現象を分類し、その評価基準を確立。既存の緩和戦略を検討し、今後の研究方向について論じる。全体として、LFMsに関連する幻覚の課題と解決策を包括的に探求。 Comment
Hallucinationを現象ごとに分類し、Hallucinationの程度の評価をする指標や、Hallucinationを軽減するための既存手法についてまとめられているらしい。
openreview: https://openreview.net/forum?id=pETSfWMUzy
[Paper Note] A Survey on Large Language Model based Autonomous Agents, Lei Wang+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-09-01 GPT Summary- LLMを活用した自律エージェントの研究を体系的に整理し、構築方法や応用例、評価戦略を概説。人間の学習に近づくための課題と今後の方向性を示す。関連文献のリポジトリも提供。 Comment
Fig1の時系列での論文数と代表的な研究のリストアップとエージェントの質の変遷、Table1のモデルの分類表など非常に分かりやすい。
[Paper Note] Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback, Stephen Casper+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning Issue Date: 2023-08-08 GPT Summary- RLHFはAIを人間の目標に合わせるための技術で、LLMsの微調整に重要。しかし、欠陥の体系的研究は少ない。本論文では、RLHFの未解決問題と限界を調査し、理解・改善手法を概説、社会的監視のための基準を提案。研究は、RLHFの限界を強調し、安全なAI開発には多面的アプローチが必要であることを示す。
[Paper Note] Aligning Large Language Models with Human: A Survey, Yufei Wang+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #PostTraining #One-Line Notes Issue Date: 2023-08-08 GPT Summary- LLMsはNLPタスクにおいて重要な解決策として台頭しているが、人間の指示を誤解したり、偏った情報を生成するリスクがある。本調査は、LLMsを人間の期待に整合させるための技術を総括し、データ収集方法、学習手法のレビュー、モデル評価方法について詳述する。結論として、人間指向のタスクに適合させるためのLLMsの整合性を深化させる有用な資源にし、関連のGitHubリンクも提供する。 Comment
LLMのAlignment手法に関するSurvey
[Paper Note] Foundational Models Defining a New Era in Vision: A Survey and Outlook, Muhammad Awais+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#ComputerVision #FoundationModel #One-Line Notes Issue Date: 2023-08-08 GPT Summary- 視覚システムの理解と推論における基盤モデルの役割をレビュー。異なるモダリティを組み合わせるアーキテクチャやトレーニング方法、プロンプティングパターンを含む。オープンな課題や研究方向性、評価の困難さ、文脈理解の限界なども議論。基盤モデルの応用を包括的にカバーし、詳細なリストはオンラインで提供。 Comment
CVにおけるfoundation modelのsurvey。残されたチャレンジと研究の方向性が議論されている
[Paper Note] Challenges and Applications of Large Language Models, Jean Kaddour+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Tutorial #NLP #LanguageModel #One-Line Notes Issue Date: 2023-07-22 GPT Summary- 大規模言語モデル(LLM)の急速な普及に伴い、課題や適用領域の特定が困難になっている。本論文は、ML研究者が現状を迅速に把握し生産的になるために、未解決の問題と成功事例の体系的な集合を提供することを目指す。 Comment
LLMのここ数年の進化早すぎわろたでキャッチアップむずいので、未解決の課題や、すでに良い感じのアプリケーションの分野分かりづらいので、まとめました論文
A Survey of Deep Learning for Mathematical Reasoning, ACL'23
Paper/Blog Link My Issue
#NLP #NumericReasoning #ACL Issue Date: 2023-07-18 GPT Summary- 数学的な推論とディープラーニングの関係についての調査論文をレビューし、数学的な推論におけるディープラーニングの進歩と将来の研究方向について議論しています。数学的な推論は機械学習と自然言語処理の分野で重要であり、ディープラーニングモデルのテストベッドとして機能しています。また、大規模なニューラル言語モデルの進歩により、数学的な推論に対するディープラーニングの利用が可能になりました。既存のベンチマークと方法を評価し、将来の研究方向についても議論しています。
Reasoning with Language Model Prompting: A Survey, ACL'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #Reasoning #ACL Issue Date: 2023-07-18 GPT Summary- 本論文では、推論に関する最新の研究について包括的な調査を行い、初心者を支援するためのリソースを提供します。また、推論能力の要因や将来の研究方向についても議論します。リソースは定期的に更新されています。
[TACL] Abstractive Meeting Summarization: A Survey, TACL'23
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Abstractive #Conversation #TACL Issue Date: 2023-07-15 GPT Summary- 会議の要約化において、深層学習の進歩により抽象的要約が改善された。本論文では、抽象的な会議の要約化の課題と、使用されているデータセット、モデル、評価指標について概説する。
[Paper Note] A Survey of Large Language Models, Wayne Xin Zhao+, arXiv'23, 2023.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #One-Line Notes Issue Date: 2023-07-11 GPT Summary- 言語は複雑な表現体系であり、その理解・生成のためのAIアルゴリズム開発は難題である。近年、事前学習済み言語モデル(PLMs)がTransformerモデルを用いた大規模コーパスの学習により高い能力を示しており、特に大規模言語モデル(LLM)が注目されている。モデルスケーリングが性能向上をもたらし、一定のパラメータ規模を超えると新たな能力が現れることが確認されている。LLMsはAIコミュニティ全体に重要な影響を与えており、本調査ではその背景、主要な発見、技術を概説し、特に事前学習、適応調整、活用、容量評価に焦点を当てる。また、リソース整理や未解決課題についても論じる。 Comment
現状で最も詳細なLLMのサーベイ
600個のリファレンス、LLMのコレクション、promptingのtips、githubリポジトリなどがまとめられている
[Paper Note] A Comprehensive Survey on Applications of Transformers for Deep Learning Tasks, Saidul Islam+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Transformer #One-Line Notes Issue Date: 2023-07-03 GPT Summary- トランスフォーマーは自己注意機構に基づく深層ニューラルネットワークで、長期依存関係を扱い、並列処理が可能。NLPやコンピュータビジョンなど複数の分野で注目されているが、包括的な総説が不足。2017年から2022年に提案されたトランスフォーマーモデルを調査し、主要な応用領域を特定。NLP、コンピュータビジョン、マルチモーダリティ、音声処理、信号処理を含むモデルの影響を分析し、分類。研究者にトランスフォーマーの潜在能力と未来の展望を示すことを目的とする。 Comment
Transformerに関する最新サーベイ論文。Transformerが利用されているアプリケーションと、モデルのリストが列挙されている。
[Paper Note] A Review of ChatGPT Applications in Education, Marketing, Software Engineering, and Healthcare: Benefits, Drawbacks, and Research Directions, Mohammad Fraiwan+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#Education #ChatGPT Issue Date: 2023-05-04 GPT Summary- ChatGPTは深層学習を用いた人間のようなテキスト応答生成AIであり、2022年11月の登場以降、強力な能力と多様な応用、さらには悪用のリスクで注目を集めている。最近ではGoogle BardやMeta LLaMAなどの競合モデルも登場し、教育や医療、マーケティングなどの分野での変革が期待されている。本論文ではAI言語モデルの概略、応用、限界、今後の研究の方向性について考察する。
Efficient Methods for Natural Language Processing: A Survey, Treviso+, TACL'23
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #NLP #TACL #One-Line Notes Issue Date: 2023-04-25 Comment
パラメータ数でゴリ押すような方法ではなく、"Efficient"に行うための手法をまとめている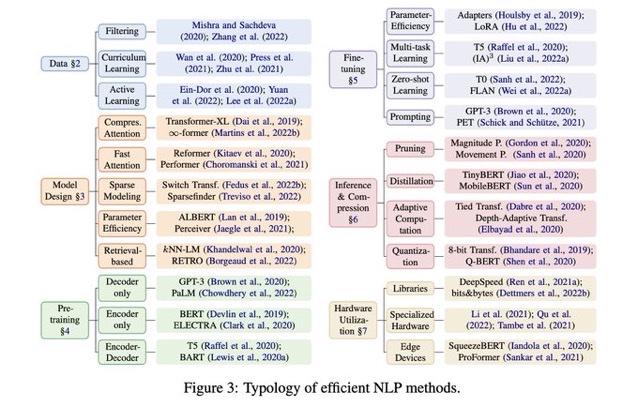
Knowledge Tracing: A Survey, ABDELRAHMAN+, Australian National University, ACM Computing Surveys'23
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #KnowledgeTracing Issue Date: 2022-08-02
[Paper Note] Efficient Transformers: A Survey, Yi Tay+, ACM Computing Surveys'22, 2022.12
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #Transformer #Attention #Sparse #SparseAttention Issue Date: 2025-11-30 GPT Summary- 本論文では、計算効率やメモリ効率を向上させることに焦点を当てた「X-former」モデル(Reformer、Linformer、Performer、Longformerなど)の大規模なセレクションを紹介し、最近の研究を体系的かつ包括的にまとめる。Transformersは自然言語処理を含む多くの分野で重要な役割を果たしている。 Comment
関連:
- [Paper Note] Efficient Transformers: A Survey, Yi Tay+, ACM Computing Surveys'22, 2022.12
- [Paper Note] Big Bird: Transformers for Longer Sequences, Manzil Zaheer+, NIPS'20, 2020.07
- [Paper Note] Reformer: The Efficient Transformer, Nikita Kitaev+, ICLR'20
- [Paper Note] Generating Long Sequences with Sparse Transformers, Rewon Child+, arXiv'19, 2019.04
- [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
Interpretable Machine Learning: Fundamental Principles and 10 Grand Challenges, Cynthia Rudin+, N_A, arXiv'21
Paper/Blog Link My Issue
#MachineLearning Issue Date: 2023-08-24 GPT Summary- 本研究では、解釈可能な機械学習(ML)の基本原則とその重要性について説明し、解釈可能なMLの10の技術的な課題を特定します。これには、疎な論理モデルの最適化、スコアリングシステムの最適化、一般化加法モデルへの制約の配置などが含まれます。また、ニューラルネットワークや因果推論のためのマッチング、データ可視化のための次元削減なども取り上げられます。この調査は、解釈可能なMLに興味のある統計学者やコンピュータサイエンティストにとっての出発点となるでしょう。
[Paper Note] Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better, Gaurav Menghani, arXiv'21, 2021.06
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Initial Impression Notes Issue Date: 2021-06-19 GPT Summary- ディープラーニングの進展に伴い、モデルのパラメータ数やリソース消費が増加しているため、効率性が重要視されている。本研究では、モデル効率性の5つのコア領域を調査し、実務者向けに最適化ガイドとコードを提供する。これにより、効率的なディープラーニングの全体像を示し、読者に改善の手助けとさらなる研究のアイデアを提供することを目指す。 Comment
学習効率化、高速化などのテクニックがまとまっているらしい
[Paper Note] A Survey of Transformers, Tianyang Lin+, arXiv'21, 2021.06
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Initial Impression Notes Issue Date: 2021-06-09 GPT Summary- トランスフォーマーの多様なバリアント(X-formers)に関する体系的な文献レビューを提供。バニラトランスフォーマーの紹介後、新しい分類法を提案し、アーキテクチャの修正、事前学習、アプリケーションの観点からX-formersを紹介。今後の研究の方向性も概説。 Comment
Transformersの様々な分野での亜種をまとめた論文
Returning the N to NLP: Towards Contextually Personalized Classification Models, Lucie Flek, Mainz University of Applied Sciences Germany, ACL'20
Paper/Blog Link My Issue
#NLP #Personalization #ACL #One-Line Notes Issue Date: 2023-04-26 Comment
NLPのけるPersonalized Classificationモデルのliteratureを振り返る論文
[Paper Note] Evaluation of Text Generation: A Survey, Asli Celikyilmaz+, arXiv'20, 2020.06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Evaluation Issue Date: 2020-08-25 GPT Summary- NLGシステムの評価方法を人間中心、自動評価、機械学習に基づく評価の3カテゴリに分類し、各カテゴリの進展と課題を議論。自動テキスト要約と長文生成の具体例を示し、今後の研究方向を提案。
[Paper Note] A Survey on Session-based Recommender Systems, Shoujin Wang+, arXiv'19
Paper/Blog Link My Issue
#RecommenderSystems #SessionBased #SequentialRecommendation Issue Date: 2019-08-02 GPT Summary- レコメンダーシステム(RS)の中で、セッションベースのレコメンダーシステム(SBRS)が短期的なユーザーの好みを捉え、より正確な推奨を提供する新たなパラダイムとして注目されている。しかし、SBRSに関する統一された問題定義や特性の詳細な説明は不足している。本研究では、SBRSのエンティティや行動、特性を探求し、一般的な問題定義やデータ特性、課題を要約し、代表的な研究を分類する方法を提案する。また、SBRS分野における新たな研究機会についても議論する。
[Paper Note] Deep Learning based Recommender System: A Survey and New Perspectives, Shuai Zhang+, ACM Computing Surveys (CSUR)'19, Vol.52, Issue 1, 2017.07
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork Issue Date: 2018-04-16 GPT Summary- レコメンダーシステムは情報過多を克服するための効果的な手段であり、深層学習の進展によりその性能が向上している。本稿では、深層学習に基づくレコメンダーシステムの研究をレビューし、推薦モデルの分類法や最先端技術をまとめ、現在のトレンドと新たな発展について考察する。
[Paper Note] A SURVEY OF ARTIFICIAL INTELLIGENCE TECHNIQUES EMPLOYED FOR ADAPTIVE EDUCATIONAL SYSTEMS WITHIN E-LEARNING PLATFORMS, Almohammadi+, JAISCR'17, 2017.01
Paper/Blog Link My Issue
#RecommenderSystems #Education Issue Date: 2018-03-30
[Paper Note] Recent Trends in Deep Learning Based Natural Language Processing, Tom Young+, arXiv'17, 2017.08
Paper/Blog Link My Issue
#NeuralNetwork #NLP Issue Date: 2018-02-04 GPT Summary- 深層学習手法の進化をレビューし、NLPタスクにおける重要なモデルと手法を要約・比較。NLPにおける深層学習の過去、現在、未来についての理解を深める。
[Paper Note] A survey of transfer learning for collaborative recommendation with auxiliary data, Pan, Neurocomputing'17
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] Recent Advances in Document Summarization, Yao+, Knowledge and Information Systems'17, 2017.11
Paper/Blog Link My Issue
#DocumentSummarization #NLP Issue Date: 2017-12-31
[Paper Note] Neural Text Generation: A Practical Guide, Ziang Xie, arXiv'17, 2017.11
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #ConceptToTextGeneration Issue Date: 2017-12-31 GPT Summary- 深層学習手法はテキスト生成タスクで成功を収めているが、デコーダーが望ましくない出力を生成する問題がある。本論文は、テキスト生成モデルの不具合を解決するための実践的なガイドを提供し、実世界のアプリケーションの実現を目指す。
[Paper Note] Survey of the State of the Art in Natural Language Generation: Core tasks, applications and evaluation, Albert Gatt+, arXiv'17, 2017.03
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #DataToTextGeneration #ConceptToTextGeneration Issue Date: 2017-12-31 GPT Summary- 本論文は、非言語的入力からテキストや音声を生成する自然言語生成(NLG)の最新技術動向を調査し、(a) NLGのコアタスクに関する研究の統合とアーキテクチャの提示、(b) NLGと他のAI分野との相乗効果による新しい研究トピックの強調、(c) NLG評価の課題と他の自然言語処理分野との関連を明らかにすることを目的としている。 Comment
割と新し目のNLGのSurvey
[Paper Note] A Survey on Artificial Intelligence and Data Mining for MOOCs, Simon Fauvel+, arXiv'16, 2016.01
Paper/Blog Link My Issue
#RecommenderSystems #Education #TechnologyEnhancedLearning Issue Date: 2018-03-30 GPT Summary- MOOCsは人気を集めており、AIとデータマイニングがその発展に寄与している。データを活用することで、MOOCの理解を深め、学習者の体験を向上させることが可能。論文では、AIとDMの最新研究をレビューし、学生のエンゲージメントや学習成果を向上させる技術を強調。さらに、MOOCsの潜在能力を引き出すための重要な研究課題とトレンドを示す。
[Paper Note] A Survey of Collaborative Filtering-Based Recommender Systems for Mobile Internet Applications, Yang+, IEEE Access'16
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] Content Selection in Data-to-Text Systems: A Survey, Dimitra Gkatzia, arXiv'16, 2016.10
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #DataToTextGeneration #ConceptToTextGeneration #Initial Impression Notes Issue Date: 2017-12-31 GPT Summary- データからテキストへのシステムは、データを自然言語で自動的にレポート生成し、ユーザーの好みに応じた出力を提供する。コンテンツ選択は重要な要素であり、どの情報を伝えるかを決定する。研究では、データからテキスト生成の分野を紹介し、システムのアーキテクチャと最先端のコンテンツ選択手法をレビューし、今後の研究機会について議論する。 Comment
Gkatzia氏の"content selection"に関するSurvey
[Paper Note] Matrix Factorization Model in Collaborative Filtering Algorithms: A Survey, Bokde+, Procedia Computer Science'15
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] セレンディピティ指向情報推薦の研究動向, 奥健太, 知能と情報'13
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] Recommender systems survey, Bobadilla+, Knowledge-Based Systems'13
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] A literature review and classification of recommender systems research, Park+, Expert Systems with Applications'12
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] Explaining the user experience of recommender systems, Knijnenburg+, User Modeling and User-Adapted Interaction'12
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] A Survey of Text Summarization Techniques, Nenkova+, Springer'12, 2012.01
Paper/Blog Link My Issue
#DocumentSummarization #NLP Issue Date: 2017-12-31
[Paper Note] Collaborative Filtering Recommender Systems, Ekstrand+ (with Joseph A. Konstan), Foundations and TrendsR in Human–Computer Interaction'11
Paper/Blog Link My Issue
#RecommenderSystems #Selected Papers/Blogs Issue Date: 2018-01-01
[Paper Note] Adaptive Educational HypermediaSystems in Technology Enhanced Learning: A Literature Review, Mulwa+, SIGITE'10, 2010.10
Paper/Blog Link My Issue
#Education #TechnologyEnhancedLearning Issue Date: 2018-03-31 Comment
よさげ
Content-based Recommender Systems: State of the Art and Trends, Lops+, Recommender Systems Handbook'10
Paper/Blog Link My Issue
#RecommenderSystems #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
RecSysの内容ベースフィルタリングシステムのユーザプロファイルについて知りたければこれ
Content-Based Recommendation Systems, Pazzani+, The Adaptive Web'07
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] A Survey of Explanations in Recommender Systems, Tintarev+, ICDEW'07
Paper/Blog Link My Issue
#RecommenderSystems #Explanation #Selected Papers/Blogs Issue Date: 2018-01-01
[Paper Note] Matrix Factorization Techniques for Recommender Systems, Koren+, Computer'07
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #MatrixFactorization #Selected Papers/Blogs #Reading Reflections Issue Date: 2018-01-01 Comment
Matrix Factorizationについてよくまとまっている
[Paper Note] An Architecture for Data to Text Systems, Ehud Reiter, ENLG'07
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #DataToTextGeneration #ConceptToTextGeneration #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-31 Comment
NLG分野で有名なReiterらのSurvey。
NLGシステムのアーキテクチャなどが、体系的に説明されている。
[Paper Note] Explanation in Recommender Systems, Mcsherry, Artificial Intelligence Review'05
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
[Paper Note] Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions, Adomavicius+, IEEE Transactions on Knowledge and Data Engineering'05
Paper/Blog Link My Issue
#RecommenderSystems #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
有名なやつ
[Paper Note] Evaluating Collaborative Filtering Recommener Systems, Herlocker+, TOIS'04
Paper/Blog Link My Issue
#RecommenderSystems #Evaluation #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
GroupLensのSurvey
[Paper Note] Hybrid Recommender Systems: Survey and Experiments, Burke+, User Modeling and User-Adapted Interaction'02
Paper/Blog Link My Issue
#RecommenderSystems Issue Date: 2018-01-01
NLP colloquium: AI Safety Survey, Masahiro Kaneko, 2026.04
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Slide #Safety Issue Date: 2026-06-05 Comment
元ポスト:
元ポスト:
APIの背後にあるモデルの隠れ層から語彙分布に変換する線形層の隠れ次元数を盗む方法があるのか...
Is Frontier Asynchronous RL Solved?, Luke J. Huang, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Blog #Selected Papers/Blogs #reading #Asynchronous #Author Thread-Post Issue Date: 2026-06-03 Comment
元ポスト:
[Paper Note] Optimization Techniques for GPU Programming, ACM Computing Surveys, Volume 55, Issue 11, 2023.03
Paper/Blog Link My Issue
#Article #SoftwareEngineering #read-later #GPUKernel Issue Date: 2026-05-27 Comment
元ポスト:
The Imitation Game: State of Policy Distillation in Language Model training, 032-Chinmay Karkar, 2026.05
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #ReinforcementLearning #Distillation #Catastrophic Forgetting #PostTraining #On-Policy #KeyPoint Notes #SelfDistillation #Author Thread-Post Issue Date: 2026-05-26 Comment
元ポスト:
- On Policy DistillationはKnowledge Distillationの一種で、教師モデルの知識を小さなモデルに蒸留する
- off policy KD Objectiveの場合は固定されたオフラインデータを用いるが、on policy distillationは生徒モデル自身が生成したデータに対するシグナルに基づいて学習される。
- off policy手法の課題はCatastrophic Forgettingと、(sequence長に対するquadraticな)エラーの蓄積がある。
- (オフポリシーRLの特殊なケースとみなすことができる)SFTはForward KLに基づいており、教師モデルの出力分布が確率を持つ部分に対して、生徒モデルの確率がゼロの場合はKLが発散するため、学習される生徒モデルの分布さスムージングされた分布になる。つまり、教師モデルの出力パターンを網羅できるように分布が学習される。
- このような手法で複数のドメインのデータで学習をした場合、分布のシフトが生じやすくCatastrophic Forgettingが生じやすい。
- on policy RLでは、Reverse KLが採用されており、この場合教師が確率が低いと考える場所に高い確率を割り振った場合のみに大きなペナルティを受けるため、教師の重要なモードをカバーしていれば、教師の他のモード全体は無視できる。これにより、学習したいモード以外の挙動に影響を与えにくく、特定のモードの学習ができる。
- (SFTがCatastrophic Forgettingが起きやすそうということは理解できるが、オフポリシーRL全体においてCatastrophic Forgettingが起きやすい問題があるという文脈で書かれている気がしており(エラーの蓄積の冒頭でオフポリシーRLのもう一つの根本的な課題は、という文脈で書かれているため)、SFTの議論がオフポリシーRL全体につながるのかがわからず、モヤっとする。が、LLMのpost-traingではCatrastrophic Forgettingが問題であるという文脈であれば理解できる)
- また、on-policyな学習ではエラーの蓄積を線形に留めることができることが示されている(off-policyな手法ではポリシーが生成したデータで訓練されていないため、inference時の冒頭でミスをすると学習時に観測していないトークンスペースを扱わなければならなくなり、さらにミスが増えモード崩壊に陥る)。
- on policy distillationは直接的にこのexposure biasのgapを小さくする。すなわち、学習時のinput(教師モデルが生成)と推論時のinput(生徒モデルが生成)の分布のgapを縮める。
- 生徒は学習時に常に自身の出力に基づいて学習するため、学習時のprefixと推論時のprefixの傾向が一致しやすい。このため生成時にエラーが起きてもin-distributionとなるため、エラーの蓄積が低減される。
以後はon policy distillation, on policy self-distillationの最新研究のサーベイと動向について記載されている。
関連:
- [Paper Note] Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting, Howard Chen+, arXiv'25, 2025.10
- [Paper Note] RL's Razor: Why Online Reinforcement Learning Forgets Less, Idan Shenfeld+, ICLR'26
- Multi-Teacher On-Policy Distillation: A New Post-Training Primitive, Yumo Xu, 2026.04
後半のサーベイパートなどで記述があったのかもしれないが、OPDでは、GRPOなどで主流なRLVRなどと比較して、報酬のシグナルがdenseであるという点も押さえておきたい。
Reliable Reasoning, Naoto Iwase, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Reasoning #read-later #Author Thread-Post Issue Date: 2026-05-20 Comment
元ポスト:
Latest Agentic AI Trends to Watch in 2026: Market Shifts, Adoption Patterns, and What Comes Next, Daya Shankar, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Infrastructure #AIAgents #Blog #read-later Issue Date: 2026-04-25 Comment
元ポスト:
Taking the Pulse of Agentic AI from the Developer Community at the End of Q1 2026, InclusionAI, 2026.04
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Library #AIAgents #GenerativeAI #Repository #read-later Issue Date: 2026-04-11 Comment
元ポスト:
Vision Language Models (Better, faster, stronger), merve+, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Blog #VisionLanguageModel #Initial Impression Notes Issue Date: 2026-04-07 Comment
元ポスト:
1年前のVLMに関するトレンドをまとめた記事のようだが、その後も同トレンドが継続している模様
Here are the 2025 AI safety papers and posts I like the most, Fabien Roger, LW, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Safety #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-03-26 Comment
元ポスト:
AI Safetyに関する研究者の方の2025年のAI Safetyハイライトとのこと。
Emergent Misalignmentなど以外にも多くの研究に⭐︎︎︎⭐︎⭐︎が付与されている。気になる。
LLM Architecture Gallery, Sebastian Raschka, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Transformer #Blog #OpenWeight #Architecture #Initial Impression Notes Issue Date: 2026-03-20 Comment
元ポスト:
Sebastian Raschka氏がいつもポストしているOpenWeight LLMのアーキテクチャ図のギャラリー。パラメータサイズ, head数などの細かい情報も含まれているので、全体を概観するのに良さそう。
State of RL for reasoning LLMs, A. Weers, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Blog #PostTraining Issue Date: 2026-03-17 Comment
元ポスト:
Awesome World Models, knightnemo,
Paper/Blog Link My Issue
#Article #ComputerVision #Robotics #WorldModels Issue Date: 2026-03-08
Awesome World Models for Robotics, leofan90,
Paper/Blog Link My Issue
#Article #ComputerVision #Robotics #WorldModels Issue Date: 2026-03-08
Awesome From Video Generation to World Model, ziqihuangg, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #Robotics #WorldModels Issue Date: 2026-03-08 Comment
元ポスト:
Chinese Open Source: A Definitive History, Kevin Xu, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #OpenWeight #read-later Issue Date: 2026-03-07
Building Olmo in the Era of Agents, Nathan Lambert, LTI Colloquim, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #AIAgents #Reasoning #Slide #OpenSource #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-02-16 Comment
元ポスト:
うーんこれは時間をとってしっかり読んで色々まとめたい・・・
new-datasets-in-machine-learning, librarian-bots, 2026.02
Paper/Blog Link My Issue
#Article #RecommenderSystems #ComputerVision #MachineLearning #InformationRetrieval #NLP #Dataset #Evaluation #SpeechProcessing #Robotics #Live Issue Date: 2026-02-09 Comment
元ポスト:
ModernBERTをFinetuningした分類器を用いてデータセットやベンチマークを提案している研究を自動分類して検索できるようにしている。有用
Knowledge Editing for LLMs Papers, zjunlp, 2024.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #KnowledgeEditing Issue Date: 2026-02-08
LLM Datasets, mlabonne, 2025.11
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #AIAgents Issue Date: 2025-11-19 Comment
元ポスト:
Awesome Spatial Intelligence in VLMs, mll-lab-nu, 2025.11
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Repository #VisionLanguageModel #SpatialUnderstanding Issue Date: 2025-11-18 Comment
元ポスト:
VLM, マルチモーダルなLLMにおけるSpatial Intelligenceに関する論文リスト
ICCV 2025 Report, Kataoka+, LIMIT.Lab, cvpaper.challenge, Visual Geometry Group (VGG), 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #Slide #read-later #ICCV Issue Date: 2025-11-01 Comment
元ポスト:
Awesome World Models, Siqiao Huang, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #WorldModels Issue Date: 2025-11-01 Comment
元ポスト:
Supercharge your OCR Pipelines with Open Models, merve+, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #OCR Issue Date: 2025-10-24 Comment
元ポスト:
STATE OF AI REPORT 2025, Nathan Benaich, 2025.10
Paper/Blog Link My Issue
#Article #LanguageModel #GenerativeAI #Blog #read-later Issue Date: 2025-10-11 Comment
元ポスト:
所見:
CoRL2025速報, robotpaper.challenge, 2025.10
Paper/Blog Link My Issue
#Article #Slide #Robotics #CoRL Issue Date: 2025-10-05 Comment
元ポスト:
Large reasoning models research at COLM 2025 - State of research in scaling reasoning, the current paradigm for improving LLMs, PRAKASH KAGITHA, 2025.09
Paper/Blog Link My Issue
#Article #LanguageModel #Blog #Reasoning #COLM Issue Date: 2025-09-15 Comment
COLM'25における30個程度のReasoningに関わる論文をカバーしたブログらしい。
元ポスト:
ここの論文のサマリのまとめといった感じなので、indexとして利用すると良さそう。
信頼できるLLM-as-a-Judgeの構築に向けた研究動向, tsurubee, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Blog #LLM-as-a-Judge #read-later Issue Date: 2025-09-04 Comment
ブログ中で解説されているサーベイ論文は下記:
- A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
August 2025 - China Open Source Highlights, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #OpenWeight #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-09-02 Comment
元ポスト:
The Hitchhiker's Guide to Autonomous Research: A Survey of Scientific Agents, Wang+, TechRxiv, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #ScientificDiscovery Issue Date: 2025-09-01 Comment
元ポスト:
Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications, Kawaharazuka+, 2025.08
Paper/Blog Link My Issue
#Article #Robotics #VisionLanguageActionModel #EmbodiedAI Issue Date: 2025-08-13 Comment
元ポスト:
【学会聴講報告】CVPR2025からみるVision最先端トレンド, Yuki Ono (Sony Corporation), 2025.07
Paper/Blog Link My Issue
#Article #Video #CVPR Issue Date: 2025-07-28 Comment
関連:
- CVPR 2025 速報, Kataoka+, 2025.06
元ポスト:
9 new policy optimization techniques, Kseniase, 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Blog Issue Date: 2025-07-27 Comment
元ポスト:
CVPR 2025 速報, Kataoka+, 2025.06
Paper/Blog Link My Issue
#Article #ComputerVision #Slide #CVPR Issue Date: 2025-06-26 Comment
元ポスト:
すごいまとめだ…
Large Vision Language Model (LVLM) に関する最新知見まとめ (Part 1), Daiki Shiono, 2024.11
Paper/Blog Link My Issue
#Article #ComputerVision #LanguageModel Issue Date: 2025-04-11
Recommendation Systems • LLM, vinjia.ai, 2025.03
Paper/Blog Link My Issue
#Article #RecommenderSystems #NLP #LanguageModel #Blog #Author Thread-Post Issue Date: 2025-03-31 Comment
8 Types of RoPE, Kseniase, 2025.03
Paper/Blog Link My Issue
#Article #Embeddings #NLP #LanguageModel #Transformer #Blog #PositionalEncoding #Initial Impression Notes Issue Date: 2025-03-23 Comment
元ポスト: https://huggingface.co/posts/Kseniase/498106595218801
RoPEについてサーベイが必要になったら見る
15 types of attention mechanisms, Kseniase, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Transformer #Attention #Blog #Initial Impression Notes Issue Date: 2025-03-18 Comment
Luongらのアテンションやsoft, globalアテンションなど、古くからあるattentionも含まれている。
2024-ai-timeline, reach-vb, 2025.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #OpenWeight #Proprietary #One-Line Notes Issue Date: 2025-01-02 Comment
月別で2024年にリリースされた主要なLLM(マルチモーダルなLLMも含む)のタイムラインがまとめられている。
API Only(プロプライエタリ)なのか、OpenWeightなのかもタグ付けされている。
LLM-as-a-Judge をサーベイする, Ayako, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog #LLM-as-a-Judge #KeyPoint Notes #Reading Reflections Issue Date: 2024-12-25 Comment
- A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
を読んだ結果を日本語でまとめてくださっている。
モデル選択について、外部APIに依存するとコストやプライバシー、再現性などの問題があるためOpenLLMをFinetuningすることで対応していることが論文中に記載されているようだが、評価能力にはまだ限界があるとのこと。
記事中ではLlama, Vicunaなどを利用している旨が記述されているが、どの程度のパラメータサイズのモデルをどんなデータでSFTし、どのようなタスクを評価したのだろうか(あとで元論文を見て確認したい)。
また、後処理としてルールマッチで抽出する必要あがるが、モデルのAlignmentが低いと成功率が下がるとのことである。
個人的には、スコアをテキストとして出力する形式の場合生成したテキストからトークンを抽出する方式ではなく、G-Eval のようにスコアと関連するトークン(e.g. 1,2,3,4,5)とその尤度の加重平均をとるような手法が後処理が楽で良いと感じる。
ICLR2025の査読にLLM-as-a-Judgeが導入されるというのは知らなかったので、非常に興味深い。
LLMが好む回答のバイアス(冗長性、位置など)別に各LLMのメタ評価をしている模様。また、性能を改善するための施策を実施した場合にどの程度メタ評価で性能が向上するかも評価している。特に説明を出力させても効果は薄く、また、複数LLMによる投票にしても位置バイアスの軽減に寄与する程度の改善しかなかったとのこと。また、複数ラウンドでの結果の要約をさせる方法がバイアスの低減に幅広く寄与したとのこと。
うーん、バイアスを低減するうまい方法がまだ無さそうなのがなかなか厳しい感じがする。
そもそも根本的に人間に人手評価をお願いする時もめちゃめちゃマニュアルとかガイドラインを作り込んだりした上でもagreementが高くなかったりするので、やはり難しそうである。
ただ、MTBenchでは人間の評価結果とLLMの評価結果の相関(agreementだっけか…?)が高かったことなどが報告されているし、LLMあるあるのタスクごとに得意不得意があります、という話な気もする。
日本語LLMまとめ, LLM-jp, 2024.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Evaluation #Repository #OpenWeight #Japanese #OpenSource #One-Line Notes Issue Date: 2024-12-02 Comment
LLM-jpによる日本語LLM(Encoder-Decoder系, BERT系, Bi-Encoders, Cross-Encodersを含む)のまとめ。
テキスト生成に使うモデル、入力テキスト処理に使うモデル、Embedding作成に特化したモデル、視覚言語モデル、音声言語モデル、日本語LLM評価ベンチマーク/データセットが、汎用とドメイン特化型に分けてまとめられている。
各モデルやアーキテクチャの原論文、学習手法の原論文もまとめられている。すごい量だ…。
LLM Self-Correction Papers, Ryo Kamoi, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Repository #SelfCorrection #One-Line Notes Issue Date: 2024-11-30 Comment
self-correctionの専門家によるself-correction関連の論文のリーディングリスト。ぜひチェックしたい。
元ポスト:
Large Vision Language Model (LVLM)に関する知見まとめ, Daiki Shiono, 2024.11
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #Slide Issue Date: 2024-11-18
ローカルLLMのリリース年表, npaka, 随時更新, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #OpenWeight #OpenSource #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-11-15 Comment
ローカルLLMを含むOpenLLMのリリース日が年表としてまとまっており、随時更新されている模様。すごい。
2026年3月現在も更新が続いている
生成AIを活用したシステム開発 の現状と展望 - 生成AI時代を見据えたシステム開発に向けて-, 株式会社日本総合研究所 先端技術ラボ, 2024.09
Paper/Blog Link My Issue
#Article #GenerativeAI #Blog #KeyPoint Notes #Reading Reflections Issue Date: 2024-10-01 Comment
ソフトウェア開発で利用され始めている生成AIのプロダクト群と、それらに関連するソースコード生成やテストコード生成、エージェントによる自動システム開発等の研究動向、今後の展望について具体的に記述されている。
SIerやITベンダー内では、実際に活用しているところも一部あるようだが、まだ検証や改革の途中の模様。要件定義に対するLLMの活用も模索されているようだが、産業側もアカデミックも研究段階。
web系では、サイバーやLINEヤフーが全社的にすでにGithub Copilotを導入しているとのこと。
Devin AIのように、Github上のオープンソースのIssueをもとにしたベンチマークで、2294件中13.86%のIssueを解決した、みたいな話を見ると、そのうちコードを書く仕事はIssueを立てる仕事に置き換わるんだろうなあ、という所感を得た(小並感
Claude Opus 4.6あたりが一つの節目で、明らかに2026年頭にかけてCoding Agentの質が上がって完全なる実用レベルに到達したという感がある。
list of recommender systems
Paper/Blog Link My Issue
#Article #RecommenderSystems #Dataset #Library #Repository #OpenSource #One-Line Notes Issue Date: 2024-08-07 Comment
推薦システムに関するSaaS, OpenSource, Datasetなどがまとめられているリポジトリ
Awesome LM with Tools
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #One-Line Notes Issue Date: 2024-03-22 Comment
Toolを利用するLMに関するNeubig氏のグループによるSurvey。
RAG-Research-Insights
Paper/Blog Link My Issue
#Article #Tutorial #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog #Reading Reflections Issue Date: 2024-03-05 Comment
RAGに関する研究が直近のものまでよくまとめられている
What are the most important LLMs to know about in March 2024?
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Post #One-Line Notes Issue Date: 2024-03-04 Comment
2024年3月時点で知っておくべきLLMに関するスレッド
awesome-generative-information-retrieval
Paper/Blog Link My Issue
#Article #Tutorial #InformationRetrieval #LanguageModel #Blog Issue Date: 2024-02-22
ML Papers Explained
Paper/Blog Link My Issue
#Article #ComputerVision #MachineLearning #NLP Issue Date: 2023-11-22 Comment
以下の分野の代表的な論文がまとめられている(基本的にはTransformer登場後のものが多い)
- 言語モデル(Transformer, Elmoなど)
- Visionモデル(ViTなど)
- CNN(AlexNetなど)
- Single Stage Object Detectors
- Region-based Convolutional Neural Networks
- DocumentAI(TableNetなど)
- Layout Transformers
- Tabular Deeplearning
Data-to-Text Datasetまとめ, Akihiko Watanabe, 2022
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #NLP #Dataset #DataToTextGeneration #Slide #One-Line Notes Issue Date: 2023-11-08 Comment
Data-to-Textのデータセットを自分用に調べていたのですが、せっかくなのでスライドにまとめてみました。特にMR-to-Text, Table-to-Textあたりは網羅的にサーベイし、データセットの概要を紹介しているので、全体像を把握するのに良いのかなぁと思います。ただし、2022年12月時点で作成したので2023年以後のデータセットは含まれていません😅
Zero-shot Learning網羅的サーベイ: CLIPが切り開いたVision & Languageの新しい世界, エクサウィザーズ Engineer Blog, 2023.05
Paper/Blog Link My Issue
#Article #ComputerVision #NaturalLanguageGeneration #NLP #LanguageModel #ImageCaptioning #DiffusionModel #Blog #Initial Impression Notes Issue Date: 2023-11-02 Comment
これはすごいまとめ…。まだ途中までしか読めていない。CLIPからスタートしてCLIPを引用している論文から重要なものを概要付きでまとめている。
[Paper Note] Instruction Tuning for Large Language Models: A Survey, Shengyu Zhang+, ACM Computing Surveys, Volume 58, Issue 7, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #InstructionTuning #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-09-05 GPT Summary- 指示調整(IT)に関する研究を総括し、LLMsの能力向上術を解説。ITは、(instruction, output)ペアを用いてLLMsを追加訓練し、人間の指示に従う能力を強化するプロセス。SFTの方法論、データセット構築、訓練、および応用を体系的にレビューし、成果に影響する要因を分析。さらに、SFTの課題や現行戦略の欠点を明らかにし、今後の研究の道筋を提案。 Comment
主要なモデルやデータセットの作り方など幅広くまとまっている(Figure1および各Table)
arxivに2023年8月に登場しその後も更新が続き、ACM Computing Surveys, Volume 58, Issue 7に2026年1月に掲載された模様
https://dl.acm.org/doi/10.1145/3777411
Anti-hype LLM Reading list, veekaybee, 2023.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #One-Line Notes Issue Date: 2023-08-27 Comment
LLMのサーベイ、BERT等の基盤モデルの論文、自前でLLMを学習するために必要な論文がコンパクトにまとめられたgist
人工知能研究の新潮流2 -基盤モデル・生成AIのインパクト-, 国立研究開発法人科学技術振興機構 研究開発戦略センター, 2023.07
Paper/Blog Link My Issue
#Article #LanguageModel #GenerativeAI #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-08-12 Comment
280ページにものぼる現在のトレンドをまとめた日本語資料
Awesome Multimodal LLMs
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #One-Line Notes Issue Date: 2023-07-03 Comment
マルチモーダルなLLMのリストがまとめられている
Extending Context is Hard…but not Impossible, kaiokendev, 2023.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ContextWindow #One-Line Notes #needs-revision Issue Date: 2023-07-01 Comment
Open source LLMのcontext lengthをどのように大きくするかに関する議論
open LLM Leaderboard
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #One-Line Notes #needs-revision Issue Date: 2023-05-12 Comment
現在はアーカイブされている
awesome-generative-information-retrieval
Paper/Blog Link My Issue
#Article #RecommenderSystems #GenerativeAI #One-Line Notes #needs-revision Issue Date: 2023-05-10 Comment
Generativeなモデルを利用したDocument RetrievalやRecSys等についてまとまっているリポジトリ
LLM ecosystem graphs
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #One-Line Notes Issue Date: 2023-05-04 Comment
様々なfonudation model、それらを利用したアプリケーション、依存関係がまとまったページ
Percy Liang氏のグループが運用してるっぽい?
Measuring the impact of online personalisation: Past, present and future
Paper/Blog Link My Issue
#Article #RecommenderSystems #InformationRetrieval #Personalization #KeyPoint Notes #needs-revision Issue Date: 2023-04-28 Comment
Personalizationに関するML, RecSys, HCI, Personalized IRといったさまざまな分野の評価方法に関するSurvey
ML + RecSys系では、オフライン評価が主流であり、よりaccuracyの高い推薦が高いUXを実現するという前提に基づいて評価されてきた。一方HCIの分野ではaccuracyに特化しすぎるとUXの観点で不十分であることが指摘されており、たとえば既知のアイテムを推薦してしまったり、似たようなアイテムばかりが選択されユーザにとって有用ではなくなる、といったことが指摘されている。このため、ML, RecSys系の評価ではdiversity, novelty, serendipity, popularity, freshness等の新たなmetricが評価されるように変化してきた。また、accuracyの工場がUXの向上に必ずしもつながらないことが多くの研究で示されている。
一方、HCIやInformation Systems, Personalized IRはuser centricな実験が主流であり、personalizationは
- 情報アクセスに対するコストの最小化
- UXの改善
- コンピュータデバイスをより効率的に利用できるようにする
という3点を実現するための手段として捉えられている。HCIの分野では、personalizationの認知的な側面についても研究されてきた。
たとえば、ユーザは自己言及的なメッセージやrelevantなコンテンツが提示される場合、両方の状況においてpersonalizationされたと認知し、後から思い出せるのはrelevantなコンテンツに関することだという研究成果が出ている。このことから、自己言及的なメッセージングでユーザをstimulusすることも大事だが、relevantなコンテンツをきちんと提示することが重要であることが示されている。また、personalizationされたとユーザが認知するのは、必ずしもpersonalizationのプロセスに依存するのではなく、結局のところユーザが期待したメッセージを受け取ったか否かに帰結することも示されている。
user-centricな評価とオフライン評価の間にも不一致が見つかっている。たとえば
- オフラインで高い精度を持つアルゴリズムはニッチな推薦を隠している
- i.e. popularityが高くrelevantな推薦した方がシステムの精度としては高く出るため
- オフライン vs. オンラインの比較で、ユーザがアルゴリズムの精度に対して異なる順位付けをする
といったことが知られている。
そのほかにも、企業ではofflineテスト -> betaテスターによるexploratoryなテスト -> A/Bテストといった流れになることが多く、Cognitive Scienceの分野の評価方法等にも触れている。
User Profiles for Personalized Information Access, Gauch+, The adaptive Web: methods and strategies of Web personalization, 2007
Paper/Blog Link My Issue
#Article #InformationRetrieval #Personalization #One-Line Notes Issue Date: 2023-04-28 Comment
IR分野におけるuser profileの構築方法についてまとめられたsurvey
- 加重キーワード
- セマンティックネットワーク
- 加重コンセプト
について記述されている。また、プロファイルの構築方法についても詳述されている。
Awesome Vector Search Engine
Paper/Blog Link My Issue
#Article #Embeddings #InformationRetrieval #Search #Library #Repository #One-Line Notes Issue Date: 2023-04-27 Comment
ベクトルの類似度を測るサービスやライブラリ等がまとまったリポジトリ
大規模言語モデル間の性能比較まとめ, mah_lab _ 西見 公宏, 2023.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #One-Line Notes Issue Date: 2023-04-27 Comment
参考になる
現状だと研究用であればllama, 商用利用ならtext-davinci-003あるいはFlanT5-xxlあたりになりそう
LLM Worksheet:
https://docs.google.com/spreadsheets/d/1kT4or6b0Fedd-W_jMwYpb63e1ZR3aePczz3zlbJW-Y4/edit#gid=0
30分で完全理解するTransformerの世界, はまなすなぎさ, Zenn, 2023.02
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Transformer Issue Date: 2023-02-14 Comment
非常に詳細で実質日本語のサーベイ論文のようなもの
A Paper List for Recommend-system PreTrained Models
Paper/Blog Link My Issue
#Article #RecommenderSystems #Pretraining #LanguageModel #pretrained-LM #Encoder #Decoder Issue Date: 2022-12-01
2010年代前半のAIの巨人達のCTR Prediction研究
Paper/Blog Link My Issue
#Article #RecommenderSystems #CTRPrediction #Reference Collection Issue Date: 2021-10-29
[Paper Note] Pre-Trained Models: Past, Present and Future, Xu Han+, AI Open‘21, 2021.06
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP Issue Date: 2021-06-17 GPT Summary- 大規模事前学習モデル(PTMs)、特にBERTやGPTは、AI分野での重要な進展を示しており、豊富な知識をタスクに応じてファインチューニングすることで下流タスクに貢献しています。本論文では、PTMsの歴史や転移学習との関係を考察し、計算能力の向上やデータの増加に基づく最新のブレークスルーをレビューします。また、PTMsに関する未解決の問題や今後の研究方向についても議論し、将来の研究の進展を促すことを目指しています。
Student Performance Prediction _ Knowledge Tracing Dataset
Paper/Blog Link My Issue
#Article #Dataset #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing Issue Date: 2021-05-29
MLP-like Architecture
Paper/Blog Link My Issue
#Article #NeuralNetwork #ComputerVision #NLP #KeyPoint Notes #Reference Collection Issue Date: 2021-05-19 Comment
gMLP:大規模なself-attentionが無いSpatial Gating Unitを搭載したシンプルなMLPでも、Transformerの性能に近づけたよ(特にCV)。つまり、self-attentionはessentialというわけではなさそうだよ。
NLPの場合はgMLPだとTransformerとperplexityでcomparable、一部downstreamタスクだと勝てなかったけど、single headのtiny attentionを追加したら、TransformerをperplexityとGLUEの一部タスクでoutperformしたよ。
つまり、Transformerみたいに大規模なself-attentionは必須ではなく、小規模のattentionで(cross sentenceの関係性を捉えるには)十分だよ。
スケーラビリティもTransformerを上回ったよ。
って感じ?
んーTransformerに勝ったみたいな言い方をSNSだと見かけるけど、評価してるタスクが少ないし、どちらかというとcomparableなdownstreamタスクが多いし、それは言い過ぎでは?
この論文が言いたいのは、大規模なself-attentionが性能を出す上でessentialなわけではないよ、ってことであり、
・CVの場合はself-attentionは必須ではない
・NLPでは、tiny attentionでも十分
という感じなのでは。
まあでもTransformerとcomparableなら、Transformer一強では無くなったよね
Spatial Gating Unit(SGU)は、トークン間の関係性を捉えるためのゲートで、SGUが無いとgMLPブロックはただの二層のFFNとなる。
SGUは、入力をspatial dimensionに対して線形変換した値と、元の入力のelement-wiseな積で表現する。この線形変換をする際は、Wの値を0の近傍で初期化し、バイアス項を1に初期化することがクリティカルだった。これは、学習の初めでは線形変換はidentical mappingに近いものとなるため、gMLPブロックはFFNに近いものとなる。これが学習が進むにつれWの重みが調整され、cross tokenの関係性を捉えたブロックへと徐々に変化していくことになる。
また、SGUへの入力はGLUのようにchannel dimensionに二分割し、片方をelement-wise積に、もう一方をspatialな線形変換に利用する(4種類試した中で一番性能が良かった)。
[Paper Note] Sequence-Aware Recommender Systems, Massimo Quadrana+, ACM Computing Surveys (CSUR), Volume 51, Issue 4, 2018.02
Paper/Blog Link My Issue
#Article #RecommenderSystems #SequentialRecommendation #Reading Reflections Issue Date: 2020-11-13 GPT Summary- レコメンドシステムは、機械学習を用いた成功したデータマイニングの応用であり、従来は単一のユーザー-アイテムインタラクションに基づいていましたが、実際のアプリケーションでは時間とともに多様なインタラクションが記録されます。本研究は、これらの逐次的なインタラクションを考慮した推薦プロセスに関する既存研究を概観し、関連するタスクと目標の分類を提案。さらに、シーケンス情報を利用したレコメンダーシステムのベンチマーク方法論と未解決の課題について議論します。 Comment
評価方法の議論が非常に参考になる。特に、Survey執筆時点において、コミュニティの中でデータ分割方法について標準化されたものがないといった話は参考になる。
10 ML & NLP Research Highlights of 2019, Sebastian Ruder, 2020.01
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #Blog Issue Date: 2020-01-13
事前学習言語モデルの動向 _ Survey of Pretrained Language Models, Kyosuke Nishida, 2019
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #LanguageModel #Slide #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2019-11-09 Comment
[2019/06まで]
・ELMo(双方向2層LSTM言語モデル)
・GPT(left-to-rightの12層Transformer自己回帰言語モデル)
・BERT(24層のTransformer双方向言語モデル)
・MT-DNN(BERTの上にマルチタスク層を追加した研究)
・XLM(パラレル翻訳コーパスを用いてクロスリンガルに穴埋めを学習)
・TransformerXL(系列長いに制限のあった既存モデルにセグメントレベルの再帰を導入し長い系列を扱えるように)
・GPT-2(48層Transformerの自己回帰言語モデル)
・ERNIE 1.0(Baidu, エンティティとフレーズの外部知識を使ってマスクに利用)
・ERNIE(Tsinghua, 知識グラフの情報をfusionしたLM)
・Glover(ドメイン、日付、著者などを条件とした生成を可能としたGPT)
・MASS(Encoder-Decoder型の生成モデルのための事前学習)
・UniLM(Sequence-to-Sequenceを可能にした言語モデル)
・XLNet(自己回帰(単方向)モデルと双方向モデルの両方の利点を得ることを目指す)
[2019/07~]
・SpanBERT(i.i.dではなく範囲でマスクし、同時に範囲の境界も予測する)
・ERNIE 2.0(Baidu, マルチタスク事前学習; 単語レベル・構造レベル・意味レベル)
・RoBERTa(BERTと同じ構造で工夫を加えることで性能向上)
- より大きなバッチサイズを使う(256から8192)
- より多くのデータを使う(16GBから160GB)
- より長いステップ数の学習をする(BERT換算で16倍)
- 次文予測(NSP)は不要
→ GLUEでBERT, XLNetをoutperform
・StructBERT (ALICE, NSPに代わる学習の目的関数を工夫)
- マスクした上で単語の順番をシャッフルし元に戻す
- ランダム・正順・逆順の3種類を分類
→ BERTと同サイズ、同データでBERT, RoBERTa超え
・DistilBERT(蒸留により、12層BERTを6層に小型化(40%減))
- BERTの出力を教師として、生徒が同じ出力を出すように学習
- 幅(隠れ層)サイズを減らすと、層数を経あrスよりも悪化
→ 推論は60%高速化、精度は95%程度を保持
・Q8BERT(精度を落とさずにfine-tuning時にBERTを8bit整数に量子化)
- Embedding, FCは8bit化、softmax, LNorm, GELUは32bitをキープ
→ モデルサイズ1/4, 速度3.7倍
・CTRL(条件付き言語モデル)
- 条件となる制御テキストを本文の前に与えて学習
- 48層/1280次元Transformer(パラメータ数1.6B)
・MegatronLM(72層、隠れ状態サイズ3072、長さ1024; BERTの24倍サイズ)
・ALBERT(BERTの層のパラメータをすべて共有することで学習を高速化; 2020年あたりのデファクト)
- Largeを超えたモデルは学習が難しいため、表現は落ちるが学習しやすくした
- 単語埋め込みを低次元にすることでパラメータ数削減
- 次文予測を、文の順序入れ替え判定に変更
→ GLUE, RACE, SQuADでSoTAを更新
・T5(NLPタスクをすべてtext-to-textとして扱い、Enc-Dec Transformerを745GBコーパスで事前学習して転移する)
- モデルはEncoder-DecoderのTransformer
- 学習タスクをエンコーダ・デコーダに合わせて変更
- エンコーダ側で範囲を欠落させて、デコーダ側で予測
→ GLUE, SuperGLUE, SQuAD1.1, CNN/DMでSoTA更新
・BART(Seq2Seqの事前学習として、トークンマスク・削除、範囲マスク、文の入れ替え、文書の回転の複数タスクで学習)
→ CNN/DMでT5超え、WMT'16 RO-ENで逆翻訳を超えてSoTA
ELMo, GPT, BERT, GPT-2, XLNet, RoBERTa, DistilBERT, ALBERT, T5あたりは良く見るような感
各データセットでの各モデルの性能も後半に記載されており興味深い。
ちなみに、CNN/DailyMail Datasetでは、T5, BARTあたりがSoTA。
R2で比較すると
- Pointer-Generator + Coverage Vectorが17,28
- LEAD-3が17.62
- BARTが21.28
- T5が21.55
となっている
NLP-Progress
Paper/Blog Link My Issue
#Article #Tutorial #Dataset #One-Line Notes Issue Date: 2019-02-12 Comment
NLPの様々なタスクのデータセット, およびSOTA(2018年時点)がまとめられている。
Educational Data Mining and Learning Analytics, Baker+, 2014
Paper/Blog Link My Issue
#Article #AdaptiveLearning #EducationalDataMining #LearningAnalytics #Selected Papers/Blogs Issue Date: 2018-12-22 Comment
Ryan BakerらによるEDM Survey
[Paper Note] Recommender Systems for Technology Enhanced Learning: Research Trends and Applications, Manouselis+, 2014.04
Paper/Blog Link My Issue
#Article #RecommenderSystems #TechnologyEnhancedLearning #AdaptiveLearning #One-Line Notes Issue Date: 2018-12-22 Comment
最近のトレンドやアプリケーションを知りたい場合はこちら
[Paper Note] Panorama of recommender systems to support learning, Drachsler+, 2015.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #Education #AdaptiveLearning #One-Line Notes Issue Date: 2018-12-22 Comment
教育分野に対するRecsysのSurvey
[Paper Note] Recommender Systems in Technology Enhanced Learning, Manouselis+, Recommender Systems Handbook, 2011.10
Paper/Blog Link My Issue
#Article #RecommenderSystems #Education #TechnologyEnhancedLearning #AdaptiveLearning Issue Date: 2018-12-22
[Paper Note] Personal recommender systems for learners in lifelong learning networks: the requirements, techniques and model, Drachsler+, Int. J. Learning Technology 3(4), 2008.07
Paper/Blog Link My Issue
#Article #RecommenderSystems #Education #AdaptiveLearning Issue Date: 2018-12-22
[Paper Note] Recommender Systems in Technology Enhanced Learning, Manouselis+, Recommender Systems Handbook: A Complete Guide for Research Scientists and Practitioners, 2011.10
Paper/Blog Link My Issue
#Article #RecommenderSystems #Education #TechnologyEnhancedLearning Issue Date: 2018-03-30
[Paper Note] Context-Aware Recommender Systems for Learning: A Survey and Future Challenges, Verbert+, IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, VOL. 5, NO. 4, OCTOBER-DECEMBER 2012.04
Paper/Blog Link My Issue
#Article #RecommenderSystems #Education #TechnologyEnhancedLearning Issue Date: 2018-03-30
[Paper Note] Opinion mining and sentiment analysis, Pang+, Foundations and Trends in Information Retrieval, 2008.01
Paper/Blog Link My Issue
#Article #InformationRetrieval #SentimentAnalysis #NLP #OpinionMining Issue Date: 2018-01-15
[Paper Note] Evaluating implicit measures to improve web search, Fox+, ACM Transactions on Imformation Systems, 2005.04
Paper/Blog Link My Issue
#Article #InformationRetrieval #RelevanceFeedback #ImplicitFeedback Issue Date: 2018-01-01
[Paper Note] A survey on the use of relevance feedback for information access systems., Ruthven+, The Knowledge Engineering Review, 2003.06
Paper/Blog Link My Issue
#Article #InformationRetrieval #RelevanceFeedback #ExplicitFeedback Issue Date: 2018-01-01
Fast and Reliable Online Learning to Rank for Information Retrieeval, Katja Hofmann, Doctoral Thesis, 2013.04
Paper/Blog Link My Issue
#Article #Tutorial #InformationRetrieval #LearningToRank #Online/Interactive Issue Date: 2018-01-01
[Paper Note] Learning to Rank for Information Retriefval, Tie-Yan Liu, 2009.03
Paper/Blog Link My Issue
#Article #InformationRetrieval #LearningToRank Issue Date: 2018-01-01
[Paper Note] 利用者の好みをとらえ活かす-嗜好抽出技術の最前線, 土方嘉徳, 2007.09
Paper/Blog Link My Issue
#Article #RecommenderSystems Issue Date: 2018-01-01
推薦システムのアルゴリズム, 神嶌, 2016.09
Paper/Blog Link My Issue
#Article #RecommenderSystems #Selected Papers/Blogs Issue Date: 2018-01-01
[Paper Note] A Survey on Challenges and Methods in News Recommendation, O¨zgo¨bek+, 2014.01
Paper/Blog Link My Issue
#Article #RecommenderSystems Issue Date: 2018-01-01
[Paper Note] A Survey and Critique of Deep Learning on Recommender Systems, Lei Zheng
Paper/Blog Link My Issue
#Article #RecommenderSystems Issue Date: 2018-01-01
A survey on Automatic Text Summarization, Das+, 2007.11
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP Issue Date: 2017-12-31
[Paper Note] Artificial neural networks in business: Two decades of research, Tkac+, Applied Soft Computing 2016.01
Paper/Blog Link My Issue
#Article #NeuralNetwork #TimeSeriesDataProcessing #One-Line Notes Issue Date: 2017-12-31 Comment
ビジネスドメイン(e.g. Stock market price prediction)におけるニューラルネットワークの活用事例をまとめたSurvey。
時系列データの取り扱いなどの参考になるかも。
[Paper Note] Personalised Information retrieval: survey and classification, Rami+, User Modeling and User-Adapted Interaction, 2012.05
Paper/Blog Link My Issue
#Article #InformationRetrieval #Personalization #KeyPoint Notes Issue Date: 2017-12-28 Comment
(以下は管理人が当時作成したスライドでのメモのスクショ)







完全に途中で力尽きている感