
DataToTextGeneration
[Paper Note] Prompting for Numerical Sequences: A Case Study on Market Comment Generation, Masayuki Kawarada+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Prompting #NumericReasoning #KeyPoint Notes Issue Date: 2024-04-04 GPT Summary- 大規模言語モデル(LLMs)を用いて時系列の数値データからテキスト生成を行う研究が進展中。特に、株価の数値列を市場コメントに変換する実験では、プログラミング言語に似たフォーマットのプロンプトが効果的であり、自然言語や長文フォーマットは効果が薄いことが明らかに。これにより、数値シーケンスからのテキスト生成におけるプロンプト作成の新たな洞察を得られる。 Comment
Data-to-Text系のタスクでは、しばしば数値列がInputとなり、そこからテキストを生成するが、この際にどのようなフォーマットで数値列をPromptingするのが良いかを調査した研究。Pythonリストなどのプログラミング言語に似たプロンプトが高い性能を示し、自然言語やhtml, latextなどのプロンプトは効果が低かったとのこと
Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey, Xi Fang+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #TabularData #One-Line Notes Issue Date: 2024-03-05 GPT Summary- 最近の大規模言語モデリングの進展により、様々なタスクにおける応用が容易になっているが、包括的なレビューが不足している。この研究は、最近の進歩をまとめ、データセット、メトリクス、方法論を調査し、将来の研究方向に洞察を提供することを目的としている。また、関連するコードとデータセットの参照も提供される。 Comment
Tabular DataにおけるLLM関連のタスクや技術等のサーベイ
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding, Zilong Wang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #TabularData #ICLR #KeyPoint Notes Issue Date: 2024-01-24 GPT Summary- LLMsを使用したChain-of-Tableフレームワークは、テーブルデータを推論チェーン内で活用し、テーブルベースの推論タスクにおいて高い性能を発揮することが示された。このフレームワークは、テーブルの連続的な進化を表現し、中間結果の構造化情報を利用してより正確な予測を可能にする。さまざまなベンチマークで最先端のパフォーマンスを達成している。 Comment
Table, Question, Operation Historyから次のoperationとそのargsを生成し、テーブルを順次更新し、これをモデルが更新の必要が無いと判断するまで繰り返す。最終的に更新されたTableを用いてQuestionに回答する手法。Questionに回答するために、複雑なテーブルに対する操作が必要なタスクに対して有効だと思われる。
Few-Shot Data-to-Text Generation via Unified Representation and Multi-Source Learning, ACL'23
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #MultitaskLearning #Zero/FewShotLearning #ACL Issue Date: 2023-07-18 GPT Summary- この論文では、構造化データからテキストを生成する新しいアプローチを提案しています。提案手法は、さまざまな形式のデータを処理できる統一された表現を提供し、マルチタスクトレーニングやゼロショット学習などのシナリオでのパフォーマンスを向上させることを目指しています。実験結果は、提案手法が他の方法と比較して優れた性能を示していることを示しています。これは、データからテキスト生成フレームワークにおける重要な進歩です。
MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation, Swarnadeep Saha+, N_A, arXiv'22
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #StructuredData Issue Date: 2023-10-28 GPT Summary- 本研究では、半構造化データからのテキスト生成における多段階の推論を行うためのMURMURという手法を提案しています。MURMURは、特定の言語的および論理的なスキルを持つニューラルモジュールと記号モジュールを組み合わせ、ベストファーストサーチ手法を使用して推論パスを生成します。実験結果では、MURMURは他のベースライン手法に比べて大幅な改善を示し、また、ドメイン外のデータでも同等の性能を達成しました。さらに、人間の評価では、MURMURは論理的に整合性のある要約をより多く生成することが示されました。
[Paper Note] Explaining Patterns in Data with Language Models via Interpretable Autoprompting, Chandan Singh+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Dataset #LanguageModel #Explanation #One-Line Notes #Data Issue Date: 2023-08-03 GPT Summary- iPromptを用いて、事前学習済みのLLMがデータを説明する自然言語文字列を生成する手法を提案。このアルゴリズムは、生成された説明の性能を再評価して最適化するプロセスを含む。実験によりiPromptが正確なデータ記述を見つけ、人間にも解釈可能なプロンプトを生成し、一般化性能に優れることが示された。特に、実世界の感情分類データセットでGPT-3並みのプロンプトを生成し、科学的発見の支援にも寄与する可能性がある。すべてのコードはGitHubで公開。 Comment
OpenReview: https://openreview.net/forum?id=GvMuB-YsiK6
データセット(中に存在するパターンの説明)をLLMによって生成させる研究


[Paper Note] DART: Open-Domain Structured Data Record to Text Generation, Linyong Nan+, NAACL'21
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Dataset #NAACL Issue Date: 2025-08-30 GPT Summary- DARTは82,000以上のインスタンスを持つオープンドメインの構造化データからテキスト生成のためのデータセットであり、表形式のデータから意味的トリプルを抽出する手法を提案。ツリーオントロジーアノテーションや質問-回答ペアの変換を活用し、最小限のポストエディティングで異種ソースを統合。DARTは新たな課題を提起し、WebNLG 2017での最先端結果を示すことで、ドメイン外の一般化を促進することを証明。データとコードは公開されている。
[Paper Note] Generating Racing Game Commentary from Vision, Language, and Structured Data, Tatsuya+, INLG'21
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NaturalLanguageGeneration #NLP #INLG #Game #3D (Video) Issue Date: 2022-09-15 GPT Summary- モーターレーシングゲームにおける自動解説生成タスクを提案し、視覚データ、数値データ、テキストデータを用いて解説を生成する。タスクは発話タイミングの特定と発話生成の2つのサブタスクに分かれ、129,226の発話を含む新しい大規模データセットを紹介。解説の特性は時間や視点によって変化し、最先端の視覚エンコーダでも正確な解説生成が難しいことが示された。データセットとベースライン実装は今後の研究のために公開される。 Comment
データセット: https://kirt.airc.aist.go.jp/corpus/ja/RacingCommentary
[Paper Note] Biomedical Data-to-Text Generation via Fine-Tuning Transformers, Ruslan Yermakov+, ACL-INLG'21, 2021.09
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Dataset #ACL #INLG #One-Line Notes Issue Date: 2022-08-18 GPT Summary- バイオメディカル分野におけるD2T生成の研究を行い、医薬品のパッケージリーフレットを用いた実世界のデータセットに対してファインチューニングされたトランスフォーマーを適用。現実的な複数文のテキスト生成が可能であることを示す一方で、重要な制限も存在。新たにバイオメディカル分野のD2T生成モデルのベンチマーク用データセット(BioLeaflets)を公開。 Comment
biomedical domainの新たなdata2textデータセットを提供。事前学習済みのBART, T5等をfinetuningすることで高精度にテキストが生成できることを示した。
[Paper Note] 過去情報の内容選択を取り入れた スポーツダイジェストの自動生成, 加藤+, NLP'21
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP Issue Date: 2021-10-08
Few-Shot NLG with Pre-Trained Language Model, Chen+, University of California, ACL'20
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #LanguageModel #pretrained-LM #Zero/FewShotLearning #Surface-level Notes Issue Date: 2022-12-01 Comment
# 概要
Neural basedなend-to-endなNLGアプローチはdata-hungryなので、Few Shotな設定で高い性能ができる手法を提案(Few shot NLG)
Table-to-Textタスク(WikiBIOデータ, 追加で収集したBook, SongドメインのWikipediaデータ)において、200程度の学習サンプル数でstrong baselineに対して8.0 point程度のBLEUスコアの向上を達成
# 手法
TabularデータのDescriptionを作成するには大きく分けて2つのスキルが必要
1. factualな情報を持つcontentをselectし、copyするスキル
2. factualな情報のコピーを含めながら、文法的に正しいテキストを生成するスキル
提案手法では、1を少量のサンプル(< 500)から学習し、2については事前学習済みの言語モデルを活用する。
encoderからコピーする確率をpcopyとし、下記式で算出する:
すなわち、encoderのcontext vectorと、decoderのinputとstateから求められる。
encoderとencoder側へのattentionはscratchから学習しなければならず、うまくコピーできるようにしっかりと”teach”しなければならないため、lossに以下を追加する:
すなわち、コピーすべき単語がちゃんとコピーできてる場合にlossが小さくなる項を追加している。
また、decoder側では、最初にTable情報のEmbeddingを入力するようにしている。
また、学習できるデータ量が限られているため、pre-trainingモデルのEmbeddingは事前学習時点のものに固定した(ただしく読解できているか不安)
# 実験
WikiBIOと、独自に収集したBook, Songに関するWikipediaデータのTable-to-Textデータを用いて実験。
このとき、Training instanceを50~500まで変化させた。
WikiBIOデータセットに対してSoTAを記録しているBase-originalを大きくoutperform(Few shot settingでは全然うまくいかない)。
inputとoutput例と、コピーに関するlossを入れた場合の効果。
人手評価の結果、Factual informationの正しさ(#Supp)、誤り(#Cont)ともに提案手法が良い。また、文法的な正しさ(Lan. Score)もコピーがない場合とcomparable
Template Guided Text Generation for Task-Oriented Dialogue, Kale+, Google, EMNLP'20
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #pretrained-LM #KeyPoint Notes Issue Date: 2022-12-01 Comment
# 概要
Dialogue Actをそのままlinearlizeして言語モデルに入力するのではなく、テンプレートをベースにしたシンプルなsentenceにして言語モデルに与えると、zero-shot, few-shotなsettingで性能が向上するという話(T5ベース)。
# 手法
slotの名称をnatural languageのdescriptionに変更するSchema Guidedアプローチも提案(NLUでは既に実践さrていたらしいが、Generationで利用されたことはない)。
# 結果
MultiWoz, E2E, SGDデータセットを利用。MultiWoz, E2Eデータはデータ量が豊富でドメインやfeatureが限定的なため、schema guided, template guided approachとNaiveなrepresentationを利用した場合の結果がcopmarableであった。
が、SGDデータセットはドメインが豊富でzero-shot, few-shotの設定で実験ができる。SGDの場合はTemplate guided representationが最も高い性能を得た。
low resourceなデータセットで活用できそう
[Paper Note] Text-to-Text Pre-Training for Data-to-Text Tasks, Mihir+, Google Research, INLG'20
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Transformer #INLG #KeyPoint Notes Issue Date: 2022-09-16 Comment
# 概要
pre-training済みのT5に対して、Data2Textのデータセットでfinetuningを実施する方法を提案。WebNLG(graph-to-text), ToTTo(table-to-text), Multiwoz(task oriented dialogue)データにおいて、simpleなTransformerでも洗練されたmulti-stageなpipelined approachをoutperformできることを示した研究。
# 手法
事前学習済みのT5に対してfine-tuningを実施した。手法はシンプルで、data-to-textタスクをtext-to-textタスクに変換した。具体的には、構造かされたデータをflatな文字列(linearization)で表現することで、text-to-textタスクに変換。各データセットに対するlinearizationのイメージは下図。デリミタや特殊文字を使って構造かされたデータをflatなstringで表現している。
# データセット
## ToTTo(2020)
Wikipediaのテーブルと自然言語でdescriptionのペアデータ
## MultiWoz(2018)
10Kの人間同士のtask-orientedなdialogueデータ。
## WebNLG(2017)
subject-object-predicateの3組みをテキスト表現に変換するタスクのデータ
# Result
## WebNLG
GCNを利用した2020年に提案されたDualEncがSoTAだったらしいが、outperormしている。
## ToTTo
[こちら](
https://github.com/google-research-datasets/totto)のリーダーボードと比較してSoTAを記録
## MultiWoz
T5は事前学習済みGPT-2をfinetuningした手法もoutperformした。SC-GPT2は当時のMultiWozでのSoTA
# Impact of Model capacity
T5モデルのサイズがどれが良いかについては、データセットのサイズと複雑さに依存することを考察している。たとえば、MultiWozデータは構造化データのバリエーションが最も少なく、データ量も56kと比較的多かった。このため、T5-smallでもより大きいモデルの性能に肉薄できている。
一方、WebNLGデータセットは、18kしか事例がなく、特徴量も約200種類程度のrelationのみである。このような場合、モデルサイズが大きくなるにつれパフォーマンスも向上した(特にUnseen test set)。特にBLEUスコアはT5-smallがT5-baseになると、10ポイントもジャンプしており、modelのcapacityがout-of-domainに対する一般化に対してcriticalであることがわかる。ToTToデータセットでも、SmallからBaseにするとパフォーマンスは改善した。
# 所感
こんな簡単なfine-tuningでSoTAを達成できてしまうとは、末恐ろしい。ベースラインとして有用。
NUBIA, EvalNLGEval'20
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #ConceptToTextGeneration #DialogueGeneration #Encoder #KeyPoint Notes Issue Date: 2021-06-02 Comment
TextGenerationに関するSoTAの性能指標。BLEU, ROUGE等と比較して、人間との相関が高い。

pretrainedされたlanguage model(GPT-2=sentence legibility, RoBERTa_MNLI=logical inference, RoBERTa_STS=semantic similarity)を使い、Fully Connected Layerを利用してquality スコアを算出する。算出したスコアは最終的にcalibrationで0~1の値域に収まるように補正される。
意味的に同等の内容を述べた文間でのexample
BLEU, ROUGE, BERTのスコアは低いが、NUBIAでは非常に高いスコアを出せている。
[Paper Note] Table-to-Text Generation with Effective Hierarchical Encoder on Three Dimensions (Row, Column and Time), Gong+, Harbin Institute of Technology, EMNLP'19
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #EMNLP #Surface-level Notes Issue Date: 2021-10-08 Comment
## 概要
既存研究では、tableをレコードの集合, あるいはlong sequenceとしてencodeしてきたが
1. other (column) dimensionの情報が失われてしまう (?)
2. table cellは時間によって変化するtime-series data
という特徴がある。
たとえば、ある選手の成績について言及する際に、その試合について着目するだけでなくて「直近3試合で二回目のダブルダブルです」というように直近の試合も考慮して言及することがあり、table cellの time dimensionについても着目しなければならず、これらはこれまでのモデルで実現できない。
そこで、この研究ではtime dimensionについても考慮し生成する手法を提案。
## モデル概要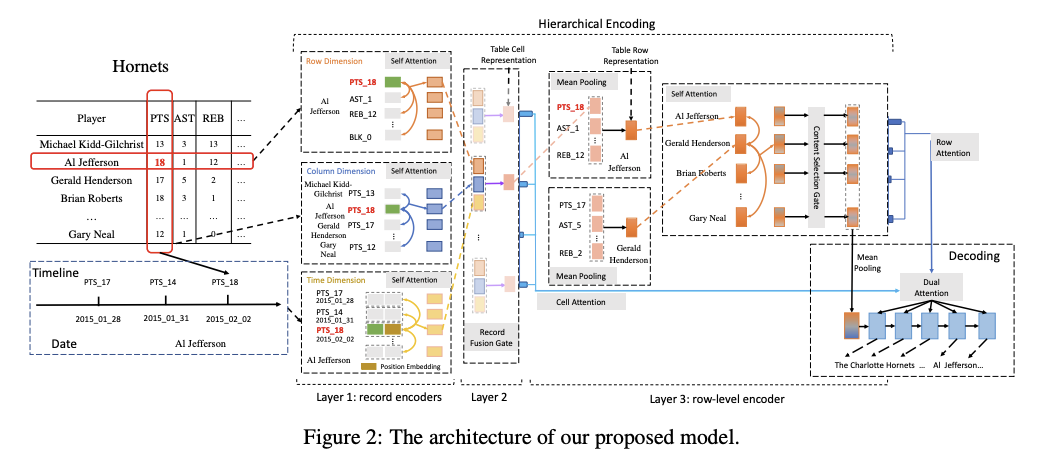
全体としては、Row Dimension Encoder, Column Dimension Encoder, Time Dimension Encoderによって構成されており、self-attentionを利用して、テーブルの各セルごとに Row-Dimension, Column-Dimension, Time-DimensionのRepresentationを獲得する。イメージとしては、
- Row Dimension Encoderによって、自身のセルと同じ行に含まれるセルとの関連度を考慮した表現
- Column Dimension Encoderによって、自身のセルと同じ列に含まれるセルとの関連度を考慮した表現
- Time Dimension Encoderによって、過去の時系列のセルとの関連度を考慮した表現
をそれぞれ獲得するイメージ。各Dimension Encoderでやっていることは、Puduppully (Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
) らのContent Selection Gate節におけるattention vector r_{att}の取得方法と同様のもの(だと思われる)。
獲得したそれぞれのdimensionの表現を用いて、まずそれらをconcatし1 layer MLPで写像することで得られるgeneral representationを取得する。その後、general representationと各dimensionの表現を同様に1 layer MLPでスコアリングすることで、各dimensionの表現の重みを求め、その重みで各representationを線形結合することで、セルの表現を獲得する。generalなrepresentationと各dimensionの表現の関連性によって重みを求めることで、より着目すべきdimensionを考慮した上で、セルの表現を獲得できるイメージなのだろうか。
その後、各セルの表現を行方向に対してMeanPoolingを施しrow-levelの表現を取得。獲得したrow-levelの表現に対し、Puduppully (Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
) らのContent Selection Gate g を適用する(これをどうやっているかがわからない)。
最終的に求めたrow-levelの表現とcell-levelの表現に対して、デコーダのhidden stateを利用してDual Attentionを行い、row-levelの表現からどの行に着目すべきか決めた後、その行の中からどのセルに着目するか決める、といったイメージで各セルの重みを求める。
論文中にはここまでしか書かれていないが、求めた各セルの重みでセルのrepresentationを重み付けして足し合わせ、最終的にそこから単語をpredictionするのだろうか・・・?よくわからない。
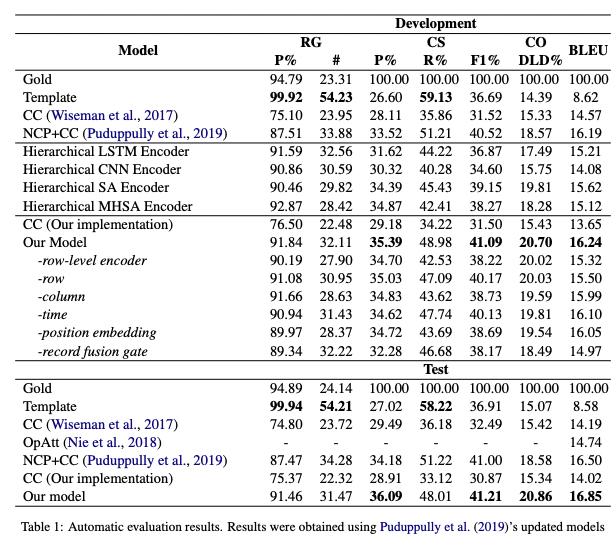
RG, CS, CO, BLEUスコア、全てにおいてBaselineを上回っている(RGのTemplateを除く)。
実装: https://github.com/ernestgong/data2text-three-dimensions/
Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #AAAI #One-Line Notes Issue Date: 2021-06-26 Comment
Rotowire Datasetに対するData2Text研究において代表的な論文の一つ。Wisemanモデル [Paper Note] Challenges in Data-to-Document Generation, Sam Wiseman+, EMNLP'17, 2017.07 と共にベースラインとして利用されることが多い。
Learning to Generate Move-by-Move Commentary for Chess Games from Large-Scale Social Forum Data, Jhamtani+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Dataset #TabularData #ACL #Encoder-Decoder Issue Date: 2025-08-06 Comment
データセットの日本語解説(過去の自分の資料): https://speakerdeck.com/akihikowatanabe/data-to-text-datasetmatome-summary-of-data-to-text-datasets?slide=66
Point precisely: Towards ensuring the precision of data in generated texts using delayed copy mechanism., Li+, Peking University, COLING'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #COLING #Surface-level Notes Issue Date: 2021-10-25 Comment
# 概要
DataToTextタスクにおいて、生成テキストのデータの精度を高める手法を提案。two stageアルゴリズムを提案。①encoder-decoerモデルでslotを含むテンプレートテキストを生成。②Copy Mechanismでslotのデータを埋める、といった手法。
①と②はそれぞれ独立に学習される。
two stageにするモチベーションは、
・これまでのモデルでは、単語の生成確率とコピー確率を混合した分布を考えていたが、どのように両者の確率をmergeするのが良いかはクリアではない。
→ 生成とコピーを分離して不確実性を減らした
・コピーを独立して考えることで、より効果的なpair-wise ranking loss functionを利用することができる
・テンプレート生成モデルは、テンプレートの生成に集中でき、slot fillingモデルはスロットを埋めるタスクに集中できる。これらはtrainingとtuningをより簡便にする。
# モデル概要
モデルの全体像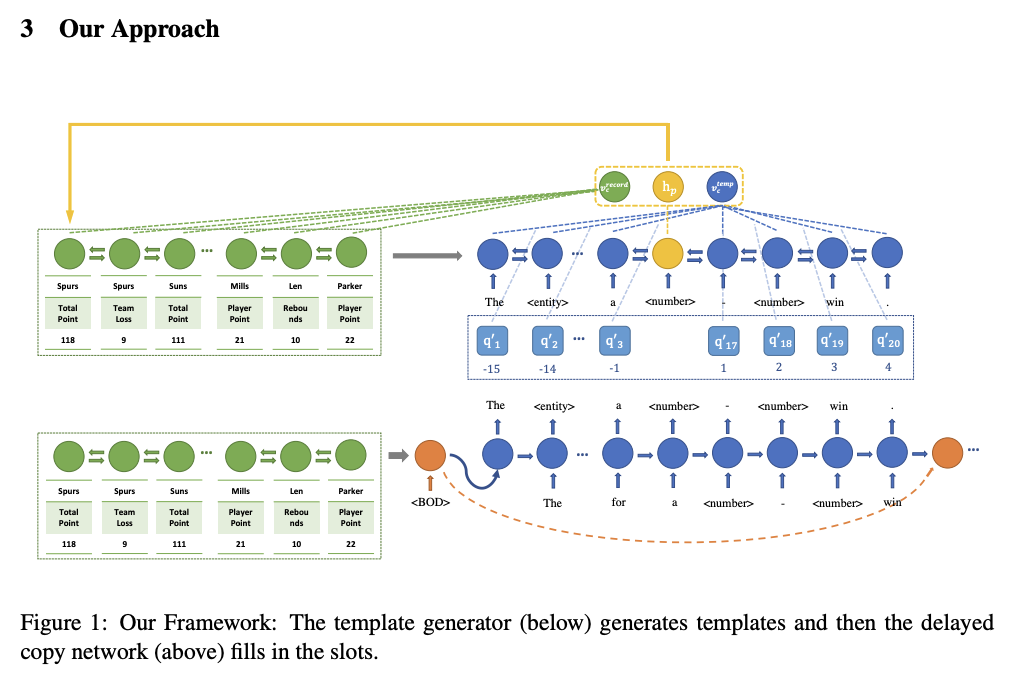
オリジナルテキストとテンプレートの例。テンプレートテキストの生成を学習するencoder-decoder(①)はTarget Templateを生成できるように学習する。テンプレートではエンティティが"
# 実験結果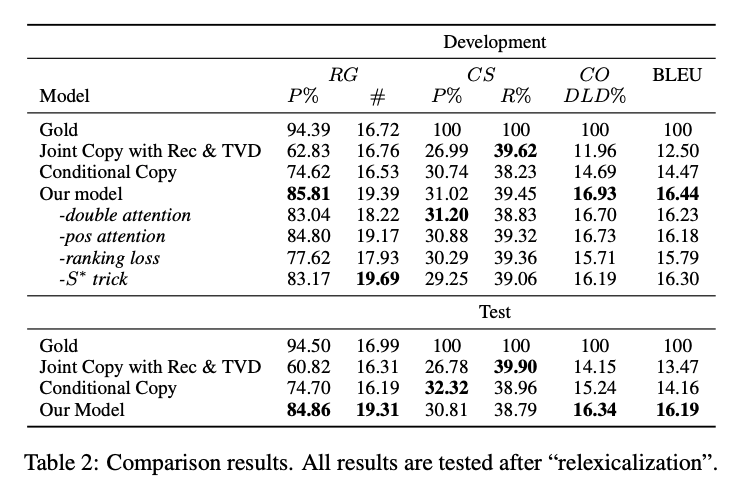
Relation Generation (RG)がCCと比べて10%程度増加しているので、data fidelityが改善されている。
また、BLEUスコアも約2ポイント改善。これはentityやnumberが適切に埋められるようになっただけでなく、テンプレートがより適切に生成されているためであると考えられる。
## 参考:
• Relation Generation (RG):出力文から(entity, value)の関係を抽出し,抽出された関係の数と,それらの関係が入力データに対して正しいかどうかを評価する (Precision).ただし entity はチーム名や選手名などの動作の主体,value は得点数やアシスト数などの記録である.
• Content Selection (CS):出力文とリファレンスから (entity, value) の関係を抽出し,出力文から抽出された関係のリファレンスから抽出された関係に対する Precision,Recall で評価する.
• Content Ordering (CO):出力文とリファレンスから (entity, value) の関係を抽出し,それらの間の正規化 DamerauLevenshtein 距離 [7] で評価する.
(from [Paper Note] 過去情報の内容選択を取り入れた スポーツダイジェストの自動生成, 加藤+, NLP'21
)
[Paper Note] Operation-guided Neural Networks for High Fidelity Data-To-Text Generation, Nie+, Sun Yat-Sen University, EMNLP'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #EMNLP #Surface-level Notes Issue Date: 2021-09-16 Comment
# 概要
既存のニューラルモデルでは、生データ、あるいはそこから推論された事実に基づいて言語を生成するといったことができていない(e.g. 金融, 医療, スポーツ等のドメインでは重要)。
たとえば下表に示した通り、"edge"という単語は、スコアが接戦(95-94=1 -> スコアの差が小さい)であったことを表現しているが、こういったことを既存のモデルでは考慮して生成ができない。
これを解決するために、演算(operation)とニューラル言語モデルを切り離す(事前に計算しておく)といったことが考えられるが、
① 全てのフィールドに対してoperationを実行すると、探索空間が膨大になり、どの結果に対して言及する価値があるかを同定するのが困難(言及する価値がある結果がほとんど存在しない探索空間ができてしまう)
② 演算結果の数値のスパンと、言語選択の対応関係を確立させるのが困難(e.g. スコアの差が1のとき"edge"と表現する、など)
といった課題がある。
①に対処するために、事前にraw dataに対して演算を適用しその結果を利用するモデルを採用。どの演算結果を利用するかを決定するために、gating-mechanismを活用する。
②に対処するために、quantization layerを採用し、演算結果の数値をbinに振り分け、その結果に応じて生成する表現をguideするようなモデルを採用する。
# モデル概要
モデルはrecord encoder(h_{i}^{ctx}を作る)、operation encoder(h_{i}^{op}を作る)、operation result encoder(h_{i}^{res}を作る)によって構成される。
## record encoder
record encoderは、wisemanらと同様に、index (e.g. row 2), column (e.g. column Points), value (e.g. 95)のword embeddingを求め、それらをconcatしたものをbi-directional RNNに入力し求める。
## operation encoder
operation encoderでは、operation op_{i}は、1) operationの名称 (e.g. minus) 2) operationを適用するcolumn (e.g. Points), 3) operationを適用するrow (e.g. {1, 2}などのrow indexの集合)によって構成されており、これらのembeddingをlookupしconcatした後、non-linear layerで変換することによってoperationのrepresentationを取得する。3)operationを適用するrowについては、複数のindexによって構成されるため、各indexのembeddingをnon-linear layerで変換したベクトルを足し合わせた結果に対してtanhを適用したベクトルをembeddingとして利用する。
## operation result encoder
operation result encoderは、scalar results(minus operationにより-1)およびindexing results (argmax operationによりindex 2)の二種類を生成する。これら二種類に対して異なるencoding方法を採用する。
### scalar results
scalar resultsに対しては、下記式でscalar valueをquantization vector(q_{i})に変換する。qutization vectorのlengthはLとなっており、Lはbinの数に相当している。つまり、quantization vectorの各次元がbinの重みに対応している。その後、quantization vectorに対してsoftmaxを適用し、quantization unit(quantization vectorの各次元)の重みを求める。最後に、quantization embeddingと対応するquantization unitの重み付き平均をとることによってh_{i}^{res}を算出する。
Q. 式を見るとW_{q}がscalar resultの値によって定数倍されるだけだから、softmaxによって求まるquantization unitの重みの序列はscalar resultによって変化しなそうに見えるが、これでうまくいくんだろうか・・・?序列は変わらなくても各quantization unit間の相対的な重みの差が変化するから、それでうまくscalar値の変化を捉えられるの・・・か・・・?
### indexing results
indexing resultsについては、h_{i}^{res}をシンプルにindexのembeddingとする。
## Decoder
context vectorの生成方法が違う。従来のモデルと比較して、context vectorを生成する際に、レコードをoperationの両方をinputとする。
operationのcontext vector c_{t}^{op}とrecordsのcontext vector c_{t}^{ctx}をdynamic gate λ_{t}によって重み付けし最終的なcontext vectorを求める。λ_{t}は、t-1時点でのデコーダのhidden stateから重みを求める。
c_{t}^{op}は次式で計算され:
c_{t}^{scl, idx}は、
よって計算される。要は、decoderのt-1のhidden stateと、operation vectorを用いて、j番目のoperationの重要度(β)を求め、operationの重要度によって重み付けしてoperation result vectorを足し合わせることによって、context vectorを算出する。
また、recordのcontext vector c_{t}^{ctx}は、h_{j}^{res}とh_{j}^{op}と、h_{j}^{ctx}に置き換えることによって算出される。 
## データセット
人手でESPN, ROTOWIRE, WIKIBIOデータセットのReferenceに対して、factを含むtext spanと、そのfactの種類を3種類にラベル付した。input factsはinput dataから直接見つけられるfact, inferred factsはinput dataから直接見つけることはできないが、導き出すことができるfact、unsupported factsはinput dataから直接あるいは導き出すことができないfact。wikibioデータセットはinferred factの割合が少ないため、今回の評価からは除外し、ROTOWIRE, ESPNを採用した。特にESPNのheadline datasetがinferred factsが多かった。
# 結果
## 自動評価
wiseman modelをOpAttがoutperformしている。また、Seq2Seq+op+quant(Seq2Seq+copyに対してoperation result encoderとquantization layerを適用したもの)はSeq2Seq+Copyを上回っているが、OpAttほとではないことから、提案手法のoperation encoderの導入とgating mechanismが有効に作用していることがわかる。
採用するoperationによって、生成されるテキストも異なるようになっている。
## 人手評価
3人のNBAに詳しいEnglish native speakerに依頼してtest dataに対する生成結果にアノテーションをしてもらった。アノテーションは、factを含むspanを同定し、そのfactがinput facts/inferred facts/unsupported factsのどれかを分類してもらった。最後に、そのfactが入力データからsupportされるかcontradicted(矛盾するか)かをアノテーションしてもらった。
提案手法が、より多くのinferred factsについて言及しながらも、少ない#Cont.であることがわかった。
# 分析
## Quantizationの効果
チーム間のスコアの差が、5つのbinのに対してどれだけの重みを持たせたかのheatmap。似たようなスコアのgapの場合は似たような重みになることがわかる。ポイント差の絶対値が小さい場合は、重みの分布の分散が大きくなるのでより一般的な単語で生成を行うのに対し、絶対値が大きい場合は分散が小さくなるため、unique wordをつかって生成するようになる。
pointのgapの大きさによって利用される単語も変化していることがわかる。ポイント差がちいさいときは"edge"、大きいときは"blow out"など。
## gating mechanismの効果
生成テキストのtimestepごとのgateの重みの例。色が濃ければ濃いほど、operation resultsの情報を多く利用していることを表す。チームリーダーを決める際や(horford)勝者を決める際に(Hawks)、operation resultsの重みが大きくなっており、妥当な重み付けだと考察している。
[Paper Note] Learning to Generate Market Comments from Stock Prices, Murakami+, ACL'17
Paper/Blog Link My Issue
#NLP #NumericReasoning #Financial #ACL #numeric #Encoder-Decoder Issue Date: 2025-11-27 GPT Summary- 株価から市場コメントを生成する新しいエンコーダ-デコーダモデルを提案。モデルは短期・長期の株価変化をエンコードし、適切な算術演算を選択して数値を生成。実験により、最良モデルが人間の生成したテキストに近い流暢さと情報量を持つことが確認された。
[Paper Note] Challenges in Data-to-Document Generation, Sam Wiseman+, EMNLP'17, 2017.07
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #EMNLP #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-01 GPT Summary- ニューラルモデルは少数のデータから短い説明文を生成するタスクで進展を見せているが、難易度の高いデータに対しては効果が限定的である。本研究では新たなデータレコードと説明文のコーパスを導入し、評価手法を提案してパフォーマンスを分析した。実験結果では、モデルは流暢なテキストを生成するものの、人間の文書には及ばず、テンプレートベースの手法が一部指標で優れていることが示された。コピーや再構築に基づく拡張が改善をもたらすことも確認された。 Comment
・RotoWire(NBAのテーブルデータ + サマリ)データを収集し公開
・Rotowireデータの統計量
【モデルの概要】
・attention-based encoder-decoder model
・BaseModel
- レコードデータ r の各要素(r.e: チーム名等のENTITY r.t: POINTS等のデータタイプ, r.m: データのvalue)からembeddingをlookupし、1-layer MLPを適用し、レコードの各要素のrepresentation(source data records)を取得
- Luongらのattentionを利用したLSTM Decoderを用意し、source data recordsとt-1ステップ目での出力によって条件付けてテキストを生成していく
- negative log likelihoodがminimizeされるように学習する
・Copying
- コピーメカニズムを導入し、生成時の確率分布に生成テキストを入力からコピーされるか否かを含めた分布からテキストを生成。コピーの対象は、入力レコードのvalueがコピーされるようにする。
- コピーメカニズムには下記式で表現される Conditional Copy Modelを利用し、p(zt|y1:t-1, s)はMLPで表現する(Conditional Copy Model 節参照)。
- またpcopyは、生成している文中にあるレコードのエンティティとタイプが出現する場合に、対応するvalueをコピーし生成されるように表現する
[Paper Note] Toward Controlled Generation of Text, Zhiting Hu+, ICML'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #Controllable #NLP #ConceptToTextGeneration #GenerativeAdversarialNetwork #ICML #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 属性に基づいて制御された自然言語文を生成するために、変分オートエンコーダと属性識別器を組み合わせた新しい生成モデルを提案。微分可能な近似を用いて解釈可能な表現を学習し、望ましい属性を持つ文を生成。定量的評価で生成の正確性を確認。 Comment
Text Generationを行う際は、現在は基本的に学習された言語モデルの尤度に従ってテキストを生成するのみで、outputされるテキストをcontrolすることができないので、できるようにしましたという論文。 VAEによるテキスト生成にGANを組み合わせたようなモデル。 decodingする元となるfeatureのある次元が、たとえばpolarityなどに対応しており、その次元の数値をいじるだけで生成されるテキストをcontrolできる。
テキストを生成する際に、生成されるテキストをコントロールするための研究。 テキストを生成する際には、基本的にはVariational Auto Encoder(VAE)を用いる。
VAEは、入力をエンコードするEncoderと、エンコードされた潜在変数zからテキストを生成するGeneratorの2つの機構によって構成されている。
この研究では、生成されるテキストをコントロールするために、VAEの潜在変数zに、生成するテキストのattributeを表す変数cを新たに導入。
たとえば、一例として、変数cをsentimentに対応させた場合、変数cの値を変更すると、生成されるテキストのsentimentが変化するような生成が実現可能。
次に、このような生成を実現できるようなパラメータを学習したいが、学習を行う際のポイントは、以下の二つ。
cで指定されたattributeが反映されたテキストを生成するように学習
潜在変数zとattributeに関する変数cの独立性を保つように学習 (cには制御したいattributeに関する情報のみが格納され、その他の情報は潜在変数zに格納されるように学習する)
1を実現するために、新たにdiscriminatorと呼ばれる識別器を用意し、VAEが生成したテキストのattributeをdiscriminatorで分類し、その結果をVAEのGeneratorにフィードバックすることで、attributeが反映されたテキストを生成できるようにパラメータの学習を行う。 (これにはラベル付きデータが必要だが、少量でも学習できることに加えて、sentence levelのデータだけではなくword levelのデータでも学習できる。)
また、2を実現するために、VAEが生成したテキストから、生成する元となった潜在変数zが再現できるようにEncoderのパラメータを学習。
実験では、sentimentとtenseをコントロールする実験が行われており、attributeを表す変数cを変更することで、以下のようなテキストが生成されており興味深い。
[sentimentを制御した例]
this movie was awful and boring. (negative)
this movie was funny and touching. (positive)
[tenseを制御した例]
this was one of the outstanding thrillers of the last decade
this is one of the outstanding thrillers of the all time
this will be one of the great thrillers of the all time
VAEは通常のAutoEncoderと比較して、奥が深くて勉強してみておもしろかった。 Reparametrization Trickなどは知らなかった。
管理人による解説資料:
[Controllable Text Generation.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1595121/Controllable.Text.Generation.pdf)
slideshare: https://www.slideshare.net/akihikowatanabe3110/towards-controlled-generation-of-text
[Paper Note] Neural Text Generation: A Practical Guide, Ziang Xie, arXiv'17, 2017.11
Paper/Blog Link My Issue
#NeuralNetwork #Survey #NaturalLanguageGeneration #NLP #ConceptToTextGeneration Issue Date: 2017-12-31 GPT Summary- 深層学習手法はテキスト生成タスクで成功を収めているが、デコーダーが望ましくない出力を生成する問題がある。本論文は、テキスト生成モデルの不具合を解決するための実践的なガイドを提供し、実世界のアプリケーションの実現を目指す。
[Paper Note] Survey of the State of the Art in Natural Language Generation: Core tasks, applications and evaluation, Albert Gatt+, arXiv'17, 2017.03
Paper/Blog Link My Issue
#Survey #NaturalLanguageGeneration #NLP #ConceptToTextGeneration Issue Date: 2017-12-31 GPT Summary- 本論文は、非言語的入力からテキストや音声を生成する自然言語生成(NLG)の最新技術動向を調査し、(a) NLGのコアタスクに関する研究の統合とアーキテクチャの提示、(b) NLGと他のAI分野との相乗効果による新しい研究トピックの強調、(c) NLG評価の課題と他の自然言語処理分野との関連を明らかにすることを目的としている。 Comment
割と新し目のNLGのSurvey
[Paper Note] Deep Match between Geology Reports and Well Logs Using Spatial Information, Tong+, CIKM'16
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Others #NLP #CIKM Issue Date: 2017-12-31
[Paper Note] Content Selection in Data-to-Text Systems: A Survey, Dimitra Gkatzia, arXiv'16, 2016.10
Paper/Blog Link My Issue
#Survey #NaturalLanguageGeneration #NLP #ConceptToTextGeneration #Initial Impression Notes Issue Date: 2017-12-31 GPT Summary- データからテキストへのシステムは、データを自然言語で自動的にレポート生成し、ユーザーの好みに応じた出力を提供する。コンテンツ選択は重要な要素であり、どの情報を伝えるかを決定する。研究では、データからテキスト生成の分野を紹介し、システムのアーキテクチャと最先端のコンテンツ選択手法をレビューし、今後の研究機会について議論する。 Comment
Gkatzia氏の"content selection"に関するSurvey
[Paper Note] Comparing Multi-label Classification with Reinforcement Learning for Summarization of Time-series Data, Gkatzia+, ACL'14
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Others #NLP #ACL Issue Date: 2017-12-31
[Paper Note] A simple domain-independent probabilistic approach to generation, Angeli+, EMNLP'10
Paper/Blog Link My Issue
#NaturalLanguageGeneration #SingleFramework #NLP #EMNLP Issue Date: 2017-12-31
[Paper Note] Training a multilingual sportscaster: Using perceptual context to learn language, Chen+, Artificial Intelligence Research'10, 2010.01
Paper/Blog Link My Issue
#NaturalLanguageGeneration #SingleFramework #NLP Issue Date: 2017-12-31
[Paper Note] Verbalizing time-series data: with an example of stock price trends, Kobayashi+, IFSA-EUSFLAT'09, 2009.01
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Others #NLP #KeyPoint Notes Issue Date: 2017-12-31 Comment
小林先生の論文
Least Square Methodによって数値データにfittingするcurveを求める。
curveの特徴から、生成するテキストのtrendsを決定する。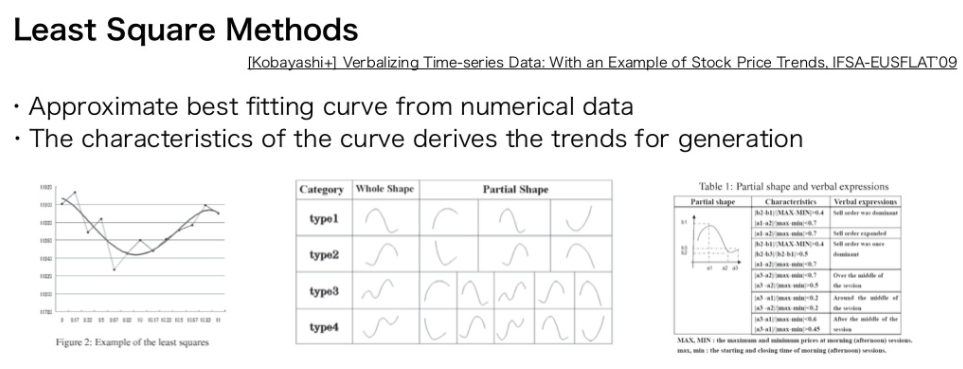
[Paper Note] Generating approximate geographic descriptions, Turner+, ENLG'09, 2009.03
Paper/Blog Link My Issue
#NaturalLanguageGeneration #RuleBased #NLP Issue Date: 2017-12-31
[Paper Note] Learning to sportscast: a test of grounded language acquisition, Chen+, ICML'08
Paper/Blog Link My Issue
#NaturalLanguageGeneration #SingleFramework #NLP #ICML Issue Date: 2017-12-31
[Paper Note] An Architecture for Data to Text Systems, Ehud Reiter, ENLG'07
Paper/Blog Link My Issue
#Survey #NaturalLanguageGeneration #NLP #ConceptToTextGeneration #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-31 Comment
NLG分野で有名なReiterらのSurvey。
NLGシステムのアーキテクチャなどが、体系的に説明されている。
[Paper Note] Choosing words in computer-generated weather forecasts, Reiter+, Artificial Intelligence'05
Paper/Blog Link My Issue
#NaturalLanguageGeneration #RuleBased #NLP #KeyPoint Notes Issue Date: 2017-12-31 Comment
## タスク
天気予報の生成, システム名 SUMTIME
## 手法概要
ルールベースな手法,weather prediction dataから(将来の気象情報をシミュレーションした数値データ),天気予報を自動生成.corpus analysisと専門家のsuggestを通じて,どのようなwordを選択して天気予報を生成するか詳細に分析したのち,ルールを生成してテキスト生成
[Paper Note] Using natural language processing to produce weather forecasts, Goldberg+, IEEE Expert: Intelligent Systems and Their Applications'94
Paper/Blog Link My Issue
#NaturalLanguageGeneration #RuleBased #NLP #KeyPoint Notes Issue Date: 2017-12-31 Comment
## タスク
天気予報の生成,システム名 FOG (EnglishとFrenchのレポートを作成できる)
## 手法概要
ルールベースな手法,weather predictinon dataから,天気予報を自動生成.Text Planner がルールに従い各sentenceに入れる情報を抽出すると同時に,sentence orderを決め,abstractiveな中間状態を生成.その後,中間状態からText Realization(grammarやdictionaryを用いる)によって,テキストを生成.
[Paper Note] Design of a knowledge-based report generator, Kukich, ACL'83
Paper/Blog Link My Issue
#NaturalLanguageGeneration #RuleBased #NLP #ACL #KeyPoint Notes Issue Date: 2017-12-31 Comment
## タスク
numerical stock market dataからstock market reportsを生成.システム名: ANA
## 手法概要
ルールベースな手法,
1) fact-generator,
2) message generator,
3) discourse organizer,
4) text generatorの4コンポーネントから成る.
2), 3), 4)はそれぞれ120, 16, 109個のルールがある. 4)ではphrasal dictionaryも使う.
1)では,入力されたpriceデータから,closing averageを求めるなどの数値的な演算などを行う.
2)では,1)で計算された情報に基づいて,メッセージの生成を行う(e.g. market was mixed).
3)では,メッセージのparagraph化,orderの決定,priorityの設定などを行う.
4)では,辞書からフレーズを選択したり,適切なsyntactic formを決定するなどしてテキストを生成.
Data2Textの先駆け論文。引用すべし。多くの研究で引用されている。
Data-to-Text Datasetまとめ, Akihiko Watanabe, 2022
Paper/Blog Link My Issue
#Article #Survey #NaturalLanguageGeneration #NLP #Dataset #Slide #One-Line Notes Issue Date: 2023-11-08 Comment
Data-to-Textのデータセットを自分用に調べていたのですが、せっかくなのでスライドにまとめてみました。特にMR-to-Text, Table-to-Textあたりは網羅的にサーベイし、データセットの概要を紹介しているので、全体像を把握するのに良いのかなぁと思います。ただし、2022年12月時点で作成したので2023年以後のデータセットは含まれていません😅
[Paper Note] Automatically generated linguistic summaries of energy consumption data, van der Heide+, In Proceedings of the Ninth International Conference on Intelligent Systems Design and Applications, pages 553-559, 2009.11
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #Others #NLP Issue Date: 2017-12-31
[Paper Note] A framework for automatic text generation of trends in physiological time series data, Banaee+, In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, 2013.10
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #Others #NLP Issue Date: 2017-12-31
[Paper Note] What to talk about and how? Selective Generation using LSTMs with Coarse-to-Fine Alignment, Hongyuan Mei+, NAACL-HLT’16, 2015.09
Paper/Blog Link My Issue
#Article #NeuralNetwork #NaturalLanguageGeneration #NLP #NAACL #Encoder-Decoder #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- エンドツーエンドのドメイン非依存型ニューラルエンコーダー-アライナー-デコーダーモデルを提案。LSTMを用いてデータベースイベントをエンコードし、アライナーで重要なレコードを特定、デコーダーで自由形式の説明を生成。WeatherGovデータセットで最良の結果を達成し、k近傍ビームフィルターでさらに改善。RoboCupデータセットでも競争力のある結果を得た。 Comment
content-selectionとsurface realizationをencoder-decoder alignerを用いて同時に解いたという話。
普通のAttention basedなモデルにRefinerとPre-Selectorと呼ばれる機構を追加。通常のattentionにはattentionをかける際のaccuracyに問題があるが、data2textではきちんと参照すべきレコードを参照し生成するのが大事なので、RefinerとPre-Selectorでそれを改善する。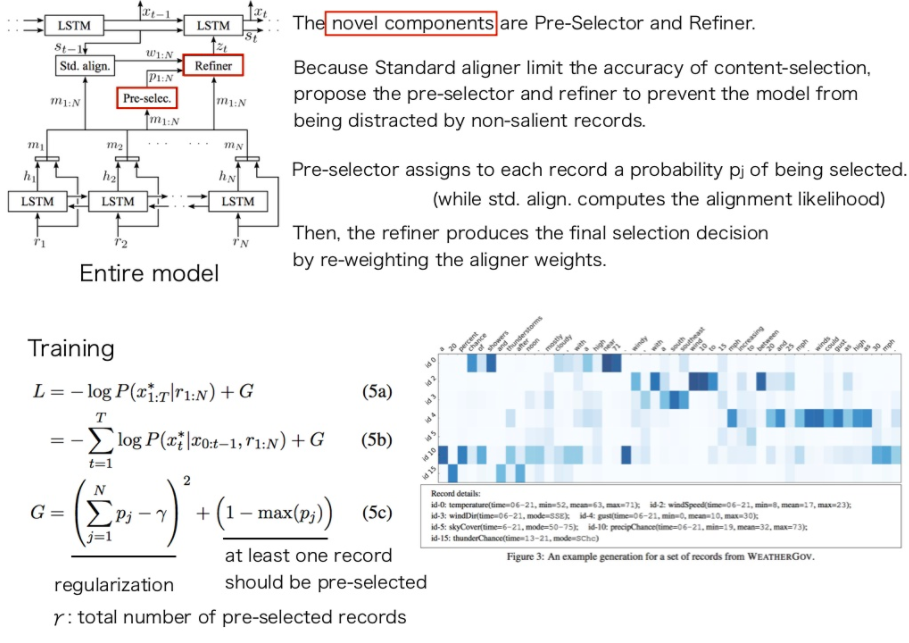
Pre-selectorは、それぞれのレコードが選択される確率を推定する(通常のattentionはalignmentの尤度を計算するのみ)。
Refinerはaligner(attention)のweightをreweightingすることで、最終的にどのレコードを選択するか決定する。
加えて、ロス関数のRegularizationのかけかたを変え、最低一つのレコードがpreselectorに選ばれるようにバイアスをかけている。
ほぼ初期のNeural Network basedなData2Text研究