
Grokking
[Paper Note] Provable Scaling Laws of Feature Emergence from Learning Dynamics of Grokking, Yuandong Tian, ICLR'26, 2025.09
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #MachineLearning #Optimizer #ICLR Issue Date: 2025-10-10 GPT Summary- grokkingの現象を理解するために、2層の非線形ネットワークにおける新しい枠組み$\mathbf{Li_2}$を提案。これには、怠惰な学習、独立した特徴学習、相互作用する特徴学習の3段階が含まれる。怠惰な学習では、モデルが隠れ表現に過剰適合し、独立した特徴が学習される。後半段階では、隠れノードが相互作用を始め、学習すべき特徴に焦点を当てることが示される。本研究は、grokkingにおけるハイパーパラメータの役割を明らかにし、特徴の出現と一般化に関するスケーリング法則を導出する。 Comment
元ポスト:
poster:
https://yuandong-tian.com/posters/poster_li2_correct.pdf
元ポスト:
[Paper Note] How much do language models memorize?, John X. Morris+, ICML'26 Outstanding Paper Honorable Mention, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Selected Papers/Blogs #Memorization #reading #One-Line Notes #Author Thread-Post #DoubleDescent Issue Date: 2025-06-05 GPT Summary- モデルがデータポイントについての知識を推定し、現代の言語モデルの容量を測定する新手法を提案。記憶を意図しない記憶と一般化に分け、一般化を排除することで記憶を計算。GPTモデルの容量はパラメータあたり約3.6ビットと推定。データセットサイズの増加に伴い、記憶が満たされると「グロッキング」が始まり、意図しない記憶が減少。数百のトランスフォーマー言語モデルを訓練し、モデル容量とデータサイズの関係を示すスケーリング則を提示。 Comment
元ポスト:
著者ポスト:
解説:
LLMはまず記憶をし、1パラメータあたり3.6ビットを超えると飽和する。飽和後は圧縮、一般化、Double Decent、Grokkingという経過を辿る、という話が解説ポストに記載されている。
openreview: https://openreview.net/forum?id=NhU661EZ9C
[Paper Note] RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs?, Yiyou Sun+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #PostTraining #RLVR Issue Date: 2025-12-09 GPT Summary- DELTA-Codeを導入し、LLMの学習可能性と移転可能性を評価する。合成コーディング問題を用いて、RL訓練されたモデルが新しい推論戦略を獲得できるかを探る。実験では、報酬がほぼゼロの後に急激な精度向上が見られ、段階的ウォームアップやカリキュラムトレーニングが重要であることが示された。移転可能性の評価では、ファミリー内での向上が見られる一方、変革的なケースでは弱点が残る。DELTAは新しいアルゴリズムスキルの獲得を理解するためのテストベッドを提供する。
Why Do You Grok? A Theoretical Analysis of Grokking Modular Addition, Mohamad Amin Mohamadi+, arXiv'24
Paper/Blog Link My Issue
Issue Date: 2024-11-13 GPT Summary- モデルの「grokking」現象を理論的に説明し、モジュラー加算問題に関連付ける。勾配降下法の初期段階では、順列不変モデルが小さな母集団誤差を達成するために一定割合のデータポイントを観察する必要があるが、最終的にはカーネル領域を脱出する。二層の二次ネットワークが限られたトレーニングポイントでゼロのトレーニング損失を達成し、良好に一般化することを示し、実証的証拠も提供。これにより、grokkingは深層ネットワークにおける勾配降下法の制限挙動への移行の結果であることが支持される。
Deep Networks Always Grok and Here is Why, Ahmed Imtiaz Humayun+, N_A, arXiv'24
Paper/Blog Link My Issue
#One-Line Notes Issue Date: 2024-02-28 GPT Summary- DNNの訓練エラーがほぼゼロに達した後に一般化が遅れて発生するグロッキング現象について、遅延頑健性という新しい概念を導入し、DNNが遅延して敵対的な例を理解し、一般化した後に頑健になる現象を説明。局所複雑性の新しい尺度に基づいて、遅延一般化と遅延頑健性の出現についての解析的な説明を提供。 Comment
Grokking関連論文
参考: hillbigさんのツイート
[Paper Note] Explaining grokking through circuit efficiency, Vikrant Varma+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #MachineLearning #One-Line Notes Issue Date: 2023-09-30 GPT Summary- グロッキングはニューラルネットワークの一般化における謎であり、訓練データでは完璧な精度を示すが一般化が乏しい状態から、追加の訓練を経て一般化が進む現象を指す。本研究では、グロッキングが一般化解と記憶化解の両方を許すタスクで生じると提案し、一般化解が学習遅延を伴いながらも効率的である一方、記憶化解は訓練データが増えると非効率的になると仮説する。また、記憶と一般化の効率が等しくなる臨界的なデータセットサイズを特定する。グロッキングに関する四つの新規予測を提示し、それを検証し、支持する証拠を提供。特に、ネットワークの精度が低下するアン・グロッキングや、部分的な検証精度へ遅れて一般化を示すセミ・グロッキングの挙動を明らかにした。 Comment
Grokkingがいつ、なぜ発生するかを説明する理論を示した研究。
理由としては、最初はmemorizationを学習していくのだが、ある時点から一般化回路であるGenに切り替わる。これが切り替わる理由としては、memorizationよりも、genの方がlossが小さくなるから、とのこと。これはより大規模なデータセットで顕著。
Grokkingが最初に報告された研究は [Paper Note] Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets, Alethea Power+, ICLR'21 Workshop, 2022.01
[Paper Note] Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets, Alethea Power+, ICLR'21 Workshop, 2022.01
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #ICLR #Workshop #One-Line Notes Issue Date: 2023-04-25 GPT Summary- 小規模データセットにおけるニューラルネットワークの一般化を探求。データ効率、記憶、一般化、学習速度に関する問題を分析し、学習過程の「グロッキング」を通じて一般化性能の改善を示す。特に、小さなデータセットではより多くの最適化が必要であることが明らかにされ、過剰パラメータ化されたネットワークの一般化メカニズムを理解するための重要な知見を提供。 Comment
学習後すぐに学習データをmemorizeして、汎化能力が無くなったと思いきや、10^3ステップ後に突然汎化するという現象(Grokking)を報告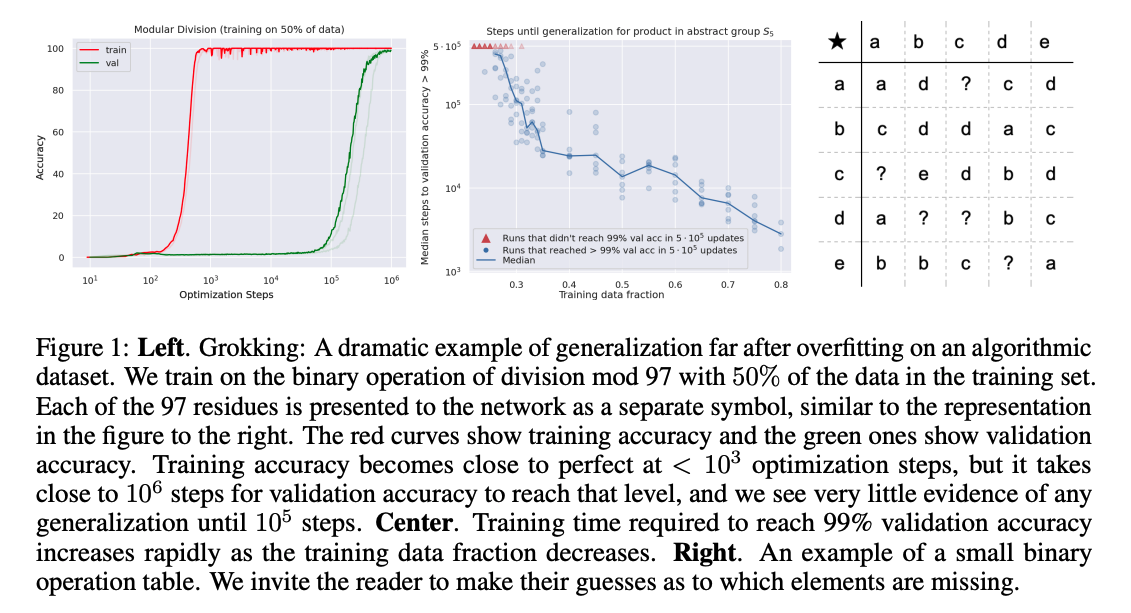
学習データが小さければ小さいほど汎化能力を獲得するのに時間がかかる模様