
Zero/Few/ManyShotPrompting
Issue Date: 2025-11-12 [Paper Note] Robot Learning from a Physical World Model, Jiageng Mao+, arXiv'25, 2025.11 GPT Summary- PhysWorldは、物理世界のモデル化を通じてビデオ生成とロボット学習を結びつけるフレームワークです。従来のビデオ生成モデルは物理を無視しがちで、ロボットの操作に不正確さをもたらしますが、PhysWorldはタスク条件付きのビデオを生成し、物理世界を再構築します。これにより、生成されたビデオの動きを物理的に正確なアクションに変換し、実際のロボットデータ収集なしでゼロショットのロボット操作を実現します。実験により、PhysWorldは操作精度を大幅に向上させることが示されました。 Comment
pj page: https://pointscoder.github.io/PhysWorld_Web/
画像とタスクプロンプトを与えて動画を生成し、生成された動画に対してworld modelを用いて物理世界の情報を再構築し、そこからロボットのアクションとして何が必要かを推定することでRLをする、結果的にzeroshotでのロボット操作が実現できる、みたいな話に見える(Figure2)
元ポスト:
#ComputerVision #Analysis #Pocket #Dataset #MultiModal #In-ContextLearning #ICCV #VisionLanguageModel
Issue Date: 2025-10-27 [Paper Note] Kaputt: A Large-Scale Dataset for Visual Defect Detection, Sebastian Höfer+, ICCV'25, 2025.10 GPT Summary- 新しい大規模データセットを提案し、小売物流における欠陥検出の課題に対応。230,000枚の画像と29,000以上の欠陥インスタンスを含み、MVTec-ADの40倍の規模。既存手法の限界を示し、56.96%のAUROCを超えない結果を得た。データセットは今後の研究を促進するために利用可能。 Comment
元ポスト:
#ComputerVision #Pocket #Dataset #Evaluation #MultiModal #In-ContextLearning #NeurIPS #read-later #Selected Papers/Blogs #OOD #Generalization #VisionLanguageModel #One-Line Notes #ObjectDetection
Issue Date: 2025-10-27 [Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05 GPT Summary- 視覚と言語のモデル(VLMs)は、一般的な物体に対して優れたゼロショット検出性能を示すが、分布外のクラスやタスクに対しては一般化が難しい。そこで、少数の視覚例と豊富なテキスト記述を用いてVLMを新しい概念に整合させる必要があると提案。Roboflow100-VLという多様な概念を持つ100のマルチモーダル物体検出データセットを導入し、最先端モデルの評価を行った。特に、難しい医療画像データセットでのゼロショット精度が低く、少数ショットの概念整合が求められることを示した。 Comment
元ポスト:
VLMが「現実世界をどれだけ理解できるか」を評価するためのobject detection用ベンチマークを構築。100のopen source datasetから構成され、それぞれにはtextでのfew shot instructionやvisual exampleが含まれている。データセットは合計で約165kの画像、約1.35M件のアノテーションが含まれ、航空、生物、産業などの事前学習ではあまりカバーされていない新規ドメインの画像が多数含まれているとのこと。
そして現在のモデルは事前学習に含まれていないOODな画像に対する汎化性能が低く、いちいちモデルを追加で学習するのではなく、ICLによって適用できた方が好ましいという考えがあり、そして結果的に現在のVLMでは、ICLがあまりうまくいかない(ICLによるOODの汎化が効果的にできない)ことがわかった、という話らしい。
が、
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
での知見と異なる。差異はなんだろうか?
以下のスレッドで議論がされている:
pj page: https://rf100-vl.org
うーんあとでしっかり読みたい、、、
元ポスト:
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #MultiModal #In-ContextLearning Issue Date: 2025-07-01 [Paper Note] SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning, Melanie Rieff+, arXiv'25 GPT Summary- マルチモーダルインコンテキスト学習(ICL)は医療分野での可能性があるが、十分に探求されていない。SMMILEという医療タスク向けの初のマルチモーダルICLベンチマークを導入し、111の問題を含む。15のMLLMの評価で、医療タスクにおけるICL能力が中程度から低いことが示された。ICLはSMMILEで平均8%、SMMILE++で9.4%の改善をもたらし、無関係な例がパフォーマンスを最大9.5%低下させることも確認。例の順序による最近性バイアスがパフォーマンス向上に寄与することも明らかになった。 Comment
元ポスト:
#ComputerVision #Analysis #Pocket #NLP #MultiModal #In-ContextLearning #VisionLanguageModel Issue Date: 2025-10-27 [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05 GPT Summary- 本研究では、マルチモーダル基盤モデルの少数ショットから多数ショットのインコンテキスト学習(ICL)の性能を評価し、2,000のデモンストレーション例を用いることで、すべてのデータセットにおいて大幅な改善を観察しました。特に、Gemini 1.5 Proは多くのデータセットで対数的に性能が向上し、オープンウェイトモデルはデモンストレーション例からの恩恵を受けないことが明らかになりました。また、複数のクエリをバッチ処理することで、ゼロショットおよび多数ショットICLの性能が向上し、コストとレイテンシが削減されました。最終的に、GPT-4oとGemini 1.5 Proは類似のゼロショット性能を示しつつ、Gemini 1.5 Proはより早く学習することが確認されました。多数ショットICLは新しいアプリケーションへの適応を効率化する可能性を示唆しています。 Comment
元ポスト:
#Pocket #NLP #LanguageModel #Prompting #In-ContextLearning #NeurIPS Issue Date: 2025-09-01 [Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24 GPT Summary- 大規模言語モデル(LLMs)は、少数ショットから多くのショットのインコンテキスト学習(ICL)において顕著な性能向上を示す。新たな設定として、モデル生成の思考過程を用いる強化されたICLと、ドメイン特有の質問のみを用いる無監督ICLを提案。これらは特に複雑な推論タスクに効果的であり、多くのショット学習は事前学習のバイアスを覆し、ファインチューニングと同等の性能を発揮することが示された。また、推論コストは線形に増加し、最前線のLLMsは多くのショットのICLから恩恵を受けることが確認された。 Comment
many-shotを提案
#Pocket #NLP #QuestionAnswering #Chain-of-Thought #RAG(RetrievalAugmentedGeneration) #Reasoning Issue Date: 2025-01-03 AutoReason: Automatic Few-Shot Reasoning Decomposition, Arda Sevinc+, arXiv'24 GPT Summary- Chain of Thought(CoT)を用いて、暗黙のクエリを明示的な質問に分解することで、LLMの推論能力を向上させる自動生成システムを提案。StrategyQAとHotpotQAデータセットで精度向上を確認し、特にStrategyQAで顕著な成果を得た。ソースコードはGitHubで公開。 Comment
元ポスト:
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #ACL #Findings Issue Date: 2025-09-24 [Paper Note] FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation, Tu Vu+, ACL'23 Findings, 2023.10 GPT Summary- 大規模言語モデル(LLMs)は変化する世界に適応できず、事実性に課題がある。本研究では、動的QAベンチマーク「FreshQA」を導入し、迅速に変化する知識や誤った前提を含む質問に対するLLMの性能を評価。評価の結果、全モデルがこれらの質問に苦労していることが明らかに。これを受けて、検索エンジンからの最新情報を組み込む「FreshPrompt」を提案し、LLMのパフォーマンスを向上させることに成功。FreshPromptは、証拠の数と順序が正確性に影響を与えることを示し、簡潔な回答を促すことで幻覚を減少させる効果も確認。FreshQAは公開され、今後も更新される予定。 #ComputerVision #Pocket #LanguageModel #Self-SupervisedLearning Issue Date: 2024-10-07 SINC: Self-Supervised In-Context Learning for Vision-Language Tasks, Yi-Syuan Chen+, N_A, ICCV'23 GPT Summary- 自己教師あり文脈内学習(SINC)フレームワークを提案し、大規模言語モデルに依存せずに文脈内学習を実現。特別に調整されたデモンストレーションを用いたメタモデルが、視覚と言語のタスクで少数ショット設定において勾配ベースの手法を上回る性能を示す。SINCは文脈内学習の利点を探求し、重要な要素を明らかにする。 #Pocket #LanguageModel #MultitaskLearning #Supervised-FineTuning (SFT) #CrossLingual #ACL #Generalization Issue Date: 2023-08-16 Crosslingual Generalization through Multitask Finetuning, Niklas Muennighoff+, N_A, ACL'23 GPT Summary- マルチタスクプロンプトフィネチューニング(MTF)は、大規模な言語モデルが新しいタスクに汎化するのに役立つことが示されています。この研究では、マルチリンガルBLOOMとmT5モデルを使用してMTFを実施し、英語のプロンプトを使用して英語および非英語のタスクにフィネチューニングすることで、タスクの汎化が可能であることを示しました。さらに、機械翻訳されたプロンプトを使用してマルチリンガルなタスクにフィネチューニングすることも調査し、モデルのゼロショットの汎化能力を示しました。また、46言語の教師ありデータセットのコンポジットであるxP3も紹介されています。 Comment
英語タスクを英語でpromptingしてLLMをFinetuningすると、他の言語(ただし、事前学習で利用したコーパスに出現する言語に限る)で汎化し性能が向上することを示した模様。

#EfficiencyImprovement #MachineLearning #NLP #In-ContextLearning Issue Date: 2023-07-13 FiD-ICL: A Fusion-in-Decoder Approach for Efficient In-Context Learning, ACL'23 GPT Summary- 大規模な事前学習モデルを使用したfew-shot in-context learning(ICL)において、fusion-in-decoder(FiD)モデルを適用することで効率とパフォーマンスを向上させることができることを検証する。FiD-ICLは他のフュージョン手法と比較して優れたパフォーマンスを示し、推論時間も10倍速くなる。また、FiD-ICLは大規模なメタトレーニングモデルのスケーリングも可能にする。 #Pocket #NLP #LanguageModel #Chain-of-Thought #ACL Issue Date: 2023-05-04 Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, Mirac Suzgun+, N_A, ACL'23 GPT Summary- BIG-Bench Hard (BBH) is a suite of 23 challenging tasks that current language models have not been able to surpass human performance on. This study focuses on applying chain-of-thought prompting to BBH tasks and found that PaLM and Codex were able to surpass human performance on 10 and 17 tasks, respectively. The study also found that CoT prompting is necessary for tasks that require multi-step reasoning and that CoT and model scale interact to enable new task performance on some BBH tasks. Comment
単なるfewshotではなく、CoT付きのfewshotをすると大幅にBIG-Bench-hardの性能が向上するので、CoTを使わないanswer onlyの設定はモデルの能力の過小評価につながるよ、という話らしい
#RecommenderSystems #LanguageModel #InstructionTuning Issue Date: 2023-11-12 Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5), Shijie Geng+, N_A, RecSys'22 GPT Summary- 我々は「Pretrain, Personalized Prompt, and Predict Paradigm」(P5)と呼ばれる柔軟で統一されたテキストからテキストへのパラダイムを提案します。P5は、共有フレームワーク内でさまざまな推薦タスクを統一し、個別化と推薦のための深い意味を捉えることができます。P5は、異なるタスクを学習するための同じ言語モデリング目標を持つ事前学習を行います。P5は、浅いモデルから深いモデルへと進化し、広範な微調整の必要性を減らすことができます。P5の効果を実証するために、いくつかの推薦ベンチマークで実験を行いました。 Comment
# 概要
T5 のように、様々な推薦タスクを、「Prompt + Prediction」のpipelineとして定義して解けるようにした研究。
P5ではencoder-decoder frameworkを採用しており、encoder側ではbidirectionalなモデルでpromptのrepresentationを生成し、auto-regressiveな言語モデルで生成を行う。
推薦で利用したいデータセットから、input-target pairsを生成し上記アーキテクチャに対して事前学習することで、推薦を実現できる。
RatingPredictionでは、MatrixFactorizationに勝てていない(が、Rating Predictionについては魔法の壁問題などもあると思うのでなんともいえない。)
Sequential RecommendationではBERT4Recとかにも勝てている模様。
# Prompt例
- Rating Predictionの例
- Sequential Recommendationの例
- Explanationを生成する例
- Zero-shotの例(Cold-Start)
#NeuralNetwork #NLP #Chain-of-Thought #Prompting #NeurIPS Issue Date: 2023-04-27 Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22 Comment
Chain-of-Thoughtを提案した論文。CoTをする上でパラメータ数が100B未満のモデルではあまり効果が発揮されないということは念頭に置いた方が良さそう。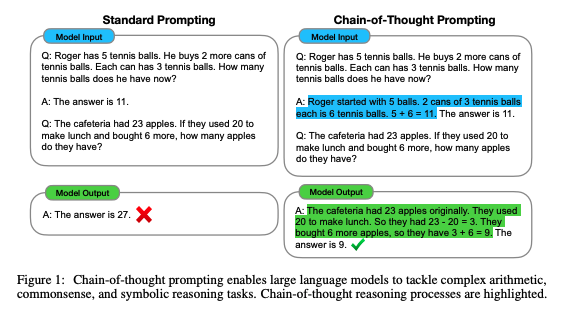
先行研究では、reasoningが必要なタスクの性能が低い問題をintermediate stepを明示的に作成し、pre-trainedモデルをfinetuningすることで解決していた。しかしこの方法では、finetuning用の高品質なrationaleが記述された大規模データを準備するのに多大なコストがかかるという問題があった。
このため、few-shot promptingによってこの問題を解決することが考えられるが、reasoning能力が必要なタスクでは性能が悪いという問題あがった。そこで、両者の強みを組み合わせた手法として、chain-of-thought promptingは提案された。
# CoTによる実験結果
以下のベンチマークを利用
- math word problem: GSM8K, SVAMP, ASDiv, AQuA, MAWPS
- commonsense reasoning: CSQA, StrategyQA, Big-bench Effort (Date, Sports), SayCan
- Symbolic Reasoning: Last Letter concatenation, Coin Flip
- Last Letter concatnation: 名前の単語のlast wordをconcatするタスク("Amy Brown" -> "yn")
- Coin Flip: コインをひっくり返す、 あるいはひっくり返さない動作の記述の後に、コインが表向きであるかどうかをモデルに回答するよう求めるタスク
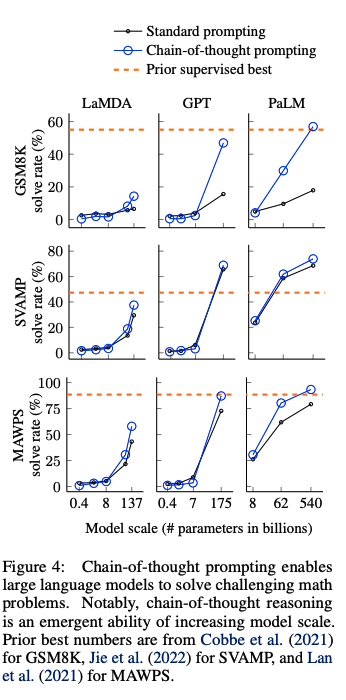
## math word problem benchmark
- モデルのサイズが大きくなるにつれ性能が大きく向上(emergent ability)することがあることがわかる
- 言い換えるとCoTは<100Bのモデルではパフォーマンスに対してインパクトを与えない
- モデルサイズが小さいと、誤ったCoTを生成してしまうため
- 複雑な問題になればなるほど、CoTによる恩恵が大きい
- ベースラインの性能が最も低かったGSM8Kでは、パフォーマンスの2倍向上しており、1 stepのreasoningで解決できるSingleOpやMAWPSでは、性能の向上幅が小さい
- Task specificなモデルをfinetuningした以前のSoTAと比較してcomparable, あるいはoutperformしている
- 
## Ablation Study
CoTではなく、他のタイプのpromptingでも同じような効果が得られるのではないか?という疑問に回答するために、3つのpromptingを実施し、CoTと性能比較した:
- Equation Only: 回答するまえに数式を記載するようなprompt
- promptの中に数式が書かれているから性能改善されているのでは?という疑問に対する検証
- => GSM8Kによる結果を見ると、equation onlyでは性能が低かった。これは、これは数式だけでreasoning stepsを表現できないことに起因している
- Variable compute only: dotのsequence (...) のみのprompt
- CoTは難しい問題に対してより多くの計算(intermediate token)をすることができているからでは?という疑問に対する検証
- variable computationとCoTの影響を分離するために、dotのsequence (...) のみでpromptingする方法を検証
- => 結果はbaselineと性能変わらず。このことから、variableの計算自体が性能向上に寄与しているわけではないことがわかる。
- Chain of Thought after answer: 回答の後にCoTを出力するようなprompting
- 単にpretrainingの際のrelevantな知識にアクセスしやすくなっているだけなのでは?という疑問を検証
- => baselineと性能は変わらず、単に知識を活性化させるだけでは性能が向上しないことがわかる。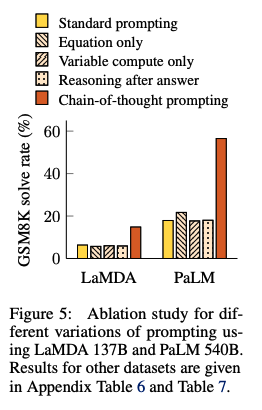
## CoTのロバスト性
人間のAnnotatorにCoTを作成させ、それらを利用したCoTpromptingとexamplarベースな手法によって性能がどれだけ変わるかを検証。standard promptingを全ての場合で上回る性能を獲得した。このことから、linguisticなstyleにCoTは影響を受けていないことがわかる。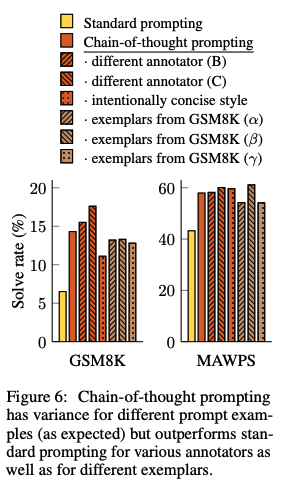
# commonsense reasoning
全てのデータセットにおいて、CoTがstandard promptingをoutperformした。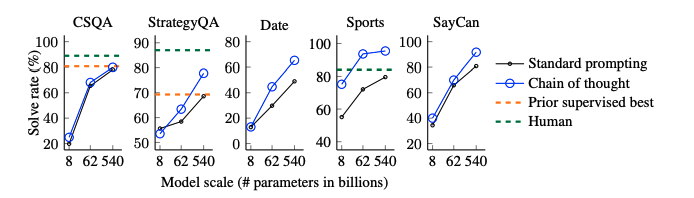
# Symbolic Reasoning
in-domain test setとout-of-domain test setの2種類を用意した。前者は必要なreasoning stepがfew-shot examplarと同一のもの、後者は必要なreasoning stepがfew-shot examplarよりも多いものである。
CoTがStandard proimptingを上回っている。特に、standard promptingではOOV test setではモデルをスケールさせても性能が向上しなかったのに対し、CoTではより大きなgainを得ている。このことから、CoTにはreasoning stepのlengthに対しても汎化能力があることがわかる。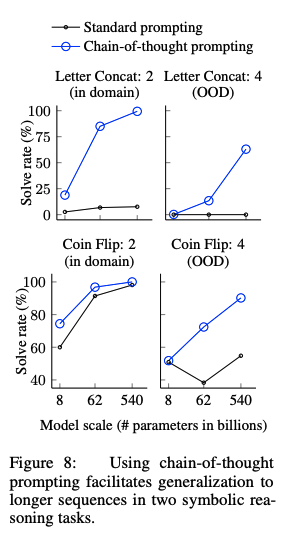
#NeuralNetwork #Pocket #NLP #LanguageModel #In-ContextLearning #NeurIPS #Selected Papers/Blogs Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 GPT Summary- GPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 Comment
In-Context Learningを提案した論文
論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。
この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。
#Article #MachineTranslation #NLP #Dataset Issue Date: 2024-11-20 Datasets: hpprc_honyaku, hpprc, 2024.11 Comment
元ポスト:
英語Wikipediaを冒頭数文を抽出し日本語に人手で翻訳(Apache2.0ライセンスであるCalmやQwenの出力を参考に、cc-by-sa-4.0ライセンスにて公開している。
テクニカルタームが日本語で存在する場合は翻訳結果に含まれるようにしたり、翻訳された日本語テキストが単体で意味が成り立つように翻訳しているとのことで、1件あたり15分もの時間をかけて翻訳したとのこと。データ量は33件。many-shotやfew-shotに利用できそう。
日英対訳コーパスはライセンスが厳しいものが多いとのことなので、非常に有用だと思う。