
MulltiModal
#ComputerVision
#Pocket
#NLP
#Dataset
#Reasoning
#EMNLP
#PostTraining
#VisionLanguageModel
Issue Date: 2025-08-21 [Paper Note] VisualWebInstruct: Scaling up Multimodal Instruction Data through Web Search, Yiming Jia+, EMNLP'25 Summary本研究では、推論に焦点を当てたマルチモーダルデータセットの不足に対処するため、VisualWebInstructという新しいアプローチを提案。30,000のシード画像からGoogle画像検索を用いて700K以上のユニークなURLを収集し、約900KのQAペアを構築。ファインチューニングされたモデルは、Llava-OVで10-20ポイント、MAmmoTH-VLで5ポイントの性能向上を示し、最良モデルMAmmoTH-VL2は複数のベンチマークで最先端の性能を達成。これにより、Vision-Language Modelsの推論能力向上に寄与することが示された。 Comment元ポスト:https://x.com/wenhuchen/status/1958317145349075446?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pocket #NLP #Dataset #LanguageModel #LLMAgent #SyntheticData #Evaluation #VisionLanguageModel #DeepResearch
Issue Date: 2025-08-14 [Paper Note] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent, Xinyu Geng+, arXiv'25 SummaryWebWatcherは、視覚と言語の推論能力を強化したマルチモーダルエージェントであり、情報探索の困難さに対処する。合成マルチモーダル軌跡を用いた効率的なトレーニングと強化学習により、深い推論能力を向上させる。新たに提案されたBrowseComp-VLベンチマークでの実験により、WebWatcherは複雑なVQAタスクで他のエージェントを大幅に上回る性能を示した。 Comment元ポスト:https://x.com/richardxp888/status/1955645614685077796?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pocket #NLP #SpeechProcessing #Reasoning #OpenWeight #VisionLanguageActionModel
Issue Date: 2025-08-12 [Paper Note] MolmoAct: Action Reasoning Models that can Reason in Space, Jason Lee+, arXiv'25 Summaryアクション推論モデル(ARMs)であるMolmoActは、知覚、計画、制御を三段階のパイプラインで統合し、説明可能で操作可能な行動を実現。シミュレーションと実世界で高いパフォーマンスを示し、特にSimplerEnv Visual Matchingタスクで70.5%のゼロショット精度を達成。MolmoAct Datasetを公開し、トレーニングによりベースモデルのパフォーマンスを平均5.5%向上。全てのモデルの重みやデータセットを公開し、ARMsの構築に向けたオープンな設計図を提供。 Comment`Action Reasoning Models (ARMs)`
元ポスト:https://x.com/gm8xx8/status/1955168414294589844?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
blog: https://allenai.org/blog/molmoact関連:
・1426models:
・https://huggingface.co/allenai/MolmoAct-7B-D-Pretrain-0812
・https://huggingface.co/allenai/MolmoAct-7B-D-0812
datasets:
・https://huggingface.co/datasets/allenai/MolmoAct-Dataset
・https://huggingface.co/datasets/allenai/MolmoAct-Pretraining-Mixture
・https://huggingface.co/datasets/allenai/MolmoAct-Midtraining-Mixtureデータは公開されているが、コードが見当たらない?
Issue Date: 2025-08-21 [Paper Note] VisualWebInstruct: Scaling up Multimodal Instruction Data through Web Search, Yiming Jia+, EMNLP'25 Summary本研究では、推論に焦点を当てたマルチモーダルデータセットの不足に対処するため、VisualWebInstructという新しいアプローチを提案。30,000のシード画像からGoogle画像検索を用いて700K以上のユニークなURLを収集し、約900KのQAペアを構築。ファインチューニングされたモデルは、Llava-OVで10-20ポイント、MAmmoTH-VLで5ポイントの性能向上を示し、最良モデルMAmmoTH-VL2は複数のベンチマークで最先端の性能を達成。これにより、Vision-Language Modelsの推論能力向上に寄与することが示された。 Comment元ポスト:https://x.com/wenhuchen/status/1958317145349075446?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pocket #NLP #Dataset #LanguageModel #LLMAgent #SyntheticData #Evaluation #VisionLanguageModel #DeepResearch
Issue Date: 2025-08-14 [Paper Note] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent, Xinyu Geng+, arXiv'25 SummaryWebWatcherは、視覚と言語の推論能力を強化したマルチモーダルエージェントであり、情報探索の困難さに対処する。合成マルチモーダル軌跡を用いた効率的なトレーニングと強化学習により、深い推論能力を向上させる。新たに提案されたBrowseComp-VLベンチマークでの実験により、WebWatcherは複雑なVQAタスクで他のエージェントを大幅に上回る性能を示した。 Comment元ポスト:https://x.com/richardxp888/status/1955645614685077796?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pocket #NLP #SpeechProcessing #Reasoning #OpenWeight #VisionLanguageActionModel
Issue Date: 2025-08-12 [Paper Note] MolmoAct: Action Reasoning Models that can Reason in Space, Jason Lee+, arXiv'25 Summaryアクション推論モデル(ARMs)であるMolmoActは、知覚、計画、制御を三段階のパイプラインで統合し、説明可能で操作可能な行動を実現。シミュレーションと実世界で高いパフォーマンスを示し、特にSimplerEnv Visual Matchingタスクで70.5%のゼロショット精度を達成。MolmoAct Datasetを公開し、トレーニングによりベースモデルのパフォーマンスを平均5.5%向上。全てのモデルの重みやデータセットを公開し、ARMsの構築に向けたオープンな設計図を提供。 Comment`Action Reasoning Models (ARMs)`
元ポスト:https://x.com/gm8xx8/status/1955168414294589844?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
blog: https://allenai.org/blog/molmoact関連:
・1426models:
・https://huggingface.co/allenai/MolmoAct-7B-D-Pretrain-0812
・https://huggingface.co/allenai/MolmoAct-7B-D-0812
datasets:
・https://huggingface.co/datasets/allenai/MolmoAct-Dataset
・https://huggingface.co/datasets/allenai/MolmoAct-Pretraining-Mixture
・https://huggingface.co/datasets/allenai/MolmoAct-Midtraining-Mixtureデータは公開されているが、コードが見当たらない?
#ComputerVision
#Pocket
#NLP
#ReinforcementLearning
#SyntheticData
#RLVR
#VisionLanguageModel
Issue Date: 2025-08-10
[Paper Note] StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models, Xiangxiang Zhang+, arXiv'25
SummaryStructVRMは、複雑な多質問推論タスクにおいて、部分的な正確性を評価するための構造化された検証可能な報酬モデルを導入。サブ質問レベルのフィードバックを提供し、微妙な部分的なクレジットスコアリングを可能にする。実験により、Seed-StructVRMが12のマルチモーダルベンチマークのうち6つで最先端のパフォーマンスを達成したことが示された。これは、複雑な推論におけるマルチモーダルモデルの能力向上に寄与する。
Comment元ポスト:https://x.com/gm8xx8/status/1954315513397760130?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q複数のsub-questionが存在するような複雑な問題に対して、既存のRLVRにおける全体に対してbinary rewardを適用する方法は報酬が荒すぎるため、よりfine-grainedなverifiableな報酬を設計することで、学習を安定化し性能も向上

以下がverifierのサンプル
 general purposeなreal worldに対するmultimodal reasoningシステムを作成するには高品質で多様なデータが必要なので、以下のようなパイプラインを用いて、学習データを合成している模様。後で読む。サマリが元ポストに記載されているので全体像をざっくり知りたい場合は参照のこと。
general purposeなreal worldに対するmultimodal reasoningシステムを作成するには高品質で多様なデータが必要なので、以下のようなパイプラインを用いて、学習データを合成している模様。後で読む。サマリが元ポストに記載されているので全体像をざっくり知りたい場合は参照のこと。
 #ComputerVision
#Pocket
#NLP
#LanguageModel
#SpeechProcessing
#OpenWeight
#VisionLanguageModel
Issue Date: 2025-07-26
[Paper Note] Ming-Omni: A Unified Multimodal Model for Perception and Generation, Inclusion AI+, arXiv'25
SummaryMing-Omniは、画像、テキスト、音声、動画を処理できる統一マルチモーダルモデルで、音声生成と画像生成において優れた能力を示す。専用エンコーダを用いて異なるモダリティからトークンを抽出し、MoEアーキテクチャで処理することで、効率的にマルチモーダル入力を融合。音声デコーダと高品質な画像生成を統合し、コンテキストに応じたチャットやテキストから音声への変換、画像編集が可能。Ming-Omniは、GPT-4oに匹敵する初のオープンソースモデルであり、研究と開発を促進するためにコードとモデルの重みを公開。
Comment
#ComputerVision
#Pocket
#NLP
#LanguageModel
#SpeechProcessing
#OpenWeight
#VisionLanguageModel
Issue Date: 2025-07-26
[Paper Note] Ming-Omni: A Unified Multimodal Model for Perception and Generation, Inclusion AI+, arXiv'25
SummaryMing-Omniは、画像、テキスト、音声、動画を処理できる統一マルチモーダルモデルで、音声生成と画像生成において優れた能力を示す。専用エンコーダを用いて異なるモダリティからトークンを抽出し、MoEアーキテクチャで処理することで、効率的にマルチモーダル入力を融合。音声デコーダと高品質な画像生成を統合し、コンテキストに応じたチャットやテキストから音声への変換、画像編集が可能。Ming-Omniは、GPT-4oに匹敵する初のオープンソースモデルであり、研究と開発を促進するためにコードとモデルの重みを公開。
Comment 元ポスト:https://x.com/gm8xx8/status/1948878025757446389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
元ポスト:https://x.com/gm8xx8/status/1948878025757446389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
現在はv1.5も公開されておりさらに性能が向上している模様?HF:https://huggingface.co/inclusionAI/Ming-Lite-Omni #Pretraining #Pocket #NLP #LanguageModel #Scaling Laws #DataMixture #VisionLanguageModel Issue Date: 2025-07-18 [Paper Note] Scaling Laws for Optimal Data Mixtures, Mustafa Shukor+, arXiv'25 Summary本研究では、スケーリング法則を用いて任意のターゲットドメインに対する最適なデータ混合比率を決定する方法を提案。特定のドメイン重みベクトルを持つモデルの損失を正確に予測し、LLM、NMM、LVMの事前訓練における予測力を示す。少数の小規模な訓練実行でパラメータを推定し、高価な試行錯誤法に代わる原則的な選択肢を提供。 #ComputerVision #Pocket #NLP #Reasoning #OpenWeight #VisionLanguageModel Issue Date: 2025-07-14 [Paper Note] Kimi-VL Technical Report, Kimi Team+, arXiv'25 SummaryKimi-VLは、効率的なオープンソースのMixture-of-Expertsビジョン・ランゲージモデルであり、2.8Bパラメータの言語デコーダーを活性化して高度なマルチモーダル推論を実現。マルチターンエージェントタスクや大学レベルの画像・動画理解において優れた性能を示し、最先端のVLMと競争。128Kの拡張コンテキストウィンドウを持ち、長い入力を処理可能。Kimi-VL-Thinking-2506は、長期的推論能力を強化するために教師ありファインチューニングと強化学習を用いて開発され、堅牢な一般能力を獲得。コードは公開されている。 Comment・2201
での性能(Vision+テキストの数学の問題)。他の巨大なモデルと比べ2.8BのActivation paramsで高い性能を達成

その他のベンチマークでも高い性能を獲得

モデルのアーキテクチャ。MoonViT (Image Encoder, 1Dのpatchをinput, 様々な解像度のサポート, FlashAttention, SigLIP-SO-400Mを継続事前学習, RoPEを採用) + Linear Projector + MoE Language Decoderの構成

学習のパイプライン。ViTの事前学習ではSigLIP loss (contrastive lossの亜種)とcaption生成のcross-entropy lossを採用している。joint cooldown stageにおいては、高品質なQAデータを合成することで実験的に大幅に性能が向上することを確認したので、それを採用しているとのこと。optimizerは
・2202


post-trainingにおけるRLでは以下の目的関数を用いており、RLVRを用いつつ、現在のポリシーモデルをreferenceとし更新をするような目的関数になっている。curriculum sampling, prioritize samplingをdifficulty labelに基づいて実施している。

 #ComputerVision
#Pocket
#NLP
#ReinforcementLearning
#Reasoning
#On-Policy
#VisionLanguageModel
Issue Date: 2025-07-12
[Paper Note] Perception-Aware Policy Optimization for Multimodal Reasoning, Zhenhailong Wang+, arXiv'25
Summary強化学習における検証可能な報酬(RLVR)は、LLMsに多段階推論能力を与えるが、マルチモーダル推論では最適な性能を発揮できない。視覚入力の認識が主なエラー原因であるため、知覚を意識したポリシー最適化(PAPO)を提案。PAPOはGRPOの拡張で、内部監視信号から学習し、追加のデータや外部報酬に依存しない。KLダイバージェンス項を導入し、マルチモーダルベンチマークで4.4%の改善、視覚依存タスクでは8.0%の改善を達成。知覚エラーも30.5%減少し、PAPOの効果を示す。研究は視覚に基づく推論を促進する新しいRLフレームワークの基盤を築く。
Comment元ポスト:https://x.com/aicia_solid/status/1943507735489974596?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QVLMにおいて、画像をマスクした場合のポリシーモデルの出力と、画像をマスクしない場合のポリシーモデルの出力のKL Divergenceを最大化することで、画像の認知能力が向上し性能向上するよ、みたいな話な模様。
#ComputerVision
#Pocket
#NLP
#ReinforcementLearning
#Reasoning
#On-Policy
#VisionLanguageModel
Issue Date: 2025-07-12
[Paper Note] Perception-Aware Policy Optimization for Multimodal Reasoning, Zhenhailong Wang+, arXiv'25
Summary強化学習における検証可能な報酬(RLVR)は、LLMsに多段階推論能力を与えるが、マルチモーダル推論では最適な性能を発揮できない。視覚入力の認識が主なエラー原因であるため、知覚を意識したポリシー最適化(PAPO)を提案。PAPOはGRPOの拡張で、内部監視信号から学習し、追加のデータや外部報酬に依存しない。KLダイバージェンス項を導入し、マルチモーダルベンチマークで4.4%の改善、視覚依存タスクでは8.0%の改善を達成。知覚エラーも30.5%減少し、PAPOの効果を示す。研究は視覚に基づく推論を促進する新しいRLフレームワークの基盤を築く。
Comment元ポスト:https://x.com/aicia_solid/status/1943507735489974596?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QVLMにおいて、画像をマスクした場合のポリシーモデルの出力と、画像をマスクしない場合のポリシーモデルの出力のKL Divergenceを最大化することで、画像の認知能力が向上し性能向上するよ、みたいな話な模様。


 #ComputerVision
#MachineLearning
#Pocket
#NLP
#LanguageModel
#Transformer
#Architecture
#VideoGeneration/Understandings
#VisionLanguageModel
Issue Date: 2025-07-06
[Paper Note] Energy-Based Transformers are Scalable Learners and Thinkers, Alexi Gladstone+, arXiv'25
Summaryエネルギーベースのトランスフォーマー(EBTs)を用いて、無監督学習から思考を学ぶモデルを提案。EBTsは、入力と候補予測の互換性を検証し、エネルギー最小化を通じて予測を行う。トレーニング中に従来のアプローチよりも高いスケーリング率を達成し、言語タスクでの性能を29%向上させ、画像のノイズ除去でも優れた結果を示す。EBTsは一般化能力が高く、モデルの学習能力と思考能力を向上させる新しいパラダイムである。
Comment元ポスト:https://x.com/hillbig/status/1941657099567845696?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QProject Page:https://energy-based-transformers.github.ioFirst Authorの方による解説ポスト:https://x.com/alexiglad/status/1942231878305714462?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#Pretraining
#Pocket
#NLP
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#RLHF
#Reasoning
#LongSequence
#mid-training
#RewardHacking
#PostTraining
#CurriculumLearning
#RLVR
#Admin'sPick
#VisionLanguageModel
Issue Date: 2025-07-03
[Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25
Summary視覚言語モデルGLM-4.1V-Thinkingを発表し、推論中心のトレーニングフレームワークを開発。強力な視覚基盤モデルを構築し、カリキュラムサンプリングを用いた強化学習で多様なタスクの能力を向上。28のベンチマークで最先端のパフォーマンスを達成し、特に難しいタスクで競争力のある結果を示す。モデルはオープンソースとして公開。
Comment元ポスト:https://x.com/sinclairwang1/status/1940331927724232712?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQwen2.5-VLよりも性能が良いVLM
#ComputerVision
#MachineLearning
#Pocket
#NLP
#LanguageModel
#Transformer
#Architecture
#VideoGeneration/Understandings
#VisionLanguageModel
Issue Date: 2025-07-06
[Paper Note] Energy-Based Transformers are Scalable Learners and Thinkers, Alexi Gladstone+, arXiv'25
Summaryエネルギーベースのトランスフォーマー(EBTs)を用いて、無監督学習から思考を学ぶモデルを提案。EBTsは、入力と候補予測の互換性を検証し、エネルギー最小化を通じて予測を行う。トレーニング中に従来のアプローチよりも高いスケーリング率を達成し、言語タスクでの性能を29%向上させ、画像のノイズ除去でも優れた結果を示す。EBTsは一般化能力が高く、モデルの学習能力と思考能力を向上させる新しいパラダイムである。
Comment元ポスト:https://x.com/hillbig/status/1941657099567845696?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QProject Page:https://energy-based-transformers.github.ioFirst Authorの方による解説ポスト:https://x.com/alexiglad/status/1942231878305714462?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#Pretraining
#Pocket
#NLP
#Supervised-FineTuning (SFT)
#ReinforcementLearning
#RLHF
#Reasoning
#LongSequence
#mid-training
#RewardHacking
#PostTraining
#CurriculumLearning
#RLVR
#Admin'sPick
#VisionLanguageModel
Issue Date: 2025-07-03
[Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25
Summary視覚言語モデルGLM-4.1V-Thinkingを発表し、推論中心のトレーニングフレームワークを開発。強力な視覚基盤モデルを構築し、カリキュラムサンプリングを用いた強化学習で多様なタスクの能力を向上。28のベンチマークで最先端のパフォーマンスを達成し、特に難しいタスクで競争力のある結果を示す。モデルはオープンソースとして公開。
Comment元ポスト:https://x.com/sinclairwang1/status/1940331927724232712?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QQwen2.5-VLよりも性能が良いVLM
 アーキテクチャはこちら。が、pretraining(データのフィルタリング, マルチモーダル→long context継続事前学習)->SFT(cold startへの対処, reasoning能力の獲得)->RL(RLVRとRLHFの併用によるパフォーマンス向上とAlignment, RewardHackingへの対処,curriculum sampling)など、全体の学習パイプラインの細かいテクニックの積み重ねで高い性能が獲得されていると考えられる。
アーキテクチャはこちら。が、pretraining(データのフィルタリング, マルチモーダル→long context継続事前学習)->SFT(cold startへの対処, reasoning能力の獲得)->RL(RLVRとRLHFの併用によるパフォーマンス向上とAlignment, RewardHackingへの対処,curriculum sampling)など、全体の学習パイプラインの細かいテクニックの積み重ねで高い性能が獲得されていると考えられる。
 #ComputerVision
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
Issue Date: 2025-07-02
[Paper Note] MARBLE: A Hard Benchmark for Multimodal Spatial Reasoning and Planning, Yulun Jiang+, arXiv'25
SummaryMARBLEという新しいマルチモーダル推論ベンチマークを提案し、MLLMsの複雑な推論能力を評価。MARBLEは、空間的・視覚的・物理的制約下での多段階計画を必要とするM-PortalとM-Cubeの2つのタスクから成る。現在のMLLMsは低いパフォーマンスを示し、視覚的入力からの情報抽出においても失敗が見られる。これにより、次世代モデルの推論能力向上が期待される。
Comment元ポスト:https://x.com/michael_d_moor/status/1940062842742526445?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QPortal2を使った新たなベンチマーク。筆者は昔このゲームを少しだけプレイしたことがあるが、普通に難しかった記憶がある😅
#ComputerVision
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
Issue Date: 2025-07-02
[Paper Note] MARBLE: A Hard Benchmark for Multimodal Spatial Reasoning and Planning, Yulun Jiang+, arXiv'25
SummaryMARBLEという新しいマルチモーダル推論ベンチマークを提案し、MLLMsの複雑な推論能力を評価。MARBLEは、空間的・視覚的・物理的制約下での多段階計画を必要とするM-PortalとM-Cubeの2つのタスクから成る。現在のMLLMsは低いパフォーマンスを示し、視覚的入力からの情報抽出においても失敗が見られる。これにより、次世代モデルの推論能力向上が期待される。
Comment元ポスト:https://x.com/michael_d_moor/status/1940062842742526445?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QPortal2を使った新たなベンチマーク。筆者は昔このゲームを少しだけプレイしたことがあるが、普通に難しかった記憶がある😅
細かいが表中のGPT-o3は正しくはo3だと思われる。
時間がなくて全然しっかりと読めていないが、reasoning effortやthinkingモードはどのように設定して評価したのだろうか。

 #ComputerVision
#Pocket
#NLP
#Dataset
#LanguageModel
#Zero/FewShotPrompting
#In-ContextLearning
Issue Date: 2025-07-01
[Paper Note] SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning, Melanie Rieff+, arXiv'25
Summaryマルチモーダルインコンテキスト学習(ICL)は医療分野での可能性があるが、十分に探求されていない。SMMILEという医療タスク向けの初のマルチモーダルICLベンチマークを導入し、111の問題を含む。15のMLLMの評価で、医療タスクにおけるICL能力が中程度から低いことが示された。ICLはSMMILEで平均8%、SMMILE++で9.4%の改善をもたらし、無関係な例がパフォーマンスを最大9.5%低下させることも確認。例の順序による最近性バイアスがパフォーマンス向上に寄与することも明らかになった。
Comment元ポスト:https://x.com/michael_d_moor/status/1939664155813839114?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#LanguageModel
Issue Date: 2025-06-26
[Paper Note] OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning, Xianhang Li+, arXiv'25
SummaryOpenVisionは、完全にオープンでコスト効果の高いビジョンエンコーダーのファミリーを提案し、CLIPと同等以上の性能を発揮します。既存の研究を基に構築され、マルチモーダルモデルの進展に実用的な利点を示します。5.9Mから632.1Mパラメータのエンコーダーを提供し、容量と効率の柔軟なトレードオフを実現します。
Comment元ポスト:https://x.com/cihangxie/status/1920575141849030882?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#Pocket
#NLP
#LanguageModel
#Tokenizer
Issue Date: 2025-06-24
[Paper Note] Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations, Jiaming Han+, arXiv'25
Summary本論文では、視覚理解と生成を統一するマルチモーダルフレームワークTarを提案。Text-Aligned Tokenizer(TA-Tok)を用いて画像を離散トークンに変換し、視覚とテキストを統一空間に統合。スケール適応型のエンコーディングとデコーディングを導入し、高忠実度の視覚出力を生成。迅速な自己回帰モデルと拡散ベースのモデルを用いたデトークナイザーを活用し、視覚理解と生成の改善を実現。実験結果では、Tarが既存手法と同等以上の性能を示し、効率的なトレーニングを達成。
Comment元ポスト:https://x.com/_akhaliq/status/1937345768223859139?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtext modalityとvision modalityを共通の空間で表現する
#ComputerVision
#Pocket
#NLP
#Dataset
#LanguageModel
#Zero/FewShotPrompting
#In-ContextLearning
Issue Date: 2025-07-01
[Paper Note] SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning, Melanie Rieff+, arXiv'25
Summaryマルチモーダルインコンテキスト学習(ICL)は医療分野での可能性があるが、十分に探求されていない。SMMILEという医療タスク向けの初のマルチモーダルICLベンチマークを導入し、111の問題を含む。15のMLLMの評価で、医療タスクにおけるICL能力が中程度から低いことが示された。ICLはSMMILEで平均8%、SMMILE++で9.4%の改善をもたらし、無関係な例がパフォーマンスを最大9.5%低下させることも確認。例の順序による最近性バイアスがパフォーマンス向上に寄与することも明らかになった。
Comment元ポスト:https://x.com/michael_d_moor/status/1939664155813839114?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#LanguageModel
Issue Date: 2025-06-26
[Paper Note] OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning, Xianhang Li+, arXiv'25
SummaryOpenVisionは、完全にオープンでコスト効果の高いビジョンエンコーダーのファミリーを提案し、CLIPと同等以上の性能を発揮します。既存の研究を基に構築され、マルチモーダルモデルの進展に実用的な利点を示します。5.9Mから632.1Mパラメータのエンコーダーを提供し、容量と効率の柔軟なトレードオフを実現します。
Comment元ポスト:https://x.com/cihangxie/status/1920575141849030882?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#Pocket
#NLP
#LanguageModel
#Tokenizer
Issue Date: 2025-06-24
[Paper Note] Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations, Jiaming Han+, arXiv'25
Summary本論文では、視覚理解と生成を統一するマルチモーダルフレームワークTarを提案。Text-Aligned Tokenizer(TA-Tok)を用いて画像を離散トークンに変換し、視覚とテキストを統一空間に統合。スケール適応型のエンコーディングとデコーディングを導入し、高忠実度の視覚出力を生成。迅速な自己回帰モデルと拡散ベースのモデルを用いたデトークナイザーを活用し、視覚理解と生成の改善を実現。実験結果では、Tarが既存手法と同等以上の性能を示し、効率的なトレーニングを達成。
Comment元ポスト:https://x.com/_akhaliq/status/1937345768223859139?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qtext modalityとvision modalityを共通の空間で表現する
 Visual Understanding/Generationのベンチで全体的に高い性能を達成
Visual Understanding/Generationのベンチで全体的に高い性能を達成
 #ComputerVision
#Embeddings
#Pocket
#NLP
#RepresentationLearning
Issue Date: 2025-06-24
[Paper Note] jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval, Michael Günther+, arXiv'25
Summary3.8億パラメータのマルチモーダル埋め込みモデル「jina-embeddings-v4」を提案。新しいアーキテクチャにより、クエリベースの情報検索やクロスモーダルの類似性検索を最適化。タスク特化型のLoRAアダプターを組み込み、視覚的に豊かなコンテンツの処理に優れた性能を発揮。新しいベンチマーク「Jina-VDR」も導入。
Comment元ポスト:https://x.com/arankomatsuzaki/status/1937342962075378014?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#Pocket
#NLP
#LanguageModel
#RLVR
#DataMixture
Issue Date: 2025-06-05
[Paper Note] MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning, Yiqing Liang+, arXiv'25
Summary検証可能な報酬を用いた強化学習(RLVR)をマルチモーダルLLMsに適用するためのポストトレーニングフレームワークを提案。異なる視覚と言語の問題を含むデータセットをキュレーションし、最適なデータ混合戦略を導入。実験により、提案した戦略がMLLMの推論能力を大幅に向上させることを示し、分布外ベンチマークで平均5.24%の精度向上を達成。
Comment元ポスト:https://x.com/_vztu/status/1930312780701413498?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qマルチモーダルな設定でRLVRを適用すると、すべてのデータセットを学習に利用する場合より、特定のタスクのみのデータで学習した方が当該タスクでは性能が高くなったり(つまりデータが多ければ多いほど良いわけでは無い)、特定のデータをablationするとOODに対する予測性能が改善したりするなど、データ間で干渉が起きて敵対的になってしまうような現象が起きる。このことから、どのように適切にデータを混合できるか?という戦略の必要性が浮き彫りになり、モデルベースなMixture戦略(どうやらデータの混合分布から学習後の性能を予測するモデルな模様)の性能がuniformにmixするよりも高い性能を示した、みたいな話らしい。
#ComputerVision
#Pocket
#NLP
#LanguageModel
#DiffusionModel
Issue Date: 2025-05-24
LaViDa: A Large Diffusion Language Model for Multimodal Understanding, Shufan Li+, arXiv'25
SummaryLaViDaは、離散拡散モデル(DM)を基にしたビジョン・ランゲージモデル(VLM)で、高速な推論と制御可能な生成を実現。新技術を取り入れ、マルチモーダルタスクにおいてAR VLMと競争力のある性能を達成。COCOキャプショニングで速度向上と性能改善を示し、AR VLMの強力な代替手段であることを証明。
Comment元ポスト:https://x.com/iscienceluvr/status/1925749919312159167?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QDiffusion Modelの波が来た同程度のサイズのARモデルをoutperform [^1]
#ComputerVision
#Embeddings
#Pocket
#NLP
#RepresentationLearning
Issue Date: 2025-06-24
[Paper Note] jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval, Michael Günther+, arXiv'25
Summary3.8億パラメータのマルチモーダル埋め込みモデル「jina-embeddings-v4」を提案。新しいアーキテクチャにより、クエリベースの情報検索やクロスモーダルの類似性検索を最適化。タスク特化型のLoRAアダプターを組み込み、視覚的に豊かなコンテンツの処理に優れた性能を発揮。新しいベンチマーク「Jina-VDR」も導入。
Comment元ポスト:https://x.com/arankomatsuzaki/status/1937342962075378014?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#ComputerVision
#Pocket
#NLP
#LanguageModel
#RLVR
#DataMixture
Issue Date: 2025-06-05
[Paper Note] MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning, Yiqing Liang+, arXiv'25
Summary検証可能な報酬を用いた強化学習(RLVR)をマルチモーダルLLMsに適用するためのポストトレーニングフレームワークを提案。異なる視覚と言語の問題を含むデータセットをキュレーションし、最適なデータ混合戦略を導入。実験により、提案した戦略がMLLMの推論能力を大幅に向上させることを示し、分布外ベンチマークで平均5.24%の精度向上を達成。
Comment元ポスト:https://x.com/_vztu/status/1930312780701413498?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qマルチモーダルな設定でRLVRを適用すると、すべてのデータセットを学習に利用する場合より、特定のタスクのみのデータで学習した方が当該タスクでは性能が高くなったり(つまりデータが多ければ多いほど良いわけでは無い)、特定のデータをablationするとOODに対する予測性能が改善したりするなど、データ間で干渉が起きて敵対的になってしまうような現象が起きる。このことから、どのように適切にデータを混合できるか?という戦略の必要性が浮き彫りになり、モデルベースなMixture戦略(どうやらデータの混合分布から学習後の性能を予測するモデルな模様)の性能がuniformにmixするよりも高い性能を示した、みたいな話らしい。
#ComputerVision
#Pocket
#NLP
#LanguageModel
#DiffusionModel
Issue Date: 2025-05-24
LaViDa: A Large Diffusion Language Model for Multimodal Understanding, Shufan Li+, arXiv'25
SummaryLaViDaは、離散拡散モデル(DM)を基にしたビジョン・ランゲージモデル(VLM)で、高速な推論と制御可能な生成を実現。新技術を取り入れ、マルチモーダルタスクにおいてAR VLMと競争力のある性能を達成。COCOキャプショニングで速度向上と性能改善を示し、AR VLMの強力な代替手段であることを証明。
Comment元ポスト:https://x.com/iscienceluvr/status/1925749919312159167?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QDiffusion Modelの波が来た同程度のサイズのARモデルをoutperform [^1]

[^1]:ただし、これが本当にDiffusion Modelを使ったことによる恩恵なのかはまだ論文を読んでいないのでわからない。必要になったら読む。ただ、Physics of Language Modelのように、完全にコントロールされたデータで異なるアーキテクチャを比較しないとその辺はわからなそうではある。 #ComputerVision #Pocket #NLP #Dataset #LanguageModel #Evaluation #ICLR #x-Use Issue Date: 2025-04-18 AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25 Summary本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 CommentAndroid環境でのPhone Useのベンチマーク #ComputerVision #Pocket #NLP #LanguageModel #SpeechProcessing #OpenWeight #Video Issue Date: 2025-03-31 Qwen2.5-Omni Technical Report, Jin Xu+, arXiv'25 Summaryマルチモーダルモデル「Qwen2.5-Omni」は、テキスト、画像、音声、動画を認識し、ストリーミング方式で自然な音声応答を生成する。音声と視覚エンコーダはブロック処理を用い、TMRoPEによる新しい位置埋め込みで音声と動画の同期を実現。Thinker-Talkerアーキテクチャにより、テキスト生成と音声出力を干渉なく行う。Qwen2.5-Omniは、エンドツーエンドで訓練され、音声指示に対する性能がテキスト入力と同等で、ストリーミングTalkerは既存手法を上回る自然さを持つ。 CommentQwen TeamによるマルチモーダルLLM。テキスト、画像、動画音声をinputとして受け取り、テキスト、音声をoutputする。

weight:https://huggingface.co/collections/Qwen/qwen25-omni-67de1e5f0f9464dc6314b36e元ポスト:https://www.linkedin.com/posts/niels-rogge-a3b7a3127_alibabas-qwen-team-has-done-it-again-this-activity-7311036679627132929-HUqy?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4 #Multi #RecommenderSystems #NeuralNetwork #Survey #Pocket #MultitaskLearning Issue Date: 2025-03-03 Joint Modeling in Recommendations: A Survey, Xiangyu Zhao+, arXiv'25 Summaryデジタル環境におけるDeep Recommender Systems(DRS)は、ユーザーの好みに基づくコンテンツ推薦に重要だが、従来の手法は単一のタスクやデータに依存し、複雑な好みを反映できない。これを克服するために、共同モデリングアプローチが必要であり、推薦の精度とカスタマイズを向上させる。本論文では、共同モデリングをマルチタスク、マルチシナリオ、マルチモーダル、マルチビヘイビアの4次元で定義し、最新の進展と研究の方向性を探る。最後に、将来の研究の道筋を示し、結論を述べる。 Comment元ポスト:https://x.com/_reachsumit/status/1896408792952410496?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pretraining #Pocket #FoundationModel #CVPR #Admin'sPick #VisionLanguageModel Issue Date: 2025-08-23 [Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24 Summary大規模視覚-言語基盤モデル(InternVL)は、60億パラメータで設計され、LLMと整合させるためにウェブ規模の画像-テキストデータを使用。視覚認知タスクやゼロショット分類、検索など32のベンチマークで最先端の性能を達成し、マルチモーダル対話システムの構築に寄与。ViT-22Bの代替として強力な視覚能力を持つ。コードとモデルは公開されている。 Comment既存のResNetのようなSupervised pretrainingに基づくモデル、CLIPのようなcontrastive pretrainingに基づくモデルに対して、text encoder部分をLLMに置き換えて、contrastive learningとgenerativeタスクによる学習を組み合わせたパラダイムを提案。

InternVLのアーキテクチャは下記で、3 stageの学習で構成される。最初にimage text pairをcontrastive learningし学習し、続いてモデルのパラメータはfreezeしimage text retrievalタスク等でモダリティ間の変換を担う最終的にQlLlama(multilingual性能を高めたllama)をvision-languageモダリティを繋ぐミドルウェアのように捉え、Vicunaをテキストデコーダとして接続してgenerative cossで学習する、みたいなアーキテクチャの模様(斜め読みなので少し違う可能性あり
 現在のVLMの主流であるvision encoderとLLMをadapterで接続する方式はここからかなりシンプルになっていることが伺える。
#ComputerVision
#Pocket
#NLP
#Dataset
#QuestionAnswering
#Evaluation
#MultiLingual
#VisionLanguageModel
#Cultural
Issue Date: 2025-08-18
[Paper Note] CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark, David Romero+, arXiv'24
SummaryCVQAは、文化的に多様な多言語のVisual Question Answeringベンチマークで、30か国からの画像と質問を含み、31の言語と13のスクリプトをカバー。データ収集にはネイティブスピーカーを関与させ、合計10,000の質問を提供。マルチモーダル大規模言語モデルをベンチマークし、文化的能力とバイアスを評価するための新たな基準を示す。
#ComputerVision
#Pocket
#NLP
#Dataset
#Evaluation
#Reasoning
#CVPR
Issue Date: 2025-08-09
[Paper Note] MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI, Xiang Yue+, CVPR'24
SummaryMMMUは、大学レベルの専門知識と意図的な推論を必要とするマルチモーダルモデルの評価のための新しいベンチマークで、11,500のマルチモーダル質問を含む。6つの主要分野をカバーし、30種類の画像タイプを使用。既存のベンチマークと異なり、専門家が直面するタスクに類似した課題を提供。GPT-4VとGeminiの評価では、56%と59%の精度にとどまり、改善の余地があることを示す。MMMUは次世代のマルチモーダル基盤モデルの構築に寄与することが期待されている。
CommentMMMUのリリースから20ヶ月経過したが、いまだに人間のエキスパートのアンサンブルには及ばないとのこと
現在のVLMの主流であるvision encoderとLLMをadapterで接続する方式はここからかなりシンプルになっていることが伺える。
#ComputerVision
#Pocket
#NLP
#Dataset
#QuestionAnswering
#Evaluation
#MultiLingual
#VisionLanguageModel
#Cultural
Issue Date: 2025-08-18
[Paper Note] CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark, David Romero+, arXiv'24
SummaryCVQAは、文化的に多様な多言語のVisual Question Answeringベンチマークで、30か国からの画像と質問を含み、31の言語と13のスクリプトをカバー。データ収集にはネイティブスピーカーを関与させ、合計10,000の質問を提供。マルチモーダル大規模言語モデルをベンチマークし、文化的能力とバイアスを評価するための新たな基準を示す。
#ComputerVision
#Pocket
#NLP
#Dataset
#Evaluation
#Reasoning
#CVPR
Issue Date: 2025-08-09
[Paper Note] MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI, Xiang Yue+, CVPR'24
SummaryMMMUは、大学レベルの専門知識と意図的な推論を必要とするマルチモーダルモデルの評価のための新しいベンチマークで、11,500のマルチモーダル質問を含む。6つの主要分野をカバーし、30種類の画像タイプを使用。既存のベンチマークと異なり、専門家が直面するタスクに類似した課題を提供。GPT-4VとGeminiの評価では、56%と59%の精度にとどまり、改善の余地があることを示す。MMMUは次世代のマルチモーダル基盤モデルの構築に寄与することが期待されている。
CommentMMMUのリリースから20ヶ月経過したが、いまだに人間のエキスパートのアンサンブルには及ばないとのこと
https://x.com/xiangyue96/status/1953902213790830931?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMMMUのサンプルはこちら。各分野ごとに専門家レベルの知識と推論が求められるとのこと。
 #ComputerVision
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
#ACL
Issue Date: 2025-01-06
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems, Chaoqun He+, ACL'24
Summary大規模言語モデル(LLMs)やマルチモーダルモデル(LMMs)の能力を測定するために、オリンピアドレベルのバイリンガルマルチモーダル科学ベンチマーク「OlympiadBench」を提案。8,476の数学と物理の問題を含み、専門家レベルの注釈が付けられている。トップモデルのGPT-4Vは平均17.97%のスコアを達成したが、物理では10.74%にとどまり、ベンチマークの厳しさを示す。一般的な問題として幻覚や論理的誤謬が指摘され、今後のAGI研究に貴重なリソースとなることが期待される。
#ComputerVision
#Pretraining
#Pocket
#NLP
#LanguageModel
Issue Date: 2024-11-25
Multimodal Autoregressive Pre-training of Large Vision Encoders, Enrico Fini+, arXiv'24
Summary新しい手法AIMV2を用いて、大規模なビジョンエンコーダの事前学習を行う。これは画像とテキストを組み合わせたマルチモーダル設定に拡張され、シンプルな事前学習プロセスと優れた性能を特徴とする。AIMV2-3BエンコーダはImageNet-1kで89.5%の精度を達成し、マルチモーダル画像理解において最先端のコントラストモデルを上回る。
#ComputerVision
#EfficiencyImprovement
#NLP
#Transformer
#SpeechProcessing
#Architecture
Issue Date: 2024-11-12
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models, Weixin Liang+, arXiv'24
Summary大規模言語モデル(LLMs)のマルチモーダル処理を効率化するために、Mixture-of-Transformers(MoT)を提案。MoTは計算コストを削減し、モダリティごとにパラメータを分離して特化した処理を実現。Chameleon 7B設定では、55.8%のFLOPsで密なベースラインに匹敵する性能を示し、音声を含む場合も37.2%のFLOPsで同様の結果を達成。さらに、Transfusion設定では、7BのMoTモデルが密なベースラインの画像性能に対してFLOPsの3分の1で匹敵し、760Mのモデルは主要な画像生成指標で上回る結果を得た。MoTは実用的な利点も示し、画像品質を47.2%、テキスト品質を75.6%の経過時間で達成。
Comment
#ComputerVision
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
#ACL
Issue Date: 2025-01-06
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems, Chaoqun He+, ACL'24
Summary大規模言語モデル(LLMs)やマルチモーダルモデル(LMMs)の能力を測定するために、オリンピアドレベルのバイリンガルマルチモーダル科学ベンチマーク「OlympiadBench」を提案。8,476の数学と物理の問題を含み、専門家レベルの注釈が付けられている。トップモデルのGPT-4Vは平均17.97%のスコアを達成したが、物理では10.74%にとどまり、ベンチマークの厳しさを示す。一般的な問題として幻覚や論理的誤謬が指摘され、今後のAGI研究に貴重なリソースとなることが期待される。
#ComputerVision
#Pretraining
#Pocket
#NLP
#LanguageModel
Issue Date: 2024-11-25
Multimodal Autoregressive Pre-training of Large Vision Encoders, Enrico Fini+, arXiv'24
Summary新しい手法AIMV2を用いて、大規模なビジョンエンコーダの事前学習を行う。これは画像とテキストを組み合わせたマルチモーダル設定に拡張され、シンプルな事前学習プロセスと優れた性能を特徴とする。AIMV2-3BエンコーダはImageNet-1kで89.5%の精度を達成し、マルチモーダル画像理解において最先端のコントラストモデルを上回る。
#ComputerVision
#EfficiencyImprovement
#NLP
#Transformer
#SpeechProcessing
#Architecture
Issue Date: 2024-11-12
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models, Weixin Liang+, arXiv'24
Summary大規模言語モデル(LLMs)のマルチモーダル処理を効率化するために、Mixture-of-Transformers(MoT)を提案。MoTは計算コストを削減し、モダリティごとにパラメータを分離して特化した処理を実現。Chameleon 7B設定では、55.8%のFLOPsで密なベースラインに匹敵する性能を示し、音声を含む場合も37.2%のFLOPsで同様の結果を達成。さらに、Transfusion設定では、7BのMoTモデルが密なベースラインの画像性能に対してFLOPsの3分の1で匹敵し、760Mのモデルは主要な画像生成指標で上回る結果を得た。MoTは実用的な利点も示し、画像品質を47.2%、テキスト品質を75.6%の経過時間で達成。
Comment #RecommenderSystems
#InformationRetrieval
#Pocket
Issue Date: 2024-11-08
MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs, Sheng-Chieh Lin+, arXiv'24
Summary本論文では、マルチモーダル大規模言語モデル(MLLM)を用いた「ユニバーサルマルチモーダル検索」の技術を提案し、複数のモダリティと検索タスクに対応する能力を示します。10のデータセットと16の検索タスクでの実験により、MLLMリトリーバーはテキストと画像のクエリを理解できるが、モダリティバイアスによりクロスモーダル検索では劣ることが判明。これを解決するために、モダリティ認識ハードネガティブマイニングを提案し、継続的なファインチューニングでテキスト検索能力を向上させました。結果として、MM-EmbedモデルはM-BEIRベンチマークで最先端の性能を達成し、NV-Embed-v1を上回りました。また、ゼロショットリランキングを通じて、複雑なクエリに対するマルチモーダル検索の改善が可能であることを示しました。これらの成果は、今後のユニバーサルマルチモーダル検索の発展に寄与するものです。
Comment
#RecommenderSystems
#InformationRetrieval
#Pocket
Issue Date: 2024-11-08
MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs, Sheng-Chieh Lin+, arXiv'24
Summary本論文では、マルチモーダル大規模言語モデル(MLLM)を用いた「ユニバーサルマルチモーダル検索」の技術を提案し、複数のモダリティと検索タスクに対応する能力を示します。10のデータセットと16の検索タスクでの実験により、MLLMリトリーバーはテキストと画像のクエリを理解できるが、モダリティバイアスによりクロスモーダル検索では劣ることが判明。これを解決するために、モダリティ認識ハードネガティブマイニングを提案し、継続的なファインチューニングでテキスト検索能力を向上させました。結果として、MM-EmbedモデルはM-BEIRベンチマークで最先端の性能を達成し、NV-Embed-v1を上回りました。また、ゼロショットリランキングを通じて、複雑なクエリに対するマルチモーダル検索の改善が可能であることを示しました。これらの成果は、今後のユニバーサルマルチモーダル検索の発展に寄与するものです。
Comment #Survey
#Pocket
#LanguageModel
#ACL
Issue Date: 2024-01-25
MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N_A, ACL'24 Findings
SummaryMM-LLMsは、コスト効果の高いトレーニング戦略を用いて拡張され、多様なMMタスクに対応する能力を持つことが示されている。本論文では、MM-LLMsのアーキテクチャ、トレーニング手法、ベンチマークのパフォーマンスなどについて調査し、その進歩に貢献することを目指している。
Comment以下、論文を斜め読みしながら、ChatGPTを通じて疑問点を解消しつつ理解した内容なので、理解が不十分な点が含まれている可能性があるので注意。
#Survey
#Pocket
#LanguageModel
#ACL
Issue Date: 2024-01-25
MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N_A, ACL'24 Findings
SummaryMM-LLMsは、コスト効果の高いトレーニング戦略を用いて拡張され、多様なMMタスクに対応する能力を持つことが示されている。本論文では、MM-LLMsのアーキテクチャ、トレーニング手法、ベンチマークのパフォーマンスなどについて調査し、その進歩に貢献することを目指している。
Comment以下、論文を斜め読みしながら、ChatGPTを通じて疑問点を解消しつつ理解した内容なので、理解が不十分な点が含まれている可能性があるので注意。
まあざっくり言うと、マルチモーダルを理解できるLLMを作りたかったら、様々なモダリティをエンコーディングして得られる表現と、既存のLLMが内部的に処理可能な表現を対応づける Input Projectorという名の関数を学習すればいいだけだよ(モダリティのエンコーダ、LLMは事前学習されたものをそのままfreezeして使えば良い)。
マルチモーダルを生成できるLLMを作りたかったら、LLMがテキストを生成するだけでなく、様々なモダリティに対応する表現も追加で出力するようにして、その出力を各モダリティを生成できるモデルに入力できるように変換するOutput Projectortという名の関数を学習しようね、ということだと思われる。
概要

ポイント
・Modality Encoder, LLM Backbone、およびModality Generatorは一般的にはパラメータをfreezeする
・optimizationの対象は「Input/Output Projector」
Modality Encoder
様々なモダリティI_Xを、特徴量F_Xに変換する。これはまあ、色々なモデルがある。

Input Projector
モダリティI_Xとそれに対応するテキストtのデータ {I_X, t}が与えられたとき、テキストtを埋め込み表現に変換んした結果得られる特徴量がF_Tである。Input Projectorは、F_XをLLMのinputとして利用する際に最適な特徴量P_Xに変換するθX_Tを学習することである。これは、LLM(P_X, F_T)によってテキストtがどれだけ生成できたか、を表現する損失関数を最小化することによって学習される。

LLM Backbone
LLMによってテキスト列tと、各モダリティに対応した表現であるS_Xを生成する。outputからt, S_Xをどのように区別するかはモデルの構造などにもよるが、たとえば異なるヘッドを用意して、t, S_Xを区別するといったことは可能であろうと思われる。

Output Projector
S_XをModality Generatorが解釈可能な特徴量H_Xに変換する関数のことである。これは学習しなければならない。
H_XとModality Generatorのtextual encoderにtを入力した際に得られる表現τX(t)が近くなるようにOutput Projector θ_T_Xを学習する。これによって、S_XとModality Generatorがalignするようにする。

Modality Generator
各ModalityをH_Xから生成できるように下記のような損失学習する。要は、生成されたモダリティデータ(または表現)が実際のデータにどれだけ近いか、を表しているらしい。具体的には、サンプリングによって得られたノイズと、モデルが推定したノイズの値がどれだけ近いかを測る、みたいなことをしているらしい。

Multi Modalを理解するモデルだけであれば、Input Projectorの損失のみが学習され、生成までするのであれば、Input/Output Projector, Modality Generatorそれぞれに示した損失関数を通じてパラメータが学習される。あと、P_XやらS_Xはいわゆるsoft-promptingみたいなものであると考えられる。 #ComputerVision #Pretraining #Pocket #NLP #Transformer #InstructionTuning #SpeechProcessing #CVPR #Encoder-Decoder #Robotics Issue Date: 2023-12-29 Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, N_A, CVPR'24 SummaryUnified-IO 2は、最初の自己回帰型のマルチモーダルモデルであり、画像、テキスト、音声、アクションを理解し生成することができます。異なるモダリティを統一するために、共有の意味空間に入力と出力を配置し、単一のエンコーダ・デコーダトランスフォーマーモデルで処理します。さまざまなアーキテクチャの改善を提案し、大規模なマルチモーダルな事前トレーニングコーパスを使用してモデルをトレーニングします。Unified-IO 2は、GRITベンチマークを含む35以上のベンチマークで最先端のパフォーマンスを発揮します。 Comment画像、テキスト、音声、アクションを理解できる初めてのautoregressive model。AllenAIモデルのアーキテクチャ図

マルチモーダルに拡張したことで、訓練が非常に不安定になったため、アーキテクチャ上でいくつかの工夫を加えている:
・2D Rotary Embedding
・Positional EncodingとしてRoPEを採用
・画像のような2次元データのモダリティの場合はRoPEを2次元に拡張する。具体的には、位置(i, j)のトークンについては、Q, Kのembeddingを半分に分割して、それぞれに対して独立にi, jのRoPE Embeddingを適用することでi, j双方の情報を組み込む。
・QK Normalization
・image, audioのモダリティを組み込むことでMHAのlogitsが非常に大きくなりatteetion weightが0/1の極端な値をとるようになり訓練の不安定さにつながった。このため、dot product attentionを適用する前にLayerNormを組み込んだ。
・Scaled Cosine Attention
・Image Historyモダリティにおいて固定長のEmbeddingを得るためにPerceiver Resamplerを扱ったているが、こちらも上記と同様にAttentionのlogitsが極端に大きくなったため、cosine類似度をベースとしたScaled Cosine Attention 2259 を利用することで、大幅に訓練の安定性が改善された。
・その他
・attention logitsにはfp32を適用
・事前学習されたViTとASTを同時に更新すると不安定につながったため、事前学習の段階ではfreezeし、instruction tuningの最後にfinetuningを実施
 目的関数としては、Mixture of Denoisers (1424)に着想を得て、Multimodal Mixture of Denoisersを提案。MoDでは、
目的関数としては、Mixture of Denoisers (1424)に着想を得て、Multimodal Mixture of Denoisersを提案。MoDでは、
・\[R\]: 通常のspan corruption (1--5 token程度のspanをmaskする)
・\[S\]: causal language modeling (inputを2つのサブシーケンスに分割し、前方から後方を予測する。前方部分はBi-directionalでも可)
・\[X\]: extreme span corruption (12>=token程度のspanをmaskする)
の3種類が提案されており、モダリティごとにこれらを使い分ける:
・text modality: UL2 (1424)を踏襲
・image, audioがtargetの場合: 2つの類似したパラダイムを定義し利用
・\[R\]: patchをランダムにx%マスクしre-constructする
・\[S\]: inputのtargetとは異なるモダリティのみの情報から、targetモダリティを生成する
訓練時には prefixとしてmodality token \[Text\], \[Image\], \[Audio\] とparadigm token \[R\], \[S\], \[X\] をタスクを指示するトークンとして利用している。また、image, audioのマスク部分のdenoisingをautoregressive modelで実施する際には普通にやるとdecoder側でリークが発生する(a)。これを防ぐには、Encoder側でマスクされているトークンを、Decoder側でteacher-forcingする際にの全てマスクする方法(b)があるが、この場合、生成タスクとdenoisingタスクが相互に干渉してしまいうまく学習できなくなってしまう(生成タスクでは通常Decoderのinputとして[mask]が入力され次トークンを生成する、といったことは起きえないが、愚直に(b)をやるとそうなってしまう)。ので、(c)に示したように、マスクされているトークンをinputとして生成しなければならない時だけ、マスクを解除してdecoder側にinputする、という方法 (Dynamic Masking) でこの問題に対処している。
 #ComputerVision
#NLP
#LanguageModel
#SpeechProcessing
#AAAI
Issue Date: 2023-04-26
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head, AAAI'24
SummaryAudioGPTは、複雑な音声情報を処理し、音声対話をサポートするマルチモーダルAIシステムである。基盤モデルとASR、TTSインターフェースを組み合わせ、音声、音楽、トーキングヘッドの理解と生成を行う。実験により、AudioGPTが多様なオーディオコンテンツの創造を容易にする能力を示した。
Commenttext, audio, imageといったマルチモーダルなpromptから、audioに関する様々なタスクを実現できるシステムマルチモーダルデータをjointで学習したというわけではなく、色々なモデルの組み合わせてタスクを実現しているっぽい
#ComputerVision
#NLP
#LanguageModel
#SpeechProcessing
#AAAI
Issue Date: 2023-04-26
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head, AAAI'24
SummaryAudioGPTは、複雑な音声情報を処理し、音声対話をサポートするマルチモーダルAIシステムである。基盤モデルとASR、TTSインターフェースを組み合わせ、音声、音楽、トーキングヘッドの理解と生成を行う。実験により、AudioGPTが多様なオーディオコンテンツの創造を容易にする能力を示した。
Commenttext, audio, imageといったマルチモーダルなpromptから、audioに関する様々なタスクを実現できるシステムマルチモーダルデータをjointで学習したというわけではなく、色々なモデルの組み合わせてタスクを実現しているっぽい

#ComputerVision #Controllable #Pocket #NLP #TextToImageGeneration Issue Date: 2025-08-07 [Paper Note] Adding Conditional Control to Text-to-Image Diffusion Models, Lvmin Zhang+, arXiv'23 SummaryControlNetは、テキストから画像への拡散モデルに空間的な条件制御を追加するためのニューラルネットワークアーキテクチャであり、事前学習済みのエンコーディング層を再利用して多様な条件制御を学習します。ゼロ畳み込みを用いてパラメータを徐々に増加させ、有害なノイズの影響を軽減します。Stable Diffusionを用いて様々な条件制御をテストし、小規模および大規模データセットに対して堅牢性を示しました。ControlNetは画像拡散モデルの制御における広範な応用の可能性を示唆しています。 CommentControlNet論文 #ComputerVision #Pretraining #Pocket #LanguageModel #Admin'sPick #ICCV Issue Date: 2025-06-29 [Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23 Summaryシンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。 CommentSigLIP論文 #ComputerVision #Pocket #NLP #Transformer #SpeechProcessing #Architecture #Normalization Issue Date: 2025-04-19 Foundation Transformers, Hongyu Wang+, PMLR'23 Summary言語、視覚、音声、マルチモーダルにおけるモデルアーキテクチャの収束が進む中、異なる実装の「Transformers」が使用されている。汎用モデリングのために、安定性を持つFoundation Transformerの開発が提唱され、Magnetoという新しいTransformer変種が紹介される。Sub-LayerNormと理論に基づく初期化戦略を用いることで、さまざまなアプリケーションにおいて優れたパフォーマンスと安定性を示した。 Commentマルチモーダルなモデルなモデルの事前学習において、PostLNはvision encodingにおいてsub-optimalで、PreLNはtext encodingにおいてsub-optimalであることが先行研究で示されており、マルタモーダルを単一のアーキテクチャで、高性能、かつ学習の安定性な高く、try and error無しで適用できる基盤となるアーキテクチャが必要というモチベーションで提案された手法。具体的には、Sub-LayerNorm(Sub-LN)と呼ばれる、self attentionとFFN部分に追加のLayerNormを適用するアーキテクチャと、DeepNetを踏襲しLayer数が非常に大きい場合でも学習が安定するような重みの初期化方法を理論的に分析し提案している。
具体的には、Sub-LNの場合、LayerNormを
・SelfAttention計算におけるQKVを求めるためのinput Xのprojectionの前とAttentionの出力projectionの前
・FFNでの各Linear Layerの前
に適用し、
初期化をする際には、FFNのW, およびself-attentionのV_projと出力のout_projの初期化をγ(=sqrt(log(2N))によってスケーリングする方法を提案している模様。
 関連:
関連:
・1900 #ComputerVision #Pocket #NLP #LanguageModel #OpenWeight Issue Date: 2025-04-11 PaLI-3 Vision Language Models: Smaller, Faster, Stronger, Xi Chen+, arXiv'23 SummaryPaLI-3は、従来のモデルに比べて10倍小型で高速な視覚言語モデル(VLM)であり、特にローカリゼーションや視覚的テキスト理解において優れた性能を示す。SigLIPベースのPaLIは、20億パラメータにスケールアップされ、多言語クロスモーダル検索で新たな最先端を達成。50億パラメータのPaLI-3は、VLMの研究を再燃させることを期待されている。 CommentOpenReview:https://openreview.net/forum?id=JpyWPfzu0b
実験的に素晴らしい性能が実現されていることは認められつつも
・比較対象がSigLIPのみでより広範な比較実験と分析が必要なこと
・BackboneモデルをContrastive Learningすること自体の有用性は既に知られており、新規性に乏しいこと
としてICLR'24にRejectされている #Pretraining #Pocket #NLP #LanguageModel #ICLR Issue Date: 2024-09-26 UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23 Summary本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 CommentOpenReview:https://openreview.net/forum?id=6ruVLB727MC[R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを持つMoD (Mixture of Denoisers)を提案
 #ComputerVision
#Pocket
#NLP
#GenerativeAI
Issue Date: 2023-12-01
SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction, Xinyuan Chen+, N_A, arXiv'23
Summary本研究では、ビデオ生成において連続した長いビデオを生成するためのジェネレーティブなトランジションと予測に焦点を当てたモデルSEINEを提案する。SEINEはテキストの説明に基づいてトランジションを生成し、一貫性と視覚的品質を確保した長いビデオを生成する。さらに、提案手法は他のタスクにも拡張可能であり、徹底的な実験によりその有効性が検証されている。
Commenthttps://huggingface.co/spaces/Vchitect/SEINE
#ComputerVision
#Pocket
#NLP
#GenerativeAI
Issue Date: 2023-12-01
SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction, Xinyuan Chen+, N_A, arXiv'23
Summary本研究では、ビデオ生成において連続した長いビデオを生成するためのジェネレーティブなトランジションと予測に焦点を当てたモデルSEINEを提案する。SEINEはテキストの説明に基づいてトランジションを生成し、一貫性と視覚的品質を確保した長いビデオを生成する。さらに、提案手法は他のタスクにも拡張可能であり、徹底的な実験によりその有効性が検証されている。
Commenthttps://huggingface.co/spaces/Vchitect/SEINE
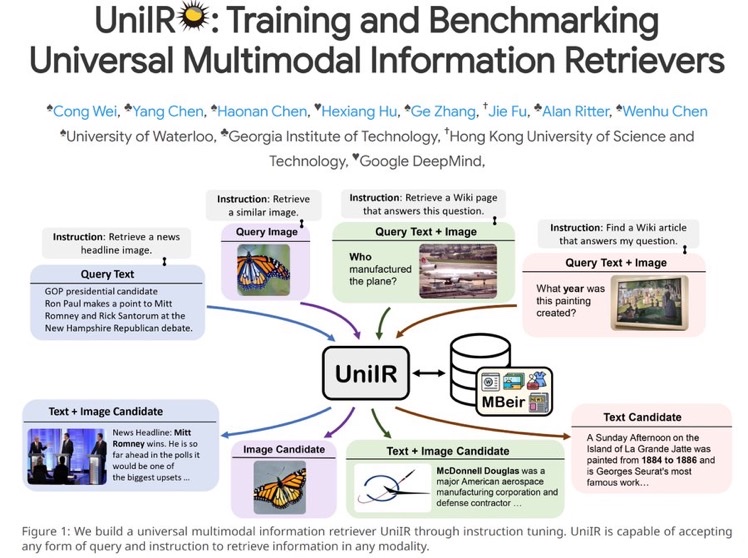
画像 + テキストpromptで、動画を生成するデモ #InformationRetrieval #Pocket #Dataset Issue Date: 2023-12-01 UniIR: Training and Benchmarking Universal Multimodal Information Retrievers, Cong Wei+, N_A, arXiv'23 Summary従来の情報検索モデルは一様な形式を前提としているため、異なる情報検索の要求に対応できない。そこで、UniIRという統一された指示に基づくマルチモーダルリトリーバーを提案する。UniIRは異なるリトリーバルタスクを処理できるように設計され、10のマルチモーダルIRデータセットでトレーニングされる。実験結果はUniIRの汎化能力を示し、M-BEIRというマルチモーダルリトリーバルベンチマークも構築された。 Comment後で読む(画像は元ツイートより
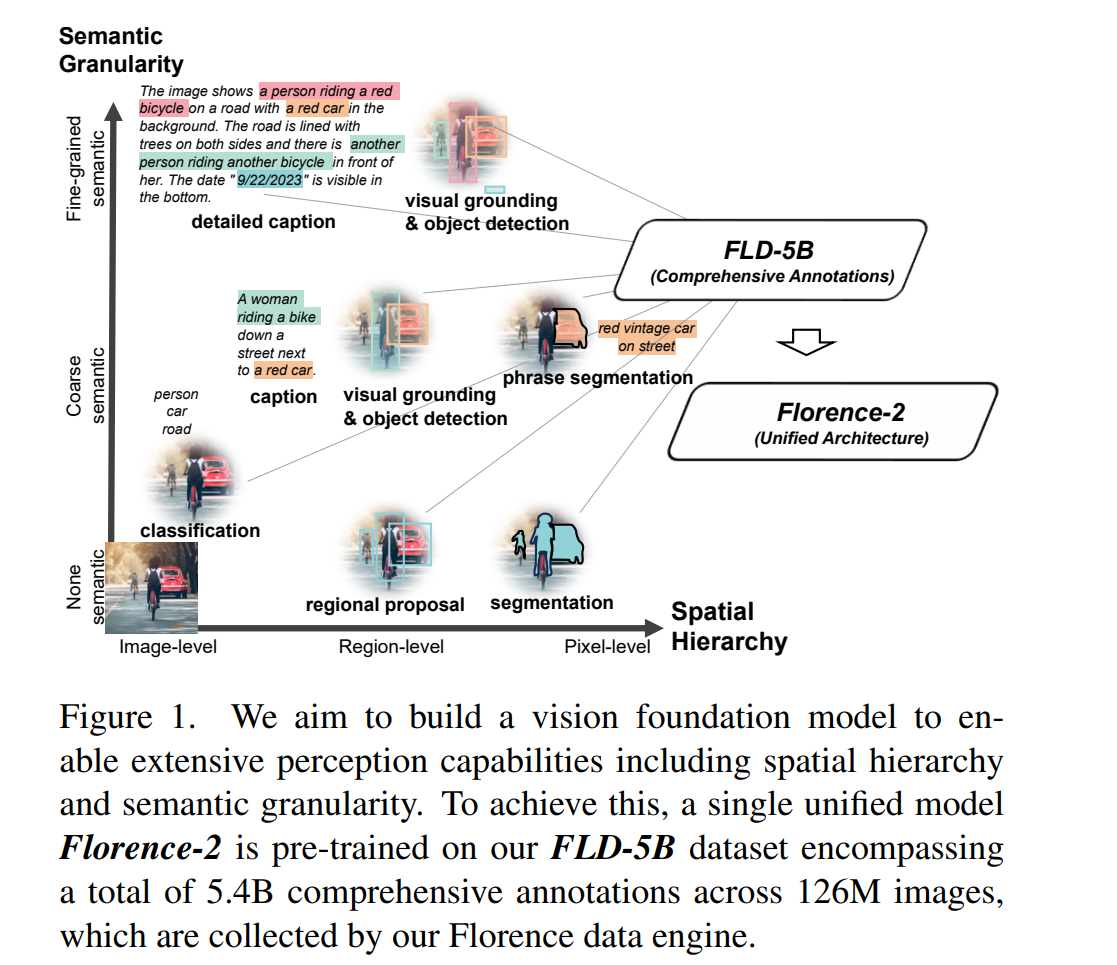
元ツイート: https://x.com/congwei1230/status/1730307767469068476?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pocket #NLP #MultitaskLearning #FoundationModel Issue Date: 2023-11-13 Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks, Bin Xiao+, N_A, arXiv'23 SummaryFlorence-2は、ビジョン基盤モデルであり、さまざまなビジョンタスクに対応するための統一されたプロンプトベースの表現を持っています。このモデルは、テキストプロンプトを受け取り、キャプショニング、オブジェクト検出、グラウンディング、セグメンテーションなどのタスクを実行し、テキスト形式で結果を生成します。また、FLD-5Bという大規模な注釈付きデータセットも開発されました。Florence-2は、多目的かつ包括的なビジョンタスクを実行するためにシーケンスツーシーケンス構造を採用しており、前例のないゼロショットおよびファインチューニングの能力を持つ強力なモデルです。 CommentVison Foundation Model。Spatialな階層構造や、Semanticを捉えられるように訓練。Image/Prompt Encoderでエンコードされ、outputはtext + location informationとなる。

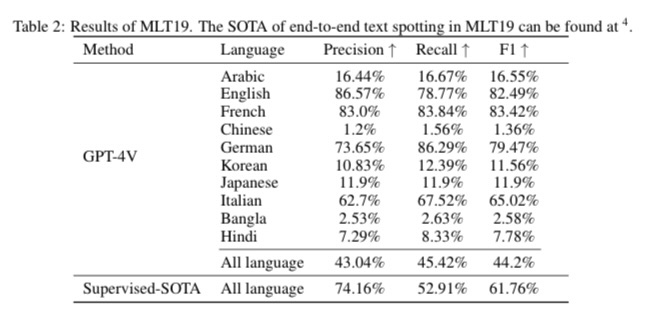
#ComputerVision #Pocket #NLP #LanguageModel #OCR Issue Date: 2023-10-26 Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, N_A, arXiv'23 Summaryこの論文では、GPT-4Vという大規模マルチモーダルモデルの光学文字認識(OCR)能力を評価します。さまざまなOCRタスクにおいてモデルのパフォーマンスを評価し、ラテン文字の認識と理解において優れた性能を示す一方、多言語や複雑なタスクには苦戦することがわかりました。これに基づいて、専門のOCRモデルの必要性やGPT-4Vを活用する戦略についても検討します。この研究は、将来のLMMを用いたOCRの研究に役立つものです。評価のパイプラインと結果は、GitHubで利用可能です。 CommentGPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
 #ComputerVision
#Pocket
#NLP
#LanguageModel
#SpokenLanguageProcessing
#SpeechProcessing
Issue Date: 2023-07-22
Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, N_A, arXiv'23
Summary本研究では、マルチモーダル学習のためのMeta-Transformerというフレームワークを提案しています。このフレームワークは、異なるモダリティの情報を処理し関連付けるための統一されたネットワークを構築することを目指しています。Meta-Transformerは、対応のないデータを使用して12のモダリティ間で統一された学習を行うことができ、テキスト、画像、ポイントクラウド、音声、ビデオなどの基本的なパーセプションから、X線、赤外線、高分光、IMUなどの実用的なアプリケーション、グラフ、表形式、時系列などのデータマイニングまで、幅広いタスクを処理することができます。Meta-Transformerは、トランスフォーマーを用いた統一されたマルチモーダルインテリジェンスの開発に向けた有望な未来を示しています。
Comment12種類のモダリティに対して学習できるTransformerを提案
#ComputerVision
#Pocket
#NLP
#LanguageModel
#SpokenLanguageProcessing
#SpeechProcessing
Issue Date: 2023-07-22
Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, N_A, arXiv'23
Summary本研究では、マルチモーダル学習のためのMeta-Transformerというフレームワークを提案しています。このフレームワークは、異なるモダリティの情報を処理し関連付けるための統一されたネットワークを構築することを目指しています。Meta-Transformerは、対応のないデータを使用して12のモダリティ間で統一された学習を行うことができ、テキスト、画像、ポイントクラウド、音声、ビデオなどの基本的なパーセプションから、X線、赤外線、高分光、IMUなどの実用的なアプリケーション、グラフ、表形式、時系列などのデータマイニングまで、幅広いタスクを処理することができます。Meta-Transformerは、トランスフォーマーを用いた統一されたマルチモーダルインテリジェンスの開発に向けた有望な未来を示しています。
Comment12種類のモダリティに対して学習できるTransformerを提案
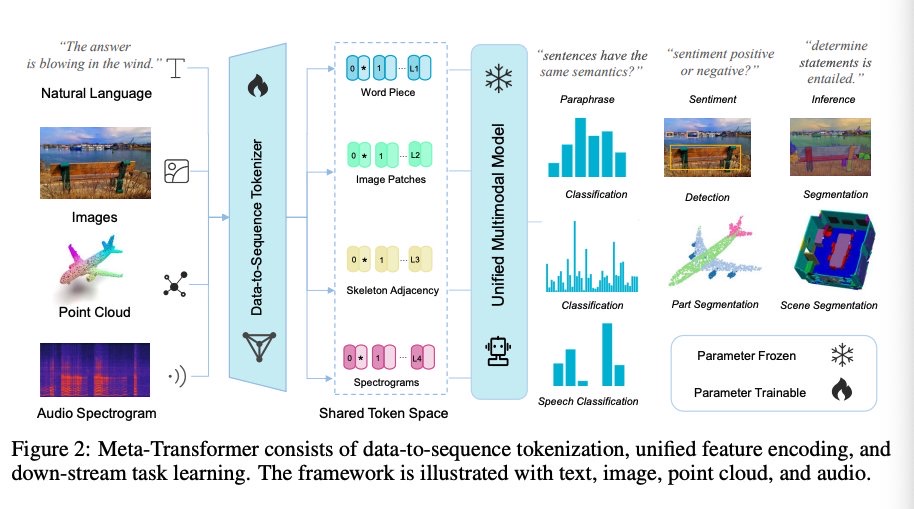
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
 #ComputerVision
#NLP
#Dataset
#Personalization
#Conversation
Issue Date: 2023-07-15
MPCHAT: Towards Multimodal Persona-Grounded Conversation, ACL'23
Summary本研究では、テキストと画像の両方を使用してパーソナを拡張し、マルチモーダルな対話エージェントを構築するためのデータセットであるMPCHATを提案します。さらに、マルチモーダルパーソナを組み込むことで、応答予測、パーソナのグラウンディング予測、話者の識別といったタスクのパフォーマンスを統計的に有意に改善できることを示します。この研究は、マルチモーダルな対話理解においてマルチモーダルパーソナの重要性を強調し、MPCHATが高品質なリソースとして役立つことを示しています。
#ComputerVision
#NaturalLanguageGeneration
#NLP
#DiffusionModel
#TextToImageGeneration
Issue Date: 2023-07-15
Learning to Imagine: Visually-Augmented Natural Language Generation, ACL'23
Summary本研究では、視覚情報を活用した自然言語生成のためのLIVEという手法を提案しています。LIVEは、事前学習済み言語モデルを使用して、テキストに基づいて場面を想像し、高品質な画像を合成する方法です。また、CLIPを使用してテキストの想像力を評価し、段落ごとに画像を生成します。さまざまな実験により、LIVEの有効性が示されています。コード、モデル、データは公開されています。
Comment>まず、テキストに基づいて場面を想像します。入力テキストに基づいて高品質な画像を合成するために拡散モデルを使用します。次に、CLIPを使用して、テキストが想像力を喚起できるかを事後的に判断します。最後に、私たちの想像力は動的であり、段落全体に1つの画像を生成するのではなく、各文に対して合成を行います。
#ComputerVision
#NLP
#Dataset
#Personalization
#Conversation
Issue Date: 2023-07-15
MPCHAT: Towards Multimodal Persona-Grounded Conversation, ACL'23
Summary本研究では、テキストと画像の両方を使用してパーソナを拡張し、マルチモーダルな対話エージェントを構築するためのデータセットであるMPCHATを提案します。さらに、マルチモーダルパーソナを組み込むことで、応答予測、パーソナのグラウンディング予測、話者の識別といったタスクのパフォーマンスを統計的に有意に改善できることを示します。この研究は、マルチモーダルな対話理解においてマルチモーダルパーソナの重要性を強調し、MPCHATが高品質なリソースとして役立つことを示しています。
#ComputerVision
#NaturalLanguageGeneration
#NLP
#DiffusionModel
#TextToImageGeneration
Issue Date: 2023-07-15
Learning to Imagine: Visually-Augmented Natural Language Generation, ACL'23
Summary本研究では、視覚情報を活用した自然言語生成のためのLIVEという手法を提案しています。LIVEは、事前学習済み言語モデルを使用して、テキストに基づいて場面を想像し、高品質な画像を合成する方法です。また、CLIPを使用してテキストの想像力を評価し、段落ごとに画像を生成します。さまざまな実験により、LIVEの有効性が示されています。コード、モデル、データは公開されています。
Comment>まず、テキストに基づいて場面を想像します。入力テキストに基づいて高品質な画像を合成するために拡散モデルを使用します。次に、CLIPを使用して、テキストが想像力を喚起できるかを事後的に判断します。最後に、私たちの想像力は動的であり、段落全体に1つの画像を生成するのではなく、各文に対して合成を行います。
興味深い #ComputerVision #Pretraining #Pocket #NLP #Transformer Issue Date: 2023-07-12 Generative Pretraining in Multimodality, Quan Sun+, N_A, arXiv'23 SummaryEmuは、マルチモーダルなコンテキストで画像とテキストを生成するためのTransformerベースのモデルです。このモデルは、単一モダリティまたはマルチモーダルなデータ入力を受け入れることができます。Emuは、マルチモーダルなシーケンスでトレーニングされ、画像からテキストへのタスクやテキストから画像へのタスクなど、さまざまなタスクで優れたパフォーマンスを示します。また、マルチモーダルアシスタントなどの拡張機能もサポートしています。 #ComputerVision #Pretraining #Pocket #NLP Issue Date: 2023-07-12 EgoVLPv2: Egocentric Video-Language Pre-training with Fusion in the Backbone, Shraman Pramanick+, N_A, arXiv'23 Summaryエゴセントリックビデオ言語の事前学習の第2世代(EgoVLPv2)は、ビデオと言語のバックボーンにクロスモーダルの融合を直接組み込むことができる。EgoVLPv2は強力なビデオテキスト表現を学習し、柔軟かつ効率的な方法でさまざまなダウンストリームタスクをサポートする。さらに、提案されたバックボーン戦略は軽量で計算効率が高い。EgoVLPv2は幅広いVLタスクで最先端のパフォーマンスを達成している。詳細はhttps://shramanpramanick.github.io/EgoVLPv2/を参照。 #ComputerVision #LanguageModel #QuestionAnswering Issue Date: 2023-07-11 SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs, Lijun Yu+, N_A, arXiv'23 Summaryこの研究では、Semantic Pyramid AutoEncoder(SPAE)を使用して、凍結されたLLMsが非言語的なモダリティを含むタスクを実行できるようにします。SPAEは、LLMの語彙から抽出されたトークンと生のピクセルデータの変換を行います。生成されたトークンは、視覚再構成に必要な意味と詳細を捉え、LLMが理解できる言語に変換します。実験結果では、我々のアプローチが画像理解と生成のタスクにおいて最先端のパフォーマンスを25%以上上回ることを示しています。 Comment画像をLLMのtokenスペースにマッピングすることで、LLMがパラメータの更新なしにvisual taskを解くことを可能にした。in context learningによって、様々なvisuataskを解くことができる。
 #ComputerVision
#LanguageModel
#QuestionAnswering
Issue Date: 2023-06-30
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language, William Berrios+, N_A, arXiv'23
Summary私たちは、LENSというモジュラーなアプローチを提案しています。このアプローチでは、大規模言語モデル(LLMs)を使用してコンピュータビジョンの問題に取り組みます。LENSは、独立したビジョンモジュールの出力に対して言語モデルを使用して推論を行います。私たちは、ゼロショットおよびフューショットのオブジェクト認識などのコンピュータビジョンの設定でLENSを評価しました。LENSは市販のLLMに適用でき、非常に競争力のあるパフォーマンスを発揮します。コードはオープンソースで提供されています。
Comment参考: https://twitter.com/hillbig/status/1674878733264781312?s=46&t=KFT8cWTu8vV69iD6Qt0NGw
#ComputerVision
#LanguageModel
#QuestionAnswering
Issue Date: 2023-06-30
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language, William Berrios+, N_A, arXiv'23
Summary私たちは、LENSというモジュラーなアプローチを提案しています。このアプローチでは、大規模言語モデル(LLMs)を使用してコンピュータビジョンの問題に取り組みます。LENSは、独立したビジョンモジュールの出力に対して言語モデルを使用して推論を行います。私たちは、ゼロショットおよびフューショットのオブジェクト認識などのコンピュータビジョンの設定でLENSを評価しました。LENSは市販のLLMに適用でき、非常に競争力のあるパフォーマンスを発揮します。コードはオープンソースで提供されています。
Comment参考: https://twitter.com/hillbig/status/1674878733264781312?s=46&t=KFT8cWTu8vV69iD6Qt0NGw #NLP
#LanguageModel
#SpeechProcessing
Issue Date: 2023-06-26
AudioPaLM: A Large Language Model That Can Speak and Listen, Paul K. Rubenstein+, N_A, arXiv'23
Summary本研究では、音声理解と生成のためのマルチモーダルアーキテクチャであるAudioPaLMを紹介する。AudioPaLMは、テキストと音声を処理および生成することができ、PaLM-2とAudioLMを統合している。テキストのみの大規模言語モデルの重みを使用してAudioPaLMを初期化することで、音声処理を改善し、多くの言語に対してゼロショット音声対テキスト翻訳を実行する能力を持つことができることを示す。また、AudioPaLMは、音声言語モデルの機能も示している。
Comment参考: https://twitter.com/hillbig/status/1673454388931891201?s=46&t=aLGqdPv6JkRbT0kxsf6Aww
#ComputerVision
#Pocket
#NLP
#QuestionAnswering
Issue Date: 2023-06-16
AVIS: Autonomous Visual Information Seeking with Large Language Models, Ziniu Hu+, N_A, arXiv'23
Summary本論文では、自律的な情報収集ビジュアル質問応答フレームワークであるAVISを提案する。AVISは、大規模言語モデル(LLM)を活用して外部ツールの利用戦略を動的に決定し、質問に対する回答に必要な不可欠な知識を獲得する。ユーザースタディを実施して収集したデータを用いて、プランナーや推論エンジンを改善し、知識集約型ビジュアル質問応答ベンチマークで最先端の結果を達成することを示している。
Comment
#NLP
#LanguageModel
#SpeechProcessing
Issue Date: 2023-06-26
AudioPaLM: A Large Language Model That Can Speak and Listen, Paul K. Rubenstein+, N_A, arXiv'23
Summary本研究では、音声理解と生成のためのマルチモーダルアーキテクチャであるAudioPaLMを紹介する。AudioPaLMは、テキストと音声を処理および生成することができ、PaLM-2とAudioLMを統合している。テキストのみの大規模言語モデルの重みを使用してAudioPaLMを初期化することで、音声処理を改善し、多くの言語に対してゼロショット音声対テキスト翻訳を実行する能力を持つことができることを示す。また、AudioPaLMは、音声言語モデルの機能も示している。
Comment参考: https://twitter.com/hillbig/status/1673454388931891201?s=46&t=aLGqdPv6JkRbT0kxsf6Aww
#ComputerVision
#Pocket
#NLP
#QuestionAnswering
Issue Date: 2023-06-16
AVIS: Autonomous Visual Information Seeking with Large Language Models, Ziniu Hu+, N_A, arXiv'23
Summary本論文では、自律的な情報収集ビジュアル質問応答フレームワークであるAVISを提案する。AVISは、大規模言語モデル(LLM)を活用して外部ツールの利用戦略を動的に決定し、質問に対する回答に必要な不可欠な知識を獲得する。ユーザースタディを実施して収集したデータを用いて、プランナーや推論エンジンを改善し、知識集約型ビジュアル質問応答ベンチマークで最先端の結果を達成することを示している。
Comment
#MachineLearning #DataAugmentation Issue Date: 2023-04-26 Learning Multimodal Data Augmentation in Feature Space, ICLR'23 Summaryマルチモーダルデータの共同学習能力は、インテリジェントシステムの特徴であるが、データ拡張の成功は単一モーダルのタスクに限定されている。本研究では、LeMDAという方法を提案し、モダリティのアイデンティティや関係に制約を設けずにマルチモーダルデータを共同拡張することができることを示した。LeMDAはマルチモーダルディープラーニングの性能を向上させ、幅広いアプリケーションで最先端の結果を達成することができる。 CommentData Augmentationは基本的に単体のモダリティに閉じて行われるが、
マルチモーダルな設定において、モダリティ同士がどう関係しているか、どの変換を利用すべきかわからない時に、どのようにデータ全体のsemantic structureを維持しながら、Data Augmentationできるか?という話らしい #NeuralNetwork #ComputerVision #MachineLearning #Pocket #NLP #MultitaskLearning #SpeechProcessing #ICLR Issue Date: 2025-07-10 [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22 Summary汎用アーキテクチャPerceiver IOを提案し、任意のデータ設定に対応し、入力と出力のサイズに対して線形にスケール可能。柔軟なクエリメカニズムを追加し、タスク特有の設計を不要に。自然言語、視覚理解、マルチタスクで強力な結果を示し、GLUEベンチマークでBERTを上回る性能を達成。 Comment当時相当話題となったさまざまなモーダルを統一された枠組みで扱えるPerceiver IO論文
 #ComputerVision
#Pocket
#NLP
#Dataset
#CLIP
#NeurIPS
Issue Date: 2025-05-06
LAION-5B: An open large-scale dataset for training next generation image-text models, Christoph Schuhmann+, NeurIPS'22
SummaryLAION-5Bは、5.85億のCLIPフィルタリングされた画像-テキストペアから成る大規模データセットで、英語のペアが2.32B含まれています。このデータセットは、CLIPやGLIDEなどのモデルの再現とファインチューニングに利用され、マルチモーダルモデルの研究を民主化します。また、データ探索やサブセット生成のためのインターフェースや、コンテンツ検出のためのスコアも提供されます。
#ComputerVision
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#LanguageModel
#Transformer
Issue Date: 2023-08-22
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision, Wonjae Kim+, N_A, ICML'21
SummaryVLP(Vision-and-Language Pre-training)のアプローチは、ビジョンと言語のタスクでのパフォーマンスを向上させているが、現在の方法は効率性と表現力の面で問題がある。そこで、本研究では畳み込みフリーのビジョンと言語のトランスフォーマ(ViLT)モデルを提案する。ViLTは高速でありながら競争力のあるパフォーマンスを示し、コードと事前学習済みの重みはGitHubで利用可能である。
Comment日本語解説:https://tech.fusic.co.jp/posts/2021-12-29-vilt/
#ComputerVision
#NLP
#ContrastiveLearning
#ICML
Issue Date: 2023-04-27
Learning Transferable Visual Models From Natural Language Supervision, Radford+, OpenAI, ICML'21
CommentCLIP論文。大量の画像と画像に対応するテキストのペアから、対象学習を行い、画像とテキスト間のsimilarityをはかれるようにしたモデル
#ComputerVision
#Pocket
#NLP
#Dataset
#CLIP
#NeurIPS
Issue Date: 2025-05-06
LAION-5B: An open large-scale dataset for training next generation image-text models, Christoph Schuhmann+, NeurIPS'22
SummaryLAION-5Bは、5.85億のCLIPフィルタリングされた画像-テキストペアから成る大規模データセットで、英語のペアが2.32B含まれています。このデータセットは、CLIPやGLIDEなどのモデルの再現とファインチューニングに利用され、マルチモーダルモデルの研究を民主化します。また、データ探索やサブセット生成のためのインターフェースや、コンテンツ検出のためのスコアも提供されます。
#ComputerVision
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#LanguageModel
#Transformer
Issue Date: 2023-08-22
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision, Wonjae Kim+, N_A, ICML'21
SummaryVLP(Vision-and-Language Pre-training)のアプローチは、ビジョンと言語のタスクでのパフォーマンスを向上させているが、現在の方法は効率性と表現力の面で問題がある。そこで、本研究では畳み込みフリーのビジョンと言語のトランスフォーマ(ViLT)モデルを提案する。ViLTは高速でありながら競争力のあるパフォーマンスを示し、コードと事前学習済みの重みはGitHubで利用可能である。
Comment日本語解説:https://tech.fusic.co.jp/posts/2021-12-29-vilt/
#ComputerVision
#NLP
#ContrastiveLearning
#ICML
Issue Date: 2023-04-27
Learning Transferable Visual Models From Natural Language Supervision, Radford+, OpenAI, ICML'21
CommentCLIP論文。大量の画像と画像に対応するテキストのペアから、対象学習を行い、画像とテキスト間のsimilarityをはかれるようにしたモデル

#ComputerVision #Pocket #NLP #Transformer #Architecture Issue Date: 2025-08-21 [Paper Note] Supervised Multimodal Bitransformers for Classifying Images and Text, Douwe Kiela+, arXiv'19 Summaryテキストと画像情報を融合する監視型マルチモーダルビットランスフォーマーモデルを提案し、さまざまなマルチモーダル分類タスクで最先端の性能を達成。特に、難易度の高いテストセットでも強力なベースラインを上回る結果を得た。 Commentテキスト+imageを用いるシンプルなtransformer #Article #ComputerVision #NLP #LanguageModel #OpenWeight #VisionLanguageModel Issue Date: 2025-08-27 MiniCPM-V-4_5, openbmb, 2025.08 Comment元ポスト:https://x.com/adinayakup/status/1960292853453672886?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #LanguageModel #ProprietaryLLM Issue Date: 2025-08-07 GPT-5 System Card, OpenAI, 2025.08 Comment日本語性能。MMLUを専門の翻訳家を各言語に翻訳。
 ざーっとシステムカードを見たが、ベンチマーク上では、Safetyをめっちゃ強化し、hallucinationが低減され、コーディング能力が向上した、みたいな印象(小並感)longContextの性能が非常に向上しているらしい
ざーっとシステムカードを見たが、ベンチマーク上では、Safetyをめっちゃ強化し、hallucinationが低減され、コーディング能力が向上した、みたいな印象(小並感)longContextの性能が非常に向上しているらしい
・https://x.com/scaling01/status/1953507426952507405?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/gdb/status/1953747271666819380?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
gpt-ossではAttentionSinkが使われていたが、GPT-5では使われているだろうか?もし使われているならlong contextの性能向上に寄与していると思われる。50% time horizonもscaling lawsに則り進展:
・https://x.com/hillbig/status/1953622811077227003?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・1842
個別のベンチが数%向上、もしくはcomparableです、ではもはやどれくらい進展したのかわからない(が、個々の能力が交互作用して最終的な出力がされると考えるとシナジーによって全体の性能は大幅に底上げされる可能性がある)からこの指標を見るのが良いのかも知れないMETR's Autonomy Evaluation Resources
・https://metr.github.io/autonomy-evals-guide/gpt-5-report/
・https://x.com/metr_evals/status/1953525150374150654?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHLEに対するツール利用でのスコアの比較に対する所見:
https://x.com/imai_eruel/status/1953511704824099157?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QDocument Understandingでの評価をしたところOutput tokenが大幅に増えている:
https://x.com/jerryjliu0/status/1953582723672814054?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGPT5 Prompting Guide:
https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guideGPT-5: Key characteristics, pricing and model card
・https://simonwillison.net/2025/Aug/7/gpt-5/
・https://x.com/simonw/status/1953512493986591195?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qシステムカード中のSWE Bench Verifiedの評価結果は、全500サンプルのうちの477サンプルでしか実施されておらず、単純にスコアを比較することができないことに注意。実行されなかった23サンプルをFailedとみなすと(実行しなかったものを正しく成功できたとはみなせない)、スコアは減少する。同じ477サンプル間で評価されたモデル間であれば比較可能だが、500サンプルで評価された他のモデルとの比較はできない。
・https://x.com/gneubig/status/1953518981232402695?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・SWE Bench リーダーボード: https://www.swebench.com
 まとめ:
まとめ:
https://x.com/scaling01/status/1953511287209558245?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q所見:
・https://x.com/dongxi_nlp/status/1953570656584417655?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/imai_eruel/status/1953777394214744198?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenHandsでの評価:
https://x.com/gneubig/status/1953883635657900289?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
SWE Bench Verifiedの性能は71.8%。全部の500サンプルで評価した結果だと思うので公式の発表より低めではある。AttentionSinkについて:
https://x.com/goro_koba/status/1954480023890780587?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qo3と比較してGPT5は約1/3の時間でポケモンレッド版で8個のバッジを獲得した模様:
https://x.com/qualzz_sam/status/1955760274142597231?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qより温かみのあるようなalignmentが実施された模様:
https://x.com/openai/status/1956461718097494196?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGPT5はlong contextになるとmarkdownよりめxmlの方が適していると公式ドキュメントに記載があるらしい:
https://x.com/mlbear2/status/1956626291408744522?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QSmallow LLM Leaderboard v2での性能:
https://x.com/chokkanorg/status/1958065332817653858?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
GPT5の性能が際立って良く、続いてQwen3, gptossも性能が良い。 #Article #ComputerVision #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #VideoGeneration/Understandings Issue Date: 2025-07-29 Wan2.2, Alibaba Wan, 2025.07 Comment元ポスト:https://x.com/alibaba_wan/status/1949827662416937443?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q初のMoEによるOpen WeightなVideo generationモデルで、直接的に明るさや、カラー、カメラの動きなどを制御でき、text to video, image to video, unified video generationをサポートしている模様 #Article #ComputerVision #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-06-30 ERNIE 4.5 Series, ERNIE TEAM, 2025.06 CommentTech Report:https://yiyan.baidu.com/blog/publication/ERNIE_Technical_Report.pdf元ポスト:https://x.com/paddlepaddle/status/1939535276197744952?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/gm8xx8/status/1939576393098023188?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-06-24 Kimi-VL-A3B-Thinking-2506, moonshotai, 2025.06 Comment元ポスト:https://x.com/reach_vb/status/1937159672932286950?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q様々なベンチマークでSoTA(gpt4o, Qwen2.5-VL-7B)を達成したReasoning VLMテクニカルペーパー:
・2200 #Article #ComputerVision #NLP #Dataset #LanguageModel #AWS #Blog #Japanese Issue Date: 2025-05-20 Webスケールの日本語-画像のインターリーブデータセット「MOMIJI」の構築 _巨大テキストデータをAWSで高速に処理するパイプライン, Turing (studio_graph), 2025.05 Comment貴重なVLMデータセット構築ノウハウ青塗りのフィルタリングタスクを具体的にどうやっているのか気になる #Article #ComputerVision #Pocket #NLP #LLMAgent #Blog #Reasoning #OpenWeight #x-Use Issue Date: 2025-04-18 Introducing UI-TARS-1.5, ByteDance, 2025.04 SummaryUI-TARSは、スクリーンショットを入力として人間のようにインタラクションを行うネイティブGUIエージェントモデルであり、従来の商業モデルに依存せず、エンドツーエンドで優れた性能を発揮します。実験では、10以上のベンチマークでSOTA性能を達成し、特にOSWorldやAndroidWorldで他のモデルを上回るスコアを記録しました。UI-TARSは、強化された知覚、統一アクションモデリング、システム-2推論、反射的オンライントレースによる反復トレーニングなどの革新を取り入れ、最小限の人間の介入で適応し続ける能力を持っています。 Commentpaper:https://arxiv.org/abs/2501.12326色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)関連
・1794元ポスト:https://x.com/_akhaliq/status/1912913195607663049?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-04-05 Llama 4 Series, Meta, 2025.04 CommentDownloads:https://www.llama.com/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4Huggingface:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164解説ポスト:https://x.com/iscienceluvr/status/1908601269004230763?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QArtificial Analysisによる性能検証:https://x.com/artificialanlys/status/1908890796415414430?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
MaverickがGPT4oと同等、ScoutがGPT4o-miniと同等
Update:https://x.com/artificialanlys/status/1909624239747182989?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q性能に関して不可解な点が多そうなので様子見をしても良いかも。性能検証(Math-Perturb):https://x.com/kaixuanhuang1/status/1909387970773234088?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q日本語にあまり強くないという情報も
元ポスト:https://x.com/gosrum/status/1909626761098494060?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QどうやらvLLMのLlama4のinferenceにバグがあったやうで、vLLMのIssue 16311にて、Llama4のinferenceに関するバグが修正され、性能が向上した模様。どのベンチを信じたら良いかまるでわからん。2025.0413現在のchatbot arenaのランクは、32位となり(chatbot arena向けにtuningされていたであろうモデルは2位だった)GPT-4oが29位であることを考慮すると上記のArtificial Intelligenceの評価とも大体一致している。
https://lmarena.ai
関連ポスト:https://x.com/tunguz/status/1911142310160855541?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-25 Qwen2.5-VL-32B-Instruct, Qwen Team, 2025.03 Comment元ポスト:https://x.com/alibaba_qwen/status/1904227859616641534?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Transformer #Supervised-FineTuning (SFT) #Blog #SSM (StateSpaceModel) Issue Date: 2025-03-24 Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03 Comment関連:
・1820TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。
56B程度のmediumサイズのモデルと、8B程度の軽量なモデルについて述べられている。特に、8BモデルでMambaとTransformerのハイブリッドモデルと、通常のTransformerモデルを比較している。学習データに15 Trillion Tokenを利用しており、このデータ量でのApple to Appleのアーキテクチャ間の比較は、現状では最も大規模なものとのこと。性能は多くのベンチマークでハイブリッドにしても同等、Commonsense Understandingでは上回っている。
また、学習したNemotron-Hをバックボーンモデルとして持つVLMについてもモデルのアーキテクチャが述べられている。 #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-18 SmolDocling-256M, IBM Research, 2025.03 Comment元ポスト:https://www.linkedin.com/posts/andimarafioti_we-just-dropped-%F0%9D%97%A6%F0%9D%97%BA%F0%9D%97%BC%F0%9D%97%B9%F0%9D%97%97%F0%9D%97%BC%F0%9D%97%B0%F0%9D%97%B9%F0%9D%97%B6%F0%9D%97%BB%F0%9D%97%B4-activity-7307415358427013121-wS8m?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4Apache-2.0ライセンス。言語はEnglishのみな模様マルチモーダルなImage-To-Textモデル。サンプルはこちら
 #Article
#ComputerVision
#NLP
#LanguageModel
#ProprietaryLLM
Issue Date: 2025-03-17
ERNIE4.5_X1, Baidu, 2025.03
Comment解説ポスト:https://x.com/ai_for_success/status/1901149459826045223?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・ERNIE4.5はGPT4.5をさまざまなベンチマークで上回り、価格がなんとGPT4.5の1%
#Article
#ComputerVision
#NLP
#LanguageModel
#ProprietaryLLM
Issue Date: 2025-03-17
ERNIE4.5_X1, Baidu, 2025.03
Comment解説ポスト:https://x.com/ai_for_success/status/1901149459826045223?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・ERNIE4.5はGPT4.5をさまざまなベンチマークで上回り、価格がなんとGPT4.5の1%
・X1はマルチモーダルなreasoningモデルでDeepSeek-R1と同等の性能で半額
らしいこのモデルは6月30日にオープン(ウェイト?)になるとスレッドで述べられている。 #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-17 sarashina2-vision-{8b, 14b}, SB Intuitions, 2025.03 Comment元ポスト:https://x.com/sei_shinagawa/status/1901467733331701966?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QVLM。Xに散見される試行例を見ると日本語の読み取り性能は結構高そうに見える。モデル構成、学習の詳細、および評価:https://x.com/sbintuitions/status/1901472307421278604?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLM(sarashina2), Vision Encoder(Qwen2-VL), Projectorの3つで構成されており、3段階の学習を踏んでいる。
最初のステップでは、キャプションデータを用いてProjectorのみを学習しVision Encoderとテキストを対応づける。続いて、日本語を含む画像や日本特有の風景などをうまく扱えるように、これらを多く活用したデータ(内製日本語OCRデータ、図表キャプションデータ)を用いて、Vision EncoderとProjectorを学習。最後にLLMのAlignmentをとるために、プロジェクターとLLMを前段のデータに加えてVQAデータ(内製合成データを含む)や日本語の指示チューニングデータを用いて学習。ProjectorやMMLLMを具体的にどのように学習するかは
・1225
を参照のこと。 #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-01-28 Janus-Series: Unified Multimodal Understanding and Generation Models, DeepSeek, 2025.01 CommentDeepSeekによる新たなVLM、Janus-Proが本日リリース。MIT LicenseJanus-Proのパフォーマンス。
github上でのパフォーマンスの図解から引用。マルチモーダル(テキスト+画像)の理解に関するベンチマークでLLaVA超え。GenEval, DPG Benchと呼ばれる画像生成ベンチマークでDALL-E 3超え。

テクニカルレポート中での詳細から引用。どのベンチマークでも基本的に最高性能なように見える。


テクニカルレポート: https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf #Article #ComputerVision #NLP #LanguageModel #FoundationModel #MultiLingual Issue Date: 2024-12-04 Introducing Amazon Nova, our new generation of foundation models, AWS, 2024.12 Comment参考:https://qiita.com/ysit/items/8433d149dbaab702d526テクニカルレポート: https://assets.amazon.science/9f/a3/ae41627f4ab2bde091f1ebc6b830/the-amazon-nova-family-of-models-technical-report-and-model-card.pdf後で個々のベンチマークとメトリックをまとめたい。
まあでもざっくり言うと、他のproprietaryモデルともおおむね同等の性能です、という感じに見える。個々のタスクレベルで見ると、得意なものと不得意なものはありそうではある。






スループットとかも、ProとGPT4oをパッと見で比較した感じ、優れているわけでもなさそう。Liteに対応するGPTはおそらくGPT4o-miniだと思われるが、スループットはLiteの方が高そう。




(画像は論文中からスクショし引用)下記ポストは独自に評価した結果や、コストと性能のバランスについて言及している。
・ProはGPT4oのコストの約1/3
・Pro, Lite, Flashはほれぞれコストパフォーマンスに非常に優れている(Quality vs. Price参照)
元ポスト:https://x.com/artificialanlys/status/1864023052818030814?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #NLP #LanguageModel #OpenWeight #VisionLanguageModel Issue Date: 2024-09-27 Molmo, AI2, 2024.09 SummaryMolmoは、オープンデータを活用した最先端のマルチモーダルAIモデルであり、特に小型モデルが大規模モデルを上回る性能を示す。Molmoは、物理的および仮想的な世界とのインタラクションを可能にし、音声ベースの説明を用いた新しい画像キャプションデータセットを導入。ファインチューニング用の多様なデータセットを使用し、非言語的手がかりを活用して質問に答える能力を持つ。Molmoファミリーのモデルは、オープンウェイトでプロプライエタリシステムに対抗する性能を発揮し、今後すべてのモデルウェイトやデータを公開予定。 Comment以下がベンチマーク結果(VLMのベンチマーク)。11 benchmarksと書かれているのは、VLMのベンチマークである点に注意。


#Article #ComputerVision #NLP #LanguageModel Issue Date: 2024-04-14 Grok-1.5 Vision Preview, 2024 Comment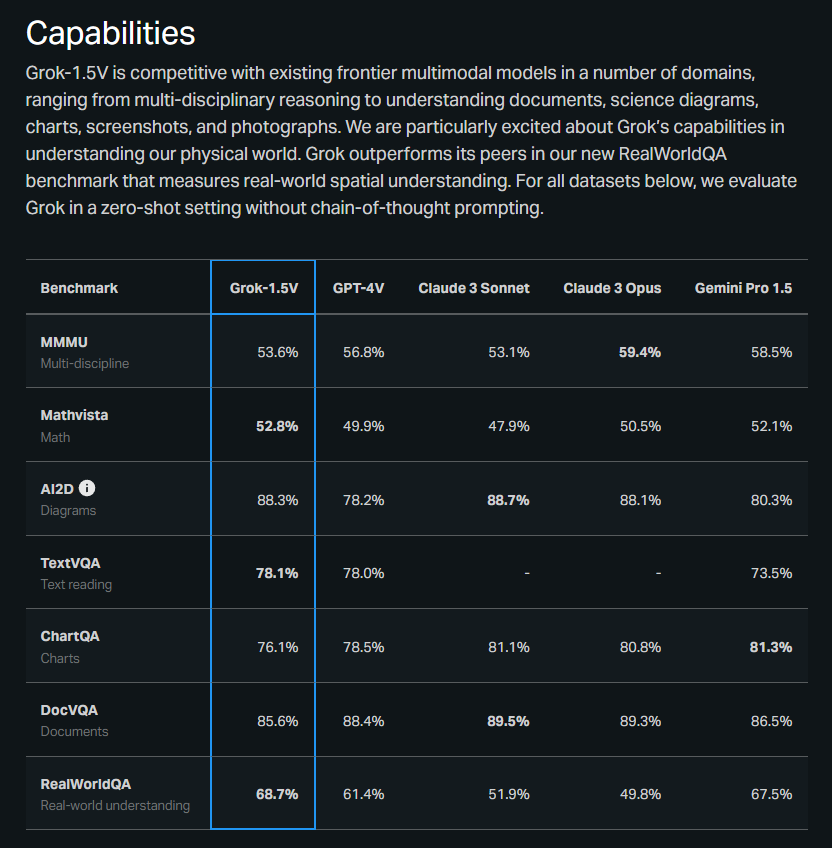
#Article #ComputerVision #NLP #Prompting #AutomaticPromptEngineering Issue Date: 2023-12-01 multimodal-maestro CommentLarge Multimodal Model (LMM)において、雑なpromptを与えるても自動的に良い感じoutputを生成してくれるっぽい?
以下の例はリポジトリからの引用であるが、この例では、"Find dog." という雑なpromptから、画像中央に位置する犬に[9]というラベルを与えました、というresponseを得られている。pipelineとしては、Visual Promptに対してまずSAMを用いてイメージのsegmentationを行い、各セグメントにラベルを振る。このラベルが振られた画像と、"Find dog." という雑なpromptを与えるだけで良い感じに処理をしてくれるようだ。

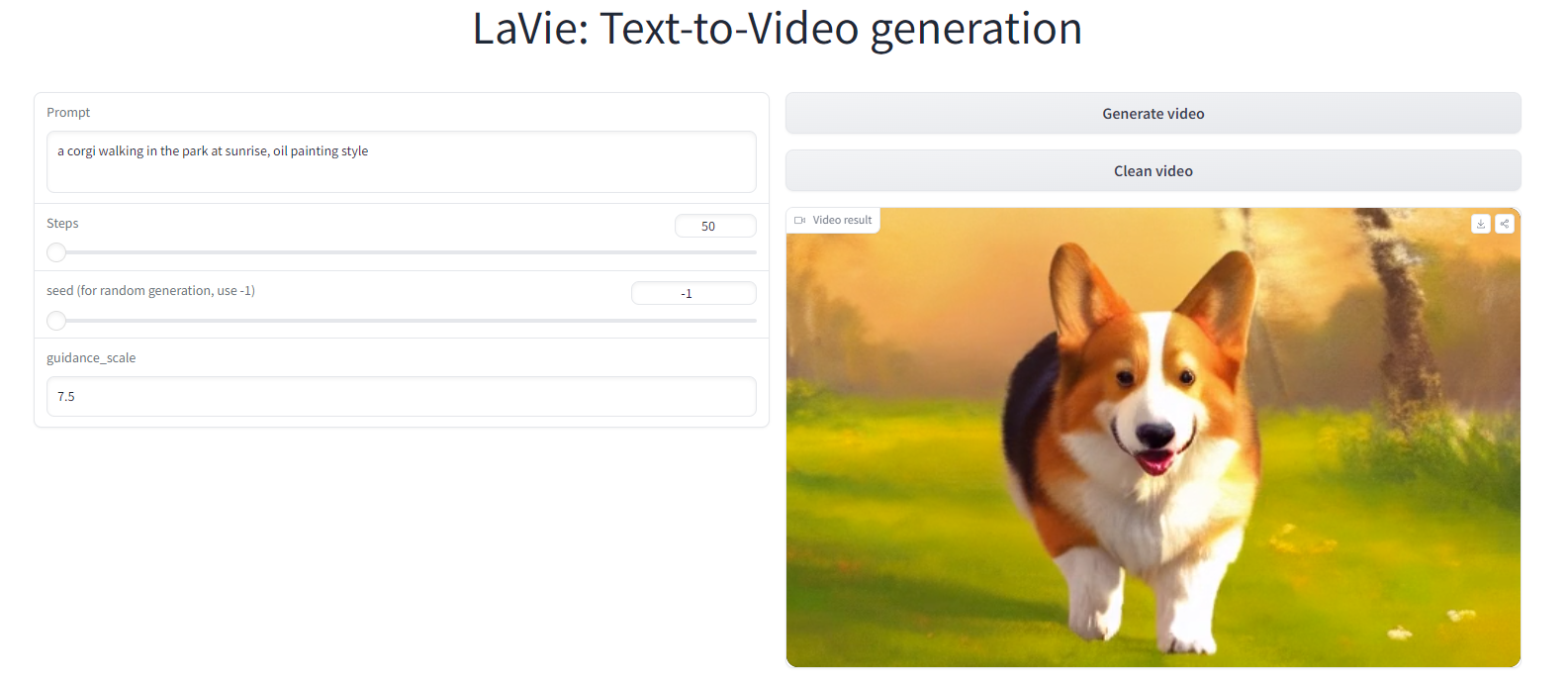
#Article #ComputerVision #NLP #GenerativeAI Issue Date: 2023-12-01 LaVie: Text-to-Video generation, demo Commentデモのデフォルトで試してみたら、3秒ほどのprompt通りの動画が生成された。
FF14の赤魔導士に変えたら、それっぽいの出てきた

#Article #EfficiencyImprovement #NLP #LanguageModel #FoundationModel #Blog Issue Date: 2023-11-01 tsuzumi, NTT’23 CommentNTT製のLLM。パラメータ数は7Bと軽量だが高性能。
MTBenchのようなGPT4に勝敗を判定させるベンチマークで、地理、歴史、政治、社会に関する質問応答タスク(図6)でgpt3.5turboと同等、国産LLMの中でトップの性能。GPT3.5turboには、コーディングや数学などの能力では劣るとのこと。
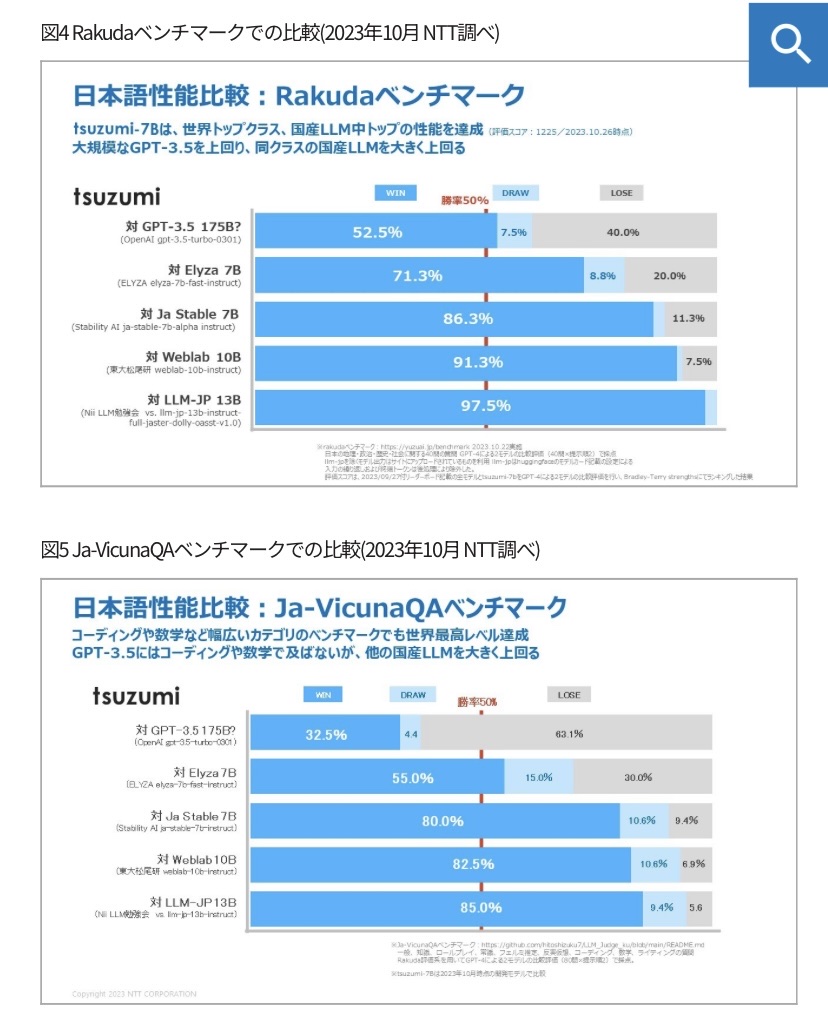

> *6 Rakudaベンチマーク
日本語の言語モデルの性能を評価するベンチマークの一つで、日本の地理・政治・歴史・社会に関する質問応答タスクによって評価を行う。
URL:https://yuzuai.jp/benchmark
>*7 Japanese Vicuna QAベンチマーク
Rakudaよりもさらに幅広いカテゴリで言語モデルのQAや指示遂行の能力を問う評価方法。一般知識、ロールプレイなど多数の質問から構成される。
URL:https://github.com/hitoshizuku7/LLM_Judge_ku/blob/main/README.mdtsuzumiはアダプタを追加することで、モデル全体のパラメータを更新することなく、さまざまな知識を持たせたり、振る舞いを変えたりできるようになるとのこと(LoRAアダプタのようなものだと思われる)。
まて、将来的に視覚や聴覚などのマルチモーダル対応も実施。思想がLoRA Hub 917 に近く、アダプタを着脱すれば柔軟に生成を変えられるのは有用だと思う。 #Article #ComputerVision #NLP #LanguageModel #ChatGPT Issue Date: 2023-09-30 OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化, AIDB, 2023.09 Commentおう…やべえな…
 #Article
#Survey
#ComputerVision
#NLP
#LanguageModel
#SpeechProcessing
Issue Date: 2023-07-03
Awesome Multimodal LLMs
CommentマルチモーダルなLLMのリストがまとめられている
#Article
#Survey
#ComputerVision
#NLP
#LanguageModel
#SpeechProcessing
Issue Date: 2023-07-03
Awesome Multimodal LLMs
CommentマルチモーダルなLLMのリストがまとめられている
以下がverifierのサンプル
現在はv1.5も公開されておりさらに性能が向上している模様?HF:https://huggingface.co/inclusionAI/Ming-Lite-Omni #Pretraining #Pocket #NLP #LanguageModel #Scaling Laws #DataMixture #VisionLanguageModel Issue Date: 2025-07-18 [Paper Note] Scaling Laws for Optimal Data Mixtures, Mustafa Shukor+, arXiv'25 Summary本研究では、スケーリング法則を用いて任意のターゲットドメインに対する最適なデータ混合比率を決定する方法を提案。特定のドメイン重みベクトルを持つモデルの損失を正確に予測し、LLM、NMM、LVMの事前訓練における予測力を示す。少数の小規模な訓練実行でパラメータを推定し、高価な試行錯誤法に代わる原則的な選択肢を提供。 #ComputerVision #Pocket #NLP #Reasoning #OpenWeight #VisionLanguageModel Issue Date: 2025-07-14 [Paper Note] Kimi-VL Technical Report, Kimi Team+, arXiv'25 SummaryKimi-VLは、効率的なオープンソースのMixture-of-Expertsビジョン・ランゲージモデルであり、2.8Bパラメータの言語デコーダーを活性化して高度なマルチモーダル推論を実現。マルチターンエージェントタスクや大学レベルの画像・動画理解において優れた性能を示し、最先端のVLMと競争。128Kの拡張コンテキストウィンドウを持ち、長い入力を処理可能。Kimi-VL-Thinking-2506は、長期的推論能力を強化するために教師ありファインチューニングと強化学習を用いて開発され、堅牢な一般能力を獲得。コードは公開されている。 Comment・2201
での性能(Vision+テキストの数学の問題)。他の巨大なモデルと比べ2.8BのActivation paramsで高い性能を達成
その他のベンチマークでも高い性能を獲得
モデルのアーキテクチャ。MoonViT (Image Encoder, 1Dのpatchをinput, 様々な解像度のサポート, FlashAttention, SigLIP-SO-400Mを継続事前学習, RoPEを採用) + Linear Projector + MoE Language Decoderの構成
学習のパイプライン。ViTの事前学習ではSigLIP loss (contrastive lossの亜種)とcaption生成のcross-entropy lossを採用している。joint cooldown stageにおいては、高品質なQAデータを合成することで実験的に大幅に性能が向上することを確認したので、それを採用しているとのこと。optimizerは
・2202
post-trainingにおけるRLでは以下の目的関数を用いており、RLVRを用いつつ、現在のポリシーモデルをreferenceとし更新をするような目的関数になっている。curriculum sampling, prioritize samplingをdifficulty labelに基づいて実施している。
細かいが表中のGPT-o3は正しくはo3だと思われる。
時間がなくて全然しっかりと読めていないが、reasoning effortやthinkingモードはどのように設定して評価したのだろうか。
[^1]:ただし、これが本当にDiffusion Modelを使ったことによる恩恵なのかはまだ論文を読んでいないのでわからない。必要になったら読む。ただ、Physics of Language Modelのように、完全にコントロールされたデータで異なるアーキテクチャを比較しないとその辺はわからなそうではある。 #ComputerVision #Pocket #NLP #Dataset #LanguageModel #Evaluation #ICLR #x-Use Issue Date: 2025-04-18 AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25 Summary本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 CommentAndroid環境でのPhone Useのベンチマーク #ComputerVision #Pocket #NLP #LanguageModel #SpeechProcessing #OpenWeight #Video Issue Date: 2025-03-31 Qwen2.5-Omni Technical Report, Jin Xu+, arXiv'25 Summaryマルチモーダルモデル「Qwen2.5-Omni」は、テキスト、画像、音声、動画を認識し、ストリーミング方式で自然な音声応答を生成する。音声と視覚エンコーダはブロック処理を用い、TMRoPEによる新しい位置埋め込みで音声と動画の同期を実現。Thinker-Talkerアーキテクチャにより、テキスト生成と音声出力を干渉なく行う。Qwen2.5-Omniは、エンドツーエンドで訓練され、音声指示に対する性能がテキスト入力と同等で、ストリーミングTalkerは既存手法を上回る自然さを持つ。 CommentQwen TeamによるマルチモーダルLLM。テキスト、画像、動画音声をinputとして受け取り、テキスト、音声をoutputする。
weight:https://huggingface.co/collections/Qwen/qwen25-omni-67de1e5f0f9464dc6314b36e元ポスト:https://www.linkedin.com/posts/niels-rogge-a3b7a3127_alibabas-qwen-team-has-done-it-again-this-activity-7311036679627132929-HUqy?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4 #Multi #RecommenderSystems #NeuralNetwork #Survey #Pocket #MultitaskLearning Issue Date: 2025-03-03 Joint Modeling in Recommendations: A Survey, Xiangyu Zhao+, arXiv'25 Summaryデジタル環境におけるDeep Recommender Systems(DRS)は、ユーザーの好みに基づくコンテンツ推薦に重要だが、従来の手法は単一のタスクやデータに依存し、複雑な好みを反映できない。これを克服するために、共同モデリングアプローチが必要であり、推薦の精度とカスタマイズを向上させる。本論文では、共同モデリングをマルチタスク、マルチシナリオ、マルチモーダル、マルチビヘイビアの4次元で定義し、最新の進展と研究の方向性を探る。最後に、将来の研究の道筋を示し、結論を述べる。 Comment元ポスト:https://x.com/_reachsumit/status/1896408792952410496?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pretraining #Pocket #FoundationModel #CVPR #Admin'sPick #VisionLanguageModel Issue Date: 2025-08-23 [Paper Note] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, Zhe Chen+, CVPR'24 Summary大規模視覚-言語基盤モデル(InternVL)は、60億パラメータで設計され、LLMと整合させるためにウェブ規模の画像-テキストデータを使用。視覚認知タスクやゼロショット分類、検索など32のベンチマークで最先端の性能を達成し、マルチモーダル対話システムの構築に寄与。ViT-22Bの代替として強力な視覚能力を持つ。コードとモデルは公開されている。 Comment既存のResNetのようなSupervised pretrainingに基づくモデル、CLIPのようなcontrastive pretrainingに基づくモデルに対して、text encoder部分をLLMに置き換えて、contrastive learningとgenerativeタスクによる学習を組み合わせたパラダイムを提案。
InternVLのアーキテクチャは下記で、3 stageの学習で構成される。最初にimage text pairをcontrastive learningし学習し、続いてモデルのパラメータはfreezeしimage text retrievalタスク等でモダリティ間の変換を担う最終的にQlLlama(multilingual性能を高めたllama)をvision-languageモダリティを繋ぐミドルウェアのように捉え、Vicunaをテキストデコーダとして接続してgenerative cossで学習する、みたいなアーキテクチャの模様(斜め読みなので少し違う可能性あり
https://x.com/xiangyue96/status/1953902213790830931?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QMMMUのサンプルはこちら。各分野ごとに専門家レベルの知識と推論が求められるとのこと。
まあざっくり言うと、マルチモーダルを理解できるLLMを作りたかったら、様々なモダリティをエンコーディングして得られる表現と、既存のLLMが内部的に処理可能な表現を対応づける Input Projectorという名の関数を学習すればいいだけだよ(モダリティのエンコーダ、LLMは事前学習されたものをそのままfreezeして使えば良い)。
マルチモーダルを生成できるLLMを作りたかったら、LLMがテキストを生成するだけでなく、様々なモダリティに対応する表現も追加で出力するようにして、その出力を各モダリティを生成できるモデルに入力できるように変換するOutput Projectortという名の関数を学習しようね、ということだと思われる。
概要
ポイント
・Modality Encoder, LLM Backbone、およびModality Generatorは一般的にはパラメータをfreezeする
・optimizationの対象は「Input/Output Projector」
Modality Encoder
様々なモダリティI_Xを、特徴量F_Xに変換する。これはまあ、色々なモデルがある。
Input Projector
モダリティI_Xとそれに対応するテキストtのデータ {I_X, t}が与えられたとき、テキストtを埋め込み表現に変換んした結果得られる特徴量がF_Tである。Input Projectorは、F_XをLLMのinputとして利用する際に最適な特徴量P_Xに変換するθX_Tを学習することである。これは、LLM(P_X, F_T)によってテキストtがどれだけ生成できたか、を表現する損失関数を最小化することによって学習される。
LLM Backbone
LLMによってテキスト列tと、各モダリティに対応した表現であるS_Xを生成する。outputからt, S_Xをどのように区別するかはモデルの構造などにもよるが、たとえば異なるヘッドを用意して、t, S_Xを区別するといったことは可能であろうと思われる。
Output Projector
S_XをModality Generatorが解釈可能な特徴量H_Xに変換する関数のことである。これは学習しなければならない。
H_XとModality Generatorのtextual encoderにtを入力した際に得られる表現τX(t)が近くなるようにOutput Projector θ_T_Xを学習する。これによって、S_XとModality Generatorがalignするようにする。
Modality Generator
各ModalityをH_Xから生成できるように下記のような損失学習する。要は、生成されたモダリティデータ(または表現)が実際のデータにどれだけ近いか、を表しているらしい。具体的には、サンプリングによって得られたノイズと、モデルが推定したノイズの値がどれだけ近いかを測る、みたいなことをしているらしい。
Multi Modalを理解するモデルだけであれば、Input Projectorの損失のみが学習され、生成までするのであれば、Input/Output Projector, Modality Generatorそれぞれに示した損失関数を通じてパラメータが学習される。あと、P_XやらS_Xはいわゆるsoft-promptingみたいなものであると考えられる。 #ComputerVision #Pretraining #Pocket #NLP #Transformer #InstructionTuning #SpeechProcessing #CVPR #Encoder-Decoder #Robotics Issue Date: 2023-12-29 Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, N_A, CVPR'24 SummaryUnified-IO 2は、最初の自己回帰型のマルチモーダルモデルであり、画像、テキスト、音声、アクションを理解し生成することができます。異なるモダリティを統一するために、共有の意味空間に入力と出力を配置し、単一のエンコーダ・デコーダトランスフォーマーモデルで処理します。さまざまなアーキテクチャの改善を提案し、大規模なマルチモーダルな事前トレーニングコーパスを使用してモデルをトレーニングします。Unified-IO 2は、GRITベンチマークを含む35以上のベンチマークで最先端のパフォーマンスを発揮します。 Comment画像、テキスト、音声、アクションを理解できる初めてのautoregressive model。AllenAIモデルのアーキテクチャ図
マルチモーダルに拡張したことで、訓練が非常に不安定になったため、アーキテクチャ上でいくつかの工夫を加えている:
・2D Rotary Embedding
・Positional EncodingとしてRoPEを採用
・画像のような2次元データのモダリティの場合はRoPEを2次元に拡張する。具体的には、位置(i, j)のトークンについては、Q, Kのembeddingを半分に分割して、それぞれに対して独立にi, jのRoPE Embeddingを適用することでi, j双方の情報を組み込む。
・QK Normalization
・image, audioのモダリティを組み込むことでMHAのlogitsが非常に大きくなりatteetion weightが0/1の極端な値をとるようになり訓練の不安定さにつながった。このため、dot product attentionを適用する前にLayerNormを組み込んだ。
・Scaled Cosine Attention
・Image Historyモダリティにおいて固定長のEmbeddingを得るためにPerceiver Resamplerを扱ったているが、こちらも上記と同様にAttentionのlogitsが極端に大きくなったため、cosine類似度をベースとしたScaled Cosine Attention 2259 を利用することで、大幅に訓練の安定性が改善された。
・その他
・attention logitsにはfp32を適用
・事前学習されたViTとASTを同時に更新すると不安定につながったため、事前学習の段階ではfreezeし、instruction tuningの最後にfinetuningを実施
・\[R\]: 通常のspan corruption (1--5 token程度のspanをmaskする)
・\[S\]: causal language modeling (inputを2つのサブシーケンスに分割し、前方から後方を予測する。前方部分はBi-directionalでも可)
・\[X\]: extreme span corruption (12>=token程度のspanをmaskする)
の3種類が提案されており、モダリティごとにこれらを使い分ける:
・text modality: UL2 (1424)を踏襲
・image, audioがtargetの場合: 2つの類似したパラダイムを定義し利用
・\[R\]: patchをランダムにx%マスクしre-constructする
・\[S\]: inputのtargetとは異なるモダリティのみの情報から、targetモダリティを生成する
訓練時には prefixとしてmodality token \[Text\], \[Image\], \[Audio\] とparadigm token \[R\], \[S\], \[X\] をタスクを指示するトークンとして利用している。また、image, audioのマスク部分のdenoisingをautoregressive modelで実施する際には普通にやるとdecoder側でリークが発生する(a)。これを防ぐには、Encoder側でマスクされているトークンを、Decoder側でteacher-forcingする際にの全てマスクする方法(b)があるが、この場合、生成タスクとdenoisingタスクが相互に干渉してしまいうまく学習できなくなってしまう(生成タスクでは通常Decoderのinputとして[mask]が入力され次トークンを生成する、といったことは起きえないが、愚直に(b)をやるとそうなってしまう)。ので、(c)に示したように、マスクされているトークンをinputとして生成しなければならない時だけ、マスクを解除してdecoder側にinputする、という方法 (Dynamic Masking) でこの問題に対処している。
#ComputerVision #Controllable #Pocket #NLP #TextToImageGeneration Issue Date: 2025-08-07 [Paper Note] Adding Conditional Control to Text-to-Image Diffusion Models, Lvmin Zhang+, arXiv'23 SummaryControlNetは、テキストから画像への拡散モデルに空間的な条件制御を追加するためのニューラルネットワークアーキテクチャであり、事前学習済みのエンコーディング層を再利用して多様な条件制御を学習します。ゼロ畳み込みを用いてパラメータを徐々に増加させ、有害なノイズの影響を軽減します。Stable Diffusionを用いて様々な条件制御をテストし、小規模および大規模データセットに対して堅牢性を示しました。ControlNetは画像拡散モデルの制御における広範な応用の可能性を示唆しています。 CommentControlNet論文 #ComputerVision #Pretraining #Pocket #LanguageModel #Admin'sPick #ICCV Issue Date: 2025-06-29 [Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23 Summaryシンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。 CommentSigLIP論文 #ComputerVision #Pocket #NLP #Transformer #SpeechProcessing #Architecture #Normalization Issue Date: 2025-04-19 Foundation Transformers, Hongyu Wang+, PMLR'23 Summary言語、視覚、音声、マルチモーダルにおけるモデルアーキテクチャの収束が進む中、異なる実装の「Transformers」が使用されている。汎用モデリングのために、安定性を持つFoundation Transformerの開発が提唱され、Magnetoという新しいTransformer変種が紹介される。Sub-LayerNormと理論に基づく初期化戦略を用いることで、さまざまなアプリケーションにおいて優れたパフォーマンスと安定性を示した。 Commentマルチモーダルなモデルなモデルの事前学習において、PostLNはvision encodingにおいてsub-optimalで、PreLNはtext encodingにおいてsub-optimalであることが先行研究で示されており、マルタモーダルを単一のアーキテクチャで、高性能、かつ学習の安定性な高く、try and error無しで適用できる基盤となるアーキテクチャが必要というモチベーションで提案された手法。具体的には、Sub-LayerNorm(Sub-LN)と呼ばれる、self attentionとFFN部分に追加のLayerNormを適用するアーキテクチャと、DeepNetを踏襲しLayer数が非常に大きい場合でも学習が安定するような重みの初期化方法を理論的に分析し提案している。
具体的には、Sub-LNの場合、LayerNormを
・SelfAttention計算におけるQKVを求めるためのinput Xのprojectionの前とAttentionの出力projectionの前
・FFNでの各Linear Layerの前
に適用し、
初期化をする際には、FFNのW, およびself-attentionのV_projと出力のout_projの初期化をγ(=sqrt(log(2N))によってスケーリングする方法を提案している模様。
・1900 #ComputerVision #Pocket #NLP #LanguageModel #OpenWeight Issue Date: 2025-04-11 PaLI-3 Vision Language Models: Smaller, Faster, Stronger, Xi Chen+, arXiv'23 SummaryPaLI-3は、従来のモデルに比べて10倍小型で高速な視覚言語モデル(VLM)であり、特にローカリゼーションや視覚的テキスト理解において優れた性能を示す。SigLIPベースのPaLIは、20億パラメータにスケールアップされ、多言語クロスモーダル検索で新たな最先端を達成。50億パラメータのPaLI-3は、VLMの研究を再燃させることを期待されている。 CommentOpenReview:https://openreview.net/forum?id=JpyWPfzu0b
実験的に素晴らしい性能が実現されていることは認められつつも
・比較対象がSigLIPのみでより広範な比較実験と分析が必要なこと
・BackboneモデルをContrastive Learningすること自体の有用性は既に知られており、新規性に乏しいこと
としてICLR'24にRejectされている #Pretraining #Pocket #NLP #LanguageModel #ICLR Issue Date: 2024-09-26 UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23 Summary本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 CommentOpenReview:https://openreview.net/forum?id=6ruVLB727MC[R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを持つMoD (Mixture of Denoisers)を提案
画像 + テキストpromptで、動画を生成するデモ #InformationRetrieval #Pocket #Dataset Issue Date: 2023-12-01 UniIR: Training and Benchmarking Universal Multimodal Information Retrievers, Cong Wei+, N_A, arXiv'23 Summary従来の情報検索モデルは一様な形式を前提としているため、異なる情報検索の要求に対応できない。そこで、UniIRという統一された指示に基づくマルチモーダルリトリーバーを提案する。UniIRは異なるリトリーバルタスクを処理できるように設計され、10のマルチモーダルIRデータセットでトレーニングされる。実験結果はUniIRの汎化能力を示し、M-BEIRというマルチモーダルリトリーバルベンチマークも構築された。 Comment後で読む(画像は元ツイートより
元ツイート: https://x.com/congwei1230/status/1730307767469068476?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #ComputerVision #Pocket #NLP #MultitaskLearning #FoundationModel Issue Date: 2023-11-13 Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks, Bin Xiao+, N_A, arXiv'23 SummaryFlorence-2は、ビジョン基盤モデルであり、さまざまなビジョンタスクに対応するための統一されたプロンプトベースの表現を持っています。このモデルは、テキストプロンプトを受け取り、キャプショニング、オブジェクト検出、グラウンディング、セグメンテーションなどのタスクを実行し、テキスト形式で結果を生成します。また、FLD-5Bという大規模な注釈付きデータセットも開発されました。Florence-2は、多目的かつ包括的なビジョンタスクを実行するためにシーケンスツーシーケンス構造を採用しており、前例のないゼロショットおよびファインチューニングの能力を持つ強力なモデルです。 CommentVison Foundation Model。Spatialな階層構造や、Semanticを捉えられるように訓練。Image/Prompt Encoderでエンコードされ、outputはtext + location informationとなる。
#ComputerVision #Pocket #NLP #LanguageModel #OCR Issue Date: 2023-10-26 Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, N_A, arXiv'23 Summaryこの論文では、GPT-4Vという大規模マルチモーダルモデルの光学文字認識(OCR)能力を評価します。さまざまなOCRタスクにおいてモデルのパフォーマンスを評価し、ラテン文字の認識と理解において優れた性能を示す一方、多言語や複雑なタスクには苦戦することがわかりました。これに基づいて、専門のOCRモデルの必要性やGPT-4Vを活用する戦略についても検討します。この研究は、将来のLMMを用いたOCRの研究に役立つものです。評価のパイプラインと結果は、GitHubで利用可能です。 CommentGPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
興味深い #ComputerVision #Pretraining #Pocket #NLP #Transformer Issue Date: 2023-07-12 Generative Pretraining in Multimodality, Quan Sun+, N_A, arXiv'23 SummaryEmuは、マルチモーダルなコンテキストで画像とテキストを生成するためのTransformerベースのモデルです。このモデルは、単一モダリティまたはマルチモーダルなデータ入力を受け入れることができます。Emuは、マルチモーダルなシーケンスでトレーニングされ、画像からテキストへのタスクやテキストから画像へのタスクなど、さまざまなタスクで優れたパフォーマンスを示します。また、マルチモーダルアシスタントなどの拡張機能もサポートしています。 #ComputerVision #Pretraining #Pocket #NLP Issue Date: 2023-07-12 EgoVLPv2: Egocentric Video-Language Pre-training with Fusion in the Backbone, Shraman Pramanick+, N_A, arXiv'23 Summaryエゴセントリックビデオ言語の事前学習の第2世代(EgoVLPv2)は、ビデオと言語のバックボーンにクロスモーダルの融合を直接組み込むことができる。EgoVLPv2は強力なビデオテキスト表現を学習し、柔軟かつ効率的な方法でさまざまなダウンストリームタスクをサポートする。さらに、提案されたバックボーン戦略は軽量で計算効率が高い。EgoVLPv2は幅広いVLタスクで最先端のパフォーマンスを達成している。詳細はhttps://shramanpramanick.github.io/EgoVLPv2/を参照。 #ComputerVision #LanguageModel #QuestionAnswering Issue Date: 2023-07-11 SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs, Lijun Yu+, N_A, arXiv'23 Summaryこの研究では、Semantic Pyramid AutoEncoder(SPAE)を使用して、凍結されたLLMsが非言語的なモダリティを含むタスクを実行できるようにします。SPAEは、LLMの語彙から抽出されたトークンと生のピクセルデータの変換を行います。生成されたトークンは、視覚再構成に必要な意味と詳細を捉え、LLMが理解できる言語に変換します。実験結果では、我々のアプローチが画像理解と生成のタスクにおいて最先端のパフォーマンスを25%以上上回ることを示しています。 Comment画像をLLMのtokenスペースにマッピングすることで、LLMがパラメータの更新なしにvisual taskを解くことを可能にした。in context learningによって、様々なvisuataskを解くことができる。
#MachineLearning #DataAugmentation Issue Date: 2023-04-26 Learning Multimodal Data Augmentation in Feature Space, ICLR'23 Summaryマルチモーダルデータの共同学習能力は、インテリジェントシステムの特徴であるが、データ拡張の成功は単一モーダルのタスクに限定されている。本研究では、LeMDAという方法を提案し、モダリティのアイデンティティや関係に制約を設けずにマルチモーダルデータを共同拡張することができることを示した。LeMDAはマルチモーダルディープラーニングの性能を向上させ、幅広いアプリケーションで最先端の結果を達成することができる。 CommentData Augmentationは基本的に単体のモダリティに閉じて行われるが、
マルチモーダルな設定において、モダリティ同士がどう関係しているか、どの変換を利用すべきかわからない時に、どのようにデータ全体のsemantic structureを維持しながら、Data Augmentationできるか?という話らしい #NeuralNetwork #ComputerVision #MachineLearning #Pocket #NLP #MultitaskLearning #SpeechProcessing #ICLR Issue Date: 2025-07-10 [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22 Summary汎用アーキテクチャPerceiver IOを提案し、任意のデータ設定に対応し、入力と出力のサイズに対して線形にスケール可能。柔軟なクエリメカニズムを追加し、タスク特有の設計を不要に。自然言語、視覚理解、マルチタスクで強力な結果を示し、GLUEベンチマークでBERTを上回る性能を達成。 Comment当時相当話題となったさまざまなモーダルを統一された枠組みで扱えるPerceiver IO論文
#ComputerVision #Pocket #NLP #Transformer #Architecture Issue Date: 2025-08-21 [Paper Note] Supervised Multimodal Bitransformers for Classifying Images and Text, Douwe Kiela+, arXiv'19 Summaryテキストと画像情報を融合する監視型マルチモーダルビットランスフォーマーモデルを提案し、さまざまなマルチモーダル分類タスクで最先端の性能を達成。特に、難易度の高いテストセットでも強力なベースラインを上回る結果を得た。 Commentテキスト+imageを用いるシンプルなtransformer #Article #ComputerVision #NLP #LanguageModel #OpenWeight #VisionLanguageModel Issue Date: 2025-08-27 MiniCPM-V-4_5, openbmb, 2025.08 Comment元ポスト:https://x.com/adinayakup/status/1960292853453672886?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #NLP #LanguageModel #ProprietaryLLM Issue Date: 2025-08-07 GPT-5 System Card, OpenAI, 2025.08 Comment日本語性能。MMLUを専門の翻訳家を各言語に翻訳。
・https://x.com/scaling01/status/1953507426952507405?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/gdb/status/1953747271666819380?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
gpt-ossではAttentionSinkが使われていたが、GPT-5では使われているだろうか?もし使われているならlong contextの性能向上に寄与していると思われる。50% time horizonもscaling lawsに則り進展:
・https://x.com/hillbig/status/1953622811077227003?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・1842
個別のベンチが数%向上、もしくはcomparableです、ではもはやどれくらい進展したのかわからない(が、個々の能力が交互作用して最終的な出力がされると考えるとシナジーによって全体の性能は大幅に底上げされる可能性がある)からこの指標を見るのが良いのかも知れないMETR's Autonomy Evaluation Resources
・https://metr.github.io/autonomy-evals-guide/gpt-5-report/
・https://x.com/metr_evals/status/1953525150374150654?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHLEに対するツール利用でのスコアの比較に対する所見:
https://x.com/imai_eruel/status/1953511704824099157?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QDocument Understandingでの評価をしたところOutput tokenが大幅に増えている:
https://x.com/jerryjliu0/status/1953582723672814054?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGPT5 Prompting Guide:
https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guideGPT-5: Key characteristics, pricing and model card
・https://simonwillison.net/2025/Aug/7/gpt-5/
・https://x.com/simonw/status/1953512493986591195?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qシステムカード中のSWE Bench Verifiedの評価結果は、全500サンプルのうちの477サンプルでしか実施されておらず、単純にスコアを比較することができないことに注意。実行されなかった23サンプルをFailedとみなすと(実行しなかったものを正しく成功できたとはみなせない)、スコアは減少する。同じ477サンプル間で評価されたモデル間であれば比較可能だが、500サンプルで評価された他のモデルとの比較はできない。
・https://x.com/gneubig/status/1953518981232402695?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・SWE Bench リーダーボード: https://www.swebench.com
https://x.com/scaling01/status/1953511287209558245?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q所見:
・https://x.com/dongxi_nlp/status/1953570656584417655?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
・https://x.com/imai_eruel/status/1953777394214744198?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenHandsでの評価:
https://x.com/gneubig/status/1953883635657900289?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
SWE Bench Verifiedの性能は71.8%。全部の500サンプルで評価した結果だと思うので公式の発表より低めではある。AttentionSinkについて:
https://x.com/goro_koba/status/1954480023890780587?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qo3と比較してGPT5は約1/3の時間でポケモンレッド版で8個のバッジを獲得した模様:
https://x.com/qualzz_sam/status/1955760274142597231?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qより温かみのあるようなalignmentが実施された模様:
https://x.com/openai/status/1956461718097494196?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QGPT5はlong contextになるとmarkdownよりめxmlの方が適していると公式ドキュメントに記載があるらしい:
https://x.com/mlbear2/status/1956626291408744522?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QSmallow LLM Leaderboard v2での性能:
https://x.com/chokkanorg/status/1958065332817653858?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
GPT5の性能が際立って良く、続いてQwen3, gptossも性能が良い。 #Article #ComputerVision #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #VideoGeneration/Understandings Issue Date: 2025-07-29 Wan2.2, Alibaba Wan, 2025.07 Comment元ポスト:https://x.com/alibaba_wan/status/1949827662416937443?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q初のMoEによるOpen WeightなVideo generationモデルで、直接的に明るさや、カラー、カメラの動きなどを制御でき、text to video, image to video, unified video generationをサポートしている模様 #Article #ComputerVision #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2025-06-30 ERNIE 4.5 Series, ERNIE TEAM, 2025.06 CommentTech Report:https://yiyan.baidu.com/blog/publication/ERNIE_Technical_Report.pdf元ポスト:https://x.com/paddlepaddle/status/1939535276197744952?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/gm8xx8/status/1939576393098023188?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-06-24 Kimi-VL-A3B-Thinking-2506, moonshotai, 2025.06 Comment元ポスト:https://x.com/reach_vb/status/1937159672932286950?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q様々なベンチマークでSoTA(gpt4o, Qwen2.5-VL-7B)を達成したReasoning VLMテクニカルペーパー:
・2200 #Article #ComputerVision #NLP #Dataset #LanguageModel #AWS #Blog #Japanese Issue Date: 2025-05-20 Webスケールの日本語-画像のインターリーブデータセット「MOMIJI」の構築 _巨大テキストデータをAWSで高速に処理するパイプライン, Turing (studio_graph), 2025.05 Comment貴重なVLMデータセット構築ノウハウ青塗りのフィルタリングタスクを具体的にどうやっているのか気になる #Article #ComputerVision #Pocket #NLP #LLMAgent #Blog #Reasoning #OpenWeight #x-Use Issue Date: 2025-04-18 Introducing UI-TARS-1.5, ByteDance, 2025.04 SummaryUI-TARSは、スクリーンショットを入力として人間のようにインタラクションを行うネイティブGUIエージェントモデルであり、従来の商業モデルに依存せず、エンドツーエンドで優れた性能を発揮します。実験では、10以上のベンチマークでSOTA性能を達成し、特にOSWorldやAndroidWorldで他のモデルを上回るスコアを記録しました。UI-TARSは、強化された知覚、統一アクションモデリング、システム-2推論、反射的オンライントレースによる反復トレーニングなどの革新を取り入れ、最小限の人間の介入で適応し続ける能力を持っています。 Commentpaper:https://arxiv.org/abs/2501.12326色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)関連
・1794元ポスト:https://x.com/_akhaliq/status/1912913195607663049?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-04-05 Llama 4 Series, Meta, 2025.04 CommentDownloads:https://www.llama.com/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4Huggingface:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164解説ポスト:https://x.com/iscienceluvr/status/1908601269004230763?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QArtificial Analysisによる性能検証:https://x.com/artificialanlys/status/1908890796415414430?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
MaverickがGPT4oと同等、ScoutがGPT4o-miniと同等
Update:https://x.com/artificialanlys/status/1909624239747182989?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q性能に関して不可解な点が多そうなので様子見をしても良いかも。性能検証(Math-Perturb):https://x.com/kaixuanhuang1/status/1909387970773234088?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q日本語にあまり強くないという情報も
元ポスト:https://x.com/gosrum/status/1909626761098494060?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QどうやらvLLMのLlama4のinferenceにバグがあったやうで、vLLMのIssue 16311にて、Llama4のinferenceに関するバグが修正され、性能が向上した模様。どのベンチを信じたら良いかまるでわからん。2025.0413現在のchatbot arenaのランクは、32位となり(chatbot arena向けにtuningされていたであろうモデルは2位だった)GPT-4oが29位であることを考慮すると上記のArtificial Intelligenceの評価とも大体一致している。
https://lmarena.ai
関連ポスト:https://x.com/tunguz/status/1911142310160855541?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-25 Qwen2.5-VL-32B-Instruct, Qwen Team, 2025.03 Comment元ポスト:https://x.com/alibaba_qwen/status/1904227859616641534?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Transformer #Supervised-FineTuning (SFT) #Blog #SSM (StateSpaceModel) Issue Date: 2025-03-24 Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03 Comment関連:
・1820TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。
56B程度のmediumサイズのモデルと、8B程度の軽量なモデルについて述べられている。特に、8BモデルでMambaとTransformerのハイブリッドモデルと、通常のTransformerモデルを比較している。学習データに15 Trillion Tokenを利用しており、このデータ量でのApple to Appleのアーキテクチャ間の比較は、現状では最も大規模なものとのこと。性能は多くのベンチマークでハイブリッドにしても同等、Commonsense Understandingでは上回っている。
また、学習したNemotron-Hをバックボーンモデルとして持つVLMについてもモデルのアーキテクチャが述べられている。 #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-18 SmolDocling-256M, IBM Research, 2025.03 Comment元ポスト:https://www.linkedin.com/posts/andimarafioti_we-just-dropped-%F0%9D%97%A6%F0%9D%97%BA%F0%9D%97%BC%F0%9D%97%B9%F0%9D%97%97%F0%9D%97%BC%F0%9D%97%B0%F0%9D%97%B9%F0%9D%97%B6%F0%9D%97%BB%F0%9D%97%B4-activity-7307415358427013121-wS8m?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4Apache-2.0ライセンス。言語はEnglishのみな模様マルチモーダルなImage-To-Textモデル。サンプルはこちら
・X1はマルチモーダルなreasoningモデルでDeepSeek-R1と同等の性能で半額
らしいこのモデルは6月30日にオープン(ウェイト?)になるとスレッドで述べられている。 #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-03-17 sarashina2-vision-{8b, 14b}, SB Intuitions, 2025.03 Comment元ポスト:https://x.com/sei_shinagawa/status/1901467733331701966?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QVLM。Xに散見される試行例を見ると日本語の読み取り性能は結構高そうに見える。モデル構成、学習の詳細、および評価:https://x.com/sbintuitions/status/1901472307421278604?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLLM(sarashina2), Vision Encoder(Qwen2-VL), Projectorの3つで構成されており、3段階の学習を踏んでいる。
最初のステップでは、キャプションデータを用いてProjectorのみを学習しVision Encoderとテキストを対応づける。続いて、日本語を含む画像や日本特有の風景などをうまく扱えるように、これらを多く活用したデータ(内製日本語OCRデータ、図表キャプションデータ)を用いて、Vision EncoderとProjectorを学習。最後にLLMのAlignmentをとるために、プロジェクターとLLMを前段のデータに加えてVQAデータ(内製合成データを含む)や日本語の指示チューニングデータを用いて学習。ProjectorやMMLLMを具体的にどのように学習するかは
・1225
を参照のこと。 #Article #ComputerVision #NLP #LanguageModel #OpenWeight Issue Date: 2025-01-28 Janus-Series: Unified Multimodal Understanding and Generation Models, DeepSeek, 2025.01 CommentDeepSeekによる新たなVLM、Janus-Proが本日リリース。MIT LicenseJanus-Proのパフォーマンス。
github上でのパフォーマンスの図解から引用。マルチモーダル(テキスト+画像)の理解に関するベンチマークでLLaVA超え。GenEval, DPG Benchと呼ばれる画像生成ベンチマークでDALL-E 3超え。
テクニカルレポート中での詳細から引用。どのベンチマークでも基本的に最高性能なように見える。
テクニカルレポート: https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf #Article #ComputerVision #NLP #LanguageModel #FoundationModel #MultiLingual Issue Date: 2024-12-04 Introducing Amazon Nova, our new generation of foundation models, AWS, 2024.12 Comment参考:https://qiita.com/ysit/items/8433d149dbaab702d526テクニカルレポート: https://assets.amazon.science/9f/a3/ae41627f4ab2bde091f1ebc6b830/the-amazon-nova-family-of-models-technical-report-and-model-card.pdf後で個々のベンチマークとメトリックをまとめたい。
まあでもざっくり言うと、他のproprietaryモデルともおおむね同等の性能です、という感じに見える。個々のタスクレベルで見ると、得意なものと不得意なものはありそうではある。
スループットとかも、ProとGPT4oをパッと見で比較した感じ、優れているわけでもなさそう。Liteに対応するGPTはおそらくGPT4o-miniだと思われるが、スループットはLiteの方が高そう。
(画像は論文中からスクショし引用)下記ポストは独自に評価した結果や、コストと性能のバランスについて言及している。
・ProはGPT4oのコストの約1/3
・Pro, Lite, Flashはほれぞれコストパフォーマンスに非常に優れている(Quality vs. Price参照)
元ポスト:https://x.com/artificialanlys/status/1864023052818030814?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Article #ComputerVision #NLP #LanguageModel #OpenWeight #VisionLanguageModel Issue Date: 2024-09-27 Molmo, AI2, 2024.09 SummaryMolmoは、オープンデータを活用した最先端のマルチモーダルAIモデルであり、特に小型モデルが大規模モデルを上回る性能を示す。Molmoは、物理的および仮想的な世界とのインタラクションを可能にし、音声ベースの説明を用いた新しい画像キャプションデータセットを導入。ファインチューニング用の多様なデータセットを使用し、非言語的手がかりを活用して質問に答える能力を持つ。Molmoファミリーのモデルは、オープンウェイトでプロプライエタリシステムに対抗する性能を発揮し、今後すべてのモデルウェイトやデータを公開予定。 Comment以下がベンチマーク結果(VLMのベンチマーク)。11 benchmarksと書かれているのは、VLMのベンチマークである点に注意。
#Article #ComputerVision #NLP #LanguageModel Issue Date: 2024-04-14 Grok-1.5 Vision Preview, 2024 Comment
#Article #ComputerVision #NLP #Prompting #AutomaticPromptEngineering Issue Date: 2023-12-01 multimodal-maestro CommentLarge Multimodal Model (LMM)において、雑なpromptを与えるても自動的に良い感じoutputを生成してくれるっぽい?
以下の例はリポジトリからの引用であるが、この例では、"Find dog." という雑なpromptから、画像中央に位置する犬に[9]というラベルを与えました、というresponseを得られている。pipelineとしては、Visual Promptに対してまずSAMを用いてイメージのsegmentationを行い、各セグメントにラベルを振る。このラベルが振られた画像と、"Find dog." という雑なpromptを与えるだけで良い感じに処理をしてくれるようだ。
#Article #ComputerVision #NLP #GenerativeAI Issue Date: 2023-12-01 LaVie: Text-to-Video generation, demo Commentデモのデフォルトで試してみたら、3秒ほどのprompt通りの動画が生成された。
FF14の赤魔導士に変えたら、それっぽいの出てきた
#Article #EfficiencyImprovement #NLP #LanguageModel #FoundationModel #Blog Issue Date: 2023-11-01 tsuzumi, NTT’23 CommentNTT製のLLM。パラメータ数は7Bと軽量だが高性能。
MTBenchのようなGPT4に勝敗を判定させるベンチマークで、地理、歴史、政治、社会に関する質問応答タスク(図6)でgpt3.5turboと同等、国産LLMの中でトップの性能。GPT3.5turboには、コーディングや数学などの能力では劣るとのこと。
> *6 Rakudaベンチマーク
日本語の言語モデルの性能を評価するベンチマークの一つで、日本の地理・政治・歴史・社会に関する質問応答タスクによって評価を行う。
URL:https://yuzuai.jp/benchmark
>*7 Japanese Vicuna QAベンチマーク
Rakudaよりもさらに幅広いカテゴリで言語モデルのQAや指示遂行の能力を問う評価方法。一般知識、ロールプレイなど多数の質問から構成される。
URL:https://github.com/hitoshizuku7/LLM_Judge_ku/blob/main/README.mdtsuzumiはアダプタを追加することで、モデル全体のパラメータを更新することなく、さまざまな知識を持たせたり、振る舞いを変えたりできるようになるとのこと(LoRAアダプタのようなものだと思われる)。
まて、将来的に視覚や聴覚などのマルチモーダル対応も実施。思想がLoRA Hub 917 に近く、アダプタを着脱すれば柔軟に生成を変えられるのは有用だと思う。 #Article #ComputerVision #NLP #LanguageModel #ChatGPT Issue Date: 2023-09-30 OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化, AIDB, 2023.09 Commentおう…やべえな…