
NaturalLanguageGeneration
[Paper Note] Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?, Momoka Furuhashi+, EMNLP'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Evaluation #EMNLP #read-later Issue Date: 2025-08-22 GPT Summary- 生成タスクの自動評価における曖昧な基準の課題を解決するため、チェックリストの使用方法を検討。6つの生成方法と8つのモデルサイズで評価し、選択的チェックリストがペアワイズ評価でパフォーマンスを改善する傾向があることを発見。ただし、直接スコアリングでは一貫性がない。人間の評価基準との相関が低いチェックリスト項目も存在し、評価基準の明確化が必要であることを示唆。 Comment
元ポスト:
pj page: https://momo0817.github.io/checklist-effectiveness-study-github.io/
[Paper Note] CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning, Kuniaki Saito+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Controllable #NLP #LanguageModel #VisionLanguageModel Issue Date: 2025-07-25 GPT Summary- CaptionSmithsは、画像キャプショニングモデルがキャプションの特性(長さ、記述性、単語の独自性)を柔軟に制御できる新しいアプローチを提案。人間の注釈なしで特性を定量化し、短いキャプションと長いキャプションの間で補間することで条件付けを実現。実証結果では、出力キャプションの特性をスムーズに変化させ、語彙的整合性を向上させることが示され、誤差を506%削減。コードはGitHubで公開。 Comment
元ポスト:
従来はDiscreteに表現されていたcaptioningにおける特性をCondition Caluculatorを導入することでcontinuousなrepresentationによって表現し、Caluculatorに人間によるinput, あるいは表現したいConditionを持つexampleをinputすることで、生成時に反映させるような手法を提案している模様。Conditionで利用するpropertyについては、提案手法ではLength, Descriptive, Uniqueness of Vocabulariesの3つを利用している(が、他のpropertyでも本手法は適用可能と思われる)。このとき、あるpropertyの値を変えることで他のpropertyが変化してしまうと制御ができなくなるため、property間のdecorrelationを実施している。これは、あるproperty Aから別のproperty Bの値を予測し、オリジナルのpropertyの値からsubtractする、といった処理を順次propertyごとに実施することで実現される。Appendixに詳細が記述されている。
[Paper Note] ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations, Yubo Wang+, COLM'25
Paper/Blog Link My Issue
#Citations #NLP #LanguageModel #Supervised-FineTuning (SFT) #COLM #AcademicWriting Issue Date: 2025-07-08 GPT Summary- ScholarCopilotは、学術的な執筆を支援するために大規模言語モデルを強化したフレームワークで、正確で文脈に関連した引用を生成します。取得トークンを用いて動的に文献を取得し、生成プロセスを補強します。評価では、取得精度が40.1%に達し、生成品質も他のモデルを大幅に上回りました。特に、ScholarCopilotはChatGPTを超える性能を示し、引用の質で100%の好ましさを達成しました。 Comment
元ポスト:
従来のRAGベースのAcademicWriting手法では、まずReferenceを検索して、その内容をcontextに含めてテキストを生成するというSequentialなパイプラインだったが、本研究では通常のNextTokenPrediction Lossに加え、特殊トークン\[RET\]を導入し、ContrastiveLearningによって、\[RET\]トークンがトリガーとなり、生成過程のContextとqueryから適切なReferenceを検索できるEmbeddingを出力し、Referenceを検索し、動的にReferenceの内容をcontextに加え、テキストを生成する手法を提案している。
データセットはarXivからlatex sourceを収集し、bibliography部分からReferenceのタイトルをQwenを用いて抽出。タイトルをarXivおよびSemanticScholarのデータベースと照合し、paperとReferenceの紐付けを実施することで構築している。
GPT-4oによるjudgeの結果、ground truthのcitationを用いた場合には及ばないが、提案手法により品質が向上し、citation retrievalのRecall@Kも大幅に改善している。
[Paper Note] Striking Gold in Advertising: Standardization and Exploration of Ad Text Generation, Masato Mita+, ACL'24
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Dataset #LanguageModel #Evaluation #LLM-as-a-Judge #KeyPoint Notes Issue Date: 2024-12-15 GPT Summary- 自動広告テキスト生成(ATG)のために、標準化されたベンチマークデータセットCAMERAを提案。これにより、マルチモーダル情報の活用と業界全体での評価が促進される。9つのベースラインを用いた実験で、現状と課題を明らかにし、LLMベースの評価者と人間の評価の一致を探求。 Comment
広告文生成タスク(Ad Text Generation)は個々のグループのプロプライエタリデータでしか評価されてこなかったことと、そもそもタスク設定が十分に規定されていないので、その辺を整備したという話らしい。
特に広告文生成のための初のオープンデータなCAMERAを構築している。
データセットを作るだけでなく、既存の手法、古典的なものからLLMまででどの程度の性能まで到達しているか、さらにはROUGEやGPT-4を用いたLLM-as-a-Judgeのような自動評価手法をメタ評価し、人手評価とオンライン評価のどの程度代替になるかも分析したとのことらしい。
Table5にメタ評価の結果が記載されている。システムレベルのcorrelationを測定している。興味深いのが、BLEU-4, ROUGE-1, BERTScoreなどの古典的or埋め込みベースのNLG評価手法がFaithfulnessとFluencyにおいて、人間の専門家と高い相関を示しているのに対し、GPT-4による評価では人間による評価と全然相関が出ていない。
既存のLLM-as-a-Judge研究では専門家と同等の評価できます、みたいな話がよく見受けられるがこれらの報告と結果が異なっていておもしろい。著者らは、OpenAIのGPTはそもそも広告ドメインとテキストでそんなに訓練されていなさそうなので、ドメインのミスマッチが一つの要因としてあるのではないか、と考察している。
また、Attractivenessでは専門家による評価と弱い相関しか示していない点も興味深い。広告文がどの程度魅力的かはBLEU, ROUGE, BERTScoreあたりではなかなか難しそうなので、GPT4による評価がうまくいって欲しいところだが、全くうまくいっていない。この論文の結果だけを見ると、(Attractivenessに関しては)自動評価だけではまだまだ広告文の評価は厳しそうに見える。
GPT4によるAttractivenessの評価に利用したプロンプトが下記。MTBenchっぽく、ペアワイズの分類問題として解いていることがわかる。この辺はLLM-as-a-Judgeの研究では他にもスコアトークンを出力し尤度で重みづけるG-Evalをはじめ、さまざまな手法が提案されていると思うので、その辺の手法を利用したらどうなるかは興味がある。
あとはそもそも手法面の話以前に、promptのコンテキスト情報としてどのような情報がAttractivenessの評価に重要か?というのも明らかになると興味深い。この辺は、サイバーエージェントの専門家部隊が、どのようなことを思考してAttractivenessを評価しているのか?というのがヒントになりそうである。
- 国際会議ACL2024参加報告, Masato Mita, Cyber Agent, 2024.12
に著者によるサマリが記載されているので参照のこと。
[Paper Note] Controllable Text Generation for Large Language Models: A Survey, Xun Liang+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Survey #Controllable #NLP Issue Date: 2024-08-25 GPT Summary- 大規模言語モデル(LLMs)のテキスト生成品質を向上させるため、制御可能なテキスト生成(CTG)技術が進化している。これにより、安全性や感情、テーマの一貫性を考慮しつつ、ユーザーの多様なニーズに応える生成が求められる。本論文はCTGの最新の進展をレビューし、コンテンツ制御と属性制御の2つのタスクに分類。また、モデル再訓練やファインチューニング、強化学習等の手法の特性を分析し、生成制御のための細かな洞察を提供する。さらに、CTGの評価方法や現状の課題にも言及し、実世界の応用に重点を置く必要があると提案している。
[Paper Note] Prompting for Numerical Sequences: A Case Study on Market Comment Generation, Masayuki Kawarada+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#NLP #DataToTextGeneration #Prompting #NumericReasoning #KeyPoint Notes Issue Date: 2024-04-04 GPT Summary- 大規模言語モデル(LLMs)を用いて時系列の数値データからテキスト生成を行う研究が進展中。特に、株価の数値列を市場コメントに変換する実験では、プログラミング言語に似たフォーマットのプロンプトが効果的であり、自然言語や長文フォーマットは効果が薄いことが明らかに。これにより、数値シーケンスからのテキスト生成におけるプロンプト作成の新たな洞察を得られる。 Comment
Data-to-Text系のタスクでは、しばしば数値列がInputとなり、そこからテキストを生成するが、この際にどのようなフォーマットで数値列をPromptingするのが良いかを調査した研究。Pythonリストなどのプログラミング言語に似たプロンプトが高い性能を示し、自然言語やhtml, latextなどのプロンプトは効果が低かったとのこと
Leveraging Large Language Models for NLG Evaluation: A Survey, Zhen Li+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #Evaluation #LLM-as-a-Judge #KeyPoint Notes Issue Date: 2024-01-24 GPT Summary- 本研究は、大規模言語モデル(LLMs)を使用した自然言語生成(NLG)の評価についての包括的な概要を提供します。既存の評価指標を整理し、LLMベースの手法を比較するためのフレームワークを提案します。さらに、未解決の課題についても議論し、より公正で高度なNLG評価技術を提唱します。 Comment
重要
NLGの評価をするモデルのアーキテクチャとして、BERTScoreのようなreferenceとhvpothesisのdistiebuted representation同士を比較するような手法(matching-based)と、性能指標を直接テキストとして生成するgenerative-basedな手法があるよ、
といった話や、そもそもreference-basedなメトリック(e.g. BLEU)や、reference-freeなメトリック(e.g. BARTScore)とはなんぞや?みたいな基礎的な話から、言語モデルを用いたテキスト生成の評価手法の代表的なものだけでなく、タスクごとの手法も整理されて記載されている。また、BLEUやROUGEといった伝統的な手法の概要や、最新手法との同一データセットでのメタ評価における性能の差なども記載されており、全体的に必要な情報がコンパクトにまとまっている印象がある。
[Paper Note] TinyStories: How Small Can Language Models Be and Still Speak Coherent English?, Ronen Eldan+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #LanguageModel #SyntheticData #SmallModel Issue Date: 2026-01-19 GPT Summary- LMは小規模モデルでは一貫性のあるテキスト生成が難しい。本研究では、3~4歳児が理解できる単語のみを含む短編小説データセット「TinyStories」を紹介。これはGPT-3.5とGPT-4で生成され、1000万パラメータ未満のモデルでも流暢な物語が生成可能であることを示す。さらに、出力評価の新たなパラダイムを提案し、学生の作品との比較を通じてさまざまな能力に対するスコアを提供。TinyStoriesはLMの研究を促進し、限られたリソースや特殊ドメインにおける言語能力の発展に寄与することが期待される。 Comment
dataset: https://huggingface.co/datasets/roneneldan/TinyStories
T5Score: Discriminative Fine-tuning of Generative Evaluation Metrics, Yiwei Qin+, N_A, EMNLP-Findings'23
Paper/Blog Link My Issue
#Metrics #NLP #Evaluation #EMNLP #Finetuning Issue Date: 2024-05-28 GPT Summary- 埋め込みベースのテキスト生成の評価には、教師付きの識別メトリクスと生成メトリクスの2つのパラダイムがあります。本研究では、教師付きと教師なしの信号を組み合わせたフレームワークを提案し、mT5をバックボーンとしてT5Scoreメトリクスを訓練しました。T5Scoreは他の既存のメトリクスと包括的な実証的比較を行い、セグメントレベルで最良のパフォーマンスを示しました。また、コードとモデルはGitHubで公開されています。 Comment
OpenReview: https://openreview.net/forum?id=2jibzAXJzH¬eId=rgNMHmjShZ
[Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Dataset #LanguageModel #Annotation #One-Line Notes Issue Date: 2024-05-15 GPT Summary- 大規模言語モデル(LLMs)の自動要約能力の背後にある要因を探り、10のモデルに対する人間評価を行った。結果、ゼロショット要約の鍵はモデルサイズではなく指示調整にあること、さらに従来の研究は低品質な参照データに制約されているため人間の性能を過小評価していることが明らかになった。高品質な要約を基にした評価では、LLMsの要約が人間の要約と同等とされることが多いとの結論に至った。 Comment
- ニュース記事の高品質な要約を人間に作成してもらい、gpt-3.5を用いてLLM-basedな要約も生成
- annotatorにそれぞれの要約の品質をスコアリングさせたデータセットを作成
INSTRUCTSCORE: Explainable Text Generation Evaluation with Finegrained Feedback, Wenda Xu+, N_A, EMNLP'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Explanation #Supervised-FineTuning (SFT) #Evaluation #EMNLP #PostTraining #One-Line Notes Issue Date: 2024-01-25 GPT Summary- 自動的な言語生成の品質評価には説明可能なメトリクスが必要であるが、既存のメトリクスはその判定を説明したり欠陥とスコアを関連付けることができない。そこで、InstructScoreという新しいメトリクスを提案し、人間の指示とGPT-4の知識を活用してテキストの評価と診断レポートを生成する。さまざまな生成タスクでInstructScoreを評価し、他のメトリクスを上回る性能を示した。驚くべきことに、InstructScoreは人間の評価データなしで最先端のメトリクスと同等の性能を達成する。 Comment
伝統的なNLGの性能指標の解釈性が低いことを主張する研究
[Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N_A, EMNLP'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #LLM-as-a-Judge #Surface-level Notes Issue Date: 2024-01-25 GPT Summary- 従来の参照ベースの評価指標では、自然言語生成システムの品質を正確に測定することが難しい。最近の研究では、大規模言語モデル(LLMs)を使用した参照ベースの評価指標が提案されているが、まだ人間との一致度が低い。本研究では、G-Evalという大規模言語モデルを使用した品質評価フレームワークを提案し、要約と対話生成のタスクで実験を行った。G-Evalは従来の手法を大幅に上回る結果を示し、LLMベースの評価器の潜在的な問題についても分析している。コードはGitHubで公開されている。 Comment
伝統的なNLGの性能指標が、人間の判断との相関が低いことを示した研究
# 手法概要
- CoTを利用して、生成されたテキストの品質を評価する手法を提案している。
- タスクのIntroductionと、評価のCriteriaをプロンプトに仕込むだけで、自動的にLLMに評価ステップに関するCoTを生成させ、最終的にフォームを埋める形式でスコアをテキストとして生成させ評価を実施する。最終的に、各スコアの生成確率によるweighted-sumによって、最終スコアを決定する。
# Scoringの問題点
たとえば、1-5のdiscreteなスコアを直接LLMにoutputさせると、下記のような問題が生じる:
1. ある一つのスコアが支配的になってしまい、スコアの分散が無く、人間の評価との相関が低くなる
2. LLMは小数を出力するよう指示しても、大抵の場合整数を出力するため、多くのテキストの評価値が同一となり、生成されたテキストの細かな差異を評価に取り入れることができない。
上記を解決するため、下記のように、スコアトークンの生成確率の重みづけ和をとることで、最終的なスコアを算出している。
# 評価
- SummEval SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
データと、Topical-Chat, QAGSデータの3つのベンチマークで評価を実施した。タスクとしては、要約と対話のresponse generationのデータとなる。
- モデルはGPT-3.5 (text-davinci-003), GPT-4を利用した
- gpt3.5利用時は、temperatureは0に設定し、GPT-4はトークンの生成確率を返さないので、`n=20, temperature=1, top_p=1`とし、20回の生成結果からトークンの出現確率を算出した。
## 評価結果
G-EVALがbaselineをoutperformし、特にGPT4を利用した場合に性能が高い。GPTScoreを利用した場合に、モデルを何を使用したのかが書かれていない。Appendixに記述されているのだろうか。
# Analysis
## G-EvalがLLMが生成したテキストを好んで高いスコアを付与してしまうか?
- 人間に品質の高いニュース記事要約を書かせ、アノテータにGPTが生成した要約を比較させたデータ ([Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
) を用いて検証
- その結果、基本的にGPTが生成した要約に対して、G-EVAL4が高いスコアを付与する傾向にあることがわかった。
- 原因1: [Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
で指摘されている通り、人間が記述した要約とLLMが記述した要約を区別するタスクは、inter-annotator agreementは`0.07`であり、極端に低く、人間でも困難なタスクであるため。
- 原因2: LLMは生成時と評価時に、共通したコンセプトをモデル内部で共有している可能性が高く、これがLLMが生成した要約を高く評価するバイアスをかけた
## CoTの影響
- SummEvalデータにおいて、CoTの有無による性能の差を検証した結果、CoTを導入した場合により高いcorrelationを獲得した。特に、Fluencyへの影響が大きい。
## Probability Normalizationによる影響
- probabilityによるnormalizationを導入したことで、kendall tauが減少した。この理由は、probabilityが導入されていない場合は多くの引き分けを生み出す。一方、kendall tauは、concordant / discordantペアの数によって決定されるが、引き分けの場合はどちらにもカウントされず、kendall tauの値を押し上げる効果がある。このため、これはモデルの真の性能を反映していない。
- 一方、probabilityを導入すると、より細かいな連続的なスコアを獲得することができ、これはspearman-correlationの向上に反映されている。
## モデルサイズによる影響
- 基本的に大きいサイズの方が高いcorrelationを示す。特に、consistencyやrelevanceといった、複雑な評価タスクではその差が顕著である。
- 一方モデルサイズが小さい方が性能が良い観点(engagingness, groundedness)なども存在した。
[Paper Note] Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23, 2023.06
Paper/Blog Link My Issue
#NLP #LLM-as-a-Judge Issue Date: 2024-01-25 GPT Summary- GEMBAは、参照翻訳の有無に関係なく使用できるGPTベースの翻訳品質評価メトリックです。このメトリックは、ゼロショットのプロンプティングを使用し、4つのプロンプトバリアントを比較します。私たちの手法は、GPT 3.5以上のモデルでのみ機能し、最先端の精度を達成します。特に、英語からドイツ語、英語からロシア語、中国語から英語の3つの言語ペアで有効です。この研究では、コード、プロンプトテンプレート、およびスコアリング結果を公開し、外部の検証と再現性を可能にします。
From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting, Griffin Adams+, N_A, arXiv'23
Paper/Blog Link My Issue
#DocumentSummarization #NLP #LanguageModel Issue Date: 2023-09-17 GPT Summary- 要約は詳細でエンティティ中心的でありながら、理解しやすくすることが困難です。この課題を解決するために、私たちは「密度の連鎖」(CoD)プロンプトを使用して、GPT-4の要約を生成します。CoDによって生成された要約は抽象的であり、リードバイアスが少なく、人間に好まれます。また、情報量と読みやすさのトレードオフが存在することも示されました。CoD要約は無料で利用できます。 Comment
論文中のprompt例。InformativeなEntityのCoverageを増やすようにイテレーションを回し、各Entityに関する情報(前ステップで不足している情報は補足しながら)を具体的に記述するように要約を生成する。
人間が好むEntityのDensityにはある程度の閾値がある模様(でもこれは人や用途によって閾値が違うようねとは思う)。
人手評価とGPT4による5-scale の評価を実施している。定性的な考察としては、主題と直接的に関係ないEntityの詳細を述べるようになっても人間には好まれない(右例)ことが述べられている。
DiscoScore: Evaluating Text Generation with BERT and Discourse Coherence, Wei Zhao+, N_A, EACL'23
Paper/Blog Link My Issue
#DocumentSummarization #MachineTranslation #Metrics #NLP #Evaluation #LM-based #Coherence Issue Date: 2023-08-13 GPT Summary- 本研究では、文章の一貫性を評価するための新しい指標であるDiscoScoreを紹介します。DiscoScoreはCentering理論に基づいており、BERTを使用して談話の一貫性をモデル化します。実験の結果、DiscoScoreは他の指標よりも人間の評価との相関が高く、システムレベルでの評価でも優れた結果を示しました。さらに、DiscoScoreの重要性とその優位性についても説明されています。
InfoMetIC: An Informative Metric for Reference-free Image Caption Evaluation, ACL'23
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #ACL Issue Date: 2023-07-22 GPT Summary- 自動画像キャプションの評価には、情報豊かなメトリック(InfoMetIC)が提案されています。これにより、キャプションの誤りや欠落した情報を詳細に特定することができます。InfoMetICは、テキストの精度スコア、ビジョンの再現スコア、および全体の品質スコアを提供し、人間の判断との相関も高いです。また、トークンレベルの評価データセットも構築されています。詳細はGitHubで公開されています。
WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning, ACL'23
Paper/Blog Link My Issue
#NLP #Factuality #ACL Issue Date: 2023-07-18 GPT Summary- 現在のテキスト生成モデルは、入力と矛盾するテキストを制御できないという課題があります。この問題を解決するために、私たちはWeCheckという弱教師付きフレームワークを提案します。WeCheckは、弱教師付きラベルを持つ言語モデルから直接訓練された実際の生成サンプルを使用します。さまざまなタスクでの実験結果は、WeCheckの強力なパフォーマンスを示し、従来の評価方法よりも高速で精度と効率を向上させています。
Improving Factuality of Abstractive Summarization without Sacrificing Summary Quality, ACL'23
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Abstractive #Factuality #ACL Issue Date: 2023-07-18 GPT Summary- 事実性を意識した要約の品質向上に関する研究はあるが、品質を犠牲にすることなく事実性を向上させる手法がほとんどない。本研究では「Effective Factual Summarization」という技術を提案し、事実性と類似性の指標の両方で大幅な改善を示すことを示した。トレーニング中に競合を防ぐために2つの指標を組み合わせるランキング戦略を提案し、XSUMのFactCCでは最大6ポイント、CNN/DMでは11ポイントの改善が見られた。また、類似性や要約の抽象性には負の影響を与えない。
Few-Shot Data-to-Text Generation via Unified Representation and Multi-Source Learning, ACL'23
Paper/Blog Link My Issue
#NLP #DataToTextGeneration #MultitaskLearning #Zero/FewShotLearning #ACL Issue Date: 2023-07-18 GPT Summary- この論文では、構造化データからテキストを生成する新しいアプローチを提案しています。提案手法は、さまざまな形式のデータを処理できる統一された表現を提供し、マルチタスクトレーニングやゼロショット学習などのシナリオでのパフォーマンスを向上させることを目指しています。実験結果は、提案手法が他の方法と比較して優れた性能を示していることを示しています。これは、データからテキスト生成フレームワークにおける重要な進歩です。
[Paper Note] An Extensible Plug-and-Play Method for Multi-Aspect Controllable Text Generation, Xuancheng Huang+, ACL'23, 2022.12
Paper/Blog Link My Issue
#Controllable #NLP #ACL Issue Date: 2023-07-18 GPT Summary- 多側面制御テキスト生成では、プレフィックスチューニングによって効率的な制御が可能だが、複数のプレフィックス間の干渉が制約を劣化させる。本研究では、干渉の理論的下限を示し、層の数が増えると干渉が増加することを実証。学習可能なゲートを用いて干渉を抑制し、トレーニング時に見えない側面の組み合わせへの拡張を容易にする方法を提案。カテゴリカルと自由形式の制約を両方扱う統一的アプローチを実施し、テキスト生成および機械翻訳において精度、品質、拡張性でベースラインを上回る結果を得た。
[Paper Note] An Invariant Learning Characterization of Controlled Text Generation, Carolina Zheng+, ACL'23, 2023.05
Paper/Blog Link My Issue
#Controllable #NLP #ACL Issue Date: 2023-07-18 GPT Summary- ユーザープロンプトに基づくコントロールされた生成では、生成されたテキストの分布が訓練された予測器の分布と異なる場合に性能が低下することを示す。本論文では、この問題を不変学習として定式化し、効果的な予測器は複数のテキスト環境において不変であるべきと論じる。実験を通じて、分布シフトの影響と不変性方法の可能性を評価した。
Abstractive Summarizers are Excellent Extractive Summarizers, ACL'23
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Abstractive #Extractive #ACL Issue Date: 2023-07-18 GPT Summary- 本研究では、抽出型要約と要約型要約の相乗効果を探求し、シーケンス・トゥ・シーケンス・アーキテクチャを使用した3つの新しい推論アルゴリズムを提案しています。これにより、要約型システムが抽出型システムを超えることができることを示しました。また、要約型システムは抽出型のオラクル要約にさらされることなく、両方の要約を単一のモデルで生成できることも示しました。これは、抽出型ラベルの必要性に疑問を投げかけるものであり、ハイブリッドモデルの有望な研究方向を示しています。
Faithfulness Tests for Natural Language Explanations, ACL'23
Paper/Blog Link My Issue
#NLP #Explanation #Evaluation #Faithfulness #ACL Issue Date: 2023-07-18 GPT Summary- 本研究では、ニューラルモデルの説明の忠実性を評価するための2つのテストを提案しています。1つ目は、カウンターファクチュアルな予測につながる理由を挿入するためのカウンターファクチュアル入力エディタを提案し、2つ目は生成された説明から入力を再構築し、同じ予測につながる頻度をチェックするテストです。これらのテストは、忠実な説明の開発において基本的なツールとなります。
Extractive is not Faithful: An Investigation of Broad Unfaithfulness Problems in Extractive Summarization, ACL'23
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Extractive #Faithfulness #ACL Issue Date: 2023-07-18 GPT Summary- 本研究では、抽出的な要約の不正確さの問題について議論し、それを5つのタイプに分類します。さらに、新しい尺度であるExtEvalを提案し、不正確な要約を検出するために使用することを示します。この研究は、抽出的な要約の不正確さに対する認識を高め、将来の研究に役立つことを目指しています。 Comment
Extractive SummarizatinoのFaithfulnessに関する研究。
>抽出的な要約は抽象的な要約の一般的な不正確さの問題にはあまり影響を受けにくいですが、それは抽出的な要約が正確であることを意味するのでしょうか?結論はノーです。
>本研究では、抽出的な要約に現れる広範な不正確さの問題(非含意を含む)を5つのタイプに分類
>不正確な共参照、不完全な共参照、不正確な談話、不完全な談話、および他の誤解を招く情報が含まれます。
>私たちは、16の異なる抽出システムによって生成された1600の英語の要約を人間にラベル付けするように依頼しました。その結果、要約の30%には少なくとも5つの問題のうちの1つが存在することがわかりました。
おもしろい。
[Paper Note] Controllable Text Generation via Probability Density Estimation in the Latent Space, Yuxuan Gu+, ACL'23, 2022.12
Paper/Blog Link My Issue
#Controllable #NLP #ACL Issue Date: 2023-07-15 GPT Summary- 潜在空間の確率密度推定を基にした新しい制御フレームワークを提案。ノーマライズフローを利用し、先行空間での柔軟な制御を実現。実験により、属性の関連性とテキストの質で強力なベースラインを上回り、柔軟な制御戦略の効果を示した。
MeetingBank: A Benchmark Dataset for Meeting Summarization, ACL'23
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Dataset #Conversation #ACL Issue Date: 2023-07-15 GPT Summary- 会議の要約技術の開発には注釈付きの会議コーパスが必要ですが、その欠如が問題となっています。本研究では、新しいベンチマークデータセットであるMeetingBankを提案しました。MeetingBankは、会議議事録を短いパッセージに分割し、特定のセグメントと対応させることで、会議の要約プロセスを管理しやすいタスクに分割することができます。このデータセットは、会議要約システムのテストベッドとして利用できるだけでなく、一般の人々が議会の意思決定の仕組みを理解するのにも役立ちます。ビデオリンク、トランスクリプト、参照要約などのデータを一般に公開し、会議要約技術の開発を促進します。
[Paper Note] On Improving Summarization Factual Consistency from Natural Language Feedback, Yixin Liu+, ACL'23, 2022.12
Paper/Blog Link My Issue
#DocumentSummarization #Controllable #NLP #Dataset #Factuality #ACL Issue Date: 2023-07-15 GPT Summary- ユーザーの期待に応えるために、言語生成モデルの出力品質を向上させることを目指す本研究では、「DeFacto」という高品質データセットを用いて、要約の事実的一貫性を強化するための自然言語フィードバックの活用を検討。また、人間のフィードバックに基づく要約編集や事実誤りの訂正を行うことで、生成タスクの改善を図る。微調整されたモデルは事実的一貫性を向上できる一方で、大規模言語モデルはゼロショット学習において課題が残ることが示された。
[Paper Note] Tailor: A Prompt-Based Approach to Attribute-Based Controlled Text Generation, Kexin Yang+, ACL'23, 2022.04
Paper/Blog Link My Issue
#Controllable #NLP #PEFT(Adaptor/LoRA) #ACL #KeyPoint Notes #SoftPrompt Issue Date: 2023-07-15 GPT Summary- 属性に基づくCTGでは、プロンプトを使用して望ましい属性を満たす文を生成。新手法Tailorは、各属性を連続ベクトルとして表し、固定PLMの生成を誘導。実験によりマルチ属性生成が実現できるが、流暢さの低下が課題。マルチ属性プロンプトマスクと再インデックス位置ID列でこのギャップを埋め、学習可能なプロンプトコネクタにより属性間の連結も可能に。11の生成タスクで強力な性能を示し、GPT-2の最小限のパラメータで有効性を確認。 Comment
Soft Promptを用いてattributeを連続値ベクトルで表現しconcatすることで生成をコントロールする。このとき、複数attuributeを指定可能である。
工夫点としては、attention maskにおいて
soft prompt同士がattendしないようにし、交互作用はMAP Connectorと呼ばれる交互作用そのものを学習するコネクタに移譲する点、(複数のsoft promptをconcatすることによる)Soft Promptのpositionのsensitivityを低減するために、末尾のsoft prompt以外はreindexしている点のようである。
Table and Image Generation for Investigating Knowledge of Entities in Pre-trained Vision and Language Models, ACL'23
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #TabularData #TextToImageGeneration #ACL Issue Date: 2023-07-15 GPT Summary- 本研究では、Vision&Language(V&L)モデルにおけるエンティティの知識の保持方法を検証するために、テーブルと画像の生成タスクを提案します。このタスクでは、エンティティと関連する画像の知識を含むテーブルを生成する第一の部分と、キャプションとエンティティの関連知識を含むテーブルから画像を生成する第二の部分があります。提案されたタスクを実行するために、Wikipediaの約20万のinfoboxからWikiTIGデータセットを作成しました。最先端のV&LモデルOFAを使用して、提案されたタスクのパフォーマンスを評価しました。実験結果は、OFAが一部のエンティティ知識を忘れることを示しています。
[Paper Note] Focused Prefix Tuning for Controllable Text Generation, Congda Ma+, ACL'23 Short, 2023.06
Paper/Blog Link My Issue
#Controllable #NLP #PEFT(Adaptor/LoRA) #ACL #Short Issue Date: 2023-07-15 GPT Summary- 制御可能なテキスト生成での無関係な学習信号を軽減するため、フォーカスプレフィックスチューニング(FPT)を提案。FPTは単一属性制御で優れた精度と流暢さを実現し、マルチ属性制御でも最先端の精度を達成。新属性の制御に既存モデルの再訓練なしで対応。 Comment
Prefix Tuning:
- [Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
Learning to Imagine: Visually-Augmented Natural Language Generation, ACL'23
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #DiffusionModel #TextToImageGeneration #ACL Issue Date: 2023-07-15 GPT Summary- 本研究では、視覚情報を活用した自然言語生成のためのLIVEという手法を提案しています。LIVEは、事前学習済み言語モデルを使用して、テキストに基づいて場面を想像し、高品質な画像を合成する方法です。また、CLIPを使用してテキストの想像力を評価し、段落ごとに画像を生成します。さまざまな実験により、LIVEの有効性が示されています。コード、モデル、データは公開されています。 Comment
>まず、テキストに基づいて場面を想像します。入力テキストに基づいて高品質な画像を合成するために拡散モデルを使用します。次に、CLIPを使用して、テキストが想像力を喚起できるかを事後的に判断します。最後に、私たちの想像力は動的であり、段落全体に1つの画像を生成するのではなく、各文に対して合成を行います。
興味深い
[TACL] How much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN, TACL'23
Paper/Blog Link My Issue
#NLP #Novelty #Evaluation #TACL Issue Date: 2023-07-14 GPT Summary- この研究では、言語モデルが生成するテキストの新規性を評価するための分析スイートRAVENを紹介しています。英語で訓練された4つのニューラル言語モデルに対して、局所的な構造と大規模な構造の新規性を評価しました。結果として、生成されたテキストは局所的な構造においては新規性に欠けており、大規模な構造においては人間と同程度の新規性があり、時には訓練セットからの重複したテキストを生成することもあります。また、GPT-2の詳細な手動分析により、組成的および類推的な一般化メカニズムの使用が示され、新規テキストが形態的および構文的に妥当であるが、意味的な問題が比較的頻繁に発生することも示されました。
Adaptive and Personalized Exercise Generation for Online Language Learning, ACL'23
Paper/Blog Link My Issue
#NLP #Education #AdaptiveLearning #KnowledgeTracing #Personalization #QuestionGeneration #ACL Issue Date: 2023-07-14 GPT Summary- 本研究では、オンライン言語学習のための適応的な演習生成の新しいタスクを研究しました。学習履歴から学生の知識状態を推定し、その状態に基づいて個別化された演習文を生成するモデルを提案しました。実データを用いた実験結果から、学生の状態に応じた演習を生成できることを示しました。さらに、教育アプリケーションでの利用方法についても議論し、学習の効率化を促進できる可能性を示しました。 Comment
Knowledge Tracingで推定された習熟度に基づいて、エクササイズを自動生成する研究。KTとNLGが組み合わさっており、非常におもしろい。
[Paper Note] Explicit Syntactic Guidance for Neural Text Generation, Yafu Li+, ACL'23, 2023.06
Paper/Blog Link My Issue
#BeamSearch #Controllable #NLP #LanguageModel #Transformer #ACL #Decoder Issue Date: 2023-07-13 GPT Summary- 本研究では、構文に基づいた生成スキーマを提案し、構成素解析木に従ってシーケンスを生成する新しいテキスト生成モデルを開発。デコーディングプロセスは、構文コンテキスト内での埋め込みテキストの予測と、構成素のマッピングによる構文構造の構築に分かれ、構造的ビームサーチ手法を用いて階層的な構文構造を探索。実験結果は、提案手法がパラフレーズ生成と機械翻訳において自己回帰型ベースラインを上回り、解釈可能性や制御可能性、多様性においても優れていることを示した。
[Paper Note] SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking, Chris Cundy+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #ICLR #One-Line Notes #needs-revision Issue Date: 2023-06-26 GPT Summary- 自己回帰モデルは高い尤度を達成するものの、最大尤度推定(MLE)が生成タスクに必ずしも適合しないことがある。MLEは分布外の振る舞いに関する指針がないため、累積誤差が生じる。これに対処するため、生成を模倣学習(IL)として定式化し、生成系列の分布とデータセット由来の系列分布間のダイバージェンスを最小化。ILフレームワークでは、バックスペースアクションを導入し、モデルが不要なトークンを戻すことを可能にする。新たに提案するSequenceMatchは、敵対的訓練やアーキテクチャの変更なしで実装でき、SequenceMatch-χ^2ダイバージェンスを適切な訓練目的として特定。実験的に、SequenceMatchは言語モデルによるテキスト生成や算術においてMLEを上回る改善を示す。 Comment
backspaceアクションをテキスト生成プロセスに組み込むことで、out of distributionを引き起こすトークンを元に戻すことで、生成エラーを軽減させることができる。
openreview: https://openreview.net/forum?id=FJWT0692hw
[Paper Note] Controlled Text Generation with Natural Language Instructions, Wangchunshu Zhou+, ICML'23, 2023.04
Paper/Blog Link My Issue
#Controllable #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #Prompting #SyntheticData #In-ContextLearning #ICML #PostTraining #One-Line Notes Issue Date: 2023-04-30 GPT Summary- 自然言語の指示に従い、多様なタスクを解決可能な大規模言語モデルの制御を改善するために、「InstructCTG」というフレームワークを提案。自然テキストの制約を抽出し、これを自然言語の指示に変換することで弱教師あり訓練データを形成。異なるタイプの制約に柔軟に対応し、生成の質や速度への影響を最小限に抑えつつ、再訓練なしで新しい制約に適応できる能力を持つ。 Comment
制約に関する指示とデモンスとレーションに関するデータを合成して追加のinstruction tuningを実施することで、promptで指示された制約を満たすような(controllableな)テキストの生成能力を高める手法
[Paper Note] Tractable Control for Autoregressive Language Generation, Honghua Zhang+, ICML'23, 2023.04
Paper/Blog Link My Issue
#Controllable #NLP #LanguageModel #ICML #KeyPoint Notes Issue Date: 2023-04-28 GPT Summary- 自己回帰型大規模言語モデルは複雑な制約を満たすテキスト生成に課題がある。これに対処するため、語彙的制約を扱う確率モデル(TPMs)を用いたGeLaToフレームワークを提案。蒸留された隠れマルコフモデルを利用し、自己回帰生成の効率的な指導を可能にし、制約付きテキスト生成において最先端の性能を達成。研究は大規模言語モデルの制御に新たな道を開き、TPMsのさらなる発展を促進する。 Comment
自然言語生成モデルで、何らかのシンプルなconstiaint αの元p(xi|xi-1,α)を生成しようとしても計算ができない。このため、言語モデルをfinetuningするか、promptで制御するか、などがおこなわれる。しかしこの方法は近似的な解法であり、αがたとえシンプルであっても(何らかの語尾を付与するなど)、必ずしも満たした生成が行われるとは限らない。これは単に言語モデルがautoregressiveな方法で次のトークンの分布を予測しているだけであることに起因している。そこで、この問題を解決するために、tractable probabilistic model(TPM)を導入し、解決した。
評価の結果、CommonGenにおいて、SoTAを達成した。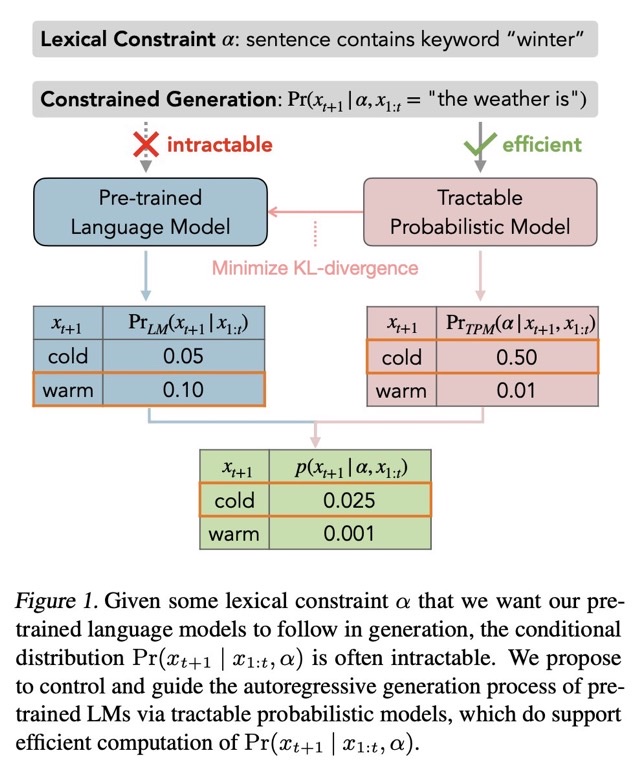
尚、TPMについては要勉強である
[Paper Note] Controlled Language Generation for Language Learning Items, Kevin Stowe+, EMNLP'22 Industry Track, 2022.11
Paper/Blog Link My Issue
#NeuralNetwork #Controllable #NLP #Education #EMNLP #Encoder-Decoder #IndustryTrack Issue Date: 2026-01-16 GPT Summary- 自然言語生成を活用し、英語学習アプリ向けに迅速に教材を生成。深層事前学習モデルを用いて、熟達度に応じた多様な文や文法テストの引数構造を制御する新手法を開発。人間評価では高い文法スコアを得て、上級モデルは基準を超える長さと複雑さを実現。多様で特注のコンテンツを提供し、強力なパフォーマンスを示す。
MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation, Swarnadeep Saha+, N_A, arXiv'22
Paper/Blog Link My Issue
#NLP #DataToTextGeneration #StructuredData Issue Date: 2023-10-28 GPT Summary- 本研究では、半構造化データからのテキスト生成における多段階の推論を行うためのMURMURという手法を提案しています。MURMURは、特定の言語的および論理的なスキルを持つニューラルモジュールと記号モジュールを組み合わせ、ベストファーストサーチ手法を使用して推論パスを生成します。実験結果では、MURMURは他のベースライン手法に比べて大幅な改善を示し、また、ドメイン外のデータでも同等の性能を達成しました。さらに、人間の評価では、MURMURは論理的に整合性のある要約をより多く生成することが示されました。
Momentum Calibration for Text Generation, Xingxing Zhang+, N_A, arXiv'22
Paper/Blog Link My Issue
#BeamSearch #NLP Issue Date: 2023-08-16 GPT Summary- 本研究では、テキスト生成タスクにおいてMoCa(Momentum Calibration)という手法を提案しています。MoCaは、ビームサーチを用いた遅く進化するサンプルを動的に生成し、これらのサンプルのモデルスコアを実際の品質に合わせるように学習します。実験結果は、MoCaが強力な事前学習済みTransformerを改善し、最先端の結果を達成していることを示しています。
[Paper Note] BRIO: Bringing Order to Abstractive Summarization, Yixin Liu+, arXiv'22, 2022.03
Paper/Blog Link My Issue
#DocumentSummarization #BeamSearch #NLP #ACL #One-Line Notes #needs-revision Issue Date: 2023-08-16 GPT Summary- 非決定論的分布を仮定し、複数の候補要約に確率を割り当てる新しい訓練パラダイムを提案。CNN/DailyMailおよびXSumデータセットで最先端のROUGEスコアを達成し、モデルが候補要約の品質と相関する確率を推定可能であることを示す。 Comment
ビーム内のトップがROUGEを最大化しているとは限らなかったため、ROUGEが最大となるような要約を選択するようにしたら性能爆上げしましたという研究。
実質現在のSoTA
SMART: Sentences as Basic Units for Text Evaluation, Reinald Kim Amplayo+, N_A, arXiv'22
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-14 GPT Summary- 本研究では、テキスト生成の評価指標の制限を緩和するために、新しい指標であるSMARTを提案する。SMARTは文を基本的なマッチング単位とし、文のマッチング関数を使用して候補文と参照文を評価する。また、ソースドキュメントの文とも比較し、評価を可能にする。実験結果は、SMARTが他の指標を上回ることを示し、特にモデルベースのマッチング関数を使用した場合に有効であることを示している。また、提案された指標は長い要約文でもうまく機能し、特定のモデルに偏りが少ないことも示されている。
InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation, Pierre Colombo+, N_A, AAAI'22
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 GPT Summary- 自然言語生成システムの品質評価は高価であり、人間の注釈に頼ることが一般的です。しかし、自動評価指標を使用することもあります。本研究では、マスクされた言語モデルを使用した評価指標であるInfoLMを紹介します。この指標は同義語を処理することができ、要約やデータ生成の設定で有意な改善を示しました。
WIDAR -- Weighted Input Document Augmented ROUGE, Raghav Jain+, N_A, ECIR'22
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 GPT Summary- 自動テキスト要約の評価において、ROUGEメトリックには制約があり、参照要約の利用可能性に依存している。そこで、本研究ではWIDARメトリックを提案し、参照要約だけでなく入力ドキュメントも使用して要約の品質を評価する。WIDARメトリックは一貫性、整合性、流暢さ、関連性の向上をROUGEと比較しており、他の最先端のメトリックと同等の結果を短い計算時間で得ることができる。
[Paper Note] Explaining Patterns in Data with Language Models via Interpretable Autoprompting, Chandan Singh+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #DataToTextGeneration #Explanation #One-Line Notes #Data Issue Date: 2023-08-03 GPT Summary- iPromptを用いて、事前学習済みのLLMがデータを説明する自然言語文字列を生成する手法を提案。このアルゴリズムは、生成された説明の性能を再評価して最適化するプロセスを含む。実験によりiPromptが正確なデータ記述を見つけ、人間にも解釈可能なプロンプトを生成し、一般化性能に優れることが示された。特に、実世界の感情分類データセットでGPT-3並みのプロンプトを生成し、科学的発見の支援にも寄与する可能性がある。すべてのコードはGitHubで公開。 Comment
OpenReview: https://openreview.net/forum?id=GvMuB-YsiK6
データセット(中に存在するパターンの説明)をLLMによって生成させる研究


[Paper Note] DART: Open-Domain Structured Data Record to Text Generation, Linyong Nan+, NAACL'21
Paper/Blog Link My Issue
#Dataset #DataToTextGeneration #NAACL Issue Date: 2025-08-30 GPT Summary- DARTは82,000以上のインスタンスを持つオープンドメインの構造化データからテキスト生成のためのデータセットであり、表形式のデータから意味的トリプルを抽出する手法を提案。ツリーオントロジーアノテーションや質問-回答ペアの変換を活用し、最小限のポストエディティングで異種ソースを統合。DARTは新たな課題を提起し、WebNLG 2017での最先端結果を示すことで、ドメイン外の一般化を促進することを証明。データとコードは公開されている。
The Perils of Using Mechanical Turk to Evaluate Open-Ended Text Generation, Marzena Karpinska+, N_A, EMNLP'21
Paper/Blog Link My Issue
#Analysis #NLP #Evaluation #Annotation #Reproducibility #KeyPoint Notes Issue Date: 2024-05-15 GPT Summary- 最近のテキスト生成の研究は、オープンエンドのドメインに注力しており、その評価が難しいため、多くの研究者がクラウドソーシングされた人間の判断を収集してモデリングを正当化している。しかし、多くの研究は重要な詳細を報告しておらず、再現性が妨げられていることがわかった。さらに、労働者はモデル生成のテキストと人間による参照テキストを区別できないことが発見され、表示方法を変更することで改善されることが示された。英語教師とのインタビューでは、モデル生成のテキストを評価する際の課題について、より深い洞察が得られた。 Comment
Open-endedなタスクに対するAMTの評価の再現性に関する研究。先行研究をSurveyしたところ、再現のために重要な情報(たとえば、workerの資格、費用、task descriptions、annotator間のagreementなど)が欠落していることが判明した。
続いて、expertsとAMT workerに対して、story generationの評価を実施し、GPT2が生成したストーリーと人間が生成したストーリーを、後者のスコアが高くなることを期待して依頼した。その結果
- AMTのratingは、モデルが生成したテキストと、人間が生成したテキストをreliableに区別できない
- 同一のタスクを異なる日程で実施をすると、高い分散が生じた
- 多くのAMT workerは、評価対象のテキストを注意深く読んでいない
- Expertでさえモデルが生成したテキストを読み判断するのには苦戦をし、先行研究と比較してより多くの時間を費やし、agreementが低くなることが分かった
- [Paper Note] Can Large Language Models Be an Alternative to Human Evaluations?, Cheng-Han Chiang+, ACL'23, 2023.05
において、低品質なwork forceが人手評価に対して有害な影響を与える、という文脈で本研究が引用されている
[Paper Note] Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation, Markus Freitag+, arXiv'21, 2021.04
Paper/Blog Link My Issue
#MachineTranslation #Analysis #Metrics #NLP #Evaluation #One-Line Notes Issue Date: 2024-01-25 GPT Summary- 機械翻訳の人間評価は難しく、標準的な手法が不足している。そこで、誤り分析に基づく評価方法論を提案し、MQMフレームワークを用いてWMT 2020の上位システム出力をプロの翻訳者による注釈で評価。分析の結果、WMTクラウドワーカーのランキングと異なる結果が得られ、人間が機械出力よりも人間の出力を好む傾向を示した。さらに、自動指標がクラウドワーカーよりも優れたことも判明し、研究用コーパスを公開。 Comment
embedding basedなNLGの性能指標が、意味の等価性や流暢性を評価できる一方、適用範囲が限定的で柔軟性に欠けることを示した研究
The Feasibility of Embedding Based Automatic Evaluation for Single Document Summarization, EMNLP-IJCNLP'21, Sun+
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #EMNLP #IJCNLP Issue Date: 2023-08-13 Comment
C-ELMO/C-SBERT
A Training-free and Reference-free Summarization Evaluation Metric via Centrality-weighted Relevance and Self-referenced Redundancy, Chen+, ACL-IJCNLP'21
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #ACL #IJCNLP Issue Date: 2023-08-13
[Paper Note] QuestEval: Summarization Asks for Fact-based Evaluation, Thomas Scialom+, arXiv'21, 2021.03
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #QA-based #EMNLP #KeyPoint Notes #needs-revision Issue Date: 2023-08-13 GPT Summary- 要約評価の課題に対し、QuestEvalという新たなフレームワークを提案。ROUGEやBERTScoreに依存せず、人間の判断との相関を四つの次元(整合性、一貫性、流暢さ、関連性)において向上させることを実験で示した。 Comment
QuestEval
# 概要
SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
によって提案されてきたメトリックがROUGEに勝てていないことについて言及し、より良い指標を提案。
- precision / recall-based な QA metricsを利用してよりロバスト
- 生成されるqueryのsaliencyを学習する手法を提案することで、information selectionの概念を導入した
- CNN/Daily Mail, XSUMで評価した結果、SoTAな結果を獲得し、特にFactual Consistencyの評価に有用なことを示した
# Question-based framework
prerainedなT5を利用しQAに回答するcomponent(question, Textがgivenな時answerを生成するモデル)を構築する。text Tに対するquery qに対してrと回答する確率をQ_A(r|T, q)とし、Q_A(T, q)をモデルによってgreedyに生成された回答とする。Questionが与えられた時、Summary内に回答が含まれているかは分からない。そのため、unanswerable token εもQA componentに含める。
QG componentとしては、answer-source documentが与えられたときに人間が生成したquestionを生成できるようfinetuningされたT5モデルを利用する。テスト時は、ソースドキュメントと、システム要約がgivenなときに、はじめにQG modelを条件付けするためのanswerのsetを選択する。Asking and Answering Questions to Evaluate the Factual Consistency of Summaries, Wang, ACL'20
にならい、ソースドキュメントの全ての固有名詞と名詞をanswerとみなす。そして、それぞれの選択されたanswerごとに、beam searchを用いてquestionを生成する。そして、QAモデルが誤った回答をした場合、そのようなquestionはフィルタリングする。text Tにおいて、Q_A(T, q) = rとなるquestion-answer pairs (q, r)の集合を、Q_G(T)と表記する。
# QuestEval metric
## Precision
source documentをD, システム要約をSとしたときに、Precision, Recallを以下の式で測る:
question生成時は要約から生成し、生成されたquestionに回答する際はsource documentを利用し、回答の正誤に対してF1スコアを測定する。F1スコアは、ground truthと予測された回答を比較することによって測定され、回答がexact matchした場合に1, common tokenが存在しない場合に0を返す。D, Sで条件付けされたときに、回答が変わってしまう場合は要約がinconsistentだとみなせる、というintuitionからきている。
## Recall
要約はfactual informationを含むべきのみならず(precision)、ソーステキストの重要な情報を含むべきである(recall)。Answers Unite! Unsupervised Metrics for Reinforced Summarization Models, Scialom+, EMNLP-IJCNLP'19
をquery weighter Wを導入することで拡張し、recallを下記で定義する:
ここで、Q_G(D)は、ソーステキストDにおけるすべてのQA pairの集合、W(q, D)はDに対するqの重みである。
## Answerability and F1
Factoid QAモデルは一般的に、predicted answerとground truthのoverlapによって(F1)評価されている。しかし"ACL"と"Association for Computational Linguistics"のように、同じ回答でも異なる方法で表現される可能性がある。この例では、F1スコアは0となる(共通のtokenがないため)。
これを回避するために、Answers Unite! Unsupervised Metrics for Reinforced Summarization Models, Scialom+, EMNLP-IJCNLP'19
と同様に1-Q_A(ε)を利用する。
QG component, QA componentで利用するT5は、それぞれ[SQuAD-v2]( https://huggingface.co/datasets/squad_v2)と、NewsQAデータセット [Paper Note] NewsQA: A Machine Comprehension Dataset, Adam Trischler+, RepL4NLP'17, 2016.11 によってfinetuningしたものを利用する。
Q2: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering, Honovich+, EMNLP'21
Paper/Blog Link My Issue
#Metrics #NLP #DialogueGeneration #Evaluation #Reference-free #QA-based #Factuality #EMNLP #KeyPoint Notes Issue Date: 2023-08-13 Comment
(knowledge-grounded; 知識に基づいた)対話に対するFactual ConsistencyをReference-freeで評価できるQGQA手法。機械翻訳やAbstractive Summarizationの分野で研究が進んできたが、対話では
- 対話履歴、個人の意見、ユーザに対する質問、そして雑談
といった外部知識に対するconsistencyが適切ではない要素が多く存在し、よりチャレンジングなタスクとなっている。
また、そもそも対話タスクはopen-endedなタスクなため、Reference-basedな手法は現実的ではなく、Reference-freeな手法が必要と主張。
手法の概要としては以下。ユーザの発話からQuestion Generation (QG)を実施し、Question-Answer Candidate Pairを作成する。そして、生成したQuestionをベースとなる知識から回答させ(QA)、その回答結果とAnswer Candidateを比較することでFactual Consistencyを測定する。
QACE: Asking Questions to Evaluate an Image Caption, Lee+, EMNLP'21
Paper/Blog Link My Issue
#ComputerVision #Metrics #NLP #Evaluation #Reference-free #QA-based #One-Line Notes Issue Date: 2023-08-13 Comment
Image Captioningを評価するためのQGQAを提案している。candidateから生成した質問を元画像, およびReferenceを用いて回答させ、candidateに基づいた回答と回答の結果を比較することで評価を実施する。
Refocusing on Relevance: Personalization in NLG, Shiran Dudy+, Department of Computer Science University of Colorado, EMNLP'21
Paper/Blog Link My Issue
#NLP #Personalization #EMNLP #One-Line Notes Issue Date: 2023-04-26 Comment
従来のNLGはソーステキストに焦点を当て、ターゲットを生成することに注力してきた。が、ユーザの意図やcontextがソーステキストだけに基づいて復元できない場合、このアプローチでは不十分であることを指摘。
この研究ではNLGシステムが追加のcontextを利用することに大きな重点をおくべきであり、IR等で活用されているrelevancyをユーザ指向のテキスト生成タスクを設計するための重要な指標として考えることを提案している。
[Paper Note] Generating Racing Game Commentary from Vision, Language, and Structured Data, Tatsuya+, INLG'21
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NLP #DataToTextGeneration #INLG #Game #3D (Video) Issue Date: 2022-09-15 GPT Summary- モーターレーシングゲームにおける自動解説生成タスクを提案し、視覚データ、数値データ、テキストデータを用いて解説を生成する。タスクは発話タイミングの特定と発話生成の2つのサブタスクに分かれ、129,226の発話を含む新しい大規模データセットを紹介。解説の特性は時間や視点によって変化し、最先端の視覚エンコーダでも正確な解説生成が難しいことが示された。データセットとベースライン実装は今後の研究のために公開される。 Comment
データセット: https://kirt.airc.aist.go.jp/corpus/ja/RacingCommentary
[Paper Note] Biomedical Data-to-Text Generation via Fine-Tuning Transformers, Ruslan Yermakov+, ACL-INLG'21, 2021.09
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Dataset #DataToTextGeneration #ACL #INLG #One-Line Notes Issue Date: 2022-08-18 GPT Summary- バイオメディカル分野におけるD2T生成の研究を行い、医薬品のパッケージリーフレットを用いた実世界のデータセットに対してファインチューニングされたトランスフォーマーを適用。現実的な複数文のテキスト生成が可能であることを示す一方で、重要な制限も存在。新たにバイオメディカル分野のD2T生成モデルのベンチマーク用データセット(BioLeaflets)を公開。 Comment
biomedical domainの新たなdata2textデータセットを提供。事前学習済みのBART, T5等をfinetuningすることで高精度にテキストが生成できることを示した。
[Paper Note] 過去情報の内容選択を取り入れた スポーツダイジェストの自動生成, 加藤+, NLP'21
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DataToTextGeneration Issue Date: 2021-10-08
[Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #ACL #PostTraining #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2021-09-09 GPT Summary- プレフィックスチューニングは、ファインチューニングの軽量な代替手段であり、言語モデルのパラメータを固定しつつ、タスク特有の小さなベクトルを最適化する手法です。これにより、少ないパラメータで同等のパフォーマンスを達成し、低データ設定でもファインチューニングを上回る結果を示しました。 Comment
言語モデルをfine-tuningする際,エンコード時に「接頭辞」を潜在表現として与え,「接頭辞」部分のみをfine-tuningすることで(他パラメータは固定),より少量のパラメータでfine-tuningを実現する方法を提案.接頭辞を潜在表現で与えるこの方法は,GPT-3のpromptingに着想を得ている.fine-tuningされた接頭辞の潜在表現のみを配布すれば良いので,非常に少量なパラメータでfine-tuningができる.
table-to-text, summarizationタスクで,一般的なfine-tuningやAdapter(レイヤーの間にアダプターを挿入しそのパラメータだけをチューニングする手法)といった効率的なfine-tuning手法と比較.table-to-textでは、250k (元のモデルの 0.1%) ほどの数のパラメータを微調整するだけで、全パラメータをfine-tuningするのに匹敵もしくはそれ以上の性能を達成.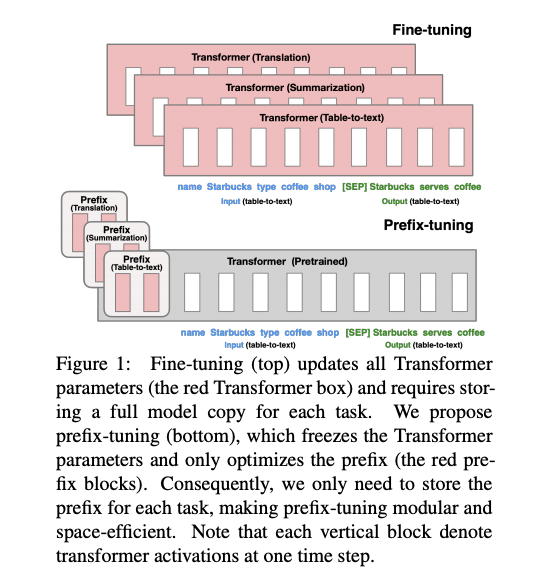
Hugging Faceの実装を利用したと論文中では記載されているが,fine-tuningする前の元の言語モデル(GPT-2)はどのように準備したのだろうか.Hugging Faceのpretrained済みのGPT-2を使用したのだろうか.
autoregressive LM (GPT-2)と,encoder-decoderモデル(BART)へPrefix Tuningを適用する場合の模式図
[Paper Note] CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning, Bill Yuchen Lin+, EMNLP'20 Findings
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Composition #EMNLP #Findings #CommonsenseReasoning Issue Date: 2025-07-31 GPT Summary- 生成的常識推論をテストするためのタスクCommonGenを提案し、35,000の概念セットに基づく79,000の常識的記述を含むデータセットを構築。タスクは、与えられた概念を用いて一貫した文を生成することを求め、関係推論と構成的一般化能力が必要。実験では、最先端モデルと人間のパフォーマンスに大きなギャップがあることが示され、生成的常識推論能力がCommonsenseQAなどの下流タスクに転送可能であることも確認。 Comment
ベンチマークの概要。複数のconceptが与えられた時に、それらconceptを利用した常識的なテキストを生成するベンチマーク。concept間の関係性を常識的な知識から推論し、Unseenなconceptの組み合わせでも意味を構成可能な汎化性能が求められる。
PJ page: https://inklab.usc.edu/CommonGen/
[Paper Note] BLEU might be Guilty but References are not Innocent, Markus Freitag+, arXiv'20, 2020.04
Paper/Blog Link My Issue
#MachineTranslation #Analysis #Metrics #NLP #Evaluation #One-Line Notes Issue Date: 2024-01-25 GPT Summary- 機械翻訳の自動評価指標の質を検証し、参照データの性質が重要であることを示す。さまざまな参照収集方法を検討し、人間評価との相関を報告。典型的な参照の偏りを打ち消すために、言語学者によるパラフレージング課題を開発。WMT 2019のデータにおいて、標準参照との相関が低い出力でも人間判断との相関が向上することを示す。また、埋め込みベースの手法を含む評価指標で相関が改善されることも明らかにし、マルチ参照BLEUの限界と新たな定式化を提示。 Comment
surface levelのNLGの性能指標がsemanticを評価できないことを示した研究
[Paper Note] Unsupervised Reference-Free Summary Quality Evaluation via Contrastive Learning, Hanlu Wu+, arXiv'20, 2020.10
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #EMNLP #needs-revision Issue Date: 2023-08-13 GPT Summary- 要約タスクの評価は重要であり、従来のROUGEは参照要約が必要である。本研究は、教師なしの対照学習を用いて参照なしで要約品質を評価する新しい指標を提案。BERTに基づき、言語的品質と意味的情報量をカバーする指標を設計し、ネガティブサンプルを使ってモデルを訓練。NewsroomとCNN/Daily Mailの実験で、提案手法が他の指標を上回ることを示し、データセット間での一般性も確認。 Comment
LS_Score
色々なメトリックが簡潔にまとまっている
Few-Shot NLG with Pre-Trained Language Model, Chen+, University of California, ACL'20
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #DataToTextGeneration #pretrained-LM #Zero/FewShotLearning #Surface-level Notes Issue Date: 2022-12-01 Comment
# 概要
Neural basedなend-to-endなNLGアプローチはdata-hungryなので、Few Shotな設定で高い性能ができる手法を提案(Few shot NLG)
Table-to-Textタスク(WikiBIOデータ, 追加で収集したBook, SongドメインのWikipediaデータ)において、200程度の学習サンプル数でstrong baselineに対して8.0 point程度のBLEUスコアの向上を達成
# 手法
TabularデータのDescriptionを作成するには大きく分けて2つのスキルが必要
1. factualな情報を持つcontentをselectし、copyするスキル
2. factualな情報のコピーを含めながら、文法的に正しいテキストを生成するスキル
提案手法では、1を少量のサンプル(< 500)から学習し、2については事前学習済みの言語モデルを活用する。
encoderからコピーする確率をpcopyとし、下記式で算出する:
すなわち、encoderのcontext vectorと、decoderのinputとstateから求められる。
encoderとencoder側へのattentionはscratchから学習しなければならず、うまくコピーできるようにしっかりと”teach”しなければならないため、lossに以下を追加する:
すなわち、コピーすべき単語がちゃんとコピーできてる場合にlossが小さくなる項を追加している。
また、decoder側では、最初にTable情報のEmbeddingを入力するようにしている。
また、学習できるデータ量が限られているため、pre-trainingモデルのEmbeddingは事前学習時点のものに固定した(ただしく読解できているか不安)
# 実験
WikiBIOと、独自に収集したBook, Songに関するWikipediaデータのTable-to-Textデータを用いて実験。
このとき、Training instanceを50~500まで変化させた。
WikiBIOデータセットに対してSoTAを記録しているBase-originalを大きくoutperform(Few shot settingでは全然うまくいかない)。
inputとoutput例と、コピーに関するlossを入れた場合の効果。
人手評価の結果、Factual informationの正しさ(#Supp)、誤り(#Cont)ともに提案手法が良い。また、文法的な正しさ(Lan. Score)もコピーがない場合とcomparable
Template Guided Text Generation for Task-Oriented Dialogue, Kale+, Google, EMNLP'20
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DataToTextGeneration #pretrained-LM #KeyPoint Notes Issue Date: 2022-12-01 Comment
# 概要
Dialogue Actをそのままlinearlizeして言語モデルに入力するのではなく、テンプレートをベースにしたシンプルなsentenceにして言語モデルに与えると、zero-shot, few-shotなsettingで性能が向上するという話(T5ベース)。
# 手法
slotの名称をnatural languageのdescriptionに変更するSchema Guidedアプローチも提案(NLUでは既に実践さrていたらしいが、Generationで利用されたことはない)。
# 結果
MultiWoz, E2E, SGDデータセットを利用。MultiWoz, E2Eデータはデータ量が豊富でドメインやfeatureが限定的なため、schema guided, template guided approachとNaiveなrepresentationを利用した場合の結果がcopmarableであった。
が、SGDデータセットはドメインが豊富でzero-shot, few-shotの設定で実験ができる。SGDの場合はTemplate guided representationが最も高い性能を得た。
low resourceなデータセットで活用できそう
[Paper Note] Text-to-Text Pre-Training for Data-to-Text Tasks, Mihir+, Google Research, INLG'20
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DataToTextGeneration #Transformer #INLG #KeyPoint Notes Issue Date: 2022-09-16 Comment
# 概要
pre-training済みのT5に対して、Data2Textのデータセットでfinetuningを実施する方法を提案。WebNLG(graph-to-text), ToTTo(table-to-text), Multiwoz(task oriented dialogue)データにおいて、simpleなTransformerでも洗練されたmulti-stageなpipelined approachをoutperformできることを示した研究。
# 手法
事前学習済みのT5に対してfine-tuningを実施した。手法はシンプルで、data-to-textタスクをtext-to-textタスクに変換した。具体的には、構造かされたデータをflatな文字列(linearization)で表現することで、text-to-textタスクに変換。各データセットに対するlinearizationのイメージは下図。デリミタや特殊文字を使って構造かされたデータをflatなstringで表現している。
# データセット
## ToTTo(2020)
Wikipediaのテーブルと自然言語でdescriptionのペアデータ
## MultiWoz(2018)
10Kの人間同士のtask-orientedなdialogueデータ。
## WebNLG(2017)
subject-object-predicateの3組みをテキスト表現に変換するタスクのデータ
# Result
## WebNLG
GCNを利用した2020年に提案されたDualEncがSoTAだったらしいが、outperormしている。
## ToTTo
[こちら](
https://github.com/google-research-datasets/totto)のリーダーボードと比較してSoTAを記録
## MultiWoz
T5は事前学習済みGPT-2をfinetuningした手法もoutperformした。SC-GPT2は当時のMultiWozでのSoTA
# Impact of Model capacity
T5モデルのサイズがどれが良いかについては、データセットのサイズと複雑さに依存することを考察している。たとえば、MultiWozデータは構造化データのバリエーションが最も少なく、データ量も56kと比較的多かった。このため、T5-smallでもより大きいモデルの性能に肉薄できている。
一方、WebNLGデータセットは、18kしか事例がなく、特徴量も約200種類程度のrelationのみである。このような場合、モデルサイズが大きくなるにつれパフォーマンスも向上した(特にUnseen test set)。特にBLEUスコアはT5-smallがT5-baseになると、10ポイントもジャンプしており、modelのcapacityがout-of-domainに対する一般化に対してcriticalであることがわかる。ToTToデータセットでも、SmallからBaseにするとパフォーマンスは改善した。
# 所感
こんな簡単なfine-tuningでSoTAを達成できてしまうとは、末恐ろしい。ベースラインとして有用。
NUBIA, EvalNLGEval'20
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #DataToTextGeneration #ConceptToTextGeneration #DialogueGeneration #Encoder #KeyPoint Notes Issue Date: 2021-06-02 Comment
TextGenerationに関するSoTAの性能指標。BLEU, ROUGE等と比較して、人間との相関が高い。

pretrainedされたlanguage model(GPT-2=sentence legibility, RoBERTa_MNLI=logical inference, RoBERTa_STS=semantic similarity)を使い、Fully Connected Layerを利用してquality スコアを算出する。算出したスコアは最終的にcalibrationで0~1の値域に収まるように補正される。
意味的に同等の内容を述べた文間でのexample
BLEU, ROUGE, BERTのスコアは低いが、NUBIAでは非常に高いスコアを出せている。
[Paper Note] Evaluation of Text Generation: A Survey, Asli Celikyilmaz+, arXiv'20, 2020.06
Paper/Blog Link My Issue
#Survey #NLP #Evaluation Issue Date: 2020-08-25 GPT Summary- NLGシステムの評価方法を人間中心、自動評価、機械学習に基づく評価の3カテゴリに分類し、各カテゴリの進展と課題を議論。自動テキスト要約と長文生成の具体例を示し、今後の研究方向を提案。
[Paper Note] CTRL: A Conditional Transformer Language Model for Controllable Generation, Nitish Shirish Keskar+, arXiv'19, 2019.09
Paper/Blog Link My Issue
#Controllable #NLP #LanguageModel #Transformer #Selected Papers/Blogs #Decoder Issue Date: 2026-01-16 GPT Summary- CTRLは、スタイルや内容、タスク特有の振る舞いを制御するコードに基づいて訓練された条件付きトランスフォーマー言語モデルで、1.63億パラメータを持つ。このモデルは、無監督学習の利点を生かしつつ、テキスト生成に対する明示的な制御を提供。CTRLは与えられたシーケンスに基づいて最も可能性のあるトレーニングデータを予測でき、データ分析の新たなアプローチを提示する。また、複数の事前訓練済みバージョンが公開されている。 Comment
Control Code(いわゆるタグ)によって条件付けることで生成されるテキストのスタイルや内容等をcontrollableにする研究の先駆け
HighRES: Highlight-based Reference-less Evaluation of Summarization, Hardy+, N_A, ACL'19
Paper/Blog Link My Issue
#DocumentSummarization #NLP #ACL Issue Date: 2023-08-13 GPT Summary- 要約の手動評価は一貫性がなく困難なため、新しい手法であるHighRESを提案する。この手法では、要約はソースドキュメントと比較して複数のアノテーターによって評価され、ソースドキュメントでは重要な内容がハイライトされる。HighRESはアノテーター間の一致度を向上させ、システム間の違いを強調することができることを示した。 Comment
人手評価の枠組み
[Paper Note] BERTScore: Evaluating Text Generation with BERT, Tianyi Zhang+, arXiv'19, 2019.04
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-based #Selected Papers/Blogs #Surface-level Notes #needs-revision Issue Date: 2023-05-10 GPT Summary- BERTScoreは、テキスト生成の自動評価指標で、候補文のトークンと参照文のトークン間の類似度を文脈埋め込みを使用して計算。363の機械翻訳と画像キャプション生成システムを評価し、人間の判断と高い相関を示し、モデル選択性能を向上。敵対的パラフレーズ検出タスクでも、既存の指標と比較して堅牢性が確認された。 Comment
# 概要
既存のテキスト生成の評価手法(BLEUやMETEOR)はsurface levelのマッチングしかしておらず、意味をとらえられた評価になっていなかったので、pretrained BERTのembeddingを用いてsimilarityを測るような指標を提案しましたよ、という話。
# prior metrics
## n-gram matching approaches
n-gramがreferenceとcandidateでどれだけ重複しているかでPrecisionとrecallを測定
### BLEU
MTで最も利用される。n-gramのPrecision(典型的にはn=1,2,3,4)と短すぎる候補訳にはペナルティを与える(brevity penalty)ことで実現される指標。SENT-BLEUといった亜種もある。BLEUと比較して、BERTScoreは、n-gramの長さの制約を受けず、潜在的には長さの制限がないdependencyをcontextualized embeddingsでとらえることができる。
### METEOR
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments, Banerjee+, CMU, ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization
METEOR 1.5では、内容語と機能語に異なるweightを割り当て、マッチングタイプによってもweightを変更する。METEOR++2.0では、学習済みの外部のparaphrase resourceを活用する。METEORは外部のリソースを必要とするため、たった5つの言語でしかfull feature setではサポートされていない。11の言語では、恥部のfeatureがサポートされている。METEORと同様に、BERTScoreでも、マッチに緩和を入れていることに相当するが、BERTの事前学習済みのembeddingは104の言語で取得可能である。BERTScoreはまた、重要度によるweightingをサポートしている(コーパスの統計量で推定)。
### Other Related Metrics
- NIST: BLEUとは異なるn-gramの重みづけと、brevity penaltyを利用する
- ΔBLEU: multi-reference BLEUを、人手でアノテーションされたnegative reference sentenceで変更する
- CHRF: 文字n-gramを比較する
- CHRF++: CHRFをword-bigram matchingに拡張したもの
- ROUGE: 文書要約で利用される指標。ROUGE-N, ROUGE^Lといった様々な変種がある。
- CIDEr: image captioningのmetricであり、n-gramのtf-idfで重みづけされたベクトルのcosine similrityを測定する
## Edit-distance based Metrics
- Word Error Rate (WER): candidateからreferenceを再現するまでに必要なedit operationの数をカウントする手法
- Translation Edit Rate (TER): referenceの単語数によってcandidateからreferenceまでのedit distanceを正規化する手法
- ITER: 語幹のマッチと、より良い正規化に基づく手法
- PER: positionとは独立したError Rateを算出
- CDER: edit operationにおけるblock reorderingをモデル化
- CHARACTER / EED: character levelで評価
## Embedding-based Metrics
- MEANT 2.0: lexical, structuralの類似度を測るために、word embeddingとshallow semantic parsesを利用
- YISI-1: MEANT 2.0と同様だが、semantic parseの利用がoptionalとなっている
これらはBERTScoreと同様の、similarityをシンプルに測るアプローチで、BERTScoreもこれにinspireされている。が、BERTScoreはContextualized Embeddingを利用する点が異なる。また、linguistic structureを生成するような外部ツールは利用しない。これにより、BERTScoreをシンプルで、新たなlanguageに対しても使いやすくしている。greedy matchingの代わりに、WMD, WMDo, SMSはearth mover's distanceに基づく最適なマッチングを利用することを提案している。greedy matchingとoptimal matchingのtradeoffについては研究されている。sentence-levelのsimilarityを計算する手法も提案されている。これらと比較して、BERTScoreのtoken-levelの計算は、重要度に応じて、tokenに対して異なる重みづけをすることができる。
## Learned Metrics
様々なmetricが、human judgmentsとのcorrelationに最適化するために訓練されてきた。
- BEER: character-ngram, word bigramに基づいたregresison modelを利用
- BLEND: 29の既存のmetricを利用してregressionを実施
- RUSE: 3種類のpre-trained sentence embedding modelを利用する手法
これらすべての手法は、コストのかかるhuman judgmentsによるsupervisionが必要となる。そして、新たなドメインにおける汎化能力の低さのリスクがある。input textが人間が生成したものか否か予測するneural modelを訓練する手法もある。このアプローチは特定のデータに対して最適化されているため、新たなデータに対して汎化されないリスクを持っている。これらと比較して、BERTScoreは特定のevaluation taskに最適化されているモデルではない。
# BERTScore
referenceとcandidateのトークン間のsimilarityの最大値をとり、それらを集約することで、Precision, Recallを定義し、PrecisionとRecallを利用してF値も計算する。Recallは、reference中のすべてのトークンに対して、candidate中のトークンとのcosine similarityの最大値を測る。一方、Precisionは、candidate中のすべてのトークンに対して、reference中のトークンとのcosine similarityの最大値を測る。ここで、類似度の式が単なる内積になっているが、これはpre-normalized vectorを利用する前提であり、正規化が必要ないからである。
また、IDFによるトークン単位でのweightingを実施する。IDFはテストセットの値を利用する。TFを使わない理由は、BERTScoreはsentence同士を比較する指標であるため、TFは基本的に1となりやすい傾向にあるためである。IDFを計算する際は出現数を+1することによるスムージングを実施。
さらに、これはBERTScoreのランキング能力には影響を与えないが、BERTScoreの値はコサイン類似度に基づいているため、[-1, 1]となるが、実際は学習したcontextual embeddingのgeometryに値域が依存するため、もっと小さなレンジでの値をとることになってしまう。そうすると、人間による解釈が難しくなる(たとえば、極端な話、スコアの0.1程度の変化がめちゃめちゃ大きな変化になってしまうなど)ため、rescalingを実施。rescalingする際は、monolingualコーパスから、ランダムにsentenceのペアを作成し(BETRScoreが非常に小さくなるケース)、これらのBERTScoreを平均することでbを算出し、bを利用してrescalingした。典型的には、rescaling後は典型的には[0, 1]の範囲でBERTScoreは値をとる(ただし数式を見てわかる通り[0, 1]となることが保証されているわけではない点に注意)。これはhuman judgmentsとのcorrelationとランキング性能に影響を与えない(スケールを変えているだけなので)。
# 実験
## Contextual Embedding Models
12種類のモデルで検証。BERT, RoBERTa, XLNet, XLMなど。
## Machine Translation
WMT18のmetric evaluation datasetを利用。149種類のMTシステムの14 languageに対する翻訳結果, gold referencesと2種類のhuman judgment scoreが付与されている。segment-level human judgmentsは、それぞれのreference-candiate pairに対して付与されており、system-level human judgmentsは、それぞれのシステムに対して、test set全体のデータに基づいて、単一のスコアが付与されている。pearson correlationの絶対値と、kendall rank correration τをmetricsの品質の評価に利用。そしてpeason correlationについてはWilliams test、kendall τについては、bootstrap re-samplingによって有意差を検定した。システムレベルのスコアをBERTScoreをすべてのreference-candidate pairに対するスコアをaveragingすることによって求めた。また、ハイブリッドシステムについても実験をした。具体的には、それぞれのreference sentenceについて、システムの中からランダムにcandidate sentenceをサンプリングした。これにより、system-level experimentをより多くのシステムで実現することができる。ハイブリッドシステムのシステムレ4ベルのhuman judgmentsは、WMT18のsegment-level human judgmentsを平均することによって作成した。BERTScoreを既存のメトリックと比較した。
通常の評価に加えて、モデル選択についても実験した。10kのハイブリッドシステムを利用し、10kのうち100をランダムに選択、そして自動性能指標でそれらをランキングした。このプロセスを100K回繰り返し、human rankingとmetricのランキングがどれだけagreementがあるかをHits@1で評価した(best systemの一致で評価)。モデル選択の指標として新たにtop metric-rated systemとhuman rankingの間でのMRR, 人手評価でtop-rated systemとなったシステムとのスコアの差を算出した。WMT17, 16のデータセットでも同様の評価を実施した。
## Image Captioning
COCO 2015 captioning challengeにおける12種類のシステムのsubmissionデータを利用。COCO validationセットに対して、それぞれのシステムはimageに対するcaptionを生成し、それぞれのimageはおよそ5個のreferenceを持っている。先行研究にならい、Person Correlationを2種類のシステムレベルmetricで測定した。
- M1: 人間によるcaptionと同等、あるいはそれ以上と評価されたcaptionの割合
- M2: 人間によるcaptionと区別がつかないcaptionの割合
BERTScoreをmultiple referenceに対して計算し、最も高いスコアを採用した。比較対象のmetricはtask-agnostic metricを採用し、BLEU, METEOR, CIDEr, BEER, EED, CHRF++, CHARACTERと比較した。そして、2種類のtask-specific metricsとも比較した:SPICE, LEIC
# 実験結果
## Machine Translation
system-levelのhuman judgmentsとのcorrelationの比較、hybrid systemとのcorrelationの比較、model selection performance
to-Englishの結果では、BERTScoreが最も一貫して性能が良かった。RUSEがcompetitiveな性能を示したが、RUSEはsupervised methodである。from-Englishの実験では、RUSEは追加のデータと訓練をしないと適用できない。
以下は、segment-levelのcorrelationを示したものである。BERTScoreが一貫して高い性能を示している。BLEUから大幅な性能アップを示しており、特定のexampleについての良さを検証するためには、BERTScoreが最適であることが分かる。BERTScoreは、RUSEをsignificantlyに上回っている。idfによる重要度のweightingによって、全体としては、small benefitがある場合があるが全体としてはあんまり効果がなかった。importance weightingは今後の課題であり、テキストやドメインに依存すると考えられる。FBERTが異なる設定でも良く機能することが分かる。異なるcontextual embedding model間での比較などは、appendixに示す。
## Image Captioning
task-agnostic metricの間では、BETRScoreはlarge marginで勝っている。image captioningはchallengingな評価なので、n-gramマッチに基づくBLEU, ROUGEはまったく機能していない。また、idf weightingがこのタスクでは非常に高い性能を示した。これは人間がcontent wordsに対して、より高い重要度を置いていることがわかる。最後に、LEICはtrained metricであり、COCO dataに最適化されている。この手法は、ほかのすべてのmetricを上回った。
## Speed
pre-trained modelを利用しているにもかかわらず、BERTScoreは比較的高速に動作する。192.5 candidate-reference pairs/secondくらい出る(GTX-1080Ti GPUで)。WMT18データでは、15.6秒で処理が終わり、SacreBLEUでは5.4秒である。計算コストそんなにないので、BERTScoreはstoppingのvalidationとかにも使える。
# Robustness analysis
BERTScoreのロバスト性をadversarial paraphrase classificationでテスト。Quora Question Pair corpus (QQP) を利用し、Word Scrambling dataset (PAWS) からParaphrase Adversariesを取得。どちらのデータも、各sentenceペアに対して、それらがparaphraseかどうかラベル付けされている。QQPの正例は、実際のduplicate questionからきており、負例は関連するが、異なる質問からきている。PAWSのsentence pairsは単語の入れ替えに基づいているものである。たとえば、"Flights from New York to Florida" は "Flights from Florida to New York" のように変換され、良いclassifierはこれらがparaphraseではないと認識できなければならない。PAWSはPAWS_QQPとPAWS_WIKIによって構成さえrており、PAWS_QQPをdevelpoment setとした。automatic metricsでは、paraphrase detection training dataは利用しないようにした。自動性能指標で高いスコアを獲得するものは、paraphraseであることを想定している。
下図はAUCのROC curveを表しており、PAWS_QQPにおいて、QQPで訓練されたclassifierはrandom guessよりも性能が低くなることが分かった。つまりこれらモデルはadversaial exampleをparaphraseだと予測してしまっていることになる。adversarial examplesがtrainingデータで与えられた場合は、supervisedなモデルも分類ができるようになる。が、QQPと比べると性能は落ちる。多くのmetricsでは、QQP ではまともなパフォーマンスを示すが、PAWS_QQP では大幅なパフォーマンスの低下を示し、ほぼrandomと同等のパフォーマンスとなる。これは、これらの指標がより困難なadversarial exampleを区別できないことを示唆している。一方、BERTSCORE のパフォーマンスはわずかに低下するだけであり、他の指標よりもロバスト性が高いことがわかる。
# Discussion
- BERTScoreの単一の設定が、ほかのすべての指標を明確に上回るということはない
- ドメインや言語を考慮して、指標や設定を選択すべき
- 一般的に、機械翻訳の評価にはFBERTを利用することを推奨
- 英語のテキスト生成の評価には、24層のRoBERTa largeモデルを使用して、BERTScoreを計算したほうが良い
- 非英語言語については、多言語のBERT_multiが良い選択肢だが、このモデルで計算されたBERTScoreは、low resource languageにおいて、パフォーマンスが安定しているとは言えない
[Paper Note] Table-to-Text Generation with Effective Hierarchical Encoder on Three Dimensions (Row, Column and Time), Gong+, Harbin Institute of Technology, EMNLP'19
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DataToTextGeneration #EMNLP #Surface-level Notes Issue Date: 2021-10-08 Comment
## 概要
既存研究では、tableをレコードの集合, あるいはlong sequenceとしてencodeしてきたが
1. other (column) dimensionの情報が失われてしまう (?)
2. table cellは時間によって変化するtime-series data
という特徴がある。
たとえば、ある選手の成績について言及する際に、その試合について着目するだけでなくて「直近3試合で二回目のダブルダブルです」というように直近の試合も考慮して言及することがあり、table cellの time dimensionについても着目しなければならず、これらはこれまでのモデルで実現できない。
そこで、この研究ではtime dimensionについても考慮し生成する手法を提案。
## モデル概要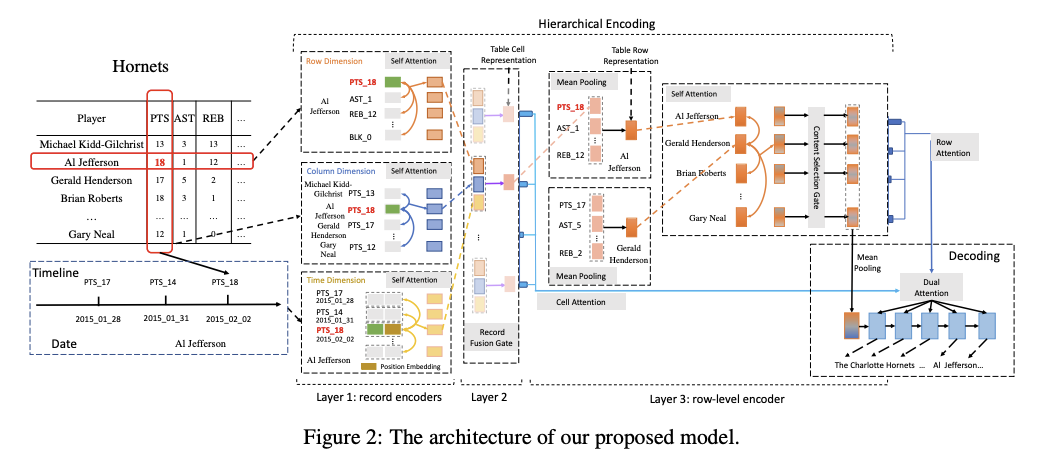
全体としては、Row Dimension Encoder, Column Dimension Encoder, Time Dimension Encoderによって構成されており、self-attentionを利用して、テーブルの各セルごとに Row-Dimension, Column-Dimension, Time-DimensionのRepresentationを獲得する。イメージとしては、
- Row Dimension Encoderによって、自身のセルと同じ行に含まれるセルとの関連度を考慮した表現
- Column Dimension Encoderによって、自身のセルと同じ列に含まれるセルとの関連度を考慮した表現
- Time Dimension Encoderによって、過去の時系列のセルとの関連度を考慮した表現
をそれぞれ獲得するイメージ。各Dimension Encoderでやっていることは、Puduppully (Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
) らのContent Selection Gate節におけるattention vector r_{att}の取得方法と同様のもの(だと思われる)。
獲得したそれぞれのdimensionの表現を用いて、まずそれらをconcatし1 layer MLPで写像することで得られるgeneral representationを取得する。その後、general representationと各dimensionの表現を同様に1 layer MLPでスコアリングすることで、各dimensionの表現の重みを求め、その重みで各representationを線形結合することで、セルの表現を獲得する。generalなrepresentationと各dimensionの表現の関連性によって重みを求めることで、より着目すべきdimensionを考慮した上で、セルの表現を獲得できるイメージなのだろうか。
その後、各セルの表現を行方向に対してMeanPoolingを施しrow-levelの表現を取得。獲得したrow-levelの表現に対し、Puduppully (Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
) らのContent Selection Gate g を適用する(これをどうやっているかがわからない)。
最終的に求めたrow-levelの表現とcell-levelの表現に対して、デコーダのhidden stateを利用してDual Attentionを行い、row-levelの表現からどの行に着目すべきか決めた後、その行の中からどのセルに着目するか決める、といったイメージで各セルの重みを求める。
論文中にはここまでしか書かれていないが、求めた各セルの重みでセルのrepresentationを重み付けして足し合わせ、最終的にそこから単語をpredictionするのだろうか・・・?よくわからない。
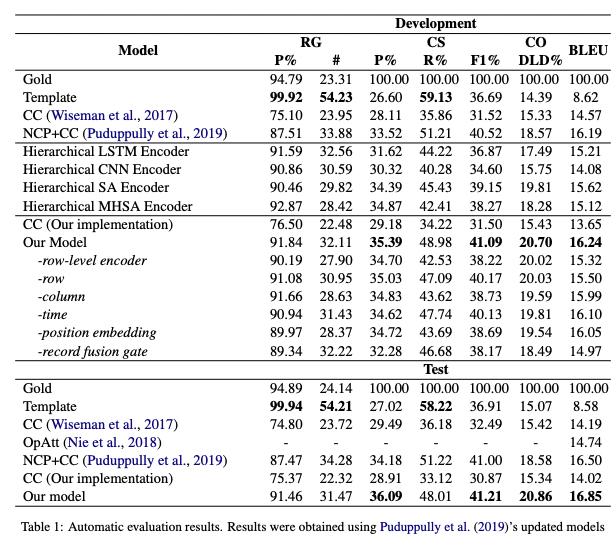
RG, CS, CO, BLEUスコア、全てにおいてBaselineを上回っている(RGのTemplateを除く)。
実装: https://github.com/ernestgong/data2text-three-dimensions/
Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DataToTextGeneration #AAAI #One-Line Notes Issue Date: 2021-06-26 Comment
Rotowire Datasetに対するData2Text研究において代表的な論文の一つ。Wisemanモデル [Paper Note] Challenges in Data-to-Document Generation, Sam Wiseman+, EMNLP'17, 2017.07 と共にベースラインとして利用されることが多い。
[Paper Note] User Preference-Aware Review Generation, Wang+, PAKDD'19
Paper/Blog Link My Issue
#NLP #ReviewGeneration Issue Date: 2019-08-17
[Paper Note] Review Response Generation in E-Commerce Platforms with External Product Information, Zhao+, WWW'19
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NLP #ReviewGeneration #WWW Issue Date: 2019-08-17
[Paper Note] Automatic Generation of Personalized Comment Based on User Profile, Wenhuan Zeng+, ACL'19 SRW
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NLP #ReviewGeneration #ACL #Workshop Issue Date: 2019-08-17 GPT Summary- ソーシャルメディアの多様なコメント生成の難しさを考慮し、ユーザープロフィールに基づくパーソナライズされたコメント生成タスク(AGPC)を提案。パーソナライズドコメント生成ネットワーク(PCGN)を用いて、ユーザーの特徴をモデル化し、外部ユーザー表現を考慮することで自然なコメントを生成。実験結果は、モデルの効果を示す。
[Paper Note] Multimodal Review Generation for Recommender Systems, Truong+, WWW'19
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NLP #ReviewGeneration #WWW #One-Line Notes Issue Date: 2019-05-31 Comment
Personalized Review Generationと、Rating Predictionを同時学習した研究(同時学習自体はすでに先行研究がある)。
また、先行研究のinputは、たいていはuser, itemであるが、multi-modalなinputとしてレビューのphotoを活用したという話。
まだあまりしっかり読んでいないが、モデルのstructureはシンプルで、rating predictionを行うDNN、テキスト生成を行うLSTM(fusion gateと呼ばれる新たなゲートを追加)、画像の畳み込むCNNのハイブリッドのように見える。
Learning to Generate Move-by-Move Commentary for Chess Games from Large-Scale Social Forum Data, Jhamtani+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Dataset #DataToTextGeneration #TabularData #ACL #Encoder-Decoder Issue Date: 2025-08-06 Comment
データセットの日本語解説(過去の自分の資料): https://speakerdeck.com/akihikowatanabe/data-to-text-datasetmatome-summary-of-data-to-text-datasets?slide=66
Point precisely: Towards ensuring the precision of data in generated texts using delayed copy mechanism., Li+, Peking University, COLING'18
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DataToTextGeneration #COLING #Surface-level Notes Issue Date: 2021-10-25 Comment
# 概要
DataToTextタスクにおいて、生成テキストのデータの精度を高める手法を提案。two stageアルゴリズムを提案。①encoder-decoerモデルでslotを含むテンプレートテキストを生成。②Copy Mechanismでslotのデータを埋める、といった手法。
①と②はそれぞれ独立に学習される。
two stageにするモチベーションは、
・これまでのモデルでは、単語の生成確率とコピー確率を混合した分布を考えていたが、どのように両者の確率をmergeするのが良いかはクリアではない。
→ 生成とコピーを分離して不確実性を減らした
・コピーを独立して考えることで、より効果的なpair-wise ranking loss functionを利用することができる
・テンプレート生成モデルは、テンプレートの生成に集中でき、slot fillingモデルはスロットを埋めるタスクに集中できる。これらはtrainingとtuningをより簡便にする。
# モデル概要
モデルの全体像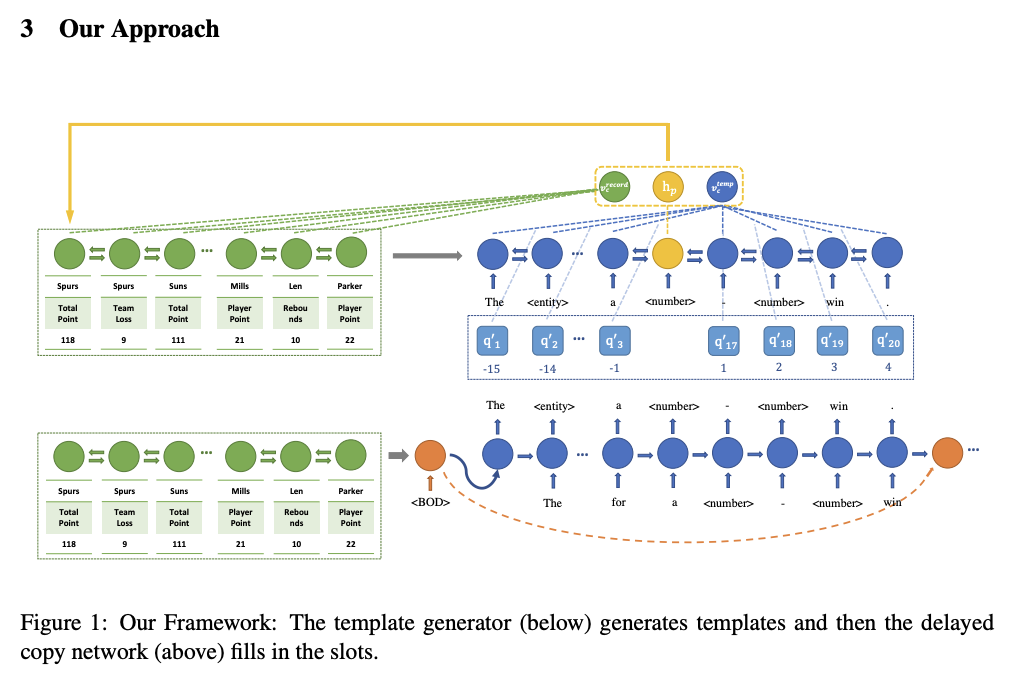
オリジナルテキストとテンプレートの例。テンプレートテキストの生成を学習するencoder-decoder(①)はTarget Templateを生成できるように学習する。テンプレートではエンティティが"
# 実験結果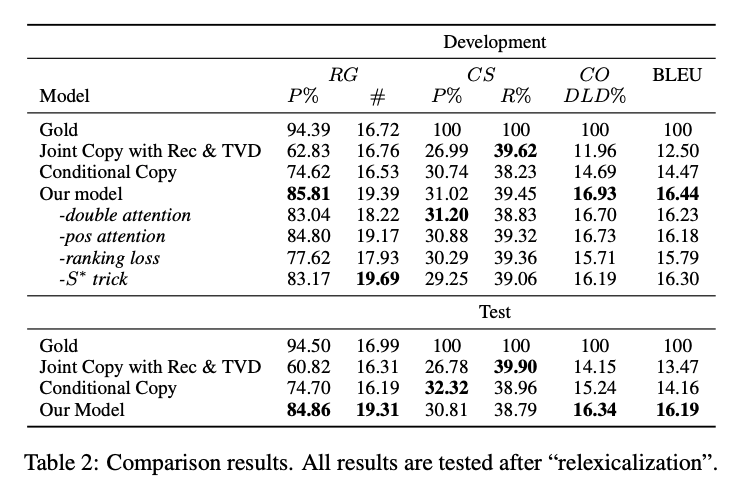
Relation Generation (RG)がCCと比べて10%程度増加しているので、data fidelityが改善されている。
また、BLEUスコアも約2ポイント改善。これはentityやnumberが適切に埋められるようになっただけでなく、テンプレートがより適切に生成されているためであると考えられる。
## 参考:
• Relation Generation (RG):出力文から(entity, value)の関係を抽出し,抽出された関係の数と,それらの関係が入力データに対して正しいかどうかを評価する (Precision).ただし entity はチーム名や選手名などの動作の主体,value は得点数やアシスト数などの記録である.
• Content Selection (CS):出力文とリファレンスから (entity, value) の関係を抽出し,出力文から抽出された関係のリファレンスから抽出された関係に対する Precision,Recall で評価する.
• Content Ordering (CO):出力文とリファレンスから (entity, value) の関係を抽出し,それらの間の正規化 DamerauLevenshtein 距離 [7] で評価する.
(from [Paper Note] 過去情報の内容選択を取り入れた スポーツダイジェストの自動生成, 加藤+, NLP'21
)
[Paper Note] Operation-guided Neural Networks for High Fidelity Data-To-Text Generation, Nie+, Sun Yat-Sen University, EMNLP'18
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DataToTextGeneration #EMNLP #Surface-level Notes Issue Date: 2021-09-16 Comment
# 概要
既存のニューラルモデルでは、生データ、あるいはそこから推論された事実に基づいて言語を生成するといったことができていない(e.g. 金融, 医療, スポーツ等のドメインでは重要)。
たとえば下表に示した通り、"edge"という単語は、スコアが接戦(95-94=1 -> スコアの差が小さい)であったことを表現しているが、こういったことを既存のモデルでは考慮して生成ができない。
これを解決するために、演算(operation)とニューラル言語モデルを切り離す(事前に計算しておく)といったことが考えられるが、
① 全てのフィールドに対してoperationを実行すると、探索空間が膨大になり、どの結果に対して言及する価値があるかを同定するのが困難(言及する価値がある結果がほとんど存在しない探索空間ができてしまう)
② 演算結果の数値のスパンと、言語選択の対応関係を確立させるのが困難(e.g. スコアの差が1のとき"edge"と表現する、など)
といった課題がある。
①に対処するために、事前にraw dataに対して演算を適用しその結果を利用するモデルを採用。どの演算結果を利用するかを決定するために、gating-mechanismを活用する。
②に対処するために、quantization layerを採用し、演算結果の数値をbinに振り分け、その結果に応じて生成する表現をguideするようなモデルを採用する。
# モデル概要
モデルはrecord encoder(h_{i}^{ctx}を作る)、operation encoder(h_{i}^{op}を作る)、operation result encoder(h_{i}^{res}を作る)によって構成される。
## record encoder
record encoderは、wisemanらと同様に、index (e.g. row 2), column (e.g. column Points), value (e.g. 95)のword embeddingを求め、それらをconcatしたものをbi-directional RNNに入力し求める。
## operation encoder
operation encoderでは、operation op_{i}は、1) operationの名称 (e.g. minus) 2) operationを適用するcolumn (e.g. Points), 3) operationを適用するrow (e.g. {1, 2}などのrow indexの集合)によって構成されており、これらのembeddingをlookupしconcatした後、non-linear layerで変換することによってoperationのrepresentationを取得する。3)operationを適用するrowについては、複数のindexによって構成されるため、各indexのembeddingをnon-linear layerで変換したベクトルを足し合わせた結果に対してtanhを適用したベクトルをembeddingとして利用する。
## operation result encoder
operation result encoderは、scalar results(minus operationにより-1)およびindexing results (argmax operationによりindex 2)の二種類を生成する。これら二種類に対して異なるencoding方法を採用する。
### scalar results
scalar resultsに対しては、下記式でscalar valueをquantization vector(q_{i})に変換する。qutization vectorのlengthはLとなっており、Lはbinの数に相当している。つまり、quantization vectorの各次元がbinの重みに対応している。その後、quantization vectorに対してsoftmaxを適用し、quantization unit(quantization vectorの各次元)の重みを求める。最後に、quantization embeddingと対応するquantization unitの重み付き平均をとることによってh_{i}^{res}を算出する。
Q. 式を見るとW_{q}がscalar resultの値によって定数倍されるだけだから、softmaxによって求まるquantization unitの重みの序列はscalar resultによって変化しなそうに見えるが、これでうまくいくんだろうか・・・?序列は変わらなくても各quantization unit間の相対的な重みの差が変化するから、それでうまくscalar値の変化を捉えられるの・・・か・・・?
### indexing results
indexing resultsについては、h_{i}^{res}をシンプルにindexのembeddingとする。
## Decoder
context vectorの生成方法が違う。従来のモデルと比較して、context vectorを生成する際に、レコードをoperationの両方をinputとする。
operationのcontext vector c_{t}^{op}とrecordsのcontext vector c_{t}^{ctx}をdynamic gate λ_{t}によって重み付けし最終的なcontext vectorを求める。λ_{t}は、t-1時点でのデコーダのhidden stateから重みを求める。
c_{t}^{op}は次式で計算され:
c_{t}^{scl, idx}は、
よって計算される。要は、decoderのt-1のhidden stateと、operation vectorを用いて、j番目のoperationの重要度(β)を求め、operationの重要度によって重み付けしてoperation result vectorを足し合わせることによって、context vectorを算出する。
また、recordのcontext vector c_{t}^{ctx}は、h_{j}^{res}とh_{j}^{op}と、h_{j}^{ctx}に置き換えることによって算出される。 
## データセット
人手でESPN, ROTOWIRE, WIKIBIOデータセットのReferenceに対して、factを含むtext spanと、そのfactの種類を3種類にラベル付した。input factsはinput dataから直接見つけられるfact, inferred factsはinput dataから直接見つけることはできないが、導き出すことができるfact、unsupported factsはinput dataから直接あるいは導き出すことができないfact。wikibioデータセットはinferred factの割合が少ないため、今回の評価からは除外し、ROTOWIRE, ESPNを採用した。特にESPNのheadline datasetがinferred factsが多かった。
# 結果
## 自動評価
wiseman modelをOpAttがoutperformしている。また、Seq2Seq+op+quant(Seq2Seq+copyに対してoperation result encoderとquantization layerを適用したもの)はSeq2Seq+Copyを上回っているが、OpAttほとではないことから、提案手法のoperation encoderの導入とgating mechanismが有効に作用していることがわかる。
採用するoperationによって、生成されるテキストも異なるようになっている。
## 人手評価
3人のNBAに詳しいEnglish native speakerに依頼してtest dataに対する生成結果にアノテーションをしてもらった。アノテーションは、factを含むspanを同定し、そのfactがinput facts/inferred facts/unsupported factsのどれかを分類してもらった。最後に、そのfactが入力データからsupportされるかcontradicted(矛盾するか)かをアノテーションしてもらった。
提案手法が、より多くのinferred factsについて言及しながらも、少ない#Cont.であることがわかった。
# 分析
## Quantizationの効果
チーム間のスコアの差が、5つのbinのに対してどれだけの重みを持たせたかのheatmap。似たようなスコアのgapの場合は似たような重みになることがわかる。ポイント差の絶対値が小さい場合は、重みの分布の分散が大きくなるのでより一般的な単語で生成を行うのに対し、絶対値が大きい場合は分散が小さくなるため、unique wordをつかって生成するようになる。
pointのgapの大きさによって利用される単語も変化していることがわかる。ポイント差がちいさいときは"edge"、大きいときは"blow out"など。
## gating mechanismの効果
生成テキストのtimestepごとのgateの重みの例。色が濃ければ濃いほど、operation resultsの情報を多く利用していることを表す。チームリーダーを決める際や(horford)勝者を決める際に(Hawks)、operation resultsの重みが大きくなっており、妥当な重み付けだと考察している。
[Paper Note] Improving Explainable Recommendations with Synthetic Reviews, Sixun Ouyang+, RecSys'18
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NLP #ReviewGeneration #RecSys Issue Date: 2019-08-17 GPT Summary- レコメンダーシステムにおいて、解釈可能な説明を提供することは信頼性向上に重要である。本研究では、ユーザーのレビューを基にした生成モデルを用いて、個別化された推薦説明を作成するフレームワークを提案。Amazonの書籍レビューデータセットを用いて、生成されたレビューが人間のレビューよりも優れた推薦性能を示すことを実証した。これは機械生成による自然言語説明の初の試みである。
[Paper Note] A Knowledge-Grounded Neural Conversation Model, Ghazvininejad+, AAAI'18,
Paper/Blog Link My Issue
#NeuralNetwork #NLP #AAAI Issue Date: 2019-01-24
[Paper Note] Response Generation by Context-aware Prototype Editing, Yu Wu+, AAAI'18, 2018.06
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ContextAware #AAAI Issue Date: 2019-01-24 GPT Summary- 「編集による応答生成」という新しいパラダイムを提案し、既存の応答プロトタイプを修正することで多様性と情報量を向上させる。応答編集モデルは、プロトタイプと現在のコンテキストの違いを考慮して編集ベクトルを形成し、生成結果を改善する。実験結果は、応答編集モデルが他の生成モデルや取得ベースのモデルより優れていることを示す。
[Paper Note] Generating Sentences by Editing Prototypes, Kelvin Guu+, TACL'18, 2017.09
Paper/Blog Link My Issue
#NeuralNetwork #NLP #TACL #Encoder-Decoder #Editing Issue Date: 2017-12-31 GPT Summary- 新しい生成モデルを提案し、トレーニングコーパスからプロトタイプ文をサンプリングして編集することで新しい文を生成。従来のモデルと異なり、困惑度を改善し、高品質な出力を実現。さらに、文の類似性や文レベルの類推を捉える編集ベクトルを生成。
Why We Need New Evaluation Metrics for NLG, EMNLP'17
Paper/Blog Link My Issue
#Metrics #NLP #Evaluation #One-Line Notes #needs-revision Issue Date: 2023-08-16 Comment
既存のNLGのメトリックがhuman judgementsとのcorrelationがあまり高くないことを指摘した研究
[Paper Note] Estimating Reactions and Recommending Products with Generative Models of Reviews, Ni+, IJCNLP'17
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #NLP #ReviewGeneration #IJCNLP #KeyPoint Notes Issue Date: 2019-02-01 Comment
Collaborative Filtering (CF) によるコンテンツ推薦とReview Generationを同時に学習し、
両者の性能を向上させる話。
非常に興味深い設定で、このような実験設定でReview Generationを行なった初めての研究。
CFではMatrix Factorization (MF) を利用し、Review Generationでは、LSTM-basedなseq2seqを利用する。MFとReview Generationのモデルにおいて、共通のuser latent factorとitem latent factorを利用することで、joint modelとしている。このとき、latent factorは、両タスクを通じて学習される。
CFでは、Implicitな設定なので、Rating Predictionではなく、binary classificationを行うことで、推薦を行う。
classificationには、Matrix Factorization (MF) を拡張したモデルを用いる。
具体的には、通常のMFでは、user latent factorとitem latent factorの内積によって、userのitemに対するpreferenceを表現するが、このときに、target userが過去に記載したレビュー・およびtarget itemに関する情報を利用する。レビューのrepresentationのaverageをとったvectorと、MFの結果をlinear layerによって写像し、最終的なclassification scoreとしている。
Review Generationでは、基本的にはseq2seqのinputのEmbeddingに対して、user latent factor, item latent factorをconcatするだけ。hidden stateに直接concatしないのは、latent factorを各ステップで考慮できるため、long, coherentなsequenceを生成できるから、と説明している。

Recommendタスクにおいては、Bayesian Personalized Ranking, Generalized Matrix Factorizationをoutperform。

Review GenerationはPerplexityにより評価している。提案手法がcharacter based lstmをoutperform。
Perplexityによる評価だと言語モデルとしての評価しかできていないので、BLEU, ROUGEなどを利用した評価などもあって良いのでは。
[Paper Note] Adversarial Ranking for Language Generation, Kevin Lin+, NIPS'17, 2017.05
Paper/Blog Link My Issue
#NeuralNetwork #LearningToRank #NLP #GenerativeAdversarialNetwork #NeurIPS #AdversarialTraining Issue Date: 2018-02-04 GPT Summary- RankGANは、高品質な言語説明を生成するための新しい生成的敵対ネットワークであり、識別器に絶対的な二値述語の代わりに相対的なランキングを用いることで、より良い評価を実現します。人間と機械の文を参照グループとして分析・ランキングすることで、生成器のパフォーマンスが向上します。ポリシーグラデント技術を通じて最適化され、複数の公的データセットで有効性が示されています。
[Paper Note] Challenges in Data-to-Document Generation, Sam Wiseman+, EMNLP'17, 2017.07
Paper/Blog Link My Issue
#NeuralNetwork #NLP #DataToTextGeneration #EMNLP #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-01 GPT Summary- ニューラルモデルは少数のデータから短い説明文を生成するタスクで進展を見せているが、難易度の高いデータに対しては効果が限定的である。本研究では新たなデータレコードと説明文のコーパスを導入し、評価手法を提案してパフォーマンスを分析した。実験結果では、モデルは流暢なテキストを生成するものの、人間の文書には及ばず、テンプレートベースの手法が一部指標で優れていることが示された。コピーや再構築に基づく拡張が改善をもたらすことも確認された。 Comment
・RotoWire(NBAのテーブルデータ + サマリ)データを収集し公開
・Rotowireデータの統計量
【モデルの概要】
・attention-based encoder-decoder model
・BaseModel
- レコードデータ r の各要素(r.e: チーム名等のENTITY r.t: POINTS等のデータタイプ, r.m: データのvalue)からembeddingをlookupし、1-layer MLPを適用し、レコードの各要素のrepresentation(source data records)を取得
- Luongらのattentionを利用したLSTM Decoderを用意し、source data recordsとt-1ステップ目での出力によって条件付けてテキストを生成していく
- negative log likelihoodがminimizeされるように学習する
・Copying
- コピーメカニズムを導入し、生成時の確率分布に生成テキストを入力からコピーされるか否かを含めた分布からテキストを生成。コピーの対象は、入力レコードのvalueがコピーされるようにする。
- コピーメカニズムには下記式で表現される Conditional Copy Modelを利用し、p(zt|y1:t-1, s)はMLPで表現する(Conditional Copy Model 節参照)。
- またpcopyは、生成している文中にあるレコードのエンティティとタイプが出現する場合に、対応するvalueをコピーし生成されるように表現する
[Paper Note] Toward Controlled Generation of Text, Zhiting Hu+, ICML'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #Controllable #NLP #DataToTextGeneration #ConceptToTextGeneration #GenerativeAdversarialNetwork #ICML #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 属性に基づいて制御された自然言語文を生成するために、変分オートエンコーダと属性識別器を組み合わせた新しい生成モデルを提案。微分可能な近似を用いて解釈可能な表現を学習し、望ましい属性を持つ文を生成。定量的評価で生成の正確性を確認。 Comment
Text Generationを行う際は、現在は基本的に学習された言語モデルの尤度に従ってテキストを生成するのみで、outputされるテキストをcontrolすることができないので、できるようにしましたという論文。 VAEによるテキスト生成にGANを組み合わせたようなモデル。 decodingする元となるfeatureのある次元が、たとえばpolarityなどに対応しており、その次元の数値をいじるだけで生成されるテキストをcontrolできる。
テキストを生成する際に、生成されるテキストをコントロールするための研究。 テキストを生成する際には、基本的にはVariational Auto Encoder(VAE)を用いる。
VAEは、入力をエンコードするEncoderと、エンコードされた潜在変数zからテキストを生成するGeneratorの2つの機構によって構成されている。
この研究では、生成されるテキストをコントロールするために、VAEの潜在変数zに、生成するテキストのattributeを表す変数cを新たに導入。
たとえば、一例として、変数cをsentimentに対応させた場合、変数cの値を変更すると、生成されるテキストのsentimentが変化するような生成が実現可能。
次に、このような生成を実現できるようなパラメータを学習したいが、学習を行う際のポイントは、以下の二つ。
cで指定されたattributeが反映されたテキストを生成するように学習
潜在変数zとattributeに関する変数cの独立性を保つように学習 (cには制御したいattributeに関する情報のみが格納され、その他の情報は潜在変数zに格納されるように学習する)
1を実現するために、新たにdiscriminatorと呼ばれる識別器を用意し、VAEが生成したテキストのattributeをdiscriminatorで分類し、その結果をVAEのGeneratorにフィードバックすることで、attributeが反映されたテキストを生成できるようにパラメータの学習を行う。 (これにはラベル付きデータが必要だが、少量でも学習できることに加えて、sentence levelのデータだけではなくword levelのデータでも学習できる。)
また、2を実現するために、VAEが生成したテキストから、生成する元となった潜在変数zが再現できるようにEncoderのパラメータを学習。
実験では、sentimentとtenseをコントロールする実験が行われており、attributeを表す変数cを変更することで、以下のようなテキストが生成されており興味深い。
[sentimentを制御した例]
this movie was awful and boring. (negative)
this movie was funny and touching. (positive)
[tenseを制御した例]
this was one of the outstanding thrillers of the last decade
this is one of the outstanding thrillers of the all time
this will be one of the great thrillers of the all time
VAEは通常のAutoEncoderと比較して、奥が深くて勉強してみておもしろかった。 Reparametrization Trickなどは知らなかった。
管理人による解説資料:
[Controllable Text Generation.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1595121/Controllable.Text.Generation.pdf)
slideshare: https://www.slideshare.net/akihikowatanabe3110/towards-controlled-generation-of-text
[Paper Note] Multi-Task Video Captioning with Video and Entailment Generation, Ramakanth Pasunuru+, ACL'17, 2017.04
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NLP #MultitaskLearning #ACL #Encoder-Decoder #3D (Video) #One-Line Notes #VideoCaptioning Issue Date: 2017-12-31 GPT Summary- ビデオキャプショニングの改善のため、教師なしビデオ予測タスクと論理的言語含意生成タスクを共有し、リッチなビデオエンコーダ表現を学習。パラメータを共有するマルチタスク学習モデルを提案し、標準データセットで大幅な改善を達成。 Comment
multitask learningで動画(かなり短め)のキャプション生成を行なった話
[Paper Note] Neural Text Generation: A Practical Guide, Ziang Xie, arXiv'17, 2017.11
Paper/Blog Link My Issue
#NeuralNetwork #Survey #NLP #DataToTextGeneration #ConceptToTextGeneration Issue Date: 2017-12-31 GPT Summary- 深層学習手法はテキスト生成タスクで成功を収めているが、デコーダーが望ましくない出力を生成する問題がある。本論文は、テキスト生成モデルの不具合を解決するための実践的なガイドを提供し、実世界のアプリケーションの実現を目指す。
[Paper Note] Survey of the State of the Art in Natural Language Generation: Core tasks, applications and evaluation, Albert Gatt+, arXiv'17, 2017.03
Paper/Blog Link My Issue
#Survey #NLP #DataToTextGeneration #ConceptToTextGeneration Issue Date: 2017-12-31 GPT Summary- 本論文は、非言語的入力からテキストや音声を生成する自然言語生成(NLG)の最新技術動向を調査し、(a) NLGのコアタスクに関する研究の統合とアーキテクチャの提示、(b) NLGと他のAI分野との相乗効果による新しい研究トピックの強調、(c) NLG評価の課題と他の自然言語処理分野との関連を明らかにすることを目的としている。 Comment
割と新し目のNLGのSurvey
Lexical Coherence Graph Modeling Using Word Embeddings, Mesgar+, NAACL'16
Paper/Blog Link My Issue
#DocumentSummarization #MachineTranslation #Metrics #NLP #Evaluation #Coherence #NAACL Issue Date: 2023-08-13
[Paper Note] Neural Headline Generation with Minimum Risk Training, Ayana+, arXiv'16, 2016.04
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NLP #Encoder-Decoder #RecurrentModels Issue Date: 2018-10-06 GPT Summary- 最小リスク訓練を用いることで、自動ヘッドライン生成におけるモデルの性能を改善。従来の手法のパラメータ最適化の制約を克服し、英語と中国語のヘッドライン生成において最先端の成果を上回ることを示した。
[Paper Note] Generating Sentences from a Continuous Space, Samuel R. Bowman+, CoNLL'16, 2015.11
Paper/Blog Link My Issue
#NeuralNetwork #NLP #VariationalAutoEncoder #CoNLL #Selected Papers/Blogs #One-Line Notes #Reference Collection #RecurrentModels Issue Date: 2018-02-14 GPT Summary- RNNベースの変分オートエンコーダ生成モデルを導入し、文全体の分散潜在表現を組み込むことで、文のスタイルやトピックなどの特性を明示的にモデル化。潜在空間を通じて新しい文を生成し、欠損単語の補完効果を実証。モデルの特性と使用に関する否定的な結果も示す。 Comment
VAEを利用して文生成
【Variational Autoencoder徹底解説】
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24
[Paper Note] Deep Match between Geology Reports and Well Logs Using Spatial Information, Tong+, CIKM'16
Paper/Blog Link My Issue
#Others #NLP #DataToTextGeneration #CIKM Issue Date: 2017-12-31
[Paper Note] Neural Text Generation from Structured Data with Application to the Biography Domain, Remi Lebret+, EMNLP'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Dataset #ConceptToTextGeneration #EMNLP #Encoder-Decoder #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 大規模なWikipediaの伝記データセットを用いて、テキスト生成のためのニューラルモデルを提案。モデルは条件付きニューラル言語モデルに基づき、固定語彙とサンプル固有の単語を組み合わせるコピーアクションを採用。提案モデルは古典的なKneser-Neyモデルを約15 BLEUポイント上回る性能を示した。 Comment
Wikipediaの人物に関するinfo boxから、その人物のbiographyの冒頭を生成するタスク。
Neural Language Modelに、新たにTableのEmbeddingを入れられるようにtable embeddingを提案し、table conditioned language modelを提案している。
inputはテーブル(図中のinput textっていうのは、少し用語がconfusingだが、言語モデルへのinputとして、過去に生成した単語の系列を入れるというのを示しているだけ)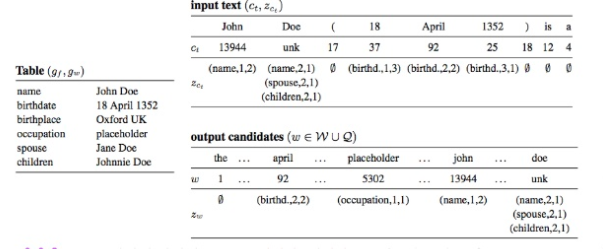
モデル全体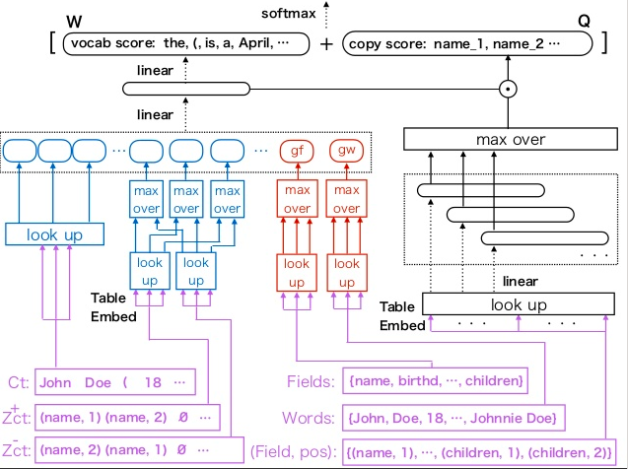
Wikipediaから生成した、Biographyに関するデータセットも公開している。
template basedなKNSmoothingを使ったベースラインよりも高いBLEUスコアを獲得。さらに、テーブルのGlobalな情報を入れる手法が、性能向上に寄与(たとえばチーム名・リーグ・ポジションなどをそれぞれ独立に見ても、バスケットボールプレイヤーなのか、ホッケープレイヤーなのかはわからないけど、テーブル全体を見ればわかるよねという気持ち)。
[Paper Note] Content Selection in Data-to-Text Systems: A Survey, Dimitra Gkatzia, arXiv'16, 2016.10
Paper/Blog Link My Issue
#Survey #NLP #DataToTextGeneration #ConceptToTextGeneration #Initial Impression Notes Issue Date: 2017-12-31 GPT Summary- データからテキストへのシステムは、データを自然言語で自動的にレポート生成し、ユーザーの好みに応じた出力を提供する。コンテンツ選択は重要な要素であり、どの情報を伝えるかを決定する。研究では、データからテキスト生成の分野を紹介し、システムのアーキテクチャと最先端のコンテンツ選択手法をレビューし、今後の研究機会について議論する。 Comment
Gkatzia氏の"content selection"に関するSurvey
chrF: character n-gram F-score for automatic MT evaluation, Mono Popovic, WMT'15
Paper/Blog Link My Issue
#DocumentSummarization #MachineTranslation #Metrics #NLP #Reference-based #ACL #Workshop #One-Line Notes Issue Date: 2023-08-13 Comment
character-basedなn-gram overlapをreferenceとシステムで計算する手法
[Paper Note] From word embeddings to document distances, Kusner+, ICML'15
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-based #One-Line Notes Issue Date: 2023-08-13 Comment
WMS/SMS/S+WMS
- [Paper Note] MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance, Zhao+, EMNLP-IJCNLP'19
はこれらからinspiredされ提案された
[Paper Note] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever+, NIPS'14
Paper/Blog Link My Issue
#NeuralNetwork #NLP #NeurIPS #Selected Papers/Blogs #Encoder-Decoder Issue Date: 2025-09-19 GPT Summary- DNNはシーケンス学習において優れた性能を示すが、シーケンス間のマッピングには限界がある。本研究では、LSTMを用いたエンドツーエンドのシーケンス学習アプローチを提案し、英語からフランス語への翻訳タスクで34.8のBLEUスコアを達成。LSTMは長文にも対応し、SMTシステムの出力を再ランク付けすることでBLEUスコアを36.5に向上させた。また、単語の順序を逆にすることで性能が向上し、短期的依存関係の最適化が容易になった。 Comment
いまさらながらSeq2Seqを提案した研究を追加
[Paper Note] CIDEr: Consensus-based Image Description Evaluation, Ramakrishna Vedantam+, arXiv'14, 2014.11
Paper/Blog Link My Issue
#DocumentSummarization #ComputerVision #NLP #Evaluation #ImageCaptioning #Reference-based #needs-revision Issue Date: 2023-05-10 GPT Summary- 画像説明の自動生成における新たな評価パラダイムを提案。人間の合意を測るトリプレット手法、合意を反映する新指標CIDEr、50文の説明を含むPASCAL-50SとABSTRACT-50Sデータセットを利用。新指標は既存のものより人間の合意を正確に捉え、最先端手法の評価に向けたベンチマークを提供。CIDEr-DはMS COCO評価サーバの一部として、体系的な評価を可能にする。
[Paper Note] Comparing Multi-label Classification with Reinforcement Learning for Summarization of Time-series Data, Gkatzia+, ACL'14
Paper/Blog Link My Issue
#Others #NLP #DataToTextGeneration #ACL Issue Date: 2017-12-31
Graph-based Local Coherence Modeling, Guinaudeau+, ACL'13
Paper/Blog Link My Issue
#DocumentSummarization #MachineTranslation #Metrics #NLP #Evaluation #Coherence #ACL Issue Date: 2023-08-13
[Paper Note] Inducing document plans for concept-to-text generation, Konstas+, EMNLP'13
Paper/Blog Link My Issue
#SingleFramework #NLP #ConceptToTextGeneration #EMNLP Issue Date: 2017-12-31
Extending Machine Translation Evaluation Metrics with Lexical Cohesion to Document Level, Wong+, EMNLP'12
Paper/Blog Link My Issue
#DocumentSummarization #MachineTranslation #Metrics #NLP #Evaluation #Coherence #EMNLP Issue Date: 2023-08-13 Comment
RC-LC
[Paper Note] Unsupervised concept-to-text generation with hypergraphs, Konstas+, NAACL-HLT'12
Paper/Blog Link My Issue
#SingleFramework #NLP #ConceptToTextGeneration #NAACL Issue Date: 2017-12-31
[Paper Note] Generative alignment and semantic parsing for learning from ambiguous supervision, Kim+, COLING'10
Paper/Blog Link My Issue
#SingleFramework #NLP #ConceptToTextGeneration #COLING Issue Date: 2017-12-31
[Paper Note] A simple domain-independent probabilistic approach to generation, Angeli+, EMNLP'10
Paper/Blog Link My Issue
#SingleFramework #NLP #DataToTextGeneration #EMNLP Issue Date: 2017-12-31
[Paper Note] Training a multilingual sportscaster: Using perceptual context to learn language, Chen+, Artificial Intelligence Research'10, 2010.01
Paper/Blog Link My Issue
#SingleFramework #NLP #DataToTextGeneration Issue Date: 2017-12-31
[Paper Note] Learning semantic correspondences with less supervision, Liang+, ACL-IJCNLP'09
Paper/Blog Link My Issue
#Others #NLP #ConceptToTextGeneration #ACL #IJCNLP Issue Date: 2017-12-31
[Paper Note] Verbalizing time-series data: with an example of stock price trends, Kobayashi+, IFSA-EUSFLAT'09, 2009.01
Paper/Blog Link My Issue
#Others #NLP #DataToTextGeneration #KeyPoint Notes Issue Date: 2017-12-31 Comment
小林先生の論文
Least Square Methodによって数値データにfittingするcurveを求める。
curveの特徴から、生成するテキストのtrendsを決定する。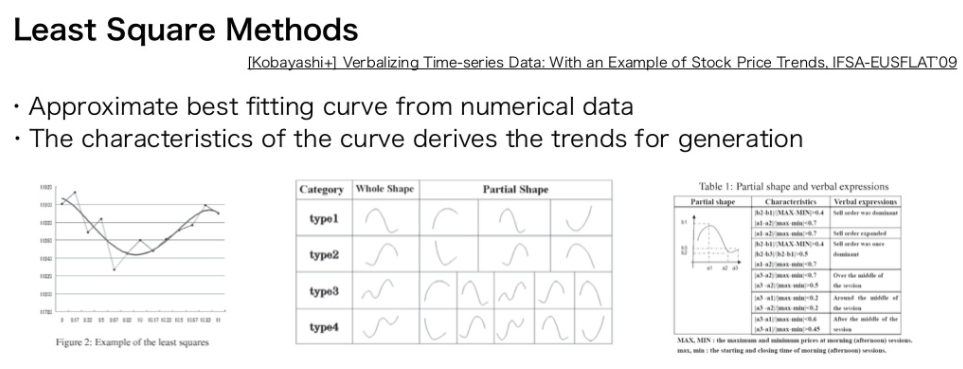
[Paper Note] Generating approximate geographic descriptions, Turner+, ENLG'09, 2009.03
Paper/Blog Link My Issue
#RuleBased #NLP #DataToTextGeneration Issue Date: 2017-12-31
[Paper Note] Automatic generation of textual summaries from neonatal intensive care data, Porter+, Artificial Intelligence'09, 2009.05
Paper/Blog Link My Issue
#SingleFramework #NLP #ConceptToTextGeneration #Initial Impression Notes Issue Date: 2017-12-31 Comment
BabyTalk論文
[Paper Note] A generative model for parsing natural language to meaning representations, Lu+, EMNLP'08
Paper/Blog Link My Issue
#Others #NLP #ConceptToTextGeneration #EMNLP Issue Date: 2017-12-31
[Paper Note] Learning to sportscast: a test of grounded language acquisition, Chen+, ICML'08
Paper/Blog Link My Issue
#SingleFramework #NLP #DataToTextGeneration #ICML Issue Date: 2017-12-31
[Paper Note] An Architecture for Data to Text Systems, Ehud Reiter, ENLG'07
Paper/Blog Link My Issue
#Survey #NLP #DataToTextGeneration #ConceptToTextGeneration #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-31 Comment
NLG分野で有名なReiterらのSurvey。
NLGシステムのアーキテクチャなどが、体系的に説明されている。
[Paper Note] Aggregation via set partitioning for natural language generation, Barzilay+, HLT-NAACL'06
Paper/Blog Link My Issue
#DataDriven #NLP #ConceptToTextGeneration #NAACL Issue Date: 2017-12-31
[Paper Note] Choosing words in computer-generated weather forecasts, Reiter+, Artificial Intelligence'05
Paper/Blog Link My Issue
#RuleBased #NLP #DataToTextGeneration #KeyPoint Notes Issue Date: 2017-12-31 Comment
## タスク
天気予報の生成, システム名 SUMTIME
## 手法概要
ルールベースな手法,weather prediction dataから(将来の気象情報をシミュレーションした数値データ),天気予報を自動生成.corpus analysisと専門家のsuggestを通じて,どのようなwordを選択して天気予報を生成するか詳細に分析したのち,ルールを生成してテキスト生成
[Paper Note] Collective content selection for concept-to-text generation, Barzilay+, HLT_EMNLP'05
Paper/Blog Link My Issue
#DataDriven #NLP #ConceptToTextGeneration #EMNLP Issue Date: 2017-12-31
[Paper Note] Coral: Using natural language generation for navigational assistance, Dale+, Australasian computer science conference'03, 2003.02
Paper/Blog Link My Issue
#RuleBased #NLP #ConceptToTextGeneration Issue Date: 2017-12-31
[Paper Note] Using natural language processing to produce weather forecasts, Goldberg+, IEEE Expert: Intelligent Systems and Their Applications'94
Paper/Blog Link My Issue
#RuleBased #NLP #DataToTextGeneration #KeyPoint Notes Issue Date: 2017-12-31 Comment
## タスク
天気予報の生成,システム名 FOG (EnglishとFrenchのレポートを作成できる)
## 手法概要
ルールベースな手法,weather predictinon dataから,天気予報を自動生成.Text Planner がルールに従い各sentenceに入れる情報を抽出すると同時に,sentence orderを決め,abstractiveな中間状態を生成.その後,中間状態からText Realization(grammarやdictionaryを用いる)によって,テキストを生成.
[Paper Note] Design of a knowledge-based report generator, Kukich, ACL'83
Paper/Blog Link My Issue
#RuleBased #NLP #DataToTextGeneration #ACL #KeyPoint Notes Issue Date: 2017-12-31 Comment
## タスク
numerical stock market dataからstock market reportsを生成.システム名: ANA
## 手法概要
ルールベースな手法,
1) fact-generator,
2) message generator,
3) discourse organizer,
4) text generatorの4コンポーネントから成る.
2), 3), 4)はそれぞれ120, 16, 109個のルールがある. 4)ではphrasal dictionaryも使う.
1)では,入力されたpriceデータから,closing averageを求めるなどの数値的な演算などを行う.
2)では,1)で計算された情報に基づいて,メッセージの生成を行う(e.g. market was mixed).
3)では,メッセージのparagraph化,orderの決定,priorityの設定などを行う.
4)では,辞書からフレーズを選択したり,適切なsyntactic formを決定するなどしてテキストを生成.
Data2Textの先駆け論文。引用すべし。多くの研究で引用されている。
OpenDevin: Code Less, Make More, 2024
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Repository #One-Line Notes Issue Date: 2024-07-04 Comment
LLMによるOpenSourceなソフトウェア生成エージェントプラットフォーム
full timeのスタッフを雇用しworldクラスのUXを目指すとのこと。楽しみ。
参考:
Open化される前の最初のDevinのツイート
Decoding Strategies that You Need to Know for Response Generation
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #One-Line Notes Issue Date: 2024-01-01 Comment
言語モデルのdecodingの方法についてよくまとまっている。まとめられているdecoding方法は以下
- Greedy, BeamSearch, RandomSampling, Temperature, Top-K Sampling, Nucleus Sampling
こちらの記事ではHuggingFaceでの実装や他のdecoding方法等、より実装面での詳細が記述されている:
https://note.com/npaka/n/n9a8c85f2ef7a
Data-to-Text Datasetまとめ, Akihiko Watanabe, 2022
Paper/Blog Link My Issue
#Article #Survey #NLP #Dataset #DataToTextGeneration #Slide #One-Line Notes Issue Date: 2023-11-08 Comment
Data-to-Textのデータセットを自分用に調べていたのですが、せっかくなのでスライドにまとめてみました。特にMR-to-Text, Table-to-Textあたりは網羅的にサーベイし、データセットの概要を紹介しているので、全体像を把握するのに良いのかなぁと思います。ただし、2022年12月時点で作成したので2023年以後のデータセットは含まれていません😅
Zero-shot Learning網羅的サーベイ: CLIPが切り開いたVision & Languageの新しい世界, エクサウィザーズ Engineer Blog, 2023.05
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NLP #LanguageModel #ImageCaptioning #DiffusionModel #Blog #Initial Impression Notes Issue Date: 2023-11-02 Comment
これはすごいまとめ…。まだ途中までしか読めていない。CLIPからスタートしてCLIPを引用している論文から重要なものを概要付きでまとめている。
走行動画を説明するLLMを作成し、80台のGPUで分散並列学習させた話, Kotaro Tanahashi, Tech Blog - Turing, 2023.07
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Blog Issue Date: 2023-08-16
[Paper Note] ArgU: A Controllable Factual Argument Generator, Sougata Saha+, ACL23, 2023.05
Paper/Blog Link My Issue
#Article #Controllable #NLP #Argument #ACL Issue Date: 2023-07-18 GPT Summary- 効果的な論証の自動生成は難しいが、Waltonの論証スキームに基づく制御コードを用いたArgUを提案。69,428の論証からなる注釈付きコーパスを公開し、多様な論証を生成可能であることを実験で示した。
StarCoderBase_StarCoder, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #FoundationModel #Blog #Coding #KeyPoint Notes #needs-revision Issue Date: 2023-05-06 Comment
・15.5Bパラメータ
・80種類以上のプログラミング言語で訓練
・Multi Query Attentionを利用
・context window size 8192
・Fill in the middle objectiveを利用
Instruction tuningがされておらず、prefixとsuffixの間を埋めるような訓練のされ方をしているので、たとえば関数名をinputして、そのmiddle(関数の中身)を出力させる、といった使い方になる模様。
paper: https://drive.google.com/file/d/1cN-b9GnWtHzQRoE7M7gAEyivY0kl4BYs/view
StarCoder:
https://huggingface.co/bigcode/starcoder
StarCoderBaseを35Bのpython tokenでfinetuningしたモデル。
既存モデルよりも高性能と主張
[Paper Note] Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL’16
Paper/Blog Link My Issue
#Article #DocumentSummarization #NeuralNetwork #NLP #ACL #KeyPoint Notes Issue Date: 2021-06-03 Comment
[Paper Note] Pointing the Unknown Words, Gulcehre+, ACL’16
と同様コピーメカニズムを提案した論文。Joint Copy ModelやCOPYNETと呼ばれる。
次の単語が "生成" されるのか "コピー" されるのかをスコアリングし、各単語がコピーされる確率と生成される確率をMixtureした同時確率分布で表現する( [Paper Note] Challenges in Data-to-Document Generation, Sam Wiseman+, EMNLP'17, 2017.07
等でも説明されている)。
コピーメカニズムを導入せるなら引用すべき。
## コピーメカニズム部分の説明(過去の管理人の論文紹介スライドより)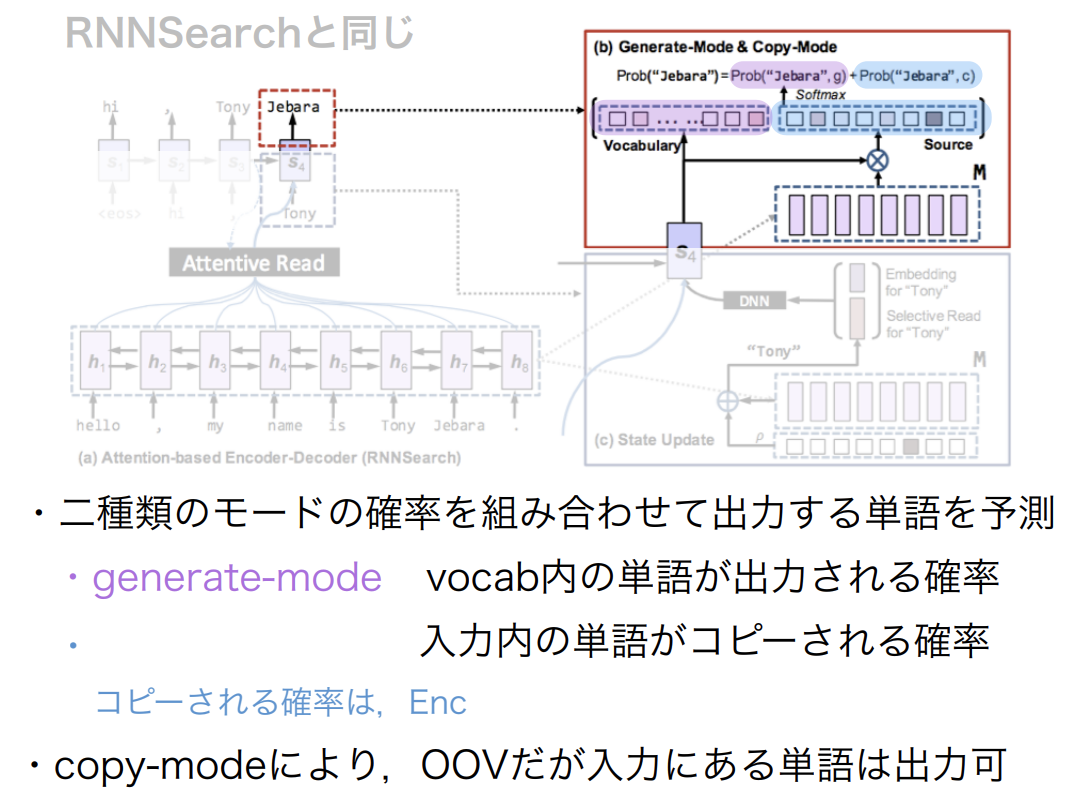

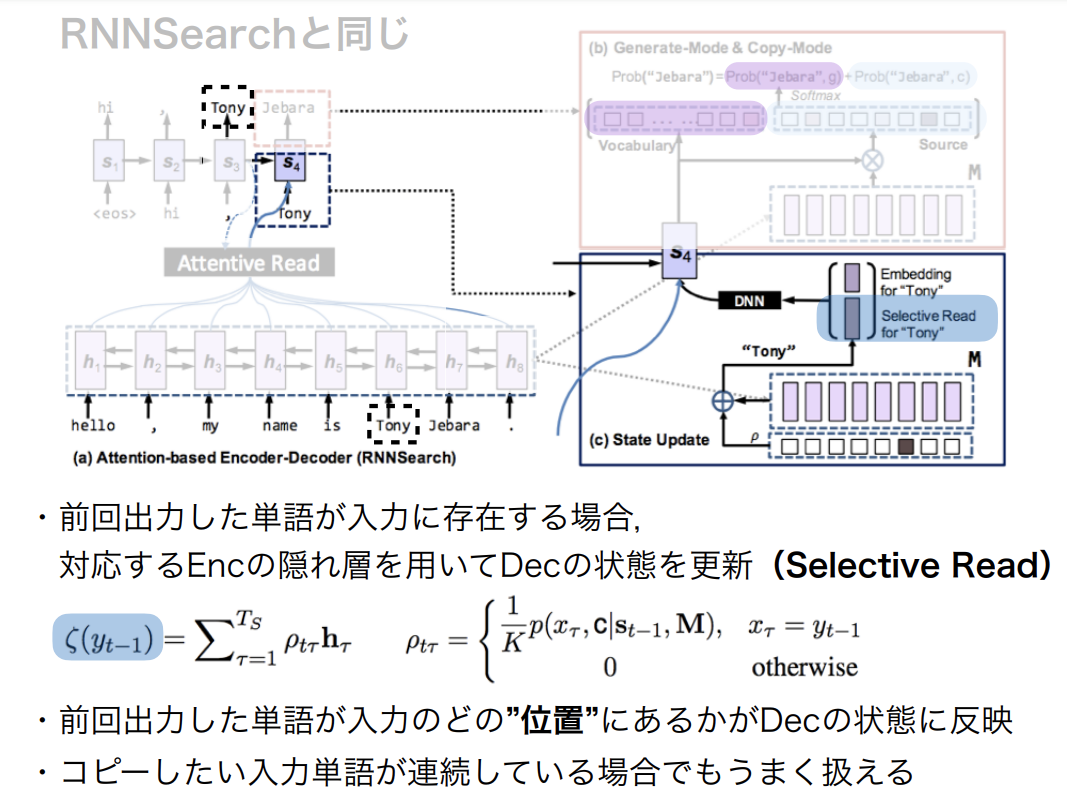
解説資料: http://www.lr.pi.titech.ac.jp/~sasano/acl2016suzukake/slides/08.pdf
[Paper Note] Pointing the Unknown Words, Gulcehre+, ACL’16
Paper/Blog Link My Issue
#Article #DocumentSummarization #NeuralNetwork #NLP #ACL #One-Line Notes Issue Date: 2021-06-02 Comment
Conditional Copy Model (Pointer Softmax)を提案した論文。
単語を生成する際に、語彙内の単語から生成する分布、原文の単語から生成する分布を求める。後者はattention distributionから。コピーするか否かを決める確率変数を導入し(sigmoid)、両生成確率を重み付けする。
コピーメカニズム入れるなら引用すべき。
解説スライド: https://www.slideshare.net/hytae/pointing-the-unknown-words
[Paper Note] Automatically generated linguistic summaries of energy consumption data, van der Heide+, In Proceedings of the Ninth International Conference on Intelligent Systems Design and Applications, pages 553-559, 2009.11
Paper/Blog Link My Issue
#Article #Others #NLP #DataToTextGeneration Issue Date: 2017-12-31
[Paper Note] A framework for automatic text generation of trends in physiological time series data, Banaee+, In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, 2013.10
Paper/Blog Link My Issue
#Article #Others #NLP #DataToTextGeneration Issue Date: 2017-12-31
[Paper Note] A Global Model for Concept-to-Text Generation, Konstas+, Journal of Artificial Intelligence Research, Vol. 48, pp.305--346, 2013.10
Paper/Blog Link My Issue
#Article #SingleFramework #NLP #ConceptToTextGeneration Issue Date: 2017-12-31
[Paper Note] What to talk about and how? Selective Generation using LSTMs with Coarse-to-Fine Alignment, Hongyuan Mei+, NAACL-HLT’16, 2015.09
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #DataToTextGeneration #NAACL #Encoder-Decoder #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- エンドツーエンドのドメイン非依存型ニューラルエンコーダー-アライナー-デコーダーモデルを提案。LSTMを用いてデータベースイベントをエンコードし、アライナーで重要なレコードを特定、デコーダーで自由形式の説明を生成。WeatherGovデータセットで最良の結果を達成し、k近傍ビームフィルターでさらに改善。RoboCupデータセットでも競争力のある結果を得た。 Comment
content-selectionとsurface realizationをencoder-decoder alignerを用いて同時に解いたという話。
普通のAttention basedなモデルにRefinerとPre-Selectorと呼ばれる機構を追加。通常のattentionにはattentionをかける際のaccuracyに問題があるが、data2textではきちんと参照すべきレコードを参照し生成するのが大事なので、RefinerとPre-Selectorでそれを改善する。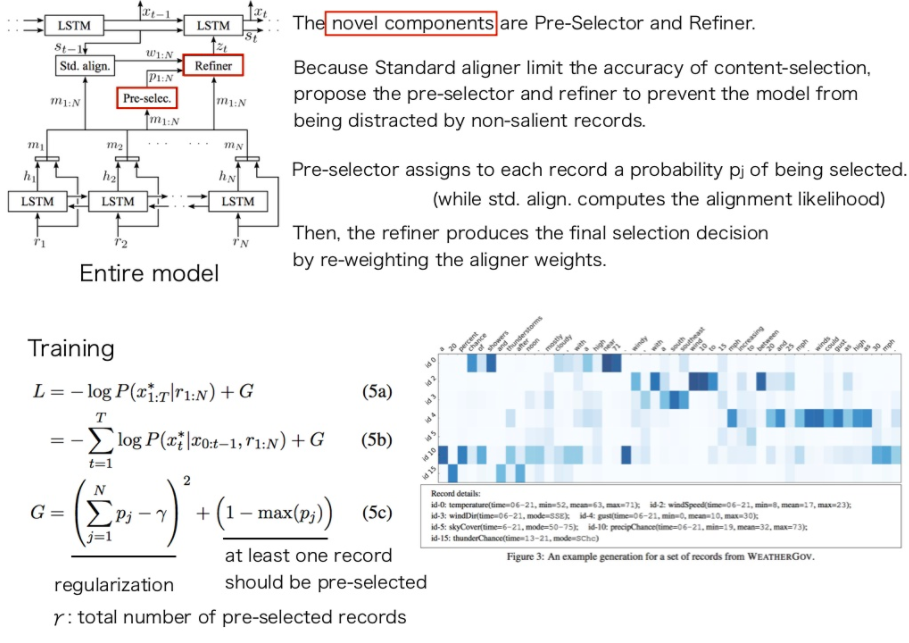
Pre-selectorは、それぞれのレコードが選択される確率を推定する(通常のattentionはalignmentの尤度を計算するのみ)。
Refinerはaligner(attention)のweightをreweightingすることで、最終的にどのレコードを選択するか決定する。
加えて、ロス関数のRegularizationのかけかたを変え、最低一つのレコードがpreselectorに選ばれるようにバイアスをかけている。
ほぼ初期のNeural Network basedなData2Text研究