
Test-Time Scaling
Issue Date: 2025-11-22 [Paper Note] SSR: Socratic Self-Refine for Large Language Model Reasoning, Haizhou Shi+, arXiv'25, 2025.11 GPT Summary- 新しいフレームワークSocratic Self-Refine(SSR)を提案し、LLMの推論を細かく評価・洗練する。SSRは応答をサブ質問・サブ回答に分解し、信頼度推定を行い、信頼性の低いステップを特定・改善することで、より正確な推論を実現。実験結果はSSRが最先端の手法を上回ることを示し、LLMの内部推論プロセスの理解を助ける。 Comment
元ポスト:
#Multi #Pocket #NLP #LanguageModel #read-later #Selected Papers/Blogs #RewardModel #Reranking #One-Line Notes #GenerativeVerifier
Issue Date: 2025-11-20 [Paper Note] Foundational Automatic Evaluators: Scaling Multi-Task Generative Evaluator Training for Reasoning-Centric Domains, Austin Xu+, arXiv'25, 2025.10 GPT Summary- 専門的な生成評価者のファインチューニングに関する研究で、250万サンプルのデータセットを用いて、シンプルな教師ありファインチューニング(SFT)アプローチでFARE(基盤自動推論評価者)をトレーニング。FARE-8Bは大規模なRLトレーニング評価者に挑戦し、FARE-20Bは新たなオープンソース評価者の標準を設定。FARE-20BはMATHでオラクルに近いパフォーマンスを達成し、下流RLトレーニングモデルの性能を最大14.1%向上。FARE-Codeはgpt-oss-20Bを65%上回る品質評価を実現。 Comment
HF: https://huggingface.co/collections/Salesforce/fare
元ポスト:
これは素晴らしい。使い道がたくさんありそうだし、RLに利用したときに特定のデータに対して特化したモデルよりも優れた性能を発揮するというのは驚き。
#Multi #Pocket #NLP #LanguageModel #AIAgents #Reasoning #One-Line Notes #LongHorizon
Issue Date: 2025-11-20 [Paper Note] Solving a Million-Step LLM Task with Zero Errors, Elliot Meyerson+, arXiv'25, 2025.11 GPT Summary- LLMの限界を克服するために、MAKERというシステムを提案。これは、100万以上のステップをゼロエラーで解決可能で、タスクを細分化し、マイクロエージェントが各サブタスクに取り組むことでエラー修正を行う。これにより、スケーリングが実現し、組織や社会の問題解決に寄与する可能性を示唆。 Comment
元ポスト:
しっかりと読めていないのだが、各タスクを単一のモデルのreasoningに頼るのではなく、
- 極端に小さなサブタスクに分解
- かつ、各サブタスクに対して複数のエージェントを走らせてvotingする
といったtest-time scalingっぽい枠組みに落とすことによってlong-horizonのタスクも解決することが可能、というコンセプトに見える。
元ポスト:
元ポスト:
pj page: https://zhouz.dev/RPC/
#Pocket #NLP #LanguageModel #Coding #LLM-as-a-Judge #One-Line Notes #Scalability Issue Date: 2025-10-19 [Paper Note] Scaling Test-Time Compute to Achieve IOI Gold Medal with Open-Weight Models, Mehrzad Samadi+, arXiv'25, 2025.10 GPT Summary- 競技プログラミングはLLMsの能力を評価する重要なベンチマークであり、IOIはその中でも特に権威ある大会です。本論文では、オープンウェイトモデルがIOI金メダルレベルのパフォーマンスを達成するためのフレームワーク「GenCluster」を提案します。このフレームワークは、生成、行動クラスタリング、ランキング、ラウンドロビン戦略を組み合わせて多様な解決空間を効率的に探索します。実験により、GenClusterは計算リソースに応じてスケールし、オープンシステムとクローズドシステムのギャップを縮小することが示され、IOI 2025で金メダルを達成する可能性を示唆しています。 Comment
元ポスト:
OpenWeight modelで初めてIOI金メダル級のパフォーマンスを実現できるフレームワークで、まずLLMに5000個程度の潜在的なsolutionを生成させ、それぞれのsolutionを100種のtest-caseで走らせて、その後solutionをbehaviorに応じてクラスタリングする。これによりアプローチのユニークさにそってクラスタが形成される。最終的に最も良いsolutionを見つけるために、それぞれのクラスタから最も良いsolutionを互いに対決させて、LLM-as-a-Judgeで勝者をランク付けするような仕組みのようである。https://github.com/user-attachments/assets/899026dd-38a9-4a1d-a871-2a37bcfeb623"
/>
#Pocket #NLP #LanguageModel #Verification #Robotics #VisionLanguageActionModel Issue Date: 2025-10-17 [Paper Note] RoboMonkey: Scaling Test-Time Sampling and Verification for Vision-Language-Action Models, Jacky Kwok+, arXiv'25, 2025.06 GPT Summary- VLAモデルの堅牢性を向上させるため、テスト時スケーリングを調査し、RoboMonkeyフレームワークを導入。小さなアクションセットをサンプリングし、VLMを用いて最適なアクションを選択。合成データ生成により検証精度が向上し、分布外タスクで25%、分布内タスクで9%の改善を達成。新しいロボットセットアップへの適応時には、VLAとアクション検証器の両方をファインチューニングすることで7%の性能向上を示した。 Comment
元ポスト:
#Analysis #EfficiencyImprovement #Pocket #NLP #LanguageModel #ReinforcementLearning #PostTraining #Diversity Issue Date: 2025-10-16 [Paper Note] Representation-Based Exploration for Language Models: From Test-Time to Post-Training, Jens Tuyls+, arXiv'25, 2025.10 GPT Summary- 強化学習(RL)が言語モデルの行動発見に与える影響を調査。事前学習されたモデルの隠れ状態を基にした表現ベースのボーナスを用いることで、多様性とpass@k率が大幅に改善されることを発見。推論時における探索が効率を向上させ、ポストトレーニングにおいてもRLパイプラインとの統合により性能が向上。意図的な探索が新しい行動の発見に寄与する可能性を示唆。 Comment
元ポスト:
探索の多様性をあげてRLこ学習効率、test time scalingの効率を上げるという話
#Analysis #Pocket #NLP #LanguageModel #Quantization #Reasoning #One-Line Notes #MemoryOptimization Issue Date: 2025-10-15 [Paper Note] Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models, Junhyuck Kim+, arXiv'25, 2025.10 GPT Summary- 4ビット量子化はメモリ最適化に有効ですが、推論モデルには適用できないことを示す。体系的な実験により、モデルサイズとKVキャッシュの影響を発見。小規模モデルは重みを優先し、大規模モデルは生成にメモリを割り当てることで精度を向上。LLMのメモリ最適化はスケールに依存し、異なるアプローチが必要であることを示唆。 Comment
元ポスト:
Reasoning Modelにおいて、メモリのbudgetに制約がある状況下において、
- モデルサイズ
- 重みの精度
- test-time compute (serial & parallel)
- KV Cacheの圧縮
において、それらをどのように配分することでモデルのAcc.が最大化されるか?という話しな模様。
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Pruning #Decoding #Parallel Issue Date: 2025-10-12 [Paper Note] DeepPrune: Parallel Scaling without Inter-trace Redundancy, Shangqing Tu+, arXiv'25, 2025.10 GPT Summary- DeepPruneという新しいフレームワークを提案し、並列スケーリングの計算非効率を解決。80%以上の推論トレースが同一の回答を生成する問題に対処し、焦点損失とオーバーサンプリング技術を用いた判定モデルで同等性を予測。オンラインの貪欲クラスタリングで冗長な経路をプルーニングし、80%以上のトークン削減を達成しつつ、精度を維持。効率的な並列推論の新基準を確立。 Comment
pj page: https://deepprune.github.io
HF: https://huggingface.co/collections/THU-KEG/deepprune-68e5c1ea71f789a6719b2c1c
元ポスト:
#Embeddings #InformationRetrieval #Pocket #Transformer #SyntheticData #Reasoning #COLM #read-later #Selected Papers/Blogs #Encoder Issue Date: 2025-10-08 [Paper Note] ReasonIR: Training Retrievers for Reasoning Tasks, Rulin Shao+, COLM'25, 2025.04 GPT Summary- ReasonIR-8Bは、一般的な推論タスク向けに特別に訓練された初のリトリーバーであり、合成データ生成パイプラインを用いて挑戦的なクエリとハードネガティブを作成。これにより、BRIGHTベンチマークで新たな最先端成果を達成し、RAGタスクでも他のリトリーバーを上回る性能を示す。トレーニングレシピは一般的で、将来のLLMへの拡張が容易である。コード、データ、モデルはオープンソース化されている。 Comment
元ポスト:
Llama3.1-8Bをbidirectional encoderに変換してpost-trainingしている。
関連:
- [Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
#Pocket #NLP #Search #LanguageModel #Reasoning #Decoding #TreeSearch Issue Date: 2025-10-08 [Paper Note] MITS: Enhanced Tree Search Reasoning for LLMs via Pointwise Mutual Information, Jiaxi Li+, arXiv'25, 2025.10 GPT Summary- 相互情報量ツリー探索(MITS)を提案し、推論経路の評価と探索を効率化。PMIに基づくスコアリング関数を用い、計算コストを抑えつつ優れた推論性能を実現。エントロピーに基づく動的サンプリング戦略でリソースを最適配分し、重み付き投票方式で最終予測を行う。MITSは多様なベンチマークでベースラインを上回る結果を示した。 Comment
元ポスト:
#Pocket #NLP #LanguageModel #DiffusionModel #read-later #MajorityVoting Issue Date: 2025-10-07 [Paper Note] Test-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts, Jihoon Lee+, arXiv'25, 2025.10 GPT Summary- dLLMsは異なる生成順序に基づく専門的な挙動を学習するが、固定された推論スケジュールは性能を低下させる。HEXという新手法を導入し、異なるブロックスケジュールでのアンサンブルを行うことで、精度を大幅に向上させる。GSM8KやMATH、ARC-C、TruthfulQAなどのベンチマークで顕著な改善を示し、テスト時スケーリングの新たなパラダイムを確立した。 Comment
元ポスト:
これは気になる👀
著者ポスト:
#Pocket #NLP #ReinforcementLearning #AIAgents #ComputerUse #VisionLanguageModel Issue Date: 2025-10-05 [Paper Note] GTA1: GUI Test-time Scaling Agent, Yan Yang+, arXiv'25, 2025.07 GPT Summary- GTA1というGUIエージェントは、ユーザーの指示を分解し、視覚要素と相互作用しながらタスクを自律的に完了します。計画の選択と視覚ターゲットとの正確な相互作用という2つの課題に対処するため、テスト時スケーリングを用いて最適なアクション提案を選び、強化学習を通じて基づけを改善します。実験により、GTA1は基づけとタスク実行の両方で最先端の性能を示しました。 Comment
元ポスト:
#Pocket #NLP #LanguageModel #read-later Issue Date: 2025-10-05 [Paper Note] Generalized Parallel Scaling with Interdependent Generations, Harry Dong+, arXiv'25, 2025.10 GPT Summary- Bridgeを提案し、並列LLM推論で相互依存する応答を生成。これにより、平均精度が最大50%向上し、一貫性が増す。訓練後は任意の生成幅にスケール可能で、独立生成よりも優れたパフォーマンスを発揮。 Comment
元ポスト:
#Pocket #NLP #LanguageModel #Ensemble #read-later #Best-of-N Issue Date: 2025-09-26 [Paper Note] Best-of-$\infty$ -- Asymptotic Performance of Test-Time Compute, Junpei Komiyama+, arXiv'25, 2025.09 GPT Summary- 大規模言語モデル(LLMs)におけるBest-of-$N$を多数決に基づいて研究し、$N \to \infty$の限界(Best-of-$\infty$)を分析。無限のテスト時間を必要とする問題に対処するため、回答の一致に基づく適応生成スキームを提案し、推論時間を効率的に配分。さらに、複数のLLMの重み付きアンサンブルを拡張し、最適な重み付けを混合整数線形計画として定式化。実験によりアプローチの有効性を実証。 Comment
pj page: https://jkomiyama.github.io/bestofinfty/
元ポスト:
#Pocket #NLP #LanguageModel #ReinforcementLearning #read-later #Selected Papers/Blogs #Verification Issue Date: 2025-09-24 [Paper Note] Heimdall: test-time scaling on the generative verification, Wenlei Shi+, arXiv'25, 2025.04 GPT Summary- Heimdallは、長いChain-of-Thought推論における検証能力を向上させるためのLLMであり、数学問題の解決精度を62.5%から94.5%に引き上げ、さらに97.5%に達する。悲観的検証を導入することで、解決策の精度を54.2%から70.0%、強力なモデルを使用することで93.0%に向上させる。自動知識発見システムのプロトタイプも作成し、データの欠陥を特定する能力を示した。 #Analysis #Pocket #NLP #LanguageModel #SamplingParams #Best-of-N #MajorityVoting Issue Date: 2025-09-24 [Paper Note] Optimizing Temperature for Language Models with Multi-Sample Inference, Weihua Du+, ICML'25, 2025.02 GPT Summary- マルチサンプル集約戦略を用いて、LLMの最適な温度を自動的に特定する手法を提案。従来の方法に依存せず、モデルアーキテクチャやデータセットを考慮した温度の役割を分析。新たに提案するエントロピーに基づく指標は、固定温度のベースラインを上回る性能を示し、確率過程モデルを用いて温度とパフォーマンスの関係を解明。 Comment
openreview: https://openreview.net/forum?id=rmWpE3FrHW¬eId=h9GETXxWDB
#EfficiencyImprovement #Controllable #Pocket #NLP #Search #LanguageModel #Decoding Issue Date: 2025-08-30 [Paper Note] Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs, Ziyue Li+, arXiv'25 GPT Summary- 事前学習済みのLLMの層をモジュールとして操作し、各サンプルに最適なアーキテクチャを構築する手法を提案。モンテカルロ木探索を用いて、数学および常識推論のベンチマークで最適な層の連鎖(CoLa)を特定。CoLaは柔軟で動的なアーキテクチャを提供し、推論効率を改善する可能性を示唆。75%以上の正しい予測に対して短いCoLaを見つけ、60%以上の不正確な予測を正すことができることが明らかに。固定アーキテクチャの限界を克服する道を開く。 Comment
解説:
事前学習済み言語モデルのforward pathにおける各layerをbuilding blocksとみなして、入力に応じてスキップ、あるいは再帰的な利用をMCTSによって選択することで、test time時のモデルの深さや、モデルの凡化性能をタスクに対して適用させるような手法を提案している模様。モデルのパラメータの更新は不要。k, r ∈ {1,2,3,4} の範囲で、"k個のlayerをskip"、あるいはk個のlayerのブロックをr回再帰する、とすることで探索範囲を限定的にしtest時の過剰な計算を抑止している。また、MCTSにおけるsimulationの回数は200回。length penaltyを大きくすることでcompactなforward pathになるように調整、10%の確率でまだ探索していない子ノードをランダムに選択することで探索を促すようにしている。オリジナルと比較して実行時間がどの程度増えてしまうのか?に興味があったが、モデルの深さという観点で推論効率は考察されているように見えたが、実行時間という観点ではざっと見た感じ記載がないように見えた。https://github.com/user-attachments/assets/0a03cdc2-141b-40a1-a11e-9560187ff7b6"
/>
以下の広範なQA、幅広い難易度を持つ数学に関するデータで評価(Appendix Bに各データセットごとに500 sampleを利用と記載がある)をしたところ、大幅に性能が向上している模様。ただし、8B程度のサイズのモデルでしか実験はされていない。
- [Paper Note] Think you have Solved Question Answering? Try ARC, the AI2 Reasoning
Challenge, Peter Clark+, arXiv'18
- [Paper Note] DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving, Yuxuan Tong+, NeurIPS'24
https://github.com/user-attachments/assets/c6d88c0a-4ae0-41b7-8526-17d041692f49"
/>
関連:
- [Paper Note] Looped Transformers are Better at Learning Learning Algorithms, Liu Yang+, ICLR'24
- [Paper Note] Looped Transformers for Length Generalization, Ying Fan+, ICLR'25
- [Paper Note] Universal Transformers, Mostafa Dehghani+, ICLR'19
- [Paper Note] Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation, Sangmin Bae+, NeurIPS'25
#Pocket #NLP #LanguageModel #ReinforcementLearning #RLVR #Diversity Issue Date: 2025-08-26 [Paper Note] Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR, Xiao Liang+, arXiv'25 GPT Summary- RLVRはLLMの複雑な推論タスクにおいて重要だが、従来のトレーニングは生成の多様性を減少させる問題がある。本研究では、ポリシーの生成の多様性を分析し、トレーニング問題を更新することでエントロピー崩壊を軽減する方法を提案。オンライン自己対戦と変分問題合成(SvS)戦略を用いることで、ポリシーのエントロピーを維持し、Pass@kを大幅に改善。AIME24およびAIME25ベンチマークでそれぞれ18.3%および22.8%の向上を達成し、12の推論ベンチマークでSvSの堅牢性を示した。 Comment
pj page: https://mastervito.github.io/SvS.github.io/
元ポスト:
ポイント解説:
#Pocket #NLP #LanguageModel #ReinforcementLearning #GRPO #read-later #Selected Papers/Blogs #Non-VerifiableRewards #RewardModel Issue Date: 2025-07-22 [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25 GPT Summary- 強化学習を用いてLLMsの推論能力を向上させるため、報酬モデリング(RM)のスケーラビリティを探求。ポイントワイズ生成報酬モデリング(GRM)を採用し、自己原則批評調整(SPCT)を提案してパフォーマンスを向上。並列サンプリングとメタRMを導入し、スケーリング性能を改善。実験により、SPCTがGRMの質とスケーラビリティを向上させ、既存の手法を上回る結果を示した。DeepSeek-GRMは一部のタスクで課題があるが、今後の取り組みで解決可能と考えられている。モデルはオープンソースとして提供予定。 Comment
- inputに対する柔軟性と、
- 同じresponseに対して多様なRewardを算出でき (= inference time scalingを活用できる)、
- Verifiableな分野に特化していないGeneralなRewardモデルである
Inference-Time Scaling for Generalist Reward Modeling (GRM) を提案。https://github.com/user-attachments/assets/18b13e49-745c-4c22-8d29-8b9bbb7fe80c"
/>
Figure3に提案手法の学習の流れが図解されておりわかりやすい。
#Pocket #NLP #LanguageModel #NeurIPS Issue Date: 2025-07-01 [Paper Note] Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search, Yuichi Inoue+, NeurIPS'25 Spotlight GPT Summary- AB-MCTSを提案し、外部フィードバックを活用して繰り返しサンプリングを改善。探索木のノードで新しい応答を「広げる」か「深める」かを動的に決定。実験により、AB-MCTSが従来の手法を上回り、LLMsの応答の多様性と解決策の洗練を強調。 Comment
元ポスト:
著者ポスト:
- 戦えるAIエージェントの作り方, Takuya Akiba, SakanaAI, 2025.10
のスライド中に解説がある。
#Pocket #NLP #LanguageModel #QuestionAnswering #KnowledgeGraph #Factuality #Reasoning #PostTraining Issue Date: 2025-05-20 Scaling Reasoning can Improve Factuality in Large Language Models, Mike Zhang+, arXiv'25 GPT Summary- 本研究では、オープンドメインの質問応答における大規模言語モデル(LLM)の推論能力を検討し、推論の痕跡を抽出してファインチューニングを行った。知識グラフからの情報を導入し、168回の実験を通じて170万の推論を分析した結果、小型モデルが元のモデルよりも事実の正確性を顕著に改善し、計算リソースを追加することでさらに2-8%の向上が確認された。実験成果は公開され、さらなる研究に寄与する。 Comment
元ポスト:
#EfficiencyImprovement #Pocket #NLP #LanguageModel #ICLR #Decoding #Verification #SpeculativeDecoding Issue Date: 2025-05-13 Faster Cascades via Speculative Decoding, Harikrishna Narasimhan+, ICLR'25 GPT Summary- カスケードと推測デコーディングは、言語モデルの推論効率を向上させる手法であり、異なるメカニズムを持つ。カスケードは難しい入力に対して大きなモデルを遅延的に使用し、推測デコーディングは並行検証で大きなモデルを活用する。新たに提案する推測カスケーディング技術は、両者の利点を組み合わせ、最適な遅延ルールを特定する。実験結果は、提案手法がカスケードおよび推測デコーディングのベースラインよりも優れたコスト品質トレードオフを実現することを示した。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=vo9t20wsmd
#Survey #Pocket #NLP #LanguageModel Issue Date: 2025-04-02 What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models, Qiyuan Zhang+, arXiv'25 GPT Summary- テスト時スケーリング(TTS)が大規模言語モデル(LLMs)の問題解決能力を向上させることが示されているが、体系的な理解が不足している。これを解決するために、TTS研究の4つのコア次元に基づく統一的なフレームワークを提案し、手法や応用シナリオのレビューを行う。TTSの発展の軌跡を抽出し、実践的なガイドラインを提供するとともに、未解決の課題や将来の方向性についての洞察を示す。 Comment
元ポスト:
とてつもない量だ…網羅性がありそう。
What to Scaleがよくあるself
consistency(Parallel Scaling), STaR(Sequential Scailng), Tree of Thought(Hybrid Scaling), DeepSeek-R1, o1/3(Internal Scaling)といった分類で、How to ScaleがTuningとInferenceに分かれている。TuningはLong CoTをSFTする話や強化学習系の話(GRPOなど)で、InferenceにもSelf consistencyやらやらVerificationやら色々ありそう。良さそう。
#Pocket #NLP #LanguageModel #LLM-as-a-Judge Issue Date: 2025-03-27 Scaling Evaluation-time Compute with Reasoning Models as Process Evaluators, Seungone Kim+, arXiv'25 GPT Summary- LMの出力品質評価が難しくなっている中、計算を増やすことで評価能力が向上するかを検討。推論モデルを用いて応答全体と各ステップを評価し、推論トークンの生成が評価者のパフォーマンスを向上させることを確認。再ランク付けにより、評価時の計算増加がLMの問題解決能力を向上させることを示した。 Comment
元ポスト:
LLM-as-a-JudgeもlongCoT+self-consistencyで性能が改善するらしい。
#Pocket #NLP #LanguageModel #ICML #Verification Issue Date: 2025-03-18 Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification, Eric Zhao+, ICML'25 GPT Summary- サンプリングベースの探索は、複数の候補応答を生成し最良のものを選ぶ手法であり、自己検証によって正確性を確認します。本研究では、この探索のスケーリング傾向を分析し、シンプルな実装がGemini v1.5 Proの推論能力を向上させることを示しました。自己検証の精度向上は、より大きな応答プールからのサンプリングによるもので、応答間の比較が有益な信号を提供することや、異なる出力スタイルが文脈に応じて役立つことを明らかにしました。また、最前線のモデルは初期の検証能力が弱く、進捗を測るためのベンチマークを提案しました。 Comment
元ポスト:
ざっくりしか読めていないが、複数の解答をサンプリングして、self-verificationをさせて最も良かったものを選択するアプローチ。最もverificationスコアが高い解答を最終的に選択したいが、tieの場合もあるのでその場合は追加のpromptingでレスポンスを比較しより良いレスポンスを選択する。これらは並列して実行が可能で、探索とself-verificationを200個並列するとGemini 1.5 Proでo1-previewよりも高い性能を獲得できる模様。Self-consistencyと比較しても、gainが大きい。具体的なアルゴリズムはAlgorithm1を参照のこと。https://github.com/user-attachments/assets/a62625e1-5503-459c-91f3-b7018aba76a6"
/>
openreview: https://openreview.net/forum?id=wl3eI4wiE5
#Pocket #NLP #LanguageModel Issue Date: 2025-02-12 Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling, Runze Liu+, arXiv'25 GPT Summary- Test-Time Scaling (TTS)は、LLMsの性能向上に寄与する手法であり、ポリシーモデルやPRM、問題の難易度がTTSに与える影響を分析。実験により、最適なTTS戦略はこれらの要素に依存し、小型モデルが大型モデルを上回る可能性を示した。具体的には、1BのLLMが405BのLLMを超える結果を得た。これにより、TTSがLLMsの推論能力を向上させる有望なアプローチであることが示された。 #Pocket #NLP #LanguageModel #Architecture #NeurIPS #LatentReasoning Issue Date: 2025-02-10 [Paper Note] Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, Jonas Geiping+, NeurIPS'25 GPT Summary- 新しい言語モデルアーキテクチャを提案し、潜在空間での暗黙的推論によりテスト時の計算をスケールさせる。再帰ブロックを反復し、任意の深さに展開することで、従来のトークン生成モデルとは異なるアプローチを採用。特別なトレーニングデータを必要とせず、小さなコンテキストウィンドウで複雑な推論を捉える。3.5億パラメータのモデルをスケールアップし、推論ベンチマークでのパフォーマンスを劇的に改善。 #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #read-later #Selected Papers/Blogs Issue Date: 2025-02-07 s1: Simple test-time scaling, Niklas Muennighoff+, arXiv'25 GPT Summary- テスト時スケーリングを用いて言語モデルのパフォーマンスを向上させる新しいアプローチを提案。小規模データセットs1Kを作成し、モデルの思考プロセスを制御する予算強制を導入。これにより、モデルは不正確な推論を修正し、Qwen2.5-32B-Instructモデルがo1-previewを最大27%上回る結果を達成。さらに、介入なしでパフォーマンスを向上させることが可能となった。モデル、データ、コードはオープンソースで提供。 Comment
解説:
#Pocket #NLP #LanguageModel #Reasoning Issue Date: 2025-01-28 Evolving Deeper LLM Thinking, Kuang-Huei Lee+, arXiv'25 GPT Summary- Mind Evolutionという進化的探索戦略を提案し、言語モデルを用いて候補応答を生成・洗練する。これにより、推論問題の形式化を回避しつつ、推論コストを制御。自然言語計画タスクにおいて、他の戦略を大幅に上回り、TravelPlannerおよびNatural Planのベンチマークで98%以上の問題を解決。 Comment
#Pocket #NLP #LanguageModel #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-11-02 [Paper Note] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling, Bradley Brown+, arXiv'24, 2024.07 GPT Summary- 言語モデルの推論能力を向上させるために、候補解を繰り返しサンプリングする手法を提案。サンプル数の増加に伴い、問題解決のカバレッジが4桁のオーダーでスケールし、対数線形の関係が示唆される。自動検証可能な回答がある領域では、カバレッジの増加がパフォーマンス向上に直結。SWE-bench Liteでの実験では、サンプル数を増やすことで解決率が大幅に向上したが、自動検証器がない領域ではサンプル数が増えても効果が頭打ちになることが確認された。 Comment
Repeated Sampling。同じプロンプトで複数回LLMを呼び出し、なんらかのverifierを用いて最も良いものを選択するtest time scaling手法。https://github.com/user-attachments/assets/73db708f-7eb2-444e-9689-bbef1f12e22d"
/>
figure2にverifierを利用しない場合と利用した場合の差が示されている。高性能なverifierが利用された場合は、サンプル数の増加に大して性能がスケールしていき、single attemptでのstrong ModelやSoTAを上回る性能が得られることがわかる。https://github.com/user-attachments/assets/2edbe1b7-26fc-47f6-a54b-642832fbe1a8"
/>
Figure8を見るとself consistency型のverifierの限界が示されている。すなわち、サンプリングする中で正しい解法が頻出しないようなものである。図を見ると、赤いbarがmajority-votingでは正解できない問題のindexを示しており、それなりの割合で存在することがわかる。https://github.com/user-attachments/assets/d087621a-dfc0-47e7-9b4d-3efd1fa9016e"
/>
この辺の話は
- [Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Outstanding Paper
とも関連していると思われる。
verifierの具体的な構築方法としてどのようなものがあるかが気になる。あとで読む。
> However, these increasingly rare correct generations are only beneficial if verifiers can “find the needle in the haystack” and identify them from collections of mostly-incorrect samples. In math word problem settings, we find that two common methods for verification (majority voting and reward models) do not possess this ability. When solving MATH [26] problems with Llama-3-8B-Instruct, coverage increases from 82.9% with 100 samples to 98.44% with 10,000 samples. However, when using majority voting or reward models to select final answers, the biggest performance increase is only from 40.50% to 41.41% over the same sample range.
上に記述されている内容は、要はverifierの性能が重要で、典型的なmajority votingやreward mode4lsによるverification手法ではスケールしないケースがある。たとえば、以下のFigure7を見ると、典型的な
- majority voting
- reward model + best-of-N
- majority voting + reward model
などのtest-time scaling手法(verification手法)がサンプル数Kを増やしてもスケールしないことを示しており、一方Oracle Verifier(=数学の問題において正解が既知の場合に正解を出力したサンプルを採用する)での結果を見ると、性能がスケールしていくことがわかる。特にGSM8K, MATHデータセットにおいては、Reward Modelを利用するverification手法はmajority votingと比較してあまり良い性能が出ていないことがわかる。https://github.com/user-attachments/assets/bc9cbc89-d31d-4b46-b7b8-f620dc95ccd7"
/>
本研究は5つのデータで検証しているが利用されているverifierは
- MiniF2F-MATH, CodeContests, SWE-Bench:
- すでに自動的なverifierが提供されており、たとえばそれはLean4 proof checker、test case, unit test suitesなどである
- GSM8K, MATH:
- これらについてはOracle Verifier(=モデルの出力が問題の正答と一致したら採用する)を利用している
本手法のスケーリングはverifierの性能に依存するため、高性能なverificationが作成できないタスクに関して適用するのは難しいと考えられる。逆に良い感じなverifierが定義できるなら相当強力な手法に見える。
#EfficiencyImprovement #Pocket #NLP #LanguageModel Issue Date: 2024-11-12 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, Charlie Snell+, arXiv'24 GPT Summary- LLMの推論時の計算をスケーリングすることで、挑戦的なプロンプトに対するパフォーマンスを改善する方法を研究。特に、密なプロセスベースの検証者報酬モデルとプロンプトに応じた応答の適応的更新を分析。プロンプトの難易度によって効果が変化し、計算最適戦略を適用することで効率を4倍以上向上。さらに、テスト時計算を用いることで小さなモデルが大きなモデルを上回ることが示された。 Comment
[Perplexity(参考;Hallucinationに注意)]( https://www.perplexity.ai/search/yi-xia-noyan-jiu-wodu-mi-nei-r-1e1euXgLTH.G0Wlp.V2iqA)
#NeuralNetwork #Pocket #NLP #LanguageModel #Chain-of-Thought #ICLR #Selected Papers/Blogs Issue Date: 2023-04-27 [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03 GPT Summary- 自己一貫性という新しいデコーディング戦略を提案し、chain-of-thought promptingの性能を向上。多様な推論経路をサンプリングし、一貫した答えを選択することで、GSM8KやSVAMPなどのベンチマークで顕著な改善を達成。 Comment
self-consistencyと呼ばれる新たなCoTのデコーディング手法を提案。
これは、難しいreasoningが必要なタスクでは、複数のreasoningのパスが存在するというintuitionに基づいている。
self-consistencyではまず、普通にCoTを行う。そしてgreedyにdecodingする代わりに、以下のようなプロセスを実施する:
1. 多様なreasoning pathをLLMに生成させ、サンプリングする。
2. 異なるreasoning pathは異なるfinal answerを生成する(= final answer set)。
3. そして、最終的なanswerを見つけるために、reasoning pathをmarginalizeすることで、final answerのsetの中で最も一貫性のある回答を見出す。
これは、もし異なる考え方によって同じ回答が導き出されるのであれば、その最終的な回答は正しいという経験則に基づいている。
self-consistencyを実現するためには、複数のreasoning pathを取得した上で、最も多いanswer a_iを選択する(majority vote)。これにはtemperature samplingを用いる(temperatureを0.5やら0.7に設定して、より高い信頼性を保ちつつ、かつ多様なoutputを手に入れる)。
temperature samplingについては[こちら](
https://openreview.net/pdf?id=rygGQyrFvH)の論文を参照のこと。
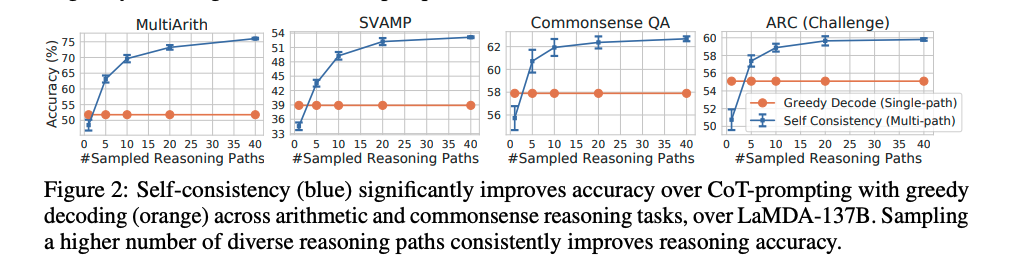
sampling数は増やせば増やすほど性能が向上するが、徐々にサチってくる。サンプリング数を増やすほどコストがかかるので、その辺はコスト感との兼ね合いになると思われる。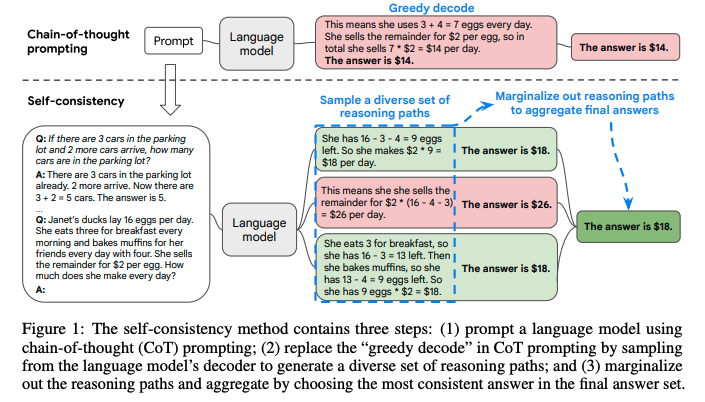
Self-consistencyは回答が閉じた集合であるような問題に対して適用可能であり、open-endなquestionでは利用できないことに注意が必要。ただし、open-endでも回答間になんらかの関係性を見出すような指標があれば実現可能とlimitationで言及している。
#Article #NLP #AIAgents #Blog #ScientificDiscovery #LongHorizon Issue Date: 2025-11-20 Previewing Locus, INTOLOGY, 2025.11 Comment
元ポスト:
所見:
#Article #Tutorial #AIAgents #Slide #One-Line Notes Issue Date: 2025-11-01 戦えるAIエージェントの作り方, Takuya Akiba, SakanaAI, 2025.10 Comment
元ポスト:
SakanaAIの研究を中心に、特に推論時スケーリング(test time scaling)の話が紹介されている。
#Article #NLP #ReinforcementLearning #Blog #Scaling Laws #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-21 How Well Does RL Scale?, Toby Ord, 2025.10 Comment
元ポスト:
OpenAIやAnthropicが公表している学習に関するplot(と筆者の様々なアカデミアの研究の知見)に基づいて、RLによるスケーリングは、事前学習やTest-time Scalingよりも計算量の観点で効率が悪い、ということを分析している模様。
> So the evidence on RL-scaling and inference-scaling supports a general pattern:
>- a 10x scaling of RL is required to get the same performance boost as a 3x scaling of inference
> - a 10,000x scaling of RL is required to get the same performance boost as a 100x scaling of inference
>
> In general, to get the same benefit from RL-scaling as from inference-scaling required twice as many orders of magnitude. That’s not good.
その上で、RLによるコストが事前学習のコストと同等かそれ以上となったときに、モデルの性能をスケールさせる場合のコストが爆発的に増加することを指摘している(初期のRLによるコストが小さければ事前学習やtest-time scalingのデータを増やすよりも効率がよいスケーリング手法となっていたが、RLのコストが大きくなってくるとスケールさせる際の金額の絶対値が大きくなりすぎるという話)。
#Article #NLP #LanguageModel #Reasoning #read-later #One-Line Notes #Test-time Learning Issue Date: 2025-10-21 Knowledge Flow: Scaling Reasoning Beyond the Context Limit, Zhuang+, 2025.10 Comment
元ポスト:
モデルのロールアウトの結果からattemptから知識リストをiterativeに更新(新たな知識を追加, 古い知識を削除 or 両方)していくことによって、過去のattemptからのinsightを蓄積し性能を改善するような新たなテストタイムスケーリングの枠組みな模様。sequential test-time scalingなどとは異なり、複数のattemptによって知識リストを更新することでスケールさせるので、context windowの制約を受けない、といった話な模様。LLM AgentにおけるTest-time learningとかなり類似したコンセプトに見える。https://github.com/user-attachments/assets/9a302c5e-ee79-4c17-99e3-0851b5f127c6"
/>
#Article #Pocket #NLP #LanguageModel #ReinforcementLearning #Selected Papers/Blogs #Aggregation-aware #KeyPoint Notes Issue Date: 2025-09-27 RECURSIVE SELF-AGGREGATION UNLOCKS DEEP THINKING IN LARGE LANGUAGE MODELS, Venkatraman+, preprint, 2025.09 Comment
N個の応答を生成し、各応答K個組み合わせてpromptingで集約し新たな応答を生成することで洗練させる、といったことをT回繰り返すtest-time scaling手法で、RLによってモデルの集約能力を強化するとより良いスケーリングを発揮する。RLでは通常の目的関数(prompt x, answer y; xから単一のreasoning traceを生成しyを回答する設定)に加えて、aggregation promptを用いた目的関数(aggregation promptを用いて K個のsolution集合 S_0を生成し、目的関数をaggregation prompt x, S_0の双方で条件づけたもの)を定義し、同時に最適化をしている(同時に最適化することは5.4節に記述されている)。つまり、これまでのRLはxがgivenな時に頑張って単一の良い感じのreasoning traceを生成しyを生成するように学習していたが(すなわち、モデルが複数のsolutionを集約することは明示的に学習されていない)、それに加えてモデルのaggregationの能力も同時に強化する、という気持ちになっている。学習のアルゴリズムはPPO, GRPOなど様々なon-poloicyな手法を用いることができる。今回はRLOOと呼ばれる手法を用いている。https://github.com/user-attachments/assets/e83406ae-91a0-414b-a49c-892a4d1f23fd"
/>
様々なsequential scaling, parallel scaling手法と比較して、RSAがより大きなgainを得ていることが分かる。ただし、Knowledge RecallというタスクにおいてはSelf-Consistency (Majority Voting)よりもgainが小さい。https://github.com/user-attachments/assets/8251f25b-472d-48d4-b7df-a6946cfbbcd9"
/>
以下がaggregation-awareなRLを実施した場合と、通常のRL, promptingのみによる場合の性能の表している。全体を通じてaggregation-awareなRLを実施することでより高い性能を発揮しているように見える。ただし、AIMEに関してだけは通常のpromptingによるRSAの性能が良い。なぜだろうか?考察まで深く読めていないので論文中に考察があるかもしれない。https://github.com/user-attachments/assets/146ab6a3-58c2-4a7f-aa84-978a5180c8f3"
/>
元ポスト:
concurrent work:
- [Paper Note] The Majority is not always right: RL training for solution aggregation, Wenting Zhao+, arXiv'25
#Article #Tutorial #NLP #LanguageModel #Blog #Reasoning Issue Date: 2025-03-09 The State of LLM Reasoning Models, Sebastian Raschka, 2025.03 #Article #Pocket #LanguageModel #Blog Issue Date: 2024-12-17 Scaling test-time-compute, Huggingface, 2024.12 Comment
これは必読
#Article #NLP #LanguageModel #Chain-of-Thought #Reasoning #KeyPoint Notes Issue Date: 2024-09-13 OpenAI o1, 2024.09 Comment
Jason Wei氏のポスト:
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
や
- Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, N/A, arXiv'23
で似たような考えはすでに提案されていたが、どのような点が異なるのだろうか?
たとえば前者は、pauseトークンと呼ばれるoutputとは関係ないトークンを生成することで、outputを生成する前にモデル内部で推論する前により多くのベクトル操作を加える(=ベクトルを縦方向と横方向に混ぜ合わせる; 以後ベクトルをこねくりまわすと呼称する)、といった挙動を実現しているようだが、明示的にCoTの教師データを使ってSFTなどをしているわけではなさそうに見える(ざっくりとしか読んでないが)。
一方、Jason Wei氏のポストからは、RLで明示的により良いCoTができるように学習をしている点が違うように見える。
**(2025.0929): 以下のtest-time computeに関するメモはo1が出た当初のものであり、私の理解が甘い状態でのメモなので現在の理解を後ほど追記します。当時のメモは改めて見返すとこんなこと考えてたんだなぁとおもしろかったので残しておきます。**
学習の計算量だけでなく、inferenceの計算量に対しても、新たなスケーリング則が見出されている模様。
テクニカルレポート中で言われている time spent thinking (test-time compute)というのは、具体的には何なのだろうか。
上の研究でいうところの、inference時のpauseトークンの生成のようなものだろうか。モデルがベクトルをこねくり回す回数(あるいは生成するトークン数)が増えると性能も良くなるのか?
しかしそれはオリジナルのCoT研究である
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
のdotのみの文字列をpromptに追加して性能が向上しなかった、という知見と反する。
おそらく、**モデル学習のデコーディング時に**、ベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすこと=time spent thinking (test-time compute) 、ということなのだろうか?
そしてそのように学習されたモデルは、推論時にベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすと性能が上がる、ということなのだろうか。
もしそうだとすると、これは
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
のpauseトークンの生成をしながらfinetuningすると性能が向上する、という主張とも合致するように思うが、うーん。
実際暗号解読のexampleを見ると、とてつもなく長いCoT(トークンの生成数が多い)が行われている。
RLでReasoningを学習させる関連研究:
- ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N/A, ACL'24
- Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N/A, ICML'24
以下o1の動きに関して考えている下記noteからの引用。
>これによって、LLMはモデルサイズやデータ量をスケールさせる時代から推論時間をスケールさせる(つまり、沢山の推論ステップを探索する)時代に移っていきそうです。
なるほど。test-compute timeとは、推論ステップ数とその探索に要する時間という見方もあるのですね。
またnote中では、CoTの性能向上のために、Process Reward Model(PRM)を学習させ、LLMが生成した推論ステップを評価できるようにし、PRMを報酬モデルとし強化学習したモデルがo1なのではないか、と推測している。
PRMを提案した研究では、推論ステップごとに0,1の正誤ラベルが付与されたデータから学習しているとのこと。
なるほど、勉強になります。
note:
https://note.com/hatti8/n/nf4f3ce63d4bc?sub_rt=share_pb
note(詳細編): https://note.com/hatti8/n/n867c36ffda45?sub_rt=share_pb
こちらのリポジトリに関連論文やXポスト、公式ブログなどがまとめられている:
https://github.com/hijkzzz/Awesome-LLM-Strawberry
これはすごい。論文全部読みたい