
Workshop
[Paper Note] MK2 at PBIG Competition: A Prompt Generation Solution, Xu+, IJCAI WS AgentScen'25, 2025.08
Paper/Blog Link My Issue
#NLP #AIAgents #Planning #Prompting #Reasoning #IJCAI #IdeaGeneration Issue Date: 2025-08-30 Comment
元ポスト:
Patentからmarket-readyなプロダクトのコンセプトを生成し評価するタスク(PBIG)に取り組んでいる。
Reasoningモデルはコストとレスポンスの遅さから利用せず(iterationを重ねることを重視)、LLMのアシストを受けながらpromptを何度もhuman in the loopでiterationしながら品質を高めていくアプローチをとり、リーダーボードで1st placeを獲得した模様。
[Paper Note] Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #ICML #One-Line Notes #Author Thread-Post Issue Date: 2025-05-27 GPT Summary- 本研究では、外部の報酬やラベルなしで大規模言語モデル(LLMs)が学習できるフレームワーク「内部フィードバックからの強化学習(RLIF)」を提案。自己確信を報酬信号として用いる「Intuitor」を開発し、無監視の学習を実現。実験結果は、Intuitorが数学的ベンチマークで優れた性能を示し、ドメイン外タスクへの一般化能力も高いことを示した。内因的信号が効果的な学習を促進する可能性を示唆し、自律AIシステムにおけるスケーラブルな代替手段を提供。 Comment
元ポスト:
おもしろそう
externalなsignalをrewardとして用いないで、モデル自身が内部的に保持しているconfidenceを用いる。人間は自信がある問題には正解しやすいという直感に基づいており、openendなquestionのようにそもそも正解シグナルが定義できないものもあるが、そういった場合に活用できるようである。
self-trainingの考え方に近いのでは
ベースモデルの段階である程度能力が備わっており、post-trainingした結果それが引き出されるようになったという感じなのだろうか。
参考:
解説スライド:
https://www.docswell.com/s/DeepLearning2023/KYVLG4-2025-09-18-112951
元ポスト:
[Paper Note] Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, Eval4NLP'25, 2024.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #ACL #Decoding #Selected Papers/Blogs #Non-Determinism #In-Depth Notes #KeyPoint Notes Issue Date: 2025-04-14 GPT Summary- 本研究では、5つの決定論的LLMにおける非決定性を8つのタスクで調査し、最大15%の精度変動と70%のパフォーマンスギャップを観察。全てのタスクで一貫した精度を提供できないことが明らかになり、非決定性が計算リソースの効率的使用に寄与している可能性が示唆された。出力の合意率を示す新たなメトリクスTARr@NとTARa@Nを導入し、研究結果を定量化。コードとデータは公開されている。 Comment
- 論文中で利用されているベンチマーク:
- [Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
- [Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
同じモデルに対して、seedを固定し、temperatureを0に設定し、同じ計算機環境に対して、同じinputを入力したら理論上はLLMの出力はdeterministicになるはずだが、deterministicにならず、ベンチマーク上の性能とそもそものraw response自体も試行ごとに大きく変化する、という話。
ただし、これはプロプライエタリLLMや、何らかのinferenceの高速化を実施したInferenceEngine(本研究ではTogetherと呼ばれる実装を使っていそう。vLLM/SGLangだとどうなるのかが気になる)を用いてinferenceを実施した場合での実験結果であり、後述の通り計算の高速化のためのさまざまな実装無しで、deterministicな設定でOpenLLMでinferenceすると出力はdeterministicになる、という点には注意。
GPTやLlama、Mixtralに対して上記ベンチマークを用いてzero-shot/few-shotの設定で実験している。Reasoningモデルは実験に含まれていない。
LLMのraw_response/multiple choiceのparse結果(i.e., 問題に対する解答部分を抽出した結果)の一致(TARr@N, TARa@N; Nはinferenceの試行回数)も理論上は100%になるはずなのに、ならないことが報告されている。
correlation analysisによって、応答の長さ と TAR{r, a}が強い負の相関を示しており、応答が長くなればなるほど不安定さは増すことが分析されている。このため、ontput tokenの最大値を制限することで出力の安定性が増すことを考察している。また、few-shotにおいて高いAcc.の場合は出力がdeterministicになるわけではないが、性能が安定する傾向とのこと。また、OpenAIプラットフォーム上でGPTのfinetuningを実施し実験したが、安定性に寄与はしたが、こちらもdeterministicになるわけではないとのこと。
deterministicにならない原因として、まずmulti gpu環境について検討しているが、multi-gpu環境ではある程度のランダム性が生じることがNvidiaの研究によって報告されているが、これはseedを固定すれば決定論的にできるため問題にならないとのこと。
続いて、inferenceを高速化するための実装上の工夫(e.g., Chunk Prefilling, Prefix Caching, Continuous Batching)などの実装がdeterministicなハイパーパラメータでもdeterministicにならない原因であると考察しており、**実際にlocalマシン上でこれらinferenceを高速化するための最適化を何も実施しない状態でLlama-8Bでinferenceを実施したところ、outputはdeterministicになったとのこと。**
論文中に記載がなかったため、どのようなInferenceEngineを利用したか公開されているgithubを見ると下記が利用されていた:
- Together:
https://github.com/togethercomputer/together-python?tab=readme-ov-file
Togetherが内部的にどのような処理をしているかまでは追えていないのだが、異なるInferenceEngineを利用した場合に、どの程度outputの不安定さに差が出るのか(あるいは出ないのか)は気になる。たとえば、transformers/vLLM/SGLangを利用した場合などである。
論文中でも報告されている通り、昔管理人がtransformersを用いて、deterministicな設定でzephyrを用いてinferenceをしたときは、出力はdeterministicになっていたと記憶している(スループットは絶望的だったが...)。
あと個人的には現実的な速度でオフラインでinference engineを利用した時にdeterministicにはせめてなって欲しいなあという気はするので、何が原因なのかを実装レベルで突き詰めてくれるととても嬉しい(KV Cacheが怪しい気がするけど)。
たとえば最近SLMだったらKVCacheしてVRAM食うより計算し直した方が効率良いよ、みたいな研究があったような。そういうことをしたらlocal llmでdeterministicにならないのだろうか。
- Defeating Nondeterminism in LLM Inference, Horace He in collaboration with others at Thinking Machines, 2025.09
においてvLLMを用いた場合にDeterministicな推論をするための解決方法が提案されている。
Byte Latent Transformer: Patches Scale Better Than Tokens, Artidoro Pagnoni+, ICML'25 Workshop Tokshop
Paper/Blog Link My Issue
#NLP #LanguageModel #ICML #Tokenizer #KeyPoint Notes #Byte-level Issue Date: 2025-01-02 GPT Summary- Byte Latent Transformer(BLT)は、バイトレベルのLLMアーキテクチャで、トークン化ベースのLLMと同等のパフォーマンスを実現し、推論効率と堅牢性を大幅に向上させる。BLTはバイトを動的にサイズ変更可能なパッチにエンコードし、データの複雑性に応じて計算リソースを調整する。最大8Bパラメータと4Tトレーニングバイトのモデルでの研究により、固定語彙なしでのスケーリングの可能性が示された。長いパッチの動的選択により、トレーニングと推論の効率が向上し、全体的にBLTはトークン化モデルよりも優れたスケーリングを示す。 Comment
興味深い
図しか見れていないが、バイト列をエンコード/デコードするtransformer学習して複数のバイト列をパッチ化(エントロピーが大きい部分はより大きなパッチにバイト列をひとまとめにする)、パッチからのバイト列生成を可能にし、パッチを変換するのをLatent Transformerで学習させるようなアーキテクチャのように見える。
また、予算によってモデルサイズが決まってしまうが、パッチサイズを大きくすることで同じ予算でモデルサイズも大きくできるのがBLTの利点とのこと。
日本語解説: https://bilzard.github.io/blog/2025/01/01/byte-latent-transformer.html?v=2
OpenReview: https://openreview.net/forum?id=UZ3J8XeRLw
[Paper Note] DiLoCo: Distributed Low-Communication Training of Language Models, Arthur Douillard+, ICML'24 Workshop WANT
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #ICML #mid-training #Selected Papers/Blogs #One-Line Notes #needs-revision #DistributedLearning Issue Date: 2025-07-15 GPT Summary- 分散最適化アルゴリズム「DiLoCo」を提案し、接続が不十分なデバイスでのLLMトレーニングを可能にする。DiLoCoは、通信量を500分の1に抑えつつ、完全同期の最適化と同等の性能をC4データセットで発揮。各ワーカーのデータ分布に対して高いロバスト性を持ち、リソースの変動にも柔軟に対応可能。 Comment
言語モデルの分散学習における通信量をいかに抑えるかにフォーカスした研究で、クライアントごとに異なるデータsplitを持ち、当該データによってモデルをローカルでAdamWを用いてH step更新。その後、更新された重みの差分をouter gradientとして共有し、重み更新の差分を平均化することでローカルモデルを集約するという処理を繰り返す。
Engaging an LLM to Explain Worked Examples for Java Programming: Prompt Engineering and a Feasibility Study, Hassany+, EDM'24 Workshop, 2024.07
Paper/Blog Link My Issue
#LanguageModel #EducationalDataMining Issue Date: 2025-01-06 Comment
元ポスト:
[Paper Note] Generative Verifiers: Reward Modeling as Next-Token Prediction, Lunjun Zhang+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfCorrection #NeurIPS #Selected Papers/Blogs #Verification #RewardModel #KeyPoint Notes #GenerativeVerifier Issue Date: 2024-09-11 GPT Summary- 検証モデルはLLMの推論性能を向上させるためによく使われ、従来のBest-of-N法に依存していますが、新たに提案された生成的検証モデル(GenRM)は、解の生成と検証を統合することで、LLMの利点を活かすことができます。GenRMは通常の識別的モデルと比較して優れた性能を発揮し、アルゴリズム課題や数学問題で大幅な改善を見せています。具体的には、GSM8Kで73%から93.4%への向上など、多様なタスクで性能を向上させ、モデルサイズと計算の増加にもしっかり対応します。 Comment
LLMがリクエストに対する回答を生成したのちに、その回答をverifyするステップ + verifyの結果から回答を修正するステップを全てconcatした学習データをnext token predictionで用いることによって、モデル自身に自分の回答をverifyする能力を身につけさせることができた結果性能が向上しました、という研究らしい。また、Self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
のように複数の異なるCoTを並列して実行させ、そのmajority votingをとることでさらに性能が向上する。
openreview: https://openreview.net/forum?id=CxHRoTLmPX
Socratic Questioning of Novice Debuggers: A Benchmark Dataset and Preliminary Evaluations, ACL-BEA'23
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Coding #ACL Issue Date: 2023-07-18 GPT Summary- 本研究では、初心者プログラマがバグのある計算問題を解決する際に、ソクラテス的な対話を行うデータセットを紹介し、GPTベースの言語モデルのデバッグ能力を評価しました。GPT-4はGPT-3.5よりも優れたパフォーマンスを示しましたが、まだ人間の専門家には及ばず、さらなる研究が必要です。
[Paper Note] Explaining black box text modules in natural language with language models, Chandan Singh+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #NeurIPS #Interpretability #needs-revision Issue Date: 2023-05-20 GPT Summary- 大規模言語モデル(LLMs)の解釈性の必要性に応えるため、テキストモジュールの入力と出力に基づいて自然言語の説明を自動生成する手法、Summarize and Score(SASC)を提案。合成モジュールへの適用で真の説明を回復し、BERTモデル内のモジュールを検査可能にし、言語刺激へのfMRI応答の説明まで可能。すべてのコードはGitHubに公開。 Comment
モデルのinterpretabilityに関するMSの新たな研究
Universal Evasion Attacks on Summarization Scoring, Wenchuan Mu+, N_A, BlackboxNLP workshop on ACL'22
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Evaluation #ACL Issue Date: 2023-08-13 GPT Summary- 要約の自動評価は重要であり、その評価は複雑です。しかし、これまで要約の評価は機械学習のタスクとは考えられていませんでした。本研究では、自動評価の堅牢性を探るために回避攻撃を行いました。攻撃システムは、要約ではない文字列を予測し、一般的な評価指標であるROUGEやMETEORにおいて優れた要約器と競合するスコアを達成しました。また、攻撃システムは最先端の要約手法を上回るスコアを獲得しました。この研究は、現在の評価システムの堅牢性の低さを示しており、要約スコアの開発を促進することを目指しています。
[Paper Note] Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets, Alethea Power+, ICLR'21 Workshop, 2022.01
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Grokking #ICLR #One-Line Notes Issue Date: 2023-04-25 GPT Summary- 小規模データセットにおけるニューラルネットワークの一般化を探求。データ効率、記憶、一般化、学習速度に関する問題を分析し、学習過程の「グロッキング」を通じて一般化性能の改善を示す。特に、小さなデータセットではより多くの最適化が必要であることが明らかにされ、過剰パラメータ化されたネットワークの一般化メカニズムを理解するための重要な知見を提供。 Comment
学習後すぐに学習データをmemorizeして、汎化能力が無くなったと思いきや、10^3ステップ後に突然汎化するという現象(Grokking)を報告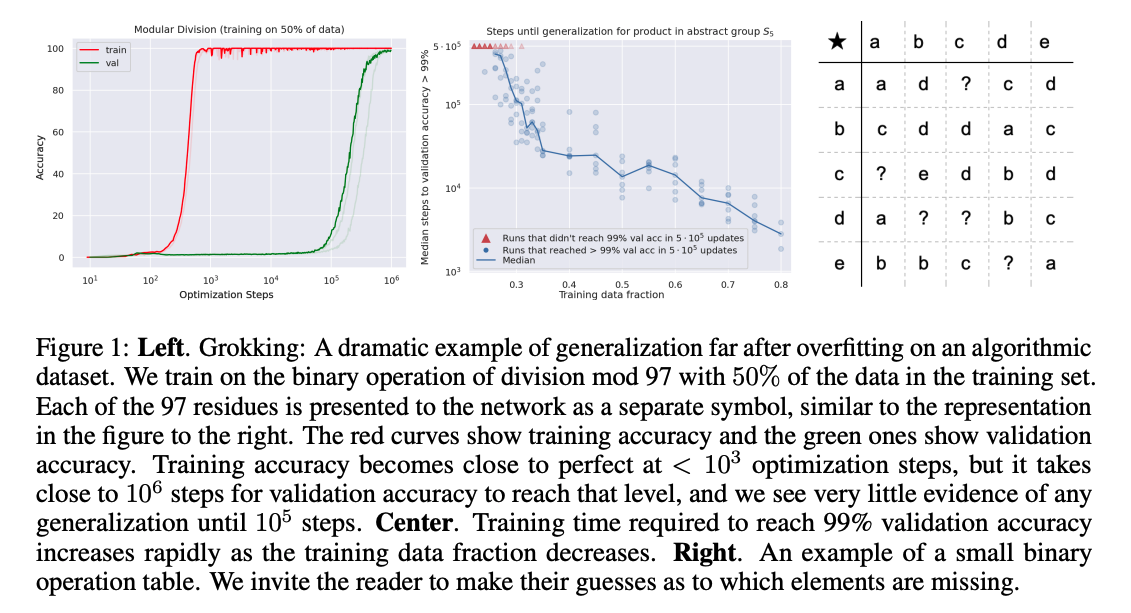
学習データが小さければ小さいほど汎化能力を獲得するのに時間がかかる模様
Do we need to go Deep? Knowledge Tracing with Big Data, Varun+, University of Maryland Baltimore County, AAAI'21 Workshop on AI Education
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #AAAI #One-Line Notes Issue Date: 2022-04-28 GPT Summary- インタラクティブ教育システム(IES)を用いて学生の知識を追跡し、パフォーマンスモデルを開発する研究が進展。深層学習モデルが従来のモデルを上回るかは未検証であり、EdNetデータセットを用いてその精度を比較。結果、ロジスティック回帰モデルが深層モデルを上回ることが確認され、LIMEを用いて予測に対する特徴の影響を解釈する研究を行った。 Comment
データ量が小さいとSAKTはDKTはcomparableだが、データ量が大きくなるとSAKTがDKTを上回る。
[Paper Note] Automatic Generation of Personalized Comment Based on User Profile, Wenhuan Zeng+, ACL'19 SRW
Paper/Blog Link My Issue
#NLP #CommentGeneration #Personalization #ACL Issue Date: 2019-09-11 GPT Summary- ソーシャルメディアの多様なコメント生成の難しさを考慮し、ユーザーのプロフィールに基づくパーソナライズされたコメント生成タスク(AGPC)を提案。パーソナライズドコメント生成ネットワーク(PCGN)を用いて、ユーザーの特徴をモデル化し、外部ユーザー表現を考慮することで自然で人間らしいコメントを生成することに成功した。
[Paper Note] Automatic Generation of Personalized Comment Based on User Profile, Wenhuan Zeng+, ACL'19 SRW
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #ACL Issue Date: 2019-08-17 GPT Summary- ソーシャルメディアの多様なコメント生成の難しさを考慮し、ユーザープロフィールに基づくパーソナライズされたコメント生成タスク(AGPC)を提案。パーソナライズドコメント生成ネットワーク(PCGN)を用いて、ユーザーの特徴をモデル化し、外部ユーザー表現を考慮することで自然なコメントを生成。実験結果は、モデルの効果を示す。
[Paper Note] TextWorld: A Learning Environment for Text-based Games, Marc-Alexandre Côté+, Workshop on Computer Games'18 Held in Conjunction with IJCAI'18, 2018.06
Paper/Blog Link My Issue
#MachineLearning #NLP #Dataset #ReinforcementLearning #Evaluation #IJCAI #Game #text Issue Date: 2025-10-26 GPT Summary- TextWorldは、テキストベースのゲームにおける強化学習エージェントのトレーニングと評価のためのサンドボックス環境であり、ゲームのインタラクティブなプレイを処理するPythonライブラリを提供します。ユーザーは新しいゲームを手作りまたは自動生成でき、生成メカニズムによりゲームの難易度や言語を制御可能です。TextWorldは一般化や転移学習の研究にも利用され、ベンチマークゲームのセットを開発し、いくつかのベースラインエージェントを評価します。 Comment
chrF: character n-gram F-score for automatic MT evaluation, Mono Popovic, WMT'15
Paper/Blog Link My Issue
#DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Reference-based #ACL #One-Line Notes Issue Date: 2023-08-13 Comment
character-basedなn-gram overlapをreferenceとシステムで計算する手法
[Paper Note] Improving Recommendation Novelty Based on Topic Taxonomy, Weng et al., WI-IAT Workshops'07, 2007.11
Paper/Blog Link My Issue
#RecommenderSystems #Novelty #WI #KeyPoint Notes Issue Date: 2017-12-28 Comment
・評価をしていない
・通常のItem-based collaborative filteringの結果に加えて,taxonomyのassociation rule mining (あるtaxonomy t1に興味がある人が,t2にも興味がある確率を獲得する)を行い,このassociation rule miningの結果をCFと組み合わせて,noveltyのある推薦をしようという話(従来のHybrid Recommender Systemsでは,contents-basedの手法を使うときはitem content similarityを使うことが多い.まあこれはよくあるcontents-basedなアプローチだろう).
・documentの中のどの部分がnovelなのかとかを同定しているわけではない.taxonomyの観点からnovelだということ.